# Transparent AI: The Case for Interpretability and Explainability
**Authors**: Dhanesh Ramachandram, Himanshu Joshi, Judy Zhu, Dhari Gandhi, Lucas Hartman, Ananya Raval
> Vector Institute for Artificial Intelligence, Toronto
(July 31, 2025)
## Abstract
As artificial intelligence systems increasingly inform high-stakes decisions across sectors, transparency has become foundational to responsible and trustworthy AI implementation. Leveraging our role as a leading institute in advancing AI research and enabling industry adoption, we present key insights and lessons learned from practical interpretability applications across diverse domains. This paper offers actionable strategies and implementation guidance tailored to organizations at varying stages of AI maturity, emphasizing the integration of interpretability as a core design principle rather than a retrospective add-on.
Contents
1. 1 Introduction
1. 1.1 Background and Motivation
1. 1.2 Scope and Objectives
1. 2 Fundamentals of Interpretability and Explainability
1. 2.1 Definitions and Key Concepts
1. 2.2 Taxonomy of Methods
1. 3 Policy Landscape and Regulatory Considerations
1. 4 Stakeholder-Specific Guidelines
1. 4.1 For Data Scientists and ML Specialists
1. 4.2 For Business Leaders and Decision Makers
1. 4.3 For Regulators and Policy Makers
1. 4.4 For End Users
1. 5 Incorporating Interpretability into AI Development Workflow
1. 5.1 Design Phase: Choosing Appropriate Models and Methods
1. 5.1.1 Problem Formulation and Requirements Analysis
1. 5.1.2 Model Architecture Selection
1. 5.1.3 Data Preparation Strategy
1. 5.2 Deployment Phase: Explaining AI in Production
1. 5.3 Monitoring and Maintenance
1. 6 Standardized Reporting Framework for Interpretable Models
1. 6.1 Proposed Reporting Template
1. 6.2 Essential Elements to Document
1. 6.3 Case Study: Implementing the Reporting Framework
1. 6.4 Medical Imaging Diagnostic Support System
1. 7 Evaluation Methods for Model Interpretability and Explainability
1. 8 Challenges and Limitations
1. 8.1 Technical Challenges
1. 8.2 The Interpretability-Performance Trade-off
1. 8.3 Human Factors and Cognitive Limitations
1. 8.4 Organizational Barriers to Adoption
1. 9 Interpretability Applications and Cross-Industry Learnings
1. 9.1 Interpretability Across Domains: Purpose and Practice
1. 9.2 Key Cross-Sector Observations and Insights
1. 9.3 Domain-Specific Highlights
1. 9.4 Learnings: Practical Adoption of Interpretability
1. 9.5 The Web Portal Initiative: One-Stop Resource for Interpretable AI
1. 9.6 Proposed Roadmap for Industry Adoption of Interpretability
1. 10 Conclusion and Recommendations
## 1 Introduction
### 1.1 Background and Motivation
The increasing reliance on artificial intelligence (AI) and machine learning (ML) systems in critical sectors such as healthcare, finance, and public administration highlights the importance of transparency in their decision-making processes [3]. A central challenge faced in deploying these technologies involves balancing model performance and interpretability. While advanced models such as deep neural networks provide exceptional predictive capabilities, their complexity often results in a lack of transparency, commonly referred to as “black box” behavior [11].
Consider, for instance, a medical diagnostic tool that boasts a mere 2% error rate but offers no explanation of its predictions compared to a human physician whose decisions have a 15% error rate but can be fully explained. Most stakeholders would hesitate to trust a system that cannot justify its decisions despite superior performance metrics. This example underscores the critical balance between performance and interpretability, a core concern in the ethical and practical deployment of AI.
The demand for explainable and interpretable AI goes beyond academic interest and is being increasingly recognized as essential for the responsible and ethical use of AI in sectors directly impacting human health, safety, and legal rights. As highlighted by [3], interpretability becomes especially crucial in situations where incorrect predictions have significant consequences, stakeholder justification is required, or regulatory frameworks demand transparency. Examples of such domains are as follows:
Healthcare Applications:
In healthcare, the importance of interpretability cannot be overstated. Clinicians, such as radiologists employing AI tools for cancer detection, require clarity not only on the prediction itself but also on the specific factors influencing that prediction. Without this insight, healthcare professionals cannot confidently integrate AI recommendations with clinical judgment, potentially risking patient outcomes through misdiagnoses or incorrect treatments. Moreover, patients and their families possess a fundamental right to clear explanations about medical decisions affecting their care. The interpretability challenge intensifies in urgent medical scenarios.
Financial Services:
In finance, interpretability addresses both regulatory compliance and ethical accountability. For example, financial institutions must justify credit decisions clearly and transparently to comply with fair lending regulations. According to [11], while 58% of studies on explainable AI involve quantitative evaluations, many do not adequately meet the stringent transparency requirements imposed by financial regulations, which demand accurate, reliable, and legally defensible explanations.
Public Sector and Justice:
Governmental use of algorithmic decision-making for allocating resources, determining eligibility for benefits, and criminal justice applications places interpretability at the forefront of public accountability. Citizens expect clear explanations for decisions impacting their lives, highlighting the democratic necessity of interpretable AI in the public sector. Transparency in these decisions not only supports fairness but also reinforces trust in public institutions.
### 1.2 Scope and Objectives
Given these challenges and imperatives, this white paper provides a high-level overview of interpretability and explainable AI, outlines essential principles for achieving transparency, discusses domain-specific considerations for effective explanations, reviews suitable evaluation methods, and offers practical insights to help organizations integrate interpretable AI responsibly into their decision-making processes. Lessons learned from conducting industry-focused interpretability application on this topic with diverse participation from the Canadian AI ecosystem are also presented. It is hoped that this whitepaper will help drive adoption of explainability and interpretable models across various industries by providing some adoption guidelines.
## 2 Fundamentals of Interpretability and Explainability
### 2.1 Definitions and Key Concepts
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Conceptual Diagram: Transparent AI Framework
### Overview
The image is a conceptual diagram illustrating the relationship between three key terms in artificial intelligence ethics and design: **Interpretability**, **Explainability**, and **Transparent AI**. It uses overlapping geometric shapes (hexagons) to visually represent how the first two concepts combine to form the third.
### Components/Axes
The diagram consists of three primary text labels, each associated with a colored hexagonal shape, and a central overlapping region.
1. **Top-Center Element:**
* **Label:** "Transparent AI"
* **Subtitle/Description:** "Models that are both understandable and justifiable"
* **Associated Shape:** A gray hexagon positioned in the center, formed by the overlap of the two larger hexagons below it.
2. **Left Element:**
* **Label:** "Interpretability"
* **Subtitle/Description:** "Model transparency and understanding"
* **Associated Shape:** A light blue hexagon positioned on the left side of the diagram.
3. **Right Element:**
* **Label:** "Explainability"
* **Subtitle/Description:** "Post-decision reasoning and justification"
* **Associated Shape:** A light green (mint) hexagon positioned on the right side of the diagram.
### Detailed Analysis
* **Spatial Layout:** The diagram is arranged with "Transparent AI" at the top. Below it, the "Interpretability" (blue) hexagon is on the left, and the "Explainability" (green) hexagon is on the right. They overlap significantly in the center.
* **Visual Metaphor:** The central gray hexagon is explicitly created by the intersection of the blue and green hexagons. This visually communicates that "Transparent AI" is the product or intersection of "Interpretability" and "Explainability."
* **Text Transcription:**
* **Top:** `Transparent AI` / `Models that are both understandable and justifiable`
* **Left:** `Interpretability` / `Model transparency and understanding`
* **Right:** `Explainability` / `Post-decision reasoning and justification`
### Key Observations
* The diagram uses a simple Venn-diagram-like logic with hexagons instead of circles.
* Color is used to differentiate the two foundational concepts (blue for Interpretability, green for Explainability) and to highlight their synthesis (gray for Transparent AI).
* The text is concise, providing a one-line definition for each term.
* The layout is balanced and symmetrical, emphasizing the equal importance of the two contributing concepts.
### Interpretation
This diagram presents a clear, hierarchical model for understanding AI transparency. It argues that **Transparent AI** is not a single property but a composite state achieved when an AI system possesses both:
1. **Interpretability:** The inherent, structural clarity of the model itself—how it works and arrives at decisions (the "understandable" part).
2. **Explainability:** The ability to provide meaningful, human-readable justifications for specific outputs or decisions after they occur (the "justifiable" part).
The visual overlap suggests these are distinct but deeply interconnected disciplines. A model might be interpretable in its architecture (e.g., a decision tree) but lack explainability for a specific prediction. Conversely, a complex "black box" model might have post-hoc explainability tools applied to it, offering justification without full inherent interpretability. The diagram posits that true, robust transparency requires both facets. The central, unified gray hexagon represents the ideal state where these two approaches converge, resulting in AI that is both comprehensible in its mechanics and accountable in its actions. This framework is crucial for building trust, ensuring fairness, and meeting regulatory requirements in AI systems.
</details>
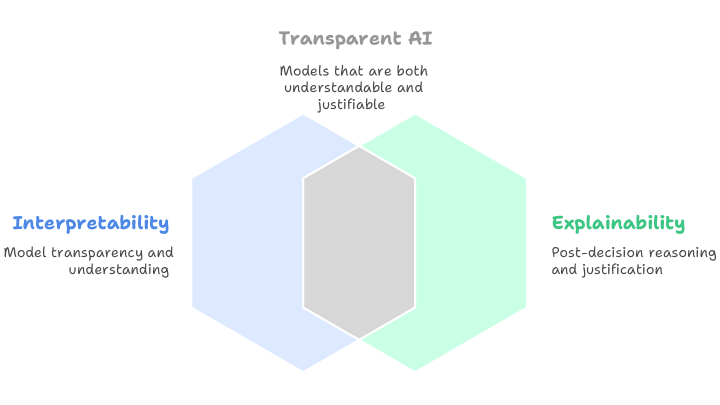
Figure 1: Relationship Between Interpretability, Explainability, and Transparent AI
Interpretability refers to how easily a human can understand the logic and decision-making processes within a machine learning model. Explainability, in contrast, pertains to the ability to provide clear and understandable reasons for specific decisions made by a model after those decisions have been made (Fig. 1).
In practical terms:
- Interpretability addresses the question: “How does the model function internally?”
- Explainability addresses the question: “Why did the model make a particular decision?”
Interpretable or glass-box models, such as decision trees and linear regression, are inherently transparent and understandable by design. In contrast, Explainable AI (XAI) typically involves supplementary techniques aimed at making the outputs and decisions of more complex, black-box models, such as neural networks, understandable and justifiable to users.
With the rapid advancements in artificial intelligence, particularly in deep learning and generative AI technologies, models have become increasingly complex. This growing complexity further underscores the critical need for transparency and interpretability in AI systems. In response to this growing need, a focused area of scientific research has emerged, aimed at developing high-performing AI models that are inherently interpretable. This direction, illustrated in Figure 2, seeks to bridge the gap between model accuracy and transparency. Low High Low High Deep Learning & LLMs Ensemble Models MLPs SVMs Bayesian Models GAMs Logistic Regression Decision Trees Rule-based Learning Ideal solution Interpretable ML research Model Interpretability Model Complexity & Performance Model Interpretability vs. Performance
Figure 2: Trade-off Between Model Interpretability and Learning Performance.
### 2.2 Taxonomy of Methods
Explanation and interpretability methods can be broadly categorized along several dimensions to help practitioners choose appropriate tools for their use case. A common distinction is between model-specific and model-agnostic methods. Model-specific techniques exploit the internal structure of a given model class and are generally more precise, whereas model-agnostic approaches treat the model as a black box and can be applied to a wider range of architectures.
Another useful categorization is local versus global explanations. Local explanations focus on individual predictions, helping users understand why a specific output was produced. Global explanations describe the overall behavior of the model, providing insights into general trends and feature influences.
Some methods also vary by whether they are post hoc applied after model training or whether they are built into the model itself (inherently interpretable). Post hoc methods can be useful for auditing and retrospective analysis, while inherently interpretable models are often designed with transparency from the outset. Understanding these distinctions is essential for selecting techniques that align with organizational goals, domain requirements, and model constraints. It is not the aim of this whitepaper to provide technical descriptions of explainability and interpretable models and for that we refer readers to recent publications [10, 5, 9, 7, 2, 8] In the next section, we discuss the current policy and regulatory landscape in the context of explainability and interpretability
## 3 Policy Landscape and Regulatory Considerations
Governments worldwide are implementing policies that mandate AI interpretability, acknowledging that transparent algorithms are necessary to safeguard individual rights and enable accountable governance. Fo example, the European Union’s proposed Artificial Intelligence Act explicitly requires transparency and explainability for high-risk AI applications, establishing legal obligations for AI system providers to ensure their systems are interpretable by users and affected parties. Similarly, emerging guidelines from healthcare regulators, including the Food and Drug Administration (FDA)’s guidance on AI/ML-based medical devices, emphasize the need for interpretable AI in medical applications where patient safety is paramount. These regulatory developments reflect a paradigm shift where interpretability is not merely a technical preference but a fundamental requirement for ethical AI deployment in society.
