# Athena: Enhancing Multimodal Reasoning with Data-efficient Process Reward Models
> Work done during the internship at AMD.Corresponding authors.
## Abstract
We present Athena-PRM, a multimodal process reward model (PRM) designed to evaluate the reward score for each step in solving complex reasoning problems. Developing high-performance PRMs typically demands significant time and financial investment, primarily due to the necessity for step-level annotations of reasoning steps. Conventional automated labeling methods, such as Monte Carlo estimation, often produce noisy labels and incur substantial computational costs. To efficiently generate high-quality process-labeled data, we propose leveraging prediction consistency between weak and strong completers as a criterion for identifying reliable process labels. Remarkably, Athena-PRM demonstrates outstanding effectiveness across various scenarios and benchmarks with just 5,000 samples. Furthermore, we also develop two effective strategies to improve the performance of PRMs: ORM initialization and up-sampling for negative data. We validate our approach in three specific scenarios: verification for test time scaling, direct evaluation of reasoning step correctness, and reward ranked fine-tuning. Our Athena-PRM consistently achieves superior performance across multiple benchmarks and scenarios. Notably, when using Qwen2.5-VL-7B as the policy model, Athena-PRM enhances performance by 10.2 points on WeMath and 7.1 points on MathVista for test time scaling. Furthermore, Athena-PRM sets the state-of-the-art (SoTA) results in VisualProcessBench and outperforms the previous SoTA by 3.9 F1-score, showcasing its robust capability to accurately assess the correctness of the reasoning step. Additionally, utilizing Athena-PRM as the reward model, we develop Athena-7B with reward ranked fine-tuning and outperforms baseline with a significant margin on five benchmarks.
## 1 Introduction
In recent years, Large Language Models (LLMs) [5, 1, 52, 30, 61] have achieved remarkable success in natural language processing. Building on this, Multimodal Large Language Models (MLLMs) [31, 26, 3, 8] have made significant strides in various vision-language tasks, such as visual question answering [2, 39] and chart understanding [38]. Despite their impressive performance, solving complex tasks involving mathematical and multi-step reasoning remains challenging.
To enhance reasoning capabilities, several approaches have been explored, including fine-tuning on long chain-of-thought (CoT) data [59, 40], offline preference optimization [56, 43], and online reinforcement learning [47, 17, 21, 51]. Another promising avenue is test time scaling (TTS), which involves generating multiple responses from a policy model and selecting the most consistent answer [58] or the solution with the highest reward using reward models [9, 28, 53, 50, 46, 55].
Reward models for TTS mainly include two types: outcome reward models (ORMs) [9] and process reward models (PRMs) [28]. ORMs evaluate the reward score for a given question and its solution, whereas PRMs provide reward scores for each intermediate reasoning step, offering fine-grained feedback. PRMs typically deliver superior performance and better out-of-distribution generalization [28]. However, obtaining high-quality data with process labels poses significant challenges. PRM800K [28] involves collecting 800K labeled steps through human annotations, which is time-consuming and requires skilled annotators, particularly for complex multi-step reasoning and mathematical tasks. Math-Shepherd [55] proposes an automated labeling method using Monte Carlo (MC) estimation. It defines the quality of an intermediate step as its potential to reach the correct answer. MC estimation for step-level labels is typically performed by sampling numerous reasoning trajectories using a language model, referred to as the completer, to estimate the probability of arriving at the correct answer. However, this approach involves significant computational overhead. Besides, another shortcoming of MC-based estimation methods is that estimated step-level labels are inevitably noisy.
We aim to address the above challenges: reducing computational costs and mitigating noisy step labels. We first find that the accuracy of step labels estimated by MC-based methods is influenced by the reasoning capability of the completer. A strong completer can arrive at the correct answer despite incorrect intermediate steps as shown in Figure 1, whereas a weak completer may struggle even with correct intermediate steps. The estimation of MC-based methods is biased toward the completers we use. However, the correctness of the intermediate step should not depend on the completer. Based on this insight, we propose using both weak and strong completers to estimate step labels, retaining only those steps where labels generated by both completers are consistent to remove the bias caused by completers. This approach improves the quality of the step label. Empirical results demonstrate that a small set of high-quality labels ( $≈$ 5K) achieves impressive performance compared to large-scale data ( $≈$ 300K) labeled by vanilla MC-based estimation [55]. In addition, our approach requires only 1/45 of the GPU hours for data synthesis and 1/60 of the GPU hours for reward model training, significantly lowering computational costs.
<details>
<summary>x1.png Details</summary>

### Visual Description
## Diagram: Mathematical Problem Snippet with Correct/Incorrect Indicators
### Overview
The image displays a partial view of what appears to be a mathematical problem or solution interface. The central visual elements are a hand-drawn style green checkmark (✓) and a red cross (✗), positioned side-by-side in the middle of a white background. To the right, three vertically stacked, color-coded text boxes contain fragments of mathematical text, which are cut off on the left side, indicating this is a cropped section of a larger document or screen.
### Components
* **Central Symbols:**
* **Green Checkmark (✓):** Located center-left. Drawn with a brush-stroke texture. Typically signifies a correct answer, step, or condition.
* **Red Cross (✗):** Located center-right, adjacent to the checkmark. Also drawn with a brush-stroke texture. Typically signifies an incorrect answer, step, or condition.
* **Text Boxes (Right Side):** Three rounded rectangular boxes are aligned vertically along the right edge of the image.
1. **Top Box (Yellow Background):** Contains mathematical text.
2. **Middle Box (Light Blue Background):** Contains a text fragment.
3. **Bottom Box (Light Orange/Peach Background):** Contains a text fragment.
### Content Details
The text within the boxes is incomplete due to cropping. The following fragments are visible:
* **Yellow Box (Top):**
* Line 1: `y² = 133.`
* Line 2: `> x - y, we` (The ">" symbol is red)
* Line 3: `13 × 10, so` (The "×" symbol is red)
* **Blue Box (Middle):**
* `two perfect`
* **Orange Box (Bottom):**
* `equations`
* `there are`
**Language:** All visible text is in English. Mathematical notation (e.g., `y²`, `×`, `>`) is used.
### Key Observations
1. **Truncated Context:** The primary observation is that the image is a fragment. The text in the colored boxes is cut off, preventing a full understanding of the mathematical problem or statement.
2. **Symbolic Contrast:** The prominent green checkmark and red cross are universal symbols for "correct" and "incorrect," suggesting the image is from an educational, testing, or verification context.
3. **Color-Coded Information:** The use of distinct background colors (yellow, blue, orange) for the text boxes likely serves to categorize different parts of the problem, such as given conditions, steps, or conclusions.
4. **Mathematical Content:** The visible text includes an equation (`y² = 133`), an inequality or comparison (`> x - y`), and an arithmetic expression (`13 × 10`). The phrase "two perfect" could relate to "perfect squares" or "perfect numbers."
### Interpretation
This image is a snapshot from a mathematical workflow, likely an online learning platform, digital textbook, or problem-solving software. The checkmark and cross are probably interactive elements or feedback indicators. The user may have been presented with a problem involving the equation `y² = 133` and a condition involving `x - y`. The step `13 × 10` might be part of a calculation or estimation (e.g., since √133 is between 11 and 12, 13 × 10 = 130 is a nearby round number).
The fragments "two perfect" and "equations there are" hint at the broader problem context. It could be asking to find two perfect squares whose difference is 133, or to solve a system of two equations. The color-coding helps segment the problem's logical flow: the yellow box may state the core equation and a derived inequality, the blue box might introduce a key concept ("perfect squares"), and the orange box could be leading to a conclusion about the number of solutions.
**In summary, the image conveys a moment of evaluation (correct vs. incorrect) within an incomplete mathematical problem focused on squares, inequalities, and possibly systems of equations.** To fully reconstruct the problem, the complete text from the colored boxes and any surrounding interface elements would be necessary.
</details>
Figure 1: Illustration of different completers under the same question and solution steps. Even if given wrong intermediate steps, the strong completer stills reach the final answer while the weak completer fails. We omitted some intermediate steps in the figure for simplicity.
After acquiring high-quality datasets, we explore two effective strategies for training PRMs: initialization from ORMs and up-sampling data with negative labels. PRMs are typically fine-tuned from pre-trained foundation models, such as LLaMA-3.1-8B-Instruct [16] in RLHF-workflow [13]. Previous studies indicate that ORMs possess some ability to assess intermediate step correctness through confidence variation [33] or parameterization [10, 63]. Inspired by this, we find that initializing PRMs from ORMs significantly boosts performance, as ORMs trained on large-scale response-level data serve as pre-training with weak supervision. And PRMs can be considered fine-tuning on high-quality, fine-grained step-level data. Additionally, we show that label imbalance exists in process-labeled solutions and we propose to up-sample data with negative step labels to address this.
Building on these methodologies, we develop our outcome reward model Athena-ORM and process reward model Athena-PRM. Leveraging Athena-PRM, we introduce Athena-7B with reward ranked fine-tuning. We validate our approach across three scenarios: 1) test time scaling [50]: where Athena-PRM ranks multiple outputs generated by policies under the Best-of-N evaluation; 2) direct evaluation of the correctness of reasoning steps using Athena-PRM; 3) reward ranked fine-tuning [12]: where Athena-PRM ranks outputs sampled from the current policy, utilizing the highest reward response for policy model fine-tuning. In the TTS scenario, we evaluate Athena-PRM on seven multimodal math and reasoning benchmarks with three different policy models ranging from 7B to 72B, demonstrating significant improvements in reasoning abilities. For instance, on the WeMath benchmark [44], Athena-PRM enhances the zero-shot baseline by 10.2 points using Qwen2.5-VL-7B [3] as the policy model. Furthermore, Athena-PRM excels in text-only benchmarks, achieving an 8.9 points improvement on a challenging math benchmark [18] with Mistral-8B. To assess its ability to judge intermediate reasoning step correctness, Athena-PRM is evaluated on the VisualProcessBench [57], showcasing strong performance and outperforming VisualPRM-8B [57], an open-source multimodal PRM, and proprietary models as judge. In the reward ranked fine-tuning scenario, our fine-tuned model Athena-7B, based on Qwen2.5-VL-7B [3], significantly enhances the policy model’s reasoning capabilities across seven math and reasoning benchmarks.
Our contributions are summarized as follows:
- We propose using prediction consistency between weak and strong completers to filter noisy process labels, enhancing the quality of the automated-labeled process data. The high-quality process labeled data shows surprising data efficiency for training PRMs.
- We introduce two effective strategies to improve the performance of PRMs: ORM initialization and negative data up-sampling.
- We develop our reward models Athena-ORM and Athena-PRM, and evaluate them under the Best-of-N setting on nine math and reasoning benchmarks across various model sizes and families, demonstrating the effectiveness of our approach. Moreover, Athena-PRM achieves state-of-the-art (SoTA) performance in assessing the correctness of intermediate steps directly on the VisualProcessBench [57].
- Leveraging Athena-PRM, we introduce Athena-7B, a MLLM with exceptional capabilities fine-tuned using reward ranked fine-tuning. Extensive experiments highlight the superiority of Athena-7B across diverse benchmarks.
## 2 Method
In this section, we first introduce basic concepts, including ORMs and PRMs in Sec. 2.1. Next, we present our method for constructing a high-quality PRM training set, along with practical training strategies to improve PRM performance in Sec. 2.2. The data collection process for training is detailed in Sec. 2.3. Finally, we discuss three application scenarios of PRMs in Sec. 2.4.
### 2.1 Reward Models for Mathematical Problem
ORMs. Given a mathematical problem $x$ with golden answer $y^*$ and its solution $a$ generated by policy $π$ , i.e., $a∼π≤ft(·\mid x\right)$ , ORMs assign a reward $r≤ft(x,y,y^*\right)$ to the final answer $y$ of $a$ to reflect the correctness of the solution. To train ORMs, we take inputs as $(x,y)$ and predict correctness $δ(y,y^*)$ of prediction with following loss function:
$$
L_ORM=δ≤ft(y,y^*\right)·\log r≤ft(x,y,y^*\right)+
≤ft(1-δ≤ft(y,y^*\right)\right)·\log≤ft(1-r≤ft(x,y,y^*
\right)\right), \tag{1}
$$
where $δ≤ft(y,y^*\right)=1$ if $y=y^*$ , otherwise $δ≤ft(y,y^*\right)=0$ .
