# From Reasoning to Generalization: Knowledge-Augmented LLMs for ARC Benchmark
Abstract
Recent reasoning-oriented LLMs have demonstrated strong performance on challenging tasks such as mathematics and science examinations. However, core cognitive faculties of human intelligence, such as abstract reasoning and generalization, remain underexplored. To address this, we evaluate recent reasoning-oriented LLMs on the Abstraction and Reasoning Corpus (ARC) benchmark, which explicitly demands both faculties. We formulate ARC as a program synthesis task and propose nine candidate solvers. Experimental results show that repeated-sampling planning-aided code generation (RSPC) achieves the highest test accuracy and demonstrates consistent generalization across most LLMs. To further improve performance, we introduce an ARC solver, Knowledge Augmentation for Abstract Reasoning (KAAR), which encodes core knowledge priors within an ontology that classifies priors into three hierarchical levels based on their dependencies. KAAR progressively expands LLM reasoning capacity by gradually augmenting priors at each level, and invokes RSPC to generate candidate solutions after each augmentation stage. This stage-wise reasoning reduces interference from irrelevant priors and improves LLM performance. Empirical results show that KAAR maintains strong generalization and consistently outperforms non-augmented RSPC across all evaluated LLMs, achieving around 5% absolute gains and up to 64.52% relative improvement. Despite these achievements, ARC remains a challenging benchmark for reasoning-oriented LLMs, highlighting future avenues of progress in LLMs.
1 Introduction
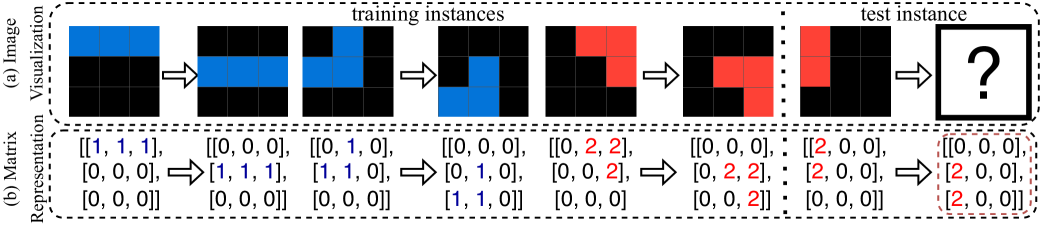
Learning from extensive training data has achieved remarkable success in major AI fields such as computer vision, natural language processing, and autonomous driving [1, 2, 3]. However, achieving human-like intelligence goes beyond learning purely from large-scale data; it requires rapid reasoning and generalizing from prior knowledge to novel tasks and situations [4]. Chollet [5] introduced Abstraction and Reasoning Corpus (ARC) to assess the generalization and abstract reasoning capabilities of AI systems. In each ARC task, the solver is required to infer generalized rules or procedures from a small set of training instances, typically fewer than five input-output image pairs, and apply them to generate output images for given input images provided in test instances (Figure 1 (a)). Each image in ARC is a pixel grid represented as a 2D matrix, where each value denotes a pixel color (Figure 1 (b)). ARC evaluates broad generalization, encompassing reasoning over individual input-output pairs and inferring generalized solutions via high-level abstraction, akin to inductive reasoning [6].
ARC is grounded in core knowledge priors, which serve as foundational cognitive faculties of human intelligence, enabling equitable comparisons between AI systems and human cognitive abilities [7]. These priors include: (1) objectness – aggregating elements into coherent, persistent objects; (2) geometry and topology – recognizing and manipulating shapes, symmetries, spatial transformations, and structural patterns (e.g., containment, repetition, projection); (3) numbers and counting – counting, sorting, comparing quantities, performing basic arithmetic, and identifying numerical patterns; and (4) goal-directedness – inferring purposeful transformations between initial and final states without explicit temporal cues. Incorporating these priors allows ARC solvers to replicate human cognitive processes, produce behavior aligned with human expectations, address human-relevant problems, and demonstrate human-like intelligence through generalization and abstract reasoning [5]. These features highlight ARC as a crucial benchmark for assessing progress toward general intelligence.
Chollet [5] suggested approaching ARC tasks as instances of program synthesis, which studies automatically generating a program that satisfies a high-level specification [8]. Following this proposal, recent studies [9, 10] have successfully solved partial ARC tasks by searching for program solutions encoded within object-centric domain-specific languages (DSLs). Reasoning-oriented LLMs integrate chain-of-thought (CoT) reasoning [11], often trained via reinforcement learning, further advancing program synthesis performance. Common approaches using LLMs for code generation include repeated sampling, where multiple candidate programs are generated [12], followed by best-program selection strategies [13, 14, 15, 16], and code refinement, where initial LLM-generated code is iteratively improved using error feedback from execution results [17, 18] or LLM-generated explanations [17, 19, 18]. We note that ARC presents greater challenges than existing program synthesis benchmarks such as HumanEval [12], MBPP [20], and LiveCode [21], due to its stronger emphasis on generalization and abstract reasoning grounded in core knowledge priors, which remain underexplored. This gap motivates our evaluation of recent reasoning-oriented LLMs on the ARC benchmark, and our proposed knowledge augmentation approach to improve their performance.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Image and Matrix Representation of Training and Test Instances
### Overview
The image illustrates the transformation of image data into matrix representations for training and testing purposes. It shows a sequence of 3x3 pixel images, each represented by a corresponding 3x3 matrix. The images transition from blue pixels (represented by '1' in the matrix) to red pixels (represented by '2' in the matrix), demonstrating a pattern recognition process. The final step presents a test instance with a question mark, indicating a prediction task.
### Components/Axes
* **(a) Image Visualization:** This section displays the images as 3x3 grids of colored pixels.
* **(b) Matrix Representation:** This section shows the corresponding 3x3 matrices representing the pixel values.
* **Training Instances:** A sequence of images and matrices used for training a model.
* **Test Instance:** A final image and matrix for which a prediction is to be made.
* **Pixel Colors:** Blue pixels are represented by the number '1', red pixels are represented by the number '2', and black pixels are represented by the number '0'.
* **Arrows:** Arrows indicate the progression from one training instance to the next, and finally to the test instance.
### Detailed Analysis
The diagram is structured into two rows: the top row shows the image visualization, and the bottom row shows the corresponding matrix representation. The diagram progresses from left to right, showing a sequence of training instances followed by a test instance.
**Image Visualization (Top Row):**
1. **Instance 1:** A 3x3 grid with the top row filled with blue pixels. The rest of the pixels are black.
2. **Instance 2:** A 3x3 grid with the middle row filled with blue pixels. The rest of the pixels are black.
3. **Instance 3:** A 3x3 grid with an L-shape of blue pixels in the bottom-left corner. The rest of the pixels are black.
4. **Instance 4:** A 3x3 grid with an L-shape of blue pixels in the bottom-left corner. The rest of the pixels are black.
5. **Instance 5:** A 3x3 grid with an L-shape of red pixels in the top-right corner. The rest of the pixels are black.
6. **Instance 6:** A 3x3 grid with an L-shape of red pixels in the top-left corner. The rest of the pixels are black.
7. **Test Instance:** A 3x3 grid with a large question mark in the center, indicating an unknown pattern.
**Matrix Representation (Bottom Row):**
Each matrix corresponds to the image above it, with '1' representing blue pixels, '2' representing red pixels, and '0' representing black pixels.
1. **Instance 1:** `[[1, 1, 1], [0, 0, 0], [0, 0, 0]]`
2. **Instance 2:** `[[0, 0, 0], [1, 1, 1], [0, 0, 0]]`
3. **Instance 3:** `[[0, 1, 0], [1, 1, 0], [0, 0, 0]]`
4. **Instance 4:** `[[0, 0, 0], [0, 1, 0], [1, 1, 0]]`
5. **Instance 5:** `[[0, 2, 2], [0, 0, 2], [0, 0, 0]]`
6. **Instance 6:** `[[0, 0, 0], [2, 2, 2], [0, 0, 2]]`
7. **Test Instance:** `[[0, 0, 0], [2, 0, 0], [2, 0, 0]]`
### Key Observations
* The diagram demonstrates a transformation of visual data into numerical matrix representations.
* The training instances show a progression of patterns, initially blue and then red.
* The test instance requires the model to predict the pattern based on the training data.
* The matrix representation accurately reflects the pixel arrangement in the images.
### Interpretation
The diagram illustrates a simplified machine learning process where images are converted into numerical data (matrices) for training a model. The model learns patterns from the training instances and then uses this knowledge to predict the pattern in the test instance. The transition from blue to red pixels suggests a change in the feature being learned. The question mark in the test instance highlights the core task of machine learning: prediction based on learned patterns. The diagram is a visual representation of how computers can "see" and process images by converting them into numerical data.
</details>
Figure 1: An ARC problem example (25ff71a9) with image visualizations (a), including three input-output pairs in the training instances, and one input image in the test instance, along with their corresponding 2D matrix representations (b). The ground-truth test output is enclosed in a red box.
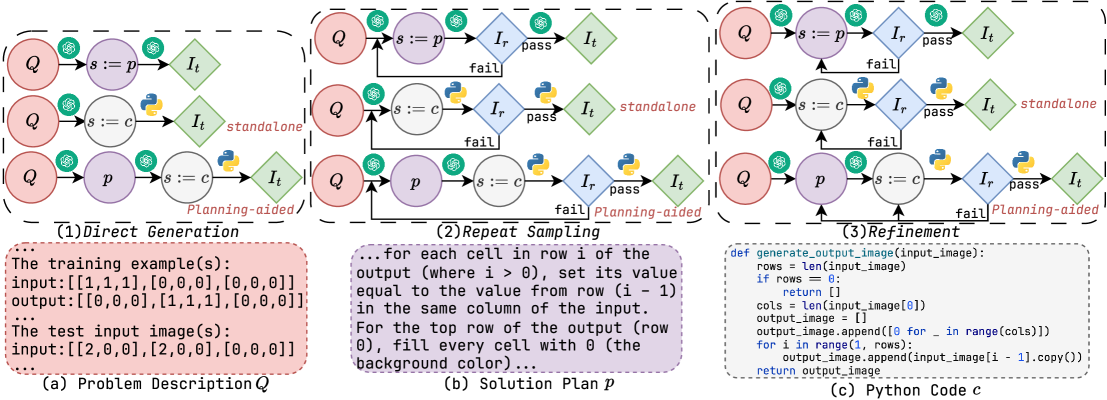
We systematically assess how reasoning-oriented LLMs approach ARC tasks within the program synthesis framework. For each ARC problem, we begin by providing 2D matrices as input. We adopt three established program generation strategies: direct generation, repeated sampling, and refinement. Each strategy is evaluated under two solution representations: a text-based solution plan and Python code. When generating code solutions, we further examine two modalities: standalone and planning-aided, where a plan is generated to guide subsequent code development, following recent advances [18, 22, 23]. In total, nine ARC solvers are considered. We evaluate several reasoning-oriented LLMs, including proprietary models, GPT-o3-mini [24, 25], and Gemini-2.0-Flash-Thinking (Gemini-2.0) [26], and open-source models, DeepSeek-R1-Distill-Llama-70B (DeepSeek-R1-70B) [27] and QwQ-32B [28]. Accuracy on test instances is reported as the primary metric. When evaluated on the ARC public evaluation set (400 problems), repeated-sampling planning-aided code generation (RSPC) demonstrates consistent generalization and achieves the highest test accuracy across most LLMs, 30.75% with GPT-o3-mini, 16.75% with Gemini-2.0, 14.25% with QwQ-32B, and 7.75% with DeepSeek-R1-70B. We treat the most competitive ARC solver, RSPC, as the solver backbone.
Motivated by the success of manually defined priors in ARC solvers [9, 10], we propose K nowledge A ugmentation for A bstract R easoning (KAAR) for solving ARC tasks using reasoning-oriented LLMs. KAAR formalizes manually defined priors through a lightweight ontology that organizes priors into hierarchical levels based on their dependencies. It progressively augments LLMs with priors at each level via structured prompting. Specifically, core knowledge priors are introduced in stages: beginning with objectness, followed by geometry, topology, numbers, and counting, and concluding with goal-directedness. After each stage, KAAR applies the ARC solver backbone (RSPC) to generate the solution. This progressive augmentation enables LLMs to gradually expand their reasoning capabilities and facilitates stage-wise reasoning, aligning with human cognitive development [29]. Empirical results show that KAAR improves accuracy on test instances across all evaluated LLMs, achieving the largest absolute gain of 6.75% with QwQ-32B and the highest relative improvement of 64.52% with DeepSeek-R1-70B over non-augmented RSPC.
We outline our contributions as follows:
- We evaluate the abstract reasoning and generalization capabilities of reasoning-oriented LLMs on ARC using nine solvers that differ in generation strategies, modalities, and solution representations.
- We introduce KAAR, a knowledge augmentation approach for solving ARC problems using LLMs. KAAR progressively augments LLMs with core knowledge priors structured via an ontology and applies the best ARC solver after augmenting same-level priors, further improving performance.
- We conduct a comprehensive performance analysis of the proposed ARC solvers, highlighting failure cases and remaining challenges on the ARC benchmark.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Image Generation Methods
### Overview
The image presents three different methods for image generation: Direct Generation, Repeat Sampling, and Refinement. Each method is illustrated as a flowchart, showing the process from problem description (Q) to the target image (It), potentially involving a solution plan (P) and iterative refinement (Ir). The image also includes examples of training data, a description of the repeat sampling method, and Python code for the refinement method.
### Components/Axes
* **Nodes:**
* Q (Problem Description): Represented as a red circle.
* P (Solution Plan): Represented as a purple circle.
* It (Target Image): Represented as a green diamond.
* Ir (Iterative Refinement): Represented as a blue diamond.
* s := p (Solution equals plan): Represented as a gray circle.
* s := c (Solution equals code): Represented as a gray circle.
* **Icons:**
* ChatGPT Logo: Indicates the use of a language model.
* Python Logo: Indicates the use of Python code.
* **Flow:** Arrows indicate the flow of the process.
* **Decision Points:** Diamonds (Ir) indicate decision points with "pass" and "fail" outcomes.
* **Text Blocks:**
* (a) Problem Description Q
* (b) Solution Plan P
* (c) Python Code c
### Detailed Analysis
#### (1) Direct Generation
* **Flow:**
* Q (red circle with ChatGPT icon) -> s := p (gray circle with ChatGPT icon) -> It (green diamond with Python icon), labeled "Planning-aided"
* Q (red circle with ChatGPT icon) -> s := c (gray circle with ChatGPT icon) -> It (green diamond), labeled "standalone"
* Q (red circle with ChatGPT icon) -> P (purple circle) -> s := c (gray circle with ChatGPT icon) -> It (green diamond with Python icon), labeled "Planning-aided"
* **Text:**
* The training example(s):
* input: `[[1,1,1], [0,0,0], [0,0,0]]`
* output: `[[0,0,0], [1,1,1], [0,0,0]]`
* The test input image(s):
* input: `[[2,0,0], [2,0,0], [0,0,0]]`
#### (2) Repeat Sampling
* **Flow:**
* Q (red circle with ChatGPT icon) -> s := p (gray circle with ChatGPT icon) -> Ir (blue diamond with ChatGPT icon), labeled "pass" -> It (green diamond with Python icon), labeled "Planning-aided"
* Ir (blue diamond with ChatGPT icon), labeled "fail" -> Q (red circle with ChatGPT icon)
* Q (red circle with ChatGPT icon) -> s := c (gray circle with ChatGPT icon) -> Ir (blue diamond with Python icon), labeled "pass" -> It (green diamond), labeled "standalone"
* Ir (blue diamond with Python icon), labeled "fail" -> Q (red circle with ChatGPT icon)
* Q (red circle with ChatGPT icon) -> P (purple circle with ChatGPT icon) -> s := c (gray circle with ChatGPT icon) -> Ir (blue diamond with Python icon), labeled "pass" -> It (green diamond with Python icon), labeled "Planning-aided"
* Ir (blue diamond with Python icon), labeled "fail" -> Q (red circle with ChatGPT icon)
* **Text:**
* "...for each cell in row i of the output (where i > 0), set its value equal to the value from row (i - 1) in the same column of the input. For the top row of the output (row 0), fill every cell with 0 (the background color)..."
#### (3) Refinement
* **Flow:**
* Q (red circle with ChatGPT icon) -> s := p (gray circle with ChatGPT icon) -> Ir (blue diamond with ChatGPT icon), labeled "pass" -> It (green diamond with Python icon), labeled "Planning-aided"
* Ir (blue diamond with ChatGPT icon), labeled "fail" -> Q (red circle with ChatGPT icon)
* Q (red circle with ChatGPT icon) -> s := c (gray circle with ChatGPT icon) -> Ir (blue diamond with Python icon), labeled "pass" -> It (green diamond), labeled "standalone"
* Ir (blue diamond with Python icon), labeled "fail" -> Q (red circle with ChatGPT icon)
* Q (red circle with ChatGPT icon) -> P (purple circle with ChatGPT icon) -> s := c (gray circle with ChatGPT icon) -> Ir (blue diamond with Python icon), labeled "pass" -> It (green diamond with Python icon), labeled "Planning-aided"
* Ir (blue diamond with Python icon), labeled "fail" -> Q (red circle with ChatGPT icon)
* **Python Code:**
```python
def generate_output_image(input_image):
rows = len(input_image)
if rows == 0:
return []
cols = len(input_image[0])
output_image = []
output_image.append([0 for _ in range(cols)])
for i in range(1, rows):
output_image.append(input_image[i - 1].copy())
return output_image
```
### Key Observations
* Each method starts with a problem description (Q).
* Direct Generation directly produces the target image (It), either using a solution plan (P) or code (c).
* Repeat Sampling and Refinement involve iterative refinement (Ir) with a "pass" or "fail" outcome, looping back to the problem description (Q) if refinement fails.
* The ChatGPT and Python logos indicate the tools used in each step.
* "Planning-aided" and "standalone" labels indicate whether the method relies on a pre-defined plan or operates independently.
### Interpretation
The diagram illustrates three distinct approaches to image generation, highlighting the role of planning, coding, and iterative refinement. Direct Generation represents a straightforward approach, while Repeat Sampling and Refinement incorporate feedback loops to improve the generated image. The use of ChatGPT and Python suggests a combination of AI-driven planning and programmatic execution. The training and test examples provide context for the type of image generation task being addressed. The Python code for the refinement method offers a concrete implementation of the iterative process. The "Planning-aided" and "standalone" labels suggest different levels of automation and human intervention in the image generation process.
```
</details>
Figure 2: An illustration of the three ARC solution generation approaches, (1) direct generation, (2) repeated sampling, and (3) refinement, with the GPT-o3-mini input and response fragments (a–c) for solving task 25ff71a9 (Figure 1). For each approach, when the solution $s$ is code, $s:=c$ , a plan $p$ is either generated from the problem description $Q$ to guide code generation (planning-aided) or omitted (standalone). Otherwise, when $s:=p$ , the plan $p$ serves as the final solution instead.
2 Problem Formulation
We formulate each ARC task as a tuple $\mathcal{P}=\langle I_{r},I_{t}\rangle$ , where $I_{r}$ and $I_{t}$ are sets of training and test instances. Each instance consists of an input-output image pair $(i^{i},i^{o})$ , represented as 2D matrices. The goal is to leverage the LLM $\mathcal{M}$ to generate a solution $s$ based on training instances $I_{r}$ and test input images $\{i^{i}\ |\ (i^{i},i^{o})∈ I_{t}\}$ , where $s$ maps each test input $i^{i}$ to its output $i^{o}$ , i.e., $s(i^{i})=i^{o}$ , for $(i^{i},i^{o})∈ I_{t}$ . We note that the test input images are visible during the generation of solution $s$ , whereas test output images become accessible only after $s$ is produced to validate the correctness of $s$ . We encode the solution $s$ in different forms, as a solution plan $p$ , or as Python code $c$ , optionally guided by $p$ . We denote each ARC problem description, comprising $I_{r}$ and $\{i^{i}\ |\ (i^{i},i^{o})∈ I_{t}\}$ , as $Q$ .
3 ARC Solver Backbone
LLMs have shown promise in solving tasks that rely on ARC-relevant priors [30, 31, 32, 33]. We initially assume that reasoning-oriented LLMs implicitly encode sufficient core knowledge priors to solve ARC tasks. We cast each ARC task as a program synthesis problem, which involves generating a solution $s$ from a problem description $Q$ without explicitly prompting for priors. We consider established LLM-based code generation approaches [17, 18, 19, 23] as candidate ARC solution generation strategies, illustrated at the top of Figure 2. These include: (1) direct generation, where the LLM produces the solution $s$ in a single attempt, and then validates it on test instances $I_{t}$ ; (2) repeated sampling, where the LLM samples solutions until one passes training instances $I_{r}$ , and then evaluates it on $I_{t}$ ; and (3) refinement, where the LLM iteratively refines an initial solution $s$ based on failures on $I_{r}$ until it succeeds, followed by evaluation on $I_{t}$ . In addition, we extend the solution representation beyond code to include text-based solution plans. Given the problem description $Q$ as input (Figure 2, block (a)), all strategies prompt the LLM to generate a solution $s$ , represented either as a natural language plan $p$ (block (b)), $s:=p$ , or as a Python code $c$ (block (c)), $s:=c$ . For $s:=p$ , the solution is derived directly from $Q$ . For $s:=c$ , we explore two modalities: the LLM either generates $c$ directly from $Q$ (standalone), or first generates a plan $p$ for $Q$ , which is then concatenated with $Q$ to guide subsequent code development (planning-aided), a strategy widely adopted in recent work [18, 22, 23].
Repeated sampling and refinement iteratively produce new solutions based on the correctness of $s$ on training instances $I_{r}$ , and validate $s$ on test instances $I_{t}$ once it passes $I_{r}$ or the iteration limit is reached. When $s:=p$ , its correctness is evaluated by prompting the LLM to generate each output image $i^{o}$ given its corresponding input $i^{i}$ and the solution plan $p$ , where $(i^{i},i^{o})∈ I_{r}$ or $(i^{i},i^{o})∈ I_{t}$ . Alternatively, when $s:=c$ , its correctness is assessed by executing $c$ on $I_{r}$ or $I_{t}$ . In repeated sampling, the LLM iteratively generates a new plan $p$ and code $c$ from the problem description $Q$ without additional feedback. In contrast, refinement revises $p$ and $c$ by prompting the LLM with the previously incorrect $p$ and $c$ , concatenated with failed training instances. In total, nine ARC solvers are employed to evaluate the performance of reasoning-oriented LLMs on the ARC benchmark.
4 Knowledge Augmentation
Xu et al. [34] improved LLM performance on the ARC benchmark by prompting object-based representations for each task derived from graph-based object abstractions. Building on this insight, we propose KAAR, a knowledge augmentation approach for solving ARC tasks using reasoning-oriented LLMs. KAAR leverages Generalized Planning for Abstract Reasoning (GPAR) [10], a state-of-the-art object-centric ARC solver, to generate the core knowledge priors. GPAR encodes priors as abstraction-defined nodes enriched with attributes and inter-node relations, which are extracted using standard image processing algorithms. To align with the four knowledge dimensions in ARC, KAAR maps GPAR-derived priors into their categories. In detail, KAAR adopts fundamental abstraction methods from GPAR to enable objectness. Objects are typically defined as components based on adjacency rules and color consistency (e.g., 4-connected or 8-connected components), while also including the entire image as a component. KAAR further introduces additional abstractions: (1) middle-vertical, which vertically splits the image into two equal parts, and treats each as a distinct component; (2) middle-horizontal, which applies the same principle along the horizontal axis; (3) multi-lines, which segments the image using full-length rows or columns of uniform color, and treats each resulting part as a distinct component; and (4) no abstraction, which considers only raw 2D matrices. Under no abstraction, KAAR degrades to the ARC solver backbone without incorporating any priors. KAAR inherits GPAR’s geometric and topological priors, including component attributes (size, color, shape) and relations (spatial, congruent, inclusive). It further extends the attribute set with symmetry, bounding box, nearest boundary, and hole count, and augments the relation set with touching. For numeric and counting priors, KAAR follows GPAR, incorporating the largest/smallest component sizes, and the most/least frequent component colors, while extending them with statistical analysis of hole counts and symmetry, as well as the most/least frequent sizes and shapes.
<details>
<summary>x3.png Details</summary>

### Visual Description
## Flow Diagram: Task Categorization and Color Change Rules
### Overview
The image presents a flow diagram outlining a process for categorizing tasks, specifically focusing on tasks involving color changes. The diagram guides the user through a series of questions and selections to define the task's nature and the rules governing color modifications.
### Components/Axes
* **Nodes:** The diagram consists of rectangular nodes with rounded corners, containing instructions and questions. These nodes are outlined in a dashed orange line.
* **Flow Arrows:** Arrows indicate the flow of the process, directing the user from one node to the next.
* **ChatGPT Icons:** A green ChatGPT icon is present after each selection node.
* **Action Schema:** A vertical label on the right side of the diagram indicates the "action schema."
* **Selection Categories:** The diagram is divided into three main categories: (a) Action(s) Selection, (b) Component(s) Selection, and (c) Color Change Rule.
* **Color Coding:** The text "color 0" is colored red in the diagram.
### Detailed Analysis or ### Content Details
1. **Top Node:**
* Text: "Please determine which category or categories this task belongs to. Please select from the following predefined categories..."
* Category: (a) Action(s) Selection
2. **First Selection Node:**
* ChatGPT Icon
* Flows to: "This task involves color change." (gray box with dashed outline)
3. **Second Node:**
* Text: "If this task involves color change: 1. Which components require color change? 2. Determine the conditions used to select these target components:..."
* Category: (b) Component(s) Selection
4. **Second Selection Node:**
* ChatGPT Icon
* Flows to: "Components (color 0) with the minimum and maximum sizes." (gray box with dashed outline)
5. **Third Node:**
* Text: "If this task involves color change, please determine which source color maps to which target color for the target components. 2. Determine the conditions used to dictate this color change:..."
* Category: (c) Color Change Rule
6. **Third Selection Node:**
* ChatGPT Icon
* Flows to:
* "- minimum-size component (from color 0) to 7." (gray box with dashed outline)
* "- maximum-size component (from color 0) to 8." (gray box with dashed outline)
7. **Action Schema:**
* Vertical label on the right side of the diagram connecting the second and third selection nodes.
### Key Observations
* The diagram outlines a decision-making process for tasks involving color changes.
* The process is divided into three main categories: Action Selection, Component Selection, and Color Change Rule.
* The diagram uses ChatGPT icons to indicate selection points.
* The "action schema" label suggests a structured approach to defining actions related to color changes.
* The color "color 0" is specifically highlighted in red.
* The final step involves defining color changes for minimum and maximum size components, with the color changing from "color 0" to 7 and 8, respectively.
### Interpretation
The diagram provides a structured approach to categorizing and defining tasks that involve color changes. It guides the user through a series of questions and selections to determine the specific actions, components, and rules associated with the color modification. The use of "color 0" as a starting point suggests a baseline color from which changes are made. The final step focuses on defining color changes for components of different sizes, indicating that size is a relevant factor in the color change process. The "action schema" label implies a standardized framework for describing and implementing these color change actions.
</details>
Figure 3: The example of goal-directedness priors augmentation in KAAR with input and response fragments from GPT-o3-mini.
GPAR approaches goal-directedness priors by searching for a sequence of program instructions [35] defined in a DSL. Each instruction supports conditionals, branching, looping, and action statements. KAAR incorporates the condition and action concepts from GPAR, and enables goal-directedness priors by augmenting LLM knowledge in two steps: 1) It prompts the LLM to identify the most relevant actions for solving the given ARC problem from ten predefined action categories (Figure 3 block (a)), partially derived from GPAR and extended based on the training set, such as color change, movement, and extension; 2) For each selected action, KAAR prompts the LLM with the associated schema to resolve implementation details. For example, for a color change action, KAAR first prompts the LLM to identify the target components (Figure 3 blocks (b)), and then specify the source and target colors for modification based on the target components (Figure 3 blocks (c)). We note that KAAR also prompts the LLM to incorporate condition-aware reasoning when determining action implementation details, using knowledge derived from geometry, topology, numbers, and counting priors. This enables fine-grained control, for example, applying color changes only to black components conditioned on the maximum or minimum size: from black (value 0) to blue (value 8) if largest, or to orange (value 7) if smallest. Figure 3 shows fragments of the goal-directedness priors augmentation. See Appendix A.2 for the full set of priors in KAAR.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Diagram: ARC Example and Augmentation Process
### Overview
The image presents an example of an Abstraction and Reasoning Corpus (ARC) problem, along with a diagram illustrating an augmentation process using Knowledge-Augmented Abstract Reasoning (KAAR). It also includes descriptions related to objectness, geometry/topology, and number/counting aspects of the ARC problem.
### Components/Axes
* **(a) ARC example:** Shows three pairs of input-output grids. The first two pairs are complete, while the third pair has a question mark in the output grid, indicating the task is to predict the output. The grids consist of black, gray, and other colored cells.
* **(b) Augmentation process in KAAR:** A flowchart-like diagram showing the process of augmenting the ARC problem. It starts with a "Q" (likely representing the question or problem), which is fed into an "ARC solver backbone". The process includes checks for failure ("fail on Ir") and passing ("Pass Ir"), leading to iterative refinements. The output of each stage is denoted as "It". The process is enclosed in a dashed box.
* **(c) Objectness:** A text block describing how 4-connected black pixels (value 0) are considered components. It provides examples of component locations for Training Pair 1 input image, specifically Component 1: Locations=[(0,0), (0,1)] and Component 8: Locations=[(4, 14)].
