# Experience-based Knowledge Correction for Robust Planning in Minecraft
footnotetext: Corresponding author: Jungseul Ok <jungseul@postech.ac.kr>
Abstract
Large Language Model (LLM)-based planning has advanced embodied agents in long-horizon environments such as Minecraft, where acquiring latent knowledge of goal (or item) dependencies and feasible actions is critical. However, LLMs often begin with flawed priors and fail to correct them through prompting, even with feedback. We present XENON (eXpErience-based kNOwledge correctioN), an agent that algorithmically revises knowledge from experience, enabling robustness to flawed priors and sparse binary feedback. XENON integrates two mechanisms: Adaptive Dependency Graph, which corrects item dependencies using past successes, and Failure-aware Action Memory, which corrects action knowledge using past failures. Together, these components allow XENON to acquire complex dependencies despite limited guidance. Experiments across multiple Minecraft benchmarks show that XENON outperforms prior agents in both knowledge learning and long-horizon planning. Remarkably, with only a 7B open-weight LLM, XENON surpasses agents that rely on much larger proprietary models. Project page: https://sjlee-me.github.io/XENON
1 Introduction
Large Language Model (LLM)-based planning has advanced in developing embodied AI agents that tackle long-horizon goals in complex, real-world-like environments (Szot et al., 2021; Fan et al., 2022). Among such environments, Minecraft has emerged as a representative testbed for evaluating planning capability that captures the complexity of such environments (Wang et al., 2023b; c; Zhu et al., 2023; Yuan et al., 2023; Feng et al., 2024; Li et al., 2024b). Success in these environments often depends on agents acquiring planning knowledge, including the dependencies among goal items and the valid actions needed to obtain them. For instance, to obtain an iron nugget
<details>
<summary>x1.png Details</summary>

### Visual Description
Icon/Small Image (23x20)
</details>
, an agent should first possess an iron ingot
<details>
<summary>x2.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
, which can only be obtained by the action smelt.
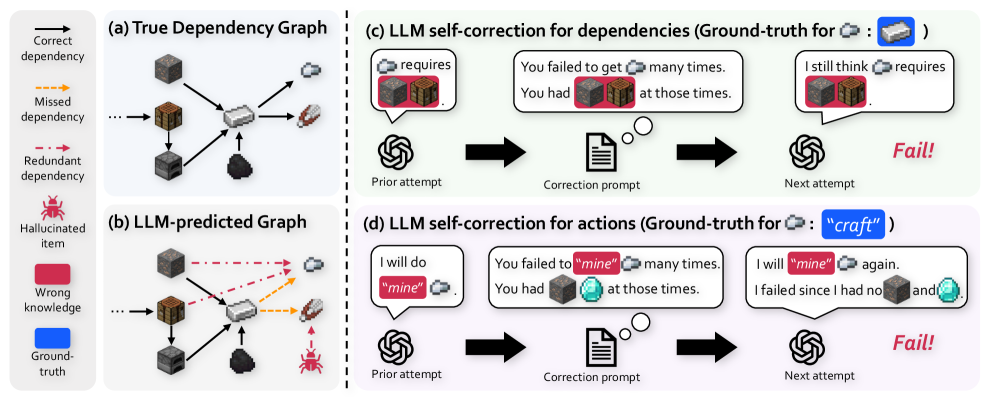
However, LLMs often begin with flawed priors about these dependencies and actions. This issue is indeed critical, since a lack of knowledge for a single goal can invalidate all subsequent plans that depend on it (Guss et al., 2019; Lin et al., 2021; Mao et al., 2022). We find several failure cases stemming from these flawed priors, a problem that is particularly pronounced for the lightweight LLMs suitable for practical embodied agents. First, an LLM often fails to predict planning knowledge accurately enough to generate a successful plan (Figure ˜ 1 b), resulting in a complete halt in progress toward more challenging goals. Second, an LLM cannot robustly correct its flawed knowledge, even when prompted to self-correct with failure feedback (Shinn et al., 2023; Chen et al., 2024), often repeating the same errors (Figures 1 c and 1 d). To improve self-correction, one can employ more advanced techniques that leverage detailed reasons for failure (Zhang et al., 2024; Wang et al., 2023a). Nevertheless, LLMs often stubbornly adhere to their erroneous parametric knowledge (i.e. knowledge implicitly stored in model parameters), as evidenced by Stechly et al. (2024) and Du et al. (2024).
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: LLM Dependency and Action Prediction
### Overview
The image presents a comparison between true dependency graphs and Large Language Model (LLM)-predicted graphs for Minecraft item crafting, along with examples of LLM self-correction attempts for dependencies and actions. The image is divided into four sections: (a) True Dependency Graph, (b) LLM-predicted Graph, (c) LLM self-correction for dependencies, and (d) LLM self-correction for actions.
### Components/Axes
**Legend (Left Side):**
* **Correct dependency:** Solid black arrow.
* **Missed dependency:** Dashed orange arrow.
* **Redundant dependency:** Dashed red arrow.
* **Hallucinated item:** Red bug-like icon.
* **Wrong knowledge:** Red filled square.
* **Ground-truth:** Blue filled square.
**Section (a): True Dependency Graph**
* Nodes: Minecraft items (stone, planks, iron ingot, furnace, coal, flint and steel).
* Edges: Solid black arrows indicating correct dependencies.
**Section (b): LLM-predicted Graph**
* Nodes: Minecraft items (stone, planks, iron ingot, furnace, coal, flint and steel, spider).
* Edges: Solid black arrows, dashed orange arrows, and dashed red arrows indicating correct, missed, and redundant dependencies, respectively.
**Section (c): LLM self-correction for dependencies**
* Flow: Prior attempt (LLM icon) -> Correction prompt (document icon) -> Next attempt (LLM icon).
* Speech bubbles containing LLM output.
**Section (d): LLM self-correction for actions**
* Flow: Prior attempt (LLM icon) -> Correction prompt (document icon) -> Next attempt (LLM icon).
* Speech bubbles containing LLM output.
### Detailed Analysis
**Section (a): True Dependency Graph**
* Planks require stone.
* Iron ingot requires furnace and coal.
* Flint and steel requires iron ingot.
* Furnace requires stone.
**Section (b): LLM-predicted Graph**
* Planks require stone.
* Iron ingot requires furnace and coal.
* Iron ingot requires planks (correct dependency).
* Flint and steel requires iron ingot (correct dependency).
* Flint and steel requires planks (missed dependency).
* Flint and steel requires spider (redundant dependency).
**Section (c): LLM self-correction for dependencies (Ground-truth for: Iron Ingot)**
* **Prior attempt:** "requires" [Stone] and [Planks].
* **Correction prompt:** "You failed to get [Iron Ingot] many times. You had [Stone] and [Planks] at those times."
* **Next attempt:** "I still think [Stone] and [Planks] requires [Iron Ingot]." Result: Fail!
**Section (d): LLM self-correction for actions (Ground-truth for: "craft")**
* **Prior attempt:** "I will do "mine" [Iron Ingot]."
* **Correction prompt:** "You failed to "mine" [Iron Ingot] many times. You had [Stone] and [Diamond] at those times."
* **Next attempt:** "I will "mine" [Iron Ingot] again. I failed since I had no [Stone] and [Diamond]." Result: Fail!
### Key Observations
* The LLM-predicted graph in (b) contains both correct and incorrect dependencies, including a "hallucinated item" (spider) as a dependency for flint and steel.
* The self-correction attempts in (c) and (d) fail to achieve the ground-truth dependencies and actions, respectively.
### Interpretation
The image highlights the challenges faced by LLMs in accurately predicting dependencies and actions in a complex environment like Minecraft crafting. The LLM exhibits both correct and incorrect knowledge, and its self-correction mechanisms are not always effective in rectifying errors. The presence of "hallucinated items" and incorrect dependencies suggests that the LLM may be prone to generating information that is not grounded in the true relationships between items and actions. The failure of the self-correction attempts indicates that the LLM struggles to learn from feedback and adjust its predictions accordingly.
</details>
Figure 1: An LLM exhibits flawed planning knowledge and fails at self-correction. (b) The dependency graph predicted by Qwen2.5-VL-7B (Bai et al., 2025) contains multiple errors (e.g., missed dependencies, hallucinated items) compared to (a) the ground truth. (c, d) The LLM fails to correct its flawed knowledge about dependencies and actions from failure feedbacks, often repeating the same errors. See Appendix ˜ B for the full prompts and LLM’s self-correction examples.
In response, we propose XENON (eXpErience-based kNOwledge correctioN), an agent that robustly learns planning knowledge from only binary success/failure feedback. To this end, instead of relying on an LLM for correction, XENON algorithmically and directly revises its external knowledge memory using its own experience, which in turn guides its planning. XENON learns this planning knowledge through two synergistic components. The first component, Adaptive Dependency Graph (ADG), revises flawed dependency knowledge by leveraging successful experiences to propose plausible new required items. The second component, Failure-aware Action Memory (FAM), builds and corrects its action knowledge by exploring actions upon failures. In the challenging yet practical setting of using only binary feedbacks, FAM enables XENON to disambiguate the cause of a failure, distinguishing between flawed dependency knowledge and invalid actions, which in turn triggers a revision in ADG for the former.
Extensive experiments in three Minecraft testbeds show that XENON excels at both knowledge acquisition and planning. XENON outperforms prior agents in learning knowledge, showing unique robustness to LLM hallucinations and modified ground-truth environmental rules. Furthermore, with only a 7B LLM, XENON significantly outperforms prior agents that rely on much larger proprietary models like GPT-4 in solving diverse long-horizon goals. These results suggest that robust algorithmic knowledge management can be a promising direction for developing practical embodied agents with lightweight LLMs (Belcak et al., 2025).
Our contributions are as follows. First, we propose XENON, an LLM-based agent that robustly learns planning knowledge from experience via algorithmic knowledge correction, instead of relying on the LLM to self-correct its own knowledge. We realize this idea through two synergistic mechanisms that explicitly store planning knowledge and correct it: Adaptive Dependency Graph (ADG) for correcting dependency knowledge based on successes, and Failure-aware Action Memory (FAM) for correcting action knowledge and disambiguating failure causes. Second, extensive experiments demonstrate that XENON significantly outperforms prior state-of-the-art agents in both knowledge learning and long-horizon goal planning in Minecraft.
2 Related work
2.1 LLM-based planning in Minecraft
Prior work has often address LLMs’ flawed planning knowledge in Minecraft using impractical methods. For example, such methods typically involve directly injecting knowledge through LLM fine-tuning (Zhao et al., 2023; Feng et al., 2024; Liu et al., 2025; Qin et al., 2024) or relying on curated expert data (Wang et al., 2023c; Zhu et al., 2023; Wang et al., 2023a).
Another line of work attempts to learn planning knowledge via interaction, by storing the experience of obtaining goal items in an external knowledge memory. However, these approaches are often limited by unrealistic assumptions or lack robust mechanisms to correct the LLM’s flawed prior knowledge. For example, ADAM and Optimus-1 artificially simplify the challenge of predicting and learning dependencies via shortcuts like pre-supplied items, while also relying on expert data such as learning curriculum (Yu and Lu, 2024) or Minecraft wiki (Li et al., 2024b). They also lack a robust way to correct wrong action choices in a plan: ADAM has none, and Optimus-1 relies on unreliable LLM self-correction. Our most similar work, DECKARD (Nottingham et al., 2023), uses an LLM to predict item dependencies but does not revise its predictions for items that repeatedly fail, and when a plan fails, it cannot disambiguate whether the failure is due to incorrect dependencies or incorrect actions. In contrast, our work tackles the more practical challenge of learning planning knowledge and correcting flawed priors from only binary success/failure feedback.
2.2 LLM-based self-correction
LLM self-correction, i.e., having an LLM correct its own outputs, is a promising approach to overcome the limitations of flawed parametric knowledge. However, for complex tasks like planning, LLMs struggle to identify and correct their own errors without external feedback (Huang et al., 2024; Tyen et al., 2024). To improve self-correction, prior works fine-tune LLMs (Yang et al., 2025) or prompt LLMs to correct themselves using environmental feedback (Shinn et al., 2023) and tool-execution results (Gou et al., 2024). While we also use binary success/failure feedbacks, we directly correct the agent’s knowledge in external memory by leveraging experience, rather than fine-tuning the LLM or prompting it to self-correct.
3 Preliminaries
We aim to develop an agent capable of solving long-horizon goals by learning planning knowledge from experience. As a representative environment which necessitates accurate planning knowledge, we consider Minecraft as our testbed. Minecraft is characterized by strict dependencies among game items (Guss et al., 2019; Fan et al., 2022), which can be formally represented as a directed acyclic graph $\mathcal{G}^{*}=(\mathcal{V}^{*},\mathcal{E}^{*})$ , where $\mathcal{V}^{*}$ is the set of all items and each edge $(u,q,v)∈\mathcal{E}^{*}$ indicates that $q$ quantities of an item $u$ are required to obtain an item $v$ . In our actual implementation, each edge also stores the resulting item quantity, but we omit it from the notation for presentation simplicity, since most edges have resulting item quantity 1 and this multiplicity is not essential for learning item dependencies. A goal is to obtain an item $g∈\mathcal{V}^{*}$ . To obtain $g$ , an agent must possess all of its prerequisites as defined by $\mathcal{G}^{*}$ in its inventory, and perform the valid high-level action in $\mathcal{A}=\{\text{``mine'', ``craft'', ``smelt''}\}$ .
Framework: Hierarchical agent with graph-augmented planning
We employ a hierarchical agent with an LLM planner and a low-level controller, adopting a graph-augmented planning strategy (Li et al., 2024b; Nottingham et al., 2023). In this strategy, agent maintains its knowledge graph $\mathcal{G}$ and plans with $\mathcal{G}$ to decompose a goal $g$ into subgoals in two stages. First, the agent identifies prerequisite items it does not possess by traversing $\hat{\mathcal{G}}$ backward from $g$ to nodes with no incoming edges (i.e., basic items with no known requirements), and aggregates them into a list of (quantity, item) tuples, $((q_{1},u_{1}),...,(q_{L_{g}},u_{L_{g}})=(1,g))$ . Second, the planner LLM converts this list into executable language subgoals $\{(a_{l},q_{l},u_{l})\}_{l=1}^{L_{g}}$ , where it takes each $u_{l}$ as input and outputs a high-level action $a_{l}$ to obtain $u_{l}$ . Then the controller executes each subgoal, i.e., it takes each language subgoal as input and outputs a sequence of low-level actions in the environment to achieve it. After each subgoal execution, the agent receives only binary success/failure feedback.
Problem formulation: Dependency and action learning
To plan correctly, the agent must acquire knowledge of the true dependency graph $\mathcal{G}^{*}$ . However, $\mathcal{G}^{*}$ is latent, making it necessary for the agent to learn this structure from experience. We model this as revising a learned graph, $\hat{\mathcal{G}}=(\hat{\mathcal{V}},\hat{\mathcal{E}})$ , where $\hat{\mathcal{V}}$ contains known items and $\hat{\mathcal{E}}$ represents the agent’s current belief about item dependencies. Following Nottingham et al. (2023), whenever the agent obtains a new item $v$ , it identifies the experienced requirement set $\mathcal{R}_{\text{exp}}(v)$ , the set of (item, quantity) pairs consumed during this item acquisition. The agent then updates $\hat{\mathcal{G}}$ by replacing all existing incoming edges to $v$ with the newly observed $\mathcal{R}_{\text{exp}}(v)$ . The detailed update procedure is in Appendix C.
We aim to maximize the accuracy of learned graph $\hat{\mathcal{G}}$ against true graph $\mathcal{G}^{*}$ . We define this accuracy $N_{true}(\hat{\mathcal{G}})$ as the number of items whose incoming edges are identical in $\hat{\mathcal{G}}$ and $\mathcal{G}^{*}$ , i.e.,
$$
\displaystyle N_{true}(\hat{\mathcal{G}}) \displaystyle\coloneqq\sum_{v\in\mathcal{V}^{*}}\mathbb{I}(\mathcal{R}(v,\hat{\mathcal{G}})=\mathcal{R}(v,\mathcal{G}^{*}))\ , \tag{1}
$$
where the dependency set, $\mathcal{R}(v,\mathcal{G})$ , denotes the set of all incoming edges to the item $v$ in the graph $\mathcal{G}$ .
4 Methods
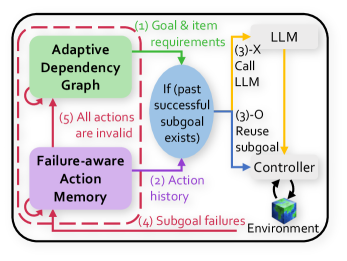
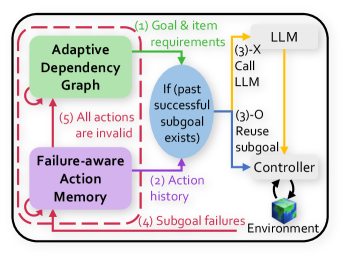
XENON is an LLM-based agent with two core components: Adaptive Dependency Graph (ADG) and Failure-aware Action Memory (FAM), as shown in Figure ˜ 3. ADG manages dependency knowledge, while FAM manages action knowledge. The agent learns this knowledge in a loop that starts by selecting an unobtained item as an exploratory goal (detailed in Appendix ˜ G). Once an item goal $g$ is selected, ADG, our learned dependency graph $\mathcal{G}$ , traverses itself to construct $((q_{1},u_{1}),...,(q_{L_{g}},u_{L_{g}})=(1,g))$ . For each $u_{l}$ in this list, FAM either reuses a previously successful action for $u_{l}$ or, if none exists, the planner LLM selects a high-level action $a_{l}∈\mathcal{A}$ given $u_{l}$ and action histories from FAM. The resulting actions form language subgoals $\{(a_{l},q_{l},u_{l})\}_{l=1}^{L_{g}}$ . The controller then takes each subgoal as input, executes a sequence of low-level actions to achieve it, and returns binary success/failure feedback, which is used to update both ADG and FAM. The full procedure is outlined in Algorithm ˜ 1 in Appendix ˜ D. We next detail each component, beginning with ADG.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Diagram: Adaptive Dependency Graph with Failure-Aware Action Memory
### Overview
The image presents a diagram illustrating an adaptive dependency graph integrated with a failure-aware action memory system, interacting with a Large Language Model (LLM) and a controller within an environment. The diagram outlines the flow of information and control between these components.
### Components/Axes
* **Adaptive Dependency Graph:** Located in the top-left, represented by a green box.
* **Failure-aware Action Memory:** Located in the bottom-left, represented by a purple box.
* **LLM:** Located in the top-right, represented by a gray box.
* **Controller:** Located in the center-right, connected to the environment.
* **Environment:** Located in the bottom-right, represented by a cube.
* **Conditional Check:** An oval shape in the center, labeled "If (past successful subgoal exists)".
* **Arrows:** Indicate the flow of information and control.
### Detailed Analysis
1. **(1) Goal & item requirements:** A green arrow flows from the Adaptive Dependency Graph to the conditional check.
2. **(2) Action history:** A purple arrow flows from the Failure-aware Action Memory to the conditional check.
3. **(3)-X Call LLM:** A yellow arrow flows from the conditional check to the LLM.
4. **(3)-O Reuse subgoal:** A yellow arrow flows from the conditional check to the Controller.
5. **(4) Subgoal failures:** A purple arrow flows from the Controller to the Failure-aware Action Memory.
6. **(5) All actions are invalid:** A green arrow flows from the Failure-aware Action Memory back to the Adaptive Dependency Graph.
7. **Environment Interaction:** The Controller interacts with the Environment.
8. **Feedback Loops:** Red arrows indicate feedback loops between the Adaptive Dependency Graph and the Failure-aware Action Memory.
### Key Observations
* The Adaptive Dependency Graph provides goal and item requirements.
* The Failure-aware Action Memory stores action history and receives subgoal failures.
* The conditional check determines whether to call the LLM or reuse a subgoal based on past successful subgoals.
* The Controller interacts with the environment and provides feedback on subgoal failures.
### Interpretation
The diagram illustrates a system designed to adapt and learn from failures. The Adaptive Dependency Graph manages the goals, while the Failure-aware Action Memory stores and utilizes past action history to avoid repeating unsuccessful actions. The conditional check acts as a decision point, leveraging past successes to either reuse subgoals or call the LLM for new solutions. The feedback loops between the components enable the system to continuously learn and improve its performance within the environment. The system aims to optimize the interaction with the environment by learning from past failures and adapting its strategies accordingly.
</details>
Figure 2: Overview. XENON updates Adaptive Dependency Graph and Failure-aware Action Memory with environmental experiences.
4.1 Adaptive Dependency Graph (ADG)
<details>
<summary>x5.png Details</summary>
### Visual Description
## Diagram: Adaptive Dependency Graph with Failure-Aware Action Memory and LLM Interaction
### Overview
The image presents a diagram illustrating an adaptive dependency graph system that incorporates failure-aware action memory and interacts with a Large Language Model (LLM). The system appears to be designed for goal-oriented tasks within an environment, with mechanisms for adapting to failures and reusing successful subgoals.
### Components/Axes
The diagram consists of the following key components:
* **Adaptive Dependency Graph (Top-Left, Green):** This component likely represents a dynamic structure that models dependencies between actions or subgoals.
* **Failure-aware Action Memory (Bottom-Left, Purple):** This component stores information about past actions and their outcomes, enabling the system to learn from failures.
* **LLM (Top-Right, Gray):** A Large Language Model, used for generating or selecting actions.
* **Controller (Right, Blue):** This component manages the execution of actions and interacts with the environment.
* **Environment (Bottom-Right, Green/Blue):** The external environment in which the system operates.
* **Conditional Check (Center, Blue):** A check for past successful subgoals.
The diagram also includes labeled arrows indicating the flow of information:
* **(1) Goal & item requirements (Top, Green):** Input to the Adaptive Dependency Graph.
* **(2) Action history (Bottom, Purple):** Input to the Failure-aware Action Memory.
* **(3)-X Call LLM (Top-Right, Yellow):** Interaction with the LLM.
* **(3)-O Reuse subgoal (Right, Yellow):** Reuse of a subgoal.
* **(4) Subgoal failures (Bottom, Purple):** Feedback from the environment to the Failure-aware Action Memory.
* **(5) All actions are invalid (Left, Green):** Feedback from the Failure-aware Action Memory to the Adaptive Dependency Graph.
### Detailed Analysis
* **Adaptive Dependency Graph:** Receives "Goal & item requirements" as input. It likely uses this information to construct or update its dependency graph.
* **Failure-aware Action Memory:** Receives "Action history" and "Subgoal failures" as input. This suggests it learns from past experiences, adapting its behavior based on failures.
* **LLM:** Interacts with the Controller via "Call LLM" and "Reuse subgoal" pathways. The LLM likely provides suggestions or actions to the Controller.
* **Controller:** Interacts with the Environment, executing actions and receiving feedback. It also interacts with the LLM and the "Reuse subgoal" pathway.
* **Conditional Check:** The "If (past successful subgoal exists)" component acts as a gate, determining whether a previously successful subgoal can be reused.
### Key Observations
* The system is designed to adapt to failures and reuse successful subgoals.
* The LLM plays a role in generating or selecting actions.
* The Adaptive Dependency Graph and Failure-aware Action Memory are key components for learning and adaptation.
### Interpretation
The diagram illustrates a sophisticated system for goal-oriented tasks that leverages an adaptive dependency graph, failure-aware action memory, and a large language model. The system's ability to learn from failures and reuse successful subgoals suggests a robust and efficient approach to problem-solving in dynamic environments. The interaction with the LLM indicates the potential for leveraging the model's knowledge and reasoning capabilities to improve performance. The system is designed to dynamically adjust its strategy based on past performance and environmental feedback.
</details>
Figure 3: Overview. XENON updates Adaptive Dependency Graph and Failure-aware Action Memory with environmental experiences.
Dependency graph initialization
To make the most of the LLM’s prior knowledge, albeit incomplete, we initialize the learned dependency graph $\hat{\mathcal{G}}=(\hat{\mathcal{V}},\hat{\mathcal{E}})$ using an LLM. We follow the initialization process of DECKARD (Nottingham et al., 2023), which consists of two steps. First, $\hat{\mathcal{V}}$ is assigned $\mathcal{V}_{0}$ , which is the set of goal items whose dependencies must be learned, and $\hat{\mathcal{E}}$ is assigned $\emptyset$ . Second, for each item $v$ in $\hat{\mathcal{V}}$ , the LLM is prompted to predict its requirement set (i.e. incoming edges of $v$ ), aggregating them to construct the initial graph.
However, those LLM-predicted requirement sets often include items not present in the initial set $\mathcal{V}_{0}$ , which is a phenomenon overlooked by DECKARD. Since $\mathcal{V}_{0}$ may be an incomplete subset of all possible game items $\mathcal{V}^{*}$ , we cannot determine whether such items are genuine required items or hallucinated items which do not exist in the environment. To address this, we provisionally accept all LLM requirement set predictions. We iteratively expand the graph by adding any newly mentioned item to $\hat{\mathcal{V}}$ and, in turn, querying the LLM for its own requirement set. This expansion continues until a requirement set has been predicted for every item in $\hat{\mathcal{V}}$ . Since we assume that the true graph $\mathcal{G}^{*}$ is a DAG, we algorithmically prevent cycles in $\hat{\mathcal{G}}$ ; see Section ˜ E.2 for the cycle-check procedure. The quality of this initial LLM-predicted graph is analyzed in detail in Appendix K.1.
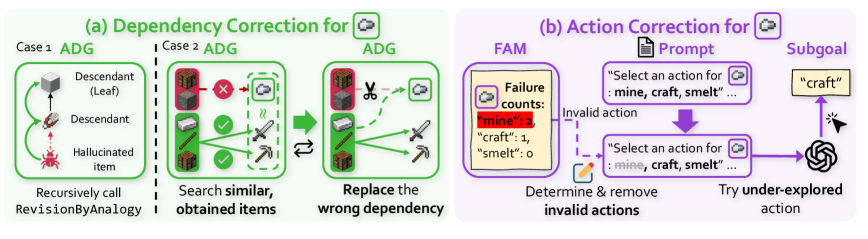
Dependency graph revision
Correcting the agent’s flawed dependency knowledge involves two challenges: (1) detecting and handling hallucinated items from the graph initialization, and (2) proposing a new requirement set. Simply prompting an LLM for corrections is ineffective, as it often predicts a new, flawed requirement set, as shown in Figures 1 c and 1 d. Therefore, we revise $\hat{\mathcal{G}}$ algorithmically using the agent’s experiences, without relying on the LLM.
To implement this, we introduce a dependency revision procedure called RevisionByAnalogy and a revision count $C(v)$ for each item $v∈\hat{\mathcal{V}}$ . This procedure outputs a revised graph by taking item $v$ whose dependency needs to be revised, its revision count $C(v)$ , and the current graph $\hat{\mathcal{G}}$ as inputs, leveraging the required items of previously obtained items. When a revision for an item $v$ is triggered by FAM (Section ˜ 4.2), the procedure first discards $v$ ’s existing requirement set ( $\text{i.e}.\hbox{},\mathcal{R}(v,\hat{\mathcal{G}})←\emptyset$ ). It increments the revision count $C(v)$ for $v$ . Based on whether $C(v)$ exceeds a hyperparameter $c_{0}$ , RevisionByAnalogy proceeds with one of the following two cases:
- Case 1: Handling potentially hallucinated items ( $C(v)>c_{0}$ ). If an item $v$ remains unobtainable after excessive revisions, the procedure flags it as inadmissible to signify that it may be a hallucinated item. This reveals a critical problem: if $v$ is indeed a hallucinated item, any of its descendants in $\hat{\mathcal{G}}$ become permanently unobtainable. To enable XENON to try these descendant items through alternative paths, we recursively call RevisionByAnalogy for all of $v$ ’s descendants in $\hat{\mathcal{G}}$ , removing their dependency on the inadmissible item $v$ (Figure ˜ 4 a, Case 1). Finally, to account for cases where $v$ may be a genuine item that is simply difficult to obtain, its requirement set $\mathcal{R}(v,\hat{\mathcal{G}})$ is reset to a general set of all resource items (i.e. items previously consumed for crafting other items), each with a quantity of hyperparameter $\alpha_{i}$ .
- Case 2: Plausible revision for less-tried items ( $C(v)≤ c_{0}$ ). The item $v$ ’s requirement set, $\mathcal{R}(v,\hat{\mathcal{G}})$ , is revised to determine both a plausible set of new items and their quantities. First, for plausible required items, we use an idea that similar goals often share similar preconditions (Yoon et al., 2024). Therefore, we set the new required items referencing the required items of the top- $K$ similar, successfully obtained items (Figure ˜ 4 a, Case 2). We compute this item similarity as the cosine similarity between the Sentence-BERT (Reimers and Gurevych, 2019) embeddings of item names. Second, to determine their quantities, the agent should address the trade-off between sufficient amounts to avoid failures and an imperfect controller’s difficulty in acquiring them. Therefore, the quantities of those new required items are determined by gradually scaling with the revision count, $\alpha_{s}C(v)$ .
Here, the hyperparameter $c_{0}$ serves as the revision count threshold for flagging an item as inadmissible. $\alpha_{i}$ and $\alpha_{s}$ control the quantity of each required item for inadmissible items (Case 1), and for less-tried items (Case 2), respectively, to maintain robustness when dealing with an imperfect controller. $K$ determines the number of similar, successfully obtained items to reference for (Case 2). Detailed pseudocode of RevisionByAnalogy is in Section ˜ E.3, Algorithm ˜ 3.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Diagram: Dependency and Action Correction
### Overview
The image presents two diagrams illustrating correction mechanisms for dependency and action errors. Diagram (a) focuses on "Dependency Correction for ADG" (Action Dependency Graph), showing two cases where dependencies are corrected. Diagram (b) focuses on "Action Correction for FAM" (Failure Aware Module), detailing how invalid actions are identified and removed.
### Components/Axes
**Diagram (a): Dependency Correction for ADG**
* **Title:** (a) Dependency Correction for
* **Sub-titles:** Case 1 ADG, Case 2 ADG, ADG
* **Elements:**
* **Case 1:**
* A cube labeled "Descendant (Leaf)"
* A brown item labeled "Descendant"
* A red bug labeled "Hallucinated item"
* Arrows indicating the flow of dependency
* Text: "Recursively call RevisionByAnalogy"
* **Case 2:**
* A set of Minecraft blocks (wood, stone) marked with a red "X"
* A sword and pickaxe marked with a green checkmark
* An arrow indicating a search for similar obtained items
* Text: "Search similar, obtained items"
* **ADG (Corrected):**
* A cloud icon
* A pair of scissors cutting the dependency
* A sword and pickaxe
* An arrow indicating the replacement of the wrong dependency
* Text: "Replace the wrong dependency"
**Diagram (b): Action Correction for FAM**
* **Title:** (b) Action Correction for
* **Labels:** FAM, Prompt, Subgoal
* **Elements:**
* **FAM (Failure Aware Module):**
* A box labeled "Failure counts:"
* "mine": 2 (highlighted in red)
* "craft": 1
* "smelt": 0
* **Prompt:**
* A document icon
* Text: "Select an action for: mine, craft, smelt..." (repeated twice)
* A purple arrow indicating the flow of action selection
* **Subgoal:**
* A box labeled "craft"
* A cursor pointing towards the "craft" subgoal
* An icon resembling a neural network
* **Text:**
* "Determine & remove invalid actions"
* "Try under-explored action"
* "Invalid action" (associated with a dashed line)
### Detailed Analysis or ### Content Details
**Diagram (a):**
* **Case 1:** Illustrates a scenario where a hallucinated item is identified and removed from the dependency graph. The flow starts from the "Descendant (Leaf)" and goes down to the "Hallucinated item."
* **Case 2:** Shows a scenario where incorrect dependencies (wood and stone blocks) are replaced with correct ones (sword and pickaxe). The process involves searching for similar obtained items and then replacing the wrong dependency.
**Diagram (b):**
* The "Failure counts" box indicates the number of times each action ("mine," "craft," "smelt") has failed. "mine" has failed twice, "craft" once, and "smelt" zero times.
* The process involves selecting an action from a prompt, identifying invalid actions based on failure counts, removing them, and then trying under-explored actions to achieve the subgoal.
### Key Observations
* **Dependency Correction:** Focuses on correcting errors in the dependency graph by identifying and replacing incorrect or hallucinated items.
* **Action Correction:** Focuses on improving action selection by learning from past failures and prioritizing under-explored actions.
* **Failure Counts:** The "mine" action has the highest failure count, suggesting it is the most problematic action.
### Interpretation
The diagrams illustrate two different approaches to error correction in a system, likely related to AI or game playing. The dependency correction aims to ensure the accuracy of the underlying dependency graph, while the action correction focuses on improving the decision-making process by learning from past failures. The combination of these two correction mechanisms likely leads to a more robust and efficient system. The red highlighting of "mine": 2 suggests that the system prioritizes addressing the "mine" action due to its high failure rate.
</details>
Figure 4: XENON’s algorithmic knowledge correction. (a) Dependency Correction via RevisionByAnalogy. Case 1: For an inadmissible item (e.g., a hallucinated item), its descendants are recursively revised to remove the flawed dependency. Case 2: A flawed requirement set is revised by referencing similar, obtained items. (b) Action Correction via FAM. FAM prunes invalid actions from the LLM’s prompt based on failures, guiding it to select an under-explored action.
4.2 Failure-aware Action Memory (FAM)
FAM is designed to address two challenges of learning only from binary success/failure feedback: (1) discovering valid high-level actions for each item, and (2) disambiguating the cause of persistent failures between invalid actions and flawed dependency knowledge. This section first describes FAM’s core mechanism, and then details how it addresses each of these challenges in turn.
Core mechanism: empirical action classification
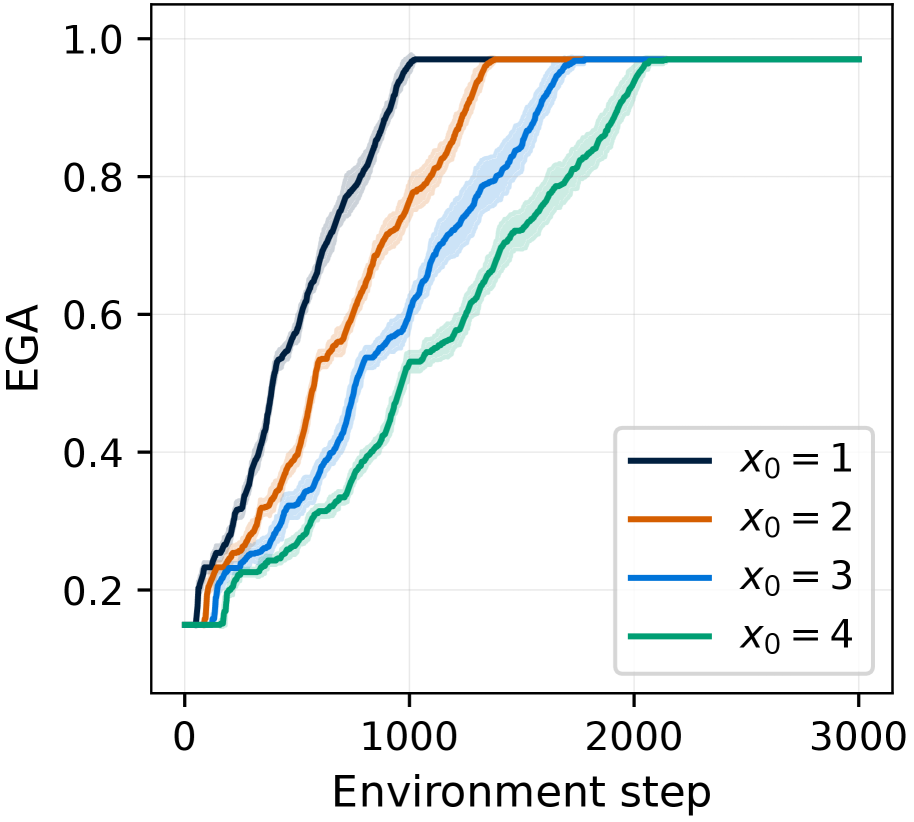
FAM classifies actions as either empirically valid or empirically invalid for each item, based on their history of past subgoal outcomes. Specifically, for each item $v∈\hat{\mathcal{V}}$ and action $a∈\mathcal{A}$ , FAM maintains the number of successful and failed outcomes, denoted as $S(a,v)$ and $F(a,v)$ respectively. Based on these counts, an action $a$ is classified as empirically invalid for $v$ if it has failed repeatedly, (i.e., $F(a,v)≥ S(a,v)+x_{0}$ ); otherwise, it is classified as empirically valid if it has succeeded at least once (i.e., $S(a,v)>0$ and $S(a,v)>F(a,v)-x_{0}$ ). The hyperparameter $x_{0}$ controls the tolerance for this classification, accounting for the possibility that an imperfect controller might fail even with an indeed valid action.
