# Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens
**Authors**: Chengshuai Zhao, Zhen Tan, Pingchuan Ma, Dawei Li, Bohan Jiang, Yancheng Wang, Yingzhen Yang, Huan Liu
> Arizona State University
\pdftrailerid
redacted Corresponding author: {czhao93, ztan36, pingchua, daweili5, bjiang14, yancheng.wang, yingzhen.yang, huanliu}@asu.edu
Abstract
Chain-of-Thought (CoT) prompting has been shown to improve Large Language Model (LLM) performance on various tasks. With this approach, LLMs appear to produce human-like reasoning steps before providing answers (a.k.a., CoT reasoning), which often leads to the perception that they engage in deliberate inferential processes. However, some initial findings suggest that CoT reasoning may be more superficial than it appears, motivating us to explore further. In this paper, we study CoT reasoning via a data distribution lens and investigate if CoT reasoning reflects a structured inductive bias learned from in-distribution data, allowing the model to conditionally generate reasoning paths that approximate those seen during training. Thus, its effectiveness is fundamentally bounded by the degree of distribution discrepancy between the training data and the test queries. With this lens, we dissect CoT reasoning via three dimensions: task, length, and format. To investigate each dimension, we design DataAlchemy, an isolated and controlled environment to train LLMs from scratch and systematically probe them under various distribution conditions. Our results reveal that CoT reasoning is a brittle mirage that vanishes when it is pushed beyond training distributions. This work offers a deeper understanding of why and when CoT reasoning fails, emphasizing the ongoing challenge of achieving genuine and generalizable reasoning. Our code is available at GitHub: https://github.com/ChengshuaiZhao0/DataAlchemy.
1 Introduction
Recent years have witnessed Large Language Models’ (LLMs) dominant role in various domains (Zhao et al., 2023; Li et al., 2025b; Zhao et al., 2025; Ting et al., 2025) through versatile prompting techniques (Wei et al., 2022; Yao et al., 2023; Kojima et al., 2022). Among these, Chain-of-Thought (CoT) prompting (Wei et al., 2022) has emerged as a prominent method for eliciting structured reasoning from LLMs (a.k.a., CoT reasoning). By appending a simple cue such as “Let’s think step by step,” LLMs decompose complex problems into intermediate steps, producing outputs that resemble human-like reasoning. It has been shown to be effective in tasks requiring logical inference Xu et al. (2024), mathematical problem solving (Imani et al., 2023), and commonsense reasoning (Wei et al., 2022). The empirical successes of CoT reasoning lead to the perception that LLMs engage in deliberate inferential processes (Yu et al., 2023; Zhang et al., 2024a; Ling et al., 2023; Zhang et al., 2024c).
However, a closer examination reveals inconsistencies that challenge this optimistic view. Consider this straightforward question: “The day the US was established is in a leap year or a normal year?” When prompted with the CoT prefix, the modern LLM Gemini responded: “The United States was established in 1776. 1776 is divisible by 4, but it’s not a century year, so it’s a leap year. Therefore, the day the US was established was in a normal year.” This response exemplifies a concerning pattern: the model correctly recites the leap year rule and articulates intermediate reasoning steps, yet produces a logically inconsistent conclusion (i.e., asserting 1776 is both a leap year and a normal year). Such inconsistencies suggest that there is a distinction between human-like inference and CoT reasoning.
An expanding body of analyses reveals that LLMs tend to rely on surface-level semantics and clues rather than logical procedures (Bentham et al., 2024; Chen et al., 2025b; Lanham et al., 2023). LLMs construct superficial chains of logic based on learned token associations, often failing on tasks that deviate from commonsense heuristics or familiar templates (Tang et al., 2023). In the reasoning process, performance degrades sharply when irrelevant clauses are introduced, which indicates that models cannot grasp the underlying logic (Mirzadeh et al., 2024). This fragility becomes even more apparent when models are tested on more complex tasks, where they frequently produce incoherent solutions and fail to follow consistent reasoning paths (Shojaee et al., 2025). Collectively, these pioneering works deepen the skepticism surrounding the true nature of CoT reasoning.
In light of this line of research, we question the CoT reasoning by proposing an alternative lens through data distribution and further investigating why and when it fails. We hypothesize that CoT reasoning reflects a structured inductive bias learned from in-distribution data, allowing the model to conditionally generate reasoning paths that approximate those seen during training. As such, its effectiveness is inherently limited by the nature and extent of the distribution discrepancy between training data and the test queries. Guided by this data distribution lens, we dissect CoT reasoning via three dimensions: (i) task —To what extent CoT reasoning can handle tasks that involve transformations or previously unseen task structures. (2) length —how CoT reasoning generalizes to chains with length different from that of training data; and (3) format —how sensitive CoT reasoning is to surface-level query form variations. To evaluate each aspect, we introduce DataAlchemy, a controlled and isolated experiment that allows us to train LLMs from scratch and systematically probe them under various distribution shifts.
Our findings reveal that CoT reasoning works effectively when applied to in-distribution or near in-distribution data but becomes fragile and prone to failure even under moderate distribution shifts. In some cases, LLMs generate fluent yet logically inconsistent reasoning steps. The results suggest that what appears to be structured reasoning can be a mirage, emerging from memorized or interpolated patterns in the training data rather than logical inference. These insights carry important implications for both practitioners and researchers. For practitioners, our results highlight the risk of relying on CoT as a plug-and-play solution for reasoning tasks and caution against equating CoT-style output with human thinking. For researchers, the results underscore the ongoing challenge of achieving reasoning that is both faithful and generalizable, motivating the need to develop models that can move beyond surface-level pattern recognition to exhibit deeper inferential competence. Our contributions are summarized as follows:
- Novel perspective. We propose a data distribution lens for CoT reasoning, illuminating that its effectiveness stems from structured inductive biases learned from in-distribution training data. This framework provides a principled lens for understanding why and when CoT reasoning succeeds or fails.
- Controlled environment. We introduce DataAlchemy, an isolated experimental framework that enables training LLMs from scratch and systematically probing CoT reasoning. This controlled setting allows us to isolate and analyze the effects of distribution shifts on CoT reasoning without interference from complex patterns learned during large-scale pre-training.
- Empirical validation. We conduct systematic empirical validation across three critical dimensions— task, length, and format. Our experiments demonstrate that CoT reasoning exhibits sharp performance degradation under distribution shifts, revealing that seemingly coherent reasoning masks shallow pattern replication.
- Real-world implication. This work reframes the understanding of contemporary LLMs’ reasoning capabilities and emphasizes the risk of over-reliance on COT reasoning as a universal problem-solving paradigm. It underscores the necessity for proper evaluation methods and the development of LLMs that possess authentic and generalizable reasoning capabilities.
2 Related Work
2.1 LLM Prompting and Co
Chain-of-Thought (CoT) prompting revolutionized how we elicit reasoning from Large Language Models by decomposing complex problems into intermediate steps (Wei et al., 2022). By augmenting few-shot exemplars with reasoning chains, CoT showed substantial performance gains on various tasks (Xu et al., 2024; Imani et al., 2023; Wei et al., 2022). Building on this, several variants emerged. Zero-shot CoT triggers reasoning without exemplars using instructional prompts (Kojima et al., 2022), and self-consistency enhances performance via majority voting over sampled chains (Wang et al., 2023). To reduce manual effort, Auto-CoT generates CoT exemplars using the models themselves (Zhang et al., 2023). Beyond linear chains, Tree-of-Thought (ToT) frames CoT as a tree search over partial reasoning paths (Yao et al., 2023), enabling lookahead and backtracking. SymbCoT combines symbolic reasoning with CoT by converting problems into formal representations (Xu et al., 2024). Recent work increasingly integrates CoT into the LLM inference process, generating long-form CoTs (Jaech et al., 2024; Team, 2024; Guo et al., 2025; Team et al., 2025). This enables flexible strategies like mistake correction, step decomposition, reflection, and alternative reasoning paths (Yeo et al., 2025; Chen et al., 2025a). The success of prompting techniques and long-form CoTs has led many to view them as evidence of emergent, human-like reasoning in LLMs. In this work, we challenge that viewpoint by adopting a data-centric perspective and demonstrating that CoT behavior arises largely from pattern matching over training distributions.
2.2 Discussion on Illusion of LLM Reasoning
While Chain-of-Thought prompting has led to impressive gains on complex reasoning tasks, a growing body of work has started questioning the nature of these improvements. One major line of research highlights the fragility of CoT reasoning. Minor and semantically irrelevant perturbations such as distractor phrases or altered symbolic forms can cause significant performance drops in state-of-the-art models (Mirzadeh et al., 2024; Tang et al., 2023). Models often incorporate such irrelevant details into their reasoning, revealing a lack of sensitivity to salient information. Other studies show that models prioritize the surface form of reasoning over logical soundness; in some cases, longer but flawed reasoning paths yield better final answers than shorter, correct ones (Bentham et al., 2024). Similarly, performance does not scale with problem complexity as expected—models may overthink easy problems and give up on harder ones (Shojaee et al., 2025). Another critical concern is the faithfulness of the reasoning process. Intervention-based studies reveal that final answers often remain unchanged even when intermediate steps are falsified or omitted (Lanham et al., 2023), a phenomenon dubbed the illusion of transparency (Bentham et al., 2024; Chen et al., 2025b). Together, these findings suggest that LLMs are not principled reasoners but rather sophisticated simulators of reasoning-like text. However, a systematic understanding of why and when CoT reasoning fails is still a mystery.
2.3 OOD Generalization of LLMs
Out-of-distribution (OOD) generalization, where test inputs differ from training data, remains a key challenge in machine learning, particularly for large language models (LLMs) Yang et al. (2024, 2023); Budnikov et al. (2025); Zhang et al. (2024b). Recent studies show that LLMs prompted to learn novel functions often revert to similar functions encountered during pretraining (Wang et al., 2024; Garg et al., 2022). Likewise, LLM generalization frequently depends on mapping new problems onto familiar compositional structures (Song et al., 2025). CoT prompting improves OOD generalization (Wei et al., 2022), with early work demonstrating length generalization for multi-step problems beyond training distributions (Yao et al., 2025; Shen et al., 2025). However, this ability is not inherent to CoT and heavily depends on model architecture and training setups. For instance, strong generalization in arithmetic tasks was achieved only when algorithmic structures were encoded into positional encodings (Cho et al., 2024). Similarly, finer-grained CoT demonstrations during training boost OOD performance, highlighting the importance of data granularity (Wang et al., 2025a). Theoretical and empirical evidence shows that CoT generalizes well only when test inputs share latent structures with training data; otherwise, performance declines sharply (Wang et al., 2025b; Li et al., 2025a). Despite its promise, CoT still struggles with genuinely novel tasks or formats. In the light of these brilliant findings, we propose rethinking CoT reasoning through a data distribution lens: decomposing CoT into task, length, and format generalization, and systematically investigating each in a controlled setting.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: Task and Format Generalization for Sequence Transformation
### Overview
This diagram illustrates a framework for generalizing sequence transformation tasks. It breaks down the generalization process into four key areas: Task Generalization, Length Generalization, and Format Generalization, building upon a foundation of "Basic atoms A". The diagram uses visual representations of sequences (represented as blocks with letters) and transformations to explain the concepts.
### Components/Axes
The diagram is divided into four main sections, arranged horizontally:
1. **Basic atoms A:** A grid of letters from A to Z.
2. **Task Generalization:** Illustrates generalization across different task types (ID, Comp, POOD, OOD).
3. **Length Generalization:** Demonstrates generalization across varying sequence lengths.
4. **Format Generalization:** Shows generalization across different sequence formats (Insertion, Deletion, Modify).
A legend on the top-right defines color-coding:
* **Red:** Input
* **Blue:** Output
* **Light Red:** Training
* **Light Blue:** Testing
Additionally, the diagram includes labels for transformations (f1, f2, f3, f6) and arrows indicating the direction of transformations.
### Detailed Analysis or Content Details
**1. Basic atoms A:**
* A 26-letter grid, representing the alphabet.
* Label: "Element / = 5" is positioned below the sequence "APPLE", indicating the element number is 5.
**2. Task Generalization:**
* **ID (Identity):** Input sequence "ABCD" transforms to "ABCD". Transformation: f1 -> f1.
* **Comp (Composition):** Input sequence "ABCD" transforms to "DCBA". Transformation: f1 -> f2, f2 -> f1.
* **POOD (Partial Out-of-Distribution):** Input sequence "ABCD" transforms to "ABCE". Transformation: f1 -> f2, f2 -> f2.
* **OOD (Out-of-Distribution):** Input sequence "ABCD" transforms to "ABCE". Transformation: f1 -> f2, f2 -> f2.
* The input sequences are represented by red blocks, and the output sequences by blue blocks. Training data is light red, and testing data is light blue.
**3. Length Generalization:**
* Demonstrates transformations on sequences of varying lengths.
* Sequence 1: "ABCD" transforms to "ABCDA". Transformation: f6.
* Sequence 2: "ABC" transforms to "ABCDA". Transformation: f6.
* Sequence 3: "ABCA" transforms to "ABCDA". Transformation: f6.
* The transformation f6 is shown as a series of blocks, with the input sequence on top and the output sequence below.
**4. Format Generalization:**
* Illustrates generalization across different sequence formats.
* **Insertion:** "ABCD" transforms to "ABC?CD".
* **Deletion:** "ABCD" transforms to "ACD".
* **Modify:** "ABCD" transforms to "ABC?".
* The question mark (?) indicates a modified or unknown element.
**Transformations:**
* **f1:** ROT Transformation +13 (shown with a circular arrow).
* **f2:** Cyclic Shift +1 (shown with a circular arrow).
* **f6:** A more complex transformation represented by a series of blocks.
### Key Observations
* The diagram emphasizes the modularity of sequence transformations, showing how different transformations can be combined and generalized.
* The color-coding clearly distinguishes between input, output, training, and testing data.
* The use of visual representations of sequences makes the concepts more intuitive.
* The diagram highlights the importance of generalizing across different task types, sequence lengths, and sequence formats.
### Interpretation
The diagram presents a framework for building robust sequence transformation models. It suggests that by explicitly addressing task, length, and format generalization, models can be made more adaptable to unseen data and real-world scenarios. The use of transformations like ROT and Cyclic Shift provides concrete examples of how sequences can be manipulated. The distinction between training and testing data emphasizes the importance of evaluating generalization performance. The diagram implies that a successful model should be able to perform well on tasks, lengths, and formats that were not explicitly seen during training. The use of "Basic atoms A" suggests a foundational approach, building up complexity from simple elements. The diagram is a conceptual illustration, and does not provide specific numerical data or performance metrics. It is a high-level overview of a research approach to sequence transformation.