Multiple jurisdictions have established comprehensive AI interpretability requirements across general and sector-specific regulations. Canada’s proposed AIDA emphasizes risk-based governance with interpretability assessments during development phases. Sector-specific regulations include FDA guidance requiring clear documentation of AI/ML medical device decision-making and financial regulators expecting interpretable AI-driven risk models under frameworks like Basel III. The EU AI Act mandates transparency for high-risk AI systems and grants individuals the right to clear and meaningful explanations of algorithmic decisions. The US White House Blueprint for AI Bill of Rights (2022) establishes interpretability as a fundamental civil right, requiring notice and explanation for impactful algorithmic systems.
These frameworks converge on several core demands: risk-based transparency requirements where higher-risk applications face stricter interpretability standards, mandatory human oversight capabilities, and individual rights to understand algorithmic decisions affecting them. Practitioners can fulfill these requirements by designing interpretability into systems from the development phase rather than retrofitting, providing clear documentation of decision-making processes, conducting impact assessments to determine appropriate interpretability levels for specific use cases, and ensuring explanations are accessible and understandable to affected parties. The key shift is treating interpretability as a fundamental design requirement rather than an optional technical feature.
Although many regulations call for transparency, few provide clear definitions of what constitutes“sufficient” explanation. Standardizing definitions and evaluation metrics is an ongoing challenge. Most regulatory documents do not explicitly specify how explainability of models should be evaluated, nor what metrics should be used and how these results should be reported. This is possibly due to the multitude of AI-driven applications that exists and may require case-specific evaluation criteria.
Next, we discuss stakeholder specific guidelines pertaining to explainability of ML models and how these stakeholders can play unique roles in furthering this cause for responsible AI.
## 4 Stakeholder-Specific Guidelines
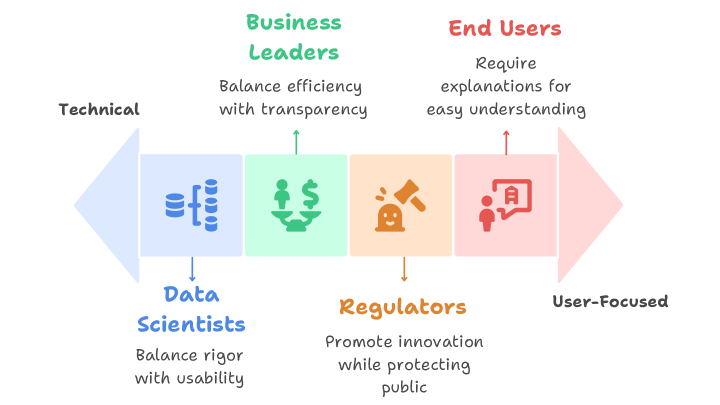
Effective implementation of interpretable and explainable AI depends not only on technical solutions, but also on the collaborative efforts of diverse stakeholder groups. Each group—whether technical experts, business leaders, regulators, or end users—brings unique priorities, constraints, and responsibilities that shape the expectations and requirements for transparency (Fig. 3). Recognizing and addressing these differing perspectives is essential for designing AI systems that are not only accurate but also trusted, understandable, and aligned with real-world needs. These roles are not isolated; rather, they intersect and reinforce one another in the shared pursuit of responsible, transparent AI.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Stakeholder Priorities Spectrum
### Overview
The image is a conceptual diagram illustrating four key stakeholder groups in a technical or business context, positioned along a spectrum from "Technical" to "User-Focused." Each group is represented by a colored block containing an icon, a label, and a core priority statement. The diagram visually maps how different roles balance competing objectives within a system or project.
### Components/Axes
* **Horizontal Spectrum Axis:**
* **Left Anchor:** Labeled "Technical" in black text.
* **Right Anchor:** Labeled "User-Focused" in black text.
* A large, faint arrow in the background points from left to right, reinforcing the directional spectrum.
* **Stakeholder Blocks (arranged left to right along the spectrum):**
1. **Data Scientists (Blue Block):**
* **Icon:** A blue database/server icon.
* **Label:** "Data Scientists" in blue text below the block.
* **Priority Statement:** "Balance rigor with usability" in black text below the label.
* **Position:** Closest to the "Technical" end.
2. **Business Leaders (Green Block):**
* **Icon:** A green icon of hands holding a dollar sign.
* **Label:** "Business Leaders" in green text above the block.
* **Priority Statement:** "Balance efficiency with transparency" in black text below the label.
3. **Regulators (Orange Block):**
* **Icon:** An orange gavel icon.
* **Label:** "Regulators" in orange text below the block.
* **Priority Statement:** "Promote innovation while protecting public" in black text below the label.
4. **End Users (Red Block):**
* **Icon:** A red icon of a person with a speech bubble containing a document.
* **Label:** "End Users" in red text above the block.
* **Priority Statement:** "Require explanations for easy understanding" in black text below the label.
* **Position:** Closest to the "User-Focused" end.
* **Connectors:** Thin, colored arrows point from each stakeholder block to its corresponding priority statement.
### Detailed Analysis
The diagram is structured to show a progression of priorities:
* **Technical End (Left):** The **Data Scientists** are positioned here. Their core tension is between methodological "rigor" and practical "usability," reflecting a need to make complex models both valid and functional.
* **Center-Left:** **Business Leaders** occupy this space. Their focus is on operational "efficiency" balanced with "transparency," indicating a need for systems that are both cost-effective and explainable to stakeholders.
* **Center-Right:** **Regulators** are placed here. Their mandate is dual: fostering "innovation" while "protecting the public," highlighting a governance role that must manage risk and progress.
* **User-Focused End (Right):** **End Users** are at this extreme. Their primary need is for "explanations for easy understanding," emphasizing clarity, accessibility, and usability over technical complexity.
### Key Observations
1. **Spectrum Logic:** The left-to-right arrangement creates a logical flow from creation and analysis (Data Scientists) through management and governance (Business Leaders, Regulators) to consumption and application (End Users).
2. **Color Coding:** Each stakeholder group is consistently associated with a unique color (blue, green, orange, red) for its icon, label, and connecting arrow, enhancing visual differentiation.
3. **Iconography:** The icons are simple, symbolic representations of each group's primary function or concern (data, money, law, communication).
4. **Balancing Acts:** Three of the four priority statements explicitly mention balancing two concepts (rigor/usability, efficiency/transparency, innovation/protection), underscoring the inherent trade-offs in complex systems.
### Interpretation
This diagram serves as a stakeholder alignment model, likely for projects involving data, AI, or complex systems. It argues that successful implementation requires navigating the distinct and sometimes conflicting priorities of these four groups.
* **Underlying Narrative:** The spectrum suggests that as a project or product moves from development (technical) toward deployment (user-focused), the primary concerns shift from internal validity and efficiency to external clarity, safety, and accessibility.
* **Peircean Investigation:** The diagram is a **symbolic** representation (using icons and colors) that makes an **indexical** claim about the relationship between roles and priorities (e.g., Data Scientists are *indexed* to the technical end). Its intended **interpretant** is for a viewer to understand that technical projects must consciously address this full spectrum of needs to be viable and ethical.
* **Notable Implication:** The placement of "Regulators" between "Business Leaders" and "End Users" is significant. It positions regulatory oversight as a bridge between commercial interests and public/user welfare, suggesting its role is to mediate and ensure that business efficiency does not compromise public good or user understanding.
* **Anomaly/Gap:** The diagram does not show conflict or overlap between the groups, presenting their priorities as a clean, linear progression. In reality, these priorities often conflict directly (e.g., Data Scientists' rigor vs. End Users' need for simplicity), and the diagram simplifies these complex negotiations into a spatial model.
</details>
Figure 3: Interpretability Needs Across Stakeholder Groups
### 4.1 For Data Scientists and ML Specialists
Data scientists and ML specialists serve as the primary architects of explainable AI systems, requiring them to balance technical rigor with practical usability while remaining aware of downstream stakeholder needs across diverse application domains. These practitioners face the critical challenge of designing systems that meet both performance requirements and interpretability standards.
When developing interpretable machine learning models, practitioners should prioritize inherently interpretable architectures over post-hoc explanations whenever performance requirements allow, as these approaches provide more reliable and accurate representations of the underlying decision process. Interpretability strategies must be adapted to the specific context in which a model is applied, as domain-specific constraints and the nature of the data heavily shape what is feasible and effective [12]. For example, rule-based models or monotonic constraints may be well-suited for financial risk scoring due to regulatory demands and structured data, whereas in natural language processing, attention mechanisms in LLMs can offer insight into how models weigh different parts of a sentence. These variations highlight the need for technical teams to align their interpretability methods with the practical and technical demands of each domain.
To ensure these interpretable systems deliver meaningful value, data scientists should establish comprehensive evaluation frameworks that extend beyond traditional accuracy metrics. These evaluation pipelines must systematically assess both technical performance and stakeholder understanding, including how explanation quality correlates with model performance indicators and prediction reliability [6]. This holistic evaluation approach ensures that interpretability efforts translate into genuine improvements in user comprehension and decision-making support rather than merely satisfying technical requirements.
### 4.2 For Business Leaders and Decision Makers
Business leaders must balance operational efficiency with transparency requirements while ensuring organizational readiness for explainable AI adoption. Not all machine learning applications require interpretability, particularly for low-stakes decisions or applications with trivial explanations and perfect reliability. We present the following guidelines which are appropriate for leaders and decision makers:
- Risk Assessment: Leaders should categorize AI applications by risk level and regulatory requirements. High-stakes applications involving safety or significant consequences require mandatory explainability protocols, as the lack of explanations during system failures can create serious problems. The task of defining which are high-stakes applications in the organization must be decided upon by technology leaders in collaboration with other relevant stakeholders.
- Resource Allocation: Time-sensitive applications require careful consideration of computational resources for explanation generation. Organizations must balance explanation quality with operational efficiency constraints [6]. For example, in emergency medical diagnosis systems, radiologists must rapidly interpret critical imaging results for stroke patients where every minute affects patient outcomes. While comprehensive explanations showing detailed feature attributions across multiple image regions could provide complete understanding of the AI’s decision-making process, generating such explanations creates significant delays. Organizations must therefore choose between explanation completeness and clinical workflow efficiency, often opting for faster, targeted explanations that provide sufficient insight without delaying life-critical treatment decisions.
- Change Management: Users integrate AI-generated evidence into their existing decision-making processes for various downstream tasks. Organizations must prepare workflows that accommodate AI explanations within established procedures. As an example illustrating this, consider a bank loan officer who traditionally evaluates loan applications by reviewing credit scores, income statements, and employment history in a specific sequence, then makes approval decisions based on established criteria. When AI is introduced to assist with risk assessment, the officer now receives an AI recommendation along with explanations highlighting key risk factors. The organization must modify the existing loan approval workflow to include a step where officers review and interpret the AI explanation, understand how it relates to their traditional evaluation criteria, and decide whether to follow, modify, or override the AI recommendation. This requires training officers on how to incorporate AI insights into their established decision-making process and updating procedures to document how AI explanations influenced final decisions.
- Governance and Oversight: Business leaders should establish clear governance structures that define accountability for AI decisions and explanations. This includes setting up review processes for model updates and ensuring ongoing compliance with evolving regulatory requirements.
### 4.3 For Regulators and Policy Makers
Regulators face the fundamental challenge of creating frameworks that promote innovation while protecting public interests, requiring a nuanced approach that recognizes the technical realities of AI development. Research indicates that interpretability and accuracy are not necessarily in conflict when considering the complete data science process, and this balance can be adjusted based on user preferences and domain requirements. Given that interpretability needs vary significantly across domains and applications, regulatory frameworks must be flexible enough to accommodate these differences while maintaining consistent protection standards.
To achieve meaningful transparency, regulations should prioritize end-user comprehension over technical complexity, ensuring explanations are accessible without requiring specialized expertise and align with professional decision-making patterns. This user-centered approach necessitates standardized testing protocols that assess both technical performance and real-world usability of explanations across different stakeholder groups. Furthermore, while regulations should encourage the development of inherently interpretable models as the preferred approach, they must also address the limitations of post-hoc explanations for black-box models, which can create misleading characterizations and inappropriate confidence in opaque systems, potentially undermining the very transparency goals these regulations seek to achieve.
