# FairPFN: A Tabular Foundation Model for Causal Fairness
Abstract
Machine learning (ML) systems are utilized in critical sectors, such as healthcare, law enforcement, and finance. However, these systems are often trained on historical data that contains demographic biases, leading to ML decisions that perpetuate or exacerbate existing social inequalities. Causal fairness provides a transparent, human-in-the-loop framework to mitigate algorithmic discrimination, aligning closely with legal doctrines of direct and indirect discrimination. However, current causal fairness frameworks hold a key limitation in that they assume prior knowledge of the correct causal model, restricting their applicability in complex fairness scenarios where causal models are unknown or difficult to identify. To bridge this gap, we propose FairPFN, a tabular foundation model pre-trained on synthetic causal fairness data to identify and mitigate the causal effects of protected attributes in its predictions. FairPFN’s key contribution is that it requires no knowledge of the causal model and still demonstrates strong performance in identifying and removing protected causal effects across a diverse set of hand-crafted and real-world scenarios relative to robust baseline methods. FairPFN paves the way for promising future research, making causal fairness more accessible to a wider variety of complex fairness problems.
1 Introduction
Algorithmic discrimination is among the most pressing AI-related risks of our time, manifesting when machine learning (ML) systems produce outcomes that disproportionately disadvantage historically marginalized groups Angwin et al. (2016). Despite significant advancements by the fairness-aware ML community, critiques highlight the contextual limitations and lack of transferability of current statistical fairness measures to practical legislative frameworks Weerts et al. (2023). In response, the field of causal fairness has emerged, providing a transparent and human-in-the-loop causal framework for assessing and mitigating algorithmic bias with a strong analogy to existing anti-discrimination legal doctrines Plecko & Bareinboim (2024).
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: FairPFN Pre-training Pipeline
### Overview
This diagram illustrates the pre-training pipeline for FairPFN, a model designed for real-world inference with a focus on fairness. The pipeline consists of three main stages: data generation, transformer input, fair prediction, and then a visual representation of the process using a Structural Causal Model (SCM), an Observational Dataset, the FairPFN model itself, and the calculation of a pre-training loss.
### Components/Axes
The diagram is segmented into four main sections:
1. **Data Generation (a):** Describes the process of creating the dataset.
2. **Transformer Input (b):** Explains how the observational dataset is used as input to a transformer model.
3. **Fair Prediction (c):** Details the prediction process and loss calculation.
4. **Real-world Inference:** A visual representation of the pipeline with the SCM, Observational Dataset, FairPFN, and Pre-training Loss.
The key elements within the "Real-world Inference" section are:
* **Structural Causal Model (SCM):** Nodes labeled A₀, U₂, X₁, X₂, X₃, Yb, and Yf, with directed edges representing causal relationships.
* **Observational Dataset:** A table with columns A, X₁, X₂, X₃, and Yb.
* **FairPFN:** A complex network of interconnected nodes.
* **Pre-training Loss:** Represented by the symbols Ŷf and Yf.
### Detailed Analysis or Content Details
**a) Data Generation:**
* A dataset is generated comprising a protected attribute *A*, potentially biased observables *Xb*, and biased outcome *Yb*.
* A fair outcome *Yf* is sampled by removing the outgoing edges of *A*.
**b) Transformer Input:**
* The observational dataset *D* is partitioned into training and validation splits.
* Given in-context examples *Dtrain*, the transformer makes predictions on the inference set *Dval* = (*Aval*, *Xval*).
**c) Fair Prediction:**
* The transformer makes predictions Ŷf on the validation set.
* The pre-training loss is calculated with respect to the fair outcomes in the validation set.
* The transformer learns the mapping *Xb* → *Yf*.
**Real-world Inference - SCM:**
* The SCM shows causal relationships:
* U₂ influences X₁, X₂, and X₃.
* A₀ influences X₁.
* X₁, X₂, and X₃ influence Yb.
* Yb influences Yf.
**Real-world Inference - Observational Dataset:**
* The dataset table has 5 columns: A, X₁, X₂, X₃, and Yb.
* The table is filled with a heatmap-like color gradient. The colors range from dark blue to dark red, indicating varying values. It's difficult to extract precise numerical values from the color gradient without a legend, but the color intensity suggests a range of values.
* The table appears to have approximately 10-15 rows.
**Real-world Inference - FairPFN:**
* The FairPFN is a complex network of interconnected nodes. The nodes are colored in shades of green and purple.
* The network has multiple layers and connections.
**Real-world Inference - Pre-training Loss:**
* Ŷf (predicted fair outcome) is connected to Yf (fair outcome).
* The arrow indicates the calculation of the pre-training loss.
**Mathematical Formula:**
* p(*Yf* | *Xb*, *Db*) ∝ ∫ p(*Yf* | *Xb*, φ)p(*D♭* | φ) dφ
### Key Observations
* The diagram emphasizes the importance of fairness by explicitly generating a "fair outcome" (*Yf*) and using it for loss calculation.
* The SCM visually represents the causal relationships between variables, highlighting the potential for bias introduced by the protected attribute *A*.
* The heatmap-like representation of the observational dataset suggests that the data is high-dimensional and potentially complex.
* The FairPFN model is a complex neural network, likely designed to capture intricate relationships in the data.
### Interpretation
The diagram illustrates a pipeline for training a fair machine learning model. The core idea is to mitigate bias by explicitly modeling the causal relationships between variables and using a "fair outcome" as the target for training. The SCM provides a visual representation of these relationships, while the observational dataset provides the data for training. The FairPFN model learns to predict the fair outcome, and the pre-training loss ensures that the model is aligned with the desired fairness criteria. The mathematical formula suggests a probabilistic approach to fairness, where the model aims to estimate the probability of the fair outcome given the observed data. The use of a transformer model suggests that the pipeline is designed to handle sequential or contextual data. The diagram suggests a sophisticated approach to fairness that goes beyond simply removing the protected attribute from the training data. It attempts to address the underlying causal mechanisms that lead to bias.
</details>
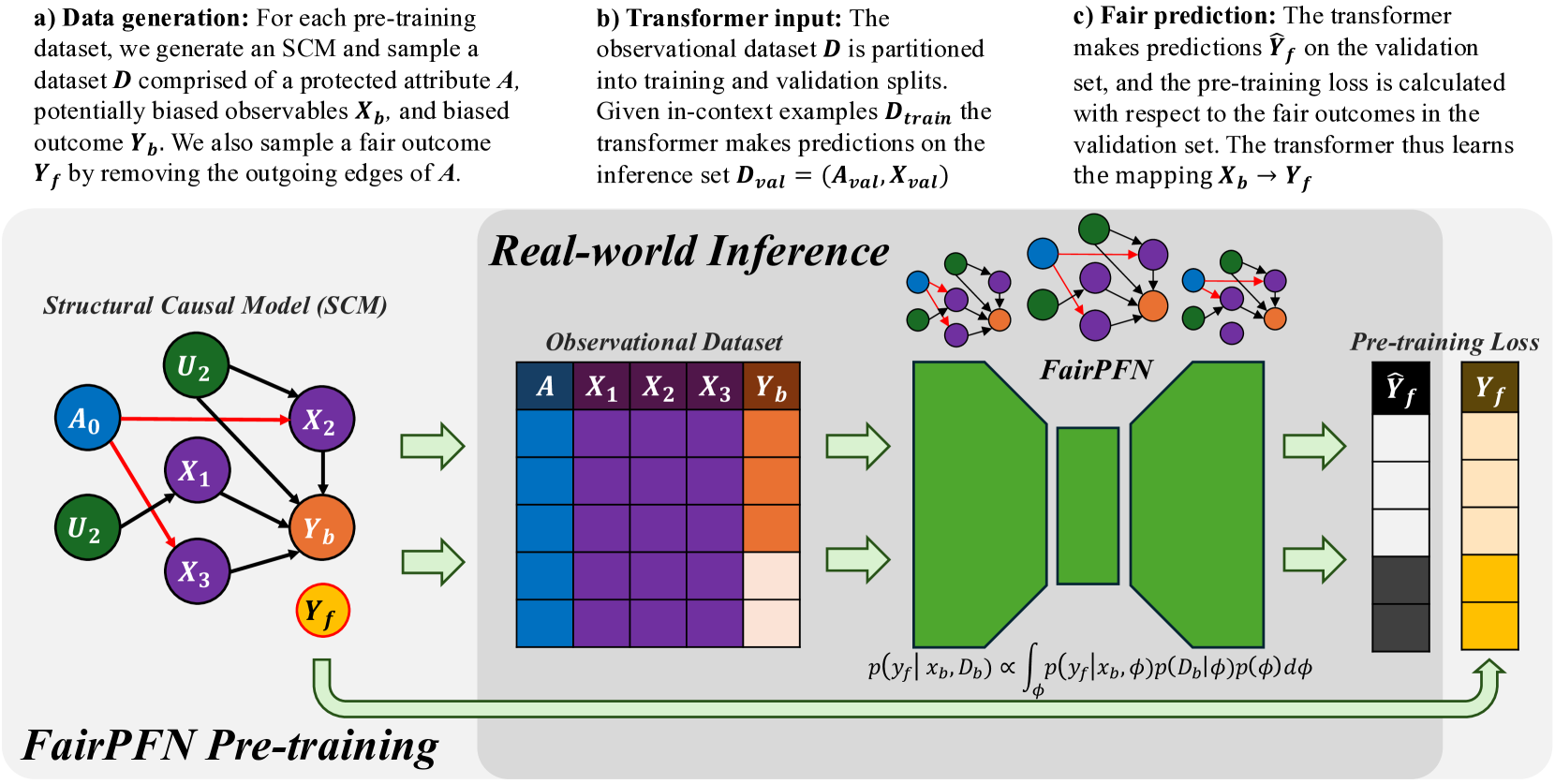
Figure 1: FairPFN Overview: FairPFN is a foundation model for causal fairness, pre-trained on synthetic datasets generated from sparse MLPs that represent SCMs with exogenous protected attributes (a). A biased dataset is created for each MLP/SCM and supplied as context to the transformer (b), with loss computed based on fair outcomes obtained by excluding the causal influence of the protected attribute (c). In practice, (d) FairPFN takes in only an observational dataset to predict fair targets by integrating over the simplest causal explanations for the biased data.
A recent review comparing outcome-based and causal fairness approaches (Castelnovo et al., 2022) argues that the non-identifiability of causal models from observational data Pearl (2009) limits the usage of current causal fairness frameworks in practical applications. In practice, users must provide full or partial information about the underlying causal model, a challenging task given the complexity of systemic inequalities. Furthermore, an incorrectly presumed causal graph, such as one falsely assuming a variable is independent of a protected attribute, can invalidate causal fairness metrics Ma et al. (2023); Binkytė-Sadauskienė et al. (2022), resulting in fairwashing and fostering a false sense of security and trust.
This paper takes a bold new perspective on achieving causal fairness. Our key contribution is FairPFN, a tabular foundation model for causal fairness, pre-trained on synthetic causal fairness data to learn to identify and remove the causal effects of protected attributes in tabular classification settings. When used on a new dataset, FairPFN does not rely on a user-specified causal model or graph, instead solely relying on the causally-generated data it has seen during pre-training. We demonstrate through extensive experiments that FairPFN effectively and consistently mitigates the causal impact of protected attributes across various hand-crafted and real-world scenarios, yielding causally fair predictions without user-specified causal information. We summarize our various contributions:
1. PFNs for Causal Fairness We propose a paradigm shift for algorithmic fairness, in which a transformer is pre-trained on synthetic causal fairness data.
1. Causal Fairness Prior: We introduce a synthetic causal data prior which offers a comprehensive representation for fairness datasets, modeling protected attributes as binary exogenous causes.
1. Foundation Model: We present FairPFN, a foundation model for causal fairness which, given only observational data, identifies and removes the causal effect of binary, exogenous protected attributes in predictions, and demonstrates strong performance in terms of both causal fairness and predictive accuracy on a combination of hand-crafted and real-world causal scenarios. We provide a prediction interface to evaluate and assess our pre-trained model, as well as code to generate and visualize our pre-training data at https://github.com/jr2021/FairPFN.
2 Related Work
In recent years, causality has gained prominence in the field of algorithmic fairness, providing fairness researchers with a structural framework to reason about algorithmic discrimination. Unlike traditional fairness research Kamishima et al. (2012); Agarwal et al. (2018); Hardt et al. (2016), which focuses primarily on optimizing statistical fairness measures, causal fairness frameworks concentrate on the structure of bias. This approach involves modeling causal relationships among protected attributes, observed variables, and outcomes, assessing the causal effects of protected attributes, and mitigating biases using causal methods, such as optimal transport Plecko & Bareinboim (2024) or latent variable estimation Kusner et al. (2017); Ma et al. (2023); Bhaila et al. (2024).
Counterfactual fairness, introduced by Kusner et al. (2017), posits that predictive outcomes should remain invariant between the actual world and a counterfactual scenario in which a protected attribute assumes an alternative value. This notion has spurred interest within the fairness research community, resulting in developments like path-specific extensions Chiappa (2019) and the application of Variational Autoencoders (VAEs) to create counterfactually fair latent representations Ma et al. (2023).
The initial counterfactual fairness framework necessitates comprehensive knowledge of the causal model. In contrast, the Causal Fairness Analysis (CFA) framework Plecko & Bareinboim (2024) relaxes this requirement by organizing variables within a Standard Fairness Model (SFM) for bias assessment and mitigation. Moreover, the CFA framework presents the Fairness Cookbook, which defines causal fairness metrics—Indirect-Effect, Direct-Effect, and Spurious-Effect—that directly align with US legal doctrines of disparate impact and treatment. Furthermore, the CFA framework challenges Kusner et al. (2017) ’s modeling of protected attributes as exogenous causes, permitting correlations between protected attributes and confounding variables that contribute to the legally admissible Spurious-Effect.
3 Background
This section establishes the scientific foundation of FairPFN, including terminology relevant to algorithmic fairness, causal ML, counterfactual fairness, and prior-data fitted networks (PFNs).
Algorithmic Fairness
Algorithmic discrimination occurs when historical biases against demographic groups (e.g., ethnicity, sex) are reflected in the training data of ML algorithms, leading to the perpetuation and amplification of these biases in predictions Barocas et al. (2023). Fairness research focuses on measuring algorithmic bias and developing fairness-aware ML models that produce non-discriminatory predictions. Practitioners have established over 20 fairness metrics, which generally break down into group-level and individual-level metrics Castelnovo et al. (2022). These metrics can be used to optimize predictive models, balancing the commonly observed trade-off between fairness and predictive accuracy Weerts et al. (2024).
Causal Machine Learning Causal ML is a developing field that leverages modern ML methods for causal reasoning Pearl (2009), facilitating advancements in causal discovery, causal inference, and causal reasoning Peters et al. (2014). Causal mechanisms are often represented as Structural Causal Models (SCMs), defined as $\mathcal{M}=(U,O,F)$ , where $U$ are unobservables, $O$ are observables, and $F$ is a set of structural equations. These equations are expressed as $f_{j}:X_{j}=f_{j}(PA_{j},N_{j})$ , indicating that an outcome variable $F$ depends on its parent variables $PA$ and independent noise $N_{j}$ . Non-linearities in the set of structural equations $F$ influence data complexity and identifiability of causal quantities from observational data Schölkopf et al. (2012). In an SCM, interventions can be made by setting $X← x_{1}$ and propagating this value through the model $\mathcal{M}$ , posing the question of "what will happen if I do something?". Counterfactuals expand upon the idea of interventions and are relevant when a value of $X$ is already observed, instead posing the question of "what would have happened if something had been different?" In addition to posing a slightly different question, counterfactuals require that exogenous noise terms are held constant, and thus classically require full knowledge of the causal model. In the context of algorithmic fairness, we are limited to level of counterfactuals as protected attributes are typically given and already observed.
In causal reasoning frameworks, one major application of counterfactuals is the estimation of causal effects such as the individual and average treatment effects (ITE and ATE) which quantify the difference and expected difference between outcomes under different values of $X$ .
$$
ITE:\tau=Y_{X\leftarrow x}-Y_{X\leftarrow x^{\prime}} \tag{1}
$$
$$
ATE:E[\tau]=E[Y_{X\leftarrow x}]-E[Y_{X\leftarrow x^{\prime}}]. \tag{2}
$$
Counterfactual Fairness
is a foundational notion of causal fairness introduced by Kusner et al. (2017), requiring that an individual’s predictive outcome should match that in a counterfactual scenario where they belong to a different demographic group. This notion is formalized in the theorem below.
**Theorem 1 (Unit-level/probabilistic)**
*Given an SCM $\mathcal{M}=(U,O,F)$ where $O=A\cup X$ , a predictor $\hat{Y}$ is counterfactually fair on the unit-level if $∀\hat{y}∈\hat{Y},∀ x,a,a^{\prime}∈ A$
$$
P(\hat{y}_{A\rightarrow a}(u)|X,A=x,a)=P(\hat{y}_{A\rightarrow a^{\prime}}(u)|%
X,A,=x,a)
$$*
Kusner et al. (2017) notably choose to model protected attributes as exogenous, which means that they may not be confounded by unobserved variables with respect to outcomes. We note that the definition of counterfactual fairness in Theorem 1 is the unit-level probabilistic one as clarified by Plecko & Bareinboim (2024), because counterfactual outcomes are generated deterministically with fixed unobservables $U=u$ . Theorem 1 can be applied on the dataset level to form the population-level version also provided by Plecko & Bareinboim (2024) which measures the alignment of natural and counterfactual predictive distributions.
**Theorem 2 (Population-level)**
*Given an SCM $\mathcal{M}=(U,O,F)$ where $O=A\cup X$ , a predictor $\hat{Y}$ is counterfactually fair on the population-level if $∀\hat{y}∈\hat{Y},∀ x,a,a^{\prime}∈ A$
$$
P(\hat{y}_{A\rightarrow a}|X,A=x,a)=P(\hat{y}_{A\rightarrow a^{\prime}}|X,A=x,a)
$$*
Theorem 1 can also be transformed into a counterfactual fairness metric by quantifying the difference between natural and counterfactual predictive distributions. In this study we quantify counterfactual fairness as the distribution of the counterfactual absolute error (AE) between predictions in each distribution.
**Definition 1 (Absolute Error (AE))**
*Given an SCM $\mathcal{M}=(U,O,F)$ where $O=A\cup X$ , the counterfactual absolute error of a predictor $\hat{Y}$ is the distribution
$$
AE=|P(\hat{y}_{A\rightarrow a}(u)|X,A=x,a)-P(\hat{y}_{A\rightarrow a^{\prime}}%
(u)|X,A=x,a)|
$$*
We note that because the outcomes are condition on the same noise terms $u$ our definition of AE builds off of Theorem 1. Intuitively, when the AE is skewed towards zero, then most individuals receive the same prediction in both the natural and counterfactual scenarios.
Kusner et al. (2017) present various implementations of Counterfactually Fair Prediction (CFP). The three levels of CFP can be achieved by fitting a predictive model $\hat{Y}$ to observable non-descendants if any exist (Level-One), inferred values of an exogenous unobserved variable $K$ (Level-Two), or additive noise terms (Level-Three). Kusner et al. (2017) acknowledge that in practice, Level-One rarely occurs. Level-Two requires that the causal model be invertible, which allows the unobservable $K$ to be inferred by abduction. Level-Three models the scenario as an Additive Noise Model, and thus is the strongest in terms of representational capacity, allowing more degrees of freedom than in Level-Two to represent fair terms. The three levels of CFP are depicted in Appendix Figure 22.
Causal Fairness The Causal Fairness Analysis (CFA) framework Plecko & Bareinboim (2024) introduces the Standard Fairness Model (SFM), which classifies variables as protected attributes $A$ , mediators $X_{med}$ , confounders $X_{conf}$ , and outcomes $Y$ . This framework includes a Fairness Cookbook of causal fairness metrics with a strong analogy to the legal notions of direct and indirect discrimination and business necessity as illustrated in Appendix Figure 23. Plecko & Bareinboim (2024) refute the modeling choice of Kusner et al. (2017) by their inclusion of confounders $X_{conf}$ in the SFM, arguing that these variables contribute to the legally admissible Spurious-Effect (SE).
For simplicity of our experimental results, we follow the modeling of Kusner et al. (2017), and focus on the elimination of the Total-Effect (TE) of protected attributes as defined by Plecko & Bareinboim (2024), while noting in Section 6 the importance of relaxing this assumption in future extensions.
Prior-data Fitted Networks Prior-data Fitted Networks (PFNs) Müller et al. (2022) and TabPFN Hollmann et al. (2023, 2025) represent a paradigm shift from traditional ML with a causal motivation, namely that simple causal models offer a quality explanation for real-world data. PFNs incorporate prior knowledge into transformer models by pre-training on datasets from a specific prior distribution Müller et al. (2022). TabPFN, a popular application of PFNs, applies these ideas to small tabular classification tasks by training a transformer on synthetic datasets derived from sparse Structural Causal Models (SCMs). As noted in Hollmann et al. (2023), a key advantage of TabPFN is its link to Bayesian Inference; where the transformer approximates the Posterior Predictive Distribution (PPD), thus achieving state-of-the-art performance by integrating over simple causal explanations for the data.
4 Methodology
In this section, we introduce FairPFN, a foundation model for legally or ethically sensitive tabular classification problems that draws inspiration from PFNs and principles of causal fairness. We introduce our pre-training scheme, synthetic data prior, and draw connections to Bayesian Inference to explain the inner workings of FairPFN.
4.1 FairPFN Pre-Training
First, we present our pre-training scheme, where FairPFN is fit to a prior of synthetic causal fairness data to identify and remove the causal effects of protected attributes in practice from observational data alone. We provide pseudocode for our pre-training algorithm in Algorithm 2, and outline the steps below.
Input:
Number of pre-training epochs $E$ and steps $S$
Transformer $\mathcal{M}$ with weights $\theta$
Hypothesis space of SCMs $\phi∈\Phi$
begin
for $epoch=1$ to $E$ do
for $step=1$ to $S$ do
Draw a random SCM $\phi$ from $\Phi$
Sample $D_{bias}=(A,X_{bias},Y_{bias})$ from $\phi$ where A $\{a_{0},a_{1}\}$ is an exogenous binary protected attribute
Sample $Y_{fair}$ from $\phi$ by performing dropout on outgoing edges of $A$ if any exist
Partition $D_{bias}$ and $D_{fair}$ into $train/val$
Pass $D_{bias}^{train}$ into $\mathcal{M}$ as context
Pass $D_{bias}^{val}$ into $\mathcal{M}$ to generate $Y_{pred}^{val}$
Calculate loss $L=CE(Y_{pred}^{val},Y_{fair}^{val})$
Update weights $\theta$ w.r.t $∇_{\theta}L$
end for
end for
Output: Transformer $\mathcal{M}:X_{bias}→ Y_{fair}$
Algorithm 1 FairPFN Pre-training
Data Generating Mechanisms FairPFN pre-training begins by creating synthetic datasets that capture the causal mechanisms of bias in real-world data. Following the approach of Hollmann et al. (2023), we use Multi-Layer Perceptrons (MLPs) to model Structural Causal Models (SCMs) via the structural equation $f=z(P· W^{T}x+\epsilon)$ , where $W$ denotes activation weights, $\epsilon$ represents Gaussian noise, $P$ is a dropout mask sampled from a log-scale to promote sparsity, and $z$ is a non-linearity. Figure 1 illustrates the connection among sampled MLPs, their corresponding SCMs, and the resulting synthetic pre-training data generated. We note that independent noise terms are not visualized in Figure 1.
Biased Data Generation An MLP is randomly sampled and sparsity is induced through dropout on select edges. The protected attribute is defined as a binary exogenous variable $A∈\{a_{0},a_{1}\}$ at the input layer. We uniformly select $m$ features $X$ from the second hidden layer onwards to capture rich representations of exogenous causes. The target variable $Y$ is chosen from the output layer and discretized into a binary variable using a random threshold. A forward pass through the MLP produces a dataset $D_{bias}=(A,X_{bias},Y_{bias})$ with $n$ samples containing the causal influence of the protected attribute.
Fair Data Generation
A second forward pass generates a fair dataset $D_{fair}$ by applying dropout to the outgoing edges of the protected attribute $A$ in the MLP, as shown by the red edges in Figure 1. This dropout, similar to that in TabPFN, masks the causal weight of $A$ to zero, effectively reducing its influence to Gaussian noise $\epsilon$ . This increases the influence of fair exogenous causes $U_{0}$ and $U_{1}$ and independent noise terms all over the MLP visualized in Figure 1. We note that $A$ is sampled from an arbitrary distribution $A∈\{a_{0},a_{1}\}$ , as opposed to $A∈\{0,1\}$ , since both functions $f=0· wx+\epsilon$ and $f=p· 0x+\epsilon$ yield equivalent outcomes. Only after generating the pre-training dataset is $A$ converted to a binary variable for processing by the transformer.
In-Context Learning After generating $D_{bias}$ and $D_{fair}$ , we partition them into training and validation sets: $D_{bias}^{train}$ , $D_{bias}^{val}$ , $D_{fair}^{train}$ , and $D_{fair}^{val}$ . We pass $D_{bias}^{train}$ as context to the transformer to provide information about feature-target relationships. To simulate inference, we input $X_{bias}^{val}$ into the transformer $\mathcal{M}$ , yielding predictions $Y_{pred}$ . We then compute the binary-cross-entropy (BCE) loss $L(Y_{pred},Y_{fair}^{val})$ against the fair outcomes $Y_{fair}^{val}$ , which do not contain effects of the protected attribute. Thus, the transformer $\mathcal{M}$ learns the mapping $\mathcal{M}:X_{bias}→ Y_{fair}$ .
1
Input:
- Number of exogenous causes $U$
- Number of endogenous variables $U× H$
- Number of features and samples $M× N$
begin
- Define MLP $\phi$ with depth $H$ and width $U$
- Initialize random weights $W:(U× U× H-1)$
- Sample sparsity masks $P$ with same dimensionality as weights
- Sample $H$ per-layer non-linearities $z_{i}\sim\{Identity,ReLU,Tanh\}$
- Initialize output matrix $X:(U× H)$
- Sample location $k$ of protected attribute in $X_{0}$
- Sample locations of features $X_{biased}$ in $X_{1:H-1}$ , and outcome $y_{bias}$ in $X_{H}$
- Sample protected attribute threshold $a_{t}$ and binary values $\{a_{0},a_{1}\}$
for $n=0$ to $N$ samples do
- Sample values of exogenous causes $X_{0}:(U× 1)$
- Sample values of additive noise terms $\epsilon:(U× H)$
for $i=0$ to $H-1$ layers do
- Pass intermediate representation through hidden layer $X_{i+1}=z_{i}(P_{i}· W_{i}^{T}X_{i}+\epsilon_{i})$
end for
- Select prot. attr. $A$ , features $X_{bias}$ and outcome $y_{bias}$ from $X_{0}$ , $X_{1:H-1}$ , and $X_{H}$
- Binarize $A∈\{a_{0},a_{1}\}$ over threshold $a_{t}$
- Set input weights in row $k$ of $W_{0}$ to 0
for $j=0$ to $H-1$ layers do
- Pass intermediate representation through hidden layer $X_{j+1}=z_{i}(P_{i}· W_{j}^{T}X_{j}+\epsilon_{j})$
end for
2 - Select the fair outcome $y_{fair}$ from $X_{H}$
end for
- Binarize $y_{fair}∈\{0,1\}$ and $y_{bias}∈\{0,1\}$ over randomly sampled output threshold $y_{t}$
3 Output: $D_{bias}=(A,X_{bias},y_{bias})$ and $y_{fair}$
Algorithm 2 FairPFN Synthetic Data Generation
Prior-Fitting The transformer is trained for approximately 3 days on an RTX-2080 GPU on approximately 1.5 million different synthetic data-generating mechanisms, in which we vary the MLP architecture, the number of features $m$ , the sample size $n$ , and the non-linearities $z$ .
Real-World Inference During real-world inference, FairPFN requires no knowledge of causal mechanisms in the data, but instead only takes as input a biased observational dataset and implicitly infers potential causal explanations for the data (Figure 1 d) based on the causally generated data it has seen during pre-training. Crucially, FairPFN is provided information regarding which variable is the protected attribute, which is represented in a protected attribute encoder step in the transformer. A key advantage of FairPFN is its alignment with Bayesian Inference, as transformers pre-trained in the PFN framework have been shown to approximate the Posterior Predictive Distribution (PPD) Müller et al. (2022).
FairPFN thus approximates a modified PPD, predicting a causally fair target $y_{f}$ given biased features $X_{b}$ and a biased dataset $D_{b}$ by integrating over hypotheses for the SCM $\phi∈\Phi$ :
$$
p(y_{f}|x_{b},D_{b})\propto\int_{\Phi}p(y_{f}|x_{b},\phi)p(D_{b}|\phi)p(\phi)d\phi \tag{3}
$$
This approach has two advantages: it reduces the necessity of precise causal model inference, thereby lowering the risk of fairwashing from incorrect models Ma et al. (2023), and carries with it regularization-related performance improvements observed in Hollmann et al. (2023). We also emphasize that FairPFN is a foundation model and thus does not need to be trained for new fairness problems in practice. Instead, FairPFN performs predictions in a single forward pass of the data through the transformer.
5 Experiments
This section assesses FairPFN’s performance on synthetic and real-world benchmarks, highlighting its capability to remove the causal influence of protected attributes without user-specified knowledge of the causal model, while maintaining high predictive accuracy.
5.1 Baselines
We implement several baselines to compare FairPFN against a diverse set of traditional ML models, causal-fairness frameworks, and fairness-aware ML approaches. We summarize our baselines below, and provide a visualization of our baselines applied to the Fair Observable benchmark in Appendix Figure 25.
- Unfair: Fit the entire training set $(X,A,Y)$ .
- Unaware: Fit to the entire training set $(X,A,Y)$ . Inference returns the average of predictions on the original test set $(X,A)$ and the test set with alternative protected attribute values $(X,A→ a^{\prime})$ .
- Avg. Cnft: Fit to the entire training set $(X,A,Y)$ . Inference returns the average (avg.) of predictions on the original test set $(X,A)$ and the counterfactual (cntf) test set $(X_{A→ a^{\prime}},A→ a^{\prime})$ .
- Constant: Always predicts the majority class
- Random: Randomly predicts the target
- CFP: Combination of the three-levels of CFP as proposed in Kusner et al. (2017). Fit to non-descendant observables, unobservables, and independent noise terms $(X_{fair},U_{fair},\epsilon_{fair},Y)$ .
- EGR: Exponentiated Gradient Reduction (EGR) as proposed by Agarwal et al. (2018) is fit to non-protected attributes $(X,Y)$ with XGBoost Chen & Guestrin (2016) as a base model.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Diagram: Fairness Scenarios in Machine Learning
### Overview
The image presents a series of six diagrams illustrating different scenarios related to fairness in machine learning models. Each scenario depicts a causal diagram with nodes representing protected attributes, unfair observable features, fair observable features, outcomes, and error terms. The diagrams aim to visualize how different types of bias and unfairness can manifest in a model's decision-making process.
### Components/Axes
The diagrams share the following components:
* **Protected Attribute (Prot. Attr):** Represented by a teal-colored circle labeled "A".
* **Outcome:** Represented by a purple circle labeled "Y".
* **Unfair Observable:** Represented by an orange circle labeled "X<sub>b</sub>".
* **Fair Observable:** Represented by a yellow circle labeled "X<sub>f</sub>".
* **Error Terms:** Represented by small, light-blue circles labeled "ε<sub>x</sub>" and "ε<sub>y</sub>".
* **Arrows:** Indicate causal relationships between variables.
* **Legend:** Located at the bottom-right, defining the color-coding for each component.
* **Mathematical Equations:** Below each diagram, defining the relationships between variables.
* **Titles:** Above each diagram, indicating the fairness scenario (1) Biased, (2) Direct-Effect, (3) Indirect-Effect, (4) Fair Observable, (5) Fair Unobservable, (6) Fair Additive Noise.
### Content Details
Here's a breakdown of each scenario, including the equations:
**1) Biased:**
* A -> X<sub>b</sub> -> Y
* A -> X<sub>f</sub> -> Y
* Equation: A ~ U(0,1), ε<sub>x</sub>, ε<sub>y</sub> ~ N(μ,0), σ, X<sub>b</sub> = W<sub>A</sub><sup>2</sup> + ε<sub>x</sub>, X<sub>f</sub> = W<sub>A</sub><sup>2</sup> + ε<sub>x</sub>, Y = W<sub>x</sub>X<sub>b</sub> + W<sub>x</sub>X<sub>f</sub> + ε<sub>y</sub>, Y = 1(Y ≥ γ)
**2) Direct-Effect:**
* A -> X<sub>b</sub> -> Y
* A -> X<sub>f</sub>
* Equation: A ~ U(0,1), X<sub>b</sub> ~ N(μ<sub>A</sub>,0), X<sub>f</sub> ~ N(μ<sub>0</sub>,0), X<sub>f</sub> = N(μ<sub>0</sub>), Y = W<sub>x</sub>X<sub>b</sub> + W<sub>x</sub>X<sub>f</sub> + ε<sub>y</sub>, Y = 1(Y ≥ γ)
**3) Indirect-Effect:**
* A -> X<sub>f</sub> -> X<sub>b</sub> -> Y
* Equation: ε<sub>x</sub>, ε<sub>y</sub> ~ N(μ,0), A ~ U(0,1), X<sub>f</sub> ~ N(μ<sub>0</sub>), X<sub>b</sub> = W<sub>A</sub><sup>2</sup> + ε<sub>x</sub>, Y = W<sub>x</sub>X<sub>b</sub> + W<sub>x</sub>X<sub>f</sub> + ε<sub>y</sub>, Y = 1(Y ≥ γ)
**4) Fair Observable:**
* A -> X<sub>f</sub> -> Y
* Equation: ε<sub>x</sub>, ε<sub>y</sub> ~ N(μ,0), A ~ U(0,1), X<sub>f</sub> ~ N(μ<sub>0</sub>), X<sub>b</sub> = W<sub>A</sub><sup>2</sup> + ε<sub>x</sub>, Y = W<sub>x</sub>X<sub>b</sub> + W<sub>x</sub>X<sub>f</sub> + ε<sub>y</sub>, Y = 1(Y ≥ γ)
**5) Fair Unobservable:**
* A -> U -> X<sub>b</sub> -> Y
* Equation: ε<sub>x</sub>, ε<sub>y</sub> ~ N(μ,0), A ~ U(0,1), U ~ N(μ<sub>0</sub>), X<sub>b</sub> = W<sub>A</sub><sup>2</sup> + W<sub>U</sub><sup>1</sup> + ε<sub>x</sub>, Y = W<sub>x</sub>X<sub>b</sub> + W<sub>x</sub>X<sub>f</sub> + ε<sub>y</sub>, Y = 1(Y ≥ γ)
**6) Fair Additive Noise:**
* A -> X<sub>b</sub> -> Y
* Equation: ε<sub>x</sub>, ε<sub>y</sub> ~ N(μ,0), A ~ U(0,1), X<sub>b</sub> = W<sub>A</sub><sup>2</sup> + ε<sub>x</sub>, X<sub>f</sub> = W<sub>A</sub><sup>2</sup> + ε<sub>x</sub>, Y = W<sub>x</sub>X<sub>b</sub> + W<sub>x</sub>X<sub>f</sub> + ε<sub>y</sub>, Y = 1(Y ≥ γ)
### Key Observations
* The diagrams consistently use the same node representations and causal arrow style.
* The mathematical equations provide a formal definition of the relationships depicted in each diagram.
* The scenarios vary in how the protected attribute (A) influences the outcome (Y), either directly, indirectly, or through observable/unobservable features.
