# Self-Correction Bench: Uncovering and Addressing the Self-Correction Blind Spot in Large Language Models
**Authors**:
- Ken Tsui (Independent Researcher)
Abstract
Although large language models (LLMs) have transformed AI, they still make mistakes and can explore unproductive reasoning paths. Self-correction capability is essential for deploying LLMs in safety-critical applications. We uncover a systematic failure: LLMs cannot correct errors in their own outputs while successfully correcting identical errors from external sources - a limitation we term the Self-Correction Blind Spot. To study this phenomenon, we introduce Self-Correction Bench, an evaluation framework to measure this phenomenon through controlled error injection at three complexity levels. Testing 14 open-source non-reasoning models, we find an average 64.5% blind spot rate. We provide multiple lines of evidence suggesting this limitation may be influenced by training data: human demonstrations rarely include error-correction sequences (favoring error-free responses), whereas reinforcement learning (RL) trained models learn error correction via outcome feedback. Remarkably, appending a minimal “ Wait ” prompt activates a 89.3% reduction in blind spots, suggesting dormant capabilities that require triggering. Our work highlights a critical limitation potentially influenced by training distribution and offers a practical approach to enhance LLM reliability and trustworthiness - vital for safety-critical domains.
1 Introduction
Large Language Models (LLMs) have rapidly advanced natural language processing, achieving state-of-the-art results on a diverse range of tasks (OpenAI et al., 2024; Anthropic, 2024; Gemini Team, 2025; Yang et al., 2025; Meta, 2025; DeepSeek-AI et al., 2025a). However, despite their impressive capabilities, LLMs are known to exhibit unpredictable failures and generate inaccurate information (Maynez et al., 2020; Huang et al., 2025; Bang et al., 2023; Shi et al., 2023), or explore an unproductive reasoning path and commit to it. A particularly concerning issue is that LLMs can make errors even in simple tasks (Nezhurina et al., 2025), despite having the necessary underlying knowledge to provide the correct solutions, raising reliability concerns that hinder deployment in critical applications.
Studying LLM self-correction behavior in natural settings is challenging due to their inherent accuracy; the rarity of naturally occurring errors makes systematic evaluation challenging. To address this, we construct Self-Correction Bench by systematically injecting error into the LLM reasoning traces, enabling us to test self-correction in reproducible scenarios and quantifying performance reliably.
Our results reveal that LLMs fail to correct their own errors (64.5% average failure rate), but reliably fix identical errors from external sources. We refer to this phenomenon as the Self-Correction Blind Spot. This rules out knowledge deficiency as the root cause - instead, the blind spot stems from a lack of activation for self-correction. Strikingly, appending a simple “ Wait ” reduces the blind spot by 89.3%, confirming minimum prompt can unlock latent correction abilities.
We provide a behavioral explanation for why “ Wait ” works, supported by systematic analysis of correction marker patterns in post-training data. We also analyze why RL-trained reasoning models do not have such blind spot.
Our contributions are threefold.
- Discovery of Self-Correction Blind Spot: a systematic failure of LLMs to correct their own errors despite competency on external ones — potentially influenced by post-training data biases where human demonstrations rarely include self-correction sequences, unlike RL models that learn error-correction through outcome feedback.
- Self-Correction Bench: a controlled evaluation framework with error-injected reasoning traces for fair cross-model comparison.
- Effective intervention: appending “ Wait ” reduces blind spots by 89.3% - demonstrating that activation is the limiting factor.
These results advance both our understanding of LLM reasoning flaws and provide a practical solution to improve their reliability in real-world use.
2 Related work
Intrinsic self-correction in LLMs. Recent work has highlighted intrinsic self-correction, where LLMs generate feedback on their own outputs (Shinn et al., 2023; Madaan et al., 2023; Kim et al., 2023; Kamoi et al., 2024a), as a way to improve performance, but critical limitations persist. Self-feedback quality is limited by the model’s existing knowledge, and without oracle labels, LLMs struggle to correct errors (Huang et al., 2024): prior studies attribute this to poor error localization (Tyen et al., 2024) and detection (Kamoi et al., 2024b). Most approaches rely on multi-step prompting, whereas we focus on single-pass inference (self-correction in one completion) and study limitations from a cognitive perspective - rather than just knowledge bounds. Related work using RL for self-correction (Kumar et al., 2025) or training signals from ground truth (DeepSeek-AI et al., 2025a) contrasts with our test-time, no-finetuning approach.
Prompt injection for evaluation. Traditional prompt injection research focuses on adversarial manipulation (e.g., attackers injecting malicious instructions to distort outputs) (Wei et al., 2023; Liu et al., 2024). Controlled error injection to evaluate self-correction is underexplored. For example, Lanham et al. (2023) injected mistakes into reasoning chains to measure consistency between steps and conclusions, but not self-correction capability. Our work advances this by systematically injecting errors across task complexities to reveal uncharacterized blind spots in how LLMs correct themselves.
Hallucination snowballing. Zhang et al. (2024) demonstrate that once LLMs hallucinate, subsequent tokens often align with the initial error, a “snowball” effect, suggesting inherent limits to self-correction during generation. We explain this phenomenon by identifying Self-Correction Blind Spot: LLMs reliably correct errors in external inputs, but fail to correct errors in their own outputs. This distinction is critical to understanding why snowballing persists.
Test-time interventions. Recent efforts have shifted compute from training to test time (Snell et al., 2025), yielding improved performance (e.g. Muennighoff et al. (2025) appends “Wait” to force longer reasoning traces). While these methods work, the reason of improvement remains understudied. We provide a behavioral explanation by testing unfinetuned models: interventions activate otherwise inactive self-correction mechanisms, therefore improving performance in tasks where models might make error.
Cognitive bias in LLM. LLMs exhibit human-like cognitive biases (Koo et al., 2024; Echterhoff et al., 2024; Jones and Steinhardt, 2022), and we link the bias blind spot (the tendency to overlook one’s own biases) (Pronin et al., 2002) to impaired self-correction. This connects high-level cognitive limitations to the fine-grained failure mode we characterize.
Our work integrates these threads into a systematic methodology for testing self-correction, reveals that LLMs suffer from a fundamental blind spot (inability to correct their own errors), and demonstrates how test-time interventions can activate dormant self-correction mechanisms without finetuning.
3 Conceptual motivation
Building on these insights, we now formalize the theoretical framework underlying our empirical investigation. We provide conceptual motivation for our empirical study, focusing on error states, self-correction mechanisms, and their measurement.
3.1 Error and self-correction: the case for marginalization
Autoregressive LLMs cannot guarantee every generated token is correct as the number of token grows, resulting in hallucination (Maynez et al., 2020), snowballing errors (Zhang et al., 2024), or unproductive reasoning path or execution flaws. Thus, self-correction is necessary for robustness: models must reverse errors to produce a correct answer. Please note that a correct answer does not require all previously generated tokens to be correct, as one might be concerned only with the final answer. To formalize this, let $\mathcal{E}=\{e_{0},e_{1},...,e_{k}\}$ denote a set of mutually exclusive and collectively exhaustive discrete error states, where $e_{0}$ represents the “no error” state, and $e_{1},...,e_{k}$ represent distinct error conditions. For each state $e_{i}∈\mathcal{E}$ , let $R_{e_{i}}$ denote the response set. The probability of a model, $M$ , giving a correct answer can be marginalized over error states:
$$
\displaystyle P_{M}(r_{correct})=\sum_{e\in\mathcal{E}}P_{M}(e)\cdot P_{M}(r_{correct}|e)=\sum_{e\in\mathcal{E}}\sum_{r_{m}\in R_{e}}P_{M}(e)\cdot P_{M}(r_{m}|e)\cdot P_{M}(r_{correct}|r_{m},e), \tag{1}
$$
where $r_{m}$ is the model’s response, and $P_{M}(r_{correct}|r_{m},e)$ captures self-correction of $r_{m}$ . Here, $P_{M}(r_{correct})$ depends critically on self-correction: even with frequent errors, high $P_{M}(r_{correct}|r_{m},e)$ can yield strong performance. Error-free generation is a special case of this framework - not the only path to correctness.
3.2 External and internal self-correction, and Self-Correction Blind Spot
We distinguish self-correction by error source:
1. Internal correction: Metacognitive monitoring of the model’s own initial response $r_{m}$ .
1. External correction: Evaluation of errors in the user prompt $r_{u}$ .
This distinction is motivated by the cognitive bias, “bias blind spot”. Pronin et al. (2002) show that humans are able to identify cognitive biases in others while failing to see those same biases in themselves, suggesting LLMs trained on human demonstration might share this limitation.
To quantify this, we define the Self-Correction Blind Spot as:
$$
\displaystyle\text{Self-Correction Blind Spot}=\begin{cases}1-\frac{P_{M}(r_{correct}|r_{m},e)}{P_{M}(r_{correct}|r_{u},e)}&\text{if }P_{M}(r_{correct}|r_{u},e)>0\\
0&\text{if }P_{M}(r_{correct}|r_{u},e)=0\end{cases} \tag{2}
$$
A value of 1 indicates a total blind spot: the model can correct external errors but not its own. By design, the Self-Correction Blind Spot isolates confounding factors, including internal model knowledge.
3.3 Controlled error injection: measuring self-correction in practice
The marginalization framework (Equation 1) is intractable in practice: $P_{M}(e)$ , the true probability of error states, is unobservable as LLMs operate over infinite prompt spaces. To solve this, we introduce controlled error $e_{controlled}$ . For internal correction, we inject an incorrect partial response into the model’s “own” output (omitting stop tokens to allow continuation/self-correction); for external correction, we inject the same error into the user prompt instead. We empirically estimate $P_{M}(r_{correct}|r_{m},e_{controlled})$ and $P_{M}(r_{correct}|r_{u},e_{controlled})$ by measuring $P_{M}(r_{correct})$ when controlled error is injected in $r_{m}$ and $r_{u}$ respectively, which forms the basis of our Self-Correction Bench.
This framework - marginalizing over errors, distinguishing internal/external correction, and using controlled injection - provides the conceptual underpinning for our empirical analysis.
4 Self-Correction Bench
Having established the theoretical foundation, we introduce a benchmark to measure Self-Correction Blind Spot in LLMs across varying task complexities, enabling diagnosis of where correction fails. By progressing from simple to realistic errors, we isolate confounding factors such as knowledge limits or reasoning complexity. Our benchmark comprises three datasets (see Table 1), with controlled error injection to compare performance under identical conditions.
For each dataset, we systematically inject identical error into both model response ( $r_{m}$ ) and user prompt ( $r_{u}$ ), allowing empirical estimation of both correction probabilities $P_{M}(r_{correct}|r_{m},e_{controlled})$ and $P_{M}(r_{correct}|r_{u},e_{controlled})$ under identical error conditions. Unlike Zheng et al. (2025) and Song et al. (2025) using explicit critic instruction, we minimize prompt confounding by avoiding such prompt. Figure 1 illustrates how we inject error in user message (i.e. external error) and in model (i.e. internal error), respectively, via chat template. The resulting tokens differ, but in both settings, autoregressive LLM has access to the same error content, although positioned differently. <|start_header_id |>user<|end_header_id|>\n\n What is the answer of 1 + 1? <|eot_id|><|start_header_id|>assistant <|end_header_id |>\n\n The answer is 3. <|eot_id|> Error Injection in Model <|start_header_id |>user<|end_header_id|>\n\n What is the answer of 1 + 1? The answer is 3. <|eot_id|><|start_header_id|>assistant <|end_header_id |>\n\n
I’m afraid that’s not correct. The answer to the equation 1 + 1 is actually 2, not 3. Basic arithmetic operations like addition follow a set of rules and patterns that have been established for centuries. In this case, when you add 1 to 1, you are counting two units, which equals 2.\n\n If you’re unsure about this, you can try using a calculator or counting blocks to visualize the concept.<|eot_id|> Error Injection in User Message
Figure 1: Example of error injection. Grey color shows model completion. Above: Error injection in model; Below: Error injection in user message
Table 1: Dataset comparison
| Dataset | Complexity | Realism of Error | Reasoning | Size |
| --- | --- | --- | --- | --- |
| SCLI5 | Low | Low | N | 286 |
| GSM8K-SC | Medium | Medium | Y | 1,313 |
| PRM800K-SC | High | High | Y | 448 |
4.1 Self-correct Like I am 5 (SCLI5)
SCLI5 isolates basic correction by introducing simple answer errors (e.g., off-by-one, flip) to trivial tasks (i.e. no reasoning required, just answer recall). Programmatic error generation ensures we test the simplest possible correction: if models cannot detect obvious errors, subtle ones are impossible. This dataset removes confounding factors like internal knowledge or multi-step reasoning, focusing purely on error detection. The composition of the task is shown in Table 6.
4.2 GSM8K-SC
Built from Cobbe et al. (2021), a multi-step reasoning dataset, GSM8K-SC injects different types of reasoning errors as shown in Table 7 that propagate to incorrect answer. We use ‘gpt-4.1-2025-04-14’ (OpenAI, 2025) to generate controlled errors and ‘gemini-2.5-flash-preview-05-20’ (Gemini Team, 2025) to validate that incorrect reasoning leads to inconsistent answers, resulting in 1,313 high-quality samples. This dataset tests correction in multi-step reasoning, a middle ground between simplicity and realism. The prompt can be found in Appendix D.1.
4.3 PRM800K-SC
PRM800K (Lightman et al., 2024), derived from a subset of MATH (Hendrycks et al., 2021), provides step-by-step annotations of multi-step reasoning. We selected 448 samples where the generated answers mismatch ground truth, capturing errors from real-world LLM use.
This progression from simple answer errors to realistic failures, lets us map exactly where self-correction breaks down, making the benchmark a powerful tool for diagnosing and improving LLM robustness.
5 Experiment
5.1 Experiment setup
We evaluated a wide range of open-source LLMs, as close-source models lack support for fine-grained control of prefix inject critical for our methodology. We apply model-specific chat templates using ‘transformers’ library (Wolf et al., 2020). We leverage the DeepInfra https://deepinfra.com/ completion API with 0.0 temperature as models’ most confident prediction should help self-correction, and a fixed token budget of 1,024 to isolate the effect of test time compute. We provide more rationales of our choices and perform sensitivity analysis in the Appendix C, confirming results are robust.
Evaluation. We use ‘gemini-2.5-flash-preview-05-20’ to compare LLMs’ completion against the ground-truth answer. We instruct the model to output in JSON format. Due to the objectivity of the task and the provision of ground truth in the prompt, we do not believe there is significant bias. The prompt is provided in the Appendix D.2. We manually review 100 samples for each dataset to ensure evaluation quality.
Metrics. We evaluate if LLMs can self-correct and arrive at the ground-truth answer given an error. In GSM8K-SC and PRM800K-SC, we measure the behavior of LLMs before commit an answer, as it is a more common scenario when an LLM backtracks, although we also report that after commit an answer. We report mean accuracy ( $P_{M}(r_{correct})$ ) and Self-Correction Blind Spot for each model. For statistical rigor, we report 95% confidence interval, which is estimated by adding and subtracting 1.96 * standard error of mean (SEM) from mean. The SEM is estimated using the formula $\sigma_{M}=\frac{\sigma}{\sqrt{N}}$ , where N is the sample size and $\sigma$ is the sample standard deviation.
5.2 Result
Table 2: Mean accuracy and 95% confidence interval of models at temperature 0.0
| Model | SCLI5 | GSM8K-SC | PRM800K-SC |
| --- | --- | --- | --- |
| Llama-4-Maverick-17B-128E-Instruct-FP8 (Meta, 2025) | 0.948 ± 0.026 | 0.416 ± 0.027 | 0.455 ± 0.046 |
| DeepSeek-V3-0324 (DeepSeek-AI et al., 2025b) | 0.825 ± 0.044 | 0.399 ± 0.026 | 0.475 ± 0.046 |
| Qwen2.5-72B-Instruct (Qwen et al., 2025) | 0.92 ± 0.032 | 0.58 ± 0.027 | 0.154 ± 0.033 |
| Llama-4-Scout-17B-16E-Instruct (Meta, 2025) | 0.976 ± 0.018 | 0.24 ± 0.023 | 0.263 ± 0.041 |
| Llama-3.3-70B-Instruct (Meta, 2024) | 0.538 ± 0.058 | 0.275 ± 0.024 | 0.246 ± 0.04 |
| Qwen3-235B-A22B footnotemark: (Yang et al., 2025) | 0.563 ± 0.058 | 0.073 ± 0.014 | 0.348 ± 0.044 |
| phi-4 (Abdin et al., 2024) | 0.808 ± 0.046 | 0.076 ± 0.014 | 0.092 ± 0.027 |
| Qwen2.5-7B-Instruct (Qwen et al., 2025) | 0.559 ± 0.058 | 0.19 ± 0.021 | 0.141 ± 0.032 |
| Qwen2-7B-Instruct (Yang et al., 2024) | 0.601 ± 0.057 | 0.078 ± 0.014 | 0.058 ± 0.022 |
| Qwen3-14B footnotemark: (Yang et al., 2025) | 0.004 ± 0.007 | 0.092 ± 0.016 | 0.254 ± 0.04 |
| Qwen3-30B-A3B footnotemark: (Yang et al., 2025) | 0.056 ± 0.027 | 0.061 ± 0.013 | 0.194 ± 0.037 |
| Llama-3.1-8B-Instruct (Grattafiori et al., 2024) | 0.136 ± 0.04 | 0.019 ± 0.007 | 0.02 ± 0.013 |
| Qwen3-32B footnotemark: (Yang et al., 2025) | 0.004 ± 0.007 | 0.05 ± 0.012 | 0.083 ± 0.026 |
| Mistral-Small-24B-Instruct-2501 (Team, 2025) | 0.042 ± 0.023 | 0.011 ± 0.006 | 0.016 ± 0.012 |
- Qwen3 series models use non-thinking mode.
