# Reasoning in Neurosymbolic AI
**Authors**: Son Tran, Edjard Mota, Artur d’Avila Garcez
> School of Information Technology, Deakin University, Victoria, 3125, Melbourne, Australia
> Instituto de Computação, Universidade Federal do Amazonas, 69067-005, Manaus, Brazil
## Abstract
Knowledge representation and reasoning in neural networks have been a long-standing endeavor which has attracted much attention recently. The principled integration of reasoning and learning in neural networks is a main objective of the area of neurosymbolic Artificial Intelligence (AI). In this chapter, a simple energy-based neurosymbolic AI system is described that can represent and reason formally about any propositional logic formula. This creates a powerful combination of learning from data and knowledge and logical reasoning. We start by positioning neurosymbolic AI in the context of the current AI landscape that is unsurprisingly dominated by Large Language Models (LLMs). We identify important challenges of data efficiency, fairness and safety of LLMs that might be addressed by neurosymbolic reasoning systems with formal reasoning capabilities. We then discuss the representation of logic by the specific energy-based system, including illustrative examples and empirical evaluation of the correspondence between logical reasoning and energy minimization using Restricted Boltzmann Machines (RBM). The system, called Logical Boltzmann Machine (LBM), can find all satisfying assignments of a class of logical formulae by searching through a very small percentage of the possible truth-value assignments. Learning from data and knowledge in LBM is also evaluated empirically and compared with a purely-symbolic, a purely-neural and a state-of-the-art neurosymbolic system, achieving better learning performance in five out of seven data sets. Results reported in this chapter in an accessible way are expected to reignite the research on the use of neural networks as massively-parallel models for logical reasoning and to promote the principled integration of reasoning and learning in deep networks. LBM is also evaluated in the role of an interpretable neural module that can be added on top of complex neural networks such as convolutional networks and encoder-decoder networks to implement any given set of logical constraints e.g. fairness or safety requirements. LBM is further evaluated when deployed in the solution of the connectionist Boolean satisfiability (SAT) problem, maximum satisfiability (MaxSAT) and approximate optimization problems when certain logical rules may be given a higher priority or a penalty according to a confidence value. We conclude the chapter with a discussion of the importance of positioning neurosymbolic AI within a broader framework of formal reasoning and accountability in AI, discussing the challenges for neurosynbolic AI to tackle the various known problems of reliability of deep learning. We close with an opinion on the risks of AI and future opportunities for neurosymbolic AI. Keywords: Neurosymbolic AI, Restricted Boltzmann Machines, Logical Reasoning, SAT solving, MaxSAT, Energy-based Learning, Constrained Optimization, Modular Deep Learning.
## 1 What is Reasoning in Neural Networks?
Increasing attention has been devoted in recent years to knowledge representation and reasoning in neural networks. The principled integration of reasoning and learning in neural networks is a main objective of the field of neurosymbolic Artificial Intelligence (AI) [9, 34]. In neurosymbolic AI, typically, an algorithm is provided that translates some form of symbolic knowledge representation into the architecture and initial set of parameters of a neural network. Ideally, a theorem then shows that the neural network can be used as a massively-parallel model of computation capable of reasoning about such knowledge. Finally, when trained with data and knowledge, the network is expected to produce better performance, either a higher accuracy or faster learning than when trained from data alone. Symbolic knowledge may be provided to a neural network in the form of general rules which are known to be true in a given domain, or rules which are expected to be true across domains when performing transfer and continual learning. When rules are not available to start with, they can be extracted from a trained network. When rules are contradicted by data, they can be revised as part of the learning process. This has been shown to offer a flexible framework whereby knowledge and data, neural networks and symbolic descriptions are combined, leading to a better understanding of complex network models with the interplay between learning and reasoning.
This chapter includes a general discussion of how neurosymbolic AI can contribute to the goals of reasoning in neural networks and a specific illustration of a neurosymbolic system for reasoning in propositional logic with restricted Boltzmann machines (RBMs) [44]. We will describe a neurosymbolic system, called Logical Boltzmann Machines (LBM), capable of (i) representing any propositional logic formula into a restricted Boltzmann machine, (ii) reasoning efficiently from such formula, and (iii) learning from such knowledge representation and data. LBM comes with an algorithm to translate any set of propositional logical formulae into a Boltzmann machine and a proof of equivalence between the logical formulae and the energy-based connectionist model; in other words, a proof of soundness of the translation algorithm from logical formulae to neural networks. Specifically, the network is shown to assign minimum energy to the assignments of truth-values that satisfy the formulae. This provides a new way of performing reasoning in symmetrical neural networks by employing the network to search for the models of a logical theory, that is, to search for the assignments of truth-values that map the logical formulae to $true$ . We use the term model to refer to logical models and to neural network models. When the intended meaning is not clear from the context, we shall use the term logical model. If the number of variable is small, inference can be carried out analytically by sorting the free-energy of all possible truth-value assignments. Otherwise, Gibbs sampling is applied in the search for logical models. We start, however, with a general discussion of reasoning in current AI including large language models.
### 1.1 Reasoning in Large Language Models
Since the release of GPT4 by OpenAI in March 2023, a fierce debate developed around the risks of AI, Big Tech companies released various proprietary and open-source competitors to ChatGPT, and the European Union passed the regulatory AI Act in record time. Leading figures disagreed on what should be done about the risks of AI. Some claimed that Big Tech is best placed to take care of safety, others argued in favor of open source, and others still argued for regulation of AI and social media. As society contemplates the impact of AI on everyday life, the secrecy surrounding AI technology fueled fears of existential risk and even claims of an upcoming AI bubble burst. Large Language Models (LLMs) such as ChatGPT, Gemini, Claude, Mistral and DeepSeek are a great engineering achievement, are impressive at text summarization and language translation, may improve productivity of those who are knowledgeable enough to spot the LLM’s mistakes, but have great potential to deceive those who aren’t.
There are various technical and non-technical reasons why LLMs and current AI may not be deployed in practice: lack of trust or fairness, reliability issues and public safety as in the case of self-driving cars that use the same technology as LLMs. Fixing reliability issues case-by-case with Reinforcement Learning has proved to be too costly. A common risk mitigation strategy has been to adopt a human-in-the-loop approach: making sure that a human is ultimately responsible for decision making. However, in the age of Agentic AI, where at least some decisions are made by the machine, simply apportioning blame or liability to a human does not address the problem. It is necessary to empower the user of AI, the data scientist and the domain expert to be able to interpret, question and if necessary intervene in the AI system. Neural networks that are accompanied by symbolic descriptions and sound reasoning capabilities will be an important tool in this process of empowering users of AI.
Consider LLMs’ ability to produce code. If GPT4 was allowed to work, not as a stand-alone computer program, but in a loop whereby the code can be executed and data collected from execution to improve the code automatically, one can see how such self-improving LLM with autonomy may pose a serious risk to current computer systems. Recent experiments, however, indicated that the opposite, self-impairing, may also happen in practice, producing a degradation in performance. We will argue that the emerging field of neurosymbolic AI can address such failures and that there must be a better way, other than very costly post-hoc model alignment, of achieving AI that can offer certain logical guarantees to network training.
LLMs have been considered to be general purpose because they will provide an answer to any question. They do that by doing only one thing: predicting the probability of the next word (token) in a sentence. Having made a choice of the next word, LLMs will apply the same calculations recursively to build larger sentences. They are called auto-regressive machine learning models because they perform regression on the discrete tokens to learn such probabilities, and apply recursively the learned function $f$ to choose the word that comes at time t+1 given the words that are available at time t, that is, $x_t+1=f(x_t)$ . Artificial General Intelligence (AGI), however, is best measured by the ability to adapt to novelty. It will require effective learning from fewer data, the ability to reason reliably about the knowledge that has been learned, the extraction of compact descriptions from trained networks and the consolidation of knowledge learned from multiple tasks, using analogy to enable extrapolation to new situations at an adequate level of abstraction. It has been almost two years since GPT4 was released. The competition has caught up. Reliable data seem to have been exhausted. Performance increments obtained with increase in scale have not produced AGI. It is fair to say that the “scale is all you need” claim has not been confirmed. Notwithstanding, domain-specific AI systems that can exhibit intelligence at the level of humans or higher already exist. These systems exhibit intelligence in specialized tasks: targeted medical diagnoses, protein folding, various closed-world two-player strategy games.
When LLMs make stuff up such as non-existing citations, they are said to hallucinate. AGI will require systems that never hallucinate (that is, reason reliably), that can form long term plans and act on those plans to achieve a goal, and that can handle exceptions as they materialize, addressing shifts in data distribution not case-by-case, but requiring far less data labeling. This is very different from current LLMs that seem to have difficulty handling exceptions. For this reason, hallucinations are not going away and the cost of post-hoc model alignment has spiraled in the last two years.
As a case in point, take the o1 LLM system released by OpenAI in September 2024; o1 was claimed to “think before it answers” and to be capable of “truly general reasoning”. Widely seen as a re-branding of the much anticipated GPT5, which was promised to be at AGI level, the little that we know about o1 is that it improved on reasoning and code generation benchmarks, and yet it can be stubbornly poor at simple tasks such as multiplication, formal reasoning, planning or the formidable ARC AGI challenge (see https://arcprize.org/). Let’s assume that OpenAI’s o1 system is best described as “GPT-Go”, a pre-trained transformer to which a tree search is incorporated in the style of Google DeepMind’s earlier Alpha-Go system. The tree search uses “Chain of Thought” (CoT) prompting: generation of synthetic data using the transformer neural network itself in a chain that breaks down a prompt into sub-prompts (sub-problems to be solved in stages). o1’s “thinking” time is presumably needed to build the tree for the CoT. And it’s this breaking of the problem into sub-problems that is expected to improve performance on reasoning tasks since this is how reasoning tasks are solved.
Leaving aside the practical question of how long users will be happy to wait for an answer, the main issue with o1 and successors is a lack of reliability of the synthetic data generation and combinatorial nature of CoT: CoT may solve one reasoning task well today only to fail at an analogous reasoning task tomorrow due to simple naming variations [31]. With synthetic data generation from GPT-like auto-regressive models having been shown to impair model performance, the quality of the data decreases and the model continues to hallucinate [42].
What we are seeing in practice is that eliminating hallucinations is very difficult. And there is another concern: regurgitation. The New York Times (NYT) lawsuit against OpenAI argues that ChatGPT can basically reproduce (regurgitate) copyrighted NYT texts with minimal prompting. Whether regurgitation can be fixed remains to be seen. Efforts in this direction have been focused on a simple technique called RAG (Retrieval Augmented Generation) that fetches facts from external sources. What is clear is that further research is needed to make sense of how LLMs generalize to new situations, to find out whether performance depends on task familiarity or true generalization. In the meantime, there will be many relevant but domain-specific applications of LLMs in areas where the system has been deemed to have been controlled reasonably well or where controlling it isn’t crucial.
In neurosymbolic AI, instead of adjusting the input to fix a misbehaving LLM as done with CoT, the idea is to control the architecture or the loss function of the system. Neurosymbolic AI integrates learning and reasoning to make model development parsimonious by following this recipe: (1) extract symbolic descriptions as learning progresses, (2) reason formally about what has been learned, (3) compress the neural network as knowledge is instilled back into the network. Reasoning in neurosymbolic AI follows the tradition of knowledge representation in AI. It requires the definition of a semantics for deep learning and it measures the capabilities of neural networks w.r.t. formally-defined, sound and approximate reasoning, providing a much needed measure of the accumulation of errors in the AI system.
### 1.2 AI from a Neurosymbolic Perspective
It is paradoxical that computers have been invented to provide fast calculations and sound reasoning, and yet the latest AI may fail at calculations as simple as multiplication (even though a typical artificial neural network will rely on millions of correct multiplications as part of its internal computations). The first wave of AI in the 1980s was knowledge-based, well-founded and inefficient if compared with deep learning. The second wave from the 2010s was data-driven, distributed and efficient but unsound if compared with knowledge-bases. It is clear that neural networks are here to stay, but the problems with deep learning have been stubbornly difficult to fix using neural networks alone. Next, we discuss how solving these problems will require the use of symbolic AI alongside neural networks. The third wave of AI, we argue, will be neurosymbolic [15].
In order to understand the achievements and limitations of AI, it is helpful to consider the AGI debate https://www.youtube.com/watch?v=JGiLz_Jx9uI. with its focus on what is missing from current AI systems, i.e. the technological innovation that may bring about better AI or AGI. Simply put, such innovation may be described as the ability to apply knowledge learned from a task by a neural network to a novel task without requiring too much data.
As AI experts John Hopfield and Geoff Hinton are awarded the 2024 Nobel Prize for Physics, and AI expert Demis Hassabis is awarded the 2024 Nobel Prize for Chemistry (with David Baker and John Jumper), one can say that the era of computation as the language of science has began. Hassabis led the team at Google DeepMind that created AlphaFold, an AI model capable of predicting with high accuracy the 3D structure of proteins given their amino acid sequence. AlphaFold is arguably the greatest achievement of AI to date, even though it is squarely an application specific (or narrow) AI by comparison with LLMs. From particle physics to drug discovery, energy efficiency and novel materials, AI is being adopted as the process by which scientific research is carried out. However, as noted above, the lack of a description or explanation capable of conveying a deeper sense of understanding of the solution being offered by AI is something that is very unsatisfactory. Computer scientists in a great feat of engineering will solve to a high degree of accuracy very challenging problems in science without necessarily improving their own understanding of the solutions provided by very large neural networks trained on vast amounts of data that are not humanly possible to inspect.
The risks of current AI together with this unsatisfactory lack of explainability confirm the need for neurosymbolic AI as an alternative approach. As mentioned, neurosymbolic AI uses the technology of knowledge extraction to interpret, ask what-if questions and if necessary intervene in the AI system, controlling learning in ways that can offer correctness or fairness guarantees and, with this process, producing a more compact, data efficient system. We start to see a shift towards such explainable neurosymbolic AI systems being deployed as part of a risk-based approach. As argued in [36], effective regulation goes hand in hand with accountability in AI, the definition of a risk mitigation strategy and the use of technology itself such as explainable AI technology [33] to mitigate risks. We shall return to this discussion at the end of the paper.
For more than 20 years, a small group of researchers have been advocating for neurosymbolic AI. Already around the turn of the 21st century, the importance of artificial neural networks as an efficient computational model for learning was clear to that group. But the value of symbol manipulation and abstract reasoning offered by symbolic logic was also obvious to them. Many before them have contributed to neurosymbolic AI. In fact, it could be argued that neurosymbolic AI starts together with connectionism itself, with the aptly titled 1943 paper by McCulloch and Pitts, A Logical Calculus of the Ideas Immanent in Nervous Activity, and with John Von Neumann’s 1952 Lectures on Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components, indicating that the gap between distributed vector representations (embeddings) and localist symbolic representations in logic was not as big as some might imagine. Even Alan Turing’s 1948 Intelligent Machinery introduced a type of neural network called a B-type machine. All of this, of course, before the term Artificial Intelligence was coined ahead of the now famous Dartmouth Workshop in 1956. Since then the field has separated into two: symbolic AI and connectionist AI (or neural networks). This has slowed progress as the two research communities went their separate ways with different conferences, journals and associations. Following the temporary success of symbolic AI in the 1980’s and the success of deep learning since 2015 with its now obvious limitations, the time is right for revisiting the approaches of the founding fathers of computer science and developing neurosymbolic AI that is fit for the 21st century. As a step in this direction, in what follows, we illustrate how a single bi-directional network layer in the form of a restricted Boltzmann machine can implement the full semantics of propositional logic, formally defined.
## 2 Background: Logic and Restricted Boltzmann Machines
Differently from general-purpose Large Language Models, domain specific Artificial Intelligence, such as the protein folding AlphaFold system, aims to develop systems for specific purposes, enabling human abilities to handle tasks that might otherwise take many years to solve. This goal of domain specific AI is analogous to the invention of the Archimedean lever, which enhanced physical strength capabilities and has enabled humanity to make leaps in construction, mobility and physical labor. AI can be a mental lever that enhances our ability to deal with problems requiring mental activity in volume or intensity that is difficult to accomplish in feasible time or with precision. Modeling such abstract human mental activity is a highly complex task and we shall focus on representing two well-studied aspects: learning and reasoning.
A key step in this endeavor is to choose an appropriate language to represent the problem at hand. In the context of this paper, such a choice will be deemed to be suitable if it allows the development of efficient algorithms to perform learning from data and reasoning about what was learned or if it allows one to identify patterns of solutions that will lead to adequate decisions. Traditional AI has separated the study of reasoning and learning with a focus on either knowledge elicitation by hand for the purpose of sound reasoning or statistical learning from large amounts of data. In neurosymbolic AI this artificial separation is removed. The neurosymbolic cycle seeks to enable AI systems to learn a little and reason a little in integrated fashion. Learning takes place in the usual way within a neural network but reasoning has to be formalized, whether taking place inside or outside the network. Instead of simply measuring reasoning capabilities of the networks using benchmarks, neurosymbolic AI networks seek to offer reasoning guarantees of correctness. It is crucial to pay attention to the many years of research in knowledge representation and reasoning within Computer Science logic. While learning may benefit from the use of natural language and other available multimodal data, sound reasoning requires a formal language. A choice of language adequate to the problem influences the system’s ability to find a solution.
Formal logic, particularly Propositional Logic, is the most straightforward language for representing propositions about the problem domain. Propositional logic is the simplest formal language for representation, a branch of mathematics and logic that deals with simple declarative statements, called propositions, which can be true or false. As we shall see, in the context of neurosymbolic systems, statements are not purely true or false, but are associated with confidence values, probability intervals or degrees of truth denoting the intrinsic uncertainly of AI problems. It is therefore incorrect to assume that the use of logic is incompatible with uncertainty reasoning or limited to crisp, true or false statements. In its most general form, logic includes fuzzy and many-valued logics and various other forms of non-classical reasoning. We start however with propositional logic.
Think of propositions as the fundamental building blocks for reasoning. For instance, “it is raining” is a proposition because its truth can be determined by examining the current weather conditions. We typically use symbols such as $P$ , $Q$ , or $R$ to represent these propositions. Any symbol, including indices, can be used as long as it is clear that they represent a specific proposition. To combine or modify these propositions, we use logical connectives or operators: AND ( $∧$ ), OR ( $∨$ ), NOT ( $\lnot$ ), IMPLICATION ( $→$ ), and BI-CONDITIONAL ( $↔$ ). For example, if $P$ represents “it is raining” and $Q$ represents “I have an umbrella,” then $P∧ Q$ means “it is raining AND I have an umbrella”. The operators allow us to compose complex relationships among ideas in a precise way.
A syntactically correct expression in logic is said to be a Well-Formed Formula (WFF). A WFF in propositional logic is constructed according to the following rules:
1. Any atomic proposition (e.g, $P$ , $Q$ , $R$ ) is a WFF.
1. If $A$ is a WFF then $\lnot A$ (the negation of $A$ ) is also a WFF.
1. If $A$ and $B$ are WFFs then $(A∧ B)$ , $(A∨ B)$ , $(A→ B)$ , and $(A↔ B)$ are also WFFs.
1. Nothing else is a WFF.
For example, the expression $(P∧ Q)→ R$ is a WFF because it follows these rules: $P$ , $Q$ , and $R$ are atomic propositions, $(P∧ Q)$ is a valid combination using the AND operator, and the entire expression forms a valid implication. On the other hand, expressions like $P∧∨ Q$ are not WFFs because they violate the rules.
Propositional logic is also known as Boolean Logic, named after George Boole, a pioneer in the formalization of logical reasoning. Interestingly, George Boole is the great-great-grandfather of Geoffrey Hinton, a leading figure in the field of neural networks. Boole proposed his Laws of Thought using a simplified notation where $1$ and $0 0$ denote true and false, respectively. This binary representation aligns naturally with the semantic interpretation of neural networks and fits seamlessly into the reasoning method to be presented in this paper.
By adhering to the rules of WFFs, we ensure that our logical expressions are unambiguous and well-structured (compositional), providing a solid foundation for further exploration of propositional logic and its applications. In the remainder of this paper, unless otherwise specified, we shall use WFF to refer specifically to a subset of WFFs consisting only of formulas constructed using combinations of negation ( $\lnot$ ), conjunction ( $∧$ ), and disjunction ( $∨$ ). If other logical connectives, such as implication ( $→$ ) or bi-conditional ( $↔$ ), are included, we will explicitly clarify this deviation from the specific subset, noting that in Classical Logic $A↔ B$ is equavelent to $(A→ B)∧(B→ A)$ and that $A→ B$ is equivalent to $¬ A∨ B$ .
### 2.1 Illustrating Logical Reasoning with the Sudoku Puzzle
Sudoku is more than just a number puzzle (see Figure 1); it is a gateway to understanding the power of logical thinking. This globally beloved puzzle challenges us to impose order on apparent chaos, using nothing but numbers and logic. At its core, Sudoku is about solving constraints, ensuring that every row, column, and sub-grid (or block) adheres to a simple strict rule (containing one and only one of the elements of a given set). The same principle of constraint satisfaction is a cornerstone of Artificial Intelligence and computational problem-solving. By learning how to express Sudoku’s rules logically, we unlock the secrets of this captivating game and the tools to tackle more complex problem solving. Let’s explore how propositional logic can elegantly capture the rules of Sudoku as a way to illustrate structured reasoning.
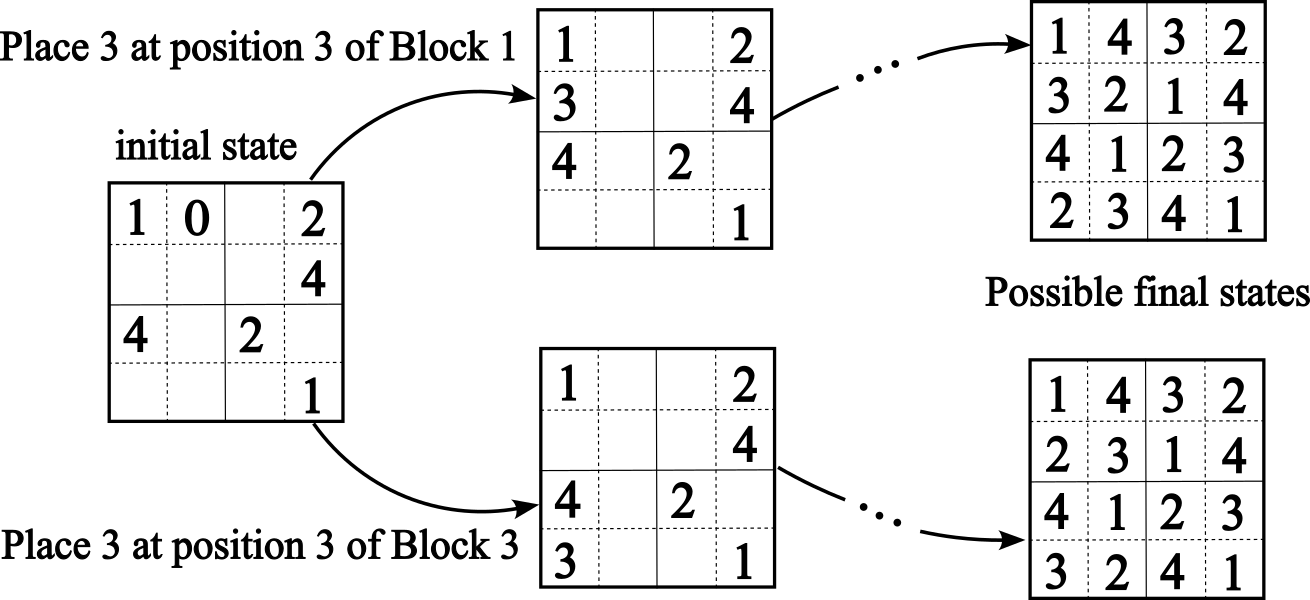
For simplicity, we consider a smaller version of Sudoku, using a $4× 4$ grid instead of the standard $9× 9$ . This simplified puzzle divides the board into four $2× 2$ blocks or sub-grids, each containing four positions (or cells). Blocks are counted from left to right and top to bottom: block 1 is on top of block 3, and block 2 is on top of block 4. Positions within each block are also counted from left to right and top to bottom. Each cell in the grid must contain a number from 1 to 4, with no repetition allowed in any row, column, or $2× 2$ block. In the real Sudoku puzzle, each block is $3× 3$ and the set of possible elements is {1,2,…,9} with the board having 9 blocks in total. Figure 1 depicts an example of an initial setting for a Sudoku $4× 4$ board, followed by two possible transitions placing number 3 in two possible cells satisfying the constraints. Two possible final states are also shown, each derived from the above two states if every movement satisfies the constraints of the puzzle.
<details>
<summary>extracted/6466920/figs/Sudoku-4x4-sol03.png Details</summary>
### Visual Description
## Diagram: State Transition Flowchart for a 4x4 Grid Puzzle
### Overview
The image is a technical diagram illustrating a state transition process for a 4x4 grid-based puzzle or algorithm. It shows an "initial state" grid, two distinct branching operations ("Place 3 at position 3 of Block 1" and "Place 3 at position 3 of Block 3"), each leading to an intermediate grid state, and then to a set of "Possible final states." The diagram uses arrows to indicate the flow of operations and dotted lines within the grids to suggest sub-blocks (likely 2x2 blocks, common in puzzles like Sudoku).
### Components/Axes
* **Layout:** The diagram flows from left to right.
* **Left:** A single grid labeled "initial state".
* **Center:** Two parallel branches, each starting with a text instruction and leading to an intermediate grid.
* **Right:** Two final grids, each labeled collectively as "Possible final states".
* **Grid Structure:** Each grid is a 4x4 matrix. Dotted lines divide each grid into four 2x2 quadrants or "blocks."
* **Text Labels:**
* "initial state" (above the leftmost grid)
* "Place 3 at position 3 of Block 1" (above the top branch arrow)
* "Place 3 at position 3 of Block 3" (below the bottom branch arrow)
* "Possible final states" (below the two rightmost grids)
* **Arrows:** Solid black arrows show the direction of state transition. Ellipses ("...") on the arrows from intermediate to final states indicate additional, unstated steps.
### Detailed Analysis
**1. Initial State Grid (Leftmost)**
A 4x4 grid with the following numbers placed (row, column):
* Row 1: `1`, `0`, ` `, `2`
* Row 2: ` `, ` `, ` `, `4`
* Row 3: `4`, ` `, `2`, ` `
* Row 4: ` `, ` `, ` `, `1`
*(Note: Empty cells are represented by a space. The `0` is unusual and may represent a blank or a special value.)*
**2. Top Branch: "Place 3 at position 3 of Block 1"**
* **Instruction:** This operation targets "Block 1" (the top-left 2x2 quadrant) and places the number `3` at its "position 3." Assuming positions are numbered left-to-right, top-to-bottom within a block, position 3 would be the bottom-left cell of that block (Row 2, Column 1).
* **Intermediate Grid (Top Center):** The result of applying the instruction to the initial state.
* Row 1: `1`, ` `, ` `, `2`
* Row 2: `3`, ` `, ` `, `4`
* Row 3: `4`, ` `, `2`, ` `
* Row 4: ` `, ` `, ` `, `1`
* *Change from Initial:* The `0` in (R1,C2) is gone. A `3` appears in (R2,C1), consistent with the instruction.
* **Possible Final State (Top Right):** One possible grid after further unspecified steps.
* Row 1: `1`, `4`, `3`, `2`
* Row 2: `3`, `2`, `1`, `4`
* Row 3: `4`, `1`, `2`, `3`
* Row 4: `2`, `3`, `4`, `1`
* *Observation:* This is a complete, valid Latin square (each number 1-4 appears exactly once in each row and column).
**3. Bottom Branch: "Place 3 at position 3 of Block 3"**
* **Instruction:** This operation targets "Block 3" (the bottom-left 2x2 quadrant) and places the number `3` at its "position 3." This would be the bottom-left cell of that block (Row 4, Column 1).
* **Intermediate Grid (Bottom Center):** The result of applying this different instruction to the initial state.
* Row 1: `1`, ` `, ` `, `2`
* Row 2: ` `, ` `, ` `, `4`
* Row 3: `4`, ` `, `2`, ` `
* Row 4: `3`, ` `, ` `, `1`
* *Change from Initial:* The `0` in (R1,C2) is gone. A `3` appears in (R4,C1), consistent with the instruction.
* **Possible Final State (Bottom Right):** One possible grid after further unspecified steps.
* Row 1: `1`, `4`, `3`, `2`
* Row 2: `2`, `3`, `1`, `4`
* Row 3: `4`, `1`, `2`, `3`
* Row 4: `3`, `2`, `4`, `1`
* *Observation:* This is also a complete, valid Latin square, but it differs from the top final state in rows 2 and 4.
### Key Observations
1. **Branching Decision Point:** The core of the diagram is a single decision: where to place the number `3` in the initial state. This choice creates two distinct solution paths.
2. **Identical Starting Point:** Both branches begin from the exact same "initial state" grid.
3. **Divergent Intermediates:** The two instructions produce different intermediate grids, differing only in the location of the newly placed `3` and the removal of the `0`.
4. **Convergent Structure, Divergent Content:** Both paths lead to a fully solved grid (a Latin square). The final states share the same first and third rows (`1,4,3,2` and `4,1,2,3`) but have different second and fourth rows.
5. **Role of the "0":** The `0` in the initial state is removed in both intermediate states, suggesting it might be a placeholder or an error that is corrected by the placement of a `3`.
### Interpretation
This diagram is a **decision tree for a constraint satisfaction problem**, likely a variant of a 4x4 Sudoku or a Latin square puzzle with pre-filled clues. It demonstrates how a single, early choice (the placement of the number `3`) propagates through the system and fundamentally alters the final solution space.
* **What it demonstrates:** The puzzle has multiple valid solutions. The diagram explicitly maps two distinct solution pathways originating from one initial configuration. The "..." implies that the solver must make further logical deductions after placing the initial `3` to reach the final state.
* **Relationship between elements:** The "initial state" is the root. The "Place 3..." instructions are the first branching operations. The "intermediate states" are the direct results of those operations. The "Possible final states" are the end products of completing the puzzle along each branch.
* **Notable Anomalies/Patterns:** The presence of `0` in the initial state is atypical for such puzzles and is treated as a cell to be filled. The fact that both final states are valid Latin squares confirms the puzzle's consistency. The diagram's purpose is likely pedagogical or analytical, showing how backtracking or choice points work in puzzle-solving algorithms. It visually argues that the solution is not unique and depends critically on early decisions.
</details>
Figure 1: An initial Sudoku board and two branches generated by placing a 3 at position 3 of blocks 1 and 3, respectively, and corresponding final states satisfying the constraints of the game.
Solving Sudoku involves reasoning about these constraints, making it a good example for introducing logical notation. To model the problem using propositional logic, one can systematically represent the constraints in terms of propositional variables encoding the relationships between numbers, positions, rows, columns and blocks. The rules dictate that every row, column and block must include the numbers 1 to 4 exactly once. By encoding the problem in this way, one can use symbolic logical reasoning to systematically explore possible solutions while respecting all constraints. The rules are encoded as follows:
Logical Variables:
Let the proposition $B_i,j,k$ denote that the block $i$ at position $j$ (that is, the cell $(i,j)$ ) contains the number $k$ . Formally, $B_i,j,k$ is true if and only if $k∈\{1,2,3,4\}$ is in position $j$ of block $i$ , $1≤ i≤ 4$ , $1≤ j≤ 4$ . Logical Constraints:
The constraints ensure that the numbers are placed correctly according to the rules of Sudoku. These constraints can be grouped into four categories:
1. Each cell must contain a number (cell $(i,j)$ contains a 1 or a 2 or a 3 or a 4): $B_i,j,1∨ B_i,j,2∨ B_i,j,3∨ B_i,j,4$ . When needed, we shall write:
$$
\bigvee_k=1^4B_i,j,k as shorthand notation for B_i,j,1∨ B
_i,j,2∨ B_i,j,3∨ B_i,j,4.
$$
There cannot be two or more numbers on the same cell Notice that $¬(A\wedge B)$ implies $¬(A\wedge B\wedge C)$ .:
$$
¬(B_i,j,k_1\wedge B_i,j,k_2), for all k_1≠ k_2.
$$
The above two rules can be written compactly as:
$$
≤ft(\bigvee_k=1^4B_i,j,k\right)\wedge≤ft(\bigwedge_k_{1<k_2}¬
(B_i,j,k_1\wedge B_i,j,k_2)\right),
$$
where $\bigwedge_ix_i$ is shorthand for $x_1\wedge x_2\wedge...$ and $k_1<k_2$ is used to avoid repetition. Notice that $A\wedge B$ is logically equivalent to $B\wedge A$ .
1. Each number appears exactly once per row. For each row across the entire board and each number $k$ , exactly one position in that row must contain $k$ . This is expressed as:
$$
\bigvee_j=1^4B_i,j,k
$$
along with the constraint that there cannot be two or more occurrences of the same number on the same row:
$$
¬(B_i,j_{1,k}\wedge B_i,j_{2,k}), for all j_1≠ j_2.
$$
In compact form:
$$
≤ft(\bigvee_j=1^4B_i,j,k\right)\wedge≤ft(\bigwedge_j_{1<j_2}¬
(B_i,j_{1,k}\wedge B_i,j_{2,k})\right).
$$
1. Each number appears exactly once per column. In compact form (as above):
$$
≤ft(\bigvee_i=1^4B_i,j,k\right)\wedge≤ft(\bigwedge_i_{1<i_2}¬
(B_i_{1,j,k}\wedge B_i_{2,j,k})\right).
$$
1. Each number appears exactly once per block. For each $2× 2$ block and each number $k$ , exactly one position within the block must contain $k$ . For example, for the top-left block:
$$
\bigvee_(i,j)∈\{(1,1),(1,2),(2,1),(2,2)\}B_i,j,k,
$$
along with the constraint:
$$
¬(B_i_{1,j_1,k}\wedge B_i_{2,j_2,k}),for all distinct pairs
(i_1,j_1)≠(i_2,j_2).
$$
In compact form:
$$
≤ft(\bigvee_(i,j)∈blockB_i,j,k\right)\wedge≤ft(\bigwedge_(i_
{1,j_1)<(i_2,j_2)}¬(B_i_{1,j_1,k}\wedge B_i_{2,j_2,k})\right).
$$
The complete set of constraints for the $4× 4$ Sudoku puzzle is the conjunction of all the above conditions over all cells, rows, columns and blocks. This logical formula guarantees that every number appears exactly once in each row, column, and block, satisfying the rules of Sudoku. It also provides a systematic framework for reasoning about the puzzle.
