# : A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models
**Authors**: Alibaba Group
## Abstract
Trinity-RFT is a general-purpose, unified and easy-to-use framework designed for reinforcement fine-tuning (RFT) of large language models. It is built with a modular and decoupled design, consisting of (1) an RFT-core that unifies and generalizes synchronous/asynchronous, on-policy/off-policy, and online/offline modes of RFT; (2) seamless integration for agent-environment interaction with high efficiency and robustness; and (3) systematic data pipelines optimized for RFT. Trinity-RFT can be easily adapted for diverse application scenarios, and serves as a unified platform for development and research of advanced reinforcement learning paradigms at both macroscopic and microscopic levels. This technical report outlines the vision, features, design and implementations of Trinity-RFT, accompanied by extensive examples, applications and experiments that demonstrate its functionalities and user-friendliness.
footnotetext: Equal contribution. footnotetext: Corresponding author. {chenyanxi.cyx,panxuchen.pxc,daoyuanchen.cdy,yaliang.li,bolin.ding}@alibaba-inc.com
GitHub: https://github.com/modelscope/Trinity-RFT
Documentation: https://modelscope.github.io/Trinity-RFT
Note: Trinity-RFT is currently under active development. This technical report corresponds to commit id 63d4920 (July 14, 2025) of the GitHub repository, and will be continuously updated as the codebase evolves. Comments, suggestions and contributions are welcome!
## 1 Introduction
Reinforcement learning (RL) has achieved remarkable success in the development of large language models (LLMs). Examples include aligning LLMs with human preferences via reinforcement learning from human feedback (RLHF) [24], and training long-CoT reasoning models via RL with rule-based or verifiable rewards (RLVR) [5, 35]. However, such approaches are limited in their abilities to handle dynamic, agentic and continuous learning in the real world.
We envision a future where AI agents learn by interacting directly with environments, collecting lagged or complex reward signals, and continuously refining their behavior through RL based on the collected experiences [32]. For example, imagine an AI scientist who designs an experiment, executes it, waits for feedback (while working on other tasks concurrently), and iteratively updates itself based on true environmental rewards and feedback when the experiment is finally finished.
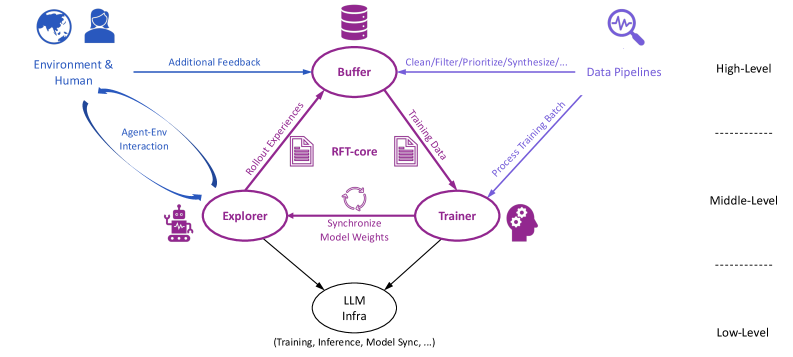
This vision motivates us to develop Trinity-RFT, a reinforcement fine-tuning (RFT) framework that aims to offer a path into this future. The modular, decoupled and trinity design of Trinity-RFT illustrated in Figure 1, along with its various features, makes it a promising solution for realizing such a vision.
<details>
<summary>x2.png Details</summary>
### Visual Description
## System Architecture Diagram: Reinforcement Learning Training Pipeline
### Overview
This image is a technical system architecture diagram illustrating a multi-level reinforcement learning or model training pipeline. It depicts the flow of data, feedback, and model updates between distinct functional components, organized into three hierarchical levels: High-Level, Middle-Level, and Low-Level. The diagram uses a combination of labeled components (represented by icons and text), directional arrows with descriptive labels, and a clear spatial layout to explain the system's operation.
### Components/Axes
The diagram is structured vertically into three distinct tiers, separated by horizontal dashed lines.
**High-Level (Top Section):**
* **Components:**
* **Environment & Human:** Located top-left, represented by a globe and a person icon.
* **Buffer:** Located top-center, represented by a database cylinder icon.
* **Data Pipelines:** Located top-right, represented by a magnifying glass over a waveform icon.
* **Flow/Connections:**
* An arrow labeled **"Additional Feedback"** flows from *Environment & Human* to *Buffer*.
* An arrow labeled **"Clean/Filter/Prioritize/Synthesize/..."** flows from *Data Pipelines* to *Buffer*.
* A bidirectional arrow labeled **"Agent-Env Interaction"** connects *Environment & Human* to the *Explorer* component in the Middle-Level.
**Middle-Level (Center Section):**
* **Components:**
* **Explorer:** Located center-left, represented by a robot icon.
* **RFT-core:** Located at the very center, represented by two document icons with a circular arrow between them.
* **Trainer:** Located center-right, represented by a human head with gears icon.
* **Flow/Connections:**
* An arrow labeled **"Robust Experiences"** flows from *Explorer* to *Buffer* (High-Level).
* An arrow labeled **"Trained Data"** flows from *Buffer* (High-Level) to *Trainer*.
* An arrow labeled **"Process Training Batch"** flows from *Data Pipelines* (High-Level) to *Trainer*.
* A bidirectional arrow labeled **"Synchronize Model Weights"** connects *Explorer* and *Trainer*.
* Arrows flow from both *Explorer* and *Trainer* down to the *LLM Infra* component in the Low-Level.
**Low-Level (Bottom Section):**
* **Components:**
* **LLM Infra:** Located bottom-center, represented by a simple oval.
* **Text/Notes:**
* Below the *LLM Infra* oval, the text reads: **"(Training, Inference, Model Sync, ...)"**.
### Detailed Analysis
The diagram explicitly maps the data and control flow for a training system:
1. **Data Ingestion & Curation (High-Level):** Raw data or signals enter via *Data Pipelines* and are processed (cleaned, filtered, etc.) before being sent to the central *Buffer*. Concurrently, the *Environment & Human* provide *Additional Feedback* directly to the *Buffer*.
2. **Experience Generation & Training (Middle-Level):**
* The *Explorer* component interacts with the *Environment & Human* (via the "Agent-Env Interaction" loop) to generate experiences.
* These experiences are sent as **"Robust Experiences"** to the *Buffer*.
* The *Buffer* acts as a central repository, sending curated **"Trained Data"** to the *Trainer*.
* The *Trainer* also receives a direct feed of processed data via the **"Process Training Batch"** arrow from *Data Pipelines*.
* The *Explorer* and *Trainer* maintain synchronized model weights, indicated by the bidirectional arrow.
* The central **RFT-core** (likely standing for Reinforcement Fine-Tuning core) is positioned between the *Explorer* and *Trainer*, suggesting it is the core algorithm or logic coordinating their interaction.
3. **Infrastructure Layer (Low-Level):** Both the *Explorer* and *Trainer* components depend on the underlying **LLM Infra**, which handles fundamental operations like training runs, inference serving, and model synchronization.
### Key Observations
* **Central Buffer:** The *Buffer* is a critical hub, receiving inputs from three sources (*Data Pipelines*, *Environment & Human*, *Explorer*) and providing output to the *Trainer*.
* **Dual Data Paths to Trainer:** The *Trainer* receives data from two distinct sources: curated data from the *Buffer* and a direct processed batch from *Data Pipelines*.
* **Synchronization Emphasis:** The explicit "Synchronize Model Weights" link between *Explorer* and *Trainer* highlights the importance of keeping these two active components aligned.
* **Hierarchical Abstraction:** The three-level structure clearly separates high-level data/feedback sources, middle-level processing agents, and low-level infrastructure.
### Interpretation
This diagram outlines a sophisticated, closed-loop system for training a large language model (LLM) using reinforcement learning or interactive fine-tuning. The **Explorer** likely acts as an agent that explores an environment (which could be a simulation, a user interface, or a dataset) to generate novel experiences or data. These experiences are stored and refined in the **Buffer**. The **Trainer** uses this buffered data, along with directly processed batches, to update the model. The constant synchronization ensures the exploring agent and the training module are working with the same model version.
The system is designed for continuous improvement: the model's interactions generate new training data, which is used to improve the model, which in turn leads to better interactions. The inclusion of **Human** and **Environment** feedback at the high level indicates this is likely a human-in-the-loop or interactive learning system, where external feedback directly influences the training data pool. The **RFT-core** is the central nervous system, orchestrating the exchange of experiences and training data between the explorer and trainer. The entire process is built upon a shared **LLM Infra** foundation.
</details>
Figure 1: The high-level design of Trinity-RFT.
### 1.1 Key Features of Trinity-RFT
Trinity-RFT is a general-purpose, unified, scalable and user-friendly RL framework that can be easily adapted for diverse experimental or real-world scenarios. It integrates both macroscopic and microscopic RL methodologies in one place; roughly speaking, the former deals with natural language and plain text, while the latter handles torch.Tensor (such as token probabilities, gradients, and model weights of LLMs) Many prior RL works for games/control/LLMs focus mainly on the microscopic aspect, e.g., designing policy loss functions or optimization techniques for updating the policy model. On the other hand, pre-trained LLMs, as generative models with rich prior knowledge of natural language and the world, open up numerous opportunities at the macroscopic level, e.g., experience synthesis by reflection or reasoning with environmental feedback [4], leveraging existing text processing methods like deduplication and quality filtering [2], among others.. The key features of Trinity-RFT are presented below, which will be further elaborated in Section 2 and exemplified in Section 3.
An RFT-core that unifies and generalizes diverse RL modes.
Trinity-RFT implements diverse RL methodologies in a unified manner, supporting synchronous/asynchronous, on-policy/off-policy, and online/offline training. These RL modes can be flexibly generalized, e.g., a hybrid mode that incorporates expert trajectories to accelerate an online RL process [21, 46]. This unification is made possible partly by our decoupled design (which will soon be introduced in Section 2.1) that allows rollout and training to be executed separately and scaled up independently on different devices, while having access to the same stand-alone experience buffer. The efficacy of various RL modes has been validated empirically by our experiments in Section 3.3, which particularly highlight the efficiency gains by off-policy or asynchronous methods.
Agent-environment interaction as a first-class citizen.
Trinity-RFT allows delayed rewards and environmental feedback in multi-step/time-lagged feedback loop, handles long-tailed latencies and the straggler effect via asynchronous and streaming LLM inference, and deals with environment/agent failures gracefully via dedicated timeout/retry/skip mechanisms. These together ensure efficiency and robustness of continuous agent-environment interaction in complex real-world scenarios.
Systematic data pipelines optimized for RFT.
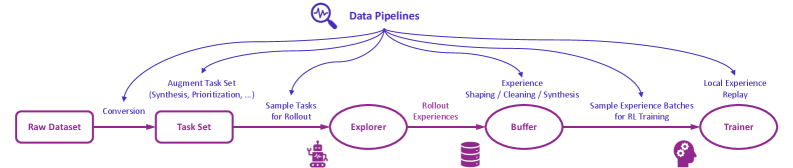
Figure 2 illustrates the high-level design of data pipelines in Trinity-RFT, which regard rollout tasks and experiences as dynamic assets to be actively managed throughout the RFT lifecycle. Trinity-RFT empowers users to: (1) curate tasks for curriculum learning, e.g., by prioritizing easier tasks at the beginning of training to stabilize and accelerate the learning process; (2) actively manipulate experience by cleaning, filtering, or synthesizing new experiences, such as repairing failed trajectories or amplifying successful ones; (3) perform online reward shaping by augmenting sparse environmental rewards with dense, computed signals, such as quality or diversity scores; (4) customize interfaces for human-in-the-loop curation and utilize an agentic paradigm for RFT data processing that translates high-level natural language commands (e.g., “improve response diversity and safety for coding scenarios”) into complex data pipelines, powered by established community tools like Data-Juicer [2]. For instance, Section 3.4 presents experiments that demonstrate the efficacy of task prioritization and reward shaping empowered by Trinity-RFT.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Data Pipelines Flowchart
### Overview
The image displays a flowchart titled "Data Pipelines," illustrating the sequential and cyclical process of data flow in a machine learning or reinforcement learning (RL) training system. The diagram uses a left-to-right flow with a feedback loop, connecting various processing stages represented by rounded rectangles and ovals, annotated with descriptive labels and icons.
### Components/Axes
* **Title:** "Data Pipelines" (top-center, accompanied by a magnifying glass icon).
* **Primary Flow Nodes (from left to right):**
1. `Raw Dataset` (rounded rectangle, far left).
2. `Task Set` (rounded rectangle).
3. `Explorer` (oval, with a small robot/character icon to its lower-left).
4. `Buffer` (oval, with a database/cylinder icon below it).
5. `Trainer` (oval, far right, with a gear/settings icon to its lower-left).
* **Connecting Arrows & Process Labels:**
* Arrow from `Raw Dataset` to `Task Set`: Labeled **"Conversion"**.
* Arrow from `Task Set` to `Explorer`: Labeled **"Sample Tasks for Rollout"**.
* Arrow from `Explorer` to `Buffer`: Labeled **"Rollout Experiences"**.
* Arrow from `Buffer` to `Trainer`: Labeled **"Sample Experience Batches for RL Training"**.
* Arrow from `Trainer` looping back to `Buffer`: Labeled **"Local Experience Replay"**.
* **Additional Annotations:**
* Text above the `Raw Dataset` to `Task Set` arrow: **"Augment Task Set (Synthesis, Prioritization, ...)"**.
### Detailed Analysis
The diagram outlines a five-stage pipeline for processing data to train a reinforcement learning agent:
1. **Data Ingestion & Preparation:** The process begins with a `Raw Dataset`. This data undergoes **"Conversion"** to become a structured `Task Set`. This stage is enhanced by an external process to **"Augment Task Set"**, with examples given as **"(Synthesis, Prioritization, ...)"**.
2. **Task Execution & Experience Generation:** Specific tasks are selected from the `Task Set` via **"Sample Tasks for Rollout"** and passed to the `Explorer` component. The `Explorer` (likely an agent or policy) interacts with the environment, generating **"Rollout Experiences"**.
3. **Experience Storage:** The generated experiences are stored in a `Buffer`, which acts as a replay memory.
4. **Training:** The `Trainer` component retrieves data by **"Sample Experience Batches for RL Training"** from the `Buffer` to update the learning model.
5. **Feedback Loop:** A critical cyclical element is shown where the `Trainer` sends **"Local Experience Replay"** back to the `Buffer`, indicating that newly generated or processed experiences from the training phase are fed back into the memory for future sampling.
### Key Observations
* **Cyclical Nature:** The pipeline is not strictly linear; the "Local Experience Replay" arrow creates a closed loop between the `Trainer` and `Buffer`, emphasizing continuous learning and experience reuse.
* **Component Specialization:** Each node has a distinct role: storage (`Raw Dataset`, `Buffer`), structuring (`Task Set`), acting (`Explorer`), and learning (`Trainer`).
* **Augmentation Point:** The "Augment Task Set" process is highlighted as an external input that enriches the task generation phase, suggesting importance in curriculum learning or task prioritization.
* **Iconography:** Simple icons (magnifying glass, robot, database, gear) provide visual cues for the function of each component (search/analysis, agent, storage, configuration/training).
### Interpretation
This diagram represents a standard architecture for data-driven reinforcement learning systems. It visually explains how raw data is transformed into actionable tasks, how an agent generates experiential data through interaction, and how that data is stored and utilized for training. The inclusion of a feedback loop (`Local Experience Replay`) is a key design pattern in RL (like in algorithms such as DQN) to improve sample efficiency and stabilize learning by breaking temporal correlations in sequential data. The "Augment Task Set" step suggests an advanced pipeline where tasks are not just sampled but actively curated or generated to guide the learning process effectively. The entire flow emphasizes the transformation of static data (`Raw Dataset`) into dynamic, learning-generating experiences (`Rollout Experiences`) that are continuously recycled to improve the agent's policy.
</details>
Figure 2: The high-level design of data pipelines in Trinity-RFT.
User-friendliness as a top priority.
For development and research, the modular and decoupled design of Trinity-RFT allows the user to develop new RFT methodologies by adding one or a few small, plug-and-play classes (modified from built-in templates) that implement the essential functionalities of interest, with minimal code duplication or intrusive changes to the codebase. An example can be found in Section 3.2, which shows that three compact python classes (with around 200 lines of code in total) suffice for implementing a hybrid RL process that leverages samples from multiple data sources and updates the policy model with a customized loss function. For applications, the user can adapt Trinity-RFT to a new scenario by simply implementing a single Workflow class that specifies the logic of agent-environment interaction, as will be exemplified in Section 3.1. To further enhance usability, Trinity-RFT incorporates various graphical user interfaces to support low-code usage and development, enhance transparency of the RFT process, and facilitate easy monitoring and tracking.
### 1.2 Related Works
There exist numerous open-source RLHF frameworks, such as veRL [30], OpenRLHF [13], TRL [40], ChatLearn [1], Asynchronous RLHF [23], among others. Some of them have been further adapted for training long-CoT reasoning models or for agentic RL more recently.
Concurrent to Trinity-RFT, some recent works on LLM reinforcement learning also advocate a decoupled and/or asynchronous design; examples include StreamRL [50], MiMo [44], AReaL [9], ROLL [37], LlamaRL [43], Magistral [18], AsyncFlow [12], among others.
Complementary to this huge number of related works, Trinity-RFT provides the community with a new solution that is powerful, easy-to-use, and unique in certain aspects. In a nutshell, Trinity-RFT aims to be general-purpose and applicable to diverse application scenarios, while unifying various RFT modes, RFT methodologies at macroscopic and microscopic levels, and RFT-core/agent-environment interaction/data pipelines. Such a system-engineering perspective makes Trinity-RFT particularly useful for handling the whole RFT pipeline in one place. We also hope that some specific features of Trinity-RFT, such as data persistence in the experience buffer, and distributed deployment of multiple independent explorers, will open up new opportunities for LLM reinforcement fine-tuning.
## 2 Design and Implementations
The overall design of Trinity-RFT exhibits a trinity consisting of (1) RFT-core, (2) agent-environment interaction, and (3) data pipelines, which are illustrated in Figure 1 and elaborated in this section.
### 2.1 RFT-Core
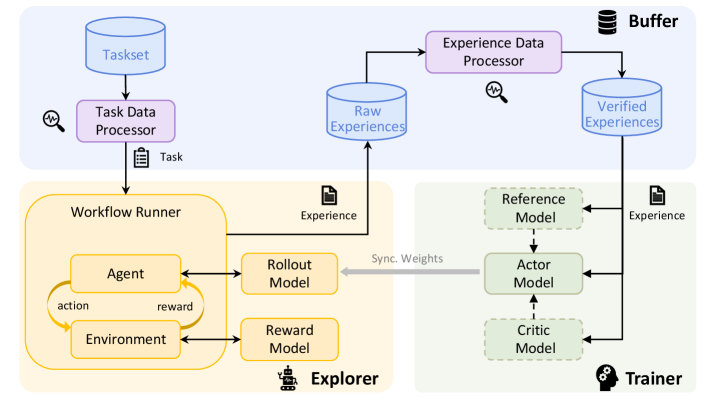
RFT-core is the component of Trinity-RFT, highlighted at the center of Figure 1, where the core RFT process happens. Its design also exhibits a trinity, consisting of the explorer, buffer, and trainer.
- The explorer, powered by a rollout model, takes a task as input and solves it by executing a workflow that specifies the logic of agent-environment interaction, thereby collecting experiences (including rollout trajectories, rewards, and other useful information) to be stored in the buffer.
- The buffer stores experiences that can be generated by the explorer or by other sources, such as human experts. It can be realized in various forms, such as a non-persistent ray.Queue or a persistent SQLite database. It also assists with fetching training samples for the trainer, and can be integrated with advanced sampling strategies and post-processing operations.
- The trainer, backed by a policy model, samples batches of experiences from the buffer and updates the policy model via RL algorithms.
Our implementations allow the explorer and trainer to be deployed on separate machines and act independently. They are only connected via (1) access to the same experience buffer with a customizable sampling strategy, and (2) model weight synchronization by a customizable schedule. See Figure 3 for an illustration. This decoupled design of RFT-core offers support for diverse RFT modes with great flexibility.
<details>
<summary>x4.png Details</summary>
### Visual Description
## System Architecture Diagram: Reinforcement Learning Workflow with Experience Buffer
### Overview
The image displays a technical system architecture diagram illustrating a reinforcement learning (RL) workflow. The diagram is segmented into three primary colored regions representing distinct functional modules: a **Data Processing Layer** (light blue, top), an **Explorer Module** (yellow, left), and a **Trainer Module** (light green, right). The flow depicts how tasks are processed, experiences are generated and stored, and models are trained and synchronized.
### Components/Regions
The diagram is organized into three main spatial regions:
1. **Top Region (Light Blue Background): Data Processing & Buffer**
* **Components:**
* `Taskset` (Cylinder/Database icon, top-left)
* `Task Data Processor` (Purple rectangle, below Taskset)
* `Experience Data Processor` (Purple rectangle, top-center)
* `Raw Experiences` (Cylinder/Database icon, center)
* `Verified Experiences` (Cylinder/Database icon, top-right)
* `Buffer` (Database icon with label, top-right corner)
* **Flow & Labels:** An arrow from `Taskset` to `Task Data Processor` is labeled with a document icon and the word `Task`. An arrow from `Raw Experiences` to `Experience Data Processor` has a magnifying glass icon. An arrow from `Experience Data Processor` to `Verified Experiences` also has a magnifying glass icon. An arrow from `Verified Experiences` points to the `Buffer` icon.
2. **Left Region (Yellow Background): Explorer**
* **Components:**
* `Workflow Runner` (Large yellow rounded rectangle)
* `Agent` (Yellow rectangle inside Workflow Runner)
* `Environment` (Yellow rectangle inside Workflow Runner, below Agent)
* `Rollout Model` (Yellow rectangle, right of Workflow Runner)
* `Reward Model` (Yellow rectangle, below Rollout Model)
* **Flow & Labels:** Inside the `Workflow Runner`, a circular flow is shown: an arrow from `Agent` to `Environment` is labeled `action`, and an arrow from `Environment` back to `Agent` is labeled `reward`. A double-headed arrow connects `Agent` and `Rollout Model`. A double-headed arrow connects `Environment` and `Reward Model`. An arrow from `Rollout Model` points to the `Raw Experiences` database in the top region, labeled with a document icon and the word `Experience`. A robot icon is placed near the `Reward Model`.
3. **Right Region (Light Green Background): Trainer**
* **Components:**
* `Reference Model` (Green dashed rectangle, top)
* `Actor Model` (Green dashed rectangle, center)
* `Critic Model` (Green dashed rectangle, bottom)
* **Flow & Labels:** All three models (`Reference Model`, `Actor Model`, `Critic Model`) receive input via arrows originating from the `Verified Experiences` database. These arrows are each labeled with a document icon and the word `Experience`. A thick, gray, double-headed arrow labeled `Sync. Weights` connects the `Actor Model` (in the Trainer region) to the `Rollout Model` (in the Explorer region). A head-with-gears icon is placed in the bottom-right corner of this region.
### Detailed Analysis: Component Relationships and Data Flow
The diagram defines a closed-loop system for training RL agents using stored experiences.
