# Lost at the Beginning of Reasoning
> Equal contribution. Correspondence to: Baohao Liao (b.liao@uva.nl).
Abstract
Recent advancements in large language models (LLMs) have significantly advanced complex reasoning capabilities, particularly through extended chain-of-thought (CoT) reasoning that incorporates mechanisms such as backtracking, self-reflection, and self-correction. Despite these developments, the self-correction abilities of LLMs during long CoT reasoning remain underexplored. And recent findings on overthinking suggest that such models often engage in unnecessarily redundant reasoning. In this work, we empirically show that the first reasoning step exerts a disproportionately large influence on the final prediction—errors introduced at this stage can substantially degrade subsequent reasoning quality. This phenomenon is consistently observed across various state-of-the-art open- and closed-source reasoning models. Leveraging this insight, we propose an efficient sampling strategy that leverages a reward model to identify and retain high-quality first reasoning steps while discarding suboptimal ones, achieving up to a 70% reduction in inference cost without sacrificing any accuracy. Our work highlights the central role of the first reasoning step in generating a high-quality reasoning trajectory, and thus enabling significantly efficient sampling.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Reasoning Process Visualization
### Overview
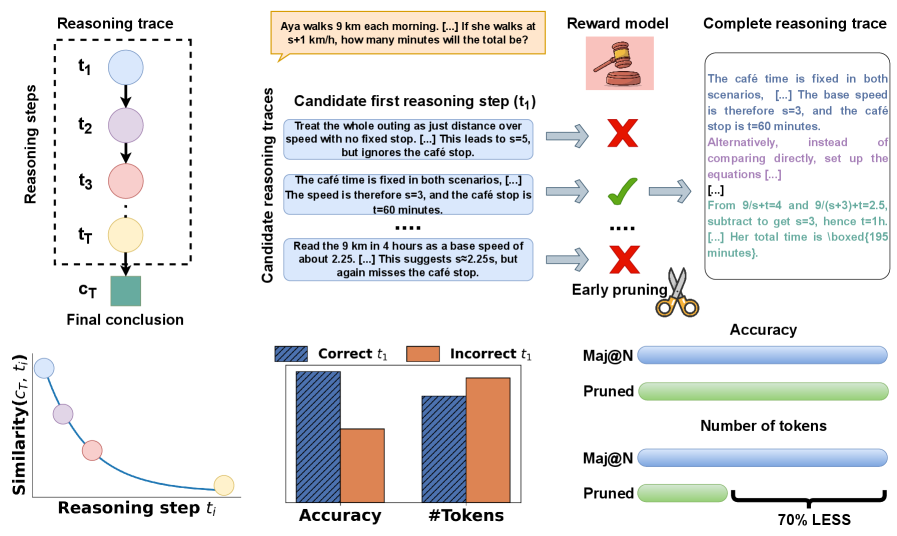
The image presents a visualization of a reasoning process, including a diagram of reasoning steps, examples of candidate reasoning traces, and bar graphs comparing the accuracy and number of tokens for correct and incorrect first reasoning steps. It also includes a comparison of "Maj@N" and "Pruned" approaches in terms of accuracy and number of tokens.
### Components/Axes
**1. Reasoning Trace Diagram (Top-Left):**
* **Title:** Reasoning trace
* **Nodes:** t1, t2, t3, tT (Reasoning steps), cT (Final conclusion)
* **Description:** A directed graph showing a sequence of reasoning steps leading to a final conclusion. The nodes are represented as circles, except for the final conclusion, which is a square.
**2. Candidate Reasoning Traces (Top-Center):**
* **Title:** Candidate reasoning traces
* **Context:** "Aya walks 9 km each morning. [...] If she walks at s+1 km/h, how many minutes will the total be?"
* **Candidate First Reasoning Step (t1):**
* "Treat the whole outing as just distance over speed with no fixed stop. [...] This leads to s=5, but ignores the café stop." (Marked with a red "X")
* "The café time is fixed in both scenarios, [...] The speed is therefore s=3, and the café stop is t=60 minutes." (Marked with a green checkmark)
* "Read the 9 km in 4 hours as a base speed of about 2.25. [...] This suggests s≈2.25s, but again misses the café stop." (Marked with a red "X")
* **Reward Model:** An image of a gavel.
* **Early Pruning:** An image of scissors.
**3. Complete Reasoning Trace (Top-Right):**
* **Title:** Complete Reasoning trace
* **Text:** "The café time is fixed in both scenarios, [...] The base speed is therefore s=3, and the café stop is t=60 minutes. Alternatively, instead of comparing directly, set up the equations [...]. [...] From 9/s+t=4 and 9/(s+3)+t=2.5, subtract to get s=3, hence t=1h. [...] Her total time is \boxed{195 minutes}."
**4. Similarity Plot (Bottom-Left):**
* **X-axis:** Reasoning step ti
* **Y-axis:** Similarity(cT, ti)
* **Description:** A plot showing the similarity between the final conclusion (cT) and each reasoning step (ti). The similarity decreases as the reasoning step gets further from the final conclusion.
**5. Bar Graphs (Bottom-Center):**
* **X-axis:** Accuracy, #Tokens
* **Y-axis:** Implicit, representing the count or percentage.
* **Legend:**
* Blue (diagonal lines): Correct t1
* Orange: Incorrect t1
* **Data:**
* Accuracy: Correct t1 bar is significantly higher than Incorrect t1 bar.
* #Tokens: Correct t1 bar is slightly higher than Incorrect t1 bar.
**6. Accuracy and Number of Tokens Comparison (Bottom-Right):**
* **Labels:** Accuracy, Number of tokens
* **Data:**
* Maj@N (Blue): Represented by a longer horizontal bar.
* Pruned (Green): Represented by a shorter horizontal bar.
* "70% LESS" indicates the Pruned approach uses significantly fewer tokens.
### Detailed Analysis
**1. Reasoning Trace Diagram:**
The diagram illustrates a sequential reasoning process. Each step (t1, t2, t3, tT) builds upon the previous one, leading to the final conclusion (cT).
**2. Candidate Reasoning Traces:**
This section provides examples of different approaches to solving a problem. The green checkmark indicates a correct first step, while the red "X" indicates incorrect steps. The problem involves calculating the total time for Aya's morning walk, considering a café stop.
**3. Complete Reasoning Trace:**
This section shows the full, correct reasoning process, including the equations and calculations needed to arrive at the final answer of 195 minutes.
**4. Similarity Plot:**
The plot shows that the earlier reasoning steps (closer to t1) have lower similarity to the final conclusion (cT) compared to the later steps (closer to tT). This suggests that the reasoning becomes more focused and aligned with the final answer as the process progresses.
**5. Bar Graphs:**
The bar graphs compare the accuracy and number of tokens for correct and incorrect first reasoning steps. The data indicates that correct first steps lead to higher overall accuracy. The number of tokens is slightly higher for correct first steps, suggesting that more detailed or precise reasoning may be required for a correct start.
**6. Accuracy and Number of Tokens Comparison:**
This section compares the "Maj@N" and "Pruned" approaches. The "Pruned" approach achieves a comparable accuracy with significantly fewer tokens (70% less), indicating a more efficient reasoning process.
### Key Observations
* Correct initial reasoning steps (t1) are crucial for achieving higher accuracy.
* The similarity between reasoning steps and the final conclusion increases as the reasoning process progresses.
* The "Pruned" approach offers a more efficient reasoning process by using significantly fewer tokens while maintaining comparable accuracy.
### Interpretation
The image demonstrates the importance of accurate initial reasoning steps in problem-solving. The candidate reasoning traces highlight different approaches, with the correct approach leading to a successful solution. The similarity plot visualizes how the reasoning process converges towards the final conclusion. The bar graphs and the "Maj@N" vs. "Pruned" comparison emphasize the trade-off between accuracy and efficiency in reasoning, suggesting that pruning techniques can significantly reduce the computational cost without sacrificing accuracy. The "Pruned" approach is more efficient, suggesting that it is a better method for reasoning.
</details>
Figure 1: Overview of our observation and efficient sampling. The first reasoning step $t_{1}$ heavily shapes the entire reasoning trajectory: a strong first step typically yields accurate solutions with fewer tokens (bottom left). Building on this observation, we propose to generate multiple candidate first steps, evaluate them with a reward model, and discard weaker candidates early (top right). This method maintains accuracy while substantially reducing token consumption by 70% (bottom right).
1 Introduction
Large language models (LLMs) have demonstrated remarkable performance across a variety of reasoning tasks, ranging from mathematical problem solving to multi-hop question answering (Hestness et al., 2017; Kaplan et al., 2020; Hoffmann et al., 2022). More recently, the advent of reasoning-oriented LLMs capable of performing long chain-of-thought (long-CoT) reasoning at test time has led to substantial advancements in these domains (Brown et al., 2020; Hurst et al., 2024; Anthropic, 2025; Team et al., 2024; Guo et al., 2025; Yang et al., 2025a; Wen et al., 2025; He et al., 2025). A widely held hypothesis attributes this progress to the models’ ability to backtrack, self-reflect, and self-correct, effectively leveraging contextual feedback to iteratively refine their responses.
However, recent studies suggest that long-CoT reasoning can also introduce inefficiencies. Models often “overthink” by producing unnecessarily extended reasoning processes to solve problems (Chiang & Lee, 2024; Zhang et al., 2024a; Wang et al., 2025b; Liao et al., 2025b; a). This observation raises questions about the model’s capacity for backtracking, self-reflection, and self-correction. It suggests that LLMs may lack awareness of the information they have already processed, leading to redundant or inefficient reasoning. Moreover, Liu et al. (2024a) demonstrate that LLMs are prone to the “lost-in-the-middle” phenomenon, wherein information located in the middle of a long context is often overlooked. While their analysis is conducted in the context of information retrieval, it remains an open question whether similar positional biases affect long CoT as well.
In this work, we introduce a novel and previously underexplored perspective on long-CoT reasoning: many reasoning failures in long-CoT LLMs stem not from errors made mid-chain, but rather from flaws at the beginning of reasoning. Our experiments demonstrate that the first reasoning step has the most significant influence on the final prediction. When this first step is incorrect, the model is considerably more likely to arrive at an incorrect final answer (40% accuracy drop), highlighting the limited self-correction capabilities of current long-CoT LLMs. Notably, this phenomenon is consistently observed from five open- and closed-source long-CoT LLM families.
Motivated by this insight, we propose an efficient early pruning algorithm that exploits the predictive power of the first reasoning step. Specifically, by evaluating the quality of the first step, we identify and discard less promising reasoning traces early, continuing generation only for the more promising ones. This approach significantly reduces inference cost. Across five open-sourced long-CoT LLM families and five challenging mathematical, scientific reasoning and programming benchmarks, our method maintains accuracy while reducing inference budget by up to 70%. Our results show that the first step is not just the beginning of reasoning, but a key factor that influences both accuracy and efficiency, making it an important focus for future reasoning models.
Contributions. Our main contributions are as follows: (1) To the best of our knowledge, we firstly empirically establish a strong positive correlation between the first reasoning step and the final prediction across various open- and closed-sourced long-CoT LLM families (§ 3); (2) Inspired by this observation, we propose an efficient early pruning algorithm that halts generation for less promising initial steps, thereby improving inference efficiency while maintaining the accuracy (§ 4); (3) Both observation and proposed efficient sampling method are extensively validated on various long-CoT LLMs across different reasoning tasks, with necessary control experiments to disentangle the confounding factors.
2 Related work
Lost in the middle. Liu et al. (2024a) introduced the ”lost in the middle” effect, demonstrating that LLMs tend to overlook information in the middle of long contexts, performing better when relevant content appears at the beginning or end. This positional bias is evident across tasks like arithmetic reasoning (Shen et al., 2023; Liao & Monz, 2024), multiple-choice QA (Zheng et al., 2024; Pezeshkpour & Hruschka, 2023), text evaluation (Wang et al., 2024; Shi et al., 2024), passage ranking (Zhang et al., 2024b), and instructional prompt positioning (Liu et al., 2024b; Chen et al., 2024b). Additionally, studies have documented primacy and recency biases, where models disproportionately allocate attention to the first or final tokens, independent of their semantic relevance (Xiao et al., 2024; Qin et al., 2023; Barbero et al., 2025). While previous studies have primarily examined positional biases in external context, we investigate whether analogous biases emerge in internal reasoning trajectories of long chain-of-thought models. Different from attention-level analyses that focus on how the first input token shapes representations, our work shows that the first generated reasoning step greatly influences subsequent reasoning and final outcomes.
Efficient test-time reasoning. Test-time scaling methods aim to improve the accuracy–compute trade-off by adapting sampling and aggregation. One line of work increases self-consistency efficiency by reducing sample counts (Li et al., 2024; Wan et al., 2025; Aggarwal et al., 2023; Xue et al., 2023), while another shortens chain-of-thought depth via fine-tuning or inference-only optimizations (Chen et al., 2024a; Luo et al., 2025; Hou et al., 2025; Fu et al., 2025a; Yang et al., 2025b). These methods, however, still rely on generating full reasoning traces. DeepConf (Fu et al., 2025b) instead uses local confidence to filter low-quality traces and terminate generation early. Our method takes a different focus: we assess the quality of the initial reasoning step, which strongly shapes subsequent reasoning, and prune weak starts before long traces unfold.
3 Lost at the beginning of reasoning
Motivated by the finding of Liu et al. (2024a), which demonstrates that query-relevant information is more impactful when positioned at either the beginning or end of an LLM’s context window, we first investigate whether a similar positional effect exists in long-CoT reasoning (§ 3.1). Our analysis reveals that the first reasoning step has great impact to the final conclusion. To validate this observation, we further perform two ablation studies, confirming the critical role of the first step in determining the model’s final prediction (§ 3.2 and § 3.3).
Notation. Let $p$ represent the input prompt, consisting of both a system instruction and a user query. A reasoning model $\mathcal{M}$ produces a sequence of CoT reasoning steps $t=[t_{1},t_{2},...,t_{T}]$ , followed by a final conclusion $c_{T}$ , such that the complete model output is given by $t\oplus c_{T}=\mathcal{M}(p)$ , where $\oplus$ means concatenation. In models such as DeepSeek-R1 (Guo et al., 2025) and Qwen3 (Team, 2025), the input-output format adheres to the following:
$$
p\ \mathrm{{<}think{>}}\ t_{1},t_{2},\ldots,t_{T}\ \mathrm{{<}/think{>}}\ c_{T}
$$
The final prediction $q_{T}$ is then derived by applying an extraction function $g$ to the conclusion, i.e., $q_{T}=g(c_{T})$ , where $g$ may, for example, extract values enclosed within \boxed{}.
The conclusion $c_{T}$ can be interpreted as a summary of the essential reasoning steps leading to the final prediction. This raises an interesting question: Is there a positional bias in how reasoning steps contribute to the conclusion? In other words, do certain steps have a disproportionately greater influence on $c_{T}$ than others?
3.1 Similarity between reasoning steps and the final conclusion
To understand how different reasoning steps contribute to the final conclusion, we measure the semantic similarity between each reasoning step $\{t_{i}\}_{i=1}^{T}$ and the final conclusion $c_{T}$ .
To assess how intermediate reasoning contributes to the final outcome, we measure the semantic similarity between each reasoning step $\{t_{i}\}_{i=1}^{T}$ and the final conclusion $c_{T}$ . This analysis reveals whether the reasoning process gradually aligns with the correct answer or diverges along the way.
Experimental setup. We evaluate 60 questions from AIME24 and AIME25 (MAA Committees, 2025) using DeepSeek-R1-Distill-Qwen-7B (abbreviated as DS-R1-Qwen-7B in the remainder of this paper) (Guo et al., 2025), Qwen3-8B (Yang et al., 2025a), Claude-3.7-Sonnet with thinking (Anthropic, 2025), GPT-OSS-20B (Agarwal et al., 2025), and Magistral-Small (Rastogi et al., 2025). For reproducibility, the exact model identifiers are provided in Appendix B. Generations are produced with temperature=1.0, top_p=0.9, min_p=0.05, and max_tokens=32768; for Claude-3.7-Sonnet, only max_tokens is set. All subsequent experiments adopt this hyperparameter configuration.