</details>
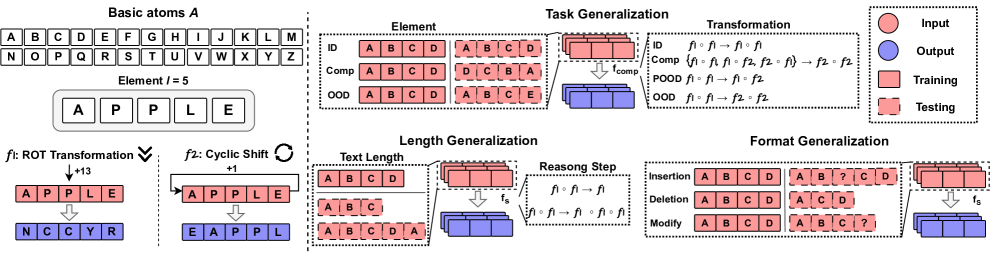
Figure 1: Framework of DataAlchemy. It creates an isolated and controlled environment to train LLMs from scratch and probe the task, length, and format generalization.
3 The Data Distribution Lens
We propose a fundamental reframing to understand what CoT actually represents. We hypothesize that the underlying mechanism is better understood through the lens of data distribution: rather than executing explicit reasoning procedures, CoT operates as a pattern-matching process that interpolates and extrapolates from the statistical regularities present in its training distribution. Specifically, we posit that CoT’s success stems not from a model’s inherent reasoning capacity, but from its ability to generalize conditionally to out-of-distribution (OOD) test cases that are structurally similar to in-distribution exemplars.
To formalize this view, we model CoT prompting as a conditional generation process constrained by the distributional properties of the training data. Let $\mathcal{D}_{\text{train}}$ denote the training distribution over input-output pairs $(x,y)$ , where $x$ represents a reasoning problem and $y$ denotes the solution sequence (including intermediate reasoning steps). The model learns an approximation $f_{\theta}(x)≈ y$ by minimizing empirical risk over samples drawn from $\mathcal{D}_{\text{train}}$ .
Let the expected training risk be defined as:
$$
R_{\text{train}}(f_{\theta})=\mathbb{E}_{(x,y)\sim\mathcal{D}_{\text{train}}}[\ell(f_{\theta}(x),y)], \tag{1}
$$
where $\ell$ is a task-specific loss function (e.g., cross-entropy, token-level accuracy). At inference time, given a test input $a_{\text{test}}$ sampled from a potentially different distribution $\mathcal{D}_{\text{test}}$ , the model generates a response $y_{\text{test}}$ conditioned on patterns learned from $\mathcal{D}_{\text{train}}$ . The corresponding expected test risk is:
$$
R_{\text{test}}(f_{\theta})=\mathbb{E}_{(x,y)\sim\mathcal{D}_{\text{test}}}[\ell(f_{\theta}(x),y)]. \tag{2}
$$
The degree to which the model generalizes from $\mathcal{D}_{\text{train}}$ to $\mathcal{D}_{\text{test}}$ is governed by the distributional discrepancy between the two, which we quantify using divergence measures:
**Definition 3.1 (Distributional Discrepancy)**
*Given training distribution $\mathcal{D}_{\text{train}}$ and test distribution $\mathcal{D}_{\text{test}}$ , the distributional discrepancy is defined as:
$$
\Delta(\mathcal{D}_{\text{train}},\mathcal{D}_{\text{test}})=\mathcal{H}(\mathcal{D}_{\text{train}}\parallel\mathcal{D}_{\text{test}}) \tag{3}
$$
where $\mathcal{H}(·\parallel·)$ is a divergence measure (e.g., KL divergence, Wasserstein distance) that quantifies the statistical distance between the two distributions.*
**Theorem 3.1 (CoT Generalization Bound)**
*Let $f_{\theta}$ denote a model trained on $\mathcal{D}_{\text{train}}$ with expected training risk $R_{\text{train}}(f_{\theta})$ . For a test distribution $\mathcal{D}_{\text{test}}$ , the expected test risk $R_{\text{test}}(f_{\theta})$ is bounded by:
$$
R_{\text{test}}(f_{\theta})\leq R_{\text{train}}(f_{\theta})+\Lambda\cdot\Delta(\mathcal{D}_{\text{train}},\mathcal{D}_{\text{test}})+\mathcal{O}\left(\sqrt{\frac{\log(1/\delta)}{n}}\right) \tag{4}
$$
where $\Lambda>0$ is a Lipschitz constant that depends on the model architecture and task complexity, $n$ is the training sample size, and the bound holds with probability $1-\delta$ , where $\delta$ is the failure propability.*
The proof is provided in Appendix A.1
Building on this data distribution perspective, we identify three critical dimensions along which distributional shifts can occur, each revealing different aspects of CoT’s pattern-matching nature: ➊ Task generalization examines how well CoT transfers across different types of reasoning tasks. Novel tasks may have unique elements and underlying logical structure, which introduces distributional shifts that challenge the model’s ability to apply learned reasoning patterns. ➋ Length generalization investigates CoT’s robustness to reasoning chains of varying lengths. Since training data typically contains reasoning sequences within a certain length range, test cases requiring substantially longer or shorter reasoning chains represent a form of distributional shift along the sequence length dimension. This length discrepancy could result from the reasoning step or the text-dependent solution space. ➌ Format generalization explores how sensitive CoT is to variations in prompt formulation and structure. Due to various reasons (e.g., sophistical training data or diverse background of users), it is challenging for LLM practitioners to design a golden prompt to elicit knowledge suitable for the current case. Their detailed definition and implementation are given in subsequent sections.
Each dimension provides a unique lens for understanding the boundaries of CoT’s effectiveness and the mechanisms underlying its apparent reasoning capabilities. By systematically varying these dimensions in controlled experimental settings, we can empirically validate our hypothesis that CoT performance degrades predictably as distributional discrepancy increases, thereby revealing its fundamental nature as a pattern-matching rather than reasoning system.
4 DataAlchemy: An Isolated and Controlled Environment
To systematically investigate the influence of distributional shifts on CoT reasoning capabilities, we introduce DataAlchemy, a synthetic dataset framework designed for controlled experimentation. This environment enables us to train language models from scratch under precisely defined conditions, allowing for rigorous analysis of CoT behavior across different OOD scenarios. The overview is shown in Figure 1.
4.1 Basic Atoms and Elements
Let $\mathcal{A}=\{\texttt{A},\texttt{B},\texttt{C},...,\texttt{Z}\}$ denote the alphabet of 26 basic atoms. An element $\mathbf{e}$ is defined as an ordered sequence of atoms:
$$
\mathbf{e}=(a_{0},a_{1},\ldots,a_{l-1})\quad\text{where}\quad a_{i}\in\mathcal{A},\quad l\in\mathbb{Z}^{+} \tag{5}
$$
This design provides a versatile manipulation for the size of the dataset $\mathcal{D}$ (i.e., $|\mathcal{D}|=|\mathcal{A}|^{l}$ ) by varying element length $l$ to train language models with various capacities. Meanwhile, it also allows us to systematically probe text length generalization capabilities.
4.2 Transformations
A transformation is an operation that operates on elements $F:\mathbf{e}→\hat{\mathbf{e}}$ . In this work, we consider two fundamental transformations: the ROT Transformation and the Cyclic Position Shift. To formally define the transformations, we introduce a bijective mapping $\phi:\mathcal{A}→\mathbb{Z}_{26}$ , where $\mathbb{Z}_{26}=\{0,1,...,25\}$ , such that $\phi(c)$ maps a character to its zero-based alphabetical index.
**Definition 4.1 (ROT Transformation)**
*Given an element $\mathbf{e}=(a_{0},\\
...,a_{l-1})$ and a rotation parameter $n∈\mathbb{Z}$ , the ROT Transformation $f_{\text{rot}}$ produces an element $\hat{\mathbf{e}}=(\hat{a}_{0},...,\hat{a}_{l-1})$ . Each atom $\hat{a}_{i}$ is:
$$
\hat{a}_{i}=\phi^{-1}((\phi(a_{i})+n)\pmod{26}) \tag{6}
$$
This operation cyclically shifts each atom $n$ positions forward in alphabetical order. For example, if $\mathbf{e}=(\texttt{A},\texttt{P},\texttt{P},\texttt{L},\texttt{E})$ and $n=13$ , then $f_{\text{rot}}(\mathbf{e},13)=(\texttt{N},\texttt{C},\texttt{C},\texttt{Y},\texttt{R})$ .*
**Definition 4.2 (Cyclic Position Shift)**
*Given an element $\mathbf{e}=(a_{0},\\
...,a_{l-1})$ and a shift parameter $n∈\mathbb{Z}$ , the Cyclic Position Shift $f_{\text{pos}}$ produces an element $\hat{\mathbf{e}}=(\hat{a}_{0},...,\hat{a}_{l-1})$ . Each atom $\hat{a}_{i}$ is defined by a cyclic shift of indices:
$$
\hat{a}_{i}=a_{(i-n)\pmod{l}} \tag{7}
$$
This transformation cyclically shifts the positions of the atoms within the sequence by $n$ positions to the right. For instance, if $\mathbf{e}=(\texttt{A},\texttt{P},\texttt{P},\texttt{L},\texttt{E})$ and $n=1$ , then $f_{\text{pos}}(\mathbf{e},1)=(\texttt{E},\texttt{A},\texttt{P},\texttt{P},\texttt{L})$ .*
**Definition 4.3 (Generalized Compositional Transformation)**
*To model multi-step reasoning, we define a compositional transformation as the successive application of a sequence of operations. Let $S=(f_{1},f_{2},...,f_{k})$ be a sequence of operations, where each $f_{i}$ is one of the fundamental transformations $\mathcal{F}=\{f_{\text{rot}},f_{\text{pos}}\}$ with its respective parameters. The compositional transformation $f_{\text{S}}$ for the sequence $S$ is the function composition:
$$
f_{\text{S}}=f_{k}\circ f_{k}\circ\cdots\circ f_{1} \tag{8}
$$
The resulting element $\hat{\mathbf{e}}$ is obtained by applying the operations sequentially to an initial element $\mathbf{e}$ :
$$
\hat{\mathbf{e}}=f_{k}(f_{k-1}(\ldots(f_{1}(\mathbf{e}))\ldots)) \tag{9}
$$*
This design enables the construction of arbitrarily complex transformation chains by varying the type, parameters, order, and length of operations within the sequence. At the sample time, we can naturally acquire the COT reasoning step by decomposing the intermediate process:
$$
\underbrace{f_{\text{S}}(\mathbf{e}):}_{\text{Query}}\quad\underbrace{\mathbf{e}\xrightarrow{f_{1}}\mathbf{e}^{(1)}\xrightarrow{f_{2}}\mathbf{e}^{(2)}\cdots\xrightarrow{f_{k-1}}\mathbf{e}^{(k-1)}\xrightarrow{f_{k}}}_{\text{COT reasoning steps}}\underbrace{\boxed{\hat{\mathbf{e}}}}_{\text{Answer}} \tag{1}
$$
4.3 Environment Setting
Through systematic manipulation of elements and transformations, DataAlchemy offers a flexible and controllable framework for training LLMs from scratch, facilitating rigorous investigation of diverse OOD scenarios. Without specification, we employ a decoder-only language model GPT-2 (Radford et al., 2019) with a configuration of 4 layers, 32 hidden dimensions, and 4 attention heads. We utilize a Byte-Pair Encoding (BPE) tokenizer. Both LLMs and the tokenizer follow the general modern LLM pipeline. During the inference time, we set the temperature to 1e-5. For rigor, we also study LLMs with various parameters, architectures, and temperatures in Section 8. Details of the implementation are provided in the Appendix B. We consider that each element consists of 4 basic atoms, which produces 456,976 samples for each dataset with varied transformations and token amounts. We initialize the two transformations $f_{1}=f_{\text{rot}}(e,13)$ and $f_{2}=f_{\text{pos}}(e,1)$ . We consider the exact match rate, Levenshtein distance (i.e., edit distance) (Yujian and Bo, 2007), and BLEU score (Papineni et al., 2002) as metrics and evaluate the produced reasoning step, answer, and full chain. Examples of the datasets and evaluations are shown in Appendix C
5 Task Generalization
Task generalization represents a fundamental challenge for CoT reasoning, as it directly tests a model’s ability to apply learned concepts and reasoning patterns to unseen scenarios. In our controlled experiments, both transformation and elements could be novel. Following this, we decompose task generalization into two primary dimensions: element generalization and transformation generalization.
Task Generalization Complexity. Guided by the data distribution lens, we first introduce a measure for generalization difficulty:
**Proposition 5.1 (Task Generalization Complexity)**
*For a reasoning chain $f_{S}$ operating on elements $\mathbf{e}=(a_{0},...,a_{l-1})$ , define:
$$
\displaystyle\operatorname{TGC}(C)= \displaystyle\alpha\sum_{i=1}^{m}\mathbb{I}\left[a_{i}\notin\mathcal{E}^{i}_{\text{train }}\right]+\beta\sum_{j=1}^{n}\mathbb{I}\left[f_{j}\notin\mathcal{F}_{\text{train }}\right]+\gamma\mathbb{I}\left[\left(f_{1},f_{2},\ldots,f_{k}\right)\notin\mathcal{P}_{\text{train }}\right]+C_{T} \tag{11}
$$
as a measurement of task discrepancy $\Delta_{task}$ , where $\alpha,\beta,\gamma$ are weighting parameters for different novelty types and $C_{T}$ is task specific constant. $\mathcal{E}^{i}_{\text{train }},\mathcal{F}_{\text{train }},$ and $\mathcal{P}_{\text{train }}$ denote the bit-wise element set, relation set and the order of relation set used during training.*
We establish a critical threshold beyond which CoT reasoning fails exponentially:
**Theorem 5.1 (Task Generalization Failure Threshold)**
*There exists a threshold $\tau$ such that when $\text{TGC}(C)>\tau$ , the probability of correct CoT reasoning drops exponentially:
$$
P(\text{correct}|C)\leq e^{-\delta(\text{TGC}(C)-\tau)} \tag{12}
$$*
The proof is provided in Appendix A.2.
5.1 Transformation Generalization
Transformation generalization evaluates the ability of CoT reasoning to effectively transfer when models encounter novel transformations during testing, which is an especially prevalent scenario in real-world applications.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Scatter Plot: BLEU Score vs. Edit Distance with Distribution Shift
### Overview
The image presents a scatter plot visualizing the relationship between BLEU score and Edit Distance, with a third dimension represented by color-coding based on Distribution Shift. The plot consists of numerous data points, each representing a specific instance or observation. The points are colored according to their Distribution Shift value, ranging from blue (low shift) to red (high shift).
### Components/Axes
* **X-axis:** Edit Distance, ranging from approximately 0.00 to 0.30.
* **Y-axis:** BLEU Score, ranging from approximately 0.20 to 1.00.
* **Color Scale (Legend):** Distribution Shift, ranging from approximately 0.2 to 0.8. The legend is positioned on the right side of the plot.
