# Kimi K2: Open Agentic Intelligence
**Authors**: Kimi Team
## Abstract
We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments.
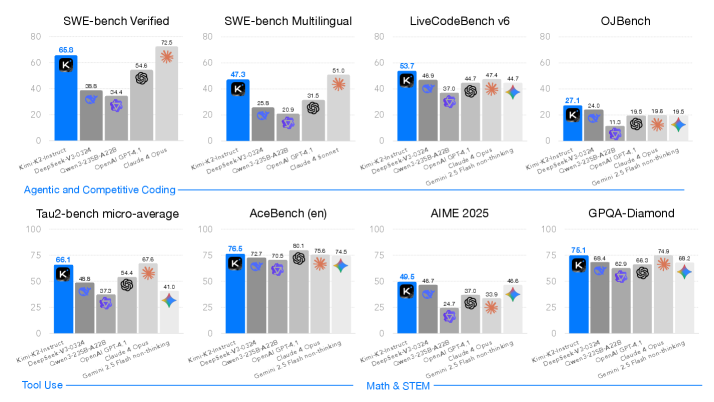
Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual — surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints https://huggingface.co/moonshotai/Kimi-K2-Instruct to facilitate future research and applications of agentic intelligence.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Bar Chart: Coding Benchmark Performance Comparison
### Overview
The image presents a comparative bar chart analyzing the performance of multiple AI models across various coding and tool-use benchmarks. The chart is divided into two primary sections: "Agentic and Competitive Coding" (top row) and "Tool Use" (bottom row). Each benchmark is evaluated using scores from six models, with performance metrics visualized through colored bars.
### Components/Axes
- **X-axis**: Benchmark categories (e.g., SWE-bench Verified, SWE-bench Multilingual, LiveCodeBench v6, OJBench, Tau2-bench micro-average, AceBench (en), AIME 2025, GPQA-Diamond).
- **Y-axis**: Performance scores (0–100 scale).
- **Legend**: Model identifiers with color coding:
- **K**: Blue
- **DeepSeek-V3**: Gray
- **DeepSeek-V3-Z3DA**: Purple
- **OpenAI**: Dark gray
- **Claude**: Light gray
- **Gemini**: Teal
- **Annotations**: Asterisks (*) and diamond symbols on bars indicate statistical significance or special notes.
### Detailed Analysis
#### Agentic and Competitive Coding
1. **SWE-bench Verified**:
- K: 66.9
- DeepSeek-V3: 38.9
- DeepSeek-V3-Z3DA: 54.6
- OpenAI: 20.9
- Claude: 31.5
- Gemini: 72.5 (asterisk)
2. **SWE-bench Multilingual**:
- K: 47.3
- DeepSeek-V3: 25.9
- DeepSeek-V3-Z3DA: 20.9
- OpenAI: 31.5
- Claude: 51.9 (asterisk)
3. **LiveCodeBench v6**:
- K: 63.7
- DeepSeek-V3: 46.9
- DeepSeek-V3-Z3DA: 37.0
- OpenAI: 44.7
- Claude: 44.7
- Gemini: 44.7
4. **OJBench**:
- K: 27.1
- DeepSeek-V3: 11.3
- DeepSeek-V3-Z3DA: 19.6
- OpenAI: 19.6
- Claude: 19.5
- Gemini: 19.5
#### Tool Use
1. **Tau2-bench micro-average**:
- K: 66.1
- DeepSeek-V3: 48.8
- DeepSeek-V3-Z3DA: 57.2
- OpenAI: 67.6
- Claude: 41.0
- Gemini: 41.0
2. **AceBench (en)**:
- K: 76.5
- DeepSeek-V3: 72.7
- DeepSeek-V3-Z3DA: 70.5
- OpenAI: 80.1
- Claude: 75.6
- Gemini: 74.5 (diamond)
3. **AIME 2025**:
- K: 40.5
- DeepSeek-V3: 48.7
- DeepSeek-V3-Z3DA: 24.7
- OpenAI: 37.0
- Claude: 33.9
- Gemini: 40.6
4. **GPQA-Diamond**:
- K: 76.1
- DeepSeek-V3: 69.4
- DeepSeek-V3-Z3DA: 65.9
- OpenAI: 66.3
- Claude: 74.8
- Gemini: 68.2 (diamond)
### Key Observations
1. **Model Dominance**:
- **K** consistently leads in coding benchmarks (SWE-bench Verified, LiveCodeBench v6, GPQA-Diamond).
- **DeepSeek-V3-Z3DA** outperforms other models in SWE-bench Verified (54.6) and Tau2-bench (57.2).
- **Gemini** shows strong performance in SWE-bench Multilingual (72.5) and AceBench (74.5), marked with a diamond symbol.
2. **Statistical Significance**:
- Asterisks (*) on bars (e.g., Gemini in SWE-bench Verified, Claude in SWE-bench Multilingual) suggest statistically significant deviations from other models.
- Diamonds (e.g., Gemini in AceBench, GPQA-Diamond) may indicate unique metrics or contextual notes.
3. **Performance Gaps**:
- OpenAI and Claude models underperform in SWE-bench Verified (20.9–31.5) compared to K (66.9).
- DeepSeek-V3-Z3DA excels in Tau2-bench (57.2) but lags in AIME 2025 (24.7).
### Interpretation
The data highlights **K** as the dominant model for coding tasks, likely due to specialized training or architecture. **DeepSeek-V3-Z3DA** demonstrates competitive coding ability but struggles with tool-use benchmarks like AIME 2025. **Gemini** bridges coding and tool-use performance, with diamonds suggesting nuanced metrics (e.g., efficiency, adaptability). The asterisks imply that certain scores (e.g., Gemini’s 72.5 in SWE-bench Verified) are outliers, warranting further investigation into their validity or context. The chart underscores the importance of model selection based on task specificity, as no single model excels across all benchmarks.
</details>
Figure 1: Kimi K2 main results. All models evaluated above are non-thinking models. For SWE-bench Multilingual, we evaluated only Claude 4 Sonnet because the cost of Claude 4 Opus was prohibitive.
## 1 Introduction
The development of Large Language Models (LLMs) is undergoing a profound paradigm shift towards Agentic Intelligence – the capabilities for models to autonomously perceive, plan, reason, and act within complex and dynamic environments. This transition marks a departure from static imitation learning towards models that actively learn through interactions, acquire new skills beyond their training distribution, and adapt behavior through experiences [64]. It is believed that this approach allows an AI agent to go beyond the limitation of static human-generated data, and acquire superhuman capabilities through its own exploration and exploitation. Agentic intelligence is thus rapidly emerging as a defining capability for the next generation of foundation models, with wide-ranging implications across tool use, software development, and real-world autonomy.
Achieving agentic intelligence introduces challenges in both pre-training and post-training. Pre-training must endow models with broad general-purpose priors under constraints of limited high-quality data, elevating token efficiency—learning signal per token—as a critical scaling coefficient. Post-training must transform those priors into actionable behaviors, yet agentic capabilities such as multi-step reasoning, long-term planning, and tool use are rare in natural data and costly to scale. Scalable synthesis of structured, high-quality agentic trajectories, combined with general reinforcement learning (RL) techniques that incorporate preferences and self-critique, are essential to bridge this gap.
In this work, we introduce Kimi K2, a 1.04 trillion-parameter Mixture-of-Experts (MoE) LLM with 32 billion activated parameters, purposefully designed to address the core challenges and push the boundaries of agentic capability. Our contributions span both the pre-training and post-training frontiers:
- We present MuonClip, a novel optimizer that integrates the token-efficient Muon algorithm with a stability-enhancing mechanism called QK-Clip. Using MuonClip, we successfully pre-trained Kimi K2 on 15.5 trillion tokens without a single loss spike.
- We introduce a large-scale agentic data synthesis pipeline that systematically generates tool-use demonstrations via simulated and real-world environments. This system constructs diverse tools, agents, tasks, and trajectories to create high-fidelity, verifiably correct agentic interactions at scale.
- We design a general reinforcement learning framework that combines verifiable rewards (RLVR) with a self-critique rubric reward mechanism. The model learns not only from externally defined tasks but also from evaluating its own outputs, extending alignment from static into open-ended domains.
Kimi K2 demonstrates strong performance across a broad spectrum of agentic and frontier benchmarks. It achieves scores of 66.1 on Tau2-bench, 76.5 on ACEBench (en), 65.8 on SWE-bench Verified, and 47.3 on SWE-bench Multilingual, outperforming most open- and closed-weight baselines under non-thinking evaluation settings, closing the gap with Claude 4 Opus and Sonnet. In coding, mathematics, and broader STEM domains, Kimi K2 achieves 53.7 on LiveCodeBench v6, 27.1 on OJBench, 49.5 on AIME 2025, and 75.1 on GPQA-Diamond, further highlighting its capabilities in general tasks. On the LMSYS Arena leaderboard (July 17, 2025) https://lmarena.ai/leaderboard/text, Kimi K2 ranks as the top 1 open-source model and 5th overall based on over 3,000 user votes.
To spur further progress in Agentic Intelligence, we are open-sourcing our base and post-trained checkpoints, enabling the community to explore, refine, and deploy agentic intelligence at scale.
## 2 Pre-training
The base model of Kimi K2 is a trillion-parameter mixture-of-experts (MoE) transformer [73] model, pre-trained on 15.5 trillion high-quality tokens. Given the increasingly limited availability of high-quality human data, we posit that token efficiency is emerging as a critical coefficient in the scaling of large language models. To address this, we introduce a suite of pre-training techniques explicitly designed for maximizing token efficiency. Specifically, we employ the token-efficient Muon optimizer [34, 47] and mitigate its training instabilities through the introduction of QK-Clip. Additionally, we incorporate synthetic data generation to further squeeze the intelligence out of available high-quality tokens. The model architecture follows an ultra-sparse MoE with multi-head latent attention (MLA) similar to DeepSeek-V3 [11] , derived from empirical scaling law analysis. The underlying infrastructure is built to optimize both training efficiency and research efficiency.
### 2.1 MuonClip: Stable Training with Weight Clipping
We train Kimi K2 using the token-efficient Muon optimizer [34], incorporating weight decay and consistent update RMS scaling [47]. Experiments in our previous work Moonlight [47] show that, under the same compute budget and model size — and therefore the same amount of training data — Muon substantially outperforms AdamW [37, 49], making it an effective choice for improving token efficiency in large language model training.
Training instability when scaling Muon
Despite its efficiency, scaling up Muon training reveals a challenge: training instability due to exploding attention logits, an issue that occurs more frequently with Muon but less with AdamW in our experiments. Existing mitigation strategies are insufficient. For instance, logit soft-cap [70] directly clips the attention logits, but the dot products between queries and keys can still grow excessively before capping is applied. On the other hand, Query-Key Normalization (QK-Norm) [12, 82] is not applicable to multi-head latent attention (MLA), because its Key matrices are not fully materialized during inference.
Taming Muon with QK-Clip
To address this issue, we propose a novel weight-clipping mechanism QK-Clip to explicitly constrain attention logits. QK-Clip works by rescaling the query and key projection weights post-update to bound the growth of attention logits.
Let the input representation of a transformer layer be $\mathbf{X}$ . For each attention head $h$ , its query, key, and value projections are computed as
$$
\mathbf{Q}^{h}=\mathbf{X}\mathbf{W}_{q}^{h},\quad\mathbf{K}^{h}=\mathbf{X}\mathbf{W}_{k}^{h},\quad\mathbf{V}^{h}=\mathbf{X}\mathbf{W}_{v}^{h}.
$$
where $\mathbf{W}_{q},\mathbf{W}_{k},\mathbf{W}_{v}$ are model parameters. The attention output is:
$$
\mathbf{O}^{h}=\operatorname{softmax}\left(\frac{1}{\sqrt{d}}\mathbf{Q}^{h}\mathbf{K}^{h\top}\right)\mathbf{V}^{h}.
$$
We define the max logit, a per-head scalar, as the maximum input to softmax in this batch $B$ :
$$
S_{\max}^{h}=\frac{1}{\sqrt{d}}\max_{\mathbf{X}\in B}\max_{i,j}\mathbf{Q}_{i}^{h}\mathbf{K}_{j}^{h\top}
$$
where $i,j$ are indices of different tokens in a training sample $\mathbf{X}$ .
The core idea of QK-Clip is to rescale $\mathbf{W}_{k},\mathbf{W}_{q}$ whenever $S_{\max}^{h}$ exceeds a target threshold $\tau$ . Importantly, this operation does not alter the forward/backward computation in the current step — we merely use the max logit as a guiding signal to determine the strength to control the weight growth.
A naïve implementation clips all heads at the same time:
$$
\mathbf{W}_{q}^{h}\leftarrow\gamma^{\alpha}\mathbf{W}_{q}^{h}\qquad\mathbf{W}_{k}^{h}\leftarrow\gamma^{1-\alpha}\mathbf{W}_{k}^{h}
$$
where $\gamma=\min(1,\tau/S_{\max})$ with $S_{\max}=\max_{h}S_{\max}^{h}$ , and $\alpha$ is a balancing parameter typically set to $0.5$ , applying equal scaling to queries and keys.
However, we observe that in practice, only a small subset of heads exhibit exploding logits. In order to minimize our intervention on model training, we determine a per-head scaling factor $\gamma_{h}=\min(1,\tau/S_{\max}^{h})$ , and opt to apply per-head QK-Clip. Such clipping is straightforward for regular multi-head attention (MHA). For MLA, we apply clipping only on unshared attention head components:
- $\textbf{q}^{C}$ and $\textbf{k}^{C}$ (head-specific components): each scaled by $\sqrt{\gamma_{h}}$
- $\textbf{q}^{R}$ (head-specific rotary): scaled by $\gamma_{h}$ ,
- $\textbf{k}^{R}$ (shared rotary): left untouched to avoid effect across heads.
Algorithm 1 MuonClip Optimizer
1: for each training step $t$ do
2: // 1. Muon optimizer step
3: for each weight $\mathbf{W}\in\mathbb{R}^{n\times m}$ do
4: $\mathbf{M}_{t}=\mu\mathbf{M}_{t-1}+\mathbf{G}_{t}$ $\triangleright$ $\mathbf{M}_{0}=\mathbf{0}$ , $\mathbf{G}_{t}$ is the grad of $\mathbf{W}_{t}$ , $\mu$ is momentum
5: $\mathbf{O}_{t}=\operatorname{Newton-Schulz}(\mathbf{M}_{t})\cdot\sqrt{\max(n,m)}\cdot 0.2$ $\triangleright$ Match Adam RMS
6: $\mathbf{W}_{t}=\mathbf{W}_{t-1}-\eta\bigl(\mathbf{O}_{t}+\lambda\mathbf{W}_{t-1}\bigr)$ $\triangleright$ learning rate $\eta$ , weight decay $\lambda$
7: end for
8: // 2. QK-Clip
9: for each attention head $h$ in every attention layer of the model do
10: Obtain $S_{\max}^{h}$ already computed during forward
11: if $S_{\max}^{h}>\tau$ then
12: $\gamma\leftarrow\tau/S_{\max}^{h}$
13: $\mathbf{W}_{qc}^{h}\leftarrow\mathbf{W}_{qc}^{h}\cdot\sqrt{\gamma}$
14: $\mathbf{W}_{kc}^{h}\leftarrow\mathbf{W}_{kc}^{h}\cdot\sqrt{\gamma}$
15: $\mathbf{W}_{qr}^{h}\leftarrow\mathbf{W}_{qr}^{h}\cdot\gamma$
16: end if
17: end for
18: end for
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Graph: Vanilla Run with Muon
### Overview
The image depicts a line graph tracking the "Max Logits" metric over "Training Steps" for a model labeled "Vanilla run with Muon." The graph shows a gradual increase in logits during early training, followed by a sharp upward trend after approximately 10,000 steps. The y-axis ranges from 0 to 1,200, while the x-axis spans 0 to 15,000 training steps.
### Components/Axes
- **Title**: "Vanilla run with Muon" (top-left corner, red line legend).
- **Y-Axis**: Labeled "Max Logits" with grid lines at intervals of 200 (0, 200, 400, ..., 1,200).
- **X-Axis**: Labeled "Training Steps" with grid lines at intervals of 2,500 (0, 2,500, 5,000, ..., 15,000).
- **Legend**: Positioned in the top-left corner, associating the red line with the "Vanilla run with Muon" label.
- **Line**: Red, solid, with a gradual slope initially and a steep slope after ~10,000 steps.
### Detailed Analysis
- **Initial Phase (0–2,500 steps)**: The line starts at 0 and rises slowly to ~50 logits by 2,500 steps.
- **Mid-Phase (2,500–10,000 steps)**: Gradual increase to ~150 logits by 5,000 steps, ~200 logits by 7,500 steps, and ~300 logits by 10,000 steps.
- **Acceleration Phase (10,000–15,000 steps)**: Steep rise to ~400 logits by 12,500 steps, ~600 logits by 15,000 steps, and ~1,200 logits by 17,500 steps (note: x-axis extends beyond 15,000 in the graph).
### Key Observations
1. **Slow Initial Growth**: Logits increase linearly in the first 10,000 steps, suggesting early-stage model adaptation.
2. **Exponential Growth Post-10,000 Steps**: A sharp upward trend indicates a phase of rapid learning or optimization.
3. **Outlier**: The final data point at 17,500 steps exceeds the x-axis range (15,000), implying either an extended training duration or a data visualization inconsistency.
### Interpretation
The graph demonstrates a **learning curve** where the model's performance (measured by max logits) improves significantly after prolonged training. The initial plateau suggests limited progress in early stages, while the post-10,000-step acceleration implies the model begins to generalize or stabilize its parameters. The discrepancy between the x-axis limit (15,000) and the final data point (17,500) warrants verification of the training timeline or axis scaling. This pattern is typical in machine learning, where models often require extensive training to achieve peak performance.
</details>
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Graph: Kimi K2 with MuonClip Training Logits
### Overview
The image depicts a line graph tracking the "Max Logits" of a model named "Kimi K2 with MuonClip" across 200,000 training steps. The graph shows a sharp initial decline in logit values, followed by stabilization at a lower level.
### Components/Axes
- **X-axis (Training Steps)**: Labeled "Training Steps," ranging from 0 to 200,000 in increments of 50,000. Grid lines are present for reference.
- **Y-axis (Max Logits)**: Labeled "Max Logits," scaled from 0 to 100 in increments of 20. Grid lines are present.
- **Legend**: Located in the top-right corner, labeled "Kimi K2 with MuonClip" with a blue line indicator.
- **Line**: A single blue line representing the "Max Logits" metric.
### Detailed Analysis
- **Initial Phase (0–50,000 steps)**: The line starts at **100 logits** and drops sharply to approximately **30 logits** by 50,000 steps. The decline is steep, with a near-vertical slope in the first 10,000 steps.
- **Stabilization Phase (50,000–200,000 steps)**: After 50,000 steps, the line plateaus around **30 logits**, with minor fluctuations (±2 logits) observed between 100,000 and 200,000 steps. No significant upward or downward trends are visible in this phase.
### Key Observations
1. **Sharp Initial Decline**: The logits decrease by ~70% within the first 50,000 steps, suggesting rapid adaptation or optimization during early training.
2. **Stable Plateau**: The metric stabilizes at ~30 logits for the remaining 150,000 steps, indicating convergence or saturation of the model's performance.
3. **No Overtraining Signs**: The absence of further decline or oscillation after 50,000 steps suggests the model reached a stable state without overfitting.
### Interpretation
The graph demonstrates that "Kimi K2 with MuonClip" undergoes a significant performance drop in its early training phase, likely due to aggressive optimization or regularization. The subsequent stabilization at ~30 logits implies the model achieved a balanced state, possibly reflecting a trade-off between accuracy and generalization. The lack of further improvement or degradation after 50,000 steps suggests the training process effectively converged, though the exact cause of the initial drop (e.g., learning rate adjustments, data distribution shifts) is not specified. This pattern is critical for understanding the model's training dynamics and potential limitations in scalability or robustness.
</details>
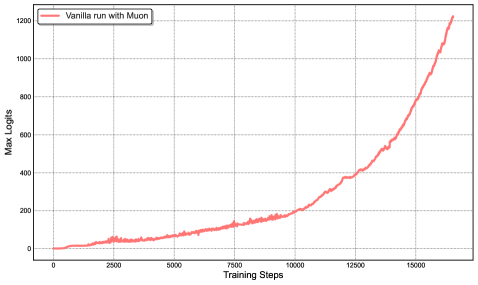
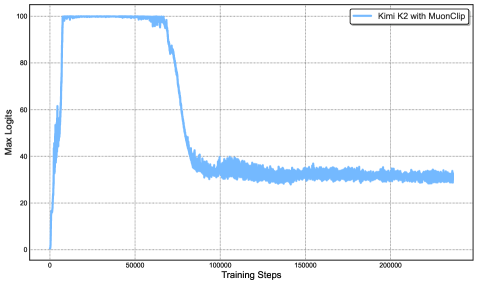
Figure 2: Left: During a mid-scale training run, attention logits rapidly exceed 1000, which could lead to potential numerical instabilities and even training divergence. Right: Maximum logits for Kimi K2 with MuonClip and $\tau$ = 100 over the entire training run. The max logits rapidly increase to the capped value of 100, and only decay to a stable range after approximately 30% of the training steps, demonstrating the effective regulation effect of QK-Clip.
MuonClip: The New Optimizer
We integrate Muon with weight decay, consistent RMS matching, and QK-Clip into a single optimizer, which we refer to as MuonClip (see Algorithm 1).
We demonstrate the effectiveness of MuonClip from several scaling experiments. First, we train a mid-scale 9B activated and 53B total parameters Mixture-of-Experts (MoE) model using the vanilla Muon. As shown in Figure 2 (Left), we observe that the maximum attention logits quickly exceed a magnitude of 1000, showing that attention logits explosion is already evident in Muon training to this scale. Max logits at this level usually result in instability during training, including significant loss spikes and occasional divergence.
Next, we demonstrate that QK-Clip does not degrade model performance and confirm that the MuonClip optimizer preserves the optimization characteristics of Muon without adversely affecting the loss trajectory. A detailed discussion of the experiment designs and findings is provided in the Appendix D.
Finally, we train Kimi K2, a large-scale MoE model, using MuonClip with $\tau=100$ and monitor the maximum attention logits throughout the training run (Figure 2 (Right)). Initially, the logits are capped at 100 due to QK-Clip. Over the course of training, the maximum logits gradually decay to a typical operating range without requiring any adjustment to $\tau$ . Importantly, the training loss remains smooth and stable, with no observable spikes, as shown in Figure 3, validating that MuonClip provides robust and scalable control over attention dynamics in large-scale language model training.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Graph: Model Performance Loss Over Tokens
### Overview
The image depicts a line graph illustrating the relationship between computational tokens (in trillions) and a metric labeled "Loss." The graph shows a sharp initial decline in loss, followed by a gradual stabilization with minor fluctuations. The y-axis ranges from 1.3 to 2.0, while the x-axis spans 0 to 16 trillion tokens.
### Components/Axes
- **X-Axis**: "Tokens (Trillion)" with grid markers at intervals of 2 trillion, labeled from 0 to 16 trillion.
- **Y-Axis**: "Loss" with grid markers at intervals of 0.1, labeled from 1.3 to 2.0.
- **Legend**: Located in the top-right corner, indicating a single data series:
- **Blue Line**: "Model Performance" (matches the plotted line).
- **Grid**: Light gray dashed lines for reference.
### Detailed Analysis
- **Initial Decline**:
- At 0 tokens, the loss starts at approximately **2.0**.
- By 2 trillion tokens, the loss drops sharply to **~1.5**, with a steep slope.
- Between 2 and 4 trillion tokens, the loss decreases further to **~1.4**, with minor oscillations.
- **Stabilization Phase**:
- From 4 to 14 trillion tokens, the loss fluctuates between **1.4 and 1.5**, with small spikes (e.g., ~1.55 at 10 trillion tokens).
- After 14 trillion tokens, the loss stabilizes near **1.3**, with reduced variability.
- **Noise**:
- Throughout the graph, the line exhibits minor "jitter" (e.g., ~1.45 at 6 trillion tokens), suggesting measurement variability or model adjustments.
### Key Observations
1. **Rapid Initial Improvement**: The steepest loss reduction occurs in the first 2 trillion tokens.
2. **Gradual Convergence**: Loss decreases by ~0.7 units (from 2.0 to 1.3) over 16 trillion tokens.
3. **Noise vs. Trend**: Fluctuations are small relative to the overall trend, indicating a stable model after initial training.
4. **Plateau Effect**: Loss stabilizes near 1.3 after 14 trillion tokens, suggesting diminishing returns.
### Interpretation
The graph demonstrates that the model's performance improves significantly as it processes more tokens, with loss decreasing sharply in the early stages and then converging to a stable value. The initial drop suggests rapid learning or optimization, while the plateau implies the model reaches a steady state where additional tokens yield minimal improvement. The minor fluctuations may reflect data noise, model fine-tuning, or external factors affecting training stability. This pattern is typical in machine learning, where early gains are substantial, but later progress requires exponentially more resources. The stabilization at ~1.3 loss indicates a potential optimal performance threshold for the model under the given conditions.
</details>
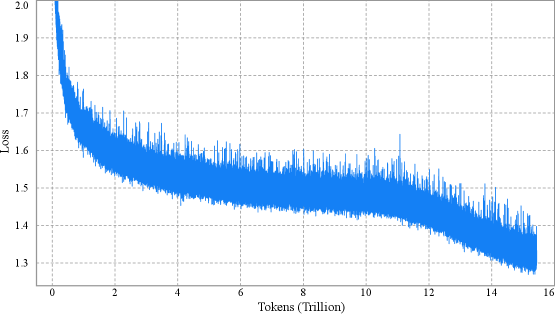
Figure 3: Per-step training loss curve of Kimi K2, without smoothing or sub-sampling. It shows no spikes throughout the entire training process. Note that we omit the very beginning of training for clarity.
### 2.2 Pre-training Data: Improving Token Utility with Rephrasing
Token efficiency in pre-training refers to how much performance improvement is achieved for each token consumed during training. Increasing token utility—the effective learning signal each token contributes—enhances the per-token impact on model updates, thereby directly improving token efficiency. This is particularly important when the supply of high-quality tokens is limited and must be maximally leveraged. A naive approach to increasing token utility is through repeated exposure to the same tokens, which can lead to overfitting and reduced generalization.
