# Taming the Untamed: Graph-Based Knowledge Retrieval and Reasoning for MLLMs to Conquer the Unknown
**Authors**: Mitsubishi Electric Corp., Japan
Abstract
The real value of knowledge lies not just in its accumulation, but in its potential to be harnessed effectively to conquer the unknown. Although recent multimodal large language models (MLLMs) exhibit impressing multimodal capabilities, they often fail in rarely encountered domain-specific tasks due to limited relevant knowledge. To explore this, we adopt visual game cognition as a testbed and select “Monster Hunter: World” as the target to construct a multimodal knowledge graph (MH-MMKG), which incorporates multi-modalities and intricate entity relations. We also design a series of challenging queries based on MH-MMKG to evaluate the models’ ability for complex knowledge retrieval and reasoning. Furthermore, we propose a multi-agent retriever that enables a model to autonomously search relevant knowledge without additional training. Experimental results show that our approach significantly enhances the performance of MLLMs, providing a new perspective on multimodal knowledge-augmented reasoning and laying a solid foundation for future research. The dataset and code at https://github.com/wbw520/MH-MMKG.
1 Introduction
Recent multimodal large language models (MLLMs) [54], particularly closed-source ones [1, 2], have demonstrated human-like multimodal capabilities, achieving outstanding performance on benchmarks related to commonsense [42], scientific facts [55], etc. Meanwhile, for domain-specific tasks or rarely seen data [14, 9], relying solely on their own perception and built-in knowledge is inadequate for predicting accurate answers and is hardly interpretable [49, 19].
To alleviate these issues, multimodal RAG (mRAG) [57, 58] has been introduced to improve MLLM performance through heuristic [20, 10, 6] or agent-based methods [44, 33]. However, as with RAG for LLMs [18], such knowledge retrieval approaches often suffer from knowledge redundancy and low relevance [40]. As a result, knowledge graph retrieval [28, 15] has gained increasing attention. Knowledge graphs (KGs) [24], storing knowledge in a structured and comprehensive manner, offer models with more context-rich information. As a substantial multimodal extension, multimodal KGs (MMKGs) [13, 38] can offer a knowledge foundation for enhancing MLLMs.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Zinogre Attack Prediction
### Overview
The image is a diagram illustrating a system for predicting Zinogre's (a monster from the Monster Hunter game) attack patterns based on battle screen information, knowledge retrieval, and a Multi-Modal Large Language Model (MLLM). It shows the flow of information from the game screen to the MLLM, then to a knowledge graph, and finally to a prediction of Zinogre's next attack.
### Components/Axes
* **Top-Left:** Battle screen images with a question mark icon and the question: "Based on the battle screen, what are Zinogre possible continues attacks?"
* **Top-Center:** MLLM (Multi-Modal Large Language Model) represented by a cartoon robot.
* **Top-Right:** Text box containing the MLLM's prediction: "Zinogre is going to unleash the Counter Attack action. Based on this, it is speculated that in its Super Charged state, it may follow up with a Fist Combo, or continues attacks including a Tail Slam and a Back Slam." A green checkmark is present in the top-right corner of this box.
* **Center:** "Knowledge Retrieval" section showing a flow diagram of Zinogre's attack patterns.
* Nodes: Zinogre, Super Charged, Counter Attack, Fist Combo, Tail Slam, 360 Spin, Back Slam, Headbutt, Back Jump.
* Edges: Arrows indicating the flow of attacks, labeled with "phase", "atk of", and "cont." (continues). Red "X" marks indicate attacks that are not possible.
* **Bottom-Left:** Monster Hunter logo.
* **Bottom-Center:** "Knowledgeable Players" represented by silhouettes of hunters.
* **Bottom-Right:** MH-MMKG (Monster Hunter Multi-Modal Knowledge Graph) represented by a network graph. A magnifying glass points from the MH-MMKG to the "Back Slam" node in the Knowledge Retrieval section.
### Detailed Analysis
* **Battle Screen Images:** Three images showing different perspectives of a battle scene in Monster Hunter.
* **MLLM:** The MLLM receives information from the battle screen images and generates a prediction about Zinogre's next attack.
* **Knowledge Retrieval Flow Diagram:**
* Zinogre transitions to a "Super Charged" phase.
* From "Super Charged", Zinogre can perform a "Counter Attack".
* "Counter Attack" can continue into a "Fist Combo".
* "Super Charged" can also lead to a "Tail Slam".
* "Tail Slam" can continue into a "Back Slam".
* "Tail Slam" cannot lead to a "360 Spin".
* "Super Charged" cannot lead to "Headbutt" or "Back Jump".
* **MH-MMKG:** The knowledge graph provides information to the Knowledge Retrieval section, specifically about the "Back Slam" attack.
### Key Observations
* The diagram illustrates a system that combines visual information from the game screen with a knowledge graph to predict Zinogre's attacks.
* The MLLM plays a central role in processing the visual information and generating predictions.
* The Knowledge Retrieval section provides a structured representation of Zinogre's attack patterns.
* The MH-MMKG provides additional information to refine the attack prediction.
### Interpretation
The diagram demonstrates a system for intelligent prediction of enemy behavior in a video game. By integrating visual data, a large language model, and a knowledge graph, the system can anticipate the monster's next move. This has implications for improving gameplay, creating more challenging AI, and developing assistive tools for players. The red "X" marks are important because they explicitly rule out certain attack combinations, which helps to narrow down the possible attack sequences and improve the accuracy of the prediction. The magnifying glass pointing to the "Back Slam" node suggests that the MH-MMKG is used to provide detailed information about this specific attack, potentially including its animation, damage, and other relevant properties.
</details>
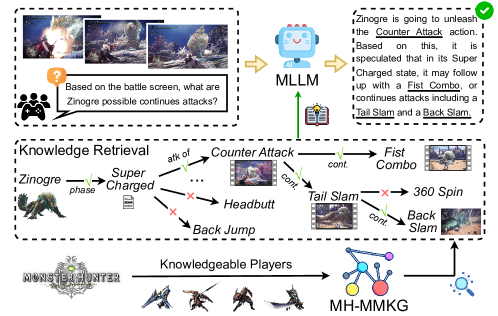
Figure 1: Our MH-MMKG is curated by knowledgeable players. By leveraging a multi-agents retriever, the MLLM’s responses can be augmented.
One major challenge MLLMs with MMKGs is the unavailability of robust benchmarks. Existing work primarily relies on VQA datasets [29] or web resources [5, 17] for constructing MMKGs. It is highly plausible that such knowledge has already been learned by current MLLMs, making them less useful in evaluating the effectiveness of MMKGs. Additionally, existing MMKGs primarily incorporate text and images, lacking more information-rich modalities, such as video [39], which reduces their suitability for increasingly complex multimodal tasks.
Another challenge is how to retrieve knowledge accurately. The mainstream approach embeds entities in MMKGs to find relevant subgraphs [23, 21, 31, 30]. However, training an effective retriever is data-intensive and unrealistic for low-resource domains. In addition, incorporating graphs about rarely seen domains into powerful closed-source models remains impractical.
This work aims to endeavor the ability of MLLMs to tackle domain-specific tasks by leveraging well-structured external knowledge sources. To achieve this, we build a testbed with a well-known game title [9] as illustrated in Figure 1 for two reasons: First, the visual modality exhibits a large gap from real-world scenes as its visual world is computer graphics-generated mostly with imaginary cultures, creatures, etc. to which MLLMs’ perception module is not well exposed. Second, the knowledge of the game’s world can be different from the real world, which makes the MLLMs’ built-in knowledge less useful. We in this work use “Monster Hunter: World” for our testbed as the game series offers abundant knowledge about the fantasy world. As one of the most popular game titles, current MLLMs have already learned some knowledge about it. We will experimentally show its impact.
To this end, we construct MH-MMKG, which integrates text, images, videos, and intricate entity relations curated by knowledgeable players. Additionally, we design 238 carefully crafted question-answer pairs as benchmark that cover various sub-tasks, including fine-grained visual cognition, conditional reasoning, etc. Importantly, the knowledge required to answer these questions is encompassed in MH-MMKG. An MLLM can answer most questions with perfect knowledge retrieval and comprehension. MH-MMKG, as well as the benchmark, offers a new dimension of challenges for the community: MH-MMKG requires flexible perception to comprehend the visual modality in an (almost) unseen domain as well as reasoning without relying on the built-in knowledge of the MLLM.
Multi-modal knowledge retrieval through graph is the foundation for tackling this new set of challenges. We thus develop a multi-agent method, which harnesses the self-searching capabilities [26, 45, 16] of MLLMs, allowing them to autonomously retrieve relevant knowledge without training. On both close- and open-source leading MLLMs, we experimentally show the effectiveness of our method, qualifying it as a strong baseline.
Our contribution lies in developing a high-quality benchmark and exploring MLLMs’ ability to find knowledge from MMKG for solving rarely seen domain-specific tasks. These tasks require not only advanced multimodal perception but also a deep understanding of complex dependencies, conditions, and rules within MH-MMKG. Our benchmark, together with the baseline, provides a strong foundation for advancing MLLMs toward real-world challenges.
2 Related Works
2.1 Multimodal Retrieval Augmented Generation
Recent literature shows a growing surge of interest in MLLMs [54]. Despite their advancements, even sophisticated models like GPT-4o face difficulty in handling domain-specific tasks [14, 9] or reasoning [49, 19]. To mitigate these issues, mRAG [57, 58] seeks to enhance AI systems by providing more reliable, comprehensive, accurate, and up-to-date knowledge from external sources [42, 11].
Heuristic mRAG often relies on predefined retrieval strategies that prioritize grounding across multiple modalities into a single primary modality [20, 10, 6, 7], which limits their capacity to deliver precise and contextually rich knowledge. Recent studies [44, 51, 33] propose more adaptable pipelines for knowledge retrieval, utilizing multi-agent cooperation [46] to harness the model’s intrinsic capacity for knowledge exploration. Despite differences in strategy, all these methods depend on retrieving unstructured external knowledge sources, leading to knowledge redundancy and a lack of precision [40]. In contrast, KGs offer a structured format for knowledge storage [24], particularly MMKGs [60], which can be more efficient support for MLLMs to enhance their response.
2.2 Multimodal Knowledge Graph
Compared to KGs, MMKGs incorporate diverse multimodal data, making them more suitable for complex scenarios that require multimodal collaboration. The evolution from conventional KGs to MMKGs has also been extensively explored [13, 38]. Researchers often use densely annotated VQA datasets [29] or web-based resources [5, 17] to automatically construct MMKGs [35, 4]. Ongoing efforts have demonstrated the effectiveness of them in tasks such as VQA [34], image classification [41], cross-modal retrieval [56], etc. Additionally, some studies focused on embedding MMKGs into feature vectors to enhance the reasoning capabilities of MLLMs, yielding impressive results [30, 27].
Notwithstanding these considerable achievements, current works primarily focus on integrating text and image modalities [38] via web data, which may already embedded in the knowledge of MLLMs. The exploration of additional modalities, such as audio and video, as well as practical applications of recent MLLMs for complex real-world tasks, remains limited. Our meticulously crafted MH-MMKG incorporates multiple modalities alongside complex relations as a knowledge base for a domain-specific task.
2.3 Retrieve Knowledge on Graph
By offering reliable and structured information, retrieval over KGs assists LLMs in preserving better factual accuracy [28, 15]. Common approaches include retrieving relevant subgraphs [25, 22] or integrating the graph into the model’s learning process [37] —techniques that have also been extended to MMKGs to improve MLLMs’ task completion capabilities [23, 30]. However, training an effective retriever is highly data-intensive, especially for modalities like video. Moreover, adding new KGs into powerful closed-source MLLMs is infeasible. Recent work aims to evoke the model’s self-searching ability to autonomously navigate toward the necessary knowledge [45, 45, 48]. These approaches typically involve route planning [26, 45] or self-refinement mechanisms [16, 8] to improve retrieval accuracy. We extend these ideas to MMKGs and propose a multi-agent self-searching method for knowledge retrieval.
3 Datasets
The “Monster Hunter” is a popular game series and we choose “Monster Hunter: World” as our testbed to explore the potential of MLLMs in tackling the gaps in visual and knowledge using MMKGs.
3.1 MH-MMKG
<details>
<summary>x2.png Details</summary>
### Visual Description
## Concept Diagram: Rathian Relationships and Attacks
### Overview
The image is a concept diagram centered around the "Rathian" monster, likely from a video game. It illustrates relationships with other monsters (Rathalos, Pink Rathian), elemental weaknesses/resistances (Ice, Fire), material usage (Fire Element Weapon), and attack types (Triple Rush, Bite, Triple Fireballs). The diagram uses arrows to indicate the direction and type of relationship.
### Components/Axes
* **Central Node:** Rathian (with an image of the monster)
* **Related Monsters:**
* Rathalos (top-left, with an image of the monster)
* Pink Rathian (left, with an image of the monster)
* **Elemental Affinities:**
* Ice Element (bottom-left, with an ice crystal icon)
* Fire Element (bottom-left, with a fire icon)
* **Material Usage:**
* Fire Element Weapon (bottom, with a weapon icon)
* **Attacks:**
* Triple Rush (top-right, with a sword icon and video stills)
* Bite (right, with a sword icon and video still)
* Triple Fireballs (bottom-right, with a sword icon and video stills)
* **Relationship Arrows:** Arrows connect Rathian to other elements, labeled with relationship types (e.g., "mated with," "subspecies," "weaken with," "resistant with," "material for," "attack of").
* **Text Boxes:** Contain context, captions, or descriptions related to specific elements.
### Detailed Analysis or Content Details
* **Rathian Relationships:**
* Rathian is "mated with" Rathalos.
* Pink Rathian is a "subspecies" of Rathian.
* Rathian is "weaken with" Ice Element.
* Rathian is "resistant with" Fire Element.
* Rathian provides "material for" Fire Element Weapon.
* **Rathian Attacks:**
* Rathian has an "attack of" Triple Rush. Caption: "Rathian rushes forward, up three times..."
* Rathian has an "attack of" Bite. Caption: "Rathian use a lunge bite..." Context: "if hunter hit by this attack,..."
* Rathian has an "attack of" Triple Fireballs "when angry". Caption: "Rathian throws fireballs from its mouth in a rapid sequence,..."
* **Context Box (Top Center):** "Context: Rathian perches on the ground with powerful legs. Her flame attacks..."
### Key Observations
* The diagram focuses on Rathian's relationships, weaknesses, resistances, and attacks.
* Arrows clearly indicate the direction and type of relationship.
* Images and icons are used to visually represent the elements.
* Text boxes provide additional context and descriptions.
### Interpretation
The diagram serves as a quick reference guide for understanding the Rathian monster in the context of a game. It highlights key relationships with other monsters, elemental affinities, and attack patterns. This information would be useful for players strategizing how to fight or utilize Rathian. The diagram effectively uses visual elements and concise text to convey complex information in an easily digestible format.
</details>
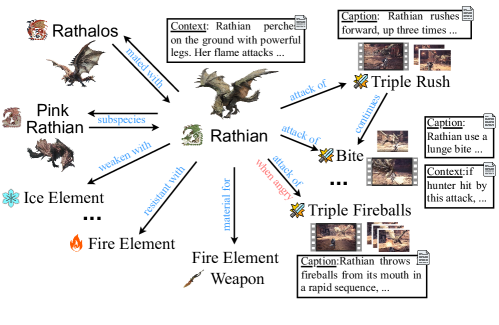
Figure 2: The subgraph for monster “Rathian” in MH-MMKG.
Our MH-MMKG is an attribute-based MMKG [60] as shown in Figure 2, where names of elements that appear in the game, such as monsters and attack actions, are treated as entities. A pair of entities can be linked with a particular relation, forming an edge between them. An entity may come with some additional information, i.e., videos related to the entity and textual context to supply more details on the entity, both of which are treated as attributes. Three knowledgeable players were recruited to build the knowledge graph: Each player built subgraphs for single monsters. Figure 2 illustrates the subgraph for “Rathian,” showing intricate relationships such as attack conditions, combos, and inter-subgraph connections. We collected 22 subgraphs, which were merged together to make MH-MMKG.