1. **Task Initiation:** The process begins with a `Taskset` (a collection of tasks). The `Task Data Processor` extracts a specific `Task` and sends it to the `Workflow Runner` within the Explorer.
2. **Experience Generation (Explorer):** Inside the `Workflow Runner`, an `Agent` interacts with an `Environment` by taking `action`s and receiving `reward`s. This interaction loop generates experience data. The `Rollout Model` (likely responsible for generating trajectories) and the `Reward Model` (for evaluating states/actions) are part of this process. The `Rollout Model` sends generated `Experience` data to the `Raw Experiences` database.
3. **Experience Processing (Buffer):** The `Experience Data Processor` retrieves data from `Raw Experiences`, processes or filters it (indicated by the magnifying glass icons), and outputs cleaned `Verified Experiences` into a `Buffer` for later use.
4. **Model Training (Trainer):** The `Verified Experiences` from the buffer are used as training data for three models in the Trainer module: the `Reference Model`, the `Actor Model`, and the `Critic Model`. This suggests a model-based or actor-critic RL training paradigm.
5. **Synchronization:** A critical feedback loop is shown by the `Sync. Weights` arrow. The trained `Actor Model`'s parameters are synchronized back to the `Rollout Model` in the Explorer, updating it for future experience generation. This creates an iterative cycle of experience collection and model improvement.
### Key Observations
* **Modular Design:** The system is cleanly separated into data handling, exploration (data generation), and training (model improvement) modules.
* **Central Role of Experience Buffer:** The `Buffer` containing `Verified Experiences` acts as the central hub, decoupling the Explorer and Trainer. This allows for asynchronous data generation and training.
* **Model Synchronization:** The explicit `Sync. Weights` connection highlights that the policy being executed in the environment (`Rollout Model`) is periodically updated with the improved policy learned by the `Actor Model`.
* **Iconography:** Icons are used consistently to denote data types: a document icon for `Task` and `Experience`, a magnifying glass for processing/inspection, a robot for the Explorer module, and a head with gears for the Trainer module.
### Interpretation
This diagram represents a sophisticated reinforcement learning system designed for stability and efficiency. The architecture addresses several key challenges in RL:
1. **Experience Replay & Stability:** By storing experiences in a `Buffer` and using a `Verified Experiences` database, the system can break temporal correlations in data and reuse past experiences for training, which stabilizes learning.
2. **Parallelization Potential:** The separation of Explorer and Trainer suggests these processes could run in parallel or on different resources. The Explorer can continuously generate new data while the Trainer improves models using stored data.
3. **Policy Iteration:** The core learning loop is clearly depicted: the current policy (in the `Rollout Model`) generates experiences, which are used to train an improved policy (in the `Actor Model`), which is then synced back to become the new data-generating policy. This is a classic policy iteration scheme.
4. **Model-Based Elements:** The presence of a `Reward Model` and `Reference Model` alongside the standard `Actor` and `Critic` suggests this might be a model-based RL setup or one that uses auxiliary tasks and reward shaping to improve learning efficiency and performance.
In essence, the diagram illustrates a production-oriented RL pipeline that emphasizes data management, modular component design, and a continuous cycle of experience collection and policy refinement.
</details>
Figure 3: The architecture of RFT-core in Trinity-RFT.
#### 2.1.1 Unified Support for Diverse RFT Modes
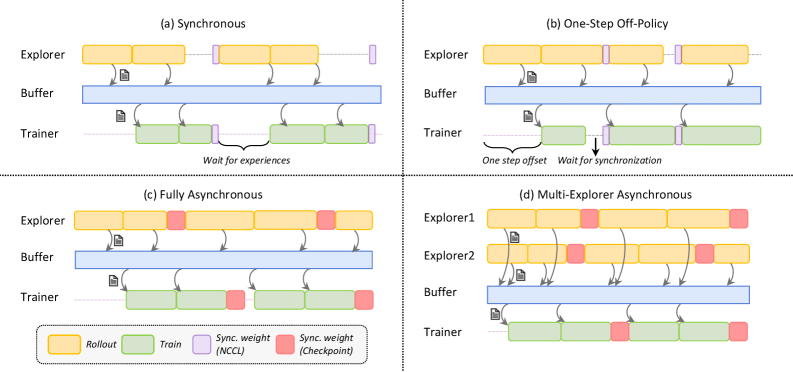
We present the RFT modes supported by Trinity-RFT, some of which are demonstrated in Figure 4.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Diagram: Distributed Training Synchronization Strategies
### Overview
The image is a technical diagram illustrating four different synchronization architectures for distributed reinforcement learning (RL) or similar agent-based training systems. It compares how data collection ("Explorer"), experience storage ("Buffer"), and model training ("Trainer") components are coordinated in time. The diagram is divided into four quadrants, each labeled with a strategy name: (a) Synchronous, (b) One-Step Off-Policy, (c) Fully Asynchronous, and (d) Multi-Explorer Asynchronous.
### Components/Axes
The diagram does not have traditional axes. It uses a consistent visual language across all four sub-diagrams:
* **Primary Components (Vertical Layout):**
* **Explorer:** Top row. Represents the data collection or rollout process.
* **Buffer:** Middle row. Represents the experience replay buffer where collected data is stored.
* **Trainer:** Bottom row. Represents the model training process.
* **Temporal Flow:** Time progresses from left to right. Horizontal bars represent the duration of a process phase.
* **Legend (Bottom Center):**
* **Yellow Bar:** `Rollout` (Data collection phase by Explorer).
* **Green Bar:** `Train` (Model training phase by Trainer).
* **Purple Bar:** `Sync. weight (NCCL)` (Synchronization of model weights using NCCL, a high-speed communication library).
* **Red Bar:** `Sync. weight (Checkpoint)` (Synchronization via saving/loading model checkpoints to/from storage).
* **Data Flow Arrows:** Curved arrows indicate the flow of data (experiences) from Explorer to Buffer and from Buffer to Trainer. Small document icons next to arrows signify data batches.
* **Synchronization Annotations:** Text labels and vertical dashed lines indicate waiting periods and synchronization points.
### Detailed Analysis
#### Sub-diagram (a): Synchronous
* **Flow:** The Explorer completes a `Rollout` (yellow), sends data to the Buffer, and then waits. The Trainer then performs a `Train` step (green) using data from the Buffer. After training, the Trainer sends updated weights (purple `Sync. weight (NCCL)`) back to the Explorer. The Explorer cannot start its next rollout until it receives these updated weights.
* **Key Annotation:** A brace under the Trainer's timeline is labeled `"Wait for experiences"`, indicating the Trainer is idle until new data arrives from the Explorer.
* **Pattern:** Strictly sequential and locked-step. The system throughput is limited by the slowest component in each cycle.
#### Sub-diagram (b): One-Step Off-Policy
* **Flow:** Similar to (a), but with a critical offset. The Explorer starts its next `Rollout` immediately after sending data to the Buffer, without waiting for the Trainer to finish. The Trainer runs `Train` steps on slightly older data from the Buffer.
* **Key Annotations:**
* `"One step offset"` with a downward arrow points to the start of the Trainer's first `Train` block, showing it lags one rollout behind the Explorer.
* `"Wait for synchronization"` with a brace shows the Explorer pausing before its second rollout, waiting for a `Sync. weight (NCCL)` (purple) from the Trainer.
* **Pattern:** Introduces a one-step delay (off-policy) to allow some parallelism, but still requires periodic weight synchronization.
#### Sub-diagram (c): Fully Asynchronous
* **Flow:** The Explorer continuously performs `Rollout` phases (yellow) and sends data to the Buffer without any waiting. The Trainer continuously performs `Train` phases (green) on data from the Buffer. There are no purple `Sync. weight (NCCL)` bars. Instead, red `Sync. weight (Checkpoint)` bars appear at the end of some `Train` phases, indicating asynchronous checkpoint-based weight updates.
* **Pattern:** Fully decoupled Explorer and Trainer. They operate independently at their own pace. Weight synchronization is infrequent and happens via checkpoints, not direct communication.
#### Sub-diagram (d): Multi-Explorer Asynchronous
* **Flow:** This extends the asynchronous model. Two Explorers (`Explorer1`, `Explorer2`) operate in parallel, both performing `Rollout` phases (yellow) and sending data to a shared Buffer. Their timelines are offset. A single Trainer performs `Train` phases (green) on the aggregated data. Like (c), synchronization uses red `Sync. weight (Checkpoint)` bars.
* **Pattern:** Maximizes data collection throughput by parallelizing explorers. The Trainer consumes data from multiple sources asynchronously.
### Key Observations
1. **Increasing Asynchrony:** The progression from (a) to (d) shows a clear trend towards decoupling the Explorer and Trainer processes to improve system utilization and throughput.
2. **Synchronization Mechanism Shift:** Strategies (a) and (b) rely on fast, direct weight synchronization (`NCCL`, purple). Strategies (c) and (d) abandon this for less frequent, checkpoint-based synchronization (`Checkpoint`, red), which is simpler but introduces greater model staleness.
3. **Bottleneck Identification:** In (a), the "Wait for experiences" annotation explicitly identifies the Trainer as the bottleneck when it's idle. The other designs aim to eliminate such idle times.
4. **Complexity vs. Performance:** The architectures trade off implementation complexity and algorithmic stability (synchronous is simpler and more stable) for potential performance gains (asynchronous can be faster but may suffer from stale gradients or data).
### Interpretation
This diagram is a conceptual guide for designing distributed RL training systems. It visually argues that moving from synchronous to asynchronous architectures can alleviate system bottlenecks and increase training speed.
* **Synchronous (a):** Represents the baseline. It's easy to reason about and stable but inefficient, as the entire system waits for the slowest operation in each cycle.
* **One-Step Off-Policy (b):** A pragmatic compromise. It introduces a small, controlled delay (one step) to enable overlap between collection and training, boosting efficiency while maintaining relatively tight coupling for model updates.
* **Fully Asynchronous (c) & Multi-Explorer (d):** Represent high-performance, scalable designs. They treat the Explorer and Trainer as independent services communicating through a shared buffer. This maximizes hardware utilization but introduces challenges like training on stale data (the "staleness" problem in distributed ML) and requires careful tuning to ensure learning stability. The multi-explorer variant (d) further scales data ingestion, which is often the primary bottleneck in real-world RL.
The choice between these strategies involves a fundamental trade-off between **system throughput** and **learning efficiency/stability**. The diagram helps engineers visualize this trade-off by mapping the flow of data and control, making it easier to select an architecture based on their specific constraints (e.g., number of GPUs, need for training speed vs. final model performance).
</details>
Figure 4: A visualization of diverse RFT modes supported by Trinity-RFT, including: (a) synchronous mode, with sync_interval=2; (b) one-step off-policy mode, with sync_interval=1 and sync_offset=1; (c) fully asynchronous mode, with sync_interval=2; (d) multi-explorer asynchronous mode, with sync_interval=2. The buffer supports, in principle, arbitrary management and sampling strategies for experiences.
Synchronous mode.
In the synchronous mode shown in Figure 4 (a), the explorer and trainer get launched simultaneously, work in close coordination, and synchronize their model weights once every sync_interval training steps. Within each synchronization period, the explorer continuously generates sync_interval batches of rollout experiences and stores them in the buffer, which are then retrieved and utilized by the trainer for updating the policy model. If sync_interval=1, this is a strictly on-policy RL process, whereas if sync_interval>1, it becomes off-policy (akin to the mode adopted in [35]) and can be accelerated by pipeline parallelism between the explorer and trainer. This mode can be activated by setting the configuration parameter mode=both.
One-step off-policy mode.
This mode, demonstrated in Figure 4 (b), closely resembles the synchronous mode, except for an offset of one batch between the explorer and trainer. This allows the trainer to sample experiences from the buffer immediately after model weight synchronization, thereby streamlining the execution of explorer and trainer with smaller pipeline bubbles, at the cost of slight off-policyness. The visualization in Figure 4 (b) corresponds to configuration parameters sync_interval=1 and sync_offset=1, both of which can take more general values in Trinity-RFT.
Asynchronous mode.
In the fully asynchronous mode shown in Figure 4 (c), the explorer and trainer act almost independently. The explorer continuously generates rollout experiences and stores them in the buffer, while the trainer continuously samples experiences from the buffer and uses them for training the policy model. External experiences, e.g., those generated by expert models or humans, can be continuously incorporated into the buffer as well. The explorer and trainer independently load or save model weights from the checkpoint directory every sync_interval steps, keeping the distribution of rollout experiences up to date. This mode can be activated by setting mode=explore/train and launching the explorer and trainer separately on different GPUs.
Multi-explorer asynchronous mode.
One benefit brought by the decoupled design is that explorers and trainers can scale up independently on separate devices. As a proof-of-concept, Trinity-RFT offers support for a multi-explorer asynchronous mode, as demonstrated in Figure 4 (d), where multiple explores send the generated rollout experiences to the same buffer. Scaling up the number of independent and distributed explorers can be particularly useful for resolving data scarcity and speeding up the generation of experiences in real-world scenarios where rollout trajectories have to be sampled via interaction with the physical world, or in an environment with sparse and lagged feedback. Another by-product of this multi-explorer mode is 24-hour non-interrupted service for real-world online serving situations: since the explorers can pause and update model weights at different moments, it can be guaranteed that there is always one explorer ready to serve an incoming request immediately whenever it arrives. This is in contrast to a single-explorer mode, where online service has to be paused when the explorer is updating its model weights.
Benchmark mode.
Trinity-RFT supports a benchmark mode that allows the user to evaluate one or multiple checkpoints on arbitrary benchmarks, after the RFT training process has finished. To activate this mode, the user simply needs to set mode=bench and specify the paths for the evaluation datasets in the configurations. This mode can be particularly useful for experimental purposes; for example, the user might want to try out different RFT techniques or configurations quickly (with limited evaluation on hold-out data) during training, identify which RFT trials have achieved stable convergence and high rewards, and then conduct more thorough evaluations only for the checkpoints of these successful trials.
Train-only mode.
In certain scenarios, the user would like to train the policy model without further exploration, using experiences that have already been collected and stored in the buffer. This train-only mode can be activated by setting the configuration parameter mode $=$ train and launching the trainer alone. Offline methods like Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) [25] can be regarded as special cases of such scenarios, both of which are natively supported by Trinity-RFT. For another example, consider an online RFT process that expands over a long period, where the explorer alone is launched during the daytime for serving human users and collecting experiences, while the trainer alone is launched at night for updating the policy model (which will be thoroughly validated and evaluated before it can be actually deployed as the rollout model for the next day).
Discussions.
We conclude this subsection with two remarks. (1) Given the unified implementation of various RFT modes, it is easy to design and implement a hybrid mode with Trinity-RFT that combines multiple modes into a single learning process. One example is learning with both online rollout data and offline-collected expert data, via jointly optimizing two loss terms corresponding to these two data sources. Section 3.2 illustrates how to implement this conveniently in Trinity-RFT. (2) We take a system-algorithm co-design perspective in the development of Trinity-RFT, aiming to unify and generalize diverse RFT methodologies in this framework. RFT-core provides the necessary infrastructure for achieving this goal. This technical report focuses on the system perspective, and we refer interested readers to the literature for recent algorithmic developments in off-policy / asynchronous RL for LLMs [21, 6, 26, 35, 7, 23, 42, 45, 46, 47].
#### 2.1.2 Implementations of RFT-Core
We present some implementation details of RFT-core in the following.
Inference and training engines.
The current version of Trinity-RFT leverages vLLM [15] as the inference engine for the explorer, which offers features including paged attention, continuous batching [49], asynchronous and concurrent inference for multiple rollout trajectories, among others. Trinity-RFT also leverages verl [30] as the training engine for the trainer, which gracefully handles model placement (for the policy, critic and reference models) and incorporates various performance optimizations for training (such as dynamic batching, management of padding and unpadding, etc.). Trinity-RFT stands on the shoulders of these excellent open-source projects, and will continue to benefit from their future development.
Experience buffer.
Trinity-RFT supports multiple types of experience buffers, ranging from a non-persistent ray.Queue to persistent SQLite or Redis databases. While using a basic first-in-first-out queue is the most straightforward approach, data persistence with a database opens up many new opportunities (e.g., advanced sampling strategies), as discussed throughout this report. Trinity-RFT has provided dedicated read/write control to prevent any conflict in accessing the buffer.
Model weight synchronization.
Trinity-RFT supports model weight synchronization between the explorer and trainer by NCCL [22], or by checkpoint saving and loading. The former is faster (when available), while the latter is generally more flexible and widely applicable, especially for asynchronous RFT modes.
### 2.2 Agent-Environment Interaction
To adapt Trinity-RFT to a new downstream scenario, the user mainly needs to define and register a customized workflow (by inheriting the base class Workflow or MultiTurnWorkflow) where the logic of agent-environment interaction for this particular scenario is implemented. Advanced methods for experience synthesis with environmental feedback [4] can be implemented in the same way as well. See Section 3.1 for detailed examples. The workflow will then be executed by workflow runners within the explorer for generating experiences, as shown in Figure 3.
Numerous challenges arise when one tries to build an RFT framework that can efficiently and robustly handle real-world interaction between the LLM-powered agent and the environment. These include long-tailed latencies, agent/environment failures, and lagged reward signals, among others. Trinity-RFT regards agent-environment interaction as a first-class citizen and incorporates various solutions to tackle these challenges, for example:
- The workflow runners in Trinity-RFT support asynchronous and streaming generation of rollout trajectories for multiple tasks. This helps mitigate the straggler effect caused by the long-tailed latencies in rollout generation and agent-environment interaction, thereby accelerating the RFT process. Load balancing among multiple LLM inference engines within one RFT training course is also taken care of, and would be one direction for further optimizing the utilization of computational resources.
- Trinity-RFT incorporates various timeout/retry/skip mechanisms for fault tolerance and robustness, which ensure that continuous rollout generation would not be interrupted or blocked by individual failures in certain rounds of agent-environment interaction. This is crucial for stable and efficient learning in real-world scenarios, e.g., when the agent interacts with a large number of MCP services [17] that differ vastly in quality and availability.
- Trinity-RFT is built to provide native support for asynchronous RFT modes, which allow great flexibility in the paces of the explorer and trainer. This can boost the overall efficiency of the RFT process, compared to synchronous modes where the slower one among the explorer and trainer can block the progress of the other and cause waste of computational resources.
- For lagged reward signals, the trinity design of RFT-core offers a natural solution. As soon as the rollout trajectory (without reward values) has been generated, it is saved into the experience buffer, but marked as “not ready for training”. The explorer is now free from this task and may continue to collect experiences for other tasks. When the reward signals from the environment finally arrive, they are written to the buffer, and the corresponding experience is now marked as “ready for training”.
- For multi-turn conversations and ReAct-style workflows [48], Trinity-RFT supports concatenating multiple rounds of agent-environment interaction compactly into a single sequence, with proper masking that indicates which tokens need to be incorporated into the training objective of RL algorithms. This avoids unnecessary recomputation and thus improves training efficiency, compared to a vanilla approach that represents a $K$ -turn rollout trajectory with $K$ separate samples.
- As another performance optimization, the implementation of Trinity-RFT allows resetting the environment in a workflow, rather than re-initializing it every time. This is especially useful for scenarios where setting up the environment is costly.
### 2.3 Data Pipelines
The data pipelines in Trinity-RFT aim to address fundamental challenges in RFT scenarios, such as managing heterogeneous data dynamics across interaction workflows, enabling delayed reward integration, and facilitating continuous data curation. Our solutions center on four core aspects: end-to-end data transformation, task curation, active experience shaping, and human-in-the-loop curation, each corresponding to key requirements identified in our development of RFT-core (Section 2.1).
#### 2.3.1 End-to-end Data Transformation
To support the diverse RFT modes (e.g., synchronous or asynchronous) in Trinity-RFT, we establish a service-oriented data pipeline architecture as illustrated in Figure 5. It decouples data pipeline logic from procedure control to enable flexible RL-oriented data transformations with two key modules:
- The Formatter Module unifies disparate data sources into RFT-compatible formats, providing convenient conversion between raw inputs (e.g., meta-prompts, domain-specific corpora, and QA pairs with tagged rewards) and structured RFT representations. For efficient RFT workloads, we utilize buffer-based persistent storage (Section 2.1) to support different data models, such as ExperienceModel for prioritized rollout trajectories and DPODataModel for preference pairs. The conversion logic and data models are highly customizable to meet diverse requirements for managing experience data. This flexibility enables robust metadata recording and field normalization, which is essential for advanced scenarios such as asynchronous RFT in trainer-explorer environments, agent self-evolution from a cold start using meta-prompts, and knowledge injection from structurally complex domain-specific corpora.
- The Controller Module manages the complete data pipeline lifecycle through distributed server initialization, declarative configuration, and automated dataset persistence. It implements dynamic control mechanisms for asynchronous scenarios and protection against resource exhaustion, with configurable termination conditions based on compute quota or data quantity. This modular design enables Trinity-RFT to handle data transformations flexibly while maintaining consistency across different RFT modes.
The Formatter-Controller duality mirrors the explorer-trainer decoupling in RFT-core, enabling parallel data ingestion and model updating. This design also allows Trinity-RFT to handle delayed rewards through version-controlled experience updates while maintaining low-latency sampling for the trainer.
<details>
<summary>x6.png Details</summary>
### Visual Description
## System Architecture Diagram: Dual-Loop Learning Pipeline
### Overview
The image is a technical system architecture diagram illustrating a dual-loop learning or training pipeline. It depicts two primary, parallel processing stages—"Task Curation & Prioritization" and "Experience Shaping"—that interact with a central "Buffer" and two agent-like components, an "Explorer" and a "Trainer." The flow suggests a continuous cycle of data processing, exploration, and model training.
### Components/Axes
The diagram is organized into distinct regions and components:
1. **Top-Left Region: "Task Curation & Prioritization"**
* Enclosed in a purple dashed rectangle.
* **Data Processor** (Purple box with magnifying glass icon): Central processing unit.
* **Raw Data** (Blue cylinder): Input data store.
* **Taskset** (Blue cylinder): Output data store for curated tasks.
* **Flow:** `Raw Data` -> `Data Processor` -> `Taskset`.
* **Data Processor Functions (Bullet Points):**
* Convert format
* Clean & augment
* Online Scoring
* ...
2. **Top-Right Region: "Experience Shaping"**
* Enclosed in a purple dashed rectangle.
* **Data Processor** (Purple box with magnifying glass icon): Central processing unit.
* **Raw Experience** (Blue cylinder): Input data store.
* **Experience** (Blue cylinder): Output data store for shaped experiences.
* **Flow:** `Raw Experience` -> `Data Processor` -> `Experience`.
* **Data Processor Functions (Bullet Points):**
* Dense rewards
* Human-in-the-loop
* Counterfactual, dynamic synthesis
* ...
3. **Central Horizontal Band: "Buffer"**
* A light blue shaded area spanning the width of the diagram, positioned below the two main processing regions.
* It acts as a shared memory or communication channel between the upper processing loops and the lower agent components.
4. **Bottom Components:**
* **Explorer** (Yellow box with robot icon): Positioned centrally below the Buffer.
* **Trainer** (Light green box with head/gears icon): Positioned to the right of the Explorer.
5. **Data & Feedback Flows (Arrows and Icons):**
* **Task Flow:** `Taskset` (in Buffer) -> `Explorer` (downward arrow with clipboard icon).