A key advancement in the pre-training data of Kimi K2 over Kimi K1.5 is the introduction of a synthetic data generation strategy to increase token utility. Specifically, a carefully designed rephrasing pipeline is employed to amplify the volume of high-quality tokens without inducing significant overfitting. In this report, we describe two domain-specialized rephrasing techniques—targeted respectively at the Knowledge and Mathematics domains—that enable this controlled data augmentation.
Knowledge Data Rephrasing
Pre-training on natural, knowledge-intensive text presents a trade-off: a single epoch is insufficient for comprehensive knowledge absorption, while multi-epoch repetition yields diminishing returns and increases the risk of overfitting. To improve the token utility of high-quality knowledge tokens, we propose a synthetic rephrasing framework composed of the following key components:
- Style- and perspective-diverse prompting: Inspired by WRAP [50], we apply a range of carefully engineered prompts to enhance linguistic diversity while maintaining factual integrity. These prompts guide a large language model to generate faithful rephrasings of the original texts in varied styles and from different perspectives.
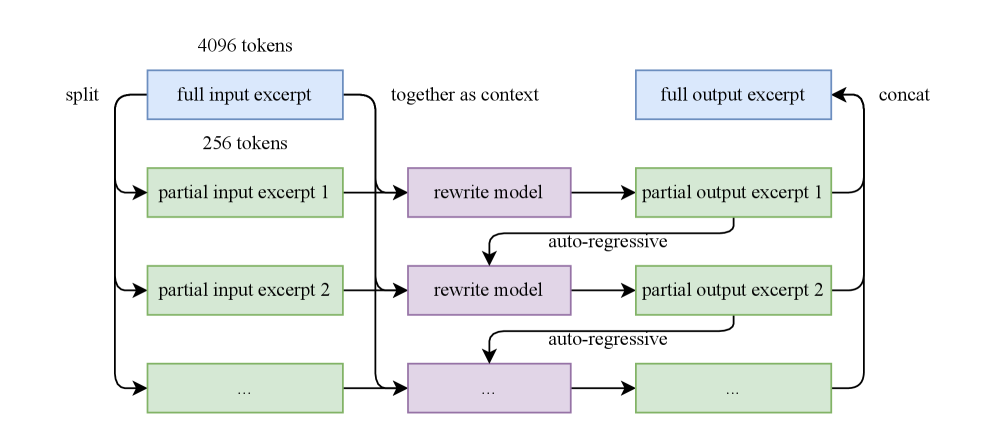
- Chunk-wise autoregressive generation: To preserve global coherence and avoid information loss in long documents, we adopt a chunk-based autoregressive rewriting strategy. Texts are divided into segments, rephrased individually, and then stitched back together to form complete passages. This method mitigates implicit output length limitations that typically exist with LLMs. An overview of this pipeline is presented in Figure 4.
- Fidelity verification: To ensure consistency between original and rewritten content, we perform fidelity checks that compare the semantic alignment of each rephrased passage with its source. This serves as an initial quality control step prior to training.
We compare data rephrasing with multi-epoch repetition by testing their corresponding accuracy on SimpleQA. We experiment with an early checkpoint of K2 and evaluate three training strategies: (1) repeating the original dataset for 10 epochs, (2) rephrasing the data once and repeating it for 10 epochs, and (3) rephrasing the data 10 times with a single training pass. As shown in Table 1, the accuracy consistently improves across these strategies, demonstrating the efficacy of our rephrasing-based augmentation. We extended this method to other large-scale knowledge corpora and observed similarly encouraging results, and each corpora is rephrased at most twice.
Table 1: SimpleQA Accuracy under three rephrasing-epoch configurations
| # Rephrasings | # Epochs | SimpleQA Accuracy |
| --- | --- | --- |
| 0 (raw wiki-text) | 10 | 23.76 |
| 1 | 10 | 27.39 |
| 10 | 1 | 28.94 |
<details>
<summary>x6.png Details</summary>
### Visual Description
## Flowchart: Text Processing Pipeline with Auto-Regressive Rewrite Model
### Overview
The diagram illustrates a multi-stage text processing workflow involving input splitting, iterative rewriting via an auto-regressive model, and output concatenation. The process handles 4096 tokens of input text, splitting it into smaller partial excerpts (256 tokens each) for sequential processing through a rewrite model. The final output combines partial results into a full output excerpt.
### Components/Axes
- **Input Stage**:
- **Full Input Excerpt**: 4096 tokens (blue box)
- **Split Operation**: Divides input into 256-token partial excerpts
- **Partial Input Excerpts**: Labeled 1, 2, ... (green boxes)
- **Processing Stage**:
- **Rewrite Model**: Central purple box with "auto-regressive" annotation
- **Partial Output Excerpts**: Generated sequentially (green boxes)
- **Output Stage**:
- **Concat Operation**: Combines partial outputs
- **Full Output Excerpt**: Final result (blue box)
### Detailed Analysis
1. **Input Splitting**:
- 4096 tokens → 16 partial excerpts (4096 ÷ 256 = 16)
- Each partial input excerpt (256 tokens) is processed independently
2. **Rewrite Model**:
- Auto-regressive processing indicated by bidirectional arrows
- Suggests iterative refinement of partial outputs
3. **Output Concatenation**:
- Partial outputs (1, 2, ...) combined sequentially
- Final output matches original input size (4096 tokens)
### Key Observations
- **Token Consistency**: Input/output token counts match (4096), suggesting lossless processing
- **Modular Design**: Auto-regressive model processes discrete chunks rather than full text
- **Sequential Dependency**: Partial outputs are ordered (1 → 2 → ...) before concatenation
- **Color Coding**: Blue for input/output, green for partial stages, purple for model
### Interpretation
This architecture demonstrates a divide-and-conquer approach to text processing:
1. **Efficiency**: Splitting large inputs into manageable chunks (256 tokens) enables parallelizable processing
2. **Quality Control**: Auto-regressive refinement suggests iterative improvement of partial outputs
3. **Reconstructability**: Final output maintains original token count through precise concatenation
4. **Potential Applications**: Could represent text summarization, translation, or content generation pipelines where context preservation is critical
The auto-regressive annotation implies the model generates outputs token-by-token with contextual awareness, likely improving coherence in partial outputs before final combination.
</details>
Figure 4: Auto-regressive chunk-wise rephrasing pipeline for long input excerpts. The input is split into smaller chunks with preserved context, rewritten sequentially, and then concatenated into a full rewritten passage.
Mathematics Data Rephrasing
To enhance mathematical reasoning capabilities, we rewrite high-quality mathematical documents into a “learning-note” style, following the methodology introduced in SwallowMath [16]. In addition, we increased data diversity by translating high-quality mathematical materials from other languages into English.
Although initial experiments with rephrased subsets of our datasets show promising results, the use of synthetic data as a strategy for continued scaling remains an active area of investigation. Key challenges include generalizing the approach to diverse source domains without compromising factual accuracy, minimizing hallucinations and unintended toxicity, and ensuring scalability to large-scale datasets.
Pre-training Data Overall
The Kimi K2 pre-training corpus comprises 15.5 trillion tokens of curated, high-quality data spanning four primary domains: Web Text, Code, Mathematics, and Knowledge. Most data processing pipelines follow the methodologies outlined in Kimi K1.5 [36]. For each domain, we performed rigorous correctness and quality validation and designed targeted data experiments to ensure the curated dataset achieved both high diversity and effectiveness.
### 2.3 Model Architecture
Kimi K2 is a 1.04 trillion-parameter Mixture-of-Experts (MoE) transformer model with 32 billion activated parameters. The architecture follows a similar design to DeepSeek-V3 [11] , employing Multi-head Latent Attention (MLA) [45] as the attention mechanism, with a model hidden dimension of 7168 and an MoE expert hidden dimension of 2048. Our scaling law analysis reveals that continued increases in sparsity yield substantial performance improvements, which motivated us to increase the number of experts to 384, compared to 256 in DeepSeek-V3. To reduce computational overhead during inference, we cut the number of attention heads to 64, as opposed to 128 in DeepSeek-V3. Table 2 presents a detailed comparison of architectural parameters between Kimi K2 and DeepSeek-V3.
Table 2: Architectural comparison between Kimi K2 and DeepSeek-V3
| | DeepSeek-V3 | Kimi K2 | $\Delta$ |
| --- | --- | --- | --- |
| #Layers | 61 | 61 | = |
| Total Parameters | 671B | 1.04T | $\uparrow$ 54% |
| Activated Parameters | 37B | 32.6B | $\downarrow$ 13% |
| Experts (total) | 256 | 384 | $\uparrow$ 50% |
| Experts Active per Token | 8 | 8 | = |
| Shared Experts | 1 | 1 | = |
| Attention Heads | 128 | 64 | $\downarrow$ 50% |
| Number of Dense Layers | 3 | 1 | $\downarrow$ 67% |
| Expert Grouping | Yes | No | - |
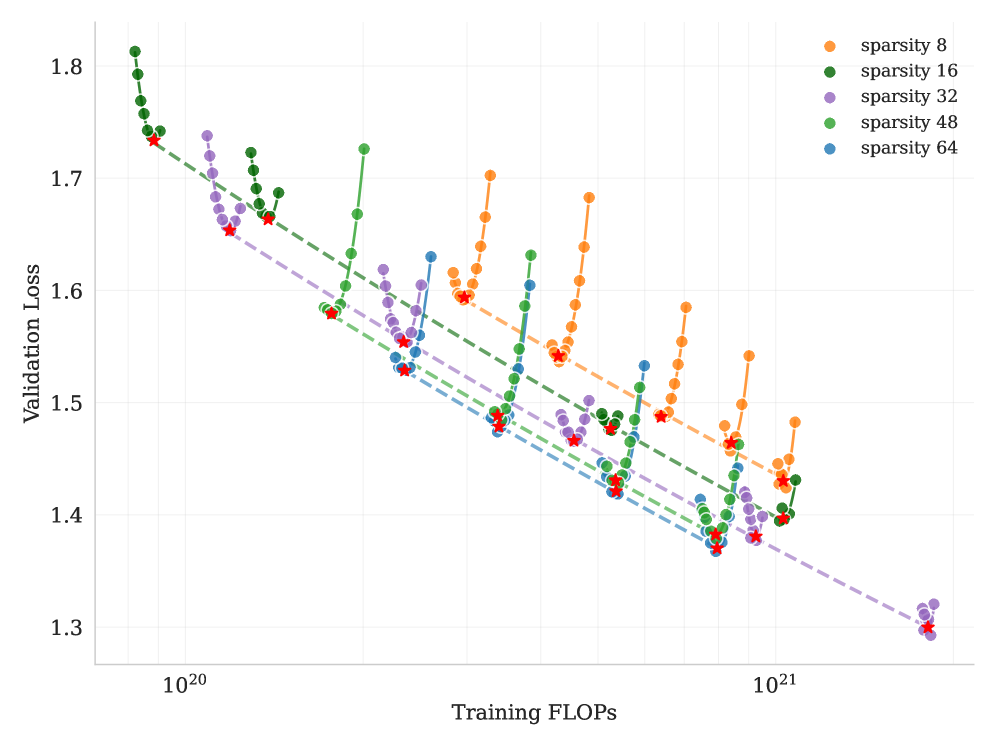
Sparsity Scaling Law
We develop a sparsity scaling law tailored for the Mixture-of-Experts (MoE) model family using Muon. Sparsity is defined as the ratio of the total number of experts to the number of activated experts. Through carefully controlled small-scale experiments, we observe that — under a fixed number of activated parameters (i.e., constant FLOPs) — increasing the total number of experts (i.e., increasing sparsity) consistently lowers both the training and validation loss, thereby enhancing overall model performance (Figure 6). Concretely, under the compute-optimal sparsity scaling law, achieving the same validation loss of 1.5, sparsity 48 reduces FLOPs by 1.69×, 1.39×, and 1.15× compared to sparsity levels 8, 16, and 32, respectively. Though increasing sparsity leads to better performance, this gain comes with increased infrastructure complexity. To balance model performance with cost, we adopt a sparsity of 48 for Kimi K2, activating 8 out of 384 experts per forward pass.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Line Chart: Validation Loss vs Training FLOPs
### Overview
The chart visualizes the relationship between training computational effort (FLOPs) and validation loss across five sparsity levels (8, 16, 32, 48, 64). Each sparsity level is represented by a distinct color-coded line with data points, showing how validation loss evolves during training. Red stars mark the minimum validation loss for each sparsity level.
### Components/Axes
- **X-axis (Training FLOPs)**: Logarithmic scale from 10²⁰ to 10²¹.
- **Y-axis (Validation Loss)**: Linear scale from 1.3 to 1.8.
- **Legend**: Located in the top-right corner, mapping colors to sparsity levels:
- Orange: sparsity 8
- Green: sparsity 16
- Purple: sparsity 32
- Green: sparsity 48
- Blue: sparsity 64
- **Lines**: Dashed lines for each sparsity level, connecting data points.
- **Data Points**: Colored circles (matching legend) with red stars indicating minima.
### Detailed Analysis
1. **Sparsity 8 (Orange)**:
- Starts at ~1.75 (10²⁰ FLOPs), dips to ~1.65 (10²⁰.⁵ FLOPs), then rises to ~1.7 (10²¹ FLOPs).
- Minimum validation loss: **1.65** at ~10²⁰.⁵ FLOPs.
2. **Sparsity 16 (Green)**:
- Begins at ~1.78 (10²⁰ FLOPs), decreases to ~1.68 (10²⁰.² FLOPs), then increases to ~1.72 (10²¹ FLOPs).
- Minimum validation loss: **1.68** at ~10²⁰.² FLOPs.
3. **Sparsity 32 (Purple)**:
- Starts at ~1.75 (10²⁰ FLOPs), drops to ~1.62 (10²⁰.⁴ FLOPs), then rises to ~1.68 (10²¹ FLOPs).
- Minimum validation loss: **1.62** at ~10²⁰.⁴ FLOPs.
4. **Sparsity 48 (Green)**:
- Begins at ~1.72 (10²⁰ FLOPs), decreases to ~1.58 (10²⁰.³ FLOPs), then increases to ~1.64 (10²¹ FLOPs).
- Minimum validation loss: **1.58** at ~10²⁰.³ FLOPs.
5. **Sparsity 64 (Blue)**:
- Starts at ~1.7 (10²⁰ FLOPs), dips to ~1.55 (10²⁰.² FLOPs), then rises to ~1.6 (10²¹ FLOPs).
- Minimum validation loss: **1.55** at ~10²⁰.² FLOPs.
### Key Observations
- **Inverse Relationship**: Higher sparsity levels (e.g., 64) generally achieve lower validation loss minima compared to lower sparsity levels (e.g., 8), despite the latter having more parameters.
- **Optimal Training FLOPs**: Each sparsity level reaches its minimum validation loss at distinct FLOP thresholds (e.g., sparsity 64 at ~10²⁰.² FLOPs).
- **Fluctuations**: Data points show non-monotonic trends, with validation loss increasing after initial decreases for most sparsity levels.
### Interpretation
The data suggests that **higher sparsity correlates with better validation performance**, contradicting the intuitive expectation that reduced sparsity (more parameters) would improve model accuracy. This could indicate:
1. **Efficiency vs. Performance Tradeoff**: Higher sparsity may enable faster convergence or better generalization despite fewer parameters.
2. **Training Dynamics**: The minima for higher sparsity occur earlier in training (lower FLOPs), suggesting these models stabilize faster.
3. **Anomalies**: The green lines for sparsity 16 and 48 overlap in color but show distinct trends, highlighting potential ambiguities in legend labeling or data grouping.
The red stars emphasize that optimal performance for each sparsity level is achieved at specific training stages, guiding resource allocation for model training.
</details>
Figure 5: Sparsity Scaling Law. Increasing sparsity leads to improved model performance. We fixed the number of activated experts to 8 and the number of shared experts to 1, and varied the total number of experts, resulting in models with different sparsity levels.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Line Chart: Validation Loss vs Training Tokens
### Overview
The chart illustrates the relationship between validation loss and training tokens for different model configurations and computational budgets. It shows multiple data series with distinct trends, highlighting how model architecture and computational resources impact performance.
### Components/Axes
- **Y-axis**: Validation Loss (1.35 to 1.75)
- **X-axis**: Training Tokens (10¹¹ to 10¹²)
- **Legend**:
- Blue squares: Models with attention heads equal to number of layers
- Blue circles: Counterparts with doubled attention heads
- Pink squares: 2.2e+20 FLOPs
- Green squares: 4.5e+20 FLOPs
- Orange squares: 9.0e+20 FLOPs
- Blue dotted line: 1.2e+20 FLOPs
### Detailed Analysis
1. **Blue Squares (Models with attention heads = layers)**:
- Starts at ~1.74 validation loss at 10¹¹ tokens
- Dips to ~1.65 at 10¹² tokens
- Shows a U-shaped curve with a minimum around 10¹¹.5 tokens
2. **Blue Circles (Doubled attention heads)**:
- Starts at ~1.64 validation loss at 10¹¹ tokens
- Dips to ~1.58 at 10¹² tokens
- Maintains lower loss than blue squares throughout
3. **Pink Squares (2.2e+20 FLOPs)**:
- Starts at ~1.62 validation loss at 10¹¹ tokens
- Dips to ~1.56 at 10¹² tokens
- Shows gradual improvement with more tokens
4. **Green Squares (4.5e+20 FLOPs)**:
- Starts at ~1.50 validation loss at 10¹¹ tokens
- Dips to ~1.45 at 10¹² tokens
- Maintains lowest loss among FLOPs-based series
5. **Orange Squares (9.0e+20 FLOPs)**:
- Starts at ~1.42 validation loss at 10¹¹ tokens
- Dips to ~1.38 at 10¹² tokens
- Shows U-shaped curve with minimum at 10¹¹.5 tokens
6. **Blue Dotted Line (1.2e+20 FLOPs)**:
- Starts at ~1.74 validation loss at 10¹¹ tokens
- Dips to ~1.65 at 10¹² tokens
- Shows consistent downward trend
### Key Observations
- **Architecture Impact**: Models with doubled attention heads (blue circles) consistently outperform standard configurations (blue squares) across all token ranges.
- **FLOPs Correlation**: Higher computational budgets (orange > green > pink) correlate with lower validation loss.
- **Training Token Effect**: All series show improved performance with more training tokens, though the rate of improvement varies.
- **1.2e+20 FLOPs Trend**: The blue dotted line demonstrates the most significant improvement (1.74 → 1.65) with increased tokens.
### Interpretation
The data suggests a complex interplay between model architecture and computational resources:
1. **Attention Head Scaling**: Doubling attention heads provides a ~0.06 validation loss advantage over standard configurations, indicating architectural efficiency gains.
2. **FLOPs vs Architecture**: While higher FLOPs generally improve performance, the 9.0e+20 FLOPs series (orange) shows diminishing returns compared to architectural improvements (blue circles).
3. **Training Token Efficiency**: The 1.2e+20 FLOPs series (blue dotted line) demonstrates that even with limited computational resources, extended training can yield substantial improvements.
4. **U-Shaped Curves**: Multiple series show initial improvement followed by plateauing, suggesting optimal performance at mid-range token counts before potential overfitting or diminishing returns.
This analysis reveals that both architectural choices (attention head scaling) and computational investment (FLOPs) significantly impact model performance, with architectural improvements often providing better returns than raw computational power alone.
</details>
Figure 6: Scaling curves for models with number of attention heads equals to number of layers and their counterparts with doubled attention heads. Doubling the number of attention heads leads to a reduction in validation loss of approximately $0.5\$ to $1.2\$ .
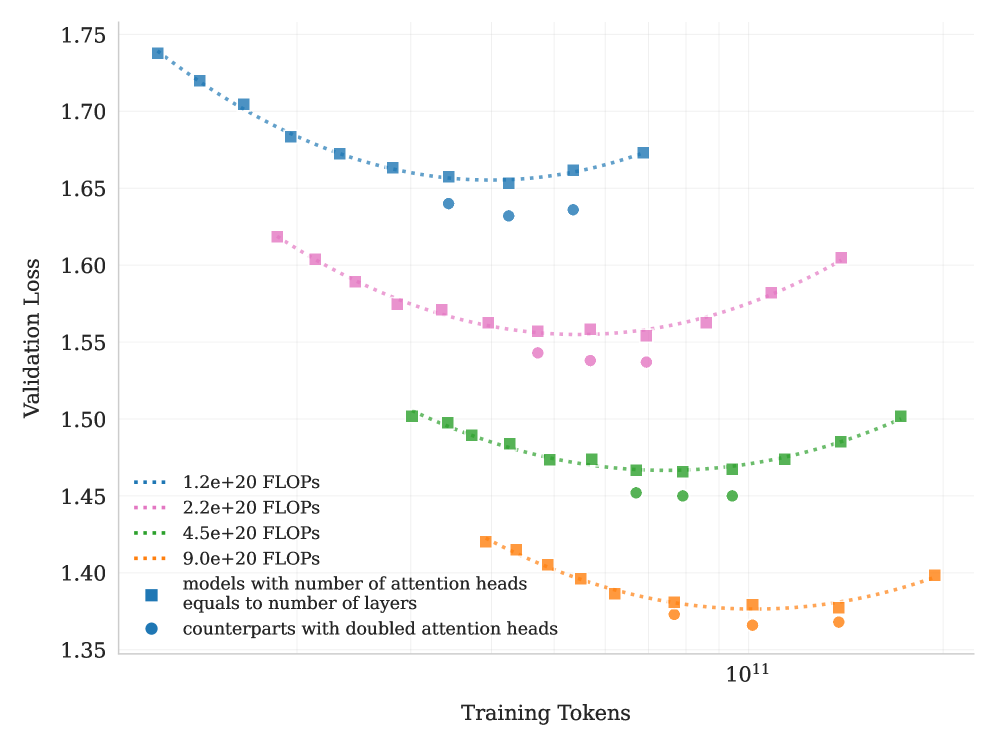
Number of Attention Heads
DeepSeek-V3 [11] sets the number of attention heads to roughly twice the number of model layers to better utilize memory bandwidth and enhance computational efficiency. However, as the context length increases, doubling the number of attention heads leads to significant inference overhead, reducing efficiency at longer sequence lengths. This becomes a major limitation in agentic applications, where efficient long context processing is essential. For example, with a sequence length of 128k, increasing the number of attention heads from 64 to 128, while keeping the total expert count fixed at 384, leads to an 83% increase in inference FLOPs. To evaluate the impact of this design, we conduct controlled experiments comparing configurations where the number of attention heads equals the number of layers against those with double number of heads, under varying training FLOPs. Under iso-token training conditions, we observe that doubling the attention heads yields only modest improvements in validation loss (ranging from 0.5% to 1.2%) across different compute budgets (Figure 6). Given that sparsity 48 already offers strong performance, the marginal gains from doubling attention heads do not justify the inference cost. Therefore we choose to 64 attention heads.
### 2.4 Training Infrastructure
#### 2.4.1 Compute Cluster
Kimi K2 was trained on a cluster equipped with NVIDIA H800 GPUs. Each node in the H800 cluster contains 2 TB RAM and 8 GPUs connected by NVLink and NVSwitch within nodes. Across different nodes, $\text{8}\!\times\!\text{400}~\text{Gbps}$ RoCE interconnects are utilized to facilitate communications.
#### 2.4.2 Parallelism for Model Scaling
Training of large language models often progresses under dynamic resource availability. Instead of optimizing one parallelism strategy that’s only applicable under specific amount of resources, we pursue a flexible strategy that allows Kimi K2 to be trained on any number of nodes that is a multiple of 32. Our strategy leverages a combination of 16-way Pipeline Parallelism (PP) with virtual stages [29, 54, 39, 58, 48, 22], 16-way Expert Parallelism (EP) [40], and ZeRO-1 Data Parallelism [61].
Under this setting, storing the model parameters in BF16 and their gradient accumulation buffer in FP32 requires approximately 6 TB of GPU memory, distributed over a model-parallel group of 256 GPUs. Placement of optimizer states depends on the training configurations. When the total number of training nodes is large, the optimizer states are distributed, reducing its per-device memory footprint to a negligible level. When the total number of training nodes is small (e.g., 32), we can offload some optimizer states to CPU.
This approach allows us to reuse an identical parallelism configuration for both small- and large-scale experiments, while letting each GPU hold approximately 30 GB of GPU memory for all states. The rest of the GPU memory are used for activations, as described in Sec. 2.4.3. Such a consistent design is important for research efficiency, as it simplifies the system and substantially accelerates experimental iteration.
EP communication overlap with interleaved 1F1B
By increasing the number of warm-up micro-batches, we can overlap EP all-to-all communication with computation under the standard interleaved 1F1B schedule [22, 54]. In comparison, DualPipe [11] doubles the memory required for parameters and gradients, necessitating an increase in parallelism to compensate. Increasing PP introduces more bubbles, while increasing EP, as discussed below, incurs higher overhead. The additional costs are prohibitively high for training a large model with over 1 trillion parameters and thus we opted not to use DualPipe.
However, interleaved 1F1B splits the model into more stages, introducing non-trivial PP communication overhead. To mitigate this cost, we decouple the weight-gradient computation from each micro-batch’s backward pass and execute it in parallel with the corresponding PP communication. Consequently, all PP communications can be effectively overlapped except for the warm-up phase.
Smaller EP size
To ensure full computation-communication overlap during the 1F1B stage, the reduced attention computation time in K2 (which has 64 attention heads compared to 128 heads in DeepSeek-V3) necessitates minimizing the time of EP operations. This is achieved by adopting the smallest feasible EP parallelization strategy, specifically EP = 16. Utilizing a smaller EP group also relaxes expert-balance constraints, allowing for near-optimal speed to be achieved without further tuning.
#### 2.4.3 Activation Reduction
After reserving space for parameters, gradient buffers, and optimizer states, the remaining GPU memory on each device is insufficient to hold the full MoE activations. To ensure the activation memory fits within the constraints, especially for the initial pipeline stages that accumulate the largest activations during the 1F1B warm-up phase, the following techniques are employed.
Selective recomputation
Recomputation is applied to inexpensive, high-footprint stages, including LayerNorm, SwiGLU, and MLA up-projections [11]. Additionally, MoE down-projections are recomputed during training to further reduce activation memory. While optional, this recomputation maintains adequate GPU memory, preventing crashes caused by expert imbalance in early training stages.
