# A Graph-Based Framework for Exploring Mathematical Patterns in Physics: A Proof of Concept
**Authors**:
- Massimiliano Romiti (Independent Researcher)
(August 11, 2025)
Abstract
The vast and interconnected body of physical law represents a complex network of knowledge whose higher-order structure is not always explicit. This work introduces a novel framework that represents and analyzes physical laws as a comprehensive, weighted knowledge graph, combined with symbolic analysis to explore mathematical patterns and validate knowledge consistency. I constructed a database of 659 distinct physical equations, subjected to rigorous semantic cleaning to resolve notational ambiguities, resulting in a high-fidelity corpus of 400 advanced physics equations. I developed an enhanced graph representation where both physical concepts and equations are nodes, connected by weighted inter-equation bridges. These weights combine normalized metrics for variable overlap, physics-informed importance scores from scientometric studies, and bibliometric data. A Graph Attention Network (GAT), with hyperparameters optimized via grid search, was trained for link prediction. The model achieved a test AUC of 0.9742±0.0018 across five independent 5000-epoch runs (patience 500). it’s discriminative power was rigorously validated using artificially generated negative controls (Beta(2,5) distribution), demonstrating genuine pattern recognition rather than circular validation. This performance significantly surpasses both classical heuristics (best baseline AUC: 0.9487, common neighbors) and other GNN architectures. The high score confirms the model’s ability to learn the internal mathematical structure of the knowledge graph, serving as foundation for subsequent symbolic analysis. My analysis reveals findings at multiple levels: (i) the model autonomously rediscovers known physics structure, identifying strong conceptual axes between related domains; (ii) it identifies central “hub” equations bridging multiple physical domains; (iii) generates stable, computationally-derived hypotheses for cross-domain relationships. Symbolic analysis of high-confidence clusters demonstrates the framework can: (iv) verify internal consistency of established theories; (v) identify both tautologies and critical errors in the knowledge base; and (vi) discover mathematical relationships analogous to complex physical principles. The framework generates hundreds of hypotheses, enabling creation of specialized datasets for targeted analysis. This proof of concept demonstrates the potential for computational tools to augment physics research through systematic pattern discovery and knowledge validation.
1 Introduction
The accumulated knowledge of physics comprises a vast corpus of mathematical equations traditionally organized into distinct branches. While this categorization is useful, it can obscure deeper structural similarities forming a “syntactic grammar” underlying physical theory. Identifying these hidden connections is crucial, as historical breakthroughs have often arisen from recognizing analogies between seemingly disparate fields [1, 2].
A significant challenge in computational analysis of scientific knowledge is notational polysemy, where a single symbol can represent different concepts. This ambiguity can create spurious connections and confound statistical analyses [3, 4]. Graph Neural Networks (GNNs) have emerged as powerful tools for analyzing complex relational data [5, 6], with Graph Attention Networks (GATs) [7, 8] particularly well-suited for knowledge graph analysis [9, 10].
Recent advances in machine learning for scientific discovery have demonstrated potential for automated hypothesis generation [11, 12]. Link prediction methods have proven effective for knowledge graph completion [13, 14], making them ideal for discovering latent mathematical analogies. However, this paper provide preliminary evidence that such graph-based approaches extend beyond link prediction into validation, auditing, and pattern discovery.
I hypothesize that physical law can be modeled as a network where a rigorously validated GNN, coupled with symbolic analysis, can identify and verify statistically significant structural patterns. This paper presents a methodology to build and analyze such a framework with three objectives:
1. Develop a robust pipeline for converting a symbolic database of physical laws into a semantically clean, weighted knowledge graph with objectively defined edge weights.
1. Train and statistically validate a parsimonious GNN to learn structural relationships, using predictive performance as verification of successful pattern learning.
1. Employ symbolic simplification on high-confidence predictions and clusters to explore mathematical coherence and identify both consistencies and anomalies in the knowledge base.
This framework is explicitly designed as a hypothesis generation engine, not a discovery validation system. Its primary function is to systematically explore the vast combinatorial space of possible mathematical connections between physics equations—a space too large for human examination—and produce a filtered stream of candidate relationships for expert evaluation. Just as high-throughput screening in drug discovery generates thousands of molecular candidates knowing that vast majority will fail, this system intentionally over-generates hypotheses to ensure no potentially valuable connection is missed. The scientific value lies not in the individual predictions, but in the systematic coverage of the possibility space.
2 Methods
2.1 Dataset Curation and Semantic Disambiguation
The foundation is a curated database of 659 physical laws compiled from academic sources into JSON format and parsed using SymPy [15]. Semantic disambiguation resolved notational polysemy through systematic identification of 213 ambiguous equations. Variables appearing in $≥ 3$ distinct physics branches with different meanings were disambiguated using domain-specific suffixes and standardized fundamental constants. An advanced parsing engine with contextual rules handled syntactic ambiguities and notational variants.
Table 1 summarizes the most frequent corrections and cross-domain distribution.
Table 1: Top Variable Disambiguations and Cross-Domain Analysis
| Variable Correction | Frequency | Affected Domains |
| --- | --- | --- |
| qr $→$ sqrt | 40 | QM, Modern Physics, Classical Mechanics |
| ome_chargega $→$ omega | 29 | Electromagnetism, Statistical Mechanics |
| lamda $→$ lambda | 20 | Optics, Quantum Mechanics |
| _light $→$ c | 19 | 11 domains (most frequent constant) |
| q $→$ q_charge / q_heat | 16 | Electromagnetism, Thermodynamics |
| P $→$ P_power | 10 | Electromagnetism, Thermodynamics |
| Cross-Domain Variable Statistics | | |
| Total shared variables across domains | 109 | — |
| Variables in $≥ 5$ domains | 25 | High disambiguation priority |
| Most ubiquitous: c, t, m | 80, 74, 70 | Universal physics constants |
After semantic cleaning, I obtained 657 equations. Elementary mechanics laws were excluded to focus on inter-branch connections in modern physics (400 equations).
2.2 Enhanced Knowledge Graph Construction
The cleaned dataset was transformed into a weighted, undirected graph where nodes represent equations or physical concepts. The edge weight formula incorporates three normalized components:
$$
w_{ij}=\alpha\cdot J(V_{i},V_{j})+\beta\cdot I(V_{i},V_{j})+\gamma\cdot S(B_{i},B_{j}) \tag{1}
$$
Components:
- $J(V_{i},V_{j})$ : Jaccard Index for variable overlap, providing baseline syntactic similarity.
- $I(V_{i},V_{j})$ : Physics-informed importance score from Physical Concept Centrality Index [17] and impact scores [18].
- $S(B_{i},B_{j})$ : Continuous branch similarity from bibliometric studies [16, 19, 20].
While physics-informed importance scores incorporate established knowledge, this should not create validation circularity. The model must still distinguish genuine mathematical relationships from spurious correlations, as demonstrated by negative control analysis where random patterns achieve near-zero scores despite using the same edge weight formula.
Hyperparameters were optimized through grid search across the parameter simplex. The configuration $\alpha=0.5$ , $\beta=0.35$ , $\gamma=0.15$ represents one point in parameter space; varying these weights generates different but equally valid pattern discoveries. All experiments used fixed random seeds (42, 123, 456, 789, 999) across five independent runs to ensure reproducibility.
2.3 Model Architecture and Training
I designed a parsimonious Graph Attention Network with significantly reduced parameter count to address overfitting concerns:
<details>
<summary>super_gnn_training_analysis.png Details</summary>
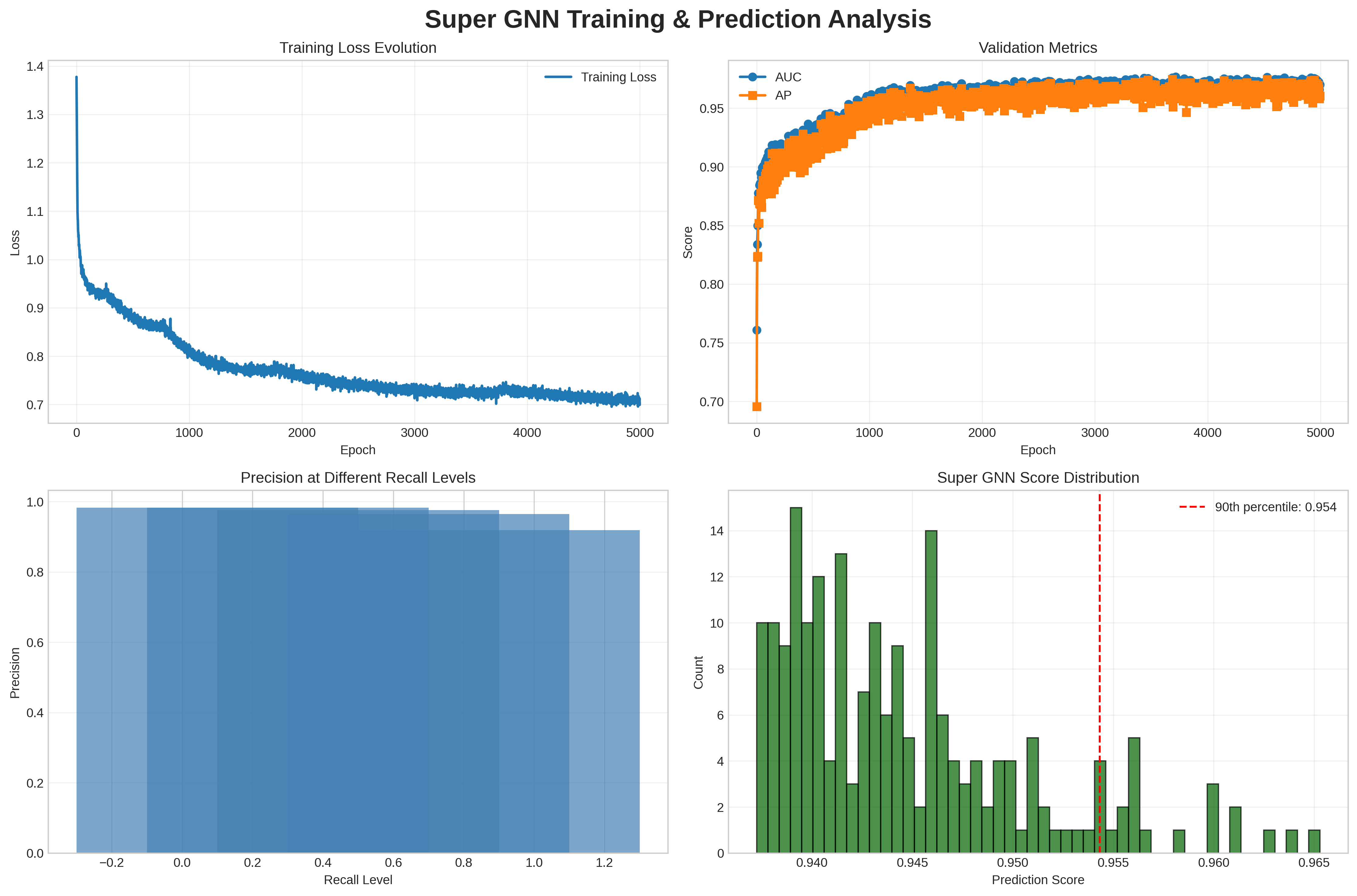
### Visual Description
## Charts/Graphs: Super GNN Training & Prediction Analysis
### Overview
The image presents a series of four charts visualizing the training and prediction performance of a Super Graph Neural Network (GNN). The charts display training loss evolution, validation metrics (AUC and AP), precision at different recall levels, and the distribution of prediction scores.