**Example 1**
*For block 1, position 1, we have: - $B_1,1,1∨ B_1,1,2∨ B_1,1,3∨ B_1,1,4$
- $¬ B_1,1,1∨¬ B_1,1,2$
- $¬ B_1,1,1∨¬ B_1,1,3$
- $¬ B_1,1,1∨¬ B_1,1,4$
- $¬ B_1,1,2∨¬ B_1,1,3$
- $¬ B_1,1,2∨¬ B_1,1,4$
- $¬ B_1,1,3∨¬ B_1,1,4$*
Some observations about this representation:
- This notation provides a framework whereby each possible combination of $B$ with indices is assigned to True or False.
- Each rule above is called a clause (a disjunction of logic literals) and the complete set of clauses would be significantly larger to cover all rows, columns and blocks.
- This representation can be used as input to a satisfiability (SAT) solver to find solutions to the Sudoku puzzle, that is, assignments of truth-values True or False to each literal that will provably satisfy the puzzle’s constraints.
This Boolean logic representation allows us to express the Sudoku problem as a set of constraints that must be satisfied simultaneously. By finding a truth assignment to the variables that satisfy all the clauses, we determine a valid solution to the Sudoku puzzle.
### 2.2 Sudoku with Strategies of Sampling
1. Reasoning Strategy based on Unused Numbers:
To control which number to pick based on the bank of numbers not yet placed on the board, let us illustrate how additional constraints may be introduced that ensure unused numbers are considered first. A strategy such as this could be learned from observation of game plays as well as specified by hand.
For each empty cell $(i,j)$ , define $U(i,j)$ as the set of numbers $k$ such that $k$ is not already used in the corresponding row, column or block of cell $(i,j)$ .
The constraint ensuring the selection of an unused number $k$ can be expressed as:
$$
\bigvee_k∈ U(i,j)B_i,j,k
$$
where $U(i,j)$ is defined as:
$$
U(i,j)=\{k\mid k∉\{B_i,j^\prime,k^{\prime}\mid j^\prime≠ j\}
∧ k∉\{B_i^\prime,j,k^{\prime}\mid i^\prime≠ i\}
$$
$$
∧ k∉\{B_i^\prime,j^{\prime,k^\prime}\mid(i^\prime,j^\prime)
∈block(i,j)\}\}.
$$
Here, $block(i,j)$ denotes the set of positions in the same block as $(i,j)$ .
1. Priority Constraint for Unused Numbers:
To prioritize the use of unused numbers, we can add a preference rule that assigns higher priority to considering numbers from $U(i,j)$ ahead of other possibilities.
Formally, let $P(i,j,k)$ represent the priority of placing number $k$ in cell $(i,j)$ . The priority can be defined as:
$$
P(i,j,k)=\begin{cases}1&if k∈ U(i,j)\\
0&otherwise\end{cases}
$$
The constraint ensuring that the highest priority is given to unused numbers can be expressed as:
$$
\bigvee_k∈ U(i,j)(P(i,j,k)\wedge B_i,j,k)
$$
The complete set of logical constraints for the 4x4 Sudoku puzzle now includes the original Sudoku constraints along with additional reasoning strategies that prioritize the use of unused numbers. These constraints ensure that every number appears exactly once in each row, column, and block while also guiding the generation of solutions (that is, the assignment of truth-values to the literals) by leveraging the bank of unused numbers. By incorporating these, the Sudoku solving process becomes systematic and more efficient as it should reduce the likelihood of the process getting stuck and having to backtrack when searching for a solution, or analogously in the case of a neural network getting stuck in local minima.
### 2.3 Restricted Boltzmann Machines
An RBM [44] is a two-layer neural network with bidirectional (symmetric) connections, which is characterised by a function called the energy of the RBM:
$$
{\it E}(x,h)=-∑_i,jw_ijx_ih_j-∑_ia_ix_i-
∑_jb_jh_j \tag{1}
$$
where $a_i$ and $b_j$ are the biases of input unit $x_i$ and hidden unit $h_j$ , respectively, and $w_ij$ is the connection weight between $x_i$ and $h_j$ . This RBM represents a joint probability distribution $p(x,h)=\frac{1}{Z}e^-\frac{1{τ}{\it E}(x, h)}$ where $Z=∑_x\mathbf{h}e^-\frac{1{τ}{\it E}(x,h)}$ is the partition function and parameter $τ$ is called the temperature of the RBM, $x=\{x_i\}$ is the set of visible units and $h=\{h_j\}$ is the set of hidden units of the RBM.
Training RBMs normally makes use of the Contrastive Divergence learning algorithm [19], whereby each input vector from the training set is propagated to the hidden layer of the network and back to the input a number of times ( $n$ ) using a probabilistic selection rule to decide at each time whether or not a neuron should be activated (with activation value in $\{0,1\}$ ). The weight assigned to the connection between input neuron $x_i$ and hidden neuron $h_j$ is adjusted according to a simple update rule based on the difference between the value of $x_ih_j$ at time $1$ and time $n$ . More precisely, $Δ W_ij=η((x_ih_j)_1-(x_ih_j)_n)$ , where $η$ is a learning rate (a small positive real number).
## 3 Symbolic Reasoning with Energy-based Neural Networks
The content of this section is based on [52].
Over the years, many neurosymbolic approaches have used a form of knowledge representation based on if-then rules [49, 13, 50, 12, 56, 29, 51], written $B← A$ (make $B$ $True$ if $A$ is $True$ ) to distinguish from classical implication ( $A→ B$ ). Under the convention that $1$ represents $True$ and $0 0$ represents $False$ , given $B← A$ and input $1$ to neuron $A$ , a neurosymbolic system would infer that neuron $B$ should have activation value approximately $1$ . Given input $0 0$ to neuron $A$ , it would infer that $B$ should have activation approximately $0 0$ .
Logical Boltzmann Machines (LBM) allow for a richer representation than if-then rules by using full propositional logic. Next, we review LBM’s immediate related work, define a mapping from any logical formulae to LBMs, and describe how reasoning takes place by sampling and energy minimization. We also evaluate scalability of reasoning in LBM and learning by combining knowledge and data, evaluating results on benchmarks in comparison with a symbolic, another neurosymbolic and a neural network-based approach.
### 3.1 Related Work
One of the earliest work on the integration of neural networks and symbolic knowledge is known as KBANN (Knowledge-based Artificial Neural Network [49]), which encodes if-then rules into a hierarchical multilayer perceptron. In another early approach [8], a single-hidden layer recurrent neural network is proposed to support logic programming rules. An extension of that approach to work with first-order logic programs, called Connectionist Inductive Logic Programming (CILP++) [13], uses the concept of propositionalisation from Inductive Logic Programming (ILP), whereby first-order variables can be treated as propositional atoms in the neural network. Also based on first-order logic programs, [12] propose a differentiable ILP approach that can be implemented by neural networks, and [6] maps stochastic logic programs into a differentiable function also trainable by neural networks. These are all supervised learning approaches.
Early work in neurosymbolic AI has also shown a correspondence between propositional logic and symmetrical neural networks [38], in particular Hopfield networks, which nevertheless did not scale well with the number of variables. Among unsupervised learning approaches, Penalty Logic [37] was the first work to integrate nonmonotonic logic in the form of weighted if-then rules into symmetrical neural networks. However, Penalty Logic required the use of higher-order Hopfield networks, which can be difficult to construct Building such higher-order networks requires transforming the energy function into quadratic form by adding hidden variables not present in the original logic formulae. and inefficient to train with the learning algorithm for Boltzmann machines. More recently, several attempts have been made to extract and encode symbolic knowledge into RBMs trained with the more efficient Contrastive Divergence learning algorithm [35, 50]. Such approaches explored the structural similarity between symmetric networks and logical rules with bi-conditional implication but do not have a proof of soundness. By contrast, and similarly to Penalty Logic, LBM is provably equivalent to the logic formulae encoded in the RBM. Differently from Penalty Logic, LBM does not require the use of higher-order networks.
Alongside the above approaches, which translate symbolic representations into neural networks (normally if-then rules translated into a feedforward or recurrent network), there are hybrid approaches that combine neural networks and symbolic AI systems as communicating modules of a neurosymbolic system. These include DeepProbLog [29] and Logic Tensor Networks (LTN) [41]. DeepProbLog adds a neural network module to probabilistic logic programming such that an atom of the logic program can be represented by a network module. LTN and various approaches derived from it use real-valued logic to constrain the loss function of the neural network given statements in firt-order logic. Both DeepProbLog and LTNs use backpropagation, differently from the approach adopted here which uses Contrastive Divergence.
Finally, approaches focused on reasoning include SAT solving using neural networks. In [17, 7], the maximum satisfiability problem is mapped onto Boltzmann machines and higher-order Boltzmann machines, which are used to solve the combinatorial optimization task in parallel, similarly to [38]. In [53], the SAT problem is redefined as a soft (differentiable) task and solved approximately by deep networks with the objective of integrating logical reasoning and learning, as in the case of the approaches discussed earlier. This soft version of the SAT problem is therefore different from the satisfiability problem. A preliminary evaluation of our approach in comparison with symbolic SAT solvers shows that our approach allows the use of up to approximately 100 variables. This is well below the capability of symbolic SAT solvers. A way of improving the performance of neural SAT solvers may well be to consider approximate solutions as done by soft SAT solvers, including neuroSAT [40]. Although still not beating SAT solvers, neuroSAT showed promise at addressing out-of-distribution learning after training on random SAT problems.
In our experiments on learning, the focus is on benchmark neurosymbolic AI tasks with available data and knowledge, obtained from [13]. We therefore compare LBM with a state-of-the-art ILP symbolic system ALEPH [46], standard RBMs as a purely-neural approach closest to LBM, and with CILP++ as a neurosymbolic system. It is worth noting, however, that CILP++ is a neurosymbolic system for supervised learning while LBMs use unsupervised learning, and it is worth investigating approaches for semi-supervised learning and other combinations of such systems. Further comparisons and evaluations on both reasoning and learning are underway.
### 3.2 Knowledge Representation in RBMs
Before we present LBM, let’s contrast the simple $B← A$ example used earlier with classical logic. Given $A→ B$ as knowledge In classical logic, $A→ B$ is equivalent to $¬ A\vee B$ , i.e. True if $A$ is False regardless of the truth-value of $B$ ., if neuron $A$ is assigned input value $1$ in the corresponding neurosymbolic network, we expect the network to converge to a stable state where neuron $B$ has value approximately $1$ , similarly to the example seen earlier. This is because the truth-value of WFF $A→ B$ is True given an assignment of truth-values True to its constituent literals $A$ and $B$ . Now, $A→ B$ is False when $A$ is True and $B$ is False. If neuron $B$ is assigned input $0 0$ , we expect the network to converge to a stable state where $A$ is approximately $0 0$ ( $A→ B$ is True when $A$ is False and $B$ is False). What if $A$ is assigned input $0 0$ (or $B$ is assigned input $1$ )? In these cases, $A→ B$ is satisfied if $B$ is either $1$ or $0 0$ (or if $A$ is either $1$ or $0 0$ ). Differently from $B← A$ , the network will converge to one of the two options that satisfy the formulae.
From this point forward, unless stated otherwise, we will treat assignments of truth-values to logical literals and binary input vectors denoting the activation states of neurons indistinguishably.
**Definition 1**
*Let $s_φ(x)∈\{0,1\}$ denote the truth-value of a WFF $φ$ given an assignment of truth-values $x$ to the literals of $φ$ , where truth-value $True$ is mapped to 1 and truth-value $False$ is mapped to 0. Let ${\it E}(x,h)$ denote the energy function of an energy-based neural network $N$ with visible units $x$ and hidden units $h$ . $φ$ is said to be equivalent to $N$ if and only if for any assignment of values to $x$ there exists a function $ψ$ such that $s_φ(x)=ψ({\it E}(x,h))$ .*
Definition 1 is similar to that of Penalty Logic [37], where all assignments of truth-values satisfying a WFF $φ$ are mapped to global minima of the energy function of network $N$ . In our case, by construction, assignments that do not satisfy the WFF will, in addition, be mapped to maxima of the energy function. To see how this is the case, it will be useful to define strict and full DNFs, as follows.
**Definition 2**
*A strict DNF (SDNF) is a DNF with at most one conjunctive clause (a conjunction of literals) that maps to $True$ for any choice of assignment of truth-values $x$ . A full DNF is a DNF where each propositional variable (a positive or negative literal) must appear at least once in every conjunctive clause (sometimes called a canonical DNF).*
For example, to turn DNF $A\vee B$ into an equivalent full DNF, one needs to map it to $(A\wedge¬ B)\vee(¬ A\wedge B)\vee(A\wedge B)$ , according to the truth-table for $A\vee B$ . For any given assignment of truth-values to $A$ and $B$ , at most one of the above three conjunctive clauses will be $True$ , by definition of the truth-table. Not every SDNF is also a full DNF though, e.g. $(a\wedge b)\vee¬ b$ is a SDNF that is not a full DNF.
**Lemma 1**
*Let $S_T_{j}$ denote the set of indices of the positive literals $x_t$ in a conjunctive clause $j$ . Let $S_K_{j}$ denote the set of indices of the negative literals $x_k$ in $j$ . Any SDNF $φ≡\bigvee_j(\bigwedge_tx_t\wedge\bigwedge_k¬ x_k)$ can be mapped onto an energy function: $$
{\it E}(x)=-∑_j(∏_t∈S_T_{j}x_t∏_k∈
S_K_{j}(1-x_k)).
$$*
Proof: Each conjunctive clause $\bigwedge_tx_t\wedge\bigwedge_k¬x_k$ in $φ$ corresponds to the product $∏_tx_t∏_k(1-x_k)$ which maps to $1$ if and only if $x_t$ is $True$ ( $x_t=1$ ) and $x_k$ is $False$ ( $x_k=0$ ) for all $t∈S_T_{j}$ and $k∈S_K_{j}$ . Since $φ$ is SDNF, $φ$ is $True$ if and only if one conjunctive clause is $True$ and $∑_j(∏_t∈S_T_{j}x_t∏_k∈S_K_{j}(1 -x_k))=1$ . Hence, the neural network with energy function ${\it E}$ is such that $s_φ(x)=-{\it E}(x)$ . ∎
**Theorem 1**
*Any SDNF $φ≡\bigvee_j(\bigwedge_tx_t\wedge\bigwedge_k¬ x_k)$ can be mapped onto an RBM with energy function:
$$
{\it E}(x,h)=-∑_jh_j(∑_t∈S_T_{j}x_
{t}-∑_k∈S_K_{j}x_k-|S_T_{j}|+ε), \tag{2}
$$
such that $s_φ(x)=-{\it E}(x)$ , where $0<ε<1$ and $|S_T_{j}|$ is the number of positive literals in conjunctive clause $j$ of $φ$ .*
Proof: Lemma 1 states that any SDNF $φ$ can be mapped onto energy function ${\it E}=-∑_j(∏_t∈S_T_{j}x_t∏_k∈S_ K_{j}(1-x_k))$ . For each expression $\tilde{e}_j(x)=-∏_t∈S_T_{j}x_t∏_k∈ S_K_{j}(1-x_k)$ , we define an energy expression associated with hidden unit $h_j$ as $e_j(x,h_j)=-h_j(∑_t∈S_T_{j}x_t-∑_k∈ S_K_{j}x_k-|S_T_{j}|+ε)$ . The term $e_j(x,h_j)$ is minimized with value $-ε$ when $h_j=1$ , written $min_h_{j}(e_j(x,h_j))=-ε$ . This is because $-(∑_t∈S_T_{j}x_t-∑_k∈S_K_{j}x_k-| S_T_{j}|+ε)=-ε$ if and only if $x_t=1$ and $x_k=0$ for all $t∈S_T_{j}$ and $k∈S_K_{j}$ . Otherwise, $-(∑_tx_t∈S_T_{j}-∑_k∈S_K_{j}x_k-| S_T_{j}|+ε)>0$ and $min_h_{j}(e_j(x,h_j))=0$ with $h_j=0$ . By repeating this process for each $\tilde{e}_j(x)$ we obtain that the energy function ${\it E}(x,h)=-∑_jh_j(∑_t∈S_T_{j}x_ {t}-∑_k∈S_K_{j}x_k-|S_T_{j}|+ε)$ is such that $s_φ(x)=-\frac{1}{ε}min_h{\it E}(x, h)$ . ∎
It is well-known that any WFF $φ$ can be converted into DNF. Then, if $φ$ is not SDNF, by definition there is more than one conjunctive clause in $φ$ that map to $True$ when $φ$ is satisfied. This group of conjunctive clauses can always be converted into a full DNF according to its truth-table. By definition, any such full DNF is also a SDNF. Therefore, any WFF can be converted into SDNF. From Theorem 1, it follows that any WFF can be represented by the energy function of an RBM. The conversion of WFFs into full DNF can be computationally expensive. Sometimes, the logic is provided already in canonical DNF form or in Conjunctive Normal Form (CNF), i.e. conjunctions of disjunctions. We will see later that any WFF expressed in CNF can be converted into an RBM’s energy function efficiently without the need to convert into SDNF first. This covers the most common forms of propositional knowledge representation. Next, we describe a method for converting logical formulae into SDNF, which we use in the empirical evaluations that will follow. Consider a clause $γ$ such that:
$$
γ≡\bigvee_t∈S_T¬x_t\vee\bigvee_k∈
S_Kx_k \tag{3}
$$
where $S_T$ now denotes the set of indices of the negative literals, and $S_K$ denotes the set of indices of the positive literals in the clause (dually to the conjunctive clause case). Clause $γ$ can be rearranged into $γ≡γ^\prime\veex^\prime$ , where $γ^\prime$ is obtained by removing $x^\prime$ from $γ$ ( $x^\prime$ can be either $¬x_t$ or $x_k$ for any $t∈S_T$ and $k∈S_K$ ). We have:
$$
γ≡(¬γ^\prime\wedgex^\prime)\veeγ^\prime \tag{4}
$$
because $(¬γ^\prime\wedgex^\prime)\veeγ^\prime≡(γ ^\prime\vee¬γ^\prime)\wedge(γ^\prime\veex^\prime )≡ True\wedge(γ^\prime\veex^\prime)$ . By De Morgan’s law ( $¬(a\veeb)≡¬a\wedge¬b$ ), we can always convert $¬γ^\prime$ (and therefore $¬γ^\prime\wedgex^\prime$ ) into a conjunctive clause.
By applying (4) repeatedly, each time we eliminate a variable out of the clause by moving it into a new conjunctive clause. Given an assignment of truth-values, either the clause $γ^\prime$ will be True or the conjunctive clause ( $¬γ^\prime\wedgex^\prime$ ) will be True, e.g. $a\vee b≡ a\vee(¬ a\wedge b)$ . Therefore, the SDNF for clause $γ$ in Eq. (3) is:
$$
\bigvee_p∈S_T∪\mathcal{S_K}(\bigwedge_t∈S_T
\backslash px_t\wedge\bigwedge_k∈S_K\backslash p
¬x_k\wedgex^\prime_p) \tag{5}
$$
where $S\backslash p$ denotes a set $S$ from which element $p$ has been removed. If $p∈S_T$ then $x^\prime_p≡¬x_p$ . Otherwise, $x^\prime_p≡x_p$ . As an example of the translation into SDNF, consider the translation of an if-then statement (logical implication) below.
**Example 2**
*Translation of if-then rules into SDNF. Consider the formula $γ≡(x_1\wedge x_2\wedge¬ x_3)→ y$ . Using our notation: $$
γ≡(\bigwedge_t∈\{1,2\}x_t\wedge\bigwedge_k∈\{3\}
¬x_k)→y \tag{6}
$$ Converting to DNF: $$
(y\wedge\bigwedge_t∈\{1,2\}x_t\wedge\bigwedge_k∈\{3
\}¬x_k)\vee\bigvee_t∈\{1,2\}¬x_t\vee\bigvee_
k∈\{3\}x_k \tag{7}
$$ Applying the variable elimination method to the clause $¬x_1\vee¬x_2\veex_3$ , we obtain the SDNF for $γ$ : $$
\displaystyle(y\wedge\bigwedge_t∈S_Tx_t
\bigwedge_k∈S_K¬x_k)\vee(¬x_1)\vee
(x_1\wedge¬x_2)\vee(x_1\wedgex_2
\wedgex_3) \tag{8}
$$*
### 3.3 Reasoning in RBMs
We have seen how propositional logic formula can be mapped onto the energy functions of RBMs. In this section, we discuss the deployment of such RBMs for logical reasoning.
#### 3.3.1 Reasoning as Sampling
There is a direct relationship between inference in RBMs and logical satisfiability, as follows.
**Lemma 2**
*Let $N$ be an RBM with energy function $E$ . Let $φ$ be a WFF such that $s_φ(x)=-{\it E}(x)$ . Let $A$ be a set of indices of variables in $φ$ that have been assigned to either True or False. We use $x_A$ to denote the set $\{x_α|α∈A\}$ ). Let $B$ be a set of indices of variables that have not been assigned a truth-value in $φ$ . We use $x_B$ to denote $\{x_β|β∈B\}$ ). Performing Gibbs sampling on $N$ given $x_A$ is equivalent to searching for an assignment of truth-values for $x_B$ that satisfies $φ$ .*
Proof: Theorem 1 has shown that the assignments of truth-values to $φ$ are partially ordered according to the RBM’s energy function such that the models of $φ$ (mapping $φ$ to 1) correspond to minima of the energy function. We say that the satisfiability of $φ$ is inversely proportional to the RBM’s rank function. When the satisfiability of $φ$ is maximum ( $s_φ(x)=1$ ) ranking the output of $-{\it E}(x)$ produces the highest rank. A value of $x_B$ that minimises the energy function also maximises satisfiability: $s_φ(x_B,x_A)∝-min_ h{\it E}(x_B,x_A,h)$ because:
$$
\displaystylex_B^*=\operatorname*{arg min}_x
_B_\mathbf{h}{\it E}(x_B,x_
A,h)=\operatorname*{arg max}_x_B(s
_φ(x_B,x_A)) \tag{9}
$$
We can consider an iterative process to search for truth-values $x_B^*$ by minimising an RBM’s energy function. This can be done using gradient descent or contrastive divergence with Gibbs sampling. The goal is to update the values of $h$ and then $x_B$ in parallel until convergence to minimise ${\it E}(x_B,x_A,h)$ while keeping the other variables ( $x_A$ ) fixed. The gradients amount to:
$$
\displaystyle\frac{∂-{\it E}(x_B,x_
A,h)}{∂ h_j} \displaystyle=∑_i∈A∪\mathcal{B}x_iw_ij+θ_j \displaystyle\frac{∂-{\it E}(x_B,x_
A,h)}{∂ x_β} \displaystyle=∑_jh_jw_β j+theta_β \tag{10}
$$
In the case of Gibbs sampling, given the assigned variables $x_A$ , the process starts with a random initialization of $x_B$ and proceeds to infer values for the hidden units $h_j$ and then the unassigned variables $x_β$ in the visible layer of the RBM, using the conditional distributions $h_j∼ p(h_j|x)$ and $x_β∼ p(x_β|h)$ , respectively, where $x=\{x_A,x_B\}$ and:
$$
\displaystyle p(h_j|x) \displaystyle=\frac{1}{1+e^-\frac{1{τ}∑_ix_iw_ij+θ_j}}=
\frac{1}{1+e^-\frac{1{τ}\frac{∂-{\it E}(x_B,
x_A,h)}{∂ h_j}}} \displaystyle p(x_β|h) \displaystyle=\frac{1}{1+e^-\frac{1{τ}∑_jh_jw_β j+θ_
β}}=\frac{1}{1+e^-\frac{1{τ}\frac{∂-{\it E}(x_
B,x_A,h)}{∂ x_β}}} \tag{11}
$$
It can be seen from Eq.(11) that the distributions are monotonic functions of the negative energy’s gradient over $h$ and $x_B$ . Therefore, performing Gibbs sampling on them can be seen as moving towards a local minimum that is equivalent to an assignment of truth-values that satisfies $φ$ . Each step of Gibbs sampling, calculating $h$ and then $x$ to reduce the energy, should intuitively generate an assignment of truth-values that gets closer to satisfying the formula $φ$ . ∎
#### 3.3.2 Reasoning as Lowering Free Energy
When the number of unassigned variables is not large, it should be possible to calculate the above probabilities directly. In this case, one can infer the assignments of $x_B$ using the conditional distribution:
$$
P(x_B|x_A)=\frac{e^-F_
\mathcal{B(x_A,x_B)}}{∑_
x^\prime_Be^F_\mathcal{B}(x_
A,x^\prime_B)} \tag{12}
$$
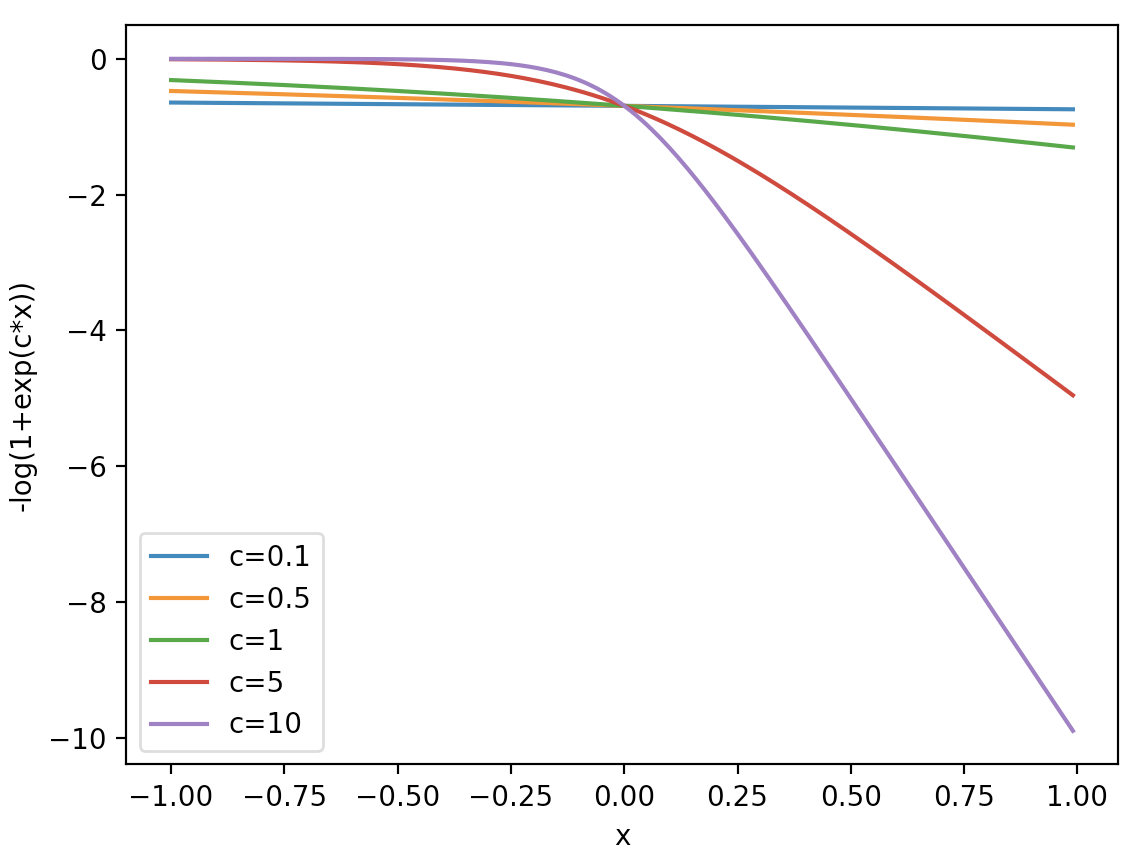
where $F_B=-∑_j(-\log(1+e^(c∑_i∈A∪ \mathcal{Bw_ijx_i+θ_j)}))$ is known as the free energy; $x^\prime_B$ denotes all the combinations of truth-value assignments to the literals in $x_B$ , and $c$ is a non-negative real number that we call a confidence value. The free energy term $-\log(1+e^(c∑_i∈A∪\mathcal{Bw_ijx_i+θ_j)})$ is a negative softplus function scaled by $c$ as shown in Figure 2. It returns a negative output for a positive input and a close-to-zero output for a negative input.
<details>
<summary>extracted/6466920/figs/confidence_smoothing.png Details</summary>
### Visual Description
\n
## Line Graph: Negative Logarithm of One Plus Exponential Function
### Overview
The image is a 2D line graph plotting the mathematical function `-log(1+exp(c*x))` against the variable `x` for five different values of the parameter `c`. The graph demonstrates how the shape of this function changes as the scaling factor `c` increases.
### Components/Axes
* **X-Axis:**
* **Label:** `x`
* **Range:** -1.00 to 1.00
* **Major Tick Marks:** -1.00, -0.75, -0.50, -0.25, 0.00, 0.25, 0.50, 0.75, 1.00
* **Y-Axis:**
* **Label:** `-log(1+exp(c*x))`
* **Range:** Approximately -10 to 0
* **Major Tick Marks:** -10, -8, -6, -4, -2, 0
* **Legend:**
* **Position:** Bottom-left corner of the plot area.
* **Content:** A list of five colored lines with corresponding parameter values.
* **Entries (from top to bottom in legend):**
1. Blue line: `c=0.1`
2. Orange line: `c=0.5`
3. Green line: `c=1`
4. Red line: `c=5`
5. Purple line: `c=10`
### Detailed Analysis
The graph displays five distinct curves, each corresponding to a different `c` value. All curves intersect at the point (0, -log(2)) ≈ (0, -0.693).
1. **c=0.1 (Blue Line):**
* **Trend:** Nearly horizontal, with a very slight downward slope.
* **Data Points (Approximate):** At x=-1.00, y ≈ -0.65. At x=1.00, y ≈ -0.75. The line remains close to y = -0.7 across the entire domain.
2. **c=0.5 (Orange Line):**
* **Trend:** Gentle, consistent downward slope.
* **Data Points (Approximate):** At x=-1.00, y ≈ -0.55. At x=1.00, y ≈ -0.95.
3. **c=1 (Green Line):**
* **Trend:** Moderate downward slope, steeper than the c=0.5 line.
* **Data Points (Approximate):** At x=-1.00, y ≈ -0.35. At x=1.00, y ≈ -1.35.
4. **c=5 (Red Line):**
* **Trend:** For negative x, the line is nearly flat and close to y=0. After x=0, it slopes downward steeply and linearly.
* **Data Points (Approximate):** At x=-1.00, y ≈ -0.01. At x=0.00, y ≈ -0.69. At x=1.00, y ≈ -5.0.
5. **c=10 (Purple Line):**
* **Trend:** Similar to the c=5 line but with a more extreme transition. It is flat near y=0 for negative x and then plummets with a very steep, linear downward slope for positive x.
* **Data Points (Approximate):** At x=-1.00, y ≈ -0.00005 (effectively 0). At x=0.00, y ≈ -0.69. At x=1.00, y ≈ -10.0.
### Key Observations
* **Intersection Point:** All five curves pass through the same point at x=0, where the function value is `-log(2)`.
* **Effect of Parameter `c`:** As `c` increases, the function's behavior bifurcates. For negative `x`, higher `c` values make the function approach 0. For positive `x`, higher `c` values cause the function to decrease (become more negative) much more rapidly.
* **Linearity for Positive x:** For `c=5` and `c=10`, the function appears to become linear for `x > 0`, with a slope approximately equal to `-c`.
* **Symmetry Breaking:** The function is not symmetric around x=0. The asymmetry becomes dramatically more pronounced as `c` increases.
### Interpretation
This graph visualizes the behavior of a function commonly encountered in statistics and machine learning, often related to loss functions (like the logistic loss) or softplus functions. The parameter `c` acts as a scaling or "sharpness" factor.
* **Low `c` (0.1, 0.5, 1):** The function is smooth and changes gradually across the entire domain of `x`. It provides a gentle penalty that increases as `x` moves away from zero in either direction.
* **High `c` (5, 10):** The function approximates a "hinge" or a rectifier. It is essentially zero (no penalty) for all negative inputs (`x < 0`) and then imposes a severe, linear penalty for positive inputs (`x > 0`). This mimics behavior like a ReLU activation or a hard margin loss, where only one side of the input space is penalized.
The plot effectively demonstrates how a single mathematical form can transition from a smooth, symmetric-like function to a sharp, asymmetric one simply by adjusting a scaling parameter. This is crucial for understanding model behavior in optimization contexts, where `c` might control the trade-off between margin and loss.
</details>
Figure 2: Free energy term $-\log(1+e^cx)$ for different confidence values $c$ .
Each free energy term is associated with a conjunctive clause in the SDNF through the weighted sum $∑_i∈A∪\mathcal{B}w_ijx_i+θ_j$ . Therefore, if a truth-value assignment of $x_B$ does not satisfy the formula $φ$ , all energy terms will be close to zero. When $φ$ is satisfied, one free energy term will be $-\log(1+e^cε)$ , for a choice of $0<ε<1$ from Theorem 1. Thus, the more likely that a truth assignment is to satisfying the formula, the lower the free energy. Formally:
$$
s_φ(x)=-\frac{1}{cε}min_hE(x
,h)=\lim_c→∞-\frac{1}{cε}F(\mathbf
{x}) \tag{13}
$$
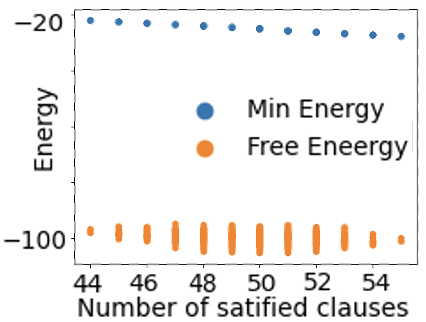
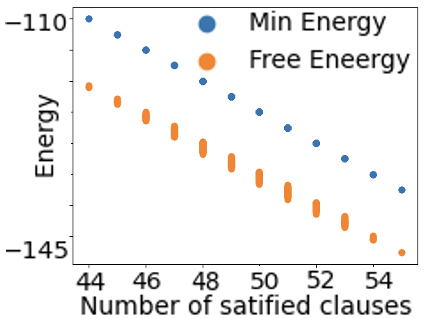
Figure 3 shows the average values of the energy function and free energy for CNFs with 55 clauses as the number of satisfied clauses increases. The CNF is satisfied if and only if all 55 clauses are satisfied. As can be seen, the relationships are linear. Minimum energy and free energy values converge with an increasing value of $c$ .