* **Environment Feedback:** `Explorer` -> `Buffer` (dotted arrow pointing left, labeled "Environment Feedback").
* **Experience Flow:** `Explorer` -> `Raw Experience` (in Buffer) (upward arrow with document icon).
* **Shaped Experience Flow:** `Experience` (in Buffer) -> `Trainer` (downward arrow with document icon).
* **Model Feedback:** `Trainer` -> `Buffer` (dotted arrow pointing left, labeled "Model Feedback").
### Detailed Analysis
The diagram describes a closed-loop system with two distinct data processing pipelines that feed into and are informed by an interactive agent loop.
* **Left Pipeline (Task Curation):** Focuses on preparing structured tasks from raw data. The "Data Processor" here performs data engineering and prioritization tasks (format conversion, cleaning, scoring) to create a "Taskset."
* **Right Pipeline (Experience Shaping):** Focuses on processing experiential data, likely from interactions. The "Data Processor" here applies reward shaping, human feedback, and synthetic data generation techniques to create refined "Experience."
* **Central Buffer:** Serves as the integration point. It holds the `Taskset` for the Explorer, receives `Raw Experience` from the Explorer, and holds the shaped `Experience` for the Trainer.
* **Agent Interaction:**
* The **Explorer** consumes tasks from the `Taskset` and interacts with an external environment (implied by "Environment Feedback"). Its interactions generate `Raw Experience`.
* The **Trainer** consumes the shaped `Experience` to update a model. It provides "Model Feedback" back into the system, which likely influences future task curation or experience shaping.
### Key Observations
1. **Symmetry and Duality:** The two top processing blocks are structurally symmetrical (Data Processor + two cylinders) but functionally distinct (task preparation vs. experience refinement).
2. **Feedback Loops:** The system contains multiple feedback loops: Environment Feedback to the Buffer, Model Feedback to the Buffer, and the overarching cycle from Task -> Explorer -> Experience -> Trainer.
3. **Role of the Buffer:** The Buffer is not just a passive store; it's the central nervous system routing information between the curation, shaping, exploration, and training modules.
4. **Iconography:** Icons are used consistently to denote component types (magnifying glass for processors, cylinders for storage, robot for explorer, head/gears for trainer) and data types (clipboard for tasks, document for experiences).
### Interpretation
This diagram represents a sophisticated framework for **interactive machine learning or reinforcement learning**. It moves beyond a simple data->train pipeline by introducing two critical, specialized preprocessing stages:
1. **Proactive Task Curation:** Instead of feeding random data, the system actively curates and prioritizes tasks (`Taskset`) for the Explorer. This suggests an emphasis on efficient exploration or curriculum learning.
2. **Reactive Experience Shaping:** Raw interaction data (`Raw Experience`) is not used directly for training. It undergoes significant transformation (`Experience`) using advanced techniques like dense reward modeling and counterfactual synthesis. This is crucial for stabilizing learning and improving sample efficiency.
The **Explorer** acts as the embodied agent or data collector, while the **Trainer** is the learning algorithm. The **Buffer** and the two **Data Processors** form an intelligent middleware layer that manages the *quality* and *relevance* of both the inputs to the agent (tasks) and the inputs to the model (training experiences). The dual feedback loops (Environment and Model) allow the entire system to adapt dynamically, potentially enabling the task curation and experience shaping strategies to evolve based on the agent's performance and the model's learning progress. This architecture is designed for complex, interactive environments where data efficiency and strategic exploration are paramount.
</details>
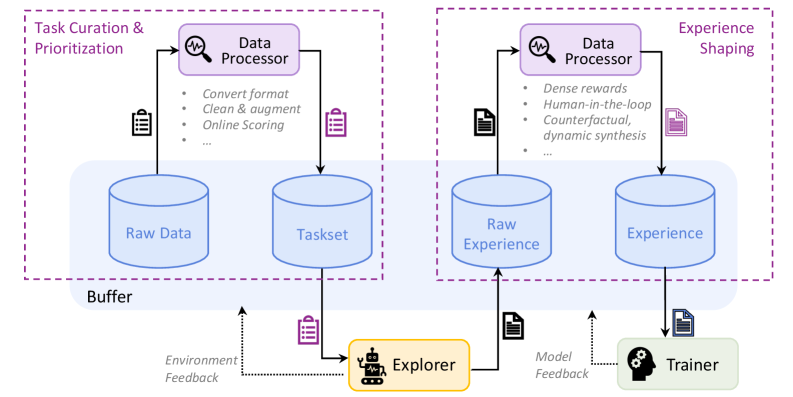
Figure 5: The interaction of data processor and data buffers in Trinity-RFT, divided into two key stages. Left: Task Curation & Prioritization prepares the initial tasks for the explorer. Right: Experience Shaping processes the collected trajectories from the explorer before they are used by the trainer. The data processor is a central component that operates on different buffers at different stages.
#### 2.3.2 Task Curation and Prioritization
Before the RFT loop begins, it is crucial to prepare a high-quality set of initial tasks. This stage, depicted on the left side of Figure 5, transforms raw data into an optimized task set for the explorer.
The process begins with raw data sources (e.g., prompts, domain corpora), which are ingested into a buffer. The Data Processor, powered by over 100 operators from Data-Juicer [2], reads from this buffer to perform various curation tasks. It provides composable building blocks for experience cleaning (e.g., length filters, duplication removal), safety alignment (e.g., toxicity detection, ethics checks), and preference data synthesis (e.g., critique-conditioned augmentation). By treating Data-Juicer as a modular data processing operator pool rather than a central dependency, Trinity-RFT provides RL-specific abstractions and coherence, while benefiting from well-established data tools.
The processed data is then organized into a structured task buffer. This stage effectively implements a form of curriculum learning by allowing users to prioritize tasks (e.g., from easy to hard), guiding the explorer towards a more efficient and stable learning trajectory from the outset. This entire workflow is managed by a service-oriented architecture that decouples data logic from procedural control, ensuring flexibility and scalability, especially in asynchronous and distributed settings.
#### 2.3.3 Active Experience Shaping
Once the explorer begins interacting with the environment, it generates a continuous stream of experience data. To maximize learning efficiency, this raw experience must be actively shaped before it reaches the trainer. This stage is shown on the right side of Figure 5.
Generated experiences are first collected in a buffer. The Data Processor is applied again with a series of transformations to clean, augment, or synthesize these experiences. This is where the core of RFT data intelligence lies. Key capabilities include:
- Agent-Driven Data Processing: Trinity-RFT introduces a powerful agentic paradigm for data manipulation. Users can define complex processing pipelines through high-level objectives, specified as either natural language commands (e.g., “improve safety” or “increase response diversity”) or explicit Data-Juicer configurations. The framework automatically translates these commands into executable workflows backed by its modular components like DataCleaner and DataSynthesizer. This design provides a user-friendly abstraction layer over the underlying Data-Juicer operators, making advanced processing functionalities accessible to both RFT users familiar with Data-Juicer and those who are not. It also facilitates the flexible injection of user-defined inductive biases into the learning process, unlocking new research directions for self-evolving agents, as we will discuss later in Section 2.3.5.
- Online Reward Shaping: The data processor can dynamically augment the reward signal. Instead of relying on a single, often sparse, task-completion reward, users can add dense rewards based on quality, diversity, or safety scores computed on the fly. This enriched feedback provides a much stronger learning signal for the trainer.
- Prioritized Experience Replay: Experiences are not treated equally. Trinity-RFT allows for flexible, multi-dimensional utility scoring to prioritize the most valuable samples for training. The DataActiveIterator supports version-controlled experience reuse and cross-task data lineage tracking, ensuring that the trainer always learns from the most informative data available. This mechanism is also critical for handling delayed rewards, as experience utilities can be updated asynchronously as new feedback arrives.
#### 2.3.4 Human-AI Collaboration
In scenarios where human feedback is irreplaceable, Trinity-RFT establishes a bi-directional human-AI collaboration loop that provides first-class support for human annotations, based on Label Studio [39] and Data-Juicer’s HumanOPs.
- Multi-stage annotation. Trinity-RFT implements configurable procedures combining automatic pre-screening and human verification. Typical stages include preference annotation (comparative assessment of model responses), quality auditing (human verification of automated cleaning/synthesis results), and cold-start bootstrapping (initial dataset curation through expert demonstrations).
- Native asynchronism support. As the collection of human feedback is generally slower than AI/model feedback, we provide dedicated capabilities to handle both synchronous and asynchronous feedback modes, with configurable timeout and polling parameters. The feedback collaboration is based on an event-driven design, with automatic task creation upon data state changes, configurable notifications via email/Slack/webhook, and an atomic transaction model for annotation batches.
- Customization. Different applications may involve humans in heterogeneous ways. We thus prioritize flexibility in both the interaction-interface and service levels. Examples include rich built-in interfaces that can be extended in a visualized style with XML-like tags provided by Label Studio, fine-grained quality scoring for reward shaping, free-form feedback attachment for dataset shaping, among others. Moreover, for easy deployment, we provide local Label Studio instance management with automatic environment setup via Docker/pip; optimized SDK interactions with batch request coalescing; unified logging across annotation tools and ML services; and concurrent annotation campaigns through priority-based task routing, while maintaining full data lineage preserved via LineageTracker.
The decoupled design of Trinity-RFT, and the presence of a standalone experience buffer in particular, enable human feedback to participate in RL loops without breaking the asynchronous execution model. For instance, human-verified samples can be prioritized for training while fresh experiences are being collected, which is a critical capability for real-world deployment scenarios with mixed feedback sources. Further details for human-AI collaboration in Trinity-RFT will be illustrated in Section 3.5.
#### 2.3.5 Discussion: Unlocking New Research & Development Directions
The modular design of our data pipelines and the powerful data processor open up promising research and development avenues to be further explored.
One direction is about effective management of experience data. While prior RFT works often treat the experience as a static log, Trinity-RFT enables a more sophisticated, full-lifecycle approach to data, from selective acquisition to efficient representation:
- Intelligent Perception and Collection: In an open-ended environment, what experience is “worth” recording? Storing everything creates a low signal-to-noise ratio and burdens the trainer. Trinity-RFT ’s architecture allows researchers to implement active collection strategies. For instance, one could design a data processor operator that evaluates incoming experiences from the explorer based on metrics like surprise, uncertainty, or information gain, and only commits the most salient trajectories to the replay buffer. This transforms data collection from passive logging into a targeted, intelligent process.
- Adaptive Representation: Raw experience is often high-dimensional and redundant (e.g., long dialogues, complex code generation traces). How can this be distilled into a format that an agent can efficiently learn from? The data processor in Trinity-RFT acts as a powerful transformation engine. Researchers can use it to explore various representation learning techniques, such as automatically summarizing trajectories, extracting causal chains from tool usage, or converting a multi-turn dialogue into a structured preference pair. This not only makes training more efficient but also opens the door to building meta-experience (more abstract and reusable knowledge) from raw interaction data.
- Agentic Workflows: Trinity-RFT ’s agent-driven processing enables the research and development of self-improving agents, e.g., by configuring the policy agent to also serve as the “processing agent” for LLM-based Data-Juicer operators. Such an agent could perform its own critique and dynamically curate its own training data, creating a truly autonomous learning and data management loop.
Another direction is about synthetic and counterfactual experience processing. The integration of synthesis operators enables research into creating “better-than-real” data. Instead of relying solely on the agent’s own trial-and-error, our framework facilitates exploring questions like:
- Dynamic and Composable Rewarding: With our framework, researchers can move beyond static, hand-crafted rewards. It is now possible to investigate dynamic reward shaping, where auxiliary signals like novelty, complexity, or alignment scores are automatically extracted from trajectories and composed into a dense reward function. How to define “good” experience and how can we learn the optimal combination of these reward components as the agent’s policy evolves?
- Experience Reorganization: Can successful sub-trajectories from different tasks be “spliced” together to solve a novel, composite task? For example, can an agent that has learned to “open a door” and “pick up a cup” synthesize a new trajectory to "enter the room and fetch the cup"?
- Failure Repair: Can the data processor identify where errors occur in a failed trajectory, and synthesize a corrected version for the trainer to learn from, effectively turning failures into valuable lessons?
- Success Amplification: Can a single successful experience be augmented into multiple diverse yet successful variants, thereby improving the generalization and robustness of the learned policy?
By providing dedicated capabilities for such advanced data and reward manipulation, Trinity-RFT aims to facilitates flexible processing of “experience data” for the next generation of self-evolving LLMs.
### 2.4 User-Friendliness
Trinity-RFT has been designed with user-friendliness as a top priority.
For development and research:
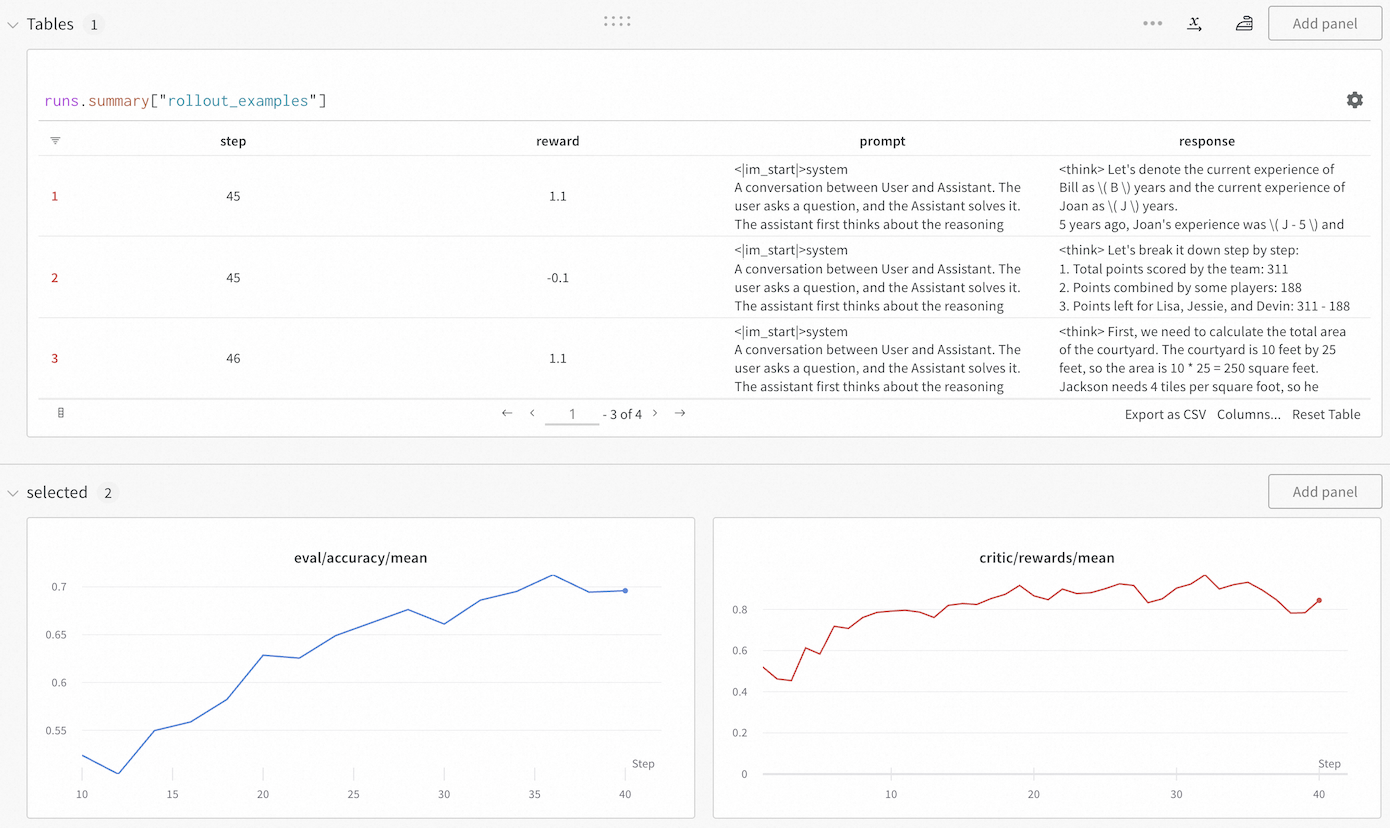
The modular and decoupled design of Trinity-RFT allows users to develop a new algorithm for a specific aspect of RFT by adding one or a few new classes that implement the essential functionalities of interest, without concerning about other aspects of RFT or intrusive modifications of the original codebase. In addition, we include a monitor (built upon Wandb [41] and TensorBoard [38]) that makes it easy to track the progress of an RFT process, both quantitatively (e.g., via learning curves for rewards and other metrics) and qualitatively (e.g., via concrete examples of rollout trajectories generated at different RL steps). See Figure 6 for an example snapshot of the monitor.
For RFT applications:
Trinity-RFT offers extensive graphical user interfaces to support low-code usage of the framework, and to maximize transparency of the RFT process. For example, we implement a configuration manager, as shown in Figure 7, that allows the user to create configuration files conveniently via a front-end interface. We also provide Trinity-Studio, an all-in-one unified UI (including the aforementioned monitor and configuration manager) that allows the user to configure and run data inspection, data processing, RFT learning process, etc., all by clicking the mouse and filling forms, without writing any code. An example for using Trinity-Studio will be introduced in Section 3.6. Such functionalities, of course, can be useful not only for applications but also for development and research.
<details>
<summary>figs/wandb_screencut.png Details</summary>
### Visual Description
\n
## Dashboard Screenshot: Training Metrics and Rollout Examples
### Overview
The image displays a monitoring dashboard, likely from a machine learning or AI training platform. It consists of two main sections: a data table at the top showing specific training rollout examples, and two line charts at the bottom tracking aggregate metrics over training steps. The interface includes controls for adding panels, exporting data, and navigating the table.
### Components/Axes
**Top Section - Table Panel:**
* **Panel Title:** `Tables 1`
* **Table Query/Label:** `runs.summary["rollout_examples"]`
* **Table Columns:**
1. (Index Column - unlabeled header)
2. `step`
3. `reward`
4. `prompt`
5. `response`
* **Table Navigation:** Shows rows 1-3 of 4 total (`1 - 3 of 4`). Navigation arrows (`<`, `>`) and a page number (`1`) are present.
* **Table Actions:** `Export as CSV`, `Columns...`, `Reset Table`.
**Bottom Section - Charts Panel:**
* **Panel Title:** `selected 2`
* **Left Chart:**
* **Title:** `eval/accuracy/mean` (text color matches the blue line).
* **Y-Axis:** Labeled with values from `0.55` to `0.7` in increments of `0.05`.
* **X-Axis:** Labeled `Step` with major ticks at `10`, `15`, `20`, `25`, `30`, `35`, `40`.
* **Data Series:** A single blue line.
* **Right Chart:**
* **Title:** `critic/rewards/mean` (text color matches the red line).
* **Y-Axis:** Labeled with values from `0` to `0.8` in increments of `0.2`.
* **X-Axis:** Labeled `Step` with major ticks at `10`, `20`, `30`, `40`.
* **Data Series:** A single red line.
### Detailed Analysis
**Table Content (Visible Rows):**
* **Row 1:**
* `step`: 45
* `reward`: 1.1
* `prompt`: `<im_start>system\nA conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning`
* `response`: `<think> Let's denote the current experience of Bill as \( B \) years and the current experience of Joan as \( J \) years.\n5 years ago, Joan's experience was \( J - 5 \) and` (text is truncated).
* **Row 2:**
* `step`: 45
* `reward`: -0.1
* `prompt`: `<im_start>system\nA conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning`
* `response`: `<think> Let's break it down step by step:\n1. Total points scored by the team: 311\n2. Points combined by some players: 188\n3. Points left for Lisa, Jessie, and Devin: 311 - 188` (text is truncated).
* **Row 3:**
* `step`: 46
* `reward`: 1.1
* `prompt`: `<im_start>system\nA conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning`
* `response`: `<think> First, we need to calculate the total area of the courtyard. The courtyard is 10 feet by 25 feet, so the area is 10 * 25 = 250 square feet.\nJackson needs 4 tiles per square foot, so he` (text is truncated).
**Chart Data Trends:**
* **`eval/accuracy/mean` (Blue Line):**
* **Trend:** Shows a clear, generally upward trend with some minor fluctuations.
* **Data Points (Approximate):**
* Step 10: ~0.53
* Step 15: ~0.55
* Step 20: ~0.63
* Step 25: ~0.66
* Step 30: ~0.67
* Step 35: ~0.71 (peak)
* Step 40: ~0.70
* **`critic/rewards/mean` (Red Line):**
* **Trend:** Shows an overall upward trend but with significantly higher volatility and more pronounced dips compared to the accuracy chart.
* **Data Points (Approximate):**
* Step 10: ~0.50
* Step 15: ~0.70
* Step 20: ~0.80
* Step 25: ~0.85
* Step 30: ~0.80
* Step 35: ~0.90 (peak)
* Step 40: ~0.85
### Key Observations
1. **Correlated Improvement:** Both the evaluation accuracy and the mean critic reward show a positive correlation with training steps, suggesting the model is improving on both metrics.
2. **Volatility Discrepancy:** The critic reward signal (`critic/rewards/mean`) is much noisier than the evaluation accuracy (`eval/accuracy/mean`). This is common in reinforcement learning setups where the critic's estimates can be unstable.
3. **Training Step Alignment:** The table shows specific rollout examples from steps 45 and 46, which are beyond the range displayed in the charts (which end at step 40). This indicates the dashboard is showing a snapshot of ongoing training.
4. **Reward Variance in Table:** The table reveals high variance in rewards for similar prompts at the same step (Step 45 has rewards of 1.1 and -0.1), highlighting the granularity of the training signal.
5. **Prompt Structure:** All visible prompts share an identical system message prefix, indicating a standardized evaluation or training format.
### Interpretation
This dashboard provides a multi-faceted view of an AI model's training progress, likely within a reinforcement learning from human feedback (RLHF) or similar framework.
* **The Charts** show the macroscopic view: the model is successfully learning, as evidenced by rising accuracy and reward trends. The volatility in the critic reward is a key diagnostic point; while the trend is positive, the instability might require tuning of the reward model or training hyperparameters to ensure stable convergence.
* **The Table** provides a microscopic, qualitative view. It links specific training steps (`step`) to the model's performance on individual examples (`prompt` and `response`), quantified by a `reward`. The presence of both positive (1.1) and negative (-0.1) rewards at the same step demonstrates the model's mixed performance on different tasks during this phase of training. The truncated `response` fields suggest the model is generating step-by-step reasoning (`<think>` tags), which is being evaluated.
* **Synthesis:** The combination allows a practitioner to correlate aggregate metrics with concrete examples. For instance, the dip in critic reward around step 30 on the chart might be investigable by examining rollout tables from that step. The dashboard is designed for iterative debugging and monitoring, enabling a user to move from high-level trends to specific failure or success cases. The "Add panel" buttons suggest this is a customizable monitoring environment.
</details>
Figure 6: A snapshot of the monitor implemented in Trinity-RFT.
<details>
<summary>figs/config_manager_beginner.jpg Details</summary>
### Visual Description
## Screenshot: Trinity-RFT Config Generator Interface
### Overview
The image is a screenshot of a web-based configuration interface titled "Trinity-RFT Config Generator." It appears to be a tool for setting up parameters for a machine learning or AI training process, specifically for a project named "Trinity-RFT." The interface is in "Beginner Mode" and displays a form with several required and optional configuration fields.
