# Agent-as-Tool: A Study on the Hierarchical Decision Making with Reinforcement Learning
**Authors**:
- Yanfei Zhang (Independent Researcher)
Abstract
Large Language Models (LLMs) have emerged as one of the most significant technological advancements in artificial intelligence in recent years. Their ability to understand, generate, and reason with natural language has transformed how we interact with AI systems. With the development of LLM-based agents and reinforcement-learning-based reasoning models, the study of applying reinforcement learning in agent frameworks has become a new research focus. However, all previous studies face the challenge of deciding the tool calling process and the reasoning process simultaneously, and the chain of reasoning was solely relied on the unprocessed raw result with redundant information and symbols unrelated to the task from the tool, which impose a heavy burden on the model’s capability to reason. Therefore, in our research, we proposed a hierarchical framework Agent-as-tool that detach the tool calling process and the reasoning process, which enables the model to focus on the verbally reasoning process while the tool calling process is handled by another agent. Our work had achieved comparable results with only a slight reinforcement fine-tuning on 180 samples, and had achieved exceptionally well performance in Bamboogle (Brown et al., 2020) with 63.2% of exact match and 75.2% in cover exact match, exceeding Search-R1 by 4.8% in exact match and 3.2% in cover exact match.
1 Introduction
Large Language Models (LLMs) have achieved remarkable progress in a wide range of natural language understanding and generation tasks (Liu et al., 2025; Zhang et al., 2024). As the complexity of tasks increases, a common approach is to augment LLMs with access to external tools, such as web search engines, calculators, or code interpreters. This tool-augmented paradigm enables agents to interact with the environment and perform planning, reasoning, and execution steps beyond the model’s pretraining distribution.
Recent advancements have explored integrating reinforcement learning (RL) into these agent frameworks, aiming to improve decision-making over tool usage and multi-hop reasoning steps (Guo et al., 2025; Jin et al., 2025). However, a major limitation remains: existing RL-enhanced agents conflate the tool invocation process with the verbal reasoning process. This tight coupling leads to several challenges: (1) The agent must learn tool selection, input construction, and reasoning jointly, which increases training difficulty and noise; (2) Reasoning often proceeds over noisy, unstructured outputs returned directly from external tools, which degrades answer quality.
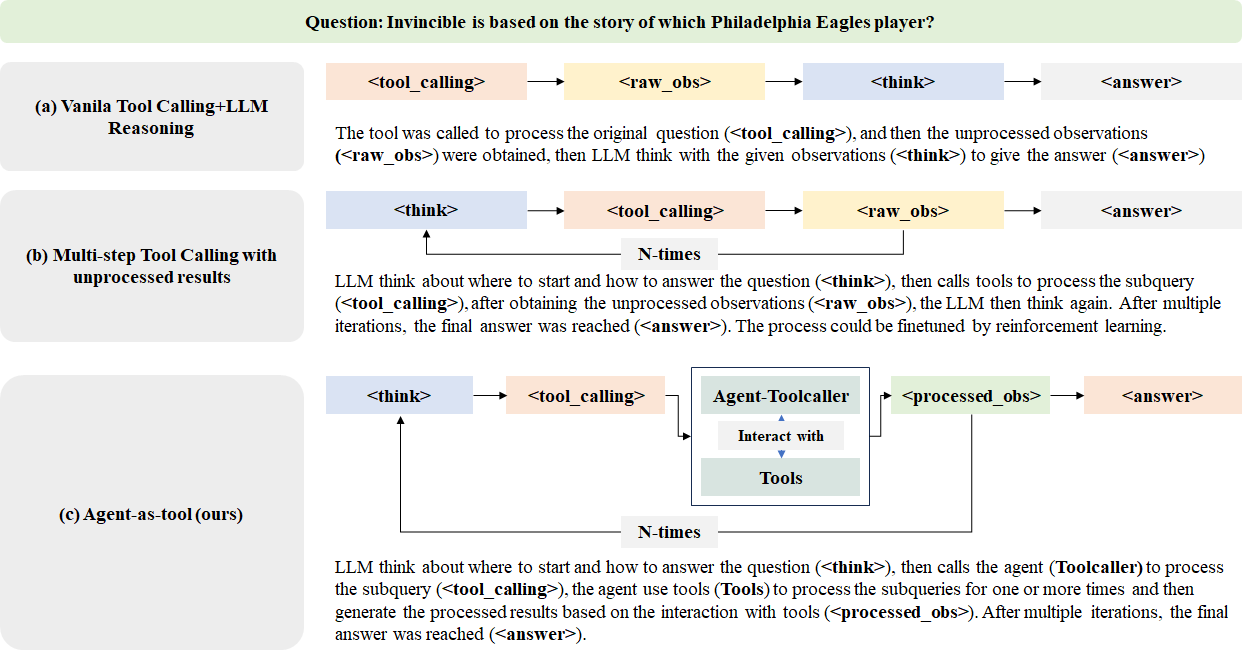
To address these challenges, we propose Agent-as-tool, a hierarchical reasoning architecture in which reasoning and tool execution are explicitly decoupled as shown in Figure 1. The framework introduces a Planner and a Toolcaller as two separate agent components. The Planner focuses on natural language reasoning and high-level decision-making, while the Toolcaller is responsible for managing the tool interface (e.g., invoking web search) and returning structured observations.
The advantages of this design are twofold: (1) It simplifies the RL optimization process by assigning each sub-agent a focused objective; (2) It improves reasoning accuracy by allowing the Planner to operate on cleaner, more structured inputs. Furthermore, we apply a lightweight reinforcement fine-tuning procedure using GRPO on just 180 samples to demonstrate the efficiency of our framework.
This paper makes the following contributions:
- We propose Agent-as-tool, a hierarchical agent framework that separates reasoning and tool usage via a Planner and a Toolcaller.
- We introduce a reinforcement learning protocol that enhances Planner behavior while masking Toolcaller outputs to preserve credit assignment integrity.
- We empirically validate our framework on multiple multi-hop QA datasets and achieve state-of-the-art performance on Bamboogle.
- We provide qualitative insights showing that hierarchical decoupling improves reasoning clarity and decomposition over existing baselines like Search-R1.
<details>
<summary>extracted/6585337/model_graph.png Details</summary>
### Visual Description
\n
## Diagram: LLM Reasoning Approaches
### Overview
The image presents a comparative diagram illustrating three different approaches to Large Language Model (LLM) reasoning: Vanilla Tool Calling+LLM Reasoning, Multi-step Tool Calling with unprocessed results, and Agent-as-tool (the authors' approach). Each approach is depicted as a flow diagram showing the sequence of steps involved in answering a question. The question posed is: "Invincible is based on the story of which Philadelphia Eagles player?".
