# GM-PRM: A Generative Multimodal Process Reward Model for Multimodal Mathematical Reasoning
> Corresponding author.
Abstract
Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities but often struggle with complex, multi-step mathematical reasoning, where minor errors in visual perception or logical deduction can lead to complete failure. While Process Reward Models (PRMs) offer step-by-step supervision, existing multimodal PRMs are limited to being binary verifiers that can identify but not correct errors, offering little explanatory power. To address these deficiencies, we introduce the Generative Multimodal Process Reward Model (GM-PRM), a novel paradigm that transforms the PRM from a passive judge into an active reasoning collaborator. Instead of a simple scalar score, GM-PRM provides a fine-grained, interpretable analysis of each reasoning step, evaluating its step intent, visual alignment, and logical soundness. More critically, GM-PRM is trained to generate a corrected version of the first erroneous step it identifies. This unique corrective capability enables our new test-time inference strategy, Refined Best-of-N (Refined-BoN). This framework actively enhances solution quality by using the PRM’s generated correction to guide the policy model toward a more promising reasoning trajectory, thereby improving the diversity and correctness of the solution pool. We demonstrate that GM-PRM achieves state-of-the-art results on multiple multimodal math benchmarks, significantly boosting policy model performance with remarkable data efficiency, requiring only a 20K-sample training dataset. Our code will be released upon acceptance.
1 Introduction
The advent of Multimodal Large Language Models (MLLMs) has marked a significant milestone in artificial intelligence, demonstrating remarkable capabilities in integrating and understanding visual and textual information (Caffagni et al. 2024; Yan et al. 2024c; Yan and Lee 2024; Huo et al. 2024; Zheng et al. 2024b). While these models excel at general-purpose tasks such as image captioning and visual question answering, they often falter when confronted with complex, multi-step reasoning challenges, particularly within specialized domains like mathematics (Wang et al. 2024; Yan et al. 2024a, 2025a; Ahn et al. 2024). Solving multimodal mathematical problems requires not only accurate perception of visual elements (e.g., geometric figures, function graphs) but also a rigorous, step-by-step logical deduction process (Shi et al. 2024; Zhuang et al. 2025; Yan et al. 2025b). Minor errors in either image interpretation or logical inference can cascade, leading to entirely incorrect final answers.
<details>
<summary>figures/comparison.png Details</summary>
### Visual Description
## Diagram: Model Comparison for Multimodal Question Answering
### Overview
The image presents a comparative diagram illustrating three different reward models for multimodal question answering, specifically focusing on mathematical questions. The models are labeled as (a) Outcome Reward Model (ORM), (b) Multimodal Process Reward Model (PRM), and (c) GM-PRM (the authors' proposed model). The diagram highlights the flow of information, the reward mechanisms, and the key differences in their approaches.
### Components/Axes
The diagram is structured into three horizontal sections, each representing a different model. Each section contains the following components:
* **Input:** Multimodal Math Questions or a single Question.
* **Process:** A series of steps (Step 1, Step 2, ... Step T) leading to an Answer.
* **Model Representation:** A stylized robot icon representing the reward model.
* **Reward:** An arrow indicating the reward signal.
* **Annotations:** Text labels describing the model's characteristics and limitations.
### Detailed Analysis or Content Details
**(a) Outcome Reward Model (ORM)**
* **Input:** A single question represented by the equation "E=mc²" within a rectangular box.
* **Process:** The question flows directly to an "Answer" box.
* **Model:** A robot icon labeled "ORM".
* **Reward:** A yellow arrow labeled "Reward" points from the "Answer" box to the "ORM".
* **Annotation:** "ONLY Reward Final Ans" is written next to the reward arrow.
**(b) Multimodal Process Reward Model (PRM)**
* **Input:** Multiple multimodal math questions are shown within rectangular boxes: "√4", "(x+y)²", "πr²/π", "m/v".
* **Process:** The questions flow through a series of "Step 1", "Step 2", ... "Step T" boxes, culminating in an "Answer" box. The steps are connected by purple arrows.
* **Model:** A robot icon labeled "PRM".
* **Reward:** A yellow arrow labeled "Reward" points from the "Answer" box to the "PRM".
* **Annotations:** "Limited Explainability" and "No Correction Mechanism" are written to the right of the "PRM".
**(c) GM-PRM (Ours)**
* **Input:** Similar to (b), multiple multimodal math questions are shown: "√4", "(x+y)²", "πr²/π", "m/v".
* **Process:** The questions flow through a series of "Step 1", "Step 2", ... "Step T" boxes. A dashed red arrow labeled "After Correction" indicates a feedback loop from a later step to an earlier step, suggesting a correction mechanism.
* **Model:** A robot icon labeled "GM-PRM" with a refined brain (BoN) inside.
* **Reward:** A yellow arrow labeled "Reward" points from the "Answer" box to the "GM-PRM".
* **Annotations:** "Refined & Corrected Version" is written to the right of the "GM-PRM".
* **Bottom Legend:** A colored legend is present:
* **Step Intent:** Purple
* **Image Alignment:** Teal
* **Reasoning Logic:** Orange
### Key Observations
* The ORM is the simplest model, only rewarding the final answer.
* The PRM introduces a process reward but lacks explainability and a correction mechanism.
* The GM-PRM builds upon the PRM by adding a correction mechanism and incorporating analysis and judgement based on step intent, image alignment, and reasoning logic.
* The dashed red arrow in the GM-PRM indicates a key difference: the ability to revisit and correct earlier steps.
* The legend at the bottom suggests that the GM-PRM utilizes these three components (Step Intent, Image Alignment, Reasoning Logic) during the process.
### Interpretation
The diagram illustrates the evolution of reward models for multimodal question answering. The ORM represents a basic approach, while the PRM attempts to improve upon it by rewarding intermediate steps. However, the GM-PRM, proposed by the authors, addresses the limitations of the PRM by incorporating a correction mechanism and leveraging step intent, image alignment, and reasoning logic. This suggests that a more nuanced approach, which considers the entire reasoning process and allows for self-correction, is crucial for achieving better performance in multimodal question answering tasks. The use of color-coding in the GM-PRM section highlights the importance of these three components in the model's decision-making process. The diagram effectively communicates the advantages of the GM-PRM over its predecessors, positioning it as a more sophisticated and effective solution.
</details>
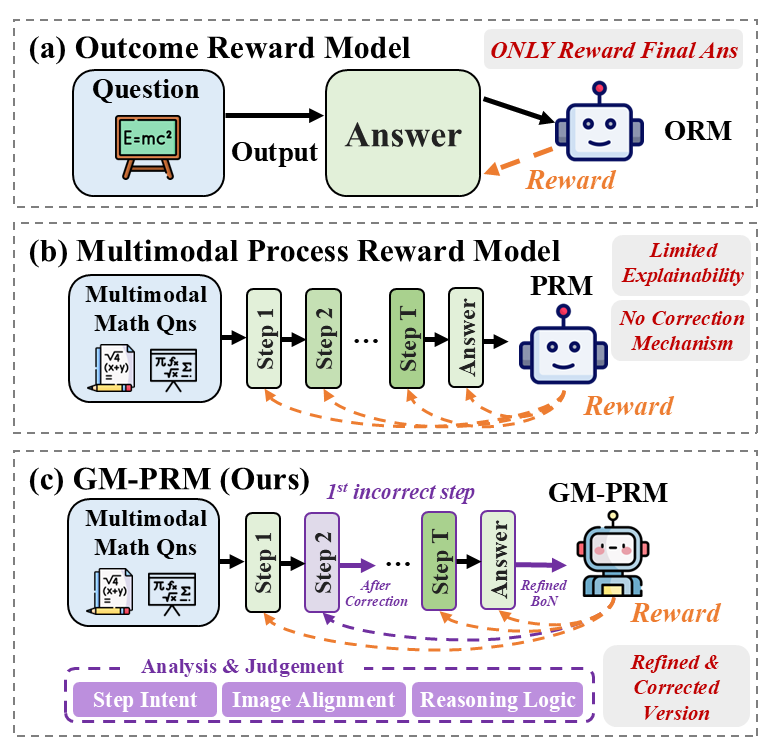
Figure 1: Comparison among ORM (a), PRM (b), and our proposed GM-PRM (c) for multimodal math reasoning.
To mitigate these reasoning deficiencies, Process Reward Models (PRMs) have emerged as a promising paradigm (Gao et al. 2024; Zhong et al. 2025). Unlike outcome-based models that only reward correct final answers (shown in Figure 1 (a)), PRMs provide fine-grained supervision by evaluating the correctness of each intermediate step in a reasoning chain (Zheng et al. 2024a; Lambert et al. 2024; Yan et al. 2024b), as shown in Figure 1 (b). This approach has proven effective in the language domain (Zeng et al. 2025; Yuan et al. 2024; Zhang et al. 2025a). However, extending PRMs to the multimodal context presents unique challenges (Miao et al. 2025; Du et al. 2025; Li et al. 2025b; Cao et al. 2025). Existing multimodal PRMs often function as binary classifiers, assigning a simple correct/incorrect label to each step, which offers limited explanatory power. Furthermore, they typically possess the ability to identify errors but lack the mechanism to correct them, leaving the reasoning process fundamentally broken. This limitation constrains their utility, especially within mechanisms like Best-of-N (BoN) sampling, which remain passive selection processes over a static set of potentially flawed solutions.
In this work, we introduce a novel G enerative M ultimodal P rocess R eward M odel (GM-PRM) to address these limitations, as illustrated in Figure 1 (c). Our model transcends the role of a simple verifier and acts as an active reasoning collaborator. Instead of merely outputting a scalar score, our GM-PRM leverages its generative capabilities to produce a detailed, interpretable analysis for each reasoning step. This analysis deconstructs the step into three critical aspects: its fundamental step intent, the correctness of its image alignment, and the soundness of its reasoning logic. More importantly, our model is trained not only to identify errors but also to generate a refined, corrected version of the first incorrect step it encounters.
This unique corrective capability enables us to propose a new test-time inference strategy: the Refined Best-of-N (Refined-BoN) process. This dynamic framework moves beyond passive selection by actively enhancing the quality of candidate solutions. When our GM-PRM identifies a flawed step within a generated solution, it intervenes by providing a corrected step, which is then used to guide the policy model in generating a new, more promising reasoning trajectory. This iterative refinement process significantly improves the diversity and correctness of the solution pool, leading to a substantial boost in the policy model’s problem-solving performance. Furthermore, we demonstrate that this powerful capability can be achieved with remarkable data efficiency, requiring a significantly smaller training dataset than previous approaches. Our primary contributions are as follows:
- We develop a generative multimodal PRM called GM-PRM that provides fine-grained, interpretable feedback for mathematical reasoning. It analyzes each step’s purpose, image alignment, and logical validity, moving beyond simple binary classification to offer deeper insight into the model’s thought process.
- We introduce a novel Refined-BoN framework that leverages the PRM’s generative power to actively correct errors at test time. It enhances the policy model’s ability to find correct solutions by iteratively improving flawed reasoning paths.
- We demonstrate the effectiveness and data efficiency of GM-PRM, achieving state-of-the-art results on multiple multimodal math benchmarks. Our approach requires only a 20K sample dataset, highlighting the quality of data curation and the power of generative supervision strategy.
2 Related Work
Process Reward Models (PRMs)
PRMs have been proposed to evaluate the fine-grained step level for model reasoning. During the implementation process, annotating and obtaining a high-quality training dataset incurs a high cost. PRM800K (Lightman et al. 2023) is the first process supervision dataset completely annotated by humans. To mitigate annotation costs, Math-Shepherd (Wang et al. 2023) proposes Monte Carlo (MC) estimation, while OmegaPRM (Luo et al. 2024) leverages Monte Carlo Tree Search (MCTS) to automatically evaluate each reasoning step, both utilizing the generation capabilities of Large Language Models (LLMs). Subsequent research has enhanced the effectiveness of PRMs through various methods, including VersaPRM (Zeng et al. 2025), Implicit PRM (Yuan et al. 2024), OpenPRM (Zhang et al. 2025a), PQM (Li and Li 2024), PAV (Setlur et al. 2024), and others. In addition, GenRM (Zhao et al. 2025) utilizes the generation ability of reward models to analyze each reasoning step and obtain the score of each step by taking the probability of the special evaluation token. Furthermore, GenPRM (Zhao et al. 2025), ThinkPRM (Khalifa et al. 2025), R-PRM (She et al. 2025) extend the method of using model generation analysis to evaluate steps to PRMs. There are also many studies on benchmarks of PRMs such as ProcessBench (Zheng et al. 2024a), PRMBench (Song et al. 2025), and Socratic-PRMBench (Li et al. 2025a).
