# Binaural Localization Model for Speech in Noise
ATF Acoustic Transfer Function AED Auto Encoder-Decoder BCCTN Binaural Complex Convolutional Transformer Network BiTasNet Binaural TasNet BMWF Binaural MWF BRIRs Binaural Room Impulse Responses BSOBM Binaural STOI-Optimal Masking BTE behind-the-ear CED Convolutional Encoder-Decoder CNN Convolutional Neural Network CRM Complex Ratio Mask CRN Convolutional Recurrrent Network CASA Computational Auditory Scene Analysis DFT Discrete Fourier Transform DNN Deep Neural Network DOA Direction of Arrival ERB Equivalent Rectangular Bandwidth EVD Eigenvalue Decomposition FAL Frequency Attention Layer FTB Frequency Transformation Block FTM Frequency Transformation Matrix fwSegSNR Frequency-weighted Segmental SNR FCIM Fixed Cylindrical Isotropic MVDR GCC-PHAT Generalized Cross-Correlation with Phase Transform method of estimating TDoA GRU Gated Recurrent Unit GOMVDR Guided OMVDR GFCIM Guided FCIM GiN Group in Noise GMVDR Guided MVDR GCC Generalized Cross-Correlation GMM Gaussian Mixture Model HATS Head and Torso Simulator HRIRs Head Related Impulse Response HSWOBM High-resolution Stochastic WSTOI-optimal Binary Mask IBM Ideal Binary Mask IDFT Inverse Discrete Fourier Transform ILD Interaural Level Difference IPD Interaural Phase Difference IRM Ideal Ratio Mask ISTFT Inverse STFT ITD Interaural Time Differences ISPD Interaural Signal Phase Difference iSNR input SNR LSA Log Spectral Amplitude LSTM Long Short-Term Memory MBSTOI Modified Binaural STOI MIMO Multiple Input Multiple Output MLP Multi-Layer Perceptrons MSC Magnitude Squared Coherence MVDR Minimum Variance Distortionless Response MWF Multichannel Wiener Filter MBCCTN Multichannel Binaural Complex Convolutional Transformer Network NCM Noise Covariance Matrix NLP Natural Language Processing NPM Normalized Projection Misalignment NH Normal Hearing OM-LSA Optimally-modified Log Spectral Amplitude OMVDR Oracle MVDR PESQ Preceptual Evalution of Speech Quality PReLU Parametric Rectified Linear Unit PSD Power Spectral Density ReLU Rectified Linear Unit RIR Room Impulse Responses RNN Recurrent Neural Network RTF Relative Transfer Function SI-SNR Scale-Invariant SNR SegSNR Segmental SNR SNR Signal-to-Noise Ratio SOBM STOI-optimal Binary Mask SPP Speech Presence Probability SSN Speech Shaped Noise STFT Short Time Fourier Transform STOI Short-Time Objective Intelligibility SRP Steered Response Power SRP-PHAT Steered Response Power with Phase Transform TF Time-Frequency TNN Transformer Neural Networks VAD Voice Activity Detector VSSNR Voiced-Speech-plus-Noise to Noise Ratio WGN White Gaussian Noise WSTOI Weighted STOI
## Abstract
Binaural acoustic source localization is important to human listeners for spatial awareness, communication and safety. In this paper, an end-to-end binaural localization model for speech in noise is presented. A lightweight convolutional recurrent network that localizes sound in the frontal azimuthal plane for noisy reverberant binaural signals is introduced. The model incorporates additive internal ear noise to represent the frequency-dependent hearing threshold of a typical listener. The localization performance of the model is compared with the steered response power algorithm, and the use of the model as a measure of interaural cue preservation for binaural speech enhancement methods is studied. A listening test was performed to compare the performance of the model with human localization of speech in noisy conditions.
Keywords: Binaural source localization, reverberation, human hearing, interaural cues, spatial hearing
## 1 Introduction
Binaural localization has garnered significant attention in the field of Computational Auditory Scene Analysis (CASA), which is influenced by principles underlying the perceptual organization of sound by human listeners. The two primary cues for sound localization are the Interaural Time Differences (ITD), also known as the time difference of arrival, and the Interaural Level Difference (ILD), which arises due to the influence of the head, torso, and outer ear. Differences between localization methods often stem from varying assumptions about environmental factors such as sound propagation, background noise, and microphone configuration. Localizing sound sources using binaural input in noise and reverberation is a challenging problem with important applications in hearing aids, spatial sound reproduction, and mobile robotics.
It is well established that the noise and reverberation in typical listening environments can mask signals and negatively affect both binaural and monaural spectral cues, leading to reduced sound localization accuracy and speech comprehension even for individuals with normal hearing [1, 2, 3]. Research has shown that localization accuracy declines as the Signal-to-Noise Ratio (SNR) decreases. For instance, [1] studied three normal hearing listeners who were asked to localize broadband click trains in an anechoic chamber under one quiet and nine noisy conditions with SNR s ranging from -13 to +14 dB. Their findings revealed that localization accuracy was poorest in the lateral horizontal plane and began to deteriorate at SNR s below +8 dB. Similarly, [2] investigated the effect of SNR on localization ability in normal hearing listeners, finding that typical environments characterized by both noise and reverberation can further degrade localization cues and impair performance. In [4], it is suggested that the combined effects of noise and reverberation could further reduce localization accuracy.
<details>
<summary>x1.png Details</summary>

### Visual Description
\n
## Diagram: Audio Source Localization Pipeline
### Overview
This diagram illustrates a pipeline for localizing audio sources. It takes two input audio signals (left and right) and processes them through several stages, including noise estimation, cross-correlation, convolutional neural networks (CNNs), recurrent neural networks (RNNs), and a multi-layer perceptron (MLP) to ultimately estimate the source azimuth angle (θ).
### Components/Axes
The diagram consists of four main blocks, arranged horizontally from left to right:
1. **Input:** Two audio signals, denoted as y<sub>L</sub> (left, blue) and y<sub>R</sub> (right, red). Also includes "In-ear noise" with plots of the signals.
2. **GCC-PHAT:** A Generalized Cross-Correlation with Phase Transform (GCC-PHAT) block, taking the left and right signals as input and producing g<sub>LR</sub>.
3. **CNN-RNN-MLP Network:** A deep learning network consisting of three convolutional layers (Conv. 1, Conv. 2, Conv. 3), a flatten layer, a recurrent neural network (RNN), and a multi-layer perceptron (MLP).
4. **Output:** Source Azimuth Vectors, represented by the angle θ.
The CNN-RNN-MLP network block also includes dimension annotations: 64, T, 128, 1024, 128, and 2.
