# RynnEC: Bringing MLLMs into Embodied World
**Authors**: Ronghao Dang, Yuqian Yuan, Yunxuan Mao, Kehan Li, Jiangpin Liu, Zhikai Wang, Fan Wang, Deli Zhao, Xin Li
1]DAMO Academy, Alibaba Group 2]Hupan Lab 3]Zhejiang University \contribution [*]Equal contribution
(November 18, 2025)
Abstract
We introduce RynnEC, a video multimodal large language model designed for embodied cognition. Built upon a general-purpose vision-language foundation model, RynnEC incorporates a region encoder and a mask decoder, enabling flexible region-level video interaction. Despite its compact architecture, RynnEC achieves state-of-the-art performance in object property understanding, object segmentation, and spatial reasoning. Conceptually, it offers a region-centric video paradigm for the brain of embodied agents, providing fine-grained perception of the physical world and enabling more precise interactions. To mitigate the scarcity of annotated 3D datasets, we propose an egocentric video based pipeline for generating embodied cognition data. Furthermore, we introduce RynnEC-Bench, a region-centered benchmark for evaluating embodied cognitive capabilities. We anticipate that RynnEC will advance the development of general-purpose cognitive cores for embodied agents and facilitate generalization across diverse embodied tasks. The code, model checkpoints, and benchmark are available at: https://github.com/alibaba-damo-academy/RynnEC
<details>
<summary>x1.png Details</summary>
### Visual Description
## Flowchart: Multimodal Question-Answering System with Object Masking
### Overview
The image depicts a technical diagram of a multimodal question-answering system that integrates visual processing, object masking, and natural language understanding. The system processes visual inputs (e.g., images/videos) to answer contextual questions about object locations, quantities, and spatial relationships. Two example tasks demonstrate practical applications: organizing items on a bookshelf and preparing a kitchen task.
---
### Components/Axes
1. **Central Diagram**:
- **Visual Encoder**: Processes raw visual input (images/videos).
- **Mask Encoder**: Identifies and isolates specific objects in the visual input (e.g., "object mask").
- **Large Language Model (LLM)**: Integrates masked visual data with textual queries to generate answers.
- **Mask Decoder**: Converts masked tokens into natural language responses.
- **Arrows**: Indicate data flow (e.g., visual input → mask encoder → LLM → mask decoder).
2. **Left Panel**:
- **Steps 1–7**: Textual Q&A examples with numbered objects (e.g., "How many panes of glass are there on the window?").
- **Objects**: Labeled with numbers (e.g., "3" for soy sauce, "6" for storage box).
3. **Right Panel**:
- **Tasks 1–2**: Practical instructions with step-by-step actions (e.g., "stick window stickers," "stir-fry with soy sauce").
- **Objects**: Labeled with numbers (e.g., "5" for storage box, "7" for pot lid).
4. **Color Coding**:
- **Blue**: Visual Encoder.
- **Green**: Mask Encoder.
- **Orange**: Large Language Model.
- **Purple**: Mask Decoder.
---
### Detailed Analysis
1. **Visual Encoder**:
- Inputs: Images/videos (e.g., kitchen scenes, bookshelf arrangements).
- Output: Feature vectors for object detection.
2. **Mask Encoder**:
- Identifies objects via bounding boxes (e.g., "object mask" for soy sauce).
- Output: Mask tokens (e.g., `<object mask>`).
3. **Large Language Model**:
- Integrates masked visual tokens with textual queries (e.g., "Which is the nearest plant to <object mask>?").
- Output: Contextualized answers (e.g., "It’s 1.3 meters away").
4. **Mask Decoder**:
- Converts mask tokens into natural language (e.g., "A: It’s <mask token>" → "A: It’s 1.3 meters away").
5. **Tasks**:
- **Task 1**: Organizing items (e.g., placing glass panes, moving a teddy bear).
- **Task 2**: Cooking instructions (e.g., pouring soy sauce, using a spray bottle).
---
### Key Observations
1. **Object Labeling**: Objects are consistently labeled with numbers (e.g., "3" for soy sauce, "6" for storage box) across steps and tasks.
2. **Spatial Reasoning**: Questions require understanding relative positions (e.g., "nearest plant to <object mask>").
3. **Temporal Flow**: Tasks involve sequential actions (e.g., "pour soy sauce → cover with lid → spray bottle").
4. **Modular Design**: The system separates visual processing (encoders) from language processing (LLM, decoder).
---
### Interpretation
This system demonstrates a hybrid approach to multimodal reasoning:
- **Visual-Language Integration**: The LLM bridges visual object masks (e.g., soy sauce) with textual queries, enabling context-aware answers.
- **Practical Applications**: Tasks 1 and 2 show real-world use cases, such as home organization and cooking, where spatial and temporal reasoning are critical.
- **Scalability**: The modular architecture (encoders, LLM, decoder) suggests adaptability to diverse inputs (e.g., different objects, environments).
The system’s strength lies in its ability to handle ambiguous queries (e.g., "Which stove is the frying pan located on?") by combining visual grounding with linguistic context. However, the reliance on numbered object labels implies a need for precise annotation in training data.
</details>
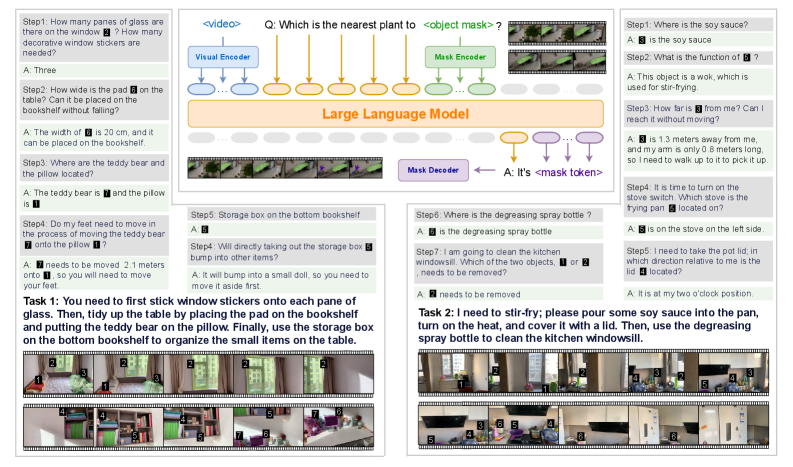
Figure 1: RynnEC is a video multi-modal large language model (MLLM) specifically designed for embodied cognition tasks. It can accept inputs interwoven from video, region masks, and text, and produce output in the form of text or masks based on the question. RynnEC is capable of addressing a diverse range of object and spatial questions within embodied contexts and plays a significant role in indoor embodied tasks.
1 Introduction
In recent years, Multi-modal Large Language Models (MLLMs) Wu et al. [2023], Zhang et al. [2024a] have experienced rapid development, leading to the emergence of models such as Gemini Team et al. [2024] and GPT-4o OpenAI et al. [2024] that can handle image and even video inputs. These MLLMs are attracting increasing attention from researchers due to their powerful contextual understanding Doveh et al. [2025] and generalization Zhang et al. [2024c] abilities. Researchers in embodied intelligence are also beginning to explore the use of MLLMs as the brains of robots Han et al. [2025b], Jin et al. [2024], enabling them to perceive the real world through visual inputs like humans do. However, the current mainstream MLLMs are trained on extensive internet images and lack the foundational visual cognition to match the physical world Dang et al. [2025], Yuan et al. [2025b].
Some works have begun exploring how MLLMs can be applied to ego-centric embodied scenarios. Models like Exo2Ego Zhang et al. [2025b] and EgoLM Hong et al. [2025] enhance the understanding of ego-centric dynamic environment interactions. SpatialVLM Chen et al. [2024a] and SpatialRGPT Cheng et al. [2024a] focus on addressing spatial understanding challenges within embodied contexts. However, these approaches are challenging to directly implement in physical robots to perform complex tasks. The main limitations are as follows:
1. Lack of flexible visual interaction: In complex embodied scenarios, relying solely on textual communication is prone to ambiguity or vagueness. Direct visual interaction references, such as masks or points, can more accurately and flexibly index entities within a scene, facilitating precise task execution.
1. Insufficient detailed understanding of objects: During task execution, objects typically serve as the smallest operational units, making comprehensive and detailed understanding of objects crucial. As illustrated in Task 1 Step 1 in Fig. 1, recognizing the number of panes in a window is essential to determine the quantity of window decals needed.
1. Absence of video-based coherent spatial awareness: For humans, spatial cognition arises from continuous visual perception Pasqualotto and Proulx [2012]. Current methods in spatial intelligence Zhang et al. [2025c], Xu et al. [2025] primarily focus on single or discrete images, lacking the capacity for spatial understanding in high-continuity videos. For example, in Task 1 Step 4 in Fig. 1, the absolute distance between the teddy bear and the pillow requires a spatial scale concept derived from the entire video to be properly inferred.
Thus, we propose RynnEC, an embodied cognitive MLLM designed to enhance robotic understanding of the physical world. As illustrated in Fig. 1, RynnEC is a large video understanding model whose visual encoder and foundational parameters are derived from VideoLLaMA3 Zhang et al. [2025a]. To enable flexible visual interaction, we incorporate an encoder and decoder specifically for region masks in videos, allowing RynnEC to achieve precise instance-level comprehension and grounding.
Within this framework, RynnEC is designed to perform diverse cognitive tasks in embodied scenarios. We categorize embodied cognitive abilities into two essential components: object cognition and spatial cognition. Object cognition necessitates MLLMs’ understanding of object attributes, quantities, and their relationships with the environment, alongside accurate object grounding. Spatial cognition is further divided into world-centric and ego-centric perspectives. World-centric spatial cognition requires the model to grasp absolute scales and relative positions within scenes, as exemplified by object size estimations in Task 1 Step 2 (Fig. 1). Ego-centric spatial cognition connects the robot’s physical embodiment with the world, thereby assisting in behavioral decisions. For example, as depicted in Fig. 1, the reachability estimation in Task 2 Step 3 and the orientation estimation in Task 2 Step 5 assist the robot in clearly defining its relationship with interactive objects. Equipped with enhanced object and spatial reasoning, RynnEC supports more efficient execution of complex, real-world robotic tasks.
Regrettably, the development of embodied cognition models has been slow due to a lack of ego-centric videos and high-quality annotations. Efforts such as Multi-SpatialMLLM Xu et al. [2025], Spatial-MLLM Wu et al. [2025a], and SpaceR Ouyang et al. [2025] leverage open-source datasets with comprehensive 3D point cloud and annotations to generate training data. However, in an era of scarce 3D annotations Hou et al. [2025], Lyu et al. [2024], this approach cannot achieve rapid and cost-effective expansion of data scale. Hence, we propose a data generation pipeline that transforms ego-centric RGB videos into embodied cognition question-answering datasets. This pipeline begins with instance segmentation from videos and diverges into two branches: one generating object cognition data and the other producing spatial cognition data. Ultimately, data from both branches are integrated into a comprehensive embodied cognition dataset. From over 200 households, we collect more than 20,000 egocentric videos. A subset from ten households is manually verified and balanced to create RynnEC-Bench, a fine-grained embodied cognition benchmark encompassing 22 tasks in object and spatial cognition.
Extensive experiments demonstrate that RynnEC significantly outperforms both general OpenAI et al. [2024], Bai et al. [2025], Zhu et al. [2025] and task-specific Yuan et al. [2025a, c], Team et al. [2025] MLLMs in cognitive abilities within embodied scenarios, showcasing scalable application potential. Additionally, we observe notable advantages in multi-task training with RynnEC and identify preliminary signs of emergence in more challenging embodied cognition tasks. Finally, we highlight the potential of RynnEC in facilitating robots to undertake large-scale, long-range tasks.
2 Related Work
2.1 MLLMs for Video Understanding
Early MLLMs primarily relied on sparse sampling and simple connectors, such as MLPs Lin et al. [2023], Ataallah et al. [2024], Maaz et al. [2023] and Q-Formers Zhang et al. [2023], Li et al. [2024b], to integrate visual representation with large language models. Subsequently, to tackle the problem of long video understanding, Zhang et al. [2024b] directly expanded the context window of language models, while Zhang et al. [2024d] introduced pooling in the spatial and temporal dimensions to compress the number of video tokens. As the need for more fine-grained understanding emerged, some studies (VideoRefer Yuan et al. [2025c], DAM Lian et al. [2025] and PAM Lin et al. [2025]) employed region-level feature encoders enabling video MLLMs to accept masked inputs and comprehend the semantic features of objects within the masks. Although these video MLLMs have demonstrated superior capabilities in high-level semantic capture and temporal modeling, they lack robust physical-world comprehension in egocentric embodied scenarios.
2.2 Embodied Scene Understanding Benchmarks
Some studies Ren et al. [2024a], Li et al. [2024c], Han et al. [2025a] have begun to explore leveraging MLLMs to assist robots in solving embodied tasks. However, determining whether these MLLMs possess the ability to understand and interact with the physical world is challenging. Consequently, several benchmarks have emerged to evaluate the capability of MLLMs to perceive the physical world. OpenEQA Majumdar et al. [2024] and IndustryEQA Li et al. [2025a] focus on several key competencies in home and industrial settings, respectively, and manually designed open-vocabulary questions. VSI-Bench Yang et al. [2025c] centers on assessing the spatial cognitive abilities of MLLMs. STI-Bench Li et al. [2025b] introduces more complex kinematic (e.g. velocity) problems. ECBench Dang et al. [2025] systematically categorizes embodied cognitive abilities into static environments, dynamic environments, and overcoming hallucinations, offering a comprehensive evaluation across 30 sub-competencies. While these benchmarks encompass a wide range of abilities, they are unable to assess more fine-grained, region-level understanding capabilities in embodied scenarios. Compared to purely textual question-answering, region-level visual interaction can more accurately refer to targets in the complex real world.
2.3 Improving MLLMs for Embodied Cognition
The aforementioned embodied benchmarks have highlighted the cognitive limitations of current MLLMs in embodied scenarios. Consequently, some studies have started to investigate diverse strategies for enhancing MLLMs’ understanding of the physical world. GPT4Scene Qi et al. [2025] improves MLLMs’ consistent global scene understanding by explicitly adding instance marks between video frames. SAT Ray et al. [2024] explores multi-frame dynamic spatial reasoning in simulated environments. Spatial-MLLM Wu et al. [2025a], Multi-SpatialMLLM Xu et al. [2025], and SpaceR Ouyang et al. [2025] leverage 3D datasets with detailed annotations (e.g., ScanNet Yeshwanth et al. [2023]) to construct the suite of spatial-intelligence tasks introduced in VSI-Bench. In contrast, our data generation pipeline based on RGB videos yields more realistic and scalable training data. More importantly, RynnEC is designed not just to handle selected capabilities in embodied scenarios, but to cover a broad swath of the world cognition required for embodied task execution under a single paradigm.