Multimodal PRMs
After achieving certain results and progress in the research of language modality in PRMs, research on PRMs has also begun to shift towards multimodal tasks. M-STAR (Liu et al. 2024a) proposes and implements multimodal PRM on multimodal problems. URSA (Luo et al. 2025) constructs a dataset by inserting errors and utilizes it to train a multimodal PRM. VisualPRM (Wang et al. 2025b) not only uses MC estimation to construct a multimodal VisualPRM400K training dataset, but also proposes a benchmark for multimodal PRMs called VisualProcessBench, which is entirely annotated by humans. Athena-PRM (Wang et al. 2025a) proposes using prediction consistency between strong and weak completers to enhance the quality of automatically annotated data based on MC estimation and improving multimodal PRM by ORM initialization and negative data up-sampling. Moreover, PRM-BAS (Hu et al. 2025), MM-PRM (Du et al. 2025) and DreamPRM (Cao et al. 2025) also improve the capability of multimodal PRMs. Although several studies have explored multimodal PRMs, applying them to multimodal tasks effectively remains certain challenges, such as insufficient interpretability of the labels assigned to each reasoning step and the inability to correct identified erroneous steps. In our work, we introduce a generative multimodal PRM, GM-PRM to solve the above problems.
<details>
<summary>figures/Case.png Details</summary>

### Visual Description
\n
## Geometry Problem: Translation of a Triangle
### Overview
The image presents a geometry problem involving the translation of a triangle ABC on a coordinate plane. It includes a visual representation of the triangle and its translation, a textual problem statement with multiple-choice answers, an "Original Solution" with step-by-step explanations and feedback, and a "Refined Solution" with corrected steps. The image also features a section labeled "GM-PRM: Analysis & Judgement" providing meta-cognitive analysis of the solution steps.
### Components/Axes
* **Coordinate Plane:** X-axis ranges from 0 to 10, Y-axis ranges from 0 to 8.
* **Triangle ABC:** Vertices are approximately A(3,4), B(8,1), and C(1,1).
* **Translated Triangle:** The translated triangle has vertices approximately at A'(7,7), B'(12,4), and C'(5,4).
* **Problem Statement:** Textual description of the translation and question.
* **Multiple Choice Answers:** A. (5,4); B. (8,5); C. (7,7); D. No correct answer.
* **Original Solution:** Step-by-step solution with checkmarks and crosses indicating correctness.
* **Refined Solution:** Corrected step-by-step solution.
* **GM-PRM: Analysis & Judgement:** Meta-cognitive analysis of the solution steps.
### Detailed Analysis or Content Details
**1. Problem Statement:**
"As shown in the diagram, triangle ABC is first translated 4 units to the right and then 3 units upwards. The position of vertex A after the translation, represented as a coordinate pair is ()."
**2. Original Solution:**
* **Step 1:** "To solve this problem, we need to understand the concept of translation in geometry. Translation means moving a figure without rotating or changing its size. It involves adding a fixed amount (in this case, 4 units horizontally and 3 units vertically) to each coordinate of the vertices." - Marked with a green checkmark.
* **Step 2:** "Let's analyze the coordinates of vertex A before the translations: Vertex A is at the origin, so its initial coordinates are (0, 0)." - Marked with a red cross.
**3. Refined Solution:**
* **Step 2:** "Let's analyze the coordinates of vertex A before the translations: Vertex A is initially at the point (3, 4) according to the image." - Marked with a green checkmark.
* **Step 3:** "Apply the first translation (4 units to the right): x- To translate a point (x, y) 4 units to the right, we add 4 to the x-coordinate. Therefore, (3, 4) becomes (3 + 4, 4) = (7, 4)." - Marked with a green checkmark.
* **Step 6:** "Final answer: C"
**4. GM-PRM: Analysis & Judgement:**
* **Statement analysis:** "This step identifies the initial coordinates of vertex A before any translation occurs."
* **Image alignment analysis:** "The image shows vertex A located at the point (3, 4), not (0, 0)."
* **Reasoning logic analysis:** "..." (truncated)
**5. Coordinate Values (Approximate):**
* A: (3, 4)
* B: (8, 1)
* C: (1, 1)
* A': (7, 7)
* B': (12, 4)
* C': (5, 4)
### Key Observations
* The original solution incorrectly identified the initial coordinates of vertex A as (0,0) instead of (3,4).
* The refined solution correctly applies the translation rules to find the new coordinates of vertex A.
* The GM-PRM section provides valuable feedback on the reasoning process.
* The correct answer is C. (7,7).
### Interpretation
The image demonstrates a common geometry problem involving translations. The inclusion of both an incorrect and a corrected solution, along with the "GM-PRM" analysis, highlights the importance of careful observation and accurate application of mathematical principles. The problem tests the understanding of coordinate plane geometry and the concept of translation. The GM-PRM section is a novel approach to teaching problem-solving skills by explicitly analyzing the reasoning behind each step. The image serves as a learning tool, showcasing a common mistake and how to correct it. The visual representation of the triangle and its translation aids in understanding the concept. The problem is designed to assess the student's ability to translate a geometric figure and determine the new coordinates of its vertices. The error in the original solution emphasizes the importance of accurately reading the information presented in the diagram.
</details>
Figure 2: The illustration of a representative example before and after applying GM-PRM. In particular, GM-PRM first judges the steps of the original solution generated by the policy model. Subsequently, GM-PRM finds that the second step is incorrect and refines the second step to generate the correct version. The correct steps are input to the policy model to generate the refined solution, and finally the correct answer is obtained.
3 Methodology
In this section, we first describe how to utilize PRMs and generative PRMs combined with the BoN method to improve the performance of policy models for mathematical problems in Section 3.1. Then, we introduce our process to implement multimodal generative PRM, including data construction and model training in Section 3.2. Finally, we propose a novel Refined-BoN framework for PRMs to enhance its performance beyond traditional BoN method in Section 3.3.
3.1 PRMs for Mathematical Problem
In this section, we present the implementation methods of PRM and GM-PRM, and provide formal explanations of their usage through mathematical notation.
Problem and Reasoning Steps Generation
Let $Q$ denote a mathematical problem. Firstly, an LLM $\pi$ is involved in solving the mathematical problem $Q$ . To facilitate reasoning, the problem is combined with a prompt $P$ , which includes specific instructions guiding the generation of a step-by-step reasoning process and a final answer. This composite input is then fed into the LLM. When generating a response, $\pi$ generates a sequence of reasoning steps, denoted as $R=\{r_{1},r_{2},...,r_{T}\}$ , where $T$ represents the total number of reasoning steps to the given mathematical problem. The above process can be explained as follows:
$$
R=\pi(Q\parallel P), \tag{1}
$$
where $\parallel$ denotes the concatenation of the problem $Q$ and the prompt $P$ , and $\pi(·)$ represents the inference of LLM.
PRM
A single instance in a training dataset $\mathcal{D}$ to train a PRM comprises three components: (1) a problem statement, (2) a generated response consisting of multiple inference steps, and (3) a corresponding set of binary labels, each taking a value of either 0 or 1, indicating whether the associated reasoning step is incorrect or correct, respectively.
During training, the PRM is optimized using cross-entropy loss and supervised to align its predictions with the ground-truth labels. After being trained, the PRM model is capable of processing new reasoning steps generated by the LLM in response to a given mathematical problem, which means that the PRM is able to assign a scalar score to each individual reasoning step, reflecting the model’s confidence in the correctness of each step:
$$
f_{\text{PRM}}:(Q,R)\mapsto(s_{1},s_{2},\dots,s_{T}), \tag{2}
$$
where $f_{\text{PRM}}:(·)$ represents the inference of PRM, $s_{i}∈[0,1]$ denotes the confidence score assigned to the $i$ -th reasoning step $r_{i}$ , and $T$ denotes the number of reasoning steps.
For generative PRM, the binary labels in the training dataset are replaced with textual analyses and judgments, each formulated as a textual choice such as “incorrect” or “correct”. During inference, generative PRM also generates textual critiques and judgments for each step.
GM-PRM
By extending generative PRMs from the textual modality to a multimodal setting, we introduce GM-PRM. In this setting, mathematical problems are represented using both textual and visual information. The input to the policy model comprises the image of the problem, its textual description and task-specific instructions, which are processed jointly to generate reasoning steps. Similarly, during both training and inference, it is essential to provide GM-PRM with inputs from both visual and textual modalities, enabling it to perform cross-modal analysis when assigning correctness labels to each reasoning step:
$$
f_{\text{{GM-PRM}}}:(Q,I,R)\mapsto(c_{1},j_{1},\dots,c_{T},j_{T}), \tag{3}
$$
where $f_{\text{{GM-PRM}}}:(·)$ represents the inference of GM-PRM, $I$ denotes the image of the mathematical problem, $c_{i}$ denotes the critique of the $i$ -th reasoning step $r_{i}$ , and $j_{i}$ denotes the textual judgment assigned to the $i$ -th reasoning step $r_{i}$ .
3.2 Data Construction
In this section, we present our methodology employed to construct the training data for GM-PRM. The process consists of three key stages: (1) the selection of appropriate types and quantities of question data from the VisualPRM400K dataset (Wang et al. 2025b); (2) the generation of textual analysis and judgment data using GPT-4o; and (3) the filtering of the generated data through MC estimation and LLM-as-a-judge techniques to ensure quality and reliability.
Data Selection
VisualPRM400K is a large-scale dataset containing approximately 400,000 multimodal process supervision samples. In our work, we select plane geometry- and function-related problems from VisualPRM400K to construct a specialized subset and supplement it with corresponding textual analysis for training GM-PRM. This targeted subset with textual critiques supports the effective training of GM-PRM, yielding strong performance on geometric and function-based mathematical reasoning tasks.
Generation of Analysis and Judgment
To obtain textual analyses and judgments, we employ GPT-4o to critique each reasoning step from 4 key aspects: step intent, image alignment, reasoning logic, and step refinement.
The aspect of step intent indicates identifying the purpose of each reasoning step. This initial analysis establishes a foundation that allows GM-PRM to interpret and evaluate each reasoning step in context more effectively. Furthermore, this level of understanding facilitates subsequent error detection and correction tasks, thereby enhancing the overall effectiveness of GM-PRM.
The second aspect is image alignment. When MLLMs are used for inference in solving multimodal problems, MLLMs often make errors in image alignment, such as misidentifying parallel relationships or incorrectly annotating angles, which leads to flawed solutions. To address this, we employ GPT-4o to produce textual analysis and judgments in image alignment for inference steps, to form the dataset for training GM-PRM.
Reasoning logic is an indispensable presence in the step-by-step problem-solving process of MLLMs. However, the occurrences of logical inconsistencies and errors, such as miscalculations and incorrect inferences significantly impact the correctness of the reasoning steps and the final answers. Therefore, it is crucial for GM-PRM to be capable of identifying such logical flaws and making accurate judgments regarding the validity of the reasoning logic for each step. In our work, we employ GPT-4o to generate textual analysis and judgments of each step in reasoning logic to form the training dataset. The above process can be formulated as follows:
$$
\mathcal{F}:(Q,I,R\parallel P)\mapsto\{SI_{i},IA_{i},RL_{i},FJ_{i}\}_{i=1}^{t}, \tag{4}
$$
where $\mathcal{F}:(·)$ represents the inference of GPT-4o, $SI_{i}$ denotes the textual analysis of step intent for the $i$ -th reasoning step, $t$ denotes the number of the first incorrect step or the last step, $1≤slant t≤slant T$ , $IA_{i}=\{IAC_{i},IAJ_{i}\}$ denotes the analysis which contains critique $IAC_{i}$ and judgment $IAJ_{i}$ in image alignment of the $i$ -th reasoning step, $RL_{i}=\{RLC_{i},RLJ_{i}\}$ denotes the analysis which contains critique $RLC_{i}$ and judgment $RLJ_{i}$ in image alignment of the $i$ -th reasoning step, $FJ_{i}$ denotes the final judgment of the $i$ -th reasoning step.
Building on aforementioned three aspects, we further aim for GM-PRM to correct the first identified erroneous step. The above information enables GM-PRM to generate corrected reasoning steps that are logically coherent, visually accurate, and semantically aligned with the original step intent. The resulting corrected steps can then be used to construct more diverse and accurate inference solutions and ultimately produce more reliable final answers. In our work, we employ GPT-4o to generate a corrected version of the first identified error step in a reasoning process if the first error step is detected to exist by GPT-4o:
$$
\mathcal{F}:(Q,I,R\parallel P)\mapsto\begin{cases}RS,&\text{if incorrect step exists},\\
\emptyset,&\text{otherwise}.\end{cases} \tag{5}
$$
where $RS$ denotes refined step of the first error step in a reasoning process.