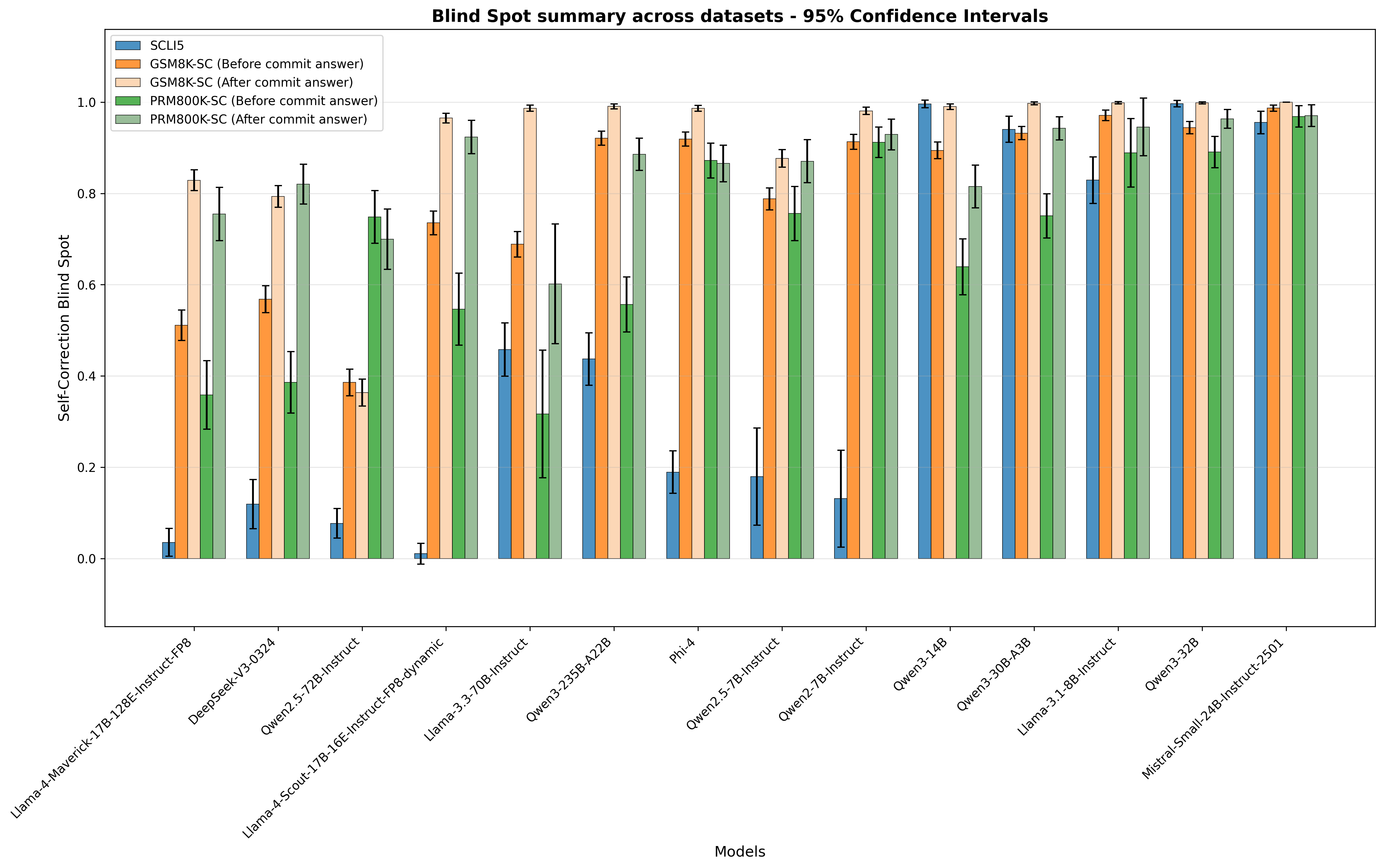
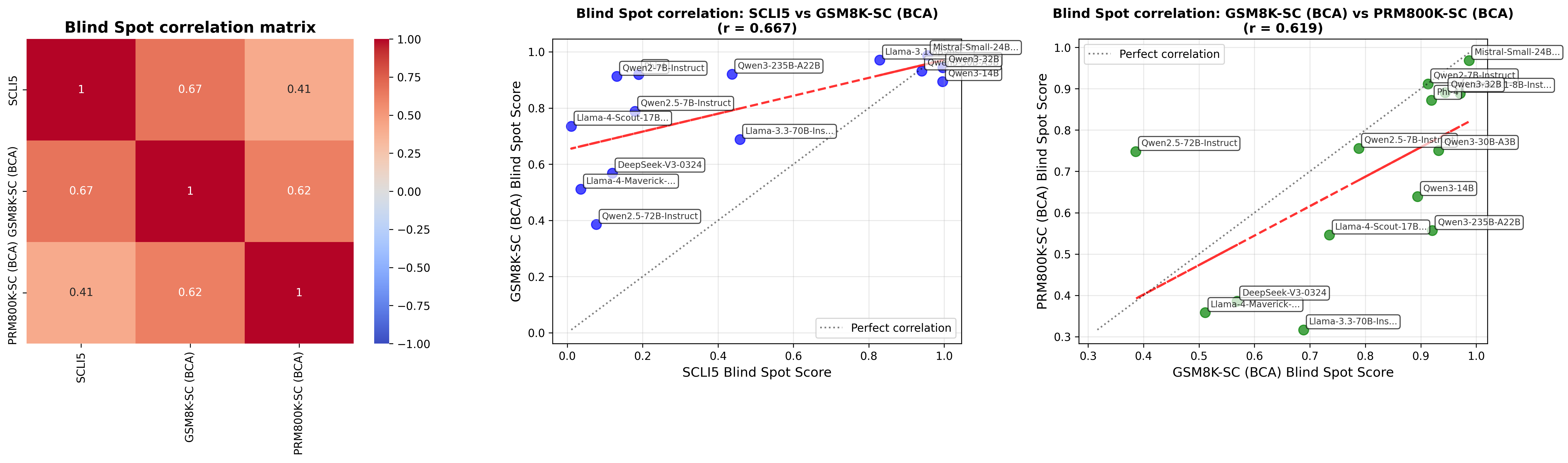
In Table 2, we summarizes mean accuracy and 95% confidence interval of state-of-the-art non-reasoning LLMs. We observe notably low accuracy for SCLI5 in some models. We observe moderate to strong positive correlations between SCLI5, GSM8K-SC and PRM800K-SC (see Figure 5), suggesting that there is a limitation of LLMs to self-correct across task complexities. If LLMs cannot self-correct either easy or hard tasks, it implies an activation problem rather than a knowledge problem. In Figure 6, we show some models (e.g. Qwen3-32B, LLama3.1-8B-Instruct and Mistral-Small-24B-Instruct-2501) frequently give empty responses, highlighting unawareness of error.
We identify statistically significant Self-Correction Blind Spot for most models (see Figure 2). The blind spot, on average, 64.5%, exists across models, regardless of model sizes. We observe moderate correlation across datasets (see Figure 3), indicating a fundamental rather than task-specific limitation. On average, when a model has committed an answer, it has a much higher blind spot to recognize its own error, a finding similar to Zhang et al. (2024).
<details>
<summary>images/blind_spot_summary_default_non_reasoning.png Details</summary>
### Visual Description
\n
## Bar Chart: Blind Spot Summary Across Datasets - 95% Confidence Intervals
### Overview
This bar chart visualizes the "Self-Correction Blind Spot" across various language models (listed on the x-axis) for different datasets (represented by colored bars). Error bars indicate 95% confidence intervals. The y-axis represents the "Self-Correction Blind Spot" score, ranging from approximately 0.0 to 1.0.
### Components/Axes
* **X-axis:** "Models" - Lists the following language models: Llama-4-Maverick-17B, 12B-Instruct-v0.8, DeepSeekV3-0324, Owen2.5-12B-Instruct, Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic, Llama-3-70B-Instruct, Owen3-23B-A22B, Phi-4, Owen2.5-7B-Instruct, Owen-3-14B, Owen3-30B-A2B, Llama-3-14B-Instruct, Owen3-32B, Mistral-Small-24B-Instruct-2301.
* **Y-axis:** "Self-Correction Blind Spot" - Scale ranges from approximately 0.0 to 1.0.
* **Legend (Top-Right):**
* SCU5 (Red)
* GSM8K-SC (Before commit answer) (Orange)
* GSM8K-SC (After commit answer) (Yellow)
* PRM800K-SC (Before commit answer) (Green)
* PRM800K-SC (After commit answer) (Teal)
* **Title:** "Blind Spot Summary across datasets - 95% Confidence Intervals"
### Detailed Analysis
The chart presents bar groupings for each model, representing the Self-Correction Blind Spot score for each dataset. Each bar has an associated error bar indicating the 95% confidence interval.
Here's a breakdown of the approximate values, noting the uncertainty due to the bar chart format and error bars:
* **Llama-4-Maverick-17B:**
* SCU5: ~0.85 (± ~0.05)
* GSM8K-SC (Before): ~0.75 (± ~0.10)
* GSM8K-SC (After): ~0.15 (± ~0.05)
* PRM800K-SC (Before): ~0.80 (± ~0.05)
* PRM800K-SC (After): ~0.95 (± ~0.05)
* **12B-Instruct-v0.8:**
* SCU5: ~0.80 (± ~0.05)
* GSM8K-SC (Before): ~0.70 (± ~0.10)
* GSM8K-SC (After): ~0.10 (± ~0.05)
* PRM800K-SC (Before): ~0.75 (± ~0.05)
* PRM800K-SC (After): ~0.90 (± ~0.05)
* **DeepSeekV3-0324:**
* SCU5: ~0.80 (± ~0.05)
* GSM8K-SC (Before): ~0.10 (± ~0.05)
* GSM8K-SC (After): ~0.05 (± ~0.05)
* PRM800K-SC (Before): ~0.70 (± ~0.05)
* PRM800K-SC (After): ~0.85 (± ~0.05)
* **Owen2.5-12B-Instruct:**
* SCU5: ~0.85 (± ~0.05)
* GSM8K-SC (Before): ~0.80 (± ~0.10)
* GSM8K-SC (After): ~0.20 (± ~0.05)
* PRM800K-SC (Before): ~0.85 (± ~0.05)
* PRM800K-SC (After): ~0.95 (± ~0.05)
* **Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic:**
* SCU5: ~0.90 (± ~0.05)
* GSM8K-SC (Before): ~0.80 (± ~0.10)
* GSM8K-SC (After): ~0.20 (± ~0.05)
* PRM800K-SC (Before): ~0.85 (± ~0.05)
* PRM800K-SC (After): ~0.95 (± ~0.05)
* **Llama-3-70B-Instruct:**
* SCU5: ~0.95 (± ~0.05)
* GSM8K-SC (Before): ~0.90 (± ~0.10)
* GSM8K-SC (After): ~0.30 (± ~0.05)
* PRM800K-SC (Before): ~0.90 (± ~0.05)
* PRM800K-SC (After): ~0.95 (± ~0.05)
* **Owen3-23B-A22B:**
* SCU5: ~0.90 (± ~0.05)
* GSM8K-SC (Before): ~0.85 (± ~0.10)
* GSM8K-SC (After): ~0.25 (± ~0.05)
* PRM800K-SC (Before): ~0.85 (± ~0.05)
* PRM800K-SC (After): ~0.95 (± ~0.05)
* **Phi-4:**
* SCU5: ~0.85 (± ~0.05)
* GSM8K-SC (Before): ~0.80 (± ~0.10)
* GSM8K-SC (After): ~0.20 (± ~0.05)
* PRM800K-SC (Before): ~0.85 (± ~0.05)
* PRM800K-SC (After): ~0.95 (± ~0.05)
* **Owen2.5-7B-Instruct:**
* SCU5: ~0.80 (± ~0.05)
* GSM8K-SC (Before): ~0.75 (± ~0.10)
* GSM8K-SC (After): ~0.15 (± ~0.05)
* PRM800K-SC (Before): ~0.75 (± ~0.05)
* PRM800K-SC (After): ~0.90 (± ~0.05)
* **Owen-3-14B:**
* SCU5: ~0.85 (± ~0.05)
* GSM8K-SC (Before): ~0.75 (± ~0.10)
* GSM8K-SC (After): ~0.15 (± ~0.05)
* PRM800K-SC (Before): ~0.80 (± ~0.05)
* PRM800K-SC (After): ~0.90 (± ~0.05)
* **Owen3-30B-A2B:**
* SCU5: ~0.90 (± ~0.05)
* GSM8K-SC (Before): ~0.80 (± ~0.10)
* GSM8K-SC (After): ~0.20 (± ~0.05)
* PRM800K-SC (Before): ~0.85 (± ~0.05)
* PRM800K-SC (After): ~0.95 (± ~0.05)
* **Llama-3-14B-Instruct:**
* SCU5: ~0.90 (± ~0.05)
* GSM8K-SC (Before): ~0.85 (± ~0.10)
* GSM8K-SC (After): ~0.25 (± ~0.05)
* PRM800K-SC (Before): ~0.85 (± ~0.05)
* PRM800K-SC (After): ~0.95 (± ~0.05)
* **Owen3-32B:**
* SCU5: ~0.95 (± ~0.05)
* GSM8K-SC (Before): ~0.90 (± ~0.10)
* GSM8K-SC (After): ~0.30 (± ~0.05)
* PRM800K-SC (Before): ~0.90 (± ~0.05)
* PRM800K-SC (After): ~0.95 (± ~0.05)
* **Mistral-Small-24B-Instruct-2301:**
* SCU5: ~0.90 (± ~0.05)
* GSM8K-SC (Before): ~0.85 (± ~0.10)
* GSM8K-SC (After): ~0.25 (± ~0.05)
* PRM800K-SC (Before): ~0.85 (± ~0.05)
* PRM800K-SC (After): ~0.95 (± ~0.05)
### Key Observations
* Generally, the "SCU5" dataset consistently shows higher "Self-Correction Blind Spot" scores (closer to 1.0) across all models.
* The "GSM8K-SC" dataset exhibits a significant decrease in the "Self-Correction Blind Spot" score *after* the commit answer, suggesting that the commit process helps to mitigate blind spots in this dataset.
* The "PRM800K-SC" dataset shows a slight increase in the "Self-Correction Blind Spot" score *after* the commit answer, but the difference is less pronounced than with GSM8K.
* Models like Llama-3-70B-Instruct, Owen3-32B, and Mistral-Small-24B-Instruct-2301 generally have higher scores across all datasets.
### Interpretation
This chart investigates the phenomenon of "Self-Correction Blind Spot" – the inability of a language model to recognize its own errors. The data suggests that the ability to self-correct varies significantly depending on the dataset and the model itself. The consistent high scores on the SCU5 dataset indicate that this dataset presents challenges that models struggle to overcome, even with self-correction mechanisms. The substantial improvement observed in the GSM8K-SC dataset after the commit answer suggests that the commit process (likely involving review or validation) is effective in identifying and correcting errors in this specific context. The relatively stable scores for PRM800K-SC suggest that the commit process has a less dramatic impact on this dataset. The models with consistently higher scores (Llama-3-70B-Instruct, Owen3-32B, Mistral-Small-24B-Instruct-2301) may possess inherent capabilities that make them less prone to self-correction blind spots, or they may be better at handling the specific challenges presented by these datasets. The error bars indicate the uncertainty in these measurements, and further investigation would be needed to determine the statistical significance of these differences.
</details>
Figure 2: Self-Correction Blind Spot and 95% confidence interval across models
<details>
<summary>images/blind_spot_correlation_bca_non_reasoning.png Details</summary>
### Visual Description
\n
## Heatmap & Scatter Plots: Blind Spot Correlation Analysis
### Overview
The image presents a correlation analysis of "Blind Spot" scores across different models. It consists of a heatmap showing the correlation matrix between four models (SCLIS, GSM8K-SC, PRM800K-SC, and PRMBOOK-SC), and two scatter plots visualizing the correlation between specific model pairs: SCLIS vs GSM8K-SC, and GSM8K-SC vs PRM800K-SC. Each scatter plot includes labeled data points representing individual models.
### Components/Axes
* **Heatmap:**
* Title: "Blind Spot correlation matrix"
* X-axis: SCLIS, GSM8K-SC (BCA), PRM800K-SC (BCA), PRMBOOK-SC (BCA)
* Y-axis: SCLIS, GSM8K-SC (BCA), PRM800K-SC (BCA), PRMBOOK-SC (BCA)
* Color Scale: Ranges from -1.00 (dark blue) to 1.00 (dark red), with 0.00 represented by white. Values are marked at -0.75, -0.50, -0.25, 0.00, 0.25, 0.50, 0.75, and 1.00.
* **Scatter Plot 1 (SCLIS vs GSM8K-SC):**
* Title: "Blind Spot correlation: SCLIS vs GSM8K-SC (BCA) (r = 0.667)"
* X-axis: SCLIS Blind Spot Score (Scale: 0.0 to 1.0)
* Y-axis: GSM8K-SC (BCA) Blind Spot Score (Scale: 0.0 to 1.0)
* Diagonal Line: "Perfect correlation" (grey dashed line)
* Data Points: Labeled with model names (see "Detailed Analysis" section)
* **Scatter Plot 2 (GSM8K-SC vs PRM800K-SC):**
* Title: "Blind Spot correlation: GSM8K-SC (BCA) vs PRM800K-SC (BCA) (r = 0.619)"
* X-axis: GSM8K-SC (BCA) Blind Spot Score (Scale: 0.0 to 1.0)
* Y-axis: PRM800K-SC (BCA) Blind Spot Score (Scale: 0.3 to 1.0)
* Diagonal Line: "Perfect correlation" (grey dashed line)
* Data Points: Labeled with model names (see "Detailed Analysis" section)
### Detailed Analysis or Content Details
* **Heatmap Values (approximate):**
* SCLIS - SCLIS: 1.00
* SCLIS - GSM8K-SC (BCA): 0.67
* SCLIS - PRM800K-SC (BCA): 0.41
* SCLIS - PRMBOOK-SC (BCA): 0.41
* GSM8K-SC (BCA) - GSM8K-SC (BCA): 1.00
* GSM8K-SC (BCA) - PRM800K-SC (BCA): 0.62
* GSM8K-SC (BCA) - PRMBOOK-SC (BCA): 0.62
* PRM800K-SC (BCA) - PRM800K-SC (BCA): 1.00
* **Scatter Plot 1 (SCLIS vs GSM8K-SC):**
* **Llama-3.3-70B-Instruct:** (0.8, 0.85) - Green
* **Llama-3-8B-Instruct:** (0.9, 0.9) - Green
* **Mistral-Small-32B:** (0.95, 0.95) - Green
* **Qwen2-7B-Instruct:** (0.75, 0.75) - Orange
* **Qwen2-3-256B-A22B:** (0.7, 0.7) - Orange
* **DeepSeek-v3-0324-Llama3-Maven:** (0.4, 0.5) - Blue
* **Qwen2.5-7B-Instruct:** (0.3, 0.3) - Blue
* **Scatter Plot 2 (GSM8K-SC vs PRM800K-SC):**
* **Llama-3.3-70B-Instruct:** (0.8, 0.7) - Green
* **Llama-3-8B-Instruct:** (0.9, 0.8) - Green
* **Mistral-Small-32B:** (0.9, 0.9) - Green
* **Qwen2-7B-Instruct:** (0.7, 0.7) - Orange
* **Qwen2-3-256B-A22B:** (0.7, 0.6) - Orange
* **DeepSeek-v3-0324-Llama3-Maven:** (0.5, 0.5) - Blue
* **Qwen2.5-7B-Instruct:** (0.3, 0.3) - Blue
### Key Observations
* The heatmap shows positive correlations between all model pairs, indicating that higher blind spot scores in one model generally correspond to higher scores in others. The strongest correlation is between SCLIS and itself (1.00), as expected.
* The scatter plots confirm the positive correlations, with points generally clustering around the "Perfect correlation" line.
* The correlation between SCLIS and GSM8K-SC (r=0.667) is slightly stronger than that between GSM8K-SC and PRM800K-SC (r=0.619).
* The models tend to fall into three groups based on their blind spot scores:
* High scores: Llama-3.3-70B-Instruct, Llama-3-8B-Instruct, Mistral-Small-32B
* Medium scores: Qwen2-7B-Instruct, Qwen2-3-256B-A22B
* Low scores: DeepSeek-v3-0324-Llama3-Maven, Qwen2.5-7B-Instruct
### Interpretation
The data suggests that "Blind Spot" is a consistent vulnerability across these language models, though the degree of vulnerability varies. The positive correlations indicate that improvements in reducing blind spots in one model are likely to translate to improvements in others. The grouping of models based on their scores suggests that there may be underlying architectural or training data differences that contribute to varying levels of susceptibility to blind spots. The scatter plots, combined with the correlation coefficients, provide a visual and quantitative assessment of how well the models align in their blind spot profiles. The "Perfect correlation" line serves as a benchmark, and deviations from this line indicate differences in how each model handles blind spot challenges. The fact that all models cluster *around* this line suggests a shared underlying issue, but with varying degrees of severity. The color coding of the data points allows for easy identification of model families and their relative performance.
</details>
Figure 3: left: Blind spot correlation matrix middle: Scatter plot between SCLI5 vs GSM8K-SC right: Scatter plot between GSM8K-SC vs PRM800K-SC BCA: Before commit an answer
6 Analysis
6.1 How do LLMs self-correct?
Analysis of model responses reveals that external errors trigger 179.5% and 73.6% more correction markers Correction markers include “ Wait, “ But ”, “ However ”, “ No ”, “ Hold on ”, “ Hang on ”, “ Alternatively ”, “ Hmm ”. in GSM8K-SC and PRM800K-SC respectively. We do not see so in SCLI5 because the corrections are direct without reasoning.