### Detailed Analysis or Content Details
1. **Input Signals:** The left signal (y<sub>L</sub>) is represented in blue, and the right signal (y<sub>R</sub>) is represented in red. The "In-ear noise" block contains two plots, one for each signal, showing their waveforms.
2. **GCC-PHAT Block:** This block takes the left and right signals and outputs g<sub>LR</sub>. The block is light green.
3. **CNN-RNN-MLP Network:**
* **Conv. 1:** Input dimension T, output dimension 128. The block is colored in shades of orange.
* **Conv. 2:** Input dimension 128, output dimension 128.
* **Conv. 3:** Input dimension 128, output dimension 64.
* **Flatten:** Converts the output of Conv. 3 into a 1024-dimensional vector.
* **RNN:** Takes the 1024-dimensional vector as input and outputs a 128-dimensional vector. The RNN block is colored in red.
* **MLP:** Takes the 128-dimensional vector as input and outputs a 2-dimensional vector. The MLP block is colored in blue.
4. **Output:** The output is "Source Azimuth Vectors" represented by the angle θ. The block is light blue.
### Key Observations
The diagram shows a clear flow of information from the input audio signals through a series of processing stages to the final output of source azimuth angle. The deep learning network is the core of the pipeline, utilizing CNNs for feature extraction, an RNN for temporal modeling, and an MLP for final prediction. The dimension annotations provide insight into the network's architecture.
### Interpretation
This diagram represents a system for sound source localization, likely intended for applications like hearing aids or robotics. The use of GCC-PHAT suggests a time-delay-of-arrival (TDOA) based approach, which is then refined by the deep learning network. The CNNs likely extract relevant features from the GCC-PHAT output, the RNN captures temporal dependencies in the audio signal, and the MLP maps these features to the final azimuth angle. The dimension annotations suggest a relatively compact network architecture. The system aims to estimate the direction (azimuth angle θ) from which a sound is originating. The "In-ear noise" block suggests that the system is designed to operate in noisy environments.
</details>
Figure 1: Block diagram of the model architecture.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Charts: Frequency Response - Magnitude and Phase
### Overview
The image presents two charts stacked vertically. Both charts depict the relationship between Frequency (kHz) and another variable. The top chart shows Magnitude (dB) versus Frequency, while the bottom chart shows Phase (rad.) versus Frequency. Both charts use a blue line to represent the data.
### Components/Axes
* **Top Chart:**
* X-axis: Frequency (kHz), ranging from 0 to 8 kHz. Markers are present at 1, 2, 3, 4, 5, 6, 7, and 8 kHz.
* Y-axis: Magnitude (dB), ranging from 0 to 20 dB. Markers are present at 0, 5, 10, 15, and 20 dB.
* **Bottom Chart:**
* X-axis: Frequency (kHz), ranging from 0 to 8 kHz. Markers are present at 1, 2, 3, 4, 5, 6, 7, and 8 kHz.
* Y-axis: Phase (rad.), ranging from -2 to 2 rad. Markers are present at -1, 0, 1, and 2 rad.
### Detailed Analysis
* **Top Chart (Magnitude vs. Frequency):**
* The blue line starts at approximately 6 dB at 0 kHz.
* The line slopes upward, reaching a peak of approximately 21 dB at around 4 kHz.
* After the peak, the line slopes downward, decreasing to approximately 8 dB at 8 kHz.
* Approximate data points:
* 0 kHz: 6 dB
* 1 kHz: 11 dB
* 2 kHz: 16 dB
* 3 kHz: 19 dB
* 4 kHz: 21 dB
* 5 kHz: 19 dB
* 6 kHz: 14 dB
* 7 kHz: 10 dB
* 8 kHz: 8 dB
* **Bottom Chart (Phase vs. Frequency):**
* The blue line starts at approximately 1.8 rad. at 0 kHz.
* The line decreases, becoming approximately 0.2 rad. at 8 kHz.
* The line exhibits a relatively smooth, downward trend.
* Approximate data points:
* 0 kHz: 1.8 rad.
* 1 kHz: 1.4 rad.
* 2 kHz: 1.0 rad.
* 3 kHz: 0.7 rad.
* 4 kHz: 0.4 rad.
* 5 kHz: 0.2 rad.
* 6 kHz: 0.1 rad.
* 7 kHz: 0.05 rad.
* 8 kHz: 0.2 rad.
### Key Observations
* The magnitude response shows a peak around 4 kHz, indicating a resonant frequency or amplification in that region.
* The phase response decreases with increasing frequency, suggesting a time delay that increases as frequency increases.
* Both charts show smooth curves without any abrupt changes or discontinuities.
### Interpretation
The charts likely represent the frequency response of a filter or system. The magnitude plot indicates the gain or attenuation of the system at different frequencies, while the phase plot shows the phase shift introduced by the system. The peak in the magnitude response suggests that the system is particularly sensitive to frequencies around 4 kHz. The decreasing phase response indicates that higher frequencies experience a greater time delay. This could be a characteristic of a low-pass filter, a band-pass filter, or a more complex system. The data suggests a system that boosts frequencies around 4kHz and introduces a frequency-dependent phase shift. The smooth curves suggest a well-behaved system without significant non-linearities.
</details>
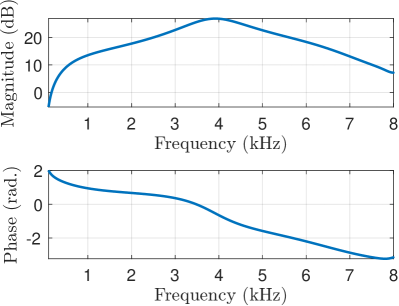
Figure 2: Magnitude and phase response of filter used to simulate the listener’s hearing threshold.
A well-known method for localisation using ITD estimation is the Generalized Cross-Correlation with Phase Transform (GCC-PHAT) approach, which assumes ideal single-path propagation. Although Generalized Cross-Correlation (GCC) and similar methods can be applied to any setup with two or more microphones, some recent research has focused on localization models specifically designed for binaural systems [5, 6]. Recent efforts have integrated azimuth-dependent models of ITD and ILD, demonstrating that jointly considering both cues enhances azimuth estimation compared to using ITD alone [7, 6, 5]. However, these models often require prior training or calibration with the binaural input due to the significant variability in the frequency-dependent patterns of ITD s and ILD s across individuals, which can lead to performance degradation in different binaural setups. Methods also differ in how they integrate interaural information across time and frequency, with these variations largely reflecting different assumptions about source activity and interaction. In [5], authors proposed a framework that determines the likelihood of each source location based on a Gaussian Mixture Model (GMM) classifier, which learns the azimuth-dependent distribution of ITD s and ILD s from joint analysis of both binaural cues. However, many binaural localization methods have focused on scenarios with minimal reverberation or background noise. One approach to improving localization in more complex environments involves using model-based information about the spectral characteristics of sound sources in the acoustic scene to selectively weight binaural cues. This involves estimating models for both target and background sources during a training stage, using spectral features derived from isolated source signals [6]. In [8], an end-to-end binaural localization algorithm that estimates the azimuth using Convolutional Neural Network (CNN)s to extract features from the binaural signal was introduced.
