# SwS: Self-aware Weakness-driven Problem Synthesis in Reinforcement Learning for LLM Reasoning
**Authors**: Xiao Liang1∗1 1 ∗, Zhong-Zhi Li2∗2 2 ∗, Yeyun Gong, Yang Wang, Hengyuan Zhang, Los AngelesSchool of Artificial Intelligence
∗ Equal contribution. Work done during Xiao’s and Zhongzhi’s internships at Microsoft. † Corresponding authors: Yeyun Gong and Weizhu Chen. 🖂: yegong@microsoft.com; wzchen@microsoft.com
Abstract: Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective for training large language models (LLMs) on complex reasoning tasks, such as mathematical problem solving. A prerequisite for the scalability of RLVR is a high-quality problem set with precise and verifiable answers. However, the scarcity of well-crafted human-labeled math problems and limited-verification answers in existing distillation-oriented synthetic datasets limit their effectiveness in RL. Additionally, most problem synthesis strategies indiscriminately expand the problem set without considering the model’s capabilities, leading to low efficiency in generating useful questions. To mitigate this issue, we introduce a S elf-aware W eakness-driven problem S ynthesis framework (SwS) that systematically identifies model deficiencies and leverages them for problem augmentation. Specifically, we define weaknesses as questions that the model consistently fails to learn through its iterative sampling during RL training. We then extract the core concepts from these failure cases and synthesize new problems to strengthen the model’s weak areas in subsequent augmented training, enabling it to focus on and gradually overcome its weaknesses. Without relying on external knowledge distillation, our framework enables robust generalization by empowering the model to self-identify and address its weaknesses in RL, yielding average performance gains of 10.0% and 7.7% on 7B and 32B models across eight mainstream reasoning benchmarks.
| | Code | https://github.com/MasterVito/SwS |
| --- | --- | --- |
| Project | https://MasterVito.SwS.github.io | |
<details>
<summary>x1.png Details</summary>
### Visual Description
## Radar Charts: Performance Comparison Across Benchmarks and Domains
### Overview
Two radar charts compare the performance of five AI models across different benchmarks (left) and academic domains (right). The charts use color-coded lines to represent models, with SwS-32B (red) consistently outperforming others in most categories.
### Components/Axes
**Legend (Top-Left of Both Charts):**
- Qwen2.5-32B (Gray dashed)
- Qwen2.5-32B-IT (Blue dashed)
- ORZ-32B (Orange dashed)
- SimpleRL-32B (Green dashed)
- Baseline-32B (Purple dashed)
- SwS-32B (Red solid)
**Chart (a) - Performance across Benchmarks:**
- **Axes (Clockwise from Top):**
1. GSM8K (96.3)
2. MATH (89.4)
3. AIME@32 (31.2)
4. AMC23 (90.0)
5. GaoKao 2023 (80.3)
6. Olympiad Bench (60.5)
7. Minerva Math (47.1)
**Chart (b) - Performance across Domains:**
- **Axes (Clockwise from Top):**
1. Prealgebra (96.3)
2. Intermediate Algebra (84.1)
3. Number Theory (66.5)
4. Precalculus (72.3)
5. Counting & Probability (57.1)
6. Geometry (60.8)
7. Algebra (76.6)
### Detailed Analysis
**Chart (a) Trends:**
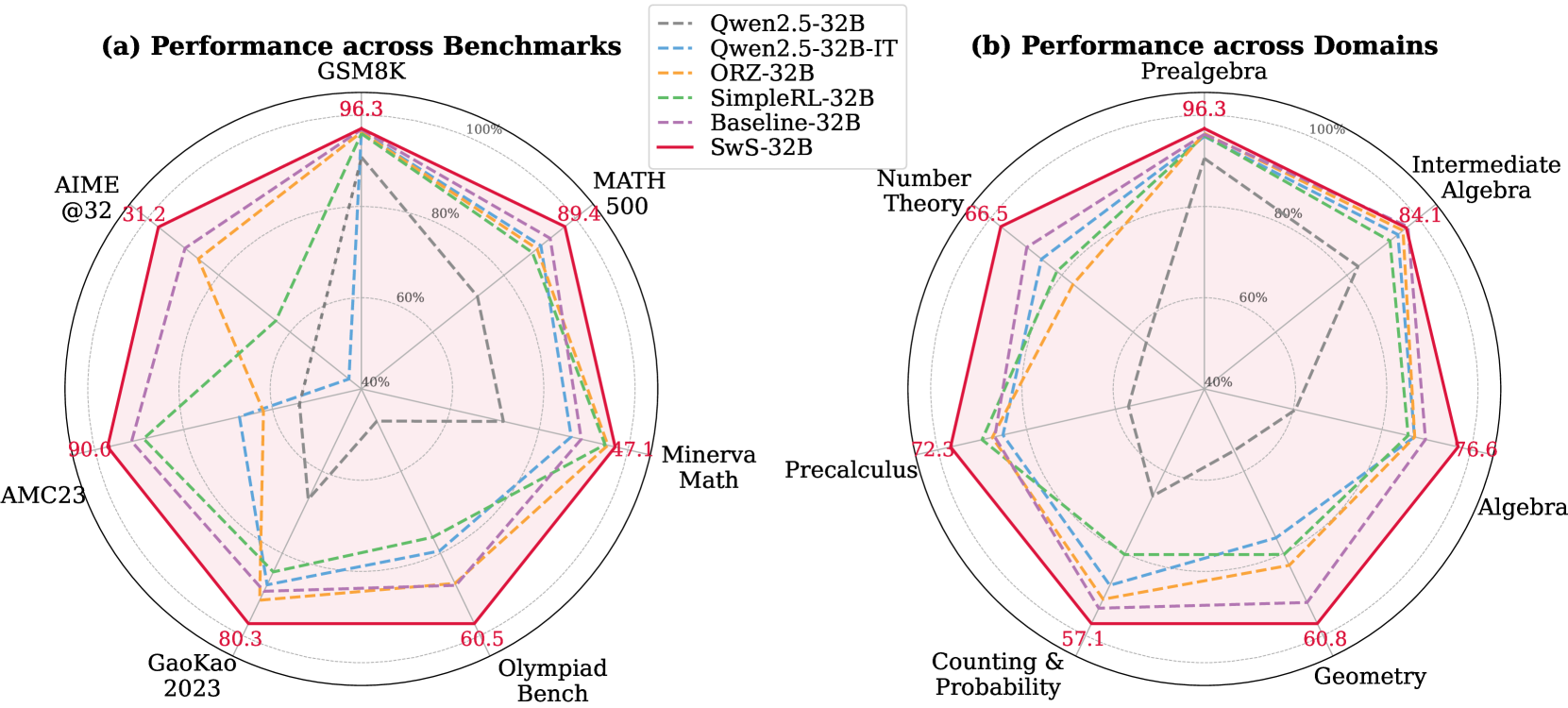
- SwS-32B (Red) dominates all benchmarks, peaking at 96.3 (GSM8K) and maintaining >80% in 5/7 categories.
- Qwen2.5-32B-IT (Blue) shows strong performance in MATH (89.4) but struggles in Minerva Math (47.1).
- Baseline-32B (Purple) has the lowest scores, with 31.2 (AIME@32) and 60.5 (Olympiad Bench).
- ORZ-32B (Orange) and SimpleRL-32B (Green) show mid-tier performance, with ORZ-32B excelling in AMC23 (90.0).
**Chart (b) Trends:**
- SwS-32B maintains dominance, with 96.3 (Prealgebra) and 84.1 (Intermediate Algebra).
- Qwen2.5-32B-IT (Blue) performs best in Number Theory (66.5) but weakest in Geometry (60.8).
- Baseline-32B (Purple) scores lowest in Counting & Probability (57.1) and Geometry (60.8).
- ORZ-32B (Orange) shows consistent mid-range performance (72.3-84.1).
### Key Observations
1. **SwS-32B Superiority:** Red line consistently leads in both charts, suggesting it's optimized for these tasks.
2. **Qwen2.5-32B-IT Variability:** Blue line shows high variance (e.g., 89.4 in MATH vs. 47.1 in Minerva Math).
3. **Baseline-32B Weakness:** Purple line underperforms across all categories, indicating fundamental limitations.
4. **Domain-Specific Gaps:** Minerva Math (47.1) and Geometry (60.8) are weak points for most models.
### Interpretation
The data reveals SwS-32B as the most robust model across both benchmarks and academic domains, likely due to specialized training. Qwen2.5-32B-IT's performance suggests it excels in specific areas (e.g., MATH) but lacks generalization. The Baseline-32B's poor results highlight the importance of architectural complexity. Notably, Minerva Math and Geometry represent systemic challenges for current models, possibly due to insufficient training data or task complexity. These insights could guide targeted model improvements or domain-specific adaptations.
</details>
Figure 1: 32B model performance across mainstream reasoning benchmarks and different domains.
## 1 Introduction
"Give me six hours to chop down a tree and I will spend the first four sharpening the axe."
—Abraham Lincoln
Large-scale Reinforcement Learning with Verifiable Rewards (RLVR) has substantially advanced the reasoning capabilities of large language models (LLMs) [16, 10, 46], where simple rule-based rewards can effectively induce complex reasoning skills. The success of RLVR for eliciting models’ reasoning capabilities heavily depends on a well-curated problem set with proper difficulty levels [63, 28, 55], where each problem is paired with an precise and verifiable reference answer [14, 31, 63, 10]. However, existing reasoning-focused datasets for RLVR suffer from three main issues: (1) High-quality, human-labeled mathematical problems are scarce, and collecting large-scale, well-annotated datasets with precise reference answers is cost-intensive. (2) Most reasoning-focused synthetic datasets are created for SFT distillation, where reference answers are rarely rigorously verified, making them suboptimal for RLVR, which relies heavily on the correctness of the final answer as the training signal. (3) Existing problem augmentation strategies typically involve rephrasing or generating variants of human-written questions [62, 30, 38, 27], or sampling concepts from existing datasets [15, 45, 20, 73], without explicitly considering the model’s reasoning capabilities. Consequently, the synthetic problems may be either too trivial or overly challenging, limiting their utility for model improvement in RL.
More specifically, in RL, it is essential to align the difficulty of training tasks with the model’s current capabilities. When using group-level RL algorithms such as GPRO [40], the advantage of each response is calculated based on its comparison with other responses in the same group. If all responses are either entirely correct or entirely incorrect, the token-level advantages within each rollout collapse to 0, leading to gradient vanishing and degraded training efficiency [28, 63], and potentially harming model performance [55]. Therefore, training on problems that the model has fully mastered or consistently fails to solve does not provide useful learning signals for improvement. However, a key advantage of the failure cases is that, unlike the overly simple questions with little opportunity for improvement, persistently failed problems reveal specific areas of weakness in the model and indicate directions for further enhancement. This raises the following research question: How can we effectively utilize these consistently failed cases to address the model’s reasoning deficiencies? Could they be systematically leveraged for data synthesis that targets the enhancement of the model’s weakest capabilities?
To answer these questions, we propose a S elf-aware W eakness-driven Problem S ynthesis (SwS) framework, which leverages the model’s self-identified weaknesses in RL to generate synthetic problems for training augmentation. Specifically, we record problems that the model consistently struggles to solve or learns inefficiently through iterative sampling during a preliminary RL training phase. These failed problems, which reflect the model’s weakest areas, are grouped by categories, leveraged to extract common concepts, and to synthesize new problems with difficulty levels tailored to the model’s capabilities. To further improve weakness mitigation efficiency during training, the augmentation budget for each category is allocated based on the model’s relative performance across them. Compared with existing problem synthesis strategies for LLM reasoning [73, 45], our framework explicitly targets the model’s capabilities and self-identified weaknesses, enabling more focused and efficient improvement in RL training.
To validate the effectiveness of SwS, we conducted experiments across model sizes ranging from 3B to 32B and comprehensively evaluated performance on eight popular mathematical reasoning benchmarks, showing that its weakness-driven augmentation strategy benefits models across all levels of reasoning capability. Notably, our models trained on the augmented problem set consistently surpass both the base models and those trained on the original dataset across all benchmarks, achieving a substantial average absolute improvement of 10.0% for the 7B model and 7.7% for the 32B model, even surpassing their counterparts trained on carefully curated human-labeled problem sets [14, 6]. We also analyze the model’s performance on previously failed problems and find that, after training on the augmented problem set, it is able to solve up to 20.0% more problems it had consistently failed in its weak domain when trained only on the original dataset. To further demonstrate the robustness and adaptability of the proposed SwS pipeline, we extend it to explore the potential of Weak-to-Strong Generalization, Self-evolving, and Weakness-driven Selection settings, with detailed experimental results and analysis presented in Section 4.
Contributions. (i) We propose a Self-aware Weakness-driven Problem Synthesis (SwS) framework that utilizes the model’s self-identified weaknesses to generate synthetic problems for enhanced RLVR training, paving the way for utilizing high-quality and targeted synthetic data for RL training. (ii) We comprehensively evaluate the SwS framework across diverse model sizes on eight mainstream reasoning benchmarks, demonstrating its effectiveness and generalizability. (iii) We explore the potential of extending our SwS framework to Weak-to-Strong Generalization, Self-evolving, and Weakness-driven Selection settings, highlighting its adaptability through detailed analysis.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Reinforcement Learning Policy Training with Verification
### Overview
The diagram illustrates a reinforcement learning (RL) training process for a policy (Policyθ) designed to solve a fencing optimization problem. The policy generates answers, which are verified for accuracy. The process includes two training epochs (t₁, t₂, t₃) with corresponding accuracy metrics, a "Failed set" indicator, and a "Verifier" component. The goal is to maximize the enclosed area of a rectangular tennis court using exactly 300 feet of fencing, with constraints on minimum length (80 ft) and width (40 ft).
---
### Components/Axes
1. **Policyθ**: A green box representing the RL policy generating answers.
2. **Verifier**: A purple box evaluating the correctness of answers.
3. **Answer Stacks**: Blue rectangles labeled "Answer₁,₁" to "Answerₖ,₁" representing generated solutions.
4. **Accuracy Graphs**:
- **X-axis**: Training epochs (t₁, t₂, t₃).
- **Y-axis**: Accuracy values (0.0 to 1.0).
- **Legend**: Red "X" (failed) and green "✓" (successful).
5. **Failed Set**: A red cylinder labeled "Failed set" indicating rejected answers.
---
### Detailed Analysis
#### Accuracy Trends
- **First Training Epoch (t₁)**:
- Accuracy values: 0.3, 0.5, 0.3, 0.2.
- **Trend**: Low and inconsistent accuracy, with a final value of 0.2 (red "X" indicating failure).
- **Second Training Epoch (t₁ to t₃)**:
- Accuracy values: 0.3 → 0.8 → 0.9 → 1.0.
- **Trend**: Steady improvement, culminating in perfect accuracy (1.0) by t₃ (green "✓" indicating success).
#### Spatial Grounding
- **Accuracy Graphs**: Positioned to the right of the policy/verifier flowchart.
- **Legend**: Located above the accuracy graphs, with red "X" (failed) and green "✓" (successful).
- **Failed Set**: Positioned to the far right, connected to the first epoch's failure.
---
### Key Observations
1. **Initial Failure**: The first epoch (t₁) shows poor performance, with accuracy dropping to 0.2, leading to a "Failed set."
2. **Improvement with Retraining**: Subsequent epochs (t₂, t₃) demonstrate significant accuracy gains, reaching 1.0 by the final epoch.
3. **Verifier Role**: The verifier acts as a feedback mechanism, rejecting low-accuracy answers and enabling policy refinement.
---
### Interpretation
The diagram demonstrates how RL policies improve iteratively through verification feedback. The initial failure (t₁) highlights the need for retraining, while the subsequent accuracy surge (t₂–t₃) underscores the effectiveness of the RL process. The "Failed set" and verifier interaction suggest a mechanism to discard invalid solutions, ensuring only high-accuracy answers propagate. This aligns with the fencing problem's constraints, where optimal area maximization requires precise policy adjustments. The perfect accuracy in the final epoch implies the policy successfully learned to balance fencing length and area constraints.
</details>
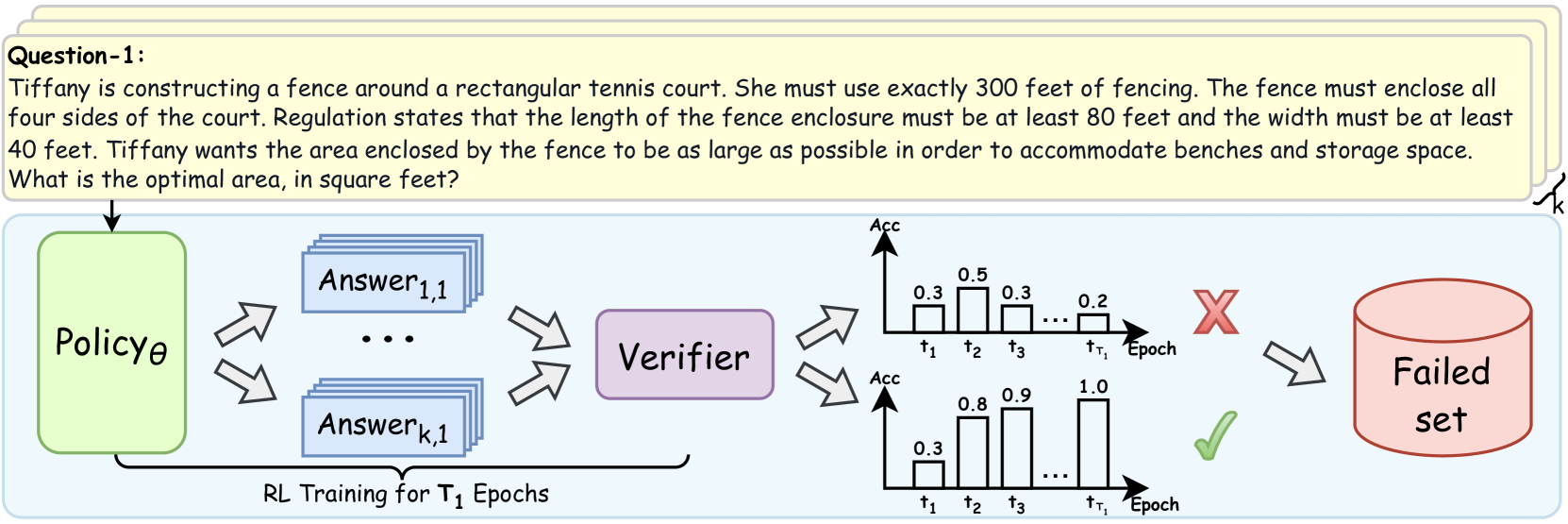
Figure 2: Illustration of the self-aware weakness identification during a preliminary RL training.
## 2 Method
### 2.1 Preliminary
Group Relative Policy Optimization (GRPO). GRPO [40] is an efficient optimization algorithm tailored for RL in LLMs, where the advantages for each token are computed in a group-relative manner without requiring an additional critic model to estimate token values. Specifically, given an input prompt $x$ , the policy model $\pi_{\theta_{\text{old}}}$ generates a group of $G$ responses $\mathbf{Y}=\{y_{i}\}_{i=1}^{G}$ , with acquired rewards $\mathbf{R}=\{r_{i}\}_{i=1}^{G}$ . The advantage $A_{i,t}$ for each token in response $y_{i}$ is computed as the normalized rewards:
$$
A_{i,t}=\frac{r_{i}-\text{mean}(\{r_{i}\}_{i=1}^{G})}{\text{std}(\{r_{i}\}_{i=
1}^{G})}. \tag{1}
$$
To improve the stability of policy optimization, GRPO clips the probability ratio $k_{i,t}(\theta)=\frac{\pi_{\theta}(y_{i,t}\mid x,y_{i,<t})}{\pi_{\theta_{\text {old}}}(y_{i,t}\mid x,y_{i,<t})}$ within a trust region [39], and constrains the policy distribution from deviating too much from the reference model using a KL term. The optimization objective is defined as follows:
$$
\displaystyle\mathcal{J}_{\text{GRPO}}(\theta) \displaystyle=\mathbb{E}_{x\sim\mathcal{D},\mathbf{Y}\sim\pi_{\theta_{\text{
old}}}(\cdot\mid x)} \displaystyle\Bigg{[}\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|y_{i}|}\sum_{t=1}^{|y_
{i}|}\Bigg{(}\min\Big{(}k_{i,t}(\theta)A_{i,t},\ \text{clip}\Big{(}k_{i,t}(
\theta),1-\varepsilon,1+\varepsilon\Big{)}A_{i,t}\Big{)}-\beta D_{\text{KL}}(
\pi_{\theta}||\pi_{\text{ref}})\Bigg{)}\Bigg{]}. \tag{2}
$$
Inspired by DAPO [63], in all experiments of this work, we omit the KL term during optimization, while incorporating the clip-higher, token-level loss and dynamic sampling strategies to enhance the training efficiency of RLVR. Our RLVR training objective is defined as follows:
$$
\displaystyle\mathcal{J}(\theta)=\mathbb{E}_{x\sim\mathcal{D},\,\mathbf{Y}\sim
\pi_{\theta_{\text{old}}}(\cdot\mid x)}\ \displaystyle\Bigg{[}\frac{1}{\sum_{i=1}^{G}|y_{i}|}\sum_{i=1}^{G}\sum_{t=1}^{
|y_{i}|}\Big{(}\min\big{(}k_{i,t}(\theta)A_{i,t},\ \text{clip}(k_{i,t}(\theta)
,1-\varepsilon,1+\varepsilon^{h})A_{i,t}\big{)}\Big{)}\Bigg{]} \displaystyle\text{s.t.}\leavevmode\nobreak\ \leavevmode\nobreak\ \text{acc}_{
\text{lower}}<\left|\left\{y_{i}\in\mathbf{Y}\;\middle|\;\texttt{is\_accurate}
(x,y_{i})\right\}\right|<\text{acc}_{\text{upper}}. \tag{3}
$$
where $\varepsilon^{h}$ denotes the upper clipping threshold for importance sampling ratio $k_{i,t}(\theta)$ , and $\text{acc}_{\text{lower}}$ and $\text{acc}_{\text{upper}}$ are thresholds used to filter target prompts for subsequent policy optimization.