* Blue: ~0.2
* Light Purple: ~0.4
* Pink: ~0.6
* Red: ~0.8
### Detailed Analysis
The data points are clustered in a few areas.
* **Cluster 1 (Top-Left):** A small cluster of points with very low Edit Distance (around 0.00-0.05) and high BLEU scores (around 0.95-1.00). These points are colored blue, indicating a low Distribution Shift (approximately 0.2).
* **Cluster 2 (Center-Left):** A larger cluster of points with Edit Distance ranging from approximately 0.10 to 0.20 and BLEU scores ranging from approximately 0.40 to 0.70. The color of these points transitions from light purple to pink, indicating a Distribution Shift ranging from approximately 0.4 to 0.6.
* **Cluster 3 (Center-Right):** A cluster of points with Edit Distance ranging from approximately 0.20 to 0.30 and BLEU scores ranging from approximately 0.30 to 0.60. These points are colored pink to red, indicating a Distribution Shift ranging from approximately 0.6 to 0.8.
* **Trend:** As Edit Distance increases, BLEU score generally decreases. There is a clear negative correlation between the two variables. The color gradient suggests that higher Edit Distance is associated with higher Distribution Shift.
Here's a more detailed breakdown of approximate data points (with uncertainty due to visual estimation):
| Edit Distance (approx.) | BLEU Score (approx.) | Distribution Shift (approx.) |
|---|---|---|
| 0.02 | 0.98 | 0.2 |
| 0.03 | 1.00 | 0.2 |
| 0.04 | 0.95 | 0.2 |
| 0.12 | 0.65 | 0.4 |
| 0.15 | 0.50 | 0.5 |
| 0.18 | 0.45 | 0.5 |
| 0.20 | 0.60 | 0.6 |
| 0.22 | 0.40 | 0.6 |
| 0.25 | 0.55 | 0.7 |
| 0.27 | 0.35 | 0.7 |
| 0.30 | 0.30 | 0.8 |
### Key Observations
* The points with the highest BLEU scores have very low Edit Distance and low Distribution Shift.
* As Edit Distance increases, BLEU scores tend to decrease, and Distribution Shift tends to increase.
* There is a noticeable spread in the data, indicating variability in the relationship between the variables.
* The data does not appear to be linearly correlated, but rather shows a general downward trend.
### Interpretation
This scatter plot likely represents the performance of a machine translation or text generation system. BLEU score is a common metric for evaluating the quality of machine-generated text, while Edit Distance measures the number of edits (insertions, deletions, substitutions) required to transform one string into another. Distribution Shift refers to the difference between the training data distribution and the test data distribution.
The plot suggests that when the Edit Distance between the generated text and the reference text is low (meaning the generated text is similar to the reference text), the BLEU score is high, and the Distribution Shift is low. This indicates that the system performs well when the test data is similar to the training data. However, as the Edit Distance increases (meaning the generated text is less similar to the reference text), the BLEU score decreases, and the Distribution Shift increases. This suggests that the system's performance degrades when the test data is different from the training data.
The presence of a Distribution Shift is a critical factor affecting the performance of the system. When the test data distribution differs significantly from the training data distribution, the system may struggle to generate accurate and fluent text. This highlights the importance of considering Distribution Shift when evaluating and deploying machine translation or text generation systems. The outliers may represent cases where the system performs unexpectedly well or poorly, potentially due to specific characteristics of the input data or the system's architecture.
</details>
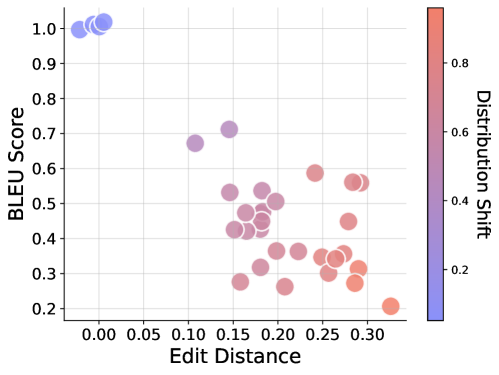
Figure 2: Performance of CoT reasoning on transformation generalization. Efficacy of CoT reasoning declines as the degree of distributional discrepancy increases.
Experimental Setup. To systematically evaluate the impact of transformations, we conduct experiments by varying transformations between training and testing sets while keeping other factors constant (e.g., elements, length, and format). Guided by the intuition formalized in Proposition 5.1, we define four incremental levels of distribution shift in transformations as shown in Figure 1: (i) In-Distribution (ID): The transformations in the test set are identical to those observed during training, e.g., $f_{1}\circ f_{1}→ f_{1}\circ f_{1}$ . (ii) Composition (CMP): Test samples comprise novel compositions of previously encountered transformations, though each individual transformation remains familiar, e.g., ${f_{1}\circ f_{1},f_{1}\circ f_{2},f_{2}\circ f_{1}}→ f_{2}\circ f_{2}$ . (iii) Partial Out-of-Distribution (POOD): Test data include compositions involving at least one novel transformation not seen during training, e.g., $f_{1}\circ f_{1}→ f_{1}\circ f_{2}$ . (iv) Out-of-Distribution (OOD): The test set contains entirely novel transformation types that are unseen in training, e.g., $f_{1}\circ f_{1}→ f_{2}\circ f_{2}$ .
Table 1: Full chain evaluation under different scenarios for transformation generalization.
| $f_{1}\circ f_{1}→ f_{1}\circ f_{1}$ $\{f_{2}\circ f_{2},f_{1}\circ f_{2},f_{2}\circ f_{1}\}→ f_{1}\circ f_{1}$ $f_{1}\circ f_{2}→ f_{1}\circ f_{1}$ | ID CMP POOD | 100.00% 0.01% 0.00% | 0 0.1326 0.1671 | 1 0.6867 0.4538 |
| --- | --- | --- | --- | --- |
| $f_{2}\circ f_{2}→ f_{1}\circ f_{1}$ | OOD | 0.00% | 0.2997 | 0.2947 |
Findings. Figure 2 illustrates the performance of the full chain under different distribution discrepancies computed by task generalize complexities (normalized between 0 and 1) in Definition 5.1. We can observe that, in general, the effectiveness of CoT reasoning decreases when distribution discrepancy increases. For the instance shown in Table 1, from in-distribution to composition, POOD, and OOD, the exact match decreases from 1 to 0.01, 0, and 0, and the edit distance increases from 0 to 0.13, 0.17 when tested on data with transformation $f_{1}\circ f_{1}$ . Apart from ID, LLMs cannot produce a correct full chain in most cases, while they can produce correct CoT reasoning when exposed to some composition and POOD conditions by accident. As shown in Table 2, from $f_{1}\circ f_{2}$ to $f_{2}\circ f_{2}$ , the LLMs can correctly answer 0.1% of questions. A close examination reveals that it is a coincidence, e.g., the query element is A, N, A, N, which happened to produce the same result for the two operations detailed in the Appendix D.1. When further analysis is performed by breaking the full chain into reasoning steps and answers, we observe strong consistency between the reasoning steps and answers. For example, under the composition generalization setting, the reasoning steps are entirely correct on test data distribution $f_{1}\circ f_{1}$ and $f_{2}\circ f_{2}$ , but with wrong answers. Probe these insistent cases in Appendix D.1, we can find that when a novel transformation (say $f_{1}\circ f_{1}$ ) is present, LLMs try to generalize the reasoning paths based on the most similar ones (i.e., $f_{1}\circ f_{2}$ ) seen during training, which leads to correct reasoning paths, yet incorrect answer, which echo the example in the introduction. Similarly, generalization from $f_{1}\circ f_{2}$ to $f_{2}\circ f_{1}$ or vice versa allows LLMs to produce correct answers that are attributed to the commutative property between the two orthogonal transformations with unfaithful reasoning paths. Collectively, the above results indicate that the CoT reasoning fails to generalize to novel transformations, not even to novel composition transforms. Rather than demonstrating a true understanding of text, CoT reasoning under task transformations appears to reflect a replication of patterns learned during training.
Table 2: Evaluation on different components in CoT reasoning on transformation generalization. CoT reasoning shows inconsistency with the reasoning steps and answers.
| $\{f_{1}\circ f_{1},f_{1}\circ f_{2},f_{2}\circ f_{1}\}→ f_{2}\circ f_{2}$ $\{f_{1}\circ f_{2},f_{2}\circ f_{1},f_{2}\circ f_{2}\}→ f_{1}\circ f_{1}$ $f_{1}\circ f_{2}→ f_{2}\circ f_{1}$ | 100.00% 100.00% 0.00% | 0.01% 0.01% 100.00% | 0.01% 0.01% 0.00% | 0.000 0.000 0.373 | 0.481 0.481 0.000 | 0.133 0.133 0.167 |
| --- | --- | --- | --- | --- | --- | --- |
| $f_{2}\circ f_{1}→ f_{1}\circ f_{2}$ | 0.00% | 100.00% | 0.00% | 0.373 | 0.000 | 0.167 |
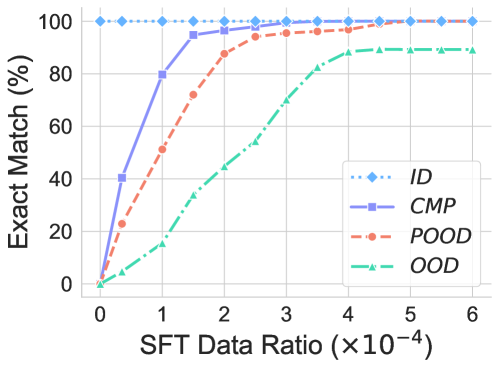
Experiment settings. To further probe when CoT reasoning can generalize to unseen transformations, we conduct supervised fine-tuning (SFT) on a small portion $\lambda$ of unseen data. In this way, we can decrease the distribution discrepancy between the training and test sets, which might help LLMs to generalize to test queries.
Findings. As shown in Figure 3, we can find that generally a very small portion ( $\lambda=1.5e^{-4}$ ) of data can make the model quickly generalize to unseen transformations. The less discrepancy between the training and testing data, the quicker the model can generalize. This indicates that a similar pattern appears in the training data, helping LLMs to generalize to the test dataset.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Chart: Exact Match vs. SFT Data Ratio
### Overview
The image presents a line chart illustrating the relationship between the SFT (Supervised Fine-Tuning) Data Ratio and the Exact Match percentage for four different models/metrics: ID, CMP, POOD, and OOD. The chart demonstrates how the performance (Exact Match) of each model improves as the amount of SFT data increases.
### Components/Axes
* **X-axis:** SFT Data Ratio (×10⁻⁴). Scale ranges from approximately 0 to 6.
* **Y-axis:** Exact Match (%). Scale ranges from 0 to 100.
* **Legend:** Located in the top-right corner. Contains the following labels and corresponding colors:
* ID (Blue, dotted line)
* CMP (Purple, solid line)
* POOD (Orange, dashed line)
* OOD (Teal, dash-dot line)
* **Gridlines:** Present to aid in reading values.
### Detailed Analysis
* **ID (Blue, dotted):** The line starts at approximately 100% Exact Match at an SFT Data Ratio of 0. It remains relatively stable at around 100% throughout the entire range of SFT Data Ratios.
* (0, 100)
* (1, 100)
* (2, 100)
* (3, 100)
* (4, 100)
* (5, 100)
* (6, 100)
* **CMP (Purple, solid):** The line begins at approximately 40% Exact Match at an SFT Data Ratio of 0. It rapidly increases to approximately 95% at an SFT Data Ratio of 1. It plateaus around 95-98% for the remainder of the SFT Data Ratio range.
* (0, 40)
* (1, 95)
* (2, 98)
* (3, 98)
* (4, 98)
* (5, 98)
* (6, 98)
* **POOD (Orange, dashed):** The line starts at approximately 0% Exact Match at an SFT Data Ratio of 0. It increases sharply to approximately 85% at an SFT Data Ratio of 2. It continues to increase, but at a slower rate, reaching approximately 95% at an SFT Data Ratio of 6.
* (0, 0)
* (1, 40)
* (2, 85)
* (3, 90)
* (4, 93)
* (5, 95)
* (6, 95)
* **OOD (Teal, dash-dot):** The line begins at approximately 0% Exact Match at an SFT Data Ratio of 0. It steadily increases, reaching approximately 75% at an SFT Data Ratio of 6. This line exhibits the slowest rate of increase among the four models.
* (0, 0)
* (1, 15)
* (2, 40)
* (3, 60)
* (4, 75)
* (5, 80)
* (6, 85)
### Key Observations
* The ID model consistently achieves 100% Exact Match regardless of the SFT Data Ratio.
* CMP demonstrates the fastest improvement in Exact Match with increasing SFT Data Ratio, reaching a plateau quickly.
* POOD and OOD show a more gradual improvement, with POOD outperforming OOD across all SFT Data Ratios.
* OOD requires the most SFT data to achieve a reasonable level of Exact Match.
### Interpretation
The chart suggests that increasing the amount of SFT data generally improves the performance of the models, as measured by Exact Match. However, the extent of improvement varies significantly between models. The ID model appears to be already highly optimized or inherently capable of achieving perfect matches, while CMP benefits the most from SFT. POOD and OOD show a more moderate improvement, indicating they may require more data or different optimization strategies to reach the same level of performance as ID and CMP. The differences in performance between the models could be due to variations in their architectures, training data, or the specific tasks they are designed to perform. The chart highlights the importance of SFT in enhancing model accuracy and the potential for diminishing returns as the SFT Data Ratio increases. The fact that ID remains at 100% suggests it may be a baseline or a model that has already reached its maximum potential.
</details>
Figure 3: Performance on unseen transformation using SFT in various levels of distribution shift. Introducing a small amount of unseen data helps CoT reasoning to generalize across different scenarios.
5.2 Element Generalization
Element generalization is another critical factor to consider when LLMs try to generalize to new tasks.
Experiment settings. Similar to transformation generalization, we fix other factors and consider three progressive distribution shifts for elements: ID, CMP, and OOD, as shown in Figure 1. It is noted that in composition, we test if CoT reasoning can be generalized to novel combinations when seeing all the basic atoms in the elements, e.g., $(\texttt{A},\texttt{B},\texttt{C},\texttt{D})→(\texttt{B},\texttt{C},\texttt{D},\texttt{A})$ . Based on the atom order in combination (can be measured by edit distance $n$ ), the CMP can be further developed. While for OOD, atoms that constitute the elements are totally unseen during the training.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Heatmap: BLEU Score and Exact Match Percentage
### Overview
The image presents two heatmaps, stacked vertically. The top heatmap displays BLEU scores, while the bottom heatmap shows Exact Match percentages. Both heatmaps share the same x and y axes, representing different transformations and scenarios. The color intensity in each heatmap corresponds to the value of the metric.