3 Methodology
RynnEC is a robust video embodied cognition model capable of processing and outputting various video object proposals. This enables it to flexibly address embodied questions about objects and space. Due to a paucity of research in this domain, we comprehensively present the construction process of RynnEC from four perspectives: data generation (Sec. 3.1), evaluation framework establishment (Sec. 3.2), model architecture (Sec. 3.3), and training (Sec. 3.4).
<details>
<summary>x2.png Details</summary>

### Visual Description
## Flowchart: Video Instance Segmentation and Object/Spatial QA Generation Pipeline
### Overview
The diagram illustrates a multi-stage pipeline for video instance segmentation and question-answering (QA) generation, integrating computer vision, natural language processing (NLP), and spatial reasoning. It is divided into three main sections: **Video Instance Segmentation**, **Generate Object QA**, and **Generate Spatial QA**, with bidirectional feedback loops and cross-component dependencies.
---
### Components/Axes
#### **1. Video Instance Segmentation**
- **Input**: Video frames (40s duration) with objects (e.g., stools, furniture).
- **Processes**:
- **Extract Object Name**: Identifies objects in frames (e.g., "stool").
- **Grounding DINO**: Localizes objects in 2D space using a one-second interval.
- **Segment Anything 2**: Segments objects into masks.
- **Output**: Segmented object instances with temporal alignment.
#### **2. Generate Object QA**
- **Input**: Keyframes of segmented objects (e.g., stools in different colors/materials).
- **Processes**:
- **Qwen 2.5-VL**: Generates captions (e.g., "The object is a small footrest...").
- **Qwen 3**: Produces situational questions (e.g., "How many legs does the object have?").
- **Object Referring Expressions**: Creates references (e.g., "The green leather footstool beside the sofa").
- **Output**: Textual QA pairs and references.
#### **3. Generate Spatial QA**
- **Input**: 3D spatial data from **Mast3r-SLAM** and **Mask 2D to 3D** conversion.
- **Processes**:
- **Ground Level Calibration**: Aligns 3D coordinates (X, Y, Z axes).
- **Spatial Cognition Questions**: Generates egocentric/world-centric queries (e.g., "Which object is closer?" or "Height difference between objects?").
- **Output**: Spatial reasoning QA pairs.
#### **Cross-Component Elements**
- **Prompt**: Connects video segmentation to QA generation.
- **Template**: Integrates spatial data into QA templates.
- **Arrows**: Indicate flow (e.g., video frames → object names → QA generation).
---
### Detailed Analysis
#### **Video Instance Segmentation**
- **Key Trends**:
- Temporal alignment via 1-second intervals ensures consistency across frames.
- **Grounding DINO** and **Segment Anything 2** work iteratively to refine object localization and segmentation.
- **Notable Details**:
- Example objects include stools with varying colors (green, dark) and materials (leather, fabric).
#### **Generate Object QA**
- **Key Trends**:
- **Qwen 2.5-VL** focuses on descriptive captions (shape, color, material).
- **Qwen 3** generates context-aware questions (e.g., "Is the object exposed to sunlight?").
- **Notable Details**:
- Situational referencing includes hypothetical scenarios (e.g., a child climbing furniture).
#### **Generate Spatial QA**
- **Key Trends**:
- **Mast3r-SLAM** and 3D grounding enable spatial reasoning (e.g., height differences of 1.2 meters).
- Egocentric questions prioritize user perspective (e.g., "Which object is closer?").
---
### Key Observations
1. **Integration of Modalities**: The pipeline bridges video analysis (2D segmentation) with spatial reasoning (3D grounding) for holistic QA.
2. **Temporal Consistency**: 1-second intervals in video segmentation ensure alignment with QA generation.
3. **Hierarchical Questioning**: Object QA progresses from simple descriptions to situational reasoning, while spatial QA focuses on positional relationships.
---
### Interpretation
This pipeline demonstrates a **multi-modal AI system** capable of:
- **Understanding Video Content**: Segmenting objects and extracting attributes (color, material).
- **Generating Contextual Questions**: Using NLP models (Qwen) to create practical and situational queries.
- **Spatial Reasoning**: Leveraging 3D data (Mast3r-SLAM) to answer questions about object placement and dimensions.
The bidirectional arrows suggest iterative refinement: QA outputs may feedback into segmentation (e.g., clarifying ambiguous objects). The emphasis on **egocentric/world-centric questions** highlights adaptability to user perspectives, critical for applications like robotics or augmented reality.
---
### Uncertainties
- No numerical data or confidence scores are provided for segmentation or QA accuracy.
- The exact role of "Ground Level Calibration" in spatial reasoning is implied but not quantified.
</details>
Figure 2: Embodied Cognition Question-Answer (QA) Data Generation Pipeline: First, objects within the scene are segmented from the video. Subsequently, object and spatial QA pairs are generated via two distinct branches.
3.1 Embodied Cognition Data Generation
Our embodied cognition dataset construction (Fig. 2) begins with egocentric video collection and instance segmentation. One branch employs a human-in-the-loop streaming generation approach to construct various object cognition QA pairs. The other branch utilizes a monocular dense 3D reconstruction method and diverse question templates to generate spatial cognition task QA pairs.
3.1.1 Video Collection and Instance Segmentation
Our egocentric video collection encompasses $200+$ houses, with approximately 100 videos per house. To ensure video quality, we require a resolution of at least 1080p and a frame rate no less than 30fps, using a gimbal to maintain shooting stability. To achieve diversity among different video trajectories, each house is divided into multiple zones, with filming trajectories categorized into single-zone, dual-zone, and tri-zone types. Cross-zone filming enhances diversity by altering the sequence of traversed zones. Additionally, we randomly vary lighting conditions and camera height under different trajectories. We require that each video includes both vertical and horizontal rotations, as well as at least two close-ups of objects, simulating the variable field of view in robotic task execution. Ultimately, we collect 20,832 egocentric videos of indoor movement. To control video length, these videos are segmented every 40 seconds.
Previous works Luo et al. [2025], Wang et al. [2024] adopted a strategy of designing separate data generation processes for each task type, leading to limited data reusability and continuity. We aim to create a lineage among different types of foundational data to reduce unnecessary redundancy in data generation. Therefore, this paper proposes a mask-centric embodied cognition QA generation pipeline. This pipeline initiates with the generation of object masks from video instance segmentation within a scene. First, Qwen2.5-VL Bai et al. [2025] observes the raw video and outputs an object list containing the names of all entity categories in the scene. Utilizing this object list, Grounding DINO 1.5 Ren et al. [2024b] detects objects in key frames at one-second intervals. SAM2 Ravi et al. [2024] assists in segmenting and tracking the objects detected by Grounding DINO 1.5 during the intervening one-second interval. To ensure consistency of instance IDs, the tracking results of old instances are compared with the segmentation results of newly detected instances at key frames. If an instance is found to have overlapping masks (IOU > 0.5), it retains the ID of the old tracking instance. Due to the performance limitations of Grounding DINO 1.5, newly detected object instances may already have appeared in preceding frames yet were missed. Thus, SAM2 conducts a reverse four-second instance tracking for each new object in key frames, thereby achieving full lifecycle instance tracking. In total, we obtain 1.14 million video instance masks from all the egocentric videos.
3.1.2 Object QA Generation
In this work, we generate three types of object-related tasks: object captioning, object comprehension QA, and referring video object segmentation. For each instance, we first divide all frames containing the instance into eight equal parts in chronological order. Within each frame group, an instance key frame is selected based on two factors: the size of the instance in the frame and the distance between the instance center and the frame center. Consequently, each instance is associated with eight instance key frames, featuring good instance visibility and diverse viewing angles. Half of these frames have the instance cropped out using a mask, while the other four highlight the instance using a red bounding box and background dimming technique. The final set of object cue images is displayed within the blue box in Fig. 2.
Due to the limitation of SAM2 in consistent object tracking in egocentric videos, the same instance may be assigned multiple IDs if the instance appears intermittently in the video. We employ an object category filtering method that limits each video to a maximum of two instances per object category, thereby minimizing duplicate instances. The presence of multiple video segments per house leads to repeated occurrences of certain salient objects, causing a pronounced long-tail distribution. We downsample object categories that occur frequently to prevent extreme object distribution. After the aforementioned filtering, the cue image sets of retained instances are input into Qwen2.5-VL Bai et al. [2025], generating object caption and object comprehension QA through various prompts. It is noteworthy that in the object comprehension QA, counting QA task is particularly unique and requires specially designed prompts. Subsequently, based on each instance’s caption and QAs, Qwen3 Yang et al. [2025a] generates two types of referring expressions: simple referring expressions and situational referring expressions. Simple referring expressions identify objects through a combination of features such as spatial location and category. Situational referring expressions establish a task scenario, requiring the model to infer the instance needed by the user within this context. Each type of QA undergoes manual filtering post-output to ensure data quality. Detailed prompts are provided in the Appendix A.2.
3.1.3 Spatial QA Generation
Unlike object QA, spatial QA requires more precise 3D information concerning the global scene context. Therefore, we utilize MASt3R-SLAM Murai et al. [2025] to reconstruct 3D point clouds from RGB videos and obtain camera extrinsic parameters. Subsequently, by projecting 2D pixel points to 3D coordinates, the segmentation of each instance in the video can be mapped onto the point cloud. However, it is important to note that the world coordinate system established by MASt3R-SLAM for the 3D point cloud is not aligned with the floor. Therefore, the Random Sample Consensus (RANSAC) Fischler and Bolles [1981] algorithm is implemented to identify inlier points for plane fitting through ten iterative executions. In each iteration, the detected planar surface and its inliers are removed from the point cloud for subsequent plane detection. Given that the initial camera pose was approximately horizontal but not perpendicular to the ground, the ground plane is selected based on minimal angular deviation between its normal vector and the initial camera Y-axis orientation. The point cloud is then aligned to ensure orthogonality between the world coordinate Z-axis and the detected ground plane.
RynnEC dataset encompasses 10 fundamental spatial abilities, each of which is further divided into quantitative and qualitative variants. We construct spatial QA in a template-based manner. Diverse QA templates are designed according to the characteristics of each task, and the missing attributes within the templates (e.g., distance, height) can be calculated from the 3D point cloud. We denote each instance in the format <Object X>. Furthermore, to obtain purely textual spatial QA pairs, we replace <Object X> with simple referring expressions generated in the above object QA pipeline. These texts are then further refined and diversified using GPT-4o, resulting in the final natural language spatial QA data. With training on these data, RynnEC is able to answer spatial questions in various input forms. Examples of the generated spatial QAs are illustrated in Fig. 2, and more examples as well as detailed templates are provided in the Appendix A.3.
Building on insights from prior works Wu et al. [2025a], Ouyang et al. [2025], we recognize that spatial cognition tasks are highly challenging. Therefore, in addition to constructing a large-scale video-based spatial QA dataset, we also develop a relatively simpler image-based spatial QA dataset. This combination of tasks with varying levels of difficulty is intended to improve learning efficiency and enhance model robustness. Specifically, we collect 500k indoor images from 39k houses. Leveraging the single-image-to-3D reconstruction and calibration methods from SpatialRGPT Cheng et al. [2024a], we obtain the 3D spatial relationships between objects in each image. We then select tasks from the video-based spatial cognition set that can also be addressed via single images, and design corresponding QA templates. The format of the image-based spatial QA is kept consistent with that of the video-based spatial QA.
3.2 RynnEC-Bench
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: RynEC Bench Cognitive Framework
### Overview
The image depicts a circular diagram titled "RynEC Bench" with concentric layers representing cognitive domains. Four quadrants (Situational Referring, Direct Referring, Historical, Future) contain Q&A examples, while the central wheel categorizes cognitive aspects. The diagram integrates spatial, temporal, and object-centric cognition through color-coded sections.
### Components/Axes
1. **Central Wheel (Core Cognition)**:
- **Object Properties Cognition**: Color, Material, Shape, Size, Position, Surface, Detail, Counting
- **Spatial Cognition**: Distance, Positional Relationship, Size
- **World-Centric Cognition**: Function, State, Category
- **Ego-Centric Cognition**: Present, Future, Historical
- **Spatiotemporal Cognition**: Direct Referring, Situational Referring
2. **Quadrants (Cognitive Domains)**:
- **Situational Referring**: Q1 (travel clothes), Q3 (white clothes count)
- **Direct Referring**: Q2 (silver suitcase), Q4 (object function)
- **Historical**: Q5 (walking distance), Q7 (tallest object)
- **Future**: Q6 (orientation after turn), Q8 (object proximity)
3. **Legend**:
- Colors map to cognitive domains (e.g., blue for Situational Referring, orange for Historical). No explicit legend is visible, but color coding is implied by quadrant labels.
### Detailed Analysis
- **Quadrant Examples**:
- **Situational Referring**:
- Q1: "If I want to travel and need to carry a lot of clothes, which item should I take?" → A: "A. It is" (referring to a suitcase).
- Q3: "How many white clothes are near the [object]?" → A: "3."
- **Direct Referring**:
- Q2: "Where is the silver suitcase with a black bag on top?" → A: "A. It is" (direct reference to an object).
- Q4: "What is the function of [object]?" → A: "To provide a flat, heat-resistant surface for ironing clothes and removing wrinkles."
- **Historical**:
- Q5: "How far have you walked in total?" → A: "2.3m."
- Q7: "Among three objects, which is tallest?" → A: "A. reaches the greatest height."
- **Future**:
- Q6: "After a 90-degree left turn, where will [object] be?" → A: "11 o'clock direction."
- Q8: "Which is closer, [object 1] or [object 2]?" → A: "A. is closer."
- **Central Wheel Categories**:
- **Object Properties**: Color, Material, Shape, Size, Position, Surface, Detail, Counting
- **Spatial**: Distance, Positional Relationship, Size
- **World-Centric**: Function, State, Category
- **Ego-Centric**: Present, Future, Historical
- **Spatiotemporal**: Direct Referring, Situational Referring
### Key Observations
1. **Cognitive Integration**: The diagram emphasizes cross-domain cognition, linking object properties (e.g., color, size) with spatial reasoning (distance, positional relationships) and temporal context (historical vs. future).
2. **Practical Applications**: Q&A examples suggest use cases in robotics, navigation, or AI systems requiring multi-modal understanding (e.g., identifying objects, predicting movements).
3. **Ambiguity in Answers**: Some answers (e.g., "A. It is") lack specificity, implying the framework may prioritize contextual inference over explicit data.