Let $\mathcal{G}=(\mathcal{E},\mathcal{V},\mathcal{R})$ denote our whole KG, where $\mathcal{E}$ is the set of entities, $\mathcal{V}$ is the set of edges, and $\mathcal{R}$ is the set of relations. $\mathcal{E}$ consists of two types of entities: 1) monsters in $\mathcal{E}_{\text{o}}$ and 2) other entities in $\mathcal{E}_{\text{a}}$ . An edge $v=(e,r,e^{\prime})∈\mathcal{V}$ represents $e∈\mathcal{E}$ has relation $r∈\mathcal{R}$ with $e^{\prime}∈\mathcal{E}$ . The attribute associated with an entity $e$ is denoted as $A(e)=(c,u)$ , which comprises a video clip $c$ and/or textual context $u$ . A video clip describes the entity $e$ , recorded in 60 fps and 4k. As current MLLMs are not able to handle videos directly, the dataset also offers human-selected keyframes (no more than 10 frames) as well as human-written captions about $c$ . The knowledgeable players who curated the dataset also selected the keyframes and wrote the captions. The textual context $u$ provides knowledge about the entity but is not included in $c$ . We denote a set of all attribute as $\mathcal{A}=\{A(e)|e∈\mathcal{E}\}$ .
Table 1: The six sub-tasks in our MH benchmark.
| I: Individual Information | Retrieve the textual information of a monster, e.g., nick name, habitat, and skill mechanics. | 24 |
| --- | --- | --- |
| II: Attack Recognition | Recognize the about to, ongoing or finished attack action of a monster. | 109 |
| III: Combo Premonition | Predict upcoming attack sequences based on the monster’s current action or previous action track. | 28 |
| IV: Condition Awareness | Detect status on monsters or surrounding environment, e.g., whether angry, terrain or phase changes, to anticipate future battle. | 29 |
| V: Proc Effect Insight | Analyze the effects such as environment and attack on monster status and movement patterns. | 35 |
| VI: Cross Monster Analysis | Compare attack patterns or behaviors across different monsters to optimize hunting strategies. | 13 |
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Zinogre Attack Action Prediction
### Overview
The image is a diagram illustrating a system for predicting attack actions of the Zinogre monster in a video game. It outlines a process involving perception, knowledge retrieval, and summarization to anticipate the monster's next move. The diagram uses a combination of text, icons, and flowcharts to depict the system's components and their interactions.
### Components/Axes
* **Perceiver (Top-Left)**: Takes input from a "Caption" that reads: "Zinogre raises it right claw, move it to the left part of the body and put it firmly against the ground on left..." and visual input from a series of images. It also receives a question: "Tell me what will happen next within this attack action?".
* **Topic Selection (Center-Left)**: Selects the relevant monster (Zinogre) from a set of possible monsters.
* **Retrieved Knowledge (Bottom-Left)**: Contains textualized knowledge about the monster's attack patterns.
* **Expansion (Center)**: Expands the knowledge base with information about different phases of the Zinogre's attacks (Charging Phase, Charged Phase, Super Charged).
* **Multi-agents Retriever (Bottom-Right)**: Retrieves relevant information based on the current state and predicts the next action.
* **Summarizer (Bottom-Left)**: Provides a summary of the predicted action: "Zinogre will jump and slams the ground, and then repeat the attack action again."
* **Attack Actions (Top-Right)**: Lists possible attack actions: Headbutt, Devour, Heavy Pawslam, Double Slam.
### Detailed Analysis
* **Perceiver**: The perceiver takes in both textual and visual information. The caption describes the current action of the Zinogre. The images provide visual context. The question prompts the system to predict the next action.
* **Topic Selection**: The system identifies the relevant monster, Zinogre, from a set of possible monsters. Other monsters are present in the diagram, but are crossed out with a red "X".
* **Retrieved Knowledge**: The system retrieves knowledge about Zinogre's attack patterns. This knowledge is textualized, meaning it is converted into a textual format that can be processed by the system.
* **Expansion**: The system expands the knowledge base with information about different phases of Zinogre's attacks. The phases listed are Charging Phase, Charged Phase, and Super Charged. Stygian Zinogre is also mentioned.
* **Multi-agents Retriever**: This component uses the retrieved knowledge to predict the next action. It considers factors such as the current phase of the attack and the monster's behavior.
* **Summarizer**: The summarizer provides a concise description of the predicted action.
* **Attack Actions**: The diagram lists possible attack actions that the Zinogre might perform. These include Headbutt, Devour, Heavy Pawslam, and Double Slam.
### Key Observations
* The diagram illustrates a complex system that combines perception, knowledge retrieval, and summarization to predict the attack actions of a monster in a video game.
* The system uses a variety of techniques, including natural language processing, computer vision, and machine learning.
* The diagram highlights the importance of knowledge representation and reasoning in predicting complex events.
### Interpretation
The diagram presents a system designed to anticipate the actions of a virtual creature, the Zinogre, within a game environment. The system leverages a multi-faceted approach, integrating visual perception, textual analysis, and a knowledge base to forecast the monster's next move.
The "Perceiver" acts as the initial data intake, processing both descriptive text ("Zinogre raises its right claw...") and visual frames from the game. This dual-input mechanism allows the system to understand the Zinogre's current state and context. The "Topic Selection" module then focuses the system's attention on the specific entity of interest, the Zinogre, filtering out irrelevant information.
The "Retrieved Knowledge" component is crucial, as it provides the system with pre-existing information about the Zinogre's attack patterns and behaviors. This knowledge is "textualized," suggesting a conversion into a machine-readable format for efficient processing. The "Expansion" module builds upon this foundation by incorporating details about different phases of the Zinogre's attacks (Charging, Charged, Super Charged), adding depth and nuance to the prediction process.
The "Multi-agents Retriever" is the core of the prediction engine. It synthesizes the information gathered from the previous modules to anticipate the Zinogre's next action. Finally, the "Summarizer" translates this prediction into a concise and human-understandable statement ("Zinogre will jump and slam...").
The diagram highlights the complexity involved in creating an intelligent system capable of understanding and predicting behavior in a dynamic environment. By combining perception, knowledge retrieval, and reasoning, the system aims to provide a more immersive and challenging gaming experience. The system is designed to predict the next action of the Zinogre, which could be a Headbutt, Devour, Heavy Pawslam, or Double Slam. The system uses a combination of textual and visual information to make its predictions.
</details>
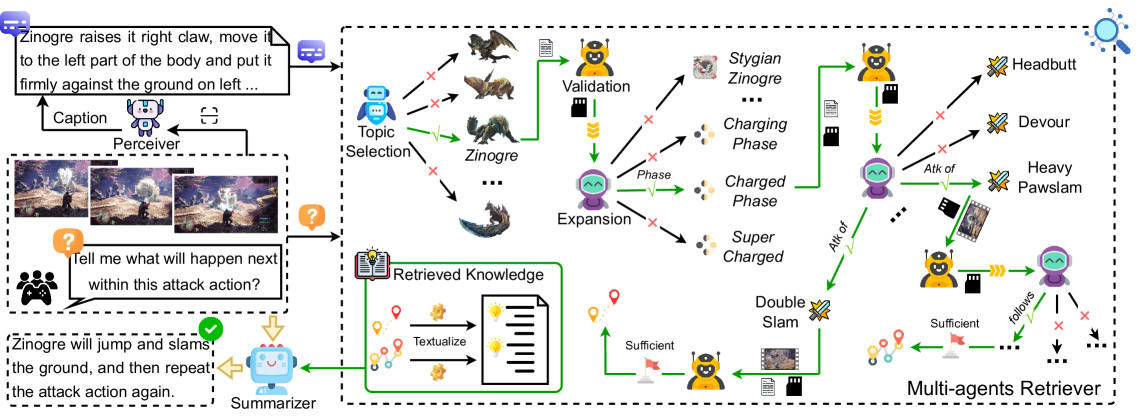
Figure 3: Our method first converts the query media into a textual caption. Next, a multi-agent self-search mechanism retrieves relevant knowledge associated with the query. Finally, the retrieved knowledge is utilized to enhance the model’s response.
<details>
<summary>images/fast-forward-button.png Details</summary>

### Visual Description
## Diagram: Triple Arrow Icon
### Overview
The image is a simple diagram featuring three identical, stylized arrows pointing to the right. The arrows are a solid yellow color and are evenly spaced against a light gray background. The arrows are oriented horizontally.
### Components/Axes
* **Arrows:** Three identical yellow arrows, each pointing to the right. The arrows have a rounded rectangular shape with an angled point.
* **Background:** Light gray background.
* **Orientation:** Horizontal.
### Detailed Analysis
* The arrows are arranged in a row, with each arrow slightly offset from the previous one to create a sense of movement or progression.
* The arrows are a bright yellow color, which contrasts with the light gray background.
* The arrows are stylized, with rounded corners and a simple, geometric design.
### Key Observations
* The image is simple and uncluttered, with a clear focus on the three arrows.
* The arrows are the dominant element in the image, and they are arranged in a way that draws the eye across the image from left to right.
* The image is likely intended to convey a sense of direction, movement, or progression.
### Interpretation
The image is a simple and effective way to communicate the concept of direction or movement. The three arrows suggest a sequence of steps or a progression from one point to another. The bright yellow color of the arrows makes them stand out against the light gray background, and the stylized design gives them a modern and professional look. The image could be used in a variety of contexts, such as a website, a presentation, or a marketing campaign.
</details>
means the continue of search and
<details>
<summary>images/sd-card.png Details</summary>

### Visual Description
## Diagram: SD Card Icon
### Overview
The image is a simple, black silhouette of an SD card against a light gray background. It depicts the standard shape and features of an SD card, including the notched corner and contact points.
### Components/Axes
* **Shape:** Rectangular with a notched corner on the top-left.
* **Color:** Black silhouette.
* **Background:** Light gray.
* **Contact Points:** Three rectangular cutouts at the top of the card.
### Detailed Analysis
The SD card is represented as a solid black shape. The top-left corner is angled, creating a notch. The top edge has three evenly spaced rectangular cutouts, representing the contact points. The rest of the card is a solid rectangle with rounded corners.
### Key Observations
* The image is a simplified representation of an SD card.
* The key features of an SD card (shape, notch, contact points) are clearly depicted.
### Interpretation
The image serves as a clear and recognizable icon for an SD card. It is suitable for use in user interfaces, technical documentation, or any context where a simple representation of an SD card is needed. The simplicity of the design makes it easily scalable and recognizable at various sizes.
</details>
represents the aggregated knowledge upon current entity.
3.2 MH Benchmark
We also designed 238 carefully crafted queries involving knowledge within MH-MMKG. They cover six challenging sub-tasks, as shown in Table 1 (some samples are available in Figure 5). As shown in Figure 3, each input query $Q=(q,d,z)$ consists of 1) a question $q$ , 2) a video or images $d$ , which serves as a visual reference for $q$ , and auxiliary information $z$ , which contains relevant monster’s name $e∈\mathcal{E}_{o}$ as well as additional information that cannot be inferred purely from $d$ . The auxiliary information $z$ provides additional context to an MLLM for finding the correct subgraph. By default, we assume that $z$ is available as it facilitates knowledge retrieval and in the real scenarios players generally know them We analyze their impacts in the supplementary material.. Note that, visual data in $Q$ is different from MH-MMKG’s.
To answer $q$ without built-in knowledge about the game’s world, a model needs to go through multiple entities and edges of $\mathcal{G}$ . For example, to answer question “Which attack follows?” with a visual context in which a monster Rathian perform attack action Triple Rush, the knowledge will be:
$$
\displaystyle\textit{Rathian}\xrightarrow{\text{attack of}}\textit{Triple Rush}\xrightarrow{\text{continues}}\textit{Bite}, \tag{1}
$$
as shown in Figure 2. Therefore, finding the correct paths over $\mathcal{G}$ is essential for this task. Each query is annotated with a subgraph $\mathcal{I}$ of $\mathcal{G}$ as ground-truth knowledge for answering $q$ , textual descriptions $s$ of $d$ written by the knowledgeable game players, and the ground-truth answer $y$ . $\mathcal{I}$ comes with a root entity $e_{0}$ , and the paths from $e_{0}$ to each leaf is deemed as a bunch of knowledge. The details of MH-MMKG and the MH benchmark are available in the supplementary material.
3.3 Task Definition
We define three task variants over MH benchmark with different levels of supplementary information.
Knowledgeable (Know.) variant simulates a model with sufficient perception for the game’s visual domain and sufficient (built-in) knowledge about the world to answer the given question. This idealized setting assesses how well the model reasons the answer $\hat{y}$ from perfect external knowledge and perception. Together with $Q$ and $\mathcal{G}$ , we provide a model with 1) the annotated subgraph $\mathcal{I}$ as well as 2) the textual description $s$ of $Q$ ’s visual reference $d$ , and 3) the set of all human-written caption for $c$ in $\mathcal{G}$ so that it can access to ones associated with entities in $\mathcal{I}$ without visual perception, i.e.:
$$
\hat{y}=M(Q,s,\mathcal{I},\mathcal{G},\mathcal{A}). \tag{2}
$$
Perceptive variant also assumes a model’s sufficient perception but without knowledge to answer the question. This setting evaluates the model’s knowledge retrieval (i.e., to find $\mathcal{I}$ ) ability and the knowledge comprehension ability. The model is supplied with human-written caption for all $c$ so that it can find textual descriptions associated with entities, and is required to output both the final response $\hat{y}$ and the retrieved $\hat{\mathcal{I}}$ :
$$
\hat{y},\hat{\mathcal{I}}=M(Q,s,\mathcal{G},\mathcal{A}). \tag{3}
$$
Unaided is the most challenging variant, where the model relies entirely on its own visual perception (for both $d$ and $c$ ) to interpret the visual world and retrieve external knowledge. As with the perceptive variant, the output are both $\hat{y}$ and $\hat{\mathcal{I}}$ . This variant is formulated as:
$$
\hat{y},\hat{\mathcal{I}}=M(Q,\mathcal{G}). \tag{4}
$$
4 Method
Figure 3 illustrates the overall pipeline of our method to address our task. It is designed as a baseline method for the MH Benchmark and we describe it for the unaided variant, while it can easily adapted to the others. Given an input query $Q$ , the visual reference $d∈ Q$ is first converted into a textual caption by a perceiver. Then, a multi-agent retriever, consisting of topic selection, validation, and expansion agents, retrieves relevant knowledge for $Q$ . Finally, a summarizer generates $\hat{y}$ using retrieved knowledge.
The perceiver $P$ is designed to transform $d$ in $Q$ into textual description. While retaining the original visual data could provide richer information, on-the-fly perception in the visual modality can incur high computational costs; therefore, we choose to convert $d$ into the text as a more efficient representation. The transformed text is demoted as $\hat{s}=P(Q)$ . We detail the multi-agent retriever and summarizer in the following sections.
4.1 Multi-agents Retriever
We design a fully automated search algorithm with three agents to find the subgraph of $\mathcal{G}$ to answer $q$ . First, the topic selection agent $L$ analyzes the input question $q$ to identify the topic entity $e_{0}=L(q,z,\mathcal{E}_{o})$ , which serves as the root for knowledge retrieval. Then, the expansion and validation agents are alternately activated to grow the subgraph with breadth first search, starting from $e_{0}$ , to include necessary knowledge. The expansion agent finds all plausible neighboring entities for each open entities. The validation agent, in turn, validate if the current path from the root to each open entities is enough to answer $q$ .
We denote the subgraph of $\mathcal{G}$ after the $t$ -th round by $\mathcal{K}_{t}=(\mathcal{E}^{\prime}_{t},\mathcal{V}^{\prime}_{t})$ , where $\mathcal{E}^{\prime}_{t}⊂eq\mathcal{E}$ , $\mathcal{V}^{\prime}_{t}⊂eq\mathcal{V}$ , and $\mathcal{K}_{0}=(\{e_{0}\},\emptyset)$ . We also denote the set of open entities after the $t$ -th round by $\mathcal{O}_{t}⊂\mathcal{E}^{\prime}_{t}$ , which is a (sub)set of newly added entities at the $t$ -th round and is required to explore further expansion.