<details>
<summary>extracted/6466920/figs/energies_versus_sat_clauses_c1.png Details</summary>
### Visual Description
## Scatter Plot: Energy vs. Number of Satisfied Clauses
### Overview
The image is a scatter plot comparing two energy metrics ("Min Energy" and "Free Eneergy") against the "Number of satisfied clauses." The plot displays two distinct, non-overlapping clusters of data points, indicating a clear separation between the two energy types across the range of satisfied clauses.
### Components/Axes
* **X-Axis:**
* **Title:** "Number of satisfied clauses"
* **Scale:** Linear, ranging from approximately 44 to 54.
* **Major Tick Marks:** 44, 46, 48, 50, 52, 54.
* **Y-Axis:**
* **Title:** "Energy"
* **Scale:** Linear, ranging from approximately -100 to -20.
* **Major Tick Marks:** -100, -80, -60, -40, -20.
* **Legend:**
* **Position:** Center-right of the plot area.
* **Entries:**
1. **Blue Circle:** "Min Energy"
2. **Orange Circle:** "Free Eneergy" (Note: Contains a typo; "Eneergy" should be "Energy").
### Detailed Analysis
* **Data Series 1: Min Energy (Blue Circles)**
* **Spatial Grounding:** Located in the upper portion of the plot, near the y-axis value of -20.
* **Trend Verification:** The series shows a very slight downward trend. As the number of satisfied clauses increases from 44 to 54, the energy value decreases marginally.
* **Approximate Data Points:**
* At x=44, y ≈ -18
* At x=46, y ≈ -19
* At x=48, y ≈ -19.5
* At x=50, y ≈ -20
* At x=52, y ≈ -20.5
* At x=54, y ≈ -21
* **Data Series 2: Free Eneergy (Orange Circles)**
* **Spatial Grounding:** Located in the lower portion of the plot, clustered near the y-axis value of -100.
* **Trend Verification:** The series shows no strong upward or downward trend. The points are distributed in a roughly horizontal band with some vertical scatter.
* **Approximate Data Points:** The points are densely clustered. For each x-value (44, 46, 48, 50, 52, 54), there are multiple orange points forming a vertical "smear" or distribution. The central tendency for all clusters is approximately y = -100, with individual points ranging from roughly -95 to -105.
### Key Observations
1. **Clear Separation:** There is a large, consistent gap of approximately 80 energy units between the "Min Energy" and "Free Eneergy" data series. They do not overlap at any point.
2. **Different Behaviors:** "Min Energy" shows a weak, systematic dependence on the number of satisfied clauses (slight decrease). "Free Eneergy" appears largely independent of this variable, maintaining a stable average value with local variance.
3. **Data Density:** The "Free Eneergy" series has multiple data points for each x-value, suggesting it may represent a distribution or multiple trials per clause count. The "Min Energy" series has a single point per x-value.
4. **Label Typo:** The legend contains a clear spelling error ("Eneergy").
### Interpretation
This plot likely originates from a computational or optimization context, possibly related to constraint satisfaction problems (e.g., SAT solvers) or statistical physics models. The "Number of satisfied clauses" is a common metric in such fields.
* **Min Energy:** This likely represents the lowest possible energy state found for a given number of satisfied clauses. The slight downward trend suggests that as more clauses are satisfied, the system can settle into a marginally lower (more optimal) energy configuration.
* **Free Eneergy:** This likely represents the free energy of the system, a thermodynamic quantity that balances internal energy and entropy. Its stability around -100, despite changes in satisfied clauses, indicates that the overall thermodynamic potential of the system is robust or insensitive to this specific measure of solution quality within the observed range. The vertical scatter suggests fluctuations or a distribution of free energy values for a fixed number of satisfied clauses.
* **Relationship:** The vast separation between the two energies is the most striking feature. It implies that the system's ground state ("Min Energy") is far removed from its typical or equilibrium state ("Free Eneergy") under the conditions modeled. The system does not naturally settle near its minimum energy configuration.
</details>
(a) (c=1)
<details>
<summary>extracted/6466920/figs/energies_versus_sat_clauses_c5.png Details</summary>
### Visual Description
\n
## Scatter Plot: Energy vs. Number of Satisfied Clauses
### Overview
The image is a scatter plot comparing two energy metrics ("Min Energy" and "Free Eneergy") against the "Number of satisfied clauses." The plot shows a clear negative correlation for both data series, where energy values decrease as the number of satisfied clauses increases.
### Components/Axes
* **X-Axis:**
* **Label:** "Number of satisfied clauses"
* **Scale:** Linear, ranging from 44 to 54.
* **Major Tick Marks:** 44, 46, 48, 50, 52, 54.
* **Y-Axis:**
* **Label:** "Energy"
* **Scale:** Linear, ranging from approximately -145 to -110.
* **Major Tick Marks:** -145, -130, -110.
* **Legend:**
* **Position:** Top-right corner of the plot area.
* **Series 1:** "Min Energy" represented by blue circles.
* **Series 2:** "Free Eneergy" represented by orange circles. (Note: "Eneergy" appears to be a typographical error for "Energy").
### Detailed Analysis
The plot contains two distinct data series, each with 11 data points corresponding to integer values of the x-axis from 44 to 54.
**1. Data Series: "Min Energy" (Blue Circles)**
* **Visual Trend:** The blue points form a line that slopes downward from left to right, indicating a consistent decrease in "Min Energy" as the number of satisfied clauses increases.
* **Approximate Data Points (x, y):**
* (44, -110)
* (45, -112)
* (46, -114)
* (47, -116)
* (48, -118)
* (49, -120)
* (50, -122)
* (51, -124)
* (52, -126)
* (53, -128)
* (54, -130)
**2. Data Series: "Free Eneergy" (Orange Circles)**
* **Visual Trend:** The orange points also form a line that slopes downward from left to right, parallel to but consistently below the "Min Energy" series. This indicates "Free Eneergy" is always lower than "Min Energy" for the same number of satisfied clauses.
* **Approximate Data Points (x, y):**
* (44, -118)
* (45, -120)
* (46, -122)
* (47, -124)
* (48, -126)
* (49, -128)
* (50, -130)
* (51, -132)
* (52, -134)
* (53, -136)
* (54, -138)
### Key Observations
1. **Strong Negative Correlation:** Both energy metrics exhibit a near-perfect linear decrease as the number of satisfied clauses increases.
2. **Consistent Offset:** The "Free Eneergy" values are consistently lower than the "Min Energy" values by approximately 8 units across the entire range.
3. **Data Density:** There is exactly one data point for each integer value on the x-axis from 44 to 54, suggesting a systematic evaluation.
4. **Label Typo:** The legend contains a clear spelling error ("Eneergy").
### Interpretation
This chart likely originates from a field like computational physics, optimization theory, or machine learning (e.g., evaluating models like Boltzmann machines or energy-based models). The "Number of satisfied clauses" suggests a problem involving constraint satisfaction (like SAT solving).
The data demonstrates a fundamental trade-off: achieving a higher degree of constraint satisfaction (more clauses met) is associated with a lower system energy state. In many physical and computational systems, lower energy corresponds to a more stable or optimal configuration. The consistent gap between "Min Energy" and "Free Eneergy" suggests these are two related but distinct calculations of the system's energy, with "Free Eneergy" (likely "Free Energy," a key concept in statistical mechanics) being a more relaxed or entropic measure that is always lower than the strict "Min Energy." The linearity of the relationship is striking and implies a direct, predictable coupling between the objective (satisfying clauses) and the system's energy landscape.
</details>
(b) (c=5)
<details>
<summary>extracted/6466920/figs/energies_versus_sat_clauses_c10.png Details</summary>
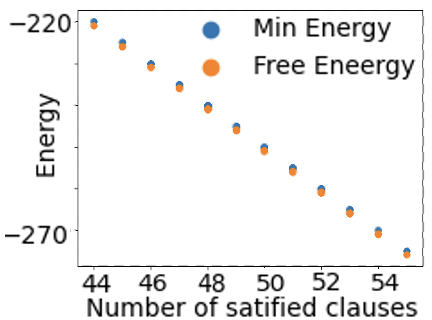
### Visual Description
\n
## Scatter Plot: Energy vs. Number of Satisfied Clauses
### Overview
The image is a scatter plot comparing two energy metrics—"Min Energy" and "Free Energy"—against the "Number of satisfied clauses." The plot shows a clear inverse relationship: as the number of satisfied clauses increases, both energy values decrease (become more negative). The data points for both series are closely aligned, with "Free Energy" consistently slightly higher (less negative) than "Min Energy" for the same number of satisfied clauses.
### Components/Axes
* **Chart Type:** Scatter plot with two data series.
* **X-Axis:**
* **Label:** "Number of satisfied clauses"
* **Scale:** Linear, ranging from approximately 44 to 54.
* **Major Ticks:** 44, 46, 48, 50, 52, 54.
* **Y-Axis:**
* **Label:** "Energy"
* **Scale:** Linear, ranging from approximately -220 to -270.
* **Major Ticks:** -220, -270.
* **Legend:**
* **Position:** Top-right corner of the plot area.
* **Series 1:** Blue circle, labeled "Min Energy".
* **Series 2:** Orange circle, labeled "Free Eneergy" (note: "Energy" is misspelled as "Eneergy" in the image).
* **Data Points:** Each series consists of 11 data points, plotted as filled circles.
### Detailed Analysis
**Trend Verification:** Both data series exhibit a strong, consistent downward (negative) linear trend. As the x-value increases, the y-value decreases.
**Data Point Extraction (Approximate Values):**
The following table lists the approximate coordinates for each data point, read from the graph. The "Min Energy" (blue) points are consistently slightly lower (more negative) than the "Free Energy" (orange) points at each x-value.
| Number of Satisfied Clauses (X) | Min Energy (Y, Blue) | Free Energy (Y, Orange) |
| :--- | :--- | :--- |
| 44 | -220 | -219 |
| 45 | -225 | -224 |
| 46 | -230 | -229 |
| 47 | -235 | -234 |
| 48 | -240 | -239 |
| 49 | -245 | -244 |
| 50 | -250 | -249 |
| 51 | -255 | -254 |
| 52 | -260 | -259 |
| 53 | -265 | -264 |
| 54 | -270 | -269 |
**Uncertainty Note:** Values are estimated based on visual alignment with the axis ticks. The actual values may differ by ±1-2 units.
### Key Observations
1. **Perfect Correlation:** The two series are perfectly correlated in trend and nearly identical in value, differing by a near-constant offset of approximately 1 energy unit.
2. **Linear Relationship:** The relationship between "Number of satisfied clauses" and "Energy" appears to be strongly linear for both metrics within the observed range.
3. **Data Density:** The points are evenly spaced along the x-axis at integer intervals from 44 to 54.
4. **Label Typo:** The legend contains a clear typographical error: "Free Eneergy" instead of "Free Energy."
### Interpretation
This chart likely originates from a computational or optimization context, such as constraint satisfaction problems (e.g., SAT solvers) or statistical physics models. The "Number of satisfied clauses" is a common metric in Boolean satisfiability, where a higher number indicates a better solution. "Energy" is a cost function to be minimized.
The data demonstrates a fundamental trade-off or relationship: achieving a higher number of satisfied clauses (a better solution state) is associated with a lower system energy (a more stable or optimal state). The near-identical values of "Min Energy" and "Free Energy" suggest that in this specific scenario or model, the two calculated quantities converge to almost the same result, with "Free Energy" being marginally higher. The perfect linearity implies a very direct, predictable relationship between the solution quality (clauses satisfied) and the system's energy cost within this parameter range. The chart effectively visualizes the optimization landscape, showing that progress (more clauses) is directly and uniformly rewarded with lower energy.
</details>
(c) (c=10)
Figure 3: Linear correlation between satisfiability of a CNF and minimization of the free energy function for various confidence values $c$ . Source: [52].
### 3.4 Logical Boltzmann Machines
We are now in position to present a translation algorithm to build an RBM from logical formulae. The energy function of the RBM will be derived based on Theorem 1 given a formula in SDNF. The weights and biases of the RBM will be obtained from the energy function $E(x,h)=-(∑_iθ_ix_i+∑_jθ_j h_j+∑_ijx_iW_ijh_j)$ , where $θ_i$ are the biases of the visible units, $θ_j$ are the biases of the hidden units, and $W_ij$ is the symmetric weight between a visible and a hidden unit. For each conjunctive clause in the formula of the form $\bigwedge_t∈S_Tx_t\wedge\bigwedge_k∈S_ {K} ¬x_k$ , we create an energy term $-h_j(∑_t∈S_Tx_t-∑_k∈ S_Kx_k-| S_T|+ε)$ . The disjunctions in the SDNF are implemented in the RBM simply by creating a hidden neuron $h_j$ for each disjunct in the SDNF.
Learning in LBM uses learning from data $D$ combined with knowledge provided by the logical formulae. Learning with data and knowledge is expected to improve accuracy or training time. If the logical formula is empty, the weights and biases are initialized randomly and one has a standard RBM. Learning in this case is an approximation of parameters $Θ$ over a set of preferred models $D=\{x^(n)|n=1,..,N\}$ of an unknown formula $φ^*$ . Consider the case where the data set $D$ is complete, i.e. it contains all preferred models of an unknown $φ^*$ . We will show that learning an RBM to represent the SDNF of $φ^*$ is possible. Consider the gradient of the negative log-likelihood ( $-\ell$ ) of an RBM:
$$
\frac{∂{-}\ell}{∂Θ}=E[\frac{∂{\it E}(
x,h)}{∂Θ}]_h|\mathbf{x∈D}
-E[\frac{∂{\it E}(x,h)}{∂Θ}]_
h,\mathbf{x} \tag{14}
$$
where $E$ denotes the expected value. This function is not convex. Therefore, the RBM may not always converge to $φ^*$ . Consider now the case where $D$ is incomplete. At a local minimum, we have that $\frac{∂-\ell}{∂ w_ij}=-\frac{1}{N}∑_x∈ Dx_ip(h_j|x)+∑_xx_ip(h_j|x) p(x)≈ 0$ . A solution to this is $p(h_j|x)p(x)≈\frac{p(h_j|x)}{N} if x∈D, and 0 otherwise.$ This can be achieved by either having $p(h_j|x)≈ 0$ or $p(x)≈ 0$ for all $x∉D$ and $p(x)≈\frac{1}{N}$ for $x∈D$ . Since $p(x)=\frac{1}{Z}∑_h\exp(-{\it E}(x,h))$ then for a training example (preferred model) $x$ we have $∑_x∑_h\exp(-{\it E}(x,h))≈ N ∑_h\exp(-{\it E}(x,h))$ . Hence, a solution is obtained if $∑_h\exp(-{\it E}(x,h))$ is equally large for all $x∈D$ , and much smaller otherwise. We can further factorize this sum to get $∑_h\exp(-{\it E}(x,h))∝∏_j(1+\exp( ∑_iw_ijx_i+θ_j))$ . Now, suppose that an LBM with parameters $Θ=(W^*,θ^*)$ represents an unknown formula $φ^*$ . Assuming that the LBM has large and equal confidence values $c_∞$ for its free-energy function (as discussed in Section 3.3.2), this LBM would allow only one hidden unit to be activated for a satisfying assignment $x$ . In the case of an unsatisfiable assignment, all hidden units would be deactivated. Therefore, one can choose $c_∞$ large enough to guarantee that a solution is found because $∏_j(1+\exp(∑_iw^*_ijx_i+b^*_j))≈\exp(c_∞ ε) if x∈D.$
**Example 3**
*We use the symbol $⊕$ to denote exclusive-or, that is $x⊕y≡((x\wedge¬y)\vee(¬ x\wedgey))$ . The formula $φ≡(x⊕y)↔z$ can be converted into the SDNF: $$
φ≡(¬x\wedge¬y\wedge¬z)\vee(¬
x\wedgey\wedgez)\vee(x\wedge¬y
\wedgez)\vee(x\wedgey\wedge¬z)
$$ For each conjunctive clause in $φ$ , a corresponding term is added to the energy function. An RBM for the XOR formula $φ$ can be built as shown in Figure 4 for a choice of $ε=0.5$ and zero bias for the visible units ( $θ_i=0$ ). The energy function of this RBM is: | | $\displaystyle{\it E}$ | $\displaystyle=-h_1(-x-y-z+0.5)-h_2(x+y-z-1.5)-$ | |
| --- | --- | --- | --- |
<details>
<summary>extracted/6466920/figs/xor_rbm.png Details</summary>
### Visual Description
## Diagram: Neural Network Architecture with Weights and Biases
### Overview
The image displays a schematic diagram of a simple feedforward neural network (or a single layer of one). It consists of two layers of nodes (neurons) connected by weighted edges. The bottom layer is the input layer, and the top layer is a hidden or output layer. Each node in the top layer receives a bias input. All text and numerical values are in English.
### Components/Axes
* **Layers:**
* **Input Layer (Bottom):** Three nodes, represented as white circles. They are labeled from left to right: **x**, **y**, **z**.
* **Hidden/Output Layer (Top):** Four nodes, represented as gray circles. They are labeled from left to right: **h₁**, **h₂**, **h₃**, **h₄**.
* **Connections (Edges):** Directed lines (arrows) connect every node in the input layer to every node in the top layer, forming a fully connected bipartite graph. Each connection has an associated numerical weight.
* **Biases:** Each node in the top layer (**h₁** to **h₄**) has an incoming arrow from the left, representing a bias input. Each bias has an associated numerical value.
### Detailed Analysis
**1. Bias Values (Applied to Top Layer Nodes):**
* Node **h₁**: Bias = **0.5**
* Node **h₂**: Bias = **-1.5**
* Node **h₃**: Bias = **-1.5**
* Node **h₄**: Bias = **-1.5**
**2. Connection Weights (From Input Layer to Top Layer):**
The weights are labeled on the lines. The pattern is consistent: all connections from a given input node to the top layer nodes share the same weight value.
* **From Input Node x:**
* To **h₁**: Weight = **-1**
* To **h₂**: Weight = **-1**
* To **h₃**: Weight = **-1**
* To **h₄**: Weight = **-1**
* **From Input Node y:**
* To **h₁**: Weight = **1**
* To **h₂**: Weight = **1**
* To **h₃**: Weight = **1**
* To **h₄**: Weight = **1**
* **From Input Node z:**
* To **h₁**: Weight = **-1**
* To **h₂**: Weight = **-1**
* To **h₃**: Weight = **-1**
* To **h₄**: Weight = **-1**
**3. Spatial Layout:**
* The four top-layer nodes (**h₁**-**h₄**) are arranged horizontally across the top of the diagram.
* The three input nodes (**x**, **y**, **z**) are arranged horizontally across the bottom.
* Bias arrows enter each **h** node from the immediate left.
* Connection lines cross the central space, creating a dense web. Lines from **x** and **z** slope upward inward, while lines from **y** go straight up.
### Key Observations
1. **Symmetry and Pattern:** The network exhibits a strong, deliberate pattern. The input node **y** has a positive weight (+1) to all top nodes, while input nodes **x** and **z** have a negative weight (-1) to all top nodes.
2. **Bias Uniformity:** Three of the four top nodes (**h₂**, **h₃**, **h₄**) share an identical bias of **-1.5**. Only **h₁** has a different bias (**0.5**).
3. **Fully Connected:** Every input is connected to every output neuron, which is standard for a dense layer.
4. **No Activation Function Shown:** The diagram depicts the linear transformation (weights and biases) but does not specify an activation function (e.g., sigmoid, ReLU) that would typically follow.
### Interpretation
This diagram represents the **linear transformation stage** of a neural network layer. The computation for each output neuron **hᵢ** is a weighted sum of the inputs plus a bias:
`hᵢ = (w_ix * x) + (w_iy * y) + (w_iz * z) + bᵢ`
Given the specific weights and biases:
* The network is configured to respond strongly to the input **y** (positive weight) and be suppressed by inputs **x** and **z** (negative weights).
* The identical parameters for **h₂**, **h₃**, and **h₄** suggest they might be redundant or part of a mechanism where multiple neurons compute the same function, possibly for increased capacity or as part of a specific architectural pattern (like an ensemble within a layer).
* The distinct bias for **h₁** makes it functionally different from the other three neurons, potentially allowing it to detect a different feature or threshold.
* This could be a simplified illustration for educational purposes, a snapshot of a network's weights after training for a specific task (e.g., a classifier where **y** is a key positive feature), or a component of a larger, more complex model. The symmetry suggests it might be a constructed example to demonstrate how weights and biases combine.
</details>
Figure 4: An RBM equivalent to the XOR formula $(x⊕y)↔z$ . Table 1 shows the equivalence between $min_h{\it E}(x,h)$ and the truth-table for the XOR formula. The above example illustrates in a simple case the value of using SDNF, in that it produces a direct translation into an RBM, as also illustrated below.
Table 1: Energy function and truth-table for the formula $((x\wedge¬y)\vee(¬x\wedgey)) ↔z$ .
| $0 0$ $0 0$ $0 0$ | $0 0$ $0 0$ $1$ | $0 0$ $1$ $0 0$ | $True$ $False$ $False$ | $-0.5$ $0 0$ $0 0$ |
| --- | --- | --- | --- | --- |
| $0 0$ | $1$ | $1$ | $True$ | $-0.5$ |
| $1$ | $0 0$ | $0 0$ | $False$ | $0 0$ |
| $1$ | $0 0$ | $1$ | $True$ | $-0.5$ |
| $1$ | $1$ | $0 0$ | $True$ | $-0.5$ |
| $1$ | $1$ | $1$ | $False$ | $0 0$ |*
**Example 4**
*We have seen that the SDNF of $(x_1\wedgex_2\wedge¬x_3)→\mathrm {y}$ is $(y\wedgex_1\wedgex_2\wedge¬x _3)\vee(x_1\wedgex_2\wedgex_3)\vee(\mathrm {x}_1\wedge¬x_2)\vee¬x_1$ . We need an RBM with only 3 hidden units In the case of $¬ x_1$ , or any term of the energy function with a single variable, the term is implemented in the RBM via the bias of $x_1$ . For a positive literal $x$ , the energy term $-h(x-1+ε)$ can be replaced by $-xε$ . For a negative literal $¬ x$ , the energy term $-h(-x+ε)$ can be replaced by $-(1-x)ε$ . This is possible because in order to minimize the energy, $h=1$ if and only if $x=0$ (in the case of $¬ x$ ), thus $h=1-x$ . Therefore, $-h(-x+ε)=-(1-x)(-x+ε)=-(-x+ε+x^2-xε)=-(1-x)ε$ , because $x=x^2$ . to represent this SDNF. The energy function with $ε=0.5$ is: | | $\displaystyle E=e_y+∑_i=1^3e_i,where$ | |
| --- | --- | --- | The number of hidden units grows linearly with the number of disjuncts in the formula. The computationally expensive part is the translation from WFF to SDNF in case it is needed.*
### 3.5 Experimental Results
#### 3.5.1 Reasoning
We deployed LBM to search for satisfying truth assignments of variables in large formulae. Let us define a class of formulae as:
$$
φ≡\bigwedge_i=1^Mx_i\wedge(\bigvee_j=M+1^M+N
x_j) \tag{15}
$$
A formula in this class consists of $2^M+N$ possible truth assignments of the variables, with $2^N-1$ of them mapping the formula to $true$ (call this the satisfying set). Converting to SDNF as done before but now for the class of formulae, we obtain:
$$
φ≡\bigvee_j=M+1^M+N(\bigwedge_i=1^Mx_i\wedge
\bigwedge_j^\prime=j+1^M+N¬x_j^\prime\wedgex_j) \tag{16}
$$
<details>
<summary>extracted/6466920/figs/completeness.png Details</summary>
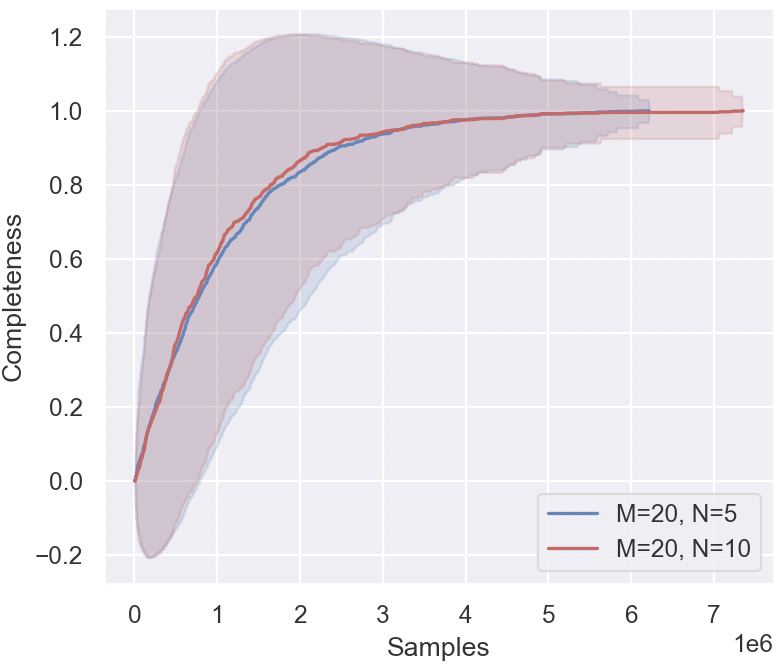
### Visual Description
## Line Chart: Completeness vs. Samples for Two Parameter Sets
### Overview
The image displays a line chart plotting "Completeness" against the number of "Samples" for two different experimental conditions. Each condition is represented by a central trend line and a shaded region indicating the confidence interval or variance around that trend. The chart demonstrates how a completeness metric evolves and converges as the number of samples increases.
### Components/Axes
* **Chart Type:** Line chart with shaded confidence intervals.
* **X-Axis:**
* **Label:** "Samples"
* **Scale:** Linear scale from 0 to 7,000,000 (7 x 10⁶). Major tick marks are at 0, 1, 2, 3, 4, 5, 6, and 7 million.
* **Y-Axis:**
* **Label:** "Completeness"
* **Scale:** Linear scale from -0.2 to 1.2. Major tick marks are at -0.2, 0.0, 0.2, 0.4, 0.6, 0.8, 1.0, and 1.2.
* **Legend:**
* **Position:** Bottom-right corner of the plot area.
* **Entries:**
1. **Blue Line:** Label "M=20, N=5"
2. **Red Line:** Label "M=20, N=10"
* **Data Series:**
1. **Series 1 (Blue):** Corresponds to "M=20, N=5". Consists of a solid blue central line and a light blue shaded confidence band.
2. **Series 2 (Red):** Corresponds to "M=20, N=10". Consists of a solid red central line and a light red/pink shaded confidence band.
### Detailed Analysis
**Trend Verification & Data Points:**
* **Both Series Trend:** Both the blue and red lines exhibit a logarithmic-like growth pattern. They start near a completeness of 0.0 at 0 samples, rise steeply initially, and then gradually plateau, approaching an asymptote near a completeness value of 1.0.
* **Blue Line (M=20, N=5):**
* **Trend:** Slopes upward sharply from the origin, crossing 0.4 completeness at ~500,000 samples, 0.8 at ~2,000,000 samples, and 0.95 at ~4,000,000 samples. It appears to plateau very close to 1.0 from approximately 5,000,000 samples onward.
* **Confidence Interval (Blue Shading):** The shaded region is very wide at low sample counts, spanning from approximately -0.2 to +1.2 at its peak around 1,000,000 samples. This indicates high variance or uncertainty in the early stages. The band narrows significantly as samples increase, becoming a tight band around the central line after ~4,000,000 samples.
* **Red Line (M=20, N=10):**
* **Trend:** Follows a very similar path to the blue line but appears to rise slightly faster in the initial phase (0 to 1,500,000 samples). It crosses 0.4 completeness at ~400,000 samples and 0.8 at ~1,800,000 samples. It converges with the blue line's trajectory around 3,000,000 samples and plateaus at the same level (~1.0).
* **Confidence Interval (Red Shading):** The shaded region is also wide initially but appears slightly narrower than the blue band in the very early stage (0-500,000 samples). It narrows as samples increase, following a similar convergence pattern to the blue band.
### Key Observations
1. **Convergence:** Both parameter sets (M=20 with N=5 and N=10) lead to the same final completeness level (~1.0) given a sufficient number of samples (approximately 5 million or more).
2. **Early-Stage Difference:** The series with N=10 (red) shows a marginally faster initial increase in completeness compared to N=5 (blue) for the same number of samples below ~2 million.
3. **High Initial Variance:** Both series exhibit extremely high variance (wide confidence intervals) when the sample count is low (< 2 million), suggesting the completeness metric is highly unstable or uncertain with sparse data.
4. **Stability with Scale:** The variance diminishes dramatically as the sample size grows, indicating the measurement becomes stable and reliable with large datasets.
5. **Parameter Impact:** Holding M constant at 20, increasing N from 5 to 10 appears to improve the *rate* of completeness acquisition in the data-scarce regime but does not affect the ultimate achievable completeness.
### Interpretation
This chart likely illustrates the performance of a sampling-based algorithm or estimation process where "Completeness" measures how much of the target information or solution space has been captured. The parameters M and N could represent dimensions of the problem, such as the number of features (M) and the number of samples per feature or a similar constraint (N).
The data suggests that **increasing the sample size is the primary driver for achieving high completeness**, with both configurations eventually reaching near-perfect completeness (~1.0). The **parameter N influences efficiency**: a higher N (10 vs. 5) provides a slight advantage in the early learning phase, allowing the system to reach a given completeness level with fewer samples. However, this advantage diminishes as the sample count grows large.
The **massive initial confidence intervals** are a critical finding. They imply that any single run or small set of runs with fewer than ~2 million samples could yield wildly different completeness scores, from near-zero to near-perfect. This highlights the necessity of large sample sizes not just for high completeness, but for *reliable and reproducible* results. The convergence of both the means and the confidence bands at high sample counts indicates the process becomes deterministic and predictable with enough data.
**In summary:** For this system, prioritize collecting a large number of samples (>5 million) to guarantee high and stable completeness. If computational resources are limited and only a smaller sample budget is available (<2 million), using the configuration with the higher N value (N=10) may yield slightly better, though still highly variable, results.
</details>
<details>
<summary>extracted/6466920/figs/completeness_2.png Details</summary>
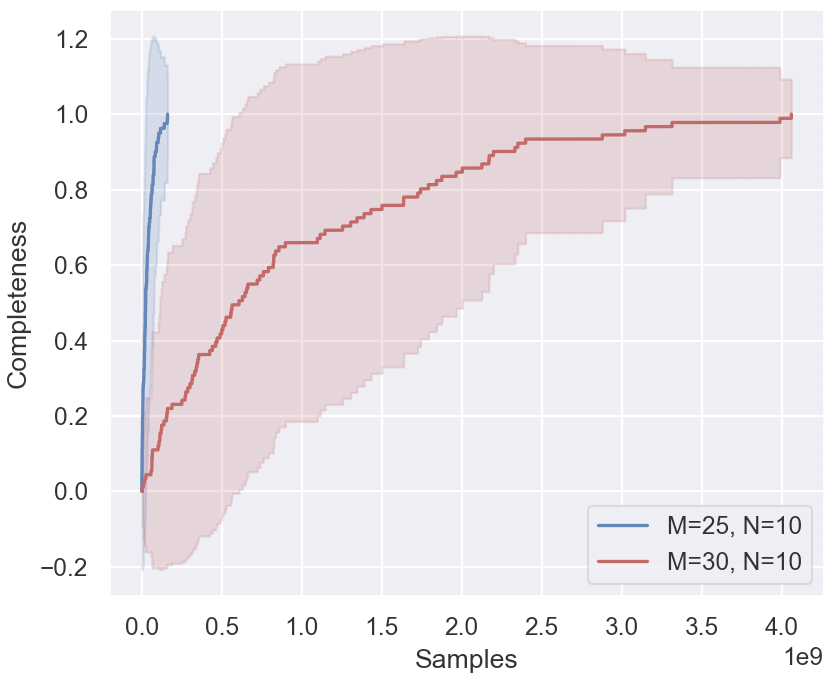
### Visual Description
## Line Chart: Completeness vs. Samples for Two Parameter Sets
### Overview
The image displays a line chart comparing the progression of a metric called "Completeness" over an increasing number of "Samples" for two different experimental configurations. Each configuration is represented by a central line (likely a mean or median) surrounded by a shaded region indicating variance, confidence intervals, or a range of outcomes.
### Components/Axes
* **Chart Type:** Line chart with shaded confidence/error bands.
* **X-Axis:**
* **Label:** "Samples"
* **Scale:** Linear scale.
* **Range:** 0.0 to 4.0 x 10⁹ (4 billion).
* **Major Tick Marks:** 0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0 (all multiplied by 1e9).
* **Y-Axis:**
* **Label:** "Completeness"
* **Scale:** Linear scale.
* **Range:** -0.2 to 1.2.
* **Major Tick Marks:** -0.2, 0.0, 0.2, 0.4, 0.6, 0.8, 1.0, 1.2.
* **Legend:**
* **Position:** Bottom-right corner of the plot area.
* **Entry 1:** A blue line labeled "M=25, N=10".
* **Entry 2:** A red line labeled "M=30, N=10".
### Detailed Analysis
**1. Data Series: M=25, N=10 (Blue Line & Shading)**
* **Trend Verification:** The blue line exhibits an extremely steep, near-vertical ascent from the origin, followed by a sharp knee and a flat plateau.
* **Data Points & Behavior:**
* Starts at approximately (0 samples, 0.0 completeness).
* Rises with extreme rapidity. By approximately 0.1 x 10⁹ (100 million) samples, the completeness value is already near 0.9.
* Reaches a plateau at a completeness value of approximately 0.95 to 1.0 by around 0.2 x 10⁹ (200 million) samples.