### Interpretation
The RynEC Bench framework appears designed to evaluate or simulate cognitive processes in dynamic environments. By combining object properties, spatial reasoning, and temporal context, it likely supports tasks like:
- **Object Recognition**: Identifying items via color, shape, or function.
- **Navigation**: Predicting future positions or orientations.
- **Contextual Inference**: Linking historical data (e.g., walking distance) to current decisions.
The lack of explicit numerical data suggests the diagram is conceptual, focusing on cognitive architecture rather than empirical results. The emphasis on "Direct Referring" and "Situational Referring" implies applications in human-robot interaction or augmented reality systems requiring real-time environmental understanding.
</details>
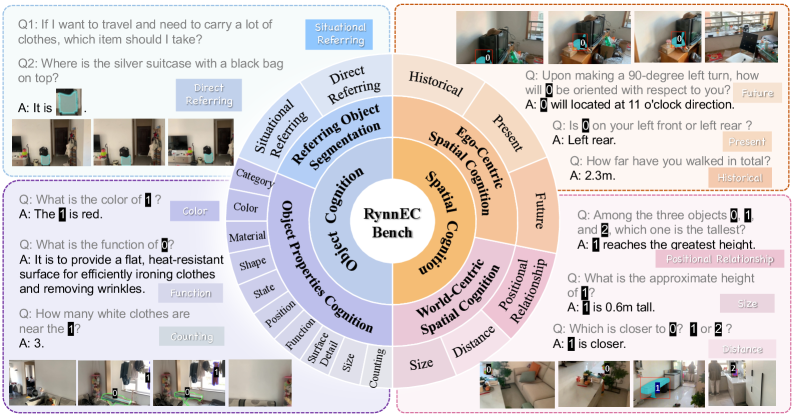
Figure 3: Overview of embodied cognition dimensions in RynnEC-Bench. RynnEC-Bench includes two subsets: object cognition and spatial cognition, evaluating a total of 22 embodied cognitive abilities.
As this work is the first to propose a comprehensive set of fine-grained embodied video tasks, a robust evaluation framework for assessing MLLMs’ overall capabilities in this domain is currently lacking. To address this, we propose RynnEC-Bench, which evaluates fine-grained embodied understanding models from the perspectives of object cognition and spatial cognition in open-world scenarios. Fig. 3 provides a detailed illustration of the capability taxonomy in RynnEC-Bench.
3.2.1 Capability Taxonomy
Object cognition is divided into two tasks: object properties cognition and referring object segmentation. During embodied task execution, robots often require a clear understanding of key objects’ functions, locations, quantities, surface details, relationships with the surrounding environment, etc. Accordingly, the object properties recognition tasks comprehensively and meticulously construct questions in these aspects. In the processes of robotic manipulation and navigation, identifying operation instances and target instances is an essential step. Precise instance segmentation in videos serves as the best approach to indicate the positions of these key objects. Specifically, the referring object segmentation task is categorized into direct referring problems and situational referring problems. Direct referring problems involve only combinations of descriptions for the instance, while situational referring problems are set within a scenario, requiring MLLMs to perform reasoning in order to identify the target object.
Spatial cognition requires MLLMs to derive a 3D spatial awareness from egocentric video. We categorize it into ego-centric and world-centric spatial cognition. Ego-centric spatial cognition maintains awareness of agent-environment spatial relations and supports spatial reasoning and mental simulation; by temporal scope, we consider past, present, and future cases. World-centric spatial cognition focuses on understanding the 3D layout and scale of the physical world, which we further evaluate in terms of size, distance, and positional relations.
3.2.2 Data Balance
The videos in RynnEC-Bench are collected from ten houses that do not overlap with those in the training set. When evaluating object cognition, we observe substantial variation in object-category distributions across houses, making results highly sensitive to which houses are sampled. To mitigate this bias and better reflect real-world deployment, we introduce a physical-world-based evaluation protocol. We first define a taxonomy of 12 coarse and 119 fine-grained indoor object categories. Using GPT-4o, we then estimate an empirical category-frequency distribution by parsing 500,000 indoor images from 39,000 houses; given the scale, this serves as a close approximation to real-world indoor object frequencies. Finally, we perform frequency-proportional sampling so that the object-category distribution in RynnEC-Bench closely matches the empirical distribution, enabling a more objective and realistic evaluation. Specifically, counting questions with answers of 1 or 2 are reduced by 50% to achieve a more balanced difficulty distribution. All QA pairs in RynnEC-Bench are further subjected to meticulous human screening to ensure high quality. Additional implementation details are available in Appendix B.
3.2.3 Evaluation Framework
The questions are categorized into three types based on the nature of their answers: numerical questions, textual questions, and segmentation questions. For numerical questions such as distance estimation and direction estimation, we directly use the formula to calculate the precise indicators. For scale-related questions, Mean Relative Accuracy (MRA) Yang et al. [2025c], Everingham et al. [2010] is used to calculate the scores. Specifically, given a model’s prediction $\hat{y}$ , ground truth $y$ , and a confidence threshold $\theta$ , relative accuracy is calculated by considering $\hat{y}$ correct if the relative error rate, defined as $|\hat{y}-y|/y$ , is less than $1-\theta$ . As single-confidence-threshold accuracy only considers relative error within a narrow scope, the MRA averages the relative accuracy across a range of confidence thresholds $\mathcal{C}=\{0.5,\,0.55,\,...,\,0.95\}$ :
$$
MRA=\frac{1}{|\mathcal{C}|}\sum_{\theta\in\mathcal{C}}\mathbb{I}\Bigg(\frac{|\hat{y}-y|}{y}<1-\theta\Bigg) \tag{1}
$$
where $\mathbb{I}(·)$ is the indicator function. For angle-related questions, MRA is not suitable due to the cyclic nature of angular measurements. We therefore designed a rotational accuracy metric (RoA).
$$
RoA=1-min\Bigg(\frac{min(|\widehat{y}-y|,360-|\widehat{y}-y|)}{90},1\Bigg) \tag{2}
$$
RoA assigns a score only when the angular difference is less than 90 degrees, ensuring consistency in task difficulty across different settings.
Textual questions are further categorized into close-ended and open-ended questions. For the close-ended part, we prompt GPT-4o to assign a straightforward binary score of either 0 or 1. For the open-ended part, answers are scored by GPT-4o on a scale from 0 to 1 in increments of 0.2. This question-type-adaptive evaluation approach enables the metrics of RynnEC-Bench to be both precise and consistent.
For segmentation evaluation, prior work Yuan et al. [2025a], Yan et al. [2024] typically reports the $\mathcal{J}\&\mathcal{F}$ measure, combining region-overlap ( $\mathcal{J}$ ) and boundary-accuracy ( $\mathcal{F}$ ) scores. However, the conventional frame-averaged $\mathcal{J}\&\mathcal{F}$ treats empty frames (i.e., frames with no ground-truth mask) in a binary manner: if any predicted mask appears, the frame score is set to 0; otherwise it is set to 1. This evaluation method fails to account for the actual size of erroneous masks in empty frames, which can have a significant impact on embodied segmentation tasks. To address this, we propose the Global IoU metric, defined as
$$
\overline{\mathcal{J}}=\frac{\sum_{i=1}^{N}|\mathcal{S}_{i}\cap\mathcal{G}_{i}|}{\sum_{i=1}^{N}|\mathcal{S}_{i}\cup\mathcal{G}_{i}|}, \tag{3}
$$
where $N$ is the total number of video frames, $\mathcal{S}_{i}$ denotes the predicted segmentation mask for frame $i$ , and $\mathcal{G}_{i}$ denotes the ground truth mask for frame $i$ . For the boundary accuracy metric $\overline{\mathcal{F}}$ , we compute the average only over non-empty frames. The mean of $\overline{\mathcal{J}}$ and $\overline{\mathcal{F}}$ , denoted as $\overline{\mathcal{J}}\&\overline{\mathcal{F}}$ , provides an accurate reflection of segmentation quality, especially in egocentric videos where the target object appears in relatively few frames.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Screenshot: Multi-Stage Visual Understanding Workflow
### Overview
The image depicts a four-stage workflow for visual understanding tasks, each stage featuring a caption, image, and technical components. The stages progress from basic mask alignment to complex referring segmentation, with increasing reliance on language models (LLM) and spatial reasoning.
### Components/Axes
- **Stage Titles**:
1. Mask Alignment
2. Object Understanding
3. Spatial Understanding
4. Referring Segmentation
- **UI Elements**:
- Purple buttons labeled "LLM" (with flame icon) in all stages.
- "LoRA" button (with flame icon) only in Stage 4.
- Labels: "Vision Encoder", "Region Encoder", "Mask Decoder" (with flame icons).
- Video/image icons (play/picture symbols) in bottom-left of each stage.
- Text blocks for captions, questions, and answers.
### Detailed Analysis
#### Stage 1: Mask Alignment
- **Caption**: "A single black kettle on the table."
- **Image**: Kitchen scene with a kettle highlighted in yellow.
- **Components**:
- "Vision Encoder" (left) and "Region Encoder" (center) with flame icons.
#### Stage 2: Object Understanding
- **Question**: "What is the purpose of <object>?"
- **Answer**: "It enhances flavor, adding umami and richness to dishes."
- **Image**: Kitchen with multiple objects (pot, kettle, etc.).
- **Components**: Same as Stage 1.
#### Stage 3: Spatial Understanding
- **Question**: "What is the distance of <object0> and <object1>?"
- **Answer**: "0.7m."
- **Image**: Room with furniture (table, chair) highlighted in yellow/green.
- **Components**: Same as Stage 1.
#### Stage 4: Referring Segmentation
- **Question**: "Can you segment the brown teddy bear located on the table in this video?"
- **Answer**: "Sure, it is [SEG]."
- **Image**: Video frame with a teddy bear highlighted in green.
- **Components**:
- "Mask Decoder" (center) with flame icon.
- Combined "LLM + LoRA" button (purple).
### Key Observations
1. **Progression**: Each stage increases in complexity, from single-object alignment (Stage 1) to multi-object spatial reasoning (Stage 3) and video-based segmentation (Stage 4).
2. **LLM Integration**: "LLM" buttons appear in all stages, suggesting language model involvement in understanding and segmentation.
3. **LoRA Addition**: Stage 4 introduces "LoRA", implying a specialized model variant for segmentation tasks.
4. **Visual Encoding**: Consistent use of "Vision Encoder" and "Region Encoder" across stages indicates foundational visual processing.
### Interpretation
This workflow illustrates a hierarchical approach to visual-language tasks:
- **Stage 1** focuses on basic object localization (mask alignment).
- **Stage 2** adds semantic understanding (object purpose).
- **Stage 3** introduces spatial relationships (distance measurement).
- **Stage 4** combines temporal and spatial reasoning for video segmentation.
The inclusion of "LoRA" in Stage 4 suggests a fine-tuned model for precise segmentation, while the consistent use of "LLM" highlights its role in bridging vision and language. The flame icons may symbolize computational intensity or model efficiency.
No numerical data or charts are present; the image emphasizes textual and visual components of a technical pipeline.
</details>
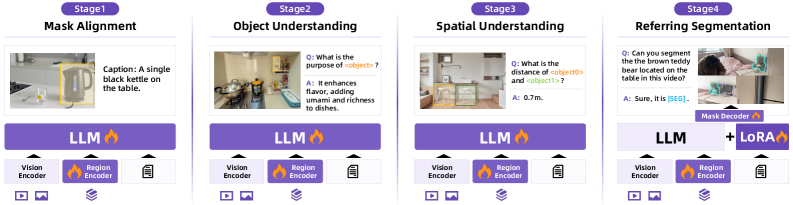
Figure 4: Training paradigm of RynnEC. The model is trained in four progressive stages: 1) Mask Alignment, 2) Object Understanding, 3) Spatial Understanding, and 4) Referring Segmentation.
3.3 RynnEC Architecture
RynnEC consists of three core components: the foundational vision-language model for basic multimodal comprehension, a region-aware encoder for fine-grained object-centric representation learning, an adaptive mask decoder for video segmentation tasks. Notably, the latter two modules are designed as plug-and-play components with independent parameter spaces, ensuring architectural flexibility and modular extensibility.
Foundational Vision-Language Model. We ultilize VideoLLaMA3-Image Zhang et al. [2025a] as the foundational vision-language model for RynnEC, which consists of three main modules: a Vision Encoder, the Projector and the Large Language Model (LLM). For the vision encoder, we use VL3-SigLIP-NaViT Zhang et al. [2025a], which leverages an any-resolution vision tokenization strategy to flexibly encode images of varying resolutions. As the LLM, we employ Qwen2.5-1.5B-Instruct Yang et al. [2024] and Qwen2.5-7B-Instruct Yang et al. [2024], enabling scalable trade-offs between performance and computational cost.
Region Encoder. Egocentric videos often feature cluttered scenes with similar objects that are difficult to distinguish using linguistic cues alone. To address this, we introduce a dedicated object encoder for specific object representation. This facilitates more precise cross-modal alignment during training and enables intuitive, fine-grained user interaction at inference time. Following Yuan et al. [2024, 2025c], we use a simple yet efficient MaskPooling for object tokenization, followed by a two-layer projector to align object features with LLM embedding space. During training, object masks spanning multiple frames in a video are utilized to achieve accurate representations. At inference, the encoder offers flexibility, operating effectively with either single-frame or multi-frame object masks.
Mask Decoder. Accurate object localization is critical for egocentric video understanding. To incorporate robust visual grounding capabilities without degrading the model’s pretrained performance, we fine-tune the LLM with LoRA. Our mask decoder is based on the architecture of SAM2 Ravi et al. [2024], which has demonstrated strong generalization capabilities and prior knowledge in purely visual segmentation tasks. For a given video and the instruction, we adpot a [SEG] token as a specifical token to trigger mask generation for the corresponding visual region. To facilitate this process, an additional linear layer is introduced to align the [SEG] token with SAM2’s feature space.
3.4 Training and Inference
As illustrated in Fig. 4, RynnEC is trained using a progressive four-stage pipeline: 1) Mask Alignment, 2) Object Understanding, 3) Spatial Understanding, and 4) Referring Segmentation. The first three stages are designed to incrementally enhance fine-grained, object-centric understanding, while the final stage focuses on equipping the model with precise object-level segmentation capabilities. This curriculum-based approach ensures gradual integration of visual, spatial, and grounding knowledge without overfitting to a single task. The datasets used in each stage are summarized in Tab. 1. The details of each training stage are as follows:
1) Mask Alignment. The goal of this initial stage is to encourage the model to attend to region-specific tokens rather than relying solely on global visual features. We fine-tune both the region encoder and the LLM on a large-scale object-level captioning dataset, where each caption is explicitly aligned with a specific object mask. This alignment training conditions the model to associate object-centric embeddings with corresponding linguistic descriptions, laying the foundation for localized reasoning in later stages.