Human auditory cognition includes complex neurological processes for localization. Although ILD s and ITD s are widely accepted to be the primary interaural cues that influence human sound source localization [1], there is no standardized way to characterise them. Precedence effect, spectral cues, head movement and other psychoacoustical processes affect sound localization in humans. There is no universally accepted method of measuring the correlation between human sound localization and the frequency-varying interaural cues. In [9, 10], to demonstrate the preservation of spatial cues, the error in interaural cues of the enhanced speech was computed using an Ideal Binary Mask (IBM) that selects the speech-active regions in the signal.
A relevant approach to measuring the accuracy with which spatial information is preserved and the subsequent accuracy of localization of speech sources in noisy and enhanced speech signals would be to employ a model that predicts the localization of the speech-in-noise in a manner highly correlated to a human listener. This paper sets out to research methods of Direction of Arrival (DOA) estimation that are not necessarily the best-performing but specifically follow the performance of the human listener in terms of binaural localization. The paper will focus on an end-to-end binaural localization model for speech in noisy and reverberant conditions, introducing a lightweight Convolutional Recurrrent Network (CRN) that utilizes input features based on GCC-PHAT, which is a first step towards this goal. The model adds synthetic internal ear noise to an audio signal to simulate the effects of the frequency-dependent hearing threshold of a normal listener. The model is trained on binaural speech data to directly predict the source azimuth without limiting the localization to a predetermined azimuth-dependent distribution of interaural cues. The approach is evaluated using a listening test that was conducted using 15 normal hearing listeners, in which the participants were tasked to localize a target speaker in simulated noisy and reverberant conditions.
## 2 System Description
### 2.1 Signal model
A binaural system is comprises a left and a right channel. The time-domain signal $y_{L}$ received by the left channel is modeled as
$$
\displaystyle y_{L}(n)=s_{L}(n)+v_{L}(n), \tag{1}
$$
where $s_{L}$ is the anechoic clean speech signal, $v_{L}$ is the noise and $n$ is the discrete-time index. The in-ear noise added signal $\tilde{{y}_{L}}$ is given by
$$
\displaystyle\bar{y}_{L}(n)=h_{e}(n)\ast y_{L}(n)+e_{L}(n) \tag{2}
$$
where $h_{e}(n)$ is the impulse response of the filter depicted in Fig. 2 and $e_{L}(n)$ is the white noise added to the filtered noisy signal. The right channel is described similarly with a $R$ subscript. The model adds fictitious internal ear noise to an audio signal to simulate the effects of the frequency-dependent hearing threshold of a normal listener, assuming that the input speech in the stronger channel is at the normal level defined in [11] to be 62.35 dB SPL”. The noise spectrum is taken from [12, 11] and, at a particular frequency, equals the pure-tone hearing threshold minus $10\log_{10}(C)$ where $C$ is the critical ratio. The critical ratio, $C$ , is the power of a pure tone divided by the power spectral density of a white noise that masks it; this ratio is approximately independent of level. Hearing loss can also be taken into account here by modifying the filter that reduces the signal level by the hearing loss at each frequency. To avoid having to add very high noise levels at low and high frequencies, it instead filters the input signal by the inverse of the desired noise spectrum and then adds white noise with 0 dB power spectral density. Figure 1 shows the block diagram of the proposed system. The raw time-domain signal is filtered with the in-ear frequency response shown in Fig. 2. The online implementation (v_earnoise.m Matlab function) of the ear-noise filter can be found in [13]. The in-ear noise-added signal is then used as the input to the neural network, which determines the target azimuth in the frontal azimuthal plane.
### 2.2 Localization network
#### 2.2.1 Input Feature Set
The input feature of the proposed network consists of the GCC-PHAT for the pair of microphone signal frames $(\mathbf{\bar{y}_{L}},\mathbf{\bar{y}_{R})}$ , defined as
$$
\mathbf{g}_{LR}=\text{IDFT}\bigg{(}\frac{\bar{\mathbf{Y}}_{L}}{\lvert\bar{\mathbf{Y}}_{L}\rvert}\odot\frac{\bar{\mathbf{Y}}^{*}_{R}}{\lvert\bar{\mathbf{Y}}_{R}\rvert}\bigg{)}, \tag{3}
$$
the Inverse Discrete Fourier Transform (IDFT) of the element-wise product of the normalized frequency-domain frames ${\mathbf{Y}_{L}}$ and $\mathbf{{Y}}_{R}$ , where $\mathbf{\bar{{Y}}}=\text{DFT}(\bar{\mathbf{{y}}})$ and $\lvert{\mathbf{Y}}\rvert$ is the element-wise magnitude.
#### 2.2.2 Network architecture
As shown in Fig. 1, the network is composed of a set of convolutional blocks, followed by an operation of flattening of the frequency and channel dimension. The resulting tensor is then used as input for a Gated Recurrent Unit (GRU) Recurrent Neural Network (RNN). Finally, a linear layer is applied to produce a 2-D output vector, $\mathbf{\hat{v}}$ , representing the direction of the source’s azimuth.
### 2.3 Loss function
The proposed model is trained using a modification of the cosine similarity given by
$$
\displaystyle\mathcal{L}({\mathbf{v},\hat{\mathbf{v}}})=1-\lVert\frac{\mathbf{v}\cdot{\mathbf{\hat{v}}}}{|\mathbf{v}||{\mathbf{\hat{v}}}|}\rVert \tag{4}
$$
between the true and estimated directions $\mathbf{v}$ and $\hat{\mathbf{v}}$ . The loss function (4) was designed so that the absolute value of the cosine similarity between the vectors is minimized, therefore not penalizing the effects caused by the front-back ambiguity, which are expected when employing only two microphones.