PRMs. Different from ORMs, PRMs aim to predict the correctness of each step in the solution. Specifically, we sample response $a∼π≤ft(·\mid x\right)$ . A response $a$ usually consists of multiple reasoning steps separated by a delimiter (e.g. \n\n), a.k.a $a=(a_1,a_2,\dots,a_K)$ when $K$ is the number of reasoning steps. To predict the correctness of each step, we train PRMs with the cross-entropy loss for each step in the solution. Formally, we get the following loss function:
$$
L_PRM=∑_i=1^Kδ_i·\log r≤ft(x,a_i\right)+
≤ft(1-δ_i\right)·\log≤ft(1-r≤ft(x,a_i\right)\right), \tag{2}
$$
where $δ_i=1$ if the step $a_i$ is correct, otherwise $δ_i=0$ .
### 2.2 Automated Data Scaling of PRMs
Compared with ORMs, PRMs usually achieve better performance and exhibit stronger out-of-distribution generalization [28]. However, collecting high-quality data with process labels is challenging. Human annotation provides accurate supervision signals [28], but it requires expensive human labeling and difficult to scale up. Math-Shepherd [55] proposes to use a Monte Carlo (MC) sampling method to estimate the correctness of each step without human supervision. Specifically, to estimate the correctness of step $a_i$ , we use a completer $φ$ to finalize the reasoning process from step $a_i$ , and get the final answer $y$ . We repeat sampling $T$ times and get corresponding answers $Y=\{y_j\}_j=1^T$ . There are two ways to estimate the correctness of $a_i$ : soft estimation and hard estimation.
For soft estimation, we assume that the frequency of getting the correct answer could dictate the quality of a step:
$$
δ_i^soft=\frac{∑_j=1^TI(y_j=y^*)}{T}. \tag{3}
$$
For hard estimation, we assume that the correct answer is right when the step could reach the answer in $T$ samples:
$$
δ_i^hard=\begin{cases}1&if ∃ y_j∈Y,y_j=y
^*,\\
0&otherwise.\end{cases} \tag{4}
$$
In this paper, we mainly discuss the hard estimation for PRMs because it allows us to use standard language modeling loss to train PRMs and eliminates the adjustments of the training pipeline.
MC-based estimation methods provide an automated and scalable labeling strategy for intermediate reasoning steps. However, automatically labeled data often contain incorrect labels, and MC-based methods typically incur substantial computational costs due to extensive sampling requirements. For instance, when processing a solution $a$ with $K$ steps, the completer $φ$ must generate $T× K$ solutions, which produces $T× K$ times computation cost compared with ORMs.
To enhance the accuracy of the labeling process and reduce the computational burden of data synthesis, our central approach is to utilize a smaller set of high-quality data with process labels. We improve the quality of automatically labeled process labels by introducing consistency filtering between weak and strong completers. The rationale is straightforward: the results of hard estimation depend on the number of samples $T$ , the difficulty of the problem $x$ , and the ability of the completer $φ$ . A strong completer can arrive at the correct answer even when provided with incorrect steps, as shown in Figure 1, whereas a weak completer struggles to find the final answer even when given correct steps. We aim to enhance the quality of process labels through prediction consistency between weak and strong completers. Specifically, we only use steps whose assigned labels are consistent between different completers.
To validate our method, we conducted a simple experiment using the PRM800K dataset [28]. We employed Mistral-7B-Instruct [22] as the weak completer ( $φ_w$ ) and Qwen2.5-72B-Instruct [61] as the strong completer ( $φ_s$ ), setting the number of samples $T=8$ for MC-based estimation. We randomly sampled 50 queries and reported the accuracy of estimated process labels:
| | Weak Completer $φ_w$ | Strong Completer $φ_s$ | Consistency Filter |
| --- | --- | --- | --- |
| Accuracy (%) | 78.2 | 83.4 | 94.1 |
Our experiments show that label quality improves significantly after applying the consistency filter. Empirically, we demonstrate that a small number of high-quality labels is sufficient to achieve superior performance, thereby reducing computational costs compared to the vanilla MC-based estimation [55]. Results of more strategies and combination of completers are provided in Appendix A.1.
Additional strategies for PRMs. We offer two strategies for enhancing the performance of PRMs: initialization from ORMs and negative data up-sampling. First, initializing PRMs with ORMs trained on large-scale sample-level annotated data improves performance. It is shown that initialization from ORMs will improve performance with different datasets, see verification in Table 5. Previous work indicates that ORMs possess a certain capacity to assess the correctness of intermediate steps [10, 33, 63]. We empirically show that PRMs benefit from a few high-quality examples when initialized with ORMs. Large-scale sample-level annotation data provides weaker supervision, with outcome supervision acting as a simplified form of process supervision. Training ORMs on large-scale sample-level annotations serves as a “pre-training”, while training PRMs from pre-trained ORMs acts as“fine-tuning” with high-quality process-level annotated data. Secondly, our findings reveal that label imbalance is prevalent in most process-labeled datasets, such as PRM800K [28] and our synthetic data, where correct steps are more common than errors. We provide a detailed distribution of process labels in Table 9. Empirically, slightly up-sampling data with negative labels improves performance with minimal additional computation.
### 2.3 Data Collection
To construct a diverse and high-quality dataset, we first gather data from various public multimodal and text-only datasets. For multimodal datasets, we collect from MathV360k [48], UniGeo [7], Geometry3k [34], CLEVR-Math [29], ScienceQA [35], GeomVerse [24], GeoQA-plus [6], and DocVQA [39]. For text-only datasets, we utilize GSM8K [9], MATH [18], and NuminaMath-1.5. https://huggingface.co/datasets/AI-MO/NuminaMath-1.5 If the original dataset includes different splits, we use only the training portion to prevent test set contamination. We remove all judgment questions and convert multiple-choice questions to open-ended ones to deter policy models from “guessing” answers. Then, for each query, we sample 8 responses from the policy model. To ensure dataset diversity, we employ multiple models as policies, including InternVL2.5-8B/78B [8], Qwen2.5-VL-7/72B-Instruct [3], LLaVA-OneVision-7B/72B [26] for multimodal datasets, and Qwen2.5-7/72B-Instruct [61] for text-only datasets.
Next, we apply carefully designed filtering rules to all responses. We exclude responses with too many or too few tokens and eliminate those exhibiting repetitive patterns. We employ $n$ -gram deduplication to remove similar responses and enhance diversity. Ultimately, we obtain approximately 600K queries with corresponding responses. We parse answers from responses and assign correctness labels of 0 or 1 to each query-response pair. We refer to this dataset as Athena-600K and employ it to train our outcome reward model Athena-ORM.
For training PRMs, we generate process labels using the proposed method introduced in Sec. 2.2. We use Qwen2.5-VL-7B [3] as the weak completer ( $φ_w$ ) and Qwen2.5-VL-72B [3] as the strong completer ( $φ_s$ ). Finally, we collect approximately 5K samples for training our process reward model Athena-PRM. We also compare with PRMs trained using approximately 300K samples estimated by the vanilla MC-based method outlined in [55]. We denote these datasets as Athena-5K and MC-300K, respectively, and compare their performance and computational cost in Sec. 3.4.
### 2.4 Application
Following reward model training, we assess the performance of ORMs and PRMs in three scenarios: test time scaling [50], direct judgment, and reward ranked fine-tuning [12].
Verification for test time scaling. We adopt a Best-of-N evaluation paradigm. Specifically, given a problem $x$ in the test set, we sample $N$ solutions from the policy $π$ . All solutions are scored using a reward model, and we choose the solution with the highest score. For ORMs, we directly use the outputs from ORMs as the reward of solutions. For PRMs, the minimum reward across all steps is used to rank all solutions. We test different choices, including the reward from the last step, the minimum reward across all steps, or the product of the rewards from all steps, as the reward for solutions in Appendix A.3.
Direct judgment for reasoning steps. Besides verification at test time under the Best-of-N setting, Athena-PRM can also be used to directly identify erroneous steps in the mathematical reasoning process. Given a solution $a$ with $K$ steps as input, Athena-PRM outputs the correctness score $\{δ_i\}_i=1^K$ for each step $\{a_i\}_i=1^K$ in a single forward pass.
Response ranking for reward ranked fine-tuning. We explore the use of PRMs for data synthesis in reward ranked fine-tuning [12, 64, 49, 66]. Using the current policy $π$ , we generate $M=8$ solutions for an input problem $x$ . Subsequently, we filter out solutions with incorrect answers and apply deduplication to remove highly similar responses, enhancing the diversity of the remaining solutions. We retain queries where 2 to 6 out of 8 responses are correct, excluding those with too few or too many correct answers, as such cases are either too easy or too challenging for the current policy $π$ . Following this filtering step, we use Athena-PRM to score all solutions for each query and select the solution with the highest reward as the corresponding label. The policy $π$ is fine-tuned using the synthetic data generated as described above.
## 3 Experiments
Table 1: Results on seven multimodal reasoning benchmarks under Best-of-N (N=8) evaluation. $†$ denotes that the results are from [57]. We mark our results and highlight the best result.
| | WeMath | MathVista | MathVision | MathVerse | DynaMath | MMMU | LogicVista |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Qwen2.5-VL-7B [3] | 36.2 | 68.1 | 25.4 | 41.1 | 21.8 | 58.0 | 47.9 |
| Self-consistency [58] | 44.7 | 71.6 | 28.6 | 43.7 | 22.9 | 60.1 | 49.5 |
| $VisualPRM-8B^†$ [57] | 39.8 | 70.3 | 31.3 | 44.3 | 23.0 | 58.6 | 48.3 |
| Athena-ORM | 45.1 | 72.8 | 29.8 | 44.1 | 23.1 | 62.7 | 51.3 |
| Athena-PRM | 46.4 | 75.2 | 32.5 | 46.3 | 23.4 | 63.8 | 53.0 |
| InternVL2.5-8B [8] | 23.5 | 64.5 | 17.0 | 22.8 | 9.4 | 56.2 | 36.0 |
| Self-consistency [58] | 28.4 | 66.1 | 21.1 | 24.7 | 13.8 | 57.8 | 40.2 |
| $VisualPRM-8B^†$ [57] | 36.5 | 68.5 | 25.7 | 35.8 | 18.0 | 60.2 | 43.8 |
| Athena-ORM | 28.6 | 66.9 | 22.0 | 25.8 | 15.2 | 59.1 | 40.8 |
| Athena-PRM | 30.1 | 71.4 | 23.4 | 26.1 | 18.7 | 60.3 | 44.4 |
| Qwen2.5-VL-72B [3] | 49.1 | 74.2 | 39.3 | 47.3 | 35.9 | 70.2 | 55.7 |
| Self-consistency [58] | 54.8 | 77.0 | 43.1 | 50.8 | 37.6 | 71.1 | 59.6 |
| Athena-ORM | 55.6 | 77.8 | 43.0 | 51.2 | 39.6 | 72.3 | 60.1 |
| Athena-PRM | 58.7 | 79.1 | 44.8 | 54.6 | 42.5 | 75.8 | 60.9 |
Table 2: Results on text-only math benchmarks under Best-of-N (N=8) evaluation. $†$ denotes that the results are from [57]. We mark our results and highlight the best result.
(a) Qwen2.5-7B
| | GSM8K | MATH |
| --- | --- | --- |
| Qwen2.5-7B [61] | 91.6 | 75.5 |
| Self-consistency [58] | 93.4 | 79.9 |
| $VisualPRM-8B^†$ [57] | 94.5 | 81.6 |
| Athena-ORM | 94.0 | 81.1 |
| Athena-PRM | 94.8 | 82.4 |
(b) Ministral-8B
| | GSM8K | MATH |
| --- | --- | --- |
| Ministral-8B | 85.6 | 54.5 |
| Self-consistency [58] | 90.7 | 62.0 |
| Athena-ORM | 91.4 | 63.2 |
| Athena-PRM | 93.1 | 65.4 |
(c) Qwen2.5-72B
| | GSM8K | MATH |
| --- | --- | --- |
| Qwen2.5-72B [61] | 95.8 | 83.1 |
| Self-consistency [58] | 96.0 | 86.0 |
| $VisualPRM-8B^†$ [57] | 96.5 | 85.2 |
| Athena-ORM | 96.0 | 86.2 |
| Athena-PRM | 97.0 | 87.4 |
To comprehensively evaluate the proposed method, we assess Athena-ORM and Athena-PRM under the Best-of-N setting on seven multimodal benchmarks and two text-only benchmarks in Sec. 3.1. Furthermore, we evaluate Athena-PRM on VisualProcessBench, comparing its performance with MLLMs as judges and a recent open-source multimodal PRM, VisualPRM-8B [57], as described in Sec. 3.2. We assess the capability of Athena-7B on multimodal math and reasoning tasks in Sec. 3.3. To validate the effectiveness of our designs for Athena-PRM, an in-depth analysis is provided in Sec. 3.4.