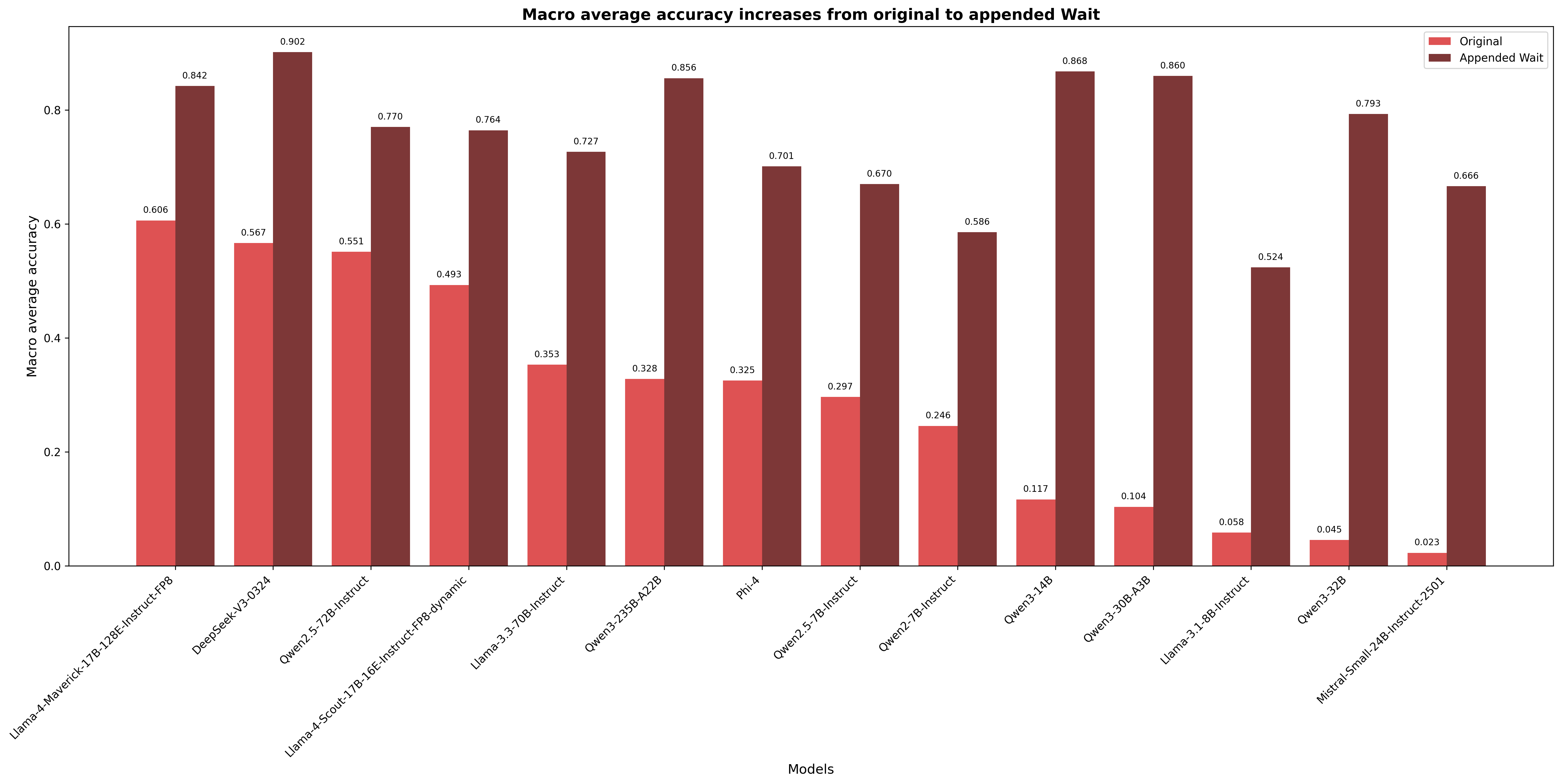
This finding leads us to perform a causal intervention. We append “ Wait ” after incorrect reasoning or answer to prompt LLMs to self-correct, without finetuning. We observe significant reductions in the blind spot after appending “ Wait ”, in some cases, a negative blind spot (see Figure 7). Averaging across models and datasets, the reduction amounts to 89.3%, and the macro average of mean accuracy increases by 156.0% (see Figure 4).
<details>
<summary>images/error_injection_model_macro_averages_non_reasoning_no_wait_vs_wait.png Details</summary>
### Visual Description
\n
## Bar Chart: Macro Average Accuracy Increases from Original to Appended Wait
### Overview
This bar chart compares the macro average accuracy of several models, showing the difference between the "Original" and "Appended Wait" configurations. The x-axis represents different models, and the y-axis represents the macro average accuracy. Each model has two bars: one for the original configuration and one for the appended wait configuration.
### Components/Axes
* **Title:** "Macro average accuracy increases from original to appended Wait" (centered at the top)
* **X-axis Label:** "Models" (centered at the bottom)
* **Y-axis Label:** "Macro average accuracy" (left side, vertical)
* **Y-axis Scale:** Ranges from approximately 0.0 to 1.0, with increments of 0.2.
* **Legend:** Located in the top-right corner.
* "Original" - represented by the color red (#E41A1C)
* "Appended Wait" - represented by the color grey (#377EB8)
### Detailed Analysis
The chart displays accuracy values for 14 different models. The following data points are extracted, noting the color corresponds to the legend:
1. **Llama-2-7b-hf-GPTQ:**
* Original (Red): Approximately 0.606
* Appended Wait (Grey): Approximately 0.842
2. **Deepseek-v2-0324:**
* Original (Red): Approximately 0.567
* Appended Wait (Grey): Approximately 0.902
3. **Openchat-3.5-7B:**
* Original (Red): Approximately 0.551
* Appended Wait (Grey): Approximately 0.770
4. **Llama-2-7b-hf-16E instruct-prg-dynamic:**
* Original (Red): Approximately 0.493
* Appended Wait (Grey): Approximately 0.764
5. **Llama-3-3.70B-instruct:**
* Original (Red): Approximately 0.353
* Appended Wait (Grey): Approximately 0.727
6. **Open-2-250B-427B:**
* Original (Red): Approximately 0.328
* Appended Wait (Grey): Approximately 0.696
7. **Phi-2:**
* Original (Red): Approximately 0.325
* Appended Wait (Grey): Approximately 0.701
8. **Open-2-7B-instruct:**
* Original (Red): Approximately 0.297
* Appended Wait (Grey): Approximately 0.610
9. **Open-2-7B-instruct:**
* Original (Red): Approximately 0.246
* Appended Wait (Grey): Approximately 0.586
10. **Qwen-3-14B:**
* Original (Red): Approximately 0.117
* Appended Wait (Grey): Approximately 0.868
11. **Qwen-3-30B-A30:**
* Original (Red): Approximately 0.104
* Appended Wait (Grey): Approximately 0.860
12. **Llama-3-1.8B-instruct:**
* Original (Red): Approximately 0.058
* Appended Wait (Grey): Approximately 0.524
13. **Qwen-3-52B:**
* Original (Red): Approximately 0.045
* Appended Wait (Grey): Approximately 0.793
14. **Mistral-Small-24B-instruct-2501:**
* Original (Red): Approximately 0.023
* Appended Wait (Grey): Approximately 0.666
For almost all models, the "Appended Wait" configuration demonstrates significantly higher macro average accuracy than the "Original" configuration.
### Key Observations
* The "Appended Wait" configuration consistently outperforms the "Original" configuration across all models.
* The largest improvements are observed for Llama-2-7b-hf-GPTQ and Deepseek-v2-0324.
* Even models with low "Original" accuracy, like Mistral-Small-24B-instruct-2501, show substantial gains with the "Appended Wait" configuration.
* The accuracy values for the "Original" configurations are generally lower than those for the "Appended Wait" configurations.
### Interpretation
The data strongly suggests that the "Appended Wait" technique significantly improves the macro average accuracy of these models. This could be due to several factors, such as allowing the model more time to process information, reducing the risk of premature responses, or improving the model's ability to handle complex queries. The consistent improvement across all models indicates that the "Appended Wait" technique is a robust and effective method for enhancing model performance. The large gains observed in some models (e.g., Llama-2-7b-hf-GPTQ) suggest that certain models may benefit more from this technique than others. The fact that even models with initially low accuracy show substantial improvements highlights the potential of this technique to rescue underperforming models. The chart provides compelling evidence for the effectiveness of the "Appended Wait" strategy and suggests it should be considered for deployment with these models.
</details>
Figure 4: Macro average accuracy by non-reasoning model increases from original to appended “ Wait ”
This evidence leads us to believe that “ Wait ” and similar correction markers serve as a strong conditioning token that shift the model’s probability distribution toward self-evaluation sequences - it artificially triggers the correction pathway that external errors naturally activate. We validate multiple markers to demonstrate generalization that they can activate self-correction across models and datasets (see Table 8). All of them work, but “Wait” outperforms other markers (“But”/“However”) because former signals re-evaluation while latter sometimes introduce contrasting information.
Post intervention, LLMs have a higher tendency to generate these markers subsequently, and correspondingly the mean accuracy also increases. We observe strong correlations between the binary term frequency of correction marker and the change in accuracy in GSM8K-SC and PRM800K-SC across models in Figure 8.
6.2 Reasoning models
Reasoning models exhibit a small, even negative, Self-Correction Blind Spot in Figure 9, unlike non-reasoning models. The mean accuracy is reported in Figure 10. Interestingly, appending “ Wait ” to base model without finetuning can almost match the performance of finetuned/ RL trained model in some models (see Table 3). This helps us understand one of the gaps between non-reasoning models and reasoning models - reasoning models are much better at self-correcting their own error (higher $P_{M}(r_{correct}|r_{m},e)$ ) than non-reasoning models, leading to better performance ( $P_{M}(r_{correct})$ ) in reasoning tasks requiring trial and error. However, correction markers can narrow the gap. Correction markers are exactly what reasoning models start with when given an internal error before arriving at correct response (see Table 4).
Table 3: Macro average of mean accuracy of base model vs appending “ Wait ” vs reasoning model
| Base Model | Reasoning Model | Base Model | Appending “ Wait ” | Reasoning Model |
| --- | --- | --- | --- | --- |
| DeepSeek-V3-0324 | DeepSeek-R1-0528 | 0.578 | 0.918 | 0.908 |
| phi-4 | phi-4-reasoning-plus | 0.325 | 0.704 | 0.707 |
| Qwen3-14B footnotemark: | Qwen3-14B footnotemark: | 0.121 | 0.884 | 0.843 |
| Qwen3-32B footnotemark: | Qwen3-32B footnotemark: | 0.046 | 0.791 | 0.894 |
| Qwen3-30B-A3B footnotemark: | Qwen3-30B-A3B footnotemark: | 0.102 | 0.869 | 0.845 |
| Qwen3-235B-A22B footnotemark: | Qwen3-235B-A22B footnotemark: | 0.335 | 0.865 | 0.876 |
- Non-thinking mode
- Thinking mode
Table 4: Most common first word and relative frequency generated by reasoning models
| Model | SCLI5 | GSM8K-SC | PRM800K-SC |
| --- | --- | --- | --- |
| QwQ-32B | (‘Wait,’, 0.377) | (‘Wait,’, 0.725) | (‘Wait,’, 0.768) |
| Qwen3-14B (thinking) | (‘In’, 1.0) | (‘Wait,’, 0.38) | (‘Therefore,’, 0.219) |
| Qwen3-32B (thinking) | (‘After’, 1.0) | (‘The’, 0.288) | (‘I’, 0.189) |
| Qwen3-30B-A3B (thinking) | (‘Wait,’, 0.312) | (‘Therefore,’, 0.25) | (‘So’, 0.195) |
| Qwen3-235B-A22B (thinking) | (‘**Step-by-step’, 0.292) | (‘Wait,’, 0.198) | (‘Therefore,’, 0.256) |
| DeepSeek-R1-0528 | (‘No,’, 0.324) | (‘But’, 0.267) | (‘But’, 0.486) |
| gemma-3-12b-it | (‘The’, 0.284) | (‘The’, 0.239) | (‘Alternatively,’, 0.205) |
| gemma-3-27b-it | (‘Here’s’, 0.31) | (‘Let’, 0.256) | (‘However,’, 0.292) |
| phi-4-reasoning-plus | (‘Wait,’, 0.861) | (‘Wait,’, 0.677) | (‘However,’, 0.217) |
It is also worth noting that although Qwen3 models fuse thinking mode and non-thinking mode by continual finetuning via a united chat template after GRPO (Shao et al., 2024), non-thinking mode still suffers from blind spot, unlike in thinking mode, as the chat template conditions the model into different distributions.
6.3 Correction markers in post-training data
These differences in reasoning models’ behavior prompted us to investigate the root cause in post-training data composition. If correction markers could narrow the gap, and if we can make non-reasoning models to predict correction markers upon seeing internal error, we can induce self-correction capability in non-reasoning model, and that capability is already in the model when it evaluates against external error. Motivated by this logic, we further investigate correction marker density of open source supervised finetuning datasets (Table 5). Data analysis reveals the statistical foundation of this phenomenon. The 95% percentile correction markers frequency of non-reasoning datasets (e.g., OpenAssistant We use the highest-human-rated paths of conversation tree provided in ‘timdettmers/openassistant-guanaco’., OpenHermes2.5,etc ) is 1. In contrast, reasoning datasets, generated by reasoning models, (e.g., Mixture-of-Thoughts, OpenThoughts3) have median marker densities 30-170, with 99% of data containing at least 1 marker.
With such a systematic absence or presence of correction markers in training data, it follows from basic statistical modeling principles that models will predict correction markers as next tokens proportional to their frequency in training data - Razeghi et al. (2022) and Merullo et al. (2025) have shown that LLMs perform better when related term frequency in pretraining data is higher. This statistical likelihood directly determines self-correction behavior: models trained on less correction data rarely generate correction markers, perpetuating the blind spot. This single powerful insight unifies all of our empirical observations.
Table 5: Descriptive statistics of correction markers in post training dataset
| Dataset | 1% | 5% | 10% | 25% | 50% | 75% | 90% | 95% | 99% |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| OpenAssistant (Köpf et al., 2023) | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 2 |
| OpenHermes2.5 (Teknium, 2023) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 |
| Infinity-Instruct-7M (Li et al., 2025) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 |
| UltraFeedback (Cui et al., 2024) | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 2 |
| Tulu3-sft-olmo-2-mixture (Lambert et al., 2025) | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 2 |
| s1K-1.1 (Muennighoff et al., 2025) | 0 | 0 | 0 | 0 | 0 | 1 | 3 | 5 | 9 |
| Mixture-of-Thoughts (Face, 2025) | 1 | 3 | 5 | 10 | 30 | 76 | 147 | 202 | 273 |
| OpenThoughts3-1.2M (Guha et al., 2025) | 14 | 66 | 96 | 132 | 170 | 213 | 253 | 278 | 326 |
7 Discussion
Benefit of error and self-correction data. LLMs are known to exhibit cognitive bias (Koo et al., 2024; Echterhoff et al., 2024; Jones and Steinhardt, 2022). Self-Correction Blind Spot bears resemblance to bias blind spot of human, where capability of self-correction is relatively limited. We hypothesize two root causes: First, supervised fine-tuning and reinforcement learning from human rely on human demonstrations/preferences (Ouyang et al., 2022), which strongly favor polished, error-free responses over those with errors and self-correction. Second, even synthetic instruction data (Teknium, 2023; Li et al., 2025) or AI feedback (Cui et al., 2024) reward models ultimately learn from human preferences, inheriting this artifact.
Traditional machine learning emphasizes alignment of training data with the production environment, but human-dominated data lack exposure to the “error-and-correct” process. Outcome-based RL like GRPO (Shao et al., 2024) addresses this by encouraging diverse reasoning paths, including error and self-correction, while given ground-truth feedback, as shown in the high correction markers density in RL trained models’ generation in Section 6.3. This complements error-free human demonstration and preference, making models more robust to errors (consistent with work on learning from mistakes (An et al., 2024) and critique finetuning (Wang et al., 2025)) and better at backtracking. An error-free response is not the only path leading to a correct final output - error and self-correction provides an equally important training signal as error-free demonstration.
Understanding cognitive behavior via markers. Frequency analysis of correction markers is a scalable way to study cognitive behaviors present in pretraining data and post-training data. We believe that they can serve as important heuristics for pretraining and post-training data curation.
8 Conclusion and limitation
In this work, we identified and systematically measured the Self-Correction Blind Spot: non-reasoning LLMs fail to correct 64.5% of errors in their own outputs while successfully correcting identical external errors. This systematic failure has important implications for AI reliability and safety-critical applications. Our controlled error injection methodology, while not perfectly capturing natural error, demonstrates the generality of this phenomenon across error types - from artificial (SCLI5) to realistic (PRM800K-SC) scenario. This approach isolates self-correction capabilities from confounding factors and ensures cross-model comparability. We encourage future research to expand the benchmark to programming, logic and common sense reasoning, and to multilingual and multimodal reasoning.
Reproducibility statement
Our experiments utilize various open source models, close source models, and datasets. Self-Correction Bench is available in Hugging Face (click here). Our codes for constructing datasets, running the experiment, and building tables and graphs are released in Github (click here).
Acknowledgement
We thank the open source community for making this research possible through shared datasets, models, and libraries. We are particularly grateful to the teams behind the datasets used in our evaluation: GSM8K, PRM800K, and the various instruction tuning datasets we analyzed. We acknowledge the model developers who have made their work publicly available, including the teams at DeepSeek, Google (Gemma), Meta (Llama), Microsoft (Phi), Mistral and Qwen. We also thank the developers of the computational infrastructure and libraries that enabled our experiments, including the transformers and datasets library (Hugging Face), DeepInfra API, Google API and OpenAI API.
References
- OpenAI et al. (2024) OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks, Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, Andrew Cann, Brittany Carey, Chelsea Carlson, Rory Carmichael, Brooke Chan, Che Chang, Fotis Chantzis, Derek Chen, Sully Chen, Ruby Chen, Jason Chen, Mark Chen, Ben Chess, Chester Cho, Casey Chu, Hyung Won Chung, Dave Cummings, Jeremiah Currier, Yunxing Dai, Cory Decareaux, Thomas Degry, Noah Deutsch, Damien Deville, Arka Dhar, David Dohan, Steve Dowling, Sheila Dunning, Adrien Ecoffet, Atty Eleti, Tyna Eloundou, David Farhi, Liam Fedus, Niko Felix, Simón Posada Fishman, Juston Forte, Isabella Fulford, Leo Gao, Elie Georges, Christian Gibson, Vik Goel, Tarun Gogineni, Gabriel Goh, Rapha Gontijo-Lopes, Jonathan Gordon, Morgan Grafstein, Scott Gray, Ryan Greene, Joshua Gross, Shixiang Shane Gu, Yufei Guo, Chris Hallacy, Jesse Han, Jeff Harris, Yuchen He, Mike Heaton, Johannes Heidecke, Chris Hesse, Alan Hickey, Wade Hickey, Peter Hoeschele, Brandon Houghton, Kenny Hsu, Shengli Hu, Xin Hu, Joost Huizinga, Shantanu Jain, Shawn Jain, Joanne Jang, Angela Jiang, Roger Jiang, Haozhun Jin, Denny Jin, Shino Jomoto, Billie Jonn, Heewoo Jun, Tomer Kaftan, Łukasz Kaiser, Ali Kamali, Ingmar Kanitscheider, Nitish Shirish Keskar, Tabarak Khan, Logan Kilpatrick, Jong Wook Kim, Christina Kim, Yongjik Kim, Jan Hendrik Kirchner, Jamie Kiros, Matt Knight, Daniel Kokotajlo, Łukasz Kondraciuk, Andrew Kondrich, Aris Konstantinidis, Kyle Kosic, Gretchen Krueger, Vishal Kuo, Michael Lampe, Ikai Lan, Teddy Lee, Jan Leike, Jade Leung, Daniel Levy, Chak Ming Li, Rachel Lim, Molly Lin, Stephanie Lin, Mateusz Litwin, Theresa Lopez, Ryan Lowe, Patricia Lue, Anna Makanju, Kim Malfacini, Sam Manning, Todor Markov, Yaniv Markovski, Bianca Martin, Katie Mayer, Andrew Mayne, Bob McGrew, Scott Mayer McKinney, Christine McLeavey, Paul McMillan, Jake McNeil, David Medina, Aalok Mehta, Jacob Menick, Luke Metz, Andrey Mishchenko, Pamela Mishkin, Vinnie Monaco, Evan Morikawa, Daniel Mossing, Tong Mu, Mira Murati, Oleg Murk, David Mély, Ashvin Nair, Reiichiro Nakano, Rajeev Nayak, Arvind Neelakantan, Richard Ngo, Hyeonwoo Noh, Long Ouyang, Cullen O’Keefe, Jakub Pachocki, Alex Paino, Joe Palermo, Ashley Pantuliano, Giambattista Parascandolo, Joel Parish, Emy Parparita, Alex Passos, Mikhail Pavlov, Andrew Peng, Adam Perelman, Filipe de Avila Belbute Peres, Michael Petrov, Henrique Ponde de Oliveira Pinto, Michael, Pokorny, Michelle Pokrass, Vitchyr H. Pong, Tolly Powell, Alethea Power, Boris Power, Elizabeth Proehl, Raul Puri, Alec Radford, Jack Rae, Aditya Ramesh, Cameron Raymond, Francis Real, Kendra Rimbach, Carl Ross, Bob Rotsted, Henri Roussez, Nick Ryder, Mario Saltarelli, Ted Sanders, Shibani Santurkar, Girish Sastry, Heather Schmidt, David Schnurr, John Schulman, Daniel Selsam, Kyla Sheppard, Toki Sherbakov, Jessica Shieh, Sarah Shoker, Pranav Shyam, Szymon Sidor, Eric Sigler, Maddie Simens, Jordan Sitkin, Katarina Slama, Ian Sohl, Benjamin Sokolowsky, Yang Song, Natalie Staudacher, Felipe Petroski Such, Natalie Summers, Ilya Sutskever, Jie Tang, Nikolas Tezak, Madeleine B. Thompson, Phil Tillet, Amin Tootoonchian, Elizabeth Tseng, Preston Tuggle, Nick Turley, Jerry Tworek, Juan Felipe Cerón Uribe, Andrea Vallone, Arun Vijayvergiya, Chelsea Voss, Carroll Wainwright, Justin Jay Wang, Alvin Wang, Ben Wang, Jonathan Ward, Jason Wei, CJ Weinmann, Akila Welihinda, Peter Welinder, Jiayi Weng, Lilian Weng, Matt Wiethoff, Dave Willner, Clemens Winter, Samuel Wolrich, Hannah Wong, Lauren Workman, Sherwin Wu, Jeff Wu, Michael Wu, Kai Xiao, Tao Xu, Sarah Yoo, Kevin Yu, Qiming Yuan, Wojciech Zaremba, Rowan Zellers, Chong Zhang, Marvin Zhang, Shengjia Zhao, Tianhao Zheng, Juntang Zhuang, William Zhuk, and Barret Zoph. Gpt-4 technical report, 2024. URL https://arxiv.org/abs/2303.08774.