### Components/Axes
The diagram is structured into three horizontal sections, each representing a different reasoning approach (a, b, c). Each section contains a flow diagram with arrows indicating the sequence of operations. The key components within each flow are labeled as follows:
* `<tool_calling>`: Represents the process of calling a tool.
* `<raw_obs>`: Represents the raw observations obtained.
* `<think>`: Represents the LLM's thinking or reasoning step.
* `<answer>`: Represents the final answer generated.
* `Agent-Toolcaller`: A component specific to the "Agent-as-tool" approach, representing an agent that interacts with tools.
* `<processed_obs>`: Represents the processed observations obtained through tool interaction.
* "Interact with Tools": Describes the interaction between the Agent-Toolcaller and the tools.
* "N-times": Indicates that a certain process is repeated multiple times.
### Detailed Analysis or Content Details
**(a) Vanilla Tool Calling+LLM Reasoning:**
* The flow starts with `<tool_calling>`, followed by `<raw_obs>`, then `<think>`, and finally `<answer>`.
* The accompanying text states: "The tool was called to process the original question (<tool_calling>), and then the unprocessed observations (<raw_obs>) were obtained, then LLM think with the given observations (<think>) to give the answer (<answer>)".
**(b) Multi-step Tool Calling with unprocessed results:**
* The flow starts with `<think>`, then `<tool_calling>`, followed by `<raw_obs>`, then `<think>`, and finally `<answer>`. This sequence is repeated "N-times".
* The accompanying text states: "LLM think about where to start and how to answer the question (<think>), then calls tools to process the subquery (<tool_calling>), after obtaining the unprocessed observations (<raw_obs>), the LLM then think again. After multiple iterations, the final answer was reached (<answer>). The process could be finetuned by reinforcement learning."
**(c) Agent-as-tool (ours):**
* The flow starts with `<think>`, then `<tool_calling>`, which leads to an "Agent-Toolcaller" component.
* The "Agent-Toolcaller" interacts with "Tools" and produces `<processed_obs>`.
* `<processed_obs>` then leads to `<answer>`. This sequence is repeated "N-times".
* The accompanying text states: "LLM think about where to start and how to answer the question (<think>), then calls the agent (Toolcaller) to process the subquery (<tool_calling>), the agent use tools (Tools) to process the subqueries for one or more times and then generate the processed results based on the interaction with tools (<processed_obs>). After multiple iterations, the final answer was reached (<answer>)".
### Key Observations
* The "Vanilla" approach is the simplest, with a single iteration of tool calling and reasoning.
* The "Multi-step" approach involves multiple iterations of tool calling and reasoning with unprocessed results.
* The "Agent-as-tool" approach introduces an agent that mediates the interaction with tools, resulting in processed observations before the final answer.
* All three approaches involve an initial "think" step and a final "answer" step.
* The "N-times" notation indicates that the iterative processes in (b) and (c) can be repeated an arbitrary number of times.
### Interpretation
The diagram illustrates a progression in complexity of LLM reasoning approaches. The "Vanilla" approach represents a basic form of tool use, while the "Multi-step" approach attempts to improve reasoning through iterative refinement. The "Agent-as-tool" approach, presented as the authors' contribution, introduces a more sophisticated architecture with an agent that manages tool interactions and processes the results, potentially leading to more accurate and reliable answers. The use of "N-times" suggests that these approaches are designed to handle complex questions that require multiple steps of reasoning and tool use. The diagram highlights the importance of both the LLM's reasoning capabilities and the effective use of external tools in achieving robust question answering. The introduction of the "Agent-Toolcaller" suggests a move towards more modular and controllable LLM systems. The diagram is a conceptual illustration of the different approaches and does not provide any quantitative data on their performance.
</details>
Figure 1: The trajectory of a single sample from a batch of questions processed in different research configurations. In our Agent-as-tool method, we employed the agent as a tool instead of calling the tool directly. The Planner is responsible for the tool calling process and the reasoning process, and the Toolcaller is responsible for the tool calling process to provide sufficient processed observations.
2 Literature Review
2.1 Agent Frameworks based on Pre-defined Reasoning Steps
There are several agent researches that are designed to perform tasks with pre-trained LLMs and with pre-defined reasoning steps, including the CAMEL (Li et al., 2023a), OpenManus (Liang et al., 2025) and MetaGPT (Hong et al., 2023). These works tend to extend the capabilities of the pre-trained LLM with additional rule-based reasoning steps to ’stimulate’ the internal reasoning capabilities of the LLM to achieve better performances.
Specifically, considering the search and information retrieval for task completion scenario, there are also considerable works, including the Search-o1 (Li et al., 2025a), OpenResearcher (Zheng et al., 2024) (majorly focusing on the scientific research scenario).
2.2 RL Reasoning Agents
With the development of RL training frameworks and the Deepseek-R1 (Guo et al., 2025) setting, there are also considerable works to implement R1-style training paradigms on the LLM-based agents. The searching and information retrieval tasks were the first to be considered in this scenario, including the R1-searcher (Song et al., 2025) and DeepResearcher (Zheng et al., 2025).
There are also several works that integrate other external tools under the framework to complete different tasks, including the ToRL (Li et al., 2025b) that integrate the python interpreter tool, ToolRL (Qian et al., 2025) that flexibly integrate different toolkits with different pre-defined datasets (e.g. API-Bank (Li et al., 2023b)), SWiRL (Goldie et al., 2025) that control the tool selection process with different labels (<calculator> for calculator tool, and <search_query> for web search tool).
The generic process of calling an agent in these researches can be concluded as a sequence of thinking <think>, followed by a tool calling query enclosed with <tool_query>, then the tool returns observations <obs>. With the reasoning on each step, the final answer could be reached whenever the agent think the ground truths are sufficient enough to give the final answer. It is a much simpler configuration with a ReAct-like tool calling process (Yao et al., 2023), then reinforcement learning are applied to explore whether the model could exhibit the capabilities beyond simple reasoning to reach the next hop, as shown in Figure 1 as Multi-step Tool Calling with Unprocessed Results.
3 Methodology
We propose the Agent-as-tool framework as a hierarchical design for multi-hop reasoning tasks. It separates the planning and tool usage responsibilities between two agent components: a high-level Planner and a subordinate Toolcaller. The Planner manages reasoning and task decomposition, while the Toolcaller executes external actions such as web search. This section outlines the design of both components and the reinforcement learning procedure employed to optimize the Planner.
3.1 Agent Architecture
3.1.1 Planner
The Planner is a language model agent responsible for high-level reasoning and tool invocation decisions. It reasons about the current task state and emits tool usage instructions in natural language.
Reasoning: The Planner conducts internal reasoning enclosed in <think>...</think> tags, in line with DeepSeek-R1 conventions (Guo et al., 2025). It uses previous observations and the original query to plan the next subtask.
Tool Invocation: Tool calls are expressed as sub-queries wrapped in <tool_calling>...</tool_calling> tags. These queries are interpreted by the Toolcaller, and the results are returned to the Planner as <obs>...</obs> blocks for further reasoning.