Addressing challenge 1: discovering valid actions
FAM helps XENON discover valid actions by avoiding repeatedly failed actions when making a subgoal $sg_{l}=(a_{l},q_{l},u_{l})$ . Only when FAM has no empirically valid action for $u_{l}$ , XENON queries the LLM to select an under-explored action for constructing $sg_{l}$ . To accelerate this search for a valid action, we query the LLM with (i) the current subgoal item $u_{l}$ , (ii) empirically valid actions for top- $K$ similar items successfully obtained and stored in FAM (using Sentence-BERT similarity as in Section ˜ 4.1), and (iii) candidate actions for $u_{l}$ that remain after removing all empirically invalid actions from $\mathcal{A}$ (Figure ˜ 4 b). We prune action candidates rather than include the full failure history because LLMs struggle to effectively utilize long prompts (Li et al., 2024a; Liu et al., 2024). If FAM already has an empirically valid one, XENON reuses it to make $sg_{l}$ without using LLM. Detailed procedures and prompts are in Appendix ˜ F.
Addressing challenge 2: disambiguating failure causes
By ensuring systematic action exploration, FAM allows XENON to determine that persistent subgoal failures stem from flawed dependency knowledge rather than from the actions. Specifically, once FAM classifies all actions in $\mathcal{A}$ for an item as empirically invalid, XENON concludes that the error lies within ADG and triggers its revision. Subsequently, XENON resets the item’s history in FAM to allow for a fresh exploration of actions with the revised ADG.
4.3 Additional technique: context-aware reprompting (CRe) for controller
In real-world-like environments, an imperfect controller can stall (e.g., in deep water). To address this, XENON employs context-aware reprompting (CRe), where an LLM uses the current image observation and the controller’s language subgoal to decide whether to replace the subgoal and propose a new temporary subgoal to escape the stalled state (e.g., “get out of the water”). Our CRe is adapted from Optimus-1 (Li et al., 2024b) to be suitable for smaller LLMs, with two differences: (1) a two-stage reasoning process that captions the observation first and then makes a text-only decision on whether to replace the subgoal, and (2) a conditional trigger that activates only when the subgoal for item acquisition makes no progress, rather than at fixed intervals. See Appendix ˜ H for details.
5 Experiments
5.1 Setups
Environments
We conduct experiments in three Minecraft environments, which we separate into two categories based on their controller capacity. First, as realistic, visually-rich embodied AI environments, we use MineRL (Guss et al., 2019) and Mineflayer (PrismarineJS, 2023) with imperfect low-level controllers: STEVE-1 (Lifshitz et al., 2023) in MineRL and hand-crafted codes (Yu and Lu, 2024) in Mineflayer. Second, we use MC-TextWorld (Zheng et al., 2025) as a controlled testbed with a perfect controller. Each experiment in this environment is repeated over 15 runs; in our results, we report the mean and standard deviation, omitting the latter when it is negligible. In all environments, the agent starts with an empty inventory. Further details on environments are provided in Appendix ˜ J. Additional experiments in a household task planning domain other than Minecraft are reported in Appendix ˜ A, where XENON also exhibits robust performance.
Table 1: Comparison of knowledge correction mechanisms across agents. ○: Our proposed mechanism (XENON), $\triangle$ : LLM self-correction, ✗: No correction, –: Not applicable.
| Agent | Dependency Correction | Action Correction |
| --- | --- | --- |
| XENON | ○ | ○ |
| SC | $\triangle$ | $\triangle$ |
| DECKARD | ✗ | ✗ |
| ADAM | - | ✗ |
| RAND | ✗ | ✗ |
Evaluation metrics
For both dependency learning and planning evaluations, we utilize the 67 goals from 7 groups proposed in the long-horizon task benchmark (Li et al., 2024b). To evaluate dependency learning with an intuitive performance score between 0 and 1, we report $N_{\text{true}}(\hat{\mathcal{G}})/67$ , where $N_{\text{true}}(\hat{\mathcal{G}})$ is defined in Equation ˜ 1. We refer to this normalized score as Experienced Graph Accuracy (EGA). To evaluate planning performance, we follow the benchmark setting (Li et al., 2024b): at the beginning of each episode, a goal item is specified externally for the agent, and we measure the average success rate (SR) of obtaining this goal item in MineRL. See Table ˜ 10 for the full list of goals.
Implementation details
For the planner, we use Qwen2.5-VL-7B (Bai et al., 2025). The learned dependency graph is initialized with human-written plans for three goals (“craft an iron sword
<details>
<summary>x7.png Details</summary>
### Visual Description
Icon/Small Image (20x20)
</details>
”, “craft a golden sword
<details>
<summary>x8.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
,” “mine a diamond
<details>
<summary>x9.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
”), providing minimal knowledge; the agent must learn dependencies for over 80% of goal items through experience. We employ CRe only for long-horizon goal planning in MineRL. All hyperparameters are kept consistent across experiments. Further details on hyperparameters and human-written plans are in Appendix ˜ I.
Baselines
As no prior work learns dependencies in our exact setting, we adapt four baselines, whose knowledge correction mechanisms are summarized in Table 1. For dependency knowledge, (1) LLM Self-Correction (SC) starts with an LLM-predicted dependency graph and prompts the LLM to revise it upon failures; (2) DECKARD (Nottingham et al., 2023) also relies on an LLM-predicted graph but with no correction mechanism; (3) ADAM (Yu and Lu, 2024) assumes that any goal item requires all previously used resource items, each in a sufficient quantity; and (4) RAND, the simplest baseline, uses a static graph similar to DECKARD. Regarding action knowledge, all baselines except for RAND store successful actions. However, only the SC baseline attempts to correct its flawed knowledge upon failures. The SC prompts the LLM to revise both its dependency and action knowledge using previous LLM predictions and interaction trajectories, as done in many self-correction methods (Shinn et al., 2023; Stechly et al., 2024). See Appendix ˜ B for the prompts of SC and Section ˜ J.1 for detailed descriptions of these baselines. To evaluate planning on diverse long-horizon goals, we further compare XENON with recent planning agents that are provided with oracle dependencies: DEPS Wang et al. (2023b), Jarvis-1 Wang et al. (2023c), Optimus-1 Li et al. (2024b), and Optimus-2 Li et al. (2025b).
5.2 Robust dependency learning against flawed prior knowledge
<details>
<summary>x10.png Details</summary>
### Visual Description
## Line Chart: EGA vs Episode
### Overview
The image is a line chart comparing the performance of five different algorithms (XENON, SC, DECKARD, ADAM, and RAND) over a series of episodes. The y-axis represents EGA (likely a performance metric), and the x-axis represents the episode number. The chart shows how the EGA value changes for each algorithm as the number of episodes increases.
### Components/Axes
* **Title:** There is no explicit title on the chart.
* **X-axis:**
* Label: "Episode"
* Scale: 000, 100, 200, 300, 400
* **Y-axis:**
* Label: "EGA"
* Scale: 0.2, 0.4, 0.6, 0.8, 1.0
* **Legend:** Located in the top-left corner.
* XENON (light blue line with circle markers)
* SC (light pink line with diamond markers)
* DECKARD (light green line with square markers)
* ADAM (light orange line with asterisk-like markers)
* RAND (dark gray line with plus-like markers)
### Detailed Analysis
* **XENON (light blue line with circle markers):** The line starts at approximately 0.15 EGA at episode 0, increases to approximately 0.35 at episode 100, then to approximately 0.5 at episode 200, then to approximately 0.55 at episode 300, and finally reaches approximately 0.63 at episode 400. The trend is generally upward.
* **SC (light pink line with diamond markers):** The line starts at approximately 0.15 EGA at episode 0, increases to approximately 0.38 at episode 100, then remains relatively constant at approximately 0.4 at episodes 200, 300, and 400.
* **DECKARD (light green line with square markers):** The line starts at approximately 0.15 EGA at episode 0, increases to approximately 0.42 at episode 100, then remains relatively constant at approximately 0.42 at episodes 200, 300, and 400.
* **ADAM (light orange line with asterisk-like markers):** The line starts at approximately 0.15 EGA at episode 0 and remains relatively constant at approximately 0.15 across all episodes (100, 200, 300, 400).
* **RAND (dark gray line with plus-like markers):** The line starts at approximately 0.15 EGA at episode 0 and remains relatively constant at approximately 0.16 across all episodes (100, 200, 300, 400).
### Key Observations
* XENON shows the most significant improvement in EGA as the number of episodes increases.
* SC and DECKARD show a significant initial increase in EGA but then plateau.
* ADAM and RAND show very little change in EGA across all episodes.
* All algorithms start at approximately the same EGA value at episode 0.
### Interpretation
The chart demonstrates the learning performance of different algorithms over a series of episodes. XENON appears to be the most effective algorithm, as it shows the greatest improvement in EGA as the number of episodes increases. SC and DECKARD show some initial learning but then plateau, suggesting they may have reached their performance limit or require further tuning. ADAM and RAND show very little learning, indicating they may not be suitable for this particular task or require significant modifications. The fact that all algorithms start at approximately the same EGA value suggests a fair comparison at the beginning of the training process.
</details>
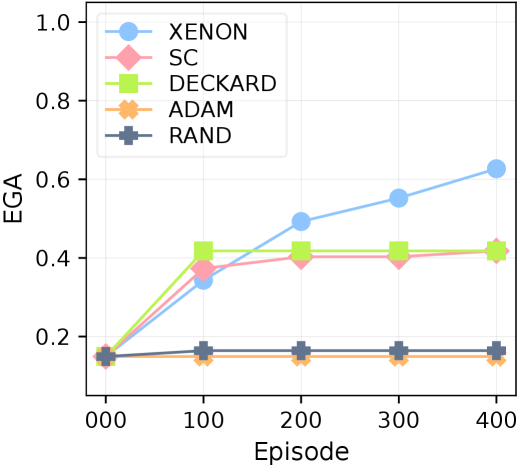
(a) MineRL
<details>
<summary>x11.png Details</summary>
### Visual Description
## Line Chart: EGA vs Episode
### Overview
The image is a line chart displaying the relationship between Episode (x-axis) and EGA (y-axis) for four different data series, each represented by a distinct color and marker. The chart shows how EGA changes over the course of 400 episodes for each series.
### Components/Axes
* **X-axis:** Episode, with markers at 0, 100, 200, 300, and 400.
* **Y-axis:** EGA, ranging from 0.0 to 1.0, with markers at 0.2 intervals.
* **Data Series:**
* Blue line with circle markers.
* Orange line with cross markers.
* Light Green line with square markers.
* Pink line with diamond markers.
* Dark Grey line with plus markers.
### Detailed Analysis
* **Blue Line (Circle Markers):**
* Trend: Initially increases sharply, then plateaus.
* Data Points:
* Episode 0: EGA ~0.15
* Episode 100: EGA ~0.7
* Episode 200: EGA ~0.9
* Episode 300: EGA ~0.9
* Episode 400: EGA ~0.9
* **Orange Line (Cross Markers):**
* Trend: Increases sharply initially, then remains relatively constant.
* Data Points:
* Episode 0: EGA ~0.15
* Episode 100: EGA ~0.65
* Episode 200: EGA ~0.65
* Episode 300: EGA ~0.65
* Episode 400: EGA ~0.65
* **Light Green Line (Square Markers):**
* Trend: Increases gradually, then plateaus.
* Data Points:
* Episode 0: EGA ~0.15
* Episode 100: EGA ~0.4
* Episode 200: EGA ~0.42
* Episode 300: EGA ~0.44
* Episode 400: EGA ~0.44
* **Pink Line (Diamond Markers):**
* Trend: Increases gradually, then plateaus.
* Data Points:
* Episode 0: EGA ~0.15
* Episode 100: EGA ~0.35
* Episode 200: EGA ~0.4
* Episode 300: EGA ~0.43
* Episode 400: EGA ~0.43
* **Dark Grey Line (Plus Markers):**
* Trend: Increases slightly, then plateaus.
* Data Points:
* Episode 0: EGA ~0.15
* Episode 100: EGA ~0.2
* Episode 200: EGA ~0.2
* Episode 300: EGA ~0.21
* Episode 400: EGA ~0.21
### Key Observations
* The blue line (circle markers) shows the highest EGA values and the most significant initial increase.
* The orange line (cross markers) also shows a significant initial increase but plateaus at a lower EGA value than the blue line.
* The light green and pink lines (square and diamond markers, respectively) show more gradual increases in EGA.
* The dark grey line (plus markers) shows the lowest EGA values and the least change over the episodes.
* All lines start at approximately the same EGA value (~0.15) at Episode 0.
* All lines plateau after approximately 200 episodes.
### Interpretation
The chart compares the performance of four different strategies or algorithms (represented by the different colored lines) in terms of EGA (likely a performance metric) over a series of episodes. The blue line represents the most effective strategy, achieving the highest EGA values and a rapid initial improvement. The orange line is also effective initially but plateaus at a lower level. The light green, pink, and dark grey lines represent less effective strategies, with lower EGA values and slower improvement. The fact that all lines start at the same EGA value suggests that all strategies begin with similar initial performance. The plateauing of all lines indicates that the strategies reach a point of diminishing returns, where further episodes do not lead to significant improvements in EGA.
</details>
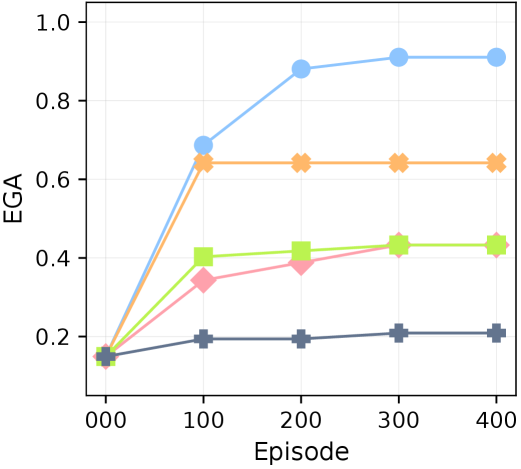
(b) Mineflayer
Figure 5: Robustness against flawed prior knowledge. EGA over 400 episodes in (a) MineRL and (b) Mineflayer. XENON consistently outperforms the baselines.
Table 2: Robustness to LLM hallucinations. The number of correctly learned dependencies of items that are descendants of a hallucinated item in the initial LLM-predicted dependency graph (out of 12).
| Agent | Learned descendants of hallucinated items |
| --- | --- |
| XENON | 0.33 |
| SC | 0 |
| ADAM | 0 |
| DECKARD | 0 |
| RAND | 0 |
XENON demonstrates robust dependency learning from flawed prior knowledge, consistently outperforming baselines with an EGA of approximately 0.6 in MineRL and 0.9 in Mineflayer (Figure ˜ 5), despite the challenging setting with imperfect controllers. This superior performance is driven by its algorithmic correction mechanism, RevisionByAnalogy, which corrects flawed dependency knowledge while also accommodating imperfect controllers by gradually scaling required items quantities. The robustness of this algorithmic correction is particularly evident in two key analyses of the learned graph for each agent from the MineRL experiments. First, as shown in Table ˜ 2, XENON is uniquely robust to LLM hallucinations, learning dependencies for descendant items of non-existent, hallucinated items in the initial LLM-predicted graph. Second, XENON outperforms the baselines in learning dependencies for items that are unobtainable by the initial graph, as shown in Table ˜ 13.
Our results demonstrate the unreliability of relying on LLM self-correction or blindly trusting an LLM’s flawed knowledge; in practice, SC achieves the same EGA as DECKARD, with both plateauing around 0.4 in both environments.
We observe that controller capacity strongly impacts dependency learning. This is evident in ADAM, whose EGA differs markedly between MineRL ( $≈$ 0.1), which has a limited controller, and Mineflayer ( $≈$ 0.6), which has a more competent controller. While ADAM unrealistically assumes a controller can gather large quantities of all resource items before attempting a new item, MineRL’s controller STEVE-1 (Lifshitz et al., 2023) cannot execute this demanding strategy, causing ADAM’s EGA to fall below even the simplest baseline, RAND. Controller capacity also accounts for XENON’s lower EGA in MineRL. For instance, XENON learns none of the dependencies of the Redstone group items, as STEVE-1 cannot execute XENON’s strategy for inadmissible items (Section ˜ 4.1). In contrast, the more capable Mineflayer controller executes this strategy successfully, allowing XENON to learn the correct dependencies for 5 of 6 Redstone items. This difference highlights the critical role of controllers for dependency learning, as detailed in our analysis in Section ˜ K.3
5.3 Effective planning to solve diverse goals
Table 3: Performance on long-horizon task benchmark. Average success rate of each group on the long-horizon task benchmark Li et al. (2024b) in MineRL. Oracle indicates that the true dependency graph is known in advance, Learned indicates that the graph is learned via experience across 400 episodes. For fair comparison across LLMs, we include Optimus-1 †, our reproduction of Optimus-1 using Qwen2.5-VL-7B. Due to resource limits, results for DEPS, Jarvis-1, Optimus-1, and Optimus-2 are cited directly from (Li et al., 2025b). See Section ˜ K.12 for the success rate on each goal.
| Method | Dependency | Planner LLM | Overall |
<details>
<summary>x12.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
|
<details>
<summary>x13.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
|
<details>
<summary>x14.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
|
<details>
<summary>x15.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
|
<details>
<summary>x16.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
|
<details>
<summary>x17.png Details</summary>
### Visual Description
Icon/Small Image (20x20)
</details>
|
<details>
<summary>x18.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
|
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Wood | Stone | Iron | Diamond | Gold | Armor | Redstone | | | | |
| DEPS | - | Codex | 0.22 | 0.77 | 0.48 | 0.16 | 0.01 | 0.00 | 0.10 | 0.00 |
| Jarvis-1 | Oracle | GPT-4 | 0.38 | 0.93 | 0.89 | 0.36 | 0.08 | 0.07 | 0.15 | 0.16 |
| Optimus-1 | Oracle | GPT-4V | 0.43 | 0.98 | 0.92 | 0.46 | 0.11 | 0.08 | 0.19 | 0.25 |
| Optimus-2 | Oracle | GPT-4V | 0.45 | 0.99 | 0.93 | 0.53 | 0.13 | 0.09 | 0.21 | 0.28 |
| Optimus-1 † | Oracle | Qwen2.5-VL-7B | 0.34 | 0.92 | 0.80 | 0.22 | 0.10 | 0.09 | 0.17 | 0.04 |
| XENON ∗ | Oracle | Qwen2.5-VL-7B | 0.79 | 0.95 | 0.93 | 0.83 | 0.75 | 0.73 | 0.61 | 0.75 |
| XENON | Learned | Qwen2.5-VL-7B | 0.54 | 0.85 | 0.81 | 0.46 | 0.64 | 0.74 | 0.28 | 0.00 |
As shown in Table ˜ 3, XENON significantly outperforms baselines in solving diverse long-horizon goals despite using the lightweight Qwen2.5-VL-7B LLM (Bai et al., 2025), while the baselines rely on large proprietary models such as Codex (Chen et al., 2021), GPT-4 (OpenAI, 2024), and GPT-4V (OpenAI, 2023). Remarkably, even with its learned dependency knowledge (Section ˜ 5.2), XENON surpasses the baselines with the oracle knowledge on challenging late-game goals, achieving high SRs for item groups like Gold (0.74) and Diamond (0.64).
XENON’s superiority stems from two key factors. First, its FAM provides systematic, fine-grained action correction for each goal. Second, it reduces reliance on the LLM for planning in two ways: it shortens prompts and outputs by requiring it to predict one action per subgoal item, and it bypasses the LLM entirely by reusing successful actions from FAM. In contrast, the baselines lack a systematic, fine-grained action correction mechanism and instead make LLMs generate long plans from lengthy prompts—a strategy known to be ineffective for LLMs (Wu et al., 2024; Li et al., 2024a). This challenge is exemplified by Optimus-1 †. Despite using a knowledge graph for planning like XENON, its long-context generation strategy causes LLM to predict incorrect actions or omit items explicitly provided in its prompt, as detailed in Section ˜ K.5.
We find that accurate knowledge is critical for long-horizon planning, as its absence can make even a capable agent ineffective. The Redstone group from Table ˜ 3 provides an example: while XENON ∗ with oracle knowledge succeeds (0.75 SR), XENON with learned knowledge fails entirely (0.00 SR), because it failed to learn the dependencies for Redstone goals due to the controller’s limited capacity in MineRL (Section ˜ 5.2). This finding is further supported by our comprehensive ablation study, which confirms that accurate dependency knowledge is most critical for success across all goals (See Table ˜ 17 in Section ˜ K.7).
5.4 Robust dependency learning against knowledge conflicts
<details>
<summary>x19.png Details</summary>

### Visual Description
## Legend: Algorithm Identification
### Overview
The image presents a legend that identifies different algorithms using distinct colors and markers. This legend is likely associated with a chart or graph comparing the performance of these algorithms.
### Components/Axes
The legend contains the following entries, each with a specific color and marker:
* **XENON**: Light blue with a circle marker.
* **SC**: Light pink with a diamond marker.
* **ADAM**: Light orange with a pentagon marker.
* **DECKARD**: Light green with a square marker.
* **RAND**: Gray with a plus marker.
### Detailed Analysis or ### Content Details
The legend is horizontally oriented. Each algorithm name is paired with a colored line and a corresponding marker shape. The order of the algorithms in the legend is: XENON, SC, ADAM, DECKARD, and RAND.
### Key Observations
The legend provides a clear mapping between algorithm names, colors, and markers. This is essential for interpreting any associated chart or graph.
### Interpretation
The legend serves as a key for understanding which data series in a chart or graph corresponds to which algorithm. The use of distinct colors and markers helps to visually differentiate the algorithms and facilitates comparison of their performance.
</details>
<details>
<summary>x20.png Details</summary>
### Visual Description
## Line Chart: EGA vs. Perturbed Items and Action
### Overview
The image is a line chart displaying the relationship between EGA (likely representing some form of effectiveness or accuracy) and the number of perturbed items and action. The x-axis represents the perturbed items and action,
</details>
(a) Perturbed True Required Items
<details>
<summary>x21.png Details</summary>
### Visual Description
## Line Chart: EGA vs Perturbed (required items, action)
### Overview
The image is a line chart displaying the relationship between EGA (Expected Goal Achievement) and "Perturbed (required items, action)". There are four distinct data series represented by different colored lines: light blue, light orange, light pink, light green, and dark grey. The x-axis represents the "Perturbed (required items, action)" with values (0, 0), (0, 1), (0, 2), and (0, 3). The y-axis represents EGA, ranging from 0.2 to 1.0.
### Components/Axes
* **X-axis:** "Perturbed (required items, action)" with labels (0, 0), (0, 1), (0, 2), and (0, 3).
* **Y-axis:** "EGA" (Expected Goal Achievement) with values 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Data Series:**
* Light Blue: Constant value across all x-axis points.
* Light Orange: Decreases sharply from (0, 0) to (0, 1) and then remains constant.
* Light Pink: Decreases gradually from (0, 0) to (0, 3).
* Light Green: Decreases gradually from (0, 0) to (0, 3).
* Dark Grey: Remains relatively constant across all x-axis points.
### Detailed Analysis or ### Content Details
* **Light Blue Line:**
* Trend: Horizontal, indicating a constant EGA value.
* Values: Approximately 0.98 at (0, 0), (0, 1), (0, 2), and (0, 3).
* **Light Orange Line:**
* Trend: Decreases sharply from (0, 0) to (0, 1) and then remains constant.
* Values: Approximately 0.68 at (0, 0), approximately 0.15 at (0, 1), approximately 0.15 at (0, 2), and approximately 0.15 at (0, 3).
* **Light Pink Line:**
* Trend: Decreases gradually.
* Values: Approximately 0.62 at (0, 0), approximately 0.43 at (0, 1), approximately 0.28 at (0, 2), and approximately 0.22 at (0, 3).
* **Light Green Line:**
* Trend: Decreases gradually.
* Values: Approximately 0.48 at (0, 0), approximately 0.38 at (0, 1), approximately 0.24 at (0, 2), and approximately 0.22 at (0, 3).
* **Dark Grey Line:**
* Trend: Relatively constant.
* Values: Approximately 0.24 at (0, 0), approximately 0.24 at (0, 1), approximately 0.24 at (0, 2), and approximately 0.22 at (0, 3).
### Key Observations
* The light blue line maintains a consistently high EGA value regardless of the "Perturbed (required items, action)".
* The light orange line experiences a significant drop in EGA between (0, 0) and (0, 1), after which it stabilizes at a low value.
* The light pink and light green lines show a gradual decrease in EGA as the "Perturbed (required items, action)" increases.
* The dark grey line remains relatively stable, with a slight decrease at the end.
### Interpretation
The chart illustrates how different strategies or configurations (represented by the colored lines) perform under varying levels of perturbation. The light blue line represents a highly robust strategy, maintaining high EGA even when the "Perturbed (required items, action)" increases. The light orange line represents a strategy that is highly sensitive to initial perturbations, with performance plummeting after the first perturbation. The light pink and light green lines represent strategies that are moderately affected by perturbations, with a gradual decline in performance. The dark grey line represents a strategy that is consistently stable, but at a lower EGA level. The data suggests that the light blue strategy is the most resilient to perturbations, while the light orange strategy is the most vulnerable.
</details>
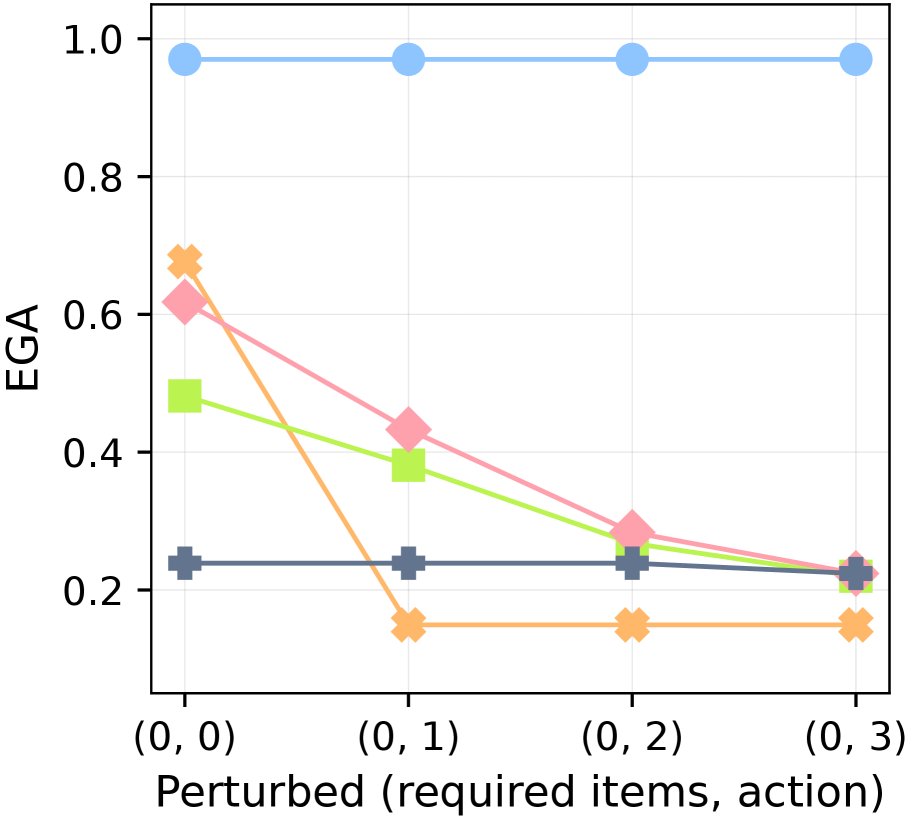
(b) Perturbed True Actions
<details>
<summary>x22.png Details</summary>
### Visual Description
## Line Chart: EGA vs Perturbed (required items, action)
### Overview
The image is a line chart showing the relationship between EGA (Expected Goal Achievement) and the level of perturbation, represented as "(required items, action)". There are four distinct data series, each represented by a different color and marker. The x-axis represents the perturbation level, increasing from (0, 0) to (3, 3). The y-axis represents the EGA, ranging from 0.0 to 1.0.
### Components/Axes
* **X-axis:** "Perturbed (required items, action)" with markers at (0, 0), (1, 1), (2, 2), and (3, 3).
* **Y-axis:** "EGA" ranging from 0.2 to 1.0 in increments of 0.2.
* **Data Series:** Four distinct lines with different colors and markers. The legend is missing, so the colors are described below.
### Detailed Analysis
* **Light Blue (Circles):** This line remains constant at approximately EGA = 0.98 across all perturbation levels.
* (0, 0): 0.98
* (1, 1): 0.98
* (2, 2): 0.98
* (3, 3): 0.98
* **Orange (X):** This line shows a decreasing trend as the perturbation level increases.
* (0, 0): 0.68
* (1, 1): 0.12
* (2, 2): 0.08
* (3, 3): 0.07
* **Pink (Diamonds):** This line also shows a decreasing trend as the perturbation level increases.
* (0, 0): 0.62
* (1, 1): 0.40
* (2, 2): 0.22
* (3, 3): 0.15
* **Lime Green (Squares):** This line shows a decreasing trend as the perturbation level increases.
* (0, 0): 0.48
* (1, 1): 0.35
* (2, 2): 0.20
* (3, 3): 0.15
* **Dark Grey (Plus Signs):** This line shows a slight decreasing trend as the perturbation level increases.
* (0, 0): 0.24
* (1, 1): 0.21
* (2, 2): 0.18
* (3, 3): 0.14
### Key Observations
* The light blue line representing one of the strategies maintains a high EGA regardless of the perturbation level.
* The orange, pink, and lime green lines show a significant decrease in EGA as the perturbation level increases.
* The dark grey line shows a slight decrease in EGA as the perturbation level increases.
### Interpretation
The chart suggests that some strategies (represented by the light blue line) are robust to perturbations, maintaining a high expected goal achievement even when the required items or actions are altered. Other strategies (represented by the orange, pink, and lime green lines) are highly sensitive to perturbations, with their EGA decreasing significantly as the perturbation level increases. The dark grey line represents a strategy that is somewhat sensitive to perturbations, but not as much as the orange, pink, and lime green lines. The data demonstrates the varying degrees of robustness of different strategies to changes in the environment or task requirements.
</details>
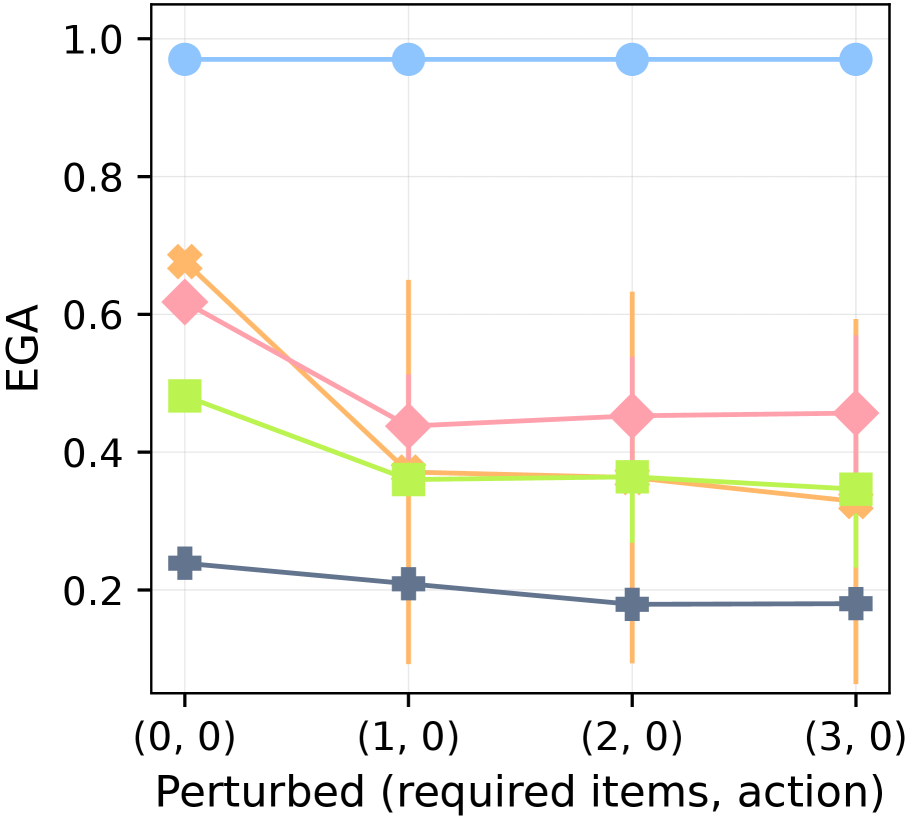
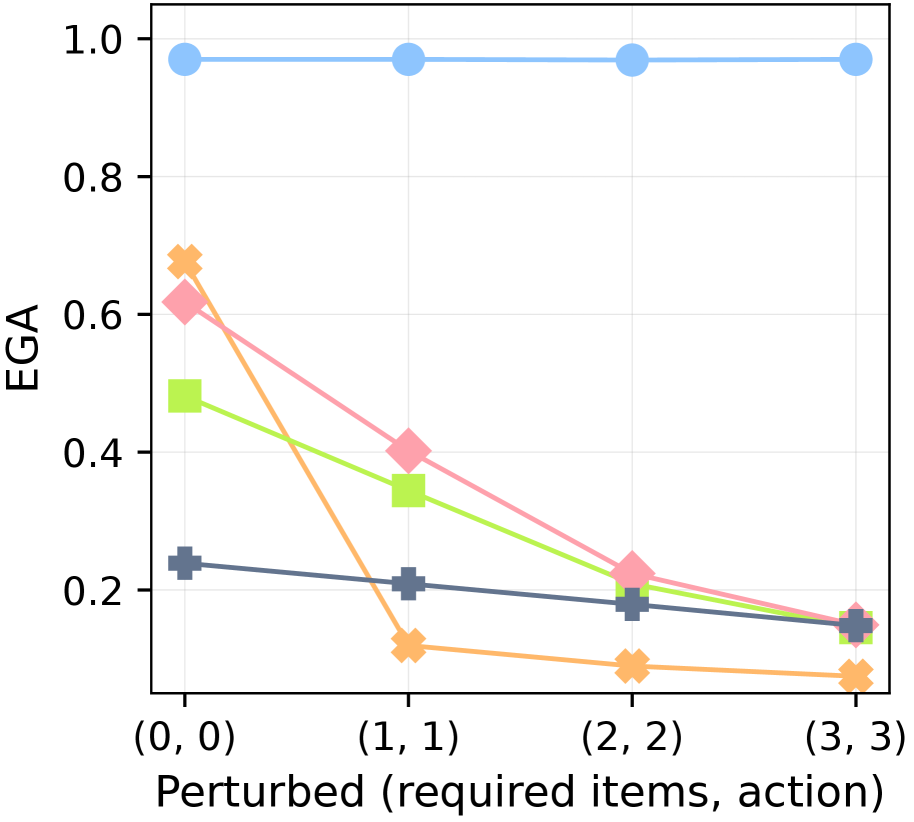
(c) Perturbed Both Rules
Figure 6: Robustness against knowledge conflicts. EGA after 3,000 environment steps in MC-TextWorld under different perturbations of the ground-truth rules. The plots show performance with increasing intensities of perturbation applied to: (a) requirements only, (b) actions only, and (c) both (see Table ˜ 4).