### 3.1 Best-of-N Evaluation
Benchmarks. We evaluate Athena-ORM and Athena-PRM across multiple multimodal mathematical and logical reasoning benchmarks, including MathVista [36], MathVision [54], MathVerse [68], WeMath [44], DynaMath [70], LogicVista [60], and MMMU [65]. To validate the effectiveness of Athena-ORM and Athena-PRM in the text-only scenario, we conduct experiments on the GSM8K [9] and MATH [18] under the BoN settings. Further details can be found in Appendix A.2.
Settings. We employ Athena-ORM and Athena-PRM as the reward model for BoN evaluation, sampling $N=8$ solutions for every problem by default. For decoding, we set the temperature to 0.8 and use nucleus sampling [20] with top- $p$ set to 0.9, and report the average of five runtimes. For multimodal benchmarks, we choose Qwen2.5-VL-7B/72B [3] and InternVL2.5-8B [8] as policy models. All models used in this paper are “instruct” version. For simplicity, we ignore “instruct” in the text. For text-only datasets, we choose Qwen2.5-7/72B [61] and Ministral-8B https://huggingface.co/mistralai/Ministral-8B-Instruct-2410 as policy models. Zero-shot and self-consistency [58] serve as our baselines, alongside a recent public multimodal process reward model, VisualPRM-8B [57].
Training details. To train ORMs and PRMs, we fine-tune Qwen2.5-VL-7B on our dataset as introduced in Sec. 2.3. We use the AdamW optimizer [32] with the weight decay as 0 and set the learning rate as $1e^-6$ with cosine decay. We train all models with one epoch and set the global batch size to 64. We use DeepSpeed with zero2 [45] and flash-attention-2 [11] to improve training efficiency. To train ORMs, a new special token <step> is added at the end of solutions for ORMs training. This makes a consistent formulation for ORMs and PRMs. For PRMs, <step> is added to separate all reasoning steps and assign labels to corresponding tokens. We use “ $+$ ” and “ $-$ ” as labels to denote the correctness of each step. We use $8×$ AMD-MI250 GPUs for training and data synthesis.
Results. Table 1 demonstrates that Athena-ORM and Athena-PRM generally enhance the reasoning performance of MLLMs across policy models of different sizes and benchmarks. Notably, Athena-PRM achieves a +10.2 points improvement on the WeMath dataset with Qwen2.5-VL-7B [3] as the policy model, compared to the zero-shot baseline. ORMs also exhibit general improvement across all benchmarks and policy models, although some gains are limited, such as +0.4 points on MathVerse with Qwen2.5-VL-72B [3]. In contrast, PRMs consistently show substantial performance gains over ORMs, illustrating the benefits of fine-grained rewards in test-time scaling.
Table 2 highlights that Athena-PRM enhances reasoning abilities for text-only inputs in both the Qwen2.5 series and Ministral-8B models. Specifically, Athena-PRM achieves +9.9 points improvement for Ministral-8B on the challenging MATH [18] benchmark, demonstrating its effectiveness in text-only scenarios.
Table 3: Results on VisualProcessBench. We report the F1-score on different dataset and macro F1 in overall. We highlight the best result across all models.
| | MMMU | MathVision | MathVerse | DynaMath | WeMath | Overall |
| --- | --- | --- | --- | --- | --- | --- |
| Random Guessing | 50.0 | 50.0 | 50.0 | 50.0 | 50.0 | 50.0 |
| Proprietary Models as Judge | | | | | | |
| GPT-4o-mini [41] | 53.6 | 58.9 | 57.1 | 56.7 | 58.5 | 57.9 |
| GPT-4o [41] | 56.3 | 60.2 | 59.7 | 59.0 | 63.3 | 60.3 |
| Gemini-2.0-Flash [15] | 58.5 | 60.1 | 62.8 | 66.7 | 58.7 | 62.3 |
| Open-source Models as Judge | | | | | | |
| MiniCPM-V2.6-8B [62] | 44.9 | 50.9 | 58.9 | 46.7 | 57.4 | 50.4 |
| LLaVA-OV-7B [26] | 45.7 | 43.0 | 42.2 | 44.7 | 52.5 | 44.4 |
| LLaVA-OV-72B [26] | 46.1 | 48.4 | 53.0 | 57.0 | 57.3 | 52.3 |
| Qwen2.5-VL-7B [3] | 53.1 | 51.8 | 47.8 | 51.3 | 54.2 | 51.0 |
| Qwen2.5-VL-72B [3] | 59.2 | 59.0 | 59.7 | 62.9 | 62.3 | 60.5 |
| InternVL2.5-8B [8] | 47.1 | 45.5 | 47.8 | 50.3 | 50.8 | 48.0 |
| InternVL2.5-26B [8] | 48.8 | 47.4 | 49.2 | 50.4 | 51.4 | 49.2 |
| InternVL2.5-38B [8] | 51.5 | 48.4 | 50.9 | 51.8 | 52.5 | 50.8 |
| InternVL2.5-78B [8] | 52.0 | 51.7 | 53.7 | 50.8 | 52.5 | 52.6 |
| Multimodal PRMs | | | | | | |
| VisualPRM-8B [57] | 58.5 | 62.1 | 61.0 | 62.7 | 61.8 | 62.0 |
| Athena-PRM | 74.1 | 61.2 | 60.7 | 72.7 | 73.8 | 65.9 |
### 3.2 Evaluation on Direct Judgment of Steps
Setup. In addition to Best-of-N evaluation, we assess Athena-PRM on VisualProcessBench [57], comparing it with general MLLMs and VisualPRM-8B [57]. VisualProcessBench [57] aims to evaluate the ability to directly judge the correctness of each step. For MLLMs, we prompt the model to analyze and judge the correctness of each step. We report the F1-score for every subset and the micro-F1 score overall.
Results. The results of VisualProcessBench are presented in Table 3. It is evident that current general open-source MLLMs struggle to judge the correctness of reasoning steps, with most $\scriptstyle∼$ 7B models performing no better than the random guessing baseline. Conversely, multimodal process reward models achieve superior performance, rivaling proprietary models. Notably, our process reward model Athena-PRM, with only 7B parameters, achieves a +3.9 points improvement compared to VisualPRM-8B [57], even outperforming proprietary models as judges.
### 3.3 Evaluation on the Fine-tuned Model
Table 4: Comparison of multimodal reasoning and mathematical performance across different models. $Δ$ denotes improvements compared to Qwen2.5-VL-7B [61]. We highlight improvements at least +0.5 points with green.
| | MMMU | WeMath | MathVista | MathVision | MathVerse | DynaMath | LogicVista |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Proprietary Models | | | | | | | |
| GPT-4o [41] | 72.9 | 50.6 | 71.6 | 43.8 | 49.9 | 48.5 | 64.4 |
| Claude-3.7-Sonnet [1] | 71.0 | 49.3 | 66.8 | 41.9 | 46.7 | 39.7 | 58.2 |
| Gemini-2.0-Pro [15] | 72.6 | 56.5 | 71.3 | 48.1 | 67.3 | 43.3 | 53.2 |
| Open-source Models (>70B) | | | | | | | |
| InternVL2.5-78B-MPO [56] | 68.2 | 37.6 | 76.6 | 36.2 | 43.7 | 21.2 | 50.8 |
| InternVL2.5-78B [8] | 70.1 | 39.8 | 70.6 | 32.2 | 39.2 | 19.2 | 49.0 |
| Qwen2.5-VL-72B [3] | 68.2 | 49.1 | 74.2 | 39.3 | 47.3 | 35.9 | 55.7 |
| Open-source Models (~7B) | | | | | | | |
| InternVL2.5-8B [8] | 56.2 | 20.2 | 58.3 | 20.0 | 20.4 | 9.2 | 33.6 |
| MiniCPM-o-2.6-8B [62] | 50.9 | 25.2 | 73.3 | 21.7 | 35.0 | 10.4 | 36.0 |
| Qwen2.5-VL-7B [3] | 58.0 | 36.2 | 68.1 | 25.4 | 41.1 | 21.8 | 47.9 |
| Athena-7B | 61.1 | 43.0 | 71.4 | 25.7 | 45.7 | 21.9 | 51.3 |
| $Δ$ | +3.1 | +6.8 | +3.3 | +0.3 | +4.6 | +0.1 | +3.4 |
Setup. We select Qwen2.5-VL-7B [3] as the initial policy model, obtaining training data as outlined in Sec. 2.4. We use AdamW [32] optimizer and set the learning rate as $1e^-6$ with cosine decay. The batch size is set to 128, and the number of epochs is set to one. We denote our fine-tuned model as Athena-7B and evaluate it on the same benchmarks as Sec. 3.1 in the zero-shot setting. For evaluation, we use VLMEvalKit [14] to evaluate Athena-7B and report the results of all baselines from the open leaderboard. https://huggingface.co/spaces/opencompass/Open_LMM_Reasoning_Leaderboard
Results. As shown in Table 4, Athena-7B consistently improves upon Qwen2.5-VL-7B [3] across all benchmarks, with significant enhancements of at least $+$ 0.5 points on five benchmarks. Athena-7B outperforms large open-source models (e.g. InternVL2.5-78B [8]) on five benchmarks. On the MathVista [36], Athena-7B even achieves the comparable performance with proprietary models such as Gemini-2.0-Pro [15], Claude-3.7-Sonnet [1], and GPT-4o [41].
### 3.4 Analysis
Test time scaling. To evaluate the scalability of Athena-ORM and Athena-PRM, we compare their performance using different numbers of samples ranging from 4 to 64 on the MathVista [36]. As shown in Figure 2, reward ranking for solutions at test time improves reasoning performance across different policy models and number of samples. Specifically, ORMs and PRMs improve the self-consistency [58] baseline by 0.8 and 2.1 points with Qwen2.5-VL-72B [3] using eight samples, respectively. As the sample size increases, the performance improves steadily. However, the performance gain of ORMs is markedly lower than that of PRMs. For instance, Athena-PRM achieves 82.4% with Qwen2.5-VL-72B [3] using 64 samples, while Athena-ORM achieves similar performance with self-consistency [58] baseline. These findings underscore the advancements and scalability of PRMs in test-time scaling scenarios.
<details>
<summary>x2.png Details</summary>
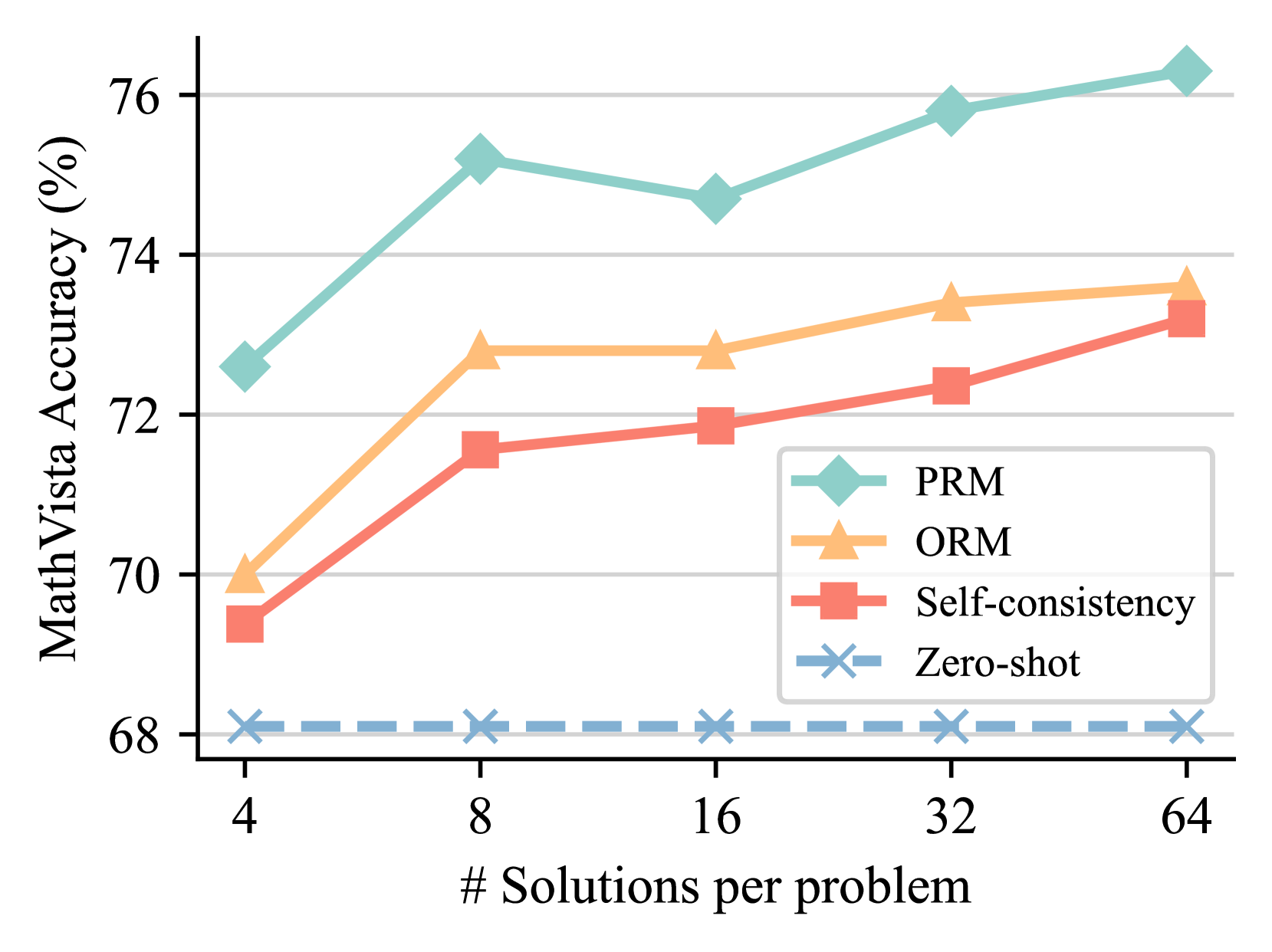
### Visual Description
## Line Chart: MathVista Accuracy vs. Number of Solutions per Problem
### Overview
The image is a line chart comparing the performance of four different methods on the MathVista benchmark. The chart plots accuracy (as a percentage) against the number of solutions generated per problem. The data suggests that generating more solutions generally improves accuracy for most methods, but with varying degrees of effectiveness and diminishing returns.