FP8 storage for insensitive activations
Inputs of MoE up-projections and SwiGLU are compressed to FP8-E4M3 in 1 $\times$ 128 tiles with FP32 scales. Small-scale experiments show no measurable loss increase. Due to potential risks of performance degradation that we observed during preliminary study, we do not apply FP8 in computation.
<details>
<summary>x9.png Details</summary>

### Visual Description
## Diagram: Computational Process Flow with Offload/Onload Stages
### Overview
The diagram illustrates a multi-stage computational process involving computation, communication, and offload/onload operations. It includes a grid representing sequential steps (1-8) with color-coded operations (forward pass, backward pass, PP communication, EP dispatch/combined). Three primary sections at the top define computational stages, while the grid below maps the flow of operations across iterations.
---
### Components/Axes
1. **Top Sections**:
- **Computation**: Contains blocks labeled `Attn` (Attention), `MLP` (Multi-Layer Perceptron), `EP-D` (EP Dispatch), and `EP-C` (EP Combine).
- **Communication**: Includes `EP-D`, `EP-C`, and `PP` (Parameter Passing).
- **Offload/Onload**: Labeled `Offload` (yellow) and `Onload` (yellow), with `WGrad` (Weight Gradient) in red.
2. **Grid**:
- **Rows**: Labeled `VPP + 1 warmup` (Vertical Pipeline Parallelism + 1 warmup step).
- **Columns**: Numbered 1-8, representing sequential steps.
- **Colors**:
- Blue: Forward pass
- Red: Backward pass
- Green: PP communication
- Yellow: EP dispatch/combined (EP-D, EP-C)
3. **Legend**:
- Located at the bottom, mapping colors to operations:
- Blue: Forward pass
- Red: Backward pass
- Green: PP communication
- Yellow: EP dispatch/combined (EP-D, EP-C)
---
### Detailed Analysis
1. **Top Sections**:
- **Computation**:
- Leftmost section: `Attn` (blue), `MLP` (blue), `EP-D` (blue), `EP-C` (blue).
- Middle section: `Attn` (red), `MLP` (red), `EP-D` (red), `EP-C` (red).
- Rightmost section: `MLP` (red), `Attn` (red), `WGrad` (red), `EP-C` (red), `PP` (green).
- **Communication**:
- Repeats `EP-D` (blue), `EP-C` (blue), `PP` (green) across stages.
- **Offload/Onload**:
- Left: `Offload` (yellow).
- Middle: `Offload` (yellow) and `Onload` (yellow).
- Right: `Onload` (yellow).
2. **Grid**:
- **Rows**:
- Row 1: `1 2 3 4 1 2 3 4` (blue).
- Row 2: `1 2 3 4 1 2 3 4` (blue).
- Row 3: `1 2 3 4 1 2 3 4` (blue).
- Row 4: `1 2 3 4 1 2 3 4` (blue).
- **Columns**:
- Columns 1-4: Blue (forward pass).
- Columns 5-8: Red (backward pass), with green (PP communication) in column 7, row 4.
3. **Color Consistency**:
- Blue blocks in the grid align with "Forward pass" in the legend.
- Red blocks align with "Backward pass."
- Green blocks (e.g., column 7, row 4) match "PP communication."
- Yellow blocks in the top sections correspond to "EP dispatch/combined."
---
### Key Observations
1. **Sequential Flow**:
- The grid shows a repetitive pattern of forward pass (blue) in steps 1-4, followed by backward pass (red) in steps 5-8.
- PP communication (green) occurs in step 7, row 4, indicating a parameter-passing step mid-process.
2. **Offload/Onload Dynamics**:
- Offload (yellow) appears in the left and middle sections, suggesting data transfer out of the computation stage.
- Onload (yellow) in the middle and right sections indicates data retrieval into the computation stage.
3. **WGrad and PP**:
- `WGrad` (red) in the rightmost computation section highlights weight gradient computation during backward pass.
- `PP` (green) in the communication section emphasizes parameter synchronization.
---
### Interpretation
The diagram models a distributed training workflow, likely for neural networks, with stages for computation, communication, and data transfer. The grid represents iterative steps (1-8) where:
- **Forward pass** (blue) dominates early steps, executing attention and MLP layers.
- **Backward pass** (red) follows, computing gradients and updating weights.
- **PP communication** (green) occurs mid-process, synchronizing parameters between pipeline stages.
- **EP dispatch/combined** (yellow) manages data offloading/onloading, optimizing resource usage.
The `VPP + 1 warmup` row suggests a pipeline parallelism strategy with an initial warmup phase to stabilize computation. The repetition of steps 1-4 in blue and 5-8 in red implies a two-phase workflow (forward/backward), while the green and yellow blocks highlight critical communication and data transfer points. This structure balances computational efficiency with communication overhead, typical in large-scale machine learning systems.
</details>
Figure 7: Computation, communication and offloading overlapped in different PP phases.
Activation CPU offload
All remaining activations are offloaded to CPU RAM. A copy engine is responsible for streaming the offload and onload, overlapping with both computation and communication kernels. During the 1F1B phase, we offload the forward activations of the previous micro-batch while prefetching the backward activations of the next. The warm-up and cool-down phases are handled similarly and the overall pattern is shown in Figure 7. Although offloading may slightly affect EP traffic due to PCIe traffic congestion, our tests show that EP communication remains fully overlapped.
### 2.5 Training recipe
We pre-trained the model with a 4,096-token context window using the MuonClip optimizer (Algorithm 1) and the WSD learning rate schedule [26], processing a total of 15.5T tokens. The first 10T tokens were trained with a constant learning rate of 2e-4 after a 500-step warm-up, followed by 5.5T tokens with a cosine decay from 2e-4 to 2e-5. Weight decay was set to 0.1 throughout, and the global batch size was held at 67M tokens. The overall training curve is shown in Figure 3.
Towards the end of pre-training, we conducted an annealing phase followed by a long-context activation stage. The batch size was kept constant at 67M tokens, while the learning rate was decayed from 2e-5 to 7e-6. In this phase, the model was trained on 400 billion tokens with a 4k sequence length, followed by an additional 60 billion tokens with a 32k sequence length. To extend the context window to 128k, we employed the YaRN method [56].
## 3 Post-Training
### 3.1 Supervised Fine-Tuning
We employ the Muon optimizer [34] in our post-training and recommend its use for fine-tuning with K2. This follows from the conclusion of our previous work [47] that a Muon-pre-trained checkpoint produces the best performance with Muon fine-tuning.
We construct a large-scale instruction-tuning dataset spanning diverse domains, guided by two core principles: maximizing prompt diversity and ensuring high response quality. To this end, we develop a suite of data generation pipelines tailored to different task domains, each utilizing a combination of human annotation, prompt engineering, and verification processes. We adopt K1.5 [36] and other in-house domain-specialized expert models to generate candidate responses for various tasks, followed by LLMs or human-based judges to perform automated quality evaluation and filtering. For agentic data, we create a data synthesis pipeline to teach models tool-use capabilities through multi-step, interactive reasoning.
#### 3.1.1 Large-Scale Agentic Data Synthesis for Tool Use Learning
A critical capability of modern LLM agents is their ability to autonomously use unfamiliar tools, interact with external environments, and iteratively refine their actions through reasoning, execution, and error correction. Agentic tool use capability is essential for solving complex, multi-step tasks that require dynamic interaction with real-world systems. Recent benchmarks such as ACEBench [7] and $\tau$ -bench [86] have highlighted the importance of comprehensive tool-use evaluation, while frameworks like ToolLLM [59] and ACEBench [7] have demonstrated the potential of teaching models to use thousands of tools effectively.
However, training such capabilities at scale presents a significant challenge: while real-world environments provide rich and authentic interaction signals, they are often difficult to construct at scale due to cost, complexity, privacy and accessibility constraints. Recent work on synthetic data generation (AgentInstruct [52]; Self-Instruct [76]; StableToolBench [21]; ZeroSearch [67]) has shown promising results in creating large-scale data without relying on real-world interactions. Building on these advances and inspired by ACEBench [7] ’s comprehensive data synthesis framework, we developed a pipeline that simulates real-world tool-use scenarios at scale, enabling the generation of tens of thousands of diverse and high-quality training examples.
<details>
<summary>x10.png Details</summary>
### Visual Description
## Flowchart: System Architecture for Tool Specification and Task Execution
### Overview
The diagram illustrates a hierarchical workflow connecting domains, applications, tool specifications, agents, and tasks with rubrics. It emphasizes the flow of data or processes from high-level domains to specific task execution, with a central "Tool Repository" acting as an intermediary.
---
### Components/Axes
- **Nodes**:
- **Domains** (topmost, purple)
- **Applications** (purple, connected to Domains)
- **MCP tools** (green, connected to Applications)
- **Real-world tool specs** (green, connected to MCP tools)
- **Synthesized tool specs** (purple, connected to Applications)
- **Tool Repository** (blue, receiving inputs from both tool specs)
- **Agents** (yellow, connected to Tool Repository)
- **Tasks with rubrics** (pink, connected to Agents)
- **Arrows**: Indicate directional flow between components.
- **Colors**:
- Purple: High-level conceptual components (Domains, Applications, Synthesized tool specs)
- Green: Real-world/tool-specific components (MCP tools, Real-world tool specs)
- Blue: Central repository (Tool Repository)
- Yellow: Processing unit (Agents)
- Pink: Output/goal (Tasks with rubrics)
---
### Detailed Analysis
1. **Flow Path**:
- **Domains** → **Applications**: High-level domains are broken down into specific applications.
- **Applications** → **MCP tools** and **Synthesized tool specs**: Applications generate both real-world tool specifications (via MCP tools) and simulated/synthesized specifications.
- **Tool specs** → **Tool Repository**: Both real and synthesized specifications are stored or processed in a central repository.
- **Tool Repository** → **Agents**: The repository supplies data to agents.
- **Agents** → **Tasks with rubrics**: Agents execute tasks defined by rubrics (performance criteria).
2. **Key Relationships**:
- The **Tool Repository** serves as a convergence point for real and synthesized tool specifications, suggesting a unified system for managing diverse data sources.
- **Agents** act as intermediaries between the repository and task execution, implying automation or decision-making capabilities.
- **Tasks with rubrics** are the final output, indicating that agent performance is evaluated against predefined standards.
---
### Key Observations
- **Dual Inputs to Tool Repository**: The system integrates both real-world and synthesized tool specifications, enabling flexibility for testing or hybrid workflows.
- **Agent-Centric Design**: Agents are positioned to process repository data and execute tasks, highlighting their role as autonomous or semi-autonomous components.
- **Rubric-Driven Tasks**: The inclusion of rubrics suggests a focus on measurable outcomes or quality control in task execution.
---
### Interpretation
This diagram represents a system architecture where **domains** are decomposed into **applications**, which define **tool specifications** (both real and simulated). These specifications are centralized in a **Tool Repository**, enabling **Agents** to execute **Tasks with rubrics**. The structure implies:
- **Modularity**: Components are decoupled (e.g., Domains → Applications → Tool specs).
- **Scalability**: The repository can handle diverse inputs, supporting both real and synthetic data.
- **Evaluation Focus**: Rubrics in tasks emphasize performance metrics, suggesting the system is designed for optimization or validation.
The absence of numerical data or explicit trends indicates the diagram is conceptual, focusing on workflow design rather than quantitative analysis.
</details>
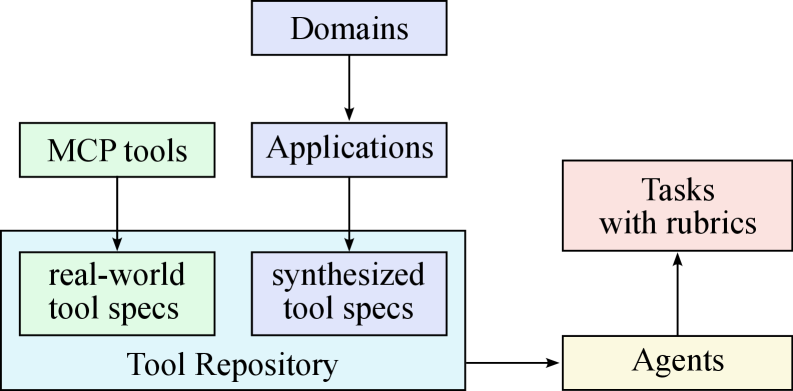
(a) Synthesizing tool specs, agents and tasks
<details>
<summary>x11.png Details</summary>
### Visual Description
## Flowchart: Agent Workflow and Evaluation System
### Overview
The diagram illustrates a multi-component system for agent interaction, task execution, and data validation. It features two primary sections: a left-side agent workflow and a right-side evaluation process, connected through data trajectories.
### Components/Axes
1. **Left Section (Agent Workflow)**
- **User Agent** (green box): Initiates interactions
- **Agent** (yellow box): Core processing unit
- **Tool Simulator** (blue box): Execution environment
- Arrows indicate:
- `interaction` (User Agent → Agent)
- `observation` (Agent → Tool Simulator)
- `call` (Agent → Tool Simulator)
2. **Right Section (Evaluation Process)**
- **Task** (red box): Defined objectives
- **Rubrics** (red box): Evaluation criteria
- **Judge Agent** (purple box): Validation component
- **Filtered Data** (green box): Output
- Arrows indicate:
- `trajectories` (Tool Simulator → Judge Agent)
- Evaluation flow (Rubrics → Judge Agent → Filtered Data)
3. **Connectivity**
- Task box connects to User Agent
- Judge Agent receives trajectories from Tool Simulator
- Filtered Data is the final output
### Detailed Analysis
- **Agent Workflow**:
- User Agent initiates task interactions
- Agent observes tool simulator outputs and makes calls
- Tool Simulator executes actions based on agent instructions
- **Evaluation Process**:
- Task definition originates from User Agent
- Rubrics provide evaluation framework
- Judge Agent analyzes trajectories against rubrics
- Filtered Data represents validated results
### Key Observations
1. **Modular Architecture**: Clear separation between execution (left) and evaluation (right)
2. **Data Flow**: Trajectories from tool execution feed directly into judgment
3. **Validation Layer**: Judge Agent acts as quality control between raw data and final output
4. **Color Coding**:
- Green = User-facing components (User Agent, Filtered Data)
- Red = Task definition and evaluation criteria
- Blue/Purple = Technical components (Tool Simulator, Judge Agent)
### Interpretation
This system implements a closed-loop validation framework where:
1. The User Agent defines tasks and receives final outputs
2. The Agent executes actions through a simulated environment
3. All trajectories are independently validated by the Judge Agent using predefined rubrics
4. The separation of execution and evaluation ensures objective assessment
5. Filtered Data represents both task completion and quality assurance
The architecture suggests a focus on reliable AI agent systems where outputs must meet explicit criteria before being considered valid results. The use of separate evaluation criteria (rubrics) implies potential applications in educational technology, automated grading systems, or quality control for AI-generated content.
</details>
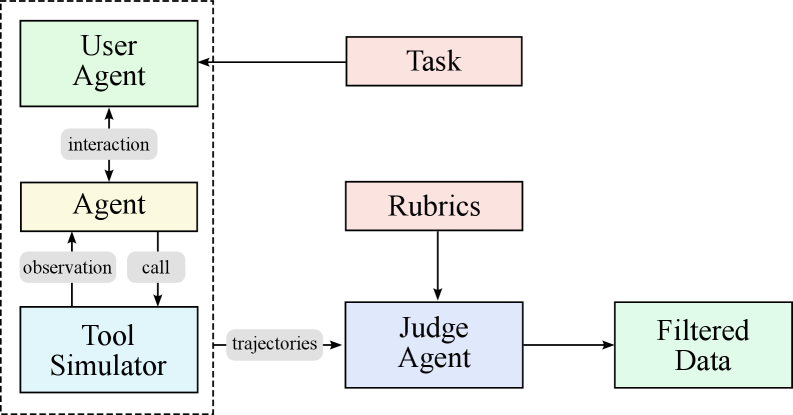
(b) Generating agent trajectories
Figure 8: Data synthesis pipeline for tool use. (a) Tool specs are from both real-world tools and LLMs; agents and tasks are the generated from the tool repo. (b) Multi-agent pipeline to generate and filter trajectories with tool calling.
<details>
<summary>x12.png Details</summary>
### Visual Description
## Scatter Plot: t-SNE of MCP Tools by Category
### Overview
The image is a 2D t-SNE (t-distributed Stochastic Neighbor Embedding) visualization of Machine Control Platform (MCP) tools categorized by functionality. Points are colored by category, with a legend on the right. The plot reveals clustering patterns, indicating relationships between tool categories in a reduced-dimensional space.
### Components/Axes
- **X-axis**: Labeled "t-SNE 1" (horizontal), ranging approximately from -75 to 75.
- **Y-axis**: Labeled "t-SNE 2" (vertical), ranging approximately from -60 to 80.
- **Legend**: Located in the top-right corner, listing 40+ categories (e.g., "databases," "cloud-platforms," "finance") with distinct colors. Colors include light blue, dark blue, green, yellow, red, purple, pink, orange, and gray.
### Detailed Analysis
1. **Clustering Patterns**:
- **Central Cluster**: A dense mix of colors (e.g., yellow, green, blue) dominates the center, suggesting overlapping similarities between categories like "research-and-data," "developer-tools," and "cloud-storage."
- **Outliers**:
- **"Other" Category**: A small cluster in the bottom-left quadrant (t-SNE 1 ≈ -70, t-SNE 2 ≈ -50).
- **"Finance" Category**: A distinct cluster in the top-right quadrant (t-SNE 1 ≈ 60, t-SNE 2 ≈ 60).
- **"Image-and-Video-Processing"**: Scattered points in the upper-left quadrant (t-SNE 1 ≈ -50, t-SNE 2 ≈ 40).
- **Distinct Groups**:
- **"Search" and "Ecommerce-and-Retail"**: Clustered near the center (t-SNE 1 ≈ 0–20, t-SNE 2 ≈ -20 to 20).
- **"Blockchain" and "Cryptocurrency"**: Located in the upper-right quadrant (t-SNE 1 ≈ 40–50, t-SNE 2 ≈ 30–40).
2. **Color-Legend Consistency**:
- All legend colors match their corresponding data points. For example:
- "Databases" (light blue) appears in the lower-left quadrant.
- "Marketing" (yellow) is concentrated in the upper-right quadrant.
### Key Observations
- **Dominant Categories**: "Research-and-data" (yellow) and "developer-tools" (blue) form the largest central cluster.
- **Outliers**: "Other" and "Finance" are spatially isolated, indicating low similarity to other categories.
- **Overlap**: Categories like "cloud-platforms" (green) and "cloud-storage" (orange) are intermingled, suggesting functional overlap.
- **Sparse Regions**: The bottom-left quadrant has fewer points, indicating underrepresented categories.
### Interpretation
The t-SNE plot demonstrates that MCP tools with similar functionalities (e.g., "research-and-data" and "developer-tools") are grouped closely, while distinct categories like "Finance" and "Image-and-Video-Processing" occupy separate regions. The "Other" category’s isolation suggests it contains tools that do not align well with the primary functional groups. The central cluster’s diversity implies many tools share hybrid functionalities, reflecting the interdisciplinary nature of modern MCP ecosystems. Outliers like "Finance" highlight niche domains requiring specialized tooling. This visualization aids in identifying tool redundancies, gaps, and potential integration opportunities.
</details>
(a) t-SNE visualization of real MCP tools, colored by their original source categories
<details>
<summary>x13.png Details</summary>
### Visual Description
## t-SNE Plot: Synthetic Tools by Category
### Overview
The image is a t-SNE (t-distributed Stochastic Neighbor Embedding) visualization of synthetic tools categorized by domain. The plot uses two principal components (t-SNE 1 and t-SNE 2) to represent high-dimensional data in 2D space. Each point represents a synthetic tool, colored by its associated category. The legend on the right maps 15 categories to distinct colors.
### Components/Axes
- **Axes**:
- X-axis: t-SNE 1 (range: -100 to 100)
- Y-axis: t-SNE 2 (range: -100 to 100)
- **Legend**:
- Positioned on the right, with 15 categories mapped to colors (e.g., `enterprise_business_intelligence` = light blue, `transportation_logistics` = teal, `iphone_android` = yellow, etc.).
- Includes an "unknown" category (gray) and a "gaming_entertainment" category (bright yellow).
### Detailed Analysis
- **Data Distribution**:
- **Bottom-left quadrant** (t-SNE 1 < -50, t-SNE 2 < -50): Dominated by `education_e-learning` (green) and `software_apps` (blue).
- **Top-left quadrant** (t-SNE 1 < -50, t-SNE 2 > 50): Clustered `iphone_android` (yellow) and `smart_home` (purple).
- **Top-right quadrant** (t-SNE 1 > 50, t-SNE 2 > 50): Concentrated `real_estate_property` (red) and `agriculture_environmental` (pink).
- **Bottom-right quadrant** (t-SNE 1 > -50, t-SNE 2 < -50): Spread of `financial_trading` (orange) and `robot_control` (dark green).
- **Center**: Mixed clusters of `healthcare_medical` (light gray), `manufacturing_industrial_iot` (dark purple), and `legal_compliance` (orange).
- **Outliers**:
- `desktop_systems` (dark purple) and `website_control` (bright yellow) appear scattered across all quadrants.
- `unknown` (gray) points are dispersed throughout the plot, suggesting unclassified or ambiguous tools.
### Key Observations
1. **Clustering Patterns**:
- `iphone_android` (yellow) and `real_estate_property` (red) form tight clusters, indicating high similarity within their categories.
- `education_e-learning` (green) and `software_apps` (blue) are tightly grouped but separated from other domains.
2. **Dispersion**:
- `unknown` (gray) and `desktop_systems` (dark purple) show the widest dispersion, suggesting heterogeneity or overlap with multiple categories.
3. **Color Consistency**:
- All legend colors match their corresponding data points (e.g., `transportation_logistics` = teal, `legal_compliance` = orange).
### Interpretation
The t-SNE plot reveals distinct groupings of synthetic tools by domain, with some categories (e.g., `iphone_android`, `real_estate_property`) exhibiting strong internal cohesion. The widespread distribution of `unknown` and `desktop_systems` suggests either ambiguous categorization or tools that span multiple domains. The separation of `education_e-learning` and `software_apps` from other categories implies these tools may have unique characteristics or applications. The plot highlights the need for further analysis to resolve overlaps and refine category definitions, particularly for the "unknown" group.
</details>
(b) t-SNE visualization of synthetic tools, colored by pre-defined domain categories
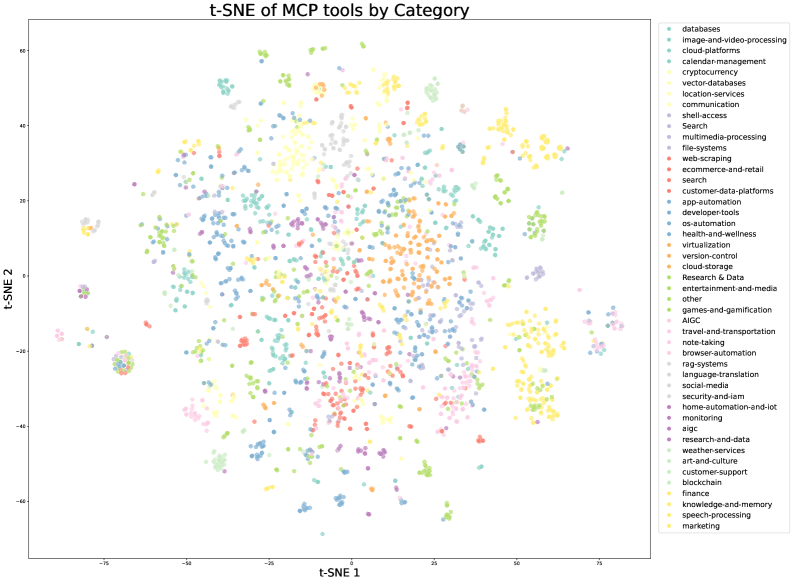
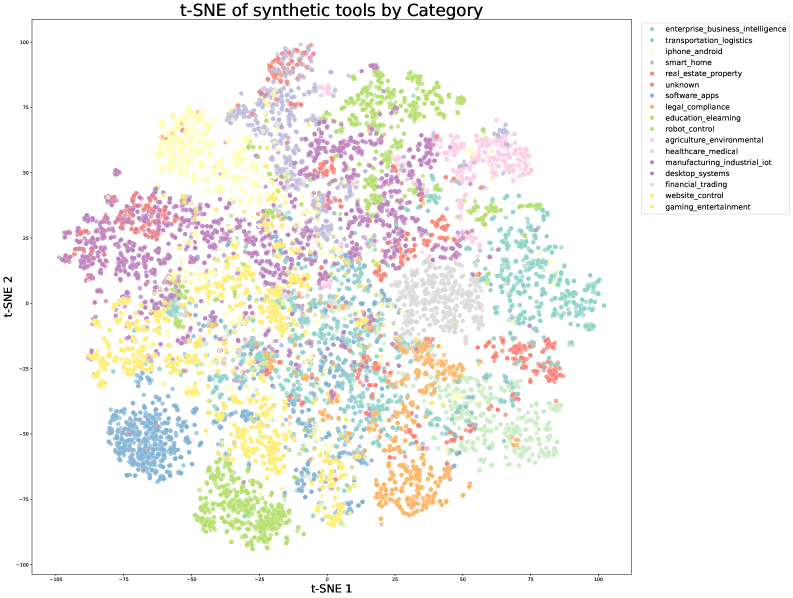
Figure 9: t-SNE visualizations of tool embeddings. (a) Real-world MCP tools exhibit natural clustering based on their original source categories. (b) Synthetic tools are organized into pre-defined domain categories, providing systematic coverage of the tool space. Together, they ensure comprehensive representation across different tool functionalities.
There are three stages in our data synthesis pipeline, depicted in Fig. 8.
- Tool spec generation: we first construct a large repository of tool specs from both real-world tools and LLM-synthetic tools;
- Agent and task generation: for each tool-set sampled from the tool repository, we generate an agent to use the toolset and some corresponding tasks;
- Trajectory generation: for each agent and task, we generate trajectories where the agent finishes the task by invoking tools.
Domain Evolution and Tool Generation.
