# Leveraging Large Language Models for Tacit Knowledge Discovery in Organizational Contexts ††thanks: This work was funded by the authors’ individual grants from Kunumi.
**Authors**: Gianlucca Zuin13, Saulo Mastelini23, Túlio Loures13, Adriano Veloso
> 1Universidade Federal de Minas Gerais (UFMG), Brazil 2Instituto de Ciências Matemáticas e de Computação, Universidade de São Paulo (ICMC-USP), Brazil 3Kunumi, Brazil Email: {gianlucca, saulo, tulio,
## Abstract
Documenting tacit knowledge in organizations can be a challenging task due to incomplete initial information, difficulty in identifying knowledgeable individuals, the interplay of formal hierarchies and informal networks, and the need to ask the right questions. To address this, we propose an agent-based framework leveraging large language models (LLMs) to iteratively reconstruct dataset descriptions through interactions with employees. Modeling knowledge dissemination as a Susceptible-Infectious (SI) process with waning infectivity, we conduct 864 simulations across various synthetic company structures and different dissemination parameters. Our results show that the agent achieves 94.9% full-knowledge recall, with self-critical feedback scores strongly correlating with external literature critic scores. We analyze how each simulation parameter affects the knowledge retrieval process for the agent. In particular, we find that our approach is able to recover information without needing to access directly the only domain specialist. These findings highlight the agent’s ability to navigate organizational complexity and capture fragmented knowledge that would otherwise remain inaccessible.
Index Terms: Organizational Knowledge, Agent-based simulations, Large Language Models
©2025 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
## I Introduction
In current fast-paced and knowledge-driven organizations, efficient management and sharing of knowledge remain challenging tasks. While explicit knowledge is easily documented, tacit knowledge — rooted in personal experiences and expertise — often proves difficult to systematically capture and disseminate. Sociological theories of organizational structure, including Max Weber’s bureaucratic model [1] and Frederick Taylor’s scientific management [2], provide valuable insights into how both formal and informal systems influence the flow of information. Weber emphasized the efficiency of rigid hierarchies in structuring authority and information flow, while Taylor focused on the benefits of standardizing knowledge to boost productivity. However, both perspectives highlight inherent challenges: rigid hierarchies can create bottlenecks, while more flexible systems risk fostering knowledge silos.
Organizational structures, whether hierarchical, flat, or matrixed, impact how knowledge is disseminated within a company. These structures define the pathways of interaction among employees and influence knowledge’s accessibility and retention. Research has shown that knowledge dissemination in cooperative learning networks resembles the spread of disease through a crowd [3, 4]. Thus, by drawing on sociology and network theory, we illustrate information flow within organizations using epidemic models. The works of Polanyi [5] and Nonaka and Takeuchi [6] further underline the complexity of capturing and sharing tacit knowledge. Polanyi’s assertion that “we can know more than we can tell” underscores the implicit nature of such knowledge, while Nonaka and Takeuchi’s SECI model demonstrates how organizations could convert tacit knowledge into explicit forms through socialization, externalization, combination, and internalization.
On the other hand, Large Language Models (LLMs) have demonstrated remarkable capabilities across a variety of tasks, including natural language understanding, translation, summarization, and creative writing [7]. Their proficiency in processing and generating human-like text has opened new possibilities in areas such as automated content creation, human-computer interaction, and educational technologies [8, 9]. In this study, we introduce a novel method that leverages an LLM-based agent to uncover and document tacit knowledge within organizational contexts. To validate our approach, we allow the agent to navigate virtual company hierarchies, engaging with simulated employees—also modeled as LLMs—to iteratively gather and refine details about the structure, purpose, and possible applications of a data table, particularly in the realm of machine learning tasks.
<details>
<summary>extracted/6597023/Figures/fluxo_conversation3.png Details</summary>
### Visual Description
## Flowchart: Conversation Loop for AutomotivePerformance Table Description
### Overview
The diagram illustrates a multi-step process for refining a table description through iterative questioning, employee consultation, self-reflection, and scoring. It begins with a user (Miguel Torres) requesting clarification about columns in an "AutomotivePerformance" table, followed by an AI agent's inability to answer, a suggestion to consult an employee (Sophia Chen), and subsequent refinement of the description based on feedback.
### Components/Axes
1. **Conversation Loop** (Top Section)
- Contains two speech bubbles:
- **User Query**: "Hello Miguel Torres! I'm excited to work with you on building the table description for AutomotivePerformance. Let's get started!"
- **Agent Response**: "Miguel, could you explain what each of the columns like 'VCLN', 'PMAX', 'FRF', 'UREV', and 'SYSTEM' specifically represents in relation to automotive performance? Additionally, what types of data do you expect in each column (e.g., numeric, categorical)?"
2. **Question Asking** (Left Section)
- Arrows point to **Employee** (right section) with:
- **Suggested Action**: "switch"
- **Suggested User**: "Sophia Chen"
- **Reasoning**: The agent lacks knowledge about the columns and recommends consulting Sophia Chen for detailed insights.
3. **Flow Decision-making** (Central Section)
- Arrows connect **Employee** to **Description Parsing** and **Scoring + Critic**.
4. **Self-reflection** (Bottom Left)
- Lists five improvement elements for the description:
1. Define data types (e.g., integer, float)
2. Explain column purposes
3. Include relationships with other tables
4. Mention constraints (e.g., primary keys)
5. Add example values
5. **Description Parsing** (Bottom Right)
- Contains a critic's feedback:
- **Critic Score**: 2/5
- **Criticism**: The description lacks data types, purposes, and relationships for columns like VCLN, PMAX, FRF, and UREV. The suggestion to consult Sophia Chen does not compensate for the missing information.
### Detailed Analysis
- **Initial Interaction**: Miguel Torres initiates the conversation, requesting clarification about specific columns in the AutomotivePerformance table.
- **Agent Limitation**: The agent acknowledges its inability to answer due to insufficient knowledge about the columns' data types and purposes.
- **Employee Consultation**: The agent suggests switching to Sophia Chen, implying she has expertise in the table's structure.
- **Self-Reflection**: The agent identifies five critical gaps in the description, emphasizing the need for technical details (data types, constraints, examples).
- **Scoring**: The critic assigns a low score (2/5) due to the absence of essential metadata, highlighting the description's inadequacy for practical use.
### Key Observations
1. **Knowledge Gaps**: The agent's inability to answer basic questions about column definitions suggests either incomplete training data or a lack of access to domain-specific documentation.
2. **Human-AI Collaboration**: The process relies on human experts (Sophia Chen) to fill knowledge gaps, indicating a hybrid workflow where AI handles routine tasks while deferring complex queries to specialists.
3. **Iterative Improvement**: The self-reflection phase demonstrates a feedback loop where the agent actively works to enhance its outputs based on structured criteria.
### Interpretation
This flowchart represents a **knowledge refinement system** where an AI agent collaborates with human experts to document technical data structures. The low critic score underscores the importance of **explicit metadata** (data types, purposes, relationships) for usability. The process highlights two critical insights:
1. **AI Limitations**: Without access to domain-specific knowledge, AI systems cannot reliably interpret or describe complex datasets.
2. **Human-in-the-Loop Necessity**: Technical documentation requires human expertise to validate and contextualize information, especially for specialized tables like AutomotivePerformance.
The diagram also reveals a **workflow dependency** between AI agents and human experts, where the agent acts as a triage system—identifying when human intervention is necessary and facilitating knowledge transfer. The self-reflection phase suggests an attempt to automate quality assurance, though its effectiveness depends on the agent's ability to implement the suggested improvements.