* **(d) Geometry and Topology:** A text block describing the shape and relationship between components. For Training Pair 1 input image, it states that Component 1 has a horizontal line shape and is different from all others. It also specifies the relative positions of Component 1 and Component 2.
* **(e) Numbers and Counting:** A text block describing the size and frequency of components. For Training Pair 1 input image, it mentions component 5 with a maximum size of 10 and component 8 with a minimum size of 1. It also notes the presence of two components, 4 and 6, each of size 7, appearing most frequently (twice).
### Detailed Analysis
* **ARC Example (a):**
* The first input grid has a pattern of black and gray cells. The corresponding output grid has blue cells in place of some of the gray cells.
* The second input grid has a different pattern of black and gray cells. The corresponding output grid has blue and orange cells in place of some of the gray cells.
* The third input grid has a pattern of black and gray cells, and the corresponding output grid is marked with a question mark.
* **Augmentation Process (b):**
* The process starts with "Q" (red circle), which feeds into an "ARC solver backbone" (yellow rounded rectangle).
* A green circle with a chat bubble icon is placed above each "ARC solver backbone".
* The output of the backbone is checked for failure ("fail on Ir"). If it fails, the process loops back to the backbone.
* If it passes ("Pass Ir"), the output is "It" (green diamond).
* This process is repeated three times.
* **Objectness (c):**
* Defines components as 4-connected black pixels (value 0).
* Provides specific locations for components in Training Pair 1 input image.
* **Geometry and Topology (d):**
* Describes the shape and relationships between components.
* Component 1 is a horizontal line and is different from all others.
* Component 1 is not touching Component 2.
* Component 1 is at the top-left of Component 2, and Component 2 is at the bottom-right of Component 1.
* **Numbers and Counting (e):**
* Describes the size and frequency of components.
* Component 5 has a maximum size of 10.
* Component 8 has a minimum size of 1.
* Components 4 and 6, each of size 7, appear most frequently (twice).
### Key Observations
* The ARC example demonstrates a pattern recognition and reasoning task.
* The augmentation process uses an iterative approach to refine the solution.
* The descriptions of objectness, geometry/topology, and number/counting provide specific details about the components and their relationships.
### Interpretation
The image illustrates a system for solving ARC problems using an augmentation process. The ARC example highlights the type of pattern recognition and reasoning required. The augmentation process demonstrates an iterative approach to refining the solution, likely involving multiple attempts and checks for failure. The descriptions of objectness, geometry/topology, and number/counting provide specific details about the components and their relationships, which are likely used by the ARC solver backbone to generate the output. The system leverages different aspects of the problem (objectness, geometry, numbers) to improve its problem-solving capabilities.
</details>
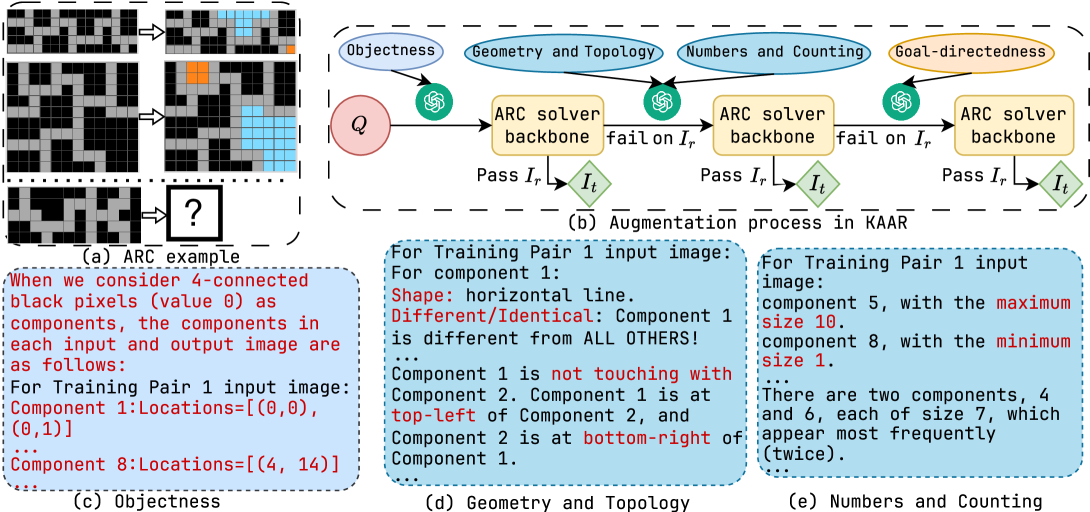
Figure 4: Augmentation process in KAAR (block (b)) and the corresponding knowledge augmentation fragments (blocks (c-e)) for ARC problem 62ab2642 (block (a)).
KAAR encodes the full set of core knowledge priors assumed in ARC into an ontology, where priors are organized into three hierarchical levels based on their dependencies. KAAR prompts LLMs with priors at each level to enable incremental augmentation. This reduces context interference and supports stage-wise reasoning aligned with human cognitive development [29]. Figure 4, block (b), illustrates the augmentation process in KAAR alongside the augmented prior fragments used to solve the problem shown in block (a). KAAR begins augmentation with objectness priors, encoding images into components with detailed coordinates based on a specific abstraction method (block (c)). KAAR then prompts geometry and topology priors (block (d)), followed by numbers and counting priors (block (e)). These priors are ordered by dependency while residing at the same ontological level, as they all build upon objectness. Finally, KAAR augments goal-directedness priors, as shown in Figure 3, where target components are derived from objectness analysis and conditions are inferred from geometric, topological, and numerical analyses. After augmenting each level of priors, KAAR invokes the ARC solver backbone to generate solutions. If any solution passes training instances $I_{r}$ , it is validated on the test instances $I_{t}$ ; otherwise, augmentation proceeds to the next level of priors.
While the ontology provides a hierarchical representation of priors, it may also introduce hallucinations, such as duplicate abstractions, irrelevant component attributes or relations, and inapplicable actions. To address this, KAAR integrates restrictions from GPAR to filter out inapplicable priors. KAAR adopts GPAR’s duplicate-checking strategy, retaining only abstractions that yield distinct components by size, color, or shape, in at least one training instance. In KAAR, each abstraction is associated with a set of applicable priors. For instance, when the entire image is treated as a component, relation priors are excluded, and actions such as movement and color change are omitted, whereas symmetry and size attributes are retained and actions such as flipping and rotation are considered. In contrast, 4-connected and 8-connected abstractions include all component attributes and relations, and the full set of ten action priors. See Appendix A.3 for detailed restrictions.
| \hlineB 2 GPT-o3-mini | $I_{r}$ | Direct Generation P - | Repeated Sampling C - | Refinement PC - | P 35.50 | C 52.50 | PC 35.50 | P 31.00 | C 47.25 | PC 32.00 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $I_{t}$ | 20.50 | 24.50 | 22.25 | 23.75 | 32.50 | 30.75 | 24.75 | 29.25 | 25.75 | |
| $I_{r}\&I_{t}$ | - | - | - | 22.00 | 31.75 | 29.25 | 21.75 | 28.50 | 25.00 | |
| Gemini-2.0 | $I_{r}$ | - | - | - | 36.50 | 39.50 | 21.50 | 15.50 | 25.50 | 15.50 |
| $I_{t}$ | 7.00 | 6.75 | 6.25 | 10.00 | 14.75 | 16.75 | 8.75 | 12.00 | 11.75 | |
| $I_{r}\&I_{t}$ | - | - | - | 9.50 | 14.25 | 16.50 | 8.00 | 10.50 | 10.75 | |
| QwQ-32B | $I_{r}$ | - | - | - | 19.25 | 13.50 | 15.25 | 16.75 | 15.00 | 14.25 |
| $I_{t}$ | 9.50 | 7.25 | 5.75 | 11.25 | 13.50 | 14.25 | 11.00 | 14.25 | 14.00 | |
| $I_{r}\&I_{t}$ | - | - | - | 9.25 | 12.75 | 13.00 | 8.75 | 13.00 | 11.75 | |
| DeepSeek-R1-70B | $I_{r}$ | - | - | - | 8.75 | 6.75 | 7.75 | 6.25 | 5.75 | 7.75 |
| $I_{t}$ | 4.25 | 4.75 | 4.50 | 4.25 | 7.25 | 7.75 | 4.75 | 5.75 | 7.75 | |
| $I_{r}\&I_{t}$ | - | - | - | 3.50 | 6.50 | 7.25 | 4.25 | 5.25 | 7.00 | |
| \hlineB 2 | | | | | | | | | | |
Table 1: Performance of nine ARC solvers measured by accuracy on $I_{r}$ , $I_{t}$ , and $I_{r}\&I_{t}$ using four reasoning-oriented LLMs. For each LLM, the highest accuracy on $I_{r}$ and $I_{r}\&I_{t}$ is in bold; the highest accuracy on $I_{t}$ is in red. Accuracy is reported as a percentage. P denotes the solution plan; C and PC refer to standalone and planning-aided code generation, respectively.
5 Experiments
In ARC, each task is unique and solvable using only core knowledge priors [5]. We begin by comparing nine candidate solvers on the full ARC public evaluation set of 400 tasks. This offers broader insights than previous studies limited to subsets of 400 training tasks [10, 9, 36], given the greater difficulty of the evaluation set [37]. We experiment with recent reasoning-oriented LLMs, including proprietary models, GPT-o3-mini and Gemini 2.0 Flash-Thinking (Gemini-2.0), and open-source models, DeepSeek-R1-Distill-Llama-70B (DeepSeek-R1-70B) and QwQ-32B. We compute accuracy on test instances $I_{t}$ as the primary evaluation metric. It measures the proportion of problems where the first solution successfully solves $I_{t}$ after passing the training instances $I_{r}$ ; otherwise, if none pass $I_{r}$ within 12 iterations, the last solution is evaluated on $I_{t}$ , applied to both repeated sampling and refinement. We also report accuracy on $I_{r}$ and $I_{r}\&I_{t}$ , measuring the percentage of problems whose solutions solve $I_{r}$ and both $I_{r}$ and $I_{t}$ . See Appendix A.4 for parameter settings.
Table 1 reports the performance of nine ARC solvers across four reasoning-oriented LLMs. For direct generation methods, accuracy on $I_{r}$ and $I_{r}\&I_{t}$ is omitted, as solutions are evaluated directly on $I_{t}$ . GPT-o3-mini consistently outperforms all other LLMs, achieving the highest accuracy on $I_{r}$ (52.50%), $I_{t}$ (32.50%), and $I_{r}\&I_{t}$ (31.75%) under repeated sampling with standalone code generation (C), highlighting its strong abstract reasoning and generalization capabilities. Notably, QwQ-32B, the smallest model, outperforms DeepSeek-R1-70B across all solvers and surpasses Gemini-2.0 under refinement. Among the nine ARC solvers, repeated sampling-based methods generally outperform those based on direct generation or refinement. This diverges from previous findings where refinement dominated conventional code generation tasks that lack abstract reasoning and generalization demands [10, 17, 19]. Within repeated sampling, planning-aided code generation (PC) yields the highest accuracy on $I_{t}$ across most LLMs. It also demonstrates the strongest generalization with GPT-o3-mini and Gemini-2.0, as evidenced by the smallest accuracy gap between $I_{r}$ and $I_{r}\&I_{t}$ , compared to solution plan (P) and standalone code generation (C). A similar trend is observed for QwQ-32B and DeepSeek-R1-70B, where both C and PC generalize effectively across repeated sampling and refinement. Overall, repeated sampling with planning-aided code generation, denoted as RSPC, shows the best performance and thus serves as the ARC solver backbone.
| \hlineB 2 GPT-o3-mini | RSPC | $I_{r}$ Acc 35.50 | $I_{t}$ $\Delta$ - | $I_{r}\&I_{t}$ $\gamma$ - | Acc 30.75 | $\Delta$ - | $\gamma$ - | Acc 29.25 | $\Delta$ - | $\gamma$ - |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| KAAR | 40.00 | 4.50 | 12.68 | 35.00 | 4.25 | 13.82 | 33.00 | 3.75 | 12.82 | |
| Gemini-2.0 | RSPC | 21.50 | - | - | 16.75 | - | - | 16.50 | - | - |
| KAAR | 25.75 | 4.25 | 19.77 | 21.75 | 5.00 | 29.85 | 20.50 | 4.00 | 24.24 | |
| QwQ-32B | RSPC | 15.25 | - | - | 14.25 | - | - | 13.00 | - | - |
| KAAR | 22.25 | 7.00 | 45.90 | 21.00 | 6.75 | 47.37 | 19.25 | 6.25 | 48.08 | |
| DeepSeek-R1-70B | RSPC | 7.75 | - | - | 7.75 | - | - | 7.25 | - | - |
| KAAR | 12.25 | 4.50 | 58.06 | 12.75 | 5.00 | 64.52 | 11.50 | 4.25 | 58.62 | |
| \hlineB 2 | | | | | | | | | | |
Table 2: Comparison of RSPC (repeated-sampling planning-aided code generation) and its knowledge-augmented variant, KAAR, in terms of accuracy (Acc) on $I_{r}$ , $I_{t}$ , and $I_{r}\&I_{t}$ . $\Delta$ and $\gamma$ denote the absolute and relative improvements over RSPC, respectively. All values are reported as percentages. The best results for $I_{r}$ and $I_{r}\&I_{t}$ are in bold; the highest for $I_{t}$ is in red.
We further compare the performance of RSPC with its knowledge-augmented variant, KAAR. For each task, KAAR begins with simpler abstractions, i.e., no abstraction and whole image, and progresses to complicated 4-connected and 8-connected abstractions, consistent with GPAR. KAAR reports the accuracy on test instances $I_{t}$ based on the first abstraction whose solution solves all training instances $I_{r}$ ; otherwise, it records the final solution from each abstraction and selects the one that passes the most $I_{r}$ to evaluate on $I_{t}$ . KAAR allows the solver backbone (RSPC) up to 4 iterations per invocation, totaling 12 iterations, consistent with the non-augmented setting. See Appendix A.5 for KAAR execution details. As shown in Table 2, KAAR consistently outperforms non-augmented RSPC across all LLMs, yielding around 5% absolute gains on $I_{r}$ , $I_{t}$ , and $I_{r}\&I_{t}$ . This highlights the effectiveness and model-agnostic nature of the augmented priors. KAAR achieves the highest accuracy using GPT-o3-mini, with 40% on $I_{r}$ , 35% on $I_{t}$ , and 33% on $I_{r}\&I_{t}$ . KAAR shows the greatest absolute improvements ( $\Delta$ ) using QwQ-32B and the largest relative gains ( $\gamma$ ) using DeepSeek-R1-70B across all evaluated metrics. Moreover, KAAR maintains generalization comparable to RSPC across all LLMs, indicating that the augmented priors are sufficiently abstract and expressive to serve as basis functions for reasoning, in line with ARC assumptions.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Heatmap: Model Coverage Comparison
### Overview
The image presents two heatmaps comparing the coverage of different language models (GPT-03-mini, Gemini-2.0, QwQ-32B, and DeepSeek-R1-70B) on two datasets: RSPC (left) and KAAR (right). The heatmaps visualize the pairwise coverage between these models, with darker shades indicating higher coverage. A color bar on the right indicates the coverage scale, ranging from 0.0 to 1.0.
### Components/Axes
* **Models (Rows/Columns):** GPT-03-mini, Gemini-2.0, QwQ-32B, DeepSeek-R1-70B. These models are listed on both the x and y axes of each heatmap.
* **Heatmap Cells:** Each cell represents the coverage score between two models.
* **Color Scale:** A vertical color bar on the right side of the image indicates the coverage values, ranging from 0.0 (lightest) to 1.0 (darkest).
* **Titles:** (a) RSPC, (b) KAAR
* **Coverage Scale:** The color bar is labeled "Coverage" and ranges from 0.0 to 1.0, with a tick mark at 0.5.
### Detailed Analysis
**Heatmap (a) RSPC:**
| Model 1 | Model 2 | Coverage |
| -------------- | -------------- | -------- |
| GPT-03-mini | GPT-03-mini | 1.00 |
| GPT-03-mini | Gemini-2.0 | 0.50 |
| GPT-03-mini | QwQ-32B | 0.40 |
| GPT-03-mini | DeepSeek-R1-70B | 0.22 |
| Gemini-2.0 | GPT-03-mini | 0.91 |
| Gemini-2.0 | Gemini-2.0 | 1.00 |
| Gemini-2.0 | QwQ-32B | 0.60 |
| Gemini-2.0 | DeepSeek-R1-70B | 0.40 |
| QwQ-32B | GPT-03-mini | 0.86 |
| QwQ-32B | Gemini-2.0 | 0.70 |
| QwQ-32B | QwQ-32B | 1.00 |
| QwQ-32B | DeepSeek-R1-70B | 0.44 |
| DeepSeek-R1-70B | GPT-03-mini | 0.87 |
| DeepSeek-R1-70B | Gemini-2.0 | 0.87 |
| DeepSeek-R1-70B | QwQ-32B | 0.81 |
| DeepSeek-R1-70B | DeepSeek-R1-70B | 1.00 |
**Heatmap (b) KAAR:**
| Model 1 | Model 2 | Coverage |
| -------------- | -------------- | -------- |
| GPT-03-mini | GPT-03-mini | 1.00 |
| GPT-03-mini | Gemini-2.0 | 0.55 |
| GPT-03-mini | QwQ-32B | 0.54 |
| GPT-03-mini | DeepSeek-R1-70B | 0.34 |
| Gemini-2.0 | GPT-03-mini | 0.89 |
| Gemini-2.0 | Gemini-2.0 | 1.00 |
| Gemini-2.0 | QwQ-32B | 0.72 |
| Gemini-2.0 | DeepSeek-R1-70B | 0.48 |
| QwQ-32B | GPT-03-mini | 0.88 |
| QwQ-32B | Gemini-2.0 | 0.74 |
| QwQ-32B | QwQ-32B | 1.00 |
| QwQ-32B | DeepSeek-R1-70B | 0.53 |
| DeepSeek-R1-70B | GPT-03-mini | 0.92 |
| DeepSeek-R1-70B | Gemini-2.0 | 0.82 |
| DeepSeek-R1-70B | QwQ-32B | 0.88 |
| DeepSeek-R1-70B | DeepSeek-R1-70B | 1.00 |
### Key Observations
* **Diagonal Values:** All diagonal values are 1.00, indicating that each model has perfect coverage with itself.
* **RSPC vs. KAAR:** The coverage scores generally appear higher in the KAAR dataset compared to the RSPC dataset.
* **GPT-03-mini Coverage:** GPT-03-mini tends to have lower coverage when compared to other models, especially with DeepSeek-R1-70B.
* **DeepSeek-R1-70B Coverage:** DeepSeek-R1-70B shows relatively high coverage with other models.
### Interpretation
The heatmaps provide a visual comparison of the coverage between different language models on two datasets. The higher coverage scores on the KAAR dataset suggest that the models may perform better or have a more comprehensive understanding of the KAAR dataset compared to the RSPC dataset. The lower coverage of GPT-03-mini with other models, particularly DeepSeek-R1-70B, indicates potential differences in their understanding or approach to the tasks represented by these datasets. The high self-coverage (diagonal values of 1.00) is expected and serves as a baseline for comparison. The differences in coverage between models and datasets could be attributed to factors such as model architecture, training data, or the specific characteristics of the datasets themselves.
</details>
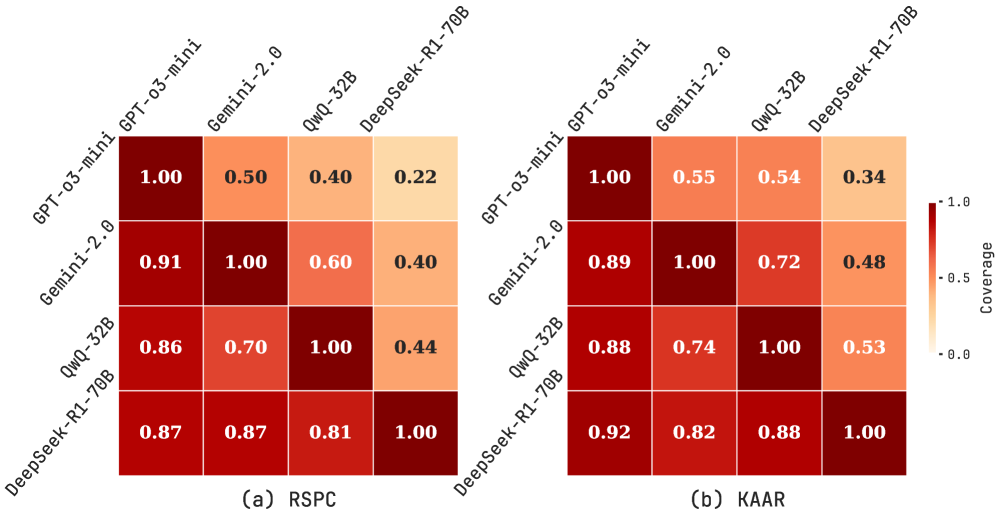
Figure 5: Asymmetric relative coverage matrices for RSPC (a) and KAAR (b), showing the proportion of problems whose test instances are solved by the row model that are also solved by the column model, across four LLMs.
We compare relative problem coverage across evaluated LLMs under RSPC and KAAR based on successful solutions on test instances. As shown in Figure 5, each cell $(i,j)$ represents the proportion of problems solved by the row LLM that are also solved by the column LLM. This is computed as $\frac{|A_{i}\cap A_{j}|}{|A_{i}|}$ , where $A_{i}$ and $A_{j}$ are the sets of problems solved by the row and column LLMs, respectively. Values near 1 indicate that the column LLM covers most problems solved by the row LLM. Under RSPC (Figure 5 (a)), GPT-o3-mini exhibits broad coverage, with column values consistently above 0.85. Gemini-2.0 and QwQ-32B also show substantial alignment, with mutual coverage exceeding 0.6. In contrast, DeepSeek-R1-70B shows lower alignment, with column values below 0.45 due to fewer solved problems. Figure 5 (b) illustrates that KAAR generally improves or maintains inter-model overlap compared to RSPC. Notably, KAAR raises the minimum coverage between GPT-o3-mini and DeepSeek-R1-70B from 0.22 under RSPC to 0.34 under KAAR. These results highlight the effectiveness of KAAR in improving cross-model generalization, with all evaluated LLMs solving additional shared problems. In particular, it enables smaller models such as QwQ-32B and DeepSeek-R1-70B to better align with stronger LLMs on the ARC benchmark.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Bar Chart: Accuracy on It (%)
### Overview
The image is a bar chart comparing the accuracy of different language models (GPT-o3-mini, Gemini-2.0, QwQ-32B, and DeepSeek-R1-70B) on four types of image transformations: Movement, Extension, Recolor, and Others. The accuracy is measured as a percentage. Each model is evaluated using two different configurations: RSPC and KAAR.
### Components/Axes
* **Y-axis:** "Accuracy on It (%)", ranging from 0 to 40%. Horizontal grid lines are present at intervals of 10%.
* **X-axis:** Four categories: "Movement", "Extension", "Recolor", and "Others". Below each category is the total number of images in that category: 55, 129, 115, and 101, respectively.
* **Legend:** Located at the top of the chart.
* Blue: GPT-o3-mini: RSPC
* Light Blue: GPT-o3-mini: KAAR
* Green: Gemini-2.0: RSPC
* Light Green: Gemini-2.0: KAAR
* Purple: QwQ-32B: RSPC
* Light Purple: QwQ-32B: KAAR
* Orange: DeepSeek-R1-70B: RSPC
* Light Orange: DeepSeek-R1-70B: KAAR
### Detailed Analysis
**1. Movement**
* GPT-o3-mini RSPC (Blue): 41.8%
* GPT-o3-mini KAAR (Light Blue): 3.6%
* Gemini-2.0 RSPC (Green): 20.0%
* Gemini-2.0 KAAR (Light Green): 12.7%
* QwQ-32B RSPC (Purple): 18.2%
* QwQ-32B KAAR (Light Purple): 14.5%
* DeepSeek-R1-70B RSPC (Orange): 10.9%
* DeepSeek-R1-70B KAAR (Light Orange): 9.1%
**2. Extension**
* GPT-o3-mini RSPC (Blue): 38.8%
* GPT-o3-mini KAAR (Light Blue): 0.8%
* Gemini-2.0 RSPC (Green): 19.4%
* Gemini-2.0 KAAR (Light Green): 1.6%
* QwQ-32B RSPC (Purple): 17.8%
* QwQ-32B KAAR (Light Purple): 2.3%
* DeepSeek-R1-70B RSPC (Orange): 7.8%
* DeepSeek-R1-70B KAAR (Light Orange): 1.6%
**3. Recolor**
* GPT-o3-mini RSPC (Blue): 24.3%
* GPT-o3-mini KAAR (Light Blue): 7.8%
* Gemini-2.0 RSPC (Green): 13.9%
* Gemini-2.0 KAAR (Light Green): 6.1%
* QwQ-32B RSPC (Purple): 10.4%
* QwQ-32B KAAR (Light Purple): 7.8%
* DeepSeek-R1-70B RSPC (Orange): 4.3%
* DeepSeek-R1-70B KAAR (Light Orange): 7.0%
**4. Others**
* GPT-o3-mini RSPC (Blue): 21.8%
* GPT-o3-mini KAAR (Light Blue): 5.0%
* Gemini-2.0 RSPC (Green): 14.9%
* Gemini-2.0 KAAR (Light Green): 4.0%
* QwQ-32B RSPC (Purple): 11.9%
* QwQ-32B KAAR (Light Purple): 7.9%
* DeepSeek-R1-70B RSPC (Orange): 9.9%
* DeepSeek-R1-70B KAAR (Light Orange): 5.0%
### Key Observations
* GPT-o3-mini RSPC consistently shows the highest accuracy across all categories.
* GPT-o3-mini KAAR consistently shows the lowest accuracy across all categories.
* The "Movement" category has the highest accuracy for GPT-o3-mini RSPC, while "Recolor" has the lowest.
* The "Extension" category has the largest total number of images (129), while "Movement" has the smallest (55).
### Interpretation
The data suggests that the choice of language model and configuration (RSPC vs. KAAR) significantly impacts the accuracy of image transformation tasks. GPT-o3-mini with the RSPC configuration appears to be the most effective model for these tasks. The substantial difference in accuracy between RSPC and KAAR configurations for GPT-o3-mini indicates that the configuration plays a crucial role in the model's performance. The varying accuracy across different transformation types (Movement, Extension, Recolor, Others) suggests that some transformations are inherently more challenging for these models than others. The total number of images per category might also influence the observed accuracy, as larger datasets could provide more robust training and evaluation.
</details>
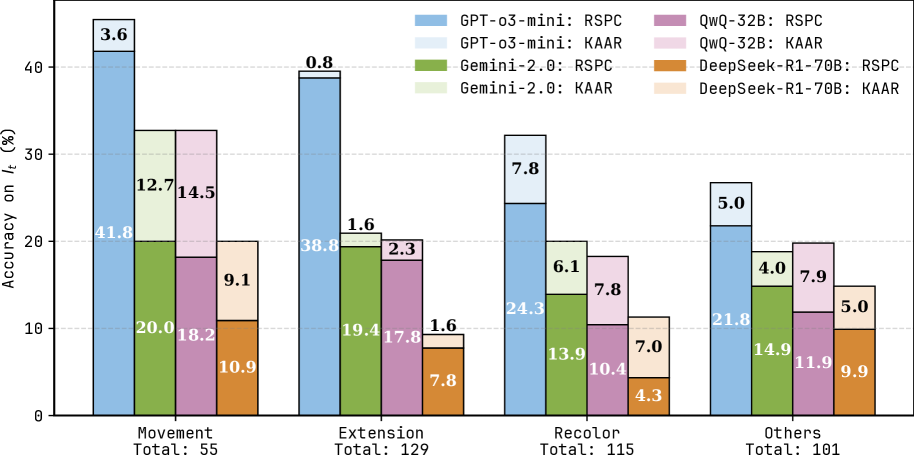
Figure 6: Accuracy on test instances $I_{t}$ for RSPC and KAAR across the movement, extension, recolor, and others categories using four LLMs. Each stacked bar shows RSPC accuracy (darker segment) and the additional improvement from KAAR (lighter segment).
Following prior work [9, 10], we categorize 400 problems in the ARC public evaluation set into four classes based on their primary transformations: (1) movement (55 problems), (2) extension (129 problems), (3) recolor (115 problems), and (4) others (101 problems). The others category comprises infrequent tasks such as noise removal, selection, counting, resizing, and problems with implicit patterns that hinder systematic classification into the aforementioned categories. See Appendix A.7 for examples of each category. Figure 6 illustrates the accuracy on test instances $I_{t}$ for RSPC and KAAR across four categories with evaluated LLMs. Each stacked bar represents RSPC accuracy and the additional improvement achieved by KAAR. KAAR consistently outperforms RSPC with the largest accuracy gain in movement (14.5% with QwQ-32B). In contrast, KAAR shows limited improvements in extension, since several problems involve pixel-level extension, which reduces the reliance on component-level recognition. Moreover, extension requires accurate spatial inference across multiple components and poses greater difficulty than movement, which requires mainly direction identification. Although KAAR augments spatial priors, LLMs still struggle to accurately infer positional relations among multiple components, consistent with prior findings [38, 39, 40]. Overlaps from component extensions further complicate reasoning, as LLMs often fail to recognize truncated components as unified wholes, contrary to human perceptual intuition.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Bar Chart: Accuracy on It (%) vs. Average Image Size Interval
### Overview
The image is a bar chart comparing the accuracy of two models (GPT-o3-mini and QwQ-32B) on image data, broken down by average image size interval (width x height). Each model has two configurations, RSPC and KAAR. The chart displays accuracy on the y-axis and image size intervals on the x-axis. The total number of images in each size interval is also provided.