In summary, we design a structured prompt for GPT-4o to generate comprehensive analysis data across four dimensions based on the provided problems, associated images, and step-by-step solutions:
$$
\mathcal{F}:(Q,I,R\parallel P)\mapsto\mathcal{D}, \tag{6}
$$
where $\mathcal{D}$ denotes the generated training dataset:
$$
\mathcal{D}=\{(\{SI_{i}^{k},IA_{i}^{k},RL_{i}^{k},FJ_{i}^{k}\}_{i=1}^{t},RS^{k})\}_{k=1}^{K}, \tag{7}
$$
where $k∈\{1,2,...,K\}$ represents the $k$ -th sample in the dataset, and $K$ denotes the number of the training instances.
Data Filtering
The process of constructing training data using GPT-4o can be regarded as an implementation of LLM-as-a-judge methodology. Inspired by the combination of LLM-as-a-judge and MC estimation techniques (Zhang et al. 2025b), we employ the MC estimation technique proposed by Math-Shepherd (Wang et al. 2023) to effectively filter and curate the generated data.
Monte Carlo estimation is a strategy for automated annotation that leverages LLMs or MLLMs to generate multiple subsequent solutions for each step. When applying MC estimation to evaluate a step $r_{i}$ , we use an LLM or an MLLM as a ‘completer’ to finalize multiple subsequent reasoning processes from this step:
$$
f_{comleter}\mapsto\{(r_{i+1}^{j},\dots,r_{L_{j}}^{j},a^{j})\}_{j=1}^{m}, \tag{8}
$$
where $a^{j}$ is the final answer of the $j$ -th finalized solution and $L_{j}$ is the total number of steps.
Within MC estimation, one type of evaluation method is commonly applied: hard estimation. In hard estimation, a step $r_{i}$ is deemed correct if at least one subsequent solution reaches the correct final answer $a^{*}$ ; otherwise, it is considered incorrect:
$$
l_{i}^{HE}=\begin{cases}1,&\exists a_{j},a_{j}=a^{*},\\
0,&\text{otherwise}.\end{cases} \tag{9}
$$
In our data construction process, we employ hard estimation to label the correctness of individual reasoning steps. By integrating LLM-as-a-judge technique and MC estimation, we compare the labels acquired by MC estimation and judgments generated by GPT-4o. Data samples that receive consistent evaluations from both methods are selected as our final training dataset. By integrating these two methods, we aim to further enhance the reliability and quality of the training data, ensuring better performance of GM-PRM.
3.3 Refined-BoN Process
When applying Test-time Scaling (TTS) for LLMs and MLLMs, a widely adopted method is Best-of-N (BoN) approach. In the BoN process, a policy model is employed to generate N candidate solutions, which are then evaluated by reward models or self-consistency to select the optimal solution. However, during the BoN process, policy models are under identical prompting conditions when generating multiple solutions, which leads to the problem that the solutions often lack diversity and may exhibit limited correctness. In our work, we propose a novel Refined-BoN framework utilizing TTS techniques to enhance the diversity and accuracy of generated solutions, thereby improving the reasoning capabilities of policy models.
Refined-BoN Method
As shown in Figure 2, in Refined-BoN process, we first employ an MLLM as the policy model to generate $N/2$ initial solutions to a multimodal problem, and then these solutions are evaluated step-by-step by GM-PRM. For the subsequent $N/2$ solutions, the policy model generates them under varying conditions, informed by the evaluation of the preceding $N/2$ solutions: If GM-PRM identifies an incorrect reasoning step within a solution, it stops evaluating and refines the first erroneous step by generating a corrected version. This corrected step, along with all previously validated correct steps, is then input back into the policy model to continue the solution generation process. Conversely, if GM-PRM determines that all steps in a particular solution are correct, we employ the policy model to generate a new solution using the same prompt. Through this regeneration mechanism, we obtain the additional $N/2$ solutions. Subsequently, we employ GM-PRM to evaluate the subsequent $N/2$ solutions.
Solution Selection
After applying the Refined-BoN process, we obtain $N$ solutions for each problem, each accompanied by step-level correctness judgments. Moreover, we divide all the solutions into two categories: one where GM-PRM judges that it contains incorrect steps, and the other where GM-PRM judges that all its steps are correct. Furthermore, we take the probability of GM-PRM generating the associated “Correct” and “Incorrect” tokens as the score of each step.
Among the $N$ generated solutions, if there exist solutions in which all reasoning steps are judged correct, we calculate the average of the scores of all steps in these solutions as the overall score of the solution, and select the solution with the highest average score as the optimal solution.
For N solutions to a problem, if GM-PRM determines that all $N$ solutions contain incorrect steps, we calculate the average score of all steps in a solution as the overall score of the solution, and select the solution with the highest overall score as the final answer.
4 Experiments
| MiniCPM-V2.6-8B + GM-PRM (Ours) Improvements | 44.3 51.0 +6.7 | 16.0 18.1 +2.1 | 18.9 24.4 +5.5 | 22.6 25.7 +3.1 | 38.6 51.0 +12.4 | 28.1 34.0 +5.9 |
| --- | --- | --- | --- | --- | --- | --- |
| Llama-3.2-11B-Vision | 44.5 | 14.3 | 16.5 | 28.4 | 46.1 | 30.0 |
| + GM-PRM (Ours) | 49.5 | 18.2 | 18.8 | 32.7 | 53.4 | 34.5 |
| Improvements | +5.0 | +3.9 | +2.3 | +4.3 | +7.3 | +4.5 |
| Qwen2.5-VL-7B | 63.2 | 25.1 | 32.8 | 35.0 | 60.6 | 43.3 |
| + GM-PRM (Ours) | 65.0 | 28.2 | 37.4 | 39.2 | 69.0 | 47.8 |
| Improvements | +1.8 | +3.1 | +4.6 | +4.2 | +8.4 | +4.5 |
| InternVL3-8B | 50.6 | 20.3 | 25.0 | 27.0 | 50.9 | 34.8 |
| + GM-PRM (Ours) | 55.7 | 22.2 | 31.7 | 33.4 | 59.2 | 40.4 |
| Improvements | +5.1 | +1.9 | +6.7 | +6.4 | +8.3 | +5.6 |
| InternVL3-38B | 68.3 | 34.9 | 37.8 | 40.1 | 66.4 | 49.5 |
| + GM-PRM (Ours) | 69.9 | 37.0 | 39.1 | 43.1 | 72.9 | 52.4 |
| Improvements | +1.6 | +2.1 | +1.3 | +3.0 | +6.5 | +2.9 |
| InternVL3-78B | 68.0 | 34.6 | 36.0 | 38.1 | 65.7 | 48.5 |
| + GM-PRM (Ours) | 70.7 | 37.1 | 40.6 | 39.9 | 72.2 | 52.1 |
| Improvements | +2.7 | +2.5 | +4.6 | +1.8 | +6.5 | +3.6 |
Table 1: Percentage accuracy scores (%) of multiple MLLMs across five datasets. For each MLLM, the first row shows the baseline, the second shows the final result with GM-PRM, and the third shows the improvement. Only positive improvements are underlined. The best results are highlighted in bold. All values are reported after rounding to three decimal places.
In this section, we introduce our experimental setup to assess GM-PRM under the Refined-BoN process on five multimodal mathematical benchmarks in Section 4.1. In addition, we present the results of our experiments and three conclusions analyzed from the results in Section 4.2. Finally, we show the ablation studies in Section 4.3.
4.1 Experimental Setup
Benchmarks.
We evaluate GM-PRM across five datasets, including MathVista (Lu et al. 2023), MathVision (Wang et al. 2024), MathVerse (Zhang et al. 2024), DynaMath (Zou et al. 2024) and WeMath (Qiao et al. 2024). The datasets contain diverse problem types, such as plane geometry, functions, puzzle tests, etc. We use Vision-Only subset of MathVerse dataset and Plane-Geometry subset of DynaMath.
Settings.
We employ GM-PRM as the critic model for Refined-BoN evaluation and set N to 8 by default. For MLLMs, we select six models as the policy models to generate step-by-step reasoning processes. When reasoning, we set the temperature of the policy models to 0.7 and top-p to 0.9. For comparison, we use the average accuracy of N sets of answers generated by policy models as baselines.
Training Details.
To train GM-PRM, we use Qwen2.5-VL-7B-Instruct as our base model and perform supervised fine-tuning (SFT) with all parameters trainable except for the frozen Vision Transformer (ViT) encoder. During the training process, we utilize bfloat16 mixed-precision and DeepSpeed with zero3 technology and set the training consists of 2 epochs. For batch size, the batch size on each training device is set to 2, and through gradient accumulation, the effective batch size is extended to 16. Moreover, we use two A800 GPUs to train GM-PRM, and the AdamW optimizer is used with an initial learning rate of $1× 10^{-5}$ . The learning rate schedule involves a linear warm-up with the warm-up ratio equal to 0.05 followed by linear decay.
4.2 Main Results
As shown in Table 1, integrating GM-PRM with the Refined-BoN process consistently improves performance across five benchmark datasets for six different MLLMs. On average, our method yields notable accuracy gains, with improvements of +5.9 for MiniCPM-V2.6-8B, +4.5 for Llama-3.2-11B-Vision, +4.5 for Qwen2.5-VL-7B, and +5.6 for InternVL3-8B.
A closer look at dataset-level results reveals that the improvements are not uniform. The WeMath benchmark shows the most significant enhancement, with MiniCPM-V2.6-8B improving by +12.4 points, highlighting the ability of our method to strengthen mathematical reasoning on challenging problems. Similarly, MathVerse and DynaMath exhibit consistent gains of +4.5–6.7 points across multiple models, suggesting that our approach particularly benefits datasets requiring complex symbolic manipulation and multi-step reasoning. In contrast, MathVision improvements are more modest (+1.9–3.9), indicating that the visual reasoning component may already be relatively strong in baseline models.
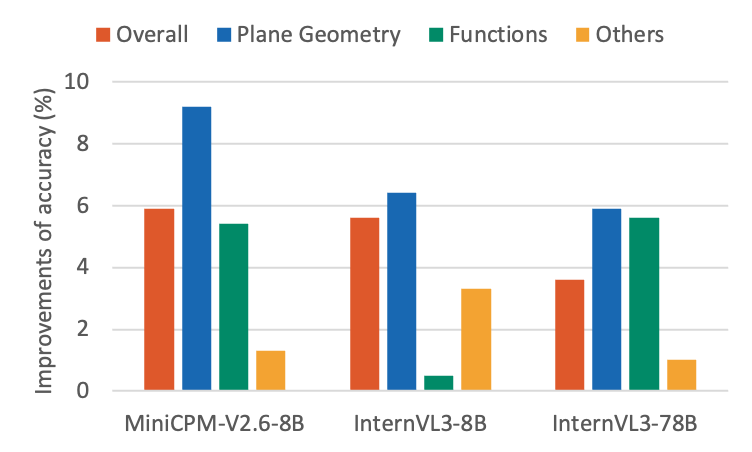
GM-PRM combined with the Refined-BoN process demonstrates strong generalization across diverse multimodal mathematical problems, with particularly remarkable gains in plane geometry tasks. As illustrated in Figure 3, even after excluding plane geometry and function problems, policy models still achieve notable improvements across the datasets. This indicates that although GM-PRM is primarily trained on a dataset composed of plane geometry and function problems, it generalizes effectively to other types of multimodal mathematical problems. Moreover, as shown by the averaged results in Figure 3, the improvements achieved by GM-PRM with Refined-BoN on plane geometry problems consistently exceed those on the overall dataset, function problems, and other categories, underscoring the exceptional effectiveness of our method in tackling plane geometry tasks.
<details>
<summary>figures/Question_types.png Details</summary>
### Visual Description
\n
## Bar Chart: Accuracy Improvements of Different Models
### Overview
This bar chart compares the improvements in accuracy (%) for three different models – MiniCPM-V2.6-8B, InternVL3-8B, and InternVL3-78B – across four categories: Overall, Plane Geometry, Functions, and Others. The chart uses colored bars to represent each category for each model, allowing for a visual comparison of performance.
### Components/Axes
* **X-axis:** Model Names - MiniCPM-V2.6-8B, InternVL3-8B, InternVL3-78B
* **Y-axis:** Improvements of accuracy (%) - Scale ranges from 0 to 10, with increments of 2.
* **Legend:** Located at the top-right corner of the chart.
* Overall (Orange)
* Plane Geometry (Blue)
* Functions (Green)
* Others (Yellow)
### Detailed Analysis
The chart consists of 12 bars, grouped by model and category.