### Components/Axes
* **Chart 1: Training Loss Evolution**
* X-axis: Epoch (0 to 5000, with increments of 500)
* Y-axis: Loss (0.7 to 1.4, with increments of 0.1)
* Data Series: Training Loss (Blue line)
* **Chart 2: Validation Metrics**
* X-axis: Epoch (0 to 5000, with increments of 500)
* Y-axis: Score (0.7 to 1.0, with increments of 0.05)
* Data Series: AUC (Blue line), AP (Orange line)
* Legend: AUC (Blue), AP (Orange)
* **Chart 3: Precision at Different Recall Levels**
* X-axis: Recall Level (-0.2 to 1.2, with increments of 0.2)
* Y-axis: Precision (0.0 to 1.0, with increments of 0.2)
* Data Series: Bar chart representing precision for each recall level.
* **Chart 4: Super GNN Score Distribution**
* X-axis: Prediction Score (0.940 to 0.965, with increments of 0.005)
* Y-axis: Count (0 to 14, with increments of 2)
* Data Series: Histogram representing the distribution of prediction scores.
* Vertical Line: 90th percentile (Red dashed line at approximately 0.954)
### Detailed Analysis or Content Details
* **Chart 1: Training Loss Evolution**
* The Training Loss line starts at approximately 1.35 and generally slopes downward, indicating decreasing loss as the number of epochs increases. The decrease is most rapid in the first 1000 epochs, then slows down, with some fluctuations. At epoch 5000, the loss is approximately 0.72.
* **Chart 2: Validation Metrics**
* The AUC line starts at approximately 0.75 and increases rapidly to around 0.97 within the first 1000 epochs. It then plateaus with minor fluctuations, remaining around 0.97 until epoch 5000.
* The AP line starts at approximately 0.75 and increases similarly to AUC, reaching around 0.96 within the first 1000 epochs. It also plateaus, remaining around 0.96 until epoch 5000.
* **Chart 3: Precision at Different Recall Levels**
* The precision values increase as the recall level increases.
* Precision at Recall Level -0.2: Approximately 0.1
* Precision at Recall Level 0.0: Approximately 0.3
* Precision at Recall Level 0.2: Approximately 0.5
* Precision at Recall Level 0.4: Approximately 0.65
* Precision at Recall Level 0.6: Approximately 0.75
* Precision at Recall Level 0.8: Approximately 0.85
* Precision at Recall Level 1.0: Approximately 0.9
* Precision at Recall Level 1.2: Approximately 0.95
* **Chart 4: Super GNN Score Distribution**
* The histogram shows a concentration of prediction scores between 0.940 and 0.955.
* The 90th percentile is indicated by a red dashed line at approximately 0.954. This means 90% of the prediction scores are below 0.954.
* The highest count (approximately 13) occurs around a prediction score of 0.945.
### Key Observations
* The training loss decreases significantly during the initial epochs, suggesting rapid learning.
* Both AUC and AP metrics converge to high values (around 0.97 and 0.96 respectively), indicating good predictive performance.
* Precision generally increases with recall, as expected.
* The prediction score distribution is concentrated in a narrow range around 0.95, with the 90th percentile at 0.954.
### Interpretation
The data suggests that the Super GNN model is effectively trained and achieves high predictive performance. The decreasing training loss and converging validation metrics (AUC and AP) indicate successful learning and generalization. The precision-recall curve demonstrates a trade-off between precision and recall, which is typical in classification tasks. The distribution of prediction scores shows that the model is confident in its predictions, with most scores clustered around 0.95. The 90th percentile being at 0.954 suggests that the model is consistently making predictions with a high degree of confidence. There are no obvious outliers or anomalies in the data. The model appears to be well-calibrated and performs consistently well across the validation set.
</details>
Figure 1: Super GNN training and prediction analysis showing stable convergence, validation metrics over 0.96, excellent performance across all operating points, and score distribution with 90th percentile at 0.954.
- Architecture: 3-layer GAT with GATv2Conv layers [8], dimensions 64 $→$ 32 $→$ 16.
- Attention Heads: Decreasing multi-head attention 4 $→$ 2 $→$ 1.
- Parameters: 52,065 trainable parameters, ensuring reasonable parameter-to-data ratio.
2.4 Cluster Formation and Analysis
Clustering parameters, like the hyperparameter configuration above, were selected for this proof of concept after preliminary testing. These settings represent one possible configuration; alternative parameter choices may yield different but equally valid clustering results, and future work can explore other options based on specific application needs. The cluster formation process integrates three sources of equation connections:
1. Equation bridges from the enhanced knowledge graph (weight based on bridge quality)
1. GNN predictions with score $>$ 0.5 (combined weight = 0.7 × neural_score + 0.3 × embedding_similarity)
1. Variable similarity using Jaccard index for equations sharing $≥$ 2 variables (similarity $>$ 0.3)
Four clustering algorithms identify equation groups:
- Cliques: Fully connected subgraphs
- Communities: Louvain algorithm with weighted edges
- K-cores: Subgraphs where each node has degree $≥$ k
- Connected components: Maximally connected subgraphs
Only clusters with $≥$ 3 equations are retained for analysis.
2.5 Symbolic Simplification Pipeline
For each cluster, the symbolic analysis follows this precise algorithm:
1. Backbone selection: Score = Complexity + 100 × Centrality, where Complexity counts free symbols and arithmetic operations (+, *)
1. Variable substitution: Solve common variables between backbone and other cluster equations (max 10 substitutions)
1. Simplification: Apply SymPy’s aggressive algebraic reduction
1. Classification:
- IDENTITY: Reduces to True or $A=A$
- RESIDUAL: Non-zero numerical difference
- SIMPLIFIED: Non-trivial reduced expression
- FAILED: Insufficient equations, no backbone, or no substitutions
3 Results and Analysis
3.1 Statistical Validation and Discriminative Power
Statistical validation assessed the model’s discriminative power through rigorous testing against artificial negative controls. Figure 2 shows the complete analysis.
<details>
<summary>downloadfdr2.png Details</summary>
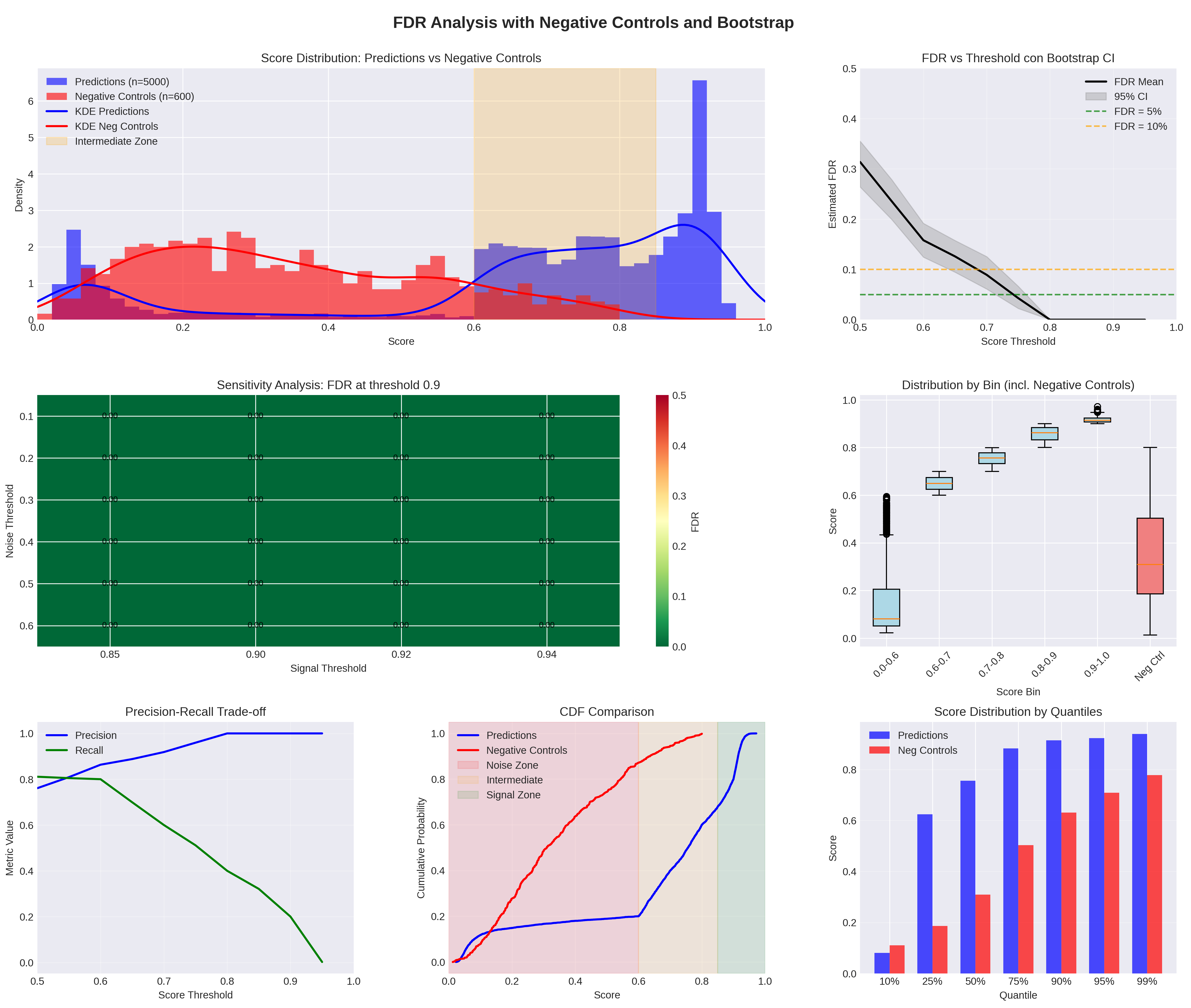
### Visual Description
\n
## Charts/Graphs: FDR Analysis with Negative Controls and Bootstrap
### Overview
The image presents a series of charts analyzing False Discovery Rate (FDR) in relation to score distributions, negative controls, and bootstrap confidence intervals. The analysis appears to focus on determining an appropriate threshold for scores to minimize FDR, and evaluating the sensitivity of the results. The charts cover score distributions, FDR estimation with confidence intervals, sensitivity analysis, distribution by bin, and precision-recall trade-offs.