Segmentation of reasoning steps. We define a reasoning step as a complete logical leap or self-contained unit (Xiong et al., 2025), and segment reasoning traces with GPT-5. By default, we use GPT-5 mini for step segmentation; for GPT-OSS-20B, we instead use GPT-5, as the mini variant is incompatible. To complement this setup, we also employ heuristic segmentation based on reasoning switch keywords (Wang et al., 2025a), with details provided in Appendix A.
Similarity computation. We compute semantic similarity between each step $t_{i}$ and the conclusion $c_{T}$ by taking the cosine similarity of their embeddings obtained from all-MiniLM-L6-v2 (Reimers & Gurevych, 2019; Wang et al., 2020). To avoid inflated similarity from problem restatement, we use GPT-5 mini to remove question-overlap text at the beginning of traces. As a robustness check, we also report results with SPLADE similarity (Formal et al., 2021) in Appendix C, confirming that our findings are not specific to dense embeddings. Since traces vary in length, similarity curves are interpolated to a fixed number of steps (either the average or maximum length) for visualization.
This setup allows us to capture how reasoning trajectories semantically converge toward—or deviate from—the final answer across different models.
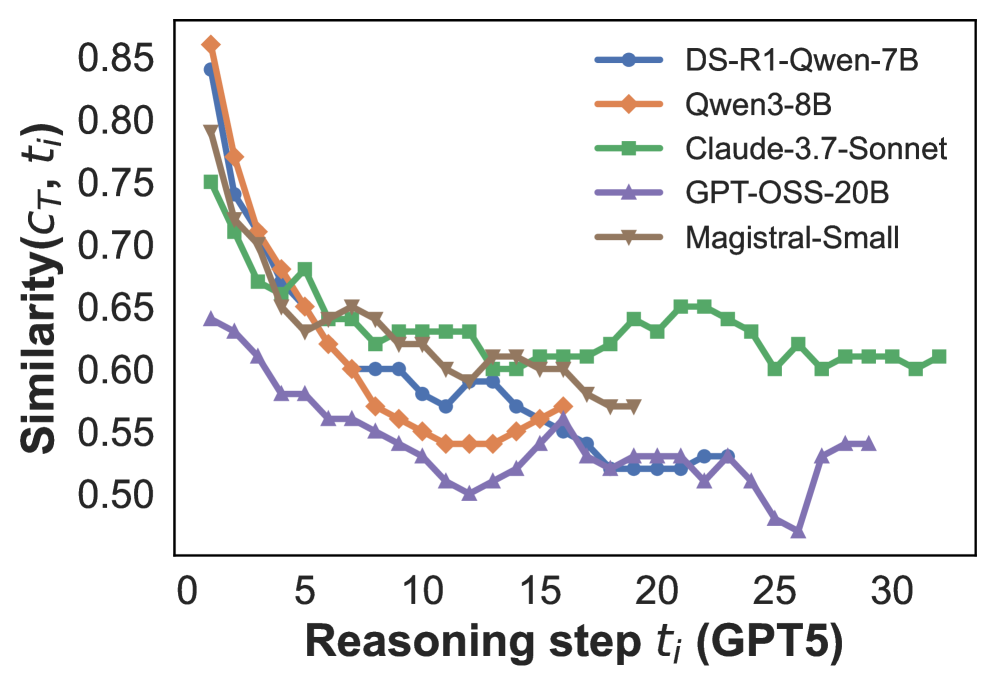
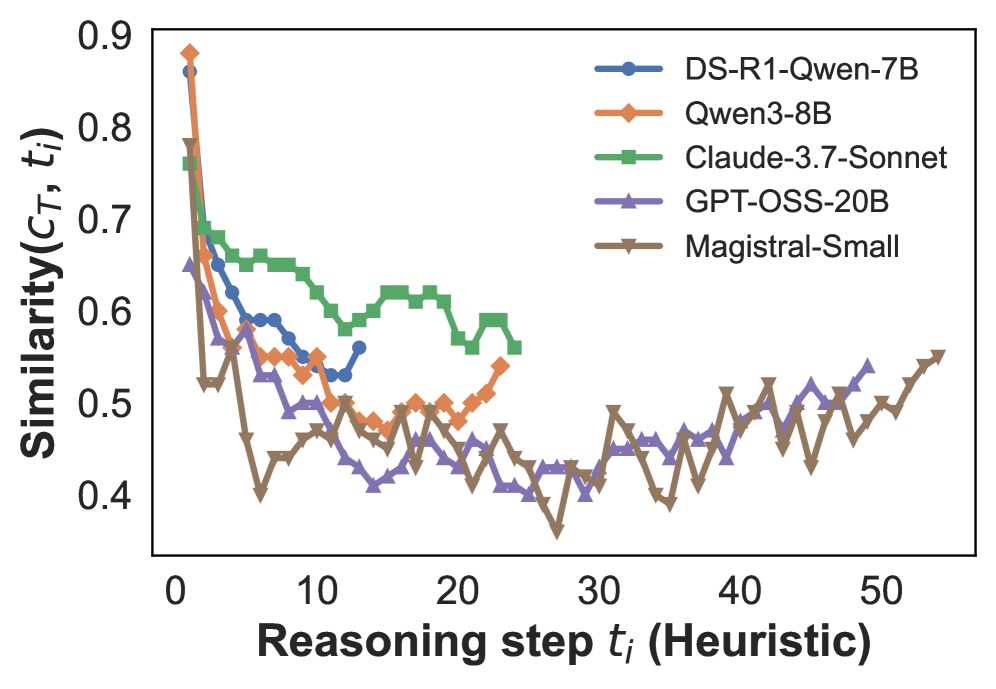
Result. Figure 2 shows that the first reasoning step exhibits the highest similarity to the final conclusion, after which similarity drops sharply. Beyond the initial few steps, similarity stabilizes at a lower level, with only minor fluctuations across the remainder of the reasoning process. These results suggest that the first step $t_{1}$ is most closely aligned with the final conclusion and likely sets the overall direction of the reasoning. Subsequent steps appear to introduce exploratory or redundant content that deviates from the final answer. Additional results using SPLADE similarities (Figure C.2) show the same trend, confirming that this pattern is robust across similarity metrics. Taken together, these findings show that the first reasoning step plays a disproportionately important role in shaping the final conclusion.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Line Chart: Similarity vs. Reasoning Step
### Overview
The image is a line chart comparing the similarity scores of five different language models (DS-R1-Qwen-7B, Qwen3-8B, Claude-3.7-Sonnet, GPT-OSS-20B, and Magistral-Small) across a range of reasoning steps (t_i) from 0 to 30, presumably using GPT5. The y-axis represents the similarity score, ranging from 0.50 to 0.85. All models show a decrease in similarity score as the reasoning step increases, with varying degrees of fluctuation.
### Components/Axes
* **X-axis:** Reasoning step t_i (GPT5). Scale ranges from 0 to 30, with tick marks at intervals of 5.
* **Y-axis:** Similarity(C_T, t_i). Scale ranges from 0.50 to 0.85, with tick marks at intervals of 0.05.
* **Legend:** Located at the top-right of the chart, identifying each line by model name and a corresponding color/marker:
* Blue with circle markers: DS-R1-Qwen-7B
* Orange with diamond markers: Qwen3-8B
* Green with square markers: Claude-3.7-Sonnet
* Purple with triangle markers: GPT-OSS-20B
* Brown with pentagon markers: Magistral-Small
### Detailed Analysis
* **DS-R1-Qwen-7B (Blue, Circle):**
* Trend: Initially decreases sharply, then fluctuates between 0.57 and 0.62 until reasoning step 15, then decreases to 0.52 at step 25, and increases slightly to 0.54 at step 30.
* Data Points: Starts at approximately 0.84 at step 0, drops to approximately 0.62 by step 5, fluctuates around 0.60 until step 15, reaches a low of approximately 0.52 at step 25, and ends at approximately 0.54 at step 30.
* **Qwen3-8B (Orange, Diamond):**
* Trend: Decreases sharply initially, then decreases more gradually and fluctuates.
* Data Points: Starts at approximately 0.85 at step 0, drops to approximately 0.68 by step 5, fluctuates around 0.55-0.60 between steps 10 and 20, and ends at approximately 0.54 at step 30.
* **Claude-3.7-Sonnet (Green, Square):**
* Trend: Decreases sharply initially, then stabilizes and fluctuates around a relatively constant value.
* Data Points: Starts at approximately 0.75 at step 0, drops to approximately 0.68 by step 5, fluctuates between approximately 0.61 and 0.65 between steps 10 and 20, and ends at approximately 0.61 at step 30.
* **GPT-OSS-20B (Purple, Triangle):**
* Trend: Decreases steadily, with some fluctuations, and then increases at the end.
* Data Points: Starts at approximately 0.64 at step 0, drops to approximately 0.58 by step 5, fluctuates around 0.52-0.56 between steps 10 and 25, and ends at approximately 0.54 at step 30.
* **Magistral-Small (Brown, Pentagon):**
* Trend: Decreases sharply initially, then stabilizes and fluctuates.
* Data Points: Starts at approximately 0.79 at step 0, drops to approximately 0.65 by step 5, fluctuates around 0.58-0.60 between steps 10 and 20, and ends at approximately 0.60 at step 30.
### Key Observations
* All models exhibit a decrease in similarity as the reasoning step increases, particularly in the initial steps.
* Claude-3.7-Sonnet and Magistral-Small maintain relatively higher similarity scores compared to the other models after the initial drop.
* GPT-OSS-20B shows the most significant fluctuation and the lowest similarity scores overall.
* Qwen3-8B starts with the highest similarity score but drops significantly in the initial reasoning steps.
### Interpretation
The chart suggests that the similarity between the models' outputs and a target output (C_T) decreases as the number of reasoning steps increases. This could indicate that the models' performance degrades with longer reasoning chains, possibly due to error accumulation or increased complexity. The different models exhibit varying degrees of robustness to this degradation, with Claude-3.7-Sonnet and Magistral-Small showing more stable performance compared to GPT-OSS-20B. The initial sharp drop in similarity for all models suggests that the first few reasoning steps are critical for maintaining accuracy. The data implies that model architecture and size (as indicated by the model names) play a role in the ability to maintain similarity across multiple reasoning steps.
</details>
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Chart: Similarity vs. Reasoning Step for Different Models
### Overview
The image is a line chart comparing the similarity scores of five different language models across a series of reasoning steps. The x-axis represents the reasoning step (heuristic), and the y-axis represents the similarity score. Each model is represented by a different colored line with a distinct marker.
### Components/Axes
* **X-axis:** Reasoning step *t<sub>i</sub>* (Heuristic). Scale ranges from 0 to 50, with tick marks every 10 units.
* **Y-axis:** Similarity(*C<sub>T</sub>*, *t<sub>i</sub>*). Scale ranges from 0.4 to 0.9, with tick marks every 0.1 units.
* **Legend:** Located in the top-right corner, identifying each model by color and name:
* Blue with circle markers: DS-R1-Qwen-7B
* Orange with diamond markers: Qwen3-8B
* Green with square markers: Claude-3.7-Sonnet
* Purple with triangle markers: GPT-OSS-20B
* Brown with inverted triangle markers: Magistral-Small
### Detailed Analysis
* **DS-R1-Qwen-7B (Blue, Circle):** Starts at approximately 0.67 at step 0, decreases to around 0.52 by step 10, and then fluctuates between 0.52 and 0.56 until step 50.
* Step 0: ~0.67
* Step 10: ~0.52
* Step 50: ~0.56
* **Qwen3-8B (Orange, Diamond):** Starts at approximately 0.88 at step 0, decreases to around 0.48 by step 10, then increases and fluctuates between 0.45 and 0.52 until step 50.
* Step 0: ~0.88
* Step 10: ~0.48
* Step 20: ~0.50
* Step 50: ~0.52
* **Claude-3.7-Sonnet (Green, Square):** Starts at approximately 0.78 at step 0, decreases to around 0.62 by step 5, then fluctuates between 0.55 and 0.63 until step 25, after which the data ends.
* Step 0: ~0.78
* Step 5: ~0.62
* Step 25: ~0.55
* **GPT-OSS-20B (Purple, Triangle):** Starts at approximately 0.65 at step 0, decreases to around 0.42 by step 10, then fluctuates between 0.38 and 0.55 until step 50.
* Step 0: ~0.65
* Step 10: ~0.42
* Step 30: ~0.40
* Step 50: ~0.55
* **Magistral-Small (Brown, Inverted Triangle):** Starts at approximately 0.52 at step 0, decreases to around 0.40 by step 5, then fluctuates between 0.38 and 0.55 until step 50.
* Step 0: ~0.52
* Step 5: ~0.40
* Step 30: ~0.42
* Step 50: ~0.55
### Key Observations
* All models except Claude-3.7-Sonnet show a significant drop in similarity score within the first 10 reasoning steps.
* Claude-3.7-Sonnet maintains a relatively higher similarity score compared to the other models, but its data is only available up to step 25.
* GPT-OSS-20B and Magistral-Small exhibit similar performance, with overlapping fluctuations in similarity scores.
* After the initial drop, the similarity scores of all models tend to fluctuate within a narrower range.
### Interpretation
The chart illustrates how the similarity between a model's reasoning process and a target solution changes as the model progresses through reasoning steps. The initial drop in similarity suggests that the models initially diverge from the target solution. The subsequent fluctuations indicate that the models are exploring different reasoning paths, with varying degrees of similarity to the target. Claude-3.7-Sonnet's higher initial similarity and slower decline may indicate a more robust or aligned reasoning process, at least for the initial steps. The convergence of GPT-OSS-20B and Magistral-Small suggests that these models may be employing similar reasoning strategies. The data suggests that the models' reasoning processes become less similar to the target solution as the number of reasoning steps increases, highlighting the challenge of maintaining alignment in complex reasoning tasks.
</details>
Figure 2: Cosine similarity between the embeddings of the $i$ -th reasoning step $t_{i}$ and the final conclusion $c_{T}$ , using the average number of reasoning steps for interpolation. The reasoning steps are segmented either by GPT-5 (left) or by heuristic rules (right). See Figure C.1 for results based on the maximum number of reasoning steps used for interpolation.
Given the strong alignment between early reasoning steps—particularly the first—and the final conclusion, we hypothesize that the first step may significantly influence whether the reasoning model can arrive at a correct prediction.
3.2 Correlation between the first reasoning step and the final prediction
Given that the first reasoning step closely resembles the final conclusion, we investigate whether the essential reasoning required for the final prediction is already encapsulated in the first step. To this end, we analyze the prediction when conditioned solely on the first reasoning step. Specifically, we compute $c_{1}=\mathcal{M}(p\mathrm{{<}think{>}}t_{1}\mathrm{{<}/think{>}})$ , and derive the corresponding prediction $q_{1}=g(c_{1})$ , which we compare against the ground truth $a$ . Based on this comparison, we categorize each first reasoning step as either first correct (if $q_{1}=a$ ) or first incorrect (otherwise).
Experimental setup. To better analyze the correlation, we sample 64 CoT traces per question using the same datasets in § 3.1. We exclude questions for which all 64 CoT traces result in either correct or incorrect predictions, as these are considered either too easy or too difficult, respectively, yielding 38 questions for DS-R1-Qwen-7B and 37 for Qwen3-8B. For each remaining question and its corresponding first reasoning step $t_{1}$ , we obtain the initial prediction $q_{1}$ as previously described. While GPT-5 provides more reliable segmentation, it is costly and difficult to reproduce. We therefore adopt the heuristic segmentation method in all subsequent experiments, which is shown to have compariable results with GPT5 segmentation in § 3.1. To better visualize the final outcomes, we categorize the questions into three groups based on the pass@1 accuracy of the final prediction $q_{T}$ , That is, the average accuracy across 64 CoT traces. corresponding to the intervals (0, 33%], (33%, 67%], and (67%, 100%). A higher pass@1 indicates a simpler question. This grouping allows us to assess whether our observations hold consistently across varying levels of question difficulty.