3.1.2 Toolcaller
The Toolcaller is a dedicated LLM-based agent designed to interface with external tools. In our implementation, it wraps a web search tool and processes queries issued by the Planner.
We implement the Toolcaller using a CAMEL-style chat agent (Li et al., 2023a), powered by GPT-4o-mini (Hurst et al., 2024). It could retrieve top- k search results multiple times and returns structured summaries to the Planner. Although our current prototype uses only web search, the architecture supports extension to tools like calculators or code interpreters, also including MCP-based tool servers.
3.2 Reinforcement Learning with GRPO
3.2.1 Training Objective
We employ Generalized Reinforcement Policy Optimization (GRPO) (Shao et al., 2024) to fine-tune the Planner. The objective is:
$$
\begin{split}\mathcal{J}(\Theta)&=\mathbb{E}_{x\sim\mathcal{D},\{y_{i}\}_{i=1}%
^{G}\sim\pi_{\text{old}}(\cdot|x)}\Bigg{[}\frac{1}{G}\sum_{i=1}^{G}\Big{[}\\
&\min\left(\frac{\pi_{\Theta}(y_{i}|x)}{\pi_{\text{old}}(y_{i}|x)}A_{i},\text{%
clip}\left(\frac{\pi_{\Theta}(y_{i}|x)}{\pi_{\text{old}}(y_{i}|x)},1-%
\varepsilon,1+\varepsilon\right)A_{i}\right)\\
&-\beta D_{\text{KL}}(\pi_{\Theta}||\pi_{\text{ref}})\Big{]}\Bigg{]}\end{split} \tag{1}
$$
where $x$ is sampled from dataset $\mathcal{D}$ , $y_{i}$ is a rollout, $A_{i}$ is the advantage, $\varepsilon$ is the clipping threshold, and $\beta$ regulates KL penalty.
3.2.2 Observation Masking
To prevent reward leakage through Toolcaller-generated outputs, we mask the <obs> blocks during reward modeling and training. These segments are replaced with special token <fim_pad>, which is trained to embed close to zero.
3.2.3 Reward Function
Our reward function balances correctness and formatting constraints:
$$
\text{Reward}=\begin{cases}\text{F1 score}&\text{if answer is correctly %
formatted}\\
-2&\text{otherwise}\end{cases} \tag{2}
$$
The model receives a high reward when generating a valid and correct response, and a penalty when output is malformed.
4 Experiments
4.1 Experiment Settings
4.1.1 Model and Hyperparameters
We use Qwen-2.5-7B-Instruct (Qwen et al., 2025) as our base model. The training is conducted by an customized implementation of rollout and a customized implementation of GRPO on trl (von Werra et al., 2020). At each training step, we sample a batch of training data from the training set and calculate the reward for each rollout. Then, we update the policy by maximizing the reward.
The batch size is set to 3 for each training step and each sample contains 12 rollouts for each prompt. Each rollout contains at most 10 rounds of tool calling.
4.1.2 Training Settings
We conducted quite a small scale of training for the Agent-as-tool. We trained the Agent-as-tool for 60 steps with each step containing 3 training samples, and each training sample contains 12 rollouts, with total size of only 180 samples and 2160 rollouts. The training data entries were selected from the HotpotQA (Yang et al., 2018) and 2WikiMultiHopQA (Ho et al., 2020) datasets with the same ratio as the R1-searcher (Song et al., 2025).
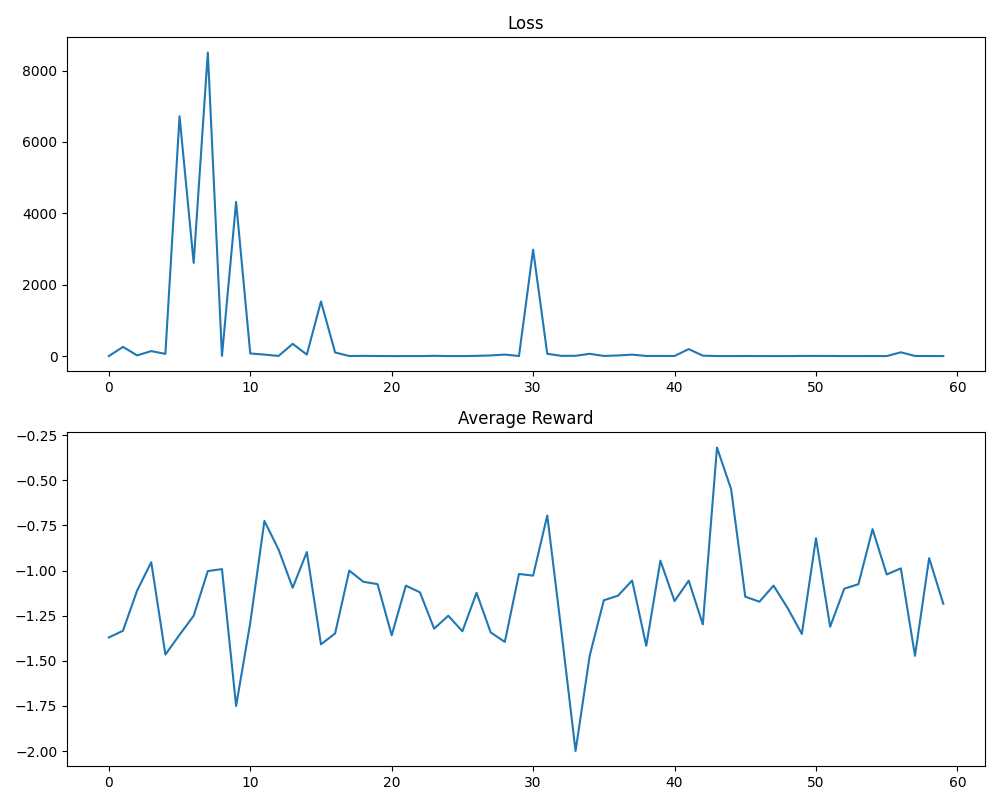
During the training process, we observed that the loss of the Agent-as-tool is not stable for the first 30 steps, which is likely due to the small training data, but after 30 steps, the loss is stable and close to 0 and the performance of the Agent-as-tool also stabilized.
<details>
<summary>extracted/6585337/training_graph.png Details</summary>
### Visual Description
\n
## Line Chart: Training Metrics - Loss and Average Reward
### Overview
The image presents two line charts stacked vertically. The top chart displays the 'Loss' metric over a range of approximately 0 to 60 units on the x-axis. The bottom chart shows the 'Average Reward' metric, also over a range of approximately 0 to 60 units on the x-axis. Both charts share the same x-axis scale.