### 4.4 For End Users
End users, whether clinicians, loan officers, or other domain experts, represent the ultimate beneficiaries of explainable AI systems and require explanations designed for easy understanding without technical knowledge in machine learning or programming. These users naturally assess explanation reasonableness as a way to evaluate AI decision quality, enabling various utilities including decision verification, trust calibration, bias identification, and knowledge discovery. For explanations to be truly effective, they must align with existing professional decision-making processes—for example, medical image interpretation involves systematic feature extraction and diagnostic reasoning that explanations should directly support rather than disrupt. Most critically, interpretable models should enable informed trust decisions rather than promoting automatic trust or distrust, as both overly trusting AI systems (known as automation bias) and users ignoring alarms (alarm fatigue) can lead to dangerous outcomes where critical errors go undetected or legitimate warnings are dismissed. Therefore, users must be properly trained to evaluate and act on AI explanations based on their quality and reliability, ensuring that transparency translates into improved decision-making outcomes rather than blind acceptance or rejection of AI recommendations.
Recent research [4] reveals a critical gap in how different user groups interpret AI explanations, with laypeople basing their trust on explanation faithfulness (how accurately the explanation represents the underlying model) while domain experts rely on explanation alignment (how well explanations match their prior knowledge), suggesting that domain experts may experience cognitive biases due to their expertise. This finding is problematic because faithfulness should be the primary criterion before considering alignment with prior knowledge, yet domain experts in high-stakes domains like medicine may be trusting explanations for the wrong reasons. To address these cognitive biases and interpretation gaps, organizations must implement comprehensive training programs that help all end users understand both the capabilities and limitations of AI explanations, including developing skills for recognizing when explanations may be misleading, when additional verification is needed, and how to properly evaluate explanation faithfulness regardless of their domain expertise.
## 5 Incorporating Interpretability into AI Development Workflow
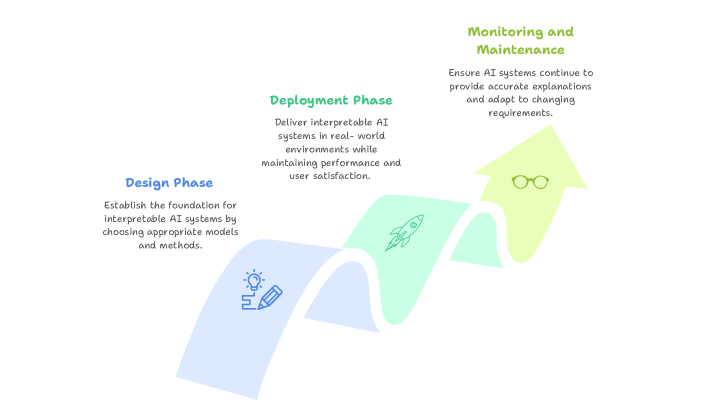
The integration of interpretability into AI development requires a systematic approach that spans the entire machine learning lifecycle. Rather than treating explainability as an afterthought, organizations must embed interpretability considerations from initial design through ongoing maintenance (Fig. 4).
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: AI System Lifecycle Phases
### Overview
The image is a process flow diagram illustrating three sequential phases in the lifecycle of developing and maintaining interpretable AI systems. The diagram uses a single, continuous, upward-curving arrow divided into three colored segments to represent the progression from initial design to ongoing maintenance.
### Components/Axes
The diagram consists of three primary components, each associated with a specific phase and color:
1. **Design Phase (Bottom-Left Segment)**
* **Color:** Light blue
* **Title Text:** "Design Phase" (in blue font)
* **Description Text:** "Establish the foundation for interpretable AI systems by choosing appropriate models and methods."
* **Icon:** A line drawing of a lightbulb (representing an idea) with a pencil (representing design/creation).
2. **Deployment Phase (Middle Segment)**
* **Color:** Light green
* **Title Text:** "Deployment Phase" (in green font)
* **Description Text:** "Deliver interpretable AI systems in real-world environments while maintaining performance and user satisfaction."
* **Icon:** A line drawing of a rocket ship (representing launch and delivery).
3. **Monitoring and Maintenance (Top-Right Segment)**
* **Color:** Light yellow
* **Title Text:** "Monitoring and Maintenance" (in olive green font)
* **Description Text:** "Ensure AI systems continue to provide accurate explanations and adapt to changing requirements."
* **Icon:** A line drawing of a pair of eyeglasses (representing observation and oversight).
**Flow and Spatial Layout:** The arrow originates at the bottom-left with the "Design Phase," curves upward through the middle "Deployment Phase," and terminates at the top-right with "Monitoring and Maintenance." This spatial arrangement visually communicates a forward and upward progression through time or stages of maturity.
### Detailed Analysis
The diagram is purely conceptual and does not contain numerical data, charts, or axes. It presents a high-level, three-stage model for AI system management.
* **Phase 1 (Design):** Focuses on foundational choices—selecting models and methods that prioritize interpretability from the outset.
* **Phase 2 (Deployment):** Focuses on implementation—taking the designed system into practical, real-world use while balancing two key metrics: performance and user satisfaction.
* **Phase 3 (Monitoring & Maintenance):** Focuses on sustainability—ongoing oversight to ensure the system's explanations remain accurate and the system itself can evolve with new requirements.
### Key Observations
* The process is depicted as linear and sequential, with each phase leading directly into the next.
* The upward curve of the arrow suggests progress, improvement, or increasing system maturity over time.
* Each phase is given equal visual weight, implying they are of comparable importance in the overall lifecycle.
* The icons are simple, universal symbols that reinforce the core activity of each phase (ideation, launch, observation).
### Interpretation
This diagram presents a framework for responsible AI development that emphasizes **interpretability as a continuous concern**, not just a design-time feature. It argues that building a trustworthy AI system requires:
1. **Proactive Foundation:** Interpretability must be engineered in from the start ("Design Phase").
2. **Practical Validation:** The system must prove its value and usability in the real world ("Deployment Phase").
3. **Adaptive Governance:** The work isn't done at launch; systems require vigilant monitoring and updates to remain accurate and relevant ("Monitoring and Maintenance").
The model highlights a critical insight: the interpretability of an AI system is not a static property. It can degrade if not maintained, or if the environment it operates in changes. Therefore, the lifecycle extends indefinitely beyond deployment, requiring ongoing resources for monitoring and adaptation. This framework is likely intended for project managers, AI engineers, and stakeholders to structure their development and operational processes.
</details>
Figure 4: Integrating Interpretability Across the AI Lifecycle
### 5.1 Design Phase: Choosing Appropriate Models and Methods
The design phase establishes the foundation for interpretable AI systems by making informed decisions about model architecture, data pre-processing, and explanation methods based on stakeholder requirements and domain constraints.
#### 5.1.1 Problem Formulation and Requirements Analysis
The first step involves defining interpretability requirements based on the application domain and stakeholder needs. Interpretable models incorporate domain-specific constraints that facilitate human understanding, and these constraints vary significantly across different applications. Organizations should conduct thorough stakeholder analysis to understand who will interact with the AI system and what types of explanations they require.
For high-stakes applications, the choice between inherently interpretable models and post-hoc explanation methods becomes critical. Low-stakes decisions may not require interpretability, but applications involving human safety, legal compliance, or medical decisions should prioritize inherently interpretable models.
#### 5.1.2 Model Architecture Selection
The choice of model architecture significantly impacts interpretability potential. Different data types require different interpretability approaches; sparse representations work well for tabular data, while computer vision applications benefit from specialized interpretable neural network architectures. Different model types offer varying levels of inherent interpretability, each with distinct advantages and limitations across application domains. Linear models provide direct coefficient interpretation that works well for tabular data and simple NLP tasks but may lack expressiveness for complex relationships found in image analysis or natural language understanding. Tree-based models offer rule-based explanations that mirror human decision processes, making them particularly effective for structured data applications and some object recognition tasks where decision boundaries can be clearly articulated. Ensemble methods balance predictive power with interpretability through feature importance measures, proving valuable across diverse applications from text classification to medical diagnosis. Neural networks, while powerful for complex tasks like computer vision, advanced NLP, and language generation, typically require specialized architectures or post-hoc methods for interpretability, with techniques ranging from attention mechanisms in transformers for language processing to convolutional layer visualization for image analysis. The choice of model type should therefore align with both the complexity requirements of the specific application domain and the interpretability needs of the end users, whether they are analyzing financial data, interpreting medical images, or understanding automated text generation.
#### 5.1.3 Data Preparation Strategy
Data preprocessing decisions significantly impact subsequent interpretability. Feature engineering should prioritize meaningful, domain-relevant variables that align with stakeholder mental models. The creation of interpretable features often requires domain expertise and close collaboration with end users to ensure explanations will be comprehensible and actionable.
### 5.2 Deployment Phase: Explaining AI in Production
The deployment phase addresses the practical challenges of delivering interpretable AI systems in real-world environments while maintaining performance, reliability, and user satisfaction. Successful production deployment requires careful orchestration of technical architecture, user interface design, and quality assurance processes that collectively ensure explanation systems can operate effectively under operational constraints.
Production architecture design must balance explanation quality with stringent system performance requirements, particularly in time-sensitive applications where computational resources and latency constraints significantly impact explanation generation capabilities. Effective caching strategies become essential, involving pre-computation of explanations for common scenarios to minimize real-time processing overhead and reduce response latency. This approach requires sophisticated prediction of likely explanation requests and intelligent storage management that can quickly retrieve relevant pre-computed explanations while maintaining freshness and accuracy.
Adaptive complexity mechanisms provide another crucial architectural component, enabling systems to deliver different explanation depths based on user expertise levels, available time constraints, and specific decision contexts. Novice users may require comprehensive, step-by-step explanations with extensive contextual information, while expert users might prefer concise summaries that highlight only the most critical decision factors. This adaptability must be implemented through scalable patterns that ensure explanation systems can handle production-level traffic without degrading performance, incorporating load balancing, resource allocation strategies, and efficient processing pipelines that can scale horizontally as demand increases.
Robust fallback mechanisms represent a critical safety consideration, maintaining core system functionality even when explanation generation encounters failures or experiences unexpected delays. These mechanisms might include simplified explanation alternatives, cached historical explanations for similar cases, or graceful degradation that allows the AI system to continue operating with reduced interpretability rather than complete failure.
Seamless user interface integration ensures that explanations enhance rather than disrupt existing workflows, requiring deep understanding of how users naturally inspect AI-generated evidence and incorporate it into their decision-making processes for various downstream tasks. Contextual presentation strategies display explanations at optimal points in user workflows, providing relevant information precisely when users need it without overwhelming them with unnecessary detail or interrupting critical decision processes.
Progressive disclosure techniques allow users to access different levels of explanation detail according to their immediate needs and available cognitive resources. Initial presentations might provide high-level summaries with options to drill down into specific aspects of the decision process, enabling users to control the depth of information they receive based on their confidence levels, time constraints, and expertise. Multi-modal communication approaches combine visual representations, textual descriptions, and interactive explanation formats to accommodate different learning styles and decision-making preferences, while customization options enable users to adjust explanation preferences based on their domain expertise, role requirements, and personal preferences.
Comprehensive quality assurance and testing protocols ensure explanation systems maintain reliability and accuracy under realistic operational conditions. This encompasses stress testing explanation generation capabilities under high computational loads to identify performance bottlenecks and ensure graceful degradation under extreme conditions. Validation procedures verify explanation consistency across different system configurations, deployment environments, and user access patterns, ensuring that explanations remain stable and reliable regardless of the specific technical infrastructure or user interaction modalities.
Continuous verification processes become particularly critical as underlying AI models undergo updates, retraining, or architectural modifications, requiring systematic testing to ensure that explanations remain accurate representations of updated model behavior. This ongoing quality assurance must account for the dynamic nature of production AI systems, where model performance, data distributions, and user requirements may evolve over time, demanding explanation systems that can adapt while maintaining their interpretive fidelity and user utility.
### 5.3 Monitoring and Maintenance
The monitoring and maintenance phase ensures that interpretable AI systems continue to provide accurate, useful explanations throughout their operational lifecycle while adapting to changing requirements and conditions.
Explanation Quality Monitoring: Continuous monitoring systems should track explanation quality metrics to detect degradation or inconsistencies. This includes automated checks for explanation stability, user feedback analysis, and periodic validation against ground truth when available. Organizations should establish thresholds for explanation quality metrics and implement alerting systems when these thresholds are exceeded.