### Components/Axes
* **Chart Type:** Multi-series line chart.
* **Y-Axis (Vertical):**
* **Label:** `MathVista Accuracy (%)`
* **Scale:** Linear, ranging from approximately 68% to 76%.
* **Major Ticks:** 68, 70, 72, 74, 76.
* **X-Axis (Horizontal):**
* **Label:** `# Solutions per problem`
* **Scale:** Logarithmic (base 2), with discrete points.
* **Data Points (Categories):** 4, 8, 16, 32, 64.
* **Legend:**
* **Position:** Bottom-right corner of the plot area.
* **Series & Markers:**
1. **PRM:** Teal line with diamond markers (◆).
2. **ORM:** Orange line with upward-pointing triangle markers (▲).
3. **Self-consistency:** Red line with square markers (■).
4. **Zero-shot:** Blue dashed line with 'X' markers (✕).
### Detailed Analysis
**Trend Verification & Data Points (Approximate Values):**
1. **PRM (Teal, Diamond ◆):**
* **Trend:** Shows the highest overall accuracy. It increases sharply from 4 to 8 solutions, dips slightly at 16, then rises steadily to its peak at 64 solutions.
* **Data Points:**
* 4 solutions: ~72.5%
* 8 solutions: ~75.2%
* 16 solutions: ~74.7%
* 32 solutions: ~75.8%
* 64 solutions: ~76.3%
2. **ORM (Orange, Triangle ▲):**
* **Trend:** Starts lower than PRM but follows a similar upward trajectory. It sees a significant jump from 4 to 8 solutions, plateaus between 8 and 16, then increases gradually.
* **Data Points:**
* 4 solutions: ~70.0%
* 8 solutions: ~72.8%
* 16 solutions: ~72.8%
* 32 solutions: ~73.4%
* 64 solutions: ~73.7%
3. **Self-consistency (Red, Square ■):**
* **Trend:** Shows a consistent, nearly linear upward trend across all data points. It starts as the lowest-performing method at 4 solutions but closes the gap significantly by 64 solutions.
* **Data Points:**
* 4 solutions: ~69.4%
* 8 solutions: ~71.6%
* 16 solutions: ~71.9%
* 32 solutions: ~72.3%
* 64 solutions: ~73.2%
4. **Zero-shot (Blue Dashed, Cross ✕):**
* **Trend:** This is the baseline method. Its performance is essentially flat, showing no improvement as the number of solutions per problem increases. It remains constant at approximately 68.1% across all x-axis values.
### Key Observations
* **Performance Hierarchy:** PRM is consistently the top-performing method at every data point. Zero-shot is consistently the lowest.
* **Impact of Scaling:** For PRM, ORM, and Self-consistency, increasing the number of solutions from 4 to 8 yields the most substantial accuracy gains. The rate of improvement generally diminishes beyond 8 or 16 solutions.
* **Convergence:** The performance gap between ORM and Self-consistency narrows considerably as the number of solutions increases. At 4 solutions, ORM is ~0.6% higher; at 64 solutions, the difference is only ~0.5%.
* **Anomaly:** The PRM method shows a slight performance dip at 16 solutions compared to 8, which is not observed in the other improving methods.
* **Baseline Behavior:** The Zero-shot line serves as a control, demonstrating that the improvements seen in the other methods are due to the multi-solution strategy (and the associated ranking/selection mechanisms like PRM/ORM), not simply from generating more samples.
### Interpretation
This chart demonstrates the effectiveness of "generate-and-rank" strategies for improving mathematical reasoning in AI models. The key takeaways are:
1. **Multi-Solution Generation is Beneficial:** Simply generating multiple candidate solutions (Self-consistency) and selecting the best one improves accuracy over a single (zero-shot) attempt.
2. **Advanced Ranking Models Add Significant Value:** Using a dedicated Process Reward Model (PRM) or Outcome Reward Model (ORM) to rank the generated solutions provides a substantial additional boost in accuracy over simple self-consistency voting. PRM appears to be the most effective ranking method shown.
3. **Diminishing Returns:** There is a clear point of diminishing returns. The most cost-effective gains are achieved by moving from 4 to 8 solutions per problem. Scaling to 64 solutions provides further improvement but at a much lower rate, which must be weighed against the increased computational cost.
4. **The Value of Process vs. Outcome:** The consistent lead of PRM over ORM suggests that evaluating the reasoning *process* step-by-step may be more reliable for mathematical problems than evaluating only the final *outcome*, especially as the number of candidate solutions grows.
In summary, the data argues for a strategy that combines generating a moderate number of solution candidates (e.g., 8-16) with a sophisticated process-based reward model to select the best one, as this approach yields the highest accuracy on the MathVista benchmark.
</details>
(a) Qwen2.5-VL-7B
<details>
<summary>x3.png Details</summary>
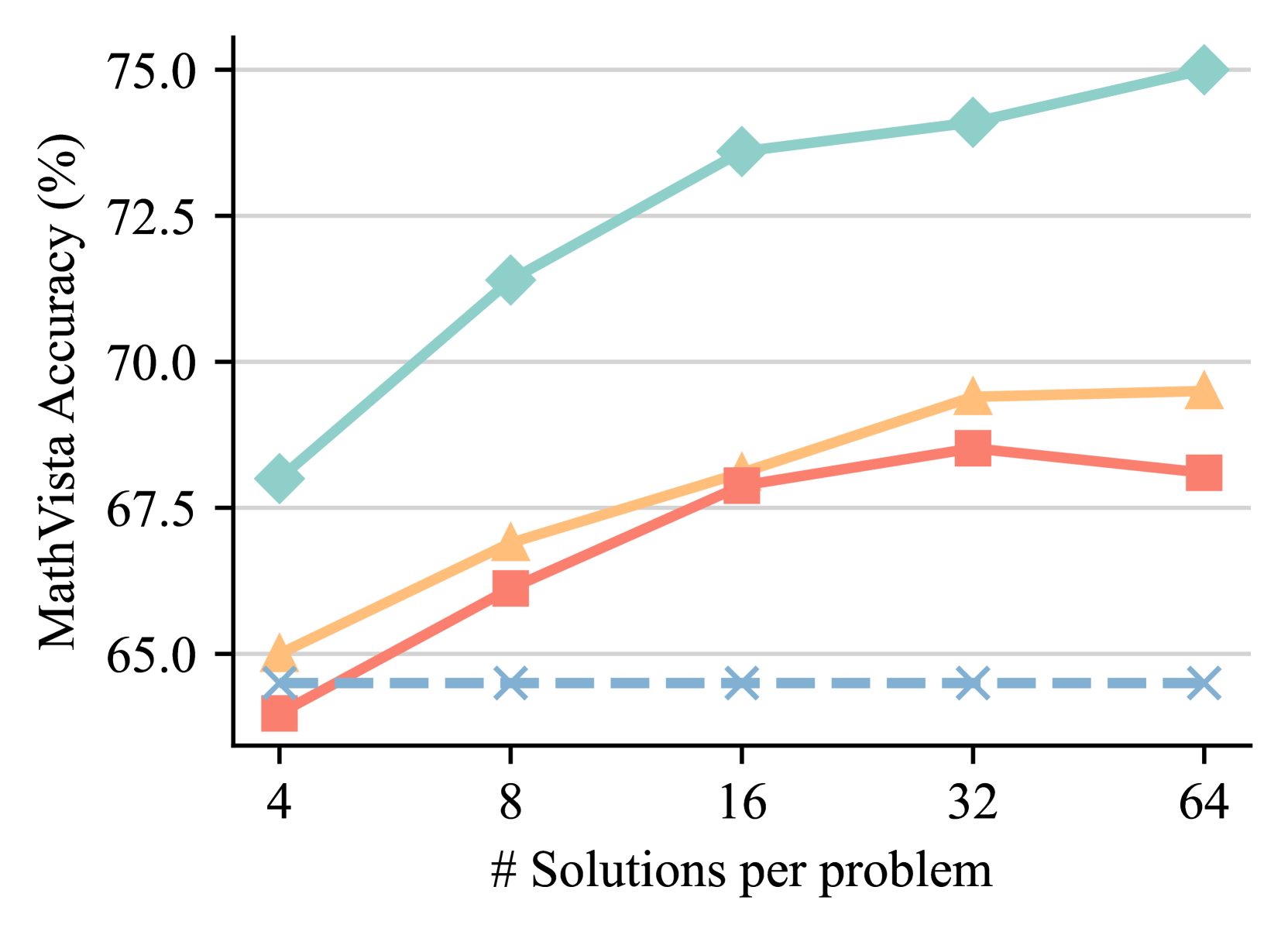
### Visual Description
## Line Chart: MathVista Accuracy vs. Number of Solutions per Problem
### Overview
The image is a line chart plotting "MathVista Accuracy (%)" against the "# Solutions per problem". It displays the performance of four distinct methods or models, differentiated by line color, style, and marker shape. The chart demonstrates how accuracy changes as the number of solutions generated per problem increases from 4 to 64.
### Components/Axes
* **Y-Axis (Vertical):** Labeled "MathVista Accuracy (%)". The scale ranges from 65.0 to 75.0, with major grid lines at intervals of 2.5 (65.0, 67.5, 70.0, 72.5, 75.0).
* **X-Axis (Horizontal):** Labeled "# Solutions per problem". It features discrete, non-linearly spaced data points at values: 4, 8, 16, 32, and 64.
* **Data Series (Legend Not Visible):** The chart contains four distinct series. As no legend is present in the image, they are identified by their visual attributes:
1. **Teal Line with Diamond Markers:** Solid line.
2. **Orange Line with Triangle Markers:** Solid line.
3. **Red Line with Square Markers:** Solid line.
4. **Blue Dashed Line with 'X' Markers:** Dashed line.
### Detailed Analysis
**Data Point Extraction (Approximate Values):**
| # Solutions | Teal (Diamond) | Orange (Triangle) | Red (Square) | Blue Dashed (X) |
| :--- | :--- | :--- | :--- | :--- |
| **4** | ~68.0% | ~65.0% | ~64.0% | ~64.5% |
| **8** | ~71.5% | ~67.0% | ~66.0% | ~64.5% |
| **16** | ~73.5% | ~68.0% | ~68.0% | ~64.5% |
| **32** | ~74.0% | ~69.5% | ~68.5% | ~64.5% |
| **64** | ~75.0% | ~69.5% | ~68.0% | ~64.5% |
**Trend Verification:**
* **Teal (Diamond):** Shows a strong, consistent upward trend. The slope is steepest between 4 and 16 solutions, then continues to rise at a slightly slower rate to 64 solutions.
* **Orange (Triangle):** Shows a steady upward trend from 4 to 32 solutions, after which it plateaus (accuracy at 32 and 64 solutions is nearly identical).
* **Red (Square):** Increases from 4 to 32 solutions, but then shows a slight decrease in accuracy when moving from 32 to 64 solutions.
* **Blue Dashed (X):** Exhibits a flat, horizontal trend. Accuracy remains constant at approximately 64.5% across all tested numbers of solutions.
### Key Observations
1. **Performance Hierarchy:** The Teal method is the top performer at every data point, followed generally by Orange, then Red, with Blue consistently at the bottom.
2. **Diminishing Returns:** Both the Orange and Red methods show signs of performance saturation. The Orange method's gain plateaus after 32 solutions, while the Red method's performance slightly regresses.