### Components/Axes
* **X-axis:** Transformation. Categories are: f1, f2, f1•f1, f1•f2, f2•f1, f2•f2.
* **Y-axis:** Scenario. Categories are: ID, CMP, OOD.
* **Top Heatmap:** BLEU Score. Color scale ranges from 0.0 (blue) to 1.0 (red).
* **Bottom Heatmap:** Exact Match (%). Color scale ranges from 0 (blue) to 100 (red).
* **Legend (Top-Right):** BLEU Score colorbar.
* **Legend (Bottom-Right):** Exact Match (%) colorbar.
### Detailed Analysis or Content Details
**Top Heatmap (BLEU Score):**
* **ID Scenario:**
* f1: 1.00
* f2: 1.00
* f1•f1: 1.00
* f1•f2: 1.00
* f2•f1: 1.00
* f2•f2: 1.00
* **CMP Scenario:**
* f1: 0.71
* f2: 0.62
* f1•f1: 0.65
* f1•f2: 0.68
* f2•f1: 0.32
* f2•f2: 0.16
* **OOD Scenario:**
* f1: 0.00
* f2: 0.00
* f1•f1: 0.46
* f1•f2: 0.35
* f2•f1: 0.40
* f2•f2: 0.35
**Bottom Heatmap (Exact Match %):**
* **ID Scenario:**
* f1: 100
* f2: 100
* f1•f1: 100
* f1•f2: 100
* f2•f1: 100
* f2•f2: 100
* **CMP Scenario:**
* f1: 70
* f2: 60
* f1•f1: 65
* f1•f2: 70
* f2•f1: 30
* f2•f2: 15
* **OOD Scenario:**
* f1: 0
* f2: 0
* f1•f1: 45
* f1•f2: 35
* f2•f1: 40
* f2•f2: 35
### Key Observations
* The ID scenario consistently achieves the highest BLEU scores (1.00) and Exact Match percentages (100%) across all transformations.
* The OOD scenario consistently exhibits the lowest BLEU scores (0.00 for f1 and f2) and Exact Match percentages (0 for f1 and f2).
* The CMP scenario shows intermediate values for both metrics.
* The BLEU score and Exact Match percentage generally decrease as the transformations become more complex (from f1/f2 to f1•f2/f2•f2) within the CMP and OOD scenarios.
* The f2•f1 and f2•f2 transformations consistently yield lower scores than f1•f1 and f1•f2 in the CMP and OOD scenarios.
### Interpretation
The data suggests that the model performs perfectly when the scenario is "In Distribution" (ID), meaning the input data is similar to the training data. However, performance degrades significantly when the scenario is "Out of Distribution" (OOD), indicating the model struggles to generalize to unseen data. The "CMP" scenario represents a middle ground, where the model performs reasonably well but not perfectly.
The transformations (f1, f2, etc.) likely represent different types of data manipulation or augmentation. The decreasing performance with more complex transformations suggests that the model is sensitive to changes in the input data distribution. The difference between f1•f1/f1•f2 and f2•f1/f2•f2 suggests that the order of transformations matters, or that certain transformation combinations are more challenging for the model.
The correlation between BLEU score and Exact Match percentage indicates that these two metrics are measuring similar aspects of model performance. A higher BLEU score generally corresponds to a higher Exact Match percentage, suggesting that the model is producing more accurate and relevant outputs when it performs well. The data highlights the importance of considering out-of-distribution scenarios and the robustness of models to data transformations.
</details>
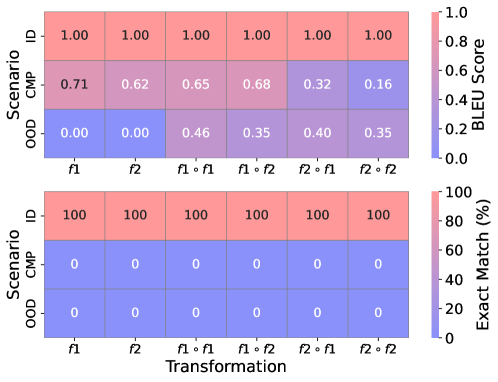
Figure 4: Element generalization results on various scenarios and relations.
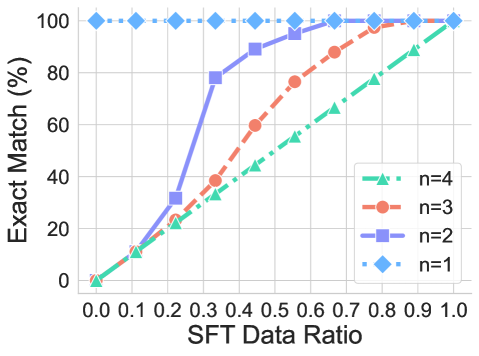
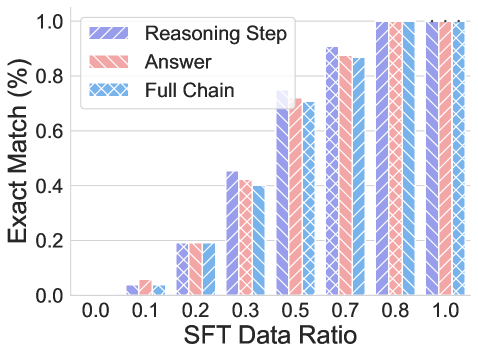
Findings. Similar to transformation generalization, the performances degrade sharply when facing the distribution shift consistently across all transformations, as shown in Figure 4. From ID to CMP and OOD, the exact match decreases from 1.0 to 0 and 0, for all cases. Most strikingly, the BLEU score is 0 when transferred to $f_{1}$ and $f_{2}$ transformations. A failure case in Appendix D.1 shows that the models cannot respond to any words when novel elements are present. We further explore when CoT reasoning can generalize to novel elements by conducting SFT. The results are summarized in Figure 5. We evaluate the performance under three exact matches for the full chain under three scenarios, CMP based on the edit distance n. The result is similar to SFT on transformation. The performance increases rapidly when presented with similar (a small $n$ ) examples in the training data. Interestingly, the exact match rate for CoT reasoning aligns with the lower bound of performance when $n=3$ , which might suggest the generalization of CoT reasoning on novel elements is very limited, even SFT on the downstream task. When we further analyze the exact match of reasoning, answer, and token during the training for $n=3$ , as summarized in Figure 5b. We find that there is a mismatch of accuracy between the answer and the reasoning step during the training process, which somehow might provide an explanation regarding why CoT reasoning is inconsistent in some cases.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: Exact Match (%) vs. SFT Data Ratio
### Overview
This line chart illustrates the relationship between the SFT (Supervised Fine-Tuning) Data Ratio and the Exact Match percentage, for different values of 'n'. The chart displays four lines, each representing a different value of 'n' (1, 2, 3, and 4). The x-axis represents the SFT Data Ratio, ranging from 0.0 to 1.0, while the y-axis represents the Exact Match percentage, ranging from 0% to 100%.
### Components/Axes
* **X-axis Title:** SFT Data Ratio
* **Y-axis Title:** Exact Match (%)
* **X-axis Markers:** 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0
* **Y-axis Markers:** 0, 20, 40, 60, 80, 100
* **Legend:** Located in the top-right corner of the chart.
* n=4 (Green Triangle)
* n=3 (Red Circle)
* n=2 (Purple Square)
* n=1 (Blue Diamond)
### Detailed Analysis
* **n=1 (Blue Diamond):** The line starts at approximately (0.0, 100%) and remains relatively flat at 100% until approximately SFT Data Ratio of 0.8, where it begins to slightly decrease to approximately 98% at 1.0.
* **n=2 (Purple Square):** The line starts at approximately (0.0, 98%) and increases rapidly between SFT Data Ratio 0.2 and 0.4, reaching approximately 85% at 0.3 and 95% at 0.4. It then plateaus around 98-100% for the remainder of the range.
* **n=3 (Red Circle):** The line starts at approximately (0.0, 15%) and increases steadily, reaching approximately 40% at 0.3, 80% at 0.5, 90% at 0.6, 95% at 0.7, and plateaus around 98% for the remainder of the range.
* **n=4 (Green Triangle):** The line starts at approximately (0.0, 5%) and increases gradually, reaching approximately 30% at 0.3, 60% at 0.5, 80% at 0.7, 90% at 0.8, and 95% at 0.9. It reaches approximately 98% at 1.0.
### Key Observations
* Higher values of 'n' generally result in higher Exact Match percentages, especially at lower SFT Data Ratios.
* The lines converge towards 100% as the SFT Data Ratio increases, indicating that all values of 'n' achieve high Exact Match percentages with sufficient SFT data.
* n=1 consistently maintains a very high Exact Match percentage across all SFT Data Ratios.
* n=4 shows the slowest initial increase in Exact Match percentage, requiring a higher SFT Data Ratio to achieve comparable results to other values of 'n'.
### Interpretation
The data suggests that increasing the SFT Data Ratio improves the Exact Match percentage, and that the value of 'n' influences the rate of improvement. The parameter 'n' likely represents the number of samples or iterations used in the supervised fine-tuning process. The chart demonstrates a diminishing return effect: while increasing the SFT Data Ratio always helps, the benefit is smaller at higher ratios. The consistent high performance of n=1 suggests that even a small amount of supervised fine-tuning can be highly effective, especially when combined with a sufficient SFT Data Ratio. The convergence of the lines at higher SFT Data Ratios indicates that the impact of 'n' becomes less significant as more supervised data is available. This could be due to the model reaching a saturation point where additional fine-tuning provides minimal improvement. The initial lower performance of n=4 suggests that more iterations or samples may be needed initially to achieve comparable results, but it eventually catches up with other values of 'n' as the SFT Data Ratio increases.
</details>
(a) Performance on unseen element via SFT in various CMP scenarios.
<details>
<summary>x6.png Details</summary>
### Visual Description
\n
## Bar Chart: Exact Match (%) vs. SFT Data Ratio
### Overview
This bar chart displays the relationship between the SFT (Supervised Fine-Tuning) Data Ratio and the Exact Match (%) for three different components: Reasoning Step, Answer, and Full Chain. The chart uses grouped bar representations to compare the Exact Match percentages for each component at different SFT Data Ratios.
### Components/Axes
* **X-axis:** SFT Data Ratio, with markers at 0.1, 0.2, 0.3, 0.5, 0.7, 0.8, and 1.0.
* **Y-axis:** Exact Match (%), ranging from 0.0 to 1.0.
* **Legend:**
* Reasoning Step (Light Blue, hatched bars)
* Answer (Light Red, hatched bars)
* Full Chain (Medium Blue, hatched bars)
### Detailed Analysis
The chart consists of seven groups of three bars, each corresponding to a specific SFT Data Ratio.
* **SFT Data Ratio = 0.1:**
* Reasoning Step: Approximately 0.04 Exact Match.
* Answer: Approximately 0.01 Exact Match.
* Full Chain: Approximately 0.02 Exact Match.
* **SFT Data Ratio = 0.2:**
* Reasoning Step: Approximately 0.16 Exact Match.
* Answer: Approximately 0.08 Exact Match.
* Full Chain: Approximately 0.12 Exact Match.
* **SFT Data Ratio = 0.3:**
* Reasoning Step: Approximately 0.42 Exact Match.
* Answer: Approximately 0.40 Exact Match.
* Full Chain: Approximately 0.41 Exact Match.
* **SFT Data Ratio = 0.5:**
* Reasoning Step: Approximately 0.70 Exact Match.
* Answer: Approximately 0.68 Exact Match.
* Full Chain: Approximately 0.69 Exact Match.
* **SFT Data Ratio = 0.7:**
* Reasoning Step: Approximately 0.86 Exact Match.
* Answer: Approximately 0.83 Exact Match.
* Full Chain: Approximately 0.85 Exact Match.
* **SFT Data Ratio = 0.8:**
* Reasoning Step: Approximately 0.96 Exact Match.
* Answer: Approximately 0.94 Exact Match.
* Full Chain: Approximately 0.95 Exact Match.
* **SFT Data Ratio = 1.0:**
* Reasoning Step: Approximately 0.98 Exact Match.
* Answer: Approximately 0.96 Exact Match.
* Full Chain: Approximately 0.97 Exact Match.
All three data series (Reasoning Step, Answer, and Full Chain) exhibit a clear upward trend as the SFT Data Ratio increases. The Reasoning Step consistently shows the highest Exact Match percentage, followed closely by the Full Chain, and then the Answer.
### Key Observations
* The Exact Match percentage increases significantly with increasing SFT Data Ratio for all three components.
* The Reasoning Step consistently outperforms the Answer and Full Chain in terms of Exact Match.
* The differences between the Exact Match percentages of the three components become smaller as the SFT Data Ratio approaches 1.0.
### Interpretation
The data suggests a strong positive correlation between the amount of Supervised Fine-Tuning (SFT) data used and the accuracy (as measured by Exact Match) of the Reasoning Step, Answer, and Full Chain components. This indicates that increasing the amount of labeled data used for fine-tuning improves the performance of the model in all three areas. The consistently higher performance of the Reasoning Step suggests that this component benefits the most from SFT, or that it is inherently more accurate than the other two. The convergence of the Exact Match percentages at higher SFT Data Ratios implies that all components reach a performance plateau with sufficient training data. This chart is valuable for understanding the impact of data quantity on model performance and for guiding decisions about data collection and model training strategies.
</details>
(b) Evaluation of CoT reasoning in SFT.
Figure 5: SFT performances for element generalization. SFT helps to generalize to novel elements.
6 Length Generalization
Length generalization examines how CoT reasoning degrades when models encounter test cases that differ in length from their training distribution. The difference in length could be introduced from the text space or the reasoning space of the problem. Therefore, we decompose length generalization into two complementary aspects: text length generalization and reasoning step generalization. Guided by instinct, we first propose to measure the length discrepancy.
Length Extrapolation Bound. We establish a power-law relationship for length extrapolation:
**Proposition 6.1 (Length Extrapolation Gaussian Degradation)**
*For a model trained on chain-of-thought sequences of fixed length $L_{\text{train}}$ , the generalization error at test length $L$ follows a Gaussian distribution:
$$
\mathcal{E}(L)=\mathcal{E}_{0}+\left(1-\mathcal{E}_{0}\right)\cdot\left(1-\exp\left(-\frac{\left(L-L_{\text{train }}\right)^{2}}{2\sigma^{2}}\right)\right) \tag{13}
$$
where $\mathcal{E}_{0}$ is the in-distribution error at $L=L_{\text{train}}$ , $\sigma$ is the length generalization width parameter, and $L$ is the test sequence length*
The proof is provided in Appendix A.3.
6.1 Text Length Generalization
Text length generalization evaluates how CoT performance varies when the input text length (i.e., the element length $l$ ) differs from training examples. Considering the way LLMs process long text, this aspect is crucial because real-world problems often involve varying degrees of complexity that manifest as differences in problem statement length, context size, or information density.
