# StepProof: Step-by-step verification of natural language mathematical proofs
**Authors**:
- Xiaolin Hu (School of Computing and Mathematical Sciences)
- Leicester, UK
- &Qinghua Zhou (Department of Mathematics)
- London, UK
- &Bogdan Grechuk (School of Computing and Mathematical Sciences)
- Leicester, UK
- &Ivan Y. Tyukin (Department of Mathematics)
- London, UK
## Abstract
Interactive theorem provers (ITPs) are powerful tools for the formal verification of mathematical proofs down to the axiom level. However, their lack of a natural language interface remains a significant limitation. Recent advancements in large language models (LLMs) have enhanced the understanding of natural language inputs, paving the way for autoformalization—the process of translating natural language proofs into formal proofs that can be verified. Despite these advancements, existing autoformalization approaches are limited to verifying complete proofs and lack the capability for finer, sentence-level verification. To address this gap, we propose StepProof, a novel autoformalization method designed for granular, step-by-step verification. StepProof breaks down complete proofs into multiple verifiable subproofs, enabling sentence-level verification. Experimental results demonstrate that StepProof significantly improves proof success rates and efficiency compared to traditional methods. Additionally, we found that minor manual adjustments to the natural language proofs, tailoring them for step-level verification, further enhanced StepProof’s performance in autoformalization. Our project is available on https://github.com/r1nIGa/STEP-PROOF
K eywords Autoformalization $·$ Theorem Prover $·$ Natural Language Processing
## 1 Introduction
Mathematics is the basic tool for the development of science, and the reliability of its conclusions affects the stable growth of various disciplines. With the development of the mathematical edifice, mathematical proofs have become more complex and lengthy. The verification of mathematical proof often requires years of careful verification to ensure the accuracy of the work. However, reading a mathematical work requires a large amount of knowledge, and in the face of the many branches of mathematics today, traditional manual verification has become increasingly disastrous. Thus, an idea arose to validate mathematical work written in natural language automatically.
At present, there are two kinds of automatic verification of mathematical proof. One is to write the mathematical certificate into a machine code that can be verified by a specific expert system, which is called the interactive theorem prover (HARRISON2014135, ). After more than 40 years of development, the interactive theorem prover has begun to take shape and has been used in the verification of many mathematical works (maric2015survey, ). However, because such machine-verifiable proofs need to be written in a specific programming language, whose learning cost is relatively high, interactive theorem provers are only used by a small number of mathematicians at present (nawaz2019survey, ).
On the other hand, after the advent of the large language model (zhao2023survey, ), through prompt engineering (liu2023pre, ) and few shot learning (wang2020generalizing, ), large language model can be applied to many natural language processing tasks, and achieved considerable performance (achiam2023gpt, ). However, due to the hallucination problem of large language model (ji2023survey, ), its performance in mathematics and strong logic-related work is not good enough (huang2023large, ), so the lack of reliability of large language model to verify mathematical work is easy to cause a lot of errors. In this context, a method that combines large language models and theorem provers gradually comes into people’s view, which is called autoformalization verification (li2024survey, ).
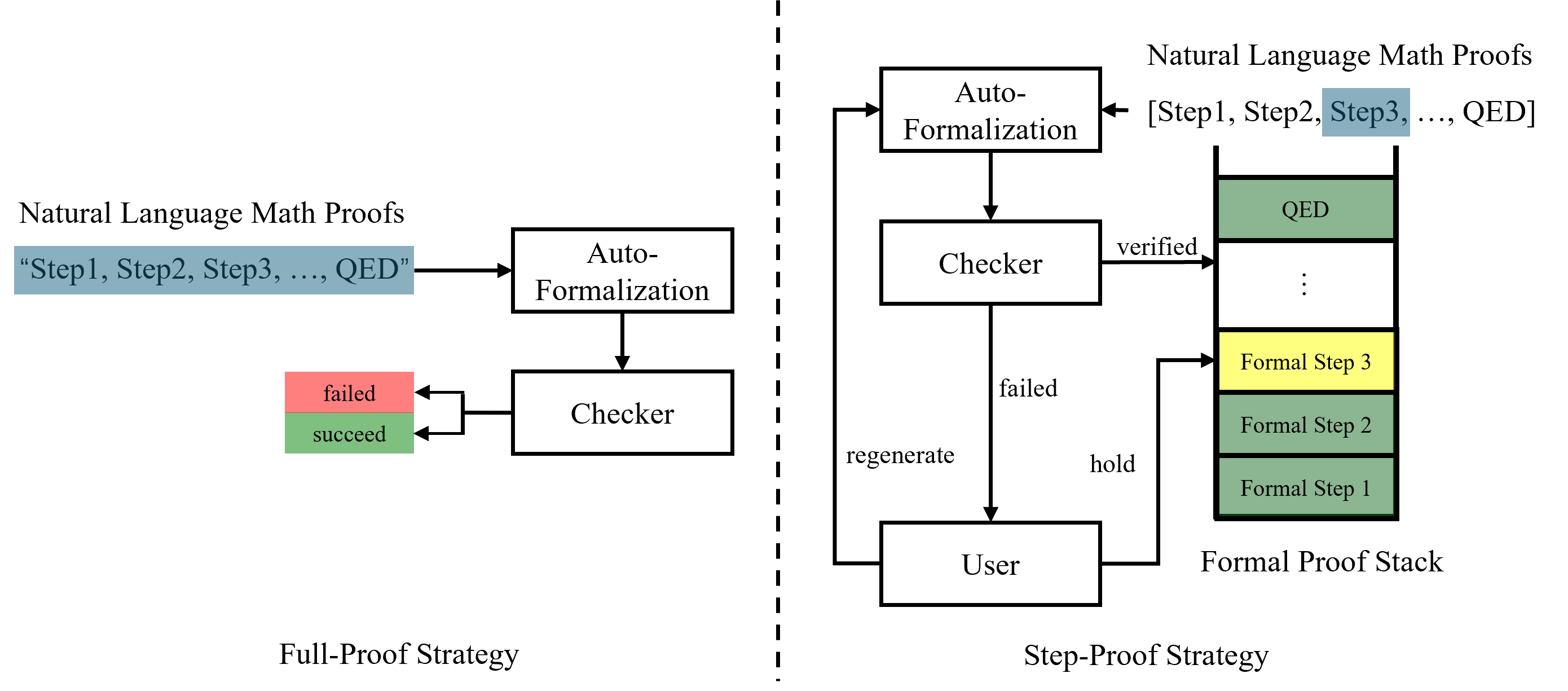
At present, the existing automatic formal verification work generally adopts a FULL-PROOF strategy. Although such a strategy has achieved some impressive performance in some studies, there are still many problems in the stability of its proof and the fine-grained verification. Aiming at the problems existing in FULL-PROOF, we innovatively propose a new automatic formal proof strategy, STEP-PROOF. And the performance of StepProof is better than traditional methods in several aspects.
In summary, our contributions mainly include the following points: 1. We pioneered a novel natural language mathematical verification method StepProof, which realizes informal mathematical proof verification at the sentence level. 2. We were the first to realize the test of automatic formalization capabilities on small open-source LLMs. 3. Compared with existing methods, the StepProof method has been significantly improved in all aspects of performance.
In this paper, we will first make a brief summary of the existing relevant works and the technical background in Chapter 2. In Chapter 3, we will give a detailed introduction to the two types of strategies, FULL-PROOF and STEP-PROOF, and point out many problems faced by traditional methods. In Chapter 4, we set up a series of experiments to verify the performance of STEP-PROOF in verification tasks and its superiority over FULL-PROOF. At the same time, we also carried out a detailed analysis of some phenomena observed in the experiment to further explain the reason for the advantages. In the end, we analyze and look forward to the current limitations and future development direction.
## 2 Related Work
Theorem Prover: Theorem provers can be roughly divided into two types, interactive theorem provers (ITPs) in which the user can enter and verify the existing proof (asperti2009survey, ), and automated theorem provers (ATPs) that try to prove the statements fully automatically (harrison2013survey, ). The two types of theorem provers are not mutually exclusive (nawaz2019survey, ). Most ITPs such as Isabelle (paulson1994isabelle, ), Coq (huet1997coq, ) and Lean (de2015lean, ) are supported by ATPs that try to automatically prove ”obviously” intermediate steps in the proof entered by the user. The entered proofs are rigorously verified back to the axioms of mathematics. Different ITPs use different axiomatic foundations, e.g. set theory, first-order logic, higher-order logic, etc. Each ITP use its own language and syntax, which makes the learning cost of theorem prover high, and precludes ITPs from being widely used (yushkovskiy2018comparison, ).