3. **Baseline Performance:** The Blue dashed line represents a baseline or a method whose accuracy is unaffected by increasing the number of solutions per problem.
4. **Convergence at Low Solutions:** At the lowest setting (4 solutions), the performance gap between the top (Teal) and bottom (Blue) methods is approximately 3.5 percentage points. This gap widens significantly to over 10 percentage points at 64 solutions.
### Interpretation
This chart likely compares different strategies for solving problems in the MathVista benchmark, where each strategy involves generating multiple candidate solutions and then selecting or aggregating them.
* The **Teal method** demonstrates superior scalability; its accuracy benefits significantly from generating more solutions, suggesting an effective mechanism for leveraging additional computational effort (more solutions) to improve final answer quality.
* The **Orange and Red methods** also benefit from more solutions initially, but hit a performance ceiling. The slight drop for Red at 64 solutions could indicate noise or overfitting in the aggregation process when too many candidates are considered.
* The **Blue dashed line** serves as a control, representing a single-solution or non-aggregation baseline. Its flat line confirms that the improvements seen in the other methods are indeed due to the multi-solution approach.
The key takeaway is that for this task, the choice of method for handling multiple solutions is critical. Simply generating more solutions is not enough; the underlying algorithm (represented by the Teal line) must be capable of effectively distilling the correct answer from the increased candidate pool to achieve substantial gains in accuracy.
</details>
(b) InternVL2.5-8B
<details>
<summary>x4.png Details</summary>
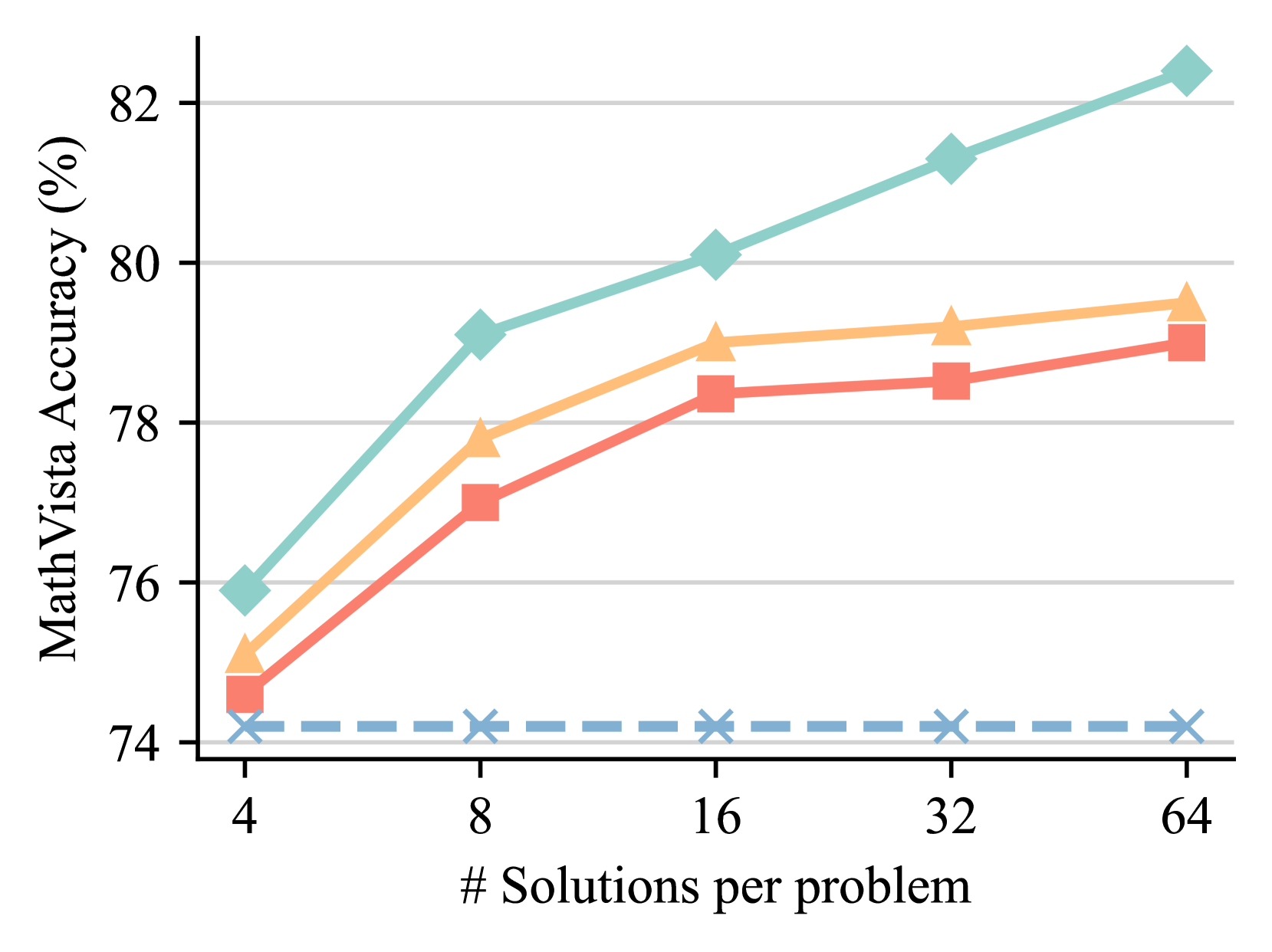
### Visual Description
## Line Chart: MathVista Accuracy vs. Number of Solutions per Problem
### Overview
The image is a line chart displaying the relationship between the number of solutions generated per problem (x-axis) and the resulting accuracy percentage on the MathVista benchmark (y-axis). It compares the performance of four distinct methods or models, each represented by a unique line color and marker style. The chart demonstrates a clear positive correlation between increased computational effort (more solutions) and improved accuracy for three of the four methods.
### Components/Axes
* **Y-Axis (Vertical):**
* **Label:** "MathVista Accuracy (%)"
* **Scale:** Linear scale ranging from 74 to 82.
* **Major Ticks:** 74, 76, 78, 80, 82.
* **Grid Lines:** Horizontal grid lines are present at each major tick mark.
* **X-Axis (Horizontal):**
* **Label:** "# Solutions per problem"
* **Scale:** Logarithmic scale (base 2), with values doubling at each step.
* **Major Ticks:** 4, 8, 16, 32, 64.
* **Data Series (Lines):** There are four distinct lines. **Note:** The chart does not contain a legend to explicitly label what each line represents. The analysis below describes them by their visual properties.
1. **Teal Line with Diamond Markers:** Solid line, teal color (#7FC8B8 approx.), diamond-shaped markers.
2. **Orange Line with Triangle Markers:** Solid line, light orange color (#F5C28A approx.), upward-pointing triangle markers.
3. **Red Line with Square Markers:** Solid line, salmon/red color (#E88A7A approx.), square markers.
4. **Blue Dashed Line with 'X' Markers:** Dashed line, light blue color (#8CB4D8 approx.), 'X' shaped markers.
### Detailed Analysis
**Trend Verification & Data Point Extraction (Approximate Values):**
* **Teal Line (Diamonds):** Shows a strong, consistent upward trend. Accuracy increases significantly with more solutions.
* At 4 solutions: ~76.0%
* At 8 solutions: ~79.1%
* At 16 solutions: ~80.1%
* At 32 solutions: ~81.3%
* At 64 solutions: ~82.4%
* **Orange Line (Triangles):** Shows a clear upward trend that begins to plateau after 16 solutions.
* At 4 solutions: ~75.1%
* At 8 solutions: ~77.8%
* At 16 solutions: ~79.0%
* At 32 solutions: ~79.2%
* At 64 solutions: ~79.5%
* **Red Line (Squares):** Shows a steady upward trend, consistently performing slightly below the orange line.
* At 4 solutions: ~74.6%
* At 8 solutions: ~77.0%
* At 16 solutions: ~78.4%
* At 32 solutions: ~78.6%
* At 64 solutions: ~79.1%
* **Blue Dashed Line ('X's):** Shows a flat, horizontal trend. Accuracy remains essentially constant regardless of the number of solutions.
* At 4 solutions: ~74.2%
* At 8 solutions: ~74.2%
* At 16 solutions: ~74.2%
* At 32 solutions: ~74.2%
* At 64 solutions: ~74.2%
### Key Observations
1. **Performance Hierarchy:** There is a clear and consistent performance ranking across all tested solution counts: Teal (best) > Orange > Red > Blue (worst).
2. **Diminishing Returns:** The orange and red lines show signs of diminishing returns. The accuracy gain from 32 to 64 solutions is much smaller than the gain from 4 to 8 solutions.
3. **Baseline Performance:** The blue dashed line acts as a baseline, showing no improvement from increased solution generation. This suggests it represents a method that does not benefit from this scaling technique (e.g., a single-solution baseline or a different approach).
4. **Scaling Efficacy:** The teal line demonstrates the most effective scaling, maintaining a strong positive slope even at higher solution counts (32 to 64), suggesting its underlying method benefits most robustly from increased computational resources.
### Interpretation
This chart illustrates the impact of a "best-of-N" or similar sampling strategy on model accuracy for a visual math reasoning benchmark (MathVista). The core finding is that generating multiple candidate solutions and selecting among them (presumably via a verifier or voting mechanism) generally improves performance.
* **What the data suggests:** Three of the four methods (Teal, Orange, Red) benefit from this scaling approach, with accuracy improving as more solutions are sampled. The magnitude of improvement varies, indicating differences in the quality or diversity of the generated solution pools or the effectiveness of the selection mechanism.
* **How elements relate:** The x-axis represents increased computational cost (generating more solutions). The y-axis represents the payoff in accuracy. The diverging lines show that not all methods scale equally well with this added cost.
* **Notable outliers/trends:** The flat blue line is the critical outlier. It establishes that the improvement seen in the other lines is not automatic and is a property of the specific methods being tested. The teal line's continued strong upward trend at 64 solutions is notable, as it suggests the performance ceiling for that method has not yet been reached within the tested range.
* **Underlying implication:** The results argue for the value of scaling inference-time computation for complex reasoning tasks. However, the plateauing of the orange and red lines indicates that simply generating more solutions is not infinitely effective; the quality of the base model and the verification process are crucial limiting factors. The chart likely comes from a research paper comparing different model architectures or inference strategies for multimodal mathematical reasoning.
</details>
(c) Qwen2.5-VL-72B
Figure 2: Best-of-N results on the MathVista [36] across different policies. The number of solutions we sample is from 4 to 64.
Table 5: Ablation study of our design choices on the MathVista [54] and WeMath [44] with Qwen2.5-VL-7B [3] as the policy model.
| Method | Data | ORM init | Up-sample | MathVista | WeMath |
| --- | --- | --- | --- | --- | --- |
| Zero-shot | - | - | - | 68.1 | 36.2 |
| Self-consistency | - | - | - | 71.6 | 44.7 |
| Athena-ORM | Athena-600K | - | - | 72.8 | 45.1 |
| Athena-PRM | Random 5K | ✘ | ✘ | 73.1 | 45.2 |
| Athena-5K | ✘ | ✘ | 74.1 | 45.8 | |
| Random 5K | ✔ | ✘ | 73.6 | 45.4 | |
| Athena-5K | ✔ | ✘ | 74.8 | 46.2 | |
| Athena-5K | ✔ | ✔ | 75.2 | 46.4 | |
| MC-300K | ✔ | ✔ | 75.5 | 46.4 | |
The effectiveness of our design choices. Table 5 presents results under various design choices. Our findings indicate that PRMs trained with selectively chosen 5K samples significantly outperform those trained with randomly selected samples, achieving scores 74.1 vs. 73.1 and 74.8 vs. 73.6 when initialized from ORMs. Moreover, a large-scale dataset of 300K samples labeled using vanilla MC-based methods yields similar performance to our selected 5K samples. With these selected samples, ORM initialization enhances performance by 0.7 points (74.8 vs. 74.1), and up-sampling negative labels further boosts performance by 0.4 points on the MathVista [36].
Computation cost analysis. Vanilla MC-based estimation [55] incurs substantial computational demands to estimate the correctness of intermediate steps. Our prediction consistency filter strategy significantly reduces this burden, requiring only 5K samples for training, thereby lowering the computational cost by a factor of 60. For data synthesis, we employ vLLM primarily [25] to accelerate MLLM inference. Compared to the MC-300K dataset, our Athena-5K dataset reduces GPU hours by approximately 45-fold while achieving similar performance.
## 4 Related Work
Test time scaling. While scaling data and model parameters during training has been extensively studied [23, 19], scaling computation at test time has garnered interest more recently [50, 46]. TTS enables language models to leverage additional computational resources when faced with challenging questions. Our study primarily focuses on parallel scaling [67], wherein language models generate multiple outputs simultaneously and aggregate them into a final answer. This aggregation can involve selecting the most common outcome [58] or using reward models [50] to rank solutions, selecting the one with the highest reward, as demonstrated in our Best-of-N settings.