### Components/Axes
* **Top Chart:**
* Title: "Loss" (centered at the top)
* X-axis: Unlabeled, representing training steps or iterations (range: 0 to 60)
* Y-axis: Unlabeled, representing Loss values (range: 0 to 8000)
* Data Series: A single blue line representing the Loss.
* **Bottom Chart:**
* Title: "Average Reward" (centered at the top)
* X-axis: Unlabeled, representing training steps or iterations (range: 0 to 60)
* Y-axis: Unlabeled, representing Average Reward values (range: -2.0 to -0.25)
* Data Series: A single blue line representing the Average Reward.
### Detailed Analysis or Content Details
* **Loss Chart:**
* The Loss line starts at approximately 8000 at x=0.
* It rapidly decreases to approximately 500 at x=5.
* There's a significant spike to approximately 8000 at x=8.
* The Loss then decreases again, reaching a minimum of approximately 0 at x=15.
* The Loss fluctuates between approximately 0 and 500 from x=15 to x=30.
* There's another spike to approximately 2000 at x=30.
* From x=30 to x=60, the Loss remains relatively stable, fluctuating around 100-300, and trending slightly downwards.
* **Average Reward Chart:**
* The Average Reward line starts at approximately -1.0 at x=0.
* It fluctuates between approximately -1.0 and -1.5 from x=0 to x=10.
* There's a dip to approximately -1.75 at x=12.
* The Average Reward increases to approximately -0.75 at x=30.
* There's a spike to approximately -0.25 at x=40.
* From x=40 to x=60, the Average Reward fluctuates between approximately -0.75 and -1.25, with a generally downward trend.
### Key Observations
* The Loss and Average Reward appear to be inversely correlated. When the Loss is high, the Average Reward is low, and vice versa.
* The Loss exhibits several large spikes, indicating potential instability or significant updates during training.
* The Average Reward shows a general trend of improvement, but with considerable fluctuations.
* Both metrics appear to stabilize after approximately x=40.
### Interpretation
The charts likely represent the training progress of a reinforcement learning agent or a similar machine learning model. The Loss chart indicates how well the model is learning to predict or approximate the desired output. The Average Reward chart shows the performance of the agent in its environment.
The initial high Loss and low Average Reward suggest the agent is initially performing poorly. As training progresses, the Loss decreases and the Average Reward increases, indicating learning. The spikes in Loss could be caused by significant changes in the model's parameters or by encountering challenging scenarios in the environment. The stabilization of both metrics after x=40 suggests that the training process is converging, and the agent is reaching a stable level of performance.
The inverse correlation between Loss and Average Reward is expected, as a lower Loss generally corresponds to a higher reward. The fluctuations in both metrics indicate that the training process is not perfectly smooth and that the agent is still exploring and adapting to its environment. The overall trend suggests that the agent is learning and improving over time.
</details>
Figure 2: Training progress of the Agent-as-tool model showing loss convergence over training steps. The loss becomes stable after approximately 30 training steps.
The training curve illustrated in Figure 2 shows the convergence behavior of our model during the reinforcement learning process.
4.1.3 Benchmark Settings
In order to evaluate the performance of the Agent-as-tool, we conducted experiments on the open-domain question-answering task. We selected multiple multi-hop reasoning tasks to evaluate the performance of the Agent-as-tool, including the HotpotQA (Yang et al., 2018), 2WikiMultiHopQA (Ho et al., 2020), MuSiQue (Trivedi et al., 2022), and bamboogle (Press et al., 2023).
4.1.4 Baseline Settings
We have 1 information retrival tool: web search.
We then compare the performance of the Agent-as-tool with the following baselines:
- direct IO: This baseline employs the direct output of the Qwen-2.5-7B-Instruct (Qwen et al., 2025) as the answer without any external tool calling.
- direct IO with web search: This baseline employs the direct output of the Qwen-2.5-7B-Instruct (Qwen et al., 2025), but enables the web search to process the original question and return the top-k results as additional observations.
- CAMEL Agent: This baseline employs the CAMEL (Li et al., 2023a) chat agent driven by the GPT-4o-mini (Hurst et al., 2024).
- CAMEL Agent with web search: This baseline employs the CAMEL (Li et al., 2023a) chat agent driven by the GPT-4o-mini (Hurst et al., 2024) and the same tool setting as the Agent-as-tool with web search tool only. This baseline is used as the reference for multi-hop reasoning tasks conducted with the rule-based agent framework.
- Search-R1: We directly compare the performance of the Agent-as-tool with the Search-R1 (Jin et al., 2025) in our configurations with web search tool for a fair comparison. As Search-R1 cannot be directly integrated with the CAMEL (Li et al., 2023a) chat agent, we would directly returns the search results as the answer instead of using another Toolcaller.
We conducted experiments with Agent-as-tool with pre-finetuned and post-finetuned models.
In align with the Deepseek-R1 setting (Guo et al., 2025), we adopted the same prompt setting for all the baselines and the Agent-as-tool except Search-R1 (Jin et al., 2025) that is equipped with its orignal prompt setting, and we also modified the tool calling process to enable Search-R1 to accesss the unprocessed web search results.
4.1.5 Evaluation Metrics
In this paper, we focus on the performance of the Agent-as-tool in terms of the correctness of the answer, therefore, we employed the exact match metric (EM), the cover exact match metric (CEM) to evaluate the performance of the Agent-as-tool.
4.2 Quantitative Experiment Results
The qualitative results are shown in LABEL:tab:all_datasets_complete. Based on the results, we can see that the Agent-as-tool outperforms most of the baselines except for the EM metric in the HotpotQA, 2WikiMultiHopQA, and MuSiQue datasets, where Search-R1 still has the best performance. However, in terms of the CEM metric, our model has a substantial improvement over all the baselines, except in HotpotQA where Search-R1 still has the best performance (64.2% vs 57.4%). And in the Bamboogle dataset (Press et al., 2023), the Agent-as-tool with web search tool integrated to the Toolcaller (CAMEL (Li et al., 2023a) agent) achieves the best performance with EM of 63.2% and CEM of 75.2%.