Large Language Model: In recent years, large language models (LLMs) have achieved outstanding performance in many downstream tasks of natural language processing. LLMs such as Llama (dubey2024llama, ), GPT series (ye2023comprehensive, ) and GLM 4 (glm2024chatglm, ) are trained on large databases to understand user input in natural language and produce the related output. While large language models perform well in general tasks such as translation, their performance in dealing with logic problems has been limited. A lot of work has also shown that large language models are prone to a variety of problems when dealing with logic problems (yan2024large, ; wan2024b, ). Although in the subsequent iteration of the model, the developers provided a large amount of high-quality logic-related data to improve the logic capability of the model, the effect that could be achieved was still very limited (lappin2024assessing, ). Therefore, it has become a trend to add an expert system to the model to improve its accuracy, such as RAG (fan2024survey, ), which is currently commonly used in question-answering systems. On the other hand, step-by-step reasoning has been proven can improve the reasoning ability of existing LLMs (wei2022chain, ; khot2022decomposed, ), which gives us a hint to apply in autoformalization.
Autoformalization: The definition of automatic formalization is very broad, but can be roughly seen as understanding and extracting translation from natural language to obtain the required structured data or formal language, such as entity relation extraction (nguyen2015relation, ). Early automatic formalization work involved extracting logical propositions from natural language in addition to entity relation extraction (singh2020exploring, ; lu2022parsing, ). However, the main problem in this kind of work is that the extracted logical propositions lack corresponding symbols for derivation and application, so the output of the automatic formalization output cannot be directly applied. With the launch of pre-trained language models such as transformer and BERT, language models have a stronger understanding ability. Wang et al. (wang2020exploration, ) conducted an early automatic formalization attempt for the theorem prover Mizar. However, due to the limited size and training expectations of the models at that time, the effects they could achieve were very limited. With the rapid expansion of the scale of models and predictions, many new and better performance automatic formalization work has emerged, such as the Majority Voting method by Lewkowycz et al. (lewkowycz2022solvingquantitativereasoningproblems, ), the DSP method by Jiang et al. (jiang2022draft, )., and the method proposed by Zhou et al. (zhou2024don, ), in DTV (Don’t Trust: Verify). They further improved the automatic formalization of the system by combining large models with some syntax-modifying filters. However, on the one hand, all these works are tested in the closed-source large model Minerva, which lacks the testing work of open source model and small model. Meanwhile, all these works adopt the strategy of FULL-PROOF, which has poor controllability for the formal output of the model, and it is difficult to locate the error point of non-formal proof. Qinghua et al. proposed a problem location method based on the FULL-PROOF strategy in SlideRule. However, this method relies heavily on the format and quality of the generated formal content, so it cannot achieve 100% problem locations detected. To solve these problems, we propose StepProof, an automatic formalization strategy that can realize sentence-level verification, to realize the verification of natural language mathematical proofs. Moreover, LEGO-Prover (wang2023lego, ) proposed a new methodology to decompose the whole proof into several sub-proofs. Although the idea of step-proof is taking shape, it still requires some extra generation of the sub-proof formal statement generation, which increases the error probability of formalization.
## 3 StepProof
In this chapter, we will provide a detailed introduction to the workflow design of StepProof. We will also compare the STEP-PROOF strategy used by StepProof with the FULL-PROOF strategy adopted by existing autoformalization systems, highlighting the problems with traditional strategies and the advantages of STEP-PROOF over FULL-PROOF.
### 3.1 FULL-PROOF
Current research on natural language proofs formal verification predominantly employs the FULL-PROOF strategy, as seen in methods like DSP and DTV. The workflow of FULL-PROOF method can be roughly illustrated as the left of Figure 1. Users submit a provable problem along with its proof process. The problem is first formalized, then the informal problem, the formalized problem, and the entire informal proof are packaged as inputs to a large language model for formalization. After obtaining the formal proof, it is combined with the formalized problem and input into a theorem prover for rule-based formal verification. The verification results are then returned to the user. Despite the clarity and simplicity of the FULL-PROOF workflow, it has significant drawbacks.
<details>
<summary>extracted/6582548/strategy.png Details</summary>
### Visual Description
## Diagram: Comparison of Full-Proof vs. Step-Proof Strategies for Formalizing Mathematical Proofs
### Overview
The image is a technical diagram comparing two distinct strategies for converting natural language mathematical proofs into formal, machine-verifiable proofs. The diagram is split vertically by a dashed line. The left side illustrates the "Full-Proof Strategy," a linear, all-or-nothing process. The right side illustrates the "Step-Proof Strategy," an iterative, step-by-step process involving user interaction and a proof stack.
### Components/Axes
The diagram contains no traditional chart axes. It is composed of labeled boxes, arrows indicating flow, and text labels.
**Left Side (Full-Proof Strategy):**
* **Input Label (Top-Left):** "Natural Language Math Proofs"
* **Input Data (Below label, in a blue box):** `"Step1, Step2, Step3, ..., QED"`
* **Process Box 1 (Center-Left):** "Auto-Formalization"
* **Process Box 2 (Below Box 1):** "Checker"
* **Output Labels (Left of Checker, stacked):**
* Top (Red box): "failed"
* Bottom (Green box): "succeed"
* **Strategy Label (Bottom-Left):** "Full-Proof Strategy"
**Right Side (Step-Proof Strategy):**
* **Input Label (Top-Right):** "Natural Language Math Proofs"
* **Input Data (Below label):** `[Step1, Step2, Step3, ..., QED]` (Note: "Step3" is highlighted with a blue background).
* **Process Box 1 (Top-Center):** "Auto-Formalization"
* **Process Box 2 (Center):** "Checker"
* **Process Box 3 (Bottom-Center):** "User"
* **Data Structure (Right side, vertical stack):** Labeled "Formal Proof Stack" at the bottom. It contains stacked blocks:
* Top block (Green): "QED"
* Middle blocks (Grey with vertical ellipsis "⋮"): Representing intermediate steps.
* Highlighted block (Yellow): "Formal Step 3"
* Lower blocks (Green): "Formal Step 2", "Formal Step 1"
* **Flow Labels (On arrows):**
* From "Checker" to "Formal Proof Stack": "verified"
* From "Checker" to "User": "failed"
* From "User" to "Auto-Formalization": "regenerate"
* From "User" to "Formal Proof Stack": "hold"
* **Strategy Label (Bottom-Right):** "Step-Proof Strategy"
### Detailed Analysis
**Full-Proof Strategy Flow:**
1. The entire natural language proof (`"Step1, Step2, Step3, ..., QED"`) is fed as a single input into the "Auto-Formalization" module.
2. The output of "Auto-Formalization" goes to a "Checker".
3. The "Checker" produces a binary outcome: either the entire formalized proof is accepted ("succeed", green) or it is rejected ("failed", red). There is no intermediate state or recovery mechanism shown.
**Step-Proof Strategy Flow:**
1. The natural language proof is presented as a list of steps: `[Step1, Step2, Step3, ..., QED]`.
2. The process begins with "Auto-Formalization" (presumably for the current step).
3. The output goes to the "Checker".
4. **If verification succeeds:** The formalized step (e.g., "Formal Step 3") is added to the "Formal Proof Stack" (indicated by the "verified" arrow). The stack is built from the bottom up ("Formal Step 1" at the base, "QED" at the top).
5. **If verification fails:** The flow goes to the "User" (indicated by the "failed" arrow).
6. The "User" has two options:
* **"regenerate":** Send a request back to "Auto-Formalization" to try formalizing the step again.
* **"hold":** Manually intervene and place a step (e.g., "Formal Step 3") into the "Formal Proof Stack". This suggests the user can override or manually input a formal step.
### Key Observations
1. **Granularity:** The Full-Proof Strategy operates on the entire proof as a monolithic block. The Step-Proof Strategy decomposes the proof into individual steps (`Step1`, `Step2`, etc.).
2. **Feedback Loop:** The Step-Proof Strategy introduces a critical feedback loop involving a "User" upon failure, enabling iteration ("regenerate") and manual intervention ("hold"). The Full-Proof Strategy has no such loop; failure is terminal.
3. **State Management:** The Step-Proof Strategy maintains state via the "Formal Proof Stack," which accumulates verified formal steps. The Full-Proof Strategy is stateless, with only a final pass/fail result.
4. **Visual Emphasis:** In the Step-Proof Strategy's input, "Step3" is highlighted in blue, and its corresponding formal output "Formal Step 3" is highlighted in yellow in the stack. This visually links a specific natural language step to its formal counterpart in the process.
5. **Color Coding:** Green consistently indicates success/verification ("succeed", "QED", verified steps in the stack). Red indicates failure. Yellow highlights a specific step of interest within the iterative process.
### Interpretation
This diagram contrasts two philosophical and practical approaches to the challenge of auto-formalization (translating informal human math into formal logic).
* **The Full-Proof Strategy** represents a "black box" or一次性 (one-shot) approach. It is simple and automated but brittle. If any part of the proof is problematic, the entire process fails, offering no diagnostic path or partial success. It mirrors attempting to compile a whole program at once; a single syntax error fails the build.
* **The Step-Proof Strategy** represents an interactive, incremental, and collaborative approach. It acknowledges that formalizing complex proofs is error-prone and benefits from human-in-the-loop oversight. By breaking the problem down, it allows for:
* **Progressive Verification:** Building a correct proof one step at a time.
* **Error Isolation:** Identifying exactly which step (`Step3` in the example) is causing failure.