</details>
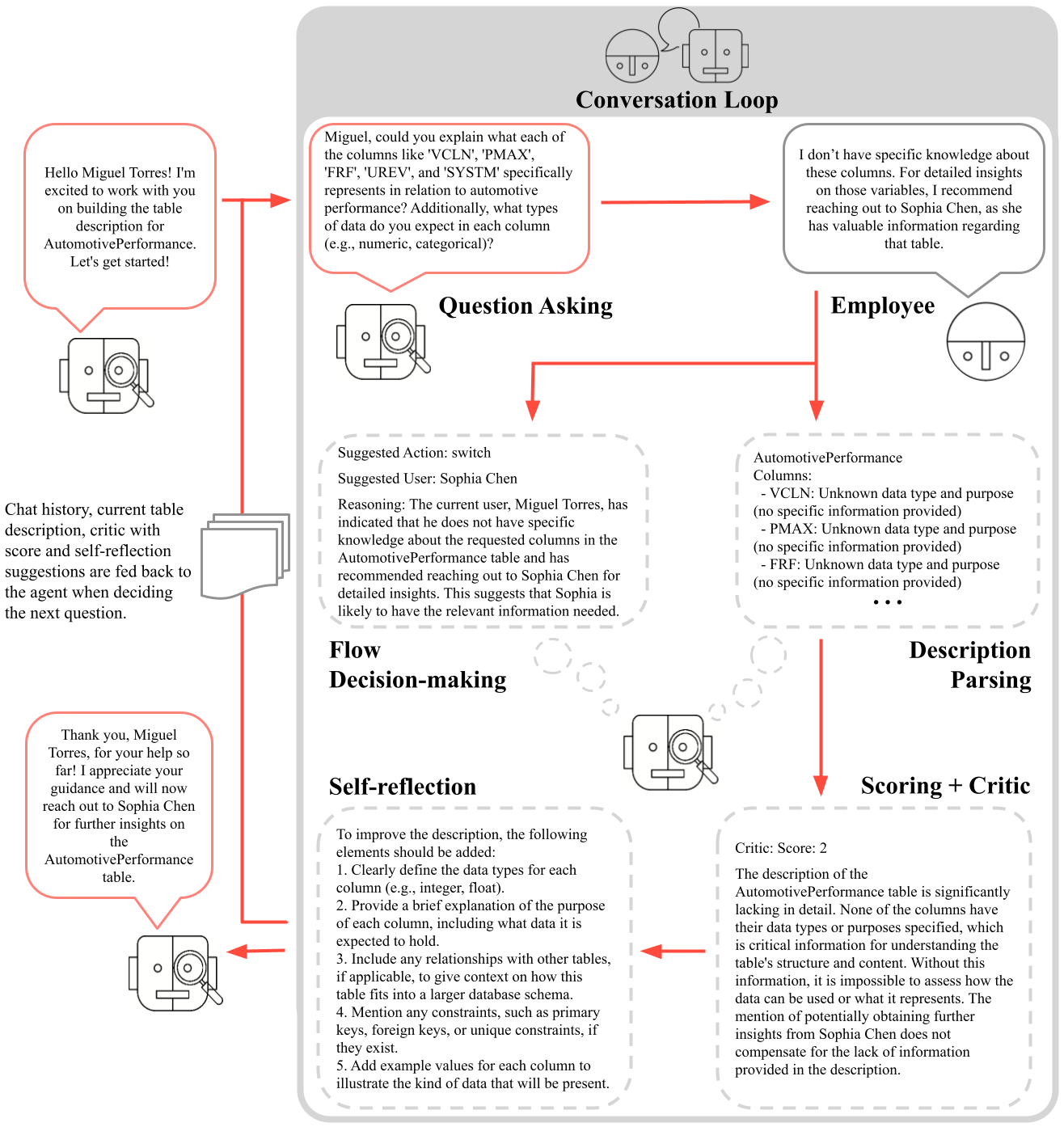
Figure 1: The agent iteratively builds knowledge and decides on its next course of action as it interacts with company employees in a conversation loop.
Our simulation-based approach reflects the complexities of real-world organizations. Employees modeled as LLMs interact with the agent, responding to inquiries, redirecting questions, or providing insights on specific aspects of the data. After each interaction, the agent assesses its progress, generating critiques and suggestions for improvement before determining the next steps as illustrated in Figure 1. This iterative process not only addresses knowledge gaps but also simulates human-like reasoning [10, 11], allowing the agent to adapt to various organizational structures and communication styles. Rather than relying on a human to locate the appropriate domain specialist within an organization—an often difficult and time-consuming task—our method facilitates the crowdsourcing of this process using LLM agents, creating a comprehensive repository of organizational knowledge.
To evaluate the effectiveness of our method, we conducted 864 simulations across diverse synthetic organizational structures, knowledge dissemination strategies, and data configurations. Our LLM agent achieved a success rate of 94.9% in acquiring complete knowledge about the queried tables. These simulations encompassed over 300,000 interactions, including self-reasoning steps, producing a dataset exceeding 45 million words. This dataset serves as a valuable resource for advancing research into LLM-agent interactions and the relationship between organizational structures and knowledge management practices. For access to the full simulation chat log and prompts, see the Code and Data Availability statement.
## II Related Work
Max Weber’s seminal work on social and economic organization [1] offers key insights into the functioning of bureaucratic and hierarchical structures. A central focus of Weber’s work is in his concept of authority, which includes traditional authority, rooted in customs, and rational-legal authority, based on formal rules and laws. Both of these forms of authority are highly relevant to companies and economic organizations. Weber highlights bureaucracy as the primary model of rational-legal authority, emphasizing its efficiency, hierarchy, specialization, and reliance on impersonal procedures. Weber’s concept of Verstehen (German for “interpretive understanding”) stresses the need to understand social actions through the subjective meanings individuals give to their behaviors. Additionally, his use of “ideal types” of behavior as a methodological tool help analyze many social and economic phenomena. These theories form the basis for understanding the formal mechanisms that govern information flow within organizations. Many other works in organizational theory build upon Weber’s ideas to explore additional aspects of organizational behavior, power dynamics, and decision-making processes. For instance, Peter M. Blau’s theories of social exchange [12] emphasize the informal dynamics of interaction, where reciprocity and trust become critical in sharing tacit knowledge. Blau’s analysis reveals how interpersonal relationships complement formal structures, resulting in collaboration and knowledge transfer.
Diefenbach and Sillince [13] discuss the interplay between formal and informal hierarchies, which is crucial for understanding how knowledge propagates. They highlight that formal hierarchies are founded on clearly delineated roles and command chains, whereas informal hierarchies emerge from social interactions and shared norms. Hedlund [14] introduced the concept of heterarchies, challenging traditional hierarchical assumptions and providing a framework to analyze knowledge flow in multinational corporations. This perspective aligns with the need to model both structured and unstructured interactions in simulations. Mihm et al. [15] explored hierarchical structures and search processes, highlighting the challenges of navigating complex organizational networks. Their study employs simulations to reveal how hierarchy impacts solution stability, quality, and speed in problem-solving, showcasing the importance of adapting organizational structures to meet search requirements effectively.
Incorporating these social theory perspectives provides a realistic foundation for constructing synthetic company hierarchies that reflect both structured and dynamic relationships. As such, the parameter choices in our simulations are heavily influenced by these foundational works—from Weber’s concept of bureaucratic organizations to Blau’s and Diefenbach and Sillince’s emphasis on informal connections. These theoretical frameworks not only ground our models in established sociological principles, but complement the emerging computational approaches to simulating human behavior.
Recent work demonstrates LLM’s ability to model complex social systems in realistic simulations. Park et al. [16] proposed generative agents that simulate human behavior through dynamic memory mechanisms, enabling decision-making in a sandbox setting inspired by the game The Sims. These agents autonomously perform tasks, establish social relationships, and adapt behaviors through experiential learning. Dai et al. [17] investigated LLM-driven social evolution under Hobbesian Social Contract Theory, illustrates LLMs’ capacity to simulate foundational theories of societal dynamics and demonstrating agents transitioning from conflict in a “state of nature” to cooperative social orders via emergent contractual agreements. Qian et al. [18] introduced ChatDev, a framework where role-based LLM agents collaborate through structured dialogues to complete software development phases. Collectively, these studies establish LLMs as tools for emulating social behaviors across individual, organizational, and societal scales. However, to our knowledge, no previous literature proposes a method for simulating the human behaviors of interest to this work in synthetic organizational structures, namely, knowledge extraction processes.
Regarding LLM themselves, advances in prompting strategies have shown to enhance its reasoning capabilities. Prompt-chains [19] iteratively refine solutions through task-specific prompts, while least-to-most prompting [20] decomposes problems into sequential subproblems. Chain-of-thought prompting [21] improves logical inference by generating intermediate reasoning steps. These divide-and-conquer approaches increase precision and reliability, particularly for iterative problem-solving contexts. Further, techniques to introduce reasoning into LLMs have also been shown to improve results. The self-reflection paradigm [11] enables LLMs to evaluate and critique their own reasoning processes. Similarly, self-critique and self-scoring mechanisms [16] have proven effective in assessing the quality of information generated by LLMs, demonstrating the advantages of feedback and iterative refinement. Building on these strategies, our approach develops a robust agent system to extract tacit knowledge from human specialists, consolidate it into documents, and validate its efficacy. These works also show how LLM-based simulations closely mimic human interactions, making them a suitable surrogate for testing and refining such methods.
## III Proposed Approach
The challenge of documenting tacit knowledge within an organization requires a process that accounts for both incomplete initial knowledge and the dynamic nature of organizational networks. In our proposed approach, we introduce an agent-based framework designed to gather and document knowledge about dataset tables through iterative interactions with employees. The agent starts with a limited understanding and progressively refines its knowledge by engaging with the organization. However, real-world case studies can be difficult to obtain. To evaluate the effectiveness of this methodology, we employ simulations of organizational knowledge dissemination, modeling both formal and informal networks. In this section, we describe the key aspects of our agent design and the simulations conducted to assess its performance.
### III-A Prompt-chaining to build an Agent
Our approach employs a prompt-chaining technique to develop an LLM-based agent for documenting tacit knowledge. Specifically, we wish to build a description for a table known to the organization. The agent operates in a partially observable environment. While such an environment holds access to the current table description (the true knowledge $k^{*}$ ), each employee’s expertise and network connections are uncertain. The agent does, however, know a subset of the network: the company’s hierarchical structure. This scenario can be modeled using a framework inspired by a Markov Decision Process (MDP). Briefly, it consists of:
- Knowledge States ( $\mathcal{K}$ ): Represent the agent’s current understanding of the knowledge domain.