### 2.2 Overview
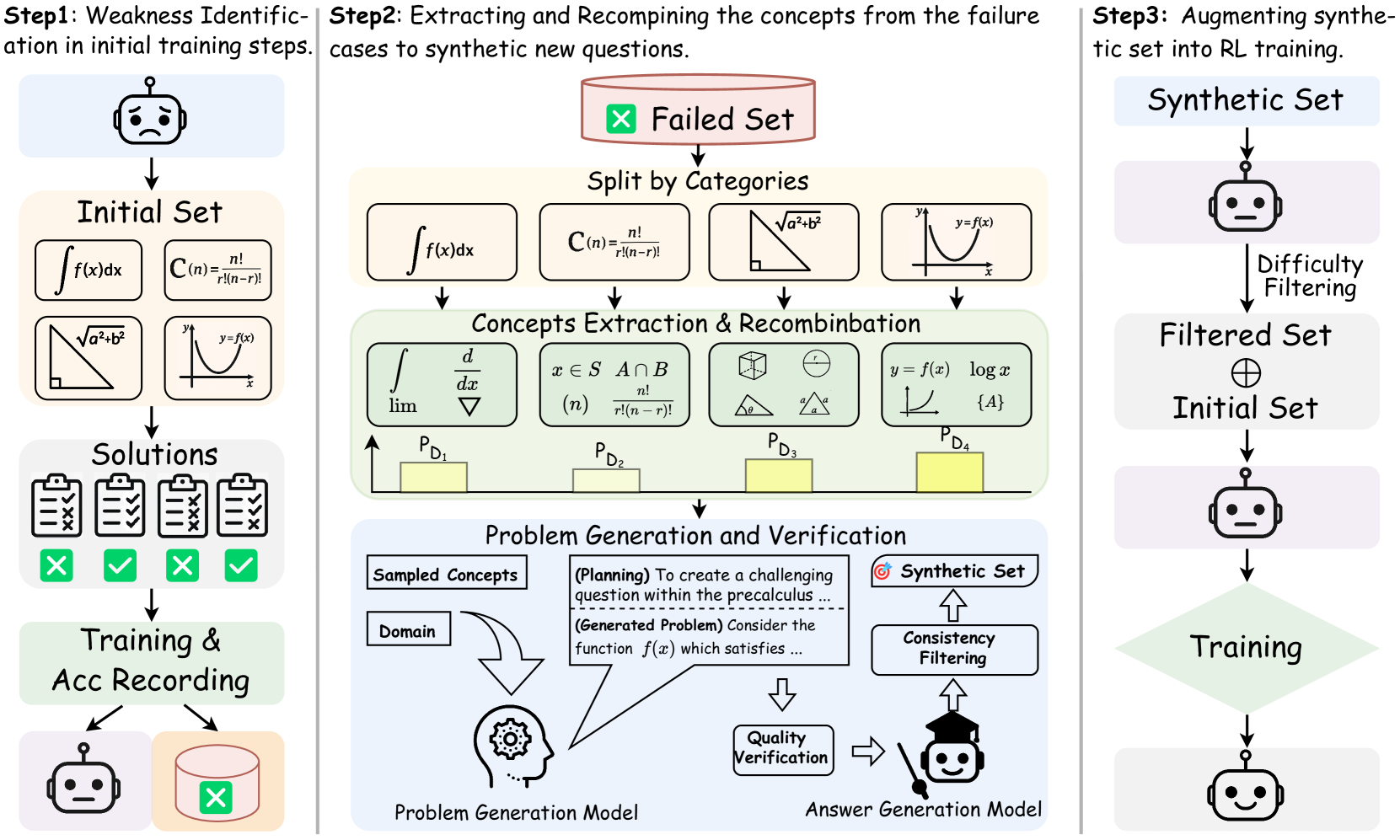
Figure 3 presents an overview of our SwS framework, which generates targeted training samples to enhance the model’s reasoning capabilities in RLVR. The framework initiates with a Self-aware Weakness Identification stage, where the model undergoes preliminary RL training on an initial problem set covering diverse categories. During this stage, the model’s weaknesses are identified as problems it consistently fails to solve or learns ineffectively. Based on failure cases that reflect the model’s weakest capabilities, in the subsequent Targeted Problem Synthesis stage, we group them by category, extract their underlying concepts, and recombine these concepts to synthesize new problems that target the model’s learning and mitigation of its weaknesses. In the final Augmented Training with Synthetic Problems stage, the model receives continuous training with the augmented high-quality synthetic problems, thereby enhancing its general reasoning abilities through more targeted training.
### 2.3 Self-aware Weakness Identification
Utilizing the policy model itself to identify its weakest capabilities, we begin by training it in a preliminary RL phase using an initial problem set $\mathbf{X}_{S}$ , which consists of mathematical problems from $n$ diverse categories ${\mathbf{\{D\}}}_{i=0}^{n}$ , each paired with a ground-truth answer $a$ . As illustrated in Figure 2, we record the average accuracy $a_{i,t}$ of the model’s responses to each prompt $x_{i}$ at each epoch $t\in\{0,1,\dots,T_{1}\}$ , where $T_{1}$ is the number of training epochs in this phase. We track the Failure Rate $F$ for each problem in the training set to identify those that the model consistently struggles to learn, which are considered its weaknesses. Specifically, such problems are defined as those the model consistently struggles to solve during RL training, which meet two criteria: (1) The model never reaches a response accuracy of 50% at any training epoch, and (2) The accuracy trend decreases over time, indicated by a negative slope:
$$
F(x_{i})=\mathbb{I}\left[\max_{t\in[1,T]}a_{i,t}<0.5\;\land\;\text{slope}\left
(\{a_{i,t}\}_{t=1}^{T}\right)<0\right] \tag{4}
$$
This metric captures both problems the model consistently fails to solve and those showing no improvement during sampling-based RL training, making them appropriate targets for training augmentation. After the weakness identification phase via the preliminary training on the initial training set $\mathbf{X}_{S}$ , we employ the collected problems $\mathbf{X}_{F}=\left\{x_{i}\in\mathbf{X}_{S}\;\middle|\;F_{r}(x_{i})=1\right\}$ as seed problems for subsequent weakness-driven problem synthesis.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Flowchart: Iterative Machine Learning Training Process with Synthetic Data Augmentation
### Overview
The diagram illustrates a three-step iterative process for improving machine learning model training through synthetic data generation and failure analysis. It combines mathematical concept extraction, problem generation, and reinforcement learning (RL) augmentation.
### Components/Axes
**Step 1: Weakness Identification**
- **Initial Set**: Contains mathematical concepts (integrals, combinations, geometric shapes)
- **Solutions**: Checkmarked (✓) and failed (✗) problem attempts
- **Training & Acc Recording**: Robot icon and database symbol
**Step 2: Concept Extraction & Recombination**
- **Split by Categories**: Integrals, combinations, geometric shapes
- **Concepts Extraction**: Mathematical operations (limits, intersections, geometric transformations)
- **Problem Generation**: Planning module with precalculus constraints
- **Verification**: Quality check with robot icon
**Step 3: Synthetic Set Augmentation**
- **Synthetic Set**: Robot icon with difficulty filtering
- **Filtered Set**: Cross (+) symbol
- **Training**: Robot icon with graduation cap
**Flow Arrows**: Connect components between steps (e.g., Initial Set → Solutions → Training → Step 2 → Step 3)
### Detailed Analysis
**Step 1 Elements**:
- Initial Set contains:
- Integral notation: ∫f(x)dx
- Combination formula: C(n) = n! / [r!(n-r)!]
- Geometric shapes (triangle, parabola)
- Solutions show 4 attempts with mixed ✓/✗ results
- Training & Acc Recording connects to database
**Step 2 Elements**:
- Split by Categories includes:
- Integral: ∫f(x)dx
- Combination formula
- Geometric shapes (triangle, parabola)
- Concepts Extraction shows:
- Limit notation: lim d/dx
- Set intersection: x∈S ∧ A∩B
- Geometric figures (cube, circle)
- Problem Generation includes:
- Planning module with precalculus constraints
- Generated problem example: "Consider function f(x) satisfying..."
- Quality Verification connects to Answer Generation Model
**Step 3 Elements**:
- Synthetic Set includes:
- Robot icon with difficulty filtering
- Filtered Set symbol (+)
- Training connects back to Initial Set
### Key Observations
1. **Iterative Feedback Loop**: Training results feed back into Initial Set through synthetic data
2. **Failure Analysis**: Failed solutions (✗) trigger concept extraction
3. **Mathematical Rigor**: Explicit mathematical notation used throughout
4. **Automation**: Robot icons represent automated processes
5. **Quality Control**: Multiple verification stages (quality check, consistency filtering)
### Interpretation
This flowchart demonstrates a sophisticated approach to machine learning model improvement through:
1. **Weakness Identification**: Initial training reveals problem areas through solution attempts
2. **Conceptual Recombination**: Failed cases are analyzed to extract mathematical concepts
3. **Synthetic Problem Generation**: New challenging problems are created within mathematical constraints
4. **Quality Filtering**: Generated problems undergo rigorous verification
5. **Reinforcement Learning**: Synthetic data is filtered and integrated back into training
The process creates a closed-loop system where model weaknesses directly inform synthetic data generation, which in turn strengthens the model through targeted training. The use of mathematical notation suggests this could be applied to STEM-focused machine learning applications, particularly in domains requiring precise problem-solving capabilities.
</details>
Figure 3: An overview of our proposed weakness-driven problem synthesis framework that targets at mitigating the model’s reasoning limitations within the RLVR paradigm.
### 2.4 Targeted Problem Synthesis
Concept Extraction and Recombination. We synthesize new problems by extracting the underlying concepts $\mathbf{C}_{F}$ from the collected seed questions $\mathbf{X}_{F}$ and strategically recombining them to generate questions that target similar capabilities. Specifically, the extracted concepts are first categorized into their respective categories $\mathbf{D}_{i}$ (e.g., mathematical topics such as Algebra or Geometry) based on the corresponding seed problem $x_{i}$ , and are subsequently sampled and recombined to generate problems within the same category. Inspired by [15, 73], we enhance the coherence and semantic fluency of synthetic problems by computing co-occurrence probabilities and embedding similarities among concepts within each category, enabling more appropriate sampling and recombination of relevant concepts. This targeted sampling approach ensures that the synthesized problems remain semantically coherent and avoids combining concepts from unrelated sub-topics or irrelevant knowledge points, which could otherwise result in invalid or confusing questions. Further details on the co-occurrence calculation and sampling algorithm are provided in Appendix E.
Intuitively, categories exhibiting more pronounced weaknesses demand additional learning support. To optimize the efficiency of targeted problem synthesis and weakness mitigation in subsequent RL training, we allocate the augmentation budget, i.e., the concept combinations used as inputs for problem synthesis, across categories based on the model’s category-specific failure rates $F_{\mathbf{D}}$ from the preliminary training phase. Specifically, we normalize these failure rates $F_{\mathbf{D}}$ across categories to determine the allocation weights for problem synthesis. Given a total augmentation budget $|\mathbf{X}_{T}|$ , the number of concept combinations allocated to domain $\mathbf{D}_{i}$ is computed as:
$$
|\mathbf{X}_{T,\mathbf{D}_{i}}|=|\mathbf{X}_{T}|\cdot P_{\mathbf{D}_{i}}=|
\mathbf{X}_{T}|\cdot\frac{F_{\mathbf{D}_{i}}}{\sum_{j}^{n}F_{\mathbf{D}_{j}}}, \tag{5}
$$
where $F_{\mathbf{D}_{i}}$ is the failure rate of problems in category $\mathbf{D}_{i}$ within the initial training set. The sampled and recombined concepts then serve as inputs for subsequent problem generation.
Problem Generation and Quality Verification. After extracting and recombining the concepts associated with the model’s weakest capabilities, we employ a strong instruction model, which does not perform deep reasoning, to generate new problems based on the category label and the recombined concepts. We instruct the model to first generate rationales that explore how the concept combinations can be integrated to produce a well-formed problem. To ensure the synthetic problems align with the RLVR setting, the model is also instructed to avoid generating multiple-choice, multi-part, or proof-based questions [1]. Detailed prompt used for the concept-based problem generation please refer to the Appendix J. For quality verification of the synthetic problems, we prompt general instruction LLMs multiple times to evaluate each problem and its rationale across multiple dimensions, including concept coverage, factual accuracy, and solvability, assigning an overall rating of bad, acceptable, or perfect. Only problems receiving ‘perfect’ ratings above a predefined threshold and no ‘bad’ ratings are retained for subsequent utilization.
Reference Answer Generation. Since alignment between the model’s final answer and the reference answer is the primary training signal in RLVR, a rigorous verification of the reference answers for synthetic problems is essential to ensure training stability and effectiveness. To this end, we employ a strong reasoning model (e.g., QwQ-32B [47]) to label reference answers for synthetic problems through a self-consistency paradigm. Specifically, we prompt it to generate multiple responses for each problem and use Math-Verify to assess answer equivalence, which ensures that consistent answers of different forms (e.g., fractions and decimals) are correctly recognized as equal. Only problems with at least 50% consistent answers are retained, as highly inconsistent answers are unreliable as ground truth and may indicate that the problems are excessively complex or unsolvable.
Difficulty Filtering. The most prevalently used RLVR algorithms, such as GRPO, compute the advantage of each token in a response by comparing its reward to those of other responses for the same prompt. When all responses yield identical accuracy—either all correct or all incorrect—the advantages uniformly degrade to zero, leading to gradient vanishing for policy updates and resulting in training inefficiency [40, 63]. Recent study [53] further shows that RLVR training can be more efficient with problems of appropriate difficulty. Considering this, we select synthetic problems of appropriate difficulty based on the initially trained model’s accuracy on them. Specifically, we sample multiple responses per synthetic problem using the initially trained model and retain only those whose accuracy falls within a target range $[\text{acc}_{\text{low}},\text{acc}_{\text{high}}]$ (e.g., $[25\$ ). This strategy ensures that the model engages with learnable problems, enhancing both the stability and efficiency of RLVR training.
### 2.5 Augmented Training with Synthetic Problems
After the rigorous problem generation, answer generation, and verification, the allocation budget of synthetic problems in each category is further adjusted using the weights in Eq. 5 to ensure their comprehensive and efficient utilization, resulting in $\mathbf{X}^{\prime}_{T}$ . We incorporate the retained synthetic problems $\mathbf{X}^{\prime}_{T}$ into the initial training set $\mathbf{X}_{S}$ , forming the augmented training set $\mathbf{X}_{A}=[\mathbf{X}_{S};\mathbf{X}^{\prime}_{T}]$ . We then continue training the initially trained model on $\mathbf{X}_{A}$ in a second stage of augmented RLVR, targeting to mitigate the model’s weaknesses through exploration of the synthetic problems.
## 3 Experiments
| Model | GSM8K | MATH 500 | Minerva Math | Olympiad Bench | GaoKao 2023 | AMC23 | AIME24 (Avg@ 1 / 32) | AIME25 (Avg@ 1 / 32) | Avg. |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Qwen 2.5 3B Base | | | | | | | | | |
| Qwen2.5-3B | 69.9 | 46.0 | 18.8 | 19.9 | 34.8 | 27.5 | 0.0 / 2.2 | 0.0 / 1.5 | 27.1 |
| Qwen2.5-3B-IT | 84.2 | 62.2 | 26.5 | 27.9 | 53.5 | 32.5 | 6.7 / 5.0 | 0.0 / 2.3 | 36.7 |
| BaseRL-3B | 86.3 | 66.0 | 25.4 | 31.3 | 57.9 | 40.0 | 10.0 / 9.9 | 6.7 / 3.5 | 40.4 |
| SwS-3B | 87.0 | 69.6 | 27.9 | 34.8 | 59.7 | 47.5 | 10.0 / 8.4 | 6.7 / 7.1 | 42.9 |
| $\Delta$ | +0.7 | +3.6 | +2.5 | +3.5 | +1.8 | +7.5 | +0.0 / -1.5 | +0.0 / +3.6 | +2.5 |
| Qwen 2.5 7B Base | | | | | | | | | |
| Qwen2.5-7B | 88.1 | 63.0 | 27.6 | 30.5 | 55.8 | 35.0 | 6.7 / 5.4 | 0.0 / 1.2 | 38.3 |
| Qwen2.5-7B-IT | 91.7 | 75.6 | 38.2 | 40.6 | 63.9 | 50.0 | 16.7 / 10.5 | 13.3 / 6.7 | 48.8 |
| Open-Reasoner-7B | 93.6 | 80.4 | 39.0 | 45.6 | 72.0 | 72.5 | 10.0 / 16.8 | 13.3 / 17.9 | 53.3 |
| SimpleRL-Base-7B | 90.8 | 77.2 | 35.7 | 41.0 | 66.2 | 62.5 | 13.3 / 14.8 | 6.7 / 6.7 | 49.2 |
| BaseRL-7B | 92.0 | 78.4 | 36.4 | 41.6 | 63.4 | 45.0 | 10.0 / 14.5 | 6.7 / 6.5 | 46.7 |
| SwS-7B | 93.9 | 82.6 | 41.9 | 49.6 | 71.7 | 67.5 | 26.7 / 18.3 | 20.0 / 18.5 | 56.7 |
| $\Delta$ | +1.9 | +4.2 | +5.5 | +8.0 | +8.3 | +22.5 | +16.7 / +3.8 | +13.3 / +12.0 | +10.0 |
| Qwen 2.5 7B Math | | | | | | | | | |
| Qwen2.5-Math-7B | 43.2 | 72.0 | 35.7 | 17.6 | 31.4 | 47.5 | 10.0 / 9.4 | 0.0 / 2.9 | 32.2 |
| Qwen2.5-Math-7B-IT | 93.3 | 80.6 | 36.8 | 36.6 | 64.9 | 45.0 | 6.7 / 7.2 | 13.3 / 6.2 | 47.2 |
| PRIME-RL-7B | 93.2 | 82.0 | 41.2 | 46.1 | 67.0 | 60.0 | 23.3 / 16.1 | 13.3 / 16.2 | 53.3 |
| SimpleRL-Math-7B | 89.8 | 78.0 | 27.9 | 43.4 | 64.2 | 62.5 | 23.3 / 24.5 | 20.0 / 15.6 | 51.1 |
| Oat-Zero-7B | 90.1 | 79.4 | 38.2 | 42.4 | 67.8 | 70.0 | 43.3 / 29.3 | 23.3 / 11.8 | 56.8 |
| BaseRL-Math-7B | 90.2 | 78.8 | 37.9 | 43.6 | 64.4 | 57.5 | 26.7 / 23.0 | 20.0 / 14.0 | 51.9 |
| SwS-Math-7B | 91.9 | 83.8 | 41.5 | 47.7 | 71.4 | 70.0 | 33.3 / 25.9 | 26.7 / 18.2 | 58.3 |
| $\Delta$ | +1.7 | +5.0 | +3.6 | +4.1 | +7.0 | +12.5 | +6.7 / +2.9 | +6.7 / +4.2 | +6.4 |
| Qwen 2.5 32B base | | | | | | | | | |
| Qwen2.5-32B | 90.1 | 66.8 | 34.9 | 29.8 | 55.3 | 50.0 | 10.0 / 4.2 | 6.7 / 2.5 | 42.9 |
| Qwen2.5-32B-IT | 95.6 | 83.2 | 42.3 | 49.5 | 72.5 | 62.5 | 23.3 / 15.0 | 20.0 / 13.1 | 56.1 |
| Open-Reasoner-32B | 95.5 | 82.2 | 46.3 | 54.4 | 75.6 | 57.5 | 23.3 / 23.5 | 33.3 / 31.7 | 58.5 |
| SimpleRL-Base-32B | 95.2 | 81.0 | 46.0 | 47.4 | 69.9 | 82.5 | 33.3 / 26.2 | 20.0 / 15.0 | 59.4 |
| BaseRL-32B | 96.1 | 85.6 | 43.4 | 54.7 | 73.8 | 85.0 | 40.0 / 30.7 | 6.7 / 24.6 | 60.7 |
| SwS-32B | 96.3 | 89.4 | 47.1 | 60.5 | 80.3 | 90.0 | 43.3 / 33.0 | 40.0 / 31.8 | 68.4 |
| $\Delta$ | +0.2 | +3.8 | +3.7 | +5.8 | +6.5 | +5.0 | +3.3 / +2.3 | +33.3 / +7.2 | +7.7 |
Table 1: We report the detailed performance of our SwS implementation across various base models and multiple benchmarks. AIME is evaluated using two metrics: Avg@1 (single-run performance) and Avg@32 (average over 32 runs).
### 3.1 Experimental Setup
Models and Datasets. We employ the Qwen2.5-base series [57, 58] with model sizes from 3B to 32B in our experiments. For concept extraction and problem generation, we employ the LLaMA-3.3-70B-Instruct model [8], and for concept embedding, we use the LLaMA-3.1-8B-base model. To verify the quality of the synthetic questions, we use both the LLaMA-3.3-70B-Instruct and additionally Qwen-2.5-72B-Instruct [57] to evaluate them and filter out the low-quality samples. For answer generation, we use Skywork-OR1-Math-7B [12] for training models with sizes up to 7B, and QwQ-32B [47] for the 32B model experiments. We employ the SwS pipeline to generate 40k synthetic problems for each base model. All the prompts for each procedure in SwS can be found in Appendix J. We adopt GRPO [40] as the RL algorithm, and full implementation details are in Appendix B.
For the initial training set used in the preliminary RL training for weaknesses identification, we employ the MATH-12k [13] for models with sizes up to 7B. As the 14B and 32B models show early saturation on MATH-12k, we instead use a combined dataset of 17.5k samples from the DAPO [63] English set and the LightR1 [53] Stage-2 set.