Table 4: Effect of ground-truth perturbations on prior knowledge.
| Perturbation Intensity | Goal items obtainable via prior knowledge |
| --- | --- |
| 0 | 16 (no perturbation) |
| 1 | 14 (12 %) |
| 2 | 11 (31 %) |
| 3 | 9 (44 %) |
To isolate dependency learning from controller capacity, we shift to the MC-TextWorld environment with a perfect controller. In this setting, we test each agent’s robustness to conflicts with its prior knowledge (derived from the LLM’s initial predictions and human-written plans) by introducing arbitrary perturbations to the ground-truth required items and actions. These perturbations are applied with an intensity level; a higher intensity affects a greater number of items, as shown in Table ˜ 4. This intensity is denoted by a tuple (r,a) for required items and actions, respectively. (0,0) represents the vanilla setting with no perturbations. See Figure ˜ 21 for the detailed perturbation process.
Figure ˜ 6 shows XENON’s robustness to knowledge conflicts, as it maintains a near-perfect EGA ( $≈$ 0.97). In contrast, the performance of all baselines degrades as perturbation intensity increases across all three perturbation scenarios (required items, actions, or both). We find that prompting an LLM to self-correct is ineffective when the ground truth conflicts with its parametric knowledge: SC shows no significant advantage over DECKARD, which lacks a correction mechanism. ADAM is vulnerable to action perturbations; its strategy of gathering all resource items before attempting a new item fails when the valid actions for those resources are perturbed, effectively halting its learning.
5.5 Ablation studies on knowledge correction mechanisms
Table 5: Ablation study of knowledge correction mechanisms. ○: XENON; $\triangle$ : LLM self-correction; ✗: No correction. All entries denote the EGA after 3,000 environment steps. Columns denote the perturbation setting (r,a). For LLM self-correction, we use the same prompt as the SC baseline (see Appendix ˜ B).
| Dependency Correction | Action Correction | (0,0) | (3,0) | (0,3) | (3,3) |
| --- | --- | --- | --- | --- | --- |
| ○ | ○ | 0.97 | 0.97 | 0.97 | 0.97 |
| ○ | $\triangle$ | 0.93 | 0.93 | 0.12 | 0.12 |
| ○ | ✗ | 0.84 | 0.84 | 0.12 | 0.12 |
| $\triangle$ | ○ | 0.57 | 0.30 | 0.57 | 0.29 |
| ✗ | ○ | 0.53 | 0.13 | 0.53 | 0.13 |
| ✗ | ✗ | 0.46 | 0.13 | 0.19 | 0.11 |
As shown in Table ˜ 5, to analyze XENON’s knowledge correction mechanisms for dependencies and actions, we conduct ablation studies in MC-TextWorld. While dependency correction is generally more important for overall performance, action correction becomes vital under action perturbations. In contrast, LLM self-correction is ineffective for complex scenarios: it offers minimal gains for dependency correction even in the vanilla setting and fails entirely for perturbed actions. Its effectiveness is limited to simpler scenarios, such as action correction in the vanilla setting. These results demonstrate that our algorithmic knowledge correction approach enables robust learning from experience, overcoming the limitations of both LLM self-correction and flawed initial knowledge.
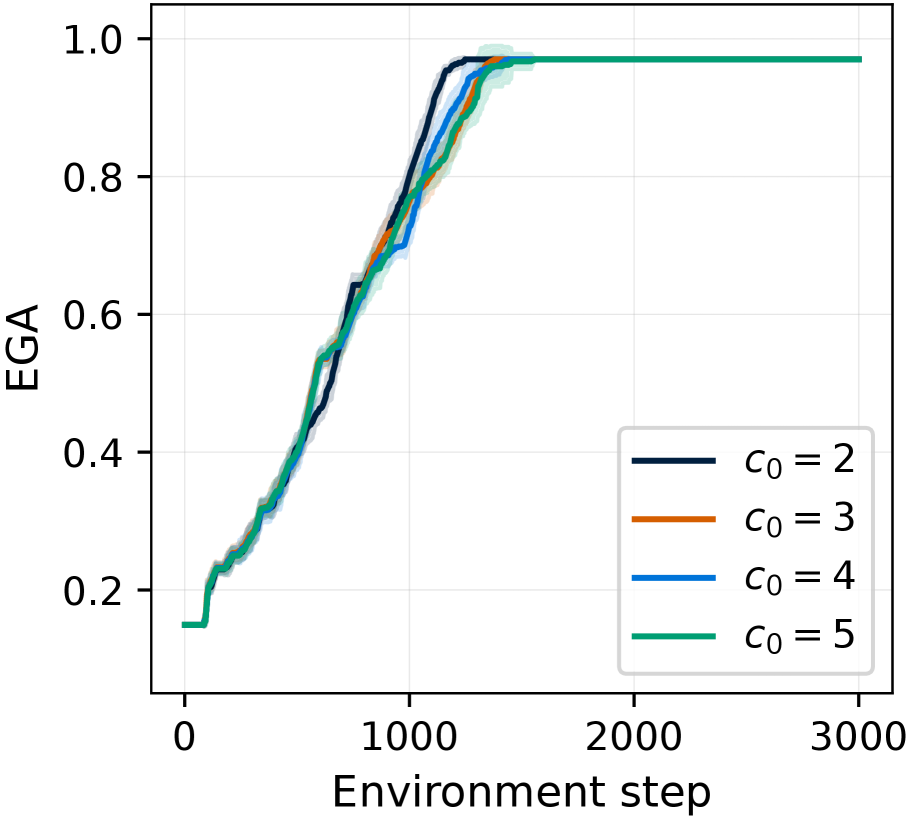
5.6 Ablation studies on hyperparameters
<details>
<summary>x23.png Details</summary>
### Visual Description
## Line Chart: EGA vs. Environment Step for Different c0 Values
### Overview
The image is a line chart that plots EGA (likely an abbreviation for an evaluation metric) against the environment step for four different values of a parameter denoted as "c0". The chart compares the performance of a system or algorithm under varying conditions, showing how EGA changes as the environment step increases. The chart includes a legend in the bottom-right corner that identifies each line by its corresponding c0 value.
### Components/Axes
* **X-axis:** "Environment step", ranging from 0 to 3000, with tick marks at intervals of 1000.
* **Y-axis:** "EGA", ranging from 0.2 to 1.0, with tick marks at intervals of 0.2.
* **Legend:** Located in the bottom-right corner, it identifies the lines by their c0 values:
* c0 = 2 (Dark Blue)
* c0 = 3 (Orange)
* c0 = 4 (Blue)
* c0 = 5 (Teal)
### Detailed Analysis
* **c0 = 2 (Dark Blue):** The line starts at an EGA of approximately 0.2 around environment step 0. It then increases steadily, reaching an EGA of approximately 0.95 around environment step 1500. After that, it plateaus at around 0.97.
* **c0 = 3 (Orange):** The line starts at an EGA of approximately 0.2 around environment step 0. It then increases steadily, reaching an EGA of approximately 0.9 around environment step 1200. After that, it plateaus at around 0.97.
* **c0 = 4 (Blue):** The line starts at an EGA of approximately 0.2 around environment step 0. It then increases steadily, reaching an EGA of approximately 0.95 around environment step 1400. After that, it plateaus at around 0.97.
* **c0 = 5 (Teal):** The line starts at an EGA of approximately 0.15 around environment step 0. It then increases steadily, reaching an EGA of approximately 0.97 around environment step 1500. After that, it plateaus at around 0.97.
### Key Observations
* All four lines show a similar trend: a rapid increase in EGA in the early environment steps, followed by a plateau at a high EGA value.
* The c0 = 5 line (Teal) starts at a slightly lower EGA value than the other lines.
* The c0 = 3 line (Orange) seems to increase slightly faster than the other lines initially.
* All lines converge to a similar EGA value (approximately 0.97) after around 1500 environment steps.
### Interpretation
The chart suggests that the parameter "c0" influences the initial learning rate or performance of the system, but its impact diminishes as the environment step increases. Specifically, a higher c0 value (c0 = 5) seems to result in a slightly lower initial EGA, while a c0 value of 3 results in a slightly faster initial increase in EGA. However, regardless of the c0 value, the system eventually achieves a similar high level of performance (EGA ≈ 0.97) after a sufficient number of environment steps. This indicates that the system is robust to variations in the c0 parameter in the long run.
</details>
(a) $c_{0}$
<details>
<summary>x24.png Details</summary>
### Visual Description
## Line Chart: EGA vs. Environment Step for Different Alpha Values
### Overview
The image is a line chart that plots the Expected Goal Achievement (EGA) against the Environment Step for four different values of alpha (α): 7, 8, 9, and 10. The chart shows how the EGA changes over time (environment steps) for each alpha value. The legend is located in the bottom-right corner of the chart.
### Components/Axes
* **X-axis:** Environment step, ranging from 0 to 3000 in increments of 1000.
* **Y-axis:** EGA (Expected Goal Achievement), ranging from 0.2 to 1.0 in increments of 0.2.
* **Legend:** Located in the bottom-right corner, indicating the alpha values:
* Dark Blue: αᵢ = 7
* Orange: αᵢ = 8
* Blue: αᵢ = 9
* Teal: αᵢ = 10
### Detailed Analysis
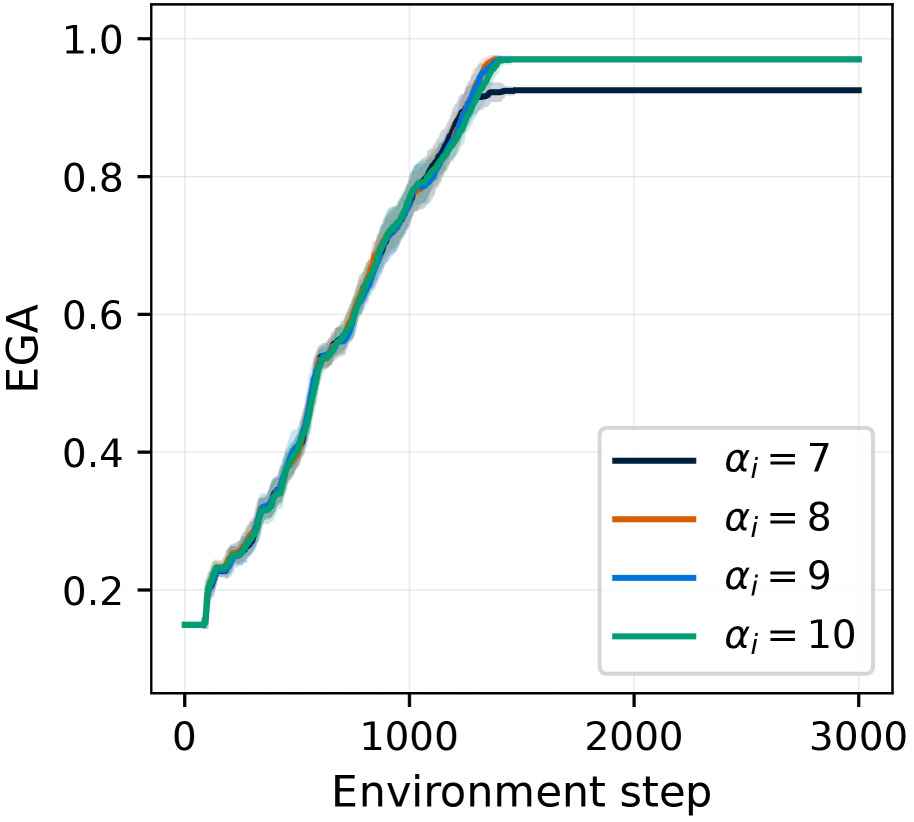
* **αᵢ = 7 (Dark Blue):** The EGA starts at approximately 0.2, increases steadily until around environment step 1500 where it reaches approximately 0.95, and then plateaus at approximately 0.95 for the remainder of the steps.
* **αᵢ = 8 (Orange):** The EGA starts at approximately 0.15, increases steadily until around environment step 1500 where it reaches approximately 0.95, and then plateaus at approximately 0.95 for the remainder of the steps.
* **αᵢ = 9 (Blue):** The EGA starts at approximately 0.15, increases steadily until around environment step 1500 where it reaches approximately 0.97, and then plateaus at approximately 0.97 for the remainder of the steps.
* **αᵢ = 10 (Teal):** The EGA starts at approximately 0.15, increases steadily until around environment step 1500 where it reaches approximately 0.98, and then plateaus at approximately 0.98 for the remainder of the steps.
### Key Observations
* All four alpha values show a similar trend: a rapid increase in EGA up to around 1500 environment steps, followed by a plateau.
* Higher alpha values (9 and 10) achieve slightly higher EGA plateaus compared to lower alpha values (7 and 8).
* The shaded regions around each line indicate the variance or uncertainty in the EGA values.
### Interpretation
The chart suggests that increasing the alpha value generally leads to a slightly higher Expected Goal Achievement. However, the difference in EGA between the different alpha values is relatively small, especially after the initial learning phase (up to 1500 environment steps). The plateauing of EGA indicates that after a certain number of environment steps, further training does not significantly improve the agent's performance, regardless of the alpha value. The alpha values of 9 and 10 appear to perform slightly better than 7 and 8.
</details>
(b) $\alpha_{i}$
<details>
<summary>x25.png Details</summary>
### Visual Description
## Line Chart: EGA vs. Environment Step for Different Alpha Values
### Overview
The image is a line chart that plots the EGA (Expected Goal Achievement) on the y-axis against the Environment Step on the x-axis. There are four lines, each representing a different value of alpha (αs): 1, 2, 3, and 4. The chart illustrates how the EGA changes over time (environment steps) for each alpha value. The chart includes a legend in the bottom-right corner that identifies each line by its corresponding alpha value.
### Components/Axes
* **X-axis:** Environment step, ranging from 0 to 3000, with major ticks at 0, 1000, 2000, and 3000.
* **Y-axis:** EGA (Expected Goal Achievement), ranging from 0.2 to 1.0, with major ticks at 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Legend:** Located in the bottom-right corner, the legend identifies each line by its alpha value:
* Dark Blue: αs = 1
* Orange: αs = 2
* Blue: αs = 3
* Green: αs = 4
### Detailed Analysis
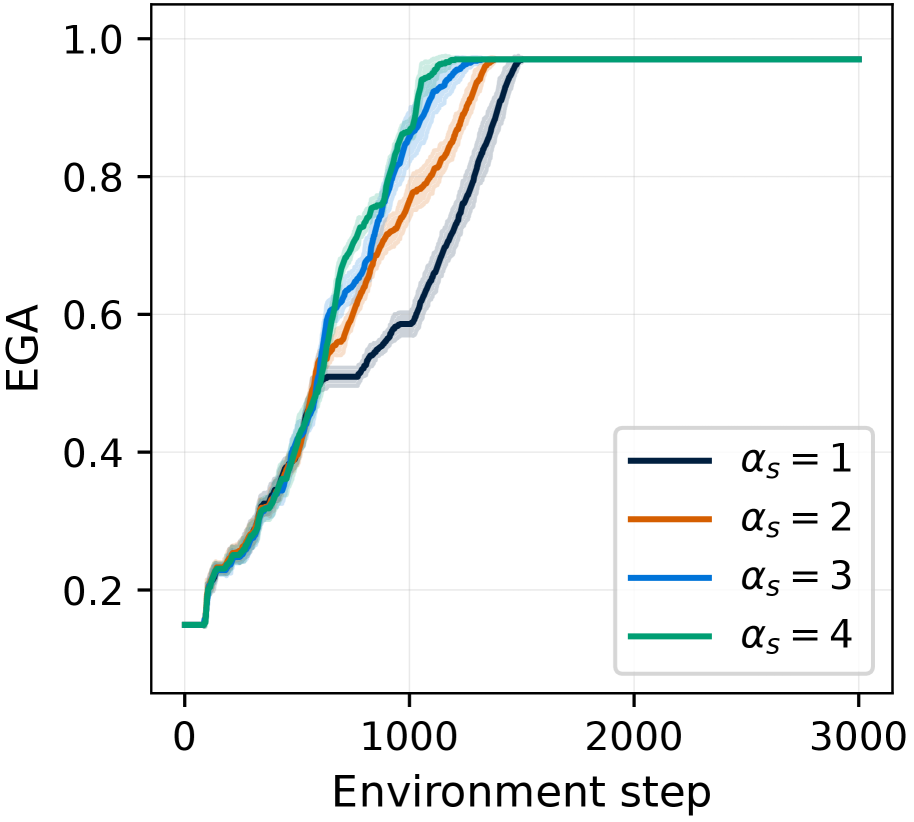
* **αs = 1 (Dark Blue):** The EGA starts around 0.2, remains relatively flat until approximately environment step 500, then increases steadily until it reaches approximately 0.95 around environment step 1500, after which it plateaus.
* **αs = 2 (Orange):** The EGA starts around 0.2, remains relatively flat until approximately environment step 500, then increases steadily until it reaches approximately 0.95 around environment step 1250, after which it plateaus.
* **αs = 3 (Blue):** The EGA starts around 0.2, remains relatively flat until approximately environment step 500, then increases steadily until it reaches approximately 0.95 around environment step 1000, after which it plateaus.
* **αs = 4 (Green):** The EGA starts around 0.15, remains relatively flat until approximately environment step 250, then increases steadily until it reaches approximately 0.97 around environment step 1000, after which it plateaus.
### Key Observations
* All four lines show a similar trend: a period of low EGA followed by a rapid increase and then a plateau.
* The alpha values affect the speed at which the EGA increases. Higher alpha values (3 and 4) reach the plateau faster than lower alpha values (1 and 2).
* The final EGA value is approximately the same for all alpha values, around 0.95 to 0.97.
* The shaded regions around each line likely represent the standard deviation or confidence interval, indicating the variability in the EGA for each alpha value.
### Interpretation
The chart suggests that the alpha value influences the learning rate or the speed at which the agent achieves a high EGA. Higher alpha values lead to faster learning, as indicated by the steeper increase in EGA at earlier environment steps. However, the final EGA achieved is similar across all alpha values, suggesting that the alpha value primarily affects the learning speed rather than the ultimate performance. The shaded regions indicate the variability in the learning process, which is also influenced by the alpha value. The data demonstrates that increasing alpha beyond a certain point (likely between 3 and 4) provides diminishing returns in terms of learning speed, as the green line (αs = 4) plateaus only slightly earlier than the blue line (αs = 3).
</details>
(c) $\alpha_{s}$
<details>
<summary>x26.png Details</summary>
### Visual Description
## Line Chart: EGA vs Environment Step for Different Initial Conditions
### Overview
The image is a line chart that plots EGA (likely an abbreviation for an evaluation metric) against the Environment step. There are four lines on the chart, each representing a different initial condition denoted as x₀ = 1, x₀ = 2, x₀ = 3, and x₀ = 4. The chart shows how EGA changes with the environment step for each of these initial conditions. Each line has a shaded region around it, indicating the uncertainty or variance in the data.
### Components/Axes
* **Y-axis:** EGA, ranging from 0.0 to 1.0 with increments of 0.2.
* **X-axis:** Environment step, ranging from 0 to 3000 with an increment of 1000.
* **Legend (bottom-right):**
* Black line: x₀ = 1
* Orange line: x₀ = 2
* Blue line: x₀ = 3
* Green line: x₀ = 4
### Detailed Analysis
* **x₀ = 1 (Black):** The EGA starts at approximately 0.2 and rapidly increases to 0.6 by around environment step 500. It then continues to increase, reaching 0.95 by step 1000, and plateaus at approximately 0.98.
* **x₀ = 2 (Orange):** The EGA starts at approximately 0.2 and increases more gradually than x₀ = 1. It reaches 0.6 by around environment step 800, and plateaus at approximately 0.97 by step 1500.
* **x₀ = 3 (Blue):** The EGA starts at approximately 0.2 and increases similarly to x₀ = 2, but slightly slower. It reaches 0.6 by around environment step 1000, and plateaus at approximately 0.97 by step 2000.
* **x₀ = 4 (Green):** The EGA starts at approximately 0.15 and increases the slowest among all the conditions. It reaches 0.6 by around environment step 1200, and plateaus at approximately 0.97 by step 2200.
### Key Observations
* All four initial conditions eventually reach a similar EGA plateau value of approximately 0.97-0.98.
* The initial condition x₀ = 1 results in the fastest increase in EGA, while x₀ = 4 results in the slowest.
* The shaded regions around each line indicate some variability in the EGA for each initial condition.
### Interpretation
The chart demonstrates the impact of different initial conditions (x₀) on the learning rate or performance (EGA) of a system as it interacts with its environment. The initial condition x₀ = 1 leads to the quickest learning, while x₀ = 4 results in the slowest. However, all conditions eventually converge to a similar level of performance. This suggests that while the initial condition affects the speed of learning, it does not significantly impact the final performance level. The shaded regions indicate that there is some variability in the learning process, which could be due to factors such as randomness in the environment or the learning algorithm itself.
</details>
(d) $x_{0}$
Figure 7: Hyperparameter ablation study in MC-TextWorld. EGA over 3,000 environment steps under different hyperparameters. The plots show EGA when varying: (a) $c_{0}$ (revision count threshold for inadmissible items), (b) $\alpha_{i}$ (required items quantities for inadmissible items), (c) $\alpha_{s}$ (required items quantities for less-tried items), and (d) $x_{0}$ (invalid action threshold). Each study varies one hyperparameter while keeping the others fixed to their default values ( $c_{0}=3$ , $\alpha_{i}=8$ , $\alpha_{s}=2$ , $x_{0}=2$ ).
<details>
<summary>x27.png Details</summary>
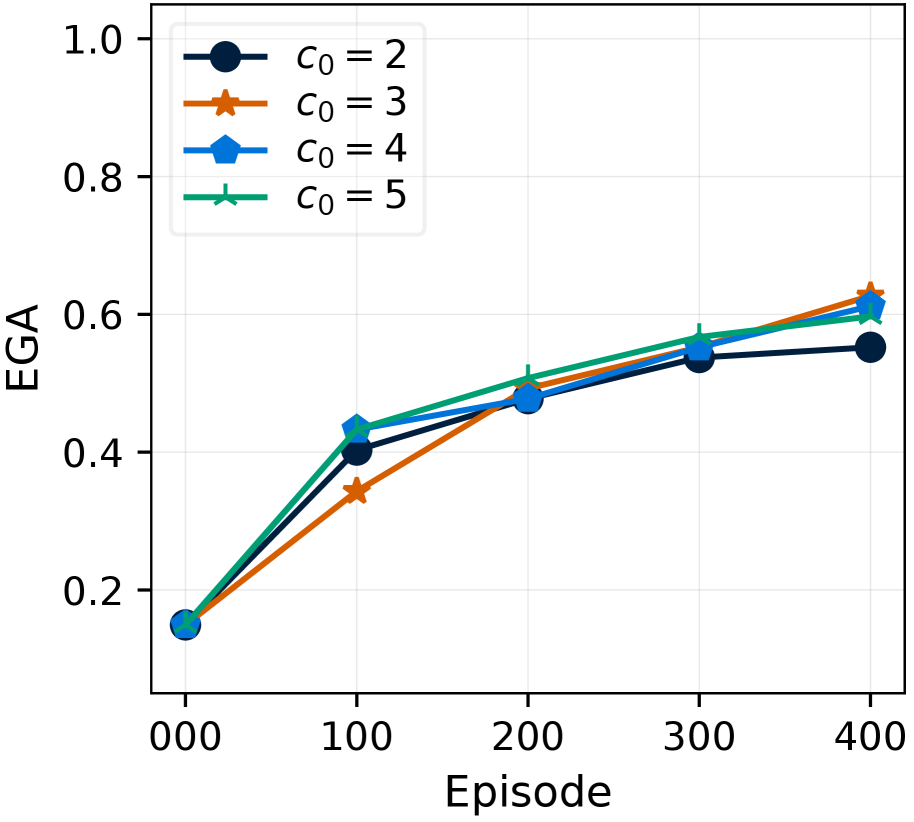
### Visual Description
## Line Chart: EGA vs Episode for different c0 values
### Overview
The image is a line chart showing the relationship between EGA (Estimated Generalization Ability) and Episode number for four different values of a parameter 'c0'. The chart displays how EGA changes over the course of episodes for each c0 value.
### Components/Axes
* **X-axis (Horizontal):** Episode, with markers at 0, 100, 200, 300, and 400.
* **Y-axis (Vertical):** EGA, ranging from 0.0 to 1.0, with markers at 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Legend (Top-Left):**
* Black line with circle marker: c0 = 2
* Orange line with star marker: c0 = 3
* Blue line with pentagon marker: c0 = 4
* Teal line with plus marker: c0 = 5
### Detailed Analysis
* **c0 = 2 (Black line, circle marker):**
* At Episode 0, EGA is approximately 0.15.
* At Episode 100, EGA is approximately 0.40.
* At Episode 200, EGA is approximately 0.48.
* At Episode 300, EGA is approximately 0.54.
* At Episode 400, EGA is approximately 0.56.
* Trend: The line slopes upward, with a decreasing rate of increase.
* **c0 = 3 (Orange line, star marker):**
* At Episode 0, EGA is approximately 0.15.
* At Episode 100, EGA is approximately 0.35.
* At Episode 200, EGA is approximately 0.50.
* At Episode 300, EGA is approximately 0.56.
* At Episode 400, EGA is approximately 0.63.
* Trend: The line slopes upward, with a decreasing rate of increase.
* **c0 = 4 (Blue line, pentagon marker):**
* At Episode 0, EGA is approximately 0.15.
* At Episode 100, EGA is approximately 0.43.
* At Episode 200, EGA is approximately 0.50.
* At Episode 300, EGA is approximately 0.56.
* At Episode 400, EGA is approximately 0.62.
* Trend: The line slopes upward, with a decreasing rate of increase.
* **c0 = 5 (Teal line, plus marker):**
* At Episode 0, EGA is approximately 0.15.
* At Episode 100, EGA is approximately 0.44.
* At Episode 200, EGA is approximately 0.51.
* At Episode 300, EGA is approximately 0.57.
* At Episode 400, EGA is approximately 0.60.
* Trend: The line slopes upward, with a decreasing rate of increase.
### Key Observations
* All lines start at approximately the same EGA value (0.15) at Episode 0.
* The EGA values for all c0 values increase as the number of episodes increases.
* The rate of increase in EGA decreases as the number of episodes increases.
* The lines for c0 = 3, c0 = 4, and c0 = 5 are relatively close to each other, while the line for c0 = 2 is slightly lower, especially at higher episode numbers.
### Interpretation
The chart suggests that increasing the number of episodes generally improves the Estimated Generalization Ability (EGA). However, the improvement diminishes over time, indicating a potential saturation point. The parameter 'c0' influences the EGA, with higher values of c0 (3, 4, and 5) resulting in slightly higher EGA values compared to c0 = 2, especially as the number of episodes increases. This implies that 'c0' plays a role in the learning process and its ability to generalize. The similarity in EGA trends for c0 = 3, 4, and 5 suggests that there might be a diminishing return in increasing 'c0' beyond a certain point.
</details>
(e) $c_{0}$
<details>
<summary>x28.png Details</summary>
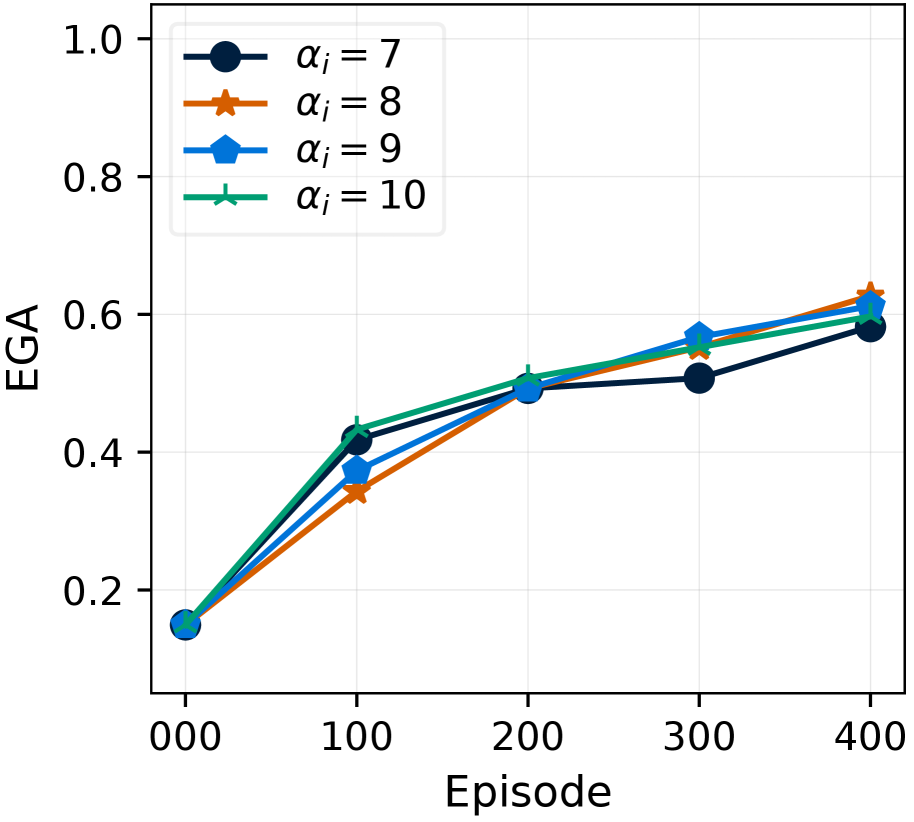
### Visual Description
## Line Chart: EGA vs Episode for Different Alpha Values
### Overview
The image is a line chart showing the relationship between EGA (Estimated Generalization Ability) and Episode number for four different values of alpha (αᵢ = 7, 8, 9, 10). The chart displays how EGA changes over the course of episodes for each alpha value.
### Components/Axes
* **X-axis (Horizontal):** Episode, with markers at 000, 100, 200, 300, and 400.
* **Y-axis (Vertical):** EGA, ranging from 0.0 to 1.0, with markers at 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Legend (Top-Left):**
* Dark Blue (circle marker): αᵢ = 7
* Orange (star marker): αᵢ = 8
* Blue (pentagon marker): αᵢ = 9
* Teal (plus marker): αᵢ = 10
### Detailed Analysis
* **αᵢ = 7 (Dark Blue, circle marker):**
* Trend: Generally increasing.
* Data Points:
* Episode 000: EGA ≈ 0.15
* Episode 100: EGA ≈ 0.42
* Episode 200: EGA ≈ 0.50
* Episode 300: EGA ≈ 0.51
* Episode 400: EGA ≈ 0.58
* **αᵢ = 8 (Orange, star marker):**
* Trend: Generally increasing.
* Data Points:
* Episode 000: EGA ≈ 0.15
* Episode 100: EGA ≈ 0.35
* Episode 200: EGA ≈ 0.49
* Episode 300: EGA ≈ 0.56
* Episode 400: EGA ≈ 0.62
* **αᵢ = 9 (Blue, pentagon marker):**
* Trend: Generally increasing.
* Data Points:
* Episode 000: EGA ≈ 0.15
* Episode 100: EGA ≈ 0.38
* Episode 200: EGA ≈ 0.50
* Episode 300: EGA ≈ 0.57
* Episode 400: EGA ≈ 0.60
* **αᵢ = 10 (Teal, plus marker):**
* Trend: Generally increasing.
* Data Points:
* Episode 000: EGA ≈ 0.15
* Episode 100: EGA ≈ 0.42
* Episode 200: EGA ≈ 0.50
* Episode 300: EGA ≈ 0.55
* Episode 400: EGA ≈ 0.61
### Key Observations
* All lines start at approximately the same EGA value (0.15) at Episode 000.
* The EGA values for all alpha values increase as the number of episodes increases.
* The lines converge towards the end of the episode range (300-400).
* αᵢ = 8 shows the highest EGA value at Episode 400.
* αᵢ = 7 shows the lowest EGA value at Episode 400.
### Interpretation
The chart suggests that increasing the alpha value initially leads to a faster increase in EGA, as seen in the early episodes. However, as the number of episodes increases, the differences in EGA between the different alpha values become smaller, and the lines converge. This indicates that the choice of alpha value has a more significant impact on the initial learning phase, but its influence diminishes as the agent learns over more episodes. The fact that αᵢ = 8 achieves the highest EGA at the end suggests that there might be an optimal alpha value for maximizing generalization ability in this particular scenario. The convergence of the lines also implies that with enough training episodes, the agent's performance becomes less sensitive to the initial alpha value.
</details>
(f) $\alpha_{i}$
<details>
<summary>x29.png Details</summary>
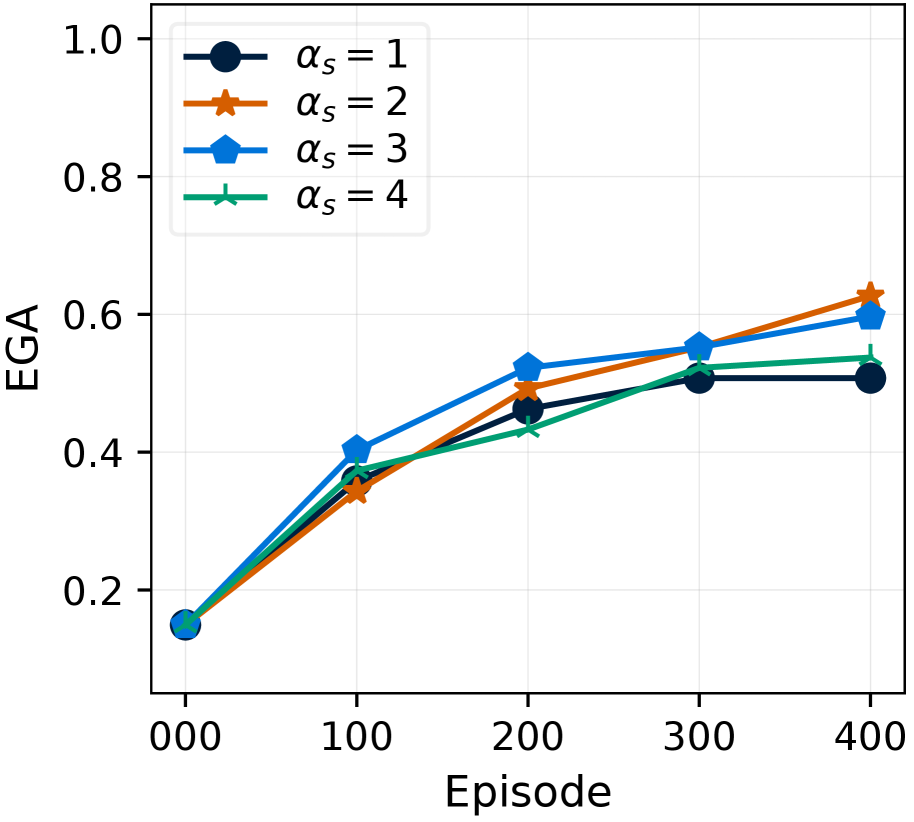
### Visual Description
## Line Chart: EGA vs Episode for Different Alpha Values
### Overview
The image is a line chart showing the relationship between EGA (Estimated Generalization Ability) and Episode number for four different values of alpha (αs = 1, 2, 3, 4). The chart displays how EGA changes over episodes for each alpha value.