**MiniCPM-V2.6-8B:**
* Overall: Approximately 6.2% improvement. (Orange bar)
* Plane Geometry: Approximately 9.2% improvement. (Blue bar)
* Functions: Approximately 5.4% improvement. (Green bar)
* Others: Approximately 1.4% improvement. (Yellow bar)
**InternVL3-8B:**
* Overall: Approximately 6.2% improvement. (Orange bar)
* Plane Geometry: Approximately 6.4% improvement. (Blue bar)
* Functions: Approximately 0.4% improvement. (Green bar)
* Others: Approximately 3.2% improvement. (Yellow bar)
**InternVL3-78B:**
* Overall: Approximately 3.6% improvement. (Orange bar)
* Plane Geometry: Approximately 6.2% improvement. (Blue bar)
* Functions: Approximately 5.8% improvement. (Green bar)
* Others: Approximately 1.2% improvement. (Yellow bar)
### Key Observations
* **Plane Geometry** consistently shows the highest improvement across all three models, ranging from approximately 6.2% to 9.2%.
* **Functions** shows a significant difference in performance between models. MiniCPM-V2.6-8B and InternVL3-78B show improvements around 5.4% and 5.8% respectively, while InternVL3-8B shows a very low improvement of approximately 0.4%.
* **Others** consistently shows the lowest improvement across all models, ranging from approximately 1.2% to 3.2%.
* InternVL3-78B has the lowest overall improvement at approximately 3.6%.
* MiniCPM-V2.6-8B and InternVL3-8B have the same overall improvement at approximately 6.2%.
### Interpretation
The data suggests that all three models demonstrate improvements in accuracy, but the extent of these improvements varies significantly depending on the category. The consistent high performance in "Plane Geometry" indicates that these models are particularly effective at tasks related to this domain. The large variation in "Functions" performance suggests that this category is more sensitive to model architecture or training data. The relatively low improvements in "Others" suggest that this category represents more challenging or diverse tasks.
The lower overall improvement of InternVL3-78B, despite its larger size, is an interesting observation. This could indicate that model size alone is not sufficient for achieving higher accuracy, and other factors such as training data quality or model architecture play a crucial role. The fact that InternVL3-8B and MiniCPM-V2.6-8B have the same overall improvement suggests that they are comparable in overall performance, despite potentially different architectures.
The chart provides a comparative analysis of model performance across different task categories, highlighting strengths and weaknesses of each model. This information can be valuable for selecting the most appropriate model for a specific application or for guiding further model development efforts.
</details>
Figure 3: Improvements of the average percentage accuracy (%) of multiple MLLMs across different question types in MathVista, MathVision and MathVerse datasets.
The Refined-BoN process yields disproportionately larger gains for models with lower baseline performance. As shown in Table 1, InternVL3-38B starts with the highest initial average accuracy among all policy models (49.5%) and achieves a modest improvement of +2.9 points (+5.9%). In contrast, Qwen2.5-VL-7B, which has the highest baseline accuracy (43.3%) among models with fewer than 12 billion parameters, improves by +4.5 points (+10.4%), surpassing the relative gains of InternVL3-38B. Notably, MiniCPM-V-2.6-8B demonstrates the most significant relative improvement, achieving +5.9 points (+21.0%), despite its lower initial score. These results suggest that models with weaker baseline performance benefit more from the refinement mechanism of GM-PRM with Refined-BoN, likely because the process effectively corrects errors in reasoning steps, leaving greater room for improvement.
<details>
<summary>figures/MiniCPM-BoN.png Details</summary>
### Visual Description
\n
## Line Chart: Accuracy vs. Number of Solutions
### Overview
This line chart compares the accuracy of two methods, GM-PRM and Self-Consistency, as the number of solutions per problem increases. The x-axis represents the number of solutions, ranging from 1 to 8, while the y-axis represents accuracy, measured in percentage (%).
### Components/Axes
* **X-axis Title:** "# Solutions per Problem"
* **Y-axis Title:** "Accuracy (%)"
* **X-axis Markers:** 1, 4, 6, 8
* **Y-axis Markers:** 38, 40, 42, 44, 46, 48, 50, 52
* **Legend:**
* GM-PRM (Blue Line)
* Self-Consistency (Orange Line)
* **Legend Position:** Bottom-right corner of the chart.
### Detailed Analysis
**GM-PRM (Blue Line):** The blue line representing GM-PRM shows an upward trend, indicating increasing accuracy as the number of solutions increases.
* At 1 solution: Approximately 40% accuracy.
* At 4 solutions: Approximately 46% accuracy.
* At 6 solutions: Approximately 47.5% accuracy.
* At 8 solutions: Approximately 51.5% accuracy.
**Self-Consistency (Orange Line):** The orange line representing Self-Consistency shows an initial increase in accuracy, followed by a plateau.
* At 1 solution: Approximately 38.5% accuracy.
* At 4 solutions: Approximately 43.5% accuracy.
* At 6 solutions: Approximately 44% accuracy.
* At 8 solutions: Approximately 44.5% accuracy.
### Key Observations
* GM-PRM consistently outperforms Self-Consistency across all tested numbers of solutions.
* The accuracy of GM-PRM continues to increase with more solutions, while Self-Consistency's accuracy plateaus after 4 solutions.
* The difference in accuracy between the two methods widens as the number of solutions increases.
### Interpretation
The data suggests that GM-PRM benefits more from increasing the number of solutions per problem than Self-Consistency does. This could indicate that GM-PRM is better at leveraging multiple perspectives or approaches to arrive at a more accurate solution. The plateau in Self-Consistency's accuracy suggests that it reaches a limit in its ability to improve with more solutions, potentially due to inherent constraints in its methodology. The widening gap in accuracy between the two methods highlights the potential advantages of GM-PRM for tasks where generating multiple solutions is feasible. The chart demonstrates a clear performance difference between the two methods, with GM-PRM showing a more robust and scalable approach to improving accuracy.
</details>
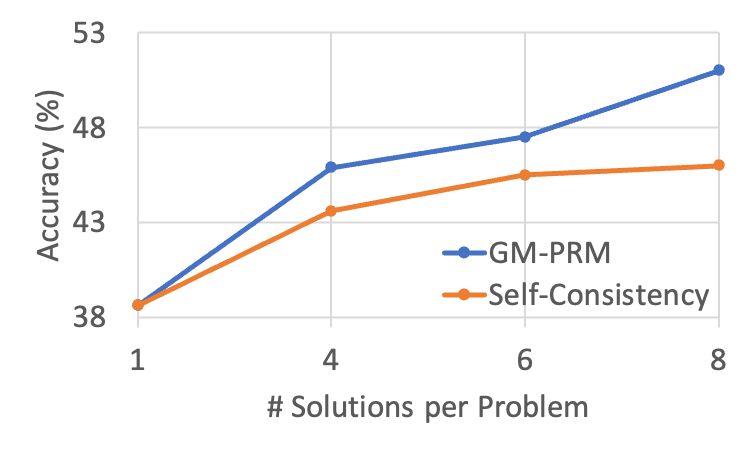
(a) MiniCPM-V-2.6-8B
<details>
<summary>figures/QwenVL-BoN.png Details</summary>
### Visual Description
\n
## Line Chart: Accuracy vs. Number of Solutions
### Overview
This image presents a line chart comparing the accuracy of two methods, GM-PRM and Self-Consistency, as the number of solutions per problem increases. The chart displays accuracy as a percentage on the y-axis and the number of solutions per problem on the x-axis.
### Components/Axes
* **X-axis Title:** "# Solutions per Problem"
* Scale: 1, 4, 6, 8
* **Y-axis Title:** "Accuracy (%)"
* Scale: 60, 62, 64, 66, 68, 70
* **Legend:** Located in the top-right corner.
* GM-PRM (Blue Line)
* Self-Consistency (Orange Line)
### Detailed Analysis
* **GM-PRM (Blue Line):** The line slopes upward, indicating increasing accuracy with more solutions.
* At 1 solution: Approximately 61% accuracy.
* At 4 solutions: Approximately 66.5% accuracy.
* At 6 solutions: Approximately 68% accuracy.
* At 8 solutions: Approximately 69.5% accuracy.
* **Self-Consistency (Orange Line):** The line also slopes upward, but at a slower rate than GM-PRM.
* At 1 solution: Approximately 60.5% accuracy.
* At 4 solutions: Approximately 64.5% accuracy.
* At 6 solutions: Approximately 66% accuracy.
* At 8 solutions: Approximately 67% accuracy.
### Key Observations
* GM-PRM consistently outperforms Self-Consistency across all tested numbers of solutions.
* The rate of accuracy improvement diminishes as the number of solutions increases for both methods.
* The difference in accuracy between the two methods is most pronounced at lower numbers of solutions (1 and 4).
### Interpretation
The data suggests that both GM-PRM and Self-Consistency benefit from considering multiple solutions per problem, leading to increased accuracy. However, GM-PRM demonstrates a more significant improvement in accuracy with each additional solution, indicating it is more effective at leveraging multiple perspectives. The diminishing returns observed at higher solution counts suggest there's a point where adding more solutions provides only marginal gains. This could be due to redundancy in the generated solutions or limitations in the methods' ability to effectively integrate them. The initial gap in performance between the two methods suggests that GM-PRM may have a more robust approach to problem-solving, even with limited information. This chart provides evidence that increasing the number of solutions considered can improve the performance of these methods, but also highlights the importance of the method itself in maximizing the benefits of this approach.
</details>
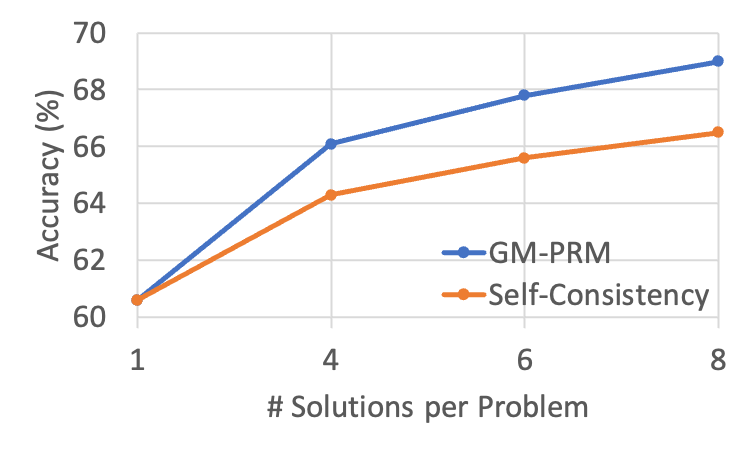
(b) Qwen2.5-VL-7B
<details>
<summary>figures/InternVL3-78B-BoN.png Details</summary>
### Visual Description
\n
## Line Chart: Accuracy vs. Number of Solutions
### Overview
This line chart depicts the relationship between the number of solutions generated per problem and the resulting accuracy for two different methods: GM-PRM and Self-Consistency. The chart shows how accuracy changes as the number of solutions increases.
### Components/Axes
* **X-axis:** "# Solutions per Problem" with markers at 1, 4, 6, and 8.
* **Y-axis:** "Accuracy (%)" with a scale ranging from 65 to 73.
* **Data Series 1:** GM-PRM (represented by a blue line with circular markers).
* **Data Series 2:** Self-Consistency (represented by an orange line with circular markers).
* **Legend:** Located in the top-right corner, associating colors with the methods.
### Detailed Analysis
**GM-PRM (Blue Line):**
The GM-PRM line slopes upward, indicating increasing accuracy with more solutions.
* At 1 solution, accuracy is approximately 66%.
* At 4 solutions, accuracy jumps to approximately 71%.
* At 6 solutions, accuracy is approximately 71.5%.
* At 8 solutions, accuracy reaches approximately 72.5%.
**Self-Consistency (Orange Line):**
The Self-Consistency line shows a slight upward trend, but is much flatter than the GM-PRM line.
* At 1 solution, accuracy is approximately 66%.
* At 4 solutions, accuracy increases to approximately 68%.
* At 6 solutions, accuracy remains around 68%.
* At 8 solutions, accuracy is approximately 68%.
### Key Observations
* GM-PRM consistently outperforms Self-Consistency across all numbers of solutions.
* The accuracy improvement for GM-PRM is most significant between 1 and 4 solutions. After 4 solutions, the gains diminish.
* Self-Consistency shows minimal improvement in accuracy as the number of solutions increases.
* Both methods start with similar accuracy at 1 solution.