### Components/Axes
The interface is structured as a vertical form with the following labeled sections and input elements:
1. **Header Section:**
* **Title:** "Trinity-RFT Config Generator" (Top-left, large bold font). A small link/chain icon is present to the right of the title.
* **Mode Toggle:** Two buttons below the title.
* "Beginner Mode" (Left button, active state with a red border and red text).
* "Expert Mode" (Right button, inactive state with a grey border and black text).
2. **Essential Configs Section:**
* **Section Header:** "Essential Configs" (Left-aligned, bold).
* **Form Fields (in order from top to bottom):**
* **Project:** Label "Project" above a text input field containing the value `Trinity-RFT`.
* **Experiment Name:** Label "Experiment Name" above a text input field containing the value `qwen2.5-1.5B`.
* **Model Path:** Label "Model Path" above an empty text input field. Below it, a yellow-highlighted placeholder message reads: "Please input model path."
* **Checkpoint Path:** Label "Checkpoint Path" above an empty text input field. Below it, a yellow-highlighted placeholder message reads: "Please input checkpoint path."
* **Taskset Path:** Label "Taskset Path" above an empty text input field. Below it, a yellow-highlighted placeholder message reads: "Please input taskset path."
* **Algorithm Type:** Label "Algorithm Type" above a dropdown menu currently set to `ppo`.
* **SFT Warmup Steps:** Label "SFT Warmup Steps" above a numeric input field set to `0`, with decrement (`-`) and increment (`+`) buttons.
* **Monitor Type:** Label "Monitor Type" above a dropdown menu currently set to `tensorboard`.
### Detailed Analysis
* **Form State:** The form is partially filled. The "Project" and "Experiment Name" fields have been populated. The three path fields ("Model Path," "Checkpoint Path," "Taskset Path") are empty and display validation/placeholder messages indicating they are required.
* **Default/Selected Values:**
* Algorithm Type: `ppo` (Proximal Policy Optimization, a common reinforcement learning algorithm).
* SFT Warmup Steps: `0` (SFT likely stands for Supervised Fine-Tuning).
* Monitor Type: `tensorboard` (A popular visualization toolkit for machine learning).
* **Layout:** The layout is a single-column, left-aligned form. Labels are positioned directly above their corresponding input fields. The placeholder messages for empty required fields are visually distinct with a light yellow background.
### Key Observations
1. **Active Mode:** The interface is currently in "Beginner Mode," which likely simplifies the available configuration options compared to "Expert Mode."
2. **Required Fields:** The three path fields are mandatory, as indicated by the persistent placeholder messages.
3. **Technical Context:** The field names and values (`Trinity-RFT`, `qwen2.5-1.5B`, `ppo`, `SFT`, `tensorboard`) strongly suggest this is a configuration generator for a Reinforcement Learning from Human Feedback (RLHF) or similar fine-tuning pipeline for a large language model (the experiment name references "qwen2.5-1.5B," which is likely a 1.5-billion parameter model from the Qwen series).
4. **UI Design:** The design is clean and functional, using a light theme with clear typography and subtle color cues (red for active mode, yellow for required field warnings).
### Interpretation
This image captures the initial state of a configuration workflow for an AI model training or fine-tuning job. The user is expected to provide critical file system paths (to the base model, a checkpoint, and a task dataset) before generating a valid configuration file. The pre-filled values for algorithm, warmup steps, and monitoring tool represent sensible defaults for a beginner-level setup. The existence of an "Expert Mode" implies that more granular hyperparameters and advanced settings are available but hidden to reduce complexity for new users. The tool's purpose is to abstract away the complexity of writing configuration files manually, reducing errors and streamlining the setup process for the "Trinity-RFT" framework.
</details>
(a) The “beginner” mode.
<details>
<summary>figs/config_manager_expert.jpg Details</summary>
### Visual Description
## Screenshot: Trinity-RFT Config Generator Web Interface
### Overview
This image is a screenshot of a web-based configuration tool titled "Trinity-RFT Config Generator." The interface is designed for setting up parameters for a machine learning or AI training system, likely related to Reinforcement Fine-Tuning (RFT). The current view shows the "Model" configuration tab in "Expert Mode."
### Components/Axes
The interface is structured into several distinct sections:
1. **Header:**
* **Title:** "Trinity-RFT Config Generator" (top-left, large bold font).
* **Link Icon:** A small chain-link icon is positioned to the right of the title.
* **Mode Selector:** Two buttons below the title:
* "Beginner Mode" (left, grey outline).
* "Expert Mode" (right, red outline and text, indicating it is the active selection).
2. **Navigation Tabs:** A horizontal tab bar below the mode selector.
* **Tabs (from left to right):** "Model", "Buffer", "Explorer and Synchronizer", "Trainer".
* **Active Tab:** "Model" is underlined in red, indicating it is the currently selected view.
3. **Configuration Form (Model Tab):** The main content area consists of labeled input fields and controls.
* **Project:** Label "Project" with a pre-filled text input containing "Trinity-RFT".
* **Experiment Name:** Label "Experiment Name" with a pre-filled text input containing "qwen2.5-1.5B".
* **Model Path:** Label "Model Path" with an empty text input field. Below it, a yellow notification box contains the text: "Please input model path."
* **Critic Model Path:** Label "Critic Model Path (defaults to `model_path`)" with an empty text input field. The text "`model_path`" is styled in a monospace font.
* **Checkpoint Path:** Label "Checkpoint Path" with an empty text input field. Below it, a yellow notification box contains the text: "Please input checkpoint path."
* **Monitor Type:** Label "Monitor Type" with a dropdown menu currently set to "tensorboard".
* **Node Num:** Label "Node Num" with a numeric input field set to "1", accompanied by minus (`-`) and plus (`+`) buttons.
* **GPU Per Node:** Label "GPU Per Node" with a numeric input field set to "8", accompanied by minus (`-`) and plus (`+`) buttons.
* **Max Prompt Tokens:** Label "Max Prompt Tokens" with a numeric input field set to "1024", accompanied by minus (`-`) and plus (`+`) buttons.
* **Max Response Tokens:** Label "Max Response Tokens" with a numeric input field set to "1024", accompanied by minus (`-`) and plus (`+`) buttons.
### Detailed Analysis
* **Form State:** The form is in a partially filled state. The "Project" and "Experiment Name" fields have default or user-provided values. The "Model Path" and "Checkpoint Path" fields are empty and have triggered validation warnings (yellow boxes).
* **Default Values:** The system provides default values for several parameters:
* `Critic Model Path` defaults to the value entered in `Model Path`.
* `Monitor Type` defaults to "tensorboard".
* `Node Num` defaults to 1.
* `GPU Per Node` defaults to 8.
* `Max Prompt Tokens` and `Max Response Tokens` both default to 1024.
* **UI Controls:** Numeric fields use stepper controls (`-` and `+` buttons) for adjustment. The "Monitor Type" uses a standard dropdown selector.
### Key Observations
1. **Required Fields:** The yellow notification boxes explicitly identify "Model Path" and "Checkpoint Path" as required fields that must be filled before proceeding.
2. **Expert Mode:** The interface is in "Expert Mode," suggesting that the "Beginner Mode" might hide or simplify some of these configuration options.
3. **Training Context:** The parameters (Node Num, GPU Per Node, Max Tokens) strongly indicate this configures a distributed training job for a large language model (LLM), specifically the "qwen2.5-1.5B" model as noted in the Experiment Name.
4. **Layout:** The form uses a clean, two-column layout for the first row (Project, Experiment Name) and switches to a single-column layout for subsequent path fields. The final row of numeric parameters is arranged in a three-column layout.
### Interpretation
This screenshot captures the initial setup phase for a Trinity-RFT training experiment. The user is expected to provide critical file system paths (for the base model and training checkpoints) to define the experiment's assets. The pre-filled values suggest a specific experiment targeting the Qwen 2.5 1.5B parameter model.
The configuration reveals the technical requirements of the underlying system: it is designed for distributed training across multiple nodes (each with multiple GPUs), uses TensorBoard for monitoring, and has defined limits for input (prompt) and output (response) sequence lengths. The existence of a "Critic Model Path" hints at a reinforcement learning or reward-model-based training methodology, where a separate critic model evaluates the outputs of the primary model being trained.
The interface is functional and validation-aware, guiding the user to complete essential steps. To generate a valid configuration file, the user must resolve the two validation warnings by providing the model and checkpoint paths.
</details>
(b) The “expert” mode.
Figure 7: Snapshots of the configuration manager.
## 3 Examples, Applications, and Experiments
This section demonstrates the utilities and user-friendliness of Trinity-RFT and exemplifies some concepts introduced in previous sections, through a diverse range of examples, applications and experiments. Additional step-by-step tutorials can be found on the documentation website https://modelscope.github.io/Trinity-RFT, or the examples folder of the GitHub repository https://github.com/modelscope/Trinity-RFT/tree/main/examples.
### 3.1 Customizing Agent-Environment Interaction
With a modular design, Trinity-RFT can be easily adapted to a new downstream scenario by implementing the logic of agent-environment interaction in a single workflow class, without modifications to other components of the codebase. This approach is also sufficient for macroscopic RL algorithm design that targets high-quality experience synthesis with environmental feedback [4]. We provide some concrete examples in the rest of this subsection.
#### 3.1.1 Single-turn Scenarios
In a simple yet common scenario, a user of Trinity-RFT would like to train an LLM for completing single-turn tasks, where the LLM generates one response to each input query. For this purpose, the user mainly needs to (1) define and register a single-turn workflow class (by inheriting the base class Workflow) tailored to the targeted tasks, and (2) specify the tasksets (for training and/or evaluation) and the initial LLM, both of which are compatible with HuggingFace [14] and ModelScope [19] formats.
Listing 1 gives a minimal example for implementing a single-turn workflow. Suppose that each task is specified by a <question, answer> tuple. The run() method of ExampleWorkflow calls the LLM once to generate a response for the question, calculates its reward, and returns an Experience instance that consists of the response itself, the reward value, and the log-probabilities of response tokens predicted by the rollout model (which is necessary for certain RL algorithms, such as PPO [28] and GRPO [29]). Some built-in workflows and reward functions have been implemented in Trinity-RFT, e.g., the MathWorkflow class for math-related tasks.
In some cases, the user wants to utilize auxiliary LLMs in the workflow, e.g., for computing rewards via LLM-as-a-judge, or for playing the roles of other agents in a multi-agent scenario. For these purposes, the user can specify auxiliary_models via APIs when initializing the workflow.
⬇
1 @WORKFLOWS. register_module ("example_workflow")
2 class ExampleWorkflow (Workflow):
3
4 def __init__ (
5 self,
6 model: ModelWrapper,
7 task: Task,
8 auxiliary_models: Optional [List [openai. OpenAI]] = None,
9 ):
10 super (). __init__ (model, task, auxiliary_models)
11 self. question = task. raw_task. get ("question")
12 self. answer = task. raw_task. get ("answer")
13
14 def calculate_reward_by_rule (self, response: str, truth: str) -> float:
15 return 1.0 if response == truth else 0.0
16
17 def calculate_reward_by_llm_judge (self, response: str, truth: str) -> float:
18 judge_model = self. auxiliary_models [0]
19 PROMPT_FOR_JUDGE = "" "Please evaluate..." ""
20 completion = judge_model. chat. completions. create (
21 model = "gpt-4", # Or another suitable judge model
22 messages =[{"role": "user", "content": PROMPT_FOR_JUDGE}],
23 )
24 reward_str = completion. choices [0]. message. content. strip ()
25 reward = float (reward_str)
26 return reward
27
28 def run (self) -> List [Experience]:
29 response = self. model. chat (
30 [
31 {
32 "role": "user",
33 "content": f "Question:\n{self.question}",
34 }
35 ],
36 ** self. rollout_args,
37 )
38 reward: float = self. calculate_reward_by_rule (response. response_text, self. answer)
39 # reward: float = self.calculate_reward_by_llm_judge(response.response_text, self.answer)
40 return [
41 Experience (
42 tokens = response. tokens,
43 prompt_length = response. prompt_length,
44 reward = reward,
45 logprobs = response. logprobs,
46 )
47 ]
Listing 1: A minimal example for implementing a customized workflow.
#### 3.1.2 Multi-turn Scenarios
In more advanced cases, the user would like to train an LLM-powered agent that solves multi-turn tasks by repeatedly interacting with the environment. In Trinity-RFT, achieving this is mostly as simple as in the single-turn case, except that the user needs to define and register a multi-turn workflow class by inheriting the base class MultiTurnWorkflow. Listing 2 provides one such example using the ALFWorld dataset [31]. For training efficiency, the process_messages_to_experience() method concatenates multiple rounds of agent-environment interactions compactly into an Experience instance consisting of a single token sequence with proper masking, which can readily be consumed by standard RL algorithms like PPO and GRPO.
For more detailed examples of multi-turn cases, please refer to the documentation https://modelscope.github.io/Trinity-RFT/tutorial/example_multi_turn.html.
⬇
1 @WORKFLOWS. register_module ("alfworld_workflow")
2 class AlfworldWorkflow (MultiTurnWorkflow):
3 "" "A workflow for the ALFWorld task." ""
4
5 def generate_env_inference_samples (self, env, rollout_num) -> List [Experience]:
6 print ("Generating env inference samples...")
7 experience_list = []
8 for i in range (rollout_num):
9 observation, info = env. reset ()
10 final_reward = -0.1
11 memory = []
12 memory. append ({"role": "system", "content": AlfWORLD_SYSTEM_PROMPT})
13 for r in range (self. max_env_steps):
14 format_obs = format_observation (observation)
15 memory = memory + [{"role": "user", "content": format_obs}]
16 response_text = self. model. chat (memory, n =1)[0]. response_text
17 memory. append ({"role": "assistant", "content": response_text})
18 action = parse_action (response_text)
19 observation, reward, done, info = env. step (action)
20 if done:
21 final_reward = reward
22 break
23 experience = self. process_messages_to_experience (
24 memory, final_reward, {"env_rounds": r, "env_done": 1 if done else 0}
25 )
26 experience_list. append (experience)
27 # Close the env to save CPU memory
28 env. close ()
29 return experience_list
30
31 def run (self) -> List [Experience]:
32 # ...
33 game_file_path = self. task_desc
34 rollout_n = self. repeat_times
35 # ...
36 env = create_environment (game_file_path)
37 return self. generate_env_inference_samples (env, rollout_n)
Listing 2: An implementation of a multi-turn workflow for ALFWorld [31].
#### 3.1.3 Experience Synthesis in Workflows
As mentioned in Section 1.1, Trinity-RFT has been designed to streamline RL algorithm design and development at both macroscopic and microscopic levels. One example for the former is experience synthesis: at each RL step, the agent (backed by the rollout LLM) iteratively generates refined responses to a query by incorporating feedback or guidance from the environment, which can be in the form of plain text rather than numerical reward values. The resulting data will then be utilized for updating the policy model, e.g., by a standard SFT or RL loss. Such a macroscopic RL approach is made possible by pre-trained LLMs’ generative nature and rich prior knowledge about natural language. Closely related to this idea is Agent-RLVR [4], a contemporary work that applies such an approach to software engineering scenarios.
Within Trinity-RFT, this process of experience synthesis can be regarded as a particular way of agent-environment interaction, and thus can be realized by simply implementing a Workflow class. As a minimal demonstration, suppose that we want to implement this approach for a math reasoning scenario, where the agent generates multiple rollout responses to an input query, receives feedback from the environment regarding correctness of the responses, reflects on the gathered information, and generates a final response to the query. Listing 3 presents an implementation of this approach within Trinity-RFT.
⬇
1 @WORKFLOWS. register_module ("reflect_once_workflow")
2 class ReflectOnceWorkflow (Workflow):
3
4 def run (self) -> List [Experience]:
5 experiences = []
6
7 # Stage 1: K-rollout generation
8 rollout_messages = self. create_rollout_messages ()
9 responses = self. model. chat (
10 rollout_messages,
11 n = self. k_rollouts,
12 temperature = self. temperature,
13 logprobs = self. logprobs,
14 max_tokens = self. task. rollout_args. max_tokens,
15 )
16 rollout_responses = [response. response_text. strip () for response in responses]
17
18 # Stage 2: Verification
19 verification_results = []
20 for rollout_response in rollout_responses:
21 is_correct = self. verify_answer (rollout_response, self. ground_truth)
22 verification_results. append (is_correct)
23
24 # Stage 3: Reflection
25 reflection_messages = self. create_reflection_messages (
26 rollout_responses,
27 verification_results,
28 )
29 reflection_responses = self. model. chat (
30 reflection_messages,
31 n =1,
32 temperature = self. temperature,
33 logprobs = self. logprobs,
34 max_tokens = self. task. rollout_args. max_tokens,
35 )
36 reflection_response = reflection_responses [0]
37
38 # Verify the reflection response
39 reflection_text = reflection_response. response_text. strip ()
40 reflection_is_correct = self. verify_answer (reflection_text, self. ground_truth)
41
42 if reflection_is_correct:
43 sharegpt_message = [
44 {
45 "role": "system",
46 "content": self. task. format_args. system_prompt
47 },
48 {
49 "role": "user",
50 "content": self. question
51 },
52 {
53 "role": "assistant",
54 "content": reflection_text
55 }
56 ]
57 experience = self. process_messages_to_experience (sharegpt_message)
58 experiences. append (experience)
59
60 # Save experience to file
61 if self. exp_file and sharegpt_message is not None:
62 exp_data = sharegpt_message
63 self. exp_file. write (json. dumps (exp_data, ensure_ascii = False) + "\n")
64 self. exp_file. flush ()
65 return experiences
Listing 3: A toy implementation of experience synthesis with environmental feedback.
### 3.2 RL Algorithm Development with Trinity-RFT
To support RL algorithm development, Trinity-RFT allows researchers and developers to focus on designing and implementing the essential logic of a new RL algorithm, without the need to care about the internal engineering details about Trinity-RFT.
As an example, suppose that we want to implement a MIX algorithm that seamlessly integrates online RL and offline SFT into a single learning process. In its most basic form, the MIX algorithm requires that (1) the trainer samples from two sources of experiences, i.e., the rollout experiences collected online and the high-quality expert trajectories collected offline; and (2) the trainer updates its policy model with a loss function that handles both sources of experiences properly, e.g., a weighted sum of GRPO loss for the on-policy rollout experiences and SFT loss for the expert trajectories.
Variants of this MIX algorithm include adaptive weighting of multiple loss terms [10], alternating between RL and SFT [16], incorporating expert trajectories into RL loss [21, 34, 46], or incorporating SFT loss for high-reward rollout trajectories generated by older versions of the rollout model [27]. Such approaches have proved to be effective in accelerating the online RL process with only a small amount of expert experiences, or to enhance stability and plasticity in continual learning.
<details>
<summary>x7.png Details</summary>
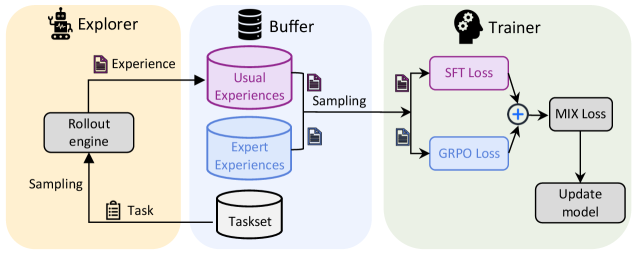
### Visual Description
## System Architecture Diagram: Reinforcement Learning Training Pipeline
### Overview
The image is a technical system architecture diagram illustrating a three-stage pipeline for training a machine learning model, likely a reinforcement learning agent. The diagram is divided into three distinct, color-coded sections representing different functional modules: **Explorer** (yellow background), **Buffer** (light blue background), and **Trainer** (light green background). The flow of data and processes moves from left to right.
### Components/Axes
The diagram is not a chart with axes but a flow diagram with labeled components and directional arrows.
**1. Explorer Module (Left, Yellow Background)**
* **Icon:** A robot head.
* **Title:** `Explorer`
* **Components:**
* `Rollout engine`: A central processing unit.
* `Task`: An input represented by a clipboard icon.
* **Flow:**
* An arrow labeled `Sampling` points from the `Task` input to the `Rollout engine`.
* An arrow labeled `Experience` (with a document icon) points from the `Rollout engine` to the `Buffer` module.
**2. Buffer Module (Center, Light Blue Background)**
* **Icon:** A database cylinder.
* **Title:** `Buffer`
* **Components:**
* `Usual Experiences`: A pink cylinder.
* `Expert Experiences`: A blue cylinder.
* `Taskset`: A white cylinder at the bottom.
* **Flow:**
* The `Experience` arrow from the Explorer feeds into the `Usual Experiences` cylinder.
* An arrow labeled `Sampling` (with a document icon) points from both the `Usual Experiences` and `Expert Experiences` cylinders to the `Trainer` module.
* An arrow points from the `Taskset` cylinder to the `Task` input in the Explorer module, indicating task sourcing.
**3. Trainer Module (Right, Light Green Background)**
* **Icon:** A head with gears.
* **Title:** `Trainer`
* **Components:**
* `SFT Loss`: A pink box.
* `GRPO Loss`: A blue box.
* `MIX Loss`: A gray box.
* `Update model`: A gray box.
* **Flow:**
* Two arrows from the Buffer's `Sampling` step feed into the Trainer. One goes to `SFT Loss` and the other to `GRPO Loss`.
* The outputs of `SFT Loss` and `GRPO Loss` converge at a circle with a plus sign (`+`), indicating summation or combination.
* The result of this combination flows into `MIX Loss`.
* The output of `MIX Loss` flows into `Update model`.
### Detailed Analysis
The diagram depicts a closed-loop training system:
1. **Task Initiation:** A `Task` is drawn from the `Taskset` in the Buffer and sent to the Explorer.
2. **Experience Generation:** The Explorer's `Rollout engine` executes the task, generating `Experience` data.
3. **Experience Storage:** This experience is stored in the Buffer, specifically in the `Usual Experiences` repository.
4. **Training Data Sampling:** The Trainer samples data from both `Usual Experiences` and a separate repository of `Expert Experiences`.
5. **Dual-Loss Training:** The sampled data is used to compute two distinct loss functions:
* `SFT Loss` (likely Supervised Fine-Tuning Loss).
* `GRPO Loss` (likely a variant of Policy Optimization Loss, such as Generalized Reinforcement Policy Optimization).
6. **Loss Combination & Model Update:** The two losses are combined into a `MIX Loss`, which is then used to `Update model`. The updated model presumably informs future rollouts, completing the cycle.
### Key Observations
* **Color-Coding Consistency:** The color of the loss boxes (`SFT Loss` - pink, `GRPO Loss` - blue) matches the color of the experience cylinders they primarily sample from (`Usual Experiences` - pink, `Expert Experiences` - blue). This visually reinforces the data source for each loss component.
* **Separation of Experience Types:** The system explicitly separates `Usual Experiences` (generated by its own explorer) from `Expert Experiences` (presumably from an external or pre-collected source), suggesting a hybrid training approach.
* **Centralized Buffer:** The `Buffer` acts as the central hub, managing both the task supply and the experience repositories for training.