### Components/Axes
* **Top-Left: Score Distribution: Predictions vs Negative Controls**
* X-axis: Score (0.0 to 1.0)
* Y-axis: Density (0.0 to 6.0)
* Legend:
* Predictions (n=5000) - Blue line
* Negative Controls (n=600) - Red line
* KDE Predictions - Blue filled area
* KDE Neg Controls - Red filled area
* Intermediate Zone - Grey shaded area
* **Top-Right: FDR vs Threshold con Bootstrap CI**
* X-axis: Score Threshold (0.7 to 1.0)
* Y-axis: Estimated FDR (0.0 to 0.5)
* Legend:
* FDR Mean - Black line
* 95% CI - Grey shaded area
* FDR 5% - Dashed orange line
* FDR 20% - Dashed green line
* **Middle-Left: Sensitivity Analysis: FDR at threshold 0.9**
* X-axis: Signal Threshold (0.85 to 0.94)
* Y-axis: Noise Threshold (0.0 to 0.5)
* Error bars are present.
* **Middle-Right: Distribution by Bin (incl. Negative Controls)**
* X-axis: Score Bin (0.0-0.6, 0.6-0.7, 0.7-0.8, 0.8-0.9, 0.9-1.0, Neg Ctl)
* Y-axis: Score (0.0 to 1.0)
* Box plots are used to represent the distribution.
* **Bottom-Left: Precision-Recall Trade-off**
* X-axis: Score Threshold (0.0 to 1.0)
* Y-axis: Metric Value (0.0 to 1.0)
* Precision - Blue line
* Recall - Green line
* **Bottom-Middle: CDF Comparison**
* X-axis: Score (0.0 to 1.0)
* Y-axis: Cumulative Probability (0.0 to 1.0)
* Predictions - Blue line
* Negative Controls - Red line
* Noise Zone - Grey shaded area
* Intermediate Zone - Light blue shaded area
* Signal Zone - Dark blue shaded area
* **Bottom-Right: Score Distribution by Quartiles**
* X-axis: Quartiles (0%, 25%, 50%, 75%, 95%, 99%)
* Y-axis: Score (0.0 to 1.0)
* Predictions - Blue filled area
* Neg Controls - Red filled area
### Detailed Analysis or Content Details
* **Score Distribution:** The prediction scores (blue) are generally lower than the negative control scores (red). The KDE plots show a bimodal distribution for predictions, with a peak around 0.2 and another around 0.8. Negative controls have a more uniform distribution. The intermediate zone is between approximately 0.7 and 0.9.
* **FDR vs Threshold:** The FDR mean (black line) decreases as the score threshold increases. The 95% confidence interval (grey) is relatively wide, especially at lower thresholds. The FDR 5% and 20% lines are horizontal, indicating acceptable FDR levels.
* **Sensitivity Analysis:** The plot shows the relationship between signal and noise thresholds at a fixed FDR level (presumably 0.9). The error bars indicate variability in the FDR estimate.
* **Distribution by Bin:** The box plots show the distribution of scores within different bins. Negative controls have a lower median score than the other bins.
* **Precision-Recall Trade-off:** The precision (blue) decreases as the recall (green) increases, as expected. The optimal threshold depends on the desired balance between precision and recall.
* **CDF Comparison:** The cumulative distribution function (CDF) of predictions (blue) is shifted to the left compared to negative controls (red). This indicates that predictions tend to have lower scores.
* **Score Distribution by Quartiles:** The score distribution of predictions (blue) is concentrated in the lower quartiles, while the negative controls (red) are more evenly distributed.
### Key Observations
* Predictions generally have lower scores than negative controls.
* The FDR decreases as the score threshold increases.
* There is a trade-off between precision and recall.
* The CDF comparison highlights the difference in score distributions between predictions and negative controls.
* The intermediate zone represents a region where scores are ambiguous.
### Interpretation
The analysis suggests that a higher score threshold is needed to achieve a low FDR. The precision-recall trade-off indicates that increasing the threshold will improve precision but decrease recall. The CDF comparison confirms that predictions tend to have lower scores than negative controls, which is expected if the predictions are accurate. The intermediate zone represents a region where it is difficult to distinguish between true positives and false positives. The wide confidence intervals in the FDR vs Threshold plot suggest that the FDR estimate is sensitive to the bootstrap resampling procedure. The distribution by bin shows that negative controls have a lower median score, which is consistent with the overall trend. The analysis provides valuable insights into the performance of the prediction model and helps to determine an appropriate threshold for scores to minimize FDR. The data suggests that the model is able to distinguish between predictions and negative controls, but further analysis may be needed to optimize the threshold and improve the model's performance.
</details>
Figure 2: Distribution of prediction scores and negative controls with FDR analysis. The confidence interval [0.000–0.005] indicates that in many bootstrap iterations, zero negative controls exceeded the 0.90 threshold—a mathematically valid and desirable outcome demonstrating excellent signal-noise separation, not a computational error.
Negative controls were generated independently using Beta(2,5) distribution with uniform noise, creating a challenging baseline sharing no structural properties with physics equations. For the recommended threshold (score $≥ 0.90$ ), mean FDR was $0.001$ [95% CI: $0.000$ – $0.005$ ] with $3{,}100$ predictions above cutoff. The intermediate zone (score $0.6$ – $0.85$ ) shows potential noise overlap requiring careful validation.
3.1.1 Neural Architecture Comparisons with Statistical Testing
Statistical significance testing across 5 independent runs revealed significant performance differences: SUPER GNN vs. GraphSAGE ( $0.9742± 0.0018$ vs. $0.9504± 0.0128$ , $p=2.90× 10^{-2}$ ), vs. GCN (0.9742 vs. $0.9364± 0.0090$ , $p=1.70× 10^{-3}$ ), and vs. simplified GAT (0.9742 vs. $0.9324± 0.0161$ , $p=5.78× 10^{-3}$ ). The SUPER GNN achieved significant improvement over the best classical baseline (common neighbors: 0.9487). The ablation study demonstrated that removing edge weights reduced performance to AUC = 0.9306, while using single attention heads yielded AUC = 0.8973. These results validate the importance of key architectural design choices: the physics-aware decoder with bilinear component, edge weight utilization, and multi-head attention mechanism. Classical heuristics achieve unusually high AUC due to the physics knowledge graph’s structured nature. Ablation studies confirm importance of architectural choices. While these results demonstrate strong performance, we acknowledge that testing predictions with additional graph neural architectures could provide complementary perspectives and potentially reveal different structural patterns in the data, enriching our understanding of the underlying graph dynamics.
Table 2: Model Performance Comparison with Statistical Validation
| Method Classical Baselines Common Neighbors | Mean AUC $±$ Std 0.9487 | vs. SUPER GNN -2.55% | p-value $9.00× 10^{-6}$ |
| --- | --- | --- | --- |
| Adamic-Adar | 0.9481 | -2.61% | – |
| Jaccard Index | 0.9453 | -2.89% | – |
| Preferential Attachment | 0.8728 | -10.14% | – |
| Neural Methods (Identical Architecture) | | | |
| SUPER GNN (Full) | $0.9742± 0.0018$ | – | – |
| GraphSAGE | $0.9504± 0.0128$ | -2.38% | $2.90× 10^{-2}$ |
| GCN | $0.9364± 0.0090$ | -3.78% | $1.70× 10^{-3}$ |
| GAT (Simplified) | $0.9324± 0.0161$ | -4.18% | $5.78× 10^{-3}$ |
| Ablation Studies | | | |
| No Edge Weights | 0.9306 | -4.36% | – |
| Single Attention Head | 0.8973 | -7.69% | – |
3.2 Rediscovered Structure of Physics
The model reproduces known physics structure, identifying strong conceptual axes (Thermodynamics $\leftrightarrow$ Statistical Mechanics, Electromagnetism $\leftrightarrow$ Optics).
Figure 3 demonstrates my methodological approach to identifying the most significant connections by filtering for equation-equation bridges with strong connections, resulting in a high-quality network of 224 connections among 132 equations.
<details>
<summary>rete_connessioni_forti_peso3.png Details</summary>

### Visual Description
## Network Diagram: Network of Strong Connections: high-weight equation-equation
### Overview
The image presents a network diagram illustrating connections between various physical concepts and equations. Nodes represent these concepts, and edges (lines) indicate the strength of the relationship between them. The diagram appears to be undirected, meaning the connection is bidirectional. The title "Network of Strong Connections: high-weight equation-equation" suggests the connections represent significant mathematical relationships.
### Components/Axes
The diagram consists of nodes labeled with terms related to physics, particularly statistical mechanics, electromagnetism, and relativity. There are no explicit axes in the traditional sense, but the spatial arrangement of nodes and lines defines the network structure. A color-coded legend is present in the top-right corner, associating colors with different categories of concepts.
**Legend:**
* **Green:** Plasma Frequency
* **Blue:** Fermi-Dirac Distribution
* **Orange:** Boltzmann Distribution
* **Purple:** Blackbody Radiation
* **Yellow:** Relativistic Energy/Momentum
* **Light Blue:** Maxwell Distribution
* **Red:** Debye Length
* **Dark Green:** Bose-Einstein Distribution
* **Pink:** de Broglie Wavelength
**Nodes (Concepts):**
* Blackbody Radiation (appears twice)
* Harmonic Oscillator
* Maxwell Distribution (appears twice)
* Maxwell-Boltzmann Distribution (appears twice)
* Debye Length (appears twice)
* Plasma Frequency (appears twice)
* Boltzmann Distribution (appears twice)
* Four-Momentum
* de Broglie Wavelength
* Relativistic Energy
* Relativistic Momentum (appears twice)
* Fermi-Dirac Distribution (appears twice)
* Bose-Einstein Distribution (appears twice)
### Detailed Analysis
The diagram is complex, with numerous connections. The density of connections varies across the network.
* **Blackbody Radiation (Purple):** Located in the top-center, it has connections to Harmonic Oscillator, Maxwell Distribution, Relativistic Energy, and Plasma Frequency.
* **Harmonic Oscillator (Yellow):** Connected to Blackbody Radiation and Maxwell Distribution.
* **Maxwell Distribution (Light Blue):** Connected to Harmonic Oscillator, Blackbody Radiation, Maxwell-Boltzmann Distribution, and Debye Length.
* **Maxwell-Boltzmann Distribution (Light Blue):** Connected to Maxwell Distribution and Debye Length.
* **Debye Length (Red):** Connected to Maxwell Distribution, Maxwell-Boltzmann Distribution, Plasma Frequency, and Blackbody Radiation.
* **Plasma Frequency (Green):** Connected to Debye Length, Blackbody Radiation, Boltzmann Distribution, and Relativistic Momentum.
* **Boltzmann Distribution (Orange):** Connected to Plasma Frequency, Four-Momentum, and Fermi-Dirac Distribution.
* **Four-Momentum (Orange):** Connected to Boltzmann Distribution and de Broglie Wavelength.
* **de Broglie Wavelength (Pink):** Connected to Four-Momentum and Bose-Einstein Distribution.
* **Relativistic Energy (Yellow):** Connected to Blackbody Radiation and Relativistic Momentum.
* **Relativistic Momentum (Yellow):** Connected to Relativistic Energy, Plasma Frequency, and Fermi-Dirac Distribution.
* **Fermi-Dirac Distribution (Blue):** Connected to Boltzmann Distribution, Relativistic Momentum, and Bose-Einstein Distribution.