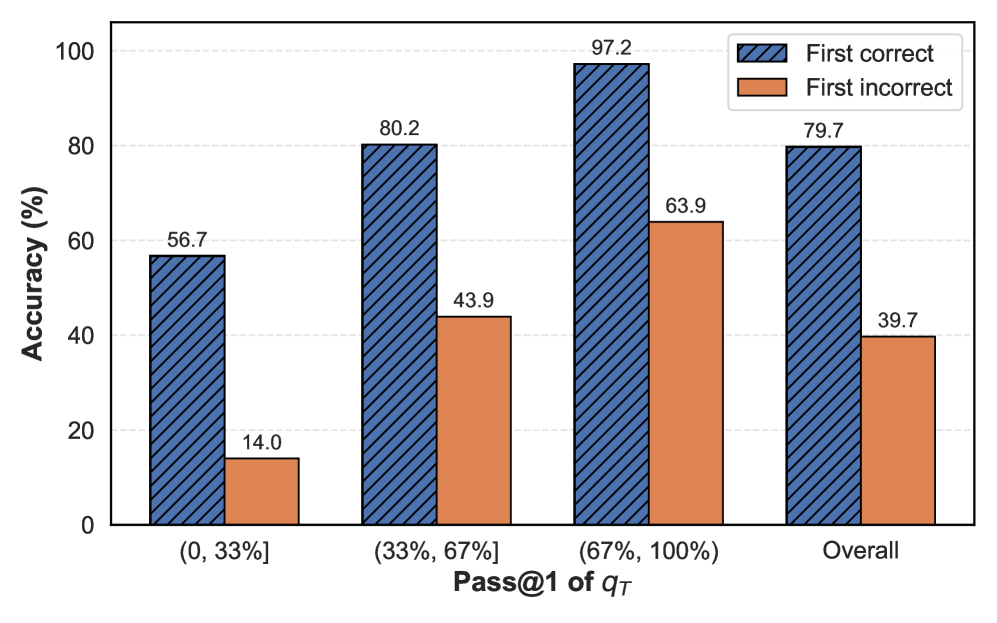
Result. As shown in Figure 3 (Left), the commonly assumed self-correction capability of reasoning models appears to be overstated. When the first reasoning step is incorrect, the model’s final prediction is also likely to be incorrect. On average, final prediction accuracy drops by 40% when the first reasoning step is incorrect, with the most substantial decrease (43%) occurring for difficult questions (0–33% range) and a notable decline (33%) even for easier questions (67–100% range). In addition, we also compute the Pearson correlation between the correctness of the first prediction $p_{1}$ and the final prediction $p_{T}$ over all questions. The coefficient $r=0.60$ and p-value $p=0.0$ denote a moderately strong positive correlation. All these results underscore the pivotal role of the first reasoning step in steering the model toward a correct final answer, particularly in more complex instances where recovery from early mistakes is more challenging. Extending this analysis to DeepSeek and Qwen models of different sizes yields consistent trends: final accuracy remains substantially higher when the first step is correct, and the accuracy gap persists as model scale increases (Figure D.2).
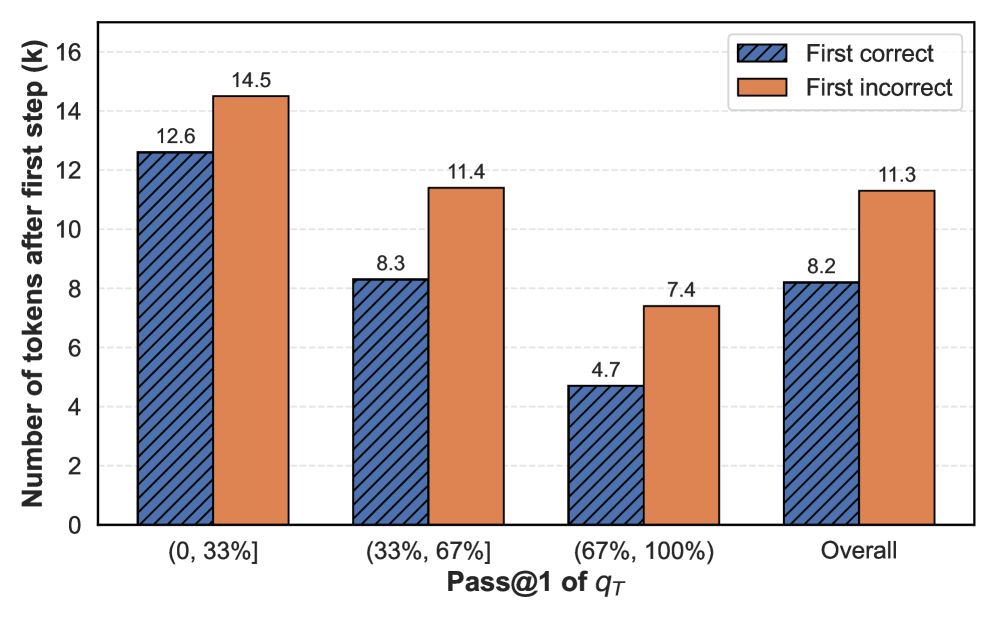
Figure 3 (Right) further illustrates the model’s tendency toward overthinking. Even when the first reasoning step is sufficient to arrive at the correct answer, the model continues to generate a substantial number of additional reasoning tokens—the same scale in length to those generated following an incorrect first step. Both findings are also observed for Qwen3-8B in Figure D.1, reinforcing this pattern across models.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Bar Chart: Accuracy vs. Pass@1 of qT
### Overview
The image is a bar chart comparing the accuracy of "First correct" and "First incorrect" results across different ranges of "Pass@1 of qT" values, as well as an overall accuracy. The x-axis represents the "Pass@1 of qT" in percentage ranges, and the y-axis represents the accuracy in percentage.
### Components/Axes
* **X-axis:** "Pass@1 of qT" with categories: (0, 33%], (33%, 67%], (67%, 100%], and Overall.
* **Y-axis:** "Accuracy (%)" with a scale from 0 to 100 in increments of 20.
* **Legend:** Located in the top-right corner.
* Blue, diagonally striped bars: "First correct"
* Orange bars: "First incorrect"
### Detailed Analysis
The chart presents accuracy data for two categories: "First correct" and "First incorrect," across different ranges of "Pass@1 of qT."
* **(0, 33%] Range:**
* "First correct": 56.7%
* "First incorrect": 14.0%
* **(33%, 67%] Range:**
* "First correct": 80.2%
* "First incorrect": 43.9%
* **(67%, 100%] Range:**
* "First correct": 97.2%
* "First incorrect": 63.9%
* **Overall:**
* "First correct": 79.7%
* "First incorrect": 39.7%
**Trend Verification:**
* The "First correct" accuracy generally increases as the "Pass@1 of qT" range increases.
* The "First incorrect" accuracy also increases as the "Pass@1 of qT" range increases.
### Key Observations
* The "First correct" accuracy is consistently higher than the "First incorrect" accuracy across all "Pass@1 of qT" ranges and overall.
* The highest "First correct" accuracy is observed in the (67%, 100%] range.
* The lowest "First correct" accuracy is observed in the (0, 33%] range.
* The difference between "First correct" and "First incorrect" accuracy is largest in the (0, 33%] range and smallest in the (67%, 100%] range.
### Interpretation
The data suggests that as the "Pass@1 of qT" increases, the accuracy of both "First correct" and "First incorrect" results improves. This indicates a positive correlation between "Pass@1 of qT" and accuracy. The higher "First correct" accuracy compared to "First incorrect" accuracy across all ranges suggests that the model is generally more successful in providing correct answers on the first attempt. The increasing "First incorrect" accuracy with increasing "Pass@1 of qT" might indicate that even when the first attempt is incorrect, the model's performance improves with higher "Pass@1 of qT." The overall accuracy values provide a general measure of the model's performance across all "Pass@1 of qT" ranges.
</details>
<details>
<summary>x5.png Details</summary>
### Visual Description
## Bar Chart: Number of Tokens After First Step
### Overview
The image is a bar chart comparing the number of tokens after the first step for "First correct" and "First incorrect" scenarios, categorized by "Pass@1 of qT" ranges and an overall average. The y-axis represents the number of tokens (in thousands), and the x-axis represents the Pass@1 ranges.
### Components/Axes
* **Y-axis:** "Number of tokens after first step (k)". The scale ranges from 0 to 16, with tick marks at every increment of 2.
* **X-axis:** "Pass@1 of qT". The categories are:
* (0, 33%]
* (33%, 67%]
* (67%, 100%]
* Overall
* **Legend:** Located at the top-right of the chart.
* Blue (with diagonal lines): "First correct"
* Orange: "First incorrect"
### Detailed Analysis
* **Category (0, 33%]:**
* "First correct" (Blue): 12.6
* "First incorrect" (Orange): 14.5
* **Category (33%, 67%]:**
* "First correct" (Blue): 8.3
* "First incorrect" (Orange): 11.4
* **Category (67%, 100%]:**
* "First correct" (Blue): 4.7
* "First incorrect" (Orange): 7.4
* **Category Overall:**
* "First correct" (Blue): 8.2
* "First incorrect" (Orange): 11.3
### Key Observations
* For all Pass@1 ranges, the "First incorrect" scenario consistently has a higher number of tokens after the first step compared to the "First correct" scenario.
* The number of tokens for both "First correct" and "First incorrect" decreases as the Pass@1 range increases from (0, 33%] to (67%, 100%].
* The "Overall" category shows values between the (33%, 67%] and (0, 33%] Pass@1 ranges.
### Interpretation
The data suggests that when the initial pass rate (Pass@1) of a query is low, the number of tokens required to reach the first correct or incorrect step is higher. This could indicate that more processing or iterations are needed when the initial query is less accurate. The "First incorrect" scenario consistently requiring more tokens might imply that correcting an initial mistake involves more steps than achieving a correct result from the start. The overall values provide a general average across all pass rate ranges.
</details>
Figure 3: Accuracy and number of tokens on DS-R1-Qwen-7B. Left: The relationship between the accuracy of the final prediction ( $q_{T}$ ) and the correctness of the prediction solely based on the first reasoning step ( $q_{1}$ ) across different difficulty levels. If $q_{1}$ is incorrect, $q_{T}$ is more likely incorrect. Right: The number of tokens used for the final prediction after the first reasoning step $t_{1}$ , i.e., the number of tokens used for $[t_{2},t_{3},...,t_{T}]$ . Although $q_{1}$ is correct, the model still consumes a large amount of tokens for the following reasoning steps–overthinking.
3.3 Minor perturbation to the correct first step leads to significant loss
Building on our findings in § 3.2, which demonstrate a positive correlation between the model’s first and final predictions, we further investigate the significance of the first reasoning step by introducing minor perturbations. Specifically, we slightly alter an initially correct reasoning step and provide it as input to the model to assess whether it can recover from such errors.
Experimental setup. Unlike § 3.2, where we analyze the correctness of the first reasoning step $t_{1}$ , here we treat the final correct conclusion $c_{T}$ —which satisfies $q_{T}=g(c_{T})=a$ —as the new first reasoning step, denoted $t^{\prime}_{1}$ . This choice ensures that the step contains all necessary reasoning for arriving at the correct answer, which cannot be guaranteed for $t_{1}$ . As illustrated in Figure 3 (Left), an initially correct reasoning step can still lead to an incorrect final prediction. To construct $t^{\prime}_{1}$ , we apply the following perturbations to $c_{T}$ (see Appendix G for an example): (1) we remove not only the explicit answer formatting (e.g., \boxed{a}) but also any surrounding sentences that may directly disclose or repeat the final answer; (2) the resulting text from (1) is treated as the correct version of $t^{\prime}_{1}$ (serving as our baseline); (3) we generate an incorrect version by replacing the correct answer $a$ in the remaining reasoning with $a± 1$ or $a± 10$ . The answer of AIME question is integer in the range of $[0,999)$ .
Table 1: Perturbation experiments. Reported accuracy (%) with correct vs. incorrect first step. Even minor perturbations cause significant drops.
| DS-R1-Qwen-1.5B DS-R1-Qwen-7B DS-R1-Qwen-32B | 95.4 94.8 100.0 | 64.4 28.5 85.8 |
| --- | --- | --- |
| Qwen3-1.7B | 96.0 | 46.6 |
| Qwen3-8B | 71.4 | 37.0 |
| Qwen3-30B-A3B | 100.0 | 74.7 |
| Qwen3-235B-A22B | 100.0 | 78.7 |
These perturbations are minimal, as they preserve the core reasoning structure while only altering the final prediction in the incorrect variant. We then combine the prompt $p$ with the modified first reasoning step $t^{\prime}_{1}$ and input it to the model as $\mathcal{M}(p\mathrm{{<}think{>}}t^{\prime}_{1}\mathrm{Alternatively})$ to assess subsequent reasoning behavior.
Result. As shown in Table 1, we make two key observations: (1) Smaller models rarely reach 100% accuracy even when the first reasoning step is correct, suggesting that they may revise or deviate from their initial reasoning. In contrast, larger models (e.g., DS-R1-32B) consistently achieve 100% accuracy given a correct first step, indicating greater stability. (2) There is a substantial drop in accuracy when the first reasoning step is incorrect, highlighting that even minor errors early in the reasoning process can significantly affect the final prediction. These findings further indicate that the LLM’s ability to self-correct has been overestimated.
In this section, we observe that the reasoning model is particularly vulnerable at the initial stage of the reasoning process; an error in the first step can propagate and substantially degrade the final prediction. Can we develop a method to identify and retain more promising first reasoning steps while discarding suboptimal ones to enhance the overall generation efficiency?
4 Early pruning with hint from first step
In this section, we propose an efficient and straightforward sampling method to identify a promising first reasoning step. By doing so, we can terminate the generation process early when a suboptimal first step is detected, thereby reducing unnecessary computational overhead.
4.1 Problem definition
In contrast to the notation introduced in § 3, we incorporate a random seed $\epsilon$ to introduce stochasticity into the sampling process. Specifically, a sampled trace is computed as $t\oplus c_{T}=\mathcal{M}(p,\epsilon)$ . By varying the random seed $\epsilon^{n}$ , we obtain diverse generations, denoted as $t^{n}\oplus c^{n}_{T}=\mathcal{M}(p,\epsilon^{n})$ , where $t^{n}=[t^{n}_{1},t^{n}_{2},...,t^{n}_{T}]$ . In prior experiments, we sampled 64 CoT traces per question using 64 distinct random seeds $\{\epsilon^{n}\}_{n=1}^{64}$ .
A widely adopted technique for reasoning tasks is majority voting or self-consistency generation (Wang et al., 2022). To promote exploration of the reasoning space, models are typically sampled at high temperatures, resulting in diverse outputs. Majority voting then serves to aggregate these outputs by selecting the most frequent final prediction. Formally, majority voting over $K$ samples is defined as:
$$
q_{\text{maj@}K}=\text{mode}(\{q^{n}_{T}\}_{n=1}^{K})\quad\text{where}\quad q^{n}_{T}=g(c^{n}_{T})
$$
However, for models generating long CoT traces, majority voting becomes computationally expensive, as it requires sampling $N$ complete reasoning paths independently. In this section, we propose a more efficient approach that samples only $M$ full traces, where $M<N$ , while maintaining comparable majority voting performance to the one with $N$ samplings.
4.2 Methodology
In § 3, we demonstrated a strong positive correlation between the first reasoning step and the final prediction. This observation motivates a method that identifies the top $M$ most promising first reasoning steps out of a total of $N$ , and continues generation only for these selected $M$ candidates, while discarding the remaining $(N-M)$ .