Key monitoring activities include:
- Drift Detection: Monitor for changes in explanation patterns that may indicate model or data drift
- User Engagement Tracking: Analyze how users interact with explanations to identify improvement opportunities
- Performance Impact Assessment: Continuously evaluate the computational cost of explanation generation
- Error Rate Monitoring: Track instances where explanations may have misled users or contributed to incorrect decisions
Adaptive Improvement Processes: Interpretable AI systems should incorporate feedback mechanisms that enable continuous improvement of explanation quality and relevance. This includes collecting user feedback on explanation usefulness, analyzing patterns in user behavior with explanations, and updating explanation methods based on new research and best practices.
Regulatory Compliance Maintenance: As regulatory requirements evolve, organizations must ensure their interpretable AI systems remain compliant. This requires ongoing assessment of explanation adequacy against current regulations, documentation of explanation methodologies for audit purposes, and implementation of processes for updating explanation systems to meet new requirements.
The maintenance phase should also include regular reviews of interpretability requirements with stakeholders, as user needs and domain understanding may evolve over time. Organizations should establish processes for systematically updating explanation methods and retraining models while maintaining explanation quality and consistency.
## 6 Standardized Reporting Framework for Interpretable Models
### 6.1 Proposed Reporting Template
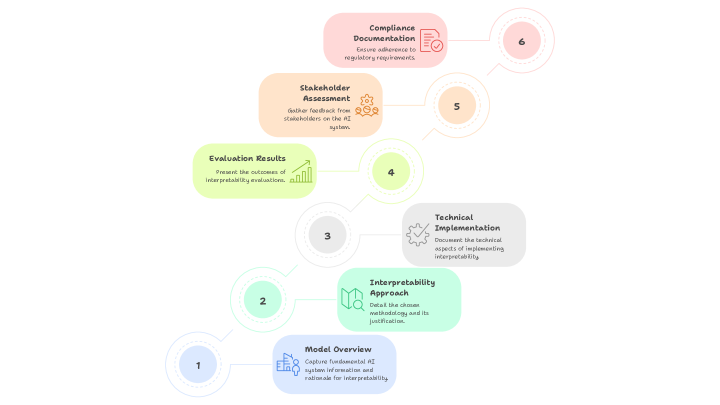
To ensure consistent documentation and evaluation of interpretable AI systems across organizations and domains, we propose a standardized reporting template that captures essential elements of model interpretability. This template serves as a comprehensive guide for practitioners to document their interpretable AI implementations, enabling better transparency, reproducibility, and compliance with regulatory requirements.
The proposed template consists of six major sections: Model Overview, Interpretability Approach, Technical Implementation, Evaluation Results, Stakeholder Assessment, and Compliance Documentation (Fig. 5). Each section contains specific fields and requirements designed to capture the most critical aspects of interpretable AI systems while remaining flexible enough to accommodate diverse application domains and organizational contexts.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Process Diagram: AI Interpretability Documentation Workflow
### Overview
The image displays a six-step sequential process diagram illustrating the workflow for documenting AI system interpretability. The steps are arranged in a zigzag pattern, ascending from the bottom-left to the top-right of the frame. Each step is contained within a rounded rectangular box of a distinct pastel color, connected by thin, curved lines to numbered circles that indicate the sequence. The overall aesthetic is clean, modern, and uses a soft color palette.
### Components/Axes
The diagram consists of six primary components (steps), each with a title, a descriptive text block, and an associated icon. The steps are connected by lines to numbered circles (1 through 6) which establish the order of operations.
**Numbered Sequence Circles:**
* **1:** Light blue circle, bottom-left.
* **2:** Light green circle, positioned above and to the right of step 1.
* **3:** Light grey circle, positioned above and to the right of step 2.
* **4:** Light yellow-green circle, positioned above and to the right of step 3.
* **5:** Light orange circle, positioned above and to the right of step 4.
* **6:** Light pink circle, top-right.
**Process Steps (in sequential order):**
1. **Step 1 (Bottom-Left):**
* **Color:** Light blue box.
* **Title:** `Model Overview`
* **Description:** `Capture fundamental AI model characteristics and rationale for interpretability.`
* **Icon:** A simple line drawing of a brain or neural network.
2. **Step 2:**
* **Color:** Light green box.
* **Title:** `Interpretability Approach`
* **Description:** `Detail the chosen interpretability method and its justification.`
* **Icon:** A magnifying glass over a document or chart.
3. **Step 3:**
* **Color:** Light grey box.
* **Title:** `Technical Implementation`
* **Description:** `Document the technical aspects of implementing interpretability.`
* **Icon:** A gear or cogwheel.
4. **Step 4:**
* **Color:** Light yellow-green box.
* **Title:** `Evaluation Results`
* **Description:** `Present the outcomes of interpretability evaluations.`
* **Icon:** A bar chart with an upward trend.
5. **Step 5:**
* **Color:** Light orange box.
* **Title:** `Stakeholder Assessment`
* **Description:** `Gather feedback from relevant stakeholders on the AI system.`
* **Icon:** A group of three stylized people figures.
6. **Step 6 (Top-Right):**
* **Color:** Light pink box.
* **Title:** `Compliance Documentation`
* **Description:** `Ensure adherence to regulatory requirements.`
* **Icon:** A document with a checkmark seal.
### Detailed Analysis
The diagram outlines a linear, six-phase documentation process for AI interpretability. The flow is clearly directional, moving from foundational understanding (Model Overview) through method selection, technical execution, results evaluation, human feedback, and finally to regulatory formalization.
* **Spatial Flow:** The process begins at the bottom-left (Step 1) and progresses diagonally upward to the top-right (Step 6), suggesting a building or ascending workflow.
* **Visual Grouping:** Each step is visually distinct due to its unique color, but the consistent shape and connecting lines unify them as parts of a single process.
* **Text Transcription:** All text within the six boxes has been transcribed verbatim above. The language is technical and action-oriented (e.g., "Capture," "Detail," "Document," "Present," "Gather," "Ensure").
### Key Observations
1. **Logical Progression:** The sequence follows a logical project lifecycle: define the subject (1), choose a method (2), build it (3), test it (4), get user input (5), and finalize for audit (6).
2. **Stakeholder Inclusion:** Step 5 explicitly introduces human elements ("Stakeholder Assessment") after the technical work is evaluated, indicating that interpretability is not just a technical exercise but also a communicative and social one.
3. **Regulatory Endpoint:** The final step is "Compliance Documentation," highlighting that the ultimate goal of this interpretability process may be to meet external legal or ethical standards.
4. **Iconography:** Each step has a simple, relevant icon that reinforces its title (e.g., a gear for "Technical Implementation," people for "Stakeholder Assessment").
### Interpretation
This diagram represents a **structured framework for creating comprehensive documentation for an AI system's interpretability features.** It is not a generic software development lifecycle but a specialized process focused on making an AI model's decisions understandable and accountable.
The workflow suggests that true AI interpretability requires more than just technical implementation (Step 3). It necessitates:
* **A clear starting rationale** (Why do we need to interpret this model? - Step 1).
* **A justified methodology** (How will we interpret it? - Step 2).
* **Validation through evaluation** (Did our method work? - Step 4).
* **Social validation** (Do stakeholders understand and trust the explanations? - Step 5).
* **Formalization for governance** (Can we prove compliance? - Step 6).
The placement of "Compliance Documentation" as the final output implies that the entire process is geared towards producing an auditable artifact. This positions AI interpretability as a critical component of responsible AI governance, risk management, and regulatory adherence. The diagram serves as a checklist or roadmap for teams to ensure they address all necessary dimensions—technical, evaluative, social, and legal—when documenting how and why their AI models make decisions.
</details>
Figure 5: Key Components of a Standardized Reporting Template for Interpretable AI Systems
Section 1: Model Overview This section captures fundamental information about the AI system, including the problem domain, intended use case, target users, and business context. It should specify the model architecture, data sources, training methodology, and performance characteristics. Additionally, it documents the rationale for requiring interpretability in this specific application and the expected benefits for stakeholders.
Section 2: Interpretability Approach This section details the chosen interpretability methodology, whether inherently interpretable models or post-hoc explanation techniques. It should justify the selection of specific interpretability approaches based on domain requirements, user needs, and technical constraints. The documentation should include a clear mapping between interpretability techniques and their intended purposes, such as global model understanding, local prediction explanations, or feature importance analysis.
### 6.2 Essential Elements to Document
The standardized reporting framework requires documentation of twelve essential elements that collectively provide a comprehensive view of the interpretable AI system’s design, implementation, and effectiveness.
Interpretability Requirements and Justification: Document the specific reasons why interpretability is necessary for this application, including regulatory requirements, stakeholder needs, risk assessment outcomes, and business objectives. This section should clearly articulate the expected benefits of interpretability and how they align with organizational goals.
Stakeholder Analysis: Identify all stakeholders who will interact with or be affected by the AI system’s explanations, including their technical background, domain expertise, decision-making responsibilities, and specific information needs. This analysis should inform the design of explanation interfaces and content.
Model Architecture and Design Decisions: Provide detailed documentation of the chosen model architecture, including the rationale for selecting inherently interpretable models versus complex models with post-hoc explanations. Document any architectural modifications made to enhance interpretability and their impact on model performance.
Explanation Generation Methods: Describe the specific techniques used to generate explanations, including their theoretical foundations, implementation details, computational requirements, and limitations. For post-hoc methods, document validation procedures used to ensure explanation fidelity and reliability.
Technical Performance Metrics: Report both predictive performance metrics (accuracy, precision, recall, etc.) and interpretability-specific metrics (fidelity, stability, consistency, completeness). Include statistical significance tests and confidence intervals where appropriate, and acknowledge any trade-offs between performance and interpretability.
Human-Centered Evaluation Results: Document the results of user studies, including task performance measurements, trust calibration assessments, mental model alignment evaluations, and actionability assessments. Report both quantitative metrics and qualitative feedback from actual end users.
Deployment Architecture: Describe the technical infrastructure used to deliver explanations in production, including caching strategies, performance optimization techniques, fallback mechanisms, and scalability considerations. Document any limitations or constraints that affect explanation availability or quality.
Quality Assurance Procedures: Detail the processes used to ensure explanation quality, including validation protocols, monitoring systems, alerting mechanisms, and continuous improvement procedures. Document quality thresholds and the actions taken when these thresholds are exceeded.
Regulatory Compliance: Provide evidence of compliance with relevant regulations and standards, including documentation of explanation adequacy, audit trails, and processes for maintaining compliance as requirements evolve. Include references to specific regulatory frameworks and their requirements.
Risk Assessment and Mitigation: Document potential risks associated with the interpretable AI system, including risks of misleading explanations, over-reliance on AI recommendations, or misinterpretation of explanations. Describe mitigation strategies and monitoring procedures for each identified risk.
Maintenance and Update Procedures: Outline processes for maintaining explanation quality over time, including procedures for updating explanation methods, retraining models, monitoring explanation drift, and incorporating user feedback. Document version control procedures and change management processes.
Limitations and Known Issues: Acknowledge limitations of the interpretability approach, including scenarios where explanations may be incomplete or misleading, technical constraints that affect explanation quality, and areas where further research or development is needed.
### 6.3 Case Study: Implementing the Reporting Framework
To demonstrate the practical application of the standardized reporting framework, we present a case study of its implementation in a healthcare AI system for diagnostic imaging. This case study illustrates how the framework can be adapted to specific domain requirements while maintaining consistency and comprehensiveness.
### 6.4 Medical Imaging Diagnostic Support System
Model Overview: The system assists radiologists in detecting lung cancer in chest X-rays, serving as a second opinion tool in a hospital radiology department. The target users are board-certified radiologists with varying levels of experience in chest imaging. The business context involves improving diagnostic accuracy while maintaining radiologist autonomy in final decision-making.
Interpretability Approach: Given the high-stakes medical context and regulatory requirements, the team selected an inherently interpretable ensemble model combining generalized additive models with attention-based neural networks. This hybrid approach enables both global feature understanding and local explanation of specific predictions while maintaining competitive diagnostic accuracy.
Technical Implementation: The model processes chest X-rays through a specialized interpretable neural network architecture that generates pixel-level attribution maps highlighting regions most relevant to the cancer detection decision. Global explanations show the model’s overall decision patterns across different demographic groups and imaging conditions.
Evaluation Results: The system achieved 94.2
Regulatory Compliance: The system meets FDA requirements for AI/ML-based medical devices, with comprehensive documentation of explanation methodologies and validation procedures. Regular audits ensure ongoing compliance with evolving regulations.