Table 1: Performance Comparison Across Different Datasets
| Bamboogle | Direct IO | 17.6 | 26.4 |
| --- | --- | --- | --- |
| Direct IO + Web Search | 29.6 | 42.4 | |
| CAMEL | 36.8 | 47.2 | |
| CAMEL + Web Search | 51.2 | 62.4 | |
| Search-R1 + Web Search | 58.4 | 72.0 | |
| Agent-as-tool-Base + Web Search | 60.0 | 71.2 | |
| Agent-as-tool-Instruct + Web Search | 63.2 | 75.2 | |
| HotpotQA | Direct IO | 20.0 | 27.2 |
| Direct IO + Web Search | 32.6 | 52.8 | |
| CAMEL | 23.2 | 44.2 | |
| CAMEL + Web Search | 32.4 | 59.4 | |
| Search-R1 + Web Search | 47.2 | 64.2 | |
| Agent-as-tool-Base + Web Search | 35.0 | 55.2 | |
| Agent-as-tool-Instruct + Web Search | 37.2 | 57.4 | |
| 2WikiMultiHopQA | Direct IO | 22.6 | 25.4 |
| Direct IO + Web Search | 27.2 | 40.2 | |
| CAMEL | 20.8 | 34.6 | |
| CAMEL + Web Search | 35.0 | 69.4 | |
| Search-R1 + Web Search | 52.4 | 68.0 | |
| Agent-as-tool-Base + Web Search | 42.8 | 68.0 | |
| Agent-as-tool-Instruct + Web Search | 44.6 | 70.0 | |
| MuSiQue | Direct IO | 4.8 | 9.0 |
| Direct IO + Web Search | 14.0 | 18.0 | |
| CAMEL | 9.2 | 18.8 | |
| CAMEL + Web Search | 16.0 | 29.4 | |
| Search-R1 + Web Search | 20.8 | 28.6 | |
| Agent-as-tool-Base + Web Search | 15.6 | 28.8 | |
| Agent-as-tool-Instruct + Web Search | 18.4 | 29.8 | |
We compared the performance of the Agent-as-tool before and after the reinforcement fine-tuning process. The table is shown in 2. Based on the results, we can see that the Reinforcement fine-tuning based on GRPO (Shao et al., 2024) substantially improves the performance of the Agent-as-tool in all datasets with an average improvement of 2.5% in EM and 2.3% in CEM.
Table 2: Performance improvements after reinforcement fine-tuning
| Dataset | Pre-finetuned | Post-finetuned | Improvement | | | |
| --- | --- | --- | --- | --- | --- | --- |
| EM | CEM | EM | CEM | EM | CEM | |
| (%) | (%) | (%) | (%) | (%) | (%) | |
| Bamboogle | 60.0 | 71.2 | 63.2 | 75.2 | +3.2 | +4.0 |
| HotpotQA | 35.0 | 55.2 | 37.2 | 57.4 | +2.2 | +2.2 |
| 2WikiMultiHopQA | 42.8 | 68.0 | 44.6 | 70.0 | +1.8 | +2.0 |
| MuSiQue | 15.6 | 28.8 | 18.4 | 29.8 | +2.8 | +1.0 |
| Average | 38.4 | 55.8 | 40.9 | 58.1 | +2.5 | +2.3 |
Comparing with the CAMEL baseline with web search tool integrated (CAMEL + Web Search), the Agent-as-tool pre-finetuned and post-finetuned achieved a substantial improvement in EM and CEM, stating the necessity that the Agent-as-tool that enables the model to control when and what to be called in a tool calling is a more effective framework for multi-hop reasoning tasks.
Comparing with the Search-R1 baseline (Search-R1 + Web Search), which is the current best performing research of its kind, the Agent-as-tool-Instruct has substantial improvements over the Bamboogle dataset, which improves the EM by 4.8% and CEM by 3.2%, stating the effectiveness of the Agent-as-tool in multi-hop reasoning tasks. Besides, the Agent-as-tool conducted fine-tuning with 180 samples, which indicates the efficiency of the fine-tuning process.
4.3 Qualitative Results Inspection and Analysis
4.3.1 Comparison of the Agent-as-tool and the Search-R1
Comparing with Search-R1 baseline (Search-R1 + Web Search), the Agent-as-tool-Instruct had several advantages qualitatively:
- The Agent-as-tool-Instruct could reason with less fuzzy and more structured observations, comparing with the Search-R1 + Web Search which would need to reason with the unprocessed web search results with fuzzy and unstructured symbols or other unrelated details.
- As the Agent-as-tool-Instruct adopt a hierarchical reasoning process which segragate the reasoning process and the tool calling process, the agent could have a better linearly text-based reasoning process comparing with the Search-R1 + Web Search.
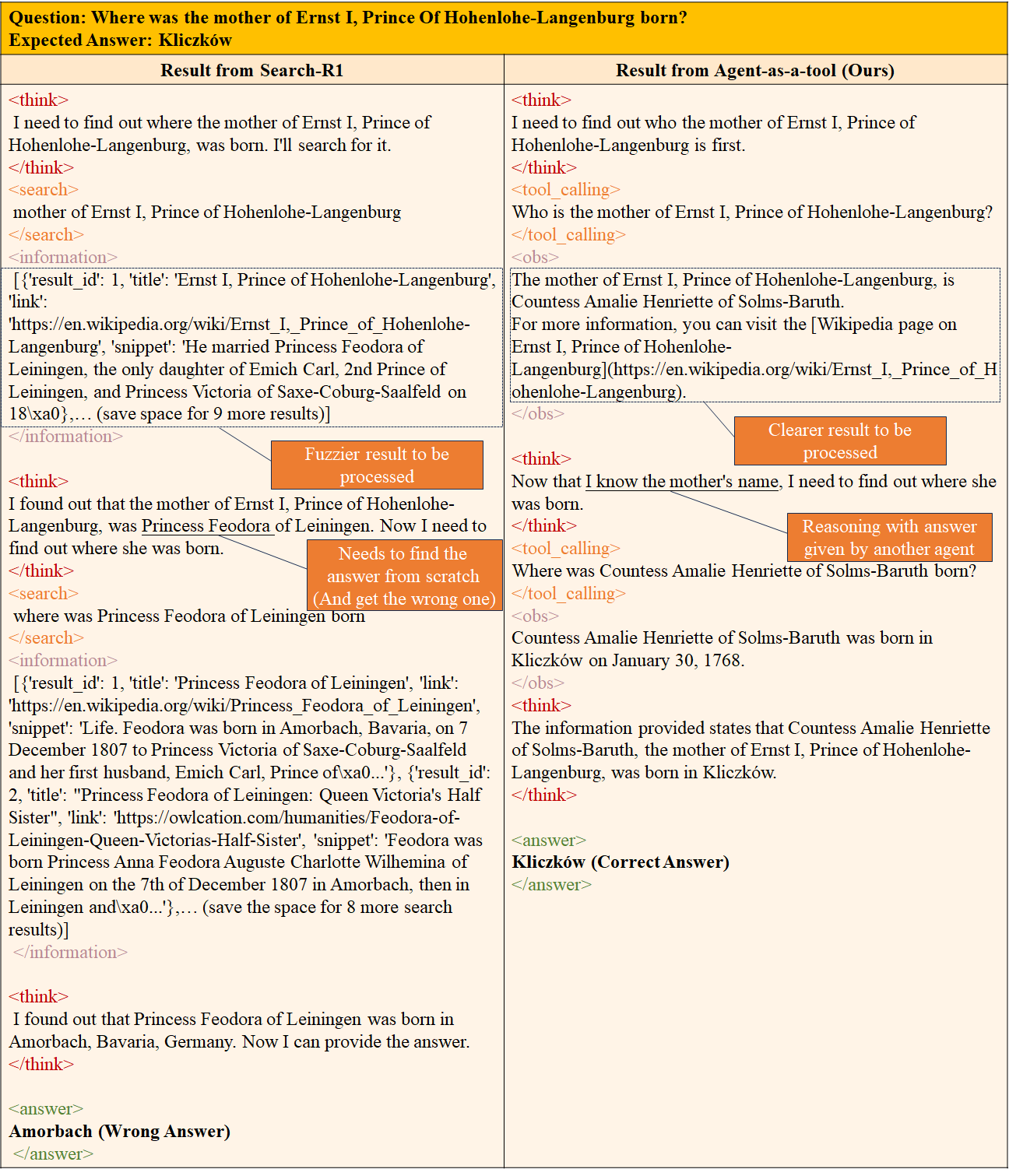
The qualitative comparison as a example is shown in Figure 3 (in Appendix). The Agent-as-tool-Instruct could reason with less fuzzy and more structured observations, comparing with the Search-R1 + Web Search which would need to reason with the unprocessed web search results with fuzzy and unstructured symbols or other unrelated details.