Process reward models. Reward models are crucial in reinforcement learning [17, 47, 55, 42, 4, 13] and test time scaling [46, 28, 55, 9, 50]. Outcome reward models [9] assign a scalar value to question-response pairs, whereas process reward models evaluate each step, typically achieving superior performance and generalization [28, 37, 46, 27]. While better performance and generalization are achieved, collecting data to train PRMs is challenging. PRM800K [28] is the first open-source process supervision dataset annotated by humans, but scaling it is challenging due to the time and skill required for annotating reasoning steps. Math-Shepherd [55] proposes an automated method for estimating intermediate step correctness using Monte Carlo estimation, though it generates some incorrect labels and demands extensive computational resources. Our work explores strategies to reduce computational costs while improving process label accuracy.
## 5 Conclusion
In this paper, we introduce Athena-PRM, trained on 5K high-quality data with process labels. To automatically obtain accurate process labels, we employ a data filtering method based on consistency between weak and strong completers. This strategy significantly reduces computational costs for training and data synthesis while ensuring precise process labels for training PRMs. Additionally, we present two effective strategies for training PRMs: ORM initialization and negative data up-sampling. Athena-PRM demonstrates substantial performance improvements in Best-of-N evaluations, achieving state-of-the-art results on VisualProcessBench. Leveraging Athena-PRM, we train Athena-7B, fine-tuned from Qwen2.5-VL-7B using a reward ranked fine-tuning approach, markedly enhancing the reasoning capabilities of Qwen2.5-VL-7B. Extensive experiments confirm the effectiveness of our proposed methods.
## References
- Anthropic [2025] Anthropic. Claude 3.7 sonnet and claude code, 2025. URL https://www.anthropic.com/news/claude-3-7-sonnet. Accessed on Feb 25, 2025.
- Antol et al. [2015] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. VQA: Visual question answering. In ICCV, 2015.
- Bai et al. [2025] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025.
- Bai et al. [2022] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In NeurIPS, 2020.
- Cao and Xiao [2022] Jie Cao and Jing Xiao. An augmented benchmark dataset for geometric question answering through dual parallel text encoding. In Proceedings of the 29th international conference on computational linguistics, pages 1511–1520, 2022.
- Chen et al. [2022] Jiaqi Chen, Tong Li, Jinghui Qin, Pan Lu, Liang Lin, Chongyu Chen, and Xiaodan Liang. Unigeo: Unifying geometry logical reasoning via reformulating mathematical expression. arXiv preprint arXiv:2212.02746, 2022.
- Chen et al. [2024] Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271, 2024.
- Cobbe et al. [2021] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Cui et al. [2025] Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, et al. Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456, 2025.
- Dao [2024] Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. In ICLR, 2024.
- Dong et al. [2023] Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, KaShun SHUM, and Tong Zhang. RAFT: Reward ranked finetuning for generative foundation model alignment. Transactions on Machine Learning Research, 2023.
- Dong et al. [2024] Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, and Tong Zhang. RLHF workflow: From reward modeling to online RLHF. Transactions on Machine Learning Research, 2024.
- Duan et al. [2024] Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. VLMEvalKit: An open-source toolkit for evaluating large multi-modality models. In ACM MM, 2024.
- Gemini Team [2023] Gemini Team. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- Grattafiori et al. [2024] Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Guo et al. [2025] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
- Hendrycks et al. [2021] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. In NeurIPS, 2021.
- Hoffmann et al. [2022] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- Holtzman et al. [2020] Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. In ICLR, 2020.
- Hu [2025] Jian Hu. Reinforce++: A simple and efficient approach for aligning large language models. arXiv preprint arXiv:2501.03262, 2025.
- Jiang et al. [2023] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- Kaplan et al. [2020] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Kazemi et al. [2023] Mehran Kazemi, Hamidreza Alvari, Ankit Anand, Jialin Wu, Xi Chen, and Radu Soricut. Geomverse: A systematic evaluation of large models for geometric reasoning. arXiv preprint arXiv:2312.12241, 2023.
- Kwon et al. [2023] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023.
- Li et al. [2025] Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. LLaVA-onevision: Easy visual task transfer. Transactions on Machine Learning Research, 2025.
- Li and Li [2025] Wendi Li and Yixuan Li. Process reward model with q-value rankings. In ICLR, 2025.
- Lightman et al. [2024] Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In ICLR, 2024.
- Lindström and Abraham [2022] Adam Dahlgren Lindström and Savitha Sam Abraham. Clevr-math: A dataset for compositional language, visual and mathematical reasoning. arXiv preprint arXiv:2208.05358, 2022.
- Liu et al. [2024] Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024.
- Liu et al. [2023] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In NeurIPS, 2023.
- Loshchilov and Hutter [2019] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In ICLR, 2019.
- Lu et al. [2024a] Jianqiao Lu, Zhiyang Dou, Hongru WANG, Zeyu Cao, Jianbo Dai, Yunlong Feng, and Zhijiang Guo. AutoPSV: Automated process-supervised verifier. In NeurIPS, 2024a.
- Lu et al. [2021] Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning. arXiv preprint arXiv:2105.04165, 2021.
- Lu et al. [2022] Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. In NeurIPS, 2022.
- Lu et al. [2024b] Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. In ICLR, 2024b.
- Luo et al. [2024] Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, et al. Improve mathematical reasoning in language models by automated process supervision. arXiv preprint arXiv:2406.06592, 2024.
- Masry et al. [2022] Ahmed Masry, Do Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. In ACL, 2022.
- Mathew et al. [2021] Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. In WACV, 2021.
- Muennighoff et al. [2025] Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling. arXiv preprint arXiv:2501.19393, 2025.
- OpenAI [2024] OpenAI. Hello gpt-4o. https://openai.com/index/hello-gpt-4o/, 2024. Accessed: 2024-02-09, 2024-02-11, 2024-02-12.
- Ouyang et al. [2022] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Gray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In NeurIPS, 2022.
- Pang et al. [2024] Richard Yuanzhe Pang, Weizhe Yuan, He He, Kyunghyun Cho, Sainbayar Sukhbaatar, and Jason E Weston. Iterative reasoning preference optimization. In NeurIPS, 2024.
- Qiao et al. [2024] Runqi Qiao, Qiuna Tan, Guanting Dong, Minhui Wu, Chong Sun, Xiaoshuai Song, Zhuoma GongQue, Shanglin Lei, Zhe Wei, Miaoxuan Zhang, et al. We-math: Does your large multimodal model achieve human-like mathematical reasoning? arXiv preprint arXiv:2407.01284, 2024.
- Rajbhandari et al. [2020] Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: memory optimizations toward training trillion parameter models. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2020.
- Setlur et al. [2025] Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. Rewarding progress: Scaling automated process verifiers for LLM reasoning. In ICLR, 2025.
- Shao et al. [2024] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- Shi et al. [2024] Wenhao Shi, Zhiqiang Hu, Yi Bin, Junhua Liu, Yang Yang, See Kiong Ng, Lidong Bing, and Roy Lee. Math-llava: Bootstrapping mathematical reasoning for multimodal large language models. In EMNLP, 2024.
- Singh et al. [2024] Avi Singh, John D Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J Liu, James Harrison, Jaehoon Lee, Kelvin Xu, Aaron T Parisi, Abhishek Kumar, Alexander A Alemi, Alex Rizkowsky, Azade Nova, Ben Adlam, Bernd Bohnet, Gamaleldin Fathy Elsayed, Hanie Sedghi, Igor Mordatch, Isabelle Simpson, Izzeddin Gur, Jasper Snoek, Jeffrey Pennington, Jiri Hron, Kathleen Kenealy, Kevin Swersky, Kshiteej Mahajan, Laura A Culp, Lechao Xiao, Maxwell Bileschi, Noah Constant, Roman Novak, Rosanne Liu, Tris Warkentin, Yamini Bansal, Ethan Dyer, Behnam Neyshabur, Jascha Sohl-Dickstein, and Noah Fiedel. Beyond human data: Scaling self-training for problem-solving with language models. Transactions on Machine Learning Research, 2024.
- Snell et al. [2025] Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. In ICLR, 2025.
- Team et al. [2025] Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599, 2025.
- Touvron et al. [2023] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Uesato et al. [2022] Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275, 2022.
- Wang et al. [2024a] Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. In NeurIPS, 2024a.
- Wang et al. [2024b] Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. In ACL, 2024b.
- Wang et al. [2024c] Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Yu Qiao, et al. Enhancing the reasoning ability of multimodal large language models via mixed preference optimization. arXiv preprint arXiv:2411.10442, 2024c.
- Wang et al. [2025] Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Shenglong Ye, Xizhou Zhu, et al. VisualPRM: An effective process reward model for multimodal reasoning. arXiv preprint arXiv:2503.10291, 2025.
- Wang et al. [2023] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In ICLR, 2023.
- Wei et al. [2022] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In NeurIPS, 2022.
- Xiao et al. [2024] Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. Logicvista: Multimodal llm logical reasoning benchmark in visual contexts. arXiv preprint arXiv:2407.04973, 2024.
- Yang et al. [2024] An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115, 2024.
- Yao et al. [2024] Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800, 2024.
- Yuan et al. [2024] Lifan Yuan, Wendi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao Peng. Free process rewards without process labels. arXiv preprint arXiv:2412.01981, 2024.
- Yuan et al. [2023] Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Keming Lu, Chuanqi Tan, Chang Zhou, and Jingren Zhou. Scaling relationship on learning mathematical reasoning with large language models. arXiv preprint arXiv:2308.01825, 2023.
- Yue et al. [2024] Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In CVPR, 2024.
- Zeng et al. [2025] Weihao Zeng, Yuzhen Huang, Lulu Zhao, Yijun Wang, Zifei Shan, and Junxian He. B-STar: Monitoring and balancing exploration and exploitation in self-taught reasoners. In ICLR, 2025.
- Zhang et al. [2025a] Qiyuan Zhang, Fuyuan Lyu, Zexu Sun, Lei Wang, Weixu Zhang, Zhihan Guo, Yufei Wang, Irwin King, Xue Liu, and Chen Ma. What, how, where, and how well? a survey on test-time scaling in large language models. arXiv preprint arXiv:2503.24235, 2025a.
- Zhang et al. [2024] Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? In ECCV, 2024.
- Zhang et al. [2025b] Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. arXiv preprint arXiv:2501.07301, 2025b.
- Zou et al. [2025] Chengke Zou, Xingang Guo, Rui Yang, Junyu Zhang, Bin Hu, and Huan Zhang. Dynamath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models. In ICLR, 2025.
## Appendix A More Experiments and Details
### A.1 Choices of Completers
Here we verify the effect of combining different completers on the accuracy of estimated labels. Results are listed in Table 6. From Table 6, it is noted that the consistency filter for two completers usually improves the accuracy of estimated labels. For example, combining two weak or strong completers improves accuracy by almost two points in general. Furthermore, the accuracy of estimated labels is improved by combining one weak and one strong completer, achieving the most competitive accuracy, e.g., 95.2% with weak completer $φ_w^2$ and strong completer $φ_s^1$ . This shows that the proposed consistency filter strategy is effective across all combinations of different completers and achieves the best performance when we combine a weak completer and a strong completer.
Table 6: The accuracy of estimated process labels with Different completers combination. In Two Completers, we use consistency filter introduced in Sec. 2.2. $φ_w^1$ , $φ_w^2$ , $φ_s^1$ , and $φ_w^2$ denote Mistral-7B-Instruct, Qwen2-7B-Instruct, Qwen2.5-72B-Instruct and Llama-3-70B-Instruct, respectively.
| | Weak Completer | Strong Completer | Accuracy(%) | | |
| --- | --- | --- | --- | --- | --- |
| $φ_w^1$ | $φ_w^2$ | $φ_s^1$ | $φ_s^2$ | | |
| Single Completer | ✔ | | | | 78.2 |
| ✔ | | | 80.1 | | |
| ✔ | | 83.4 | | | |
| ✔ | 84.7 | | | | |
| Two Completers | ✔ | ✔ | | | 82.3 |
| ✔ | ✔ | 85.6 | | | |
| ✔ | | ✔ | | 94.1 | |
| ✔ | | | ✔ | 93.8 | |
| ✔ | ✔ | | 95.2 | | |
| ✔ | | ✔ | 94.7 | | |
### A.2 Benchmarks
We provide more details about used benchmarks in Table 7.
