# Diffusion Language Models Know the Answer Before Decoding
**Authors**:
- Soroush Vosoughi, Shiwei Liu (The Hong Kong Polytechnic University Dartmouth College University of Surrey Sun Yat-sen University)
Abstract
Diffusion language models (DLMs) have recently emerged as an alternative to autoregressive approaches, offering parallel sequence generation and flexible token orders. However, their inference remains slower than that of autoregressive models, primarily due to the cost of bidirectional attention and the large number of refinement steps required for high-quality outputs. In this work, we highlight and leverage an overlooked property of DLMs— early answer convergence: in many cases, the correct answer can be internally identified by half steps before the final decoding step, both under semi-autoregressive and random re-masking schedules. For example, on GSM8K and MMLU, up to 97% and 99% of instances, respectively, can be decoded correctly using only half of the refinement steps. Building on this observation, we introduce Prophet, a training-free fast decoding paradigm that enables early commit decoding. Specifically, Prophet dynamically decides whether to continue refinement or to go “all-in” (i.e., decode all remaining tokens in one step), using the confidence gap between the top-2 prediction candidates as the criterion. It integrates seamlessly into existing DLM implementations, incurs negligible overhead, and requires no additional training. Empirical evaluations of LLaDA-8B and Dream-7B across multiple tasks show that Prophet reduces the number of decoding steps by up to 3.4 $×$ while preserving high generation quality. These results recast DLM decoding as a problem of when to stop sampling, and demonstrate that early decode convergence provides a simple yet powerful mechanism for accelerating DLM inference, complementary to existing speedup techniques. Our code is available at https://github.com/pixeli99/Prophet.
1 Introduction
Along with the rapid evolution of diffusion models in various domains (Ho et al., 2020; Nichol & Dhariwal, 2021; Ramesh et al., 2021; Saharia et al., 2022; Jing et al., 2022), Diffusion language models (DLMs) have emerged as a compelling and competitively efficient alternative to autoregressive (AR) models for sequence generation (Austin et al., 2021a; Lou et al., 2023; Shi et al., 2024; Sahoo et al., 2024; Nie et al., 2025; Gong et al., 2024; Ye et al., 2025). Primary strengths of DLMs over AR models include, but are not limited to, efficient parallel decoding and flexible generation orders. More specifically, DLMs decode all tokens in parallel through iterative denoising and remasking steps. The remaining tokens are typically refined with low-confidence predictions over successive rounds (Nie et al., 2025).
Despite the speed-up potential of DLMs, the inference speed of DLMs is slower than AR models in practice, due to the lack of KV-cache mechanisms and the significant performance degradation associated with fast parallel decoding (Israel et al., 2025a). Recent endeavors have proposed excellent algorithms to enable KV-cache (Ma et al., 2025a; Liu et al., 2025a; Wu et al., 2025a) and improve the performance of parallel decoding (Wu et al., 2025a; Wei et al., 2025a; Hu et al., 2025).
In this paper, we aim to accelerate the inference of DLMs from a different perspective, motivated by an overlooked yet powerful phenomenon of DLMs— early answer convergence. Through extensive analysis, we observed that: a strikingly high proportion of samples can be correctly decoded during the early phase of decoding for both semi-autoregressive remasking and random remasking. This trend becomes more significant for random remasking. For example, on GSM8K and MMLU, up to 97% and 99% of instances, respectively, can be decoded correctly using only half of the refinement steps.
Motivated by this finding, we introduce Prophet, a training-free fast decoding strategy designed to capitalize on early answer convergence. Prophet continuously monitors the confidence gap between the top-2 answer candidates throughout the decoding trajectory, and opportunistically decides whether it is safe to decode all remaining tokens at once. By doing so, Prophet achieves substantial inference speed-up (up to 3.4 $×$ ) while maintaining high generation quality. Our contributions are threefold:
- Empirical observations of early answer convergence: We demonstrate that a strikingly high proportion of samples (up to 99%) can be correctly decoded during the early phase of decoding for both semi-autoregressive remasking and random remasking. This underscores a fundamental redundancy in conventional full-length slow decoding.
- A fast decoding paradigm enabling early commit decoding: We propose Prophet, which evaluates at each step whether the remaining answer is accurate enough to be finalized immediately, which we call Early Commit Decoding. We find that the confidence gap between the top-2 answer candidates serves as an effective metric to determine the right time of early commit decoding. Leveraging this metric, Prophet dynamically decides between continued refinement and immediate answer emission.
- Substantial speed-up gains with high-quality generation: Experiments across diverse benchmarks reveal that Prophet delivers up to 3.4 $×$ reduction in decoding steps. Crucially, this acceleration incurs negligible degradation in accuracy-affirming that early commit decoding is not just computationally efficient but also semantically reliable for DLMs.
2 Related Work
2.1 Diffusion Large Language Model
The idea of adapting diffusion processes to discrete domains traces back to the pioneering works of Sohl-Dickstein et al. (2015); Hoogeboom et al. (2021). A general probabilistic framework was later developed in D3PM (Austin et al., 2021a), which modeled the forward process as a discrete-state Markov chain progressively adding noise to the clean input sequence over time steps. The reverse process is parameterized to predict the clean text sequence based on the current noisy input by maximizing the Evidence Lower Bound (ELBO). This perspective was subsequently extended to the continuous-time setting. Campbell et al. (2022) reinterpreted the discrete chain within a continuous-time Markov chain (CTMC) formulation. An alternative line of work, SEDD (Lou et al., 2023), focused on directly estimating likelihood ratios and introduced a denoising score entropy criterion for training. Recent analyses in MDLM (Shi et al., 2024; Sahoo et al., 2024; Zheng et al., 2024) and RADD (Ou et al., 2024) demonstrate that multiple parameterizations of MDMs are in fact equivalent.
Motivated by these groundbreaking breakthroughs, practitioners have successfully built product-level DLMs. Notable examples include commercial releases such as Mercury (Labs et al., 2025), Gemini Diffusion (DeepMind, 2025), and Seed Diffusion (Song et al., 2025b), as well as open-source implementations including LLaDA (Nie et al., 2025) and Dream (Ye et al., 2025). However, DLMs face an efficiency-accuracy tradeoff that limits their practical advantages. While DLMs can theoretically decode multiple tokens per denoising step, increasing the number of simultaneously decoded tokens results in degraded quality. Conversely, decoding a limited number of tokens per denoising step leads to high inference latency compared to AR models, as DLMs cannot naively leverage key-value (KV) caching or other advanced optimization techniques due to their bidirectional nature.
2.2 Acceleration Methods for Diffusion Language Models
To enhance the inference speed of DLMs while maintaining quality, recent optimization efforts can be broadly categorized into three complementary directions. One strategy leverages the empirical observation that hidden states exhibit high similarity across consecutive denoising steps, enabling approximate caching (Ma et al., 2025b; Liu et al., 2025b; Hu et al., 2025). The alternative strategy restructures the denoising process in a semi-autoregressive or block-autoregressive manner, allowing the system to cache states from previous context or blocks. These methods may optionally incorporate cache refreshing that update stored cache at regular intervals (Wu et al., 2025b; Arriola et al., 2025; Wang et al., 2025b; Song et al., 2025a). The second direction reduces attention cost by pruning redundant tokens. For example, DPad (Chen et al., 2025) is a training-free method that treats future (suffix) tokens as a computational ”scratchpad” and prunes distant ones before computation. The third direction focuses on optimizing sampling methods or reducing the total denoising steps through reinforcement learning (Song et al., 2025b). Sampling optimization methods aim to increase the number of tokens decoded at each denoising step through different selection strategies. These approaches employ various statistical measures—such as confidence scores or entropy—as thresholds for determining the number of tokens to decode simultaneously. The token count can also be dynamically adjusted based on denoising dynamics (Wei et al., 2025b; Huang & Tang, 2025), through alignment with small off-the-shelf AR models (Israel et al., 2025b) or use the DLM itself as a draft model for speculative decoding (Agrawal et al., 2025).
Different from the above optimization methods, our approach stems from the observation that DLMs can correctly predict the final answer at intermediate steps, enabling early commit decoding to reduce inference time. Note that the early answer convergence has also been discovered by an excellent concurrent work (Wang et al., 2025a), where they focus on averaging predictions across time steps for improved accuracy, whereas we develop an early commit decoding method that reduces computational steps while maintaining quality.
3 Preliminary
3.1 Background on Diffusion Language Models
Concretely, let $x_{0}\sim p_{\text{data}}(x_{0})$ be a clean input sequence. At an intermediate noise level $t∈[0,T]$ , we denote by $x_{t}$ the corrupted version obtained after applying a masking procedure to a subset of its tokens.
Forward process.
The corruption mechanism can be expressed as a Markov chain
$$
\displaystyle q(x_{1:T}\mid x_{0})\;=\;\prod_{t=1}^{T}q(x_{t}\mid x_{t-1}), \tag{1}
$$
which gradually transforms the original sample $x_{0}$ into a maximally degraded representation $x_{T}$ . At each step, additional noise is injected, so that the sequence becomes progressively more masked as $t$ increases.