* The line remains flat at this high completeness level for the remainder of the x-axis range (up to 4.0e9 samples).
* **Shaded Region (Uncertainty):** The blue shaded area is very narrow, tightly hugging the central line. It suggests low variance or high confidence in the result for this configuration. The band spans roughly ±0.05 in completeness at its widest point near the plateau.
**2. Data Series: M=30, N=10 (Red Line & Shading)**
* **Trend Verification:** The red line shows a much more gradual, logarithmic-like growth curve. It rises steadily but at a significantly slower rate than the blue line.
* **Data Points & Behavior:**
* Starts at approximately (0 samples, 0.0 completeness).
* Shows a steady, concave-down increase. Key approximate milestones:
* ~0.5e9 samples: Completeness ≈ 0.35
* ~1.0e9 samples: Completeness ≈ 0.65
* ~2.0e9 samples: Completeness ≈ 0.85
* ~3.0e9 samples: Completeness ≈ 0.95
* ~4.0e9 samples: Completeness ≈ 0.98 (approaching 1.0).
* **Shaded Region (Uncertainty):** The red shaded area is very broad, indicating high variance or uncertainty in the outcomes for this configuration.
* The band is asymmetrical. The lower bound rises slowly, reaching ~0.8 completeness only near 4.0e9 samples.
* The upper bound rises more quickly, crossing 1.0 completeness around 1.5e9 samples and peaking near 1.2 before slightly declining.
* The width of the band suggests that individual runs with parameters M=30, N=10 can produce a wide range of completeness values for the same number of samples.
### Key Observations
1. **Dramatic Performance Difference:** The configuration with M=25 achieves near-maximal completeness orders of magnitude faster (in terms of samples) than the configuration with M=30. The blue line's plateau is reached before the red line has even achieved 0.4 completeness.
2. **Variance Disparity:** The M=25 configuration shows highly consistent, predictable results (narrow band). The M=30 configuration shows highly variable, unpredictable results (wide band).
3. **Asymptotic Behavior:** Both series appear to asymptotically approach a completeness value of 1.0, but at vastly different rates. The M=25 series effectively reaches this limit almost immediately on the chart's scale.
4. **Y-Axis Range:** The y-axis extends to -0.2 and 1.2, likely to fully contain the wide variance of the red (M=30) series, whose lower confidence bound dips slightly below 0.0 initially and whose upper bound exceeds 1.0.
### Interpretation
This chart likely illustrates a trade-off in a computational or sampling-based process (e.g., Monte Carlo simulation, optimization, machine learning training) governed by parameters M and N.
* **Parameter Impact:** The parameter M appears to have a critical, non-linear impact on **sample efficiency**. A lower M (25) leads to extremely fast convergence to high completeness. A higher M (30) drastically slows convergence and introduces significant uncertainty.
* **What "Completeness" Represents:** "Completeness" is a normalized metric (0 to 1) indicating how much of a solution, coverage, or target has been achieved. A value of 1.0 represents full completion.
* **Practical Implication:** If the goal is to achieve high completeness quickly (with fewer samples), the M=25, N=10 configuration is vastly superior. However, the high variance of the M=30 configuration suggests that while it is slower on average, some individual runs might achieve very high completeness (upper red band >1.0) earlier, though this comes with the risk of very poor performance (lower red band).
* **Underlying Mechanism:** The stark difference suggests M might control a complexity or dimensionality factor. A higher M could make the problem space much larger or more difficult to explore, requiring exponentially more samples for the same progress and leading to less predictable outcomes. The chart serves as a strong visual argument for selecting M=25 over M=30 for this particular process, assuming the goal is rapid and reliable convergence.
</details>
Figure 5: Percentage coverage as a measure of completeness as sampling progresses in the RBM. 100% coverage is achieved for the class of formulae with different values for M and N averaged over 100 runs. The number of samples needed to achieve $100\$ coverage is much lower than the number of possible assignments ( $2^M+N$ ). For example, when M=20, N=10, all satisfying assignments are found after approximately $7.5× 10^6$ samples are provided as input to the RBM, whereas the number of possible assignments is approximately 1 billion, a ratio of sample size to the search space of $0.75\$ . The ratio for M=30, N=10 is even lower at $0.37\$ . Source: [52].
Applying Theorem 1 to construct an RBM from $φ$ , we use Gibbs sampling to find the models of a formula given random initial truth assignments to all the variables. A sample is accepted as a satisfying assignment (a model) if its free energy is lower than or equal to $-\log(1+\exp(cε)$ with $c=5,ε=0.5$ . We evaluate the coverage and accuracy of accepted samples. Coverage is measured as the proportion of the satisfying set that is accepted over time. In this experiment, this is the number of satisfying assignments in the set of accepted samples divided by $2^N-1$ . It can be seen as a measure of completeness. Accuracy is measured as the percentage of samples accepted by the RBM that do satisfy the logical formula.
We test different values of $M∈\{20,25,30\}$ and $N∈\{3,4,5,6,7,8,9,10\}$ . LBM achieves $100\$ accuracy in all cases, meaning that all accepted samples do satisfy the formula, as expected (given Theorem 1). Figure 5 shows the coverage as Gibbs sampling progresses (after each time that a number of random samples is collected). Four cases are considered: M=20 and N=5, M=20 and N=10, M=25 and N=10, M=30 and N=10.
In each case, we run the sampling process 100 times and report the average results with standard deviations. The satisfying set and therefore the number of samples needed to achieve $100\$ coverage is much lower than the number of possible assignments ( $2^M+N$ ). For example, when M=20, N=10, all satisfying assignments are found after 7.5 million samples are collected, whereas the number of possible assignments is approximately 1 billion, producing a ratio of sample size to the search space size of just $0.75\$ . The ratio for M=30, N=10 is even lower at $0.37\$ w.r.t. $10^12$ possible assignments.
<details>
<summary>extracted/6466920/figs/time.png Details</summary>
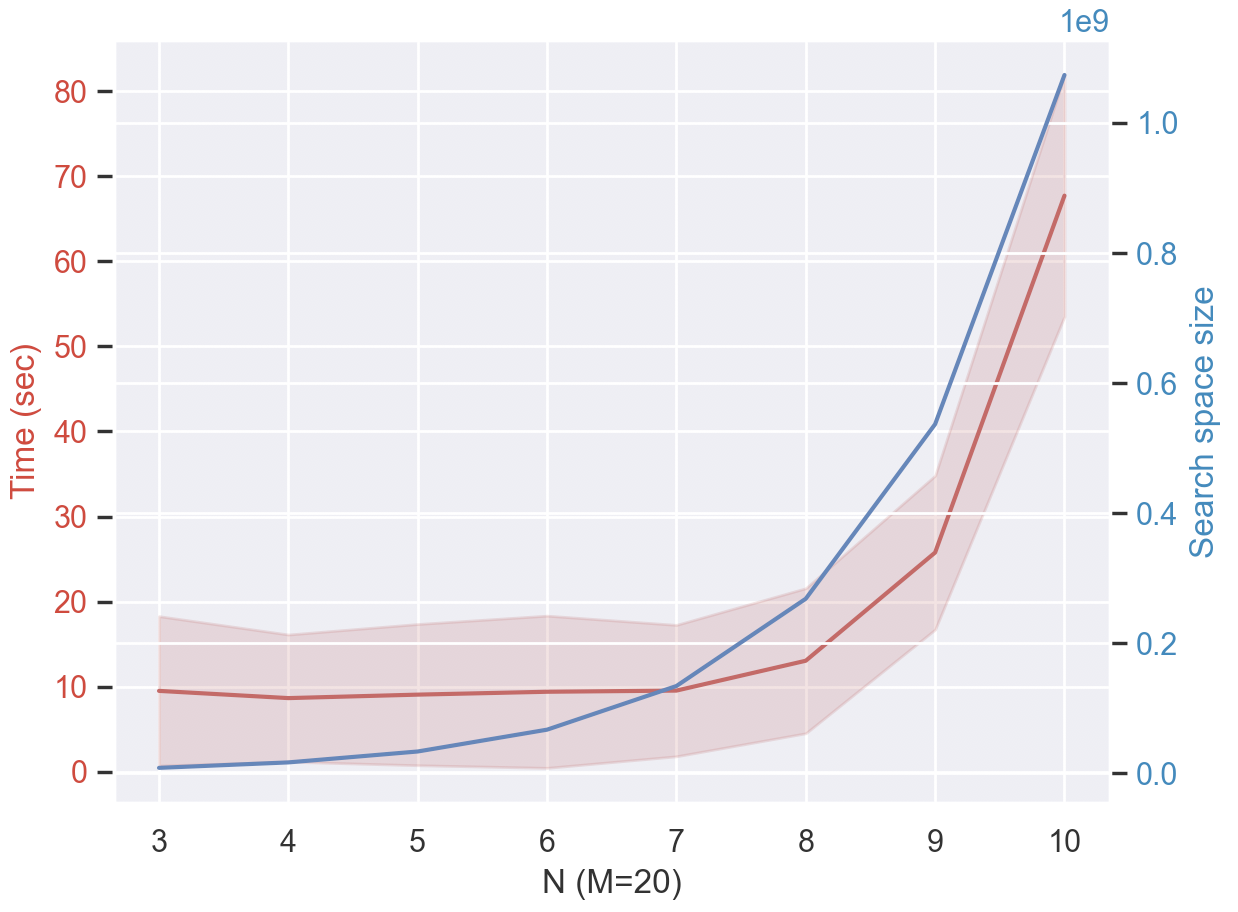
### Visual Description
\n
## Dual-Axis Line Chart: Computation Time vs. Search Space Size
### Overview
This image is a dual-axis line chart plotting two dependent variables against a common independent variable, `N`. The chart demonstrates the relationship between computational time (in seconds) and the size of a search space as the parameter `N` increases, with a fixed parameter `M=20`. The data suggests an exponential relationship, particularly for the search space size.
### Components/Axes
* **X-Axis (Bottom):** Labeled `N (M=20)`. It has discrete integer markers from 3 to 10.
* **Primary Y-Axis (Left):** Labeled `Time (sec)` in red text. The scale is linear, ranging from 0 to 80 with major tick marks every 10 units.
* **Secondary Y-Axis (Right):** Labeled `Search space size` in blue text. The scale is linear but represents values multiplied by `1e9` (1 billion), as indicated by the `1e9` notation at the top of the axis. The scale ranges from 0.0 to 1.0, corresponding to 0 to 1,000,000,000.
* **Data Series 1 (Red Line):** Represents `Time (sec)`. It is plotted against the left y-axis. The line is accompanied by a semi-transparent red shaded area, likely indicating a confidence interval, standard deviation, or range of measured times.
* **Data Series 2 (Blue Line):** Represents `Search space size`. It is plotted against the right y-axis.
* **Legend:** There is no explicit legend box. The color-coding is implicitly defined by the axis labels: red for Time, blue for Search space size.
### Detailed Analysis
**Data Series: Time (sec) - Red Line**
* **Trend:** The line shows a gradual, near-linear increase from N=3 to N=8, followed by a sharp, exponential-like increase from N=8 to N=10.
* **Approximate Data Points (with uncertainty from shaded area):**
* N=3: ~10 sec (Range: ~5 to ~18 sec)
* N=4: ~9 sec (Range: ~4 to ~16 sec)
* N=5: ~9 sec (Range: ~4 to ~17 sec)
* N=6: ~10 sec (Range: ~5 to ~18 sec)
* N=7: ~10 sec (Range: ~5 to ~17 sec)
* N=8: ~13 sec (Range: ~5 to ~20 sec)
* N=9: ~26 sec (Range: ~16 to ~36 sec)
* N=10: ~68 sec (Range: ~53 to ~82 sec)
**Data Series: Search Space Size - Blue Line**
* **Trend:** The line exhibits clear exponential growth. The increase is slow for lower N values but becomes extremely steep after N=7.
* **Approximate Data Points (values on right axis, multiply by 1e9):**
* N=3: ~0.01 (10,000,000)
* N=4: ~0.02 (20,000,000)
* N=5: ~0.05 (50,000,000)
* N=6: ~0.12 (120,000,000)
* N=7: ~0.25 (250,000,000)
* N=8: ~0.45 (450,000,000)
* N=9: ~0.75 (750,000,000)
* N=10: ~1.05 (1,050,000,000)
### Key Observations
1. **Correlated Growth:** Both computation time and search space size increase with N. The growth of the search space appears to be the primary driver for the increase in computation time.
2. **Phase Change at N=8:** There is a distinct inflection point around N=8. Before this point, time increases modestly. After N=8, both metrics, but especially time, increase dramatically.
3. **Uncertainty in Time:** The shaded red area indicates significant variability or uncertainty in the measured computation time, especially at lower N values (N=3 to N=8). The relative uncertainty (the width of the band compared to the mean value) decreases as N and the mean time increase.
4. **Exponential vs. Super-Exponential:** The search space size (blue) follows a smooth exponential curve. The computation time (red) appears to follow a steeper, possibly super-exponential curve after N=8, suggesting that the algorithm's time complexity may be worse than polynomial relative to the search space size.
### Interpretation
This chart likely visualizes the performance scaling of a search or optimization algorithm (e.g., in planning, constraint satisfaction, or combinatorial problems) where `N` is a problem size parameter and `M` is a fixed branching factor or similar constant.
The data demonstrates the classic "combinatorial explosion" problem. The search space grows exponentially with `N`, which is a fundamental challenge in computer science. More importantly, the chart shows that the *actual computation time* does not just track the search space size linearly; it accelerates even faster after a certain problem size (N=8). This could indicate:
* **Algorithmic Overhead:** The algorithm has a time complexity that is a higher-order function of the search space size (e.g., O(S^2) where S is the search space).
* **Resource Saturation:** At N=8, the problem may have exceeded the capacity of a fast memory cache (like L2/L3), leading to more costly memory accesses and a sharp slowdown.
* **Increased Difficulty:** The problems at N>8 may be intrinsically harder to solve, requiring more processing per node in the search space.
The significant variance in time at lower N suggests that problem difficulty is highly instance-dependent for smaller sizes, while for larger N, the sheer scale of the problem dominates, leading to more consistent (but very long) runtimes. This chart is a powerful argument for the need for heuristic improvements, better pruning strategies, or more computational resources when tackling problems where N must be large.
</details>
Figure 6: Time taken by LBM to collect all satisfying assignments compared with the size of the search space (i.e. the number of possible assignments up to 1 billion (1e9)) as N increases from 3 to 10 with fixed M=20. LBM only needs around 10 seconds for $N<=8$ , $∼ 25$ seconds for $N=9$ , and $∼ 68$ seconds for $N=10$ . The curve grows exponentially, similarly to the search space size, but at a much lower scale. Source: [52].
Figure 6 shows the time taken to collect all satisfying assignments for different N in $\{3,4,5,6,7,8,9,10\}$ with $M=20$ . LBM needed around 10 seconds for $N<=8$ , $25$ seconds for $N=9$ , and $68$ seconds for $N=10$ . As expected, the curve grows exponentially similarly to the search space curve, but at a much smaller scale.
#### 3.5.2 Learning from Data and Knowledge
We now evaluate LBM at learning the same Inductive Logic Programming (ILP) benchmark tasks used by neurosymbolic system CILP++ [13] in comparison with ILP state-of-the-art system Aleph [46]. As mentioned earlier, the systems Aleph, CILP++ and a fully-connected standard RBM were chosen as the natural symbolic, neurosymbolic and neural system, respectively, for comparison. An initial LBM is constructed from the clauses provided as background knowledge. This process creates one hidden neuron per clause. Further hidden neurons are added using random weights for training and validation from data. Satisfying assignments can be selected from each clause as a training or validation example, for instance given clause $x_1\wedge¬x_2→ y$ , assignment $x_1=True,x_2=False,y=True$ is converted into vector $[x_1,x_2,y]=(1,0,1)$ for training or validation. Both the LBM and the standard RBM are trained discriminatively using the conditional distribution $p(y|x)$ for inference as in [26]. In both cases, all network weights are free parameters for learning, with some weights having been initialized by the background knowledge in the case of the LBM, that is, the background knowledge can be revised during learning from data.
Seven data sets with available data and background knowledge (BK) are used: Mutagenesis (examples of molecules tested for mutagenicity and BK provided in the form of rules describing relationships between atom bonds) [47], KRK (King-Rook versus King chess endgame with examples provided by the coordinates of the pieces on the board and BK in the form of row and column differences) [3], UW-CSE (Entity-Relationship diagram with data about students, courses taken, professors, etc. and BK describing the relational structure) [39], and the Alzheimer’s benchmark: Amine, Acetyl, Memory and Toxic (a set of examples for each of four properties of a drug design for Alzheimer’s disease with BK describing bonds between the chemical structures) [23]. With the clauses converted into their equivalent set of preferred models in the form of vectors such as $[x_1,x_2,y]$ above, and combined with the available data, for the Mutagenesis and KRK tasks, $2.5\$ of the data is used to build the initial LBM. For the larger data sets UW-CSE and Alzheimer’s, $10\$ of the data is used as BK. The remaining data are used for training and validation based on 10-fold cross validation for each data set, except for UW-CSE that uses 5 folds for the sake of comparison. The number of hidden units added to the LBM is chosen arbitrarily at $50$ . The standard RBM without BK is given a higher degree of freedom with $100$ hidden units. Results are shown in Table 2. The results for Aleph and CILP++ are obtained from [13]. It can be seen that LBM has the best performance in 5 out of 7 data sets. Some of the results of the LBM and RBM are comparable when the BK can be learned from the examples, as in the case of the Alzheimer’s amine data set. In these cases, training the LBM is faster than the RBM. Aleph is better than all other models in the alz-acetyl data set. This task must rely more heavily on the correctness of the BK than the data. CILP++ however is considerably faster than Aleph and it can achieve comparable results. Although direct comparisons of running times are not possible to make between CILP++ and LBM, LBM’s running times look promising.
Table 2: Cross-validation performance of LBM against purely-symbolic system Aleph, neurosymbolic system CILP++ and a standard RBM on 7 benchmark data sets for neurosymbolic AI. We run cross-validation on RBM and LBM 100 times and report the average results with $95\$ confidence interval. Source: [52].
| Mutagenesis KRK UW-CSE | ${80.85}$ ( $± 10.5$ ) ${99.60}(± 0.51)$ ${84.91}(± 7.32)$ | ${91.70}(± 5.84)$ ${98.42}(± 1.26)$ ${70.01}(± 2.2)$ | ${95.55}(± 1.36)$ ${99.70}(± 0.11)$ ${89.14}(± 0.46)$ | ${96.28}(± 1.21)$ ${99.80}(± 0.09)$ ${\textbf{89.43}}(± 0.42)$ |
| --- | --- | --- | --- | --- |
| alz-amine | ${78.71}(± 5.25)$ | ${78.99}(± 4.46)$ | ${\textbf{79.13}}(± 1.14)$ | ${78.25}(± 1.07)$ |
| alz-acetyl | ${\textbf{69.46}}(± 3.6)$ | ${65.47}(± 2.43)$ | ${62.93}(± 0.31)$ | ${66.82}(± 0.28)$ |
| alz-memory | ${68.57}(± 5.7)$ | ${60.44}(± 4.11)$ | ${68.54}(± 0.97)$ | ${71.84}(± 0.88)$ |
| alz-toxic | ${80.50}(± 3.98)$ | ${81.73}(± 4.68)$ | $82.71(± 1.18)$ | $84.95(± 1.04)$ |
### 3.6 Extensions of Logical Boltzmann Machines
#### 3.6.1 Translating CNF into RBMs
In the general case, translation to SDNF can be costly. When knowledge is provided in CNF form, it is useful to be able to translate the CNF directly into the RBM without the need for an intermediate step.
Every WFF can be converted into CNF. A CNF is a conjunction of clauses. Formally:
$$
φ_CNF≡\bigwedge_m=1^M(\bigvee_t∈S^m_T
x_t\vee\bigvee_k∈S^m_K¬ x_k) \tag{17}
$$
We will apply the same transformation process into SDNF to each conjunctive clause in the CNF. The result will be a conjunction of $M$ SDNFs (itself not an SDNF), as follows:
$$
\displaystyleφ_CNF≡\bigwedge_m=1^M(\bigvee_t∈
S^m_T¬x_t\vee\bigvee_k∈S^m_K
x_k)≡\bigwedge_m=1^M(\bigvee_p∈S^m_T∪
\mathcal{S^m_K}(\bigwedge_t∈S^m_T\backslash px
_t\wedge\bigwedge_k∈S^m_K\backslash p¬x_k
\wedgex^\prime_p)) \tag{18}
$$
where $x^\prime_p≡¬x_p$ if $p∈S^m_T$ ; otherwise $x^\prime_p≡x_p$ .
This transformation would increase the space complexity from $O(M× N)$ to $O(M× N^2)$ , where $M$ is the number of clauses and $N$ is the number of variables. This should not be a problem for current computing systems, especially when inference with RBMs can be highly parallelized.
Although the formula in Eq.(18) is not a SDNF, the equivalence between the CNF and the LBM still holds:
$$
s_φ=\begin{dcases*}1&when $-\frac{1}{ε}min_hE(
x,h)=M$\\
0&otherwise\end{dcases*} \tag{19}
$$
Eq.(19) holds because the CNF is satisfied if and only if all $M$ SDNFs are satisfied. Under such circumstances, $min_hE(x,h)=-Mε$ . Otherwise, $min_hE(x,h)=-M^\primeε$ , where $M^\prime<M$ .
When a confidence value c is used, the number of satisfied clauses in CNF will be proportional to the minimized energy function, and to the free-energy function when c increases.
#### 3.6.2 Towards using LBM as a SAT Solver
The Boolean satisfiability (SAT) problem is a fundamental problem in Computer Science. It was the first problem that was proven to be NP complete. A formula is satisfiable if and only if there exists an assignment of truth-values mapping the formula to True. In practice, formulae in SAT problems are represented as Conjunctive Normal Forms (CNFs).
As discussed in Section 3.6.1, a formula in Conjunctive Normal Form (CNF) can be converted into a Logical Boltzmann Machine (LBM). The number of satisfied clauses in the CNF formula is proportional to the minimized energy function and the free-energy function of the LBM. This relationship allows us to solve SAT problems by transforming them into an optimization task: finding the minimum of the energy or free-energy function.
To make this approach computationally feasible, we focus on minimizing the free-energy function, as it is both easier to compute and differentiable. This transformation converts the discrete SAT problem into a continuous optimization problem. Instead of searching for solutions in a Boolean space (where variables $x$ are either 0 or 1), we search in a continuous space for parameters $θ$ , where each Boolean variable $x$ is represented as a sigmoid function:
$$
x=σ(θ)=\frac{1}{1+\exp(-θ)}.
$$
This mapping ensures that $x$ smoothly transitions between 0 and 1 as $θ$ changes, enabling gradient-based optimization techniques to be applied. To illustrate this process, consider a simple SAT problem with two variables:
$$
(¬ x_1∨¬ x_2)∧(x_1∨¬ x_2)∧(¬ x_1∨ x_2).
$$
Figure 7 visualizes the landscape of the LBM’s energy and free-energy functions for different values of $θ_1$ and $θ_2$ , where $x_1=σ(θ_1)$ and $x_2=σ(θ_2)$ . The plots reveal that when both $θ_1$ and $θ_2$ are more negative (corresponding to $x_1,x_2≈ 0$ ), the functions approach their minima. This corresponds to a satisfying assignment of the CNF formula, illustrating how the optimization process identifies valid solutions.
We also analyze the impact of confidence values $c$ on the landscapes of the energy and free-energy functions. Figures 7(a), 7(b), 7(c), and 7(d) show that confidence values do not significantly alter the landscape of the energy function. However, for the free-energy function (Figures 7(e), 7(f), 7(g), 7(h)), smaller values of $c$ result in smoother landscapes. While this smoothing effect can facilitate optimization by reducing sharp transitions, it also narrows the gap between local minima and the global minimum. Conversely, higher values of $c$ increase the boundaries between optimal regions, making it more challenging to locate the global optimum. This trade-off highlights the importance of carefully selecting $c$ based on the specific characteristics of the SAT problem being solved.
In summary, the LBM framework provides an approach to solving SAT problems by converting them into continuous optimization tasks. By leveraging the differentiability of the free-energy function and the flexibility of sigmoid mappings, this approach bridges logical reasoning and numerical optimization. Future work should explore adaptive strategies for adjusting confidence values to balance smoothness and optimality and consider ways to enhance performance in the case of specific classes of SAT problems.
<details>
<summary>extracted/6466920/figs/emin_2var_c0.1.png Details</summary>
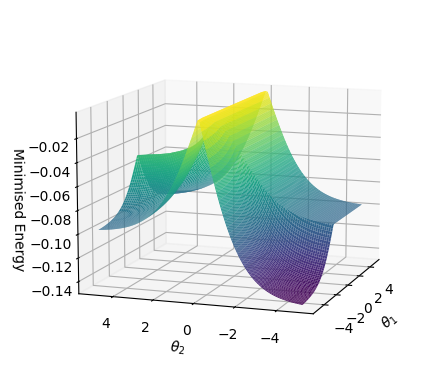
### Visual Description
## 3D Surface Plot: Minimised Energy Landscape
### Overview
The image displays a three-dimensional surface plot visualizing a function of two variables, θ₁ and θ₂. The plot represents an "energy landscape," where the vertical axis shows the "Minimised Energy" value. The surface is colored according to its height (energy value), creating a topographical map of the function's behavior across the parameter space.
### Components/Axes
* **Chart Type:** 3D Surface Plot.
* **Vertical Axis (Z-axis):**
* **Label:** "Minimised Energy"
* **Scale:** Linear, ranging from approximately -0.14 at the bottom to -0.02 at the top.
* **Markers:** Ticks are present at intervals of 0.02 (e.g., -0.14, -0.12, -0.10, -0.08, -0.06, -0.04, -0.02).
* **Horizontal Axes (X and Y axes):**
* **Axis 1 (Right side, receding into the distance):** Labeled "θ₁". Scale ranges from -4 to 4, with major ticks at -4, -2, 0, 2, 4.
* **Axis 2 (Left side, foreground):** Labeled "θ₂". Scale ranges from -4 to 4, with major ticks at -4, -2, 0, 2, 4.
* **Color Mapping:** The surface uses a continuous color gradient (a "heatmap" applied to the 3D surface) to represent the Z-axis (Energy) value.
* **Yellow/Light Green:** Corresponds to higher (less negative) energy values, near the top of the scale (~ -0.02 to -0.04).
* **Green/Teal:** Corresponds to mid-range energy values (~ -0.06 to -0.08).
* **Blue/Purple:** Corresponds to lower (more negative) energy values, near the bottom of the scale (~ -0.10 to -0.14).
* **Grid:** A wireframe grid is plotted on the surface, following the contours of the function and aligning with the θ₁ and θ₂ axes, aiding in depth perception and value estimation.
* **Perspective:** The plot is viewed from an angled perspective, looking down onto the surface from a position where both θ₁ and θ₂ axes are visible.
### Detailed Analysis
* **Surface Topology:** The surface is not flat; it exhibits significant curvature with distinct peaks, valleys, and saddle points.
* **General Trend:** The energy value generally decreases (becomes more negative) as one moves away from the central region (θ₁ ≈ 0, θ₂ ≈ 0) towards the edges of the plotted domain, particularly along the θ₂ axis.
* **Key Features:**
1. **Central Ridge/Saddle Point:** There is a prominent ridge or saddle point structure near the center of the plot (θ₁ ≈ 0, θ₂ ≈ 0). The energy here is relatively high (yellow/green, approx. -0.04 to -0.06).
2. **Deep Valley along θ₂:** A pronounced, deep valley runs roughly parallel to the θ₂ axis. The lowest energy points (dark purple, approx. -0.12 to -0.14) are found in this valley, which appears to be centered around θ₂ ≈ -2 to -4, extending across a range of θ₁ values.
3. **Secondary Valley/Depression:** Another region of lower energy (blue/purple) is visible on the far side of the central ridge, suggesting a second, possibly shallower, valley.
4. **Asymmetry:** The landscape is not symmetric. The descent into the primary valley along negative θ₂ is steeper and deeper than the changes observed along the θ₁ axis.
### Key Observations
* The function being plotted has multiple local minima (the valleys) and at least one saddle point (the central ridge).
* The global minimum within this visible window appears to be located in the deep valley at negative θ₂ values.
* The color gradient effectively highlights the steepness of the slopes; rapid color changes indicate steep gradients in the energy function.
* The grid lines become densely packed in the steep valley regions, visually confirming the high rate of change.
### Interpretation
This plot visualizes the solution space of an optimization or physical system where "Minimised Energy" is the objective function to be minimized with respect to two parameters, θ₁ and θ₂.
* **What it demonstrates:** The landscape shows that finding the lowest energy state is non-trivial. A simple gradient descent algorithm starting from the central region (θ₁≈0, θ₂≈0) could get trapped on the saddle point or roll into one of the valleys depending on the initial direction. The deep valley at negative θ₂ represents the most stable (lowest energy) configuration for the system within the explored parameter range.
* **Relationship between elements:** The θ₁ and θ₂ parameters are coupled; the energy value depends on a specific combination of both, not on each independently. The shape of the valleys and ridges defines this coupling.
* **Notable Anomalies/Patterns:** The most striking pattern is the dominant, deep valley aligned with the θ₂ axis. This suggests that the system's energy is more sensitive to changes in θ₂ than to changes in θ₁, especially in the negative θ₂ region. The saddle point indicates an unstable equilibrium—a small perturbation would cause the system to "roll down" into one of the adjacent valleys. This type of landscape is common in problems involving molecular conformations, machine learning loss functions, or control system stability analysis.
</details>
(a) c=0.1
<details>
<summary>extracted/6466920/figs/emin_2var_c0.5.png Details</summary>
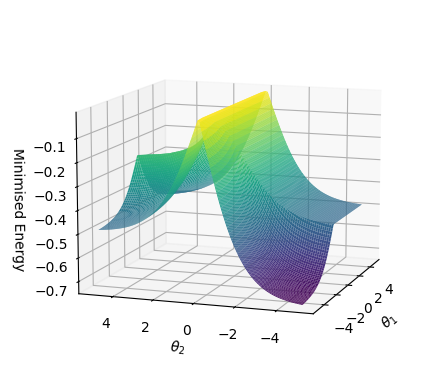
### Visual Description
## 3D Surface Plot: Minimised Energy vs. θ₁ and θ₂
### Overview
The image displays a three-dimensional surface plot illustrating the relationship between a dependent variable, "Minimised Energy," and two independent variables, θ₁ and θ₂. The surface is rendered with a color gradient that maps directly to the energy value, providing a visual representation of the energy landscape across the parameter space defined by θ₁ and θ₂.
### Components/Axes
* **Vertical Axis (Z-axis):**
* **Label:** "Minimised Energy"
* **Scale:** Linear, ranging from approximately **-0.7** at the bottom to **-0.1** at the top.
* **Tick Marks:** Clearly marked at intervals of 0.1: -0.7, -0.6, -0.5, -0.4, -0.3, -0.2, -0.1.
* **Horizontal Axis 1 (X-axis, front-left):**
* **Label:** "θ₂"
* **Scale:** Linear, ranging from **-4** to **4**.
* **Tick Marks:** Labeled at -4, -2, 0, 2, 4.
* **Horizontal Axis 2 (Y-axis, front-right):**
* **Label:** "θ₁"
* **Scale:** Linear, ranging from **-4** to **4**.
* **Tick Marks:** Labeled at -4, -2, 0, 2, 4.
* **Color Legend (Implicit):** The surface color serves as a direct legend for the "Minimised Energy" value.
* **Yellow/Bright Green:** Corresponds to the highest energy values on the plot, near **-0.1**.
* **Green/Teal:** Corresponds to mid-range energy values, around **-0.3 to -0.4**.
* **Blue/Dark Purple:** Corresponds to the lowest energy values, near **-0.7**.
### Detailed Analysis
The surface exhibits a complex, non-linear topology with distinct features:
1. **Primary Peak (Local Maximum):** A prominent, sharp peak is located near the center of the parameter space, approximately at coordinates **(θ₁ ≈ 0, θ₂ ≈ 0)**. The apex of this peak is colored bright yellow, indicating the highest "Minimised Energy" value on the plot, estimated at **≈ -0.1**.
2. **Primary Valley (Global Minimum):** A deep, broad valley is situated in the region where **θ₂ is negative** and **θ₁ is near zero**. The lowest point appears to be around **(θ₁ ≈ 0, θ₂ ≈ -4)**. This area is colored dark purple/blue, corresponding to the lowest energy value of **≈ -0.7**.
3. **Secondary Features:**
* A secondary, lower ridge or shoulder extends from the main peak towards positive θ₂ values.
* The surface slopes downward from the central peak in all directions, but the descent is steepest towards the primary valley (negative θ₂).
* The surface appears relatively smooth, with no visible discontinuities or sharp cliffs outside of the main peak structure.
**Trend Verification:**
* **Series (The Surface):** The visual trend shows energy increasing to a sharp maximum at the center (θ₁=0, θ₂=0) and decreasing to a broad minimum at the edge of the plotted space (θ₁=0, θ₂=-4). The gradient is not symmetric; the drop towards negative θ₂ is more pronounced than towards positive θ₂.
### Key Observations
* **Asymmetry:** The energy landscape is not symmetric about the θ₁=0 or θ₂=0 planes. The most significant feature (the deep valley) is located in the negative θ₂ half of the space.
* **Single Dominant Extremum:** The plot is dominated by one clear local maximum (the peak) and one clear global minimum (the valley).
* **Color-Value Correlation:** The color mapping is consistent and effectively reinforces the numerical data on the Z-axis, making the topography intuitive to read.
* **Spatial Grounding:** The legend (color scale) is integrated into the surface itself. The highest point (yellow) is spatially located at the center of the θ₁-θ₂ grid. The lowest point (dark purple) is located at the front-left edge of the grid, corresponding to θ₂ = -4.
### Interpretation
This plot visualizes the output of an optimization or energy minimization function over a two-dimensional parameter space (θ₁, θ₂). The "Minimised Energy" likely represents a cost function, loss function, or physical energy state that the system is trying to minimize.