* **Composite Objective:** The final training signal (`MIX Loss`) is not a single objective but a combination of two different learning signals (SFT and GRPO).
### Interpretation
This diagram illustrates a sophisticated reinforcement learning or imitation learning framework designed for iterative improvement. The architecture suggests a system that learns from both its own interactions (`Usual Experiences` via `SFT Loss`) and from high-quality demonstrations (`Expert Experiences` via `GRPO Loss`). The `MIX Loss` indicates a multi-objective optimization strategy, potentially balancing stability (from supervised learning on expert data) with exploration and policy improvement (from reinforcement learning on its own experiences).
The pipeline is cyclical and self-reinforcing: the model updated by the Trainer will be used in the next iteration of the Rollout engine, generating new experiences to fill the buffer. The inclusion of a `Taskset` implies the system can be trained on a curriculum or distribution of tasks. This design is characteristic of advanced agent training systems aiming for robust and sample-efficient learning by leveraging both expert guidance and autonomous exploration.
</details>
Figure 8: A visualization of the MIX algorithm.
The MIX algorithm is visualized in Figure 8, where we integrate GRPO loss for usual experiences generated by the rollout model and SFT loss for expert experiences into a unified training pipeline. It requires dealing with different sources of experiences, and two types of loss functions; fortunately, to implement such an algorithm in Trinity-RFT, we only need to define three new classes — MixSampleStrategy, MIXPolicyLossFn, and MIXAlgorithm — as demonstrated in Listing 4. With these components, Trinity-RFT enables a seamless integration of online RL and offline SFT within the same training loop. More details of the MIX algorithm are referred to the documentation https://modelscope.github.io/Trinity-RFT/tutorial/example_mix_algo.html.
⬇
1 @SAMPLE_STRATEGY. register_module ("mix")
2 class MixSampleStrategy (SampleStrategy):
3 def __init__ (self, buffer_config: BufferConfig, trainer_type: str, ** kwargs):
4 # ...
5 self. usual_exp_buffer = get_buffer_reader (
6 buffer_config. trainer_input. experience_buffer, usual_buffer_config
7 )
8 self. expert_exp_buffer = get_buffer_reader (
9 buffer_config. trainer_input. sft_warmup_dataset, expert_buffer_config
10 )
11 # ...
12
13 def sample (self, step: int) -> Tuple [Any, Dict, List]:
14 "" "Sample a batch composed of rollout experiences and expert trajectories" ""
15 usual_exp_list = self. usual_exp_buffer. read ()
16 expert_exp_list = self. expert_exp_buffer. read ()
17 exp_list = usual_exp_list + expert_exp_list
18 exps = Experiences. gather_experiences (exp_list, self. pad_token_id)
19 # ...
20
21
22 @POLICY_LOSS_FN. register_module ("mix")
23 class MIXPolicyLossFn (PolicyLossFn):
24 def __init__ (self, mu: float = 0.1, ...):
25 # ...
26 self. mu = mu
27 self. grpo_loss_fn = PPOPolicyLossFn (...)
28 self. sft_loss_fn = SFTLossFn (...)
29
30 def __call__ (
31 self,
32 logprob: torch. Tensor,
33 old_logprob: torch. Tensor,
34 action_mask: torch. Tensor,
35 advantages: torch. Tensor,
36 is_expert_mask: torch. Tensor,
37 ** kwargs,
38 ) -> Tuple [torch. Tensor, Dict]:
39 "" "Calculate a weighted sum of GRPO loss and SFT loss" ""
40 # ...
41 grpo_loss, grpo_metrics = self. grpo_loss_fn (
42 logprob [~ is_expert_mask],
43 old_logprob [~ is_expert_mask],
44 action_mask [~ is_expert_mask],
45 advantages [~ is_expert_mask],
46 ** kwargs,
47 )
48 sft_loss, sft_metrics = self. sft_loss_fn (
49 logprob [is_expert_mask],
50 action_mask [is_expert_mask],
51 )
52 loss = (1 - self. mu) * grpo_loss + self. mu * sft_loss
53 # ...
54 return loss, metrics
55
56 @ALGORITHM_TYPE. register_module ("mix")
57 class MIXAlgorithm (AlgorithmType):
58 "" "MIX algorithm." ""
59
60 use_critic: bool = False
61 use_reference: bool = True
62 use_advantage: bool = True
63 can_balance_batch: bool = True
64 schema: type = ExperienceModel
65
66 @classmethod
67 def default_config (cls) -> Dict:
68 return {
69 "repeat_times": 8,
70 "policy_loss_fn": "mix", # Specify the MIX loss function
71 "advantage_fn": "grpo",
72 "sample_strategy": "mix", # Specify the MIX sampling strategy
73 }
Listing 4: An implementation of the MIX algorithm with Trinity-RFT.
### 3.3 Unified Support for Diverse RL Modes
As explained previously in Section 2.1.1, Trinity-RFT offers support for synchronous/asynchronous, on-policy/off-policy, and online/offline RL, controlled by a few configuration parameters. In this subsection, we conduct experiments for comparing the following RL modes:
- The synchronous mode: mode=both, sync_interval={1,2,10}, sync_offset=0;
- The one-step off-policy mode: mode=both, sync_interval=1, sync_offset=1;
- The fully asynchronous mode: the explorer and trainer are launched with mode=explore and train respectively, with sync_interval=10.
Our experiments include dummy learning processes (which will soon be explained) for performance profiling, as well as real learning processes with vanilla GRPO [29] in different modes.
#### 3.3.1 Experiments: Performance Profiling
Settings.
We aim to measure and compare the efficiency of different RL modes under controlled settings. It is noteworthy that, even with all other variables controlled, different RL modes can still result in different trained models — and thus different rollout response lengths — during the learning processes, which have direct impacts on performance metrics like wall-clock time and GPU utilization rate.
To mitigate this, we conduct performance profiling with dummy learning processes, where the learning rate is set to zero. A dummy learning process closely resembles a real learning process, in that all necessary computation and communication (e.g., rollout generation, gradient computation, model weight synchronization) are executed; the only difference is that the rollout model (and thus the distribution of rollout trajectories) remains fixed throughout and same across different RL modes.
To show the performance of Trinity-RFT in diverse scenarios, we consider both math reasoning task (GSM8k [3]) and multi-turn agentic task (ALFWorld [31]). In the experiments, we use the Qwen2.5-Instruct [36] model series of different sizes (1.5B, 3B, and 7B), and run the GRPO [5] algorithm (with 8 rollout trajectories per task) in all modes. We choose a 100-step training trace to evaluate the performance and report the following metrics: (1) end-to-end wall-clock time and time speedup: the wall-clock time from the start of running the command to the end of finishing 100 training steps; (2) GPU utilization: the GPU utilization in percent for each GPU; (3) GPU power usage: the GPU power usage as a percentage of its power capacity for each GPU. Metrics for GPU utilization and power usage were extracted from WandB https://docs.wandb.ai/guides/models/app/settings-page/system-metrics/ and averaged over all GPUs. We run each experiment for three random trials and report the mean and standard deviation. Unless specified otherwise, each experiment uses 8 NVIDIA A100-80G GPUs.
Results for GSM8k.
We use the 2/6 GPU partition for explorer/trainer. While this configuration is not the optimal one for all experiments, it is sufficient to show the difference between several RL modes. In our GSM8k experiments, the batch size is 96 tasks, and the temperature is 1.0. The results for both Qwen2.5-1.5B-Instruct and Qwen2.5-7B-Instruct models are shown in Table 1.
We observe that in the synchronous mode (with sync_offset=0), a less frequent synchronization (i.e., a larger sync_interval) effectively improves the efficiency, GPU utilization, and GPU power usage. This is mainly because, as shown in Figure 4 (a), the impacts of pipeline bubbles in this mode can be effectively reduced by using a lower synchronization frequency. Besides, Table 1 shows that one-step off-policy and fully asynchronous modes also accelerate the training process with higher GPU utilization, compared to a strictly on-policy mode. In one-step off-policy mode, the trainer leverages the one-step off-policy data stored in the buffer without needing to wait for new experiences generated by the explorer after weight synchronization, which significantly reduces the GPU idle ratio. In fully asynchronous mode, the explorer and trainer operate almost independently while fully leveraging GPU resources, except when loading or saving model checkpoints.
Table 1: Performance profiling for GSM8k with 2/6 GPU partition for explorer/trainer.
| Mode | Qwen2.5-1.5B-Instruct | | | |
| --- | --- | --- | --- | --- |
| Speedup $↑$ | Time (Minutes) $↓$ | GPU Utilization (%) $↑$ | GPU Power Usage (%) $↑$ | |
| Sync. (sync_interval=1) | $1.00×$ | $38.70± 0.34$ | $33.64± 2.15$ | $35.85± 1.83$ |
| Sync. (sync_interval=2) | $1.24×$ | $31.19± 0.08$ | $36.05± 0.49$ | $38.74± 1.47$ |
| Sync. (sync_interval=10) | $1.59×$ | $24.28± 0.16$ | $38.27± 0.98$ | $44.41± 0.81$ |
| One-step off-policy | $1.25×$ | $30.84± 0.20$ | $32.39± 1.17$ | $39.70± 0.78$ |
| Fully async. | $1.61×$ | $23.97± 0.03$ | $36.04± 0.61$ | $43.91± 0.48$ |
| Mode | Qwen2.5-7B-Instruct | | | |
| --- | --- | --- | --- | --- |
| Speedup $↑$ | Time (Minutes) $↓$ | GPU Utilization (%) $↑$ | GPU Power Usage (%) $↑$ | |
| Sync. (sync_interval=1) | $1.00×$ | $68.71± 0.54$ | $55.61± 0.80$ | $52.88± 0.29$ |
| Sync. (sync_interval=2) | $1.31×$ | $52.44± 0.41$ | $64.88± 1.35$ | $61.90± 1.32$ |
| Sync. (sync_interval=10) | $1.85×$ | $37.17± 0.15$ | $78.44± 1.03$ | $77.77± 0.96$ |
| One-step off-policy | $1.69×$ | $40.73± 0.57$ | $77.19± 2.26$ | $76.17± 1.56$ |
| Fully async. | $1.63×$ | $42.17± 1.06$ | $73.90± 2.00$ | $72.74± 1.82$ |
Table 2: Performance profiling for ALFWorld with 4/4 GPU partition for explorer/trainer.
| Mode | Batch_Size = 4 | | | |
| --- | --- | --- | --- | --- |
| Speedup $↑$ | Time (Minutes) $↓$ | GPU Utilization (%) $↑$ | GPU Power Usage (%) $↑$ | |
| Sync. (sync_interval=1) | $1.00×$ | $333.68± 0.06$ | $17.19± 0.58$ | $28.44± 0.37$ |
| Sync. (sync_interval=2) | $1.70×$ | $196.64± 0.59$ | $21.69± 0.18$ | $31.35± 0.06$ |
| Sync. (sync_interval=10) | $5.21×$ | $64.09± 0.39$ | $32.85± 0.18$ | $40.86± 0.58$ |
| One-step off-policy | $0.98×$ | $340.12± 3.99$ | $14.63± 1.17$ | $28.21± 0.48$ |
| Fully async. | $5.45×$ | $61.27± 0.35$ | $36.46± 0.10$ | $\textbf{42.51}± 0.72$ |
| Mode | Batch_Size = 32 | | | |
| --- | --- | --- | --- | --- |
| Speedup $↑$ | Time (Minutes) $↓$ | GPU Utilization (%) $↑$ | GPU Power Usage (%) $↑$ | |
| Sync. (sync_interval=1) | $1.00×$ | $561.21± 2.04$ | $39.37± 0.89$ | $39.93± 0.22$ |
| Sync. (sync_interval=2) | $1.13×$ | $496.80± 0.36$ | 37.74 $± 0.39$ | $41.90± 0.44$ |
| Sync. (sync_interval=10) | $1.59×$ | $352.11± 0.49$ | $44.50± 0.58$ | $49.95± 0.61$ |
| One-step off-policy | $1.14×$ | $494.13± 0.28$ | $34.89± 0.75$ | $43.05± 0.81$ |
| Fully async. | $1.65×$ | $339.51± 0.24$ | $45.55± 0.20$ | $\textbf{50.77}± 0.45$ |
Results for ALFWorld.
A particular feature of ALFWorld is the long-horizon multi-turn interaction with the environment. To accommodate the heavy computational demands in rollout, we use the 4/4 GPU partition for explorer/trainer. In our ALFWorld experiments, we use the Qwen2.5-3B-Instruct model and set the rollout temperature to 1.0.
The results with different batch sizes are shown in Table 2. One observation is that, when the batch size is 4 tasks, the one-step off-policy mode exhibits no efficiency advantage over the synchronous mode with sync_interval=1. This phenomenon can be attributed to the computational imbalance between the explorer and trainer. In ALFWorld, the larger computation latency of the explorer emerges primarily from (1) the inherent complexity of multi-turn environment interactions, and (2) the long-tailed latency distribution when certain tasks require extended rollout durations, whose effect is further exacerbated by a small batch size. The one-step off-policy mode cannot eliminate pipeline bubbles caused by long-tailed latencies in the explorer, whereas this can be mitigated by the synchronous mode with a large sync_interval as well as by the asynchronous mode, thanks to the implementation of streaming rollout generation in Trinity-RFT. Another observation, due to the same reason, is that when scaling the batch size from 4 to 32, all modes incur a small increase (much smaller than $8×$ ) in wall-clock time for the same number of training steps, thanks to better GPU usage.
#### 3.3.2 Experiments: Real Learning with Vanilla GRPO
Settings.
We aim to compare the real learning processes by different RL modes. For simplicity and controlled variability, we use the vanilla GRPO [29] algorithm for all RL modes, without specific algorithm design for asynchronous or off-policy cases. GRPO mainly relies on the mechanism of clipping probability ratio (defaults to the range of $1± 0.2$ ) to handle the off-policyness of experiences. For future works, we will investigate more advanced off-policy or asynchronous RL algorithms, and develop new ones to accommodate diverse RL modes. To encourage the exploration of the rollout model, we disable the Kullback-Leibler (KL) penalty or loss in our experiments.
Training.
For each RL mode, we fine-tune the Qwen2.5-7B-Instruct model for one epoch on the OpenR1-Math-46k [46] https://huggingface.co/datasets/Elliott/Openr1-Math-46k-8192 dataset, a filtered version of the OpenR1-Math-220k https://huggingface.co/datasets/open-r1/OpenR1-Math-220k dataset. The allocated GPU ratio for the explorer and trainer is 4/4. We set the batch size to 120 tasks, the rollout number per task to 32, and the learning rate to 1e-6.
Evaluation.
For each RL mode, we save the checkpoint of the rollout model once every 100 steps, evaluate the checkpoints using the bench mode, and report the best results among the checkpoints. The models are evaluated on several math benchmarks, including AIME2024 https://huggingface.co/datasets/math-ai/aime25, AIME2025 https://huggingface.co/datasets/math-ai/aime25, AMC https://huggingface.co/datasets/math-ai/amc23, and MATH500 https://huggingface.co/datasets/HuggingFaceH4/MATH-500. For AIME2024, AIME2025, and AMC, we generate 32 responses (with temperature 0.6) per task and report the average accuracy (Avg@32), to ensure the accuracy of the evaluation process; for MATH500, we report Avg@4 as the dataset is relatively large. For more detailed comparisons, we also plot some training metrics, including reward, response length, gradient norm, and KL distance from the initial LLM, with the wall-clock time as the X-axis.
Results.
Figure 9 presents the training curves. It is observed that several RL modes show increasing trends in terms of rewards and response lengths. The synchronous mode with sync_interval=1 exhibits longer responses and larger KL divergence than other RL modes, likely because it updates the rollout model most frequently and leverages on-policy data in each step.
Table 3 presents the evaluation results. We observe that, for the synchronous mode with sync_offset=0, increasing sync_interval reduces the total training time for one epoch, at the cost of slightly compromising the average evaluation performance. In contrast, the one-step off-policy mode with sync_interval=1 achieves comparable or better performance than the other modes on several benchmarks, while achieving around $2.66×$ speedup in wall-clock time over the strictly on-policy mode.
<details>
<summary>x8.png Details</summary>
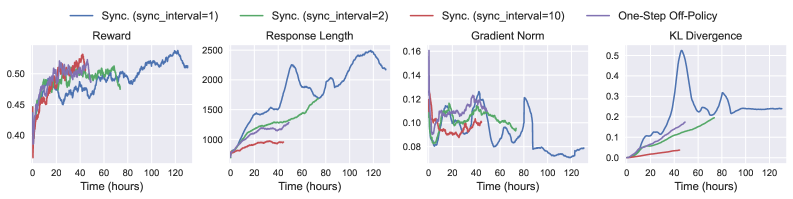
### Visual Description
\n
## Multi-Panel Line Chart: Training Metrics Over Time
### Overview
The image displays a set of four line charts arranged horizontally, comparing the performance of different reinforcement learning training configurations over time. The charts track four distinct metrics: Reward, Response Length, Gradient Norm, and KL Divergence. The x-axis for all charts is "Time (hours)", ranging from 0 to approximately 130 hours. A shared legend at the top identifies four data series.
### Components/Axes
* **Legend (Top Center):** Positioned above the charts, it defines four lines:
* **Blue Line:** `Sync. (sync_interval=1)`
* **Green Line:** `Sync. (sync_interval=2)`
* **Red Line:** `Sync. (sync_interval=10)`
* **Purple Line:** `One-Step Off-Policy`
* **Chart 1 (Left): Reward**
* **Title:** "Reward"
* **Y-axis:** Unlabeled, but numerical scale from 0.40 to 0.50.
* **X-axis:** "Time (hours)" with markers at 0, 20, 40, 60, 80, 100, 120.
* **Chart 2 (Center-Left): Response Length**
* **Title:** "Response Length"
* **Y-axis:** Unlabeled, but numerical scale from 0 to 2500.
* **X-axis:** "Time (hours)" with markers at 0, 20, 40, 60, 80, 100, 120.
* **Chart 3 (Center-Right): Gradient Norm**
* **Title:** "Gradient Norm"
* **Y-axis:** Unlabeled, but numerical scale from 0.08 to 0.16.
* **X-axis:** "Time (hours)" with markers at 0, 20, 40, 60, 80, 100, 120.
* **Chart 4 (Right): KL Divergence**
* **Title:** "KL Divergence"
* **Y-axis:** Unlabeled, but numerical scale from 0.0 to 0.5.
* **X-axis:** "Time (hours)" with markers at 0, 20, 40, 60, 80, 100, 120.
### Detailed Analysis
**1. Reward Chart:**
* **Trend Verification:** The blue line (`sync_interval=1`) shows a strong, consistent upward trend. The green (`sync_interval=2`) and red (`sync_interval=10`) lines rise initially but then plateau with high variance. The purple line (`One-Step Off-Policy`) is not visible in this chart.
* **Data Points (Approximate):**
* Blue: Starts ~0.40, ends ~0.50 at 120h.
* Green: Peaks ~0.48 around 40h, ends ~0.47 at 120h.
* Red: Peaks ~0.48 around 30h, ends ~0.46 at 120h.
**2. Response Length Chart:**
* **Trend Verification:** The blue line shows a dramatic, near-linear increase. The green line increases steadily but at a lower rate. The red line increases very slowly and remains low.
* **Data Points (Approximate):**
* Blue: Starts ~500, ends ~2500 at 120h.
* Green: Starts ~500, ends ~1800 at 120h.
* Red: Starts ~500, ends ~1000 at 120h.
**3. Gradient Norm Chart:**
* **Trend Verification:** All lines show high volatility. The blue line exhibits the most extreme swings, with a notable dip below 0.08 around 90h. The green and red lines are more stable within the 0.08-0.14 range.
* **Data Points (Approximate):**
* Blue: Fluctuates between ~0.07 and ~0.16.
* Green: Fluctuates between ~0.09 and ~0.13.
* Red: Fluctuates between ~0.09 and ~0.12.
**4. KL Divergence Chart:**
* **Trend Verification:** The blue line shows a sharp, significant spike. The green line increases gradually. The red line remains very low and flat.
* **Data Points (Approximate):**
* Blue: Spikes to ~0.5 at ~40h, then settles to ~0.25 by 120h.
* Green: Increases steadily to ~0.2 by 120h.
* Red: Remains below ~0.05 throughout.
### Key Observations
1. **Performance Hierarchy:** The `Sync. (sync_interval=1)` configuration (blue) achieves the highest Reward and Response Length but at the cost of the highest Gradient Norm volatility and a massive spike in KL Divergence.
2. **Stability vs. Performance Trade-off:** Increasing the sync interval (green, red) leads to more stable training (lower KL Divergence, less Gradient Norm variance) but results in lower final Reward and much shorter Response Lengths.
3. **One-Step Off-Policy:** This series (purple) is only visible in the legend. Its lines are either perfectly overlapping another series (unlikely) or, more plausibly, are not plotted in these specific charts, suggesting this figure may be part of a larger set where that series is shown elsewhere.
4. **Critical Event:** The blue line's KL Divergence spike at ~40 hours coincides with its steepest increase in Response Length, suggesting a potential policy shift or instability event at that point in training.
### Interpretation
This data demonstrates a clear trade-off in distributed reinforcement learning between synchronization frequency and training stability/performance. A very frequent sync (`interval=1`) drives aggressive policy improvement (high reward, long responses) but introduces significant instability, as evidenced by exploding gradients and a large divergence from the prior policy. Less frequent syncing (`interval=2, 10`) acts as a regularizer, producing more stable but less performant policies. The charts suggest that the optimal sync interval is a balance point, not simply the most frequent option. The absence of the `One-Step Off-Policy` data in the plots is a notable gap, preventing a full comparison of synchronous vs. asynchronous update strategies.
</details>
Figure 9: Results of training for one epoch by vanilla GRPO in different RL modes. The results are smoothed using a 40-step moving average for clarity.
Table 3: Performance comparison of different RL modes.
| | AIME2024 | AIME2025 | AMC | MATH500 | Average | Runtime (Hours) |
| --- | --- | --- | --- | --- | --- | --- |
| Qwen2.5-7B-Instruct | 11.15 | 6.95 | 51.35 | 70.96 | 35.10 | N/A |
| Sync. (sync_interval=1) | 14.58 | 14.06 | 61.25 | 76.25 | 41.54 | 130.33 |
| Sync. (sync_interval=2) | 15.52 | 11.67 | 57.97 | 75.15 | 40.08 | 73.57 |
| Sync. (sync_interval=10) | 14.38 | 12.71 | 57.66 | 75.05 | 39.95 | 44.43 |
| One-Step Off-Policy | 16.88 | 12.19 | 59.92 | 74.55 | 40.89 | 48.98 |
### 3.4 Data Processors for Tasks and Experiences
We present practical examples to demonstrate how the data pipeline concepts described in Section 2.3 are applied in Trinity-RFT. These use cases highlight how manipulating data at both the task and experience level directly improves RFT performance and provides granular control over the agent’s learning process.
#### 3.4.1 Static Task Prioritization for Curriculum Learning
A common strategy for effective training is to present tasks in increasing order of difficulty. This use case demonstrates how Trinity-RFT facilitates curriculum learning by prioritizing tasks before exploration begins. This is particularly crucial for RFT, as it helps stabilize the initial learning phase of the explorer and prevents it from getting stuck on overly complex tasks, leading to a more efficient exploration path.