### Components/Axes
* **Y-axis:** "Accuracy on It (%)", ranging from 0 to 80. Horizontal gridlines are present at intervals of 10.
* **X-axis:** "Average Image Size Interval (width x height)". The intervals are:
* (0,25]
* (25,100]
* (100,225]
* (225,400]
* (400,625]
* (625,900]
* **Total Images:** Below each interval, the total number of images in that interval is provided.
* **Legend:** Located at the top-right of the chart.
* Blue: GPT-o3-mini RSPC
* Light Blue: GPT-o3-mini KAAR
* Purple: QwQ-32B RSPC
* Light Purple: QwQ-32B KAAR
### Detailed Analysis
The chart presents accuracy data for each model and configuration across different image size intervals. The values are read from the top of each bar segment.
* **(0,25] Interval (Total: 19)**
* GPT-o3-mini RSPC (Blue): 73.7
* GPT-o3-mini KAAR (Light Blue): 5.3
* QwQ-32B RSPC (Purple): 42.1
* QwQ-32B KAAR (Light Purple): 15.8
* **(25,100] Interval (Total: 139)**
* GPT-o3-mini RSPC (Blue): 48.9
* GPT-o3-mini KAAR (Light Blue): 5.0
* QwQ-32B RSPC (Purple): 23.7
* QwQ-32B KAAR (Light Purple): 11.5
* **(100,225] Interval (Total: 129)**
* GPT-o3-mini RSPC (Blue): 24.8
* GPT-o3-mini KAAR (Light Blue): 4.7
* QwQ-32B RSPC (Purple): 8.5
* QwQ-32B KAAR (Light Purple): 6.2
* **(225,400] Interval (Total: 51)**
* GPT-o3-mini RSPC (Blue): 11.8
* GPT-o3-mini KAAR (Light Blue): 5.9
* QwQ-32B RSPC (Purple): 9.8
* QwQ-32B KAAR (Light Purple): 2.0
* **(400,625] Interval (Total: 39)**
* GPT-o3-mini RSPC (Blue): 5.1
* GPT-o3-mini KAAR (Light Blue): 0 (approximate)
* QwQ-32B RSPC (Purple): 0 (approximate)
* QwQ-32B KAAR (Light Purple): 0 (approximate)
* **(625,900] Interval (Total: 23)**
* GPT-o3-mini RSPC (Blue): 4.3
* GPT-o3-mini KAAR (Light Blue): 0 (approximate)
* QwQ-32B RSPC (Purple): 0 (approximate)
* QwQ-32B KAAR (Light Purple): 0 (approximate)
### Key Observations
* GPT-o3-mini RSPC (Blue) consistently outperforms the other configurations, especially for smaller image sizes.
* The accuracy of all configurations generally decreases as the average image size interval increases.
* GPT-o3-mini KAAR (Light Blue) and QwQ-32B KAAR (Light Purple) have the lowest accuracy across all intervals.
* The performance difference between RSPC and KAAR configurations is more pronounced for GPT-o3-mini than for QwQ-32B.
### Interpretation
The data suggests that the GPT-o3-mini model with the RSPC configuration is more effective at processing smaller images. The decreasing accuracy with increasing image size indicates a potential limitation in handling larger images for both models and configurations. The KAAR configuration appears to be significantly less accurate than the RSPC configuration, suggesting that the RSPC configuration is better suited for this task. The total number of images in each interval varies, which could influence the accuracy results. The models perform poorly on the largest image sizes.
</details>
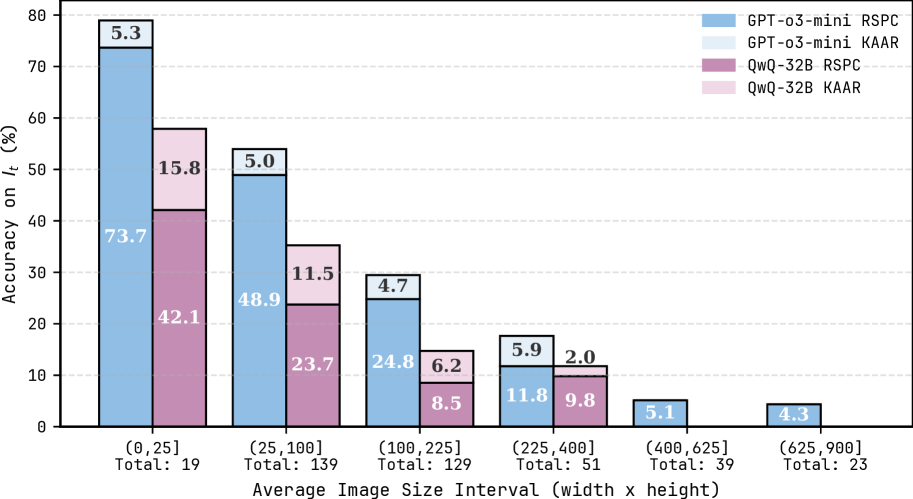
Figure 7: Accuracy on test instances $I_{t}$ for RSPC and KAAR across average image size intervals, evaluated using GPT-o3-mini and QwQ-32B. See Figure 12 in Appendix for the results with the other LLMs.
A notable feature of ARC is the variation in image size both within and across problems. We categorize tasks by averaging the image size per problem, computed over both training and test image pairs. We report the accuracy on $I_{t}$ for RSPC and KAAR across average image size intervals using GPT-o3-mini and QwQ-32B, the strongest proprietary and open-source models in Tables 1 and 2. As shown in Figure 7, both LLMs experience performance degradation as image size increases. When the average image size exceeds 400 (20×20), GPT-o3-mini solves only three problems, while QwQ-32B solves none. In ARC, isolating relevant pixels in larger images, represented as 2D matrices, requires effective attention mechanisms in LLMs, which remains an open challenge noted in recent work [41, 34]. KAAR consistently outperforms RSPC on problems with average image sizes below 400, benefiting from object-centric representations. By abstracting each image into components, KAAR reduces interference from irrelevant pixels, directs attention to salient components, and facilitates component-level transformation analysis. However, larger images often produce both oversized and numerous components after abstraction, which continue to challenge LLMs during reasoning. Oversized components hinder transformation execution, and numerous components complicate the identification of target components.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Line Chart: Accuracy on Ir&It (%) vs. # Iterations
### Overview
The image is a line chart comparing the accuracy of two models, GPT-o3-mini and QwQ-32B, on different tasks (RSPC and KAAR) across varying numbers of iterations. The x-axis represents the number of iterations, while the y-axis represents the accuracy percentage. The chart is divided into three sections representing different task categories: Objectness, Geometry/Topology/Numbers and Counting, and Goal-directedness.
### Components/Axes
* **Title:** Accuracy on Ir&It (%)
* **X-axis:** # Iterations, with labels 1, 4, 8, and 12. The x-axis is divided into three sections:
* Objectness (between 1 and 4)
* Geometry, Topology, Numbers and Counting (between 4 and 8)
* Goal-directedness (between 8 and 12)
* **Y-axis:** Accuracy on Ir&It (%), with a scale from 0 to 35, incrementing by 5.
* **Legend:** Located in the bottom-right corner.
* **Blue with Circle:** GPT-o3-mini: RSPC
* **Light Blue with Triangle:** GPT-o3-mini: KAAR
* **Purple with Triangle:** QwQ-32B: RSPC
* **Light Purple with Square:** QwQ-32B: KAAR
### Detailed Analysis
* **GPT-o3-mini: RSPC (Blue with Circle):**
* Trend: Generally increasing, plateaus after 8 iterations.
* Data Points:
* Iteration 1: 17.5%
* Iteration 2: 20.75%
* Iteration 4: 26.25%
* Iteration 6: 27.5%
* Iteration 8: 28.25%
* Iteration 10: 29.25%
* Iteration 12: 29.25%
* **GPT-o3-mini: KAAR (Light Blue with Triangle):**
* Trend: Increasing, plateaus after 8 iterations.
* Data Points:
* Iteration 1: 18%
* Iteration 2: 21.25%
* Iteration 4: 26.75%
* Iteration 6: 29.25%
* Iteration 8: 30%
* Iteration 10: 32%
* Iteration 12: 33%
* **QwQ-32B: RSPC (Purple with Triangle):**
* Trend: Increases initially, then plateaus after 4 iterations.
* Data Points:
* Iteration 1: 3.5%
* Iteration 2: 6.25%
* Iteration 4: 11.5%
* Iteration 6: 12.5%
* Iteration 8: 12.75%
* Iteration 10: 13%
* Iteration 12: 13%
* **QwQ-32B: KAAR (Light Purple with Square):**
* Trend: Increasing, plateaus after 8 iterations.
* Data Points:
* Iteration 1: 4.5%
* Iteration 2: 8.5%
* Iteration 4: 13.75%
* Iteration 6: 15.25%
* Iteration 8: 15.5%
* Iteration 10: 19%
* Iteration 12: 19.25%
### Key Observations
* GPT-o3-mini models (both RSPC and KAAR) consistently outperform QwQ-32B models across all iterations and task categories.
* The accuracy of all models tends to plateau after 8 iterations.
* The "Objectness" task category (iterations 1-4) shows a steeper initial increase in accuracy for all models compared to the other categories.
* The KAAR task generally yields higher accuracy than the RSPC task for both models.
### Interpretation
The data suggests that the GPT-o3-mini architecture is more effective than the QwQ-32B architecture for the given tasks. The plateauing of accuracy after 8 iterations indicates a point of diminishing returns, suggesting that further iterations may not significantly improve performance. The difference in performance between RSPC and KAAR tasks could be attributed to the inherent complexity or nature of these tasks. The initial rapid increase in accuracy during the "Objectness" phase may indicate that this task is relatively easier for the models to learn initially.
</details>
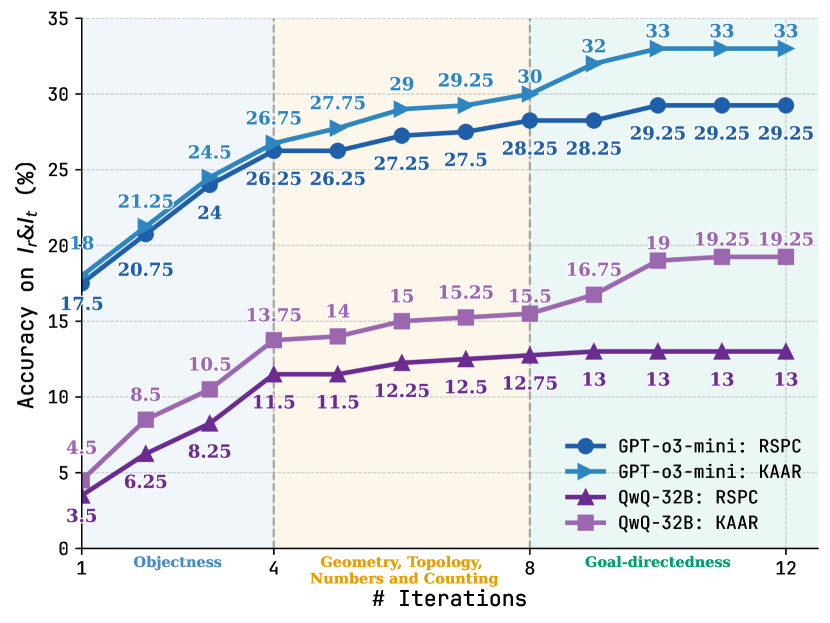
Figure 8: Variance in accuracy on $I_{r}\&I_{t}$ with increasing iterations for RSPC and KAAR using GPT-o3-mini and QwQ-32B. See Figure 13 in Appendix for the results with the other LLMs.
Figure 8 presents the variance in accuracy on $I_{r}\&I_{t}$ for RSPC and KAAR as iteration count increases using GPT-o3-mini and QwQ-32B. For each task under KAAR, we include only iterations from the abstraction that solves both $I_{r}$ and $I_{t}$ . For KAAR, performance improvements across each 4-iteration block are driven by the solver backbone invocation after augmenting an additional level of priors: iterations 1–4 introduce objectness; 5–8 incorporate geometry, topology, numbers, and counting; 9–12 further involve goal-directedness. RSPC shows rapid improvement in the first 4 iterations and plateaus around iteration 8. At each iteration, the accuracy gap between KAAR and RSPC reflects the contribution of accumulated priors via augmentation. KAAR consistently outperforms RSPC, with the performance gap progressively increasing after new priors are augmented and peaking after the integration of goal-directedness. We note that objectness priors alone yield marginal gains with GPT-o3-mini. However, the inclusion of object attributes and relational priors (iterations 4–8) leads to improvements in KAAR over RSPC. This advantage is further amplified after the augmentation of goal-directedness priors (iterations 9–12). These results highlight the benefits of KAAR. Representing core knowledge priors through a hierarchical, dependency-aware ontology enables KAAR to incrementally augment LLMs, perform stage-wise reasoning, and improve solution accuracy. Compared to augmentation at once and non-stage-wise reasoning, KAAR consistently yields superior accuracy, as detailed in Appendix A.6.
6 Discussion
ARC and KAAR. ARC serves as a visual abstract reasoning benchmark, requiring models to infer transformations from few examples for each unique task, rather than fitting to a closed rule space as in RAVEN [42] and PGM [43]. ARC assumes tasks are solvable using core knowledge priors. However, the problems are intentionally left undefined to preclude encoding complete solution rules [5]. This pushes models beyond closed-form rule fitting and toward truly domain-general capabilities. While some of the knowledge in KAAR is tailored to ARC, its central contribution lies in representing knowledge through a hierarchical, dependency-aware ontology that enables progressive augmentation. This allows LLMs to gradually expand their reasoning scope and perform stage-wise inference, improving performance on ARC without relying on an exhaustive rule set. Moreover, the ontology of KAAR is transferable to other domains requiring hierarchical reasoning, such as robotic task planning [44], image captioning [45], and visual question answering [46], where similar knowledge priors and dependencies from ARC are applicable. In KAAR, knowledge augmentation increases token consumption, while the additional tokens remain relatively constant since all priors, except goal-directedness, are generated via image processing algorithms from GPAR. On GPT-o3-mini, augmentation tokens constitute around 60% of solver backbone token usage, while on QwQ-32B, this overhead decreases to about 20%, as the solver backbone consumes more tokens. See Appendix A.8 for a detailed discussion. Incorrect abstraction selection in KAAR also leads to wasted tokens. However, accurate abstraction inference often requires validation through viable solutions, bringing the challenge back to solution generation.
<details>
<summary>x9.png Details</summary>

### Visual Description
## Diagram: Pattern Recognition Puzzle
### Overview
The image presents a pattern recognition puzzle consisting of three rows. Each row contains two pixelated images separated by a right-pointing arrow. The left image in each row shows a blue shape on a black grid. The right image in the first two rows shows the same shape with the bottom portion colored red. The third row presents a blue shape on the left and a question mark within a white square on the right, implying the need to deduce the pattern and predict the corresponding shape.
### Components/Axes
* **Pixelated Images:** Each image is composed of a grid of pixels, with blue and red pixels forming shapes against a black background.
* **Arrows:** Right-pointing arrows indicate a transformation or relationship between the left and right images in each row.
* **Question Mark:** A question mark inside a white square signifies an unknown element to be determined based on the established pattern.
### Detailed Analysis
**Row 1:**
* **Left Image:** A blue "W" shape is formed on a black grid. The "W" is approximately 7 pixels wide and 5 pixels tall.
* **Right Image:** The top portion of the "W" remains blue, while the bottom portion is colored red. The red portion is approximately 2 pixels tall.
**Row 2:**
* **Left Image:** A blue "O" shape is formed on a black grid. The "O" is approximately 5 pixels wide and 5 pixels tall.
* **Right Image:** The top portion of the "O" remains blue, while the bottom portion is colored red. The red portion is approximately 2 pixels tall.
**Row 3:**
* **Left Image:** A blue oval shape is formed on a black grid. The oval is approximately 7 pixels wide and 3 pixels tall.
* **Right Image:** A white square with a black border contains a black question mark.
### Key Observations
* The pattern involves taking a blue shape and coloring the bottom portion red.
* The height of the red portion appears to be consistent across the first two rows, approximately 2 pixels.
### Interpretation
The puzzle challenges the viewer to identify the pattern of coloring the bottom portion of a shape red and apply it to the oval shape in the third row. Based on the pattern, the solution would be an oval shape with the top portion blue and the bottom portion red. The height of the red portion should be consistent with the previous rows, approximately 2 pixels.
</details>
Figure 9: Fragment of ARC problem e7dd8335.
Solution Analysis. RSPC achieves over 30% accuracy across evaluated metrics using GPT-o3-mini, even without knowledge augmentation. To assess its alignment with core knowledge priors, we manually reviewed RSPC-generated solution plans and code that successfully solve $I_{t}$ with GPT-o3-mini. RSPC tends to solve problems without object-centric reasoning. For instance, in Figure 1, it shifts each row downward by one and pads the top with zeros, rather than reasoning over objectness to move each 4-connected component down by one step. Even when applying objectness, RSPC typically defaults to 4-connected abstraction, failing on the problem in Figure 9, where the test input clearly requires 8-connected abstraction. We note that object recognition in ARC involves grouping pixels into task-specific components based on clustering rules, differing from feature extraction approaches [47] in conventional computer vision tasks. Recent work seeks to bridge this gap by incorporating 2D positional encodings and object indices into Vision Transformers [41]. However, its reliance on data-driven learning weakens generalization, undermining ARC’s core objective. In contrast, KAAR enables objectness through explicitly defined abstractions, implemented via standard image processing algorithms, thus ensuring both accuracy and generalization.
Generalization. For all evaluated ARC solvers, accuracy on $I_{r}$ consistently exceeds that on $I_{r}\&I_{t}$ , revealing a generalization gap. Planning-aided code generation methods, such as RSPC and KAAR, exhibit smaller gaps than other solvers, though the issue persists. One reason is that solutions include low-level logic for the training pairs, thus failing to generalize. See Appendix A.9 for examples. Another reason is the usage of incorrect abstractions. For example, reliance solely on 4-connected abstraction leads RSPC to solve only $I_{r}$ in Figure 9. KAAR similarly fails to generalize in this case. It selects 4-connected abstraction, the first one that solves $I_{r}$ , to report accuracy on $I_{t}$ , instead of the correct 8-connected abstraction, as the former is considered simpler. Table 1 also reveals that LLMs differ in their generalization across ARC solvers. While a detailed analysis of these variations is beyond the scope of this study, investigating the underlying causes could offer insights into LLM inference and alignment with intended behaviors, presenting a promising direction for future work.
7 Conclusion
We explored the generalization and abstract reasoning capabilities of recent reasoning-oriented LLMs on the ARC benchmark using nine candidate solvers. Experimental results show that repeated-sampling planning-aided code generation (RSPC) achieves the highest test accuracy and demonstrates consistent generalization across most evaluated LLMs. To further improve performance, we propose KAAR, which progressively augments LLMs with core knowledge priors organized into hierarchical levels based on their dependencies, and applies RSPC after augmenting each level of priors to enable stage-wise reasoning. KAAR improves LLM performance on the ARC benchmark while maintaining strong generalization compared to non-augmented RSPC. However, ARC remains challenging even for the most capable reasoning-oriented LLMs, given its emphasis on abstract reasoning and generalization, highlighting current limitations and motivating future research.
References
- Khan et al. [2021] Abdullah Ayub Khan, Asif Ali Laghari, and Shafique Ahmed Awan. Machine learning in computer vision: A review. EAI Endorsed Transactions on Scalable Information Systems, 8(32), 2021.
- Otter et al. [2020] Daniel W Otter, Julian R Medina, and Jugal K Kalita. A survey of the usages of deep learning for natural language processing. IEEE transactions on neural networks and learning systems, 32(2):604–624, 2020.
- Grigorescu et al. [2020] Sorin Grigorescu, Bogdan Trasnea, Tiberiu Cocias, and Gigel Macesanu. A survey of deep learning techniques for autonomous driving. Journal of field robotics, 37(3):362–386, 2020.
- Lake et al. [2017] Brenden M Lake, Tomer D Ullman, Joshua B Tenenbaum, and Samuel J Gershman. Building machines that learn and think like people. Behavioral and brain sciences, 40:e253, 2017.
- Chollet [2019] François Chollet. On the measure of intelligence. arXiv preprint arXiv:1911.01547, 2019.
- Peirce [1868] Charles S Peirce. Questions concerning certain faculties claimed for man. The Journal of Speculative Philosophy, 2(2):103–114, 1868.
- Spelke and Kinzler [2007] Elizabeth S Spelke and Katherine D Kinzler. Core knowledge. Developmental science, 10(1):89–96, 2007.
- Gulwani et al. [2017] Sumit Gulwani, Oleksandr Polozov, Rishabh Singh, et al. Program synthesis. Foundations and Trends® in Programming Languages, 4:1–119, 2017.
- Xu et al. [2023a] Yudong Xu, Elias B Khalil, and Scott Sanner. Graphs, constraints, and search for the abstraction and reasoning corpus. In Proceedings of the 37th AAAI Conference on Artificial Intelligence, AAAI, pages 4115–4122, 2023a.
- Lei et al. [2024a] Chao Lei, Nir Lipovetzky, and Krista A Ehinger. Generalized planning for the abstraction and reasoning corpus. In Proceedings of the 38th AAAI Conference on Artificial Intelligence, AAAI, pages 20168–20175, 2024a.
- Wei et al. [2022] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th Advances in Neural Information Processing Systems, NeurIPS, pages 24824–24837, 2022.
- Chen et al. [2021] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- Li et al. [2022] Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode. Science, 378:1092–1097, 2022.
- Chen et al. [2023] Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. Codet: Code generation with generated tests. In Proceedings of the 11th International Conference on Learning Representations, ICLR, pages 1–19, 2023.
- Zhang et al. [2023] Tianyi Zhang, Tao Yu, Tatsunori Hashimoto, Mike Lewis, Wen-tau Yih, Daniel Fried, and Sida Wang. Coder reviewer reranking for code generation. In Proceedings of the 40th International Conference on Machine Learning, ICML, pages 41832–41846, 2023.
- Ni et al. [2023] Ansong Ni, Srini Iyer, Dragomir Radev, Veselin Stoyanov, Wen-tau Yih, Sida Wang, and Xi Victoria Lin. Lever: Learning to verify language-to-code generation with execution. In Proceedings of the 40th International Conference on Machine Learning, ICML, pages 26106–26128, 2023.
- Zhong et al. [2024a] Li Zhong, Zilong Wang, and Jingbo Shang. Debug like a human: A large language model debugger via verifying runtime execution step by step. In Findings of the Association for Computational Linguistics: ACL 2024, pages 851–870, 2024a.
- Lei et al. [2024b] Chao Lei, Yanchuan Chang, Nir Lipovetzky, and Krista A Ehinger. Planning-driven programming: A large language model programming workflow. arXiv preprint arXiv:2411.14503, 2024b.
- Chen et al. [2024] Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug. In Proceedings of the 12th International Conference on Learning Representations, ICLR, 2024.
- Austin et al. [2021] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- Jain et al. [2025] Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. In Proceedings of the 13th International Conference on Learning Representations, ICLR, 2025.
- Jiang et al. [2023] Xue Jiang, Yihong Dong, Lecheng Wang, Fang Zheng, Qiwei Shang, Ge Li, Zhi Jin, and Wenpin Jiao. Self-planning code generation with large language models. ACM Transactions on Software Engineering and Methodology, 33(7):1–28, 2023.
- Islam et al. [2024] Md. Ashraful Islam, Mohammed Eunus Ali, and Md Rizwan Parvez. MapCoder: Multi-agent code generation for competitive problem solving. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, ACL, pages 4912–4944, 2024.
- Zhong et al. [2024b] Tianyang Zhong, Zhengliang Liu, Yi Pan, Yutong Zhang, Yifan Zhou, Shizhe Liang, Zihao Wu, Yanjun Lyu, Peng Shu, Xiaowei Yu, et al. Evaluation of openai o1: Opportunities and challenges of agi. arXiv preprint arXiv:2409.18486, 2024b.
- OpenAI [2025] OpenAI. Openai o3-mini. OpenAI, 2025. URL https://openai.com/index/openai-o3-mini/. Accessed: 2025-03-22.
- DeepMind [2024] Google DeepMind. Gemini 2.0 flash thinking. Google DeepMind, 2024. URL https://deepmind.google/technologies/gemini/flash-thinking/. Accessed: 2025-03-22.
- Guo et al. [2025] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
- Cloud [2025] Alibaba Cloud. Alibaba cloud unveils qwq-32b: A compact reasoning model with cutting-edge performance. Alibaba Cloud, 2025. URL https://www.alibabacloud.com/blog/alibaba-cloud-unveils-qwq-32b-a-compact-reasoning-model-with-cutting-edge-performance_602039. Accessed: 2025-03-22.
- Babakr et al. [2019] Zana H Babakr, Pakstan Mohamedamin, and Karwan Kakamad. Piaget’s cognitive developmental theory: Critical review. Education Quarterly Reviews, 2(3):517–524, 2019.
- Deng et al. [2024] Hourui Deng, Hongjie Zhang, Jie Ou, and Chaosheng Feng. Can llm be a good path planner based on prompt engineering? mitigating the hallucination for path planning. arXiv preprint arXiv:2408.13184, 2024.
- Meng et al. [2024] Silin Meng, Yiwei Wang, Cheng-Fu Yang, Nanyun Peng, and Kai-Wei Chang. LLM-a*: Large language model enhanced incremental heuristic search on path planning. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 1087–1102, 2024.
- Ahn et al. [2024] Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, and Wenpeng Yin. Large language models for mathematical reasoning: Progresses and challenges. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop, EACL, pages 225–237, 2024.
- Zang et al. [2025] Yuhang Zang, Wei Li, Jun Han, Kaiyang Zhou, and Chen Change Loy. Contextual object detection with multimodal large language models. International Journal of Computer Vision, 133(2):825–843, 2025.
- Xu et al. [2023b] Yudong Xu, Wenhao Li, Pashootan Vaezipoor, Scott Sanner, and Elias B Khalil. Llms and the abstraction and reasoning corpus: Successes, failures, and the importance of object-based representations. arXiv preprint arXiv:2305.18354, 2023b.
- Lei et al. [2023] Chao Lei, Nir Lipovetzky, and Krista A Ehinger. Novelty and lifted helpful actions in generalized planning. In Proceedings of the International Symposium on Combinatorial Search, SoCS, pages 148–152, 2023.
- Wang et al. [2024] Ruocheng Wang, Eric Zelikman, Gabriel Poesia, Yewen Pu, Nick Haber, and Noah Goodman. Hypothesis search: Inductive reasoning with language models. In Proceedings of the 12 th International Conference on Learning Representations, ICLR, 2024.
- LeGris et al. [2024] Solim LeGris, Wai Keen Vong, Brenden M Lake, and Todd M Gureckis. H-arc: A robust estimate of human performance on the abstraction and reasoning corpus benchmark. arXiv preprint arXiv:2409.01374, 2024.
- Yamada et al. [2024] Yutaro Yamada, Yihan Bao, Andrew Kyle Lampinen, Jungo Kasai, and Ilker Yildirim. Evaluating spatial understanding of large language models. Transactions on Machine Learning Research, 2024.
- Cohn and Hernandez-Orallo [2023] Anthony G Cohn and Jose Hernandez-Orallo. Dialectical language model evaluation: An initial appraisal of the commonsense spatial reasoning abilities of llms. arXiv preprint arXiv:2304.11164, 2023.
- Bang et al. [2023] Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, Quyet V. Do, Yan Xu, and Pascale Fung. A multitask, multilingual, multimodal evaluation of ChatGPT on reasoning, hallucination, and interactivity. In Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, IJCNLP-AACL, pages 675–718, 2023.
- Li et al. [2024a] Wenhao Li, Yudong Xu, Scott Sanner, and Elias Boutros Khalil. Tackling the abstraction and reasoning corpus with vision transformers: the importance of 2d representation, positions, and objects. arXiv preprint arXiv:2410.06405, 2024a.
- Raven [2000] John Raven. The raven’s progressive matrices: change and stability over culture and time. Cognitive psychology, 41(1):1–48, 2000.
- Barrett et al. [2018] David Barrett, Felix Hill, Adam Santoro, Ari Morcos, and Timothy Lillicrap. Measuring abstract reasoning in neural networks. In Proceedings of the 37th International conference on machine learning, ICML, pages 511–520, 2018.
- Cui et al. [2025] Yongcheng Cui, Ying Zhang, Cui-Hua Zhang, and Simon X Yang. Task cognition and planning for service robots. Intelligence & Robotics, (1):119–142, 2025.
- Stefanini et al. [2022] Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Silvia Cascianelli, Giuseppe Fiameni, and Rita Cucchiara. From show to tell: A survey on deep learning-based image captioning. IEEE transactions on pattern analysis and machine intelligence, (1):539–559, 2022.
- Huynh et al. [2025] Ngoc Dung Huynh, Mohamed Reda Bouadjenek, Sunil Aryal, Imran Razzak, and Hakim Hacid. Visual question answering: from early developments to recent advances–a survey. arXiv preprint arXiv:2501.03939, 2025.
- Zhao et al. [2019] Zhong-Qiu Zhao, Peng Zheng, Shou-tao Xu, and Xindong Wu. Object detection with deep learning: A review. IEEE transactions on neural networks and learning systems, 30(11):3212–3232, 2019.