For the $(t+1)$ -th round, the expansion agent $W$ retrieves the set $\mathcal{N}(e)$ of all plausible neighboring entities for each open entity $e∈\mathcal{O}_{t}$ as:
$$
\displaystyle\mathcal{N}(e)=W(e,\mathcal{K}_{t};Q,\mathcal{G},\mathcal{A}), \tag{5}
$$
where $W$ is an MLLM with a designated prompt (detailed in the supplementary material) to judge if the knowledge aggregated over the path on $\mathcal{G}$ from $e_{0}$ to each $e^{\prime}∈\{e^{\prime}|(e,e^{\prime})∈\mathcal{V}\}$ is useful to answer $q$ . $\mathcal{N}(e)$ is a set of entities that are judged to be useful. To build $\mathcal{K}_{t+1}=(\mathcal{E}^{\prime}_{t+1},\mathcal{V}^{\prime}_{t+1})$ , we first aggregate all neighboring entities and add them to $\mathcal{E}^{\prime}_{t}$ as:
$$
\displaystyle\mathcal{E}^{\prime}_{t+1}=\mathcal{E}^{\prime}_{t}\cup\{e^{\prime}|e\in\mathcal{O}_{t},e^{\prime}\in\mathcal{N}(e)\}, \tag{6}
$$
where duplicated entities are removed to make entities in $\mathcal{E}^{\prime}_{t+1}$ unique. $\mathcal{V}^{\prime}_{t+1}$ includes additional links to newly added entities, given by:
$$
\displaystyle\mathcal{V}^{\prime}_{t+1}=\mathcal{V}^{\prime}_{t}\cup\{\nu(e,e^{\prime})|e\in\mathcal{O}_{t},e^{\prime}\in\mathcal{N}(e)\}, \tag{7}
$$
where $\nu(e,e^{\prime})$ gives $v∈\mathcal{V}$ identified by $(e,e^{\prime})$ .
The validation agent $U$ checks if each path from $e_{0}$ to $e∈\mathcal{O}_{t+1}$ provides sufficient knowledge to answer $q$ :
$$
\displaystyle o(e)=U(e,\mathcal{K}_{t+1};Q,\mathcal{G},\mathcal{A}), \tag{8}
$$
where $U$ again is an MLLM with a carefully designed prompt. $o(e)=\textit{Yes}$ if the knowledge is good enough and no more expansion is needed; otherwise, $o(e)=\textit{No}$ and continues the expansion $U$ also output a caption for $c$ of the entity $e$ in unaided-online setting..
The open set $\mathcal{O}_{t+1}$ basically is the set of newly added entities in the $(t+1)$ -th round. If a newly added entity $e$ is already in $\mathcal{E}^{\prime}_{t}$ and also in $\mathcal{O}_{t}$ , the subgraph forms a loop. In this case, $e$ does not need further expansion as it is already in $\mathcal{E}^{\prime}_{t}$ . Meanwhile, $e$ may be included in the neighbor sets of multiple $e∈\mathcal{O}_{t}$ . In this case, the subgraph also forms a loop, but $e$ has not yet been explored. Thus, it should be in $\mathcal{O}_{t+1}$ . Taking these cases into account, $\mathcal{O}_{t+1}$ is given by:
$$
\displaystyle\mathcal{O}_{t+1}=\mathcal{E}^{\prime}_{t+1}\backslash\mathcal{E}^{\prime}_{t}, \tag{9}
$$
where the operator “ $\backslash$ ” represents set subtraction.
This multi-agent retrieval runs until no open entity is found (i.e., $\mathcal{O}_{t}=\emptyset$ ). The retrieved subgraph is given by:
$$
\hat{\mathcal{I}}=\mathcal{K}_{t}. \tag{10}
$$
4.2 Reasoning via Knowledge Augmentation
For answer reasoning, we aggregate knowledge on $\hat{\mathcal{I}}$ and represent it in text, which is fed into an LLM. The knowledge augments the reasoning process: the LLM does not need to rely on built-in knowledge about the game’s world but (almost) pure reasoning ability is required. This is formally denoted by:
$$
\hat{y}=\text{MLLM}(Q,\aleph(\hat{\mathcal{I}},\mathcal{G},\mathcal{A},\alpha)), \tag{11}
$$
where $\hat{y}$ is the predicted answer for $Q$ , and $\aleph$ transforms each path from $e_{0}$ to each leaf of $\hat{I}$ into text given the entire knowledge (i.e., $\mathcal{G}$ and $\mathcal{A}$ ). The parameter $\alpha$ limited the number of paths in $\hat{\mathcal{I}}$ used for reasoning (defaulted as 5).
5 Results
Table 2: The experimental settings of query and knowledge retrieval. “Vision” indicates that $d$ is used, while “H-Cap.” uses $s$ . For MMKG, “Path” means a model can access annotated subgraphs $\mathcal{I}$ . “H-Cap.” means a model use human-written captions (for $c$ ) in $\mathcal{A}$ . “Vis.-Off.” and “Vis.-On.” represent how a model’s captions are generated (offline and online).
| Methods | Query Vision | MMKG H-Cap. | Path | H-Cap. | Vis.-Off | Vis.-On |
| --- | --- | --- | --- | --- | --- | --- |
| Vanilla | ✔ | | | | | |
| Vanilla + | | ✔ | | | | |
| Know. | | ✔ | ✔ | ✔ | | |
| Perceptive | | ✔ | | ✔ | | |
| Unaided-Offline | ✔ | | | | ✔ | |
| Unaided-Online | ✔ | | | | | ✔ |
Table 3: Experimental results are reported for both leading closed-source and open-source MLLMs. The Vanilla, Vanilla +, and Knowledgeable (Know.) experiments are evaluated solely on Acc., while all other experiments are assessed based on both $Acc.$ and knowledge consistency. Results improved in Online than Offline are highlighted with light green.
| Models GPT-4o [1] | Vanilla Acc. .3122 | Vanilla + Pre. .3924 | Know. Rec. .8565 | Perceptive Acc. .7383 | Unaided-Offline Pre. .5061 | Unaided-Online Rec. .7046 | Acc. .4050 | Pre. .2595 | Rec. .4416 | .5105 | .2756 | .5625 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| GPT-4o mini [1] | .3218 | .4135 | .8481 | .6877 | .2963 | .5450 | .4514 | .2059 | .5028 | .3544 | .1626 | .3009 |
| Claude 3.7 Sonnet [2] | .2827 | .3375 | .8987 | .7004 | .5817 | .6322 | .3628 | .2775 | .3270 | .4388 | .2911 | .4029 |
| Claude 3.5 Sonnet [2] | .2869 | .3755 | .8776 | .7215 | .5922 | .6800 | .3966 | .3215 | .4008 | .3966 | .2330 | .3270 |
| Claude 3.5 Haiku [2] | .2356 | .3206 | .8823 | .6455 | .3739 | .5007 | .3544 | .2002 | .3164 | .3670 | .1735 | .3361 |
| Gemini 2.0 Flash [47] | .1983 | .2995 | .8438 | .6919 | .3507 | .6146 | .3839 | .1703 | .4092 | .3713 | .1515 | .3663 |
| Gemini 1.5 Pro [47] | .2194 | .2700 | .8438 | .6962 | .4761 | .6033 | .3164 | .1615 | .2194 | .4050 | .2122 | .4585 |
| Step-1o [43] | .2436 | .2815 | .8235 | .5747 | .4372 | .5095 | .3025 | .1831 | .2483 | .3403 | .2204 | .2987 |
| InternVL2.5-78B-MPO [12] | .1603 | .2616 | .8649 | .5991 | .4198 | .5428 | .2700 | .1729 | .2250 | .3080 | .1556 | .2378 |
| Qwen2.5-VL-72B [3] | .1476 | .2616 | .8734 | .6244 | .4602 | .4908 | .3206 | .2139 | .2383 | .3164 | .1615 | .1814 |
| Ovis2-16B [36] | .1645 | .2573 | .8902 | .7046 | .5407 | .5949 | .2869 | .1963 | .2383 | .3459 | .1853 | .2878 |
| MiniCPM-o-2.6 [53] | .1139 | .2405 | .8312 | .4683 | .3183 | .4001 | .2194 | .1311 | .2376 | .1687 | .0189 | .0210 |
| DeepSeek-VL2-Small [52] | .1139 | .2362 | .6455 | .3586 | .1419 | .1708 | .1814 | .0400 | .0759 | .1181 | .0042 | .0042 |
| Human (Knowledgeable) | .5252 | — | — | — | — | — | — | — | — | .9033 | .9207 | .8535 |
| Human (Random) | .0336 | — | — | — | — | — | — | — | — | .6092 | .7113 | .6457 |
5.1 Experimental Settings
We evaluated both leading closed-source models (showing in api: gpt-4o-2024-11-20, gpt-4o-mini-2024-07-18 [1], claude-3-7-sonnet-20250219, claude-3-5-sonnet-20240620, claude-3-5-haiku-20241022 [2], gemini-1.5-pro-002, gemini-2.0-flash-001 [47], and step-1o-vision-32k [43]) and open-source models (InternVL2.5-78B-MPO [12], Qwen2.5-VL-72B [3], Ovis2-16B [36], and DeepSeek-VL2 [52]) with our baseline over MH Benchmark. A single model serves as all agents and functionalities (i.e., the perceiver, summarize, as well as the topic selection, validation, and expansion agents in the multi-agent retriever) via different prompts. We use images solely as visual references because current MLLMs do not support videos as input. Due to input size limitations in most models, all images are resized to 1K for our experiments.
Evaluation Metrics. We use accuracy (Acc.) to measure the correctness of predicted answers $\hat{y}$ compared to the ground-truth answer $y$ . Since the questions in our benchmark follow an open-ended question-answering format, we employ GPT-4o as a judge with few-shot samples [59]. Knowledge consistency is also used to calculate the consistency between $\mathcal{\hat{I}}$ and $\mathcal{I}$ using precision (Pre.) and recall (Rec.), demonstrating the efficiency in searching relevant knowledge. Human evaluation for GPT-4o as a judge and metric definition are shown in the supplementary material.
5.2 Performance of MLLMs
In addition to the three tasks defined in 3.3, we evaluate the models’ performance without external knowledge (vanilla). Vanilla + isolates the effect of the model’s visual ability. Furthermore, the Unaided task includes two variants: 1) Offline variant relies on pre-extracted captions (for all $c$ in MMKG) of an MLLM without access to the query $Q$ or any information obtained during knowledge retrieval. Online variant generates captions for $c$ during knowledge retrieval (i.e., in $U$ ). Table 2 summarizes the experimental setups. We also include human performance for the vanilla and unaided-online settings. We recruited voluntary participants: One is knowledgeable, and the other has not played the game series. They first answered the questions only with $Q$ and then were allowed to look into $\mathcal{G}$ .
As shown in Table 3, with the vanilla setting, all methods hardly predicted correct answers. GPT-4o achieves the best performance with an accuracy of 0.31, whereas the knowledgeable human attains 0.53. The closed-source models generally outperform open-source ones, implying that the closed-source models have richer built-in knowledge about the game. With the vanilla + setting, which allows human captions $s$ instead of images $d$ , most models’ performance improved, which means that MH Benchmark requires comprehension of visual context. In the knowledgeable experiment, the models achieved an accuracy of roughly 0.9. We thus argue that MH-MMKG provides sufficient knowledge to answer the questions in MH Benchmark.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Bar Chart: MH Benchmark Sub-tasks Accuracy
### Overview
The image is a bar chart comparing the accuracy of different language models (GPT-4o, Claude 3.7, and Gemini 1.5) across six sub-tasks of the MH Benchmark. The chart also includes data points for "Pre." and "Re." which are represented as scatter plots.
### Components/Axes
* **X-axis:** "MH Benchmark Sub-tasks" with categories I, II, III, IV, V, and VI.
* **Y-axis:** "Accuracy" ranging from 0.0 to 1.0 in increments of 0.2.
* **Legend:** Located at the top of the chart.
* Yellow Star: "Pre."
* Gray Circle: "Re."
* Blue: "GPT-4o"
* Orange: "Claude 3.7"
* Green: "Gemini 1.5"
### Detailed Analysis
Here's a breakdown of the accuracy for each sub-task and model:
* **Sub-task I:**
* GPT-4o (Blue): Accuracy ~ 0.88
* Claude 3.7 (Orange): Accuracy ~ 0.95
* Gemini 1.5 (Green): Accuracy ~ 0.62
* Pre. (Yellow Star): Accuracy ~ 0.88
* Re. (Gray Circle): Accuracy ~ 0.88
* **Sub-task II:**
* GPT-4o (Blue): Accuracy ~ 0.37
* Claude 3.7 (Orange): Accuracy ~ 0.36
* Gemini 1.5 (Green): Accuracy ~ 0.36
* Pre. (Yellow Star): Accuracy ~ 0.22
* Re. (Gray Circle): Accuracy ~ 0.42
* **Sub-task III:**
* GPT-4o (Blue): Accuracy ~ 0.29
* Claude 3.7 (Orange): Accuracy ~ 0.18
* Gemini 1.5 (Green): Accuracy ~ 0.24
* Pre. (Yellow Star): Accuracy ~ 0.11
* Re. (Gray Circle): Accuracy ~ 0.27
* **Sub-task IV:**
* GPT-4o (Blue): Accuracy ~ 0.35
* Claude 3.7 (Orange): Accuracy ~ 0.41
* Gemini 1.5 (Green): Accuracy ~ 0.31
* Pre. (Yellow Star): Accuracy ~ 0.28
* Re. (Gray Circle): Accuracy ~ 0.50
* **Sub-task V:**
* GPT-4o (Blue): Accuracy ~ 0.72
* Claude 3.7 (Orange): Accuracy ~ 0.40
* Gemini 1.5 (Green): Accuracy ~ 0.39
* Pre. (Yellow Star): Accuracy ~ 0.21
* Re. (Gray Circle): Accuracy ~ 0.49
* **Sub-task VI:**
* GPT-4o (Blue): Accuracy ~ 0.54
* Claude 3.7 (Orange): Accuracy ~ 0.61
* Gemini 1.5 (Green): Accuracy ~ 0.69
* Pre. (Yellow Star): Accuracy ~ 0.03
* Re. (Gray Circle): Accuracy ~ 0.04
### Key Observations
* Claude 3.7 performs best in sub-task I, while Gemini 1.5 performs best in sub-task VI.
* GPT-4o shows the highest accuracy in sub-task V.
* All models have relatively low accuracy in sub-task III.
* The "Pre." values are consistently lower than the model scores, especially in sub-task VI.
* The "Re." values vary across sub-tasks, sometimes exceeding the model scores (e.g., sub-task IV).
### Interpretation
The chart illustrates the varying performance of different language models across different sub-tasks within the MH Benchmark. The differences in accuracy suggest that each model has strengths and weaknesses depending on the specific task. The "Pre." and "Re." data points likely represent baseline or reference scores, indicating the improvement achieved by the language models. The significant difference between "Pre." and model scores in sub-task VI suggests that the models have made substantial progress in this area. The "Re." values, sometimes exceeding model scores, could indicate the presence of a regression or a different evaluation metric.
</details>
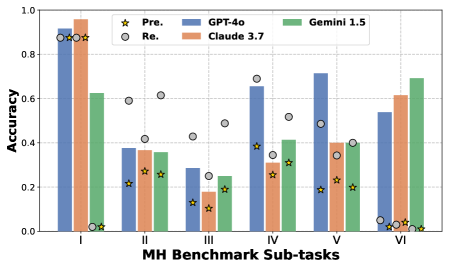
Figure 4: Performance comparison of GPT-4o, Claude 3.7 Sonnet, and Gemini 1.5 Pro across 6 sub-tasks in MH Benchmark.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Question Answering Performance on Monster Hunter World Attacks
### Overview
The image presents a comparison between "Vanilla Answer" and "Augmented Answer" approaches to question answering about Monster Hunter World attacks. It showcases six different scenarios (Individual Information, Action Recognition, Combo Premonition, Condition Awareness, Proc Effect Insight, and Cross Monster Analysis), each with a question, a "Vanilla Answer" (presumably a baseline or simpler approach), and an "Augmented Answer" (presumably a more sophisticated approach). Each scenario also includes a "Retrieved Paths" diagram illustrating the reasoning or knowledge graph used to generate the "Augmented Answer". The performance of the "Augmented Answer" is quantified by Recall and Precision metrics.
### Components/Axes
Each of the six scenarios follows a similar structure:
* **Scenario Title:** (e.g., "I: Individual Information") Located at the top-left of each scenario block.
* **Question:** A question related to Monster Hunter World.
* **"Online" Icon:** A magnifying glass icon with the word "Online" next to it, suggesting the information is retrieved from online sources.
* **"Vanilla Answer":** A text box containing the answer generated by a baseline approach. It is marked with a red "X" indicating an incorrect or incomplete answer.