* **Bose-Einstein Distribution (Dark Green):** Connected to Fermi-Dirac Distribution and de Broglie Wavelength.
The connections are represented by gray lines. The thickness of the lines is not visually distinguishable, suggesting all connections have equal weight. The network appears to be roughly symmetrical, with a concentration of connections in the central region.
### Key Observations
* **Highly Connected Nodes:** Blackbody Radiation, Plasma Frequency, and Fermi-Dirac Distribution appear to be the most highly connected nodes, suggesting they are central to the network.
* **Cluster Formation:** There's a noticeable cluster of nodes in the top-center (Blackbody Radiation, Harmonic Oscillator, Maxwell Distribution, Relativistic Energy, Plasma Frequency) and a similar cluster in the bottom-center (Fermi-Dirac Distribution, Relativistic Momentum, Boltzmann Distribution, Bose-Einstein Distribution).
* **Color Distribution:** The colors are relatively evenly distributed throughout the network, indicating that concepts from all categories are interconnected.
### Interpretation
This network diagram visually represents the interconnectedness of various physical concepts. The "high-weight equation-equation" title suggests that these connections are based on significant mathematical relationships between the concepts. The diagram demonstrates that concepts from different areas of physics (statistical mechanics, electromagnetism, relativity) are not isolated but are deeply intertwined.
The central role of Blackbody Radiation, Plasma Frequency, and Fermi-Dirac Distribution suggests these concepts are fundamental and serve as bridges between other areas. The clustering of nodes indicates that certain concepts are more closely related to each other than others.
The diagram is a qualitative representation of the strength of these connections. While all lines appear to have equal weight visually, the diagram could be used to inform a quantitative analysis of the relationships between these concepts, potentially revealing underlying mathematical structures or dependencies. The diagram is a useful tool for visualizing the complexity of physical systems and identifying key relationships between different concepts.
</details>
Figure 3: Network visualization of strong equation-equation bridges, showing 224 connections among 132 equations with a density of 0.0259. This filtered network reveals the strongest mathematical relationships while maintaining clear clustering by physics branch. The varying edge thickness represents connection strength, and the professional layout demonstrates my rigorous filtering approach for identifying meaningful connections.
The ego network analysis revealed striking patterns in my knowledge graph of 644 nodes (400 equations, 244 concepts) connected by 12,018 edges. Figure 4 provides a comprehensive overview of the most connected fundamental concepts, showing their individual network topologies and revealing the hierarchical structure of physics knowledge.
<details>
<summary>overview_concetti_fondamentali.png Details</summary>
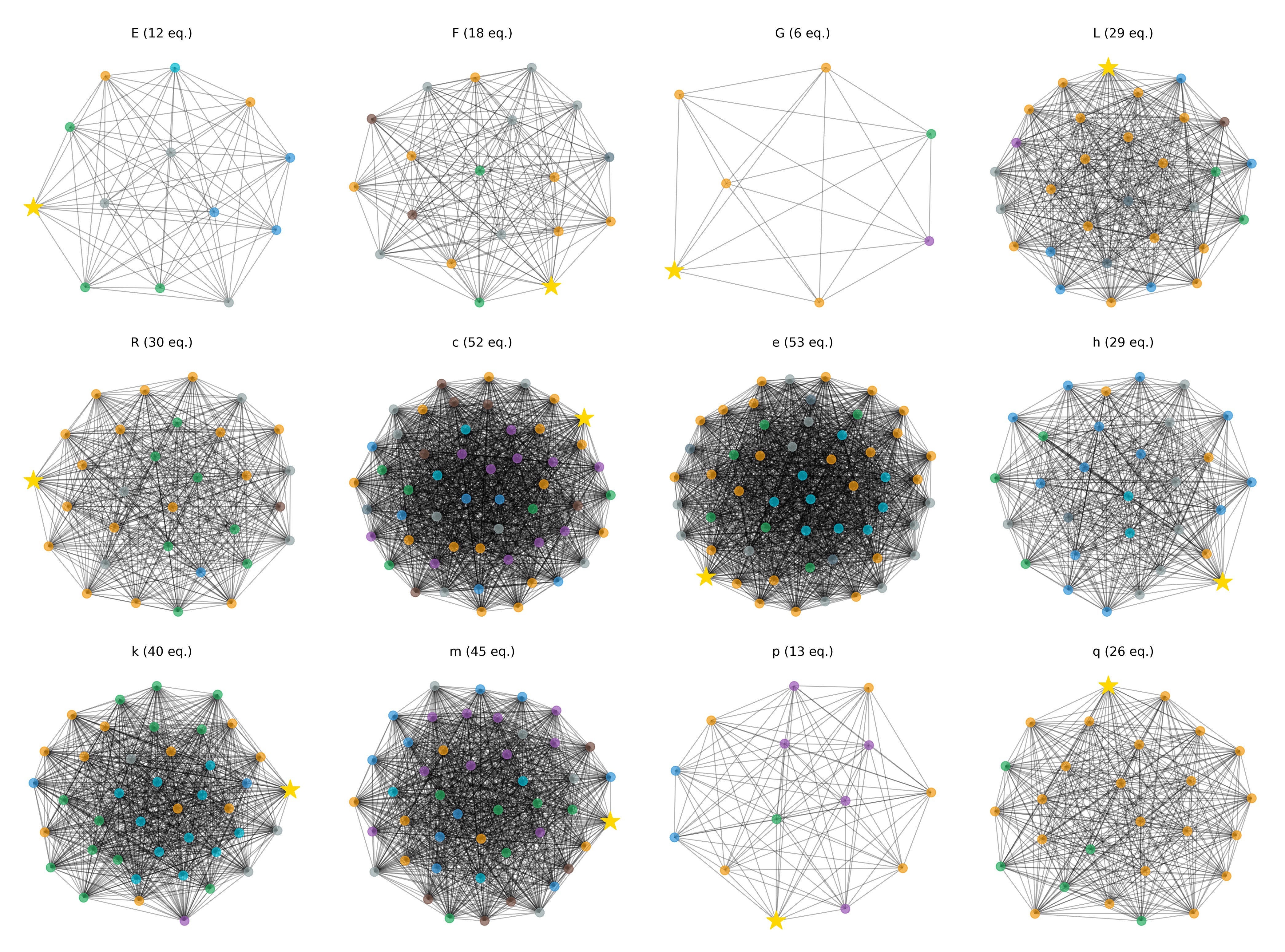
### Visual Description
## Network Diagrams: Various Network Structures
### Overview
The image presents a 3x4 grid of network diagrams. Each diagram depicts a network of nodes connected by edges. Each diagram is labeled with a letter (E, F, G, L, R, C, e, h, k, m, p, q) and a number of equations (eq.). A single node in each diagram is highlighted with a yellow star. The diagrams vary significantly in their density of connections and overall structure.
### Components/Axes
There are no explicit axes in these diagrams. The components are:
* **Nodes:** Represented by small circles.
* **Edges:** Represented by lines connecting the nodes.
* **Labels:** Each diagram is labeled with a letter and the number of equations.
* **Highlighted Node:** A yellow star indicates a specific node within each network.
The labels and their corresponding equation counts are:
* E (12 eq.)
* F (18 eq.)
* G (6 eq.)
* L (29 eq.)
* R (30 eq.)
* C (52 eq.)
* e (53 eq.)
* h (29 eq.)
* k (40 eq.)
* m (45 eq.)
* p (13 eq.)
* q (26 eq.)
### Detailed Analysis or Content Details
Each diagram will be analyzed individually. Due to the complexity of visually extracting precise node counts and edge counts, only qualitative descriptions of the network structure will be provided.
* **E (12 eq.):** A relatively sparse network with nodes arranged in a roughly circular pattern. The highlighted node is near the top.
* **F (18 eq.):** A network with a more regular structure, resembling a polygon with nodes at each vertex and some internal connections. The highlighted node is near the top.
* **G (6 eq.):** A very sparse network, almost a star graph, with the highlighted node at the center.
* **L (29 eq.):** A dense network with nodes arranged in a circular pattern. The highlighted node is near the top.
* **R (30 eq.):** A very dense network, almost fully connected. The highlighted node is near the top.
* **C (52 eq.):** An extremely dense network, appearing almost as a solid mass of connections. The highlighted node is near the top.
* **e (53 eq.):** Similar to 'C', an extremely dense network. The highlighted node is near the top.
* **h (29 eq.):** A dense network with nodes arranged in a circular pattern. The highlighted node is near the top.
* **k (40 eq.):** A very dense network, almost fully connected. The highlighted node is near the top.
* **m (45 eq.):** An extremely dense network, appearing almost as a solid mass of connections. The highlighted node is near the top.
* **p (13 eq.):** A relatively sparse network with nodes arranged in a roughly circular pattern. The highlighted node is near the top.
* **q (26 eq.):** A dense network with nodes arranged in a circular pattern. The highlighted node is near the top.
All highlighted nodes appear to be positioned near the top of their respective diagrams.
### Key Observations
* The networks vary significantly in their density, ranging from very sparse (G) to extremely dense (C, e, m).
* The number of equations (eq.) appears to correlate with the density of the network; denser networks generally have higher equation counts.
* The highlighted node is consistently positioned near the top of each diagram, suggesting a potential focus on nodes with similar characteristics or roles within each network.
* The arrangement of nodes in many diagrams suggests a circular or polygonal structure.
### Interpretation
The image likely represents a comparison of different network structures, possibly derived from various mathematical models or real-world systems. The "eq." label suggests that these networks are associated with a set of equations that define their behavior or properties. The varying densities and structures indicate different levels of connectivity and complexity.
The consistent highlighting of nodes near the top of each diagram could indicate that these nodes represent key elements or central points within their respective networks. This could be due to their degree (number of connections), centrality (importance within the network), or other relevant metrics.
The correlation between network density and the number of equations suggests that more complex networks require more equations to describe their behavior. This is consistent with the idea that the number of parameters needed to model a system increases with its complexity.
The image could be used to illustrate the diversity of network structures and the trade-offs between complexity, connectivity, and the number of parameters needed to model a system. It could also be used to explore the role of key nodes in different network topologies. The image does not provide any information about the meaning of the letters (E, F, G, etc.) or the specific context of these networks. Further information would be needed to fully interpret the significance of these diagrams.
</details>
Figure 4: Overview of fundamental physics concepts showing ego networks for 12 key variables. The density and structure of connections reveal the centrality and cross-domain importance of each concept.
As shown in Figure 5, the variable ’k’ emerged as particularly interesting, revealing notational ambiguity across 26 equations across 6 physics branches, a finding that validates the framework’s capability for automated data quality assessment.
