# Agent-as-Tool: A Study on the Hierarchical Decision Making with Reinforcement Learning
**Authors**:
- Yanfei Zhang (Independent Researcher)
## Abstract
Large Language Models (LLMs) have emerged as one of the most significant technological advancements in artificial intelligence in recent years. Their ability to understand, generate, and reason with natural language has transformed how we interact with AI systems. With the development of LLM-based agents and reinforcement-learning-based reasoning models, the study of applying reinforcement learning in agent frameworks has become a new research focus. However, all previous studies face the challenge of deciding the tool calling process and the reasoning process simultaneously, and the chain of reasoning was solely relied on the unprocessed raw result with redundant information and symbols unrelated to the task from the tool, which impose a heavy burden on the model’s capability to reason. Therefore, in our research, we proposed a hierarchical framework Agent-as-tool that detach the tool calling process and the reasoning process, which enables the model to focus on the verbally reasoning process while the tool calling process is handled by another agent. Our work had achieved comparable results with only a slight reinforcement fine-tuning on 180 samples, and had achieved exceptionally well performance in Bamboogle (Brown et al., 2020) with 63.2% of exact match and 75.2% in cover exact match, exceeding Search-R1 by 4.8% in exact match and 3.2% in cover exact match.
## 1 Introduction
Large Language Models (LLMs) have achieved remarkable progress in a wide range of natural language understanding and generation tasks (Liu et al., 2025; Zhang et al., 2024). As the complexity of tasks increases, a common approach is to augment LLMs with access to external tools, such as web search engines, calculators, or code interpreters. This tool-augmented paradigm enables agents to interact with the environment and perform planning, reasoning, and execution steps beyond the model’s pretraining distribution.
Recent advancements have explored integrating reinforcement learning (RL) into these agent frameworks, aiming to improve decision-making over tool usage and multi-hop reasoning steps (Guo et al., 2025; Jin et al., 2025). However, a major limitation remains: existing RL-enhanced agents conflate the tool invocation process with the verbal reasoning process. This tight coupling leads to several challenges: (1) The agent must learn tool selection, input construction, and reasoning jointly, which increases training difficulty and noise; (2) Reasoning often proceeds over noisy, unstructured outputs returned directly from external tools, which degrades answer quality.
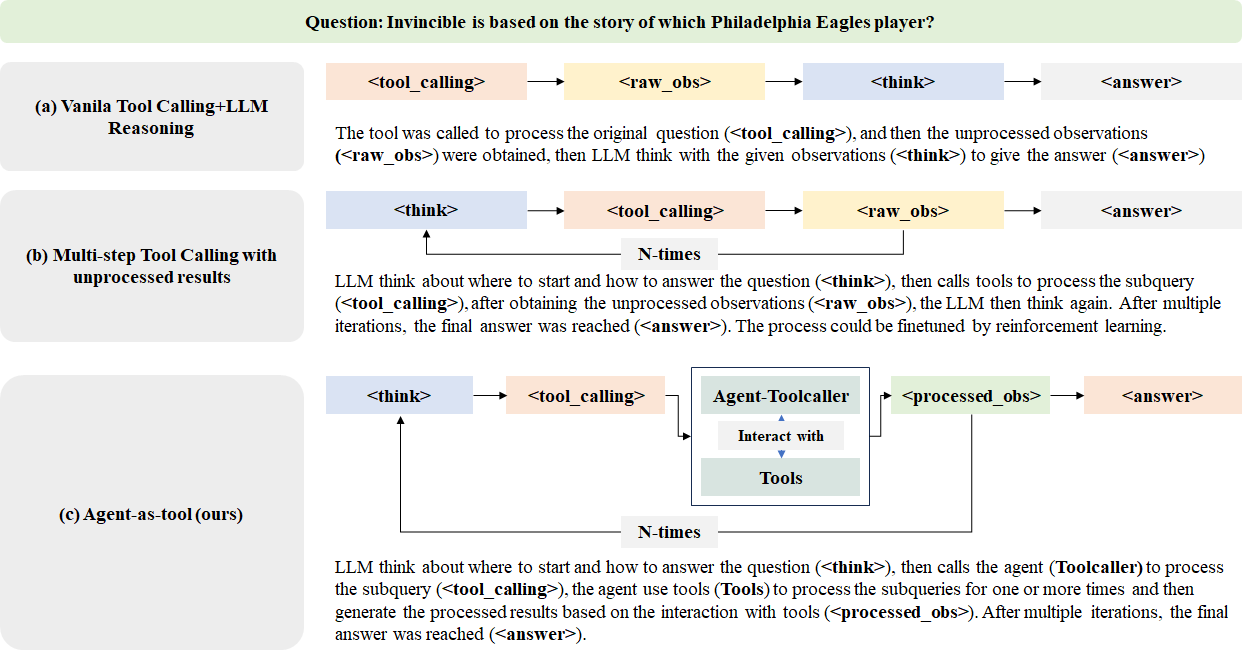
To address these challenges, we propose Agent-as-tool, a hierarchical reasoning architecture in which reasoning and tool execution are explicitly decoupled as shown in Figure 1. The framework introduces a Planner and a Toolcaller as two separate agent components. The Planner focuses on natural language reasoning and high-level decision-making, while the Toolcaller is responsible for managing the tool interface (e.g., invoking web search) and returning structured observations.
The advantages of this design are twofold: (1) It simplifies the RL optimization process by assigning each sub-agent a focused objective; (2) It improves reasoning accuracy by allowing the Planner to operate on cleaner, more structured inputs. Furthermore, we apply a lightweight reinforcement fine-tuning procedure using GRPO on just 180 samples to demonstrate the efficiency of our framework.
This paper makes the following contributions:
- We propose Agent-as-tool, a hierarchical agent framework that separates reasoning and tool usage via a Planner and a Toolcaller.
- We introduce a reinforcement learning protocol that enhances Planner behavior while masking Toolcaller outputs to preserve credit assignment integrity.
- We empirically validate our framework on multiple multi-hop QA datasets and achieve state-of-the-art performance on Bamboogle.
- We provide qualitative insights showing that hierarchical decoupling improves reasoning clarity and decomposition over existing baselines like Search-R1.
<details>
<summary>extracted/6585337/model_graph.png Details</summary>
### Visual Description
\n
## Diagram: Comparison of AI Reasoning and Tool-Calling Architectures
### Overview
The image is a technical diagram comparing three different architectural approaches for an AI system (likely a Large Language Model) to answer a question by using external tools. The diagram is structured into three horizontal sections, each detailing a distinct method. A sample question is provided at the top as a common test case for all three methods.
### Components/Axes
The diagram is organized into three main rows, each with a title on the left and a corresponding flowchart on the right.
**Top Header:**
* **Question:** "Question: Invincible is based on the story of which Philadelphia Eagles player?"
**Section (a): Vanilla Tool Calling+LLM Reasoning**
* **Title (Left Column):** "(a) Vanilla Tool Calling+LLM Reasoning"
* **Flowchart (Right Column):** A linear sequence of four colored boxes connected by right-pointing arrows.
1. `<tool_calling>` (Light Orange Box)
2. `<raw_obs>` (Light Yellow Box)
3. `<think>` (Light Blue Box)
4. `<answer>` (Light Orange Box)
* **Descriptive Text:** "The tool was called to process the original question (`<tool_calling>`), and then the unprocessed observations (`<raw_obs>`) were obtained, then LLM think with the given observations (`<think>`) to give the answer (`<answer>`)"
**Section (b): Multi-step Tool Calling with unprocessed results**
* **Title (Left Column):** "(b) Multi-step Tool Calling with unprocessed results"
* **Flowchart (Right Column):** A cyclical sequence. It starts with a `<think>` box, which points to `<tool_calling>`, which points to `<raw_obs>`. An arrow from `<raw_obs>` loops back to `<think>`, labeled "N-times". A final arrow from `<raw_obs>` points to `<answer>`.