Let a reasoning model generate $N$ candidate first reasoning step $\{t_{1}^{1},t_{1}^{2},...,t_{1}^{N}\}$ from a prompt $p$ with different random seeds $\{\epsilon^{n}\}_{n=1}^{N}$ . Each $t_{1}^{n}$ is the first reasoning step of a full reasoning trajectory. We define a scoring function $r:t_{1}^{n}→\mathbb{R}$ that estimates the promise of a first step, e.g., rating from a reward model. We then select the top $M$ first steps based on their scores:
$$
\mathcal{R}_{\text{top}}=\text{TopM}(\{r(t_{1}^{n})\}_{n=1}^{N})
$$
Only the selected $M$ first steps $\{t_{1}^{n}\mid n∈\mathcal{R}_{\text{top}}\}$ are used for further multi-step generation. The remaining $(N-M)$ are discarded. Since the first step typically requires only a small number of tokens to generate, this selection approach efficiently reduces computation by avoiding full sampling for the less promising $(N-M)$ candidates.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Chart Grid: Model Performance vs. K Value
### Overview
The image presents a grid of line charts comparing the performance of two models, "Vanilla N" and "TopM," across different tasks and model sizes. The x-axis represents the value of 'K', and the y-axis represents the "Maj@K accuracy (%)". Each chart shows how the accuracy changes as 'K' varies for a specific task and model configuration.
### Components/Axes
* **X-axis:** 'K' (values: 1, 4, 8, 16, 32, 64). Logarithmic scale.
* **Y-axis:** Maj@K accuracy (%). The scale varies between charts, but generally spans a range of 20-30 percentage points.
* **Legend:** Located in the top-left chart ("Average").
* Vanilla N (orange line with downward-pointing triangle markers)
* TopM (blue line with circle markers)
* **Chart Titles (Top Row):** Average, AIME24, AIME25, HMMT, GPQA
* **Model Size Labels (Right Column):** (These are in pink text)
* DS-R1-Qwen-1.5B
* DS-R1-Qwen-32B
* Qwen3-8B
* SW-OR1-7B-Preview
* **Vertical Dashed Line:** Appears in each chart at K=8.
### Detailed Analysis
The grid is organized as follows:
* **Rows:** Each row corresponds to a different model size (as indicated by the labels in the right column).
* **Columns:** Each column corresponds to a different task or evaluation metric (as indicated by the titles in the top row).
**Individual Chart Analysis (Examples):**
* **Average, DS-R1-Qwen-1.5B (Top-Left):**
* Vanilla N (orange): Starts at approximately 25% accuracy at K=1, rises sharply to approximately 40% at K=8, then plateaus around 41% for K=16 to K=64.
* TopM (blue): Starts at approximately 25% accuracy at K=1, rises sharply to approximately 37% at K=4, then rises more gradually to approximately 42% at K=16, and plateaus around 42% for K=32 to K=64.
* **AIME24, DS-R1-Qwen-1.5B:**
* Vanilla N (orange): Starts at approximately 30% accuracy at K=1, rises sharply to approximately 60% at K=8, then plateaus around 60% for K=16 to K=64.
* TopM (blue): Starts at approximately 30% accuracy at K=1, rises sharply to approximately 60% at K=8, then plateaus around 60% for K=16 to K=64.
* **GPQA, SW-OR1-7B-Preview (Bottom-Right):**
* Vanilla N (orange): Starts at approximately 45% accuracy at K=1, rises sharply to approximately 52% at K=4, then decreases slightly to approximately 51% at K=8, and plateaus around 51% for K=16 to K=64.
* TopM (blue): Starts at approximately 50% accuracy at K=1, rises sharply to approximately 53% at K=4, then decreases slightly to approximately 52% at K=8, and plateaus around 52% for K=16 to K=64.
**General Trends:**
* Both models generally show a rapid increase in accuracy as 'K' increases from 1 to 8.
* Beyond K=8, the accuracy tends to plateau or increase only slightly.
* The TopM model often outperforms the Vanilla N model, especially at lower values of K.
* The specific accuracy values and the magnitude of the improvement vary significantly depending on the task and model size.
### Key Observations
* **Diminishing Returns:** Increasing 'K' beyond 8 provides diminishing returns in terms of accuracy improvement.
* **Model Preference:** TopM generally performs better than Vanilla N, especially at lower K values.
* **Task Dependence:** The absolute accuracy values and the relative performance of the models are highly dependent on the specific task (Average, AIME24, AIME25, HMMT, GPQA).
* **Model Size Dependence:** The model size (DS-R1-Qwen-1.5B, DS-R1-Qwen-32B, Qwen3-8B, SW-OR1-7B-Preview) also influences the accuracy, but the relationship is not immediately clear from these charts alone.
### Interpretation
The charts suggest that using a higher value of 'K' can improve the accuracy of both Vanilla N and TopM models, but the benefits are most pronounced at lower values of 'K'. The TopM model appears to be generally more effective than Vanilla N. The optimal value of 'K' and the choice of model may depend on the specific task and the available computational resources. The vertical dashed line at K=8 highlights a point of diminishing returns, suggesting that this value might be a reasonable trade-off between accuracy and computational cost. Further analysis would be needed to determine the precise relationship between model size and performance.
</details>
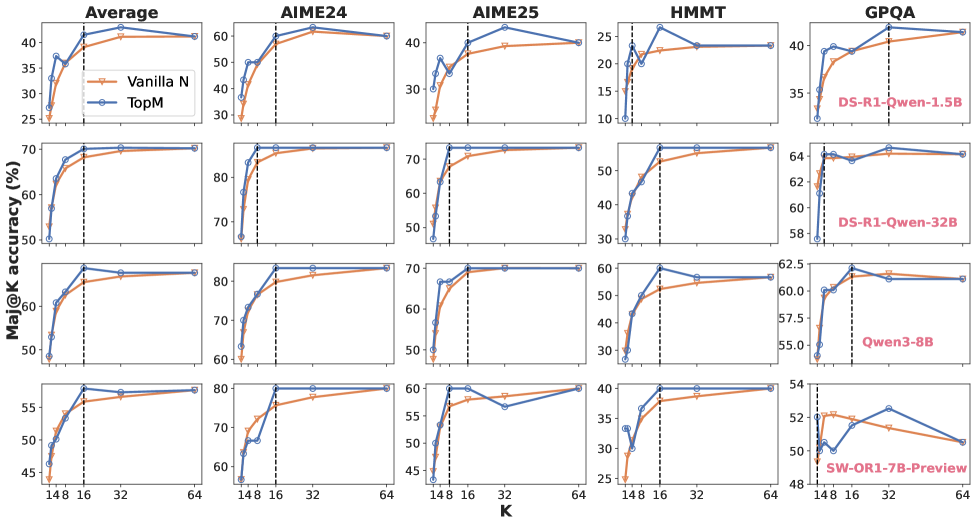
Figure 4: Majority voting accuracy with different number of samplings for four LLMs. The vertical dashed line denotes the smallest $M$ whose accuracy is equal to or larger than the accuracy of $N=64$ .
4.3 Experiments
Setup. We evaluate five families of reasoning models—DS-R1-Qwen (Guo et al., 2025), Qwen3 (Yang et al., 2025a), Skywork-OR1 (SW-OR1) (He et al., 2025), Magistral (Rastogi et al., 2025) and GPT-OSS (Agarwal et al., 2025) —on five challenging reasoning benchmarks spanning mathematics, science and programming: AIME24, AIME25 (MAA Committees, 2025), HMMT Feb 2025 (Balunović et al., 2025), the GPQA Diamond set (Rein et al., 2024) and LiveCodeBench Latest release, containing problems from Jan–Apr 2025. (Jain et al., 2024), consisting of 30, 30, 30, 198, and 175 problems, respectively. For decoding, we adopt each model’s recommended temperature and top_p, with a maximum generation length of 32K tokens.
We consider values of $N$ and $M$ from the set $\{1,2,4,8,16,32,64\}$ . For early pruning, we fix $N=64$ and select the top $M$ most promising first-step candidates using reward scores predicted by a process reward model (PRM), Qwen2.5-Math-PRM-7B (Zhang et al., 2025). When $M=64$ , the accuracy is exactly the same as the one for $N=64$ , since all candidates are chosen. For PRM, a “step” is defined as a segment of text ending with “ \n\n ”, and each step receives an individual reward score. The trajectory $t^{n}_{1}$ contains multiple such steps, and we use the score of its final step as the overall reward, $r(t^{n}_{1})$ . Notably, using a PRM to score $t^{n}_{1}$ is really cheap, because $t^{n}_{1}$ is short, and its computation is similar to generate one token with input $p\oplus t^{n}_{1}$ .
Unlike the definition used in § 3, where $t^{n}_{1}$ terminates upon generating the keyword “Alternatively”, we redefine $t^{n}_{1}$ in this section to have a fixed token length, $\text{len}(t^{n}_{1})$ . The previous definition made it difficult to control the computational budget for generating first steps, as the trigger phrase might not appear or could occur late in the sequence. By fixing the token length, we achieve precise control over the generation budget when sampling $N$ candidate first steps. By default, $\text{len}(t^{n}_{1})=512$ .
4.3.1 Main results
In Figure 4, we analyze the performance as $M$ varies. We find that selecting the top 16 first reasoning steps from 64 candidates and continuing generation from them achieves accuracy on par with, or even exceeding, conventional sampling with $N=64$ . This trend is consistent across diverse LLMs and benchmarks. Interestingly, for certain cases—such as HMMT on DS-R1-Qwen-1.5B, and AIME24, AIME25, and GPQA on DS-R1-Qwen-32B—using as few as $M≤ 8$ suffices to match the performance obtained with all 64 samples.
Table 2: Early pruning accuracy and efficiency. We select $M=16$ first steps with the highest reward scores out of $N=64$ candidate first steps. The number of tokens used for the 48 discarded first steps is also included for the early pruning method. Early pruning maintains the accuracy, even improves sometimes, while only requiring $<30\%$ original inference budget.
| DS-R1-Qwen-1.5B | $N=64$ | 60.0 | 40.0 | 23.3 | 41.4 | 41.2 | $×$ 1.00 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| $N=16$ | 57.0 | 37.6 | 22.4 | 39.4 | 39.1 (-2.1) | $×$ 0.25 | |
| $M=16$ | 60.0 | 40.0 | 26.7 | 39.4 | 41.5 (+0.3) | $×$ 0.28 | |
| DS-R1-Qwen-32B | $N=64$ | 86.7 | 73.3 | 56.7 | 64.1 | 70.2 | $×$ 1.00 |
| $N=16$ | 85.4 | 70.9 | 52.6 | 63.9 | 68.2 (-2.0) | $×$ 0.25 | |
| $M=16$ | 86.7 | 73.3 | 56.7 | 63.6 | 70.1 (-0.1) | $×$ 0.29 | |
| Qwen3-8B | $N=64$ | 83.3 | 70.0 | 56.7 | 61.1 | 67.8 | $×$ 1.00 |
| $N=16$ | 79.8 | 69.0 | 52.3 | 61.3 | 65.6 (-2.2) | $×$ 0.25 | |
| $M=16$ | 83.3 | 70.0 | 60.0 | 62.1 | 68.9 (+1.1) | $×$ 0.28 | |
| SW-OR1-7B | $N=64$ | 80.0 | 60.0 | 40.0 | 50.5 | 57.6 | $×$ 1.00 |
| $N=16$ | 75.7 | 58.0 | 37.9 | 51.9 | 55.9 (-1.7) | $×$ 0.25 | |
| $M=16$ | 80.0 | 60.0 | 40.0 | 52.5 | 57.9 (+0.3) | $×$ 0.29 | |
| Magistral-Small | $N=64$ | 86.7 | 83.3 | 76.7 | 70.2 | 79.2 | $×$ 1.00 |
| $N=16$ | 87.1 | 82.6 | 71.1 | 69.2 | 77.5 (-1.7) | $×$ 0.25 | |
| $M=16$ | 86.7 | 83.3 | 73.3 | 70.2 | 78.4 (-0.8) | $×$ 0.28 | |
| GPT-OSS-20B | $N=64$ | 86.7 | 83.3 | 80.0 | 73.2 | 80.8 | $×$ 1.00 |
| $N=16$ | 85.3 | 81.7 | 73.3 | 72.7 | 78.3 (-2.5) | $×$ 0.25 | |
| $M=16$ | 86.7 | 83.3 | 80.0 | 73.2 | 80.8 (-0.0) | $×$ 0.27 | |
<details>
<summary>x7.png Details</summary>
### Visual Description
## Chart: Pass@K Performance Comparison
### Overview
The image presents three line charts comparing the "pass@K" performance of different language models: DS-R1-Qwen-32B, Qwen3-8B, and GPT-OSS-20B. Each chart plots "pass@K" (y-axis) against "K" (x-axis) for two methods: "Vanilla N" and "TopM". The charts show how the performance changes as K increases.
### Components/Axes
* **Titles:**
* Left Chart: DS-R1-Qwen-32B
* Middle Chart: Qwen3-8B
* Right Chart: GPT-OSS-20B
* **X-axis:**
* Label: K
* Scale: 1, 3, 5, 7, 9, 11, 13, 15
* **Y-axis:**
* Label: pass@K
* Scale: 40, 45, 50, 55, 60
* **Legend:** Located in the center-left of the image.
* Vanilla N (Orange Line with Triangle Markers)
* TopM (Blue Line with Circle Markers)
### Detailed Analysis
**Chart 1: DS-R1-Qwen-32B**
* **Vanilla N (Orange):** The line starts at approximately 49 at K=1, rises sharply to approximately 56 at K=5, and then gradually increases to approximately 61 at K=15.
* **TopM (Blue):** The line starts at approximately 49 at K=1, rises sharply to approximately 58 at K=5, and then gradually increases to approximately 63 at K=15.
**Chart 2: Qwen3-8B**
* **Vanilla N (Orange):** The line starts at approximately 42 at K=1, rises sharply to approximately 49 at K=5, and then gradually increases to approximately 53 at K=15.
* **TopM (Blue):** The line starts at approximately 42 at K=1, rises sharply to approximately 52 at K=5, and then gradually increases to approximately 55 at K=15.
**Chart 3: GPT-OSS-20B**
* **Vanilla N (Orange):** The line starts at approximately 40 at K=1, rises sharply to approximately 54 at K=5, and then gradually increases to approximately 60 at K=15.
* **TopM (Blue):** The line starts at approximately 43 at K=1, rises sharply to approximately 56 at K=5, and then gradually increases to approximately 61 at K=15.
### Key Observations
* In all three charts, the "TopM" method (blue line) consistently outperforms the "Vanilla N" method (orange line) across all values of K.
* The performance gain from increasing K diminishes as K gets larger. The curves flatten out after K=9.
* The DS-R1-Qwen-32B model achieves the highest "pass@K" scores, followed by GPT-OSS-20B, and then Qwen3-8B.
### Interpretation
The charts demonstrate the impact of the "TopM" sampling method on the "pass@K" performance of different language models. The data suggests that "TopM" consistently improves performance compared to the "Vanilla N" method. The diminishing returns as K increases indicate that there is a point beyond which increasing the number of samples (K) provides little additional benefit. The relative performance of the models suggests that DS-R1-Qwen-32B is the most effective among the three, followed by GPT-OSS-20B and Qwen3-8B. This could be due to differences in model size, architecture, or training data.
</details>
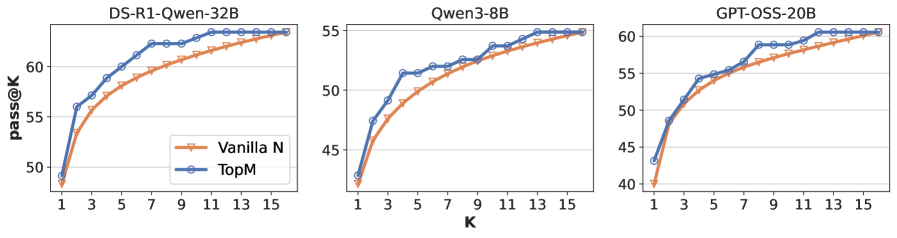
Figure 5: The pass rate on LiveCodeBench, where we set $N=16$ for early pruning (TopM).
<details>
<summary>x8.png Details</summary>
### Visual Description
## Line Charts: Average maj@K accuracy vs. K
### Overview
The image contains two line charts comparing the average maj@K accuracy (%) against K. The left chart compares different model architectures (Vanilla N, Qwen2.5-Math-PRM-7B, Qwen2.5-Math-PRM-72B, Qwen2.5-Math-RM-72B). The right chart compares different sequence lengths (len(t1)=256, len(t1)=512, len(t1)=1024) against a baseline (Vanilla N). Both charts share the same x-axis (K) and y-axis (Average maj@K accuracy (%)).