- Actions ( $\mathcal{A}$ ): Consist of the set of Actions that an agent can take.
- Transition Model ( $P(k^{\prime}|k,a)$ ): Probabilistic changes in knowledge state due to the actions made and changes in the environment.
- Reward Function ( $R(k,a)$ ): Measures the completeness and accuracy of the knowledge state given the actions.
Formally, let $\mathcal{K}$ represent the set of possible states that define the agent’s current knowledge level, and $\mathcal{A}$ represent the set of actions or prompts the agent can take. The transition probability, $P(k^{\prime}|k,a)$ , defines the likelihood of transitioning from state $k$ to state $k^{\prime}$ after taking action $a$ . The reward function, $R(k,a)$ , quantifies the benefit of the action in a particular state, reflecting the knowledge acquired. The process terminates when the agent reaches a terminal state $k_{t}$ , where all relevant knowledge about the proposed application is acquired. This is measured by $R(k_{t},a)\geq\epsilon$ , where $\epsilon$ represents the minimum score for a suitable table description. The agent’s goal is to maximize the accumulated reward by formulating an optimal policy $\pi^{*}$ , which guides its decisions implicitly.
The agent begins with a basic understanding $k_{0}$ of the table or organizational knowledge, knowing only the table’s name and columns. As the agent interacts with employees, it refines its state $k$ by incorporating new information and identifying gaps. The actions ( $\mathcal{A}$ ) involve generating questions aimed at filling these gaps. The agent uses its current state to formulate questions that address specific gaps in its understanding. Additionally, the agent’s self-critical assessments, which include quality scores, explanations, and suggestions for improvement, guide it in this task. The Transition Model ( $P(k^{\prime}|k,a)$ ) accounts for the probabilistic nature of state transitions after an action is taken. Due to the variability in LLM outputs and employee responses, these transitions are non-deterministic. The LLM manages these uncertainties by dynamically adjusting itself and its strategies in response to the feedback it receives. The Reward Function ( $R(k,a)$ ) evaluates actions, measuring alignment between the agent’s understanding and the expected complete knowledge.
While these components are not explicitly modeled in the agent framework, they describe how the LLM organizes and selects prompts. The key goal is to maximize the accumulated reward, which helps guide the agent toward more effective knowledge acquisition. The agent interacts with employees based on their position in the hierarchy, structured as a stack, and prefers to start with those at lower levels to avoid burdening their superiors. However, if an employee is mentioned during a conversation - for instance, someone who likely holds relevant information about the table - the agent updates its knowledge of the company structure and moves this person to the top of the stack. Once someone with at least partial knowledge is found, the agent can move from one recommended employee to another, severely trimming the search space. The entire process is structured as a sequence of prompts and tasks:
1. Greet the employee to establish rapport;
1. Formulate a question about the data table;
1. Process the employee’s response and update self internal knowledge, building a new table description;
1. Critique the new updated description through:
1. Scoring the new description to evaluate its quality;
1. Criticizing it to identify gaps or inconsistencies;
1. Suggesting areas for improvement.
1. Decide whether to continue the conversation with the current employee or switch to another.
A core aspect of this process is the self-critical feedback loop. After each interaction, the agent integrates the updated description, critique, score, suggestions, and chat history as inputs for the next question-generation step. These inputs, combined with the agent’s internal knowledge, guide the formulation of the next question, focusing on areas in which the understanding is lacking. This step involves using a meta-prompt to assess the completeness and relevance of the acquired information and evaluate its current knowledge state critically. Figure 2 illustrates the prompt used during this self-critical step. The agent then proceeds to self-reflect over the generated critic in order to evaluate the next course of action.
Self-critic prompt
You will review the table description and assess how complete it is. Here’s how to give feedback: - Score: Rate the quality of the description from 0 to 10, with 10 being excellent. - Reasoning: Explain why you gave this score, including any areas for improvement. - Suggestions: If the description score is below 8, suggest what can be added or refined to improve it. Aim for a balanced approach: emphasize what’s good, but point out areas where we can improve. Focus on understanding the table deeply and capturing its essence in the description. Do not use * or other characters. Use the exact same format as the one above. To reach a score of 5, we should know mostly everything about all columns. This includes column names, their meaning, and data types. If we also know some example values, then we can reach even a 6 or a 7. To reach a score of 8, we should also have tacit knowledge. Good variables to use, meaningful interactions, and so on. Guesswork is not allowed. If the description’s author mentions that they are not very certain about something, i.e., they are guessing what a column (or columns) mean, the score should be automatically lower. Be critical and do not be lenient. To reach a high score, a description should be really good and complete. Not knowing all the data types of the columns immediately implies a low score.
Task: Critique the completeness of the description.
Current table description
Figure 2: Meta-prompt used in the self-critical stage. The agent critically assesses the current table description while providing suggestions on aspects to improve.
### III-B Simulating company structures
We simulate the dissemination of tacit knowledge across a synthetic company network using epidemic models [22]. Specifically, we employ the Susceptible-Infectious (SI) model with waning infectivity [23, 24]. In this context, knowledge about a dataset table is treated as a collection of “diseases”, where each column of the table represents a distinct “fact” (a unit of information). The dynamics of the SI model in this framework are defined as follows:
- S (Susceptible): Individuals who are unaware of a specific fact in the table.
- I (Infectious): Individuals who know a fact and can share it. The likelihood of sharing decreases with time.
The dissemination process begins with a “patient zero”, an individual who possesses complete knowledge (i.e., all facts corresponding to all columns of the table). Knowledge spreads through the organizational network, which consists of two components. The Hierarchy Network represents the formal organizational structure, explicitly known to the LLM agent; and the Relationship Network is a hidden network of informal connections (e.g., frequent interactions among colleagues) that the agent infers through its interactions. Intuitively, employees who work under the same team know each other, which leads to the Hierarchy Network being a sub-graph of the more complete Relationship Network.
Before allowing the LLM to traverse the network, we disseminate knowledge using the epidemic model across the complete Relationship Network. The key feature of this model is the waning infectivity, where an individual’s ability to share knowledge diminishes over time. To simulate this, the time-dependent transmission rate $\beta(t)$ is modeled as:
$$
\beta(t)=\beta_{0}e^{-\gamma t} \tag{1}
$$
where $\beta_{0}$ is the initial transmission rate, and $\gamma$ determines how quickly the ability to share knowledge wanes. This SI model is used to simulate the uneven distribution of knowledge within the relationship network. Since the ability to transmit knowledge quickly wanes, over time some employees will know specific facts about the dataset table (i.e., become “infected”), while others will remain unaware. As such, we consider both:
- Knowledge Transfer: Susceptible individuals S become informed about a fact at a rate proportional to $\beta(t)SI$ , where $\beta(t)$ decays over time.
- Knowledge Loss: Infected individuals gradually lose their ability to spread a specific fact as $\beta(t)$ decreases.
The agent’s task is to traverse this network after convergence using the initially incomplete knowledge about the evaluated table and employee relationships, hold conversations, and reconstruct the full table documentation by piecing together the facts that have spread across different individuals. To simulate diverse organizational structures, we define key parameters that allow us to model companies ranging from startups to large multinational corporations, from highly formal bureaucracies to agile, informal networks.
- Max Hierarchical Depth: Shallow hierarchies represent organizations inspired by Taylor’s principles of functional management, emphasizing task specialization, direct oversight, and higher interconnectivity among employees. These structures are often seen in manufacturing setups or flat startups. Deep hierarchies reflect Weber’s bureaucratic organization theory, characterized by formal authority, strict adherence to rules, and clear chains of command. These structures reduce interconnectivity, with knowledge flow restricted to well-defined channels. By adjusting the hierarchical depth, we can simulate a spectrum of companies, from flat startups fostering innovation to rigid bureaucracies prioritizing stability and control.
- Number of Employees: This parameter spans small teams to large multinational corporations. Smaller organizations model the dynamics of startups, where knowledge is often centralized or informally shared. Larger organizations allow us to explore the complexities of scale, including silos, multi-layered decision-making, and formalized processes. We assume balanced tree-like structures as the hierarchy. Thus, we infer the branching factor $b_{d}$ (that is, the number of people working under each boss) as:
$$
b_{d}\approx\sqrt[hierarchy\text{ }depth]{number\text{ }of\text{ }employees} \tag{2}
$$
- Alpha and Decay: These parameters govern how knowledge spreads and wanes in the relationship network. Slow decay mimics organizations with stable knowledge-sharing practices. High decay represents environments where knowledge quickly becomes obsolete, such as fast-paced industries or competitive workplaces. In our simulation, decay is directly tied to how far the knowledge can spread from the initial patient zero, while alpha governs the probability of knowledge being shared.