We construct a comprehensive tool repository through two complementary approaches. First, we directly fetch 3000+ real MCP (Model Context Protocol) tools from GitHub repositories, leveraging existing high-quality tool specs. Second, we systematically evolve [83] synthetic tools through a hierarchical domain generation process: we begin with key categories (e.g., financial trading, software applications, robot control), then evolve multiple specific application domains within each category. Specialized tools are then synthesized for each domain, with clear interfaces, descriptions, and operational semantics. This evolution process produces over 20,000 synthetic tools. Figure 9 visualizes the diversity of our tool collection through t-SNE embeddings, demonstrating that both MCP and synthetic tools cover complementary regions of the tool space.
Agent Diversification.
We generate thousands of distinct agents by synthesizing various system prompts and equipping them with different combinations of tools from our repository. This creates a diverse population of agents with varied capabilities, areas of expertise, and behavioral patterns, ensuring a broad coverage of potential use cases.
Rubric-Based Task Generation.
For each agent configuration, we generate tasks that range from simple to complex operations. Each task is paired with an explicit rubric that specifies success criteria, expected tool-use patterns, and evaluation checkpoints. This rubric-based approach ensures a consistent and objective evaluation of agent performance.
Multi-turn Trajectory Generation.
We simulate realistic tool-use scenarios through several components:
- User Simulation: LLM-generated user personas with distinct communication styles and preferences engage in multi-turn dialogues with agents, creating naturalistic interaction patterns.
- Tool Execution Environment: A sophisticated tool simulator (functionally equivalent to a world model) executes tool calls and provides realistic feedback. The simulator maintains and updates state after each tool execution, enabling complex multi-step interactions with persistent effects. It introduces controlled stochasticity to produce varied outcomes including successes, partial failures, and edge cases.
Quality Evaluation and Filtering.
An LLM-based judge evaluates each trajectory against the task rubrics. Only trajectories that meet the success criteria are retained for training, ensuring high-quality data while allowing natural variation in task-completion strategies.
Hybrid Approach with Real Execution Environments.
While simulation provides scalability, we acknowledge the inherent limitation of simulation fidelity. To address this, we complement our simulated environments with real execution sandboxes for scenarios where authenticity is crucial, particularly in coding and software engineering tasks. These real sandboxes execute actual code, interact with genuine development environments, and provide ground-truth feedback through objective metrics such as test suite pass rates. This combination ensures that our models learn from both the diversity of simulated scenarios and the authenticity of real executions, significantly strengthening practical agent capabilities.
By leveraging this hybrid pipeline that combines scalable simulation with targeted real-world execution, we generate diverse, high-quality tool-use demonstrations that balance coverage and authenticity. The scale and automation of our synthetic data generation, coupled with the grounding provided by real execution environments, effectively implements large-scale rejection sampling [27, 88] through our quality filtering process. This high-quality synthetic data, when used for supervised fine-tuning, has demonstrated significant improvements in the model’s tool-use capabilities across a wide range of real-world applications.
### 3.2 Reinforcement Learning
Reinforcement learning (RL) is believed to have better token efficiency and generalization than SFT. Based on the work of K1.5 [36], we continue to scale RL in both task diversity and training FLOPs in K2. To support this, we develop a Gym-like extensible framework that facilitates RL across a wide range of scenarios. We extend the framework with a large number of tasks with verifiable rewards. For tasks that rely on subjective preferences, such as creative writing and open-ended question answering, we introduce a self-critic reward in which the model performs pairwise comparisons to judge its own outputs. This approach allows tasks from various domains to all benefit from the RL paradigm.
#### 3.2.1 Verifiable Rewards Gym
Math, STEM and Logical Tasks
For math, stem and logical reasoning domains, our RL data preparation follows two key principles, diverse coverage and moderate difficulty.
Diverse Coverage. For math and stem tasks, we collect high-quality QA pairs using a combination of expert annotations, internal QA extraction pipelines, and open datasets [42, 53]. During the collection process, we leverage a tagging system to deliberately increase coverage of under-covered domains. For logical tasks, our dataset comprises a variety of formats, including structured data tasks (e.g., multi-hop tabular reasoning, cross-table aggregation) and logic puzzles (e.g., the 24-game, Sudoku, riddles, cryptarithms, and Morse-code decoding).
Moderate Difficulty. The RL prompt-set should be neither too easy nor too hard, both of which may produce little signal and reduce learning efficiency. We assess the difficulty of each problem using the SFT model’s pass@k accuracy and select only problems with moderate difficulty.
Complex Instruction Following
Effective instruction following requires not only understanding explicit constraints but also navigating implicit requirements, handling edge cases, and maintaining consistency over extended dialogues. We address these challenges through a hybrid verification framework that combines automated verification with adversarial detection, coupled with a scalable curriculum generation pipeline. Our approach employs a dual-path system to ensure both precision and robustness:
Hybrid Rule Verification. We implement two verification mechanisms: (1) deterministic evaluation via code interpreters for instructions with verifiable outputs (e.g., length, style constraints), and (2) LLM-as-judge evaluation for instructions requiring nuanced understanding of constraints. To address potential adversarial behaviors where models might claim instruction fulfillment without actual compliance, we incorporate an additional hack-check layer that specifically detects such deceptive claims.
Multi-Source Instruction Generation. To construct our training data, we employ three distinct generation strategies to ensure comprehensive coverage: (1) expert-crafted complex conditional prompts and rubrics developed by our data team (2) agentic instruction augmentation inspired by AutoIF [13], and (3) a fine-tuned model specialized for generating additional instructions that probe specific failure modes or edge cases. This multipronged approach ensures both breadth and depth in instruction coverage.
Faithfulness
Faithfulness is essential for an agentic model operating in scenarios such as multi-turn tool use, self-generated reasoning chains, and open-environment interactions. Inspired by the evaluation framework from FACTS Grounding [31], we train a sentence-level faithfulness judge model to perform automated verification. The judge is effective in detecting sentences that make a factual claim without supporting evidence in context. It serves as a reward model to enhance overall faithfulness performance.
Coding & Software Engineering
To enhance our capability in tackling competition-level programming problems, we gather problems and their judges from both open-source datasets [28, 84] and synthetic sources. To ensure the diversity of the synthetic data and the correctness of reward signals, we incorporate high-quality human-written unit tests retrieved from pre-training data.
For software engineering tasks, we collect a vast amount of pull requests and issues from GitHub to build software development environment that consists of user prompts/issues and executable unit tests. This environment was built on a robust sandbox infrastructure, powered by Kubernetes for scalability and security. It supports over 10,000 concurrent sandbox instances with stable performance, making it ideal for both competitive coding and software engineering tasks.
Safety
Our work to enhance the safety begins with a human-curated set of seed prompts, manually crafted to encompass prevalent risk categories such as violence, fraud, and discrimination.
To simulate sophisticated jailbreak attempts (e.g., role-playing, literary narratives, and academic discourse), we employ an automated prompt evolution pipeline with three key components:
- Attack Model: Iteratively generates adversarial prompts designed to elicit unsafe responses from the target LLM.
- Target Model: Produces responses to these prompts, simulating potential vulnerabilities.
- Judge Model: Evaluates the interaction to determine if the adversarial prompt successfully bypasses safety mechanisms.
Each interaction is assessed using a task-specific rubric, enabling the judge model to provide a binary success/failure label.
#### 3.2.2 Beyond Verification: Self-Critique Rubric Reward
To extend model alignment beyond tasks with verifiable reward, we introduce a framework for general reinforcement learning from self-critic feedbacks. This approach is designed to align LLMs with nuanced human preferences, including helpfulness, creativity, depth of reasoning, factuality, and safety, by extending the capabilities learned from verifiable scenarios to a broader range of subjective tasks. The framework operates using a Self-Critique Rubric Reward mechanism, where the model evaluates its own outputs to generate preference signals. To bootstrap K2 as a competent judge, we curated a mixture of open-source and in-house preference datasets and initialize its critic capability in the SFT stage.
Self-Critiqued Policy Optimization
In the first core process of the learning loop, the K2 actor generates responses for general prompts that cover a wide range of use cases. The K2 critic then ranks all results by performing pairwise evaluations against a combination of rubrics, which incorporates both core rubrics (Appendix. F.1), which represent the fundamental values of our AI assistant that Kimi cherish, prescriptive rubrics (Appendix. F.2) that aim to eliminate reward hacking, and human-annotated rubrics crafted by our data team for specific instructional contexts. Although certain rubrics can be designated as mandatory, K2 retains the flexibility to weigh them against its internal priors. This capacity enables a dynamic and continuous alignment with its evolving on-policy behavior, ensuring that the model’s responses remain coherent with its core identity while adapting to specific instructions.
Closed-Loop Critic Refinement and Alignment
During RL training, the critic model is refined using verifiable signals. On-policy rollouts generated from verifiable-reward prompts are used to continuously update the critic, a crucial step that distills objective performance signals from RLVR directly into its evaluation model. This transfer learning process grounds its more subjective judgments in verifiable data, allowing the performance gains from verifiable tasks to enhance the critic’s judgment on complex tasks that lack explicit reward signals. This closed-loop process ensures that the critic continuously recalibrates its evaluation standards in lockstep with the policy’s evolution. By grounding subjective evaluation in verifiable data, the framework enables robust and scalable alignment with complex, non-verifiable human objectives.
Consequently, this holistic alignment yields comprehensive performance improvements across a wide spectrum of domains, including user intent understanding, creative writing, complex reasoning, and nuanced language comprehension.
#### 3.2.3 RL Algorithm
We adopt the policy optimization algorithm introduced in K1.5 [36] as the foundation for K2. For each problem $x$ , we sample $K$ responses $\{y_{1},\dots,y_{k}\}$ from the previous policy $\pi_{\mathrm{old}}$ , and optimize the model $\pi_{\theta}$ with respect to the following objective:
| | $\displaystyle L_{\mathrm{RL}}(\theta)=\mathbb{E}_{x\sim\mathcal{D}}\left[\frac{1}{K}\sum_{i=1}^{K}\left[\left(r(x,y_{i})-\bar{r}(x)-\tau\log\frac{\pi_{\theta}(y_{i}|x)}{{\pi}_{\mathrm{old}}(y_{i}|x)}\right)^{2}\right]\right]\,,$ | |
| --- | --- | --- |
where $\bar{r}(x)=\frac{1}{k}\sum_{i=1}^{k}r(x,y_{i})$ is the mean rewards of the sampled responses, $\tau>0$ is a regularization parameter that promotes stable learning. As in SFT, we employ the Muon optimizer [34] to minimize this objective. As we scale RL training to encompass a broader range of tasks in K2, a primary challenge is achieving consistent performance improvements across all domains. To address this, we introduce several additions to the RL algorithm.
Budget Control
It has been widely observed that RL often results in a substantial increase in the length of model-generated responses [36, 20]. While longer responses can enable the model to utilize additional test-time compute for improved performance on complex reasoning tasks, the benefits often do not justify its inference cost in non-reasoning domains. To encourage the model to properly distribute inference budget, we enforce a per-sample maximum token budget throughout RL training, where the budget is determined based on the type of task. Responses that exceed this token budget are truncated and assigned a penalty, which incentivizes the model to generate solutions within the specified limit. Empirically, this approach significantly enhances the model’s token efficiency, encouraging concise yet effective solutions across all domains.
PTX Loss
To prevent the potential forgetting of valuable, high-quality data during joint RL training, we curate a dataset comprising hand-selected, high-quality samples and integrate it into the RL objective through an auxiliary PTX loss [55]. This strategy not only leverages the advantages of high-quality data, but also mitigates the risk of overfitting to the limited set of tasks explicitly present in the training regime. This augmentation substantially improves the model’s generalization across a broader range of domains.
Temperature Decay
For tasks such as creative writing and complex reasoning, we find that promoting exploration via a high sampling temperature during the initial stages of training is crucial. A high temperature allow the model to generate diverse and innovative responses, thereby facilitating the discovery of effective strategies and reducing the risk of premature convergence to suboptimal solutions. However, retaining a high temperature in the later stages of training or during evaluation can be detrimental, as it introduces excessive randomness and compromises the reliability and consistency of the model’s outputs. To address this, we employ a temperature decay schedule, to shift from exploration to exploitation throughout the training. This strategy ensures that the model leverages exploration when it is most beneficial, while ultimately converge on stable and high-quality outputs.
### 3.3 RL Infrastructure
#### 3.3.1 Colocated Architecture
Similar to K1.5 [36], we adopt a hybrid colocated architecture for our synchronized RL training, where the training and inference engines live on the same workers. When one engine is actively working, the other engine releases or offloads its GPU resources to accommodate. In each iteration of RL training, a centralized controller first calls the inference engine to generate new data for training. It then notifies the training engine to train on the new data, and send updated parameters to the inference engine for the next iteration.
Each engine is heavily optimized for throughput. In addition, as the model scales to the size of K2, the latency of engine switching and failure recovery becomes significant. We present our system design considerations in these aspects.
#### 3.3.2 Efficient Engine Switching
During rollout, the parameters of the training engine are offloaded to DRAM. Bringing up the training engine is therefore a simple step of H2D transmission. However, bringing up the inference engine is a bigger challenge, as it must obtain updated parameters from the training engine with a different sharding paradigm.
<details>
<summary>x14.png Details</summary>
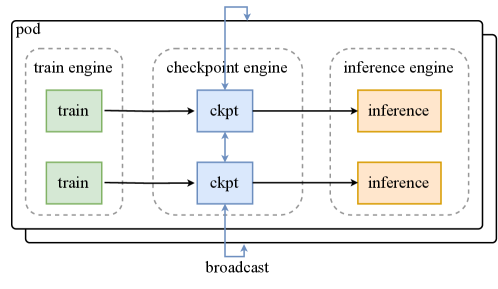
### Visual Description
## Diagram: System Architecture for Training and Inference Workflow
### Overview
The diagram illustrates a distributed system architecture with three primary components: **train engine**, **checkpoint engine**, and **inference engine**. These components are interconnected via labeled blocks ("train," "ckpt," "inference") and directional arrows, with a "broadcast" mechanism linking the checkpoint engine to the inference engine. The system is encapsulated within a "pod" boundary.
### Components/Axes
- **Pod**: Outer boundary enclosing all components.
- **Train Engine**: Contains two green blocks labeled "train," connected to the checkpoint engine.
- **Checkpoint Engine**: Contains two blue blocks labeled "ckpt," acting as intermediaries between train and inference engines.
- **Inference Engine**: Contains two orange blocks labeled "inference," receiving input from the checkpoint engine.
- **Broadcast**: A bidirectional arrow connecting the checkpoint engine to the inference engine, indicating data sharing.
- **Legend**: Located at the bottom-right corner, mapping colors to labels:
- Green: "train"
- Blue: "ckpt"
- Orange: "inference"
### Detailed Analysis
1. **Train Engine**:
- Two parallel "train" blocks (green) process data and send outputs to the checkpoint engine.
- No explicit input source is shown; assumed to receive raw data externally.
2. **Checkpoint Engine**:
- Two "ckpt" blocks (blue) receive data from the train engine.
- Outputs are split:
- One path connects to the inference engine.
- Another path loops back to the train engine (dashed line), suggesting iterative training or feedback.
3. **Inference Engine**:
- Two "inference" blocks (orange) receive data from the checkpoint engine.
- No explicit output is shown; assumed to produce results externally.
4. **Broadcast Mechanism**:
- A bidirectional arrow links the checkpoint engine to the inference engine, enabling shared access to checkpoint data.
### Key Observations
- **Parallelism**: Each engine contains two identical blocks, implying parallel processing or redundancy.
- **Feedback Loop**: The dashed line from "ckpt" to "train" suggests iterative refinement of training data.
- **Shared Checkpoints**: The broadcast arrow indicates checkpoint data is reused across inference tasks.
### Interpretation
This architecture optimizes resource efficiency by:
1. **Decoupling Training and Inference**: Separating compute-heavy training (train engine) from real-time inference (inference engine).
2. **Leveraging Checkpoints**: The checkpoint engine acts as a mediator, storing intermediate states (ckpt) for reuse, reducing redundant computations.
3. **Scalability**: Parallel blocks in each engine allow horizontal scaling (e.g., distributed training/inference).
4. **Iterative Improvement**: The feedback loop from checkpoints to training enables model refinement using inference-derived insights.
The system prioritizes modularity and reusability, common in machine learning pipelines where training and inference are resource-intensive and require coordination.
</details>
Figure 10: Parameter update utilizing a checkpoint engine
Given the scale of K2 and the vast number of devices involved, using a network file system for resharding and broadcasting parameters is impractical. The aggregate bandwidth required to keep overhead low reaches several petabytes per second. To address this challenge, we developed a distributed checkpoint engine co-located on training nodes to manage parameter states. To perform a parameter update, each checkpoint engine worker obtains a local copy of parameters from the training engine, then broadcasts the full parameter set across all checkpoint engine workers. Subsequently, the inference engine retrieves only the parameter shard it requires from the checkpoint engine. This process is illustrated in Figure 10. To enable this for a 1T model, updates are performed parameter-by-parameter in a pipelined manner, minimizing memory footprint (see Appendix G).
We opt to broadcast the full parameter set across the entire cluster, regardless of the specific sharding schemes on each inference worker. While this transfers several times more data than a theoretically optimal approach, it offers a simpler system design that is less intrusive to the training and inference engines. We chose to trade off this minor overhead to fully decouple the training engine and the inference engine, significantly simplifying maintenance and testing.
Notably, this approach outperforms the transfer-what-you-need method due to reduced synchronization overhead and higher network bandwidth utilization. Our system can complete a full parameter update for Kimi K2 with less than 30 seconds, a negligible duration for a typical RL training iteration. The source code for the checkpoint engine is available on Github https://github.com/MoonshotAI/checkpoint-engine.
#### 3.3.3 Efficient System Startup
As large-scale training is prone to system failure, optimizing the startup time is crucial for models as large as Kimi K2.
To start the training engine, we let each training worker selectively read part or none of the parameters from disk, and broadcast necessary parameters to its peers. The design goal is to ensure all workers collectively read the checkpoint only once, minimizing expensive disk IO.
As the inference engines are independent replicas, we would like to avoid introducing extra synchronization barriers between them. Therefore, we opt to reuse checkpoint engine for startup: we let checkpoint engine collectively read the checkpoint from disk, similar to how the training engine starts. Then it updates the state of the uninitialized inference engine, using the approach introduced in the previous section. By leveraging the dedicated checkpoint engine, the system also becomes robust to single-point failures, because an inference replica can restart without communicating with other replicas.
#### 3.3.4 Agentic Rollout
Our RL infrastructure supports the training of long-horizon, multi-turn agentic tasks. During rollout, these tasks present distinct challenges, such as complex environmental interactions and prolonged rollout durations. Here we introduce a few optimizations to alleviate these issues.
Due to the diversity of environments, certain interactions may be blocked on waiting for environment feedback (e.g., a virtual machine or a code interpreter), leaving the GPUs idle. We employ two strategies to maximize GPU utilization: (i) we deploy heavy environments as dedicated services that can scale up more easily; (ii) we employ a large number of concurrent rollouts to amortize the latency induced by certain expensive interactions.
Another challenge in agentic rollout is that individual rollout trajectories can be extremely long. To prevent long-tail trajectories from blocking the entire rollout process, we employ the partial rollout [36] technique. This strategy allows long-tail unfinished tasks to be paused, and resumed in the next RL iteration.
To improve research efficiency, we also design a unified interface inspired by the OpenAI Gym framework [5] to streamline the integration of new environments. We hope to scale our RL infrastructure to more diverse interactive environments in the future.
## 4 Evaluations
This section begins with the post-training evaluation of Kimi-K2-Instruct, followed by a brief overview of the capabilities of Kimi-K2-Base. We conclude with a comprehensive safety evaluation.
### 4.1 Post-training Evaluations
#### 4.1.1 Evaluation Settings
Benchmarks
We assess Kimi-K2-Instruct across different areas. For coding, we adopt LiveCodeBench v6 [32] (questions from August 2024 to May 2025), OJBench [78], MultiPL-E [6], SWE-bench Verified [33, 85], TerminalBench [72], Multi-SWE-bench [87], SWE-Lancer [51], PaperBench [66], and Aider-Polyglot [17]. For tool use tasks, we evaluate performance on $\tau^{2}$ -Bench [3] and AceBench [7], which emphasize multi-turn tool-calling capabilities. In reasoning, we include a wide range of mathematical, science and logical tasks: AIME 2024/2025, MATH-500, HMMT 2025, CNMO 2024, PolyMath-en, ZebraLogic [44], AutoLogi [92], GPQA-Diamond [62], SuperGPQA [14], and Humanity’s Last Exam (Text-Only) [57]. We benchmark the long-context capabilities on: MRCR https://huggingface.co/datasets/openai/mrcr for long-context retrieval, and DROP [15], FRAMES [38] and LongBench v2 [2] for long-context reasoning. For factuality, we evaluate FACTS Grounding [31], the Vectara Hallucination Leaderboard [74], and FaithJudge [69]. Finally, general capabilities are assessed using MMLU [24], MMLU-Redux [18], MMLU-Pro [77], IFEval [91], Multi-Challenge [65], SimpleQA [79], and LiveBench [81] (as of 2024-11-25).
Baselines
We benchmark against both open-source and proprietary frontier models, ensuring every candidate is evaluated under its non-thinking configuration to eliminate additional gains from test-time compute. Open-source baselines: DeepSeek-V3-0324 and Qwen3-235B-A22B, with the latter run in the vendor-recommended no-thinking regime. Proprietary baselines: Claude Sonnet 4, Claude Opus 4, GPT-4.1, and Gemini 2.5 Flash Preview (2025-05-20). Each invoked in its respective non-thinking mode via official APIs under unified temperature and top-p settings.
Evaluation Configurations All runs query models in their non-thinking mode. Output token length is capped at 8192 tokens everywhere except SWE-bench Verified (Agentless), which is raised to 16384. For benchmarks with high per-question variance, we adopt repeated sampling $k$ times and average the results to obtain stable scores, denoted as Avg@k. For long-context tasks, we set the context window size to 128K tokens during evaluation, truncating any input that exceeds this limit to fit within the window. SWE-bench Verified is evaluated in two modes: Agentless Coding via Single Patch without Test (Acc) and Agentic Coding via bash/editor tools under both Single Attempt (Acc) and Multiple Attempts (Acc) using best-of-N selection with an internal verifier; SWE-bench Multilingual is tested only in the single-attempt agentic setting. Some data points have been omitted due to prohibitively expensive evaluation costs.
Table 3: Performance comparison of Kimi-K2-Instruct against leading open-source and proprietary models across diverse tasks. Bold denotes the global SOTA; underlined bold indicates the best open-source result. Data points marked with * are taken directly from the model’s technical report or blog.
| | Open Source | Proprietary | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Benchmark | Kimi-K2-Instruct | DeepSeek-V3-0324 | Qwen3-235B-A22B | Claude Sonnet 4 | Claude Opus 4 | GPT-4.1 | Gemini 2.5 Flash |
| Coding Tasks | | | | | | | |
| LiveCodeBench v6 (Pass@1) | 53.7 | 46.9 | 37.0 | 48.5 | 47.4 | 44.7 | 44.7 |
| OJBench (Pass@1) | 27.1 | 24.0 | 11.3 | 15.3 | 19.6 | 19.5 | 19.5 |
| MultiPL-E (Pass@1) | 85.7 | 83.1 | 78.2 | 88.6 | 89.6 | 86.7 | 85.6 |
| SWE-bench Verified Agentless-Single-Patch (Pass@1) | 51.8 | 36.6 | 39.4 | 50.2 | 53.0 | 40.8 | 32.6 |
| SWE-bench Verified Agentic-Single-Attempt (Pass@1) | 65.8 | 38.8 | 34.4 | 72.7* | 72.5* | 54.6 | — |
| SWE-bench Verified Agentic-Multi-Attempt (Pass@1) | 71.6 | — | — | 80.2* | 79.4* | — | — |
| SWE-bench Multilingual (Pass@1) | 47.3 | 25.8 | 20.9 | 51.0 | — | 31.5 | — |
| Multi-SWE-bench (Pass@1) | 18.3 | 8.0 | 9.0 | 29.2 | — | 11.7 | 14.0 |
| SWE-Lancer (Pass@1) | 39.1 | 30.5 | 24.1 | 40.8 | — | 23.0 | 38.5 |
| Paper Bench Code-Dev (Acc.) | 27.8 | 12.2 | 13.2 | 43.3 | — | 29.9 | 5.7 |
| Terminal Bench In-House (Acc.) | 30.0 | — | — | 35.5 | 43.2 | 8.3 | — |
| Terminal Bench Terminus (Acc.) | 25.0 | 16.3 | 6.6 | — | — | 30.3 | 16.8 |
| Aider-Polyglot (Acc.) | 60.0 | 55.1 | 61.8 | 56.4 | 70.7 | 52.4 | 44.0 |
| Tool Use Tasks | | | | | | | |
| Tau2 retail (Avg@4) | 70.6 | 69.1 | 57.0 | 75.0 | 81.8 | 74.8 | 64.3 |
| Tau2 airline (Avg@4) | 56.5 | 39.0 | 26.5 | 55.5 | 60.0 | 54.5 | 42.5 |
| Tau2 telecom (Avg@4) | 65.8 | 32.5 | 22.1 | 45.2 | 57.0 | 38.6 | 16.9 |
| AceBench (Acc.) | 76.5 | 72.7 | 70.5 | 76.2 | 75.6 | 80.1 | 74.5 |
| Math & STEM Tasks | | | | | | | |
| AIME 2024 (Avg@64) | 69.6 | 59.4* | 40.1* | 43.4 | 48.2 | 46.5 | 61.3 |
| AIME 2025 (Avg@64) | 49.5 | 46.7 | 24.7* | 33.1* | 33.9* | 37.0 | 46.6 |
| MATH-500 (Acc.) | 97.4 | 94.0* | 91.2* | 94.0 | 94.4 | 92.4 | 95.4 |
| HMMT 2025 (Avg@32) | 38.8 | 27.5 | 11.9 | 15.9 | 15.9 | 19.4 | 34.7 |
| CNMO 2024 (Avg@16) | 74.3 | 74.7 | 48.6 | 60.4 | 57.6 | 56.6 | 75.0 |
| PolyMath-en (Avg@4) | 65.1 | 59.5 | 51.9 | 52.8 | 49.8 | 54.0 | 49.9 |
| ZebraLogic (Acc.) | 89.0 | 84.0 | 37.7* | 79.7 | 59.3 | 58.5 | 57.9 |
| AutoLogi (Acc.) | 89.5 | 88.9 | 83.3* | 89.8 | 86.1 | 88.2 | 84.1 |
| GPQA-Diamond (Avg@8) | 75.1 | 68.4* | 62.9* | 70.0* | 74.9* | 66.3 | 68.2 |
| SuperGPQA (Acc.) | 57.2 | 53.7 | 50.2 | 55.7 | 56.5 | 50.8 | 49.6 |
| Humanity’s Last Exam (Acc.) | 4.7 | 5.2 | 5.7 | 5.8 | 7.1 | 3.7 | 5.6 |
| General Tasks | | | | | | | |
| MMLU (EM) | 89.5 | 89.4 | 87.0 | 91.5 | 92.9 | 90.4 | 90.1 |
| MMLU-Redux (EM) | 92.7 | 90.5 | 89.2* | 93.6 | 94.2 | 92.4 | 90.6 |
| MMLU-Pro (EM) | 81.1 | 81.2* | 77.3 | 83.7 | 86.6 | 81.8 | 79.4 |
| IFEval (Prompt Strict) | 89.8 | 81.1 | 83.2* | 87.6 | 87.4 | 88.0 | 84.3 |
| Multi-Challenge (Acc.) | 54.1 | 31.4 | 34.0 | 46.8 | 49.0 | 36.4 | 39.5 |
| SimpleQA (Correct) | 31.0 | 27.7 | 13.2 | 15.9 | 22.8 | 42.3 | 23.3 |
| Livebench (Pass@1) | 76.4 | 72.4 | 67.6 | 74.8 | 74.6 | 69.8 | 67.8 |
| Arena Hard v2.0 Hard Prompt (Win rate) | 54.5 | 39.9 | 39.9 | 51.6 | 59.7 | 51.7 | 48.7 |
| Arena Hard v2.0 Creative Writing (Win rate) | 85.0 | 59.3 | 59.8 | 54.6 | 68.5 | 61.5 | 72.8 |
| FACTS Grounding (Adjusted) | 88.5 | 68.3 | 68.5 | 83.6 | — | 79.2 | 86.6 |
| HHEM v2.1 (1-Hallu.) | 98.9 | 88.9 | 94.5 | 94.5 | — | 96.7 | 97.8 |
| FaithJudge (1-Hallu.) | 92.6 | 83.4 | 75.7 | 83.0 | — | 91.0 | 93.2 |
| LongBench v2 (Acc.) | 49.1 | 51.1 | — | 52.5 | — | 54.3 | 55.5 |
| FRAMES (Acc.) | 77.1 | 79.2 | — | 76.3 | — | 87.4 | 72.9 |
| MRCR (Acc.) | 55.0 | 50.8 | — | 74.4 | — | 66.9 | 81.7 |
| DROP (Acc.) | 93.5 | 91.2 | 84.3 | 92.0 | — | 79.1 | 81.7 |
#### 4.1.2 Evaluation Results
A comprehensive evaluation results of Kimi-K2-Instruct is shown in Table 3, with detailed explanation provided in the Appendix C. Below, we highlight key results across four core domains:
Agentic and Competitive Coding
Kimi-K2-Instruct demonstrates state-of-the-art open-source performance on real-world SWE tasks. It outperforms most baselines on SWE-bench Verified (65.8%, 71.6% with multiple attemps), SWE-bench Multilingual (47.3%), and SWE-lancer (39.1%), significantly closing the gap with Claude 4 Opus and Sonnet. On competitive coding benchmarks (e.g., LiveCodeBench v6 53.7%, OJBench 27.1%), it also leads among all models, highlighting its practical coding proficiency across difficulty levels.