<details>
<summary>ego_network_k.png Details</summary>
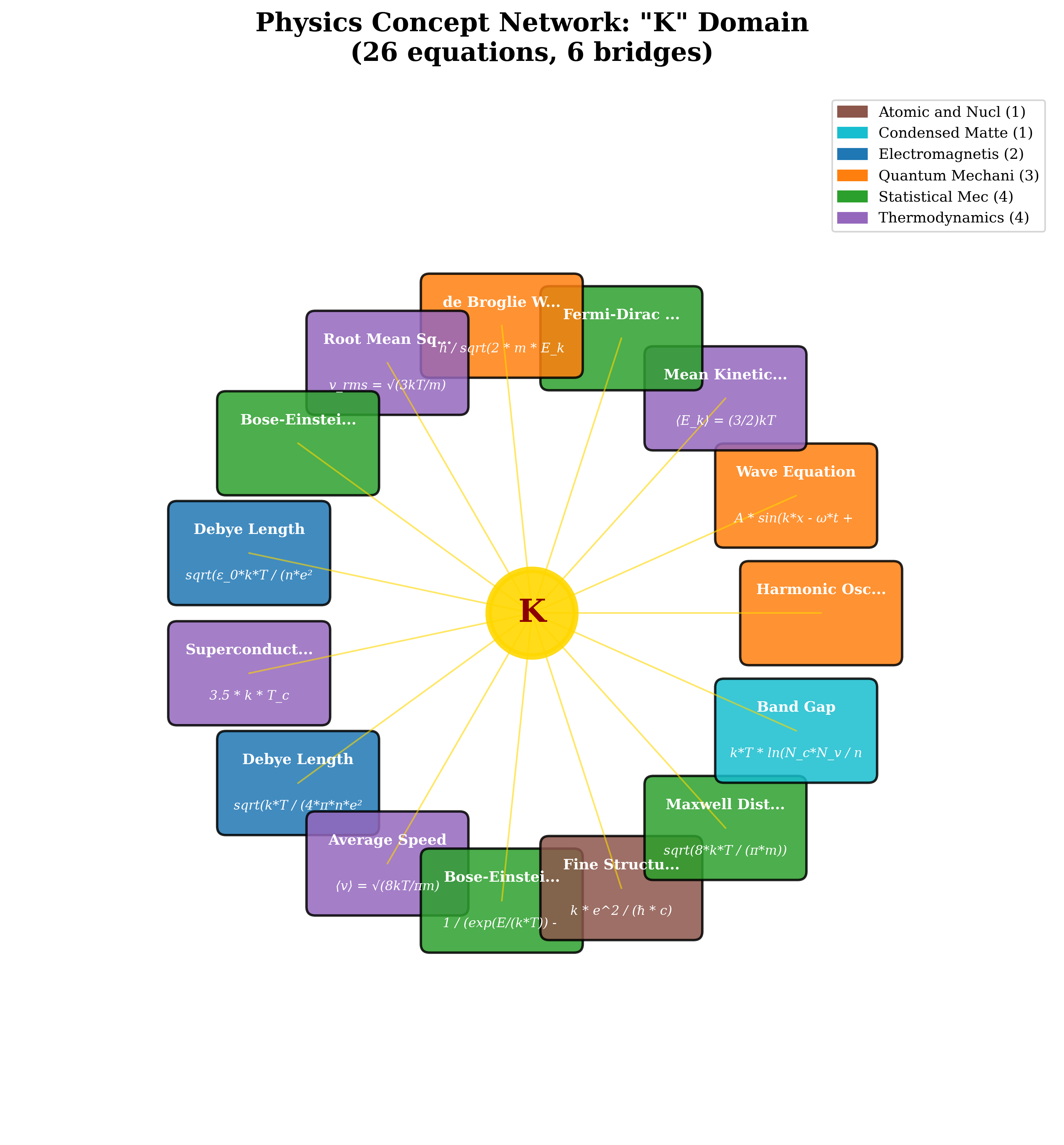
### Visual Description
## Diagram: Physics Concept Network - "K" Domain
### Overview
This diagram represents a concept network centered around the variable "K" in physics. It visually connects various physics concepts and equations to "K" through radial lines. The concepts are color-coded based on their respective physics domains. The diagram states that it represents 26 equations and 9 bridges.
### Components/Axes
* **Central Node:** "K" – positioned at the center of the diagram.
* **Radial Lines:** Connecting "K" to various physics concepts.
* **Concept Nodes:** Representing different physics concepts, each with an associated equation.
* **Legend (Top-Right):**
* Red: Atomic and Nuclear (1)
* Orange: Condensed Matter (1)
* Yellow: Electromagnetism (2)
* Green: Quantum Mechanics (3)
* Blue: Statistical Mechanics (4)
* Purple: Thermodynamics (4)
* **Title (Top-Center):** "Physics Concept Network: “K” Domain"
* **Subtitle (Below Title):** "(26 equations, 9 bridges)"
### Detailed Analysis / Content Details
The diagram shows the following concepts connected to "K":
1. **Root Mean Square Speed (Red):** `v_rms = √(3kT/m)`
2. **de Broglie Wavelength (Green):** `π / sqrt(2 * m * E_k)`
3. **Fermi-Dirac (Green):** (Text only, no equation)
4. **Mean Kinetic Energy (Green):** `(E_k) = (3/2)kT`
5. **Wave Equation (Green):** `A * sin(kx - ωt)`
6. **Harmonic Oscillator (Green):** (Text only, no equation)
7. **Band Gap (Orange):** `k*T * ln(N_c*N_v / n)`
8. **Debye Length (Red):** `sqrt(ε_0*k*T / (4*π*n*e^2))`
9. **Superconductivity (Orange):** `3.5 * k * T_c`
10. **Debye Length (Red):** `sqrt(k*T / (4*π*n*e^2))`
11. **Average Speed (Blue):** `(v) = √(8kT/πm)`
12. **Maxwell Distribution (Blue):** `sqrt(8*k*T / (π*m))`
13. **Fine Structure (Yellow):** `1 / (exp(E/(k*T)) - k * e^2 / (h * c))`
14. **Bose-Einstein… (Blue):** (Text only, no equation)
15. **Bose-Einstein… (Blue):** (Text only, no equation)
The lines connecting the concepts to "K" are all approximately the same length, suggesting equal importance or a similar degree of relationship to "K". The color coding indicates the domain of physics each concept belongs to.
### Key Observations
* Quantum Mechanics (Green) has the most connections (3), indicating a strong relationship between "K" and concepts within this domain.
* Statistical Mechanics (Blue) and Thermodynamics (Purple) each have 4 connections.
* Atomic and Nuclear (Red) and Condensed Matter (Orange) have the fewest connections (1 each).
* Several concepts only have a textual label and no equation is provided.
* The diagram uses "…" to indicate that the concept name is truncated.
### Interpretation
This diagram illustrates the central role of the variable "K" (likely Boltzmann constant or a related parameter) in connecting various areas of physics. The network structure suggests that "K" is a fundamental constant that appears in equations across different disciplines. The varying number of connections per domain highlights the relative importance of "K" within those fields. The presence of both equations and textual labels suggests a mix of well-defined quantitative relationships and more conceptual connections. The diagram serves as a visual map of how different physics concepts are interrelated through the common parameter "K". The truncation of some concept names ("Bose-Einstein…") suggests that the diagram is a simplified representation of a more complex network. The number of equations and bridges (26 and 9 respectively) provides a quantitative measure of the network's complexity.
</details>
Figure 5: Partial ego network for the variable ’k’ showing a subset of its connections across multiple physics domains. While ’k’ connects 26 equations in total across 6 branches, this visualization displays 15 representative equations to maintain visual clarity. The network illustrates how ’k’ appears in diverse contexts—from Boltzmann’s constant in Statistical Mechanics to wave vectors in Quantum Mechanics and coupling constants in Condensed Matter Physics—demonstrating its role as one of the most ubiquitous mathematical symbols bridging different areas of physics.
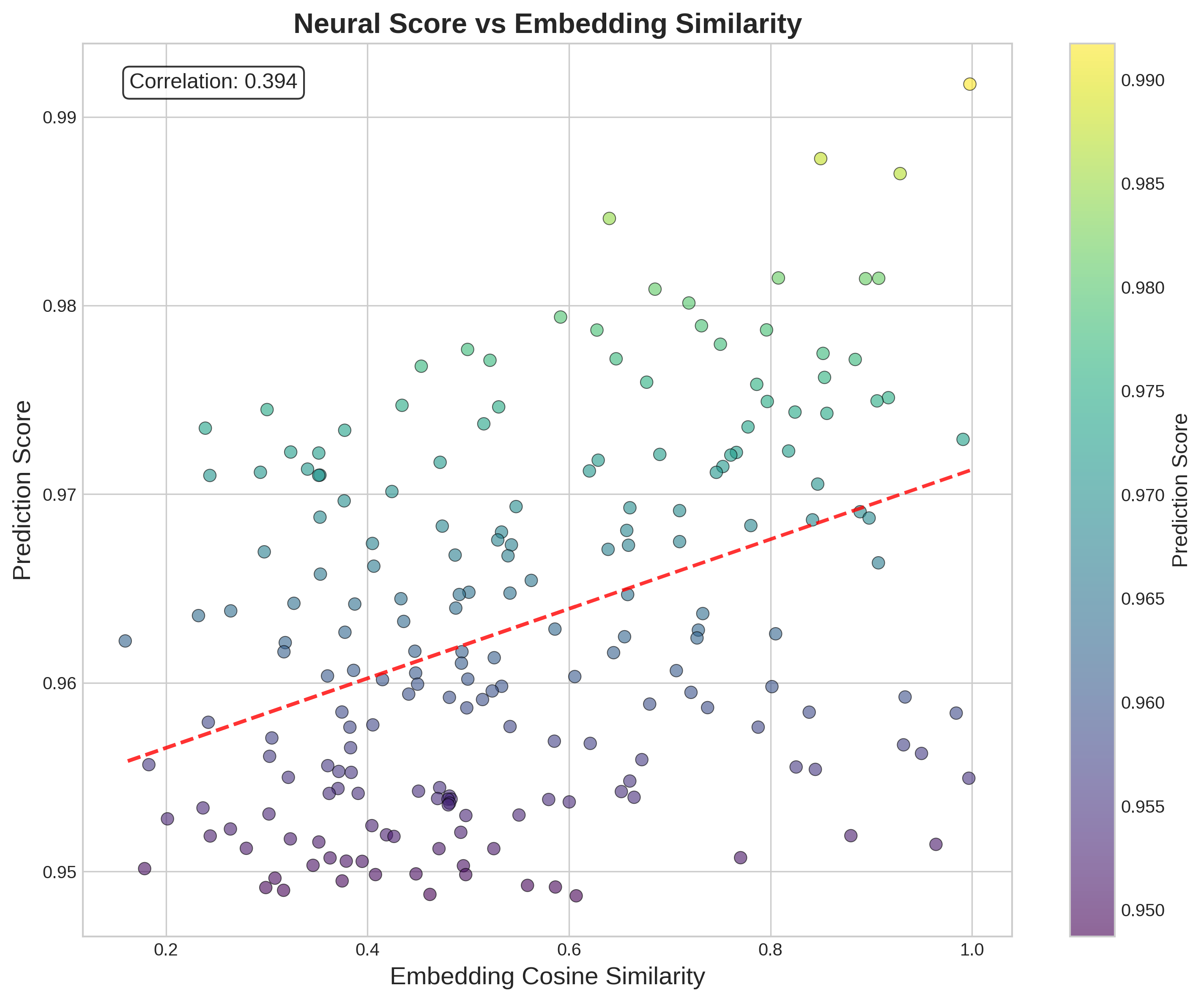
Figure 6 shows the relationship between neural predictions and embedding similarity, revealing a moderate correlation (0.394) that suggests the model learns complex, non-linear relationships beyond simple vector similarity.