4.3.2 Comparison of the Results before and after the Reinforcement Fine-tuning
Comparing with Agent-as-tool-Base, the Agent-as-tool-Instruct had several advantages qualitatively:
- The Agent-as-tool-Instruct identify the correct decomposition of the question to identify the first hop and the second hop to be solved by the agent, comparing with the Agent-as-tool-Base which would not be able to decompose the multi-hop question correctly so it directly feed the agent with the whole question (only a sightly change from the original manner). If the agent is not capable of reasoning the multi-hop question correctly, the Agent-as-tool-Base would not be able to answer the question correctly.
- As the Agent-as-tool-Instruct was instructed to reason with the agent powered by the pretrained model, the fine-tuned model could give a more structured and reasonable question to be answered by the agent comparing with the Agent-as-tool-Base.
The qualitative comparison as a example is shown in Figure 4 (in Appendix). The Agent-as-tool-Instruct could correctly decompose the question to identify the first hop and the second hop, comparing with the Agent-as-tool-Base which would not be able to decompose the multi-hop question correctly so it directly feed the agent with the whole question.
5 Conclusions and Future Work
5.1 Conclusions
In this paper, we majorly studied the multi-hop reasoning tasks with the Agent-as-tool framework. We found that the Agent-as-tool could achieve a substantial improvement in the performance of the multi-hop reasoning tasks, especially in the Bamboogle dataset (Press et al., 2023). We also found that the Agent-as-tool could reason with less fuzzy and more structured observations, comparing with the Search-R1 + Web Search which would need to reason with the unprocessed web search results with fuzzy and unstructured symbols or other unrelated details.
5.2 Limitations and Future Work
This paper only assigns the search tool to the agent (or in another word, the search agent) so the scope is limited to the open-domain multi-hop search tasks. While because only 1 model was provided, the dynamic assignment of the tool to the agent is not considered. Therefore in our future work more tools would be considered to be assigned to the agent, while we would also explore the dynamic assignment of the tool to the agent, in another word, make the Planner as a Tool Orchestrator.
References
- Brown et al. [2020] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Goldie et al. [2025] A. Goldie, A. Mirhoseini, H. Zhou, I. Cai, and C. D. Manning. Synthetic data generation and multi-step rl for reasoning and tool use, 2025. URL https://arxiv.org/abs/2504.04736.
- Guo et al. [2025] D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
- Ho et al. [2020] X. Ho, A.-K. D. Nguyen, S. Sugawara, and A. Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. arXiv preprint arXiv:2011.01060, 2020.
- Hong et al. [2023] S. Hong, X. Zheng, J. Chen, Y. Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, et al. Metagpt: Meta programming for multi-agent collaborative framework. arXiv preprint arXiv:2308.00352, 3(4):6, 2023.
- Hurst et al. [2024] A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024.
- Jin et al. [2025] B. Jin, H. Zeng, Z. Yue, J. Yoon, S. Arik, D. Wang, H. Zamani, and J. Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning, 2025. URL https://arxiv.org/abs/2503.09516.
- Li et al. [2023a] G. Li, H. Hammoud, H. Itani, D. Khizbullin, and B. Ghanem. Camel: Communicative agents for” mind” exploration of large language model society. Advances in Neural Information Processing Systems, 36:51991–52008, 2023a.
- Li et al. [2023b] M. Li, Y. Zhao, B. Yu, F. Song, H. Li, H. Yu, Z. Li, F. Huang, and Y. Li. Api-bank: A comprehensive benchmark for tool-augmented llms, 2023b. URL https://arxiv.org/abs/2304.08244.
- Li et al. [2025a] X. Li, G. Dong, J. Jin, Y. Zhang, Y. Zhou, Y. Zhu, P. Zhang, and Z. Dou. Search-o1: Agentic search-enhanced large reasoning models, 2025a. URL https://arxiv.org/abs/2501.05366.
- Li et al. [2025b] X. Li, H. Zou, and P. Liu. Torl: Scaling tool-integrated rl. arXiv preprint arXiv:2503.23383, 2025b.
- Liang et al. [2025] X. Liang, J. Xiang, Z. Yu, J. Zhang, S. Hong, S. Fan, and X. Tang. Openmanus: An open-source framework for building general ai agents, 2025. URL https://doi.org/10.5281/zenodo.15186407.
- Liu et al. [2025] B. Liu, X. Li, J. Zhang, J. Wang, T. He, S. Hong, H. Liu, S. Zhang, K. Song, K. Zhu, et al. Advances and challenges in foundation agents: From brain-inspired intelligence to evolutionary, collaborative, and safe systems. arXiv preprint arXiv:2504.01990, 2025.
- Press et al. [2023] O. Press, M. Zhang, S. Min, L. Schmidt, N. A. Smith, and M. Lewis. Measuring and narrowing the compositionality gap in language models, 2023. URL https://arxiv.org/abs/2210.03350.
- Qian et al. [2025] C. Qian, E. C. Acikgoz, Q. He, H. Wang, X. Chen, D. Hakkani-Tür, G. Tur, and H. Ji. Toolrl: Reward is all tool learning needs. arXiv preprint arXiv:2504.13958, 2025.
- Qwen et al. [2025] Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Wan, Y. Liu, Z. Cui, Z. Zhang, and Z. Qiu. Qwen2.5 technical report, 2025. URL https://arxiv.org/abs/2412.15115.
- Shao et al. [2024] Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- Song et al. [2025] H. Song, J. Jiang, Y. Min, J. Chen, Z. Chen, W. X. Zhao, L. Fang, and J.-R. Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning. arXiv preprint arXiv:2503.05592, 2025.