Agentic Tool Use
On multi-turn tool-use benchmarks, Kimi-K2-Instruct sets a new standard. It achieves 66.1 Pass@1 on $\tau^{2}$ -Bench and 76.5 on ACEBench, substantially outperforming all baselines. These results affirm its strength in grounded, controlled, and agent-driven tool orchestration across domains.
General Capabilities
Kimi-K2-Instruct exhibits strong, balanced performance across general knowledge, math, instruction following, and long-context tasks. It surpasses open-source peers on SimpleQA (31.0%), MMLU (89.5%) and MMLU-Redux (92.7%), and leads all models on instruction benchmarks (IFEval: 89.8%, Multi-Challenge: 54.1%). In math and STEM, it achieves top-tier scores (AIME 2024: 69.6%, GPQA-Diamond: 75.1%), and remains competitive on long-context factuality and retrieval (DROP: 93.5%, MRCR: 55.0%). These results position Kimi-K2-Instruct as a well-rounded and capable generalist across both short- and long-context settings.
Open-Ended Evaluation
On the LMSYS Arena leaderboard (July 17, 2025), Kimi-K2-Instruct ranks as the top-1 open-source model and 5th overall based on over 3,000 user votes. This real-world preference signal—across diverse, blind prompts—underscores Kimi-K2’s strengths in generating high-quality responses on open-ended tasks.
### 4.2 Pre-training Evaluations
#### 4.2.1 Evaluation Settings
Benchmarks
We evaluate Kimi-K2-Base across diverse capability areas. For general capabilities, we assess on MMLU [24], MMLU-Pro [77], MMLU-Redux [18], BBH [68], TriviaQA [35], SuperGPQA [14], SimpleQA [79], HellaSwag [89], AGIEval [90], GPQA-Diamond [62], ARC-Challenge [9], and WinoGrande [63]. For coding capabilities, we employ EvalPlus [46] (averaging HumanEval [8], MBPP [1], HumanEval+, and MBPP+), LiveCodeBench v6 [32], and CRUXEval [19]. For mathematical reasoning, we utilize GSM8K [10], GSM8K-Platinum [75], MATH [25], and CMATH [80]. For Chinese language capabilities, we evaluate on C-Eval [30], CMMLU [41], and CSimpleQA [23].
Baselines
We benchmark against leading open-source foundation models: DeepSeek-V3-Base [11], Qwen2.5-72B-Base [60] (Note that Qwen3-235B-A22B-Base is not open-sourced, and the largest open-sourced base model in the Qwen series is Qwen2.5-72B-Base), and Llama 4-Maverick [71] (Llama 4-Behemoth is also not open-sourced). All models are evaluated under identical configurations to ensure fair comparison.
Evaluation Configurations
We employ perplexity-based evaluation for MMLU, MMLU-Redux, GPQA-Diamond, HellaSwag, ARC-Challenge, C-Eval, and CMMLU. Generation-based evaluation is used for MMLU-Pro, SuperGPQA, TriviaQA, BBH, CSimpleQA, MATH, CMATH, GSM8K, GSM8K-Platinum, CRUXEval, LiveCodeBench, and EvalPlus. To mitigate the high variance inherent to GPQA-Diamond, we report the mean score across eight independent runs. All evaluations are conducted using our internal framework derived from LM-Harness-Evaluation [4], ensuring consistent settings across all models.
#### 4.2.2 Evaluation Results
Table 4 presents a comprehensive comparison of Kimi-K2-Base against leading open-source foundation models across diverse evaluation benchmarks. The results demonstrate that Kimi-K2-Base achieves state-of-the-art performance across the majority of evaluated tasks, establishing it as a leading foundation model in the open-source landscape.
General Language Understanding
Kimi-K2-Base achieves state-of-the-art performance on 10 out of 12 English language benchmarks. Notable results include MMLU (87.79%), MMLU-Pro (69.17%), MMLU-Redux (90.17%), SuperGPQA (44.67%), and SimpleQA (35.25%), significantly outperforming all baselines.
Coding Capabilities
On coding benchmarks, Kimi-K2-Base sets new standards with leading performance across all metrics. It achieves 74.00% on CRUXEval-I-cot, 83.50% on CRUXEval-O-cot, 26.29% on LiveCodeBench v6, and 80.33% on EvalPlus, demonstrating superior code generation and comprehension abilities, particularly in scenarios requiring step-by-step reasoning.
Mathematical Reasoning
Kimi-K2-Base exhibits exceptional mathematical capabilities, leading on three out of four benchmarks: MATH (70.22%), GSM8K (92.12%), and GSM8K-Platinum (94.21%). It maintains competitive performance on CMATH (90.26%), narrowly behind DeepSeek-V3-Base (90.53%). These results highlight the model’s robust mathematical problem-solving abilities across varying difficulty levels.
Chinese Language Understanding
The model demonstrates superior multilingual capabilities, achieving state-of-the-art results across all Chinese language benchmarks: C-Eval (92.50%), CMMLU (90.90%), and CSimpleQA (77.57%). These results establish Kimi-K2-Base as a leading model for Chinese language understanding while maintaining strong performance across other languages.
Table 4: Performance comparison of Kimi-K2-Base against leading open-source models across diverse tasks.
| | Benchmark (Metric) | #Shots | Kimi-K2-Base | DeepSeek-V3-Base | Llama4-Maverick-Base | Qwen2.5-72B-Base |
| --- | --- | --- | --- | --- | --- | --- |
| Architecture | - | MoE | MoE | MoE | Dense | |
| # Activated Params | - | 32B | 37B | 17B | 72B | |
| # Total Params | - | 1043B | 671B | 400B | 72B | |
| English | MMLU | 5-shots | 87.79 | 87.10 | 84.87 | 86.08 |
| MMLU-pro | 5-shots | 69.17 | 60.59 | 63.47 | 62.80 | |
| MMLU-redux | 5-shots | 90.17 | 89.53 | 88.18 | 87.77 | |
| SuperGPQA | 5-shots | 44.67 | 39.20 | 38.84 | 34.23 | |
| GPQA-Diamond(avg@8) | 5-shots | 48.11 | 50.51 | 49.43 | 40.78 | |
| SimpleQA | 5-shots | 35.25 | 26.49 | 23.74 | 10.31 | |
| TriviaQA | 5-shots | 85.09 | 84.11 | 79.25 | 76.03 | |
| BBH | 3-shots | 88.71 | 88.37 | 87.10 | 84.09 | |
| HellaSwag | 5-shots | 94.60 | 89.44 | 86.02 | 95.27 | |
| AGIEval | - | 84.23 | 81.57 | 67.55 | 76.87 | |
| ARC-Challenge | 0-shot | 95.73 | 93.77 | 94.03 | 95.56 | |
| WinoGrande | 5-shots | 85.32 | 84.21 | 77.58 | 84.14 | |
| Code | CRUXEval-I-cot | 0-shots | 74.00 | 62.75 | 67.13 | 61.12 |
| CRUXEval-O-cot | 0-shots | 83.50 | 75.25 | 75.88 | 66.13 | |
| LiveCodeBench(v6) | 1-shots | 26.29 | 24.57 | 25.14 | 22.29 | |
| EvalPlus | - | 80.33 | 65.61 | 65.48 | 66.04 | |
| Math | MATH | 4-shots | 70.22 | 61.70 | 63.02 | 62.68 |
| GSM8k | 8-shots | 92.12 | 91.66 | 86.35 | 90.37 | |
| GSM8k-platinum | 8-shots | 94.21 | 93.38 | 88.83 | 92.47 | |
| CMATH | 6-shots | 90.26 | 90.53 | 88.07 | 86.98 | |
| Chinese | C-Eval | 5-shots | 92.50 | 90.04 | 80.91 | 90.86 |
| CMMLU | 5-shots | 90.90 | 88.84 | 81.24 | 90.55 | |
| CSimpleQA | 5-shots | 77.57 | 72.13 | 53.47 | 50.53 | |
### 4.3 Safety Evaluation
#### 4.3.1 Experiment Settings
We conducted red-teaming evaluations on Kimi K2 compare with other open-source LLMs. The evaluation covered a range of attack scenarios—including harmful content, privacy content, and security content, as well as different attack strategies such as prompt injection and iterative jailbreak.
We choose Promptfoo https://github.com/promptfoo/promptfoo to generate adversarial prompts and analyze the responses. By this way, we can evaluate model in a scalable ways.
Model Selection We compare Kimi K2 with three other open-source LLMs: DeepSeek-V3, DeepSeek-R1, and Qwen3.
Promptfoo Settings Table 5 lists plugins and strategies evaluated, with each plugin paired with all strategies to assess their performance.
Table 5: Enabled Plugins and Strategies
| Plugin | Harmful | Graphic Content, Harassment and Bullying, Hate Speech, Insults, Profanity, Radicalization, Self Harm, Sexual Content, ToxicChat |
| --- | --- | --- |
| Criminal | Chemical&Biological Weapons, Child Exploitation, Copyright Violations, Cybercrime, Illegal Activities, Illegal Drugs, Indiscriminate Weapons, Intellectual Property Violation, Non-Violent Crime, Violent Crime, Sex Crimes | |
| Misinformation | Competitor Endorsement, Unsupervised Contracts, Excessive Agency, Hallucination, Misinformation and Disinformation, Specialized Advice, Unsafe Practices, Imitation, Overreliance, Political Opinions, Religious Sensitivity | |
| Privacy | Privacy Violation, PII in API/Database, Direct PII Exposure, PII in Session Data, PII via Social Engineering | |
| Security | ASCII Smuggling, CyberSecEval, Harmbench, Debug Access, Divergent Repetition, DoNotAnswer, Malicious Code, Pliny, Prompt Extraction, Reasoning DoS, Tool Discovery | |
| Strategy | Basic, Prompt Injection, Iterative Jailbreak, Crescendo | |
Test Case Count Given the inherent non-determinism of large language model inference, single-pass outputs may exhibit variability. To account for this, we generated 3 attack prompts per plugin for each strategy.
Prompt Language Settings We pre-tested the language compatibility for each plugin-strategy combination. Some plugins support both English and Chinese, while others only support English. For combinations that support both, we generated 3 prompts in each language, resulting in 6 prompts per combination.
Manual Review We incorporated human review into the evaluation process. To minimize subjectivity problem, we conducted multiple rounds of review and assigned the same reviewer to evaluate all cases within a given test set to ensure consistency and reduce variability in judgment.
#### 4.3.2 Safety Evaluation Results
Table 6 presents the passing rates of different models under various plugin–strategy combinations.
Table 6: Safety Evaluation Results
| Plugin | Strategy | Kimi-K2-Instruct | DeepSeek-V3-0324 | DeepSeek-R1 | Qwen3-235B-A22B |
| --- | --- | --- | --- | --- | --- |
| Harmful | Basic | 98.04 | 90.45 | 99.02 | 98.53 |
| Base64 | 100 | 90.20 | 100 | 100 | |
| Prompt Injection | 93.14 | 100 | 95.10 | 99.02 | |
| Iterative Jailbreak | 92.16 | 66.67 | 72.55 | 74.51 | |
| Crescendo | 64.71 | 64.71 | 80.39 | 86.27 | |
| Criminal | Basic | 100 | 99.62 | 95.45 | 99.24 |
| Base64 | 96.97 | 89.39 | 84.85 | 98.48 | |
| Prompt Injection | 75.76 | 91.67 | 69.70 | 98.47 | |
| Iterative Jailbreak | 57.57 | 21.21 | 25.76 | 53.03 | |
| Crescendo | 56.06 | 31.81 | 42.42 | 59.09 | |
| Misinformation | Basic | 97.28 | 92.57 | 92.46 | 94.84 |
| Base64 | 98.48 | 90.48 | 96.83 | 93.65 | |
| Prompt Injection | 98.39 | 86.51 | 93.65 | 93.65 | |
| Iterative Jailbreak | 63.97 | 53.97 | 84.13 | 69.84 | |
| Crescendo | 85.71 | 55.56 | 88.89 | 84.13 | |
| Privacy | Basic | 100 | 100 | 100 | 100 |
| Base64 | 100 | 100 | 100 | 100 | |
| Prompt Injection | 88.33 | 98.33 | 100 | 91.67 | |
| Iterative Jailbreak | 76.67 | 100 | 93.33 | 96.67 | |
| Crescendo | 96.67 | 100 | 96.67 | 100 | |
| Security | Basic | 77.84 | 75.57 | 70.46 | 90.09 |
| Base64 | 82.93 | 82.93 | 63.41 | 95.12 | |
| Prompt Injection | 87.80 | 97.56 | 65.85 | 84.13 | |
| Iterative Jailbreak | 43.90 | 60.97 | 43.90 | 78.04 | |
| Crescendo | 68.29 | 87.80 | 68.29 | 87.80 | |
Without targeted optimization for specific evaluation scenarios, the passing rate of some complex cases (e.g., Harmful–Iterative Jailbreak) was relatively higher compared to other models.
Across different attack strategies, the models exhibited varying trends. Under the Base64 strategy, passing rates generally approached or reached 100%, suggesting that encoding transformations had minimal impact on the models’ basic robustness. In contrast, the Crescendo strategy led to a general drop in passing rates, indicating stronger adversarial effectiveness.
In addition, complex attack strategies do not always outperform basic prompts. Some originally adversarial prompts may lose their intended meaning after multiple rounds of transformation, rendering the resulting model outputs less meaningful.
Automated Red-teaming Limitations Due to the involvement of human review, the evaluation results inevitably contain a degree of subjectivity. Additionally, certain plugin types involve API misuse or external tool invocation, which are more suitable for evaluating agent models with tool-calling capabilities. In the context of base LLMs, such tests may have limited relevance.
## 5 Limitations
In our internal tests, we have identified some limitations in current Kimi K2 models. When dealing with hard reasoning tasks or unclear tool definition, the model may generate excessive tokens, sometimes leading to truncated outputs or incomplete tool calls. Additionally, performance may decline on certain tasks if tool use is unnecessarily enabled. When building complete software projects, the success rate of one-shot prompting is not as good as using K2 under an agentic coding framework. We are working to address these issues in future releases and looking forward to more feedbacks.
## 6 Conclusions
We introduced Kimi K2, a 1T-parameter open-weight MoE model built for agentic intelligence. Leveraging the token-efficient MuonClip optimizer and a 15.5T-token high-quality dataset, Kimi K2 achieves stable, scalable pre-training. Post-training combines large-scale synthetic tool-use data with a unified RL framework using both verifiable rewards and self-critic feedbacks. Kimi K2 sets new state-of-the-art on agentic and reasoning benchmarks, establishing itself as the most capable open-weight LLM to date.
## 7 Acknowledgments
We would like to acknowledge the valuable support provided by the OpenHands and Multi-SWE-bench teams in evaluating the SWE-bench Verified and Multi-SWE-bench experimental results.
## References
- [1] J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, and C. Sutton (2021) Program synthesis with large language models. External Links: 2108.07732, Link Cited by: §4.2.1.
- [2] Y. Bai, S. Tu, J. Zhang, H. Peng, X. Wang, X. Lv, S. Cao, J. Xu, L. Hou, Y. Dong, J. Tang, and J. Li (2025) LongBench v2: towards deeper understanding and reasoning on realistic long-context multitasks. External Links: 2412.15204, Link Cited by: §4.1.1.
- [3] V. Barres, H. Dong, S. Ray, X. Si, and K. Narasimhan (2025) $\tau^{2}$ -Bench: evaluating conversational agents in a dual-control environment. External Links: 2506.07982, Link Cited by: §4.1.1.
- [4] S. Biderman, H. Schoelkopf, L. Sutawika, L. Gao, J. Tow, B. Abbasi, A. F. Aji, P. S. Ammanamanchi, S. Black, J. Clive, et al. (2024) Lessons from the trenches on reproducible evaluation of language models. arXiv preprint arXiv:2405.14782. Cited by: §4.2.1.
- [5] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba (2016) OpenAI gym. External Links: 1606.01540, Link Cited by: §3.3.4.
- [6] F. Cassano, J. Gouwar, D. Nguyen, S. Nguyen, L. Phipps-Costin, D. Pinckney, M. Yee, Y. Zi, C. J. Anderson, M. Q. Feldman, A. Guha, M. Greenberg, and A. Jangda (2023) MultiPL-e: a scalable and polyglot approach to benchmarking neural code generation. IEEE Transactions on Software Engineering 49 (7), pp. 3675–3691. External Links: Document Cited by: §4.1.1.
- [7] C. Chen, X. Hao, W. Liu, X. Huang, X. Zeng, S. Yu, D. Li, S. Wang, W. Gan, Y. Huang, et al. (2025) ACEBench: who wins the match point in tool learning?. arXiv e-prints, pp. arXiv–2501. Cited by: §3.1.1, §3.1.1, §4.1.1.
- [8] M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Herbert-Voss, W. H. Guss, A. Nichol, A. Paino, N. Tezak, J. Tang, I. Babuschkin, S. Balaji, S. Jain, W. Saunders, C. Hesse, A. N. Carr, J. Leike, J. Achiam, V. Misra, E. Morikawa, A. Radford, M. Knight, M. Brundage, M. Murati, K. Mayer, P. Welinder, B. McGrew, D. Amodei, S. McCandlish, I. Sutskever, and W. Zaremba (2021) Evaluating large language models trained on code. External Links: 2107.03374 Cited by: §4.2.1.
- [9] P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord (2018) Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457. Cited by: §4.2.1.
- [10] K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman (2021) Training verifiers to solve math word problems. External Links: 2110.14168, Link Cited by: §4.2.1.
- [11] DeepSeek-AI (2024) DeepSeek-v3 technical report. External Links: 2412.19437, Link Cited by: §2.3, §2.3, §2.4.2, §2.4.3, §2, §4.2.1.
- [12] M. Dehghani, J. Djolonga, B. Mustafa, P. Padlewski, J. Heek, J. Gilmer, A. P. Steiner, M. Caron, R. Geirhos, I. Alabdulmohsin, et al. (2023) Scaling vision transformers to 22 billion parameters. In International conference on machine learning, pp. 7480–7512. Cited by: §2.1.
- [13] G. Dong, K. Lu, C. Li, T. Xia, B. Yu, C. Zhou, and J. Zhou (2024) Self-play with execution feedback: improving instruction-following capabilities of large language models. External Links: 2406.13542, Link Cited by: §3.2.1.
- [14] X. Du, Y. Yao, K. Ma, B. Wang, T. Zheng, K. Zhu, M. Liu, Y. Liang, X. Jin, Z. Wei, et al. (2025) Supergpqa: scaling llm evaluation across 285 graduate disciplines. arXiv preprint arXiv:2502.14739. Cited by: §4.1.1, §4.2.1.
- [15] D. Dua, Y. Wang, P. Dasigi, G. Stanovsky, S. Singh, and M. Gardner (2019) DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. CoRR abs/1903.00161. External Links: Link, 1903.00161 Cited by: §4.1.1.
- [16] K. Fujii, Y. Tajima, S. Mizuki, H. Shimada, T. Shiotani, K. Saito, M. Ohi, M. Kawamura, T. Nakamura, T. Okamoto, S. Ishida, K. Hattori, Y. Ma, H. Takamura, R. Yokota, and N. Okazaki (2025) Rewriting pre-training data boosts llm performance in math and code. External Links: 2505.02881, Link Cited by: §2.2.
- [17] P. Gauthier (2025) Aider llm leaderboards. blog. Note: https://aider.chat/docs/leaderboards/ Cited by: §4.1.1.
- [18] A. P. Gema, J. O. J. Leang, G. Hong, A. Devoto, A. C. M. Mancino, R. Saxena, X. He, Y. Zhao, X. Du, M. R. G. Madani, et al. (2024) Are we done with mmlu?. arXiv preprint arXiv:2406.04127. Cited by: §4.1.1, §4.2.1.
- [19] A. Gu, B. Rozière, H. Leather, A. Solar-Lezama, G. Synnaeve, and S. I. Wang (2024) Cruxeval: a benchmark for code reasoning, understanding and execution. arXiv preprint arXiv:2401.03065. Cited by: §4.2.1.
- [20] D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. (2025) Deepseek-r1: incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948. Cited by: §3.2.3.
- [21] Z. Guo, S. Cheng, H. Wang, S. Liang, Y. Qin, P. Li, Z. Liu, M. Sun, and Y. Liu (2025) StableToolBench: towards stable large-scale benchmarking on tool learning of large language models. arXiv preprint arXiv:2403.07714. Cited by: §3.1.1.
- [22] A. Harlap, D. Narayanan, A. Phanishayee, V. Seshadri, N. Devanur, G. Ganger, and P. Gibbons (2018) Pipedream: fast and efficient pipeline parallel dnn training. arXiv preprint arXiv:1806.03377. Cited by: §2.4.2, §2.4.2.
- [23] Y. He, S. Li, J. Liu, Y. Tan, W. Wang, H. Huang, X. Bu, H. Guo, C. Hu, B. Zheng, et al. Chinese simpleqa: a chinese factuality evaluation for large language models, 2024a. URL https://arxiv. org/abs/2411.07140. Cited by: §4.2.1.
- [24] D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt (2020) Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300. Cited by: §4.1.1, §4.2.1.
- [25] D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt (2021) Measuring mathematical problem solving with the math dataset. External Links: 2103.03874, Link Cited by: §4.2.1.
- [26] S. Hu, Y. Tu, X. Han, C. He, G. Cui, X. Long, Z. Zheng, Y. Fang, Y. Huang, W. Zhao, et al. (2024) Minicpm: unveiling the potential of small language models with scalable training strategies. arXiv preprint arXiv:2404.06395. Cited by: §2.5.
- [27] J. Huang, S. S. Gu, L. Hou, Y. Wu, X. Wang, H. Yu, and J. Han (2022) Large language models can self-improve. arXiv preprint arXiv:2210.11610. Cited by: §3.1.1.
- [28] S. Huang, T. Cheng, J. K. Liu, J. Hao, L. Song, Y. Xu, J. Yang, J. Liu, C. Zhang, L. Chai, R. Yuan, Z. Zhang, J. Fu, Q. Liu, G. Zhang, Z. Wang, Y. Qi, Y. Xu, and W. Chu (2025) OpenCoder: the open cookbook for top-tier code large language models. External Links: 2411.04905, Link Cited by: §3.2.1.
- [29] Y. Huang, Y. Cheng, A. Bapna, O. Firat, D. Chen, M. Chen, H. Lee, J. Ngiam, Q. V. Le, Y. Wu, et al. (2019) Gpipe: efficient training of giant neural networks using pipeline parallelism. Advances in neural information processing systems 32. Cited by: §2.4.2.
- [30] Y. Huang, Y. Bai, Z. Zhu, J. Zhang, J. Zhang, T. Su, J. Liu, C. Lv, Y. Zhang, J. Lei, Y. Fu, M. Sun, and J. He (2023) C-eval: a multi-level multi-discipline chinese evaluation suite for foundation models. External Links: 2305.08322, Link Cited by: §4.2.1.