<details>
<summary>neural_score_vs_embedding_similarity.png Details</summary>
### Visual Description
\n
## Scatter Plot: Neural Score vs Embedding Similarity
### Overview
This image presents a scatter plot visualizing the relationship between "Embedding Cosine Similarity" and "Prediction Score". A trendline is overlaid on the data points, and the plot includes a colorbar representing "Prediction Score". The correlation coefficient between the two variables is displayed in the top-left corner.
### Components/Axes
* **Title:** Neural Score vs Embedding Similarity
* **X-axis:** Embedding Cosine Similarity (ranging approximately from 0.15 to 1.0)
* **Y-axis:** Prediction Score (ranging approximately from 0.95 to 0.99)
* **Correlation:** 0.394 (displayed in a box in the top-left corner)
* **Colorbar:** Represents Prediction Score, ranging from approximately 0.950 (purple) to 0.990 (yellow). The colorbar is positioned on the right side of the plot.
* **Trendline:** A dashed red line representing the general trend of the data.
### Detailed Analysis
The scatter plot contains approximately 150 data points. The points are colored based on their Prediction Score, as indicated by the colorbar.
* **Trendline Analysis:** The trendline slopes upward, indicating a positive correlation between Embedding Cosine Similarity and Prediction Score. However, the correlation coefficient of 0.394 suggests a weak positive correlation.
* **Data Point Distribution:**
* Points with low Embedding Cosine Similarity (around 0.2) generally have lower Prediction Scores (around 0.95 - 0.96). These are colored in shades of purple.
* Points with high Embedding Cosine Similarity (around 0.9 - 1.0) generally have higher Prediction Scores (around 0.97 - 0.99). These are colored in shades of yellow and light green.
* There is significant scatter around the trendline, indicating that Embedding Cosine Similarity is not a strong predictor of Prediction Score.
* **Specific Data Points (approximate values):**
* (0.2, 0.955) - Purple
* (0.4, 0.965) - Blue/Purple
* (0.6, 0.97) - Green
* (0.8, 0.975) - Yellow/Green
* (1.0, 0.985) - Yellow
### Key Observations
* The correlation between Embedding Cosine Similarity and Prediction Score is weak (0.394).
* There is a general trend of increasing Prediction Score with increasing Embedding Cosine Similarity, but the relationship is not strong.
* The data points are widely scattered, indicating a high degree of variability.
* The colorbar shows a gradient of Prediction Scores, with purple representing lower scores and yellow representing higher scores.
### Interpretation
The plot suggests that while there is a slight positive relationship between the similarity of embeddings and the accuracy of predictions, this relationship is not particularly strong. The weak correlation indicates that other factors likely play a more significant role in determining the Prediction Score. The wide scatter of data points suggests that the Embedding Cosine Similarity alone is not a reliable indicator of Prediction Score. The trendline provides a general sense of the relationship, but individual data points deviate significantly from it. The visualization is useful for understanding the distribution of Prediction Scores across different levels of Embedding Cosine Similarity, but it does not provide a strong predictive model. The data suggests that the embedding similarity is only one of many factors influencing the prediction score.
</details>
Figure 6: Neural prediction scores vs embedding cosine similarity for 400 equation pairs. The moderate correlation (0.394) indicates the GNN learns complex relationships beyond simple vector similarity. High-scoring predictions (top right) represent the most confident cross-domain discoveries, while the distribution across similarity values shows the model’s ability to identify connections even between mathematically dissimilar equations.
3.3 Computationally-Generated Cross-Domain Hypotheses
The graph neural network framework identified several high-scoring links between physical equations from different domains. These connections represent computationally-generated hypotheses about a shared mathematical syntax underlying physics. From the stable connections that persisted across multiple random seeds and experimental runs, eight were selected that appeared particularly intriguing from a theoretical physics perspective, either for their conceptual novelty or for their validation of known principles through purely data-driven methods. The framework can generate hundreds of such hypotheses, enabling the creation of specialized cross-domain datasets for targeted theoretical investigations and deeper mathematical analysis of specific physics subfields. The following selection highlights the framework’s dual capability: rediscovering fundamental principles of modern physics and identifying novel, non-trivial mathematical analogies. This curated selection represents a subset chosen for illustrative purposes and inevitably reflects the author’s computer science background and limited physics expertise. The complete list of stable connections across seeds AUC ¿ 0.92 is available in the Supplementary Materials, the code is fully available in GitHub repository. Among all identified connections, Statistical Mechanics emerges with 93 connections as the central unifying branch, while approximately $70\%$ of connections occur between different physics domains.
3.3.1 Debye Length and Dirac Equation (Score: 0.9691)
The model identifies an intriguing connection between the Debye screening length in plasma physics (adv_0146: $\lambda_{D}=\sqrt{\epsilon_{0}kT/(ne^{2})}$ ) and the Dirac equation for relativistic fermions (adv_0179: $(i\gamma^{\mu}∂_{\mu}-mc/\hbar)\psi=0$ ). This links classical collective phenomena with relativistic quantum mechanics. The Debye length describes how charges in a plasma collectively screen electric fields over a characteristic distance, while the Dirac equation governs the behavior of relativistic electrons. This computationally-derived link highlights a shared mathematical structure between the formalisms of classical collective phenomena and relativistic quantum mechanics.
3.3.2 Hydrostatic Pressure and Maxwell Distribution (Score: 0.9690)
A conceptually significant connection was found between the hydrostatic pressure formula (adv_0116: $P=P_{0}+\rho gh$ ) and the Maxwell-Boltzmann velocity distribution (adv_0160: $f(v)=4\pi n\left(\frac{m}{2\pi kT}\right)^{3/2}v^{2}e^{-mv^{2}/2kT}$ ). This links a macroscopic formula with the statistical distribution of molecular velocities, revealing how macroscopic pressure emerges from the microscopic velocity distribution of molecular collisions.
3.3.3 Maxwell Distribution and Adiabatic Process (Score: 0.9687)
A significant connection was identified between the Maxwell-Boltzmann distribution (adv_0160: $f(v)=4\pi n\left(\frac{m}{2\pi kT}\right)^{3/2}v^{2}e^{-mv^{2}/2kT}$ ) and the adiabatic process for ideal gases (bal_0129: $PV^{\gamma}=\text{constant}$ ). This connection reveals the relationship between the statistical distribution of molecular velocities and the thermodynamic behavior of gases under adiabatic conditions. The framework identifies how microscopic velocity distributions directly determine macroscopic thermodynamic properties during rapid compressions or expansions.
3.3.4 Doppler Effect and Four-Momentum (Score: 0.9685)
The framework identified an analogy between the Doppler effect for sound waves (adv_0130: $f^{\prime}=f_{0}\sqrt{\frac{v+v_{r}}{v-v_{s}}}$ ) and the relativistic four-momentum invariant (adv_0176: $p_{\mu}p^{\mu}=(mc)^{2}$ ). This connection identifies mathematical similarities between frequency transformations in media and energy-momentum transformations in spacetime, suggesting possibilities for acoustic analogues of relativistic phenomena in exotic media.
3.3.5 Blackbody Radiation and Terminal Velocity (Score: 0.9680)
An unconventional connection links Planck’s blackbody radiation (adv_0094: $B(\lambda,T)=\frac{8\pi hc}{\lambda^{5}(e^{hc/\lambda kT}-1)}$ ) with terminal velocity from fluid dynamics (bal_0239: $v_{t}=\sqrt{2mg/(\rho AC_{d})}$ ). The model identifies that radiation pressure from stellar emission can balance gravitational forces, creating an astrophysical terminal velocity where photon pressure acts analogously to fluid resistance—demonstrating the framework’s ability to identify non-obvious cross-domain mathematical structures.
3.3.6 Blackbody Radiation and Navier-Stokes (Score: 0.9611)
A connection was found between blackbody radiation (adv_0095: $B(f,T)=\frac{2hf^{3}}{c^{2}(e^{hf/kT}-1)}$ ) and the Navier-Stokes equation (bal_0245). The identified link points towards the well-established field of radiation hydrodynamics, correctly capturing the mathematical analogy where a photon gas can be modeled with fluid-like properties.
3.3.7 Radioactive Decay and Induced EMF (Score: 0.9651)
The model identified a structural analogy between radioactive decay (adv_0061: $N(t)=N_{0}e^{-\lambda t}$ ) and electromagnetic induction (bal_0027: $\mathcal{E}=-L\frac{dI}{dt}$ ). Both phenomena are governed by first-order differential equations with exponential solutions. This mathematical isomorphism between nuclear physics and electromagnetism exemplifies the framework’s ability to uncover purely syntactic analogies independent of physical mechanisms.
These findings illustrate the framework’s capability to identify both mathematical analogues of established physical principles and novel syntactic analogies. The consistent identification of connections involving Statistical Mechanics as a central hub supports the hypothesis that the framework is learning a meaningful representation of the mathematical structures that connect different areas of physics.