- Mialon et al. [2023] Grégoire Mialon, Roberto Dessi, Maria Lomeli, Christoforos Nalmpantis, Ramakanth Pasunuru, Roberta Raileanu, Baptiste Roziere, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, Edouard Grave, Yann LeCun, and Thomas Scialom. Augmented language models: a survey. Transactions on Machine Learning Research, 2023. ISSN 2835-8856.
- Zhu et al. [2025] Yuqi Zhu, Shuofei Qiao, Yixin Ou, Shumin Deng, Shiwei Lyu, Yue Shen, Lei Liang, Jinjie Gu, Huajun Chen, and Ningyu Zhang. KnowAgent: Knowledge-augmented planning for LLM-based agents. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 3709–3732, 2025.
- Vu et al. [2024] Tu Vu, Mohit Iyyer, Xuezhi Wang, Noah Constant, Jerry Wei, Jason Wei, Chris Tar, Yun-Hsuan Sung, Denny Zhou, Quoc Le, and Thang Luong. FreshLLMs: Refreshing large language models with search engine augmentation. In Findings of the Association for Computational Linguistics: ACL 2024, pages 13697–13720, 2024.
- Li et al. [2024b] Xingxuan Li, Ruochen Zhao, Yew Ken Chia, Bosheng Ding, Shafiq Joty, Soujanya Poria, and Lidong Bing. Chain-of-knowledge: Grounding large language models via dynamic knowledge adapting over heterogeneous sources. In Proceedings of the 12th International Conference on Learning Representations, ICLR, 2024b.
- Trivedi et al. [2023] Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, ACL, pages 10014–10037, 2023.
- Qiao et al. [2024] Shuofei Qiao, Honghao Gui, Chengfei Lv, Qianghuai Jia, Huajun Chen, and Ningyu Zhang. Making language models better tool learners with execution feedback. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NNACL, pages 3550–3568, 2024.
- Wind [2020] J S Wind. 1st place solution + code and official documentation. https://www.kaggle.com/competitions/abstraction-and-reasoning-challenge/discussion/154597, 2020. Accessed: 2025-03-22.
- Camposampiero et al. [2023] Giacomo Camposampiero, Loic Houmard, Benjamin Estermann, Joël Mathys, and Roger Wattenhofer. Abstract visual reasoning enabled by language. arXiv preprint arXiv:2306.04091, 2023.
- Min [2023] Tan John Chong Min. An approach to solving the abstraction and reasoning corpus (arc) challenge. arXiv preprint arXiv:2306.03553, 2023.
- Tan and Motani [2024] John Chong Min Tan and Mehul Motani. Llms as a system of multiple expert agents: An approach to solve the abstraction and reasoning corpus (arc) challenge. In Proceedings of the 2024 IEEE Conference on Artificial Intelligence, CAI, pages 782–787, 2024.
- Bikov et al. [2024] Kiril Bikov, Mikel Bober-Irizar, and Soumya Banerjee. Reflection system for the abstraction and reasoning corpus. In Proceedings of the 2nd AI4Research Workshop: Towards a Knowledge-grounded Scientific Research Lifecycle, 2024.
- Franzen et al. [2024] Daniel Franzen, Jan Disselhoff, and David Hartmann. The llm architect: Solving arc-agi is a matter of perspective. https://github.com/da-fr/arc-prize-2024/blob/main/the_architects.pdf, 2024. Accessed: 2025-03-22.
- Hodel [2024] Michael Hodel. Addressing the abstraction and reasoning corpus via procedural example generation. arXiv preprint arXiv:2404.07353, 2024.
- Moskvichev et al. [2023] Arseny Moskvichev, Victor Vikram Odouard, and Melanie Mitchell. The conceptarc benchmark: Evaluating understanding and generalization in the arc domain. arXiv preprint arXiv:2305.07141, 2023.
- Li et al. [2025] Wen-Ding Li, Keya Hu, Carter Larsen, Yuqing Wu, Simon Alford, Caleb Woo, Spencer M. Dunn, Hao Tang, Wei-Long Zheng, Yewen Pu, and Kevin Ellis. Combining induction and transduction for abstract reasoning. In Proceedings of the 13th International Conference on Learning Representations, ICLR, 2025.
- Barke et al. [2024] Shraddha Barke, Emmanuel Anaya Gonzalez, Saketh Ram Kasibatla, Taylor Berg-Kirkpatrick, and Nadia Polikarpova. Hysynth: Context-free llm approximation for guiding program synthesis. In Proceedings of the 38th Advances in Neural Information Processing Systems, NeurIPS, pages 15612–15645, 2024.
Appendix A Appendix
A.1 Related Work
Knowledge-Augmented LLMs. Augmenting LLMs with external knowledge can improve reasoning capabilities and mitigate hallucination in text generation [48]. Previous studies achieve this by incorporating domain-specific knowledge, designed by human experts [49], retrieved via search engines [50], or extracted from Wikipedia documents [51]. Trivedi et al. [52] demonstrated that interleaving knowledge augmentation within reasoning steps further reduces model hallucination, resulting in more accurate multi-step reasoning. Additionally, augmenting LLMs with execution feedback improves performance on both question answering [53] and program synthesis tasks [10, 17, 19].
Search in DSL. An abstract, expressive, and compositional representation of core knowledge priors is essential for solving ARC tasks [5]. Previous studies have manually encoded these priors into domain-specific languages (DSLs) with lifted relational representations [9, 10, 54]. Various program synthesis methods have been proposed to search for valid solution programs within their DSLs, including DAG-based search [54], graph-based constraint-guided search [9], and generalized planning [10]. Hand-crafted DSLs encode core knowledge priors with high precision and interpretability, enabling structured program synthesis. However, comprehensive DSLs induce large search spaces, limiting synthesis efficiency.
LLMs for ARC. Recent studies have explored using LLMs as ARC solvers to directly generate test output matrices and have prompted LLMs with different problem descriptions to improve output accuracy. Camposampiero et al. [55] employed LLMs to generate output grids from textual task descriptions, derived from a vision module which is designed to capture human-like visual priors. Min [56] prompted LLMs with the raw 2D matrices of each task, along with transformation and abstraction examples. Xu et al. [34] demonstrated that object representations derived from predefined abstractions can improve LLM performance on ARC tasks. Recent advances in code generation by LLMs [18, 17, 14] highlight their potential to replace search-based program synthesis, addressing efficiency limitations. Tan and Motani [57] evaluated LLM performance on the ARC benchmark by generating Python program solutions. Additionally, Wang et al. [36] approached ARC as an inductive reasoning problem and introduced hypothesis search, where program solutions are generated by selecting LLM-generated hypotheses encoded as functions.
Training-Based Methods. To further improve LLM performance, Bikov et al. [58] fine-tuned LLMs on augmented ARC tasks using standard techniques such as rotation, flipping, and permutation. Beyond these methods, Franzen et al. [59] fine-tuned LLMs on large-scale synthetic ARC tasks [60] and ARC-related datasets such as Concept-ARC [61] and ARC-Heavy [62], achieving a state-of-the-art 56% accuracy on the private evaluation set of 200 tasks. Instead of fine-tuning LLMs, Barke et al. [63] trained a probabilistic context-free grammar (PCFG) using LLM-generated plausible solutions to learn weighted functions. This enables the synthesizer to efficiently generate final program solutions. However, this approach requires a dedicated synthesizer for each DSL, limiting its generalization.
When leveraging LLMs as ARC solvers, existing studies tend to emphasize accuracy on partial training set problems and overlook the core principle of ARC, where solutions should be constructed using core knowledge priors [5]. LLMs still lack these priors, such as objectness, as evidenced by RSPC-generated solutions. Although fine-tuning approaches have achieved state-of-the-art performance, their failure to incorporate core knowledge priors remains a fundamental limitation. KAAR addresses this gap by progressively augmenting LLMs with structured core knowledge priors introduced by GPAR, along with exclusive implementations of goal-directedness priors. It interleaves augmentation within the reasoning process by applying an advanced LLM-based program synthesis solver tailored to the ARC benchmark after augmenting priors at each level. KAAR achieves strong performance, 32.5% test accuracy on the full evaluation set of 400 problems using GPT-o3-mini, demonstrates substantial generalization, and produces solutions aligned with core knowledge priors.
A.2 Core Knowledge Priors in KAAR
KAAR incorporates abstractions to enable objectness priors; component attributes, relations, and statistical analysis of component attributes to encode geometry, topology, numbers, and counting priors; and predefined actions to support goal-directedness priors. Table 5 presents all abstractions used in KAAR, organized by their prioritization. KAAR incorporates fundamental abstractions, such as 4-connected and 8-connected components, from GPAR, and extends them with additional abstractions unique to KAAR, highlighted in red. Table 6 introduces geometry, topology, numbers, and counting priors, and ten predefined transformations used in KAAR. For each action, KAAR augments the LLM with its corresponding schema to resolve implementation details. The actions and their schemas are detailed in Table A.12. Most actions can be specified within three steps, keeping them tractable for LLMs.
<details>
<summary>x10.png Details</summary>

### Visual Description
## Diagram: Pattern Transformation Sequence
### Overview
The image depicts a sequence of transformations applied to a 3x3 grid pattern. The grid cells are colored in black, blue, gray, and red. The sequence shows how the initial pattern changes through a series of steps, indicated by right-pointing arrows. The final step is represented by a question mark, implying a need to predict the next pattern in the sequence.
### Components/Axes
* **Grid:** A 3x3 grid representing the pattern.
* **Colors:** Black, blue, gray, and red.
* **Arrows:** Right-pointing arrows indicating the sequence of transformations.
* **Question Mark:** Indicates the unknown next pattern in the sequence.
### Detailed Analysis
The image shows a sequence of six 3x3 grids, each representing a state in a transformation process. The grids are separated by right-pointing arrows, indicating the direction of the transformation. The cells within each grid are colored black, blue, gray, or red. The final grid is followed by an arrow pointing to a square containing a question mark, indicating that the final state is unknown and needs to be determined.
1. **Initial State:** The first grid has the following color arrangement:
* Top row: Blue, Black, Gray
* Middle row: Black, Blue, Black
* Bottom row: Blue, Black, Gray
2. **Transformation 1:** The second grid has the following color arrangement:
* Top row: Black, Black, Black
* Middle row: Black, Red, Black
* Bottom row: Black, Black, Black
3. **Transformation 2:** The third grid has the following color arrangement:
* Top row: Blue, Black, Gray
* Middle row: Blue, Blue, Blue
* Bottom row: Blue, Black, Gray
4. **Transformation 3:** The fourth grid has the following color arrangement:
* Top row: Black, Red, Black
* Middle row: Red, Black, Red
* Bottom row: Black, Red, Black
5. **Transformation 4:** The fifth grid has the following color arrangement:
* Top row: Gray, Black, Black
* Middle row: Blue, Blue, Blue
* Bottom row: Gray, Black, Black
6. **Transformation 5:** The sixth grid has the following color arrangement:
* Top row: Black, Black, Black
* Middle row: Red, Black, Red
* Bottom row: Black, Black, Black
### Key Observations
* The sequence involves changes in the color arrangement within the 3x3 grid.
* The transformations appear to follow a specific rule or pattern.
* The final state is unknown and needs to be predicted based on the observed pattern.
### Interpretation
The image presents a pattern recognition problem. The goal is to identify the rule governing the transformations and predict the color arrangement of the final grid. The transformations seem to alternate between a state with a central red square and a state with a blue cross. The final state should be a grid with the following color arrangement:
* Top row: Blue, Black, Gray
* Middle row: Black, Blue, Black
* Bottom row: Blue, Black, Gray
</details>
Figure 10: ARC problem 0520fde7
A.3 Restrictions in KAAR
For certain abstractions, some priors are either inapplicable or exclusive. The specific priors assigned to some abstractions are detailed in Table 8. For the whole image abstraction, few priors apply as only a single component is present. In contrast, the 4/8-connected-multi-color-non-background abstractions retain most priors. The highlighted priors that capture per-component color diversity are used exclusively for 4/8-connected-multi-color-non-background abstractions, while priors tailored to a single-color component, such as components with same color, components with most frequent color, and components with least frequent color, are excluded. For the middle-vertical and middle-horizontal abstractions, where the image is evenly divided into two components, flipping and movement actions are enabled to facilitate reasoning over overlapping components. For instance, in the problem shown in Figure 10, the solution involves splitting the image along a middle-vertical grid line and moving one component to overlap the other. In the resulting component, a pixel is colored red if the overlapping pixels in both components are blue; otherwise, it is colored black.
A.4 Parameter Settings
KAAR operates on all LLMs through API access with the full conversational history. For proprietary models, GPT-o3-mini and Gemini-2.0 Flash-Thinking (Gemini-2.0), we use default parameter settings. For open-source models, DeepSeek-R1-Distill-Llama-70B (DeepSeek-R1-70B) and QwQ-32B, we set temperature to 0.6, top-p to 0.95, and top-k to 40 to reduce repetitive outputs and filter rare tokens while preserving generation diversity. We conduct experiments on a virtual machine with 4 NVIDIA A100 80GB GPUs.
A.5 KAAR
Algorithm 1 presents the pseudocode of KAAR. For each abstraction, KAAR incrementally augments the LLM with core knowledge priors, structured into three dependency-aware levels: beginning with objectness (Line 5), followed by geometry and topology (Lines 10 and 12), numbers and counting (Line 14), and concluding with goal-directedness priors(Line 18). We note that KAAR encodes geometry and topology priors through component attributes (Line 9) and relations (Line 11). The full set of priors is detailed in Tables 5, 6, and A.12. After augmenting each level of priors, KAAR invokes the solver backbone (RSPC) at Lines 6, 15, and 19 to generate code solutions guided by text-based plans, allowing up to 4 iterations (Lines 25–37). In each iteration, the solver backbone first validates the generated code on the training instances $I_{r}$ ; if successful, it then evaluates the solution on the test instances $I_{t}$ . The solver backbone returns solve if the generated solution successfully solves $I_{t}$ after passing $I_{r}$ ; pass if only $I_{r}$ is solved; or continues to the next iteration if the solution fails on $I_{r}$ . If the solver backbone fails to solve $I_{r}$ within the allotted 4 iterations at Lines 6 and 15, KAAR augments the next level of priors. KAAR proceeds to the next abstraction when the solver backbone fails to solve $I_{r}$ at Line 19, after the 4-iteration limit. KAAR terminates abstraction iteration upon receiving either pass or solve from the solver backbone and reports accuracy on $I_{r}$ , $I_{t}$ , and $I_{r}\&I_{t}$ accordingly. If no abstraction fully solves $I_{r}$ , KAAR records the final code solution for each abstraction (Line 22), selects the one that passes the most training instances (Line 23), and evaluates it on $I_{t}$ to determine additional accuracy gains (Line 24).
KAAR generates priors offline using image processing algorithms introduced in GPAR at Lines 4, 9, 11 and 13. In contrast, KAAR enables goal-directedness priors at Line 18 by prompting the LLM to select the most suitable actions and identify their implementation details, as described in Table A.12. KAAR iterates over abstractions from simpler to more complex, following the order specified in Table 5. We note that the highest-priority abstraction is no abstraction, where KAAR degrades to the solver backbone (RSPC) as no priors are applied.
Input : LLM $\mathcal{M}$ ; ARC problem $\mathcal{P}=(I_{r},I_{t})$ ; description $Q=(I_{r},\{i^{i}\ |\ (i^{i},i^{o})∈ I_{t}\})$ ; abstraction list $\mathcal{A}$ ; max iterations $t=4$
1
2 Function KnowledgeAugmentation ( $\mathcal{M}$ , $Q$ , $\mathcal{P}$ , $\mathcal{A}$ , $t$ ):
3 solutionList $←[]$ ;
4 foreach abstraction $abs$ in $\mathcal{A}$ do
5 objectnessPriors $←$ GenerateObjectnessPriors( $Q$ , $abs$ );
6 AugmentKnowledge( $\mathcal{M}$ , objectnessPriors);
7 result, code, passedCount $←$ SolverBackbone ( $\mathcal{M}$ , $\mathcal{P}$ , $Q$ , $t$ );
8 if result $≠$ failure then
9 return result
10
11 attributePriors $←$ GenerateAttributePriors( $Q$ , $abs$ );
12 AugmentKnowledge( $\mathcal{M}$ , attributePriors);
13 relationPriors $←$ GenerateRelationPriors( $Q$ , $abs$ );
14 AugmentKnowledge( $\mathcal{M}$ , relationPriors);
15 numberPriors $←$ GenerateNumbersCountingPriors( $Q$ , $abs$ );
16 AugmentKnowledge( $\mathcal{M}$ , numberPriors);
17 result, code, passedCount $←$ SolverBackbone ( $\mathcal{M}$ , $\mathcal{P}$ , $Q$ , $t$ );
18 if result $≠$ failure then
19 return result
20
21 AugmentGoalPriors $←$ ( $\mathcal{M}$ , $Q$ , $abs$ );
22
23 result, code, passedCount $←$ SolverBackbone ( $\mathcal{M}$ , $\mathcal{P}$ , $Q$ , $t$ );
24 if result $≠$ failure then
25 return result
26
27 solutionList.append((code, passedCount));
28
29 bestCode $←$ SelectMostPassed(solutionList);
30 return EvaluateOnTest(bestCode, $I_{t}$ );
31
32
33 Function SolverBackbone ( $\mathcal{M}$ , $\mathcal{P}$ , $Q$ , $t$ ):
34 i $← 0$ ;
35 while i < t do
36 plan $←\mathcal{M}$ .generatePlan( $Q$ );
37 code $←\mathcal{M}$ .generateCode( $Q$ , plan);
38 passedCount $←$ EvaluateOnTrain(code, $I_{r}$ );
39 if passedCount == $|I_{r}|$ then
40 if EvaluateOnTest(code, $I_{t}$ ) then
41 return solve, code, passedCount;
42
43 else
44 return pass, code, passedCount;
45
46
47 i $←$ i + 1;
48
49 return failure, code, passedCount;
50
Algorithm 1 KAAR
| Gemini-2.0 $I_{t}$ $I_{r}\&I_{t}$ | $I_{r}$ 21.75 20.50 | 25.75 19.00 18.00 | 23.00 -2.75 -2.50 | -2.75 |
| --- | --- | --- | --- | --- |
| QwQ-32B | $I_{r}$ | 22.25 | 18.50 | -3.75 |
| $I_{t}$ | 21.00 | 17.75 | -3.25 | |
| $I_{r}\&I_{t}$ | 19.25 | 16.25 | -3.00 | |
| DeepSeek-R1-70B | $I_{r}$ | 12.25 | 9.00 | -3.25 |
| $I_{t}$ | 12.75 | 9.00 | -3.75 | |
| $I_{r}\&I_{t}$ | 11.50 | 8.50 | -3.00 | |
| \hlineB 2 | | | | |
Table 3: Accuracy on $I_{r}$ , $I_{t}$ , and $I_{r}\&I_{t}$ for KAAR and KAAR ∗ across three LLMs. KAAR ∗ invokes the solver backbone (RSPC) only after all knowledge priors are augmented. $\Delta$ denotes the performance drop relative to KAAR. All values are reported as percentages.
A.6 Ablation Study
Table 3 reports the accuracy decrease resulting from removing incremental knowledge augmentation and stage-wise reasoning in KAAR, denoted as KAAR ∗. Unlike KAAR, which invokes the solver backbone (RSPC) after augmenting each level of priors to enable stage-wise reasoning, KAAR ∗ uses RSPC to solve the problem within 12 iterations after augmenting all priors at once. We evaluate KAAR ∗ using the same reasoning-oriented LLMs as in Tables 1 and 2, excluding GPT-o3-mini due to its computational cost. KAAR ∗ shows decreased accuracy on all metrics, $I_{r}$ , $I_{t}$ , and $I_{r}\&I_{t}$ , for all evaluated LLMs. These results underscore the effectiveness of progressive augmentation and stage-wise reasoning. Presenting all knowledge priors simultaneously introduces superfluous information, which may obscure viable solutions and impair the LLM reasoning accuracy. We note that we construct the ontology of core knowledge priors based on their dependencies, thereby establishing a fixed augmentation order.
<details>
<summary>x11.png Details</summary>
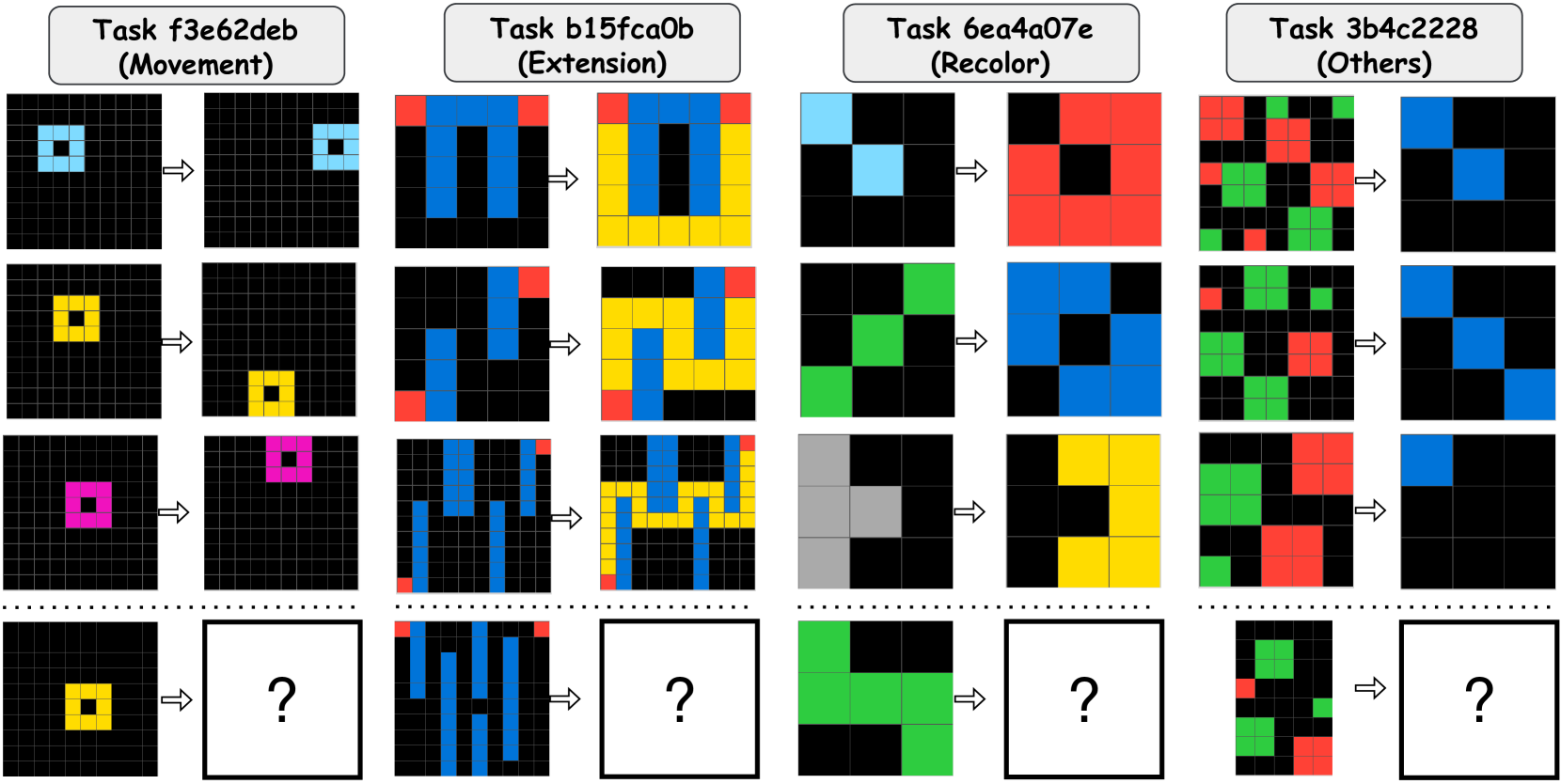
### Visual Description
## Abstract Reasoning Visual Task Examples
### Overview
The image presents a series of abstract reasoning tasks, each demonstrating a different type of transformation applied to a grid-based input. The tasks are categorized into "Movement," "Extension," "Recolor," and "Others." Each task category displays three examples of input-output pairs, followed by a question mark indicating a missing output for a given input. The grid size appears to be 7x7.
### Components/Axes
* **Task Categories (Headers):**
* Task f3e62deb (Movement) - Top-left
* Task b15fca0b (Extension) - Top-middle-left
* Task 6ea4a07e (Recolor) - Top-middle-right
* Task 3b4c2228 (Others) - Top-right
* **Grid:** Each input and output is represented on a 7x7 grid.
* **Arrow:** An arrow separates the input and output grids, indicating the transformation.
* **Question Mark:** A question mark in a white box indicates the missing output.
### Detailed Analysis
**Task f3e62deb (Movement):**
* **Example 1:** A light blue square moves from the top-left to the top-right of the grid.
* **Example 2:** A yellow square moves from the top-left to the center of the grid.
* **Example 3:** A magenta square moves from the bottom-left to the center of the grid.
* **Question:** A yellow square is in the top-left.
**Task b15fca0b (Extension):**
* **Example 1:** A single red square on the top-left extends into a complex shape using blue and yellow.
* **Example 2:** A single red square on the top-left extends into a different complex shape using blue and yellow.
* **Example 3:** A single red square on the top-left extends into a different complex shape using blue and yellow.
* **Question:** A single red square is on the top-left.
**Task 6ea4a07e (Recolor):**
* **Example 1:** A light blue square in the top-left becomes a red square in the top-right.
* **Example 2:** A green square in the top-left becomes a blue square in the top-right.
* **Example 3:** A gray square in the top-left becomes a yellow square in the top-right.
* **Question:** A green and red pattern is in the top-left.
**Task 3b4c2228 (Others):**
* **Example 1:** A green and red pattern transforms into a blue pattern.
* **Example 2:** A green and red pattern transforms into a blue pattern.
* **Example 3:** A green and red pattern transforms into a blue pattern.
* **Question:** A green and red pattern is in the top-left.
### Key Observations
* Each task category demonstrates a different type of transformation.
* The "Movement" task involves moving a single colored square.
* The "Extension" task involves expanding a single red square into a more complex shape.
* The "Recolor" task involves changing the color of a square.
* The "Others" task involves more complex transformations.
* The question mark indicates a missing output that needs to be predicted based on the given examples.
### Interpretation
The image presents a set of abstract reasoning problems designed to test pattern recognition and problem-solving skills. The tasks require identifying the underlying rules governing the transformations and applying those rules to predict the missing outputs. The different categories highlight various types of transformations, including movement, extension, recoloring, and more complex operations. The consistent grid structure and clear input-output format facilitate the analysis and comparison of different tasks. The presence of question marks encourages active engagement and critical thinking to determine the logical continuation of each pattern.
</details>
Figure 11: Example ARC tasks for movement, extension, recolor, and others categories.
A.7 Example Tasks by Category in the ARC Evaluation Set
ARC comprises 1000 unique tasks, with 400 allocated to the training set and 600 to the evaluation set. The evaluation set is further divided into a public subset (400 tasks) and a private subset (200 tasks). Figure 11 illustrates example ARC tasks for the movement, extension, recolor, and others categories in the public evaluation set. In the movement example, components are shifted to the image boundary in directions determined by their colors. The extension example is more complex, requiring LLMs to find the shortest path between two red pixels while avoiding obstacles, which presents challenges for current reasoning-oriented models. Additionally, reliance on pixel-level recognition weakens the effectiveness of KAAR, which is designed to facilitate component identification. The recolor example involves changing non-black components to black and updating black components based on original non-black colors. The others example requires generating a blue diagonal line whose length depends on the number of 4-connected components in the input image that are green and have a size greater than one. The combination of numerical reasoning and structural pattern generation makes this task difficult to classify within the other three categories.
| GPT-o3-mini Gemini QwQ-32B | 66K 58K 79K | 106K 110K 427K |
| --- | --- | --- |
| DeepSeek-R1-70B | 66K | 252K |
| \hlineB 2 | | |
Table 4: Average token cost for knowledge augmentation and solver backbone (RSPC) in KAAR across four evaluated LLMs. K is $10^{3}$ .
A.8 Cost Analysis
Table 4 reports the average token cost, including both prompts and LLM responses, for knowledge augmentation and the solver backbone (RSPC), when using KAAR as the ARC solver. For each ARC task, we consider the abstraction whose solution solves $I_{t}$ ; if none succeed, the one that passes $I_{r}$ ; otherwise, the abstraction with the lowest token usage is selected. Except for goal-directedness priors, all core knowledge priors in KAAR are generated offline using image processing algorithms from GPAR, resulting in comparable augmentation costs across all evaluated models. In contrast, token usage by the solver backbone varies substantially due to differences in the LLMs’ abstract reasoning and generalization capabilities. GPT-o3-mini solves most tasks efficiently, with the lowest token consumption by the solver backbone, where tokens used for knowledge augmentation account for approximately 62% of the solver backbone’s token usage. However, the solver backbone consumes more tokens with QwQ-32B, as QwQ-32B consistently generates longer reasoning traces. In this case, tokens used for knowledge augmentation constitute only 19% of the solver backbone’s token usage. Figure 14 illustrates the average token cost for augmenting priors at each level in KAAR.