### Components/Axes
* **X-axis (Horizontal):** Episode, with markers at 000, 100, 200, 300, and 400.
* **Y-axis (Vertical):** EGA, ranging from 0.0 to 1.0, with markers at 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Legend (Top-Left):**
* Dark Blue line with circle marker: αs = 1
* Orange line with star marker: αs = 2
* Blue line with pentagon marker: αs = 3
* Green line with plus marker: αs = 4
### Detailed Analysis
* **αs = 1 (Dark Blue, Circle):**
* Trend: Increases from Episode 0 to Episode 200, then plateaus.
* Data Points:
* Episode 0: EGA ≈ 0.15
* Episode 100: EGA ≈ 0.37
* Episode 200: EGA ≈ 0.51
* Episode 300: EGA ≈ 0.51
* Episode 400: EGA ≈ 0.51
* **αs = 2 (Orange, Star):**
* Trend: Increases steadily from Episode 0 to Episode 400.
* Data Points:
* Episode 0: EGA ≈ 0.15
* Episode 100: EGA ≈ 0.37
* Episode 200: EGA ≈ 0.47
* Episode 300: EGA ≈ 0.55
* Episode 400: EGA ≈ 0.63
* **αs = 3 (Blue, Pentagon):**
* Trend: Increases sharply from Episode 0 to Episode 200, then plateaus.
* Data Points:
* Episode 0: EGA ≈ 0.15
* Episode 100: EGA ≈ 0.41
* Episode 200: EGA ≈ 0.53
* Episode 300: EGA ≈ 0.56
* Episode 400: EGA ≈ 0.60
* **αs = 4 (Green, Plus):**
* Trend: Increases from Episode 0 to Episode 200, then plateaus.
* Data Points:
* Episode 0: EGA ≈ 0.15
* Episode 100: EGA ≈ 0.35
* Episode 200: EGA ≈ 0.45
* Episode 300: EGA ≈ 0.51
* Episode 400: EGA ≈ 0.59
### Key Observations
* All alpha values start at approximately the same EGA value (0.15) at Episode 0.
* αs = 3 (Blue) shows the highest EGA values up to Episode 400.
* αs = 1 (Dark Blue) plateaus early, showing the lowest EGA values after Episode 200.
* αs = 2 (Orange) shows a steady increase in EGA throughout the episodes.
* αs = 4 (Green) increases and then plateaus, ending with a value between αs = 1 and αs = 3.
### Interpretation
The chart suggests that the choice of alpha value significantly impacts the Estimated Generalization Ability (EGA) over training episodes. An alpha value of 3 appears to provide the best EGA performance initially, but αs = 2 catches up by episode 400. Alpha values of 1 and 4 result in lower EGA values and plateau earlier, indicating that they might not be as effective for long-term generalization. The data implies that there is an optimal alpha value for maximizing EGA, and this value may depend on the number of training episodes.
</details>
(g) $\alpha_{s}$
<details>
<summary>x30.png Details</summary>
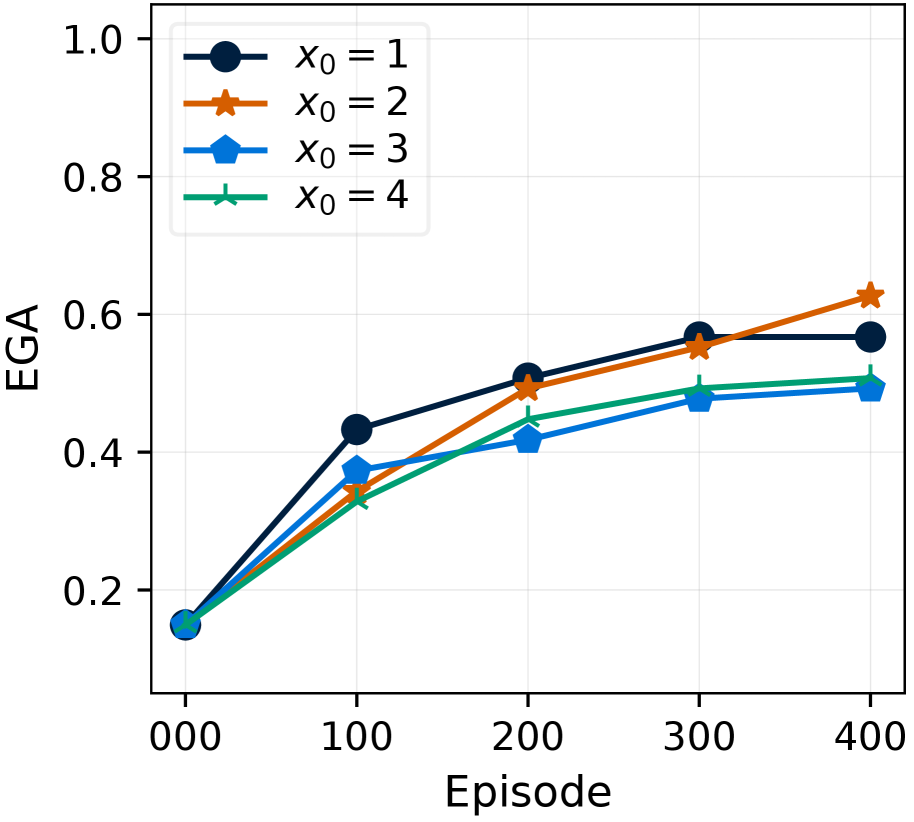
### Visual Description
## Line Chart: EGA vs Episode for Different Initial Conditions
### Overview
The image is a line chart showing the relationship between EGA (Estimated Goal Achievement) and Episode number for four different initial conditions, denoted as x₀ = 1, x₀ = 2, x₀ = 3, and x₀ = 4. The chart illustrates how EGA changes over episodes for each initial condition.
### Components/Axes
* **X-axis:** Episode, with markers at 0, 100, 200, 300, and 400.
* **Y-axis:** EGA (Estimated Goal Achievement), ranging from 0.0 to 1.0, with markers at 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Legend:** Located in the top-left corner, indicating the initial conditions (x₀) corresponding to each line color:
* Dark Blue: x₀ = 1 (marked with circles)
* Orange: x₀ = 2 (marked with stars)
* Blue: x₀ = 3 (marked with pentagons)
* Green: x₀ = 4 (marked with plus signs)
### Detailed Analysis
* **x₀ = 1 (Dark Blue):** The line starts at approximately 0.15 at Episode 0, increases to approximately 0.43 at Episode 100, reaches approximately 0.51 at Episode 200, rises to approximately 0.57 at Episode 300, and ends at approximately 0.57 at Episode 400. The trend is generally upward, with a plateau towards the end.
* **x₀ = 2 (Orange):** The line starts at approximately 0.15 at Episode 0, increases to approximately 0.37 at Episode 100, reaches approximately 0.51 at Episode 200, rises to approximately 0.57 at Episode 300, and ends at approximately 0.62 at Episode 400. The trend is generally upward.
* **x₀ = 3 (Blue):** The line starts at approximately 0.15 at Episode 0, increases to approximately 0.35 at Episode 100, reaches approximately 0.42 at Episode 200, rises to approximately 0.48 at Episode 300, and ends at approximately 0.50 at Episode 400. The trend is generally upward, but with a less steep slope than x₀ = 1 and x₀ = 2.
* **x₀ = 4 (Green):** The line starts at approximately 0.15 at Episode 0, increases to approximately 0.37 at Episode 100, reaches approximately 0.48 at Episode 200, rises to approximately 0.50 at Episode 300, and ends at approximately 0.51 at Episode 400. The trend is generally upward, similar to x₀ = 3.
### Key Observations
* All lines start at the same EGA value (approximately 0.15) at Episode 0.
* The EGA values for x₀ = 1 and x₀ = 2 are generally higher than those for x₀ = 3 and x₀ = 4 across all episodes.
* The lines for x₀ = 3 and x₀ = 4 are very close to each other, suggesting similar performance.
* The rate of increase in EGA decreases as the number of episodes increases for all initial conditions.
### Interpretation
The chart suggests that the initial conditions (x₀) have an impact on the Estimated Goal Achievement (EGA). Specifically, x₀ = 1 and x₀ = 2 lead to higher EGA values compared to x₀ = 3 and x₀ = 4. The convergence of the lines towards the end of the episode range indicates that the impact of the initial conditions diminishes over time, and the system's performance stabilizes. The diminishing rate of increase in EGA suggests that there are diminishing returns to training as the number of episodes increases.
</details>
(h) $x_{0}$
Figure 8: Hyperparameter ablation study in MineRL. EGA over 400 episodes under different hyperparameters. The plots show EGA when varying: (a) $c_{0}$ (revision count threshold for inadmissible items), (b) $\alpha_{i}$ (required items quantities for inadmissible items), (c) $\alpha_{s}$ (required items quantities for less-tried items), and (d) $x_{0}$ (invalid action threshold). Each study varies one hyperparameter while keeping the others fixed to their default values ( $c_{0}=3,\alpha_{i}=8,\alpha_{s}=2,x_{0}=2$ ).
To validate XENON’s stability to its hyperparameters, we conduct comprehensive ablation studies in both MC-TextWorld and MineRL. In these studies, we vary one hyperparameter at a time while keeping the others fixed to their default values ( $c_{0}=3$ , $\alpha_{i}=8$ , $\alpha_{s}=2$ , $x_{0}=2$ ).
Our results (Figure ˜ 8, Figure ˜ 8) show that although XENON is generally stable across hyperparameters, an effective learning strategy should account for controller capacity when the controller is imperfect. In MC-TextWorld (Figure ˜ 8), XENON maintains near-perfect EGA across a wide range of all tested hyperparameters, confirming its stability when a perfect controller is used. In MineRL (Figure ˜ 8), with an imperfect controller, the results demonstrate two findings. First, while influenced by hyperparameters, XENON still demonstrates robust performance, showing EGA after 400 episodes for all tested values remains near or above 0.5, outperforming baselines that plateau around or below 0.4 (Figure ˜ 5(a)). Second, controller capacity should be considered when designing dependency and action learning strategies. For example, the ablation on $\alpha_{s}$ (Figure ˜ 7(g)) shows that while gathering a sufficient quantity of items is necessary ( $\alpha_{s}=1$ ), overburdening the controller with excessive items ( $\alpha_{s}=4$ ) also degrades performance. Similarly, the ablation on $x_{0}$ (Figure ˜ 7(h)) shows the need to balance tolerating controller failures against wasting time on invalid actions.
We provide additional ablations in the Appendix on dependency and action learning—when initializing the dependency graph from an external source mismatched to the environment (Figure ˜ 23), when scaling to more goals/actions (Figure ˜ 24), and when using a smaller 4B planner LLM (Figure ˜ 26)—as well as an ablation of action selection methods for subgoal construction (Figure ˜ 25).
6 Conclusion
We address the challenge of robust planning via experience-based algorithmic knowledge correction. With XENON, we show that directly revising external knowledge through experience enables an LLM-based agent to overcome flawed priors and sparse feedback, surpassing the limits of LLM self-correction. Experiments across diverse Minecraft benchmarks demonstrate that this approach not only strengthens knowledge acquisition and long-horizon planning, but also enables an agent with a lightweight 7B open-weight LLM to outperform prior methods that rely on much larger proprietary models. Our work delivers a key lesson for building robust LLM-based embodied agents: LLM priors should be treated with skepticism and continuously managed and corrected algorithmically.
Limitations
Despite its contributions, XENON faces a limitation. XENON’s performance is influenced by the underlying controller; in MineRL, STEVE-1 (Lifshitz et al., 2023) controller struggles with spatial exploration tasks, making a performance gap compared to more competent controllers like Mineflayer. Future work could involve jointly training the planner and controller, potentially using hierarchical reinforcement learning.
Acknowledgments
This work was supported by the Institute of Information & Communications Technology Planning & Evaluation (IITP) and IITP-ITRC (Information Technology Research Center) grant funded by the Korea government (MSIT) (No. RS-2019-II191906, Artificial Intelligence Graduate School Program (POSTECH); IITP-2026-RS-2024-00437866; RS-2024-00509258, Global AI Frontier Lab), by a grant from the Korea Institute for Advancement of Technology (KIAT), funded by the Ministry of Trade, Industry and Energy (MOTIE), Republic of Korea (RS-2025-00564342), and by Seoul R&BD Program (SP240008) through the Seoul Business Agency (SBA) funded by The Seoul Metropolitan Government.
References
- S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y. Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y. Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin (2025) Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923. Cited by: Figure 26, §K.1, §K.11, Figure 1, §5.1, §5.3.
- B. Baker, I. Akkaya, P. Zhokhov, J. Huizinga, J. Tang, A. Ecoffet, B. Houghton, R. Sampedro, and J. Clune (2022) Video pretraining (vpt): learning to act by watching unlabeled online videos. External Links: 2206.11795, Link Cited by: §J.2.1.
- P. Belcak, G. Heinrich, S. Diao, Y. Fu, X. Dong, S. Muralidharan, Y. C. Lin, and P. Molchanov (2025) Small language models are the future of agentic ai. External Links: 2506.02153, Link, Document Cited by: §1.
- M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Herbert-Voss, W. H. Guss, A. Nichol, A. Paino, N. Tezak, J. Tang, I. Babuschkin, S. Balaji, S. Jain, W. Saunders, C. Hesse, A. N. Carr, J. Leike, J. Achiam, V. Misra, E. Morikawa, A. Radford, M. Knight, M. Brundage, M. Murati, K. Mayer, P. Welinder, B. McGrew, D. Amodei, S. McCandlish, I. Sutskever, and W. Zaremba (2021) Evaluating large language models trained on code. External Links: 2107.03374 Cited by: §5.3.
- M. Chen, Y. Li, Y. Yang, S. Yu, B. Lin, and X. He (2024) AutoManual: constructing instruction manuals by llm agents via interactive environmental learning. External Links: 2405.16247 Cited by: §E.1, §1.
- M. Côté, Á. Kádár, X. Yuan, B. Kybartas, T. Barnes, E. Fine, J. Moore, R. Y. Tao, M. Hausknecht, L. E. Asri, M. Adada, W. Tay, and A. Trischler (2018) TextWorld: a learning environment for text-based games. CoRR abs/1806.11532. Cited by: Appendix A.
- K. Du, V. Snæbjarnarson, N. Stoehr, J. White, A. Schein, and R. Cotterell (2024) Context versus prior knowledge in language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), L. Ku, A. Martins, and V. Srikumar (Eds.), Bangkok, Thailand, pp. 13211–13235. External Links: Link, Document Cited by: §1.
- L. Fan, G. Wang, Y. Jiang, A. Mandlekar, Y. Yang, H. Zhu, A. Tang, D. Huang, Y. Zhu, and A. Anandkumar (2022) MineDojo: building open-ended embodied agents with internet-scale knowledge. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, External Links: Link Cited by: §1, §3.
- Y. Feng, Y. Wang, J. Liu, S. Zheng, and Z. Lu (2024) LLaMA-rider: spurring large language models to explore the open world. In Findings of the Association for Computational Linguistics: NAACL 2024, K. Duh, H. Gomez, and S. Bethard (Eds.), Mexico City, Mexico, pp. 4705–4724. External Links: Link, Document Cited by: §1, §2.1.
- Z. Gou, Z. Shao, Y. Gong, Y. Shen, Y. Yang, N. Duan, and W. Chen (2024) CRITIC: large language models can self-correct with tool-interactive critiquing. External Links: 2305.11738, Link Cited by: §2.2.
- W. H. Guss, B. Houghton, N. Topin, P. Wang, C. Codel, M. Veloso, and R. Salakhutdinov (2019) MineRL: a large-scale dataset of minecraft demonstrations. External Links: 1907.13440, Link Cited by: §J.2.2, §J.2.5, §1, §3, §5.1.
- J. Huang, X. Chen, S. Mishra, H. S. Zheng, A. W. Yu, X. Song, and D. Zhou (2024) Large language models cannot self-correct reasoning yet. External Links: 2310.01798, Link Cited by: §2.2.
- J. Li, Q. Wang, Y. Wang, X. Jin, Y. Li, W. Zeng, and X. Yang (2025a) Open-world reinforcement learning over long short-term imagination. In ICLR, Cited by: §J.2.1.
- T. Li, G. Zhang, Q. D. Do, X. Yue, and W. Chen (2024a) Long-context llms struggle with long in-context learning. External Links: 2404.02060 Cited by: §4.2, §5.3.
- Z. Li, Y. Xie, R. Shao, G. Chen, D. Jiang, and L. Nie (2024b) Optimus-1: hybrid multimodal memory empowered agents excel in long-horizon tasks. Advances in neural information processing systems 37, pp. 49881–49913. Cited by: §J.2.2, §J.2.3, §J.2.5, Appendix H, §1, §2.1, §3, §4.3, §5.1, §5.1, Table 3.
- Z. Li, Y. Xie, R. Shao, G. Chen, D. Jiang, and L. Nie (2025b) Optimus-2: multimodal minecraft agent with goal-observation-action conditioned policy. In 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Cited by: §5.1, Table 3.
- S. Lifshitz, K. Paster, H. Chan, J. Ba, and S. McIlraith (2023) STEVE-1: a generative model for text-to-behavior in minecraft. External Links: 2306.00937 Cited by: §5.1, §5.2, §6.
- Z. Lin, J. Li, J. Shi, D. Ye, Q. Fu, and W. Yang (2021) Juewu-mc: playing minecraft with sample-efficient hierarchical reinforcement learning. arXiv preprint arXiv:2112.04907. Cited by: §J.2.1, §1.
- N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang (2024) Lost in the middle: how language models use long contexts. Transactions of the Association for Computational Linguistics 12, pp. 157–173. External Links: Link, Document Cited by: §4.2.
- S. Liu, Y. Li, K. Zhang, Z. Cui, W. Fang, Y. Zheng, T. Zheng, and M. Song (2025) Odyssey: empowering minecraft agents with open-world skills. In International Joint Conference on Artificial Intelligence, Cited by: §2.1.
- H. Mao, C. Wang, X. Hao, Y. Mao, Y. Lu, C. Wu, J. Hao, D. Li, and P. Tang (2022) Seihai: a sample-efficient hierarchical ai for the minerl competition. In Distributed Artificial Intelligence: Third International Conference, DAI 2021, Shanghai, China, December 17–18, 2021, Proceedings 3, pp. 38–51. Cited by: §J.2.1, §1.
- Microsoft, :, A. Abouelenin, A. Ashfaq, A. Atkinson, H. Awadalla, N. Bach, J. Bao, A. Benhaim, M. Cai, V. Chaudhary, C. Chen, D. Chen, D. Chen, J. Chen, W. Chen, Y. Chen, Y. Chen, Q. Dai, X. Dai, R. Fan, M. Gao, M. Gao, A. Garg, A. Goswami, J. Hao, A. Hendy, Y. Hu, X. Jin, M. Khademi, D. Kim, Y. J. Kim, G. Lee, J. Li, Y. Li, C. Liang, X. Lin, Z. Lin, M. Liu, Y. Liu, G. Lopez, C. Luo, P. Madan, V. Mazalov, A. Mitra, A. Mousavi, A. Nguyen, J. Pan, D. Perez-Becker, J. Platin, T. Portet, K. Qiu, B. Ren, L. Ren, S. Roy, N. Shang, Y. Shen, S. Singhal, S. Som, X. Song, T. Sych, P. Vaddamanu, S. Wang, Y. Wang, Z. Wang, H. Wu, H. Xu, W. Xu, Y. Yang, Z. Yang, D. Yu, I. Zabir, J. Zhang, L. L. Zhang, Y. Zhang, and X. Zhou (2025) Phi-4-mini technical report: compact yet powerful multimodal language models via mixture-of-loras. External Links: 2503.01743, Link Cited by: Figure 26, §K.11.
- K. Nottingham, P. Ammanabrolu, A. Suhr, Y. Choi, H. Hajishirzi, S. Singh, and R. Fox (2023) Do embodied agents dream of pixelated sheep? embodied decision making using language guided world modelling. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. Cited by: §J.1, Table 8, Appendix C, Appendix G, §2.1, §3, §3, §4.1, §5.1.
- OpenAI (2023) Gpt-4v(ision) system card. External Links: Link Cited by: §5.3.
- OpenAI (2024) GPT-4 technical report. External Links: 2303.08774, Link Cited by: §5.3.
- PrismarineJS (2023) Prismarinejs/mineflayer. Note: https://github.com/PrismarineJS/mineflayer External Links: Link Cited by: §J.3, §5.1.
- Y. Qin, E. Zhou, Q. Liu, Z. Yin, L. Sheng, R. Zhang, Y. Qiao, and J. Shao (2024) Mp5: a multi-modal open-ended embodied system in minecraft via active perception. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 16307–16316. Cited by: §2.1.
- N. Reimers and I. Gurevych (2019) Sentence-bert: sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, External Links: Link Cited by: Appendix I, 2nd item.
- N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao (2023) Reflexion: language agents with verbal reinforcement learning. External Links: 2303.11366 Cited by: §J.1, §1, §2.2, §5.1.
- K. Stechly, K. Valmeekam, and S. Kambhampati (2024) On the self-verification limitations of large language models on reasoning and planning tasks. External Links: 2402.08115, Link Cited by: §J.1, §1, §5.1.
- A. Szot, A. Clegg, E. Undersander, E. Wijmans, Y. Zhao, J. Turner, N. Maestre, M. Mukadam, D. Chaplot, O. Maksymets, A. Gokaslan, V. Vondrus, S. Dharur, F. Meier, W. Galuba, A. Chang, Z. Kira, V. Koltun, J. Malik, M. Savva, and D. Batra (2021) Habitat 2.0: training home assistants to rearrange their habitat. In Advances in Neural Information Processing Systems (NeurIPS), Cited by: §1.
- G. Tyen, H. Mansoor, V. Carbune, P. Chen, and T. Mak (2024) LLMs cannot find reasoning errors, but can correct them given the error location. In Findings of the Association for Computational Linguistics: ACL 2024, L. Ku, A. Martins, and V. Srikumar (Eds.), Bangkok, Thailand, pp. 13894–13908. External Links: Link, Document Cited by: §2.2.
- G. Wang, Y. Xie, Y. Jiang, A. Mandlekar, C. Xiao, Y. Zhu, L. Fan, and A. Anandkumar (2023a) Voyager: an open-ended embodied agent with large language models. arXiv preprint arXiv: Arxiv-2305.16291. Cited by: §1, §2.1.
- Z. Wang, S. Cai, G. Chen, A. Liu, X. (. Ma, and Y. Liang (2023b) Describe, explain, plan and select: interactive planning with llms enables open-world multi-task agents. Advances in Neural Information Processing Systems 36, pp. 34153–34189. Cited by: §J.2.5, §1, §5.1.
- Z. Wang, S. Cai, A. Liu, Y. Jin, J. Hou, B. Zhang, H. Lin, Z. He, Z. Zheng, Y. Yang, X. Ma, and Y. Liang (2023c) JARVIS-1: open-world multi-task agents with memory-augmented multimodal language models. arXiv preprint arXiv: 2311.05997. Cited by: §1, §2.1, §5.1.
- Y. Wu, M. S. Hee, Z. Hu, and R. K. Lee (2024) LongGenBench: benchmarking long-form generation in long context llms. External Links: 2409.02076, Link Cited by: §5.3.
- L. Yang, Z. Yu, T. Zhang, M. Xu, J. E. Gonzalez, B. Cui, and S. Yan (2025) SuperCorrect: supervising and correcting language models with error-driven insights. In International Conference on Learning Representations, Cited by: §2.2.
- Y. Yoon, G. Lee, S. Ahn, and J. Ok (2024) Breadth-first exploration on adaptive grid for reinforcement learning. In Forty-first International Conference on Machine Learning, Cited by: 2nd item.
- S. Yu and C. Lu (2024) ADAM: an embodied causal agent in open-world environments. arXiv preprint arXiv:2410.22194. Cited by: §J.1, §J.3.1, Table 8, §K.1, §2.1, §5.1, §5.1.
- H. Yuan, C. Zhang, H. Wang, F. Xie, P. Cai, H. Dong, and Z. Lu (2023) Plan4MC: skill reinforcement learning and planning for open-world Minecraft tasks. arXiv preprint arXiv:2303.16563. Cited by: §1.
- Y. Zhang, M. Khalifa, L. Logeswaran, J. Kim, M. Lee, H. Lee, and L. Wang (2024) Small language models need strong verifiers to self-correct reasoning. In Findings of the Association for Computational Linguistics: ACL 2024, L. Ku, A. Martins, and V. Srikumar (Eds.), Bangkok, Thailand, pp. 15637–15653. External Links: Link, Document Cited by: §1.
- A. Zhao, D. Huang, Q. Xu, M. Lin, Y. Liu, and G. Huang (2024) ExpeL: llm agents are experiential learners. In Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2024, February 20-27, 2024, Vancouver, Canada, M. J. Wooldridge, J. G. Dy, and S. Natarajan (Eds.), pp. 19632–19642. External Links: Link, Document Cited by: §E.1.
- Z. Zhao, W. Chai, X. Wang, L. Boyi, S. Hao, S. Cao, T. Ye, J. Hwang, and G. Wang (2023) See and think: embodied agent in virtual environment. arXiv preprint arXiv:2311.15209. Cited by: §2.1.
- X. Zheng, H. Lin, K. He, Z. Wang, Z. Zheng, and Y. Liang (2025) MCU: an evaluation framework for open-ended game agents. External Links: 2310.08367, Link Cited by: §J.4, §5.1.
- X. Zhu, Y. Chen, H. Tian, C. Tao, W. Su, C. Yang, G. Huang, B. Li, L. Lu, X. Wang, Y. Qiao, Z. Zhang, and J. Dai (2023) Ghost in the minecraft: generally capable agents for open-world environments via large language models with text-based knowledge and memory. arXiv preprint arXiv:2305.17144. Cited by: §1, §2.1.
This appendix is organized as follows:
- Appendix ˜ A: Experiments in a domain other than Minecraft (Microsoft TextWorld Cooking).
- Appendix ˜ B: Prompts and qualitative results of LLM self-correction in our experiments.
- Appendix ˜ C: Detailed procedure for experienced requirement set determination and dependency graph updates, as discussed in Section ˜ 3.
- Appendix ˜ E: Detailed pseudocode and the prompt for ADG in Section ˜ 4.1.
- Appendix ˜ F: Detailed pseudocode and the prompt for step-by-step planning using FAM in Section ˜ 4.2.
- Appendix ˜ H: Detailed descriptions and the prompt for CRe in Section ˜ 4.3.
- Appendix ˜ I: Detailed descriptions of implementation, human-written plans, and hyperparameters.
- Appendix ˜ J: Detailed descriptions of the baselines and experimental environments in Section ˜ 5.
- Appendix ˜ K: Analysis of experimental results and additional experimental results.
- Appendix ˜ L: Descriptions about LLM usage.
Appendix A Additional experiments in another domain
To assess generalization beyond Minecraft, we evaluate XENON on the Microsoft TextWorld Cooking environment (Côté et al., 2018), a text-based household task planning benchmark. We demonstrate XENON can correct an LLM’s flawed knowledge of preconditions (e.g., required tools) and valid actions for plans using ADG and FAM in this domain as well. We note that XENON is applied with minimal modification: FAM is applied without modification, while ADG is adapted from its original design, which supports multiple incoming edges (preconditions) for a node, to one that allows only a single incoming edge, as this domain requires only a single precondition per node.
A.1 Experiment Setup
Environment Rules
The goal is to prepare and eat a meal by reading a cookbook, which provides a plan as a list of (action, ingredient) pairs, e.g., (“fry”, “pepper”). We note that an agent cannot succeed by naively following this plan. This is because the agent must solve two key challenges: (1) it must discover the valid tool required for each cookbook action, and (2) it must discover the valid, executable action for each cookbook action, as some cookbook actions are not directly accepted by the environment (i.e., not in its action space).
Specifically, to succeed a cookbook’s (action, ingredient) pair, an agent must make a subgoal, formatted as (executable action, ingredient, tool), where the executable action and tool must be valid for the cookbook action. For example, the cookbook’s (“fry”, “pepper”) pair requires the agent to make a subgoal (cook, “pepper”, stove). The available executable action space consists of { “chop”, “close”, “cook”, “dice”, “drop”, “eat”, “examine”, “slice”, “prepare” }, and the available tools are { “knife”, “oven”, “stove”, “fridge”, “table”, “counter” }.
Baselines and Evaluation
All agents use an LLM (Qwen2.5-VL-7B) to make subgoals. The tool for each cookbook action is predicted by the LLM from the available tools before an episode begins. At each timestep during the episode, given a cookbook action, the LLM predicts an executable action from the executable action space, constructing a subgoal from this predicted executable action, the input ingredient, and the predicted tool.
To isolate the challenge of planning knowledge correction, we assume a competent controller gathers all ingredients and tools; thus, an agent starts each episode with all necessary ingredients and tools. An episode (max 50 timesteps) is successful if the agent completes the plan.
A.2 Results
Table 6: Success rates in the TextWorld Cooking environment, comparing XENON against the SC (LLM self-correction) and DECKARD baselines from Section ˜ 5.1. We report the mean $±$ standard deviation over 3 independent runs, where each run consists of 100 episodes.
| | DECKARD | SC | XENON |
| --- | --- | --- | --- |
| Success Rate | $0.09± 0.02$ | $0.75± 0.04$ | $1.00± 0.00$ |
Table ˜ 6 shows that XENON achieves a perfect success rate ( $1.00± 0.00$ ), significantly outperforming both SC ( $0.75± 0.04$ ) and DECKARD ( $0.09± 0.02$ ). These results demonstrate that XENON’s core mechanisms (ADG and FAM) are generalizable, effectively correcting flawed planning knowledge in a domain that requires the agent to discover valid symbolic actions and preconditions. Notably, the SC baseline fails to achieve high performance, even in the TextWorld Cooking environment which is simpler than Minecraft. This reinforces our claim that relying on LLM self-correction is less reliable than XENON’s experience-based algorithmic knowledge correction.
Appendix B Prompts and qualitative results of LLM self-correction
B.1 Dependency correction
Figure ˜ 9 shows the prompt used for dependency correction.
⬇
1 You are a professional game analyst. For a given < item _ name >, you need to make < required _ items > to get the item.
2 If you make < required _ items > well, I will give you 1 $.
3
4 I will give you recent transitions.
5 % Recent failed trajectories are given
6 [Failed example]
7 < item _ name >: {item _ name}
8 < hypothesized _ required _ items >: {original _ prediction}
9 < inventory >: {inventory}
10 < plan >: {failed _ subgoal}
11 < success >: false
12
13 I will give you learned items similar to < item _ name >, and their validated required items, just for reference.
14 % K similar experienced items and their requirements are given
15 [Success Example]
16 < item _ name >: {experienced _ item}
17 < required _ items > {experienced _ requirements}
18
19 % Make a new predicted requirement set
20 [Your turn]
21 Here is < item _ name >, you MUST output < required _ items > to obtain the item in JSON format. Remember < required _ items > MUST be in JSON format.
22
23 < item _ name >: {item _ name}
24 < required _ items >:
Figure 9: Prompt used for LLM self-correction about dependencies.
We provide some examples of actual prompts and LLM outputs in Figure ˜ 10, Figure ˜ 11
⬇
1 You are a professional game analyst. For a given < item _ name >, you need to make < required _ items > to get the item.
2 If you make < required _ items > well, I will give you 1 $.
3
4 I will give you recent transitions.
5
6 [Failed example]
7 < item _ name >: iron _ nugget
8 < hypothesized _ required _ items >: {’ iron _ ore ’: 1, ’ crafting _ table ’: 1}
9 < inventory >: {’ crafting _ table ’: 1, ’ wooden _ sword ’: 1, ’ wooden _ pickaxe ’: 1, ’ torch ’: 4, ’ furnace ’: 1, ’ stone _ pickaxe ’: 1, ’ iron _ axe ’: 1, ’ iron _ shovel ’: 1, ’ stick ’: 2, ’ iron _ pickaxe ’: 1, ’ diamond ’: 3, ’ iron _ ingot ’: 2, ’ iron _ ore ’: 2, ’ gold _ ore ’: 1, ’ coal ’: 1}
10 < plan >: dig down and mine iron _ nugget
11 < success >: false
12
13 I will give you learned items similar to < item _ name >, and their validated required items, just for reference.
14 [Success Example]
15 < item _ name >:
16 iron _ ingot
17 < required _ items >:
18 {’ recipe ’: {’ furnace ’: 1, ’ iron _ ore ’: 1, ’ coals ’: 1}}
19 [Success Example]
20 < item _ name >:
21 iron _ pickaxe
22 < required _ items >:
23 {’ recipe ’: {’ stick ’: 2, ’ iron _ ingot ’: 3, ’ crafting _ table ’: 1}}
24 [Success Example]
25 < item _ name >:
26 iron _ shovel
27 < required _ items >:
28 {’ recipe ’: {’ stick ’: 2, ’ iron _ ingot ’: 1, ’ crafting _ table ’: 1}}
29
30 [Your turn]
31 Here is < item _ name >, you MUST output < required _ items > to obtain the item in JSON format. Remember < required _ items > MUST be in JSON format.
32
33 < item _ name >:
34 iron _ nugget
35 < required _ items >:
36 % LLM output: {’recipe’: {’iron_ore’: 1, ’crafting_table’: 1}}
Figure 10: Example of dependency self-correction for iron_nugget.
⬇
1 You are a professional game analyst. For a given < item _ name >, you need to make < required _ items > to get the item.
2 If you make < required _ items > well, I will give you 1 $.
3
4 I will give you recent transitions.
5
6 [Failed example]
7 < item _ name >: charcoal
8 < hypothesized _ required _ items >: {’ oak _ log ’: 8}
9 < inventory >: {’ dirt ’: 1, ’ oak _ log ’: 2, ’ crafting _ table ’: 1, ’ wooden _ hoe ’: 1, ’ wooden _ pickaxe ’: 1, ’ torch ’: 4, ’ stone _ axe ’: 1, ’ furnace ’: 1, ’ stone _ pickaxe ’: 1, ’ stick ’: 2, ’ iron _ pickaxe ’: 1, ’ diamond ’: 1, ’ iron _ ingot ’: 3, ’ iron _ ore ’: 2, ’ coal ’: 2}
10 < action >: craft charcoal
11 < success >: false
12
13 I will give you learned items similar to < item _ name >, and their validated required items, just for reference.
14 [Success Example]
15 < item _ name >:
16 coals
17 < required _ items >:
18 {’ recipe ’: {’ wooden _ pickaxe ’: 1}}
19 [Success Example]
20 < item _ name >:
21 furnace
22 < required _ items >:
23 {’ recipe ’: {’ cobblestone ’: 8, ’ crafting _ table ’: 1}}
24 [Success Example]
25 < item _ name >:
26 diamond
27 < required _ items >:
28 {’ recipe ’: {’ iron _ pickaxe ’: 1}}
29
30 [Your turn]
31 Here is < item _ name >, you MUST output < required _ items > to achieve charcoal in JSON format. Remember < required _ items > MUST be in JSON format.