- Number of Informal Connections: Informal connections mimic agile or networked organizations with significant ad-hoc collaboration, enabling knowledge flow outside formal channels. A low number of informal connections represents traditional, hierarchical organizations, where interactions align strictly with reporting structures. By varying the balance between formal and informal connections, we can simulate environments from rigid bureaucracies to dynamic, innovation-driven teams.
These parameters enable the simulation of various company types, including startups (flat, highly interconnected structures with informal knowledge-sharing dynamics), large multinationals (deep hierarchies, rigid formal connections, and slow diffusion of knowledge), or even agile organizations (high mean degrees, shallow hierarchies, and dynamic knowledge-sharing networks). As per Max Weber’s social theory, these simulations capture the dichotomy between traditional bureaucracies (emphasizing stability and control) and more modern, flexible organizations.
## IV Experiments
To evaluate the effectiveness of our approach, we conducted experiments with various configurations of company structures, knowledge, and dissemination rates. Figure 3 illustrate an example of a synthetic organization. For each of the parameters discussed, we elected a range of possible values and iterate over all possible combinations. We assess the statistical significance of our measurements through a pairwise t-test with p-value $\leq 0.05$ over 3 repetitions of each simulated environment and agent’s interaction. In particular, we consider:
- Hierarchical Depth: 2, 5, 10, 20 (from shallow to deep)
- Number of Employees: 20, 75, 200 (small, medium, and large organizations)
- Alpha: 0.1, 0.5
- Decay: 0.5, 0.8
- Number of Informal Connections: 0, 2.5, 5 (from formal to heavily informal)
- Number of Table Columns: 5, 20
<details>
<summary>extracted/6597023/Figures/kwoledgelevel_1_.png Details</summary>
### Visual Description
## Hierarchical Diagram: Node-Based Structure with Color-Coded Levels
### Overview
The image depicts a hierarchical tree structure with nodes labeled numerically (0–24) and connected by directed arrows. Nodes are color-coded in gradients of red, orange, and white, suggesting categorical or hierarchical distinctions. The root node (0) branches into two primary subtrees, with subsequent nodes forming a multi-level hierarchy.
### Components/Axes
- **Nodes**: Labeled 0–24, each representing discrete entities or decision points.
- **Arrows**: Directed edges indicating parent-child relationships or flow direction.
- **Color Gradient**:
- **White**: Node 0 (root).
- **Dark Red**: Nodes 4, 8.
- **Red**: Nodes 5, 6, 7.
- **Orange**: Nodes 1, 2, 3, 9, 10, 11, 12.
- **Light Orange**: Nodes 13–18, 19–24.
- **No Explicit Legend**: Color meanings are inferred from positional hierarchy and visual grouping.
### Detailed Analysis
1. **Root Node (0)**:
- Positioned at the top, connected to nodes 1 and 2.
- White color may denote the highest authority or starting point.
2. **First-Level Branches**:
- **Node 1 (Orange)**: Branches into nodes 3, 5, 6, 7, 8.
- **Node 2 (Orange)**: Branches into nodes 9, 10, 11, 12.
3. **Second-Level Branches**:
- **Node 3 (Orange)**: Connects to nodes 13, 14, 15 (light orange).
- **Node 5 (Red)**: Connects to nodes 16, 17, 18 (light orange).
- **Node 6 (Red)**: Connects to nodes 19, 20, 21, 22, 23, 24 (light orange).
- **Node 7 (Red)**: No further branches.
- **Node 8 (Dark Red)**: No further branches.
4. **Leaf Nodes**:
- Nodes 13–24 are terminal (no outgoing arrows), all light orange.
### Key Observations
- **Hierarchical Depth**: The tree has at least three levels (root → first-level → second-level).
- **Color Correlation**: Darker colors (red, dark red) cluster at higher levels, while lighter colors (orange, light orange) dominate lower levels.
- **Node 6 Complexity**: Node 6 has the most children (6 nodes), suggesting it may represent a critical or highly branched decision point.
- **Symmetry**: Nodes 1 and 2 have similar branching patterns, but node 1’s subtree is more complex.
### Interpretation
The diagram likely represents an organizational structure, decision tree, or workflow. The color gradient may indicate:
- **Hierarchical Priority**: Darker colors for higher authority (e.g., executives in white/dark red, managers in red, subordinates in orange).
- **Categorization**: Colors could denote departments, risk levels, or stages in a process.
- **Flow Dynamics**: The branching pattern suggests decision-making pathways, with node 6’s extensive children implying a high-stakes or multifaceted decision.
The absence of a legend limits precise interpretation of colors, but the structural symmetry and color progression imply a deliberate design to visualize hierarchy and relationships. Node 6’s prominence highlights its potential role as a pivotal node in the system.
</details>
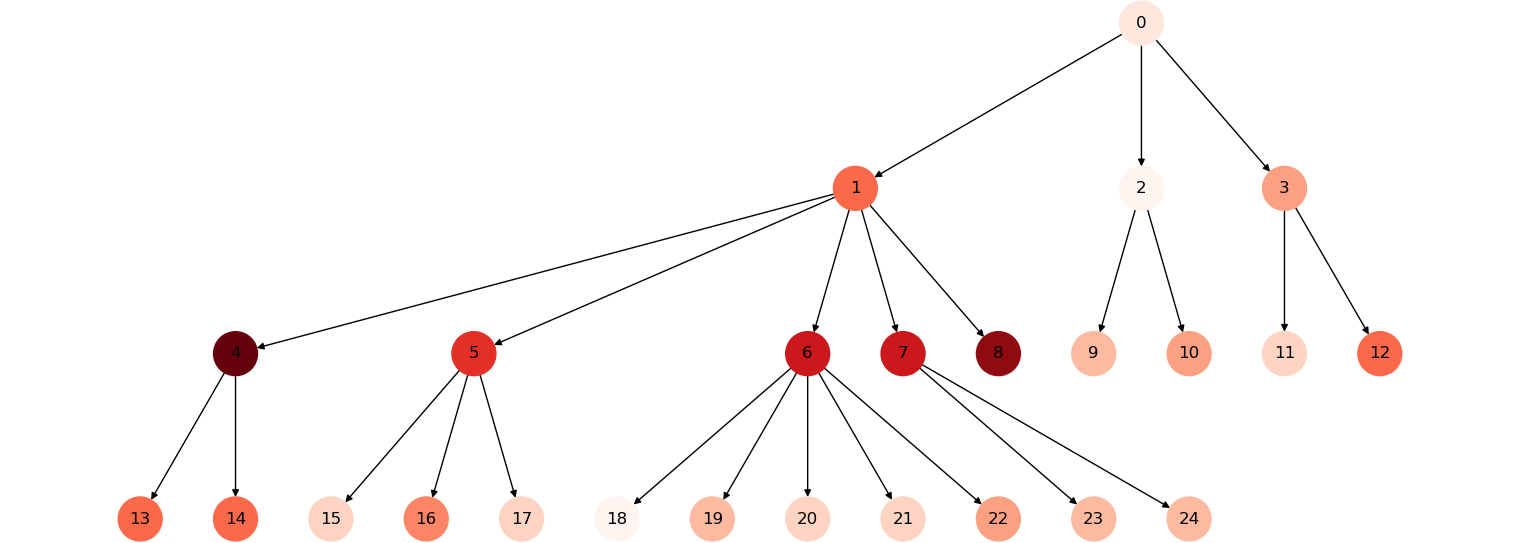
(a) Hierarchy and knowledge levels.
<details>
<summary>extracted/6597023/Figures/relationships_1_.png Details</summary>
### Visual Description
## Network Diagram: Hierarchical Node Structure
### Overview
The image depicts a network diagram with 25 nodes labeled 0–24, connected by black lines. Nodes are represented as green circles with numerical labels. The diagram exhibits a hierarchical structure, with node 0 at the top, followed by tiers of interconnected nodes. The lower tier (nodes 13–24) forms a densely connected subnetwork. No textual labels, legends, or axis markers are present.
### Components/Axes
- **Nodes**: 25 green circles labeled 0–24.
- **Edges**: Black lines connecting nodes.
- **Layout**:
- **Top Tier**: Node 0 (root) connected to nodes 1, 2, 3.
- **Middle Tier**: Nodes 1–12, each connected to subsets of nodes 4–12.
- **Bottom Tier**: Nodes 13–24, forming a dense, fully connected subnetwork.
- **No legend, axis titles, or textual annotations** are visible.
### Detailed Analysis
- **Node 0**: Positioned at the top, directly connected to nodes 1, 2, and 3.
- **Nodes 1–3**: Each connected to three nodes in the middle tier (e.g., node 1 connects to 4, 5, 6).
- **Nodes 4–12**: Form a secondary tier, with each node connected to multiple nodes in the bottom tier (e.g., node 4 connects to 13, 14, 15).
- **Nodes 13–24**: Fully interconnected, with every node linked to every other node in this tier.
- **Edge Density**: The bottom tier has the highest edge density, suggesting a highly interactive subnetwork.
### Key Observations
1. **Hierarchical Structure**: The diagram follows a top-down hierarchy, with node 0 as the central hub.