A.9 Generalization
Figures 15 and 16 illustrate two ARC problems, 695367ec and b1fc8b8e, where both RSPC and KAAR successfully solve the training instances $I_{r}$ but fail on the test instances $I_{t}$ when using GPT-o3-mini. For problem 695367ec, the correct solution involves generating a fixed 15×15 output image by repeatedly copying the input image, changing its color to black, and adding internal horizontal and vertical lines colored with the original input image’s color. However, the RSPC-generated code applies a distinct rule to each input image size without considering generalization. For problem b1fc8b8e, the solution requires accurate object recognition despite component contact, and correctly placing each component into one of the four corners. However, RSPC fails to recognize objectness, and its solution deviates from human intuition, being overfitted to $I_{r}$ . For problems 695367ec and b1fc8b8e, KAAR exhibits the same limitations, although it adopts abstractions to enable objectness. KAAR begins with the simplest abstraction, no abstraction, where KAAR degrades to RSPC. As a result, it generates the same solution as RSPC and terminates without attempting other abstractions, since the solution already solves $I_{r}$ and is then evaluated on $I_{t}$ , resulting in overfitting.
A.10 Problem Coverage across ARC Solvers
We report the relative problem coverage across nine ARC solvers based on successful test instance solutions using GPT-o3-mini (Figure 17), Gemini-2.0 (Figure 18), QwQ-32B (Figure 19), and DeepSeek-R1-70B (Figure 20). Each cell $(i,j)$ indicates the proportion of problems solved by the row solver that are also solved by the column solver. This is computed as $\frac{|A_{i}\cap A_{j}|}{|A_{i}|}$ , where $A_{i}$ and $A_{j}$ are the sets of problems solved by the row and column solvers, respectively, following the same method used in Figure 5. Values close to 1 indicate that the column solver covers most problems solved by the row solver. GPT-o3-mini demonstrates the strongest overall coverage, with pairwise overlap consistently exceeding 0.55. Among all solvers, repeated sampling with standalone (P) and planning-aided code generation (PC) show the highest coverage, with column values consistently above 0.8 for GPT-o3-mini. This trend persists across Gemini-2.0, QwQ-32B, and DeepSeek-R1-70B. Under these models, repeated sampling with planning-aided code generation exhibits better alignment than its standalone code generation counterpart, generally yielding higher coverage values. However, planning-aided code generation under the direct generation setting shows weaker alignment, with column values around 0.40 for Gemini-2.0 and 0.35 for QwQ-32B. Among the four evaluated LLMs, DeepSeek-R1-70B demonstrates the lowest average off-diagonal coverage (i.e., $i≠ j$ ) of 0.603, suggesting potential output instability and variation attributable to solver choice.
A.11 Performance Analysis
Table 1 highlights performance variations across reasoning-oriented LLMs and ARC solvers with respect to both accuracy and generalization. Notably, the ARC solver, repeated sampling with standalone code generation, exhibits a substantial accuracy gap between $I_{r}$ and $I_{r}\&I_{t}$ , indicating limited generalization capability when using GPT-o3-mini and Gemini-2.0. In contrast, repeated sampling with planning-aided code generation demonstrates markedly improved generalization by preventing solutions from directly replicating the output matrices of training instances, as illustrated in Figure 21. This output copying, observed under repeated sampling with standalone code generation, accounts for approximately 24% and 95% of 83 and 101 overfitting problems with GPT-o3-mini and Gemini-2.0, respectively. When planning is incorporated, output copying is reduced to around 8% and 35% of 25 and 20 overfitting problems with GPT-o3-mini and Gemini-2.0, respectively. Additionally, the incorporation of planning facilitates accurate code generation. For example, in Figure 22, repeated sampling with planning-aided code generation produces a correct solution using GPT-o3-mini by replicating the input image horizontally or vertically based on the presence of a uniform row or column, as specified in the plan and implemented accordingly in code. In contrast, without planning assistance, standalone code generation produces incomplete logic, considering only whether the first column is uniform to determine the replication direction, which leads to failure on the test instance.
For the ARC benchmark, repeated sampling–based methods achieve higher accuracy on $I_{r}$ , $I_{t}$ , and $I_{r}\&I_{t}$ compared to refinement-based approaches when using GPT-o3-mini and Gemini-2.0. Figure 23 presents an ARC problem where repeated sampling with planning-aided code generation yields a correct solution, whereas its refinement variant fails to correct the initial erroneous code, and the flawed logic persists across subsequent refinements when using GPT-o3-mini. Previous studies have shown that refinement can benefit from control flow graph information [17] and verified plans [18], which assist LLMs in locating and correcting bugs. However, these methods typically incur substantial token consumption, making them difficult to scale affordably.
A.12 Limitations
KAAR improves the performance of reasoning-oriented LLMs on ARC tasks by progressively prompting with core knowledge priors. Although this inevitably increases token usage, the trade-off can be justified, as the exploration of LLM generalization remains in its early stages. KAAR integrates diverse abstraction methods to enable objectness and iteratively applies abstractions in order of increasing complexity. In contrast, humans typically infer appropriate abstractions directly from training instances, rather than leveraging exhaustive search. To address this, we prompt different LLMs with raw 2D matrices of each ARC problem to select one or three relevant abstractions, but the results are unsatisfactory. As previously discussed, accurate abstraction inference often depends on validation through viable solutions, thereby shifting the challenge back to solution generation. Additionally, KAAR augments core knowledge priors through prompting but lacks mechanisms to enforce LLM adherence to these priors during reasoning. While the KAAR-generated solutions generally conform to core knowledge priors, the intermediate reasoning processes may deviate from the intended patterns. Future work could explore fine-tuning or reinforcement learning to better align model behavior with the desired reasoning patterns.
| No Abstraction | - |
| --- | --- |
| Whole Image | We consider the whole image as a component. |
| Middle-Vertical | We vertically split the image into two equal parts, treating each as a distinct component. |
| Middle-Horizontal | We horizontally split the image into two equal parts, treating each as a distinct component. |
| Multi-Lines | We use rows or columns with a uniform color to divide the input image into multiple components. |
| 4-Connected ∗ | We consider the 4-adjacent pixels of the same color as a component. |
| 4-Connected-Non-Background ∗ | We consider the 4-adjacent pixels of the same color as a component, excluding components with the background color. |
| 4-Connected-Non-Background-Edge ∗ | We consider the 4-adjacent pixels of the same color as a component, containing components with the background color when they are not attached to the edges of the image. |
| 4-Connected-Multi-Color-Non-Background ∗ | We consider 4-adjacent pixels as a component, which may contain different colors, while excluding components with the background color. |
| 4-Connected-Bounding-Box ∗ | We consider 4-adjacent pixels of the same color, and treat all pixels within their bounding box as a component, which may include different colors. |
| 4-Connected-With-Black ∗ | We consider the 4-adjacent pixels of black color, represented by the value 0, as a component, excluding components with other colors. |
| Same-Color | We consider pixels of the same color as a component, excluding components with the background color. |
| \hlineB 2 | |
Table 5: Abstractions in KAAR. The superscript “ ∗ ” denotes that the 8-connected version is considered. The background color is black if black exists; otherwise, it is the most frequent color in the image. We present abstractions according to their prioritization in KAAR, where the order is given by the table from top to bottom, and making 8-connected abstraction to follow that of the corresponding 4-connected abstraction at the end of the sequence. Abstractions highlighted in red are exclusive to KAAR.
| Geometry and Topology | Size (Width and Height); Color; Shape (One Pixel; Horizontal Line; Vertical Line; Diagonal Line; Square; Rectangle; Cross; Irregular Shape); Symmetry (Horizontal Symmetry; Vertical Symmetry; Diagonal Symmetry; Anti-Diagonal Symmetry; Central Symmetry); Bounding Box; Hole Count; Nearest Boundary; Different/Identical with Other Components; Touching; Inclusive; Spatial (Horizontally Aligned to the Right; Horizontally Aligned to the Left; Vertically Aligned Below; Vertically Aligned Above; Top-Left; Top-Right; Bottom-Left; Bottom-Right; Same Position) |
| --- | --- |
| Numbers and Counting | Component Size Counting; Components with Same Size; Components with Most Frequent Size; Components with Least Frequent Size; Components with Maximum Size; Components with Minimum Size; Component Color Counting; Components with Same Color; Components with Same Number of Colors; Components with Most Frequent Color; Components with Least Frequent Color; Component with Most Distinct Colors; Component with Fewest Distinct Colors; Component Shape Counting; Components with Same Shape; Components with Most Frequent Shape; Components with Least Frequent Shape; Component Hole Number Counting; Components with Same Number of Holes; Components with Maximum Number of Holes; Components with Minimum Number of Holes; Component Symmetry Counting |
| Goal-directedness | Color Change (modifying component value); Movement (shifting component’s position); Extension (expanding component’s area); Completing (filling in missing parts of a component); Resizing (altering component size); Selecting (isolating a component); Copying (duplicating a component); Flipping (mirroring a component); Rotation (rotating a component); Cropping (cutting part of a component) |
| \hlineB 2 | |
Table 6: KAAR priors classified into geometry and topology, numbers and counting, and goal-directedness. For goal-directedness, we incorporate ten predefined actions, with their corresponding action schemas detailed in Table A.12.
| Color Change Movement Extension | Targets Targets Targets | Source and Target Colors Direction Direction | Start and End Locations Start and End Locations | Pattern Pattern | Order Order | Overlapping Intersection |
| --- | --- | --- | --- | --- | --- | --- |
| Completing | Targets | Pattern | | | | |
| Resizing | Targets | Source and Target Sizes | | | | |
| Selecting | Targets | | | | | |
| Copying | Targets | Locations | Overlapping | | | |
| Flipping | Targets | Flipping Axis | Overlapping | | | |
| Rotation | Targets | Degrees | | | | |
| Cropping | Targets | Subsets | | | | |
| \hlineB 2 | | | | | | |
Table 7: Actions in KAAR and their schemas (implementation details). Each action schema is presented according to its prompting order in KAAR (left to right). Some actions include a pattern schema that prompts the LLM to identify underlying logic rules, such as repeating every two steps in movement or extension, or completing based on three-color repetition. Targets denote the target components.
| whole image | Symmetry, Size | - | Flipping; Rotation; Extension; Completing, Cropping |
| --- | --- | --- | --- |
| middle-vertical | Size | - | Flipping; Movement |
| middle-horizontal | Size | - | Flipping; Movement |
| multi-lines | Size; Color; Shape; Symmetry; Bounding Box; Hole Count | ALL | ALL |
| 4-connected-multi-color-non-background ∗ | ALL | … Component Color Counting; Components with Same Number of Colors; Component with Most Distinct Colors; Component with Fewest Distinct Colors … | ALL |
Table 8: Abstractions with their assigned knowledge priors. “–” denotes no priors, while “ALL” indicates all priors in the corresponding category, as defined in Table 6. The superscript “ ∗ ” indicates that the 8-connected version is also applicable. The highlighted priors apply exclusively to their corresponding abstractions. For the 4/8-connected-multi-color-non-background abstractions, we present color-counting priors specific to multi-colored components, while all other non-color-counting priors follow those in Table 6.
<details>
<summary>x12.png Details</summary>
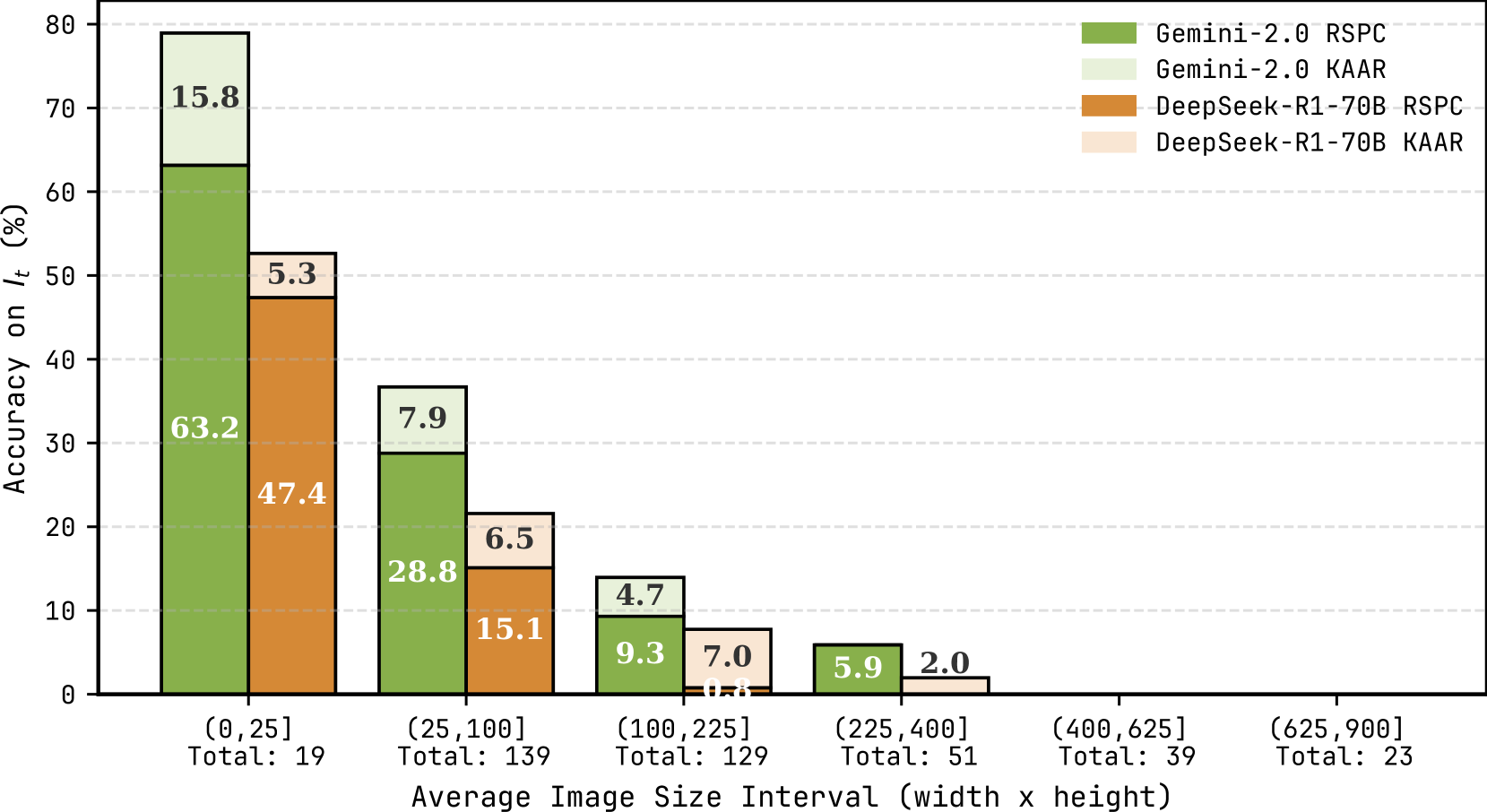
### Visual Description
## Bar Chart: Accuracy on Image Size Intervals
### Overview
The image is a bar chart comparing the accuracy of two models, Gemini-2.0 and DeepSeek-R1-70B, on images of varying sizes. The accuracy is measured on two different tasks, RSPC and KAAR. The x-axis represents the average image size interval (width x height), and the y-axis represents the accuracy on It (%).
### Components/Axes
* **Y-axis:** "Accuracy on It (%)", ranging from 0 to 80, with tick marks at intervals of 10.
* **X-axis:** "Average Image Size Interval (width x height)". The categories are:
* (0,25] Total: 19
* (25,100] Total: 139
* (100,225] Total: 129
* (225,400] Total: 51
* (400,625] Total: 39
* (625,900] Total: 23
* **Legend:** Located at the top-right of the chart.
* Green: Gemini-2.0 RSPC
* Light Green: Gemini-2.0 KAAR
* Orange: DeepSeek-R1-70B RSPC
* Light Orange: DeepSeek-R1-70B KAAR
### Detailed Analysis
The chart displays the accuracy of each model on each image size interval. The bars are stacked, with the RSPC accuracy shown as the base and the KAAR accuracy stacked on top.
* **(0,25] Total: 19**
* Gemini-2.0 RSPC: 63.2
* Gemini-2.0 KAAR: 15.8
* DeepSeek-R1-70B RSPC: 47.4
* DeepSeek-R1-70B KAAR: 5.3
* **(25,100] Total: 139**
* Gemini-2.0 RSPC: 28.8
* Gemini-2.0 KAAR: 7.9
* DeepSeek-R1-70B RSPC: 15.1
* DeepSeek-R1-70B KAAR: 6.5
* **(100,225] Total: 129**
* Gemini-2.0 RSPC: 9.3
* Gemini-2.0 KAAR: 4.7
* DeepSeek-R1-70B RSPC: 1.8
* DeepSeek-R1-70B KAAR: 7.0
* **(225,400] Total: 51**
* Gemini-2.0 RSPC: 5.9
* Gemini-2.0 KAAR: Not visible, assumed to be 0
* DeepSeek-R1-70B RSPC: Not visible, assumed to be 0
* DeepSeek-R1-70B KAAR: 2.0
* **(400,625] Total: 39**
* Gemini-2.0 RSPC: Not visible, assumed to be 0
* Gemini-2.0 KAAR: Not visible, assumed to be 0
* DeepSeek-R1-70B RSPC: Not visible, assumed to be 0
* DeepSeek-R1-70B KAAR: Not visible, assumed to be 0
* **(625,900] Total: 23**
* Gemini-2.0 RSPC: Not visible, assumed to be 0
* Gemini-2.0 KAAR: Not visible, assumed to be 0
* DeepSeek-R1-70B RSPC: Not visible, assumed to be 0
* DeepSeek-R1-70B KAAR: Not visible, assumed to be 0
### Key Observations
* Gemini-2.0 performs significantly better than DeepSeek-R1-70B on smaller images (0,25] and (25,100].
* The accuracy of both models decreases as the image size increases.
* For larger image sizes, the accuracy of both models is very low, approaching zero.
* The "Total" values below each interval indicate the number of images in that size range.
### Interpretation
The chart suggests that Gemini-2.0 is better suited for processing smaller images, while both models struggle with larger images. The decreasing accuracy with increasing image size could be due to factors such as increased computational complexity, memory limitations, or the presence of more noise or irrelevant information in larger images. The performance difference between RSPC and KAAR tasks is also notable, with RSPC generally showing higher accuracy. The number of images in each size interval varies, which could also influence the overall accuracy observed for each interval.
</details>
Figure 12: Accuracy on test instances $I_{t}$ for RSPC and KAAR across average image size intervals, evaluated with Gemini-2.0 and DeepSeek-R1-70B.
<details>
<summary>x13.png Details</summary>
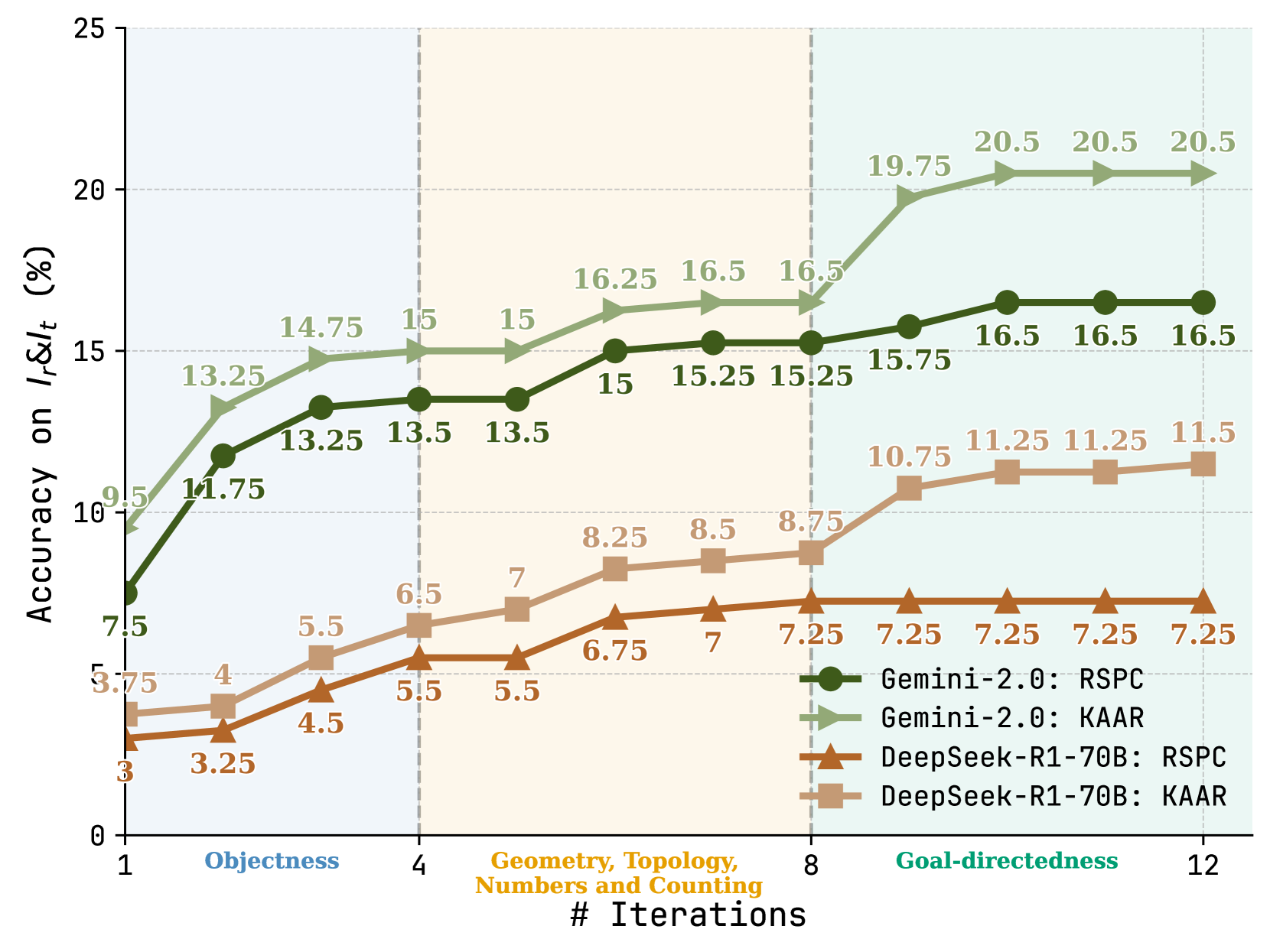
### Visual Description
## Line Chart: Accuracy on Ir< (%) vs. # Iterations
### Overview
The image is a line chart comparing the accuracy of different models (Gemini-2.0 and DeepSeek-R1-70B) on various tasks (RSPC and KAAR) across an increasing number of iterations. The x-axis represents the number of iterations, and the y-axis represents the accuracy percentage. The chart is divided into three sections representing different task categories: Objectness, Geometry/Topology/Numbers and Counting, and Goal-directedness.
### Components/Axes
* **Title:** Accuracy on Ir< (%)
* **X-axis:** # Iterations, with labels 1, 4, 8, and 12. The axis is divided into three sections:
* Objectness (light blue background)
* Geometry, Topology, Numbers and Counting (light orange background)
* Goal-directedness (light green background)
* **Y-axis:** Accuracy on Ir< (%) with labels from 0 to 25, incrementing by 5.
* **Legend:** Located at the bottom-right of the chart.
* Dark Green (circle marker): Gemini-2.0: RSPC
* Light Green (triangle marker): Gemini-2.0: KAAR
* Brown (triangle marker): DeepSeek-R1-70B: RSPC
* Tan (square marker): DeepSeek-R1-70B: KAAR
### Detailed Analysis
**1. Gemini-2.0: RSPC (Dark Green Line with Circle Markers)**
* Trend: Generally increasing, plateaus after 8 iterations.
* Data Points:
* Iteration 1: 7.5%
* Iteration 4: 13.5%
* Iteration 8: 15.25%
* Iteration 12: 16.5%
**2. Gemini-2.0: KAAR (Light Green Line with Triangle Markers)**
* Trend: Increasing sharply initially, then plateaus after 8 iterations.
* Data Points:
* Iteration 1: 9.5%
* Iteration 4: 15%
* Iteration 8: 16.5%
* Iteration 12: 20.5%
**3. DeepSeek-R1-70B: RSPC (Brown Line with Triangle Markers)**
* Trend: Gradually increasing, plateaus after 8 iterations.
* Data Points:
* Iteration 1: 3%
* Iteration 4: 5.5%
* Iteration 8: 7%
* Iteration 12: 7.25%
**4. DeepSeek-R1-70B: KAAR (Tan Line with Square Markers)**
* Trend: Increasing, plateaus after 8 iterations.
* Data Points:
* Iteration 1: 3.75%
* Iteration 4: 6.5%
* Iteration 8: 8.75%
* Iteration 12: 11.5%
### Key Observations
* Gemini-2.0 models (both RSPC and KAAR) consistently outperform DeepSeek-R1-70B models across all iterations.
* The accuracy of all models tends to plateau after 8 iterations.
* Gemini-2.0: KAAR shows the highest accuracy among all models, reaching 20.5% at 12 iterations.
* DeepSeek-R1-70B: RSPC has the lowest accuracy among all models, reaching only 7.25% at 12 iterations.
* The transition from "Objectness" to "Geometry, Topology, Numbers and Counting" shows a performance increase for all models.
### Interpretation
The chart demonstrates the performance of two different models (Gemini-2.0 and DeepSeek-R1-70B) on different tasks (RSPC and KAAR) as the number of training iterations increases. The data suggests that Gemini-2.0 models are more effective than DeepSeek-R1-70B models for these specific tasks. The plateauing of accuracy after 8 iterations indicates a point of diminishing returns, suggesting that further training beyond this point may not significantly improve performance. The different task categories ("Objectness," "Geometry, Topology, Numbers and Counting," and "Goal-directedness") appear to influence the models' performance, with a noticeable jump in accuracy when transitioning from "Objectness" to the other categories. This could indicate that the models find the "Objectness" tasks more challenging or that the subsequent tasks benefit from the knowledge gained during the initial "Objectness" phase.
</details>
Figure 13: Variance in accuracy on $I_{r}\&I_{t}$ with increasing iterations for RSPC and KAAR using Gemini-2.0 and DeepSeek-R1-70B.
<details>
<summary>x14.png Details</summary>
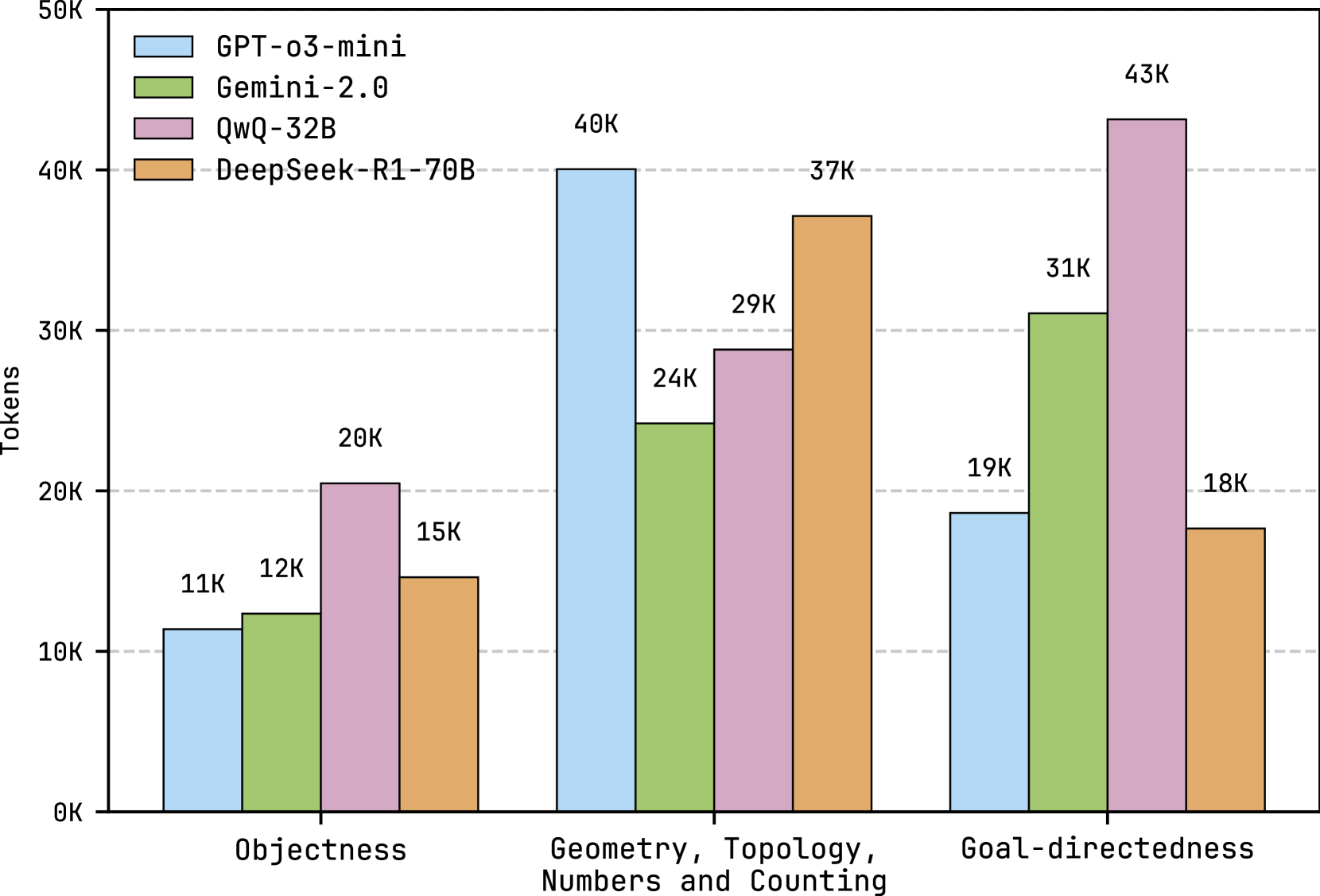
### Visual Description
## Bar Chart: Model Performance on Different Tasks
### Overview
The image is a bar chart comparing the performance of four different language models (GPT-o3-mini, Gemini-2.0, QwQ-32B, and DeepSeek-R1-70B) across three tasks: Objectness, Geometry/Topology/Numbers/Counting, and Goal-directedness. The y-axis represents the number of tokens, ranging from 0K to 50K in increments of 10K. Each task has four bars representing the token count for each model.