* **"Augmented Answer":** A text box containing the answer generated by the augmented approach. It is marked with a green checkmark indicating a correct or more complete answer.
* **"Retrieved Paths":** A diagram illustrating the reasoning or knowledge graph used to generate the "Augmented Answer".
* **Recall and Precision:** Metrics quantifying the performance of the "Augmented Answer".
**Diagram Components (Retrieved Paths):**
* Nodes: Represent entities (e.g., monsters, attacks, states).
* Edges: Represent relationships between entities (e.g., "has", "continues", "mated pair").
* Directional Arrows: Indicate the direction of the relationship.
* Images: Small images of the monsters or attacks are sometimes included in the nodes.
### Detailed Analysis or ### Content Details
Here's a breakdown of each scenario:
**I: Individual Information**
* **Question:** "What is the nickname of Tigrex in Monster Hunter World?"
* **Vanilla Answer:** "The nickname of Tigrex in 'Monster Hunter: World' is 'The Roaring Wyvern'." (Incorrect)
* **Augmented Answer:** "The nickname of Tigrex in the game is the 'Absolutely Strong One'." (Correct)
* **Retrieved Paths:** A node for "Tigrex" connected to a text box containing information about Tigrex, including the nickname "Absolutely Strong One".
* **Recall:** 1
* **Precision:** 1
**II: Action Recognition**
* **Question:** "... showing the beginning of a attack of Kushala Daora. What will happen next within this attack action?"
* **Vanilla Answer:** "Kushala Daora will perform a wind-based attack, likely creating a wind pressure or tornado effect in the area." (Incorrect)
* **Augmented Answer:** "Kushala Daora will execute the Aerial Crash attack, charging toward hunter seamlessly transitioning into the Ground Phase." (Correct)
* **Retrieved Paths:** A diagram showing the flow of Kushala Daora's attacks: Aerial Phase -> Aerial Triple Breath Attack, Aerial Kick, Aerial Super Breath Attack, Aerial Crash -> Ground Phase.
* **Recall:** 1
* **Precision:** 0.25
**III: Combo Premonition**
* **Question:** "Analyze all possible continues attacks of Zinogre in charged phase after the showing attack."
* **Vanilla Answer:** "Zinogre may follow up with the following possible attack actions: Thunder Slam, Pounce Attack, Electric Charge ..." (Incorrect)
* **Augmented Answer:** "In charged phase, the possible continued attack actions of Zinogre are: Shoulder Charge and Thunder Charge." (Correct)
* **Retrieved Paths:** A diagram showing the possible attacks Zinogre can perform in the charged phase: Zinogre -> Charged Phase -> Thunder Charge, Leap Attack, Shoulder Charge, Heavy Pawslam.
* **Recall:** 0.5
* **Precision:** 0.5
**IV: Condition Awareness**
* **Question:** "Predict the ongoing attack action Frostfang Barioth will release."
* **Vanilla Answer:** "Frostfang Barioth is preparing to release a lunging ice breath attack! soon." (Incorrect)
* **Augmented Answer:** "Frostfang Barioth is preparing the 'Aerial Ice Breath' attack or 'Leap Attack'." (Correct)
* **Retrieved Paths:** A diagram showing the possible attacks Frostfang Barioth can perform: Frostfang Barioth -> Backstep Ice Breath, Leap Attack, Aerial Ice Breath, Super Fan Slam.
* **Recall:** 1
* **Precision:** 0.4
**V: Proc Effect Insight**
* **Question:** "What will happens to hunter if hit by Yian Garuga's current attack action?"
* **Vanilla Answer:** "If the hunter is hit by this attack, they will take heavy physical damage and potentially be knocked down." (Incorrect)
* **Augmented Answer:** "Being hit by Yian Garuga's current attack action will leave the hunter with a poisonous effect." (Correct)
* **Retrieved Paths:** A diagram showing the possible effects of Yian Garuga's attacks: Yian Garuga -> Bird Missile, Somersault, Poke, Tail Swing, Enhanced Flame Breath.
* **Recall:** 1
* **Precision:** 0.25
**VI: Cross Monster Analysis**
* **Question:** "What is the difference between Lunastra and her mated pair for current attack's pattern?"
* **Vanilla Answer:** "Lunastra's attack patterns involve creating wide, fiery explosions..., while her mated pair, Teostra, typically ..." (Incorrect)
* **Augmented Answer:** "The main differences between... Flame color and effects: Lunastra produces blue flames,.. while Teostra produces orange-yellow flames..." (Correct)
* **Retrieved Paths:** A diagram showing the relationship between Lunastra and Teostra and their attacks: Lunastra -> Fire Breath Sweep, Teostra -> Fire Breath, Super Noa, Fire Breath Sweep.
* **Recall:** 0.5
* **Precision:** 0.25
### Key Observations
* The "Augmented Answer" consistently provides more accurate or complete answers than the "Vanilla Answer".
* The "Retrieved Paths" diagrams illustrate the knowledge graph and reasoning process used by the "Augmented Answer" approach.
* The Recall and Precision metrics vary across the scenarios, indicating different levels of performance for the "Augmented Answer" approach depending on the complexity of the question.
* The "Online" icon suggests that the information is retrieved from online sources, highlighting the importance of external knowledge in answering these questions.
### Interpretation
The image demonstrates the effectiveness of using a knowledge graph and reasoning process to improve the accuracy and completeness of question answering about Monster Hunter World attacks. The "Augmented Answer" approach, which leverages the "Retrieved Paths" diagrams, consistently outperforms the "Vanilla Answer" approach. This suggests that incorporating external knowledge and reasoning capabilities is crucial for answering complex questions about game-related topics. The varying Recall and Precision scores indicate that the performance of the "Augmented Answer" approach is influenced by the complexity of the question and the structure of the underlying knowledge graph. The red X and green checkmarks visually reinforce the superiority of the "Augmented Answer" approach.
</details>
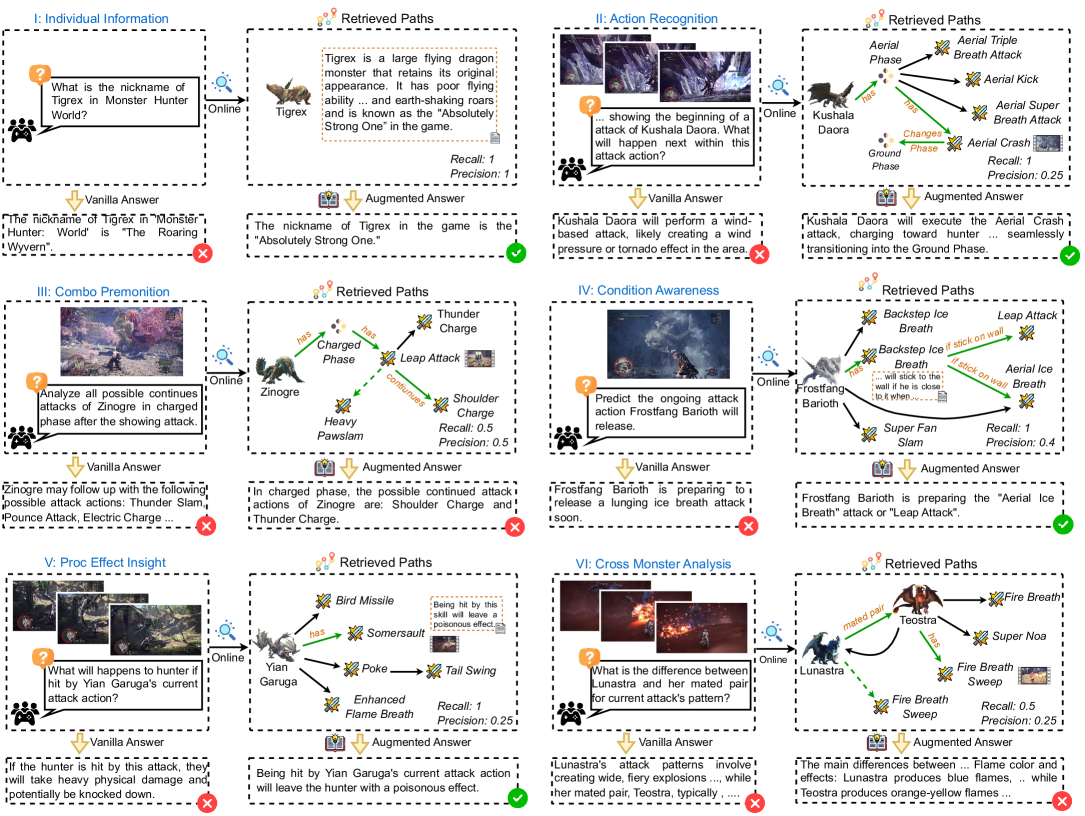
Figure 5: Examples of the 6 sub-tasks in the MH Benchmark, each generated by GPT-4o for both the Vanilla Answer and the Augmented Answer using an unaided-online retrieval.
The perceptive, unaided-offline, and unaided-online settings evaluate a model’s ability to retrieve relevant knowledge In the perceptive setting, which uses human captions for both queries and knowledge, all models demonstrated a strong capacity to identify relevant knowledge, significantly improving performance compared to vanilla +. Additionally, the models exhibit high knowledge consistency. In the unaided-offline setting, all models performed worse than in the perceptive setting, suggesting that visual perception plays a crucial role in knowledge retrieval. Nevertheless, they are still still better than the vanilla setting, demonstrating the benefits of knowledge retrieval. The unaided-online setting further challenges the models’ visual perception to generate captions with richer context (i.e., $Q$ and the knowledge on the path in $\hat{\mathcal{I}}$ ) compared to the unaided-offline. Our results show that only some models surpassed the offline variant (highlighted in green), yet the improvement is evident–GPT-4o improves by 0.1, and Claude 3.7 Sonnet by 0.07. This suggests that knowing what to do enhances a model’s visual perception, strengthening its planning ability, and ultimately results in improved reasoning ability. Additionally, we find that recall is consistently higher than precision, suggesting that models tend to retrieve more knowledge. On the contrary, humans showed higher precision (though both precision and recall are high compared to MLLMs).
We also analyzed the performance differences in the unaided-online setting across six sub-tasks over GPT-4o, Claude 3.7 Sonnet, and Gemini 1.5 Pro, as illustrated in Figure 4. GPT-4o achieves the best performance in all sub-tasks except I and VI. It is particularly strong in sub-tasks IV and V, which are more reliant on fine-grained visual perception. Additionally, sub-task I is the simplest, involving only a single relationship $v$ , for which the models generally perform well. For sub-task VI, although the accuracy is high, models fail to find the correct path (model uses its inherent knowledge for response). These results suggest that visual perception remains a key challenge for MH benchmark.
Figure 5 presents six examples (one per sub-task) in the vanilla and unaided-online settings, where all predictions are by GPT-4o. In the retrieved path panes, the green paths are both in $\mathcal{I}$ and $\hat{\mathcal{I}}$ (i.e., correctly retrieved paths), the dotted green paths are in $\mathcal{I}$ but not in $\hat{\mathcal{I}}$ , and the black paths are in $\hat{\mathcal{I}}$ but not in $\mathcal{I}$ . The key relationship or essential information for deriving the correct answer is highlighted in orange. We report the precision and recall metrics for each example. GPT-4o retrieves many knowledge paths, capturing all relevant knowledge for prediction, though precision is low. Interestingly, for challenging cases like sub-tasks II, GPT-4o successfully recognized detailed visual concepts (e.g., the monster flying backward and the monster sticking to the wall) and generated plausible captions, which require fine-grained visual perception.
5.3 Analysis of Factors Affecting Performance
Impact of Captioning Ability. Table 4 compares performance of captioning, where the metric similarity (Sim.) measures the similarity between generated and human captions using GPT-4o (see supplementary for details). The table also summarizes the accuracy and knowledge consistency scores. The results indicate that the unaided-online setting consistently gives higher similarity scores than the unaided-offline, suggesting that awareness of query $Q$ and retrieval process consistently enhances captioning performance. Also, the similarity scores positively correlated with the reasoning accuracy scores. We also evaluated the unaided-offline variant on GPT-4o but its offline captions are replaced with ones by video models InternVideo2.5 [50] and VideoChat-Flash [32]. The results showed lower performance than the original GPT-4o across all metrics, indicating that current video models have limited capability in visual comprehension for MH Benchmark.
Table 4: Reasoning and knowledge consistency performance and captioning performance. Improved performance scores due to online captioning are highlighted in green.
| Model GPT-4o [1] GPT-4o [1] | Vis.-Off ✔ | Vis.-On ✔ | Acc. .4050 .5105 | Pre. .2595 .2756 | Rec. .4416 .5625 | Sim. .2806 .2948 |
| --- | --- | --- | --- | --- | --- | --- |
| Claude 3.7 Sonnet [2] | ✔ | | .3628 | .2775 | .3270 | .2776 |
| Claude 3.7 Sonnet [2] | | ✔ | .4388 | .2911 | .4029 | .3208 |
| Gemini 1.5 Pro [47] | ✔ | | .3164 | .1615 | .2194 | .1608 |
| Gemini 1.5 Pro [47] | | ✔ | .4050 | .2122 | .4585 | .1746 |
| InternVideo2.5 [50] | ✔ | | .3697 | .1960 | .2959 | .0525 |
| VideoChat-Flash [32] | ✔ | | .3445 | .2135 | .2863 | .0644 |
Keyframe Selection. Due to the limited number of input tokens, current MLLMs cannot handle videos, and keyframe sampling is necessary. MH-MMKG provides human-selected keyframes to facilitate the evaluation on this point. To show the difference between human-selected keyframes and typically-adopted equal-interval sampling, Table 5 summarizes the results on GPT-4o, where sampling is done in two frames per second, and the maximum number of frames is capped at ten frames. The keyframe selection strategy does impact the performance: Human-selected keyframes seem to provide more informative visual cues, though the difference is not substantial.
Table 5: Impact of Keyframes selection.
| Human Sampling | .4050 .3725 | .2595 .2199 | .4416 .3893 | .5105 .4840 | .2756 .2388 | .5625 .5254 |
| --- | --- | --- | --- | --- | --- | --- |
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Chart: GPT and Claude Performance vs. Top K Retrieved Knowledge
### Overview
The image is a line chart comparing the performance of GPT and Claude models based on "Top K Retrieved Knowledge." The chart displays two metrics: "Accuracy" (left y-axis) and "Number of Data" (right y-axis), plotted against "Top K Retrieved Knowledge" (x-axis). There are four data series in total: GPT Accuracy, Claude Accuracy, GPT Number of Data, and Claude Number of Data.
### Components/Axes
* **X-axis:** "Top K Retrieved Knowledge" ranging from 1 to 8.
* **Left Y-axis:** "Accuracy" ranging from 0.3 to 0.7, with gridlines at intervals of 0.1.
* **Right Y-axis:** "Number of Data" ranging from 0 to 238, with gridlines at intervals of approximately 50.
* **Legend (Top-Right):**
* Blue circle marker, solid line: "GPT Acc"
* Orange square marker, solid line: "Claude Acc"
* Light blue triangle marker, dashed line: "GPT Num"
* Light orange diamond marker, dashed line: "Claude Num"
### Detailed Analysis
* **GPT Acc (Blue, Solid Line):** The accuracy of GPT increases as the Top K Retrieved Knowledge increases.
* K=1: Accuracy ≈ 0.32
* K=2: Accuracy ≈ 0.39
* K=3: Accuracy ≈ 0.47
* K=4: Accuracy ≈ 0.50
* K=5: Accuracy ≈ 0.51
* K=6: Accuracy ≈ 0.52
* K=7: Accuracy ≈ 0.52
* K=8: Accuracy ≈ 0.52
* **Claude Acc (Orange, Solid Line):** The accuracy of Claude also increases with Top K Retrieved Knowledge, but plateaus earlier than GPT.
* K=1: Accuracy ≈ 0.31
* K=2: Accuracy ≈ 0.39
* K=3: Accuracy ≈ 0.43
* K=4: Accuracy ≈ 0.44
* K=5: Accuracy ≈ 0.44
* K=6: Accuracy ≈ 0.44
* K=7: Accuracy ≈ 0.44
* K=8: Accuracy ≈ 0.44
* **GPT Num (Light Blue, Dashed Line):** The number of data points for GPT decreases as Top K Retrieved Knowledge increases.