Evaluation. We evaluated the models on a wide range of mathematical reasoning benchmarks, including GSM8K [4], MATH-500 [26], Minerva Math [19], Olympiad-Bench [11], Gaokao-2023 [71], AMC [33], and AIME [34]. We report Pass@1 (Avg@1) accuracy across all benchmarks and additionally include the Avg@32 metric for the competition-level AIME benchmark to enhance evaluation robustness. For detailed descriptions of the evaluation benchmarks, see Appendix I.
Baseline Setting. Our baselines include the base model, its post-trained Instruct version (e.g., Qwen2.5-7B-Instruct), and the initial trained model further trained on the initial dataset for the same number of steps as our augmented RL training as the baselines. To further highlight the effectiveness of the SwS framework, we compare the model trained on the augmented problem set against recent advanced RL-based models, including SimpleRL [67], Open Reasoner [14], PRIME [6], and Oat-Zero [28].
### 3.2 Main Results
The overall experimental results are presented in Table 1. Our SwS framework enables consistent performance improvements across benchmarks of varying difficulty and model scales, with the most significant gains observed in models greater than 7B parameters. Specifically, SwS-enhanced versions of the 7B and 32B models show absolute improvements of +10.0% and +7.7%, respectively, underscoring the effectiveness and scalability of the framework. When initialized with MATH-12k, SwS yields strong gains on competition-level benchmarks, achieving +16.7% and +13.3% on AIME24 and AIME25 with Qwen2.5-7B. These results highlight the quality and difficulty of the synthesized samples compared to well-crafted human-written ones, demonstrating the effectiveness of generating synthetic data based on model capabilities to enhance training.
### 3.3 Weakness Mitigation from Augmented Training
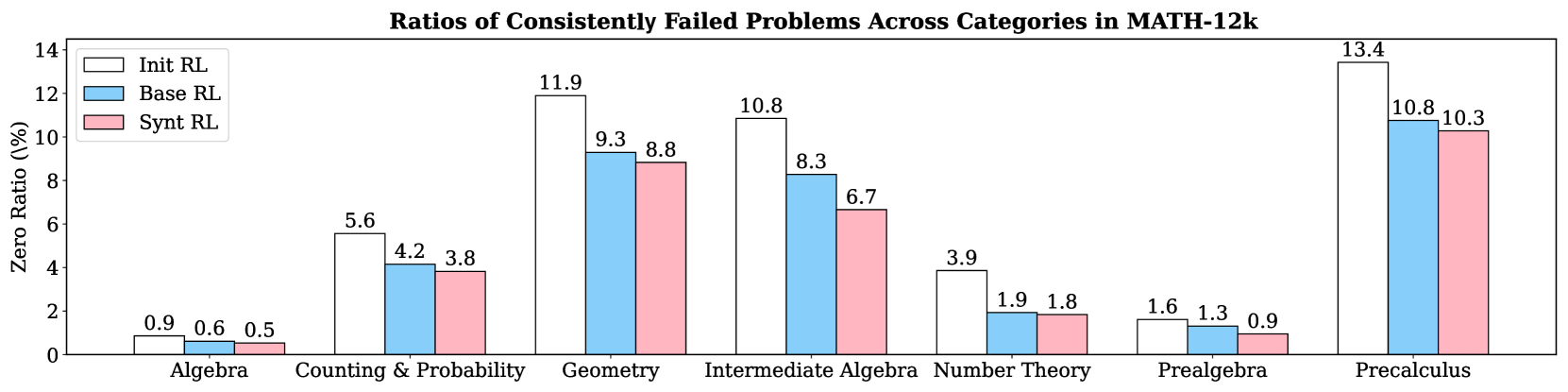
The motivation behind SwS is to mitigate model weaknesses by explicitly targeting failure cases during training. To demonstrate its effectiveness, we use Qwen2.5-7B to analyze the ratios of consistently failed problems in the initial training set (MATH-12k) across three models: the initially trained model, the model continued trained on the initial training set, and the model trained on the augmented set with synthetic problems from the SwS pipeline. As shown in Figure 4, continued training on the augmented set enables the model to solve a greater proportion of previously failed problems across most domains compared to training on the initial set alone, with the greatest gains observed in Intermediate Algebra (20%), Geometry (5%), and Precalculus (5%) as its weakest areas. Notably, these improvements are achieved even though each original problem is sampled four times less frequently in the augmented set than in training on the original dataset alone, highlighting the efficiency of SwS-generated synthetic problems in RL training.
## 4 Extensions and Analysis
| Model | GSM8K | AIME24 (Pass@32) | Prealgebra | Intermediate Algebra | Algebra | Precalculus | Number Theory | Counting & Probability | Geometry |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Strong Student | 92.0 | 13.8 | 87.7 | 58.7 | 93.8 | 63.2 | 86.4 | 71.2 | 66.8 |
| Weak Teacher | 93.3 | 7.2 | 88.2 | 64.3 | 95.5 | 71.2 | 93.0 | 81.4 | 63.0 |
| Trained Student | 93.6 | 17.5 | 90.5 | 64.4 | 97.7 | 74.6 | 95.1 | 80.4 | 67.5 |
Table 2: Performance on two representative benchmarks and category-specific results on MATH-500 of the weak teacher model and the strong student model.
| Model | GSM8K | MATH 500 | Minerva Math | Olympiad Bench | GaoKao 2023 | AMC23 | AIME24 (Avg@ 1 / 32) | AIME25 (Avg@ 1 / 32) | Avg. |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Qwen2.5-14B-IT | 94.7 | 79.6 | 41.9 | 45.6 | 68.6 | 57.5 | 16.7 / 11.6 | 6.7 / 10.9 | 51.4 |
| + BaseRL | 94.5 | 85.4 | 44.1 | 52.1 | 71.7 | 65.0 | 20.0 / 21.6 | 20.0 / 22.3 | 56.6 |
| + SwS-SE | 95.6 | 85.0 | 46.0 | 53.5 | 74.8 | 67.5 | 20.0 / 19.8 | 20.0 / 17.8 | 57.8 |
| $\Delta$ | +1.1 | -0.4 | +1.9 | +1.4 | +3.1 | +2.5 | +0.0 / -1.8 | +0.0 / -4.5 | +1.2 |
Table 3: Experimental results of extending the SwS framework to the Self-evolving paradigm on the Qwen2.5-14B-Instruct model.
### 4.1 Weak-to-Strong Generalization for SwS
Employing a powerful frontier model like QwQ [47] helps ensure answer quality. However, when training the top-performing reasoning model, no stronger model exists to produce reference answers for problems identified as its weaknesses. To explore the potential of applying our SwS pipeline to enhancing state-of-the-art models, we extend it to the Weak-to-Strong Generalization [2] setting by using a generally weaker teacher that may outperform the stronger model in specific domains to label reference answers for the synthetic problems.
Intuitively, using a weaker teacher may result in mislabeled answers, which could significantly impair subsequent RL training. However, during the difficulty filtering stage, this risk is mitigated by using the initially trained policy to assess the difficulty of synthetic problems, as it rarely reproduces the same incorrect answers provided by the weaker teacher. As a byproduct, mislabeled cases are naturally filtered out alongside overly complex samples through accuracy-based screening. The experimental analysis on the validity of difficulty-level filtering in ensuring label correctness is presented in Table 5.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Bar Chart: Ratios of Consistently Failed Problems Across Categories in MATH-12k
### Overview
The chart compares failure rates (Zero Ratio %) of three reinforcement learning (RL) methods—Init RL, Base RL, and Synt RL—across seven math categories in the MATH-12k dataset. Bars are color-coded (white = Init RL, blue = Base RL, pink = Synt RL) and labeled with exact values.
### Components/Axes
- **X-axis**: Math categories (Algebra, Counting & Probability, Geometry, Intermediate Algebra, Number Theory, Prealgebra, Precalculus).
- **Y-axis**: Zero Ratio (%) from 0 to 14.
- **Legend**: Top-left corner, mapping colors to RL methods.
- **Bars**: Grouped by category, with three bars per category (one per RL method).
### Detailed Analysis
1. **Algebra**:
- Init RL: 0.9%
- Base RL: 0.6%
- Synt RL: 0.5%
2. **Counting & Probability**:
- Init RL: 5.6%
- Base RL: 4.2%
- Synt RL: 3.8%
3. **Geometry**:
- Init RL: 11.9%
- Base RL: 9.3%
- Synt RL: 8.8%
4. **Intermediate Algebra**:
- Init RL: 10.8%
- Base RL: 8.3%
- Synt RL: 6.7%
5. **Number Theory**:
- Init RL: 3.9%
- Base RL: 1.9%
- Synt RL: 1.8%
6. **Prealgebra**:
- Init RL: 1.6%
- Base RL: 1.3%
- Synt RL: 0.9%
7. **Precalculus**:
- Init RL: 13.4%
- Base RL: 10.8%
- Synt RL: 10.3%
### Key Observations
- **Highest Failure Rates**:
- Precalculus dominates for all methods (13.4% Init RL, 10.8% Base RL, 10.3% Synt RL).
- Geometry also shows high failure rates (11.9% Init RL, 9.3% Base RL, 8.8% Synt RL).
- **Lowest Failure Rates**:
- Algebra has minimal failures (0.9% Init RL, 0.6% Base RL, 0.5% Synt RL).
- **Trends**:
- **Init RL** consistently has the highest failure ratios across all categories.
- **Synt RL** generally outperforms Base RL, with the largest gap in Intermediate Algebra (6.7% vs. 8.3%).
- Precalculus is an outlier, with all methods failing at rates >10%.
### Interpretation
The data suggests that **Synt RL** is the most robust method, reducing failure rates by ~20-30% compared to Init RL in most categories. However, **Precalculus remains a systemic challenge**, indicating either inherent complexity or insufficient training data for this category. The consistent underperformance of Init RL implies it may lack critical optimizations present in Base RL and Synt RL. Geometry and Precalculus warrant further investigation to address their high failure rates.
</details>
Figure 4: The ratios of consistently failed problems from different categories in the MATH-12k training set under different training configurations. (Base model: Qwen2.5-7B).
We use the initially trained Qwen2.5-7B-Base as the student and Qwen2.5-Math-7B-Instruct as the teacher. Table 2 presents their performance on popular benchmarks and MATH-12k categories, where the student model generally outperforms the teacher. However, as shown in Table 2, the student policy further improves after training on weak teacher-labeled problems. This improvement stems from the difficulty filtering process, which removes problems with consistent student-teacher disagreement and retains those where the teacher is reliable but the student struggles, enabling targeted training on weaknesses. Detailed analysis can be found in Appendix 11.
### 4.2 Self-evolving Targeted Problem Synthesis
In this section, we explore the potential of utilizing the Self-evolving paradigm to address model weaknesses by executing the full SwS pipeline using the policy itself. This self-evolving paradigm for identifying and mitigating weaknesses leverages self-consistency to guide itself to generate effective trajectories toward accurate answers [75], while also integrating general instruction-following capabilities from question generation and quality filtering to enhance reasoning.
We use Qwen2.5-14B-Instruct as the base policy due to its balance between computational efficiency and instruction-following performance. The results are shown in Table 3, where the self-evolving SwS pipeline improves the baseline performance by 1.2% across all benchmarks, especially on the middle-level benchmarks like Gaokao and AMC. Although performance declines on AIME, we attribute this to the initial training data from DAPO and LightR1 already being specifically tailored to that benchmark. For further discussion of the Self-evolve SwS framework, refer to Appendix G.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: Overall Accuracy (%)
### Overview
The chart visualizes the convergence of two training strategies ("Target All Pass@1" and "Random All Pass@1") over 140 training steps, showing their average accuracy percentages. Both lines exhibit rapid initial improvement followed by plateauing performance, with the Target strategy consistently outperforming the Random strategy.
### Components/Axes
- **X-axis**: Training Steps (0–140, increments of 20)
- **Y-axis**: Average Accuracy (%) (25–55%, increments of 2%)
- **Legend**:
- Red dots: Target All Pass@1
- Teal dots: Random All Pass@1
- **Placement**: Legend in bottom-right corner
### Detailed Analysis
1. **Target All Pass@1 (Red Line)**:
- Starts at ~30% accuracy at 0 steps.
- Sharp rise to ~43% by 20 steps.
- Gradual increase to ~49% by 140 steps, with minor fluctuations (e.g., ~48.5% at 100 steps).
- Final plateau near 50% accuracy.
2. **Random All Pass@1 (Teal Line)**:
- Begins at ~28% accuracy at 0 steps.
- Rapid ascent to ~43% by 20 steps.
- Slower convergence to ~49% by 140 steps, with notable variability (e.g., ~48.2% at 120 steps, ~48.8% at 140 steps).
- Slight downward trend after 100 steps.
### Key Observations
- **Performance Gap**: Target strategy maintains ~1–2% higher accuracy than Random across all steps.
- **Convergence**: Both lines plateau near 49% accuracy, suggesting diminishing returns after ~80 steps.
- **Volatility**: Random strategy shows larger fluctuations (e.g., ~47.5% at 60 steps vs. ~49.2% at 80 steps).
### Interpretation
The data demonstrates that the Target All Pass@1 strategy achieves superior and more stable performance compared to Random All Pass@1. The rapid early improvement for both methods indicates effective initial learning, while the plateau suggests saturation of model capacity or data complexity limits. The Random strategy's volatility may reflect sensitivity to initialization or data shuffling, whereas the Target strategy's consistency implies robust optimization. The ~1% accuracy gap highlights the importance of targeted training over random approaches in this context.
</details>
<details>
<summary>x6.png Details</summary>
### Visual Description
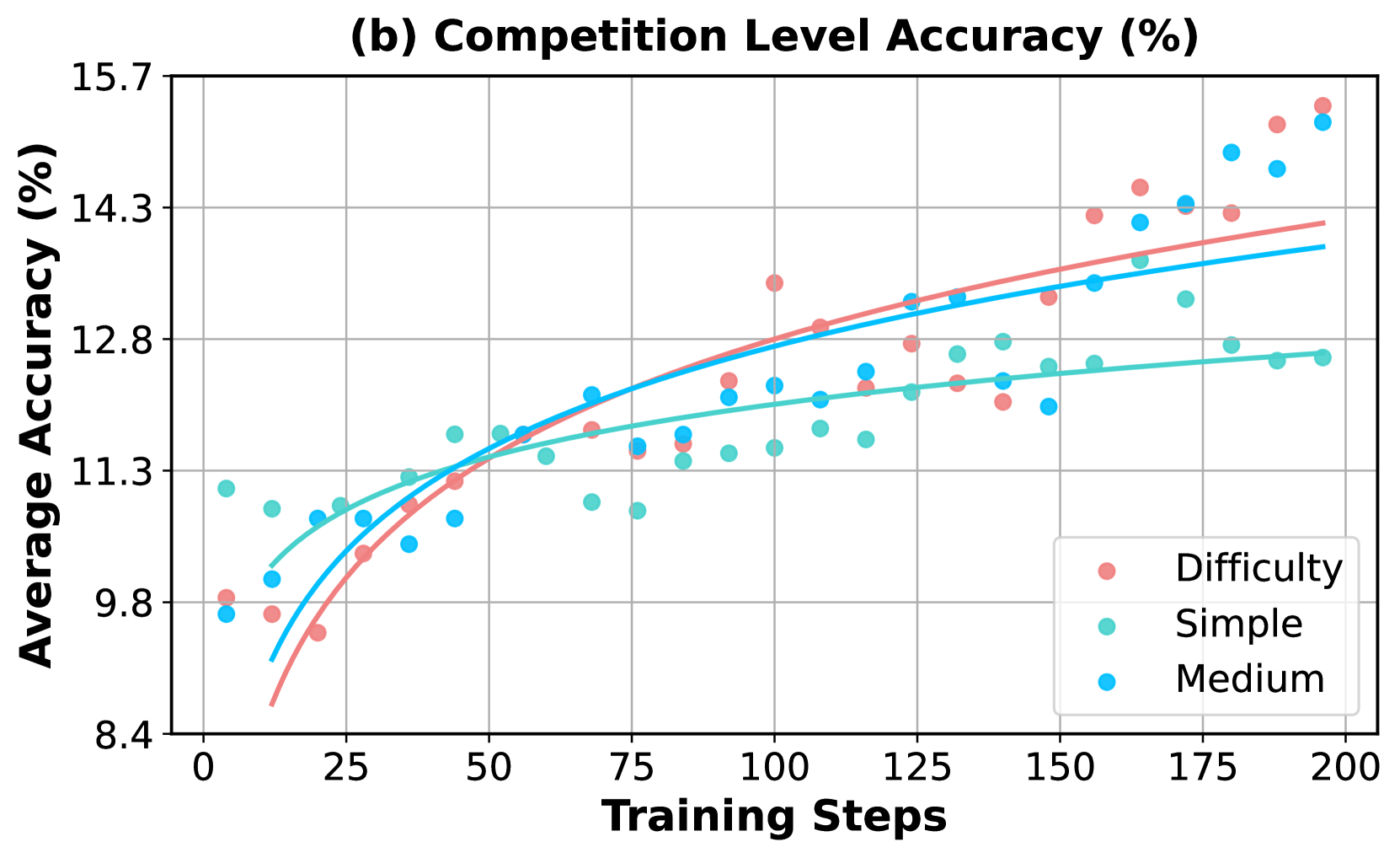
## Line Chart: Competition Level Accuracy (%)
### Overview
The chart illustrates the relationship between training steps and average accuracy for two competition levels: "Target Comp Avg@32" (red) and "Random Comp Avg@32" (teal). Both metrics show increasing trends, but "Target Comp" consistently outperforms "Random Comp" across all training steps.
### Components/Axes
- **X-axis**: Training Steps (0 to 140, increments of 20)
- **Y-axis**: Average Accuracy (%) (1.0 to 16.0, increments of 2.0)
- **Legend**:
- Red: Target Comp Avg@32
- Teal: Random Comp Avg@32
- **Data Points**:
- Red dots (Target Comp) and teal dots (Random Comp) plotted along the curve
- Smooth lines connect the dots for each series
### Detailed Analysis
1. **Target Comp Avg@32 (Red)**:
- Starts at ~3.8% accuracy at 0 steps.
- Rises sharply to ~10% by 20 steps.
- Gradually increases to ~15% at 140 steps.
- Key data points:
- 40 steps: ~11%
- 80 steps: ~12.5%
- 120 steps: ~14%
2. **Random Comp Avg@32 (Teal)**:
- Starts at ~3.8% accuracy at 0 steps.
- Slower growth, reaching ~12% at 140 steps.
- Key data points:
- 40 steps: ~10%
- 80 steps: ~11.5%
- 120 steps: ~12.5%
### Key Observations
- **Performance Gap**: Target Comp accuracy exceeds Random Comp by ~2-3% at all steps beyond 20.
- **Saturation**: Both metrics plateau near 15% (Target) and 12% (Random) after 100 steps.
- **Initial Growth**: Target Comp gains ~6% accuracy in the first 20 steps, while Random Comp gains ~6% over 40 steps.
### Interpretation
The data demonstrates that "Target Comp Avg@32" achieves significantly higher accuracy than "Random Comp Avg@32" as training progresses. The steeper initial growth of Target Comp suggests it adapts more efficiently to training data. The plateau at ~15% for Target Comp implies diminishing returns after extensive training, while Random Comp’s slower improvement highlights its inferior optimization. This trend is critical for evaluating model selection in competitive scenarios, where Target Comp’s efficiency could reduce computational costs without sacrificing performance.
</details>
<details>
<summary>x7.png Details</summary>
### Visual Description
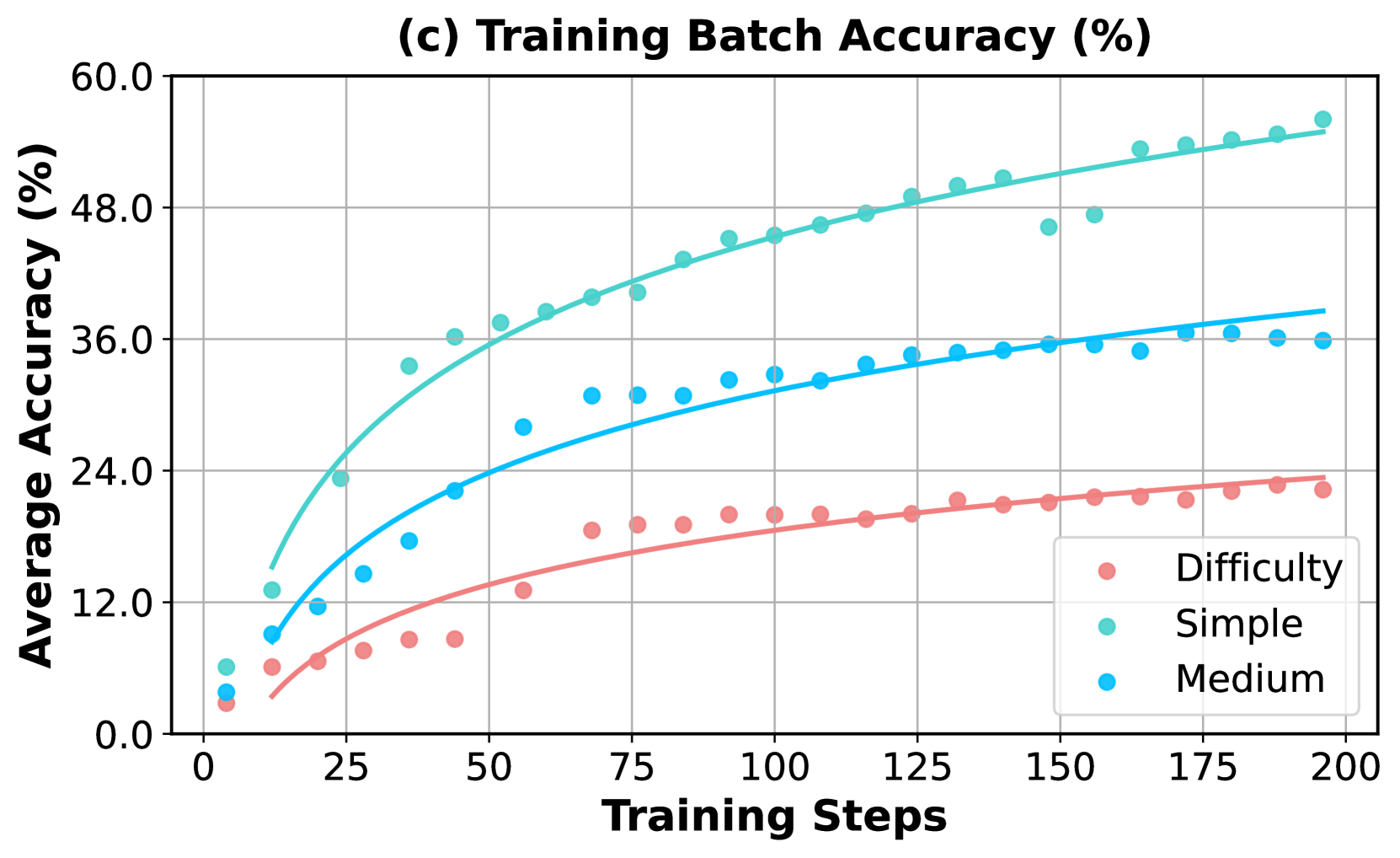
## Line Chart: Training Batch Accuracy (%)
### Overview
The chart illustrates the progression of training batch accuracy over training steps for two methods: "Target Training Acc" (red line) and "Random Training Acc" (teal line). Both lines show increasing accuracy with more training steps, with the teal line achieving higher final accuracy.