### Components/Axes
* **Y-axis:** "Tokens", ranging from 0K to 50K with tick marks at 0K, 10K, 20K, 30K, 40K, and 50K.
* **X-axis:** Categorical axis with three categories: "Objectness", "Geometry, Topology, Numbers and Counting", and "Goal-directedness".
* **Legend:** Located at the top-left of the chart.
* GPT-o3-mini: Light blue bar
* Gemini-2.0: Light green bar
* QwQ-32B: Light purple bar
* DeepSeek-R1-70B: Light orange bar
### Detailed Analysis
Here's a breakdown of the token counts for each model on each task:
* **Objectness:**
* GPT-o3-mini: 11K
* Gemini-2.0: 12K
* QwQ-32B: 20K
* DeepSeek-R1-70B: 15K
* **Geometry, Topology, Numbers and Counting:**
* GPT-o3-mini: 40K
* Gemini-2.0: 24K
* QwQ-32B: 29K
* DeepSeek-R1-70B: 37K
* **Goal-directedness:**
* GPT-o3-mini: 19K
* Gemini-2.0: 31K
* QwQ-32B: 43K
* DeepSeek-R1-70B: 18K
### Key Observations
* GPT-o3-mini performs best on Geometry, Topology, Numbers and Counting, with 40K tokens.
* Gemini-2.0 performs best on Goal-directedness, with 31K tokens.
* QwQ-32B performs best on Goal-directedness, with 43K tokens.
* DeepSeek-R1-70B performs best on Geometry, Topology, Numbers and Counting, with 37K tokens.
* QwQ-32B consistently has higher token counts than the other models on Objectness and Goal-directedness.
* GPT-o3-mini has the lowest token count for Goal-directedness.
### Interpretation
The bar chart illustrates the varying strengths of different language models across different tasks. QwQ-32B seems to excel in tasks related to objectness and goal-directedness, while GPT-o3-mini shows a relative advantage in geometry, topology, numbers, and counting. The data suggests that the models have been trained or are better suited for specific types of tasks. The differences in token counts could reflect the complexity of the tasks for each model or the models' inherent biases.
</details>
Figure 14: Average token cost for augmenting priors at each level across four LLMs. K is $10^{3}$ .
<details>
<summary>x15.png Details</summary>

### Visual Description
## Image Transformation Task
### Overview
The image presents a task involving the transformation of colored grid images based on a provided code solution. The left side shows input grid images of different colors (green, blue, red, yellow) and sizes, each followed by an arrow indicating a transformation. The right side shows the corresponding transformed images, except for the last yellow grid, which is followed by a question mark, indicating the task is to determine the correct transformation. The code solution provides a Python function to perform this transformation.
### Components/Axes
* **Task Title:** "Task 695367ec" (top-left)
* **Code Solution Title:** "Code Solution" (top-right)
* **Input Images:** A series of colored grid images on the left. The colors are green, blue, red, and yellow.
* **Transformation Arrows:** Arrows pointing from the input images to the transformed images.
* **Transformed Images:** A series of black and colored grid images on the right, corresponding to the input images. The colors match the input images. The last transformed image is a white square with a question mark.
* **Code Block:** A Python code snippet defining the `generate_output_image` function.
### Detailed Analysis or Content Details
**Input Images and Transformations:**
1. **Green Grid (Top):** A 3x3 green grid transforms into a 15x15 grid with green horizontal and vertical lines on a black background. The green lines appear at indices approximately 3, 7, and 11.
2. **Blue Grid (Middle):** A 4x4 blue grid transforms into a 15x15 grid with blue horizontal and vertical lines on a black background. The blue lines appear at indices approximately 4, 9, and 14.
3. **Red Grid (Third):** A 2x2 red grid transforms into a 15x15 grid with red horizontal and vertical lines on a black background. The red lines appear at indices approximately 2, 5, 8, 11, and 14.
4. **Yellow Grid (Bottom):** A 5x5 yellow grid transforms into an unknown image, represented by a question mark.
**Code Analysis:**
The Python code defines a function `generate_output_image(input_image)` that takes an input image (presumably a 2D array representing the grid) and returns a transformed 15x15 image.
* The code first determines the color value `v` from the input image's top-left pixel (`input_image[0][0]`).
* It gets the input image dimension `n` (assumed square) using `len(input_image)`.
* The output image size `out_size` is fixed at 15.
* The code then defines `grid_indices` based on the input dimension `n`.
* If `n` is 2 or 5, `grid_indices` is set to `{2, 5, 8, 11, 14}`.
* If `n` is 3, `grid_indices` is set to `{3, 7, 11}`.
* If `n` is 4, `grid_indices` is set to `{4, 9, 14}`.
* Otherwise (default case), it calculates `block_size` as `out_size // (n + 1)` and generates `grid_indices` using a list comprehension: `{(i + 1) * block_size - 1 for i in range(n)}`.
* The code creates the 15x15 output image by iterating through rows and columns.
* If the row index `r` is in `grid_indices`, it creates a separator row by repeating the color value `v` `out_size` times.
* Otherwise, it creates a pattern row. For each column index `c`, if `c` is in `grid_indices`, it appends the color value `v`; otherwise, it appends 0 (presumably representing black).
### Key Observations
* The transformation involves creating a 15x15 grid with colored lines on a black background.
* The positions of the colored lines are determined by the size of the input grid.
* The code provides a specific mapping for input sizes 2, 3, 4, and 5.
* The default case calculates the line positions based on `block_size`.
### Interpretation
The task is to understand the transformation logic implemented in the Python code and apply it to the yellow 5x5 grid to determine the correct output image.
For the yellow 5x5 grid:
* `n = 5`
* The code will use the `if n in (2, 5)` condition, so `grid_indices = {2, 5, 8, 11, 14}`.
* The output image will be a 15x15 grid with yellow lines at indices 2, 5, 8, 11, and 14.
Therefore, the question mark should be replaced with a 15x15 grid with yellow horizontal and vertical lines at indices 2, 5, 8, 11, and 14 on a black background.
</details>
Figure 15: ARC problem 695367ec, where RSPC and KAAR generate the same code solution that passes the training instances but fails on the test instance using GPT-o3-mini.
<details>
<summary>x16.png Details</summary>

### Visual Description
## Image Transformation Task with Code Solution
### Overview
The image presents a task (b1fc8b8e) involving the transformation of 6x6 pixel grids into 5x5 pixel grids, guided by a provided Python code snippet. The left side of the image shows three examples of input 6x6 grids and their corresponding output 5x5 grids. The bottom-left shows an input 6x6 grid with a question mark indicating the desired output. The right side of the image shows the code solution that defines the transformation logic.
### Components/Axes
* **Task Identifier:** "Task b1fc8b8e" (located at the top-left)
* **Code Solution:** A Python code snippet titled "Code Solution" (located at the top-right)
* **Input/Output Grids:** 6x6 input grids on the left, transformed into 5x5 output grids on the right. The grids use two colors: light blue and black.
* **Transformation Arrows:** Arrows pointing from the input grids to the output grids, indicating the transformation process.
### Detailed Analysis or ### Content Details
**1. Input/Output Grid Examples:**
* **Example 1:**
* Input (6x6): Top row has 3 light blue pixels.
* Output (5x5): A cross pattern with light blue pixels.
* **Example 2:**
* Input (6x6): Top row has 5 light blue pixels.
* Output (5x5): A cross pattern with light blue pixels.
* **Example 3:**
* Input (6x6): Top row has 2 light blue pixels.
* Output (5x5): A cross pattern with light blue pixels.
* **Example 4 (Incomplete):**
* Input (6x6): Top row has 3 light blue pixels.
* Output (5x5): Marked with a question mark, indicating the desired output.
**2. Code Solution:**
The Python code defines a function `generate_output_image(input_image)` that transforms a 6x6 input image into a 5x5 output image. The code logic is as follows:
* **Determine Border Pattern:** The code determines the border pattern based on the top row of the 6x6 input image.
* **Count '8's:** It counts how many '8's appear in the first row of the input image. `count_eights = sum(1 for pixel in input_image[0] if pixel == 8)`
* **Conditional Logic:**
* If `count_eights >= 2`: It uses the "full-active" pattern for active rows.
* `active_pattern = [8, 8, 0, 8, 8]`
* `top_active = active_pattern`
* `second_active = active_pattern`
* Else: It uses the "softer-border" pattern.
* `top_active = [0, 8, 0, 0, 8]`
* `second_active = [8, 8, 0, 8, 8]`
* **Blank Row:** Defines a blank row (middle row) as all zeros. `blank = [0, 0, 0, 0, 0]`
* **Construct Output Image:** The final 5x5 output image consists of:
* The first active row (`top_active`)
* The second active row (`second_active`)
* A middle blank row (`blank`)
* The vertical mirror of the active rows (top\_active then second\_active).
* **Output:** The function returns the `output_image`.
**3. Annotation:**
A red box surrounds a portion of the code with the following text:
* "No objective-centric reasoning."
* "Rules are only applied to training instances."
### Key Observations
* The code solution transforms a 6x6 input grid into a 5x5 output grid based on the number of light blue pixels (represented as '8' in the code) in the top row of the input.
* If the count of light blue pixels is greater than or equal to 2, a "full-active" pattern is used. Otherwise, a "softer-border" pattern is used.
* The output image is constructed by combining active rows, a blank row, and a mirrored version of the active rows.
* The annotation suggests that the rules are specifically designed for the training instances and may not generalize well to other scenarios.
### Interpretation
The image presents a task where a pixel grid transformation is performed based on a set of rules defined in the provided code. The code solution uses a simple heuristic (counting light blue pixels in the top row) to determine the output pattern. The annotation highlights a potential limitation of this approach, suggesting that the rules are tailored to the training data and may not be robust or generalizable. The task likely aims to assess the ability to understand and apply the given code logic to predict the output for a new input grid.
For the incomplete example, the top row has 3 light blue pixels, so the "full-active" pattern will be used. The output should be:
```
[8, 8, 0, 8, 8]
[8, 8, 0, 8, 8]
[0, 0, 0, 0, 0]
[8, 8, 0, 8, 8]
[8, 8, 0, 8, 8]
```
This corresponds to a light blue cross pattern.
</details>
Figure 16: ARC problem b1fc8b8e, where RSPC and KAAR generate the same code solution that passes the training instances but fails on the test instance using GPT-o3-mini.
<details>
<summary>x17.png Details</summary>
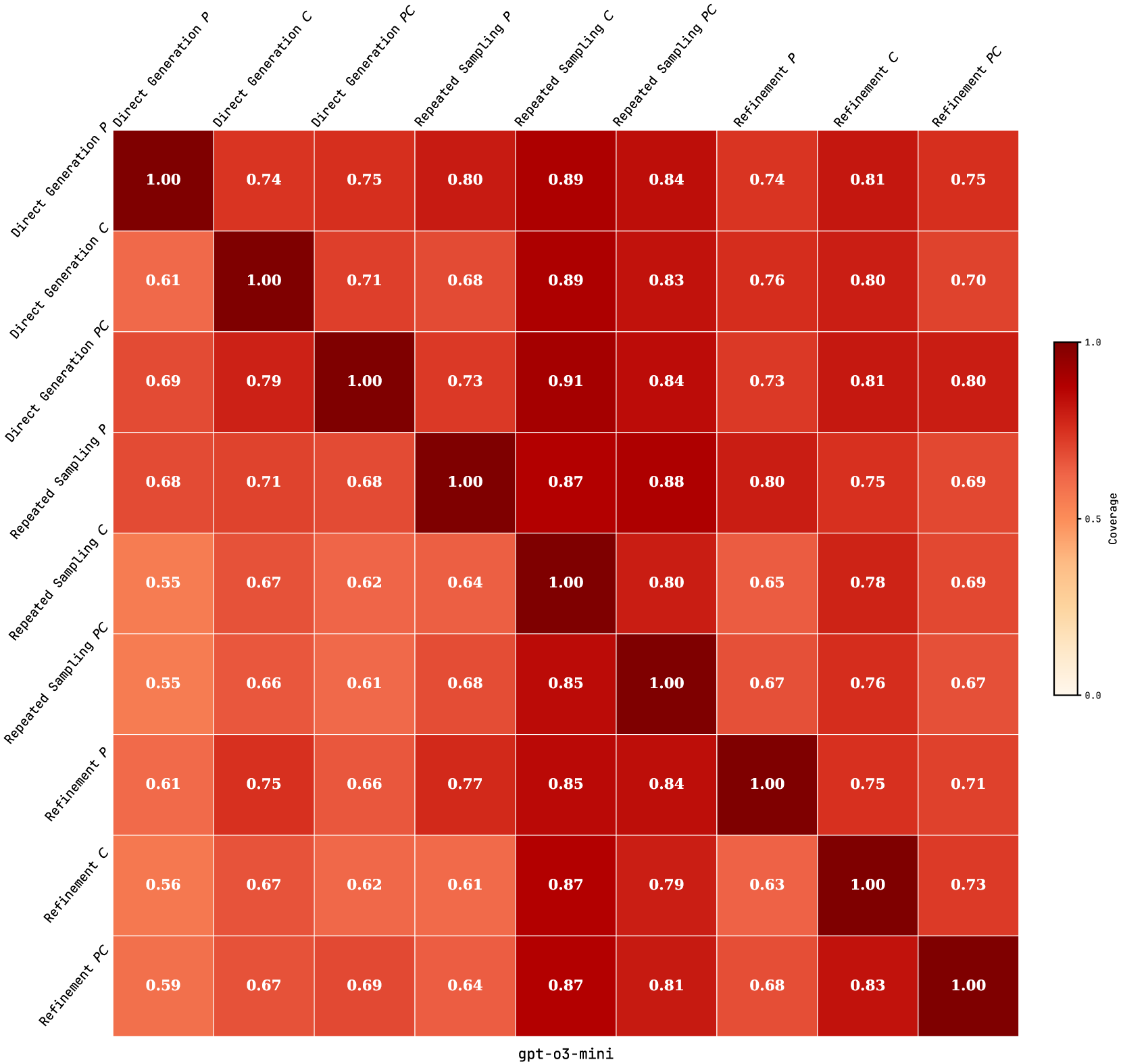
### Visual Description
## Heatmap: Coverage of Different Generation Methods
### Overview
The image is a heatmap displaying the coverage between different text generation methods using the "gpt-03-mini" model. The heatmap shows the pairwise coverage scores, with darker red shades indicating higher coverage and lighter shades indicating lower coverage. The methods compared are Direct Generation, Repeated Sampling, and Refinement, each using P, C, and PC configurations.
### Components/Axes
* **X-axis (Columns):** Text generation methods: "Direct Generation P", "Direct Generation C", "Direct Generation PC", "Repeated Sampling P", "Repeated Sampling C", "Repeated Sampling PC", "Refinement P", "Refinement C", "Refinement PC".
* **Y-axis (Rows):** Text generation methods: "Direct Generation P", "Direct Generation C", "Direct Generation PC", "Repeated Sampling P", "Repeated Sampling C", "Repeated Sampling PC", "Refinement P", "Refinement C", "Refinement PC".
* **Color Scale (Legend):** Located on the right side of the heatmap. The scale ranges from 0.0 (lightest shade) to 1.0 (darkest shade), representing the "Coverage" score.
* **Model Name:** "gpt-03-mini" is printed at the bottom center of the heatmap.
### Detailed Analysis
The heatmap presents a matrix of coverage scores between different text generation methods. Each cell contains a numerical value representing the coverage between the method on the Y-axis (row) and the method on the X-axis (column). The diagonal elements, where the row and column methods are the same, have a coverage of 1.00, indicated by the darkest red color.
Here's a breakdown of the coverage scores:
* **Direct Generation P:**
* Coverage with Direct Generation P: 1.00
* Coverage with Direct Generation C: 0.74
* Coverage with Direct Generation PC: 0.75
* Coverage with Repeated Sampling P: 0.80
* Coverage with Repeated Sampling C: 0.89
* Coverage with Repeated Sampling PC: 0.84
* Coverage with Refinement P: 0.74
* Coverage with Refinement C: 0.81
* Coverage with Refinement PC: 0.75
* **Direct Generation C:**
* Coverage with Direct Generation P: 0.61
* Coverage with Direct Generation C: 1.00
* Coverage with Direct Generation PC: 0.71
* Coverage with Repeated Sampling P: 0.68
* Coverage with Repeated Sampling C: 0.89
* Coverage with Repeated Sampling PC: 0.83
* Coverage with Refinement P: 0.76
* Coverage with Refinement C: 0.80
* Coverage with Refinement PC: 0.70
* **Direct Generation PC:**
* Coverage with Direct Generation P: 0.69
* Coverage with Direct Generation C: 0.79
* Coverage with Direct Generation PC: 1.00
* Coverage with Repeated Sampling P: 0.73
* Coverage with Repeated Sampling C: 0.91
* Coverage with Repeated Sampling PC: 0.84
* Coverage with Refinement P: 0.73
* Coverage with Refinement C: 0.81
* Coverage with Refinement PC: 0.80
* **Repeated Sampling P:**
* Coverage with Direct Generation P: 0.68
* Coverage with Direct Generation C: 0.71
* Coverage with Direct Generation PC: 0.68
* Coverage with Repeated Sampling P: 1.00
* Coverage with Repeated Sampling C: 0.87
* Coverage with Repeated Sampling PC: 0.88
* Coverage with Refinement P: 0.80
* Coverage with Refinement C: 0.75
* Coverage with Refinement PC: 0.69
* **Repeated Sampling C:**
* Coverage with Direct Generation P: 0.55
* Coverage with Direct Generation C: 0.67
* Coverage with Direct Generation PC: 0.62
* Coverage with Repeated Sampling P: 0.64
* Coverage with Repeated Sampling C: 1.00
* Coverage with Repeated Sampling PC: 0.80
* Coverage with Refinement P: 0.65
* Coverage with Refinement C: 0.78
* Coverage with Refinement PC: 0.69
* **Repeated Sampling PC:**
* Coverage with Direct Generation P: 0.55
* Coverage with Direct Generation C: 0.66
* Coverage with Direct Generation PC: 0.61
* Coverage with Repeated Sampling P: 0.68
* Coverage with Repeated Sampling C: 0.85
* Coverage with Repeated Sampling PC: 1.00
* Coverage with Refinement P: 0.67
* Coverage with Refinement C: 0.76
* Coverage with Refinement PC: 0.67
* **Refinement P:**
* Coverage with Direct Generation P: 0.61
* Coverage with Direct Generation C: 0.75
* Coverage with Direct Generation PC: 0.66
* Coverage with Repeated Sampling P: 0.77
* Coverage with Repeated Sampling C: 0.85
* Coverage with Repeated Sampling PC: 0.84
* Coverage with Refinement P: 1.00
* Coverage with Refinement C: 0.75
* Coverage with Refinement PC: 0.71
* **Refinement C:**
* Coverage with Direct Generation P: 0.56
* Coverage with Direct Generation C: 0.67
* Coverage with Direct Generation PC: 0.62
* Coverage with Repeated Sampling P: 0.61
* Coverage with Repeated Sampling C: 0.87
* Coverage with Repeated Sampling PC: 0.79
* Coverage with Refinement P: 0.63
* Coverage with Refinement C: 1.00
* Coverage with Refinement PC: 0.73
* **Refinement PC:**
* Coverage with Direct Generation P: 0.59
* Coverage with Direct Generation C: 0.67
* Coverage with Direct Generation PC: 0.69
* Coverage with Repeated Sampling P: 0.64
* Coverage with Repeated Sampling C: 0.87
* Coverage with Repeated Sampling PC: 0.81
* Coverage with Refinement P: 0.68
* Coverage with Refinement C: 0.83
* Coverage with Refinement PC: 1.00
### Key Observations
* The diagonal elements are all 1.00, indicating perfect coverage when comparing a method to itself.
* Repeated Sampling C generally shows high coverage scores with other methods, particularly with Direct Generation PC (0.91), Direct Generation P (0.89), Direct Generation C (0.89), Repeated Sampling P (0.87), Refinement C (0.87), and Repeated Sampling PC (0.85).
* Direct Generation P, C, and PC have relatively lower coverage scores with Repeated Sampling C, Refinement C, and Refinement PC compared to Repeated Sampling P and Refinement P.
* The lowest coverage scores are generally observed between Direct Generation methods and Repeated Sampling or Refinement methods.
### Interpretation
The heatmap provides insights into the similarity and overlap between the outputs of different text generation methods. Higher coverage scores suggest that the methods produce similar outputs, while lower scores indicate more distinct outputs.
The high coverage of Repeated Sampling C with other methods suggests that it might generate outputs that are more representative or inclusive of the outputs from other methods. Conversely, the lower coverage between Direct Generation and other methods might indicate that Direct Generation produces more unique or specialized outputs.
The "P", "C", and "PC" suffixes likely refer to different configurations or parameters within each generation method. The differences in coverage scores between these configurations suggest that these parameters have a significant impact on the output of each method.
The model name "gpt-03-mini" indicates that these coverage scores are specific to this particular language model. The results might vary with different models or datasets.
</details>
Figure 17: Asymmetric relative coverage matrix of nine ARC solvers using GPT-o3-mini, showing the proportion of problems whose test instances are solved by the row solver that are also solved by the column solver. P denotes the solution plan; C and PC refer to standalone and planning-aided code generation, respectively.
<details>
<summary>x18.png Details</summary>
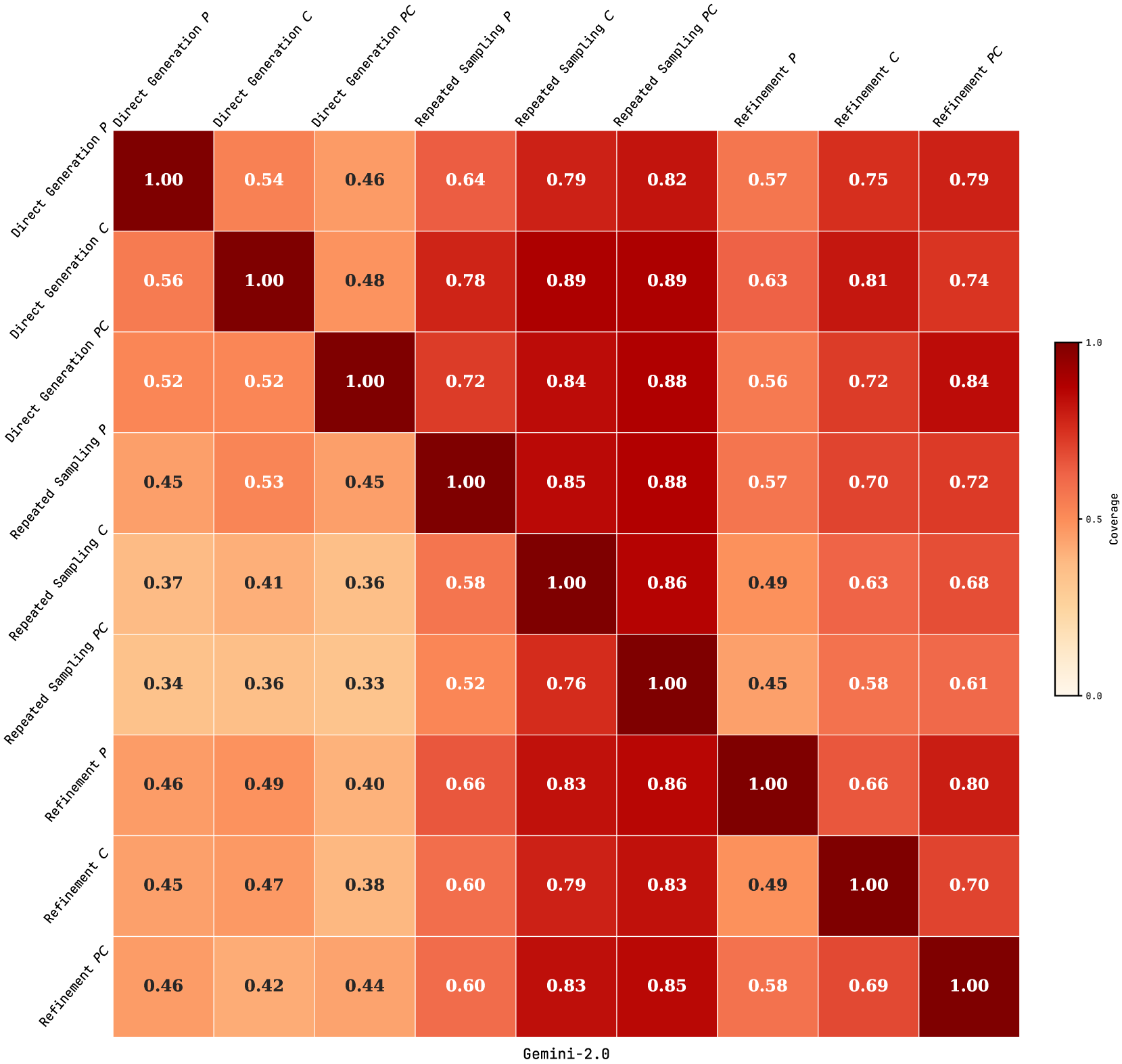
### Visual Description
## Heatmap: Coverage of Different Generation and Sampling Methods
### Overview
The image is a heatmap showing the coverage between different generation and sampling methods. The methods include Direct Generation, Repeated Sampling, and Refinement, each with variations P, C, and PC. The heatmap uses a color gradient from light beige (0.0) to dark red (1.0) to represent the coverage values.
### Components/Axes
* **Rows and Columns:** The rows and columns represent the different generation and sampling methods:
* Direct Generation P
* Direct Generation C
* Direct Generation PC
* Repeated Sampling P
* Repeated Sampling C
* Repeated Sampling PC
* Refinement P
* Refinement C
* Refinement PC
* **Color Scale (Legend):** Located on the right side of the heatmap.
* Light beige corresponds to a coverage of 0.0.
* Dark red corresponds to a coverage of 1.0.
* Intermediate colors represent coverage values between 0.0 and 1.0.
* **Numerical Values:** Each cell in the heatmap contains a numerical value representing the coverage between the corresponding row and column methods.
### Detailed Analysis
Here's a breakdown of the coverage values between the different methods:
* **Direct Generation:**
* Direct Generation P vs. Direct Generation P: 1.00
* Direct Generation P vs. Direct Generation C: 0.54
* Direct Generation P vs. Direct Generation PC: 0.46
* Direct Generation P vs. Repeated Sampling P: 0.64
* Direct Generation P vs. Repeated Sampling C: 0.79
* Direct Generation P vs. Repeated Sampling PC: 0.82
* Direct Generation P vs. Refinement P: 0.57
* Direct Generation P vs. Refinement C: 0.75
* Direct Generation P vs. Refinement PC: 0.79
* Direct Generation C vs. Direct Generation P: 0.56
* Direct Generation C vs. Direct Generation C: 1.00
* Direct Generation C vs. Direct Generation PC: 0.48
* Direct Generation C vs. Repeated Sampling P: 0.78
* Direct Generation C vs. Repeated Sampling C: 0.89
* Direct Generation C vs. Repeated Sampling PC: 0.89
* Direct Generation C vs. Refinement P: 0.63
* Direct Generation C vs. Refinement C: 0.81
* Direct Generation C vs. Refinement PC: 0.74
* Direct Generation PC vs. Direct Generation P: 0.52
* Direct Generation PC vs. Direct Generation C: 0.52
* Direct Generation PC vs. Direct Generation PC: 1.00
* Direct Generation PC vs. Repeated Sampling P: 0.72
* Direct Generation PC vs. Repeated Sampling C: 0.84
* Direct Generation PC vs. Repeated Sampling PC: 0.88
* Direct Generation PC vs. Refinement P: 0.56
* Direct Generation PC vs. Refinement C: 0.72
* Direct Generation PC vs. Refinement PC: 0.84
* **Repeated Sampling:**
* Repeated Sampling P vs. Direct Generation P: 0.45
* Repeated Sampling P vs. Direct Generation C: 0.53
* Repeated Sampling P vs. Direct Generation PC: 0.45
* Repeated Sampling P vs. Repeated Sampling P: 1.00
* Repeated Sampling P vs. Repeated Sampling C: 0.85
* Repeated Sampling P vs. Repeated Sampling PC: 0.88
* Repeated Sampling P vs. Refinement P: 0.57
* Repeated Sampling P vs. Refinement C: 0.70
* Repeated Sampling P vs. Refinement PC: 0.72
* Repeated Sampling C vs. Direct Generation P: 0.37
* Repeated Sampling C vs. Direct Generation C: 0.41
* Repeated Sampling C vs. Direct Generation PC: 0.36
* Repeated Sampling C vs. Repeated Sampling P: 0.58
* Repeated Sampling C vs. Repeated Sampling C: 1.00
* Repeated Sampling C vs. Repeated Sampling PC: 0.86
* Repeated Sampling C vs. Refinement P: 0.49
* Repeated Sampling C vs. Refinement C: 0.63
* Repeated Sampling C vs. Refinement PC: 0.68
* Repeated Sampling PC vs. Direct Generation P: 0.34
* Repeated Sampling PC vs. Direct Generation C: 0.36
* Repeated Sampling PC vs. Direct Generation PC: 0.33
* Repeated Sampling PC vs. Repeated Sampling P: 0.52
* Repeated Sampling PC vs. Repeated Sampling C: 0.76
* Repeated Sampling PC vs. Repeated Sampling PC: 1.00
* Repeated Sampling PC vs. Refinement P: 0.45
* Repeated Sampling PC vs. Refinement C: 0.58
* Repeated Sampling PC vs. Refinement PC: 0.61
* **Refinement:**
* Refinement P vs. Direct Generation P: 0.46
* Refinement P vs. Direct Generation C: 0.49
* Refinement P vs. Direct Generation PC: 0.40
* Refinement P vs. Repeated Sampling P: 0.66
* Refinement P vs. Repeated Sampling C: 0.83
* Refinement P vs. Repeated Sampling PC: 0.86
* Refinement P vs. Refinement P: 1.00
* Refinement P vs. Refinement C: 0.66
* Refinement P vs. Refinement PC: 0.80
* Refinement C vs. Direct Generation P: 0.45
* Refinement C vs. Direct Generation C: 0.47
* Refinement C vs. Direct Generation PC: 0.38
* Refinement C vs. Repeated Sampling P: 0.60
* Refinement C vs. Repeated Sampling C: 0.79
* Refinement C vs. Repeated Sampling PC: 0.83
* Refinement C vs. Refinement P: 0.49
* Refinement C vs. Refinement C: 1.00
* Refinement C vs. Refinement PC: 0.70
* Refinement PC vs. Direct Generation P: 0.46
* Refinement PC vs. Direct Generation C: 0.42
* Refinement PC vs. Direct Generation PC: 0.44
* Refinement PC vs. Repeated Sampling P: 0.60
* Refinement PC vs. Repeated Sampling C: 0.83
* Refinement PC vs. Repeated Sampling PC: 0.85
* Refinement PC vs. Refinement P: 0.58
* Refinement PC vs. Refinement C: 0.69
* Refinement PC vs. Refinement PC: 1.00
### Key Observations
* The diagonal elements are all 1.00, indicating perfect coverage when a method is compared to itself.