Experiment settings. We pre-train LLMs on the dataset with text length merely on $l=4$ while fixing other factors and evaluate the performance on a variety of lengths. We consider three different padding strategies during the pre-training: (i) None: LLMs do not use any padding. (ii) Padding: We pad LLM to the max length of the context window. (iii) Group: We group the text and truncate it into segments with a maximum length.
Table 3: Evaluation for text length generalization.
| 2 3 4 | 0.00% 0.00% 100.00% | 0.00% 0.00% 100.00% | 0.00% 0.00% 100.00% | 0.3772 0.2221 0.0000 | 0.4969 0.3203 0.0000 | 0.5000 0.2540 0.0000 | 0.4214 0.5471 1.0000 | 0.1186 0.1519 1.0000 | 0.0000 0.0000 1.0000 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 5 | 0.00% | 0.00% | 0.00% | 0.1818 | 0.2667 | 0.2000 | 0.6220 | 0.1958 | 0.2688 |
| 6 | 0.00% | 0.00% | 0.00% | 0.3294 | 0.4816 | 0.3337 | 0.4763 | 0.1174 | 0.2077 |
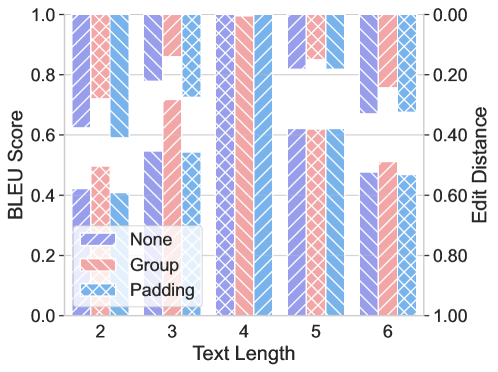
Findings. As illustrated in the Table 3, the CoT reasoning failed to directly generate two test cases even though those lengths present a mild distribution shift. Further, the performance declines as the length discrepancy increases shown in Figure 6. For instance, from data with $l=4$ to those with $l=3$ or $l=5$ , the BLEU score decreases from 1 to 0.55 and 0.62. Examples in Appendix D.1 indicate that LLMs attempt to produce CoT reasoning with the same length as the training data by adding or removing tokens in the reasoning chains. The efficacy of CoT reasoning length generalization deteriorates as the discrepancy increases. Moreover, we consider using a different padding strategy to decrease the divergence between the training data and test cases. We found that padding to the max length doesn’t contribute to length generalization. However, the performance increases when we replace the padding with text by using the group strategy, which indicates its effectiveness.
<details>
<summary>x7.png Details</summary>
### Visual Description
\n
## Bar Chart: BLEU Score and Edit Distance vs. Text Length
### Overview
This image presents a bar chart comparing BLEU scores and Edit Distance for different text lengths and data augmentation techniques (None, Group, Padding). The chart uses a dual y-axis to display both metrics simultaneously.
### Components/Axes
* **X-axis:** Text Length, with markers at 2, 3, 4, 5, and 6.
* **Left Y-axis:** BLEU Score, ranging from 0.0 to 1.0, with markers at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Right Y-axis:** Edit Distance, ranging from 0.00 to 1.00, with markers at 0.00, 0.20, 0.40, 0.60, 0.80, and 1.00.
* **Legend:** Located in the center-left of the chart, identifying the data series:
* "None" (represented by a light purple color with diagonal stripes)
* "Group" (represented by a light red color with diagonal stripes)
* "Padding" (represented by a light blue color with diagonal stripes)
### Detailed Analysis
The chart displays three data series for each text length.
* **Text Length 2:**
* None: BLEU Score ≈ 0.40, Edit Distance ≈ 0.65
* Group: BLEU Score ≈ 0.95, Edit Distance ≈ 0.05
* Padding: BLEU Score ≈ 0.95, Edit Distance ≈ 0.05
* **Text Length 3:**
* None: BLEU Score ≈ 0.55, Edit Distance ≈ 0.50
* Group: BLEU Score ≈ 0.70, Edit Distance ≈ 0.30
* Padding: BLEU Score ≈ 0.95, Edit Distance ≈ 0.05
* **Text Length 4:**
* None: BLEU Score ≈ 0.95, Edit Distance ≈ 0.05
* Group: BLEU Score ≈ 0.95, Edit Distance ≈ 0.05
* Padding: BLEU Score ≈ 0.95, Edit Distance ≈ 0.05
* **Text Length 5:**
* None: BLEU Score ≈ 0.60, Edit Distance ≈ 0.40
* Group: BLEU Score ≈ 0.95, Edit Distance ≈ 0.05
* Padding: BLEU Score ≈ 0.95, Edit Distance ≈ 0.05
* **Text Length 6:**
* None: BLEU Score ≈ 0.50, Edit Distance ≈ 0.50
* Group: BLEU Score ≈ 0.95, Edit Distance ≈ 0.05
* Padding: BLEU Score ≈ 0.95, Edit Distance ≈ 0.05
### Key Observations
* The "Group" and "Padding" augmentation techniques consistently achieve high BLEU scores (close to 1.0) and low Edit Distances (close to 0.0) for text lengths 3, 4, 5, and 6.
* The "None" augmentation technique exhibits lower BLEU scores and higher Edit Distances, particularly for text lengths 2, 3, 5, and 6.
* The BLEU score for "None" is relatively stable around 0.5 for text lengths 2, 3, 5, and 6.
* The Edit Distance for "None" is relatively stable around 0.5 for text lengths 2, 3, 5, and 6.
### Interpretation
The data suggests that the "Group" and "Padding" data augmentation techniques significantly improve the performance of a model, as measured by BLEU score and Edit Distance, compared to using no augmentation ("None"). The BLEU score, a measure of similarity between machine-generated text and reference text, is maximized by the augmentation techniques, while the Edit Distance, a measure of the number of edits required to transform one string into another, is minimized.
The consistent high performance of "Group" and "Padding" across various text lengths indicates their robustness. The lower performance of "None" suggests that the model benefits substantially from the additional data diversity provided by these augmentation methods. The slight variations in BLEU score and Edit Distance for "None" across different text lengths might indicate that the model's performance is more sensitive to text length when no augmentation is used.
The chart demonstrates a clear trade-off between BLEU score and Edit Distance: higher BLEU scores generally correspond to lower Edit Distances, and vice versa. This is expected, as a more accurate translation (higher BLEU score) will require fewer edits to match the reference text (lower Edit Distance).
</details>
Figure 6: Performance of text length generalization across various padding strategies. Group strategies contribute to length generalization.
6.2 Reasoning Step Generalization
The reasoning step generalization investigates whether models can extrapolate to reasoning chains requiring different steps $k$ from those observed during training. which is a popular setting in multi-step reasoning tasks.
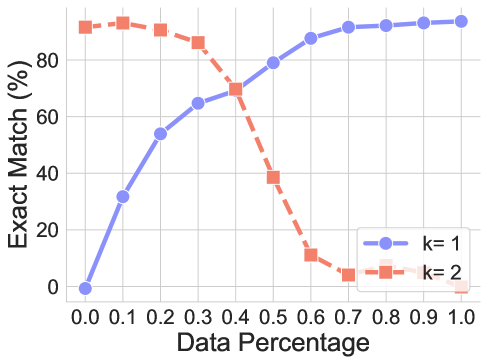
Experiment settings. Similar to text length generalization, we first pre-train the LLM with reasoning step $k=2$ , and evaluate on data with reasoning step $k=1$ or $k=3$ .
<details>
<summary>x8.png Details</summary>
### Visual Description
## Line Chart: Exact Match vs. Data Percentage
### Overview
The image presents a line chart illustrating the relationship between "Data Percentage" (x-axis) and "Exact Match" (y-axis) for two different values of 'k' (k=1 and k=2). The chart shows how the percentage of exact matches changes as the amount of data used increases.
### Components/Axes
* **X-axis:** "Data Percentage", ranging from 0.0 to 1.0, with increments of 0.1.
* **Y-axis:** "Exact Match (%)", ranging from 0 to 100, with increments of 20.
* **Lines:** Two lines are plotted:
* Blue line with circular markers, labeled "k = 1"
* Red line with square markers, labeled "k = 2"
* **Legend:** Located in the bottom-right corner, identifying the lines and their corresponding 'k' values.
### Detailed Analysis
**Line k = 1 (Blue):**
The blue line starts at approximately (0.0, 0) and exhibits a steep upward trend until around (0.4, 65). It continues to rise, but at a decreasing rate, reaching approximately (0.8, 92) and leveling off to approximately (1.0, 94).
* (0.0, 0)
* (0.1, 40)
* (0.2, 60)
* (0.3, 67)
* (0.4, 70)
* (0.5, 78)
* (0.6, 85)
* (0.7, 89)
* (0.8, 92)
* (0.9, 93)
* (1.0, 94)
**Line k = 2 (Red):**
The red line begins at approximately (0.0, 88) and remains relatively stable until around (0.4, 85). It then experiences a rapid decline, dropping to approximately (0.6, 40) and continuing to decrease to approximately (0.7, 10). It reaches approximately (0.8, 5) and (1.0, 2).
* (0.0, 88)
* (0.1, 88)
* (0.2, 85)
* (0.3, 82)
* (0.4, 75)
* (0.5, 45)
* (0.6, 40)
* (0.7, 10)
* (0.8, 5)
* (0.9, 3)
* (1.0, 2)
### Key Observations
* The "k = 1" line consistently shows a positive correlation between data percentage and exact match, increasing as more data is used.
* The "k = 2" line initially has a high exact match but rapidly decreases as data percentage increases.
* The lines intersect around the data percentage of 0.4, where the exact match is approximately 70% for k=1 and 75% for k=2.
* The "k = 2" line demonstrates a significant drop in exact match with increasing data percentage, suggesting a potential overfitting or instability issue.
### Interpretation
The chart likely represents the performance of a model or algorithm with two different parameter settings (k=1 and k=2) as the amount of training data increases. The "Exact Match" metric indicates the accuracy of the model's predictions.
The results suggest that:
* For smaller datasets, the model with k=2 performs slightly better than the model with k=1.
* As the dataset grows, the model with k=1 becomes more accurate and stable, while the model with k=2 suffers a dramatic decrease in accuracy. This could indicate that k=2 is more sensitive to noise or outliers in the data, leading to overfitting.
* The optimal value of 'k' appears to be 1, as it provides a more consistent and reliable performance across different data sizes.
The chart highlights the importance of choosing appropriate model parameters and considering the impact of data size on model performance. The rapid decline of the k=2 line suggests that increasing the complexity of the model (potentially through a higher 'k' value) does not always lead to better results, especially with larger datasets.
</details>
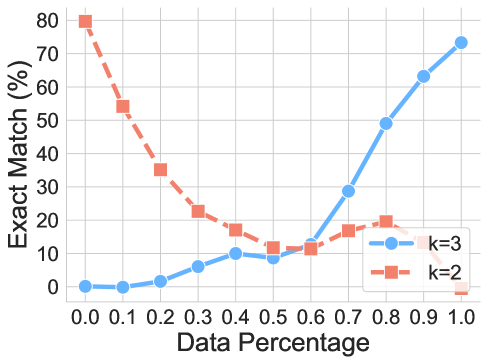
(a) Reasoning step. From k=2 to k=1
<details>
<summary>x9.png Details</summary>
### Visual Description
\n
## Line Chart: Exact Match vs. Data Percentage
### Overview
This image presents a line chart illustrating the relationship between "Data Percentage" on the x-axis and "Exact Match (%)" on the y-axis, for two different values of 'k' (k=2 and k=3). The chart appears to demonstrate how the percentage of exact matches changes as the amount of data used increases.
### Components/Axes
* **X-axis:** "Data Percentage", ranging from 0.0 to 1.0, with increments of 0.1.
* **Y-axis:** "Exact Match (%)", ranging from 0 to 80, with increments of 10.
* **Line 1 (Blue):** Represents data for k=3.
* **Line 2 (Orange/Red):** Represents data for k=2.
* **Legend:** Located in the bottom-right corner, clearly labeling each line with its corresponding 'k' value and color.
### Detailed Analysis
**Line k=3 (Blue):**
The blue line starts at approximately 1% Exact Match at 0.0 Data Percentage. It exhibits a generally upward trend, with some fluctuations.
* 0.0 Data Percentage: ~1% Exact Match
* 0.1 Data Percentage: ~2% Exact Match
* 0.2 Data Percentage: ~4% Exact Match
* 0.3 Data Percentage: ~7% Exact Match
* 0.4 Data Percentage: ~9% Exact Match
* 0.5 Data Percentage: ~11% Exact Match
* 0.6 Data Percentage: ~13% Exact Match
* 0.7 Data Percentage: ~29% Exact Match
* 0.8 Data Percentage: ~49% Exact Match
* 0.9 Data Percentage: ~69% Exact Match
* 1.0 Data Percentage: ~74% Exact Match
**Line k=2 (Orange/Red):**
The orange/red line begins at approximately 79% Exact Match at 0.0 Data Percentage and demonstrates a steep downward trend initially.
* 0.0 Data Percentage: ~79% Exact Match
* 0.1 Data Percentage: ~57% Exact Match
* 0.2 Data Percentage: ~41% Exact Match
* 0.3 Data Percentage: ~27% Exact Match
* 0.4 Data Percentage: ~22% Exact Match
* 0.5 Data Percentage: ~16% Exact Match
* 0.6 Data Percentage: ~14% Exact Match
* 0.7 Data Percentage: ~18% Exact Match
* 0.8 Data Percentage: ~22% Exact Match
* 0.9 Data Percentage: ~33% Exact Match
* 1.0 Data Percentage: ~40% Exact Match
### Key Observations
* The k=2 line starts with a very high Exact Match percentage but rapidly decreases as the Data Percentage increases.
* The k=3 line starts with a low Exact Match percentage but steadily increases as the Data Percentage increases.
* The lines intersect around a Data Percentage of 0.7, where the Exact Match percentages are approximately equal.
* At 1.0 Data Percentage, the k=3 line has a significantly higher Exact Match percentage than the k=2 line.
### Interpretation
The chart suggests that using a larger 'k' value (k=3) leads to a higher percentage of exact matches when a larger percentage of the data is considered. Conversely, a smaller 'k' value (k=2) provides a high initial Exact Match percentage but quickly degrades as more data is included. This could indicate that k=2 is more sensitive to noise or variations in the data, while k=3 is more robust. The intersection point around 0.7 suggests that for data percentages above this threshold, k=3 is the preferable choice for maximizing exact matches. The 'k' parameter likely represents a threshold or a parameter in a matching algorithm, and the chart demonstrates the trade-offs between initial accuracy and robustness to data volume. The chart is likely demonstrating the performance of a similarity search or matching algorithm as the amount of data increases.
</details>
(b) Reasoning step. From k=2 to k=3
Figure 7: SFT performances for reasoning step generalization.