## 3 Experiments
### 3.1 Dataset
To generate binaural speech data, monaural clean speech signals were obtained from the CSTR VCTK corpus [14] and spatialized using the measured Binaural Room Impulse Responses (BRIRs) from [15] for training. The VCTK corpus contains approximately 13 hours of speech data from 110 English speakers with various accents. These recordings were used to create 2 s speech utterances, which were spatialized to produce left and right ear channels. The resulting dataset comprised 20,000 speech utterances, which were divided into training (70%), validation (15%), and testing (15%) sets. Diffuse isotropic speech-shaped noise was generated using uncorrelated noise sources uniformly distributed every $5^{\circ}$ in the azimuthal plane [16], utilizing BRIRs from [15] which were recorded in a listening room with a $T_{60}$ of $460$ ms. The binaural signals were generated with the target speech positioned at a random azimuth in the frontal plane ( $-90^{\circ}$ to $+90^{\circ}$ ) with the source positioned at a distance of 100 cm. For the training process, isotropic noise was added so that the average in dB of $(SNR_{L},~SNR_{R})$ , ranged between -25 dB and 25 dB. The evaluation set comprised speech signals spatialized with BRIRs from [17] with random target azimuths and isotropic noise added at random SNR s between -25 dB and 25 dB. The speaker was positioned at a $0^{\circ}$ elevation and at a distance of 3 m. This ensured that training and evaluation sets contained binaural signals generated using different BRIRs to verify that the network generalised to different heads.
### 3.2 Training Setup
The 2 s input signals were sampled at 16 kHz, and a window size of 512 was used to generate the signal frames with a 75% overlap for a hop size of 25 ms. The parameters for the localization network are detailed in Fig. 1, which includes the tensor output shapes for each layer of the network. Convolutional layers employed a kernal size of (3, 3) throughout. Max pooling with a kernel size of 2 was applied to all convolutional layers except the last one. The Parametric Rectified Linear Unit (PReLU) activation function was utilized in all layers of the network, except for the RNN and Multi-Layer Perceptrons (MLP) output layers, which used hyperbolic tangent ( $\tanh$ ) activation, and the output layer, which employed sigmoidal activation. This architecture was taken from [18] and modified to work for binaural signals. The network has 850K parameters and is implemented using the PyTorch library, and the Adam optimizer was used for backpropagation. The network was trained for 80 epochs. The code for implementation is available online https://github.com/VikasTokala/BiL.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Bar Charts: RMS Error vs. iSNR for BIL and SRP
### Overview
The image presents two separate bar charts, stacked vertically. Both charts depict the relationship between RMS Error (in degrees) and iSNR (signal-to-noise ratio). The top chart represents data for "BIL" (likely an algorithm or method), while the bottom chart represents data for "SRP". Each bar includes error bars indicating the variability of the data.
### Components/Axes
* **X-axis (Both Charts):** iSNR, ranging from -25 to 25, with markers at -25, -20, -15, -10, -5, 0, 5, 10, 15, 20, and 25.
* **Y-axis (Top Chart):** RMS Error [deg], ranging from 0 to 15, with markers at 0, 5, 10, and 15.
* **Y-axis (Bottom Chart):** RMS Error [deg], ranging from 0 to 60, with markers at 0, 10, 20, 30, 40, 50, and 60.
* **Legend (Top Chart):** "BIL" - represented by a light blue color.
* **Legend (Bottom Chart):** "SRP" - represented by a light red color.
* **Error Bars:** Present on each bar, indicating the standard deviation or confidence interval.
### Detailed Analysis or Content Details
**Top Chart (BIL):**
The bars for BIL show a decreasing trend in RMS Error as iSNR increases.
* iSNR = -25: RMS Error ≈ 11.5 ± 1.5 deg
* iSNR = -20: RMS Error ≈ 6.5 ± 0.8 deg
* iSNR = -15: RMS Error ≈ 4.5 ± 0.6 deg
* iSNR = -10: RMS Error ≈ 4.0 ± 0.5 deg
* iSNR = -5: RMS Error ≈ 3.5 ± 0.4 deg
* iSNR = 0: RMS Error ≈ 3.0 ± 0.3 deg
* iSNR = 5: RMS Error ≈ 2.5 ± 0.2 deg
* iSNR = 10: RMS Error ≈ 2.0 ± 0.2 deg
* iSNR = 15: RMS Error ≈ 1.5 ± 0.1 deg
* iSNR = 20: RMS Error ≈ 1.0 ± 0.1 deg
* iSNR = 25: RMS Error ≈ 0.5 ± 0.1 deg
**Bottom Chart (SRP):**
The bars for SRP also show a decreasing trend in RMS Error as iSNR increases, but the error values are significantly higher than those for BIL.
* iSNR = -25: RMS Error ≈ 40 ± 5 deg
* iSNR = -20: RMS Error ≈ 45 ± 6 deg
* iSNR = -15: RMS Error ≈ 30 ± 4 deg
* iSNR = -10: RMS Error ≈ 25 ± 3 deg
* iSNR = -5: RMS Error ≈ 20 ± 3 deg
* iSNR = 0: RMS Error ≈ 18 ± 2 deg
* iSNR = 5: RMS Error ≈ 15 ± 2 deg
* iSNR = 10: RMS Error ≈ 12 ± 2 deg
* iSNR = 15: RMS Error ≈ 10 ± 1 deg
* iSNR = 20: RMS Error ≈ 8 ± 1 deg
* iSNR = 25: RMS Error ≈ 6 ± 1 deg
### Key Observations
* The RMS Error for BIL is consistently and substantially lower than that for SRP across all iSNR values.
* Both methods exhibit a negative correlation between RMS Error and iSNR – as the signal-to-noise ratio increases, the error decreases.
* The error bars indicate greater variability in the SRP data, particularly at lower iSNR values.
* The error bars for BIL are consistently smaller, suggesting more stable performance.
### Interpretation
The data suggests that the BIL method is significantly more accurate than the SRP method in estimating the target parameter, as indicated by the lower RMS Error. Both methods benefit from increased iSNR, but the improvement is more pronounced for SRP, likely due to its higher initial error. The larger error bars for SRP suggest that its performance is more sensitive to noise or other variations in the input data.
The charts likely represent the performance of two different algorithms or techniques for a specific task (e.g., object localization, signal processing). The iSNR represents the quality of the input signal, and the RMS Error quantifies the difference between the estimated value and the true value. The results indicate that BIL is a more robust and accurate method, especially in noisy environments (low iSNR). The decreasing trend for both methods highlights the importance of signal quality for accurate estimation.
</details>
(a)
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Bar Chart: RMS Error vs. iSNR for Localization Performance
### Overview
This bar chart compares the Root Mean Square (RMS) error in degrees for sound source localization performance under different Input Signal-to-Noise Ratio (iSNR) levels. Three conditions are compared: Listeners, SRP (Steered Response Power), and BIL (Binaural Intensity Level). Error bars represent the variability in the measurements.
### Components/Axes
* **X-axis:** iSNR (Input Signal-to-Noise Ratio) with markers at -15, 0, and 15.
* **Y-axis:** RMS Error [deg] (Root Mean Square Error in degrees), ranging from 0 to 45.