Table 7: Details of all benchmarks used and corresponding metrics.
| | Split | # Samples | Metric |
| --- | --- | --- | --- |
| MathVista [36] | Testmini | 1000 | Accuracy |
| MathVision [54] | Full | 3040 | Accuracy |
| MathVerse [68] | Vision-Only | 788 | Accuracy |
| DynaMath [70] | Full | 5050 | Accuracy |
| WeMath [44] | Testmini | 1740 | Score (Strict) |
| LogicVista [60] | Full | 448 | Accuracy |
| MMMU [65] | Validation | 900 | Accuracy |
| GSM8K [9] | Test | 1319 | Accuracy |
| MATH [18] | Test | 5000 | Accuracy |
| VisualProcessBench [57] | - | 2866 | F1-score |
### A.3 Reward Choice
In this paper, we consider three reward choices of Athena-PRM for aggregating step scores into a final score [69], including PRM-minium, PRM-last, and PRM-product. For all reasoning steps $\{a_i\}_i=1^K$ , its corresponding reward for each step is $\{r_i\}_i=1^K$ , the reward $r$ for each solution with different scoring methods are calculated as follows: 1) PRM-minium uses the minium reward across all steps, i.e., $r=\min\{r_i\}_i=1^K$ ; 2) PRM-last uses the reward of last step, i.e., $r=r_K$ ; 3) PRM-product uses the reward product of all steps, i.e. $r=∏_i=1^Kr_i$ .
We list results in Table 8. It is shown that different choices of selecting a reward for PRMs could produce different performance. In all other experiments, we use the minimum reward across all steps as the reward for the solution unless otherwise specified.
Table 8: Best-of-8 performance comparison on the MathVista [36] with Qwen2.5-VL-7B [3] with different reward choices: last step reward, minium reward across all steps and product of all rewards. Default settings are marked in gray.
| Method | Accuracy(%) |
| --- | --- |
| Zero-shot | 68.1 |
| Self-consistency | 71.6 |
| ORM | 72.8 |
| PRM-product | 74.5 |
| PRM-last | 75.1 |
| PRM-minium | 75.2 |
### A.4 Label Distribution
We present the distribution of process labels in Table 9. It is shown that label imbalance exists in PRM800K and Athena-300K. We try different up-sample rates (e.g. $× 2$ ) for samples with error steps and find that slightly up-sampling negative data is beneficial for training PRMs, as shown in Table 10. We find that increasing the up-sample rate will not improve performance. We set the up-sample rate to 2 for other experiments.
Table 9: Distribution of labels across different datasets. Good, neutral, and bad denote different process labels.
| Dataset | Good | Neutral | Bad |
| --- | --- | --- | --- |
| PRM800K [28] | 76% | 12% | 12% |
| Athena-300K | 81% | - | 19% |
| Athena-5K | 79% | - | 21% |
Table 10: Results on MathVista under Best-of-8 setting with different up-sampling rate. We use Athena-5K as training dataset and Qwen-2.5-VL-7B as the policy model. Default settings are marked in gray.
| Method | Up-sample rate | Accuracy(%) |
| --- | --- | --- |
| Zero-shot | - | 68.1 |
| Self-consistency | - | 71.6 |
| Athena-ORM | - | 72.8 |
| Athena-PRM | ✘ | 74.8 |
| Athena-PRM | $× 2$ | 75.2 |
| Athena-PRM | $× 5$ | 75.2 |
| Athena-PRM | $× 10$ | 74.9 |
## Appendix B Limitations and Social Impacts
Limitations. Athena-PRM achieves impressive performance across various scenarios and benchmarks. However, Athena-PRM is specifically designed to enhance the reasoning capabilities of LLMs and MLLMs. Its application may be limited to solving problems with clear answers, such as multi-step reasoning and math problems. Effectively assigning rewards for intermediate steps in open-ended text generation tasks remains an open problem, and we leave this for future research.
In addition, how to define a step for complex multi-step reasoning is still underexplored. Existing PRMs typically split solutions into multiple steps using predefined symbols (e.g., “\n\n”) or fixed numbers of tokens or lines. This approach may result in steps that lack sufficient information. To prevent steps from containing too little information, we design a simple strategy that merges steps with too few tokens or without any mathematical symbols. However, better splitting strategies without human-designed rules still need to be explored.
Social Impacts. The paper introduces an effective method for generating high-quality, process-labeled data for reasoning problems. Our approach enhances the efficiency and effectiveness of training PRMs. We hope that our research will have a broader impact on improving the reasoning abilities of foundation models. Since our method focuses on general improvements in the reasoning capabilities of foundation models, it does not directly produce negative societal impacts.
## Appendix C Case Study
We provide some examples from VisualProcessBench and MathVista to help readers understand how PRMs work, see Figure 3, 4, 5, 6.
<details>
<summary>extracted/6532028/fig/example_fig/images_MathVision_MINI_15.png Details</summary>
### Visual Description
## Diagram: Insect Grid Path Puzzle
### Overview
The image is a composite of seven panels. The first five panels (`<image1>` to `<image5>`) display individual insect or object icons. The sixth panel (`<image6>`) contains the primary diagram: a 7x7 grid with a checkerboard pattern (alternating gray and white squares) featuring various insects placed on specific squares and a directed path indicated by arrows. The seventh panel (`<image7>`) presents five multiple-choice options, each pairing a letter (A-E) with an insect icon.
### Components/Axes
**Grid Structure:**
- A 7x7 grid with alternating gray and white squares, resembling a chessboard.
- Rows are numbered 1 to 7 from top to bottom.
- Columns are numbered 1 to 7 from left to right.
**Insect Icons & Positions (Coordinates as Row, Column):**
1. **Bee** (yellow and black striped): Located at (1, 2).
2. **Ladybug** (red with black spots): Located at (2, 6).
3. **Butterfly** (orange and blue wings): Located at (3, 7).
4. **Snail** (brown shell): Located at (5, 4).
5. **Ant** (red, holding a tool): Located at (6, 1). This is the starting point of the path.
6. **Frog** (green): Located at (6, 6).
7. **Caterpillar** (green, segmented): Located at (7, 4).
**Path (Directed by Black Arrows):**
The path originates from the Ant at (6, 1) and follows this sequence:
1. Move **RIGHT** from (6, 1) to (6, 3).
2. Move **UP** from (6, 3) to (4, 3).
3. Move **RIGHT** from (4, 3) to (4, 5).
4. Move **UP** from (4, 5) to (2, 5).
5. Move **RIGHT** from (2, 5) to (2, 6), terminating at the Ladybug.
**Multiple-Choice Options (`<image7>`):**
- **(A)** Butterfly icon
- **(B)** Bee icon
- **(C)** Caterpillar icon
- **(D)** Snail icon
- **(E)** Frog icon
### Detailed Analysis
**Spatial Layout of Insects:**
- The **Bee** is isolated in the top-left quadrant.
- The **Ladybug** and **Butterfly** are in the top-right quadrant, with the Butterfly at the far right edge.
- The **Snail** and **Caterpillar** are in the central column (column 4), with the Snail above the Caterpillar.
- The **Ant** (start) and **Frog** are in the bottom half of the grid, on the same row (row 6) but separated by several columns.
**Path Trajectory:**
The path is a stepped, rightward-and-upward trajectory. It moves exclusively through white squares (based on the checkerboard pattern). It does not intersect or pass through any other insect icons; all intermediate squares on the path are empty.
### Key Observations
1. **Destination Mismatch:** The path's clear destination is the **Ladybug** at (2, 6). However, the Ladybug is **not** among the multiple-choice options (A-E).
2. **Path Avoidance:** The path is carefully plotted to avoid all other insects on the grid.
3. **Grid Pattern:** The checkerboard pattern is consistent, with the top-left square (1,1) being gray.
4. **Icon Consistency:** The insect icons in the grid match those shown in the individual panels (`<image1>`, `<image3>`, `<image4>`) and the options panel (`<image7>`).
### Interpretation
This diagram represents a **grid-based navigation or pathfinding puzzle**, likely from an educational or logic game context. The core task implied by the visual elements is to follow the directed path from the starting point (Ant) to its endpoint.
The presence of the multiple-choice options (A-E) suggests a question was posed alongside this diagram, such as "Which insect is at the end of the path?" or "Which insect does the path lead to?". However, the visual data creates a logical discrepancy: the path ends at the Ladybug, which is not an option. This could indicate one of several possibilities:
- The question might be about an insect *encountered* along the path, but the path passes through empty squares only.
- The question might be about the *next* insect if the path were extended, but this is speculative.
- There may be an error in the puzzle's design or in the provided options.
From a technical standpoint, the diagram effectively communicates spatial relationships, a defined start point, and a clear directional sequence. The use of a checkerboard grid aids in coordinate reference. The primary informational content is the **specific path coordinates** and the **fixed positions of all objects** on the grid. The puzzle's intended solution, however, cannot be determined from the image alone due to the mismatch between the path's destination and the provided answer choices.
</details>
| Hint: Please answer the question and provide the correct option letter, e.g., A, B, C, D, at the end. Question: When the ant <image1> walks from home <image2> along the arrows $→ 3,↑ 3,→ 3,↑ 1$ , he gets to the ladybird <image3>. Which animal does the ant <image1> get to when he walks from home <image2> along the following arrows: $→ 2,↓ 2,→ 3,↑ 3,→ 2,↑ 2$ ? <image6> <image7> Choices:(A) A (B) B (C) C (D) D (E) E (Answer: A) | | |
| --- | --- | --- |
| Step | Reward | Label |
| To determine which animal the ant reaches, we will follow the given movements step-by-step on the grid: | 0.95 | ✔ |
| 1. Start at the home position (‘<image2>‘), which is at the bottom-left corner of the grid. | 0.99 | ✔ |
| 2. Follow the arrows: - $→ 2$ : Move 2 squares to the right. - $↓ 2$ : Move 2 squares down. - $→ 3$ : Move 3 squares to the right. - $↑ 3$ : Move 3 squares up. - $→ 2$ : Move 2 squares to the right. - $↑ 2$ : Move 2 squares up. | 0.99 | ✔ |
| 3. Trace the movement: - Start at the bottom-left corner. - Move 2 squares right: You are now in the third column of the first row. - Move 2 squares down: You are now in the third column of the third row. - Move 3 squares right: You are now in the sixth column of the third row. - Move 3 squares up: You are now in the sixth column of the top row. - Move 2 squares right: You are now in the eighth column of the top row. - Move 2 squares up: You are now in the eighth column of the top row (still at the butterfly position). | 0.12 | ✘ |
| The ant reaches the butterfly, which corresponds to option A. | 0.87 | ✔ |
| ### Final Answer: A | 0.75 | ✔ |
Figure 3: A case study from VisualProcessBench [57].
<details>
<summary>extracted/6532028/fig/example_fig/images_MathVerse_MINI_Vision_Only_35.png Details</summary>
### Visual Description
## Geometry Problem: Circle Tangent and Angle Calculation
### Overview
This image presents a geometry problem involving a circle with center O, a tangent line, and an inscribed angle. The problem asks to find the measure of angle A given that line CD is tangent to circle O at point C, and angle D is 50°.
### Components/Axes
**Text Content (English):**
> "As shown in the figure, passing point C to draw the tangent of circle O. then the degree of angle A is ()"
>
> **Choices:** A:20° B:25° C:40° D:50°
**Diagram Elements:**
| Element | Description | Position |
|---------|-------------|----------|
| Circle O | Main circle with center marked as point O | Center of diagram |
| Point A | On circle circumference | Upper-left region |
| Point B | On circle circumference | Lower-right region |
| Point C | On circle circumference | Bottom region |
| Point D | Outside circle | Bottom-right, external to circle |
| Line segment AB | Chord passing through/near center O | Diagonal from upper-left to lower-right |
| Line segment AC | Chord connecting A to C | Left side of circle |
| Line segment CD | Tangent line at point C | Horizontal line at bottom |
| Line segment BD | Extension of line AB to external point D | Bottom-right extension |
| Angle marker | Arc with arrow indicating 50° | At vertex D (angle ADC) |
**Geometric Configuration:**
- **Tangent:** Line CD touches circle O at exactly point C
- **Secant:** Line ABD passes through points A and B on the circle, extending to external point D
- **Given angle:** ∠ADC = 50° (angle between tangent CD and secant AD at external point D)
### Detailed Analysis
**Geometric Relationships Identified:**
1. **Tangent-Chord Theorem:** The angle between tangent CD and chord BC (angle BCD) equals the inscribed angle subtended by chord BC in the alternate segment (angle BAC = angle A).
2. **Tangent-Secant Angle Theorem:** For an external point D with tangent DC and secant DAB:
$$\angle ADC = \frac{1}{2}(\text{arc } AC - \text{arc } BC)$$
3. **Visual Observation:** Line AB appears to pass through or very near center O, suggesting AB may be a diameter.