2. **Dense Subnetwork**: Nodes 13–24 exhibit a complete graph structure, indicating maximum connectivity.
3. **No Directionality**: Edges are undirected (no arrows), implying bidirectional relationships.
4. **Missing Metadata**: Absence of labels, legends, or axis titles limits contextual interpretation.
### Interpretation
The diagram likely represents a hierarchical network system, such as:
- **Organizational Structure**: Node 0 could represent a central authority, with tiers reflecting management levels.
- **Data Flow Architecture**: Node 0 as a central server, nodes 1–12 as intermediate nodes, and nodes 13–24 as peripheral devices or data clusters.
- **Social Network**: Node 0 as a central influencer, with lower tiers representing communities or subgroups.
The dense connectivity in the bottom tier suggests a critical subnetwork for redundancy or specialized interactions. The lack of labels or legends makes it challenging to assign specific roles to nodes, but the structural patterns imply a system designed for scalability and modularity.
**Note**: Without additional context (e.g., node labels, edge weights, or directional arrows), the diagram’s purpose remains speculative. Further annotations would enhance interpretability.
</details>
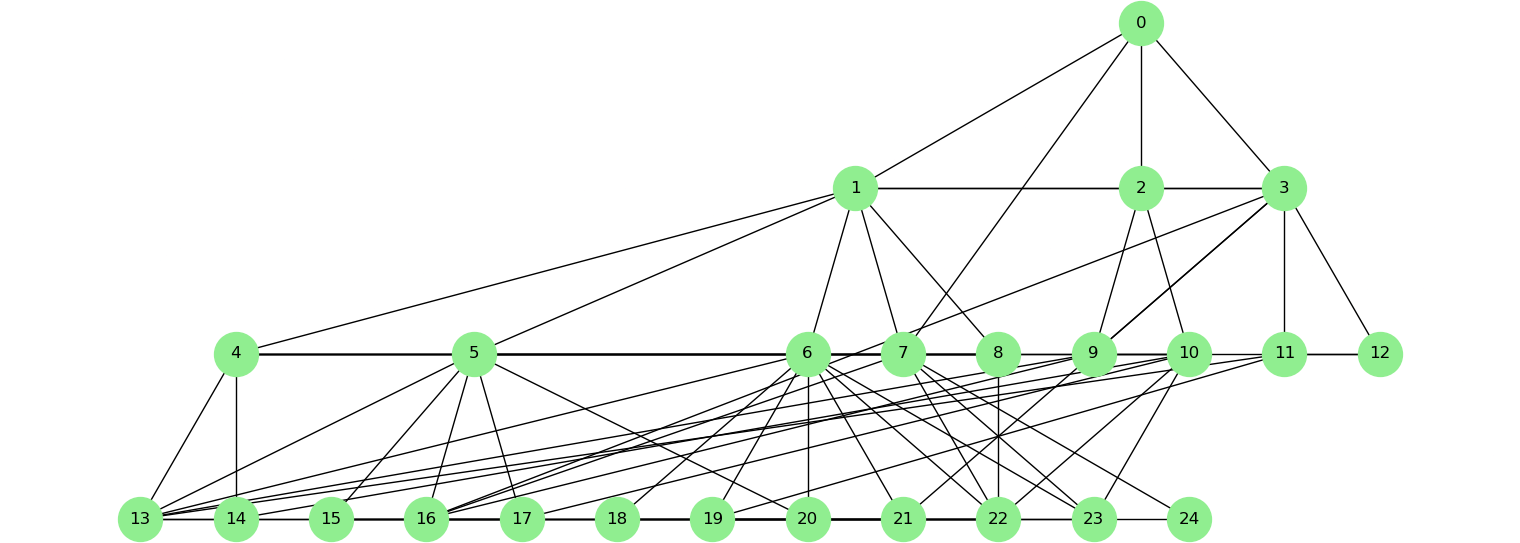
(b) Relationships graph.
Figure 3: A synthetic organization with 25 employees, 4 hierarchical steps and 2.5 $\times$ informal connections. Red shades indicate the amount of knowledge (e.g.: number of columns known) that an employee holds. Decay 0.8, alpha 0.1.
For each repetition, a table subject was randomly selected from a predefined list, which was then used to generate the simulated complete knowledge $s^{*}$ through an LLM. This includes the overall table description, each column (with the respective type, meaning, and examples), as well as its possible variable relations. The possible table subjects for the generated knowledge include: aerospace, agriculture, automotive, business, construction, finances, food service, healthcare, machinery, mining, oil, packaging, energy, retail, sports, transportation, tourism, and tech. These subjects were selected following common industry sectors, as defined both in literature [25, 26, 27] and by the International Labour Organization https://www.ilo.org/industries-and-sectors.
Given a parameter configuration, we then build the respective company structure, including the Hierarchy Network and the Relationship Network. In sequence, the individual facts from the original knowledge $k^{*}$ are disseminated in the company network using the SI epidemic model throughout the constructed company. These steps follow the methodology described in Section III-B. We also generate a textual background description for each employee, according to a job role as defined by the hierarchy and a randomized personality archetype, as well as a description of the information relevant to the problem they have access to: what partial knowledge of the table the individual has, their connections in the company’s network, and what partial knowledge they are aware their connections have (determined probabilistically). These backgrounds are intended to make responses more human-like and also serve as context to answer the main agent’s questions during the simulation. Finally, using the built structures and generated descriptions, we begin the conversation as described in Section III-A by assigning the questioning agent a random starting employee from the bottom of the hierarchy. All experiments were conducted on OpenAI’s GPT-4o mini model.
## V Discussion
After conducting repeated conversational experiments with varying fictional company structures, we summarized the conversational statistics by averaging the results for each company structural parameter. We collected the self-critical score values generated during the conversations and other aspects that describe how the agent navigated the companies’ internal structures. In Table I, Len(path) represents the average number of non-unique fictitious employees contacted by the agent during inquiries about the data. In some cases, the agent contacted certain employees multiple times, effectively making these simulated individuals act as hubs within the conversational graph. We measured the average number of hubs (# Hubs) observed during the simulations. Additionally, we calculated the minimum distance between the first person contacted by the agent and “patient zero”, who possesses all the knowledge about the table’s columns. In the table, this metric is labeled Min. dist. and was obtained using the Dijkstra algorithm [28] applied to the relationship graph of each simulated company. We measured the percentage of times the conversational agent reached “patient zero” (% p0) and reported the average and mean self-critical score produced.
TABLE I: Overview of statistics grouped and averaged for different simulated companies’ parameters. NIC: number of informal connections; MHD: maximum hierarchical depth.
| Parameter | Value | Len(path) | # Hubs | Min. dist. | % p0 | Avg. score | Final score |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Alpha | 0.1 | 31.6 | 1.26 | 3.94 | 0.38 | 5.49 | 6.79 |
| 0.5 | 16.0 | 0.59 | 3.95 | 0.22 | 6.34 | 8.07 | |
| NIC | 0.0 | 36.34 | 1.32 | 5.89 | 0.41 | 5.35 | 6.79 |
| 2.5 | 19.69 | 0.82 | 3.06 | 0.26 | 6.1 | 7.66 | |
| 5.0 | 15.38 | 0.65 | 2.89 | 0.23 | 6.3 | 7.84 | |
| Decay | 0.5 | 27.81 | 1.06 | 3.91 | 0.34 | 5.67 | 7.2 |
| 0.8 | 19.8 | 0.79 | 3.99 | 0.25 | 6.16 | 7.66 | |
| MHD | 2 | 13.81 | 0.65 | 2.72 | 0.24 | 6.37 | 7.97 |
| 5 | 25.0 | 1.01 | 4.01 | 0.32 | 5.8 | 7.36 | |
| 10 | 27.85 | 1.06 | 4.39 | 0.29 | 5.74 | 7.19 | |
| 20 | 28.56 | 0.98 | 4.66 | 0.33 | 5.75 | 7.21 | |
| # Employees | 20 | 8.66 | 0.6 | 2.77 | 0.48 | 6.06 | 7.57 |
| 75 | 26.67 | 1.08 | 4.05 | 0.28 | 5.94 | 7.59 | |
| 200 | 36.09 | 1.1 | 5.02 | 0.14 | 5.74 | 7.13 | |
| # Features | 5 | 25.13 | 0.91 | 4.01 | 0.28 | 6.2 | 7.6 |
| 20 | 22.48 | 0.95 | 3.88 | 0.31 | 5.64 | 7.26 | |
Regarding the parametization of the SI model, we observe that the average conversational path length tends to decrease as the alpha value increases, while the description scores tend to improve. Analogously, the number of non-unique employees contacted by the conversational agent decreases as the decay of knowledge transmission increases. The same decrease is observed for the number of hubs within the organization. These observations suggests that knowledge is more evenly distributed within the companies’ structure, which aligns with our expectations. There does not appear to be a clear relationship between changes in the alpha value and the minimum distance to patient zero. However, patient zero becomes less likely to be reached as the alpha value increases and the agent has more options to explore before reaching the employee holding all the information about a table. Additionally, the number of hubs decreases with an increase in alpha.