* **Recovery and Intervention:** The user can either ask the system to try again or manually supply the correct formal step, ensuring progress isn't halted by a single difficult step.
The "Formal Proof Stack" is a key metaphor, visualizing the proof as a structure being constructed layer by layer. The diagram argues that for robust and practical auto-formalization, a stepwise, verifiable, and user-guided process (Step-Proof) is superior to a monolithic, all-or-nothing one (Full-Proof). It highlights the importance of interactivity and incremental state management in complex AI-assisted reasoning tasks.
</details>
Figure 1: Full-Proof Strategy generate from the whole proof and only provide proof result instead of detailed feedback to help user improve the proof. While Step-Proof separate the whole proof into sub-proof to proof from the bottom to the top and enable the user to get more detailed feedback and fine-grained operation.
First, in the FULL-PROOF automated formalization process, the highly structured and formalized nature of the input and output, coupled with the numerous similarities in solving mathematical equations, often leads to excessive noise in the output. To obtain the desired formalized content, numerous filters must be set up, which results in considerable waste and contamination of generated content. This can also cause generation loops, where the same content is repeatedly generated, a common issue in FULL-PROOF strategies.
Additionally, the length of proofs varies, and LLMs in FULL-PROOF struggle to adjust the output’s max_new_tokens effectively based on input length. This leads to shorter proofs not being truncated in time, thus generating repetitive or noisy content, and longer proofs lacking sufficient max_new_tokens.
Lastly, the stability of FULL-PROOF generation is poor. For instance, a full proof might be almost entirely correct except for a minor error in a small step, leading to the failure of the entire formal proof. Users attempting regeneration may find previously correct parts presenting erroneous. Thus, FULL-PROOF requires highly accurate one-time generation of the entire content.
Moreover, the correlation between formal and informal content generated by FULL-PROOF is weak, making it difficult for users to map formal feedback to corresponding informal content. Although LLMs can generate formal proofs with annotations to map back to informal proofs as Qinghua et al proposed the failure step detection method in SlideRule, this approach is unstable in practice and increases the required token count.
### 3.2 STEP-PROOF
<details>
<summary>extracted/6582548/user_interface.png Details</summary>
### Visual Description
## Screenshot: Step Proof Software Interface
### Overview
The image displays a graphical user interface (GUI) of a software application named "Step Proof." The application appears to be a proof assistant or educational tool for constructing and verifying mathematical proofs. The interface shows a completed step-by-step proof for a number theory problem concerning integer divisibility and the greatest common divisor (GCD).
### Components/Axes (UI Elements)
The interface is structured into several distinct regions:
1. **Window Frame & Title Bar:**
* Title: "Step Proof"
* Standard window control buttons (minimize, maximize, close) are visible in the top-right corner.
2. **Menu Bar:**
* Contains a single menu item: "File".
3. **Problem Statement Area:**
* A button labeled "Upload Problem" is centered above the main text area.
* The problem is stated in a monospaced font:
* **Header:** "PROBLEM:"
* **Statement:** "Let $a, b, n$ be integers. Prove that if $a | n$ and $b | n$ with $gcd(a, b) = 1$ then $ab | n$."
* **Header:** "PROOFS:"
4. **Proof Construction Area (Main Text Box):**
* This area contains the user-written or generated proof, with completed logical steps highlighted in green.
* The text is a mix of natural language and mathematical notation (using `$` as inline math delimiters).
* **Transcription of Proof Text:**
* "Since $a|n$, $n$ could be rewritten as $(n/a)*a$."
* "Therefore, $b|n$ is equal to $b|(n/a)*a$."
* "Since $gcd(a,b)=1$ and $b|(n/a)*a$, it means that $b|(n/a)$."
* "By multiple $a$ on the both side of $b|(n/a)$, we will know that $b*a|(n/a)*a$ and we can get $a*b|n$."
* "QED"
5. **Interactive Proof Step Panel ("Add Proof"):**
* This section below the main text box breaks the proof into discrete, interactive steps. Each step has a descriptive line and a corresponding formal tactic line.
* **Step h1:**
* Description: "Since $a|n$, $n$ could be rewritten as $(n/a)*a$."
* Tactic: `have h1: "n = n div a * a" using assms(1) sledgehammer`
* **Step h2:**
* Description: "Therefore, $b|n$ is equal to $b|(n/a)*a$."
* Tactic: `have h2: "b dvd n div a * a" using assms(2) sledgehammer`
* **Step h3:**
* Description: "Since $gcd(a,b)=1$ and $b|(n/a)*a$, it means that $b|(n/a)$."
* Tactic: `have h3: "b dvd n div a" using assms(3) h2 sledgehammer`
* **Step h4:**
* Description: "By multiple $a$ on the both side of $b|(n/a)$, we will know that $b*a|(n/a)*a$ and we can get $a*b|n$."
* Tactic: `have h4: "a * b dvd n" using h3 sledgehammer`
* **Final Step:**
* Text: "QED"
* Tactic: `then show ?thesis by auto`
* **Control Buttons:** Each proof step (h1-h4 and the final step) is accompanied by a row of five buttons: `PROOF`, `HIDE`, `REGEN`, `HOLD`, `UNDO`.
6. **Status Bar:**
* Located at the very bottom of the window.
* Text: "Status: Proof has been completed."
### Detailed Analysis / Content Details
* **Problem Type:** The problem is a classic theorem in elementary number theory: If two coprime integers (`a` and `b`) both divide a third integer (`n`), then their product (`ab`) also divides `n`.
* **Proof Logic:** The proof follows a standard structure:
1. Express `n` as `a * (n/a)` using the premise `a | n`.
2. Substitute this into the premise `b | n` to get `b | a*(n/a)`.
3. Apply Euclid's Lemma (which relies on `gcd(a,b)=1`) to conclude `b | (n/a)`.
4. Multiply both sides of the divisibility relation by `a` to arrive at `ab | n`.
* **Software Functionality:** The interface suggests an interactive theorem prover. The "sledgehammer" tactic references indicate the use of automated reasoning tools to find proofs. The buttons (`PROOF`, `REGEN`, etc.) imply users can step through, regenerate, or modify individual proof steps.
### Key Observations
1. **Visual Feedback:** The green highlighting in the main text box clearly indicates which parts of the informal proof have been successfully formalized or verified by the system.
2. **Dual Representation:** The software maintains both a human-readable, informal proof description and a corresponding formal, machine-oriented tactic script for each step.
3. **Proof Completion:** The status bar and the final "QED" / `show ?thesis by auto` step confirm the proof has been successfully completed and verified by the system.
4. **Language:** The primary language of the interface and proof text is English. The mathematical notation is language-agnostic.
### Interpretation
This screenshot captures a successful interaction with a sophisticated educational or research tool for formal mathematics. It demonstrates how such software bridges the gap between intuitive, human-written proofs and the rigorous, step-by-step verification required by a computer.
The data (the proof steps) shows a logically sound and complete argument. The interface elements reveal the tool's pedagogical or exploratory nature: it allows users to construct proofs incrementally, get automated assistance ("sledgehammer"), and review or modify each step. The clear separation between the informal reasoning and the formal tactics helps users learn how to translate mathematical ideas into a formal system.
The "Upload Problem" button suggests this is part of a larger workflow where users can input their own theorems to prove. The overall state—"Proof has been completed"—represents the successful endpoint of that workflow for this specific divisibility theorem.