### Interpretation
The data suggests that the GM-PRM method benefits significantly from generating multiple solutions per problem, with the largest gains observed when increasing from 1 to 4 solutions. This indicates that exploring a wider solution space improves the accuracy of GM-PRM. In contrast, the Self-Consistency method appears to be less sensitive to the number of solutions generated, suggesting that its performance plateaus quickly. This could be due to the inherent limitations of the Self-Consistency approach or the specific problem domain being evaluated. The difference in performance between the two methods highlights the importance of solution diversity and exploration in achieving higher accuracy. The diminishing returns of GM-PRM after 4 solutions suggest an optimal point beyond which additional solutions do not contribute significantly to accuracy gains.
</details>
(c) InternVL3-78B
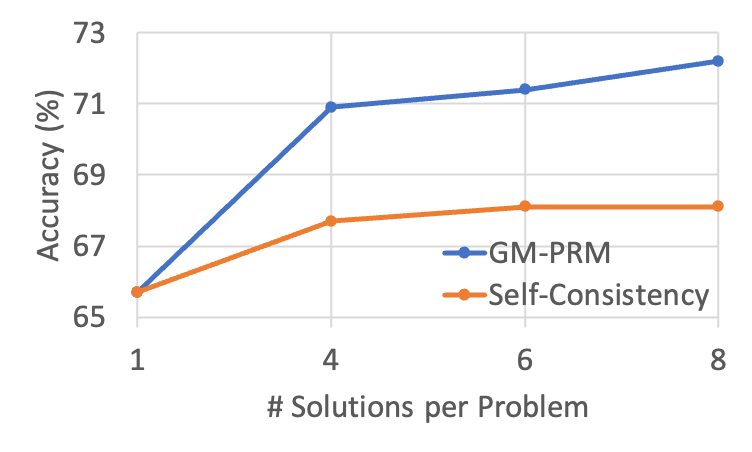
Figure 4: The results of changing the value of N in the Refined-BoN process on the WeMath across different policies. As N increases, the effectiveness of GM-PRM in enhancing accuracy improves and surpasses that of Self-Consistency.
4.3 Hyperparameter & Ablation Study
Number of solution samples N in Refined BoN.
Following Test-time Scaling technique, we vary the number of N in the Refined-BoN process to evaluate the performance of GM-PRM in comparison to the Self-Consistency baseline.
Figure 4 depicts WeMath accuracy as the number of sampled solutions per problem ( $N$ ) increases from 1 to 8. Across all three backbones—MiniCPM‑V‑2.6‑8B, Qwen2.5‑VL‑7B, and InternVL3‑78B—both GM-PRM and the Self‑Consistency (SC) baseline benefit from a larger sampling budget, yet GM-PRM exhibits a noticeably steeper growth curve.
Under the widely adopted Best‑of‑8 setting, GM-PRM delivers gains of 4.9 and 3.5 over SC on MiniCPM‑V‑2.6‑8B and Qwen2.5‑VL‑7B, respectively. Even for the 78B‑parameter InternVL3, GM-PRM maintains a substantial 4.1 margin. These results indicate that the proposed refinement strategy not only scales to larger models but also converts additional candidate solutions into accuracy more effectively than Self‑Consistency, thereby underscoring the robustness and versatility of GM-PRM.
Furthermore, for MiniCPM-V-2.6-8B, GM-PRM surpasses the self-consistency baseline by 2.1, 2.2, and 4.9 points under the Best-of-4, Best-of-6, and Best-of-8 settings, respectively, indicating a steadily increasing performance gap between GM-PRM and self-consistency as N increases.
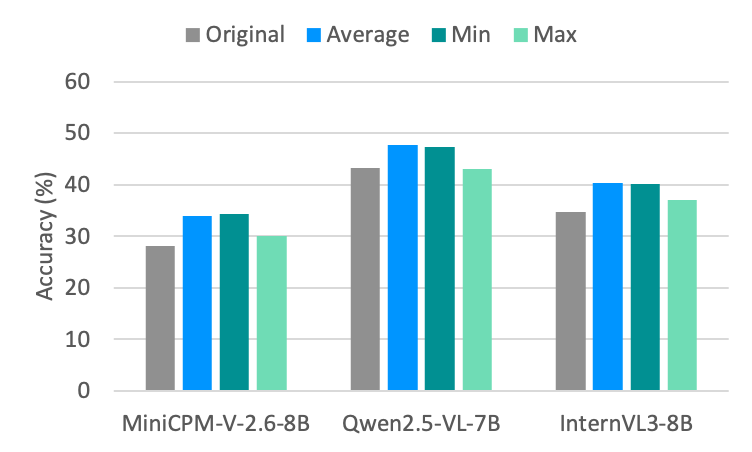
Methods for aggregating step scores.
For PRMs, the method used to aggregate step scores into an overall solution score plays a critical role. In this part, we compare several different aggregation strategies, including averaging step scores, selecting the maximum step score, and selecting the minimum step score. Since step-by-step solutions that contain steps judged incorrect are often not evaluated or scored for all steps, this experiment focuses exclusively on solutions where all steps are judged correct.
<details>
<summary>figures/Aggregation.png Details</summary>
### Visual Description
\n
## Bar Chart: Accuracy Comparison of Language Models
### Overview
This bar chart compares the accuracy of three language models – MiniCPM-V-2.6-8B, Qwen2.5-VL-7B, and InternVL3-8B – based on four metrics: Original, Average, Minimum, and Maximum accuracy. The accuracy is measured in percentage (%).
### Components/Axes
* **X-axis:** Represents the language models: MiniCPM-V-2.6-8B, Qwen2.5-VL-7B, and InternVL3-8B.
* **Y-axis:** Represents the Accuracy (%), ranging from 0 to 60, with tick marks at intervals of 10.
* **Legend:** Located at the top-left corner, defines the color-coding for each metric:
* Original (Grey)
* Average (Blue)
* Min (Teal)
* Max (Green)
### Detailed Analysis
The chart consists of three groups of four bars, one group for each language model. Within each group, each bar represents one of the four accuracy metrics.
**MiniCPM-V-2.6-8B:**
* Original: Approximately 29%
* Average: Approximately 33%
* Min: Approximately 32%
* Max: Approximately 35%
**Qwen2.5-VL-7B:**
* Original: Approximately 43%
* Average: Approximately 48%
* Min: Approximately 45%
* Max: Approximately 49%
**InternVL3-8B:**
* Original: Approximately 36%
* Average: Approximately 41%
* Min: Approximately 40%
* Max: Approximately 43%
### Key Observations
* Qwen2.5-VL-7B consistently demonstrates the highest accuracy across all metrics.
* The difference between the minimum and maximum accuracy is relatively small for all models, suggesting a stable performance.
* The "Average" accuracy is consistently higher than the "Original" accuracy for each model.
* MiniCPM-V-2.6-8B exhibits the lowest accuracy across all metrics.
### Interpretation
The data suggests that Qwen2.5-VL-7B is the most accurate language model among the three tested, based on the metrics provided. The consistent difference between "Original" and "Average" accuracy might indicate that the model's performance varies depending on the input data, with the average representing a more robust measure. The small gap between "Min" and "Max" suggests that the model's performance is relatively consistent across different scenarios. The lower accuracy of MiniCPM-V-2.6-8B could be due to its architecture, training data, or other factors. This chart provides a comparative performance overview, but further investigation would be needed to understand the underlying reasons for these differences. The metrics used (Original, Average, Min, Max) are not explicitly defined, so the precise meaning of each metric is unclear without additional context.
</details>
Figure 5: Average percentage accuracy (%) of MLLMs via different aggregation methods across five datasets.
The results are illustrated in the Figure 5. Across all policy models and datasets, we find that both averaging the step scores and selecting the minimum score significantly outperform the strategy of selecting the maximum score. This suggests that either the average or the minimum score provides a more accurate reflection of the overall quality of a solution than the maximum score. Between the minimum and average aggregation methods, we observe that averaging performs slightly better. This improvement may stem from the fact that the average score takes into account all problem-solving steps, providing a more comprehensive evaluation, whereas the minimum score reflects only the step with the lowest score and thus offers a less holistic assessment.
Refined-BoN vs. BoN.
The Refined-BoN process aims to enhance the diversity of N candidate solutions by refining the steps judged incorrect and integrating the refined steps with the steps judged correct into the prompt for the policy models. In this part, we use the Pass@k metric to evaluate the diversity and accuracy of policy models in generating multiple solutions to the given problems.
The results are summarized in the Table 2. Overall, the Refined-BoN process improves Pass@8 scores compared to the standard BoN process across multiple policy models and five benchmark datasets. Specifically, it increases the average Pass@8 values of MiniCPM-V-2.6-8B, Llama-3.2-11B-Vision, and InternVL3-8B by 0.9, 1.3, and 0.9 points, respectively, across the five datasets, demonstrating the effectiveness of the Refined-BoN approach in enhancing the diversity and correctness of the generated solutions.
| MiniCPM-V-2.6-8B Llama-3.2-11B-Vision InternVL3-8B | 62.5 62.7 65.3 | 63.4 64.0 66.2 | +0.9 +1.3 +0.9 |
| --- | --- | --- | --- |
Table 2: Average percentage Pass@8 scores of BoN and Refined-BoN across five datasets for different models.
5 Conclusion
In this work, we introduced GM-PRM, a novel paradigm that transforms the reward model from a passive judge into an active reasoning collaborator for multimodal mathematics. By providing fine-grained, interpretable analysis and, more critically, generating corrections for erroneous steps, GM-PRM moves beyond simple binary verification. This unique corrective capability powers our Refined Best-of-N (Refined-BoN) framework, which actively improves flawed reasoning trajectories at test time. Our experiments demonstrate that this approach achieves state-of-the-art results on multiple benchmarks, significantly boosting policy model performance with remarkable data efficiency. The consistent gains across diverse models and problem types underscore the robustness and generalizability of our method. This shift from passive error detection to generative, collaborative correction represents a crucial advance in multimodal reasoning.
\nobibliography
*
References
- Ahn et al. (2024) Ahn, J.; Verma, R.; Lou, R.; Liu, D.; Zhang, R.; and Yin, W. 2024. Large language models for mathematical reasoning: Progresses and challenges. arXiv preprint arXiv:2402.00157.
- Bai et al. (2023) Bai, J.; Bai, S.; Chu, Y.; Cui, Z.; Dang, K.; Deng, X.; Fan, Y.; Ge, W.; Han, Y.; Huang, F.; Hui, B.; Ji, L.; Li, M.; Lin, J.; Lin, R.; Liu, D.; Liu, G.; Lu, C.; Lu, K.; Ma, J.; Men, R.; Ren, X.; Ren, X.; et al. 2023. Qwen Technical Report. arXiv:2309.16609.
- Bai et al. (2025) Bai, S.; Chen, K.; Liu, X.; Wang, J.; Ge, W.; Song, S.; Dang, K.; Wang, P.; Wang, S.; Tang, J.; Zhong, H.; Zhu, Y.; Yang, M.; Li, Z.; Wan, J.; Wang, P.; Ding, W.; Fu, Z.; Xu, Y.; Ye, J.; Zhang, X.; Xie, T.; et al. 2025. Qwen2.5-VL Technical Report. arXiv:2502.13923.
- Caffagni et al. (2024) Caffagni, D.; Cocchi, F.; Barsellotti, L.; Moratelli, N.; Sarto, S.; Baraldi, L.; Cornia, M.; and Cucchiara, R. 2024. The revolution of multimodal large language models: a survey. arXiv preprint arXiv:2402.12451.
- Cao et al. (2025) Cao, Q.; Wang, R.; Zhang, R.; Somayajula, S. A.; and Xie, P. 2025. DreamPRM: Domain-Reweighted Process Reward Model for Multimodal Reasoning. arXiv preprint arXiv:2505.20241.
- Chen et al. (2024) Chen, Z.; Wu, J.; Wang, W.; Su, W.; Chen, G.; Xing, S.; Zhong, M.; Zhang, Q.; Zhu, X.; Lu, L.; Li, B.; Luo, P.; Lu, T.; Qiao, Y.; and Dai, J. 2024. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks. arXiv:2312.14238.
- Du et al. (2025) Du, L.; Meng, F.; Liu, Z.; Zhou, Z.; Luo, P.; Zhang, Q.; and Shao, W. 2025. MM-PRM: Enhancing Multimodal Mathematical Reasoning with Scalable Step-Level Supervision. arXiv preprint arXiv:2505.13427.
- Gao et al. (2024) Gao, J.; Xu, S.; Ye, W.; Liu, W.; He, C.; Fu, W.; Mei, Z.; Wang, G.; and Wu, Y. 2024. On designing effective rl reward at training time for llm reasoning. arXiv preprint arXiv:2410.15115.