### Components/Axes
- **X-axis**: Training Steps (0 to 140, increments of 20)
- **Y-axis**: Average Accuracy (%) (0 to 80, increments of 16)
- **Legend**: Located at bottom-right, with red for "Target Training Acc" and teal for "Random Training Acc"
- **Lines**:
- Red line (Target Training Acc) starts at (0, 0) and rises steadily.
- Teal line (Random Training Acc) starts at (5, 15) and rises with a slight dip around 20 steps.
### Detailed Analysis
- **Target Training Acc (Red Line)**:
- Data points at:
- (0, 0), (10, ~30), (20, ~48), (30, ~52), (40, ~56), (50, ~58), (60, ~60), (70, ~62), (80, ~64), (90, ~65), (100, ~66), (110, ~67), (120, ~68), (130, ~69), (140, ~72).
- Trend: Smooth upward curve with minimal fluctuations.
- **Random Training Acc (Teal Line)**:
- Data points at:
- (5, 15), (10, 48), (20, ~46), (30, ~58), (40, ~60), (50, ~62), (60, ~64), (70, ~65), (80, ~67), (90, ~68), (100, ~69), (110, ~70), (120, ~71), (130, ~72), (140, ~78).
- Trend: Initial dip at 20 steps (~46%), then steady rise. Final accuracy surpasses the target method.
### Key Observations
1. Both methods show increasing accuracy with training steps.
2. The teal line (Random Training Acc) starts lower but overtakes the red line after ~50 steps.
3. At 140 steps, teal line reaches ~78% accuracy vs. red line's ~72%.
4. Teal line exhibits a minor dip at 20 steps (~46%) before resuming growth.
### Interpretation
The data suggests that while the "Target Training Acc" method provides consistent improvement, the "Random Training Acc" method achieves higher final accuracy despite an initial dip. The convergence of the lines at later steps implies that both approaches may yield similar results with sufficient training, though the random method demonstrates greater efficiency in the long term. The dip in the teal line at 20 steps could indicate transient instability or noise in early training phases.
</details>
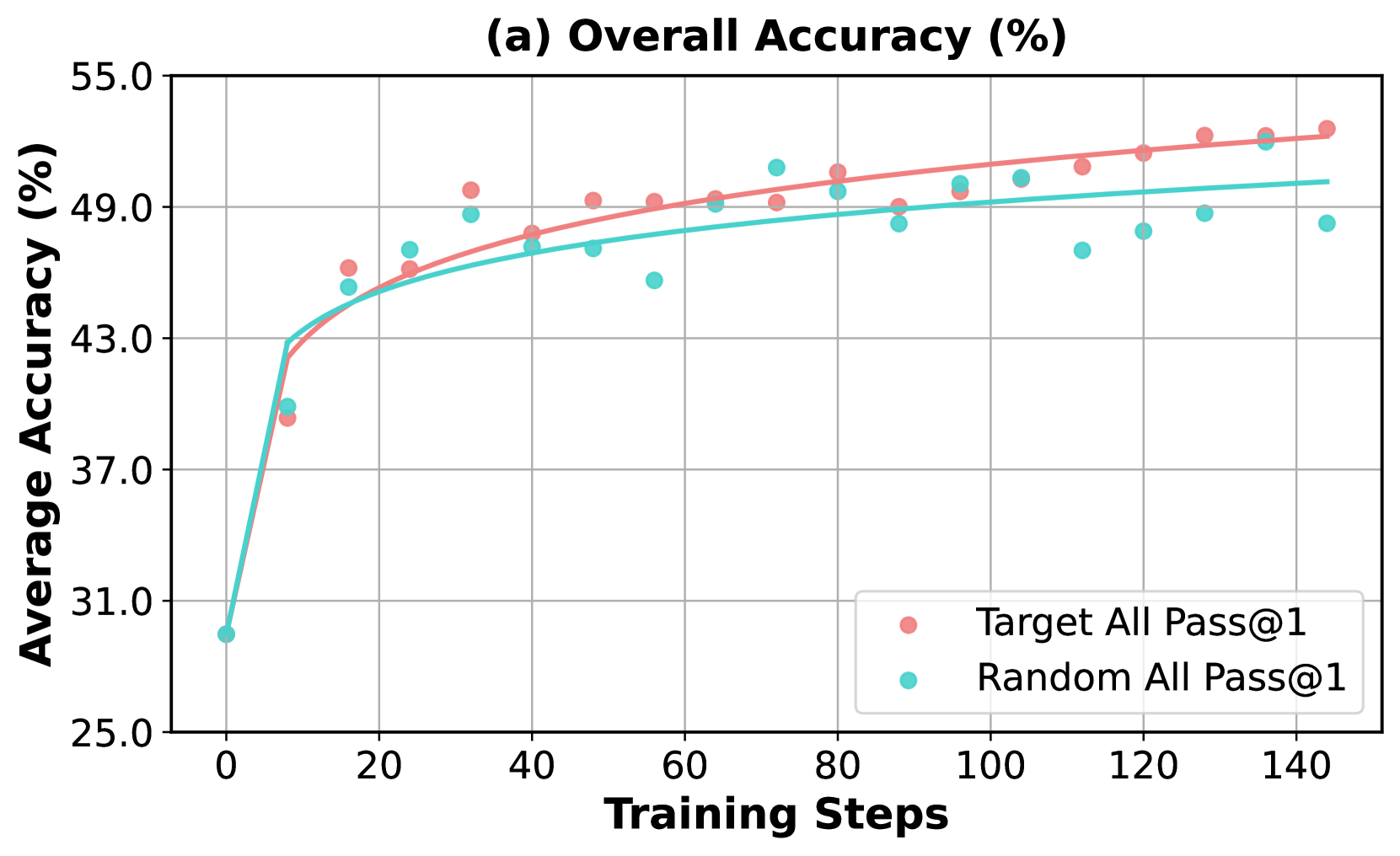
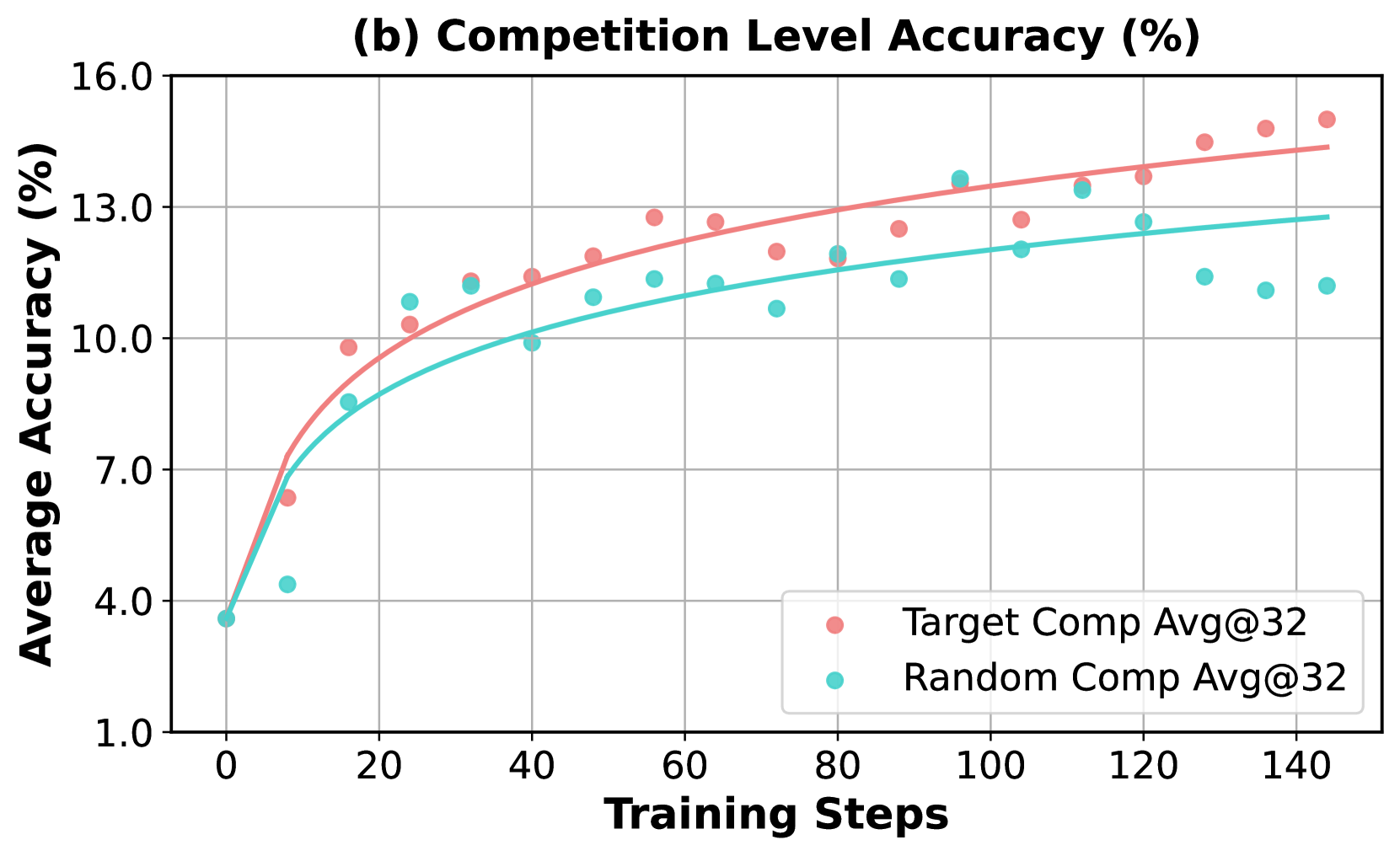
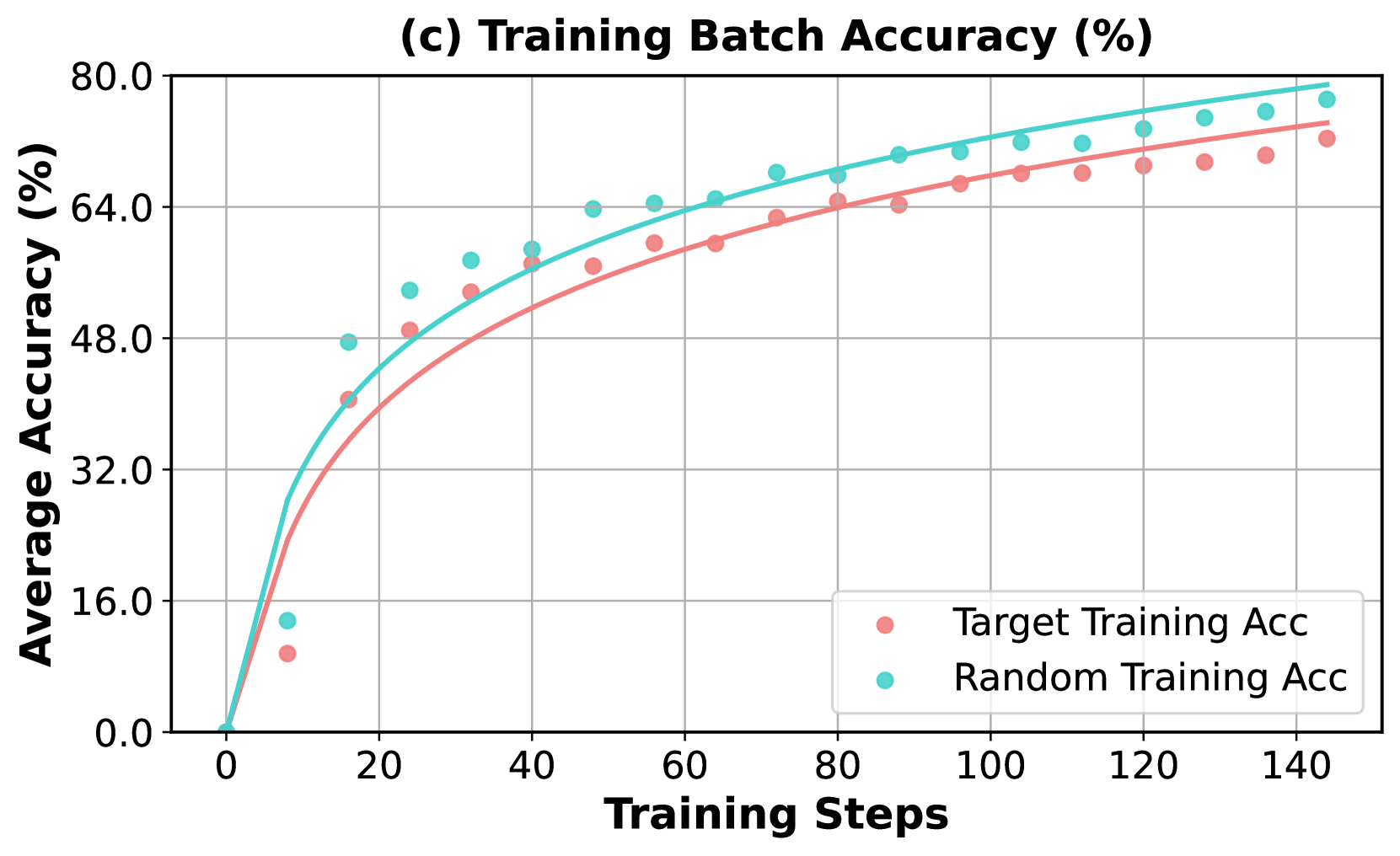
Figure 5: Comparison of accuracy improvements using (a) Pass@1 on full benchmarks evaluated in Table 1 and (b) Avg@32 on the competition-level benchmarks. (c) illustrates the proportion of prompts within a batch that achieved 100% correctness across multiple rollouts during training.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Line Graph: (a) Overall Accuracy (%)
### Overview
The image depicts a line graph titled "(a) Overall Accuracy (%)" that visualizes the relationship between training steps and average accuracy across three difficulty categories: Difficulty (red), Simple (teal), and Medium (blue). The graph includes data points, trend lines, and a legend for categorical differentiation.
### Components/Axes
- **X-axis (Training Steps)**: Ranges from 0 to 200 in increments of 25.
- **Y-axis (Average Accuracy %)**: Ranges from 45.2% to 53.2% in increments of 1%.
- **Legend**: Located in the bottom-right corner, with three categories:
- **Red**: Difficulty
- **Teal**: Simple
- **Blue**: Medium
### Detailed Analysis
1. **Difficulty (Red)**:
- **Trend**: Steep upward slope from ~46.5% (at 0 steps) to ~51.8% (at 200 steps).
- **Data Points**: Scattered but align closely with the trend line. Notable values include ~47.5% at 50 steps and ~51.2% at 150 steps.
- **Uncertainty**: Values approximate ±0.3% due to data point dispersion.
2. **Simple (Teal)**:
- **Trend**: Gradual upward slope from ~47.5% (at 0 steps) to ~51.2% (at 200 steps).
- **Data Points**: More dispersed than Difficulty, with values like ~49.0% at 100 steps and ~50.8% at 175 steps.
- **Uncertainty**: Values approximate ±0.4%.
3. **Medium (Blue)**:
- **Trend**: Moderate upward slope from ~47.2% (at 0 steps) to ~51.6% (at 200 steps).
- **Data Points**: Consistent alignment with the trend line, e.g., ~49.5% at 100 steps and ~51.0% at 175 steps.
- **Uncertainty**: Values approximate ±0.2%.
### Key Observations
- **Trend Verification**: All three categories show positive correlation between training steps and accuracy. The Difficulty series exhibits the steepest improvement, followed by Medium and Simple.
- **Outliers**: No significant outliers; data points generally cluster around trend lines.
- **Spatial Grounding**: The legend is positioned in the bottom-right, ensuring clear association with line colors. Data points match legend colors exactly (e.g., red points for Difficulty).
### Interpretation
The graph demonstrates that increased training steps improve model performance across all difficulty levels. The Difficulty category shows the most pronounced improvement, suggesting that complex tasks benefit disproportionately from extended training. The trend lines indicate a logarithmic-like growth pattern, where early training steps yield larger accuracy gains, which plateau as steps increase. This implies diminishing returns in later training phases. The Medium category’s consistent performance highlights its stability compared to the more variable Simple and Difficulty categories.
</details>
<details>
<summary>x9.png Details</summary>
### Visual Description
## Line Chart: Competition Level Accuracy (%)
### Overview
The chart illustrates the relationship between training steps and average accuracy (%) across three competition levels: Difficulty (red), Simple (teal), and Medium (blue). Data points are plotted with corresponding trend lines, showing performance progression over 200 training steps.
### Components/Axes
- **Title**: "(b) Competition Level Accuracy (%)" (top-center)
- **Y-Axis**: "Average Accuracy (%)" (left, 8.4–15.7 range)
- **X-Axis**: "Training Steps" (bottom, 0–200 range)
- **Legend**: Bottom-right corner, with color-coded labels:
- Red: Difficulty
- Teal: Simple
- Blue: Medium
### Detailed Analysis
1. **Difficulty (Red)**:
- Starts at ~9.8% accuracy at 0 steps.
- Peaks at ~14.5% at 200 steps.
- Trend line shows steady upward slope with moderate curvature.
- Data points cluster tightly around the line, with minor scatter.
2. **Medium (Blue)**:
- Begins at ~9.8% at 0 steps.
- Reaches ~14.3% at 200 steps.
- Trend line is smoother and less curved than Difficulty.
- Data points exhibit slightly more variability, especially at mid-steps (e.g., ~11.5% at 50 steps).
3. **Simple (Teal)**:
- Starts at ~11.3% at 0 steps.
- Ends at ~12.2% at 200 steps.
- Trend line has gentle upward slope with minimal curvature.
- Data points are more dispersed, with outliers at lower steps (~10.5% at 25 steps).
### Key Observations
- **Performance Trends**: All categories improve with training steps, but Difficulty shows the steepest gain (+4.7% over 200 steps vs. +0.9% for Simple).
- **Accuracy Gaps**: At 200 steps, Difficulty outperforms Medium by ~0.2% and Simple by ~2.3%.
- **Early Variability**: Simple category has lower initial accuracy but stabilizes faster than Medium/Difficulty.
- **Outliers**: Teal data points at 25 steps (~10.5%) and 75 steps (~11.0%) deviate slightly below trend lines.
### Interpretation
The data demonstrates that increased training steps correlate with higher accuracy across all competition levels. However, the **Difficulty** category achieves the highest performance gains, suggesting it may represent more complex or optimized training scenarios. The **Simple** category’s slower improvement implies inherent limitations in its training framework, despite starting with higher baseline accuracy. The **Medium** category acts as an intermediary, showing balanced progression. The tight clustering of red data points indicates consistent training efficacy for Difficulty, while teal’s dispersion highlights potential instability in simpler models. This chart underscores the importance of training duration and complexity in achieving competitive accuracy.
</details>
<details>
<summary>x10.png Details</summary>
### Visual Description
## Line Chart: Training Batch Accuracy (%)
### Overview
The chart visualizes the relationship between training steps and average accuracy for three categories: "Difficulty," "Simple," and "Medium." Accuracy is plotted on the y-axis (0–60%) against training steps (0–200) on the x-axis. Three colored lines (red, teal, blue) represent the categories, with data points marked along each line.
### Components/Axes
- **Title**: "Training Batch Accuracy (%)" (top-center).
- **X-axis**: "Training Steps" (0–200, linear scale).
- **Y-axis**: "Average Accuracy (%)" (0–60, linear scale).
- **Legend**: Located in the bottom-right corner, with:
- Red: "Difficulty"
- Teal: "Simple"
- Blue: "Medium"
### Detailed Analysis
1. **Difficulty (Red Line)**:
- Starts at ~2% accuracy at 0 steps.
- Gradually increases to ~22% at 200 steps.
- Slope: Gentle upward trend with minimal curvature.
- Data points: Consistent spacing along the line.
2. **Simple (Teal Line)**:
- Starts at ~8% accuracy at 0 steps.
- Rises sharply to ~54% at 200 steps.
- Slope: Steeper than other lines, with slight curvature.
- Data points: Densely packed in early steps, spacing increases later.
3. **Medium (Blue Line)**:
- Starts at ~4% accuracy at 0 steps.
- Increases to ~36% at 200 steps.
- Slope: Moderate upward trend, smoother than "Simple."
- Data points: Evenly distributed along the line.
### Key Observations
- **Trend Verification**:
- All lines show upward trends, confirming improved accuracy with more training steps.
- "Simple" outperforms "Medium" and "Difficulty" across all steps.
- "Difficulty" has the slowest growth rate.
- **Notable Patterns**:
- "Simple" achieves ~54% accuracy by 200 steps, nearly double the "Medium" line (~36%).
- "Difficulty" remains the lowest-performing category throughout.