32
33 < item _ name >:
34 charcoal
35 < required _ items >:
36 % LLM output: {’recipe’: {’oak_log’: 8}}
Figure 11: Example of dependency self-correction for charcoal.
B.2 Action correction
Figure ˜ 12 shows the prompt used self-reflection for failed actions.
⬇
1 % LLM self-reflection to analyze failure reasons
2 You are a professional game analyst.
3 For a given < item _ name > and < inventory >, you need to analyze why < plan > failed to get the item.
4 I will give you examples of analysis as follow.
5
6 [Example]
7 < item _ name >: wooden _ pickaxe
8 < inventory >: {’ stick ’: 4, ’ planks ’: 4, ’ crafting _ table ’: 1}
9 < plan >: smelt wooden _ pickaxe
10 < failure _ analysis >
11 {" analysis ": " You failed because you cannot smelt a wooden _ pickaxe. You should craft it instead."}
12
13 [Example]
14 < item _ name >: stone _ pickaxe
15 < inventory >: {’ stick ’: 4, ’ planks ’: 4, ’ crafting _ table ’: 1}
16 < plan >: craft stone _ pickaxe
17 < failure _ analysis >
18 {" analysis ": " You failed because you do not have enough cobblestones."}
19
20 [Your turn]
21 Here is < item _ name >, < inventory > and < plan >, you MUST output < failure _ analysis > concisely in JSON format.
22
23 < item _ name >: {item _ name}
24 < inventory >: {inventory}
25 < plan >: {plan}
26 < failure _ analysis >
27
28 % Then, using the self-reflection results, LLM self-correct its actions.
29 For an item name, you need to make a plan, by selecting one among provided options.
30 I will give you examples of which plans are needed to achieve an item, just for reference.
31 [Example]
32 < item name >
33 {similar _ item}
34 < task planning >
35 {successful _ plan
36
37 Here are some analyses on previous failed plans for this item.
38 [Analysis]
39 {’ item _ name ’: {item}, ’ inventory ’: {inventory}, ’ plan ’: ’{plan}’, ’ failure _ analysis ’: ’{self - reflection}’}
40
41 [Your turn]
42 Here is < item name >, you MUST select one from below < options >, to make < task planning >.
43 you MUST select one from below < options >. DO NOT MAKE A PLAN NOT IN < options >.
44
45 < options >:
46 1: {" task ": " dig down and mine {item}", " goal ": [{item}, {quantity}]}
47 2: {" task ": " craft {item}", " goal ": [{item}, {quantity}]}
48 3: {" task ": " smelt {item}", " item ": [{item}, {quantity}}
49
50 < item name >
51 {item}
52 < task planning >
Figure 12: Prompts used for LLM self-correction about actions.
We provide some examples of actual prompts and LLM outputs in Figure ˜ 13, Figure ˜ 14
⬇
1 For an item name, you need to make a plan, by selecting one among provided options.
2 I will give you examples of which plans are needed to achieve an item, just for reference.
3
4 [Example]
5 < item name >
6 iron _ ingot
7 < task planning >
8 {" task ": " smelt iron _ ingot ", " goal ": [" iron _ ingot ", 1]}
9
10 [Example]
11 < item name >
12 iron _ pickaxe
13 < task planning >
14 {" task ": " craft iron _ pickaxe ", " goal ": [" iron _ pickaxe ", 1]}
15
16 [Example]
17 < item name >
18 iron _ shovel
19 < task planning >
20 {" task ": " craft iron _ shovel ", " goal ": [" iron _ shovel ", 1]}
21
22 Here are some analyses on previous failed plans for this item.
23 [Analysis]
24 {’ item _ name ’: ’ iron _ nugget ’,
25 ’ inventory ’: {’ crafting _ table ’: 1, ’ wooden _ sword ’: 1, ’ wooden _ pickaxe ’: 1, ’ torch ’: 4, ’ furnace ’: 1, ’ stone _ pickaxe ’: 1, ’ iron _ axe ’: 1, ’ iron _ shovel ’: 1, ’ stick ’: 2, ’ iron _ pickaxe ’: 1, ’ diamond ’: 3, ’ iron _ ingot ’: 2, ’ iron _ ore ’: 2, ’ gold _ ore ’: 1, ’ coal ’: 1},
26 ’ plan ’: ’ dig down and mine iron _ nugget ’,
27 ’ failure _ analysis ’: ’ You failed because you do not have any iron ore or diamond ore to mine for iron nuggets.’}
28
29 [Your turn]
30 Here is < item name >, you MUST select one from below < options >, to make < task planning >.
31 you MUST select one from below < options >. DO NOT MAKE A PLAN NOT IN < options >.
32
33 < options >
34 1. {" task ": " dig down and mine iron _ nugget ", " goal ": [" iron _ nugget ", 1]}
35 2. {" task ": " craft iron _ nugget ", " goal ": [" iron _ nugget ", 1]}
36 3. {" task ": " smelt iron _ nugget ", " goal ": [" iron _ nugget ", 1]}
37
38 < item name >
39 iron _ nugget
40 % LLM output: ’{"task": "dig down and mine iron_nugget", "goal": ["iron_nugget", 1]}’
Figure 13: Example of action self-correction for iron_nugget.
⬇
1 For an item name, you need to make a plan, by selecting one among provided options.
2 I will give you examples of which plans are needed to achieve an item, just for reference.
3
4 [Example]
5 < item name >
6 coals
7 < task planning >
8 {" task ": " dig down and mine coals ", " goal ": [" coals ", 1]}
9
10 [Example]
11 < item name >
12 furnace
13 < task planning >
14 {" task ": " craft furnace ", " goal ": [" furnace ", 1]}
15
16 [Example]
17 < item name >
18 diamond
19 < task planning >
20 {" task ": " dig down and mine diamond ", " goal ": [" diamond ", 1]}
21
22 Here are some analyses on previous failed plans for this item.
23 [Analysis]
24 {’ item _ name ’: ’ charcoal ’,
25 ’ inventory ’: {’ dirt ’: 1, ’ oak _ log ’: 2, ’ crafting _ table ’: 1, ’ wooden _ hoe ’: 1, ’ wooden _ pickaxe ’: 1, ’ torch ’: 4, ’ stone _ axe ’: 1, ’ furnace ’: 1, ’ stone _ pickaxe ’: 1, ’ stick ’: 2, ’ iron _ pickaxe ’: 1, ’ diamond ’: 1, ’ iron _ ingot ’: 3, ’ iron _ ore ’: 2, ’ coal ’: 2},
26 ’ plan ’: ’ mine iron _ nugget ’,
27 ’ failure _ analysis ’: ’ You failed because you already have enough charcoal.’}
28
29
30 [Your turn]
31 Here is < item name >, you MUST select one from below < options >, to make < task planning >.
32 you MUST select one from below < options >. DO NOT MAKE A PLAN NOT IN < options >.
33
34 < options >
35 1. {" task ": " mine iron _ nugget ", " goal ": [" charcoal ", 1]}
36 2. {" task ": " craft charcoal ", " goal ": [" charcoal ", 1]}
37 3. {" task ": " smelt charcoal ", " goal ": [" charcoal ", 1]}
38
39 < item name >
40 charcoal
41 < task planning >
42 % LLM output: ’{"task": "craft charcoal", "goal": ["charcoal", 1]}’
Figure 14: Example of action self-correction for charcoal.
Appendix C Experienced requirement set and dependency graph update
We note that the assumptions explained in this section are largely similar to those in the implementation of DECKARD (Nottingham et al., 2023) https://github.com/DeckardAgent/deckard.
Determining experienced requirement set
When the agent obtains item $v$ while executing a subgoal $(a,q,u)$ , it determines the experienced requirement set $\mathcal{R}_{exp}(v)$ differently depending on whether the high-level action $a$ is “mine” or falls under “craft” or “smelt”. If $a$ is “mine”, the agent determines $\mathcal{R}_{exp}(v)$ based on the pickaxe in its inventory. If no pickaxe is held, $\mathcal{R}_{exp}(v)$ is $\emptyset$ . Otherwise, $\mathcal{R}_{exp}(v)$ becomes $\{(\text{the highest-tier pickaxe the agent has},1)\}$ , where the highest-tier pickaxe is determined following the hierarchy: “wooden_pickaxe”, “stone_pickaxe”, “iron_pickaxe”, “diamond_pickaxe”. If $a$ is “craft” or “smelt”, the agent determines the used items and their quantities as $\mathcal{R}_{exp}(v)$ by observing inventory changes when crafting or smelting $v$ .
Dependency graph update
When the agent obtains an item $v$ and its $\mathcal{R}_{exp}(v)$ for the first time, it updates its dependency graph $\hat{\mathcal{G}}=(\hat{\mathcal{V}},\hat{\mathcal{E}})$ . Since $\mathcal{R}_{\text{exp}}(v)$ only contains items acquired before $v$ , no cycles can be introduced to ADG during learning. The update proceeds as follows: The agent adds $v$ to both the set of known items $\hat{\mathcal{V}}$ . Then, it updates the edge set $\hat{\mathcal{E}}$ by replacing $v$ ’s incoming edges with $\mathcal{R}_{exp}(v)$ : it removes all of $v$ ’s incoming edges $(u,·,v)∈\hat{\mathcal{E}}$ and adds new edges $(u_{i},q_{i},v)$ to $\hat{\mathcal{E}}$ for every $(u_{i},q_{i})∈\mathcal{R}_{exp}(v)$ .
Appendix D Full procedure of XENON
input : invalid action threshold $x_{0}$ , inadmissible item threshold $c_{0}$ , less-explored item scale $\alpha_{s}$ , inadmissible item scale $\alpha_{i}$
1 Initialize dependency $\hat{\mathcal{G}}←(\hat{\mathcal{V}},\hat{\mathcal{E}})$ , revision counts $C[v]← 1$ for all $v∈\hat{\mathcal{V}}$
2 Initialize memory $S(a,v)=0,F(a,v)=0$ for all $v∈\hat{\mathcal{V}},a∈\mathcal{A}$
3 while learning do
4 Get an empty inventory $inv$
$v_{g}←\texttt{SelectGoalWithDifficulty}(\hat{\mathcal{G}},C[·])$
// DEX Appendix ˜ G
5 while $H_{episode}$ do
6 if $v_{g}∈ inv$ then
7 $v_{g}←\texttt{SelectGoalWithDifficulty}(\hat{\mathcal{G}},C[·])$
8
9
Series of aggregated requirements $((q_{l},u_{l}))_{l=1}^{L_{v_{g}}}$ using $\hat{\mathcal{G}}$ and $inv$
// from Section ˜ 3
10 Plan $P←((a_{l},q_{l},u_{l}))_{l=1}^{L_{v_{g}}}$ by selecting $a_{l}$ for each $u_{l}$ , using LLM, $S$ , $F$ , $x_{0}$
11 foreach subgoal $(a,q,u)∈ P$ do
12 Execute $(a,q,u)$ then get the execution result $success$
Get an updated inventory $inv$ , dependency graph $\hat{\mathcal{G}}$
// from Section ˜ 3
13
14 if success then $S(a,u)← S(a,u)+1$
15 else $F(a,u)← F(a,u)+1$
16
17 if not $success$ then
18 if All actions are invalid then
$\hat{\mathcal{G}},C←\texttt{RevisionByAnalogy}(\hat{\mathcal{G}},u,C[·],c_{0},\alpha_{s},\alpha_{i})$
// ADG Section ˜ 4.1
19 Reset memory $S(·,u)← 0,F(·,u)← 0$
20 $v_{g}←\texttt{SelectGoalWithDifficulty}(\hat{\mathcal{G}},C[·])$
21 break
22
23
24
25
Algorithm 1 Pseudocode of XENON
The full procedure of XENON is outlined in Algorithm ˜ 1
Appendix E Details in Adaptive Dependency Graph (ADG)
E.1 Rationale for initial knowledge
In real-world applications, a human user may wish for an autonomous agent to accomplish certain goals, yet the user themselves may have limited or no knowledge of how to achieve them within a complex environment. We model this scenario by having a user specify goal items without providing the detailed requirements, and then the agent should autonomously learn how to obtain these goal items. The set of 67 goal item names ( $\mathcal{V}_{0}$ ) provided to the agent represents such user-specified goal items, defining the learning objectives.
To bootstrap learning in complex environments, LLM-based planning literature often utilizes minimal human-written plans for initial knowledge (Zhao et al., 2024; Chen et al., 2024). In our case, we provide the agent with 3 human-written plans (shown in Appendix ˜ I). By executing these plans, our agent can experience items and their dependencies, thereby bootstrapping the dependency learning process.
E.2 Details in dependency graph initialization
Keeping ADG acyclic during initialization
During initialization, XENON prevents cycles in ADG algorithmically and maintains ADG as a directed acyclic graph, by, whenever adding an LLM-predicted requirement set for an item, discarding any set that would make a cycle and instead assign an empty requirement set to that item. Specifically, we identify and prevent cycles in three steps when adding LLM-predicted incoming edges for an item $v$ . First, we tentatively insert the LLM-predicted incoming edges of $v$ into the current ADG. Second, we detect cycles by checking whether any of $v$ ’s parents now appears among $v$ ’s descendants in the updated graph. Third, if a cycle is detected, we discard the LLM-predicted incoming edges for $v$ and instead assign an empty set of incoming edges to $v$ in the ADG.
Pseudocode is shown in Algorithm ˜ 2. The prompt is shown in Figure ˜ 15.
1
input : Goal items $\mathcal{V}_{0}$ , (optional) human written plans $\mathcal{P}_{0}$
output : Initialized dependency graph $\hat{\mathcal{G}}=(\hat{\mathcal{V}},\hat{\mathcal{E}})$ , experienced items $\mathcal{V}$
2
3 Initialize a set of known items $\hat{\mathcal{V}}←\mathcal{V}_{0}$ , edge set $\hat{\mathcal{E}}←\emptyset$
4 Initialize a set of experienced items $\mathcal{V}←\emptyset$
5
6 foreach plan in $\mathcal{P}_{0}$ do
7 Execute the plan and get experienced items and their experienced requirement sets $\bigl\{(v_{n},\mathcal{R}_{exp}(v_{n}))\bigr\}_{n=1}^{N}$
8 foreach $(v,\mathcal{R}_{exp}(v))∈\bigl\{(v_{n},\mathcal{R}_{exp}(v_{n}))\bigr\}_{n=1}^{N}$ do
9 if $v∉\mathcal{V}$ then
/* graph update from Appendix ˜ C */
10 $\mathcal{V}←\mathcal{V}\cup\{v\}$ , $\hat{\mathcal{V}}←\hat{\mathcal{V}}\cup\{v\}$
11 Add edges to $\hat{\mathcal{E}}$ according to $\mathcal{R}_{exp}(v)$
12
13
/* Graph construction using LLM predictions */
14 while $∃ v∈\hat{\mathcal{V}}\setminus\mathcal{V}$ whose requirement set $\mathcal{R}(v)$ has not yet been predicted by the LLM do
15 Select such an item $v∈\hat{\mathcal{V}}\setminus\mathcal{V}$ (i.e., $\mathcal{R}(v)$ has not yet been predicted)
16 Select $\mathcal{V}_{K}⊂eq\mathcal{V}$ based on Top-K semantic similarity to $v$ , $|\mathcal{V}_{K}|=K$
17 Predict $\mathcal{R}(v)← LLM(v,\{\big(u,\mathcal{R}(u,\hat{\mathcal{G}})\big)\}_{u∈\mathcal{V}_{K}})$
18
19 foreach $(u_{j},q_{j})∈\mathcal{R}(v)$ do
20 $\hat{\mathcal{E}}←\hat{\mathcal{E}}\cup\{(u_{j},q_{j},v)\}$
21 if $u_{j}∉\hat{\mathcal{V}}$ then
22 $\hat{\mathcal{V}}←\hat{\mathcal{V}}\cup\{u_{j}\}$
23
24
25
Algorithm 2 GraphInitialization
⬇
1 You are a professional game analyst. For a given < item _ name >, you need to make < required _ items > to get the item.
2 If you make < required _ items > well, I will give you 1 $.
3
4 I will give you some examples < item _ name > and < required _ items >.
5
6 [Example] % TopK similar experienced items are given as examples
7 < item _ name >: {experienced _ item}
8 < required _ items >: {experienced _ requirement _ set}
9
10 [Your turn]
11 Here is a item name, you MUST output < required _ items > in JSON format. Remember < required _ items > MUST be in JSON format.
12
13 < item _ name >: {item _ name}
14 < required _ items >:
Figure 15: Prompt for requirement set prediction for dependency graph initialization
E.3 Pseudocode of RevisionByAnalogy
Pseudocode is shown in Algorithm ˜ 3.
1
input : Dependency graph $\hat{\mathcal{G}}=(\hat{\mathcal{V}},\hat{\mathcal{E}})$ , an item to revise $v$ , exploration counts $C[·]$ , inadmissible item threshold $c_{0}$ , less-explored item scale $\alpha_{s}$ , inadmissible item scale $\alpha_{i}$
output : Revised dependency graph $\hat{\mathcal{G}}=(\hat{\mathcal{V}},\hat{\mathcal{E}})$ , exploration counts $C[·]$
2
3 Consider cases based on $C[v]$ :
4 if $C[v]>c_{0}$ then
/* $v$ is inadmissible */
5
/* resource set: items previously consumed for crafting other items */
6 $\mathcal{R}(v)←\{(u,\alpha_{i})\mid u∈\text{``resource'' set}\}$
/* Remove all incoming edges to $v$ in $\hat{\mathcal{E}}$ and add new edges */
7 $\hat{\mathcal{E}}←\hat{\mathcal{E}}\setminus\{(x,q,v)\mid(x,q,v)∈\hat{\mathcal{E}}\}$
8 foreach $(u,\alpha_{i})∈\mathcal{R}(v)$ do
9 $\hat{\mathcal{E}}←\hat{\mathcal{E}}\cup\{(u,\alpha_{i},v)\}$
10
11
/* Revise requirement sets of descendants of $v$ */
12 Find the set of all descendants of $v$ in $\hat{\mathcal{G}}$ (excluding $v$ ): $\mathcal{W}←\text{FindAllDescendants}(v,\hat{\mathcal{G}})$
13
14 for each item $w$ in $\mathcal{W}$ do
15 Invoke RevisionByAnalogy for $w$
16
17
18 else
/* $v$ is less explored yet. Revise based on analogy */
19 Find similar successfully obtained items $\mathcal{V}_{K}⊂eq\hat{\mathcal{V}}$ based on Top-K semantic similarity to $v$
20
Candidate items $U_{cand}←\{u\mid∃ w∈\mathcal{V}_{K},(u,·,w)∈\hat{\mathcal{E}}\}$ /* all items required to obtain similar successfully obtained items $\mathcal{V}_{K}$ */
21
22 Start to construct a requirement set, $\mathcal{R}(v)←\emptyset$
23 for each item $u$ in $U_{cand}$ do
24 if $u$ is in “resource” set then
25 Add $(u,\alpha_{s}× C[v])$ to $\mathcal{R}(v)$
26
27 else
28 Add $(u,1)$ to $\mathcal{R}(v)$
29
30
31 Update $\hat{\mathcal{G}}$ : Remove all incoming edges to $v$ in $\hat{\mathcal{E}}$ , and add new edges $(u,q,v)$ to $\hat{\mathcal{E}}$ for each $(u,q)∈\mathcal{R}(v)$
32
33
Algorithm 3 RevisionByAnalogy
Appendix F Step-by-step planning using FAM
Given a sequence of aggregated requirements $((q_{l},v_{l}))_{l=1}^{L}$ , XENON employs a step-by-step planning approach, iteratively selecting an high-level action $a_{l}$ for each requirement item $v_{l}$ to make a subgoal $(a_{l},q_{l},v_{l})$ . This process considers the past attempts to obtain $v_{l}$ using specific actions. Specifically, for a given item $v_{l}$ , if FAM has an empirically valid action, XENON reuses it without prompting the LLM. Otherwise, XENON prompts the LLM to select an action, leveraging information from (i) valid actions for items semantically similar to $v_{l}$ , (ii) empirically invalid actions for $v_{l}$ .
The pseudocode for this action selection process is detailed in Algorithm ˜ 4. The prompt is shown in Figure ˜ 16.
1
Input : An item $v$ , Action set $\mathcal{A}$ , Success/Failure counts from FAM $S(·,·)$ and $F(·,·)$ , Invalid action threshold $x_{0}$
Output : Selected action $a_{selected}$
2
/* 1. Classify actions based on FAM history (S and F counts) */
3 $\mathcal{A}^{valid}_{v}←\{a∈\mathcal{A}\mid S(a,v)>0\land S(a,v)>F(a,v)-x_{0}\}$
4 $\mathcal{A}^{invalid}_{v}←\{a∈\mathcal{A}\mid F(a,v)≥ S(a,v)+x_{0}\}$
5
6 if $\mathcal{A}^{valid}_{v}≠\emptyset$ then
/* Reuse the empirically valid action if it exists */
7 Select $a_{selected}$ from $\mathcal{A}^{valid}_{v}$
8 return $a_{selected}$
9
10 else
/* Otherwise, query LLM with similar examples and filtered candidates */
11
/* (i) Retrieve valid actions from other items for examples */
12 $\mathcal{V}_{source}←\{u∈\hat{V}\setminus\{v\}\mid∃ a^{\prime},S(a^{\prime},u)>0\land S(a^{\prime},u)>F(a^{\prime},u)-x_{0}\}$
13 Identify $\mathcal{V}_{topK}⊂eq\mathcal{V}_{source}$ as the $K$ items most similar to $v$ (using S-BERT)
14 $\mathcal{D}_{examples}←\{(u,a_{valid})\mid u∈\mathcal{V}_{topK},a_{valid}∈\mathcal{A}^{valid}_{u}\}$
15
/* (ii) Prune invalid actions to form candidates */
16 $\mathcal{A}^{cand}_{v}←\mathcal{A}\setminus\mathcal{A}^{invalid}_{v}$
17
18 if $\mathcal{A}^{cand}_{v}=\emptyset$ then
19 $\mathcal{A}^{cand}_{v}←\mathcal{A}$
20
21 $a_{selected}←\text{LLM}(v,\mathcal{D}_{examples},\mathcal{A}^{cand}_{v})$
22 return $a_{selected}$
23
Algorithm 4 Step-by-step Planning with FAM
⬇
1 For an item name, you need to make a plan, by selecting one among provided options.
2 I will give you examples of which plans are needed to achieve an item, just for reference.
3
4 % Similar items and their successful plans are given
5 [Example]
6 < item name >
7 {similar _ item}
8 < task planning >
9 {successful _ plan}
10
11 [Your turn]
12 Here is < item name >, you MUST select one from below < options >, to make < task planning >.
13 you MUST select one from below < options >. DO NOT MAKE A PLAN NOT IN < options >.
14
15 % Three actions are given, excluding any that were empirically invalid
16 < options >:
17 1: {" task ": " dig down and mine {item}", " goal ": [{item}, {quantity}]}
18 2: {" task ": " craft {item}", " goal ": [{item}, {quantity}]}
19 3: {" task ": " smelt {item}", " item ": [{item}, {quantity}}
20
21 < item name >
22 {item}
23 < task planning >
Figure 16: Prompt for action selection
Appendix G Difficulty-based Exploration (DEX)
{omhx}
For autonomous dependency learning, we introduce DEX. DEX strategically selects items that (1) appear easier to obtain, prioritizing those (2) under-explored for diversity and (3) having fewer immediate prerequisite items according to the learned graph $\hat{\mathcal{G}}$ . (line 5 in Algorithm ˜ 1). First, DEX defines the previously unobtained items but whose required items are all obtained according to learned dependency $\hat{\mathcal{G}}$ as the frontier $F$ . Next, the least explored frontier set $\mathcal{F}_{min}\coloneqq\{f∈ F\mid C(f)=\min_{f^{\prime}∈ F}C(f^{\prime})\}$ is identified, based on revision counts $C(·)$ . For items $f^{\prime}∈\mathcal{F}_{min}$ , difficulty $D(f^{\prime})$ is estimated as $L_{f^{\prime}}$ , the number of distinct required items needed to obtain $f^{\prime}$ according to $\hat{\mathcal{G}}$ . The intrinsic goal $g$ is then selected as the item in $\mathcal{F}_{min}$ with the minimum estimated difficulty: $g=\arg\min_{f^{\prime}∈\mathcal{F}_{min}}D(f^{\prime})$ . Ties are broken uniformly at random.
While our frontier concept is motivated by DECKARD (Nottingham et al., 2023), DEX’s selection process differs significantly. DECKARD selects randomly from $\{v∈\mathcal{F}\mid C(v)≤ c_{0}\}$ , but if this set is empty, it selects randomly from the union of frontier set and previously obtained item set. This risks inefficient attempts on already obtained items. In contrast, DEX exclusively selects goals from $\mathcal{F}_{\text{min}}$ , inherently avoiding obtained items. This efficiently guides exploration towards achievable, novel dependencies.
Appendix H Context-aware Reprompting (CRe)
Minecraft, a real-world-like environment can lead to situations where the controller stalls (e.g., when stuck in deep water or a cave). To assist the controller, the agent provides temporary prompts to guide it (e.g., "get out of the water and find trees"). XENON proposes a context-aware reprompting scheme. It is inspired by Optimus-1 Li et al. (2024b) but introduces two key differences:
1. Two-stage reasoning. When invoked, in Optimus-1, LLM simultaneously interprets image observations, decides whether to reprompt, and generates new prompts. XENON decomposes this process into two distinct steps:
1. the LLM generates a caption for the current image observation, and
1. using text-only input (the generated caption and the current subgoal prompt), the LLM determines if reprompting is necessary and, if so, produces a temporary prompt.
1. Trigger. Unlike Optimus-1, which invokes the LLM at fixed intervals, XENON calls the LLM only if the current subgoal item has not been obtained within that interval. This approach avoids unnecessary or spurious interventions from a smaller LLM.
The prompt is shown in Figure ˜ 17.
⬇
1 % Prompt for the first step: image captioning
2 Given a Minecraft game image, describe nearby Minecraft objects, like tree, grass, cobblestone, etc.
3 [Example]
4 " There is a large tree with dark green leaves surrounding the area."
5 " The image shows a dark, cave - like environment in Minecraft. The player is digging downwards. There are no visible trees or grass in this particular view."
6 " The image shows a dark, narrow tunnel made of stone blocks. The player is digging downwards."
7 [Your turn]
8 Describe the given image, simply and clearly like the examples.
9
10 % Prompt for the second step: reasoning whether reprompting is needed or not
11 Given < task > and < visual _ description >, determine if the player needs intervention to achieve the goal. If intervention is needed, suggest a task that the player should perform.
12 I will give you examples.
13 [Example]
14 < task >: chop tree
15 < visual _ description >: There is a large tree with dark green leaves surrounding the area.
16 < goal _ item >: logs
17 < reasoning >:
18 {{
19 " need _ intervention ": false,
20 " thoughts ": " The player can see a tree and can chop it down to get logs.",
21 " task ": "",
22}}
23 [Example]
24 < task >: chop tree
25 < visual _ description >: The image shows a dirt block in Minecraft. There is a tree in the image, but it is too far from here.
26 < goal _ item >: logs
27 < reasoning >:
28 {{
29 " need _ intervention ": true,
30 " thoughts ": " The player is far from trees. The player needs to move to the trees.",
31 " task ": " explore to find trees ",
32}}
33 [Example]
34 < task >: dig down to mine iron _ ore
35 < visual _ description >: The image shows a dark, narrow tunnel made of stone blocks. The player is digging downwards.
36 < goal _ item >: iron _ ore
37 < reasoning >:
38 {{
39 " need _ intervention ": false,
40 " thoughts ": " The player is already digging down and is likely to find iron ore.",
41 " task ": "",
42}}
43 [Your turn]
44 Here is the < task >, < visual _ description >, and < goal _ item >.
45 You MUST output the < reasoning > in JSON format.
46 < task >: {task} % current prompt for the controller
47 < visual _ description >: {visual _ description} % caption from the step 1
48 < goal _ item >: {goal _ item} % current subgoal item
49 < reasoning >:
Figure 17: Prompt for context-aware reprompting
Appendix I Implementation details
To identify similar items, semantic similarity between two items is computed as the cosine similarity of their Sentence-BERT (all-MiniLM-L6-v2 model) embeddings (Reimers and Gurevych, 2019). This metric is utilized whenever item similarity comparisons are needed, such as in Algorithm ˜ 2, Algorithm ˜ 3, and Algorithm ˜ 4.
I.1 Hyperparameters
Table 7: Hyperparameters used in our experiments.
| Hyperparameter | Notation | Value |
| --- | --- | --- |
| Failure threshold for invalid action | $x_{0}$ | $2$ |
| Revision count threshold for inadmissible items | $c_{0}$ | $3$ |
| Required items quantity scale for less explored items | $\alpha_{s}$ | $2$ |
| Required items quantity scale for inadmissible items | $\alpha_{i}$ | $8$ |
| Number of top-K similar experienced items used | $K$ | $3$ |
For all experiments, we use consistent hyperparameters across environments. The hyperparameters, whose values are determined with mainly considering robustness against imperfect controllers. All hyperparameters are listed in Table ˜ 7. The implications of increasing each hyperparameter’s value are detailed below:
- $x_{0}$ (failure threshold for empirically invalid action): Prevents valid actions from being misclassified as invalid due to accidental failures from an imperfect controller or environmental stochasticity. Values that are too small or large hinder dependency learning and planning by hampering the discovery of valid actions.
- $c_{0}$ (exploration count threshold for inadmissible items): Ensures an item is sufficiently attempted before being deemed ’inadmissible’ and triggering a revision for its descendants. Too small/large values could cause inefficiency; small values prematurely abandon potentially correct LLM predictions for descendants, while large values prevent attempts on descendant items.
- $\alpha_{s}$ (required items quantity scale for less explored items): Controls the gradual increase of required quantities for revised required items. Small values make learning inefficient by hindering item obtaining due to insufficient required items, yet large values lower robustness by overburdening controllers with excessive quantity demands.
- $\alpha_{i}$ (required items quantity scale for inadmissible items): Ensures sufficient acquisition of potential required items before retrying inadmissible items to increase the chance of success. Improper values reduce robustness; too small leads to failure in obtaining items necessitating many items; too large burdens controllers with excessive quantity demands.
- $K$ (Number of similar items to retrieve): Determines how many similar, previously successful experiences are retrieved to inform dependency revision (Algorithm ˜ 3) and action selection (Algorithm ˜ 4).
I.2 Human-written plans
We utilize three human-written plans (for iron sword, golden sword, and diamond, shown in Plan 18, 19, and 20, respectively), the format of which is borrowed from the human-written plan examples in the publicly released Optimus-1 repository https://github.com/JiuTian-VL/Optimus-1/blob/main/src/optimus1/example.py. We leverage the experiences gained from executing these plans to initialize XENON’s knowledge.
⬇
1 iron_sword: str = "" "
2 <goal>: craft an iron sword.
3 <requirements>:
4 1. log: need 7
5 2. planks: need 21
6 3. stick: need 5
7 4. crafting_table: need 1
8 5. wooden_pickaxe: need 1
9 6. cobblestone: need 11
10 7. furnace: need 1
11 8. stone_pickaxe: need 1
12 9. iron_ore: need 2
13 10. iron_ingot: need 2
14 11. iron_sword: need 1
15 <plan>
16 {
17 " step 1 ": {" prompt ": " mine logs ", " item ": [" logs ", 7]},
18 " step 2 ": {" prompt ": " craft planks ", " item ": [" planks ", 21]},
19 " step 3 ": {" prompt ": " craft stick ", " item ": [" stick ", 5]},
20 " step 4 ": {" prompt ": " craft crafting_table ", " item ": [" crafting_table ", 1]},
21 " step 5 ": {" prompt ": " craft wooden_pickaxe ", " item ": [" wooden_pickaxe ", 1]},
22 " step 6 ": {" prompt ": " mine cobblestone ", " item ": [" cobblestone ", 11]},
23 " step 7 ": {" prompt ": " craft furnace ", " item ": [" furnace ", 1]},
24 " step 8 ": {" prompt ": " craft stone_pickaxe ", " item ": [" stone_pickaxe ", 1]},
25 " step 9 ": {" prompt ": " mine iron_ore ", " item ": [" iron_ore ", 2]},
26 " step 10 ": {" prompt ": " smelt iron_ingot ", " item ": [" iron_ingot ", 2]},
27 " step 11 ": {" prompt ": " craft iron_sword ", " item ": [" iron_sword ", 1]}
28}
29 " ""
Figure 18: Human-written plan for crafting an iron sword.
⬇
1 golden_sword: str = "" "
2 <goal>: craft a golden sword.
3 <requirements>:
4 1. log: need 9
5 2. planks: need 27
6 3. stick: need 7
7 4. crafting_table: need 1
8 5. wooden_pickaxe: need 1
9 6. cobblestone: need 11
10 7. furnace: need 1
11 8. stone_pickaxe: need 1
12 9. iron_ore: need 3
13 10. iron_ingot: need 3
14 11. iron_pickaxe: need 1
15 12. gold_ore: need 2
16 13. gold_ingot: need 2
17 14. golden_sword: need 1
18 <plan>
19 {
20 " step 1 ": {" prompt ": " mine logs ", " item ": [" logs ", 7]},
21 " step 2 ": {" prompt ": " craft planks ", " item ": [" planks ", 21]},
22 " step 3 ": {" prompt ": " craft stick ", " item ": [" stick ", 5]},
23 " step 4 ": {" prompt ": " craft crafting_table ", " item ": [" crafting_table ", 1]},
24 " step 5 ": {" prompt ": " craft wooden_pickaxe ", " item ": [" wooden_pickaxe ", 1]},
25 " step 6 ": {" prompt ": " mine cobblestone ", " item ": [" cobblestone ", 11]},
26 " step 7 ": {" prompt ": " craft furnace ", " item ": [" furnace ", 1]},
27 " step 8 ": {" prompt ": " craft stone_pickaxe ", " item ": [" stone_pickaxe ", 1]},
28 " step 9 ": {" prompt ": " mine iron_ore ", " item ": [" iron_ore ", 3]},
29 " step 10 ": {" prompt ": " smelt iron_ingot ", " item ": [" iron_ingot ", 3]},
30 " step 11 ": {" task ": " craft iron_pickaxe ", " goal ": [" iron_pickaxe ", 1]},
31 " step 12 ": {" prompt ": " mine gold_ore ", " item ": [" gold_ore ", 2]},
32 " step 13 ": {" prompt ": " smelt gold_ingot ", " item ": [" gold_ingot ", 2]},
33 " step 14 ": {" task ": " craft golden_sword ", " goal ": [" golden_sword ", 1]}
34}
35 " ""
Figure 19: Human-written plan for crafting a golden sword.
⬇
1 diamond: str = "" "
2 <goal>: mine a diamond.