### Components/Axes
**Left Chart:**
* **X-axis:** K, with tick marks at 1, 4, 8, 16, 32, and 64.
* **Y-axis:** Average maj@K accuracy (%), ranging from 45% to 75% with tick marks at 45, 50, 55, 60, 65, and 70.
* **Legend (top-right):**
* Vanilla N (tan line with downward triangle markers)
* Qwen2.5-Math-PRM-7B (light blue line with circle markers)
* Qwen2.5-Math-PRM-72B (dark blue line with square markers)
* Qwen2.5-Math-RM-72B (pink line with diamond markers)
* A vertical dashed line is present at K=16.
**Right Chart:**
* **X-axis:** K, with tick marks at 1, 4, 8, 16, 32, and 64.
* **Y-axis:** Average maj@K accuracy (%), ranging from 45% to 75% with tick marks at 45, 50, 55, 60, 65, and 70.
* **Legend (bottom-right):**
* Vanilla N (tan line with downward triangle markers)
* len(t1)=256 (dark blue line with square markers)
* len(t1)=512 (light blue line with circle markers)
* len(t1)=1024 (pink line with diamond markers)
### Detailed Analysis
**Left Chart:**
* **Vanilla N (tan):** Starts at approximately 48% at K=1, rises to approximately 67% at K=8, and then plateaus around 72% for K=32 and K=64.
* **Qwen2.5-Math-PRM-7B (light blue):** Starts at approximately 48% at K=1, rises to approximately 69% at K=8, and then plateaus around 72% for K=32 and K=64.
* **Qwen2.5-Math-PRM-72B (dark blue):** Starts at approximately 50% at K=1, rises to approximately 70% at K=8, and then plateaus around 71% for K=32 and K=64.
* **Qwen2.5-Math-RM-72B (pink):** Starts at approximately 44% at K=1, rises to approximately 68% at K=8, and then plateaus around 72% for K=32 and K=64.
**Right Chart:**
* **Vanilla N (tan):** Starts at approximately 48% at K=1, rises to approximately 67% at K=8, and then plateaus around 72% for K=32 and K=64.
* **len(t1)=256 (dark blue):** Starts at approximately 52% at K=1, rises to approximately 68% at K=4, and then plateaus around 71% for K=32 and K=64.
* **len(t1)=512 (light blue):** Starts at approximately 48% at K=1, rises to approximately 70% at K=8, and then plateaus around 73% for K=32 and K=64.
* **len(t1)=1024 (pink):** Starts at approximately 51% at K=1, rises to approximately 69% at K=8, and then plateaus around 73% for K=32 and K=64.
### Key Observations
* All models and sequence lengths show a significant increase in average maj@K accuracy as K increases from 1 to 8.
* Beyond K=16, the accuracy plateaus for all models and sequence lengths.
* In the left chart, the Qwen models generally outperform Vanilla N, especially at lower values of K.
* In the right chart, longer sequence lengths (512 and 1024) tend to perform slightly better than the shorter sequence length (256) and Vanilla N.
### Interpretation
The charts suggest that increasing K initially leads to a substantial improvement in the average maj@K accuracy. However, there is a point of diminishing returns, as the accuracy plateaus beyond K=16. The left chart indicates that the Qwen models are more effective than the Vanilla N model, particularly at lower K values. The right chart suggests that longer sequence lengths can lead to slightly better performance compared to shorter sequence lengths and the Vanilla N model. The vertical dashed line at K=16 might indicate a threshold or a point of interest for analysis.
</details>
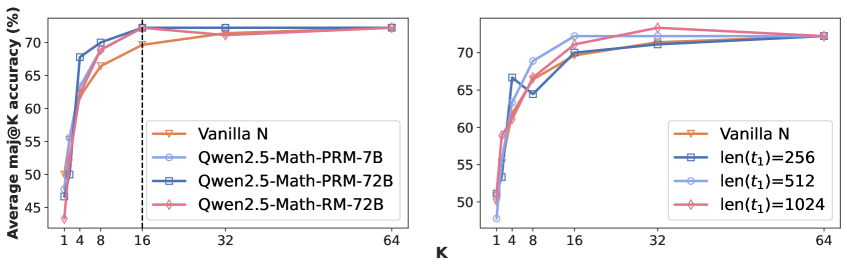
Figure 6: Average accuracy across AIME24, AIME25 and HMMT on DS-R1-Qwen-32B. Left: Comparison of reward signals derived from different reward models. The choice of reward model has minimal impact on overall performance. Right: Effect of varying the length of the first reasoning step. Using a very short first step, like 256 tokens, leads to suboptimal performance, likely because it provides insufficient reasoning context to effectively evaluate the quality of the step.
Table 2 reports the detailed accuracy and token consumption of different methods. When using $M=16$ , early pruning consistently matches the accuracy of $N=64$ across a range of LLMs and benchmarks, while substantially outperforming $N=16$ under a comparable token budget. Notably, for Qwen3-8B, early pruning even yields a 1.1% improvement in average accuracy. Importantly, these gains come at less than 30% of the inference cost of majority voting with $N=64$ , underscoring the strong efficiency advantage of our method.
For the code generation benchmark, LiveCodeBench, where majority voting is not applicable, we present the pass rate in Figure 5. Early pruning consistently surpasses standard sampling given the same number of complete sampling.
4.3.2 Ablation studies
Here we further validate our default settings.
Choice of reward model. In Figure 6 (Left), we evaluate two additional reward models: a larger PRM, Qwen2.5-Math-PRM-72B, and an outcome reward model, Qwen2.5-Math-RM-72B (Yang et al., 2024). The results indicate that the choice of reward model has minimal impact on performance. Notably, the smaller 7B PRM achieves comparable results, highlighting the efficiency of our approach.
Length of first step. In Figure 6 (Right), we examine the impact of varying the length of the first reasoning step. We observe that the shortest first step (i.e., $\text{len}(t^{n}_{1})=256$ ) leads to degraded performance. We hypothesize that shorter $t^{n}_{1}$ sequences lack sufficient reasoning content, making them less informative for reliable reward model evaluation. Nevertheless, setting $\text{len}(t^{n}_{1})≥ 512$ tokens yields consistently better performance than vanilla sampling.
Table 3: Average maj@K for early pruning, with first step defined by length or phrase.
| DS-R1-Qwen-1.5B DS-R1-Qwen-32B Qwen3-8B | 41.5 70.1 68.9 | 43.8 70.4 68.2 |
| --- | --- | --- |
| SW-OR1-7B | 57.9 | 57.7 |
Effect of first step split. Table 3 examines how defining the first step influences early pruning performance. The heuristic approach follows the method described in § 3. Overall, both definitions yield comparable results. Nevertheless, we recommend using the token-count–based definition, as it provides a clearer way to manage the token budget across candidate first steps. Moreover, trigger phrases that signal step boundaries may vary across LLMs.
Table 4: Time spent by early pruning.
| DS-R1-Qwen-1.5B Qwen3-8B | $×$ 1.00 $×$ 1.00 | $×$ 0.27 $×$ 0.37 |
| --- | --- | --- |
Overhead from reward model. Relative to vanilla sampling, early pruning requires scoring the first step with a reward model, which introduces additional overhead. To ensure a fair comparison, we avoid using extra GPUs for deploying the reward model. Instead, our procedure is as follows: (1) load the reasoning model to generate candidate first steps and then offload it; (2) load the reward model on the same GPU to evaluate these steps and offload it; and (3) reload the reasoning model to continue generation from the selected first steps. The timing results are reported in Table 4. Notably, early pruning remains efficient both in terms of token usage and runtime, since evaluating the first step with the reward model is inexpensive—comparable to computing embeddings for the short first steps.
5 Conclusion
In this paper, we empirically demonstrate that the first reasoning step plays a critical role in determining the final outcome of a model’s reasoning process. Errors introduced early can significantly degrade overall performance. Motivated by this observation, we propose an efficient sampling strategy that identifies and retains high-quality first reasoning steps, reducing the inference computation up to 70% across three model families. These findings suggest that improving or exploiting the very first step is a promising direction for building more accurate and efficient reasoning LLMs.
Acknowledgements
This research was partly supported by the Netherlands Organization for Scientific Research (NWO) under project number VI.C.192.080, 024.004.022, NWA.1389.20.183, and KICH3.LTP.20.006, and the European Union under grant agreements No. 101070212 (FINDHR) and No. 101201510 (UNITE). We are very grateful for the computation support from eBay. Views and opinions expressed are those of the author(s) only and do not necessarily reflect those of their respective employers, funders and/or granting authorities.
References
- Agarwal et al. (2025) Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card. arXiv preprint arXiv:2508.10925, 2025.
- Aggarwal et al. (2023) Pranjal Aggarwal, Aman Madaan, Yiming Yang, et al. Let’s sample step by step: Adaptive-consistency for efficient reasoning and coding with llms. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 12375–12396, 2023.
- Anthropic (2025) Anthropic. Claude 3.7 sonnet system card. 2025. URL https://api.semanticscholar.org/CorpusID:276612236.
- Balunović et al. (2025) Mislav Balunović, Jasper Dekoninck, Ivo Petrov, Nikola Jovanović, and Martin Vechev. Matharena: Evaluating llms on uncontaminated math competitions, February 2025. URL https://matharena.ai/.
- Barbero et al. (2025) Federico Barbero, Alvaro Arroyo, Xiangming Gu, Christos Perivolaropoulos, Michael Bronstein, Petar Veličković, and Razvan Pascanu. Why do llms attend to the first token? arXiv preprint arXiv:2504.02732, 2025.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Chen et al. (2024a) Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, et al. Do not think that much for 2+ 3=? on the overthinking of o1-like llms. arXiv preprint arXiv:2412.21187, 2024a.
- Chen et al. (2024b) Xinyi Chen, Baohao Liao, Jirui Qi, Panagiotis Eustratiadis, Christof Monz, Arianna Bisazza, and Maarten de Rijke. The SIFo benchmark: Investigating the sequential instruction following ability of large language models. In Findings of the Association for Computational Linguistics: EMNLP 2024, pp. 1691–1706. Association for Computational Linguistics, 2024b. URL https://aclanthology.org/2024.findings-emnlp.92/.
- Chiang & Lee (2024) Cheng-Han Chiang and Hung-yi Lee. Over-reasoning and redundant calculation of large language models. In Yvette Graham and Matthew Purver (eds.), Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 161–169, St. Julian’s, Malta, March 2024. Association for Computational Linguistics. URL https://aclanthology.org/2024.eacl-short.15/.
- Formal et al. (2021) Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. Splade: Sparse lexical and expansion model for first stage ranking. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 2288–2292, 2021.
- Formal et al. (2022) Thibault Formal, Carlos Lassance, Benjamin Piwowarski, and Stéphane Clinchant. From distillation to hard negative sampling: Making sparse neural ir models more effective, 2022. URL https://arxiv.org/abs/2205.04733.
- Fu et al. (2025a) Yichao Fu, Junda Chen, Yonghao Zhuang, Zheyu Fu, Ion Stoica, and Hao Zhang. Reasoning without self-doubt: More efficient chain-of-thought through certainty probing. In ICLR 2025 Workshop on Foundation Models in the Wild, 2025a. URL https://openreview.net/forum?id=wpK4IMJfdX.
- Fu et al. (2025b) Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. Deep think with confidence. arXiv preprint arXiv:2508.15260, 2025b.
- Guo et al. (2025) Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
- He et al. (2025) Jujie He, Jiacai Liu, Chris Yuhao Liu, Rui Yan, Chaojie Wang, Peng Cheng, Xiaoyu Zhang, Fuxiang Zhang, Jiacheng Xu, Wei Shen, Siyuan Li, Liang Zeng, Tianwen Wei, Cheng Cheng, Yang Liu, and Yahui Zhou. Skywork open reasoner series. https://capricious-hydrogen-41c.notion.site/Skywork-Open-Reaonser-Series-1d0bc9ae823a80459b46c149e4f51680, 2025. Notion Blog.
- Hestness et al. (2017) Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409, 2017.
- Hoffmann et al. (2022) Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- Hou et al. (2025) Bairu Hou, Yang Zhang, Jiabao Ji, Yujian Liu, Kaizhi Qian, Jacob Andreas, and Shiyu Chang. Thinkprune: Pruning long chain-of-thought of llms via reinforcement learning. arXiv preprint arXiv:2504.01296, 2025.
- Hurst et al. (2024) Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024.
- Jain et al. (2024) Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974, 2024.
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Li et al. (2024) Yiwei Li, Peiwen Yuan, Shaoxiong Feng, Boyuan Pan, Xinglin Wang, Bin Sun, Heda Wang, and Kan Li. Escape sky-high cost: Early-stopping self-consistency for multi-step reasoning. In ICLR, 2024.
- Liao & Monz (2024) Baohao Liao and Christof Monz. 3-in-1: 2d rotary adaptation for efficient finetuning, efficient batching and composability. arXiv preprint arXiv:2409.00119, 2024.
- Liao et al. (2025a) Baohao Liao, Hanze Dong, Yuhui Xu, Doyen Sahoo, Christof Monz, Junnan Li, and Caiming Xiong. Fractured chain-of-thought reasoning. arXiv preprint arXiv:2505.12992, 2025a.
- Liao et al. (2025b) Baohao Liao, Yuhui Xu, Hanze Dong, Junnan Li, Christof Monz, Silvio Savarese, Doyen Sahoo, and Caiming Xiong. Reward-guided speculative decoding for efficient LLM reasoning. arXiv preprint arXiv:2501.19324, 2025b.
- Liu et al. (2024a) Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157–173, 2024a. doi: 10.1162/tacl˙a˙00638. URL https://aclanthology.org/2024.tacl-1.9/.
- Liu et al. (2024b) Yijin Liu, Xianfeng Zeng, Chenze Shao, Fandong Meng, and Jie Zhou. Instruction position matters in sequence generation with large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Findings of the Association for Computational Linguistics: ACL 2024, pp. 11652–11663, Bangkok, Thailand, August 2024b. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-acl.693. URL https://aclanthology.org/2024.findings-acl.693/.
- Luo et al. (2025) Haotian Luo, Li Shen, Haiying He, Yibo Wang, Shiwei Liu, Wei Li, Naiqiang Tan, Xiaochun Cao, and Dacheng Tao. O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning. arXiv preprint arXiv:2501.12570, 2025.
- MAA Committees (2025) MAA Committees. AIME Problems and Solutions. https://artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions, 2025.
- Muennighoff et al. (2025) Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling. arXiv preprint arXiv:2501.19393, 2025.
- Pezeshkpour & Hruschka (2023) Pouya Pezeshkpour and Estevam Hruschka. Large language models sensitivity to the order of options in multiple-choice questions. arXiv preprint arXiv:2308.11483, 2023.
- Qin et al. (2023) Guanghui Qin, Yukun Feng, and Benjamin Van Durme. The NLP task effectiveness of long-range transformers. In Andreas Vlachos and Isabelle Augenstein (eds.), Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pp. 3774–3790. Association for Computational Linguistics, 2023. doi: 10.18653/v1/2023.eacl-main.273. URL https://aclanthology.org/2023.eacl-main.273/.
- Rastogi et al. (2025) Abhinav Rastogi, Albert Q Jiang, Andy Lo, Gabrielle Berrada, Guillaume Lample, Jason Rute, Joep Barmentlo, Karmesh Yadav, Kartik Khandelwal, Khyathi Raghavi Chandu, et al. Magistral. arXiv preprint arXiv:2506.10910, 2025.
- Reimers & Gurevych (2019) Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2019. URL https://arxiv.org/abs/1908.10084.
- Rein et al. (2024) David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. GPQA: A graduate-level Google-proof Q&A benchmark. In First Conference on Language Modeling, 2024.
- Shen et al. (2023) Ruoqi Shen, Sébastien Bubeck, Ronen Eldan, Yin Tat Lee, Yuanzhi Li, and Yi Zhang. Positional description matters for transformers arithmetic. arXiv preprint arXiv:2311.14737, 2023.