* **Legend:** Located in the top-right corner, identifying the three conditions:
* Listeners (Purple)
* SRP (Red)
* BIL (Light Blue)
* **Error Bars:** Black vertical lines extending above and below each bar, indicating the standard error or confidence interval.
### Detailed Analysis
The chart presents three groups of bars for each iSNR value (-15, 0, 15). Each group represents the RMS error for Listeners, SRP, and BIL.
**iSNR = -15:**
* Listeners: The bar is approximately 20 degrees tall, with an error bar extending from roughly 15 to 26 degrees.
* SRP: The bar is approximately 28 degrees tall, with an error bar extending from roughly 22 to 34 degrees.
* BIL: The bar is approximately 6 degrees tall, with an error bar extending from roughly 4 to 8 degrees.
**iSNR = 0:**
* Listeners: The bar is approximately 16 degrees tall, with an error bar extending from roughly 12 to 20 degrees.
* SRP: The bar is approximately 26 degrees tall, with an error bar extending from roughly 20 to 32 degrees.
* BIL: The bar is approximately 4 degrees tall, with an error bar extending from roughly 2 to 6 degrees.
**iSNR = 15:**
* Listeners: The bar is approximately 14 degrees tall, with an error bar extending from roughly 10 to 18 degrees.
* SRP: The bar is approximately 17 degrees tall, with an error bar extending from roughly 13 to 21 degrees.
* BIL: The bar is approximately 2 degrees tall, with an error bar extending from roughly 0 to 4 degrees.
### Key Observations
* BIL consistently exhibits the lowest RMS error across all iSNR levels.
* SRP consistently exhibits the highest RMS error across all iSNR levels.
* The RMS error for Listeners falls between that of BIL and SRP.
* As iSNR increases from -15 to 15, the RMS error generally decreases for all three conditions, although the error bars overlap significantly.
* The error bars are relatively large, indicating substantial variability in the localization performance.
### Interpretation
The data suggests that BIL provides the most accurate sound source localization performance, while SRP provides the least accurate performance. Human listeners fall in between these two methods. The improvement in localization accuracy with increasing iSNR suggests that noise negatively impacts localization performance for all three conditions. The large error bars indicate that individual listener performance varies considerably, and the differences between the conditions may not always be statistically significant. The chart demonstrates the impact of signal quality (iSNR) on the effectiveness of different localization algorithms and human perception. The consistent performance of BIL suggests it is more robust to noise than SRP or human listeners. The overlap in error bars suggests that, while there are general trends, the performance of each method can vary significantly.
</details>
(b)
<details>
<summary>x5.png Details</summary>
### Visual Description
## Bar Chart: RMS Error vs. iSNR for Different Methods
### Overview
The image presents two bar charts comparing the Root Mean Square (RMS) error in degrees for different methods – Noisy + BIL, BCCTN + BIL, BiTasNet + BIL, and SpecSub + BIL – across varying input Signal-to-Noise Ratio (iSNR) levels. The top chart focuses on the first three methods, while the bottom chart displays results for SpecSub + BIL. Error bars are included, indicating the variability of the results.
### Components/Axes
* **X-axis (both charts):** iSNR (Input Signal-to-Noise Ratio), ranging from -15 to 15 in increments of 5.
* **Y-axis (top chart):** RMS Error [deg] (Root Mean Square Error in degrees), ranging from 0 to 10.
* **Y-axis (bottom chart):** RMS Error [deg] (Root Mean Square Error in degrees), ranging from 0 to 80.
* **Legend (top chart):**
* Blue: Noisy + BIL
* Orange: BCCTN + BIL
* Brown: BiTasNet + BIL
* **Legend (bottom chart):**
* Light Blue: SpecSub + BIL
### Detailed Analysis or Content Details
**Top Chart (Noisy + BIL, BCCTN + BIL, BiTasNet + BIL):**
* **Noisy + BIL (Blue):** The RMS error starts at approximately 6 degrees at iSNR = -15, decreases to around 2 degrees at iSNR = 0, and remains relatively stable around 1-2 degrees for iSNR values from 0 to 15.
* **BCCTN + BIL (Orange):** The RMS error begins at approximately 4.5 degrees at iSNR = -15, decreases to around 1.5 degrees at iSNR = 0, and remains relatively stable around 1-2 degrees for iSNR values from 0 to 15.
* **BiTasNet + BIL (Brown):** The RMS error starts at approximately 8 degrees at iSNR = -15, decreases to around 2.5 degrees at iSNR = 0, and remains relatively stable around 1.5-2.5 degrees for iSNR values from 0 to 15. The error bars are notably larger for BiTasNet + BIL at iSNR = -15.
**Bottom Chart (SpecSub + BIL):**
* **SpecSub + BIL (Light Blue):** The RMS error remains relatively constant across all iSNR levels, fluctuating between approximately 40 and 45 degrees. The error bars are consistently large, indicating significant variability.
### Key Observations
* All three methods (Noisy + BIL, BCCTN + BIL, BiTasNet + BIL) demonstrate a decreasing trend in RMS error as iSNR increases, leveling off at higher iSNR values.
* BCCTN + BIL consistently exhibits the lowest RMS error across all iSNR levels in the top chart.
* SpecSub + BIL exhibits a significantly higher and relatively constant RMS error compared to the other three methods.
* The error bars for SpecSub + BIL are consistently large, suggesting high variability in its performance.
* BiTasNet + BIL has the largest error bar at the lowest iSNR (-15), indicating the most variance in performance at low signal-to-noise ratios.
### Interpretation
The data suggests that BCCTN + BIL is the most robust method for reducing RMS error across a range of iSNR levels, consistently outperforming Noisy + BIL and BiTasNet + BIL. The performance of all three methods improves as the iSNR increases, indicating that they are all sensitive to noise. SpecSub + BIL, however, consistently exhibits a high RMS error and significant variability, suggesting it is less effective than the other methods in this context.
The consistent high error and large error bars for SpecSub + BIL could indicate that this method is fundamentally limited in its ability to handle noisy data, or that its performance is highly dependent on specific data characteristics not captured by the iSNR metric. The larger error bar for BiTasNet + BIL at iSNR = -15 suggests that this method is particularly sensitive to low signal-to-noise ratios.
The leveling off of RMS error for Noisy + BIL, BCCTN + BIL, and BiTasNet + BIL at higher iSNR values suggests that there is a limit to the improvement that can be achieved by increasing the signal-to-noise ratio. This could be due to other factors, such as limitations in the underlying algorithms or the inherent noise in the data itself.