- Grattafiori et al. (2024) Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; Yang, A.; Fan, A.; Goyal, A.; Hartshorn, A.; Yang, A.; Mitra, A.; Sravankumar, A.; Korenev, A.; et al. 2024. The Llama 3 Herd of Models. arXiv:2407.21783.
- Hu et al. (2025) Hu, P.; Zhang, Z.; Chang, Q.; Liu, S.; Ma, J.; Du, J.; Zhang, J.; Liu, Q.; Gao, J.; Ma, F.; et al. 2025. PRM-BAS: Enhancing Multimodal Reasoning through PRM-guided Beam Annealing Search. arXiv preprint arXiv:2504.10222.
- Huo et al. (2024) Huo, J.; Yan, Y.; Hu, B.; Yue, Y.; and Hu, X. 2024. Mmneuron: Discovering neuron-level domain-specific interpretation in multimodal large language model. arXiv preprint arXiv:2406.11193.
- Khalifa et al. (2025) Khalifa, M.; Agarwal, R.; Logeswaran, L.; Kim, J.; Peng, H.; Lee, M.; Lee, H.; and Wang, L. 2025. Process Reward Models That Think. arXiv:2504.16828.
- Lambert et al. (2024) Lambert, N.; Pyatkin, V.; Morrison, J.; Miranda, L.; Lin, B. Y.; Chandu, K.; Dziri, N.; Kumar, S.; Zick, T.; Choi, Y.; et al. 2024. Rewardbench: Evaluating reward models for language modeling. arXiv preprint arXiv:2403.13787.
- Li et al. (2024) Li, Q.; Chen, Z.; Wang, W.; Wang, W.; Ye, S.; Jin, Z.; Chen, G.; He, Y.; Gao, Z.; Cui, E.; Yu, J.; Tian, H.; Zhou, J.; Xu, C.; Wang, B.; Wei, X.; Li, W.; Zhang, W.; Zhang, B.; Cai, P.; Wen, L.; et al. 2024. OmniCorpus: A Unified Multimodal Corpus of 10 Billion-Level Images Interleaved with Text. arXiv:2406.08418.
- Li and Li (2024) Li, W.; and Li, Y. 2024. Process reward model with q-value rankings. arXiv preprint arXiv:2410.11287.
- Li et al. (2025a) Li, X.; Yu, H.; Zhang, X.; Huang, Z.; He, S.; Liu, K.; Zhao, J.; Huang, F.; and Li, Y. 2025a. Socratic-PRMBench: Benchmarking Process Reward Models with Systematic Reasoning Patterns. arXiv preprint arXiv:2505.23474.
- Li et al. (2025b) Li, Z.; Wen, X.; Lou, J.; Ji, Y.; Lu, Y.; Han, X.; Zhang, D.; and Sun, L. 2025b. The devil is in the details: Tackling unimodal spurious correlations for generalizable multimodal reward models. arXiv preprint arXiv:2503.03122.
- Lightman et al. (2023) Lightman, H.; Kosaraju, V.; Burda, Y.; Edwards, H.; Baker, B.; Lee, T.; Leike, J.; Schulman, J.; Sutskever, I.; and Cobbe, K. 2023. Let’s verify step by step. In The Twelfth International Conference on Learning Representations.
- Liu et al. (2024a) Liu, W.; Li, J.; Zhang, X.; Zhou, F.; Cheng, Y.; and He, J. 2024a. Diving into Self-Evolving Training for Multimodal Reasoning. arXiv:2412.17451.
- Liu et al. (2024b) Liu, Y.; Cao, Y.; Gao, Z.; Wang, W.; Chen, Z.; Wang, W.; Tian, H.; Lu, L.; Zhu, X.; Lu, T.; Qiao, Y.; and Dai, J. 2024b. MMInstruct: a high-quality multi-modal instruction tuning dataset with extensive diversity. Science China Information Sciences, 67(12).
- Liu et al. (2023) Liu, Z.; He, Y.; Wang, W.; Wang, W.; Wang, Y.; Chen, S.; Zhang, Q.; Lai, Z.; Yang, Y.; Li, Q.; Yu, J.; Li, K.; Chen, Z.; Yang, X.; Zhu, X.; Wang, Y.; Wang, L.; Luo, P.; Dai, J.; and Qiao, Y. 2023. InternGPT: Solving Vision-Centric Tasks by Interacting with ChatGPT Beyond Language. arXiv:2305.05662.
- Lu et al. (2023) Lu, P.; Bansal, H.; Xia, T.; Liu, J.; Li, C.; Hajishirzi, H.; Cheng, H.; Chang, K.-W.; Galley, M.; and Gao, J. 2023. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. arXiv preprint arXiv:2310.02255.
- Luo et al. (2024) Luo, L.; Liu, Y.; Liu, R.; Phatale, S.; Guo, M.; Lara, H.; Li, Y.; Shu, L.; Zhu, Y.; Meng, L.; Sun, J.; and Rastogi, A. 2024. Improve Mathematical Reasoning in Language Models by Automated Process Supervision. arXiv:2406.06592.
- Luo et al. (2025) Luo, R.; Zheng, Z.; Wang, Y.; Ni, X.; Lin, Z.; Jiang, S.; Yu, Y.; Shi, C.; Chu, R.; Zeng, J.; and Yang, Y. 2025. URSA: Understanding and Verifying Chain-of-thought Reasoning in Multimodal Mathematics. arXiv:2501.04686.
- Miao et al. (2025) Miao, B.; Wu, Y.; Gao, M.; Yu, Q.; Bu, W.; Zhang, W.; Li, Y.; Tang, S.; Chua, T.-S.; and Li, J. 2025. Boosting Virtual Agent Learning and Reasoning: A Step-Wise, Multi-Dimensional, and Generalist Reward Model with Benchmark. arXiv preprint arXiv:2503.18665.
- Qiao et al. (2024) Qiao, R.; Tan, Q.; Dong, G.; Wu, M.; Sun, C.; Song, X.; GongQue, Z.; Lei, S.; Wei, Z.; Zhang, M.; et al. 2024. We-math: Does your large multimodal model achieve human-like mathematical reasoning? arXiv preprint arXiv:2407.01284.
- Setlur et al. (2024) Setlur, A.; Nagpal, C.; Fisch, A.; Geng, X.; Eisenstein, J.; Agarwal, R.; Agarwal, A.; Berant, J.; and Kumar, A. 2024. Rewarding progress: Scaling automated process verifiers for llm reasoning. arXiv preprint arXiv:2410.08146.
- She et al. (2025) She, S.; Liu, J.; Liu, Y.; Chen, J.; Huang, X.; and Huang, S. 2025. R-PRM: Reasoning-Driven Process Reward Modeling. arXiv:2503.21295.
- Shi et al. (2024) Shi, W.; Hu, Z.; Bin, Y.; Liu, J.; Yang, Y.; Ng, S.-K.; Bing, L.; and Lee, R. K.-W. 2024. Math-llava: Bootstrapping mathematical reasoning for multimodal large language models. arXiv preprint arXiv:2406.17294.
- Song et al. (2025) Song, M.; Su, Z.; Qu, X.; Zhou, J.; and Cheng, Y. 2025. PRMBench: A fine-grained and challenging benchmark for process-level reward models. arXiv preprint arXiv:2501.03124.
- Tian et al. (2024) Tian, C.; Zhu, X.; Xiong, Y.; Wang, W.; Chen, Z.; Wang, W.; Chen, Y.; Lu, L.; Lu, T.; Zhou, J.; Li, H.; Qiao, Y.; and Dai, J. 2024. MM-Interleaved: Interleaved Image-Text Generative Modeling via Multi-modal Feature Synchronizer. arXiv:2401.10208.
- Touvron et al. (2023a) Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; Rodriguez, A.; Joulin, A.; Grave, E.; and Lample, G. 2023a. LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971.
- Touvron et al. (2023b) Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; Bikel, D.; Blecher, L.; Ferrer, C. C.; Chen, M.; Cucurull, G.; Esiobu, D.; Fernandes, J.; Fu, J.; et al. 2023b. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv:2307.09288.
- Wang et al. (2024) Wang, K.; Pan, J.; Shi, W.; Lu, Z.; Ren, H.; Zhou, A.; Zhan, M.; and Li, H. 2024. Measuring multimodal mathematical reasoning with math-vision dataset. Advances in Neural Information Processing Systems, 37: 95095–95169.
- Wang et al. (2023) Wang, P.; Li, L.; Shao, Z.; Xu, R.; Dai, D.; Li, Y.; Chen, D.; Wu, Y.; and Sui, Z. 2023. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. CoRR, abs/2312.08935.
- Wang et al. (2025a) Wang, S.; Liu, Z.; Wei, J.; Yin, X.; Li, D.; and Barsoum, E. 2025a. Athena: Enhancing Multimodal Reasoning with Data-efficient Process Reward Models. arXiv:2506.09532.
- Wang et al. (2025b) Wang, W.; Gao, Z.; Chen, L.; Chen, Z.; Zhu, J.; Zhao, X.; Liu, Y.; Cao, Y.; Ye, S.; Zhu, X.; et al. 2025b. Visualprm: An effective process reward model for multimodal reasoning. arXiv preprint arXiv:2503.10291.
- Yan and Lee (2024) Yan, Y.; and Lee, J. 2024. Georeasoner: Reasoning on geospatially grounded context for natural language understanding. In Proceedings of the 33rd ACM international conference on information and knowledge management, 4163–4167.
- Yan et al. (2024a) Yan, Y.; Su, J.; He, J.; Fu, F.; Zheng, X.; Lyu, Y.; Wang, K.; Wang, S.; Wen, Q.; and Hu, X. 2024a. A survey of mathematical reasoning in the era of multimodal large language model: Benchmark, method & challenges. arXiv preprint arXiv:2412.11936.
- Yan et al. (2024b) Yan, Y.; Wang, S.; Huo, J.; Li, H.; Li, B.; Su, J.; Gao, X.; Zhang, Y.-F.; Xu, T.; Chu, Z.; et al. 2024b. Errorradar: Benchmarking complex mathematical reasoning of multimodal large language models via error detection. arXiv preprint arXiv:2410.04509.
- Yan et al. (2025a) Yan, Y.; Wang, S.; Huo, J.; Ye, J.; Chu, Z.; Hu, X.; Yu, P. S.; Gomes, C.; Selman, B.; and Wen, Q. 2025a. Position: Multimodal large language models can significantly advance scientific reasoning. arXiv preprint arXiv:2502.02871.
- Yan et al. (2025b) Yan, Y.; Wang, S.; Huo, J.; Yu, P. S.; Hu, X.; and Wen, Q. 2025b. Mathagent: Leveraging a mixture-of-math-agent framework for real-world multimodal mathematical error detection. arXiv preprint arXiv:2503.18132.
- Yan et al. (2024c) Yan, Y.; Wen, H.; Zhong, S.; Chen, W.; Chen, H.; Wen, Q.; Zimmermann, R.; and Liang, Y. 2024c. Urbanclip: Learning text-enhanced urban region profiling with contrastive language-image pretraining from the web. In Proceedings of the ACM Web Conference 2024, 4006–4017.
- Yao et al. (2024) Yao, Y.; Yu, T.; Zhang, A.; Wang, C.; Cui, J.; Zhu, H.; Cai, T.; Li, H.; Zhao, W.; He, Z.; Chen, Q.; Zhou, H.; Zou, Z.; Zhang, H.; Hu, S.; Zheng, Z.; Zhou, J.; Cai, J.; Han, X.; Zeng, G.; Li, D.; Liu, Z.; and Sun, M. 2024. MiniCPM-V: A GPT-4V Level MLLM on Your Phone. arXiv:2408.01800.
- Yuan et al. (2024) Yuan, L.; Li, W.; Chen, H.; Cui, G.; Ding, N.; Zhang, K.; Zhou, B.; Liu, Z.; and Peng, H. 2024. Free process rewards without process labels. arXiv preprint arXiv:2412.01981.
- Zeng et al. (2025) Zeng, T.; Zhang, S.; Wu, S.; Classen, C.; Chae, D.; Ewer, E.; Lee, M.; Kim, H.; Kang, W.; Kunde, J.; et al. 2025. Versaprm: Multi-domain process reward model via synthetic reasoning data. arXiv preprint arXiv:2502.06737.
- Zhang et al. (2025a) Zhang, K.; Zhang, J.; Li, H.; Zhu, X.; Hua, E.; Lv, X.; Ding, N.; Qi, B.; and Zhou, B. 2025a. Openprm: Building open-domain process-based reward models with preference trees. In The Thirteenth International Conference on Learning Representations.