* **What the data suggests:** The system has a stable, low-energy configuration (the global minimum) when θ₂ is strongly negative (-4) and θ₁ is near zero. Conversely, the configuration at (θ₁=0, θ₂=0) is unstable or high-energy, representing a local maximum or a saddle point from which the system would readily "roll down" towards lower energy states.
* **Relationship between elements:** The two parameters θ₁ and θ₂ are coupled in their effect on the energy. The energy is most sensitive to changes in θ₂ when θ₁ is held near zero, as evidenced by the steep gradient along the θ₂ axis at θ₁=0.
* **Notable implications:** If this represents a machine learning loss landscape, training would aim to find parameters in the dark purple valley. The presence of a sharp central peak suggests a region of parameter space to avoid. The smoothness of the surface implies that gradient-based optimization methods would likely be effective. The asymmetry indicates that the parameters θ₁ and θ₂ are not interchangeable and have distinct roles in determining the system's energy.
</details>
(b) c=0.5
<details>
<summary>extracted/6466920/figs/emin_2var_c1.0.png Details</summary>
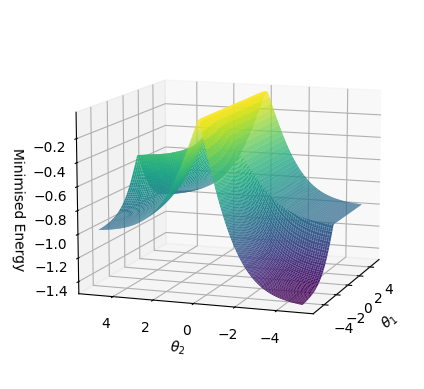
### Visual Description
## 3D Surface Plot: Minimised Energy vs. θ₁ and θ₂
### Overview
The image displays a three-dimensional surface plot visualizing the relationship between two independent variables, θ₁ and θ₂, and a dependent variable labeled "Minimised Energy." The plot uses a color gradient to represent the energy value at each coordinate pair.
### Components/Axes
* **Vertical Axis (Z-axis):** Labeled "Minimised Energy." The scale runs from approximately -1.4 at the bottom to -0.2 at the top, with major tick marks at intervals of 0.2 (-1.4, -1.2, -1.0, -0.8, -0.6, -0.4, -0.2).
* **Horizontal Axis 1 (X-axis, front-left):** Labeled "θ₂". The scale runs from -4 to 4, with major tick marks at -4, -2, 0, 2, 4.
* **Horizontal Axis 2 (Y-axis, front-right):** Labeled "θ₁". The scale runs from -4 to 4, with major tick marks at -4, -2, 0, 2, 4.
* **Color Mapping:** The surface color corresponds to the "Minimised Energy" value. A gradient is used where:
* **Yellow/Light Green:** Represents higher energy values (closer to -0.2).
* **Teal/Green:** Represents mid-range energy values (around -0.6 to -0.8).
* **Blue/Purple:** Represents lower energy values (closer to -1.4).
### Detailed Analysis
The surface exhibits a complex, non-linear topology with distinct features:
1. **Primary Peak (Global Maximum):** A prominent, sharp peak is located near the center of the θ₁-θ₂ plane, approximately at coordinates (θ₁ ≈ 0, θ₂ ≈ 0). This peak is colored bright yellow, indicating the highest "Minimised Energy" value on the plot, estimated to be between -0.2 and -0.3.
2. **Secondary Ridge:** A lower, elongated ridge extends from the primary peak along the positive θ₂ direction (towards θ₂ = 4). This ridge is colored light green/yellow-green, suggesting energy values in the range of -0.4 to -0.5.
3. **Deep Valley (Global Minimum):** A significant depression or valley is located in the quadrant where both θ₁ and θ₂ are negative. The lowest point appears near (θ₁ ≈ -2, θ₂ ≈ -2). This area is deep purple, corresponding to the lowest energy values, estimated between -1.3 and -1.4.
4. **General Trend:** The surface generally slopes downward from the central peak towards the corners of the plotted domain, particularly towards the (-θ₁, -θ₂) quadrant. The gradient is steepest descending from the peak into the deep valley.
### Key Observations
* The relationship between the parameters (θ₁, θ₂) and the "Minimised Energy" is highly non-convex, featuring multiple local minima and maxima.
* The global minimum energy state is not at the origin (0,0) but is offset into the negative parameter space.
* The surface is symmetric about the θ₂ axis to a degree, but not perfectly symmetric about the θ₁ axis, as the deep valley is more pronounced on the negative θ₁ side.
* The color gradient provides a clear visual cue for the energy landscape, making the peaks and valleys immediately identifiable.
### Interpretation
This plot likely represents the energy landscape of a system governed by two parameters, θ₁ and θ₂. In contexts like optimization, machine learning, or physics, such a landscape shows how a cost or energy function varies with changes in its inputs.
* **What it demonstrates:** The system has a complex optimization surface. Finding the global minimum (the deepest purple valley) would be the goal of an optimization algorithm. The presence of a high central peak and other ridges indicates that simple gradient-based methods could easily get stuck in local minima if not properly initialized or designed.
* **Relationship between elements:** The θ₁ and θ₂ parameters jointly determine the system's energy. Their interaction is non-linear, as evidenced by the curved, saddle-like shapes. The "Minimised Energy" is the output metric being minimized or analyzed.
* **Notable anomalies:** The sharp, isolated nature of the central peak is notable. It suggests a specific, unstable configuration of parameters (θ₁≈0, θ₂≈0) that results in a high-energy state, surrounded by more stable, lower-energy configurations. The deep, localized valley indicates a very specific, favorable parameter combination for minimizing energy.
**Language Note:** All text in the image is in English.
</details>
(c) c=1
<details>
<summary>extracted/6466920/figs/emin_2var_c5.0.png Details</summary>
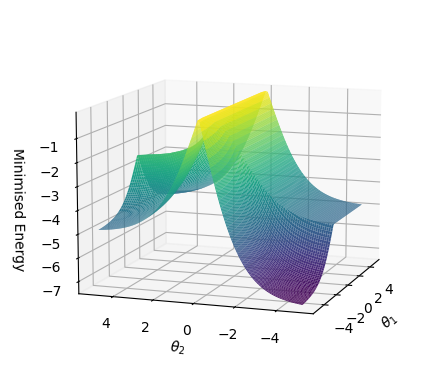
### Visual Description
## 3D Surface Plot: Minimised Energy Landscape
### Overview
The image displays a three-dimensional surface plot visualizing a function of two variables, θ₁ and θ₂. The plot illustrates how a quantity labeled "Minimised Energy" varies across a two-dimensional parameter space. The surface is rendered with a color gradient that maps directly to the energy value, providing an intuitive visual cue for the function's topography.
### Components/Axes
* **Chart Type:** 3D Surface Plot.
* **Axes:**
* **X-axis (Foreground, Left-Right):** Labeled **θ₂**. The axis spans from approximately **-4** to **+4**, with major tick marks at intervals of 2 (-4, -2, 0, 2, 4).
* **Y-axis (Depth, Front-Back):** Labeled **θ₁**. The axis spans from approximately **-4** to **+4**, with major tick marks at intervals of 2 (-4, -2, 0, 2, 4).
* **Z-axis (Vertical):** Labeled **Minimised Energy**. The axis spans from **-7** to **-1**, with major tick marks at intervals of 1 (-7, -6, -5, -4, -3, -2, -1).
* **Legend/Color Mapping:** There is no separate legend box. The surface itself uses a continuous color gradient to represent the Z-axis (Minimised Energy) value. The gradient transitions from **dark blue/purple** at the lowest energy values (near -7) through **teal/green** at intermediate values, to **bright yellow** at the highest energy values (near -1).
### Detailed Analysis
* **Surface Topology:** The surface exhibits a complex, saddle-like shape with distinct features:
* A prominent **peak** (local maximum) is located in the quadrant where both θ₁ and θ₂ are positive. The peak's apex is colored bright yellow, indicating the highest minimised energy value on the plot, approximately **-1.5 to -1.0**.
* A deep **valley** (global minimum within the visible range) is located in the quadrant where θ₁ is negative and θ₂ is positive. This region is colored dark blue/purple, indicating the lowest energy value, approximately **-7.0**.
* The surface slopes downward from the peak towards this valley and also towards the edges of the parameter space.
* **Trend Verification:**
* Moving from the valley (θ₁ ≈ -2, θ₂ ≈ +2) towards the peak (θ₁ ≈ +2, θ₂ ≈ +2), the surface slopes **steeply upward**, with the color shifting from dark blue to yellow.
* Moving along the θ₂ axis at a fixed, positive θ₁ (e.g., θ₁ ≈ +2), the energy first increases to a ridge and then decreases, forming a curved "hill."
* Moving along the θ₁ axis at a fixed, negative θ₂ (e.g., θ₂ ≈ -2), the energy shows a more gradual, undulating change.
* **Spatial Grounding:** The vertical Z-axis is positioned on the left side of the plot. The θ₂ axis runs along the bottom front edge, and the θ₁ axis recedes into the depth on the right side. The highest point (yellow peak) is in the upper-right quadrant of the 3D space. The lowest point (dark blue valley) is in the lower-right quadrant.
### Key Observations
1. **Non-Convex Landscape:** The energy function is clearly non-convex, featuring at least one significant local maximum (the peak) and one deep global minimum (the valley) within the plotted domain.
2. **Parameter Sensitivity:** The energy is highly sensitive to changes in both θ₁ and θ₂, as evidenced by the steep gradients (sharp color changes) on the surface, particularly around the peak and leading into the valley.
3. **Asymmetric Features:** The landscape is not symmetric. The valley is deeper and more pronounced than any other depression, and the peak is a singular, sharp feature.
### Interpretation
This plot likely represents the **loss or energy landscape** of a machine learning model or a physical system, where θ₁ and θ₂ are two parameters (e.g., weights in a neural network, coordinates in a physical system). The "Minimised Energy" is the objective function being optimized.
* **The Goal:** In optimization contexts, the goal is typically to find the parameter set (θ₁, θ₂) that **minimizes** this energy. The deep blue valley represents the optimal (or a highly favorable) solution region.
* **The Challenge:** The presence of the prominent yellow peak illustrates a significant **local maximum** or a region of high loss. An optimization algorithm starting near this peak could get stuck or have difficulty navigating towards the global minimum in the valley, highlighting a potential challenge for gradient-based methods.
* **Relationship Between Parameters:** The curved, interconnected shape of the surface shows that the effect of changing θ₁ on the energy depends strongly on the current value of θ₂, and vice-versa. They are **interdependent parameters** in this system.
* **Notable Anomaly:** The most striking feature is the sharp, isolated peak. In a typical loss landscape for well-behaved problems, one might expect smoother transitions or multiple similar minima. This pronounced maximum could indicate a specific, unstable configuration of the parameters that is highly undesirable.
**In summary, the image provides a visual map of a complex optimization problem, revealing a challenging landscape with a clear target (the deep minimum) and a significant obstacle (the high peak) that an optimization process must navigate.**
</details>
(d) c=5
<details>
<summary>extracted/6466920/figs/fe_2var_c0.1.png Details</summary>
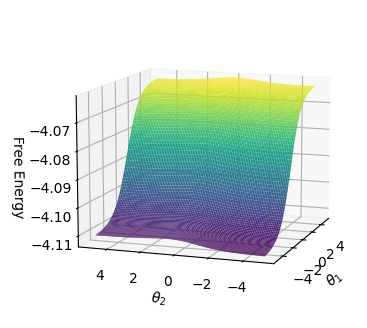
### Visual Description
## 3D Surface Plot: Free Energy Landscape
### Overview
The image displays a three-dimensional surface plot illustrating the relationship between "Free Energy" and two parameters, labeled θ₁ (theta-one) and θ₂ (theta-two). The plot visualizes a smooth, continuous surface that forms a valley or basin, indicating a region of minimum free energy.
### Components/Axes
* **Vertical Axis (Z-axis):** Labeled "Free Energy". The scale is numerical, with major tick marks at -4.11, -4.10, -4.09, -4.08, and -4.07. The values are negative, indicating the energy scale.
* **Horizontal Axis 1 (X-axis, front-left):** Labeled "θ₂". The scale ranges from -4 to 4, with major tick marks at -4, -2, 0, 2, and 4.
* **Horizontal Axis 2 (Y-axis, front-right):** Labeled "θ₁". The scale also ranges from -4 to 4, with major tick marks at -4, -2, 0, 2, and 4.
* **Color Legend:** A vertical color bar is positioned on the right side of the plot. It maps the Free Energy value to a color gradient:
* **Purple/Dark Blue:** Corresponds to the lowest Free Energy values (approximately -4.11).
* **Teal/Green:** Corresponds to intermediate Free Energy values (approximately -4.09 to -4.08).
* **Yellow:** Corresponds to the highest Free Energy values shown (approximately -4.07).
* **Grid:** A 3D wireframe grid is present on the plot's bounding box to aid in spatial orientation.
### Detailed Analysis
* **Surface Topology:** The surface is bowl-shaped, with its lowest point (minimum Free Energy) located near the center of the θ₁-θ₂ plane, where both parameters are close to 0.
* **Trend Verification:**
* As one moves away from the origin (θ₁=0, θ₂=0) in any direction along the θ₁ or θ₂ axes, the Free Energy value increases (becomes less negative).
* The slope of the surface is gentlest near the minimum and becomes steeper as the distance from the center increases.
* The color gradient confirms this trend: the central region is dark purple (lowest energy), transitioning through teal and green to yellow (highest energy) at the corners of the plotted domain.
* **Data Point Estimation (Approximate):**
* **Minimum:** At (θ₁ ≈ 0, θ₂ ≈ 0), Free Energy ≈ -4.11.
* **At Extremes:** At the corners of the plotted cube, such as (θ₁ = 4, θ₂ = 4) or (θ₁ = -4, θ₂ = -4), the Free Energy rises to approximately -4.07.
* **Along Axes:** Moving along the θ₁ axis while holding θ₂=0 (or vice versa), the energy increases from ~-4.11 at the center to ~-4.08 at θ=±4.
### Key Observations
1. **Single Global Minimum:** The landscape features one clear, broad minimum basin centered at the origin.
2. **Symmetry:** The surface appears roughly symmetric with respect to both the θ₁=0 and θ₂=0 planes, suggesting the underlying function is even in both parameters.
3. **Smoothness:** The surface is smooth and continuous, with no visible discontinuities, sharp ridges, or local minima within the displayed range.
4. **Parameter Sensitivity:** The gradient (rate of change) of Free Energy appears similar with respect to changes in θ₁ and θ₂, indicating comparable sensitivity of the system to both parameters.
### Interpretation
This plot represents an **energy landscape** or **cost function** common in fields like statistical mechanics, optimization, and machine learning.
* **What it Demonstrates:** The system's "Free Energy" is minimized when both control parameters, θ₁ and θ₂, are set to zero. This point (0,0) represents the most stable or optimal state of the system under the modeled conditions.
* **Relationship Between Elements:** The two parameters (θ₁, θ₂) are independent variables that jointly determine the system's state (Free Energy). The 3D surface maps every possible combination of these parameters to an energy value.
* **Underlying Meaning:** The bowl shape implies that any deviation from the optimal parameter set (0,0) increases the system's energy, making it less stable. The smoothness suggests the system can be optimized using gradient-based methods. The symmetry might indicate that the parameters play analogous roles in the underlying physical or mathematical model. This type of visualization is crucial for understanding the stability of a solution and the behavior of an optimization algorithm navigating this landscape.
</details>
(e) c=0.1
<details>
<summary>extracted/6466920/figs/fe_2var_c0.5.png Details</summary>
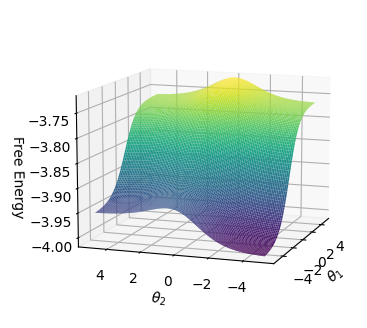
### Visual Description
\n
## 3D Surface Plot: Free Energy Landscape
### Overview
The image displays a three-dimensional surface plot visualizing "Free Energy" as a function of two parameters, θ₁ and θ₂. The plot is rendered in a perspective view, showing a continuous, curved surface that represents the relationship between the three variables. The surface is colored with a gradient that maps to the Free Energy value.
### Components/Axes
* **Vertical Axis (Z-axis):**
* **Label:** "Free Energy"
* **Scale:** Linear, ranging from approximately **-4.00** at the bottom to **-3.75** at the top.
* **Markers:** Major ticks are visible at -4.00, -3.95, -3.90, -3.85, -3.80, and -3.75.
* **Horizontal Axis 1 (X-axis, front-right):**
* **Label:** "θ₁" (Theta subscript 1)
* **Scale:** Linear, ranging from **-4** to **4**.
* **Markers:** Major ticks at -4, -2, 0, 2, 4.
* **Horizontal Axis 2 (Y-axis, front-left):**
* **Label:** "θ₂" (Theta subscript 2)
* **Scale:** Linear, ranging from **-4** to **4**.
* **Markers:** Major ticks at -4, -2, 0, 2, 4.
* **Color Mapping (Implicit Legend):**
* The surface color corresponds directly to the Free Energy (Z) value.
* **Dark Purple/Blue:** Represents the lowest Free Energy values (near **-4.00**).
* **Teal/Green:** Represents mid-range Free Energy values (around **-3.90**).
* **Yellow:** Represents the highest Free Energy values (near **-3.75**).
### Detailed Analysis
The surface forms a smooth, continuous landscape with a distinct topological feature.
* **Global Minimum:** The lowest point on the surface (deepest purple) is located at the coordinate **(θ₁ ≈ 0, θ₂ ≈ 0)**. The Free Energy at this point is approximately **-4.00**.
* **General Trend:** Moving away from the origin (0,0) in any direction along the θ₁-θ₂ plane generally results in an increase in Free Energy. The surface slopes upward from the central minimum.
* **Asymmetry and Ridge:** The increase is not uniform. There is a pronounced ridge or saddle point running diagonally. The surface rises more steeply towards the positive θ₁, positive θ₂ quadrant (back corner) and the negative θ₁, negative θ₂ quadrant (front corner), reaching its highest values (yellow) in these regions. The rise is more gradual along the anti-diagonal (positive θ₁, negative θ₂ and negative θ₁, positive θ₂).
* **Spatial Grounding:** The highest point (yellow) appears to be near **(θ₁ ≈ 4, θ₂ ≈ 4)** and **(θ₁ ≈ -4, θ₂ ≈ -4)**, with Free Energy values approaching **-3.75**. The lowest point is clearly at the center of the grid.
### Key Observations
1. **Single Well Potential:** The landscape depicts a single, broad energy well centered at the origin, suggesting a stable equilibrium point at (0,0).
2. **Anisotropic Curvature:** The "walls" of the well are not symmetrical. The curvature is tighter (steeper slope) along the θ₁ = θ₂ diagonal compared to the θ₁ = -θ₂ diagonal.
3. **No Local Minima:** Within the plotted range, there are no other local minima or maxima besides the global minimum at the center. The surface is smooth and convex in the region shown.
### Interpretation
This plot likely represents an **energy landscape or cost function** from fields like statistical mechanics, optimization theory, or machine learning.
* **What it demonstrates:** The function has a clear, unique minimum at θ₁ = 0, θ₂ = 0. This is the optimal state where the system's "Free Energy" (or cost, error) is minimized. Any deviation from these parameter values increases the energy/cost.
* **Relationship between elements:** The two parameters θ₁ and θ₂ are coupled. Changing one affects the Free Energy, and the effect depends on the value of the other parameter, as shown by the curved, non-planar surface. The diagonal ridge indicates that certain combinations of parameters (e.g., both large and positive) are particularly "costly."
* **Potential Context:** In an optimization context, this would be a straightforward landscape to minimize using gradient-based methods, as there are no deceptive local minima. In a physical context, it could represent the free energy of a system as a function of two order parameters, with (0,0) being the stable phase. The asymmetry suggests the system's response to perturbations is direction-dependent.
</details>
(f) c=0.5
<details>
<summary>extracted/6466920/figs/fe_2var_c1.0.png Details</summary>
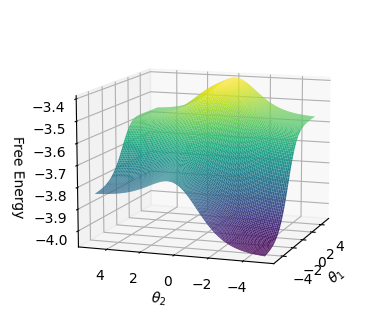
### Visual Description
## 3D Surface Plot: Free Energy Landscape over Parameters θ₁ and θ₂
### Overview
The image displays a three-dimensional surface plot visualizing a scalar field, "Free Energy," as a function of two independent parameters, θ₁ and θ₂. The plot uses a color gradient to represent the magnitude of the Free Energy, creating a topographical map of an energy landscape.
### Components/Axes
* **Vertical Axis (Z-axis):**
* **Label:** "Free Energy"
* **Scale:** Linear, ranging from -4.0 at the bottom to -3.4 at the top. Major tick marks are at intervals of 0.1 (-4.0, -3.9, -3.8, -3.7, -3.6, -3.5, -3.4).
* **Horizontal Axis 1 (X-axis, front-left):**
* **Label:** "θ₂"
* **Scale:** Linear, ranging from -4 to 4. Major tick marks are at -4, -2, 0, 2, 4.
* **Horizontal Axis 2 (Y-axis, front-right):**
* **Label:** "θ₁"
* **Scale:** Linear, ranging from -4 to 4. Major tick marks are at -4, -2, 0, 2, 4.
* **Legend / Color Bar:**
* **Position:** Located on the right side of the plot.
* **Title:** "Free Energy"
* **Scale:** A vertical gradient bar mapping color to numerical Free Energy values. The scale matches the Z-axis, from -4.0 (dark blue/purple) at the bottom to -3.4 (bright yellow) at the top.
### Detailed Analysis
The surface represents a continuous function Free Energy = f(θ₁, θ₂). Its shape is characterized by:
* **Global Minimum:** The lowest point on the surface (deepest blue/purple) is located approximately at coordinates **(θ₁ ≈ -2, θ₂ ≈ 2)**, where the Free Energy is near **-4.0**.
* **Global Maximum:** The highest point (brightest yellow) is located approximately at the opposite corner, **(θ₁ ≈ 4, θ₂ ≈ -4)**, where the Free Energy is near **-3.4**.
* **Surface Topography:** The surface forms a saddle-like shape or a valley. From the minimum at (θ₁≈-2, θ₂≈2), the energy increases as one moves away in most directions. There is a noticeable ridge or saddle point running roughly diagonally across the parameter space.
* **Color Gradient:** The color transitions smoothly from dark blue/purple (lowest energy) through teal and green to yellow (highest energy), providing a direct visual correlation between position on the surface and the Free Energy value.
### Key Observations
1. **Clear Minimum:** There is a well-defined, broad minimum region in the parameter space, suggesting a stable or optimal configuration around θ₁ ≈ -2, θ₂ ≈ 2.
2. **Asymmetric Landscape:** The energy landscape is not symmetric. The gradient (rate of change) appears steeper when moving from the minimum towards the high-energy corner (θ₁=4, θ₂=-4) compared to other directions.
3. **Parameter Correlation:** The shape indicates a strong correlation between θ₁ and θ₂ in determining the Free Energy. The path of lowest energy does not follow a simple axis-aligned direction.
4. **Bounded Domain:** The plot is rendered over a square domain where both θ₁ and θ₂ range from -4 to 4.
### Interpretation
This plot visualizes the "energy landscape" of a system governed by two parameters, θ₁ and θ₂. In fields like statistical mechanics, machine learning (e.g., loss landscapes), or optimization, such a plot is fundamental.
* **What it demonstrates:** The system has a preferred state (the energy minimum) at specific parameter values. The surrounding landscape shows how the system's energy (or cost, or instability) changes as parameters are varied. The saddle shape is characteristic of many complex systems, indicating that there are directions in parameter space where the system is stable (moving along the valley) and directions where it is unstable (moving up the steep slopes).
* **Relationship between elements:** The two parameters θ₁ and θ₂ are coupled; their joint values determine the system's state. The Free Energy is the dependent variable, a single metric summarizing the system's "goodness" or stability for a given (θ₁, θ₂) pair.
* **Notable implications:** The existence of a single, broad minimum suggests the system has a robust optimal operating point. The steep rise to the maximum at (4, -4) indicates that this region of parameter space is highly unfavorable. An optimization algorithm starting from a random point would be expected to "roll down" the surface towards the dark blue minimum region. The plot provides a complete visual summary of the system's stability and the sensitivity of its state to parameter changes.
</details>
(g) c=1
<details>
<summary>extracted/6466920/figs/fe_2var_c5.0.png Details</summary>
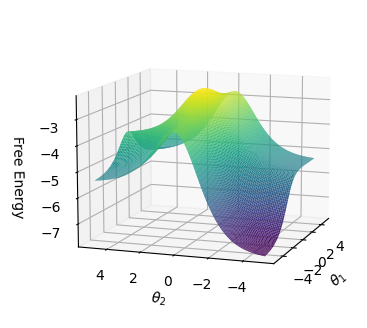
### Visual Description
## 3D Surface Plot: Free Energy Landscape
### Overview
The image displays a three-dimensional surface plot visualizing a function of two variables, θ₁ and θ₂. The plot illustrates how "Free Energy" varies across a parameter space defined by these two variables. The surface is rendered with a color gradient that maps directly to the Free Energy value, providing an intuitive visual guide to the function's topography.
### Components/Axes
* **Vertical Axis (Z-axis):** Labeled **"Free Energy"**. The scale is numerical, with major tick marks at **-3, -4, -5, -6, and -7**. The values are negative, indicating the plotted quantity is likely a negative energy or a log-probability.
* **Horizontal Axis 1 (X-axis, front-left):** Labeled **"θ₂"** (theta subscript two). The scale ranges from **-4 to 4**, with major tick marks at **-4, -2, 0, 2, and 4**.
* **Horizontal Axis 2 (Y-axis, front-right):** Labeled **"θ₁"** (theta subscript one). The scale also ranges from **-4 to 4**, with major tick marks at **-4, -2, 0, 2, and 4**.
* **Surface & Color Mapping:** The plotted surface is a continuous mesh. Its color corresponds to the Free Energy value (Z-axis):
* **Yellow/Green:** Represents the highest values of Free Energy (approximately -3 to -4).
* **Teal/Blue:** Represents mid-range values (approximately -4 to -6).
* **Dark Blue/Purple:** Represents the lowest values of Free Energy (approximately -6 to -7).
* **Grid:** A 3D wireframe grid provides spatial reference, with planes corresponding to the major tick marks on all three axes.
### Detailed Analysis
* **Spatial Grounding & Trend Verification:** The surface exhibits a single, prominent **peak** (a local and likely global maximum) located near the center of the parameter space, at approximately **(θ₁ ≈ 0, θ₂ ≈ 0)**. At this peak, the Free Energy is at its highest, visually estimated to be **≈ -3.2**.
* From this central peak, the surface **slopes downward** in all directions as the absolute values of θ₁ and θ₂ increase. The descent is not perfectly symmetric.
* The **lowest points** (global minima) appear to be located near the four corners of the plotted domain, specifically where both |θ₁| and |θ₂| are large (e.g., near (4,4), (4,-4), (-4,4), (-4,-4)). At these corners, the Free Energy reaches its minimum value of **≈ -7.0**.
* The surface appears smooth and continuous, with no visible discontinuities, sharp ridges, or secondary peaks within the displayed range.
### Key Observations
1. **Central Maximum:** The most notable feature is the single, smooth peak at the origin (0,0). This suggests the system has a unique state of highest Free Energy when both parameters are zero.
2. **Symmetry:** The landscape shows approximate, but not perfect, symmetry around the θ₁=0 and θ₂=0 planes. The shape resembles a rounded, inverted mountain or a broad hill.
3. **Monotonic Decrease:** Moving away from the origin along any radial direction results in a monotonic decrease in Free Energy.
4. **Color as Value Guide:** The color gradient is a direct and effective visual encoding of the Z-axis value, making the topography immediately interpretable.
### Interpretation
This plot likely represents an **energy landscape** or a **negative log-likelihood surface** from a statistical or machine learning model (e.g., a variational autoencoder, a physics-based model, or an optimization problem).
* **What it Suggests:** The central peak at (θ₁=0, θ₂=0) represents an **unstable equilibrium point** or a state of maximum "surprise"/energy. The system would naturally tend to move away from this state towards regions of lower Free Energy (the valleys).
* **Relationship of Elements:** The two parameters, θ₁ and θ₂, are coupled in defining the system's state. The smooth, convex-like shape around the peak suggests that simple gradient-based optimization methods would efficiently find the minima from most starting points.
* **Notable Implications:** The absence of multiple local minima (within this view) implies the optimization problem is relatively simple, with a clear global solution (or set of degenerate solutions at the corners). The landscape's shape is crucial for understanding the dynamics, stability, and learnability of the underlying system. The negative Free Energy values are standard in statistical physics and variational inference, where minimizing Free Energy is equivalent to maximizing a lower bound on model evidence or minimizing an energy function.
</details>
(h) c=5
Figure 7: Energy function and free-energy function with different confidence values.
#### 3.6.3 Comparison to Other Approaches
Unlike recent neural network-based approaches for SAT solving [40, 53], which rely on large datasets generated by traditional SAT solvers for training, our method eliminates this dependency. Instead, we directly convert SAT problems (typically expressed in CNF) into LBM representations. This data-independent transformation should simplify the workflow by reducing the need for extensive pre-processing or model training. When compared with other SAT-solving methods that utilize Boltzmann Machines (BM), such as those in [17, 7], our approach leverages the much simpler structure of Restricted Boltzmann Machines (RBMs). These earlier methods often employ dense or higher-order structures, which are computationally complex and challenging to implement. By contrast, our use of RBMs maintains a streamlined architecture without requiring modifications to the network (e.g. adding configurations) to map SAT problems to BMs. Finally, while LBM is not yet competitive with state-of-the-art SAT solvers in terms of raw performance, it seems to open up a promising direction for further research. Unlike traditional SAT solvers, LBM is in essence a neural network. This should enable a seamless integration of reasoning and learning. Furthermore, LBM does not require prior knowledge of SAT problem structures or specific solving tactics such as backtracking or unit propagation. It is important to notice that our current implementation relies solely on off-the-shelf optimization methods, with room for significant improvements through parallelization optimization and the incorporation of advanced SAT-solving strategies.
#### 3.6.4 SAT Solving Methodology and Initial Experimental Results
We used random SAT problems [1] as a case study. To solve SAT problems using LBM, we follow these steps:
- Convert a CNF into an RBM using the transformation described earlier.
- Apply various inference and optimization techniques to find satisfying assignments or determine unsatisfiability. Specifically:
- Use Gibbs sampling to minimize the energy function and search for satisfying assignments.
- Employ gradient-based methods from TensorFlow to optimize the differentiable free energy function.
- Utilize stochastic optimization methods from the Scipy library, such as dual_annealing and differential_evolution.
Our experiments produced the following results:
- Gibbs Sampling:
- Gibbs sampling can find satisfying assignments for CNFs with fewer than 40 variables. For larger formulas, Gibbs sampling often gets stuck in local minima, making it challenging to determine satisfiability. In such cases, if the free energy function does not decrease after 1000 steps of Gibbs sampling, we conclude that the formula is likely unsatisfiable.
- Gradient-Based Optimization (TensorFlow):
- Gradient-based methods are applied to minimize the differentiable free energy function. However, these methods are prone to getting trapped in local minima, especially for SAT problems with more than 20 variables.
- Attempts to smoothing the energy landscape by adjusting confidence values did not significantly improve performance, highlighting a difficulty in solving larger SAT instances with this approach.
- Stochastic Optimization (Scipy):
- Among the stochastic optimization methods available in Scipy, dual_annealing and differential_evolution showed better scalability. These methods successfully solved SAT problems with up to 100 variables.
- This suggests that stochastic global optimization techniques may offer a viable alternative for solving larger SAT instances with RBMs.
#### 3.6.5 Implementing Penalty Logic in LBM
The closest work to LBM is Penalty Logic [37], which represents propositional formulae in Hopfield networks and Boltzmann machines. In its first step, Penalty Logic creates hidden variables to reduce a formula $φ$ to a conjunction of sub-formulas $\bigwedge_iφ_i$ , each with at most three variables. This naming step makes conversion into an energy function easier, but some of the terms in the energy function may consist of hidden variables and therefore cannot be converted into an RBM. For example, a negative term $-h_1xy$ of a higher-order Boltzmann Machine would be transformed into the quadratic term $-h_2h_1-h_2x-h_2y+5h_2$ with $-h_2h_1$ forming a connection between two hidden units, which is not allowed in RBMs. The three-variable term $-h_1xy$ is implemented in the higher-order network as a hypergraph. The variable $h_2$ is introduced to turn the hyper-edge into normal edges between each of the three variables and $h_2$ with an appropriate bias value for the new node $h_2$ , in this example a value of 5. Contrast the LBM for XOR in Figure 4 with the RBM for XOR built using Penalty Logic: first, one computes the higher-order energy function: ${\it E}^p=4xyz-2xy-2xz-2yz+x+y+z,$ then transforms it to quadratic form by adding a hidden variable $h_1$ to obtain: ${\it E}^p=2xy-2xz-2yz-8xh_1-8yh_1+8zh_1+x+y+z+12h_1,$ which is not an energy function of an RBM, so one keeps adding hidden variables until the energy function of an RBM might be obtained, in this case: ${\it E}^p=-8xh_1-8yh_1+8zh_1+12h_1-4xh_2+4yh_2+2h_2-4yh_3-4 zh_3+6h_3-4xh_4-4zh_4+6h_4+3x+y+z.$
The LBM system converts any set of formulae $Φ=\{φ_1,...,φ_n\}$ into an RBM by applying Theorem 1 to each formula $φ_i∈Φ$ . In the case of Penalty Logic, formulae are weighted. Given a set of weighted formulae $Φ=\{w_1:φ_1,...,w_n:φ_n\}$ , one can also construct an equivalent RBM where each energy term generated from formula $φ_i$ is multiplied by $w_i$ . In both cases, the assignments that minimise the energy of the RBM are the assignments that maximise the satifiability of $Φ$ , i.e. the (weighted) sum of the truth-values of the formula.