</details>
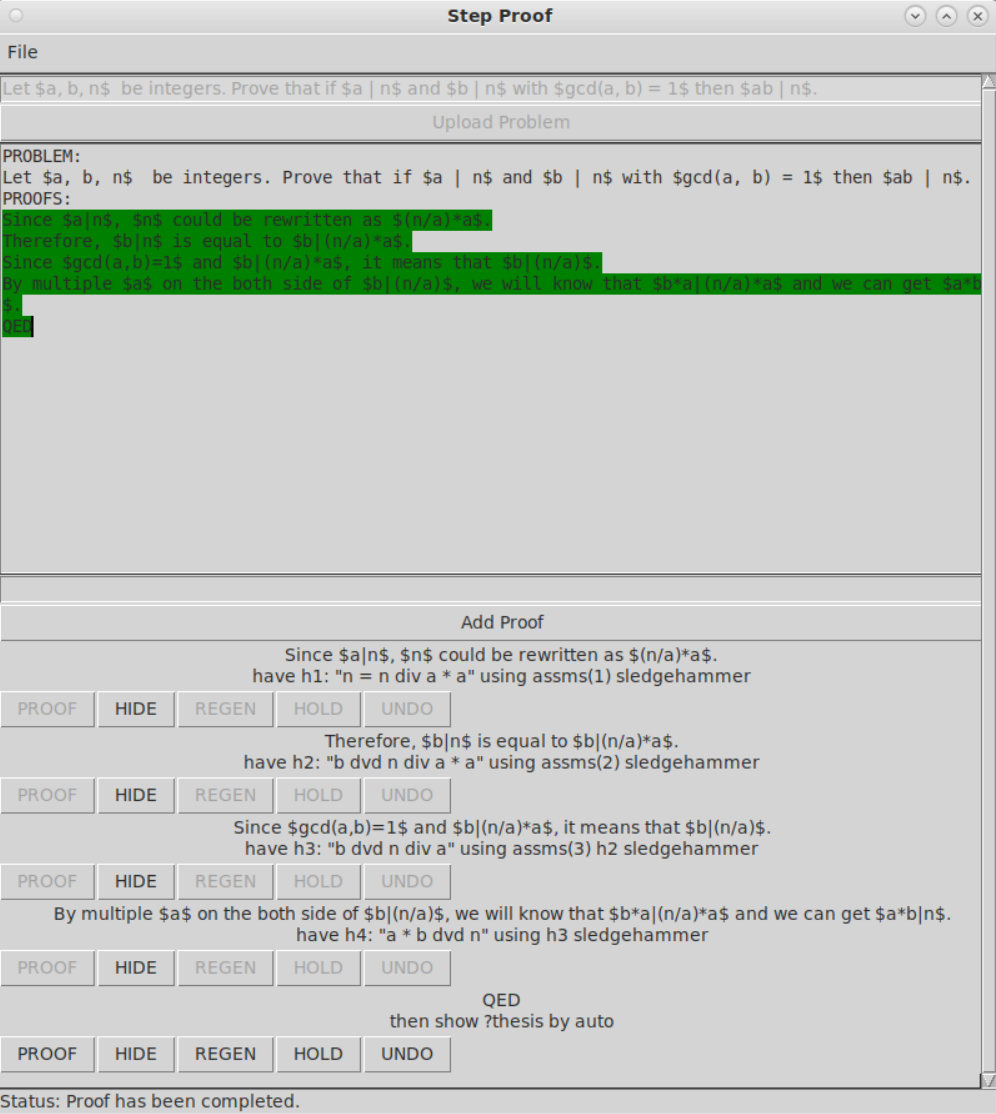
Figure 2: User Interface of StepProof
To address the numerous issues faced by the FULL-PROOF strategy, we innovatively propose STEP-PROOF. STEP-PROOF employs a step-by-step generation and verification strategy, offering better performance and stability compared to FULL-PROOF. The workflow of STEP-PROOF is illustrated in the right of Figure 1.
Unlike the one-time generation and verification of FULL-PROOF, STEP-PROOF assumes each sentence in the proof is a verifiable sub-proposition. Each step is formalized and pushed onto a formal proof stack, where it is verified along with other sub-propositions in the stack. Upon successful verification, the formalized proof and informal proof are packaged as inputs for the next step. For failed steps, the Step Proof allows users to backtrack, retaining previously verified steps and only clearing the erroneous step from the stack. The StepProof can then either re-formalize or optimize the existing informal step as needed.
STEP-PROOF offers several advantages over FULL-PROOF. First, it only needs to formalize single sentences in context, resulting in shorter, less noisy, and more stable output. The step-by-step generation strategy also means that each step’s length is relatively fixed, eliminating the need for adjusting max_new_tokens and allowing the use of smaller max_new_tokens for formalizing longer theorems.
Moreover, STEP-PROOF’s incremental generation and verification tolerate step errors well. Only the specific erroneous step needs to be retracted, rather than regenerating the entire content, enhancing robustness and efficiency. Finally, Step Proof ensures high correspondence between each informal and formal proof step, providing users with finer operational granularity. For instance, users can suspend a correct but incomplete step and assume it is correct to proceed, a functionality almost impossible under the FULL-PROOF strategy.
We also designed a simple and user-friendly interactive interface for the user, as shown in Figure 2. Users can complete the natural language proof of the problem through interface interaction, and each step of the proof will be formally verified after submission, and the verified proof step will be marked in green in the background to indicate that the current step has passed the verification and is reliable. If the current step does not pass the automatic validation but the user thinks it is true and wants to continue, you can select HOLD, and the current step will be highlighted in yellow in the background to indicate that the current step is in a suspended state. After completing all the proof steps, the user can input QED to indicate that the system has completed the proof, and the system will combine all the steps to perform the final verification of the proof target. Through the interactive interface, the user can also realize the PDF export of the proof process.
## 4 Experiment
### 4.1 Experiment Setup
To validate the performance advantages of the STEP-PROOF strategy over FULL-PROOF, and to compare StepProof’s overall performance against existing automated formal proof methods, we conducted both strategy performance tests and baseline tests using the same dataset and model settings.
For the test dataset, we used GSM8K, which includes a large number of informal mathematical problems and their correct informal proofs. These informal proofs can be easily segmented into a series of sub-steps. We chose Llama3 8B-Instruct as the large language model for automated formalization. Existing autoformalization tests use closed-source models, and we aim to fill this gap by using an open-source small LLMs.
We set the temperature to 0.3 to balance stability and flexibility. Given the small parameter count of 8B, we used a single example for the few-shot in strategy performance tests. With proof steps in GSM8K (cobbe2021gsm8k, ) averaging 4-5 steps, we set the max_new_tokens for FULL-PROOF to 1024, and 256 for each step in Step Proof. The test environment consisted of a single NVIDIA A4000 16GB, 8 cores of AMD5800X, and 32GB DDR4 3200 RAM. Isabelle2024 was used as the formal theorem prover with only Main prove library as the theorem base Here, we only use Main as the proof library, considering that the use of different libraries will greatly affect the formal verification ability of the theorem prover, in order to provide a relatively standard index. In StepProof, we do not introduce other libraries to further improve the proof ability of the theorem prover. Introducing more libraries in practice will greatly improve the proof ability of the theorem prover, and also improve the proof ability of the whole system to some extent., with Isabelle-client (shminke2022python, ) as the testing service proxy.
In the strategy performance tests, we evaluated the performance of FULL-PROOF and STEP-PROOF on the GSM8K test set using the following metrics: 1. One-attempt generation proof pass rate $r_p$ . 2. Average formalization time for passed proofs $μ_f$ . 3. Variance in formalization time $σ_f^2$ . 4. Average proof time for passed proofs $μ_p$ . 5. Variance in proof time $σ_p^2$ .
In the baseline tests, we compared the multi-attempt test results of GSM8K by Lewkowycz et al. (lewkowycz2022solvingquantitativereasoningproblems, ) in Majority Voting and Zhou et al. (zhou2024don, ) in DTV with our results. We evaluated the performance based on the number of attempts and multi-round proof pass rate, allowing up to 10 retries for each failed step in each formalization attempt.
At the same time, considering that StepProof has better granularity than traditional proof tasks, we not only evaluated the overall proof passing rate but also counted the proportion of step-proof passing. For example, if a 6-step proofs can be verified to be true in 3 steps, then we will mark that the step pass rate of the proof is 0.5. In this way, we quantify the formal proof capability of the method more comprehensively rather than the Proof Passing Rate.
In addition, to verify the influence of the writing method of non-formal proof on the passing rate of StepProof formal proof, we extracted 100 questions from the Number theory of MATH (hendrycksmath2021, ) and made simple manual modifications to make the proof step more consistent with the proof requirement of StepProof.
### 4.2 Experiment Results
| | Proof Passing Rate $r_p$ | Formalization Time $μ_f±σ_f^2$ | Proof Time $μ_p±σ_p^2$ |
| --- | --- | --- | --- |
| FULL-PROOF | 5.30% | 9.54 ± 12.64s | 214.93 ± 20864.97s |
| STEP-PROOF | 6.10% | 5.83 ± 4.24s | 130.12 ± 5271.65s |
Table 1: Performance Test of Full-Proof and Step-Proof
In strategy performance tests, the STEP-PROOF strategy outperformed the FULL-PROOF strategy across the board on the GSM8K test set. As shown in Table 1, the STEP-PROOF strategy improved the one-attempt proof pass rate by 15.1% compared to FULL-PROOF. In terms of average formalization time, STEP-PROOF required 38.9% less time than FULL-PROOF. For average proof time, STEP-PROOF achieved a 39.5% performance improvement over FULL-PROOF. Additionally, STEP-PROOF showed more stability in both formalization and proof time compared to FULL-PROOF. These results confirm that our strategy offers better performance, efficiency and stability.
| Majority Voting Don’t Trust:Verify* StepProof | 64 64 10 | 16.2% 25.3% 22.0% | - 31.3% 100% | Minerva 8B Llama3 8B GLM4 9B(4bit) |
| --- | --- | --- | --- | --- |
| StepProof | 10 | 27.9% | 100% | Llama3 8B |
Table 2: Baseline Test in GSM8K
In the baseline test as shown in Table 2, Step Proof surpassed DTV in multi-round verification tests on GSM8K, achieving a 10.3% performance improvement. Moreover, StepProof required fewer attempts compared to DTV Don’t Trust: Verify (DTV) originally used two close source models–GPT3.5 as the problem generation model and Minerva 8B as the proof generation model, while due to the Minerva being inaccessible and GPT3.5 being costing, we use the same method in DTV, but replace the LLM into Llama3., demonstrating its superior proof capability and further validating the advantages of the StepProof methods.