3 <requirements>:
4 1. log: need 7
5 2. planks: need 21
6 3. stick: need 6
7 4. crafting_table: need 1
8 5. wooden_pickaxe: need 1
9 6. cobblestone: need 11
10 7. furnace: need 1
11 8. stone_pickaxe: need 1
12 9. iron_ore: need 3
13 10. iron_ingot: need 3
14 11. iron_pickaxe: need 1
15 12. diamond: need 1
16 <plan>
17 {
18 " step 1 ": {" prompt ": " mine logs ", " item ": [" logs ", 7]},
19 " step 2 ": {" prompt ": " craft planks ", " item ": [" planks ", 21]},
20 " step 3 ": {" prompt ": " craft stick ", " item ": [" stick ", 5]},
21 " step 4 ": {" prompt ": " craft crafting_table ", " item ": [" crafting_table ", 1]},
22 " step 5 ": {" prompt ": " craft wooden_pickaxe ", " item ": [" wooden_pickaxe ", 1]},
23 " step 6 ": {" prompt ": " mine cobblestone ", " item ": [" cobblestone ", 11]},
24 " step 7 ": {" prompt ": " craft furnace ", " item ": [" furnace ", 1]},
25 " step 8 ": {" prompt ": " craft stone_pickaxe ", " item ": [" stone_pickaxe ", 1]},
26 " step 9 ": {" prompt ": " mine iron_ore ", " item ": [" iron_ore ", 2]},
27 " step 10 ": {" prompt ": " smelt iron_ingot ", " item ": [" iron_ingot ", 2]},
28 " step 11 ": {" prompt ": " craft iron_pickaxe ", " item ": [" iron_pickaxe ", 1]},
29 " step 12 ": {" prompt ": " mine diamond ", " item ": [" diamond ", 1]}
30}
31 " ""
Figure 20: Human-written plan for mining a diamond.
Appendix J Details for experimental setup
J.1 Compared baselines for dependency learning
We compare our proposed method, XENON, against four baselines: LLM self-correction (SC), DECKARD Nottingham et al. (2023), ADAM (Yu and Lu, 2024), and RAND (the simplest baseline). As no prior baselines were evaluated under our specific experimental setup (i.e., empty initial inventory, pre-trained low-level controller), we adapted their implementation to align with our environment. SC is implemented following common methods that prompt the LLM to correct its own knowledge upon plan failures (Shinn et al., 2023; Stechly et al., 2024). A summary of all methods compared in our experiments is provided in Table ˜ 8. All methods share the following common experimental setting: each episode starts with an initial experienced requirements for some items, derived from human-written plans (details in Appendix ˜ I). Additionally, all agents begin each episode with an initial empty inventory.
Table 8: Summary of methods compared in our experiments.
$$
\times \tag{2024}
$$
LLM self-correction (SC)
While no prior work specifically uses LLM self-correction to learn Minecraft item dependencies in our setting, we include this baseline to demonstrate the unreliability of this approach. For predicted requirements, similar to XENON, SC initializes its dependency graph with LLM-predicted requirements for each item. When a plan for an item fails repeatedly, it attempts to revise the requirements using LLM. SC prompts the LLM itself to perform the correction, providing it with recent trajectories and the validated requirements of similar, previously obtained items in the input prompt. SC’s action memory stores both successful and failed actions for each item. Upon a plan failure, the LLM is prompted to self-reflect on the recent trajectory to determine the cause of failure. When the agent later plans to obtain an item on which it previously failed, this reflection is included in the LLM’s prompt to guide its action selection. Intrinsic goals are selected randomly from the set of previously unobtained items. The specific prompts used for the LLM self-correction and self-reflection in this baseline are provided in Appendix ˜ B.
DECKARD
The original DECKARD utilizes LLM-predicted requirements for each item but does not revise these initial predictions. It has no explicit action memory for the planner; instead, it trains and maintains specialized policies for each obtained item. It selects an intrinsic goal randomly from less explored frontier items (i.e., $\{v∈\mathcal{F}\mid C(v)≤ c_{0}\}$ ). If no such items are available, it selects randomly from the union of experienced items and all frontier items.
In our experiments, the DECKARD baseline is implemented to largely mirror the original version, with the exception of its memory system. Its memory is implemented to store only successful actions without recording failures. This design choice aligns with the original DECKARD’s approach, which, by only learning policies for successfully obtained items, lacks policies for unobtained items.
ADAM
The original ADAM started with an initial inventory containing 32 quantities of experienced resource items (i.e., items used for crafting other items) and 1 quantity of tool items (e.g., pickaxes, crafting table), implicitly treating those items as a predicted requirement set for each item. Its memory recorded which actions were used for each subgoal item without noting success or failure, and its intrinsic goal selection was guided by an expert-defined exploration curriculum.
In our experiments, ADAM starts with an empty initial inventory. The predicted requirements for each goal item in our ADAM implementation assume a fixed quantity of 8 for all resource items. This quantity was chosen to align with $\alpha_{i}$ , the hyperparameter for the quantity scale of requirement items for inadmissible items, thereby ensuring a fair comparison with XENON. The memory stores successful actions for each item, but did not record failures. This modification aligns the memory mechanism with SC and DECKARD baselines, enabling a more consistent comparison across baselines in our experimental setup. Intrinsic goal selection is random, as we do not assume such an expert-defined exploration curriculum.
RAND
RAND is a simple baseline specifically designed for our experimental setup. It started with an empty initial inventory and an LLM-predicted requirement set for each item. RAND did not incorporate any action memory. Its intrinsic goal selection involved randomly selecting from unexperienced items.
J.2 MineRL environment
J.2.1 Basic rules
Minecraft has been adopted as a suitable testbed for validating performance of AI agents on long-horizon tasks (Mao et al., 2022; Lin et al., 2021; Baker et al., 2022; Li et al., 2025a), largely because of the inherent dependency in item acquisition where agents must obtain prerequisite items before more advanced ones. Specifically, Minecraft features multiple technology levels—including wood, stone, iron, gold, diamond, etc. —which dictate item and tool dependencies. For instance, an agent must first craft a lower-level tool like a wooden pickaxe to mine materials such as stone. Subsequently, a stone pickaxe is required to mine even higher-level materials like iron. An iron pickaxe is required to mine materials like gold and diamond. Respecting the dependency is crucial for achieving complex goals, such as crafting an iron sword or mining a diamond.
J.2.2 Observation and action space
First, we employ MineRL (Guss et al., 2019) with Minecraft version 1.16.5.
Observation
When making a plan, our agent receives inventory information (i.e., item with their quantities) as text. When executing the plan, our agent receives an RGB image with dimensions of $640× 360$ , including the hotbar, health indicators, food saturation, and animations of the player’s hands.
Action space
Following Optimus-1 (Li et al., 2024b), our low-level action space primarily consists of keyboard and mouse controls, except for craft and smelt high-level actions. Crucially, craft and smelt actions are included into our action space, following (Li et al., 2024b). This means these high-level actions automatically succeed in producing an item if the agent possesses all the required items and a valid actions for that item is chosen; otherwise, they fail. This abstraction removes the need for complex, precise low-level mouse control for these specific actions. For low-level controls, keyboard presses control agent movement (e.g., jumping, moving forward, backward) and mouse movements control the agent’s perspective. The mouse’s left and right buttons are used for attacking, using, or placing items. The detailed action space is described in Table ˜ 9.
Table 9: Action space in MineRL environment
| Index | Action | Human Action | Description |
| --- | --- | --- | --- |
| 1 | Forward | key W | Move forward. |
| 2 | Back | key S | Move back. |
| 3 | Left | key A | Move left. |
| 4 | Right | key D | Move right. |
| 5 | Jump | key Space | Jump. When swimming, keeps the player afloat. |
| 6 | Sneak | key left Shift | Slowly move in the current direction of movement. |
| 7 | Sprint | key left Ctrl | Move quickly in the direction of current movement. |
| 8 | Attack | left Button | Destroy blocks (hold down); Attack entity (click once). |
| 9 | Use | right Button | Place blocks, entity, open items or other interact actions defined by game. |
| 10 | hotbar [1-9] | keys 1-9 | Selects the appropriate hotbar item. |
| 11 | Open/Close Inventory | key E | Opens the Inventory. Close any open GUI. |
| 12 | Yaw | move Mouse X | Turning; aiming; camera movement.Ranging from -180 to +180. |
| 13 | Pitch | move Mouse Y | Turning; aiming; camera movement.Ranging from -180 to +180. |
| 14 | Craft | - | Execute crafting to obtain new item |
| 15 | Smelt | - | Execute smelting to obtain new item. |
J.2.3 Goals
We consider 67 goals from the long-horizon tasks benchmark suggested in (Li et al., 2024b). These goals are categorized into 7 groups based on Minecraft’s item categories: Wood
<details>
<summary>x31.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
, Stone
<details>
<summary>x32.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
, Iron
<details>
<summary>x33.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
, Gold
<details>
<summary>x34.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
, Diamond
<details>
<summary>x35.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
, Redstone
<details>
<summary>x36.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
, and Armor
<details>
<summary>x37.png Details</summary>
### Visual Description
Icon/Small Image (20x20)
</details>
. All goal items within each group are listed in Table ˜ 10.
Table 10: Setting of 7 groups encompassing 67 Minecraft long-horizon goals.
| Group | Goal Num. | All goal items |
| --- | --- | --- |
|
<details>
<summary>x38.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
Wood | 10 | bowl, crafting_table, chest, ladder, stick, wooden_axe, wooden_hoe, wooden_pickaxe, wooden_shovel, wooden_sword |
|
<details>
<summary>x39.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
Stone | 9 | charcoal, furnace, smoker, stone_axe, stone_hoe, stone_pickaxe, stone_shovel, stone_sword, torch |
|
<details>
<summary>x40.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
Iron | 16 | blast_furnace, bucket, chain, hopper, iron_axe, iron_bars, iron_hoe, iron_nugget, iron_pickaxe, iron_shovel, iron_sword, rail, shears, smithing_table, stonecutter, tripwire_hook |
|
<details>
<summary>x41.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
Gold | 6 | gold_ingot, golden_axe, golden_hoe, golden_pickaxe, golden_shovel, golden_sword |
|
<details>
<summary>x42.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
Redstone | 6 | activator_rail, compass, dropper, note_block, piston, redstone_torch |
|
<details>
<summary>x43.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
Diamond | 7 | diamond, diamond_axe, diamond_hoe, diamond_pickaxe, diamond_shovel, diamond_sword, jukebox |
|
<details>
<summary>x44.png Details</summary>
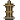
### Visual Description
Icon/Small Image (20x20)
</details>
Armor | 13 | diamond_boots, diamond_chestplate, diamond_helmet, diamond_leggings, golden_boots, golden_chestplate, golden_helmet, golden_leggings, iron_boots, iron_chestplate, iron_helmet, iron_leggings, shield |
Additional goals for scalability experiments.
To evaluate the scalability of XENON with respect to the number of goals Section ˜ K.9, we extend the above 67-goal set (Table ˜ 10) by adding additional goal items to construct two larger settings with 100 and 120 goals; the added goals are listed in Table 11.
Specifically, in the setting with 100 goals, we add 33 goals in total by introducing new “leather”, “paper”, and “flint” groups and by adding more items to the existing “wood” and “stone” groups. In the setting with 120 goals, we further add 20 goals in the “iron”, “gold”, “redstone”, and “diamond” groups.
Table 11: Additional goals used for the scalability experiments. The setting with 100 goals extends the 67-goal set in Table 10 by adding all items in the top block; the setting with 120 goals further includes both the top and bottom blocks.
| Group | Goal Num. | Added goal items |
| --- | --- | --- |
| Additional items in the setting with 100 goals (33 items) | | |
| leather | 7 | leather, leather_boots, leather_chestplate, leather_helmet, leather_leggings, leather_horse_armor, item_frame |
| paper | 5 | map, book, cartography_table, bookshelf, lectern |
| flint | 4 | flint, flint_and_steel, fletching_table, arrow |
| wood | 8 | bow, boat, wooden_slab, wooden_stairs, wooden_door, wooden_sign, wooden_fence, woodenfence_gate |
| stone | 9 | cobblestone_slab, cobblestone_stairs, cobblestone_wall, lever, stone_slab, stone_button, stone_pressure_plate, stone_bricks, grindstone |
| Additional items only in the setting with 120 goals (20 more items) | | |
| iron | 7 | iron_trapdoor, heavy_weighted_pressure_plate, iron_door, crossbow, minecart, cauldron, lantern |
| gold | 4 | gold_nugget, light_weighted_pressure_plate, golden_apple, golden_carrot |
| redstone | 7 | redstone, powered_rail, target, dispenser, clock, repeater, detector_rail |
| diamond | 2 | obsidian, enchanting_table |
J.2.4 Episode horizon
The episode horizon varies depending on the experiment phase: dependency learning or long-horizon goal planning. During the dependency learning phase, each episode has a fixed horizon of 36,000 steps. In this phase, if the agent successfully achieves an intrinsic goal within an episode, it is allowed to select another intrinsic goal and continue exploration without the episode ending. After dependency learning, when measuring the success rate of goals from the long-horizon task benchmark, the episode horizon differs based on the goal’s category group. And in this phase, the episode immediately terminates upon success of a goal. The specific episode horizons for each group are as follows: Wood: 3,600 steps; Stone: 7,200 steps; Iron: 12,000 steps; and Gold, Diamond, Redstone, and Armor: 36,000 steps each.
J.2.5 Item spawn probability details
Following Optimus-1’s public implementation, we have modified environment configuration different from original MineRL environment (Guss et al., 2019). In Minecraft, obtaining essential resources such as iron, gold, and diamond requires mining their respective ores. However, these ores are naturally rare, making them challenging to obtain. This inherent difficulty can significantly hinder an agent’s goal completion, even with an accurate plan. This challenge in resource gathering due to an imperfect controller is a common bottleneck, leading many prior works to employ environmental modifications to focus on planning. For example, DEPS (Wang et al., 2023b) restricts the controller’s actions based on the goal items https://github.com/CraftJarvis/MC-Planner/blob/main/controller.py. Optimus-1 (Li et al., 2024b) also made resource items easier to obtain by increasing item ore spawn probabilities. To focus on our primary goal of robust planning and isolate this challenge, we follow Optimus-1 and adopt its item ore spawn procedure directly from the publicly released Optimus-1 repository, without any modifications to its source code https://github.com/JiuTian-VL/Optimus-1/blob/main/src/optimus1/env/wrapper.py.
The ore spawn procedure probabilistically spawns ore blocks in the vicinity of the agent’s current coordinates $(x,y,z)$ . Specifically, at each timestep, the procedure has a 10% chance of activating. When activated, it spawns a specific type of ore block based on the agent’s y-coordinate. Furthermore, for any given episode, the procedure is not activate more than once at the same y-coordinate. The types of ore blocks spawned at different y-levels are as follows:
-
<details>
<summary>x45.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
Coal Ore: between y=45 and y=50.
-
<details>
<summary>x46.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
Iron Ore: between y=26 and y=43.
-
<details>
<summary>x47.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
Gold Ore: between y=15 and y=26
-
<details>
<summary>x48.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
Redstone Ore: between y=15 and y=26
-
<details>
<summary>x49.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
Diamond Ore: below y=14
J.3 Mineflayer Environment
We use the Mineflayer (PrismarineJS, 2023) environment with Minecraft version 1.19. In Mineflayer, resource item spawn probabilities do not need to be adjusted, unlike in MineRL Section ˜ J.2.5. This is because the controller, JavaScript APIs provided by Mineflayer, is competent to gather many resource items.
J.3.1 Observation and Action Space
The agent’s observation space is multimodal. For planning, the agent receives its current inventory (i.e., item names and their quantities) as text. For plan execution, it receives a first-person RGB image that includes the hotbar, health and food indicators, and player hand animations. For action space, following ADAM (Yu and Lu, 2024), we use the JavaScript APIs provided by Mineflayer for low-level control. Specifically, our high-level actions, such as “craft”, “smelt”, and “mine”, are mapped to corresponding Mineflayer APIs like craftItem, smeltItem, and mineBlock.
J.3.2 Episode Horizon
For dependency learning, each episode has a fixed horizon of 30 minutes, which is equivalent to 36,000 steps in the MineRL environment. If the agent successfully achieves a goal within this horizon, it selects another exploratory goal and continues within the same episode.
J.4 MC-TextWorld
MC-Textworld is a text-based environment based on Minecraft game rules (Zheng et al., 2025). We employ Minecraft version 1.16.5. In this environment, basic rules and goals are the same as those in the MineRL environment Section ˜ J.2. Furthermore, resource item spawn probabilities do not need to be adjusted, unlike in MineRL Section ˜ J.2.5. This is because an agent succeeds in mining an item immediately without spatial exploration, if it has a required tool and “mine” is a valid action for that item.
In the following subsections, we detail the remaining aspects of experiment setups in this environment: the observation and action space, and the episode horizon.
J.4.1 Observation and action space
The agent receives a text-based observation consisting of inventory information (i.e., currently possessed items and their quantities). Actions are also text-based, where each action is represented as an high-level action followed by an item name (e.g., "mine diamond"). Thus, to execute a subgoal specified as $(a,q,v)$ (high-level action $a$ , quantity $q$ , item $v$ ), the agent repeatedly performs the action $(a,v)$ until $q$ units of $v$ are obtained.
J.4.2 Episode horizon
In this environment, we conduct experiments for dependency learning only. Each episode has a fixed horizon of 3,000 steps. If the agent successfully achieves an intrinsic goal within an episode, it is then allowed to select another intrinsic goal and continue exploration, without termination of the episode.
J.4.3 Perturbation on ground truth rules
<details>
<summary>x50.png Details</summary>
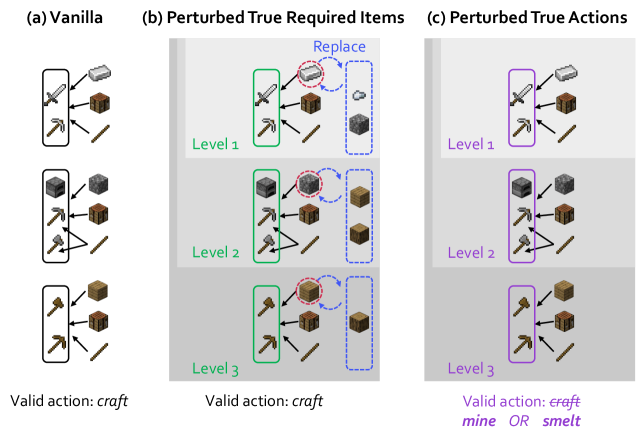
### Visual Description
## Diagram: Minecraft Action Comparison
### Overview
The image presents a comparison of Minecraft actions across three scenarios: "Vanilla" (unperturbed), "Perturbed True Required Items," and "Perturbed True Actions." Each scenario is divided into three levels, visually representing crafting or mining processes. The diagram illustrates how perturbing either the required items or the actions themselves affects the gameplay.
### Components/Axes
* **Titles:**
* (a) Vanilla
* (b) Perturbed True Required Items
* (c) Perturbed True Actions
* **Levels:** Level 1, Level 2, Level 3 (displayed vertically in each scenario)
* **Items:** Minecraft items such as swords, pickaxes, wood, cobblestone, iron ingots, planks, furnace, and sticks.
* **Actions:** Craft, mine, smelt
* **Visual Cues:**
* Arrows indicate the flow or transformation of items.
* Colored boxes highlight the core items or actions at each level.
* Dashed lines and circular arrows indicate replacements.
* **Colors:**
* Green: Used to highlight the initial set of items required.
* Blue: Used to highlight the items that are replaced.
* Purple: Used to highlight the initial set of actions required.
* Red: Used to highlight the items that are being replaced.
### Detailed Analysis
**Column (a): Vanilla**
* **Level 1:** A sword, wood, and a stick are enclosed in a black box. Arrows indicate the crafting process.
* Valid action: craft
* **Level 2:** A furnace, cobblestone, a pickaxe, wood, and a stick are enclosed in a black box. Arrows indicate the crafting process.
* Valid action: craft
* **Level 3:** A hammer, wood, a pickaxe, and a stick are enclosed in a black box. Arrows indicate the crafting process.
* Valid action: craft
**Column (b): Perturbed True Required Items**
* **Level 1:** A sword, wood, and a pickaxe are enclosed in a green box. An iron ingot is replaced by cobblestone (indicated by a red circle and blue dashed box).
* Valid action: craft
* **Level 2:** A furnace, cobblestone, a pickaxe, and a hammer are enclosed in a green box. Cobblestone is replaced by wood planks (indicated by a red circle and blue dashed box).
* Valid action: craft
* **Level 3:** A hammer, a pickaxe, and wood are enclosed in a green box. Wood is replaced by a single wood plank (indicated by a red circle and blue dashed box).
* Valid action: craft
**Column (c): Perturbed True Actions**
* **Level 1:** A sword, wood, and a pickaxe are enclosed in a purple box.
* Valid action: craft
* **Level 2:** A furnace, cobblestone, a pickaxe, and a hammer are enclosed in a purple box.
* Valid action: craft
* **Level 3:** A hammer, a pickaxe, and wood are enclosed in a purple box.
* Valid action: mine OR smelt
### Key Observations
* The "Vanilla" scenario represents the standard crafting recipes in Minecraft.
* The "Perturbed True Required Items" scenario shows how changing the required items affects the crafting process.
* The "Perturbed True Actions" scenario demonstrates how altering the valid actions (e.g., changing "craft" to "mine" or "smelt") impacts the gameplay.
* The perturbations are consistent within each column, with specific item replacements or action changes applied across all levels.
### Interpretation
The diagram illustrates the impact of modifying the core mechanics of Minecraft, specifically the required items and valid actions for crafting. By perturbing these elements, the diagram highlights how changes to the game's rules can alter the player's experience and the strategies they must employ. The "Perturbed True Required Items" scenario demonstrates how substituting one item for another can still allow for crafting, albeit with potentially different outcomes. The "Perturbed True Actions" scenario shows how changing the fundamental actions required can force the player to adapt and use different methods to achieve their goals. The diagram suggests that even small changes to the game's mechanics can have a significant impact on gameplay.
</details>
Figure 21: Illustration of the ground-truth rule perturbation settings. (a) in the vanilla setting, goal items (black boxes) have standard required items (incoming edges) and “craft” is the valid action; (b) in the Perturbed Requirements setting, one required item (red dashed circle) is replaced by a new one randomly from a candidate pool (blue dashed box); (c) in the Perturbed Actions setting, the valid action is changed to either “mine” or “smelt”.
To evaluate each agent’s robustness to conflicts with its prior knowledge, we perturb the ground-truth rules (required items and actions) for a subset of goal items, as shown in Figure ˜ 21. The perturbation is applied at different intensity levels (from 1 to 3), where higher levels affect a greater number of items. These levels are cumulative, meaning a Level 2 perturbation includes all perturbations from Level 1 plus additional ones.
- Vanilla Setting: In the setting with no perturbation (Figure ˜ 21, a), the ground-truth rules are unmodified. In the figure, items in the black solid boxes are the goal items, and those with arrows pointing to them are their true required items. Each goal item has “craft” as a valid action.
- Perturbed True Required Items: In this setting (Figure ˜ 21, b), one of the true required items (indicated by a red dashed circle) for a goal is replaced. The new required item is chosen uniformly at random from a candidate pool (blue dashed box). The valid action remains craft.
- Perturbed True Actions: In this setting (Figure ˜ 21, c), the valid action for a goal is randomly changed from “craft” to either “mine” or “smelt”. The required items are not modified.
- Perturbed Both Rules: In this setting, both the required items and the valid actions are modified according to the rules described above.
Appendix K Additional experimental results
K.1 LLM-predicted initial dependency graph analysis
Table 12: Performance analysis for the initial LLM-predicted requirement sets over 75 Minecraft items, used to build the initial dependency graph. Note that while we began the prediction process with 67 goal items, the total number of predicted items expanded to 75. This expansion occurred because, as the LLM predicted requirement sets for items in the dependency graph (initially for those goal items), any newly mentioned items that were not yet part of the graph are also included. This iterative process is detailed in Section ˜ 4.1 (Dependency graph initialization) of our method.
| Metric | Value |
| --- | --- |
| Requirement Set Prediction Accuracy | |
| Correct items (ignoring quantities) | 23% |
| Exact items & quantities | 8% |
| Non-existent Item Rates | |
| Non-existent items | 8% |
| Descendants of non-existent items | 23% |
| Required Items Errors | |
| Unnecessary items included | 57% |
| Required items omitted | 57% |
| Required Item Quantity Prediction Errors | |
| Standard deviation of quantity error | 2.74 |
| Mean absolute quantity error | 2.05 |
| Mean signed quantity error | -0.55 |
The initial dependency graph, constructed from predictions by Qwen2.5-VL-7B (Bai et al., 2025), forms the initial planning knowledge for XENON (Section ˜ 4.1). This section analyzes its quality, highlighting limitations that necessitate our adaptive dependency learning.
As shown in Table ˜ 12, the 7B LLM’s initial requirement sets exhibit significant inaccuracies. Accuracy for correct item types was 23%, dropping to 8% for exact items and quantities. Errors in dependency among items are also prevalent: 57% of items included unnecessary items, and 57% omitted required items. Furthermore, 8% of predicted items were non-existent (hallucinated), making 23% of descendant items unattainable. Quantity predictions also showed substantial errors, with a mean absolute error of 2.05.
These results clearly demonstrate that the LLM-generated initial dependency graph is imperfect. Its low accuracy and high error rates underscore the unreliability of raw LLM knowledge for precise planning, particularly for smaller models like the 7B LLM which are known to have limited prior knowledge on Minecraft, as noted in previous work (ADAM, Yu and Lu (2024), Appendix A. LLMs’ Prior Knowledge on Minecraft). This analysis therefore highlights the importance of the adaptive dependency learning within XENON, which is designed to refine this initial, imperfect knowledge for robust planning.
Table 13: Ratio of dependencies learned for items which are unobtainable by the flawed initial dependency graph (out of 51). Analysis is based on the final learned graphs from the MineRL experiments.
| Agent | Learned ratio (initially unobtainable items) |
| --- | --- |
| XENON | 0.51 |
| SC | 0.25 |
| DECKARD | 0.25 |
| ADAM | 0.00 |
| RAND | 0.02 |
K.2 Additional analysis of learned dependency graph
As shown in Table ˜ 13, XENON demonstrates significantly greater robustness to the LLM’s flawed prior knowledge compared to all baselines. It successfully learned the correct dependencies for over half (0.51) of the 51 items that were initially unobtainable by the flawed graph. In contrast, both DECKARD (with no correction) and the SC baseline (with LLM self-correction) learned only a quarter of these items (0.25). This result strongly indicates that relying on the LLM to correct its own errors is as ineffective as having no correction mechanism at all in this setting. The other baselines, ADAM and RAND, failed almost completely, highlighting the difficulty of this challenge.
K.3 Impact of controller capacity on dependency learning
We observe that controller capacity significantly impacts an agent’s ability to learn dependencies from interaction. Specifically, in our MineRL experiments, we find that ADAM fails to learn any new dependencies due to the inherent incompatibility between its strategy and the controller’s limitations. In our realistic setting with empty initial inventories, ADAM’s strategy requires gathering a sufficient quantity (fixed at 8, same with our hyperparameter $\alpha_{i}$ The scaling factor for required item quantities for inadmissible items.) of all previously used resources before attempting a new item. This list of required resource items includes gold ingot
<details>
<summary>x51.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
, because of an initially provided human-written plan for golden sword; however, the controller STEVE-1 never managed to collect more than seven units of gold in a single episode across all our experiments. Consequently, this controller bottleneck prevents ADAM from ever attempting to learn new items, causing its dependency learning to stall completely.
Although XENON fails to learn dependencies for the Redstone group items in MineRL, our analysis shows this stems from controller limitations rather than algorithmic ones. Specifically, in MineRL, STEVE-1 cannot execute XENON’s exploration strategy for inadmissible items, which involves gathering a sufficient quantity of all previously used resources before a retry (Section ˜ 4.1). The Redstone group items become inadmissible because the LLM’s initial predictions for them are entirely incorrect. This lack of a valid starting point prevents XENON from ever experiencing the core item, redstone, being used as a requirement for any other item. Consequently, our RevisionByAnalogy mechanism has no analogous experience to propose redstone as a potential required item for other items during its revision process.
In contrast, with more competent controllers, XENON successfully overcomes even such severely flawed prior knowledge to learn the challenging Redstone group dependencies, as demonstrated in Mineflayer and MC-TextWorld. First, in Mineflayer, XENON learns the correct dependencies for 5 out of 6 Redstone items. This success is possible because its more competent controller can execute the exploration strategy for inadmissible items, which increases the chance of possessing the core required item (redstone) during resource gathering. Second, with a perfect controller in MC-TextWorld, XENON successfully learns the dependencies for all 6 Redstone group items in every single episode.
K.4 Impact of Controller Capacity in Long-horizon Goal Planning
Table 14: Long-horizon task success rate (SR) comparison between the Modified MineRL (a setting where resource items are easier to obtain) and Standard MineRL environments. All methods are provided with the correct dependency graph. DEPS $\dagger$ and Optimus-1 $\dagger$ are our reproductions of the respective methods using Qwen2.5-VL-7B as a planner. OracleActionPlanner, which generates the correct plan for all goals, represents the performance upper bound. SR for Optimus-1 $\dagger$ and XENON ∗ in the Modified MineRL column are taken from Table ˜ 3 in Section ˜ 5.3.
| Method | Dependency | Modified MineRL | Standard MineRL | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Iron | Diamond | Gold | Iron | Diamond | Gold | | |
| DEPS $\dagger$ | - | 0.02 | 0.00 | 0.01 | 0.01 | 0.00 | 0.00 |
| Optimus-1 $\dagger$ | Oracle | 0.23 | 0.10 | 0.11 | 0.13 | 0.00 | 0.00 |
| XENON ∗ | Oracle | 0.83 | 0.75 | 0.73 | 0.24 | 0.00 | 0.00 |
| OracleActionPlanner | Oracle | - | - | - | 0.27 | 0.00 | 0.00 |
Because our work focuses on building a robust planner, to isolate the planning from the significant difficulty of item gathering—a task assigned to the controller—our main experiments for long-horizon tasks (Section ˜ 5.3) uses a modified MineRL environment following the official implementation of Optimus-1. This modification makes essential resource items like iron, gold, and diamond easier for the controller to find, allowing for a clearer evaluation of planning algorithms (modifications are detailed in Section ˜ J.2.5). However, to provide a more comprehensive analysis, we also evaluated our agent and baselines in the unmodified, standard MineRL environment. In this setting, items like iron, gold, and diamond are naturally rare, making item gathering a major bottleneck.
The results are shown in Table ˜ 14. Most importantly, XENON ∗ consistently outperforms the baselines in both the modified and standard MineRL. Notably, in the standard environment, XENON ∗ ’s performance on the Iron group (0.24 SR) is comparable to that of the OracleActionPlanner (0.27 SR), which always generates correct plans for all goals. This comparison highlights the severity of the controller bottleneck: even the OracleActionPlanner achieves a 0.00 success rate for the Diamond and Gold groups in the standard MineRL. This shows that the failures are due to the controller’s inability to gather rare resources in the standard environment.
K.5 Long-horizon task benchmark experiments analysis
This section provides a detailed analysis of the performance differences observed in Table ˜ 3 between Optimus-1 † and XENON ∗ on long-horizon tasks, even when both access to a true dependency graph and increased item spawn probabilities (Section ˜ J.2.5). We specifically examine various plan errors encountered when reproducing Optimus-1 † using Qwen2.5-VL-7B as the planner, and explain how XENON ∗ robustly constructs plans through step-by-step planning with FAM.
Table 15: Analysis of primary plan errors observed in Optimus-1 † and XENON ∗ during long-horizon tasks benchmark experiments. This table presents the ratio of specified plan error among the failed episodes for Optimus-1 † and XENON ∗ respectively. Invalid Action indicates errors where an invalid action is used for an item in a subgoal. Subgoal Omission refers to errors where a necessary subgoal for a required item is omitted from the plan. Note that these plan error values are not exclusive; one episode can exhibit multiple types of plan errors.
| Plan Error Type | Optimus-1 † Error Rate (%) | XENON ∗ Error Rate (%) |
| --- | --- | --- |
| Invalid Action | 37 | 2 |
| Subgoal Omission | 44 | 0 |
Optimus-1 † has no fine-grained action knowledge correction mechanism. Furthermore, Optimus-1 † ’s LLM planner generates a long plan at once with a long input prompt including a sequence of aggregated requirements $((q_{1},u_{1}),...,(q_{L_{v}},u_{L_{v}})=(1,v))$ for the goal item $v$ . Consequently, as shown in Table ˜ 15, Optimus-1 generates plans with invalid actions for required items, denoted as Invalid Action. Furthermore, Optimus-1 omits necessary subgoals for required items, even they are in the input prompts, denoted as Subgoal Omission.
In contrast, XENON discovers valid actions by leveraging FAM, which records the outcomes of each action for every item, thereby enabling it to avoid empirically failed ones and and reuse successful ones. Furthermore, XENON mitigates the problem of subgoal omission through constructing a plan by making a subgoal for each required item one-by-one.
K.6 Robust Dependency learning under dynamic true knowledge
<details>
<summary>x52.png Details</summary>

### Visual Description
## Chart Legend: Algorithm Identification
### Overview
The image is a legend for a chart, identifying different algorithms by color and name.
### Components/Axes
The legend is composed of five entries, each representing an algorithm. Each entry consists of a colored line with a marker and the algorithm's name. The legend entries are arranged horizontally.
* **XENON:** Represented by a light blue line with a circular marker.
* **SC:** Represented by a light pink line with a diamond marker.
* **ADAM:** Represented by a light orange line with a pentagon marker.
* **DECKARD:** Represented by a light green line with a square marker.
* **RAND:** Represented by a gray line with a cross marker.
### Detailed Analysis or ### Content Details
The legend provides a clear mapping between algorithm names and their corresponding visual representations (color and marker).
### Key Observations
The legend is straightforward and easy to understand. It uses distinct colors and markers to differentiate between the algorithms.
### Interpretation
The legend is a key component for interpreting a chart that compares the performance of the five listed algorithms. By referencing the legend, one can easily identify which data series corresponds to which algorithm.
</details>
<details>
<summary>x53.png Details</summary>
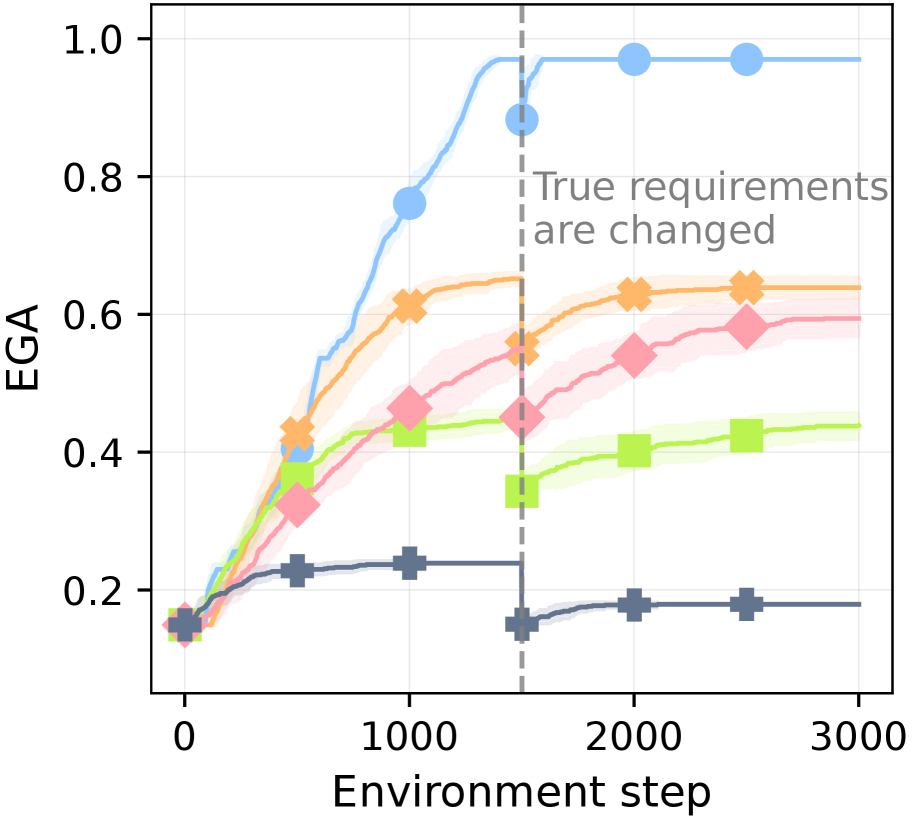
### Visual Description
## Line Chart: EGA vs. Environment Step
### Overview
The image is a line chart showing the relationship between EGA (likely an evaluation metric) and the environment step. There are five distinct data series, each represented by a different color and marker. A vertical dashed line indicates a change in true requirements. The chart visualizes how different strategies or algorithms perform over time, and how they are affected by the change in requirements.