While the forward process in Eq.(1) is straightforward, its exact reversal is typically inefficient because it unmasks only one position per step (Campbell et al., 2022; Lou et al., 2023). To accelerate generation, a common remedy is to use the $\tau$ -leaping approximation (Gillespie, 2001), which enables multiple masked positions to be recovered simultaneously. Concretely, transitioning from corruption level $t$ to an earlier level $s<t$ can be approximated as
$$
\displaystyle q_{s|t} \displaystyle=\prod_{i=1}^{n}q_{s|t}({x}_{s}^{i}\mid{x}_{t}),\quad q_{s|t}({x}_{s}^{i}\mid{x}_{t})=\begin{cases}1,&{x}_{t}^{i}\neq[\text{MASK}],~{x}_{s}^{i}={x}_{t}^{i},\\[4.0pt]
\frac{s}{t},&{x}_{t}^{i}=[\text{MASK}],~{x}_{s}^{i}=[\text{MASK}],\\[4.0pt]
\frac{t-s}{t}\,q_{0|t}({x}_{s}^{i}\mid{x}_{t}),&{x}_{t}^{i}=[\text{MASK}],~{x}_{s}^{i}\neq[\text{MASK}].\end{cases} \tag{2}
$$
Here, $q_{0|t}({x}_{s}^{i}\mid{x}_{t})$ is a predictive distribution over the vocabulary, supplied by the model itself, whenever a masked location is to be unmasked. In conditional generation (e.g., producing a response ${x}_{0}$ given a prompt $p$ ), this predictive distribution additionally depends on $p$ , i.e., $q_{0|t}({x}_{s}^{i}\mid{x}_{t},p)$ .
Reverse generation.
To synthesize text, one needs to approximate the reverse dynamics. The generative model is parameterized as
This reverse process naturally decomposes into two complementary components. i. Prediction step. The model $p_{\theta}(x_{0}\mid x_{t})$ attempts to reconstruct a clean sequence from the corrupted input at level $t$ . We denote the predicted sequence after this step by $x_{0}^{t}$ , i.e. $x_{0}^{t}=p_{\theta}(x_{0}\mid x_{t})$ . (2) ii. Re-masking step. Once a candidate reconstruction $x_{0}^{t}$ is obtained, the forward noising mechanism is reapplied in order to produce a partially corrupted sequence $x_{t-1}$ that is less noisy than $x_{t}$ . This “re-masking” can be implemented in various ways, such as masking tokens uniformly at random or selectively masking low-confidence positions (Nie et al., 2025). Through the interplay of these two steps—prediction and re-masking—the model iteratively refines an initially noisy sequence into a coherent text output.
3.2 Early Answer Convergency
In this section, we investigate the early emergence of correct answers in DLMs. We conduct a comprehensive analysis using LLaDA-8B (Nie et al., 2025) on two widely used benchmarks: GSM8K (Cobbe et al., 2021) and MMLU (Hendrycks et al., 2021). Specifically, we examine the decoding dynamics, that is, how the top 1 predicted token evolves across positions at each decoding step, and report the percentage of the full decoding process at which the top 1 predicted tokens first match the ground truth answer tokens. In this study, we only consider samples where the final output contains the ground truth answer.
For low confidence remasking, we set Answer length at 256 and Block length at 32 for GSM8K, and Answer length at 128 and Block length to 128 for MMLU. For random remasking, we set Answer length at 256 and Block length at 256 for GSM8K, and Answer length at 128 and Block length at 128 for MMLU.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Histogram: First Correct Answer Emergence
### Overview
The image presents a histogram illustrating the distribution of the percentage of total decoding steps required for the first correct answer to emerge across a set of samples. The x-axis represents the percentage of total decoding steps, ranging from 0% to 100%, while the y-axis represents the number of samples. The histogram is annotated with two vertical lines and corresponding text boxes highlighting key percentiles.
### Components/Axes
* **X-axis Title:** "First Correct Answer Emergence (% of Total Decoding Steps)"
* **Y-axis Title:** "Number of Samples"
* **X-axis Scale:** Linear, from 0 to 100, with increments of 10.
* **Y-axis Scale:** Linear, from 0 to 125, with increments of 25.
* **Annotation 1:** A red dashed vertical line at approximately 20% with a text box stating "7.9% of samples get correct answer by 25% decoding steps".
* **Annotation 2:** An orange dashed vertical line at approximately 50% with a text box stating "24.2% of samples get correct answer by 50% decoding steps".
* **Annotation 3:** A curved black line pointing to the peak of the distribution, with a yellow text box stating "24.2% of samples get correct answer by 50% decoding steps".
### Detailed Analysis
The histogram shows a distribution that is skewed to the right. The number of samples is low for decoding steps between 0% and 20%. The number of samples increases from approximately 20% to 60%, peaking around 60-70%. After 70%, the number of samples gradually decreases.
Here's a breakdown of approximate sample counts for each 10% interval:
* 0-10%: ~5 samples
* 10-20%: ~12 samples
* 20-30%: ~20 samples
* 30-40%: ~30 samples
* 40-50%: ~40 samples
* 50-60%: ~60 samples
* 60-70%: ~75 samples
* 70-80%: ~70 samples
* 80-90%: ~50 samples
* 90-100%: ~30 samples
### Key Observations
* The distribution is not symmetrical.
* The majority of samples require more than 50% of the decoding steps to produce a correct answer.
* A small percentage of samples (7.9%) achieve a correct answer within the first 25% of decoding steps.
* Approximately 24.2% of samples achieve a correct answer within the first 50% of decoding steps.
* The peak of the distribution is between 60% and 70%, indicating that this is the most common range for the first correct answer to emerge.
### Interpretation
The data suggests that the process of obtaining a correct answer is not immediate and often requires a significant portion of the total decoding steps. The right skew indicates that there's a tail of samples that require a very high percentage of decoding steps to arrive at a correct answer. The annotations highlight key milestones: the percentage of samples that achieve a correct answer relatively quickly (within 25% and 50% of decoding steps) and the peak of the distribution. This could be indicative of the complexity of the decoding process, where initial steps may not be sufficient to identify the correct answer, and a substantial amount of processing is needed. The fact that the peak is around 60-70% suggests that, for most samples, the correct answer emerges after a considerable amount of decoding has been performed. The data could be used to evaluate the efficiency of the decoding algorithm or to identify areas for improvement.
</details>
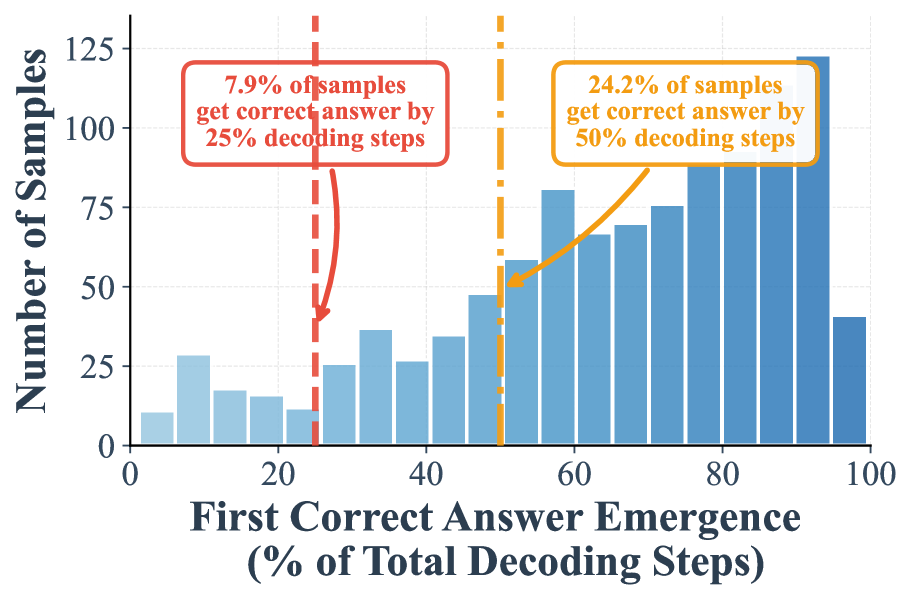
(a) w/o suffix prompt (low-confidence remasking)
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Bar Chart: First Correct Answer Emergence
### Overview
The image presents a bar chart illustrating the distribution of the percentage of total decoding steps required for the first correct answer to emerge. The chart shows the number of samples (y-axis) against the percentage of total decoding steps (x-axis). An orange line overlays the bar chart, representing the cumulative percentage of samples achieving a correct answer by a given decoding step. Two vertical dashed lines highlight specific decoding step percentages (25% and 50%) with corresponding percentages of samples achieving a correct answer.
### Components/Axes
* **X-axis Title:** "First Correct Answer Emergence (% of Total Decoding Steps)" - Scale ranges from 0 to 100, with increments of 10.
* **Y-axis Title:** "Number of Samples" - Scale ranges from 0 to 500, with increments of 100.
* **Bar Chart:** Represents the frequency distribution of the percentage of decoding steps at which the first correct answer emerges.
