# Mutual Information Surprise: Rethinking Unexpectedness in Autonomous Systems
**Authors**: Yinsong Wang, Quan Zeng, Xiao Liu, Yu Ding, H. Milton Stewart School of Industrial and Systems Engineering, Georgia Institute of Technology, Atlanta & 30332, USA
Abstract
Recent breakthroughs in autonomous experimentation have demonstrated remarkable physical capabilities, yet their cognitive control remains limited—often relying on static heuristics or classical optimization. A core limitation is the absence of a principled mechanism to detect and adapt to the unexpectedness. While traditional surprise measures—such as Shannon or Bayesian Surprise—offer momentary detection of deviation, they fail to capture whether a system is truly learning and adapting. In this work, we introduce Mutual Information Surprise (MIS), a new framework that redefines surprise not as anomaly detection, but as a signal of epistemic growth. MIS quantifies the impact of new observations on mutual information, enabling autonomous systems to reflect on their learning progression. We develop a statistical test sequence to detect meaningful shifts in estimated mutual information and propose a mutual information surprise reaction policy (MISRP) that dynamically governs system behavior through sampling adjustment and process forking. Empirical evaluations—on both synthetic domains and a dynamic pollution map estimation task—show that MISRP-governed strategies significantly outperform classical surprise-based approaches in stability, responsiveness, and predictive accuracy. By shifting surprise from reactive to reflective, MIS offers a path toward more self-aware and adaptive autonomous systems.
1 Introduction
In July 2020, Nature published a cover story (?) about an autonomous robotic chemist—locked in a lab for a week with no external communication—independently conducting experiments to search for improved photocatalysts for hydrogen production from water. In the years that followed, Nature featured three more articles (?, ?, ?) highlighting the transformative role of autonomous systems in materials discovery, experimentation, and even manufacturing, each reporting orders-of-magnitude improvements in efficiency. These reports spotlighted the intensifying global race to advance autonomous technologies beyond the already well-established domain of self-driving cars (?, ?, ?, ?). Nature was not alone; numerous other outlets have documented the surge in autonomous research and innovation (?, ?, ?). This rapid expansion is a natural consequence of recent advances in robotics and artificial intelligence, which continue to push the boundaries of what autonomous systems can accomplish.
The systems featured in the Nature publications demonstrate highly capable bodies that can perform complex tasks. Recall that an autonomous system comprises two fundamental components: a brain and a body—colloquial terms for its control mechanism and its sensing-action capabilities, respectively. Unlike traditional automation systems, which follow predefined instructions to execute simple, repetitive tasks, true autonomy requires a higher level of cognitive capacity—an autonomous system is supposedly capable of making decisions with minimal human intervention. However, their brain function, while more sophisticated than rigid pre-programmed instructions, remains relatively limited.
Surveying the literature over the past decade, we found that (?), (?), and (?) rely on classical Bayesian optimization to guide system decisions—a technique that, although effective, does not constitute full autonomy, i.e., completely eliminating human involvement. More recent works in Nature (?, ?) continue in a similar vein, adopting active learning frameworks akin to Bayesian optimization, without fundamentally enhancing the cognitive capabilities of these systems. The conceptual limitations of their decision-making mechanisms continue to impede progress toward genuine autonomy. (?) argue that a core deficiency of current autonomous systems is the absence of a “surprise” mechanism—the capacity to detect and adapt to unforeseen situations. Without this capability, true autonomy remains out of reach.
What is a “surprise,” and how does it differ from existing measures governing automation? Surprise is a fundamental psychological trigger that enables humans to react to unexpected events. Intuitively, it arises when observations deviate from expectations. Traditionally, unexpectedness has been loosely equated with anomalies—quantifying inconsistencies between new observations and historical data. Common approaches to anomaly detection include statistical methods such as z-scores (?) and hypothesis testing (?, ?); distance-based techniques (?), including Euclidean (?) and Mahalanobis distances (?, ?); and machine learning-based models (?, ?), which learn patterns to identify and filter out anomalous data. However, researchers increasingly recognize that simply detecting and discarding unexpected events is insufficient for achieving higher levels of autonomy. In human cognition, unexpectedness is not inherently undesirable; in fact, surprise often signals opportunities for discovery rather than error. Although mathematically similar to anomaly measures, surprise is conceptually distinct: it is not merely a deviation to be rejected, but a valuable learning signal that can enhance adaptation and decision-making.
This shift in perspective aligns with formal definitions of surprise in information theory and computational psychology, such as Shannon surprise (?), Bayesian surprise (?), Bayes Factor surprise (?), and Confidence-Corrected surprise (?). These surprise definitions quantify unexpectedness by modeling deviations from prior beliefs or probability distributions. In the following section, we will delve deeper into these existing measures and evaluate whether they truly serve the intended role of identifying opportunities, as human surprise does, more than merely flagging anomalies. Using current surprise definitions, (?) demonstrated that treating surprising events not as noise to be removed but as catalysts for learning can significantly enhance a system’s learning speed. Additional empirical evidence shows that incorporating surprise as a learning mechanism can improve autonomy in domains such as autonomous driving (?, ?, ?) and manufacturing (?, ?).
In our research, we find that existing definitions of surprise require significant improvement. Their close resemblance to anomaly detection measures suggests that they may not effectively support higher levels of autonomy. Specifically, a robust surprise measure should emphasize knowledge acquisition and adaptability, rather than treating unexpectedness merely as a deviation from the norm—an approach that current surprise definitions tend to adopt. We therefore argue that it is essential to develop a novel surprise metric that inherently fosters learning and deepens an autonomous system’s understanding of the underlying processes it encounters. To capture this dynamic capability, we introduce the Mutual Information Surprise (MIS)—a new framework that redefines how autonomous systems interpret and respond to unexpected events. MIS quantifies the degree of both frustration and enlightenment associated with new observations, measuring their impact on refining the system’s internal understanding of its environment. We also demonstrate the differences that arise when applying mutual information surprise, as opposed to relying solely on classical surprise definitions, highlighting MIS’s potential to meaningfully enhance autonomous learning and decision-making.
The paper is organized as follows. In Section 2, we revisit the concept of surprise by presenting a taxonomy of existing surprise measures and introducing the intuition, mathematical formulation, and limitations of classical definitions. In Section 3, we formally define the Mutual Information Surprise (MIS) and derive a testing sequence for detecting multiple types of system changes in autonomous systems. We also design an MIS reaction policy (MISRP) that provides high-level guidance to complement existing exploration-exploitation active learning strategies. In Section 4, we compare MIS with classical surprise measures to illustrate its numerical stability and enhanced cognitive capability. We further demonstrate the effectiveness of the MIS reaction policy through a pollution map estimation simulation. In Section 5, we conclude the paper.
2 Current Surprise Definitions and Their Limitations
Classical definitions of surprise, such as Shannon and Bayesian Surprise, provide elegant mathematical frameworks for quantifying unexpectedness. However, these approaches often fall short in capturing the core mechanisms driving adaptive behavior: continuous learning and flexible model updating. This section revisits and analyzes existing formulations, elaborating on their conceptual foundations and outlining both their strengths and limitations.
Before proceeding with our discussion, we introduce the notation used throughout this paper. Scalars are denoted by lowercase letters (e.g., $x$ ), vectors by bold lowercase letters (e.g., $\mathbf{x}$ ), and matrices by bold uppercase letters (e.g., $\mathbf{X}$ ). Distributions in the data space are represented by uppercase letters (e.g., $P$ ), probabilities by lowercase letters (e.g., $p$ ), and distributions in the parameter space by the symbol $\pi$ . The $L_{2}$ norm is denoted by $\|·\|_{2}$ , and the absolute value or $L_{1}$ norm is denoted by $|·|$ . We use $\mathbb{E}[·]$ to denote the expectation operator and $\text{sgn}(·)$ for the sign operator. Estimators are denoted with a hat, as in $\hat{·}$ .
The Family of Shannon Surprises
The family of Shannon Surprise metrics emphasizes the improbability of observed data, typically independent of explicit model parameters. This class broadly aligns with “observation” and “probabilistic-mismatch” surprises as categorized in (?). The central question which the Shannon family of surprises tries to answer is straightforward: How unlikely is the observation?
The most widely recognized measure is Shannon Surprise (?), formally defined as:
$$
S_{\text{Shannon}}(\mathbf{x})=-\log p(\mathbf{x}), \tag{1}
$$
interpreting surprise directly through event rarity. Although conceptually clear and mathematically elegant, this definition has a significant limitation: encountering a Shannon Surprise does not inherently imply knowledge acquisition. Consider, for instance, a uniform dartboard—a stochastic yet entirely understood system. Each outcome has an equally low probability, thus appearing “surprising” under Shannon’s definition, despite humans neither genuinely finding these outcomes surprising nor gaining any additional knowledge by observing them. In other words, the focus of Shannon Surprise is statistical rarity rather than genuine knowledge gain.
To address this limitation, particularly in highly stochastic scenarios, Residual Information Surprise (?) has been introduced, which measures surprise by quantifying the gap between the minimally achievable and observed Shannon Surprises:
$$
S_{\text{Residual}}(\mathbf{x})=|\underset{\mathbf{x}^{\prime}}{\min}\{-\log p(\mathbf{x}^{\prime})\}-(-\log p(\mathbf{x}))|=\underset{\mathbf{x}^{\prime}}{\max}\log p(\mathbf{x}^{\prime})-\log p(\mathbf{x}).
$$
In the dartboard example, Residual Information Surprise becomes zero for all outcomes, as $p(\mathbf{x}^{\prime})$ remains constant for every $\mathbf{x}^{\prime}$ , accurately reflecting an absence of genuine surprise. However, this formulation introduces a conceptual challenge, as determining $\underset{\mathbf{x}^{\prime}}{\max}\log p(\mathbf{x}^{\prime})$ implicitly presumes an omniscient oracle, an assumption typically infeasible in practice.
Interestingly, Shannon Surprise serves as a foundation for various anomaly measures. For example, under Gaussian assumptions, Shannon Surprise becomes proportional to squared error:
$$
S_{\text{Shannon}}(\mathbf{x})\propto\|\mathbf{x}-\mu_{\mathbf{x}}\|_{2}^{2},
$$
thus linking surprise with deviation from the mean. Similarly, assuming a Laplace distribution recovers an absolute error interpretation, termed Absolute Error Surprise in (?):
$$
S_{\text{Shannon}}(\mathbf{x})\propto|\mathbf{x}-\mu_{\mathbf{x}}|.
$$
We note that both Squared Error Surprise and Absolute Error Surprise are commonly utilized metrics in anomaly detection literature (?, ?, ?).
The Family of Bayesian Surprises
Bayesian Surprises, by contrast, explicitly model belief updates. These measures quantify the degree to which a new observation alters the internal model, shifting the focus from event rarity to epistemic impact. This concept parallels the “belief-mismatch” surprise in the taxonomy by (?).
The canonical formulation, introduced in (?), defines Bayesian Surprise as the Kullback–Leibler divergence between the prior and posterior distributions over parameters:
$$
S_{\text{Bayes}}(\mathbf{x})=D_{\text{KL}}\left(\pi(\boldsymbol{\theta}\mid\mathbf{x})\,\|\,\pi(\boldsymbol{\theta})\right).
$$
This measure offers a principled approach to belief revision and naturally aligns with learning mechanisms. In theory, it encourages agents to reduce surprise through model updates, providing a pathway toward adaptive autonomy.
However, Bayesian Surprise is not without limitations. As data accumulates, new observations exert diminishing influence on the posterior, rendering the agent increasingly “stubborn.” This behavior can result in Bayesian Surprise overlooking rare but meaningful anomalies. For example, consider the discovery by S. S. Ting of the $J$ particle, characterized by an unusually long lifespan compared to other particles in its class. Under standard Bayesian updating, scientists’ beliefs about particle lifespans would barely shift due to this single observation. Consequently, Bayesian Surprise would classify such an event as merely an anomaly, potentially disregarding it.
To mitigate this posterior overconfidence, Confidence-Corrected (CC) Surprise (?) compares the current informed belief against that of a naïve learner with a flat prior:
$$
S_{\text{CC}}(\mathbf{x})=D_{\text{KL}}\left(\pi(\boldsymbol{\theta})\,\|\,\pi^{\prime}(\boldsymbol{\theta}\mid\mathbf{x})\right),
$$
where $\pi^{\prime}(\boldsymbol{\theta}\mid\mathbf{x})$ represents the updated belief assuming a uniform prior. This confidence-corrected formulation remains sensitive to new data irrespective of prior history. In the $J$ particle example, employing Confidence-Corrected Surprise would trigger a genuine surprise, as the posterior remains responsive to the novel observation without the inertia introduced by extensive historical data.
A related idea emerges with Bayes Factor (BF) Surprise (?), which compares likelihoods under naïve and informed beliefs:
$$
S_{\text{BF}}(\mathbf{x})=\frac{p(\mathbf{x}\mid\pi^{0}(\boldsymbol{\theta}))}{p(\mathbf{x}\mid\pi^{t}(\boldsymbol{\theta}))},
$$
where $\pi^{0}(\boldsymbol{\theta})$ represents the naïve (untrained) prior and $\pi^{t}(\boldsymbol{\theta})$ the informed belief based on all prior observations up to time $t$ (before observing $\mathbf{x}$ ). This ratio quantifies how strongly the current observation supports the naïve prior over the informed prior. In practice, the effectiveness of both Confidence-Corrected and Bayes Factor Surprises heavily depends on constructing appropriate priors—a task often challenging and subjective.
Another variant within the Bayesian Surprise family is Postdictive Surprise (?), which operates in the output space rather than parameter space as in the original Bayesian Surprise:
$$
S_{\text{Postdictive}}(\mathbf{x})=D_{\text{KL}}\left(P(\mathbf{y}\mid\boldsymbol{\theta}^{\prime},\mathbf{x})\,\|\,P(\mathbf{y}\mid\boldsymbol{\theta},\mathbf{x})\right), \tag{2}
$$
where $\boldsymbol{\theta}$ and $\boldsymbol{\theta}^{\prime}$ denote parameters before and after the update, respectively. (?) argue that computing KL divergence in the output space is more computationally tractable for variational models but potentially less expressive when output variance depends on the input (e.g., under heteroskedastic conditions).
Reflection
We acknowledge the presence of alternative categorizations of surprise definitions, notably the taxonomy in (?), which classifies surprise measures into three groups: observation surprises, probabilistic-mismatch surprises, and belief-mismatch surprises. As discussed previously, the Shannon Surprise family aligns closely with the first two categories, whereas the Bayesian Surprise family corresponds to the last.
These categorizations are not strictly delineated. For instance, Residual Information Surprise incorporates a conceptual element common to the Bayesian Surprise family—providing a baseline against which the observed data is contrasted with. On the other hand, Bayes Factor Surprise, despite being explicitly Bayesian in its formulation, closely resembles a Shannon Surprise conditioned on alternative priors. Furthermore, notwithstanding their philosophical distinctions, Bayesian and Shannon Surprises often behave similarly in practice; we provide further details on this observation in Section 4.
It is understandable that researchers initially explored these two foundational surprise definitions, each possessing inherent limitations: Shannon Surprise conflates probability with knowledge gain, while Bayesian Surprise suffers from increasing posterior stubbornness. Subsequent refinements emerged to address these shortcomings, primarily through adjusting the choice of prior to create more meaningful contrasts. The Residual Information Surprise assumes an oracle-like prior, whereas Confidence-Corrected and Bayes Factor Surprises rely on a non-informative prior. Regardless of the priors chosen, defining a suitable prior remains a challenging and unresolved issue in the research community.
Both surprise families share other critical limitations: they are single-instance measures and inherently one-sided measures. Being single instance means that they assess surprise based solely on the marginal impact of individual observations, without explicitly modeling cumulative learning dynamics over time, whereas being one-sided means that they have a decision threshold on one single side, offering limited expressiveness since human perceptions of surprise can range from positive to negative.
3 Mutual Information Surprise
In this section, we introduce the concept of Mutual Information Surprise (MIS). We first explore the intuition and motivation underlying this concept, followed by the development of a novel, theoretically grounded testing sequence. We then discuss the implications when this test sequence is violated and propose a reaction policy contingent on different types of violations. Table 1 summarizes the perspective differences between Mutual Information Surprise vs Shannon and Bayesian family of surprises.
Table 1: The perspective differences among Shannon family surprises, Bayesian family surprises, and Mutual Information Surprise.
| Surprise | Single Instance Focused | Capture Transient Changes | Aware of Learning Progression | Parametric Predictive Modeling |
| --- | --- | --- | --- | --- |
| Shannon Family | ✓ | ✗ | ✗ | ✗ |
| Bayesian Family | ✓ | ✗ | ✗ | ✓ |
| MIS | ✗ | ✓ | ✓ | ✗ |
3.1 What Do We Expect from a Surprise?
In human cognition, surprise often triggers reflection and adaptation. A computational analog should similarly prompt deeper examination and enhanced understanding, transcending mere statistical rarity and indicating an opportunity for learning.
To formalize this perspective, consider a system governed by a functional mapping $f:\mathbf{x}→\mathbf{y}$ , with observations drawn from a joint distribution $P(\mathbf{x},\mathbf{y})$ . This system is well-regulated, meaning the input distribution $P(\mathbf{x})$ , output distribution $P(\mathbf{y})$ , and joint distribution $P(\mathbf{x},\mathbf{y})$ are time-invariant. This definition expands the traditional notion of time-invariance by explicitly including consistent exposure $P(\mathbf{x})$ , aligning closely with human trust in persistent patterns across rules and experiences.
To quantify system understanding, we use mutual information (MI) (?), defined as
$$
I(\mathbf{x},\mathbf{y})=\mathbb{E}_{\mathbf{x},\mathbf{y}}\left[\log\frac{p(\mathbf{y}\mid\mathbf{x})}{p(\mathbf{y})}\right]=H(\mathbf{x})+H(\mathbf{y})-H(\mathbf{x},\mathbf{y})=H(\mathbf{y})-H(\mathbf{y}\mid\mathbf{x}), \tag{3}
$$
where $H(·)$ denotes entropy, measuring uncertainty or chaos of a random variable. Mutual information quantifies the reduction in uncertainty about $\mathbf{y}$ given knowledge of $\mathbf{x}$ . A high $I(\mathbf{x},\mathbf{y})$ indicates strong comprehension of $f$ , whereas stagnation or a decrease in $I(\mathbf{x},\mathbf{y})$ signals stalled learning. For the aforementioned well-regulated system, $I(\mathbf{x},\mathbf{y})$ remains constant.
Typically, mutual information $I(\mathbf{x},\mathbf{y})$ is estimated via maximum likelihood estimation (MLE) (?); details of the MLE estimator are provided in the Appendix. Empirical estimation of $I(\mathbf{x},\mathbf{y})$ is, however, downward biased for clean data with a low noise level (?):
$$
\mathbb{E}[\hat{I}(\mathbf{x},\mathbf{y})]\leq I(\mathbf{x},\mathbf{y}).
$$
Interestingly, this bias can serve as an informative feature: As experience accumulates, $\mathbb{E}[\hat{I}(\mathbf{x},\mathbf{y})]$ should increase and approach the true value $I(\mathbf{x},\mathbf{y})$ , determined by $p(\mathbf{x})$ and function $f$ . Thus, a monotonic growth in mutual information estimate signals learning.