- Shi et al. (2024) Lin Shi, Chiyu Ma, Wenhua Liang, Weicheng Ma, and Soroush Vosoughi. Judging the judges: A systematic investigation of position bias in pairwise comparative assessments by llms. arXiv preprint arXiv:2406.07791, 2024.
- Team et al. (2024) Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
- Team (2025) Qwen Team. Qwen3, April 2025. URL https://qwenlm.github.io/blog/qwen3/.
- Wan et al. (2025) Guangya Wan, Yuqi Wu, Jie Chen, and Sheng Li. Reasoning aware self-consistency: Leveraging reasoning paths for efficient LLM sampling. In Luis Chiruzzo, Alan Ritter, and Lu Wang (eds.), Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 3613–3635, Albuquerque, New Mexico, April 2025. Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/2025.naacl-long.184. URL https://aclanthology.org/2025.naacl-long.184/.
- Wang et al. (2024) Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 9440–9450. Association for Computational Linguistics, 2024. URL https://aclanthology.org/2024.acl-long.511/.
- Wang et al. (2020) Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. Advances in Neural Information Processing Systems, 2020. URL https://arxiv.org/abs/2002.10957.
- Wang et al. (2022) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
- Wang et al. (2025a) Yue Wang, Qiuzhi Liu, Jiahao Xu, Tian Liang, Xingyu Chen, Zhiwei He, Linfeng Song, Dian Yu, Juntao Li, Zhuosheng Zhang, et al. Thoughts are all over the place: On the underthinking of o1-like llms. arXiv preprint arXiv:2501.18585, 2025a.
- Wang et al. (2025b) Zezhong Wang, Xingshan Zeng, Weiwen Liu, Yufei Wang, Liangyou Li, Yasheng Wang, Lifeng Shang, Xin Jiang, Qun Liu, and Kam-Fai Wong. Chain-of-probe: Examining the necessity and accuracy of CoT step-by-step. In Findings of the Association for Computational Linguistics: NAACL 2025, pp. 2586–2606. Association for Computational Linguistics, 2025b. ISBN 979-8-89176-195-7. URL https://aclanthology.org/2025.findings-naacl.140/.
- Wen et al. (2025) Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, Haosheng Zou, Yongchao Deng, Shousheng Jia, and Xiangzheng Zhang. Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond. arXiv preprint arXiv:2503.10460, 2025.
- Xiao et al. (2024) Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=NG7sS51zVF.
- Xiong et al. (2025) Wei Xiong, Wenting Zhao, Weizhe Yuan, Olga Golovneva, Tong Zhang, Jason Weston, and Sainbayar Sukhbaatar. Stepwiser: Stepwise generative judges for wiser reasoning. arXiv preprint arXiv:2508.19229, 2025.
- Xue et al. (2023) Mingfeng Xue, Dayiheng Liu, Wenqiang Lei, Xingzhang Ren, Baosong Yang, Jun Xie, Yidan Zhang, Dezhong Peng, and Jiancheng Lv. Dynamic voting for efficient reasoning in large language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 3085–3104, 2023.
- Yang et al. (2024) An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122, 2024.
- Yang et al. (2025a) An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025a.
- Yang et al. (2025b) Chenxu Yang, Qingyi Si, Yongjie Duan, Zheliang Zhu, Chenyu Zhu, Qiaowei Li, Zheng Lin, Li Cao, and Weiping Wang. Dynamic early exit in reasoning models. arXiv preprint arXiv:2504.15895, 2025b.
- Zhang et al. (2024a) Yusen Zhang, Sarkar Snigdha Sarathi Das, and Rui Zhang. Verbosity $neq$ veracity: Demystify verbosity compensation behavior of large language models. arXiv preprint arXiv:2411.07858, 2024a.
- Zhang et al. (2025) Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. arXiv preprint arXiv:2501.07301, 2025.
- Zhang et al. (2024b) Zhenyu Zhang, Runjin Chen, Shiwei Liu, Zhewei Yao, Olatunji Ruwase, Beidi Chen, Xiaoxia Wu, and Zhangyang Wang. Found in the middle: How language models use long contexts better via plug-and-play positional encoding. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024b.
- Zheng et al. (2024) Chujie Zheng, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. Large language models are not robust multiple choice selectors. In The Twelfth International Conference on Learning Representations, 2024.
Appendix A Keywords for Reasoning Step Segmentation
Good reasoning switching keywords should signal a clear switch in reasoning, while should not occur too frequently which often indicate only minor digressions, or too rare to be reliable delimiters. We collect a list of reasoning switching keywords from papers (Muennighoff et al., 2025; Hou et al., 2025). To assess which reasoning switch keywords could serve a similar role, we compute their average frequency per question in model outputs. After cosidering the frequencies and manually check the segment results, we found that “alternatively” strikes a balance, appearing often enough to capture step boundaries while still reflecting shifts in reasoning, for DS-R1-Qwen-7B and Qwen3-8B. We uses both “alternatively” and “wait” for Claude-3.7-Sonnet, GPT-OSS-20B and Magistral-Small.
Table A.1: Average frequency per question of discourse markers in model outputs.
| DS-R1-Qwen-7B Qwen3-8B | but 82 91 | wait 72 66 | alternatively 14 20 | hmm 7 6 | hold on 3 1 | let me confirm $<$ 1 $<$ 1 | however 10.1 10.4 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Claude-3.7-Sonnet | 28.5 | 22.6 | 0.2 | 6.1 | 0.7 | 0.0 | 0.9 |
| Magistral-Small | 47.1 | 54.8 | 3.0 | 0.0 | 0.9 | 0.2 | 1.4 |
| GPT-OSS-20B | 171.6 | 60.5 | 4.9 | 1.2 | 0.7 | 0.0 | 5.9 |
Appendix B Model Identifiers
For reproducibility, we provide the exact model identifiers used in our experiments. The models are: DeepSeek-R1-Distill-Qwen-7B (deepseek-ai/DeepSeek-R1-Distill-Qwen-7B), Qwen3-8B (Qwen/Qwen3-8B), Claude 3.7 (claude-3-7-sonnet-20250219, accessed via the Claude API), GPT-OSS-20B (openai/gpt-oss-20b), and Magistral-Small (mistralai/Magistral-Small-2509).
Appendix C Additional Similarity Analyses
We report the cosine similarity between the embedding of the $i$ -th reasoning step $t_{i}$ and the final conclusion $c_{T}$ , interpolated using the maximum number of reasoning steps (Figure C.1).
<details>
<summary>x9.png Details</summary>
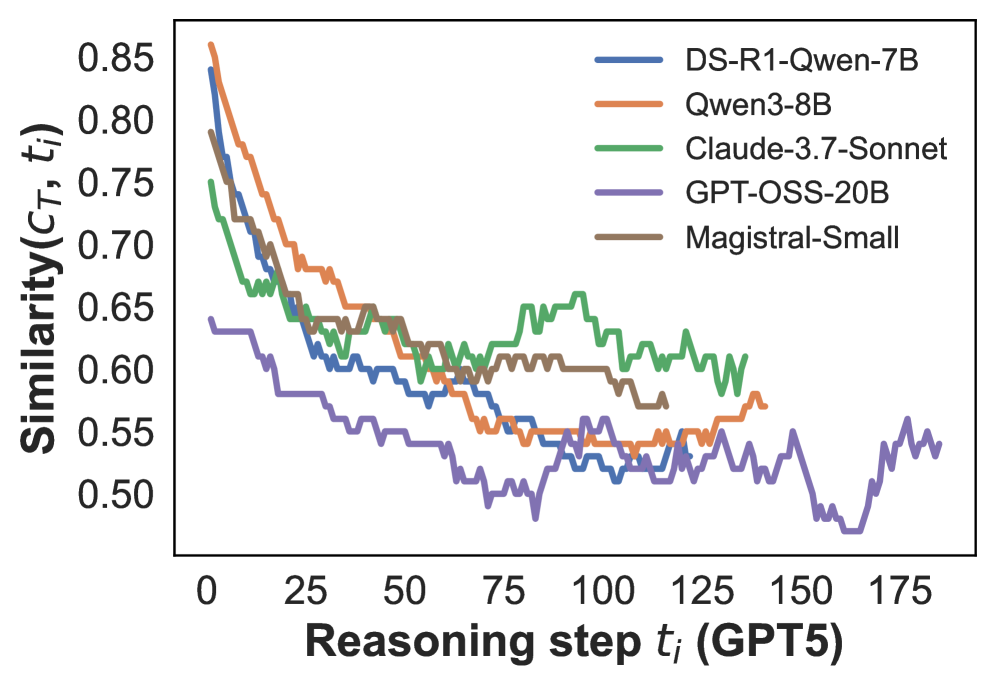
### Visual Description
## Line Chart: Similarity vs. Reasoning Step for Various Language Models
### Overview
The image is a line chart comparing the similarity scores of different language models (DS-R1-Qwen-7B, Qwen3-8B, Claude-3.7-Sonnet, GPT-OSS-20B, and Magistral-Small) over a series of reasoning steps. The x-axis represents the reasoning step, and the y-axis represents the similarity score.
### Components/Axes
* **X-axis:** Reasoning step *t<sub>i</sub>* (GPT5). Scale ranges from 0 to 175, with tick marks at intervals of 25.
* **Y-axis:** Similarity(*C<sub>T</sub>*, *t<sub>i</sub>*). Scale ranges from 0.50 to 0.85, with tick marks at intervals of 0.05.
* **Legend:** Located at the top-right of the chart.
* Blue: DS-R1-Qwen-7B
* Orange: Qwen3-8B
* Green: Claude-3.7-Sonnet
* Purple: GPT-OSS-20B
* Brown: Magistral-Small
### Detailed Analysis
* **DS-R1-Qwen-7B (Blue):** Starts at approximately 0.85 and generally decreases to around 0.55 by the end of the reasoning steps. The line shows a decreasing trend with some fluctuations.
* At step 0, the similarity is approximately 0.85.
* At step 25, the similarity is approximately 0.70.
* At step 175, the similarity is approximately 0.55.
* **Qwen3-8B (Orange):** Starts at approximately 0.85 and decreases to around 0.57 by the end of the reasoning steps. The line shows a decreasing trend with some fluctuations.
* At step 0, the similarity is approximately 0.85.
* At step 25, the similarity is approximately 0.72.
* At step 175, the similarity is approximately 0.57.
* **Claude-3.7-Sonnet (Green):** Starts at approximately 0.75 and fluctuates between 0.55 and 0.65 after step 50.
* At step 0, the similarity is approximately 0.75.
* At step 25, the similarity is approximately 0.68.
* At step 175, the similarity is approximately 0.57.
* **GPT-OSS-20B (Purple):** Starts at approximately 0.63 and decreases to around 0.50 by the end of the reasoning steps. The line shows a decreasing trend with significant fluctuations.
* At step 0, the similarity is approximately 0.63.
* At step 25, the similarity is approximately 0.58.
* At step 175, the similarity is approximately 0.53.
* **Magistral-Small (Brown):** Starts at approximately 0.75 and fluctuates between 0.57 and 0.62 after step 50.
* At step 0, the similarity is approximately 0.75.
* At step 25, the similarity is approximately 0.68.
* At step 175, the similarity is approximately 0.58.
### Key Observations
* The models DS-R1-Qwen-7B and Qwen3-8B start with the highest similarity scores.
* GPT-OSS-20B consistently has the lowest similarity scores throughout the reasoning steps.
* All models show a decrease in similarity as the reasoning step increases, especially in the initial steps.
* Claude-3.7-Sonnet and Magistral-Small exhibit more stable similarity scores after the initial drop.
### Interpretation
The chart illustrates how the similarity of language models changes over a series of reasoning steps. The decreasing trend in similarity suggests that as the models perform more reasoning steps, their responses become less similar to the initial context or target. The differences in the starting points and the rates of decline indicate variations in the models' ability to maintain consistency and relevance during extended reasoning processes. GPT-OSS-20B's lower similarity scores may indicate a weaker ability to maintain coherence or relevance compared to the other models. The stabilization of Claude-3.7-Sonnet and Magistral-Small after the initial drop suggests that these models might have a mechanism to maintain a certain level of similarity even with increasing reasoning steps.
</details>
<details>
<summary>x10.png Details</summary>
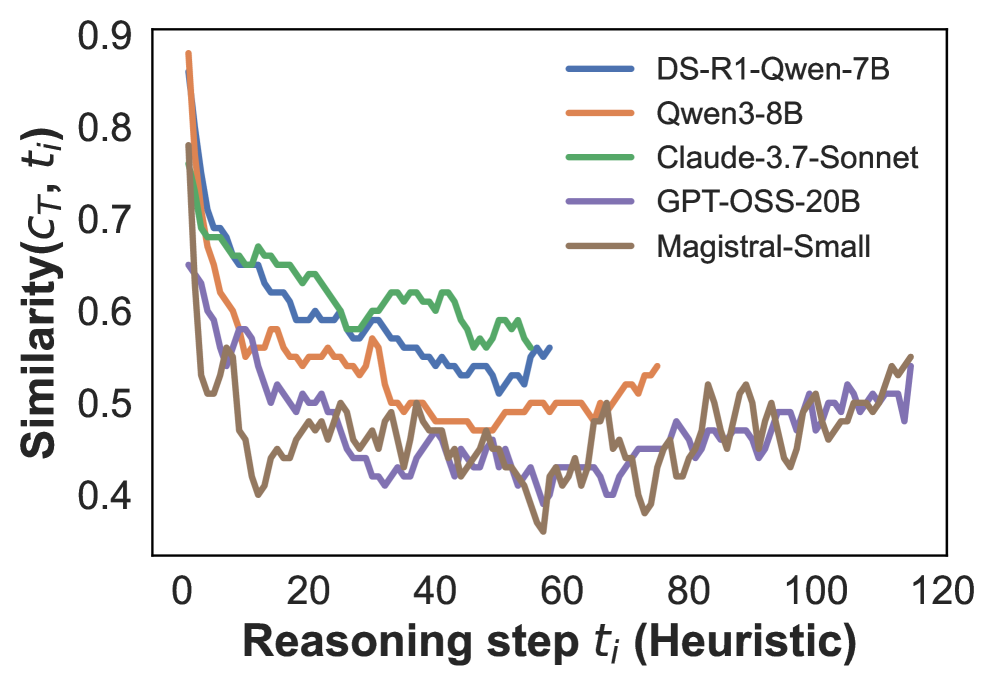
### Visual Description
## Line Chart: Similarity vs. Reasoning Step
### Overview
The image is a line chart comparing the similarity scores of five different language models (DS-R1-Qwen-7B, Qwen3-8B, Claude-3.7-Sonnet, GPT-OSS-20B, and Magistral-Small) across a range of reasoning steps. The x-axis represents the reasoning step (Heuristic), and the y-axis represents the similarity score.
### Components/Axes
* **X-axis:** Reasoning step *t<sub>i</sub>* (Heuristic). Scale ranges from 0 to 120, with tick marks at intervals of 20.
* **Y-axis:** Similarity(*C<sub>T</sub>*, *t<sub>i</sub>*). Scale ranges from 0.4 to 0.9, with tick marks at intervals of 0.1.
* **Legend:** Located at the top-right of the chart, identifying each line by model name:
* Blue: DS-R1-Qwen-7B
* Orange: Qwen3-8B
* Green: Claude-3.7-Sonnet
* Purple: GPT-OSS-20B
* Brown: Magistral-Small
### Detailed Analysis
* **DS-R1-Qwen-7B (Blue):** Starts at approximately 0.75 at step 0, decreases to around 0.55 by step 20, fluctuates between 0.5 and 0.6 until step 60, and then remains relatively stable around 0.55.
* **Qwen3-8B (Orange):** Starts at approximately 0.88 at step 0, decreases sharply to around 0.5 at step 20, fluctuates around 0.5 until step 80, and then shows a slight upward trend to approximately 0.55 by step 120.
* **Claude-3.7-Sonnet (Green):** Starts at approximately 0.7 at step 0, decreases to around 0.6 at step 10, then fluctuates between 0.6 and 0.65 until step 60, and then remains relatively stable around 0.6.