1. `<think>` (Light Blue Box)
2. `<tool_calling>` (Light Orange Box)
3. `<raw_obs>` (Light Yellow Box)
4. `<answer>` (Light Orange Box)
* **Descriptive Text:** "LLM think about where to start and how to answer the question (`<think>`), then calls tools to process the subquery (`<tool_calling>`), after obtaining the unprocessed observations (`<raw_obs>`), the LLM then think again. After multiple iterations, the final answer was reached (`<answer>`). The process could be finetuned by reinforcement learning."
**Section (c): Agent-as-tool (ours)**
* **Title (Left Column):** "(c) Agent-as-tool (ours)"
* **Flowchart (Right Column):** A cyclical sequence with a nested component. It starts with `<think>`, pointing to `<tool_calling>`. The `<tool_calling>` box points to a larger, central container labeled "Agent-Toolcaller". Inside this container are two sub-components: "Interact with" (in a white box) and "Tools" (in a light green box), connected by a double-headed vertical arrow. The "Agent-Toolcaller" container points to `<processed_obs>`, which points to `<answer>`. An arrow from `<processed_obs>` loops back to `<think>`, labeled "N-times".
1. `<think>` (Light Blue Box)
2. `<tool_calling>` (Light Orange Box)
3. **Central Component:** "Agent-Toolcaller" (Large box containing "Interact with" and "Tools")
4. `<processed_obs>` (Light Green Box)
5. `<answer>` (Light Orange Box)
* **Descriptive Text:** "LLM think about where to start and how to answer the question (`<think>`), then calls the agent (Toolcaller) to process the subquery (`<tool_calling>`), the agent use tools (`Tools`) to process the subqueries for one or more times and then generate the processed results based on the interaction with tools (`<processed_obs>`). After multiple iterations, the final answer was reached (`<answer>`)."
### Detailed Analysis
The diagram explicitly contrasts three workflows for integrating tool use with LLM reasoning:
1. **Method (a) - Vanilla:** A simple, single-pass pipeline. The LLM calls a tool once, receives raw observations, thinks about them, and produces an answer. There is no iteration or refinement.
2. **Method (b) - Multi-step with Raw Results:** An iterative loop. The LLM thinks, calls a tool, gets raw observations, and then thinks again. This loop (`<think>` -> `<tool_calling>` -> `<raw_obs>`) can repeat "N-times". The final answer is derived from the last set of raw observations. The text notes this process is suitable for reinforcement learning fine-tuning.
3. **Method (c) - Agent-as-tool (Proposed):** An iterative loop with an intermediary agent. The LLM thinks and then calls an "Agent-Toolcaller". This agent autonomously interacts with tools one or more times to produce *processed observations* (`<processed_obs>`), which are presumably more refined than raw observations. This processed output is then used by the LLM in its next thinking cycle or to generate the final answer. The loop (`<think>` -> `<tool_calling>` -> [Agent Process] -> `<processed_obs>`) also repeats "N-times".
**Key Textual Elements & Tags:**
* `<think>`: Represents the LLM's reasoning step.
* `<tool_calling>`: Represents the action of invoking an external tool or agent.
* `<raw_obs>`: Represents unprocessed output from a tool.
* `<processed_obs>`: Represents refined output from an agent's interaction with tools (unique to method c).
* `<answer>`: The final output.
* "N-times": Indicates an iterative loop in methods (b) and (c).
### Key Observations
* **Progression of Complexity:** The methods evolve from a linear pipeline (a) to a simple iterative loop (b) to a more complex loop with an encapsulated agent (c).
* **Introduction of an Agent:** The core innovation in method (c) is the "Agent-Toolcaller" component, which acts as an intermediary between the main LLM's tool-calling command and the actual tools. This agent can perform multiple interactions internally.
* **Data Refinement:** A critical distinction is the shift from `<raw_obs>` in (a) and (b) to `<processed_obs>` in (c). This implies the agent in (c) performs synthesis, filtering, or formatting on the tool outputs before returning them to the main LLM.
* **Spatial Layout:** The titles are consistently placed in a left-aligned column. The flowcharts are centered in the right area. The "Agent-Toolcaller" box in (c) is the most visually complex element, positioned centrally within its flowchart to emphasize its role as a new subsystem.
### Interpretation
This diagram illustrates a research progression in AI system design, moving from direct tool use towards more autonomous, agent-based tool orchestration.
* **What it demonstrates:** It argues for the architectural advantage of method (c), "Agent-as-tool." By delegating the multi-step interaction with tools to a specialized sub-agent, the main LLM's reasoning loop (`<think>`) is potentially simplified. It receives higher-quality, processed information (`<processed_obs>`) instead of raw data, which could lead to more accurate and efficient final answers.
* **Relationship between elements:** The LLM remains the central "reasoning engine" in all three methods. The evolution is in how it *obtains information*. Method (c) introduces a layer of abstraction—the agent—that encapsulates the complexity of tool use, making the overall system more modular and potentially more robust.
* **Notable implications:** The label "(ours)" on method (c) indicates this is the authors' proposed approach. The diagram serves as a visual thesis: that offloading tool management to an intermediary agent is a superior paradigm for complex question-answering tasks requiring external knowledge. The sample question about the movie "Invincible" acts as a concrete example of a factual query that would benefit from such a tool-augmented reasoning process.
</details>
Figure 1: The trajectory of a single sample from a batch of questions processed in different research configurations. In our Agent-as-tool method, we employed the agent as a tool instead of calling the tool directly. The Planner is responsible for the tool calling process and the reasoning process, and the Toolcaller is responsible for the tool calling process to provide sufficient processed observations.
## 2 Literature Review
### 2.1 Agent Frameworks based on Pre-defined Reasoning Steps
There are several agent researches that are designed to perform tasks with pre-trained LLMs and with pre-defined reasoning steps, including the CAMEL (Li et al., 2023a), OpenManus (Liang et al., 2025) and MetaGPT (Hong et al., 2023). These works tend to extend the capabilities of the pre-trained LLM with additional rule-based reasoning steps to ’stimulate’ the internal reasoning capabilities of the LLM to achieve better performances.
Specifically, considering the search and information retrieval for task completion scenario, there are also considerable works, including the Search-o1 (Li et al., 2025a), OpenResearcher (Zheng et al., 2024) (majorly focusing on the scientific research scenario).
### 2.2 RL Reasoning Agents
With the development of RL training frameworks and the Deepseek-R1 (Guo et al., 2025) setting, there are also considerable works to implement R1-style training paradigms on the LLM-based agents. The searching and information retrieval tasks were the first to be considered in this scenario, including the R1-searcher (Song et al., 2025) and DeepResearcher (Zheng et al., 2025).
There are also several works that integrate other external tools under the framework to complete different tasks, including the ToRL (Li et al., 2025b) that integrate the python interpreter tool, ToolRL (Qian et al., 2025) that flexibly integrate different toolkits with different pre-defined datasets (e.g. API-Bank (Li et al., 2023b)), SWiRL (Goldie et al., 2025) that control the tool selection process with different labels (<calculator> for calculator tool, and <search_query> for web search tool).