Findings. As showcased in Figure 7, CoT reasoning cannot generalize across data requiring different reasoning steps, indicating the failure of generalization. Then, we try to decrease the distribution discrepancy introduced by gradually increasing the ratio of unseen data while keeping the dataset size the same when pre-training the model. And then, we evaluate the performance on two datasets. As we can observe, the performance on the target dataset increases along with the ratio. At the same time, the LLMs can not generalize to the original training dataset because of the small amount of training data. The trend is similar when testing different-step generalization, which follows the intuition and validates our hypothesis directly.
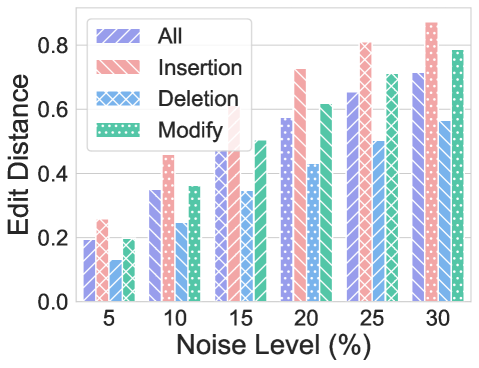
7 Format Generalization
Format generalization assesses the robustness of CoT reasoning to surface-level variations in test queries. This dimension is especially crucial for determining whether models have internalized flexible, transferable reasoning strategies or remain reliant on the specific templates and phrasings encountered during training.
Format Alignment Score. We introduce a metric for measuring prompt similarity:
**Definition 7.1 (Format Alignment Score)**
*For training prompt distribution $P_{train}$ and test prompt $p_{test}$ :
$$
\text{PAS}(p_{test})=\max_{p\in P_{train}}\cos(\phi(p),\phi(p_{test})) \tag{14}
$$
where $\phi$ is a prompt embedding function.*
<details>
<summary>x10.png Details</summary>
### Visual Description
\n
## Bar Chart: Edit Distance vs. Noise Level
### Overview
This bar chart visualizes the relationship between Edit Distance and Noise Level (%) for different types of edits: All, Insertion, Deletion, and Modify. The chart uses grouped bar representations to compare the edit distance for each edit type at various noise levels.
### Components/Axes
* **X-axis:** Noise Level (%), with markers at 5, 10, 15, 20, 25, and 30.
* **Y-axis:** Edit Distance, ranging from 0.0 to 0.8, with increments of 0.2.
* **Legend (Top-Right):**
* All (Light Blue, hatched pattern)
* Insertion (Light Red, solid pattern)
* Deletion (Light Blue, dotted pattern)
* Modify (Light Green, cross-hatched pattern)
### Detailed Analysis
The chart consists of six groups of bars, each corresponding to a specific Noise Level. Within each group, there are four bars representing the Edit Distance for All, Insertion, Deletion, and Modify edits.
* **Noise Level 5%:**
* All: Approximately 0.14
* Insertion: Approximately 0.24
* Deletion: Approximately 0.12
* Modify: Approximately 0.18
* **Noise Level 10%:**
* All: Approximately 0.36
* Insertion: Approximately 0.46
* Deletion: Approximately 0.26
* Modify: Approximately 0.32
* **Noise Level 15%:**
* All: Approximately 0.46
* Insertion: Approximately 0.54
* Deletion: Approximately 0.36
* Modify: Approximately 0.42
* **Noise Level 20%:**
* All: Approximately 0.56
* Insertion: Approximately 0.66
* Deletion: Approximately 0.44
* Modify: Approximately 0.52
* **Noise Level 25%:**
* All: Approximately 0.66
* Insertion: Approximately 0.76
* Deletion: Approximately 0.54
* Modify: Approximately 0.62
* **Noise Level 30%:**
* All: Approximately 0.72
* Insertion: Approximately 0.84
* Deletion: Approximately 0.60
* Modify: Approximately 0.70
**Trends:**
* **All:** The "All" edit distance generally increases with increasing noise level, showing an upward slope.
* **Insertion:** The "Insertion" edit distance exhibits the steepest upward slope, indicating that insertions are most affected by increasing noise.
* **Deletion:** The "Deletion" edit distance also increases with noise level, but at a slower rate than "Insertion".
* **Modify:** The "Modify" edit distance shows a similar trend to "Deletion", increasing with noise level but less steeply than "Insertion".
### Key Observations
* Insertion consistently has the highest edit distance across all noise levels.
* Deletion consistently has the lowest edit distance across all noise levels.
* The edit distance for all edit types increases as the noise level increases.
* The rate of increase in edit distance is most pronounced for insertions.
### Interpretation
The data suggests that the ability to accurately reconstruct data is significantly impacted by the level of noise present. Insertions are the most sensitive to noise, requiring the largest edit distance to correct, while deletions are the least sensitive. This could be due to the nature of the edits themselves – insertions introduce new information that is harder to verify in the presence of noise, while deletions simply remove existing information. The overall trend of increasing edit distance with noise level highlights the importance of noise reduction techniques in data processing and transmission. The chart demonstrates a clear correlation between noise and the difficulty of maintaining data integrity, as measured by edit distance. The consistent ranking of edit types (Insertion > All > Modify > Deletion) suggests inherent differences in their robustness to noise.
</details>
(a) Format generalization. Performance under various perturbation methods.
<details>
<summary>x11.png Details</summary>
### Visual Description
\n
## Line Chart: BLEU Score vs. Noise Level
### Overview
This line chart depicts the relationship between Noise Level (as a percentage) and BLEU Score for four different conditions: None, Prompt, Transformation, and Element. The chart illustrates how each condition's BLEU score degrades as the noise level increases.
### Components/Axes
* **X-axis:** Noise Level (%), ranging from 10% to 90% with increments of 10%.
* **Y-axis:** BLEU Score, ranging from 0.0 to 1.0 with increments of 0.2.
* **Legend:** Located in the center-right of the chart, identifying the four data series:
* None (Light Blue Diamonds)
* Prompt (Blue Squares)
* Transformation (Orange Circles)
* Element (Green Triangles)
* **Gridlines:** Present to aid in reading values.
### Detailed Analysis
Here's a breakdown of each data series, noting trends and approximate values:
* **None (Light Blue Diamonds):** This line is nearly flat, indicating that the BLEU score remains consistently high (approximately 1.0) regardless of the noise level.
* 10%: ~1.02
* 20%: ~1.02
* 30%: ~1.02
* 40%: ~1.02
* 50%: ~1.02
* 60%: ~1.02
* 70%: ~1.02
* 80%: ~1.02
* 90%: ~1.02
* **Prompt (Blue Squares):** This line slopes downward, indicating a decrease in BLEU score as noise level increases. The decline is more pronounced at higher noise levels.
* 10%: ~0.98
* 20%: ~0.94
* 30%: ~0.88
* 40%: ~0.82
* 50%: ~0.76
* 60%: ~0.68
* 70%: ~0.60
* 80%: ~0.52
* 90%: ~0.44
* **Transformation (Orange Circles):** This line also slopes downward, but the decrease in BLEU score is more rapid than the "Prompt" line.
* 10%: ~0.88
* 20%: ~0.82
* 30%: ~0.76
* 40%: ~0.70
* 50%: ~0.64
* 60%: ~0.58
* 70%: ~0.52
* 80%: ~0.46
* 90%: ~0.40
* **Element (Green Triangles):** This line exhibits the steepest downward slope, indicating the most significant degradation in BLEU score with increasing noise level.
* 10%: ~0.64
* 20%: ~0.48
* 30%: ~0.24
* 40%: ~0.08
* 50%: ~0.00
* 60%: ~0.00
* 70%: ~0.00
* 80%: ~0.00
* 90%: ~0.00
### Key Observations
* The "None" condition maintains a consistently high BLEU score, unaffected by noise.
* The "Element" condition is the most sensitive to noise, experiencing a rapid and complete loss of BLEU score as noise level increases.
* The "Prompt" and "Transformation" conditions fall between "None" and "Element" in terms of noise sensitivity.
* The BLEU score for "Element" drops to zero at 50% noise level.
### Interpretation
The chart demonstrates the robustness of different approaches to noise in a system. The "None" condition suggests a system that is inherently resilient to noise. The "Prompt", "Transformation", and "Element" conditions represent methods that are increasingly vulnerable to noise. The "Element" method is particularly susceptible, indicating a potential weakness in its design or implementation.
The rapid decline in BLEU score for the "Element" condition suggests that even moderate levels of noise can render it ineffective. This could be due to the method relying on subtle features that are easily disrupted by noise, or a lack of error correction mechanisms. The chart highlights the importance of considering noise robustness when selecting or designing methods for noisy environments. The data suggests that the "None" approach is the most reliable in the presence of noise, while the "Element" approach should be avoided or significantly improved.
</details>
(b) Format generalization. Performance vs. various applied perturbation areas.
Figure 8: Performance of format generalization.
Experiment settings. To systematically probe this, we introduce four distinct perturbation modes to simulate scenario in real-world: (i) insertion, where a noise token is inserted before each original token; (ii) deletion: it deletes the original token; (iii) modification: it replaces the original token with a noise token; and (iv) hybrid mode: it combines multiple perturbations. Each mode is applied for tokens with probabilities $p$ , enabling us to quantify the model’s resilience to increasing degrees of prompt distribution shift.
Findings. As shown in Figure 8a, we found that generally CoT reasoning can be easily affected by the format changes. No matter insertion, deletion, modifications, or hybrid mode, it creates a format discrepancy that affects the correctness. Among them, the deletion slightly affects the performance. While the insertions are relatively highly influential on the results. We further divide the query into several sections: elements, transformations, and prompt tokens. As shown in Figure 8b, we found that the elements and transformation play an important role in the format, whereas the changes to other tokens rarely affect the results.
8 Temperature and Model Size
Temperature and model size generalization explores how variations in sampling temperature and model capacity can influence the stability and robustness of CoT reasoning. For the sake of rigorous evaluation, we further investigate whether different choices of temperatures and model sizes may significantly affect our results.
Experiment settings. We explore the impact of different temperatures on the validity of the presented results. We adopt the same setting in the transformation generalization.
Findings. As illustrated in Figure 9a, LLMs tend to generate consistent and reliable CoT reasoning across a broad range of temperature settings (e.g., from 1e-5 up to 1), provided the values remain within a suitable range. This stability is maintained even when the models are evaluated under a variety of distribution shifts.
<details>
<summary>x12.png Details</summary>
### Visual Description
\n
## Heatmap: BLEU Score and Edit Distance vs. Scenario and Temperature
### Overview
The image presents two heatmaps arranged vertically. The top heatmap displays BLEU scores, while the bottom heatmap shows Edit Distance. Both heatmaps are indexed by "Scenario" (OOD CMP, OOD POOD CMP) on the y-axis and "Temperature" (1e-05, 0.01, 0.1, 1.0, 5.0, 10.0) on the x-axis. Each cell in the heatmaps represents a value corresponding to the intersection of a specific scenario and temperature. Color intensity indicates the magnitude of the value, with corresponding colorbars on the right side of each heatmap.
### Components/Axes
* **Y-axis (Scenarios):**
* OOD CMP
* OOD POOD CMP
* **X-axis (Temperature):**
* 1e-05
* 0.01
* 0.1
* 1.0
* 5.0
* 10.0
* **Top Heatmap:** BLEU Score
* Colorbar range: 0.00 to 0.50
* Color gradient: Blue (low) to Red (high)
* **Bottom Heatmap:** Edit Distance
* Colorbar range: 0.00 to 0.75
* Color gradient: Blue (low) to Red (high)
### Detailed Analysis
**Top Heatmap (BLEU Score):**
* **Scenario: OOD CMP**
* Temperature 1e-05: 0.687
* Temperature 0.01: 0.687
* Temperature 0.1: 0.687
* Temperature 1.0: 0.686
* Temperature 5.0: 0.019
* Temperature 10.0: 0.002
* **Scenario: OOD POOD CMP**
* Temperature 1e-05: 0.454
* Temperature 0.01: 0.454
* Temperature 0.1: 0.454
* Temperature 1.0: 0.455
* Temperature 5.0: 0.010
* Temperature 10.0: 0.002
The BLEU score remains relatively constant for temperatures 1e-05, 0.01, 0.1, and 1.0 for both scenarios. A sharp decline in BLEU score is observed at temperatures 5.0 and 10.0 for both scenarios.
**Bottom Heatmap (Edit Distance):**
* **Scenario: OOD CMP**
* Temperature 1e-05: 0.133
* Temperature 0.01: 0.133
* Temperature 0.1: 0.133
* Temperature 1.0: 0.133
* Temperature 5.0: 0.760
* Temperature 10.0: 0.830
* **Scenario: OOD POOD CMP**
* Temperature 1e-05: 0.167
* Temperature 0.01: 0.167
* Temperature 0.1: 0.167
* Temperature 1.0: 0.168
* Temperature 5.0: 0.790
* Temperature 10.0: 0.824
The Edit Distance remains relatively constant for temperatures 1e-05, 0.01, 0.1, and 1.0 for both scenarios. A sharp increase in Edit Distance is observed at temperatures 5.0 and 10.0 for both scenarios.
### Key Observations
* Both BLEU score and Edit Distance exhibit a consistent pattern across scenarios and temperatures.
* Low temperatures (1e-05 to 1.0) result in relatively high BLEU scores and low Edit Distances.
* High temperatures (5.0 and 10.0) lead to significantly lower BLEU scores and higher Edit Distances.
* The OOD POOD CMP scenario consistently exhibits higher Edit Distance values than the OOD CMP scenario across all temperatures.
### Interpretation
The data suggests that increasing the temperature parameter negatively impacts the quality of the generated output, as measured by BLEU score, and increases the difference between the generated output and the reference output, as measured by Edit Distance. The sharp decline in BLEU score and increase in Edit Distance at higher temperatures indicate that the model becomes less accurate and more prone to errors when the temperature is increased.
The consistent difference in Edit Distance between the two scenarios suggests that the "OOD POOD CMP" scenario is inherently more difficult to model, resulting in larger differences between the generated and reference outputs even at low temperatures.
The temperature parameter likely controls the randomness of the model's output. Lower temperatures lead to more deterministic and predictable outputs, while higher temperatures introduce more randomness. The results indicate that a balance must be struck between randomness and accuracy to achieve optimal performance. The optimal temperature appears to be within the range of 1e-05 to 1.0, as beyond this point, the quality of the generated output deteriorates significantly.
</details>
(a) Influences of various temperatures.