* **GPT-OSS-20B (Purple):** Starts at approximately 0.65 at step 0, decreases to around 0.45 by step 20, fluctuates between 0.4 and 0.5 until step 120.
* **Magistral-Small (Brown):** Starts at approximately 0.68 at step 0, decreases to around 0.45 by step 10, fluctuates between 0.4 and 0.55 until step 120.
### Key Observations
* All models show a decrease in similarity score in the initial reasoning steps.
* Claude-3.7-Sonnet consistently maintains the highest similarity score after the initial drop.
* GPT-OSS-20B and Magistral-Small have the lowest and most fluctuating similarity scores.
* Qwen3-8B shows a slight upward trend towards the end of the reasoning steps.
### Interpretation
The chart illustrates how the similarity of the language models' reasoning changes as the number of reasoning steps increases. The initial drop in similarity suggests that the models' reasoning becomes less consistent or accurate in the early stages. Claude-3.7-Sonnet appears to be the most stable and consistent model in terms of similarity, while GPT-OSS-20B and Magistral-Small show more variability. The slight upward trend of Qwen3-8B towards the end might indicate some improvement in reasoning consistency with more steps. The data suggests that different language models have varying levels of stability and consistency in their reasoning processes.
</details>
Figure C.1: Cosine similarity between the embeddings of the i-th reasoning step $t_{i}$ and the final conclusion $c_{T}$ , using the maximum number of reasoning steps for interpolation. The reasoning steps are segmented either by GPT-5 (left) or by heuristic rules (right).
In addition, we report SPLADE similarity (Formal et al., 2021), which provides a sparse lexical–semantic relevance signal by expanding tokens into weighted lexical features. We compute SPLADE similarity using the naver/splade-cocondenser-ensembledistil model (Formal et al., 2022), following standard practice. As shown in Figure C.2, the trends closely mirror those observed under cosine similarity. These results serve as complementary checks, confirming that our findings are not tied to dense embedding models and hold across both dense and sparse similarity measures.
<details>
<summary>x11.png Details</summary>
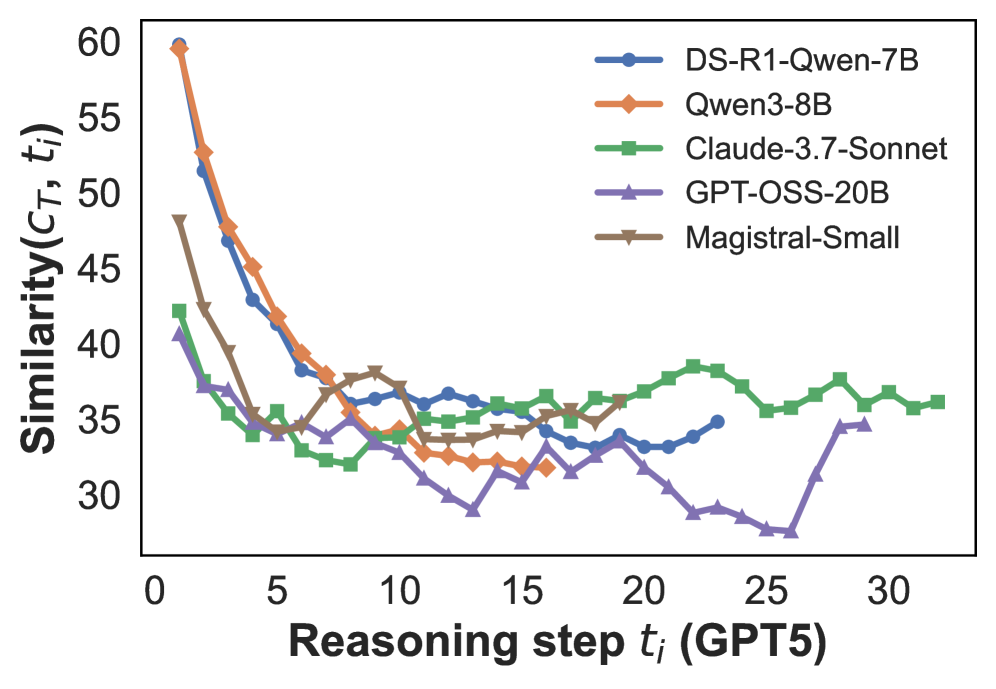
### Visual Description
## Line Chart: Similarity vs. Reasoning Step
### Overview
The image is a line chart comparing the similarity scores of five different language models across a series of reasoning steps. The x-axis represents the reasoning step, and the y-axis represents the similarity score. Each model is represented by a different colored line with distinct markers.
### Components/Axes
* **X-axis:** Reasoning step *t<sub>i</sub>* (GPT5). The axis ranges from 0 to 30, with tick marks at intervals of 5.
* **Y-axis:** Similarity(*C<sub>T</sub>*, *t<sub>i</sub>*). The axis ranges from 30 to 60, with tick marks at intervals of 5.
* **Legend:** Located at the top-right of the chart, the legend identifies each line by model name:
* Blue line with circle markers: DS-R1-Qwen-7B
* Orange line with diamond markers: Qwen3-8B
* Green line with square markers: Claude-3.7-Sonnet
* Purple line with triangle markers: GPT-OSS-20B
* Brown line with inverted triangle markers: Magistral-Small
### Detailed Analysis
* **DS-R1-Qwen-7B (Blue):** Starts at approximately 52 at step 1, decreases to around 38 by step 5, then fluctuates between 33 and 37 until step 30.
* **Qwen3-8B (Orange):** Starts at approximately 59 at step 1, decreases to around 38 by step 7, then fluctuates between 32 and 35 until step 30.
* **Claude-3.7-Sonnet (Green):** Starts at approximately 42 at step 1, decreases to around 32 by step 5, then generally increases and fluctuates between 35 and 39 until step 30.
* **GPT-OSS-20B (Purple):** Starts at approximately 40 at step 1, decreases to around 28 by step 25, then increases to around 33 by step 30.
* **Magistral-Small (Brown):** Starts at approximately 48 at step 1, decreases to around 35 by step 10, then fluctuates between 34 and 38 until step 30.
### Key Observations
* All models show a decrease in similarity score in the initial reasoning steps.
* Claude-3.7-Sonnet shows a slight upward trend after the initial decrease.
* GPT-OSS-20B experiences a significant drop and then a recovery towards the end.
* DS-R1-Qwen-7B and Qwen3-8B have similar performance trends.
* Magistral-Small has a relatively stable similarity score after the initial drop.
### Interpretation
The chart illustrates how the similarity scores of different language models change as the number of reasoning steps increases. The initial drop in similarity suggests that the models struggle to maintain consistent performance in the early stages of reasoning. The subsequent fluctuations indicate varying levels of stability and adaptability among the models. Claude-3.7-Sonnet's upward trend suggests it may be better at maintaining similarity over longer reasoning chains. The late recovery of GPT-OSS-20B could indicate a delayed adaptation or correction mechanism. The data suggests that model architecture and training influence the ability to maintain similarity across multiple reasoning steps.
</details>
<details>
<summary>x12.png Details</summary>
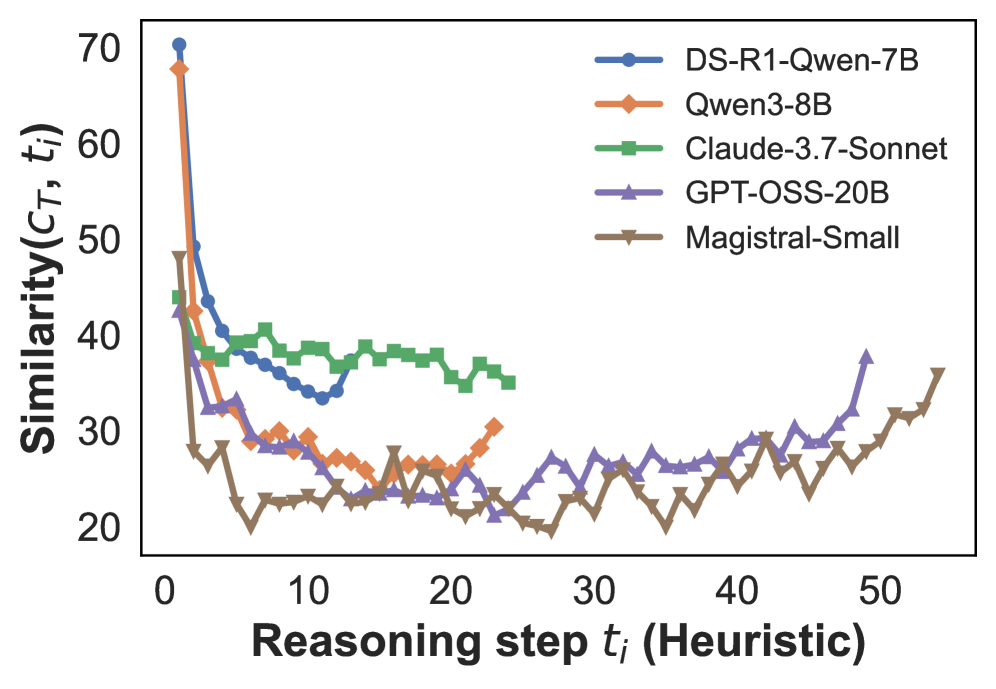
### Visual Description
## Line Chart: Similarity vs. Reasoning Step
### Overview
The image is a line chart comparing the similarity scores of five different language models across a series of reasoning steps. The x-axis represents the reasoning step (heuristic), and the y-axis represents the similarity score. The chart displays how the similarity changes as the models progress through the reasoning process.
### Components/Axes
* **X-axis:** Reasoning step tᵢ (Heuristic). Scale ranges from 0 to 50 in increments of 10.
* **Y-axis:** Similarity(C\_T, tᵢ). Scale ranges from 20 to 70 in increments of 10.
* **Legend:** Located in the top-right corner of the chart.
* Blue line with circle markers: DS-R1-Qwen-7B
* Orange line with diamond markers: Qwen3-8B
* Green line with square markers: Claude-3.7-Sonnet
* Purple line with triangle pointing up markers: GPT-OSS-20B
* Brown line with triangle pointing down markers: Magistral-Small
### Detailed Analysis
* **DS-R1-Qwen-7B (Blue):** Starts at approximately 70 and rapidly decreases to around 40 by step 5. It then fluctuates between 33 and 40 until step 20, after which it remains relatively stable.
* Step 0: ~70
* Step 5: ~40
* Step 10: ~35
* Step 20: ~38
* **Qwen3-8B (Orange):** Starts at approximately 68 and decreases to around 28 by step 10. It then fluctuates between 25 and 30 until step 25, after which it increases to around 35 by step 50.
* Step 0: ~68
* Step 10: ~28
* Step 20: ~28
* Step 50: ~35
* **Claude-3.7-Sonnet (Green):** Starts at approximately 48 and decreases to around 38 by step 5. It then fluctuates between 35 and 40 until step 25, after which it remains relatively stable.
* Step 0: ~48
* Step 5: ~38
* Step 10: ~39
* Step 20: ~38
* **GPT-OSS-20B (Purple):** Starts at approximately 44 and decreases to around 25 by step 5. It then fluctuates between 23 and 28 until step 30, after which it increases to around 38 by step 50.
* Step 0: ~44
* Step 5: ~25
* Step 10: ~30
* Step 30: ~25
* Step 50: ~38
* **Magistral-Small (Brown):** Starts at approximately 49 and decreases to around 22 by step 5. It then fluctuates between 20 and 25 until step 30, after which it increases to around 35 by step 50.
* Step 0: ~49
* Step 5: ~22
* Step 10: ~23
* Step 30: ~23
* Step 50: ~35
### Key Observations
* The models DS-R1-Qwen-7B, Qwen3-8B, and Claude-3.7-Sonnet show a rapid decrease in similarity in the initial reasoning steps, followed by a stabilization.
* The models GPT-OSS-20B and Magistral-Small show a decrease in similarity in the initial reasoning steps, followed by an increase in similarity in the later reasoning steps.
* DS-R1-Qwen-7B has the highest initial similarity, while Magistral-Small has the lowest.
* GPT-OSS-20B and Magistral-Small show a similar trend of decreasing and then increasing similarity.
### Interpretation
The chart illustrates how the similarity of different language models changes as they progress through a series of reasoning steps. The initial drop in similarity for most models suggests that the models initially struggle to maintain consistency in their reasoning. The subsequent stabilization or increase in similarity indicates that the models either adapt to the reasoning task or that the nature of the task changes, allowing for more consistent results. The differences in performance between the models may be attributed to their architecture, training data, or size. The GPT-OSS-20B and Magistral-Small models' trend of increasing similarity in later steps could indicate a learning or adaptation process that is not as pronounced in the other models.
</details>
Figure C.2: SPLADE similarity between the representations of the i-th reasoning step $t_{i}$ and the final conclusion $c_{T}$ , using the maximum number of reasoning steps for interpolation. The reasoning steps are segmented either by GPT-5 (left) or by heuristic rules (right).
Appendix D Correlation between first reasoning step and final prediction
In the main text, we reported results on DS-R1-Qwen-7B. Here we extend the analysis to Qwen3-8B (Figure D.1) and further include DeepSeek and Qwen3 models of different sizes (Figure D.2). These additional results verify that the correlation between the first reasoning step and the final prediction persists as model size scales.
<details>
<summary>x13.png Details</summary>
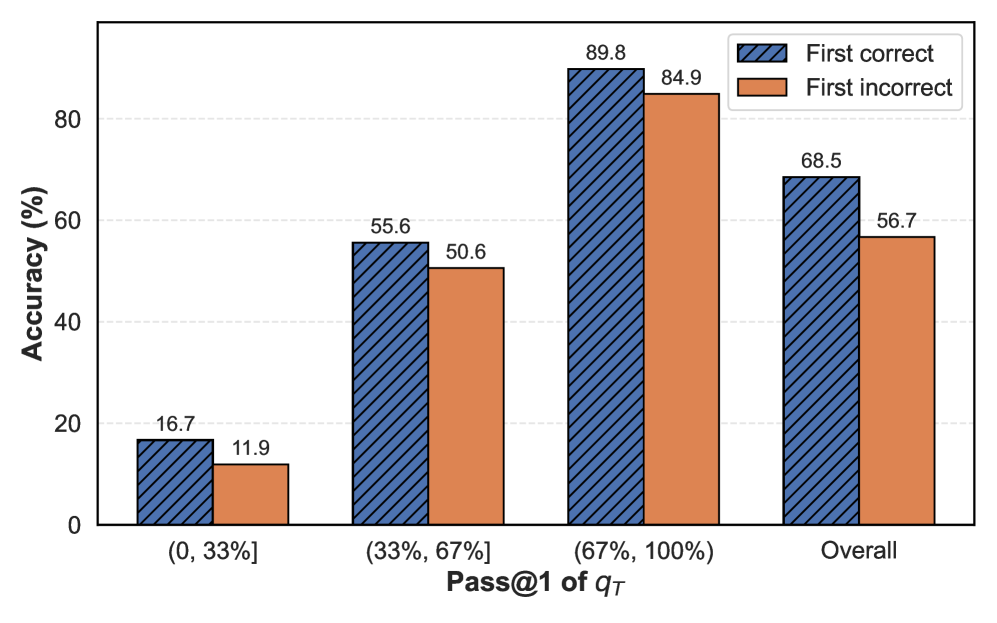
### Visual Description
## Bar Chart: Accuracy vs. Pass@1 of qT
### Overview
The image is a bar chart comparing the accuracy of "First correct" and "First incorrect" results across different percentile ranges of "Pass@1 of qT" and an overall average. The y-axis represents accuracy in percentage, and the x-axis represents the "Pass@1 of qT" ranges and the overall accuracy.
### Components/Axes
* **Y-axis:** "Accuracy (%)" with a scale from 0 to 80, incrementing by 20.
* **X-axis:** "Pass@1 of qT" with categories: "(0, 33%]", "(33%, 67%]", "(67%, 100%]", and "Overall".
* **Legend:** Located at the top-right of the chart.