### Components/Axes
* **Y-axis (Vertical):** Labeled "EGA", with a scale from 0.0 to 1.0 in increments of 0.2.
* **X-axis (Horizontal):** Labeled "Environment step", ranging from 0 to 3000 in increments of 1000.
* **Data Series:** Five distinct lines, each with a unique color and marker:
* Light Blue with Circle marker
* Orange with X marker
* Pink with Diamond marker
* Lime Green with Square marker
* Dark Blue/Gray with Plus marker
* **Vertical Dashed Line:** Located at approximately x = 1600, labeled "True requirements are changed".
### Detailed Analysis
* **Light Blue (Circle):** This line increases rapidly from approximately 0.15 at step 0 to approximately 0.9 at step 1600. After the change in requirements, it plateaus at approximately 0.98.
* (0, 0.15)
* (1600, 0.9)
* (2000, 0.98)
* (3000, 0.98)
* **Orange (X):** This line increases from approximately 0.15 at step 0 to approximately 0.65 at step 1600. After the change in requirements, it remains relatively stable at approximately 0.65.
* (0, 0.15)
* (1000, 0.6)
* (1600, 0.65)
* (2000, 0.65)
* (3000, 0.65)
* **Pink (Diamond):** This line increases from approximately 0.15 at step 0 to approximately 0.5 at step 1600. After the change in requirements, it continues to increase slightly to approximately 0.6.
* (0, 0.15)
* (500, 0.35)
* (1000, 0.4)
* (1600, 0.5)
* (2000, 0.58)
* (3000, 0.6)
* **Lime Green (Square):** This line increases from approximately 0.15 at step 0 to approximately 0.45 at step 1600. After the change in requirements, it remains relatively stable at approximately 0.45.
* (0, 0.15)
* (500, 0.3)
* (1000, 0.4)
* (1600, 0.45)
* (2000, 0.45)
* (3000, 0.45)
* **Dark Blue/Gray (Plus):** This line increases from approximately 0.15 at step 0 to approximately 0.25 at step 1600. After the change in requirements, it decreases slightly to approximately 0.18 and remains stable.
* (0, 0.15)
* (500, 0.22)
* (1000, 0.24)
* (1600, 0.25)
* (2000, 0.18)
* (3000, 0.18)
### Key Observations
* The light blue line (with circle markers) demonstrates the best performance, reaching an EGA of nearly 1.0.
* The dark blue/gray line (with plus markers) shows the worst performance, with an EGA remaining below 0.3.
* The change in requirements at step 1600 has a noticeable impact on the dark blue/gray line, causing a slight decrease in EGA. The light blue line plateaus after this change.
* The orange, pink, and lime green lines show intermediate performance, with the orange line achieving a higher EGA than the other two.
### Interpretation
The chart compares the performance of five different strategies or algorithms (represented by the different colored lines) in an environment where the requirements change at step 1600. The light blue strategy appears to be the most effective, quickly reaching a high EGA and maintaining it even after the requirements change. The dark blue/gray strategy is the least effective. The change in requirements has a varying impact on the different strategies, suggesting that some are more robust to changes in the environment than others. The shaded regions around each line likely represent the variance or uncertainty in the EGA values.
</details>
(a) Dynamic True Required Items
<details>
<summary>x54.png Details</summary>
### Visual Description
## Line Chart: EGA vs Environment Step
### Overview
The image is a line chart displaying the Effective Goal Achievement (EGA) on the y-axis against the Environment Step on the x-axis. There are five distinct data series represented by different colored lines with markers. A vertical dashed line indicates a point where "True actions are changed". The chart shows how EGA changes over time for each series, with a clear shift in behavior after the vertical line.
### Components/Axes
* **X-axis:** Environment step, ranging from 0 to 3000. Markers are present at 0, 1000, 2000, and 3000.
* **Y-axis:** EGA (Effective Goal Achievement), ranging from 0.0 to 1.0. Markers are present at 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Data Series:** Five distinct lines, each with a unique color and marker.
* Light Blue line with circle markers
* Orange line with cross markers
* Pink line with diamond markers
* Lime Green line with square markers
* Dark Grey line with plus markers
* **Vertical Dashed Line:** Located at approximately x = 1600, labeled "True actions are changed".
### Detailed Analysis
**Light Blue Line (Circle Markers):**
* Trend: Initially slopes sharply upward, reaching near 1.0 EGA before the vertical dashed line. After the line, it plateaus at approximately 0.98 EGA.
* Data Points:
* (0, ~0.15)
* (750, ~0.75)
* (1500, ~0.98)
* (2000, ~0.98)
* (3000, ~0.98)
**Orange Line (Cross Markers):**
* Trend: Slopes upward, but less steeply than the light blue line. After the vertical dashed line, it plateaus at approximately 0.55 EGA.
* Data Points:
* (0, ~0.15)
* (1000, ~0.60)
* (1500, ~0.65)
* (2000, ~0.55)
* (3000, ~0.55)
**Pink Line (Diamond Markers):**
* Trend: Slopes upward, similar to the orange line, but plateaus at a lower EGA. After the vertical dashed line, it plateaus at approximately 0.52 EGA.
* Data Points:
* (0, ~0.15)
* (1000, ~0.40)
* (1500, ~0.50)
* (2000, ~0.52)
* (3000, ~0.52)
**Lime Green Line (Square Markers):**
* Trend: Slopes upward, plateaus at a lower EGA than the pink line. After the vertical dashed line, it plateaus at approximately 0.38 EGA.
* Data Points:
* (0, ~0.15)
* (1000, ~0.40)
* (1500, ~0.45)
* (2000, ~0.38)
* (3000, ~0.38)
**Dark Grey Line (Plus Markers):**
* Trend: Slopes upward slightly, then plateaus at a low EGA. After the vertical dashed line, it plateaus at approximately 0.15 EGA.
* Data Points:
* (0, ~0.15)
* (1000, ~0.23)
* (1500, ~0.25)
* (2000, ~0.15)
* (3000, ~0.15)
### Key Observations
* All lines start at approximately the same EGA value (~0.15).
* The light blue line achieves the highest EGA, while the dark grey line achieves the lowest.
* The vertical dashed line at Environment step ~1600 marks a point where the behavior of all lines changes, generally plateauing after this point.
* There are shaded regions around each line, indicating uncertainty or variance in the data.
### Interpretation
The chart illustrates the performance of different strategies or algorithms (represented by the colored lines) in achieving a goal (EGA) as the environment changes (Environment step). The vertical line signifies a change in the environment or task ("True actions are changed"). The data suggests that the light blue strategy is the most effective, consistently achieving a high EGA. The other strategies show varying degrees of success, with the dark grey strategy being the least effective. The change in environment at step ~1600 appears to stabilize the EGA for all strategies, preventing further significant improvement. The shaded regions indicate the variability in performance for each strategy, suggesting that some strategies are more consistent than others.
</details>
(b) Dynamic True Actions
<details>
<summary>x55.png Details</summary>
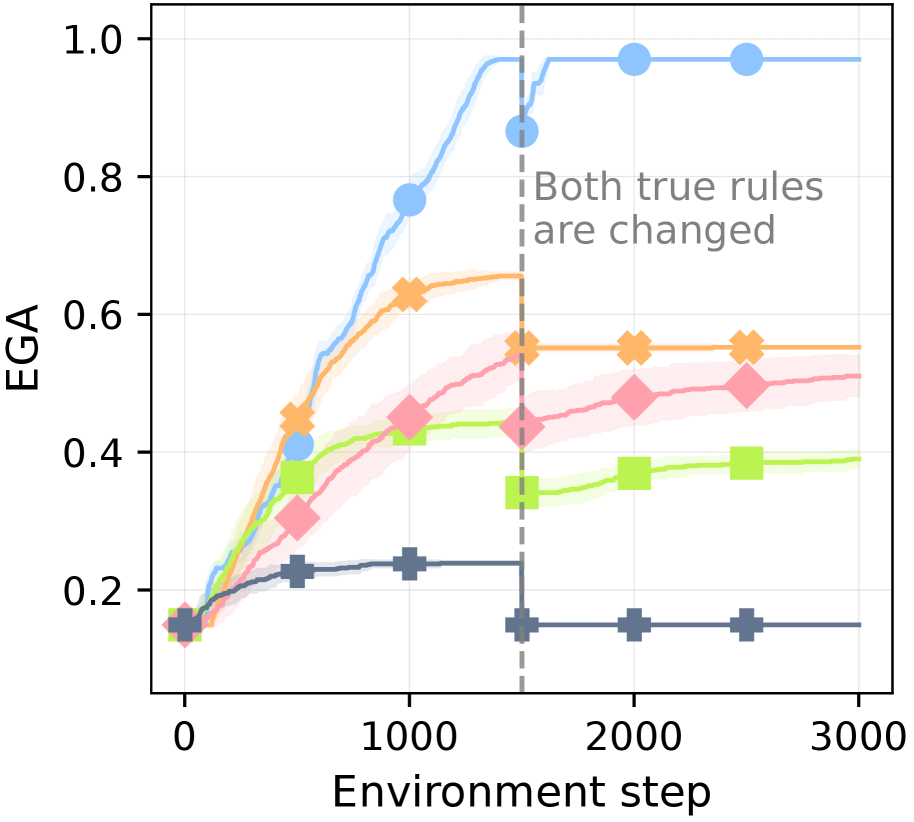
### Visual Description
## Line Chart: EGA vs. Environment Step
### Overview
The image is a line chart that plots EGA (likely an acronym for a performance metric) against the Environment step. There are five distinct data series, each represented by a different colored line with unique markers. A vertical dashed line indicates a point where "Both true rules are changed." The chart illustrates how EGA changes over time (environment steps) for each series, with a clear shift in behavior after the rule change.
### Components/Axes
* **Y-axis (Vertical):** Labeled "EGA," ranging from 0.0 to 1.0 in increments of 0.2.
* **X-axis (Horizontal):** Labeled "Environment step," ranging from 0 to 3000 in increments of 1000.
* **Data Series:** Five distinct data series, each with a unique color and marker:
* Blue line with circle markers
* Orange line with cross markers
* Pink line with diamond markers
* Green line with square markers
* Dark Blue/Gray line with plus markers
* **Vertical Dashed Line:** Located at approximately x = 1500, labeled "Both true rules are changed."
* **Shaded Regions:** Each line has a shaded region around it, indicating uncertainty or variance.
### Detailed Analysis
**Blue Line (Circles):**
* **Trend:** The blue line shows a rapid increase in EGA from approximately 0.15 to 0.9 between environment steps 0 and 1500. After the vertical line (rule change), the EGA plateaus at approximately 0.98.
* **Data Points:**
* (0, ~0.15)
* (750, ~0.75)
* (1500, ~0.9)
* (2250, ~0.98)
* (3000, ~0.98)
**Orange Line (Crosses):**
* **Trend:** The orange line shows a steady increase in EGA from approximately 0.15 to 0.65 between environment steps 0 and 1500. After the rule change, the EGA remains relatively constant at approximately 0.55.
* **Data Points:**
* (0, ~0.15)
* (750, ~0.45)
* (1500, ~0.65)
* (2250, ~0.55)
* (3000, ~0.55)
**Pink Line (Diamonds):**
* **Trend:** The pink line shows a gradual increase in EGA from approximately 0.15 to 0.5 between environment steps 0 and 1500. After the rule change, the EGA remains relatively constant at approximately 0.5.
* **Data Points:**
* (0, ~0.15)
* (750, ~0.3)
* (1500, ~0.45)
* (2250, ~0.5)
* (3000, ~0.5)
**Green Line (Squares):**
* **Trend:** The green line shows a gradual increase in EGA from approximately 0.15 to 0.45 between environment steps 0 and 1500. After the rule change, the EGA remains relatively constant at approximately 0.38.
* **Data Points:**
* (0, ~0.15)
* (750, ~0.38)
* (1500, ~0.45)
* (2250, ~0.38)
* (3000, ~0.38)
**Dark Blue/Gray Line (Plus Signs):**
* **Trend:** The dark blue/gray line shows a slight increase in EGA from approximately 0.15 to 0.25 between environment steps 0 and 1500. After the rule change, the EGA drops to approximately 0.15 and remains constant.
* **Data Points:**
* (0, ~0.15)
* (750, ~0.23)
* (1500, ~0.25)
* (2250, ~0.15)
* (3000, ~0.15)
### Key Observations
* All data series start at approximately the same EGA value (~0.15) at the beginning of the environment steps.
* The vertical line at Environment step 1500, indicating a change in "Both true rules," has a noticeable impact on all data series. The blue line plateaus, the orange and pink lines stabilize, the green line stabilizes, and the dark blue/gray line drops.
* The blue line achieves the highest EGA value, reaching nearly 1.0.
* The dark blue/gray line performs the worst, with the lowest EGA value throughout the experiment.
### Interpretation
The chart demonstrates the impact of changing "Both true rules" on the EGA performance of five different strategies or algorithms. Before the rule change, all strategies show some level of improvement in EGA as the environment steps increase. However, the rule change at step 1500 significantly alters the performance trajectory of each strategy.
The blue line, representing one strategy, benefits the most from the rule change, quickly reaching and maintaining a high EGA value. The other strategies (orange, pink, and green) show a stabilization or slight decrease in EGA after the rule change, suggesting that the new rules do not favor these strategies as much. The dark blue/gray line shows a clear negative impact from the rule change, indicating that this strategy is particularly sensitive to the change in rules.
The shaded regions around each line likely represent the variance or uncertainty in the EGA values for each strategy. The narrower the shaded region, the more consistent the performance of that strategy.
Overall, the chart suggests that the choice of strategy is highly dependent on the specific rules of the environment. The rule change highlights the robustness and adaptability of the blue strategy compared to the others.
</details>
(c) Dynamic Both Rules
Figure 22: Robustness against dynamic true knowledge. EGA over 3,000 environment steps in the where the true item acquisition rules are changed during the learning process.
Table 16: The ratio of correctly learned dependencies among whose rules are dynamically changed (out of 7 total) by each agent. Columns correspond to the type of ground-truth rules changed during learning: requirements only, actions only, or both.
| Agent | (3,0) | (0,3) | (3,3) |
| --- | --- | --- | --- |
| XENON | 1.0 | 1.0 | 1.0 |
| SC | 0.80 | 0.0 | 0.0 |
| ADAM | 0.83 | 0.0 | 0.0 |
| DECKARD | 0.49 | 0.0 | 0.0 |
| RAND | 0.29 | 0.0 | 0.0 |
Additionally, We show XENON is also applicable to scenarios where the latent true knowledge changes dynamically. We design three dynamic scenarios where the environment begins with the vanilla setting, (0,0), for the first 1,500 steps, then transitions to a level-3 perturbation setting for the subsequent 1,500 steps: either required items-only (3,0), action-only (0,3), or both (3,3). Upon this change, the agent is informed of which items’ rules are modified but not what the new rules are, forcing it to relearn from experience. As shown in Figure ˜ 22, XENON rapidly adapts by re-learning the new dependencies and recovering its near-perfect EGA in all three scenarios. In contrast, all baselines fail to adapt effectively, with their performance remaining significantly degraded after the change. Specifically, for the 7 items whose rules are altered, Table ˜ 16 shows that XENON achieves a perfect re-learning ratio of 1.0 in all scenarios, while all baselines score 0.0 whenever actions are modified.
K.7 Ablation studies for long-horzion goal planning
Table 17: Ablation experiment results for long-horizon goal planning in MineRL. Without Learned Dependency, XENON employs a dependency graph initialized with LLM predictions and human-written examples. Without Action Correction, XENON saves and reuses successful actions in FAM, but it does not utilize the information of failed actions.
| Learned Dependency | Action Correction | CRe |
<details>
<summary>x56.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
|
<details>
<summary>x57.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
|
<details>
<summary>x58.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
|
<details>
<summary>x59.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
|
<details>
<summary>x60.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
|
<details>
<summary>x61.png Details</summary>
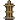
### Visual Description
Icon/Small Image (20x20)
</details>
|
<details>
<summary>x62.png Details</summary>

### Visual Description
Icon/Small Image (20x20)
</details>
|
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Wood | Stone | Iron | Diamond | Gold | Armor | Redstone | | | |
| 0.54 | 0.39 | 0.10 | 0.26 | 0.45 | 0.0 | 0.0 | | | |
| 0.54 | 0.38 | 0.09 | 0.29 | 0.45 | 0.0 | 0.0 | | | |
| 0.82 | 0.69 | 0.36 | 0.59 | 0.69 | 0.22 | 0.0 | | | |
| 0.82 | 0.79 | 0.45 | 0.59 | 0.68 | 0.21 | 0.0 | | | |
| 0.85 | 0.81 | 0.46 | 0.64 | 0.74 | 0.28 | 0.0 | | | |
To analyze how each of XENON’s components contributes to its long-horizon planning, we conducted an ablation study in MineRL, with results shown in Table ˜ 17. The findings first indicate that without accurate dependency knowledge, our action correction using FAM provides no significant benefit on its own (row 1 vs. row 2). The most critical component is the learned dependency graph, which dramatically improves success rates across all item groups (row 3). Building on this, adding FAM’s action correction further boosts performance, particularly for the Stone and Iron groups where it helps overcome the LLM’s flawed action priors (row 4). Finally, Context-aware Reprompting (CRe, Section ˜ 4.3) provides an additional performance gain on more challenging late-game items, such as Iron, Gold, and Armor. This is likely because their longer episode horizons offer more opportunities for CRe to rescue a stalled controller.
K.8 The Necessity of Knowledge Correction even with External Sources
<details>
<summary>x63.png Details</summary>
### Visual Description
## Chart: Experienced Items Ratio vs. Environment Step
### Overview
The image is a line chart comparing the "Experienced Items Ratio" of five different algorithms (XENON, SC, ADAM, DECKARD, and RAND) over a range of "Environment steps". The chart shows how the ratio changes as the environment step increases.
### Components/Axes
* **X-axis:** "Environment step", ranging from 0 to 3000.
* **Y-axis:** "Experienced Items Ratio", ranging from 0.0 to 1.0.
* **Legend:** Located in the top-left corner, associating each algorithm with a specific color.
* XENON: Light blue
* SC: Light red
* ADAM: Light orange
* DECKARD: Light green
* RAND: Dark gray
* **Gridlines:** Light gray, providing visual reference points.
### Detailed Analysis
* **XENON (Light Blue):** The line starts near 0.0 and gradually increases until approximately environment step 1000. It then exhibits a steeper increase, reaching nearly 1.0 around environment step 2500. There is a shaded region around the line, indicating variance or confidence intervals.
* At step 0, ratio ~ 0.0
* At step 1000, ratio ~ 0.15
* At step 2000, ratio ~ 0.6
* At step 2500, ratio ~ 0.95
* At step 3000, ratio ~ 0.98
* **SC (Light Red):** The line remains relatively flat and close to 0.0 throughout the entire range of environment steps.
* At step 0, ratio ~ 0.0
* At step 3000, ratio ~ 0.02
* **ADAM (Light Orange):** The line also remains relatively flat and close to 0.0 throughout the entire range of environment steps, slightly higher than SC.
* At step 0, ratio ~ 0.0
* At step 3000, ratio ~ 0.04
* **DECKARD (Light Green):** The line increases slightly in the beginning, then plateaus around 0.1.
* At step 0, ratio ~ 0.0
* At step 500, ratio ~ 0.1
* At step 3000, ratio ~ 0.1
* **RAND (Dark Gray):** The line increases slightly in the beginning, then plateaus around 0.12.
* At step 0, ratio ~ 0.0
* At step 500, ratio ~ 0.1
* At step 3000, ratio ~ 0.12
### Key Observations
* XENON significantly outperforms the other algorithms in terms of "Experienced Items Ratio".
* SC and ADAM have very low "Experienced Items Ratio" throughout the experiment.
* DECKARD and RAND perform similarly, with a slightly higher ratio than SC and ADAM, but significantly lower than XENON.
* The shaded region around the XENON line indicates variability in its performance.
### Interpretation
The chart demonstrates the effectiveness of the XENON algorithm in experiencing items within the environment compared to the other algorithms tested. The XENON algorithm shows a clear upward trend, indicating that it learns and explores the environment more efficiently as the number of environment steps increases. In contrast, SC, ADAM, DECKARD, and RAND show minimal improvement in the "Experienced Items Ratio," suggesting they are less effective at exploring or learning from the environment. The shaded region around the XENON line suggests that its performance may vary across different runs or conditions, but it consistently outperforms the other algorithms.
</details>
Figure 23: Ratio of goal items obtained in one MC-TextWorld episode when each agent’s dependency graph is initialized from an oracle graph while the environment’s ground-truth dependency graph is perturbed. Solid lines denote the mean over 15 runs; shaded areas denote the standard deviation.
Even when an external source is available to initialize an agent’s knowledge, correcting that knowledge from interaction remains essential for dependency and action learning, because such sources can be flawed or outdated. To support this, we evaluate XENON and the baselines in the MC-TextWorld environment where each agent’s dependency graph is initialized from an oracle graph, while the environment’s ground-truth dependency graph is perturbed (perturbation level 3 in Table ˜ 4). We measure performance as the ratio of the 67 goal items obtained within a single episode. We use an intrinsic exploratory item selection method for all agents (i.e., which item each agent chooses on its own to try to obtain next): they choose, among items not yet obtained in the current episode, the one with the fewest attempts so far.
As shown in Figure ˜ 23, this experiment demonstrates that, even when an external source is available, (1) interaction experience-based knowledge correction remains crucial when the external source is mismatched with the environment, and (2) XENON is also applicable and robust in this scenario. By continually revising its dependency knowledge, XENON achieves a much higher ratio of goal items obtained in an episode than all baselines. In contrast, the baselines either rely on unreliable LLM self-correction (e.g., SC) or do not correct flawed knowledge at all (e.g., DECKARD, ADAM, RAND), and therefore fail to obtain many goal items. Their performance is especially poor because there are dependencies between goals: for example, when the true required items for stone pickaxe and iron pickaxe are perturbed, the baselines cannot obtain these items and thus cannot obtain other goal items that depend on them.
K.9 Scalability of Dependency and Action Learning with More Goals and Actions
<details>
<summary>x64.png Details</summary>
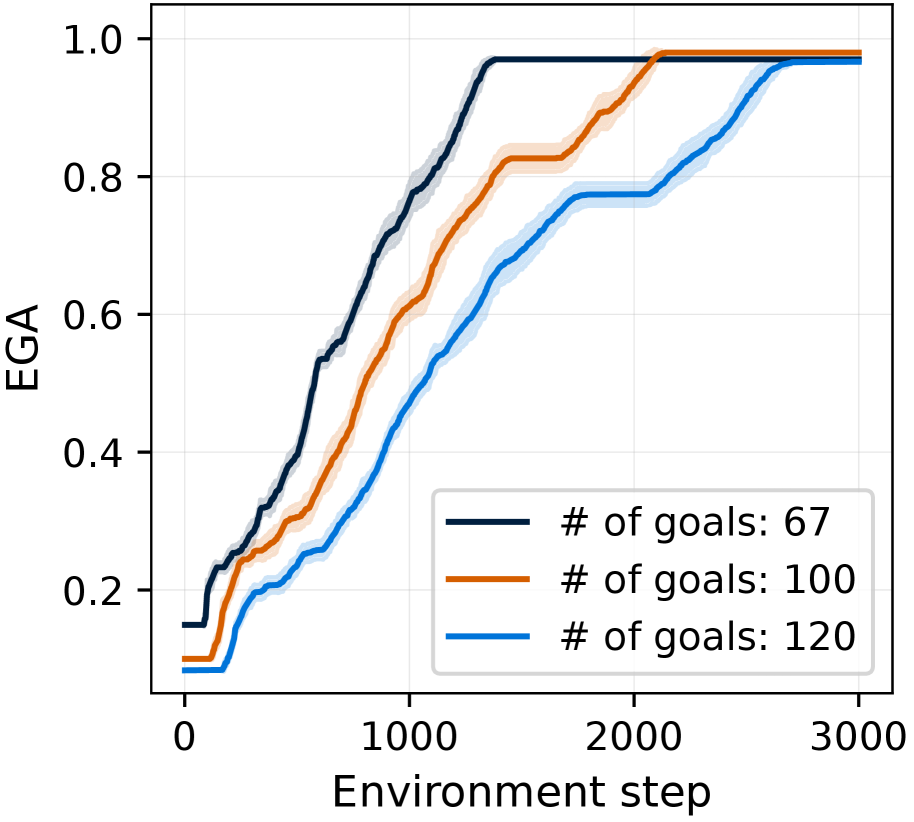
### Visual Description
## Line Chart: EGA vs. Environment Step for Different Numbers of Goals
### Overview
The image is a line chart comparing the EGA (likely standing for Environment Goal Achievement) against the Environment Step for three different scenarios, each representing a different number of goals: 67, 100, and 120. The chart shows how the EGA changes as the environment step increases for each of these goal settings. Each line has a shaded region around it, indicating the variance or uncertainty in the data.
### Components/Axes
* **X-axis:** "Environment step" ranging from 0 to 3000, with tick marks at 0, 1000, 2000, and 3000.
* **Y-axis:** "EGA" (Environment Goal Achievement) ranging from 0.0 to 1.0, with tick marks at 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Legend:** Located in the bottom-right corner, it identifies the three lines by the number of goals:
* Dark Blue line: "# of goals: 67"
* Orange line: "# of goals: 100"
* Blue line: "# of goals: 120"
### Detailed Analysis
* **Dark Blue Line (# of goals: 67):**
* Trend: The line generally slopes upward, indicating an increase in EGA as the environment step increases. It starts at approximately 0.1 and reaches a plateau near 1.0 around environment step 2000.
* Data Points:
* Environment step 0: EGA ~0.1
* Environment step 500: EGA ~0.6
* Environment step 1000: EGA ~0.8
* Environment step 2000: EGA ~0.98
* Environment step 3000: EGA ~0.98
* **Orange Line (# of goals: 100):**
* Trend: The line also slopes upward, but it appears to increase more gradually than the dark blue line. It starts at approximately 0.1 and reaches a plateau near 0.98 around environment step 2500.
* Data Points:
* Environment step 0: EGA ~0.1
* Environment step 500: EGA ~0.4
* Environment step 1000: EGA ~0.65
* Environment step 2000: EGA ~0.85
* Environment step 3000: EGA ~0.98
* **Blue Line (# of goals: 120):**
* Trend: The line slopes upward, starting slower than the other two, and plateaus last. It starts at approximately 0.08 and reaches a plateau near 0.98 around environment step 3000.
* Data Points:
* Environment step 0: EGA ~0.08
* Environment step 500: EGA ~0.3
* Environment step 1000: EGA ~0.45
* Environment step 2000: EGA ~0.75
* Environment step 3000: EGA ~0.98
### Key Observations
* The EGA generally increases with the environment step for all three scenarios.
* The dark blue line (# of goals: 67) reaches a high EGA value faster than the other two lines.
* The blue line (# of goals: 120) increases more slowly initially but eventually reaches a similar EGA value as the other two.
* All three lines plateau near an EGA of 1.0, indicating that the environment goal is eventually achieved in all scenarios.
* The shaded regions around each line suggest some variability in the EGA at each environment step, but the overall trends are consistent.
### Interpretation
The chart suggests that the number of goals in the environment affects the rate at which the environment goal is achieved. With fewer goals (67), the EGA increases more rapidly, indicating faster learning or achievement. As the number of goals increases (100 and 120), the EGA increases more gradually, suggesting that it takes more environment steps to achieve the same level of performance. However, all three scenarios eventually reach a similar level of EGA, indicating that the environment goal can be achieved regardless of the number of goals, given enough environment steps. The shaded regions indicate that there is some variability in the EGA at each environment step, which could be due to factors such as randomness in the environment or the learning algorithm.
</details>
(a) Effect of increasing the number of goals
<details>
<summary>x65.png Details</summary>
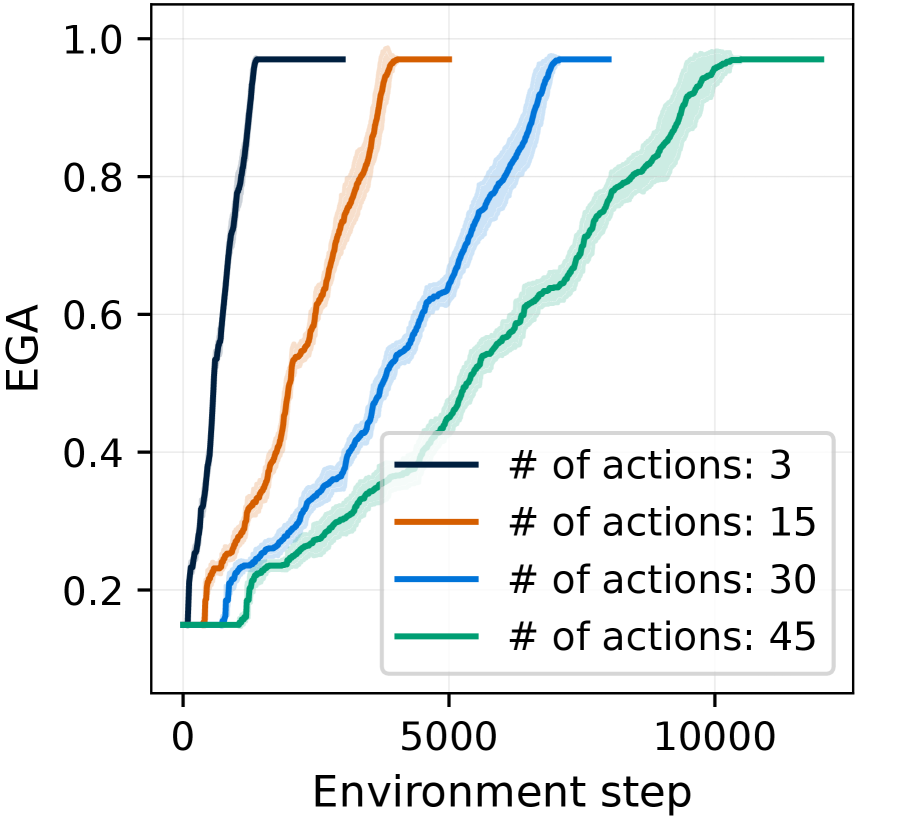
### Visual Description
## Line Chart: EGA vs. Environment Step for Different Numbers of Actions
### Overview
The image is a line chart that plots EGA (likely an abbreviation for an evaluation metric) against the environment step for different numbers of actions (3, 15, 30, and 45). The chart shows how the EGA changes over time (environment steps) for each action configuration.
### Components/Axes
* **X-axis:** Environment step, ranging from 0 to 10000.
* **Y-axis:** EGA, ranging from 0 to 1.0.
* **Legend (bottom-right):**
* Dark Blue: # of actions: 3
* Orange: # of actions: 15
* Blue: # of actions: 30
* Green: # of actions: 45
### Detailed Analysis
* **Dark Blue Line (# of actions: 3):**
* The line starts at an EGA of approximately 0.15.
* It quickly rises to an EGA of approximately 0.97 around environment step 500.
* The line then plateaus at approximately 0.97 for the remainder of the environment steps.
* **Orange Line (# of actions: 15):**
* The line starts at an EGA of approximately 0.15.
* It rises more gradually than the dark blue line, reaching an EGA of approximately 0.97 around environment step 4000.
* The line then plateaus at approximately 0.97 for the remainder of the environment steps.
* **Blue Line (# of actions: 30):**
* The line starts at an EGA of approximately 0.15.
* It rises even more gradually than the orange line, reaching an EGA of approximately 0.97 around environment step 8000.
* The line then plateaus at approximately 0.97 for the remainder of the environment steps.
* **Green Line (# of actions: 45):**
* The line starts at an EGA of approximately 0.15.
* It rises the most gradually of all the lines, reaching an EGA of approximately 0.97 around environment step 10000.
* The line then plateaus at approximately 0.97 for the remainder of the environment steps.
### Key Observations
* All lines eventually reach a similar EGA value of approximately 0.97.
* The number of actions significantly affects the rate at which the EGA increases. Fewer actions lead to a faster increase in EGA.
* The shaded regions around each line likely represent the variance or standard deviation of the EGA for each action configuration.
### Interpretation
The chart suggests that using fewer actions leads to faster learning (as measured by EGA) in the environment. However, all configurations eventually reach a similar level of performance. This could indicate that while fewer actions allow for quicker initial progress, the ultimate performance ceiling is similar regardless of the number of actions. The shaded regions indicate the variability in performance, which could be due to factors like randomness in the environment or the learning algorithm. The data demonstrates a trade-off between the speed of learning and the number of actions.
</details>
(b) Effect of increasing the number of actions
Figure 24: Scalability of XENON with more goals and actions. EGA over environment steps in MC-TextWorld when (a) increasing the number of goal items and (b) increasing the number of available actions. In (a), we keep the three actions (“mine”, “craft”, “smelt”) fixed, while in (b) we keep the 67 goal items fixed. Solid lines denote the mean over 15 runs; shaded areas denote the standard deviation.
To evaluate the scalability of XENON’s dependency and action learning, we vary the number of goal items and available actions in the MC-TextWorld environment. For the goal-scaling experiment, we increase the number of goals from 67 to 100 and 120 by adding new goal items (see Table ˜ 11 for the added goals), while keeping the original three actions “mine”, “craft”, and “smelt” fixed. For the action-scaling experiment, we increase the available actions from 3 to 15, 30, and 45 (e.g., “harvest”, “hunt”, “place”), while keeping the original 67 goals fixed.
The results in Figure ˜ 24 show that XENON maintains high EGA as both the number of goals and the number of actions grow, although the number of environment steps required for convergence naturally increases. As seen in Figure ˜ 24(a), increasing the number of goals from 67 to 100 and 120 only moderately delays convergence (from around 1,400 to about 2,100 and 2,600 steps). In contrast, Figure ˜ 24(b) shows a larger slowdown when increasing the number of actions (from about 1,400 steps with 3 actions to roughly 4,000, 7,000, and 10,000 steps with 15, 30, and 45 actions), which is expected because XENON only revises an item’s dependency after all available actions for that item have been classified as empirically invalid by FAM. We believe this convergence speed could be improved with minimal changes, such as by lowering $x_{0}$ , the failure count threshold for classifying an action as invalid, or by triggering dependency revision once the agent has failed to obtain an item a fixed number of times, regardless of which actions were tried in subgoals.