* The inclusion of error terms (ε<sub>x</sub>, ε<sub>y</sub>) acknowledges the inherent noise and uncertainty in real-world data.
* The use of U(0,1) indicates a uniform distribution, while N(μ,σ) indicates a normal distribution.
### Interpretation
These diagrams illustrate different ways in which bias can enter a machine learning model and affect its fairness. They highlight the importance of considering causal relationships when evaluating and mitigating bias.
* **Scenario 1 (Biased):** Demonstrates a simple case where the protected attribute directly influences both observable features and the outcome, leading to potential discrimination.
* **Scenario 2 (Direct-Effect):** Shows a direct causal link between the protected attribute and the outcome, bypassing observable features.
* **Scenario 3 (Indirect-Effect):** Illustrates how the protected attribute can indirectly influence the outcome through a fair observable feature.
* **Scenario 4 (Fair Observable):** Suggests a scenario where fairness is achieved by ensuring that the observable features are independent of the protected attribute.
* **Scenario 5 (Fair Unobservable):** Introduces an unobservable variable (U) that mediates the relationship between the protected attribute and the outcome.
* **Scenario 6 (Fair Additive Noise):** Represents a scenario where fairness is achieved by adding noise to the model's predictions.
The diagrams, combined with the mathematical equations, provide a rigorous framework for analyzing and addressing fairness concerns in machine learning. They emphasize the need to understand the underlying causal mechanisms that drive bias and to develop interventions that target those mechanisms effectively. The "Seen by FairPFN" label at the bottom right suggests these diagrams are related to a specific fairness-aware machine learning framework or algorithm.
</details>
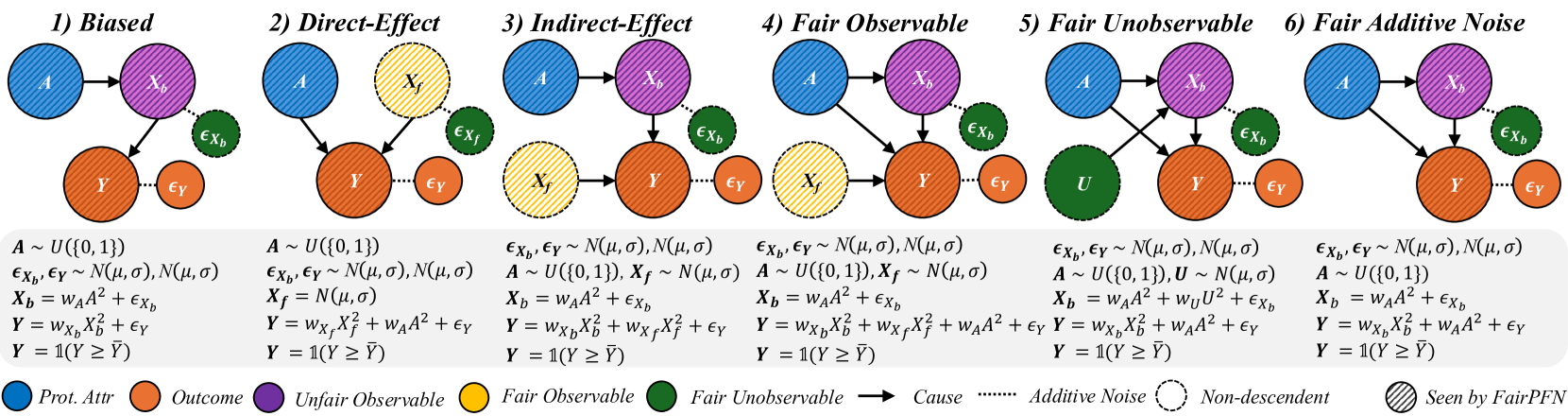
Figure 2: Causal Case Studies: Visualization and data generating processes of synthetic causal case studies, a handcrafted set of benchmarks designed to evaluate FairPFN’s ability to remove various sources of bias in causally generated data. For each group, 100 independent datasets are sampled, varying the number of samples, the standard deviation of noise terms $\sigma$ and the base causal effect $w_{A}$ of the protected attribute.
In the CFP, Unfair, Unaware, and Avg. Cntf. baselines, we employ FairPFN with a random noise term passed as a "protected attribute." We opt to use this UnfairPFN instead of TabPFN so as to not introduce any TabPFN-specific behavioral characteristics or artifacts. We show in Appendix Figure 17 that this reverts FairPFN to a normal tabular classifier with competitive peformance to TabPFN. We also note that our Unaware baseline is not the standard approach of dropping the protected attribute. We opt for our own implementation of Unaware as it shows improved causal effect removal to the standard approach (Appendix Figure 17).
5.2 Causal Case Studies
We first evaluate FairPFN using synthetic causal case studies to establish an experimental setting where the data-generating processes and all causal quantities are known, presenting a series of causal case studies with increasing difficulty to evaluate FairPFN’s capacity to remove various sources of bias in causally generated data. The data-generating processes and structural equations are illustrated in Figure 2, following the notation: $A$ for protected attributes, $X_{b}$ for biased-observables, $X_{f}$ for fair-observables, $U$ for fair-unobservables, $\epsilon_{X}$ for additive noise terms, and $Y$ for the outcome, discretized as $Y=\mathbb{1}(Y≥\bar{Y})$ . We term a variable $X$ "fair" iff $A∉ anc(X)$ . The structural equations in Figure 2 contain exponential non-linearities to ensure the direction of causality is identifiable Peters et al. (2014), distinguishing the Fair Unobservable and Fair Additive Noise scenarios, with the former including an unobservable yet identifiable causal effect $U$ .
For a robust evaluation, we generate 100 datasets per case study, varying causal weights of protected attributes $w_{A}$ , sample sizes $m∈(100,10000)$ (sampled on a log-scale), and the standard deviation $\sigma∈(0,1)$ (log-scale) of additive noise terms. We also create counterfactual versions of each dataset to assess FairPFN and its competitors across multiple causal and counterfactual fairness metrics, such as average treatment effect (ATE) and absolute error (AE) between predictions on observational and counterfactual datasets. We highlight that because our synthetic datasets are created from scratch, the fair causes, additive noise terms, counterfactual datasets, and ATE are ground truth. As a result, our baselines that have access to causal quantities are more precise in our causal case studies than in real-world scenarios where this causal information must be inferred.
<details>
<summary>extracted/6522797/figures/trade-off_by_group_synthetic.png Details</summary>
### Visual Description
## Charts: Performance Comparison of Fairness Interventions
### Overview
The image presents six individual scatter plots, each representing the performance of different fairness interventions under varying causal effect (ATE) levels. The y-axis represents "Error (1-AUC)", and the x-axis represents "Causal Effect (ATE)". Each plot focuses on a specific fairness setting: Biased, Direct-Effect, Indirect-Effect, Fair Observable, Fair Unobservable, and Fair Additive Noise. Multiple data series are plotted on each chart, representing different fairness algorithms. Error bars are present on some data points.
### Components/Axes
* **X-axis Label (all charts):** "Causal Effect (ATE)" - Scale ranges from 0.00 to 0.25, with markers at 0.05, 0.10, 0.15, 0.20.
* **Y-axis Label (all charts):** "Error (1-AUC)" - Scale ranges from 0.20 to 0.50, with markers at 0.20, 0.30, 0.40, 0.50.
* **Chart Titles:** 1. Biased, 2. Direct-Effect, 3. Indirect-Effect, 4. Fair Observable, 5. Fair Unobservable, 6. Fair Additive Noise.
* **Legend (bottom-center):**
* Blue Circle: Unfair
* Red Downward Triangle: Unaware
* Green Upward Triangle: Constant
* Blue Square: EGR
* Yellow Diamond: CFP
* Brown Downward Triangle: Random
* Star: FairPFN
* Light Green Diamond: Cnt. Avg.
### Detailed Analysis
Each chart will be analyzed individually, noting trends and approximate data points.
**1. Biased:**
* **Unfair (Blue Circle):** Starts at approximately (0.00, 0.35) and increases to approximately (0.25, 0.35). Relatively flat trend.
* **Unaware (Red Downward Triangle):** Starts at approximately (0.00, 0.45) and decreases to approximately (0.25, 0.30). Downward sloping trend.
* **Constant (Green Upward Triangle):** Starts at approximately (0.00, 0.40) and decreases to approximately (0.25, 0.35). Downward sloping trend.
* **FairPFN (Star):** Starts at approximately (0.00, 0.45) and decreases to approximately (0.25, 0.40). Downward sloping trend.
**2. Direct-Effect:**
* **Unfair (Blue Circle):** Starts at approximately (0.00, 0.25) and increases to approximately (0.25, 0.35). Upward sloping trend.
* **Unaware (Red Downward Triangle):** Starts at approximately (0.00, 0.40) and decreases to approximately (0.25, 0.30). Downward sloping trend.
* **Constant (Green Upward Triangle):** Starts at approximately (0.00, 0.40) and decreases to approximately (0.25, 0.35). Downward sloping trend.
* **FairPFN (Star):** Starts at approximately (0.00, 0.40) and decreases to approximately (0.25, 0.35). Downward sloping trend.
**3. Indirect-Effect:**
* **Unfair (Blue Circle):** Starts at approximately (0.00, 0.35) and increases to approximately (0.25, 0.35). Relatively flat trend.
* **Unaware (Red Downward Triangle):** Starts at approximately (0.00, 0.40) and decreases to approximately (0.25, 0.30). Downward sloping trend.
* **Constant (Green Upward Triangle):** Starts at approximately (0.00, 0.40) and decreases to approximately (0.25, 0.35). Downward sloping trend.
* **FairPFN (Star):** Starts at approximately (0.00, 0.40) and decreases to approximately (0.25, 0.35). Downward sloping trend.
**4. Fair Observable:**
* **Unfair (Blue Circle):** Starts at approximately (0.00, 0.35) and increases to approximately (0.25, 0.40). Upward sloping trend.
* **Unaware (Red Downward Triangle):** Starts at approximately (0.00, 0.40) and decreases to approximately (0.25, 0.30). Downward sloping trend.
* **Constant (Green Upward Triangle):** Starts at approximately (0.00, 0.35) and decreases to approximately (0.25, 0.30). Downward sloping trend.
* **FairPFN (Star):** Starts at approximately (0.00, 0.30) and increases to approximately (0.25, 0.35). Upward sloping trend.
**5. Fair Unobservable:**
* **Unfair (Blue Circle):** Starts at approximately (0.00, 0.30) and increases to approximately (0.25, 0.40). Upward sloping trend.
* **Unaware (Red Downward Triangle):** Starts at approximately (0.00, 0.40) and decreases to approximately (0.25, 0.30). Downward sloping trend.
* **Constant (Green Upward Triangle):** Starts at approximately (0.00, 0.40) and decreases to approximately (0.25, 0.35). Downward sloping trend.
* **FairPFN (Star):** Starts at approximately (0.00, 0.30) and increases to approximately (0.25, 0.30). Relatively flat trend.
**6. Fair Additive Noise:**
* **Unfair (Blue Circle):** Starts at approximately (0.00, 0.30) and increases to approximately (0.25, 0.40). Upward sloping trend.
* **Unaware (Red Downward Triangle):** Starts at approximately (0.00, 0.40) and decreases to approximately (0.25, 0.30). Downward sloping trend.
* **Constant (Green Upward Triangle):** Starts at approximately (0.00, 0.35) and decreases to approximately (0.25, 0.30). Downward sloping trend.
* **FairPFN (Star):** Starts at approximately (0.00, 0.30) and increases to approximately (0.25, 0.35). Upward sloping trend.
### Key Observations
* The "Unaware" algorithm consistently shows a decreasing error rate as the causal effect (ATE) increases across all fairness settings.
* The "Unfair" algorithm generally exhibits an increasing error rate with increasing causal effect, particularly in the "Fair Observable", "Fair Unobservable", and "Fair Additive Noise" settings.
* FairPFN generally performs better than Unfair and Unaware in the "Fair" settings.
* Error bars are present, indicating some variance in the results.
### Interpretation
The charts demonstrate the performance of various fairness interventions under different causal effect scenarios. The "Unaware" algorithm, while reducing error with increasing causal effect, likely does so by ignoring the fairness constraints. The "Unfair" algorithm's increasing error suggests that fairness interventions become more challenging as the causal effect grows. FairPFN appears to be a promising approach, maintaining relatively low error rates across different fairness settings. The differences in performance across the fairness settings highlight the importance of choosing an intervention appropriate for the specific causal structure of the data. The error bars suggest that the results are not deterministic and that further investigation is needed to understand the robustness of these interventions. The consistent downward trend of the "Unaware" algorithm suggests a trade-off between fairness and accuracy, as it achieves lower error by not explicitly addressing fairness concerns.
</details>
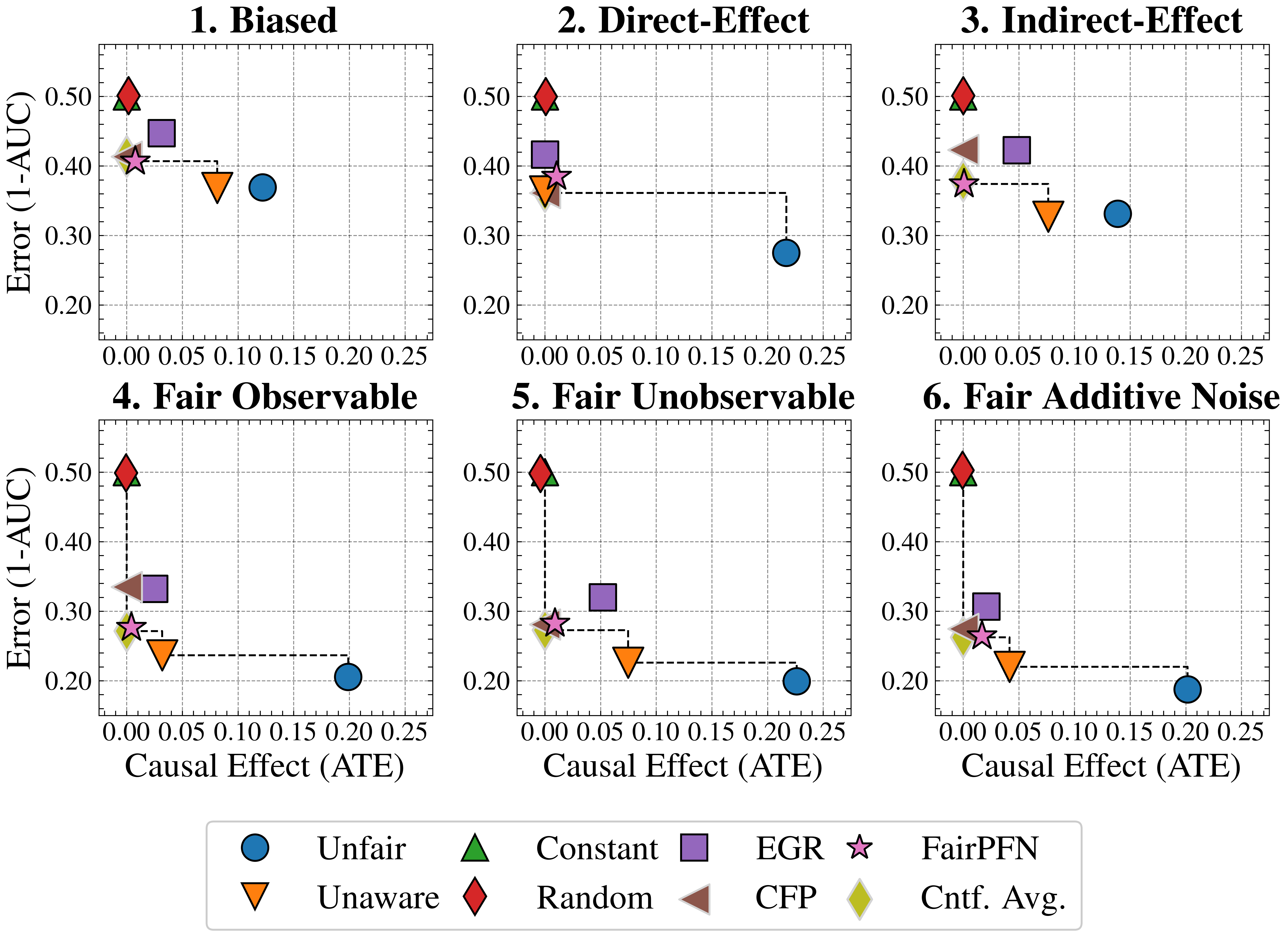
Figure 3: Fairness Accuracy Trade-Off (Synthetic): Average Treatment Effect (ATE) of predictions, predictive error (1-AUC), and Pareto Front performance of FairPFN versus baselines in our causal case studies. Baselines which have access to causal information are indicated by a light border. FairPFN is on the Pareto Front on 40% of synthetic datasets using only observational data, demonstrating competitive performance with the CFP and Cntf. Avg. baselines that utilize causal quantities from the true data-generating process.
Fairness-Accuracy Trade-Off
Figure 3 presents the fairness-accuracy trade-off for FairPFN and its baselines, displaying the mean absolute treatment effect (ATE) and mean predictive error (1-AUC) observed across synthetic datasets, along with the Pareto Front of non-dominated solutions. FairPFN (which only uses observational data) attains Pareto Optimal performance in 40% of the 600 synthetic datasets, exhibiting a fairness-accuracy trade-off competitive with CFP and Cntf. Avg., which use causal quantities from the true data-generating process. This is even the case in the Fair Unobservable and Fair Additive Noise benchmark groups, producing causally fair predictions using only observational variables that are either a protected attribute or a causal ancestor of it. This indicates FairPFN’s capacity to infer latent unobservables, which we further investigate in Section 5.3. We also highlight how the Cntf. Avg. baseline achieves lower error than CFP. We believe that this is due to Cntf. Avg. having access to both the observational and counterfactual datasets, which implicitly contains causal weights and non-linearities, while CFP is given only fair unobservables and must infer this causal information. The fact that a PFN is used as a base model in Cntf. Avg. could further explain this performance gain, as access to more observable variables helps guide the PFN toward accurate predictions realistic for the data. We suggest that this Cntf. Avg. as an alternative should be explored in future studies.
<details>
<summary>extracted/6522797/figures/tce_by_group_synthetic_new.png Details</summary>
### Visual Description
\n
## Box Plots: Causal Effect Analysis under Different Fairness Constraints
### Overview
The image presents six box plots, each representing the distribution of causal effects (ATE - Average Treatment Effect) under different fairness scenarios. Each plot compares four different algorithms: FairPFN, EGR, Unaware, and Unfair. The x-axis represents the average rank of each algorithm, and the y-axis represents the causal effect. A horizontal gray dashed line at y=0 serves as a reference point.
### Components/Axes
* **Y-axis:** "Causal Effect (ATE)" ranging from -0.5 to 0.75.
* **X-axis:** "Avg. Rank (ATE)" with values 1, 2, 3, and 4.
* **Titles:** Each subplot is titled with a fairness scenario: "1. Biased", "2. Direct-Effect", "3. Indirect-Effect", "4. Fair Observable", "5. Fair Unobservable", "6. Fair Additive Noise".
* **Legend:** Located at the bottom center of the image.
* FairPFN: Purple, labeled "1.88/4"
* EGR: Green, labeled "2.11/4"
* Unaware: Orange, labeled "2.16/4"
* Unfair: Blue, labeled "3.42/4"
### Detailed Analysis
Each subplot displays box plots for the four algorithms. The box plots show the median, quartiles, and outliers of the causal effect distribution.
**1. Biased:**
* FairPFN (Purple): Median around 0.1, IQR from approximately 0 to 0.25. Several outliers above 0.5.
* EGR (Green): Median around 0.2, IQR from approximately 0 to 0.3.
* Unaware (Orange): Median around 0, IQR from approximately -0.1 to 0.15.
* Unfair (Blue): Median around 0.25, IQR from approximately 0.1 to 0.4.
**2. Direct-Effect:**
* FairPFN (Purple): Median around 0.25, IQR from approximately 0.1 to 0.4.
* EGR (Green): Median around 0.25, IQR from approximately 0.1 to 0.4.
* Unaware (Orange): Median around 0, IQR from approximately -0.1 to 0.1.
* Unfair (Blue): Median around 0.25, IQR from approximately 0.1 to 0.4.
**3. Indirect-Effect:**
* FairPFN (Purple): Median around 0.2, IQR from approximately 0 to 0.3.
* EGR (Green): Median around 0.2, IQR from approximately 0 to 0.3.
* Unaware (Orange): Median around 0, IQR from approximately -0.1 to 0.1.
* Unfair (Blue): Median around 0.2, IQR from approximately 0 to 0.3.
**4. Fair Observable:**
* FairPFN (Purple): Median around 0.25, IQR from approximately 0.1 to 0.4.
* EGR (Green): Median around 0.2, IQR from approximately 0 to 0.3.
* Unaware (Orange): Median around 0, IQR from approximately -0.1 to 0.1.
* Unfair (Blue): Median around 0.2, IQR from approximately 0 to 0.3.
**5. Fair Unobservable:**
* FairPFN (Purple): Median around 0.2, IQR from approximately 0 to 0.3.
* EGR (Green): Median around 0.2, IQR from approximately 0 to 0.3.
* Unaware (Orange): Median around 0, IQR from approximately -0.1 to 0.1.
* Unfair (Blue): Median around 0.2, IQR from approximately 0 to 0.3.
**6. Fair Additive Noise:**
* FairPFN (Purple): Median around 0.2, IQR from approximately 0 to 0.3.
* EGR (Green): Median around 0.2, IQR from approximately 0 to 0.3.
* Unaware (Orange): Median around 0, IQR from approximately -0.1 to 0.1.
* Unfair (Blue): Median around 0.2, IQR from approximately 0 to 0.3.
### Key Observations
* The "Unfair" algorithm consistently exhibits a higher median causal effect than the other algorithms across most scenarios.
* The "Unaware" algorithm generally has a median causal effect close to zero.
* FairPFN and EGR show similar distributions in most scenarios.
* The average rank values in the legend indicate that FairPFN performs best (lowest rank) on average, followed by EGR and Unaware, with Unfair performing worst.
* Outliers are present in several box plots, particularly for FairPFN, suggesting variability in the causal effect.
### Interpretation
The data suggests that the "Unfair" algorithm consistently produces a higher causal effect, potentially indicating a bias in its predictions. The "Unaware" algorithm, which does not consider fairness constraints, tends to have a neutral causal effect. FairPFN and EGR, designed with fairness in mind, achieve comparable performance and generally exhibit lower causal effects than the "Unfair" algorithm. The average rank values confirm that FairPFN is the best-performing algorithm overall, followed by EGR. The presence of outliers suggests that the causal effect can vary significantly depending on the specific data instance. The different fairness scenarios (Biased, Direct-Effect, etc.) highlight the importance of considering different types of fairness constraints when evaluating and comparing algorithms. The consistent performance of FairPFN and EGR across these scenarios suggests their robustness to different fairness challenges.
</details>
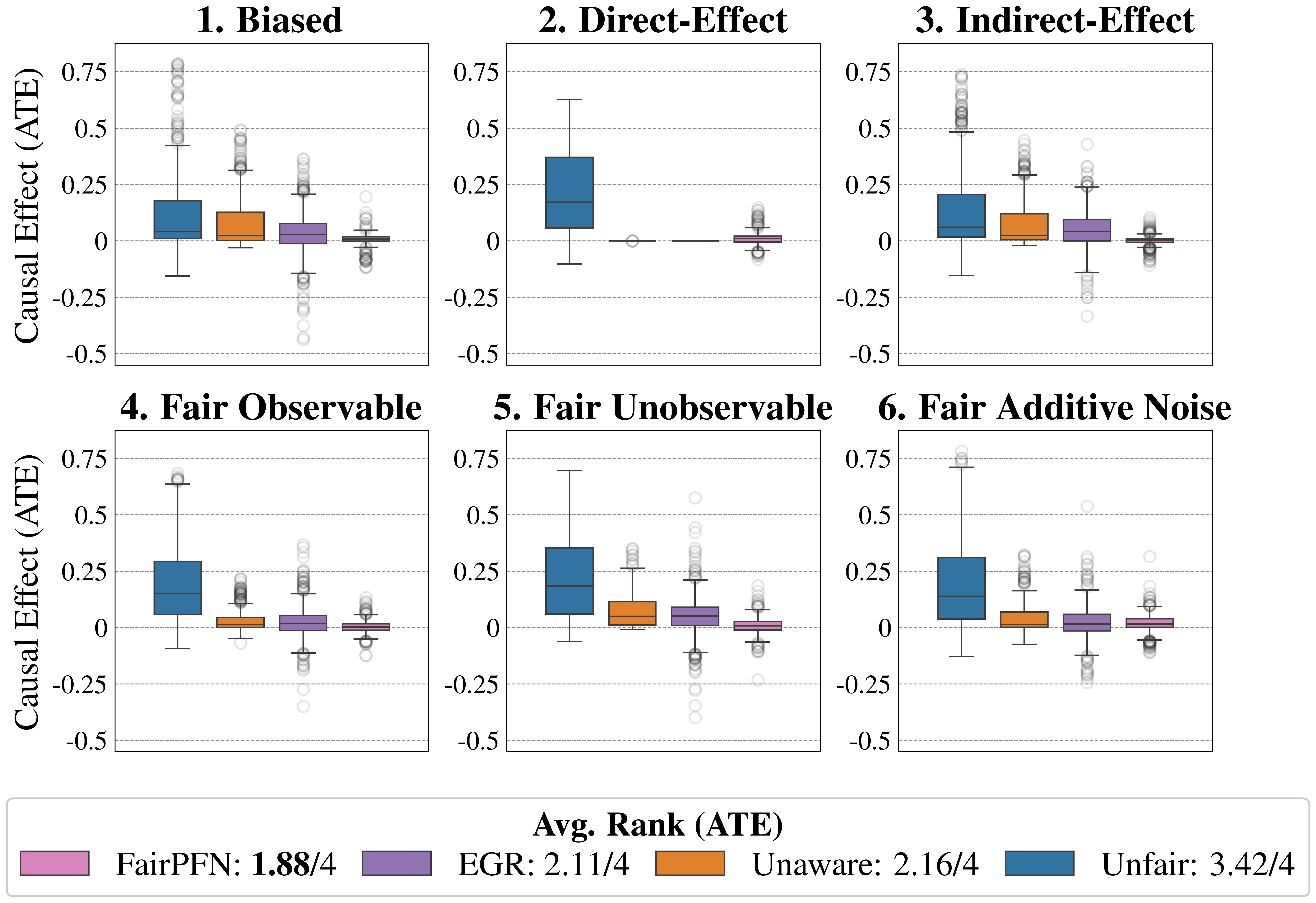
Figure 4: Causal Fairness (Synthetic): Average Treatment Effect (ATE) of predictions of FairPFN compared to baselines which do not have access to causal information. FairPFN consistently removes the causal effect with a margin of error of (-0.2, 0.2) and achieves an average rank of 1.88 out of 4, only to be outperformed on the Direct-Effect benchmark where Unaware is the optimal strategy.
Causal Effect Removal We evaluate FairPFN’s efficacy in causal effect removal by analyzing box plots depicting the median, interquartile range (IQR), and average treatment effect (ATE) of predictions, compared to baseline predictive models that also do not access causal information (Figure 4). We observe that FairPFN exhibits a smaller IQR than the state-of-the-art bias mitigation method EGR. In an average rank test across 600 synthetic datasets, FairPFN achieves an average rank of 1.88 out of 4. We provide a comparison of FairPFN against all baselines in Figure 24. We note that our case studies crucially fit our prior assumptions about the causal representation of protected attributes. We show in Appendix Figure 13 that FairPFN reverts to a normal classifier when, for example, the exogeneity assumption is violated.
Ablation Study
We finally conduct an ablation study to evaluate FairPFN’s performance in causal effect removal across synthetic datasets with varying size, noise levels, and base rates of causal effect. Results indicate that FairPFN maintains consistent performance across different noise levels and base rates, improving in causal effect removal as dataset size increases and causal effects become easier to distinguish from spurious correlations Dai et al. (1997). We note that the variance of FairPFN, illustrated by box-plot outliers in Figure 4 that extend to 0.2 and -0.2, is primarily arises from small datasets with fewer than 250 samples (Appendix Figure 11), limiting FairPFN’s ability to identify causal mechanisms. We also show in Appendix Figure 14 that FairPFN’s fairness behavior remains consistent as graph complexity increases, though accuracy drops do to the combinatorially increasing problem complexity.
For a more in-depth analysis of these results, we refer to Appendix B.
5.3 Real-World Data
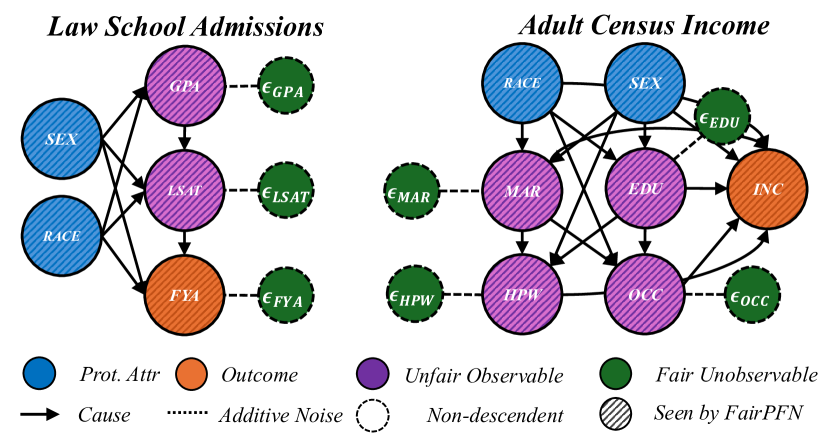
This section evaluates FairPFN’s causal effect removal, predictive error, and correlation with fair latent variables on two real-world datasets with established causal graphs (Figure 5). For a description of our real-world datasets and the methods we use to obtain causal models, see Appendix A.
Fairness-Accuracy Trade-Off
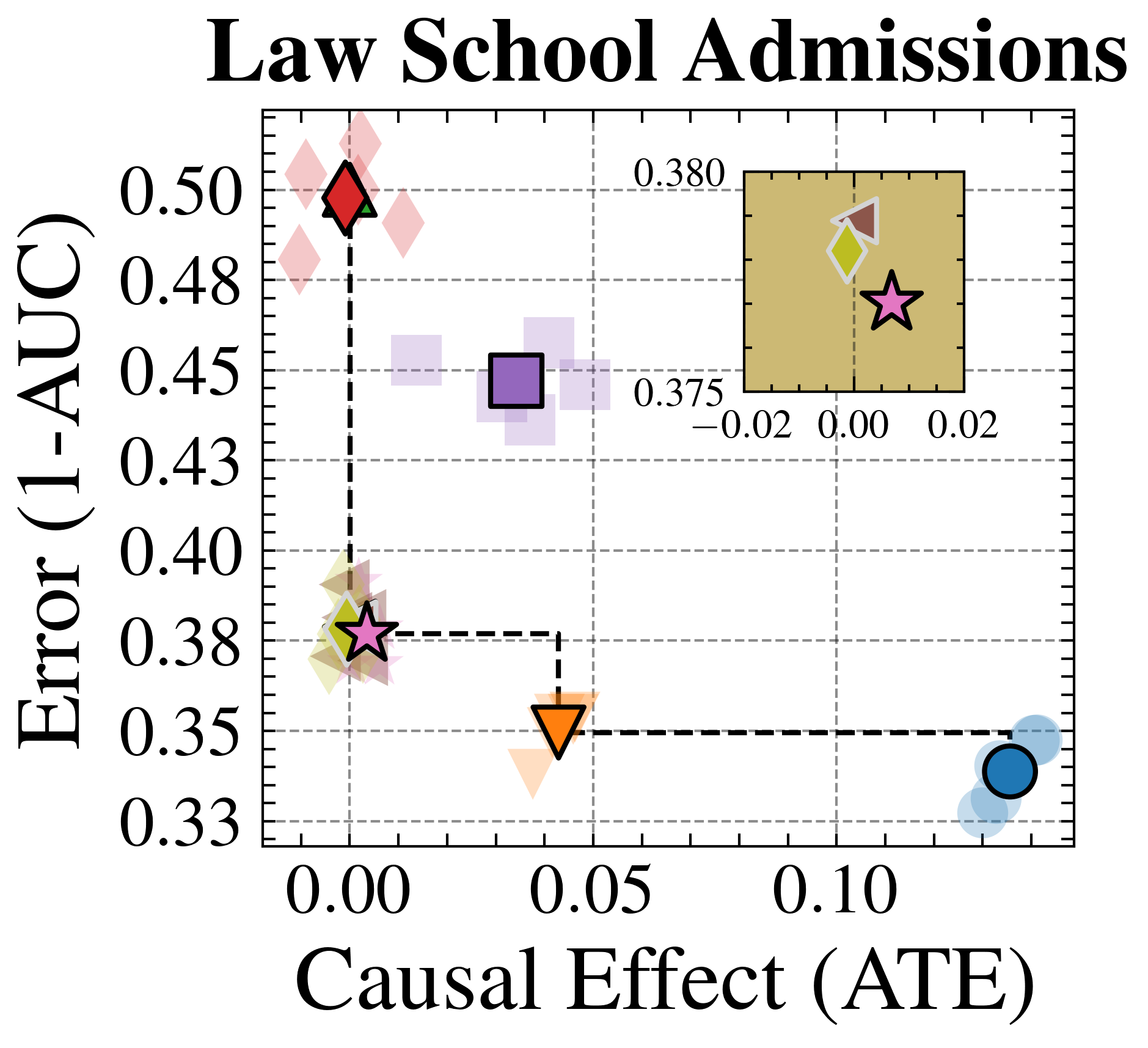
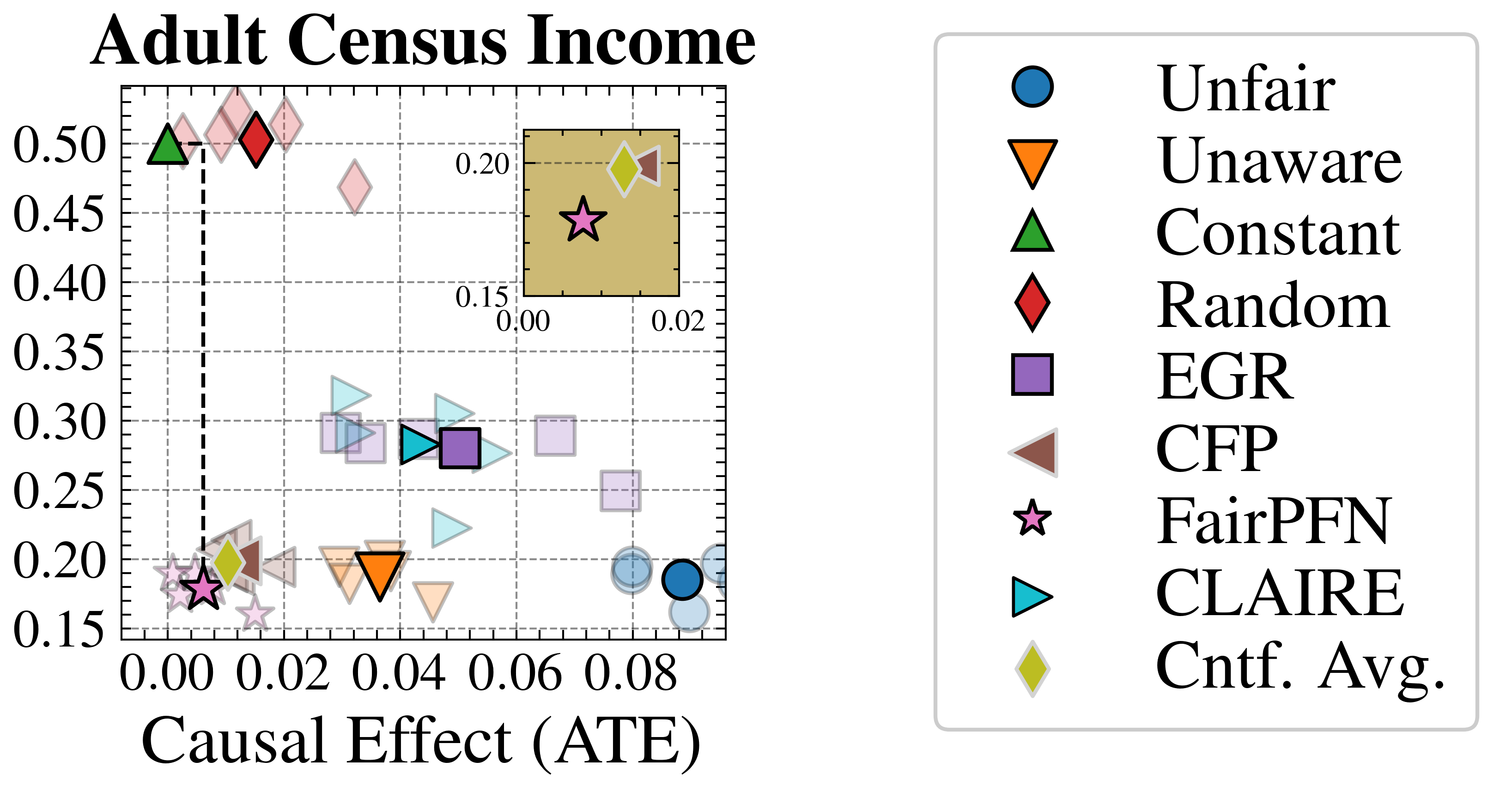
We evaluate FairPFN’s effectiveness on real-world data in reducing the causal impact of protected attributes while maintaining strong predictive accuracy. Figure 6 shows the mean prediction average treatment effect (ATE) and predictive error (1-AUC) across 5 K-fold cross-validation iterations. FairPFN achieves a prediction ATE below 0.01 on both datasets and maintains accuracy comparable to Unfair. Furthermore, FairPFN exhibits lower variability in prediction ATE across folds compared to EGR, indicating stable causal effect removal We note that we also evaluate a pre-trained version of CLAIRE Ma et al. (2023) on the Adult Census income dataset, but observe little improvement to EGR.