</details>
(c)
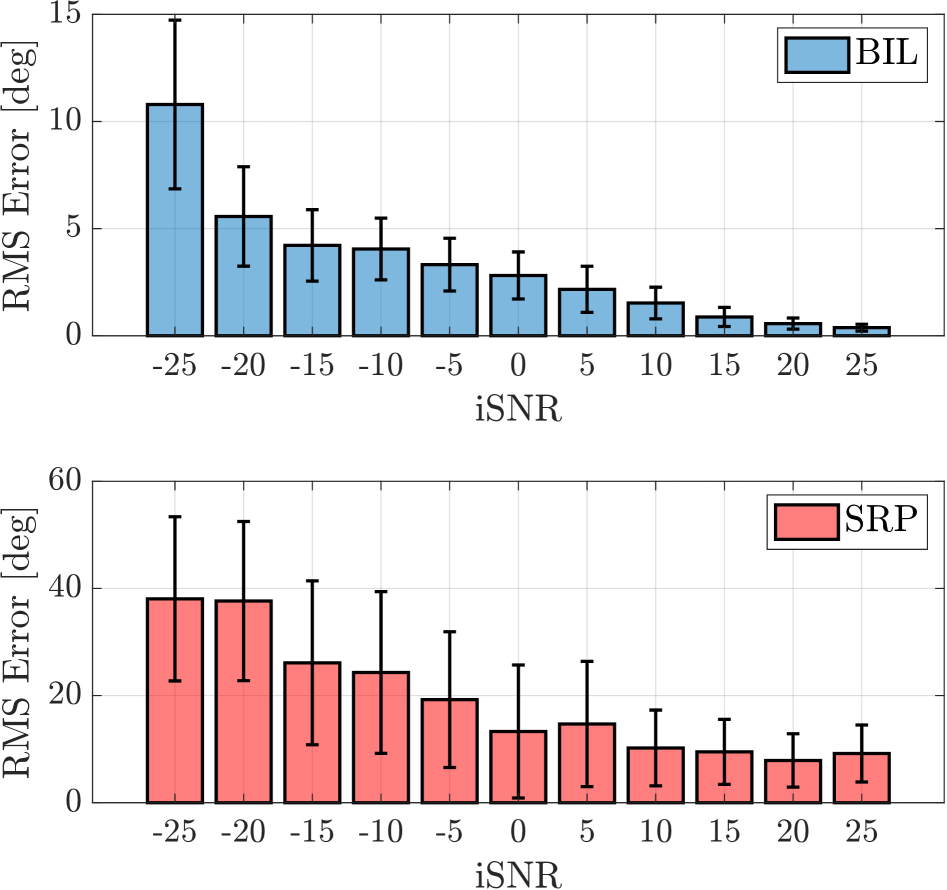
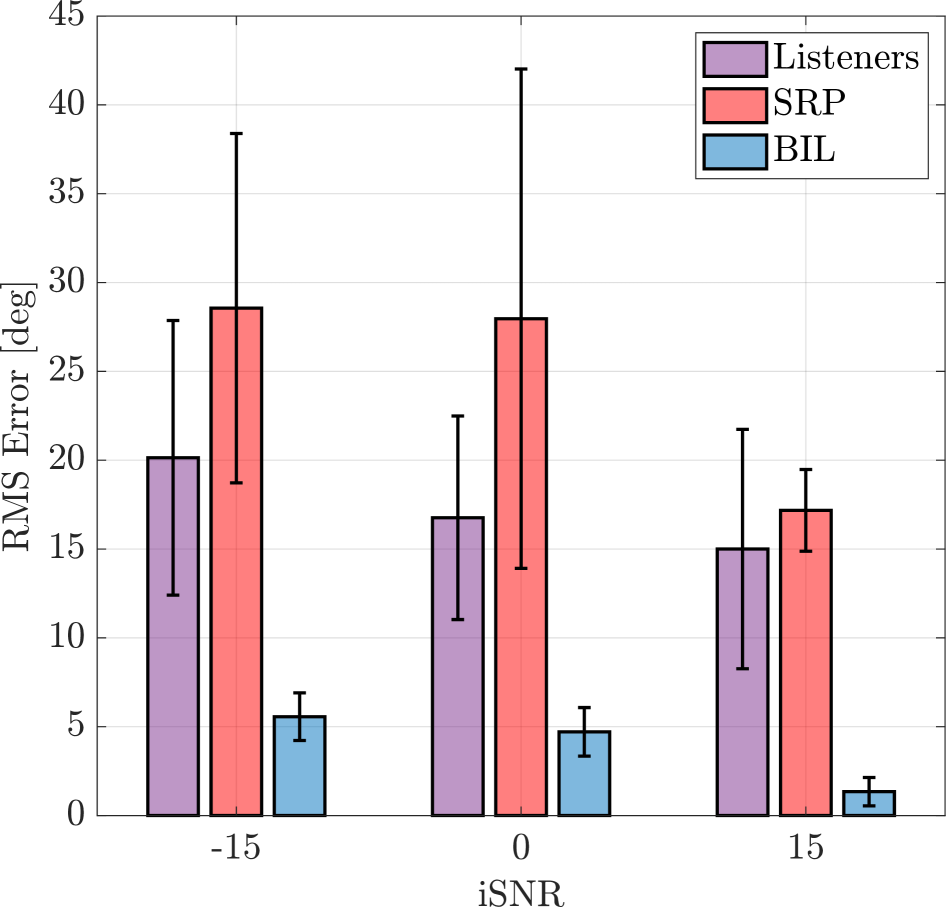
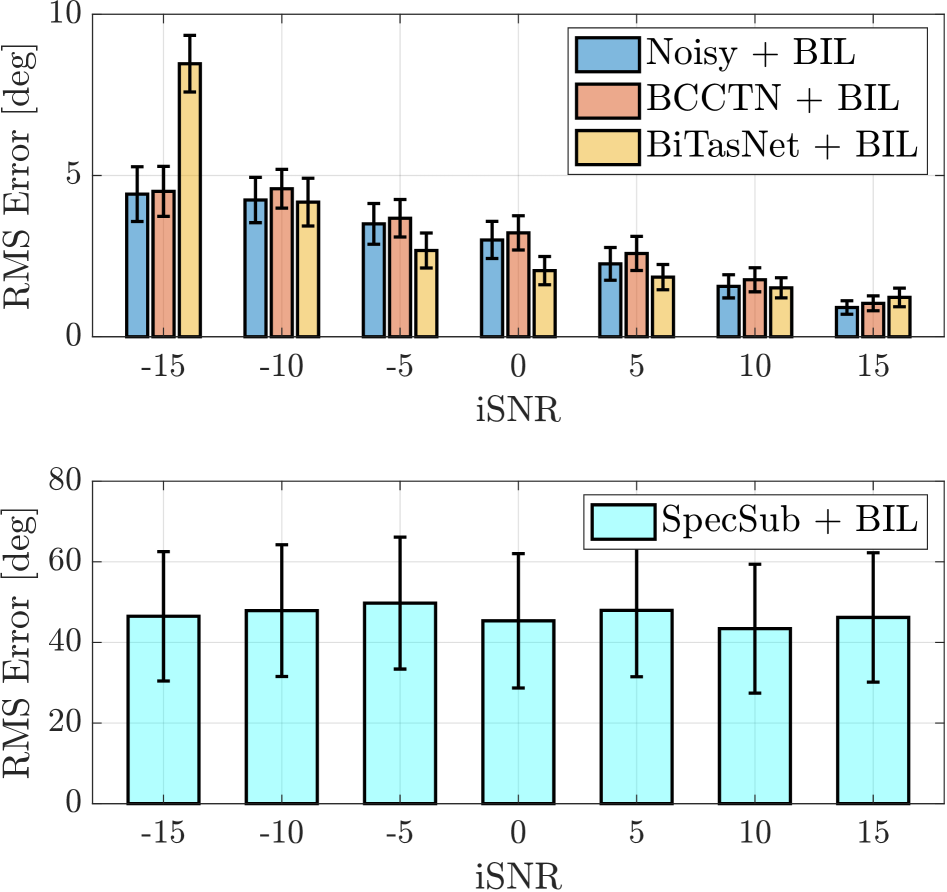
Figure 3: The plots show the localization error in noisy reverberant conditions (a) for the proposed method (BIL) and SRP, (b) for listeners compared with the proposed method and SRP and, (c) for signals processed by different enhancement methods evaluated by BIL.