### Interpretation
The data suggests that "Simple" tasks or models achieve higher training efficiency, reaching near-peak accuracy faster than "Medium" or "Difficulty." The steep slope of the "Simple" line implies rapid learning in early stages, while "Difficulty" struggles to improve even after 200 steps. This could reflect inherent complexity in "Difficulty" tasks or suboptimal training strategies for those cases. The "Medium" category balances performance and complexity, showing moderate gains. No outliers are observed, indicating consistent training dynamics across all categories.
</details>
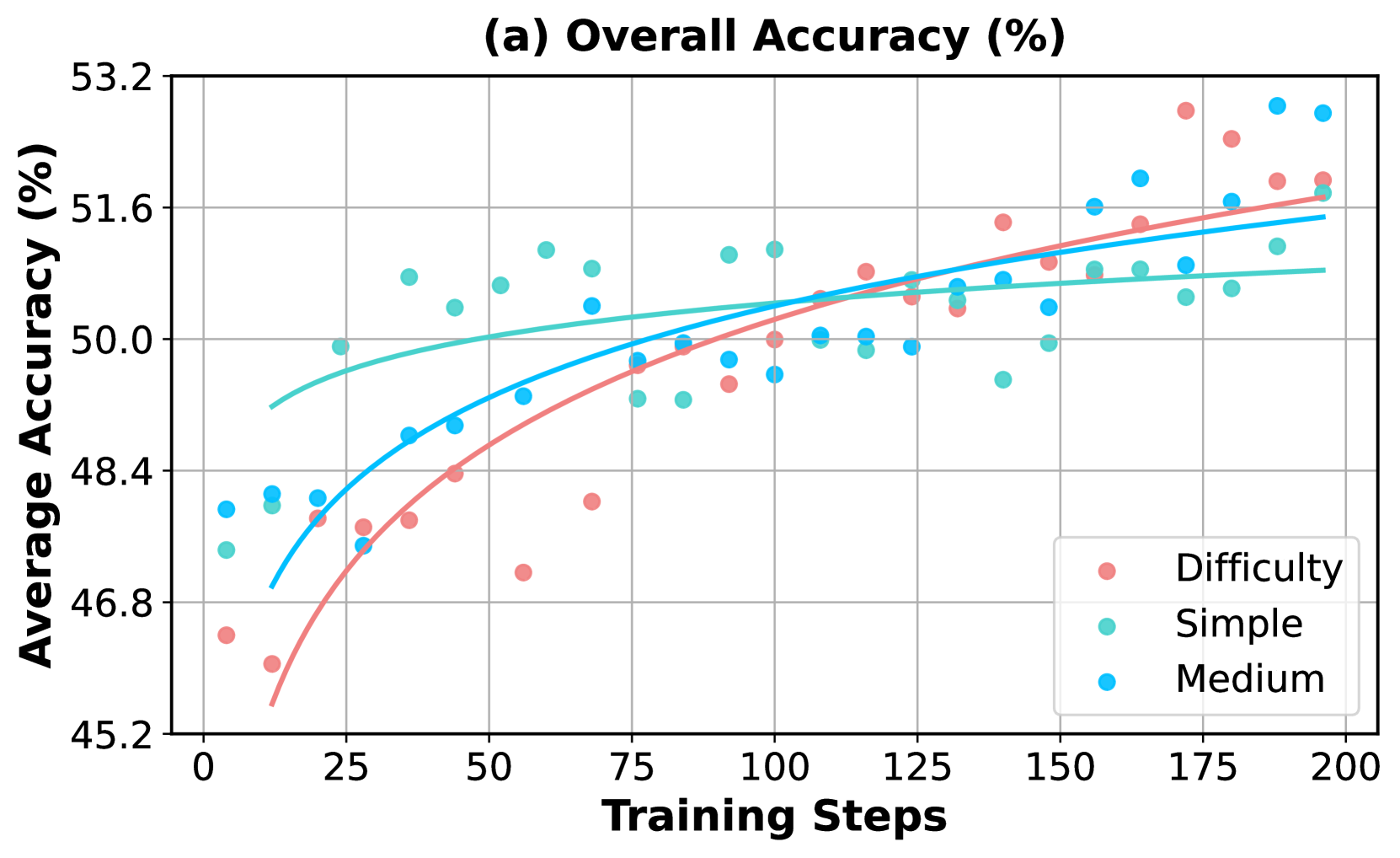
Figure 6: Comparison of incorporating synthetic problems of varying difficulty levels during the augmented RL training. For a detailed description of accuracy trends on evaluation benchmarks and the training set, refer to the caption in Figure 5.
### 4.3 Weakness-driven Selection
In this section, we explore an alternative extension that augments the initial training set using identified weaknesses and a larger mathematical reasoning dataset. Specifically, we use the Qwen2.5-7B model, identify its weaknesses on the MATH-12k training set, and retrieve augmented problems from Big-Math [1] that align with its failure cases, incorporating them into the initial training set for augmentation. We employ a category-specific selection strategy similar to the budget allocation in Eq. 5, using KNN [5] to identify the most relevant problems within each category. The total augmentation budget is also set to 40k. We compare this approach to a baseline where the model is trained on an augmented set incorporated with randomly selected problems from Big-Math. Details of the selection procedure are provided in Appendix H.
As shown in Figure 5, the model trained with weakness-driven augmentation outperforms the random augmentation strategy in terms of accuracy on both the whole evaluated benchmarks (Figure 5.a) and the competition-level subset (Figure 5.b), demonstrating the effectiveness of the weakness-driven selection strategy. In Figure 5.c, it is worth noting that the model quickly fits the randomly selected problems in training, which then cease to provide meaningful training signals in the GRPO algorithm. In contrast, since the failure cases highlight specific weaknesses of the model’s capabilities, the problems selected based on them remain more challenging and more aligned with its deficiencies, providing richer learning signals and promoting continued development of reasoning skills.
### 4.4 Impact of Question Difficulty
We ablate the impact of the difficulty levels of synthetic problems used in the augmented RL training. In this section, we define the difficulty of a synthetic problem based on the accuracy of multiple rollouts generated by the initially trained model, base from Qwen2.5-7B. We incorporate synthetic problems of three predefined difficulty levels—simple, medium, and hard—into the augmented RL training. These levels correspond to accuracy ranges of $[5,7]$ , $[3,5]$ , and $[1,4]$ out of 8 sampled responses, respectively. For each level, we sample 40k examples and combine them with the initial training set for a second training stage lasting 200 steps.
The experimental results are shown in Figure 6. Similar to the findings in Section 4.3, the model fits more quickly on the simple augmented set and initially achieves the best performance across all evaluation benchmarks, including competition-level tasks, but then saturates with no further improvement. In contrast, the medium and hard augmented sets lead to slower convergence on the training set but result in more sustained performance gains on the evaluation set, with the hardest problems providing the longest-lasting training benefits.
<details>
<summary>x11.png Details</summary>

### Visual Description
## Diagram: Synthetic Geometry Problem Set with Difficulty Levels
### Overview
The image presents a structured comparison of a complex 3D geometry problem (Original Problem) and four synthetic problems of varying difficulty levels (Simple, Medium, Hard, Unsolvable). Each synthetic problem includes a geometric scenario, a numerical answer, and a "Model Accuracy" percentage. The Original Problem involves an equilateral triangle in 3D space with constraints on points and planes, while the synthetic problems test concepts like similarity, tangents, incenters, and midpoints.
### Components/Axes
- **Left Panel**:
- **Original Problem**: Describes an equilateral triangle ΔABC (side length 600) with points P and Q outside the plane, forming a 120° dihedral angle between planes ΔPAB and ΔQAB. A point O equidistant to A, B, C, P, Q is introduced.
- **Extracted Concepts**: Lists geometric principles (equilateral triangles, 3D distance formulas, perpendicular planes).
- **Right Panel**:
- **Synthetic Problems**: Four problems categorized by difficulty (Simple to Unsolvable), each with:
- **Problem Statement**: Geometric scenario (e.g., similar cones, circle tangents, triangle incenters).
- **Answer**: Numerical solution (e.g., \(k^2\), \(2r\), 2, \(15/2\)).
- **Model Accuracy**: Percentage (100%, 50%, 6.25%, 0%).
- **Color Gradient**: A vertical red gradient bar on the right, likely indicating difficulty progression (green to red).
### Detailed Analysis
#### Original Problem
- **Key Details**:
- ΔABC is equilateral (side 600).
- Points P and Q lie on opposite sides of the plane, equidistant from A, B, C (PA=PB=PC, QA=QB=QC).
- Planes ΔPAB and ΔQAB form a 120° dihedral angle.
- Point O is equidistant (\(d\)) from A, B, C, P, Q.
#### Synthetic Problems
1. **Simple**:
- **Problem**: Similar cones A and B (radius \(r\), height \(h\) for A). Ratio of heights \(h_B/h_A = k\). Find surface area ratio of B to A.
- **Answer**: \(k^2\), Model Accuracy: 100%.
2. **Medium**:
- **Problem**: Circle radius \(r\), tangents from point P form 60° angle. Tangent length \(r\sqrt{3}\). Find distance from P to center.
- **Answer**: \(2r\), Model Accuracy: 50%.
3. **Hard**:
- **Problem**: Triangle ABC with incenter I and excenter E opposite A. Given AE=5, AI=3, EI tangent to incircle. Find radius.
- **Answer**: 2, Model Accuracy: 6.25%.
4. **Unsolvable**:
- **Problem**: Triangle ABC (AB=7, AC=9, ∠A=60°). D is midpoint of BC. BD = DC + 3. Find AD.
- **Answer**: \(15/2\), Model Accuracy: 0%.
### Key Observations
- **Difficulty Correlation**: Model accuracy decreases as problem complexity increases (100% → 0%).
- **Unsolvable Anomaly**: The "Unsolvable" problem has a non-zero answer (\(15/2\)) but 0% accuracy, suggesting a contradiction or unsolvable nature.
- **Color Gradient**: The red gradient on the right visually reinforces the difficulty progression.
### Interpretation
The diagram illustrates a pedagogical framework for testing geometric reasoning across difficulty tiers. The Original Problem emphasizes 3D spatial reasoning, while synthetic problems isolate specific concepts (similarity, tangents, triangle centers). The drastic drop in model accuracy for harder problems highlights challenges in automated problem-solving for complex scenarios. The "Unsolvable" problem’s 0% accuracy despite a numerical answer suggests either a mislabeled problem or a test of edge-case handling. The extracted concepts align with the synthetic problems, indicating a curated focus on foundational geometry principles.
</details>
Figure 7: Illustration of a geometry problem from the MATH-12k failed set, with extracted concepts and conceptually linked synthetic problems across different difficulty levels.
### 4.5 Case Study
Figure 7 presents an illustration of a geometry failure case from the MATH-12k training set, accompanied by extracted concepts and our weakness-driven synthetic questions of varying difficulty levels, all closely aligned with the original question. The question focuses on three-dimensional distance and triangle understanding, with key concepts such as “Properties of equilateral triangles” and “Distance and midpoint formulas in 3D space” representing essential knowledge required to solve the problem. Notably, the corresponding synthetic questions exhibit similar semantics—such as “finding distance” in Medium and “understanding triangles” in Hard. Practicing on such targeted problems helps mitigate weaknesses and enhances reasoning capabilities within the relevant domain.
## 5 Conclusion
In this work, we introduce a S elf-aware W eakness-driven Problem S ynthesis (SwS) framework (SwS) in reinforcement learning for LLM reasoning, which synthesizes problems based on weaknesses identified from the model’s failure cases during a preliminary training phase and includes them into subsequent augmented training. We conduct a detailed analysis of incorporating such synthetic problems into training and find that focusing on the model’s failures can enhance its reasoning generalization and mitigate its weaknesses, resulting in overall performance improvements. Furthermore, we extend the framework to the paradigms of Weak-to-Strong Generalization, Self-evolving, and Weakness-driven Selection, demonstrating its comprehensiveness and robustness.
## 6 Discussions, Limitations and Future Work
This paper presents a comprehensive Self-aware Weakness-driven Problem Synthesis (SwS) framework to address the model’s reasoning deficiencies through reinforcement learning (RL) training. Although the SwS framework is effective across a wide range of model sizes, there are still several limitations to it: (1) Employing both a strong instruction model and an answer-labeling reasoning model may lead to computation and time costs. (2) Our framework mainly focuses on the RL setting, as our primary goal is to mitigate the model’s weaknesses by fully activating its inherent reasoning abilities without distilling external knowledge. Exploring how to leverage a similar pipeline for enhancing model capabilities through fine-tuning or distillation remains an open direction for future research. (3) The synthetic problems generated by open-source instruction models in the SwS framework may still lack sufficient complexity to elicit the deeper reasoning capabilities of the model, especially on more challenging problems. This limitation is pronounced in the Self-evolving setting in Section 4.2, which relies solely on a 14B model for problem generation, with performance improvements limited to only moderate or simple benchmarks. This raises questions about the actual utility of problems generated from the LLaMA-3.3-70B-Instruct in the main experiments on top-challenging benchmarks like AIME. One potential strategy is to use Evolve-Instruct [56, 30] to further refine the generated problems to the desired level of difficulty. However, how to effectively raise the upper bound of difficulty in synthetic problems generated by instruction models remains an open problem and warrants further exploration.
In the future, we aim to identify model weaknesses from multiple perspectives beyond simple answer accuracy, with the goal of synthesizing more targeted problems to improve sample efficiency. Additionally, we plan to extend the SwS framework to more general tasks beyond reasoning, incorporating an off-the-shelf reward model to provide feedback instead of verifiable answers. Lastly, we also seek to implement the SwS pipeline in more advanced reasoning models equipped with Long-CoT capabilities, further pushing the boundaries of open-source large reasoning models.
## References
- Albalak et al. [2025] Alon Albalak, Duy Phung, Nathan Lile, Rafael Rafailov, Kanishk Gandhi, Louis Castricato, Anikait Singh, Chase Blagden, Violet Xiang, Dakota Mahan, et al. Big-math: A large-scale, high-quality math dataset for reinforcement learning in language models. arXiv preprint arXiv:2502.17387, 2025.
- Burns et al. [2023] Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold Aschenbrenner, Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, et al. Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. arXiv preprint arXiv:2312.09390, 2023.
- Chu et al. [2025] Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training. arXiv preprint arXiv:2501.17161, 2025.
- Cobbe et al. [2021] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Cover and Hart [1967] Thomas Cover and Peter Hart. Nearest neighbor pattern classification. IEEE transactions on information theory, 13(1):21–27, 1967.
- Cui et al. [2025] Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, et al. Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456, 2025.
- Face [2025] Hugging Face. Open r1: A fully open reproduction of deepseek-r1, January 2025. URL https://github.com/huggingface/open-r1.
- Grattafiori et al. [2024] Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Guan et al. [2025] Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. rstar-math: Small llms can master math reasoning with self-evolved deep thinking. arXiv preprint arXiv:2501.04519, 2025.
- Guo et al. [2025] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
- He et al. [2024] Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems, 2024.
- He et al. [2025] Jujie He, Jiacai Liu, Chris Yuhao Liu, Rui Yan, Chaojie Wang, Peng Cheng, Xiaoyu Zhang, Fuxiang Zhang, Jiacheng Xu, Wei Shen, Siyuan Li, Liang Zeng, Tianwen Wei, Cheng Cheng, Bo An, Yang Liu, and Yahui Zhou. Skywork open reasoner series. https://capricious-hydrogen-41c.notion.site/Skywork-Open-Reaonser-Series-1d0bc9ae823a80459b46c149e4f51680, 2025. Notion Blog.
- Hendrycks et al. [2021] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. Sort, 2(4):0–6, 2021.
- Hu et al. [2025] Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model. arXiv preprint arXiv:2503.24290, 2025.
- Huang et al. [2024] Yiming Huang, Xiao Liu, Yeyun Gong, Zhibin Gou, Yelong Shen, Nan Duan, and Weizhu Chen. Key-point-driven data synthesis with its enhancement on mathematical reasoning. arXiv preprint arXiv:2403.02333, 2024.
- Jaech et al. [2024] Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024.
- Kang et al. [2023] Minki Kang, Seanie Lee, Jinheon Baek, Kenji Kawaguchi, and Sung Ju Hwang. Knowledge-augmented reasoning distillation for small language models in knowledge-intensive tasks. Advances in Neural Information Processing Systems, 36:48573–48602, 2023.
- Kwon et al. [2023] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023.
- Lewkowycz et al. [2022] Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models. Advances in Neural Information Processing Systems, 35:3843–3857, 2022.
- Li et al. [2024a] Chen Li, Weiqi Wang, Jingcheng Hu, Yixuan Wei, Nanning Zheng, Han Hu, Zheng Zhang, and Houwen Peng. Common 7b language models already possess strong math capabilities. arXiv preprint arXiv:2403.04706, 2024a.
- Li et al. [2024b] Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, et al. From generation to judgment: Opportunities and challenges of llm-as-a-judge. arXiv preprint arXiv:2411.16594, 2024b.
- Li et al. [2025a] Xuefeng Li, Haoyang Zou, and Pengfei Liu. Limr: Less is more for rl scaling. arXiv preprint arXiv:2502.11886, 2025a.
- Li et al. [2025b] Zhong-Zhi Li, Xiao Liang, Zihao Tang, Lei Ji, Peijie Wang, Haotian Xu, Haizhen Huang, Weiwei Deng, Ying Nian Wu, Yeyun Gong, et al. Tl; dr: Too long, do re-weighting for effcient llm reasoning compression. arXiv preprint arXiv:2506.02678, 2025b.
- Li et al. [2025c] Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, et al. From system 1 to system 2: A survey of reasoning large language models. arXiv preprint arXiv:2502.17419, 2025c.
- Liang et al. [2024] Xiao Liang, Xinyu Hu, Simiao Zuo, Yeyun Gong, Qiang Lou, Yi Liu, Shao-Lun Huang, and Jian Jiao. Task oriented in-domain data augmentation. arXiv preprint arXiv:2406.16694, 2024.
- Lightman et al. [2023] Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In The Twelfth International Conference on Learning Representations, 2023.
- Liu et al. [2025a] Haoxiong Liu, Yifan Zhang, Yifan Luo, and Andrew C Yao. Augmenting math word problems via iterative question composing. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24605–24613, 2025a.
- Liu et al. [2025b] Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. arXiv preprint arXiv:2503.20783, 2025b.
- Lu et al. [2025] Dakuan Lu, Xiaoyu Tan, Rui Xu, Tianchu Yao, Chao Qu, Wei Chu, Yinghui Xu, and Yuan Qi. Scp-116k: A high-quality problem-solution dataset and a generalized pipeline for automated extraction in the higher education science domain, 2025. URL https://arxiv.org/abs/2501.15587.
- Luo et al. [2023] Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583, 2023.
- Luo et al. [2025] Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y. Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Li Erran Li, Raluca Ada Popa, and Ion Stoica. Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl. DeepScaleR Notion Page, 2025. Notion Blog.
- Luong et al. [2024] Trung Quoc Luong, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, and Hang Li. Reft: Reasoning with reinforced fine-tuning. arXiv preprint arXiv:2401.08967, 3, 2024.
- MAA [a] MAA. American mathematics competitions (AMC 10/12). Mathematics Competition Series, 2023a. URL https://maa.org/math-competitions/amc.
- MAA [b] MAA. American invitational mathematics examination (AIME). Mathematics Competition Series, 2024b. URL https://maa.org/math-competitions/aime.
- Muennighoff et al. [2025] Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling. arXiv preprint arXiv:2501.19393, 2025.
- Nguyen et al. [2025] Hieu Nguyen, Zihao He, Shoumik Atul Gandre, Ujjwal Pasupulety, Sharanya Kumari Shivakumar, and Kristina Lerman. Smoothing out hallucinations: Mitigating llm hallucination with smoothed knowledge distillation. arXiv preprint arXiv:2502.11306, 2025.
- Ouyang et al. [2022] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- Pei et al. [2025] Qizhi Pei, Lijun Wu, Zhuoshi Pan, Yu Li, Honglin Lin, Chenlin Ming, Xin Gao, Conghui He, and Rui Yan. Mathfusion: Enhancing mathematic problem-solving of llm through instruction fusion. arXiv preprint arXiv:2503.16212, 2025.
- Schulman et al. [2017] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Shao et al. [2024] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- Shen et al. [2025] Wei Shen, Guanlin Liu, Zheng Wu, Ruofei Zhu, Qingping Yang, Chao Xin, Yu Yue, and Lin Yan. Exploring data scaling trends and effects in reinforcement learning from human feedback. arXiv preprint arXiv:2503.22230, 2025.
- Sheng et al. [2024] Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv:2409.19256, 2024.
- Shi et al. [2025] Taiwei Shi, Yiyang Wu, Linxin Song, Tianyi Zhou, and Jieyu Zhao. Efficient reinforcement finetuning via adaptive curriculum learning. arXiv preprint arXiv:2504.05520, 2025.
- Tan et al. [2024] Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Mansooreh Karami, Jundong Li, Lu Cheng, and Huan Liu. Large language models for data annotation and synthesis: A survey. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 930–957, 2024.
- Tang et al. [2024] Zhengyang Tang, Xingxing Zhang, Benyou Wang, and Furu Wei. Mathscale: Scaling instruction tuning for mathematical reasoning. In International Conference on Machine Learning, pages 47885–47900. PMLR, 2024.
- Team et al. [2025] Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599, 2025.
- Team [2025] Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, March 2025. URL https://qwenlm.github.io/blog/qwq-32b/.
- Tong et al. [2024] Yuxuan Tong, Xiwen Zhang, Rui Wang, Ruidong Wu, and Junxian He. Dart-math: Difficulty-aware rejection tuning for mathematical problem-solving. Advances in Neural Information Processing Systems, 37:7821–7846, 2024.
- Toshniwal et al. [2024] Shubham Toshniwal, Ivan Moshkov, Sean Narenthiran, Daria Gitman, Fei Jia, and Igor Gitman. Openmathinstruct-1: A 1.8 million math instruction tuning dataset. Advances in Neural Information Processing Systems, 37:34737–34774, 2024.
- Wang et al. [2023] Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. arXiv preprint arXiv:2312.08935, 2023.