- Zhang et al. (2024) Zhang, R.; Jiang, D.; Zhang, Y.; Lin, H.; Guo, Z.; Qiu, P.; Zhou, A.; Lu, P.; Chang, K.-W.; Qiao, Y.; et al. 2024. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? In European Conference on Computer Vision, 169–186. Springer.
- Zhang et al. (2025b) Zhang, Z.; Zheng, C.; Wu, Y.; Zhang, B.; Lin, R.; Yu, B.; Liu, D.; Zhou, J.; and Lin, J. 2025b. The Lessons of Developing Process Reward Models in Mathematical Reasoning. arXiv:2501.07301.
- Zhao et al. (2025) Zhao, J.; Liu, R.; Zhang, K.; Zhou, Z.; Gao, J.; Li, D.; Lyu, J.; Qian, Z.; Qi, B.; Li, X.; and Zhou, B. 2025. GenPRM: Scaling Test-Time Compute of Process Reward Models via Generative Reasoning. arXiv:2504.00891.
- Zheng et al. (2024a) Zheng, C.; Zhang, Z.; Zhang, B.; Lin, R.; Lu, K.; Yu, B.; Liu, D.; Zhou, J.; and Lin, J. 2024a. Processbench: Identifying process errors in mathematical reasoning. arXiv preprint arXiv:2412.06559.
- Zheng et al. (2024b) Zheng, K.; Chen, J.; Yan, Y.; Zou, X.; and Hu, X. 2024b. Reefknot: A comprehensive benchmark for relation hallucination evaluation, analysis and mitigation in multimodal large language models. arXiv preprint arXiv:2408.09429.
- Zhong et al. (2025) Zhong, J.; Shen, W.; Li, Y.; Gao, S.; Lu, H.; Chen, Y.; Zhang, Y.; Zhou, W.; Gu, J.; and Zou, L. 2025. A comprehensive survey of reward models: Taxonomy, applications, challenges, and future. arXiv preprint arXiv:2504.12328.
- Zhu et al. (2023) Zhu, W.; Hessel, J.; Awadalla, A.; Gadre, S. Y.; Dodge, J.; Fang, A.; Yu, Y.; Schmidt, L.; Wang, W. Y.; and Choi, Y. 2023. Multimodal C4: An Open, Billion-scale Corpus of Images Interleaved with Text. arXiv:2304.06939.
- Zhuang et al. (2025) Zhuang, W.; Huang, X.; Zhang, X.; and Zeng, J. 2025. Math-puma: Progressive upward multimodal alignment to enhance mathematical reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, 26183–26191.
- Zou et al. (2024) Zou, C.; Guo, X.; Yang, R.; Zhang, J.; Hu, B.; and Zhang, H. 2024. Dynamath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models. arXiv preprint arXiv:2411.00836.
Appendix A Appendix
A.1 More Related Work
Multimodal Large Language Models (MLLMs)
The advancement of artificial intelligence has advanced the development of Multimodal Large Language Models (MLLMs). MLLMs extend the capabilities of language-centric models by integrating multiple sensory inputs, primarily visual and auditory, with text. Unlike traditional Large Language Models (LLMs) which process solely textual data, MLLMs are designed to perceive and reason across modalities such as vision and language, thereby achieving the fusion and interaction of multimodal information. The development of MLLMs has been driven by extensive efforts, including enhancements across model structure and data curation. In terms of model structure, multiple studies (Bai et al. 2025; Liu et al. 2023; Yao et al. 2024) achieve notable performance through a method that utilizing connectors to align the embeddings of vision from Vision Foundation Models (VFMs) (Chen et al. 2024) with the latent space of LLMs (Bai et al. 2023; Touvron et al. 2023a, b). Alternatively, another line of research (Grattafiori et al. 2024; Tian et al. 2024) enhances pre-trained LLMs by adding supplementary layers to integrate visual features, which reduces the number of visual tokens but incurs additional training costs. Regarding dataset curation, recent research has achieved substantial advancements. Specifically, MultimodalC4 (Zhu et al. 2023) extends C4 corpus containing only text with images and constructs a corpus that supports pre-training for MLLMs. Furthermore, OmniCorpus (Li et al. 2024) delivers a large-scale yet noisy multimodal dataset suitable for pre-training, and MMInstruct (Liu et al. 2024b) presents an open-source collection of high-quality data designed for instruction tuning. The majority of research efforts have been concentrated on the training processes of MLLMs, leaving significant room for exploration in Test-Time Scaling (TTS) technique. In our work, we investigate the potential of enhancing the performance of MLLMs by incorporating Process Reward Model (PRM) into the TTS framework.
A.2 Benchmark
We provide more details about the Refined-BoN test benchmarks in Table 3:
| DynaMath | Plane Geometry | 770 |
| --- | --- | --- |
| MathVerse | Vision-Only | 788 |
| MathVista | Testmini | 1000 |
| WeMath | Testmini | 1740 |
| MathVision | Full | 3040 |
Table 3: More details about the Refined-BoN test benchmarks.
A.3 Dataset
To ensure a balanced distribution of process labels, we carefully construct the training dataset. The final dataset used to train GM-PRM contains 19,614 samples in total, comprising 9,061 solutions that contain incorrect steps—as jointly identified by GPT-4o and Monte Carlo (MC) estimation—and 10,553 solutions in which all steps are judged to be correct.
A.4 Prompt
In this section, we introduce the prompts used to construct the training dataset and generate the reasoning processes and final answers. The prompt we guide the policy models to generate reasoning processes and final answers of multi-choice problems is represented in Figure 6.
<details>
<summary>figures/Prompt_multi_choice.png Details</summary>

### Visual Description
\n
## Screenshot: Prompt for Generating Reasoning of Multi-Choice Problems
### Overview
The image is a screenshot of a text prompt designed for a multimodal AI system capable of solving mathematical problems. The prompt outlines the system's role as an expert in multimodal mathematical problem-solving and details the expected input and output format.
### Components/Axes
The screenshot is divided into two main sections:
1. **Prompt Instructions:** This section, enclosed in a dashed-line box, describes the AI's role and the expected workflow.
2. **Problem Placeholder:** This section, labeled "Problem:", contains a placeholder `<Question>` indicating where the actual mathematical problem would be inserted.
### Detailed Analysis or Content Details
The text within the prompt instructions can be transcribed as follows:
"Prompt for generating reasoning of multi-choice problems:
------------------------------------------------------------------
You are an expert in solving multimodal mathematical problems. I will provide a mathematical problem along with its corresponding image. According to the problem and the image, please first conduct step-by-step reasoning, and after your reasoning, please provide the correct option letter (e.g., A, B, C, D, E) using the format: "Final answer: ..."
Problem:
<Question>"
### Key Observations
The prompt emphasizes a two-step process: reasoning followed by a final answer selection. The system is expected to utilize both textual problem statements and accompanying images to arrive at a solution. The expected output format is strictly defined as "Final answer: [letter]".
### Interpretation
This prompt is designed to test an AI's ability to integrate visual and textual information to solve mathematical problems. The requirement for step-by-step reasoning suggests an emphasis on explainability and transparency in the AI's decision-making process. The prompt's structure is clear and concise, aiming to minimize ambiguity and ensure consistent responses from the AI system. The use of a placeholder `<Question>` indicates that the prompt is a template intended for use with various mathematical problems. The prompt does not contain any factual data or trends; it is a set of instructions.
</details>
Figure 6: Prompt for policy models to generate reasoning and final answers of multi-choice problem.
The prompt we guide the policy models to generate reasoning processes and final answers of free-form problems is represented in Figure 7.
<details>
<summary>figures/Prompt_free_form.png Details</summary>

### Visual Description
\n
## Screenshot: Prompt for Multimodal Mathematical Problem Solving
### Overview
The image is a screenshot of a text prompt designed for a multimodal AI system capable of solving mathematical problems. The prompt outlines the system's role as an expert in multimodal mathematical problem solving and details the expected input and output format.
### Components/Axes
The screenshot is divided into three main sections:
1. **Header:** Contains the title "Prompt for generating reasoning of free-form problems:" enclosed in a dashed-line box.
2. **Instructions:** A paragraph describing the system's expertise and the expected workflow (reasoning followed by a final answer).
3. **Problem Placeholder:** A section labeled "Problem:" with a placeholder "<Question>".
### Detailed Analysis or Content Details
The text content is as follows:
"Prompt for generating reasoning of free-form problems:
---------------------------------------------------------------------
You are an expert in solving multimodal mathematical problems. I will provide a mathematical problem along with its corresponding image. According to the problem and the image, please first conduct step-by-step reasoning, and after your reasoning, please provide your final answer using the format: "Final answer: ..."
Problem:
<Question>"
### Key Observations
The image does not contain any data, charts, or diagrams. It is purely textual, presenting instructions for an AI system. The placeholder "<Question>" indicates that the actual mathematical problem is not included in the image.
### Interpretation
The image represents a meta-prompt – a prompt designed to instruct an AI model on *how* to respond to a mathematical problem presented with an image. It emphasizes the importance of showing the reasoning process before providing the final answer. The use of a placeholder suggests that the prompt is intended to be used dynamically with different mathematical problems and corresponding images. The prompt is designed to elicit a structured response from the AI, making it easier to evaluate the model's problem-solving capabilities. The prompt is in English.
</details>
Figure 7: Prompt for policy models to generate reasoning and final answers of free-form problem.
The prompt we use to employ GPT-4o to generate the training dataset is shown in Figure 8.
<details>
<summary>figures/Prompt.png Details</summary>

### Visual Description
\n
## Document: Prompt for GPT-4o to construct training dataset
### Overview
The image presents a document outlining the task and format for constructing a training dataset for GPT-4o, specifically focused on multimodal mathematical problem-solving. It details the steps involved in analyzing a problem and its solution, including correctness checks and error correction. The document is structured with headings and bullet points, and includes example output formatting.
### Components/Axes
The document is primarily text-based. Key components include:
* **Title:** "Prompt for GPT-4o to construct training dataset:"
* **Task:** A description of the tasks to be performed.
* **Question:** Placeholder for the multimodal mathematical problem.
* **Solution Steps:** Placeholder for the multiple-step solution.
* **Output Format:** Instructions on how to format the output.
* **Step Headings:** "### Step 1 ###", "### Step 2 ###", etc.
* **Analysis Categories:** Step intent analysis, Image alignment analysis, Judgement of image alignment, Reasoning logic analysis, Judgement of reasoning logic, Final judgement of the current step.
* **Correction Section:** Instructions for correcting the first incorrect step.
### Detailed Analysis or Content Details
Here's a transcription of the document's content, broken down by section:
**Task:**
"The tasks you need to do are:
1. Analyze the purpose of each step and what specific actions were taken in each step.
2. Analyze each step’s correctness in terms of image alignment and reasoning logic.
- Image alignment: Whether the information and reasoning used in the step are consistent with the content of the provided image.
- Reasoning logic: Whether the reasoning is logically sound, calculations are correct, and information used matches that from previous steps and question.
When outputting judgements, you must choose one output from “Correct” or “Incorrect”.
3. For the first incorrect step, correct it based on your analysis of its error, and output the corrected step at the end of your output."
**Question:**
"The multimodal mathematical problem is as follows:
<Question>"
**Solution Steps:**
"The multiple-step solution is as follows:
<Solution Steps>"
**Output Format:**
"You must output your content in the following format:
### Step 1 ###
Step intent analysis:[Describe what the step aims to do and the specific actions]
Image alignment analysis:[Analyze the consistency of image alignment]
Judgement of image alignment:[Correct/Incorrect]
Reasoning logic analysis:[Analyze the rationality of logic, correctness of calculations and consistency with prior step]
Judgement of reasoning logic:[Correct/Incorrect]
Final judgement of the current step:[Correct/Incorrect]
### Step 2 ###
…"
**Corrected step of the first incorrected step in solution:**
"Step n:[assume that the first incorrect step is step n, and fill in the corrected step n in the square bracket]"
### Key Observations
The document is a procedural guide. It emphasizes a rigorous evaluation process involving both visual (image alignment) and logical (reasoning) checks. The output format is highly structured, requiring specific analyses for each step. The inclusion of a correction step indicates an iterative refinement process.
### Interpretation
This document outlines a methodology for creating a high-quality training dataset for a multimodal AI model (GPT-4o) designed to solve mathematical problems. The focus on both image alignment and reasoning logic suggests the model is expected to integrate information from both visual and textual sources. The structured output format is designed to facilitate automated evaluation and analysis of the model's performance. The iterative correction process is crucial for improving the model's accuracy and reliability. The placeholders for "Question" and "Solution Steps" indicate that this is a template to be populated with specific problem instances. The document is a meta-level instruction set, not presenting data *per se*, but rather defining how data should be generated and evaluated.