* K=1: Number of Data ≈ 225
* K=2: Number of Data ≈ 150
* K=3: Number of Data ≈ 90
* K=4: Number of Data ≈ 70
* K=5: Number of Data ≈ 60
* K=6: Number of Data ≈ 25
* K=7: Number of Data ≈ 15
* K=8: Number of Data ≈ 10
* **Claude Num (Light Orange, Dashed Line):** The number of data points for Claude also decreases as Top K Retrieved Knowledge increases.
* K=1: Number of Data ≈ 210
* K=2: Number of Data ≈ 80
* K=3: Number of Data ≈ 40
* K=4: Number of Data ≈ 30
* K=5: Number of Data ≈ 20
* K=6: Number of Data ≈ 15
* K=7: Number of Data ≈ 10
* K=8: Number of Data ≈ 5
### Key Observations
* GPT accuracy consistently outperforms Claude accuracy as K increases beyond 2.
* The number of data points decreases for both models as K increases.
* GPT's accuracy continues to increase slightly even after Claude's accuracy plateaus.
* The number of data points for GPT is slightly higher than Claude for K values greater than 4.
### Interpretation
The chart suggests that increasing the "Top K Retrieved Knowledge" initially improves the accuracy of both GPT and Claude models. However, the number of data points used to calculate the accuracy decreases as K increases. This could indicate that while the models are leveraging more knowledge, they are doing so on a smaller and potentially more selective dataset. GPT appears to benefit more from higher K values, achieving better accuracy than Claude, even though the number of data points is decreasing. The plateau in Claude's accuracy suggests a limit to how much it can benefit from additional retrieved knowledge, or perhaps a diminishing return given the decreasing data size. The relationship between accuracy and the number of data points is crucial; a high accuracy based on very few data points might not be as reliable as a slightly lower accuracy based on a larger dataset.
</details>
(a) Using K paths as knowledge.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of three language models (GPT-4o, Claude 3.7, and Gemini Pro) using two different search strategies: Breadth-First Search (BFS) and Depth-First Search (DFS). For each model, there are two bars representing the accuracy achieved with BFS (teal) and DFS (light red). Additionally, precision (Pre.) and recall (Re.) are marked with star and circle symbols, respectively, for each model and search strategy.
### Components/Axes
* **X-axis (Models):** Categorical axis representing the language models: GPT-4o, Claude 3.7, and Gemini Pro.
* **Y-axis (Accuracy):** Numerical axis representing the accuracy, ranging from 0.2 to 0.6 with increments of 0.1.
* **Legend (Top-Left):**
* Star symbol: "Pre." (Precision)
* Circle symbol: "Re." (Recall)
* Teal bar: "BFS." (Breadth-First Search)
* Light Red bar: "DFS." (Depth-First Search)
### Detailed Analysis
Here's a breakdown of the data for each model and search strategy, including precision and recall:
* **GPT-4o:**
* BFS (Teal): Accuracy is approximately 0.51. Precision (yellow star) is approximately 0.33. Recall (gray circle) is approximately 0.49.
* DFS (Light Red): Accuracy is approximately 0.45. Precision (yellow star) is approximately 0.29. Recall (gray circle) is approximately 0.42.
* **Claude 3.7:**
* BFS (Teal): Accuracy is approximately 0.43. Precision (yellow star) is approximately 0.33. Recall (gray circle) is approximately 0.43.
* DFS (Light Red): Accuracy is approximately 0.41. Precision (yellow star) is approximately 0.32. Recall (gray circle) is approximately 0.40.
* **Gemini Pro:**
* BFS (Teal): Accuracy is approximately 0.35. Precision (yellow star) is approximately 0.25. Recall (gray circle) is approximately 0.39.
* DFS (Light Red): Accuracy is approximately 0.31. Precision (yellow star) is approximately 0.24. Recall (gray circle) is approximately 0.35.
### Key Observations
* GPT-4o achieves the highest accuracy with both BFS and DFS.
* For all models, BFS generally results in higher accuracy than DFS.
* Precision is consistently lower than recall across all models and search strategies.
* Gemini Pro has the lowest accuracy among the three models for both search strategies.
### Interpretation
The chart suggests that GPT-4o is the most accurate model among the three tested, regardless of the search strategy used. The fact that BFS consistently outperforms DFS indicates that, for these models and tasks, exploring broadly before diving deep yields better results. The lower precision compared to recall suggests that the models tend to retrieve more relevant items than they retrieve exclusively relevant items, indicating a potential area for improvement in refining the search algorithms. The performance difference between the models highlights the varying capabilities of different language models in the context of these search strategies.
</details>
(b) BFS vs DFS
Figure 6: Ablation experiments for proposed multi-agents search.
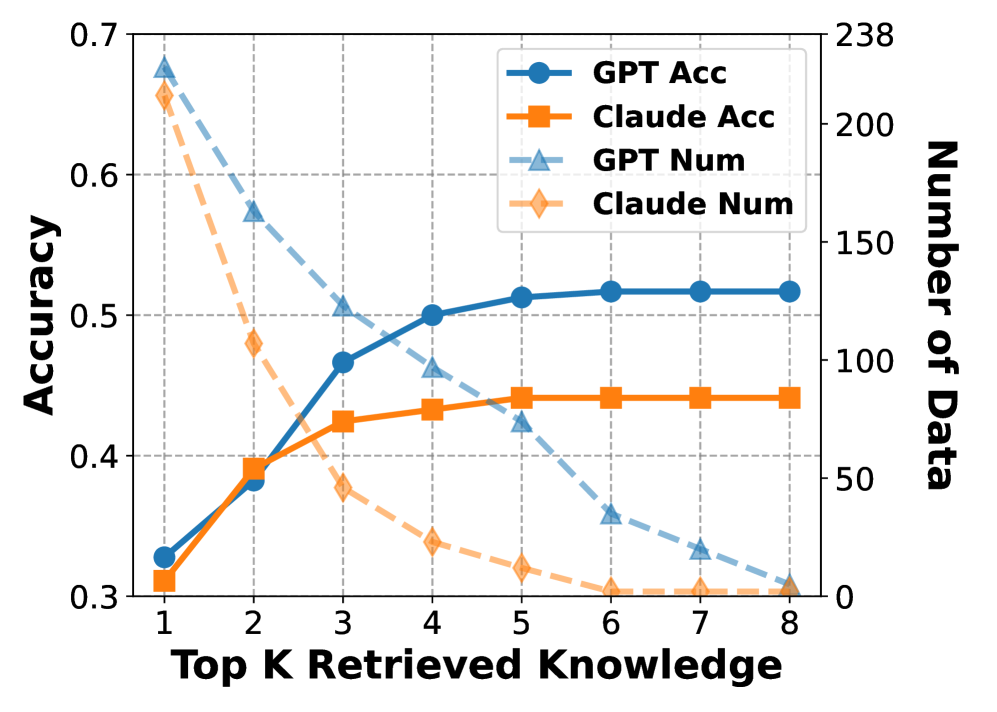
The Number of Paths Used in Reasoning. In our experiments, the number of the paths in $\hat{\mathcal{I}}$ used for reasoning is limited. All evaluations so far used 5 paths, though this number can change the performance Our baseline uses the first 5 paths. A shorter path is thus preferred.. Figure 6(a) shows the relationship between the number of paths and the reasoning accuracy. GPT-4o gives the optimal performance when 5 paths are used. We also show in the figure the number of queries $Q$ for which at least a certain number of paths are retrieved. GPT-4o tends to find more paths as its knowledge (the recall is higher), while Claude 3.7 is more conservative in retrieval (the precision is higher).
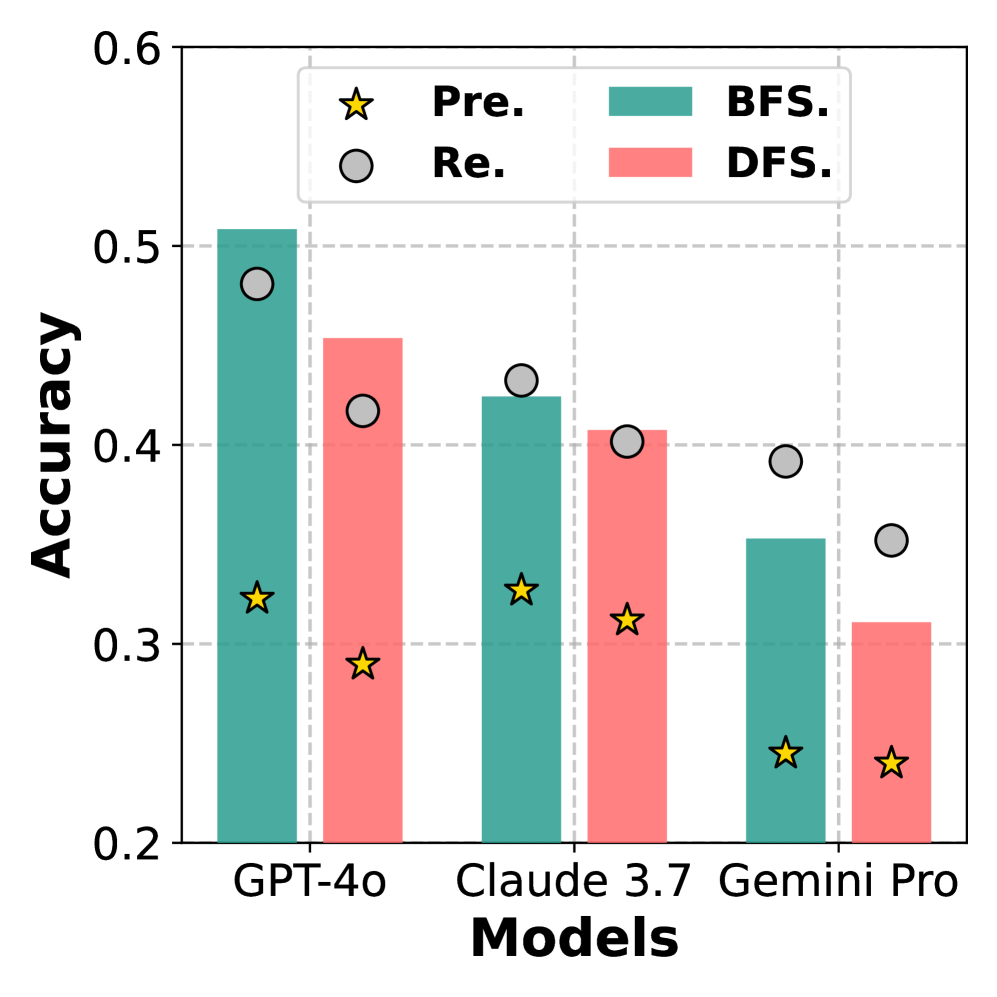
BFS versus DFS. The retrieval strategy can also impact performance. BFS finds shorter paths first, while depth-first search (DFS) can find longer paths at the early stage of retrieval. We evaluated the performance for BFS (the proposed baseline) and DFS when three paths are used. As shown in Figure 6(b), BFS consistently performs better. This means that our queries can be answered within fewer hops in $\mathcal{G}$ , which can be seen as a limitation of our MH Benchmark, as it only requires fewer steps of reasoning.
6 Conclusion
This work explores the ability of MLLMs to handle domain-specific tasks by retrieving knowledge from MMKG. We introduce MH-MMKG and the MH benchmark as a testbed. Additionally, we propose a baseline with a multi-agent knowledge retriever that allows MLLMs to autonomously access relevant knowledge without requiring additional training. Experimental results on both highlight the importance of visual perception of MLLMs and finding relevant knowledge for reasoning. Our work paves the way for more adaptable and context-aware MLLMs in complex real-world scenarios. Future research may focus on expanding the benchmark size, incorporating a wider range of knowledge types, exploring the potential of video modalities, and developing more advanced knowledge retrieval methods.
Acknowledgement
This work is supported by World Premier International Research Center Initiative (WPI), MEXT, Japan. This work is also supported by JST ACT-X Grant No. JPMJAX24C8, JSPS KAKENHI No. 24K20795, CREST Grant No. JPMJCR20D3, and JST FOREST Grant No. JPMJFR216O.
References
- Achiam et al. [2023] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Anthropic [2024] Anthropic. The claude 3 model family: Opus, sonnet, haiku. 2024.
- Bai et al. [2025] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025.
- Baumgartner et al. [2020] Matthias Baumgartner, Luca Rossetto, and Abraham Bernstein. Towards using semantic-web technologies for multi-modal knowledge graph construction. In ACM Multimedia, pages 4645–4649, 2020.
- Bollacker et al. [2008] Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. Freebase: a collaboratively created graph database for structuring human knowledge. In SIGMOD, pages 1247–1250, 2008.
- Bonomo and Bianco [2025] Mirco Bonomo and Simone Bianco. Visual rag: Expanding mllm visual knowledge without fine-tuning. arXiv preprint arXiv:2501.10834, 2025.
- Caffagni et al. [2024] Davide Caffagni, Federico Cocchi, Nicholas Moratelli, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. Wiki-llava: Hierarchical retrieval-augmented generation for multimodal llms. In CVPR, pages 1818–1826, 2024.
- Chen et al. [2025] Liyi Chen, Panrong Tong, Zhongming Jin, Ying Sun, Jieping Ye, and Hui Xiong. Plan-on-graph: Self-correcting adaptive planning of large language model on knowledge graphs. In AAAI, 2025.
- Chen et al. [2024a] Peng Chen, Pi Bu, Jun Song, Yuan Gao, and Bo Zheng. Can vlms play action role-playing games? take black myth wukong as a study case. arXiv preprint arXiv:2409.12889, 2024a.
- Chen et al. [2022] Wenhu Chen, Hexiang Hu, Xi Chen, Pat Verga, and William Cohen. Murag: Multimodal retrieval-augmented generator for open question answering over images and text. In EMNLP, pages 5558–5570, 2022.
- Chen et al. [2023] Yang Chen, Hexiang Hu, Yi Luan, Haitian Sun, Soravit Changpinyo, Alan Ritter, and Ming-Wei Chang. Can pre-trained vision and language models answer visual information-seeking questions? In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023.
- Chen et al. [2024b] Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271, 2024b.
- Chen et al. [2024c] Zhuo Chen, Yichi Zhang, Yin Fang, Yuxia Geng, Lingbing Guo, Xiang Chen, Qian Li, Wen Zhang, Jiaoyan Chen, Yushan Zhu, et al. Knowledge graphs meet multi-modal learning: A comprehensive survey. arXiv preprint arXiv:2402.05391, 2024c.
- Cui et al. [2024] Can Cui, Yunsheng Ma, Xu Cao, Wenqian Ye, Yang Zhou, Kaizhao Liang, Jintai Chen, Juanwu Lu, Zichong Yang, Kuei-Da Liao, et al. A survey on multimodal large language models for autonomous driving. In WACV, pages 958–979, 2024.
- Edge et al. [2024] Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130, 2024.
- Fang et al. [2024] Siyuan Fang, Kaijing Ma, Tianyu Zheng, Xinrun Du, Ningxuan Lu, Ge Zhang, and Qingkun Tang. Karpa: A training-free method of adapting knowledge graph as references for large language model’s reasoning path aggregation. arXiv preprint arXiv:2412.20995, 2024.
- Ferrada et al. [2017] Sebastián Ferrada, Benjamin Bustos, and Aidan Hogan. Imgpedia: a linked dataset with content-based analysis of wikimedia images. In ISWC, pages 84–93, 2017.
- Gao et al. [2023] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2023.
- Guan et al. [2024] Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In CVPR, pages 14375–14385, 2024.
- Gui et al. [2022] Liangke Gui, Borui Wang, Qiuyuan Huang, Alexander G Hauptmann, Yonatan Bisk, and Jianfeng Gao. Kat: A knowledge augmented transformer for vision-and-language. In NAACL, pages 956–968, 2022.
- Guo et al. [2021] Hao Guo, Jiuyang Tang, Weixin Zeng, Xiang Zhao, and Li Liu. Multi-modal entity alignment in hyperbolic space. Neurocomputing, 461:598–607, 2021.
- He et al. [2024] Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh V Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan Hooi. G-retriever: Retrieval-augmented generation for textual graph understanding and question answering. In NeurIPS, 2024.
- Ishiwatari et al. [2020] Taichi Ishiwatari, Yuki Yasuda, Taro Miyazaki, and Jun Goto. Relation-aware graph attention networks with relational position encodings for emotion recognition in conversations. In EMNLP, pages 7360–7370, 2020.