Returning to our core question—what do we expect from a surprise? Unlike classical surprise measures (Shannon or Bayesian), which focus narrowly on conditional distributions and rarity, we posit that a surprise measure should reflect whether learning occurred. Noticing the connection between mutual information growth and learning, we define surprise as a deviation from expected mutual information growth. Specifically, we define Mutual Information Surprise (MIS) as the difference in mutual information estimates after incorporating new observations:
$$
\text{MIS}\triangleq\hat{I}_{n+m}-\hat{I}_{n}, \tag{4}
$$
where $\hat{I}_{n}$ is the estimation of mutual information $I_{n}$ at the time of the first $n$ observations, and $\hat{I}_{n+m}$ for $I_{m+n}$ after observing $m$ additional points. Starting from here, we omit the variable terms, $\mathbf{x}$ and $\mathbf{y}$ , in the notations of mutual information and its estimation for the sake of simplicity. A large (relative to sample size $m$ and $n$ ) positive MIS signals enlightenment, indicating significant learning, whereas a near-zero or negative MIS indicates frustration, suggesting stalled progress. Hence, MIS provides operational insight into whether a system evolves as expected, transforming it into a practical autonomy test. Significant deviations from the expected MIS trajectory indicate meaningful changes or system stagnation.
3.2 Bounding MIS
Mutual information estimation is inherently challenging: it is high-dimensional, nonlinear, and exhibits complex variance. The standard method, though principled, is a computationally expensive permutation test (?, ?), involving repeatedly shuffling $m+n$ observations into two groups, calculating MI differences, and evaluating rejection probabilities:
$$
p=\frac{1}{B}\sum_{i=1}^{B}\mathbf{1}(|\Delta\hat{I}|>|\Delta\hat{I}|_{i}),
$$
where $\Delta\hat{I}=\hat{I}_{n}-\hat{I}_{m}$ represents the actual differences between mutual information estimations, and $\Delta\hat{I}_{i}$ represents the $i$ th permuted difference. $\mathbf{1}(·)$ is the indicator function. In real-time streaming scenarios, however, permutation tests become impractical due to their computational load. Moreover, when $m\ll n$ , permutation tests lose effectiveness, yielding noisy outcomes.
An alternative is standard deviation-based testing. For MLE mutual information estimator $\hat{I}_{n}$ , its estimation standard deviation satisfies (?):
$$
\sigma\lesssim\frac{\log n}{\sqrt{n}}, \tag{5}
$$
where $\lesssim$ stands for less or equal to (in terms of order), which yields an analytical test on the mutual information change when omitting the bias term (brief derivation provided in the Appendix),
$$
\hat{I}_{m+n}-\hat{I}_{n}\in\pm\sqrt{\frac{\log^{2}(m+n)}{m+n}+\frac{\log^{2}n}{n}}\cdot z_{\alpha}\asymp\mathcal{O}\left(\frac{\log n}{\sqrt{n}}\right), \tag{6}
$$
where $z_{\alpha}$ represents the standard normal random variable at confidence level $\alpha$ and $\asymp$ represents equal in order. But this test too is unsatisfying, because the above bound is so loose that it rarely gets violated. The root cause is the loose upper bound shown in Eq. (5), where empirical evidence suggests the true estimation standard deviation is usually much smaller than the theoretical bound. We provide the empirical evidence in the Appendix.
So, we turn to a new path for bounding MIS as follows. First, we impose several mild assumptions on the observations and the physical process.
**Assumption 1**
*We impose the following assumptions on the sampling process and physical system. 1. We assume that the existing observations are typical in the sense of the Asymptotic Equipartition Property (?), meaning that empirical statistics computed from the data are representative of their corresponding expected values under the experimental design’s intended distribution, i.e., $\hat{I}_{n}≈\mathbb{E}[\hat{I}_{n}]$ . This is true when we regard the initial observations as true system information.
1. The number of existing observations $n$ is much smaller than cardinality of space $\mathcal{X},\mathcal{Y}$ . $n\ll|\mathcal{X}|,|\mathcal{Y}|$
1. The number of new observations $m$ is much smaller than the number of existing observations. $m\ll n$ .*
**Theorem 1**
*Consider a well-regulated autonomous system defined in Section 3.1, which satisfies the conditions in Assumption 1. With probability at least $1-\rho$ , the change in MLE-based mutual information estimates satisfies:
$$
\hat{I}_{n+m}-\hat{I}_{n}\in\left(\log(m+n)-\log n\right)\pm\frac{\sqrt{2m\log\frac{2}{\rho}}\log(m+n)}{m+n}\triangleq MIS_{\pm}.
$$
$MIS_{±}$ denotes the upper and lower bound for the test sequence.*
The proof of Theorem 1 is shown in the Appendix. These bounds are both tighter ( $\mathcal{O}(\frac{\log n}{n})$ instead of $\mathcal{O}(\frac{\log n}{\sqrt{n}})$ ) and more efficient (analytical test sequence) than previous methods. The bounds offer theoretically grounded thresholds within which we expect MI to evolve. When these bounds $MIS_{±}$ are breached—either from below or from above—we know the system has encountered something.
Some may argue that for an oversampled system, Assumption 2 does not hold. That is true, and as a result, the expectation term in Theorem 1, $\log(m+n)-\log n$ , needs to be adjusted. For a noise-free system with limited outcome and large number of existing observations, one needs to replace the expectation term with $(|\mathcal{Y}|-1)(\frac{1}{n}-\frac{1}{m+n})$ and the bounds in Theorem 1 still works.
3.3 What Does MIS Actually Tell Us?
When the quantity $\text{MIS}=\hat{I}_{n+m}-\hat{I}_{n}$ falls outside the established bounds $MIS_{±}$ —either exceeding the upper bound or falling below the lower bound—the system is considered to be surprised, thereby triggering a Mutual Information Surprise (MIS). Essentially, Theorem 1 functions as a statistical hypothesis test: the null hypothesis posits that the underlying system remains well-regulated, implying $\Delta I=I_{n+m}-I_{n}=0$ , where $I_{n}$ denotes the true mutual information at the time of $n$ observations. Any violation indicates a significant shift, with negative deviations ( $\Delta I<0$ ) and positive deviations ( $\Delta I>0$ ) each carrying distinct implications.
Recall that mutual information can be expressed in terms of entropy, as shown in Eq. (3), so changes in $\Delta I$ may result from variations in $H(\mathbf{x})$ , $H(\mathbf{y})$ , and $H(\mathbf{y}\mid\mathbf{x})$ . In this subsection, we examine the implications of MIS under different driving forces.
Violation from Below: Learning Has Stalled or Regressed
If
$$
\text{MIS}<\text{MIS}_{-},
$$
this implies $\Delta I(\mathbf{x},\mathbf{y})<0$ , signifying a downward shift in mutual information. A negative surprise indicates diminished or stalled learning, potentially due to:
1. Stagnation in Exploration: A downward shift driven by a decrease in input entropy $\Delta H(\mathbf{x})<0$ suggests the system repeatedly samples in a limited region, thus gathering redundant data with minimal new information.
1. Increased Noise or Process Drift: A downward shift could also result from increased conditional entropy $\Delta H(\mathbf{y}\mid\mathbf{x})>0$ , indicating greater uncertainty in predicting $\mathbf{y}$ given $\mathbf{x}$ . Practically, this often signifies increased external noise or a fundamental change in the underlying process.
Violation from Above: Sudden Growth in Understanding
If
$$
\text{MIS}>\text{MIS}_{+},
$$
this implies $\Delta I(\mathbf{x},\mathbf{y})>0$ , indicating an upward shift in mutual information. This positive surprise can result from:
1. Aggressive Exploration: If the increase is driven by higher input entropy $\Delta H(\mathbf{x})>0$ , the system is likely exploring previously unvisited regions aggressively, potentially inflating knowledge gains without sufficient validation.
1. Reduction in Noise: An increase due to reduced conditional entropy $\Delta H(\mathbf{y}\mid\mathbf{x})<0$ signals a desirable decrease in uncertainty, thus generally representing a beneficial development.
1. Novel Discovery: An increase in output entropy $\Delta H(\mathbf{y})>0$ suggests discovery of novel and previously rare outputs—particularly valuable in exploratory or scientific contexts.
Summary Table
| Violation from Below | Stagnation in exploration | $\downarrow H(\mathbf{x})\Rightarrow\downarrow I(\mathbf{x},\mathbf{y})$ |
| --- | --- | --- |
| Increased noise / process drift | $\uparrow H(\mathbf{y}\mid\mathbf{x})\Rightarrow\downarrow I(\mathbf{x},\mathbf{y})$ | |
| Violation from Above | Aggressive exploration | $\uparrow H(\mathbf{x})\Rightarrow\uparrow I(\mathbf{x},\mathbf{y})$ |
| Noise reduction | $\downarrow H(\mathbf{y}\mid\mathbf{x})\Rightarrow\uparrow I(\mathbf{x},\mathbf{y})$ | |
| Novel discovery | $\uparrow H(\mathbf{y})\Rightarrow\uparrow I(\mathbf{x},\mathbf{y})$ | |
The table above summarizes potential causes for MIS violations and their implications. These patterns help the system differentiate between meaningful learning and misleading deviations, expanding beyond the capacity of classical surprise measures and providing a road map to corrective or adaptive responses for higher level autonomy. We purposely omit the case where a decrease in $H(\mathbf{y})$ causes violation from below, as this scenario typically lacks independent significance. Instead, its happening is generally caused by changes in sampling strategy or underlying processes, which we have already discussed.
3.4 Reaction Policy: A Three-Pronged Approach
Following the identification of potential causes behind MIS triggers (Section 3.3), the next question is how the system should respond. Naturally, the system’s reaction should align with the dominant entropy component contributing to the change. In practice, we identify the dominant entropy change by computing and ranking the ratios
$$
\frac{\text{sgn}(\text{MIS})\Delta\hat{H}(\mathbf{x})}{|\text{MIS}|},\quad\frac{\text{sgn}(\text{MIS})\Delta\hat{H}(\mathbf{y})}{|\text{MIS}|},\quad\text{and}\quad\frac{\text{sgn}(\text{MIS})\Delta\hat{H}(\mathbf{y}\mid\mathbf{x})}{|\text{MIS}|},
$$
where $\Delta\hat{H}(·)=\hat{H}_{m+n}(·)-\hat{H}_{n}(·)$ denotes the estimated entropy change.
We do not prescribe a specific reaction when $\Delta\hat{H}(\mathbf{y})$ dominates the MIS, as an increase in $H(\mathbf{y})$ is typically a passive consequence of changes in $H(\mathbf{x})$ and $H(\mathbf{y}\mid\mathbf{x})$ . When both $H(\mathbf{x})$ and $H(\mathbf{y}\mid\mathbf{x})$ remain relatively stable, a rise in $H(\mathbf{y})$ indicates that the current sampling strategy is effectively uncovering novel information; thus, no change in action is required.
For $\Delta\hat{H}(\mathbf{x})$ and $\Delta\hat{H}(\mathbf{y}\mid\mathbf{x})$ , situations may arise where their contributions are similar, i.e., no clear dominant entropy component exists and we need a resolution mechanism to break the tie. To address all these scenarios, we propose a three-pronged reaction policy that serves as a supervisory layer, compatible with existing exploration–exploitation sampling strategies:
1. Sampling Adjustment. The first policy addresses variations in input entropy $H(\mathbf{x})$ . If $\Delta\hat{H}(\mathbf{x})>0$ dominates MIS, indicating overly aggressive exploration, the system should moderate exploration and emphasize exploitation to prevent fitting to noise. Conversely, if $\Delta\hat{H}(\mathbf{x})<0$ , suggesting redundant sampling, the system should enhance exploration to restore sample diversity.
2. Process Forking. The second policy responds to variations in conditional entropy $H(\mathbf{y}\mid\mathbf{x})$ , i.e., changes in function mapping. Upon surprise triggered by $\Delta\hat{H}(\mathbf{y}\mid\mathbf{x})$ , the system forks into two subprocesses, each consisting of $n$ existing observations and $m$ new observations divided at the surprise moment (Theorem 1). The two subprocesses represent the prior process (existing observations) and the likely altered process (new observations), and will continue their sampling separately. The subprocess first encountering a $\Delta\hat{H}(\mathbf{y}\mid\mathbf{x})$ -triggered surprise is discarded, and the remaining subprocess continues as the main process. In the extremely rare case when both subprocesses trigger a $\Delta\hat{H}(\mathbf{y}\mid\mathbf{x})$ dominated MIS surprise at the same time, we discard the process with fewer observations, and continues with the subprocess with more observations.
3. Coin Toss Resolution. There are occasions where changes in $\Delta\hat{H}(\mathbf{x})$ and $\Delta\hat{H}(\mathbf{y}\mid\mathbf{x})$ are comparable, making selecting a reaction policy challenging. Instead of arbitrarily favoring the slightly larger change, we always use a biased coin toss approach, stochastically selecting which entropy to address based on the magnitude of changes:
$$
p_{\text{adjust}}=\frac{|\Delta\hat{H}(\mathbf{x})|}{|\Delta\hat{H}(\mathbf{x})|+|\Delta\hat{H}(\mathbf{y}\mid\mathbf{x})|},\quad p_{\text{fork}}=1-p_{\text{adjust}}.
$$
The decision variable $z$ is sampled as $z\sim\text{Bernoulli}(P_{\text{adjust}})$ , with $z=1$ indicating sampling adjustment and $z=0$ indicating process forking. This mechanism ensures balanced reactions, robustness, and prevents overreactions to marginal signals.
The description above provides a brief summary of the MIS reaction policy. In the remaining portion of this subsection, we will present the specific MIS reaction policy in an algorithm. To do that, we first need to define a sampling process formally and then present the detailed algorithmic implementation of this reaction policy in Algorithm 1.
**Definition 1**
*A sampling process $\mathcal{P}(\mathbf{X},g(·))$ consists of two components: existing observations $\mathbf{X}$ and a sampling function $g(·)$ , where the next sample location is determined by
$$
\mathbf{x}_{\text{next}}\sim g(\mathbf{X}),
$$
with $\mathbf{x}_{\text{next}}$ drawn from the stochastic oracle $g(\mathbf{X})$ . If $g(·)$ is deterministic, $\sim$ is replaced by equality ( $=$ ). For clarity, a sampling process with $n$ existing observations is denoted $\mathcal{P}_{n}$ .*
Algorithm 1 Mutual Information Surprise Reaction Policy (MISRP)
1: A sampling process $\mathcal{P}(\mathbf{Z},g(·))$ , where $\mathbf{Z}$ consists of $k$ pairs of input $\mathbf{X}$ and output $\mathbf{Y}$ ; A maximum reflection threshold $T$ ; Reflection period $m=2$
2: while $m≤\min(T,\frac{k}{2})$ do
3: Set $n=k-m$ ; Compute $MIS=\hat{I}_{m+n}-\hat{I}_{n}$ ; Record $\Delta\hat{H}(\mathbf{x})$ , $\Delta\hat{H}(\mathbf{y})$ , and $\Delta\hat{H}(\mathbf{y}\mid\mathbf{x})$
4: if $MIS\not∈ MIS_{±}$ and $\frac{\text{sgn}(\text{MIS})\Delta\hat{H}(\mathbf{y})}{|\text{MIS}|}≠\max\big{\{}\frac{\text{sgn}(\text{MIS})\Delta\hat{H}(\mathbf{x})}{|\text{MIS}|},\frac{\text{sgn}(\text{MIS})\Delta\hat{H}(\mathbf{y})}{|\text{MIS}|},\frac{\text{sgn}(\text{MIS})\Delta\hat{H}(\mathbf{y}\mid\mathbf{x})}{|\text{MIS}|}\big{\}}$ then
5: Compute bias: $p←\frac{|\Delta\hat{H}(\mathbf{x})|}{|\Delta\hat{H}(\mathbf{x})|+|\Delta\hat{H}(\mathbf{y}\mid\mathbf{x})|}$
6: Sample $z\sim\text{Bernoulli}(p)$
7: if $z=1$ then $\triangleright$ Sampling Adjustment
8: if $MIS>MIS_{+}$ then
9: Modify $g$ to reduce exploration and increase exploitation
10: else
11: Modify $g$ to increase exploration and reduce redundancy
12: end if
13: break while
14: else $\triangleright$ Process Forking
15: if $\mathcal{P}$ is forked and the other process is not requesting Process Forking then
16: Delete $\mathcal{P}$ ; Merge the other process as the main process
17: break while
18: end if
19: if $\mathcal{P}$ is forked and the other process is requesting Process Forking then
20: Delete the $\mathcal{P}$ with fewer data; Merge the other one as the main process
21: break while
22: end if
23: Fork process into two branches: $\mathcal{P}_{n}$ and $\mathcal{P}_{m}$
24: Call $\text{MISRP}(\mathcal{P}_{n},t)$ and $\text{MISRP}(\mathcal{P}_{m},t)$
25: break while
26: end if
27: else
28: No action required (surprise within expected bounds)
29: end if
30: $m=m+1$
31: end while
We offer several remarks on the MIS reaction policy $\text{MISRP}(\mathcal{P},t)$ :
- In the pseudocode, we introduce two additional notations: the maximum reflection threshold $T$ and the total number of observations $k$ . In practice, MIS is computed retroactively, that is, given a sequence of $k$ observations, we partition them into $m$ recent observations and $n=k-m$ older observations to compute the MIS. We term the $m$ recent observation as the reflection period and we increment $m$ to iterate over different partition points. The reflection period $m$ is constrained to be no greater than $\min(T,\frac{k}{2})$ . This constraint is motivated by the comparative behavior of test statistics derived from Theorem 1 and the variance-based test in Eq. (6). Specifically, when $m=n$ , both our proposed test and the variance-based test yield statistics of order $\mathcal{O}\left(\frac{\log n}{\sqrt{n}}\right)$ . As discussed in Section 3.2, such statistics are typically too loose to be violated in practice, thereby diminishing the sensitivity advantage of our method. Consequently, evaluating MIS beyond $m=\frac{k}{2}$ is unnecessary and computationally inefficient. The reflection threshold $T$ is introduced to ensure computational feasibility, and we recommend selecting $T$ as large as computational resources permit.
- Note that the reflection period $m$ starts at $2$ . This implies that the reaction policy does not respond to a single-instance surprise. Mathematically, this is because the derivation of the bound in Theorem 1 is ill-defined for $m=1$ . Intuitively, MIS measures the progression of learning in a sampling process, and it is impossible to determine whether a single observation is informative or erroneous without additional verification. Therefore, the MIS policy always take at least two additional samples to start to react. One may argue that this requirement for an extra sample imposes additional cost in conducting experiments. That is true. But recall one insight from the study in (?) is the benefit of “ the extra resources spent on deciding the nature of an observation ” in the long run.
- It is important to emphasize that bot the sampling adjustment and process forking approaches are rooted in the active learning literature and practice. Balancing exploration and exploitation, i.e., sampling adjustment, has long been a key topic in Bayesian optimization and active learning (?), whereas discarding irrelevant observations, as we do in process forking, is a common practice in the dataset drift literature (?, ?, ?, ?, ?). Our Mutual Information Surprise reaction framework provides a principled mechanism for autonomous systems to determine how to balance exploration versus exploitation and when or what to discard (i.e., forget).
4 Numerical Analysis
In this section, we illustrate the merits of Mutual Information Surprise (MIS). Section 4.1 demonstrates the strength of MIS compared to classical surprise measures. Section 4.2 showcases the advantages of the MIS reaction policy in the context of dynamically estimating a pollution map using data generated from a physics-based simulator.