<details>
<summary>x13.png Details</summary>
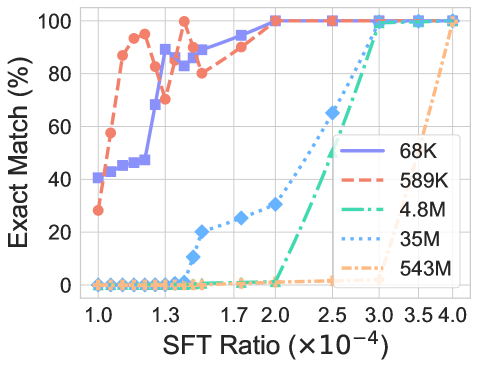
### Visual Description
## Line Chart: Exact Match vs. SFT Ratio
### Overview
This chart displays the relationship between the SFT (Supervised Fine-Tuning) Ratio and the Exact Match percentage for several model sizes. The x-axis represents the SFT Ratio, and the y-axis represents the Exact Match percentage. Multiple lines, each representing a different model size, show how the Exact Match percentage changes as the SFT Ratio increases.
### Components/Axes
* **X-axis:** SFT Ratio (×10⁻⁴). Scale ranges from approximately 1.0 to 4.0, with markers at 1.0, 1.3, 1.7, 2.0, 2.5, 3.0, 3.5, and 4.0.
* **Y-axis:** Exact Match (%). Scale ranges from 0 to 100, with markers at 0, 20, 40, 60, 80, and 100.
* **Legend:** Located in the top-right corner, listing the model sizes:
* 68K (Purple)
* 589K (Red, dashed)
* 4.8M (Green, dashed)
* 35M (Blue, dotted)
* 543M (Orange, dotted)
### Detailed Analysis
* **68K (Purple):** The line starts at approximately 40% at an SFT Ratio of 1.0. It rises sharply to around 85% at an SFT Ratio of 1.3, plateaus around 90-95% between SFT Ratios of 1.7 and 3.0, and remains relatively stable at approximately 95% up to an SFT Ratio of 4.0.
* **589K (Red, dashed):** This line exhibits a very steep increase. Starting at approximately 5% at an SFT Ratio of 1.0, it quickly rises to a peak of around 90% at an SFT Ratio of 1.3. It then declines to approximately 80% at an SFT Ratio of 2.0, and remains relatively stable around 80-90% for higher SFT Ratios.
* **4.8M (Green, dashed):** This line starts at approximately 0% at an SFT Ratio of 1.0. It increases gradually to around 20% at an SFT Ratio of 2.0, then rises sharply to approximately 95% at an SFT Ratio of 2.5, and remains stable at around 95-100% for higher SFT Ratios.
* **35M (Blue, dotted):** This line begins at approximately 0% at an SFT Ratio of 1.0. It increases slowly to around 20% at an SFT Ratio of 2.0, then rises rapidly to approximately 98% at an SFT Ratio of 3.0, and remains stable at around 98-100% for higher SFT Ratios.
* **543M (Orange, dotted):** This line starts at approximately 0% at an SFT Ratio of 1.0. It increases gradually to around 10% at an SFT Ratio of 2.0, then rises more steeply to approximately 85% at an SFT Ratio of 3.5, and reaches approximately 95% at an SFT Ratio of 4.0.
### Key Observations
* The 68K model reaches a high Exact Match percentage relatively quickly, but plateaus early.
* The 589K model shows a rapid initial increase, followed by a decline and stabilization.
* Larger models (4.8M, 35M, and 543M) require higher SFT Ratios to achieve high Exact Match percentages, but ultimately reach similar or higher levels of performance.
* The 35M model achieves the highest Exact Match percentage, reaching nearly 100% at an SFT Ratio of 3.0.
* There is a clear positive correlation between model size and the SFT Ratio required to achieve a given Exact Match percentage.
### Interpretation
The chart demonstrates the impact of Supervised Fine-Tuning (SFT) on the performance of models of varying sizes, as measured by the Exact Match percentage. It suggests that larger models generally require more SFT to reach high levels of accuracy, but ultimately have the potential to achieve better performance. The differing curves for each model size indicate that the optimal SFT strategy may vary depending on the model's capacity. The initial rapid gains observed in some models (e.g., 589K) may be due to learning basic patterns, while the continued improvement in larger models (e.g., 35M, 543M) suggests they are capable of learning more complex relationships. The plateauing of the 68K model suggests it may have reached its capacity for improvement with SFT. The data suggests a trade-off between model size, SFT cost, and performance.
</details>
(b) Influences of various sizes.
Figure 9: Temperature and model size. The findings hold under different temperatures and model sizes.
Experiment settings. We further examine the influence of model size by employing the same experimental configuration as used in the novel relation SFT study. In particular, we first pretrain models of different sizes using the transformation $f_{1}\circ f_{1}$ , and subsequently perform SFT on $f_{2}\circ f_{2}$ while varying the SFT ratios.
Finding. Fig. 9b shows the accuracy of models with different sizes using different SFT ratios, which closely matches the result of our default model size across all evaluated settings and configurations.
9 Discussion and Implication
Our investigation, conducted through the controlled environment of DataAlchemy, reveals that the apparent reasoning prowess of Chain-of-Thought (CoT) is largely a brittle mirage. The findings across task, length, and format generalization experiments converge on a conclusion: CoT is not a mechanism for genuine logical inference but rather a sophisticated form of structured pattern matching, fundamentally bounded by the data distribution seen during training. When pushed even slightly beyond this distribution, its performance degrades significantly, exposing the superficial nature of the “reasoning” it produces.
While our experiments utilized models trained from scratch in a controlled environment, the principles uncovered are extensible to large-scale pre-trained models. We summarize the implications for practitioners as follows.
Guard Against Over-reliance and False Confidence. CoT should not be treated as a “plug-and-play” module for robust reasoning, especially in high-stakes domains like medicine, finance, or legal analysis. The ability of LLMs to produce “fluent nonsense” —plausible but logically flawed reasoning chains—can be more deceptive and damaging than an outright incorrect answer, as it projects a false aura of dependability. Sufficient auditing from domain experts is indispensable.
Prioritize Out-of-Distribution (OOD) Testing. Standard validation practices, where the test set closely mirrors the training set, are insufficient to gauge the true robustness of a CoT-enabled system. Practitioners must implement rigorous adversarial and OOD testing that systematically probes for vulnerabilities across task, length, and format variations.
Recognize Fine-Tuning as a Patch, Not a Panacea. Our results show that Supervised Fine-Tuning (SFT) can quickly “patch” a model’s performance on a new, specific data distribution. However, this should not be mistaken for achieving true generalization. It simply expands the model’s “in-distribution” bubble slightly. Relying on SFT to fix every OOD failure is an unsustainable and reactive strategy that fails to address the core issue: the model’s lack of abstract reasoning capability.
10 Conclusion
In this paper, we critically examine the COT reasoning of LLMs through the lens of data distribution, revealing that the perceived structured reasoning capability largely arises from inductive biases shaped by in-distribution training data. We propose a controlled environment, DataAlchemy, allowing systematic probing of CoT reasoning along three crucial dimensions: task structure, reasoning length, and query format. Empirical findings consistently demonstrate that CoT reasoning effectively reproduces reasoning patterns closely aligned with training distributions but suffers significant degradation when faced with distributional deviations. Such observations reveal the inherent brittleness and superficiality of current CoT reasoning capabilities. We provide insights that emphasize real-world implications for both practitioners and researchers.
\nobibliography
*
References
- Bentham et al. (2024) O. Bentham, N. Stringham, and A. Marasovic. Chain-of-thought unfaithfulness as disguised accuracy. Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=ydcrP55u2e. Reproducibility Certification.
- Budnikov et al. (2025) M. Budnikov, A. Bykova, and I. P. Yamshchikov. Generalization potential of large language models. Neural Computing and Applications, 37(4):1973–1997, 2025.
- Chen et al. (2025a) Q. Chen, L. Qin, J. Liu, D. Peng, J. Guan, P. Wang, M. Hu, Y. Zhou, T. Gao, and W. Che. Towards reasoning era: A survey of long chain-of-thought for reasoning large language models. arXiv preprint arXiv:2503.09567, 2025a.
- Chen et al. (2025b) Y. Chen, J. Benton, A. Radhakrishnan, J. Uesato, C. Denison, J. Schulman, A. Somani, P. Hase, M. Wagner, F. Roger, et al. Reasoning models don’t always say what they think. arXiv preprint arXiv:2505.05410, 2025b.
- Cho et al. (2024) H. Cho, J. Cha, P. Awasthi, S. Bhojanapalli, A. Gupta, and C. Yun. Position coupling: Improving length generalization of arithmetic transformers using task structure. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=5cIRdGM1uG.
- Garg et al. (2022) S. Garg, D. Tsipras, P. S. Liang, and G. Valiant. What can transformers learn in-context? a case study of simple function classes. Advances in neural information processing systems, 35:30583–30598, 2022.
- Guo et al. (2025) D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
- Imani et al. (2023) S. Imani, L. Du, and H. Shrivastava. Mathprompter: Mathematical reasoning using large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track), pages 37–42, 2023.
- Jaech et al. (2024) A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024.
- Kojima et al. (2022) T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213, 2022.
- Lanham et al. (2023) T. Lanham, A. Chen, A. Radhakrishnan, B. Steiner, C. Denison, D. Hernandez, D. Li, E. Durmus, E. Hubinger, J. Kernion, et al. Measuring faithfulness in chain-of-thought reasoning. arXiv preprint arXiv:2307.13702, 2023.
- Li et al. (2025a) H. Li, S. Lu, P.-Y. Chen, X. Cui, and M. Wang. Training nonlinear transformers for chain-of-thought inference: A theoretical generalization analysis. In The Thirteenth International Conference on Learning Representations, 2025a. URL https://openreview.net/forum?id=n7n8McETXw.
- Li et al. (2025b) Y. Li, Z. Lai, W. Bao, Z. Tan, A. Dao, K. Sui, J. Shen, D. Liu, H. Liu, and Y. Kong. Visual large language models for generalized and specialized applications. arXiv preprint arXiv:2501.02765, 2025b.
- Ling et al. (2023) Z. Ling, Y. Fang, X. Li, Z. Huang, M. Lee, R. Memisevic, and H. Su. Deductive verification of chain-of-thought reasoning. Advances in Neural Information Processing Systems, 36:36407–36433, 2023.
- Mirzadeh et al. (2024) I. Mirzadeh, K. Alizadeh, H. Shahrokhi, O. Tuzel, S. Bengio, and M. Farajtabar. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models. arXiv preprint arXiv:2410.05229, 2024.
- Papineni et al. (2002) K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002.
- Radford et al. (2019) A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Shen et al. (2025) Z. Shen, H. Yan, L. Zhang, Z. Hu, Y. Du, and Y. He. Codi: Compressing chain-of-thought into continuous space via self-distillation. arXiv preprint arXiv:2502.21074, 2025.
- Shojaee et al. (2025) P. Shojaee, I. Mirzadeh, K. Alizadeh, M. Horton, S. Bengio, and M. Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity. arXiv preprint arXiv:2506.06941, 2025.
- Song et al. (2025) J. Song, Z. Xu, and Y. Zhong. Out-of-distribution generalization via composition: a lens through induction heads in transformers. Proceedings of the National Academy of Sciences, 122(6):e2417182122, 2025.
- Tang et al. (2023) X. Tang, Z. Zheng, J. Li, F. Meng, S.-C. Zhu, Y. Liang, and M. Zhang. Large language models are in-context semantic reasoners rather than symbolic reasoners. arXiv preprint arXiv:2305.14825, 2023.
- Team et al. (2025) K. Team, A. Du, B. Gao, B. Xing, C. Jiang, C. Chen, C. Li, C. Xiao, C. Du, C. Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599, 2025.
- Team (2024) Q. Team. Qwq: Reflect deeply on the boundaries of the unknown. Hugging Face, 2024.
- Ting et al. (2025) L. P.-Y. Ting, C. Zhao, Y.-H. Zeng, Y. J. Lim, and K.-T. Chuang. Beyond rag: Reinforced reasoning augmented generation for clinical notes. arXiv preprint arXiv:2506.05386, 2025.
- Wang et al. (2024) Q. Wang, Y. Wang, Y. Wang, and X. Ying. Can in-context learning really generalize to out-of-distribution tasks? arXiv preprint arXiv:2410.09695, 2024.
- Wang et al. (2023) X. Wang, J. Wei, D. Schuurmans, Q. V. Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=1PL1NIMMrw.
- Wang et al. (2025a) Y. Wang, F.-C. Chang, and P.-Y. Wu. Chain-of-thought prompting for out-of-distribution samples: A latent-variable study. arXiv e-prints, pages arXiv–2504, 2025a.
- Wang et al. (2025b) Y. Wang, F.-C. Chang, and P.-Y. Wu. A theoretical framework for ood robustness in transformers using gevrey classes. arXiv preprint arXiv:2504.12991, 2025b.
- Wei et al. (2022) J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- Xu et al. (2024) J. Xu, H. Fei, L. Pan, Q. Liu, M.-L. Lee, and W. Hsu. Faithful logical reasoning via symbolic chain-of-thought. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13326–13365, 2024.
- Yang et al. (2024) J. Yang, K. Zhou, Y. Li, and Z. Liu. Generalized out-of-distribution detection: A survey. International Journal of Computer Vision, 132(12):5635–5662, 2024.
- Yang et al. (2023) L. Yang, Y. Song, X. Ren, C. Lyu, Y. Wang, J. Zhuo, L. Liu, J. Wang, J. Foster, and Y. Zhang. Out-of-distribution generalization in natural language processing: Past, present, and future. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4533–4559, 2023.
- Yao et al. (2023) S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y. Cao, and K. Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems, 36:11809–11822, 2023.
- Yao et al. (2025) X. Yao, R. Ren, Y. Liao, and Y. Liu. Unveiling the mechanisms of explicit cot training: How chain-of-thought enhances reasoning generalization. arXiv e-prints, pages arXiv–2502, 2025.
- Yeo et al. (2025) E. Yeo, Y. Tong, M. Niu, G. Neubig, and X. Yue. Demystifying long chain-of-thought reasoning in llms. arXiv preprint arXiv:2502.03373, 2025.
- Yu et al. (2023) Z. Yu, L. He, Z. Wu, X. Dai, and J. Chen. Towards better chain-of-thought prompting strategies: A survey. arXiv preprint arXiv:2310.04959, 2023.
- Yujian and Bo (2007) L. Yujian and L. Bo. A normalized levenshtein distance metric. IEEE transactions on pattern analysis and machine intelligence, 29(6):1091–1095, 2007.
- Zhang et al. (2024a) X. Zhang, C. Du, T. Pang, Q. Liu, W. Gao, and M. Lin. Chain of preference optimization: Improving chain-of-thought reasoning in llms. Advances in Neural Information Processing Systems, 37:333–356, 2024a.
- Zhang et al. (2024b) Y. Zhang, H. Wang, S. Feng, Z. Tan, X. Han, T. He, and Y. Tsvetkov. Can llm graph reasoning generalize beyond pattern memorization? In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 2289–2305, 2024b.