The generic process of calling an agent in these researches can be concluded as a sequence of thinking <think>, followed by a tool calling query enclosed with <tool_query>, then the tool returns observations <obs>. With the reasoning on each step, the final answer could be reached whenever the agent think the ground truths are sufficient enough to give the final answer. It is a much simpler configuration with a ReAct-like tool calling process (Yao et al., 2023), then reinforcement learning are applied to explore whether the model could exhibit the capabilities beyond simple reasoning to reach the next hop, as shown in Figure 1 as Multi-step Tool Calling with Unprocessed Results.
## 3 Methodology
We propose the Agent-as-tool framework as a hierarchical design for multi-hop reasoning tasks. It separates the planning and tool usage responsibilities between two agent components: a high-level Planner and a subordinate Toolcaller. The Planner manages reasoning and task decomposition, while the Toolcaller executes external actions such as web search. This section outlines the design of both components and the reinforcement learning procedure employed to optimize the Planner.
### 3.1 Agent Architecture
#### 3.1.1 Planner
The Planner is a language model agent responsible for high-level reasoning and tool invocation decisions. It reasons about the current task state and emits tool usage instructions in natural language.
Reasoning: The Planner conducts internal reasoning enclosed in <think>...</think> tags, in line with DeepSeek-R1 conventions (Guo et al., 2025). It uses previous observations and the original query to plan the next subtask.
Tool Invocation: Tool calls are expressed as sub-queries wrapped in <tool_calling>...</tool_calling> tags. These queries are interpreted by the Toolcaller, and the results are returned to the Planner as <obs>...</obs> blocks for further reasoning.
#### 3.1.2 Toolcaller
The Toolcaller is a dedicated LLM-based agent designed to interface with external tools. In our implementation, it wraps a web search tool and processes queries issued by the Planner.
We implement the Toolcaller using a CAMEL-style chat agent (Li et al., 2023a), powered by GPT-4o-mini (Hurst et al., 2024). It could retrieve top- k search results multiple times and returns structured summaries to the Planner. Although our current prototype uses only web search, the architecture supports extension to tools like calculators or code interpreters, also including MCP-based tool servers.
### 3.2 Reinforcement Learning with GRPO
#### 3.2.1 Training Objective
We employ Generalized Reinforcement Policy Optimization (GRPO) (Shao et al., 2024) to fine-tune the Planner. The objective is:
$$
\begin{split}\mathcal{J}(\Theta)&=\mathbb{E}_{x\sim\mathcal{D},\{y_{i}\}_{i=1}
^{G}\sim\pi_{\text{old}}(\cdot|x)}\Bigg{[}\frac{1}{G}\sum_{i=1}^{G}\Big{[}\\
&\min\left(\frac{\pi_{\Theta}(y_{i}|x)}{\pi_{\text{old}}(y_{i}|x)}A_{i},\text{
clip}\left(\frac{\pi_{\Theta}(y_{i}|x)}{\pi_{\text{old}}(y_{i}|x)},1-
\varepsilon,1+\varepsilon\right)A_{i}\right)\\
&-\beta D_{\text{KL}}(\pi_{\Theta}||\pi_{\text{ref}})\Big{]}\Bigg{]}\end{split} \tag{1}
$$
where $x$ is sampled from dataset $\mathcal{D}$ , $y_{i}$ is a rollout, $A_{i}$ is the advantage, $\varepsilon$ is the clipping threshold, and $\beta$ regulates KL penalty.
#### 3.2.2 Observation Masking
To prevent reward leakage through Toolcaller-generated outputs, we mask the <obs> blocks during reward modeling and training. These segments are replaced with special token <fim_pad>, which is trained to embed close to zero.
#### 3.2.3 Reward Function
Our reward function balances correctness and formatting constraints:
$$
\text{Reward}=\begin{cases}\text{F1 score}&\text{if answer is correctly
formatted}\\
-2&\text{otherwise}\end{cases} \tag{2}
$$
The model receives a high reward when generating a valid and correct response, and a penalty when output is malformed.
## 4 Experiments
### 4.1 Experiment Settings
#### 4.1.1 Model and Hyperparameters
We use Qwen-2.5-7B-Instruct (Qwen et al., 2025) as our base model. The training is conducted by an customized implementation of rollout and a customized implementation of GRPO on trl (von Werra et al., 2020). At each training step, we sample a batch of training data from the training set and calculate the reward for each rollout. Then, we update the policy by maximizing the reward.
The batch size is set to 3 for each training step and each sample contains 12 rollouts for each prompt. Each rollout contains at most 10 rounds of tool calling.
#### 4.1.2 Training Settings
We conducted quite a small scale of training for the Agent-as-tool. We trained the Agent-as-tool for 60 steps with each step containing 3 training samples, and each training sample contains 12 rollouts, with total size of only 180 samples and 2160 rollouts. The training data entries were selected from the HotpotQA (Yang et al., 2018) and 2WikiMultiHopQA (Ho et al., 2020) datasets with the same ratio as the R1-searcher (Song et al., 2025).
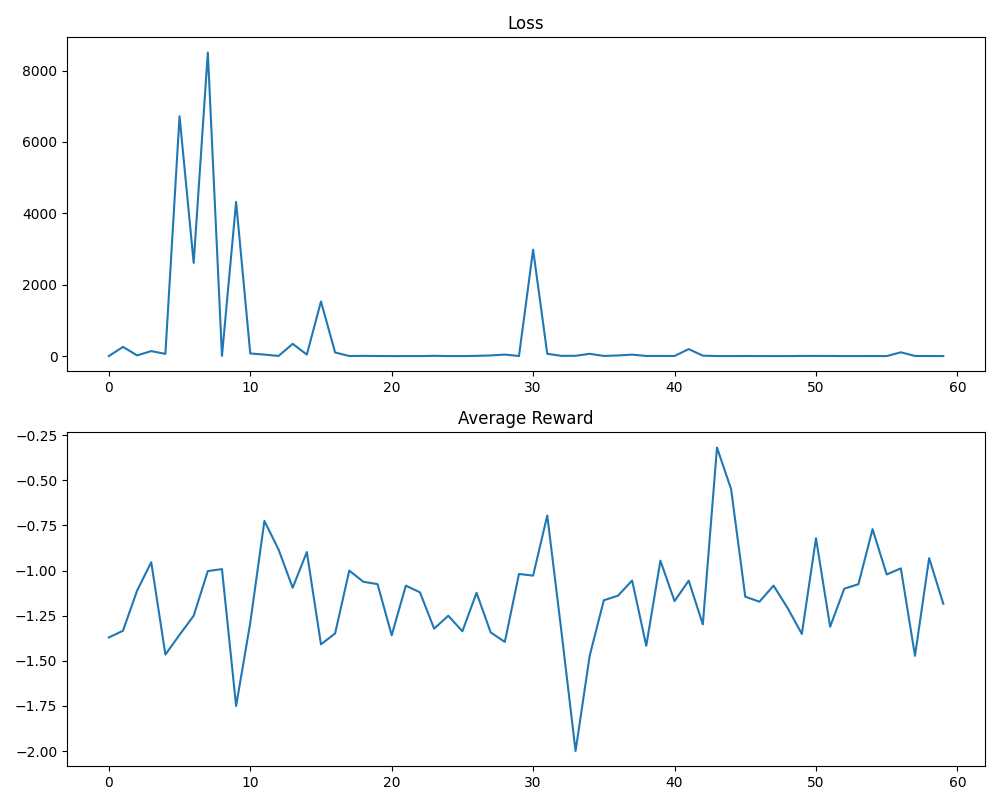
During the training process, we observed that the loss of the Agent-as-tool is not stable for the first 30 steps, which is likely due to the small training data, but after 30 steps, the loss is stable and close to 0 and the performance of the Agent-as-tool also stabilized.