4.1 Putting Surprise to the Test
To compare MIS with classical surprise measures—principally Shannon and Bayesian Surprises—we conduct a series of controlled simulations using a simple yet interpretable system, designed to reveal how each measure behaves under varying conditions. The system is governed by the mapping
$$
y=x\mod 10, \tag{7}
$$
chosen for its simplicity, modifiability, and clarity of interpretation. The first four scenarios are fully deterministic, while the final two introduce noise and perturbations, enabling an assessment of whether each surprise measure responds meaningfully to new observations, structural changes, or stochastic disturbances. Each simulation begins with $100$ samples drawn uniformly from $x∈[0,30]$ to establish the system’s initial knowledge. We then progressively introduce new data under different conditions, recording the response of each surprise measure. As the magnitudes of MIS, Shannon Surprise, and Bayesian Surprise differ in scale, our analysis focuses on behavioral trends —how each measure changes, spikes, or saturates—rather than on their absolute values.
The surprise measures are computed as follows. Shannon Surprise is calculated using its classical definition in Eq. (1), as the negative log-likelihood of the true label under a Gaussian Process predictive model. Bayesian Surprise is computed as Postdictive Surprise, defined in Eq. (2), using the KL divergence between the prior and posterior predictive distributions of $y$ at each input $x$ . The same Gaussian Process predictive model is used for both, using a Matérn $\nu=2.5$ kernel with a constant noise level set to $0.1$ . After each surprise computation, the model is re-trained with all currently available data.
For MIS, we treat the initial $100$ observations as the initial sample size $n=100$ , as defined in Section 3.1. As sampling continues, the number of new observations $m$ increases (represented in the ticks of the X-axis in the figures). The output space has cardinality $|\mathcal{Y}|=10$ , corresponding to the ten possible outcomes of the modulus function, except in Scenario 6 where $|\mathcal{Y}|=20$ . MIS is calculated as defined in Eq. (4). When the theoretical bound in Theorem 1 is used, the probability level is set to $\rho=0.1$ . The bias term is adjusted as discussed in Section 3.2, since $n\gg|\mathcal{Y}|$ in this setting.
Scenario 1: Standard Exploration.
New data is randomly sampled from $x∈[30,100]$ , expanding the domain without altering the underlying function or aggressively exploring unfamiliar regions. This represents a system exploring new yet consistent areas of its environment.
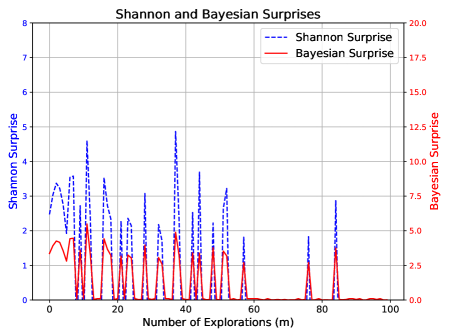
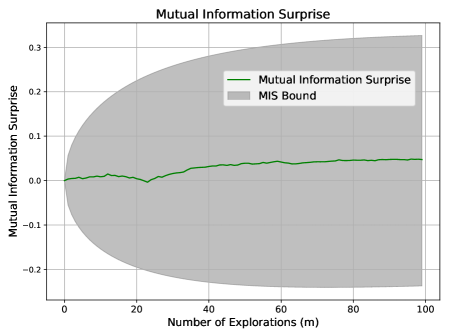
Expected behavior: A well-calibrated surprise measure should indicate ongoing learning without abrupt fluctuations. We do not expect MIS to be violated.
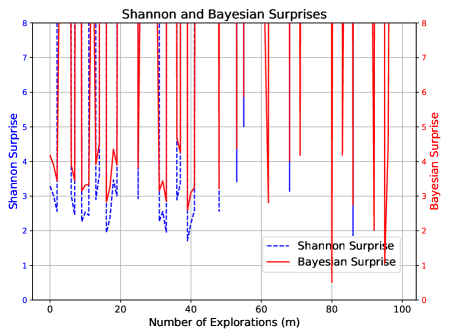
As shown in Figure 1, MIS progresses steadily within its expected bounds, reflecting a stable and well-regulated learning process. In contrast, Shannon and Bayesian Surprises fluctuate erratically, often spiking without clear justification.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Line Chart: Shannon and Bayesian Surprises
### Overview
The image is a line chart comparing Shannon Surprise and Bayesian Surprise over a number of explorations. The x-axis represents the "Number of Explorations (m)" ranging from 0 to 100. The left y-axis represents "Shannon Surprise" ranging from 0 to 8, while the right y-axis represents "Bayesian Surprise" ranging from 0.0 to 20.0. The Shannon Surprise is represented by a dashed blue line, and the Bayesian Surprise is represented by a solid red line.
### Components/Axes
* **Title:** Shannon and Bayesian Surprises
* **X-axis:**
* Label: Number of Explorations (m)
* Range: 0 to 100
* Ticks: 0, 20, 40, 60, 80, 100
* **Left Y-axis:**
* Label: Shannon Surprise
* Range: 0 to 8
* Ticks: 0, 1, 2, 3, 4, 5, 6, 7, 8
* **Right Y-axis:**
* Label: Bayesian Surprise
* Range: 0.0 to 20.0
* Ticks: 0.0, 2.5, 5.0, 7.5, 10.0, 12.5, 15.0, 17.5, 20.0
* **Legend:** Located in the top-right corner.
* Shannon Surprise: Dashed blue line
* Bayesian Surprise: Solid red line
### Detailed Analysis
* **Shannon Surprise (Dashed Blue Line):**
* Trend: Highly variable, with several peaks and troughs, generally decreasing after around exploration 40.
* Approximate Data Points:
* Exploration 0: ~2.5
* Exploration 10: ~3.5
* Exploration 20: ~2.0
* Exploration 30: ~3.5
* Exploration 40: ~5.0
* Exploration 50: ~2.0
* Exploration 60: ~1.0
* Exploration 70: ~0.5
* Exploration 80: ~2.5
* Exploration 90: ~1.0
* Exploration 100: ~0.2
* **Bayesian Surprise (Solid Red Line):**
* Trend: Generally low with occasional spikes, decreasing to near zero after exploration 60.
* Approximate Data Points:
* Exploration 0: ~4.0
* Exploration 5: ~3.0
* Exploration 10: ~1.0
* Exploration 20: ~3.0
* Exploration 30: ~1.0
* Exploration 40: ~2.0
* Exploration 50: ~3.0
* Exploration 60: ~0.1
* Exploration 70: ~0.1
* Exploration 80: ~0.1
* Exploration 90: ~0.1
* Exploration 100: ~0.1
### Key Observations
* The Shannon Surprise exhibits more frequent and larger fluctuations compared to the Bayesian Surprise.
* Both Shannon and Bayesian Surprise tend to decrease as the number of explorations increases, especially after exploration 60.
* The Bayesian Surprise is generally lower than the Shannon Surprise, except for the initial explorations.
### Interpretation
The chart illustrates how Shannon and Bayesian Surprises change with an increasing number of explorations. The Shannon Surprise, which measures information gain, shows high variability, suggesting that the agent frequently encounters unexpected information. The Bayesian Surprise, which measures the change in belief, is generally lower and decreases more consistently, indicating that the agent's beliefs stabilize as it explores the environment. The decrease in both surprises over time suggests that the agent is learning and becoming more familiar with the environment, leading to fewer unexpected events and smaller belief updates. The spikes in Bayesian Surprise indicate specific instances where the agent's beliefs were significantly altered, possibly due to encountering critical new information.
</details>
<details>
<summary>x2.png Details</summary>
### Visual Description
## Chart: Mutual Information Surprise
### Overview
The image is a line chart showing the "Mutual Information Surprise" as a function of the "Number of Explorations (m)". The chart also displays a gray shaded region representing the "MIS Bound". The x-axis represents the number of explorations, ranging from 0 to 100. The y-axis represents the mutual information surprise, ranging from -0.2 to 0.3.
### Components/Axes
* **Title:** Mutual Information Surprise
* **X-axis:**
* Label: Number of Explorations (m)
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **Y-axis:**
* Label: Mutual Information Surprise
* Scale: -0.2 to 0.3, with tick marks at -0.2, -0.1, 0.0, 0.1, 0.2, and 0.3.
* **Legend:** Located in the top-right portion of the chart.
* Green Line: Mutual Information Surprise
* Gray Area: MIS Bound
### Detailed Analysis
* **Mutual Information Surprise (Green Line):**
* Trend: Initially fluctuates around 0, dips slightly around x=20, then gradually increases and plateaus around 0.04-0.05 for x > 60.
* Data Points:
* At x=0, y ≈ 0.00
* At x=20, y ≈ -0.01
* At x=40, y ≈ 0.02
* At x=60, y ≈ 0.03
* At x=80, y ≈ 0.04
* At x=100, y ≈ 0.04
* **MIS Bound (Gray Area):**
* The gray area forms a shape that widens from x=0 to approximately x=40, then remains relatively constant. The area is centered around y=0.
* The upper bound of the gray area starts at approximately y=0.0 at x=0 and increases to approximately y=0.28 at x=40, then remains constant.
* The lower bound of the gray area starts at approximately y=0.0 at x=0 and decreases to approximately y=-0.24 at x=40, then remains constant.
### Key Observations
* The Mutual Information Surprise remains within the MIS Bound throughout the entire range of explorations.
* The Mutual Information Surprise initially fluctuates near zero, dips slightly, and then gradually increases before plateauing.
* The MIS Bound widens initially and then stabilizes, indicating a range of possible values for the Mutual Information Surprise.
### Interpretation
The chart illustrates how the Mutual Information Surprise changes as the number of explorations increases. The MIS Bound provides a range within which the Mutual Information Surprise is expected to fall. The fact that the Mutual Information Surprise stays within the MIS Bound suggests that the system is behaving as expected. The initial fluctuations and subsequent plateau in the Mutual Information Surprise may indicate an initial learning phase followed by a stabilization of information gain. The widening of the MIS Bound in the early stages suggests greater uncertainty, which decreases as more explorations are performed.
</details>
Figure 1: Surprise measures during standard exploration.
Scenario 2: Over-Exploitation.
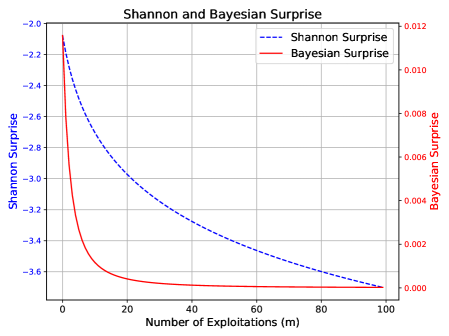
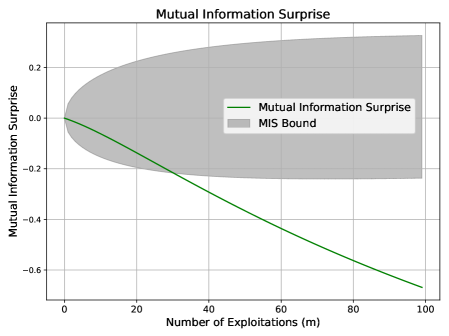
In this scenario, the system repeatedly samples a previously seen point from $x∈[0,30]$ , specifically observing the pair $(x,y)=(7,7)$ one hundred times. This simulates stagnation.
Expected behavior: Surprise should diminish as no new information is gained. This mirrors the stagnation case in Section 3.3, and we expect MIS to violate its lower bound.
Figure 2 shows that MIS falls below its lower bound, signaling a lack of knowledge gain. While Shannon and Bayesian Surprises also trend downward, they lack a defined lower threshold, limiting their reliability for flagging such behavior. Recall that both Shannon and Bayesian Surprises are inherently one-sided, as noted in (?) and (?).
<details>
<summary>x3.png Details</summary>
### Visual Description
## Chart: Shannon and Bayesian Surprise
### Overview
The image is a line chart comparing Shannon Surprise and Bayesian Surprise as a function of the number of exploitations. The chart has two y-axes, one for each type of surprise. The x-axis represents the number of exploitations.
### Components/Axes
* **Title:** Shannon and Bayesian Surprise
* **X-axis:** Number of Exploitations (m), ranging from 0 to 100 in increments of 20.
* **Left Y-axis:** Shannon Surprise, ranging from -3.6 to -2.0 in increments of 0.2.
* **Right Y-axis:** Bayesian Surprise, ranging from 0.000 to 0.012 in increments of 0.002.
* **Legend:** Located at the top-right of the chart.
* Shannon Surprise (blue dashed line)
* Bayesian Surprise (red solid line)
### Detailed Analysis
* **Shannon Surprise (blue dashed line):**
* Trend: Decreases as the number of exploitations increases.
* At 0 exploitations, the Shannon Surprise is approximately -2.1.
* At 20 exploitations, the Shannon Surprise is approximately -3.1.
* At 40 exploitations, the Shannon Surprise is approximately -3.3.
* At 60 exploitations, the Shannon Surprise is approximately -3.45.
* At 80 exploitations, the Shannon Surprise is approximately -3.55.
* At 100 exploitations, the Shannon Surprise is approximately -3.65.
* **Bayesian Surprise (red solid line):**
* Trend: Decreases rapidly initially and then plateaus as the number of exploitations increases.
* At 0 exploitations, the Bayesian Surprise is approximately 0.0115.
* At 20 exploitations, the Bayesian Surprise is approximately 0.0003.
* At 40 exploitations, the Bayesian Surprise is approximately 0.0001.
* At 60 exploitations, the Bayesian Surprise is approximately 0.00005.
* At 80 exploitations, the Bayesian Surprise is approximately 0.00002.
* At 100 exploitations, the Bayesian Surprise is approximately 0.00001.
### Key Observations
* Both Shannon Surprise and Bayesian Surprise decrease as the number of exploitations increases.
* Bayesian Surprise decreases much more rapidly than Shannon Surprise, especially in the initial stages of exploitation.
* Bayesian Surprise approaches zero as the number of exploitations increases, while Shannon Surprise approaches a negative value.
### Interpretation
The chart illustrates how surprise, as measured by Shannon Surprise and Bayesian Surprise, changes with the number of exploitations. The rapid decrease in Bayesian Surprise suggests that the model quickly learns and becomes less surprised by new data as it is exploited. The slower decrease in Shannon Surprise indicates that there is still some uncertainty or information gain even after many exploitations. The difference in the rate of decrease and the final values suggests that the two measures of surprise capture different aspects of the learning process. Bayesian Surprise seems to be more sensitive to initial learning, while Shannon Surprise reflects a more persistent level of uncertainty.
</details>
<details>
<summary>x4.png Details</summary>
### Visual Description
## Chart: Mutual Information Surprise
### Overview
The image is a line chart showing the "Mutual Information Surprise" as a function of the "Number of Exploitations (m)". It also displays a shaded region representing the "MIS Bound". The x-axis represents the number of exploitations, ranging from 0 to 100. The y-axis represents the mutual information surprise, ranging from approximately -0.7 to 0.3.
### Components/Axes
* **Title:** Mutual Information Surprise
* **X-axis:** Number of Exploitations (m), ranging from 0 to 100 in increments of 20.
* **Y-axis:** Mutual Information Surprise, ranging from -0.6 to 0.2 in increments of 0.2.
* **Legend:** Located in the top-right quadrant of the chart.
* Green line: Mutual Information Surprise
* Grey shaded area: MIS Bound
### Detailed Analysis
* **Mutual Information Surprise (Green Line):** The green line starts at approximately 0 when the number of exploitations is 0. It then decreases steadily as the number of exploitations increases. At 100 exploitations, the Mutual Information Surprise is approximately -0.67.
* **MIS Bound (Grey Shaded Area):** The grey shaded area represents the MIS Bound. It starts at approximately +/- 0.15 when the number of exploitations is 0. The bound widens as the number of exploitations increases, reaching a maximum width at approximately 40 exploitations. After that, the bound remains relatively constant. The upper bound reaches approximately 0.25, and the lower bound reaches approximately -0.25.
### Key Observations
* The Mutual Information Surprise decreases as the number of exploitations increases.
* The MIS Bound widens initially and then stabilizes.
* The Mutual Information Surprise line stays within the MIS Bound.
### Interpretation
The chart illustrates how the mutual information surprise changes with an increasing number of exploitations. The decreasing trend of the green line suggests that as the agent explores more, the surprise associated with new information decreases. The MIS Bound provides a range within which the mutual information surprise is expected to fall. The fact that the green line remains within the grey area suggests that the observed surprise is within the expected bounds. The widening of the MIS Bound initially could indicate that the uncertainty or variability in the surprise is higher during the initial stages of exploration.
</details>
Figure 2: Surprise measures under over-exploitation.
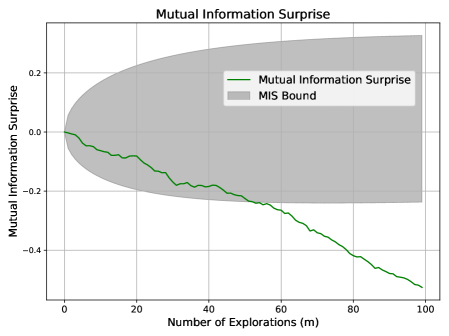
Scenario 3: Noisy Exploration.
We perform standard exploration over $x∈[30,100]$ but apply random corruption to the outputs $\mathbf{y}$ , replacing each with a uniformly random digit between $0$ and $9$ . This simulates exploration without informative feedback.
Expected behavior: Despite novel inputs, the system should register confusion if understanding fails to improve. This mirrors the noise-increase case in Section 3.3, and we expect MIS to violate its lower bound.
Figure 3 confirms the following: MIS drops below its expected range, accurately signaling lack of learning. In contrast, Shannon and Bayesian Surprises again display erratic behavior without consistent trends.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Chart: Shannon and Bayesian Surprises
### Overview
The image is a line chart comparing Shannon Surprise and Bayesian Surprise over a number of explorations. The x-axis represents the number of explorations (m), ranging from 0 to 100. The left y-axis represents Shannon Surprise, and the right y-axis represents Bayesian Surprise, both ranging from 0 to 8. The chart displays two data series: Shannon Surprise (blue dashed line) and Bayesian Surprise (red solid line).
### Components/Axes
* **Title:** Shannon and Bayesian Surprises
* **X-axis:** Number of Explorations (m), with ticks at 0, 20, 40, 60, 80, and 100.
* **Left Y-axis:** Shannon Surprise, with ticks at 0, 1, 2, 3, 4, 5, 6, 7, and 8.
* **Right Y-axis:** Bayesian Surprise, with ticks at 0, 1, 2, 3, 4, 5, 6, 7, and 8.
* **Legend:** Located at the bottom-center of the chart.
* Shannon Surprise: Represented by a blue dashed line.
* Bayesian Surprise: Represented by a red solid line.
### Detailed Analysis
* **Shannon Surprise (Blue Dashed Line):**
* Trend: Initially decreases with fluctuations, then remains relatively low with occasional spikes.
* Values:
* At 0 explorations: approximately 3.5
* At 10 explorations: fluctuates between 2.2 and 3.2
* At 20 explorations: fluctuates between 2.0 and 3.5
* At 30 explorations: fluctuates between 2.0 and 3.0
* At 40 explorations: fluctuates between 1.7 and 3.0
* At 60 explorations: approximately 3.8
* At 80 explorations: approximately 5.8
* At 100 explorations: approximately 8.0
* **Bayesian Surprise (Red Solid Line):**
* Trend: Starts relatively high, drops, and then exhibits frequent spikes reaching the maximum value of 8.
* Values:
* At 0 explorations: approximately 4.0
* At 5 explorations: approximately 3.2
* At 10 explorations: approximately 4.2
* At 15 explorations: approximately 4.5
* At 20 explorations: approximately 3.2
* At 25 explorations: approximately 4.5
* At 30 explorations: approximately 3.2
* At 35 explorations: approximately 4.5
* At 40 explorations: approximately 3.2
* Frequent spikes to 8.0 throughout the exploration range.
### Key Observations
* Bayesian Surprise frequently spikes to its maximum value (8) throughout the exploration range.