Counterfactual Fairness
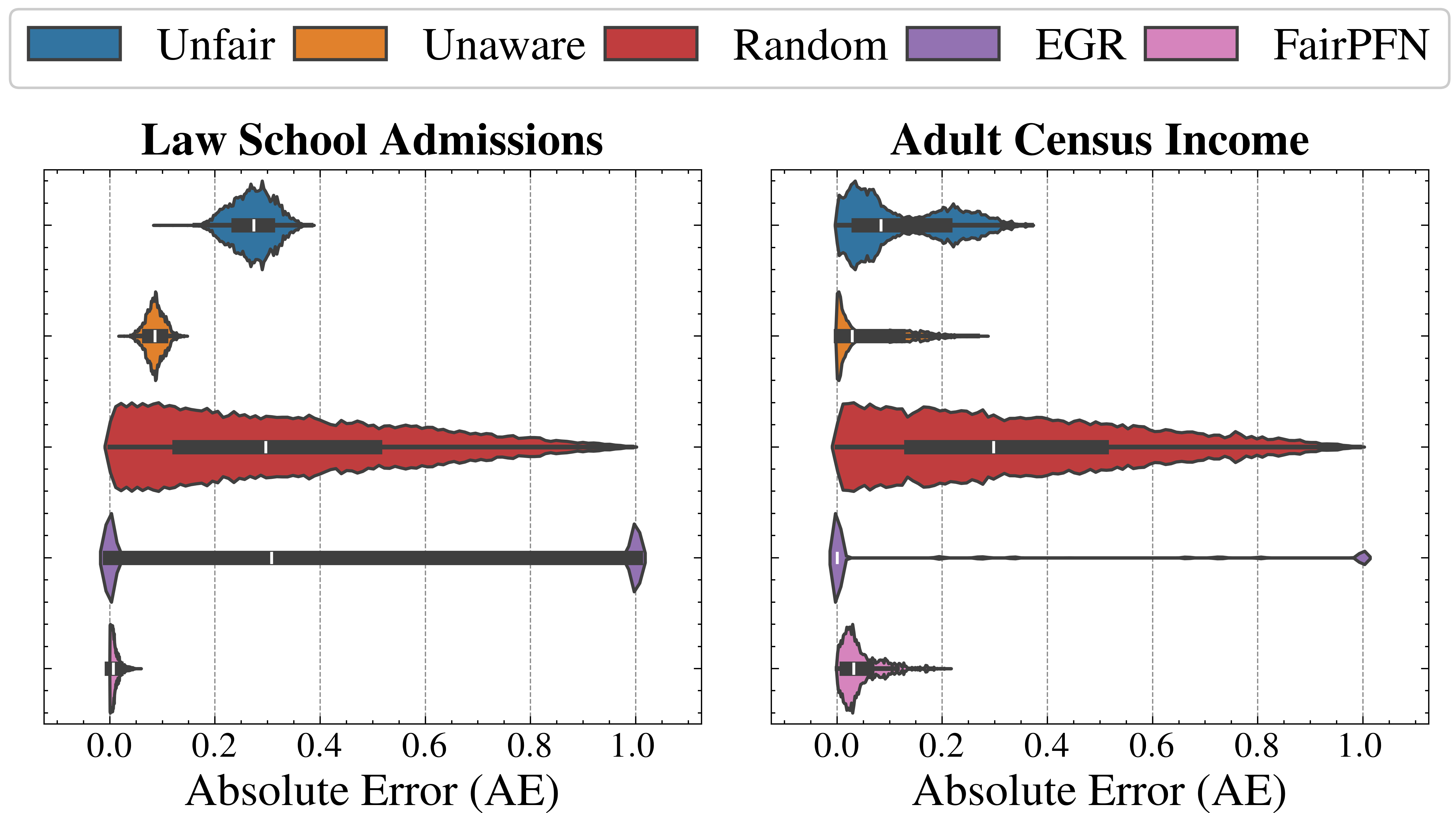
Next, we evaluate the counterfactual fairness of FairPFN on real-world datasets as introduced in Section 3, noting that the following analysis is conducted at the individual sample level, rather than at the dataset level. Figure 7 illustrates the distribution of Absolute Error (AE) achieved by FairPFN and baselines that do not have access to causal information. FairPFN significantly reduces this error in both datasets, achieving maximum divergences of less than 0.05 on the Law School dataset and 0.2 on the Adult Census Income dataset. For a visual interpretation of the AE on our real-world datasets we refer to Appendix Figure 16.
In contrast, EGR performs similarly to Random in terms of counterfactual divergence, confirming previous studies which show that optimmizing for group fairness metrics does not optimize for individual level criteria Robertson et al. (2024). Interestingly, in an evaluation of group fairness metric Statistical Parity (DSP) FairPFN outperforms EGR on both our real-world data and causal case studies, a baseline was specifically optimized for this metric (Appendix Figures 20 and 21).
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Diagram: Causal Diagrams for Law School Admissions and Adult Census Income
### Overview
The image presents two causal diagrams, side-by-side. The left diagram models factors influencing Law School Admissions, while the right diagram models factors influencing Adult Census Income. Both diagrams use nodes to represent variables and arrows to represent causal relationships. The diagrams also include elements representing noise and visibility to a fairness-focused model (FairPFN).
### Components/Axes
The diagrams utilize the following components, as indicated by the legend at the bottom:
* **Prot. Attr.** (Protected Attribute): Represented by blue circles.
* **Outcome:** Represented by orange circles.
* **Unfair Observable:** Represented by purple circles.
* **Fair Unobservable:** Represented by green circles.
* **Cause:** Represented by solid arrows (→).
* **Additive Noise:** Represented by dashed arrows (---).
* **Non-descendent:** Represented by dashed circles.
* **Seen by FairPFN:** Represented by diagonally striped circles.
**Law School Admissions Diagram:**
* Variables: SEX, RACE, GPA, LSAT, FYA (First Year Attendance), εGPA, εLSAT, εFYA
* Title: "Law School Admissions"
**Adult Census Income Diagram:**
* Variables: RACE, SEX, EDU (Education), MAR (Marital Status), OCC (Occupation), INC (Income), εEDU, εMAR, εHPW, εOCC
* Title: "Adult Census Income"
### Detailed Analysis or Content Details
**Law School Admissions Diagram:**
* RACE (blue) → SEX (blue)
* RACE (blue) → GPA (purple) → εGPA (dashed arrow)
* RACE (blue) → LSAT (purple) → εLSAT (dashed arrow)
* RACE (blue) → FYA (orange) → εFYA (dashed arrow)
* SEX (blue) → GPA (purple) → εGPA (dashed arrow)
* SEX (blue) → LSAT (purple) → εLSAT (dashed arrow)
* SEX (blue) → FYA (orange) → εFYA (dashed arrow)
**Adult Census Income Diagram:**
* RACE (blue) → SEX (blue)
* RACE (blue) → EDU (purple) → εEDU (dashed arrow)
* RACE (blue) → MAR (purple) → εMAR (dashed arrow)
* RACE (blue) → OCC (purple) → εOCC (dashed arrow)
* SEX (blue) → EDU (purple) → εEDU (dashed arrow)
* SEX (blue) → MAR (purple) → εMAR (dashed arrow)
* SEX (blue) → OCC (purple) → εOCC (dashed arrow)
* EDU (purple) → INC (orange)
* MAR (purple) → INC (orange)
* OCC (purple) → INC (orange)
* HPW (purple) → INC (orange)
### Key Observations
* Both diagrams share a similar structure, with protected attributes (RACE and SEX) influencing observable and unobservable factors that ultimately affect an outcome (FYA for Law School, INC for Income).
* The diagrams highlight the potential for indirect discrimination through multiple pathways.
* The inclusion of noise terms (εGPA, εLSAT, εFYA, εEDU, εMAR, εHPW, εOCC) acknowledges the inherent uncertainty and randomness in these relationships.
* The diagrams do not provide any quantitative data, only the structure of the causal relationships.
### Interpretation
These diagrams are conceptual models used to analyze fairness in machine learning. They illustrate how protected attributes like race and sex can influence outcomes, even if those attributes are not directly used in a predictive model. The noise terms represent unmeasured factors that contribute to the outcome. The diagrams are likely used to evaluate the fairness of algorithms designed to predict law school admissions or income, and to identify potential sources of bias. The "Seen by FairPFN" component (diagonally striped circles) suggests that a specific fairness-aware model (FairPFN) has access to certain variables, which may be used to mitigate bias. The diagrams are not about specific data points, but about the *relationships* between variables and the potential for unfairness. The diagrams are a tool for reasoning about causality and fairness, rather than a presentation of empirical results.
</details>
Figure 5: Real-World Scenarios: Assumed causal graphs of real-world datasets Law School Admissions and Adult Census Income.
<details>
<summary>extracted/6522797/figures/trade-off_lawschool.png Details</summary>
### Visual Description
\n
## Scatter Plot: Law School Admissions
### Overview
This image presents a scatter plot visualizing the relationship between "Causal Effect (ATE)" and "Error (1-AUC)" in the context of Law School Admissions. The plot features several data points represented by different geometric shapes and colors. A zoomed-in section highlights a cluster of points near the origin.
### Components/Axes
* **Title:** "Law School Admissions" (Top-center)
* **X-axis:** "Causal Effect (ATE)" - Ranges from approximately -0.02 to 0.12.
* **Y-axis:** "Error (1-AUC)" - Ranges from approximately 0.33 to 0.50.
* **Data Points:** Represented by various shapes (diamond, star, triangle, circle, square) and colors (red, green, orange, blue, purple).
* **Zoomed-in Section:** A rectangular region (approximately from -0.02 to 0.02 on the x-axis and 0.375 to 0.380 on the y-axis) highlights a cluster of data points.
* **Value Label:** "0.380" is displayed within the zoomed-in section.
* **Value Label:** "0.375" is displayed within the zoomed-in section.
### Detailed Analysis
The scatter plot displays the following data points (approximate values, based on visual estimation):
* **Red Diamond:** (Causal Effect: -0.01, Error: 0.49)
* **Light Red Diamond:** (Causal Effect: 0.02, Error: 0.46)
* **Purple Square:** (Causal Effect: 0.04, Error: 0.44)
* **Green Star:** (Causal Effect: -0.01, Error: 0.38)
* **Orange Triangle:** (Causal Effect: 0.06, Error: 0.35)
* **Blue Circle:** (Causal Effect: 0.11, Error: 0.34)
* **Yellow Hexagon:** (Causal Effect: 0.01, Error: 0.378) - Located within the zoomed-in section.
* **Green Star:** (Causal Effect: 0.01, Error: 0.378) - Located within the zoomed-in section.
The overall trend is not strongly linear. There appears to be a general tendency for higher Causal Effect values to correspond with lower Error values, but with significant variation.
### Key Observations
* The data points are scattered, indicating a complex relationship between Causal Effect and Error.
* The zoomed-in section suggests a concentration of data points with low Causal Effect and Error values.
* The red diamond has the highest Error value, while the blue circle has the highest Causal Effect value.
* There is a noticeable spread in Error values for similar Causal Effect values, and vice versa.
### Interpretation
The plot likely represents the performance of different models or methods in estimating the causal effect of some intervention in Law School Admissions, as measured by the Average Treatment Effect (ATE). The Error (1-AUC) represents the model's accuracy.
The data suggests that achieving a higher Causal Effect (more accurately estimating the impact of an intervention) often comes at the cost of increased Error (lower accuracy). The spread of the data points indicates that there is no single "best" method, and the optimal trade-off between Causal Effect and Error depends on the specific application.
The zoomed-in section highlights a region where both Causal Effect and Error are relatively low, suggesting that some methods perform well in this range. The presence of multiple data points in this region indicates that there are several viable options.
The outlier (red diamond) suggests that some methods may have high Error even with a low Causal Effect, potentially due to biases or limitations in the data or model. The blue circle suggests that a high causal effect can be achieved, but at the cost of a higher error.
</details>
<details>
<summary>extracted/6522797/figures/trade-off_adult.png Details</summary>
### Visual Description
## Scatter Plot: Adult Census Income
### Overview
This image presents a scatter plot visualizing the relationship between "Causal Effect (ATE)" on the x-axis and an unnamed y-axis, presumably representing some measure of fairness or performance. The plot compares several different fairness-aware algorithms and baseline methods. A zoomed-in inset plot highlights a specific region of the data.
### Components/Axes
* **Title:** "Adult Census Income" (top-center)
* **X-axis Label:** "Causal Effect (ATE)" (bottom-center)
* **Y-axis Label:** Not explicitly labeled, but the scale ranges from approximately 0.15 to 0.52.
* **Legend:** Located in the top-right corner, listing the following algorithms/methods with corresponding marker shapes and colors:
* Unfair (Blue Circle)
* Unaware (Orange Downward Triangle)
* Constant (Green Upward Triangle)
* Random (Red Diamond)
* EGR (Purple Square)
* CFP (Gray Circle)
* FairPFN (White Star)
* CLAIRE (Blue Downward Triangle)
* Cntf. Avg. (Yellow Diamond)
* **Inset Plot:** A zoomed-in section of the main plot, located in the top-right quadrant, with x-axis ranging from approximately 0.00 to 0.02 and y-axis ranging from approximately 0.15 to 0.20.
### Detailed Analysis
The main plot displays data points for each of the algorithms listed in the legend.
* **Unfair (Blue Circle):** Located near (0.08, 0.20).
* **Unaware (Orange Downward Triangle):** Located near (0.04, 0.48).
* **Constant (Green Upward Triangle):** Located near (0.00, 0.50).
* **Random (Red Diamond):** Several points are scattered between approximately (0.02, 0.25) and (0.08, 0.35).
* **EGR (Purple Square):** Located near (0.06, 0.30).
* **CFP (Gray Circle):** Located near (0.04, 0.25).
* **FairPFN (White Star):** Located near (0.06, 0.42) and (0.00, 0.18).
* **CLAIRE (Blue Downward Triangle):** Located near (0.04, 0.30).
* **Cntf. Avg. (Yellow Diamond):** Several points are scattered between approximately (0.02, 0.20) and (0.08, 0.30).
**Trends:**
* The "Constant" method consistently shows the highest y-axis values.
* The "Unaware" method generally has higher y-axis values than "Unfair".
* "FairPFN" has two distinct data points, one with a high y-axis value and one with a low y-axis value.
* The "Random" and "Cntf. Avg." methods exhibit a wider spread of values.
**Inset Plot:**
* The inset plot focuses on a region with lower "Causal Effect (ATE)" values.
* A "FairPFN" (White Star) data point is visible at approximately (0.01, 0.18).
### Key Observations
* There is a noticeable spread in the data, indicating that different algorithms perform differently in terms of the measured metrics.
* The "Constant" method appears to achieve the highest values on the y-axis, but it's unclear what this axis represents without further context.
* The presence of multiple data points for "FairPFN" suggests variability in its performance.
* The inset plot highlights the performance of "FairPFN" in a specific region of the "Causal Effect (ATE)" range.
### Interpretation
The scatter plot likely aims to compare the trade-offs between fairness and causal effect for different algorithmic approaches on the Adult Census Income dataset. The x-axis, "Causal Effect (ATE)", represents the average treatment effect, indicating the impact of a decision on an individual's income. The y-axis likely represents a fairness metric, where higher values indicate better fairness.
The plot suggests that achieving high fairness (high y-axis values) may come at the cost of a lower causal effect (lower x-axis values). The "Constant" method, while achieving the highest fairness, has a relatively low causal effect. The "Unaware" method, which does not explicitly consider fairness, has a higher causal effect but potentially lower fairness.
The two data points for "FairPFN" suggest that its performance is sensitive to certain conditions or parameters. The inset plot focuses on a region where "FairPFN" performs relatively well, indicating that it may be a viable option for achieving both fairness and a reasonable causal effect in specific scenarios.
The spread of data points for "Random" and "Cntf. Avg." indicates that these methods are less consistent in their performance. The overall goal of the visualization is to help decision-makers choose the most appropriate algorithm based on their specific priorities and constraints.
</details>
Figure 6: Fairness-Accuracy Trade-off (Real-World): Average Treatment Effect (ATE) of predictions, predictive error (1-AUC), and Pareto Front of the performance of FairPFN compared to our baselines on each of 5 validation folds (light) and across all five folds (solid) of our real-world datasets. Baselines which have access to causal information have a light border. FairPFN matches the performance of baselines which have access to inferred causal information with only access to observational data.
<details>
<summary>extracted/6522797/figures/kl_real.png Details</summary>
### Visual Description
\n
## Violin Plots: Absolute Error Comparison for Fairness Metrics
### Overview
The image presents two violin plots side-by-side, comparing the distribution of Absolute Error (AE) for different fairness metrics across two datasets: "Law School Admissions" and "Adult Census Income". The fairness metrics being compared are Unfair, Unaware, Random, EGR, and FairPFN. Each plot visualizes the AE distribution for each metric within a specific dataset.
### Components/Axes
* **X-axis:** Labeled "Absolute Error (AE)", ranging from 0.0 to 1.0 with increments of 0.2.
* **Y-axis:** Represents the density of the Absolute Error distribution. No explicit label is provided, but it is implied to be a density scale.
* **Title (Left Plot):** "Law School Admissions"
* **Title (Right Plot):** "Adult Census Income"
* **Legend (Top-Left):** A horizontal legend indicating the color mapping for each fairness metric:
* Unfair: Dark Blue
* Unaware: Orange
* Random: Red
* EGR: Gray
* FairPFN: Magenta
### Detailed Analysis or Content Details
**Law School Admissions (Left Plot):**
* **Unfair (Dark Blue):** The distribution is bimodal, with a peak around 0.05 and another around 0.25. The violin extends to approximately 0.4.
* **Unaware (Orange):** The distribution is also bimodal, with peaks around 0.02 and 0.2. The violin extends to approximately 0.35.
* **Random (Red):** A broad, relatively flat distribution spanning from 0.0 to approximately 0.8. The highest density is around 0.2-0.4.
* **EGR (Gray):** A narrow distribution centered around 0.25, with a violin extending to approximately 0.4.
* **FairPFN (Magenta):** A very concentrated distribution centered around 0.0, with a violin extending to approximately 0.1.
**Adult Census Income (Right Plot):**
* **Unfair (Dark Blue):** Similar to the Law School Admissions plot, bimodal with peaks around 0.05 and 0.25. The violin extends to approximately 0.4.
* **Unaware (Orange):** Bimodal, with peaks around 0.02 and 0.2. The violin extends to approximately 0.35.
* **Random (Red):** Broad, relatively flat distribution spanning from 0.0 to approximately 0.8. The highest density is around 0.2-0.4.
* **EGR (Gray):** A narrow distribution centered around 0.25, with a violin extending to approximately 0.4.
* **FairPFN (Magenta):** A very concentrated distribution centered around 0.0, with a violin extending to approximately 0.1.
### Key Observations
* **FairPFN consistently exhibits the lowest Absolute Error** across both datasets, indicating the best performance in terms of minimizing error.
* **Unfair and Unaware show similar distributions** in both datasets, with bimodal shapes and higher error values compared to FairPFN.
* **Random has the broadest distribution**, suggesting the most variability in Absolute Error.
* **EGR shows a relatively narrow distribution** centered around a moderate error value.
* The shapes of the distributions are remarkably similar between the two datasets for each fairness metric.
### Interpretation
The data suggests that the FairPFN fairness metric significantly reduces Absolute Error compared to other metrics (Unfair, Unaware, Random, and EGR) in both the Law School Admissions and Adult Census Income datasets. This implies that FairPFN is more effective at achieving accurate predictions while maintaining fairness. The bimodal distributions observed for Unfair and Unaware suggest potential issues with these metrics, possibly indicating a trade-off between fairness and accuracy. The broad distribution of Random indicates that it is the least predictable in terms of error. The similarity in distributions across both datasets suggests that the observed patterns are not specific to either dataset but are likely generalizable to other similar scenarios. The concentrated distributions of FairPFN indicate a consistent and low error rate, making it a potentially desirable choice for applications where accuracy and fairness are critical.
</details>
Figure 7: Counterfactual Fairness (Real-World): Distributions of Absolute Error (AE) between predictive distributions on observational and counterfactual datasets. Compared to baselines that do not have access to causal information, FairPFN achieves the lowest median and maximum AE on both datasets.
Trust & Interpretability
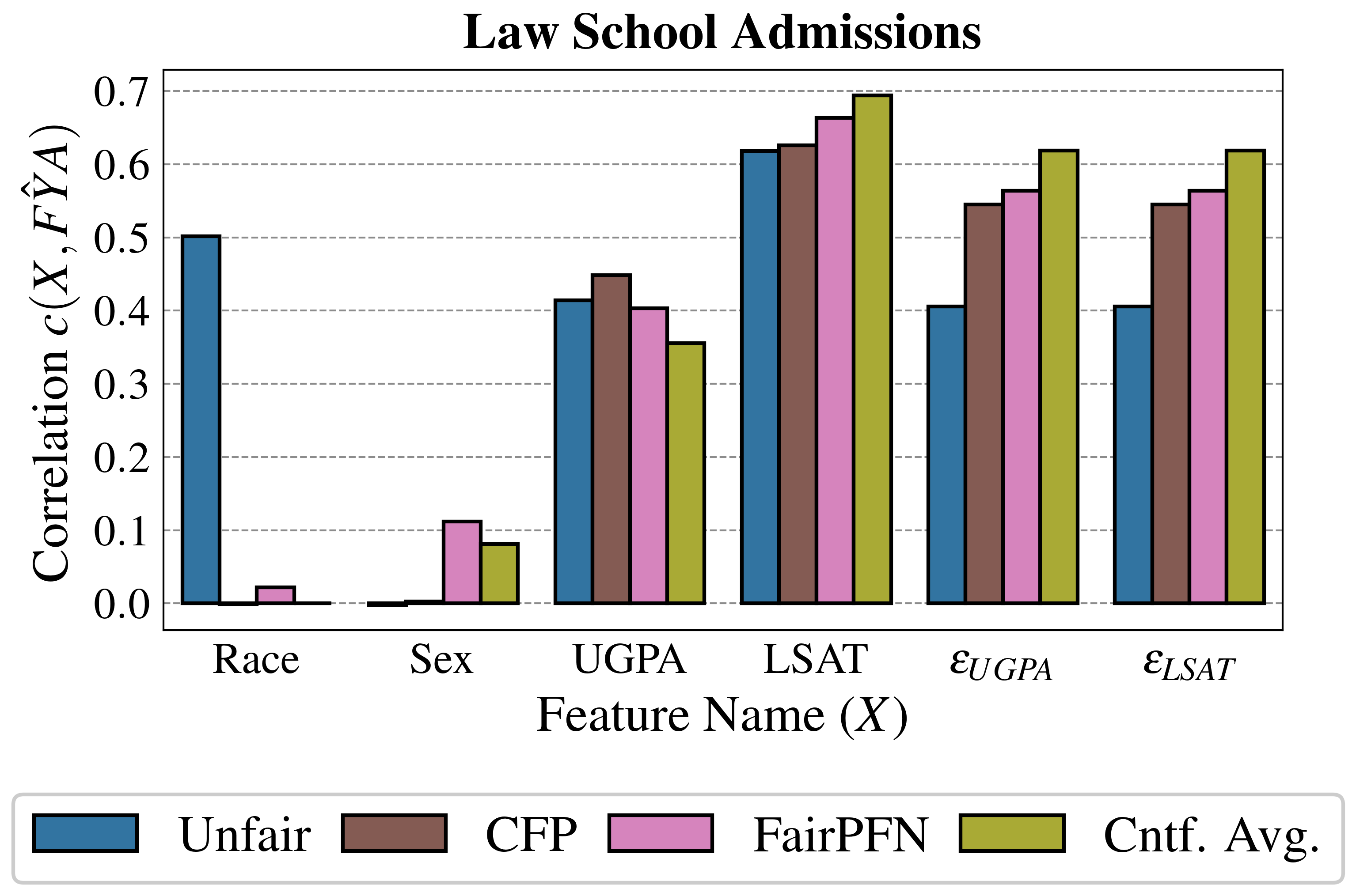
In order to build trust in FairPFN and explain its internal workings, we first perform a feature correlation analysis of FairPFN and baseline models using the Law School Admissions dataset. We measure the Kendall rank correlation between observable variables "LSAT" and "UGPA," and inferred noise terms $\epsilon_{LSAT}$ and $\epsilon_{UGPA}$ , with predicted admission probabilities $\hat{FYA}$ .
Figure 8 shows that despite only having access to observational data, FairPFN’s predictions correlate with fair noise terms similarly to CFP which was fit solely to these variables. This result suggests FairPFN’s ability to not only integrate over realistic causal explanations for the data, but also correctly remove the causal effect of the protected attribute such that its predictions are influenced only by fair exogenous causes. We note that while FairPFN mitigates the effect of "Race," it increases the correlation of "Sex" compared to the Unfair and CFP baselines. We discuss how future versions of FairPFN can tackle the problem of intersectionality in Section 6. We also further investigate this result in Appendix Figure 12, which confirms that FairPFN does not remove the effect of additional protected attributes other than the one specified.
We also observe in Figure 3 and 6 the strong performance of our Cntf. Avg. baseline, which predicts the average outcome probability in the observational and counterfactual worlds. We thus carry out a similarity test to Cntf. Avg. in Appendix Tables 1 and 2, calculating for each other baseline the mean difference in predictions, the standard deviation of this distribution, and the percentage of outliers. We find that FairPFN’s predictions are among the closest to this target, with a mean error on synthetic datasets of 0.00±0.06 with 1.87% of samples falling outside of three standard deviations, and a mean error on real-world datasets of 0.02±0.04 with 0.36% of outlying samples.
<details>
<summary>extracted/6522797/figures/lawschool_corr.png Details</summary>
### Visual Description
## Bar Chart: Law School Admissions - Correlation Analysis
### Overview
This bar chart visualizes the correlation between various features (Race, Sex, UGPA, LSAT, εUGPA, εLSAT) and the predicted admission outcome (ŶA) under different fairness constraints. The chart compares the correlation coefficients for "Unfair", "CFP", "FairPFN", and "Cntf. Avg." models. The y-axis represents the correlation coefficient, while the x-axis lists the features.
### Components/Axes
* **Title:** Law School Admissions
* **X-axis:** Feature Name (X) - Categories: Race, Sex, UGPA, LSAT, εUGPA, εLSAT
* **Y-axis:** Correlation c(X, ŶA) - Scale: 0.0 to 0.7 (with increments of 0.1)
* **Legend:**
* Unfair (Blue)
* CFP (Gray)
* FairPFN (Magenta/Pink)
* Cntf. Avg. (Light Green)
### Detailed Analysis
The chart consists of six groups of four bars, one group for each feature. Each bar represents the correlation coefficient for a specific fairness constraint.
**Race:**
* Unfair: Approximately 0.52
* CFP: Approximately 0.02
* FairPFN: Approximately 0.01
* Cntf. Avg.: Approximately 0.01
**Sex:**
* Unfair: Approximately 0.11
* CFP: Approximately 0.08
* FairPFN: Approximately 0.05
* Cntf. Avg.: Approximately 0.09
**UGPA:**
* Unfair: Approximately 0.45
* CFP: Approximately 0.42
* FairPFN: Approximately 0.44
* Cntf. Avg.: Approximately 0.43
**LSAT:**
* Unfair: Approximately 0.64
* CFP: Approximately 0.62
* FairPFN: Approximately 0.66
* Cntf. Avg.: Approximately 0.65
**εUGPA:**
* Unfair: Approximately 0.67
* CFP: Approximately 0.64
* FairPFN: Approximately 0.68
* Cntf. Avg.: Approximately 0.66
**εLSAT:**
* Unfair: Approximately 0.61
* CFP: Approximately 0.59
* FairPFN: Approximately 0.63
* Cntf. Avg.: Approximately 0.62
### Key Observations
* The "Unfair" model consistently exhibits the highest correlation coefficients across all features, indicating a strong predictive power without fairness considerations.
* The "CFP" model generally shows the lowest correlation coefficients, particularly for "Race" and "Sex", suggesting a significant reduction in predictive power when attempting to achieve fairness.
* "FairPFN" and "Cntf. Avg." models demonstrate intermediate correlation values, balancing predictive power and fairness.
* The correlation for "Race" is substantially reduced in the "CFP", "FairPFN", and "Cntf. Avg." models compared to the "Unfair" model.
* The correlation for "Sex" is relatively low across all models.
* "LSAT" and "εLSAT" show the highest correlation values overall, indicating they are strong predictors of admission outcome.
### Interpretation
This chart demonstrates the trade-off between fairness and predictive accuracy in law school admissions. The "Unfair" model, while most accurate, may perpetuate existing biases. Fairness-aware models ("CFP", "FairPFN", "Cntf. Avg.") reduce the correlation with sensitive attributes like "Race" and "Sex", but at the cost of overall predictive power. The choice of which model to use depends on the specific priorities of the institution – maximizing accuracy versus minimizing bias.
The features εUGPA and εLSAT likely represent errors or noise in the UGPA and LSAT scores, respectively. The high correlation with these features suggests that even with noise, these scores remain strong predictors. The significant drop in correlation for "Race" when using fairness constraints suggests that race is a strong predictor in the "Unfair" model, but that this predictive power can be mitigated through fairness interventions. The relatively low correlation for "Sex" across all models suggests that sex is a weaker predictor of admission outcome.
</details>
Figure 8: Feature Correlation (Law School): Kendall Tau rank correlation between feature values and the predictions FairPFN compared to our baseline models. FairPFN produces predictions that correlate with fair noise terms $\epsilon_{UGPA}$ and $\epsilon_{LSAT}$ to a similar extent as the CFP baseline, variables which it has never seen in context-or at inference.
6 Future Work & Discussion
This study introduces FairPFN, a tabular foundation model pretrained to minimize the causal influence of protected attributes in binary classification tasks using solely observational data. FairPFN overcomes a key limitation in causal fairness by eliminating the need for user-supplied knowledge of the true causal graph, facilitating its use in complex, unidentifiable causal scenarios. This approach enhances the applicability of causal fairness and opens new research avenues.
Extended Problem Scope We limit our experimental scope to a simple testable setting with a single, binary protected attribute but believe that our prior and transformer architecture can be extended to handle multiple, non-binary protected attributes, addressing both their individual effects and intersectional interactions. We also suggest that FairPFN is capable of predicting not only a fair binary target but also accommodating multi-objective scenarios Lin et al. (2019), regression problems Hollmann et al. (2025), and time series Hoo et al. (2025). Additionally, FairPFN can generate causally fair versions of previously unfair observables, improving prediction explainability. This enables practitioners to use FairPFN as a fairness preprocessing technique while employing their preferred predictive models in practical applications.
PFNs for Causal ML FairPFN implicitly provides evidence for the efficacy of PFNs to perofm causal tasks, and we believe that our methodology can be extended to more complex challenges both within and outside of algorithmic fairness. In algorithmic fairness, one promising extension could be path-specific effect removal Chiappa (2019). For example, in medical diagnosis, distinguishing social effects of sex (e.g., sampling bias, male-focus of clinical studies) from biological effects (e.g., symptom differences across sex) is essential for fair and individualized treatment and care. Beyond fairness, we believe PFNs can predict interventional and counterfactual effects, with the latter potentially facilitating FairPFN’s evaluation in real-world contexts without relying on estimated causal models. Currently, FairPFN can also mitigate the influence of binary exogenous confounders, such as smoking, on the prediction of treatment success.
Alignment to Anti-Discrimination Law Future versions of FairPFN could also relax the assumption of exogenous protected attributes, enabling differentiation between legally admissible spurious effects and direct or indirect effects. Another key concept proposed by Plecko & Bareinboim (2024) introduces "Business Necessity" (BN) variables that allow the impact of the protected attribute to indirectly contribute to outcomes to achieve a specified business objectives, such as a research company hiring doctorate holders. In EU law, the analogous concept of "objective justification" necessitates a "proportionality test," asserting that justifiable indirect effects must persist only as necessary Weerts et al. (2023). We contend that proportionality bears a causal interpretation, akin to counterfactual explanations Wachter et al. (2018).
Broader Impact
This study attempts to overcome a current limitation in causal fairness, making what we believe is a useful framework for addressing algorithmic discrimination, more accessible to a wider variety of complex fairness problems. While the goal of this work is to have a positive impact on a problem we think is crucial, we acknowledge that we our perspective on fairness is limited in scope to align with EU/US legal doctrines of anti-discrimination. These doctrines are not representative of the world as a whole, and even within these systems, there are vastly different normative viewpoints regarding what constitutes algorithmic fairness and justice.
Acknowledgements
The authors of this work would like to thank the reviewers, editors and organizers of ICML ’25 for the opportunity to share our work and receive valuable feedback from the community. We would like to additionally thank the Zuse School ELIZA Master’s Scholarship Program for their financial and professional support of our main author. We would finally like to thank Sai Prasanna, Magnus Bühler, and Prof. Dr. Thorsten Schmidt for their insights, feedback, and discussion.
References
- Agarwal et al. (2018) Agarwal, A., Beygelzimer, A., Dudík, M., Langford, J., and Wallach, H. A reductions approach to fair classification. In Dy, J. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning (ICML’18), volume 80, pp. 60–69. Proceedings of Machine Learning Research, 2018.
- Angwin et al. (2016) Angwin, J., Larson, J., Mattu, S., and Kirchner, L. Machine bias. ProPublica, May, 23(2016):139–159, 2016.