4 Symbolic Analysis of Physics Equation Clusters: From Computational Patterns to Physical Insights
4.1 Overview and Significance
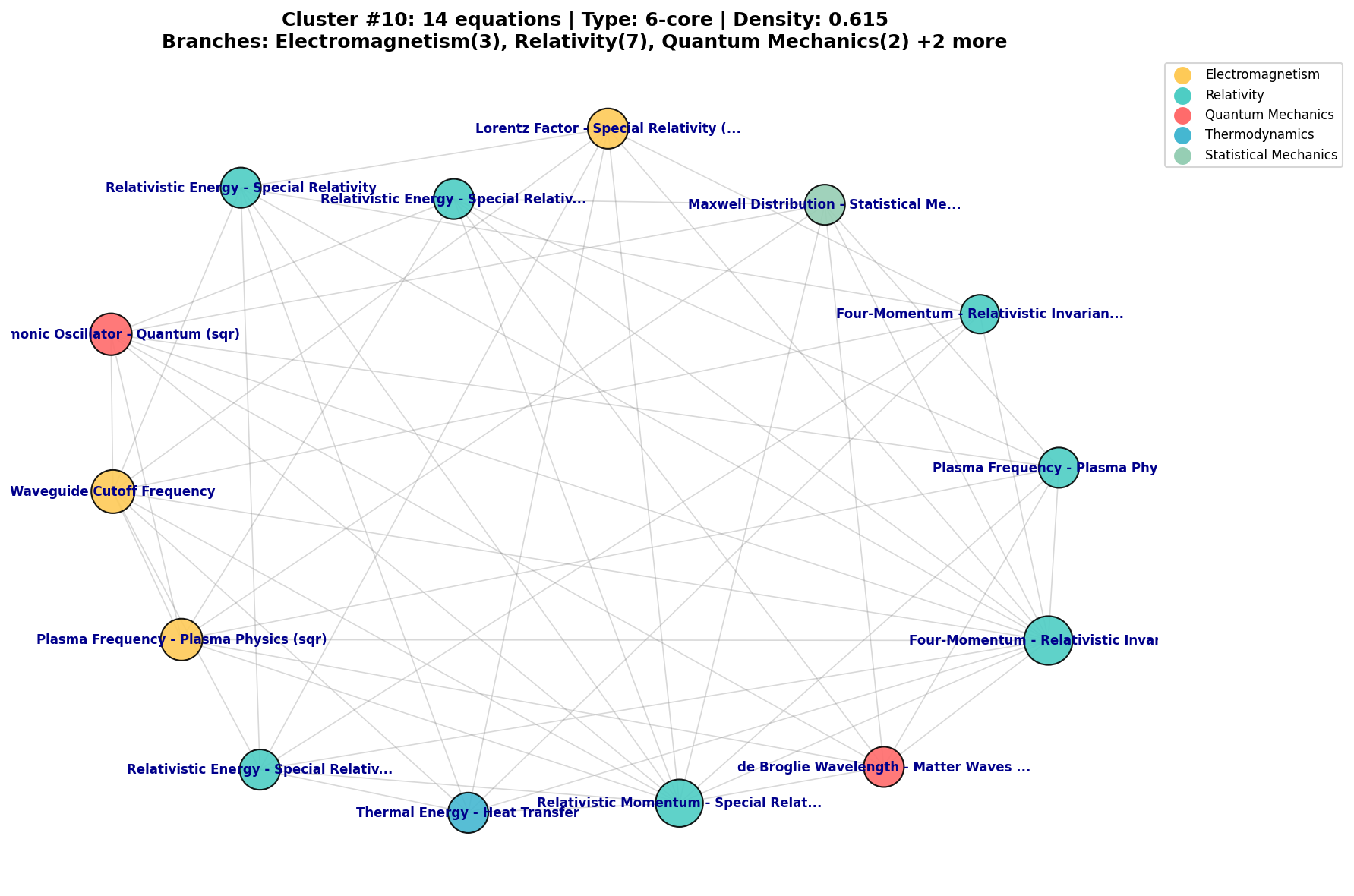
The core preliminary findings of this paper emerge from the symbolic analysis of 30 high-confidence equation clusters. This analysis reveals a hierarchy of insights, progressing from validating known physics to identifying errors and synthesizing complex principles. Figure 7 shows a typical dense cluster passed to this analysis stage.
<details>
<summary>cluster_10.png Details</summary>
### Visual Description
\n
## Network Graph: Cluster #10 - Equation Relationships
### Overview
The image presents a network graph visualizing relationships between equations, categorized by scientific domain. The graph consists of nodes representing equations or concepts, connected by edges indicating relationships. Node color represents the primary scientific domain. The graph is titled "Cluster #10: 14 equations | Type: 6-core | Density: 0.615" and indicates branches in Electromagnetism, Relativity, Quantum Mechanics, Thermodynamics, and Statistical Mechanics.
### Components/Axes
* **Title:** Cluster #10: 14 equations | Type: 6-core | Density: 0.615
* **Branches:** Electromagnetism (3), Relativity (7), Quantum Mechanics (2) + 2 more
* **Legend (Top-Right):**
* Teal: Electromagnetism
* Red: Relativity
* Yellow: Quantum Mechanics
* Green: Thermodynamics
* Light Blue: Statistical Mechanics
* **Nodes:** Represent equations or concepts.
* **Edges:** Represent relationships between equations/concepts.
### Detailed Analysis
The graph contains 14 nodes, each labeled with a descriptive phrase. The nodes are interconnected by numerous edges, forming a complex network. The positioning of nodes appears to be determined by the strength or nature of their relationships, though a precise metric is not provided.
Here's a breakdown of the nodes and their connections, categorized by color (and therefore domain):
**Relativity (Red):**
* Lorentz Factor - Special Relativity (...): Connected to Relativistic Energy - Special Relativity, Relativistic Energy - Special Relativ...
* Relativistic Energy - Special Relativity: Connected to Lorentz Factor - Special Relativity (...), Relativistic Energy - Special Relativ..., Four-Momentum - Relativistic Invarian...
* Relativistic Energy - Special Relativ...: Connected to Relativistic Energy - Special Relativity
* Four-Momentum - Relativistic Invarian...: Connected to Relativistic Energy - Special Relativity, Four-Momentum - Relativistic Invar
* Four-Momentum - Relativistic Invar: Connected to Four-Momentum - Relativistic Invarian...
* Relativistic Momentum - Special Relat...: Connected to de Broglie Wavelength - Matter Waves ...
* de Broglie Wavelength - Matter Waves ...: Connected to Relativistic Momentum - Special Relat...
**Quantum Mechanics (Yellow):**
* Harmonic Oscillator - Quantum (sqr): Connected to Waveguide Cutoff Frequency
* Waveguide Cutoff Frequency: Connected to Harmonic Oscillator - Quantum (sqr), Plasma Frequency - Plasma Physics (sqr)
* Plasma Frequency - Plasma Physics (sqr): Connected to Waveguide Cutoff Frequency, Plasma Frequency - Plasma Phy
**Thermodynamics (Green):**
* Thermal Energy - Heat Transfer: Connected to Relativistic Energy - Special Relativ...
**Electromagnetism (Teal):**
* Maxwell Distribution - Statistical Me...: Connected to Relativistic Energy - Special Relativity
**Statistical Mechanics (Light Blue):**
* Plasma Frequency - Plasma Phy: Connected to Plasma Frequency - Plasma Physics (sqr)
The graph's density is reported as 0.615, suggesting a relatively high degree of interconnectedness between the nodes.
### Key Observations
* Relativity is the most represented domain with 7 nodes.
* The "Relativistic Energy" node appears to be a central hub, connected to multiple other nodes.
* Quantum Mechanics and Thermodynamics have fewer nodes and connections, suggesting less direct interaction within this cluster.
* The graph is relatively dense, indicating many relationships between the equations.
### Interpretation
This network graph illustrates the interconnectedness of concepts across different branches of physics. The central role of "Relativistic Energy" suggests its fundamental importance in linking various equations and theories. The graph likely represents a simplified view of a more complex system, focusing on the most significant relationships within a specific cluster of equations. The density of the graph indicates a strong interplay between these concepts. The categorization by color allows for a quick visual assessment of the dominant domains within the cluster. The presence of "(sqr)" in some labels suggests these equations involve square root operations. The graph could be used to identify potential areas for further research or to visualize the structure of a complex physical system. The "6-core" type suggests that the graph is a core structure, meaning it represents the most important connections within a larger network.
</details>
Figure 7: An example of a high-density (0.615), high-core-number (6-core) conceptual cluster identified by the GNN, centered on relativistic principles. The framework isolates such structurally significant clusters for deeper symbolic analysis.
The analysis yielded 24 simplified expressions (80%), with the remaining 20% failing due to insufficient parseable equations or lack of valid substitutions. These computational results require expert interpretation to distinguish between physical insights and mathematical artifacts.
4.2 Foundational Results
4.2.1 The Klein-Gordon/Dirac Hierarchy (Cluster #5)
Cluster #5 connected the Klein-Gordon and Dirac equations. The system selected the Klein-Gordon equation as backbone:
$$
\left(\partial_{\mu}\partial^{\mu}+\frac{m^{2}c^{2}}{\hbar^{2}}\right)\psi=0 \tag{2}
$$
where $∂_{\mu}∂^{\mu}$ is the d’Alembertian operator. The system performed the following substitutions from equations within the cluster:
- $m=\gamma\hbar/c^{2}$ (from Dirac Equation - Relativistic Fermions)
- $\psi=0$ (from Dirac Equation - Relativistic Fermions)
- $\hbar=c^{2}m/\gamma$ (from Dirac Equation - Relativistic Fermions)
- $c=(\gamma^{2}v^{r^{2}}/(\gamma^{2}-1))^{r^{-2}}$ (from Lorentz Factor)
The substitution $\psi=0$ reduces the expression to the identity True.
This result confirms the known relationship where the Dirac equation:
$$
(i\gamma^{\mu}\partial_{\mu}-mc/\hbar)\psi=0 \tag{3}
$$
represents the “square root” of the Klein-Gordon equation. Applying the Dirac operator twice:
$$
(i\gamma^{\nu}\partial_{\nu}+m)(i\gamma^{\mu}\partial_{\mu}-m)\psi=(-\gamma^{\nu}\gamma^{\mu}\partial_{\nu}\partial_{\mu}-m^{2})\psi=0 \tag{4}
$$
Using the anticommutation relations $\{\gamma^{\mu},\gamma^{\nu}\}=2\eta^{\mu\nu}$ , this reduces to $(∂_{\mu}∂^{\mu}+m^{2})\psi=0$ . Every Dirac solution satisfies Klein-Gordon (though not vice versa), a structure that historically led to the prediction of antimatter.
4.2.2 Maxwell’s Self-Consistency (Clusters #1, #2)
The two largest clusters (99 and 83 equations) centered on Maxwell’s equations, confirming the internal consistency of electromagnetic theory. The system identified complex relationships between the wave equation for electromagnetic fields and Maxwell’s equations through multiple substitutions, though the resulting expressions contain parsing artifacts that require further investigation. These clusters validate the framework’s ability to recognize the mathematical coherence of established physical theories.
4.2.3 Electromagnetic-Fluid Coupling (Cluster #8)
Cluster #8 revealed an unexpected synthesis between fluid dynamics and electromagnetism, identified by an earlier version of the code that still had parsing issues but nonetheless uncovered this intriguing connection (full report in Supplementary Materials). Starting with Reynolds number as backbone:
$$
Re=\frac{\rho vL}{\eta} \tag{5}
$$
The system applied the following substitutions from electromagnetic equations in the cluster:
- $E=-Bv+F/q$ (from Lorentz Force (Complete))
- $t=I\epsilon/L$ (from Inductance EMF)
- $v=\epsilon/(BL)$ (from Motional EMF)
- $t=-d\epsilon/d\Phi_{B}$ (from Faraday’s Law)
- $t=-\epsilon/\Phi$ (from Lenz’s Law Direction)
This produced the simplified expression:
$$
\frac{\epsilon\rho}{B\eta} \tag{6}
$$
This result represents a dimensionless parameter coupling electromagnetic and fluid properties, analogous to the Magnetic Reynolds Number in magnetohydrodynamics, demonstrating how the framework can identify cross-domain mathematical structures even without understanding the underlying physics.