</details>
Figure 8: Prompt for GPT-4o to construct training dataset.
A.5 More Cases
We collect 2 more cases of GM-PRM and the Refined-BoN process illustrated in Figure 9 and 10.
<details>
<summary>figures/More_Cases_1.png Details</summary>
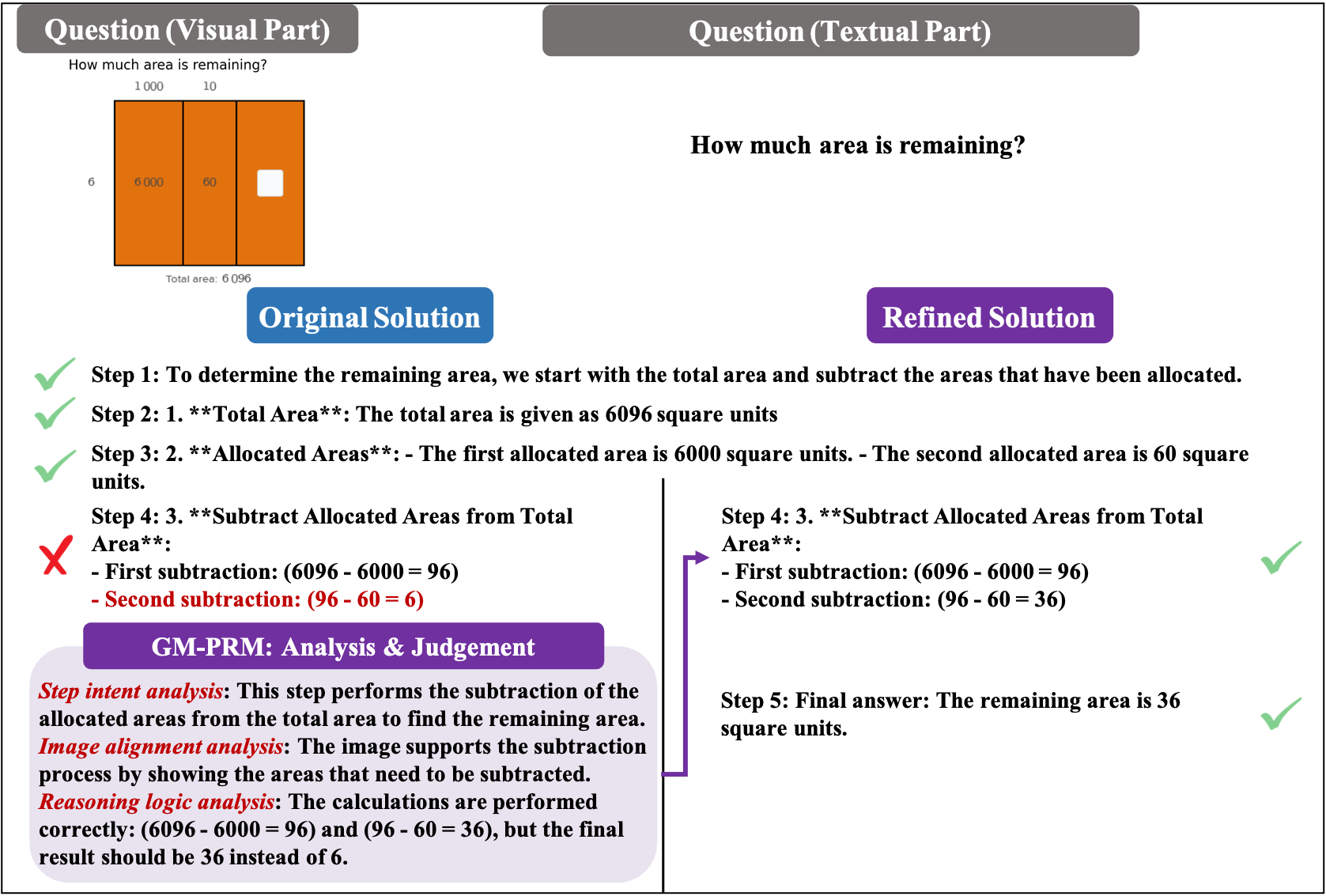
### Visual Description
\n
## Problem Solving Illustration: Area Calculation
### Overview
This image presents a visual and textual breakdown of a problem-solving process for calculating the remaining area after subtracting allocated areas from a total area. It contrasts an "Original Solution" with a "Refined Solution," highlighting a correction in the calculation. The image is divided into two main sections: a visual representation of the area calculation on the left and a textual explanation of the steps on the right.
### Components/Axes
The image contains the following components:
* **Question (Visual Part):** "How much area is remaining?" with a visual representation of rectangles representing areas of 6000, 60, and 10 square units. The total area is labeled as 6096.
* **Question (Textual Part):** Repeats "How much area is remaining?".
* **Original Solution:** A step-by-step solution with checkmarks and an "X" indicating an error.
* **Refined Solution:** A corrected step-by-step solution with checkmarks.
* **GM-PRM: Analysis & Judgement:** A section providing analysis of the problem-solving steps.
### Detailed Analysis or Content Details
**Visual Part:**
* Rectangle 1: Area = 6000 square units (approximate).
* Rectangle 2: Area = 60 square units (approximate).
* Rectangle 3: Area = 10 square units (approximate).
* Total Area: 6096 square units.
**Original Solution:**
* Step 1: "To determine the remaining area, we start with the total area and subtract the areas that have been allocated." (Checkmark)
* Step 2: "**Total Area**": "The total area is given as 6096 square units." (Checkmark)
* Step 3: "**Allocated Areas**": "The first allocated area is 6000 square units. – The second allocated area is 60 square units." (Checkmark)
* Step 4: "**Subtract Allocated Areas from Total Area**":
* First subtraction: (6096 - 6000 = 96) (Checkmark)
* Second subtraction: (96 - 60 = 6) (X - indicating an error)
**Refined Solution:**
* Step 4: "**Subtract Allocated Areas from Total Area**":
* First subtraction: (6096 - 6000 = 96) (Checkmark)
* Second subtraction: (96 - 60 = 36) (Checkmark)
* Step 5: "Final answer: The remaining area is 36 square units." (Checkmark)
**GM-PRM: Analysis & Judgement:**
* "Step intent analysis: This step performs the subtraction of the allocated areas from the total area to find the remaining area."
* "Image alignment analysis: The image supports the subtraction process by showing the areas that need to be subtracted."
* "Reasoning logic analysis: The calculations are performed correctly (6096 - 6000 = 96) and (96 - 60 = 36), but the final result should be 36 instead of 6."
### Key Observations
* The original solution incorrectly calculates the final remaining area as 6 square units instead of the correct answer of 36 square units.
* The refined solution provides the correct calculation and final answer.
* The "GM-PRM" section explicitly identifies the error in the original solution and confirms the correctness of the refined solution.
* The visual representation of the areas reinforces the subtraction process.
### Interpretation
The image demonstrates a common problem-solving technique: identifying and correcting errors in calculations. The comparison between the "Original Solution" and the "Refined Solution" highlights the importance of careful attention to detail and verification of results. The "GM-PRM" section provides a meta-cognitive analysis of the problem-solving process, explaining the intent of each step and identifying the source of the error. The visual component aids in understanding the problem and the subtraction process. The image serves as an educational tool for illustrating the importance of accuracy and critical thinking in mathematical problem-solving. The use of checkmarks and an "X" provides clear visual feedback on the correctness of each step.
</details>
Figure 9: The illustration of a representative example before and after applying GM-PRM. In particular, GM-PRM first judges the steps of the original solution generated by the policy model. Subsequently, GM-PRM finds that the forth step is incorrect regarding reasoning logic and refines the forth step to generate the correct version. The correct steps are input to the policy model to generate the refined solution, and finally the correct answer is obtained.
<details>
<summary>figures/More_Cases_2.png Details</summary>

### Visual Description
\n
## Problem Solving Analysis: Rainfall, Mosquitoes, and Bats
### Overview
The image presents a problem involving two equations representing rainfall and the populations of mosquitoes and bats. It shows a visual representation of the equations as graphs, an original attempted solution, a refined solution, and a section for analysis and judgement. The problem asks for the rainfall amount where the mosquito and bat populations are equal, beyond the known 0cm point.
### Components/Axes
* **Graph:**
* X-axis: Labeled "x" with markings from -5 to 5 in increments of 1.
* Y-axis: Labeled "y" with markings from -5 to 10 in increments of 1.
* Equation 1 (Mosquitoes): y = 5x - x² (represented by a solid blue line)
* Equation 2 (Bats): y = 3x - 0.5x² (represented by a solid orange line)
* **Textual Problem Statement:** Describes the scenario and the question.
* **Original Solution:** A step-by-step solution attempt, marked with checkmarks for completed steps.
* **Refined Solution:** A corrected step-by-step solution, also marked with checkmarks.
* **GP-MR: Analysis & Judgement:** A section providing analysis of the solution process.
### Detailed Analysis or Content Details
**1. Graph Analysis:**
* The blue line (mosquitoes) starts at (0,0), rises to a maximum around x=2.5, and then decreases.
* The orange line (bats) starts at (0,0), rises to a maximum around x=3, and then decreases.
* The lines intersect at approximately x=0 and x=4.
**2. Textual Problem Statement:**
"In both equations x represents rainfall (in centimeters). When there is 0cm of rainfall, the number of mosquitoes is the same as the number of bats. What is another rainfall amount where the number of mosquitoes is the same as the number of bats? Round your answer to the nearest half centimeter."
**3. Original Solution:**
* Step 1: "To solve the problem, we need to find the point where the number of bats equals the number of mosquitoes, other than the known 0 cm of rainfall."
* Step 2: 1. **Identify the equations for mosquitoes and bats**:: Mosquitoes: (y = 5x - x²) - Bats: (y = 3x - 0.5x²)
* Step 3: 2. **Set the equations equal to each other to find the points of intersection**: [5x - x² = 3x - 0.5x²]
* Step 4: 3. **Simplify the equation**: [5x - x² = 3x - 0.5x²] Rearrange to collect like terms: [5x - x² + 0.5x² = 0] [5x - 0.5x² - x² = 0] [5x - x - 0.5x² = 0] [5x - x - 0.5x = 0]
* Step 4: 3. **Simplify the equation**: [5x - x² = 3x - 0.5x²] Rearrange to collect like terms: [5x - x² + 0.5x² = 0] [5x - 0.5x² - x² = 0] [5x - x - 0.5x² = 0] [5x - x - 0.5x = 0]
**4. Refined Solution:**
* Step 4: 3. **Simplify the equation**: [5x - x² = 3x - 0.5x²] Rearrange to collect like terms: [5x - x² - 3x + 0.5x² = 0] [2x - 0.5x² = 0] [0.5x(4 - x) = 0] This corrected simplification should lead to the correct roots for further analysis.
* Step 5: **Solve for x**: [0.5x(4 - x) = 0] This gives us two possible solutions for x: (1) x = 0 (2) (0.5x = 2) -> 0.5x = 2 -> x = 4
* Step 8: Final answer: (4) cm.
**5. GP-MR: Analysis & Judgement:**
* Step intent analysis: This step simplifies the equation set in Step 3 to prepare it for solving.
* Image alignment analysis: The simplification process should reflect the intersection points seen in the image.
* Reasoning logic analysis: There is a mistake in the simplification process. The rearrangement and simplification steps contain errors in algebraic manipulation.
### Key Observations
* The original solution contains algebraic errors in simplifying the equation, leading to an incorrect path.
* The refined solution correctly simplifies the equation and finds the intersection point at x = 4.
* The graph visually confirms the intersection points at approximately x = 0 and x = 4.
* The analysis section correctly identifies the error in the original solution.
### Interpretation
The image demonstrates a problem-solving process involving the intersection of two quadratic equations. The visual representation (graph) provides a valuable check for the algebraic solution. The "GP-MR" section highlights the importance of careful algebraic manipulation and error detection. The refined solution showcases a correct approach to solving the problem, leading to the answer of 4 cm, which corresponds to the second intersection point observed on the graph. The problem illustrates a real-world application of quadratic equations, modeling the relationship between rainfall and population sizes. The error in the original solution emphasizes the need for rigorous verification of each step in the problem-solving process. The analysis section provides a meta-cognitive layer, demonstrating how to evaluate and correct one's own work.
</details>
Figure 10: The illustration of a representative example before and after applying GM-PRM. In particular, GM-PRM first judges the steps of the original solution generated by the policy model. Subsequently, GM-PRM finds that the forth step is incorrect regarding reasoning logic and refines the forth step to generate the correct version. The correct steps are input to the policy model to generate the refined solution, and finally the correct answer is obtained.