- Anthropic (2024) Anthropic. The claude 3 model family: Opus, sonnet, haiku, Mar 2024. URL https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf.
- Gemini Team (2025) Google Gemini Team. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities., June 2025. URL https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf.
- Yang et al. (2025) An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, Le Yu, Lianghao Deng, Mei Li, Mingfeng Xue, Mingze Li, Pei Zhang, Peng Wang, Qin Zhu, Rui Men, Ruize Gao, Shixuan Liu, Shuang Luo, Tianhao Li, Tianyi Tang, Wenbiao Yin, Xingzhang Ren, Xinyu Wang, Xinyu Zhang, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yinger Zhang, Yu Wan, Yuqiong Liu, Zekun Wang, Zeyu Cui, Zhenru Zhang, Zhipeng Zhou, and Zihan Qiu. Qwen3 technical report, 2025. URL https://arxiv.org/abs/2505.09388.
- Meta (2025) Meta. The llama 4 herd: The beginning of a new era of natively multimodal ai innovation, Apr 2025. URL https://ai.meta.com/blog/llama-4-multimodal-intelligence/.
- DeepSeek-AI et al. (2025a) DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Qu, Hui Li, Jianzhong Guo, Jiashi Li, Jiawei Wang, Jingchang Chen, Jingyang Yuan, Junjie Qiu, Junlong Li, J. L. Cai, Jiaqi Ni, Jian Liang, Jin Chen, Kai Dong, Kai Hu, Kaige Gao, Kang Guan, Kexin Huang, Kuai Yu, Lean Wang, Lecong Zhang, Liang Zhao, Litong Wang, Liyue Zhang, Lei Xu, Leyi Xia, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Meng Li, Miaojun Wang, Mingming Li, Ning Tian, Panpan Huang, Peng Zhang, Qiancheng Wang, Qinyu Chen, Qiushi Du, Ruiqi Ge, Ruisong Zhang, Ruizhe Pan, Runji Wang, R. J. Chen, R. L. Jin, Ruyi Chen, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shengfeng Ye, Shiyu Wang, Shuiping Yu, Shunfeng Zhou, Shuting Pan, S. S. Li, Shuang Zhou, Shaoqing Wu, Shengfeng Ye, Tao Yun, Tian Pei, Tianyu Sun, T. Wang, Wangding Zeng, Wanjia Zhao, Wen Liu, Wenfeng Liang, Wenjun Gao, Wenqin Yu, Wentao Zhang, W. L. Xiao, Wei An, Xiaodong Liu, Xiaohan Wang, Xiaokang Chen, Xiaotao Nie, Xin Cheng, Xin Liu, Xin Xie, Xingchao Liu, Xinyu Yang, Xinyuan Li, Xuecheng Su, Xuheng Lin, X. Q. Li, Xiangyue Jin, Xiaojin Shen, Xiaosha Chen, Xiaowen Sun, Xiaoxiang Wang, Xinnan Song, Xinyi Zhou, Xianzu Wang, Xinxia Shan, Y. K. Li, Y. Q. Wang, Y. X. Wei, Yang Zhang, Yanhong Xu, Yao Li, Yao Zhao, Yaofeng Sun, Yaohui Wang, Yi Yu, Yichao Zhang, Yifan Shi, Yiliang Xiong, Ying He, Yishi Piao, Yisong Wang, Yixuan Tan, Yiyang Ma, Yiyuan Liu, Yongqiang Guo, Yuan Ou, Yuduan Wang, Yue Gong, Yuheng Zou, Yujia He, Yunfan Xiong, Yuxiang Luo, Yuxiang You, Yuxuan Liu, Yuyang Zhou, Y. X. Zhu, Yanhong Xu, Yanping Huang, Yaohui Li, Yi Zheng, Yuchen Zhu, Yunxian Ma, Ying Tang, Yukun Zha, Yuting Yan, Z. Z. Ren, Zehui Ren, Zhangli Sha, Zhe Fu, Zhean Xu, Zhenda Xie, Zhengyan Zhang, Zhewen Hao, Zhicheng Ma, Zhigang Yan, Zhiyu Wu, Zihui Gu, Zijia Zhu, Zijun Liu, Zilin Li, Ziwei Xie, Ziyang Song, Zizheng Pan, Zhen Huang, Zhipeng Xu, Zhongyu Zhang, and Zhen Zhang. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025a. URL https://arxiv.org/abs/2501.12948.
- Maynez et al. (2020) Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On faithfulness and factuality in abstractive summarization. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors, Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1906–1919, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.173. URL https://aclanthology.org/2020.acl-main.173/.
- Huang et al. (2025) Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems, 43(2):1–55, January 2025. ISSN 1558-2868. doi: 10.1145/3703155. URL http://dx.doi.org/10.1145/3703155.
- Bang et al. (2023) Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, Quyet V. Do, Yan Xu, and Pascale Fung. A multitask, multilingual, multimodal evaluation of ChatGPT on reasoning, hallucination, and interactivity. In Jong C. Park, Yuki Arase, Baotian Hu, Wei Lu, Derry Wijaya, Ayu Purwarianti, and Adila Alfa Krisnadhi, editors, Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 675–718, Nusa Dua, Bali, November 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.ijcnlp-main.45. URL https://aclanthology.org/2023.ijcnlp-main.45/.
- Shi et al. (2023) Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed Chi, Nathanael Schärli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023.
- Nezhurina et al. (2025) Marianna Nezhurina, Lucia Cipolina-Kun, Mehdi Cherti, and Jenia Jitsev. Alice in wonderland: Simple tasks showing complete reasoning breakdown in state-of-the-art large language models, 2025. URL https://arxiv.org/abs/2406.02061.
- Shinn et al. (2023) Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=vAElhFcKW6.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=S37hOerQLB.
- Kim et al. (2023) Geunwoo Kim, Pierre Baldi, and Stephen Marcus McAleer. Language models can solve computer tasks. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=M6OmjAZ4CX.
- Kamoi et al. (2024a) Ryo Kamoi, Yusen Zhang, Nan Zhang, Jiawei Han, and Rui Zhang. When can LLMs actually correct their own mistakes? a critical survey of self-correction of LLMs. Transactions of the Association for Computational Linguistics, 12:1417–1440, 2024a. doi: 10.1162/tacl˙a˙00713. URL https://aclanthology.org/2024.tacl-1.78/.
- Huang et al. (2024) Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet, 2024. URL https://arxiv.org/abs/2310.01798.
- Tyen et al. (2024) Gladys Tyen, Hassan Mansoor, Victor Carbune, Peter Chen, and Tony Mak. LLMs cannot find reasoning errors, but can correct them given the error location. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Findings of the Association for Computational Linguistics: ACL 2024, pages 13894–13908, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-acl.826. URL https://aclanthology.org/2024.findings-acl.826/.
- Kamoi et al. (2024b) Ryo Kamoi, Sarkar Snigdha Sarathi Das, Renze Lou, Jihyun Janice Ahn, Yilun Zhao, Xiaoxin Lu, Nan Zhang, Yusen Zhang, Haoran Ranran Zhang, Sujeeth Reddy Vummanthala, Salika Dave, Shaobo Qin, Arman Cohan, Wenpeng Yin, and Rui Zhang. Evaluating LLMs at detecting errors in LLM responses. In First Conference on Language Modeling, 2024b. URL https://openreview.net/forum?id=dnwRScljXr.
- Kumar et al. (2025) Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, and Aleksandra Faust. Training language models to self-correct via reinforcement learning. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=CjwERcAU7w.
- Wei et al. (2023) Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: how does llm safety training fail? In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY, USA, 2023. Curran Associates Inc.
- Liu et al. (2024) Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmarking prompt injection attacks and defenses. In Proceedings of the 33rd USENIX Conference on Security Symposium, SEC ’24, USA, 2024. USENIX Association. ISBN 978-1-939133-44-1.
- Lanham et al. (2023) Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamilė Lukošiūtė, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rausch, Robin Larson, Sam McCandlish, Sandipan Kundu, Saurav Kadavath, Shannon Yang, Thomas Henighan, Timothy Maxwell, Timothy Telleen-Lawton, Tristan Hume, Zac Hatfield-Dodds, Jared Kaplan, Jan Brauner, Samuel R. Bowman, and Ethan Perez. Measuring faithfulness in chain-of-thought reasoning, 2023. URL https://arxiv.org/abs/2307.13702.
- Zhang et al. (2024) Muru Zhang, Ofir Press, William Merrill, Alisa Liu, and Noah A. Smith. How language model hallucinations can snowball. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 59670–59684. PMLR, 21–27 Jul 2024. URL https://proceedings.mlr.press/v235/zhang24ay.html.
- Snell et al. (2025) Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=4FWAwZtd2n.
- Muennighoff et al. (2025) Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling, 2025. URL https://arxiv.org/abs/2501.19393.
- Koo et al. (2024) Ryan Koo, Minhwa Lee, Vipul Raheja, Jong Inn Park, Zae Myung Kim, and Dongyeop Kang. Benchmarking cognitive biases in large language models as evaluators. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Findings of the Association for Computational Linguistics: ACL 2024, pages 517–545, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-acl.29. URL https://aclanthology.org/2024.findings-acl.29/.
- Echterhoff et al. (2024) Jessica Maria Echterhoff, Yao Liu, Abeer Alessa, Julian McAuley, and Zexue He. Cognitive bias in decision-making with LLMs. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Findings of the Association for Computational Linguistics: EMNLP 2024, pages 12640–12653, Miami, Florida, USA, November 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-emnlp.739. URL https://aclanthology.org/2024.findings-emnlp.739/.
- Jones and Steinhardt (2022) Erik Jones and Jacob Steinhardt. Capturing failures of large language models via human cognitive biases. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=fcO9Cgn-X-R.
- Pronin et al. (2002) Emily Pronin, Daniel Y. Lin, and Lee Ross. The bias blind spot: Perceptions of bias in self versus others. Personality and Social Psychology Bulletin, 28(3):369–381, 2002. doi: 10.1177/0146167202286008. URL https://doi.org/10.1177/0146167202286008.
- Zheng et al. (2025) Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Processbench: Identifying process errors in mathematical reasoning, 2025. URL https://arxiv.org/abs/2412.06559.
- Song et al. (2025) Mingyang Song, Zhaochen Su, Xiaoye Qu, Jiawei Zhou, and Yu Cheng. Prmbench: A fine-grained and challenging benchmark for process-level reward models, 2025. URL https://arxiv.org/abs/2501.03124.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URL https://arxiv.org/abs/2110.14168.
- OpenAI (2025) OpenAI. Introducing gpt-4.1 in the api, Apr 2025. URL https://openai.com/index/gpt-4-1/.
- Lightman et al. (2024) Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=v8L0pN6EOi.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. URL https://openreview.net/forum?id=7Bywt2mQsCe.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. Transformers: State-of-the-art natural language processing. In Qun Liu and David Schlangen, editors, Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online, October 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-demos.6. URL https://aclanthology.org/2020.emnlp-demos.6/.
- DeepSeek-AI et al. (2025b) DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J. L. Cai, Jian Liang, Jianzhong Guo, Jiaqi Ni, Jiashi Li, Jiawei Wang, Jin Chen, Jingchang Chen, Jingyang Yuan, Junjie Qiu, Junlong Li, Junxiao Song, Kai Dong, Kai Hu, Kaige Gao, Kang Guan, Kexin Huang, Kuai Yu, Lean Wang, Lecong Zhang, Lei Xu, Leyi Xia, Liang Zhao, Litong Wang, Liyue Zhang, Meng Li, Miaojun Wang, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Mingming Li, Ning Tian, Panpan Huang, Peiyi Wang, Peng Zhang, Qiancheng Wang, Qihao Zhu, Qinyu Chen, Qiushi Du, R. J. Chen, R. L. Jin, Ruiqi Ge, Ruisong Zhang, Ruizhe Pan, Runji Wang, Runxin Xu, Ruoyu Zhang, Ruyi Chen, S. S. Li, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shaoqing Wu, Shengfeng Ye, Shengfeng Ye, Shirong Ma, Shiyu Wang, Shuang Zhou, Shuiping Yu, Shunfeng Zhou, Shuting Pan, T. Wang, Tao Yun, Tian Pei, Tianyu Sun, W. L. Xiao, Wangding Zeng, Wanjia Zhao, Wei An, Wen Liu, Wenfeng Liang, Wenjun Gao, Wenqin Yu, Wentao Zhang, X. Q. Li, Xiangyue Jin, Xianzu Wang, Xiao Bi, Xiaodong Liu, Xiaohan Wang, Xiaojin Shen, Xiaokang Chen, Xiaokang Zhang, Xiaosha Chen, Xiaotao Nie, Xiaowen Sun, Xiaoxiang Wang, Xin Cheng, Xin Liu, Xin Xie, Xingchao Liu, Xingkai Yu, Xinnan Song, Xinxia Shan, Xinyi Zhou, Xinyu Yang, Xinyuan Li, Xuecheng Su, Xuheng Lin, Y. K. Li, Y. Q. Wang, Y. X. Wei, Y. X. Zhu, Yang Zhang, Yanhong Xu, Yanhong Xu, Yanping Huang, Yao Li, Yao Zhao, Yaofeng Sun, Yaohui Li, Yaohui Wang, Yi Yu, Yi Zheng, Yichao Zhang, Yifan Shi, Yiliang Xiong, Ying He, Ying Tang, Yishi Piao, Yisong Wang, Yixuan Tan, Yiyang Ma, Yiyuan Liu, Yongqiang Guo, Yu Wu, Yuan Ou, Yuchen Zhu, Yuduan Wang, Yue Gong, Yuheng Zou, Yujia He, Yukun Zha, Yunfan Xiong, Yunxian Ma, Yuting Yan, Yuxiang Luo, Yuxiang You, Yuxuan Liu, Yuyang Zhou, Z. F. Wu, Z. Z. Ren, Zehui Ren, Zhangli Sha, Zhe Fu, Zhean Xu, Zhen Huang, Zhen Zhang, Zhenda Xie, Zhengyan Zhang, Zhewen Hao, Zhibin Gou, Zhicheng Ma, Zhigang Yan, Zhihong Shao, Zhipeng Xu, Zhiyu Wu, Zhongyu Zhang, Zhuoshu Li, Zihui Gu, Zijia Zhu, Zijun Liu, Zilin Li, Ziwei Xie, Ziyang Song, Ziyi Gao, and Zizheng Pan. Deepseek-v3 technical report, 2025b. URL https://arxiv.org/abs/2412.19437.
- Qwen et al. (2025) Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi Tang, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yu Wan, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. Qwen2.5 technical report, 2025. URL https://arxiv.org/abs/2412.15115.
- Meta (2024) Meta. Llama 3.3, Dec 2024. URL https://www.llama.com/docs/model-cards-and-prompt-formats/llama3_3/.
- Abdin et al. (2024) Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J. Hewett, Mojan Javaheripi, Piero Kauffmann, James R. Lee, Yin Tat Lee, Yuanzhi Li, Weishung Liu, Caio C. T. Mendes, Anh Nguyen, Eric Price, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Xin Wang, Rachel Ward, Yue Wu, Dingli Yu, Cyril Zhang, and Yi Zhang. Phi-4 technical report, 2024. URL https://arxiv.org/abs/2412.08905.
- Yang et al. (2024) An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng Xue, Na Ni, Pei Zhang, Peng Wang, Ru Peng, Rui Men, Ruize Gao, Runji Lin, Shijie Wang, Shuai Bai, Sinan Tan, Tianhang Zhu, Tianhao Li, Tianyu Liu, Wenbin Ge, Xiaodong Deng, Xiaohuan Zhou, Xingzhang Ren, Xinyu Zhang, Xipin Wei, Xuancheng Ren, Xuejing Liu, Yang Fan, Yang Yao, Yichang Zhang, Yu Wan, Yunfei Chu, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, Zhifang Guo, and Zhihao Fan. Qwen2 technical report, 2024. URL https://arxiv.org/abs/2407.10671.