2) Object Understanding. In this stage, the focus shifts to enriching the model’s egocentric object knowledge, encompassing attributes such as color, shape, material, size, and functional properties. The region encoder and the LLM are jointly fine-tuned to integrate this object-level information more effectively into the cross-modal embedding space. This stage is the basic for spatial understanding.
3) Spatial Understanding. Building on the previous stage, this phase equips the model with spatial reasoning abilities, enabling it to understand and reason about the relative positions and configurations of objects within a scene. We use a large amount of spatial QA we generated and the previous stage data as well as general VQA to maintain the ability to follow instructions.
4) Referring Segmentation. In the final stage, we integrate the Mask Decoder module after the LLM to endow the model with fine-grained referring segmentation capabilities. The LLM is fine-tuned via LoRA to minimize interference with its pretrained reasoning abilities. The training data includes not only segmentation-specific datasets but also samples from earlier stages to mitigate catastrophic forgetting. This multi-task mixture ensures that segmentation performance is improved without sacrificing the model’s object and spatial understanding.
Table 1: Datasets used at four training stages. IM and OM indicate whether the task involves the input mask and output mask, respectively.
| Training Stage | Task | IM | OM | # Samples | Datasets |
| --- | --- | --- | --- | --- | --- |
| Mask Alignment (Stage-1) | General Mask Captioning | ✓ | ✗ | 1.17M | RefCOCO Yu et al. [2016], Mao et al. [2016], VideoRefer-Caption Yuan et al. [2025c], DAM Lian et al. [2025], Osprey-Caption Yuan et al. [2024], MDVP-Data Lin et al. [2024], HC-STVG Tang et al. [2021] |
| Scene Instance Captioning | ✓ | ✗ | 0.14M | RynnEC-Caption | |
| Object Understanding (Stage-2) | Basic Properties QA | ✓ | ✗ | 1.49M | RynnEC-Object |
| Object-Centric Counting | ✓ | ✗ | 0.25M | RynnEC-Counting | |
| Spatial Understanding (Stage-3) | Our Stage-2 | ✓ | ✗ | 0.30M | RynnEC-Object, RynnEC-Counting |
| Spatial QA | ✓ | ✗ | 0.60M | RynnEC-Spatial (Image), RynnEC-Spatial (Video) | |
| ✗ | ✗ | 0.54M | VLM-3R-Data Fan et al. [2025] | | |
| General VQA | ✗ | ✗ | 0.74M | LLaVA-OV-SI Li et al. [2024a], LLaVA-Video Zhang et al. [2024e], ShareGPT-4o-video Chen et al. [2024b], VideoGPT-plus Maaz et al. [2024], FineVideo Farré et al. [2024], CinePile Rawal et al. [2024], ActivityNet Caba Heilbron et al. [2015], YouCook2 Zhou et al. [2018], LLaVA-SFT Liu et al. [2023] | |
| Referring Segmentation (Stage-4) | Our Stage-2 & Stage-3 | ✓ | ✗ | 0.60M | RynnEC-Object, RynnEC-Counting, RynnEC-Spatial |
| General Segmentation | ✗ | ✓ | 0.32M | ADE20K Zhou et al. [2017], COCOStuff Caesar et al. [2018], Mapillary Neuhold et al. [2017], PACO-LVIS Ramanathan et al. [2023], PASCAL-Part Chen et al. [2014] | |
| Embodied Segmentation | ✗ | ✓ | 0.31M | RynnEC-Segmentation | |
| General VQA | ✗ | ✗ | 0.80M | LLaVA-OV-SI Li et al. [2024a], LLaVA-Video Zhang et al. [2024e], ShareGPT-4o-video Chen et al. [2024b], VideoGPT-plus Maaz et al. [2024], FineVideo Farré et al. [2024], CinePile Rawal et al. [2024], ActivityNet Caba Heilbron et al. [2015], YouCook2 Zhou et al. [2018], LLaVA-SFT Liu et al. [2023] | |
4 Experiments
Table 2: Main evaluation results on RynnEC-Bench. We evaluate in two major categories: Object Cognition and Spatial Cognition. DR and SR represent Direct Referring and Situational Referring. PR represents Positional Relationship.
| Model | Overall Mean | Object Cognition | Spatial Cognition | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Object Properties | Segmentation | Mean | Ego-Centric | World-Centric | Mean | | | | | | | |
| DR | SR | His. | Pres. | Fut. | Size | Dis. | PR | | | | | |
| Proprietary Generalist MLLMs | | | | | | | | | | | | |
| GPT-4o OpenAI et al. [2024] | 28.3 | 41.1 | — | — | 33.9 | 13.4 | 22.8 | 6.0 | 24.3 | 16.7 | 36.1 | 22.2 |
| GPT-4.1 OpenAI et al. [2024] | 33.5 | 45.9 | — | — | 37.8 | 17.2 | 27.6 | 6.1 | 35.9 | 30.4 | 45.7 | 28.8 |
| Seed1.5-VL Guo et al. [2025] | 34.7 | 52.1 | — | — | 42.8 | 8.2 | 27.7 | 4.3 | 32.9 | 19.1 | 27.9 | 26.1 |
| Genimi-2.5 Pro Comanici et al. [2025] | 45.5 | 64.0 | — | — | 52.7 | 9.3 | 36.7 | 8.1 | 47.0 | 29.9 | 69.3 | 37.8 |
| Open-source Generalist MLLMs | | | | | | | | | | | | |
| VideoLLaMA3-7B Zhang et al. [2025a] | 27.3 | 36.7 | — | — | 30.2 | 5.1 | 26.8 | 1.2 | 30.0 | 19.0 | 34.9 | 24.1 |
| InternVL3-78B Zhu et al. [2025] | 29.0 | 45.3 | — | — | 37.3 | 9.0 | 31.8 | 2.2 | 10.9 | 30.9 | 26.0 | 20.0 |
| Qwen2.5-VL-72B Bai et al. [2025] | 36.4 | 54.2 | — | — | 44.7 | 11.3 | 24.8 | 7.2 | 27.2 | 22.9 | 83.7 | 27.4 |
| Open-source Object-Level MLLMs | | | | | | | | | | | | |
| DAM-3B Lian et al. [2025] | 15.6 | 22.2 | — | — | 18.3 | 2.8 | 14.1 | 1.3 | 28.7 | 6.1 | 18.3 | 12.6 |
| VideoRefer-VL3-7B Yuan et al. [2025c] | 32.9 | 44.1 | — | — | 36.3 | 5.8 | 29.0 | 6.1 | 38.1 | 30.7 | 28.8 | 29.3 |
| Referring Video Object Segmentation MLLMs | | | | | | | | | | | | |
| Sa2VA-4B Yuan et al. [2025a] | 4.9 | 5.9 | 35.3 | 14.8 | 9.4 | 0.0 | 0.0 | 1.3 | 0.0 | 0.0 | 0.0 | 0.0 |
| VideoGlaMM-4B Munasinghe et al. [2025] | 9.0 | 16.4 | 5.8 | 4.2 | 14.4 | 4.1 | 4.7 | 1.4 | 0.8 | 0.0 | 0.3 | 3.2 |
| RGA3-7B Wang et al. [2025] | 10.5 | 15.2 | 32.8 | 23.4 | 17.5 | 0.0 | 5.5 | 6.1 | 1.2 | 0.9 | 0.0 | 3.0 |
| Open-source Embodied MLLMs | | | | | | | | | | | | |
| RoboBrain-2.0-32B Team et al. [2025] | 24.2 | 25.1 | — | — | 20.7 | 8.8 | 34.1 | 0.2 | 37.2 | 30.4 | 3.6 | 28.0 |
| RynnEC-2B | 54.4 | 59.3 | 46.2 | 36.9 | 56.3 | 30.1 | 47.2 | 23.8 | 67.4 | 31.2 | 85.8 | 52.3 |
| RynnEC-7B | 56.2 | 61.4 | 45.3 | 36.1 | 57.8 | 40.9 | 50.2 | 22.3 | 67.1 | 39.2 | 89.7 | 54.5 |
4.1 Implementation Details
4.1.1 Training
In this part, we briefly introduce the implementation details of each training stage. For all stages, we adopt the cosine learning rate scheduler. The warm up ratio of the learning rate is set as 0.03. The maximum token length is set to 16384, while the maximum token length for vision tokens is set to 8192. In Stage 1, both the vision encoder and the LLM are initialized with pretrained weights from VideoLLaMA3-Image. During this stage, we train the LLM, the projector, and the region encoder, using learning rates of $1× 10^{-5}$ , $1× 10^{-5}$ , and $4× 10^{-5}$ , respectively. In Stages 2 and 3, the learning rates for the LLM, projector, and region encoder are adjusted to $4× 10^{-5}$ , $1× 10^{-5}$ , and $1× 10^{-5}$ , respectively. In the final stage, the LLM is fine-tuned using LoRA with the same learning rates as in Stage 3. The learning rate of Mask Decoder is set to $4× 10^{-5}$ .
4.1.2 Evaluation
We present a comprehensive evaluation of five MLLM categories on RynnEC-Bench, including both general-purpose models and those fine-tuned for region-level understanding and segmentation. For models that do not accept direct region-based inputs, we uniformly highlight target objects using bounding boxes in the video. Multiple objects are distinguished by different colored boxes, which are referenced in the question prompt. We observe that general-purpose MLLMs are incapable of localizing objects in videos; thus, only specialist models fine-tuned for this ability are evaluated on the RynnEC-Bench segmentation subset. To ensure a consistent evaluation protocol, videos are sampled at 1 fps up to a maximum of 30 frames. If the initial sampling exceeds the 30-frame limit, these target-containing frames are kept, and the remaining frames are selected via uniform sampling from the rest of the video.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Radar Charts: Object Cognition and Spatial Cognition Performance Comparison
### Overview
The image contains two radar charts comparing the performance of seven AI models across cognitive tasks. Chart (a) focuses on **Object Cognition** (e.g., color, shape, counting), while chart (b) evaluates **Spatial Cognition** (e.g., relative position, trajectory review, egocentric direction). Each axis represents a cognitive dimension, with values ranging from 0 to 100. Models are color-coded (e.g., purple for RynEC-7B, orange for Genimi-2.5-Pro).
---
### Components/Axes
#### Chart (a): Object Cognition
- **Axes**:
1. Category
2. Color
3. Material
4. Shape
5. State
6. Position
7. Function
8. Surface
9. Size
10. Counting
11. Direct Seg
12. Situational Seg
- **Legend**:
- Orange: Genimi-2.5-Pro
- Green: Owen2.5-VL-72B
- Blue: VideoRefer-VL3-7B
- Red: RoboBrain-2.0-32B
- Gray: RGA3-7B
- Purple: RynEC-7B (Ours)
#### Chart (b): Spatial Cognition
- **Axes**:
1. Relative Position
2. Trajectory Review
3. Egocentric Direction
4. Egocentric Distance
5. Movement Imagery
6. Spatial Imagery
7. Object Height
8. Object Size
9. Object Distance
10. Absolute Position
11. Ego-Centric Direction
- **Legend**: Same as Chart (a).
---
### Detailed Analysis
#### Chart (a): Object Cognition
- **Genimi-2.5-Pro (Orange)**:
- Peaks at **77** (Counting) and **75** (Size).
- Weak in **Material** (32.8) and **Shape** (36).
- **Owen2.5-VL-72B (Green)**:
- Strong in **Material** (68) and **Color** (63).
- Low in **Function** (53) and **Surface** (49).
- **VideoRefer-VL3-7B (Blue)**:
- High in **Direct Seg** (45) and **Situational Seg** (36).
- Weak in **Counting** (30) and **Shape** (33).
- **RoboBrain-2.0-32B (Red)**:
- Balanced performance (e.g., **54** in Size, **44** in Shape).
- **RGA3-7B (Gray)**:
- Strong in **Function** (70) and **Position** (66).
- **RynEC-7B (Purple)**:
- Highest in **Size** (75) and **Counting** (77).
#### Chart (b): Spatial Cognition
- **Genimi-2.5-Pro (Orange)**:
- Peaks at **90** (Relative Position) and **77** (Trajectory Review).
- Weak in **Movement Imagery** (15).
- **Owen2.5-VL-72B (Green)**:
- Strong in **Egocentric Direction** (77) and **Relative Position** (90).
- Low in **Object Height** (21).
- **VideoRefer-VL3-7B (Blue)**:
- High in **Egocentric Distance** (59) and **Spatial Imagery** (48).
- **RoboBrain-2.0-32B (Red)**:
- Balanced but lower scores (e.g., **31** in Trajectory Review).
- **RGA3-7B (Gray)**:
- Strong in **Absolute Position** (66) and **Egocentric Distance** (59).
- **RynEC-7B (Purple)**:
- Highest in **Egocentric Direction** (90) and **Movement Imagery** (15).
---
### Key Observations
1. **RynEC-7B (Ours)** dominates in **Spatial Cognition** (e.g., 90 in Egocentric Direction) and **Object Cognition** (77 in Counting).
2. **Genimi-2.5-Pro** excels in **Counting** and **Size** but struggles with **Material** and **Shape**.
3. **Owen2.5-VL-72B** leads in **Material** and **Egocentric Direction** but lags in **Object Height**.
4. **RoboBrain-2.0-32B** shows moderate performance across tasks but no clear strengths.
5. **VideoRefer-VL3-7B** performs well in **Egocentric Distance** and **Spatial Imagery** but poorly in **Counting**.
---
### Interpretation
The charts reveal significant variability in model performance across cognitive domains. **RynEC-7B (Ours)** outperforms others in both Object and Spatial Cognition, suggesting superior generalization. **Genimi-2.5-Pro** and **Owen2.5-VL-72B** specialize in specific tasks (e.g., counting, material recognition), while **VideoRefer-VL3-7B** and **RGA3-7B** show niche strengths in spatial reasoning. The data implies that no single model universally excels, highlighting the need for task-specific model selection. Outliers like RoboBrain-2.0-32B’s low **Trajectory Review** score (31) may indicate architectural limitations in dynamic spatial reasoning.