As expected, the average path length and the distance to “patient zero” increase as the maximum hierarchy depth increases. This indicates that the agent needs to contact more employees to retrieve the desired knowledge. Additionally, the overall description score decreases slightly with an increase in maximum hierarchy depth, hinting at knowledge fragmentation within the company structure. On the other hand, the score values remain relatively stable despite changes in the number of employees, highlighting the robustness of the description extraction procedure regardless of company size.
We likewise observe that a higher Number of Informal Connections (NIC) corresponds to a higher self-critical score obtained at the end of the simulations. Additionally, as the NIC increases in the simulated company structure, the number of conversational hubs and the overall conversation path length decrease. Similarly, the minimum distance between the starting employee and patient zero decreases as the number of connections increases. These results are expected since a higher NIC increases the likelihood of quickly reaching employees who hold specific information about the data at hand. The number of times the employee with all the information is contacted decreases with a higher NIC, suggesting that information is more likely to be distributed among employees when they are more interconnected. However, this observation, constrained by our simulation setup, only accounts for the target knowledge sought by the conversational agent. In real-world scenarios, informal connections are more likely to imply shared informal knowledge rather than business knowledge.
Apart from a slight decrease in score quality as the number of features increases, varying the number of features does not strongly correlate with other experimental parameters. This is expected, as these parameters primarily influence the companies’ structure rather than the knowledge retrieval task.
After analyzing the simulated conversations through which the agents reconstructed the original knowledge, we also evaluated the quality of the reproduced table descriptions that were generated at the end of each experiment run. This helps us to consider whether the proposed methodology can effectively achieve its desired goal of recovering the disseminated knowledge. For that purpose, we compare the final description $k_{t}$ generated by the agent with the original knowledge description $k^{*}$ for that table according to the following metrics:
#### Full-knowledge recall
We first checked if the agent was able to generate a table description that included a mention of every column originally disseminated in the company’s network. An agent is considered to have achieved full-knowledge recall in an experiment run if it succeeded in at least reproducing all table columns in its final report.
#### METEOR
We also measure the METEOR score [29] of the descriptions for each column in the table. The score creates word alignments between the candidate and reference texts, using not only exact matches, but also stems and WordNet synonyms and calculates the harmonic combination of precision and recall for those alignments. The METEOR scores for all columns are averaged to arrive at an overall score cMETEOR for the generated description $k_{t}$ .
#### G-Eval
We then used an LLM-as-judge approach to better capture the semantic equivalency between the original and generated descriptions. For that, we apply the G-Eval LLM evaluation framework [30] to score each column description according to prompted definitions of textual quality. The G-Eval framework uses LLMs with Chain-of-Thought to fill out a form and generate a final score between 1 and 5 according to the given definition. The G-Eval scores for all columns are averaged to arrive at an overall score for the generated description $k_{t}$ , which we refer to as cGEvalCoh, for a definition of “coherence”, and cGEvalFaith, for a definition of “faithfulness”.
#### Self-critical with context
Finally, to directly compare how having access to the official table $k^{*}$ can change the agent’s own evaluation, we altered the self-critic LLM prompts to give the evaluation score for the same final description $k_{t}$ , but now having access to the original description as context.
From the 864 simulations executed, the LLM agent achieved full-knowledge recall in 820 of them (94.9%). As such, in the vast majority of cases, the agent at a minimum retained some mention of every column present in the original table $k^{*}$ . In the remaining 44 cases, the final description $k_{t}$ retained $\sim 77\$ of the expected columns on average.
The agent-generated descriptions measured on average $0.17$ on the column-based METEOR score, $2.65$ for column-based G-Eval Coherence and $4.37$ for G-Eval Faithfulness. In addition, adding the original description to the self-critical evaluation reduced the average score from $7.43$ to $6.75$ . While looking directly at the value of those metrics is insufficient to evaluate the quality of the created texts definitively, we can analyze their values in relation to each other and to additional attributes of the simulation runs.
Table II shows the rank correlation between the final score given by the self-critic agent during the simulation and the evaluation metrics based on the original knowledge. We identify a strong correlation between the self-critical score with and without context, indicating that the agent’s own evaluation during the conversation partly maintains its relative ranking once it gains access to the original knowledge, even if the absolute score does get reduced. We also observe that the cMETEOR and cGEvalCoh metrics are strongly correlated, indicating that both the word alignment-based metric and the LLM-as-judge method similarly measure the correspondence between the target and reference texts in this context. cGEvalFaith also showed a moderate correlation with the other evaluation metrics, such as $0.66$ to the score with context.
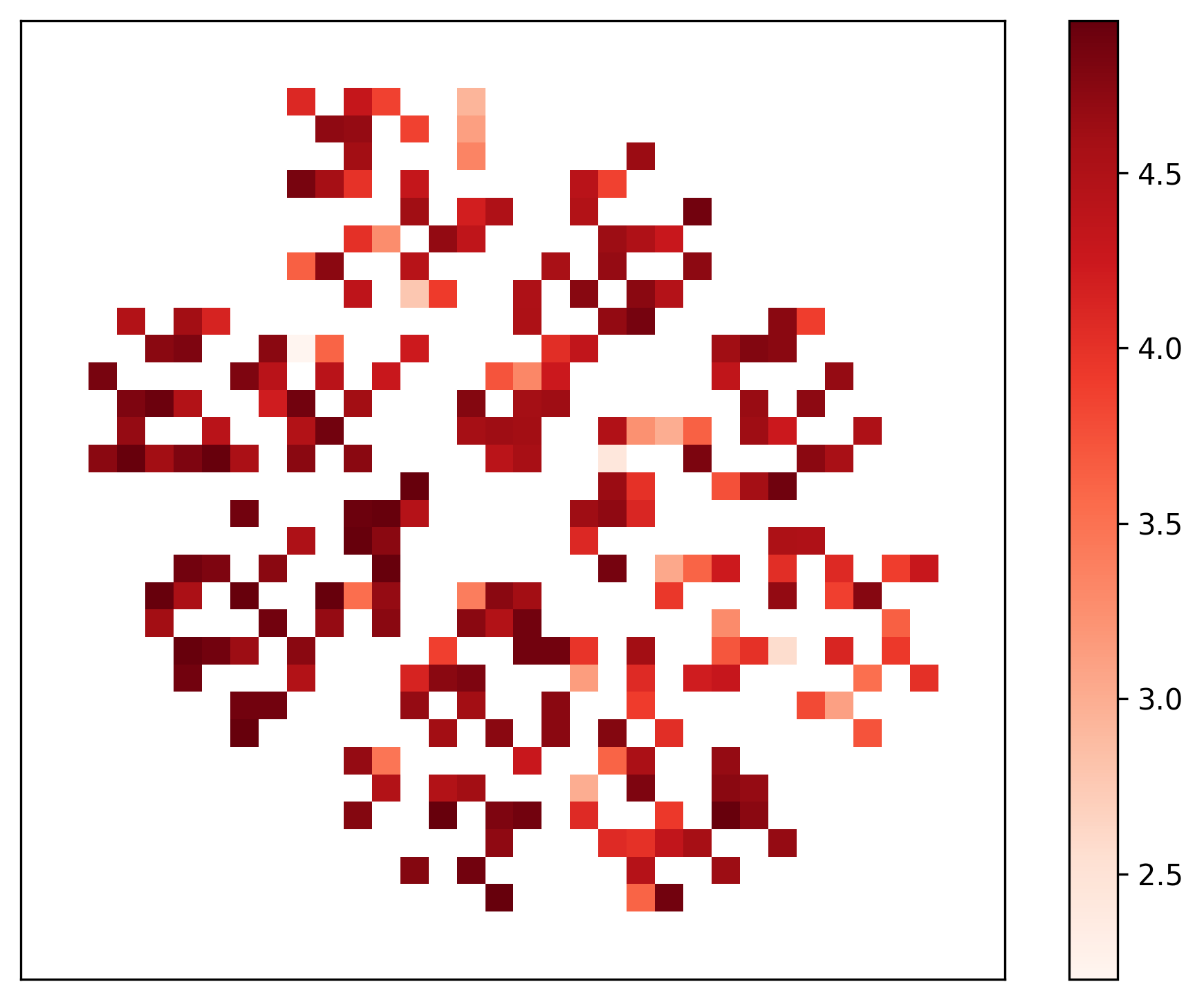
Lastly, we assess the effectiveness of our proposed autonomous agent-based knowledge retrieval process by evaluating how the quality of the obtained descriptions is affected by interacting with patient zero or not. In our simulated setup, once the agent reaches patient zero, the task becomes trivial. Ideally, the agent should be able to retrieve high-quality descriptions from employees who do not hold full knowledge. We use the company simulation parameters discussed in Table I as inputs for dimensionality reduction with the UMAP algorithm [31] and aggregated points over a grid with colors representing either cGEvalFaith or % p0 (averaged over the three repetitions performed for each configuration). The resulting projections are shown side by side in Figure 4. We identify areas with high-quality descriptions where patient zero was never contacted (e.g., the center region of the projected points). Conversely, we also observe areas where patient zero was contacted and the obtained cGEvalFaith was high. These findings, along with the low correlation ( $-0.06$ ) between the compared metrics, reinforce that the effectiveness of the proposed agent does not depend on reaching the employee $p_{0}$ who possesses complete knowledge.