- [31] A. Jacovi, A. Wang, C. Alberti, C. Tao, J. Lipovetz, K. Olszewska, L. Haas, M. Liu, N. Keating, A. Bloniarz, C. Saroufim, C. Fry, D. Marcus, D. Kukliansky, G. S. Tomar, J. Swirhun, J. Xing, L. Wang, M. Gurumurthy, M. Aaron, M. Ambar, R. Fellinger, R. Wang, Z. Zhang, S. Goldshtein, and D. Das (2025) The facts grounding leaderboard: benchmarking llms’ ability to ground responses to long-form input. External Links: 2501.03200, Link Cited by: §3.2.1, §4.1.1.
- [32] N. Jain, K. Han, A. Gu, W. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica (2024) Livecodebench: holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974. Cited by: §4.1.1, §4.2.1.
- [33] C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan (2024) SWE-bench: can language models resolve real-world github issues?. In The Twelfth International Conference on Learning Representations, External Links: Link Cited by: §4.1.1.
- [34] K. Jordan, Y. Jin, V. Boza, J. You, F. Cesista, L. Newhouse, and J. Bernstein (2024) Muon: an optimizer for hidden layers in neural networks. External Links: Link Cited by: §2.1, §2, §3.1, §3.2.3.
- [35] M. Joshi, E. Choi, D. S. Weld, and L. Zettlemoyer (2017) TriviaQA: a large scale distantly supervised challenge dataset for reading comprehension. External Links: 1705.03551, Link Cited by: §4.2.1.
- [36] Kimi Team (2025) Kimi k1. 5: scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599. Cited by: §2.2, §3.1, §3.2.3, §3.2.3, §3.2, §3.3.1, §3.3.4.
- [37] D. P. Kingma and J. Ba (2015) Adam: A method for stochastic optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, Y. Bengio and Y. LeCun (Eds.), External Links: Link Cited by: §2.1.
- [38] S. Krishna, K. Krishna, A. Mohananey, S. Schwarcz, A. Stambler, S. Upadhyay, and M. Faruqui (2025) Fact, fetch, and reason: a unified evaluation of retrieval-augmented generation. External Links: 2409.12941, Link Cited by: §4.1.1.
- [39] J. Lamy-Poirier (2023) Breadth-first pipeline parallelism. Proceedings of Machine Learning and Systems 5, pp. 48–67. Cited by: §2.4.2.
- [40] D. Lepikhin, H. Lee, Y. Xu, D. Chen, O. Firat, Y. Huang, M. Krikun, N. Shazeer, and Z. Chen (2020) Gshard: scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668. Cited by: §2.4.2.
- [41] H. Li, Y. Zhang, F. Koto, Y. Yang, H. Zhao, Y. Gong, N. Duan, and T. Baldwin (2024) CMMLU: measuring massive multitask language understanding in chinese. External Links: 2306.09212, Link Cited by: §4.2.1.
- [42] J. Li, E. Beeching, L. Tunstall, B. Lipkin, R. Soletskyi, S. Huang, K. Rasul, L. Yu, A. Q. Jiang, Z. Shen, et al. (2024) Numinamath: the largest public dataset in ai4maths with 860k pairs of competition math problems and solutions. Hugging Face repository 13 (9), pp. 9. Cited by: §3.2.1.
- [43] T. Li, W. Chiang, E. Frick, L. Dunlap, T. Wu, B. Zhu, J. E. Gonzalez, and I. Stoica (2024) From crowdsourced data to high-quality benchmarks: arena-hard and benchbuilder pipeline. arXiv preprint arXiv:2406.11939. Cited by: Appendix C.
- [44] B. Y. Lin, R. L. Bras, K. Richardson, A. Sabharwal, R. Poovendran, P. Clark, and Y. Choi (2025) ZebraLogic: on the scaling limits of llms for logical reasoning. External Links: 2502.01100, Link Cited by: §4.1.1.
- [45] A. Liu, B. Feng, B. Wang, B. Wang, B. Liu, C. Zhao, C. Dengr, C. Ruan, D. Dai, D. Guo, et al. (2024) Deepseek-v2: a strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434. Cited by: §2.3.
- [46] J. Liu, C. S. Xia, Y. Wang, and L. Zhang (2023) Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Advances in Neural Information Processing Systems 36, pp. 21558–21572. Cited by: §4.2.1.
- [47] J. Liu, J. Su, X. Yao, Z. Jiang, G. Lai, Y. Du, Y. Qin, W. Xu, E. Lu, J. Yan, et al. (2025) Muon is scalable for llm training. arXiv preprint arXiv:2502.16982. Cited by: §2.1, §2, §3.1.
- [48] Z. Liu, S. Cheng, H. Zhou, and Y. You (2023-11) Hanayo: harnessing wave-like pipeline parallelism for enhanced large model training efficiency. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’23, pp. 1–13. External Links: Link, Document Cited by: §2.4.2.
- [49] I. Loshchilov and F. Hutter (2019) Decoupled weight decay regularization. In International Conference on Learning Representations, External Links: Link Cited by: §2.1.
- [50] P. Maini, S. Seto, H. Bai, D. Grangier, Y. Zhang, and N. Jaitly (2024) Rephrasing the web: a recipe for compute and data-efficient language modeling. External Links: 2401.16380, Link Cited by: 1st item.
- [51] S. Miserendino, M. Wang, T. Patwardhan, and J. Heidecke (2025) SWE-lancer: can frontier llms earn $1 million from real-world freelance software engineering?. arXiv preprint arXiv:2502.12115. Cited by: §4.1.1.
- [52] A. Mitra, L. Del Corro, G. Zheng, S. Mahajan, D. Rouhana, A. Codas, Y. Lu, W. Chen, O. Vrousgos, C. Rosset, et al. (2024) Agentinstruct: toward generative teaching with agentic flows. arXiv preprint arXiv:2407.03502. Cited by: §3.1.1.
- [53] I. Moshkov, D. Hanley, I. Sorokin, S. Toshniwal, C. Henkel, B. Schifferer, W. Du, and I. Gitman (2025) Aimo-2 winning solution: building state-of-the-art mathematical reasoning models with openmathreasoning dataset. arXiv preprint arXiv:2504.16891. Cited by: §3.2.1.
- [54] D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V. Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro, et al. (2021) Efficient large-scale language model training on gpu clusters using megatron-lm. In Proceedings of the international conference for high performance computing, networking, storage and analysis, pp. 1–15. Cited by: §2.4.2, §2.4.2.
- [55] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. (2022) Training language models to follow instructions with human feedback. Advances in neural information processing systems 35, pp. 27730–27744. Cited by: §3.2.3.
- [56] B. Peng, J. Quesnelle, H. Fan, and E. Shippole (2023) Yarn: efficient context window extension of large language models. arXiv preprint arXiv:2309.00071. Cited by: §2.5.
- [57] L. Phan, A. Gatti, Z. Han, N. Li, J. Hu, H. Zhang, C. B. C. Zhang, M. Shaaban, J. Ling, S. Shi, M. Choi, A. Agrawal, A. Chopra, A. Khoja, R. Kim, R. Ren, J. Hausenloy, O. Zhang, M. Mazeika, D. Dodonov, T. Nguyen, J. Lee, D. Anderson, M. Doroshenko, A. C. Stokes, M. Mahmood, O. Pokutnyi, O. Iskra, J. P. Wang, J. Levin, M. Kazakov, F. Feng, S. Y. Feng, H. Zhao, M. Yu, V. Gangal, C. Zou, Z. Wang, S. Popov, R. Gerbicz, G. Galgon, J. Schmitt, W. Yeadon, Y. Lee, S. Sauers, A. Sanchez, F. Giska, M. Roth, S. Riis, S. Utpala, N. Burns, G. M. Goshu, M. M. Naiya, C. Agu, Z. Giboney, A. Cheatom, F. Fournier-Facio, S. Crowson, L. Finke, Z. Cheng, J. Zampese, R. G. Hoerr, M. Nandor, H. Park, T. Gehrunger, J. Cai, B. McCarty, A. C. Garretson, E. Taylor, D. Sileo, Q. Ren, U. Qazi, L. Li, J. Nam, J. B. Wydallis, P. Arkhipov, J. W. L. Shi, A. Bacho, C. G. Willcocks, H. Cao, S. Motwani, E. de Oliveira Santos, J. Veith, E. Vendrow, D. Cojoc, K. Zenitani, J. Robinson, L. Tang, Y. Li, J. Vendrow, N. W. Fraga, V. Kuchkin, A. P. Maksimov, P. Marion, D. Efremov, J. Lynch, K. Liang, A. Mikov, A. Gritsevskiy, J. Guillod, G. Demir, D. Martinez, B. Pageler, K. Zhou, S. Soori, O. Press, H. Tang, P. Rissone, S. R. Green, L. Brüssel, M. Twayana, A. Dieuleveut, J. M. Imperial, A. Prabhu, J. Yang, N. Crispino, A. Rao, D. Zvonkine, G. Loiseau, M. Kalinin, M. Lukas, C. Manolescu, N. Stambaugh, S. Mishra, T. Hogg, C. Bosio, B. P. Coppola, J. Salazar, J. Jin, R. Sayous, S. Ivanov, P. Schwaller, S. Senthilkuma, A. M. Bran, A. Algaba, K. V. den Houte, L. V. D. Sypt, B. Verbeken, D. Noever, A. Kopylov, B. Myklebust, B. Li, L. Schut, E. Zheltonozhskii, Q. Yuan, D. Lim, R. Stanley, T. Yang, J. Maar, J. Wykowski, M. Oller, A. Sahu, C. G. Ardito, Y. Hu, A. G. K. Kamdoum, A. Jin, T. G. Vilchis, Y. Zu, M. Lackner, J. Koppel, G. Sun, D. S. Antonenko, S. Chern, B. Zhao, P. Arsene, J. M. Cavanagh, D. Li, J. Shen, D. Crisostomi, W. Zhang, A. Dehghan, S. Ivanov, D. Perrella, N. Kaparov, A. Zang, I. Sucholutsky, A. Kharlamova, D. Orel, V. Poritski, S. Ben-David, Z. Berger, P. Whitfill, M. Foster, D. Munro, L. Ho, S. Sivarajan, D. B. Hava, A. Kuchkin, D. Holmes, A. Rodriguez-Romero, F. Sommerhage, A. Zhang, R. Moat, K. Schneider, Z. Kazibwe, D. Clarke, D. H. Kim, F. M. Dias, S. Fish, V. Elser, T. Kreiman, V. E. G. Vilchis, I. Klose, U. Anantheswaran, A. Zweiger, K. Rawal, J. Li, J. Nguyen, N. Daans, H. Heidinger, M. Radionov, V. Rozhoň, V. Ginis, C. Stump, N. Cohen, R. Poświata, J. Tkadlec, A. Goldfarb, C. Wang, P. Padlewski, S. Barzowski, K. Montgomery, R. Stendall, J. Tucker-Foltz, J. Stade, T. R. Rogers, T. Goertzen, D. Grabb, A. Shukla, A. Givré, J. A. Ambay, A. Sen, M. F. Aziz, M. H. Inlow, H. He, L. Zhang, Y. Kaddar, I. Ängquist, Y. Chen, H. K. Wang, K. Ramakrishnan, E. Thornley, A. Terpin, H. Schoelkopf, E. Zheng, A. Carmi, E. D. L. Brown, K. Zhu, M. Bartolo, R. Wheeler, M. Stehberger, P. Bradshaw, J. Heimonen, K. Sridhar, I. Akov, J. Sandlin, Y. Makarychev, J. Tam, H. Hoang, D. M. Cunningham, V. Goryachev, D. Patramanis, M. Krause, A. Redenti, D. Aldous, J. Lai, S. Coleman, J. Xu, S. Lee, I. Magoulas, S. Zhao, N. Tang, M. K. Cohen, O. Paradise, J. H. Kirchner, M. Ovchynnikov, J. O. Matos, A. Shenoy, M. Wang, Y. Nie, A. Sztyber-Betley, P. Faraboschi, R. Riblet, J. Crozier, S. Halasyamani, S. Verma, P. Joshi, E. Meril, Z. Ma, J. Andréoletti, R. Singhal, J. Platnick, V. Nevirkovets, L. Basler, A. Ivanov, S. Khoury, N. Gustafsson, M. Piccardo, H. Mostaghimi, Q. Chen, V. Singh, T. Q. Khánh, P. Rosu, H. Szlyk, Z. Brown, H. Narayan, A. Menezes, J. Roberts, W. Alley, K. Sun, A. Patel, M. Lamparth, A. Reuel, L. Xin, H. Xu, J. Loader, F. Martin, Z. Wang, A. Achilleos, T. Preu, T. Korbak, I. Bosio, F. Kazemi, Z. Chen, B. Bálint, E. J. Y. Lo, J. Wang, M. I. S. Nunes, J. Milbauer, M. S. Bari, Z. Wang, B. Ansarinejad, Y. Sun, S. Durand, H. Elgnainy, G. Douville, D. Tordera, G. Balabanian, H. Wolff, L. Kvistad, H. Milliron, A. Sakor, M. Eron, A. F. D. O., S. Shah, X. Zhou, F. Kamalov, S. Abdoli, T. Santens, S. Barkan, A. Tee, R. Zhang, A. Tomasiello, G. B. D. Luca, S. Looi, V. Le, N. Kolt, J. Pan, E. Rodman, J. Drori, C. J. Fossum, N. Muennighoff, M. Jagota, R. Pradeep, H. Fan, J. Eicher, M. Chen, K. Thaman, W. Merrill, M. Firsching, C. Harris, S. Ciobâcă, J. Gross, R. Pandey, I. Gusev, A. Jones, S. Agnihotri, P. Zhelnov, M. Mofayezi, A. Piperski, D. K. Zhang, K. Dobarskyi, R. Leventov, I. Soroko, J. Duersch, V. Taamazyan, A. Ho, W. Ma, W. Held, R. Xian, A. R. Zebaze, M. Mohamed, J. N. Leser, M. X. Yuan, L. Yacar, J. Lengler, K. Olszewska, C. D. Fratta, E. Oliveira, J. W. Jackson, A. Zou, M. Chidambaram, T. Manik, H. Haffenden, D. Stander, A. Dasouqi, A. Shen, B. Golshani, D. Stap, E. Kretov, M. Uzhou, A. B. Zhidkovskaya, N. Winter, M. O. Rodriguez, R. Lauff, D. Wehr, C. Tang, Z. Hossain, S. Phillips, F. Samuele, F. Ekström, A. Hammon, O. Patel, F. Farhidi, G. Medley, F. Mohammadzadeh, M. Peñaflor, H. Kassahun, A. Friedrich, R. H. Perez, D. Pyda, T. Sakal, O. Dhamane, A. K. Mirabadi, E. Hallman, K. Okutsu, M. Battaglia, M. Maghsoudimehrabani, A. Amit, D. Hulbert, R. Pereira, S. Weber, Handoko, A. Peristyy, S. Malina, M. Mehkary, R. Aly, F. Reidegeld, A. Dick, C. Friday, M. Singh, H. Shapourian, W. Kim, M. Costa, H. Gurdogan, H. Kumar, C. Ceconello, C. Zhuang, H. Park, M. Carroll, A. R. Tawfeek, S. Steinerberger, D. Aggarwal, M. Kirchhof, L. Dai, E. Kim, J. Ferret, J. Shah, Y. Wang, M. Yan, K. Burdzy, L. Zhang, A. Franca, D. T. Pham, K. Y. Loh, J. Robinson, A. Jackson, P. Giordano, P. Petersen, A. Cosma, J. Colino, C. White, J. Votava, V. Vinnikov, E. Delaney, P. Spelda, V. Stritecky, S. M. Shahid, J. Mourrat, L. Vetoshkin, K. Sponselee, R. Bacho, Z. Yong, F. de la Rosa, N. Cho, X. Li, G. Malod, O. Weller, G. Albani, L. Lang, J. Laurendeau, D. Kazakov, F. Adesanya, J. Portier, L. Hollom, V. Souza, Y. A. Zhou, J. Degorre, Y. Yalın, G. D. Obikoya, Rai, F. Bigi, M. C. Boscá, O. Shumar, K. Bacho, G. Recchia, M. Popescu, N. Shulga, N. M. Tanwie, T. C. H. Lux, B. Rank, C. Ni, M. Brooks, A. Yakimchyk, Huanxu, Liu, S. Cavalleri, O. Häggström, E. Verkama, J. Newbould, H. Gundlach, L. Brito-Santana, B. Amaro, V. Vajipey, R. Grover, T. Wang, Y. Kratish, W. Li, S. Gopi, A. Caciolai, C. S. de Witt, P. Hernández-Cámara, E. Rodolà, J. Robins, D. Williamson, V. Cheng, B. Raynor, H. Qi, B. Segev, J. Fan, S. Martinson, E. Y. Wang, K. Hausknecht, M. P. Brenner, M. Mao, C. Demian, P. Kassani, X. Zhang, D. Avagian, E. J. Scipio, A. Ragoler, J. Tan, B. Sims, R. Plecnik, A. Kirtland, O. F. Bodur, D. P. Shinde, Y. C. L. Labrador, Z. Adoul, M. Zekry, A. Karakoc, T. C. B. Santos, S. Shamseldeen, L. Karim, A. Liakhovitskaia, N. Resman, N. Farina, J. C. Gonzalez, G. Maayan, E. Anderson, R. D. O. Pena, E. Kelley, H. Mariji, R. Pouriamanesh, W. Wu, R. Finocchio, I. Alarab, J. Cole, D. Ferreira, B. Johnson, M. Safdari, L. Dai, S. Arthornthurasuk, I. C. McAlister, A. J. Moyano, A. Pronin, J. Fan, A. Ramirez-Trinidad, Y. Malysheva, D. Pottmaier, O. Taheri, S. Stepanic, S. Perry, L. Askew, R. A. H. Rodríguez, A. M. R. Minissi, R. Lorena, K. Iyer, A. A. Fasiludeen, R. Clark, J. Ducey, M. Piza, M. Somrak, E. Vergo, J. Qin, B. Borbás, E. Chu, J. Lindsey, A. Jallon, I. M. J. McInnis, E. Chen, A. Semler, L. Gloor, T. Shah, M. Carauleanu, P. Lauer, T. Đ. Huy, H. Shahrtash, E. Duc, L. Lewark, A. Brown, S. Albanie, B. Weber, W. S. Vaz, P. Clavier, Y. Fan, G. P. R. e Silva, Long, Lian, M. Abramovitch, X. Jiang, S. Mendoza, M. Islam, J. Gonzalez, V. Mavroudis, J. Xu, P. Kumar, L. P. Goswami, D. Bugas, N. Heydari, F. Jeanplong, T. Jansen, A. Pinto, A. Apronti, A. Galal, N. Ze-An, A. Singh, T. Jiang, J. of Arc Xavier, K. P. Agarwal, M. Berkani, G. Zhang, Z. Du, B. A. de Oliveira Junior, D. Malishev, N. Remy, T. D. Hartman, T. Tarver, S. Mensah, G. A. Loume, W. Morak, F. Habibi, S. Hoback, W. Cai, J. Gimenez, R. G. Montecillo, J. Łucki, R. Campbell, A. Sharma, K. Meer, S. Gul, D. E. Gonzalez, X. Alapont, A. Hoover, G. Chhablani, F. Vargus, A. Agarwal, Y. Jiang, D. Patil, D. Outevsky, K. J. Scaria, R. Maheshwari, A. Dendane, P. Shukla, A. Cartwright, S. Bogdanov, N. Mündler, S. Möller, L. Arnaboldi, K. Thaman, M. R. Siddiqi, P. Saxena, H. Gupta, T. Fruhauff, G. Sherman, M. Vincze, S. Usawasutsakorn, D. Ler, A. Radhakrishnan, I. Enyekwe, S. M. Salauddin, J. Muzhen, A. Maksapetyan, V. Rossbach, C. Harjadi, M. Bahaloohoreh, C. Sparrow, J. Sidhu, S. Ali, S. Bian, J. Lai, E. Singer, J. L. Uro, G. Bateman, M. Sayed, A. Menshawy, D. Duclosel, D. Bezzi, Y. Jain, A. Aaron, M. Tiryakioglu, S. Siddh, K. Krenek, I. A. Shah, J. Jin, S. Creighton, D. Peskoff, Z. EL-Wasif, R. P. V, M. Richmond, J. McGowan, T. Patwardhan, H. Sun, T. Sun, N. Zubić, S. Sala, S. Ebert, J. Kaddour, M. Schottdorf, D. Wang, G. Petruzella, A. Meiburg, T. Medved, A. ElSheikh, S. A. Hebbar, L. Vaquero, X. Yang, J. Poulos, V. Zouhar, S. Bogdanik, M. Zhang, J. Sanz-Ros, D. Anugraha, Y. Dai, A. N. Nhu, X. Wang, A. A. Demircali, Z. Jia, Y. Zhou, J. Wu, M. He, N. Chandok, A. Sinha, G. Luo, L. Le, M. Noyé, M. Perełkiewicz, I. Pantidis, T. Qi, S. S. Purohit, L. Parcalabescu, T. Nguyen, G. I. Winata, E. M. Ponti, H. Li, K. Dhole, J. Park, D. Abbondanza, Y. Wang, A. Nayak, D. M. Caetano, A. A. W. L. Wong, M. del Rio-Chanona, D. Kondor, P. Francois, E. Chalstrey, J. Zsambok, D. Hoyer, J. Reddish, J. Hauser, F. Rodrigo-Ginés, S. Datta, M. Shepherd, T. Kamphuis, Q. Zhang, H. Kim, R. Sun, J. Yao, F. Dernoncourt, S. Krishna, S. Rismanchian, B. Pu, F. Pinto, Y. Wang, K. Shridhar, K. J. Overholt, G. Briia, H. Nguyen, David, S. Bartomeu, T. C. Pang, A. Wecker, Y. Xiong, F. Li, L. S. Huber, J. Jaeger, R. D. Maddalena, X. H. Lù, Y. Zhang, C. Beger, P. T. J. Kon, S. Li, V. Sanker, M. Yin, Y. Liang, X. Zhang, A. Agrawal, L. S. Yifei, Z. Zhang, M. Cai, Y. Sonmez, C. Cozianu, C. Li, A. Slen, S. Yu, H. K. Park, G. Sarti, M. Briański, A. Stolfo, T. A. Nguyen, M. Zhang, Y. Perlitz, J. Hernandez-Orallo, R. Li, A. Shabani, F. Juefei-Xu, S. Dhingra, O. Zohar, M. C. Nguyen, A. Pondaven, A. Yilmaz, X. Zhao, C. Jin, M. Jiang, S. Todoran, X. Han, J. Kreuer, B. Rabern, A. Plassart, M. Maggetti, L. Yap, R. Geirhos, J. Kean, D. Wang, S. Mollaei, C. Sun, Y. Yin, S. Wang, R. Li, Y. Chang, A. Wei, A. Bizeul, X. Wang, A. O. Arrais, K. Mukherjee, J. Chamorro-Padial, J. Liu, X. Qu, J. Guan, A. Bouyamourn, S. Wu, M. Plomecka, J. Chen, M. Tang, J. Deng, S. Subramanian, H. Xi, H. Chen, W. Zhang, Y. Ren, H. Tu, S. Kim, Y. Chen, S. V. Marjanović, J. Ha, G. Luczyna, J. J. Ma, Z. Shen, D. Song, C. E. Zhang, Z. Wang, G. Gendron, Y. Xiao, L. Smucker, E. Weng, K. H. Lee, Z. Ye, S. Ermon, I. D. Lopez-Miguel, T. Knights, A. Gitter, N. Park, B. Wei, H. Chen, K. Pai, A. Elkhanany, H. Lin, P. D. Siedler, J. Fang, R. Mishra, K. Zsolnai-Fehér, X. Jiang, S. Khan, J. Yuan, R. K. Jain, X. Lin, M. Peterson, Z. Wang, A. Malusare, M. Tang, I. Gupta, I. Fosin, T. Kang, B. Dworakowska, K. Matsumoto, G. Zheng, G. Sewuster, J. P. Villanueva, I. Rannev, I. Chernyavsky, J. Chen, D. Banik, B. Racz, W. Dong, J. Wang, L. Bashmal, D. V. Gonçalves, W. Hu, K. Bar, O. Bohdal, A. S. Patlan, S. Dhuliawala, C. Geirhos, J. Wist, Y. Kansal, B. Chen, K. Tire, A. T. Yücel, B. Christof, V. Singla, Z. Song, S. Chen, J. Ge, K. Ponkshe, I. Park, T. Shi, M. Q. Ma, J. Mak, S. Lai, A. Moulin, Z. Cheng, Z. Zhu, Z. Zhang, V. Patil, K. Jha, Q. Men, J. Wu, T. Zhang, B. H. Vieira, A. F. Aji, J. Chung, M. Mahfoud, H. T. Hoang, M. Sperzel, W. Hao, K. Meding, S. Xu, V. Kostakos, D. Manini, Y. Liu, C. Toukmaji, J. Paek, E. Yu, A. E. Demircali, Z. Sun, I. Dewerpe, H. Qin, R. Pflugfelder, J. Bailey, J. Morris, V. Heilala, S. Rosset, Z. Yu, P. E. Chen, W. Yeo, E. Jain, R. Yang, S. Chigurupati, J. Chernyavsky, S. P. Reddy, S. Venugopalan, H. Batra, C. F. Park, H. Tran, G. Maximiano, G. Zhang, Y. Liang, H. Shiyu, R. Xu, R. Pan, S. Suresh, Z. Liu, S. Gulati, S. Zhang, P. Turchin, C. W. Bartlett, C. R. Scotese, P. M. Cao, A. Nattanmai, G. McKellips, A. Cheraku, A. Suhail, E. Luo, M. Deng, J. Luo, A. Zhang, K. Jindel, J. Paek, K. Halevy, A. Baranov, M. Liu, A. Avadhanam, D. Zhang, V. Cheng, B. Ma, E. Fu, L. Do, J. Lass, H. Yang, S. Sunkari, V. Bharath, V. Ai, J. Leung, R. Agrawal, A. Zhou, K. Chen, T. Kalpathi, Z. Xu, G. Wang, T. Xiao, E. Maung, S. Lee, R. Yang, R. Yue, B. Zhao, J. Yoon, S. Sun, A. Singh, E. Luo, C. Peng, T. Osbey, T. Wang, D. Echeazu, H. Yang, T. Wu, S. Patel, V. Kulkarni, V. Sundarapandiyan, A. Zhang, A. Le, Z. Nasim, S. Yalam, R. Kasamsetty, S. Samal, H. Yang, D. Sun, N. Shah, A. Saha, A. Zhang, L. Nguyen, L. Nagumalli, K. Wang, A. Zhou, A. Wu, J. Luo, A. Telluri, S. Yue, A. Wang, and D. Hendrycks (2025) Humanity’s last exam. External Links: 2501.14249, Link Cited by: §4.1.1.