This case study demonstrates how the reporting framework captures essential information while remaining practical for real-world implementation. The standardized format enables comparison across different systems and domains while ensuring that critical aspects of interpretable AI are consistently documented and evaluated.
## 7 Evaluation Methods for Model Interpretability and Explainability
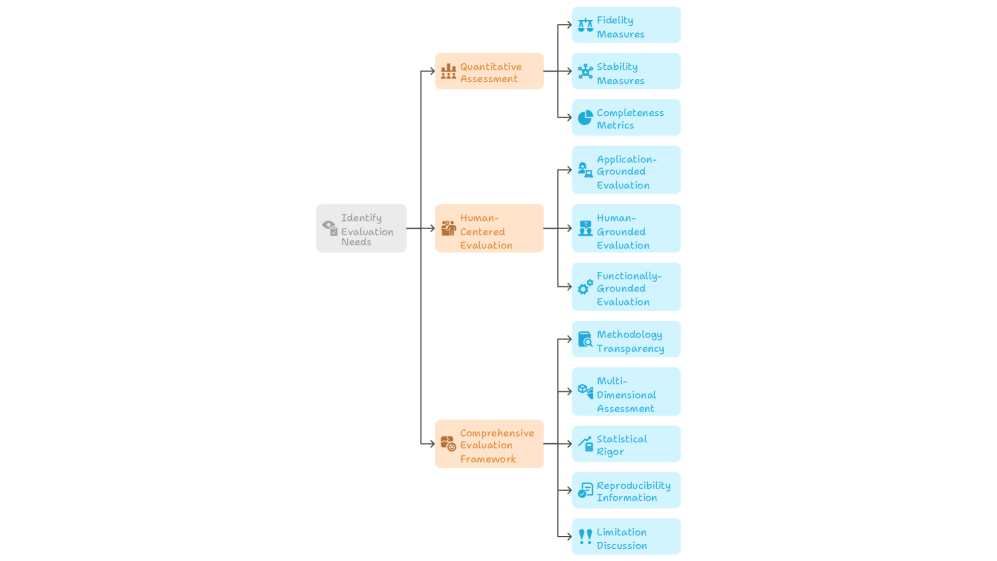
The evaluation of explainable artificial intelligence (XAI) methods presents unique challenges as it requires measuring subjective qualities like comprehensibility, faithfulness, and usefulness rather than traditional predictive performance metrics. Quantitative assessment methods provide objective measures through functionally-grounded evaluation, including fidelity measures that test how faithfully explanations represent model behavior through perturbation-based approaches, stability measures that assess explanation robustness across similar inputs, and completeness metrics that evaluate whether explanations capture the full scope of model behaviour [3, 13, 1]. For specialized domains like time-series data, novel metrics such as area under the top curve and modified F1 scores have been developed to address temporal dependencies and sequential relationships [14].
Human-centered evaluation directly assesses explanation quality from the user perspective, recognizing that interpretability ultimately depends on human comprehension and utility. This approach follows a three-level framework: application-grounded evaluation with real end-users performing actual domain tasks, human-grounded evaluation using simplified tasks with lay participants, and functionally-grounded evaluation using computational proxies. Task-based evaluations include forward simulation where participants predict model outputs from explanations, counterfactual reasoning to test understanding of decision boundaries, and trust assessment to measure appropriate calibration of user confidence in model predictions [3, 11].
A comprehensive evaluation framework organizes explanation quality into twelve properties (Co-12) across content dimensions (correctness, completeness, consistency), presentation aspects (compactness, composition, confidence), and user considerations (context, coherence, controllability). The selection of evaluation methods should align with application context, employing multiple quantitative metrics for general-purpose assessment, prioritizing human-centered evaluation with domain experts for specific applications, and using functionally-grounded methods for iterative research and development [11, 15].
Comprehensive evaluation reporting should include:
Methodology Transparency: Clearly describe evaluation procedures, including data preprocessing, perturbation strategies, and baseline comparisons. Report both positive and negative results to avoid publication bias.
Multi-Dimensional Assessment: Report metrics across multiple Co-12 properties rather than focusing on single measures. Acknowledge trade-offs between different quality aspects.
Statistical Rigor: Include confidence intervals, significance tests, and multiple random seeds when applicable. Report both individual instance results and aggregate statistics.
Reproducibility Information: Provide sufficient implementation details, dataset descriptions, and code availability to enable replication studies.
Limitation Discussion: Explicitly acknowledge evaluation limitations, including cases where methods may not generalize or where evaluation metrics may not capture all relevant quality aspects.
The field continues evolving toward more standardized evaluation practices, with growing recognition that comprehensive assessment requires combining multiple evaluation approaches rather than relying on single metrics or methodologies.
<details>
<summary>x5.png Details</summary>
### Visual Description
\n
## Diagram: Evaluation Needs Framework
### Overview
The image displays a hierarchical flowchart or mind map that outlines a structured framework for identifying and categorizing evaluation needs. The diagram flows from left to right, starting with a central objective that branches into three primary assessment approaches, each of which further subdivides into specific evaluation components or criteria. The visual uses a color-coded system with icons to differentiate between levels of the hierarchy.
### Components/Axes
The diagram is organized into three distinct hierarchical levels, connected by directional arrows indicating a flow from general to specific.
**Level 1 (Root Node):**
* **Position:** Left-center of the image.
* **Label:** "Identify Evaluation Needs"
* **Color:** Light gray box.
* **Icon:** A magnifying glass over a document.
**Level 2 (Primary Assessment Categories):**
Three orange boxes branch from the root node.
1. **Top Branch:** "Quantitative Assessment"
* **Icon:** A bar chart.
2. **Middle Branch:** "Human-Centered Evaluation"
* **Icon:** A group of people.
3. **Bottom Branch:** "Comprehensive Evaluation Framework"
* **Icon:** A clipboard with a checklist.
**Level 3 (Specific Components/Metrics):**
Each Level 2 category branches into several light blue boxes, representing specific evaluation dimensions.
* **From "Quantitative Assessment":**
1. "Fidelity Measures" (Icon: Scales)
2. "Stability Measures" (Icon: A star or spark)
3. "Completeness Metrics" (Icon: A pie chart)
* **From "Human-Centered Evaluation":**
1. "Application-Grounded Evaluation" (Icon: A person with a gear)
2. "Human-Grounded Evaluation" (Icon: Two people)
3. "Functionally-Grounded Evaluation" (Icon: A gear)
* **From "Comprehensive Evaluation Framework":**
1. "Methodology Transparency" (Icon: A document with an eye)
2. "Multi-Dimensional Assessment" (Icon: A cube or 3D shape)
3. "Statistical Rigor" (Icon: A line graph trending upward)
4. "Reproducibility Information" (Icon: Two circular arrows)
5. "Limitation Discussion" (Icon: An exclamation mark in a triangle)
### Detailed Analysis
The diagram presents a complete taxonomy for evaluation planning. The flow is strictly hierarchical and non-cyclical.
* **Spatial Grounding:** The legend (color and icon coding) is embedded directly within the diagram's structure. The root is gray, primary categories are orange, and specific components are blue. Icons are consistently placed to the left of each text label within their respective boxes.
* **Trend Verification:** As a structural diagram, there are no numerical trends. The "trend" is the logical decomposition from a broad goal ("Identify Evaluation Needs") into increasingly specific and actionable evaluation strategies and metrics.
* **Component Isolation:**
* **Header/Root:** The single starting point.
* **Main Body:** The three parallel branches representing distinct philosophical or methodological approaches to evaluation (quantitative, human-centered, comprehensive).
* **Leaves/Details:** The eleven specific blue boxes that constitute the actual checklist or framework components to be addressed.
### Key Observations
1. **Symmetry and Balance:** The framework is visually balanced, with the "Human-Centered Evaluation" branch placed centrally, suggesting it may be a core or integrative component between purely quantitative and broadly comprehensive approaches.
2. **Comprehensiveness:** The "Comprehensive Evaluation Framework" branch contains the most sub-components (5), indicating it is the most detailed or multifaceted category, encompassing procedural (Transparency, Reproducibility), analytical (Statistical Rigor, Multi-Dimensional), and reflective (Limitation Discussion) elements.
3. **Iconography:** Each label is paired with a simple, representative icon, aiding in quick visual recognition of the concept (e.g., scales for "Fidelity," people for "Human-Grounded").
### Interpretation
This diagram represents a **systematic and multi-faceted approach to evaluation design**, likely for a technical system, research study, or complex project. It argues that robust evaluation cannot rely on a single method.
* **What it suggests:** Effective evaluation requires starting from a clear identification of needs, then pursuing at least three parallel tracks: 1) objective, numerical measurement (**Quantitative**), 2) assessment based on user experience, context, and practical application (**Human-Centered**), and 3) a holistic framework ensuring methodological soundness, transparency, and critical self-assessment (**Comprehensive**).
* **Relationships:** The three Level-2 categories are presented as complementary, not mutually exclusive. A thorough evaluation plan would likely incorporate elements from all three branches. The "Comprehensive" branch acts as a meta-framework, ensuring the processes behind both the quantitative and human-centered evaluations are rigorous and credible.
* **Notable Implication:** The inclusion of "Limitation Discussion" and "Reproducibility Information" as explicit components highlights an understanding that evaluation is not just about reporting successes, but also about providing context, acknowledging boundaries, and enabling verification—a sign of mature scientific or engineering practice. This framework moves beyond simple metric reporting to advocate for a responsible and transparent evaluation culture.
</details>
Figure 6: Multi-Level Evaluation Framework for Interpretability Methods
## 8 Challenges and Limitations
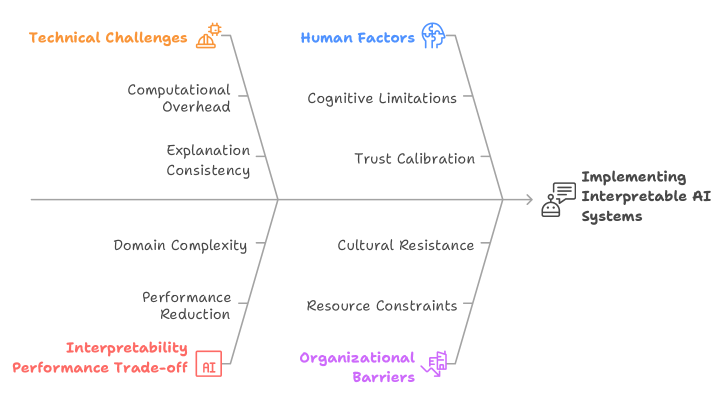
Despite growing interest and advancements in interpretable AI, several technical, human, and organizational barriers continue to impede its widespread implementation. These challenges are often interdependent and must be addressed holistically to build AI systems that are not only accurate but also trustworthy, transparent, and aligned with human values. Key challenges across four dimensions emerge: technical limitations, trade-offs with performance, human cognitive factors, and institutional constraints—that impact the effective integration of interpretability into AI systems(Fig. 7).
<details>
<summary>x6.png Details</summary>
### Visual Description
## Fishbone Diagram: Challenges in Implementing Interpretable AI Systems
### Overview
The image is a fishbone (Ishikawa) diagram illustrating the multifaceted challenges associated with "Implementing Interpretable AI Systems." The diagram organizes these challenges into four primary categories, each branching off a central spine that points to the main effect or goal. The visual style is clean and schematic, using color-coding and icons to differentiate the categories.
### Components/Axes
* **Central Spine & Effect:** A horizontal line runs from left to right, terminating in an arrow pointing to the main subject: **"Implementing Interpretable AI Systems"**. This text is accompanied by a small icon depicting a person at a computer with a document.
* **Primary Categories (Bones):** Four main branches connect to the central spine. Each is labeled with a category title, a distinct color, and a small thematic icon.
1. **Top-Left Branch (Orange):** Labeled **"Technical Challenges"** with a gear/cog icon.
2. **Top-Right Branch (Blue):** Labeled **"Human Factors"** with a head/brain icon.
3. **Bottom-Left Branch (Red):** Labeled **"Interpretability Performance Trade-off"** with an "AI" icon inside a box.
4. **Bottom-Right Branch (Purple):** Labeled **"Organizational Barriers"** with an icon of a building or organization chart.
* **Sub-Factors (Smaller Bones):** Each primary category has two specific challenges listed as text along its branch.