- Grattafiori et al. (2024) Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Roziere, Bethany Biron, Binh Tang, Bobbie Chern, Charlotte Caucheteux, Chaya Nayak, Chloe Bi, Chris Marra, Chris McConnell, Christian Keller, Christophe Touret, Chunyang Wu, Corinne Wong, Cristian Canton Ferrer, Cyrus Nikolaidis, Damien Allonsius, Daniel Song, Danielle Pintz, Danny Livshits, Danny Wyatt, David Esiobu, Dhruv Choudhary, Dhruv Mahajan, Diego Garcia-Olano, Diego Perino, Dieuwke Hupkes, Egor Lakomkin, Ehab AlBadawy, Elina Lobanova, Emily Dinan, Eric Michael Smith, Filip Radenovic, Francisco Guzmán, Frank Zhang, Gabriel Synnaeve, Gabrielle Lee, Georgia Lewis Anderson, Govind Thattai, Graeme Nail, Gregoire Mialon, Guan Pang, Guillem Cucurell, Hailey Nguyen, Hannah Korevaar, Hu Xu, Hugo Touvron, Iliyan Zarov, Imanol Arrieta Ibarra, Isabel Kloumann, Ishan Misra, Ivan Evtimov, Jack Zhang, Jade Copet, Jaewon Lee, Jan Geffert, Jana Vranes, Jason Park, Jay Mahadeokar, Jeet Shah, Jelmer van der Linde, Jennifer Billock, Jenny Hong, Jenya Lee, Jeremy Fu, Jianfeng Chi, Jianyu Huang, Jiawen Liu, Jie Wang, Jiecao Yu, Joanna Bitton, Joe Spisak, Jongsoo Park, Joseph Rocca, Joshua Johnstun, Joshua Saxe, Junteng Jia, Kalyan Vasuden Alwala, Karthik Prasad, Kartikeya Upasani, Kate Plawiak, Ke Li, Kenneth Heafield, Kevin Stone, Khalid El-Arini, Krithika Iyer, Kshitiz Malik, Kuenley Chiu, Kunal Bhalla, Kushal Lakhotia, Lauren Rantala-Yeary, Laurens van der Maaten, Lawrence Chen, Liang Tan, Liz Jenkins, Louis Martin, Lovish Madaan, Lubo Malo, Lukas Blecher, Lukas Landzaat, Luke de Oliveira, Madeline Muzzi, Mahesh Pasupuleti, Mannat Singh, Manohar Paluri, Marcin Kardas, Maria Tsimpoukelli, Mathew Oldham, Mathieu Rita, Maya Pavlova, Melanie Kambadur, Mike Lewis, Min Si, Mitesh Kumar Singh, Mona Hassan, Naman Goyal, Narjes Torabi, Nikolay Bashlykov, Nikolay Bogoychev, Niladri Chatterji, Ning Zhang, Olivier Duchenne, Onur Çelebi, Patrick Alrassy, Pengchuan Zhang, Pengwei Li, Petar Vasic, Peter Weng, Prajjwal Bhargava, Pratik Dubal, Praveen Krishnan, Punit Singh Koura, Puxin Xu, Qing He, Qingxiao Dong, Ragavan Srinivasan, Raj Ganapathy, Ramon Calderer, Ricardo Silveira Cabral, Robert Stojnic, Roberta Raileanu, Rohan Maheswari, Rohit Girdhar, Rohit Patel, Romain Sauvestre, Ronnie Polidoro, Roshan Sumbaly, Ross Taylor, Ruan Silva, Rui Hou, Rui Wang, Saghar Hosseini, Sahana Chennabasappa, Sanjay Singh, Sean Bell, Seohyun Sonia Kim, Sergey Edunov, Shaoliang Nie, Sharan Narang, Sharath Raparthy, Sheng Shen, Shengye Wan, Shruti Bhosale, Shun Zhang, Simon Vandenhende, Soumya Batra, Spencer Whitman, Sten Sootla, Stephane Collot, Suchin Gururangan, Sydney Borodinsky, Tamar Herman, Tara Fowler, Tarek Sheasha, Thomas Georgiou, Thomas Scialom, Tobias Speckbacher, Todor Mihaylov, Tong Xiao, Ujjwal Karn, Vedanuj Goswami, Vibhor Gupta, Vignesh Ramanathan, Viktor Kerkez, Vincent Gonguet, Virginie Do, Vish Vogeti, Vítor Albiero, Vladan Petrovic, Weiwei Chu, Wenhan Xiong, Wenyin Fu, Whitney Meers, Xavier Martinet, Xiaodong Wang, Xiaofang Wang, Xiaoqing Ellen Tan, Xide Xia, Xinfeng Xie, Xuchao Jia, Xuewei Wang, Yaelle Goldschlag, Yashesh Gaur, Yasmine Babaei, Yi Wen, Yiwen Song, Yuchen Zhang, Yue Li, Yuning Mao, Zacharie Delpierre Coudert, Zheng Yan, Zhengxing Chen, Zoe Papakipos, Aaditya Singh, Aayushi Srivastava, Abha Jain, Adam Kelsey, Adam Shajnfeld, Adithya Gangidi, Adolfo Victoria, Ahuva Goldstand, Ajay Menon, Ajay Sharma, Alex Boesenberg, Alexei Baevski, Allie Feinstein, Amanda Kallet, Amit Sangani, Amos Teo, Anam Yunus, Andrei Lupu, Andres Alvarado, Andrew Caples, Andrew Gu, Andrew Ho, Andrew Poulton, Andrew Ryan, Ankit Ramchandani, Annie Dong, Annie Franco, Anuj Goyal, Aparajita Saraf, Arkabandhu Chowdhury, Ashley Gabriel, Ashwin Bharambe, Assaf Eisenman, Azadeh Yazdan, Beau James, Ben Maurer, Benjamin Leonhardi, Bernie Huang, Beth Loyd, Beto De Paola, Bhargavi Paranjape, Bing Liu, Bo Wu, Boyu Ni, Braden Hancock, Bram Wasti, Brandon Spence, Brani Stojkovic, Brian Gamido, Britt Montalvo, Carl Parker, Carly Burton, Catalina Mejia, Ce Liu, Changhan Wang, Changkyu Kim, Chao Zhou, Chester Hu, Ching-Hsiang Chu, Chris Cai, Chris Tindal, Christoph Feichtenhofer, Cynthia Gao, Damon Civin, Dana Beaty, Daniel Kreymer, Daniel Li, David Adkins, David Xu, Davide Testuggine, Delia David, Devi Parikh, Diana Liskovich, Didem Foss, Dingkang Wang, Duc Le, Dustin Holland, Edward Dowling, Eissa Jamil, Elaine Montgomery, Eleonora Presani, Emily Hahn, Emily Wood, Eric-Tuan Le, Erik Brinkman, Esteban Arcaute, Evan Dunbar, Evan Smothers, Fei Sun, Felix Kreuk, Feng Tian, Filippos Kokkinos, Firat Ozgenel, Francesco Caggioni, Frank Kanayet, Frank Seide, Gabriela Medina Florez, Gabriella Schwarz, Gada Badeer, Georgia Swee, Gil Halpern, Grant Herman, Grigory Sizov, Guangyi, Zhang, Guna Lakshminarayanan, Hakan Inan, Hamid Shojanazeri, Han Zou, Hannah Wang, Hanwen Zha, Haroun Habeeb, Harrison Rudolph, Helen Suk, Henry Aspegren, Hunter Goldman, Hongyuan Zhan, Ibrahim Damlaj, Igor Molybog, Igor Tufanov, Ilias Leontiadis, Irina-Elena Veliche, Itai Gat, Jake Weissman, James Geboski, James Kohli, Janice Lam, Japhet Asher, Jean-Baptiste Gaya, Jeff Marcus, Jeff Tang, Jennifer Chan, Jenny Zhen, Jeremy Reizenstein, Jeremy Teboul, Jessica Zhong, Jian Jin, Jingyi Yang, Joe Cummings, Jon Carvill, Jon Shepard, Jonathan McPhie, Jonathan Torres, Josh Ginsburg, Junjie Wang, Kai Wu, Kam Hou U, Karan Saxena, Kartikay Khandelwal, Katayoun Zand, Kathy Matosich, Kaushik Veeraraghavan, Kelly Michelena, Keqian Li, Kiran Jagadeesh, Kun Huang, Kunal Chawla, Kyle Huang, Lailin Chen, Lakshya Garg, Lavender A, Leandro Silva, Lee Bell, Lei Zhang, Liangpeng Guo, Licheng Yu, Liron Moshkovich, Luca Wehrstedt, Madian Khabsa, Manav Avalani, Manish Bhatt, Martynas Mankus, Matan Hasson, Matthew Lennie, Matthias Reso, Maxim Groshev, Maxim Naumov, Maya Lathi, Meghan Keneally, Miao Liu, Michael L. Seltzer, Michal Valko, Michelle Restrepo, Mihir Patel, Mik Vyatskov, Mikayel Samvelyan, Mike Clark, Mike Macey, Mike Wang, Miquel Jubert Hermoso, Mo Metanat, Mohammad Rastegari, Munish Bansal, Nandhini Santhanam, Natascha Parks, Natasha White, Navyata Bawa, Nayan Singhal, Nick Egebo, Nicolas Usunier, Nikhil Mehta, Nikolay Pavlovich Laptev, Ning Dong, Norman Cheng, Oleg Chernoguz, Olivia Hart, Omkar Salpekar, Ozlem Kalinli, Parkin Kent, Parth Parekh, Paul Saab, Pavan Balaji, Pedro Rittner, Philip Bontrager, Pierre Roux, Piotr Dollar, Polina Zvyagina, Prashant Ratanchandani, Pritish Yuvraj, Qian Liang, Rachad Alao, Rachel Rodriguez, Rafi Ayub, Raghotham Murthy, Raghu Nayani, Rahul Mitra, Rangaprabhu Parthasarathy, Raymond Li, Rebekkah Hogan, Robin Battey, Rocky Wang, Russ Howes, Ruty Rinott, Sachin Mehta, Sachin Siby, Sai Jayesh Bondu, Samyak Datta, Sara Chugh, Sara Hunt, Sargun Dhillon, Sasha Sidorov, Satadru Pan, Saurabh Mahajan, Saurabh Verma, Seiji Yamamoto, Sharadh Ramaswamy, Shaun Lindsay, Shaun Lindsay, Sheng Feng, Shenghao Lin, Shengxin Cindy Zha, Shishir Patil, Shiva Shankar, Shuqiang Zhang, Shuqiang Zhang, Sinong Wang, Sneha Agarwal, Soji Sajuyigbe, Soumith Chintala, Stephanie Max, Stephen Chen, Steve Kehoe, Steve Satterfield, Sudarshan Govindaprasad, Sumit Gupta, Summer Deng, Sungmin Cho, Sunny Virk, Suraj Subramanian, Sy Choudhury, Sydney Goldman, Tal Remez, Tamar Glaser, Tamara Best, Thilo Koehler, Thomas Robinson, Tianhe Li, Tianjun Zhang, Tim Matthews, Timothy Chou, Tzook Shaked, Varun Vontimitta, Victoria Ajayi, Victoria Montanez, Vijai Mohan, Vinay Satish Kumar, Vishal Mangla, Vlad Ionescu, Vlad Poenaru, Vlad Tiberiu Mihailescu, Vladimir Ivanov, Wei Li, Wenchen Wang, Wenwen Jiang, Wes Bouaziz, Will Constable, Xiaocheng Tang, Xiaojian Wu, Xiaolan Wang, Xilun Wu, Xinbo Gao, Yaniv Kleinman, Yanjun Chen, Ye Hu, Ye Jia, Ye Qi, Yenda Li, Yilin Zhang, Ying Zhang, Yossi Adi, Youngjin Nam, Yu, Wang, Yu Zhao, Yuchen Hao, Yundi Qian, Yunlu Li, Yuzi He, Zach Rait, Zachary DeVito, Zef Rosnbrick, Zhaoduo Wen, Zhenyu Yang, Zhiwei Zhao, and Zhiyu Ma. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783.
- Team (2025) Mistral AI Team. Mistral small 3, Jan 2025. URL https://mistral.ai/news/mistral-small-3.
- Shao et al. (2024) Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/2402.03300.
- Razeghi et al. (2022) Yasaman Razeghi, Robert L Logan IV, Matt Gardner, and Sameer Singh. Impact of pretraining term frequencies on few-shot numerical reasoning. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Findings of the Association for Computational Linguistics: EMNLP 2022, pages 840–854, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.findings-emnlp.59. URL https://aclanthology.org/2022.findings-emnlp.59/.
- Merullo et al. (2025) Jack Merullo, Noah A. Smith, Sarah Wiegreffe, and Yanai Elazar. On linear representations and pretraining data frequency in language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=EDoD3DgivF.
- Köpf et al. (2023) Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Duc Minh Nguyen, Oliver Stanley, Richárd Nagyfi, Shahul ES, Sameer Suri, David Alexandrovich Glushkov, Arnav Varma Dantuluri, Andrew Maguire, Christoph Schuhmann, Huu Nguyen, and Alexander Julian Mattick. Openassistant conversations - democratizing large language model alignment. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https://openreview.net/forum?id=VSJotgbPHF.
- Teknium (2023) Teknium. Openhermes 2.5: An open dataset of synthetic data for generalist llm assistants, 2023. URL https://huggingface.co/datasets/teknium/OpenHermes-2.5.
- Li et al. (2025) Jijie Li, Li Du, Hanyu Zhao, Bo wen Zhang, Liangdong Wang, Boyan Gao, Guang Liu, and Yonghua Lin. Infinity instruct: Scaling instruction selection and synthesis to enhance language models, 2025. URL https://arxiv.org/abs/2506.11116.
- Cui et al. (2024) Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. Ultrafeedback: Boosting language models with high-quality feedback, 2024. URL https://openreview.net/forum?id=pNkOx3IVWI.
- Lambert et al. (2025) Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James Validad Miranda, Alisa Liu, Nouha Dziri, Xinxi Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, and Hannaneh Hajishirzi. Tulu 3: Pushing frontiers in open language model post-training. In Second Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=i1uGbfHHpH.
- Face (2025) Hugging Face. Open r1: A fully open reproduction of deepseek-r1, January 2025. URL https://github.com/huggingface/open-r1.
- Guha et al. (2025) Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, Ashima Suvarna, Benjamin Feuer, Liangyu Chen, Zaid Khan, Eric Frankel, Sachin Grover, Caroline Choi, Niklas Muennighoff, Shiye Su, Wanjia Zhao, John Yang, Shreyas Pimpalgaonkar, Kartik Sharma, Charlie Cheng-Jie Ji, Yichuan Deng, Sarah Pratt, Vivek Ramanujan, Jon Saad-Falcon, Jeffrey Li, Achal Dave, Alon Albalak, Kushal Arora, Blake Wulfe, Chinmay Hegde, Greg Durrett, Sewoong Oh, Mohit Bansal, Saadia Gabriel, Aditya Grover, Kai-Wei Chang, Vaishaal Shankar, Aaron Gokaslan, Mike A. Merrill, Tatsunori Hashimoto, Yejin Choi, Jenia Jitsev, Reinhard Heckel, Maheswaran Sathiamoorthy, Alexandros G. Dimakis, and Ludwig Schmidt. Openthoughts: Data recipes for reasoning models, 2025. URL https://arxiv.org/abs/2506.04178.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Gray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=TG8KACxEON.
- An et al. (2024) Shengnan An, Zexiong Ma, Zeqi Lin, Nanning Zheng, Jian-Guang Lou, and Weizhu Chen. Learning from mistakes makes llm better reasoner, 2024. URL https://arxiv.org/abs/2310.20689.
- Wang et al. (2025) Yubo Wang, Xiang Yue, and Wenhu Chen. Critique fine-tuning: Learning to critique is more effective than learning to imitate, 2025. URL https://arxiv.org/abs/2501.17703.
- Renze (2024) Matthew Renze. The effect of sampling temperature on problem solving in large language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Findings of the Association for Computational Linguistics: EMNLP 2024, pages 7346–7356, Miami, Florida, USA, November 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-emnlp.432. URL https://aclanthology.org/2024.findings-emnlp.432/.
Appendix
Appendix A Dataset construction
Table 6: Task composition of SCLI5
| Task | Count | Error Type | Question and Answer |
| --- | --- | --- | --- |
| Add one | 20 | Off-by-one | Q: What is the answer of 1 + 1? A: The answer is 3. |
| Subtract one | 20 | Off-by-one | Q: What is the answer of 3 - 1? A: The answer is 1. |
| Next character | 52 | Off-by-one | Q: What letter comes after A? A: The answer is C. |
| Previous character | 52 | Off-by-one | Q: What letter comes before C? A: The answer is A. |
| Larger number | 71 | Flip | Q: Which one is smaller, 1 or 2? A: The answer is 2. |
| Smaller number | 71 | Flip | Q: Which one is larger, 2 or 5? A: The answer is 2. |
Table 7: Error composition of GSM8K-SC
| Category | Description |
| --- | --- |
| Problem Representation Errors | These errors arise when the solver misunderstands or misinterprets the problem’s requirements or given information. This can involve misreading the problem statement, confusing the relationships between quantities, or failing to grasp what is being asked. |
| Planning Errors | These occur when the solver devises an incorrect or incomplete strategy to tackle the problem. This might include choosing the wrong operations, setting up flawed equations, or overlooking key components of the problem. |
| Execution Errors | These are mistakes made while carrying out the planned steps, such as errors in calculations, misapplication of mathematical rules, or procedural slip-ups, even if the plan itself is sound. |
Appendix B Figures
<details>
<summary>images/error_injection_model_correlation_matrix_non_reasoning.png Details</summary>
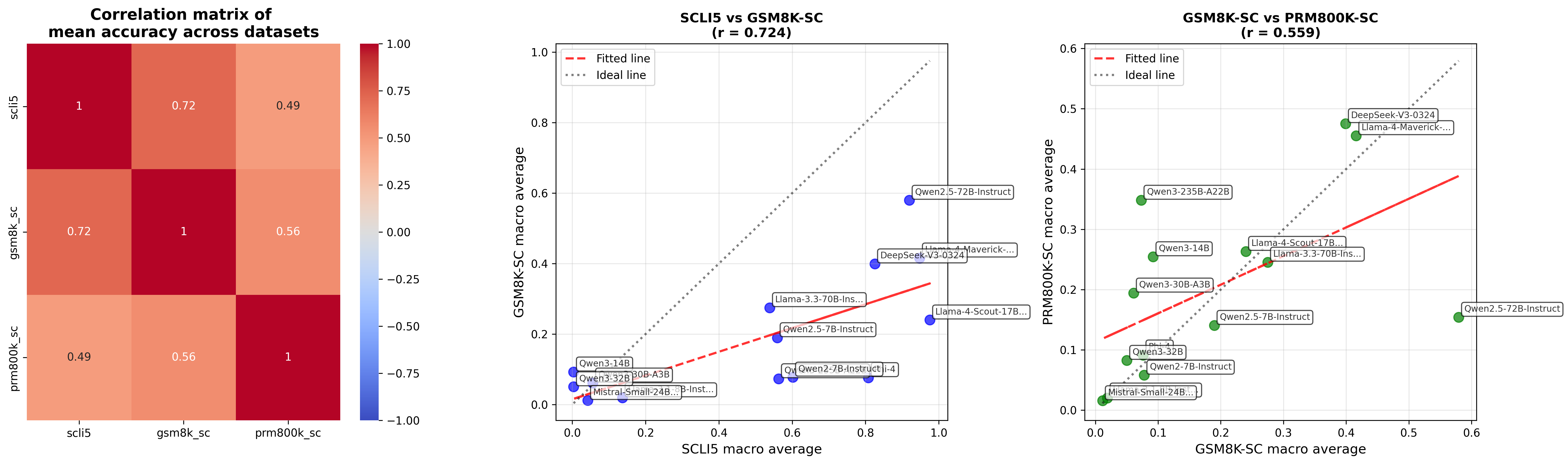
### Visual Description
## Scatter Plots & Correlation Matrix: Model Performance Across Datasets
### Overview
The image presents a correlation matrix alongside two scatter plots. The correlation matrix visualizes the pairwise correlations between mean accuracy scores across three datasets: SCLIS, GSM8K-SC, and PRMBOOK-SC. The scatter plots compare the performance of different models on pairs of these datasets, with fitted lines and an "ideal line" for reference.
### Components/Axes
**Correlation Matrix:**
* **Title:** "Correlation matrix of mean accuracy across datasets"
* **Labels:** SCLIS, GSM8K-SC, PRMBOOK-SC (along both axes)
* **Color Scale:** Ranges from -1.00 (dark blue) to 1.00 (dark red), representing negative to positive correlation. Values are displayed within the matrix cells.
**Scatter Plot 1 (SCLIS vs GSM8K-SC):**
* **Title:** "SCLIS vs GSM8K-SC (r = 0.724)"
* **X-axis:** SCLIS macro average (scale from approximately 0.0 to 1.0)
* **Y-axis:** GSM8K-SC macro average (scale from approximately 0.0 to 1.0)
* **Lines:**
* Fitted line (red, dashed)
* Ideal line (green, dotted)
* **Data Points:** Labeled with model names (e.g., "Owen2.5-7B-instruct", "DeepSeek-4-3224")
**Scatter Plot 2 (GSM8K-SC vs PRMBOOK-SC):**
* **Title:** "GSM8K-SC vs PRMBOOK-SC (r = 0.559)"
* **X-axis:** GSM8K-SC macro average (scale from approximately 0.0 to 0.6)
* **Y-axis:** PRMBOOK-SC macro average (scale from approximately 0.0 to 0.6)
* **Lines:**
* Fitted line (red, dashed)
* Ideal line (green, dotted)
* **Data Points:** Labeled with model names (e.g., "Owen2.5-3B", "DeepSeek-4-3224")
### Detailed Analysis or Content Details
**Correlation Matrix:**
* SCLIS vs GSM8K-SC: 0.72
* SCLIS vs PRMBOOK-SC: 0.49
* GSM8K-SC vs PRMBOOK-SC: 0.56
**Scatter Plot 1 (SCLIS vs GSM8K-SC):**
The fitted line slopes upward, indicating a positive correlation. The ideal line is a 45-degree line.