As shown in Listing 5, a user can configure this pipeline with a simple YAML file The full configuration files can be accessed at baseline_run and priority_run.. Here, we use the GSM8K mathematical reasoning dataset. The user provides a natural language instruction via dj_process_desc: “Please compute difficulty scores for these math questions.”. Trinity-RFT ’s data service then orchestrates a three-phase process:
1. The data processor invokes an LLM (Qwen-Max) to score the difficulty of each math problem.
1. The system prioritizes samples with lower difficulty scores, creating an easy-to-hard ordering (by setting ‘priority_weights["difficulty"]: -1.0’).
1. The curated and prioritized data is formatted into an RL-ready task set for the explorer.
As shown in Figure 10, this simple curation strategy yields more stable performance gains. This pattern is highly extensible: users can easily customize the difficulty metric, apply it to their own datasets, or even make the prioritization dynamic by re-ranking tasks periodically based on the agent’s current performance.
⬇
1 # Core dataset configuration
2 data_processor:
3 data_workflow_url: "http://127.0.0.1:5005/data_workflow"
4 task_pipeline:
5 # I/O buffers
6 input_buffers:
7 - name: "raw_input"
8 path: "openai/gsm8k"
9 storage_type: "file"
10 raw: true
11 output_buffer:
12 name: "raw_output"
13 path: "outputs/task_pipeline_output/prioritized_gsm8k.jsonl"
14 storage_type: "file"
15 format:
16 prompt_key: "question"
17 response_key: "answer"
18 # data active iterator related
19 dj_process_desc: "Please compute difficulty scores for these math questions."
20 agent_model_name: "qwen-max"
21 clean_strategy: "iterative"
22 priority_weights:
23 difficulty: -1.0 # easy-to-hard
Listing 5: Data processor configuration, applied on customizable buffers.
<details>
<summary>figs/data-pipelines/data-flow-static-priority-res.jpg Details</summary>
### Visual Description
## Line Charts: Training Metrics Dashboard
### Overview
The image displays a dashboard containing three separate line charts arranged horizontally. Each chart tracks a different metric over what appears to be training steps or epochs (x-axis, ranging from 0 to 30). Each chart contains two data series, represented by a red line and a blue line. The charts are presented in a clean, grid-based interface with light gray grid lines and minimal UI controls (pin, expand, and menu icons) in the top-right corner of each panel.
### Components/Axes
**Common Elements:**
* **X-Axis (All Charts):** Labeled with numerical markers at intervals of 5: `0, 5, 10, 15, 20, 25, 30`. The axis likely represents training steps, epochs, or iterations. No explicit axis title (e.g., "Steps") is visible.
* **Data Series:** Two lines per chart: one **red** and one **blue**. No legend is present within the chart areas. The color assignment is consistent across all three charts.
* **Grid:** A light gray grid is present in the background of each chart.
**Chart 1 (Left):**
* **Title:** `eval/math-eval/accuracy/mean` (Top-left corner).
* **Y-Axis:** Numerical scale from approximately `0.25` to `0.35`, with major ticks at `0.25, 0.3, 0.35`.
**Chart 2 (Center):**
* **Title:** `actor/entropy_loss` (Top-left corner).
* **Y-Axis:** Numerical scale from `0` to `0.2`, with major ticks at `0, 0.05, 0.1, 0.15, 0.2`.
**Chart 3 (Right):**
* **Title:** `actor/kl_loss` (Top-left corner).
* **Y-Axis:** Numerical scale from `0` to `1.2`, with major ticks at `0, 0.2, 0.4, 0.6, 0.8, 1, 1.2`.
### Detailed Analysis
**Chart 1: eval/math-eval/accuracy/mean**
* **Trend Verification:** Both lines show an initial sharp increase, followed by a plateau or slower growth.
* **Blue Line:** Starts near `0.22` at step 0. Rises steeply to ~`0.33` by step 5. Peaks at ~`0.35` around step 12. Then declines slightly and plateaus at ~`0.32` from step 15 to 25, ending at ~`0.31` at step 30.
* **Red Line:** Starts near `0.24` at step 0. Rises steeply to ~`0.325` by step 5. Continues a steadier climb, surpassing the blue line around step 15. Reaches a peak of ~`0.355` around step 20, dips slightly to ~`0.33` at step 25, and ends at ~`0.35` at step 30.
* **Key Data Points (Approximate):**
* Step 5: Blue ~0.33, Red ~0.325
* Step 15: Blue ~0.32, Red ~0.34
* Step 20: Blue ~0.32, Red ~0.355
* Step 30: Blue ~0.31, Red ~0.35
**Chart 2: actor/entropy_loss**
* **Trend Verification:** Both lines show a general downward trend, indicating decreasing entropy loss over time.
* **Blue Line:** Starts very high (off-chart, >`0.2`) at step 0. Drops sharply to ~`0.13` by step 5. Continues a fluctuating decline, reaching ~`0.07` by step 10. Shows a minor rise to ~`0.09` around step 15, then a steady decline to its lowest point of ~`0.02` at step 30.
* **Red Line:** Also starts high (off-chart). Drops to ~`0.11` by step 5. Fluctuates between ~`0.06` and `0.11` from steps 5 to 25, with a notable peak of ~`0.12` around step 22. Ends at ~`0.06` at step 30.
* **Key Data Points (Approximate):**
* Step 5: Blue ~0.13, Red ~0.11
* Step 15: Blue ~0.09, Red ~0.07
* Step 22: Blue ~0.07, Red ~0.12 (peak)
* Step 30: Blue ~0.02, Red ~0.06
**Chart 3: actor/kl_loss**
* **Trend Verification:** The blue line shows a large, pronounced hump-shaped trend. The red line shows a much smaller, flatter increase and plateau.
* **Blue Line:** Starts near `0` at step 0. Rises steadily to ~`0.5` by step 10. Accelerates sharply, peaking at ~`1.05` around step 20. Then declines steadily to ~`0.55` at step 30.
* **Red Line:** Starts near `0`. Rises to ~`0.5` by step 5. Fluctuates in a narrow band between ~`0.4` and `0.6` for the remainder of the chart, ending at ~`0.4` at step 30.
* **Key Data Points (Approximate):**
* Step 5: Blue ~0.2, Red ~0.5
* Step 10: Blue ~0.5, Red ~0.55
* Step 20: Blue ~1.05 (peak), Red ~0.45
* Step 30: Blue ~0.55, Red ~0.4
### Key Observations
1. **Performance Divergence (Chart 1):** The red line achieves a higher final accuracy (~0.35) than the blue line (~0.31), despite the blue line having an early lead.
2. **Entropy Loss Behavior (Chart 2):** The blue line's entropy loss decreases more consistently and reaches a much lower final value (~0.02) than the red line (~0.06), suggesting the policy associated with the blue line becomes more deterministic.
3. **KL Loss Anomaly (Chart 3):** The blue line exhibits a dramatic, temporary surge in KL loss, peaking at over 1.0, while the red line's KL loss remains relatively stable below 0.6. This indicates a period of significant policy divergence for the blue line's agent.
4. **Correlation of Trends:** The period of highest KL loss for the blue line (steps 15-25) corresponds roughly to the period where its accuracy (Chart 1) plateaus and its entropy loss (Chart 2) reaches its lowest values.
### Interpretation
This dashboard likely compares the training performance of two different agents, models, or hyperparameter settings (Red vs. Blue) in a reinforcement learning or fine-tuning context, possibly for a math reasoning task.
* **What the data suggests:** The **Red** configuration appears to yield better final task performance (higher accuracy) and maintains a more stable policy (lower, stable KL loss). The **Blue** configuration learns a more deterministic policy (very low final entropy loss) but experiences a large, destabilizing shift in its policy mid-training (high KL loss peak), which may have hindered its final accuracy.
* **Relationship between elements:** The charts together tell a story of trade-offs. Maximizing policy certainty (low entropy, Blue line) does not guarantee better task performance and may come at the cost of training stability (high KL divergence). The Red line's approach, maintaining slightly higher entropy and very controlled KL change, resulted in better final outcomes.
* **Notable anomalies:** The massive spike in KL loss for the Blue line is the most significant anomaly. It suggests a potential instability in the training process for that configuration, such as an aggressive learning rate, a problematic batch of data, or an inherent instability in the algorithm being used. The fact that accuracy plateaus during this spike reinforces the idea that this policy shift was detrimental to learning the task.
</details>
Figure 10: Performance on a math reasoning task. Prioritizing tasks from easy to hard (red line) leads to faster and better convergence compared to the default setting (blue line).
#### 3.4.2 Dynamic Experience and Reward Shaping
While task curation primes the model before exploration, experience shaping refines the learning signal after each agent-environment interaction. This is critical for RFT algorithms that rely on rich feedback, as standard rewards (e.g., binary pass/fail) are often too sparse to guide learning effectively. We demonstrate how to augment rewards with metrics for quality and diversity, transforming a sparse signal into a dense, multi-faceted one that provides clearer guidance to the trainer.
Use Case 1: Quality Reward Augmentation.
To encourage the model to generate high-quality responses, we can augment the base reward with a quality score. As illustrated in Figure 11, during each RFT step, we use the data processor to evaluate the quality of each generated rollout. For our experiment, we trained a Qwen2.5-1.5B model and used a more powerful Qwen3-32B as the scorer LLM. Specifically, we invoked the llm_quality_filter from Data-Juicer, which normalized the quality scores to the range [-0.5, 0.5] and added them to the original reward.
Crucially, this processing is applied to the experience buffer at each RFT step. This allows the reward signal to adapt dynamically to the policy model’s evolving capabilities, a more responsive approach than one-time static processing. With a sync_interval of 3 over 36 steps on the Math-500 validation set, the results in Figure 12 show that: (1) The model with quality reward augmentation (red line) achieves higher accuracy. (2) The introduced quality reward itself improves over time, confirming it is a learnable signal. (3) We observe a slight increase in response length, which likely reflects an inductive bias from the larger scorer model being implicitly distilled into the smaller policy model.
<details>
<summary>x9.png Details</summary>
### Visual Description
## Diagram: GRPO Method for Multi-Reward Response Evaluation
### Overview
The image is a technical flowchart illustrating a process named **GRPO** (likely an acronym for a reinforcement learning or model training method). The diagram depicts a pipeline that starts with a sample from the GSM8K dataset, generates multiple responses, and evaluates them using a composite reward system involving three distinct reward components. The flow moves from left to right.
### Components/Axes
The diagram is composed of labeled boxes, arrows indicating flow, and text annotations. There are no traditional chart axes.
**1. Left Region (Input & Generation):**
* **Box (Top-Left):** "GSM8K Sample" – This is the input data point.
* **Arrow & Label:** An arrow points right from the "GSM8K Sample" box, labeled "Rollout".
* **Annotation (Below Arrow):** A logo and text "Qwen2.5 1.5B" – This indicates the model used for the "Rollout" (response generation) step is the Qwen2.5 model with 1.5 billion parameters.
* **Text (Bottom-Left Corner):** "GRPO" in large, bold font – This is the name of the overall method or framework being illustrated.
**2. Center Region (Generated Responses):**
* A vertical stack of three boxes, representing multiple outputs from the rollout process.
* **Top Box:** "Response 1"
* **Middle Box:** "Response 2"
* **Bottom Box:** "Response n" – The "n" signifies that an arbitrary number of responses can be generated.
**3. Right Region (Reward Evaluation):**
* A dashed-line rectangle encloses the reward components, indicating they form a unified evaluation module.
* Three boxes are stacked vertically inside this rectangle, connected by plus signs (`+`), suggesting their scores are summed or combined.
* **Top Box (Blue outline):** "Math Acc Reward" – Likely a reward based on mathematical accuracy.
* **Middle Box (Blue outline):** "Format Reward" – A reward for adhering to a required output format.
* **Bottom Box (Red outline):** "DJ-Quality Reward" – A reward for quality, with "DJ" possibly being an acronym for a specific metric or model. This box is highlighted with a red outline, drawing attention to it.
* **Annotation (Below Reward Boxes):** An arrow points up to the "DJ-Quality Reward" box from the text "LLM Scorer" and a logo with text "Qwen3 32B". This specifies that the "DJ-Quality Reward" is computed by a separate, larger language model (Qwen3 with 32 billion parameters) acting as a scorer.
### Detailed Analysis
The process flow is as follows:
1. A sample is taken from the **GSM8K** dataset (a benchmark for grade-school math problems).
2. The **Qwen2.5 1.5B** model performs a "Rollout," generating `n` different candidate responses (`Response 1` to `Response n`) for that sample.
3. Each generated response is evaluated by a composite reward function. This function is the sum of three distinct rewards:
* **Math Acc Reward:** Evaluates correctness of the mathematical solution.
* **Format Reward:** Evaluates structural compliance (e.g., using specific tags or a step-by-step format).
* **DJ-Quality Reward:** Evaluates a broader quality dimension (e.g., reasoning clarity, explanation depth). This specific reward is not computed by the smaller Qwen2.5 model but is instead scored by a much larger **Qwen3 32B** model, which acts as an "LLM Scorer."
### Key Observations
* **Model Hierarchy:** There is a clear two-model architecture. A smaller, efficient model (1.5B) generates candidate responses, while a larger, more powerful model (32B) is used as a judge to provide a sophisticated quality reward.
* **Multi-Faceted Evaluation:** The system doesn't rely on a single metric. It combines accuracy, format, and a separate quality judgment, suggesting a holistic approach to training or evaluating the response generator.
* **Highlighted Component:** The "DJ-Quality Reward" is visually emphasized with a red outline, indicating it may be the novel or most critical component of the GRPO method being presented.
* **Scalability:** The use of "Response n" implies the method is designed to work with a variable number of candidate responses per input sample.
### Interpretation
This diagram outlines a **reinforcement learning from AI feedback (RLAIF)** or **model alignment** pipeline. The GRPO method appears to be a technique for improving a smaller language model (Qwen2.5 1.5B) by generating multiple solutions to math problems and scoring them using a composite reward signal. The key innovation seems to be the integration of a high-quality reward signal ("DJ-Quality") derived from a much larger "teacher" model (Qwen3 32B). This allows the smaller student model to learn not just from simple correctness (Math Acc) and formatting, but also from nuanced quality judgments that only a larger model can reliably provide. The process likely involves using these combined rewards to perform reinforcement learning (e.g., PPO) or best-response selection to fine-tune the Qwen2.5 model, aiming to make it more accurate, well-formatted, and high-quality in its reasoning outputs, particularly for mathematical tasks.
</details>
Figure 11: The enhanced math workflow with quality-reward shaping from data processor, where DJ indicates DataJuicer [2], from which more operators can be utilized to extend this worklow.
<details>
<summary>x10.png Details</summary>
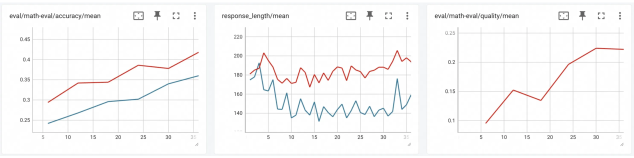
### Visual Description
\n
## Line Charts: Model Evaluation Metrics Over Training Steps
### Overview
The image displays three horizontally aligned line charts, each tracking a different metric over what appears to be training steps or epochs (x-axis, labeled 5 to 35). The charts share a common visual style with a white background, light gray grid lines, and two data series (red and blue lines) in the first two charts, and a single red line in the third. The charts are likely from a machine learning experiment dashboard, showing the progression of model performance.
### Components/Axes
**Common Elements:**
* **X-Axis:** All three charts have an x-axis with numerical markers at intervals of 5, ranging from 5 to 35. The axis is not explicitly labeled with a title (e.g., "Epoch" or "Step").
* **Chart Titles:** Each chart has a title at the top center.
* **Grid:** A light gray grid is present in the plot area of each chart.
* **Toolbar Icons:** Each chart has a small toolbar in the top-right corner with icons for view options (e.g., fullscreen, download).
**Chart 1 (Left):**
* **Title:** `eval/math-eval/accuracy/mean`
* **Y-Axis:** Labeled from 0.25 to 0.45 in increments of 0.05. Represents mean accuracy.
* **Data Series:** Two lines.
* **Red Line:** Positioned above the blue line throughout.
* **Blue Line:** Positioned below the red line throughout.
**Chart 2 (Center):**
* **Title:** `response_length/mean`
* **Y-Axis:** Labeled from 140 to 220 in increments of 20. Represents mean response length (likely in tokens).
* **Data Series:** Two lines.
* **Red Line:** Positioned above the blue line throughout.
* **Blue Line:** Positioned below the red line throughout.
**Chart 3 (Right):**
* **Title:** `eval/math-eval/quality/mean`
* **Y-Axis:** Labeled from 0.1 to 0.25 in increments of 0.05. Represents mean quality score.
* **Data Series:** One line.
* **Red Line:** The only data series in this chart.
### Detailed Analysis
**Chart 1: eval/math-eval/accuracy/mean**
* **Trend Verification:** Both lines show a clear, consistent upward trend from left to right, indicating improving accuracy over the measured steps.
* **Data Points (Approximate):**
* **Red Line:** Starts at ~0.30 (x=5). Rises steadily to ~0.35 (x=15), then to ~0.38 (x=25), and ends at its peak of ~0.42 (x=35).
* **Blue Line:** Starts at ~0.25 (x=5). Rises to ~0.28 (x=15), ~0.31 (x=25), and ends at ~0.35 (x=35).
* **Relationship:** The red line maintains a consistent lead of approximately 0.05-0.07 accuracy points over the blue line across the entire range.
**Chart 2: response_length/mean**
* **Trend Verification:** Both lines are highly volatile with no clear long-term upward or downward trend. They fluctuate within a defined band. The red line is consistently higher than the blue line.
* **Data Points (Approximate):**
* **Red Line:** Fluctuates primarily between 180 and 220. Notable peaks near 220 at x≈5 and x≈33. Notable troughs near 180 at x≈10 and x≈20.
* **Blue Line:** Fluctuates primarily between 140 and 180. Shows similar volatile patterns to the red line but at a lower magnitude. Has a sharp dip to ~140 at x≈32.
* **Relationship:** The two lines appear to be correlated in their short-term fluctuations (rising and falling together), but the red line maintains a significant offset, averaging about 40-50 units higher in response length.
**Chart 3: eval/math-eval/quality/mean**
* **Trend Verification:** The single red line shows a strong upward trend, with a notable temporary decline in the middle.
* **Data Points (Approximate):**
* Starts at ~0.10 (x=5).
* Rises to a local peak of ~0.15 (x=15).
* Dips to a local trough of ~0.13 (x=20).
* Rises sharply thereafter, reaching ~0.23 by x=30 and plateauing near ~0.23 at x=35.
### Key Observations
1. **Performance Improvement:** Both evaluation metrics (accuracy and quality) show clear improvement over the training steps, suggesting the model is learning effectively on the math evaluation task.
2. **Consistent Model Comparison:** In the first two charts, the red series consistently outperforms (higher accuracy) and differs in behavior (longer responses) from the blue series. This likely represents two different models, model variants, or training configurations (e.g., "Model A" vs. "Model B", or "With Feature X" vs. "Without").
3. **Response Length Volatility:** The mean response length is highly variable for both series and does not correlate directly with the steady improvement in accuracy/quality. The dip in the blue line's length at x≈32 is an outlier.
4. **Quality Metric Dip:** The temporary decline in the quality score around step 20 is an anomaly amidst an otherwise strong upward trend. This could indicate a period of instability or a temporary setback in training.
### Interpretation
The data suggests a successful training run where the primary model (red line) is improving its mathematical reasoning capabilities, as evidenced by rising accuracy and quality scores. The comparison model (blue line) also improves but lags behind.
The lack of correlation between the volatile response length and the steadily improving quality/accuracy is insightful. It indicates that **longer responses are not inherently better** for this task; the model is learning to produce more accurate and higher-quality answers, not just longer ones. The quality metric's dip around step 20, while accuracy continued to rise, might suggest the model temporarily sacrificed answer quality (e.g., coherence, correctness of steps) for raw correctness, or encountered a difficult batch of evaluation data.
The charts collectively tell a story of model progression, comparative performance, and the nuanced relationship between different evaluation metrics. To fully interpret the results, one would need the legend labels (e.g., what "red" and "blue" represent) and the definition of the x-axis (e.g., "Training Steps" or "Epochs").
</details>
Figure 12: Experimental results for quality-reward shaping. Augmenting the reward with a quality score (red line) improves final accuracy and provides a learnable reward signal.
Use Case 2: Diversity Reward Augmentation.
A common failure mode in RFT is policy collapse, where the agent repeatedly generates similar, suboptimal responses. To counteract this, we introduce a diversity reward that encourages the explorer to explore different solution paths. As shown in Figure 13, we used the GTE-Qwen2-1.5B model to convert rollouts into semantic embeddings. The diversity reward was calculated based on the cosine similarity of a rollout’s embedding to the mean embedding of its group, with lower similarity (i.e., higher diversity) yielding a higher reward.
To prevent exploration from becoming chaotic, we applied a simple decay schedule to the diversity reward’s weight, starting at 0.5 and decaying to 0.3 over the training steps. The experiment, using the same setting as before, yielded compelling results (Figure 14): (1) The diversity-augmented model (red line) shows a significant performance improvement over the baseline. (2) The response length is consistently longer, indicating the reward encourages more elaborate answers. (3) Most importantly, the actor entropy loss remains consistently higher, providing strong evidence that the model is maintaining a healthier, more diverse exploration strategy, which helps it escape local optima.
<details>
<summary>x11.png Details</summary>
### Visual Description
## Process Flow Diagram: GRPO (Group Relative Policy Optimization) Method for Math Problem Solving
### Overview
The image is a technical flowchart illustrating the architecture and data flow of a method labeled "GRPO" (likely Group Relative Policy Optimization). The diagram depicts a reinforcement learning or model training pipeline that starts with a sample from the GSM8K math dataset, processes it through a language model (Qwen2.5 1.5B), generates multiple responses, computes embeddings, and calculates a composite reward signal based on format, mathematical accuracy, and diversity.
### Components/Axes
The diagram is structured as a left-to-right flowchart with the following labeled components and connections:
**1. Input & Initial Processing (Left Region):**
* **Box:** `GSM8K Sample` (Top-left). This is the starting data point.
* **Arrow & Label:** An arrow labeled `Rollout` points from the GSM8K Sample to the next component.
* **Model Icon & Label:** A small icon of a robot head labeled `Qwen2.5 1.5B`. This indicates the language model used for generating responses.
**2. Response Generation & Embedding (Central Region):**
* **Parallel Processing Blocks:** Three vertically stacked, identical structures represent multiple generated responses (Res) and their embeddings (Ebd).
* Top: `Res 1` → `Ebd 1`
* Middle: `Res 2` → `Ebd 2`
* Bottom: `Res n` → `Ebd n`
* **Connecting Text:** The word `Embedding` is written between the `Res` and `Ebd` blocks, clarifying the transformation.
* **Averaging Block:** All `Ebd` blocks feed into a central block labeled `Ebd Avg` (Embedding Average).
* **Similarity Calculation:** An arrow from `Ebd Avg` points to the text `Cos Similarity` (Cosine Similarity).