<details>
<summary>extracted/6585337/training_graph.png Details</summary>
### Visual Description
## Line Charts: Training Loss and Average Reward Over Iterations
### Overview
The image displays two vertically stacked line charts sharing a common x-axis, likely representing training iterations or epochs (0 to 60). The top chart tracks a "Loss" metric, and the bottom chart tracks "Average Reward." The data suggests a machine learning or reinforcement learning training process.
### Components/Axes
**Top Chart: "Loss"**
* **Title:** "Loss" (centered above the chart).
* **Y-axis:** Numerical scale from 0 to 8000, with major tick marks at 0, 2000, 4000, 6000, and 8000.
* **X-axis:** Numerical scale from 0 to 60, with major tick marks at 0, 10, 20, 30, 40, 50, and 60.
* **Data Series:** A single blue line representing the loss value over iterations.
**Bottom Chart: "Average Reward"**
* **Title:** "Average Reward" (centered above the chart).
* **Y-axis:** Numerical scale from -2.00 to -0.25, with major tick marks at -2.00, -1.75, -1.50, -1.25, -1.00, -0.75, -0.50, and -0.25.
* **X-axis:** Identical to the top chart (0 to 60).
* **Data Series:** A single blue line representing the average reward value over iterations.
**Spatial Layout:** The "Loss" chart occupies the top half of the image. The "Average Reward" chart occupies the bottom half. There is no legend, as each chart contains only one data series.
### Detailed Analysis
**Loss Chart Trend & Data Points:**
The loss line exhibits extreme volatility in the first third of training before stabilizing at a very low value.
* **Initial Phase (x=0 to ~15):** Characterized by massive spikes.
* Starts near 0 at x=0.
* First major spike: Peaks at approximately **6500** around x=5.
* Second, highest spike: Peaks at approximately **8500** around x=7-8.
* Third spike: Peaks at approximately **4200** around x=9.
* Fourth spike: Peaks at approximately **1500** around x=15.
* **Stabilization Phase (x=~15 to 60):** After the spike at x=15, the loss drops dramatically and remains consistently low.
* A notable, isolated spike occurs around **x=30**, reaching approximately **3000**.
* For the majority of iterations from x=16 onward (excluding the spike at 30), the loss value appears to be **below 500**, often hovering near or just above 0.
**Average Reward Chart Trend & Data Points:**
The average reward line shows persistent, high-frequency oscillation throughout the entire training period, with no clear upward or downward trend.
* **Range:** The reward fluctuates primarily between **-1.75 and -0.75**.
* **Notable Extremes:**
* **Global Minimum:** A sharp dip to approximately **-2.00** occurs around **x=33**.
* **Global Maximum:** A sharp peak to approximately **-0.30** occurs around **x=43**.
* **Pattern:** The line is jagged, indicating significant variance in reward from one iteration to the next. It does not show signs of convergence to a stable value.
### Key Observations
1. **Divergent Behavior:** The two metrics show completely different behaviors. Loss converges to near-zero after an initial volatile period, while Average Reward remains highly volatile and does not improve (increase) over time.
2. **Loss Spike Anomaly:** The isolated loss spike at iteration 30 is significant, as it occurs after the metric had already stabilized, suggesting a temporary instability in the training process.
3. **Reward Volatility:** The lack of any discernible trend in the Average Reward is a critical observation. The model's performance, as measured by reward, is not improving despite the decreasing loss.
4. **Temporal Correlation:** The period of highest loss volatility (x=0-15) corresponds to a period of relatively lower-magnitude reward fluctuations. The most extreme reward values (both min and max) occur later, during the period of low loss.
### Interpretation
This pair of charts likely depicts a **reinforcement learning (RL) training run**. The "Loss" typically measures the error in the agent's policy or value function predictions, while "Average Reward" measures the actual performance in the environment.
* **What the data suggests:** The agent is successfully learning to minimize its internal prediction error (loss), as evidenced by the convergence after iteration 15. However, this improved prediction accuracy is **not translating into better task performance** (higher reward). The agent may be "overfitting" to its prediction targets or experiencing a **misalignment between its loss function and the true reward objective**.
* **Relationship between elements:** The charts reveal a potential flaw in the training setup. The loss metric is being optimized effectively, but it is a poor proxy for the ultimate goal of maximizing reward. This is a classic problem in RL known as **"reward hacking"** or a **mis-specified objective function**.
* **Notable Anomaly:** The spike in loss at x=30, which does not correspond to a dramatic change in the reward trend, further indicates that the loss signal can be decoupled from environmental performance.
* **Conclusion:** The training process is unstable from a reward perspective. While the learning algorithm is reducing its internal error, it is not consistently improving the agent's behavior. This suggests the need to re-examine the reward function, the policy gradient algorithm, or the exploration strategy to ensure that minimizing loss correlates with maximizing reward.
</details>
Figure 2: Training progress of the Agent-as-tool model showing loss convergence over training steps. The loss becomes stable after approximately 30 training steps.
The training curve illustrated in Figure 2 shows the convergence behavior of our model during the reinforcement learning process.
#### 4.1.3 Benchmark Settings
In order to evaluate the performance of the Agent-as-tool, we conducted experiments on the open-domain question-answering task. We selected multiple multi-hop reasoning tasks to evaluate the performance of the Agent-as-tool, including the HotpotQA (Yang et al., 2018), 2WikiMultiHopQA (Ho et al., 2020), MuSiQue (Trivedi et al., 2022), and bamboogle (Press et al., 2023).
#### 4.1.4 Baseline Settings
We have 1 information retrival tool: web search.
We then compare the performance of the Agent-as-tool with the following baselines:
- direct IO: This baseline employs the direct output of the Qwen-2.5-7B-Instruct (Qwen et al., 2025) as the answer without any external tool calling.
- direct IO with web search: This baseline employs the direct output of the Qwen-2.5-7B-Instruct (Qwen et al., 2025), but enables the web search to process the original question and return the top-k results as additional observations.
- CAMEL Agent: This baseline employs the CAMEL (Li et al., 2023a) chat agent driven by the GPT-4o-mini (Hurst et al., 2024).
- CAMEL Agent with web search: This baseline employs the CAMEL (Li et al., 2023a) chat agent driven by the GPT-4o-mini (Hurst et al., 2024) and the same tool setting as the Agent-as-tool with web search tool only. This baseline is used as the reference for multi-hop reasoning tasks conducted with the rule-based agent framework.
- Search-R1: We directly compare the performance of the Agent-as-tool with the Search-R1 (Jin et al., 2025) in our configurations with web search tool for a fair comparison. As Search-R1 cannot be directly integrated with the CAMEL (Li et al., 2023a) chat agent, we would directly returns the search results as the answer instead of using another Toolcaller.
We conducted experiments with Agent-as-tool with pre-finetuned and post-finetuned models.
In align with the Deepseek-R1 setting (Guo et al., 2025), we adopted the same prompt setting for all the baselines and the Agent-as-tool except Search-R1 (Jin et al., 2025) that is equipped with its orignal prompt setting, and we also modified the tool calling process to enable Search-R1 to accesss the unprocessed web search results.
#### 4.1.5 Evaluation Metrics
In this paper, we focus on the performance of the Agent-as-tool in terms of the correctness of the answer, therefore, we employed the exact match metric (EM), the cover exact match metric (CEM) to evaluate the performance of the Agent-as-tool.