- Barocas et al. (2023) Barocas, S., Hardt, M., and Narayanan, A. Fairness and Machine Learning: Limitations and opportunities. MIT Press, 2023.
- Bhaila et al. (2024) Bhaila, K., Van, M., Edemacu, K., Zhao, C., Chen, F., and Wu, X. Fair in-context learning via latent concept variables. 2024.
- Binkytė-Sadauskienė et al. (2022) Binkytė-Sadauskienė, R., Makhlouf, K., Pinzón, C., Zhioua, S., and Palamidessi, C. Causal discovery for fairness. 2022.
- Castelnovo et al. (2022) Castelnovo, A., Crupi, R., Greco, G., Regoli, D., Penco, I. G., and Cosentini, A. C. A clarification of the nuances in the fairness metrics landscape. Scientific Reports, 12(1), 2022.
- Chen & Guestrin (2016) Chen, T. and Guestrin, C. Xgboost: A scalable tree boosting system. In Krishnapuram, B., Shah, M., Smola, A., Aggarwal, C., Shen, D., and Rastogi, R. (eds.), Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’16), pp. 785–794, 2016.
- Chiappa (2019) Chiappa, S. Path-specific counterfactual fairness. In Hentenryck, P. V. and Zhou, Z.-H. (eds.), Proceedings of the Thirty-Third Conference on Artificial Intelligence (AAAI’19), volume 33, pp. 7801–7808. AAAI Press, 2019.
- Dai et al. (1997) Dai, H., Korb, K. B., Wallace, C. S., and Wu, X. A study of causal discovery with weak links and small samples. In Pollack, M. E. (ed.), Proceedings of the 15th International Joint Conference on Artificial Intelligence (IJCAI’95), 1997.
- Ding et al. (2021) Ding, F., Hardt, M., Miller, J., and Schmidt, L. Retiring adult: New datasets for fair machine learning. In Ranzato, M., Beygelzimer, A., Nguyen, K., Liang, P., Vaughan, J., and Dauphin, Y. (eds.), Proceedings of the 35th International Conference on Advances in Neural Information Processing Systems (NeurIPS’21), volume 34, pp. 6478–6490, 2021.
- Dua & Graff (2017) Dua, D. and Graff, C. Uci machine learning repository, 2017.
- Hardt et al. (2016) Hardt, M., Price, E., and Srebro, N. Equality of opportunity in supervised learning. In Lee, D., Sugiyama, M., von Luxburg, U., Guyon, I., and Garnett, R. (eds.), Proceedings of the 30th International Conference on Advances in Neural Information Processing Systems (NeurIPS’16), pp. 3323–3331, 2016.
- Hollmann et al. (2023) Hollmann, N., Müller, S., Eggensperger, K., and Hutter, F. Tabpfn: A transformer that solves small tabular classification problems in a second. In International Conference on Learning Representations (ICLR’23), 2023. Published online: iclr.cc.
- Hollmann et al. (2025) Hollmann, N., Müller, S., Purucker, L., Krishnakumar, A., Körfer, M., Hoo, S. B., Schirrmeister, R. T., and Hutter, F. Accurate predictions on small data with a tabular foundation model. Nature, 637(8045):319–326, 2025.
- Hoo et al. (2025) Hoo, S. B., Müller, S., Salinas, D., and Hutter, F. The tabular foundation model tabpfn outperforms specialized time series forecasting models based on simple features. 2025.
- Hoyer et al. (2008) Hoyer, P. O., Janzing, D., Mooij, J. M., Peters, J., and Schölkopf, B. Nonlinear causal discovery with additive noise models. In Platt, J. and Koller, D. (eds.), Proceedings of the 22 International Conference on Advances in Neural Information Processing Systems (NeurIPS’08), pp. 689–696, 2008.
- Kamishima et al. (2012) Kamishima, T., Akaho, S., Asoh, H., and Sakuma, J. Fairness-aware classifier with prejudice remover regularizer. In Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2012, Bristol, UK, September 24-28, 2012. Proceedings, Part II 23, pp. 35–50. Springer, 2012.
- Kusner et al. (2017) Kusner, M., Loftus, J., Russell, C., and Silva, R. Counterfactual fairness. In Guyon, I., von Luxburg, U., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R. (eds.), Proceedings of the 31st International Conference on Advances in Neural Information Processing Systems (NeurIPS’17), pp. 4069–4079, 2017.
- Lin et al. (2019) Lin, X., Zhen, H.-L., Li, Z., Zhang, Q., and Kwong, S. Pareto multi-task learning. 2019.
- Ma et al. (2023) Ma, J., Guo, R., Zhang, A., and Li, J. Learning for counterfactual fairness from observational data. In Singh, A. K., Sun, Y., Akoglu, L., Gunopulos, D., Yan, X., Kumar, R., Ozcan, F., and Ye, J. (eds.), Proceedings of the 29th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’23), pp. 1620–1630, 2023.
- Müller et al. (2022) Müller, S., Hollmann, N., Arango, S., Grabocka, J., and Hutter, F. Transformers can do bayesian inference. In Proceedings of the International Conference on Learning Representations (ICLR’22), 2022. Published online: iclr.cc.
- Pearl (2009) Pearl, J. Causality: Models, Reasoning and Inference. Cambridge University Press, 2009.
- Peters et al. (2011) Peters, J., Janzing, D., and Schölkopf, B. Causal inference on discrete data using additive noise models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(12):2436–2450, 2011.
- Peters et al. (2014) Peters, J., Mooij, J. M., Janzing, D., and Schölkopf, B. Causal discovery with continuous additive noise models. Journal of Machine Learning Research, 15:2009–2053, 2014.
- Plecko & Bareinboim (2024) Plecko, D. and Bareinboim, E. Causal fairness analysis. Foundations and Trends in Machine Learning, 17:304–589, 2024.
- Robertson et al. (2024) Robertson, J., Schmidt, T., Hutter, F., and Awad, N. A human-in-the-loop fairness-aware model selection framework for complex fairness objective landscapes. In Das, S., Green, B. P., Varshney, K., Ganapini, M., and Renda, A. (eds.), Proceedings of the Seventh AAAI/ACM Conference on AI, Ethics, and Society (AIES-24) - Full Archival Papers, October 21-23, 2024, San Jose, California, USA - Volume 1, pp. 1231–1242. AAAI Press, 2024.
- Schölkopf et al. (2012) Schölkopf, B., Janzing, D., Peters, J., Sgouritsa, E., Zhang, K., and Mooij, J. On causal and anticausal learning. In Langford, J. and Pineau, J. (eds.), Proceedings of the 29th International Conference on Machine Learning (ICML’12). Omnipress, 2012.
- Sharma & Kiciman (2020) Sharma, A. and Kiciman, E. Dowhy: An end-to-end library for causal inference. arXiv:2011.04216 [stat.ME], 2020.
- Wachter et al. (2018) Wachter, S., Mittelstadt, B., and Russell, C. Counterfactual explanations without opening the black box: Automated decisions and the gdpr. Harvard Journal of Law and Technology, 15:842–887, 2018.
- Weerts et al. (2023) Weerts, H., Xenidis, R., Tarissan, F., Olsen, H. P., and Pechenizkiy, M. Algorithmic unfairness through the lens of eu non-discrimination law. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, pp. 805–816, 2023.
- Weerts et al. (2024) Weerts, H., Pfisterer, F., Feurer, M., Eggensperger, K., Bergman, E., Awad, N., Vanschoren, J., Pechenizkiy, M., Bischl, B., and Hutter, F. Can fairness be automated? guidelines and opportunities for fairness-aware automl. Journal of Artificial Intelligence Research, 79:639–677, 2024.
- Wightman (1998) Wightman, L. F. Lsac national longitudinal bar passage study. lsac research report series, 1998.
Appendix A Real-World Datasets
Law School Admissions
The first dataset is the Law School Admissions dataset from the 1998 LSAC National Longitudinal Bar Passage Study Wightman (1998), which includes admissions data fr approximately 30,000 US law school applicants, revealing disparities in bar passage rates and first-year averages by ethnicity. We generate counterfactual data and measure causal effects using a slightly different causal model than what was originally proposed by Kusner et al. (2017), which additionally includes edges $\text{"UGPA"}→\text{"LSAT"}$ and $\text{"LSAT"}→\text{"FYA"}$ . These edges have a plausible temporal explanation, and create a more realistic scenario where "Race" and "Sex" have both a direct and indirect effect on first year averages.
Causal Modeling with DoWhy
We use the causal graph in Figure 5 (left) and observational data as inputs for the dowhy.gcm module Sharma & Kiciman (2020), employing an automated search using the dowhy.gcm.auto, which selects the best predictive model in a model zoo of non-linear tree-based models to represent each edge, minimizing either the MSE or negative F1-score depending on the distribution of target following Hoyer et al. (2008) and Peters et al. (2011). We apply each models generate counterfactual datasets, allowing for the estimation of the Average Treatment Effect (ATE) and absolute error (AE). We also use the compute_noise function to estimate noise terms $\epsilon_{GPA}$ and $\epsilon_{LSAT}$ for our CFP baseline.
Adult Census Income
The second dataset, derived from the 1994 US Census, is the Adult Census Income problem Dua & Graff (2017), containing demographic and income outcome data ( $INC≥ 50K$ ) for nearly 50,000 individuals We note that Adult has been heavily criticized in the fairness literature Ding et al. (2021) due to evidence of sampling bias and an arbitrary chosen income threshold, but elect to include it due to its widely accepted causal model and appearance as a benchmark in other similar studies Ma et al. (2023). We fit a causal model to assess the Average Treatment Effect (ATE) of the protected attribute $RACE$ , generate a counterfactual dataset, and calculate noise term values $\epsilon$ .
Appendix B Ablation Study
To evaluate FairPFN’s performance across datasets with varying characteristics, we conduct an ablation study comparing the prediction Average Treatment Effect (ATE) of FairPFN and Unfair under different noise levels, base rates of the protected attribute’s causal effect, and dataset sizes.
Base Rate Causal Effect
We analyze the distributions of prediction ATE from FairPFN and Unfair across five quintiles (Q1-Q5) of base ATE (Figure 9). FairPFN’s prediction ATE remains stable, while Unfair ’s prediction ATE increases linearly. In datasets within the Biased, Direct Effect, Level-Two, and Level-Three benchmark groups, where the protected attribute has a high base ATE (Q5), FairPFN exhibits a greater tendency for positive discrimination, resulting in negative prediction ATE values.
<details>
<summary>extracted/6522797/figures/effect_effect.png Details</summary>
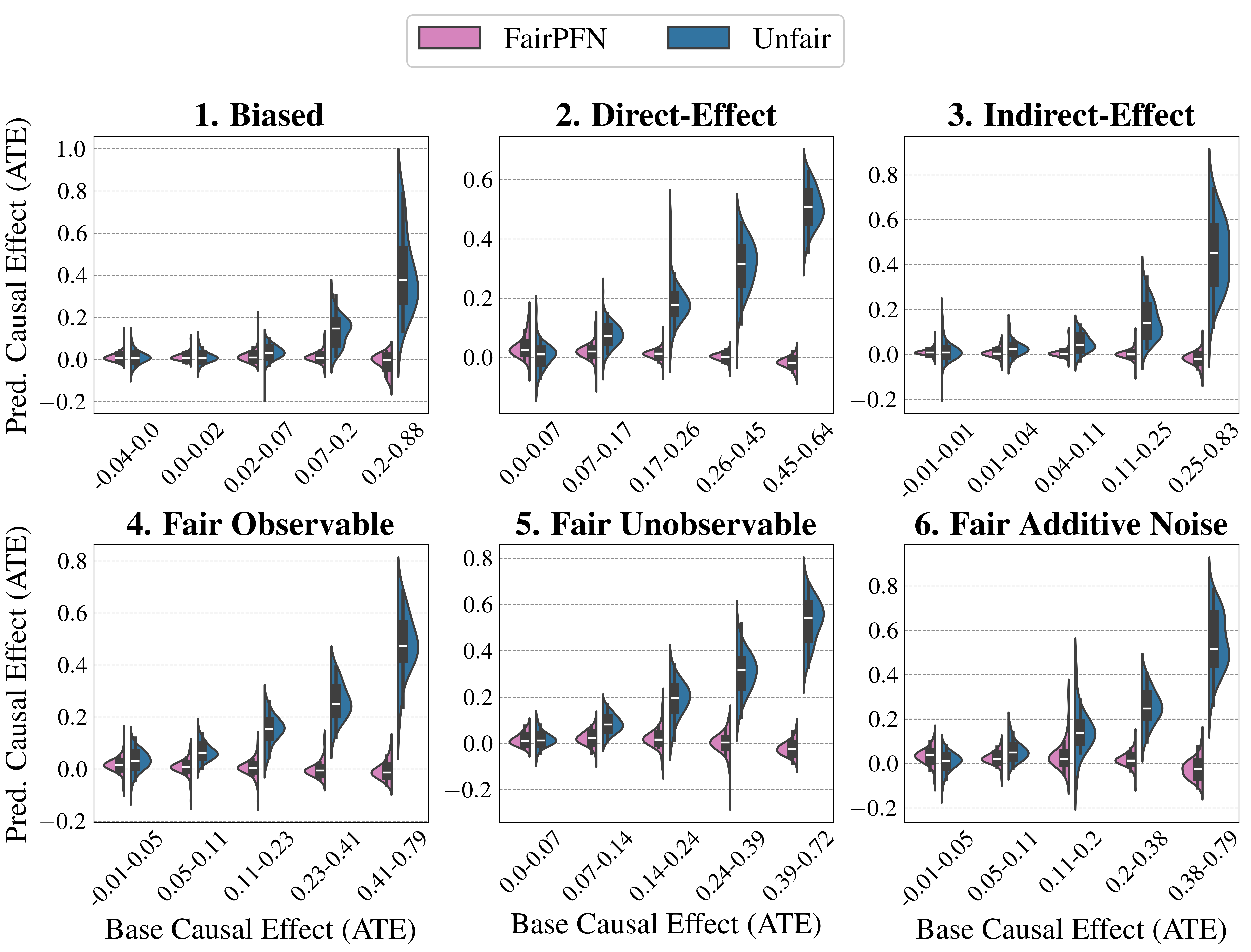
### Visual Description
## Violin Plots: Predicted Causal Effect vs. Base Causal Effect for Fairness Evaluation
### Overview
The image presents six violin plots, each comparing the predicted causal effect (ATE) against the base causal effect (ATE) under different fairness scenarios. Each plot is labeled with a number (1-6) and a descriptive title indicating the fairness setting being evaluated. The plots visually represent the distribution of predicted causal effects for varying base causal effects. Two colors are used: a purple shade representing "FairPFN" and a teal shade representing "Unfair". A legend is positioned in the top-right corner of the image.
### Components/Axes
* **X-axis:** "Base Causal Effect (ATE)". The scale ranges from approximately -0.04 to 0.88, with varying ranges for each subplot.
* **Y-axis:** "Pred. Causal Effect (ATE)". The scale ranges from approximately -0.2 to 1.0, with varying ranges for each subplot.
* **Legend:**
* Color: Purple (approximately #D87093) - Label: "FairPFN"
* Color: Teal (approximately #4682B4) - Label: "Unfair"
* **Subplot Titles:**
1. Biased
2. Direct-Effect
3. Indirect-Effect
4. Fair Observable
5. Fair Unobservable
6. Fair Additive Noise
### Detailed Analysis or Content Details
**Plot 1: Biased**
* The violin plot shows a distribution of points. The teal ("Unfair") distribution is wider and extends further into negative values than the purple ("FairPFN") distribution.
* Base Causal Effect (ATE) ranges from -0.04 to 0.02 for the teal distribution and 0.02 to 0.88 for the purple distribution.
* Predicted Causal Effect (ATE) ranges from -0.2 to 0.8 for both distributions.
**Plot 2: Direct-Effect**
* The teal ("Unfair") distribution is concentrated around lower base causal effects (0.00 to 0.17) and shows a wider spread in predicted causal effects. The purple ("FairPFN") distribution is more concentrated around higher base causal effects (0.17 to 0.45).
* Base Causal Effect (ATE) ranges from 0.00 to 0.45.
* Predicted Causal Effect (ATE) ranges from -0.2 to 0.6.
**Plot 3: Indirect-Effect**
* The teal ("Unfair") distribution is more spread out across the base causal effect range (0.01 to 0.83) and shows a wider range of predicted causal effects. The purple ("FairPFN") distribution is more concentrated around higher base causal effects (0.25 to 0.83).
* Base Causal Effect (ATE) ranges from 0.01 to 0.83.
* Predicted Causal Effect (ATE) ranges from -0.2 to 0.8.
**Plot 4: Fair Observable**
* Both the teal ("Unfair") and purple ("FairPFN") distributions are relatively similar, with a concentration of points around lower base causal effects (0.00 to 0.23).
* Base Causal Effect (ATE) ranges from -0.01 to 0.79.
* Predicted Causal Effect (ATE) ranges from -0.2 to 0.4.
**Plot 5: Fair Unobservable**
* The teal ("Unfair") distribution is more spread out across the base causal effect range (0.00 to 0.39) and shows a wider range of predicted causal effects. The purple ("FairPFN") distribution is more concentrated around higher base causal effects (0.24 to 0.39).
* Base Causal Effect (ATE) ranges from 0.00 to 0.39.
* Predicted Causal Effect (ATE) ranges from -0.2 to 0.4.
**Plot 6: Fair Additive Noise**
* The teal ("Unfair") distribution is concentrated around lower base causal effects (0.01 to 0.11) and shows a wider spread in predicted causal effects. The purple ("FairPFN") distribution is more concentrated around higher base causal effects (0.24 to 0.38).
* Base Causal Effect (ATE) ranges from -0.01 to 0.79.
* Predicted Causal Effect (ATE) ranges from -0.2 to 0.4.
### Key Observations
* In the "Biased" scenario (Plot 1), the "Unfair" distribution extends significantly into negative predicted causal effects, suggesting a potential for under-prediction.
* The "Direct-Effect" (Plot 2), "Indirect-Effect" (Plot 3), and "Fair Additive Noise" (Plot 6) scenarios show a clear separation between the "FairPFN" and "Unfair" distributions, with "FairPFN" generally predicting higher causal effects for higher base causal effects.
* The "Fair Observable" (Plot 4) scenario shows the least difference between the "FairPFN" and "Unfair" distributions.
* The "Fair Unobservable" (Plot 5) scenario shows a moderate difference between the "FairPFN" and "Unfair" distributions.
### Interpretation
The plots demonstrate the impact of different fairness settings on the predicted causal effect. The "FairPFN" method appears to mitigate bias in scenarios with direct and indirect effects, as well as additive noise, by aligning the predicted causal effect more closely with the base causal effect. The "Unfair" method, in contrast, exhibits more variability and potential for under-prediction, particularly in the "Biased" scenario. The "Fair Observable" scenario suggests that fairness is easier to achieve when the relevant variables are directly observable. The plots highlight the importance of considering fairness when developing and deploying causal inference models, and the potential benefits of using fairness-aware methods like "FairPFN". The violin plots effectively visualize the distribution of predicted causal effects under different conditions, allowing for a clear comparison of the performance of the "FairPFN" and "Unfair" methods. The varying ranges on the x-axis suggest that the base causal effect distributions differ across the scenarios.
</details>
Figure 9: Effect of Base ATE (Synthetic): Distributions of prediction ATE produced by FairPFN and Unfair over quintiles (Q1-Q5) of the protected attributes’s base causal effect (base ATE). FairPFN remains consistent across quintiles, sometimes over-correcting and producing a negative prediction ATE in Q5.
Dataset Noise
Analyzing dataset noise, indicated by the standard deviation (STD) $\sigma$ of exogenous noise in the structural equations Figure 10 shows that FairPFN retains consistency across varying noise levels. Conversely, Unfair exhibits decreased and more peaked distributions of prediction ATE as noise increases from Q1 to Q5, suggests that noise terms may obscure causal effects and diminish their observed impact in the data.
<details>
<summary>extracted/6522797/figures/noise-effect_by_group_synthetic.png Details</summary>
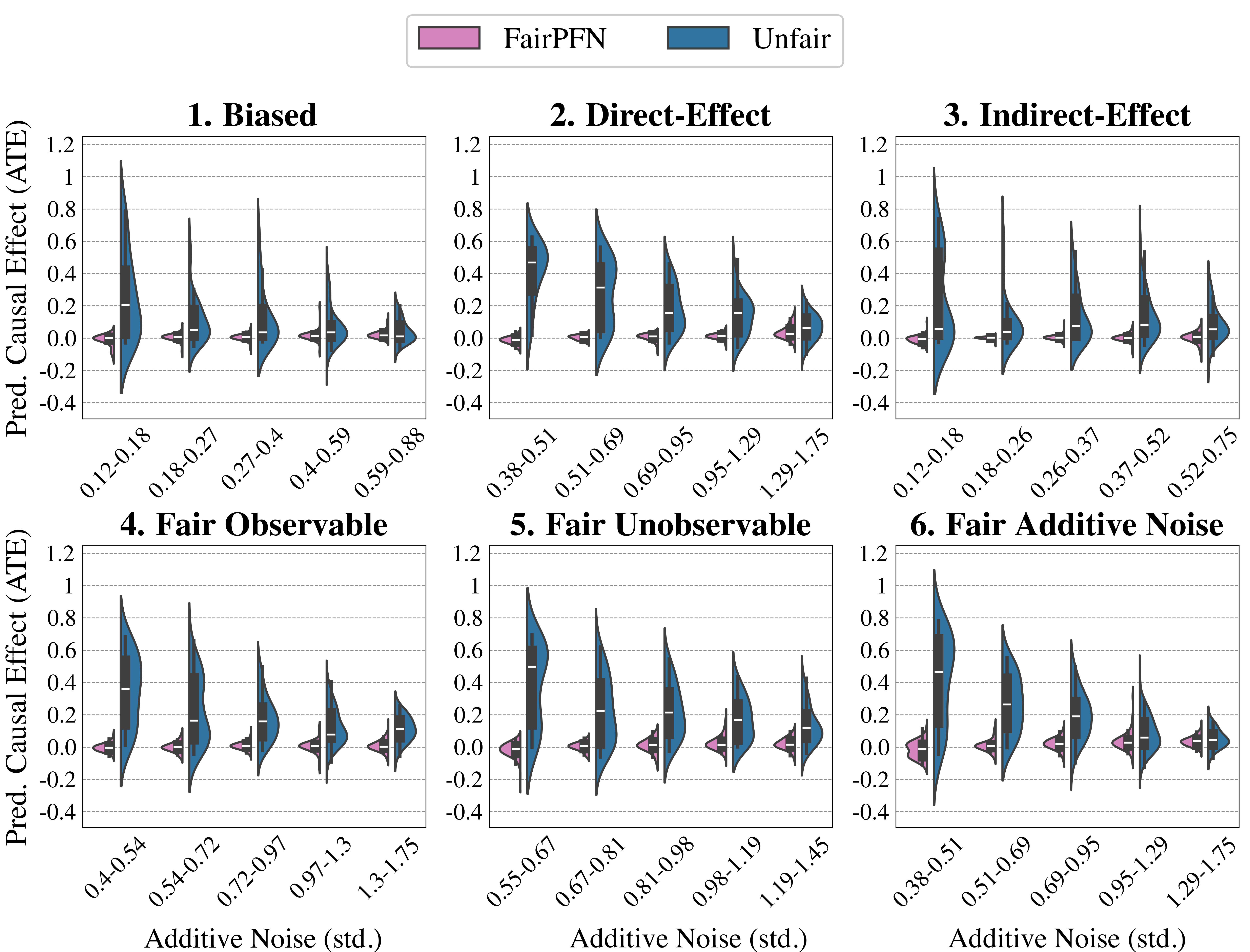
### Visual Description
## Violin Plots: Predicted Causal Effect (ATE) vs. Additive Noise
### Overview
The image presents six violin plots, arranged in a 2x3 grid, illustrating the relationship between predicted causal effect (Average Treatment Effect - ATE) and additive noise (standard deviation). Each plot represents a different scenario: Biased, Direct-Effect, Indirect-Effect, Fair Observable, Fair Unobservable, and Fair Additive Noise. Within each plot, data is presented for two conditions: "FairPFN" (represented in purple) and "Unfair" (represented in teal). Each violin plot also includes a black triangle indicating the mean value.
### Components/Axes
* **X-axis:** Additive Noise (std.) - Ranges vary for each plot, representing different standard deviation values.
* **Y-axis:** Pred. Causal Effect (ATE) - Scale from -0.4 to 1.2.
* **Legend (Top-Left):**
* FairPFN: Purple color
* Unfair: Teal color
* **Plot Titles:** Each plot is numbered (1-6) and labeled with a scenario name (Biased, Direct-Effect, Indirect-Effect, Fair Observable, Fair Unobservable, Fair Additive Noise).
### Detailed Analysis
**1. Biased:**
* X-axis: 0.2-0.18, 0.27-0.4, 0.59-0.88
* FairPFN (Purple): The violin shape is wide, indicating a broad distribution. The mean (black triangle) is approximately 0.4. The distribution appears to be centered around 0.4, with values ranging from approximately 0.1 to 0.8.
* Unfair (Teal): The violin shape is also wide. The mean is approximately 0.0. The distribution ranges from approximately -0.2 to 0.6.
**2. Direct-Effect:**
* X-axis: 0.38-0.51, 0.51-0.69, 0.69-0.95, 0.95-1.29, 1.29-1.75
* FairPFN (Purple): The violin shape is relatively narrow. The mean is approximately 0.6. The distribution is centered around 0.6, ranging from approximately 0.3 to 0.9.
* Unfair (Teal): The violin shape is narrow. The mean is approximately 0.0. The distribution ranges from approximately -0.2 to 0.4.
**3. Indirect-Effect:**
* X-axis: 0.12-0.18, 0.18-0.26, 0.26-0.37, 0.37-0.52, 0.52-0.75
* FairPFN (Purple): The violin shape is wide. The mean is approximately 0.4. The distribution ranges from approximately 0.1 to 0.8.
* Unfair (Teal): The violin shape is wide. The mean is approximately -0.1. The distribution ranges from approximately -0.3 to 0.4.
**4. Fair Observable:**
* X-axis: 0.4-0.54, 0.54-0.72, 0.72-0.97, 0.97-1.3, 1.3-1.75
* FairPFN (Purple): The violin shape is narrow. The mean is approximately 0.2. The distribution ranges from approximately -0.1 to 0.5.
* Unfair (Teal): The violin shape is narrow. The mean is approximately 0.0. The distribution ranges from approximately -0.2 to 0.3.
**5. Fair Unobservable:**
* X-axis: 0.55-0.67, 0.67-0.81, 0.81-0.98, 0.98-1.19, 1.19-1.45
* FairPFN (Purple): The violin shape is narrow. The mean is approximately 0.1. The distribution ranges from approximately -0.1 to 0.4.
* Unfair (Teal): The violin shape is narrow. The mean is approximately 0.0. The distribution ranges from approximately -0.2 to 0.3.
**6. Fair Additive Noise:**
* X-axis: 0.38-0.51, 0.51-0.69, 0.69-0.95, 0.95-1.29, 1.29-1.75
* FairPFN (Purple): The violin shape is narrow. The mean is approximately 0.1. The distribution ranges from approximately -0.1 to 0.4.
* Unfair (Teal): The violin shape is narrow. The mean is approximately 0.0. The distribution ranges from approximately -0.2 to 0.3.
### Key Observations
* In all scenarios, the "FairPFN" condition generally exhibits a higher predicted causal effect (ATE) than the "Unfair" condition.
* The "Unfair" condition often has a distribution centered around or below 0, suggesting a potential for negative or negligible causal effects.
* The width of the violin plots varies across scenarios, indicating different levels of variability in the predicted causal effects.
* The "Biased" and "Indirect-Effect" scenarios show the widest distributions for both conditions.
* As additive noise increases, the distributions tend to become more concentrated around the mean in the "Fair" scenarios.
### Interpretation
The plots demonstrate the impact of different fairness interventions ("FairPFN" vs. "Unfair") on predicted causal effects under varying conditions. The consistent positive shift in ATE for "FairPFN" suggests that the intervention is effective in mitigating bias and promoting fairer causal estimates. The scenarios (Biased, Direct-Effect, Indirect-Effect, etc.) likely represent different types of causal structures or confounding factors. The additive noise represents the level of randomness or uncertainty in the data.
The wider distributions in the "Biased" and "Indirect-Effect" scenarios suggest that these conditions are more sensitive to confounding or bias, requiring more robust fairness interventions. The narrowing of distributions with increasing additive noise in the "Fair" scenarios indicates that the fairness intervention is more stable and reliable in the presence of noise.
The consistent centering of the "Unfair" distributions around zero or below suggests that without fairness interventions, causal estimates may be systematically biased towards zero or even negative, potentially leading to incorrect conclusions about the effectiveness of treatments or interventions. The data suggests that the FairPFN method is effective in reducing bias and improving the accuracy of causal effect estimates, particularly in scenarios where bias is more prevalent.
</details>
Figure 10: Effect of Dataset Noise (Synthetic): Distributions of prediction ATE produced by FairPFN and Unfair over quintiles (Q1-Q5) of the standard deviation (std.) of exogenous noise terms in the data. FairPFN remains consistent across quintiles, while increased noise decreases the prediction ATE of Unfair
.
Dataset Size
Ablation studies on dataset size (Figure 11) show that FairPFN’s prediction ATE displays a tighter distribution with larger datasets, indicating improved performance in causal effect removal. This improvement arises from better identification of causal mechanisms as data availability increases, enabling the transformer to distinguish noise from causal effects.
Appendix C Future Extensions
In this section we expand upon our discussion of future extensions of FairPFN, in order to encourage the community to build upon and expand our approach.
Regression Problems
FairPFN can be pre-trained as a regression model with very little architectural changes by discretizing continuous output distributions into piecewise intervals and calculating misclassification costs in order to reflect the natural ordering between categories . Thoroughly evaluated in Hollmann et al. (2025), such post-proccessing strategies have shown strong performance in tabular regression problems and enable the effective use of classification architectures for continuous targets.
Protected Attributes in the Wild
While we limit the scope of this study to binary classification tasks with single, binary protected attributes, we acknowledge that real-world fairness-aware ML problems are often more complex than that. More precisely, protected attributes can be not only binary, but continuous or mulit-category, and discrimination may occur not only with respect to individual protected attributes but with respect to multiple and the interactions between them. Our prior is currently extensible to handle multiple by changing the number of protected attributes that are sampled into each synthetic dataset, removing the outgoing edges of all protected attributes to generate $y_{fair}$ , and informing the transformer about which variables are protected attributes. Changing the distribution of protected attributes is also possible, and simply requires transporting the protected attribute into the distribution(s) of choice either before or after its natural continuous value is propagated through the MLP during pre-training.
<details>
<summary>extracted/6522797/figures/size-effect_by_group_synthetic.png Details</summary>
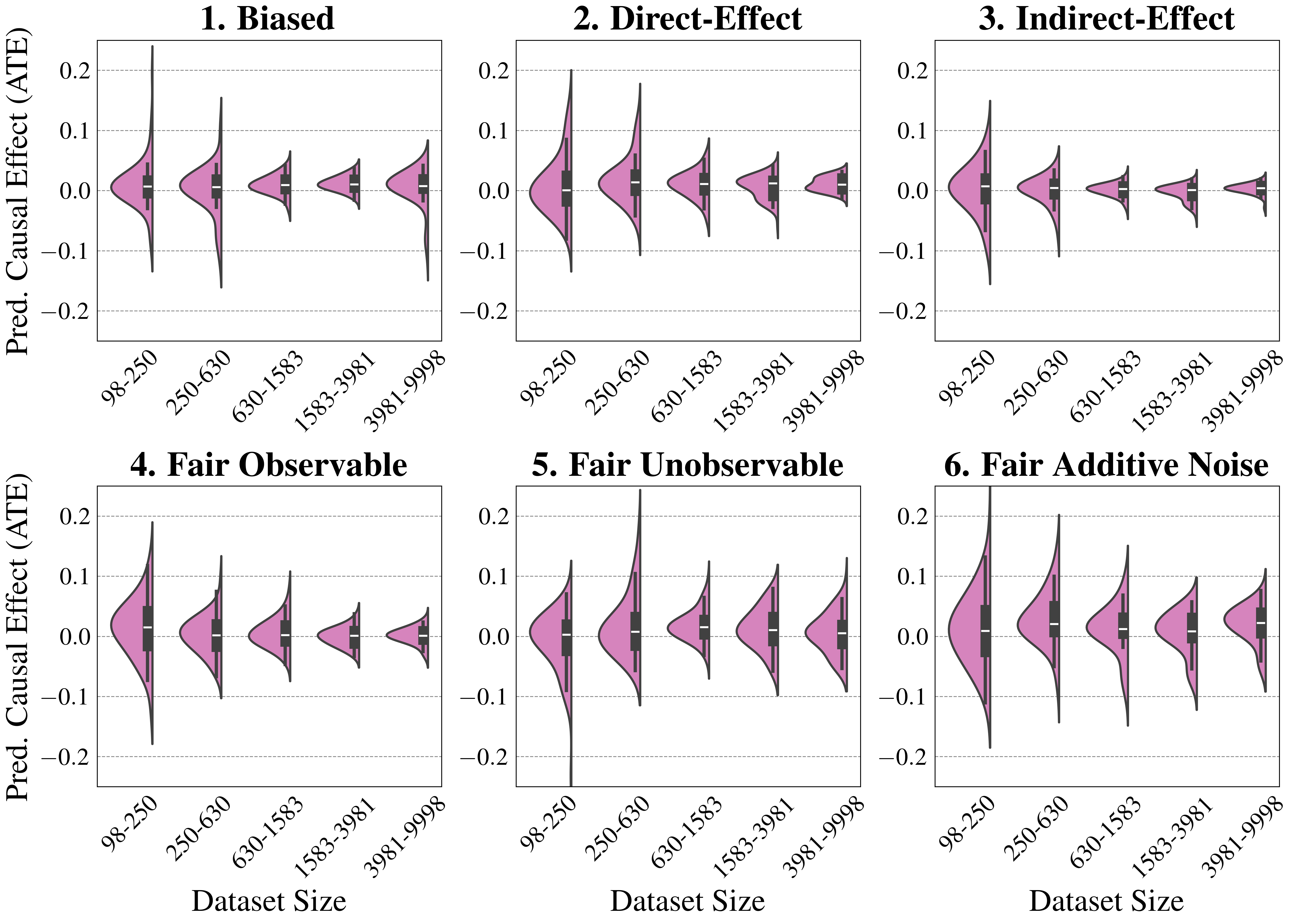
### Visual Description
## Violin Plots: Predicted Causal Effect (ATE) vs. Dataset Size
### Overview
The image presents six violin plots arranged in a 2x3 grid. Each plot visualizes the relationship between "Dataset Size" (x-axis) and "Pred. Causal Effect (ATE)" (y-axis) under different algorithmic conditions: Biased, Direct-Effect, Indirect-Effect, Fair Observable, Fair Unobservable, and Fair Additive Noise. Each violin plot also includes a black line representing the median and a gray triangle marking the mean.
### Components/Axes
* **X-axis Label:** "Dataset Size" with markers: 98-250, 250-630, 630-1583, 1583-3981, 3981-9998.
* **Y-axis Label:** "Pred. Causal Effect (ATE)" ranging from approximately -0.2 to 0.2.
* **Plot Titles:** 1. Biased, 2. Direct-Effect, 3. Indirect-Effect, 4. Fair Observable, 5. Fair Unobservable, 6. Fair Additive Noise. These are positioned at the top-center of each respective plot.