### 3.3 Listening Tests
In the listening tests, 15 participants with normal hearing were tasked with localizing a target speaker within the frontal azimuthal plane. Using Beyerdynamic DT1990 Pro open-back headphones, the audio signals were delivered in a soundproof booth through an RME Fireface UCX II audio interface. The participants were required to listen to the noisy speech utterances and select the perceived azimuth using a MATLAB-based GUI. The azimuths were quantized at $15^{\circ}$ intervals. Each participant listened to 36 speech utterances, which were evenly distributed across different SNR s and randomly assigned azimuths in the frontal azimuth plane. Three conditions of input SNR (iSNR) were used in the test: -15, 0 and +15 dB iSNR corresponding to “very noisy”, “noisy” and “low noise” conditions, respectively.
## 4 Results and Discussion
| SRP-PHAT WaveLoc-GTF [8] WaveLoc-CONV [8] | $10.2^{\circ}$ $3.0^{\circ}$ $2.3^{\circ}$ |
| --- | --- |
| BIL | $1.2^{\circ}$ |
Table 1: Localization error compared to WaveLoc [8] methods.
The model was evaluated using 275 speech utterances for each noisy input SNR ranging from -25 dB to +25 dB in steps of 5 dB. The localization error for the proposed method, denoted as BIL, is shown in Fig. 3(a) for different iSNR s. The azimuth $\theta$ of the target speaker’s DOA in the frontal azimuth plane is then estimated using the Steered Response Power with Phase Transform (SRP-PHAT) algorithm [19, 20] and used for comparison. In extremely noisy conditions, such as -25 dB, the proposed method achieves a localization error of approximately $15^{\circ}$ . Under similar iSNR conditions, the localization error for Steered Response Power (SRP) is considerably higher, around $40^{\circ}$ . As the iSNR improves, the localization error for the proposed method decreases to below $5^{\circ}$ , eventually reaching just under $1^{\circ}$ at 25 dB iSNR. In contrast, the SRP method maintains an error between $10^{\circ}$ and $20^{\circ}$ even at higher iSNR s. The reduced performance of SRP at higher iSNR s can be attributed to reverberation, which causes multiple peaks in the correlation [18]. 1 shows the comparison of localization error with the WaveLoc methods proposed in [8]. These methods are also evaluated on BRIRs from [15] without the addition of external noise, and the values shown are taken from [8]. For similar conditions, the proposed method has lower error and outperforms both versions of the WaveLoc methods.
Figure 3(b) shows the localization error of human listeners compared with the proposed method and SRP for the three conditions of noisy signals as described in Sec. 3.3. The proposed method has a significantly lower localization error for all the iSNR conditions. Listeners had an average error of $20^{\circ}$ in the very noisy condition of -15 dB and an average error of $15^{\circ}$ in the low noise condition of 15 dB, given that there was no head movement to assist them. SRP -based localization had the highest localization error and standard deviation for the test samples. Previous studies have shown that human localization of speech and tones can have a localization error of up to $40^{\circ}$ when noise and reverberation are present [1, 2, 3]. If the signals processed by enhancement methods produce a low localization error with the proposed method, it is very likely that the interaural cues of the signal are preserved, and human listeners will still localize the target speaker in the same azimuth as the original noisy signal.
Figure 3(c) demonstrates how the proposed method can be used to assess the performance of binaural speech enhancement methods in preserving the interaural cues and the spatial information of the target speaker. While there are well-known objective measures to evaluate noise reduction, speech intelligibility and quality, there are no standardised measures to assess the preservation of binaural cues after they are processed by enhancement algorithms. The upper plot in Fig. 3(c) shows the localization error for noisy signals at the iSNR s from -15 dB to 15 dB and the signals processed by Binaural Complex Convolutional Transformer Network (BCCTN) [9] and Binaural TasNet (BiTasNet) [21] at the same iSNR s. The binaural enhancement algorithms are designed to preserve the interaural cues in the noisy signal while enhancement, and they show a low localization error. At -15 dB, the BiTasNet shows a higher error compared to the noisy input signal, which indicates disruption in the interaural cues, and this is expected as the method was not designed to perform enhancement at -15 dB. As the iSNR improves, all the binaural enhancement methods show localization error under $5^{\circ}$ , which signifies the preservation of interaural cues. From Fig 3(a) - Fig. 3(c), it is evident that the proposed model has a monotonic relationship to SNR, i.e., the localization error decreases with increasing iSNR. Furthermore, other studies, including [1, 2, 3], show that human localization capability is monotonically proportional to SNR. Hence, the proposed method has been seen to be, as desired, highly correlated with human binaural localization - a conclusion which is supported by the subjective listening tests conducted. The lower plot in Fig. 3(c) shows the localization error obtained when the noisy signals are processed with bilateral spectral subtraction (SpecSub) [22], where no attempt is made at preserving binaural cues. The localization error is obtained around $45^{\circ}$ as the testset contains signals which have azimuths distributed randomly between $\pm 90^{\circ}$ . If the binaural enhancement methods are being used for purposes other than human listening, the addition of in-ear noise can be omitted before performing localization.