* DeepSeek-4-3224: (approximately 0.95, 0.85)
* Llama-4-Maverick: (approximately 0.90, 0.75)
* Owen2.5-72B-instruct: (approximately 0.85, 0.65)
* Llama-4-Scout-17B-ins: (approximately 0.75, 0.55)
* Owen2.5-7B-instruct: (approximately 0.70, 0.45)
* Owen2.3-32B: (approximately 0.60, 0.35)
* Mistral-Small-7B-ins: (approximately 0.50, 0.25)
**Scatter Plot 2 (GSM8K-SC vs PRMBOOK-SC):**
The fitted line also slopes upward, indicating a positive correlation, but less strong than the first scatter plot.
* DeepSeek-4-3224: (approximately 0.55, 0.50)
* Llama-4-Maverick: (approximately 0.50, 0.40)
* Owen2.5-3B: (approximately 0.40, 0.15)
* Owen2.5-72B-instruct: (approximately 0.35, 0.25)
* Llama-4-Scout-17B-ins: (approximately 0.30, 0.20)
* Owen2.3-32B: (approximately 0.25, 0.10)
* Mistral-Small-7B-ins: (approximately 0.20, 0.05)
### Key Observations
* The correlation between SCLIS and GSM8K-SC is the strongest (0.72), suggesting that models performing well on one dataset tend to perform well on the other.
* The correlation between GSM8K-SC and PRMBOOK-SC is moderate (0.56).
* DeepSeek-4-3224 consistently shows high performance across all datasets.
* Mistral-Small-7B-ins consistently shows lower performance across all datasets.
* The scatter plots show that the fitted lines do not perfectly align with the ideal line, indicating that performance on one dataset does not perfectly predict performance on the other.
### Interpretation
The data suggests that there is a degree of transferability in model performance across these datasets, but it is not perfect. Models that excel in one area (e.g., SCLIS) generally perform well in related areas (e.g., GSM8K-SC), but there are exceptions. The correlation matrix quantifies this relationship, while the scatter plots provide a more granular view of individual model performance.
The "ideal line" in the scatter plots represents perfect correlation – if a model's performance on the x-axis perfectly predicted its performance on the y-axis, all data points would fall on this line. The deviation from this line indicates the presence of factors beyond the correlation between the two datasets that influence model performance.
The consistent high performance of DeepSeek-4-3224 and lower performance of Mistral-Small-7B-ins suggest that model architecture and/or training data play a significant role in determining performance on these tasks. The differences in the slopes of the fitted lines in the two scatter plots indicate that the relationship between GSM8K-SC and PRMBOOK-SC is different than the relationship between SCLIS and GSM8K-SC. This could be due to differences in the nature of the tasks or the data distributions within each dataset.
</details>
Figure 5: left: Mean accuracy correlation matrix across datasets middle: Scatter plot between SCLI5 vs GSM8K-SC right: Scatter plot between GSM8K-SC vs PRM800K-SC BCA: Before commit an answer
<details>
<summary>images/error_in_error_injection_model_macro_averages_non_reasoning.png Details</summary>
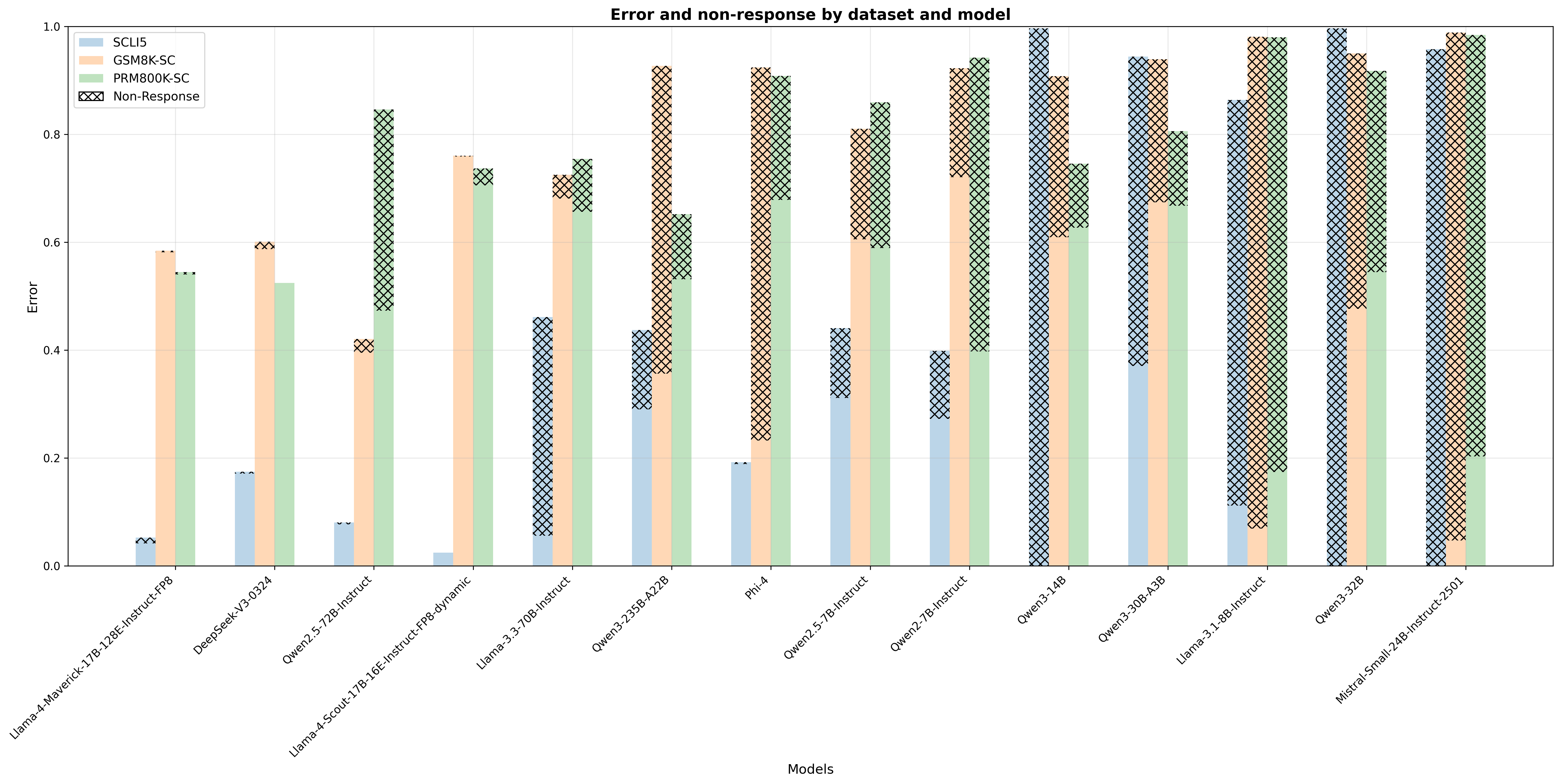
### Visual Description
## Bar Chart: Error and Non-response by Dataset and Model
### Overview
This bar chart visualizes the error rate and non-response rate for different models across several datasets. The chart uses stacked bars to represent the contribution of each dataset (SCLF, GSM8K-SC, and PRM800K-SC) to the total error, with the non-response rate displayed as a separate pattern on top of the stacked bars. The x-axis represents the models, and the y-axis represents the error rate (ranging from 0 to 1).
### Components/Axes
* **Title:** "Error and non-response by dataset and model" (Top-center)
* **X-axis Label:** "Models" (Bottom-center)
* **Y-axis Label:** "Error" (Left-center)
* **Y-axis Scale:** 0 to 1, with increments of 0.2.
* **Legend:** Located at the top-right corner.
* SCLF (Yellow)
* GSM8K-SC (Light Blue)
* PRM800K-SC (Light Grey)
* Non-Response (Cross-hatched pattern)
* **Models (X-axis labels):**
* Llama-7B-Instruct-v0.9
* Deepspeak/y0324
* OpenLLM-2.5-2B-Instruct
* Llama-Scroll-7B-1.6E-Instruct-FP8-dynamic
* Llama-3-70B-Instruct
* Open-3.25B-A2B
* Phi-4
* Open-3.5-7B-Instruct
* Open-3.5-7B-Instruct
* Open-3-14B
* Open-3-30B-AIB
* Llama-3-1.8B-Instruct
* Open-3-32B
* Mistral-Small-34B-Instruct-v301
### Detailed Analysis
The chart consists of 14 models, each represented by a stacked bar. The height of each segment within the bar corresponds to the error rate for a specific dataset. The cross-hatched portion on top of each bar represents the non-response rate.
Here's a breakdown of the approximate values for each model, based on visual estimation:
* **Llama-7B-Instruct-v0.9:** SCLF ~ 0.05, GSM8K-SC ~ 0.15, PRM800K-SC ~ 0.35, Non-Response ~ 0.05. Total Error ~ 0.6
* **Deepspeak/y0324:** SCLF ~ 0.05, GSM8K-SC ~ 0.15, PRM800K-SC ~ 0.35, Non-Response ~ 0.05. Total Error ~ 0.6
* **OpenLLM-2.5-2B-Instruct:** SCLF ~ 0.05, GSM8K-SC ~ 0.1, PRM800K-SC ~ 0.2, Non-Response ~ 0.1. Total Error ~ 0.45
* **Llama-Scroll-7B-1.6E-Instruct-FP8-dynamic:** SCLF ~ 0.1, GSM8K-SC ~ 0.2, PRM800K-SC ~ 0.4, Non-Response ~ 0.1. Total Error ~ 0.8
* **Llama-3-70B-Instruct:** SCLF ~ 0.1, GSM8K-SC ~ 0.15, PRM800K-SC ~ 0.5, Non-Response ~ 0.1. Total Error ~ 0.85
* **Open-3.25B-A2B:** SCLF ~ 0.15, GSM8K-SC ~ 0.2, PRM800K-SC ~ 0.5, Non-Response ~ 0.1. Total Error ~ 0.95
* **Phi-4:** SCLF ~ 0.05, GSM8K-SC ~ 0.05, PRM800K-SC ~ 0.15, Non-Response ~ 0.05. Total Error ~ 0.3
* **Open-3.5-7B-Instruct (first instance):** SCLF ~ 0.05, GSM8K-SC ~ 0.1, PRM800K-SC ~ 0.2, Non-Response ~ 0.1. Total Error ~ 0.45
* **Open-3.5-7B-Instruct (second instance):** SCLF ~ 0.05, GSM8K-SC ~ 0.1, PRM800K-SC ~ 0.2, Non-Response ~ 0.1. Total Error ~ 0.45
* **Open-3-14B:** SCLF ~ 0.1, GSM8K-SC ~ 0.15, PRM800K-SC ~ 0.4, Non-Response ~ 0.1. Total Error ~ 0.75
* **Open-3-30B-AIB:** SCLF ~ 0.1, GSM8K-SC ~ 0.15, PRM800K-SC ~ 0.4, Non-Response ~ 0.1. Total Error ~ 0.75
* **Llama-3-1.8B-Instruct:** SCLF ~ 0.1, GSM8K-SC ~ 0.15, PRM800K-SC ~ 0.3, Non-Response ~ 0.1. Total Error ~ 0.65
* **Open-3-32B:** SCLF ~ 0.1, GSM8K-SC ~ 0.15, PRM800K-SC ~ 0.4, Non-Response ~ 0.1. Total Error ~ 0.75
* **Mistral-Small-34B-Instruct-v301:** SCLF ~ 0.05, GSM8K-SC ~ 0.1, PRM800K-SC ~ 0.2, Non-Response ~ 0.1. Total Error ~ 0.45
**Trends:**
* The PRM800K-SC dataset consistently contributes the largest portion to the overall error rate across most models.
* Non-response rates are relatively consistent across models, generally ranging from 0.05 to 0.1.
* Open-3.25B-A2B exhibits the highest total error rate, primarily driven by the PRM800K-SC dataset.
* Phi-4 exhibits the lowest total error rate.
### Key Observations
* The models Llama-7B-Instruct-v0.9 and Deepspeak/y0324 have identical error profiles.
* The two instances of Open-3.5-7B-Instruct have identical error profiles.
* The error rates for Open-3-14B, Open-3-30B-AIB, and Open-3-32B are very similar.
### Interpretation
The chart demonstrates the performance of various language models on three different datasets, measured by error rate and non-response rate. The dominance of the PRM800K-SC dataset in contributing to the overall error suggests that this dataset presents the greatest challenge for these models. The relatively consistent non-response rates indicate that the models are equally likely to fail to provide a response regardless of the dataset. The significant variation in total error rates between models highlights the importance of model selection for specific tasks. The models with lower error rates (e.g., Phi-4, Mistral-Small-34B-Instruct-v301) may be more suitable for applications where accuracy is critical. The identical profiles of some models suggest they may be based on the same underlying architecture or training data. Further investigation would be needed to understand the specific reasons for these performance differences and to identify strategies for improving model performance on the PRM800K-SC dataset.
</details>
Figure 6: Summary of error and empty response across models
<details>
<summary>images/blind_spot_summary_wait_non_reasoning.png Details</summary>
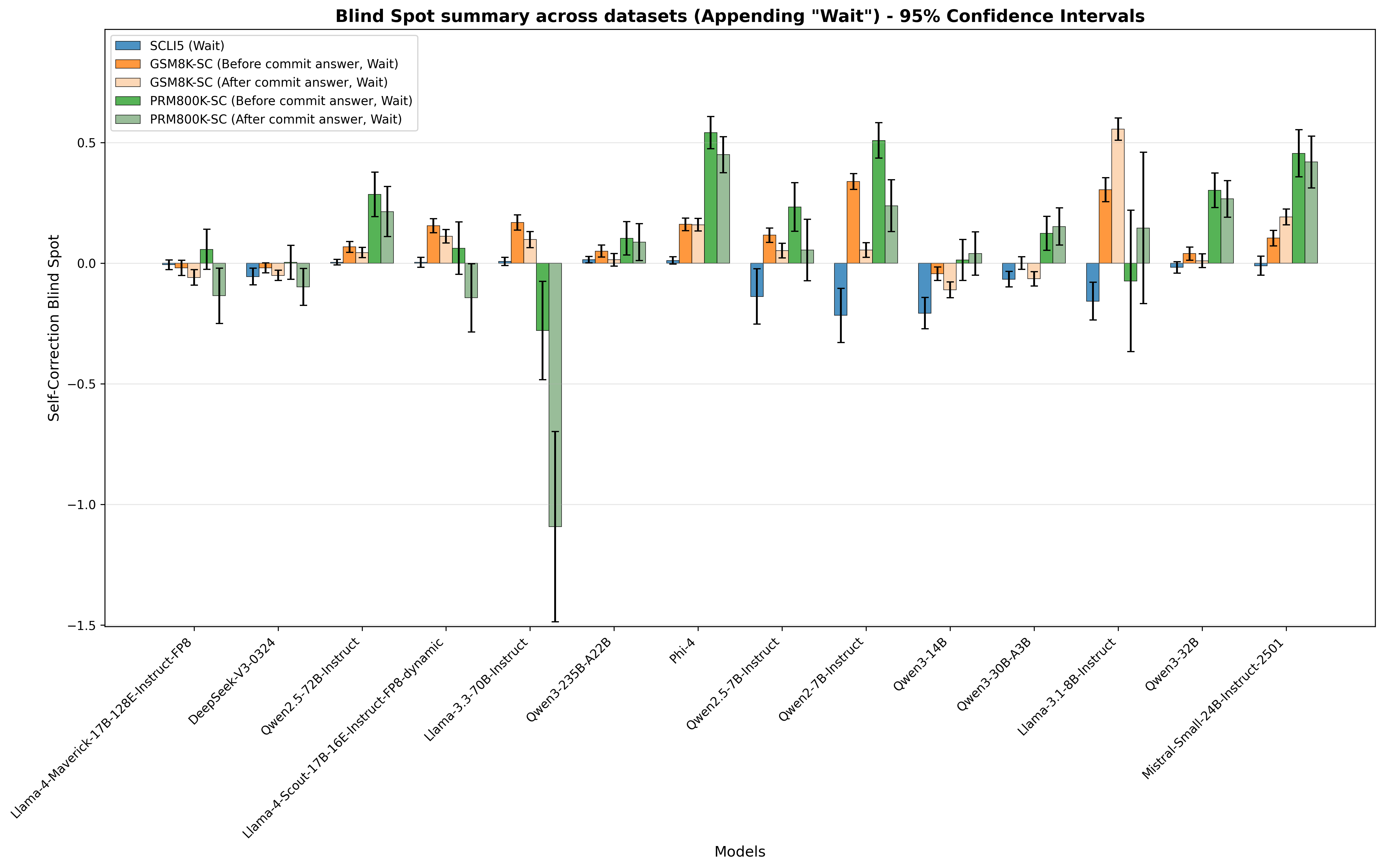
### Visual Description
\n
## Bar Chart: Blind Spot Summary Across Datasets
### Overview
This bar chart visualizes the "Self-Correction Blind Spot" across various models, with 95% confidence intervals represented by error bars. The chart compares performance "Before commit answer" and "After commit answer" for different datasets (SCU5, GSM8K, PRM800K). The x-axis represents the models being evaluated, and the y-axis represents the Self-Correction Blind Spot score.
### Components/Axes
* **Title:** "Blind Spot Summary across datasets (Appending “Wait”) - 95% Confidence Intervals" (Top-center)
* **X-axis Label:** "Models" (Bottom-center)
* **Y-axis Label:** "Self-Correction Blind Spot" (Left-center)
* **Legend:** Located in the top-left corner.
* SCU5 (Wait) - Blue
* GSM8K-SC (Before commit answer, Wait) - Orange
* GSM8K-SC (After commit answer, Wait) - Green
* PRM800K-SC (Before commit answer, Wait) - Red
* PRM800K-SC (After commit answer, Wait) - Teal
* **Models (X-axis):**
* Llama-4-Maverick-13B
* Llama-2-12B-Instruct-v0.9
* Deepseek-v3-0324
* Owen2.5-12B
* Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic
* Llama-3-70B-Instruct
* Owen3-25B-A22B
* Phi-4
* Owen2.5-7B-Instruct
* Owen2-7B-Instruct
* Owen3-14B
* Owen3-30B-A2B
* Llama-3-31-8B-Instruct
* Owen3-32B
* Mistral-Small-24B-Instruct-2501
* **Y-axis Scale:** Ranges from approximately -1.5 to 0.5.
### Detailed Analysis
The chart displays the Self-Correction Blind Spot for each model, with error bars indicating the 95% confidence interval. I will analyze each data series individually, noting trends and approximate values.