* Shannon Surprise generally remains lower than Bayesian Surprise, especially after the initial explorations.
* Both Shannon and Bayesian Surprise exhibit fluctuations, indicating variability in the surprise levels during exploration.
### Interpretation
The chart compares two different measures of "surprise" during a series of explorations. Bayesian Surprise, which is based on a probabilistic model, shows frequent high surprise values, suggesting that the model often encounters unexpected outcomes. Shannon Surprise, which is based on information theory, generally remains lower, indicating a more consistent level of uncertainty or information gain. The fluctuations in both measures suggest that the exploration process involves periods of both predictable and unpredictable events. The data suggests that the Bayesian model is more sensitive to unexpected events than the Shannon measure.
</details>
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Chart: Mutual Information Surprise
### Overview
The image is a line chart titled "Mutual Information Surprise". It displays the relationship between the number of explorations (m) and the mutual information surprise. The chart includes a green line representing the "Mutual Information Surprise" and a gray shaded area representing the "MIS Bound". The green line shows a decreasing trend as the number of explorations increases. The gray area represents the bounds within which the mutual information surprise is expected to fall.
### Components/Axes
* **Title:** Mutual Information Surprise
* **X-axis:** Number of Explorations (m), with tick marks at 0, 20, 40, 60, 80, and 100.
* **Y-axis:** Mutual Information Surprise, with tick marks at -0.4, -0.2, 0.0, and 0.2.
* **Legend:** Located in the top-right quadrant of the chart.
* Green line: Mutual Information Surprise
* Gray area: MIS Bound
### Detailed Analysis
* **Mutual Information Surprise (Green Line):**
* The line starts at approximately 0.0 at 0 explorations.
* The line generally slopes downward.
* At 20 explorations, the value is approximately -0.1.
* At 40 explorations, the value is approximately -0.2.
* At 60 explorations, the value is approximately -0.3.
* At 80 explorations, the value is approximately -0.4.
* At 100 explorations, the value is approximately -0.5.
* **MIS Bound (Gray Area):**
* The gray area starts at approximately +/- 0.15 at 0 explorations.
* The gray area widens as the number of explorations increases.
* At 100 explorations, the gray area extends from approximately -0.25 to 0.25.
### Key Observations
* The Mutual Information Surprise decreases as the number of explorations increases.
* The MIS Bound widens as the number of explorations increases.
* The Mutual Information Surprise line remains within the MIS Bound throughout the range of explorations.
### Interpretation
The chart suggests that as the number of explorations increases, the mutual information surprise decreases. This could indicate that the agent is becoming less surprised by the environment as it explores more. The widening MIS Bound suggests that the uncertainty about the mutual information surprise increases with the number of explorations. The fact that the Mutual Information Surprise line remains within the MIS Bound indicates that the observed surprise is within the expected range.
</details>
Figure 3: Surprise measures under noisy exploration.
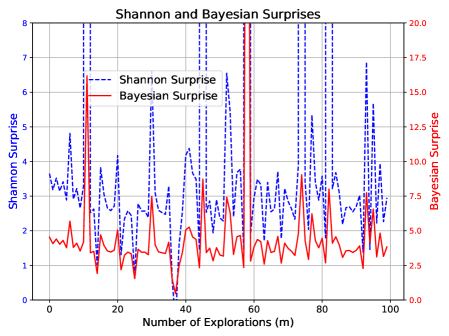
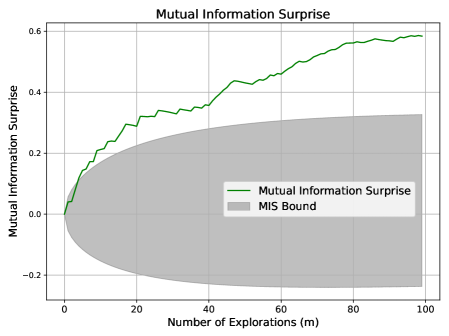
Scenario 4: Aggressive Exploration.
This scenario enforces strict exploration over $x∈[30,500]$ , where each new sample is far from all observed points (i.e., outside the $± 1$ neighborhood range).
Expected behavior: Aggressive exploration without verification can lead to overconfidence. This mirrors the aggressive exploration case in Section 3.3, and we expect MIS to exceed its upper bound.
Figure 4 shows MIS surpassing its upper bound, consistent with this expectation. Shannon and Bayesian Surprises again fluctuate unpredictably.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Line Chart: Shannon and Bayesian Surprises
### Overview
The image is a line chart comparing Shannon Surprise and Bayesian Surprise over a number of explorations (m). The chart displays two data series: Shannon Surprise (represented by a blue dashed line) and Bayesian Surprise (represented by a solid red line). The x-axis represents the number of explorations, ranging from 0 to 100. The left y-axis represents Shannon Surprise, ranging from 0 to 8. The right y-axis represents Bayesian Surprise, ranging from 0 to 20.
### Components/Axes
* **Title:** Shannon and Bayesian Surprises
* **X-axis:**
* Label: Number of Explorations (m)
* Scale: 0 to 100, with tick marks at intervals of 20.
* **Left Y-axis:**
* Label: Shannon Surprise
* Scale: 0 to 8, with tick marks at intervals of 1.
* **Right Y-axis:**
* Label: Bayesian Surprise
* Scale: 0.0 to 20.0, with tick marks at intervals of 2.5.
* **Legend:** Located in the top-left corner of the chart.
* Shannon Surprise: Blue dashed line
* Bayesian Surprise: Red solid line
### Detailed Analysis
* **Shannon Surprise (Blue Dashed Line):**
* Trend: The Shannon Surprise fluctuates significantly throughout the explorations. It starts around 3, rises sharply, then oscillates with several peaks and troughs.
* Data Points:
* At m=0, Shannon Surprise ≈ 3.2
* At m=10, Shannon Surprise ≈ 3.3
* At m=20, Shannon Surprise ≈ 2.5
* At m=40, Shannon Surprise ≈ 0.1
* At m=60, Shannon Surprise ≈ 4.5
* At m=80, Shannon Surprise ≈ 3.0
* At m=100, Shannon Surprise ≈ 2.2
* **Bayesian Surprise (Red Solid Line):**
* Trend: The Bayesian Surprise also fluctuates, but generally stays lower than the Shannon Surprise. It has some sharp peaks, but overall, it remains relatively stable.
* Data Points:
* At m=0, Bayesian Surprise ≈ 4.0
* At m=10, Bayesian Surprise ≈ 4.0
* At m=20, Bayesian Surprise ≈ 3.0
* At m=40, Bayesian Surprise ≈ 1.0
* At m=60, Bayesian Surprise ≈ 5.0
* At m=80, Bayesian Surprise ≈ 3.0
* At m=100, Bayesian Surprise ≈ 3.0
### Key Observations
* The Shannon Surprise exhibits higher volatility compared to the Bayesian Surprise.
* Both surprise metrics show peaks, indicating moments of unexpected information during the explorations.
* There are instances where both metrics spike simultaneously, suggesting shared moments of surprise.
### Interpretation
The chart compares two different measures of surprise (Shannon and Bayesian) during a series of explorations. The Shannon Surprise, based on information theory, quantifies the unexpectedness of an event based on its probability. The Bayesian Surprise, on the other hand, measures the change in belief after observing new data.
The higher volatility of the Shannon Surprise suggests that it is more sensitive to individual unexpected events. The Bayesian Surprise, being a measure of belief change, is smoother and reflects a more cumulative understanding of the environment.
The simultaneous spikes in both metrics indicate significant events that are both unexpected and cause a substantial shift in beliefs. The differences in their magnitudes and patterns suggest that they capture different aspects of surprise, providing a more comprehensive understanding of the exploration process.
</details>
<details>
<summary>x8.png Details</summary>
### Visual Description
## Chart: Mutual Information Surprise
### Overview
The image is a line chart that plots "Mutual Information Surprise" against "Number of Explorations (m)". It shows how the mutual information surprise changes as the number of explorations increases. A shaded area represents the "MIS Bound".
### Components/Axes
* **Title:** Mutual Information Surprise
* **X-axis:** Number of Explorations (m), with ticks at 0, 20, 40, 60, 80, and 100.
* **Y-axis:** Mutual Information Surprise, with ticks at -0.2, 0.0, 0.2, 0.4, and 0.6.
* **Legend:** Located in the center-right of the chart.
* Green line: Mutual Information Surprise
* Gray area: MIS Bound
### Detailed Analysis
* **Mutual Information Surprise (Green Line):**
* Trend: The line starts at approximately 0.0 and increases rapidly initially. The rate of increase slows down as the number of explorations increases, eventually plateauing around 0.57.
* Data Points:
* At 0 explorations, the value is approximately 0.0.
* At 20 explorations, the value is approximately 0.33.
* At 40 explorations, the value is approximately 0.36.
* At 60 explorations, the value is approximately 0.44.
* At 80 explorations, the value is approximately 0.54.
* At 100 explorations, the value is approximately 0.57.
* **MIS Bound (Gray Area):**
* The shaded gray area represents a bound. It starts at approximately 0.0 at 0 explorations, expands both positively and negatively, and then plateaus.
* The upper bound plateaus at approximately 0.32.
* The lower bound plateaus at approximately -0.22.
### Key Observations
* The Mutual Information Surprise increases rapidly at first and then plateaus.
* The MIS Bound provides a range within which the Mutual Information Surprise is expected to fall.
* The Mutual Information Surprise line remains above the lower bound of the MIS Bound throughout the range of explorations.
### Interpretation
The chart suggests that as the number of explorations increases, the mutual information surprise initially increases rapidly, indicating that the agent is learning quickly. However, as the number of explorations continues to increase, the rate of learning slows down, and the mutual information surprise plateaus. The MIS Bound provides a measure of the uncertainty or variability in the mutual information surprise. The fact that the Mutual Information Surprise line remains within the MIS Bound suggests that the agent's learning is consistent with the expected range of variability. The plateauing of the Mutual Information Surprise suggests that the agent may have reached a point of diminishing returns, where further explorations do not lead to significant improvements in learning.
</details>
Figure 4: Surprise measures during aggressive exploration.
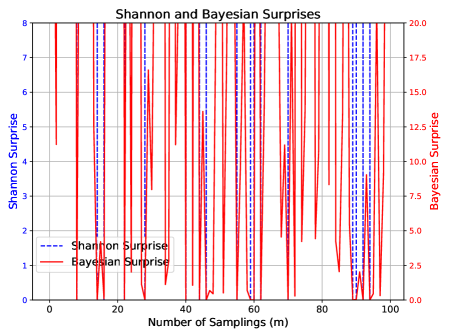
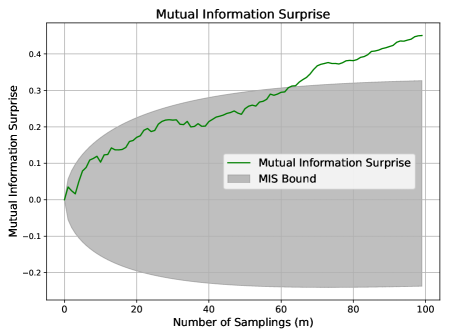
Scenario 5: Noise Decrease.
To simulate noise reduction, we begin with $100$ initial observations from $x∈[0,30]$ , paired with a randomly assigned output $y∈[0,9]$ . New samples are drawn from the same $x$ range but the new $y$ is produced using the deterministic modulus function in Eq. (7).
Expected behavior: Reduced noise implies stronger input-output dependency and we thus expect MIS to exceed its upper bound.
Figure 5 confirms this: MIS grows beyond its bound. Shannon and Bayesian Surprises continue to spike erratically.
<details>
<summary>x9.png Details</summary>
### Visual Description
## Line Chart: Shannon and Bayesian Surprises
### Overview
The image is a line chart comparing Shannon Surprise and Bayesian Surprise over a number of samplings. The x-axis represents the number of samplings, while the left y-axis represents Shannon Surprise and the right y-axis represents Bayesian Surprise. The chart displays two data series: Shannon Surprise (blue dashed line) and Bayesian Surprise (red solid line).
### Components/Axes
* **Title:** Shannon and Bayesian Surprises
* **X-axis:** Number of Samplings (m), ranging from 0 to 100 in increments of 20.
* **Left Y-axis:** Shannon Surprise, ranging from 0 to 8 in increments of 1.
* **Right Y-axis:** Bayesian Surprise, ranging from 0.0 to 20.0 in increments of 2.5.
* **Legend:** Located in the bottom-left corner.
* Shannon Surprise (blue dashed line)
* Bayesian Surprise (red solid line)
### Detailed Analysis
* **Shannon Surprise (blue dashed line):** The Shannon Surprise line is mostly at the maximum value of 8, with occasional drops to lower values. The drops appear to be sharp and instantaneous.
* The line starts at approximately 8.
* It drops to approximately 0 around x=10.
* It returns to 8 until x=20.
* It drops to approximately 0 around x=20.
* It returns to 8 until x=30.
* It drops to approximately 0 around x=30.
* It returns to 8 until x=40.
* It drops to approximately 0 around x=40.
* It returns to 8 until x=50.
* It drops to approximately 0 around x=50.
* It returns to 8 until x=60.
* It drops to approximately 0 around x=60.
* It returns to 8 until x=70.
* It drops to approximately 0 around x=70.
* It returns to 8 until x=80.
* It drops to approximately 0 around x=80.
* It returns to 8 until x=90.
* It drops to approximately 0 around x=90.
* It returns to 8 until x=100.
* **Bayesian Surprise (red solid line):** The Bayesian Surprise line fluctuates significantly, with many sharp drops to near 0 and rapid returns to higher values.
* The line starts at approximately 8.
* It drops to approximately 4.5 around x=5.
* It returns to 8 until x=10.
* It drops to approximately 0 around x=10.
* It returns to 8 until x=15.
* It drops to approximately 0 around x=15.
* It returns to 8 until x=20.
* It drops to approximately 0 around x=20.
* It returns to 8 until x=25.
* It drops to approximately 0 around x=25.
* It returns to 8 until x=30.
* It drops to approximately 0 around x=30.
* It returns to 8 until x=35.
* It drops to approximately 0 around x=35.
* It returns to 8 until x=40.
* It drops to approximately 0 around x=40.
* It returns to 8 until x=45.
* It drops to approximately 0 around x=45.
* It returns to 8 until x=50.
* It drops to approximately 0 around x=50.
* It returns to 8 until x=55.
* It drops to approximately 0 around x=55.
* It returns to 8 until x=60.
* It drops to approximately 0 around x=60.
* It returns to 8 until x=65.
* It drops to approximately 0 around x=65.
* It returns to 8 until x=70.
* It drops to approximately 0 around x=70.
* It returns to 8 until x=75.
* It drops to approximately 0 around x=75.
* It returns to 8 until x=80.
* It drops to approximately 0 around x=80.
* It returns to 8 until x=85.
* It drops to approximately 0 around x=85.
* It returns to 8 until x=90.
* It drops to approximately 0 around x=90.
* It returns to 8 until x=95.
* It drops to approximately 0 around x=95.
* It returns to 8 until x=100.
### Key Observations
* Both Shannon Surprise and Bayesian Surprise exhibit frequent and sharp drops, indicating moments of high surprise.
* The Shannon Surprise tends to stay at its maximum value more often than the Bayesian Surprise.
* The Bayesian Surprise fluctuates more frequently and to a greater extent than the Shannon Surprise.
### Interpretation
The chart compares two different measures of "surprise" over a series of samplings. The frequent drops in both lines suggest that surprising events are common. The difference in the frequency and magnitude of fluctuations between the two lines indicates that Bayesian Surprise is more sensitive to changes in the data than Shannon Surprise. This could be because Bayesian Surprise incorporates prior knowledge or beliefs, making it more responsive to unexpected events. The data suggests that while both measures capture surprise, they do so in different ways, potentially reflecting different underlying assumptions or sensitivities to the data.
</details>
<details>
<summary>x10.png Details</summary>
### Visual Description
## Chart: Mutual Information Surprise
### Overview
The image is a line chart displaying the "Mutual Information Surprise" as a function of the "Number of Samplings (m)". It also shows a shaded region representing the "MIS Bound". The x-axis represents the number of samplings, ranging from 0 to 100. The y-axis represents the mutual information surprise, ranging from -0.2 to 0.4.
### Components/Axes
* **Title:** Mutual Information Surprise
* **X-axis:** Number of Samplings (m), with ticks at 0, 20, 40, 60, 80, and 100.
* **Y-axis:** Mutual Information Surprise, with ticks at -0.2, -0.1, 0.0, 0.1, 0.2, 0.3, and 0.4.
* **Legend:** Located in the center-right of the chart.
* Green line: Mutual Information Surprise
* Gray shaded area: MIS Bound
### Detailed Analysis
* **Mutual Information Surprise (Green Line):**
* The line starts at approximately 0 when the number of samplings is 0.
* It increases rapidly initially, reaching approximately 0.2 around 20 samplings.
* The line continues to increase, but at a slower rate, reaching approximately 0.3 at 60 samplings.
* The line continues to increase, reaching approximately 0.45 at 100 samplings.
* **MIS Bound (Gray Shaded Area):**
* The shaded area forms an approximate ellipse centered around the x-axis.
* The lower bound starts at approximately -0.15 at 0 samplings, decreasing to approximately -0.22 at 40 samplings, then increasing back to approximately -0.15 at 100 samplings.
* The upper bound starts at approximately 0.15 at 0 samplings, increasing to approximately 0.3 at 40 samplings, then decreasing back to approximately 0.32 at 100 samplings.
### Key Observations
* The Mutual Information Surprise generally increases with the number of samplings.
* The MIS Bound forms a confidence interval around the x-axis, initially wide and then narrowing as the number of samplings increases.
* The Mutual Information Surprise line stays within the MIS Bound for the initial samplings, but then exceeds the upper bound of the MIS Bound after approximately 40 samplings.
### Interpretation
The chart suggests that as the number of samplings increases, the mutual information surprise also increases. The MIS Bound provides a measure of uncertainty, which initially decreases as more samples are collected. However, the fact that the Mutual Information Surprise exceeds the MIS Bound after a certain number of samplings could indicate that the model is becoming more confident in its predictions, or that the bound is not accurately capturing the true uncertainty. The initial rapid increase in Mutual Information Surprise suggests that the first few samples are the most informative.
</details>
Figure 5: Surprise measures during noise decrease.
Scenario 6: Discovery of New Output Values.
We modify the function in the unexplored region ( $x>30$ ) to $y=x\mod 10-10$ , introducing a different behavior while keeping the original function unchanged in $[0,30]$ .
Expected behavior: A competent surprise measure should register this new structure as a meaningful discovery. This mirrors the novel discovery case in Section 3.3, and we expect MIS to exceed its upper bound.
Figure 6 shows MIS sharply exceeding its expected trajectory, signaling successful identification of a structural shift. Shannon and Bayesian Surprises again fail to provide consistent or interpretable responses.
<details>
<summary>x11.png Details</summary>
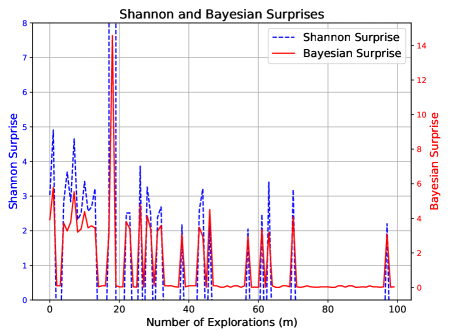
### Visual Description
## Line Chart: Shannon and Bayesian Surprises
### Overview
The image is a line chart comparing Shannon Surprise and Bayesian Surprise over a number of explorations. The x-axis represents the number of explorations, while the left y-axis represents Shannon Surprise and the right y-axis represents Bayesian Surprise. The chart displays how both surprise metrics change with increasing explorations.