**Lemma 3**
*Given a weighted knowledge-base $Φ=\{w_1:φ_1,...,w_n:φ_n\}$ , there exists an equivalent RBM $N$ such that $s_Φ(x)=-\frac{1}{ε}min_h{\it E}(x, h)$ , where $s_Φ(x)$ is the sum of the weights of the formulae in $Φ$ that are satisfied by assignment $x$ .*
A formula $φ_i$ can be decomposed into a set of (weighted) conjunctive clauses from its SDNF. If there exist two conjunctive clauses such that one is subsumed by the other then the subsumed clause is removed and the weight of the remaining clause is replaced by the sum of their weights. Identical conjunctive clauses are treated in the same way: one of them is removed and the weights are added. From Theorem 1, we know that a conjunctive clause $\bigwedge_t∈S_T_{j}x_t\wedge\bigwedge_k∈\mathcal {S_K_{j}}¬x_k$ is equivalent to an energy term $e_j(x,h_j)=-h_j(∑_t∈S_T_{j}x_t-∑_k∈ S_K_{j}x_k-|S_T_{j}|+ε)$ where $0<ε<1$ . A weighted conjunctive clause $w^\prime:\bigwedge_t∈S_T_{j}x_t\wedge\bigwedge_k ∈S_K_{j}¬x_k$ , therefore, is equivalent to an energy term $w^\primee_j(x,h_j)$ . For each weighted conjunctive clause, we can add a hidden unit $j$ to an RBM with connection weights $w_tj=w^\prime$ for all $t∈S_T_{j}$ , and $w_kj=-w^\prime$ for all $k∈S_K_{j}$ . The bias for this hidden unit will be $w^\prime(-|S_T_{j}|+ε)$ . The weighted knowledge-base and the RBM are equivalent because $s_Φ(x)∝-\frac{1}{ε}min_h{\it E}( x,h)$ , where $s_Φ(x)$ is the sum of the weights of the clauses that are satisfied by $x$ .
**Example 5**
*(Nixon diamond problem) Consider the following weighted knowledge-base from the original Penalty Logic paper [37] (the weights of 1000 and 10 are given and have been taken from the original paper):
| | $\displaystyle 1000:n→r Nixon is a Republican.$ | |
| --- | --- | --- |
<details>
<summary>extracted/6466920/figs/diamond.png Details</summary>
### Visual Description
## Directed Weighted Graph: Network Flow or Cost Analysis
### Overview
The image displays a directed graph (network diagram) with 9 nodes and 20 directed edges. The nodes are labeled with single letters: `n`, `q`, `r`, `p`, and `h1` through `h8`. The edges are labeled with numerical weights, which include both positive and negative integers. The graph has a symmetrical, diamond-like structure with a central vertical axis.
### Components/Axes
* **Nodes (Vertices):**
* **Primary Nodes:** `n` (top-center), `q` (left), `r` (right), `p` (bottom-center).
* **Intermediate Nodes:** `h1`, `h2`, `h3`, `h4`, `h5`, `h6`, `h7`, `h8`. These are arranged in a ring between the primary nodes.
* **Edges (Directed Connections) & Weights:** Each edge is represented by a line with an arrow indicating direction. The numerical weight is placed adjacent to the line. All text is in English numerals.
### Detailed Analysis
The graph's structure and all edge weights are as follows. The analysis is segmented by the originating node for clarity.
**1. From Node `n` (Top-Center):**
* `n` → `h1`: Weight `1000`
* `n` → `h2`: Weight `2000`
* `n` → `h3`: Weight `1000`
* `n` → `h4`: Weight `1000`
**2. From Node `q` (Left):**
* `q` → `h7`: Weight `5`
* `q` → `h8`: Weight `10`
**3. From Node `r` (Right):**
* `r` → `h5`: Weight `5`
* `r` → `h6`: Weight `10`
**4. From Node `p` (Bottom-Center):**
* `p` → `h6`: Weight `-10`
* `p` → `h8`: Weight `10`
**5. Connections Among Intermediate Nodes (`h1`-`h8`):**
* `h1` → `h2`: Weight `-1500`
* `h2` → `h3`: Weight `-1500`
* `h3` → `h4`: Weight `1000`
* `h4` → `p`: Weight `1000`
* `h5` → `r`: Weight `1000`
* `h5` → `h6`: Weight `-5`
* `h6` → `h5`: Weight `-5` (Note: This creates a bidirectional negative-weight cycle between `h5` and `h6`).
* `h7` → `q`: Weight `1000`
* `h7` → `h8`: Weight `-5`
* `h8` → `h7`: Weight `-5` (Note: This creates a bidirectional negative-weight cycle between `h7` and `h8`).
**6. Other Connections:**
* `h1` → `r`: Weight `1000`
* `h3` → `q`: Weight `1000`
### Key Observations
1. **Symmetry:** The graph exhibits approximate left-right symmetry between the `q-h7-h8` and `r-h5-h6` subsystems.
2. **Negative Weights:** Several edges have negative weights (`-1500`, `-5`, `-10`). This is atypical for simple distance/cost graphs and suggests the weights may represent net gains/losses, profits/costs, or differential values in a flow network.
3. **Negative Cycles:** There are two distinct 2-node negative cycles: `h5 ↔ h6` (each edge `-5`) and `h7 ↔ h8` (each edge `-5`). In many network algorithms (e.g., shortest path), the presence of negative cycles indicates that an optimal path may not be well-defined, as traversing the cycle repeatedly would yield an infinitely decreasing total weight.
4. **Central Hub:** Node `n` acts as a primary source, distributing high positive weights (`1000`, `2000`) to the upper intermediate nodes (`h1-h4`).
5. **Terminal Node:** Node `p` appears to be a primary sink or terminal point, receiving a strong positive flow (`1000`) from `h4`.
### Interpretation
This diagram likely models a system involving flows, transfers, or transformations where values can be both gained and lost. The structure suggests a process starting at `n`, moving through various intermediate stages (`h1-h8`), and potentially converging at `p`, with side loops involving `q` and `r`.
* **Possible Contexts:** It could represent:
* A **financial network** with transactions (positive/negative weights as credits/debits).
* A **supply chain or logistics model** with gains (economies of scale) and losses (spoilage, cost).
* A **state transition diagram** for a system where weights represent the utility or cost of moving between states.
* A **neural network or computational graph** with weighted connections, where negative weights are standard.
* **Significance of Negative Cycles:** The cycles between `h5-h6` and `h7-h8` are critical anomalies. They imply that within these subsystems, value can be created or destroyed indefinitely by cycling, which may represent arbitrage opportunities, feedback loops, or system instabilities that require special handling in any analysis.
* **Flow Direction:** The overall macro-flow appears to be from the top (`n`) downwards towards `p`, with lateral exchanges through `q` and `r`. The high-weight edges from `h1`, `h3`, `h7`, and `h5` back to `q` and `r` (`1000` each) suggest significant feedback or return paths to these side nodes.
**In summary, this is a weighted directed graph modeling a network with complex, non-trivial dynamics due to the presence of both high-magnitude positive flows and negative cycles. Its exact meaning depends on the domain, but the structure is clearly designed to analyze paths, flows, or optimizations within a system where values are not purely additive.**
</details>
Figure 8: The RBM for the Nixon diamond problem has 4 input neurons $\{n,q,r,p\}$ and 7 hidden neurons (shown in grey) as a result of the conversion into SDNF of the 4 weighted clauses shown in Example 5. Converting all four weighted clauses above into SDNF produces eight conjunctive clauses. For example, weighted clause $1000:n→r≡ 1000:(n\wedger) \vee(¬n)$ . After adding the weights of clause ( $¬n$ ) which appears twice, an RBM is created (Figure 8) representing the following unique conjunctive clauses with their corresponding confidence values: $1000:n\wedger, 2000:¬n, 1000:n \wedgeq, 10:r\wedge¬p, 10:¬\mathrm {r}, 10:q\wedgep, 10:¬q.$ With $ε=0.5$ , this RBM has energy function: ${\it E}=-h_1(1000n+1000r-1500)-h_2(-2000n+1000)-h_3(1000n+1000q-1500)-h_ {4}(10r-10p-5)-h_5(-10r+5)-h_6(10q+10p-15)-h_7(-10q+5).$*
## 4 Logical Boltzmann Machines for MaxSAT
MaxSAT - shorthand for Maximum Satisfiability - is a computational problem that extends the classical SAT (Boolean satisfiability) problem. In MaxSAT, the goal is to find an assignment of truth values to the variables of a Boolean formula that maximizes the number of satisfied clauses. The formula is typically represented in CNF. We denote the number of satisfied clauses given a assignment $x$ as $∑_m\mathbbm{1}(x\modelsφ_m)$ . Here, $x\modelsφ_m$ denotes that an assignment $x$ satisfies the clause $φ_m$ of the CNF and $\mathbbm{1}$ is an indicator function mapping a clause-satisfying assignment to 1, and everything else to 0. Differently from SAT, where the goal is to find any satisfying assignment, MaxSAT seeks the assignment that satisfies the maximum number of clauses, making it a combinatorial optimization problem:
$$
x^*=\operatorname*{arg max}_x∑_m\mathbbm{1}(
x\modelsφ_m) \tag{20}
$$
For example, consider the CNF formula:
$$
φ=(¬ x_1∨¬ x_2)∧(¬ x_1∨ x_2)∧(x_1∨¬ x
_2)∧(x_1∨ x_2).
$$
The goal is to find an assignment $x∈\{0,1\}^n$ (where $n$ is the number of variables, in this example $n=2$ ) that maximizes the number of satisfied clauses. We know that $φ$ is unsatisfiable since each clause corresponds to exactly one assignment. An optimal solution will satisfy three of the four clauses. This relaxation of the SAT task makes MaxSAT particularly suited for real-world optimization problems where constraints may need to be prioritized or relaxed to achieve the best overall solution. However, this flexibility comes at a cost: NP-Hardness, meaning that finding exact solutions becomes computationally infeasible as the number of variables grows. Many real-world applications, however, require approximate solutions to the MaxSAT problem, with the main challenge being how to balance accuracy and computation time.
Symbolic MaxSAT solvers have been the focus of intensive research for many years, gaining popularity among researchers and finding application in various domains from AI and computer-aided design to automated reasoning. Recent advancements in MaxSAT solvers have demonstrated significant improvements, with state-of-the-art solvers capable of scaling up to handling millions of variables and clauses.
MaxSAT has proven to be valuable in software analysis [43], hardware verification [32, 22], combinatorial optimization [25], bioinformatics [45], and data analysis [4]. Despite these achievements, the growing complexity of real-world problems has spurred interest in alternative approaches, such as leveraging the differentiable capabilities of Machine Learning to address MaxSAT by transforming the discrete problem into a continuous optimization task.
In recent years, there has been a growing interest in connectionist solvers. These solvers aim to represent MaxSAT problems using neural networks to benefit from the parallel computation and learning capabilities of such ML systems and from specialized neural network accelerators, such as GPUs and TPUs, to further enhance performance. Beyond providing an alternative approach to solving complex reasoning problems, connectionist MaxSAT solvers may promote the development of interpretable classification models [28], facilitating novel neurosymbolic learning and reasoning [53, 52] with the promise of offering more transparent decision making in AI.
Deep learning-inspired MaxSAT solvers rely on real-valued weights often learned from example solutions [53]. In a related attempt, [27] seeks to train a Graph Neural Network for MaxSAT problem-solving. Unlike symbolic approaches, ML-based methods typically require a degree of supervision and may be criticized for their opacity. We take a different approach and use LBM along with a global optimization method called dual annealing, a modified version of a meta-heuristic method known as simulated annealing, to search for MaxSAT solutions. Using dual annealing, we will search the energy landscape of the RBM for a global minimum corresponding to a MaxSAT solution.
Research that has also focused on representing MaxSAT problems in connectionist networks without relying on explicit learning from examples include [18], where the MaxSAT problem is mapped to a combinatorial optimization framework based on a high-order Boltzmann Machine used to search for an approximate solution to SAT. However, the problems with efficiency of Boltzmann Machines are well-known. They have motivated the use of RBMs, first in [52] and leading up to this work. In a more recent development also using RBMs, RBMSAT was proposed to construct an RBM that represents the probability of an assignment w.r.t. the number of clauses that it satisfies [54]. The goal there is to conduct a heuristic search for solutions using block Gibbs samplings on neural network accelerators. Our goal, instead, is to make use of an interpretable RBM layer, as shown e.g. in Figure 13 where each clause can be read off the LBM with binary weights.
**Example 6**
*An AND-gate $x_1\wedge¬x_2$ is represented by a free energy $FE=-\log(1+\exp(c×(x_1-x_2-0.5)))$ . Figure 9 illustrates the correspondence between the free energy and the truth-values for different values of $c$ . Similarly, Figure 10 shows the free energy of an OR-gate (that is, a clause) $x_1\veex_2$ . This clause is transformed into SDNF $(x_1\wedge¬x_2)\veex_2$ and the corresponding free energy is $FE=-\log(1+\exp(c×(x_1-x_2-0.5)))-\log(1+\exp(c×(x_2-0.5))$ . As expected, the satisfying assignments are those that maximize the negative free energy.*
As we have seen already when using LBM as a SAT solver, a conjunctive clause $φ_m$ can be represented in an RBM with the energy function $E_m=∑_je_j$ and, therefore, the energy function of a CNF will be:
$$
{\it E}(x)=∑_mE_m \tag{21}
$$
The free energy of each clause corresponds to the truth values of the clause, i.e. $\mathbbm{1}(x\modelsφ_m)∝ FE_m(x)$ . The free energy of the entire CNF $FE(x)=∑_mFE_m(x)$ , therefore, corresponds to the number of satisfied conjunctive clauses, that is:
$$
\displaystyle∑_m\mathbbm{1}(x\modelsφ_m)∝ FE(
x) \tag{22}
$$
An assignment that maximizes the number of satisfying clauses in a MaxSAT problem also minimizes the free energy of the LBM. Consequently, solving MaxSAT problems is equivalent to searching for a state of minimum free energy in the RBM.
<details>
<summary>extracted/6466920/figs/andc1_.png Details</summary>
### Visual Description
## 3D Surface Plot: Relationship between `x₁ʳ`, `x₂ʳ`, and `True α - FE`
### Overview
The image displays a three-dimensional surface plot illustrating the relationship between two independent variables, `x₁ʳ` and `x₂ʳ`, and a dependent variable labeled `True α - FE`. The plot is rendered as a continuous, colored surface within a 3D coordinate system.
### Components/Axes
* **X-Axis (Bottom Right):** Labeled `x₁ʳ`. The scale runs from 0.0 to 1.0, with major tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0. The axis extends from the front-right corner towards the back-right.
* **Y-Axis (Bottom Left):** Labeled `x₂ʳ`. The scale runs from 0.0 to 1.0, with major tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0. The axis extends from the front-left corner towards the back-left.
* **Z-Axis (Vertical, Left Side):** Labeled `True α - FE`. The scale runs from approximately 0.3 to 0.9, with major tick marks at 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, and 0.9.
* **Surface & Color Mapping:** The plotted surface is colored with a gradient that maps to the Z-axis value (`True α - FE`). The color transitions from dark purple/blue at the lowest Z-values to bright yellow at the highest Z-values. There is no separate legend; the color is an intrinsic part of the data representation.
* **Grid:** A light gray grid is present on the three back planes of the 3D cube to aid in spatial orientation.
### Detailed Analysis
* **Surface Shape and Trend:** The surface is a smooth, continuous plane that appears to be linear or very nearly linear in its relationship with the input variables. It slopes upward from the front-left region of the plot (low `x₁ʳ`, low `x₂ʳ`) towards the back-right region (high `x₁ʳ`, high `x₂ʳ`).
* **Spatial Grounding & Data Points:**
* **Minimum Point:** The lowest point on the surface (dark purple) is located at the front corner where `x₁ʳ ≈ 0.0` and `x₂ʳ ≈ 0.0`. The corresponding `True α - FE` value is approximately **0.3**.
* **Maximum Point:** The highest point on the surface (bright yellow) is located at the back corner where `x₁ʳ ≈ 1.0` and `x₂ʳ ≈ 1.0`. The corresponding `True α - FE` value is approximately **0.9**.
* **Intermediate Trend:** As one moves from the minimum point towards the maximum point along the surface, both `x₁ʳ` and `x₂ʳ` increase, and the `True α - FE` value increases correspondingly. The color shifts smoothly from purple through teal and green to yellow, confirming the direct relationship between the spatial position on the surface and the Z-axis value.
* **Component Isolation (by Region):**
* **Header/Top:** The top of the plot is dominated by the high-value (yellow) region of the surface, corresponding to high `x₁ʳ` and `x₂ʳ`.
* **Main Chart Area:** Contains the 3D surface, axes, and grid. The surface occupies the central volume.
* **Footer/Bottom:** The axis labels (`x₁ʳ`, `x₂ʳ`) and their tick marks are located here.
### Key Observations
1. **Monotonic Increase:** The value of `True α - FE` increases monotonically as both `x₁ʳ` and `x₂ʳ` increase from 0 to 1.
2. **Apparent Linearity:** The surface appears to be a flat plane, suggesting a linear relationship of the form `True α - FE ≈ a*x₁ʳ + b*x₂ʳ + c`. The constant `c` is approximately 0.3 (the intercept when both inputs are 0).
3. **Symmetry:** The slope of the plane appears similar with respect to both the `x₁ʳ` and `x₂ʳ` axes, indicating they may have a comparable influence on the output variable.
4. **Color as Data:** The color gradient is not decorative but is a direct visual encoding of the Z-axis value, providing an immediate intuitive understanding of the surface's height.
### Interpretation
This plot visualizes a function where the output `True α - FE` is determined by the combination of two normalized input parameters, `x₁ʳ` and `x₂ʳ`. The data suggests a strong, positive, and likely linear correlation between the inputs and the output.
* **What it demonstrates:** The function maps the unit square (where both inputs range from 0 to 1) to an output range of approximately 0.3 to 0.9. The lowest output occurs when both inputs are minimal, and the highest output occurs when both are maximal.
* **Relationship between elements:** `x₁ʳ` and `x₂ʳ` act as co-determinants. Increasing either one while holding the other constant will increase the output `True α - FE`. The maximum effect is achieved when both are increased together.
* **Notable pattern:** The perfect planarity of the surface is the most notable feature. In real-world data, such a perfectly linear relationship is rare and often indicates a theoretical model, a controlled simulation, or a fundamental physical/mathematical relationship rather than noisy empirical data. The absence of curvature or interaction terms (where the effect of one variable depends on the level of the other) simplifies the interpretation significantly.
</details>
(a) c=1
<details>
<summary>extracted/6466920/figs/andc5_.png Details</summary>
### Visual Description
## 3D Surface Plot: Relationship Between \(x_1'\), \(x_2'\), and "True α - FE"
### Overview
The image displays a three-dimensional surface plot visualizing the relationship between two independent variables, \(x_1'\) and \(x_2'\), and a dependent variable labeled "True α - FE". The plot is rendered within a 3D Cartesian coordinate system with a grid. The surface exhibits a pronounced curvature, with its color mapping indicating the magnitude of the dependent variable.
### Components/Axes
* **X-axis (Bottom Right):** Labeled \(x_1'\). The scale runs from 0.0 to 1.0, with major tick marks at intervals of 0.2 (0.0, 0.2, 0.4, 0.6, 0.8, 1.0).
* **Y-axis (Bottom Left):** Labeled \(x_2'\). The scale runs from 0.0 to 1.0, with major tick marks at intervals of 0.2 (0.0, 0.2, 0.4, 0.6, 0.8, 1.0). Note: The axis is oriented such that 1.0 is on the left and 0.0 is on the right from the viewer's perspective.
* **Z-axis (Vertical, Left Side):** Labeled "True α - FE". The scale runs from 0.5 to 2.5, with major tick marks at 0.5, 1.0, 1.5, 2.0, and 2.5.
* **Surface & Color Mapping:** The plotted surface is colored with a gradient. The color serves as a redundant visual cue for the Z-axis value:
* **Dark Purple/Blue:** Corresponds to the lowest values of "True α - FE" (approximately 0.5 to 1.0).
* **Teal/Green:** Corresponds to mid-range values (approximately 1.0 to 2.0).
* **Yellow:** Corresponds to the highest values (approximately 2.0 to 2.5 and above).
* **Legend:** There is no separate, discrete legend box. The color gradient itself acts as a continuous legend for the Z-axis values.
### Detailed Analysis
* **Spatial Grounding & Trend Verification:** The surface forms a curved sheet that rises dramatically from one corner of the \(x_1'\)-\(x_2'\) plane.
* **Lowest Region:** The surface is lowest (dark purple, Z ≈ 0.5-0.8) in the region where \(x_1'\) is low (near 0.0) and \(x_2'\) is high (near 1.0). This is the front-left corner of the plotted domain.
* **Highest Region:** The surface peaks (bright yellow, Z > 2.5) at the opposite corner, where \(x_1'\) is high (1.0) and \(x_2'\) is low (0.0). This is the back-right corner of the domain.
* **Primary Trend:** The value of "True α - FE" increases sharply and non-linearly as \(x_1'\) increases and \(x_2'\) decreases. The gradient is steepest along the diagonal from the (0.0, 1.0) corner to the (1.0, 0.0) corner.
* **Secondary Trend:** Holding \(x_2'\) constant, "True α - FE" increases with \(x_1'\). Holding \(x_1'\) constant, "True α - FE" decreases as \(x_2'\) increases.
* **Data Point Approximation (Key Corners):**
* At (\(x_1'\)=0.0, \(x_2'\)=1.0): "True α - FE" ≈ 0.5 - 0.8 (estimated from the lowest purple region).
* At (\(x_1'\)=1.0, \(x_2'\)=0.0): "True α - FE" ≈ 2.5+ (the peak extends beyond the top Z-axis tick).
* At (\(x_1'\)=0.5, \(x_2'\)=0.5): "True α - FE" ≈ 1.2 - 1.5 (estimated from the teal region at the center of the domain).
### Key Observations
1. **Strong Interaction Effect:** The relationship is not additive. The effect of increasing \(x_1'\) is much more pronounced when \(x_2'\) is low. Similarly, the effect of decreasing \(x_2'\) is amplified when \(x_1'\) is high.
2. **Monotonic Surface:** The surface appears smooth and monotonic across the displayed domain—there are no visible local minima, maxima, or saddle points within the plotted range.
3. **Color as Intensity Guide:** The color gradient effectively highlights the region of maximum value (yellow peak) and the region of minimum value (purple base), making the overall trend immediately apparent.
### Interpretation
This plot demonstrates a **synergistic or multiplicative relationship** between the normalized variables \(x_1'\) and \(x_2'\) in determining the output "True α - FE". The output is maximized when \(x_1'\) is at its maximum and \(x_2'\) is at its minimum, suggesting these two conditions work together to produce the highest value.
The steep, curved surface indicates that the system being modeled is highly sensitive to changes in these parameters, especially in the region where \(x_1'\) is high and \(x_2'\) is low. Small adjustments in this region could lead to large changes in the output. Conversely, the system is less sensitive (the surface is flatter) in the region where \(x_1'\) is low and \(x_2'\) is high.
Without additional context, "True α - FE" could represent an error metric (where lower is better), a performance gain (where higher is better), or a physical quantity. The plot's primary message is the **non-linear, interactive dependence** of this quantity on the two input parameters. To optimize for a high "True α - FE", one should push \(x_1'\) toward 1.0 and \(x_2'\) toward 0.0. To minimize it, the opposite conditions are required.
</details>
(b) c=5
<details>
<summary>extracted/6466920/figs/andc10_.png Details</summary>
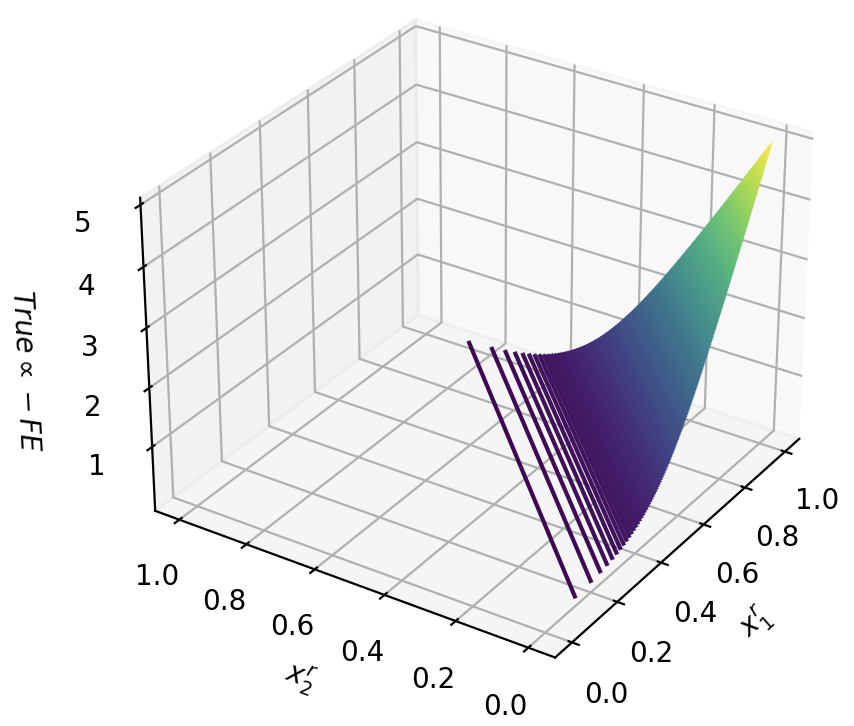
### Visual Description
## 3D Surface Plot: True α - FE vs. x₁' and x₂'
### Overview
The image displays a three-dimensional surface plot rendered within a wireframe box. The plot visualizes a mathematical function where a dependent variable, labeled "True α - FE", is plotted against two independent variables, "x₁'" and "x₂'". The surface exhibits a pronounced, smooth curvature, rising from a low value near the origin to a high peak at the opposite corner of the domain.
### Components/Axes
* **Vertical Axis (Z-axis):**
* **Label:** "True α - FE"
* **Scale:** Linear, ranging from 1 to 5. Major tick marks are present at integer intervals (1, 2, 3, 4, 5).
* **Horizontal Axis 1 (X-axis, front-left):**
* **Label:** "x₂'"
* **Scale:** Linear, ranging from 0.0 to 1.0. Major tick marks are at 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **Horizontal Axis 2 (Y-axis, front-right):**
* **Label:** "x₁'"
* **Scale:** Linear, ranging from 0.0 to 1.0. Major tick marks are at 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **Plot Area:** A 3D wireframe box defines the plotting volume. The surface is rendered as a continuous, colored mesh.
* **Color Mapping:** The surface color is mapped to the vertical axis ("True α - FE") value. The gradient runs from dark purple (low values, ~1) through blue and green to bright yellow (high values, >5).
### Detailed Analysis
* **Surface Shape and Trend:** The surface forms a smooth, upward-curving sheet. It is lowest near the corner where both x₁' and x₂' are 0.0. From there, it slopes upward with increasing steepness as both x₁' and x₂' increase. The maximum value occurs at the corner where x₁' = 1.0 and x₂' = 1.0.
* **Data Point Extraction (Approximate):**
* At (x₁' ≈ 0.0, x₂' ≈ 0.0): True α - FE ≈ 1.0 (dark purple region).
* At (x₁' ≈ 0.5, x₂' ≈ 0.5): True α - FE ≈ 2.0 - 2.5 (blue region).
* At (x₁' ≈ 1.0, x₂' ≈ 0.0): True α - FE ≈ 1.5 - 2.0 (purple-blue region).
* At (x₁' ≈ 0.0, x₂' ≈ 1.0): True α - FE ≈ 1.5 - 2.0 (purple-blue region).
* At (x₁' ≈ 1.0, x₂' ≈ 1.0): True α - FE > 5.0 (bright yellow peak). The surface extends beyond the top of the defined axis range at this point.
* **Spatial Grounding:** The legend (color bar) is implicit, mapped directly to the Z-axis. The highest point (yellow) is spatially located at the top-right-back corner of the 3D box, corresponding to the maximum values of both input variables. The lowest points (dark purple) are along the edges where at least one input variable is near 0.0.
### Key Observations
1. **Exponential-like Growth:** The relationship is highly non-linear. The increase in "True α - FE" accelerates dramatically as both x₁' and x₂' approach 1.0.
2. **Symmetry:** The surface appears roughly symmetric with respect to the x₁' = x₂' diagonal. The values along the line where x₁' = x₂' are higher than points where the variables are unequal but have the same average.
3. **Domain Coverage:** The plotted surface does not cover the entire [0,1] x [0,1] domain. It is absent from the region where x₁' is low and x₂' is high, and vice-versa, suggesting the function may be undefined or zero in those areas, or the plot is intentionally clipped.
4. **Color as Data:** The color gradient provides a strong visual cue for the magnitude of the Z-value, reinforcing the spatial trend.
### Interpretation
This plot likely represents the output of a mathematical model or simulation where the quantity "True α - FE" is a function of two normalized parameters, x₁' and x₂'. The steep, convex curvature suggests a synergistic or multiplicative interaction between the two parameters; their combined effect is greater than the sum of their individual effects.
The fact that the peak exceeds the charted Z-axis limit (5) indicates the function's value grows very rapidly in the corner of the parameter space. This could model phenomena like reaction rates, error surfaces in optimization, or sensitivity analyses where certain parameter combinations lead to extreme outcomes. The absence of the surface in parts of the domain might indicate physical constraints, regions of instability, or simply the chosen viewing angle and clipping plane of the 3D renderer. The plot effectively communicates that to maximize "True α - FE," both input parameters must be pushed to their upper limit values simultaneously, i.e., 1.0 and 1.0.
</details>
(c) c=10
Figure 9: Free energy corresponding to an AND gate with different confidence values (Example 6).
<details>
<summary>extracted/6466920/figs/c1.png Details</summary>
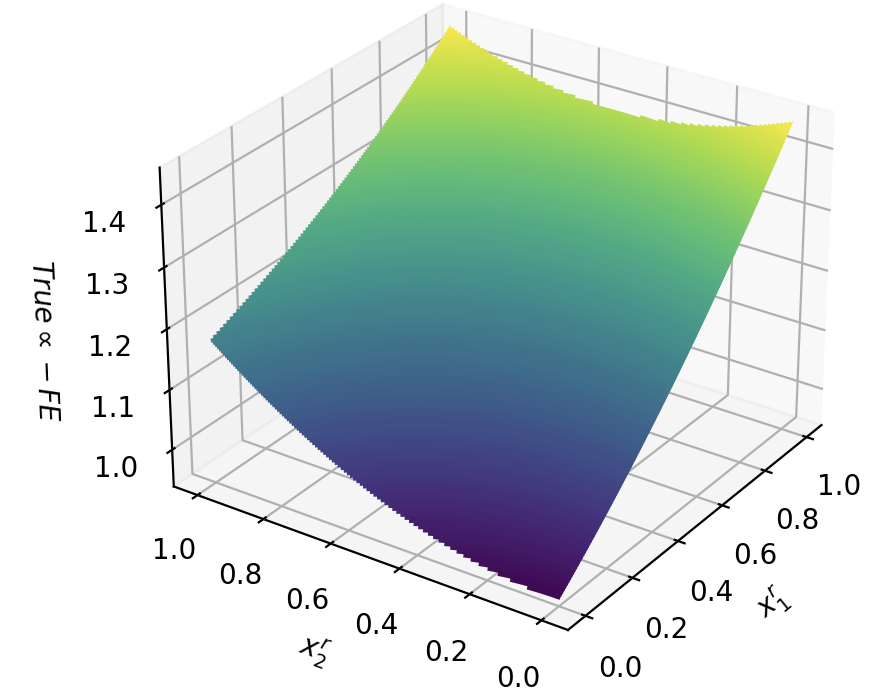
### Visual Description
\n
## 3D Surface Plot: Relationship of "True α - FE" with Normalized Parameters x̃₁ and x̃₂
### Overview
The image displays a three-dimensional surface plot. The plot visualizes how a dependent variable, labeled "True α - FE", changes as a function of two independent, normalized variables, "x̃₁" and "x̃₂". The surface is rendered with a color gradient that maps the value of the vertical axis.
### Components/Axes
* **Vertical Axis (Z-axis):**
* **Label:** `True α - FE`
* **Scale:** Linear, ranging from 1.0 to 1.4.
* **Tick Marks:** 1.0, 1.1, 1.2, 1.3, 1.4.
* **Horizontal Axis 1 (X-axis, front-left):**
* **Label:** `x̃₁` (x-tilde sub 1)
* **Scale:** Linear, ranging from 0.0 to 1.0.
* **Tick Marks:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **Horizontal Axis 2 (Y-axis, front-right):**
* **Label:** `x̃₂` (x-tilde sub 2)
* **Scale:** Linear, ranging from 0.0 to 1.0.
* **Tick Marks:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **Color Mapping:** The surface color corresponds to the Z-axis value (`True α - FE`). A gradient is used, transitioning from dark purple/blue for the lowest values (~1.0) through teal and green to bright yellow for the highest values (~1.4). There is no separate legend; the color is an intrinsic part of the data surface.
### Detailed Analysis
* **Surface Shape and Trend:** The surface forms a smooth, continuous, and slightly curved plane. It exhibits a clear monotonic trend in both horizontal dimensions.
* **Trend with x̃₁:** For any fixed value of x̃₂, the surface slopes **upward** as x̃₁ increases from 0.0 to 1.0. This indicates a positive correlation between `True α - FE` and x̃₁.
* **Trend with x̃₂:** For any fixed value of x̃₁, the surface slopes **downward** as x̃₂ increases from 0.0 to 1.0. This indicates a negative correlation between `True α - FE` and x̃₂.
* **Data Point Approximation (Spatial Grounding):**
* **Minimum Region:** The lowest point on the surface (dark purple) is located at the corner where **x̃₁ is near 0.0 and x̃₂ is near 1.0**. The corresponding `True α - FE` value is approximately **1.0**.
* **Maximum Region:** The highest point on the surface (bright yellow) is located at the opposite corner where **x̃₁ is near 1.0 and x̃₂ is near 0.0**. The corresponding `True α - FE` value is approximately **1.4**.