* Blue, diagonally striped bars: "First correct"
* Orange bars: "First incorrect"
### Detailed Analysis
* **Category (0, 33%]:**
* "First correct" accuracy: 16.7%
* "First incorrect" accuracy: 11.9%
* **Category (33%, 67%]:**
* "First correct" accuracy: 55.6%
* "First incorrect" accuracy: 50.6%
* **Category (67%, 100%]:**
* "First correct" accuracy: 89.8%
* "First incorrect" accuracy: 84.9%
* **Category Overall:**
* "First correct" accuracy: 68.5%
* "First incorrect" accuracy: 56.7%
### Key Observations
* The accuracy for both "First correct" and "First incorrect" increases as the "Pass@1 of qT" range increases.
* In all categories, "First correct" accuracy is higher than "First incorrect" accuracy.
* The largest difference between "First correct" and "First incorrect" accuracy is in the "Overall" category.
* The highest accuracy for both "First correct" and "First incorrect" is in the "(67%, 100%]" category.
* The lowest accuracy for both "First correct" and "First incorrect" is in the "(0, 33%]" category.
### Interpretation
The chart suggests a positive correlation between "Pass@1 of qT" and accuracy. As the "Pass@1 of qT" increases, the accuracy of both "First correct" and "First incorrect" results also increases. This indicates that a higher "Pass@1 of qT" is associated with better performance. The "First correct" results consistently outperform the "First incorrect" results across all categories, suggesting that the model is more accurate when it gets the answer right on the first try. The overall accuracy reflects a general performance level, while the percentile ranges provide insights into performance at different levels of "Pass@1 of qT".
</details>
<details>
<summary>x14.png Details</summary>
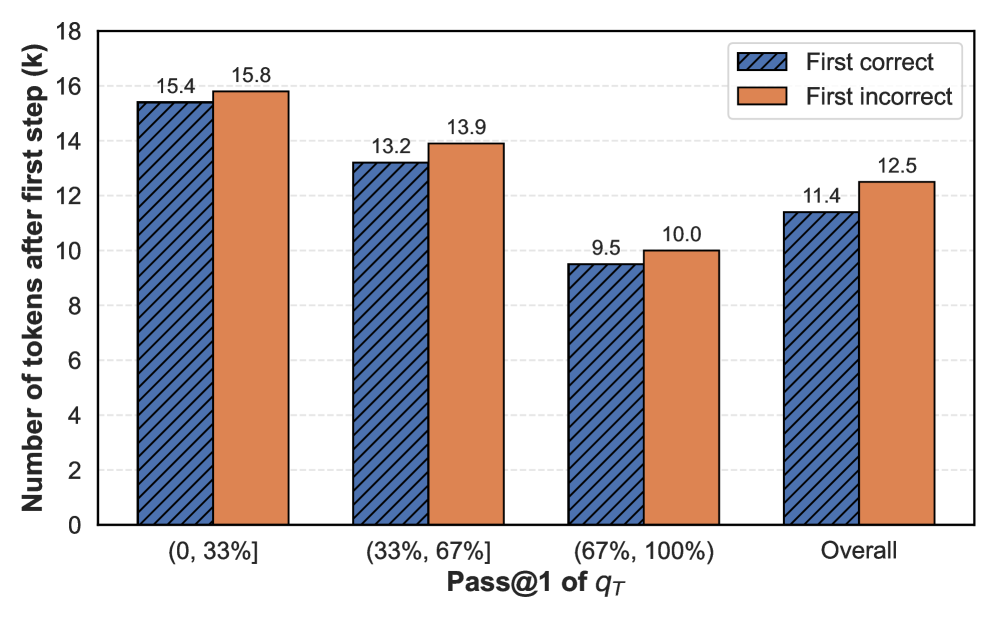
### Visual Description
## Bar Chart: Number of Tokens After First Step vs. Pass@1
### Overview
The image is a bar chart comparing the number of tokens after the first step for "First correct" and "First incorrect" scenarios, categorized by Pass@1 of qT ranges: (0, 33%], (33%, 67%], (67%, 100%], and Overall.
### Components/Axes
* **Y-axis:** "Number of tokens after first step (k)". The scale ranges from 0 to 18, with tick marks at every increment of 2.
* **X-axis:** "Pass@1 of qT". Categories are: (0, 33%], (33%, 67%], (67%, 100%], and Overall.
* **Legend:** Located at the top-right corner.
* Blue with diagonal lines: "First correct"
* Orange: "First incorrect"
### Detailed Analysis
The chart presents data for two categories: "First correct" and "First incorrect", across four "Pass@1 of qT" categories.
* **(0, 33%] Category:**
* "First correct": 15.4k tokens
* "First incorrect": 15.8k tokens
* **(33%, 67%] Category:**
* "First correct": 13.2k tokens
* "First incorrect": 13.9k tokens
* **(67%, 100%] Category:**
* "First correct": 9.5k tokens
* "First incorrect": 10.0k tokens
* **Overall Category:**
* "First correct": 11.4k tokens
* "First incorrect": 12.5k tokens
**Trend Verification:**
* **First Correct:** The number of tokens decreases as Pass@1 increases from (0, 33%] to (67%, 100%], then increases slightly for the Overall category.
* **First Incorrect:** The number of tokens also decreases as Pass@1 increases from (0, 33%] to (67%, 100%], then increases slightly for the Overall category.
### Key Observations
* For all Pass@1 categories, the number of tokens is higher when the first step is incorrect compared to when it is correct.
* The difference between "First correct" and "First incorrect" is smallest in the (67%, 100%] category.
* The number of tokens is highest in the (0, 33%] category for both "First correct" and "First incorrect".
### Interpretation
The data suggests that a higher number of tokens after the first step is associated with an incorrect first step. This could indicate that when the first step is incorrect, the model needs more tokens to correct or recover from the initial error. The trend of decreasing tokens as Pass@1 increases suggests that higher Pass@1 values are associated with fewer tokens needed after the first step, regardless of whether the first step was correct or incorrect. The "Overall" category shows a slight increase in the number of tokens compared to the (67%, 100%] category, which might reflect the distribution of Pass@1 values in the overall dataset.
</details>
Figure D.1: Accuracy and number of tokens on Qwen3-8B. Left: The relationship between the accuracy of the final prediction ( $q_{T}$ ) and the correctness of the prediction solely based on the first reasoning step ( $q_{1}$ ) across different difficulty levels. If $q_{1}$ is incorrect, $q_{T}$ is more likely incorrect. Right: The number of tokens used for the final prediction after the first reasoning step $t_{1}$ , i.e., the number of tokens used for $[t_{2},t_{3},...,t_{T}]$ . Although $q_{1}$ is correct, the model still consumes a large amount of tokens for the following reasoning steps–overthinking.
<details>
<summary>x15.png Details</summary>
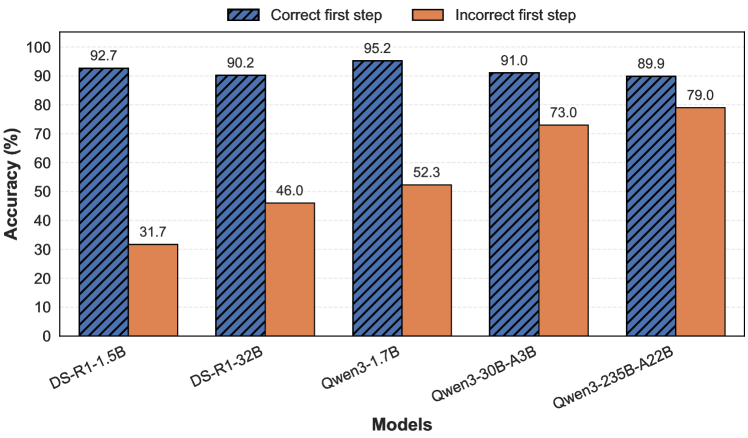
### Visual Description
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of different models based on whether the first step in a process was correct or incorrect. The chart displays the accuracy percentage on the y-axis and the model names on the x-axis. Two bars are shown for each model, one representing the accuracy when the first step was correct (blue with diagonal lines) and the other representing the accuracy when the first step was incorrect (orange).
### Components/Axes
* **X-axis:** "Models" - Categorical axis listing the models: DS-R1-1.5B, DS-R1-32B, Qwen3-1.7B, Qwen3-30B-A3B, Qwen3-235B-A22B.
* **Y-axis:** "Accuracy (%)" - Numerical axis ranging from 0 to 100, with tick marks every 10 units.
* **Legend:** Located at the top of the chart.
* Blue bar with diagonal lines: "Correct first step"
* Orange bar: "Incorrect first step"
### Detailed Analysis
Here's a breakdown of the accuracy for each model, based on the correctness of the first step:
* **DS-R1-1.5B:**
* Correct first step: 92.7%
* Incorrect first step: 31.7%
* **DS-R1-32B:**
* Correct first step: 90.2%
* Incorrect first step: 46.0%
* **Qwen3-1.7B:**
* Correct first step: 95.2%
* Incorrect first step: 52.3%
* **Qwen3-30B-A3B:**
* Correct first step: 91.0%
* Incorrect first step: 73.0%
* **Qwen3-235B-A22B:**
* Correct first step: 89.9%
* Incorrect first step: 79.0%
### Key Observations
* For all models, the accuracy is significantly higher when the first step is correct compared to when it is incorrect.
* Qwen3-1.7B has the highest accuracy when the first step is correct (95.2%).
* Qwen3-235B-A22B has the highest accuracy when the first step is incorrect (79.0%).
* The difference in accuracy between correct and incorrect first steps is smallest for Qwen3-235B-A22B.
### Interpretation
The data suggests that the correctness of the first step has a significant impact on the overall accuracy of these models. Models like DS-R1-1.5B and DS-R1-32B are particularly sensitive to errors in the first step, as indicated by the large difference in accuracy between the "correct first step" and "incorrect first step" scenarios. The Qwen3 models, especially Qwen3-235B-A22B, appear to be more robust to errors in the initial step, showing a smaller accuracy difference. This could indicate that these models have better error-correction mechanisms or are less dependent on the initial input for achieving high accuracy.
</details>
Figure D.2: More results from Qwen and DeepSeek models of different sizes. We report the relationship between the accuracy of the final prediction ( $q_{T}$ ) and the correctness of the first reasoning step ( $q_{1}$ ). If $q_{1}$ is incorrect, $q_{T}$ is more likely to be incorrect.
Appendix E Prompt Examples
The template for using the DeepSeek-R1 model is provided below. We apply the same structure to other open-source thinking models, with slight adjustments for model-specific input and output formats.
Prompt example for DeepSeek-R1: <|begin_of_sentence|>Please reason step by step, and put your final answer within \boxed{}. <|User|>[Question]<|Assistant|><think>
Appendix F Example of a incorrect First Step
Figure F.1 illustrates a case where the initial reasoning step is incorrect.
Example of incorrect first step
Question: Four unit squares form a $2× 2$ grid. Each of the 12 unit line segments forming the sides of the squares is colored either red or blue in such a way that each unit square has 2 red sides and 2 blue sides. One example is shown below (red is solid, blue is dashed). Find the number of such colorings. [asy] size(4cm); defaultpen(linewidth(1.2)); draw((0, 0) – (2, 0) – (2, 1)); draw((0, 1) – (1, 1) – (1, 2) – (2,2)); draw((0, 0) – (0, 1), dotted); draw((1, 0) – (1, 1) – (2, 1) – (2, 2), dotted); draw((0, 1) – (0, 2) – (1, 2), dotted); [/asy] First reason: Alright, so I have this problem about coloring the sides of a 2x2 grid of squares. Each square has four sides, and each of these sides is colored either red or blue. The condition is that each individual square must have exactly two red sides and two blue sides. The question is asking for the number of such colorings. First, let me visualize the grid. It’s a 2x2 grid, so there are four squares arranged in a larger square. Each square has four sides, and each side is shared with another square except for the outermost sides. But in the problem, it says there are 12 unit line segments forming the sides of the squares. Wait, let me check that: a 2x2 grid has 3 horizontal lines and 3 vertical lines, each of length 2 units. So, each horizontal line is divided into two segments, right? So, the total number of horizontal segments is 3 rows times 2 segments per row, which is 6, and similarly, the vertical segments are also 3 columns times 2 segments per column, which is another 6. So, 6 + 6 = 12 segments in total. Okay, that makes sense. Each of these 12 segments can be colored either red or blue. However, the constraint is that each of the four squares must have exactly two red sides and two blue sides. So, even though each segment can be colored independently, we have these local constraints for each square. I think a good way to approach this problem is by considering each square and the possible colorings for its sides, then seeing how they can fit together without violating the constraints. However, since the coloring of one square’s side affects the adjacent squares, this could get complicated. Maybe I can model this as a graph where each segment is a node, and the squares impose constraints on the nodes (i.e., exactly two red and two blue edges around each square). But I’m not too familiar with graph theory, so maybe that’s not the best approach. Mistakes in first reasoning step: Mistake 1 incorrectly assumes that in a $2× 2$ grid, each corner square has two shared and two unshared sides, without properly accounting for edge distribution. Mistake 2 introduces unnecessary abstraction by treating segments as “nodes,” which obscures the natural structure: the segments themselves are the edges whose colours we choose, and each square simply places a rule on its four incident edges. Working directly with those four constraints is far cleaner than introducing an extra level of abstraction.
Figure F.1: Example of incorrect first step.
Appendix G Examples for Minor Perturbation
Original final conclusion
To solve the problem, we are given triangle $ABC$ with side lengths $AB=5$ , $BC=9$ , and $AC=10$ . […] Step 4: Compute $AP$ . Since $P$ lies on line segment $AD$ , and $D$ lies outside the circle, the point $P$ lies between $A$ and $D$ . Therefore: $AP=DA-DP=\frac{325}{22}-\frac{2025}{286}.$ Find a common denominator: $\frac{325}{22}=\frac{4225}{286}\Rightarrow AP=\frac{4225-2025}{286}=\frac{2200}{286}=\frac{100}{13}.$ Final Step: Compute $m+n$ . The reduced form of $AP$ is $\frac{100}{13}$ , so: $m=100,\quad n=13\Rightarrow m+n={\color[rgb]{1,.5,0}\definecolor[named]{pgfstrokecolor}{rgb}{1,.5,0}\text{{\textbackslash boxed\{113\}}}}.$ Final Answer: \boxed{113}
New correct first reason
To solve the problem, we are given triangle $ABC$ with side lengths $AB=5$ , $BC=9$ , and $AC=10$ . […] Step 4: Compute $AP$ . Since $P$ lies on line segment $AD$ , and $D$ lies outside the circle, the point $P$ lies between $A$ and $D$ . Therefore: $AP=DA-DP=\frac{325}{22}-\frac{2025}{286}.$ Find a common denominator: $\frac{325}{22}=\frac{4225}{286}\Rightarrow AP=\frac{4225-2025}{286}=\frac{2200}{286}=\frac{100}{13}.$ Final Step: Compute $m+n$ . The reduced form of $AP$ is $\frac{100}{13}$ , so: $m=100,\quad n=13\Rightarrow m+n={\color[rgb]{1,.5,0}\definecolor[named]{pgfstrokecolor}{rgb}{1,.5,0}\text{{113}}}.$
New incorrect first reason
To solve the problem, we are given triangle $ABC$ with side lengths $AB=5$ , $BC=9$ , and $AC=10$ . […] Step 4: Compute $AP$ . Since $P$ lies on line segment $AD$ , and $D$ lies outside the circle, the point $P$ lies between $A$ and $D$ . Therefore: $AP=DA-DP=\frac{325}{22}-\frac{2025}{286}.$ Find a common denominator: $\frac{325}{22}=\frac{4225}{286}\Rightarrow AP=\frac{4225-2025}{286}=\frac{2200}{286}=\frac{100}{13}.$ Final Step: Compute $m+n$ . The reduced form of $AP$ is $\frac{100}{13}$ , so: $m=100,\quad n=13\Rightarrow m+n={\color[rgb]{1,.5,0}\definecolor[named]{pgfstrokecolor}{rgb}{1,.5,0}\text{{103}}}.$
Figure G.1: Illustration of a targeted perturbation to create correct and incorrect first reasoning steps, as discussed in § 3.3. The modified context is highlighted in orange.