### Components/Axes
* **Title:** Shannon and Bayesian Surprises
* **X-axis:** Number of Explorations (m), ranging from 0 to 100 in increments of 20.
* **Left Y-axis:** Shannon Surprise, ranging from 0 to 8 in increments of 1.
* **Right Y-axis:** Bayesian Surprise, ranging from 0 to 14 in increments of 2.
* **Legend:** Located at the top-right of the chart.
* Shannon Surprise: Represented by a dashed blue line.
* Bayesian Surprise: Represented by a solid red line.
### Detailed Analysis
* **Shannon Surprise (Dashed Blue Line):**
* The line starts at approximately 4 at exploration 0.
* It fluctuates significantly between 0 and 6 up to exploration 60.
* After exploration 60, the line remains relatively low, close to 0, with a few spikes.
* Specific data points (approximate): (0, 4), (20, 8), (40, 3), (60, 3), (80, 0.5), (100, 2).
* **Bayesian Surprise (Solid Red Line):**
* The line starts at approximately 3 at exploration 0.
* It fluctuates significantly between 0 and 3 up to exploration 60.
* After exploration 60, the line remains relatively low, close to 0, with a few spikes.
* Specific data points (approximate): (0, 3), (20, 15), (40, 2), (60, 2), (80, 0.2), (100, 1.5).
### Key Observations
* Both Shannon Surprise and Bayesian Surprise exhibit high variability in the early stages of exploration (0-60).
* After 60 explorations, both metrics tend to stabilize at lower values, indicating a decrease in surprise as the number of explorations increases.
* There are several instances where both metrics spike simultaneously, suggesting correlated surprise events.
* The Bayesian Surprise has a much higher peak at around exploration 20, reaching a value of approximately 15, while the Shannon Surprise peaks at around 8.
### Interpretation
The chart suggests that as the number of explorations increases, the environment becomes more predictable, leading to a decrease in both Shannon and Bayesian Surprise. The initial high variability indicates a period of learning and adaptation, where the agent encounters unexpected events. The stabilization of surprise metrics after 60 explorations suggests that the agent has learned the underlying structure of the environment and is no longer surprised by new experiences. The higher peak of Bayesian Surprise at exploration 20 could indicate a particularly unexpected event that significantly impacted the agent's beliefs. The correlation between spikes in both metrics suggests that these surprise events are related and reflect genuine changes in the environment.
</details>
<details>
<summary>x12.png Details</summary>
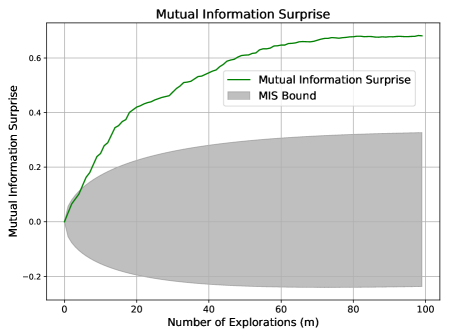
### Visual Description
## Chart: Mutual Information Surprise
### Overview
The image is a line chart that plots "Mutual Information Surprise" against "Number of Explorations (m)". It shows the trend of Mutual Information Surprise and a shaded region representing the MIS Bound.
### Components/Axes
* **Title:** Mutual Information Surprise
* **X-axis:** Number of Explorations (m), with ticks at 0, 20, 40, 60, 80, and 100.
* **Y-axis:** Mutual Information Surprise, with ticks at -0.2, 0.0, 0.2, 0.4, and 0.6.
* **Legend:** Located in the top-right of the chart.
* Mutual Information Surprise (Green Line)
* MIS Bound (Grey Shaded Area)
### Detailed Analysis
* **Mutual Information Surprise (Green Line):** The line starts at approximately 0 at 0 explorations. It increases rapidly until around 40 explorations, reaching a value of approximately 0.6. After 40 explorations, the line continues to increase, but at a much slower rate, approaching a value of approximately 0.68 at 100 explorations.
* (0, 0)
* (20, 0.4)
* (40, 0.6)
* (100, 0.68)
* **MIS Bound (Grey Shaded Area):** The shaded area starts at approximately 0 at 0 explorations. It expands both positively and negatively, reaching its maximum width around 60 explorations. The upper bound of the shaded area reaches approximately 0.32, and the lower bound reaches approximately -0.22.
* Upper Bound:
* (0, 0)
* (60, 0.32)
* (100, 0.32)
* Lower Bound:
* (0, 0)
* (60, -0.22)
* (100, -0.22)
### Key Observations
* The Mutual Information Surprise increases rapidly initially and then plateaus.
* The MIS Bound represents a range of possible values, expanding and then stabilizing.
* The Mutual Information Surprise line remains above the lower bound of the MIS Bound throughout the entire range of explorations.
### Interpretation
The chart suggests that as the number of explorations increases, the mutual information surprise initially grows rapidly, indicating a quick learning phase. As explorations continue, the surprise diminishes, suggesting that the system is converging towards a stable understanding. The MIS Bound provides a confidence interval or range of expected values, and the fact that the Mutual Information Surprise line stays within or above this bound indicates that the observed surprise is within the expected range, or even exceeds the lower bound of expectations. This could imply efficient learning or a well-designed exploration strategy.
</details>
Figure 6: Surprise measures when exploring a new region with novel outputs.
Summary
Across all scenarios, MIS reliably indicates whether the system is genuinely learning, stagnating, or encountering degradation. It responds to the structure and value of observations, more than just novelty. In contrast, Shannon and Bayesian Surprises often react to superficial fluctuations and display numerical instability. Furthermore, the MIS progression bound remains consistent and interpretable across all scenarios, while Shannon and Bayesian Surprises lack a universal scale or threshold, as reflected by their inconsistent magnitudes across Figures 1 through 6. This inconsistency limits their effectiveness as a reliable trigger. Overall, this simulation study demonstrates MIS not only as a novel metric for quantifying surprise, but also as a more trustworthy indicator of learning dynamics—making it a promising tool for autonomous system monitoring.
4.2 Pollution Estimation: A Case Study
To demonstrate the practical utility of our proposed MIS reaction policy, we apply it to a real-time pollution map estimation scenario. We evaluate the impact of integrating the MIS reaction policy on system performance in a dynamic, non-stationary environment. Specifically, we compare two approaches: a selection of baseline sampling strategies and the same strategies governed by our MIS reaction policy.
Dataset: Dynamic Pollution Maps
We utilize a synthetic pollution simulation dataset comprising $450$ time frames, each representing a $50× 50$ pollution grid. Initially, the environment contains $3$ pollution sources, each emitting high pollution at a fixed level. The rest of the field exhibits moderate and random pollution values. Over time, the pollution levels across the entire field evolve due to natural diffusion, decay, and wind effects. Moreover, every $50$ frames, a new pollution source is added to the field at a random location. These new sources elevate the overall pollution levels and alter the input-output relationship between the spatial coordinates and the pollution intensity. Figure 7 displays a snippet of the pollution map at two intermediate time points. The simulation details for the dynamic pollution map generation are provided in the Appendix.
<details>
<summary>x13.png Details</summary>
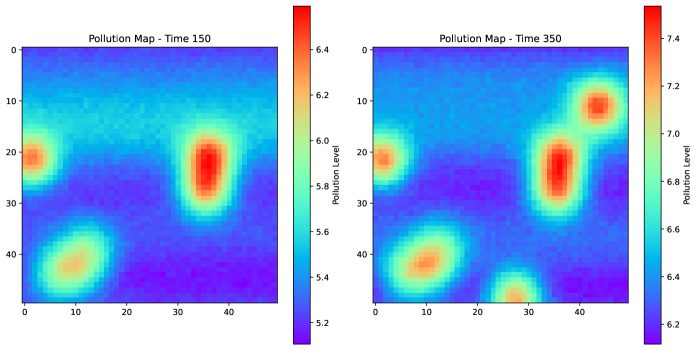
### Visual Description
## Heatmap: Pollution Maps at Time 150 and Time 350
### Overview
The image presents two heatmaps side-by-side, visualizing pollution levels at different time points (Time 150 and Time 350). The heatmaps use a color gradient to represent pollution levels, with cooler colors (purple/blue) indicating lower levels and warmer colors (yellow/red) indicating higher levels. The heatmaps show the spatial distribution of pollution, with distinct "hotspots" of higher pollution levels.
### Components/Axes
* **Titles:**
* Left Heatmap: "Pollution Map - Time 150"
* Right Heatmap: "Pollution Map - Time 350"
* **Axes:** Both heatmaps share the same axes.
* X-axis: Ranges from 0 to 40 in increments of 10.
* Y-axis: Ranges from 0 to 40 in increments of 10.
* **Colorbar/Legend:**
* Left Heatmap: "Pollution Level" ranges from 5.2 (purple) to 6.4 (red) in increments of 0.2.
* Right Heatmap: "Pollution Level" ranges from 6.2 (purple) to 7.4 (red) in increments of 0.2.
### Detailed Analysis
**Left Heatmap (Time 150):**
* **Background Pollution:** The general background pollution level is relatively low, indicated by the blue/purple color. The background pollution level is approximately 5.4.
* **Pollution Hotspots:** There are three distinct hotspots:
* Top-left: Located around coordinates (0, 20), with a pollution level of approximately 6.0.
* Center-right: Located around coordinates (40, 25), with a pollution level of approximately 6.4.
* Bottom-left: Located around coordinates (10, 45), with a pollution level of approximately 5.8.
* **Trend:** The pollution is concentrated in specific areas, with a gradual decrease in pollution levels away from the hotspots.
**Right Heatmap (Time 350):**
* **Background Pollution:** The general background pollution level is higher than in the left heatmap, indicated by the blue color. The background pollution level is approximately 6.4.
* **Pollution Hotspots:** There are three distinct hotspots:
* Top-left: Located around coordinates (0, 20), with a pollution level of approximately 6.8.
* Center-right: Located around coordinates (40, 25), with a pollution level of approximately 7.4.
* Bottom-left: Located around coordinates (10, 45), with a pollution level of approximately 7.0.
* **Trend:** The pollution is concentrated in specific areas, with a gradual decrease in pollution levels away from the hotspots. The hotspots appear to have intensified compared to Time 150.
### Key Observations
* The overall pollution level has increased from Time 150 to Time 350.
* The locations of the pollution hotspots remain relatively consistent between the two time points.
* The intensity of the pollution hotspots has increased from Time 150 to Time 350.
### Interpretation
The heatmaps suggest that pollution levels have increased over time, and the existing pollution sources have intensified. The consistent location of the hotspots indicates that the sources of pollution are likely stationary. The increase in background pollution suggests a general increase in pollution across the entire area. This data could be used to identify and address the sources of pollution, as well as to monitor the effectiveness of pollution control measures.
</details>
Figure 7: Pollution maps at time $150$ and time $350$ .
Sampling Strategies
As discussed in Section 3.4, the MIS reaction policy is designed to complement existing exploration–exploitation strategies. To demonstrate the effectiveness of the Mutual Information Surprise Reaction Policy (MISRP), we integrate it with three well-established sampling strategies. These are: the surprise-reactive (SR) sampling method proposed by (?) using either Shannon or Bayesian surprises, the subtractive clustering/entropy (SC/E) active learning strategy proposed by (?), and the greedy search/query by committee (GS/QBC) active learning strategy used in (?).
1. SR: The surprise-reactive sampling method (?) switches between exploration and exploitation modes based on observed Shannon or Bayesian Surprise. By default, SR operates in an exploration mode guided by the widely used space-filling principle (?), selecting new sampling locations via the min-max objective:
$$
\mathbf{x}^{*}=\underset{\mathbf{x}}{\operatorname{argmax}}\>\underset{\mathbf{x}_{i}\in\mathbf{X}}{\min}\>\|\mathbf{x}-\mathbf{x}_{i}\|_{2},
$$
where $\mathbf{X}$ denotes the set of existing observations. Upon encountering a surprising event (in terms of either Shannon or Bayesian Surprise), SR switches to exploitation mode, performing localized verification sampling within the neighborhood of the surprise-triggering location. This continues either for a fixed number of steps defined by an exploitation limit $t$ , or until an unsurprising event occurs. If exploitation confirms that the surprise is consistent (i.e., persistent surprise until reaching the exploitation threshold), all corresponding observations are accepted and incorporated into the pollution map estimation. Conversely, if an unsurprising event arises before the threshold is reached, the surprising observations are deemed anomalous and discarded. For Shannon Surprise, we set the triggering threshold at $1.3$ , corresponding to a likelihood of $5\%$ . For Bayesian Surprise, we use the Postdictive Surprise and adopt the threshold of $0.5$ , following (?).
MISRP: The MISRP modifies SR by dynamically adjusting the exploitation limit $t$ . When increased exploitation is needed, $t$ is incremented by $1$ . For increased exploration, $t$ is decremented by $1$ , with a lower bound of $t=1$ .
1. SC/E: The subtractive clustering/entropy active learning strategy (?) selects the next sampling location by maximizing a custom acquisition function. For an unseen region $\mathcal{X}$ and a probabilistic predictive function $\hat{f}(\mathbf{x})$ trained on the observed data, the acquisition function is defined as:
$$
a(\mathbf{x})=(1-\eta)\mathbb{E}_{\mathbf{x}^{\prime}\in\mathcal{X}}[e^{-\|\mathbf{x}-\mathbf{x}^{\prime}\|_{2}}]+\eta H(\hat{f}(\mathbf{x})),
$$
where $\eta$ is the exploitation parameter, with a default value of $0.5$ , and $H(\hat{f}(\mathbf{x}))$ denotes the entropy of the predictive distribution at $\mathbf{x}$ . A larger value of $\eta$ emphasizes sampling at locations with high predictive uncertainty near previously seen points, promoting exploitation. A smaller value favors sampling at representative locations in the unseen region, promoting exploration (?).
MISRP: The MISRP modifies SC/E by adjusting the exploitation parameter $\eta$ . For increased exploitation, $\eta$ is increased by $0.1$ , up to a maximum of $1$ . For increased exploration, $\eta$ is decreased by $0.1$ , with a minimum of $0$ .
1. GS/QBC: The greedy search/query by committee active learning strategy (?) uses a different acquisition function. Given the set of seen observations $\{\mathbf{X},\mathbf{Y}\}$ and a model committee $\mathcal{F}$ composed of multiple predictive models trained on this data, the acquisition function is defined as:
$$
a(\mathbf{x})=(1-\eta)\underset{\mathbf{x}^{\prime},\mathbf{y}^{\prime}\in\mathbf{X},\mathbf{y}}{\min}\|\mathbf{x}-\mathbf{x}^{\prime}\|_{2}\|\hat{f}(\mathbf{x})-\mathbf{y}^{\prime}\|_{2}+\eta\underset{\hat{f}(\cdot),\hat{f}^{\prime}(\cdot)\in\mathcal{F}}{\max}\|\hat{f}(\mathbf{x})-\hat{f}^{\prime}(\mathbf{x})\|_{2}, \tag{8}
$$
where the first term encourages exploration by selecting points that are distant from existing observations in both input and output space. The second term promotes exploitation by targeting locations with high disagreement among models in the committee.
MISRP: The MISRP regulates the balance between exploration and exploitation in GS/QBC in the same manner as in SC/E, by adjusting the parameter $\eta$ .
Experimental Setup
The estimation process is initialized with $10$ observed locations uniformly sampled across the pollution field. Each time frame collects $10$ new samples according to the chosen sampling strategy, representing the operation of $10$ mobile pollution sensors. The pollution field is estimated using a Gaussian Process Regressor with a Matérn kernel ( $\nu=2.5$ ) and a noise prior of $10^{-2}$ , consistently applied across all strategies. The model predicts pollution levels at specified spatial locations and is updated using both current and historical data, with a maximum of $200$ observations retained to reduce computational cost.
For the GS/QBC strategy, the model committee additionally includes regressors with a Matérn $\nu=1.5$ kernel and a Gaussian kernel with bandwidth $0.1$ , both using a noise prior of $10^{-2}$ . These two additional models are used solely for calculating disagreement in Eq. (8) and are not employed in pollution map estimation.
Shannon and Bayesian Surprise are computed following the procedure described in Section 4.1. For MIS calculations, we discretize the range of pollution values observed in the data into $100$ bins to estimate entropy.
In process forking scenarios, two separate pollution map estimates, $\hat{f}_{m}$ and $\hat{f}_{n}$ , are produced for subprocesses $\mathcal{P}_{m}$ and $\mathcal{P}_{n}$ , respectively. The final pollution map estimate is formed as a weighted combination:
$$
\hat{f}=\frac{\sqrt{m}}{\sqrt{m}+\sqrt{n}}\hat{f}_{m}+\frac{\sqrt{n}}{\sqrt{m}+\sqrt{n}}\hat{f}_{n},
$$
accounting for generalization errors that scale as $\mathcal{O}(\frac{1}{\sqrt{m}})$ and $\mathcal{O}(\frac{1}{\sqrt{n}})$ , respectively (?).
Simulation Results
We assess performance using the mean squared error (MSE) between predicted and true pollution maps at each time step. Due to the dynamic nature of the pollution field, estimation errors exhibit substantial fluctuation. To smooth these variations, we compute a 20-frame moving average of the MSE for both vanilla and MISRP-governed strategies. The results are shown in Figure 8.
<details>
<summary>x14.png Details</summary>
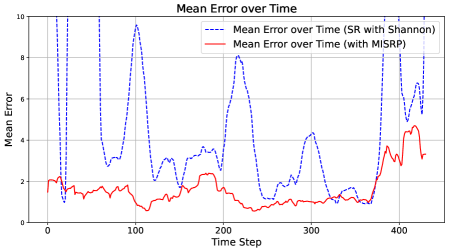
### Visual Description
## Chart: Mean Error over Time
### Overview
The image is a line chart comparing the mean error over time for two different methods: "SR with Shannon" and "with MISRP". The x-axis represents the time step, and the y-axis represents the mean error. The chart displays how the mean error changes over time for each method.
### Components/Axes
* **Title:** Mean Error over Time
* **X-axis:** Time Step, ranging from 0 to 400.
* **Y-axis:** Mean Error, ranging from 0 to 10.
* **Legend:** Located in the top-right corner.
* Blue dashed line: Mean Error over Time (SR with Shannon)
* Red solid line: Mean Error over Time (with MISRP)
* **Gridlines:** Present on the chart.
### Detailed Analysis
* **Mean Error over Time (SR with Shannon) - Blue Dashed Line:**
* The line starts at approximately 2 at time step 0.
* It rapidly increases to approximately 10 around time step 20.
* It decreases to approximately 3 around time step 70.
* It increases again to approximately 9 around time step 120.
* It decreases to approximately 2 around time step 200.
* It increases to approximately 4 around time step 280.
* It decreases to approximately 1.5 around time step 350.
* It increases to approximately 8 around time step 420.
* **Mean Error over Time (with MISRP) - Red Solid Line:**
* The line starts at approximately 2 at time step 0.
* It decreases to approximately 1 around time step 50.
* It increases to approximately 2.5 around time step 180.
* It decreases to approximately 1 around time step 350.
* It increases to approximately 4 around time step 420.
### Key Observations
* The "SR with Shannon" method (blue dashed line) exhibits significantly higher fluctuations in mean error compared to the "with MISRP" method (red solid line).
* The "with MISRP" method generally maintains a lower mean error than the "SR with Shannon" method, except for the very end of the time series.
* Both methods show an increase in mean error towards the end of the time period (around time step 400).