**3. Reward Calculation (Right Region):**
* **Numerical Values:** Three colored boxes with numerical values are positioned to the right of the central flow:
* Blue box: `+0.5`
* Green box: `+0.1`
* Red box: `+0.3`
* **Reward Components:** These values correspond to three reward types listed in a dashed-border box:
* `Format Reward` (Associated with the blue `+0.5` value)
* `Math Acc Reward` (Mathematical Accuracy Reward, associated with the green `+0.1` value)
* `Diversity Reward` (Associated with the red `+0.3` value and highlighted with a red border).
* **Final Combination:** Plus signs (`+`) connect the three reward components, indicating they are summed to form a total reward signal.
**4. Title/Label:**
* **Text:** `GRPO` is written in the bottom-left corner, serving as the title or acronym for the entire process.
### Detailed Analysis
The process flow is as follows:
1. A single sample is taken from the GSM8K math problem dataset.
2. The Qwen2.5 1.5B model performs a "rollout," generating `n` different responses (`Res 1` to `Res n`) for that sample.
3. Each response is converted into an embedding vector (`Ebd 1` to `Ebd n`).
4. These `n` embeddings are averaged to create a single representative embedding (`Ebd Avg`).
5. A `Cos Similarity` metric is computed, likely comparing the individual response embeddings to the average or to each other to measure diversity.
6. Three distinct reward signals are calculated:
* **Format Reward (+0.5):** Likely rewards responses that adhere to a specific output structure.
* **Math Acc Reward (+0.1):** Rewards responses that are mathematically correct.
* **Diversity Reward (+0.3):** Rewards responses that are different from one another, as measured by the cosine similarity step. This component is visually emphasized with a red border.
7. These three rewards are summed to produce the final training signal for the GRPO method.
### Key Observations
* **Emphasis on Diversity:** The `Diversity Reward` is the only component highlighted with a colored border (red), suggesting it is a critical or novel aspect of the GRPO method being illustrated.
* **Reward Weighting:** The numerical values (+0.5, +0.1, +0.3) imply a weighting scheme where Format is most heavily weighted, followed by Diversity, with Mathematical Accuracy having the lowest direct weight in this depiction. This is an unusual weighting for a math-focused task and may indicate that format and diversity are being used as proxies or regularizers.
* **Multi-Response Generation:** The core mechanism involves generating multiple (`n`) responses per problem, which is central to computing the diversity reward and the averaged embedding.
* **Model Specificity:** The diagram explicitly names the model architecture (`Qwen2.5 1.5B`) and references `GTE-Qwen2` (likely the embedding model), providing concrete technical details.
### Interpretation
This diagram outlines a reinforcement learning from human feedback (RLHF) or similar training strategy tailored for improving mathematical reasoning in language models. The GRPO method appears to address a common failure mode where models might converge on a single, stereotypical way of solving problems.
The key insight is the **explicit optimization for response diversity** alongside correctness and format. By rewarding a set of responses for being different from each other (high variance in embeddings), the method likely encourages the model to explore a wider solution space, discover multiple valid reasoning paths for a given problem, and avoid mode collapse. This could lead to more robust and generalizable problem-solving skills.
The relatively low weight on `Math Acc Reward` (+0.1) is provocative. It suggests that in this specific training phase or formulation, directly rewarding correctness is less important than shaping the *style* (Format) and *exploratory behavior* (Diversity) of the model. The assumption may be that a model which learns to produce diverse, well-formatted attempts will, as a consequence, improve its accuracy through broader exploration. The diagram presents a technical blueprint for implementing this specific inductive bias into a model's training loop.
</details>
Figure 13: The enhanced math workflow with diversity-reward shaping from data processor
<details>
<summary>x12.png Details</summary>
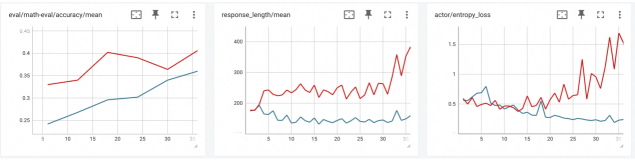
### Visual Description
## Line Charts: Model Training Metrics
### Overview
The image displays three horizontally arranged line charts, each tracking a different metric over what appears to be training steps or epochs (x-axis, labeled 0 to 30). Each chart contains two data series, represented by a red line and a blue line, suggesting a comparison between two models, conditions, or runs. The charts are presented in a dashboard or monitoring interface, with small icons (a chart, an expand/fullscreen icon, and a three-dot menu) in the top-right corner of each panel.
### Components/Axes
**Common Elements:**
* **X-Axis (All Charts):** Labeled with numerical markers at intervals of 5, ranging from 0 to 30. The axis title is not explicitly visible, but context suggests it represents training steps, epochs, or iterations.
* **Data Series:** Two lines per chart: one red, one blue. No legend is present within the chart areas to identify what each color represents.
* **Grid:** Light gray horizontal and vertical grid lines are present.
**Chart 1 (Left):**
* **Title:** `eval/math-eval/accuracy/mean`
* **Y-Axis:** Labeled from 0.25 to 0.45 in increments of 0.05. Represents mean accuracy on a math evaluation task.
* **Y-Axis Title:** Not explicitly visible.
**Chart 2 (Center):**
* **Title:** `response_length/mean`
* **Y-Axis:** Labeled from 200 to 400 in increments of 100. Represents mean length (likely in tokens) of generated responses.
* **Y-Axis Title:** Not explicitly visible.
**Chart 3 (Right):**
* **Title:** `actor/entropy_loss`
* **Y-Axis:** Labeled from 0 to 1.5 in increments of 0.5. Represents an entropy loss metric, likely from a reinforcement learning or policy gradient actor model.
* **Y-Axis Title:** Not explicitly visible.
### Detailed Analysis
**Chart 1: eval/math-eval/accuracy/mean**
* **Red Line Trend:** Starts at approximately 0.33 (x=0). Shows a general upward trend with some volatility. Key points: rises to ~0.42 (x≈12), dips to ~0.38 (x≈22), then rises again to end at its highest point, approximately 0.44 (x=30).
* **Blue Line Trend:** Starts lower at 0.25 (x=0). Shows a steadier, more consistent upward trend with less volatility than the red line. Ends at approximately 0.36 (x=30).
* **Relationship:** The red line maintains a higher accuracy than the blue line throughout the entire range. The gap between them narrows slightly in the middle but remains significant.
**Chart 2: response_length/mean**
* **Red Line Trend:** Starts around 220 (x=0). Fluctuates between approximately 200 and 300 for most of the chart. After x≈25, it exhibits a sharp, volatile spike, reaching a peak near 400 (x≈28) before ending around 350 (x=30).
* **Blue Line Trend:** Starts near 200 (x=0). Remains relatively stable and flat, hovering close to the 200 mark for the entire duration, with minor fluctuations.
* **Relationship:** The red line consistently produces longer responses than the blue line. The dramatic late-stage increase in the red line's mean response length is the most notable feature.
**Chart 3: actor/entropy_loss**
* **Red Line Trend:** Highly volatile. Starts around 0.5 (x=0). Dips to a low near 0.2 (x≈10), then begins a steep and erratic climb, surpassing 1.5 (x≈28) before ending near 1.4 (x=30).
* **Blue Line Trend:** Much more stable. Starts around 0.5 (x=0) and fluctuates mildly between approximately 0.4 and 0.6 for the entire chart, ending near 0.5.
* **Relationship:** The two lines start at a similar point. After x≈10, they diverge dramatically: the blue line's entropy loss remains controlled, while the red line's loss explodes, indicating a significant difference in the stability or exploration behavior of the underlying actor models.
### Key Observations
1. **Performance Correlation:** The model represented by the red line shows higher accuracy (Chart 1) but also exhibits much higher volatility in response length (Chart 2) and a dramatic, potentially unstable increase in actor entropy loss (Chart 3) in the later stages.
2. **Stability vs. Performance:** The blue line model demonstrates more stable and predictable behavior across all three metrics—steadily improving accuracy, consistent response length, and controlled entropy loss—but at a lower performance level (accuracy).
3. **Critical Phase Change:** A notable shift occurs around x=25 for the red line model, where both response length and entropy loss spike sharply. This suggests a possible change in training dynamics, policy shift, or onset of instability.
4. **Missing Legend:** The identity of the red and blue series (e.g., "Model A vs. Model B," "With Feature X vs. Without") is not provided in the image, limiting definitive interpretation.
### Interpretation
The data suggests a classic trade-off between performance and stability in model training. The "red" model achieves superior task performance (math accuracy) but at the cost of significantly increased behavioral volatility (erratic response lengths) and what appears to be a destabilizing increase in the actor's entropy loss. High entropy loss can indicate the policy is becoming more random or exploratory, which might be intentional but, when coupled with spiking response lengths, often signals training instability or reward hacking.
The "blue" model represents a more conservative, stable training run. Its metrics change gradually and predictably, which is desirable for reliability, but it fails to reach the same peak performance as the red model within the observed timeframe.
The simultaneous spikes in Charts 2 and 3 for the red model after step 25 are the most critical finding. This correlation implies that the mechanism driving longer responses is tightly linked to the increase in policy entropy. A technical investigator would focus on this period to understand if this represents a beneficial breakthrough in model capability or a detrimental divergence that requires intervention (e.g., adjusting entropy coefficients, reward scaling, or learning rates). The absence of a legend is a major gap; knowing what the red and blue lines represent is essential to determine if this is a comparison of algorithms, hyperparameters, or model sizes.
</details>
Figure 14: Experimental results for diversity-reward shaping. Rewarding diverse responses (red line) significantly improves task accuracy and maintains higher entropy.
### 3.5 RFT with Human in the Loop
This example demonstrates the human-in-the-loop capability in Trinity-RFT for preference modeling. As illustrated in Listing 6 and Figure 15, our framework integrates Label Studio’s annotation interface with asynchronous data pipelines through four coordinated stages: (1) task generation: auto-creating annotation batches from model rollouts; (2) interactive labeling: providing UI for side-by-side response comparison; (3) quality control: enforcing inter-annotator agreement thresholds; and (4) versioned storage: tracking preference lineage in pre-defined fields like those in DPODataModel.
This pipeline reflects Trinity-RFT ’s bi-directional collaboration feature (Section 2.3.4), backed by timeout-aware task polling and support of atomic batch commit. It enables hybrid procedures where initial AI pre-screening can reduce human workload in production deployments. Annotation activities can scale across distributed teams through event-driven task routing. The system’s flexibility benefits rapid adaptation to diverse annotation protocols, allowing developers to implement custom labeling interfaces through XML-based templates or integrate third-party annotation services via unified SDK endpoints. This capability underpins advanced use cases such as safety red-teaming datasets and online instruction tuning scenarios where human judgment remains irreplaceable for quality-critical decisions, particularly in human-centric sociocultural contexts where data quality, difficulty, and reward signals are difficult to verify logically.
⬇
1 # Human annotation configuration
2 class HumanAnnotationConfig:
3 "" "Preference annotation pipeline configuration" ""
4
5 def __init__ (self):
6 self. process = [
7 {
8 "human_preference_annotation_mapper": {
9 "wait_for_annotations": True, # Block until annotations complete
10 "timeout": 3600, # Maximum wait time in seconds
11 "prompt_key": "prompt", # Source field for prompts
12 "answer1_key": "answer1", # First candidate response
13 "chosen_key": "chosen" # Selected response key
14 }
15 }
16 ]
17
18 def get_pipeline (self) -> List [Dict]:
19 "" "Get annotation processing pipeline" ""
20 return self. process
Listing 6: Configuration for human preference annotation.
<details>
<summary>x13.png Details</summary>
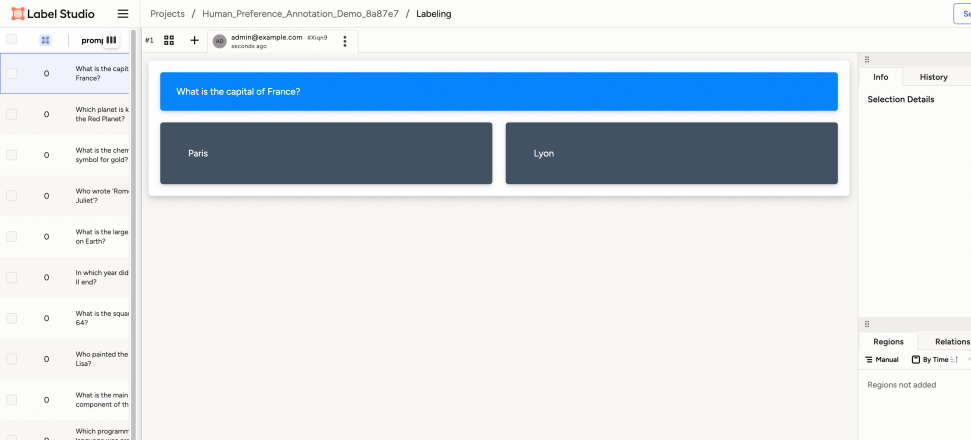
### Visual Description
## Screenshot: Label Studio Human Preference Annotation Interface
### Overview
This image is a screenshot of a web-based data labeling application called "Label Studio." The interface is displaying a task for "Human Preference Annotation," where a user is presented with a question and two possible answers to choose from. The layout is divided into several functional panels: a header, a left sidebar with a task list, a central main content area for the active task, and a right sidebar for details and history.
### Components/Axes
The interface is structured into the following distinct regions:
1. **Header (Top Bar):**
* **Left:** Label Studio logo (red icon with text "Label Studio") and a hamburger menu icon (three horizontal lines).
* **Center:** Breadcrumb navigation path: `Projects / Human_Preference_Annotation_Demo_8a87e7 / Labeling`.
* **Right:** A user indicator showing "admin@example.com" with a timestamp "XX:XX:XX seconds ago," a vertical ellipsis (three dots) menu icon, and a partially visible blue button (likely "Submit" or "Save").
2. **Left Sidebar (Task List):**
* A vertical list of tasks, each represented by a row containing a checkbox, a number, and a truncated question text.
* The first task (numbered "1") is highlighted with a light blue background, indicating it is the currently active task.
* **Visible Task List Items (from top to bottom):**
* `1` - `What is the capital of France?` (Active/Selected)
* `2` - `Which planet is known as the Red Planet?`
* `3` - `What is the chemical symbol for gold?`
* `4` - `Who wrote Romeo and Juliet?`
* `5` - `What is the largest ocean on Earth?`
* `6` - `In which year did World War II end?`
* `7` - `What is the square root of 64?`
* `8` - `Who painted the Mona Lisa?`
* `9` - `What is the main component of the Earth's atmosphere?`
* `10` - `Which programming language is...` (Text is cut off)
3. **Main Content Area (Task Workspace):**
* This is the central panel where the active task is displayed.
* **Question Panel:** A large blue rectangle at the top containing the full question text: `What is the capital of France?`
* **Answer Options:** Two large, dark grey rectangular buttons below the question, presented side-by-side.
* **Left Button:** Contains the text `Paris`.
* **Right Button:** Contains the text `Lyon`.
4. **Right Sidebar (Details Panel):**
* Contains two tabs at the top: `Info` (active) and `History`.
* Below the tabs is a section titled `Selection Details`.
* Further down, there are two more tabs: `Regions` (active) and `Relations`.
* Under the `Regions` tab, there are two sub-options: `Manual` and `By Time` (with a dropdown arrow).
* At the bottom of this panel, the text `Regions not added` is displayed, indicating no annotations have been made on this task yet.
5. **Footer (Bottom Bar):**
* A thin, empty grey bar spans the bottom of the entire application window.
### Detailed Analysis
* **Task Flow:** The interface presents a clear workflow. The user selects a task from the list on the left. The central panel then displays that task's content (a question and multiple-choice answers). The user's selection (clicking either "Paris" or "Lyon") would constitute the annotation or label for that data point.
* **UI State:** The application is in a "labeling" state, as indicated by the breadcrumb. The active task is #1. The right sidebar shows no existing annotations ("Regions not added") for the current task.
* **Text Transcription:** All visible text in the interface is in English. The text is presented clearly in a sans-serif font. Some text in the left sidebar is truncated with an ellipsis (`...`) due to space constraints.
### Key Observations
* **Purpose-Built Interface:** The layout is highly specialized for sequential data labeling, with a clear separation between task selection (left), task execution (center), and metadata/annotation details (right).
* **Minimalist Task Design:** The core task is extremely simple: a single question with two mutually exclusive answers. This suggests the demo project is designed for basic preference or knowledge testing.
* **No Annotations Present:** The "Regions not added" message in the right sidebar confirms that the current user has not yet interacted with or labeled the active task (#1).
* **User Context:** The user is logged in as `admin@example.com`, suggesting this might be a setup or demonstration view.
### Interpretation
This screenshot captures a moment in a human-in-the-loop machine learning or data curation pipeline. The "Human_Preference_Annotation_Demo" project name implies the goal is to collect human judgments on pairs of answers (like "Paris" vs. "Lyon") to train or evaluate a model. The interface is designed for efficiency, allowing an annotator to quickly move through a list of simple questions.
The structure reveals a common pattern in annotation tools: a master list of items, a focused workspace for the current item, and a contextual panel for tools and history. The absence of any added regions indicates the annotation process for this specific item has not begun. The tool is ready for the user to click on one of the two answer buttons, which would likely register as a label and automatically advance to the next task in the list.
</details>
Figure 15: An interactive interface for human preference annotation.
### 3.6 Low-Code Usage and Development with Trinity-Studio
<details>
<summary>figs/studio-showcase/dashboard.png Details</summary>
### Visual Description
## Screenshot: RFT Portal Dashboard Web Interface
### Overview
This image is a screenshot of a web application dashboard titled "RFT Portal Dashboard." It serves as a central navigation hub, providing access to three distinct tools or modules: a Training Portal, pgAdmin (for database management), and Label Studio (for data annotation). The interface is clean and card-based, with a top navigation bar.
### Components/Axes
**Top Navigation Bar (Dark Blue Background):**
* **Tabs (from left to right):**
1. `Dashboard` (currently selected, indicated by a lighter blue background)
2. `pgAdmin`
3. `Label Studio`
4. `Training Portal`
5. `Settings`
**Main Content Area (Light Gray Background):**
* **Main Title:** `RFT Portal Dashboard` (centered, large, dark blue font).
* **Three Content Cards (arranged horizontally):**
* **Card 1 (Left):**
* **Icon:** Blue circle with white text `TP`.
* **Title:** `Training Portal` (blue font).
* **Description:** `Access the training portal to manage your training data and models.`
* **Button:** Blue button with text `Open Training Portal`.
* **Card 2 (Center):**
* **Icon:** Green circle with white text `DB`.
* **Title:** `pgAdmin` (green font).
* **Description:** `Manage your PostgreSQL databases with pgAdmin.`
* **Button:** Green button with text `Open pgAdmin`.
* **Card 3 (Right):**
* **Icon:** Red/Orange circle with white text `LS`.
* **Title:** `Label Studio` (red/orange font).
* **Description:** `Label and annotate your data with Label Studio.`
* **Button:** Red/Orange button with text `Open Label Studio`.
### Detailed Analysis
The interface is structured for quick access. Each card follows an identical layout pattern: Icon -> Title -> Description -> Action Button. The color scheme is consistent per card, with the icon, title text, and button all sharing the same hue (blue for Training Portal, green for pgAdmin, red/orange for Label Studio). The navigation bar suggests the user is currently on the "Dashboard" view, with other sections available for direct navigation.
### Key Observations
1. **Consistent Card Design:** The three primary tools are presented with equal visual weight, using a consistent template that promotes intuitive understanding.
2. **Color-Coded Functionality:** Each tool is assigned a distinct color (blue, green, red/orange), creating a strong visual association between the icon, title, and action button.
3. **Clear Hierarchy:** The page title is the most prominent element, followed by the card titles, then the descriptive text, and finally the action buttons.
4. **Navigation State:** The "Dashboard" tab in the top bar is visually highlighted, confirming the user's current location within the application.
### Interpretation
This dashboard is the entry point for a workflow likely related to machine learning or data science, given the tools it connects. The "RFT" in the title could stand for "Reinforcement Fine-Tuning" or a similar process. The three modules represent key stages:
* **Training Portal (TP):** For managing the core models and training data.
* **pgAdmin (DB):** For direct database administration, suggesting data is stored in PostgreSQL.
* **Label Studio (LS):** For data labeling and annotation, a critical step in supervised learning.
The design prioritizes clarity and efficiency, allowing a user to jump directly into a specific task without navigating through multiple menus. The separation of concerns (training, data storage, data labeling) into distinct, color-coded portals indicates a structured, modular approach to the underlying project or platform.
</details>
(a) Trinity-Studio dashboard.
<details>
<summary>figs/studio-showcase/training-portal-click-run.jpg Details</summary>
### Visual Description
## [Screenshot]: Machine Learning Training Portal Configuration Interface
### Overview
This image is a screenshot of a web-based user interface for a "Training Portal," likely part of a machine learning operations (MLOps) or model training platform. The interface allows users to configure training hyperparameters, generate a configuration file, and submit a training job. A success message indicates a job has been submitted, and a partial view of the generated configuration file is visible.
### Components/Axes
The interface is structured into distinct horizontal sections:
1. **Top Navigation Bar (Dark Grey):**
* Contains five navigation links/tabs: `Dashboard`, `pgAdmin`, `Label Studio`, `Training Portal` (currently active, indicated by a subtle background highlight), and `Settings`.
2. **Application Header (Blue):**
* Left side: A hamburger menu icon (three horizontal lines) followed by the title `Training Portal`.
* Right side: A gear icon labeled `TOOLS`.
3. **Main Content Area (White Background):**
* **Hyperparameter Input Section:**
* Two labeled input fields arranged side-by-side.
* Left Field: Label is `Micro Batch Size Per GPU :blue-badge`. The input box contains the value `8` and has decrement (`-`) and increment (`+`) buttons.
* Right Field: Label is `Learning Rate :blue-badge`. The input box contains the value `1.0e-6` and has decrement (`-`) and increment (`+`) buttons.
* Below these fields is a wide button labeled `Generate Config` with a document-plus icon.
* **Generated Config Section:**
* A large heading: `Generated Config File`.
* Two action buttons below the heading: `Save` (with a download icon) and `Run` (with a play/terminal icon).
* **Status Message Box (Light Green):**
* Contains a green checkmark icon and the text: `Job submitted successfully!`.
* Below that: `View progress in the Ray Dashboard: http://127.0.0.1:8265` (the URL is a hyperlink).
* **Configuration File Preview (Light Grey Code Block):**
* Displays the beginning of a YAML-formatted configuration file. The visible lines are:
* `mode: both`
* `data:`
* ` total_epochs: 20`
* ` batch_size: 96` (The line is partially cut off at the bottom of the image).
4. **Other UI Elements:**
* A `Deploy` button with a vertical ellipsis (⋮) menu icon is visible in the upper right corner of the main content area.
* A vertical scrollbar is present on the far right edge, indicating more content exists below the visible area.
### Detailed Analysis
* **Hyperparameters:** The user has set a micro batch size of 8 per GPU and a learning rate of 1.0e-6 (0.000001).
* **Job Status:** The green notification confirms a training job was successfully submitted to a system called "Ray" (a distributed computing framework). Progress can be monitored at the local address `http://127.0.0.1:8265`.