- Wang et al. [2024] Shu Wang, Lei Ji, Renxi Wang, Wenxiao Zhao, Haokun Liu, Yifan Hou, and Ying Nian Wu. Explore the reasoning capability of llms in the chess testbed. arXiv preprint arXiv:2411.06655, 2024.
- Wang et al. [2025] Yu Wang, Nan Yang, Liang Wang, and Furu Wei. Examining false positives under inference scaling for mathematical reasoning. arXiv preprint arXiv:2502.06217, 2025.
- Wen et al. [2025] Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, et al. Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond. arXiv preprint arXiv:2503.10460, 2025.
- Wu et al. [2023] Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A Smith, Mari Ostendorf, and Hannaneh Hajishirzi. Fine-grained human feedback gives better rewards for language model training. Advances in Neural Information Processing Systems, 36:59008–59033, 2023.
- Xiong et al. [2025] Wei Xiong, Jiarui Yao, Yuhui Xu, Bo Pang, Lei Wang, Doyen Sahoo, Junnan Li, Nan Jiang, Tong Zhang, Caiming Xiong, et al. A minimalist approach to llm reasoning: from rejection sampling to reinforce. arXiv preprint arXiv:2504.11343, 2025.
- Xu et al. [2023] Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244, 2023.
- Yang et al. [2024a] An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115, 2024a.
- Yang et al. [2024b] An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122, 2024b.
- Ye et al. [2025] Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, and Pengfei Liu. Limo: Less is more for reasoning. arXiv preprint arXiv:2502.03387, 2025.
- Yeo et al. [2025] Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neubig, and Xiang Yue. Demystifying long chain-of-thought reasoning in llms. arXiv preprint arXiv:2502.03373, 2025.
- Yu et al. [2025a] Bin Yu, Hang Yuan, Yuliang Wei, Bailing Wang, Weizhen Qi, and Kai Chen. Long-short chain-of-thought mixture supervised fine-tuning eliciting efficient reasoning in large language models. arXiv preprint arXiv:2505.03469, 2025a.
- Yu et al. [2023] Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023.
- Yu et al. [2025b] Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025b.
- Yu et al. [2025c] Yiyao Yu, Yuxiang Zhang, Dongdong Zhang, Xiao Liang, Hengyuan Zhang, Xingxing Zhang, Ziyi Yang, Mahmoud Khademi, Hany Awadalla, Junjie Wang, et al. Chain-of-reasoning: Towards unified mathematical reasoning in large language models via a multi-paradigm perspective. arXiv preprint arXiv:2501.11110, 2025c.
- Yuan et al. [2025] Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, Xiangpeng Wei, et al. Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks. arXiv preprint arXiv:2504.05118, 2025.
- Yue et al. [2025] Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837, 2025.
- Zeng et al. [2025] Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild. arXiv preprint arXiv:2503.18892, 2025.
- Zhang et al. [2024a] Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, and Jie Tang. Rest-mcts*: Llm self-training via process reward guided tree search. Advances in Neural Information Processing Systems, 37:64735–64772, 2024a.
- Zhang et al. [2024b] Hengyuan Zhang, Yanru Wu, Dawei Li, Sak Yang, Rui Zhao, Yong Jiang, and Fei Tan. Balancing speciality and versatility: a coarse to fine framework for supervised fine-tuning large language model. In Findings of the Association for Computational Linguistics ACL 2024, pages 7467–7509, 2024b.
- Zhang et al. [2025] Shimao Zhang, Xiao Liu, Xin Zhang, Junxiao Liu, Zheheng Luo, Shujian Huang, and Yeyun Gong. Process-based self-rewarding language models. arXiv preprint arXiv:2503.03746, 2025.
- Zhang et al. [2023] Xiaotian Zhang, Chunyang Li, Yi Zong, Zhengyu Ying, Liang He, and Xipeng Qiu. Evaluating the performance of large language models on gaokao benchmark. arXiv preprint arXiv:2305.12474, 2023.
- Zhao et al. [2025a] Han Zhao, Haotian Wang, Yiping Peng, Sitong Zhao, Xiaoyu Tian, Shuaiting Chen, Yunjie Ji, and Xiangang Li. 1.4 million open-source distilled reasoning dataset to empower large language model training. arXiv preprint arXiv:2503.19633, 2025a.
- Zhao et al. [2025b] Xueliang Zhao, Wei Wu, Jian Guan, and Lingpeng Kong. Promptcot: Synthesizing olympiad-level problems for mathematical reasoning in large language models. arXiv preprint arXiv:2503.02324, 2025b.
- Ziegler et al. [2019] Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
- Zuo et al. [2025] Yuxin Zuo, Kaiyan Zhang, Shang Qu, Li Sheng, Xuekai Zhu, Biqing Qi, Youbang Sun, Ganqu Cui, Ning Ding, and Bowen Zhou. Ttrl: Test-time reinforcement learning, 2025. URL https://arxiv.org/abs/2504.16084. Appendix Contents for SwS
1. 1 Introduction
1. 2 Method
1. 2.1 Preliminary
1. 2.2 Overview
1. 2.3 Self-aware Weakness Identification
1. 2.4 Targeted Problem Synthesis
1. 2.5 Augmented Training with Synthetic Problems
1. 3 Experiments
1. 3.1 Experimental Setup
1. 3.2 Main Results
1. 3.3 Weakness Mitigation from Augmented Training
1. 4 Extensions and Analysis
1. 4.1 Weak-to-Strong Generalization for SwS
1. 4.2 Self-evolving Targeted Problem Synthesis
1. 4.3 Weakness-driven Selection
1. 4.4 Impact of Question Difficulty
1. 4.5 Case Study
1. 5 Conclusion
1. 6 Discussions, Limitations and Future Work
1. A Related Work
1. B Implementation Details
1. B.1 Training
1. B.2 Evaluation
1. C Motivation for Using RL in Weakness Identification
1. D Data Analysis of the SwS Framework
1. D.1 Detailed Data Workflow
1. D.2 Difficulty Distribution of Synthetic Problems
1. E Co-occurrence Based Concept Sampling
1. F Details for Weak-to-Strong Generalization in SwS
1. G Details for Self-Evolving in SwS
1. H Details for Weakness-driven Selection
1. I Evaluation Benchmark Demonstrations
1. J Prompts
1. J.1 Prompt for Category Labeling
1. J.2 Prompt for Concepts Extraction
1. J.3 Prompt for Problem Synthesis
1. J.4 Prompt for Quality Evaluation
## Appendix A Related Work
Recent advancements have significantly enhanced the integration of reinforcement learning (RL) with large language models (LLMs) [74, 37], particularly in the domains of complex reasoning and code generation [10]. Algorithms such as Proximal Policy Optimization (PPO) [39] and Generalized Reinforcement Preference Optimization (GRPO) [40] have demonstrated strong generalization and effectiveness in these applications. In contrast to supervised fine-tuning (SFT) via knowledge distillation [17, 69, 61], RL optimizes a model’s reason capabilities on its own generated outputs through reward-driven feedback, thereby prompting stronger generalization. In contrast, SFT models often depend on rote memorization of reasoning patterns and solutions [3], and may produce correct answers with flawed rationales [52]. In LLM reasoning, RL strengthens policy exploration and improves reasoning performance by using the verified correctness of the final answer in the responses as reward signals for training [32], which is commonly referred to as reinforcement learning with verifiable rewards (RLVR) [66].
Robust RLVR for LLM Reasoning. Scaling up reinforcement learning for LLMs poses significant challenges in terms of training stability and efficiency. Designing stable and efficient supervision algorithms and frameworks for LLMs has attracted widespread attention from the research community.
To address the challenge of reward sparsity in reinforcement learning, recent studies have explored not only answer-based rewards but also process-level reward modeling [4, 26, 50, 70], enabling the provision of more fine-grained reward signals throughout the entire solution process [54]. Wang et al. [50] successfully incorporated a process reward model (PRM), trained on process-level labels generated via Monte Carlo sampling at each step, into RL training and demonstrated its effectiveness. Beyond RL training, PRM can also be used to guide inference [4] and provide value estimates incorporated with search algorithms [68, 9]. However, Guo et al. [10] found that the scalability of process-level RL is limited by the ambiguous definition of “step” and the high cost of process-level labeling. How to effectively scale process-level RL remains an open question.
Recent efforts in scaling up RLVR optimization have focused on enhancing exploration [63, 65, 28, 60] and adapting RL to the Long-CoT conditions [16, 10, 24]. Yu et al. [63] found that the KL constraint may limit exploration under RLVR, while Liu et al. [28] proposed removing variance normalization in GRPO to prevent length bias. Building on PPO, Yuan et al. [65] found that pre-training the value function prior to RL training and employing a length-adaptive GAE can improve training stability and efficiency in RLVR, preventing it from degrading to a constant baseline in value estimation.
Data Construction in RLVR. Although RL training on simpler mathematical questions can partially elicit a model’s reasoning ability [67], the composition of RL training data is critical for enhancing the model’s reasoning capabilities [31, 63, 22, 14, 12, 41]. Carefully designing a problem set with difficulty levels matched to the model’s abilities and sufficient diversity can significantly improve performance. In addition, the use of curriculum learning has been shown to improve the efficiency of reinforcement learning [43]. In this work, we propose generating synthetic problems based on the model’s weaknesses for RL training, where the synthetic problems are tailored to align with the model’s capabilities and target its areas of weakness, fostering its exploration and improving performance.
Data Synthesis for LLM Reasoning Existing data synthesis strategies for enhancing LLM reasoning primarily concentrate on generating problem-response pairs [15, 45, 62, 73, 25, 30, 27, 51, 21, 44, 38] or augmenting responses to existing questions [49, 48, 12, 7, 53, 64, 23], typically by leveraging advanced LLMs to produce these synthetic examples. A prominent line of work focuses on extracting and recombining key concepts from seed problems. KP-Math [15] and MathScale [45] decompose seed problems into underlying concepts and recombine them to create new problems, leveraging advanced models to generate corresponding solutions. PromptCoT [73] also leverages underlying concepts, but focuses on generating competition-level problems. DART-Math [48] introduces a difficulty-aware framework that prioritizes the diversity and richness of synthetic responses to challenging problems.
Recently, several studies have emerged aiming to construct distilled datasets to better elicit the reasoning capabilities of LLM. [10]. Several works [7, 59, 35, 29, 72] employ advanced Long-CoT models to generate responses for distilling knowledge into smaller models. However, a significant disparity in capabilities between the teacher and student models can lead to hallucinations in the student’s outputs [36] and hinder generalization to out-of-distribution scenarios [3]. In contrast, our framework under the RL setting enables the model to identify and mitigate its own weaknesses by generating targeted synthetic problems from failure cases, thereby encouraging more effective self-improvement based on its specific weaknesses.
## Appendix B Implementation Details
<details>
<summary>x12.png Details</summary>
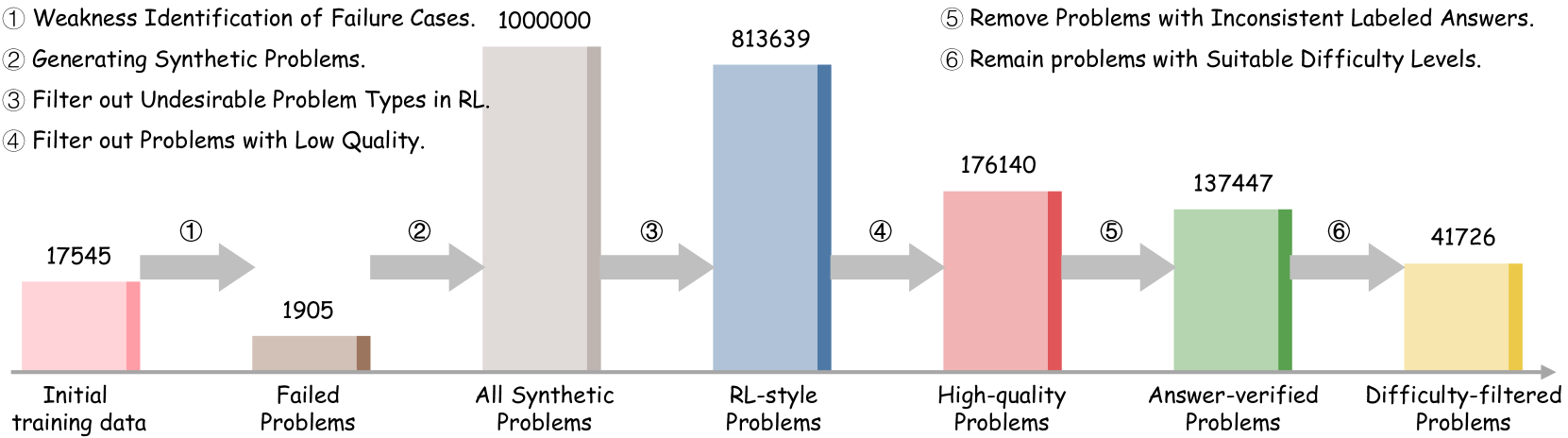
### Visual Description
## Flowchart: Data Processing Pipeline for Reinforcement Learning Problems
### Overview
The flowchart illustrates a six-stage pipeline for processing reinforcement learning (RL) problems, starting with initial training data and ending with difficulty-filtered problems. Each stage involves filtering, transformation, or verification, with numerical values representing the quantity of problems at each step.
### Components/Axes
- **X-axis**: Stages of the pipeline (categorical labels: "Initial training data," "Failed Problems," "All Synthetic Problems," "RL-style Problems," "High-quality Problems," "Answer-verified Problems," "Difficulty-filtered Problems").
- **Y-axis**: Quantity of problems (numerical values, ranging from 1,7545 to 1,000,000).
- **Colors**: Each stage is represented by a distinct color (pink, brown, gray, blue, red, green, yellow), though no explicit legend is provided. Colors are spatially grounded to their respective stages.
### Detailed Analysis
1. **Initial training data**: 17,545 problems (pink bar).
2. **Step 1 (Weakness Identification)**: 1,905 failed problems (brown bar), representing a 90% reduction from initial data.
3. **Step 2 (Generating Synthetic Problems)**: 1,000,000 problems (gray bar), a 525x increase from failed problems.
4. **Step 3 (Filter out Undesirable Types in RL)**: 813,639 problems (blue bar), a 186,361 reduction from synthetic problems.
5. **Step 4 (Filter out Low Quality)**: 176,140 problems (red bar), a 637,499 reduction from RL-style problems.
6. **Step 5 (Remove Inconsistent Answers)**: 137,447 problems (green bar), a 38,693 reduction from high-quality problems.
7. **Step 6 (Difficulty Filtering)**: 41,726 problems (yellow bar), a 95,721 reduction from answer-verified problems.
### Key Observations
- **Exponential Growth**: The largest jump occurs at Step 2 (synthetic problem generation), increasing from 1,905 to 1,000,000 problems.
- **Progressive Filtering**: Each subsequent step reduces the problem count, with the steepest drop between Steps 3 and 4 (637,499 problems filtered).
- **Final Output**: Only 41,726 problems (2.38% of initial data) survive all filters, indicating stringent criteria.
### Interpretation
This pipeline demonstrates a rigorous process for curating high-quality RL problems. The initial focus on identifying weaknesses and generating synthetic data suggests an emphasis on expanding problem diversity. However, the aggressive filtering stages (e.g., removing low-quality or inconsistent problems) highlight the importance of quality control in RL datasets. The final difficulty-filtered set likely represents a balanced subset suitable for training robust models. The 90% reduction from initial to failed problems implies that most initial data is discarded early, possibly due to irrelevance or poor quality. The pipeline’s structure aligns with best practices in machine learning, where data refinement is critical for model performance.
</details>
Figure 8: Demonstration of the SwS data workflow by tracing the process from initial training data to the final selection of synthetic problems in the 32B model experiments. For better visualization, the bar heights are scaled using the cube root of the raw data.
### B.1 Training
We conduct our experiments using the verl [42] framework and adopt GRPO [40] as the optimization algorithm. For all RL training experiments, we sample 8 rollouts per problem and use a batch size of 1024, with the policy update batch size set to 256. We employ a constant learning rate of $5\times 10^{-7}$ with a 20-step warm-up, and set the maximum prompt and response lengths to 1,024 and 8,192 tokens, respectively. We do not apply a KL penalty, as recent studies have shown it may hinder exploration and potentially cause training collapse [65, 28, 63]. In the initial training stage, we train the model for 200 steps. During augmented RL training, we continually train the initially trained model for 600 steps on the augmented dataset incorporated with synthetic problems, using only prompts with an accuracy between $\text{acc}_{\text{lower}}=10\$ and $\text{acc}_{\text{upper}}=90\$ as determined by the online policy model for updates. The probability ratio clipping ranges in Eq. 3 is set to $\varepsilon=0.20$ and $\varepsilon^{h}=0.28$ .
Since the training data for the 32B and 14B models (a combination of DAPO [63] and LightR1 [53] subsets) lack human-annotated category information, we leverage the LLaMA-3.3-70B-Instruct model to label their categories. This ensures consistency with our SwS pipeline, which combines concepts within the same category. The prompt is presented in Prompt LABEL:prompt:category-labeling.
### B.2 Evaluation
For evaluation, we utilize the vLLM framework [18] and allow for responses up to 8,192 tokens. For all the benchmarks, Pass@1 is computed using greedy decoding for baseline models and sampling (temperature 1.0, top-p 0.95) for RL-trained models. For Avg@32 on competition-level benchmarks, we sample 32 responses per model with the same sampling configuration as used in RL training. We adopt a hybrid rule-based verifier by integrating Math-Verify and the PRIME-RL verifier [6], as their complementary strengths lead to higher recall. For all the inference, we use the default chat template and enable CoT prompting by appending the instruction: “Let’s think step by step and output the final answer within “ $\backslash\text{boxed}\{\}$ ” after each question.
## Appendix C Motivation for Using RL in Weakness Identification
<details>
<summary>x13.png Details</summary>

### Visual Description
## Bar Chart: Ratios of Failed Problems of Base Model, SFT Model, and Initial RL Model in MATH-12k
### Overview
The chart compares the failure ratios of three models (Base Model, SFT Model, Initial RL Model) across seven math topics in the MATH-12k dataset. The y-axis represents failure ratios (0–60), while the x-axis lists math topics. Each topic has three grouped bars corresponding to the models.
### Components/Axes
- **X-axis (Categories)**: Algebra, Counting & Probability, Geometry, Intermediate Algebra, Number Theory, Prealgebra, Precalculus.
- **Y-axis (Value)**: Failure ratios (0–60).
- **Legend**:
- White = Base Model
- Blue = SFT Model
- Pink = Initial RL Model
- **Legend Position**: Top-left corner.
- **Bar Grouping**: Clustered bars per topic, with colors matching the legend.
### Detailed Analysis
| Topic | Base Model | SFT Model | Initial RL Model |
|------------------------|------------|-----------|------------------|
| Algebra | 0.9 | 16.5 | 0.5 |
| Counting & Probability | 9.9 | 41.3 | 3.8 |
| Geometry | 17.1 | 45.1 | 8.8 |
| Intermediate Algebra | 14.8 | 52.9 | 6.7 |
| Number Theory | 6.2 | 37.9 | 1.8 |
| Prealgebra | 2.8 | 15.6 | 0.9 |
| Precalculus | 13.3 | 48.4 | 10.3 |
### Key Observations
- **SFT Model Dominance**: The SFT Model consistently has the highest failure ratios across all topics, with peaks in Intermediate Algebra (52.9) and Precalculus (48.4).
- **Base Model Variability**: The Base Model shows mixed performance, with higher failure rates in Geometry (17.1) and Precalculus (13.3) compared to other topics.
- **Initial RL Model**: Generally the lowest failure ratios, except in Geometry (8.8) and Precalculus (10.3), where it surpasses the Base Model.
- **Outliers**:
- Intermediate Algebra has the highest SFT failure ratio (52.9).
- Geometry has the highest Base Model failure ratio (17.1).
### Interpretation
The data suggests that the SFT Model struggles most with Intermediate Algebra and Precalculus, potentially due to complex problem structures in these topics. The Base Model’s higher failure rates in Geometry and Precalculus may indicate limitations in handling spatial reasoning or advanced concepts. The Initial RL Model’s lower failure ratios overall suggest it is more robust, though its performance in Geometry and Precalculus warrants further investigation. The stark contrast between SFT and RL models highlights potential trade-offs between model complexity and reliability in specific domains.
</details>
Figure 9: An visualization of utilizing the base model (Qwen2.5-7B), SFT model and the initial RL model on weakness identification in the original training set (MATH-12k).
In our SwS framework, we propose utilizing an initial RL training phase for weakness identification. However, one might argue that there are simpler alternatives for weakness identification, such as directly sampling training problems from the base model or applying supervised fine-tuning before prompting the model to answer questions. In this section, we provide an in-depth discussion on the validity of using problems with low training efficiency during the initial RL phase as model’s weaknesses.
We first compare the performance of the Base model, SFT model, and Initial RL model by sampling on the training set, where the SFT model is obtained by fine-tuning the Base model for 1 epoch on human-written solutions. For each question, we prompt the model to generate 8 responses and report the proportion of problems for which none of the responses are correct in Figure 9. For the Base model, failures may be attributed to its insufficient alignment with reasoning-specific tasks. Results from the initial RL model show that the Base model can quickly master such questions through RL, indicating that they do not represent challenging weaknesses. Furthermore, the heavy reliance on the prompt template of the Base model [28] reduces its robustness of weakness identification. For the SFT model, there are three main drawbacks regarding weakness identification: (1) The dilemma of training epochs—too many epochs leads to memorizing labeled solutions, while too few epochs fails to align the model with the target problem distribution; (2) SFT is prone to hallucination [3, 52]; and (3) Ensuring the quality of labeled solutions is difficult, as human-written solutions may not always be the best for models [10]. For these reasons, the SFT model performs poorly on the initial training set, even yielding worse results than the Base model, let alone in utilizing its failed problems to identify model weaknesses.