### Interpretation
The chart suggests that the "with MISRP" method is more stable and generally produces lower mean errors compared to the "SR with Shannon" method. The "SR with Shannon" method is more volatile, with large swings in mean error. The increase in error for both methods towards the end of the time period could indicate a change in the underlying data or a limitation of both methods in handling certain conditions. The "with MISRP" method appears to be more robust, maintaining a lower error for most of the time steps.
</details>
<details>
<summary>x15.png Details</summary>
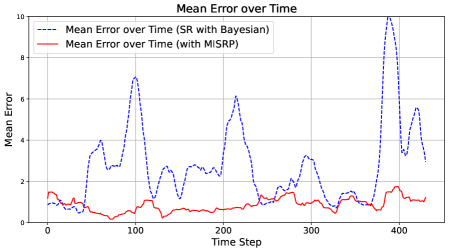
### Visual Description
## Line Chart: Mean Error over Time
### Overview
The image is a line chart comparing the mean error over time for two different methods: "SR with Bayesian" and "with MISRP". The x-axis represents the time step, and the y-axis represents the mean error. The chart displays how the mean error fluctuates over time for each method.
### Components/Axes
* **Title:** Mean Error over Time
* **X-axis:**
* Label: Time Step
* Scale: 0 to 400, with visible markers at 0, 100, 200, 300, and 400.
* **Y-axis:**
* Label: Mean Error
* Scale: 0 to 10, with visible markers at 0, 2, 4, 6, 8, and 10.
* **Legend:** Located in the top-left corner.
* Blue dashed line: Mean Error over Time (SR with Bayesian)
* Red solid line: Mean Error over Time (with MISRP)
### Detailed Analysis
* **Mean Error over Time (SR with Bayesian):** (Blue dashed line)
* Trend: Highly variable, with several peaks and troughs.
* Data Points:
* Starts around 1.5 at time step 0.
* Peaks around 7 at time step 100.
* Dips to approximately 1.5 around time step 150.
* Rises to approximately 4 around time step 200.
* Fluctuates between 1.5 and 3.5 between time steps 200 and 350.
* Peaks sharply to approximately 9.5 around time step 390.
* Drops to approximately 3 around time step 410.
* Rises again to approximately 6 around time step 420.
* **Mean Error over Time (with MISRP):** (Red solid line)
* Trend: Relatively stable, with minor fluctuations.
* Data Points:
* Starts around 1.5 at time step 0.
* Dips to approximately 0.5 around time step 50.
* Rises to approximately 1.2 around time step 100.
* Remains relatively stable between 0.5 and 1.5 from time step 100 to 400.
* Rises slightly to approximately 1.5 at time step 400.
### Key Observations
* The "SR with Bayesian" method exhibits significantly higher variability in mean error compared to the "with MISRP" method.
* The "SR with Bayesian" method experiences several sharp peaks in mean error, indicating periods of instability or poor performance.
* The "with MISRP" method maintains a relatively low and stable mean error throughout the observed time period.
### Interpretation
The chart suggests that the "with MISRP" method is more stable and reliable in terms of mean error compared to the "SR with Bayesian" method. The "SR with Bayesian" method, while potentially capable of achieving low error at times, is prone to significant fluctuations and occasional spikes in error. This could indicate that the "with MISRP" method is more robust to changes in the environment or input data. The "SR with Bayesian" method may require more careful tuning or adaptation to maintain consistent performance.
</details>
<details>
<summary>x16.png Details</summary>
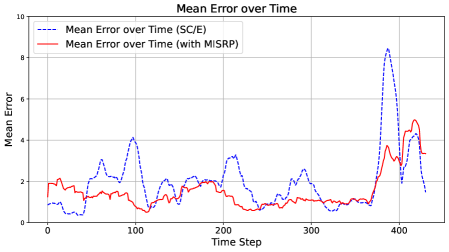
### Visual Description
## Chart: Mean Error over Time
### Overview
The image is a line chart comparing the mean error over time for two different methods: one labeled "SC/E" and the other "with MISRP". The x-axis represents the time step, and the y-axis represents the mean error. The chart displays how the mean error changes over time for each method.
### Components/Axes
* **Title:** Mean Error over Time
* **X-axis:** Time Step (ranging from 0 to 400)
* **Y-axis:** Mean Error (ranging from 0 to 10)
* **Legend:** Located in the top-left corner.
* Blue dashed line: Mean Error over Time (SC/E)
* Red solid line: Mean Error over Time (with MISRP)
* Gridlines are present on the chart.
### Detailed Analysis
* **Mean Error over Time (SC/E) - Blue Dashed Line:**
* Starts at approximately 1.75 at time step 0.
* Decreases to approximately 0.5 around time step 50.
* Increases to approximately 4.25 around time step 100.
* Fluctuates between 1.5 and 3.5 between time steps 100 and 350.
* Experiences a sharp increase to approximately 8.5 around time step 400.
* Decreases to approximately 2 around time step 410.
* Rises again to approximately 4.5 around time step 420.
* **Mean Error over Time (with MISRP) - Red Solid Line:**
* Starts at approximately 2 at time step 0.
* Decreases to approximately 1.25 around time step 50.
* Increases to approximately 2 around time step 75.
* Fluctuates between 1 and 2 between time steps 100 and 375.
* Experiences a sharp increase to approximately 5 around time step 400.
* Decreases slightly to approximately 3.5 around time step 420.
### Key Observations
* The "SC/E" method (blue dashed line) generally has a higher mean error than the "with MISRP" method (red solid line) for most of the time steps.
* Both methods experience a significant increase in mean error around time step 400, but the "SC/E" method's increase is more pronounced.
* The "SC/E" method shows more volatility in mean error compared to the "with MISRP" method.
### Interpretation
The chart suggests that the "with MISRP" method generally performs better in terms of mean error compared to the "SC/E" method. The sharp increase in error for both methods around time step 400 could indicate a critical point or change in the system being evaluated. The higher volatility of the "SC/E" method suggests it may be more sensitive to changes or disturbances in the system. The data implies that incorporating MISRP leads to a more stable and lower mean error over time, especially before the spike at time step 400.
</details>
<details>
<summary>x17.png Details</summary>
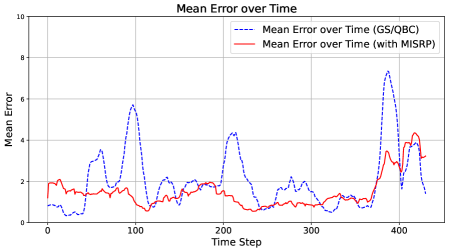
### Visual Description
## Line Chart: Mean Error over Time
### Overview
The image is a line chart comparing the mean error over time for two different methods: "GS/QBC" and "with MISRP". The x-axis represents the time step, and the y-axis represents the mean error. The chart displays the fluctuations in mean error for each method across time.
### Components/Axes
* **Title:** Mean Error over Time
* **X-axis:**
* Label: Time Step
* Scale: 0 to 400, with visible markers at 0, 100, 200, 300, and 400.
* **Y-axis:**
* Label: Mean Error
* Scale: 0 to 10, with visible markers at 0, 2, 4, 6, 8, and 10.
* **Legend:** Located in the top-right corner of the chart.
* "Mean Error over Time (GS/QBC)": Represented by a dashed blue line.
* "Mean Error over Time (with MISRP)": Represented by a solid red line.
### Detailed Analysis
* **Mean Error over Time (GS/QBC) - Dashed Blue Line:**
* Trend: Highly variable, with several peaks and troughs.
* Initial Value (Time Step 0): Approximately 0.8
* Peak 1 (Around Time Step 100): Approximately 5.7
* Value at Time Step 200: Approximately 2.2
* Value at Time Step 300: Approximately 1.0
* Peak 2 (Around Time Step 380): Approximately 7.2
* Final Value (Time Step 400): Approximately 1.8
* **Mean Error over Time (with MISRP) - Solid Red Line:**
* Trend: Relatively stable compared to GS/QBC, with fewer large fluctuations.
* Initial Value (Time Step 0): Approximately 1.8
* Value at Time Step 100: Approximately 1.4
* Value at Time Step 200: Approximately 1.8
* Value at Time Step 300: Approximately 0.9
* Peak (Around Time Step 390): Approximately 4.4
* Final Value (Time Step 400): Approximately 3.8
### Key Observations
* The GS/QBC method (dashed blue line) exhibits significantly more volatility in mean error compared to the MISRP method (solid red line).
* The GS/QBC method has higher peak error values, particularly around time steps 100 and 380.
* The MISRP method generally maintains a lower and more consistent mean error, except for a peak near time step 390.
* Both methods show a general decrease in mean error between time steps 200 and 300.
### Interpretation
The chart suggests that the MISRP method is more stable and reliable in terms of mean error over time compared to the GS/QBC method. The GS/QBC method, while potentially achieving lower error values at certain points, is prone to larger and more frequent fluctuations. This could indicate that the MISRP method is more robust to changes in the environment or input data. The peak in MISRP error near time step 390 warrants further investigation to understand the cause of this temporary instability. The data implies that for applications where consistent performance is critical, the MISRP method may be preferable.
</details>
Figure 8: Moving average estimation error over time. Top-Left: SR with Shannon Surprise. Top-Right: SR with Bayesian Surprise. Bottom-Left: SC/E. Bottom-Right: GS/QBC.
Across all comparisons, the baseline strategies display considerable volatility. In contrast, MISRP-governed counterparts produce smoother and consistently lower error curves, highlighting the stabilizing effect of MIS through its ability to facilitate adaptive responses in dynamic environments.
Table 2 presents the average estimation errors and their corresponding standard errors. The standard error is measured across $10$ Monte Carlo simulations and $450$ frames. Across all sampling strategies, incorporating the MIS reaction policy yields a substantial reduction in both mean estimation error and variability. Improvements in estimation error range from $24\%$ to $76\%$ , while reductions in standard error range from $36\%$ to $90\%$ .
To further illustrate the advantage of MISRP, we increase the per-frame sampling budget and the initial number of observed locations of the baseline strategies from $10$ to $25$ , and expand the total memory buffer from $200$ to $500$ , in order to assess whether baseline strategies can match the performance of MISRP-governed approaches. Table 3 compares the estimation error of MISRP-governed strategies (maintaining the original sampling budget of $10$ ) against the enhanced baseline strategies. Even with a $2.5×$ increase in sampling budget, the baseline strategies remain significantly outperformed by their MISRP-governed counterparts.
Table 2: Comparison of pollution map estimation errors: baseline sampling strategies versus MISRP-governed strategies.
| SR with Shannon SR with Bayesian SC/E | $6.64± 0.436$ $2.79± 0.096$ $2.02± 0.071$ | $\mathbf{1.60± 0.043}$ $\mathbf{0.87± 0.016}$ $\mathbf{1.53± 0.045}$ | $76\%$ $69\%$ $24\%$ | $90\%$ $83\%$ $36\%$ |
| --- | --- | --- | --- | --- |
| GS/QBC | $2.07± 0.071$ | $\mathbf{1.49± 0.039}$ | $28\%$ | $45\%$ |
Table 3: Error Comparison under Extended Sampling for Baseline Strategies.
| Sampling Strategy SR with Shannon SR with Bayesian | Estimation Error (MISRP-Governed, Budget 10) $\mathbf{1.60}$ $\mathbf{0.87}$ | Estimation Error (Baseline, Budget $25$ ) $6.23$ $2.72$ |
| --- | --- | --- |
| SC/E | $\mathbf{1.53}$ | $1.89$ |
| GS/QBC | $\mathbf{1.49}$ | $2.00$ |
So far we demonstrated that governing basic sampling strategies with MISRP can substantially enhance learning performance in dynamic environments. To provide a clearer view of how MISRP operates over time, we conduct an additional simulation examining its actions throughout the process.
In this experiment, we simulate a two-phase pollution map evolution governed by the same PDE used in earlier simulation. During the first phase (time $0$ – $250$ ), three pollution sources emit high levels of pollutants, and the map evolves under diffusion, decay, and wind effects. At time step $250$ , the emission sources are removed, and the decay factor is reduced to one-twentieth of its original value. The system then continues evolving for an additional $50$ steps.
When the pollution sources exists and are emitting (the dynamic phase, time $0$ – $250$ ), the underlying process is a non-stationary process in which we expect frequent MIS triggering. When the pollution sources are gone (the stationary phase, time $251$ – $300$ ), the pollutants in the area will eventually diffuse to a stationary existence, during which time MIS is expected to stop being triggered.
<details>
<summary>x18.png Details</summary>
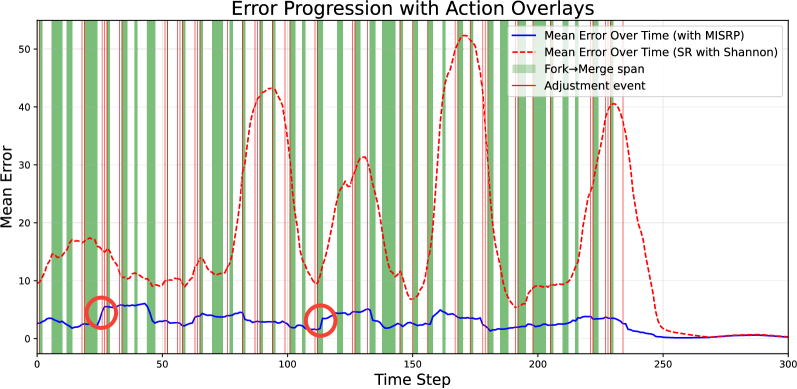
### Visual Description
## Line Chart: Error Progression with Action Overlays
### Overview
The image is a line chart showing the progression of mean error over time for two different methods: one using MISRP and the other using SR with Shannon. The chart also includes vertical bands indicating "Fork->Merge span" and "Adjustment event".
### Components/Axes
* **Title:** Error Progression with Action Overlays
* **X-axis:** Time Step, ranging from 0 to 300 in increments of 50.
* **Y-axis:** Mean Error, ranging from 0 to 50 in increments of 10.
* **Legend (Top-Right):**
* Blue solid line: Mean Error Over Time (with MISRP)
* Red dashed line: Mean Error Over Time (SR with Shannon)
* Green vertical bands: Fork->Merge span
* Red vertical lines: Adjustment event
### Detailed Analysis
* **Mean Error Over Time (with MISRP) - Blue Solid Line:**
* General Trend: Relatively stable and low error over time.
* Specific Points:
* Starts at approximately 4 at Time Step 0.
* Dips slightly around Time Step 30 to approximately 2.
* Rises slightly around Time Step 40 to approximately 4.
* Dips again around Time Step 110 to approximately 1.
* Remains relatively stable between 2 and 4 until Time Step 240.
* Decreases to approximately 0 at Time Step 270 and remains there.
* **Mean Error Over Time (SR with Shannon) - Red Dashed Line:**
* General Trend: Higher error and more volatile compared to the MISRP method. Exhibits cyclical peaks and troughs.
* Specific Points:
* Starts at approximately 12 at Time Step 0.
* Dips to approximately 8 at Time Step 50.
* Peaks at approximately 43 at Time Step 90.
* Dips to approximately 8 at Time Step 120.
* Peaks again at approximately 52 at Time Step 170.
* Dips to approximately 10 at Time Step 210.
* Peaks sharply at approximately 40 at Time Step 240.
* Decreases rapidly to approximately 0 at Time Step 270 and remains there.
* **Fork->Merge span - Green Vertical Bands:**
* These bands are distributed throughout the chart, indicating periods where a "Fork->Merge" event is occurring.
* They appear to be more frequent in the earlier time steps (0-200).
* **Adjustment event - Red Vertical Lines:**
* These lines are also distributed throughout the chart, indicating specific "Adjustment" events.
* They appear to coincide with some of the peaks and troughs in the "SR with Shannon" error line.
* **Red Circles:**
* Two red circles are present on the graph.
* One is located around Time Step 30, highlighting a point on the blue line.
* The other is located around Time Step 110, also highlighting a point on the blue line.
### Key Observations
* The MISRP method consistently maintains a lower mean error compared to the SR with Shannon method.
* The SR with Shannon method exhibits significant fluctuations in mean error, suggesting instability or sensitivity to certain events.
* The "Fork->Merge span" events are more frequent in the first half of the time series.
* "Adjustment events" appear to correlate with changes in the error rate of the SR with Shannon method.
### Interpretation
The chart suggests that the MISRP method is more stable and reliable in terms of error reduction compared to the SR with Shannon method. The fluctuations in the SR with Shannon method's error, coupled with the "Adjustment events," indicate that this method may require more frequent interventions or adjustments to maintain performance. The "Fork->Merge span" events may represent periods of increased complexity or uncertainty in the system, which could contribute to the higher error rates observed in the SR with Shannon method. The red circles highlight specific points of interest on the MISRP line, possibly indicating times where the error briefly deviates from its generally low level.
</details>
Figure 9: A visualization of estimation error progression with MISRP action overlays.
Figure 9 shows the estimation error progression with action overlays under surprise-reactive sampling based on Shannon surprise. Recall from Section 3.4 that there are two actions employed in MISRP governance: sampling adjustments and process forking. These two actions are marked as red vertical lines and green shaded regions in the plot, respectively. For clarity, we present the $20$ -frame moving average of estimation error, whereas the unsmoothed version is provided in the Appendix. Actions are displayed $20$ steps in advance, corresponding to their first observable effect on the smoothed error trajectory.
Several key observations emerge from the figure. First, both sampling adjustments and process forking occur frequently during the dynamic phase as expected, highlighting the effectiveness of MISRP’s action design in maintaining low estimation error. Second, sudden spikes in estimation error (circled) under MISRP governance are almost always followed by corrective actions that prevent further error growth, resulting in non-smooth error progressions after intervention. By contrast, the baseline sampling strategy allows estimation error to rise unchecked. Then, once the system enters the stationary phase, MISRP ceases intervention, aligning with the intuition that a balanced sampling strategy in a well-regulated system should not trigger Mutual Information Surprise.
5 Conclusion
In this work, we reimagined the concept of surprise as a mechanism for fostering understanding, rather than merely detecting anomalies. Traditional definitions—such as Shannon and Bayesian Surprises—focus on single-instance deviations and belief updates, yet fail to capture whether a system is truly growing in its understanding over time. By introducing Mutual Information Surprise (MIS), we proposed a new framework that reframes surprise as a reflection of learning progression, grounded in mutual information growth.
We developed a formal test sequence to monitor deviations in estimated mutual information, and introduced a reaction policy, MISRP, that transforms surprise into actionable system behavior. Through a synthetic case study and a real-time pollution map estimation task, we demonstrated that MIS governance offers clear advantages over conventional sampling strategies. Our results show improved stability, better responsiveness to environmental drift, and significant reductions in estimation error. These findings affirm MIS as a robust and adaptive supervisory signal for autonomous systems.
Looking forward, this work opens several promising directions for future research. A natural next step is the development of a continuous space formulation of mutual information surprise, enabling its application in large complex systems. Another direction involves designing a specialized reaction policy —one that incorporates a sampling strategy tailored directly to the structure and signals of MIS, rather than relying on existing sampling strategies. This could enhance efficiency and responsiveness in highly dynamic or resource-constrained systems. Moreover, pairing MIS with physical probing capability for specific physical systems could unlock the true potential of MIS, as MIS provides new perspectives in system characterization compared to traditional measures.
Appendix
The appendix is organized as follows. In the first section, we present empirical evidence supporting our claim in Section 3.2 that standard deviation-based tests are overly permissive. In the second section, we provide the derivation of the standard deviation-based test for mutual information. In the third section, we provide the proof of Theorem 1. The fourth section details the simulation setup for dynamic pollution map generation. In the fifth section, we provide the pseudocode for the surprise-reactive (SR) sampling strategy (?) to facilitate reproducibility.