### 4.2 Quantitative Experiment Results
The qualitative results are shown in LABEL:tab:all_datasets_complete. Based on the results, we can see that the Agent-as-tool outperforms most of the baselines except for the EM metric in the HotpotQA, 2WikiMultiHopQA, and MuSiQue datasets, where Search-R1 still has the best performance. However, in terms of the CEM metric, our model has a substantial improvement over all the baselines, except in HotpotQA where Search-R1 still has the best performance (64.2% vs 57.4%). And in the Bamboogle dataset (Press et al., 2023), the Agent-as-tool with web search tool integrated to the Toolcaller (CAMEL (Li et al., 2023a) agent) achieves the best performance with EM of 63.2% and CEM of 75.2%.
Table 1: Performance Comparison Across Different Datasets
| Bamboogle | Direct IO | 17.6 | 26.4 |
| --- | --- | --- | --- |
| Direct IO + Web Search | 29.6 | 42.4 | |
| CAMEL | 36.8 | 47.2 | |
| CAMEL + Web Search | 51.2 | 62.4 | |
| Search-R1 + Web Search | 58.4 | 72.0 | |
| Agent-as-tool-Base + Web Search | 60.0 | 71.2 | |
| Agent-as-tool-Instruct + Web Search | 63.2 | 75.2 | |
| HotpotQA | Direct IO | 20.0 | 27.2 |
| Direct IO + Web Search | 32.6 | 52.8 | |
| CAMEL | 23.2 | 44.2 | |
| CAMEL + Web Search | 32.4 | 59.4 | |
| Search-R1 + Web Search | 47.2 | 64.2 | |
| Agent-as-tool-Base + Web Search | 35.0 | 55.2 | |
| Agent-as-tool-Instruct + Web Search | 37.2 | 57.4 | |
| 2WikiMultiHopQA | Direct IO | 22.6 | 25.4 |
| Direct IO + Web Search | 27.2 | 40.2 | |
| CAMEL | 20.8 | 34.6 | |
| CAMEL + Web Search | 35.0 | 69.4 | |
| Search-R1 + Web Search | 52.4 | 68.0 | |
| Agent-as-tool-Base + Web Search | 42.8 | 68.0 | |
| Agent-as-tool-Instruct + Web Search | 44.6 | 70.0 | |
| MuSiQue | Direct IO | 4.8 | 9.0 |
| Direct IO + Web Search | 14.0 | 18.0 | |
| CAMEL | 9.2 | 18.8 | |
| CAMEL + Web Search | 16.0 | 29.4 | |
| Search-R1 + Web Search | 20.8 | 28.6 | |
| Agent-as-tool-Base + Web Search | 15.6 | 28.8 | |
| Agent-as-tool-Instruct + Web Search | 18.4 | 29.8 | |
We compared the performance of the Agent-as-tool before and after the reinforcement fine-tuning process. The table is shown in 2. Based on the results, we can see that the Reinforcement fine-tuning based on GRPO (Shao et al., 2024) substantially improves the performance of the Agent-as-tool in all datasets with an average improvement of 2.5% in EM and 2.3% in CEM.
Table 2: Performance improvements after reinforcement fine-tuning
| Dataset | Pre-finetuned | Post-finetuned | Improvement | | | |
| --- | --- | --- | --- | --- | --- | --- |
| EM | CEM | EM | CEM | EM | CEM | |
| (%) | (%) | (%) | (%) | (%) | (%) | |
| Bamboogle | 60.0 | 71.2 | 63.2 | 75.2 | +3.2 | +4.0 |
| HotpotQA | 35.0 | 55.2 | 37.2 | 57.4 | +2.2 | +2.2 |
| 2WikiMultiHopQA | 42.8 | 68.0 | 44.6 | 70.0 | +1.8 | +2.0 |
| MuSiQue | 15.6 | 28.8 | 18.4 | 29.8 | +2.8 | +1.0 |
| Average | 38.4 | 55.8 | 40.9 | 58.1 | +2.5 | +2.3 |
Comparing with the CAMEL baseline with web search tool integrated (CAMEL + Web Search), the Agent-as-tool pre-finetuned and post-finetuned achieved a substantial improvement in EM and CEM, stating the necessity that the Agent-as-tool that enables the model to control when and what to be called in a tool calling is a more effective framework for multi-hop reasoning tasks.
Comparing with the Search-R1 baseline (Search-R1 + Web Search), which is the current best performing research of its kind, the Agent-as-tool-Instruct has substantial improvements over the Bamboogle dataset, which improves the EM by 4.8% and CEM by 3.2%, stating the effectiveness of the Agent-as-tool in multi-hop reasoning tasks. Besides, the Agent-as-tool conducted fine-tuning with 180 samples, which indicates the efficiency of the fine-tuning process.
### 4.3 Qualitative Results Inspection and Analysis
#### 4.3.1 Comparison of the Agent-as-tool and the Search-R1
Comparing with Search-R1 baseline (Search-R1 + Web Search), the Agent-as-tool-Instruct had several advantages qualitatively:
- The Agent-as-tool-Instruct could reason with less fuzzy and more structured observations, comparing with the Search-R1 + Web Search which would need to reason with the unprocessed web search results with fuzzy and unstructured symbols or other unrelated details.
- As the Agent-as-tool-Instruct adopt a hierarchical reasoning process which segragate the reasoning process and the tool calling process, the agent could have a better linearly text-based reasoning process comparing with the Search-R1 + Web Search.
The qualitative comparison as a example is shown in Figure 3 (in Appendix). The Agent-as-tool-Instruct could reason with less fuzzy and more structured observations, comparing with the Search-R1 + Web Search which would need to reason with the unprocessed web search results with fuzzy and unstructured symbols or other unrelated details.
#### 4.3.2 Comparison of the Results before and after the Reinforcement Fine-tuning
Comparing with Agent-as-tool-Base, the Agent-as-tool-Instruct had several advantages qualitatively:
- The Agent-as-tool-Instruct identify the correct decomposition of the question to identify the first hop and the second hop to be solved by the agent, comparing with the Agent-as-tool-Base which would not be able to decompose the multi-hop question correctly so it directly feed the agent with the whole question (only a sightly change from the original manner). If the agent is not capable of reasoning the multi-hop question correctly, the Agent-as-tool-Base would not be able to answer the question correctly.
- As the Agent-as-tool-Instruct was instructed to reason with the agent powered by the pretrained model, the fine-tuned model could give a more structured and reasonable question to be answered by the agent comparing with the Agent-as-tool-Base.
The qualitative comparison as a example is shown in Figure 4 (in Appendix). The Agent-as-tool-Instruct could correctly decompose the question to identify the first hop and the second hop, comparing with the Agent-as-tool-Base which would not be able to decompose the multi-hop question correctly so it directly feed the agent with the whole question.
## 5 Conclusions and Future Work
### 5.1 Conclusions
In this paper, we majorly studied the multi-hop reasoning tasks with the Agent-as-tool framework. We found that the Agent-as-tool could achieve a substantial improvement in the performance of the multi-hop reasoning tasks, especially in the Bamboogle dataset (Press et al., 2023). We also found that the Agent-as-tool could reason with less fuzzy and more structured observations, comparing with the Search-R1 + Web Search which would need to reason with the unprocessed web search results with fuzzy and unstructured symbols or other unrelated details.
### 5.2 Limitations and Future Work
This paper only assigns the search tool to the agent (or in another word, the search agent) so the scope is limited to the open-domain multi-hop search tasks. While because only 1 model was provided, the dynamic assignment of the tool to the agent is not considered. Therefore in our future work more tools would be considered to be assigned to the agent, while we would also explore the dynamic assignment of the tool to the agent, in another word, make the Planner as a Tool Orchestrator.
## References
- Brown et al. [2020] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Goldie et al. [2025] A. Goldie, A. Mirhoseini, H. Zhou, I. Cai, and C. D. Manning. Synthetic data generation and multi-step rl for reasoning and tool use, 2025. URL https://arxiv.org/abs/2504.04736.