* **Orange Line:** Represents the cumulative percentage of samples that achieve a correct answer by a given decoding step. The line starts at approximately 0, increases gradually, and then rises more steeply.
* **Red Dashed Vertical Line:** Located at approximately 25% on the x-axis. Text annotation: "59.7% of samples get correct answer by 25% decoding steps".
* **Orange Dashed Vertical Line:** Located at approximately 50% on the x-axis. Text annotation: "75.8% of samples get correct answer by 50% decoding steps".
* **Bar Colors:** The bars are a light blue color.
### Detailed Analysis
The bar chart shows a distribution heavily skewed towards lower percentages of decoding steps.
* **0-10%:** Approximately 20 samples.
* **10-20%:** Approximately 180 samples.
* **20-30%:** Approximately 200 samples.
* **30-40%:** Approximately 60 samples.
* **40-50%:** Approximately 40 samples.
* **50-60%:** Approximately 20 samples.
* **60-70%:** Approximately 10 samples.
* **70-80%:** Approximately 10 samples.
* **80-90%:** Approximately 20 samples.
* **90-100%:** Approximately 60 samples.
The orange cumulative line starts at approximately 0 at 0% decoding steps.
* **25% Decoding Steps:** The line reaches approximately 60 samples.
* **50% Decoding Steps:** The line reaches approximately 370 samples.
* **75% Decoding Steps:** The line reaches approximately 440 samples.
* **100% Decoding Steps:** The line reaches approximately 500 samples.
The orange line shows a relatively flat slope from 0% to approximately 25% decoding steps, then a steeper slope from 25% to 50%, and a gradual slope from 50% to 100%.
### Key Observations
* The majority of samples achieve a correct answer within the first 20-30% of decoding steps.
* There is a significant drop in the number of samples requiring more than 50% of decoding steps.
* The cumulative percentage of samples achieving a correct answer increases rapidly between 25% and 50% decoding steps.
* The distribution is not uniform; it is heavily concentrated at lower decoding step percentages.
### Interpretation
The data suggests that the model is relatively efficient at generating correct answers, with a large proportion of samples converging on a correct answer within the first quarter of the decoding process. The steep increase in the cumulative percentage between 25% and 50% indicates a critical point where the model rapidly refines its output. The fact that 75.8% of samples achieve a correct answer by 50% decoding steps suggests that the model is generally reliable within this timeframe. The tail of the distribution extending to 100% decoding steps indicates that a small percentage of samples require a more extensive decoding process to arrive at a correct answer, potentially due to more complex or ambiguous inputs. This could be indicative of the model's limitations in handling certain types of data or the need for further optimization of the decoding algorithm. The annotations highlight key milestones in the decoding process, providing a clear understanding of the model's performance at different stages.
</details>
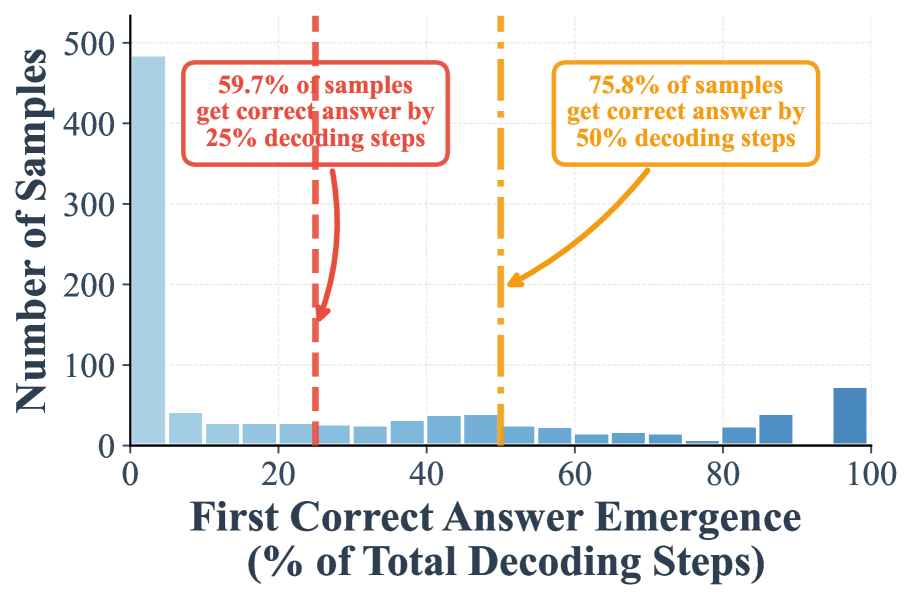
(b) w/ suffix prompt (low-confidence remasking)
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Histogram: First Correct Answer Emergence
### Overview
The image presents a histogram illustrating the distribution of the percentage of total decoding steps required for the first correct answer to emerge. It also includes annotations indicating the percentage of samples achieving a correct answer within 25% and 50% of decoding steps. An orange line shows the cumulative percentage of samples.
### Components/Axes
* **X-axis Title:** "First Correct Answer Emergence (% of Total Decoding Steps)" - Scale ranges from 0 to 100, with increments of 10.
* **Y-axis Title:** "Number of Samples" - Scale ranges from 0 to 150, with increments of 50.
* **Histogram Bars:** Represent the frequency distribution of the percentage of decoding steps.
* **Orange Line:** Represents the cumulative percentage of samples achieving a correct answer by a given decoding step percentage.
* **Red Dashed Line:** Located at approximately 20% on the x-axis, with the annotation "88.5% of samples get correct answer by 25% decoding steps".
* **Orange Dashed Line:** Located at approximately 50% on the x-axis, with the annotation "97.2% of samples get correct answer by 50% decoding steps".
### Detailed Analysis
The histogram shows a strong right skew. The majority of samples achieve a correct answer with a relatively small number of decoding steps.
* **Bar Heights (Approximate):**
* 0-10%: ~110 samples
* 10-20%: ~55 samples
* 20-30%: ~25 samples
* 30-40%: ~12 samples
* 40-50%: ~7 samples
* 50-60%: ~4 samples
* 60-70%: ~2 samples
* 70-80%: ~1 sample
* 80-90%: ~0 samples
* 90-100%: ~1 sample
* **Orange Line Trend:** The orange line starts near zero, rises steeply, and then plateaus. This indicates that a large proportion of samples achieve a correct answer quickly, and the rate of improvement slows down as more decoding steps are required.
* At 25% decoding steps, the orange line reaches approximately 88.5% (as annotated).
* At 50% decoding steps, the orange line reaches approximately 97.2% (as annotated).
* The line continues to rise slowly, approaching 100% as the decoding steps increase.
### Key Observations
* The data is heavily skewed towards lower decoding step percentages.
* A significant majority (88.5%) of samples achieve a correct answer within the first 25% of decoding steps.
* Almost all samples (97.2%) achieve a correct answer within the first 50% of decoding steps.
* Very few samples require more than 50% of the total decoding steps to achieve a correct answer.
### Interpretation
The data suggests that the decoding process is highly efficient, with most samples converging on the correct answer relatively quickly. The rapid increase in the cumulative percentage curve indicates a fast initial learning or convergence phase. The annotations highlight that a large proportion of the samples achieve a correct answer within a small fraction of the total decoding steps, suggesting that the system is effective at identifying the correct answer early in the process. The right skew indicates that while most samples converge quickly, a small number require significantly more decoding steps, potentially due to more complex or ambiguous inputs. This could be indicative of the system's limitations or the inherent difficulty of certain cases. The data implies a strong correlation between decoding steps and answer correctness, with a diminishing return as decoding steps increase.
</details>
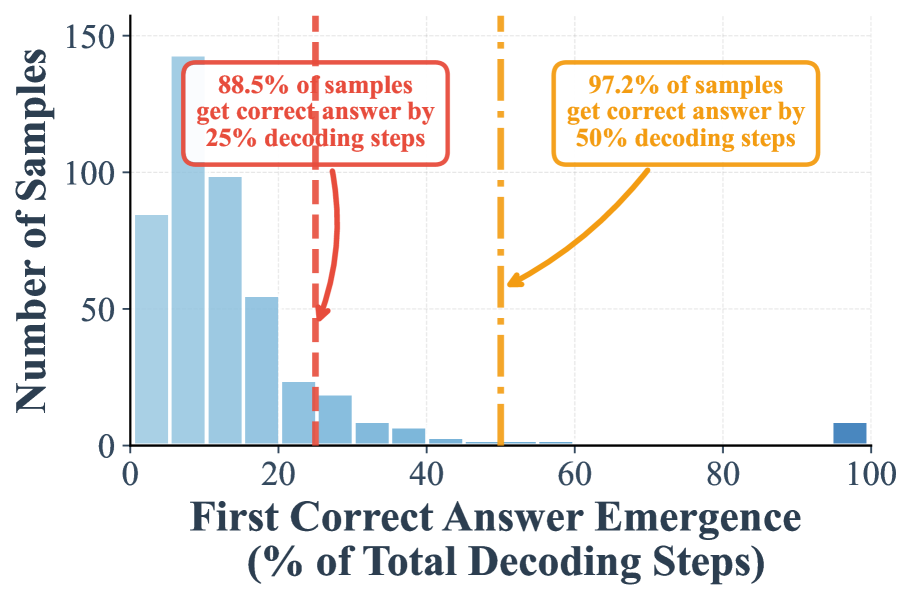
(c) w/o suffix prompt (random remasking)
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Histogram: First Correct Answer Emergence
### Overview
The image presents a histogram illustrating the distribution of the percentage of total decoding steps required for the first correct answer to emerge. The y-axis represents the number of samples, while the x-axis represents the percentage of total decoding steps. Two vertical dashed lines are present, marking 25% and 50% decoding steps, with associated percentages of samples achieving a correct answer by those steps. An orange line plots the cumulative distribution of samples.