- Ji et al. [2021] Shaoxiong Ji, Shirui Pan, Erik Cambria, Pekka Marttinen, and S Yu Philip. A survey on knowledge graphs: Representation, acquisition, and applications. TNNLS, 33(2):494–514, 2021.
- Ji et al. [2024] Yixin Ji, Kaixin Wu, Juntao Li, Wei Chen, Mingjie Zhong, Xu Jia, and Min Zhang. Retrieval and reasoning on kgs: Integrate knowledge graphs into large language models for complex question answering. In Findings of EMNLP, pages 7598–7610, 2024.
- Jiang et al. [2023] Jinhao Jiang, Kun Zhou, Zican Dong, Keming Ye, Wayne Xin Zhao, and Ji-Rong Wen. Structgpt: A general framework for large language model to reason over structured data. In EMNLP, pages 9237–9251, 2023.
- Jiang et al. [2024] Xuhui Jiang, Yinghan Shen, Zhichao Shi, Chengjin Xu, Wei Li, Huang Zihe, Jian Guo, and Yuanzhuo Wang. Mm-chatalign: A novel multimodal reasoning framework based on large language models for entity alignment. In Findings of EMNLP, pages 2637–2654, 2024.
- Jin et al. [2024] Bowen Jin, Gang Liu, Chi Han, Meng Jiang, Heng Ji, and Jiawei Han. Large language models on graphs: A comprehensive survey. TKDE, 2024.
- Krishna et al. [2017] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. IJCV, 123:32–73, 2017.
- Lee et al. [2024] Junlin Lee, Yequan Wang, Jing Li, and Min Zhang. Multimodal reasoning with multimodal knowledge graph. In ACL, pages 10767–10782, 2024.
- Li et al. [2023] Qian Li, Cheng Ji, Shu Guo, Zhaoji Liang, Lihong Wang, and Jianxin Li. Multi-modal knowledge graph transformer framework for multi-modal entity alignment. In Findings of EMNLP, pages 987–999, 2023.
- Li et al. [2024a] Xinhao Li, Yi Wang, Jiashuo Yu, Xiangyu Zeng, Yuhan Zhu, Haian Huang, Jianfei Gao, Kunchang Li, Yinan He, Chenting Wang, et al. Videochat-flash: Hierarchical compression for long-context video modeling. arXiv preprint arXiv:2501.00574, 2024a.
- Li et al. [2024b] Yangning Li, Yinghui Li, Xingyu Wang, Yong Jiang, Zhen Zhang, Xinran Zheng, Hui Wang, Hai-Tao Zheng, Philip S Yu, Fei Huang, et al. Benchmarking multimodal retrieval augmented generation with dynamic vqa dataset and self-adaptive planning agent. arXiv preprint arXiv:2411.02937, 2024b.
- Lin and Byrne [2022] Weizhe Lin and Bill Byrne. Retrieval augmented visual question answering with outside knowledge. In EMNLP, pages 11238–11254, 2022.
- Liu et al. [2019] Ye Liu, Hui Li, Alberto Garcia-Duran, Mathias Niepert, Daniel Onoro-Rubio, and David S Rosenblum. Mmkg: multi-modal knowledge graphs. In ESWC, pages 459–474. Springer, 2019.
- Lu et al. [2024] Shiyin Lu, Yang Li, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, and Han-Jia Ye. Ovis: Structural embedding alignment for multimodal large language model. arXiv:2405.20797, 2024.
- Luo et al. [2024] Linhao Luo, Zicheng Zhao, Chen Gong, Gholamreza Haffari, and Shirui Pan. Graph-constrained reasoning: Faithful reasoning on knowledge graphs with large language models. arXiv preprint arXiv:2410.13080, 2024.
- Lymperaiou and Stamou [2024] Maria Lymperaiou and Giorgos Stamou. A survey on knowledge-enhanced multimodal learning. Artificial Intelligence Review, 57(10):284, 2024.
- Nguyen et al. [2024] Thong Nguyen, Yi Bin, Junbin Xiao, Leigang Qu, Yicong Li, Jay Zhangjie Wu, Cong-Duy Nguyen, See-Kiong Ng, and Luu Anh Tuan. Video-language understanding: A survey from model architecture, model training, and data perspectives. ACL, 2024.
- Peng et al. [2024] Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang. Graph retrieval-augmented generation: A survey. arXiv preprint arXiv:2408.08921, 2024.
- Ravi et al. [2023] Sahithya Ravi, Aditya Chinchure, Leonid Sigal, Renjie Liao, and Vered Shwartz. Vlc-bert: Visual question answering with contextualized commonsense knowledge. In WACV, pages 1155–1165, 2023.
- Schwenk et al. [2022] Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. A-okvqa: A benchmark for visual question answering using world knowledge. In ECCV, pages 146–162. Springer, 2022.
- Stepfun [2024] Stepfun. Step-1o. In https://platform.stepfun.com/, 2024.
- Su et al. [2024] Cheng Su, Jinbo Wen, Jiawen Kang, Yonghua Wang, Yuanjia Su, Hudan Pan, Zishao Zhong, and M Shamim Hossain. Hybrid rag-empowered multi-modal llm for secure data management in internet of medical things: A diffusion-based contract approach. IEEE Internet of Things Journal, 2024.
- Sun et al. [2025] Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Lionel Ni, Heung-Yeung Shum, and Jian Guo. Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph. In ICLR, 2025.
- Talebirad and Nadiri [2023] Yashar Talebirad and Amirhossein Nadiri. Multi-agent collaboration: Harnessing the power of intelligent llm agents. arXiv preprint arXiv:2306.03314, 2023.
- Team et al. [2023] Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- Wang et al. [2024a] Bowen Wang, Jiuyang Chang, Yiming Qian, Guoxin Chen, Junhao Chen, Zhouqiang Jiang, Jiahao Zhang, Yuta Nakashima, and Hajime Nagahara. Direct: Diagnostic reasoning for clinical notes via large language models. In NeurIPS, pages 74999–75011, 2024a.
- Wang et al. [2024b] Yiqi Wang, Wentao Chen, Xiaotian Han, Xudong Lin, Haiteng Zhao, Yongfei Liu, Bohan Zhai, Jianbo Yuan, Quanzeng You, and Hongxia Yang. Exploring the reasoning abilities of multimodal large language models (mllms): A comprehensive survey on emerging trends in multimodal reasoning. arXiv preprint arXiv:2401.06805, 2024b.
- Wang et al. [2025] Yi Wang, Xinhao Li, Ziang Yan, Yinan He, Jiashuo Yu, Xiangyu Zeng, Chenting Wang, Changlian Ma, Haian Huang, Jianfei Gao, et al. Internvideo2. 5: Empowering video mllms with long and rich context modeling. arXiv preprint arXiv:2501.12386, 2025.
- Wang et al. [2024c] Zheng Wang, Shu Teo, Jieer Ouyang, Yongjun Xu, and Wei Shi. M-RAG: Reinforcing large language model performance through retrieval-augmented generation with multiple partitions. In ACL, pages 1966–1978, 2024c.
- Wu et al. [2024] Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding. arXiv preprint arXiv:2412.10302, 2024.
- Yao et al. [2024] Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800, 2024.
- Yin et al. [2023] Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models. arXiv preprint arXiv:2306.13549, 2023.
- Yue et al. [2024] Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In CVPR, pages 9556–9567, 2024.
- Zeng et al. [2023] Yawen Zeng, Qin Jin, Tengfei Bao, and Wenfeng Li. Multi-modal knowledge hypergraph for diverse image retrieval. In AAAI, pages 3376–3383, 2023.
- Zhao et al. [2024] Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, and Bin Cui. Retrieval-augmented generation for ai-generated content: A survey. arXiv preprint arXiv:2402.19473, 2024.
- Zhao et al. [2023] Ruochen Zhao, Hailin Chen, Weishi Wang, Fangkai Jiao, Xuan Long Do, Chengwei Qin, Bosheng Ding, Xiaobao Guo, Minzhi Li, Xingxuan Li, et al. Retrieving multimodal information for augmented generation: A survey. In Findings of EMNLP, pages 4736–4756, 2023.
- Zheng et al. [2023] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. NeurIPS, 36:46595–46623, 2023.
- Zhu et al. [2022] Xiangru Zhu, Zhixu Li, Xiaodan Wang, Xueyao Jiang, Penglei Sun, Xuwu Wang, Yanghua Xiao, and Nicholas Jing Yuan. Multi-modal knowledge graph construction and application: A survey. TKDE, 36(2):715–735, 2022.
\thetitle
Supplementary Material Contents
1. 1 Introduction
1. 2 Related Works
1. 2.1 Multimodal Retrieval Augmented Generation
1. 2.2 Multimodal Knowledge Graph
1. 2.3 Retrieve Knowledge on Graph
1. 3 Datasets
1. 3.1 MH-MMKG
1. 3.2 MH Benchmark
1. 3.3 Task Definition
1. 4 Method
1. 4.1 Multi-agents Retriever
1. 4.2 Reasoning via Knowledge Augmentation
1. 5 Results
1. 5.1 Experimental Settings
1. 5.2 Performance of MLLMs
1. 5.3 Analysis of Factors Affecting Performance
1. 6 Conclusion
1. 7 Detail of MH Benchmark Construction
1. 7.1 MH-MMKG
1. 7.2 MH Benchmark
1. 8 Experiment Details
1. 8.1 Prompt Template for Our Method
1. 8.2 Knowledge Consistency Calculation
1. 8.3 Human Evaluation of GPT-4o as a Judge
1. 8.4 Additional Experiments for MH Benchmark
1. 8.5 More Result Samples
7 Detail of MH Benchmark Construction
In this section, we detailed construction of our MH-MMKG and MH benchmark.
7.1 MH-MMKG
A total of 22 monsters are incorporated into the graph construction, with each represented as a subgraph connected through various relationships, such as species relation and elemental weaknesses. Each subgraph contains rich information crucial for successful conquests, particularly regarding attack strategies, combos, attack phases, and launch conditions. The monsters are: Anjanath, Azure Rathalos, Barroth, Bazelgeuse, Brachydios, Diablos, Frostfang Barioth, Glavenus, Kushala Daora, Legiana, Nergigante, Rathalos, Rathian, Teostra, Tigrex, Uragaan, Zinogre, Pink Rathian, Yian Garuga, Stygian Zinogre, and Radobaan from Monster Hunter World.
To ensure the quality, we hired three experienced Monster Hunter World players, each with over 200 hours of game play experience. They were tasked with gathering relevant monster information from sources such as Wiki, YouTube, and Bilibili to construct the graph. Additionally, since each monster has unique characteristics within the game, the structure of each subgraph is tailored accordingly. The entities are classified into 7 types as show in Table 6. Most of them are attack actions, making MH-MMKG more focused on battles with monsters. We also plan to explore more game elements in the future. Some entities are attached with text, image or video as its attribution. Note that all video or images are captured from Arena field. While for queries in MH Benchmark all visual media are captured from the Wild field. We also show the length statistic of video clips in Figure 7. It can be observed that most videos are around 1s to 5s.
Table 6: Types of entity in MH-MMKG.
| Topic Entity | Names of monsters that can serve as root entities for knowledge retrieval. Each entity is accompanied by an image of monster as its attribute. | 22 |
| --- | --- | --- |
| Attack Action | Possible attack movements of a monster, each accompanied by text, images (key frames for video), or a video as its attribute. Each of them also attached with human written-caption for the video. | 265 |
| Attack Phase | In different phases, a monster will have varying attack patterns, damage, combos, and other attributes. Only some monsters have unique phase settings. Textual context is attached as attribution. | 20 |
| Element | The element indicates a monster’s weakened resistance to a specific type of attack. | 9 |
| Weapon | Types of damage for weapons crafted from monster materials. | 10 |
| Props | Various types of game props for interacting with monsters. | 6 |
| Attack Effects | The effects of monster attacks or skills during battle, including generated ice patches on ground, scratches, and explosions. Textual context is attached as attribution. | 9 |
There are also 158 kinds of edges and 16 of them are base edges: “has attack action of”, “continues with attack action of”, “has attack variant of”, “has attack phase of”, “change attack phase to”, “is mostly weaken with”, “is weaken with”, “is resistant with”, “provide materials for”, “can be stopped by”, “has attack variants of”, “generates”, “cause”, “turns to”, “mated pair with”, “has subspecies of”. Some base edges (mostly the first two of them) are further combined with specific constrain mechanism to form 142 variants. The samples of constrains are: “is angry”, “hunter step into”, “is close to”, “stick on the wall”, “is knocked by”, etc. (We do not show all of them as they too many ).
<details>
<summary>x8.png Details</summary>
### Visual Description
## Density Plot: Duration Distribution
### Overview
The image is a density plot showing the distribution of durations, measured in seconds. The plot displays a single, light blue curve representing the density of the duration values. The x-axis represents duration in seconds, and the y-axis represents density.
### Components/Axes
* **X-axis:** Duration (seconds), ranging from 0.0 to 17.5, with tick marks at intervals of 2.5 seconds (0.0, 2.5, 5.0, 7.5, 10.0, 12.5, 15.0, 17.5).
* **Y-axis:** Density, ranging from 0.00 to 0.35, with tick marks at intervals of 0.05 (0.00, 0.05, 0.10, 0.15, 0.20, 0.25, 0.30, 0.35).
* **Curve:** A light blue curve showing the density distribution. It peaks around 3 seconds and has a long tail extending to the right.
### Detailed Analysis
The light blue curve represents the density of the duration values.
* The curve starts near 0 at 0 seconds.
* The curve rises sharply to a peak density of approximately 0.33 at around 3 seconds.
* The curve then decreases, forming a smaller bump around 7.5 seconds with a density of approximately 0.03.
* The curve continues to decrease, approaching 0 around 17.5 seconds.
### Key Observations
* The distribution is heavily skewed to the right, indicating that most durations are short, with a few longer durations.
* The peak density occurs around 3 seconds, suggesting that this is the most common duration.
* There is a secondary, smaller peak around 7.5 seconds, indicating a smaller cluster of durations around this value.
### Interpretation
The density plot shows that the durations are not evenly distributed. Most durations are clustered around 3 seconds, with a significant number of durations also occurring around 7.5 seconds. The long tail to the right indicates that there are some durations that are much longer than the average, but these are relatively rare. This could represent a system where most operations complete quickly, but some take significantly longer due to various factors.
</details>
Figure 7: Video clip length statistic.
<details>
<summary>x9.png Details</summary>
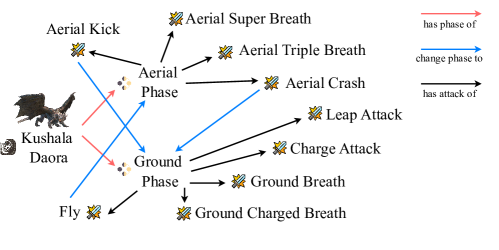
### Visual Description
## Diagram: Kushala Daora Attack and Phase Diagram
### Overview
The image is a diagram illustrating the attack patterns and phase transitions of the Kushala Daora, a monster from a video game. It shows the relationships between the monster's aerial and ground phases, as well as the attacks associated with each phase. The diagram uses arrows to indicate phase transitions and attack types.
### Components/Axes
* **Nodes:** Represent phases (Aerial Phase, Ground Phase) and attacks (Aerial Kick, Aerial Super Breath, Aerial Triple Breath, Aerial Crash, Leap Attack, Charge Attack, Ground Breath, Ground Charged Breath, Fly).
* **Kushala Daora:** An image of the monster, positioned on the left side of the diagram.
* **Arrows:** Indicate relationships between phases and attacks.
* Red arrows: "has phase of"
* Blue arrows: "change phase to"
* Black arrows: "has attack of"
* **Legend:** Located on the right side, explaining the meaning of the different colored arrows.
### Detailed Analysis
* **Kushala Daora:**
* The diagram starts with Kushala Daora.
* Kushala Daora "has phase of" both Aerial Phase and Ground Phase (indicated by red arrows).
* **Aerial Phase:**
* Aerial Phase "has attack of" Aerial Kick, Aerial Super Breath, Aerial Triple Breath, and Aerial Crash (indicated by black arrows).
* Aerial Phase "change phase to" Ground Phase (indicated by a blue arrow).
* **Ground Phase:**
* Ground Phase "has attack of" Leap Attack, Charge Attack, Ground Breath, and Ground Charged Breath (indicated by black arrows).
* Ground Phase "change phase to" Aerial Phase (indicated by a blue arrow).