TABLE II: Spearman correlation between metric pairs and metrics averaged over the simulations (bottom row). SCS: self-critical score; SCS+C: self-critical score with context.
| | cMETEOR | cGEvalCoh | cGEvalFaith | SCS | SCS+C |
| --- | --- | --- | --- | --- | --- |
| cMETEOR | – | 0.772820 | 0.436230 | 0.263699 | 0.279494 |
| cGEvalCoh | 0.772820 | – | 0.565856 | 0.347426 | 0.447342 |
| cGEvalFaith | 0.436230 | 0.565856 | – | 0.497946 | 0.665396 |
| SCS | 0.263699 | 0.347426 | 0.497946 | – | 0.729141 |
| SCS+C | 0.279494 | 0.447342 | 0.665396 | 0.729141 | – |
| Mean Overall Score | 0.1741 | 2.6531 | 4.3675 | 7.4317 | 6.7465 |
<details>
<summary>extracted/6597023/Figures/faithfulness_nolabel.png Details</summary>
### Visual Description
## Heatmap: Symmetrical Distribution of Values
### Overview
The image depicts a symmetrical heatmap composed of a grid of colored squares arranged in a radial or floral pattern. The color intensity transitions from dark red (high values) to light orange (low values), with a central region of lighter shades. The grid exhibits rotational symmetry, with darker clusters concentrated in the top-left and bottom-right quadrants.
### Components/Axes
- **Color Scale**: Vertical legend on the right, labeled from 2.5 (lightest orange) to 4.5 (darkest red).
- **Grid Structure**:
- Rows and columns form a matrix of squares.
- No explicit axis labels or categories are provided.
- Symmetry suggests a radial or mirrored design.
### Detailed Analysis
- **Value Distribution**:
- **High Values (4.0–4.5)**: Dominant in the top-left and bottom-right quadrants, forming dense clusters.
- **Medium Values (3.0–3.5)**: Found in transitional zones between high-value clusters and the center.
- **Low Values (2.5–3.0)**: Concentrated in the central region, creating a lighter core.
- **Symmetry**: The pattern mirrors itself across both horizontal and vertical axes, suggesting a designed or balanced dataset.
- **Color Gradient**: Smooth transitions between shades indicate gradual value changes, with no abrupt jumps.
### Key Observations
1. **Clustered Extremes**: The top-left and bottom-right quadrants contain the highest values, while the center has the lowest.
2. **Radial Pattern**: The symmetry implies a central focal point influencing the distribution.
3. **No Outliers**: All values fall within the 2.5–4.5 range; no isolated anomalies are visible.
### Interpretation
The heatmap likely represents a system with a central influence, where peripheral regions exhibit higher values. The symmetry suggests a balanced or cyclical process, such as:
- **Signal Strength**: A central transmitter with diminishing intensity toward the edges.
- **Stress Distribution**: A material under uniform load, with stress concentrated at specific points.
- **Data Clustering**: A dataset organized around a core category, with peripheral categories showing higher frequency or magnitude.
The absence of axis labels limits precise interpretation, but the visual pattern emphasizes a designed, symmetrical relationship between the grid positions and their corresponding values. The central "void" of low values could indicate a null or baseline state, while the outer clusters represent active or extreme conditions.
</details>
(a)
<details>
<summary>extracted/6597023/Figures/p0_reached_nolabel.png Details</summary>
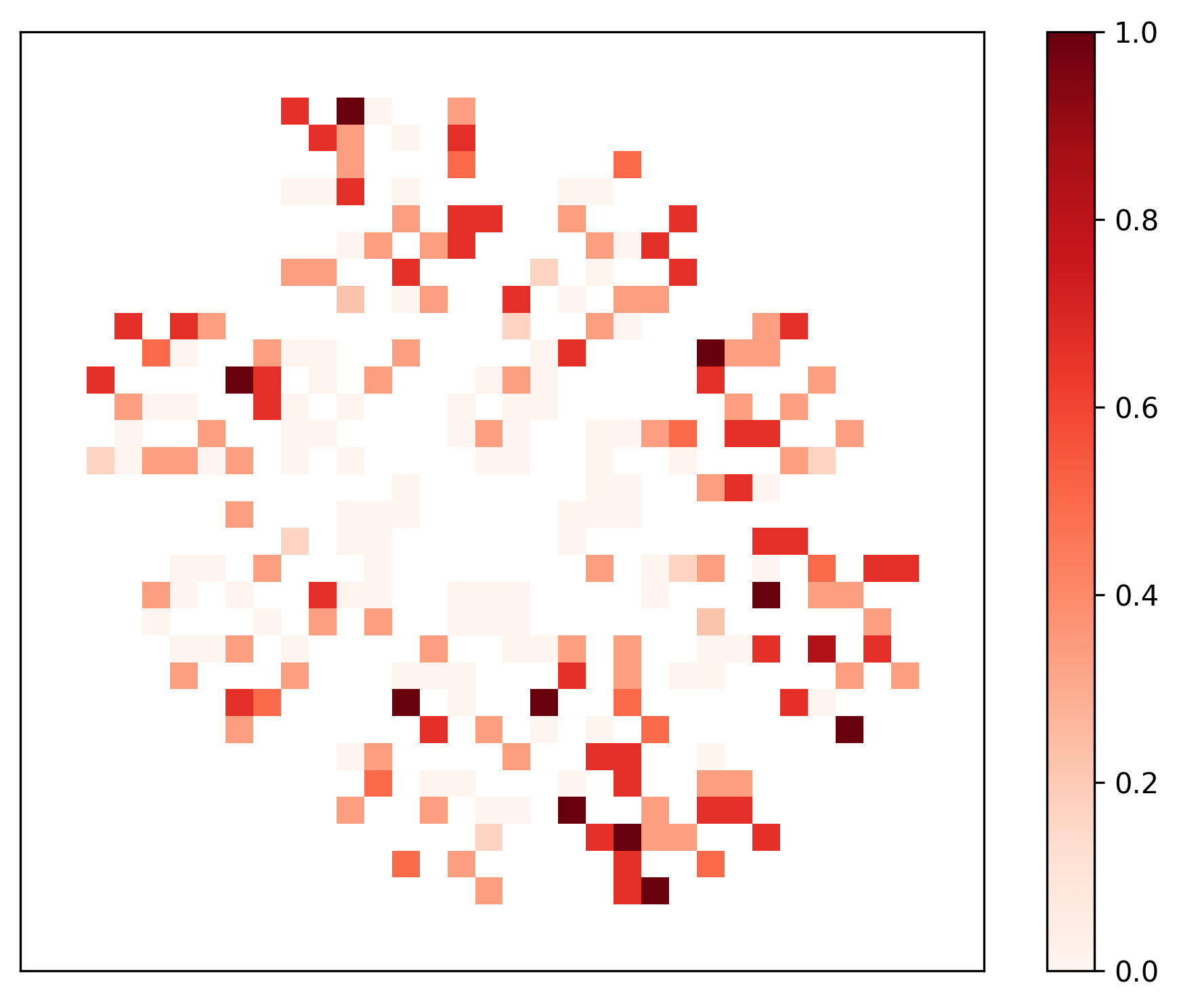
### Visual Description
## Heatmap: Unlabeled Distribution Pattern
### Overview
The image depicts a heatmap with a grid of colored squares arranged in a circular pattern. Colors range from white (low values) to dark red (high values), with a gradient scale on the right. The distribution shows clusters of high-intensity values (dark red) concentrated in specific regions, surrounded by lower-intensity areas (lighter red/white).
### Components/Axes
- **Grid**: A 2D matrix of squares with no labeled axes or categories.
- **Color Scale**: Vertical gradient on the right, ranging from **0.0 (white)** to **1.0 (dark red)**.
- **Pattern**: Circular arrangement of squares, with no textual labels, axis titles, or legends.
### Detailed Analysis
- **Color Distribution**:
- **Dark Red (0.8–1.0)**: Clusters of 5–7 squares in the central region, with isolated dark red squares scattered peripherally.
- **Medium Red (0.4–0.8)**: Surrounding the central clusters, forming a gradient transition.
- **Light Red/White (0.0–0.4)**: Dominates the outer edges, with sparse medium-red regions.
- **Spatial Grounding**:
- Color scale is positioned on the **right edge**, occupying ~20% of the image width.
- Grid occupies the remaining space, with no axis markers or legends.
### Key Observations
1. **Central Concentration**: The highest values (dark red) are tightly clustered near the center, suggesting a focal point of intensity.
2. **Peripheral Gradient**: Values decrease radially outward, with the outermost regions showing minimal intensity (white).