| $0=r_s$ $0<r_s$ $0.5≤ r_s$ | 79.6% 20.4% 14.6% | 50.5% 49.5% 38.1% | 83.9% 16.1% 13.4% | 55.4% 44.6% 41.9% |
| --- | --- | --- | --- | --- |
| $1=r_s$ | 6.1% | 27.9% | 4.8% | 22.0% |
Table 3: Step Passing Rate Distribution in GSM8K
In the step pass rate test as shown in Table 3, we found that StepProof was able to perform some degree of validation for nearly half of the proofs after 10 rounds of trying. In LLAMA3 8B, 38.1% of the proofs completed more than half of the verification, and 27.9% of the proofs completed all of the verification. Compared with a single attempt, this is a significant improvement. At the same time, we propose a new indicator-step passing rate ( $r_s$ ) for a more comprehensive evaluation of the proof of automatic formal verification methods.
| $0=r_s$ $0<r_s$ $0.5≤ r_s$ | 35% 65% 42% | 32% 68% 45% |
| --- | --- | --- |
| $1=r_s$ | 6% | 12% |
Table 4: Step Passing Rate Distribution in Number Theory
In our test to verify the influence of informal proof writing on the proof pass rate (as shown in the Table 4), we found that the proof pass rate was significantly improved after simple fitting of the informal proof. This shows that compared with FULL-PROOF, STEP-PROOF adopts proof mathematics that is more suitable for step verification, which will be more conducive to improving the pass rate of automatic formal verification.
### 4.3 Experiment Analysis
<details>
<summary>extracted/6582548/Compare.png Details</summary>
### Visual Description
## Scatter Plot Comparison: Formal and Proof Times of Two Strategies
### Overview
The image displays two side-by-side scatter plots comparing the performance of two proof strategies—"Full Proof" and "Step Proof"—across varying proof lengths. The left plot measures "Formal Time," while the right plot measures "Proof Time." Both plots share the same x-axis ("Proof Length") and legend, allowing for direct comparison of the two metrics.
### Components/Axes
**Titles:**
- Left Plot: "Formal Times of Two Strategy"
- Right Plot: "Proof Times of Two Strategy"
**Axes:**
- **X-axis (both plots):** "Proof Length". Discrete integer values from 4 to 11.
- **Y-axis (Left Plot):** "Formal Time". Linear scale from 0 to 25, with major ticks at 5, 10, 15, 20, 25.
- **Y-axis (Right Plot):** "Proof Time". Linear scale from 0 to 700, with major ticks at 100, 200, 300, 400, 500, 600, 700.
**Legend (Top-right corner of each plot):**
- Blue circle: "Full Proof"
- Green circle: "Step Proof"
### Detailed Analysis
Data points are extracted as approximate values based on visual positioning. For each proof length, the approximate y-values for each strategy are listed.
**Left Plot: Formal Times of Two Strategy**
| Proof Length | Full Proof (Blue) Approx. Formal Time | Step Proof (Green) Approx. Formal Time |
| :--- | :--- | :--- |
| 4 | 6, 8, 9, 9.5, 10, 11.5 | 3, 4, 5, 5.5, 6, 6.5, 7, 7.5, 8, 10.5 |
| 5 | 8.5, 9, 9.5, 10, 10.5, 11, 15.5 | 3.5, 4.5, 5, 5.5, 6, 6.5, 7, 7.5, 8, 8.5, 9, 9.5, 10 |
| 6 | 7.5, 9.5, 10, 13.5, 14, 24.5 | 5, 5.5, 6, 6.5, 7, 7.5, 8, 8.5 |
| 7 | 6, 7, 7.5, 8, 9, 9.5, 10.5, 12, 17.5 | 6, 6.5, 7, 7.5, 8, 8.5, 9, 9.5 |
| 8 | 10.5, 12.5, 13.5, 16.5, 18, 19 | 8.5, 10 |
| 9 | 7.5 | 15.5 |
| 10 | 10 | 8 |
| 11 | 8 | (No data) |
**Right Plot: Proof Times of Two Strategy**
| Proof Length | Full Proof (Blue) Approx. Proof Time | Step Proof (Green) Approx. Proof Time |
| :--- | :--- | :--- |
| 4 | 140, 170, 240, 325, 375, 445 | 20, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 240 |
| 5 | 200, 250, 255, 295, 550, 565 | 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 220, 225, 395 |
| 6 | 105, 180, 215, 315, 345, 355, 575 | 55, 85, 105, 120, 130, 140, 150, 160, 170, 180, 190, 200, 405 |
| 7 | 70, 185, 195, 215, 245, 285, 485 | 135, 140, 280, 290, 330 |
| 8 | 210, 320, 355, 425 | 155, 165, 170 |
| 9 | 265 | 210 |
| 10 | 405 | 140 |
| 11 | 110 | (No data) |
### Key Observations
1. **Formal Time (Left Plot):**
* **Full Proof (Blue):** Shows a wide spread of values at each proof length, with a general upward trend as length increases. Notable high outliers exist at lengths 6 (~24.5) and 8 (~19).
* **Step Proof (Green):** Values are consistently lower and more tightly clustered than Full Proof for lengths 4-8. A single high outlier appears at length 9 (~15.5). No data is present for length 11.
* **Comparison:** Step Proof generally requires less formal time than Full Proof for the same proof length, except for the outlier at length 9.
2. **Proof Time (Right Plot):**
* **Full Proof (Blue):** Exhibits extremely high variance. Times range from under 100 to over 700. There is a very high outlier at length 8 (~730). The trend is not clearly linear; high values appear across various lengths.
* **Step Proof (Green):** Also shows significant variance but is generally lower than Full Proof. The highest value is ~405 at length 6. The data density decreases sharply after length 7.
* **Comparison:** Step Proof tends to have lower proof times than Full Proof, but both strategies show high variability. The most extreme proof time in the dataset belongs to Full Proof at length 8.
3. **Data Density:** Both plots show a higher concentration of data points for lower proof lengths (4-7), with data becoming sparse for lengths 9-11. This suggests the evaluation dataset contained more examples of shorter proofs.
### Interpretation
The data suggests a clear performance difference between the two strategies. **Step Proof is generally more efficient than Full Proof** in terms of both "Formal Time" and "Proof Time" across most proof lengths. This indicates that breaking down the proof process into steps likely reduces the computational overhead compared to attempting a full proof in one go.
However, the **high variance**, especially in Proof Time, is a critical finding. It implies that the difficulty or resource consumption of a proof is not solely determined by its length. Other factors—perhaps the complexity of the logical steps, the specific theorem being proved, or the solver's state—play a significant role. The extreme outlier for Full Proof at length 8 (Proof Time ~730) is a prime example of this unpredictability.
The sparsity of data for longer proofs (lengths 9-11) limits conclusions about strategy scalability. It is unknown if the performance gap widens, narrows, or reverses for very long proofs. The single data point for Step Proof at length 9 (Formal Time ~15.5) is an outlier that contradicts the general trend and would warrant investigation.
In summary, while Step Proof appears to be the more reliable and efficient strategy on average, both methods are subject to significant performance variability. The proof length alone is a poor predictor of the time required, highlighting the need for more nuanced metrics or features to understand proof complexity.
</details>
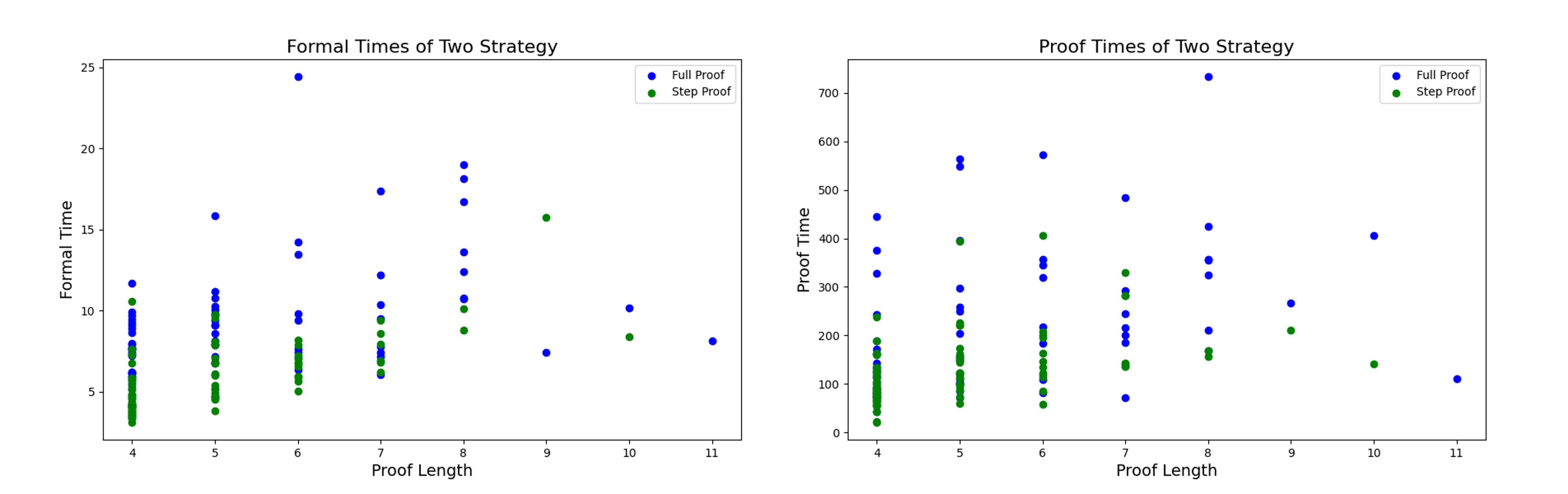
Figure 3: Time Cost of Two Strategies in Formalization and Proof
From Figure 3, we find that compared with the FULL-PROOF Strategy, STEP-PROOF takes less time to formalize and prove and is more stable. On the one hand, the generation strategy of Step-Proof makes the content generated in a single attempt less and more stable. Stable step content reduces the number of false proofs and the time to repeatedly prove successful content. Therefore, in terms of both generation efficiency and proof efficiency, STEP-PROOF is superior to FULL-PROOF.