* Kushala Daora "has attack of" Fly (indicated by a black arrow). Fly "change phase to" Aerial Phase (indicated by a blue arrow).
### Key Observations
* The diagram clearly shows the cyclical nature of the Kushala Daora's phases, transitioning between aerial and ground.
* Each phase has a distinct set of attacks associated with it.
* The "Fly" attack acts as a direct transition from the Kushala Daora to the Aerial Phase.
### Interpretation
The diagram provides a visual representation of the Kushala Daora's combat behavior. It highlights the monster's ability to switch between aerial and ground phases, each with its own set of attacks. Understanding these transitions and attack patterns is crucial for players to effectively combat the Kushala Daora. The diagram suggests that players should be prepared for both aerial and ground attacks and anticipate phase transitions to avoid being caught off guard. The "Fly" attack is a key indicator of an upcoming transition to the aerial phase.
</details>
Figure 8: Subgraph structure for Kushala Daora.
<details>
<summary>x10.png Details</summary>
### Visual Description
## Attack Diagram: Brachydios
### Overview
The image is a diagram illustrating the attack patterns and slime-related mechanics of the monster Brachydios from a video game. It shows the relationships between different attacks, slime types, and resulting explosions.
### Components/Axes
* **Monster:** Brachydios (image and name on the left)
* **Attacks:** Slime Reapply, Punch, Jump Attack, Tail Swipe, Punch Explosive, Punch Explosion, Explosive Slime, Slime Explosion
* **Slime Types:** green slime, orange slime
* **Relationships:**
* "has attack of" (black arrow)
* "has attack varaint" (teal arrow)
* "generates" (orange arrow)
* "causes" (purple arrow)
### Detailed Analysis
* **Brachydios** is the central figure, with arrows indicating its attacks.
* **Attacks originating from Brachydios:**
* Slime Reapply (top)
* Punch (top-center)
* Jump Attack (center)
* Tail Swipe (bottom)
* **Punch Attack Variants:**
* Punch attack has a green slime variant.
* Punch attack has an orange slime variant.
* **Attack Chains:**
* Punch with green/orange slime generates Punch Explosive.
* Punch with green/orange slime generates Punch Explosion.
* Punch Explosive generates Explosive Slime.
* Explosive Slime causes Slime Explosion.
### Key Observations
* The diagram focuses on the slime mechanic of Brachydios, showing how different attacks apply and detonate slime.
* The "Punch" attack is central, having two slime variants that lead to different explosion types.
### Interpretation
The diagram explains the attack flow of Brachydios, emphasizing the slime mechanic. It shows how the monster applies slime with its attacks, and how those slimes can then explode. The diagram is useful for understanding the monster's attack patterns and how to avoid or exploit them. The different colored arrows and slime types help to differentiate the various attack chains and their effects.
</details>
Figure 9: Subgraph structure for Brachydios.
We present some sub-graphs to illustrate structural diversity, focusing only on attack actions and their related entities, as the other components resemble Figure 2 in the main paper. The main paper showcases the graph structure of Zinogre, known for its extensive combo attacks. Here, we provide two additional examples: Kushala Daora and Brachydios. Kushala Daora exhibits distinct attack patterns in its Aerial Phase (attacking from the air) and Ground Phase (attacking on the ground), as shown in Figure 8. Certain attacks can transition between these phases, making this information crucial for an MLLM to accurately answer related questions. Brachydios, on the other hand, has attack variations that depend on the color of the slime on its fists or head, as illustrated in Figure 9. The color change alters both the attack variant and its effect, adding another layer of complexity to its combat behavior. MLLMs have to comprehend such complex information to correctly answer the question in MH Benchmark.
7.2 MH Benchmark
To differentiate from MH-MMKG, all visual media for queries are captured from the Wild field. Additionally, we present statistics on the average number of entities and depth of knowledge associated with each query in the MH Benchmark, as shown in Table 7. It can be observed that sub-task I is relatively simple, as it relies solely on the topic node. In contrast, sub-tasks II and VI involve a greater number of steps and deeper analysis, as they pertain to combo recognition and cross-monster comparison, both of which require more complex reasoning.
Table 7: Average number of entities and depth of knowledge for each query in MH Benchmark.
| Number avg Depth avg | 1 1 | 2.339 2.278 | 3.535 3.250 | 2.4137 2.4137 | 3.028 2.900 | 4.076 3.038 |
| --- | --- | --- | --- | --- | --- | --- |
Table 8: Prompt for perceiver agent.
| You are a professional Monster Hunter player. You are playing ‘Monster Hunter: World’. |
| --- |
| You will receive consecutive video frames displaying the battle screen with the monster {monster name}. |
| The given ‘Question’ regarding the battle screen is: {question} |
| Generate a ‘Description’ of the battle scene as your ‘Response’, detailing the monster’s limb and body movements, mouth actions, surroundings, and other relevant details. |
| Note that you should not give any assumptions for the ‘Description’. |
| Note that you should directly output your ‘Response’ and do not output any information other than your ‘Response’. |
| Now, start to complete your task. |
| Your ‘Response’: |
Table 9: Prompt for topic entity selection agent.
| You are a professional Monster Hunter player. You are playing ‘Monster Hunter: World’. |
| --- |
| You will receive consecutive video frames displaying the battle screen with the monster: {monster name}. |
| The given ‘Question’ regarding the battle screen is: {question} |
| All possible monster names ‘Options’ are structured in a list format as follows:{topic entity} |
| Note that your ‘Response’ is to directly output the name of the monster you are looking for. |
| Note that you should not output any information other than your ‘Response’. |
| Now, start to complete your task. Your ‘Response’: |
Table 10: Prompt for expansion agent.
| You are a professional Monster Hunter player. You are playing ‘Monster Hunter: World’. |
| --- |
| The text description of the battle screen is: {caption}. |
| Based on the battle screen, here is the ‘Question’ you need to answer: {question}. |
| To answer the above question, you are now searching a knowledge graph to find the route towards relevant knowledge. The following contents are the knowledge you found so far (up to current entity {entity}): |
| ***** |
| {memory} |
| ***** |
| You need to select the relevant ‘Neighbor Entity’ that may provide knowledge to answer the question. The relation and condition from current entity ’entity’ to all ‘Neighbor Entity’ are: |
| ***** |
| {neighbor entity} |
| ***** |
| Your ‘Response’ is directly output the name of all relevant ‘Neighbor Entity’ and separate them directly by ‘;’. |
| If there is no relevant ‘Neighbor Entity’, directly output ’None’. |
| Note that if the ‘Neighbor Entity’ is an attack action, always choose it (if it is not highly irrelevant). |
| Note that if the ‘Neighbor Entity’ is a phase, you can only choose one. |
| Note that you should not output any information other than your ‘Response’. |
| Now, start to complete your task. |
| Your ‘Response’: |
8 Experiment Details
In this section, we show the detailed settings of our baseline method, including prompt for each agent, additional experiments, and more samples.
8.1 Prompt Template for Our Method
We first present the prompt templates for all agents in the retrieval pipeline. Table 8 shows the prompt for the perceiver agent, which translates input images into text based on the given question. Table 9 provides the prompt for the topic selection agent, responsible for selecting the starting entity for knowledge retrieval from the graph. Table 10 contains the prompt for the expansion agent, which plans the next neighboring entity for search. Table 11 presents the prompt for the validation agent, designed to assess the efficiency of knowledge transfer from the starting entity to the current entity. Finally, Table 12 includes the prompt for the summarizer agent, which synthesizes the retrieved knowledge for final answer generation. Among these, the {monster name}, displayed in blue text, represents additional information as a part of question. The {entity} represents the name of current entity during search. The {question} refers to the input query, while {topic entities} denote the names of all topic entities. {entity infp} is the visual irrelavent additional information for an entity. The {caption} is the generated description by the perceiver agent.
The {neighbor entity} are options of neighbor for current entity. It is presented in a text format consisting of a combination of entity-edge triplets and corresponding constraints or conditions (if any). Here is a neighbor sample for monster “Frostfang Barioth” attack action entity “Straight Ice Breath”:
- “Straight Ice Breath” continues with attack action of “Super Fang Slam” (Condition: When hunter hitted by the breath…)
- “Straight Ice Breath” continues with attack action of “Tail Spin” (Condition: When Frostfang Barioth already released two…)
In our prompt, we instruct the model to select relevant neighboring entities while placing greater emphasis on attack action entities, as most tasks are designed around them. For phase entities, we allow the model to select only one, in accordance with the game mechanics.
The {memory} records the search path from the starting entity to the current entity, including entity names and all relevant information at each step. Below is an example illustrating this transition from a knowledge path:
$$
\displaystyle\textit{Zinogre}\xrightarrow{\text{phase of}}\textit{Charged Phase}\xrightarrow{\text{attack of}}\textit{Double Slam} \tag{12}
$$
will be transferred into:
- “Zinogre”: Additional Information: Zinogre has the appearance of a wild wolf and lives in the mountains full of dense trees …
- “Zinogre” has attack phase of ”Charged Phase”.
- “Charged Phase”: Additional Information: Zinogre is charged, the body will be surrounded by electric …
- “Charged Phase” has attack action of “Double Slam”.
- “Double Slam”: Action Description: Zinogre lowers his head and rubs the ground with…
Table 11: Prompt for validation agent. Content in [] is used solely for unaided-online experiments.
| You are a professional Monster Hunter player. You are playing ‘Monster Hunter: World’. |
| --- |
| The text description of the battle screen is: {caption}. |
| Based on the battle screen, here is the ‘Question’ you need to answer: {question}. |
| To answer the above question, you are now searching a knowledge graph to find the route towards relevant knowledge. |
| You are a professional Monster Hunter player. You are playing ‘Monster Hunter: World’. |
| To answer the above question, you are now searching a knowledge graph to find the route towards relevant knowledge. The following contents are the knowledge you found so far (up to current entity {entity}): |
| ***** |
| {memory} |
| ***** |
| And here is some information of current entity: {entity info}. |
| [You will also receive consecutive video frames showing the battle screen with the monster {monster name} as visual information for current entity {entity}. |
| Make a ‘Description’ (do not affected by previous text description of the battle screen for the ‘Question’) for the battle screen as a part of your ‘Response’. ‘Description’ should include monster’s limb and body movements, mouth, surrounding and others details. |
| Note that you should not give any assumptions for the ‘Description’.] |
| You have to decide whether visual and text information of this entity together with previous found knowledge is sufficient for answering this ‘Question’. |
| For sufficient analysis, your ‘Answer’ is ‘Yes’ or ‘No’. |
| [Directly output your ‘Response’ as the combination of ‘Answer’ and ‘Description’, separating them directly by ‘;’. ] |
| Note that you should not output any information other than your ‘Response’. |
| Now, start to complete your task. |
| Your ‘Response’: |
Table 12: Prompt for summarizer agent.
| You are a professional Monster Hunter player. You are playing ‘Monster Hunter: World’. |
| --- |
| You will receive consecutive video frames displaying the battle screen with the monster {monster name}. Based on the battle screen, here is the ‘Question’ you need to answer: {question}. |
| Here is the ‘Knowledge’ you retrieved from a knowledge graph for this ‘Question’: |
| ***** |
| {knowledge} |
| ***** |
| Your ‘Response’ is to provide the answer for this ‘Question’ based on the retrieved Knowledge. |
| Note that you should not give any analysis. |
| Note that you should not output any information other than your ‘Response’. |
| Now, start to complete your task. |
| Your ‘Response’: |
Note that Additional Information is the attribution of an entity (if exist). Action Description is given as human-made caption in Knowledgeable experiments, pre-extracted from visual attribution (if exist) in unaided-offline, and dynamic generated for visual attribution in unaided-online (if exist). Especially, the [] highlights the content for unaided-online that requires the model to comprehend visual references during validation and output corresponding description as the temporal visual attribution for the current entity.
As shown in Table 12, the final agent summary will treat all retrieved paths as {knowledge} using the same strategy as {memory}. Each path will be converted into a text description and attached to the query as input.
Table 13 shown the prompt template for unaided-offline experiments. It is used to pre-extract the visual reference (images or video for MLLMs or Video models, respectively in our experiments) into text description. This transition is not related to query or search memory.
Note that, the prompts for the agent pipeline were developed using InternVL2.5-78B [12], with the expectation that even open-source models, by their instruction-following capabilities, can understand these prompts and generate responses in the required format. This ensures a fair comparison for all close-source models in the main paper. We further conducted a preliminary prompt robustness analyses for GPT-4o and Claude 3.7 (unaided-online). Our observations show that Claude generally exhibited robust performance across prompt variations, particularly for agents with straightforward instructions such as Perceiver, Topic Selection, and Summarizer. However, GPT-4o exhibited sensitivity to lexical choice. For instance, in the Validation agent, the use of the term “sufficient” to determine whether the retrieved knowledge is enough and the retrieval should be stopped. When we replaced it with “necessary,” GPT-4o tended to more cautious during retrieval. This minor change led to a .0546 and .0871 drops on Acc. and Rec., respectively, though with a .0194 improvement in Pre. These findings suggest that prompt robustness is both model-specific and agent-specific.
Table 13: Prompt for offline caption pre-extraction.
| You are a professional Monster Hunter player. You are playing ‘Monster Hunter: World’. |
| --- |
| You will receive consecutive video frames showing the battle screen as visual information for {entity}. |
| Make a ‘Description’ for the battle screen as your ‘Response’. ‘Description’ should include monster’s limb and body movements, mouth, surrounding and others details. |
| Note that you should not output any information other than your ‘Response’. |
| Now, start to complete your task. |
| Your ‘Response’: |
Table 14: Prompt for accuracy calculation using GPT-4o as a judge.
| You are a professional Monster Hunter player. You are playing ‘Monster Hunter: World’. |
| --- |
| Here is a ‘Question’ need to be answered: {question}. |
| There are also two answers for this ‘Question’: |
| Answers 1: {answer gt}. |
| Answers 2: {answer pred}. |
| Your ‘Response’ is to decide whether the content of these two answers are similar. |
| If similar directly output ‘Yes’. |
| If not similar directly output ‘No’. |
| Note that you may ignore the format difference. |
| Ignore the difference of monster name before word, e.g., Zinogre Leap Attack and Leap Attack are with same meaning. |
| Here are some samples for decide similarity: |
| Sample 1: |
| ‘Question’: Tell me what is the specific name of attack action that Zinogre is performing? |
| “Answer 1”: Static Charge |
| “Answer 2”: Thunder Charge B |
| “Response”: No |
| Sample 2: |
| ‘Question’: Start with counterattack, Zinogre released the attack action shown in the input battle screen. Tell me what is the next attack action? |
| “Answer 1”: Zinogre Back Slam |
| “Answer 2”: Back Slam |
| “Response”: Yes |
| Sample 3: |
| ‘Question’: What attack action Brachydios is unleashing? |
| “Answer 1”: Brachydios is unleashing the Brachydios Ground Slime Explosion attack |
| “Answer 2”: Ground Slime Explosion |
| “Response”: Yes |
| Note that you should not output any information other than your ‘Response’. |
| Now, start to complete your task. |
| Your ‘Response’: |
Table 15: Prompt for similarity calculation between generated and human-made caption using GPT-4o as a judge.
| You are a professional Monster Hunter player. You are playing ‘Monster Hunter: World’. |
| --- |
| Here are two text description of a monster attack action. |
| Your ‘Response’ is to decide whether the content of these two text descriptions are similar. |
| Your should focus on the details of movement and some key information that can help you to discriminate the action. |
| If similar directly output ‘Yes’. |
| If not similar directly output ‘No’. |
| The First description is {truth}. |
| The Second description is {generated}. |
| Note that you should not output any information other than your ‘Response’. |
| Now, start to complete your task. |
| Your ‘Response’: |
8.2 Knowledge Consistency Calculation
As defined in the main paper, the model’s final output is a retrieved subgraph, denoted as $\hat{\mathcal{I}}$ . We consider each path from the root entity to a leaf entity as a unique knowledge instance and represent the set of such paths as $\hat{\mathcal{L}}$ . The knowledge consistency is computed between $\hat{\mathcal{L}}$ and the ground-truth knowledge paths $\mathcal{L}$ using a one-to-one matching approach.