* **Violin Plots:** Each plot displays the distribution of the predicted causal effect for a given dataset size and algorithmic condition.
* **Median Line:** A black line within each violin plot indicates the median value.
* **Mean Triangle:** A gray triangle within each violin plot indicates the mean value.
### Detailed Analysis
**1. Biased:**
* Trend: The violin plots show a slight upward trend in the median and mean as dataset size increases.
* Data Points (approximate):
* 98-250: Median ≈ -0.02, Mean ≈ -0.03
* 250-630: Median ≈ 0.00, Mean ≈ 0.01
* 630-1583: Median ≈ 0.02, Mean ≈ 0.03
* 1583-3981: Median ≈ 0.04, Mean ≈ 0.05
* 3981-9998: Median ≈ 0.06, Mean ≈ 0.07
**2. Direct-Effect:**
* Trend: The violin plots show a clear upward trend in both the median and mean as dataset size increases. The distribution also appears to narrow with increasing dataset size.
* Data Points (approximate):
* 98-250: Median ≈ -0.05, Mean ≈ -0.06
* 250-630: Median ≈ 0.00, Mean ≈ 0.01
* 630-1583: Median ≈ 0.05, Mean ≈ 0.06
* 1583-3981: Median ≈ 0.10, Mean ≈ 0.11
* 3981-9998: Median ≈ 0.15, Mean ≈ 0.16
**3. Indirect-Effect:**
* Trend: The violin plots show a relatively flat trend with some variability. The median and mean remain close to zero across dataset sizes.
* Data Points (approximate):
* 98-250: Median ≈ 0.00, Mean ≈ 0.01
* 250-630: Median ≈ 0.00, Mean ≈ 0.00
* 630-1583: Median ≈ 0.00, Mean ≈ -0.01
* 1583-3981: Median ≈ 0.00, Mean ≈ 0.00
* 3981-9998: Median ≈ 0.00, Mean ≈ 0.01
**4. Fair Observable:**
* Trend: Similar to the "Biased" plot, there's a slight upward trend in the median and mean as dataset size increases.
* Data Points (approximate):
* 98-250: Median ≈ -0.02, Mean ≈ -0.03
* 250-630: Median ≈ 0.00, Mean ≈ 0.01
* 630-1583: Median ≈ 0.02, Mean ≈ 0.03
* 1583-3981: Median ≈ 0.04, Mean ≈ 0.05
* 3981-9998: Median ≈ 0.06, Mean ≈ 0.07
**5. Fair Unobservable:**
* Trend: The violin plots show a clear upward trend in both the median and mean as dataset size increases. The distribution also appears to narrow with increasing dataset size.
* Data Points (approximate):
* 98-250: Median ≈ -0.05, Mean ≈ -0.06
* 250-630: Median ≈ 0.00, Mean ≈ 0.01
* 630-1583: Median ≈ 0.05, Mean ≈ 0.06
* 1583-3981: Median ≈ 0.10, Mean ≈ 0.11
* 3981-9998: Median ≈ 0.15, Mean ≈ 0.16
**6. Fair Additive Noise:**
* Trend: The violin plots show a relatively flat trend with some variability. The median and mean remain close to zero across dataset sizes.
* Data Points (approximate):
* 98-250: Median ≈ 0.00, Mean ≈ 0.01
* 250-630: Median ≈ 0.00, Mean ≈ 0.00
* 630-1583: Median ≈ 0.00, Mean ≈ -0.01
* 1583-3981: Median ≈ 0.00, Mean ≈ 0.00
* 3981-9998: Median ≈ 0.00, Mean ≈ 0.01
### Key Observations
* The "Direct-Effect" and "Fair Unobservable" plots exhibit the most pronounced positive correlation between dataset size and predicted causal effect.
* The "Indirect-Effect" and "Fair Additive Noise" plots show minimal change in the predicted causal effect across different dataset sizes.
* The "Biased" and "Fair Observable" plots show a moderate positive correlation.
* The distributions in the "Direct-Effect" and "Fair Unobservable" plots become narrower with increasing dataset size, suggesting greater certainty in the predicted causal effect.
### Interpretation
The plots demonstrate how different algorithmic conditions influence the relationship between dataset size and the accuracy of predicted causal effects. The "Direct-Effect" and "Fair Unobservable" conditions benefit significantly from larger datasets, showing a clear positive trend in the predicted causal effect. This suggests that these algorithms are able to more accurately estimate the causal effect as more data becomes available. Conversely, the "Indirect-Effect" and "Fair Additive Noise" conditions are largely unaffected by dataset size, indicating that the predicted causal effect is relatively stable regardless of the amount of data. The "Biased" and "Fair Observable" conditions show a moderate improvement with larger datasets, but not as pronounced as the "Direct-Effect" and "Fair Unobservable" conditions.
The narrowing of the distributions in the "Direct-Effect" and "Fair Unobservable" plots with increasing dataset size suggests that larger datasets lead to more precise estimates of the causal effect, reducing uncertainty. This highlights the importance of data quantity in achieving reliable causal inference, particularly when using algorithms that are sensitive to dataset size. The differences between the plots underscore the impact of algorithmic design choices on the robustness and accuracy of causal effect estimation.
</details>
Figure 11: Effect of Dataset Size (Synthetic): Distributions of prediction ATE produced by FairPFN over quintiles (Q1-Q5) of dataset sizes from 100-10,000 (log-scale). FairPFN becomes better at its task of removing the causal effect of protected attributes when more data is available.
<details>
<summary>x4.png Details</summary>
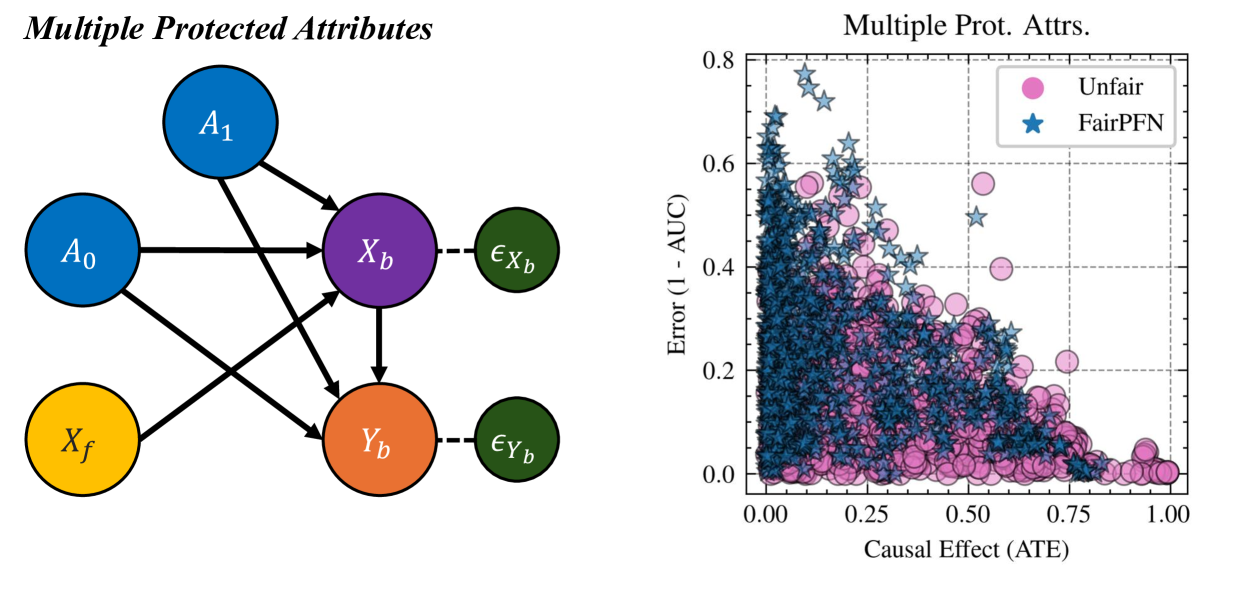
### Visual Description
\n
## Diagram & Scatter Plot: Multiple Protected Attributes & Multiple Prot. Attrs.
### Overview
The image contains two distinct visual elements: a diagram illustrating relationships between variables related to protected attributes, and a scatter plot comparing the performance of "Unfair" and "FairPFN" models based on causal effect and error.
### Components/Axes
**Diagram (Left):**
* **Nodes:** A₀ (blue), A₁ (blue), X<sub>f</sub> (yellow), X<sub>b</sub> (purple), Y<sub>b</sub> (orange), ε<sub>Xb</sub> (purple), ε<sub>Yb</sub> (orange).
* **Edges:** Arrows connecting the nodes, indicating relationships.
* **Title:** "Multiple Protected Attributes"
**Scatter Plot (Right):**
* **X-axis:** "Causal Effect (ATE)" ranging from approximately 0.00 to 1.00.
* **Y-axis:** "Error (1 - AUC)" ranging from approximately 0.00 to 0.80.
* **Legend:**
* "Unfair" (represented by red circles)
* "FairPFN" (represented by blue stars)
* **Title:** "Multiple Prot. Attrs."
### Detailed Analysis or Content Details
**Diagram (Left):**
The diagram depicts a causal model. A₀ and A₁ are protected attributes. X<sub>f</sub> represents features, and X<sub>b</sub> and Y<sub>b</sub> are intermediate variables. ε<sub>Xb</sub> and ε<sub>Yb</sub> represent error terms. The arrows indicate the following relationships:
* A₀ and A₁ both influence X<sub>b</sub>.
* X<sub>f</sub> influences X<sub>b</sub>.
* X<sub>b</sub> influences Y<sub>b</sub>.
* ε<sub>Xb</sub> directly influences X<sub>b</sub>.
* ε<sub>Yb</sub> directly influences Y<sub>b</sub>.
**Scatter Plot (Right):**
The scatter plot shows the relationship between Causal Effect (ATE) and Error (1 - AUC) for two models: Unfair and FairPFN.
* **Unfair (Red Circles):** The points generally form a downward sloping trend. At a Causal Effect of approximately 0.00, the Error is around 0.65. As the Causal Effect increases to 1.00, the Error decreases to approximately 0.05. There is significant spread in the data, indicating variability.
* **FairPFN (Blue Stars):** The points also show a downward sloping trend, but are more concentrated. At a Causal Effect of approximately 0.00, the Error is around 0.60. As the Causal Effect increases to 1.00, the Error decreases to approximately 0.10. The points are generally below the Unfair points for a given Causal Effect, suggesting better performance.
### Key Observations
* The Unfair model exhibits higher error rates, particularly at lower causal effects.
* The FairPFN model consistently demonstrates lower error rates across the range of causal effects.
* Both models show a negative correlation between Causal Effect and Error – as the causal effect increases, the error decreases.
* The spread of the Unfair model's data points is much larger than that of the FairPFN model, indicating greater instability or sensitivity to variations.
### Interpretation
The diagram illustrates a scenario where multiple protected attributes (A₀ and A₁) can influence outcomes through intermediate variables (X<sub>b</sub> and Y<sub>b</sub>). The scatter plot compares the performance of an "Unfair" model and a "FairPFN" model in this context. The results suggest that the FairPFN model is more effective at mitigating bias and achieving lower error rates, especially when the causal effect is high. The downward trend in both models indicates that as the causal effect becomes stronger, the model's ability to predict accurately improves. The larger spread in the Unfair model's data suggests that it is more susceptible to variations in the data or sensitive to the protected attributes, leading to less consistent performance.
The FairPFN model appears to be designed to address fairness concerns by reducing the error rate while maintaining a reasonable causal effect. The data suggests that it successfully achieves this goal, offering a more robust and equitable solution compared to the Unfair model. The diagram provides the theoretical context for understanding why fairness interventions are necessary, while the scatter plot demonstrates the practical benefits of using a fairness-aware model like FairPFN.
</details>
Figure 12: Multiple Protected Attributes (Synthetic): Distributions of prediction ATE and predictive accuracy produced by FairPFN vs the Unfair predictor when there are multiple protected attributes. This violates FairPFN’s prior assumptions and reverts it to a normal classifier.
<details>
<summary>x5.png Details</summary>
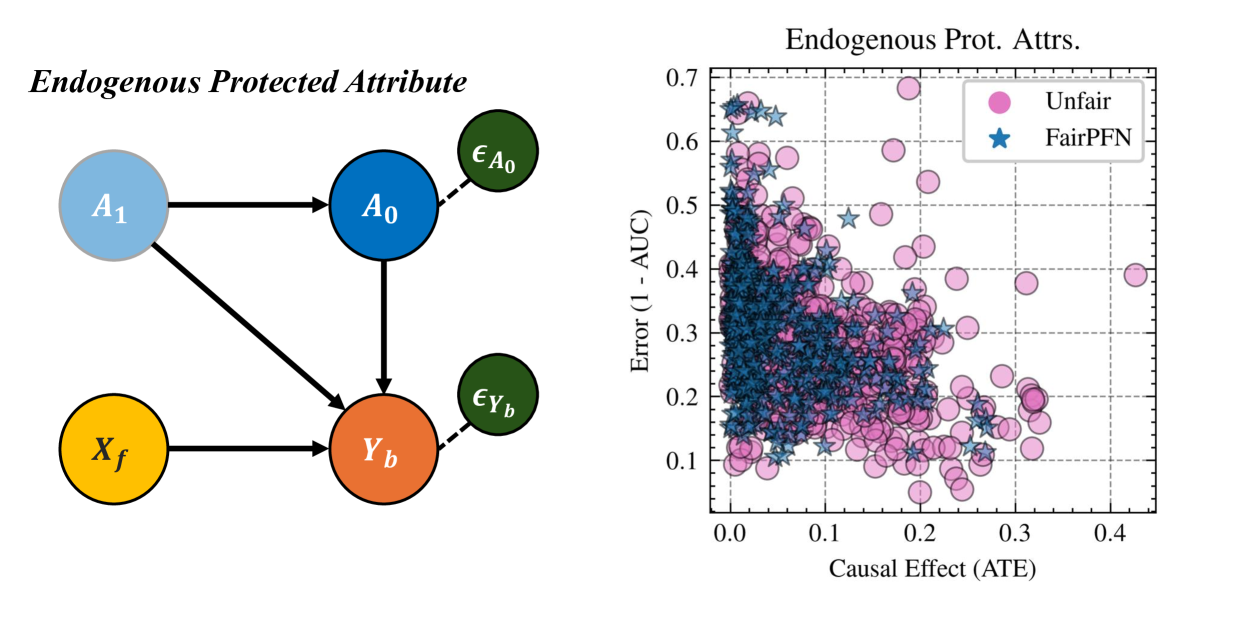
### Visual Description
## Diagram: Causal Diagram & Scatter Plot - Fairness Evaluation
### Overview
The image presents two distinct but related elements: a causal diagram illustrating the relationship between protected attributes, features, and outcomes, and a scatter plot comparing the performance of "Unfair" and "FairPFN" models based on causal effect and error.
### Components/Axes
**Causal Diagram:**
* **Nodes:** A<sub>1</sub> (light blue), A<sub>0</sub> (blue), X<sub>f</sub> (yellow), Y<sub>b</sub> (orange).
* **Edges:** Arrows indicating causal relationships.
* **Error Terms:** ε<sub>A0</sub>, ε<sub>Yb</sub> (text labels near nodes A<sub>0</sub> and Y<sub>b</sub> respectively).
* **Title:** "Endogenous Protected Attribute" (top-left).
**Scatter Plot:**
* **X-axis:** "Causal Effect (ATE)" ranging from approximately 0.0 to 0.4.
* **Y-axis:** "Error (1 - AUC)" ranging from approximately 0.05 to 0.7.
* **Legend:**
* "Unfair" (pink circles)
* "FairPFN" (blue stars)
* **Title:** "Endogenous Prot. Attrs." (top-center).
* **Grid:** A light gray grid is present in the background.
### Detailed Analysis or Content Details
**Causal Diagram:**
The diagram shows A<sub>1</sub> influencing A<sub>0</sub>, and X<sub>f</sub> influencing Y<sub>b</sub>. Both A<sub>0</sub> and X<sub>f</sub> influence Y<sub>b</sub>. The error terms ε<sub>A0</sub> and ε<sub>Yb</sub> represent unmodeled influences on A<sub>0</sub> and Y<sub>b</sub>, respectively.
**Scatter Plot:**
The scatter plot displays the relationship between Causal Effect (ATE) and Error (1 - AUC) for two model types.
* **Unfair (Pink Circles):** The pink circles are densely clustered in the top-left corner, with a general downward trend as the Causal Effect increases.
* Approximately 20-30% of the points have a Causal Effect between 0.0 and 0.1, with Error values ranging from 0.3 to 0.6.
* As the Causal Effect increases to around 0.2, the Error generally decreases, with values ranging from 0.15 to 0.4.
* At a Causal Effect of approximately 0.3, the Error values are mostly below 0.2.
* There are a few outliers with high Error values (above 0.5) even at low Causal Effect values.
* **FairPFN (Blue Stars):** The blue stars are more dispersed than the pink circles.
* The stars generally exhibit lower Error values for a given Causal Effect compared to the pink circles.
* Approximately 10-15 stars have a Causal Effect between 0.0 and 0.1, with Error values ranging from 0.1 to 0.3.
* As the Causal Effect increases to around 0.2, the Error values are generally below 0.2.
* At a Causal Effect of approximately 0.3, the Error values are mostly below 0.1.
* There are a few outliers with higher Error values (around 0.4) at higher Causal Effect values.
### Key Observations
* The "FairPFN" model consistently demonstrates lower Error values for a given Causal Effect compared to the "Unfair" model.
* The "Unfair" model exhibits a strong negative correlation between Causal Effect and Error, suggesting that increasing the Causal Effect leads to a reduction in Error.
* Both models have outliers, indicating that there are instances where their performance deviates significantly from the general trend.
* The scatter plot suggests a trade-off between Causal Effect and Error, with the "FairPFN" model offering a better balance between the two.
### Interpretation
The causal diagram illustrates a scenario where a protected attribute (A<sub>1</sub>) influences an observed attribute (A<sub>0</sub>), which in turn affects the outcome (Y<sub>b</sub>) along with other features (X<sub>f</sub>). The error terms indicate that the model doesn't capture all the factors influencing these variables. This setup is prone to unfairness if the model doesn't account for the causal relationships.
The scatter plot demonstrates the effectiveness of the "FairPFN" model in mitigating unfairness. By achieving lower Error values for a given Causal Effect, the "FairPFN" model suggests a better trade-off between predictive accuracy and fairness. The "Unfair" model, while potentially achieving lower Error values at higher Causal Effects, may be doing so at the cost of exacerbating unfairness. The outliers in both models suggest that there are specific instances where the models struggle to generalize, potentially due to unmodeled factors or data limitations.
The diagram and plot together suggest that incorporating causal reasoning into model design (as done in FairPFN) can lead to fairer and more robust predictions, especially in scenarios where protected attributes have an endogenous influence on the outcome. The plot provides empirical evidence supporting the claim that FairPFN reduces error while maintaining a reasonable causal effect.
</details>
Figure 13: Endogenous Protected Attributes (Synthetic): Distributions of prediction ATE and predictive accuracy produced by FairPFN vs the Unfair predictor when the protected attribute is endogenous. This violates FairPFN’s prior assumptions and reverts it to a normal classifier.
<details>
<summary>extracted/6522797/figures/complexity.png Details</summary>
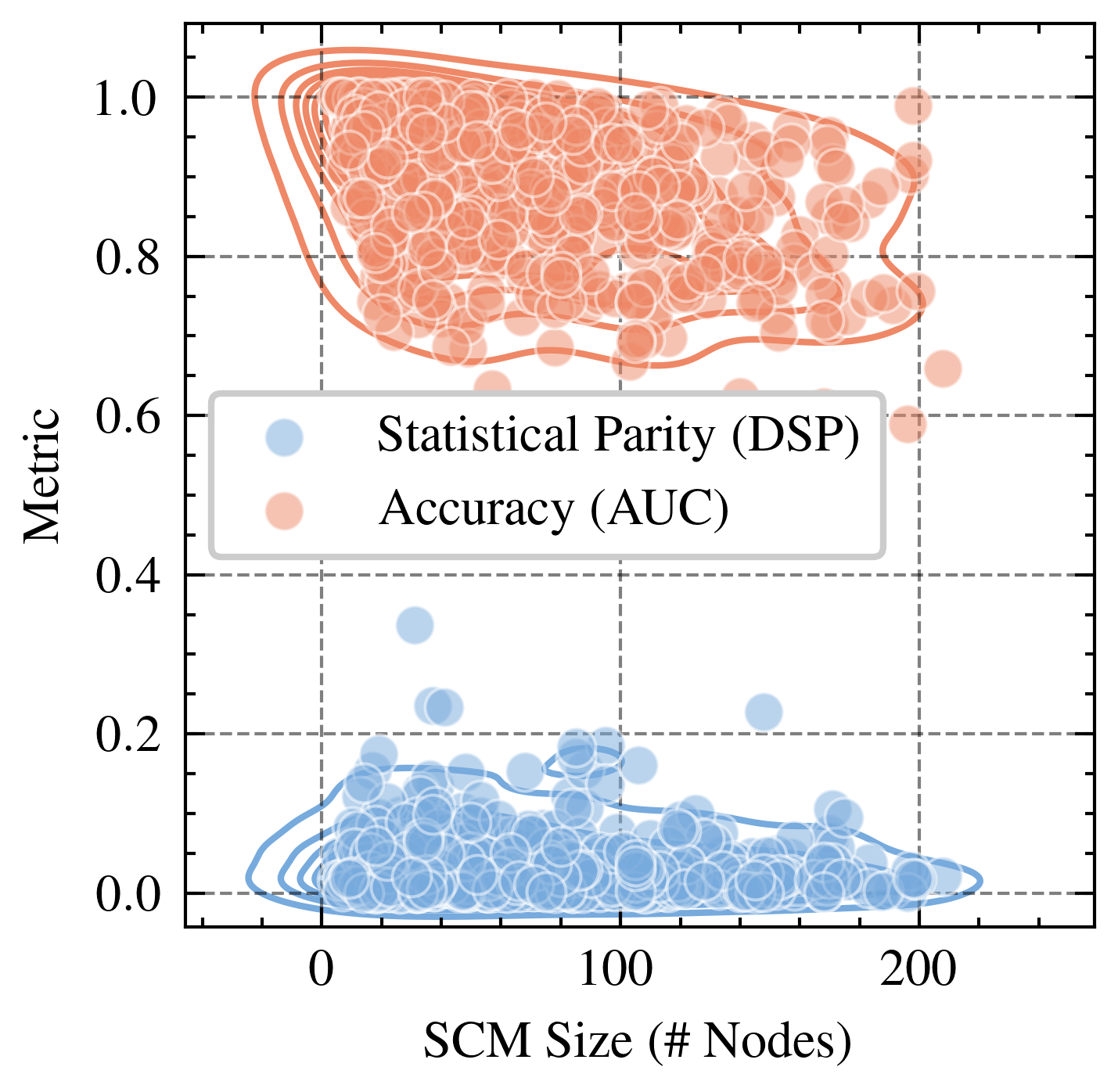
### Visual Description
\n
## Scatter Plot: Metric vs. SCM Size
### Overview
This image presents a scatter plot visualizing the relationship between "SCM Size (# Nodes)" and a "Metric" (specifically, Statistical Parity (DSP) and Accuracy (AUC)). The plot displays two distinct data series represented by differently colored scatter points.
### Components/Axes
* **X-axis:** "SCM Size (# Nodes)". Scale ranges from approximately 0 to 230.
* **Y-axis:** "Metric". Scale ranges from approximately 0 to 1.1.
* **Legend:** Located in the top-left corner.
* Blue circles: "Statistical Parity (DSP)"
* Orange circles: "Accuracy (AUC)"
* **Data Series 1:** Statistical Parity (DSP) - Represented by blue circles.
* **Data Series 2:** Accuracy (AUC) - Represented by orange circles.
* Horizontal dashed lines at Metric values of 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* Vertical dashed lines at SCM Size values of 0, 100, and 200.
### Detailed Analysis
**Statistical Parity (DSP) - Blue Circles:**
The blue data points cluster in the lower portion of the plot. The trend is relatively flat, with a slight upward slope initially, then leveling off.
* At SCM Size ≈ 0, the Metric (DSP) ranges from approximately 0.05 to 0.15.
* At SCM Size ≈ 50, the Metric (DSP) ranges from approximately 0.1 to 0.2.
* At SCM Size ≈ 100, the Metric (DSP) ranges from approximately 0.1 to 0.25.
* At SCM Size ≈ 200, the Metric (DSP) ranges from approximately 0.1 to 0.25.
There is a noticeable concentration of points around a Metric value of 0.15-0.2.
**Accuracy (AUC) - Orange Circles:**
The orange data points cluster in the upper portion of the plot. The trend is generally flat, maintaining a high Metric value.
* At SCM Size ≈ 0, the Metric (AUC) ranges from approximately 0.8 to 0.95.
* At SCM Size ≈ 50, the Metric (AUC) ranges from approximately 0.85 to 1.0.
* At SCM Size ≈ 100, the Metric (AUC) ranges from approximately 0.85 to 1.0.
* At SCM Size ≈ 200, the Metric (AUC) ranges from approximately 0.75 to 1.0.
There is a slight downward trend in the Metric (AUC) as the SCM Size increases, but it remains consistently high.
### Key Observations
* There is a clear separation between the two data series. Accuracy (AUC) consistently outperforms Statistical Parity (DSP) across all SCM sizes.
* Statistical Parity (DSP) remains relatively low, even with increasing SCM size.
* Accuracy (AUC) remains high, but shows a slight decrease as SCM size increases.
* The spread of the orange points is wider at higher SCM sizes, indicating more variability in accuracy.
### Interpretation
The data suggests a trade-off between accuracy and statistical parity as the size of the SCM (likely a model or system component) increases. While increasing the SCM size does not significantly improve statistical parity (and may even slightly decrease it), it maintains a high level of accuracy. The consistent high accuracy, contrasted with the low statistical parity, indicates a potential bias in the model or system. The slight decrease in accuracy at larger SCM sizes could be due to overfitting or increased complexity. The horizontal dashed lines provide a visual reference for the metric values, highlighting the significant difference between the two metrics. The vertical dashed lines help to visualize the relationship between the SCM size and the metrics at specific intervals. The plot demonstrates that achieving high accuracy does not necessarily equate to fairness (as measured by statistical parity). Further investigation is needed to understand the source of the bias and explore methods to improve statistical parity without sacrificing accuracy.
</details>
Figure 14: Graph Complexity (Prior): Distributions of Statistical Parity and predictive accuracy produced by FairPFN on prior samples with graph complexity between 10 and 200 nodes. As graph complexity increases, accuracy drops but fairness remains constant.
Appendix D Supplementary Results
<details>
<summary>extracted/6522797/figures/roc_by_group_synthetic_new.png Details</summary>
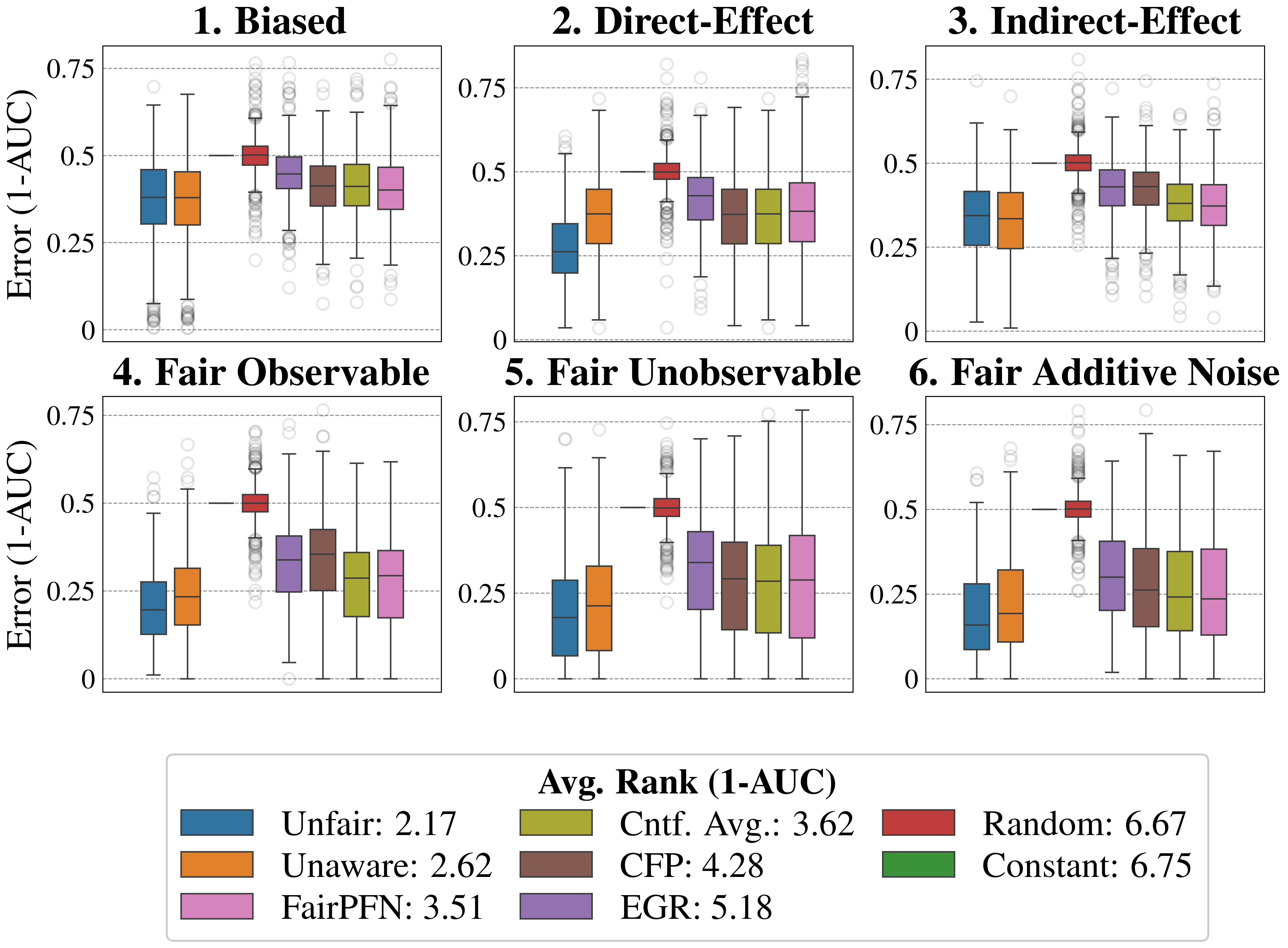
### Visual Description
## Box Plot: Error (1-AUC) Across Fairness Interventions
### Overview
This image presents a 2x3 grid of box plots, each representing the distribution of "Error (1-AUC)" for different fairness interventions under various fairness definitions. The plots compare the performance of several algorithms (Unfair, Unaware, FairPFN, CFP, EGR, Random, Constant) across six different scenarios: Biased, Direct-Effect, Indirect-Effect, Fair Observable, Fair Unobservable, and Fair Additive Noise.
### Components/Axes
* **Y-axis:** "Error (1-AUC)", ranging from approximately 0 to 0.75.
* **X-axis:** Implicitly represents the different algorithms being compared within each scenario.
* **Box Plots:** Each box plot represents the distribution of Error (1-AUC) for a specific algorithm in a specific scenario. The box represents the interquartile range (IQR), the line inside the box represents the median, and the whiskers extend to the minimum and maximum values within 1.5 times the IQR. Outliers are shown as individual points.
* **Legend:** Located at the bottom-right of the image, it maps colors to the following algorithms:
* Unfair (Light Blue): Avg. Rank (1-AUC) = 2.17
* Unaware (Orange): Avg. Rank (1-AUC) = 2.62
* FairPFN (Purple): Avg. Rank (1-AUC) = 3.51
* CFP (Dark Orange): Avg. Rank (1-AUC) = 4.28
* EGR (Violet): Avg. Rank (1-AUC) = 5.18
* Random (Red): Avg. Rank (1-AUC) = 6.67
* Constant (Dark Green): Avg. Rank (1-AUC) = 6.75
* **Titles:** Each subplot is numbered and labeled with a fairness scenario: 1. Biased, 2. Direct-Effect, 3. Indirect-Effect, 4. Fair Observable, 5. Fair Unobservable, 6. Fair Additive Noise.
### Detailed Analysis
Here's a breakdown of the trends and approximate values observed in each subplot:
**1. Biased:**
* Unfair (Light Blue): Median around 0.35, IQR from 0.25 to 0.45.
* Unaware (Orange): Median around 0.4, IQR from 0.3 to 0.5.
* FairPFN (Purple): Median around 0.5, IQR from 0.4 to 0.6.
* CFP (Dark Orange): Median around 0.55, IQR from 0.45 to 0.65.
* EGR (Violet): Median around 0.6, IQR from 0.5 to 0.7.
* Random (Red): Median around 0.5, IQR from 0.4 to 0.6.
* Constant (Dark Green): Median around 0.5, IQR from 0.4 to 0.6.
**2. Direct-Effect:**
* Unfair (Light Blue): Median around 0.3, IQR from 0.2 to 0.4.
* Unaware (Orange): Median around 0.4, IQR from 0.3 to 0.5.
* FairPFN (Purple): Median around 0.5, IQR from 0.4 to 0.6.
* CFP (Dark Orange): Median around 0.55, IQR from 0.45 to 0.65.
* EGR (Violet): Median around 0.6, IQR from 0.5 to 0.7.
* Random (Red): Median around 0.5, IQR from 0.4 to 0.6.
* Constant (Dark Green): Median around 0.5, IQR from 0.4 to 0.6.
**3. Indirect-Effect:**
* Unfair (Light Blue): Median around 0.35, IQR from 0.25 to 0.45.
* Unaware (Orange): Median around 0.4, IQR from 0.3 to 0.5.
* FairPFN (Purple): Median around 0.5, IQR from 0.4 to 0.6.
* CFP (Dark Orange): Median around 0.55, IQR from 0.45 to 0.65.
* EGR (Violet): Median around 0.6, IQR from 0.5 to 0.7.
* Random (Red): Median around 0.5, IQR from 0.4 to 0.6.
* Constant (Dark Green): Median around 0.5, IQR from 0.4 to 0.6.
**4. Fair Observable:**
* Unfair (Light Blue): Median around 0.25, IQR from 0.2 to 0.35.
* Unaware (Orange): Median around 0.3, IQR from 0.2 to 0.4.
* FairPFN (Purple): Median around 0.4, IQR from 0.3 to 0.5.
* CFP (Dark Orange): Median around 0.45, IQR from 0.35 to 0.55.
* EGR (Violet): Median around 0.5, IQR from 0.4 to 0.6.
* Random (Red): Median around 0.45, IQR from 0.35 to 0.55.
* Constant (Dark Green): Median around 0.5, IQR from 0.4 to 0.6.
**5. Fair Unobservable:**
* Unfair (Light Blue): Median around 0.3, IQR from 0.2 to 0.4.
* Unaware (Orange): Median around 0.35, IQR from 0.25 to 0.45.
* FairPFN (Purple): Median around 0.45, IQR from 0.35 to 0.55.
* CFP (Dark Orange): Median around 0.5, IQR from 0.4 to 0.6.
* EGR (Violet): Median around 0.55, IQR from 0.45 to 0.65.
* Random (Red): Median around 0.5, IQR from 0.4 to 0.6.
* Constant (Dark Green): Median around 0.5, IQR from 0.4 to 0.6.
**6. Fair Additive Noise:**
* Unfair (Light Blue): Median around 0.3, IQR from 0.2 to 0.4.
* Unaware (Orange): Median around 0.35, IQR from 0.25 to 0.45.
* FairPFN (Purple): Median around 0.45, IQR from 0.35 to 0.55.