* Repeated Sampling C and PC generally have higher coverage values compared to Direct Generation and Refinement methods.
* Direct Generation P, C, and PC have relatively low coverage when compared to Refinement P, C, and PC.
### Interpretation
The heatmap visualizes the coverage between different generation and sampling methods. The higher the coverage value, the more similar the results produced by the two methods being compared. The data suggests that Repeated Sampling methods, particularly Repeated Sampling C and PC, tend to have higher coverage with other methods compared to Direct Generation and Refinement. This could indicate that Repeated Sampling produces more consistent or comprehensive results across different scenarios. The relatively lower coverage of Direct Generation methods when compared to Refinement methods might suggest that Direct Generation is more sensitive to specific conditions or parameters. The tool used to generate this data is "Gemini-2.0".
</details>
Figure 18: Asymmetric relative coverage matrix of nine ARC solvers using Gemini-2.0, showing the proportion of problems whose test instances are solved by the row solver that are also solved by the column solver. P denotes the solution plan; C and PC refer to standalone and planning-aided code generation, respectively.
<details>
<summary>x19.png Details</summary>
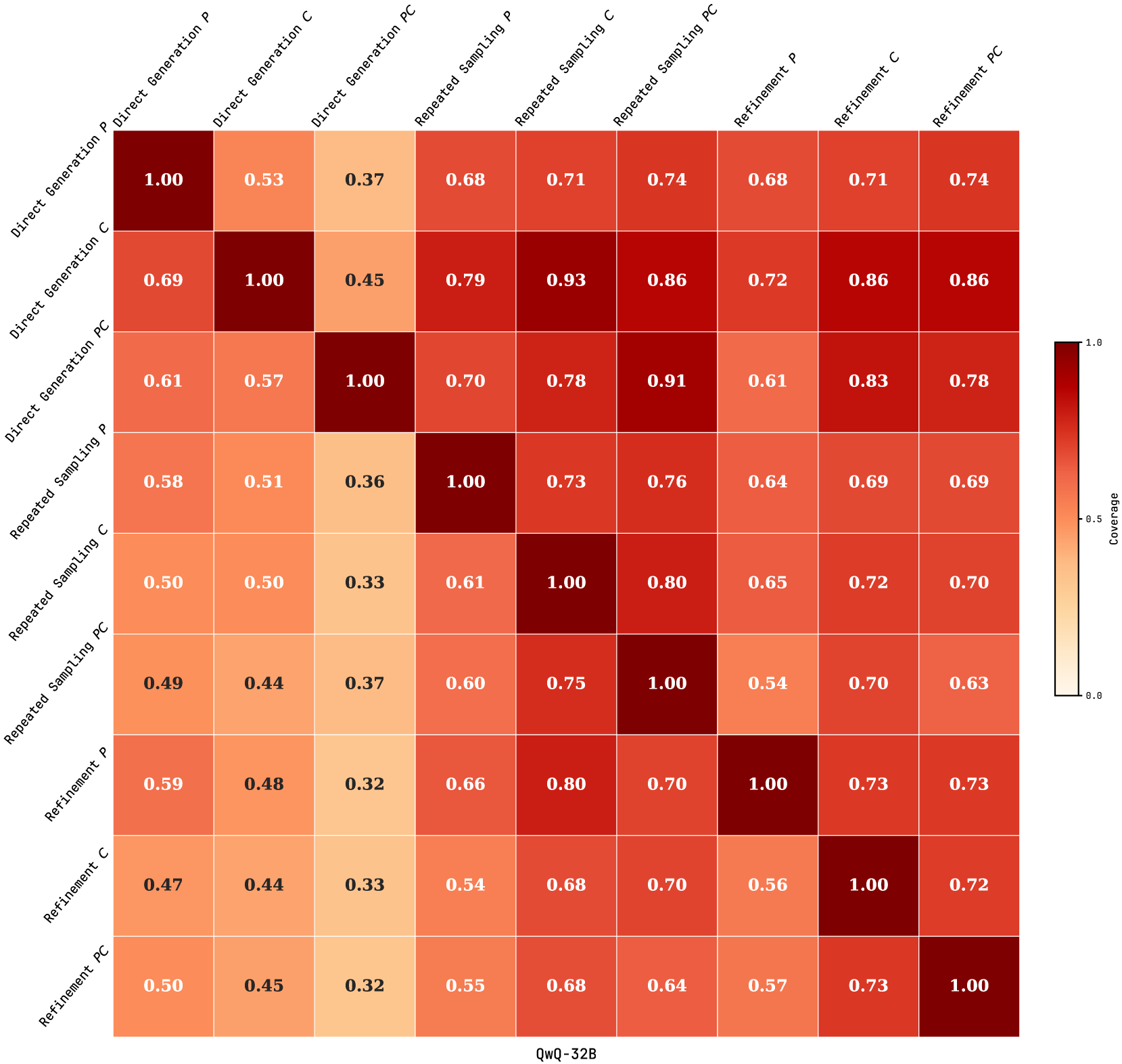
### Visual Description
## Heatmap: Coverage of Different Generation and Refinement Methods
### Overview
The image is a heatmap displaying the coverage between different combinations of generation and refinement methods. The methods include "Direct Generation," "Repeated Sampling," and "Refinement," each with variations "P," "C," and "PC." The heatmap uses a color gradient to represent coverage values, ranging from light (low coverage) to dark (high coverage). The matrix is symmetrical along the diagonal, where each method compared to itself has a coverage of 1.00.
### Components/Axes
* **Rows and Columns:** The rows and columns represent the different generation and refinement methods:
* Direct Generation P
* Direct Generation C
* Direct Generation PC
* Repeated Sampling P
* Repeated Sampling C
* Repeated Sampling PC
* Refinement P
* Refinement C
* Refinement PC
* **Color Scale (Legend):** Located on the right side of the heatmap.
* Dark Red: Represents a coverage of 1.0
* Light Yellow: Represents a coverage of 0.0
* Intermediate colors represent coverage values between 0.0 and 1.0.
* **Title:** "QwQ-32B" at the bottom center of the heatmap.
### Detailed Analysis
The heatmap displays the coverage between different combinations of generation and refinement methods. The values range from 0.32 to 1.00.
* **Direct Generation P:**
* Coverage with Direct Generation P: 1.00
* Coverage with Direct Generation C: 0.53
* Coverage with Direct Generation PC: 0.37
* Coverage with Repeated Sampling P: 0.68
* Coverage with Repeated Sampling C: 0.71
* Coverage with Repeated Sampling PC: 0.74
* Coverage with Refinement P: 0.68
* Coverage with Refinement C: 0.71
* Coverage with Refinement PC: 0.74
* **Direct Generation C:**
* Coverage with Direct Generation P: 0.69
* Coverage with Direct Generation C: 1.00
* Coverage with Direct Generation PC: 0.45
* Coverage with Repeated Sampling P: 0.79
* Coverage with Repeated Sampling C: 0.93
* Coverage with Repeated Sampling PC: 0.86
* Coverage with Refinement P: 0.72
* Coverage with Refinement C: 0.86
* Coverage with Refinement PC: 0.86
* **Direct Generation PC:**
* Coverage with Direct Generation P: 0.61
* Coverage with Direct Generation C: 0.57
* Coverage with Direct Generation PC: 1.00
* Coverage with Repeated Sampling P: 0.70
* Coverage with Repeated Sampling C: 0.78
* Coverage with Repeated Sampling PC: 0.91
* Coverage with Refinement P: 0.61
* Coverage with Refinement C: 0.83
* Coverage with Refinement PC: 0.78
* **Repeated Sampling P:**
* Coverage with Direct Generation P: 0.58
* Coverage with Direct Generation C: 0.51
* Coverage with Direct Generation PC: 0.36
* Coverage with Repeated Sampling P: 1.00
* Coverage with Repeated Sampling C: 0.73
* Coverage with Repeated Sampling PC: 0.76
* Coverage with Refinement P: 0.64
* Coverage with Refinement C: 0.69
* Coverage with Refinement PC: 0.69
* **Repeated Sampling C:**
* Coverage with Direct Generation P: 0.50
* Coverage with Direct Generation C: 0.50
* Coverage with Direct Generation PC: 0.33
* Coverage with Repeated Sampling P: 0.61
* Coverage with Repeated Sampling C: 1.00
* Coverage with Repeated Sampling PC: 0.80
* Coverage with Refinement P: 0.65
* Coverage with Refinement C: 0.72
* Coverage with Refinement PC: 0.70
* **Repeated Sampling PC:**
* Coverage with Direct Generation P: 0.49
* Coverage with Direct Generation C: 0.44
* Coverage with Direct Generation PC: 0.37
* Coverage with Repeated Sampling P: 0.60
* Coverage with Repeated Sampling C: 0.75
* Coverage with Repeated Sampling PC: 1.00
* Coverage with Refinement P: 0.54
* Coverage with Refinement C: 0.70
* Coverage with Refinement PC: 0.63
* **Refinement P:**
* Coverage with Direct Generation P: 0.59
* Coverage with Direct Generation C: 0.48
* Coverage with Direct Generation PC: 0.32
* Coverage with Repeated Sampling P: 0.66
* Coverage with Repeated Sampling C: 0.80
* Coverage with Repeated Sampling PC: 0.70
* Coverage with Refinement P: 1.00
* Coverage with Refinement C: 0.73
* Coverage with Refinement PC: 0.73
* **Refinement C:**
* Coverage with Direct Generation P: 0.47
* Coverage with Direct Generation C: 0.44
* Coverage with Direct Generation PC: 0.33
* Coverage with Repeated Sampling P: 0.54
* Coverage with Repeated Sampling C: 0.68
* Coverage with Repeated Sampling PC: 0.70
* Coverage with Refinement P: 0.56
* Coverage with Refinement C: 1.00
* Coverage with Refinement PC: 0.72
* **Refinement PC:**
* Coverage with Direct Generation P: 0.50
* Coverage with Direct Generation C: 0.45
* Coverage with Direct Generation PC: 0.32
* Coverage with Repeated Sampling P: 0.55
* Coverage with Repeated Sampling C: 0.68
* Coverage with Repeated Sampling PC: 0.64
* Coverage with Refinement P: 0.57
* Coverage with Refinement C: 0.73
* Coverage with Refinement PC: 1.00
### Key Observations
* The diagonal elements are all 1.00, indicating perfect coverage when a method is compared to itself.
* Direct Generation C has the highest coverage with Repeated Sampling C (0.93) and Refinement C (0.86).
* Direct Generation PC has the highest coverage with Repeated Sampling PC (0.91) and Refinement C (0.83).
* Refinement C and Refinement PC show relatively high coverage with each other (0.73 and 0.72, respectively).
* The lowest coverage values are generally observed between Direct Generation PC and other methods.
### Interpretation
The heatmap provides a comparative analysis of the coverage achieved by different generation and refinement methods. The high coverage values along the diagonal are expected, as they represent the self-comparison of each method. The off-diagonal values indicate the degree of overlap or similarity between the outputs of different methods.
The higher coverage between Direct Generation C and Repeated Sampling/Refinement C suggests that these methods produce more similar results. Conversely, the lower coverage between Direct Generation PC and other methods may indicate that this method generates more diverse or distinct outputs.
The data suggests that the choice of generation and refinement methods can significantly impact the coverage and similarity of the generated content. Researchers and practitioners can use this information to select the most appropriate combination of methods for their specific needs and objectives.
</details>
Figure 19: Asymmetric relative coverage matrix of nine ARC solvers using QwQ-32B, showing the proportion of problems whose test instances are solved by the row solver that are also solved by the column solver. P denotes the solution plan; C and PC refer to standalone and planning-aided code generation, respectively.
<details>
<summary>x20.png Details</summary>

### Visual Description
## Heatmap: Coverage Matrix of Different Generation and Refinement Methods
### Overview
The image is a heatmap displaying the coverage between different methods of generation and refinement. The methods include "Direct Generation," "Repeated Sampling," and "Refinement," each with three variants: "P," "C," and "PC." The heatmap uses a color gradient from light yellow (0.0) to dark red (1.0) to represent the coverage score. The matrix is symmetrical along the diagonal, where each method compared to itself has a coverage of 1.0. The heatmap is generated by "DeepSeek-R1-70B".
### Components/Axes
* **X-axis (Top)**: Lists the generation/refinement methods: "Direct Generation P," "Direct Generation C," "Direct Generation PC," "Repeated Sampling P," "Repeated Sampling C," "Repeated Sampling PC," "Refinement P," "Refinement C," "Refinement PC."
* **Y-axis (Left)**: Lists the same generation/refinement methods as the X-axis, in the same order.
* **Color Scale (Right)**: A vertical color bar labeled "Coverage" ranging from 0.0 (light yellow) to 1.0 (dark red).
### Detailed Analysis or Content Details
Here's a breakdown of the coverage values between different methods:
* **Direct Generation P:**
* vs. Direct Generation P: 1.00
* vs. Direct Generation C: 0.76
* vs. Direct Generation PC: 0.65
* vs. Repeated Sampling P: 0.65
* vs. Repeated Sampling C: 0.71
* vs. Repeated Sampling PC: 0.82
* vs. Refinement P: 0.53
* vs. Refinement C: 0.71
* vs. Refinement PC: 0.76
* **Direct Generation C:**
* vs. Direct Generation P: 0.68
* vs. Direct Generation C: 1.00
* vs. Direct Generation PC: 0.58
* vs. Repeated Sampling P: 0.58
* vs. Repeated Sampling C: 0.84
* vs. Repeated Sampling PC: 0.89
* vs. Refinement P: 0.53
* vs. Refinement C: 0.79
* vs. Refinement PC: 0.68
* **Direct Generation PC:**
* vs. Direct Generation P: 0.61
* vs. Direct Generation C: 0.61
* vs. Direct Generation PC: 1.00
* vs. Repeated Sampling P: 0.56
* vs. Repeated Sampling C: 0.72
* vs. Repeated Sampling PC: 0.72
* vs. Refinement P: 0.44
* vs. Refinement C: 0.72
* vs. Refinement PC: 0.56
* **Repeated Sampling P:**
* vs. Direct Generation P: 0.65
* vs. Direct Generation C: 0.65
* vs. Direct Generation PC: 0.59
* vs. Repeated Sampling P: 1.00
* vs. Repeated Sampling C: 0.76
* vs. Repeated Sampling PC: 0.76
* vs. Refinement P: 0.59
* vs. Refinement C: 0.71
* vs. Refinement PC: 0.65
* **Repeated Sampling C:**
* vs. Direct Generation P: 0.41
* vs. Direct Generation C: 0.55
* vs. Direct Generation PC: 0.45
* vs. Repeated Sampling P: 0.45
* vs. Repeated Sampling C: 1.00
* vs. Repeated Sampling PC: 0.66
* vs. Refinement P: 0.41
* vs. Refinement C: 0.62
* vs. Refinement PC: 0.62
* **Repeated Sampling PC:**
* vs. Direct Generation P: 0.45
* vs. Direct Generation C: 0.55
* vs. Direct Generation PC: 0.42
* vs. Repeated Sampling P: 0.42
* vs. Repeated Sampling C: 0.61
* vs. Repeated Sampling PC: 1.00
* vs. Refinement P: 0.39
* vs. Refinement C: 0.48
* vs. Refinement PC: 0.65
* **Refinement P:**
* vs. Direct Generation P: 0.64
* vs. Direct Generation C: 0.71
* vs. Direct Generation PC: 0.57
* vs. Repeated Sampling P: 0.71
* vs. Repeated Sampling C: 0.86
* vs. Repeated Sampling PC: 0.86
* vs. Refinement P: 1.00
* vs. Refinement C: 0.64
* vs. Refinement PC: 0.64
* **Refinement C:**
* vs. Direct Generation P: 0.52
* vs. Direct Generation C: 0.65
* vs. Direct Generation PC: 0.57
* vs. Repeated Sampling P: 0.52
* vs. Repeated Sampling C: 0.78
* vs. Repeated Sampling PC: 0.65
* vs. Refinement P: 0.39
* vs. Refinement C: 1.00
* vs. Refinement PC: 0.61
* **Refinement PC:**
* vs. Direct Generation P: 0.42
* vs. Direct Generation C: 0.42
* vs. Direct Generation PC: 0.32
* vs. Repeated Sampling P: 0.35
* vs. Repeated Sampling C: 0.58
* vs. Repeated Sampling PC: 0.65
* vs. Refinement P: 0.29
* vs. Refinement C: 0.45
* vs. Refinement PC: 1.00
### Key Observations
* The diagonal elements are all 1.0, indicating perfect coverage when a method is compared to itself.
* "Direct Generation C" and "Repeated Sampling PC" show relatively high coverage scores when compared to other methods.
* "Refinement PC" generally has lower coverage scores when compared to other methods, except for itself.
* The "P" variants generally have lower coverage when compared to "C" and "PC" variants.
### Interpretation
The heatmap visualizes the relationships between different generation and refinement methods in terms of coverage. A higher coverage score suggests a stronger similarity or overlap between the outputs of the two methods being compared. The data suggests that "Direct Generation C" and "Repeated Sampling PC" may produce outputs that are more similar to a wider range of other methods, while "Refinement PC" may be more distinct. The lower coverage scores for "Refinement PC" could indicate that it generates more specialized or unique outputs compared to the other methods. The differences in coverage between "P," "C," and "PC" variants may reflect the impact of different parameter settings or configurations on the generated outputs.
</details>
Figure 20: Asymmetric relative coverage matrix of nine ARC solvers using DeepSeek-R1-70B, showing the proportion of problems whose test instances are solved by the row solver that are also solved by the column solver. P denotes the solution plan; C and PC refer to standalone and planning-aided code generation, respectively.
<details>
<summary>x21.png Details</summary>

### Visual Description
## Image Processing Task: Digit Recognition and Matrix Generation
### Overview
The image presents a task involving digit recognition from pixelated images and the generation of corresponding 5x5 matrices based on the identified digit. The left side shows input images, each composed of multiple instances of a digit represented by colored pixels on a black background. An arrow points from each input image to a corresponding output image, where the digit is represented by a single color on a grid. The right side provides a Python code solution that defines a function to generate the output matrices. The final input image has a question mark, indicating the task is to determine the output image.
### Components/Axes
* **Task Title:** "Task 358ba94e" (top-left)
* **Code Title:** "Code Solution" (top-right)
* **Input Images:** A series of pixelated images on the left, each containing multiple instances of a digit. The digits are represented by different colors (orange, light blue, magenta, red, dark blue).
* **Output Images:** A series of colored square grids on the right, each representing a digit. The color of the grid corresponds to the color of the digit in the input image.
* **Arrow:** An arrow connects each input image to its corresponding output image.
* **Code:** Python code defining a function `generate_output_image(input_image)` that takes an input image and returns a 5x5 matrix representing the detected digit.
* **Question Mark:** A question mark in a square grid, indicating the task is to determine the output image for the last input image.
* **Red dashed box:** A red dashed box surrounds the code block. The text "Copy the output matrices." is inside the box.
### Detailed Analysis
**Input Images and Corresponding Output Images:**
1. **Orange Digits:** The first input image contains four orange digits. The corresponding output image is an orange grid with a single black pixel in the center.
2. **Light Blue Digits:** The second input image contains four light blue digits. The corresponding output image is a light blue grid with a single black pixel in the center.
3. **Magenta Digits:** The third input image contains four magenta digits. The corresponding output image is a magenta grid with a single black pixel in the center.
4. **Red Digits:** The fourth input image contains four red digits. The corresponding output image is a red grid with a single black pixel in the center.
5. **Dark Blue Digits:** The fifth input image contains four dark blue digits. The corresponding output image is unknown, indicated by a question mark.
**Code Analysis:**
The Python code defines a function `generate_output_image(input_image)` that performs the following steps:
1. **Frequency Calculation:** Calculates the frequency of each pixel value in the input image.
2. **Zero Pixel Check:** If there are no non-zero pixels, it returns a 5x5 matrix filled with zeros.
3. **Digit Determination:** Determines the "digit" by finding the non-zero pixel value that occurs most often.
4. **Matrix Generation:** Returns a fixed normalized 5x5 pattern corresponding to the detected digit. The code provides specific patterns for digits 7, 8, 6, 2, and 1. For any other digit, it simply fills a 5x5 matrix with that digit.
**Specific Matrix Patterns:**
* **Digit 7:**
</details>
Figure 21: ARC problem 358ba94e, where repeated sampling with standalone code generation produces an incorrect solution using GPT-o3-mini.
<details>
<summary>x22.png Details</summary>
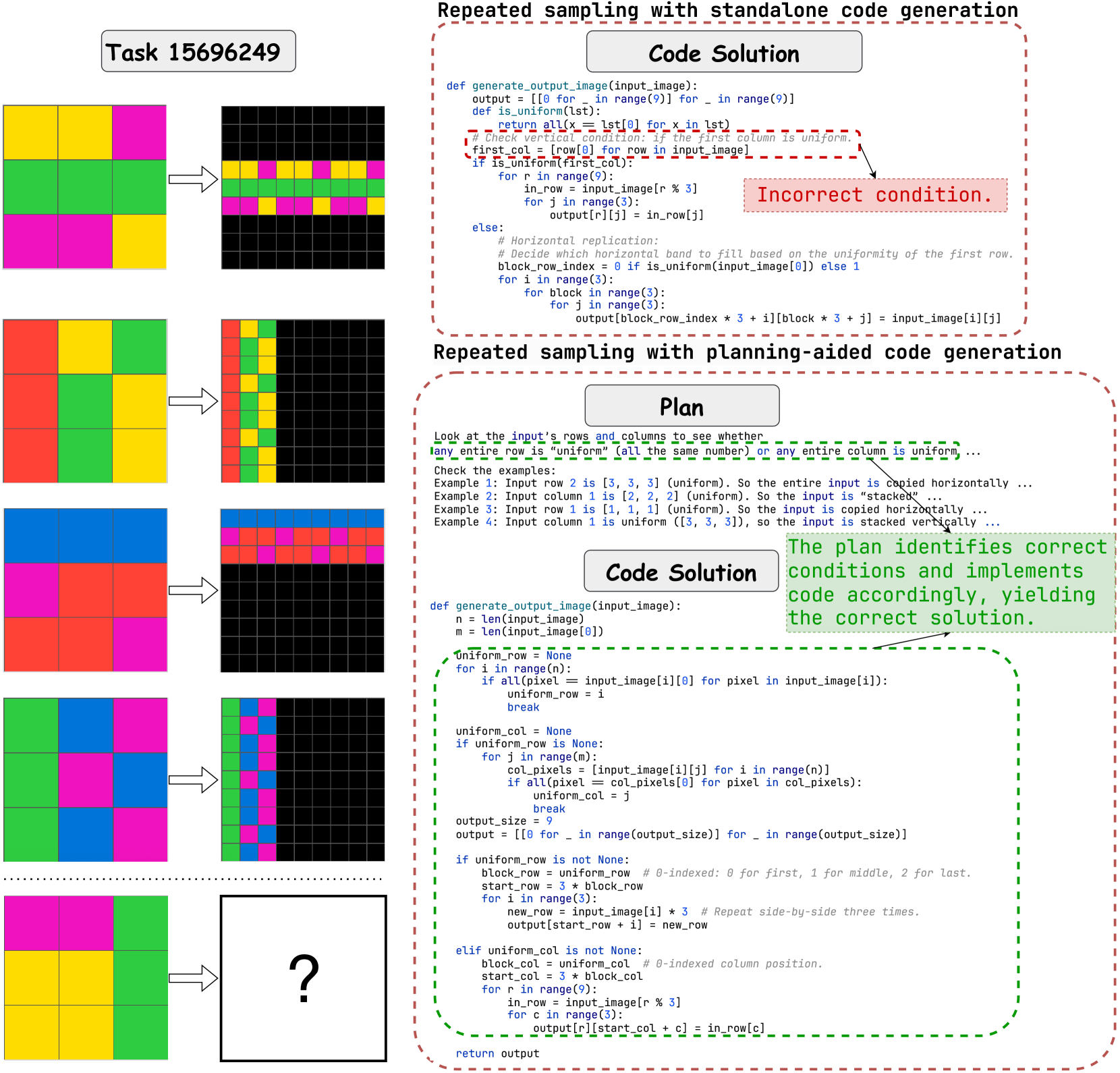
### Visual Description
## Image Analysis: Code Generation with and without Planning
### Overview
The image presents a comparison between two approaches to code generation for a pattern replication task: one using standalone code generation and the other using planning-aided code generation. It illustrates how different strategies handle the same pattern replication problem, highlighting the benefits of incorporating a planning stage. The image includes visual examples of input patterns, corresponding output patterns, code snippets, and explanatory text.
### Components/Axes
* **Title:** Task 15696249
* **Left Side:** Visual examples of input patterns (3x3 grids) and their corresponding output patterns (9x9 grids). The bottom example has a question mark in the output.
* **Top-Right:** "Repeated sampling with standalone code generation" enclosed in a dashed red rounded rectangle.
* **Code Solution:** A code snippet (Python-like) for generating the output image.
* **Annotation:** "Incorrect condition." pointing to a specific line in the code.
* **Bottom-Right:** "Repeated sampling with planning-aided code generation" enclosed in a dashed red rounded rectangle.
* **Plan:** Textual description of the planning strategy.
* **Code Solution:** A code snippet (Python-like) for generating the output image, incorporating the planning strategy.
* **Annotation:** "The plan identifies correct conditions and implements code accordingly, yielding the correct solution." pointing to the code.
### Detailed Analysis or Content Details
**1. Visual Examples (Left Side):**
* **Example 1:**
* Input: A 3x3 grid with colors (from top-left): Green, Yellow, Pink, Red, Green, Yellow, Pink, Red.
* Output: A 9x9 grid where the input pattern is replicated.
* **Example 2:**
* Input: A 3x3 grid with colors (from top-left): Red, Red, Yellow, Red, Red, Yellow, Red, Red, Yellow.
* Output: A 9x9 grid where the first column of the input is repeated.
* **Example 3:**
* Input: A 3x3 grid with colors (from top-left): Green, Blue, Green, Blue, Green, Blue, Green, Blue, Green.
* Output: A 9x9 grid where the first row of the input is repeated.
* **Example 4:**
* Input: A 3x3 grid with colors (from top-left): Yellow, Yellow, Green, Yellow, Yellow, Green, Yellow, Yellow, Green.
* Output: A 9x9 grid with a question mark.
**2. Standalone Code Generation (Top-Right):**
* **Code:**
```python
def generate_output_image(input_image):
output = [[0 for _ in range(9)] for _ in range(9)]
def is_uniform(lst):
return all(x == lst[0] for x in lst)
# Check vertical condition: if the first column is uniform.
first_col = [row[0] for row in input_image]
if is_uniform(first_col):
for r in range(9):
in_row = input_image[r % 3]
for j in range(3):
output[r][j] = in_row[j]
else:
# Horizontal replication:
# Decide which horizontal band to fill based on the uniformity of the first row.
block_row_index = 0 if is_uniform(input_image[0]) else 1
for i in range(3):
for block in range(3):
for j in range(3):
output[block_row_index * 3 + i][block * 3 + j] = input_image[i][j]
```
* **Issue:** The "Incorrect condition" annotation suggests a flaw in the logic for determining how to replicate the pattern.
**3. Planning-Aided Code Generation (Bottom-Right):**
* **Plan:**
* "Look at the input's rows and columns to see whether any entire row is 'uniform' (all the same number) or any entire column is uniform..."
* Examples:
* "Example 1: Input row 2 is [3, 3, 3] (uniform). So the entire input is copied horizontally..."
* "Example 2: Input column 1 is [2, 2, 2] (uniform). So the input is 'stacked'..."