### Detailed Analysis
**1. Technical Challenges (Orange, Top-Left):**
* **Sub-factor 1:** "Computational Overhead"
* **Sub-factor 2:** "Explanation Consistency"
**2. Human Factors (Blue, Top-Right):**
* **Sub-factor 1:** "Cognitive Limitations"
* **Sub-factor 2:** "Trust Calibration"
**3. Interpretability Performance Trade-off (Red, Bottom-Left):**
* **Sub-factor 1:** "Domain Complexity"
* **Sub-factor 2:** "Performance Reduction"
**4. Organizational Barriers (Purple, Bottom-Right):**
* **Sub-factor 1:** "Cultural Resistance"
* **Sub-factor 2:** "Resource Constraints"
### Key Observations
* The diagram presents a balanced view, attributing challenges equally to technical, human, performance, and organizational domains.
* The challenges are framed as inherent tensions or obstacles (e.g., "Trade-off," "Barriers," "Limitations," "Constraints").
* The use of color and icons provides immediate visual categorization, separating the types of challenges.
* The flow is logical: the four categories of challenges (the "causes" in fishbone terminology) all feed into the central problem or effect of implementing interpretable AI.
### Interpretation
This diagram argues that the difficulty of deploying interpretable AI is not a singular technical problem but a systemic one. It suggests that success requires navigating a complex web of interconnected issues:
* **Technical vs. Human:** Even if a technically consistent and computationally feasible explanation is generated (addressing *Technical Challenges*), it must still align with human cognitive limits and foster appropriate trust (addressing *Human Factors*).
* **Performance vs. Interpretability:** The core trade-off is highlighted, where seeking interpretability may be constrained by the complexity of the domain and could lead to a reduction in raw model performance.
* **Individual vs. Organizational:** Beyond the model and its users, broader organizational culture and resource allocation (*Organizational Barriers*) are critical, often-overlooked factors that can determine adoption.
The diagram serves as a diagnostic tool or a checklist for stakeholders. It implies that a holistic strategy—considering engineering, human-computer interaction, model validation, and change management—is essential for the successful implementation of interpretable AI systems. The absence of numerical data indicates this is a conceptual framework for identifying problem areas rather than a quantitative analysis.
</details>
Figure 7: Key Challenges to Implementing Interpretable AI Systems
### 8.1 Technical Challenges
The implementation of interpretable AI systems faces several significant technical challenges that organizations must navigate carefully. Computational overhead represents one of the most immediate concerns, as generating high-quality explanations often requires substantial processing power and time, particularly for complex models and large datasets. Real-time applications face especially acute constraints, where the latency introduced by explanation generation can compromise system responsiveness and user experience.
Explanation consistency poses another critical challenge, particularly when multiple interpretation methods are applied to the same model or decision. Different explanation techniques may yield conflicting insights about the same prediction, creating confusion for users and undermining confidence in the interpretability system. This inconsistency can arise from fundamental differences in how various methods operate, from gradient-based approaches that may be sensitive to input perturbations to sampling-based methods that introduce stochastic variation.
Scalability challenges emerge as organizations attempt to deploy interpretable AI systems across large-scale operations. Explanation methods that work well for individual predictions or small datasets may not scale effectively to enterprise-level deployments with millions of daily predictions. The infrastructure required to support explanation generation, storage, and delivery can become prohibitively expensive, particularly for organizations operating under tight budget constraints.
### 8.2 The Interpretability-Performance Trade-off
A common perception is that increasing model interpretability comes at the cost of performance. However, recent arguments suggest this is a false dichotomy. Rudin et al. (2022) advocate that in many high-stakes applications, interpretable models can match or even outperform black-box models.
The interpretability-performance trade-off manifests differently across application domains and use cases. In domains where the underlying relationships are relatively simple or well-understood, inherently interpretable models like linear regression or decision trees can achieve performance comparable to more complex alternatives while providing complete transparency. However, in domains involving high-dimensional data, complex non-linear relationships, or subtle pattern recognition tasks, the performance gap between interpretable and black-box models may be more significant.
Organizations must carefully assess this trade-off in the context of their specific requirements. For high-stakes decisions where understanding the reasoning process is paramount—such as medical diagnosis, loan approval, or criminal justice applications—accepting some performance reduction in favor of interpretability may be justified. Conversely, for applications where performance is critical and the consequences of individual errors are manageable, organizations might prioritize accuracy over interpretability.
Use of inherently interpretable models is especially crucial in domains such as medicine, where understanding and accountability are paramount. For lower-risk applications (e.g., targeted advertising), black-box models may be acceptable provided proper governance and monitoring are in place.
### 8.3 Human Factors and Cognitive Limitations
The effectiveness of interpretable AI systems is fundamentally limited by human cognitive capacity and information processing constraints. Users have finite attention spans and working memory, meaning that explanations must be carefully designed to convey the most important information without overwhelming cognitive resources. Complex explanations with too much detail can be counterproductive, leading to information overload and poor decision-making.
Cognitive biases present another significant challenge, as users may interpret explanations through the lens of their existing beliefs and expectations. Confirmation bias can lead users to focus on explanation elements that support their preconceptions while ignoring contradictory information. Anchoring bias may cause users to over-weight the first piece of explanation information they encounter, while availability bias might lead them to overestimate the importance of easily recalled examples or patterns.
Domain expertise creates additional complexity, as expert users and novices have fundamentally different information needs and interpretation patterns. Experts may prefer concise, technical explanations that align with their professional knowledge, while novices require more comprehensive, educational explanations that build understanding from basic principles. Designing explanation systems that effectively serve both audiences without compromising utility for either represents a significant challenge.
Trust calibration presents a particularly complex human factor challenge. Users must develop appropriate levels of trust in AI systems—neither over-trusting nor under-trusting the technology. Explanations play a crucial role in this calibration process, but poorly designed explanations can lead to inappropriate trust levels, whether excessive confidence in flawed systems or unnecessary skepticism toward reliable ones.
### 8.4 Organizational Barriers to Adoption
Organizations face numerous structural and cultural barriers to implementing interpretable AI systems effectively. Resource constraints often limit the ability to invest in the additional development time, computational infrastructure, and specialized expertise required for interpretable AI. Organizations operating under tight budgets or aggressive timelines may view interpretability as a luxury rather than a necessity, particularly when regulatory requirements are unclear or loosely enforced.
Cultural resistance to transparency can present significant obstacles, particularly in organizations with hierarchical decision-making structures or competitive cultures where information is viewed as power. Some stakeholders may resist interpretable AI systems because they fear that transparency will expose inefficiencies, biases, or errors in existing processes. This resistance can manifest as reluctance to provide training data, participate in user studies, or adopt new workflows that incorporate AI explanations.
Technical debt and legacy system integration pose practical implementation challenges. Organizations with established AI systems may find it difficult to retrofit interpretability capabilities without significant architectural changes. The cost and risk associated with modifying production systems can be substantial, particularly for organizations in regulated industries where system changes require extensive validation and approval processes.
Skills gaps present another significant barrier, as interpretable AI requires expertise that spans multiple disciplines including machine learning, user experience design, domain knowledge, and regulatory compliance. Organizations may struggle to find individuals with the necessary combination of skills or to develop such expertise internally. This challenge is compounded by the rapidly evolving nature of interpretability research and the lack of standardized training programs.
Change management represents a critical organizational challenge, as implementing interpretable AI often requires modifications to existing workflows, decision-making processes, and organizational roles. Users may resist adopting new tools or processes, particularly if they perceive the changes as threatening their autonomy or expertise. Successful implementation requires careful change management strategies that address user concerns, provide adequate training, and demonstrate clear benefits.
## 9 Interpretability Applications and Cross-Industry Learnings
To better understand how interpretability and explainability function in real-world applications, we analyzed case studies spanning sectors such as finance, healthcare, telecommunications, infrastructure, and human resources. These applied efforts offered valuable insights into both technical and organizational dynamics that shape the successful adoption of interpretable machine learning (ML) systems.
### 9.1 Interpretability Across Domains: Purpose and Practice
As AI systems continue to permeate a variety of sectors, from finance and healthcare to infrastructure, education, and human resources, there is a growing recognition that interpretability is not merely a desirable feature but a necessary one. The role of interpretability varies significantly depending on the domain, yet a common thread emerges: the need to understand, trust, and justify machine learning outputs in ways that align with business goals, compliance demands, and end-user expectations.
In high-stakes domains like healthcare or finance, interpretability is often motivated by regulatory scrutiny and ethical accountability. In technical domains like infrastructure or telecommunications, it supports root cause analysis and system debugging. Meanwhile, in human-centered fields such as HR and education, interpretability facilitates fairness, transparency, and improved stakeholder communication.
Interpretability applications in these diverse settings reveals that successful interpretability efforts tend to share key characteristics of deliberate planning, alignment with stakeholder needs, and integration into the broader system development process. Regardless of sector, teams that treated interpretability as a core design requirement, rather than a post-hoc addition, were better positioned to meet both technical and organizational objectives.
### 9.2 Key Cross-Sector Observations and Insights
<details>
<summary>x7.png Details</summary>
### Visual Description
## Diagram: Integrated Interpretability Framework
### Overview
The image is a conceptual circular diagram illustrating a framework for integrating interpretability into AI systems. The central theme is "Integrate Interpretability," surrounded by six interconnected components or stages, each represented by a colored segment with an icon and descriptive text. A directional arrow indicates a flow from one component to another, suggesting a process or progression.
### Components/Axes
The diagram is structured as a circle divided into six segments, each with a distinct color, icon, title, and descriptive text. The central circle contains the core concept.
**Central Element:**
* **Text:** "Integrate Interpretability"
* **Position:** Center of the diagram.
**Surrounding Segments (Clockwise from top-right):**
1. **Segment (Yellow):**
* **Title:** "Use Interpretable Models"
* **Icon:** An open book.
* **Description:** "Transparency by design is key"
* **Position:** Top-right quadrant.
2. **Segment (Orange):**
* **Title:** "Early Integration"
* **Icon:** A calendar with a checkmark.
* **Description:** "Define goals early on"
* **Position:** Right side. A blue arrow originates from this segment and points towards the "Improved Transparency" segment.
3. **Segment (Blue):**
* **Title:** "Improved Transparency"
* **Icon:** A lightbulb with a keyhole.
* **Description:** "Understandable, trustworthy AI outputs"
* **Position:** Bottom-right quadrant. This is the endpoint of the arrow from "Early Integration."
4. **Segment (Red/Pink):**
* **Title:** "Limited Understanding"
* **Icon:** A head silhouette with a question mark.
* **Description:** "AI outputs lack clarity"
* **Position:** Bottom-left quadrant.
5. **Segment (Teal/Green):**
* **Title:** "Communication Infrastructure"
* **Icon:** A megaphone.
* **Description:** "Translate insights effectively"
* **Position:** Left side.
6. **Segment (Light Green):**
* **Title:** "Visual Tools"
* **Icon:** A dashboard or chart icon.
* **Description:** "Enhance stakeholder engagement"
* **Position:** Top-left quadrant.
### Detailed Analysis
The diagram presents a non-linear but interconnected model. The central goal is to "Integrate Interpretability." The surrounding elements can be interpreted as both prerequisites and outcomes of this integration.
* **Problem State:** "Limited Understanding" (red/pink) is presented as a starting challenge or negative state where AI outputs are unclear.
* **Solution Components:** The other five segments represent actionable components or strategies to address this challenge and achieve the central goal:
* **"Use Interpretable Models"** (yellow) advocates for model selection based on inherent transparency.
* **"Early Integration"** (orange) emphasizes planning interpretability from the project's outset.
* **"Communication Infrastructure"** (teal) focuses on the systems needed to convey AI insights.
* **"Visual Tools"** (light green) highlights the role of visualization in making insights accessible.
* **Desired Outcome:** "Improved Transparency" (blue) is depicted as a direct result of "Early Integration" (via the arrow) and represents the positive end-state: trustworthy and understandable AI.
### Key Observations
1. **Circular Layout:** The circular arrangement suggests that these components are part of a continuous, holistic system rather than a strict linear sequence. They all feed into and support the central integration goal.
2. **Directional Flow:** The only explicit directional cue is the blue arrow from "Early Integration" to "Improved Transparency." This implies a strong causal or sequential relationship between defining interpretability goals early and achieving transparent outcomes.
3. **Color Coding:** Each concept is assigned a unique, distinct color, aiding in visual segmentation and recall.
4. **Iconography:** Simple, universally recognizable icons (book, calendar, lightbulb, etc.) are paired with each concept to reinforce its meaning visually.
5. **Problem-Solution Contrast:** The "Limited Understanding" segment (red/pink) is visually and conceptually contrasted with the "Improved Transparency" segment (blue), framing the diagram as a journey from a problem to a solution.