- Guo et al. [2025] D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
- Ho et al. [2020] X. Ho, A.-K. D. Nguyen, S. Sugawara, and A. Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. arXiv preprint arXiv:2011.01060, 2020.
- Hong et al. [2023] S. Hong, X. Zheng, J. Chen, Y. Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, et al. Metagpt: Meta programming for multi-agent collaborative framework. arXiv preprint arXiv:2308.00352, 3(4):6, 2023.
- Hurst et al. [2024] A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024.
- Jin et al. [2025] B. Jin, H. Zeng, Z. Yue, J. Yoon, S. Arik, D. Wang, H. Zamani, and J. Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning, 2025. URL https://arxiv.org/abs/2503.09516.
- Li et al. [2023a] G. Li, H. Hammoud, H. Itani, D. Khizbullin, and B. Ghanem. Camel: Communicative agents for” mind” exploration of large language model society. Advances in Neural Information Processing Systems, 36:51991–52008, 2023a.
- Li et al. [2023b] M. Li, Y. Zhao, B. Yu, F. Song, H. Li, H. Yu, Z. Li, F. Huang, and Y. Li. Api-bank: A comprehensive benchmark for tool-augmented llms, 2023b. URL https://arxiv.org/abs/2304.08244.
- Li et al. [2025a] X. Li, G. Dong, J. Jin, Y. Zhang, Y. Zhou, Y. Zhu, P. Zhang, and Z. Dou. Search-o1: Agentic search-enhanced large reasoning models, 2025a. URL https://arxiv.org/abs/2501.05366.
- Li et al. [2025b] X. Li, H. Zou, and P. Liu. Torl: Scaling tool-integrated rl. arXiv preprint arXiv:2503.23383, 2025b.
- Liang et al. [2025] X. Liang, J. Xiang, Z. Yu, J. Zhang, S. Hong, S. Fan, and X. Tang. Openmanus: An open-source framework for building general ai agents, 2025. URL https://doi.org/10.5281/zenodo.15186407.
- Liu et al. [2025] B. Liu, X. Li, J. Zhang, J. Wang, T. He, S. Hong, H. Liu, S. Zhang, K. Song, K. Zhu, et al. Advances and challenges in foundation agents: From brain-inspired intelligence to evolutionary, collaborative, and safe systems. arXiv preprint arXiv:2504.01990, 2025.
- Press et al. [2023] O. Press, M. Zhang, S. Min, L. Schmidt, N. A. Smith, and M. Lewis. Measuring and narrowing the compositionality gap in language models, 2023. URL https://arxiv.org/abs/2210.03350.
- Qian et al. [2025] C. Qian, E. C. Acikgoz, Q. He, H. Wang, X. Chen, D. Hakkani-Tür, G. Tur, and H. Ji. Toolrl: Reward is all tool learning needs. arXiv preprint arXiv:2504.13958, 2025.
- Qwen et al. [2025] Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Wan, Y. Liu, Z. Cui, Z. Zhang, and Z. Qiu. Qwen2.5 technical report, 2025. URL https://arxiv.org/abs/2412.15115.
- Shao et al. [2024] Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- Song et al. [2025] H. Song, J. Jiang, Y. Min, J. Chen, Z. Chen, W. X. Zhao, L. Fang, and J.-R. Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning. arXiv preprint arXiv:2503.05592, 2025.
- Trivedi et al. [2022] H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal. Musique: Multihop questions via single-hop question composition, 2022. URL https://arxiv.org/abs/2108.00573.
- von Werra et al. [2020] L. von Werra, Y. Belkada, L. Tunstall, E. Beeching, T. Thrush, N. Lambert, S. Huang, K. Rasul, and Q. Gallouédec. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl, 2020.
- Yang et al. [2018] Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600, 2018.
- Yao et al. [2023] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao. React: Synergizing reasoning and acting in language models, 2023. URL https://arxiv.org/abs/2210.03629.
- Zhang et al. [2024] J. Zhang, J. Xiang, Z. Yu, F. Teng, X. Chen, J. Chen, M. Zhuge, X. Cheng, S. Hong, J. Wang, et al. Aflow: Automating agentic workflow generation. arXiv preprint arXiv:2410.10762, 2024.
- Zheng et al. [2024] Y. Zheng, S. Sun, L. Qiu, D. Ru, C. Jiayang, X. Li, J. Lin, B. Wang, Y. Luo, R. Pan, et al. Openresearcher: Unleashing ai for accelerated scientific research. arXiv preprint arXiv:2408.06941, 2024.
- Zheng et al. [2025] Y. Zheng, D. Fu, X. Hu, X. Cai, L. Ye, P. Lu, and P. Liu. Deepresearcher: Scaling deep research via reinforcement learning in real-world environments. arXiv preprint arXiv:2504.03160, 2025.
## Appendix A The qualitative Results inspection
### A.1 The qualitative results inspection of the Agent-as-tool-Instruct + Web Search and the Search-R1 + Web Search
<details>
<summary>extracted/6585337/comparisonSearchR1andOurs.png Details</summary>
### Visual Description
\n
## Diagram: Comparative Analysis of Two AI Agent Workflows for Historical Fact Retrieval
### Overview
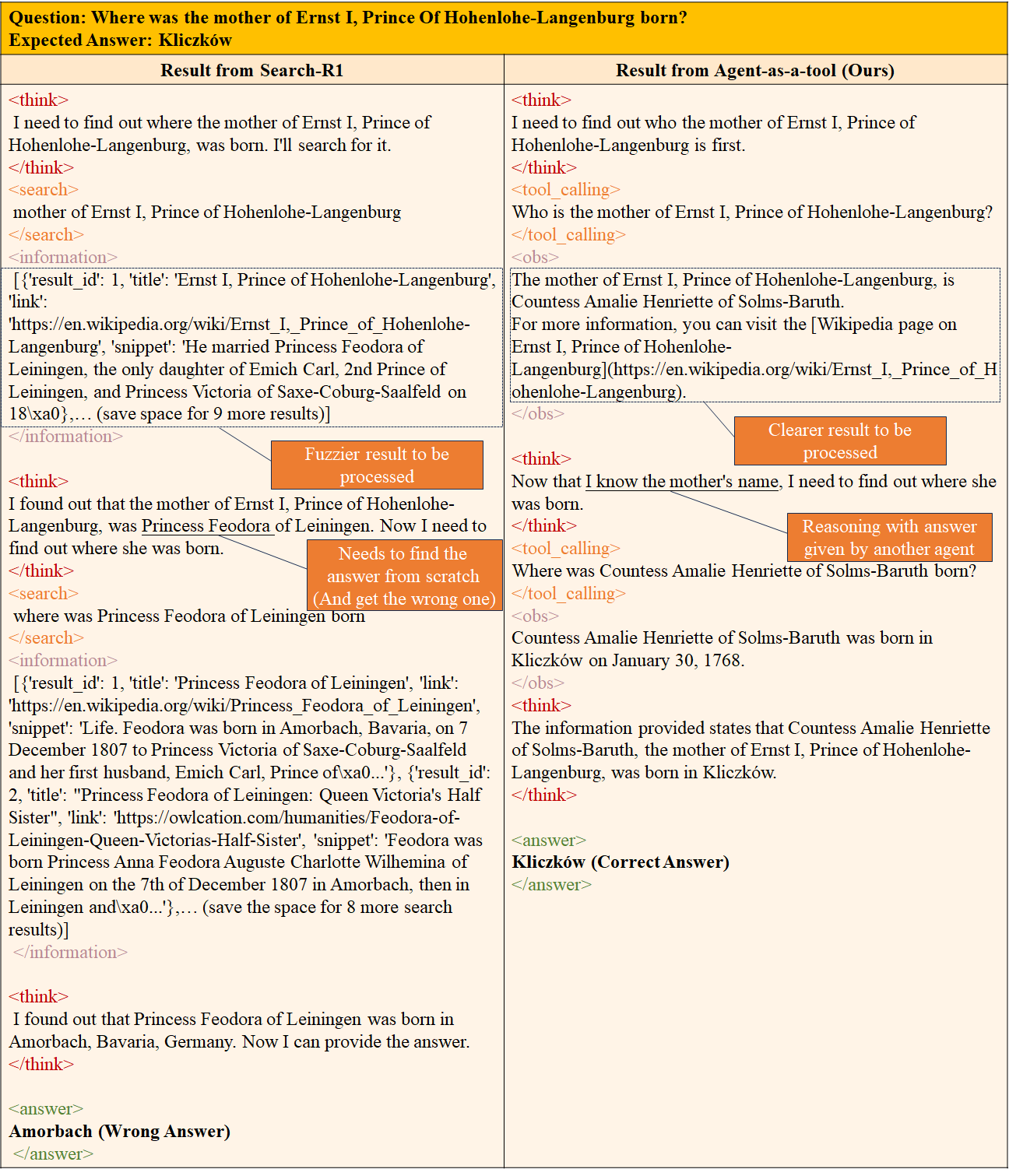
The image is a side-by-side comparison diagram illustrating two different AI agent approaches to answering the same factual question: "Where was the mother of Ernst I, Prince Of Hohenlohe-Langenburg born?" The expected correct answer is "Kliczków." The diagram contrasts a flawed process ("Search-R1") with a successful one ("Agent-as-a-tool (Ours)"), using annotated callouts to highlight critical reasoning steps and errors.