* CFP (Dark Orange): Median around 0.5, IQR from 0.4 to 0.6.
* EGR (Violet): Median around 0.55, IQR from 0.45 to 0.65.
* Random (Red): Median around 0.5, IQR from 0.4 to 0.6.
* Constant (Dark Green): Median around 0.5, IQR from 0.4 to 0.6.
### Key Observations
* The "Unfair" and "Unaware" algorithms generally exhibit lower error rates compared to the fairness-aware algorithms (FairPFN, CFP, EGR) in the "Biased", "Direct-Effect", and "Indirect-Effect" scenarios.
* In the "Fair" scenarios (Observable, Unobservable, Additive Noise), the error rates tend to increase for all algorithms, but the differences between them become less pronounced.
* The "Constant" and "Random" algorithms consistently show similar performance across all scenarios, with median error rates around 0.5.
* The average rank values in the legend indicate that "Unfair" has the lowest average rank (2.17), suggesting it performs best overall, while "Constant" and "Random" have the highest ranks (6.75 and 6.67, respectively).
### Interpretation
The data suggests a trade-off between fairness and accuracy. Algorithms that do not explicitly address fairness ("Unfair" and "Unaware") achieve lower error rates in scenarios where bias is present, but this comes at the cost of potentially perpetuating or exacerbating unfairness. Fairness-aware algorithms (FairPFN, CFP, EGR) generally have higher error rates, but they aim to mitigate bias and promote fairness.
The increased error rates in the "Fair" scenarios indicate that enforcing fairness constraints can lead to a decrease in overall accuracy. This is a common phenomenon in fairness-aware machine learning. The similar performance of the "Constant" and "Random" algorithms suggests that simply adding noise or using a constant prediction does not necessarily improve fairness or accuracy.
The average rank values provide a quantitative measure of the overall performance of each algorithm. The fact that "Unfair" has the lowest average rank highlights the accuracy-fairness trade-off. The choice of which algorithm to use depends on the specific application and the relative importance of accuracy and fairness.
</details>
Figure 15: Predictive Error (Synthetic): Predictive error (1-AUC) of FairPFN compared to our baselines. FairPFN maintains a competitive level of predictive error with traditional ML algorithms, achieving an average rank of 3.51 out of 7.
<details>
<summary>extracted/6522797/figures/lawschool_dist.png Details</summary>
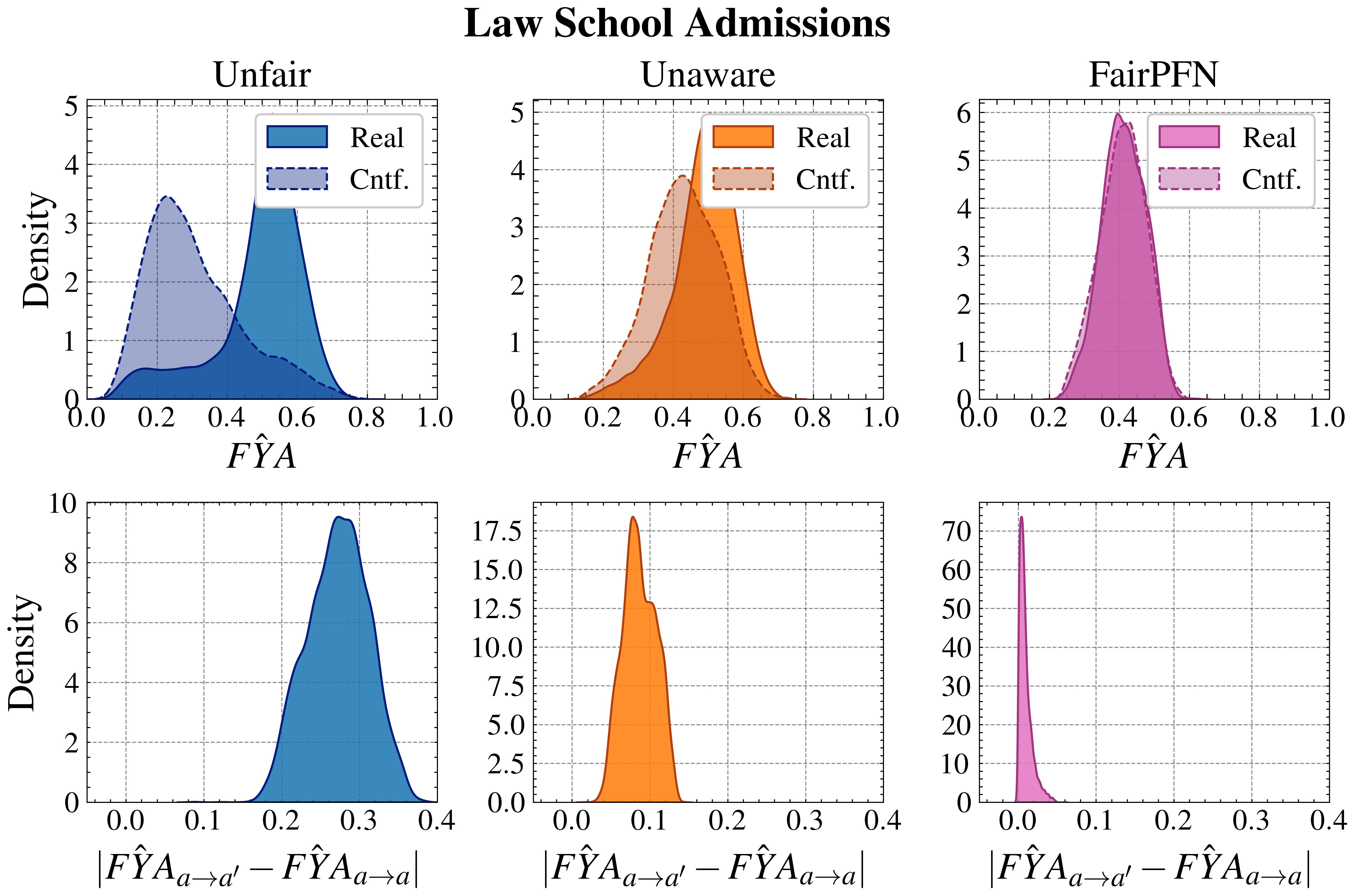
### Visual Description
## Charts: Law School Admissions - Distribution Analysis
### Overview
The image presents six density plots comparing "Real" and "Cntf." (likely representing "Counterfactual") distributions for three different scenarios: "Unfair", "Unaware", and "FairPFN". The x-axis in the top row represents "FŶA" (likely a predicted fairness metric), and the x-axis in the bottom row represents the absolute difference between two fairness predictions. The y-axis in all plots represents "Density".
### Components/Axes
* **Title:** Law School Admissions
* **Subtitles:** Unfair, Unaware, FairPFN (arranged horizontally across the top row)
* **X-axis (Top Row):** FŶA, ranging from 0.0 to 1.0, with increments of 0.1.
* **X-axis (Bottom Row):** |FŶA<sub>α→α'</sub> - FŶA<sub>α→α</sub>|, ranging from 0.0 to 0.4, with increments of 0.1.
* **Y-axis (All Plots):** Density, ranging from 0.0 to approximately 5.0 (top row) and 8.0 (bottom row).
* **Legend:**
* Blue: Real
* Hatched Blue: Cntf. (in "Unfair" plot)
* Orange: Real
* Hatched Orange: Cntf. (in "Unaware" plot)
* Magenta: Real
* Hatched Magenta: Cntf. (in "FairPFN" plot)
### Detailed Analysis
**Unfair (Top-Left)**
* **Real (Blue):** The distribution is bimodal, with peaks around 0.25 and 0.65. Density reaches a maximum of approximately 4.2 at 0.25 and 3.8 at 0.65.
* **Cntf. (Hatched Blue):** The distribution is similar to "Real" but slightly smoother, with peaks around 0.28 and 0.62. Density reaches a maximum of approximately 3.5 at 0.28 and 3.2 at 0.62.
* **Trend:** Both distributions exhibit a similar bimodal pattern.
**Unaware (Top-Center)**
* **Real (Orange):** The distribution is unimodal, peaking around 0.5. Density reaches a maximum of approximately 4.8 at 0.5.
* **Cntf. (Hatched Orange):** The distribution is also unimodal, peaking around 0.5, but is more spread out than "Real". Density reaches a maximum of approximately 3.8 at 0.5.
* **Trend:** Both distributions are unimodal, centered around 0.5.
**FairPFN (Top-Right)**
* **Real (Magenta):** The distribution is unimodal, peaking around 0.8. Density reaches a maximum of approximately 5.0 at 0.8.
* **Cntf. (Hatched Magenta):** The distribution is also unimodal, peaking around 0.8, but is more spread out than "Real". Density reaches a maximum of approximately 4.0 at 0.8.
* **Trend:** Both distributions are unimodal, centered around 0.8.
**Unfair (Bottom-Left)**
* **Real (Blue):** The distribution is unimodal, peaking around 0.1. Density reaches a maximum of approximately 7.5 at 0.1.
* **Trend:** The distribution is heavily skewed towards lower values.
**Unaware (Bottom-Center)**
* **Real (Orange):** The distribution is unimodal, peaking around 0.15. Density reaches a maximum of approximately 16.5 at 0.15.
* **Trend:** The distribution is heavily skewed towards lower values.
**FairPFN (Bottom-Right)**
* **Real (Magenta):** The distribution is unimodal, peaking around 0.05. Density reaches a maximum of approximately 65 at 0.05.
* **Trend:** The distribution is heavily skewed towards lower values, and the density is significantly higher than in the other bottom-row plots.
### Key Observations
* The "Unfair" scenario exhibits a bimodal distribution for both "Real" and "Cntf." values of FŶA, suggesting potential instability or multiple equilibrium points.
* The "Unaware" and "FairPFN" scenarios show unimodal distributions for FŶA, indicating a more consistent prediction.
* The bottom row plots, representing the absolute difference in fairness predictions, show a strong skew towards zero for all scenarios, but particularly for "FairPFN". This suggests that the fairness predictions are relatively consistent under the "FairPFN" approach.
* The density values in the bottom-right plot ("FairPFN") are significantly higher than in the other bottom-row plots, indicating a much smaller difference between the two fairness predictions.
### Interpretation
The charts compare the distributions of a fairness metric (FŶA) and the difference between two fairness predictions under different admission scenarios. The "Unfair" scenario shows a bimodal distribution, suggesting that fairness is not consistently achieved. The "Unaware" and "FairPFN" scenarios show unimodal distributions, indicating more consistent fairness predictions. The bottom row plots demonstrate that the "FairPFN" approach results in the smallest difference between the two fairness predictions, suggesting it is the most stable and consistent approach to achieving fairness in law school admissions.
The high density near zero in the "FairPFN" bottom plot suggests that the counterfactual fairness prediction is very close to the original fairness prediction, indicating a strong degree of robustness. The bimodal distribution in the "Unfair" scenario suggests that the fairness metric is sensitive to initial conditions or other factors, leading to multiple possible outcomes. The differences in the distributions highlight the impact of different fairness interventions on the consistency and stability of fairness predictions.
</details>
Figure 16: Counterfactual Distributions (Law School): Predictive distributions of Unfair, Unaware, and FairPFN on observational and counterfactual versions of the Lawschool Admissions dataset. FairPFN reduces the maximum pairwise difference between these distributions to 0.05.
<details>
<summary>extracted/6522797/figures/trade-off_by_group_synthetic_alt.png Details</summary>
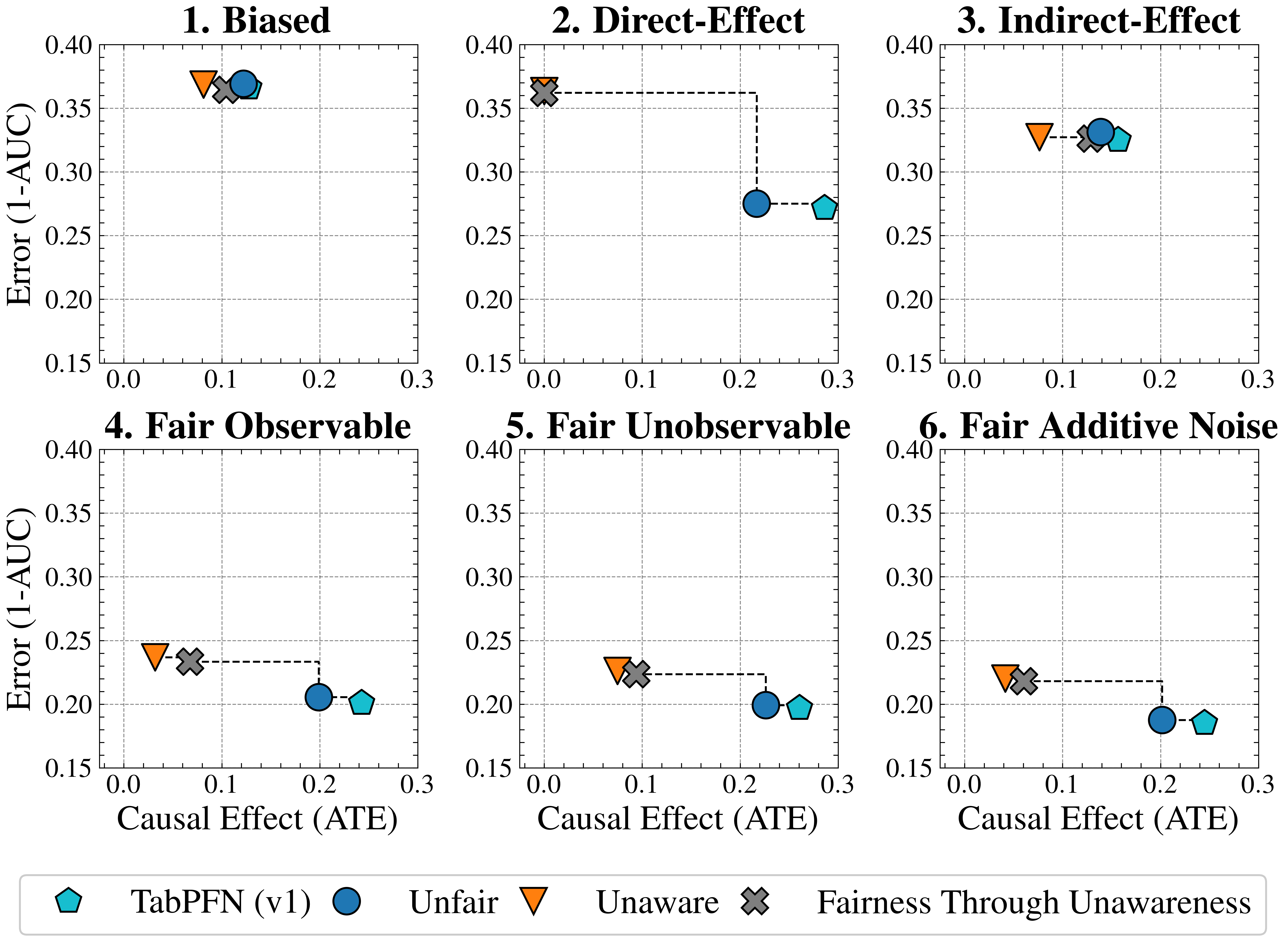
### Visual Description
\n
## Chart: Error (1-AUC) vs. Causal Effect (ATE) for Different Fairness Interventions
### Overview
The image presents six separate scatter plots, each representing a different fairness intervention scenario. Each plot displays the relationship between "Error (1-AUC)" on the y-axis and "Causal Effect (ATE)" on the x-axis. Each plot includes data points for four different methods: TabPFN (v1), Unfair, Unaware, and Fairness Through Unawareness. Each data point is connected to the origin (0,0) with a dashed line. Error bars are also present.
### Components/Axes
* **X-axis Title:** Causal Effect (ATE) - Scale ranges from 0.0 to 0.3.
* **Y-axis Title:** Error (1-AUC) - Scale ranges from 0.15 to 0.40.
* **Plot Titles:**
1. Biased
2. Direct-Effect
3. Indirect-Effect
4. Fair Observable
5. Fair Unobservable
6. Fair Additive Noise
* **Legend:** Located at the bottom-center of the image.
* TabPFN (v1) - Represented by a green square.
* Unfair - Represented by a blue circle.
* Unaware - Represented by an orange downward-pointing triangle.
* Fairness Through Unawareness - Represented by a black cross.
### Detailed Analysis or Content Details
**1. Biased:**
* TabPFN (v1): Approximately (0.15, 0.36).
* Unfair: Approximately (0.25, 0.26).
* Unaware: Approximately (0.18, 0.33).
* Fairness Through Unawareness: Approximately (0.15, 0.28).
**2. Direct-Effect:**
* TabPFN (v1): Approximately (0.18, 0.34).
* Unfair: Approximately (0.25, 0.27).
* Unaware: Approximately (0.22, 0.29).
* Fairness Through Unawareness: Approximately (0.22, 0.26).
**3. Indirect-Effect:**
* TabPFN (v1): Approximately (0.15, 0.32).
* Unfair: Approximately (0.25, 0.28).
* Unaware: Approximately (0.18, 0.31).
* Fairness Through Unawareness: Approximately (0.22, 0.30).
**4. Fair Observable:**
* TabPFN (v1): Approximately (0.15, 0.24).
* Unfair: Approximately (0.25, 0.21).
* Unaware: Approximately (0.18, 0.23).
* Fairness Through Unawareness: Approximately (0.15, 0.21).
**5. Fair Unobservable:**
* TabPFN (v1): Approximately (0.15, 0.24).
* Unfair: Approximately (0.25, 0.20).
* Unaware: Approximately (0.22, 0.23).
* Fairness Through Unawareness: Approximately (0.18, 0.22).
**6. Fair Additive Noise:**
* TabPFN (v1): Approximately (0.15, 0.22).
* Unfair: Approximately (0.25, 0.18).
* Unaware: Approximately (0.22, 0.21).
* Fairness Through Unawareness: Approximately (0.18, 0.20).
In all plots, the dashed lines connect each data point to the origin (0,0). The error bars are relatively small and consistent across all plots.
### Key Observations
* The "Unfair" method consistently exhibits higher error rates than the other methods across all scenarios.
* TabPFN (v1) generally shows the lowest error rates, particularly in the "Fair" scenarios (4, 5, and 6).
* The "Unaware" and "Fairness Through Unawareness" methods perform similarly in most scenarios, with "Fairness Through Unawareness" sometimes showing slightly lower error.
* The causal effect (ATE) appears to have a weak positive correlation with error (1-AUC) for the "Unfair" method.
### Interpretation
The charts demonstrate the impact of different fairness interventions on the trade-off between error and causal effect. The "Unfair" method, as expected, results in the highest error rates, indicating a significant bias in the model's predictions. TabPFN (v1) consistently achieves the lowest error rates, suggesting its effectiveness in mitigating bias while maintaining accuracy. The "Unaware" and "Fairness Through Unawareness" methods offer a compromise between fairness and accuracy, with "Fairness Through Unawareness" potentially providing a slight improvement in fairness without significantly sacrificing accuracy.
The consistent connection of data points to the origin suggests that as the causal effect increases, so does the error, particularly for the "Unfair" method. This implies that simply increasing the causal effect without addressing fairness concerns can lead to higher error rates. The small error bars indicate that the results are relatively stable and reliable.
The different scenarios ("Biased," "Direct-Effect," "Indirect-Effect," etc.) represent different types of fairness challenges. The consistent performance of TabPFN (v1) across these scenarios suggests its robustness and generalizability. The charts provide valuable insights for practitioners seeking to develop fair and accurate machine learning models.
</details>
Figure 17: Baseline Validation (Synthetic): Fairness-accuracy trade-off achieved by our baselines Unfair and Unaware compared to alternative choices of TabPFN (v1) and "Fairness Through Unawareness." Unfair achieves competitive performance with TabPFN (v1), while Unaware outperforms the standard strategy of dropping the protected attribute from the dataset.
<details>
<summary>extracted/6522797/figures/trade-off_lawschool_alt.png Details</summary>
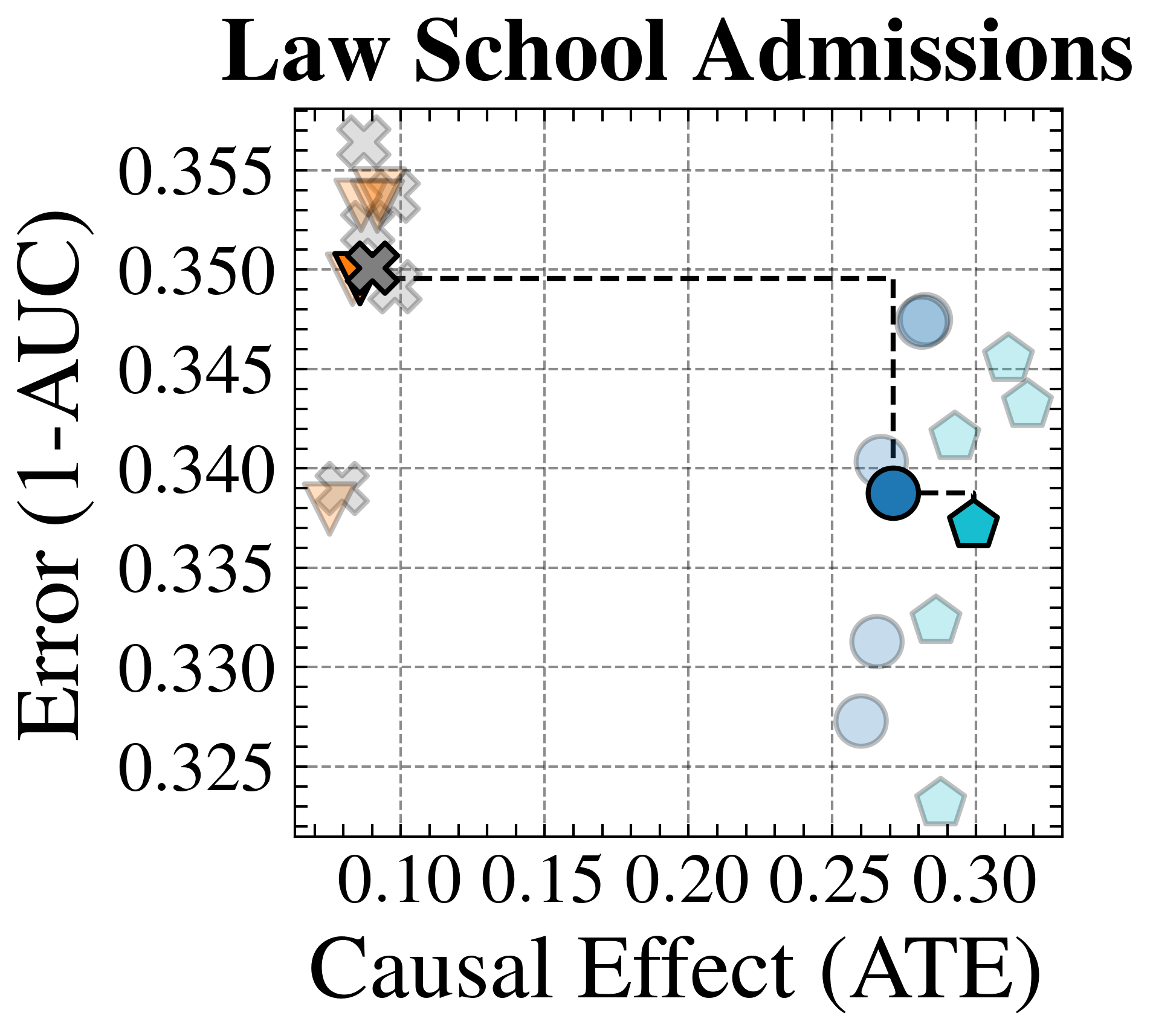
### Visual Description
## Scatter Plot: Law School Admissions
### Overview
This image presents a scatter plot visualizing the relationship between "Causal Effect (ATE)" and "Error (1-AUC)". The plot appears to represent the performance of different models or methods in the context of law school admissions, likely evaluating their ability to predict outcomes while accounting for causal effects. Data points are differentiated by shape and color, though the exact meaning of these distinctions isn't immediately clear without a legend. A dashed horizontal line is present at Error (1-AUC) = 0.35. A dashed vertical line is present at Causal Effect (ATE) = 0.25.
### Components/Axes
* **Title:** "Law School Admissions" (centered at the top)
* **X-axis:** "Causal Effect (ATE)" - ranging from approximately 0.08 to 0.32.
* **Y-axis:** "Error (1-AUC)" - ranging from approximately 0.325 to 0.355.
* **Data Points:** Scatter plot points with varying shapes (circles, diamonds, triangles, crosses, and 'x' shapes) and colors (various shades of blue and gray).
* **Horizontal Dashed Line:** Located at approximately Error (1-AUC) = 0.35.
* **Vertical Dashed Line:** Located at approximately Causal Effect (ATE) = 0.25.
* **Grid:** A light gray grid is present to aid in reading values.
### Detailed Analysis
The scatter plot contains approximately 15 data points. I will describe the trends and approximate values, noting uncertainty due to the resolution of the image.
* **Trend 1 (Dark Blue Circles):** A cluster of dark blue circles shows a general downward trend.
* Point 1: (0.27, 0.34)
* Point 2: (0.28, 0.335)
* Point 3: (0.25, 0.34)
* **Trend 2 (Light Blue Circles):** A group of light blue circles shows a general downward trend.
* Point 1: (0.26, 0.33)
* Point 2: (0.29, 0.325)
* Point 3: (0.30, 0.33)
* **Trend 3 (Gray Diamonds):** A cluster of gray diamonds shows a relatively flat trend.
* Point 1: (0.11, 0.35)
* Point 2: (0.12, 0.34)
* Point 3: (0.10, 0.335)
* **Trend 4 (Gray 'x' shapes):** A cluster of gray 'x' shapes shows a relatively flat trend.
* Point 1: (0.31, 0.345)
* Point 2: (0.30, 0.34)
* Point 3: (0.31, 0.335)
* **Trend 5 (Light Gray Triangles):** A cluster of light gray triangles shows a relatively flat trend.
* Point 1: (0.24, 0.33)
* Point 2: (0.25, 0.325)
* Point 3: (0.27, 0.33)
* **Outlier 1 (Dark Blue Diamond):** (0.11, 0.335)
* **Outlier 2 (Gray Circle):** (0.28, 0.325)
### Key Observations
* The majority of data points cluster towards the lower-right portion of the plot, indicating a negative correlation between Causal Effect (ATE) and Error (1-AUC). Higher causal effect generally corresponds to lower error.
* The dashed lines at 0.35 (Error) and 0.25 (Causal Effect) appear to divide the plot into quadrants, potentially highlighting areas of "good" or "bad" performance.
* The different shapes and colors likely represent different methods or models, but the legend is missing.
* There is a noticeable spread in the data, suggesting that the relationship between causal effect and error is not perfectly deterministic.
### Interpretation
The plot suggests that methods with a higher "Causal Effect (ATE)" tend to have lower "Error (1-AUC)" in the context of law school admissions. This implies that accounting for causal effects in the modeling process improves predictive accuracy. The dashed lines may represent thresholds for acceptable performance. The variation in data points, represented by different shapes and colors, suggests that different methods achieve varying levels of performance. The lack of a legend makes it difficult to determine the specific meaning of each shape/color. The outlier points may represent methods that perform unexpectedly well or poorly given their causal effect. Further investigation would be needed to understand the specific methods represented by each data point and the reasons for the observed variations. The plot is likely used to compare the effectiveness of different causal inference or machine learning techniques applied to the law school admissions problem.
</details>
<details>
<summary>extracted/6522797/figures/trade-off_adult_alt.png Details</summary>
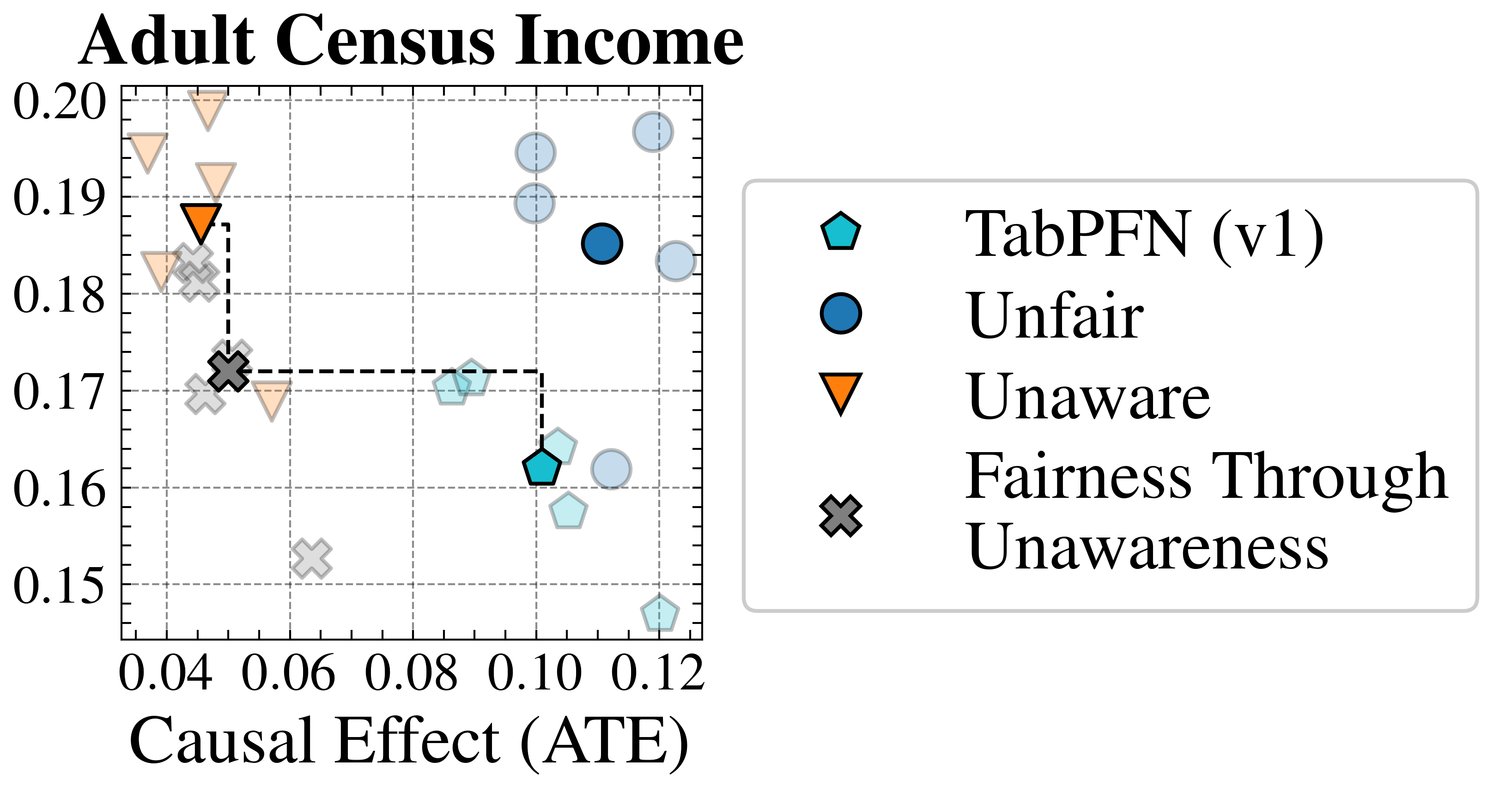
### Visual Description
## Scatter Plot: Adult Census Income
### Overview
This image presents a scatter plot visualizing data related to "Adult Census Income," likely representing the performance of different fairness-aware machine learning models. The plot compares "Causal Effect (ATE)" against an unspecified y-axis value, with data points distinguished by shape and color according to the model they represent. A dashed rectangle highlights a region of interest.
### Components/Axes
* **Title:** "Adult Census Income" (top-center)
* **X-axis Label:** "Causal Effect (ATE)" (bottom-center)
* **Y-axis:** The y-axis is not explicitly labeled, but ranges from approximately 0.15 to 0.20.
* **Legend:** Located in the top-right corner, containing the following entries:
* Light Blue Diamond: TabPFN (v1)
* Dark Blue Circle: Unfair
* Orange Downward-Pointing Triangle: Unaware
* Gray Cross: Fairness Through Unawareness
* **Dashed Rectangle:** A dashed rectangle is drawn on the plot, spanning approximately from x=0.04 to x=0.10 and y=0.16 to 0.19.
### Detailed Analysis
The plot contains several data points, each representing a model's performance.
* **TabPFN (v1) - Light Blue Diamonds:**
* Point 1: Approximately (0.04, 0.175)
* Point 2: Approximately (0.08, 0.16)
* Point 3: Approximately (0.10, 0.165)
* Point 4: Approximately (0.12, 0.155)
* Trend: The points generally show a slight upward trend, but with considerable variance.
* **Unfair - Dark Blue Circles:**
* Point 1: Approximately (0.06, 0.185)
* Point 2: Approximately (0.08, 0.19)
* Point 3: Approximately (0.10, 0.18)
* Point 4: Approximately (0.12, 0.18)
* Trend: The points show a relatively flat trend, with values clustered around 0.18-0.19.
* **Unaware - Orange Downward-Pointing Triangles:**
* Point 1: Approximately (0.05, 0.19)
* Point 2: Approximately (0.06, 0.17)
* Trend: The points show a downward trend.
* **Fairness Through Unawareness - Gray Crosses:**
* Point 1: Approximately (0.05, 0.17)
* Point 2: Approximately (0.08, 0.165)
* Trend: The points show a relatively flat trend.
### Key Observations
* The "Unfair" model consistently exhibits higher values on the y-axis compared to other models, particularly within the range of x-values from 0.06 to 0.12.
* The "Unaware" model shows a decreasing trend as the "Causal Effect (ATE)" increases.
* The dashed rectangle appears to highlight a region where the "TabPFN (v1)" and "Fairness Through Unawareness" models perform similarly.
* There is significant overlap in the y-axis values across different models, suggesting that the performance differences are not always substantial.
### Interpretation
The scatter plot likely aims to compare the trade-off between fairness and accuracy (as represented by the "Causal Effect (ATE)") for different machine learning models applied to the Adult Census Income dataset. The "Unfair" model, despite its name, appears to achieve the highest values on the y-axis, potentially indicating better performance on some metric (e.g., accuracy) but at the cost of fairness. The "Unaware" model, which doesn't explicitly account for fairness, shows a negative correlation between "Causal Effect (ATE)" and the y-axis value, suggesting that increasing the causal effect might lead to a decrease in performance. The "TabPFN (v1)" and "Fairness Through Unawareness" models represent attempts to balance fairness and accuracy, and their performance falls within a narrower range. The dashed rectangle highlights a region where these models exhibit comparable performance. The lack of explicit y-axis labeling makes it difficult to draw definitive conclusions, but the plot suggests that achieving fairness may involve a trade-off with other performance metrics.
</details>
Figure 18: Baseline Validation (Real-World): Fairness-accuracy trade-off achieved by our baselines Unfair and Unaware compared to alternative choices of TabPFN (v1) and "Fairness Through Unawareness." Our choices of baselines achieve competitive performance on the Law School Admissions problem, while alternative baselines perform slightly better on the Adult Census Income problem.