In contrast to the Base and SFT models, the Initial RL model exhibits the most robust performance on the initial training set, indicating that the failed problems expose the model’s most critical weaknesses. Additionally, the training efficiency on all problems during initial RL can also be recorded for further analysis of model weaknesses. Meanwhile, the initially trained model can also serve as the starting point for augmented RL training. Therefore, in our SwS framework, we ultimately choose to employ an initial RL phase for robust weakness identification.
## Appendix D Data Analysis of the SwS Framework
| Positive Case # 1: Let $z_{1}$ , $z_{2}$ , and $z_{3}$ be complex numbers such that $|z_{1}|=|z_{2}|=|z_{3}|=1$ and $z_{1}+z_{2}+z_{3}=0$ . Using the symmetric polynomial $s_{2}=z_{1}z_{2}+z_{1}z_{3}+z_{2}z_{3}$ , find the value of $|s_{2}|^{2}$ . |
| --- |
| Negative Case # 1: In a village, there are 10 houses, each of which can be painted one of three colors: red, blue, or green. Two houses cannot have the same color if they are directly adjacent to each other. Using combinatorial analysis and considering the constraints, find the total number of distinct ways to paint the houses, taking into account the possibility of having a sequence where the same color repeats after two different colors (e.g., red, blue, red), and assuming that the color of one of the end houses is already determined to be red, and the colors of the houses are considered different based on their positions (i.e., the configuration red, blue, green is considered different from green, blue, red). |
| Negative Case # 2: A metal’s surface requires a minimum energy of 2.5 eV to remove an electron via the photoelectric effect. If light with a wavelength of 480 nm is shone on the metal, and 1 mole of electrons is ejected, what is the total energy, in kilojoules, transferred to the electrons, given that the energy of a photon is related to its wavelength by the formula E = $hc/\lambda$ , where $h=6.626x10^{-34}$ J s and $c=3.00x10^{8}m/s$ , and Avogadro’s number is $6.02x10^{23}$ particles per mole? |
| Negative Case # 3: In triangle $ABC$ , with $\angle A=60^{\circ}$ , $\angle B=90^{\circ}$ , $AB=4$ , and $BC=7$ , use the Law of Sines to find $\angle C$ and calculate the triangle’s area. |
Table 4: Case study of quality filtering results in SwS, featuring one high-quality positive case and three low-quality negative cases. The low-quality segments are marked in pink.
### D.1 Detailed Data Workflow
Taking the 32B model experiments as an example, Figure 8 shows the comprehensive data workflow of the SwS framework, from identifying model weaknesses in the initial training data to the processing of synthetic problems. The initial training set, consisting of the DAPO and Light-R1 subsets for the Qwen2.5-32B model, contains 17,545 problem-answer pairs. During the weakness identification stage, 1,905 problems are identified as failure cases according to Eq. 4. These failure cases are subsequently used for concept extraction and targeted problem synthesis.
For problem synthesis, we set an initial budget of 1 million synthetic problems in all experiments, with allocations for each category determined as in Eq. 5. These problems then undergo several filtering stages: (1) removing multiple-choice, multi-part, or proof-required problems; (2) discarding problems evaluated as low quality; (3) filtering out problems where the answer generation model yields inconsistent answers, specifically when the most frequent answer among all generations appears less than 50%; and (4) removing problems whose difficulty levels are unsuitable for the current model in RL training. Among these, the quality-based filtering is the strictest, with a filtering rate of 78.35%, indicating that the SwS pipeline maintains rigorous quality control over the generated problems. This ensures both the stability and effectiveness of utilizing synthetic problems in subsequent training.
We present a case study of the quality-based filtering results in Table 4. As illustrated, the positive case that passed the model-based quality evaluation features a concise and precise problem description. In contrast, most synthetic problems identified as low-quality exhibit redundant and overly elaborate descriptions, sometimes including lengthy hints for solving the problem, as seen in the first negative case. Additionally, some low-quality problems incorporate excessive non-mathematical knowledge, such as Physics, as illustrated in the second negative case. The informal LaTeX formatting also contributes to their lower quality. Furthermore, problems with multiple question components, such as the third negative case, are also considered as low quality for RL training.
### D.2 Difficulty Distribution of Synthetic Problems
In this section, we study the difficulty distribution of the synthetic problems generated for base models ranging from 3B to 32B, as shown in Figure 10. The red outlines in the pie plots highlight the subset of synthetic problems selected for subsequent augmented RL training, with accuracy falling within the [25%, 75%] range. These samples account for nearly 35% of all generated problems across the four models. The two largest wedges in the pie chart represent problems that the models answered either completely correctly or completely incorrectly. These cases do not provide effective training signals in GRPO [40, 63], and are thus excluded from the later augmented RL training stage. To further enhance stability and efficiency, we also exclude problems where the model produces only one correct or one incorrect response.
Since all synthetic problems are generated using the same instruction model (LLaMA-3.3-70B-Instruct) with similar competition-level difficulty levels (as illustrated in Prompt LABEL:prompt:problem-generation), and are based on concepts derived from their respective weaknesses, the resulting difficulty distribution of the synthetic problems exhibits only minor differences across all models. Consistent with intuition, the initially trained 3B model achieved the lowest performance on the synthetic questions, with the highest ratio of all-incorrect and the lowest ratio of all-correct responses, while the 32B model showed the opposite trend, achieving the best performance.
<details>
<summary>x14.png Details</summary>
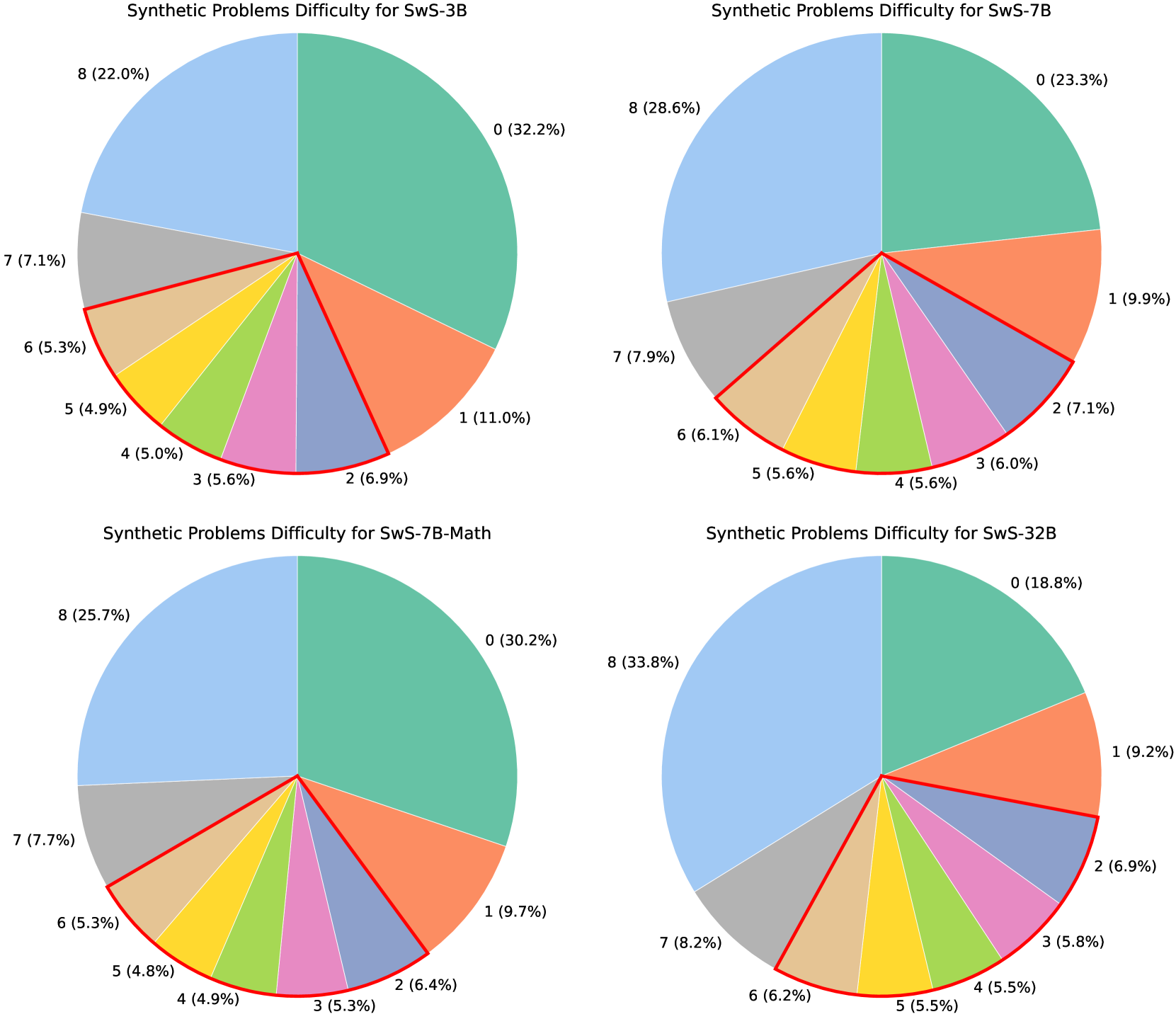
### Visual Description
## Pie Charts: Synthetic Problems Difficulty for SwS-3B, SwS-7B, SwS-7B-Math, SwS-32B
### Overview
The image contains four pie charts comparing the distribution of synthetic problem difficulty levels (0–8) across four SwS versions: SwS-3B, SwS-7B, SwS-7B-Math, and SwS-32B. Each chart uses distinct colors for difficulty levels, with percentages labeled for each segment.
### Components/Axes
- **Legend**: Integrated into each chart, with colors mapped to difficulty levels (0–8). Colors are consistent across charts for the same difficulty level (e.g., teal for 0, blue for 8).
- **Labels**: Difficulty levels (0–8) and percentages are placed clockwise around each pie chart.
- **Colors**:
- 0: Teal (#008080)
- 1: Red (#FF0000)
- 2: Light Blue (#ADD8E6)
- 3: Pink (#FFC0CB)
- 4: Green (#00FF00)
- 5: Yellow (#FFFF00)
- 6: Orange (#FFA500)
- 7: Gray (#808080)
- 8: Light Blue (#ADD8E6)
### Detailed Analysis
#### SwS-3B
- **0 (32.2%)**: Largest segment (teal).
- **8 (22.0%)**: Second-largest (light blue).
- **1 (11.0%)**: Third-largest (red).
- Remaining segments (2–7) range from 2.9% to 7.1%.
#### SwS-7B
- **0 (23.3%)**: Largest segment (teal).
- **8 (28.6%)**: Second-largest (light blue).
- **1 (9.9%)**: Third-largest (red).
- Remaining segments (2–7) range from 5.0% to 7.9%.
#### SwS-7B-Math
- **0 (30.2%)**: Largest segment (teal).
- **8 (25.7%)**: Second-largest (light blue).
- **1 (9.7%)**: Third-largest (red).
- Remaining segments (2–7) range from 4.8% to 7.7%.
#### SwS-32B
- **8 (33.8%)**: Largest segment (light blue).
- **0 (18.8%)**: Second-largest (teal).
- **1 (9.2%)**: Third-largest (red).
- Remaining segments (2–7) range from 5.5% to 8.2%.
### Key Observations
1. **Difficulty 0 Dominance**: SwS-3B and SwS-7B-Math have the highest percentages for difficulty 0 (32.2% and 30.2%, respectively), while SwS-32B has the lowest (18.8%).
2. **Difficulty 8 Trends**: SwS-32B has the highest difficulty 8 percentage (33.8%), significantly higher than SwS-7B (28.6%) and SwS-7B-Math (25.7%).
3. **Middle Difficulties**: SwS-7B and SwS-32B show more balanced distributions for difficulties 4–6 compared to SwS-3B and SwS-7B-Math.
4. **Consistency in Color Mapping**: All charts use identical color coding for the same difficulty levels, ensuring cross-chart comparability.
### Interpretation
The data suggests that SwS-32B excels at handling harder problems (difficulty 8), while SwS-3B and SwS-7B-Math are more effective at easier problems (difficulty 0). The middle difficulty levels (4–6) show less variation across models, indicating similar performance in average-difficulty problem-solving. The stark contrast in difficulty 8 performance between SwS-32B and other models highlights potential architectural or training differences optimized for complex tasks. The consistent color mapping across charts enables straightforward visual comparison of difficulty distributions.
</details>
Figure 10: Difficulty distributions of synthetic problems for models from 3B to 32B in our work.
## Appendix E Co-occurrence Based Concept Sampling
Following Huang et al. [15], Zhao et al. [73], we enhance the coherence and semantic fluency of synthetic problems by sampling concepts within the same category based on their co-occurrence probabilities and embedding similarities. Specifically, for each candidate concept $c\in\mathbf{C}$ from category $\mathbf{D}$ , we define its score based on both co-occurrence statistics and embedding similarity as:
$$
\mathrm{Score}(c)=\begin{cases}\mathrm{Co}(c)+\mathrm{Sim}(c),&\text{if }c
\notin\{c_{1},c_{2},\dots,c_{k}\}\\
-\infty,&\text{otherwise}.\end{cases}
$$
The co-occurrence term $\mathrm{Co}(c)$ is computed by summing the co-occurrence counts from a sparse matrix built over the entire corpus, generated by iterating through all available concept lists in the pool. For each list, we increment $\mathrm{CooccurMatrix}[c,c^{\prime}]$ by one for every unordered pair where $c\neq c^{\prime}$ , yielding a sparse, symmetric matrix in which each entry $\mathrm{CooccurMatrix}[c,c^{\prime}]$ records the total number of times concepts $c$ and $c^{\prime}$ co-occur across all sampled lists:
$$
\mathrm{Co}(c)=\sum_{i=1}^{k}\mathrm{CooccurMatrix}[c,c_{i}], \tag{6}
$$
while the semantic similarity is given by the cosine similarity between the candidate’s embedding and the mean embedding of the currently selected concepts:
$$
\mathrm{Sim}(c)=\cos\left(\vec{e}_{c},\frac{1}{k}\sum_{i=1}^{k}\vec{e}_{c_{i}}
\right), \tag{7}
$$
To efficiently support large-scale and high-dimensional concept spaces, we construct a sparse co-occurrence matrix over all unique concepts, where each entry represents the frequency with which a pair of concepts co-occurs within sampled concept lists. Simultaneously, concept embeddings are normalized and indexed via FAISS to facilitate fast similarity computation. During sampling, an initial seed concept is drawn in proportion to its empirical frequency. For each subsequent concept, scores are computed by efficiently summing its co-occurrence with the current set and its embedding similarity to the group mean, while previously selected concepts are masked out. The probability of sampling each candidate is determined via softmax over these scores with temperature $\tau$ :
$$
P(c)=\frac{\exp\left(\mathrm{Score}(c)/\tau\right)}{\sum_{c^{\prime}\notin\{c_
{1},\dots,c_{k}\}}\exp\left(\mathrm{Score}(c^{\prime})/\tau\right)}. \tag{8}
$$
This process iteratively constructs coherent, semantically related concept sets to serve as the inputs for synthetic problem generation, ensuring both diversity and fluency.
## Appendix F Details for Weak-to-Strong Generalization in SwS
Case Study for Weak-to-strong Generalization
Question: Compute $99^{2}+99+1$ in your head. Please reason step by step, and put your final answer within \boxed{}. Golden Answer: $\boxed{9901}$ $>>>$ Teacher Response: To compute $99^{2}+99+1$ , we can compute each part directly: $\displaystyle 99^{2}$ $\displaystyle=9801$ $\displaystyle 99^{2}+99$ $\displaystyle=9801+99=9900$ $\displaystyle 99^{2}+99+1$ $\displaystyle=9900+1=9901$ Final answer: $\boxed{9901}$ $>>>$ Student Response: Rewrite the expression using a binomial identity: $\displaystyle 99^{2}+99+1$ $\displaystyle=(99+1)^{2}=100^{2}=10000$ Final answer: $\boxed{10000}$
Figure 11: Case study in which a weak teacher provides the correct solution, while a strong student incorrectly applies a binomial identity and derives an incorrect answer.
To understand the capabilities of the weak teacher and the strong student model, we evaluated both of them on the MATH-500 test set by prompting them on each question for eight times. Although the teacher model generally exhibits weaker performance, we found that in 16.4% of problems, the weaker teacher outperforms the otherwise stronger student model. This highlights the potential for leveraging a weak teacher to distill its strengths into the student model. A case where the weaker teacher model outperforms the stronger student model is shown in Figure 11.
From the analysis of the SwS framework, as well as its Weak-to-Strong Generalization extension, we assert that the upper bound for answer labeling is a revised form of self-consistency score of the teacher model, where (1) the consistent answer must achieve an accuracy greater than 50% across all responses, and (2) the student model must provide the same answer as the teacher model’s consistent answer in at least 25% of responses. These revision procedures help ensure the correctness of the synthetic problem answers labeled by the teacher model.
In Table 5, we demonstrate the robustness of utilizing a weaker teacher for answer labeling, assuming that the MATH-500 test set serves as our synthetic problems. As in the second line, even under the self-consistency setting, the teacher model only achieves an improvement of 4.8 points. However, when we exclude problems for which self-consistency does not provide sufficient confidence—specifically, those where the most consistent answer accounts for less than 50% of all responses—the self-consistency setting yields an additional 9.0-point improvement on the remaining questions. Furthermore, in our SwS pipeline, we retain only problems where the student model achieves over 25% accuracy to ensure an appropriate level of difficulty. After filtering out problems where the student falls below this threshold, some mislabeled problems are also automatically removed, resulting in the weak teacher achieving a performance of 97.5% on the final remaining questions. The increase in labeling accuracy from 80.6% to 97.5% shows the potential of utilizing the weaker teacher model for answer labeling as well as the robustness of the SwS framework itself.
| Setting | Size | Prealgebra | Intermediate Algebra | Algebra | Precalculus | Number Theory | Counting & Probability | Geometry | All |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Pass@1 | 500 | 88.2 | 64.3 | 95.5 | 71.2 | 93.0 | 81.4 | 63.0 | 80.6 |
| + SC | 500 | 96.9 | 96.0 | 84.4 | 84.1 | 96.2 | 87.5 | 67.8 | 85.4 |
| + SC>50% | 444 | 96.9 | 97.3 | 93.2 | 94.7 | 98.0 | 94.4 | 89.6 | 94.4 |
| + SC>50% & Stu-Con | 407 | 96.8 | 97.2 | 97.7 | 100.0 | 100.0 | 96.8 | 94.9 | 97.5 |
Table 5: The performance of the weak teacher model used for answer generation on the MATH-500 test set under different strategies and their corresponding revisions. "Stu-Con" refers to filtering out problems where the student model’s accuracy falls below the defined threshold of 25%.
## Appendix G Details for Self-Evolving in SwS
As mentioned in Section 4.2, the Self-evolving SwS extension enables the policy to achieve better performance on simple to medium-level mathematical reasoning benchmarks but remains suboptimal on AIME-level competition benchmarks. In this section, we further analyze the reasons behind this phenomenon. Figure 12 visualizes the model’s self-quality assessment and difficulty evaluation within the SwS framework. Notably, the model assigns a much higher proportion of “perfect” and “acceptable” labels, and fewer “bad” labels, to its self-generated problems compared to the standard framework shown in Figure 8. This observation is consistent with findings from LLM-as-a-Judge [21], which indicate that models tend to be more favorable toward and assign higher scores to their own generations. Such behavior may result in overlooking low-quality problems or mis-classifying problems that are too complex for the model’s reasoning abilities as unsolvable or of poor quality. Beyond the risk of filtering out over-complex problems, the model may also have difficulty in accurately labeling answers through self-consistency for over-challenging problems, thereby limiting the potential of incorporating complex problems through the Self-evolving SwS framework.
Additionally, in Figure 12, it is noteworthy that the initial RL-trained model achieves nearly 50% all-correct responses on its generated problems, whereas only 31% of problems with appropriate difficulty remain for augmentation after SwS difficulty filtering. This suggests that the self-generated problems may be significantly simpler than those produced using a stronger instruction model [8], thus it could lead to data inefficiency and limit the model’s performance on more complex problems during RL training.
<details>
<summary>x15.png Details</summary>
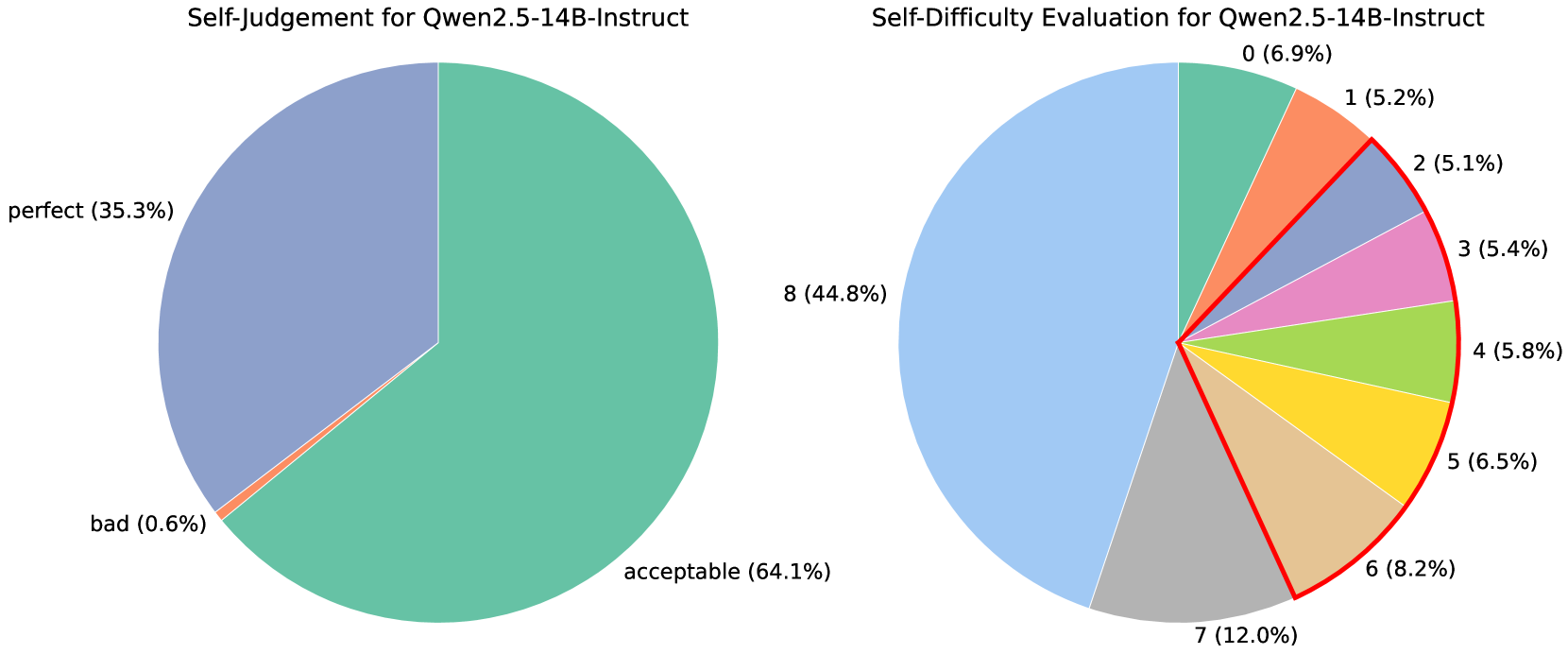
### Visual Description
## Pie Charts: Self-Judgement and Self-Difficulty Evaluation for Qwen2.5-14B-Instruct
### Overview
The image contains two pie charts comparing self-assessment metrics for the Qwen2.5-14B-Instruct model. The left chart shows self-judgement results (perfect, acceptable, bad), while the right chart displays self-difficulty evaluations (numerical scale 0–8).