### Components/Axes
* **X-axis Title:** "First Correct Answer Emergence (% of Total Decoding Steps)" - Scale ranges from 0 to 100, with markings at 0, 20, 40, 60, 80, and 100.
* **Y-axis Title:** "Number of Samples" - Scale ranges from 0 to 500, with markings at increments of 100.
* **Vertical Dashed Line 1:** Positioned at approximately 25% on the x-axis. Associated text: "94.6% of samples get correct answer by 25% decoding steps". Color: Red.
* **Vertical Dashed Line 2:** Positioned at approximately 50% on the x-axis. Associated text: "97.3% of samples get correct answer by 50% decoding steps". Color: Orange.
* **Orange Line:** Represents the cumulative distribution of samples. Starts near zero, rises gradually, then increases sharply around 50% on the x-axis, and plateaus.
* **Histogram Bars:** Represent the frequency of samples at each percentage of decoding steps.
### Detailed Analysis
The histogram shows a concentration of samples requiring a low percentage of decoding steps to achieve a correct answer.
* **0-10%:** Approximately 50 samples.
* **10-20%:** Approximately 120 samples.
* **20-30%:** Approximately 180 samples.
* **30-40%:** Approximately 100 samples.
* **40-50%:** Approximately 40 samples.
* **50-60%:** Approximately 20 samples.
* **60-70%:** Approximately 10 samples.
* **70-80%:** Approximately 5 samples.
* **80-90%:** Approximately 2 samples.
* **90-100%:** Approximately 5 samples.
The orange cumulative distribution line starts at approximately 0 samples at 0% decoding steps. It increases steadily to approximately 250 samples at 25% decoding steps. It then rises sharply, reaching approximately 485 samples at 50% decoding steps. The line continues to increase, but at a slower rate, reaching approximately 500 samples at 60% decoding steps.
### Key Observations
* The vast majority of samples (94.6%) achieve a correct answer within the first 25% of decoding steps.
* An even higher percentage (97.3%) achieve a correct answer within the first 50% of decoding steps.
* The distribution is heavily skewed towards lower decoding step percentages.
* There is a small tail of samples that require a higher percentage of decoding steps to achieve a correct answer.
### Interpretation
The data suggests that the system under evaluation is highly efficient at generating correct answers, with most answers emerging relatively quickly during the decoding process. The steep increase in the cumulative distribution around 50% indicates a rapid convergence towards correct answers. The small tail of samples requiring more decoding steps may represent more complex or ambiguous cases. The two vertical lines highlight key milestones in the decoding process, demonstrating the percentage of samples that achieve a correct answer within those thresholds. This data could be used to evaluate the performance of a language model or other decoding algorithm, and to identify areas for improvement. The fact that nearly all samples converge to a correct answer by 50% decoding steps suggests a robust and reliable system.
</details>
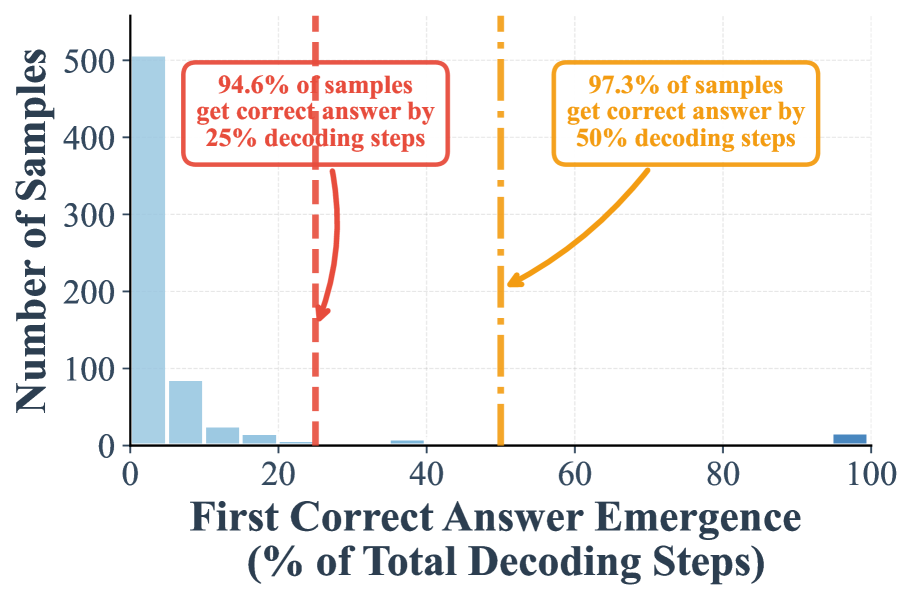
(d) w/ suffix prompt (random remasking)
Figure 1: Distribution of early correct answer detection during decoding process.. Histograms show when correct answers first emerge during diffusion decoding, measured as percentage of total decoding steps, using LLaDA 8B on GSM8K. Red and orange dashed lines indicate 50% and 70% completion thresholds, with corresponding statistics showing substantial early convergence. Suffix prompting (b,d) dramatically accelerates convergence compared to standard prompting (a,c). This early convergence pattern demonstrates that correct answer tokens stabilize as top-1 candidates well before full decoding.
I. A high proportion of samples can be correctly decoded during the early phase of decoding. Figure 1 (a) demonstrates that when remasking with the low-confidence strategy, 24.2% samples are already correctly predicted in the first half steps, and 7.9% samples can be correctly decoded in the first 25% steps. These two numbers will be further largely boosted to 97.2% and 88.5%, when shifted to random remasking as shown in Figure 1 -(c).
II. Our suffix prompt further amplifies the early emergence of correct answers. Adding the suffix prompt “Answer:” significantly improves early decoding. With low confidence remasking, the proportion of correct samples emerging by the 25% step rises from 7.9% to 59.7%, and by the 50% step from 24.2% to 75.8% (Figure 1 -(b)). Similarly, under random remasking, the 25% step proportion increases from 88.5% to 94.6%.
III. Decoding dynamics of chain-of-thought tokens. We further examine the decoding dynamics of chain-of-thought tokens in addition to answer tokens, as shown in Figure 2. First, most non-answer tokens fluctuate frequently before being finalized. Second, answer tokens change far less often and tend to stabilize earlier, remaining unchanged for the rest of the decoding process.
<details>
<summary>x5.png Details</summary>

### Visual Description
\n
## Diagram: Token Processing States
### Overview
The image presents a horizontal sequence of four colored boxes, each representing a different state in a token processing pipeline. Each box is accompanied by a textual label describing the state. This diagram visually represents the progression of a token through various stages of modification or validation.
### Components/Axes
The diagram consists of four distinct components, arranged horizontally from left to right:
1. **No Change:** Represented by a white box.
2. **Token Change:** Represented by an orange box.
3. **Token Decoded:** Represented by a blue box.
4. **Correct Answer Token:** Represented by a green box.
Each component has a corresponding text label positioned directly below it, providing a description of the state.
### Detailed Analysis or Content Details
The diagram does not contain numerical data or axes. It is a visual representation of states. The states are:
* **No Change:** Indicates the token remains unaltered.
* **Token Change:** Indicates the token has been modified.
* **Token Decoded:** Indicates the token has been successfully decoded.
* **Correct Answer Token:** Indicates the token represents the correct answer.
The boxes are arranged in a linear sequence, suggesting a sequential flow of processing.
### Key Observations
The diagram highlights a progression from an initial state ("No Change") through potential modifications ("Token Change", "Token Decoded") to a final state representing a successful outcome ("Correct Answer Token"). The color coding provides a quick visual cue for each state.
### Interpretation
This diagram likely represents a simplified workflow in a natural language processing (NLP) or machine learning system. The "tokens" could refer to words, sub-words, or other units of text. The diagram illustrates how a token might be processed, potentially undergoing changes during decoding or validation, ultimately leading to a "Correct Answer Token" if the process is successful. The diagram is conceptual and does not provide specific details about the algorithms or methods used in each state. It serves as a high-level overview of the token processing pipeline. The diagram suggests a system that aims to identify and validate correct answers from input tokens.