* "Example 3: Input row 1 is [1, 1, 1] (uniform). So the input is copied horizontally..."
* "Example 4: Input column 1 is uniform ([3, 3, 3]), so the input is stacked vertically..."
* **Code:**
```python
def generate_output_image(input_image):
n = len(input_image)
m = len(input_image[0])
uniform_row = None
for i in range(n):
if all(pixel == input_image[i][0] for pixel in input_image[i]):
uniform_row = i
break
uniform_col = None
if uniform_row is None:
for j in range(m):
col_pixels = [input_image[i][j] for i in range(n)]
if all(pixel == col_pixels[0] for pixel in col_pixels):
uniform_col = j
break
output_size = 9
output = [[0 for _ in range(output_size)] for _ in range(output_size)]
if uniform_row is not None:
block_row = uniform_row # 0-indexed: 0 for first, 1 for middle, 2 for last.
start_row = 3 * block_row
for i in range(3):
new_row = input_image[i] * 3 # Repeat side-by-side three times.
output[start_row + i] = new_row
elif uniform_col is not None:
block_col = uniform_col # 0-indexed column position.
start_col = 3 * block_col
for r in range(9):
in_row = input_image[r % 3]
for c in range(3):
output[r][start_col + c] = in_row[c]
return output
```
* **Explanation:** The annotation "The plan identifies correct conditions and implements code accordingly, yielding the correct solution" indicates that this code correctly handles the pattern replication based on the uniformity of rows or columns.
### Key Observations
* The standalone code generation approach has a flaw in its logic, leading to incorrect pattern replication.
* The planning-aided approach explicitly checks for uniform rows or columns in the input pattern and adapts the replication strategy accordingly.
* The visual examples demonstrate the expected output for different input patterns, providing a clear understanding of the task.
* The question mark in the last example suggests that the standalone code generation fails to produce the correct output for that specific input pattern.
### Interpretation
The image demonstrates the importance of a well-defined plan in code generation. The standalone code generation approach, without a clear plan, fails to handle all input patterns correctly. In contrast, the planning-aided approach, which explicitly checks for uniformity in rows or columns, successfully generates the correct output. This highlights the benefits of incorporating a planning stage in code development, especially for tasks that require adapting to different input conditions. The question mark in the last example serves as a visual indicator of the failure of the standalone approach, emphasizing the need for a more robust and adaptable solution.
</details>
Figure 22: ARC problem 15696249, where repeated sampling with standalone code generation produces an incorrect solution, whereas repeated sampling with planning-aided code generation yields the correct solution using GPT-o3-mini.
<details>
<summary>x23.png Details</summary>
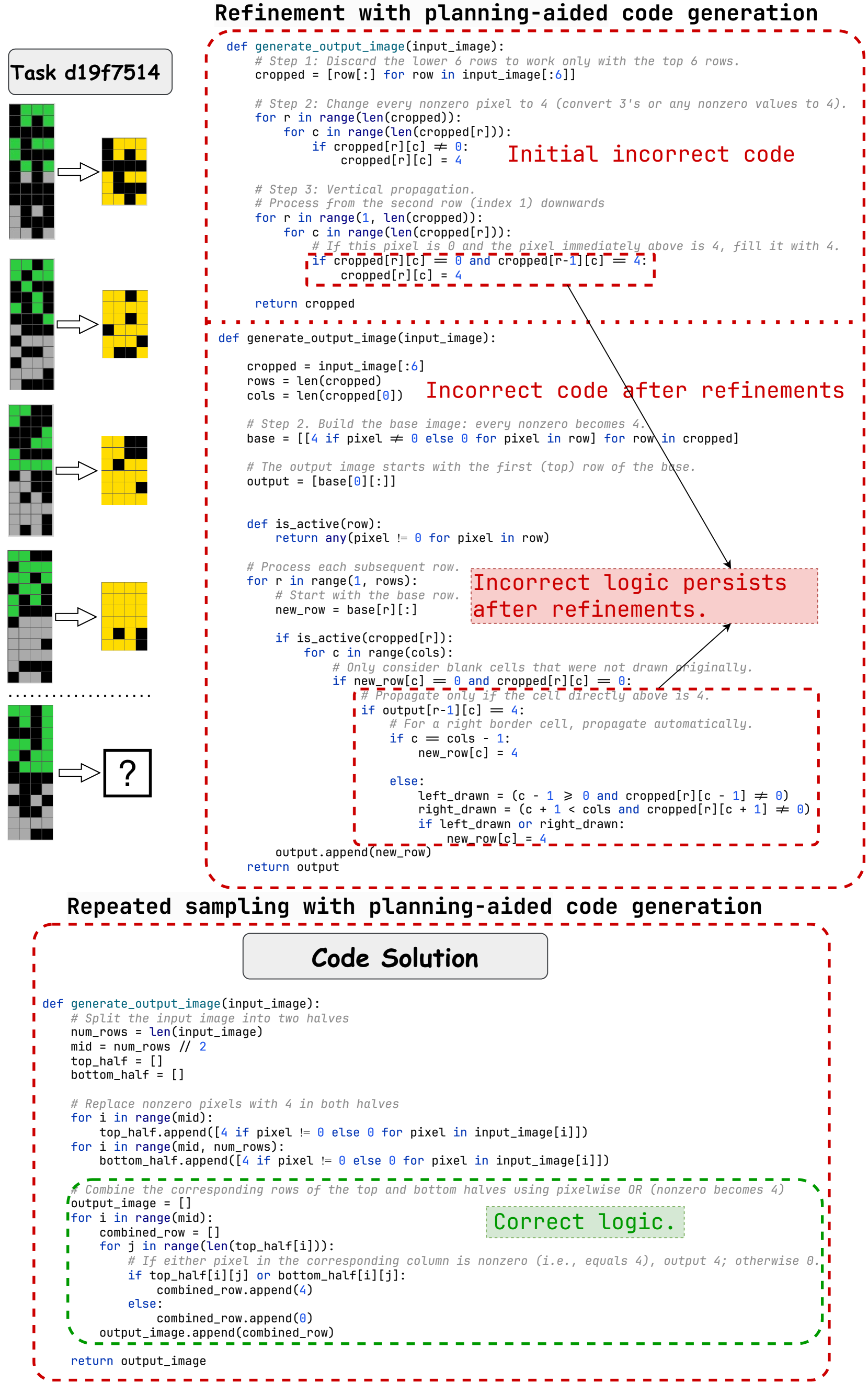
### Visual Description
## Code Comparison: Refinement vs. Repeated Sampling
### Overview
The image presents a comparison between two approaches to code generation: refinement with planning-aided code generation and repeated sampling with planning-aided code generation. It shows the evolution of code through refinement, highlighting incorrect logic at different stages, and contrasts it with a "Code Solution" achieved through repeated sampling. The image includes code snippets, visual representations of image processing steps, and annotations indicating the correctness of the logic.
### Components/Axes
* **Title:** Refinement with planning-aided code generation
* **Title:** Repeated sampling with planning-aided code generation
* **Code Snippets:** Python code for image processing functions.
* **Visual Representations:** Pixelated images representing input and output at different stages.
* **Annotations:** Textual annotations indicating "Initial incorrect code," "Incorrect code after refinements," "Incorrect logic persists after refinements," and "Correct logic."
* **Task Identifier:** "Task d19f7514"
* **Question Mark:** A pixelated image with a question mark, indicating an unknown or desired output.
### Detailed Analysis or ### Content Details
**1. Refinement with planning-aided code generation:**
* **Initial State:** The initial input image is a vertical strip of 12x1 pixels, with alternating green and gray pixels.
* **Step 1:** Discard the lower 6 rows to work only with the top 6 rows.
* `cropped = [row[:] for row in input_image[:6]]`
* **Step 2:** Change every nonzero pixel to 4 (convert 3's or any nonzero values to 4).
* The code iterates through the cropped image and sets any non-zero pixel to 4.
* ```python
for r in range (len (cropped)):
for c in range (len (cropped[r])):
if cropped[r] [c] != 0:
cropped[r] [c] = 4
```
* The resulting image is a 6x1 pixel image with alternating yellow and black pixels.
* **Step 3:** Vertical propagation.
* The code processes from the second row (index 1) downwards.
* If a pixel is 0 and the pixel immediately above is 4, fill it with 4.
* ```python
for r in range (1, len (cropped)):
for c in range(len(cropped[r])):
# If this pixel is 0 and the pixel immediately above is 4, fill it with 4.
if cropped [r] [c] == 0 and cropped [r-1][c] == 4:
cropped[r] [c] = 4
```
* **Incorrect Code Annotations:**
* "Initial incorrect code" points to the first code block.
* "Incorrect code after refinements" points to a code block that crops the input image to the top 6 rows.
* "Incorrect logic persists after refinements" points to a code block that processes each subsequent row.
* **Code Snippets:**
* The code snippets show the evolution of the image processing logic.
* The initial code attempts to change non-zero pixels to 4 and then propagate values vertically.
* The refined code includes steps to build a base image and process subsequent rows.
**2. Repeated sampling with planning-aided code generation:**
* **Code Solution:** The code splits the input image into two halves, replaces non-zero pixels with 4 in both halves, and combines the corresponding rows using pixelwise OR (nonzero becomes 4).
* **Code Snippet:**
* ```python
def generate_output_image(input_image):
# Split the input image into two halves
num_rows = len(input_image)
mid = num_rows // 2
top_half = []
bottom_half = []
# Replace nonzero pixels with 4 in both halves
for i in range(mid):
top_half.append([4 if pixel != 0 else 0 for pixel in input_image[i]])
for i in range(mid, num_rows):
bottom_half.append([4 if pixel != 0 else 0 for pixel in input_image[i]])
#Combine the corresponding rows of the top and bottom halves using pixelwise OR (nonzero becomes 4)
output_image = []
for i in range(mid):
combined_row = []
for j in range(len (top_half[i])):
# If either pixel in the corresponding column is nonzero (i.e., equals 4), output 4; otherwise 0.
if top_half[i][j] or bottom_half[i][j]:
combined_row.append(4)
else:
combined_row.append(0)
output_image.append(combined_row)
return output_image
```
* **Correct Logic Annotation:** "Correct logic" points to the code block that combines the corresponding rows of the top and bottom halves using pixelwise OR.
* **Final State:** The expected output is a 6x1 pixel image with alternating yellow and black pixels.
### Key Observations
* The refinement approach initially contains incorrect logic that is iteratively refined.
* The repeated sampling approach provides a "Code Solution" with correct logic.
* The visual representations show the transformation of the input image at different stages of the refinement process.
* The annotations highlight the correctness or incorrectness of the code logic.
### Interpretation
The image demonstrates the difference between refining an initial, flawed approach and using a repeated sampling method to arrive at a correct solution. The refinement process, while attempting to improve the code, initially contains incorrect logic that persists through multiple iterations. In contrast, the repeated sampling approach yields a "Code Solution" with correct logic, suggesting that a fresh approach can be more effective than iterative refinement in certain cases. The visual representations provide a clear understanding of how the image processing steps transform the input image. The question mark indicates that the desired output is known, and the "Code Solution" achieves this output.
</details>
Figure 23: ARC problem d19f7514, where repeated sampling with planning-aided code generation produces a correct solution, whereas its refinement variant fails to refine the initial erroneous code, and the incorrect logic persists across subsequent refinements when using GPT-o3-mini.
A.13 Prompts for LLMs
\UseRawInputEncoding
We include all prompts used by KAAR and nine ARC solvers described in Section 3. We adopt a bash-like notation for input arguments within the prompts, such as $ {test_inputs} denotes the test input 2D matrices. A brief description of the prompts used for each solver is provided below.
- Direct generation with solution plan: Prompt 1 describes how to generate the solution plan, and Prompt 2 uses the generated plan to produce the output images.
- Direct generation with standalone code: Prompt 3 describes how to generate the code to produce the output images.
- Direct generation with planning-aided code: It first generates a solution plan using Prompt 1, then uses Prompt 4 to produce code based on the generated plan.
- Repeated sampling with solution plan: It can be regarded as an iterative version of direct generation with solution plan, and thus also uses Prompts 1 and 2.
- Repeated sampling with standalone code: It can be regarded as an iterative version of direct generation with standalone code, and thus also uses Prompt 3.
- Repeated sampling with planning-aided code: It can be regarded as an iterative version of direct generation with planning-aided code, and thus also uses Prompts 1 and 4.
- Refinement with solution plan: Prompt 5 describes the process of refining the generated solution plan with the validation samples. It uses Prompts 1 and 2 to generate the initial plan and the result image.
- Refinement with the standalone code: Prompt 6 describes the process of refining the generated code with the validation samples. It uses Prompt 3 to produce the initial code solution.
- Refinement with the planning-aided code: Prompt 7 describes the process of refining the generated plan and code with the validation samples. It use Prompts 1 and 4 to generate the initial plan and produce the initial code guided by the plan, respectively.
- KAAR: Prompt 8 describes the augmentation of objectness priors. Prompts 9 and 10 introduce the augmentation of geometry and topology priors, encoded as component attributes and relations, respectively. Prompt 11 outlines the augmentation of numbers and counting priors. Prompts 12 and 13 describe action selection and target component identification in the process of augmenting goal-directedness priors. For prompts implementing each action’s implementation details, please refer to our code.
Prompt 1: Direct generation with solution plan - solution plan generation.
⬇
================================ System ================================
You are an expert in analyzing grid - based image processing tasks. Your objective is to derive a text transformation plan (not Python code) from each given input - output image pair (both represented as 2 D matrices), and then apply this plan to generate output image (s), represented as a 2 D matrix, based on the given test input image (s) (2 D matrix). Ensure that the derived plan generalizes across different cases while preserving consistency with the observed transformations.
================================= User =================================
The input data consists of a few pairs of input and output images, where the left image in each pair represents the input, and the right image represents the corresponding output. Each image can be represented as a 2 D matrix: $ {matrix}
Please note that each number in the matrix corresponds to a pixel, and its value represents the color.
Derive a text transformation plan (not Python code) that maps each given input image (2 D matrix) to its corresponding output image (2 D matrix). Ensure that the plan generalizes across different cases and the test input image (s) (2 D matrix) while maintaining consistency with the observed transformations.
The test input image (s): $ {test_inputs}
Prompt 2: Direct generation with solution plan - output image(s) generation from the plan.
⬇
================================ System ================================
You are an expert in analyzing grid - based image processing tasks. Your objective is to generate output image (s), represented as a 2 D matrix, based on the given input images (2 D matrix) and a derived text transformation plan.
================================= User =================================
Please generate the output image (s) as a 2 D matrix (not Python code) based on the given input image (s) (2 D matrix) and the text transformation plan. Output only the test output image (s) in 2 D matrix format (not Python code). For each test input image, start with [Start Output Image] and end with [End Output Image].
For example, if there is one test input image, the output image should be:
[Start Output Image]
[[0,0,0], [0,0,0], [0,0,0]]
[End Output Image]
If there are multiple (2) test input images, the the output images should be outputted as:
[Start Output Image]
[[0,0,0], [0,0,0], [0,0,0]]
[End Output Image]
[Start Output Image]
[[1,1,1], [1,1,1], [1,1,1]]
[End Output Image]
The test input image (s): $ {test_inputs}
Prompt 3: Direct generation with standalone code.
⬇
================================ System ================================
You are an expert in analyzing grid - based image processing tasks. Your goal is to generate Python code that produces output image (s), represented as a 2 D matrix, based on the given input image (s) (2 D matrix).
================================= User =================================
The input data consists of a few pairs of input and output images, where the left image in each pair represents the input and the right image represents the corresponding output.
Each image can be represented as a 2 D matrix: $ {matrix}
The test input image (s): $ {test_inputs}
Please note that each number in the matrix corresponds to a pixel, and its value represents the color.
Generate a Python script to map each input image (2 D matrix) to the corresponding output image (2 D matrix).
Ensure that the Python script generalizes across different cases and test input image (s) while maintaining consistency with the observed input - output image pairs.
Please output the Python program, starting with [Start Program] and ending with [End Program].
Include an assert statement with the function signature to verify that the generated output matches the expected result, starting with [Assert Statement].
Use placeholders like input_image and output_image for the variables representing the input and output images.
For example:
[Start Program]
def generate_output_image (input_image):
rows = len (input_image)
cols = len (input_image [0])
def dfs (r, c):
""" Depth - first search to mark all 4- connected ’1’ s to ’2’ s."""
if r < 0 or r >= rows or c < 0 or c >= cols or input_image [r][c] != 1:
return
# Change the current component from 1 to 2
input_image [r][c] = 2
# Explore neighbors (up, down, left, right)
dfs (r - 1, c) # Up
dfs (r + 1, c) # Down
dfs (r, c - 1) # Left
dfs (r, c + 1) # Right
# Traverse the image to find all components with ’1’
for r in range (rows):
for c in range (cols):
if input_image [r][c] == 1:
dfs (r, c)
return input_image
[End Program]
[Assert Statement]
assert generate_output_image (input_image) == output_image
Please note, the assert statement should strictly follow the provided format, and the output image should be represented in list format!
Please note, the script should not include an if __name__ == " __main__ ": block.
Prompt 4: Direct generation with planning-aided code - code generation based on the generated plan.
⬇
================================ System ================================
You are an expert in analyzing grid - based image processing tasks. Your goal is to generate Python code that produces output image (s) represented as a 2 D matrix, based on the given input image (s) (2 D matrix). This code should be generated using a text transformation plan inferred from a set of input - output image pairs (both represented as 2 D matrices).
================================= User =================================
Generate a Python script based on your text transformation plan to map the input image (2 D matrix) to the output image (2 D matrix). Please output the Python program, starting with [Start Program] and ending with [End Program]. Include an assert statement with the function signature to verify that the generated output matches the expected result, starting with [Assert Statement]. Use placeholders like input_image and output_image for the variables representing the input and output images.
For example:
[Start Program]
def generate_output_image (input_image):
rows = len (input_image)
cols = len (input_image [0])
def dfs (r, c):
""" Depth - first search to mark all 4- connected ’1’ s to ’2’ s."""
if r < 0 or r >= rows or c < 0 or c >= cols or input_image [r][c] != 1:
return
# Change the current component from 1 to 2
input_image [r][c] = 2
# Explore neighbors (up, down, left, right)
dfs (r - 1, c) # Up
dfs (r + 1, c) # Down
dfs (r, c - 1) # Left
dfs (r, c + 1) # Right
# Traverse the image to find all components with ’1’
for r in range (rows):
for c in range (cols):
if input_image [r][c] == 1:
dfs (r, c)
return input_image
[End Program]
[Assert Statement]
assert generate_output_image (input_image) == output_image
Please note, the assert statement should strictly follow the provided format, and the output image should be represented in list format!
Please note, the script should not include an if __name__ == " __main__ ": block.
Prompt 5: Refinement with solution plan - plan refinement.
⬇
================================ System ================================
As an expert in analyzing grid - based image processing tasks, your objective is to refine your solution plan based on the provided feedback.
================================= User =================================
The problem description:
[start problem description]
The input data consists of a few pairs of input and output images, where the left image in each pair represents the input, and the right image represents the corresponding output. Each image can be represented as a 2 D matrix: $ {matrix}
Please note that each number in the matrix corresponds to a pixel, and its value represents the color.
[end problem description]
The INCORRECT text transformation plan fails to solve some example training input and output pairs in the above problem!
[start incorrect transformation plan]
$ {plan}
[end incorrect transformation plan]
The incorrect output (s) generated by the incorrect plan:
[start incorrect output]
$ {incorrect_output}
[end incorrect output]
The generated correct output (s):
[start correct output]
$ {correct_output}
[end correct output]
Please analyze the incorrect reasoning step - by - step, and then generate the revised correct transformation plan (text only), starting with [Start Revised Transformation Plan] and ending with [End Revised Transformation Plan]. Ensure that the revised transformation plan generalizes across different cases and the test input image (s), while maintaining consistency with the observed transformations.
Prompt 6: Refinement with standalone code - code refinement.
⬇
================================ System ================================
As an expert in analyzing grid - based image processing tasks, your objective is to refine your program based on the provided feedback.
================================= User =================================
The problem description:
[start problem description]
The input data consists of a few pairs of input and output images, where the left image in each pair represents the input, and the right image represents the corresponding output. Each image can be represented as a 2 D matrix: $ {matrix}
Please note that each number in the matrix corresponds to a pixel, and its value represents the color.
[end problem description]
The generated incorrect program fails to solve some example training input and output pairs in the above problem!
[start incorrect program]
$ {code}
[end incorrect program]
The incorrect output (s) generated by the incorrect program:
[start incorrect output]
$ {incorrect_output}
[end incorrect output]
The generated correct output (s):
[start correct output]
$ {correct_output}
[end correct output]
Please analyze the incorrect reasoning step - by - step, and then generate the revised program (Python program only), starting with [Start Revised Program] and ending with [End Revised Program]. Ensure that the revised program generalizes across different cases and the test input image (s), while maintaining consistency with the observed input and output image pairs.
Please include an assert statement with the function signature to verify that the generated output matches the expected result, starting with [Assert Statement]. Use placeholders like input_image and output_image for the variables representing the input and output images.
For example:
[Start Revised Program]
def generate_output_image (input_image):
rows = len (input_image)
cols = len (input_image [0])
def dfs (r, c):
""" Depth - first search to mark all 4- connected ’1’ s to ’2’ s."""
if r < 0 or r >= rows or c < 0 or c >= cols or input_image [r][c] != 1:
return
# Change the current component from 1 to 2
input_image [r][c] = 2
# Explore neighbors (up, down, left, right)
dfs (r - 1, c) # Up
dfs (r + 1, c) # Down
dfs (r, c - 1) # Left
dfs (r, c + 1) # Right
# Traverse the image to find all components with ’1’
for r in range (rows):
for c in range (cols):
if input_image [r][c] == 1:
dfs (r, c)
return input_image
[End Revised Program]
[Assert Statement]
assert generate_output_image (input_image) == output_image
Please note, the assert statement should strictly follow the provided format, and the output image should be represented in list format!
Please note, the script should not include an if __name__ == " __main__ ": block.
Prompt 7: Refinement with planning-aided code - refinement on both generated plan and code.
⬇
================================ System ================================
As an expert in analyzing grid - based image processing tasks, your objective is to refine your transformation plan and program based on the provided feedback.
================================= User =================================
The problem description:
[start problem description]
The input data consists of a few pairs of input and output images, where the left image in each pair represents the input, and the right image represents the corresponding output. Each image can be represented as a 2 D matrix: $ {matrix}
Please note that each number in the matrix corresponds to a pixel, and its value represents the color.
[end problem description]
The generated incorrect transformation plan and program fail to solve some example training input and output pairs in the above problem!
[start incorrect transformation plan]
$ {plan}
[end incorrect transformation plan]
[start incorrect program]
$ {code}
[end incorrect program]
The incorrect output (s) generated by the incorrect transformation plan and program:
[start incorrect output]
$ {incorrect_output}
[end incorrect output]
The generated correct output (s):
[start correct output]
$ {correct_output}
[end correct output]
Please analyze the incorrect reasoning step - by - step, and then generate the revised transformation plan (text only) and program (Python program only).
For the revised transformation plan, start with [Start Revised Transformation Plan] and end with [End Revised Transformation Plan]. Ensure that the revised transformation plan generalizes across different cases and the test input image (s), while maintaining consistency with the observed transformations.
For the revised Python program, start with [Start Revised Program] and end with [End Revised Program]. Ensure that the revised program generalizes across different cases and the test input image (s), while maintaining consistency with the observed input and output image pairs.
For the revised Python program, please include an assert statement with the function signature to verify that the generated output matches the expected result, starting with [Assert Statement]. Use placeholders like input_image and output_image for the variables representing the input and output images.
For example:
[Start Revised Program]
def generate_output_image (input_image):
rows = len (input_image)
cols = len (input_image [0])
def dfs (r, c):
""" Depth - first search to mark all 4- connected ’1’ s to ’2’ s."""
if r < 0 or r >= rows or c < 0 or c >= cols or input_image [r][c] != 1:
return
# Change the current component from 1 to 2
input_image [r][c] = 2
# Explore neighbors (up, down, left, right)
dfs (r - 1, c) # Up
dfs (r + 1, c) # Down
dfs (r, c - 1) # Left
dfs (r, c + 1) # Right
# Traverse the image to find all components with ’1’
for r in range (rows):
for c in range (cols):
if input_image [r][c] == 1:
dfs (r, c)
return input_image
[End Revised Program]
[Assert Statement]
assert generate_output_image (input_image) == output_image
Please note, the assert statement should strictly follow the provided format, and the output image should be represented in list format!
Please note, the script should not include an if __name__ == " __main__ ": block.
Prompt 8: Objectness priors augmentation
⬇
================================ System ================================
You are an expert in grid - based image analysis.
================================= User =================================
The training instances consist of several pairs of input and output images, where the left image in each pair represents the input and the right image represents the corresponding output.
Please note that the test instance (s) only contains input image (s).
Each image is represented as a 2 D matrix:
$ {matrix}
Please note that each number in the matrix corresponds to a pixel and its value represents the color.
We treat the color represented by the number {background_color} as the background color.
$ {abstraction_rule}
The components in each input and output image pair are as follows:
$ {component_description}
Prompt 9: Geometry and topology priors augmentation - component attributes
⬇
================================ System ================================
You are an expert in geometry and topology analysis. Below is a summary of component attributes, including:
Size (Width and Height); Color; Shape; Symmetry; Bounding Box; Hole Count; Nearest Boundary.
================================= User =================================
$ {geometry_and_topology_priors_attributes} $
Prompt 10: Geometry and topology priors augmentation - component relations
⬇
================================ System ================================
You are an expert in geometry and topology analysis, Below is a summary of component relations, including:
Different / Identical with other components; Inclusive; Touching or or not touching with other component; Spatial Relations,
================================= User =================================
$ {geometry_and_topology_priors_relations} $
Prompt 11: Numbers and counting priors augmentation
⬇
================================ System ================================
You are an expert in numbers and counting analysis. Below is a summary of component statistics, including:
Symmetry numerical summary; Size numerical summary; Color numerical summary; Shape numerical summary; Hole counting summary.
================================= User =================================
$ {numbers_and_couting_priors} $
Prompt 12: Goal-directedness priors augmentation - action selection
⬇
================================ System ================================
You are an expert in analyzing and categorizing grid - based image tasks.
================================= User =================================
Please determine which category or categories this task belongs to. Please select from the following:
1. color change: color change involves modifying the value of a component, and the component size and position always does not change.
2. movement: movement involves shifting the position of a component to a new location within the image, and the component size always does not change.
3. extension: extending involves expanding the boundaries of a component to increase its size or reach within the image, and the component size always changes.
4. completing: completing an image involves filling in missing or incomplete parts of a component to achieve a coherent and fully formed image.
5. resizing: resizing involves altering the dimensions of a component by expanding or shrinking its size within the image.
6. selecting: selecting involves identifying and isolating a specific component within the image as the output component, and the component size and color always does not change.
7. copying: copying involves duplicating a component and either placing the duplicate in a new location or replacing the existing component within the image.
8. flipping: flipping involves mirroring a component along a specified axis to reverse its orientation within the image.
9. rotation: rotation involves turning a component around a fixed point or center by a specified angle within the image.
10. cropping: cropping involves cutting out a specific portion of a component.
Please select the best suitable one or multiple categories from the provided list that best describe the task.
Format your response by starting with [start category] and ending with [end category], numbering each category selected.
For example, if the task belongs only to " color change ", your response should be:
[start category]
1. color chang
[end category]
If the task belongs to both " selecting " and " extension ", your response should be:
[start category]
1. selecting
2. extension
[end category]
Prompt 13: Goal-directedness priors augmentation - target component idetification
⬇
================================ System ================================
You are an expert in analyzing grid - based image tasks, specifically in $ {action} components.
================================= User =================================
If this task involves $ {action}:
1. Begin by identifying WHICH COMPONENTS are to be $ {action} in all input images (training and test pairs).
- Refer to these components as TARGET components (e. g., component 1 in the first input image, component 2 and component 3 in the second input image, etc.).
- List ALL target components in each training and test input image.
- For EACH target component, provide:
- Attribute Analysis result
- Relation analysis result
- Numerical analysis result
2. Determine the CONDITIONS used to select these TARGET components for $ {action} from each training and test input image.
- These conditions must be based on common priorities across all targeted components and must differ from the unselected components.
- For example: the size of all target components might be equal to 3 while the size of the unselected components is not 3.
2.1. Analyze whether these conditions are EMPTY or not.
2.2. Evaluate if these conditions are derived from attribute analysis, including:
2.2.1. Color
2.2.2. Size
2.2.3. Shape
2.2.4. Width
2.2.5. Height
2.2.6. The number of holes
2.2.7. Bounding box
2.2.8. Symmetry
2.2.9. Nearest boundary
2.3. Evaluate if these conditions are derived from relation analysis, including:
2.3.1. Relative position with other components
2.3.2. Touching with other components
2.3.3. Whether they differ from or are identical with other components
2.3.4. Enclosure of other components
2.4. Evaluate if these conditions are derived from numerical analysis, including:
2.4.1. Symmetry numerical analysis
2.4.2. Size numerical analysis
2.4.3. Color numerical analysis
2.4.4. Shape numerical analysis
2.4.5. Hole counting analysis
You must evaluate each condition ONE by ONE and determine the best conditions.
Note:
- The conditions MUST work for ALL training and test input and output image pairs.
- Conditions CANNOT come from the output images!
- A condition can be EMPTY.
- If a condition is based on numerical features (e. g., size (width and height), or the number of holes), you may use the operators =, <, >, >=, or <=.
- For cropping or selecting tasks, consider using a bounding box to extract each component.