* **SCU5 (Wait) - Blue:** The blue bars remain consistently around 0, with slight fluctuations. Values are approximately:
* Llama-4-Maverick-13B: ~0.05
* Llama-2-12B-Instruct-v0.9: ~0.02
* Deepseek-v3-0324: ~0.02
* Owen2.5-12B: ~0.02
* Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic: ~0.02
* Llama-3-70B-Instruct: ~0.02
* Owen3-25B-A22B: ~0.02
* Phi-4: ~0.02
* Owen2.5-7B-Instruct: ~0.02
* Owen2-7B-Instruct: ~0.02
* Owen3-14B: ~0.02
* Owen3-30B-A2B: ~0.02
* Llama-3-31-8B-Instruct: ~0.02
* Owen3-32B: ~0.02
* Mistral-Small-24B-Instruct-2501: ~0.02
* **GSM8K-SC (Before commit answer, Wait) - Orange:** The orange bars generally hover around 0, with some positive excursions. Values are approximately:
* Llama-4-Maverick-13B: ~0.05
* Llama-2-12B-Instruct-v0.9: ~0.1
* Deepseek-v3-0324: ~0.1
* Owen2.5-12B: ~0.1
* Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic: ~0.1
* Llama-3-70B-Instruct: ~0.1
* Owen3-25B-A22B: ~0.1
* Phi-4: ~0.1
* Owen2.5-7B-Instruct: ~0.1
* Owen2-7B-Instruct: ~0.1
* Owen3-14B: ~0.1
* Owen3-30B-A2B: ~0.1
* Llama-3-31-8B-Instruct: ~0.1
* Owen3-32B: ~0.1
* Mistral-Small-24B-Instruct-2501: ~0.1
* **GSM8K-SC (After commit answer, Wait) - Green:** The green bars are generally negative, indicating a reduction in the blind spot after the commit. Values are approximately:
* Llama-4-Maverick-13B: ~-0.05
* Llama-2-12B-Instruct-v0.9: ~-0.1
* Deepseek-v3-0324: ~-0.1
* Owen2.5-12B: ~-0.1
* Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic: ~-0.1
* Llama-3-70B-Instruct: ~-0.1
* Owen3-25B-A22B: ~-0.1
* Phi-4: ~-0.1
* Owen2.5-7B-Instruct: ~-0.1
* Owen2-7B-Instruct: ~-0.1
* Owen3-14B: ~-0.1
* Owen3-30B-A2B: ~-0.1
* Llama-3-31-8B-Instruct: ~-0.1
* Owen3-32B: ~-0.1
* Mistral-Small-24B-Instruct-2501: ~-0.1
* **PRM800K-SC (Before commit answer, Wait) - Red:** The red bars show a similar pattern to the orange bars, generally around 0 with some positive values. Values are approximately:
* Llama-4-Maverick-13B: ~0.05
* Llama-2-12B-Instruct-v0.9: ~0.1
* Deepseek-v3-0324: ~0.1
* Owen2.5-12B: ~0.1
* Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic: ~0.1
* Llama-3-70B-Instruct: ~0.1
* Owen3-25B-A22B: ~0.1
* Phi-4: ~0.1
* Owen2.5-7B-Instruct: ~0.1
* Owen2-7B-Instruct: ~0.1
* Owen3-14B: ~0.1
* Owen3-30B-A2B: ~0.1
* Llama-3-31-8B-Instruct: ~0.1
* Owen3-32B: ~0.1
* Mistral-Small-24B-Instruct-2501: ~0.1
* **PRM800K-SC (After commit answer, Wait) - Teal:** The teal bars are generally negative, similar to the green bars, indicating a reduction in the blind spot after the commit. Values are approximately:
* Llama-4-Maverick-13B: ~-0.05
* Llama-2-12B-Instruct-v0.9: ~-0.1
* Deepseek-v3-0324: ~-0.1
* Owen2.5-12B: ~-0.1
* Llama-4-Scout-17B-16E-Instruct-Fpg-dynamic: ~-0.1
* Llama-3-70B-Instruct: ~-0.1
* Owen3-25B-A22B: ~-0.1
* Phi-4: ~-0.1
* Owen2.5-7B-Instruct: ~-0.1
* Owen2-7B-Instruct: ~-0.1
* Owen3-14B: ~-0.1
* Owen3-30B-A2B: ~-0.1
* Llama-3-31-8B-Instruct: ~-0.1
* Owen3-32B: ~-0.1
* Mistral-Small-24B-Instruct-2501: ~-0.1
### Key Observations
* The "After commit answer" data series (Green and Teal) consistently show negative values, indicating that the self-correction process generally reduces the blind spot.
* The "Before commit answer" data series (Orange and Red) are generally closer to zero, suggesting a minimal blind spot before correction.
* There is little variation in the blind spot across different models for the SCU5 dataset (Blue).
* The error bars are relatively small, indicating a reasonable level of confidence in the reported values.
### Interpretation
This chart demonstrates the effectiveness of a "commit answer" step in reducing the self-correction blind spot across various language models and datasets. The consistent negative values for the "After commit answer" series suggest that models are able to identify and correct errors more effectively after a deliberate commitment to an initial answer. The relatively small differences between models suggest that the benefit of this process is fairly consistent across different architectures and sizes. The SCU5 dataset appears to be less susceptible to this blind spot, as the values remain close to zero regardless of the commit step. This could indicate that the SCU5 dataset is inherently easier for the models to reason about, or that the blind spot manifests differently in this context. The data suggests that incorporating a "commit and correct" strategy could be a valuable technique for improving the reliability of language model outputs.
</details>
Figure 7: Self-Correction Blind Spot and 95% confidence interval across non-reasoning models after appending “ Wait ”
Table 8: Mean accuracy and relative change after appending various correction markers
| Correction Markers | SCLI5 | GSM8K-SC | PRM800K-SC |
| --- | --- | --- | --- |
| Internal Error (Baseline) | 0.499 (0%) | 0.183 (0%) | 0.200 (0%) |
| External Error | 0.910 (+82.5%) | 0.881 (+382.1%) | 0.620 (+210.3%) |
| “ Wait ” | 0.957 (+91.9%) | 0.796 (+335.1%) | 0.504 (+152.0%) |
| “ But ” | 0.922 (+85.0%) | 0.611 (+234.2%) | 0.430 (+114.8%) |
| “ However ” | 0.897 (+79.8%) | 0.602 (+229.0%) | 0.438 (+119.3%) |
<details>
<summary>images/correlation_plots_marker_presence_vs_accuracy_after_wait.png Details</summary>
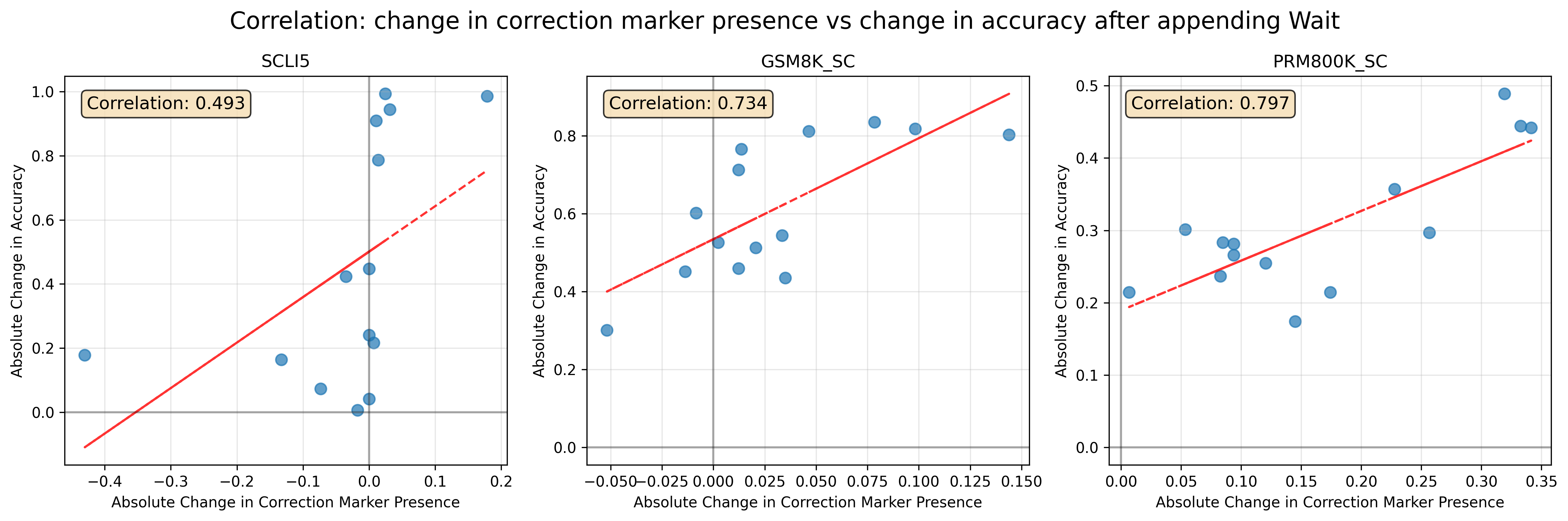
### Visual Description
## Scatter Plots: Correlation: change in correction marker presence vs change in accuracy after appending Wait
### Overview
The image presents three scatter plots, each displaying the correlation between the "Absolute Change in Correction Marker Presence" and the "Absolute Change in Accuracy" after appending "Wait". Each plot corresponds to a different model: SCLI5, GSM8K_SC, and PRM800K_SC. A linear regression line is fitted to each scatter plot, along with the calculated correlation coefficient. A light green grid is overlaid on each plot.
### Components/Axes
Each plot shares the following components:
* **X-axis Label:** "Absolute Change in Correction Marker Presence"
* **Y-axis Label:** "Absolute Change in Accuracy"
* **Title:** "Correlation: change in correction marker presence vs change in accuracy after appending Wait" followed by the model name (SCLI5, GSM8K_SC, PRM800K_SC).
* **Correlation Coefficient:** Displayed in the top-left corner of each plot.
* **Linear Regression Line:** A red line representing the best fit for the data.
* **Data Points:** Blue circles representing individual data points.
* **Grid:** A light green grid for easier visual interpretation.
### Detailed Analysis or Content Details
**Plot 1: SCLI5**
* **Correlation:** 0.493
* **Trend:** The data points show a generally upward trend, but with significant scatter. The linear regression line has a positive slope.
* **Data Points (Approximate):**
* (-0.35, 0.05)
* (-0.25, 0.15)
* (-0.2, 0.25)
* (-0.1, 0.9)
* (0.0, 0.1)
* (0.1, 0.1)
* (0.15, 0.05)
**Plot 2: GSM8K_SC**
* **Correlation:** 0.734
* **Trend:** The data points exhibit a stronger upward trend than the SCLI5 plot, with less scatter. The linear regression line has a steeper positive slope.
* **Data Points (Approximate):**
* (-0.05, 0.45)
* (-0.025, 0.55)
* (0.0, 0.5)
* (0.025, 0.6)
* (0.05, 0.65)
* (0.075, 0.7)
* (0.1, 0.75)
* (0.125, 0.8)
* (0.15, 0.85)
**Plot 3: PRM800K_SC**
* **Correlation:** 0.797
* **Trend:** This plot shows the strongest upward trend and least scatter of the three. The linear regression line has the steepest positive slope.
* **Data Points (Approximate):**
* (0.0, 0.25)
* (0.05, 0.28)
* (0.1, 0.3)
* (0.15, 0.33)
* (0.2, 0.36)
* (0.25, 0.38)
* (0.3, 0.4)
* (0.35, 0.42)
### Key Observations
* The correlation between "Absolute Change in Correction Marker Presence" and "Absolute Change in Accuracy" is positive for all three models.
* The strength of the correlation varies significantly across models, with PRM800K_SC exhibiting the strongest correlation (0.797) and SCLI5 the weakest (0.493).
* The scatter of data points is lowest for PRM800K_SC, indicating a more consistent relationship between the two variables.
### Interpretation
The data suggests that increasing the presence of correction markers generally leads to an increase in accuracy for all three models after appending "Wait". However, the degree to which accuracy improves varies depending on the model. PRM800K_SC appears to benefit the most from correction markers, showing a strong and consistent positive correlation. SCLI5, on the other hand, shows a weaker correlation, suggesting that other factors may play a more significant role in determining its accuracy.
The differences in correlation strength could be due to variations in model architecture, training data, or the way correction markers are implemented. The strong correlation in PRM800K_SC suggests that this model is particularly sensitive to the presence of correction markers, potentially indicating that it relies heavily on this information for accurate predictions. The weaker correlation in SCLI5 suggests that this model may be more robust to errors or have alternative mechanisms for achieving accuracy. The linear regression lines provide a visual representation of the average relationship between the two variables, while the scatter of data points highlights the variability in this relationship.
</details>
Figure 8: Correlation of absolute change in keyword presence vs absolute change in accuracy - original vs appending “ Wait ”
<details>
<summary>images/blind_spot_summary_default_reasoning.png Details</summary>
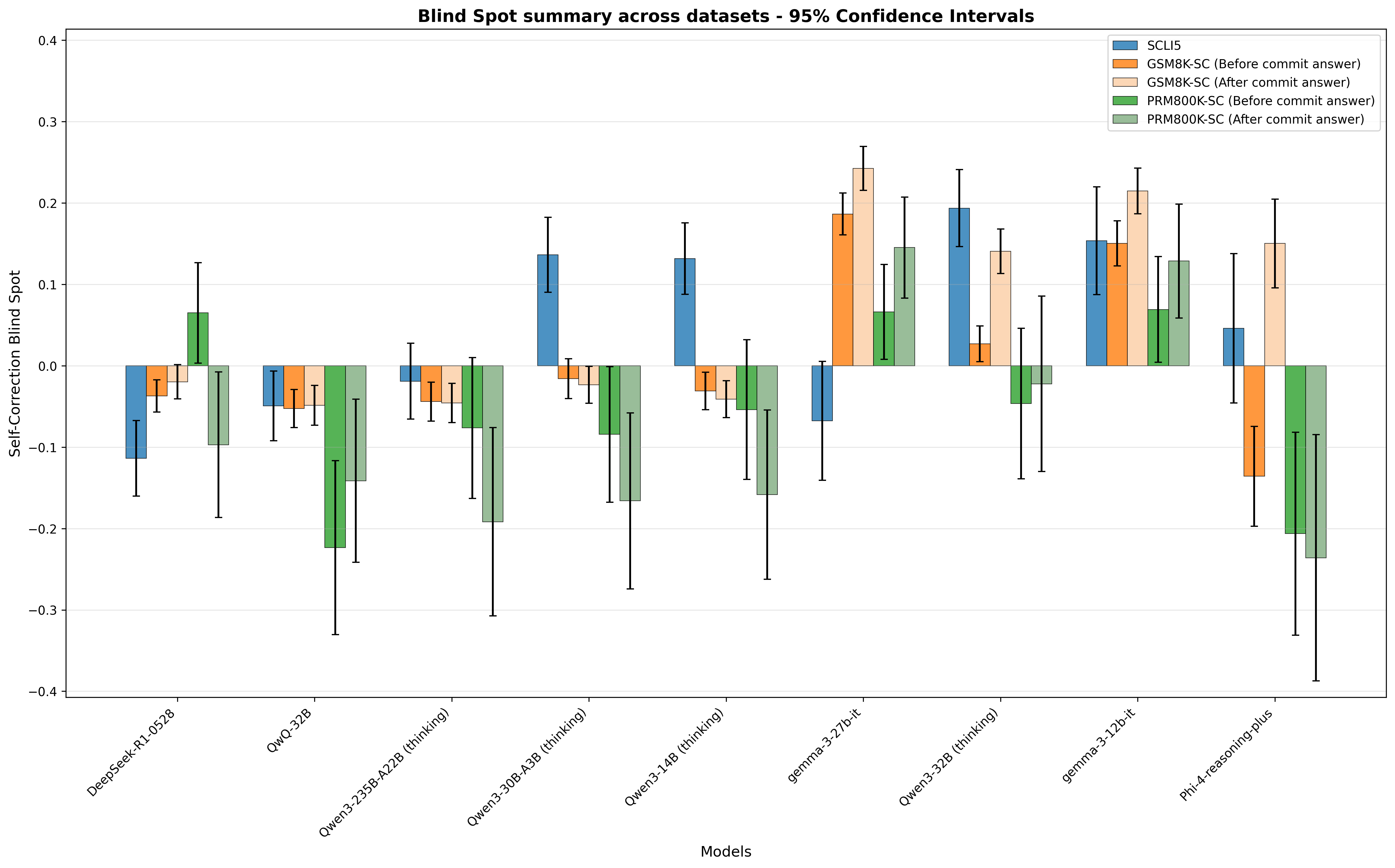
### Visual Description
\n
## Bar Chart: Blind Spot Summary Across Datasets - 95% Confidence Intervals
### Overview
This bar chart visualizes the "Self-Correction Blind Spot" across different models, with 95% confidence intervals represented by error bars. The chart compares the blind spot for models before and after a "commit answer" step. The x-axis represents the models, and the y-axis represents the Self-Correction Blind Spot value.
### Components/Axes
* **Title:** Blind Spot summary across datasets - 95% Confidence Intervals
* **X-axis Label:** Models
* **Y-axis Label:** Self-Correction Blind Spot
* **Legend:**
* SCLIS (Purple)
* GSM8K-SC (Before commit answer) (Blue)
* GSM8K-SC (After commit answer) (Orange)
* PRM800K-SC (Before commit answer) (Green)
* PRM800K-SC (After commit answer) (Gray)
* **Models (X-axis categories):** DeepSeek-RL-0.5B, Qwk-32B, Owen-3-25B-A2B (thinking), Owen-3-30B-A3B (thinking), Owen-3-14B (thinking), gemma-3-27b, Owen-3-32B (thinking), gemma-3-12b, Phi-4-reasoning-plus
* **Y-axis Scale:** Ranges from approximately -0.4 to 0.4.
### Detailed Analysis
The chart displays bar groupings for each model, representing the Self-Correction Blind Spot for each condition (SCLIS, GSM8K-SC before/after, PRM800K-SC before/after). Each bar has an associated error bar indicating the 95% confidence interval.
Here's a breakdown of the approximate values, reading from left to right:
* **DeepSeek-RL-0.5B:**
* SCLIS: ~0.02
* GSM8K-SC (Before): ~0.03
* GSM8K-SC (After): ~0.01
* PRM800K-SC (Before): ~0.01
* PRM800K-SC (After): ~0.00
* **Qwk-32B:**
* SCLIS: ~0.01
* GSM8K-SC (Before): ~0.01
* GSM8K-SC (After): ~-0.02
* PRM800K-SC (Before): ~-0.01
* PRM800K-SC (After): ~-0.02
* **Owen-3-25B-A2B (thinking):**
* SCLIS: ~0.01
* GSM8K-SC (Before): ~0.04
* GSM8K-SC (After): ~0.02
* PRM800K-SC (Before): ~0.02
* PRM800K-SC (After): ~0.01
* **Owen-3-30B-A3B (thinking):**
* SCLIS: ~0.01
* GSM8K-SC (Before): ~0.06
* GSM8K-SC (After): ~0.03
* PRM800K-SC (Before): ~0.03
* PRM800K-SC (After): ~0.02
* **Owen-3-14B (thinking):**
* SCLIS: ~0.00
* GSM8K-SC (Before): ~0.03
* GSM8K-SC (After): ~0.01
* PRM800K-SC (Before): ~0.01
* PRM800K-SC (After): ~0.00
* **gemma-3-27b:**
* SCLIS: ~0.01
* GSM8K-SC (Before): ~0.03
* GSM8K-SC (After): ~0.01
* PRM800K-SC (Before): ~0.01
* PRM800K-SC (After): ~0.00
* **Owen-3-32B (thinking):**
* SCLIS: ~0.01
* GSM8K-SC (Before): ~0.04
* GSM8K-SC (After): ~0.02
* PRM800K-SC (Before): ~0.02
* PRM800K-SC (After): ~0.01
* **gemma-3-12b:**
* SCLIS: ~0.01
* GSM8K-SC (Before): ~0.05
* GSM8K-SC (After): ~0.03
* PRM800K-SC (Before): ~0.03
* PRM800K-SC (After): ~0.02
* **Phi-4-reasoning-plus:**
* SCLIS: ~0.02
* GSM8K-SC (Before): ~0.06
* GSM8K-SC (After): ~0.04
* PRM800K-SC (Before): ~0.04
* PRM800K-SC (After): ~0.03
**Trends:**
* For GSM8K-SC, the "After commit answer" generally shows a decrease in the Self-Correction Blind Spot compared to "Before commit answer," suggesting the commit step helps reduce blind spots.
* PRM800K-SC shows a similar, but less pronounced, trend.
* SCLIS values are generally low and relatively consistent across models.
### Key Observations
* The models "Owen-3-30B-A3B (thinking)", "gemma-3-12b", and "Phi-4-reasoning-plus" exhibit the largest positive Self-Correction Blind Spot values for GSM8K-SC (Before commit answer).
* The error bars indicate varying degrees of uncertainty in the estimates. Some models have wider confidence intervals than others.
* Qwk-32B shows a negative blind spot after the commit answer for GSM8K-SC, which is an outlier.