</details>
<details>
<summary>figures/position_change_heatmap_low_conf_non_qi_700_step256_blocklen32_box.png Details</summary>
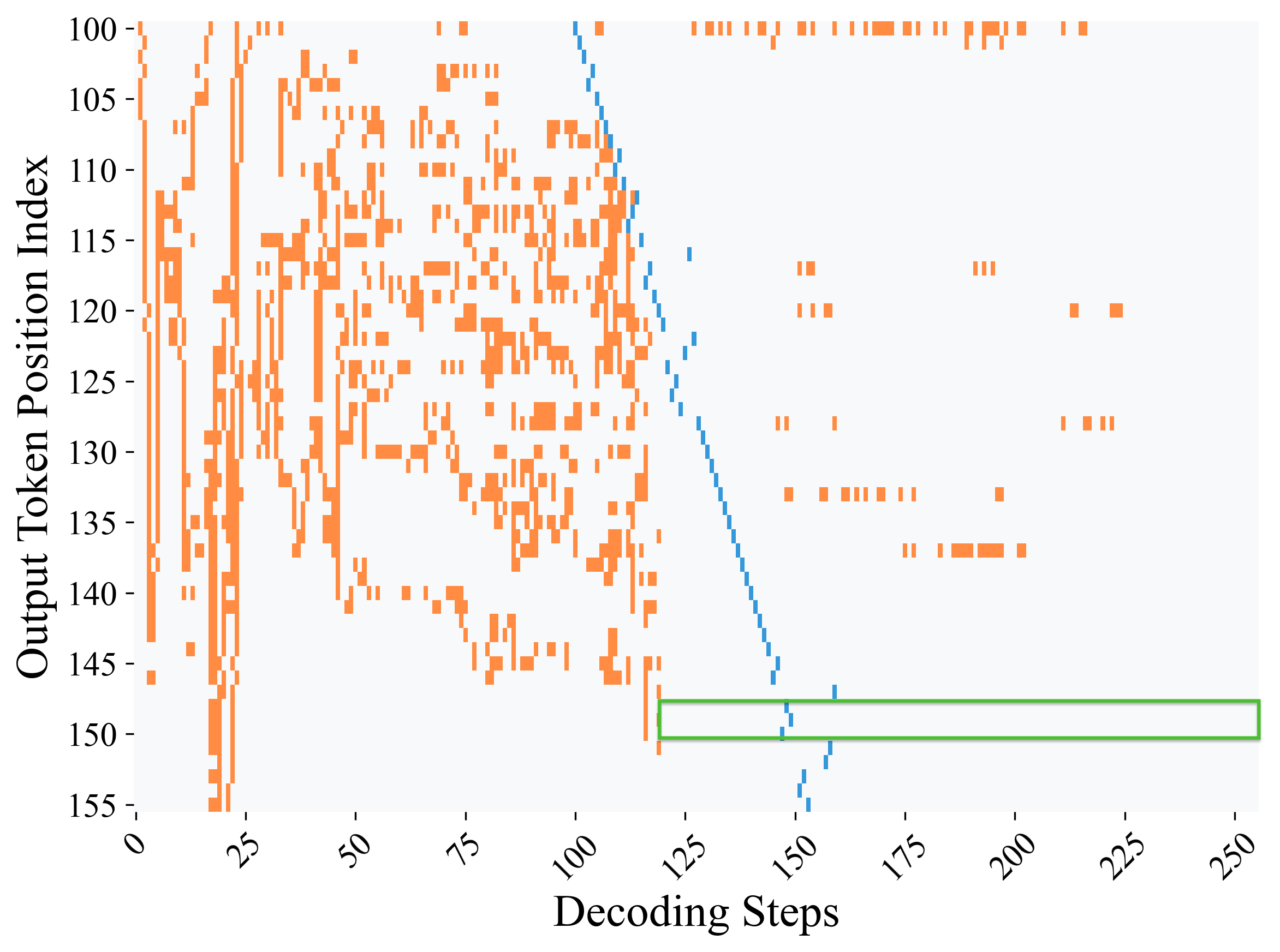
### Visual Description
\n
## Scatter Plot: Decoding Steps vs. Output Token Position Index
### Overview
The image presents a scatter plot visualizing the relationship between "Decoding Steps" and "Output Token Position Index". The plot displays three distinct colored lines, likely representing different phases or behaviors during the decoding process. The plot appears to show the progression of token generation as decoding steps increase.
### Components/Axes
* **X-axis:** "Decoding Steps" - Scale ranges from approximately 0 to 250.
* **Y-axis:** "Output Token Position Index" - Scale ranges from approximately 100 to 155.
* **Data Series 1 (Orange):** A dense scatter of points, predominantly in the lower decoding steps (0-100) and higher token positions (100-145).
* **Data Series 2 (Blue):** A line that slopes downward from approximately (100, 110) to (150, 155).
* **Data Series 3 (Green):** A line that appears after the blue line, starting around (150, 155) and extending to (250, 150).
* **No Legend:** There is no explicit legend provided in the image.
### Detailed Analysis
The orange scatter plot shows a high density of points in the initial decoding steps, with token positions ranging from approximately 100 to 145. The density of points decreases as decoding steps increase.
The blue line exhibits a clear downward trend. Starting at approximately decoding step 100 and token position 110, it descends to decoding step 150 and token position 155. The line appears to represent a transition phase.
The green line begins around decoding step 150 and token position 155, and extends horizontally to decoding step 250, with the token position remaining relatively stable around 150. This suggests a stabilization or completion phase.
**Approximate Data Points (extracted visually):**
* **Orange Scatter:**
* (0, 140) - High density
* (25, 135) - High density
* (50, 125) - Moderate density
* (75, 115) - Moderate density
* (100, 110) - Low density
* **Blue Line:**
* (100, 110)
* (125, 130)
* (150, 155)
* **Green Line:**
* (150, 155)
* (200, 150)
* (250, 150)
### Key Observations
* The orange scatter plot indicates a period of active token generation with a wide range of token positions being explored.
* The blue line represents a transition phase where token positions increase as decoding steps progress.
* The green line signifies a stabilization phase where token positions remain relatively constant.
* There is a clear sequential progression of these phases: orange (exploration), blue (transition), and green (stabilization).
### Interpretation
This plot likely represents the behavior of a decoding algorithm, such as one used in large language models. The orange scatter plot shows the initial exploration of possible token sequences. The blue line indicates a phase where the algorithm converges towards a more specific sequence, and the green line represents the final, stable output.
The downward slope of the blue line suggests that as the decoding process continues, the algorithm focuses on higher token positions, potentially indicating the completion of earlier parts of the sequence. The horizontal green line suggests that the algorithm has reached a stable state and is no longer significantly altering the token sequence.
The absence of a legend makes it difficult to definitively label these phases, but the visual trends strongly suggest they represent different stages of the decoding process. The plot provides insights into the algorithm's behavior and how it generates output sequences. The data suggests a successful decoding process, transitioning from exploration to convergence and finally to stabilization.
</details>
(a) w/o suffix prompt
<details>
<summary>figures/position_change_heatmap_low_conf_constraint_qi_700_step256_blocklen32_box.png Details</summary>
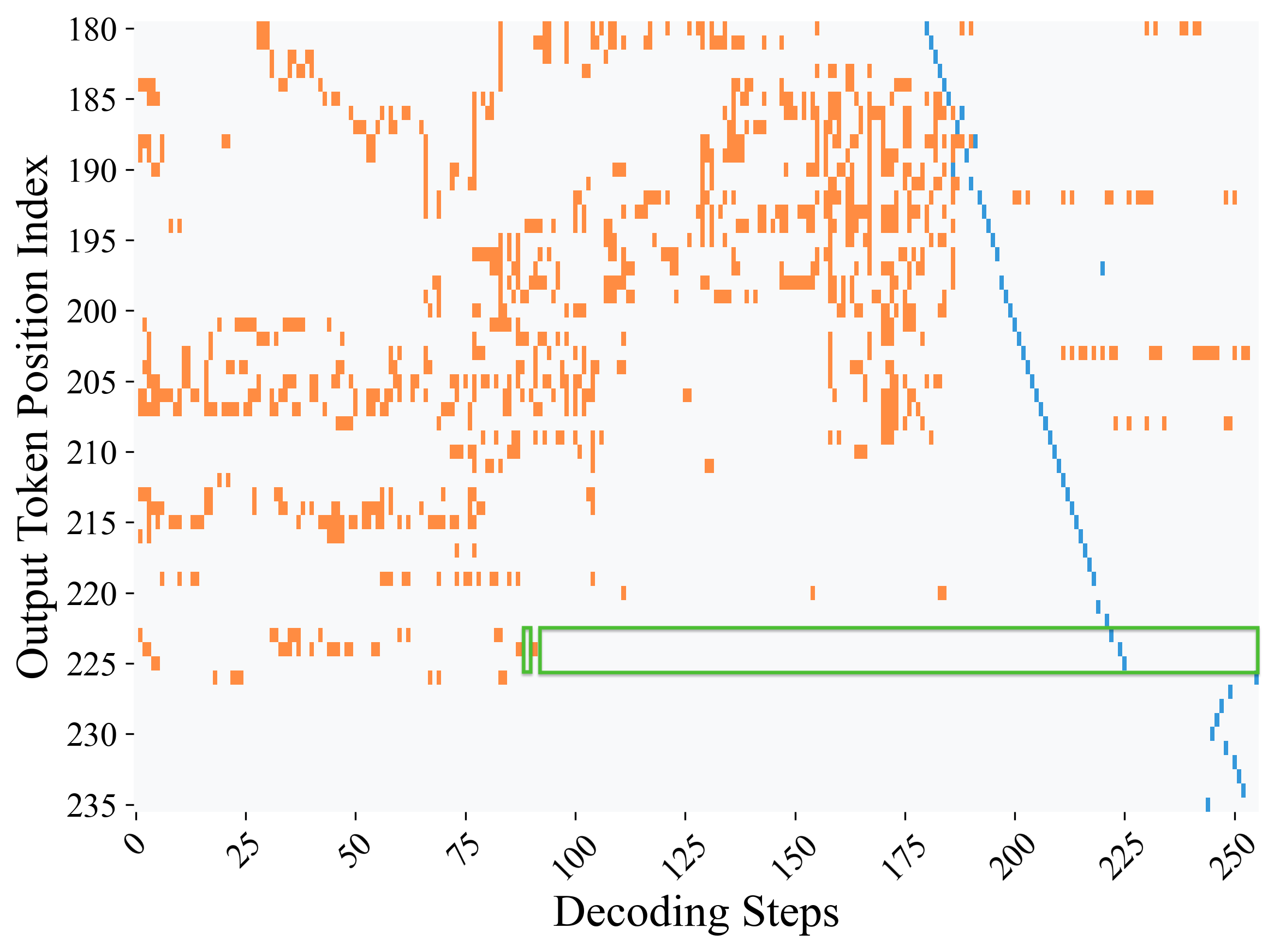
### Visual Description
\n
## Scatter Plot: Decoding Steps vs. Output Token Position
### Overview
The image presents a scatter plot visualizing the relationship between "Decoding Steps" and "Output Token Position". The plot displays a dense collection of orange data points, a green horizontal line, and a blue line that slopes downward towards the right side of the chart. The plot appears to represent the progression of a decoding process, potentially in a language model or similar system.