### Components/Axes
#### Left Chart (Self-Judgement):
- **Labels**:
- "perfect (35.3%)" (blue)
- "acceptable (64.1%)" (green)
- "bad (0.6%)" (red)
- **Legend**: Positioned on the left, with color-coded labels.
- **Structure**: Three segments, with "acceptable" dominating the chart.
#### Right Chart (Self-Difficulty Evaluation):
- **Labels**:
- Numerical scale 0–8, each with percentages:
- 8 (44.8%)
- 7 (12.0%)
- 6 (8.2%)
- 5 (6.5%)
- 4 (5.8%)
- 3 (5.4%)
- 2 (5.1%)
- 1 (5.2%)
- 0 (6.9%)
- **Legend**: Positioned on the right, with a gradient color scale (blue for 8, gray for 7, yellow-to-red gradient for 6–0).
- **Structure**: Nine segments, with 8 being the largest slice.
### Detailed Analysis
#### Left Chart:
- **Trends**:
- "acceptable" (64.1%) is the largest segment, followed by "perfect" (35.3%).
- "bad" (0.6%) is negligible.
- **Data Points**:
- Perfect: 35.3%
- Acceptable: 64.1%
- Bad: 0.6%
#### Right Chart:
- **Trends**:
- Difficulty 8 (44.8%) is the most frequent, followed by 7 (12.0%).
- Lower difficulties (0–6) collectively account for 43.1%, with 0 (6.9%) slightly higher than 1–3.
- **Data Points**:
- 8: 44.8%
- 7: 12.0%
- 6: 8.2%
- 5: 6.5%
- 4: 5.8%
- 3: 5.4%
- 2: 5.1%
- 1: 5.2%
- 0: 6.9%
### Key Observations
1. **Self-Judgement**:
- The model rates 64.1% of tasks as "acceptable" and 35.3% as "perfect," indicating high self-confidence.
- Only 0.6% of tasks are rated "bad," suggesting minimal self-criticism.
2. **Self-Difficulty Evaluation**:
- Tasks are predominantly rated as difficulty 8 (44.8%) or 7 (12.0%), implying the model perceives most tasks as highly challenging.
- Lower difficulties (0–6) are less common, with difficulty 0 (6.9%) slightly exceeding difficulties 1–3.
### Interpretation
- **Self-Judgement**: The model’s high "acceptable" and "perfect" ratings suggest it generally performs well on tasks, with minimal self-doubt.
- **Self-Difficulty**: The skew toward higher difficulty ratings (8 and 7) may indicate either:
- The tasks are inherently complex for the model.
- The model overestimates task difficulty, potentially due to calibration issues.
- **Anomalies**:
- The spike in difficulty 0 (6.9%) compared to 1–3 (5.1–5.4%) suggests some tasks were perceived as trivial, possibly due to task design or model bias.
- The dominance of difficulty 8 (44.8%) raises questions about task distribution or model limitations in handling complex scenarios.
The data highlights a discrepancy between self-judgement (high confidence) and self-difficulty (high perceived challenge), which could inform model tuning or task design strategies.
</details>
Figure 12: Illustration of the quality assessment and difficulty evaluation for Qwen2.5-14B-Instruct under the Self-evolving SwS framework.
## Appendix H Details for Weakness-driven Selection
Algorithm 1 Weakness-Driven Selection Pipeline
1: Failed Problems $\mathbf{X}_{S}$ ; Total Budget $|T|$ ; Target Set $\mathbf{T}_{X}$ ; Domains $\{\mathbf{D}_{i}\}_{i=0}^{n}$
2: Selected problems $\mathbf{T}_{S}$
3: Embed all failed problems in $\mathbf{X}_{S}$ and all questions in $\mathbf{T}_{X}$
4: for each domain $\mathbf{D}_{i}$ in $\{\mathbf{D}_{i}\}_{i=0}^{n}$ do
5: Compute selection budget $|T_{i}|$ for $\mathbf{D}_{i}$ according to Eq. 2
6: Extract failed problems $\mathbf{X}_{S,i}$ belonging to $\mathbf{D}_{i}$
7: for each $q\in\mathbf{T}_{X}$ do $\triangleright$ Domain-level KNN
8: Compute $d_{i}(q)=\min_{f\in\mathbf{X}_{S,i}}\text{distance}(\vec{e}_{q},\vec{e}_{f})$
9: end for
10: Select top $|T_{i}|$ questions from $\mathbf{T}_{X}$ with the smallest $d_{i}(q)$ as $\mathcal{S}_{i}$
11:
12: end for
13: return Selected problems $\mathbf{T}_{S}=\bigcup_{i=0}^{n}\mathcal{S}_{i}$ $\triangleright$ Final Selected Set
As described in Section 4.3, we utilize the failed problems identified by Qwen2.5-7B [57] on the MATH-12k [13] training set, which comprises 915 problems, to select additional data from Big-Math [1] to mitigate the model’s weaknesses through the augmented RL training. The complete Weakness-driven Selection extension of SwS is presented in Algorithm 1. For embedding the problems, we utilize LLaMA-3.1-8B-base [8] to encode both the collected failure cases and the problems from the target dataset. The failure cases are then grouped by categories, following the concept sampling strategy in standard SwS. We employ a binary K-Nearest Neighbors [5] algorithm to select weakness-driven problems from the target set, where the augmented problems are chosen by their embedding distances to the failure cases within each category. The selection budget for each category is also determined according to Eq. 5. We then aggregate the retrieved problems from all categories, forming a selected set of 40k problems, which are then incorporated with the initial set for the subsequent RL training.
## Appendix I Evaluation Benchmark Demonstrations
| Dataset | Size | Category | Example Problem | Answer |
| --- | --- | --- | --- | --- |
| GSM8k | 1319 | Prealgebra | The ice cream parlor was offering a deal, buy 2 scoops of ice cream, get 1 scoop free. Each scoop cost $1.50. If Erin had $6.00, how many scoops of ice cream should she buy? | $6$ |
| MATH-500 | 500 | Geometry | For a constant $c,$ in cylindrical coordinates $(r,\theta,z),$ find the shape described by the equation $z=c.$ (A) Line (B) Circle (C) Plane (D) Sphere (E) Cylinder (F) Cone. Enter the letter of the correct option. | (C) Plane |
| Minerva Math | 272 | Precalculus | If the Bohr energy levels scale as $Z^{2}$ , where $Z$ is the atomic number of the atom (i.e., the charge on the nucleus), estimate the wavelength of a photon that results from a transition from $n=3$ to $n=2$ in Fe, which has $Z=26$ . Assume that the Fe atom is completely stripped of all its electrons except for one. Give your answer in Angstroms, to two significant figures. | $9.6$ |
| Olympiad-Bench | 675 | Geometry | Given a positive integer $n$ , determine the largest real number $\mu$ satisfying the following condition: for every $4n$ -point configuration $C$ in an open unit square $U$ , there exists an open rectangle in $U$ , whose sides are parallel to those of $U$ , which contains exactly one point of $C$ , and has an area greater than or equal to $\mu$ . | $\frac{1}{2n+2}$ |
| Gaokao-2023 | 385 | Geometry | There are three points $A,B,C$ in space such that $AB=BC=CA=1$ . If 2 distinct points are chosen in space such that they, together with $A,B,C$ , form the five vertices of a regular square pyramid, how many different ways are there to choose these 2 points? | $9$ |
| AMC23 | 40 | Algebra | How many complex numbers satisfy the equation $z^{5}=\overline{z}$ , where $\overline{z}$ is the conjugate of the complex number $z$ ? | $7$ |
| AIME24 | 30 | Number Theory | Let $N$ be the greatest four-digit positive integer with the property that whenever one of its digits is changed to $1$ , the resulting number is divisible by $7$ . Let $Q$ and $R$ be the quotient and remainder, respectively, when $N$ is divided by $1000$ . Find $Q+R$ . | $699$ |
| AIME25 | 30 | Geometry | On $\triangle ABC$ points $A,D,E$ , and $B$ lie that order on side $\overline{AB}$ with $AD=4,DE=16$ , and $EB=8$ . Points $A,F,G$ , and $C$ lie in that order on side $\overline{AC}$ with $AF=13,FG=52$ , and $GC=26$ . Let $M$ be the reflection of $D$ through $F$ , and let $N$ be the reflection of $G$ through $E$ . Quadrilateral $DEGF$ has area 288. Find the area of heptagon $AFNBCEM$ . | $588$ |
Table 6: Statistics and examples of the eight evaluation benchmarks utilized in the paper.
We present the statistics and examples of the eight evaluation benchmarks used in our work in Table 6. Among these, GSM8K [4] is the simplest, comprising grade school math word problems. The MATH-500 [13], Gaokao-2023 [71], Olympiad-Bench [11], and AMC23 [33] benchmarks consist of high school mathematics problems spanning a wide range of topics and difficulty levels, while Minerva Math [19] may also include problems from other subjects. The AIME [34] benchmark is a prestigious high school mathematics competition that requires deep mathematical insight and precise problem-solving skills. An overview of all benchmarks is provided as follows.
- GSM8K: A high-quality benchmark comprising 8,500 human-written grade school math word problems that require multi-step reasoning and basic arithmetic, each labeled with a natural language solution and verified answer. The 1,319-question test set emphasizes sequential reasoning and is primarily solvable by upper-grade elementary school students.
- MATH-500: A challenging benchmark of 500 high school competition-level problems spanning seven subjects, including Algebra, Geometry, Number Theory, and Precalculus. Each problem is presented in natural language with LaTeX-formatted notation, offering a strong measure of mathematical reasoning and generalization across diverse topics.
- Minerva-Math:A high-difficulty math problem dataset consisting of 272 challenging problems. Some problems are also relevant to scientific topics in other subjects, such as physics.
- Olympiad-Bench: An Olympiad-level English and Chinese multimodal scientific benchmark featuring 8,476 problems from mathematics and physics competitions. In this work, we use only the pure language problems described in English, totaling 675 problems.
- Gaokao-2023: A dataset consists of 385 mathematics problems from the 2023 Chinese higher education entrance examination, professionally translated into English.
- AMC23: The AMC dataset consists of all 83 problems from AMC12 2022 and AMC12 2023, extracted from the AoPS wiki page. We used a subset of this data containing 40 problems.
- AIME24 & 25: Each set comprises 30 problems from the 2024 and 2025 American Invitational Mathematics Examination (AIME), a prestigious high school mathematics competition for top-performing students, which are the most challenging benchmarks used in our study. Each problem is designed to require deep mathematical insight, multi-step reasoning, and precise problem-solving skills.
## Appendix J Prompts
### J.1 Prompt for Category Labeling
Listing 1: The prompt for labeling the categories for mathematical problems, utilizing a few-shot strategy in which each category is represented by a labeled demonstration.
⬇
# CONTEXT #
I am a teacher, and I have some high - level mathematical problems.
I want to categorize the domain of these math problems.
# OBJECTIVE #
A. Provide a concise summary of the math problem, clearly identifying the key concepts or techniques involved.
B. Assign the problem to one and only one specific mathematical domain.
The following is the list of domains to choose from:
< math domains >
[" Intermediate Algebra ", " Geometry ", " Precalculus ", " Number Theory ", " Counting & Probability ", " Algebra ", " Prealgebra "]
</ math domains >
# STYLE #
Data report.
# TONE #
Professional, scientific.
# AUDIENCE #
Students. Enable them to better understand the domain of the problems.
# RESPONSE: MARKDOWN REPORT #
## Summarization
[Summarize the math problem in a brief paragraph.]
## Math domains
[Select one domain from the list above that best fits the problem.]
# ATTENTION #
- You must assign each problem to exactly one of the domains listed above.
- If you are genuinely uncertain and none of the listed categories applies, you may use " Other ", but this should be a last resort.
- Be thoughtful and accurate in your classification. Default to the listed categories whenever possible.
- Add "=== report over ===" at the end of the report.
< example math problem >
** Question **:
Let $ n (\ ge2) $ be a positive integer. Find the minimum $ m $, so that there exists $x_ {ij}(1\ le i , j \ le n) $ satisfying:
(1) For every $1 \ le i , j \ le n, x_ {ij}= max \{x_ {i1}, x_ {i2},..., x_ {ij}\} $ or $ x_ {ij}= max \{x_ {1 j}, x_ {2 j},..., x_ {ij}\}. $
(2) For every $1 \ le i \ le n$, there are at most $m$ indices $k$ with $x_ {ik}= max \{x_ {i1}, x_ {i2},..., x_ {ik}\}. $
(3) For every $1 \ le j \ le n$, there are at most $m$ indices $k$ with $x_ {kj}= max \{x_ {1 j}, x_ {2 j},..., x_ {kj}\}. $
</ example math problem >
## Summarization
The problem involves an \( n \ times n \) matrix where each element \( x_ {ij} \) is constrained by the maximum values in its respective row or column. The goal is to determine the minimum possible value of \( m \) such that, for each row and column, the number of indices attaining the maximum value is limited to at most \( m \). This problem requires understanding matrix properties, maximum functions, and combinatorial constraints on structured numerical arrangements.
## Math domains
Algebra
=== report over ===
</ example math problem >
** Question **:
In an acute scalene triangle $ABC$, points $D, E, F$ lie on sides $BC, CA, AB$, respectively, such that $AD \ perp BC, BE \ perp CA, CF \ perp AB$. Altitudes $AD, BE, CF$ meet at orthocenter $H$. Points $P$ and $Q$ lie on segment $EF$ such that $AP \ perp EF$ and $HQ \ perp EF$. Lines $DP$ and $QH$ intersect at point $R$. Compute $HQ / HR$.
</ example math problem >
## Summarization
The problem involves an acute scalene triangle with three perpendicular cevians intersecting at the orthocenter. Additional perpendicular constructions are made from specific points on segment \( EF \), leading to an intersection at point \( R \). The goal is to determine the ratio \( HQ / HR \), requiring knowledge of triangle geometry, perpendicularity, segment ratios, and properties of the orthocenter.
## Math domains
Geometry
=== report over ===
</ example math problem >
** Question **:
Three cards are dealt at random from a standard deck of 52 cards. What is the probability that the first card is a 4, the second card is a $ \ clubsuit$, and the third card is a 2?
</ example math problem >
## Summarization
This problem involves calculating the probability of a specific sequence of events when drawing three cards from a standard 52- card deck without replacement. It requires understanding conditional probability, the basic rules of counting, and how probabilities change as cards are removed from the deck.
## Math domains
Counting & Probability
=== report over ===
</ example math problem >
** Question **:
Let $x$ and $y$ be real numbers such that $3x + 2 y \ le 7 $ and $2x + 4 y \ le 8. $ Find the largest possible value of $x + y. $
</ example math problem >
## Summarization
This problem involves optimizing a linear expression \( x + y \) subject to a system of linear inequalities. It requires understanding of linear programming concepts, such as identifying feasible regions, analyzing boundary points, and determining the maximum value of an objective function within that region.
## Math domains
Intermediate Algebra
=== report over ===
</ example math problem >
** Question **:
Solve
\[\ arccos 2 x - \ arccos x = \ frac {\ pi}{3}.\] Enter all the solutions, separated by commas.
</ example math problem >
## Summarization
This problem requires solving a trigonometric equation involving inverse cosine functions. The equation relates two expressions with \( \ arccos (2 x) \) and \( \ arccos (x) \), and asks for all real solutions satisfying the given identity. It involves knowledge of inverse trigonometric functions, their domains, and properties, as well as algebraic manipulation.
## Math domains
Precalculus
=== report over ===
</ example math problem >
** Question **:
What perfect - square integer is closest to 273?
</ example math problem >
## Summarization
The problem asks for the perfect square integer closest to 273. This involves understanding the distribution and properties of perfect squares, and comparing them with a given integer. It relies on number - theoretic reasoning related to squares of integers and their proximity to a target number.
## Math domains
Number Theory
=== report over ===
</ example math problem >
Voldemort bought $6.\ overline {6} $ ounces of ice cream at an ice cream shop. Each ounce cost $ \ $0.60. $ How much money, in dollars, did he have to pay?
</ example math problem >
## Summarization
The problem involves multiplying a repeating decimal, \( 6.\ overline {6} \), by a fixed unit price, \ $0.60, to find the total cost in dollars. This requires converting a repeating decimal into a fraction or using decimal multiplication, both of which are foundational arithmetic skills.
## Math domains
Prealgebra
=== report over ===
< math problem >
{problem}
</ math problem >
### J.2 Prompt for Concepts Extraction
Listing 2: Prompt template for extracting internal concepts from a mathematical question.
⬇
As an expert in educational assessment, analyze this problem:
< problem >
{problem}
</ problem >
Break down and identify {num_concepts} foundational concepts being tested. List these knowledge points that:
- Are core curriculum concepts typically taught in standard courses,
- Are precise and measurable (not vague like " understanding math "),
- Are essential building blocks needed to solve this problem,
- Represent fundamental principles rather than problem - specific techniques.
Think through your analysis step by step, then format your response as a Python code snippet containing a list of {num_concepts} strings, where each string clearly describes one fundamental knowledge point.
### J.3 Prompt for Problem Synthesis
Listing 3: Prompt template for synthesizing math problems from specified concepts, difficulty levels, and pre-defined mathematical categories. Following [73], the difficulty levels are consistently set to the competition level to prevent the generation of overly simple questions.
⬇
### Given a set of foundational mathematical concepts, a mathematical domain, and a specified difficulty level, generate a well - constructed question that meaningfully integrates multiple listed concepts and reflects the stated level of complexity.
### Foundational Concepts:
{concepts}
### Target Difficulty Level:
{level}
### Mathematical Domain:
{domain}
### Instructions:
1. Begin by outlining which concepts you will combine and how you plan to structure the question.
2. Ensure that the question is coherent, relevant, and appropriately challenging for the specified level.
3. The question must be a single standalone problem, not split into multiple sub - questions.
4. Do not generate proof - based, multiple - choice, or true / false questions.
5. The answer to the question should be expressible using numbers and mathematical symbols.
6. Provide a final version of the question that is polished and ready for use.
### Output Format:
- First, provide your brief outline and planning for the question design.
- Then, present only the final version of the question in the following format:
‘‘‘
[Your developed question here]
’’’
Do not include any placeholder, explanatory text, hints, or solutions to the question in the output block
### J.4 Prompt for Quality Evaluation
Listing 4: The quality evaluation prompt utilized to filter out low-quality math problems. Following prior work [73], we assess synthetic problems based on five criteria: format, factual accuracy, difficulty alignment, concept coverage, and solvability. Each problem is then assigned one of three quality levels: ‘bad’, ‘acceptable’, or ‘perfect’.
⬇
As a critical expert in educational problem design, evaluate the following problem components:
=== GIVEN MATERIALS ===
1. Problem & Design Rationale:
{rationale_and_problem}
(The rationale describes the authorâs thinking process and justification in designing this problem)
2. Foundational Concepts:
{concepts}
3. Target Difficulty Level:
{level}
=== EVALUATION CRITERIA ===
Rate each criterion as: [Perfect | Acceptable | Bad]
1. FORMAT
- Verify correct implementation of markup tags:
<! â BEGIN RATIONALE â > [design thinking process] <! â END RATIONALE â >
<! â BEGIN PROBLEM â > [problem] <! â END PROBLEM â >
2. FACTUAL ACCURACY
- Check for any incorrect or misleading information in both problem and rationale
- Verify mathematical, scientific, or logical consistency
3. DIFFICULTY ALIGNMENT
- Assess if problem complexity matches the specified difficulty level
- Evaluate if cognitive demands align with target level
4. CONCEPT COVERAGE
- Evaluate how well the problem incorporates the given foundational concepts
- Check for missing concept applications
5. SOLVABILITY
- Verify if the problem has at least one valid solution
- Check if all necessary information for solving is provided
=== RESPONSE FORMAT ===
For each criterion, provide:
1. Rating: [Perfect | Acceptable | Bad]
2. Justification: Clear explanation for the rating
=== FINAL VERDICT ===
After providing all criterion evaluations, conclude your response with:
‘ Final Judgement: [verdict]’
where verdict must be one of:
- ‘ perfect ’ (if both FACTUAL ACCURACY and SOLVABILITY are Perfect, at least two other
criteria are Perfect, and no Bad ratings)
- ‘ acceptable ’ (if no Bad ratings and doesnât qualify for perfect)
- ‘ bad ’ (if ANY Bad ratings)
Note: The ‘ Final Judgement: [verdict]’ line must be the final line of your response.