<details>
<summary>extracted/6582548/Attempts.png Details</summary>
### Visual Description
## Bar Charts: Proof Passing Performance Across Attempts
### Overview
The image displays two side-by-side bar charts comparing the performance of two language models—LLAMA3 8B and GLM4 9B (4bit)—on proof-related tasks over multiple attempts. The left chart tracks the number of complete proofs passed, while the right chart tracks the number of individual proof steps passed. Both charts use a grouped bar format with attempts 1 through 10 on the x-axis.
### Components/Axes
**Common Elements:**
* **X-axis (both charts):** Labeled "Attempts". Contains categorical markers for attempts numbered 1, 2, 3, 4, 5, 6, 7, 8, 9, 10.
* **Legend (both charts):** Located in the top-right corner of each chart's plotting area.
* Blue square: **LLAMA3 8B**
* Green square: **GLM4 9B (4bit)**
**Left Chart: "Passed Proofs in Different Attempts"**
* **Y-axis:** Labeled "Passed Proofs". Linear scale with major tick marks at 0, 20, 40, 60, 80, 100, 120.
* **Data Series:** Two bars per attempt category. The blue bar (LLAMA3 8B) is positioned to the left of the green bar (GLM4 9B (4bit)) for each attempt.
**Right Chart: "Passed Step Proofs in Different Attempts"**
* **Y-axis:** Labeled "Passed Step Proofs". Linear scale with major tick marks at 0, 1000, 2000, 3000, 4000.
* **Data Series:** Two bars per attempt category. The blue bar (LLAMA3 8B) is positioned to the left of the green bar (GLM4 9B (4bit)) for each attempt.
### Detailed Analysis
**Left Chart - Passed Proofs:**
* **Trend Verification:** Both models show a clear, steeply decreasing trend in the number of passed proofs as the attempt number increases. The decline is most dramatic between attempts 1 and 3.
* **Data Points (Approximate Values):**
* **Attempt 1:** LLAMA3 8B ≈ 130, GLM4 9B (4bit) ≈ 65.
* **Attempt 2:** LLAMA3 8B ≈ 55, GLM4 9B (4bit) ≈ 48.
* **Attempt 3:** LLAMA3 8B ≈ 40, GLM4 9B (4bit) ≈ 38.
* **Attempt 4:** LLAMA3 8B ≈ 32, GLM4 9B (4bit) ≈ 29.
* **Attempt 5:** LLAMA3 8B ≈ 26, GLM4 9B (4bit) ≈ 21.
* **Attempt 6:** LLAMA3 8B ≈ 24, GLM4 9B (4bit) ≈ 21.
* **Attempt 7:** LLAMA3 8B ≈ 22, GLM4 9B (4bit) ≈ 13.
* **Attempt 8:** LLAMA3 8B ≈ 12, GLM4 9B (4bit) ≈ 15. *(Note: GLM4 value is slightly higher here)*
* **Attempt 9:** LLAMA3 8B ≈ 11, GLM4 9B (4bit) ≈ 20.
* **Attempt 10:** LLAMA3 8B ≈ 15, GLM4 9B (4bit) ≈ 20.
**Right Chart - Passed Step Proofs:**
* **Trend Verification:** Both models show an extremely sharp decline after the first attempt. The number of passed steps is orders of magnitude higher in attempt 1 compared to all subsequent attempts, which are all very low.
* **Data Points (Approximate Values):**
* **Attempt 1:** LLAMA3 8B ≈ 4300, GLM4 9B (4bit) ≈ 4250. *(Very close in value)*
* **Attempt 2:** LLAMA3 8B ≈ 250, GLM4 9B (4bit) ≈ 600.
* **Attempt 3:** LLAMA3 8B ≈ 150, GLM4 9B (4bit) ≈ 300.
* **Attempt 4:** LLAMA3 8B ≈ 100, GLM4 9B (4bit) ≈ 200.
* **Attempt 5:** LLAMA3 8B ≈ 50, GLM4 9B (4bit) ≈ 100.
* **Attempt 6:** LLAMA3 8B ≈ 50, GLM4 9B (4bit) ≈ 75.
* **Attempt 7:** LLAMA3 8B ≈ 25, GLM4 9B (4bit) ≈ 50.
* **Attempt 8:** LLAMA3 8B ≈ 25, GLM4 9B (4bit) ≈ 50.
* **Attempt 9:** LLAMA3 8B ≈ 25, GLM4 9B (4bit) ≈ 25.
* **Attempt 10:** LLAMA3 8B ≈ 10, GLM4 9B (4bit) ≈ 10.
### Key Observations
1. **Dominance of First Attempt:** The vast majority of successful outcomes (both complete proofs and proof steps) occur on the first attempt for both models. This is especially pronounced for step proofs.
2. **Model Performance Gap:** LLAMA3 8B significantly outperforms GLM4 9B (4bit) on complete proofs for the first seven attempts. The gap narrows and reverses slightly in attempts 8-10.
3. **Step Proof Parity:** For step proofs, the models perform very similarly on the first attempt. From attempts 2-8, GLM4 9B (4bit) consistently passes more steps than LLAMA3 8B, though both numbers are low.
4. **Consistent Decay Pattern:** Both metrics show a roughly exponential decay pattern, where performance drops sharply with each additional attempt required.
### Interpretation
The data suggests a fundamental difference in the nature of the tasks and model capabilities:
* **Task Difficulty:** Passing a complete proof is a much harder task than passing individual steps, as evidenced by the y-axis scales (max ~130 vs. ~4300). The charts likely represent a process where models are given multiple attempts to generate a valid proof, with "Attempts" indicating how many tries were needed.
* **Model Strengths:** LLAMA3 8B appears stronger at generating correct, complete proofs on the first or early tries. GLM4 9B (4bit), while less successful with full proofs initially, shows a relative strength in generating correct individual steps, particularly when given a second or third attempt. This could indicate different underlying capabilities: one model may be better at holistic reasoning (full proofs), while the other might be more reliable at granular, step-by-step logic.
* **Efficiency Implication:** The steep decline after attempt 1 for step proofs implies that if a model doesn't get the steps right initially, it struggles to correct itself in subsequent tries. The more gradual decline for complete proofs suggests that with more attempts, models can eventually piece together a valid proof, albeit with diminishing returns.
* **Anomaly:** The reversal in performance for complete proofs at attempts 8-10 (where GLM4 9B (4bit) slightly leads) is an interesting outlier. It may indicate that GLM4 9B (4bit) has a higher "persistence" or a different failure mode that allows it to eventually succeed on harder problems that stymie LLAMA3 8B after many tries, though the absolute numbers are very low.