</details>
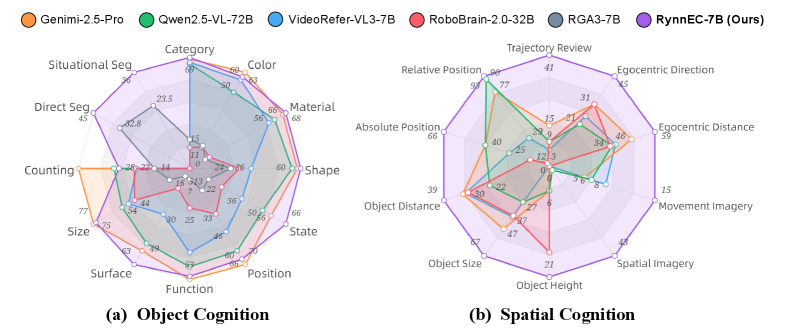
Figure 5: More granular assessments of object cognition and spatial cognition. We compare the best-performing MLLM from each category with our RynnEC-7B.
4.2 Embodied Cognition Evaluation
4.2.1 Main Results
Tab. 2 presents the evaluation results of our RynnEC model and five categories of related MLLMs on the RynnEC-Bench. Although the RynnEC model contains only 7B parameters, it demonstrates robust embodied cognitive abilities, outperforming even the most advanced proprietary model, Gemini-2.5 Pro Comanici et al. [2025], by 10.7 points. Moreover, RynnEC achieves both balanced and superior performance across various tasks. For object cognition, RynnEC achieved a score of 61.4 and possesses the ability to both understand and segment objects. In terms of spatial cognition, RynnEC achieves a score of 54.5, which is 44.2% higher than that of Gemini-2.5 Pro. To support resource-constrained settings, we present a 2B-parameter RynnEC that delivers markedly lower inference latency while maintaining near-parity performance ( $<2$ percentage points drop), enabling on-device deployment for embodied applications. In the following sections, we will introduce the performance of different types of MLLMs on RynnEC-Bench in detail.
Proprietary Generalist MLLMs
Among the four leading proprietary generalist MLLMs evaluated, Gemini-2.5 Pro establishes a clear lead with an overall score of 45.5. This represents a substantial performance margin of 25% over the best open-source generalist MLLM and 38.3% over the premier open-source object-level MLLM. Even more notably, it achieves a remarkable score of 37.8 in the notoriously difficult domain of spatial cognition. This finding provides compelling evidence that spatial awareness can emerge as a byproduct of extensive training on video comprehension tasks.
Open-source Generalist MLLMs
Qwen2.5-VL-72B Bai et al. [2025] exhibits outstanding performance, achieving a score of 36.4 and surpassing GPT-4.1 OpenAI et al. [2024]. This suggests that, in specialized capabilities such as embodied cognition, the gap between open-source and proprietary MLLMs has been significantly narrowed. Furthermore, we observe that Qwen2.5-VL and InternVL3 Zhu et al. [2025] demonstrate superior performance in positional relationship (PR) and distance perception tasks, respectively, even outperforming Gemini-2.5 Pro. Such pronounced differences in various aspects of spatial cognition may be attributed to the distribution of training data.
Open-source Object-Level MLLMs
These MLLMs are capable of accepting region masks as input, enabling more direct localization of target objects and facilitating finer-grained object perception. VideoRefer-VL3-7B Yuan et al. [2025c] is a model fine-tuned from the base model VideoLLaMA3-7B Zhang et al. [2025a]. As shown in Tab. 2, VideoRefer-VL3-7B consistently outperforms VideoLLaMA3-7B in both object cognition and spatial cognition tasks. This demonstrates that, in embodied scenarios, integrating mask understanding within the model is superior to explicit visual prompting.
Referring Video Object Segmentation MLLMs
Recently, several studies have applied MLLMs to object segmentation tasks while retaining the original multimodal understanding capabilities of MLLMs. However, the best-performing model, RGA3-7B Wang et al. [2025], achieves only 15.2 points on the object properties task. Although these MLLMs can still address some general video understanding tasks, their task generalization ability is significantly diminished following segmentation training. In contrast, our RynnEC model, which is specifically designed for embodied scenarios, maintains strong object and spatial understanding capabilities even after segmentation training.
Open-source Embodied MLLMs
With the growing demand for highly generalizable cognitive abilities in the field of embodied intelligence, a number of studies have begun to develop MLLMs specifically tailored for embodied scenarios. A representative model is RoboBrain-2.0 Team et al. [2025], which achieves 24.2 even worse than general-purpose video models such as VideoLLaMA3-7B. There are two primary reasons for this: (1) Loss of object cognition: Embodied MLLMs typically emphasize spatial perception and task planning abilities, but tend to overlook the importance of detailed object understanding. (2) Lack of fine-grained perceptual capability: In egocentric videos, RoboBrain-2.0 demonstrates limited ability to interpret region-level features.
4.2.2 Object Cognition
Fig. 5 (a) presents a more comprehensive evaluation of RynnEC’s capability in object properties cognition from multiple dimensions. Since most object properties cognition abilities are encompassed by general video understanding skills, Gemini-2.5-Pro exhibits superior performance across various competencies. However, due to the high edge deployment requirements of embodied MLLMs, the inference speed of these large-scale models becomes a bottleneck. With only 7B parameters, RynnEC achieves object properties cognition comparable to that of Gemini-2.5-Pro in most categories. Notably, for attributes such as surface details, object state, and object shape, RynnEC-2B even surpasses all other MLLMs. Moreover, most MLLMs lack video object segmentation capabilities, whereas dedicated segmentation MLLMs often sacrifice understanding abilities. RynnEC, while maintaining strong comprehension capabilities, achieves 30.9% and 57.7% improvements over state-of-the-art segmentation MLLMs in direct referring and situational referring object segmentation tasks, respectively.
4.2.3 Spatial Cognition
Fig. 5 (b) demonstrates RynnEC’s spatial cognition capabilities through more fine-grained tasks. As spatial abilities have not been formally defined or systematically explored in previous work, different MLLMs only exhibit strengths in a limited set of specific skills. Overall, spatial cognition abilities such as Spatial Imagery, Movement Imagery, and Trajectory Review are typically absent in prior MLLMs. In contrast, RynnEC possesses a more comprehensive set of spatial abilities, which can facilitate embodied agents in developing spatial awareness within complex environments.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Bar Chart: Model Performance Comparison (VideoLLaMA3-7B vs RynnEC-7B)
### Overview
The chart compares the performance of two AI models, VideoLLaMA3-7B (light blue) and RynnEC-7B (purple), across 10 distinct tasks. Scores range from 0 to 70 on the y-axis, with task categories on the x-axis. VideoLLaMA3-7B has an average score of 35.8, while RynnEC-7B averages 45.8.
### Components/Axes
- **X-Axis (Tasks)**:
- Abs. Dist.
- Route Plan
- Rel. Dir. Hard
- Rel. Dist.
- Rel. Dir. Medium
- Rel. Dir. Easy
- Obj. Count
- Obj. Size
- Room Size
- Appear. Order
- **Y-Axis (Score)**: Numerical scale from 0 to 70.
- **Legend**:
- Light blue = VideoLLaMA3-7B (Avg. Score: 35.8)
- Purple = RynnEC-7B (Avg. Score: 45.8)
- **Title**: "VideoLLaMA3-7B (Avg. Score: 35.8) vs RynnEC-7B (Avg. Score: 45.8)"
### Detailed Analysis
1. **Abs. Dist.**:
- VideoLLaMA3-7B: 23.5
- RynnEC-7B: 25.4
2. **Route Plan**:
- VideoLLaMA3-7B: 32
- RynnEC-7B: 38.7
3. **Rel. Dir. Hard**:
- VideoLLaMA3-7B: 30
- RynnEC-7B: 42.9
4. **Rel. Dist.**:
- VideoLLaMA3-7B: 39.4
- RynnEC-7B: 44.2
5. **Rel. Dir. Medium**:
- VideoLLaMA3-7B: 46.3
- RynnEC-7B: 51.9
6. **Rel. Dir. Easy**:
- VideoLLaMA3-7B: 45.2
- RynnEC-7B: 53.5
7. **Obj. Count**:
- VideoLLaMA3-7B: 41.9
- RynnEC-7B: 58.5
8. **Obj. Size**:
- VideoLLaMA3-7B: 42.2
- RynnEC-7B: 54.9
9. **Room Size**:
- VideoLLaMA3-7B: 27.1
- RynnEC-7B: 42.7
10. **Appear. Order**:
- VideoLLaMA3-7B: 31.4
- RynnEC-7B: 30.5
### Key Observations
- **RynnEC-7B Dominance**: Outperforms VideoLLaMA3-7B in 8/10 tasks, with the largest gap in "Obj. Count" (58.5 vs 41.9).
- **VideoLLaMA3-7B Weaknesses**: Lowest scores in "Abs. Dist." (23.5) and "Room Size" (27.1).
- **Consistency**: RynnEC-7B maintains higher scores across relational and object-based tasks.
- **Anomaly**: RynnEC-7B scores lower than VideoLLaMA3-7B in "Appear. Order" (30.5 vs 31.4).
### Interpretation
The data suggests RynnEC-7B excels in tasks requiring relational understanding and object manipulation, while VideoLLaMA3-7B struggles with absolute distance estimation and room size assessment. The 10-point average gap (45.8 vs 35.8) indicates RynnEC-7B’s broader capability, though both models show task-specific limitations. The near-tie in "Appear. Order" highlights potential trade-offs in model design priorities.
</details>
| Models | VSI-Bench |
| --- | --- |
| Qwen2.5-VL-7B Bai et al. [2025] | 35.9 |
| InternVL3-8B Zhu et al. [2025] | 42.1 |
| GPT-4o OpenAI et al. [2024] | 43.6 |
| Magma-8B Yang et al. [2025b] | 12.7 |
| Cosmos-Reason1-7B Azzolini et al. [2025] | 25.6 |
| VeBrain-8B Luo et al. [2025] | 26.3 |
| RoboBrain-7B-1.0 Ji et al. [2025] | 31.1 |
| RoboBrain-7B-2.0 Team et al. [2025] | 36.1 |
| M2-Reasoning-7B AI et al. [2025] | 42.3 |
| ViLaSR Wu et al. [2025b] | 45.4 |
| RynnEC-7B | 45.8 |
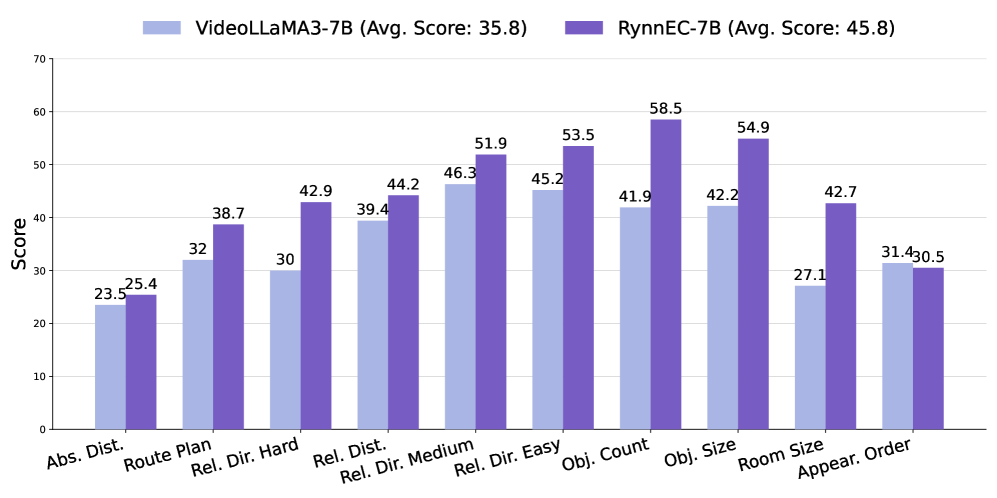
Figure 6: Performance on VSI-Bench Yang et al. [2025c]. Left: per-subtask comparison with VideoLLaMA3, the base model of our RynnEC. Right: overall comparison with generalist MLLMs and embodied MLLMs without explicit 3D encoding.
4.3 Generalization and Scalability
To investigate the generalizability of RynnEC, we conduct experiments on VSI-Bench Yang et al. [2025c], a purely textual spatial intelligence benchmark. As shown in Fig. 6, RynnEC-7B consistently surpasses VideoLLaMA3-7B across almost all capability dimensions. Notably, RynnEC is trained with a mask-centric spatial awareness paradigm, whereas all tasks in VSI-Bench involve purely textual spatial reasoning. This demonstrates that spatial awareness need not be constrained by the modality of representation, and spatial reasoning abilities can be effectively transferred across modalities. Further observation reveals substantial performance gains of RynnEC on the Route Planning task, despite this task not being included during training. This indicates that the navigation performance of embodied agents is currently constrained by foundational spatial perception capabilities, such as the understanding of direction, distance, and spatial relationships. Only with robust foundational spatial cognition can large embodied models achieve superior performance in high-level planning and decision-making tasks. Compared to other embodied MLLMs of comparable size, RynnEC-7B also achieves a leading score of 45.8.
Certain tasks, such as object segmentation and movement imagery, remain significant challenges for RynnEC. We hypothesize that the suboptimal performance on these tasks stems primarily from insufficient training data. To validate this, we conduct an empirical analysis of data scalability across different task categories. As the data volume increases progressively from 20% to 100%, the model’s performance on all tasks improves steadily. This observation motivates further expansion of the dataset to enhance RynnEC’s spatial reasoning capabilities. However, it is noteworthy that the marginal gains diminish as data volume grows, indicating a decreasing return on scale. Investigating strategies to enhance data diversity in order to sustain this scaling behavior remains a critical open challenge for future research.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Screenshot: Virtual Environment Task Instructions
### Overview
The image depicts a simulated environment interface with two distinct tasks (Task1 and Task2) presented in a step-by-step format. Each task includes visual snapshots of the environment, textual instructions, questions, answers, and corresponding actions. The layout uses color-coded annotations (red, green, blue) to highlight object interactions and spatial relationships.
### Components/Axes
- **Task1**:
- **Objective**: "Put the basketball in the white box beside the tennis racket."
- **Steps**:
1. Walk to the basketball, pick it up.
2. Walk to the white box beside the tennis racket.
3. Place the basketball in the white box.
- **Annotations**:
- Red arrows indicate object locations (e.g., basketball, white box).
- Green arrows show movement paths.
- Blue text boxes contain questions/answers (e.g., "Where is the basketball?").
- **Task2**:
- **Objective**: "Reduce the number of plates on the dining table to five, and place the removed plates to the left of the laptop."
- **Steps**:
1. Walk to the dining table, count plates.
2. Pick up a removed plate.
3. Walk to the laptop, place the plate on its left.
- **Annotations**:
- Blue arrows highlight the dining table and laptop.
- Purple text boxes contain questions/answers (e.g., "How many plates are there?").
### Detailed Analysis
#### Task1
- **Step1**:
- **Question**: "Where is the basketball?"
- **Answer**: "The basketball is <object1>."