- [58] P. Qi, X. Wan, G. Huang, and M. Lin (2023) Zero bubble pipeline parallelism. arXiv preprint arXiv:2401.10241. Cited by: §2.4.2.
- [59] Y. Qin, S. Liang, Y. Ye, K. Zhu, L. Yan, Y. Lu, Y. Lin, X. Cong, X. Tang, B. Qian, et al. (2023) Toolllm: facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789. Cited by: §3.1.1.
- [60] Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Wan, Y. Liu, Z. Cui, Z. Zhang, and Z. Qiu (2025) Qwen2.5 technical report. External Links: 2412.15115, Link Cited by: §4.2.1.
- [61] S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He (2020) Zero: memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–16. Cited by: §2.4.2.
- [62] D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y. Pang, J. Dirani, J. Michael, and S. R. Bowman (2024) Gpqa: a graduate-level google-proof q&a benchmark. In First Conference on Language Modeling, Cited by: §4.1.1, §4.2.1.
- [63] K. Sakaguchi, R. L. Bras, C. Bhagavatula, and Y. Choi (2021) Winogrande: an adversarial winograd schema challenge at scale. Communications of the ACM 64 (9), pp. 99–106. Cited by: §4.2.1.
- [64] D. Silver and R. S. Sutton (2025) Welcome to the era of experience. Google AI 1. Cited by: §1.
- [65] V. Sirdeshmukh, K. Deshpande, J. Mols, L. Jin, E. Cardona, D. Lee, J. Kritz, W. Primack, S. Yue, and C. Xing (2025) MultiChallenge: a realistic multi-turn conversation evaluation benchmark challenging to frontier llms. External Links: 2501.17399, Link Cited by: §4.1.1.
- [66] G. Starace, O. Jaffe, D. Sherburn, J. Aung, J. S. Chan, L. Maksin, R. Dias, E. Mays, B. Kinsella, W. Thompson, et al. (2025) PaperBench: evaluating ai’s ability to replicate ai research. arXiv preprint arXiv:2504.01848. Cited by: §4.1.1.
- [67] H. Sun, Z. Qiao, J. Guo, X. Fan, Y. Hou, Y. Jiang, P. Xie, Y. Zhang, F. Huang, and J. Zhou (2025) ZeroSearch: incentivize the search capability of llms without searching. External Links: 2505.04588, Link Cited by: §3.1.1.
- [68] M. Suzgun, N. Scales, N. Schärli, S. Gehrmann, Y. Tay, H. W. Chung, A. Chowdhery, Q. V. Le, E. H. Chi, D. Zhou, and J. Wei (2022) Challenging big-bench tasks and whether chain-of-thought can solve them. External Links: 2210.09261, Link Cited by: §4.2.1.
- [69] M. S. Tamber, F. S. Bao, C. Xu, G. Luo, S. Kazi, M. Bae, M. Li, O. Mendelevitch, R. Qu, and J. Lin (2025) Benchmarking llm faithfulness in rag with evolving leaderboards. arXiv preprint arXiv:2505.04847. Cited by: §4.1.1.
- [70] G. Team, M. Riviere, S. Pathak, P. G. Sessa, C. Hardin, S. Bhupatiraju, L. Hussenot, T. Mesnard, B. Shahriari, A. Ramé, et al. (2024) Gemma 2: improving open language models at a practical size. arXiv preprint arXiv:2408.00118. Cited by: §2.1.
- [71] L. Team () The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation — ai.meta.com. Note: https://ai.meta.com/blog/llama-4-multimodal-intelligence/ [Accessed 15-07-2025] Cited by: §4.2.1.
- [72] T. T. Team (2025-04) Terminal-bench: a benchmark for ai agents in terminal environments. External Links: Link Cited by: §4.1.1.
- [73] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin (2017) Attention is all you need. In Advances in Neural Information Processing Systems, I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.), Vol. 30, pp. . External Links: Link Cited by: §2.
- [74] Vectara (2024) Hallucination evaluation model (revision 7437011). Hugging Face. External Links: Link Cited by: §4.1.1.
- [75] J. Vendrow, E. Vendrow, S. Beery, and A. Madry (2025) Do large language model benchmarks test reliability?. arXiv preprint arXiv:2502.03461. Cited by: §4.2.1.
- [76] Y. Wang, Y. Kordi, S. Mishra, A. Liu, N. A. Smith, D. Khashabi, and H. Hajishirzi (2022) Self-instruct: aligning language models with self-generated instructions. arXiv preprint arXiv:2212.10560. Cited by: §3.1.1.
- [77] Y. Wang, X. Ma, G. Zhang, Y. Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, T. Li, M. Ku, K. Wang, A. Zhuang, R. Fan, X. Yue, and W. Chen (2024) MMLU-pro: a more robust and challenging multi-task language understanding benchmark. External Links: 2406.01574, Link Cited by: §4.1.1, §4.2.1.
- [78] Z. Wang, Y. Liu, Y. Wang, W. He, B. Gao, M. Diao, Y. Chen, K. Fu, F. Sung, Z. Yang, T. Liu, and W. Xu (2025) OJBench: a competition level code benchmark for large language models. External Links: 2506.16395, Link Cited by: §4.1.1.
- [79] J. Wei, N. Karina, H. W. Chung, Y. J. Jiao, S. Papay, A. Glaese, J. Schulman, and W. Fedus (2024) Measuring short-form factuality in large language models. arXiv preprint arXiv:2411.04368. Cited by: §4.1.1, §4.2.1.
- [80] T. Wei, J. Luan, W. Liu, S. Dong, and B. Wang (2023) CMATH: can your language model pass chinese elementary school math test?. External Links: 2306.16636, Link Cited by: §4.2.1.
- [81] C. White, S. Dooley, M. Roberts, A. Pal, B. Feuer, S. Jain, R. Shwartz-Ziv, N. Jain, K. Saifullah, S. Dey, Shubh-Agrawal, S. S. Sandha, S. V. Naidu, C. Hegde, Y. LeCun, T. Goldstein, W. Neiswanger, and M. Goldblum (2025) LiveBench: a challenging, contamination-free LLM benchmark. In The Thirteenth International Conference on Learning Representations, Cited by: §4.1.1.
- [82] M. Wortsman, P. J. Liu, L. Xiao, K. Everett, A. Alemi, B. Adlam, J. D. Co-Reyes, I. Gur, A. Kumar, R. Novak, et al. Small-scale proxies for large-scale transformer training instabilities, 2023. URL https://arxiv. org/abs/2309.14322. Cited by: §2.1.
- [83] C. Xu, Q. Sun, K. Zheng, X. Geng, P. Zhao, J. Feng, C. Tao, Q. Lin, and D. Jiang (2025) WizardLM: empowering large pre-trained language models to follow complex instructions. External Links: 2304.12244, Link Cited by: §3.1.1.
- [84] Z. Xu, Y. Liu, Y. Yin, M. Zhou, and R. Poovendran (2025) KodCode: a diverse, challenging, and verifiable synthetic dataset for coding. External Links: 2503.02951, Link Cited by: §3.2.1.
- [85] J. Yang, K. Lieret, C. E. Jimenez, A. Wettig, K. Khandpur, Y. Zhang, B. Hui, O. Press, L. Schmidt, and D. Yang (2025) SWE-smith: scaling data for software engineering agents. External Links: 2504.21798, Link Cited by: §4.1.1.
- [86] S. Yao, N. Shinn, P. Razavi, and K. Narasimhan (2024) Tau-bench: a benchmark for tool-agent-user interaction in real-world domains. arXiv preprint arXiv:2406.12045. Cited by: §3.1.1.
- [87] D. Zan, Z. Huang, W. Liu, H. Chen, L. Zhang, S. Xin, L. Chen, Q. Liu, X. Zhong, A. Li, et al. (2025) Multi-swe-bench: a multilingual benchmark for issue resolving. arXiv preprint arXiv:2504.02605. Cited by: §4.1.1.
- [88] E. Zelikman, Y. Wu, J. Mu, and N. Goodman (2022) Star: bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems 35, pp. 15476–15488. Cited by: §3.1.1.
- [89] R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi (2019) Hellaswag: can a machine really finish your sentence?. arXiv preprint arXiv:1905.07830. Cited by: §4.2.1.
- [90] W. Zhong, R. Cui, Y. Guo, Y. Liang, S. Lu, Y. Wang, A. Saied, W. Chen, and N. Duan (2023) Agieval: a human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364. Cited by: §4.2.1.
- [91] J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y. Luan, D. Zhou, and L. Hou (2023) Instruction-following evaluation for large language models. ArXiv abs/2311.07911. External Links: Link Cited by: §4.1.1.
- [92] Q. Zhu, F. Huang, R. Peng, K. Lu, B. Yu, Q. Cheng, X. Qiu, X. Huang, and J. Lin (2025) AutoLogi: automated generation of logic puzzles for evaluating reasoning abilities of large language models. External Links: 2502.16906, Link Cited by: §4.1.1.
## Appendix
## Appendix A Contributions
The listing of authors is in alphabetical order based on their last names.
Yifan Bai Yiping Bao Y. Charles Cheng Chen Guanduo Chen Haiting Chen Huarong Chen Jiahao Chen Ningxin Chen Ruijue Chen Yanru Chen Yuankun Chen Yutian Chen Zhuofu Chen Jialei Cui Hao Ding Mengnan Dong Ang’ang Du Chenzhuang Du Dikang Du Yulun Du Yu Fan Yichen Feng Kelin Fu Bofei Gao Chenxiao Gao Hongcheng Gao Peizhong Gao Tong Gao Yuyao Ge Shangyi Geng Qizheng Gu Xinran Gu Longyu Guan Haiqing Guo Jianhang Guo Xiaoru Hao Tianhong He Weiran He Wenyang He Yunjia He Chao Hong Hao Hu Yangyang Hu Zhenxing Hu Weixiao Huang Zhiqi Huang Zihao Huang Tao Jiang Zhejun Jiang Xinyi Jin Yongsheng Kang Guokun Lai Cheng Li Fang Li Haoyang Li Ming Li Wentao Li Yang Li Yanhao Li Yiwei Li Zhaowei Li Zheming Li Hongzhan Lin Xiaohan Lin Zongyu Lin Chengyin Liu Chenyu Liu Hongzhang Liu Jingyuan Liu Junqi Liu Liang Liu Shaowei Liu T.Y. Liu Tianwei Liu Weizhou Liu Yangyang Liu Yibo Liu Yiping Liu Yue Liu Zhengying Liu Enzhe Lu Haoyu Lu Lijun Lu Yashuo Luo Shengling Ma Xinyu Ma Yingwei Ma Shaoguang Mao Jie Mei Xin Men Yibo Miao Siyuan Pan Yebo Peng Ruoyu Qin Zeyu Qin Bowen Qu Zeyu Shang Lidong Shi Shengyuan Shi Feifan Song Jianlin Su Zhengyuan Su Lin Sui Xinjie Sun Flood Sung Yunpeng Tai Heyi Tang Jiawen Tao Qifeng Teng Chaoran Tian Chensi Wang Dinglu Wang Feng Wang Hailong Wang Haiming Wang Jianzhou Wang Jiaxing Wang Jinhong Wang Shengjie Wang Shuyi Wang Si Wang Xinyuan Wang Yao Wang Yejie Wang Yiqin Wang Yuxin Wang Yuzhi Wang Zhaoji Wang Zhengtao Wang Zhengtao Wang Zhexu Wang Chu Wei Qianqian Wei Haoning Wu Wenhao Wu Xingzhe Wu Yuxin Wu Chenjun Xiao Jin Xie Xiaotong Xie Weimin Xiong Boyu Xu Jinjing Xu L.H. Xu Lin Xu Suting Xu Weixin Xu Xinran Xu Yangchuan Xu Ziyao Xu Jing Xu (徐) Jing Xu (许) Junjie Yan Yuzi Yan Hao Yang Xiaofei Yang Yi Yang Ying Yang Zhen Yang Zhilin Yang Zonghan Yang Haotian Yao Xingcheng Yao Wenjie Ye Zhuorui Ye Bohong Yin Longhui Yu Enming Yuan Hongbang Yuan Mengjie Yuan Siyu Yuan Haobing Zhan Dehao Zhang Hao Zhang Wanlu Zhang Xiaobin Zhang Yadong Zhang Yangkun Zhang Yichi Zhang Yizhi Zhang Yongting Zhang Yu Zhang Yutao Zhang Yutong Zhang Zheng Zhang Haotian Zhao Yikai Zhao Zijia Zhao Huabin Zheng Shaojie Zheng Longguang Zhong Jianren Zhou Xinyu Zhou Zaida Zhou Jinguo Zhu Zhen Zhu Weiyu Zhuang Xinxing Zu Kimi K2
## Appendix B Token Template of Tool Calling
There are three components in the token structure for tool-calling:
- Tool declaration message: defines the list of available tools and the schema of the arguments;
- Tool invoking section in assistant message: encodes the model’s request to invoke tools;
- Tool result message: encapsulates the invoked tool’s execution result.
The raw tokens of the tool declaration message are formatted as follows:
<|im_begin|> tool_declare <|im_middle|> # Tools {{ tool declaration content }} <|im_end|>
The blue highlighted marks represent special tokens, and the green part, quoted by brackets, is the tool declaration content. We use TypeScript to express the tool declaration content, since TypeScript is a concise language with a comprehensive type system, able to express the types and constraints of tool parameters with brief text. The code 1 shows an example for two simple tools in JSON format compatible with OpenAI’s chat completion API, as a comparison, the same tools defined in TypeScript (listed in Code 2) is much shorter. To improve compatibility, part of our training data also uses JSON as the tool declaration language, so that 3rd-party frameworks need not additional development to support our tool calling scheme.
Listing 1: Tool definition with JSON in OpenAI compatible API
⬇
[{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather for a location and date",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Beijing, China"
},
"date": {
"type": "string",
"description": "Date to query, format in ‘%Y-%m-%d’"
}
},
"required": [
"location"
]
}
}
},
{
"type": "function",
"function": {
"name": "Calculator",
"description": "Simple calculator",
"parameters": {
"properties": {
"expr": {
"type": "string",
"description": "Arithmetic expression in javascript"
}
},
"type": "object"
}
}
}]
Listing 2: Tool definition in TypeScript
⬇
namespace functions {
// Get weather for a location and date
type get_weather = (_: {
// City and country e. g. Beijing, China
location: string,
// Date to query, format in ‘% Y -% m -% d ’
date?: string
}) => any;
// Simple calculator
type Calculator = (_: {
// Arithmetic expression in javascript
expr?: string
}) => any;
}
The token template of the tool invoking section in the model’s response messages is listed as follows:
<|tool_call_section_begin|> <|tool_call_begin|> // call_id part functions. {{tool name}}: {{counter}} <|tool_arguments_begin|> {{ json serialized call arguments }} <|tool_call_end|> <|tool_call_begin|> // more tool calls <|tool_call_end|> <|tool_call_section_end|>
As shown in the template, we support parallel tool calling by placing multiple tool calls in a single response turn. Each tool call has a unique call id, formatted as functions.{tool-name}:{counter}, where tool-name is the name of the tool, and counter is an auto-increasing counter of all tool calls starting from 0 in the dialog.
During inference, the model may occasionally generate unexpected tokens, leading to format errors when parsing a tool call. To solve this issue, we developed a constrained decoding module named enforcer, inspired by lm-format-enforcer https://github.com/noamgat/lm-format-enforcer. When a <tool_call_section_begin|> token is generated, it ensures that the upcoming tool-related tokens follow the predefined template, and the JSON argument string follows the declared schema.
The tool result message is simply a text message encoded with the tool’s call id and the corresponding results.
<|im_begin|> tool <|im_middle|> ## Results of {{call_id}} {{ execution result content }} <|im_end|>
## Appendix C Evaluation Details
Coding Tasks.
We evaluate Kimi-K2-Instruct’s capabilities on competitive coding benchmarks, LiveCodeBench and OJBench, where Kimi-K2-Instruct attains superior performance with scores of 53.7% and 27.1%, respectively. This excellence spans both medium-level coding challenges, such as LeetCode and AtCoder, and hard-level contests like NOI and ICPC, outperforming leading open-source and proprietary models. For multilingual programming proficiency, we employ MultiPL-E, covering languages including C++, C#, Java, JavaScript, PHP, Go, Kimi-K2-Instruct surpasses top open-source models with an accuracy of 85.7%, compared with 83.1% for DeepSeek-V3-0324 and 78.2% for Qwen3-235B-A22B. In software engineering tasks, Kimi-K2-Instruct demonstrates robust performance on SWE-bench Verified (Python), SWE-lancer (Python), SWE-bench Multilingual, and Multi-SWE-bench datasets. It significantly outperforms open-source counterparts in resolving real-world code repository issues and notably narrows the performance gap with proprietary models. For example:
- SWE-bench Verified (multiple attempts): 71.6% (Kimi-K2-Instruct) vs. 80.2% (Claude 4 Sonnet)
- SWE-bench Multilingual: 47.3% (Kimi-K2-Instruct) vs. 51.0% (Claude 4 Sonnet)
- SWE-lancer: 39.1% (Kimi-K2-Instruct) vs. 40.8% (Claude 4 Sonnet)
On PaperBench, Kimi-K2-Instruct achieves an accuracy of 27.8%, closely matching GPT-4.1 and outperforming DeepSeek-V3-0324 (12.2%) and Qwen3-235B-A22B (8.2%) by a substantial margin. In terminal interaction tasks measured by TerminalBench, Kimi-K2-Instruct attains 25.0% using the default Terminus framework and rises to 30% within Moonshot’s in-house agentic framework, underscoring its capabilities in real-world agentic programming scenarios. Moreover, on the Aider-Polyglot benchmark, Kimi-K2-Instruct attains a 60.0% accuracy while employing rigorous decontamination procedures, further illustrating its strength and reliability across diverse coding environments.
Tool Use Tasks.
We evaluate multi-turn tool use with two complementary suites: $\tau^{2}$ -Bench and ACEBench. $\tau^{2}$ -Bench extends the original $\tau$ -bench single-control setup to a dual-control environment in which both the agent and an LLM-simulated user have constrained tool affordances over a shared state, adding a realistic Telecom troubleshooting domain alongside the prior Airline/Retail TAU tasks and enabling analysis of coordination vs. pure reasoning. ACEBench is a large bilingual (En/Zh) API-grounded benchmark (4.5K APIs across 8 domains; 2K annotated eval items) partitioned into Normal (basic/personalized/atomic), Special (imperfect or out-of-scope inputs), and Agent (scenario-driven multi-turn, multi-step sandbox) tracks with automated grading of calls and outcomes. All models run in non-thinking mode; we set the temperature to 0.0, use deterministic tool adapters, score $\tau^{2}$ Airline/Retail/Telecom under Avg@4 seeds with Pass@1/4, and report overall on ACEBench English. Kimi-K2-Instruct averages 66.1 micro Pass@1 across $\tau^{2}$ vs DeepSeek-V3-0324 48.8 / Qwen3-235B-A22B 37.3. On ACEBench Overall Kimi-K2-Instruct scores 76.5 vs DeepSeek 72.7 / Qwen 70.5 and remains competitive with GPT-4.1 (80.1).
Math & STEM & Logical Tasks.
For Math tasks, Kimi-K2-Instruct achieves consistently strong performance, averaging over Geimini-2.5-Flash by 5.3 percentage points, over DeepSeek-V3-0324 by 5.5 points and over GPT4.1 by 15.8 points. For example, on AIME 2024, Kimi-K2-Instruct scores 69.6%, outperforming another two top open-source models by a large margin, DeepSeek-V3-0324 by 10.2 points and Qwen3-235B-A22B by 29.5 points. In STEM evaluations, Kimi-K2-Instruct achieves 75.1% on GPQA-Diamond, outperforming DeepSeek-V3-0324 (68.4%) and all non-thinking baselines by at least 5 percentage points. On SuperGPQA, it also exceeds the previous best open-source model, DeepSeek-V3-0324, by 3.5 points. Kimi-K2-Instruct also surpasses the other two leading models in logical reasoning. It achieves 89.0% on ZebraLogic and 89.5% on AutoLogi, exceeding DeepSeek-V3-0324 (84.0%, 88.9%) and substantially outperforming Qwen3-235B-A22B (37.7%, 83.3%).
General Tasks.
Kimi-K2-Instruct ties DeepSeek-V3-0324 on MMLU and MMLU-Pro, and takes the lead on MMLU-Redux with a 92.7 EM score—slightly ahead of GPT-4.1 (92.4) and just 1.5 points behind Claude-Opus-4. Beyond multiple-choice tasks, the model achieves 31.0% accuracy on the short-answer SimpleQA—3.3 points above DeepSeek-V3-0324 and more than twice that of Qwen3-235B-A22B—though still below GPT-4.1 (42.3%). On the adversarial free-response LiveBench (2024-11-25 snapshot), it reaches 76.4%, surpassing Claude-Sonnet 4 (74.8%) and leading Gemini 2.5 Flash Preview by 8.6 points. Across this challenging triad measuring breadth, depth, and robustness of world knowledge, Kimi-K2-Instruct secures a top-tier position among open-source models. We evaluate instruction-following with IFEval and Multi-Challenge. On IFEval, Kimi-K2-Instruct scores 89.8%, higher than DeepSeek-V3-0324 (81.1%) and GPT-4.1 (88.0%). On Multi-Challenge, which involves multi-turn dialogues with conflicting instructions, it achieves 54.1%, outperforming DeepSeek-V3-0324 (31.4%), GPT-4.1 (36.4%), and Claude-Opus-4 (49.0%). These results demonstrate that Kimi-K2-Instruct integrates strong factual knowledge with consistent instruction adherence across both single- and multi-turn settings, supporting robust and reliable real-world deployment.
Long Context and Factuality Tasks.
To evaluate the factuality of Kimi-K2-Instruct, we employ three benchmarks: FACTS Grounding, which measures adherence to provided documents using the proprietary models GPT-4o, Gemini 1.5 Pro and Claude 3.5 Sonnet; HHEM, which assesses summarization quality via the open-source HHEM-2.1-Open judge; and FaithJudge, which analyzes faithfulness in RAG tasks with o3-mini as the judge. Kimi-K2-Instruct scores 88.5 on FACTS Grounding, substantially outperforming all open-source rivals and even surpassing the closed-source Gemini 2.5 Flash. With HHEM-2.1-Open it achieves a hallucination rate of 1.1 %, reported in the tables as 1 minus the rate, i.e. 98.9. On FaithJudge’s RAG tasks the hallucination rate is 7.4 %, likewise present as 92.6 for table consistency. For long-context capabilities, Kimi-K2-Instruct outperforms all open source and proprietary models on DROP (93.5%), and exceeds DeepSeek-V3-0324 on retrieval task MRCR (55.0% vs 50.8%). For long-context reasoning tasks FRAMES and LongBench v2, Kimi-K2-Instruct (77.1%, 49.1%) lags slightly behind DeepSeek-V3-0324 by around 2%.
Open-Ended Evaluation
Beyond static, closed-ended benchmarks, we evaluate the model’s performance on open-ended, nuanced tasks that more closely resemble real-world usage.
For English scenarios, we leverage the Arena-Hard-Auto v2.0 benchmark, which use LLM-as-a-judge protocols to assess generation quality across diverse, open-ended prompts [43]. These evaluations cover a wide range of high-difficulty prompts and are widely recognized in the research community. On Arena-Hard-Auto v2.0, Kimi-K2-Instruct achieves state-of-the-art win-rate on both hard prompts (54.5%) and creative writing tasks (85.0%), outperforming all open-source models and rivaling top proprietary systems such as GPT-4.1 and Claude Sonnet. These results underscore the model’s strength in handling complex reasoning and nuanced generation under diverse, unconstrained settings.
However, Arena-Hard-Auto provides limited coverage of Chinese-specific tasks. To address this gap, we developed an in-house held-out benchmark grounded in authentic user queries. To safeguard the integrity of the evaluation, the benchmark data is access-restricted, thereby eliminating the risk of overfitting.
As shown in Figure 11, Kimi-K2-Instruct shows strong performance across all comparisons on Chinese in-house benchmarks. It outperforms ChatGPT-4o-latest with a 65.4% win rate, Claude Sonnet 4 with 64.6%, and DeepSeek-V3-0324 with 59.6%. In all cases, the loss rate stays low (around 17%), indicating that Kimi-K2-Instruct rarely falls behind. The high win rates and consistent margins demonstrate its strong ability on open-ended Chinese tasks.
In addition to controlled evaluations, we also consider real-world user preference through public human assessments. As of July 17, 2025, Kimi-K2-Instruct ranked as the top open-source model and fifth overall on the LMSYS Arena leaderboard https://lmarena.ai/leaderboard/text, based on over 3,000 blind votes from real users. Unlike LLM-as-a-judge protocols, this leaderboard reflects direct human preference on diverse, user-submitted prompts, providing a complementary perspective on practical model performance.
The results on Arena-Hard-Auto, our in-house benchmark and votes from LMSYS Arena collectively offer a comprehensive view of Kimi-K2-Instruct’s open-ended capabilities, showing that it is a highly preferred model in real-world user experience across English and Chinese.
<details>
<summary>x15.png Details</summary>
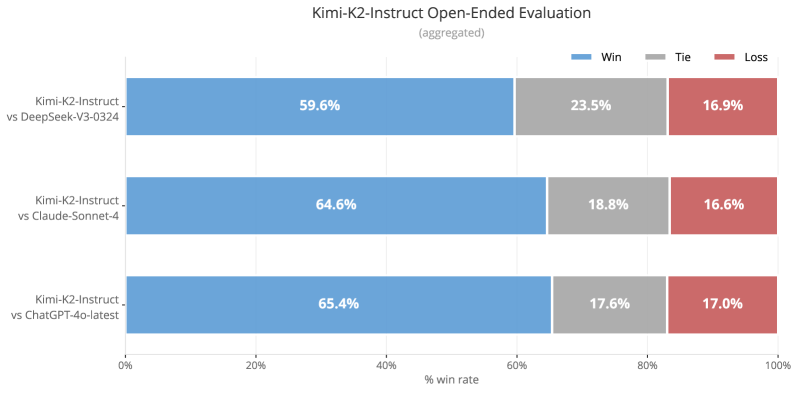
### Visual Description
## Bar Chart: Kimi-K2-Instruct Open-Ended Evaluation (aggregated)
### Overview
The chart compares the performance of **Kimi-K2-Instruct** against three language models (DeepSeek-V3-0324, Claude-Sonnet-4, ChatGPT-4o-latest) in open-ended evaluations. Results are aggregated into three categories: **Win**, **Tie**, and **Loss**, represented by colored bars. Percentages are displayed atop each bar.