- Zhang et al. (2023) Z. Zhang, A. Zhang, M. Li, and A. Smola. Automatic chain of thought prompting in large language models. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=5NTt8GFjUHkr.
- Zhang et al. (2024c) Z. Zhang, A. Zhang, M. Li, H. Zhao, G. Karypis, and A. Smola. Multimodal chain-of-thought reasoning in language models. Transactions on Machine Learning Research, 2024, 2024c.
- Zhao et al. (2025) C. Zhao, Z. Tan, C.-W. Wong, X. Zhao, T. Chen, and H. Liu. Scale: Towards collaborative content analysis in social science with large language model agents and human intervention. arXiv preprint arXiv:2502.10937, 2025.
- Zhao et al. (2023) W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
Appendix A Proof of Theorems
A.1 Proof of CoT Generalization Bound
* Proof*
Let $f_{\theta}$ be a model trained on samples from the distribution $\mathcal{D}_{\text{train}}$ using a loss function $\ell(f_{\theta}(x),y)$ that is $\Lambda$ -Lipschitz and bounded. The expected test risk is given by
$$
R_{\text{test}}(f_{\theta})=\mathbb{E}_{(x,y)\sim\mathcal{D}_{\text{test}}}\left[\ell(f_{\theta}(x),y)\right]. \tag{15}
$$
We can decompose the test risk as
$$
R_{\text{test}}(f_{\theta})=R_{\text{train}}(f_{\theta})+\left(R_{\text{test}}(f_{\theta})-R_{\text{train}}(f_{\theta})\right). \tag{16}
$$
To bound the discrepancy between $R_{\text{test}}$ and $R_{\text{train}}$ , we invoke a standard result from statistical learning theory. Given that $\ell$ is $\Lambda$ -Lipschitz and the discrepancy measure $\Delta(\mathcal{D}_{\text{train}},\mathcal{D}_{\text{test}})$ is an integral probability metric (e.g., Wasserstein-1 distance), we have
$$
\left|R_{\text{test}}(f_{\theta})-R_{\text{train}}(f_{\theta})\right|\leq\Lambda\cdot\Delta(\mathcal{D}_{\text{train}},\mathcal{D}_{\text{test}}). \tag{17}
$$
Therefore, the test risk satisfies
$$
R_{\text{test}}(f_{\theta})\leq R_{\text{train}}(f_{\theta})+\Lambda\cdot\Delta(\mathcal{D}_{\text{train}},\mathcal{D}_{\text{test}}). \tag{18}
$$ We next account for the generalization gap between the empirical training risk $\hat{R}_{\text{train}}(f_{\theta})$ and the expected training risk $R_{\text{train}}(f_{\theta})$ . By applying a concentration inequality (e.g., Hoeffding’s inequality), with probability at least $1-\delta$ , we have
$$
R_{\text{train}}(f_{\theta})\leq\hat{R}_{\text{train}}(f_{\theta})+\mathcal{O}\left(\sqrt{\frac{\log(1/\delta)}{n}}\right), \tag{19}
$$
where $n$ is the number of training samples. Combining the above, we obtain that with high probability,
$$
R_{\text{test}}(f_{\theta})\leq\hat{R}_{\text{train}}(f_{\theta})+\Lambda\cdot\Delta(\mathcal{D}_{\text{train}},\mathcal{D}_{\text{test}})+\mathcal{O}\left(\sqrt{\frac{\log(1/\delta)}{n}}\right). \tag{20}
$$
This concludes the proof. ∎
A.2 Proof of Task Generalization Failure Threshold
We establish the exponential decay bound through a probabilistic analysis of reasoning failure modes in the presence of task generalization complexity.
Let $\Omega$ denote the sample space of all possible reasoning configurations, and let $C∈\Omega$ represent a specific configuration. We define the following events: $A_{i}$ as the event that element $a_{i}$ is novel, i.e., $a_{i}∉\mathcal{E}^{i}_{\text{train}}$ ; $F_{j}$ as the event that transformation $f_{j}$ is novel, i.e., $f_{j}∉\mathcal{F}_{\text{train}}$ ; and $\mathcal{Q}$ as the event that the transformation sequence $(f_{1},f_{2},...,f_{k})$ is novel, i.e., $(f_{1},f_{2},...,f_{k})∉\mathcal{P}_{\text{train}}$ .
Here we make the assumption that the reasoning failures induced by novel arguments, functions, and patterns contribute independently to the overall failure probability and hence we model the success probability as a product of component-wise success rates:
$$
P(\text{correct}|C)=P_{0}\prod_{i=1}^{m}\rho_{a}^{\mathbb{I}[A_{i}]}\prod_{j=1}^{n}\rho_{f}^{\mathbb{I}[F_{j}]}\rho_{p}^{\mathbb{I}[\mathcal{Q}]}\rho_{c}^{C_{T}}
$$
where $P_{0}∈(0,1]$ represents the baseline success probability when all components are within the training distribution, and $\rho_{a},\rho_{f},\rho_{p},\rho_{c}∈(0,1)$ are the degradation factors associated with novel arguments, functions, patterns, and task-specific complexity, respectively.
$$
\displaystyle\ln P(\text{correct}\mid C)\;= \displaystyle\ln P_{0}+\sum_{i=1}^{m}\mathbb{I}[A_{i}]\,\ln\rho_{a}+\sum_{j=1}^{n}\mathbb{I}[F_{j}]\,\ln\rho_{f}+\mathbb{I}[\mathcal{Q}]\,\ln\rho_{p}+C_{T}\,\ln\rho_{c} \tag{21}
$$
For notational convenience, we define the positive constants:
$$
\xi_{a}:=-\ln\rho_{a}>0,\xi_{f}:=-\ln\rho_{f}>0,\xi_{p}:=-\ln\rho_{p}>0,\xi_{c}:=-\ln\rho_{c}>0
$$
hence we have:
$$
\ln P(\text{correct}|C)=\ln P_{0}-\xi_{a}\sum_{i=1}^{m}\mathbb{I}[A_{i}]-\xi_{f}\sum_{j=1}^{n}\mathbb{I}[F_{j}]-\xi_{p}\mathbb{I}[\mathcal{Q}]-\xi_{c}C_{T} \tag{22}
$$
Lemma: Relationship to TGC. The expression in equation above can be bounded in terms of $\text{TGC}(C)$ as follows:
$$
\ln P(\text{correct}|C)\leq\ln P_{0}-\delta\cdot\text{TGC}(C) \tag{23}
$$
where $\delta=\min(\frac{\xi_{a}}{\alpha},\frac{\xi_{f}}{\beta},\frac{\xi_{p}}{\gamma},\xi_{c})>0$ .
Proof of Lemma: From the definition of $\text{TGC}(C)$ in Eq. (11), we have:
$$
\text{TGC}(C)=\alpha\sum_{i=1}^{m}\mathbb{I}[A_{i}]+\beta\sum_{j=1}^{n}\mathbb{I}[F_{j}]+\gamma\mathbb{I}[\mathcal{Q}]+C_{T} \tag{24}
$$
By the definition of $\delta$ , each term in Eq. (22) satisfies:
$$
\xi_{a}\sum_{i=1}^{m}\mathbb{I}[A_{i}]\geq\delta\alpha\sum_{i=1}^{m}\mathbb{I}[A_{i}] \tag{25}
$$
$$
\xi_{f}\sum_{j=1}^{n}\mathbb{I}[F_{j}]\geq\delta\beta\sum_{j=1}^{n}\mathbb{I}[F_{j}] \tag{26}
$$
$$
\xi_{p}\mathbb{I}[\mathcal{Q}]\geq\delta\gamma\mathbb{I}[\mathcal{Q}] \tag{27}
$$
$$
\xi_{c}C_{T}\geq\delta C_{T} \tag{28}
$$
Summing these inequalities establishes Eq. (23).
We now define the threshold $\tau:=\frac{\ln P_{0}}{\delta}$ . From Eq. (23), when $\text{TGC}(C)>\tau$ , we have:
$$
\displaystyle\ln P(\operatorname{correct}\mid C) \displaystyle\leq\ln P_{0}-\delta\cdot\operatorname{TGC}(C) \displaystyle=\delta(\tau-\operatorname{TGC}(C)) \displaystyle=-\delta(\operatorname{TGC}(C)-\tau) \tag{29}
$$
Exponentiating both sides yields the desired bound: $P(\operatorname{correct}\mid C)≤ e^{-\delta(\mathrm{TGC}(C)-\tau)}$
A.3 Proof of Length Extrapolation Bound
* Proof*
Consider a transformer model $f_{\theta}$ processing sequences of length $L$ . The model implicitly learns position-dependent representations through positional encodings $\text{PE}(i)∈\mathbb{R}^{d}$ for position $i∈\{1,...,L\}$ and attention patterns $A_{ij}=\text{softmax}\left(\frac{Q_{i}K_{j}^{T}}{\sqrt{d}}\right)$ . During training on fixed length $L_{\text{train}}$ , the model learns a specific distribution:
$$
p_{\text{train}}(\mathbf{h})=p(\mathbf{h}\mid L=L_{\text{train}}) \tag{32}
$$
where $\mathbf{h}=\{h_{1},...,h_{L}\}$ represents hidden states. For sequences of length $L≠ L_{\text{train}}$ , we encounter distribution shift in two forms: (1) positional encoding mismatch, where the model has never seen positions $i>L_{\text{train}}$ if $L>L_{\text{train}}$ , and (2) attention pattern disruption, where the learned attention patterns are calibrated for length $L_{\text{train}}$ . The KL divergence between training and test distributions can be bounded:
$$
D_{KL}(p_{\text{test}}\|p_{\text{train}})\propto|L-L_{\text{train}}|^{2} \tag{33}
$$ This quadratic relationship arises from linear accumulation of positional encoding errors and quadratic growth in attention pattern misalignment due to pairwise interactions. Let $\mathcal{E}(L)$ be the prediction error at length $L$ . We decompose it as:
$$
\mathcal{E}(L)=\mathcal{E}_{\text{inherent}}(L)+\mathcal{E}_{\text{shift}}(L) \tag{34}
$$
where $\mathcal{E}_{\text{inherent}}(L)=\mathcal{E}_{0}$ is the inherent model error (constant) and $\mathcal{E}_{\text{shift}}(L)$ is the error due to distribution shift. The distribution shift error follows from the Central Limit Theorem. As the error accumulates over sequence positions, the total shift error converges to:
$$
\mathcal{E}_{\text{shift}}(L)=(1-\mathcal{E}_{0})\cdot\left(1-\exp\left(-\frac{(L-L_{\text{train}})^{2}}{2\sigma^{2}}\right)\right) \tag{35}
$$ This form ensures that $\mathcal{E}_{\text{shift}}(L_{\text{train}})=0$ (no shift at training length) and $\lim_{|L-L_{\text{train}}|→∞}\mathcal{E}_{\text{shift}}(L)=1-\mathcal{E}_{0}$ (maximum error bounded by 1). The width parameter $\sigma$ depends on:
$$
\sigma=\sigma_{0}\cdot\sqrt{\frac{d}{L_{\text{train}}}} \tag{36}
$$
where $\sigma_{0}$ is a model-specific constant, $d$ is the model dimension, and the $\sqrt{d/L_{\text{train}}}$ factor captures the concentration of measure in high dimensions. Therefore, the total error follows:
$$
\mathcal{E}(L)=\mathcal{E}_{0}+(1-\mathcal{E}_{0})\cdot\left(1-\exp\left(-\frac{(L-L_{\text{train}})^{2}}{2\sigma^{2}}\right)\right) \tag{37}
$$ This Gaussian form naturally emerges from the accumulation of position-dependent errors and matches the experimental observation of near-zero error at $L=L_{\text{train}}$ with symmetric increase in both directions. ∎
Appendix B Experiment Details
We fine-tune a GPT-2–style decoder-only Transformer with a vocabulary size of 10,000. The model supports a maximum context length of 256 tokens. The hidden dimension is 32, the number of Transformer layers is 4, and the number of attention heads is 4. Each block includes a GELU-activated feed-forward sublayer with width $4× d_{\text{model}}$ .
The model is trained using the AdamW optimiser in mixed precision (FP16). The default learning rate is $3× 10^{-3}$ , and the schedule follows a cosine decay with a 10% warm-up ratio. Training is conducted for 10 epochs, using a batch size of 1024. A weight decay of 0.01 is applied, and gradient norms are clipped at 1.0.
Appendix C Illustration of Datasets
Below are the examples of transformation $f_{1}$ and $f_{2}$ :
| Transformation[F1]: Transformation[F2]: | A A F Q [F1] <answer> N N S D A A L P [F2] <answer> A L P A |
| --- | --- |
aside from single transformation, we can composite transformations arbitrarily:
| Transformation[F1F2]: | A C I A [F1] [F2] <think> |
| --- | --- |
| N P V N [F2] <answer> | |
| P V N N | |
| Transformation[F2F2]: | N O V S [F2] [F2] <think> |
| O V S N [F2] <answer> | |
| V S N O | |
we use exact match, edit distance and BELU score to measure the discrepancy between generated tokens and the labels. For more than one transformation examples, we can further measure the discrepancy for reasoning and answering seperately.
Appendix D Additional Experimental Results
D.1 Additional Qualitative Analysis
D.1.1 Orthognal Transformation Caused Coincidence
The following case shows that even if the transformation is different, the model that trained on transformation $f_{2}\circ f_{1}$ can still provide correct answer through incorrect reasoning:
⬇
Prompt: ’ A A A B [F1] [F2] < answer >’
Generated:’ B A A A [F1] < answer > O N N N ’
Expected: ’ O N N N ’
D.1.2 Correct reasoning but failed in final answer
The following case shows that the model pretrained on the union of three transformation $f_{1}\circ f_{2},f_{2}\circ f_{1},f_{2}\circ f_{2}$ and test on $f_{1}\circ f_{1}$
⬇
Prompt: ’ A A A D [R1] [R1] < think >’
Generated: ’ N N N Q [R1] < answer > N N Q N ’
Expected: ’ N N N Q [R1] < answer > A A A D ’
D.1.3 Failure to generalize to novel element
The following case shows that the model trained on element set $a_{i}∈[A,M]$ can not generalize to unseen elements such as N or O
⬇
Prompt: ’ N N N O [F1] [F1] < think >’
Generated: ’ R V Q S [F1] < answer > E I D F ’
Expected: ’ A A A B [F1] < answer > N N N O ’
D.1.4 LLM reproduces CoT reasoning at seen lengths
The following case shows that model trained under $f_{1}\circ f_{1}$ tried to reproduce the length in training data by adding tokens in the reason chain even prompted with seen transformation $f_{1}$
⬇
Prompt: ’ A A B D [f1] < answer >’
Generated: ’ N O A Z N N O Q [f1]
< answer > A A B D ’
Expected: ’ N N O Q ’