- **Action**: "Go straight and then turn left. Crouch down and pull the ball out from under the table."
- **Step2**:
- **Question**: "Where is the white box beside the tennis racket?"
- **Answer**: "The white box is directly behind me."
- **Action**: "Turn around."
- **Step3**:
- **Question**: "How wide is the white box?"
- **Answer**: "Approximately 0.22 meters. It cannot accommodate the basketball."
- **Action**: "Carefully place the basketball on the white box."
#### Task2
- **Step1**:
- **Question**: "How many plates are on the dining table?"
- **Answer**: "Six."
- **Action**: "Turn right to view the entire dining table."
- **Step2**:
- **Question**: "Which plate is closest to me?"
- **Answer**: "<object4> is closest."
- **Action**: "Pick up <object4>."
- **Step3**:
- **Question**: "Where is the laptop?"
- **Answer**: "The laptop is 4.5 meters away, one o’clock position relative to me."
- **Action**: "Turn right by 30 degrees, then go straight for 4 meters. Place the plate on the left side of the laptop."
### Key Observations
1. **Spatial Reasoning**: Instructions rely on relative positioning (e.g., "one o’clock position," "left of the laptop").
2. **Object Interaction**: Color-coded arrows (red/green/blue) visually guide object manipulation and movement.
3. **Dynamic Adjustments**: Task2 requires removing plates to meet a target count (5), implying conditional logic.
4. **Measurement Precision**: Distances (e.g., 1.2 meters, 4.5 meters) are provided with approximate values.
### Interpretation
This interface simulates a multi-step reasoning process for an AI or robot, combining spatial navigation, object counting, and conditional actions. The integration of questions/answers suggests a feedback loop where the system verifies object locations and quantities before executing actions. The use of color-coded annotations enhances clarity in complex environments, while approximate measurements highlight real-world constraints (e.g., object size limitations). The tasks emphasize procedural logic, requiring the system to adapt to dynamic environments (e.g., reducing plate counts).
</details>
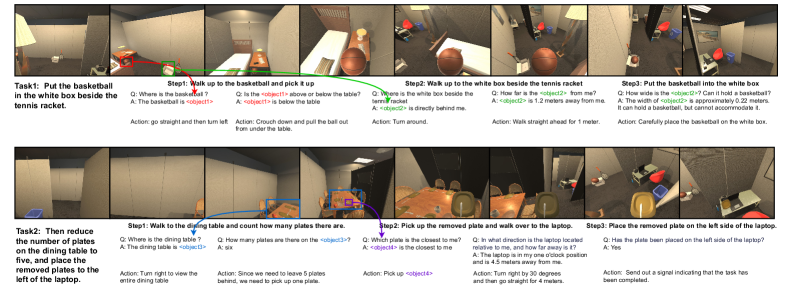
Figure 7: The example of RynnEC assisting robots in performing long-range tasks. The robot accomplishes the two designated tasks within the RoboTHOR simulator Deitke et al. [2020]. RynnEC facilitates the robot in achieving fine-grained environmental cognition throughout the task execution.
4.4 Embodied Application
Recently, some works Cheng et al. [2024b], Xiong et al. [2024] have leveraged MLLMs as the "brain" to assist robots in planning tasks, perceiving environments, and making decisions. However, current MLLMs lack key capabilities such as spatial awareness, fine-grained perception, and instance localization, which restricts these applications to limited and simple tasks. As illustrated in Fig. 7, RynnEC demonstrates the potential to assist robots in accomplishing long-horizon tasks within complex environments. From two real-time tasks performed by the robot equipped with RynnEC, we observe the following roles that RynnEC plays in task execution: (1) Fine-grained object localization and understanding enable robots to more quickly identify target objects and assess their states; (2) Direction and distance perception of targets improves navigation efficiency and precision; (3) Spatial scale estimation empowers robots to perform more delicate manipulations; (4) Counting ability facilitates the completion of tasks requiring mathematical reasoning. It is important to emphasize that the role of RynnEC in embodied tasks is far from limited to these examples. We hope that more researchers will integrate RynnEC models into robotic systems across a wide range of tasks, thereby advancing embodied intelligence toward more valuable real-world applications.
5 Conclusion and Future Works
In this paper, we introduce RynnEC, a Video MLLM for embodied cognition. Through the architectural design of a region encoder and mask decoder, RynnEC achieves flexible, fine-grained visual interaction. Meanwhile, RynnEC demonstrates robust object and spatial cognitive abilities with compact size. To address the limitations of available scene data, we employ a data generation pipeline that relies solely on RGB videos. Furthermore, to supplement the lack of fine-grained embodied cognition benchmarks, we propose RynnEC-Bench, which covers 22 categories of object and spatial cognitive abilities. During training, RynnEC progressively integrates diverse skills through a four-stage capability injection process. Importantly, we advocate that fine-grained video-based visual understanding is key to achieving generalizable cognition in the physical world. RynnEC will enable robots to accomplish more precise cognitive tasks, thereby advancing the practical development of embodied intelligence.
We regard RynnEC as a foundational step toward developing a general embodied intelligence model. Looking ahead, we plan to further advance RynnEC along two primary directions.
- Enhancing Reasoning Capabilities: Robust visual reasoning is essential for solving any complex embodied task. An important research direction is how to effectively integrate RynnEC’s diverse abilities to perform joint reasoning, thereby enabling the resolution of higher-level embodied problems.
- Unified Perception and Planning Framework: Recent studies Team et al. [2025] have started to explore training unified embodied intelligence models that combine perception and planning. However, these approaches are limited in their ability to facilitate fine-grained, video-based visual interactions. In the future, we aim to endow RynnEC with more flexible planning abilities and integrate it with VLA models to form a closed-loop embodied system.
References
- AI et al. [2025] Inclusion AI, Fudong Wang, Jiajia Liu, Jingdong Chen, Jun Zhou, Kaixiang Ji, Lixiang Ru, Qingpei Guo, Ruobing Zheng, Tianqi Li, et al. M2-reasoning: Empowering mllms with unified general and spatial reasoning. arXiv preprint arXiv:2507.08306, 2025.
- Ataallah et al. [2024] Kirolos Ataallah, Xiaoqian Shen, Eslam Abdelrahman, Essam Sleiman, Deyao Zhu, Jian Ding, and Mohamed Elhoseiny. Minigpt4-video: Advancing multimodal llms for video understanding with interleaved visual-textual tokens. arXiv preprint arXiv:2404.03413, 2024.
- Azzolini et al. [2025] Alisson Azzolini, Junjie Bai, Hannah Brandon, Jiaxin Cao, Prithvijit Chattopadhyay, Huayu Chen, Jinju Chu, Yin Cui, Jenna Diamond, Yifan Ding, et al. Cosmos-reason1: From physical common sense to embodied reasoning. arXiv preprint arXiv:2503.15558, 2025.
- Bai et al. [2025] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025. https://arxiv.org/abs/2502.13923.
- Caba Heilbron et al. [2015] Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the ieee conference on computer vision and pattern recognition, pages 961–970, 2015.
- Caesar et al. [2018] Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. Coco-stuff: Thing and stuff classes in context. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1209–1218, 2018.
- Chen et al. [2024a] Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024a.
- Chen et al. [2024b] Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Zhenyu Tang, Li Yuan, et al. Sharegpt4video: Improving video understanding and generation with better captions. Advances in Neural Information Processing Systems, 37:19472–19495, 2024b.
- Chen et al. [2014] Xianjie Chen, Roozbeh Mottaghi, Xiaobai Liu, Sanja Fidler, Raquel Urtasun, and Alan Yuille. Detect what you can: Detecting and representing objects using holistic models and body parts. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1971–1978, 2014.
- Cheng et al. [2024a] An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision language models. arXiv preprint arXiv:2406.01584, 2024a.
- Cheng et al. [2024b] Kai Cheng, Zhengyuan Li, Xingpeng Sun, Byung-Cheol Min, Amrit Singh Bedi, and Aniket Bera. Efficienteqa: An efficient approach for open vocabulary embodied question answering. arXiv preprint arXiv:2410.20263, 2024b.
- Comanici et al. [2025] Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025.
- Dang et al. [2025] Ronghao Dang, Yuqian Yuan, Wenqi Zhang, Yifei Xin, Boqiang Zhang, Long Li, Liuyi Wang, Qinyang Zeng, Xin Li, and Lidong Bing. Ecbench: Can multi-modal foundation models understand the egocentric world? a holistic embodied cognition benchmark. arXiv preprint arXiv:2501.05031, 2025.
- Deitke et al. [2020] Matt Deitke, Winson Han, Alvaro Herrasti, Aniruddha Kembhavi, Eric Kolve, Roozbeh Mottaghi, Jordi Salvador, Dustin Schwenk, Eli VanderBilt, Matthew Wallingford, Luca Weihs, Mark Yatskar, and Ali Farhadi. Robothor: An open simulation-to-real embodied ai platform, 2020.
- Doveh et al. [2025] Sivan Doveh, Shaked Perek, M Jehanzeb Mirza, Wei Lin, Amit Alfassy, Assaf Arbelle, Shimon Ullman, and Leonid Karlinsky. Towards multimodal in-context learning for vision and language models. In European Conference on Computer Vision, pages 250–267. Springer, 2025.
- Everingham et al. [2010] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88:303–338, 2010.
- Fan et al. [2025] Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Dilin Wang, Zhicheng Yan, et al. Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction. arXiv preprint arXiv:2505.20279, 2025.
- Farré et al. [2024] Miquel Farré, Andi Marafioti, Lewis Tunstall, Leandro Von Werra, and Thomas Wolf. Finevideo. https://huggingface.co/datasets/HuggingFaceFV/finevideo, 2024.
- Fischler and Bolles [1981] Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM, 24(6):381–395, 1981.
- Guo et al. [2025] Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1.5-vl technical report. arXiv preprint arXiv:2505.07062, 2025.
- Han et al. [2025a] Xiaofeng Han, Shunpeng Chen, Zenghuang Fu, Zhe Feng, Lue Fan, Dong An, Changwei Wang, Li Guo, Weiliang Meng, Xiaopeng Zhang, et al. Multimodal fusion and vision-language models: A survey for robot vision. arXiv preprint arXiv:2504.02477, 2025a.
- Han et al. [2025b] Xiaofeng Han, Shunpeng Chen, Zenghuang Fu, Zhe Feng, Lue Fan, Dong An, Changwei Wang, Li Guo, Weiliang Meng, Xiaopeng Zhang, et al. Multimodal fusion and vision-language models: A survey for robot vision. arXiv preprint arXiv:2504.02477, 2025b.
- Hong et al. [2025] Fangzhou Hong, Vladimir Guzov, Hyo Jin Kim, Yuting Ye, Richard Newcombe, Ziwei Liu, and Lingni Ma. Egolm: Multi-modal language model of egocentric motions. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 5344–5354, 2025.
- Hou et al. [2025] Xiaolu Hou, Mingcheng Li, Dingkang Yang, Jiawei Chen, Ziyun Qian, Xiao Zhao, Yue Jiang, Jinjie Wei, Qingyao Xu, and Lihua Zhang. Bloomscene: Lightweight structured 3d gaussian splatting for crossmodal scene generation. arXiv preprint arXiv:2501.10462, 2025.
- Ji et al. [2025] Yuheng Ji, Huajie Tan, Jiayu Shi, Xiaoshuai Hao, Yuan Zhang, Hengyuan Zhang, Pengwei Wang, Mengdi Zhao, Yao Mu, Pengju An, et al. Robobrain: A unified brain model for robotic manipulation from abstract to concrete. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 1724–1734, 2025.
- Jin et al. [2024] Shiyu Jin, Jinxuan Xu, Yutian Lei, and Liangjun Zhang. Reasoning grasping via multimodal large language model. arXiv preprint arXiv:2402.06798, 2024.
- Li et al. [2024a] Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024a.
- Li et al. [2024b] Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024b.
- Li et al. [2024c] Xiaoqi Li, Mingxu Zhang, Yiran Geng, Haoran Geng, Yuxing Long, Yan Shen, Renrui Zhang, Jiaming Liu, and Hao Dong. Manipllm: Embodied multimodal large language model for object-centric robotic manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18061–18070, 2024c.
- Li et al. [2025a] Yifan Li, Yuhang Chen, Anh Dao, Lichi Li, Zhongyi Cai, Zhen Tan, Tianlong Chen, and Yu Kong. Industryeqa: Pushing the frontiers of embodied question answering in industrial scenarios. arXiv preprint arXiv:2505.20640, 2025a.
- Li et al. [2025b] Yun Li, Yiming Zhang, Tao Lin, XiangRui Liu, Wenxiao Cai, Zheng Liu, and Bo Zhao. Sti-bench: Are mllms ready for precise spatial-temporal world understanding? arXiv preprint arXiv:2503.23765, 2025b.
- Lian et al. [2025] Long Lian, Yifan Ding, Yunhao Ge, Sifei Liu, Hanzi Mao, Boyi Li, Marco Pavone, Ming-Yu Liu, Trevor Darrell, Adam Yala, et al. Describe anything: Detailed localized image and video captioning. arXiv preprint arXiv:2504.16072, 2025.
- Lin et al. [2023] Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. arXiv preprint arXiv:2311.10122, 2023.
- Lin et al. [2024] Weifeng Lin, Xinyu Wei, Ruichuan An, Peng Gao, Bocheng Zou, Yulin Luo, Siyuan Huang, Shanghang Zhang, and Hongsheng Li. Draw-and-understand: Leveraging visual prompts to enable mllms to comprehend what you want. arXiv preprint arXiv:2403.20271, 2024.
- Lin et al. [2025] Weifeng Lin, Xinyu Wei, Ruichuan An, Tianhe Ren, Tingwei Chen, Renrui Zhang, Ziyu Guo, Wentao Zhang, Lei Zhang, and Hongsheng Li. Perceive anything: Recognize, explain, caption, and segment anything in images and videos, 2025.
- Liu et al. [2023] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36:34892–34916, 2023.
- Luo et al. [2025] Gen Luo, Ganlin Yang, Ziyang Gong, Guanzhou Chen, Haonan Duan, Erfei Cui, Ronglei Tong, Zhi Hou, Tianyi Zhang, Zhe Chen, et al. Visual embodied brain: Let multimodal large language models see, think, and control in spaces. arXiv preprint arXiv:2506.00123, 2025.
- Lyu et al. [2024] Ruiyuan Lyu, Jingli Lin, Tai Wang, Xiaohan Mao, Yilun Chen, Runsen Xu, Haifeng Huang, Chenming Zhu, Dahua Lin, and Jiangmiao Pang. Mmscan: A multi-modal 3d scene dataset with hierarchical grounded language annotations. Advances in Neural Information Processing Systems, 37:50898–50924, 2024.