</details>
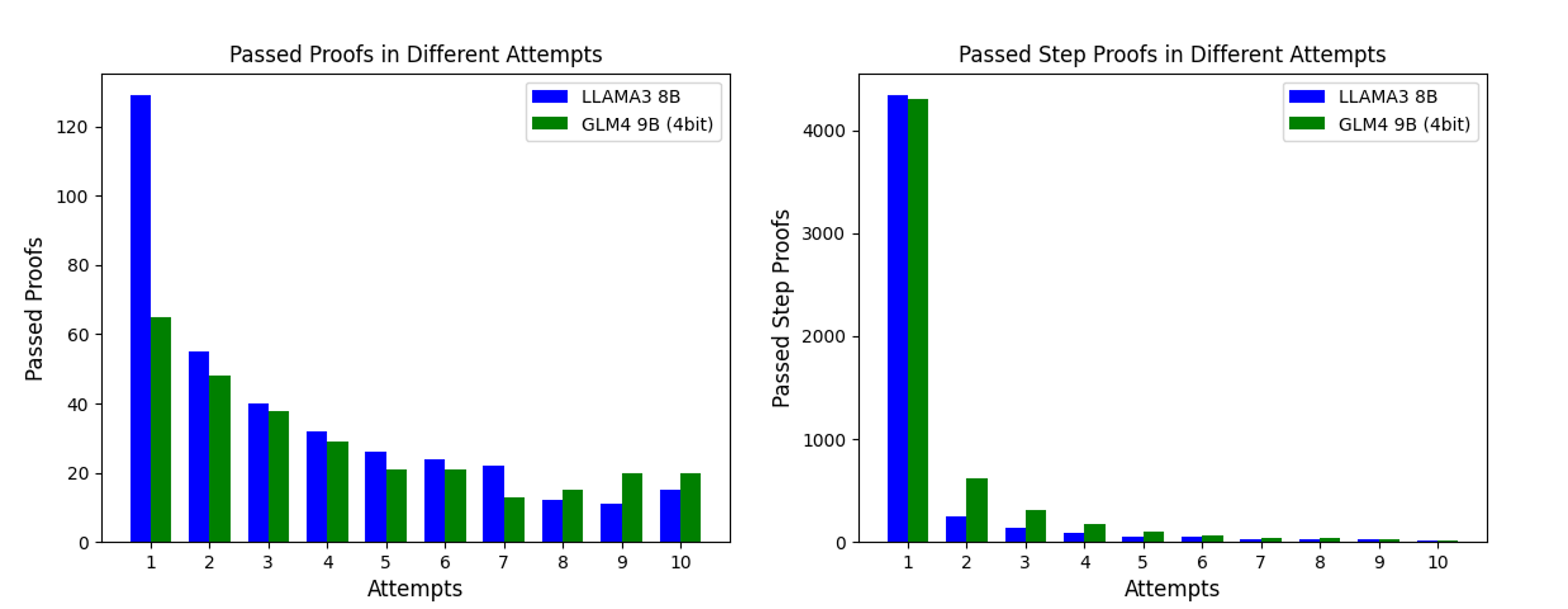
Figure 4: Passed Proofs and Steps in Different Attempts
To investigate the relation between step proof pass rate and number of attempts, we plotted Figure 4. It shows that most steps can be proven with relatively few attempts, with only a small fraction requiring multiple tries. We believe the main limitation to step pass rate lies not in the model’s formalization ability, but in whether the informal proof steps are suitable for conversion into provable formal steps. We found that many steps in the test set cannot be formalized into provable steps. These unformalizable informal steps significantly limit the further performance improvement of Step Proof. Therefore, to better achieve verification in practical applications of StepProof, each proof sub-step should be ensured to be a formally verifiable sub-proposition as much as possible.
In addition, we also found that the processing capacity of LLMs is poor when faced with the processing of continuous equations, and it is easy to fall into the generation loop during the generation process, resulting in the poor quality of the generated formal proof. Therefore, in practical applications, it is necessary to split the steps as much as possible, rather than pursue once completion. At the same time, since the automatic proof ability of automated theorem proving is also limited, resolving the proof process is not only conducive to the formalization process, but also very helpful to the verification process.
## 5 Limitations & Future Research
At present, the performance of StepProof in small models has been verified in various aspects. However, due to the lack of equipment and funds, the performance of StepProof in larger models has not been verified, although the previous relevant work verified the conclusion that FULL-PROOF strategy has better performance in larger models. However, the STEP-PROOF strategy has not yet been tested on a larger model.
In addition, StepProof is strict for users to enter proof steps, while FULL-PROOF is more flexible and can incorporate some non-proof explanatory language or prompt words into the proof. However, StepProof will make mistakes in the step proof because the prompt word is not provable.
Finally, StepProof pays more attention to the sequential proof with steps, but when faced with some structured proof methods, its performance is still limited, while FULL-PROOF can better capture the overall proof structure.
In the future, our work will mainly start from the following two points: 1. At present, we are writing a corpus for StepProof for automatic formal verification tasks oriented to step verification, and we hope that a more targeted corpus will help improve the step formalization ability of the model. 2. We will implement specific structured proof based on the structured design of the system to further improve the integrity and flexibility of StepProof proof.
## 6 Conclusion
In this paper, we innovatively propose a new automatic formal proof method called StepProof. StepProof implements sentence-level formal verification of natural language mathematical proofs, allowing users to conduct more flexible formal verification. At the same time, compared with the traditional FullProof strategy, StepProof has been significantly improved in formalization, proof efficiency and proof accuracy.
In addition, StepProof can preserve the contents of the proof that has already been verified, providing more information than the traditional Full-Proof strategy that can only indicate the passage and failure of the proof. We used a small model on the GSM8K data set to test the proof pass rate, and its performance reached the level of state-of-the-art.
We also conducted a test on the Number Theory dataset of MATH to test the effect of formal content writing on the proof pass rate. The experimental results show that by optimizing the non-formal proof for step verification, the passing rate of the non-formal proof can be significantly improved. We will further optimize the architecture of StepProof in future work to make it more flexible to handle formal verification of various non-formal mathematical proofs.
## References
- [1] John Harrison, Josef Urban, and Freek Wiedijk. History of interactive theorem proving. In Jörg H. Siekmann, editor, Computational Logic, volume 9 of Handbook of the History of Logic, pages 135–214. North-Holland, 2014.
- [2] Filip Maric. A survey of interactive theorem proving. Zbornik radova, 18(26):173–223, 2015.
- [3] M Saqib Nawaz, Moin Malik, Yi Li, Meng Sun, and M Lali. A survey on theorem provers in formal methods. arXiv preprint arXiv:1912.03028, 2019.
- [4] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
- [5] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9):1–35, 2023.
- [6] Yaqing Wang, Quanming Yao, James T Kwok, and Lionel M Ni. Generalizing from a few examples: A survey on few-shot learning. ACM computing surveys (csur), 53(3):1–34, 2020.
- [7] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [8] Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38, 2023.
- [9] Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798, 2023.
- [10] Zhaoyu Li, Jialiang Sun, Logan Murphy, Qidong Su, Zenan Li, Xian Zhang, Kaiyu Yang, and Xujie Si. A survey on deep learning for theorem proving. arXiv preprint arXiv:2404.09939, 2024.
- [11] Andrea Asperti. A survey on interactive theorem proving. URL: http://www. cs. unibo. it/~ asperti/SLIDES/itp. pdf, 2009.
- [12] John Harrison. A survey of automated theorem proving. Sat, 17:20–18, 2013.
- [13] Lawrence C Paulson. Isabelle: A generic theorem prover. Springer, 1994.
- [14] Gérard Huet, Gilles Kahn, and Christine Paulin-Mohring. The coq proof assistant a tutorial. Rapport Technique, 178, 1997.
- [15] Leonardo De Moura, Soonho Kong, Jeremy Avigad, Floris Van Doorn, and Jakob von Raumer. The lean theorem prover (system description). In Automated Deduction-CADE-25: 25th International Conference on Automated Deduction, Berlin, Germany, August 1-7, 2015, Proceedings 25, pages 378–388. Springer, 2015.
- [16] Artem Yushkovskiy. Comparison of two theorem provers: Isabelle/hol and coq. arXiv preprint arXiv:1808.09701, 2018.
- [17] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- [18] Junjie Ye, Xuanting Chen, Nuo Xu, Can Zu, Zekai Shao, Shichun Liu, Yuhan Cui, Zeyang Zhou, Chao Gong, Yang Shen, et al. A comprehensive capability analysis of gpt-3 and gpt-3.5 series models. arXiv preprint arXiv:2303.10420, 2023.
- [19] Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, Shudan Zhang, Shulin Cao, Shuxun Yang, Weng Lam Tam, Wenyi Zhao, Xiao Liu, Xiao Xia, Xiaohan Zhang, Xiaotao Gu, Xin Lv, Xinghan Liu, Xinyi Liu, Xinyue Yang, Xixuan Song, Xunkai Zhang, Yifan An, Yifan Xu, Yilin Niu, Yuantao Yang, Yueyan Li, Yushi Bai, Yuxiao Dong, Zehan Qi, Zhaoyu Wang, Zhen Yang, Zhengxiao Du, Zhenyu Hou, and Zihan Wang. Chatglm: A family of large language models from glm-130b to glm-4 all tools, 2024.
- [20] Junbing Yan, Chengyu Wang, Jun Huang, and Wei Zhang. Do large language models understand logic or just mimick context? arXiv preprint arXiv:2402.12091, 2024.
- [21] Yuxuan Wan, Wenxuan Wang, Yiliu Yang, Youliang Yuan, Jen-tse Huang, Pinjia He, Wenxiang Jiao, and Michael R Lyu. A & b== b & a: Triggering logical reasoning failures in large language models. arXiv preprint arXiv:2401.00757, 2024.
- [22] Shalom Lappin. Assessing the strengths and weaknesses of large language models. Journal of Logic, Language and Information, 33(1):9–20, 2024.
- [23] Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. A survey on rag meeting llms: Towards retrieval-augmented large language models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 6491–6501, 2024.
- [24] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- [25] Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. Decomposed prompting: A modular approach for solving complex tasks. arXiv preprint arXiv:2210.02406, 2022.