<details>
<summary>extracted/6522797/figures/adult_dist.png Details</summary>
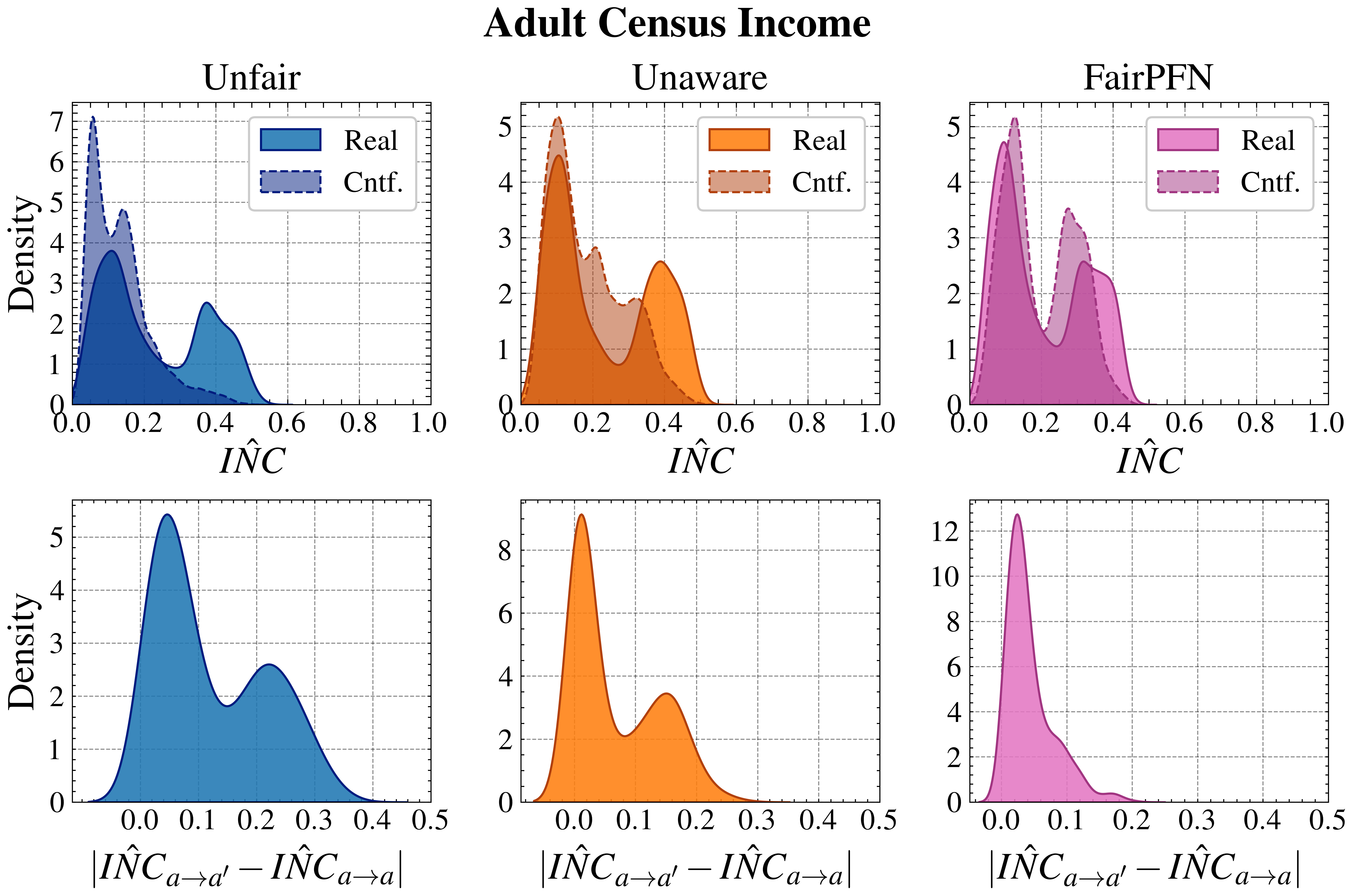
### Visual Description
## Histograms: Adult Census Income Fairness Evaluation
### Overview
The image presents six histograms arranged in a 2x3 grid, evaluating the fairness of different models ("Unfair", "Unaware", "FairPFN") in predicting adult census income. Each model is assessed using two metrics: ÎNC (likely representing an income prediction confidence score) and the absolute difference between ÎNC values under different conditions (ÎNC<sub>α→α'</sub> - ÎNC<sub>α→α</sub>). Each histogram displays the density distribution of these metrics for both "Real" data and a "Cntf." (likely counterfactual) dataset.
### Components/Axes
* **Title:** "Adult Census Income" - positioned at the top-center of the image.
* **Subtitles:** "Unfair", "Unaware", "FairPFN" - positioned above each column of histograms.
* **X-axis Label (Top Row):** "ÎNC" - appears under each histogram in the top row. Scale ranges from 0.0 to 1.0.
* **X-axis Label (Bottom Row):** "|ÎNC<sub>α→α'</sub> - ÎNC<sub>α→α</sub>|" - appears under each histogram in the bottom row. Scale ranges from 0.0 to 0.5.
* **Y-axis Label (All Histograms):** "Density" - appears on the left side of each histogram. Scale ranges from 0.0 to approximately 6.0 (varying slightly between histograms).
* **Legend (All Histograms):**
* "Real" - represented by a solid fill color (blue for "Unfair", orange for "Unaware", purple for "FairPFN").
* "Cntf." - represented by a dashed fill color (light blue for "Unfair", light orange for "Unaware", light purple for "FairPFN").
* **Gridlines:** Present on all histograms, aiding in value estimation.
### Detailed Analysis or Content Details
**Column 1: "Unfair"**
* **Top Histogram (ÎNC):** The "Real" data (blue) shows a bimodal distribution with peaks around ÎNC = 0.25 and ÎNC = 0.65. The "Cntf." data (light blue, dashed) shows a similar bimodal distribution, but with lower density overall and peaks around ÎNC = 0.3 and ÎNC = 0.7.
* **Bottom Histogram (|ÎNC<sub>α→α'</sub> - ÎNC<sub>α→α</sub>|):** The "Real" data (blue) is heavily skewed to the left, with a peak around 0.05 and a long tail extending to 0.4. The "Cntf." data (light blue, dashed) is also skewed to the left, with a peak around 0.03 and a tail extending to 0.3.
**Column 2: "Unaware"**
* **Top Histogram (ÎNC):** The "Real" data (orange) shows a unimodal distribution with a peak around ÎNC = 0.55. The "Cntf." data (light orange, dashed) shows a similar unimodal distribution, but with a broader peak around ÎNC = 0.5.
* **Bottom Histogram (|ÎNC<sub>α→α'</sub> - ÎNC<sub>α→α</sub>|):** The "Real" data (orange) is centered around 0.1, with a peak around 0.08 and a tail extending to 0.4. The "Cntf." data (light orange, dashed) is also centered around 0.1, with a peak around 0.07 and a tail extending to 0.3.
**Column 3: "FairPFN"**
* **Top Histogram (ÎNC):** The "Real" data (purple) shows a bimodal distribution with peaks around ÎNC = 0.3 and ÎNC = 0.7. The "Cntf." data (light purple, dashed) shows a similar bimodal distribution, but with a broader peak around ÎNC = 0.3 and ÎNC = 0.7.
* **Bottom Histogram (|ÎNC<sub>α→α'</sub> - ÎNC<sub>α→α</sub>|):** The "Real" data (purple) is centered around 0.15, with a peak around 0.1 and a tail extending to 0.5. The "Cntf." data (light purple, dashed) is also centered around 0.15, with a peak around 0.08 and a tail extending to 0.4.
### Key Observations
* The "Unfair" model exhibits the most pronounced bimodal distribution in ÎNC, suggesting significant disparities in confidence scores.
* The "Unaware" model shows the most concentrated distribution in ÎNC, indicating more consistent confidence scores.
* The "FairPFN" model also exhibits a bimodal distribution in ÎNC, but with a wider spread than the "Unfair" model.
* The absolute difference metric (|ÎNC<sub>α→α'</sub> - ÎNC<sub>α→α</sub>|) is generally lower for the "Unaware" model compared to the "Unfair" and "FairPFN" models, suggesting less sensitivity to changes in input conditions.
* The "Cntf." data consistently shows lower density than the "Real" data across all models and metrics.
### Interpretation
These histograms are evaluating the fairness of different income prediction models. The ÎNC metric likely represents a confidence score assigned by the model to its income prediction. The absolute difference metric quantifies the change in confidence score when a sensitive attribute is altered (represented by α and α').
The "Unfair" model's bimodal distribution in ÎNC suggests that the model assigns significantly different confidence scores to different groups, potentially indicating bias. The "Unaware" model, designed to be oblivious to sensitive attributes, exhibits a more uniform distribution, suggesting less bias. The "FairPFN" model attempts to mitigate bias through a fairness-aware algorithm, and its distribution falls between the "Unfair" and "Unaware" models.
The lower absolute difference metric for the "Unaware" model indicates that its predictions are less sensitive to changes in sensitive attributes, which is a desirable property for a fair model. The consistently lower density of the "Cntf." data suggests that the counterfactual data represents less common or more extreme scenarios.
The image demonstrates a trade-off between accuracy and fairness. While the "Unaware" model may be fairer, it might sacrifice some predictive accuracy compared to the "Unfair" model. The "FairPFN" model attempts to balance these two objectives.
</details>
Figure 19: Aligning Counterfactual Distributions (Adult): Alignment of observational and counterfactual predictive distributions $\hat{Y}$ and $\hat{Y}_{a→ a^{\prime}}$ on the Adult Census Income problem. FairPFN best aligns the predictive distributions (top) and achieves the lowest mean (0.01) and maximum (0.75) absolute error.
<details>
<summary>extracted/6522797/figures/ddsp_by_group_synthetic.png Details</summary>
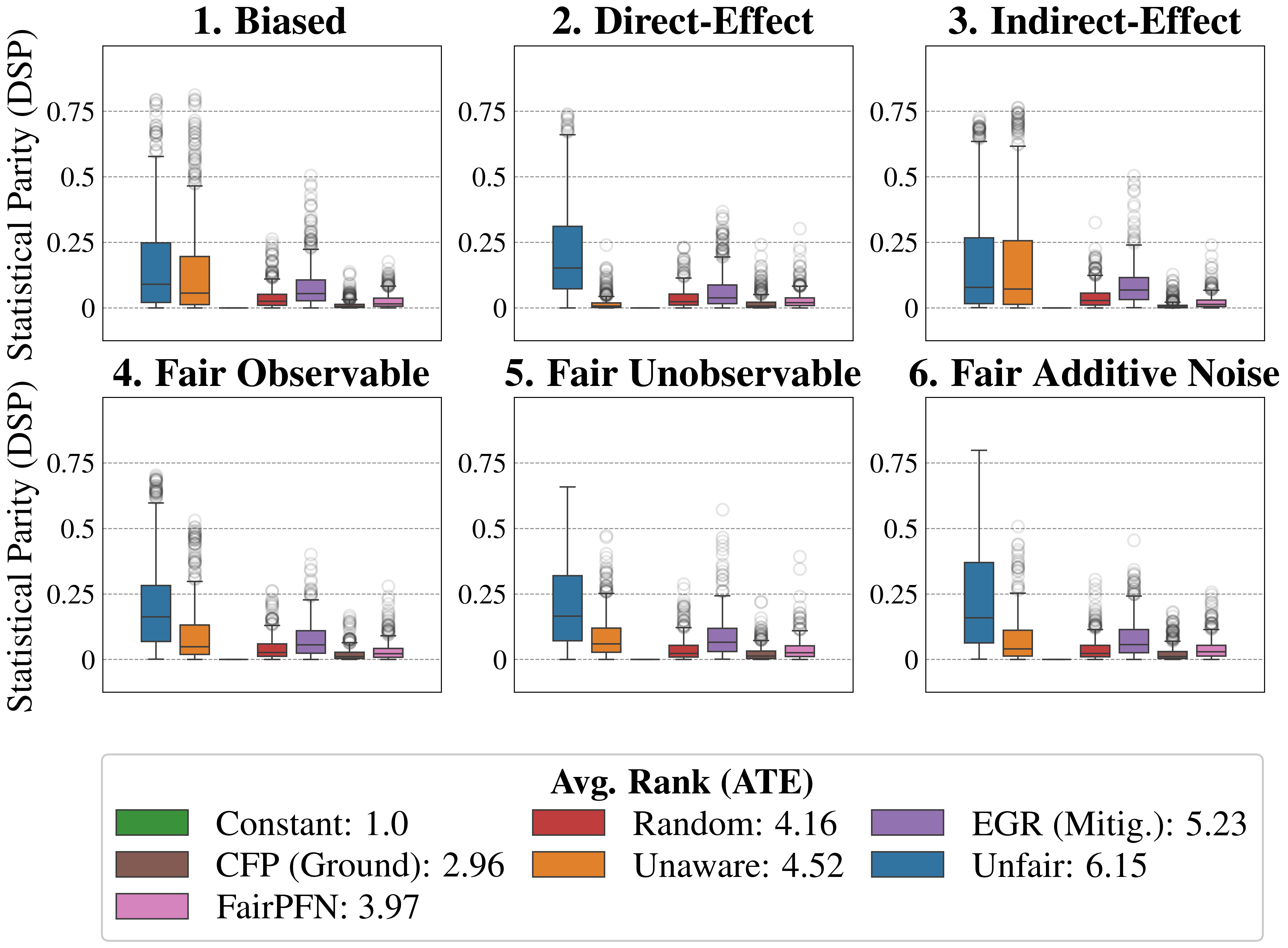
### Visual Description
\n
## Box Plot Comparison: Statistical Parity (DSP) under Different Fairness Interventions
### Overview
The image presents a 3x2 grid of box plots, each representing the distribution of Statistical Parity (DSP) scores under different fairness intervention scenarios. The plots compare the performance of several algorithms: Constant, CFP (Ground), FairPFN, EGR (Mitig.), Unaware, and Random. Each box plot displays the distribution of DSP values, with the y-axis representing the DSP score ranging from 0 to 0.75. The x-axis is implicit, representing the different algorithms being compared within each scenario.
### Components/Axes
* **Y-axis:** Statistical Parity (DSP) - Scale ranges from 0 to 0.75.
* **X-axis:** Implicitly represents the different algorithms being compared within each scenario.
* **Titles:** Each subplot is labeled with a fairness scenario: 1. Biased, 2. Direct-Effect, 3. Indirect-Effect, 4. Fair Observable, 5. Fair Unobservable, 6. Fair Additive Noise.
* **Legend:** Located at the bottom of the image, it maps colors to algorithms:
* Green: Constant (1.0)
* Brown: CFP (Ground) (2.96)
* Purple: FairPFN (3.97)
* Red: EGR (Mitig.) (5.23)
* Light Blue: Unaware (4.52)
* Gray: Random (4.16)
* **Avg. Rank (ATE):** A small text block in the bottom-center provides the average rank of each algorithm based on Average Treatment Effect (ATE).
### Detailed Analysis or Content Details
Each subplot shows a box plot for each algorithm. I will describe the trends and approximate values for each scenario.
**1. Biased:**
* Constant: Median around 0.25, interquartile range (IQR) approximately 0.15-0.4.
* CFP (Ground): Median around 0.2, IQR approximately 0.1-0.3.
* FairPFN: Median around 0.3, IQR approximately 0.2-0.45.
* EGR (Mitig.): Median around 0.6, IQR approximately 0.5-0.7.
* Unaware: Median around 0.3, IQR approximately 0.2-0.5.
* Random: Median around 0.25, IQR approximately 0.15-0.4.
**2. Direct-Effect:**
* Constant: Median around 0.1, IQR approximately 0.05-0.2.
* CFP (Ground): Median around 0.15, IQR approximately 0.1-0.25.
* FairPFN: Median around 0.25, IQR approximately 0.15-0.4.
* EGR (Mitig.): Median around 0.6, IQR approximately 0.5-0.7.
* Unaware: Median around 0.2, IQR approximately 0.1-0.3.
* Random: Median around 0.15, IQR approximately 0.1-0.3.
**3. Indirect-Effect:**
* Constant: Median around 0.1, IQR approximately 0.05-0.2.
* CFP (Ground): Median around 0.2, IQR approximately 0.1-0.3.
* FairPFN: Median around 0.3, IQR approximately 0.2-0.45.
* EGR (Mitig.): Median around 0.6, IQR approximately 0.5-0.7.
* Unaware: Median around 0.25, IQR approximately 0.15-0.4.
* Random: Median around 0.2, IQR approximately 0.1-0.3.
**4. Fair Observable:**
* Constant: Median around 0.1, IQR approximately 0.05-0.2.
* CFP (Ground): Median around 0.2, IQR approximately 0.1-0.3.
* FairPFN: Median around 0.3, IQR approximately 0.2-0.45.
* EGR (Mitig.): Median around 0.55, IQR approximately 0.45-0.65.
* Unaware: Median around 0.25, IQR approximately 0.15-0.4.
* Random: Median around 0.2, IQR approximately 0.1-0.3.
**5. Fair Unobservable:**
* Constant: Median around 0.1, IQR approximately 0.05-0.2.
* CFP (Ground): Median around 0.15, IQR approximately 0.1-0.25.
* FairPFN: Median around 0.25, IQR approximately 0.15-0.4.
* EGR (Mitig.): Median around 0.55, IQR approximately 0.45-0.65.
* Unaware: Median around 0.2, IQR approximately 0.1-0.3.
* Random: Median around 0.15, IQR approximately 0.1-0.3.
**6. Fair Additive Noise:**
* Constant: Median around 0.1, IQR approximately 0.05-0.2.
* CFP (Ground): Median around 0.2, IQR approximately 0.1-0.3.
* FairPFN: Median around 0.3, IQR approximately 0.2-0.45.
* EGR (Mitig.): Median around 0.6, IQR approximately 0.5-0.7.
* Unaware: Median around 0.25, IQR approximately 0.15-0.4.
* Random: Median around 0.2, IQR approximately 0.1-0.3.
### Key Observations
* EGR (Mitig.) consistently achieves the highest DSP scores across all scenarios, indicating the best fairness performance.
* Constant consistently has the lowest DSP scores.
* CFP (Ground), FairPFN, Unaware, and Random generally have similar DSP scores, falling between Constant and EGR (Mitig.).
* The average rank (ATE) confirms EGR (Mitig.) as the best performing algorithm (5.23), followed by Unaware (4.52), Random (4.16), FairPFN (3.97), CFP (Ground) (2.96), and Constant (1.0).
### Interpretation
The data demonstrates the effectiveness of the EGR (Mitigation) algorithm in achieving statistical parity across various fairness intervention scenarios. The consistently high DSP scores and favorable average rank suggest that EGR effectively reduces bias in the model's predictions. The Constant algorithm, unsurprisingly, performs poorly, indicating that simply ignoring fairness considerations leads to significant disparities. The other algorithms (CFP, FairPFN, Unaware, and Random) offer varying degrees of improvement over the Constant baseline, but none consistently match the performance of EGR.
The differences in DSP scores across the different fairness scenarios highlight the challenges of achieving fairness in complex systems. The "Biased," "Direct-Effect," and "Indirect-Effect" scenarios represent different sources of bias, and the algorithms' performance varies accordingly. The "Fair Observable," "Fair Unobservable," and "Fair Additive Noise" scenarios represent different approaches to mitigating bias, and the data suggests that EGR is robust to these different approaches.
The box plots reveal the variability in DSP scores for each algorithm, indicating that the fairness performance can vary depending on the specific dataset and model configuration. This underscores the importance of carefully evaluating fairness metrics and considering the potential trade-offs between fairness and accuracy.
</details>
Figure 20: Statistical Parity (Synthetic): Statistical Parity (DSP) of FairPFN compared to our baselines. FairPFN achieves a similar DSP as the Random baseline and outperforms EGR which was optimized specifically for this fairness metric, achieving an average rank of 3.97 out of 7.
<details>
<summary>extracted/6522797/figures/ddsp_lawschool.png Details</summary>
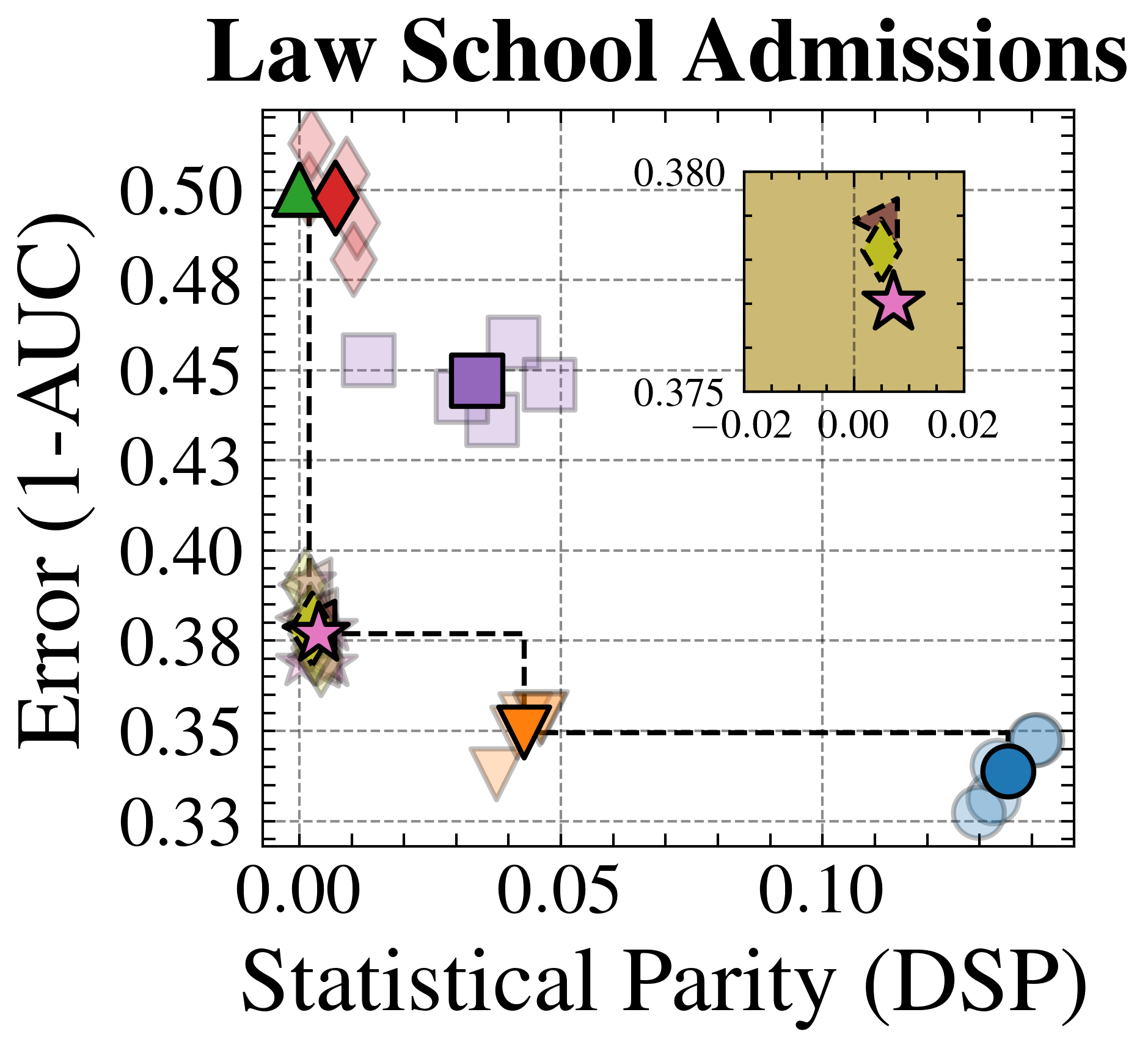
### Visual Description
## Scatter Plot: Law School Admissions
### Overview
This image presents a scatter plot visualizing the relationship between Statistical Parity (DSP) and Error (1-AUC) in the context of Law School Admissions. The plot features several data points, each represented by a distinct marker with a unique color and shape. A zoomed-in section highlights a cluster of points in the upper-right quadrant.
### Components/Axes
* **Title:** "Law School Admissions" (Top-center)
* **X-axis:** "Statistical Parity (DSP)" - Scale ranges from approximately 0.00 to 0.12.
* **Y-axis:** "Error (1-AUC)" - Scale ranges from approximately 0.33 to 0.50.
* **Legend:** Implicitly defined by the marker shapes and colors.
* **Zoomed-in Section:** A rectangular region in the upper-right corner, with x-axis ranging from approximately -0.02 to 0.02 and y-axis ranging from approximately 0.375 to 0.380.
### Detailed Analysis
The scatter plot contains the following data points (approximate values, based on visual estimation):
1. **Green Diamond:** DSP ≈ 0.00, Error ≈ 0.49
2. **Red Triangle:** DSP ≈ 0.05, Error ≈ 0.37
3. **Purple Square:** DSP ≈ 0.00, Error ≈ 0.44
4. **Light Blue Circle:** DSP ≈ 0.10, Error ≈ 0.34
5. **Yellow Star:** DSP ≈ 0.02, Error ≈ 0.48
6. **Brown Hexagon:** DSP ≈ 0.00, Error ≈ 0.38
7. **Olive Green Star:** DSP ≈ 0.00, Error ≈ 0.37
8. **Beige Triangle:** DSP ≈ 0.05, Error ≈ 0.35
Within the zoomed-in section:
* **Yellow Square:** DSP ≈ 0.00, Error ≈ 0.380
* **Dark Star:** DSP ≈ 0.00, Error ≈ 0.375
**Trends:**
* Generally, as Statistical Parity (DSP) increases, the Error (1-AUC) tends to decrease. However, this trend is not strictly linear and exhibits considerable variation.
* There is a concentration of points around DSP = 0.00, with a wide range of Error values.
* The zoomed-in section shows a cluster of points with low DSP and relatively low Error.
### Key Observations
* The data points are widely dispersed, indicating a complex relationship between Statistical Parity and Error.
* The zoomed-in section suggests that achieving very low DSP may be associated with lower Error, but this is not universally true across the entire dataset.
* The variation in Error values for a given DSP suggests that other factors may be influencing the model's performance.
### Interpretation
This scatter plot likely represents the performance of different machine learning models or algorithms used in Law School Admissions, evaluated based on two key fairness metrics: Statistical Parity and Error.
* **Statistical Parity (DSP)** measures the extent to which the model's predictions are independent of sensitive attributes (e.g., race, gender). A DSP of 0 indicates perfect parity, meaning the model's predictions are equally distributed across different groups.
* **Error (1-AUC)** represents the overall accuracy of the model, with lower values indicating better performance.
The plot suggests a trade-off between fairness (Statistical Parity) and accuracy (Error). Achieving higher Statistical Parity (moving to the right on the x-axis) generally leads to increased Error (moving down on the y-axis), and vice versa. This is a common phenomenon in fairness-aware machine learning, where attempts to mitigate bias can sometimes come at the cost of overall accuracy.
The zoomed-in section highlights a region where models achieve both relatively low DSP and low Error, suggesting that it may be possible to find models that perform well on both metrics. However, the wide dispersion of data points indicates that this is not always the case, and careful consideration must be given to the specific context and goals of the application.
The presence of outliers (points that deviate significantly from the general trend) suggests that certain models or algorithms may be particularly sensitive to specific data characteristics or biases. Further investigation would be needed to understand the reasons for these outliers and to determine whether they represent genuine opportunities for improvement or simply artifacts of the data.
</details>
<details>
<summary>extracted/6522797/figures/ddsp_adult.png Details</summary>
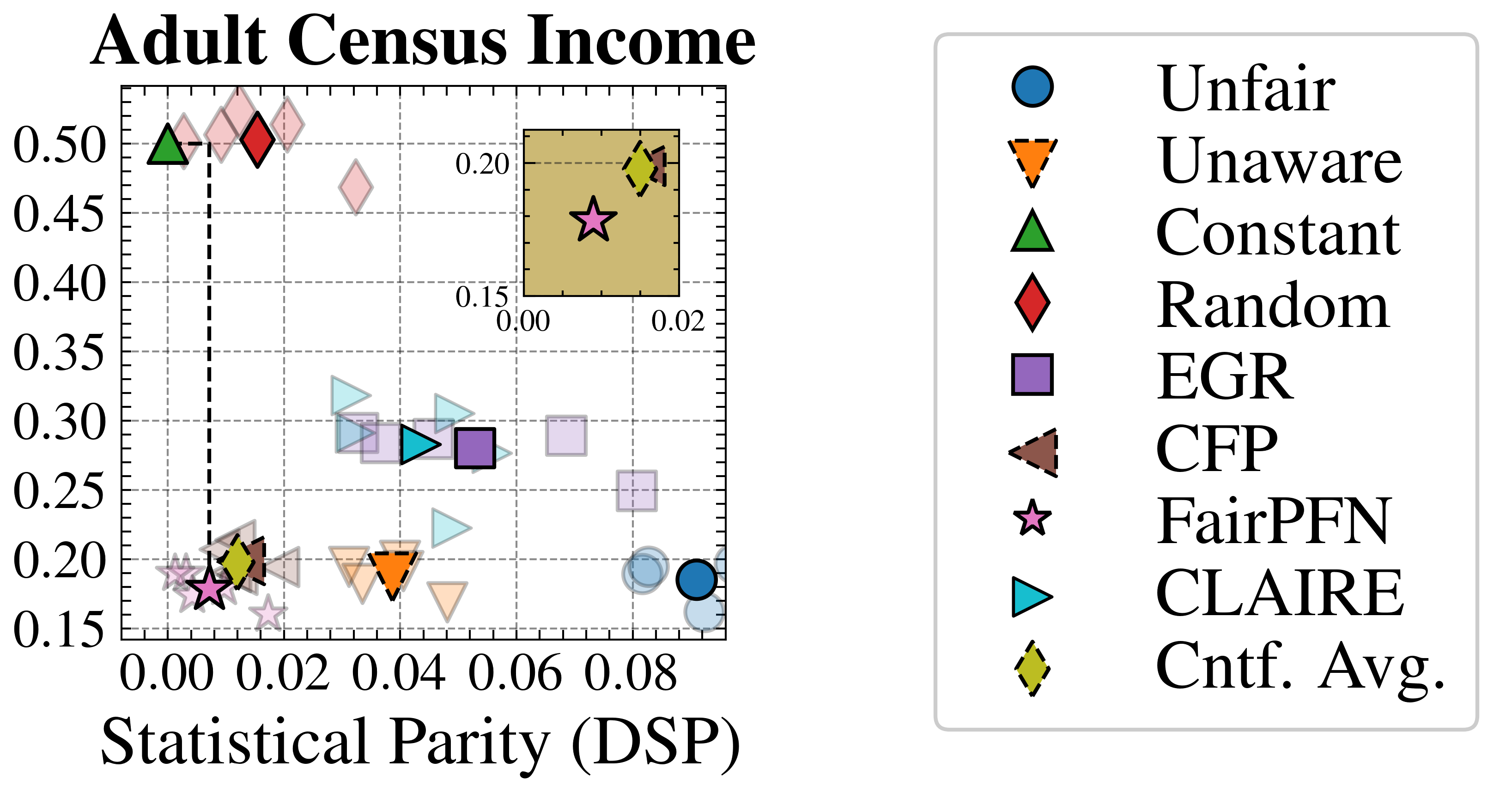
### Visual Description
## Scatter Plot: Adult Census Income
### Overview
This image presents a scatter plot visualizing the relationship between Statistical Parity (DSP) and an unnamed y-axis metric, likely representing some measure of fairness or accuracy related to income prediction. The plot compares several different algorithms or methods (Unfair, Unaware, Constant, Random, EGR, CFP, FairPFN, CLAIRE, and Cntf. Avg.) based on their performance on these two metrics. A zoomed-in inset plot highlights a specific region of the main plot.
### Components/Axes
* **Title:** "Adult Census Income" (top-center)
* **X-axis:** "Statistical Parity (DSP)" - ranging from approximately 0.00 to 0.08, with tick marks at 0.00, 0.02, 0.04, 0.06, and 0.08.
* **Y-axis:** Unlabeled, ranging from approximately 0.15 to 0.50, with tick marks at 0.15, 0.20, 0.25, 0.30, 0.35, 0.40, 0.45, and 0.50.
* **Legend:** Located in the top-right corner, listing the algorithms/methods and their corresponding marker shapes and colors:
* Blue Circle: Unfair
* Orange Inverted Triangle: Unaware
* Green Triangle: Constant
* Red Diamond: Random
* Purple Square: EGR
* Gray Triangle: CFP
* Black Star: FairPFN
* Blue Diamond: CLAIRE
* Yellow Diamond: Cntf. Avg.
* **Inset Plot:** A zoomed-in section of the main plot, located in the top-right corner, with axes ranging from 0.00 to 0.02 on the x-axis and 0.15 to 0.20 on the y-axis.
### Detailed Analysis
The main plot displays data points for each algorithm/method. Here's a breakdown of the approximate coordinates for each, based on visual estimation and cross-referencing with the legend:
* **Unfair (Blue Circle):** (0.00, 0.18), (0.08, 0.22)
* **Unaware (Orange Inverted Triangle):** (0.04, 0.22), (0.06, 0.28)
* **Constant (Green Triangle):** (0.00, 0.48), (0.04, 0.32)
* **Random (Red Diamond):** (0.04, 0.48), (0.06, 0.28)
* **EGR (Purple Square):** (0.04, 0.28), (0.06, 0.26)
* **CFP (Gray Triangle):** (0.06, 0.24), (0.08, 0.26)
* **FairPFN (Black Star):** (0.00, 0.16), (0.02, 0.18) - prominent in the inset plot.
* **CLAIRE (Blue Diamond):** (0.04, 0.26), (0.08, 0.20)
* **Cntf. Avg. (Yellow Diamond):** (0.04, 0.30), (0.08, 0.24)
**Trends:**
* The "Unfair" data points show a slight positive trend, increasing with DSP.
* "Unaware" shows a slight positive trend.
* "Constant" shows a decreasing trend.
* "Random" shows a decreasing trend.
* "EGR" appears relatively stable.
* "CFP" appears relatively stable.
* "FairPFN" appears to cluster in the lower-left corner of the main plot and is highlighted in the inset.
* "CLAIRE" shows a slight negative trend.
* "Cntf. Avg." shows a slight negative trend.
### Key Observations
* The "FairPFN" algorithm consistently exhibits low values for both Statistical Parity (DSP) and the y-axis metric, as seen in the inset plot.
* The "Constant" algorithm has the highest y-axis values, suggesting it may prioritize a different fairness criterion.
* There is a wide spread of values across the different algorithms, indicating varying trade-offs between DSP and the y-axis metric.
* The inset plot focuses on the lower-left region of the main plot, suggesting that this area is of particular interest for analysis.
### Interpretation
The scatter plot illustrates the performance of different algorithms in balancing Statistical Parity (DSP) with another fairness or accuracy metric when applied to the Adult Census Income dataset. The y-axis likely represents a measure of predictive performance or another fairness metric.
The positioning of each algorithm on the plot reveals its trade-offs. Algorithms like "Constant" may achieve high values on the y-axis but at the cost of lower DSP, potentially indicating a bias towards certain groups. Conversely, "FairPFN" demonstrates low values for both metrics, suggesting a different approach to fairness that may prioritize minimizing disparities even if it means sacrificing some accuracy.
The inset plot's focus on the lower-left corner suggests that researchers are particularly interested in algorithms that achieve both low DSP and low values on the y-axis, potentially representing a desirable region of fairness and accuracy. The wide spread of data points indicates that there is no single "best" algorithm, and the optimal choice depends on the specific priorities and constraints of the application. The dashed line at approximately DSP = 0.04 may represent a threshold or benchmark for acceptable levels of statistical parity.
</details>
Figure 21: Group-Fairness-Accuracy Trade-off (Real-World): Statistical Parity (DSP), predictive error (1-AUC), and Pareto Front of the performance of FairPFN compared to our baselines on each of 5 validation folds (light) and across all five folds (solid) of our real-world datasets. FairPFN dominates EGR which was specifically optimized for this group fairness metric.