- Maaz et al. [2023] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. arXiv preprint arXiv:2306.05424, 2023.
- Maaz et al. [2024] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Videogpt+: Integrating image and video encoders for enhanced video understanding. arXiv preprint arXiv:2406.09418, 2024.
- Majumdar et al. [2024] Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, et al. Openeqa: Embodied question answering in the era of foundation models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16488–16498, 2024.
- Mao et al. [2016] Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 11–20, 2016.
- Munasinghe et al. [2025] Shehan Munasinghe, Hanan Gani, Wenqi Zhu, Jiale Cao, Eric Xing, Fahad Shahbaz Khan, and Salman Khan. Videoglamm: A large multimodal model for pixel-level visual grounding in videos. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19036–19046, 2025.
- Murai et al. [2025] Riku Murai, Eric Dexheimer, and Andrew J Davison. Mast3r-slam: Real-time dense slam with 3d reconstruction priors. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 16695–16705, 2025.
- Neuhold et al. [2017] Gerhard Neuhold, Tobias Ollmann, Samuel Rota Bulo, and Peter Kontschieder. The mapillary vistas dataset for semantic understanding of street scenes. In Proceedings of the IEEE international conference on computer vision, pages 4990–4999, 2017.
- OpenAI et al. [2024] OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, and Alan Hayes. Gpt-4o system card, 2024.
- Ouyang et al. [2025] Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. Spacer: Reinforcing mllms in video spatial reasoning, 2025. https://arxiv.org/abs/2504.01805.
- Pasqualotto and Proulx [2012] Achille Pasqualotto and Michael J Proulx. The role of visual experience for the neural basis of spatial cognition. Neuroscience & Biobehavioral Reviews, 36(4):1179–1187, 2012.
- Qi et al. [2025] Zhangyang Qi, Zhixiong Zhang, Ye Fang, Jiaqi Wang, and Hengshuang Zhao. Gpt4scene: Understand 3d scenes from videos with vision-language models. arXiv preprint arXiv:2501.01428, 2025.
- Ramanathan et al. [2023] Vignesh Ramanathan, Anmol Kalia, Vladan Petrovic, Yi Wen, Baixue Zheng, Baishan Guo, Rui Wang, Aaron Marquez, Rama Kovvuri, Abhishek Kadian, et al. Paco: Parts and attributes of common objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7141–7151, 2023.
- Ravi et al. [2024] Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714, 2024.
- Rawal et al. [2024] Ruchit Rawal, Khalid Saifullah, Miquel Farré, Ronen Basri, David Jacobs, Gowthami Somepalli, and Tom Goldstein. Cinepile: A long video question answering dataset and benchmark. arXiv preprint arXiv:2405.08813, 2024.
- Ray et al. [2024] Arijit Ray, Jiafei Duan, Reuben Tan, Dina Bashkirova, Rose Hendrix, Kiana Ehsani, Aniruddha Kembhavi, Bryan A Plummer, Ranjay Krishna, Kuo-Hao Zeng, et al. Sat: Spatial aptitude training for multimodal language models. arXiv preprint arXiv:2412.07755, 2024.
- Ren et al. [2024a] Allen Z Ren, Jaden Clark, Anushri Dixit, Masha Itkina, Anirudha Majumdar, and Dorsa Sadigh. Explore until confident: Efficient exploration for embodied question answering. arXiv preprint arXiv:2403.15941, 2024a.
- Ren et al. [2024b] Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, Wenlong Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xiaoke Jiang, Yihao Chen, et al. Grounding dino 1.5: Advance the" edge" of open-set object detection. arXiv preprint arXiv:2405.10300, 2024b.
- Tang et al. [2021] Zongheng Tang, Yue Liao, Si Liu, Guanbin Li, Xiaojie Jin, Hongxu Jiang, Qian Yu, and Dong Xu. Human-centric spatio-temporal video grounding with visual transformers. IEEE Transactions on Circuits and Systems for Video Technology, 32(12):8238–8249, 2021.
- Team et al. [2025] BAAI RoboBrain Team, Mingyu Cao, Huajie Tan, Yuheng Ji, Minglan Lin, Zhiyu Li, Zhou Cao, Pengwei Wang, Enshen Zhou, Yi Han, et al. Robobrain 2.0 technical report. arXiv preprint arXiv:2507.02029, 2025.
- Team et al. [2024] Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, and Damien Vincent. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, 2024.
- Wang et al. [2025] Haochen Wang, Qirui Chen, Cilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, Weidi Xie, and Stratis Gavves. Object-centric video question answering with visual grounding and referring. arXiv preprint arXiv:2507.19599, 2025.
- Wang et al. [2024] Tai Wang, Xiaohan Mao, Chenming Zhu, Runsen Xu, Ruiyuan Lyu, Peisen Li, Xiao Chen, Wenwei Zhang, Kai Chen, Tianfan Xue, et al. Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19757–19767, 2024.
- Wu et al. [2025a] Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence. arXiv preprint arXiv:2505.23747, 2025a.
- Wu et al. [2023] Jiayang Wu, Wensheng Gan, Zefeng Chen, Shicheng Wan, and Philip S Yu. Multimodal large language models: A survey. In 2023 IEEE International Conference on Big Data (BigData), pages 2247–2256. IEEE, 2023.
- Wu et al. [2025b] Junfei Wu, Jian Guan, Kaituo Feng, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, and Tieniu Tan. Reinforcing spatial reasoning in vision-language models with interwoven thinking and visual drawing. arXiv preprint arXiv:2506.09965, 2025b.
- Xiong et al. [2024] Chuyan Xiong, Chengyu Shen, Xiaoqi Li, Kaichen Zhou, Jiaming Liu, Ruiping Wang, and Hao Dong. Autonomous interactive correction mllm for robust robotic manipulation. In 8th Annual Conference on Robot Learning, 2024.
- Xu et al. [2025] Runsen Xu, Weiyao Wang, Hao Tang, Xingyu Chen, Xiaodong Wang, Fu-Jen Chu, Dahua Lin, Matt Feiszli, and Kevin J Liang. Multi-spatialmllm: Multi-frame spatial understanding with multi-modal large language models. arXiv preprint arXiv:2505.17015, 2025.
- Yan et al. [2024] Cilin Yan, Haochen Wang, Shilin Yan, Xiaolong Jiang, Yao Hu, Guoliang Kang, Weidi Xie, and Efstratios Gavves. Visa: Reasoning video object segmentation via large language models. In European Conference on Computer Vision, pages 98–115. Springer, 2024.
- Yang et al. [2024] An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2 technical report. arXiv preprint arXiv:2407.10671, 2024.
- Yang et al. [2025a] An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025a.
- Yang et al. [2025b] Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, et al. Magma: A foundation model for multimodal ai agents. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 14203–14214, 2025b.
- Yang et al. [2025c] Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025c.
- Yeshwanth et al. [2023] Chandan Yeshwanth, Yueh-Cheng Liu, Matthias NieSSner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d indoor scenes, 2023.
- Yu et al. [2016] Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. In European conference on computer vision, pages 69–85. Springer, 2016.
- Yuan et al. [2025a] Haobo Yuan, Xiangtai Li, Tao Zhang, Zilong Huang, Shilin Xu, Shunping Ji, Yunhai Tong, Lu Qi, Jiashi Feng, and Ming-Hsuan Yang. Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos. arXiv preprint arXiv:2501.04001, 2025a.
- Yuan et al. [2024] Yuqian Yuan, Wentong Li, Jian Liu, Dongqi Tang, Xinjie Luo, Chi Qin, Lei Zhang, and Jianke Zhu. Osprey: Pixel understanding with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28202–28211, 2024.
- Yuan et al. [2025b] Yuqian Yuan, Ronghao Dang, Long Li, Wentong Li, Dian Jiao, Xin Li, Deli Zhao, Fan Wang, Wenqiao Zhang, Jun Xiao, and Yueting Zhuang. Eoc-bench: Can mllms identify, recall, and forecast objects in an egocentric world?, 2025b. https://arxiv.org/abs/2506.05287.
- Yuan et al. [2025c] Yuqian Yuan, Hang Zhang, Wentong Li, Zesen Cheng, Boqiang Zhang, Long Li, Xin Li, Deli Zhao, Wenqiao Zhang, Yueting Zhuang, et al. Videorefer suite: Advancing spatial-temporal object understanding with video llm. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 18970–18980, 2025c.
- Zhang et al. [2025a] Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, and Deli Zhao. Videollama 3: Frontier multimodal foundation models for image and video understanding, 2025a. https://arxiv.org/abs/2501.13106.
- Zhang et al. [2024a] Duzhen Zhang, Yahan Yu, Jiahua Dong, Chenxing Li, Dan Su, Chenhui Chu, and Dong Yu. Mm-llms: Recent advances in multimodal large language models. arXiv preprint arXiv:2401.13601, 2024a.
- Zhang et al. [2023] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023.
- Zhang et al. [2025b] Haoyu Zhang, Qiaohui Chu, Meng Liu, Yunxiao Wang, Bin Wen, Fan Yang, Tingting Gao, Di Zhang, Yaowei Wang, and Liqiang Nie. Exo2ego: Exocentric knowledge guided mllm for egocentric video understanding. arXiv preprint arXiv:2503.09143, 2025b.
- Zhang et al. [2025c] Jiahui Zhang, Yurui Chen, Yanpeng Zhou, Yueming Xu, Ze Huang, Jilin Mei, Junhui Chen, Yu-Jie Yuan, Xinyue Cai, Guowei Huang, et al. From flatland to space: Teaching vision-language models to perceive and reason in 3d. arXiv preprint arXiv:2503.22976, 2025c.
- Zhang et al. [2024b] Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision. arXiv preprint arXiv:2406.16852, 2024b.
- Zhang et al. [2024c] Xingxuan Zhang, Jiansheng Li, Wenjing Chu, Junjia Hai, Renzhe Xu, Yuqing Yang, Shikai Guan, Jiazheng Xu, and Peng Cui. On the out-of-distribution generalization of multimodal large language models. arXiv preprint arXiv:2402.06599, 2024c.
- Zhang et al. [2024d] Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713, 2024d.
- Zhang et al. [2024e] Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713, 2024e.
- Zhou et al. [2017] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 633–641, 2017.
- Zhou et al. [2018] Luowei Zhou, Chenliang Xu, and Jason Corso. Towards automatic learning of procedures from web instructional videos. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
- Zhu et al. [2025] Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xuehui Wang, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, Hao Li, and Jiahao Wang. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models, 2025. https://arxiv.org/abs/2504.10479.
\beginappendix
A Implementation Details for Data Pipeline
A.1 Instance Segmentation
As described in Section 3.1.1, instance segmentation and tracking in videos require a three-stage collaborative process. The first stage involves the extraction of an object list, which should comprehensively include the names of all objects present in the video scene. After evaluating multiple approaches, we find that directly leveraging Qwen2.5-VL to extract object category names from video frames achieves the highest efficiency and accuracy. Specifically, we uniformly sample 16 frames from each video, dividing them into two groups: even-numbered frames and odd-numbered frames. Each group is then processed independently by Qwen2.5-VL to generate a list of object category names. The prompt used to guide the extraction of the object list is in Tab. 3.
System Prompt: Please analyze the image sequence captured as I move through an indoor environment and provide a concise list of major distinct physical objects that can be detected and segmented in these scenes. You need to pay attention to the following points (1) Focus on tangible items such as furniture, appliances, and tools. Avoid nouns that denote locations and rooms like "kitchen" or "bedroom". (2) Limit the list to a maximum of 20 objects, and avoid including specific components or parts of these objects. (3) Ensure the list does not have duplicates. Your output must be a series of nouns separated by semicolons
Table 3: Prompts for object list extraction.
During our experimentation, we observe that Qwen2.5-VL occasionally produces repeated instances of the same object name or phrases sharing the same object name as a prefix. To address this, we apply a post-processing step to remove duplicate and semantically similar phrases from the model outputs, thereby ensuring the diversity and conciseness of the object list. The final object list is obtained by taking the union of the results from the odd-numbered and even-numbered frame groups, yielding a more comprehensive and robust set of detected objects. Furthermore, generic scene-level categories such as "wall" and "floor" are explicitly excluded from the final object list, as they are not considered relevant instances for downstream instance-level tracking and segmentation tasks.
A.2 Object QA Generation
We generate three categories of object-related tasks: object caption, object comprehension QA, and referring video object segmentation. The pre-annotation prompts for object caption and object comprehension QA are presented in Tab. 4. Both tasks take as input a set of keyframes in which the target object is highlighted; the only difference lies in the task-specific instruction prompts.
The referring video object segmentation task requires generating unique referring expressions for objects. We aggregate the QAs generated in the previous stage for each object, representing various attributes of the object. Subsequently, Qwen3 utilizes these QAs to generate both direct referring expressions and situational referring expressions. The specific prompt is shown in Tab. 5.
Crop Image Prompt: The above four images show a crop of the object we need to describe. Bbox Image Prompt: The four images above highlight the target object with a red bounding box and dimmed background. Task Prompt: Caption Task: Please provide a detailed description of the specified object, focusing on its color, material, shape, state, position, function, surface detail and other information. (1) Stick to a narrative format for descriptions, avoiding list-like itemizations. (2) Just output the information you are sure of, if you output the wrong information you will be fired. Comprehension QA Task: I need you to generate a series of question pairs for me about this object, using <object> to represent the object in the question pairs. You can focus on its category, color, material, shape, state, position, function, surface detail, size and other information. "Output example" Question: What color is the <object>? Answer: Mainly red, with some blue as decoration. Notes: (1) The object in all images is the same; QA should focus solely on it, without referencing specific images. (2) Ask as many questions as needed—the more details, the better. (3) Prioritize reasoning and spatial understanding questions over simple ones. (4) You can ask questions about the target object by associating it with the surrounding objects (e.g., comparison, spatial relationship, functional relationship, quantitative relationship, etc.). # Python code together with above text prompts are directly sent to LLaMA ⬇ messages = [{"role": "user", "content": [ {"type": "text", "text": "Crop Image Prompt"} + crop_image_list + {"type": "text", "text": "Bbox Image Prompt"} + bbox_image_list + {"type": "text", "text": "Task Prompt"}]}]
Table 4: Prompts for object caption and comprehension QA generation. Separate textual instructions are provided for the cropped images and the images highlighting the object via bounding boxes, respectively.