### Components/Axes
* **X-axis:** "Decoding Steps" - Ranging from 0 to 250, with tick marks at intervals of 25.
* **Y-axis:** "Output Token Position" - Ranging from 180 to 235, with tick marks at intervals of 5.
* **Data Points:** Orange squares, densely scattered throughout the plot area.
* **Green Line:** A horizontal line positioned approximately at Output Token Position 225.
* **Blue Line:** A line starting around Decoding Step 200 and sloping downwards, ending around Decoding Step 250.
### Detailed Analysis
The orange data points are distributed across the entire plot area, but are more concentrated in the upper portion (higher Output Token Positions) at lower Decoding Steps. As Decoding Steps increase, the density of orange points decreases, and they become more concentrated towards the lower portion of the plot.
* **Orange Data Points:** The points are scattered, making precise value extraction difficult. However, we can observe approximate ranges:
* From Decoding Step 0 to 50: Output Token Positions range from approximately 180 to 215.
* From Decoding Step 50 to 150: Output Token Positions range from approximately 190 to 220.
* From Decoding Step 150 to 250: Output Token Positions range from approximately 200 to 230, with a decreasing density.
* **Green Line:** The green line is a horizontal band, indicating a constant Output Token Position of approximately 225, spanning from approximately Decoding Step 75 to 225.
* **Blue Line:** The blue line exhibits a clear downward trend.
* At Decoding Step 200, the Output Token Position is approximately 195.
* At Decoding Step 225, the Output Token Position is approximately 220.
* At Decoding Step 250, the Output Token Position is approximately 230.
### Key Observations
* The density of orange data points decreases as Decoding Steps increase, suggesting a reduction in activity or the completion of a process.
* The green line represents a stable state or a threshold in the Output Token Position.
* The downward slope of the blue line indicates a change in the relationship between Decoding Steps and Output Token Position, potentially representing a finalization or convergence phase.
* There is a clear separation between the orange points and the green line, suggesting that the majority of the decoding process occurs at Output Token Positions above 225.
### Interpretation
This plot likely represents the decoding process of a sequence generation model (e.g., a language model). The "Decoding Steps" represent the iterations or steps taken to generate the output sequence, while the "Output Token Position" indicates the position of the generated token within the sequence.
The initial dense scattering of orange points suggests a period of exploration and uncertainty in the decoding process. As the decoding progresses (increasing Decoding Steps), the model converges towards a more stable state, as indicated by the decreasing density of points and the emergence of the green line. The green line could represent a point where the model has reached a certain level of confidence or has completed a significant portion of the sequence generation.
The blue line's downward trend suggests a finalization phase where the model is refining the output sequence or completing the generation process. The decreasing Output Token Position could indicate that the model is reaching the end of the sequence.
The plot suggests a successful decoding process that converges towards a stable output sequence. The absence of any significant outliers or anomalies indicates a smooth and predictable generation process. The data suggests that the model is actively generating tokens up to a certain point (around Decoding Step 200), after which it enters a refinement or finalization phase.
</details>
(b) w/ suffix prompt
Figure 2: Decoding dynamics across all positions based on maximum-probability predictions. Heatmaps track how the top-1 token changes at each position, if it is decoded at the current step, over the course of decoding. (a) Without our suffix prompts, correct answer tokens reach maximum probability at step 119. (b) With our suffix prompts, this occurs earlier at step 88, showing that the model internally identifies correct answers well before the final output. Results are shown for LLaDA 8B solving problem index 700 from GSM8K under low-confidence decoding. Gray indicates positions where the top-1 prediction remains unchanged, orange marks positions where the prediction changes to a different token, blue denotes the step at which the corresponding y-axis position is actually decoded, and green box highlights the answer region where the correct answer remains stable as the top-1 token and can be safely decoded without further changes as the decoding process progresses.
4 Methodology
<details>
<summary>x6.png Details</summary>
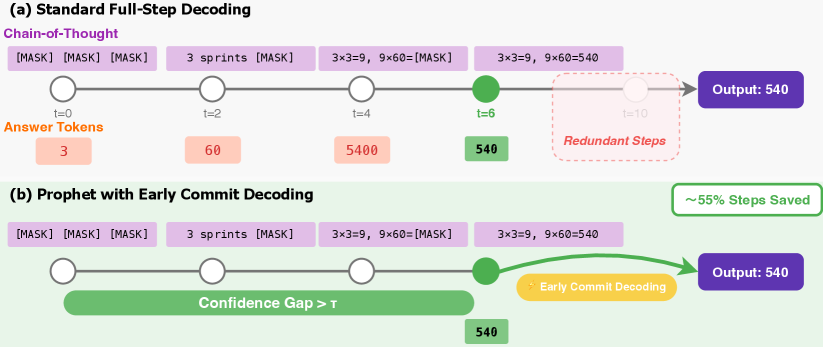
### Visual Description
## Diagram: Decoding Methods Comparison
### Overview
The image presents a comparison between two decoding methods: "Standard Full-Step Decoding" and "Prophet with Early Commit Decoding". It visually illustrates the process of reaching an output of 540 through a series of steps, highlighting the efficiency gains of the latter method. The diagram uses a timeline-like representation with labeled steps and associated "Answer Tokens" values.
### Components/Axes
The diagram consists of two main sections, labeled (a) and (b), representing the two decoding methods. Each section includes:
* **Chain-of-Thought:** A sequence of steps represented by purple boxes containing mathematical expressions.
* **Timeline:** A horizontal line with circles representing time steps (t=0, t=2, t=4, t=6, t=10).
* **Answer Tokens:** Values displayed below each time step, indicating the number of answer tokens generated.
* **Output:** A final purple box labeled "Output: 540".
* **Annotations:** Text labels describing specific aspects of each method, such as "Redundant Steps" and "Early Commit Decoding".
* **Confidence Gap > τ:** A green area indicating a confidence gap in the Prophet method.
* **Percentage Saved:** A label indicating the percentage of steps saved (~55%).
### Detailed Analysis or Content Details
**(a) Standard Full-Step Decoding**
* **t=0:** [MASK] [MASK] [MASK]. Answer Tokens: 3 (light blue).
* **t=2:** 3 sprints [MASK]. Answer Tokens: 60 (orange).
* **t=4:** 3x3=9, 9x60=[MASK]. Answer Tokens: 5400 (orange).
* **t=6:** 3x3=9, 9x60=540. Answer Tokens: 540 (orange).
* **t=10:** "Redundant Steps" annotation with a dashed arrow pointing to the final output.
* **Output:** 540 (purple).
**(b) Prophet with Early Commit Decoding**
* **t=0:** [MASK] [MASK] [MASK]. Answer Tokens: 3 (light blue).
* **t=2:** 3 sprints [MASK]. Answer Tokens: 60 (orange).
* **t=4:** 3x3=9, 9x60=[MASK]. Answer Tokens: 5400 (orange).
* **t=6:** 3x3=9, 9x60=540. Answer Tokens: 540 (orange).