* **Configuration File:** The generated YAML config specifies:
* `mode: both` - This likely indicates the job will perform both training and evaluation, or use both data sources.
* `data:` section - Defines dataset parameters.
* `total_epochs: 20` - The model will be trained for 20 full passes through the dataset.
* `batch_size: 96` - The global batch size for training is 96. Given the "Micro Batch Size Per GPU" is 8, this implies the job is configured to run on 12 GPUs (96 / 8 = 12).
### Key Observations
1. **Integrated Workflow:** The portal integrates several tools (pgAdmin for databases, Label Studio for data annotation) suggesting an end-to-end ML pipeline.
2. **Local Development/Testing:** The use of `127.0.0.1` (localhost) in the Ray Dashboard link indicates this is likely a local development or testing environment, not a production cluster.
3. **State Indication:** The `Run` button appears greyed out or inactive, which is consistent with the job having already been submitted successfully.
4. **Partial Information:** The configuration file is truncated. Critical parameters like the model architecture, dataset path, or optimizer settings are not visible in this screenshot.
### Interpretation
This interface represents a **training job submission portal** within an MLOps platform. Its primary function is to abstract the complexity of writing training scripts and cluster configuration files into a simple web form.
* **Process Flow:** The user flow is: 1) Set key hyperparameters (batch size, learning rate), 2) Click "Generate Config" to create a YAML file, 3) Click "Run" to submit the job to a Ray cluster. The system provides immediate feedback on submission success and a direct link to a monitoring dashboard.
* **Underlying System:** The mention of "Ray Dashboard" is a key indicator. Ray is an open-source framework for scaling Python applications. This portal is a custom UI built on top of Ray's job submission API, simplifying the process for data scientists or ML engineers.
* **Purpose of "blue-badge":** The `:blue-badge` text next to the hyperparameter labels is likely a UI placeholder or a tag indicating these are configurable "blue" (perhaps meaning "adjustable" or "important") parameters. It is not standard text and may be rendered as a visual badge in the live interface.
* **Missing Context:** The screenshot captures the moment after job submission. To fully understand the system, one would need to see the full configuration file, the Ray Dashboard interface, and the preceding steps where the model and dataset are defined. The `mode: both` setting is particularly ambiguous without additional documentation.
</details>
(b) Start training on the “Training Portal” page.
<details>
<summary>figs/studio-showcase/pgadmin-select-table.jpg Details</summary>
### Visual Description
## Screenshot: pgAdmin Database Interface Showing Table Structure
### Overview
This image is a screenshot of the pgAdmin 4 web interface, a management tool for PostgreSQL databases. The view is focused on displaying the structural definition of a specific table named `experience_buffer` within a database named `testdb`. The interface is divided into a top navigation bar, a left sidebar for database object navigation, and a main content area showing the table schema and a SQL query tool.
### Components/Axes (UI Sections)
1. **Top Navigation Bar (Dark Grey):**
* Contains five tabs: `Dashboard`, `pgAdmin` (currently active, highlighted), `Label Studio`, `Training Portal`, `Settings`.
2. **pgAdmin Header Bar (Blue):**
* Left side: `pgAdmin` logo/title.
* Right side: A dropdown menu displaying `Local Development` and a refresh icon.
3. **Left Sidebar (Database Navigation):**
* **Database Selector:** A dropdown labeled `Database` with `testdb` selected.
* **Tables List:** A section labeled `Tables` containing a list of table names, each with a table icon. The table `experience_buffer` is selected and highlighted.
* List of table names (from top to bottom): `xxx`, `sft_data_buffer`, `rft_dataset`, `task_buffer`, `experience_buffer`, `dpo_data_buffer`.
4. **Main Content Area:**
* **Section 1: Table Structure Display.**
* Title: `Table Structure: experience_buffer`
* A three-column table with headers: `Column`, `Type`, `Nullable`.
* **Section 2: SQL Query Tool.**
* Title: `SQL Query`
* A text input area with placeholder text: `Enter SQL query...`
* A blue button labeled `EXECUTE QUERY` with a play icon.
### Detailed Analysis
**Table Structure for `experience_buffer`:**
The table schema is presented with the following columns and their properties:
| Column Name | Data Type | Nullable |
| :--- | :--- | :--- |
| `consumed` | integer | YES |
| `priority` | double precision | YES |
| `serialized_exp` | bytea | YES |
| `id` | integer | NO |
| `reward` | double precision | YES |
| `response` | character varying | YES |
| `prompt` | character varying | YES |
**Key Data Points from Schema:**
* The primary key or unique identifier is likely the `id` column, as it is the only column marked `Nullable: NO`.
* The table stores a mix of data types: integers (`consumed`, `id`), floating-point numbers (`priority`, `reward`), binary data (`serialized_exp`), and variable-length strings (`response`, `prompt`).
* The column names strongly suggest this table is part of a reinforcement learning or AI training pipeline, designed to store "experiences" (state, action, reward) for replay or analysis.
### Key Observations
1. **Contextual Environment:** The top navigation includes tabs for `Label Studio` and `Training Portal`, indicating this database is part of a larger machine learning development and training ecosystem.
2. **Database Role:** The database is named `testdb`, suggesting it is used for development or testing purposes.
3. **Server Context:** The server connection is labeled `Local Development`, confirming the non-production environment.
4. **Table Relationships:** The list of tables in the sidebar (`sft_data_buffer`, `rft_dataset`, `dpo_data_buffer`, `task_buffer`) alongside `experience_buffer` points to a structured data storage system for different stages or types of AI model training data (e.g., SFT: Supervised Fine-Tuning, RFT: Reinforcement Fine-Tuning, DPO: Direct Preference Optimization).
### Interpretation
This screenshot documents the technical schema of a core data storage component within an AI model training infrastructure. The `experience_buffer` table is designed to log interaction data, likely between a human (or an environment) and an AI model.
* **Purpose of Columns:** The columns `prompt`, `response`, and `reward` are central to training feedback loops. `prompt` is the input, `response` is the model's output, and `reward` is a numerical score evaluating that output. `serialized_exp` likely contains a compact, binary representation of the full "experience" tuple for efficient storage and retrieval. `priority` and `consumed` are operational fields, possibly used to manage a prioritized experience replay buffer, a common technique in reinforcement learning to sample important experiences more frequently.
* **System Workflow:** The presence of this table, alongside others for different training methodologies (SFT, DPO), suggests a pipeline where raw experiences are collected, stored in buffers like this one, and then used to train or fine-tune models. The SQL query interface below the schema allows developers to directly inspect, debug, or manipulate this training data.
* **Anomaly/Note:** The table `xxx` in the sidebar appears to be a placeholder or test table, which is consistent with the `testdb` database name and `Local Development` server context.
</details>
(c) Manage data on the “pgAdmin” page.
<details>
<summary>figs/studio-showcase/label-studio-enter.jpg Details</summary>
### Visual Description
\n
## Screenshot: Label Studio Dashboard Interface
### Overview
This image is a screenshot of the web-based user interface for "Label Studio," a data annotation platform. The view is the main dashboard or home page, displaying navigation elements, a welcome message, recent project status, and resource links. The interface is clean and functional, with a dark blue top navigation bar and a white main content area.
### Components/Axes
The interface is segmented into distinct regions:
1. **Top Navigation Bar (Dark Blue Background):**
* Contains five navigation tabs: `Dashboard`, `pgAdmin`, `Label Studio` (currently active, indicated by a darker background), `Training Portal`, and `Settings`.
* Text is white.
2. **Main Header (White Background):**
* **Left:** The Label Studio logo (an orange square icon) and the text "Label Studio". Next to it is a hamburger menu icon (three horizontal lines) and the current page title "Home".
* **Right:** A circular user avatar icon with the initials "AD".
3. **Welcome Section (Left-aligned):**
* **Heading:** "Welcome 👋" (includes a waving hand emoji).
* **Subtext:** "Let's get you started."
* **Action Buttons:**
* `Create Project` (with a folder-plus icon).
* `Invite People` (with a user-plus icon).
4. **Recent Projects Section (Left-aligned, below Welcome):**
* **Heading:** "Recent Projects".
* **Link:** "View All" (aligned to the right of the heading).
* **Project List:** Two project entries are displayed.
* **Project 1:**
* **Name:** `Human_Preference_Annotation_Demo_acc038`
* **Status:** `10 of 10 Tasks (100%)`
* **Visual Indicator:** A solid green horizontal progress bar, filled to 100%.
* **Project 2:**
* **Name:** `Human_Preference_Annotation_Demo_8a87e7`
* **Status:** `10 of 10 Tasks (100%)`
* **Visual Indicator:** A solid green horizontal progress bar, filled to 100%.
5. **Resources Card (Right-aligned sidebar):**
* **Card Heading:** "Resources"
* **Card Subtext:** "Learn, explore and get help"
* **List of Links (each with an external link icon):**
* `Documentation`
* `API Documentation`
* `Release Notes`
* `LabelStud.io Blog`
* `Slack Community`
6. **Footer Information (Bottom-right corner):**
* **Text:** `Label Studio Version: Community` (preceded by the Label Studio icon).
### Detailed Analysis
* **Textual Content:** All visible text has been transcribed above. The primary language is English. No other languages are present.
* **Data Points:** The key data presented is the status of two recent projects. Both projects are named with a common prefix (`Human_Preference_Annotation_Demo`) followed by unique alphanumeric suffixes (`_acc038`, `_8a87e7`). Both show identical completion metrics: 10 out of 10 tasks completed, representing 100% progress.
* **Visual Elements:** The interface uses color functionally. The active navigation tab is highlighted. The green progress bars provide an immediate visual cue for project completion. The external link icons in the Resources section indicate that those links will open in a new context.
### Key Observations
1. **Project Completion:** Both listed projects are at 100% completion. This could indicate they are demo projects, completed test runs, or that the user has finished all assigned tasks for these specific annotation jobs.
2. **Naming Convention:** The project names suggest they are related to "Human Preference Annotation," likely a task type within the platform. The suffixes appear to be unique identifiers.
3. **Interface State:** The user is logged in (as indicated by the "AD" avatar) and is on the "Home" page of the Label Studio application, which is part of a larger suite of tools (as seen in the top nav: Dashboard, pgAdmin, etc.).
4. **Resource Accessibility:** The platform provides direct access to documentation, development resources (API docs), community updates (blog, release notes), and support (Slack community) from the main dashboard.
### Interpretation
This screenshot captures the initial landing state for a user of the Label Studio platform. It is designed to orient the user and provide quick access to core actions (creating projects, inviting collaborators) and status information (recent work).
The presence of two fully completed "Human_Preference_Annotation_Demo" projects is the most significant data point. This strongly suggests the user has either:
* Just finished working on these demo projects as part of an onboarding or testing process.
* Is viewing a pre-populated demo account where these projects showcase the platform's capability to track task completion.
The interface emphasizes productivity and support. The prominent placement of "Create Project" and "Invite People" buttons encourages collaboration and new work initiation. Simultaneously, the "Resources" sidebar ensures help and learning materials are immediately accessible, reducing friction for new users. The version note ("Community") indicates the edition of the software being used.
In essence, the image depicts a functional, user-centric dashboard for a data annotation tool, highlighting completed work and providing clear pathways to start new tasks or seek assistance.
</details>
(d) Process data on the “Label Studio” page.
Figure 16: Snapshots of Trinity-Studio.
Trinity-Studio provides visual interaction for the core capabilities of Trinity-RFT, designed to bridge the gap between system complexity and user accessibility. As shown in Figure 16(a), its three integrated modules — “Training Portal”, “pgAdmin”, and “Label Studio” — form a cohesive interface that supports low-code usage and development with Trinity-RFT, and make it easy to monitor and track the full RFT pipeline with transparency.
- “Training Portal” (Figure 16(b)) implements configuration-to-execution procedures through declarative YAML editing with auto completion and live validation that prevents misconfigurations. Furthermore, the integration of runtime metrics with tools like Wandb/TensorBoard directly helps the active data optimization feature by surfacing signals such as difficulty distribution drifts and diversity metrics mentioned in Section 3.4. This transparency ensures that users can monitor how data curation strategies impact RFT performance in real time.
- “pgAdmin” (Figure 16(c)) reflects Trinity-RFT ’s end-to-end data transformation capabilities by providing a visual panel for PostgreSQL-based storage. This design benefits the versioned data lineage requirements of RFT, particularly for scenarios involving asynchronous training (Section 2.3.3). With intuitive SQL query builders, users can easily adjust schema, audit training experiences and human annotation batches with fine-grained precision. This capability is valuable for rapid validation of active learning policies by cross-referencing training outcomes with metadata (e.g., difficulty scores and staleness in asynchronous mode).
- “Label Studio” page (Figure 16(d)) operationalizes Trinity-RFT ’s bi-directional human-AI collaboration capability (Section 2.3.4). Utilizing the provided task polling and atomic batch commit mechanisms, users can annotate the data or experiences directly, allowing an asynchronous way to involve human feedback and to dynamically influence data curation.
By unifying these capabilities in a single UI, Trinity-Studio reduces the cognitive load of managing complex RFT procedures. For example, a researcher tuning a math reasoning task could use the Training Portal to adjust difficulty scoring parameters, view the resulting distribution shifts in the pgAdmin module, and then validate human annotators’ preferences in the Label Studio page. This end-to-end visibility can be useful for debugging and iterating RFT strategies, and complements the programmatic APIs of Trinity-RFT while maintaining full compatibility with CLI procedures.
We implement Trinity-Studio with the Singe-Spa framework [33]. The modular architecture enables custom view development through JavaScript plugins and flexible extensions for general-purpose usage.
## 4 Conclusion and Next Steps
We have presented Trinity-RFT, a general-purpose, flexible, scalable and user-friendly framework for reinforcement fine-tuning of large language models. Trinity-RFT offers a path into “the era of experience” [32], by supporting applications in diverse scenarios with complex agent-environment interaction, and serving as a unified platform for exploring advanced methodologies in each stage of the complete RFT pipeline, at both macroscopic and microscopic levels.
Further development of Trinity-RFT includes incorporating more advanced RL algorithms (especially off-policy or asynchronous ones), making the choices of hyperparameters more adaptive and less reliant on manual tuning, augmenting data pipelines with smarter sampling strategies and data processing operations, and conducting more thorough experiments and evaluations with Trinity-RFT.
## Acknowledgements
Trinity-RFT is built upon many excellent open-source projects, including but not limited to: verl [30] and PyTorch’s FSDP [8] for LLM training; vLLM [15] for LLM inference; Data-Juicer [2] for data-related functionalities; AgentScope [11] for agentic workflow; and Ray [20] for distributed runtime.
## References
- [1] ChatLearn. https://github.com/alibaba/ChatLearn.
- [2] Daoyuan Chen, Yilun Huang, Zhijian Ma, Hesen Chen, Xuchen Pan, Ce Ge, Dawei Gao, Yuexiang Xie, Zhaoyang Liu, Jinyang Gao, Yaliang Li, Bolin Ding, and Jingren Zhou. Data-juicer: A one-stop data processing system for large language models. In International Conference on Management of Data, 2024.
- [3] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [4] Jeff Da, Clinton Wang, Xiang Deng, Yuntao Ma, Nikhil Barhate, and Sean Hendryx. Agent-rlvr: Training software engineering agents via guidance and environment rewards. arXiv, 2025.
- [5] DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv, 2025.
- [6] Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, KaShun SHUM, and Tong Zhang. RAFT: Reward ranked finetuning for generative foundation model alignment. Transactions on Machine Learning Research, 2023.
- [7] Yannis Flet-Berliac, Nathan Grinsztajn, Florian Strub, Bill Wu, Eugene Choi, Chris Cremer, Arash Ahmadian, Yash Chandak, Mohammad Gheshlaghi Azar, Olivier Pietquin, and Matthieu Geist. Contrastive policy gradient: Aligning LLMs on sequence-level scores in a supervised-friendly fashion. In EMNLP, 2024.
- [8] Pytorch FSDP. https://pytorch.org/docs/stable/fsdp.html.
- [9] Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, Tongkai Yang, Binhang Yuan, and Yi Wu. Areal: A large-scale asynchronous reinforcement learning system for language reasoning. arXiv, 2025.
- [10] Yuqian Fu, Tinghong Chen, Jiajun Chai, Xihuai Wang, Songjun Tu, Guojun Yin, Wei Lin, Qichao Zhang, Yuanheng Zhu, and Dongbin Zhao. Srft: A single-stage method with supervised and reinforcement fine-tuning for reasoning. arXiv, 2025.
- [11] Dawei Gao, Zitao Li, Xuchen Pan, Weirui Kuang, Zhijian Ma, Bingchen Qian, Fei Wei, Wenhao Zhang, Yuexiang Xie, Daoyuan Chen, Liuyi Yao, Hongyi Peng, Ze Yu Zhang, Lin Zhu, Chen Cheng, Hongzhu Shi, Yaliang Li, Bolin Ding, and Jingren Zhou. Agentscope: A flexible yet robust multi-agent platform. arXiv, 2024.
- [12] Zhenyu Han, Ansheng You, Haibo Wang, Kui Luo, Guang Yang, Wenqi Shi, Menglong Chen, Sicheng Zhang, Zeshun Lan, Chunshi Deng, Huazhong Ji, Wenjie Liu, Yu Huang, Yixiang Zhang, Chenyi Pan, Jing Wang, Xin Huang, Chunsheng Li, and Jianping Wu. Asyncflow: An asynchronous streaming rl framework for efficient llm post-training. arXiv, 2025.
- [13] Jian Hu, Xibin Wu, Zilin Zhu, Xianyu, Weixun Wang, Dehao Zhang, and Yu Cao. OpenRLHF: An easy-to-use, scalable and high-performance RLHF framework. arXiv, 2024.
- [14] Huggingface. https://huggingface.co/.
- [15] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023.
- [16] Lu Ma, Hao Liang, Meiyi Qiang, Lexiang Tang, Xiaochen Ma, Zhen Hao Wong, Junbo Niu, Chengyu Shen, Runming He, Bin Cui, and Wentao Zhang. Learning what reinforcement learning can’t: Interleaved online fine-tuning for hardest questions. arXiv, 2025.
- [17] Model context protocol servers. https://github.com/modelcontextprotocol/servers.
- [18] Mistral-AI. Magistral. arXiv, 2025.
- [19] Modelscope. https://www.modelscope.cn/home.
- [20] Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I. Jordan, and Ion Stoica. Ray: A distributed framework for emerging ai applications. arXiv, 2018.
- [21] Ofir Nachum, Mohammad Norouzi, Kelvin Xu, and Dale Schuurmans. Bridging the gap between value and policy based reinforcement learning. In NIPS, 2017.
- [22] Nccl. https://github.com/NVIDIA/nccl.
- [23] Michael Noukhovitch, Shengyi Huang, Sophie Xhonneux, Arian Hosseini, Rishabh Agarwal, and Aaron Courville. Asynchronous rlhf: Faster and more efficient off-policy rl for language models. In The Thirteenth International Conference on Learning Representations, 2025.
- [24] Long Ouyang, Pamela Mishkin, Jeff Wu, C L Mar, Jacob Hilton, Amanda Askell, and Paul Christiano. Training language models to follow instructions with human feedback. arXiv, 2022.
- [25] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023.
- [26] Pierre Harvey Richemond, Yunhao Tang, Daniel Guo, Daniele Calandriello, Mohammad Gheshlaghi Azar, Rafael Rafailov, Bernardo Avila Pires, Eugene Tarassov, Lucas Spangher, Will Ellsworth, Aliaksei Severyn, Jonathan Mallinson, Lior Shani, Gil Shamir, Rishabh Joshi, Tianqi Liu, Remi Munos, and Bilal Piot. Offline regularised reinforcement learning for large language models alignment. arXiv, 2024.
- [27] David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Lillicrap, and Gregory Wayne. Experience replay for continual learning. In Advances in Neural Information Processing Systems, volume 32, 2019.
- [28] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv, 2017.
- [29] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv, 2024.
- [30] Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. HybridFlow: A flexible and efficient rlhf framework. arXiv, 2024.
- [31] Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Cote, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. ALFWorld: Aligning text and embodied environments for interactive learning. In International Conference on Learning Representations, 2021.
- [32] David Silver and Richard S. Sutton. Welcome to the era of experience. https://storage.googleapis.com/deepmind-media/Era-of-Experience%20/The%20Era%20of%20Experience%20Paper.pdf, 2025.
- [33] A javascript framework for front-end microservices, 2025.
- [34] Yuda Song, Yifei Zhou, Ayush Sekhari, Drew Bagnell, Akshay Krishnamurthy, and Wen Sun. Hybrid RL: Using both offline and online data can make RL efficient. In The Eleventh International Conference on Learning Representations, 2023.
- [35] Kimi Team. Kimi k1.5: Scaling reinforcement learning with LLMs. arXiv, 2025.
- [36] Qwen Team. Qwen2.5 technical report, 2025.
- [37] ROLL Team and Other ROLL Contributors. Reinforcement learning optimization for large-scale learning: An efficient and user-friendly scaling library. arXiv, 2025.
- [38] TensorBoard. https://www.tensorflow.org/tensorboard.
- [39] Maxim Tkachenko, Mikhail Malyuk, Andrey Holmanyuk, and Nikolai Liubimov. Label Studio: Data labeling software, 2020-2025. Open source software available from https://github.com/HumanSignal/label-studio.
- [40] Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl, 2020.
- [41] Weights & Biases. https://wandb.ai/home.
- [42] Taiyi Wang, Zhihao Wu, Jianheng Liu, Jianye HAO, Jun Wang, and Kun Shao. DistRL: An asynchronous distributed reinforcement learning framework for on-device control agent. In The Thirteenth International Conference on Learning Representations, 2025.
- [43] Bo Wu, Sid Wang, Yunhao Tang, Jia Ding, Eryk Helenowski, Liang Tan, Tengyu Xu, Tushar Gowda, Zhengxing Chen, Chen Zhu, Xiaocheng Tang, Yundi Qian, Beibei Zhu, and Rui Hou. Llamarl: A distributed asynchronous reinforcement learning framework for efficient large-scale llm training. arXiv, 2025.
- [44] LLM-Core-Team Xiaomi. Mimo: Unlocking the reasoning potential of language model – from pretraining to posttraining. arXiv, 2025.
- [45] Tianbing Xu. Training large language models to reason via EM policy gradient. arXiv, 2025.
- [46] Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance. arXiv, 2025.
- [47] Chaorui Yao, Yanxi Chen, Yuchang Sun, Yushuo Chen, Wenhao Zhang, Xuchen Pan, Yaliang Li, and Bolin Ding. Group-relative reinforce is secretly an off-policy algorithm: Demystifying some myths about grpo and its friends. arXiv, 2025.
- [48] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, 2023.
- [49] Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for Transformer-Based generative models. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 521–538, 2022.
- [50] Yinmin Zhong, Zili Zhang, Xiaoniu Song, Hanpeng Hu, Chao Jin, Bingyang Wu, Nuo Chen, Yukun Chen, Yu Zhou, Changyi Wan, Hongyu Zhou, Yimin Jiang, Yibo Zhu, and Daxin Jiang. Streamrl: Scalable, heterogeneous, and elastic rl for llms with disaggregated stream generation. arXiv, 2025.