- [26] Thien Huu Nguyen and Ralph Grishman. Relation extraction: Perspective from convolutional neural networks. In Proceedings of the 1st workshop on vector space modeling for natural language processing, pages 39–48, 2015.
- [27] Hrituraj Singh, Milan Aggrawal, and Balaji Krishnamurthy. Exploring neural models for parsing natural language into first-order logic. arXiv preprint arXiv:2002.06544, 2020.
- [28] Xuantao Lu, Jingping Liu, Zhouhong Gu, Hanwen Tong, Chenhao Xie, Junyang Huang, Yanghua Xiao, and Wenguang Wang. Parsing natural language into propositional and first-order logic with dual reinforcement learning. In Proceedings of the 29th International Conference on Computational Linguistics, pages 5419–5431, 2022.
- [29] Qingxiang Wang, Chad Brown, Cezary Kaliszyk, and Josef Urban. Exploration of neural machine translation in autoformalization of mathematics in mizar. In Proceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs, pages 85–98, 2020.
- [30] Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models, 2022.
- [31] Albert Q Jiang, Sean Welleck, Jin Peng Zhou, Wenda Li, Jiacheng Liu, Mateja Jamnik, Timothée Lacroix, Yuhuai Wu, and Guillaume Lample. Draft, sketch, and prove: Guiding formal theorem provers with informal proofs. arXiv preprint arXiv:2210.12283, 2022.
- [32] Jin Peng Zhou, Charles Staats, Wenda Li, Christian Szegedy, Kilian Q Weinberger, and Yuhuai Wu. Don’t trust: Verify–grounding llm quantitative reasoning with autoformalization. arXiv preprint arXiv:2403.18120, 2024.
- [33] Haiming Wang, Huajian Xin, Chuanyang Zheng, Lin Li, Zhengying Liu, Qingxing Cao, Yinya Huang, Jing Xiong, Han Shi, Enze Xie, et al. Lego-prover: Neural theorem proving with growing libraries. arXiv preprint arXiv:2310.00656, 2023.
- [34] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [35] Boris Shminke. Python client for isabelle server. arXiv preprint arXiv:2212.11173, 2022.
- [36] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021.
- [37] Mohammadreza Pourreza and Davood Rafiei. Din-sql: Decomposed in-context learning of text-to-sql with self-correction. Advances in Neural Information Processing Systems, 36, 2024.
## Appendix A Appendix
### A.1 Additional Case of Manual Modification for Step Proof Fitting
For the following informal problem and proof:
Problem: What is the average of the two smallest positive integer solutions to the congruence $14u≡ 46±od{100}$ . Show it is 64.
Solution: Note that $14$ , $46$ , and $100$ all have a common factor of $2$ , so we can divide it out: the solutions to
$$
14u≡ 46±od{100}
$$
are identical to the solutions to
$$
7u≡ 23±od{50}.
$$
Make sure you see why this is the case.
Now we can multiply both sides of the congruence by $7$ to obtain
$$
49u≡ 161±od{50},
$$
which also has the same solutions as the previous congruence, since we could reverse the step above by multiplying both sides by $7^-1$ . (We know that $7^-1$ exists modulo $50$ because $7$ and $50$ are relatively prime.)
Replacing each side of $49u≡ 161$ by a $±od{50}$ equivalent, we have
$$
-u≡ 11±od{50},
$$
and thus
$$
u≡-11±od{50}.
$$
This is the set of solutions to our original congruence. The two smallest positive solutions are $-11+50=39$ and $-11+2· 50=89$ . Their average is $\boxed{64}$ .
In normal cases, we can cut the content according to the period to get the following sequence of non-formal proofs.
⬇
1 Note that $14$, $46$, and $100$ all have a common factor of $2$, so we can divide it out: the solutions to $$14u \ equiv 46 \ pmod {100} $$ are identical to the solutions to $$7u \ equiv 23 \ pmod {50}. $$
2
3 Make sure you see why this is the case.
4
5 Now we can multiply both sides of the congruence by $7$ to obtain $$49u \ equiv 161 \ pmod {50}, $$ which also has the same solutions as the previous congruence, since we could reverse the step above by multiplying both sides by $7 ^{-1} $.
6
7 We know that $7 ^{-1} $ exists modulo $50$ because $7$ and $50$ are relatively prime.
8
9 Replacing each side of $49u \ equiv 161 $ by a $ \ pmod {50} $ equivalent, we have $$ - u \ equiv 11\ pmod {50}, $$ and thus $$u \ equiv -11\ pmod {50}. $$
10
11 This is the set of solutions to our original congruence.
12
13 The two smallest positive solutions are $ -11+50 = 39 $ and $ -11+2\ cdot 50 = 89 $.
14
15 Their average is $ \ boxed {64} $.
However, there are many problems with such a simple decomposition. Such as the following sentences are unable to be formalized.
⬇
1 Make sure you see why this is the case.
2
3 This is the set of solutions to our original congruence.
In addition, from the point of view of the order of proof, I can see that " We know that $7^-1$ exists modulo $50$ because $7$ and $50$ are relatively prime. " is a prerequisite for " Now we can multiply both sides of the congruence by $7$ to obtain $49u≡ 161±od{50}$ , which also has the same solutions as the previous congruence, since we could reverse the step above by multiplying both sides by $7^-1$ . ", so the order of the two should be reversed.
Therefore, in order to meet the requirements of StepProof, I deleted the statements that could not be formalized and corrected the sequence to obtain the following proof sequence.
⬇
1 Note that $14$, $46$, and $100$ all have a common factor of $2$, so we can divide it out: the solutions to $$14u \ equiv 46 \ pmod {100} $$ are identical to the solutions to $$7u \ equiv 23 \ pmod {50}. $$
2
3 We know that $7 ^{-1} $ exists modulo $50$ because $7$ and $50$ are relatively prime.
4
5 Now we can multiply both sides of the congruence by $7$ to obtain $$49u \ equiv 161 \ pmod {50}, $$ which also has the same solutions as the previous congruence, since we could reverse the step above by multiplying both sides by $7 ^{-1} $.
6
7 Replacing each side of $49u \ equiv 161 $ by a $ \ pmod {50} $ equivalent, we have $$ - u \ equiv 11\ pmod {50}, $$ and thus $$u \ equiv -11\ pmod {50}. $$ This is the set of solutions to our original congruence.
8
9 The two smallest positive solutions are $ -11+50 = 39 $ and $ -11+2\ cdot 50 = 89 $.
10
11 Their average is $ \ boxed {64} $.
### A.2 Formal Content Comparison between Full-Proof and Step-Proof
Problem: Given that $1<x<2$ , show that $√{(x-1)^2}+|x-2|$ can be reduced to 1.
Solution: Since $x>1$ , we know that $√{(x-1)^2}=x-1$ . And since $x<2$ , we know that $|x-2|=2-x$ . Therefore, it can be rewritten as $x-1+2-x$ , and we know that it can be reduced to 1.
After formalize the problem we get following Isabelle statement.
⬇
1 theorem sqrt_abs_simplify:
2 assumes h0: "1 < x "
3 and h1: " x < 2"
4 shows " sqrt ((x - 1)^2) + abs (x - 2) = 1"
Using Full-Proof, we can directly obtain the following formal proof.
⬇
1 proof -
2 have h2: " sqrt ((x - 1)^2) = x - 1"
3 using h0 by (simp add: abs_of_nonneg)
4 have h3: " abs (x - 2) = 2 - x "
5 using h1 by (simp add: abs_of_nonpos)
6 have " sqrt ((x - 1)^2) + abs (x - 2) = (x - 1) + (2 - x)"
7 using h2 h3 by simp
8 also have "... = 1"
9 by simp
10 finally show ? thesis .
11 qed
In the StepProof approach, we would firstly input the first step
⬇
1 Since $x > 1 $, we know that $ \ sqrt {(x -1)^2} = x - 1 $.
Then after formalization, we can get corresponding formal proof.
⬇
1 have h2: " sqrt ((x - 1)^2) = x - 1" using h0 by simp
After this formal step has been verified, we will input the next steps in the same way.
⬇
1 And since $x < 2 $, we know that $ | x -2| = 2- x$.
⬇
1 have h3: " abs (x - 2) = 2 - x " using h1 by simp
⬇
1 Therefore, it can be rewritten as $x - 1 + 2 - x$, and we know that it can be reduced to 1.
⬇
1 show ? thesis using h2 h3 by simp
After the global goal has been proven, the system will automatically align the formal proof with the informal proof. Then we will get the over all formal proof of StepProof as following
⬇
1 proof -
2 (* Since $x > 1 $, we know that $ \ sqrt {(x -1)^2} = x - 1 $.*)
3 have h2: " sqrt ((x - 1)^2) = x - 1" using h0 by simp
4 (* And since $x < 2 $, we know that $ | x -2| = 2- x$.*)
5 have h3: " abs (x - 2) = 2 - x " using h1 by simp
6 (* Therefore, it can be rewritten as $x - 1 + 2 - x$, and we know that it can be reduced to 1.*)
7 show ? thesis using h2 h3 by simp
8
9 qed