* **Early Commit Decoding:** A curved green arrow indicating early commitment.
* **Confidence Gap > τ:** A green area spanning from t=0 to t=6.
* **Output:** 540 (purple).
* **~55% Steps Saved:** Annotation in the top-right corner.
### Key Observations
* The "Standard Full-Step Decoding" method requires an additional step (t=10) labeled as "Redundant Steps" to reach the final output.
* The "Prophet with Early Commit Decoding" method bypasses this redundant step by committing to the solution earlier, indicated by the green curved arrow.
* The "Prophet" method has a "Confidence Gap > τ" which is represented by the green area.
* The "Prophet" method saves approximately 55% of the steps compared to the standard method.
* The Answer Tokens values increase significantly at t=4, suggesting a crucial calculation step.
### Interpretation
The diagram demonstrates the efficiency of the "Prophet with Early Commit Decoding" method over the "Standard Full-Step Decoding" method. The "Prophet" method leverages a confidence gap to commit to a solution earlier, reducing the number of redundant steps required. This results in a significant reduction in computational effort, as indicated by the ~55% steps saved. The diagram suggests that the "Prophet" method is particularly effective when a certain level of confidence can be achieved before completing all steps. The [MASK] tokens suggest that the intermediate steps are not fully revealed, focusing instead on the overall process and efficiency comparison. The diagram is a visual argument for the benefits of early commitment in decoding processes, potentially in the context of large language models or similar AI systems.
</details>
Figure 3: An illustration of the Prophet’s early-commit-decoding mechanism. (a) Standard full-step decoding completes all predefined steps (e.g., 10 steps), incurring redundant computations after the answer has stabilized (at t=6). (b) Prophet dynamically monitors the model’s confidence (the “Confidence Gap”). It triggers an early commit decoding as soon as the answer converges, saving a significant portion of the decoding steps (in this case, 55%) without compromising the output quality.
Built upon the above findings, we introduce Prophet, a training-free fast decoding algorithm designed to accelerate the generation phase of DLMs. Prophet by committing to all remaining tokens in one shot and predicting answers as soon as the model’s predictions have stabilized, which we call Early Commit Decoding. Unlike conventional fixed-step decoding, Prophet actively monitors the model’s certainty at each step to make an informed, on-the-fly decision about when to finalize the generation.
Confidence Gap as a Convergence Metric.
The core mechanism of Prophet is the Confidence Gap, a simple yet effective metric for quantifying the model’s conviction for a given token. At any decoding step $t$ , the DLM produces a logit matrix $\mathbf{L}_{t}∈\mathbb{R}^{N×|\mathcal{V}|}$ , where $N$ is the sequence length and $|\mathcal{V}|$ is the vocabulary size. For each position $i$ , we identify the highest logit value, $L_{t,i}^{(1)}$ , and the second-highest, $L_{t,i}^{(2)}$ . The confidence gap $g_{t,i}$ is defined as their difference:
$$
g_{t,i}=L_{t,i}^{(1)}-L_{t,i}^{(2)}. \tag{1}
$$
This value serves as a robust indicator of predictive certainty. A large probability gap signals that the prediction has likely converged, with the top-ranked token clearly outweighing all others.
Early Commit Decoding.
The decision of when to terminate the decoding loop can be framed as an optimal stopping problem. At each step, we must balance two competing costs: the computational cost of performing additional refinement iterations versus the risk of error from a premature and potentially incorrect decision. The computational cost is a function of the remaining steps, while the risk of error is inversely correlated with the model’s predictive certainty, for which the Confidence Gap serves as a robust proxy.
Prophet addresses this trade-off with an adaptive strategy that embodies a principle of time-varying risk aversion. Let denote $p=(T_{\text{max}}-t)/T_{\text{max}}$ as the decoding progress, where $T_{\text{max}}$ is the total number of decoding steps, and $\tau(p)$ is the threshold for early commit decoding. In the early, noisy stages of decoding (when progress $p$ is small), the potential for significant prediction improvement is high. Committing to an answer at this stage carries a high risk. Therefore, Prophet acts in a risk-averse manner, demanding an exceptionally high threshold ( $\tau_{\text{high}}$ ) to justify an early commit decoding, ensuring such a decision is unequivocally safe. As the decoding process matures (as $p$ increases), two things happen: the model’s predictions stabilize, and the potential computational savings from stopping early diminish. Consequently, the cost of performing one more step becomes negligible compared to the benefit of finalizing the answer. Prophet thus becomes more risk-tolerant, requiring a progressively smaller threshold ( $\tau_{\text{low}}$ ) to confirm convergence.
This dynamic risk-aversion policy is instantiated through our staged threshold function, which maps the abstract trade-off between inference speed and generation certainty onto a concrete decision rule:
$$
\bar{g}_{t}\geq\tau(p),\quad\text{where}\quad\tau(p)=\begin{cases}\tau_{\text{high}}&\text{if }p<0.33\\
\tau_{\text{mid}}&\text{if }0.33\leq p<0.67\\
\tau_{\text{low}}&\text{if }p\geq 0.67\end{cases} \tag{5}
$$
Once the exit condition is satisfied at step $t^{*}$ , the iterative loop is terminated. The final output is then constructed in a single parallel operation by filling any remaining [MASK] tokens with the argmax of the current logits $\mathbf{L}_{t^{*}}$ .
Algorithm Summary.
The complete Prophet decoding procedure is outlined in Algorithm 1. The integration of the confidence gap check adds negligible computational overhead to the standard DLM decoding loop. Prophet is model-agnostic, requires no retraining, and can be readily implemented as a wrapper around existing DLM inference code.
Algorithm 1 Prophet: Early Commit Decoding for Diffusion Language Models
1: Input: Model $M_{\theta}$ , prompt $\mathbf{x}_{\text{prompt}}$ , max steps $T_{\text{max}}$ , generation length $N_{\text{gen}}$
2: Input: Threshold function $\tau(·)$ , answer region positions $\mathcal{A}$
3: Initialize sequence $\mathbf{x}_{T}←\text{concat}(\mathbf{x}_{\text{prompt}},\text{[MASK]}^{N_{\text{gen}}})$
4: Let $\mathcal{M}_{t}$ be the set of masked positions at step $t$ .
5: for $t=T_{\text{max}},T_{\text{max}}-1,...,1$ do
6: Compute logits: $\mathbf{L}_{t}=M_{\theta}(\mathbf{x}_{t})$
7: $\triangleright$ Prophet’s Early-Commit-Decoding Check
8: Calculate average confidence gap $\bar{g}_{t}$ over positions $\mathcal{A}$ using Eq. 4.
9: Calculate progress: $p←(T_{\text{max}}-t)/T_{\text{max}}$
10: if $\bar{g}_{t}≥\tau(p)$ then $\triangleright$ Check condition from Eq. 5
11: $\mathbf{\hat{x}}_{0}←\text{argmax}(\mathbf{L}_{t},\text{dim}=-1)$
12: $\mathbf{x}_{0}←\mathbf{x}_{t}$ . Fill positions in $\mathcal{M}_{t}$ with tokens from $\mathbf{\hat{x}}_{0}$ .
13: Return $\mathbf{x}_{0}$ $\triangleright$ Terminate and finalize
14: end if
15: $\triangleright$ Standard DLM Refinement Step
16: Determine tokens to unmask $\mathcal{U}_{t}⊂eq\mathcal{M}_{t}$ via a re-masking strategy.
17: $\mathbf{\hat{x}}_{0}←\text{argmax}(\mathbf{L}_{t},\text{dim}=-1)$
18: Update $\mathbf{x}_{t-1}←\mathbf{x}_{t}$ , replacing tokens at positions $\mathcal{U}_{t}$ with those from $\mathbf{\hat{x}}_{0}$ .
19: end for
20: Return $\mathbf{x}_{0}$ $\triangleright$ Return result after full iterations if no early commit decoding
5 Experiments
We evaluate Prophet on diffusion language models (DLMs) to validate two key hypotheses: first, that Prophet can preserve the performance of full-budget decoding while using substantially fewer denoising steps; second, that our adaptive approach provides more reliable acceleration than naive static baselines. We demonstrate that Prophet achieves notable computational savings with negligible quality degradation through comprehensive experiments across diverse benchmarks.
5.1 Experimental Setup
We conduct experiments on two state-of-the-art diffusion language models: LLaDA-8B (Nie et al., 2025) and Dream-7B (Ye et al., 2025). For each model, we compare three decoding strategies: Full uses the standard diffusion decoding with the complete step budget of $T_{\max}$ and Prophet employs early commit decoding with dynamic threshold scheduling. The threshold parameters are set to $\tau_{\text{high}}=7.5$ , $\tau_{\text{mid}}=5.0$ , and $\tau_{\text{low}}=2.5$ , with transitions occurring at 33% and 67% of the decoding progress. These hyperparameters were selected through preliminary validation experiments.