K.10 Ablation on action selection methods for making subgoals
<details>
<summary>x66.png Details</summary>

### Visual Description
## Legend: Algorithm Comparison
### Overview
The image is a legend for a chart comparing different algorithms. The legend identifies five algorithms: Random+FAM, UCB, LLM, SC, and XENON, each represented by a unique color and marker.
### Components/Axes
* **Legend Items:**
* **Random+FAM:** Brown line with triangle markers.
* **UCB:** Light purple line with star markers.
* **LLM:** Gray line with square markers.
* **SC:** Light pink line with diamond markers.
* **XENON:** Light blue line with circle markers.
### Detailed Analysis or ### Content Details
The legend is positioned horizontally. Each algorithm name is paired with a line segment of a specific color and a corresponding marker shape.
### Key Observations
The legend provides a clear mapping between algorithm names, colors, and marker shapes, which is essential for interpreting the data presented in the chart it accompanies.
### Interpretation
The legend is a key component for understanding a comparative chart. It allows the viewer to quickly identify which algorithm each data series represents. Without the legend, the chart would be uninterpretable.
</details>
<details>
<summary>x67.png Details</summary>
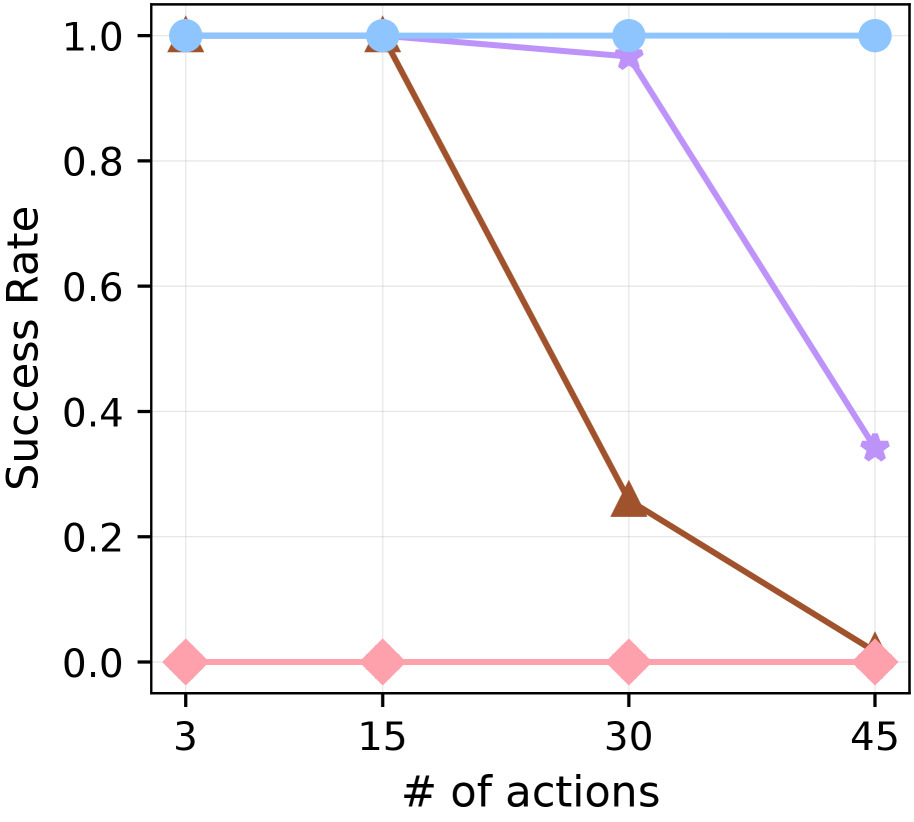
### Visual Description
## Line Chart: Success Rate vs. Number of Actions
### Overview
The image is a line chart comparing the success rate of different methods (represented by different colored lines) against the number of actions taken. The x-axis represents the number of actions, and the y-axis represents the success rate.
### Components/Axes
* **X-axis:** "# of actions" with markers at 3, 15, 30, and 45.
* **Y-axis:** "Success Rate" with markers at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Data Series:**
* Light Blue line with circle markers.
* Brown line with triangle markers.
* Light Purple line with star markers.
* Light Pink line with diamond markers.
### Detailed Analysis
* **Light Blue Line (Circle Markers):** This line remains constant at a success rate of approximately 1.0 across all numbers of actions (3, 15, 30, and 45).
* (3, 1.0)
* (15, 1.0)
* (30, 1.0)
* (45, 1.0)
* **Brown Line (Triangle Markers):** This line starts at a success rate of approximately 1.0 at 3 actions, then decreases to approximately 0.25 at 30 actions, and further decreases to approximately 0.0 at 45 actions.
* (3, 1.0)
* (15, 1.0)
* (30, 0.25)
* (45, 0.0)
* **Light Purple Line (Star Markers):** This line remains constant at a success rate of approximately 1.0 for 3 and 15 actions, then decreases to approximately 0.95 at 30 actions, and further decreases to approximately 0.35 at 45 actions.
* (3, 1.0)
* (15, 1.0)
* (30, 0.95)
* (45, 0.35)
* **Light Pink Line (Diamond Markers):** This line remains constant at a success rate of approximately 0.0 across all numbers of actions (3, 15, 30, and 45).
* (3, 0.0)
* (15, 0.0)
* (30, 0.0)
* (45, 0.0)
### Key Observations
* The light blue method maintains a perfect success rate regardless of the number of actions.
* The brown method's success rate decreases significantly as the number of actions increases.
* The light purple method's success rate also decreases as the number of actions increases, but not as drastically as the brown method.
* The light pink method consistently fails, with a success rate of 0.0 regardless of the number of actions.
### Interpretation
The chart compares the performance of four different methods based on their success rate as the number of actions increases. The light blue method is the most robust, maintaining a perfect success rate. The brown and light purple methods are sensitive to the number of actions, with their success rates decreasing as the number of actions increases. The light pink method is consistently unsuccessful. This suggests that the light blue method is the most reliable, while the brown and light purple methods may require further optimization or are only suitable for tasks requiring fewer actions. The light pink method is ineffective and should not be used.
</details>
(a) Success rate
<details>
<summary>x68.png Details</summary>
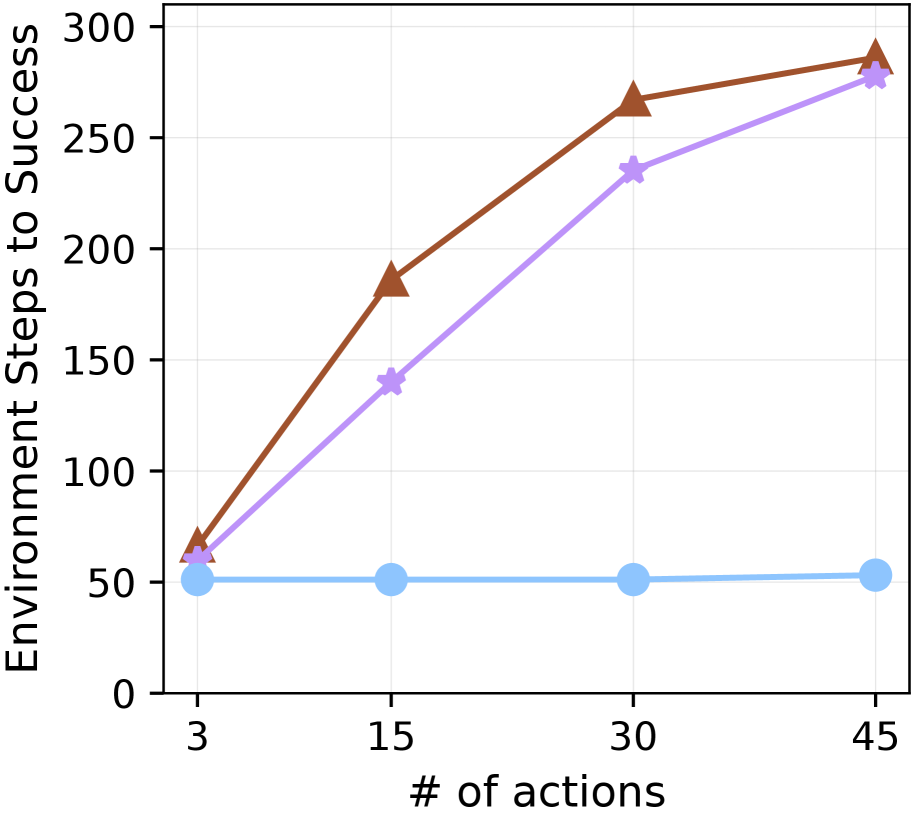
### Visual Description
## Line Chart: Environment Steps to Success vs. Number of Actions
### Overview
The image is a line chart comparing the number of environment steps to success against the number of actions taken. There are three distinct data series represented by different colored lines: brown, light purple, and light blue. The x-axis represents the number of actions, and the y-axis represents the environment steps to success.
### Components/Axes
* **X-axis:** "# of actions" with markers at 3, 15, 30, and 45.
* **Y-axis:** "Environment Steps to Success" with markers at 0, 50, 100, 150, 200, 250, and 300.
* **Data Series:**
* Brown line with triangle markers.
* Light purple line with star markers.
* Light blue line with circle markers.
### Detailed Analysis
* **Brown Line (Triangle Markers):** This line shows an upward trend, indicating that as the number of actions increases, the environment steps to success also increase.
* At 3 actions, the value is approximately 65.
* At 15 actions, the value is approximately 185.
* At 30 actions, the value is approximately 265.
* At 45 actions, the value is approximately 285.
* **Light Purple Line (Star Markers):** This line also shows an upward trend, but it is less steep than the brown line.
* At 3 actions, the value is approximately 65.
* At 15 actions, the value is approximately 140.
* At 30 actions, the value is approximately 235.
* At 45 actions, the value is approximately 285.
* **Light Blue Line (Circle Markers):** This line remains relatively flat, indicating that the environment steps to success are nearly constant regardless of the number of actions.
* At 3 actions, the value is approximately 52.
* At 15 actions, the value is approximately 52.
* At 30 actions, the value is approximately 52.
* At 45 actions, the value is approximately 54.
### Key Observations
* The brown line consistently has the highest values for environment steps to success across all numbers of actions.
* The light blue line remains almost constant, suggesting a fixed number of steps regardless of the number of actions.
* The light purple line increases steadily, approaching the brown line at 45 actions.
### Interpretation
The chart suggests that different strategies or algorithms are being compared based on the number of environment steps required to achieve success as the number of actions varies. The brown line represents a scenario where more actions lead to a higher number of steps, possibly indicating a less efficient or more complex approach. The light purple line shows a more moderate increase in steps with actions, suggesting a more efficient strategy than the brown line. The light blue line represents a highly consistent strategy where the number of steps remains nearly constant, regardless of the number of actions, potentially indicating a very simple or direct approach. The convergence of the brown and light purple lines at 45 actions might indicate a performance ceiling or a point where the benefits of additional actions diminish.
</details>
(b) Steps to success (lower is better)
Figure 25: Ablation on action selection methods for subgoal construction. We evaluate different action selection methods for solving long-horizon goals given an oracle dependency graph, as the size of the available action set increases. (a) Success rate and (b) number of environment steps per successful episode. Note that in (a), the curves for LLM and SC overlap at 0.0 because they fail on all episodes, and in (b), they are omitted since they never succeed.
We find that, while LLMs can in principle accelerate the search for valid actions, they do so effectively only when their flawed knowledge is corrected algorithmically. To support this, we study how different action selection methods for subgoal construction affect performance on long-horizon goals. In this ablation, the agent is given an oracle dependency graph and a long-horizon goal, and only needs to output one valid action from the available actions for each subgoal item to achieve that goal. Each episode specifies a single goal item, and it is counted as successful if the agent obtains this item within 300 environment steps in MC-TextWorld. To study scalability with respect to the size of the available action set, we vary the number of actions as 3, 15, 30, and 45 by gradually adding actions such as “harvest” and “hunt” to the original three actions (“mine”, “craft”, “smelt”).
Methods and metrics
We compare five action selection methods: Random+FAM (which randomly samples from available actions that have not yet repeatedly failed and reuses past successful actions), UCB, LLM without memory, LLM self-correction (SC), and XENON, which combines an LLM with FAM. We report the average success rate and the average number of environment steps to success over 20 runs per goal item, where goal items are drawn from the Redstone group.
As shown in Figure ˜ 25, among the three LLM-based methods (LLM, SC, XENON), only XENON—which corrects the LLM’s action knowledge by removing repeatedly failed actions from the set of candidate actions the LLM is allowed to select—solves long-horizon goals reliably, maintaining a success rate of 1.0 and requiring roughly 50 environment steps across all sizes of the available action set. In contrast, LLM and SC never succeed in any episode, because they keep selecting incorrect actions for subgoal items (e.g., redstone), and therefore perform worse than the non-LLM baselines, Random+FAM and UCB. Random+FAM and UCB perform well when the number of available actions is small, but become increasingly slow and unreliable as the number of actions grows, often failing to reach the goal within the episode horizon.
K.11 Robustness to Smaller Planner LLMs and Limited Initial Knowledge
<details>
<summary>x69.png Details</summary>

### Visual Description
## Chart/Diagram Type: Legend
### Overview
The image shows a legend for a chart or graph. The legend identifies five data series, each represented by a different color and marker.
### Components/Axes
The legend is displayed horizontally. The legend entries are:
- XENON (light blue circle)
- SC (light pink diamond)
- ADAM (light orange flower-like shape)
- DECKARD (light green square)
- RAND (gray plus sign)
### Detailed Analysis or ### Content Details
The legend entries are arranged from left to right in the following order: XENON, SC, ADAM, DECKARD, and RAND. Each entry consists of a colored marker followed by the name of the data series.
### Key Observations
The legend provides a clear mapping between the data series names and their corresponding visual representations (color and marker).
### Interpretation
The legend is a key component for interpreting the chart or graph it accompanies. It allows the viewer to easily identify and distinguish between the different data series being presented.
</details>
<details>
<summary>x70.png Details</summary>
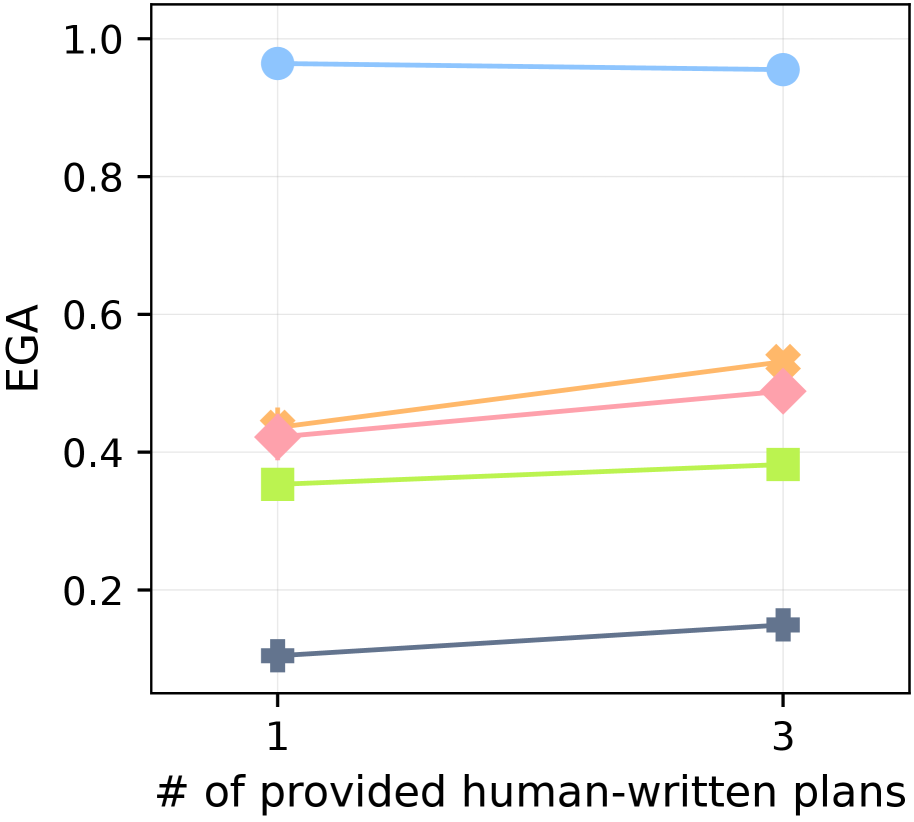
### Visual Description
## Line Chart: EGA vs. Number of Provided Human-Written Plans
### Overview
The image is a line chart comparing the EGA (Exact Goal Achievement) score against the number of provided human-written plans (1 or 3). There are five data series represented by different colored lines, each showing the EGA score for a given number of provided plans.
### Components/Axes
* **X-axis:** "# of provided human-written plans" with values 1 and 3.
* **Y-axis:** "EGA" (Exact Goal Achievement) ranging from 0.2 to 1.0 in increments of 0.2.
* **Data Series:** Five distinct data series are plotted, each represented by a different color and marker. The colors are light blue (circle marker), light orange (cross marker), light pink (diamond marker), light green (square marker), and dark blue (plus marker). There is no explicit legend, so the series are identified by color and marker type.
### Detailed Analysis
* **Light Blue (Circle Marker):** This line represents the highest EGA scores.
* At 1 plan, the EGA is approximately 0.97.
* At 3 plans, the EGA is approximately 0.96.
* Trend: Relatively flat, showing a slight decrease.
* **Light Orange (Cross Marker):** This line shows a moderate EGA score.
* At 1 plan, the EGA is approximately 0.45.
* At 3 plans, the EGA is approximately 0.54.
* Trend: Slopes upward.
* **Light Pink (Diamond Marker):** This line shows a moderate EGA score.
* At 1 plan, the EGA is approximately 0.42.
* At 3 plans, the EGA is approximately 0.51.
* Trend: Slopes upward.
* **Light Green (Square Marker):** This line shows a lower EGA score.
* At 1 plan, the EGA is approximately 0.35.
* At 3 plans, the EGA is approximately 0.38.
* Trend: Slopes slightly upward.
* **Dark Blue (Plus Marker):** This line represents the lowest EGA scores.
* At 1 plan, the EGA is approximately 0.10.
* At 3 plans, the EGA is approximately 0.15.
* Trend: Slopes upward.
### Key Observations
* The light blue series consistently achieves the highest EGA scores, regardless of the number of provided plans.
* All series except the light blue one show an increase in EGA score when the number of provided plans increases from 1 to 3.
* The dark blue series consistently has the lowest EGA scores.
### Interpretation
The chart suggests that providing more human-written plans (increasing from 1 to 3) generally improves the Exact Goal Achievement (EGA) score for most of the data series represented, except for the light blue series, which remains relatively stable. The different colored lines likely represent different models or algorithms being evaluated. The light blue series represents a model that performs well regardless of the number of provided plans, while the other models benefit from having more examples. The dark blue series consistently underperforms compared to the others.
</details>
(a) Planner LLM size: 4B
<details>
<summary>x71.png Details</summary>
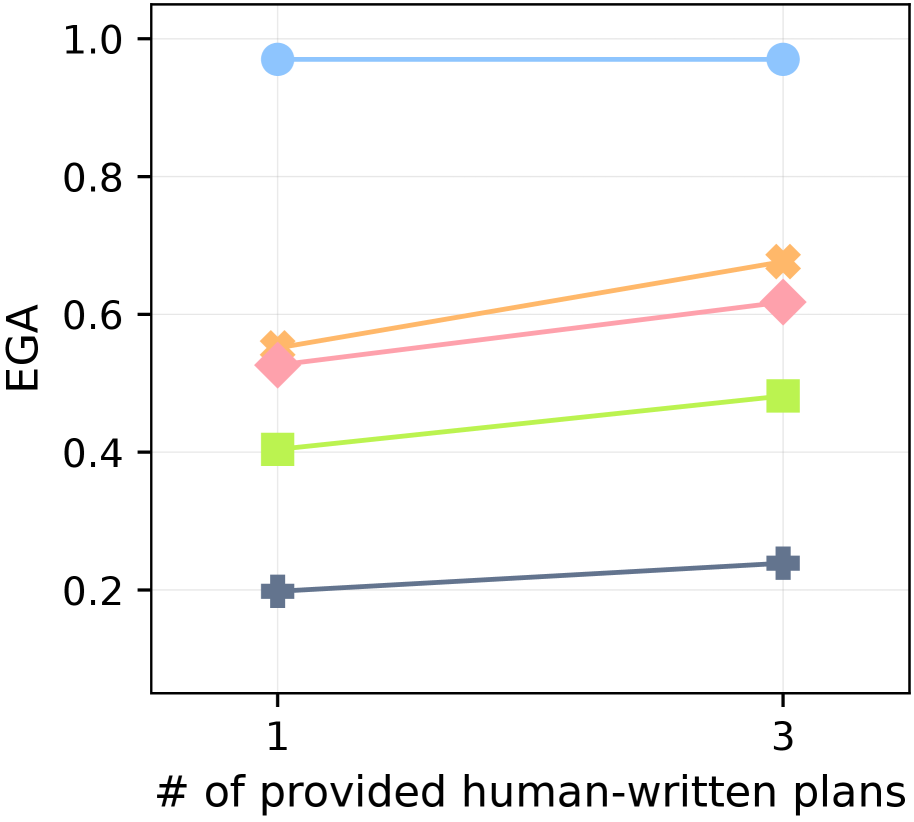
### Visual Description
## Line Chart: EGA vs. Number of Provided Human-Written Plans
### Overview
The image is a line chart comparing the EGA (Expected Goal Achievement) score against the number of provided human-written plans (1 or 3). There are four distinct data series represented by different colored lines, each showing the trend of EGA as the number of plans increases from 1 to 3.
### Components/Axes
* **X-axis:** "# of provided human-written plans" with two data points: 1 and 3.
* **Y-axis:** "EGA" (Expected Goal Achievement), ranging from 0.2 to 1.0 in increments of 0.2.
* **Data Series:** Four distinct lines, each with a unique color and marker shape:
* Light Blue: Circle marker
* Light Green: Square marker
* Light Pink: Diamond marker
* Dark Gray: Plus marker
* Light Orange: X marker
### Detailed Analysis
* **Light Blue (Circle):** This line remains almost constant at EGA ~0.98, regardless of the number of provided plans.
* (1 plan, EGA ~0.98)
* (3 plans, EGA ~0.98)
* **Light Green (Square):** This line shows an upward trend, starting at EGA ~0.4 and increasing to EGA ~0.48.
* (1 plan, EGA ~0.4)
* (3 plans, EGA ~0.48)
* **Light Pink (Diamond):** This line also shows an upward trend, starting at EGA ~0.52 and increasing to EGA ~0.62.
* (1 plan, EGA ~0.52)
* (3 plans, EGA ~0.62)
* **Dark Gray (Plus):** This line shows a slight upward trend, starting at EGA ~0.2 and increasing to EGA ~0.24.
* (1 plan, EGA ~0.2)
* (3 plans, EGA ~0.24)
* **Light Orange (X):** This line shows an upward trend, starting at EGA ~0.56 and increasing to EGA ~0.68.
* (1 plan, EGA ~0.56)
* (3 plans, EGA ~0.68)
### Key Observations
* The light blue data series (circle marker) consistently achieves a high EGA score, irrespective of the number of provided plans.
* All other data series (light green, light pink, dark gray, light orange) show an increase in EGA score when the number of provided plans increases from 1 to 3.
* The dark gray data series (plus marker) consistently has the lowest EGA scores.
### Interpretation
The chart suggests that providing more human-written plans (increasing from 1 to 3) generally improves the Expected Goal Achievement (EGA) score for most of the data series represented. However, one data series (light blue) maintains a high EGA score regardless of the number of plans provided, indicating that its performance is not significantly affected by this variable. The dark gray data series consistently underperforms compared to the others, suggesting it may represent a less effective strategy or system. The other series show moderate improvements with more plans, indicating that the additional information is beneficial but not transformative.
</details>
(b) Planner LLM size: 7B
Figure 26: Effect of planner LLM size and initial dependency graph quality in dependency and action learning. The plots show EGA after 3,000 environment steps of dependency and action learning in MC-TextWorld, obtained by varying the planner LLM size and the amount of correct knowledge in the initial dependency graph (controlled by the number of provided human-written plans). In (a), the planner is Phi-4-mini (4B) (Microsoft et al., 2025); in (b), the planner is Qwen2.5-VL-7B (7B) (Bai et al., 2025).
We further evaluate robustness of XENON and the baselines to limited prior knowledge by measuring dependency and action learning in MC-TextWorld while (i) varying the planner LLM size and (ii) degrading the quality of the initial dependency graph. For the planner LLM, we compare a 7B model (Qwen2.5-VL-7B (Bai et al., 2025)) against a 4B model (Phi-4-mini (Microsoft et al., 2025)); for the initial graph quality, we vary the number of provided human-written plans used to initialize the graph from three (“craft iron_sword”, “mine diamond”, “craft golden_sword”) to one (“craft iron_sword”).
As shown in Figure ˜ 26, XENON remains robust across all these settings: its EGA stays near-perfect even with the smaller 4B planner and the weakest initial graph, indicating that leveraging experiences can quickly compensate for weak priors. In contrast, baselines that rely on LLM self-correction (SC) or that strongly depend on the LLM or initial graph (ADAM, DECKARD) suffer substantial drops in EGA as the planner LLM becomes smaller and the initial graph contains less correct prior knowledge. This suggests that, in our setting, algorithmic knowledge correction is more critical than scaling up the planner LLM or richer initial human-provided knowledge.
K.12 Full results on the long-horizon tasks benchmark
In this section, we report XENON’s performance on each goal within the long-horizon tasks benchmark, detailing metrics such as the goal item, number of sub-goals, success rate (SR), and evaluation episodes.
Table ˜ 18 and 19 present XENON’s results when utilizing the dependency graph learned through 400 episodes of exploration. Conversely, Table ˜ 20 and 21 display XENON ∗ ’s performance, which leverages an oracle dependency graph.
Table 18: The results of XENON (with dependency graph learned via exploration across 400 episodes) on the Wood group, Stone group, and Iron group. SR denotes success rate.
| Group | Goal | Sub-Goal Num. | SR | Eval Episodes |
| --- | --- | --- | --- | --- |
| Wood | bowl | 4 | 92.68 | 41 |
| chest | 4 | 95.24 | 42 | |
| crafting_table | 3 | 95.83 | 48 | |
| ladder | 5 | 0.00 | 31 | |
| stick | 3 | 95.45 | 44 | |
| wooden_axe | 5 | 90.91 | 44 | |
| wooden_hoe | 5 | 95.35 | 43 | |
| wooden_pickaxe | 5 | 93.02 | 43 | |
| wooden_shovel | 5 | 93.75 | 48 | |
| wooden_sword | 5 | 95.35 | 43 | |
| Stone | charcoal | 8 | 87.50 | 40 |
| furnace | 7 | 88.10 | 42 | |
| smoker | 8 | 0.00 | 47 | |
| stone_axe | 7 | 97.78 | 45 | |
| stone_hoe | 7 | 90.70 | 43 | |
| stone_pickaxe | 7 | 95.45 | 44 | |
| stone_shovel | 7 | 89.58 | 48 | |
| stone_sword | 7 | 89.80 | 49 | |
| torch | 7 | 93.02 | 43 | |
| Iron | blast_furnace | 13 | 0.00 | 42 |
| bucket | 11 | 0.00 | 47 | |
| chain | 12 | 0.00 | 42 | |
| hopper | 12 | 0.00 | 47 | |
| iron_axe | 11 | 75.56 | 45 | |
| iron_bars | 11 | 80.43 | 46 | |
| iron_hoe | 11 | 89.13 | 46 | |
| iron_nugget | 11 | 79.55 | 44 | |
| iron_pickaxe | 11 | 77.08 | 48 | |
| iron_shovel | 11 | 75.56 | 45 | |
| iron_sword | 11 | 84.78 | 46 | |
| rail | 11 | 0.00 | 44 | |
| shears | 11 | 0.00 | 43 | |
| smithing_table | 11 | 93.75 | 48 | |
| stonecutter | 12 | 0.00 | 43 | |
| tripwire_hook | 11 | 78.43 | 51 | |
Table 19: The results of XENON (with dependency graph learned via exploration across 400 episodes) on the Gold group, Diamond group, Redstone group, and Armor group. SR denotes success rate.
| Group | Goal Item | Sub Goal Num. | SR | Eval Episodes |
| --- | --- | --- | --- | --- |
| Gold | gold_ingot | 13 | 76.92 | 52 |
| golden_axe | 14 | 72.00 | 50 | |
| golden_hoe | 14 | 66.67 | 48 | |
| golden_pickaxe | 14 | 76.00 | 50 | |
| golden_shovel | 14 | 71.74 | 46 | |
| golden_sword | 14 | 78.26 | 46 | |
| Diamond | diamond | 12 | 87.76 | 49 |
| diamond_axe | 13 | 72.55 | 51 | |
| diamond_hoe | 13 | 63.79 | 58 | |
| diamond_pickaxe | 13 | 60.71 | 56 | |
| diamond_shovel | 13 | 84.31 | 51 | |
| diamond_sword | 13 | 76.79 | 56 | |
| jukebox | 13 | 0.00 | 48 | |
| Redstone | activator_rail | 14 | 0.00 | 3 |
| compass | 13 | 0.00 | 3 | |
| dropper | 13 | 0.00 | 3 | |
| note_block | 13 | 0.00 | 4 | |
| piston | 13 | 0.00 | 12 | |
| redstone_torch | 13 | 0.00 | 19 | |
| Armor | diamond_boots | 13 | 64.29 | 42 |
| diamond_chestplate | 13 | 0.00 | 44 | |
| diamond_helmet | 13 | 67.50 | 40 | |
| diamond_leggings | 13 | 0.00 | 37 | |
| golden_boots | 14 | 69.23 | 39 | |
| golden_chestplate | 14 | 0.00 | 39 | |
| golden_helmet | 14 | 60.53 | 38 | |
| golden_leggings | 14 | 0.00 | 38 | |
| iron_boots | 11 | 94.44 | 54 | |
| iron_chestplate | 11 | 0.00 | 42 | |
| iron_helmet | 11 | 4.26 | 47 | |
| iron_leggings | 11 | 0.00 | 41 | |
| shield | 11 | 0.00 | 46 | |
Table 20: The results of XENON ∗ (with oracle dependency graph) on the Wood group, Stone group, and Iron group. SR denotes success rate.
| Group | Goal Item | Sub-Goal Num. | SR | Eval Episodes |
| --- | --- | --- | --- | --- |
| Wood | bowl | 4 | 94.55 | 55 |
| chest | 4 | 94.74 | 57 | |
| crafting_table | 3 | 94.83 | 58 | |
| ladder | 5 | 94.74 | 57 | |
| stick | 3 | 95.08 | 61 | |
| wooden_axe | 5 | 94.64 | 56 | |
| wooden_hoe | 5 | 94.83 | 58 | |
| wooden_pickaxe | 5 | 98.33 | 60 | |
| wooden_shovel | 5 | 96.49 | 57 | |
| wooden_sword | 5 | 94.83 | 58 | |
| Stone | charcoal | 8 | 92.68 | 41 |
| furnace | 7 | 90.00 | 40 | |
| smoker | 8 | 87.50 | 40 | |
| stone_axe | 7 | 95.12 | 41 | |
| stone_hoe | 7 | 94.87 | 39 | |
| stone_pickaxe | 7 | 94.87 | 39 | |
| stone_shovel | 7 | 94.87 | 39 | |
| stone_sword | 7 | 92.11 | 38 | |
| torch | 7 | 92.50 | 40 | |
| Iron | blast_furnace | 13 | 82.22 | 45 |
| bucket | 11 | 89.47 | 38 | |
| chain | 12 | 83.33 | 36 | |
| hopper | 12 | 77.78 | 36 | |
| iron_axe | 11 | 82.50 | 40 | |
| iron_bars | 11 | 85.29 | 34 | |
| iron_hoe | 11 | 75.68 | 37 | |
| iron_nugget | 11 | 84.78 | 46 | |
| iron_pickaxe | 11 | 83.33 | 42 | |
| iron_shovel | 11 | 78.38 | 37 | |
| iron_sword | 11 | 85.42 | 48 | |
| rail | 11 | 80.56 | 36 | |
| shears | 11 | 82.05 | 39 | |
| smithing_table | 11 | 83.78 | 37 | |
| stonecutter | 12 | 86.84 | 38 | |
| tripwire_hook | 11 | 91.18 | 34 | |
Table 21: The results of XENON ∗ (with oracle dependency graph) on the Gold group, Diamond group, Redstone group, and Armor group. SR denotes success rate.
| Group | Goal Item | Sub Goal Num. | SR | Eval Episodes |
| --- | --- | --- | --- | --- |
| Gold | gold_ingot | 13 | 78.38 | 37 |
| golden_axe | 14 | 65.12 | 43 | |
| golden_hoe | 14 | 70.27 | 37 | |
| golden_pickaxe | 14 | 75.00 | 36 | |
| golden_shovel | 14 | 78.38 | 37 | |
| Diamond | diamond | 12 | 71.79 | 39 |
| diamond_axe | 13 | 70.00 | 40 | |
| diamond_hoe | 13 | 85.29 | 34 | |
| diamond_pickaxe | 13 | 72.09 | 43 | |
| diamond_shovel | 13 | 76.19 | 42 | |
| diamond_sword | 13 | 80.56 | 36 | |
| jukebox | 13 | 69.77 | 43 | |
| Redstone | activator_rail | 14 | 67.39 | 46 |
| compass | 13 | 70.00 | 40 | |
| dropper | 13 | 75.00 | 40 | |
| note_block | 13 | 89.19 | 37 | |
| piston | 13 | 65.79 | 38 | |
| redstone_torch | 13 | 84.85 | 33 | |
| Armor | diamond_boots | 13 | 60.78 | 51 |
| diamond_chestplate | 13 | 20.00 | 50 | |
| diamond_helmet | 13 | 71.79 | 39 | |
| diamond_leggings | 13 | 33.33 | 39 | |
| golden_boots | 14 | 75.00 | 40 | |
| golden_chestplate | 14 | 0.00 | 36 | |
| golden_helmet | 14 | 54.05 | 37 | |
| golden_leggings | 14 | 0.00 | 38 | |
| iron_boots | 11 | 93.62 | 47 | |
| iron_chestplate | 11 | 97.50 | 40 | |
| iron_helmet | 11 | 86.36 | 44 | |
| iron_leggings | 11 | 97.50 | 40 | |
| shield | 11 | 97.62 | 42 | |
K.13 Experiments compute resources
All experiments were conducted on an internal computing cluster equipped with RTX3090, A5000, and A6000 GPUs. We report the total aggregated compute time from running multiple parallel experiments. For the dependency learning, exploration across 400 episodes in the MineRL environment, the total compute time was 24 days. The evaluation on the long-horizon tasks benchmark in the MineRL environment required a total of 34 days of compute. Experiments within the MC-TextWorld environment for dependency learning utilized a total of 3 days of compute. We note that these values represent aggregated compute time, and the actual wall-clock time for individual experiments was significantly shorter due to parallelization.
Appendix L The Use of Large Language Models (LLMs)
In preparing this manuscript, we used an LLM as a writing assistant to improve the text. Its role included refining grammar and phrasing, suggesting clearer sentence structures, and maintaining a consistent academic tone. All technical contributions, experimental designs, and final claims were developed by the human authors, who thoroughly reviewed and take full responsibility for the paper’s content.