* **Intermediate Values:** The surface passes through intermediate values smoothly. For example, at the center point (x̃₁=0.5, x̃₂=0.5), the color is a medium green, suggesting a `True α - FE` value of approximately **1.2**.
### Key Observations
1. **Linear-like Relationship:** The surface appears largely planar, suggesting the relationship between `True α - FE` and the two parameters (x̃₁, x̃₂) may be approximately linear or bilinear within this domain. There is no strong curvature indicating a complex, non-linear interaction.
2. **Dominant Effect of x̃₁:** The gradient of the surface appears steeper along the x̃₁ direction compared to the x̃₂ direction. This suggests that changes in x̃₁ have a stronger influence on the output variable `True α - FE` than equivalent changes in x̃₂.
3. **No Interaction Effect:** The surface does not exhibit twisting or saddle-like behavior. The effect of changing x̃₁ appears consistent regardless of the value of x̃₂, and vice-versa. This implies the two parameters likely influence the output independently (additively) rather than through a multiplicative interaction.
### Interpretation
This plot is a response surface, likely generated from a computational model or experimental design. It maps the output `True α - FE` (which could represent a true value minus a finite element approximation, a common error metric in numerical analysis) across a normalized parameter space defined by x̃₁ and x̃₂.
The data demonstrates that the error or quantity `True α - FE` is minimized (approaches 1.0) when parameter x̃₁ is low and x̃₂ is high. Conversely, it is maximized (approaches 1.4) when x̃₁ is high and x̃₂ is low. The near-planar shape indicates a predictable, systematic relationship. The stronger dependence on x̃₁ suggests it is the more critical parameter to control or understand for predicting the value of `True α - FE`. This type of visualization is crucial in sensitivity analysis, optimization, and understanding model behavior across a multi-dimensional input space.
</details>
(a) c=1
<details>
<summary>extracted/6466920/figs/c5.png Details</summary>
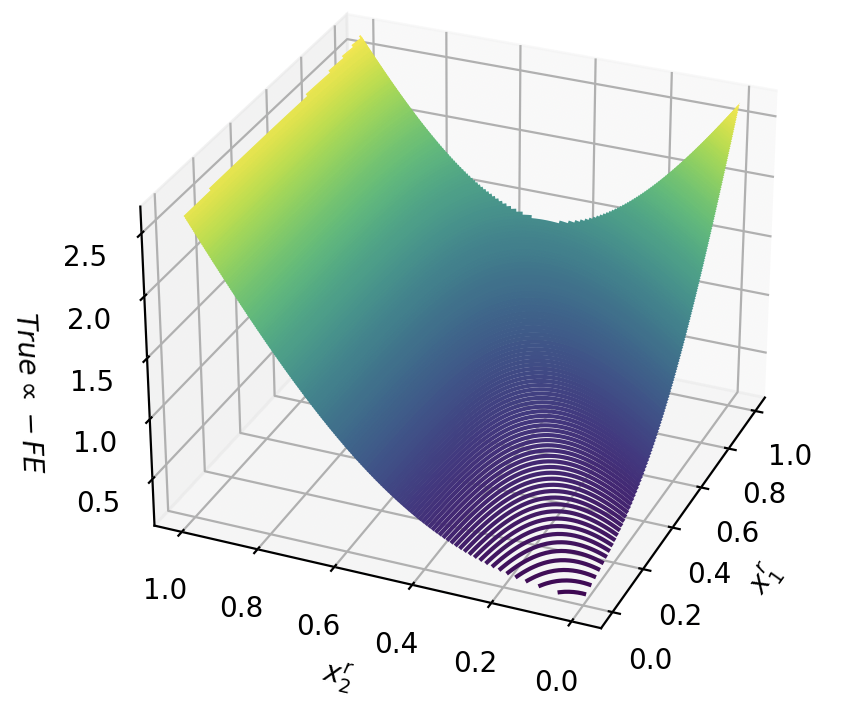
### Visual Description
## 3D Surface Plot: True α - FE as a Function of x₁ʳ and x₂ʳ
### Overview
The image displays a three-dimensional surface plot visualizing a mathematical function. The plot shows how a dependent variable, labeled "True α - FE", varies as a function of two independent variables, "x₁ʳ" and "x₂ʳ". The surface exhibits a distinct saddle shape, with high values at the corners of the domain and a low valley along the main diagonal.
### Components/Axes
* **Vertical Axis (Z-axis):**
* **Label:** `True α - FE`
* **Scale:** Linear, ranging from approximately 0.5 to 2.5.
* **Tick Marks:** 0.5, 1.0, 1.5, 2.0, 2.5.
* **Horizontal Axis 1 (X-axis, right side):**
* **Label:** `x₁ʳ`
* **Scale:** Linear, ranging from 0.0 to 1.0.
* **Tick Marks:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **Horizontal Axis 2 (Y-axis, bottom):**
* **Label:** `x₂ʳ`
* **Scale:** Linear, ranging from 0.0 to 1.0.
* **Tick Marks:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **Surface Color Mapping:** The surface color corresponds to the value of "True α - FE". There is no separate legend; the mapping is implicit.
* **Yellow/Light Green:** Represents high values (≈ 2.0 - 2.5).
* **Teal/Green:** Represents mid-range values (≈ 1.0 - 2.0).
* **Dark Blue/Purple:** Represents low values (≈ 0.5 - 1.0).
### Detailed Analysis
The surface is defined over a square domain where both `x₁ʳ` and `x₂ʳ` range from 0.0 to 1.0.
**Trend Verification & Key Data Points:**
1. **High-Value Corners:** The surface reaches its maximum height (≈ 2.5, colored yellow) at the two opposite corners of the domain:
* At `(x₁ʳ ≈ 0.0, x₂ʳ ≈ 0.0)`.
* At `(x₁ʳ ≈ 1.0, x₂ʳ ≈ 1.0)`.
2. **Low-Value Diagonal Valley:** The surface forms a deep, curved valley along the line where `x₁ʳ ≈ x₂ʳ`. The minimum value (≈ 0.5, colored dark blue/purple) appears to be at the center of this valley, near `(x₁ʳ ≈ 0.5, x₂ʳ ≈ 0.5)`.
3. **Symmetry:** The plot is symmetric about the plane `x₁ʳ = x₂ʳ`. The shape and values are mirrored across this diagonal.
4. **Gradient:** Moving perpendicularly away from the `x₁ʳ = x₂ʳ` diagonal in either direction causes the surface to rise steeply. The gradient is steepest near the center of the domain and becomes more gradual near the high-value corners.
### Key Observations
* **Saddle Shape:** The primary geometric feature is a saddle (or hyperbolic paraboloid). This indicates that the function has a minimax property: it is minimized along one direction (the diagonal) and maximized along the orthogonal direction.
* **Color as Value Indicator:** The color gradient provides a strong visual cue for the function's value, perfectly correlating with the surface height. Yellow consistently marks the highest points, and dark blue/purple marks the lowest.
* **Smoothness:** The surface appears perfectly smooth with no discontinuities, sharp edges, or outliers, suggesting the underlying function is continuous and differentiable over the given domain.
### Interpretation
This plot visualizes a function where the output `True α - FE` is minimized when the two input parameters `x₁ʳ` and `x₂ʳ` are equal. Any imbalance or difference between `x₁ʳ` and `x₂ʳ` causes the output to increase. The increase is symmetric with respect to which variable is larger.
The function's behavior suggests a system where **balance or equality between the two factors (`x₁ʳ` and `x₂ʳ`) leads to an optimal (minimal) state** of `True α - FE`. The further the system moves from this balanced state (i.e., the greater the disparity between `x₁ʳ` and `x₂ʳ`), the worse (higher) the outcome becomes. The saddle shape implies that the penalty for imbalance is severe, as the surface rises rapidly away from the diagonal valley.
Without specific context for what `True α - FE`, `x₁ʳ`, and `x₂ʳ` represent, this could model scenarios such as:
* An error or cost function in an optimization problem.
* A measure of system instability or inefficiency.
* A physical property that depends on the ratio or difference between two normalized quantities.
The plot effectively communicates that controlling for the equality of `x₁ʳ` and `x₂ʳ` is critical for minimizing the target metric.
</details>
(b) c=5
<details>
<summary>extracted/6466920/figs/c10.png Details</summary>
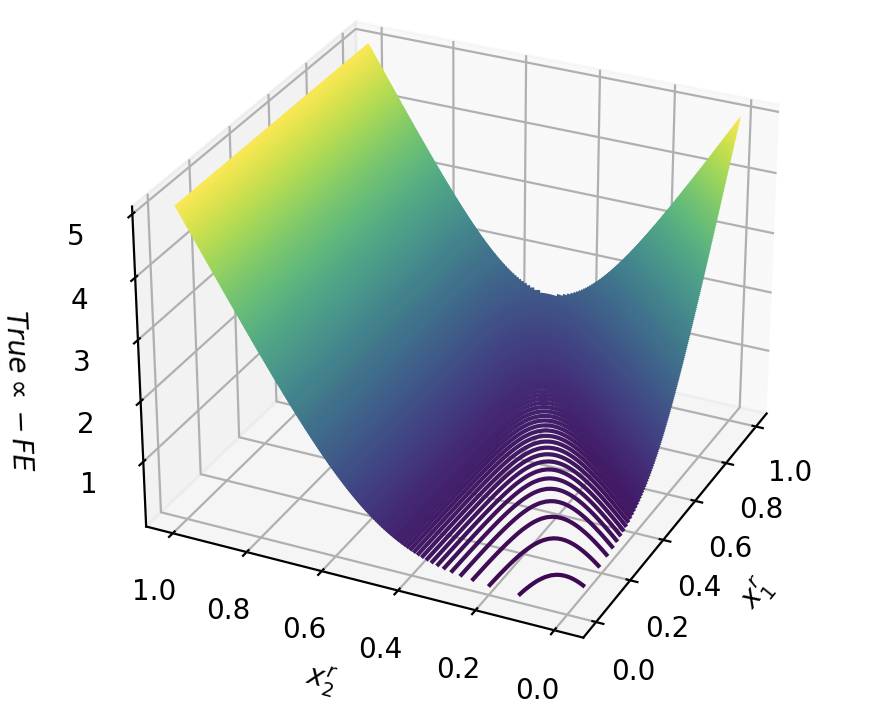
### Visual Description
## 3D Surface Plot: True α - FE vs. x₁' and x₂'
### Overview
The image displays a three-dimensional surface plot. The plot visualizes a continuous, saddle-shaped surface defined over a square domain in the x₁' and x₂' plane. The surface's height (z-axis) is represented by both vertical position and a color gradient, ranging from deep purple at the lowest points to bright yellow at the highest points.
### Components/Axes
* **X-axis (Right):** Labeled `x₁'`. The scale runs from `0.0` to `1.0` with major tick marks at intervals of 0.2 (0.0, 0.2, 0.4, 0.6, 0.8, 1.0).
* **Y-axis (Left):** Labeled `x₂'`. The scale runs from `0.0` to `1.0` with major tick marks at intervals of 0.2 (0.0, 0.2, 0.4, 0.6, 0.8, 1.0).
* **Z-axis (Vertical):** Labeled `True α - FE`. The scale runs from `1` to `5` with major tick marks at integer intervals (1, 2, 3, 4, 5).
* **Color Mapping:** The surface color corresponds to the z-axis value (`True α - FE`). The gradient transitions from dark purple (lowest values, ~1) through teal and green to bright yellow (highest values, ~5). This acts as an implicit legend for the z-axis.
* **Grid:** A light gray wireframe grid is present on the three back planes (x-z, y-z, and x-y) to aid in spatial orientation.
### Detailed Analysis
* **Surface Shape:** The surface forms a classic saddle or hyperbolic paraboloid shape. It has a minimum along the diagonal where `x₁' ≈ x₂'`. As one moves away from this diagonal towards the corners where `x₁'` and `x₂'` are most different (e.g., (1.0, 0.0) or (0.0, 1.0)), the surface rises steeply.
* **Data Trends & Values:**
* **Minimum Region:** The lowest values of `True α - FE` (approaching 1, indicated by dark purple) are found along the line where `x₁' = x₂'`. For example, at the point `(x₁'=0.5, x₂'=0.5)`, the surface is at its lowest.
* **Maximum Regions:** The highest values (approaching 5, indicated by bright yellow) occur at the two opposite corners of the domain: `(x₁'=1.0, x₂'=0.0)` and `(x₁'=0.0, x₂'=1.0)`.
* **Symmetry:** The surface is symmetric about the `x₁' = x₂'` diagonal. The value at `(a, b)` appears equal to the value at `(b, a)`.
* **Contour Lines:** At the base of the plot (on the x-y plane), a series of concentric, curved contour lines are visible. These lines represent curves of constant `True α - FE` value projected onto the domain. They are densest near the center diagonal, indicating a steep gradient, and become more spaced out towards the corners.
### Key Observations
1. **Saddle Point Topology:** The defining feature is the saddle shape, indicating that the function `True α - FE = f(x₁', x₂')` has a minimax property. It is minimized along one direction (the diagonal) and maximized along the orthogonal direction.
2. **Strong Diagonal Dependence:** The value of `True α - FE` is primarily determined by the *difference* between `x₁'` and `x₂'`. When they are equal, the value is low; when they are maximally different, the value is high.
3. **Color-Value Correlation:** The color gradient provides an immediate, intuitive reading of the z-axis magnitude, reinforcing the spatial understanding of the surface's height.
### Interpretation
This plot likely represents the behavior of a function or metric (`True α - FE`) that depends on two normalized parameters (`x₁'` and `x₂'`). The data suggests a fundamental trade-off or interaction:
* **Optimal Condition:** The system or phenomenon being modeled achieves its lowest `True α - FE` state when the two parameters are balanced or equal (`x₁' = x₂'`). This could represent a point of equilibrium, fairness, or minimal error.
* **Penalty for Imbalance:** Any deviation from this balance, where one parameter becomes larger than the other, results in a penalty measured by an increase in `True α - FE`. The penalty grows more severe as the imbalance increases.
* **Symmetry Implication:** The symmetry indicates that the roles of `x₁'` and `x₂'` are interchangeable in their effect on the output. The system does not favor one parameter over the other.
* **Potential Context:** Without specific domain knowledge, this pattern is common in optimization landscapes (showing a valley along a constraint), in fairness metrics (where disparity increases the score), or in models of competition/symbiosis where deviation from a balanced state is costly. The "True α - FE" label suggests it might be a corrected or fundamental version of a metric (α) minus some effect (FE).
</details>
(c) c=10
Figure 10: Free energy corresponding to an OR gate with different confidence values (Example 6).
### 4.1 LBM with Dual Annealing
When representing CNF in a RBM, one option for solving the MaxSAT problem is to utilize stochastic search methods like Gibbs sampling. However, in our scenario, Gibbs sampling exhibits slow convergence, necessitating potentially extensive computational resources to reach equilibrium. To mitigate this challenge, we have adopted simulated annealing, a meta-heuristic technique renowned for addressing global optimization problems [24]. Specifically, we employ dual annealing, which seamlessly integrates global and local search strategies to enhance efficiency [55].
In this approach, the search algorithm initially employs simulated annealing to identify a candidate region within the search space where global optima are likely to be situated. Subsequently, a local search is conducted to precisely pinpoint the location of the global optima. This hybrid strategy combines the exploration capabilities of simulated annealing with the exploitation capabilities of local search, offering a robust and efficient approach to solving MaxSAT problems.
#### 4.1.1 Experimental Results of LBM for MaxSAT
As a preliminary evaluation, we compare the performance of LBM at solving MaxSAT problems with Loandra, a state-of-the-art MaxSAT solver. Loandra was chosen as benchmark solver due to its performance in the MaxSAT Evaluations 2023. Experiments were carried out on a set of challenging MaxSAT instances known as MaxCut, each containing 1,260 clauses. Six distinct MaxCut problem instances were chosen from the MaxSAT 2016 benchmark. Both the LBM and Loandra solvers were run on each of the six instances with a timeout limit of 300 seconds for each run. The instances were chosen to represent diverse problem structures so as to evaluate the capabilities of the solvers without making assumptions about the CNF structure. All experiments were conducted on a standard desktop computer with a AMD ryzen7 5800X 8-core processor and 32 GB DDR4 RAM. The main evaluation metric was the number of satisfied clauses, indicating the solver’s ability to maximize clause satisfaction within the given time constraints.
<details>
<summary>extracted/6466920/figs/ClauseStats4LoandraLBM.png Details</summary>
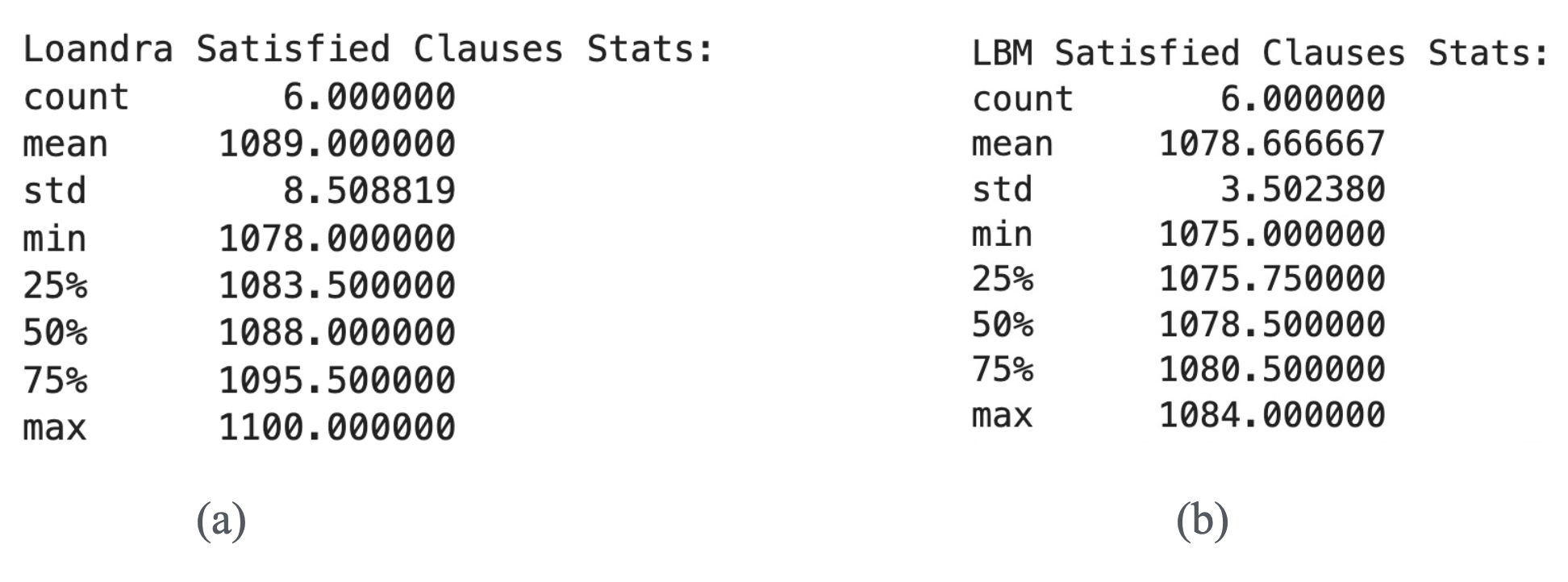
### Visual Description
\n
## Statistical Summary: Comparative Analysis of Satisfied Clauses
### Overview
The image displays two side-by-side statistical summaries, labeled (a) and (b), presenting descriptive statistics for a metric called "Satisfied Clauses" from two different sources or models: "Loandra" and "LBM". The output appears to be from a data analysis or programming environment (e.g., Python's pandas `.describe()` output).
### Components/Axes
The image is divided into two distinct vertical sections:
* **Left Section (a):** Titled "Loandra Satisfied Clauses Stats:".
* **Right Section (b):** Titled "LBM Satisfied Clauses Stats:".
Each section contains an identical set of statistical metrics listed vertically:
* `count`
* `mean`
* `std` (Standard Deviation)
* `min` (Minimum)
* `25%` (25th Percentile / First Quartile)
* `50%` (50th Percentile / Median)
* `75%` (75th Percentile / Third Quartile)
* `max` (Maximum)
### Detailed Analysis
The following table reconstructs the precise numerical data from the image:
| Metric | Loandra (a) | LBM (b) |
| :--- | :--- | :--- |
| **count** | 6.000000 | 6.000000 |
| **mean** | 1089.000000 | 1078.666667 |
| **std** | 8.508819 | 3.502380 |
| **min** | 1078.000000 | 1075.000000 |
| **25%** | 1083.500000 | 1075.750000 |
| **50%** | 1088.000000 | 1078.500000 |
| **75%** | 1095.500000 | 1080.500000 |
| **max** | 1100.000000 | 1084.000000 |
### Key Observations
1. **Sample Size:** Both datasets have an identical count of 6 observations.
2. **Central Tendency:** The mean number of satisfied clauses for Loandra (1089.0) is higher than for LBM (~1078.67). The median (50%) follows the same pattern (1088.0 vs. 1078.5).
3. **Variability:** The standard deviation for Loandra (≈8.51) is more than double that of LBM (≈3.50), indicating significantly greater spread or inconsistency in Loandra's results.
4. **Range:** Loandra's data spans a wider range (1078 to 1100, a range of 22) compared to LBM's narrower range (1075 to 1084, a range of 9).
5. **Distribution Shape:** For Loandra, the mean (1089.0) is slightly higher than the median (1088.0), suggesting a very slight positive skew. For LBM, the mean (~1078.67) and median (1078.5) are nearly identical, suggesting a symmetric distribution.
### Interpretation
This statistical comparison suggests a clear performance trade-off between the two entities (likely algorithms, models, or systems) named "Loandra" and "LBM" regarding the "Satisfied Clauses" metric.
* **Loandra demonstrates higher average performance** but with **lower consistency**. It achieves a higher mean and median score, and its maximum value (1100) is the highest in the dataset. However, its high standard deviation and wide range indicate its performance is more variable; it can produce both high and relatively low scores (its minimum is 1078).
* **LBM demonstrates lower average performance but higher consistency and reliability.** Its scores are clustered more tightly around a lower mean, as evidenced by the low standard deviation and narrow range. Its minimum score (1075) is the lowest in the dataset, but its maximum (1084) is also significantly lower than Loandra's.
**Conclusion:** The choice between Loandra and LBM would depend on the priority. If maximizing the potential number of satisfied clauses is critical and some variability is acceptable, Loandra is the better choice. If predictable, consistent performance with minimal downside risk is the priority, LBM is preferable. The data implies Loandra might be a more powerful but less stable method, while LBM is a more conservative and stable one.
</details>
Figure 11: Statistics for clause satisfaction for (a) Loandra (1089 clauses satisfied on average) and (b) LBM for MaxSAT (1078 clauses satisfied on average).
<details>
<summary>extracted/6466920/figs/SatClausesComparisons.png Details</summary>
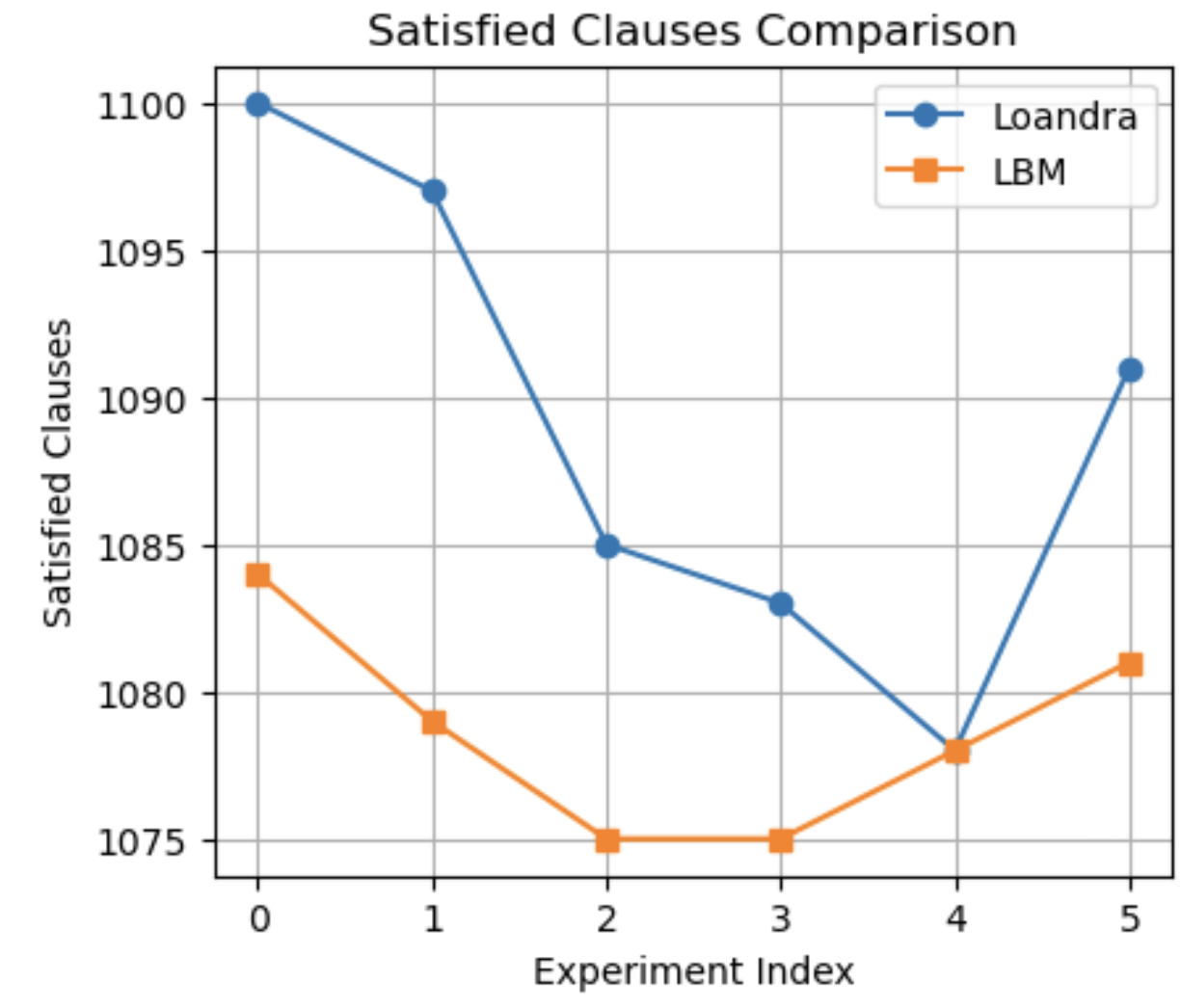
### Visual Description
\n
## Line Chart: Satisfied Clauses Comparison
### Overview
The image displays a line chart comparing the performance of two entities, "Loandra" and "LBM," across six discrete experiments. The chart plots the number of "Satisfied Clauses" against an "Experiment Index." The data shows that Loandra consistently achieves a higher number of satisfied clauses than LBM in all experiments except for experiment index 4, where their performance converges.
### Components/Axes
* **Chart Title:** "Satisfied Clauses Comparison" (centered at the top).
* **Y-Axis (Vertical):**
* **Label:** "Satisfied Clauses"
* **Scale:** Linear scale ranging from 1075 to 1100, with major gridlines and labels at intervals of 5 (1075, 1080, 1085, 1090, 1095, 1100).
* **X-Axis (Horizontal):**
* **Label:** "Experiment Index"
* **Scale:** Discrete integer values from 0 to 5, representing six distinct experiments.
* **Legend:** Located in the top-right corner of the plot area.
* **Series 1:** "Loandra" - Represented by a blue line with circular markers.
* **Series 2:** "LBM" - Represented by an orange line with square markers.
* **Grid:** A light gray grid is present for both axes, aiding in value estimation.
### Detailed Analysis
**Data Series: Loandra (Blue Line, Circular Markers)**
* **Trend:** The series shows a general downward trend from experiment 0 to 4, followed by a sharp recovery at experiment 5. It exhibits higher volatility compared to LBM.
* **Data Points (Approximate):**
* Index 0: 1100
* Index 1: ~1097
* Index 2: 1085
* Index 3: ~1083
* Index 4: ~1078
* Index 5: ~1091
**Data Series: LBM (Orange Line, Square Markers)**
* **Trend:** The series shows a steady decline from experiment 0 to 2, plateaus at experiment 3, and then shows a gradual increase through experiments 4 and 5. It is generally more stable and lower in value than Loandra.
* **Data Points (Approximate):**
* Index 0: ~1084
* Index 1: ~1079
* Index 2: 1075
* Index 3: 1075
* Index 4: ~1078
* Index 5: ~1081
### Key Observations
1. **Performance Gap:** Loandra outperforms LBM in 5 out of 6 experiments. The gap is largest at experiment 0 (~16 clauses) and smallest at experiment 4 (convergence at ~1078).
2. **Convergence Point:** At Experiment Index 4, the two lines intersect, indicating identical or nearly identical performance for that specific experiment.
3. **Divergent Recovery:** After the low point at index 4, both series show improvement at index 5, but Loandra's recovery is significantly more pronounced, jumping ~13 clauses compared to LBM's ~3-clause increase.
4. **Minimum Values:** LBM reaches its minimum value (1075) at indices 2 and 3. Loandra's minimum is at index 4 (~1078).
### Interpretation
The chart demonstrates a comparative analysis of two methods or systems (Loandra and LBM) on a metric called "Satisfied Clauses," likely from a computational logic, optimization, or constraint satisfaction problem domain.
* **Relative Effectiveness:** Loandra is generally the more effective method, satisfying more clauses in most test cases. This suggests it may have a superior underlying algorithm or heuristic for the problem class being tested.
* **Stability vs. Peak Performance:** LBM exhibits more stable, predictable performance with less variance between experiments, but at a lower average level. Loandra shows higher volatility, with a significant drop in performance in the middle experiments (2-4) before a strong rebound. This could indicate sensitivity to specific problem instances or parameters that vary across the experiment indices.
* **The Anomaly at Index 4:** The convergence at experiment 4 is a critical data point. It implies that for the specific conditions of that experiment, the inherent advantages of Loandra were nullified, or the problem instance was such that both methods performed equally. Investigating the properties of experiment 4 could reveal important limitations or edge cases for the Loandra method.
* **Experimental Design:** The use of a discrete "Experiment Index" suggests a controlled test suite where each index represents a different problem instance, configuration, or dataset. The chart effectively communicates how the methods' relative performance shifts across these different scenarios.
</details>
Figure 12: Performance of LBM and Loandra on 6 MaxCut experiments (0 to 5).
Figure 12 shows the number of clauses satisfied by the symbolic SAT solver Loandra and the LBM for MaxSAT approach in each of the 6 experiments. As a state-of-the-art solver, Loandra performed better than LBM in 5 out of 6 cases. However, the difference is relatively small and further investigation is warranted, with numerous directions for future exploration. One possible direction involves investigating alternative global optimization methods such as evolutionary strategies. Another obvious direction is the implementation of parallel computation to improve scalability of LBM search, similar to the approach employed in RBMSAT. As future work, the task of Image Sudoku introduced in [48] is an interesting extension to consider because of the interplay between object recognition and reasoning that is intrinsic to that task and aligned well with LBM’s approach integrating learning and reasoning, which we describe next.
## 5 Integrating Learning and Reasoning in Logical Boltzmann Machines
A key development in neurosymbolic AI will be the ability to add verified modules to existing networks. An RBM that can be shown to be provably equivalent to a given logical formula could act as one such module. A neurosymbolic module placed on top (at the output) of a larger network may serve to constrain that network’s output to satisfy certain properties. In this process, the specification of a neurosymbolic module may benefit from the use of a logical language that is richer (more expressive) than propositional logic. In particular, the use of first-order logic may be required.
In first-order logic, instead of using propositions and connectives alone, logical predicates are used to represent relations among quantified variables. Statements such as $∀ X∃ Y.R(X,Y)$ are used to denote compactly a relation $R$ between variables $X$ and $Y$ in a domain such that for all the values that variable $X$ may admit, there is a value (an instance) of variable $Y$ for which the relation $R$ holds True.
As an example, if we were to rewrite into first-order logic the Boolean logical notation provided earlier for the Sudoku puzzle, we could use a ternary predicate $board(B,P,V)$ , in which:
- $B$ represents the block index (1 to 4),
- $P$ represents the position index within the block (1 to 4), and
- $V$ represents the value (1 to 4),
to make the problem description a lot more compact.
A first-order representation of the constraints of the Sudoku puzzle would include:
1. Existence: $∀ B,P,∃ V.board(B,P,V)$
This ensures that every position in every block is filled with at least one value.
1. Uniqueness: $∀ B,P,V_1,V_2.(board(B,P,V_1)∧ board(B,P,V_2))→ V_ {1}=V_2$
This ensures that no position in the board can hold multiple values.
We will illustrate one way of integrating LBM as a logical layer on top of deep networks applied to a semantic image interpretation task. The task is to predict the relations between objects and their parts in an image. It requires the use of first-order logic. The knowledge base consists of symbolic facts expressing when an object type is normally part of another object type, e.g. ${part}(Screen,TV)$ , where Screen and TV are variables, denoting that TVs have screens. The knowledge base also includes a first-order rule connecting any two visual scenes ( $X_1$ and $X_2$ ) with the symbols of the logic, as follows:
$$
\displaystyle∀ X_1,X_2,∃ T_1,T_2.(({type}(X_1,T_1)
\wedge{type}(X_2,T_2))→ \displaystyle({partOf}(X_1,X_2)↔{part}(T_1,T_2))) \tag{23}
$$
where $X_1$ , $X_2$ are real-valued variables representing visual features of objects (an embedding, pixel values, etc.), as done in [41], and $T_1$ , $T_2$ are symbolic variables representing object types. Predicate ${type}$ is $True$ when an object, as defined by its visual features, is deemed to be of a given type (e.g. an object class). Given two visual scenes with their corresponding type classifications, ${type}(X_1,T_1)$ and ${type}(X_2,T_2)$ , one visual scene will be part of the other, $partOf(X_1,X_2)$ , if and only if the object type of the former is deemed to be part of the object type in the latter, ${part}(T_1,T_2)$ .