### Components/Axes
- **X-axis**: "% win rate" (0% to 100% in 20% increments).
- **Y-axis**: Three comparison groups:
1. Kimi-K2-Instruct vs DeepSeek-V3-0324
2. Kimi-K2-Instruct vs Claude-Sonnet-4
3. Kimi-K2-Instruct vs ChatGPT-4o-latest
- **Legend**:
- Blue = Win
- Gray = Tie
- Red = Loss
- **Bar Structure**: Each group contains three horizontally stacked bars (Win, Tie, Loss) with percentages labeled.
### Detailed Analysis
1. **Kimi-K2-Instruct vs DeepSeek-V3-0324**:
- Win: 59.6% (blue)
- Tie: 23.5% (gray)
- Loss: 16.9% (red)
2. **Kimi-K2-Instruct vs Claude-Sonnet-4**:
- Win: 64.6% (blue)
- Tie: 18.8% (gray)
- Loss: 16.6% (red)
3. **Kimi-K2-Instruct vs ChatGPT-4o-latest**:
- Win: 65.4% (blue)
- Tie: 17.6% (gray)
- Loss: 17.0% (red)
### Key Observations
- **Win Rates**: Kimi-K2-Instruct achieves the highest win rates across all comparisons, increasing from 59.6% (vs DeepSeek) to 65.4% (vs ChatGPT-4o-latest).
- **Tie Rates**: Decrease as opponent strength increases (23.5% → 17.6%), suggesting fewer inconclusive outcomes against stronger models.
- **Loss Rates**: Relatively stable (16.6–17.0%), indicating consistent performance even against advanced models.
### Interpretation
The data demonstrates that **Kimi-K2-Instruct** outperforms all three compared models in open-ended evaluations, with performance gains against stronger opponents (e.g., ChatGPT-4o-latest). The decline in tie rates suggests that Kimi’s interactions with advanced models result in more decisive outcomes (wins/losses) rather than ambiguous ties. The stable loss rates imply that when Kimi fails, it does so in closely contested scenarios, highlighting its robustness in competitive settings. This positions Kimi-K2-Instruct as a leading model in handling complex, open-ended tasks.
</details>
Figure 11: Chinese in-house benchmark evaluation.
## Appendix D QK-Clip Does Not Impair Model Quality
The QK-Clip design follows a minimal intervention principle: it activates only when necessary, and deactivates after training stabilizes. Empirical evidence and analysis converge on its negligible impact on model quality.
Small-Scale Ablations
<details>
<summary>x16.png Details</summary>
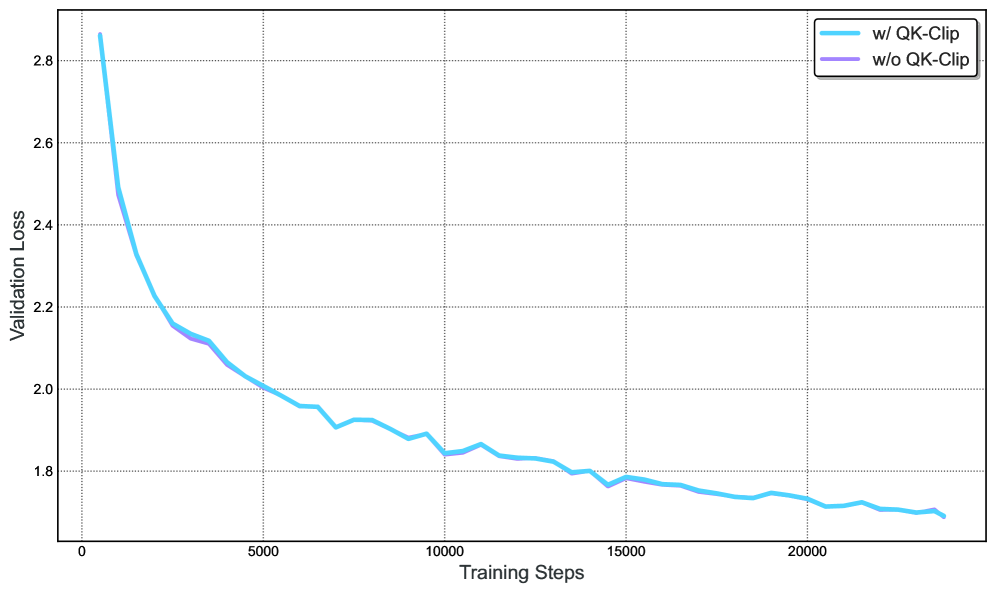
### Visual Description
## Line Graph: Validation Loss vs Training Steps with/without QK-Clip
### Overview
The image shows a line graph comparing validation loss over training steps for two scenarios: with QK-Clip (blue line) and without QK-Clip (purple line). The graph spans 20,000 training steps, with validation loss decreasing over time for both cases, but at different rates.
### Components/Axes
- **X-axis**: Training Steps (0 to 20,000, labeled "Training Steps")
- **Y-axis**: Validation Loss (1.7 to 2.8, labeled "Validation Loss")
- **Legend**: Located in the top-right corner, with:
- Blue line: "w/ QK-Clip"
- Purple line: "w/o QK-Clip"
### Detailed Analysis
1. **Initial Divergence (0–5,000 steps)**:
- At 0 steps:
- w/ QK-Clip: ~2.85
- w/o QK-Clip: ~2.45
- At 5,000 steps:
- w/ QK-Clip: ~2.0
- w/o QK-Clip: ~2.1
2. **Mid-Training (5,000–15,000 steps)**:
- w/ QK-Clip declines steadily from 2.0 to ~1.78.
- w/o QK-Clip declines more gradually from 2.1 to ~1.77.
3. **Late Training (15,000–20,000 steps)**:
- Both lines plateau near 1.7–1.8, with w/ QK-Clip slightly lower (~1.72 vs. ~1.71).
### Key Observations
- **Initial Performance Gap**: w/ QK-Clip starts with significantly higher validation loss (~2.85 vs. ~2.45) but improves faster.
- **Convergence**: By 10,000 steps, the gap narrows to ~0.02 (1.85 vs. 1.83).
- **Final Stability**: Both approaches stabilize near 1.7–1.8, but w/ QK-Clip maintains a marginal advantage.
### Interpretation
The data suggests that QK-Clip accelerates validation loss reduction in early training stages, likely due to improved optimization or regularization. However, its impact diminishes over time as both methods converge to similar performance levels. This implies QK-Clip is most beneficial during initial training phases, where it mitigates overfitting or instability. The marginal final difference (~0.01) indicates diminishing returns after ~15,000 steps, raising questions about computational cost-effectiveness for prolonged training.
</details>
Figure 12: Applying QK-Clip to Muon in a small-scale setting with an aggresive threshold ( $\tau$ = 30) has negligible impact on loss, indicating that it is a safe and effective method for constraining attention logits.
We train two small-scale 0.5B activated and 3B total parameters MoE models, one with vanilla Muon and the other with MuonClip using a low clipping threshold ( $\tau=30$ ). As shown in Figure 12, applying MuonClip has negligible effects on the loss curve, indicating that even aggressive clipping does not impair convergence or training dynamics with MuonClip. This demonstrates that MuonClip is a safe and effective method for bounding attention logits without degrading model performance. Furthermore, evaluation on downstream tasks reveals no statistically significant degradation in performance. These results collectively demonstrate that MuonClip is a safe and effective method for bounding attention logits without compromising model quality.
Self-deactivation
In Kimi K2, QK-Clip was only transiently active:
- Initial 70000 steps: $12.7\$ of attention heads triggered QK-Clip for at least once, clamping $S_{\max}$ to $100$ .
- Post-70000 steps: All heads at some point reduced their $S_{\max}$ below $100$ , rendering QK-Clip inactive.
When QK-Clip is active, it is applied per-head (rather than per-layer) to minimize potential over-regularization on other heads. After training stabilizes, QK-clip is deactivated and has no effect at all.
## Appendix E Why Muon is More Prone to Logit Explosion
Logit explosion occurs when the largest pre-softmax attention score
$$
S_{\max}=\max_{i,j}\bigl(q_{i}^{\vphantom{\top}}\!\cdot k_{j}\bigr) \tag{1}
$$
grows unboundedly during training. Since
$$
|q_{i}\!\cdot\!k_{j}|\leq\|q_{i}\|\|k_{j}\|\leq\|x_{i}\|\|x_{j}\|\|\mathbf{W}_{q}\|\|\mathbf{W}_{k}\|, \tag{2}
$$
and RMS-Norm keeps $\|x_{i}\|\|x_{j}\|$ bounded, the phenomenon is primarily driven by the growing spectral-norm of $\mathbf{W}_{q}$ or $\mathbf{W}_{k}$ . Empirically, we found that Muon is more susceptible to logit explosion. We give our hypothesis below.
Structural difference in updates
Muon produces a weight update coming from the $\mathrm{msign}$ operation; as a result, all singular values of the update matrix are equal — its effective rank is full. In contrast, a typical update matrix produced by Adam exhibits a skewed spectrum: a few large singular values dominate, and the effective rank is low. This low-rank assumption for Adam is not new; higher-order muP makes the same assumption.
Such phenomenon is verified on the 16 B Moonlight model, which shows weights trained with Muon exhibit higher singular-value entropy (i.e. higher effective rank) than those trained with Adam, corroborating the theoretical intuition.
SVD formulation
Let the parameter matrix at step $t-1$ have the singular value decomposition
$$
\mathbf{W}_{t-1}=\sum_{i}\sigma_{i}\,u_{i}v_{i}^{\top} \tag{3}
$$
We write the update matrices as
$$
\displaystyle\Delta\mathbf{W}_{t} \displaystyle=\sum_{j}\bar{\sigma}\,\bar{u}_{j}\bar{v}_{j}^{\top} \tag{4}
$$
The next parameter update is therefore
$$
\displaystyle\mathbf{W}_{t}\leftarrow\sum_{i}\sigma_{i}u_{i}v_{i}^{\top}+\sum_{j}\bar{\sigma}\,\bar{u}_{j}\bar{v}_{j}^{\top} \tag{5}
$$
In Muon, as both the weights and the updates have a higher effective rank than Adam, we hypothesize there is a higher probability for singular-vector pair $u_{i}v_{i}^{\top}$ to align with $\bar{u}_{j}\bar{v}_{j}^{\top}$ . This could cause the corresponding singular value of $\mathbf{W}_{t}$ to increase additively.
Attention-specific amplification
Attention logits are computed via the bilinear form
$$
q_{i}\cdot k_{j}=(x_{i}\mathbf{W}_{q})\cdot(x_{j}\mathbf{W}_{k}). \tag{6}
$$
The product $\mathbf{W}_{q}\mathbf{W}_{k}^{\top}$ squares the spectral norm, so any singular-value increase in either matrix is compounded. Muon’s tendency to enlarge singular values therefore translates into a higher risk of logit explosion.
## Appendix F K2 Critic Rubrics for General RL
### F.1 Core Rubrics
- Clarity and Relevance: Assesses the extent to which the response is succinct while fully addressing the user’s intent. The focus is on eliminating unnecessary detail, staying aligned with the central query, and using efficient formats such as brief paragraphs or compact lists. Unless specifically required, long itemizations should be avoided. When a choice is expected, the response should clearly offer a single, well-defined answer.
- Conversational Fluency and Engagement: Evaluates the response’s contribution to a natural, flowing dialogue that extends beyond simple question-answering. This includes maintaining coherence, showing appropriate engagement with the topic, offering relevant observations or insights, potentially guiding the conversation constructively when appropriate, using follow-up questions judiciously, handling hypothetical or personal-analogy queries gracefully, and adapting tone effectively to suit the conversational context (e.g., empathetic, formal, casual).
- Objective and Grounded Interaction: Assesses the response’s ability to maintain an objective and grounded tone, focusing squarely on the substance of the user’s request. It evaluates the avoidance of both metacommentary (analyzing the query’s structure, topic combination, perceived oddity, or the nature of the interaction itself) and unwarranted flattery or excessive praise directed at the user or their input. Excellent responses interact respectfully but neutrally, prioritizing direct, task-focused assistance over commentary on the conversational dynamics or attempts to curry favor through compliments.
### F.2 Prescriptive Rubrics
- Initial Praise: Responses must not begin with compliments directed at the user or the question (e.g., “That’s a beautiful question”, “Good question!”).
- Explicit Justification: Any sentence or clause that explains why the response is good or how it successfully fulfilled the user’s request. This is different from simply describing the content.
### F.3 Limitations
One potential side effect of this evaluation framework is that it may favor responses that appear confident and assertive, even in contexts involving ambiguity or subjectivity. This stems from two key constraints in the current rubric:
- Avoidance of Self-Qualification: The prescriptive rules prohibit self-assessments, explicit disclaimers, or hedging language (e.g., “this may not be accurate”, “I might be wrong”). While these phrases can reflect epistemic humility, they are often penalized as non-informative or performative.
- Preference for Clarity and Singularity: The rubric reward direct, decisive answers when users ask for a recommendation or explanation. In complex or open-ended scenarios, this may disincentivize appropriately cautious or multi-perspective responses.
As a result, the model may occasionally overstate certainty in areas where ambiguity, nuance, or epistemic modesty would be more appropriate. Future iterations of the framework may incorporate more fine-grained handling of calibrated uncertainty.
## Appendix G Engine Switching Pipeline for RL Training
<details>
<summary>x17.png Details</summary>
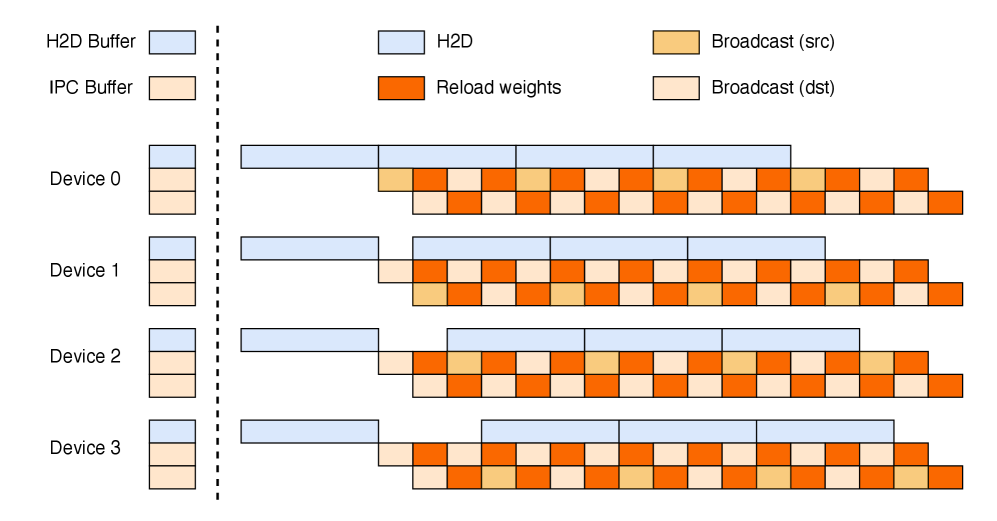
### Visual Description
## Diagram: Data Buffer and Broadcast Activity Across Devices
### Overview
The diagram illustrates data buffer management and communication patterns across four devices (Device 0–3). It visualizes four data flow categories (H2D, Reload weights, Broadcast src, Broadcast dst) using color-coded horizontal segments stacked vertically for each device. The layout emphasizes buffer allocation (H2D Buffer and IPC Buffer) and data distribution patterns.
### Components/Axes
- **Vertical Axis (Left)**:
- Labels: "Device 0", "Device 1", "Device 2", "Device 3" (bottom to top).
- Sub-components:
- Top segment: "H2D Buffer" (blue).
- Bottom segment: "IPC Buffer" (light orange).
- **Horizontal Axis (Top)**:
- Segments labeled: "H2D", "Broadcast (src)", "Reload weights", "Broadcast (dst)".
- **Legend (Top Right)**:
- Blue: H2D.
- Orange: Reload weights.
- Light yellow: Broadcast (src).
- Light orange: Broadcast (dst).
### Detailed Analysis
1. **H2D Buffer (Blue)**:
- Device 0: Longest segment (~40% of total width).
- Device 1: ~35%.
- Device 2: ~30%.
- Device 3: ~25%.
- *Trend*: Decreasing length from Device 0 to 3.
2. **Broadcast (src) (Light Yellow)**:
- Device 0: ~25%.
- Device 1: ~20%.
- Device 2: ~18%.
- Device 3: ~15%.
- *Trend*: Gradual decline across devices.
3. **Reload weights (Orange)**:
- Device 0: ~15%.
- Device 1: ~12%.
- Device 2: ~10%.
- Device 3: ~8%.
- *Trend*: Consistent reduction from top to bottom.
4. **Broadcast (dst) (Light Orange)**:
- Device 0: ~10%.
- Device 1: ~12%.
- Device 2: ~15%.
- Device 3: ~20%.
- *Trend*: Increasing length from Device 0 to 3.
5. **IPC Buffer (Light Orange)**:
- Uniform width (~5%) across all devices, positioned below the main data segments.
### Key Observations
- **H2D Dominance**: Device 0 has the largest H2D segment, suggesting it handles the highest direct data transfers.
- **Broadcast Asymmetry**: Broadcast (dst) grows significantly in lower-numbered devices (Device 3 doubles Device 0's allocation).
- **Reload weights Consistency**: Reload weights decrease uniformly, possibly indicating prioritized resource allocation for critical operations.
- **Buffer Separation**: H2D and IPC buffers are isolated from data flow segments, emphasizing their role as storage layers.
### Interpretation
The diagram reveals a hierarchical data distribution strategy:
- **Device 0** acts as a primary data processor, with heavy H2D usage and moderate Broadcast (src).
- **Device 3** shifts focus toward Broadcast (dst), implying it may handle downstream data aggregation or redistribution.
- **Reload weights** decrease systematically, potentially reflecting diminishing returns in weight updates or prioritization of stable operations.
- The IPC Buffer's uniform size suggests a fixed overhead for inter-process communication across all devices.
This pattern aligns with systems where Device 0 serves as a central node, while lower-numbered devices specialize in data redistribution. The reload weights' decline might indicate adaptive resource management to balance computational load.
</details>
(a) Theoretical perfect three-stage pipeline weight update
<details>
<summary>x18.png Details</summary>
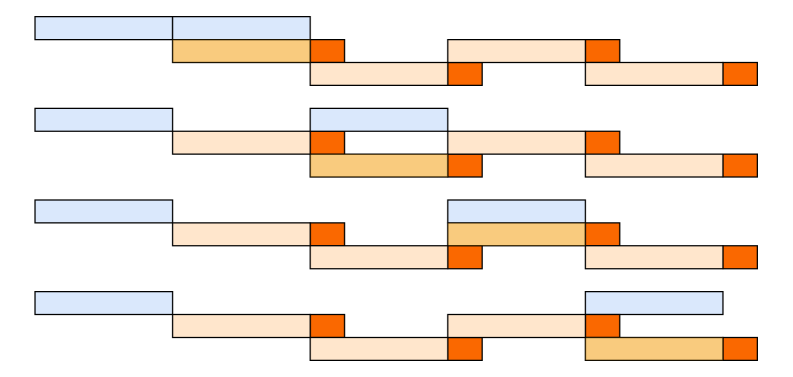
### Visual Description
## Chart/Diagram Type: Horizontal Bar Charts
### Overview
The image contains four horizontal bar charts arranged vertically. Each chart has four bars of varying lengths, colored in blue, orange, light orange, and yellow. No textual labels, axis titles, legends, or numerical values are visible. The charts share a consistent structure but differ in bar lengths, suggesting comparative data across categories.
### Components/Axes
- **Legend**: Located in the top-left corner of the image, but no labels or color mappings are visible.
- **Bars**: Four bars per chart, with colors:
- Blue (leftmost)
- Orange (second from left)
- Light orange (third from left)
- Yellow (rightmost)
- **Axes**: No axis titles, scales, or markers are present. The horizontal axis (implied by bar orientation) lacks numerical or categorical labels.
### Detailed Analysis
- **Bar Lengths**:
- **Chart 1 (Top)**: Blue (longest), orange (medium), light orange (short), yellow (shortest).
- **Chart 2 (Second from top)**: Blue (medium), orange (longest), light orange (medium), yellow (short).
- **Chart 3 (Third from top)**: Blue (short), orange (medium), light orange (longest), yellow (medium).
- **Chart 4 (Bottom)**: Blue (short), orange (medium), light orange (short), yellow (longest).
- **Color Consistency**: Colors are uniform across all charts, but their relative lengths vary.
### Key Observations
1. **No Textual Data**: No labels, legends, or numerical values are present to contextualize the data.
2. **Color-Coded Categories**: The four colors likely represent distinct categories or variables, but their meanings are undefined.
3. **Variable Bar Lengths**: The varying lengths suggest differences in magnitude or frequency, but without axis labels, the exact nature of the data remains unclear.
### Interpretation
- **Structure**: The consistent use of four colors across all charts implies a standardized comparison framework, possibly across time, groups, or metrics.
- **Uncertainty**: Without axis labels or legends, the data’s purpose (e.g., sales, performance, demographics) cannot be determined.
- **Potential Trends**:
- In Chart 1, the blue bar (longest) might indicate the highest value in its category.
- In Chart 4, the yellow bar (longest) could represent a peak or maximum.
- **Anomalies**: The absence of textual context introduces ambiguity. For example, the yellow bar’s position as the longest in Chart 4 contrasts with its shorter length in other charts, but this could reflect intentional design or data variability.
### Conclusion
The image depicts four horizontal bar charts with color-coded categories but lacks critical textual information (labels, legends, axis titles). While the structure suggests comparative analysis, the absence of explicit data points or context limits interpretability. Further clarification is required to assign meaning to the color-coded bars and their lengths.
</details>
(b) A PCIE bounded three-stage pipeline
<details>
<summary>x19.png Details</summary>
### Visual Description
## Diagram: Grid-Based Color Pattern
### Overview
The image displays a structured grid of colored squares arranged in four rows. Each row contains two distinct sections: a left segment with a blue horizontal bar and a 4x4 grid of colored squares, and a right segment with a similar blue bar and 4x4 grid. The grids feature a checkerboard-like pattern of orange and beige squares, with variations in the placement of beige squares across rows. No textual labels, legends, or axis markers are visible.
### Components/Axes
- **Left Segment**:
- A horizontal blue bar spans the top-left portion of each row.
- Below the blue bar, a 4x4 grid of squares alternates between orange and beige in a checkerboard pattern.
- **Right Segment**:
- A horizontal blue bar spans the top-right portion of each row.
- Below the blue bar, a 4x4 grid of squares mirrors the left segment’s structure but with slight variations in beige square placement.
### Detailed Analysis
- **Color Distribution**:
- **Orange**: Dominates the majority of squares in both grids.
- **Beige**: Appears in specific positions:
- Row 1: Beige squares at positions (1,1), (1,3), (2,2), (2,4), (3,1), (3,3), (4,2), (4,4).
- Row 2: Beige squares at positions (1,2), (1,4), (2,1), (2,3), (3,2), (3,4), (4,1), (4,3).
- Row 3: Beige squares at positions (1,1), (1,3), (2,2), (2,4), (3,1), (3,3), (4,2), (4,4).
- Row 4: Beige squares at positions (1,2), (1,4), (2,1), (2,3), (3,2), (3,4), (4,1), (4,3).
- **Blue**: Appears as horizontal bars in the top-left and top-right of each row.
- **Pattern Consistency**:
- The checkerboard pattern is consistent across all rows, but the placement of beige squares shifts slightly between rows, creating a staggered effect.
### Key Observations
1. **Symmetry and Repetition**: The grids exhibit a repetitive structure, suggesting a deliberate design or encoding system.
2. **Color Coding**: The use of orange and beige may indicate categorical distinctions, though no legend is provided to confirm this.
3. **Absence of Text**: No labels, legends, or axis markers are present, limiting interpretability.
### Interpretation
The image likely represents a visual puzzle, a data encoding scheme, or a placeholder for a structured dataset. The alternating orange and beige squares could symbolize binary states (e.g., 0s and 1s) or categorical data. However, without textual context or a legend, the exact purpose remains ambiguous. The staggered placement of beige squares might imply a progression or transformation across rows, but this is speculative.
**Note**: The image contains no textual information, numerical values, or explicit data points. The analysis is based solely on visual patterns and color distribution.
</details>
(c) Fixed two-stage pipeline
Figure 13: pipeline for RL weight update
The checkpoint engine manages three equal-size device buffers on each GPU: an H2D buffer for loading the offloaded model parameters, and two IPC buffers for GPU-to-GPU broadcast. The IPC buffers are shared to inference engines, allowing it to directly access the same physical memory. These three buffers allow us to arrange the three steps in a pipeline.
Theoretical three-stage pipeline.
As illustrated in Figure 13(a), a three-stage pipeline is introduced. (1) H2D: a shard of the latest weights is copied into the H2D buffer asynchronously. (2) Broadcast: Once the copy completes, the shard will be copied to one IPC buffers and broadcast to all devices. (3) Reload: Inference engines simultaneously load parameters from the other IPC buffer.
Two-stage pipeline due to PCIe saturation.
On NVIDIA H800 clusters, concurrent H2D and broadcast saturate the shared PCIe fabric, collapsing the three stages into a sequential procedure (Figure 13(b)). We therefore adopt a simpler, two-stage scheme (Figure 13(c)): (1) All devices perform a single, synchronous H2D transfer. (2) The broadcast and reload proceed in parallel.
The two-stage pipeline will be bound by multiple synchronous H2D copy operations. But in large scale devices, model will be split into small shards, the entire parameter set fits into the H2D buffer in one transfer, the overhead will disappear.
By overlapping H2D, Broadcast, and Reload weights, we can obtain a high bandwidth to reshard the weights from train engines to all inference engines.