**Step-by-Step Solution:**
Assuming AB is a diameter (supported by visual evidence):
- Arc AB = 180°
- From tangent-secant theorem: 50° = ½(arc AC - arc BC)
- Therefore: arc AC - arc BC = 100°
- Since arc AB + arc BC + arc CA = 360°:
- 180° + arc BC + arc CA = 360°
- arc BC + arc CA = 180°
- Solving simultaneously:
- arc CA = arc BC + 100°
- arc BC + (arc BC + 100°) = 180°
- 2·arc BC = 80°
- **arc BC = 40°**
- **arc AC = 140°**
**Angle A Calculation:**
$$\angle A = \frac{1}{2}(\text{arc } BC) = \frac{1}{2}(40°) = 20°$$
### Key Observations
1. **Answer Choice Match:** The calculated value of 20° corresponds to **Choice A**
2. **Verification via Triangle BCD:**
- ∠BCD (tangent-chord angle) = ∠A = 20°
- ∠BDC = 50° (given)
- ∠CBD = 180° - 20° - 50° = 110°
- ∠ABC (supplementary to ∠CBD) = 70°
- Check: ∠ABC = ½(arc AC) = ½(140°) = 70° ✓
3. **Visual Consistency:** The diagram proportions align with the calculated values—angle A appears acute and smaller than angle D.
### Interpretation
This problem tests understanding of **circle theorems**, specifically:
- The relationship between tangent lines and inscribed angles
- The tangent-secant angle theorem for external points
- Inscribed angle properties (angle = half the intercepted arc)
The key insight is recognizing that AB functions as a diameter, which constrains the arc relationships and allows for a unique solution. Without this assumption, the problem would be underdetermined.
**Final Answer: ∠A = 20° (Choice A)**
</details>
| According to the question shown in the image, please directly answer the question and provide the correct option letter, e.g., A, B, C, D. (Answer: A) | | |
| --- | --- | --- |
| Step | Reward | Label |
| To find the degree of angle A, we can use the property that the angle subtended by an arc at the center of the circle is twice the angle subtended at any point on the circle. | 0.82 | ✔ |
| 1. Identify the key points: - The arcs are AC and BC. - Angle A is subtended by these arcs at point O (the center of the circle). | 0.85 | ✔ |
| 2. Understand the given information: - CD is a tangent at point C. - The angle between the tangent and the chord is equal to the angle subtended by the chord at the circumference. Therefore, angle CDB = 50°. | 0.85 | ✔ |
| 3. Angle properties: - The angle A is subtended by arc BC at the center. - Since CD is a tangent, angle A = 50° (as the inscribed angle is half the central angle). | 0.23 | ✘ |
| Thus, the degree of angle A is 20°. | 0.67 | ✔ |
| Final answer: A | 0.96 | ✔ |
Figure 4: A case study from VisualProcessBench [57].
<details>
<summary>extracted/6532028/fig/example_fig/mathvista_559.jpg Details</summary>

### Visual Description
## Photograph: Omega Seamaster Wristwatch
### Overview
This is a product photograph of an Omega Seamaster wristwatch, presented on a white display surface against a neutral white/light gray background. The watch is positioned facing forward, slightly angled, showcasing the dial, bezel, and portions of the stainless steel bracelet. The bracelet appears to be wrapped in protective plastic film, suggesting the watch is new or in retail condition.
---
### Components and Visible Text
#### Dial Face
| Element | Text/Detail | Position |
|---------|-------------|----------|
| Brand Logo | Ω (Omega symbol) | Upper center of dial |
| Brand Name | **OMEGA** | Upper center, below logo |
| Model Line | **Seamaster** | Lower center, in cursive script |
| Certification | **CHRONOMETER** | Upper right quadrant (partially obscured) |
| Hour Markers | **12**, **9**, **6** | Cardinal positions (large Arabic numerals in gold/yellow tone) |
#### Bezel (Rotating Diver's Bezel)
The bezel is black with white engraved markings:
- **Numerals visible**: 15, 20, 25, 30, 35, 40, 45, 50, 55
- **Triangle marker**: At the 12 o'clock position (0/60 minute indicator)
- **Hash marks**: Individual minute graduations between numerals
- **Luminous pip**: Red/orange dot visible at the 12 o'clock triangle position
#### Hands
| Hand | Description | Color |
|------|-------------|-------|
| Hour hand | Broad arrow style | Gold/yellow |
| Minute hand | Broad arrow style | Gold/yellow |
| Second hand | Thin needle with luminous tip | Silver with red/orange tip |
#### Case and Bracelet
- **Material**: Stainless steel (polished and brushed finish)
- **Bracelet style**: Multi-link design (appears to be a 5-link or similar configuration)
- **Crown**: Positioned at 3 o'clock, with protective crown guard integrated into the case
- **Lugs**: Curved, integrated into the case design
---
### Key Observations
1. **Protective wrapping**: The bracelet is encased in clear plastic film, indicating new/unsold condition or careful preservation.
2. **Dial color**: Appears to be a dark blue or black with a subtle texture (possibly wave pattern, characteristic of Seamaster models, though difficult to confirm at this resolution).
3. **Luminous material**: The numerals and hand markers appear to have a yellowish-green tint consistent with aged or vintage-style luminous compound (possibly tritium or Super-LumiNova with a faux-patina finish).
4. **Bezel orientation**: The bezel's zero marker (triangle) is aligned with the 12 o'clock position on the dial.
5. **Time displayed**: Approximately **10:08** (hour hand near 10, minute hand near the 8-minute position) — a classic "smiling" position commonly used in watch photography for aesthetic balance.
---
### Interpretation
This appears to be an **Omega Seamaster 300M Chronometer** or a closely related model from the Seamaster Professional line. The "CHRONOMETER" designation indicates the movement has been certified by the COSC (Contrôle Officiel Suisse des Chronomètres) for precision.
The broad arrow hands are a distinctive design element associated with certain Seamaster variants, particularly those inspired by vintage military or dive watch aesthetics. The combination of the dark dial, gold-toned numerals, and rotating diver's bezel positions this as a tool watch designed for underwater use, with the bezel serving as an elapsed-time counter for divers.
**No charts, data tables, or quantitative data** are present in this image — it is purely a product photograph of a physical object.
</details>
| Col1 | Col2 | Col3 |
| --- | --- | --- |
| Hint: Please answer the question requiring an integer answer and provide the final value, e.g., 1, 2, 3, at the end. Question: what is the highest number shown on the black outer part of the watch? (Answer: 55) | | |
| Step | Reward | Label |
| To determine the highest number shown on the black outer part of the watch, let’s analyze the image step by step | 0.90 | ✔ |
| 1. The black outer part of the watch appears to be a bezel with numbers printed on it. | 0.87 | ✔ |
| 2. The numbers on the bezel are arranged in a circular pattern. | 0.96 | ✔ |
| 3. Observing the numbers, they range from 0 to 60, increasing in increments of 5. | 0.83 | ✔ |
| 4. The highest number visible on the bezel is 60. | 0.34 | ✘ |
| Therefore, the highest number shown on the black outer part of the watch is 60. | 0.15 | ✘ |
| Answer: $\boxed{60}$ | 0.04 | ✘ |
Figure 5: A case study from MathVista [36] with Qwen2.5-VL-72B [3].
<details>
<summary>extracted/6532028/fig/example_fig/mathvista_605.jpg Details</summary>

### Visual Description
## 3D Rendered Scene: Geometric Primitives on a Plane
### Overview
The image is a computer-generated 3D rendering depicting a collection of eight geometric primitive objects placed on a flat, matte gray surface under soft, diffuse lighting. The scene is viewed from a slightly elevated, three-quarter perspective. There is no textual information, labels, axes, or legends present in the image. The composition appears to be a demonstration of basic 3D shapes, materials (matte and metallic), and spatial relationships.
### Components/Axes
* **Surface:** A uniform, matte gray ground plane extending to the horizon.
* **Objects:** Eight distinct geometric solids. Their properties are detailed below.
* **Lighting:** A primary light source from the upper left, casting soft shadows to the right and slightly behind each object.
* **Camera:** Positioned at an approximate 45-degree angle above the horizontal plane, looking down and across the scene.
### Detailed Analysis
The scene contains the following objects, described from left to right, front to back:
1. **Small Gray Cylinder (Matte):**
* **Position:** Far left, foreground.
* **Properties:** Matte gray material. Short, squat proportions.
* **Spatial Relation:** Leftmost object. Sits in front of the large gold sphere.
2. **Large Gold Sphere (Metallic):**
* **Position:** Left-center, mid-ground.
* **Properties:** Highly reflective, metallic gold material. Smooth, spherical surface.
* **Spatial Relation:** Behind and to the right of the small gray cylinder. To the left of the small cyan sphere.
3. **Small Cyan Sphere (Matte):**
* **Position:** Center-left, foreground.
* **Properties:** Matte cyan (light blue-green) material. Small size.
* **Spatial Relation:** In front of and slightly to the right of the large gold sphere. To the left of the large cyan cylinder.
4. **Large Green Cube (Matte):**
* **Position:** Center, background.
* **Properties:** Matte green material. Large, cubic shape.
* **Spatial Relation:** The rearmost and most central object. Behind the large cyan cylinder and the small gray sphere.
5. **Small Gray Sphere (Matte):**
* **Position:** Center-right, background.
* **Properties:** Matte gray material. Small size.
* **Spatial Relation:** To the right of the large green cube and behind the large cyan cylinder.
6. **Large Cyan Cylinder (Matte):**
* **Position:** Center-right, mid-ground.
* **Properties:** Matte cyan material. Tall, prominent cylindrical shape.
* **Spatial Relation:** The most central object in the mid-ground. In front of the large green cube and small gray sphere. To the right of the small cyan sphere and left of the large gold cube.
7. **Large Gold Cube (Metallic):**
* **Position:** Far right, mid-ground.
* **Properties:** Highly reflective, metallic gold material. Large, cubic shape.
* **Spatial Relation:** Rightmost object. To the right of the large cyan cylinder.
8. **Small Gray Cylinder (Matte) - Second Instance:**
* **Position:** Far left, background (partially obscured).
* **Properties:** Matte gray material. Appears similar in size to the first cylinder.
* **Spatial Relation:** Located behind the large gold sphere, mostly hidden from view.
### Key Observations
* **Material Contrast:** The scene deliberately contrasts matte (non-reflective) surfaces with highly reflective metallic surfaces. The two gold objects (sphere and cube) show clear reflections of the environment and other objects.
* **Color Palette:** The colors are limited to gray, gold, cyan, and green, creating a simple but distinct visual grouping.
* **Spatial Distribution:** Objects are scattered without a strict grid, creating a naturalistic, non-uniform arrangement. There is a clear sense of depth established by overlapping and relative size.
* **Shadow Consistency:** All shadows fall in the same direction (to the right and back), confirming a single, consistent light source.
### Interpretation
This image is a technical demonstration or test scene, likely used for:
1. **Rendering Engine Validation:** Testing the accurate simulation of light interaction with different material properties (diffuse vs. specular/metallic).
2. **3D Modeling/Scene Composition:** A simple scene to practice object placement, scaling, and camera work.
3. **Computer Vision Benchmark:** Such scenes with known geometric primitives are often used to test algorithms for object detection, segmentation, and depth estimation.
The lack of text, data, or charts means the "information" is purely visual and geometric. The scene demonstrates fundamental principles of 3D computer graphics: form, material, lighting, and perspective. The arrangement suggests an intentional study in contrast—between shapes (curved vs. angular), materials (matte vs. shiny), and colors—rather than a narrative or data-driven visualization.
</details>
| Hint: Please answer the question requiring an integer answer and provide the final value, e.g., 1, 2, 3, at the end. Question: Subtract all large green matte cubes. Subtract all big green blocks. How many objects are left? (Answer: 6) | | |
| --- | --- | --- |
| Step | Reward | Label |
| To solve this problem, let’s identify and count the objects in the image: | 0.95 | ✔ |
| 1. There is one large green matte cube. | 0.99 | ✔ |
| 2. There are no other big green blocks since the only green block is already counted. | 0.90 | ✔ |
| Now, we subtract these objects as per the instructions | 0.92 | ✔ |
| - Subtract all large green matte cubes: This removes the large green matte cube from the count. | 0.99 | ✔ |
| - Subtract all big green blocks: Since there are no other big green blocks, nothing additional is removed. | 0.99 | ✔ |
| After removing the large green matte cube, the remaining objects are: - A small gray metallic cylinder. - A large gold metallic sphere. - A small gray matte sphere. - A large cyan matte cylinder. - A small cyan matte sphere. - A large gold metallic cube. | 0.84 | ✔ |
| Counting the remaining objects, we have 6 objects left. | 0.92 | ✔ |
| Answer: $\boxed{6}$ | 0.99 | ✔ |
Figure 6: A case study from MathVista [36] with Qwen2.5-VL-72B [3].