The recall and precision of retrieved knowledge paths are defined as follows:
$$
\text{Recall}=\frac{|\hat{\mathcal{L}}\cap\mathcal{L}|}{|\mathcal{L}|} \tag{13}
$$
$$
\text{Precision}=\frac{|\hat{\mathcal{L}}\cap\mathcal{L}|}{|\hat{\mathcal{L}}|} \tag{14}
$$
where $\hat{\mathcal{L}}\cap\mathcal{L}$ represents the set of correctly retrieved knowledge paths. Recall measures the proportion of ground-truth knowledge paths successfully retrieved by the model, while precision measures the proportion of retrieved paths that are correct.
8.3 Human Evaluation of GPT-4o as a Judge
Tables 14 and 15 present the templates for using GPT-4o as a judge [59] to assess result accuracy (Acc.) and caption similarity (Sim.). For accuracy evaluation, we prompt GPT-4o to compare the similarity between the ground-truth answer {answer gt} and the generated answer {answer pred}. Additionally, we provide three few-shot examples as references for the model.
For caption similarity assessment, GPT-4o directly compares the human-written caption {truth} with the model-generated caption {generated}. To further evaluate GPT-4o’s judging performance, we conducted a human experiment. As shown in Table 16, two knowledgeable players independently evaluated 200 randomly selected samples from GPT-4o’s judgments across all experiments for each model. A judgment was considered correct if both evaluators agreed. Our findings indicate that while there are some variations across models, GPT-4o demonstrates a high overall accuracy in judgment (0.926). Although caption similarity scoring is lower, it remains sufficiently high for such a subjective task. Overall, the results show that using GPT-4o as a judge is with high feasibility.
Table 16: Human evaluation for GPT-4o judgment accuracy. Each model’s generation for answer and caption is evaluated by 200 randomly select samples through two knowledgeable players.
| GPT-4o [1] Claude 3.7 Sonnet [2] Ovis2-16B [36] | 0.925 0.900 0.955 | 0.865 0.840 0.810 |
| --- | --- | --- |
| average | 0.926 | 0.838 |
8.4 Additional Experiments for MH Benchmark
In Table 17, we present the impact of incorporating the monster’s name (Name) and additional information (Extra) as part of the input question $q$ . The metric Top. represents the accuracy of the model in selecting the correct topic entity as the retrieval root. We observe that removing the monster’s name leads to a significant performance drop due to incorrect root entity selection (low Top.).
Additional information refers to contextual hints, such as a monster being angry, which players can infer from the game’s text. These details are generally too subtle to be captured from images by MLLMs. Removing only the additional information also results in an obvious performance drop, indicating that such visually independent cues are essential for the model to generate the correct answer. One interesting observation is that with additional information Top. can be improved than no Name and Extra setting.
Table 17: Impact of having monster name and Extra information in question. ✔ means having such information.
| Name | Extra | Unaided-Online Acc. | Pre. | Rec. | Top. |
| --- | --- | --- | --- | --- | --- |
| .2731 | .1251 | .2413 | .5210 | | |
| ✔ | .3781 | .2080 | .4434 | .7365 | |
| ✔ | | .4075 | .2120 | .4636 | 1 |
| ✔ | ✔ | .5105 | .2756 | .5625 | 1 |
Table 18 reports average retrieval time (in seconds), number of agent calls (n rounds), and per-call response time in the format of mean ± std. Experiments were conducted using GPT-4o and Gemini 2.0 Flash via API, and InternVL2.5 on a local GPU server with 2 A6000. The results reveal efficiency as a limitation of the current agent pipeline. More results will be included.
Table 18: Computational cost per sample in average.
| GPT-4o Gemeni 2.0 Flash InternVL | 92.46 ± 68.93 17.15 ± 10.92 57.06 ± 41.78 | 7.20 ± 5.01 11.04 ± 9.42 9.32 ± 3.58 | 10.92 ± 9.70 1.12 ± 0.91 7.33 ± 6.95 |
| --- | --- | --- | --- |
We also perform ablation studies to assess the impact of using cross-models for two key agents: Summarizer (knowledge utilization) and Validation (knowledge retrieval), keeping other agents fixed. Table 19 shows Acc. results across GPT-4o, Claude 3.7, and InternVL2.5, with diagonal values representing the results of original single-model pipeline. Summarizer replacement yields little change between GPT-4o and Claude, indicating that performance gains stem more from retrieved knowledge quality than summarization strength (InternVL’s column with better knowledge, the improvement is more evident than that in the rows, showing in green). In contrast, using a weaker model (InternVL) for Validation causes a sharp performance drop (in red), underscoring the importance of this role. Yet, upgrading only the Validation agent in InternVL brings limited benefit, suggesting other retrieval-stage agents affect a lot.
Table 19: Ablation for cross-models agent pipeline.
| GPT-4o Claude InternVL | .5105 .4510 .3876 | .4994 .4338 .3624 | .4864 .4086 .3080 | .5105 .5052 .3413 | .4716 .4338 .3225 | .4128 .3676 .3080 |
| --- | --- | --- | --- | --- | --- | --- |
8.5 More Result Samples
This section presents some randomly selected examples of generated answers via various models.
Figure 10 shows a sample for “Glavenus” continues attack action recognition. Both GPT-4o and Claude 3.7 output wrong answer, although GPT-4o catch the path towards true knowledge. Show models lack the ability to comprehend the knowledge.
Figure 11 shows a sample for “Bazelgeuse” attack action recognition. Although some difference in response, both GPT-4o and Gemini 1.5 Pro generate correct answer. GPT-4o find more paths as its knowledge augmentation.
Figure 12 shows a sample for “Barroth” attack action recognition. Both GPT-4o and Claude 3.7 generate the correct answer, however, GPT-4o’s answer is more clear, showing better instruct following ability.
<details>
<summary>x11.png Details</summary>
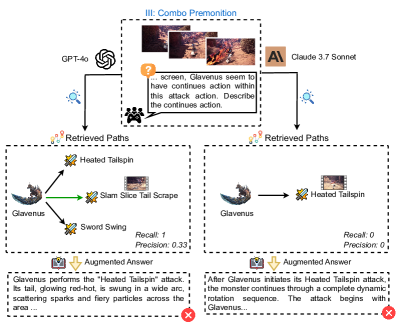
### Visual Description
## Diagram: Combo Premonition Analysis
### Overview
The image presents a diagram illustrating a "Combo Premonition" analysis, comparing the outputs of two AI models (GPT-4o and Claude 3.7 Sonnet) in predicting the continuation of an attack action by a character named Glavenus. The diagram shows the retrieved paths and augmented answers generated by each model, along with recall and precision metrics.
### Components/Axes
* **Title:** III: Combo Premonition
* **Top-Left:** GPT-4o (AI Model)
* **Top-Right:** Claude 3.7 Sonnet (AI Model)
* **Center:**
* A question mark icon.
* Text: "... screen, Glavenus seem to have continues action within this attack action. Describe the continues action."
* A group of player icons.
* **Left Side:**
* "Retrieved Paths" label with icons.
* Nodes: Glavenus, Heated Tailspin, Slam Slice Tail Scrape, Sword Swing.
* Arrows indicating the sequence of actions.
* "Recall: 1"
* "Precision: 0.33"
* "Augmented Answer" label with icon.
* Text: "Glavenus performs the "Heated Tailspin" attack. Its tail, glowing red-hot, is swung in a wide arc, scattering sparks and fiery particles across the area..."
* Red "X" icon.
* **Right Side:**
* "Retrieved Paths" label with icons.
* Nodes: Glavenus, Heated Tailspin.
* Arrow indicating the sequence of actions.
* "Recall: 0"
* "Precision: 0"
* "Augmented Answer" label with icon.
* Text: "After Glavenus initiates its Heated Tailspin attack, the monster continues through a complete dynamic rotation sequence. The attack begins with Glavenus..."
* Red "X" icon.
### Detailed Analysis
**GPT-4o Branch (Left Side):**
* **Retrieved Paths:** The diagram shows Glavenus initiating an attack, followed by "Heated Tailspin," then a choice between "Slam Slice Tail Scrape" and "Sword Swing."
* **Recall:** 1
* **Precision:** 0.33
* **Augmented Answer:** The text describes Glavenus performing the "Heated Tailspin" attack, detailing the visual effects.
**Claude 3.7 Sonnet Branch (Right Side):**
* **Retrieved Paths:** The diagram shows Glavenus initiating an attack, followed only by "Heated Tailspin."
* **Recall:** 0
* **Precision:** 0
* **Augmented Answer:** The text describes Glavenus initiating the "Heated Tailspin" attack and continuing through a dynamic rotation sequence.
**Central Question:**
* The central question prompts the AI models to describe the continuation of an attack action by Glavenus.
### Key Observations
* GPT-4o identifies a more complex sequence of actions following the initial attack, while Claude 3.7 Sonnet only identifies the "Heated Tailspin."
* GPT-4o has a higher recall (1) and precision (0.33) compared to Claude 3.7 Sonnet (recall 0, precision 0).
* Both models' augmented answers describe the "Heated Tailspin" attack, but GPT-4o provides more detail.
* Both augmented answers are marked with a red "X", indicating a negative evaluation.
### Interpretation
The diagram illustrates a comparison of two AI models in predicting the continuation of an attack action. GPT-4o demonstrates a better understanding of the potential attack sequences, as indicated by its higher recall and precision. However, the red "X" icons suggest that both models' augmented answers are considered unsatisfactory, despite GPT-4o's more comprehensive prediction. This could be due to inaccuracies in the descriptions or a failure to fully capture the nuances of the attack sequence. The diagram highlights the challenges in accurately predicting and describing complex actions, even with advanced AI models.
</details>
Figure 10: A sample for “Glavenus” continues attack recognition.
<details>
<summary>x12.png Details</summary>
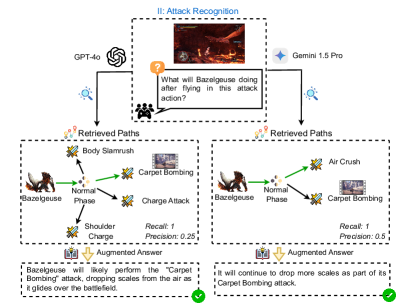
### Visual Description
## Diagram: Attack Recognition Comparison
### Overview
The image presents a comparison of two AI models, GPT-4o and Gemini 1.5 Pro, in recognizing attack patterns of a character named Bazelgeuse. It shows the retrieved paths and augmented answers provided by each model in response to a question about Bazelgeuse's actions.
### Components/Axes
* **Title:** II: Attack Recognition
* **Top-Left:** GPT-4o (with an associated logo)
* **Top-Right:** Gemini 1.5 Pro (with an associated logo)
* **Central Question:** "What will Bazelgeuse doing after flying in this attack action?" (accompanied by an image of Bazelgeuse)
* **Left Side:**
* "Retrieved Paths" label
* Attack Path Diagram:
* Nodes: Bazelgeuse, Normal Phase, Body Slamrush, Carpet Bombing, Charge Attack, Shoulder Charge
* Edges: Arrows indicating transitions between states. A green arrow goes from "Normal Phase" to "Carpet Bombing".
* Recall: 1
* Precision: 0.25
* "Augmented Answer" label
* Text: "Bazelgeuse will likely perform the 'Carpet Bombing' attack, dropping scales from the air as it glides over the battlefield."
* Green checkmark icon.
* **Right Side:**
* "Retrieved Paths" label
* Attack Path Diagram:
* Nodes: Bazelgeuse, Normal Phase, Air Crush, Carpet Bombing
* Edges: Arrows indicating transitions between states. A green arrow goes from "Normal Phase" to "Air Crush".
* Recall: 1
* Precision: 0.5
* "Augmented Answer" label
* Text: "It will continue to drop more scales as part of its Carpet Bombing attack."
* Green checkmark icon.
### Detailed Analysis
* **GPT-4o Path:**
* The diagram shows Bazelgeuse transitioning from its "Normal Phase" to potentially "Body Slamrush", "Carpet Bombing", "Charge Attack", or "Shoulder Charge".
* The green arrow indicates the model predicts a transition from "Normal Phase" to "Carpet Bombing".
* Recall is 1, Precision is 0.25.
* The augmented answer confirms the "Carpet Bombing" attack prediction.
* **Gemini 1.5 Pro Path:**
* The diagram shows Bazelgeuse transitioning from its "Normal Phase" to either "Air Crush" or "Carpet Bombing".
* The green arrow indicates the model predicts a transition from "Normal Phase" to "Air Crush".
* Recall is 1, Precision is 0.5.
* The augmented answer suggests a continuation of "Carpet Bombing" attack.
### Key Observations
* Both models correctly identify "Carpet Bombing" as a relevant attack.
* Gemini 1.5 Pro has a higher precision (0.5) compared to GPT-4o (0.25).
* The green arrows highlight the models' primary predictions for the next action.
### Interpretation
The diagram illustrates a comparison of attack recognition capabilities between GPT-4o and Gemini 1.5 Pro. Both models demonstrate an understanding of Bazelgeuse's attack patterns, but Gemini 1.5 Pro exhibits higher precision in its prediction. The "Retrieved Paths" diagrams visualize the possible attack sequences considered by each model, while the "Augmented Answer" provides a textual explanation of the predicted action. The higher precision of Gemini 1.5 Pro suggests it may be more accurate in predicting Bazelgeuse's specific actions in this scenario.
</details>
Figure 11: A sample for “Bazelgeuse” attack action recognition.
<details>
<summary>x13.png Details</summary>
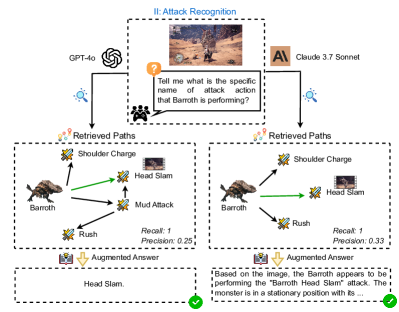
### Visual Description
## Diagram: Attack Recognition
### Overview
The image illustrates a system for attack recognition, comparing the performance of two AI models, GPT-4o and Claude 3.7 Sonnet, in identifying the specific attack action performed by a "Barroth" character. The diagram shows the question posed to the models, the retrieved paths representing possible attack actions, and the augmented answers provided by each model, along with their recall and precision scores.
### Components/Axes
* **Header:** "II: Attack Recognition"
* **AI Models:** GPT-4o (left), Claude 3.7 Sonnet (right)
* **Question:** "Tell me what is the specific name of attack action that Barroth is performing?"
* **Retrieved Paths:**
* Nodes: Barroth, Shoulder Charge, Head Slam, Mud Attack (GPT-4o only), Rush
* Edges: Arrows indicating possible attack paths. A green arrow highlights the correct path to "Head Slam".
* **Metrics:** Recall, Precision
* **Augmented Answer:** The final answer provided by each model.
### Detailed Analysis
**GPT-4o (Left Side):**
* **Retrieved Paths:**
* Barroth is connected to Shoulder Charge, Head Slam, Mud Attack, and Rush.
* The path from Barroth to Head Slam is highlighted in green, indicating the correct answer.
* Recall: 1
* Precision: 0.25
* **Augmented Answer:** "Head Slam."
**Claude 3.7 Sonnet (Right Side):**
* **Retrieved Paths:**
* Barroth is connected to Shoulder Charge, Head Slam, and Rush.
* The path from Barroth to Head Slam is highlighted in green.
* Recall: 1
* Precision: 0.33
* **Augmented Answer:** "Based on the image, the Barroth appears to be performing the "Barroth Head Slam" attack. The monster is in a stationary position with its..."
### Key Observations
* Both models correctly identify "Head Slam" as a possible attack.
* Claude 3.7 Sonnet achieves a higher precision (0.33) compared to GPT-4o (0.25).
* GPT-4o considers "Mud Attack" as a possible action, which is not present in Claude 3.7 Sonnet's retrieved paths.
* Both models achieve a recall of 1, indicating they both retrieve the relevant information.
### Interpretation
The diagram compares the performance of two AI models in recognizing the attack action of a character named Barroth. Both models successfully identify "Head Slam" as a possible attack, as indicated by the green path. However, Claude 3.7 Sonnet demonstrates higher precision, suggesting it is more accurate in its selection of relevant attack actions. The inclusion of "Mud Attack" in GPT-4o's retrieved paths, which is absent in Claude 3.7 Sonnet's, may contribute to the lower precision score. The augmented answers show that Claude 3.7 Sonnet provides a more descriptive and context-aware response.
</details>
Figure 12: A sample for “Barroth” attack action recognition.