- Trivedi et al. [2022] H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal. Musique: Multihop questions via single-hop question composition, 2022. URL https://arxiv.org/abs/2108.00573.
- von Werra et al. [2020] L. von Werra, Y. Belkada, L. Tunstall, E. Beeching, T. Thrush, N. Lambert, S. Huang, K. Rasul, and Q. Gallouédec. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl, 2020.
- Yang et al. [2018] Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600, 2018.
- Yao et al. [2023] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao. React: Synergizing reasoning and acting in language models, 2023. URL https://arxiv.org/abs/2210.03629.
- Zhang et al. [2024] J. Zhang, J. Xiang, Z. Yu, F. Teng, X. Chen, J. Chen, M. Zhuge, X. Cheng, S. Hong, J. Wang, et al. Aflow: Automating agentic workflow generation. arXiv preprint arXiv:2410.10762, 2024.
- Zheng et al. [2024] Y. Zheng, S. Sun, L. Qiu, D. Ru, C. Jiayang, X. Li, J. Lin, B. Wang, Y. Luo, R. Pan, et al. Openresearcher: Unleashing ai for accelerated scientific research. arXiv preprint arXiv:2408.06941, 2024.
- Zheng et al. [2025] Y. Zheng, D. Fu, X. Hu, X. Cai, L. Ye, P. Lu, and P. Liu. Deepresearcher: Scaling deep research via reinforcement learning in real-world environments. arXiv preprint arXiv:2504.03160, 2025.
Appendix A The qualitative Results inspection
A.1 The qualitative results inspection of the Agent-as-tool-Instruct + Web Search and the Search-R1 + Web Search
<details>
<summary>extracted/6585337/comparisonSearchR1andOurs.png Details</summary>
### Visual Description
\n
## Text Extraction: Agent-as-tool Reasoning Process
### Overview
The image presents a transcript of a reasoning process undertaken by an "Agent-as-tool" to answer the question: "Where was the mother of Ernst I, Prince of Hohenlohe-Langenburg born?". The transcript shows two columns: "Result from Search-R1" and "Result from Agent-as-tool (Ours)". Each column displays a series of "think" and "search" or "tool_calling" steps, along with associated information extracted from web searches or tool outputs. The process demonstrates a chain-of-thought approach, refining the query and utilizing intermediate results to arrive at the final answer.
### Components/Axes
The image is structured into two main columns. Each column contains a series of steps, indicated by "think", "search", "tool_calling", and "obs". The "think" steps represent the agent's reasoning, while "search" and "tool_calling" represent actions taken to gather information. "obs" represents the observed results from those actions. The document also includes a header with the question and expected answer.
### Detailed Analysis or Content Details
**Column 1: Result from Search-R1**
1. **think:** "I need to find out where the mother of Ernst I, Prince of Hohenlohe-Langenburg, was born. I'll search for it."
2. **search:** "mother of Ernst I, Prince of Hohenlohe-Langenburg"
3. **information:** A snippet from Wikipedia ([https://en.wikipedia.org/wiki/Ernst_I,_Prince_of_Hohenlohe-Langenburg](https://en.wikipedia.org/wiki/Ernst_I,_Prince_of_Hohenlohe-Langenburg)) states: "He married Princess Feodora of Leiningen, the only daughter of Emich Carl, 2nd Prince of Leiningen, and Princess Victoria of Saxe-Coburg-Saalfeld on 18xao)… (save space for 9 more results)"
4. **think:** "I found out that the mother of Ernst I, Prince of Hohenlohe-Langenburg, was Princess Feodora of Leiningen. Now I need to find out where she was born."
5. **search:** "where was Princess Feodora of Leiningen born"
6. **information:** A snippet from Wikipedia ([https://en.wikipedia.org/wiki/Princess_Feodora_of_Leiningen](https://en.wikipedia.org/wiki/Princess_Feodora_of_Leiningen)) states: "Princess Feodora of Leiningen (born 12 December 1807 in Amorbach, Bavaria, and died 13 September 1872 in Sanssouci Palace, Potsdam) was a German aristocrat and philanthropist. She was the only daughter of Emich Carl, 2nd Prince of Leiningen, and Princess Victoria of Saxe-Coburg-Saalfeld. Her siblings were Emich Charles, 3rd Prince of Leiningen, and Princess Elisabeth of Leiningen. She married Ernst I, Prince of Hohenlohe-Langenburg, and had seven children."
**Column 2: Result from Agent-as-tool (Ours)**
1. **think:** "I need to find out who the mother of Ernst I, Prince of Hohenlohe-Langenburg is first."
2. **tool_calling:** "Who is the mother of Ernst I, Prince of Hohenlohe-Langenburg?"
3. **obs:** "The mother of Ernst I, Prince of Hohenlohe-Langenburg, is Countess Amalie Henriette of Solms-Baruth."
4. **think:** "Now that I know the mother's name, I need to find out where she was born."
5. **tool_calling:** "Where was Countess Amalie Henriette of Solms-Baruth born?"
6. **obs:** "Countess Amalie Henriette of Solms-Baruth was born in Kliezków on January 30, 1768."
7. **think:** "Information provided states that Countess Amalie Henriette of Solms-Baruth was born in Kliezków. Now I need to verify the information."
8. **tool_calling:** "Where was Countess Amalie Henriette of Solms-Baruth born?"
9. **obs:** "Countess Amalie Henriette of Solms-Baruth was born in Kliezków on January 30, 1768."
**Footer:**
* **Question:** Where was the mother of Ernst I, Prince of Hohenlohe-Langenburg born?
* **Expected Answer:** Kliezków
### Key Observations
* The "Agent-as-tool" approach demonstrates a more refined and accurate process. The initial search (Search-R1) incorrectly identifies Princess Feodora of Leiningen as the mother, while the agent correctly identifies Countess Amalie Henriette of Solms-Baruth.
* The agent utilizes a "tool_calling" mechanism to query for specific information, which appears to be more effective than broad web searches.
* The agent performs verification by repeating the query, ensuring consistency of the information.
* There is a discrepancy in the initial information regarding the mother.
### Interpretation
The image illustrates the power of a structured, reasoning-based approach to information retrieval. The "Agent-as-tool" method, with its iterative querying and verification steps, outperforms a simple search-based approach. The initial incorrect result from Search-R1 highlights the importance of accurate information identification. The agent's ability to refine the query and utilize specific tools (tool_calling) leads to a more reliable answer. The repeated querying for verification demonstrates a robust methodology. The document demonstrates a complex reasoning process, and the importance of verifying information. The final answer, Kliezków, is presented as the expected answer, confirming the success of the agent's reasoning process.
</details>
Figure 3: The Agent-as-tool-Instruct could reason with less fuzzy and more structured observations, comparing with the Search-R1 + Web Search which would need to reason with the unprocessed web search results with other unrelated details. Search-R1 was misled by the unprocessed web search results to reason with the wrong answer for the second hop (Princess Feodora of Leiningen), while the Agent-as-tool-Instruct has applied the agent to preprocess the web search results and return the correct answer (Countess Amalie Henriette of Solms-Baruth) for the second hop.