### Components/Axes
The diagram is structured as a two-column table with a header row.
* **Header (Yellow Background):**
* **Question:** "Where was the mother of Ernst I, Prince Of Hohenlohe-Langenburg born?"
* **Expected Answer:** "Kliczków"
* **Column 1 (Left):** "Result from Search-R1"
* **Column 2 (Right):** "Result from Agent-as-a-tool (Ours)"
* **Content Structure:** Each column contains a sequence of XML-like tags (`<think>`, `<search>`, `<tool_calling>`, `<information>`, `<obs>`, `<answer>`) representing the agent's internal reasoning, actions, and retrieved data.
* **Annotations (Orange Callout Boxes):** These are overlaid on the diagram to provide meta-commentary on the process. They are connected to specific steps with lines.
* **Left Column Annotations:**
1. "Fuzzier result to be processed" (pointing to the first `<information>` block).
2. "Needs to find the answer from scratch (And get the wrong one)" (pointing to the second `<think>` block).
* **Right Column Annotations:**
1. "Clearer result to be processed" (pointing to the first `<obs>` block).
2. "Reasoning with answer given by another agent" (pointing to the second `<think>` block).
### Detailed Analysis: Content Transcription and Flow
#### **Left Column: "Result from Search-R1" (Flawed Process)**
1. **Initial Thought (`<think>`):** "I need to find out where the mother of Ernst I, Prince of Hohenlohe-Langenburg, was born. I'll search for it."
2. **Action (`<search>`):** Searches for "mother of Ernst I, Prince of Hohenlohe-Langenburg".
3. **Retrieved Data (`<information>`):** Returns a snippet from a Wikipedia page about Ernst I. The snippet states: "'He married Princess Feodora of Leiningen...'" This is an indirect and potentially misleading piece of information, as it mentions his wife, not his mother.
4. **Flawed Reasoning (`<think>`):** "I found out that the mother of Ernst I, Prince of Hohenlohe-Langenburg, was Princess Feodora of Leiningen. Now I need to find out where she was born." **(Error: Misidentifies the mother based on the search snippet.)**
5. **Second Action (`<search>`):** Searches for "where was Princess Feodora of Leiningen born".
6. **Second Retrieved Data (`<information>`):** Returns snippets stating Princess Feodora was born in "Amorbach, Bavaria".
7. **Final Reasoning (`<think>`):** "I found out that Princess Feodora of Leiningen was born in Amorbach, Bavaria, Germany. Now I can provide the answer."
8. **Final Answer (`<answer>`):** "Amorbach (Wrong Answer)"
#### **Right Column: "Result from Agent-as-a-tool (Ours)" (Successful Process)**
1. **Initial Thought (`<think>`):** "I need to find out who the mother of Ernst I, Prince of Hohenlohe-Langenburg is first." **(Key Difference: Focuses on identifying the person first.)**
2. **Action (`<tool_calling>`):** Calls a tool with the query: "Who is the mother of Ernst I, Prince of Hohenlohe-Langenburg?"
3. **Observation (`<obs>`):** "The mother of Ernst I, Prince of Hohenlohe-Langenburg, is Countess Amalie Henriette of Solms-Baruth. For more information, you can visit the [Wikipedia page...](https://en.wikipedia.org/wiki/Ernst_I,_Prince_of_Hohenlohe-Langenburg)." **(Clear, direct identification.)**
4. **Second Reasoning (`<think>`):** "Now that I know the mother's name, I need to find out where she was born."
5. **Second Action (`<tool_calling>`):** Calls a tool with the specific query: "Where was Countess Amalie Henriette of Solms-Baruth born?"
6. **Second Observation (`<obs>`):** "Countess Amalie Henriette of Solms-Baruth was born in Kliczków on January 30, 1768."
7. **Final Reasoning (`<think>`):** "The information provided states that Countess Amalie Henriette of Solms-Baruth, the mother of Ernst I, Prince of Hohenlohe-Langenburg, was born in Kliczków."
8. **Final Answer (`<answer>`):** "Kliczków (Correct Answer)"
### Key Observations
1. **Critical Error Point:** The "Search-R1" agent fails at the first reasoning step by incorrectly inferring the mother's identity from a search result about the son's spouse.
2. **Process Difference:** The successful agent uses a two-stage, decomposed approach: first identify the subject (the mother), then query for the specific attribute (her birthplace). The flawed agent attempts to find the final answer in one step.
3. **Data Quality:** The "Search-R1" agent processes "fuzzier" raw search snippets containing tangential information. The "Agent-as-a-tool" receives "clearer," pre-processed answers from a dedicated tool.
4. **Annotation Purpose:** The orange callouts explicitly label the methodological strengths ("Clearer result," "Reasoning with answer given by another agent") and weaknesses ("Fuzzier result," "Needs to find the answer from scratch") of each approach.
### Interpretation
This diagram serves as a technical case study in AI agent design for factual retrieval. It argues for the superiority of a modular, tool-based architecture over a monolithic search-and-infer approach.
* **The Core Argument:** The "Agent-as-a-tool" model succeeds because it separates concerns. It uses a specialized tool (likely a knowledge graph or structured database) to answer the discrete sub-question "Who is X?" before asking "Where was X born?" This prevents the propagation of initial identification errors.
* **The Failure Mode:** The "Search-R1" model demonstrates a common pitfall in retrieval-augmented generation (RAG): over-reliance on the first plausible snippet from an unstructured web search, leading to a confident but incorrect intermediate conclusion ("Princess Feodora... was the mother"). This error then cascades through the rest of the process.
* **Broader Implication:** The image suggests that for complex or precise factual queries, agents benefit from interacting with structured knowledge sources via defined tools, rather than solely parsing free-form text from general web searches. The successful agent's workflow is more robust, interpretable, and less prone to hallucination or misinterpretation of context.