## 5 Conclusion
This paper presented an end-to-end binaural localization model for speech in noisy and reverberant conditions. A CRN network utilizing GCC-PHAT features was introduced, and a listening test with 15 normal-hearing listeners showed that the model closely aligns with human perception, albeit with lower localization error. The model effectively evaluates the localization error of binaural speech enhancement algorithms, correlating with spatial information preservation and interaural cue retention. The key objective was to develop a DOA estimation method that mirrors human binaural localization rather than purely optimizing accuracy. The proposed method demonstrated significantly lower localization errors across all iSNR conditions. Listeners had average errors of $20^{\circ}$ at -15 dB and $15^{\circ}$ at 15 dB without head movement. SRP -based localization showed the highest error and variability and as iSNR improves, all binaural enhancement methods exhibit localization errors below $5^{\circ}$ , confirming interaural cue preservation. The model’s localization error follows a monotonic relationship with SNR, aligning with human performance trends.
## 6 Acknowledgments
This work was supported by funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 956369 and the UK Engineering and Physical Sciences Research Council [grant number EP/S035842/1].
## References
- [1] M. D. Good and R. H. Gilkey, “Sound localization in noise: The effect of signal-to-noise ratio,” J Acoust Soc Am, vol. 99, pp. 1108–1117, Feb. 1996.
- [2] C. Lorenzi, S. Gatehouse, and C. Lever, “Sound localization in noise in normal-hearing listeners,” J Acoust Soc Am, vol. 105, pp. 1810–1820, Mar. 1999.
- [3] M. L. Folkerts, E. M. Picou, and G. C. Stecker, “Spectral weighting functions for localization of complex sound. II. The effect of competing noise,” J Acoust Soc Am, vol. 154, pp. 494–501, July 2023.
- [4] N. Kopčo, V. Best, and S. Carlile, “Speech localization in a multitalker mixture,” J Acoust Soc Am, vol. 127, pp. 1450–1457, Mar. 2010.
- [5] T. May, S. van de Par, and A. Kohlrausch, “A Probabilistic Model for Robust Localization Based on a Binaural Auditory Front-End,” IEEE/ACM Trans. Audio, Speech, Language Process., vol. 19, pp. 1–13, Jan. 2011.
- [6] N. Ma, J. A. Gonzalez, and G. J. Brown, “Robust Binaural Localization of a Target Sound Source by Combining Spectral Source Models and Deep Neural Networks,” IEEE/ACM Trans. Audio, Speech, Language Process., vol. 26, pp. 2122–2131, Nov. 2018.
- [7] J. Woodruff and D. Wang, “Binaural Localization of Multiple Sources in Reverberant and Noisy Environments,” IEEE/ACM Trans. Audio, Speech, Language Process., vol. 20, pp. 1503–1512, July 2012.
- [8] P. Vecchiotti, N. Ma, S. Squartini, and G. J. Brown, “End-to-end Binaural Sound Localisation from the Raw Waveform,” in Proc. IEEE Int. Conf. on Acoust., Speech and Signal Process. (ICASSP), pp. 451–455, May 2019.
- [9] V. Tokala, E. Grinstein, M. Brookes, S. Doclo, J. Jensen, and P. A. Naylor, “Binaural Speech Enhancement using Deep Complex Convolutional Recurrent Networks,” in Proc. Asilomar Conf. on Signals, Syst. & Comput., (USA), 2023.
- [10] V. Tokala, E. Grinstein, M. Brookes, S. Doclo, J. Jensen, and P. A. Naylor, “Binaural Speech Enhancement using Deep Complex Convolutional Transformer Networks,” in Proc. IEEE Int. Conf. on Acoust., Speech and Signal Process. (ICASSP), (Seoul, South Korea), 2024.
- [11] ANSI, “Methods for the calculation of the speech intelligibility index,” ANSI Standard S3.5-1997 (R2007), American National Standards Institute (ANSI), 1997.
- [12] C. V. Pavlovic, “Derivation of primary parameters and procedures for use in speech intelligibility predictions,” J Acoust Soc Am, vol. 82, pp. 413–422, Aug. 1987.
- [13] D. M. Brookes, “VOICEBOX: A speech processing toolbox for MATLAB,” 1997.
- [14] J. Yamagishi, C. Veaux, and K. MacDonald, “CSTR VCTK Corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92),” University of Edinburgh. The Centre for Speech Technology Research (CSTR), 2019.
- [15] J. Francombe, “IoSR Listening Room Multichannel BRIR Dataset - University of Surrey,” 2017.
- [16] A. H. Moore, L. Lightburn, W. Xue, P. A. Naylor, and M. Brookes, “Binaural mask-informed speech enhancement for hearing aids with head tracking,” in Proc. Int. Workshop on Acoust. Signal Enhancement (IWAENC), (Tokyo, Japan), pp. 461–465, Sept. 2018.
- [17] H. Kayser, S. D. Ewert, J. Anemüller, T. Rohdenburg, V. Hohmann, and B. Kollmeier, “Database of multichannel in-ear and behind-the-Ear head-related and binaural room impulse responses,” EURASIP J. on Advances in Signal Process., vol. 2009, p. 298605, July 2009.
- [18] E. Grinstein, C. M. Hicks, T. van Waterschoot, M. Brookes, and P. A. Naylor, “The Neural-SRP Method for Universal Robust Multi-Source Tracking,” IEEE Open Journal of Signal Processing, vol. 5, pp. 19–28, 2024.
- [19] J. H. DiBiase, H. F. Silverman, and M. S. Brandstein, “Robust localization in reverberant rooms,” in Microphone Arrays (M. Brandstein and D. Ward, eds.), Digital Signal Processing, pp. 157–180, Berlin Heidelberg: Springer-Verlag, 2001.
- [20] E. Grinstein, E. Tengan, B. Çakmak, T. Dietzen, L. Nunes, T. van Waterschoot, M. Brookes, and P. A. Naylor, “Steered Response Power for Sound Source Localization: A Tutorial Review,” EURASIP J. on Audio, Speech, and Music Process., vol. submitted, May 2024.
- [21] C. Han, Y. Luo, and N. Mesgarani, “Real-Time Binaural Speech Separation with Preserved Spatial Cues,” in Proc. IEEE Int. Conf. on Acoust., Speech and Signal Process. (ICASSP), pp. 6404–6408, May 2020.
- [22] Y. Ephraim and D. Malah, “Speech enhancement using a minimum mean-square error log-spectral amplitude estimator,” IEEE Trans. Acoust., Speech, Signal Process., vol. 33, no. 2, pp. 443–445, 1985.