4.3 Error Detection as Knowledge Auditing
4.3.1 Dimensional Catastrophe (Cluster #4)
The four-momentum cluster exposed an error in the knowledge base. Starting with the relativistic invariant as backbone:
$$
\mu pp_{\mu}=c^{2}mr^{2} \tag{7}
$$
The system applied the following substitutions from equations in the cluster:
- $p=E/c-cm^{2}$ (from Four-Momentum - Relativistic Invariant)
- $m=\sqrt{E-cp}/c$ (from Four-Momentum - Relativistic Invariant)
- $c=m_{e}$ (from Compton Scattering - Wavelength Shift)
This produced:
$$
\mu pp_{\mu}=m_{e}r^{2}\sqrt{E-m_{e}p} \tag{8}
$$
With residual: $-m_{e}r^{2}\sqrt{E-m_{e}p}+\mu pp_{\mu}$
The critical error is the substitution $c=m_{e}$ , which is dimensionally incorrect—equating velocity [L/T] with mass [M]. This error originates from a mis-parsed Compton scattering equation where the system incorrectly extracted a relationship between the speed of light and electron mass, likely from the Compton wavelength formula $\lambda_{C}=h/(m_{e}c)$ where $m_{e}$ and $c$ appear together but represent fundamentally different physical quantities.
4.3.2 Category Confusion (Cluster #16)
The framework combined Bragg’s Law for crystal diffraction:
$$
2d\sin\theta=n\lambda \tag{9}
$$
with substitutions from interference equations:
- $m=d\sin\theta/\lambda$ (from Interference - Young’s Double Slit)
- $a=m\lambda/\sin\theta$ (from Single Slit Diffraction (Minima))
- $m=(d\sin\theta-\lambda/2)/\lambda$ (from Interference - Young’s Double Slit (dsi))
This produced the tautology True, but mixed different physical contexts—crystalline solids versus free space.
4.4 The Unexpected Value of Errors: Analog Gravity (Cluster #15)
Cluster #15 combined 11 equations from fluid dynamics and electromagnetism. Starting with Bernoulli’s equation:
$$
P+\frac{1}{2}\rho v^{2}+\rho gh=\text{constant} \tag{10}
$$
The system applied substitutions:
- $h=v/(gr^{2})$ (from Torricelli’s Law)
- $g=v/(hr^{2})$ (from Torricelli’s Law)
- $c=(\mu_{r}-1)/\chi_{m}$ (from Magnetic Susceptibility)
- $P=P_{0}+\rho gh$ (from Hydrostatic Pressure)
This produced:
$$
\frac{(\mu_{r}-1)^{2}}{h^{2}m^{2}} \tag{11}
$$
This mixes magnetic permeability with fluid dynamical variables—dimensionally inconsistent and physically incorrect.
However, this error points to analog gravity research, where:
- Sound waves in fluids obey equations mathematically identical to quantum fields in curved spacetime
- Fluid velocity fields create effective metrics analogous to gravitational geometry
- Sonic horizons mirror black hole event horizons
- Navier-Stokes equations in $(p+1)$ dimensions correspond to Einstein equations in $(p+2)$ dimensions
Near the horizon limit, Einstein’s equations reduce to Navier-Stokes, suggesting gravity might emerge from microscopic degrees of freedom.
4.5 Statistical Summary
Table 3: Cluster Analysis Results
| Theory Validation | 2 | Klein-Gordon/Dirac, Maxwell consistency |
| --- | --- | --- |
| Novel Synthesis | 8 | Transport phenomena, Reynolds-EMF |
| Tautologies | 5 | Planck’s Law circular substitutions |
| Dimensional Errors | 2 | $c=m_{e}$ , knowledge base errors |
| Category Errors | 3 | Bragg/Young confusion |
| Provocative Failures | 4 | Analog gravity connection |
| Insufficient Data | 6 | No valid substitutions |
| Total | 30 | 80% produced interpretable results |
The framework operates at the syntactic level, recognizing mathematical patterns without understanding physical causality. This limitation, combined with parsing issues in early iterations, requires human interpretation to distinguish profound connections from tautologies or errors. However, even computational failures can suggest legitimate research directions, as demonstrated by the analog gravity connection.
5 Discussion
This proof of concept demonstrates a framework capable of systematic pattern discovery in physics equations. The framework functions as a computational lens revealing hidden structures and inconsistencies difficult to discern at human scale. It does not replace physicists, of course, but fully developed could augment their capabilities through systematic exploration of mathematical possibility space.
The framework’s value lies not in autonomous discovery but in its role as a computational companion—a tireless explorer of mathematical possibility space that surfaces patterns, errors, and unexpected connections for human interpretation. Even its failures are productive, transforming the vast combinatorial space of physics equations into a curated set of computational hypotheses worthy of expert attention.
The transformation of mathematical pattern into physical understanding remains fundamentally human. But by automating the pattern-finding, the framework frees physicists to focus on what they do best: interpreting meaning, recognizing significance, and building the conceptual bridges that transform equations into understanding of nature.
6 Conclusion and Future Work
In this preliminary work, I have developed and tested a GNN-based framework capable of mapping the mathematical structure of physical law, and acting as a computational auditor. My GAT model achieves high performance on this novel task, and the primary contribution of this work lies in the subsequent symbolic analysis. This analysis suggests the framework has a potential multi-layered capacity to: (i) verify the internal consistency of foundational theories, (ii) help debug knowledge bases by identifying errors and tautologies, (iii) synthesize mathematical structures analogous to complex physical principles, and (iv) provide creative provocations from its own systemic failures.
6.1 Current Limitations and Future Directions
This work, while promising, represents an initial step. The path forward is clear and focuses on several key areas:
- Systematic Parameter Exploration: The framework requires systematic testing with different hyperparameter configurations to identify optimal settings for various physics domains. Different weight combinations in the importance scoring and clustering algorithms may reveal distinct classes of mathematical relationships, generating a vast number of hypotheses that require careful evaluation.
- AI-Assisted Hypothesis Screening: The system currently generates hundreds of potential cross-domain connections, many of which are spurious or trivial. Future work should integrate large language models or other AI systems to perform initial screening of these computational hypotheses, filtering out obvious errors, tautologies, and dimensionally inconsistent results before human expert review. This would create a multi-stage pipeline: graph-based generation, AI screening, and expert validation.
- Database Expansion: The immediate next step is to expand the equation database. A richer and broader corpus would enable the encoding of deeper mathematical structures, moving the analysis from a syntactic to a more profound structural level.
- Generalization as a Scientific Auditor: Future work will focus on generalizing the framework beyond physics to other formal sciences. This includes refining the disambiguation protocol to act as a general-purpose “auditor” for standardizing notational conventions across different scientific knowledge bases.
- Collaboration with Domain Experts: To bridge the gap between computational patterns and physical insight, future work must involve an expert-in-the-loop process. Collaboration with theoretical physicists is essential to validate, interpret, and build upon the most promising machine-generated analogies and audit reports.
6.2 Broader Implications
This work may open several avenues for the broader scientific community. As an auditing tool, it could potentially be used to systematically check the consistency of large-scale theories. As an educational tool, it might help students visualize the deep structural connections that unify different areas of science. More broadly, this research contributes to the emerging field of computational epistemology, developing methods to study the structure and coherence of scientific knowledge. Ultimately, this framework is presented as a tangible step toward a new synergy between human intuition and machine computation, where AI may serve as a tool to augment and stimulate the quest for scientific understanding.
7 Data and Code Availability
All code, cleaned dataset, and model weights available at: https://github.com/kingelanci/graphysics.
8 Supplementary Materials
Complete prediction distributions and analysis results available at the GitHub repository:
- Full distribution of AUC ¿ 0.92 prediction scores
- Complete symbolic analysis for all 30 clusters
- Bootstrap validation logs
- All generated cross-domain hypotheses (not just selected examples)
Correspondence
Correspondence: Massimiliano Romiti (massimiliano.romiti@acm.org).
Acknowledgments
The author thanks the arXiv endorsers for their support. Special gratitude to the ACM community for professional development resources and to online physics communities for discussions that helped clarify physical interpretations.
While AI tools were employed for auxiliary tasks such as code debugging, literature search, formatting assistance, and initial draft organization, all scientific content, analysis, interpretations, and conclusions are solely the work of the author. Any errors or misinterpretations remain the author’s responsibility.
References
- [1] Maxwell, J. C. (1865). A dynamical theory of the electromagnetic field. Philosophical transactions of the Royal Society of London, (155), 459-512.
- [2] Shannon, C. E. (1948). A mathematical theory of communication. The Bell system technical journal, 27(3), 379-423.
- [3] Schmidt, M., & Lipson, H. (2009). Distilling free-form natural laws from experimental data. Science, 324(5923), 81-85.
- [4] Udrescu, S. M., & Tegmark, M. (2020). AI Feynman: A physics-inspired method for symbolic regression. Science advances, 6(16), eaay2631.
- [5] Hamilton, W. L., Ying, R., & Leskovec, J. (2017). Inductive representation learning on large graphs. Advances in neural information processing systems, 30.
- [6] Kipf, T. N., & Welling, M. (2017). Semi-supervised classification with graph convolutional networks. International Conference on Learning Representations.
- [7] Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., & Bengio, Y. (2018). Graph attention networks. Stat, 1050(2), 10-48550.
- [8] Brody, S., Alon, U., & Yahav, E. (2021). How attentive are graph attention networks?. arXiv preprint arXiv:2105.14491.
- [9] Chen, X., Jia, S., & Xiang, Y. (2020). A review: Knowledge reasoning over knowledge graph. Expert Systems with Applications, 141, 112948.
- [10] Shen, Y., Huang, P. S., Chang, M. W., & Gao, J. (2018). Modeling large-scale structured relationships with shared memory for knowledge base completion. arXiv preprint arXiv:1809.04642.
- [11] Raghu, M., Poole, B., Kleinberg, J., Ganguli, S., & Sohl-Dickstein, J. (2019). On the expressive power of deep neural networks. International Conference on Machine Learning, 4847-4856.
- [12] Butler, K. T., Davies, D. W., Cartwright, H., Isayev, O., & Walsh, A. (2018). Machine learning for molecular and materials science. Nature, 559(7715), 547-555.
- [13] Liben-Nowell, D., & Kleinberg, J. (2007). The link-prediction problem for social networks. Journal of the American society for information science and technology, 58(7), 1019-1031.
- [14] Zhang, M., & Chen, Y. (2018). Link prediction based on graph neural networks. Advances in neural information processing systems, 31.
- [15] Meurer, A., Smith, C. P., Paprocki, M., et al. (2017). SymPy: symbolic computing in Python. PeerJ Computer Science, 3, e103.
- [16] Börner, K., Chen, C., & Boyack, K. W. (2005). Visualizing knowledge domains. Annual Review of Information Science and Technology, 37(1), 179–255.
- [17] Zeng, A., Shen, Z., Zhou, J. G., Fan, Y., Di, Z., Wang, Y., & Stanley, H. E. (2017). Ranking the importance of concepts in physics. Scientific Reports, 7(1), 42794.
- [18] Chen, C., & Börner, K. (2016). Mapping the whole of science: A new, efficient, and objective method. Journal of Informetrics, 10(4), 1165-1183.
- [19] Rosvall, M., & Bergstrom, C. T. (2008). Maps of random walks on complex networks reveal community structure. Proceedings of the National Academy of Sciences, 105(4), 1118-1123.
- [20] Palla, G., Tibély, G., Pollner, P., & Vicsek, T. (2020). The structure of physics. Nature Physics, 16(7), 745-750.