System Prompt: You are analyzing indoor objects. Given a series of QAs about a single object (marked as <object>), use the information to generate two referring expressions that uniquely identify it. The two expressions should be: •
One simple referring expression, using attributes such as category, color, material, spatial location, or function. •
One situational referring expression, involving contextual reasoning and diverse sentence structures. Input Example: Question: What is the primary function of the <object>? Answer: The <object> is primarily used for holding writing instruments like pens and pencils. (Additional QA pairs continue in a similar fashion—omitted for brevity.) Output Example: [simple expression] The cylindrical light brown pen holder on the top shelf of the desk. [complex expression] If I finish writing with a pencil, where is the best place to store it?
Table 5: Prompt for object referring expression generation.
A.3 Spatial QA Generation
As outlined in Section 3.1.3, we adopt a template-based approach for generating spatial QA. Specifically, we define 14 core spatial abilities and create a total of 30 distinct templates, with each template encompassing at least three different question structures. Some examples of QA templates are provided in Listing LABEL:lst:qa_template.
Listing 1: Template examples for Spatial QA generation.
⬇
camera_distance_questions = [
" How far have you walked in total?",
" What is the total distance you have covered walking?",
" What is the overall distance you have walked?"
]
closer_to_camera_questions = [
" Which is closer to you, [A] or [B]?",
" Between [A] and [B], which one is nearer to you?",
" Which one is closer to you, [A] or [B]?"
]
closest_to_camera_questions = [
" Which is closest to you, [A] or [B] or [C]?",
" Among [A], [B], and [C], which one is nearer to you?",
" Which of [A], [B], or [C] is closest to you?"
]
future_direction_camera_questions = [
" After you turn 90 degrees to the left, where will [A] be in relation to you?",
" If you turn left by 90- degree, in which direction will [A] be positioned?",
" Upon making a 90- degree left turn, how will [A] be oriented with respect to you?"
]
future_direction_camera_rotate_questions = [
" How many degrees clockwise do you need to turn to face the direction of [A]?",
" To face towards [A], how many degrees should you rotate in a clockwise direction?",
" What degree of clockwise rotation is necessary for you to face [A]’ s direction?"
]
distance_questions_3 = [
" Which of the three objects, [A], [B], or [C], is closest to you?",
" Among [A], [B], and [C], which object is nearest to you?",
" Between [A], [B], and [C], which one is the closest to you?",
]
height_from_ground_questions = [
" What is the height difference above ground level between [A] and [B]?",
" How much higher or lower is [A] compared to [B] above the ground?",
" By what amount does the elevation of [A] differ from that of [B]?"
]
center_distance_questions = [
" What is the distance between the centers of [A] and [B]?",
" How far apart are the centers of [A] and [B]?",
" What is the separation between the central points of [A] and [B]?"
]
tall_choice_questions_3 = [
" Among the three objects [A], [B], and [C], which one is the tallest?",
" Which of the three objects [A], [B], and [C] is tallest?",
" Out of the three objects [A], [B], and [C], which one is the tallest?",
]
above_predicate_questions = [
" Is [A] above [B]?",
" Does [A] appear over [B]?",
" Can you confirm if [A] is positioned above [B]?",
]
B Details of RynnEC-Bench Construction
As described in Section 3.2.2, we adjust the object distribution in the object properties understanding evaluation set of RynnEC-Bench based on real-world object category frequencies. The detailed object categorization strategy is presented in Tab. 6. We classify common indoor objects into 12 coarse categories and 119 fine-grained categories. Objects not falling into any of these predefined categories are assigned to an "other" class. A function-centered taxonomy is adopted: objects with similar appearances but distinct functional roles are categorized separately.
To construct this evaluation set, we follow a two-stage process. First, an initial, oversized pool of 20,000 question-answer (QA) pairs is randomly generated without distributional constraints. Following this, we downsample this pool to a target size of 10,000 pairs. The sampling is performed according to the real-world object distribution outlined previously. Specifically, we calculate the target number of samples for each object category by multiplying its frequency in the distribution by the total target size (10,000). The final dataset is then constructed by drawing the calculated number of QA pairs for each category from the initial 20,000-pair pool. This stratified sampling strategy ensures that the final evaluation set’s composition accurately mirrors the specified real-world object frequencies.
| Category | Fine-Grained Classes |
| --- | --- |
| Furniture | Bed, Chair, Sofa, Table, Nightstand, Cabinet, Shelf, Headboard, Wardrobe, Drawer, Wall, Door, Window, Mirror, Hanger, Hook, Handle, Hinge, Railing, Radiator, Light Switch |
| Appliances & Electronics | Outlet, Refrigerator, Washing Machine, Air Conditioner, Monitor, Television, Control Panel, Fan, Speaker, Lamp, Charger, Router, Cable, Oven, Toaster, Microwave, Water heater, Range Hoods, Remote Control |
| Kitchenware & Tableware | Spice Jar, Pot, Kettle, Cup, Jar, Bowl, Spoon, Knife, Plate, Chopping board, Chopstick, Stove, Rice Cooker |
| Containers | Bag, Box, Basket, Bucket, Bottle, Trash Can, Can, Lid, Ashtray |
| Bathroom & Cleaning | Faucet, Sink, Toilet, Toilet Seat, Toilet Lid, Shower, Bathtub, Mop, Broom, Brush, Sponge, Towel, Toothbrush, Toothpaste, Comb, Soap, Toilet Paper, Hose, Razor, Hair Dryer |
| Textiles & Bedding | Quilt, Blanket, Carpet, Curtain, Pillow, Cushion, Mattress |
| Stationery & Office Supplies | Book, Clock, Calendar, Pen, Sharpener, Scissors, Calculator, Mouse, Mousepad, Keyboard, LaptopPanel, Tablet Computer |
| Decor & Art | Plant, Painting, Picture, Poster, Label, Calendar, Vase |
| Daily Necessities | Phone, Hat, Slipper, Shoe, Umbrella, Headphones, Glove |
| Food | Fruit, Vegetable |
| Clothing | Shirt, Pants, Dress, Skirt, Coat, Shorts, Socks, Underwear |
| Fitness & Recreation | Treadmill, Dumbbells, Piano, Toy |
Table 6: Object category taxonomy.
C Qualitative examples
In section ˜ 4.2.1 and table ˜ 2, we show that our model can handle different types of object and spatial cognition tasks. In this section, we show more detailed qualitative examples for different abilities of our model.
C.1 Object Cognition
- Properties (figure ˜ 8, figure ˜ 9). The model discerns a wide range of object properties, including physical attributes such as size, color, and surface details, as well as functional affordances.
- Segmentation (figure ˜ 8). The system performs both simple and situational referring expression segmentation, enabling it to isolate target objects in the scene based on natural language queries.
C.2 Spatial Cognition
- Trajectory Review (figure ˜ 8). The model perceives the distance traversed by its own camera, allowing for a review of its past trajectory.
- Egocentric Direction (figure ˜ 9). It successfully determines the direction of objects relative to its own perspective.
- Egocentric Distance (figure ˜ 9). The system is capable of estimating the egocentric distance from itself to surrounding objects in the environment.
- Movement Imagery (figure ˜ 8). A key capability is the imagination of prospective movements, allowing the model to reason about future paths.
- Spatial Imagery (figure ˜ 8). The model demonstrates an ability for spatial imagination, such as inferring the layout of unseen areas.
- Object Size (figure ˜ 9). Its spatial understanding extends to estimating the absolute sizes of objects and performing relative size comparisons between them.
- Object Height (figure ˜ 8). Similarly, the model predicts and compares the heights of different objects.
- Object Distance (figure ˜ 9). The system accurately gauges the distance between multiple objects within the scene (i.e., inter-object distance).
- Absolute Position (figure ˜ 8). The model can ascertain the absolute positional relationships between objects.
- Relative Position (figure ˜ 9). Furthermore, it demonstrates a robust understanding of the relative positions of objects with respect to one another.
<details>
<summary>figures/append-qual/qual-all-1.png Details</summary>
### Visual Description
## Text-Based Q&A Dataset: Object and Spatial Cognition Analysis
### Overview
The image contains a structured dataset of questions and answers (Q&A pairs) organized into cognitive dimensions related to object and spatial cognition. Each section focuses on a specific attribute (e.g., color, shape, function) or spatial relationship (e.g., position, movement) of objects in various room settings.
### Components/Axes
- **Dimensions**: Labeled in purple text (e.g., "Object Cognition---Color", "Spatial Cognition---Spatial Imagery").
- **Questions (Q)**: Green text, asking about object attributes or spatial relationships.
- **Answers (A)**: Red text, providing factual responses based on visual context.
- **Objects**: Highlighted in cyan or magenta bounding boxes across multiple room scenes.
### Content Details
#### Object Cognition Dimensions
1. **Color**
- Q: What is the primary color of `<object0>`?
- A: The object is primarily light brown.
2. **Category**
- Q: What category does `<object0>` belong to?
- A: The object is a piece of furniture, specifically a small wooden table or stand.
3. **Shape**
- Q: What is the shape of `<object0>`?
- A: The object has a rectangular shape with a flat top and open sides.
4. **Function**
- Q: What is the function of `<object0>`?
- A: The object is used for storage.
5. **State**
- Q: What can be inferred about the state of `<object2>`?
- A: The object appears to be in a stationary state, not currently in use.
6. **Material**
- Q: What material is `<object1>` likely made of?
- A: `<object1>` is likely made of plastic.
#### Spatial Cognition Dimensions
1. **Spatial Imagery**
- Q: Positioned at `<object0>` with your view directed towards `<object1>`, in which direction is `<object2>` situated?
- A: Right front.
2. **Absolute Position**
- Q: Which one is above, `<object0>` or `<object1>`?
- A: `<object0>`.
3. **Object Height**
- Q: How much higher or lower is `<object1>` compared to `<object0>` above the ground?
- A: 1.03 meters.
4. **Movement Imagery**
- Q: After turning 90 degrees left, where will `<object1>` be in relation to you?
- A: `<object1>` will be at the 6 o’clock direction from me.
5. **Trajectory Review**
- Q: How far did you walk?
- A: 1.83 meters.
#### Additional Object Cognition Dimensions
1. **Size**
- Q: How does the size of `<object0>` compare to other items on the table?
- A: The object is relatively small compared to the coffee machine and trash bin.
2. **Position**
- Q: What is the position of `<object0>`?
- A: The object is mounted on the wall above the countertop.
3. **Object Segmentation**
- Q: If I want to drink water, which object should I look for?
- A: [No explicit answer provided in the image.]
### Key Observations
- **Consistency**: Answers are contextually grounded in visual cues (e.g., object placement, material inference).
- **Ambiguity**: Some questions (e.g., segmentation) lack answers, suggesting incomplete data.
- **Room Context**: Objects are analyzed across diverse environments (e.g., office, kitchen, living room).
### Interpretation
This dataset evaluates cognitive tasks involving object recognition (color, category, function) and spatial reasoning (position, movement). The structured Q&A format implies its use in training or benchmarking AI models for visual understanding. The absence of answers for segmentation questions highlights potential gaps in the dataset’s scope or labeling process. Spatial cognition tasks emphasize relative positioning and movement prediction, critical for robotics or augmented reality applications.
</details>
Figure 8: Visualization of question answering examples. Part 1 out of 2.
<details>
<summary>figures/append-qual/qual-all-3.png Details</summary>
### Visual Description
## Screenshot: Cognitive Question-Answer Dataset
### Overview
The image displays a structured dataset of cognitive questions and answers organized into four main sections, each focusing on different dimensions of spatial and object cognition. Each section contains three subsections with specific questions and answers, using placeholders like `<object0>`, `<object1>`, etc., to reference objects in hypothetical scenarios.
### Components/Axes
- **Sections**: Four primary categories:
1. Spatial Cognition (Egocentric Distance, Direction, Object Distance, Size)
2. Object Cognition (Surface Detail, Shape, Size, Segmentation)
3. Spatial Cognition (Relative Position, Egocentric Distance)
4. Object Cognition (Function, Relative Position)
- **Question Format**:
- **Q:** (Question text)
- **A:** (Answer text)
- **Object Placeholders**: `<object0>`, `<object1>`, `<object2>` (used to reference objects in scenarios).
### Detailed Analysis
#### Section 1: Spatial Cognition
1. **Egocentric Distance**
- **Q:** What is the distance between me and `<object0>`?
- **A:** 1.63m.
2. **Surface Detail**
- **Q:** What's the surface detail of `<object0>`?
- **A:** The surface of `<object0>` is smooth and reflective.
3. **Egocentric Direction**
- **Q:** Is `<object0>` on your left front or right front in the last frame?
- **A:** Left front.
#### Section 2: Object Cognition
1. **Shape**
- **Q:** What is the shape of `<object0>`?
- **A:** The object has a classic teddy bear shape with a round head and body, and limbs.
2. **Size Comparison**
- **Q:** What is the size of `<object0>` compared to the iPad on the desk?
- **A:** The object is larger in size compared to the iPad on the desk.
3. **Object Segmentation**
- **Q:** If I want to check the current weather and time while sitting at the desk, where should I look?
- **A:** [Image of a TV screen displaying weather/time].
#### Section 3: Spatial Cognition (Relative Position)
1. **Object Distance**
- **Q:** What is the distance between `<object0>` and `<object1>`?
- **A:** It is 1.23 meters.
2. **Object Size**
- **Q:** How tall is `<object1>`?
- **A:** It is 1.02 meters.
3. **Relative Position**
- **Q:** Is `<object0>` directly above `<object1>`?
- **A:** No, they are on the same height.
#### Section 4: Object Cognition (Function)
1. **Function**
- **Q:** What is the function of `<object0>`?
- **A:** The object provides water, which can be used for drinking or cooking.
2. **Egocentric Distance**
- **Q:** Among `<object0>`, `<object1>`, and `<object2>`, which one is nearer to you?
- **A:** `<object0>`.
### Key Observations
- **Placeholder Usage**: Objects are consistently labeled as `<objectX>` across scenarios, suggesting a template-based dataset.
- **Measurement Precision**: Distances are provided with decimal precision (e.g., 1.63m, 1.23m), indicating a focus on quantitative spatial reasoning.
- **Contextual Scenarios**: Questions simulate real-world tasks (e.g., checking weather, comparing object sizes), emphasizing practical cognitive applications.
### Interpretation
This dataset appears designed to evaluate or train models in **spatial reasoning** (e.g., egocentric distance, relative positioning) and **object cognition** (e.g., shape recognition, functional understanding). The use of placeholders allows flexibility for diverse object types, while the structured Q&A format facilitates automated evaluation. The emphasis on egocentric perspectives (e.g., "left front," "nearer to you") suggests applications in robotics, AR/VR, or assistive technologies where spatial awareness is critical.
No numerical trends or anomalies are present, as the data consists of discrete Q&A pairs rather than continuous metrics.
</details>
Figure 9: Visualization of question answering examples. Part 2 out of 2.