### Interpretation
This diagram outlines a **socio-technical framework** for making AI systems more interpretable. It argues that interpretability is not a single feature but an integrated practice requiring multiple, concurrent efforts.
* **The Core Argument:** True interpretability ("Integrate Interpretability") is achieved by simultaneously employing **technical solutions** (selecting interpretable models, building communication infrastructures, using visual tools) and **process-oriented solutions** (integrating interpretability goals early in the development lifecycle).
* **Relationship Between Elements:** The components are interdependent. For example, "Visual Tools" are useless without a "Communication Infrastructure" to deliver the insights, and both are ineffective if the underlying model is not inherently interpretable ("Use Interpretable Models"). "Early Integration" acts as the catalyst that sets this entire system in motion, leading directly to the ultimate benefit of "Improved Transparency."
* **Underlying Message:** The framework moves beyond a purely technical view of interpretability (e.g., just using SHAP values). It emphasizes that achieving trustworthy AI requires deliberate design choices, effective communication strategies, and stakeholder engagement from the very beginning of a project. The "Limited Understanding" segment serves as a warning of the consequence of neglecting this integrated approach.
</details>
Figure 8: Adoption of AI Interpretability Across Domains
Several recurring themes emerged across the case studies (Fig. 8):
- Early Integration of Interpretability is Critical: Projects that defined interpretability goals early in development were better able to align models, explanation techniques, and stakeholder needs. Delayed consideration often led to costly retrofitting and limited effectiveness.
- Inherently Interpretable Models Are Often Better Aligned with Stakeholders: Models like Explainable Boosting Machines (EBMs), Generalized Additive Models (GAMs), and Neural Additive Models (NAMs) offered transparency by design and were easier for non-technical stakeholders to understand. These were particularly effective in domains requiring high accountability.
- Trade-offs Between Accuracy and Interpretability Are Contextual: In domains like fraud detection and clinical risk prediction, interpretable models occasionally underperformed black-box counterparts but offered significant advantages in trust and compliance. Teams often had to balance predictive performance with clarity and audit-ability.
- Limitations of Post-hoc Methods in Complex Use Cases: Tools like SHAP and LIME were widely used but often struggled with stability, sensitivity to hyperparameters, and inconsistent outputs when applied to large language models or high-dimensional data. These limitations highlight the need for careful method selection based on domain and model architecture.
- Explainability for Generative Models is Still Maturing: Use cases involving large language models (e.g., LLaMA, Falcon, Mistral) revealed gaps in current interpretability tools. Techniques such as attribution mapping and perturbation helped expose token relationships but were constrained by the models’ complexity and opacity.
- Visual Tools and Communication Infrastructure Enhance Stakeholder Engagement: Projects that included dashboards, interactive plots, or structured reporting templates were more effective at translating technical insights into actionable understanding for business users, auditors, or compliance teams.
- Interpretability is a Socio-Technical Challenge: Success was often driven more by process, communication, and alignment than technical execution alone. Teams that fostered feedback loops, included domain experts early, and regularly reflected on their approach achieved more sustainable outcomes.
### 9.3 Domain-Specific Highlights
Case studies across diverse industries including finance, telecommunications, healthcare, human resources, infrastructure, and education demonstrate the varied ways in which interpretability techniques can be applied to domain-specific machine learning challenges. These applications surfaced key technical and organizational considerations, highlighting the trade-offs, limitations, and opportunities inherent in building transparent and trustworthy AI systems. Despite sector-specific complexities, the underlying techniques proved adaptable and effective across a wide range of use cases, reinforcing their relevance to any industry pursuing responsible AI adoption.
- Finance and Fraud Detection: In domains with high regulatory oversight, such as fraud detection and credit scoring, techniques like SHAP, LIME, and Explainable Boosting Machines (EBMs) were used to enhance transparency. Post-hoc tools such as SHAP provided fine-grained insight into feature importance, but frequently exhibited instability when applied to complex or imbalanced datasets. In contrast, inherently interpretable models like EBMs produced more stable, rule-based outputs that resonated better with non-technical stakeholders—even when sacrificing some predictive performance or sensitivity to rare events.
- Healthcare: Clinical applications such as patient outcome prediction and hospital readmission risk modeling leaned on techniques like Generalized Additive Models (GAMs) and Partial Dependence Plots (PDPs) to deliver transparent decision logic. These approaches proved particularly valuable in fostering clinician trust in model outputs. However, explainability was harder to maintain in contexts involving sparse or high-dimensional data, sometimes requiring simplified modeling approaches or hybrid architectures to ensure interpretability without compromising utility.
- LLMs and Document AI: Use cases such as resume screening, banking chatbot response generation, and optical character recognition (OCR) pipelines applied interpretability tools to large-scale generative models like LLaMA, Falcon, and Mistral. Token-level attribution and perturbation techniques provided partial insight into model reasoning, but their effectiveness was limited by the opaque nature of attention-based architectures. These challenges point to an urgent need for domain-specific interpretability methods tailored to generative and sequence-based models, particularly in compliance-sensitive fields like HR and financial services.
- Infrastructure and Industrial Systems: For tasks such as anomaly detection in sensor and telemetry data, glass-box models like EBMs and GAMs offered valuable interpretability benefits over black-box methods like Isolation Forests. These interpretable alternatives enabled clearer root cause analysis and better alignment with ESG (Environmental, Social, and Governance) reporting requirements. Nevertheless, teams encountered scalability challenges when attempting to embed interpretability into real-time monitoring systems—especially in environments characterized by high-volume or high-dimensional data.
Across these domains, the case studies revealed that interpretability is often as much about communication and stakeholder engagement as it is about modeling technique. While no single method universally outperformed others, the combination of case-specific model selection, visualization, and tailored explanation strategies consistently contributed to better stakeholder understanding and trust. These findings reinforce the broader thesis of this whitepaper: interpretability is a context-dependent practice requiring adaptable frameworks rather than rigid solutions.
### 9.4 Learnings: Practical Adoption of Interpretability
The collective insights drawn from applied experimentation across sectors demonstrate that interpretability is most effective when treated as a foundational component of the machine learning development process. Embedding interpretability from the outset—starting at the problem definition and model design phase—enables organizations to align techniques with their specific regulatory, operational, and stakeholder needs. Early integration also helps reduce the need for costly and less effective retrofitting later in the development cycle.
Another critical enabler of practical adoption is the development of robust communication infrastructure. Tools such as interactive dashboards, visualizations, and standardized explanation templates help translate complex model behavior into insights that are accessible to diverse stakeholders, including domain experts, auditors, and end users. These tools not only support transparency but also foster trust, a prerequisite for responsible AI deployment.
Interpretability methods must also be carefully selected based on the specific characteristics of the domain and application. There is no one-size-fits-all approach: inherently interpretable models may be better suited for some contexts, while post-hoc techniques might offer flexibility in others. Aligning methods with domain constraints, user literacy, and compliance demands ensures that interpretability delivers meaningful value rather than technical formality.
Finally, organizations benefit from building structured opportunities for reflection, evaluation, and continuous improvement into their workflows. By encouraging teams to document trade-offs, revisit decisions, and gather feedback from end users, interpretability becomes a dynamic capability—capable of adapting as data, models, and requirements evolve.
Together, these recommendations highlight that interpretability is not a fixed property of an algorithm, but a socio-technical practice grounded in context, purpose, and thoughtful design. When supported by the right processes and infrastructure, it becomes a powerful tool for improving accountability, fostering trust, and guiding the responsible adoption of machine learning systems across industries.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Diagram: Pathway to Practical AI Interpretability
### Overview
The image is a conceptual diagram illustrating a five-stage progression from an initial state of unclear goals to the achievement of practical AI interpretability. The stages are presented as a linear pathway, visualized as a dashed line connecting two cliffs, with a stick figure at each end representing the starting and ending points of the journey.
### Components/Axes
The diagram consists of five distinct stages, each presented as a column of text. Each stage has a colored title and a descriptive subtitle. The stages are arranged horizontally from left to right, indicating a sequential process.
**Stage 1 (Far Left):**
* **Title (Red):** "Unclear Interpretability Goals"
* **Subtitle:** "Vague understanding of AI transparency"
* **Visual:** A stick figure stands on the edge of a left-side cliff, looking across a chasm.
**Stage 2:**
* **Title (Orange):** "Define Goals Early"
* **Subtitle:** "Articulate purpose for interpretability"
**Stage 3 (Center):**
* **Title (Yellow):** "Invest in Communication"
* **Subtitle:** "Leverage visual tools for understanding"
**Stage 4:**
* **Title (Green):** "Align Methods with Domain"
* **Subtitle:** "Select techniques matching domain needs"
**Stage 5 (Far Right):**
* **Title (Blue):** "Practical AI Interpretability"
* **Subtitle:** "Transparent AI as integral part"
* **Visual:** A stick figure stands on the edge of a right-side cliff, having crossed the chasm.
**Connecting Element:** A horizontal dashed line runs between the two stick figures, passing through the center of the diagram. It has small vertical tick marks aligned with each of the five text stages, symbolizing the path or journey connecting the stages.
### Detailed Analysis
The diagram presents a clear, linear model for achieving AI interpretability. The progression is defined by specific actions at each stage:
1. **Starting Point (Unclear Goals):** Characterized by a "vague understanding." This is the problem state.
2. **Action 1 (Define Goals):** The first corrective step is to "articulate purpose," moving from vagueness to clarity.
3. **Action 2 (Invest in Communication):** The focus shifts to methodology, specifically using "visual tools" to bridge the gap between technical systems and human understanding.
4. **Action 3 (Align Methods):** This stage emphasizes context-awareness, requiring the selection of interpretability techniques that are appropriate for the specific "domain needs" (e.g., healthcare, finance, autonomous systems).
5. **End State (Practical Interpretability):** The goal is achieved when transparency is no longer an add-on but an "integral part" of the AI system.
The visual metaphor of crossing a chasm between two cliffs reinforces the idea that this is a significant journey requiring deliberate steps to overcome an initial gap in understanding and implementation.
### Key Observations
* **Color Coding:** The titles use a distinct color spectrum (Red -> Orange -> Yellow -> Green -> Blue), which may symbolize progression from a warning/problem state (red) to a resolved/goal state (blue).
* **Spatial Layout:** The linear, left-to-right arrangement is a universal visual metaphor for progress and sequence. The central placement of "Invest in Communication" may suggest it is a pivotal or bridging activity.
* **Symbolism:** The stick figures and cliffs are simple but effective symbols for the practitioner (the figure) and the challenge (the chasm of unclear goals). The dashed line represents the planned, step-wise pathway.
* **Text Hierarchy:** Each stage uses a clear two-line structure: a bold, colored imperative statement (the action) followed by a plain-text explanation (the rationale or outcome).
### Interpretation
This diagram is a prescriptive model for organizations or teams developing AI systems. It argues that **practical AI interpretability is not a technical feature to be added last-minute, but the result of a deliberate, structured process that begins with strategic goal-setting.**
The core message is that transparency is achieved through a combination of **early planning** ("Define Goals"), **effective communication design** ("Invest in Communication"), and **contextual technical selection** ("Align Methods"). The journey from a "vague understanding" to having transparency as an "integral part" requires crossing a conceptual gap, which this five-stage pathway is designed to facilitate.
The model places significant emphasis on the human and process elements (defining purpose, communication, domain alignment) alongside the technical, suggesting that the barriers to AI interpretability are as much about clarity of intent and cross-disciplinary collaboration as they are about algorithms. The final state—"Transparent AI as integral part"—implies a mature stage of AI development where explainability is seamlessly woven into the system's design and operation, rather than being a separate, burdensome compliance task.
</details>
Figure 9: Bridging the Interpretability Gap: Key Steps Toward Practical and Transparent AI Systems
### 9.5 The Web Portal Initiative: One-Stop Resource for Interpretable AI
Building on the comprehensive framework presented in this white paper, we propose the development of an integrated web portal that serves as a centralized resource for interpretable AI implementation. This initiative, inspired by the TransparentAI portal concept, would provide practitioners with interactive tools, comprehensive guidance, and real-world case studies to support their interpretability efforts.
The proposed portal would feature several key components designed to address the practical needs identified through our interpretability application experimentation and industry engagement. An interactive technique selection wizard would guide users through a decision tree process to identify the most appropriate interpretability methods based on their specific model types, industry contexts, and stakeholder requirements. This tool would move beyond simple recommendations to provide detailed implementation guidance, including code examples, best practices, and common pitfalls to avoid.