MLE Mutual Information Estimator Standard Deviation
In Section 3.2, we discussed the limitations of standard deviation-based tests. Specifically, the current distribution agnostic tightest bound for the standard deviation of a maximum likelihood estimator (MLE) for mutual information with $n$ observations is given by (?)
$$
\sigma\lesssim\frac{\log n}{\sqrt{n}}.
$$
Despite the best result, this bound is still too loose.
To empirically verify this statement, we perform a simple simulation as follows. We construct variable pairs $(x,y)$ where $y=x\;\text{mod}\;10$ , in the same manner as the simulation in Section 4.1. The variable $x$ is generated as random integers sampled from randomly generated probability mass functions over the domain $[0,100]$ . We generate $100$ such probability mass functions. For each probability mass function, we generate $3,000$ pairs of $(x,y)$ , repeat the process using $10$ Monte Carlo simulations, and compute the standard deviation of the MLE mutual information estimates over the $10$ simulations for varying numbers of $(x,y)$ pairs $n$ . We then plot the average standard deviation across the $100$ different probability mass functions as a function of $n$ versus the estimation bound shown in Eq. (5). The results are shown in Figure 10.
<details>
<summary>x19.png Details</summary>
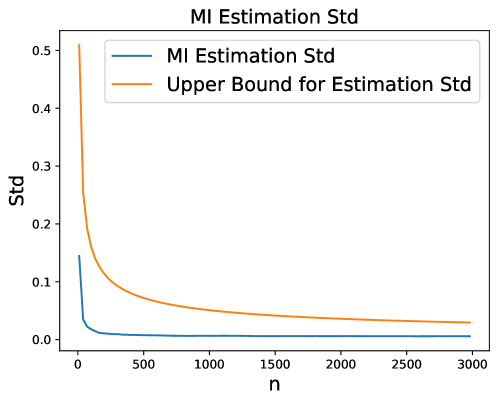
### Visual Description
## Chart: MI Estimation Std
### Overview
The image is a line chart comparing the standard deviation (Std) of MI (Mutual Information) estimation against an upper bound for the estimation standard deviation, plotted against the variable 'n'. Both lines show a decreasing trend as 'n' increases.
### Components/Axes
* **Title:** MI Estimation Std
* **X-axis:** n (ranging from 0 to 3000 in increments of 500)
* **Y-axis:** Std (ranging from 0.0 to 0.5 in increments of 0.1)
* **Legend:** Located in the top-center of the chart.
* **Blue Line:** MI Estimation Std
* **Orange Line:** Upper Bound for Estimation Std
### Detailed Analysis
* **MI Estimation Std (Blue Line):**
* Trend: Rapidly decreases initially, then plateaus to near zero.
* Approximate values:
* n = 0: Std ≈ 0.14
* n = 100: Std ≈ 0.02
* n = 500: Std ≈ 0.008
* n = 3000: Std ≈ 0.005
* **Upper Bound for Estimation Std (Orange Line):**
* Trend: Decreases rapidly at first, then decreases more gradually, approaching a non-zero value.
* Approximate values:
* n = 0: Std ≈ 0.51
* n = 100: Std ≈ 0.16
* n = 500: Std ≈ 0.08
* n = 3000: Std ≈ 0.03
### Key Observations
* Both the MI Estimation Std and its Upper Bound decrease as 'n' increases.
* The MI Estimation Std decreases much more rapidly and approaches zero, while the Upper Bound decreases more slowly and approaches a non-zero value.
* The difference between the MI Estimation Std and its Upper Bound is significant, especially for smaller values of 'n'.
### Interpretation
The chart suggests that as the variable 'n' increases, the standard deviation of the MI estimation decreases, indicating a more accurate estimation. The upper bound also decreases, but remains significantly higher than the actual MI estimation standard deviation, especially at lower values of 'n'. This implies that the upper bound is a conservative estimate of the standard deviation. The rapid decrease in the MI Estimation Std suggests that the estimation becomes much more stable and reliable as 'n' increases. The non-zero asymptote of the Upper Bound suggests there is a limit to how much the standard deviation can be reduced, even with increasing 'n'.
</details>
Figure 10: Empirical standard deviation of MLE mutual information estimates vs. the current tightest bound.
We observe that the current bound for the standard deviation of the mutual information estimate, computed using Eq. (5), is significantly larger than the empirical average standard deviation. This empirical observation supports our claim in Section 3.2 that the test in Eq. (6) is rarely violated in practice.
Standard Deviation Test Derivation
First, recall that the estimation standard deviation satisfies
$$
\sigma\lesssim\frac{\log n}{\sqrt{n}}.
$$
Therefore, we treat this worst case scenario as the baseline when deriving the test of difference between the two maximum likelihood estimators (MLE) of mutual information.
Let:
- $\hat{I}_{n}$ be the MLE estimate from a sample of size $n$ ,
- $\hat{I}_{m+n}$ be the MLE estimate from a larger sample of size $m+n$ ,
Assume the standard deviation of the MLE estimator is approximately:
$$
\sigma_{n}=\frac{\log n}{\sqrt{n}},\quad\sigma_{m+n}=\frac{\log(m+n)}{\sqrt{m+n}}
$$
We want to test the hypothesis:
$$
H_{0}:\mathbb{E}[\hat{I}_{n}]=\mathbb{E}[\hat{I}_{m+n}]\quad\text{vs.}\quad H_{1}:\mathbb{E}[\hat{I}_{n}]\neq\mathbb{E}[\hat{I}_{m+n}]
$$
Note that we are omitting the estimation bias of MLE mutual information estimators for simplicity.
Under the null hypothesis and assuming the two estimates are independent, the test statistic is:
$$
z_{\alpha}=\frac{\hat{I}_{n}-\hat{I}_{m+n}}{\sqrt{\sigma_{n}^{2}+\sigma_{m+n}^{2}}}=\frac{\hat{I}_{n}-\hat{I}_{m+n}}{\sqrt{\left(\frac{\log n}{\sqrt{n}}\right)^{2}+\left(\frac{\log(m+n)}{\sqrt{m+n}}\right)^{2}}}
$$
Moving the denominator to the left hand side will yield the form presented in Eq. (6).
Proof of Theorem 1
First, we formally introduce the maximum likelihood entropy estimator $\hat{H}$ (?) for random variable $\mathbf{x}∈\mathcal{X}$ as follows
$$
\hat{H}(\mathbf{x})=\sum_{i=1}^{|\mathcal{X}|}\hat{p}_{i}\log\hat{p}_{i},
$$
where $\hat{p}_{i}$ is the empirical probability mass of random variable $\mathbf{x}$ at category $i$ . The MLE mutual information estimator is then defined based on the MLE entropy estimator
$$
\hat{I}(\mathbf{x},\mathbf{y})=\hat{H}(\mathbf{x})+\hat{H}(\mathbf{y})-\hat{H}(\mathbf{x},\mathbf{y}).
$$
MIS test bound (Expectation):
Here, we derive the first part of the MIS test bound, representing the expectation of the MIS statistics, i.e., $\mathbb{E}[\text{MIS}]$ . The derivation involves two cases, $n\ll|\mathcal{X}|,|\mathcal{Y}|$ and $n\gg|\mathcal{X}|,|\mathcal{Y}|$ .
When $n\ll|\mathcal{X}|,|\mathcal{Y}|$ , an MLE entropy estimator $\hat{H}$ with $n$ observations will behave simply as $\log n$ (?), conditioning on the $n$ observations are selected using some kind of space filling designs, which is common for design the initial set of experimentation locations in design of experiments literature (?). We have $\mathbb{E}[\hat{H}_{n}(\mathbf{x})]=\log n$ . Hence, the mutual information estimator with $n$ observations admits
$$
\mathbb{E}[\hat{I}_{n}(\mathbf{x},\mathbf{y})]=\mathbb{E}[\hat{H}_{n}(\mathbf{x})+\hat{H}_{n}(\mathbf{y})-\hat{H}_{n}(\mathbf{x},\mathbf{y})]=\log n.
$$
Then for MIS, we have
$$
\mathbb{E}[\text{MIS}]=\mathbb{E}[\hat{I}_{m+n}]-\mathbb{E}[\hat{I}_{n}]=\log(m+n)-\log n.
$$
When $n\gg|\mathcal{X}|,|\mathcal{Y}|$ , we are facing an oversampled scenario where the samples have most likely exhausted the input and output space. In this case, we first introduce the following lemma.
**Lemma 1**
*(?) For a random variable $\mathbf{x}∈\mathcal{X}$ , the bias of an oversampled ( $n\gg|\mathcal{X}|$ ) MLE entropy estimator $\hat{H}_{n}(\mathbf{x})$ is
$$
\mathbb{E}[\hat{H}_{n}(\mathbf{x})]-H(\mathbf{x})=-\frac{|\mathcal{X}|-1}{n}+o(\frac{1}{n}). \tag{9}
$$*
With the above lemma, we can derive the following Corollary.
**Corollary 1**
*For random variable $\mathbf{x}∈\mathcal{X}$ and $\mathbf{y}∈\mathcal{Y}$ , when the $\mathbf{y}=f(\mathbf{x})$ mapping is noise free, the MLE mutual information estimator $\hat{I}_{n}$ asymptotically satisfies
$$
\mathbb{E}[\hat{I}_{n}]=I-\frac{|\mathcal{Y}|-1}{n}.
$$*
The proof of the above Corollary immediately follows observing the fact of $|\mathcal{X}|=|\mathcal{X},\mathcal{Y}|$ for noise free mapping and invoking Lemma 1.
Therefore, for MIS under the case of oversampling, we have
| | $\displaystyle\mathbb{E}[\text{MIS}]$ | $\displaystyle=\mathbb{E}[\hat{I}_{m+n}]-\mathbb{E}[\hat{I}_{n}]$ | |
| --- | --- | --- | --- |
MIS test bound (Variation):
In this part, we derive the second term of the MIS test bound, accounting for the variation of the MIS statistics. We first investigate the maximum change in mutual information estimation $\hat{I}$ when changing one observation. Here, we derive the following Lemma.
**Lemma 2**
*Let $\mathcal{S}=\{(x_{i},y_{i})\}_{i=1}^{n}$ be an i.i.d. sample from an unknown joint distribution on finite alphabets and denote by
$$
\hat{I}_{n}(\mathbf{x},\mathbf{y})\;=\;\hat{H}_{n}(\mathbf{x})+\hat{H}_{n}(\mathbf{y})-\hat{H}_{n}(\mathbf{x},\mathbf{y})
$$
the MLE estimator, where $\hat{H}_{n}$ is the empirical Shannon entropy (in nats). If $\mathcal{S}^{\prime}$ differs from $\mathcal{S}$ in exactly one observation, then with a mild abuse of notation (denoting mutual information estimator on sample set $\mathcal{S}$ with $\hat{I}_{n}(\mathcal{S})$ ),
$$
\bigl{|}\hat{I}_{n}(\mathcal{S})-\hat{I}_{n}(\mathcal{S}^{\prime})\bigr{|}\;\leq\;\frac{2\,\log n}{n}.
$$*
* Proof*
Proof For Lemma 2 We omit $\hat{·}$ for estimators during this proof for simplicity. Write $H=-\sum_{i}p_{i}\log p_{i}$ for Shannon entropy estimator with natural logarithms. Replacing a single observation does two things: 1. in one $X$ -category and one $Y$ -category the counts change by $± 1$ (all other marginal counts are unchanged);
1. in one joint cell the count changes by $-1$ and in another joint cell the count changes by $+1$ .
Step 1. How much can one empirical Shannon entropy change?
Assume a single observation is moved from category $A$ to category $B$ . Let the counts before the move be $A=a$ (with $a≥ 1$ ) and $B=b$ (with $b≥ 0$ ). After the move the counts become $a-1$ and $b+1$ . Only these two probabilities change; every other probability is fixed.
The change in entropy is therefore
| | $\displaystyle\Delta H$ | $\displaystyle=\big{(}\frac{a}{n}\log\frac{a}{n}-\frac{a-1}{n}\log\frac{a-1}{n}\big{)}-\big{(}\frac{b+1}{n}\log\frac{b+1}{n}-\frac{b}{n}\log\frac{b}{n}\big{)}.$ | |
| --- | --- | --- | --- |
We can see that the maximum difference is largest when $a=n$ and $b=0$ , i.e. when all $n$ observations initially occupy a single category and we create a brand-new one. In that worst case
$$
\displaystyle\Delta H \displaystyle=\frac{n-1}{n}\log\frac{n-1}{n}+\frac{1}{n}\log n \displaystyle\leq\frac{n-1}{n}\log\frac{n}{n}+\frac{1}{n}\log n=\frac{\log n}{n}. \tag{10}
$$
The forth equality follows the Taylor expansion of $\log(1-x)$ . Conversly, one could see that $-\frac{\log n}{n}≤\Delta H$ also holds. Therefore, the maximum absolute differences of entropy estimation under the shift of one observations is upper bounded by $\frac{\log n}{n}$ .
Step 2. Sign coupling between the three entropies.
Assume the moved observation leaves joint cell $(i,j)$ and enters cell $(k,\ell)$ . Because $(i,j)$ lies in row $i$ and column $j$ only, we have the key fact (denoting sign operator with $\text{sgn}(·)$ ):
$$
\text{sgn}\bigl{(}\Delta H(\mathbf{x},\mathbf{y})\bigr{)}\in\bigl{\{}\text{sgn}\bigl{(}\Delta H(\mathbf{x})\bigr{)},\text{sgn}\bigl{(}\Delta H(\mathbf{y})\bigr{)}\bigr{\}}.
$$
Hence $-\text{sgn}\bigl{(}\Delta H(\mathbf{x},\mathbf{y})\bigr{)}=\text{sgn}\bigl{(}\Delta H(\mathbf{x})\bigr{)}=\text{sgn}\bigl{(}\Delta H(\mathbf{y})\bigr{)}$ is impossible.
Then, with $\Delta I=\Delta H(\mathbf{x})+\Delta H(\mathbf{y})-\Delta H(\mathbf{x},\mathbf{y})$ , we can see the following fact
$$
|\Delta I|=\bigl{|}\Delta H(\mathbf{x})+\Delta H(\mathbf{y})-\Delta H(\mathbf{x},\mathbf{y})|\leq 2\max\{|\Delta H(\mathbf{x})|,|\Delta H(\mathbf{y})|,|\Delta H(\mathbf{x},\mathbf{y})|\}.
$$
Applying the one-entropy bound (10) to the two marginals,
$$
|\Delta I|\leq\frac{2\log n}{n},
$$
which is the desired inequality. ∎
Establishing Lemma 2 allows us to apply the McDiarmid’s Inequality (?), a concentration inequality for functions with bounded difference.
**Lemma 3 (McDiarmid’s Inequality)**
*If $\{\mathbf{x}_{i}∈\mathcal{X}_{i}\}_{i=1}^{n}$ are independent random variables (not necessarily identical), and a function $f:\mathcal{X}_{1}×\mathcal{X}_{2}...\mathcal{X}_{n}→\mathbb{R}$ satisfies coordinate wise bounded condition
$$
\underset{\mathbf{x}^{\prime}_{j}\in\mathcal{X}_{j}}{sup}|f(\mathbf{x}_{1},\mathbf{x}_{2},\ldots,\mathbf{x}_{j},\ldots,\mathbf{x}_{n})-f(\mathbf{x}_{1},\mathbf{x}_{2},\ldots,\mathbf{x}^{\prime}_{j},\ldots,\mathbf{x}_{n})|<c_{j},
$$
for $1≤ j≤ n$ , then for any $\epsilon≥ 0$ ,
$$
P(|f(\mathbf{x}_{1},\ldots,\mathbf{x}_{n})-\mathbb{E}[f]|>\epsilon)\leq 2e^{-2\epsilon^{2}/\sum c_{j}^{2}}. \tag{11}
$$*
To apply the McDiarmid’s Inequality, we can view the mutual information estimator with $n$ old observations and $m$ new observations, denoted with $\hat{I}_{m+n}$ , as a function of the new $m$ observations $\{\mathbf{x}_{i}∈\mathcal{X}\}_{i=1}^{m}$ . Moreover, we have already bounded the maximum differences of the mutual information estimator through Lemma 2, meaning
$$
\underset{\mathbf{x}^{\prime}_{j}\in\mathcal{X}}{sup}|\hat{I}_{m+n}(\mathbf{x}_{1},\mathbf{x}_{2},\ldots,\mathbf{x}_{j},\ldots,\mathbf{x}_{m})-\hat{I}_{m+n}(\mathbf{x}_{1},\mathbf{x}_{2},\ldots,\mathbf{x}^{\prime}_{j},\ldots,\mathbf{x}_{m})|<\frac{2\log(m+n)}{m+n}.
$$
Then, plug the upper bound into Eq. (11), we have
$$
P(|\hat{I}_{m+n}-\mathbb{E}[\hat{I}_{m+n}]|>\epsilon)\leq 2e^{-2\epsilon^{2}/\sum(\frac{2\log(m+n)}{m+n})^{2}}=2e^{-(m+n)^{2}\epsilon^{2}/2m\log^{2}(m+n)}.
$$
By setting the RHS of the above equation to $\rho$ , we can get the following statement with probability at least $1-\rho$ ,
$$
|\hat{I}_{m+n}-\mathbb{E}[\hat{I}_{m+n}]|\leq\frac{\sqrt{2m\log 2/\rho}\log(m+n)}{m+n}. \tag{12}
$$
Finally, combining the derivation in the two parts, when $n\ll|\mathcal{X}|,|\mathcal{Y}|$ , we have the following with probability at least $1-\rho$
| | $\displaystyle MIS$ | $\displaystyle=\hat{I}_{m+n}-\hat{I}_{n}$ | |
| --- | --- | --- | --- |
The second equation follows the typical sample assumption in Assumption 1. The proof of Theorem 1 is now complete.
Pollution Map Dataset
The dynamic pollution map is modeled as $u(\mathbf{x},t)$ , a function of spatial location $\mathbf{x}=(x_{1},x_{2})∈[0,1]^{2}$ . The governing partial differential equation (PDE) for the pollution map is
$$
\frac{\partial u}{\partial t}=-\mathbf{v}\cdot\nabla u+\nabla(\mathbf{D}\nabla u)-\zeta u+S(\mathbf{x}), \tag{13}
$$
where $\mathbf{v}=[1,0]$ is the advection velocity, representing wind that transports pollution horizontally to the right. The matrix $\mathbf{D}=\text{diag}(0.01,2)$ is the diagonal diffusion matrix, indicating that pollution diffuses much more rapidly in the $x_{2}$ direction than in the $x_{1}$ direction. The parameter $\zeta=2$ represents the exponential decay factor, modeling the natural decay of pollution levels over time. The term $S(\mathbf{x})$ models the spatially dependent but temporally constant pollution source at location $\mathbf{x}$ . Additionally, a base level of random pollution with mean $2$ and standard deviation $0.25$ is added to the pollution field. The evolution of the pollution map is computed in the Fourier domain by applying a discretized Fourier transformation to the PDE in Eq. (13).
In the last simulation experiment with the pollution map, we use the same PDE with modified parameters. Specifically, the pollution sources $S(\mathbf{x})$ is removed, and the decay parameter $\zeta$ is reduced to $0.1$ in the second phase.
Surprise Reactive Sampling Strategy Pseudo Code
In this section, we present the pseudocode for the SR sampling strategy in (?) for reproducibility purpose in Algorithm 2.