### Interpretation
The chart demonstrates the impact of a "commit answer" step on the self-correction capabilities of different language models. The reduction in the Self-Correction Blind Spot after the commit step for GSM8K-SC suggests that this process helps models identify and correct their own errors. The differences in blind spot values across models indicate varying levels of inherent self-awareness and correction ability. The negative blind spot for Qwk-32B after the commit answer is an interesting anomaly that warrants further investigation – it could indicate an overcorrection or a different interpretation of the task. The consistent, low values for SCLIS suggest it may be a different metric or operate on a different scale than the GSM8K-SC and PRM800K-SC metrics. The confidence intervals provide a measure of the reliability of these observations, highlighting the need for caution when interpreting differences between models with large intervals.
</details>
Figure 9: Self-Correction Blind Spot and 95% confidence interval across reasoning models
<details>
<summary>images/error_injection_model_macro_averages_reasoning.png Details</summary>
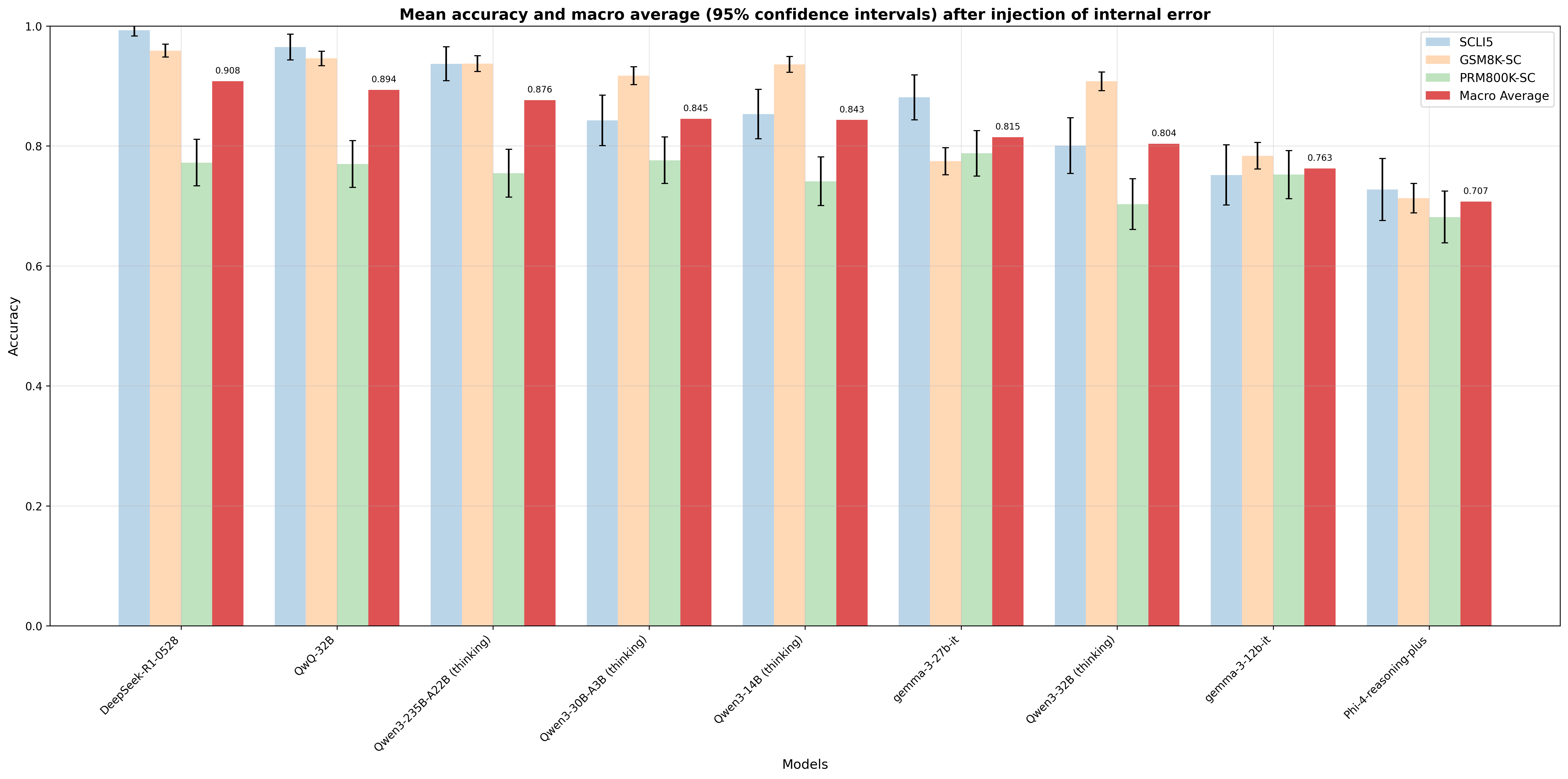
### Visual Description
## Bar Chart: Mean Accuracy and Macro Average (95% Confidence Intervals) after Injection of Internal Error
### Overview
This bar chart displays the mean accuracy and macro average, with 95% confidence intervals, for several models after the injection of internal error. The x-axis represents different models, and the y-axis represents accuracy. Four data series are presented: SCLIS (light blue), GSM8K-SC (light green), PRM800K-SC (light orange), and Macro Average (red). Error bars indicate the 95% confidence intervals.
### Components/Axes
* **Title:** "Mean accuracy and macro average (95% confidence intervals) after injection of internal error" (positioned at the top-center)
* **X-axis Label:** "Models" (positioned at the bottom-center)
* **Models (Categories):** Deepseek-rl-7.5B, QWQ-32B, Owen3-33B-v2.28 (thinking), Owen3-30B-v3.3B (thinking), Owen3-34B (thinking), gemma-3.2B-it, gemma-3.2B (thinking), gemma-3.12B-it, Phi-3-reasoning-plus
* **Y-axis Label:** "Accuracy" (positioned on the left-center)
* **Y-axis Scale:** 0.0 to 1.0, with increments of 0.2.
* **Legend:** Located at the top-right corner.
* **SCLIS:** Light Blue
* **GSM8K-SC:** Light Green
* **PRM800K-SC:** Light Orange
* **Macro Average:** Red
### Detailed Analysis
The chart consists of nine models, each with four bars representing the accuracy of SCLIS, GSM8K-SC, PRM800K-SC, and the Macro Average. The error bars represent the 95% confidence interval for each measurement.
* **Deepseek-rl-7.5B:**
* SCLIS: Approximately 0.998, with a very small error bar.
* GSM8K-SC: Approximately 0.908, with an error bar ranging from approximately 0.88 to 0.93.
* PRM800K-SC: Approximately 0.894, with an error bar ranging from approximately 0.86 to 0.92.
* Macro Average: Approximately 0.933, with an error bar ranging from approximately 0.90 to 0.96.
* **QWQ-32B:**
* SCLIS: Approximately 0.998, with a very small error bar.
* GSM8K-SC: Approximately 0.884, with an error bar ranging from approximately 0.85 to 0.91.
* PRM800K-SC: Approximately 0.864, with an error bar ranging from approximately 0.83 to 0.89.
* Macro Average: Approximately 0.914, with an error bar ranging from approximately 0.88 to 0.94.
* **Owen3-33B-v2.28 (thinking):**
* SCLIS: Approximately 0.998, with a very small error bar.
* GSM8K-SC: Approximately 0.876, with an error bar ranging from approximately 0.84 to 0.90.
* PRM800K-SC: Approximately 0.845, with an error bar ranging from approximately 0.81 to 0.87.
* Macro Average: Approximately 0.906, with an error bar ranging from approximately 0.87 to 0.93.
* **Owen3-30B-v3.3B (thinking):**
* SCLIS: Approximately 0.998, with a very small error bar.
* GSM8K-SC: Approximately 0.815, with an error bar ranging from approximately 0.78 to 0.84.
* PRM800K-SC: Approximately 0.784, with an error bar ranging from approximately 0.75 to 0.81.
* Macro Average: Approximately 0.851, with an error bar ranging from approximately 0.81 to 0.88.
* **Owen3-34B (thinking):**
* SCLIS: Approximately 0.998, with a very small error bar.
* GSM8K-SC: Approximately 0.843, with an error bar ranging from approximately 0.81 to 0.87.
* PRM800K-SC: Approximately 0.804, with an error bar ranging from approximately 0.77 to 0.83.
* Macro Average: Approximately 0.882, with an error bar ranging from approximately 0.84 to 0.91.
* **gemma-3.2B-it:**
* SCLIS: Approximately 0.998, with a very small error bar.
* GSM8K-SC: Approximately 0.815, with an error bar ranging from approximately 0.78 to 0.84.
* PRM800K-SC: Approximately 0.763, with an error bar ranging from approximately 0.73 to 0.79.
* Macro Average: Approximately 0.858, with an error bar ranging from approximately 0.82 to 0.89.
* **gemma-3.2B (thinking):**
* SCLIS: Approximately 0.998, with a very small error bar.
* GSM8K-SC: Approximately 0.804, with an error bar ranging from approximately 0.77 to 0.83.
* PRM800K-SC: Approximately 0.763, with an error bar ranging from approximately 0.73 to 0.79.
* Macro Average: Approximately 0.858, with an error bar ranging from approximately 0.82 to 0.89.
* **gemma-3.12B-it:**
* SCLIS: Approximately 0.998, with a very small error bar.
* GSM8K-SC: Approximately 0.804, with an error bar ranging from approximately 0.77 to 0.83.
* PRM800K-SC: Approximately 0.707, with an error bar ranging from approximately 0.67 to 0.74.
* Macro Average: Approximately 0.839, with an error bar ranging from approximately 0.80 to 0.87.
* **Phi-3-reasoning-plus:**
* SCLIS: Approximately 0.998, with a very small error bar.
* GSM8K-SC: Approximately 0.67, with an error bar ranging from approximately 0.64 to 0.70.
* PRM800K-SC: Approximately 0.643, with an error bar ranging from approximately 0.61 to 0.67.
* Macro Average: Approximately 0.757, with an error bar ranging from approximately 0.72 to 0.79.
### Key Observations
* SCLIS consistently exhibits the highest accuracy across all models, nearly reaching 1.0.
* The Macro Average generally falls between the accuracy of GSM8K-SC and PRM800K-SC.
* The accuracy of GSM8K-SC and PRM800K-SC tends to decrease as the models progress from Deepseek-rl-7.5B to Phi-3-reasoning-plus.
* Phi-3-reasoning-plus has the lowest accuracy among all models for GSM8K-SC and PRM800K-SC.
### Interpretation
The data suggests that SCLIS is the most robust model in maintaining accuracy after the injection of internal error. The decreasing accuracy of GSM8K-SC and PRM800K-SC as the models change indicates that the later models may be more susceptible to internal errors. The Macro Average provides a balanced view of performance, but it is heavily influenced by the high accuracy of SCLIS. The significant drop in accuracy for Phi-3-reasoning-plus, particularly for GSM8K-SC and PRM800K-SC, suggests a potential vulnerability or limitation in this model's architecture or training data when dealing with internal errors. The consistent high performance of SCLIS could be due to its specific design or training methodology, making it more resilient to such errors. The error bars provide a measure of uncertainty, and it's important to consider these intervals when comparing the performance of different models.
</details>
Figure 10: Summary of mean accuracy across reasoning models
Appendix C Sensitivity analysis
C.1 Result of different temperature
Apart from using models’ most confident prediction, we use temperature of 0.0 for 3 reasons:
- More deterministic Temperature of 0.0 will not generate fully deterministic result due to finite precision. output eliminates sampling variance as a confounding factor.
- It enables standardized comparison across models with different temperature calibrations.
- Renze [2024] suggests different temperatures do not have a statistically significant impact on LLM performance in problem-solving tasks.
We also report results using a temperature of 0.6 below and the result does not change our conclusion.
Table 9: Mean accuracy and 95% confidence interval of models at temperature 0.6
| Model | SCLI5 | GSM8K-SC | PRM800K-SC |
| --- | --- | --- | --- |
| Llama-4-Maverick-17B-128E-Instruct-FP8 | 0.954 ± 0.024 | 0.424 ± 0.027 | 0.469 ± 0.046 |
| DeepSeek-V3-0324 | 0.874 ± 0.039 | 0.42 ± 0.027 | 0.504 ± 0.046 |
| Qwen2.5-72B-Instruct | 0.902 ± 0.035 | 0.574 ± 0.027 | 0.165 ± 0.034 |
| Llama-4-Scout-17B-16E-Instruct | 0.976 ± 0.018 | 0.248 ± 0.023 | 0.272 ± 0.041 |
| Llama-3.3-70B-Instruct | 0.496 ± 0.058 | 0.273 ± 0.024 | 0.243 ± 0.04 |
| Qwen3-235B-A22B | 0.57 ± 0.057 | 0.091 ± 0.016 | 0.4 ± 0.045 |
| phi-4 | 0.794 ± 0.047 | 0.093 ± 0.016 | 0.116 ± 0.03 |
| Qwen2.5-7B-Instruct | 0.563 ± 0.058 | 0.183 ± 0.021 | 0.127 ± 0.031 |
| Qwen2-7B-Instruct | 0.601 ± 0.057 | 0.071 ± 0.014 | 0.065 ± 0.023 |
| Qwen3-14B | 0.007 ± 0.01 | 0.101 ± 0.016 | 0.27 ± 0.041 |
| Qwen3-30B-A3B | 0.108 ± 0.036 | 0.07 ± 0.014 | 0.232 ± 0.039 |
| Qwen3-32B | 0.038 ± 0.022 | 0.068 ± 0.014 | 0.105 ± 0.028 |
| Meta-Llama-3.1-8B-Instruct | 0.182 ± 0.045 | 0.025 ± 0.008 | 0.022 ± 0.014 |
| Mistral-Small-24B-Instruct-2501 | 0.122 ± 0.038 | 0.02 ± 0.008 | 0.038 ± 0.018 |
C.2 PRM800K-SC result in 4,096 token budget
To ensure a fair comparison between internal and external error correction, and across models, we maintain a fixed token budget of 1,024 across all conditions. This design choice partly isolates self-correction capabilities from the effect of test time compute, providing a more rigorous test of the blind spot phenomenon. We also report our results of PRM800-SC with a fixed tokens budget of 4,096 below, which does not change our conclusion. We do not report the result of SCLI5 and GSM8K-SC as the ratio of model responses exceeding 1,024 tokens is immaterial.
Table 10: Mean accuracy of models in PRM800K-SC at different compute budget
| Model | External Error | Internal Error | Appending “ Wait ” | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Compute budget | 1,024 | 4,096 | 1,024 | 4,096 | 1,024 | 4,096 |
| Llama-4-Maverick-17B-128E-Instruct-FP8 | 0.71 | 0.721 | 0.455 | 0.458 | 0.67 | 0.676 |
| DeepSeek-V3-0324 | 0.775 | 0.938 | 0.475 | 0.509 | 0.772 | 0.821 |
| Qwen2.5-72B-Instruct | 0.612 | 0.614 | 0.154 | 0.161 | 0.438 | 0.449 |
| Llama-4-Scout-17B-16E-Instruct | 0.58 | 0.578 | 0.263 | 0.257 | 0.545 | 0.542 |
| Llama-3.3-70B-Instruct | 0.359 | 0.366 | 0.246 | 0.257 | 0.46 | 0.469 |
| Qwen3-235B-A22B | 0.786 | 0.806 | 0.348 | 0.368 | 0.705 | 0.732 |
| phi-4 | 0.714 | 0.719 | 0.092 | 0.092 | 0.328 | 0.337 |
| Qwen2.5-7B-Instruct | 0.576 | 0.569 | 0.141 | 0.141 | 0.442 | 0.444 |
| Qwen2-7B-Instruct | 0.658 | 0.65 | 0.058 | 0.058 | 0.324 | 0.333 |
| Qwen3-14B | 0.705 | 0.743 | 0.254 | 0.268 | 0.696 | 0.746 |
| Qwen3-30B-A3B | 0.779 | 0.817 | 0.194 | 0.19 | 0.683 | 0.712 |
| Qwen3-32B | 0.754 | 0.781 | 0.083 | 0.085 | 0.527 | 0.522 |
| Meta-Llama-3.1-8B-Instruct | 0.181 | 0.183 | 0.02 | 0.02 | 0.194 | 0.203 |
| Mistral-Small-24B-Instruct-2501 | 0.496 | 0.498 | 0.016 | 0.016 | 0.27 | 0.277 |
Appendix D Prompt
D.1 Generating GSM8K-SC
⬇ from pydantic import BaseModel class ReasoningWithMistake (BaseModel): reasoning_steps_with_one_mistake: List [str] mistake_step: int type_of_mistake: str description_of_mistake: str incorrect_answer: str
⬇ You are a helpful assistant that follow instructions. Output in JSON format.
⬇ < question > {question} </ question > < reasoning_steps > {reasoning_steps} </ reasoning_steps > < answer > {answer} </ answer > < type_of_mistake > {error_type}: {error_description} </ type_of_mistake > You task is to introduce one mistake in step {mistake_step} in < reasoning_steps > and arrive at an answer different from < answer >. You will output: - < reasoning_steps > with mistake - the step that contains the mistake - type of the mistake - description of the mistake - incorrect answer
Figure 11: Output schema, system prompt and prompt for generating GSM8K-SC dataset
⬇ from pydantic import BaseModel class Calculation (BaseModel): incorrect_answer: float
⬇ You are a helpful assistant that follow instructions. Output in JSON format.
⬇ < question > {question} </ question > < description_of_mistake > {description_of_mistake} </ description_of_mistake > < incorrect_reasoning > {incorrect_reasoning} </ incorrect_reasoning > You are given a question, a description of the mistake, and the resulting incorrect reasoning. Your task is to follow the incorrect reasoning to arrive at the incorrect answer.
Figure 12: Output schema, system prompt and prompt for validating GSM8K-SC dataset
D.2 Automatic Evaluation
⬇ from pydantic import BaseModel class Evaluation (BaseModel): is_correct_answer: bool is_correct_reasoning: bool is_backtracking: bool is_admitting_mistake: bool
⬇ You are a helpful assistant that follow instructions. Output in JSON format.
Figure 13: Output schema and system prompt for automatic evaluation of error in model
⬇ # FOR SCLI5 < question > {question} </ question > < golden_answer > {golden_answer} </ golden_answer > < given_wrong_answer > {given_wrong_answer} </ given_wrong_answer > < completion_from_model > {completion_from_model} </ completion_from_model > The model was provided a wrong answer < given_wrong_answer >, and is required to self correct and arrive at the golden answer. You have to assess if < completion_from_model > : - has backtracked - has finally provided the answer that matches the < golden_answer > - has provided correct reasoning - has admitted the mistake.
⬇ # FOR GSM8K - SC AND PRM800K - SC < question > {question} </ question > < golden_answer > {golden_answer} </ golden_answer > < given_wrong_reasoning > {given_wrong_reasoning} </ given_wrong_reasoning > < completion_from_model > {completion_from_model} </ completion_from_model > The model was provided a wrong step in the reasoning process < given_wrong_reasoning >, and is required to self correct and arrive at the golden answer. You have to assess if < completion_from_model > : - has backtracked - has finally provided the answer that matches the < golden_answer > - has provided correct reasoning - has admitted the mistake.
Figure 14: Prompt for automatic evaluation of error in model
⬇ from pydantic import BaseModel class EvaluationErrorInUser (BaseModel): is_correct_answer: bool is_correct_critique: bool
⬇ You are a helpful assistant that follow instructions. Output in JSON format.
Figure 15: Output schema and system prompt for automatic evaluation of error in user
⬇ # FOR SCLI5 < question_and_user_answer > {question_and_user_answer} </ question_and_user_answer > < golden_answer > {golden_answer} </ golden_answer > < response_from_model > {response_from_model} </ response_from_model > The model was provided with < question_and_user_answer > from user. You have to assess if < response_from_model > : - contains correct answer that matches the < golden_answer > - contains correct critique of < question_and_user_answer >
⬇ # FOR GSM8K - SC AND PRM800K - SC < question_and_user_reasoning > {question_and_user_reasoning} </ question_and_user_reasoning > < golden_answer > {golden_answer} </ golden_answer > < response_from_model > {response_from_model} </ response_from_model > The model was provided with < question_and_user_reasoning > from user. You have to assess if < response_from_model > : - contains correct answer that matches the < golden_answer > - contains correct critique of < question_and_user_reasoning >
Figure 16: Prompt for automatic evaluation of error in user