In order to implement the above rule, we use Faster-RCNN to extract features from object images, from which we build two Neural Network Regressors (NNR) To represent first-order logic in LBM, we combine LBM with the Neural Network Regressors. Each NNR represents a predicate in the formulae and outputs a truth-value for that predicate. LBM takes as input the truth-values of the predicates coming from the outputs of the NNRs. In essence, LBM sits on top of the NNRs connecting the predicates according to the connectives of the corresponding logic formulae.: $N^type$ and $N^po$ , as learned functions for ${type}$ and ${partOf}$ , respectively, as done in [11]. Finally, we use an autoencoder $N^pt$ to implement the relation ${part}(T_1,T_2)$ between the symbolic variables $T_1$ and $T_2$ , following [51]. Let ${p}^po=N^po(X_1,X_2)$ , ${p}^pt=N^pt(T_1,T_2)$ , ${p}^t_1=N^type(X_1,T_1)$ , ${p}^t_2=N^type(X_2,T_2)$ , ${p}^po,{p}^pt,{p}^t_1,{p}^t_2∈\{0,1\}$ , according to some choice of threshold. The first-order rule (23) can be converted to SDNF, as follows:
| | $\displaystyle({p}^t_1\wedge{p}^t_2)→({p}^po↔ {p}^pt)≡$ | |
| --- | --- | --- |
From this SDNF, we build a LBM as the logical layer on top of the neural networks $N^type$ , $N^po$ and $N^pt$ . Figure 13 shows the overall network architecture.
<details>
<summary>extracted/6466920/figs/lbm_sii.png Details</summary>
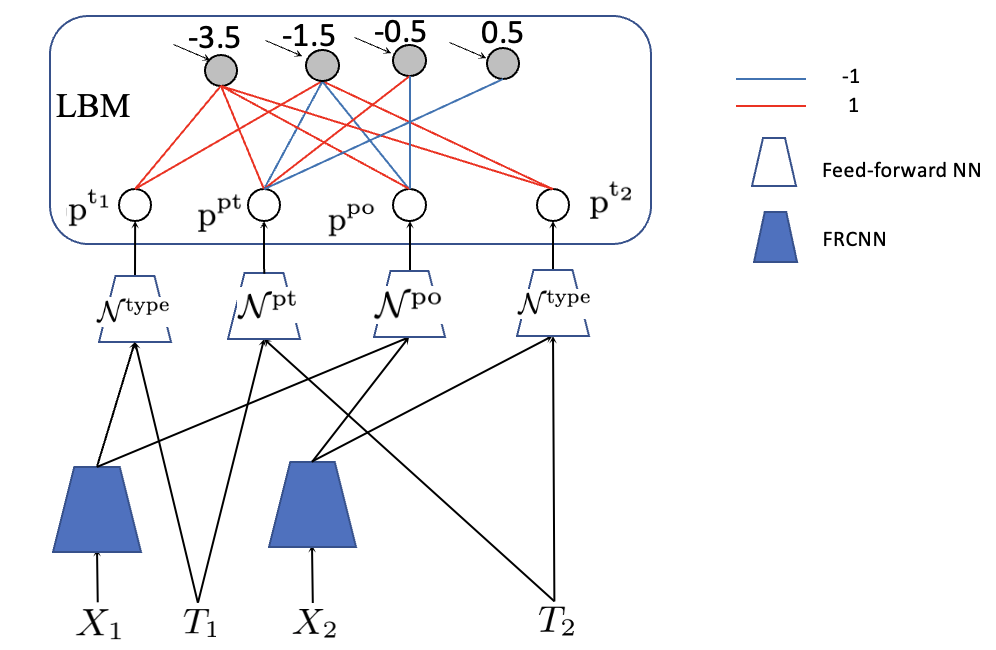
### Visual Description
## Diagram: Hybrid Neural Network Architecture with Latent Bernoulli Model (LBM)
### Overview
The image displays a technical architectural diagram of a machine learning model. It illustrates a hybrid system that combines a **Latent Bernoulli Model (LBM)** with multiple neural network components, including Feed-forward Neural Networks (NN) and what appears to be Feature Representation CNNs (FRCNN). The diagram shows the flow of data from input variables at the bottom, through various processing layers, to latent variables at the top, with weighted connections indicating relationships.
### Components/Axes
The diagram is organized into distinct layers and components:
1. **Top Layer (LBM Box):**
* A large rounded rectangle labeled **"LBM"** (likely Latent Bernoulli Model).
* Contains four **gray circles** (latent variables) with associated numerical values: **-3.5, -1.5, -0.5, 0.5**.
* Contains four **white circles** (probability nodes) labeled: **p^{t1}, p^{pt}, p^{po}, p^{t2}**.
* **Connections:** The gray circles are connected to the white circles via colored lines. A legend defines:
* **Blue line:** Weight of **-1**
* **Red line:** Weight of **1**
2. **Middle Layer (Neural Network Modules):**
* Four **white trapezoids** labeled as **Feed-forward NN** in the legend.
* Their specific labels are: **N_type, N^{pt}, N^{po}, N_type**.
* Each Feed-forward NN is connected directly above to one of the white probability circles (p^{t1}, p^{pt}, etc.).
3. **Bottom Layer (Input & FRCNN Modules):**
* Two **blue trapezoids** labeled as **FRCNN** in the legend.
* **Input Variables:** Four input labels at the very bottom: **X1, T1, X2, T2**.
* **Connections:**
* The left FRCNN receives input from **X1** and **T1**.
* The right FRCNN receives input from **X2** and **T2**.
* Outputs from both FRCNNs and the raw inputs T1 and T2 are connected to the Feed-forward NNs in the middle layer via a network of black lines.
### Detailed Analysis
**Component Isolation & Flow:**
* **Region 1 - LBM (Top):** This is a probabilistic graphical model. The four gray nodes are latent variables with fixed bias values (-3.5 to 0.5). They influence the probability nodes (p^{t1}, etc.) via binary weights (+1 or -1). For example, the leftmost gray node (-3.5) has a red (+1) connection to p^{t1} and a blue (-1) connection to p^{pt}.
* **Region 2 - Neural Network Processing (Middle):** The probability values from the LBM (p^{t1}, p^{pt}, p^{po}, p^{t2}) serve as inputs or modulators to dedicated Feed-forward Neural Networks (N_type, N^{pt}, N^{po}).
* **Region 3 - Input Processing (Bottom):** Raw input data (X1, X2, likely feature vectors) and possibly text or type data (T1, T2) are first processed by FRCNN modules. The outputs of these FRCNNs, along with the raw T1/T2 data, are then fed into the Feed-forward NNs. The crisscrossing lines indicate that each Feed-forward NN receives combined information from multiple sources (e.g., N^{pt} receives input from the left FRCNN, the right FRCNN, and T1).
**Legend Cross-Reference:**
* The legend is positioned in the **top-right** of the image.
* It accurately defines the two line colors (blue=-1, red=1) used in the LBM box.
* It correctly identifies the white trapezoid as "Feed-forward NN" and the blue trapezoid as "FRCNN". All trapezoids in the diagram match these definitions.
### Key Observations
1. **Hybrid Architecture:** The model explicitly combines a structured probabilistic model (LBM) with deep learning components (FRCNN, Feed-forward NN), suggesting a neuro-symbolic or structured prediction approach.
2. **Asymmetric Latent Biases:** The latent variables in the LBM have a clear progression of bias values from strongly negative (-3.5) to slightly positive (0.5), which will create different prior influences on the connected probability nodes.
3. **Complex Connectivity:** The Feed-forward NNs (especially N^{pt} and N^{po}) act as fusion points, integrating processed features from both FRCNN streams and direct inputs (T1, T2). This suggests these modules are responsible for combining multimodal or multi-source information.
4. **Parameter Sharing:** The label "N_type" appears twice, indicating that the same Feed-forward NN architecture (or possibly shared weights) is used for processing the "type" associated with inputs T1 and T2.
### Interpretation
This diagram represents a sophisticated model designed for tasks requiring both perception (via FRCNNs) and structured reasoning (via LBM). The LBM likely models high-level, discrete latent factors or decisions (e.g., object presence, relationship types) that have a binary (+1/-1) influence on intermediate probabilities. These probabilities, along with rich features extracted by the FRCNNs from raw data (X1, X2), are fused in the Feed-forward networks to make final predictions or generate outputs.
The architecture implies a **top-down and bottom-up information flow**: the LBM provides top-down constraints or priors, while the FRCNNs provide bottom-up data-driven features. The system could be used for tasks like visual relationship detection, where the LBM models the compatibility of object pairs (p^{pt} for "pair type"?) and the FRCNNs extract features from the object images (X1, X2). The numerical biases in the LBM would encode the prior likelihood of different relationship types. The overall goal is likely to perform joint inference over both perceptual data and abstract relational concepts.
</details>
Figure 13: Learning and reasoning about the PartOf relation in object images by grounding symbolic concepts into Convolutional Neural Networks and adding a logical layer in the form of a LBM module implementing the rule $({p}^t_1\wedge{p}^t_2)→({p}^po↔{p}^pt)$ .
Reasoning in the LBM can inform learning in $N$ by backpropagating inferred knowledge to update the weights of the CNN, regressor or autoencoder. In particular, we train the entire system by minimizing the following loss function $[N^type(x_1,t_1),N^type(x_2,t_2)]$ denotes the concatenation of the outputs from the $N^type$ networks; $||x||^2_2$ is the squared Euclidean norm.:
| | $\displaystyle||N^po(x_1,x_2)-LBM({p}^po|K(x _1,x_2)||^2_2+$ | |
| --- | --- | --- |
where $x_1,x_2$ and $K(x_1,x_2)$ are obtained from the training data; $K$ denotes the knowledge pertaining to $x_1,x_2$ , i.e. the type of $x_1$ , type of $x_2$ , and whether $x_1$ is part of $x_2$ . We use $LBM({p}^po|K(x_1,x_2))$ and $LBM({p}^t_1,{p}^t_2|K(x_1,x_2))$ to denote the application of LBM to infer the value of ${p}^po$ and of the pair $[{p}^t_1,{p}^t_2]$ , respectively. For example, the LBM is used to infer ${p}^po$ , which is used in turn to update $N^po$ .
Given, for instance, $x_1=∈cludegraphics[width=9.95863pt]{figs/screen.png}$ and $x_2=∈cludegraphics[width=9.95863pt]{figs/tvmonitor.png}$ , let’s assume that we do not know whether $x_1$ is part of $x_2$ . But, if the $N^type$ networks tell us that ${type}(x_1,Screen)≡{True}$ and ${type}(x_2,TV)≡{True}$ and $K(x_1,x_2)$ also includes ${part}(Screen,TV)$ , the LBM can infer that ${p}^po$ should be $True$ . Finally, this signal from the LBM’s reasoning, obtained from the first term of the loss function, is used to update during learning the parameters of $N^po$ . Similarly, the second term of the loss function leverages information about the type of objects to update $N^type$ .
We compared the LBM-enhanced model with three other neurosymbolic systems: Deep Logic Networks (DLN) [50], Logic Tensor Networks (LTN) [11, 2], and Compositional Neural Logic Programming (CNLP) [51]. The task and data set used were the same as in [11], with the exception of the rule $({p}^t_1\wedge{p}^t_2)→({p}^po↔{p}^pt)$ only used by LBM. The area under the curve (AUC) results shown in Table 3 indicate that the use of this single first-order rule for reasoning with the LBM and training of the Faster-RCNN model, also used in [11], produces a higher performance than LTN in the prediction of the part-of relation in images. LBM’s performance is comparable to that of CNLP. For the object type prediction, the LBM model performs better than CNLP, DLN and LTN.
Table 3: Comparison of neurosymbolic approaches; area under the curve (AUC) in the semantic image interpretation task. Source: [52].
| DLN CNLP LTN | $0.791± 0.032$ $0.816± 0.004$ $0.800$ | $0.605± 0.024$ $0.644± 0.015$ $0.598$ |
| --- | --- | --- |
| LBM | $0.828± 0.002$ | $0.645± 0.027$ |
## 6 Challenges for Neurosymbolic AI
We introduced an approach and neurosymbolic system to reason about symbolic knowledge in an energy-based neural network. Differently from most LLM approaches and CoT, where reasoning capabilities are expected to emerge and are measured post-hoc using benchmarks, we use logic to provide a formal definition of reasoning. Only once a well-defined semantics is provided, one can show correspondence between networks and various forms of reasoning. We showed equivalence between propositional logic and RBMs. The finding led to a novel system, named Logical Boltzmann Machines integrating learning and reasoning in neural networks. Future work will focus on scaling up the application to SAT and learning from data and knowledge. Extensions include applications of weighted clauses, weighted SAT with parallel implementation as well as evaluations on relational learning tasks.
Equipped with a proof and algorithm showing how RBMs can implement a category of required constraints, it is possible to imagine how an RBM may be added as a module to an existing network imposing such constraints on the network. This RBM module becomes a verifiable component of the system, implementing for example a fairness or safety requirement as argued for in [16]. Next, we discuss how this simple idea may open up directions for research addressing some of the biggest challenges for current AI: data efficiency, fairness, safety and ultimately trust.
### 6.1 Nonmonotonic Logic
Consider the task of commonsense reasoning, the human-like ability to make sense of ordinary situations, such as making judgments about the nature of objects. It encompasses intuitive psychology (e.g. reasoning about intentions) and naive physics (a natural understanding of the physical world, including spatial and temporal reasoning). Commonsense reasoning requires an ability to jump to conclusions based on incomplete information, and to retract or revise such conclusions when more information become available. There have been many attempts to formalize commonsense, not least the work of John McCarthy who was responsible for coining the term Artificial Intelligence. Because it requires jumping to conclusions and therefore handling logical inconsistencies in a non-classical way, commonsense reasoning is modeled by non-monotonic logics, some of which are undecidable. LLMs have achieved much better results than logical formalizations of commonsense on reasoning benchmarks. It turns out that it is easier to learn commonsense from data than to formalize it logically. Yet, making sense of what has been learned by LLMs has been proven to be a daunting task. Making sense of what has been learned might help tremendously with the efforts to understand the limits of the formalization of commonsense in logic. As neural networks start to be deployed successfully in various fields of scientific discovery, achieving a true understanding of the processes at play will demand such an ability to explain the network’s reasoning.
### 6.2 Planning
AGI will require the ability to plan towards a goal and the ability to ask questions in order to achieve that goal. Planning requires the ability to break-down goals into sub-goals while reasoning with partial information over time. Having a goal, in turn, requires the provision of a description of the current state and the goal state, and a mechanism that reduces the difference (e.g. some distance function) between the current state and the goal state by changing the current state in a reasonable way. If the mechanism isn’t working, one may decide to change the goal or even change the mechanism itself.
Whether in Google’s AlphaGo or Sudoku, the goal state is to win the game, and because it is a closed environment, simulation can be used to learn to minimize the distance function without the need for an explicit description. In open-ended situations, the problem becomes much harder. An explicit description is one that can be manipulated by asking questions: “what might happen if I were to make this or that change?” without making the change. An explicit description needs, therefore, to be amenable to symbolic manipulation. We argue that in open-ended scenarios, an explicit description needs furthermore to be abstracted from the situation given only a few examples. Reasoning in the form of symbol manipulation on that abstract description can then take place that will be of a different nature from reasoning carried out in terms of pattern matching with similarity and distance functions.
### 6.3 Learning from its Mistakes
An AGI system should be able to learn from its mistakes, interact with users by asking questions, describing its understanding and improving its performance in a controlled way towards a goal, even if changing the goal and the mechanism for performance improvement. Controlled at the level of its symbolic description, the system can be made safe. With reasoning taking place at both the pattern matching and the more abstract levels, as advocated by D. Kahneman’s Thinking: Fast and Slow [21], the system will be able to adapt to novelty from only a few examples, check its understanding, multi-task and reuse knowledge from one task to another thus improving data and energy efficiency in comparison with the demands of current AI systems.
Adapting to novelty (therefore solving the long-tail distribution problem and out-of-distribution problem in Machine Learning) requires creating compact representations (in the brain or the mind) but also being able to change that representation from time to time in order to obtain new insight. It is the change of representation that allows one to look at a problem from a new angle to obtain new insight. Think of the difference between two computer programs, both correct for their purpose, one so-called spaghetti code and the other an example of what programmers like to refer to as beautiful code. The former may be faster to run, but the latter needs to be neat, easy to understand and useful to update and reuse. This is the core challenge of the latest research in neurosymbolic AI: extraction of relevant descriptions at the right level of abstraction from complex neural networks, sound application of reasoning and learning with various forms of representation - spatial, temporal, epistemic, normative, multimodal, nonmonotonic - and efficient knowledge and data reuse and extrapolation to multiple tasks in different application domains.
Consider the kind of program learned by the latest GPT-based chatbots. Transformer neural networks work, in essence, by mapping sets to sets and not sequences to sequences (GPT-based chatbots require positional encoding to handle sequences). Interestingly, in neurosymbolic AI, the computation of the semantics of various logics by neural networks is also done by mapping sets to sets recursively [34]. A great innovation of deep learning was multi-headed attention which is similar to representing binary relations in neurosymbolic networks. In certain domains of application, though, such as protein interaction, having the ability to represent not just binary but n-ary relations such as e.g. bond(Compound_Name, Bond_Type, Atom_1, Atom_2) may be very useful. This is the case in the Mutagenesis task and data set, where a chemical compound may have a bond of a certain type between any two atoms and the goal is to identify mutagenic compounds given the atom bonds. Hypergraph neural networks have been used recently to represent and learn n-ary relations [10]. Finally, the neurosymbolic (NeSy) framework of fibring neural networks [14] has been shown recently to offer a common representational foundation for both graph neural networks and transformers via a proof of correspondence with propositional modal logic with self-fibring. These are some of the exciting recent developments in neurosymbolic AI (see the NeSy conference series for more [5]) contributing to both a better understanding of deep learning and the development of new formalisms for learning and reasoning.
## 7 Conclusion
Many influential leaders have been pointing out the risks of current AI and arguing for the adoption of regulation. While it is clear that worldwide regulation is not achievable in the current geopolitical climate (see [30]), an alternative argument is that digital technology itself can offer, as part of an adequate accountability ecosystem, a new path to safer AI. In this new path, neural models can be validated symbolically by adopting the neurosymbolic cycle: train a little, reason a little, repeat. This is quite different from the current scale-is-all-you-need approach or what the EU AI Act has achieved. Regulation without accountability tends to increase weak competitiveness and may not decrease risks.
At first impression, the need for accountability in AI and the risks of current AI may seem to be quite disconnected from the technical contributions of this paper. However, we argue that the kind of formalization offered here is key to accountability, fairness and ultimately a safer AI. If neurosymbolic AI can show that compact network modules behave according to a given formal semantics then these modules can be composed in ways that will offer guarantees to the overall system. Of course, this continues to be an important research challenge, but results such as the ones reported in this paper point to an alternative to the current approach to AI, best illustrated by Figure 13, where a requirement (or a guardrail) can be implemented as a neurosymbolic network module on top of an existing complex network. For this reason, we conclude with a short summary and opinion on the need for accountability in AI.
The need for accountability in AI is now center stage, as indicated by the following quote from [20]: “A long-standing concern among analysts of AI development is the possibility of a race to the bottom in which multiple players feel pressure to neglect safety and security challenges in order to remain competitive. Perceptions - and therefore signals - are key variables in this scenario. Most actors would presumably prefer to have time to ensure their AI systems are reliable, but the desire to be first, the pressure to go to market, and the idea that competitors might be cutting corners can all push developers to be less cautious. Accordingly, signaling has an important role to play in mitigating race-to-the-bottom dynamics. Parties developing AI systems could emphasize their commitment to restraint, their focus on developing safe and trustworthy systems, or both. Ideally, credible signals on these points can reassure other parties that all sides are taking due care, mitigating pressure to race to the bottom”. In [36], the authors go further, arguing for an accountability in AI ecosystem. They propose to map out the general principles of AI into industry-specific mechanisms, having stated as early as 2021: “at present the ecosystem is unbalanced, which can be seen in the failures of certain mechanisms that have been attempted by leading technology companies. By taking an ecosystem perspective, we can identify certain elements that need developing and bolstering in order for the system as a whole to function effectively. Corporate governance mechanisms such as standardized processes and internal audit frameworks, leading up to potential external accreditation, need to be made to work together in ways that go beyond regulatory requirements, especially in technologies’ early period of evolution and deployment when regulation lags practice.”
As part of a case study carried out with a global software provider operating primarily in the gambling sector with a focus on online gambling, [36] reports on the use of AI to help reduce harm from gambling. The application of AI in responsible gambling has been a relevant use case because of the high regulatory focus, divergent regulatory perspectives worldwide, and a longstanding debate over ethical dilemmas relating to an increase in gambling addiction. Results are drawn from the risk profiling of gambling behavior using neural networks and explainability. The neural network performs classification of problem gambling. Explainable AI evaluates indirect gender bias and the need for algorithmic fairness. Results are analyzed in connection with the proposed accountability ecosystem and its operationalization. The AI accountability ecosystem has as stakeholders: corporate actors, market counterparts, civil society and government, alongside mechanisms such as internal auditing, external accreditation, investigative journalism, risk-based regulation and market shaping. Two key elements of the accountability ecosystem are discussed in detail: (i) interventions to reduce bias and (ii) increased transparency via model explainability. The benefits of having an industry-specific accountability process are illustrated in that it can be documented, reviewed, benchmarked, challenged and improved upon, “both to build trust that the underlying ethical principle is being taken seriously and to identify specific areas to do more.” [36]. The paper’s conclusions support the importance of industry-specific approaches in the operationalization of accountability principles in AI, noting how different metrics, priorities and accountability processes arise in online gambling compared to what might arise in other industries. Taken alongside relevant regulatory efforts on information security and privacy, accountability in AI is expected to reduce the risks of imbalances in regulation.
Widespread use of GPT-style chatbots is expected to increase productivity but also magnify errors, as humans become complacent in the use of the technology. When trying to distinguish genuine from malicious websites, people have learned over the years to look for grammatical errors, the quality of images and other cues. Learning whether or not to trust the output of LLMs is much harder. At this unique juncture when AI leaves the research laboratory and enters everyday life, new ways of doing the things that we are used to and take for granted will need to be decided upon and implemented quickly, until a better way of doing AI comes that will offer safety guarantees to AI systems.
## References
- [1] Saeed Amizadeh, Sergiy Matusevych, and Markus Weimer. Learning to solve circuit-sat: An unsupervised differentiable approach. In ICLR, 2019.
- [2] Samy Badreddine, Artur d’Avila Garcez, Luciano Serafini, and Michael Spranger. Logic tensor networks. Artificial Intelligence, 303:103649, 2022.
- [3] Michael Bain and Stephen Muggleton. Learning optimal chess strategies. In K. Furukawa, D. Michie, and S. Muggleton, editors, Machine intelligence 13: machine intelligence and inductive learning, pages 291–309. Oxford University Press, Inc., New York, NY, USA, 1994.
- [4] Jeremias Berg, Antti Hyttinen, and Matti Jarvisalo. Applications of maxsat in data analysis. In Daniel Le Berre and Matti Jarvisalo, editors, Proceedings of Pragmatics of SAT 2015 and 2018, volume 59 of EPiC Series in Computing, pages 50–64. EasyChair, 2019.
- [5] Tarek R. Besold, Artur d’Avila Garcez, Ernesto Jiménez-Ruiz, Roberto Confalonieri, Pranava Madhyastha, and Benedikt Wagner, editors. Neural-Symbolic Learning and Reasoning - 18th International Conference, NeSy 2024, Barcelona, Spain, September 9-12, 2024, Proceedings, Part I, volume 14979 of Lecture Notes in Computer Science. Springer, 2024.
- [6] William W. Cohen, Fan Yang, and Kathryn Mazaitis. Tensorlog: Deep learning meets probabilistic dbs. CoRR, abs/1707.05390, 2017.
- [7] A. d’Anjou, M. Graña, F. J. Torrealdea, and M. C. Hernandez. Solving satisfiability via Boltzmann machines. IEEE Trans. Pattern Anal. Mach. Intell., 15(5):514–521, may 1993.
- [8] A. d’Avila Garcez, K. Broda, and D. Gabbay. Symbolic knowledge extraction from trained neural networks: A sound approach. Artif. Intel., 125(1–2):155–207, 2001.
- [9] A. d’Avila Garcez, L. C. Lamb, and D. M. Gabbay. Neural-Symbolic Cognitive Reasoning. Springer, 2009.
- [10] João Pedro Gandarela de Souza, Gerson Zaverucha, and Artur d’Avila Garcez. Hypergraph neural networks with logic clauses. In International Joint Conference on Neural Networks, IJCNN 2024, Yokohama, Japan, June 30 - July 5, 2024, pages 1–8. IEEE, 2024.
- [11] I. Donadello, L. Serafini, and A. S. d’Avila Garcez. Logic tensor networks for semantic image interpretation. In IJCAI-17, pages 1596–1602, 2017.
- [12] R. Evans and E. Grefenstette. Learning explanatory rules from noisy data. JAIR, 61:1–64, 2018.
- [13] M. França, G. Zaverucha, and A. d’Avila Garcez. Fast relational learning using bottom clause propositionalization with artificial neural networks. Mach. Learning, 94(1):81–104, 2014.
- [14] Artur d’Avila Garcez and Dov M. Gabbay. Fibring neural networks. In Proceedings of the 19th National Conference on Artifical Intelligence, AAAI’04, page 342–347. AAAI Press, 2004.
- [15] Artur d’Avila Garcez and Luís C. Lamb. Neurosymbolic AI: the 3 rd wave. Artif. Intell. Rev., 56(11):12387–12406, March 2023.
- [16] Eleonora Giunchiglia, Alex Tatomir, Mihaela Cătălina Stoian, and Thomas Lukasiewicz. Ccn+: A neuro-symbolic framework for deep learning with requirements. International Journal of Approximate Reasoning, 171:109124, 2024. Synergies between Machine Learning and Reasoning.
- [17] C. Hernandez, F. Albizuri, A. DAnjou, M. Graña, and Francisco Torrealdea. Efficient solution of max-sat and sat via higher order boltzmann. Revista Investigación Operacional, 22, 01 2001.
- [18] M. C. Hernandez, F. X. Albizuri, A. d’Anjou, M. Graña, and F. J. Torrealdea. High-order Boltzmann machines for MAX-SAT and SAT. In Stan Gielen and Bert Kappen, editors, ICANN ’93, pages 479–479, London, 1993. Springer London.
- [19] Geoffrey E. Hinton, Simon Osindero, and Yee-Whye Teh. A fast learning algorithm for deep belief nets. Neural Comput., 18(7):1527–1554, July 2006.
- [20] Andrew Imbrie, Owen Daniels, and Helen Toner. Decoding intentions. https://cset.georgetown.edu/publication/decoding-intentions/, October 2023. Center for Security and Emerging Technology [Online; accessed 20-Jan-2025].
- [21] Daniel Kahneman. Thinking, fast and slow. Farrar, Straus and Giroux, New York, 2011.
- [22] Tiepelt Marcel Kevin and Singh Tilak Raj. Finding pre-production vehicle configurations using a maxsat framework. In 18th International Configuration Workshop, pages 117––122. École des Mines d’Albi-Carmaux, 2016.
- [23] Ross D. King, Michael J. E. Sternberg, and Ashwin Srinivasan. Relating chemical activity to structure: An examination of ilp successes. New Generation Computing, 13(3), Dec 1995.
- [24] S. Kirkpatrick, C. D. Gelatt, and M. P. Vecchi. Optimization by simulated annealing. Science, 220(4598):671–680, 1983.
- [25] Mohit Kumar, Samuel Kolb, Stefano Teso, and Luc De Raedt. Learning max-sat from contextual examples for combinatorial optimisation. Proceedings of the AAAI Conference on Artificial Intelligence, 34(04):4493–4500, Apr. 2020.
- [26] Hugo Larochelle, Michael Mandel, Razvan Pascanu, and Yoshua Bengio. Learning algorithms for the classification restricted boltzmann machine. J. Mach. Learn. Res., 13(1):643–669, March 2012.
- [27] Minghao Liu, Pei Huang, Fuqi Jia, Fan Zhang, Yuchen Sun, Shaowei Cai, Feifei Ma, and Jian Zhang. Can graph neural networks learn to solve the maxsat problem? (student abstract). Proceedings of the AAAI Conference on Artificial Intelligence, 37(13):16264–16265, Sep. 2023.
- [28] Dmitry Malioutov and Kuldeep S. Meel. Mlic: A maxsat-based framework for learning interpretable classification rules. August 2018.
- [29] Robin Manhaeve, Sebastijan Dumancic, Angelika Kimmig, Thomas Demeester, and Luc De Raedt. DeepProbLog: Neural probabilistic logic programming. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems 31, pages 3749–3759. Curran Associates, Inc., 2018.
- [30] Chris Miller. Chip War: The Fight for the World’s Most Critical Technology. Scribner, New York, 2022.
- [31] Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models, 2024.
- [32] Antonio Morgado, Mark Liffiton, and Joao Marques-Silva. Maxsat-based mcs enumeration. In Armin Biere, Amir Nahir, and Tanja Vos, editors, Hardware and Software: Verification and Testing, pages 86–101, Berlin, Heidelberg, 2013. Springer Berlin Heidelberg.
- [33] Kwun Ho Ngan, James Phelan, Esma Mansouri-Benssassi, Joe Townsend, and Artur d’Avila Garcez. Closing the neural-symbolic cycle: Knowledge extraction, user intervention and distillation from convolutional neural networks. In Artur d’Avila Garcez, Tarek R. Besold, Marco Gori, and Ernesto Jiménez-Ruiz, editors, Proceedings of the 17th International Workshop on Neural-Symbolic Learning and Reasoning, La Certosa di Pontignano, Siena, Italy, July 3-5, 2023, volume 3432 of CEUR Workshop Proceedings, pages 19–43. CEUR-WS.org, 2023.
- [34] Simon Odense and Artur d’Avila Garcez. A semantic framework for neurosymbolic computation. Artif. Intell., 340:104273, 2025.
- [35] L. de Penning, A. d’Avila Garcez, L.C. Lamb, and J-J. Meyer. A neural-symbolic cognitive agent for online learning and reasoning. In IJCAI, pages 1653–1658, 2011.
- [36] Chris Percy, Simo Dragicevic, Sanjoy Sarkar, and Artur d’Avila Garcez. Accountability in AI: from principles to industry-specific accreditation. CoRR, abs/2110.09232, 2021.
- [37] G. Pinkas. Reasoning, nonmonotonicity and learning in connectionist networks that capture propositional knowledge. Artif. Intell., 77(2):203–247, 1995.
- [38] Gadi Pinkas. Symmetric neural networks and propositional logic satisfiability. Neural Comput., 3(2):282–291, June 1991.
- [39] Matthew Richardson and Pedro Domingos. Markov logic networks. Mach. Learn., 62(1-2):107–136, February 2006.
- [40] Daniel Selsam, Matthew Lamm, Benedikt Bünz, Percy Liang, Leonardo de Moura, and David L. Dill. Learning a SAT solver from single-bit supervision. In International Conference on Learning Representations, 2019.
- [41] Luciano Serafini and Artur d’Avila Garcez. Learning and reasoning with logic tensor networks. In AI*IA, pages 334–348, 2016.
- [42] Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, and Ross Anderson. The curse of recursion: Training on generated data makes models forget. ArXiv, abs/2305.17493, 2023.
- [43] Xujie Si, Xin Zhang, Radu Grigore, and Mayur Naik. Maximum satisfiability in software analysis: Applications and techniques. In Rupak Majumdar and Viktor Kuncak, editors, Computer Aided Verification - 29th International Conference, CAV 2017, Heidelberg, Germany, July 24-28, 2017, Proceedings, Part I, volume 10426 of Lecture Notes in Computer Science, pages 68–94. Springer, 2017.
- [44] P. Smolensky. Constituent structure and explanation in an integrated connectionist/symbolic cognitive architecture. In Connectionism: Debates on Psychological Explanation. 1995.
- [45] Volker Sperschneider. Bioinformatics: Problem Solving Paradigms. Springer Publishing Company, Incorporated, 2008.
- [46] A. Srinivasan. The Aleph manual. http://www.cs.ox.ac.uk/activities/machlearn/Aleph/aleph.html, 2007. Accessed: 2021-01-23.
- [47] A. Srinivasan, S. H. Muggleton, R.D. King, and M.J.E. Sternberg. Mutagenesis: Ilp experiments in a non-determinate biological domain. In Proceedings of the 4th International Workshop on Inductive Logic Programming, volume 237 of GMD-Studien, pages 217–232, 1994.
- [48] Wolfgang Stammer, Antonia Wüst, David Steinmann, and Kristian Kersting. Neural concept binder. CoRR, abs/2406.09949, 2024.
- [49] G. Towell and J. Shavlik. Knowledge-based artificial neural networks. Artif. Intel., 70:119–165, 1994.
- [50] S. Tran and A. Garcez. Deep logic networks: Inserting and extracting knowledge from deep belief networks. IEEE T. Neur. Net. Learning Syst., (29):246–258, 2018.
- [51] Son N. Tran. Compositional neural logic programming. In Zhi-Hua Zhou, editor, Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, pages 3059–3066. International Joint Conferences on Artificial Intelligence Organization, 8 2021. Main Track.
- [52] Son N. Tran and Artur d’Avila Garcez. Neurosymbolic reasoning and learning with restricted boltzmann machines. Proceedings of the AAAI Conference on Artificial Intelligence, 37(5):6558–6565, Jun. 2023.
- [53] Po-Wei Wang, Priya L. Donti, Bryan Wilder, and J. Zico Kolter. SATNet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pages 6545–6554. PMLR, 2019.
- [54] David Warde-Farley, Vinod Nair, Yujia Li, Ivan Lobov, Felix Gimeno, and Simon Osindero. Solving maxsat with matrix multiplication, 2023.
- [55] Y Xiang, D.Y Sun, W Fan, and X.G Gong. Generalized simulated annealing algorithm and its application to the thomson model. Physics Letters A, 233(3):216–220, 1997.
- [56] Fan Yang, Zhilin Yang, and William W Cohen. Differentiable learning of logical rules for knowledge base reasoning. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30, pages 2319–2328. Curran Associates, Inc., 2017.