A.2 The qualitative results inspection of the Agent-as-tool-Instruct + Web Search and the Agent-as-tool-Base + Web Search
<details>
<summary>extracted/6585337/comparisonBeforeAfter1.png Details</summary>

### Visual Description
## Agent-as-tool-Instruct Dialogue Transcript
### Overview
This image presents a transcript of a dialogue between a user and an "Agent-as-tool-Instruct" system, designed to answer the question: "Where did Edward Dunn (Bishop)'s father graduate from?". The transcript details the agent's thought process ("<think>") and actions ("<tool_calling>") as it attempts to find the answer, including multiple attempts and refinement of queries. The dialogue is structured as a series of turns, with "obs" representing the agent's observations or responses from external tools (likely a search engine or knowledge base).
### Components/Axes
The transcript is organized into two columns: "Result from Agent-as-tool-Base" and "Result from Agent-as-tool-Instruct". Each column displays the agent's internal reasoning and actions in a turn-based manner. The turns are numbered sequentially. Key elements within each turn include:
* **`<think>`**: The agent's internal thought process.
* **`<tool_calling>`**: The agent's attempt to use a tool (e.g., a search engine).
* **`obs`**: The agent's observation or the result from the tool.
### Detailed Analysis or Content Details
Here's a detailed transcription of the dialogue, turn by turn:
**Turn 1:**
* **Question:** Where did Edward Dunn (Bishop)'s father graduate from?
* **Expected Answer:** Corpus Christi College, Cambridge
**Turn 2 (Agent-as-tool-Base):**
* `<think>`: I need to find Edward Dunn's father's educational background.
* `<tool_calling>`: Can you provide information on Edward Dunn's father's education? Planner try to ask 2 hops simultaneously
* `obs`: I wasn't able to find specific information about Edward Dunn's father's education. However, I did find information related to Edward Dunn himself, including his education and achievements. If you need information on a different topic or a specific Edward Dunn, please let me know!
**Turn 3 (Agent-as-tool-Instruct):**
* `<think>`: I need to find information about Edward Dunn (Bishop)'s father.
* `<tool_calling>`: Can you provide information about Edward Dunn (Bishop)'s father? Learned to Ask the prerequisite question before the next hop
* `obs`: Edward Dunn, the bishop, was born into an ecclesiastical family. His father was Andrew Hunter Dunn, who at one time served as the Bishop of Quebec. For more details, you can read the full biography on Wikipedia ([https://en.wikipedia.org/wiki/Edward_Dunn_(bishop)](https://en.wikipedia.org/wiki/Edward_Dunn_(bishop))). The agent could answer this question easily.
**Turn 4 (Agent-as-tool-Base):**
* `<think>`: The observation did not provide the specific information I was looking for. I need to find a more direct way to get the information about Edward Dunn's father's education.
* `<tool_calling>`: Can you provide information on the educational background of Edward Dunn's father? Planner asked 2 hops in the meantime in another manner
* `obs`: I found some relevant information regarding Edward Dunn's family background, but specific details about his father's education background are limited. Here are some notable findings:
1. "*Edward T. Dunn*” – He is noted to have had theology and earned a master's degree in history and a PhD, but this relates to his own rather than his father.
2. Source: [https://books.google.com/books?id=UCwXAAAAIAAJ](https://books.google.com/books?id=UCwXAAAAIAAJ)
3. "*Hunter Dunn*” – There is a reference to a Hunter Dunn who was a graduate of Corpus Christi College, Cambridge, in 1888.
4. Source: [https://www.thepeerage.com/p28886.htm](https://www.thepeerage.com/p28886.htm)
5. However, it is not explicitly stated that this Hunter Dunn is the father of Edward Dunn (Bishop).
**Turn 5 (Agent-as-tool-Instruct):**
* `<think>`: From the observation, I can see that Edward Dunn's father was Andrew Hunter Dunn, who was the Bishop of Quebec. However, the observation does not specify where Andrew Hunter Dunn graduated from. I need to find this information.
* `<tool_calling>`: Can you provide information about where Andrew Hunter Dunn graduated from? Asked the next-hop question
* `obs`: Andrew Hunter Dunn graduated from **Corpus Christi College, Cambridge** where he earned his BA as the #25th Wrangler in 1868. For more detailed information, you can visit his [Wikipedia page](https://en.wikipedia.org/wiki/Andrew_Hunter_Dunn). [https://www.wikipedia.org/Andrew_Hunter_Dunn](https://en.wikipedia.org/wiki/Andrew_Hunter_Dunn)
(In reply to: Can you provide information about where Andrew Hunter Dunn graduated from?)
[https://en.wikipedia.org/wiki/Andrew_Hunter_Dunn](https://en.wikipedia.org/wiki/Andrew_Hunter_Dunn)
He was the son of Rev. John Dunn, DD, of Quebec.
### Key Observations
* The "Agent-as-tool-Instruct" approach demonstrates a more strategic and iterative query refinement process compared to the "Agent-as-tool-Base" approach.
* The "Instruct" agent explicitly states its reasoning for asking prerequisite questions ("Learned to Ask the prerequisite question before the next hop").
* The initial attempts by both agents failed to directly answer the question, highlighting the need for multi-hop reasoning.
* The final answer, "Corpus Christi College, Cambridge," was found through a combination of identifying the father's name (Andrew Hunter Dunn) and then querying his educational background.
* The "Instruct" agent successfully navigated ambiguous information (the existence of multiple "Hunter Dunns") to pinpoint the correct individual.
### Interpretation
This dialogue illustrates the power of agent-based systems with iterative reasoning capabilities. The "Instruct" agent's ability to break down the complex question into smaller, more manageable sub-questions, and to learn from previous failures, is crucial for achieving accurate results. The transcript demonstrates a successful application of the "Ask before the next hop" strategy, which helps to ensure that the agent has the necessary context before attempting to answer the final question. The process highlights the importance of not only retrieving information but also of understanding the relationships between different pieces of information to arrive at a correct and complete answer. The agent's ability to identify and resolve ambiguity (multiple individuals with similar names) is also a key factor in its success. The final answer confirms the expected answer provided at the beginning of the transcript.
</details>
Figure 4: The Agent-as-tool-Instruct + Web Search could correctly decompose the question to identify the first hop and the second hop, comparing with the Agent-as-tool-Base + Web Search which barely decompose the question and try to ask about the whole question in another manner, i.e. the Agent-as-tool-Base + Web Search was not able to reason the whole multi-hop question correctly, while the Agent-as-tool-Instruct + Web Search could decompose the question to identify the first hop of the question to be answered by the agent then proceed to the second hop.