</details>
Figure 3: The Agent-as-tool-Instruct could reason with less fuzzy and more structured observations, comparing with the Search-R1 + Web Search which would need to reason with the unprocessed web search results with other unrelated details. Search-R1 was misled by the unprocessed web search results to reason with the wrong answer for the second hop (Princess Feodora of Leiningen), while the Agent-as-tool-Instruct has applied the agent to preprocess the web search results and return the correct answer (Countess Amalie Henriette of Solms-Baruth) for the second hop.
### A.2 The qualitative results inspection of the Agent-as-tool-Instruct + Web Search and the Agent-as-tool-Base + Web Search
<details>
<summary>extracted/6585337/comparisonBeforeAfter1.png Details</summary>

### Visual Description
## [Diagram/Comparison]: Comparison of Two AI Agent Approaches to a Multi-Hop Question
### Overview
The image is a side-by-side comparison of the reasoning processes and outputs of two different AI agent systems ("Agent-as-tool-Base" and "Agent-as-tool-Instruct") when answering the same factual question. The comparison is presented in a structured, annotated format to highlight the differences in their problem-solving strategies and final accuracy.
### Components/Axes
The image is organized into three main sections:
1. **Header (Top Blue Bar):** Contains the core question and the ground-truth answer.
2. **Left Column:** Titled "Result from Agent-as-tool-Base". Shows the step-by-step trace of this agent's reasoning, tool use, and final answer.
3. **Right Column:** Titled "Result from Agent-as-tool-Instruct". Shows the step-by-step trace of this agent's reasoning, tool use, and final answer.
**Annotations:** Throughout both columns, orange rectangular boxes with white text provide meta-commentary on the agent's behavior at specific steps. These are connected to the relevant text with thin lines.
### Detailed Analysis
#### **Header Section**
* **Question:** "Where did Edward Dunn (Bishop)'s father graduate from?"
* **Expected Answer:** "Corpus Christi College, Cambridge"
#### **Left Column: Agent-as-tool-Base**
This column shows a process that ultimately fails to find the correct answer.
1. **Initial `<think>`:** The agent states its goal: "I need to find Edward Dunn's father's educational background."
2. **First `<tool_calling>`:** The agent asks: "Can you provide information on Edward Dunn's father's education?"
* **Annotation (Orange Box, positioned to the right):** "Planner try to ask 2 hops simultaneously"
3. **First `<obs>` (Observation):** The tool response states it couldn't find specific information about the father's education but found information about Edward Dunn himself. It offers to help with a different topic.
* **Annotation (Orange Box, positioned below the observation):** "The agent was unable to answer"
4. **Second `<think>`:** The agent acknowledges the observation didn't provide the needed information and decides to find a "more direct way."
5. **Second `<tool_calling>`:** The agent asks: "Can you provide information on the educational background of Edward Dunn's father?"
* **Annotation (Orange Box, positioned to the right):** "Planner asked 2 hops in the meantime in another manner"
6. **Second `<obs>`:** A lengthy response. It lists findings:
* 1. Information about **Edward T. Dunn** (the bishop himself), noting his studies.
* 2. Information about **Bishop Edward Dunn**, stating: "His father, Andrew Hunter Dunn, was an education graduate from Marlborough and Pembroke College, Cambridge." This is sourced from a Wikipedia link.
* 3. Notes that other sources discuss different individuals.
* **Annotation (Orange Box, positioned below this observation):** "The agent cannot get exact information"
7. **Third `<think>`:** The agent incorrectly concludes from the observation: "Edward Dunn's father, Andrew Hunter Dunn, graduated from Marlborough and Pembroke College, Cambridge."
8. **Final `<answer>`:** "Marlborough and Pembroke College, Cambridge (Wrong Answer)"
#### **Right Column: Agent-as-tool-Instruct**
This column shows a successful, stepwise process.
1. **Initial `<think>`:** The agent states its goal: "I need to find information about Edward Dunn (Bishop)'s father."
2. **First `<tool_calling>`:** The agent asks: "Can you provide information about Edward Dunn (Bishop)'s father?"
* **Annotation (Orange Box, positioned to the right):** "Learned to Ask the prerequisite question before the next hop"
3. **First `<obs>`:** The tool response identifies the father: "His father was Andrew Hunter Dunn, who at one time served as the Bishop of Quebec." It provides a Wikipedia link.
* **Annotation (Orange Box, positioned below the observation):** "The agent could answer this question easily"
4. **Second `<think>`:** The agent processes the observation, noting it now knows the father's name (Andrew Hunter Dunn) but not his graduation location. It states the need to find this next piece of information.
5. **Second `<tool_calling>`:** The agent asks the specific follow-up: "Can you provide information about where Andrew Hunter Dunn graduated from?"
* **Annotation (Orange Box, positioned to the right):** "Asked the next-hop question"
6. **Second `<obs>`:** The tool response provides the precise answer: "Andrew Hunter Dunn graduated from **Corpus Christi College, Cambridge**, where he earned his BA as the 29th Wrangler in 1863." It provides a Wikipedia link.
* **Annotation (Orange Box, positioned below the observation):** "The agent was able to answer the question easily"
7. **Third `<think>`:** The agent confirms it now has the correct information.
8. **Final `<answer>`:** "Corpus Christi College, Cambridge (Correct Answer)"
### Key Observations
1. **Strategic Difference:** The core difference is in the initial query strategy. The "Base" agent attempts to solve the multi-hop question ("father's education") in a single, broad query. The "Instruct" agent breaks it down, first identifying the father (prerequisite hop) and then querying for his education (target hop).
2. **Information Quality:** The "Base" agent's second observation contained the correct answer ("Marlborough and Pembroke College, Cambridge") but also extraneous, potentially confusing information about other individuals. The agent failed to parse it correctly.
3. **Annotation Role:** The orange annotations explicitly diagnose the "Base" agent's failure mode ("try to ask 2 hops simultaneously") and the "Instruct" agent's success strategy ("Learned to Ask the prerequisite question").
4. **Outcome:** The "Agent-as-tool-Base" produces a wrong answer, while the "Agent-as-tool-Instruct" produces the correct answer that matches the expected answer in the header.
### Interpretation
This diagram serves as a technical case study demonstrating the importance of **sequential reasoning** and **question decomposition** in AI agents designed for multi-hop question answering.
* **What it demonstrates:** It visually argues that an agent trained or instructed to break down complex queries into a series of simpler, prerequisite sub-questions ("Instruct") is more robust and accurate than an agent that attempts to resolve the entire query in one step ("Base"). The "Base" agent's approach is prone to failure because it either gets no answer or an answer mixed with irrelevant data, leading to incorrect synthesis.
* **Underlying Principle:** The success of the "Instruct" agent aligns with the Peircean investigative concept of **abductive reasoning**—forming the best explanation by sequentially gathering necessary facts. It first establishes the identity of the subject (the father) before inquiring about a property of that subject (his education).
* **Practical Implication:** For developers building AI systems that use tools (like search or databases) to answer complex questions, this comparison highlights that the agent's **planning and orchestration strategy** is as critical as the quality of the underlying tools or data. The "Instruct" agent's trace exemplifies an effective, logical workflow.
</details>
Figure 4: The Agent-as-tool-Instruct + Web Search could correctly decompose the question to identify the first hop and the second hop, comparing with the Agent-as-tool-Base + Web Search which barely decompose the question and try to ask about the whole question in another manner, i.e. the Agent-as-tool-Base + Web Search was not able to reason the whole multi-hop question correctly, while the Agent-as-tool-Instruct + Web Search could decompose the question to identify the first hop of the question to be answered by the agent then proceed to the second hop.