Algorithm 2 Surprise Reactive (SR) Sampling Strategy
1: Observation set $\mathbf{X}:\{\mathbf{x}_{i}∈\mathcal{X}\}_{i=1}^{n}$ ; Total sampling budget $k$ ; Exploitation limit $t$ ; A surprise measure $S(·)$ ; A surprise triggering threshold $s$ ; Exploration mode indicator $\xi=\text{True}$ ; Surprising location $\mathbf{x}_{s}=\text{None}$ ; Surprising location set $\mathbf{X}_{s}=\text{None}$ ; Neighborhood radius $\epsilon$ .
2: while $i<k$ ( $i$ starts from $0$ ) do
3: if $\xi$ then
4: Sample $\mathbf{x}^{*}$ as
$$
\mathbf{x}^{*}=\underset{\mathbf{x}}{\operatorname{argmax}}\>\underset{\mathbf{x}_{i}\in\mathbf{X}}{\min}\>\|\mathbf{x}-\mathbf{x}_{i}\|_{2}.
$$
5: $i=i+1$
6: Compute $S(\mathbf{x}^{*})$
7: if $S(\mathbf{x}^{*})≤ s$ then
8: $\mathbf{X}=[\mathbf{X},\mathbf{x}^{*}]$
9: else
10: $\xi=False$ , $\mathbf{x}_{s}=\mathbf{x}^{*}$ , $\mathbf{X}_{s}=[\mathbf{x}^{*}]$
11: end if
12: else
13: while $j≤ t$ ( $j$ starts from $0$ ) do
14: Sample $\mathbf{x}^{*}$ randomly in the $\epsilon$ ball centered at $\mathbf{x}_{s}$ .
15: $j=j+1$ , $i=i+1$
16: Compute $S(\mathbf{x}^{*})$
17: if $S(\mathbf{x}^{*})≤ s$ then
18: $\mathbf{X}=[\mathbf{X},\mathbf{x}^{*}]$ , $\xi=\text{True}$ , $\mathbf{X}_{s}=\text{None}$
19: Break While
20: else
21: $\mathbf{X}_{s}=[\mathbf{X}_{s},\mathbf{x}^{*}]$
22: end if
23: if $i≥ k$ then
24: Break While
25: end if
26: end while
27: if $\mathbf{X}_{s}$ is not None then
28: $\mathbf{X}=[\mathbf{X},\mathbf{X}_{s}]$ , $\xi=\text{True}$
29: end if
30: end if
31: end while
Non-smoothed Error Progression with Action Overlays
Here we present the non-smoothed estimation error progression figure with action overlays.
<details>
<summary>x20.png Details</summary>
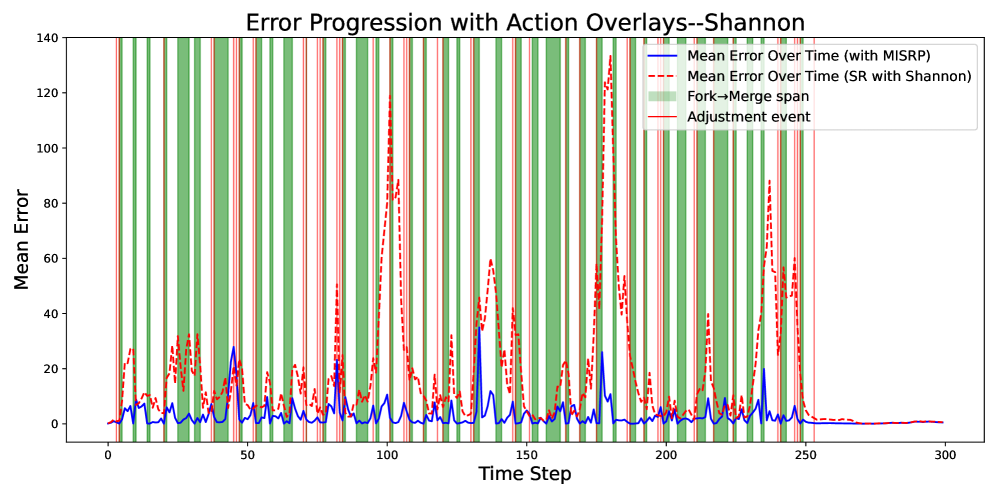
### Visual Description
## Line Chart: Error Progression with Action Overlays--Shannon
### Overview
The image is a line chart that visualizes the error progression over time for two different methods: one with MISRP and the other with SR with Shannon. The chart also indicates "Fork->Merge span" and "Adjustment event" using vertical bands.
### Components/Axes
* **Title:** Error Progression with Action Overlays--Shannon
* **X-axis:** Time Step, ranging from 0 to 300 in increments of 50.
* **Y-axis:** Mean Error, ranging from 0 to 140 in increments of 20.
* **Legend (Top-Right):**
* Blue Line: Mean Error Over Time (with MISRP)
* Red Dashed Line: Mean Error Over Time (SR with Shannon)
* Green Vertical Bands: Fork->Merge span
* Red Vertical Lines: Adjustment event
### Detailed Analysis
* **Mean Error Over Time (with MISRP) - Blue Line:**
* Trend: Generally low and relatively stable, with small spikes.
* Values: Starts around 0, fluctuates between 0 and 20 until time step 250, then stabilizes near 0.
* **Mean Error Over Time (SR with Shannon) - Red Dashed Line:**
* Trend: More volatile with significant spikes, generally higher than the MISRP error.
* Values: Starts around 0, spikes to approximately 30 around time step 25, reaches peaks of approximately 100 around time step 100, and approximately 90 around time step 240, then stabilizes near 0 after time step 260.
* **Fork->Merge span - Green Vertical Bands:**
* Position: Multiple instances throughout the time steps, indicating periods of forking and merging.
* Frequency: Occur relatively frequently, especially before time step 250.
* **Adjustment event - Red Vertical Lines:**
* Position: Multiple instances throughout the time steps.
* Frequency: Occur more frequently before time step 250.
### Key Observations
* The SR with Shannon method (red dashed line) exhibits significantly higher error spikes compared to the MISRP method (blue line).
* Both methods converge to a low error rate after time step 260.
* The "Fork->Merge span" and "Adjustment event" markers appear to correlate with periods of increased error, particularly for the SR with Shannon method.
### Interpretation
The chart suggests that the MISRP method is more stable and results in lower mean error over time compared to the SR with Shannon method, especially during periods marked by "Fork->Merge span" and "Adjustment event". The SR with Shannon method, while potentially capable of reaching low error rates, is more susceptible to error spikes during these events. The convergence of both methods to low error rates after time step 260 indicates a potential stabilization or learning phase. The "Fork->Merge span" and "Adjustment event" markers likely represent critical points in the process that significantly impact the error rate, particularly for the SR with Shannon method.
</details>
Figure 11: A non-smoothed visualization of estimation error progression with MISRP action overlays.
References and Notes
- 1. B. Burger, P. M. Maffettone, V. V. Gusev, C. M. Aitchison, Y. Bai, X. Wang, X. Li, B. M. Alston, B. Li, R. Clowes, N. Rankin, B. Harris, R. S. Sprick, and A. I. Cooper, “A mobile robotic chemist,” Nature, vol. 583, pp. 237–241, 2020.
- 2. A. Merchant, S. Batzner, S. S. Schoenholz, M. Aykol, G. Cheon, and E. D. Cubuk, “Scaling deep learning for materials discovery,” Nature, vol. 624, pp. 80–85, 2023.
- 3. N. J. Szymanski, B. Rendy, Y. Fei, R. E. Kumar, T. He, D. Milsted, M. J. McDermott, M. Gallant, E. D. Cubuk, A. Merchant, H. Kim, A. Jain, C. J. Bartel, K. Persson, Y. Zeng, and G. Ceder, “An autonomous laboratory for the accelerated synthesis of novel materials,” Nature, vol. 624, pp. 86–91, 2023.
- 4. T. Dai, S. Vijayakrishnan, F. T. Szczypiński, J.-F. Ayme, E. Simaei, T. Fellowes, R. Clowes, L. Kotopanov, C. E. Shields, Z. Zhou, J. W. Ward, and A. I. Cooper, “Autonomous mobile robots for exploratory synthetic chemistry,” Nature, vol. 635, pp. 890–897, 2024.
- 5. J. Levinson, J. Askeland, J. Becker, J. Dolson, D. Held, S. Kammel, J. Z. Kolter, D. Langer, O. Pink, V. Pratt, M. Sokolsky, G. Stanek, D. Stavens, A. Teichman, M. Werling, and S. Thrun, “Towards fully autonomous driving: Systems and algorithms,” in Proceedings of the 2011 IEEE Intelligent Vehicles Symposium, (Baden-Baden, Germany), June 2011.
- 6. B. P. MacLeod, F. G. Parlane, T. D. Morrissey, F. Häse, L. M. Roch, K. E. Dettelbach, R. Moreira, L. P. Yunker, M. B. Rooney, and J. R. Deeth, “Self-driving laboratory for accelerated discovery of thin-film materials,” Science Advances, vol. 6, no. 20, p. eaaz8867, 2020.
- 7. E. Yurtsever, J. Lambert, A. Carballo, and K. Takeda, “A survey of autonomous driving: Common practices and emerging technologies,” IEEE Access, vol. 8, pp. 58443–58469, 2020.
- 8. D. Bogdoll, M. Nitsche, and J. M. Zöllner, “Anomaly detection in autonomous driving: A survey,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (New Orleans, USA), June 2022.
- 9. H.-S. Park and N.-H. Tran, “An autonomous manufacturing system based on swarm of cognitive agents,” Journal of Manufacturing Systems, vol. 31, no. 3, pp. 337–348, 2012.
- 10. J. Leng, Y. Zhong, Z. Lin, K. Xu, D. Mourtzis, X. Zhou, P. Zheng, Q. Liu, J. L. Zhao, and W. Shen, “Towards resilience in industry 5.0: A decentralized autonomous manufacturing paradigm,” Journal of Manufacturing Systems, vol. 71, pp. 95–114, 2023.
- 11. J. Reis, Y. Cohen, N. Melão, J. Costa, and D. Jorge, “High-tech defense industries: Developing autonomous intelligent systems,” Applied Sciences, vol. 11, no. 11, p. 4920, 2021.
- 12. P. Nikolaev, D. Hooper, F. Webber, R. Rao, K. Decker, M. Krein, J. Poleski, R. Barto, and B. Maruyama, “Autonomy in materials research: A case study in carbon nanotube growth,” NPJ Computational Materials, vol. 2, p. 16031, 2016.
- 13. J. Chang, P. Nikolaev, J. Carpena-Núñez, R. Rao, K. Decker, A. E. Islam, J. Kim, M. A. Pitt, J. I. Myung, and B. Maruyama, “Efficient closed-loop maximization of carbon nanotube growth rate using Bayesian optimization,” Scientific Reports, vol. 10, p. 9040, 2020.
- 14. I. Ahmed, S. T. Bukkapatnam, B. Botcha, and Y. Ding, “Toward futuristic autonomous experimentation—a surprise-reacting sequential experiment policy,” IEEE Transactions on Automation Science and Engineering, vol. 22, pp. 7912–7926, 2025.
- 15. Z.-G. Zhou and P. Tang, “Continuous anomaly detection in satellite image time series based on z-scores of season-trend model residuals,” in Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium, (Beijing, China), July 2016.
- 16. K. Cohen and Q. Zhao, “Active hypothesis testing for anomaly detection,” IEEE Transactions on Information Theory, vol. 61, no. 3, pp. 1432–1450, 2015.
- 17. J. F. Kamenik and M. Szewc, “Null hypothesis test for anomaly detection,” Physics Letters B, vol. 840, p. 137836, 2023.
- 18. D. J. Weller-Fahy, B. J. Borghetti, and A. A. Sodemann, “A survey of distance and similarity measures used within network intrusion anomaly detection,” IEEE Communications Surveys & Tutorials, vol. 17, no. 1, pp. 70–91, 2014.
- 19. L. Montechiesi, M. Cocconcelli, and R. Rubini, “Artificial immune system via Euclidean distance minimization for anomaly detection in bearings,” Mechanical Systems and Signal Processing, vol. 76, pp. 380–393, 2016.
- 20. Y. Wang, Q. Miao, E. W. Ma, K.-L. Tsui, and M. G. Pecht, “Online anomaly detection for hard disk drives based on Mahalanobis distance,” IEEE Transactions on Reliability, vol. 62, no. 1, pp. 136–145, 2013.
- 21. Y. Hou, Z. Chen, M. Wu, C.-S. Foo, X. Li, and R. M. Shubair, “Mahalanobis distance based adversarial network for anomaly detection,” in Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, (Virtual), May 2020.
- 22. T. Schlegl, P. Seeböck, S. M. Waldstein, G. Langs, and U. Schmidt-Erfurth, “F-anoGAN: Fast unsupervised anomaly detection with generative adversarial networks,” Medical Image Analysis, vol. 54, pp. 30–44, 2019.
- 23. B. Lian, Y. Kartal, F. L. Lewis, D. G. Mikulski, G. R. Hudas, Y. Wan, and A. Davoudi, “Anomaly detection and correction of optimizing autonomous systems with inverse reinforcement learning,” IEEE Transactions on Cybernetics, vol. 53, no. 7, pp. 4555–4566, 2022.
- 24. A. Barto, M. Mirolli, and G. Baldassarre, “Novelty or surprise?,” Frontiers in Psychology, vol. 4, p. 907, 2013.
- 25. L. Itti and P. Baldi, “Bayesian surprise attracts human attention,” Vision Research, vol. 49, no. 10, pp. 1295–1306, 2009.
- 26. V. Liakoni, A. Modirshanechi, W. Gerstner, and J. Brea, “Learning in volatile environments with the Bayes factor surprise,” Neural Computation, vol. 33, no. 2, pp. 269–340, 2021.
- 27. M. Faraji, K. Preuschoff, and W. Gerstner, “Balancing new against old information: The role of puzzlement surprise in learning,” Neural Computation, vol. 30, no. 1, pp. 34–83, 2018.
- 28. O. Çatal, S. Leroux, C. De Boom, T. Verbelen, and B. Dhoedt, “Anomaly detection for autonomous guided vehicles using Bayesian surprise,” in Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems, (Las Vegas, USA), October 2020.
- 29. Y. Zamiri-Jafarian and K. N. Plataniotis, “A Bayesian surprise approach in designing cognitive radar for autonomous driving,” Entropy, vol. 24, no. 5, p. 672, 2022.
- 30. A. Dinparastdjadid, I. Supeene, and J. Engstrom, “Measuring surprise in the wild,” arXiv preprint arXiv:2305.07733, 2023.
- 31. A. S. Raihan, H. Khosravi, T. H. Bhuiyan, and I. Ahmed, “An augmented surprise-guided sequential learning framework for predicting the melt pool geometry,” Journal of Manufacturing Systems, vol. 75, pp. 56–77, 2024.
- 32. S. Jin, J. R. Deneault, B. Maruyama, and Y. Ding, “Autonomous experimentation systems and benefit of surprise-based Bayesian optimization,” in Proceedings of the 2022 International Symposium on Flexible Automation, (Yokohama, Japan), July 2022.
- 33. A. Modirshanechi, J. Brea, and W. Gerstner, “A taxonomy of surprise definitions,” Journal of Mathematical Psychology, vol. 110, p. 102712, 2022.
- 34. P. Baldi, “A computational theory of surprise,” in Information, Coding and Mathematics: Proceedings of Workshop Honoring Prof. Bob Mceliece on his 60th Birthday, pp. 1–25, 2002.
- 35. A. Prat-Carrabin, R. C. Wilson, J. D. Cohen, and R. Azeredo da Silveira, “Human inference in changing environments with temporal structure,” Psychological Review, vol. 128, no. 5, p. 879–912, 2021.
- 36. P. J. Rousseeuw and C. Croux, “Alternatives to the median absolute deviation,” Journal of the American Statistical Association, vol. 88, no. 424, pp. 1273–1283, 1993.
- 37. C. Aytekin, X. Ni, F. Cricri, and E. Aksu, “Clustering and unsupervised anomaly detection with l-2 normalized deep auto-encoder representations,” in Proceedings of the 2018 International Joint Conference on Neural Networks, (Rio de Janeiro, Brazil), October 2018.
- 38. D. T. Nguyen, Z. Lou, M. Klar, and T. Brox, “Anomaly detection with multiple-hypotheses predictions,” in Proceedings of the 36th International Conference on Machine Learning, (Long Beach, USA), June 2019.
- 39. A. Kolossa, B. Kopp, and T. Fingscheidt, “A computational analysis of the neural bases of Bayesian inference,” Neuroimage, vol. 106, pp. 222–237, 2015.
- 40. C. E. Shannon, “A mathematical theory of communication,” The Bell System Technical Journal, vol. 27, no. 3, pp. 379–423, 1948.
- 41. L. Paninski, “Estimation of entropy and mutual information,” Neural Computation, vol. 15, no. 6, pp. 1191–1253, 2003.
- 42. D. François, V. Wertz, and M. Verleysen, “The permutation test for feature selection by mutual information,” in Proceedings of the 14th European Symposium on Artificial Neural Networks, (Bruges, Belgium), April 2006.
- 43. G. Doquire and M. Verleysen, “Mutual information-based feature selection for multilabel classification,” Neurocomputing, vol. 122, pp. 148–155, 2013.
- 44. T. M. Cover, Elements of Information Theory. John Wiley & Sons, 1999.
- 45. A. Bondu, V. Lemaire, and M. Boullé, “Exploration vs. exploitation in active learning: A Bayesian approach,” in Proceedings of the 2010 International Joint Conference on Neural Networks, (Barcelona, Spain), July 2010.
- 46. J. G. Moreno-Torres, T. Raeder, R. Alaiz-Rodríguez, N. V. Chawla, and F. Herrera, “A unifying view on dataset shift in classification,” Pattern Recognition, vol. 45, no. 1, pp. 521–530, 2012.
- 47. M. Sugiyama, M. Krauledat, and K.-R. Müller, “Covariate shift adaptation by importance weighted cross validation,” Journal of Machine Learning Research, vol. 8, no. 5, pp. 985–1005, 2007.
- 48. S. Bickel, M. Brückner, and T. Scheffer, “Discriminative learning under covariate shift,” Journal of Machine Learning Research, vol. 10, no. 9, pp. 2137–2155, 2009.
- 49. I. Žliobaitė, M. Pechenizkiy, and J. Gama, “An overview of concept drift applications,” Big Data Analysis: New Algorithms for a New Society, vol. 16, pp. 91–114, 2016.
- 50. K. Zhang, A. T. Bui, and D. W. Apley, “Concept drift monitoring and diagnostics of supervised learning models via score vectors,” Technometrics, vol. 65, no. 2, pp. 137–149, 2023.
- 51. N. Cebron and M. R. Berthold, “Active learning for object classification: From exploration to exploitation,” Data Mining and Knowledge Discovery, vol. 18, pp. 283–299, 2009.
- 52. U. J. Islam, K. Paynabar, G. Runger, and A. S. Iquebal, “Dynamic exploration–exploitation trade-off in active learning regression with Bayesian hierarchical modeling,” IISE Transactions, vol. 57, no. 4, pp. 393–407, 2025.
- 53. V. R. Joseph, “Space-filling designs for computer experiments: A review,” Quality Engineering, vol. 28, no. 1, pp. 28–35, 2016.
- 54. K. Chai, “Generalization errors and learning curves for regression with multi-task Gaussian processes,” in Proceedings of the 23rd Advances in Neural Information Processing Systems, (Vancouver, Canada), December 2009.
- 55. S. P. Strong, R. Koberle, R. R. D. R. Van Steveninck, and W. Bialek, “Entropy and information in neural spike trains,” Physical Review Letters, vol. 80, p. 197, 1998.
- 56. C. McDiarmid, “On the method of bounded differences,” Surveys in Combinatorics, vol. 141, no. 1, pp. 148–188, 1989.