A comprehensive method comparison tool would allow users to evaluate different interpretability approaches side-by-side, with interactive visualizations showing how various techniques perform across different evaluation metrics and use cases. This comparative analysis capability would be particularly valuable for organizations trying to select among multiple viable interpretability approaches for their specific applications.
The portal would include a searchable database of real-world case studies spanning diverse industries and application domains, providing practitioners with concrete examples of how interpretability has been successfully implemented in similar contexts. These case studies would go beyond high-level descriptions to provide detailed technical implementations, lessons learned, and quantified outcomes that demonstrate the business value of interpretable AI.
Interactive evaluation tools would enable users to assess their current interpretability practices against established benchmarks and identify areas for improvement. These tools would provide customized recommendations based on user inputs and guide organizations through a structured improvement process that builds interpretability capabilities over time.
A regulatory compliance checker would help organizations understand and navigate the complex landscape of AI transparency requirements across different jurisdictions and industry sectors. This tool would provide up-to-date information on relevant regulations, assessment frameworks for determining compliance requirements, and guidance on implementing appropriate interpretability measures.
### 9.6 Proposed Roadmap for Industry Adoption of Interpretability
Based on the success and insights gained from interpretability application case studies, we propose a roadmap that organizations can adopt to embed interpretable AI practices into their development workflows and governance structures. This roadmap supports continuous learning, iterative experimentation, and the development of internal capacity to scale interpretable AI across diverse contexts.
<details>
<summary>x9.png Details</summary>
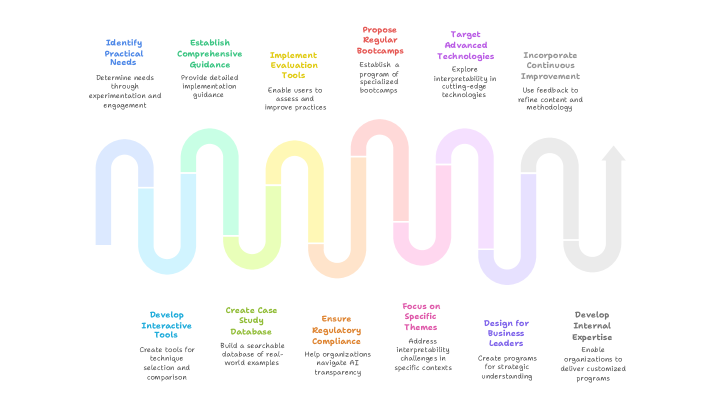
### Visual Description
## Diagram: AI Implementation Roadmap
### Overview
The image displays a conceptual process diagram illustrating a phased approach to AI implementation or governance. It features a continuous, winding horizontal path composed of six distinct colored segments. Each segment is associated with two complementary actions: one positioned above the path and one below. The diagram outlines a structured, multi-stage strategy moving from initial needs assessment to continuous improvement and internal capability building.
### Components/Axes
- **Path Structure**: A single, continuous line that curves upward and downward, flowing from left to right. It is divided into six colored segments: blue, green, yellow, orange, pink, and gray.
- **Labels**: Each colored segment has a corresponding label above and below the path. Each label consists of a bold title (in a color matching its path segment) and a descriptive subtitle in smaller, dark gray text.
- **Spatial Layout**: The labels are aligned vertically with their respective path segments. The "upper" labels are positioned above the peaks of the path, and the "lower" labels are positioned below the troughs.
### Detailed Analysis
The diagram presents a sequence of six stages, each with a paired strategic action (above) and practical implementation action (below).
**Stage 1 (Blue Segment - Leftmost)**
* **Upper Label**: **Identify Practical Needs**
* Description: Determine needs through experimentation and engagement.
* **Lower Label**: **Develop Interactive Tools**
* Description: Create tools for tool selection and comparison.
**Stage 2 (Green Segment)**
* **Upper Label**: **Establish Comprehensive Guidance**
* Description: Provide standardized implementation guidance.
* **Lower Label**: **Create Case Study Database**
* Description: Build a searchable database of real-world examples.
**Stage 3 (Yellow Segment)**
* **Upper Label**: **Implement Evaluation Tools**
* Description: Enable users to assess and improve practices.
* **Lower Label**: **Ensure Regulatory Alignment**
* Description: Help organizations navigate AI transparency.
**Stage 4 (Orange Segment)**
* **Upper Label**: **Propose Regular Bootcamps**
* Description: Establish a program of specialized bootcamps.
* **Lower Label**: **Focus on Specific Themes**
* Description: Address interpretability challenges in specific contexts.
**Stage 5 (Pink Segment)**
* **Upper Label**: **Target Advanced Technologies**
* Description: Explore interoperability in cutting-edge technologies.
* **Lower Label**: **Design for Business Impact**
* Description: Create programs for strategic understanding.
**Stage 6 (Gray Segment - Rightmost)**
* **Upper Label**: **Incorporate Continuous Improvement**
* Description: Implement mechanisms to refine content and methodology.
* **Lower Label**: **Develop Internal Expertise**
* Description: Enable organizations to deliver customized programs.
### Key Observations
1. **Dual-Track Development**: Every stage pairs a high-level, programmatic action (e.g., "Establish Guidance," "Propose Bootcamps") with a concrete, enabling deliverable (e.g., "Create Database," "Develop Tools").
2. **Color-Coded Cohesion**: The color of each label's title precisely matches the color of its corresponding path segment, creating a strong visual association between the action and its place in the sequence.
3. **Progressive Flow**: The path moves unambiguously from left to right, indicating a logical progression from foundational activities (needs identification, tool development) to advanced and sustaining activities (advanced tech, continuous improvement, internal expertise).
4. **Non-Linear Path Symbolism**: While the overall flow is linear, the winding path may symbolize that the process is iterative, adaptive, or involves navigating complexities, rather than being a rigid, straight-line procedure.
### Interpretation
This diagram outlines a holistic framework for organizations to systematically adopt and govern AI technologies. It emphasizes that successful implementation requires parallel development in two domains: **strategic scaffolding** (guidance, training programs, improvement mechanisms) and **practical infrastructure** (tools, databases, regulatory help, internal skills).
The sequence suggests a logical maturity model:
1. **Foundation (Stages 1-2)**: Understand needs and build core resources (tools, guidance, examples).
2. **Operationalization (Stages 3-4)**: Implement evaluation and compliance, then scale knowledge through training focused on specific challenges.
3. **Advancement & Sustainability (Stages 5-6)**: Integrate cutting-edge technology and business strategy, while institutionalizing knowledge and improvement processes to ensure long-term, self-sufficient capability.
The framework positions AI adoption not as a one-time technical project, but as an ongoing organizational capability-building journey that balances innovation with responsibility and external support with internal expertise development.
</details>
Figure 10: Proposed Roadmap for Driving Industry-Wide Interpretability Adoption
The roadmap encourages organizations to design internal programming such as targeted training, guided pilot projects, and structured knowledge-sharing sessions focused on specific themes or domains (Fig. 10). For example, healthcare organizations may prioritize workflows that address unique regulatory, technical, and ethical challenges, while financial institutions might focus on risk management, auditability, and fairness.
Technical workstreams can be established to explore advanced interpretability challenges such as large language models, multi-modal systems, and real-time pipelines. These efforts would focus on evaluating emerging techniques, prototyping interpretable architectures, and identifying tool-chain gaps specific to the organization’s use cases.
Leadership focused initiatives should aim to build strategic understanding among business and executive stakeholders. These can include workshops on governance frameworks, change management planning, and the business case for interpretable AI, helping align organizational vision with transparency goals.
Organizations can also foster internal forums or communities of practice to promote cross-functional learning and knowledge transfer. Sharing lessons across departments or use cases can help identify common interpretability challenges and solutions that can be generalized or adapted.
To sustain progress, organizations should incorporate continuous improvement mechanisms into their interpretability initiatives. This includes collecting regular feedback, evaluating progress against defined milestones, and iterating on frameworks, tooling, and training based on real-world implementation outcomes.
Finally, a train-the-trainer strategy can empower internal champions to lead interpretability education across the organization. By developing reusable content, tailored programming, and coaching structures, teams can scale interpretability practices in a sustainable, context-sensitive manner.
This roadmap offers a flexible and actionable foundation for industry adoption of interpretable AI—one that can be adapted to suit varying maturity levels, resource constraints, and sector-specific demands.
## 10 Conclusion and Recommendations
The advancement of AI systems into critical decision-making roles has transformed interpretability from an academic consideration into a fundamental requirement for responsible AI deployment. This whitepaper demonstrates that achieving transparent AI requires coordinated efforts across organizational, regulatory, and human dimensions. Our interpretability application experiment revealed critical insights that reshape how organizations should approach transparent AI implementation. The case studies demonstrated that technical excellence in explanation generation is necessary but insufficient. Teams that achieved meaningful outcomes invested heavily in understanding stakeholder mental models and decision-making workflows. We also propose developing an integrated web portal serving as a centralized resource for interpretable AI implementation, featuring interactive technique selection tools, comprehensive case study databases, and regulatory compliance guidance.
The transition to interpretable AI represents both opportunity and imperative. Organizations should begin by assessing current transparency practices, identifying high-priority applications where interpretability is essential, and developing implementation roadmaps.
The future of AI depends on our collective ability to build systems that humans can understand, trust, and effectively collaborate with. Organizations that embrace interpretability as a fundamental design principle will achieve better regulatory compliance and unlock the full potential of human-AI collaboration. The frameworks presented in this whitepaper provide the foundation—the journey begins with commitment and action.
## References
- [1] Julius Adebayo et al. “Sanity checks for saliency maps” In Advances in neural information processing systems 31, 2018
- [2] Jurgita Černevičienė and Audrius Kabašinskas “Explainable artificial intelligence (XAI) in finance: a systematic literature review” In Artificial Intelligence Review 57.8, 2024 DOI: 10.1007/s10462-024-10854-8
- [3] Finale Doshi-Velez and Been Kim “Considerations for evaluation and generalization in interpretable machine learning” In Explainable and interpretable models in computer vision and machine learning Springer, 2017, pp. 3–17
- [4] Tessa Han et al. “Is ignorance bliss? the role of post hoc explanation faithfulness and alignment in model trust in laypeople and domain experts” In arXiv preprint arXiv:2312.05690, 2023
- [5] Weiche Hsieh et al. “A Comprehensive Guide to Explainable AI: From Classical Models to LLMs” In arXiv preprint arXiv:2412.00800, 2024 URL: https://arxiv.org/abs/2412.00800
- [6] Weina Jin, Xiaoxiao Li, Mostafa Fatehi and Ghassan Hamarneh “Guidelines and Evaluation of Clinical Explainable AI in Medical Image Analysis” In Medical Image Analysis 84 Elsevier, 2022, pp. 102684 DOI: 10.1016/j.media.2022.102684
- [7] Uday Kamath and John Liu “Model Interpretability: Advances in Interpretable Machine Learning” In Explainable Artificial Intelligence: An Introduction to Interpretable Machine Learning, 2021, pp. 121–165 DOI: 10.1007/978-3-030-83356-5_4
- [8] Tamás Kenesei and János Abonyi “Interpretability of Neural Networks” In SpringerBriefs in Computer Science, 2015, pp. 33–48 DOI: 10.1007/978-3-319-21942-4_3
- [9] Haoyan Luo and Lucia Specia “From Understanding to Utilization: A Survey on Explainability for Large Language Models” In arXiv preprint arXiv:2401.12874, 2024 URL: https://arxiv.org/abs/2401.12874
- [10] Christoph Molnar “Interpretable machine learning” Lulu. com, 2020
- [11] Meike Nauta et al. “From anecdotal evidence to quantitative evaluation methods: A systematic review on evaluating explainable AI” In ACM Computing Surveys 55.13s ACM, 2023, pp. 1–42
- [12] Cynthia Rudin et al. “Interpretable machine learning: Fundamental principles and 10 grand challenges” In Statistics Surveys 16 Institute of Mathematical StatisticsBernoulli Society, 2022, pp. 1–85 DOI: 10.1214/21-SS133
- [13] Wojciech Samek et al. “Evaluating the visualization of what a deep neural network has learned” In IEEE transactions on neural networks and learning systems 28.11 IEEE, 2017, pp. 2660–2673
- [14] Hugues Turbé, Mina Bjelogrlic, Christian Lovis and Gianmarco Mengaldo “Evaluation of post-hoc interpretability methods in time-series classification” In Nature Machine Intelligence 5.3 Nature Publishing Group, 2023, pp. 250–260
- [15] Mythreyi Velmurugan et al. “Developing guidelines for functionally-grounded evaluation of explainable artificial intelligence using tabular data” In Data Mining and Knowledge Discovery Springer, 2024