<details>
<summary>x6.png Details</summary>
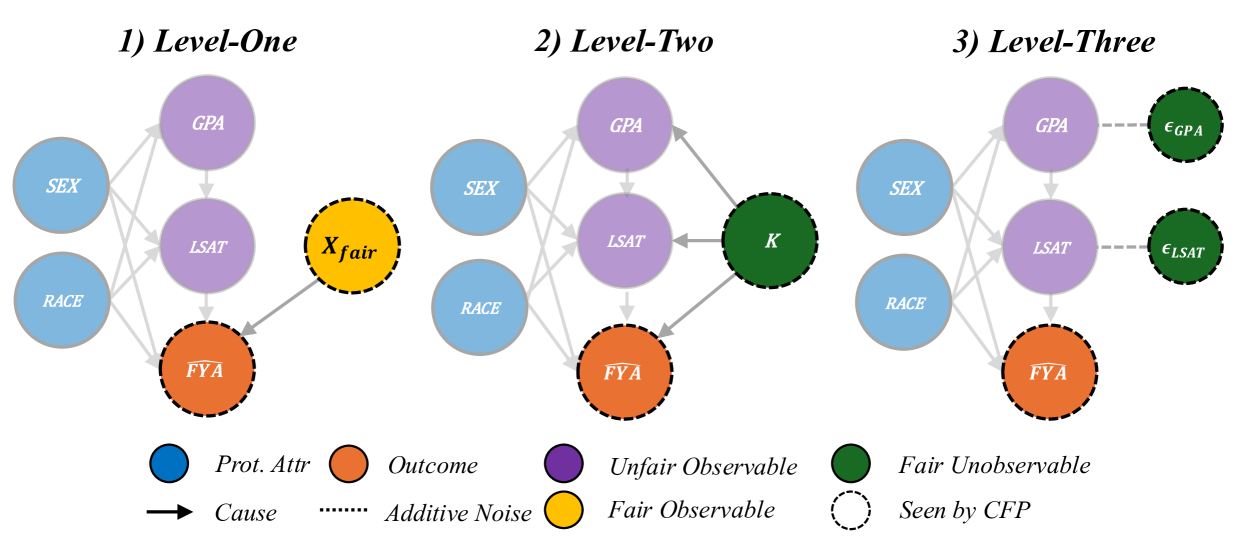
### Visual Description
\n
## Diagram: Causal Fairness Levels
### Overview
The image presents a diagram illustrating three levels of causal fairness, labeled Level-One, Level-Two, and Level-Three. Each level depicts a causal model with nodes representing variables and arrows indicating causal relationships. The diagram uses color-coding to distinguish between protected attributes, outcomes, observable and unobservable variables, and noise. The diagram aims to demonstrate how fairness can be achieved through different levels of intervention in a causal model.
### Components/Axes
The diagram consists of three panels, arranged horizontally. Each panel represents a different level of fairness. The key components are:
* **Nodes:** Represent variables such as SEX, RACE, GPA, LSAT, FYA, Xfair, and K. Nodes are color-coded as follows:
* Blue: Protected Attribute (Prot. Attr.)
* Orange: Outcome
* Purple: Unfair Observable
* Black: Unfair Unobservable
* Green: Fair Unobservable
* White: Seen by CFP (Counterfactual Fairness Policy)
* **Arrows:** Represent causal relationships (Cause). Solid arrows indicate direct causal effects.
* **Dotted Arrows:** Represent additive noise.
* **Legend:** Located at the bottom of the image, explaining the color-coding and symbols used in the diagram.
* **Level Labels:** "1) Level-One", "2) Level-Two", "3) Level-Three" are positioned above each panel.
### Detailed Analysis or Content Details
**Level-One:**
* Variables: SEX (blue), RACE (blue), GPA (purple), LSAT (purple), FYA (orange).
* Causal relationships:
* SEX -> GPA
* SEX -> LSAT
* RACE -> GPA
* RACE -> LSAT
* GPA -> FYA
* LSAT -> FYA
* Additive Noise: Dotted lines connect to GPA, LSAT, and FYA.
**Level-Two:**
* Variables: SEX (blue), RACE (blue), GPA (purple), LSAT (purple), FYA (orange), Xfair (orange).
* Causal relationships:
* SEX -> GPA
* SEX -> LSAT
* RACE -> GPA
* RACE -> LSAT
* GPA -> FYA
* LSAT -> FYA
* Xfair -> FYA
* Unfair Unobservable: K (black) influences LSAT.
* Additive Noise: Dotted lines connect to FYA.
**Level-Three:**
* Variables: SEX (blue), RACE (blue), GPA (purple), LSAT (purple), FYA (orange), εGPA (green), εLSAT (green).
* Causal relationships:
* SEX -> GPA
* SEX -> LSAT
* RACE -> GPA
* RACE -> LSAT
* GPA -> FYA
* LSAT -> FYA
* Fair Unobservable: εGPA influences GPA, εLSAT influences LSAT.
* Additive Noise: Dotted lines connect to GPA, LSAT, and FYA.
### Key Observations
* The complexity of the causal model increases from Level-One to Level-Three.
* Level-Two introduces an unobservable variable (K) that influences LSAT, representing a source of unfairness.
* Level-Three introduces fair unobservable variables (εGPA, εLSAT) that influence GPA and LSAT, respectively, suggesting a mechanism for achieving fairness.
* The outcome variable (FYA) is directly influenced by multiple variables in each level.
* The diagram illustrates a progression from a model with direct causal effects of protected attributes to a model where fairness is achieved through interventions on unobservable variables.
### Interpretation
The diagram demonstrates a hierarchical approach to achieving causal fairness. Level-One represents a naive model where protected attributes (SEX, RACE) directly influence the outcome (FYA) through observable variables (GPA, LSAT). Level-Two introduces the concept of unobserved confounding (K), highlighting a source of unfairness that is not captured by simply controlling for observable variables. Level-Three proposes a solution by introducing fair unobservable variables (εGPA, εLSAT) that can be intervened upon to mitigate the effects of unfairness.
The diagram suggests that achieving fairness requires a deeper understanding of the underlying causal mechanisms and the ability to intervene on unobservable variables. The CFP (Counterfactual Fairness Policy) is indicated as being able to "see" the white nodes, implying that it can leverage information about these variables to make fairer decisions. The progression from Level-One to Level-Three represents a shift from simply observing correlations to understanding and addressing the root causes of unfairness. The use of color-coding and symbols effectively communicates the different types of variables and their roles in the causal model. The diagram is a conceptual illustration of causal fairness and does not provide specific numerical data or quantitative analysis.
</details>
Figure 22: Counterfactually Fair Prediction (CFP): Three levels of counterfactually fair prediction (CFP) Kusner et al. (2017), obtained by fitting a predictor 1) to fair observables (if any exist; left), 2) the inferred values of fair exogenous variables (middle) and 3) the inferred values of independent noise terms (right).
<details>
<summary>x7.png Details</summary>
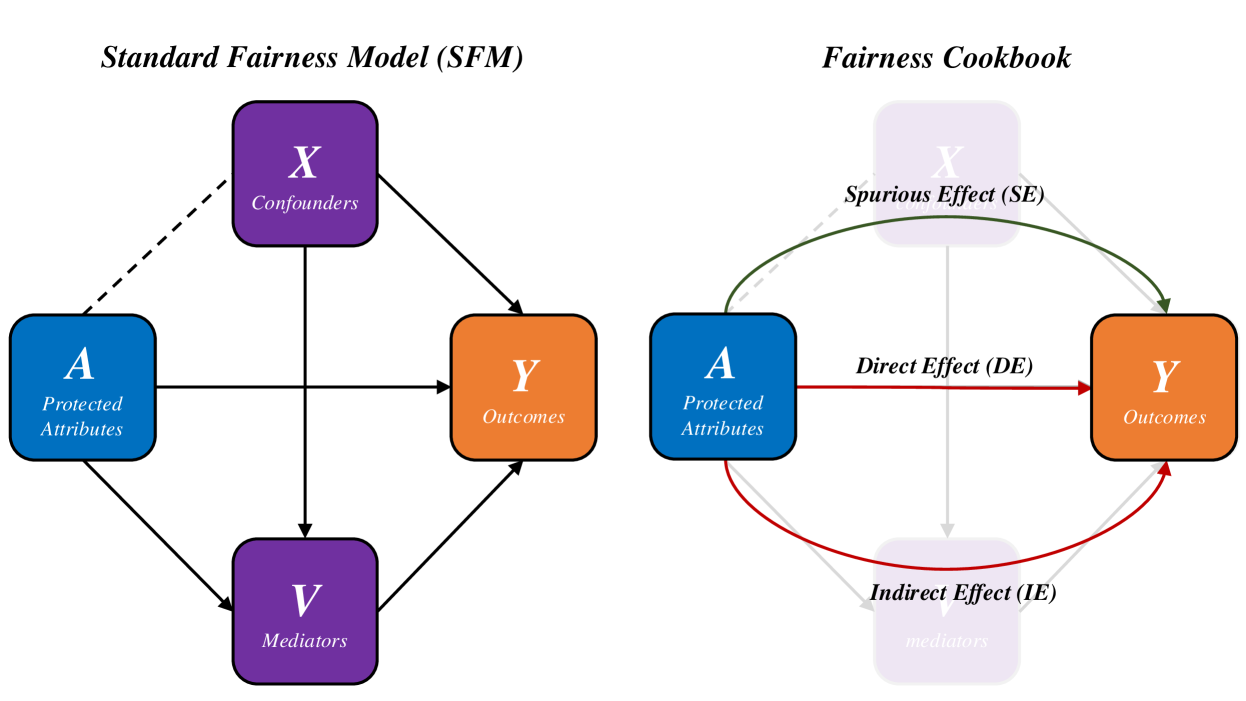
### Visual Description
\n
## Diagram: Fairness Models Comparison
### Overview
The image presents a comparative diagram illustrating two fairness models: the Standard Fairness Model (SFM) and a model from the "Fairness Cookbook." Both models depict relationships between Protected Attributes, Confounders/Spurious Effects, Mediators, and Outcomes, using directed arrows to indicate causal pathways. The diagram aims to visually contrast how these models account for potential sources of unfairness in machine learning or statistical systems.
### Components/Axes
The diagram consists of four main components, each represented by a differently shaped node:
* **Protected Attributes (A):** Represented by a blue triangle. Labeled "Protected Attributes".
* **Confounders/Spurious Effect (X):** Represented by a purple diamond. Labeled "Confounders" in the SFM and "Spurious Effect (SE)" in the Fairness Cookbook model.
* **Mediators (V/mediators):** Represented by a purple rounded rectangle. Labeled "Mediators" in the SFM and "mediators" in the Fairness Cookbook model.
* **Outcomes (Y):** Represented by a yellow circle. Labeled "Outcomes".
The arrows indicate the direction of influence between these components. Different arrow styles (solid vs. dashed, colored) denote different types of relationships.
### Detailed Analysis or Content Details
**Standard Fairness Model (SFM) - Left Side:**
* A (Protected Attributes) has a dashed arrow pointing to X (Confounders).
* X (Confounders) has a solid arrow pointing to Y (Outcomes).
* A (Protected Attributes) has a solid arrow pointing to Y (Outcomes).
* V (Mediators) has a solid arrow pointing to Y (Outcomes).
* X (Confounders) has a solid arrow pointing to V (Mediators).
* A (Protected Attributes) has a solid arrow pointing to V (Mediators).
**Fairness Cookbook Model - Right Side:**
* A (Protected Attributes) has a solid arrow pointing to Y (Outcomes) labeled "Direct Effect (DE)".
* X (Spurious Effect) has a solid arrow pointing to Y (Outcomes).
* X (Spurious Effect) has a curved, grey arrow pointing to A (Protected Attributes).
* A (Protected Attributes) has a solid arrow pointing to mediators.
* mediators has a solid arrow pointing to Y (Outcomes) labeled "Indirect Effect (IE)".
* X (Spurious Effect) has a solid arrow pointing to mediators.
### Key Observations
* The SFM shows a more direct influence of confounders on outcomes, while the Fairness Cookbook model introduces the concept of a "Spurious Effect" and emphasizes the role of mediators in both direct and indirect effects.
* The dashed line in the SFM suggests a weaker or less direct relationship between protected attributes and confounders.
* The Fairness Cookbook model explicitly labels the direct and indirect effects, providing a more granular view of the causal pathways.
* The curved grey arrow in the Fairness Cookbook model indicates a feedback loop or influence of the spurious effect on the protected attributes.
### Interpretation
The diagram illustrates a shift in thinking about fairness in machine learning. The SFM represents a more traditional view where confounders directly influence outcomes. The Fairness Cookbook model, however, acknowledges that spurious correlations can exist and that these can influence both the protected attributes themselves and the outcomes through mediators. This model highlights the importance of understanding and mitigating these indirect effects to achieve true fairness. The inclusion of "Direct Effect" and "Indirect Effect" labels in the Fairness Cookbook model suggests a focus on decomposing the total effect of protected attributes on outcomes to identify and address sources of bias. The diagram suggests that a more nuanced understanding of causal relationships is necessary to build fair and equitable systems. The grey curved arrow in the Fairness Cookbook model is particularly interesting, as it suggests that the spurious effect can reinforce existing biases in the protected attributes, creating a feedback loop that perpetuates unfairness.
</details>
Figure 23: Causal Fairness Analysis (CFA) Framework: Components of the CFA framework relevant to FairPFN’s prior and evaluation. Plecko & Bareinboim (2024) Standard Fairness Model (left; SFM), which provides a meta-model for causal fairness and heavily the design of our prior, and the Fairness Cookbook of causal fairness metrics (right).
| | 1) Biased | 2) Direct-Effect | 3) Indirect-Effect |
| --- | --- | --- | --- |
| Unfair | -0.00±0.13 (3.05%) | 0.00±0.14 (0.00%) | -0.00±0.12 (1.65%) |
| Unaware | -0.01±0.09 (2.60%) | 0.00± 0.00 (0.12%) | -0.01±0.08 (1.81%) |
| Constant | -0.36±0.34 (0.00%) | -0.27±0.43 (0.00%) | -0.38±0.34 (0.00%) |
| Random | 0.01±0.30 (0.01%) | 0.01±0.31 (0.01%) | 0.00±0.30 (0.00%) |
| EGR | -0.05±0.46 (0.00%) | -0.07±0.42 (0.00%) | -0.06±0.45 (0.00%) |
| CFP | -0.00± 0.03 (1.31%) | -0.01± 0.03 (0.56%) | -0.01±0.07 (2.29%) |
| FairPFN | 0.00±0.06 (2.03%) | -0.01± 0.03 (1.29%) | -0.00± 0.05 (2.22%) |
| | 4) Fair Observable | 5) Fair Unobservable | 6) Fair Additive Noise | Average |
| --- | --- | --- | --- | --- |
| Unfair | 0.00±0.14 (0.02%) | -0.00±0.19 (0.00%) | -0.00±0.18 (0.00%) | 0.00±0.15 (0.79%) |
| Unaware | -0.00± 0.05 (2.63%) | -0.00±0.09 (3.68%) | -0.00±0.10 (3.07%) | -0.00±0.07 (2.32%) |
| Constant | -0.49±0.18 (30.10%) | -0.38±0.30 (4.63%) | -0.37±0.33 (0.11%) | -0.38±0.32 (5.81%) |
| Random | 0.01±0.34 (0.00%) | 0.08±0.37 (0.00%) | 0.06±0.37 (0.00%) | 0.03±0.33 (0.00%) |
| EGR | -0.09±0.38 (0.00%) | -0.06±0.39 (0.00%) | -0.07±0.37 (0.00%) | -0.07±0.41 (0.00%) |
| CFP | -0.02±0.14 (1.72%) | 0.00± 0.06 (1.02%) | -0.00± 0.05 (1.00%) | -0.01± 0.06 (1.32%) |
| FairPFN | -0.01±0.07 (1.01%) | 0.01±0.07 (2.20%) | 0.01±0.09 (2.47%) | 0.00± 0.06 (1.87%) |
Table 1: Difference to Cntf. Avg. (Synthetic): Mean, standard deviation and percentage of outliers of the predictions on our causal casestudies of FairPFN and our baseline models compared to the predictions of the Cntf. Avg. baseline, which shows strong performance in causal effect removal and predictive error due to access to both observational and counterfactual datasets. FairPFN achieves predictions with an average difference to Cntf. Avg. of 0.00±0.06, with 1.87% of samples falling outside of three standard deviations.
<details>
<summary>extracted/6522797/figures/tce_by_group_synthetic.png Details</summary>
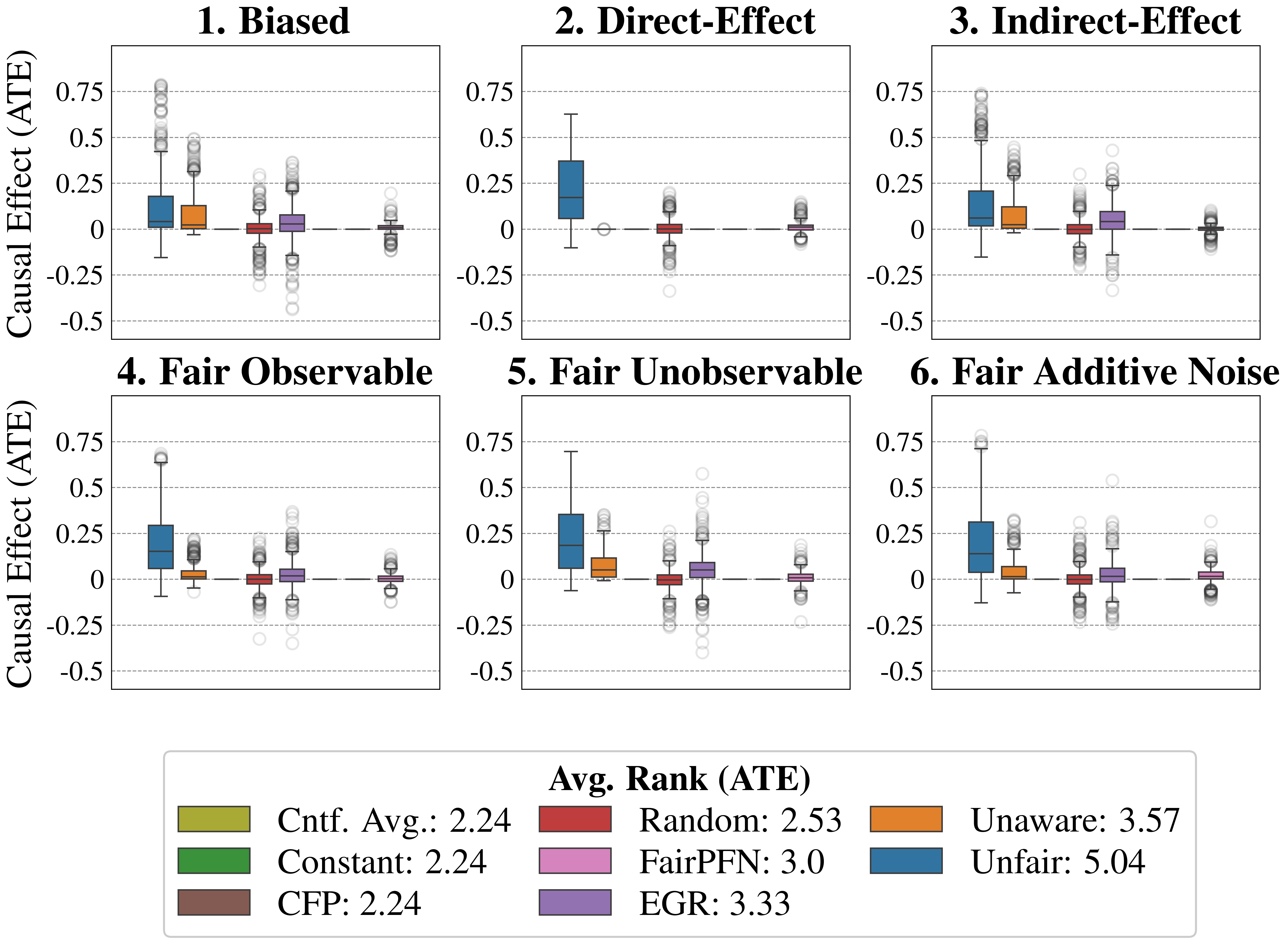
### Visual Description
## Box Plot Comparison: Causal Effect (ATE) under Different Fairness Interventions
### Overview
The image presents a 2x3 grid of box plots, each representing the distribution of the Average Treatment Effect (ATE) under different fairness interventions. The interventions are: Biased, Direct-Effect, Indirect-Effect, Fair Observable, Fair Unobservable, and Fair Additive Noise. Each box plot displays the distribution of ATE values, with the y-axis representing the "Causal Effect (ATE)" and the x-axis implicitly representing different samples or trials. A legend at the bottom of the image maps colors to different algorithms or methods used to calculate the ATE. The average rank of each method is also provided.
### Components/Axes
* **Y-axis:** "Causal Effect (ATE)" ranging from -0.5 to 0.75.
* **X-axis:** Implicitly represents different samples or trials for each intervention. No explicit labels are present.
* **Titles:** Each box plot has a numbered title indicating the fairness intervention: 1. Biased, 2. Direct-Effect, 3. Indirect-Effect, 4. Fair Observable, 5. Fair Unobservable, 6. Fair Additive Noise.
* **Legend:** Located at the bottom of the image, mapping colors to algorithms/methods:
* Green: "Cntf. Avg.: 2.24"
* Dark Green: "Constant: 2.24"
* Brown: "CFP: 2.24"
* Orange: "Random: 2.53"
* Purple: "FairPFN: 3.0"
* Dark Purple: "EGR: 3.33"
* Red-Orange: "Unaware: 3.57"
* Blue: "Unfair: 5.04"
### Detailed Analysis
Each box plot shows the distribution of ATE values. The box represents the interquartile range (IQR), the line inside the box represents the median, and the whiskers extend to the most extreme data points within 1.5 times the IQR. Points beyond the whiskers are considered outliers and are plotted individually.
1. **Biased:** The distribution is widely spread, ranging from approximately -0.4 to 0.7. The median is around 0.1. Outliers are present on both ends. Colors present: Green, Dark Green, Brown, Orange, Purple, Dark Purple, Red-Orange, Blue.
2. **Direct-Effect:** The distribution is concentrated around 0, with a narrow IQR. The median is very close to 0. Few outliers are visible. Colors present: Green, Dark Green, Brown, Orange, Purple, Dark Purple, Red-Orange, Blue.
3. **Indirect-Effect:** Similar to "Biased", the distribution is wide, ranging from approximately -0.4 to 0.7. The median is around 0.1. Outliers are present on both ends. Colors present: Green, Dark Green, Brown, Orange, Purple, Dark Purple, Red-Orange, Blue.
4. **Fair Observable:** The distribution is concentrated around 0, with a narrow IQR. The median is very close to 0. Few outliers are visible. Colors present: Green, Dark Green, Brown, Orange, Purple, Dark Purple, Red-Orange, Blue.
5. **Fair Unobservable:** The distribution is wider than "Direct-Effect" and "Fair Observable", ranging from approximately -0.3 to 0.5. The median is around 0.05. Some outliers are visible. Colors present: Green, Dark Green, Brown, Orange, Purple, Dark Purple, Red-Orange, Blue.
6. **Fair Additive Noise:** The distribution is similar to "Fair Observable", concentrated around 0, with a narrow IQR. The median is very close to 0. Few outliers are visible. Colors present: Green, Dark Green, Brown, Orange, Purple, Dark Purple, Red-Orange, Blue.
**Average Rank (ATE):**
* Cntf. Avg.: 2.24
* Constant: 2.24
* CFP: 2.24
* Random: 2.53
* FairPFN: 3.0
* EGR: 3.33
* Unaware: 3.57
* Unfair: 5.04
### Key Observations
* The "Biased" and "Indirect-Effect" interventions exhibit the widest distributions of ATE values, suggesting high variability in causal effects.
* "Direct-Effect", "Fair Observable", and "Fair Additive Noise" interventions show the most concentrated distributions around 0, indicating minimal causal effects.
* "Unfair" has the highest average rank (5.04), indicating the worst performance in terms of fairness.
* "Cntf. Avg.", "Constant", and "CFP" have the lowest average rank (2.24), suggesting better performance.
### Interpretation
The image compares the effectiveness of different fairness interventions in mitigating bias in causal effect estimation. The ATE values represent the average difference in outcomes between groups, and the goal of fairness interventions is to reduce or eliminate these differences.
The results suggest that the "Direct-Effect", "Fair Observable", and "Fair Additive Noise" interventions are most effective at reducing causal effects, as evidenced by their concentrated distributions around 0. This implies that these interventions successfully remove or mitigate the influence of sensitive attributes on the estimated treatment effects.
The "Biased" and "Indirect-Effect" interventions, on the other hand, exhibit high variability in ATE values, indicating that they are less effective at achieving fairness. The "Unfair" intervention has the highest average rank, confirming its poor performance.
The average rank values provide a quantitative measure of the effectiveness of each intervention, with lower ranks indicating better performance. The fact that "Cntf. Avg.", "Constant", and "CFP" have the lowest ranks suggests that these methods are promising approaches for achieving fairness in causal inference.
The presence of outliers in some of the box plots suggests that there may be specific cases where the interventions are less effective or even detrimental. Further investigation is needed to understand the reasons for these outliers and to develop more robust fairness interventions.
</details>
Figure 24: Causal Fairness (Synthetic-All Baselines): Average Treatment Effect (ATE) of predictions of FairPFN compared to all baselines. FairPFN consistently removes the causal effect with a margin of error of (-0.2, 0.2) and achieves an average rank of 3.0 out of 7.
<details>
<summary>x8.png Details</summary>
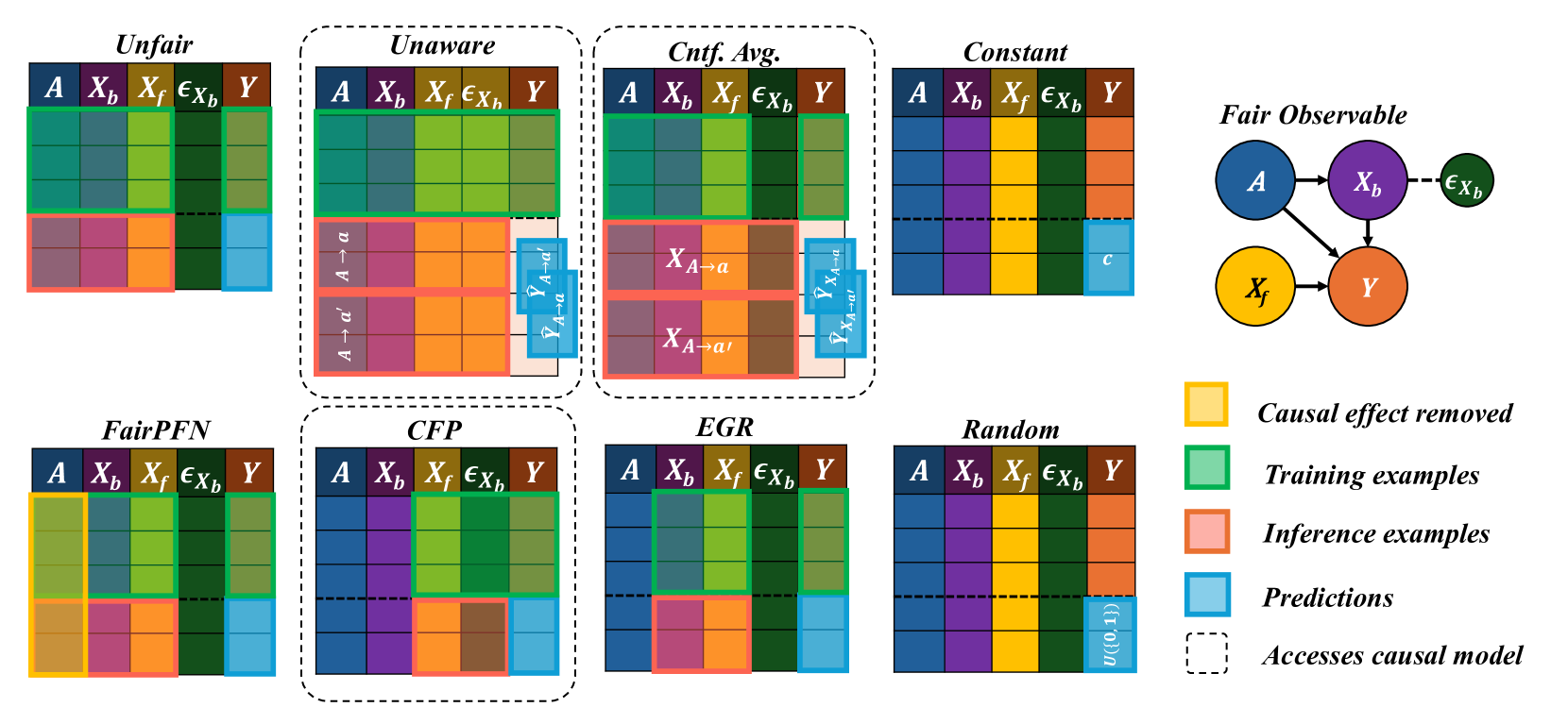
### Visual Description
\n
## Heatmap: Fairness Interventions
### Overview
The image presents a series of heatmaps comparing different fairness interventions in a causal model. Each heatmap represents a different intervention strategy (Unfair, Unaware, Cnf. Avg., Constant, FairPFN, CFP, EGR, Random) and visualizes the relationship between variables A, Xb, Xf, εXb, and Y. The color intensity indicates the strength of the relationship, with red representing strong positive correlation, blue representing strong negative correlation, and shades in between representing varying degrees of correlation. A diagram in the top-right corner illustrates the causal model being used. A legend explains the color coding for different types of data points.
### Components/Axes
* **Columns:** Represent the variables A, Xb, Xf, εXb, and Y.
* **Rows:** Represent the relationships between these variables.
* **Color Scale:** Ranges from blue (negative correlation) to red (positive correlation).
* **Legend:**
* Solid Blue: Causal effect removed.
* Green: Training examples.
* Purple: Inference examples.
* Light Blue: Predictions.
* Dashed Black: Accesses causal model.
* **Causal Model Diagram:** Shows the relationships between A, Xb, Xf, εXb, and Y.
### Detailed Analysis
Each heatmap is a 5x5 grid, representing the correlation between each pair of variables. I will describe each heatmap individually, noting the dominant color patterns and any significant deviations.
**1. Unfair:**
* Dominant colors: Red and purple.
* Strong positive correlations are visible between A and Xb, A and Xf, Xb and Y, and Xf and Y.
* Purple (inference examples) are prominent in the upper-left quadrant.
* Green (training examples) are prominent in the lower-right quadrant.
**2. Unaware:**
* Dominant colors: Red, purple, and some blue.
* Similar to "Unfair" but with some blue appearing in the A-Xb and A-Xf relationships.
* Strong positive correlations remain between Xb and Y, and Xf and Y.
**3. Cnf. Avg.:**
* Dominant colors: Red, purple, and blue.
* Significant blue appears in the A-Xb and A-Xf relationships, indicating a reduction in correlation.
* Strong positive correlations remain between Xb and Y, and Xf and Y, but are slightly less intense than in "Unfair" and "Unaware".
**4. Constant:**
* Dominant colors: Blue and purple.
* Strong negative correlations are visible between A and Xb, and A and Xf.
* The correlation between Xb and Y, and Xf and Y is significantly reduced.
**5. FairPFN:**
* Dominant colors: Blue and purple.
* Strong negative correlations are visible between A and Xb, and A and Xf.
* The correlation between Xb and Y, and Xf and Y is significantly reduced.
**6. CFP:**
* Dominant colors: Blue and purple.
* Strong negative correlations are visible between A and Xb, and A and Xf.
* The correlation between Xb and Y, and Xf and Y is significantly reduced.
**7. EGR:**
* Dominant colors: Blue and purple.
* Strong negative correlations are visible between A and Xb, and A and Xf.
* The correlation between Xb and Y, and Xf and Y is significantly reduced.
**8. Random:**
* Dominant colors: Mixed, with a relatively even distribution of red, blue, and purple.
* No clear patterns or strong correlations are visible.
**Causal Model Diagram:**
* A influences Xb and Xf.
* Xb influences Y.
* Xf influences Y.
* εXb is an error term influencing Xb.
* The diagram shows a directed acyclic graph (DAG) representing the causal relationships.
* The variable 'c' is shown as a constant.
* The variable 'u' is shown as a value of 0.10.
### Key Observations
* The "Unfair" intervention exhibits the strongest positive correlations between A and the intermediate variables (Xb, Xf) and between these variables and the outcome Y.
* Interventions like "Constant", "FairPFN", "CFP", and "EGR" effectively reduce the correlation between A and the intermediate variables, leading to a more fair outcome.
* The "Random" intervention results in a lack of clear patterns, suggesting it does not systematically address fairness.
* The color patterns consistently show a trade-off: reducing the correlation between A and the intermediate variables often leads to a weaker correlation between these variables and the outcome Y.
### Interpretation
The heatmaps demonstrate the impact of different fairness interventions on a causal model. The "Unfair" intervention represents a scenario where the model does not account for fairness, resulting in strong biases. The other interventions attempt to mitigate these biases by reducing the influence of the sensitive attribute A on the intermediate variables.
The interventions that successfully reduce the correlation between A and Xb/Xf (e.g., "Constant", "FairPFN", "CFP", "EGR") achieve fairness by removing the causal effect of A on the outcome Y. However, this often comes at the cost of predictive accuracy, as the model relies less on the intermediate variables.
The "Random" intervention highlights the importance of systematic approaches to fairness. Simply introducing randomness does not guarantee a fair outcome.
The causal model diagram provides a visual representation of the underlying relationships between the variables, helping to understand how the interventions affect the causal pathways. The diagram shows that A has a direct influence on Xb and Xf, which in turn influence Y. By intervening on these pathways, the fairness interventions aim to break the causal link between A and Y.
The data suggests that achieving fairness requires careful consideration of the trade-off between fairness and accuracy. The optimal intervention strategy will depend on the specific application and the desired balance between these two objectives. The heatmaps provide a valuable tool for visualizing and comparing the effects of different interventions, allowing for informed decision-making.
</details>
Figure 25: Baseline Models: Visualization of FairPFN and our baseline models on our Fair Observable benchmark group, in terms of which variables each model is fit to and performs inference on on.
| Unfair Unaware | Law School Admissions 0.09±0.10 (0.00%) 0.03± 0.03 (0.00%) | Adult Census Income 0.05±0.06 (0.60%) 0.02± 0.04 (1.49%) | Average 0.07±0.08 (0.30%) 0.03± 0.04 (0.75%) |
| --- | --- | --- | --- |
| Constant | -0.40±0.08 (97.51%) | -0.18±0.10 (15.69%) | -0.29±0.09 (56.60%) |
| Random | 0.10±0.30 (0.00%) | 0.32±0.31 (0.30%) | 0.21±0.31 (0.15%) |
| EGR | 0.06±0.45 (0.00%) | 0.01±0.35 (0.00%) | 0.03±0.40 (0.00%) |
| CFP | 0.09± 0.03 (49.21%) | 0.05±0.06 (2.13%) | 0.07±0.05 (25.67%) |
| FairPFN | 0.01± 0.03 (0.11%) | 0.02± 0.04 (0.60%) | 0.02± 0.04 (0.36%) |
Table 2: Difference to Cntf. Avg. (Real): Mean, standard deviation and percentage of outliers of the predictions on our real-world datasets of FairPFN and our baseline models compared to the predictions of the Cntf. Avg. baseline, which shows strong performance in causal effect removal and predictive error due to access to both observational and counterfactual data. FairPFN achieves predictions with an average difference to Cntf. Avg. of 0.02±0.04, with 0.36% of samples falling outside of three standard deviations.