3. **Cluster Variability**: Some clusters have irregular shapes (e.g., L-shaped or fragmented), while others are compact.
4. **No Textual Labels**: No categories, axis titles, or legends are present to contextualize the data.
### Interpretation
The heatmap likely represents a spatial distribution of a metric (e.g., sensor readings, population density, or resource allocation). The central clusters indicate regions of maximum intensity, while the gradient suggests a decay or dispersion effect. The absence of labels limits direct interpretation, but the pattern implies:
- **Dominant Central Phenomenon**: A core area with the highest values, possibly a hub or focal point.
- **Secondary Peaks**: Smaller clusters may represent localized secondary phenomena or outliers.
- **Boundary Effects**: The periphery’s low values could indicate a natural boundary or diminishing influence.
**Note**: Without contextual labels, the exact nature of the data (e.g., time, location, or category) remains speculative. The pattern emphasizes spatial relationships rather than categorical or temporal trends.
</details>
(b)
Figure 4: UMAP comparing the quality of the obtained table descriptions against the dependency on contacting patient zero.
## VI Conclusion
In this paper, we propose a novel approach for tacit knowledge retrieval using LLM-based agents within organizational environments. We map the problem as a task to reconstruct database table descriptions that have been disseminated through a company’s employee network. Our approach allows the agent to navigate through the company graph, engaging in natural language conversations with employees to gradually accumulate partial information of the desired table and gain context to help direct its next course of action.
To validate our proposed method, we explore a broad simulated setup that encompasses a diverse range of companies structures with different generated table descriptions. Our empirical findings show that the proposed approach is robust and effective in retrieving tacit knowledge spread within the hierarchy of the simulated companies. By evaluating the reference-free self-critical scores used by our agent during its exploration process, we observe that these scores exhibit similarities to the reference-based evaluation metrics considered in our setup. We also identify that the agent is often able to retrieve the full table description without ever directly contacting the employee that was the source of the disseminated knowledge, achieving a recall rate of $94.9\$ . These results showcase the robustness of our approach and its ability to reconstruct tacit knowledge through automated conversational interactions. For future work, we are implementing our approach at Kunumi, letting the agent interact with real employees in the company network. While further research is needed, preliminary results indicate improved documentation quality, enhancing workflows and efficiency as knowledge concentrated among managers becomes more accessible.
## Code and Data Availability
The code, data, and prompts used for the machine-learning analyses, available for non-commercial use, has been deposited at https://doi.org/10.6084/m9.figshare.28785524 [32].
## References
- [1] M. Weber, The theory of social and economic organization. Simon and Schuster, 1947.
- [2] F. W. Taylor, Scientific management. Routledge, 2004.
- [3] I. Z. Kiss, M. Broom, P. G. Craze, and I. Rafols, “Can epidemic models describe the diffusion of topics across disciplines?” Journal of Informetrics, vol. 4, no. 1, pp. 74–82, 2010.
- [4] H.-M. Zhu, S.-T. Zhang, Y.-Y. Zhang, F. Wang et al., “Tacit knowledge spreading based on knowledge spreading model on networks with consideration of intention mechanism,” Journal of Digital Information Management, vol. 13, no. 4, pp. 293–300, 2015.
- [5] M. Polanyi, “The tacit dimension,” in Knowledge in organisations. Routledge, 2009, pp. 135–146.
- [6] I. Nonaka and H. Takeuchi, “The knowledge-creating company,” Harvard business review, vol. 85, no. 7/8, p. 162, 2007.
- [7] M. U. Hadi, Q. Al Tashi, A. Shah, R. Qureshi, A. Muneer, M. Irfan, A. Zafar, M. B. Shaikh, N. Akhtar, J. Wu et al., “Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects,” Authorea Preprints, 2024.
- [8] M. S. Orenstrakh, O. Karnalim, C. A. Suarez, and M. Liut, “Detecting llm-generated text in computing education: Comparative study for chatgpt cases,” in 2024 IEEE 48th Annual Computers, Software, and Applications Conference (COMPSAC). IEEE, 2024, pp. 121–126.
- [9] J. Zamfirescu-Pereira, R. Y. Wong, B. Hartmann, and Q. Yang, “Why johnny can’t prompt: how non-ai experts try (and fail) to design llm prompts,” in Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, 2023, pp. 1–21.
- [10] T. Webb, K. J. Holyoak, and H. Lu, “Emergent analogical reasoning in large language models,” Nature Human Behaviour, vol. 7, no. 9, pp. 1526–1541, 2023.
- [11] N. Miao, Y. W. Teh, and T. Rainforth, “Selfcheck: Using llms to zero-shot check their own step-by-step reasoning,” arXiv preprint arXiv:2308.00436, 2023.
- [12] P. Blau, Exchange and power in social life. Routledge, 2017.
- [13] T. Diefenbach and J. A. Sillince, “Formal and informal hierarchy in different types of organization,” Organization studies, vol. 32, no. 11, pp. 1515–1537, 2011.
- [14] G. Hedlund, “Assumptions of hierarchy and heterarchy, with applications to the management of the multinational corporation,” in Organization theory and the multinational corporation. Springer, 1993, pp. 211–236.
- [15] J. Mihm, C. H. Loch, D. Wilkinson, and B. A. Huberman, “Hierarchical structure and search in complex organizations,” Management science, vol. 56, no. 5, pp. 831–848, 2010.
- [16] J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” in Proceedings of the 36th annual acm symposium on user interface software and technology, 2023, pp. 1–22.
- [17] G. Dai, W. Zhang, J. Li, S. Yang, S. Rao, A. Caetano, M. Sra et al., “Artificial leviathan: Exploring social evolution of llm agents through the lens of hobbesian social contract theory,” arXiv preprint arXiv:2406.14373, 2024.
- [18] C. Qian, W. Liu, H. Liu, N. Chen, Y. Dang, J. Li, C. Yang, W. Chen, Y. Su, X. Cong et al., “Chatdev: Communicative agents for software development,” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 15 174–15 186.
- [19] T. Wu, M. Terry, and C. J. Cai, “Ai chains: Transparent and controllable human-ai interaction by chaining large language model prompts,” in Proceedings of the 2022 CHI conference on human factors in computing systems, 2022, pp. 1–22.
- [20] D. Zhou, N. Schärli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, C. Cui, O. Bousquet, Q. Le et al., “Least-to-most prompting enables complex reasoning in large language models,” arXiv preprint arXiv:2205.10625, 2022.
- [21] J. Wei, X. Wang, D. Schuurmans, M. Bosma, b. ichter, F. Xia, E. Chi, Q. V. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” in Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 24 824–24 837.
- [22] W. O. Kermack and A. G. McKendrick, “A contribution to the mathematical theory of epidemics,” Proceedings of the royal society of london. Series A, Containing papers of a mathematical and physical character, vol. 115, no. 772, pp. 700–721, 1927.
- [23] M. Ehrhardt, J. Gašper, and S. Kilianová, “Sir-based mathematical modeling of infectious diseases with vaccination and waning immunity,” Journal of Computational Science, vol. 37, p. 101027, 2019.
- [24] S. Ahmetolan, A. H. Bilge, A. Demirci, and A. P. Dobie, “A susceptible–infectious (si) model with two infective stages and an endemic equilibrium,” Mathematics and Computers in Simulation, vol. 194, pp. 19–35, 2022.
- [25] D. J. Arent, R. S. Tol, E. Faust, J. P. Hella, S. Kumar, K. M. Strzepek, F. L. Tóth, D. Yan, A. Abdulla, H. Kheshgi et al., “Key economic sectors and services,” in Climate change 2014 impacts, adaptation and vulnerability: Part a: Global and sectoral aspects. Cambridge University Press 2010, 2015, pp. 659–708.
- [26] P. S. Laumas, “Key sectors in some underdeveloped countries.” Kyklos, vol. 28, no. 1, 1975.
- [27] B. Guibert, J. Laganier, and M. Volle, “An essay on industrial classifications,” Économie et statistique, vol. 20, pp. 1–18, 1971.
- [28] T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein, Introduction to algorithms. MIT press, 2022.
- [29] A. Lavie and A. Agarwal, “Meteor: an automatic metric for mt evaluation with high levels of correlation with human judgments,” in Proceedings of the Second Workshop on Statistical Machine Translation, ser. StatMT ’07. USA: Association for Computational Linguistics, 2007, p. 228–231.
- [30] Y. Liu, D. Iter, Y. Xu, S. Wang, R. Xu, and C. Zhu, “G-eval: Nlg evaluation using gpt-4 with better human alignment,” in Conference on Empirical Methods in Natural Language Processing, 2023, p. 2511.
- [31] L. McInnes, J. Healy, and J. Melville, “UMAP: Uniform manifold approximation and projection for dimension reduction,” arXiv preprint arXiv:1802.03426, 2018.
- [32] G. Zuin, “Code and data for Leveraging Large Language Models for Tacit Knowledge Discovery in Organizational Contexts,” 2025. [Online]. Available: https://doi.org/10.6084/m9.figshare.28785524