Our evaluation spans four capability domains to comprehensively assess Prophet’s effectiveness. For general reasoning, we use MMLU (Hendrycks et al., 2021), ARC-Challenge (Clark et al., 2018), HellaSwag (Zellers et al., 2019), TruthfulQA (Lin et al., 2021), WinoGrande (Sakaguchi et al., 2021), and PIQA (Bisk et al., 2020). Mathematical and scientific reasoning are evaluated through GSM8K (Cobbe et al., 2021) and GPQA (Rein et al., 2023). For code generation, we employ HumanEval (Chen et al., 2021) and MBPP (Austin et al., 2021b). Finally, planning capabilities are assessed using Countdown and Sudoku tasks (Gong et al., 2024). We follow the prompt in simple-evals for LLaDA and Dream, making the model reason step by step. Concretely, we set the generation length $L$ to 128 for general tasks, to 256 for GSM8K and GPQA, and to 512 for the code benchmarks. Unless otherwise noted, all baselines use a number of iterative steps equal to the specified generation length. All experiments employ greedy decoding to ensure deterministic and reproducible results.
5.2 Main Results and Analysis
The results of our experiments are summarized in Table 1. Across the general reasoning tasks, Prophet demonstrates its ability to match or even exceed the performance of the full baseline. For example, using LLaDA-8B, Prophet achieves 54.0% on MMLU and 83.5% on ARC-C, both of which are statistically on par with the full step decoding. Interestingly, on HellaSwag, Prophet (70.9%) not only improves upon the full baseline (68.7%) but also the half baseline (70.5%), suggesting that early commit decoding can prevent the model from corrupting an already correct prediction in later, noisy refinement steps. Similarly, Dream-7B maintains competitive performance across benchmarks, with Prophet achieving 66.1% on MMLU compared to the full model’s 67.6%—a minimal drop of 1.5% while delivering 2.47× speedup.
Prophet continues to prove its reliability in more complex reasoning tasks, including mathematics, science, and code generation. For the GSM8K dataset, Prophet with LLaDA-8B obtains an accuracy of 77.9%, outperforming the baseline’s 77.1%. This reliability also extends to code generation benchmarks. For instance, on HumanEval, Prophet perfectly matches the full baseline’s score with LLaDA-8B (30.5%) and even slightly improves it with Dream-7B (55.5% vs. 54.9%). Notably, the acceleration on these intricate tasks (e.g., 1.20× on HumanEval) is more conservative compared to general reasoning. This demonstrates Prophet’s adaptive nature: it dynamically allocates more denoising steps when a task demands further refinement, thereby preserving accuracy on complex problems. This reinforces Prophet’s role as a ”safe” acceleration method that avoids the pitfalls of premature, static termination.
In summary, our empirical results strongly support the central hypothesis of this work: DLMs often determine the correct answer long before the final decoding step. Prophet successfully capitalizes on this phenomenon by dynamically monitoring the model’s predictive confidence. It terminates the iterative refinement process as soon as the answer has stabilized, thereby achieving significant computational savings with negligible, and in some cases even positive, impact on task performance. This stands in stark contrast to static truncation methods, which risk cutting off the decoding process prematurely and harming accuracy. Prophet thus provides a robust and model-agnostic solution to accelerate DLM inference, enhancing its practicality for real-world deployment.
Table 1: Benchmark results on LLaDA-8B-Instruct and Dream-7B-Instruct. Sudoku and Countdown are evaluated using 8-shot setting; all other benchmarks use zero-shot evaluation. Detailed configuration is listed in the Appendix.
| Benchmark General Tasks MMLU | LLaDA 8B 54.1 | LLaDA 8B (Ours) 54.0 (2.34×) | Gain ( $\Delta$ ) -0.1 | Dream-7B 67.6 | Dream-7B (Ours) 66.1 (2.47×) | Gain ( $\Delta$ ) -1.5 |
| --- | --- | --- | --- | --- | --- | --- |
| ARC-C | 83.2 | 83.5 (1.88×) | +0.3 | 88.1 | 87.9 (2.61×) | -0.2 |
| Hellaswag | 68.7 | 70.9 (2.14×) | +2.2 | 81.2 | 81.9 (2.55×) | +0.7 |
| TruthfulQA | 34.4 | 46.1 (2.31×) | +11.7 | 55.6 | 53.2 (1.83×) | -2.4 |
| WinoGrande | 73.8 | 70.5 (1.71×) | -3.3 | 62.5 | 62.0 (1.45×) | -0.5 |
| PIQA | 80.9 | 81.9 (1.98×) | +1.0 | 86.1 | 86.6 (2.29×) | +0.5 |
| Mathematics & Scientific | | | | | | |
| GSM8K | 77.1 | 77.9 (1.63×) | +0.8 | 75.3 | 75.2 (1.71×) | -0.1 |
| GPQA | 25.2 | 25.7 (1.82×) | +0.5 | 27.0 | 26.6 (1.66×) | -0.4 |
| Code | | | | | | |
| HumanEval | 30.5 | 30.5 (1.20×) | 0.0 | 54.9 | 55.5 (1.44×) | +0.6 |
| MBPP | 37.6 | 37.4 (1.35×) | -0.2 | 54.0 | 54.6 (1.33×) | +0.6 |
| Planning Tasks | | | | | | |
| Countdown | 15.3 | 15.3 (2.67×) | 0.0 | 14.6 | 14.6 (2.37×) | 0.0 |
| Sudoku | 35.0 | 38.0 (2.46×) | +3.0 | 89.0 | 89.0 (3.40×) | 0.0 |
5.3 Ablation Studies
Beyond the coarse step–budget ablation above, we further dissect why Prophet outperforms static truncation by examining (i) sensitivity to the generation length $L$ and available step budget, (ii) robustness to the granularity of semi-autoregressive block updates, and (iii) compatibility with different re-masking heuristics. Together, these studies consistently show that Prophet’s adaptive early-commit rule improves the compute–quality Pareto frontier, whereas static schedules either under-compute (hurting accuracy) or over-compute (wasting steps).
Accuracy vs. step budget under different $L$ .
Table 2 (Panel A) summarizes GSM8K accuracy as we vary the number of refinement steps under two generation lengths ( $L\!=\!256$ and $L\!=\!128$ ). Accuracy under a static step cap rises monotonically with more steps (e.g., $7.7\%\!→\!22.5\%\!→\!58.8\%\!→\!76.2\%$ for 16/32/64/128 at $L\!=\!256$ ), but still underperforms either the full-budget decoding or Prophet. In contrast, Prophet stops adaptively at $≈ 160$ steps for $L\!=\!256$ (saving $≈ 38\%$ steps; $256/160\!≈\!1.63×$ ) and yields a higher score than the 256-step baseline (77.9% vs. 77.1%). When the target length is shorter ( $L\!=\!128$ ), Prophet again surpasses the 128-step baseline (72.7% vs. 71.3%) while using only $≈ 74$ steps (saving $≈ 42\%$ ; $128/74\!≈\!1.73×$ ). These results reaffirm that the gains are not a byproduct of simply using fewer steps: Prophet avoids late-stage over-refinement when the answer has already stabilized, while still allocating extra iterations when needed.
Granularity of semi-autoregressive refinement (block length).
Table 3 shows that static block schedules are brittle: accuracy peaks around moderate blocks and collapses for large blocks (e.g., 59.9 at 64 and 33.1 at 128). Prophet markedly attenuates this brittleness, delivering consistent gains across the entire range, and especially at large blocks where over-aggressive parallel updates inject more noise. For instance, at block length 64 and 128, Prophet improves accuracy by $+9.9$ and $+19.1$ points, respectively. This robustness is a direct consequence of Prophet’s time-varying risk-aversion: when coarse-grained updates raise uncertainty, the threshold schedule defers early commit; once predictions settle, Prophet exits promptly to avoid additional noisy revisions.
Re-masking strategy compatibility.
Table 2 (Panel B) evaluates three off-the-shelf re-masking heuristics (random, low-confidence, top- $k$ margin). Prophet consistently outperforms their static counterparts, with the largest gain under random re-masking (+2.8 points), aligning with our earlier observation that random schedules accentuate early answer convergence. The improvement persists under more informed heuristics (low-confidence: +1.4; top- $k$ margin: +0.7), indicating that Prophet’s stopping rule complements, rather than replaces, token-selection policies.
Table 2: GSM8K ablations. (a) Accuracy vs. step budget under two generation lengths $L$ . Prophet stops early (average steps in parentheses) yet matches/exceeds the full-budget baseline. (b) Accuracy under different re-masking strategies; Prophet complements token-selection policies.
(a) Accuracy vs. step budget and generation length
| 256 | 7.7 | 22.5 | 58.8 | 76.2 | 77.9 ( $≈$ 160; 1.63 $×$ ) | 77.1 |
| --- | --- | --- | --- | --- | --- | --- |
| 128 | 21.8 | 50.3 | 67.9 | 71.3 | 72.7 ( $≈$ 74; 1.73 $×$ ) | 71.3 |
(b) Re-masking strategy
| Random Low-confidence Top- $k$ margin | 63.8 71.3 72.4 | 66.6 72.7 73.1 |
| --- | --- | --- |
Table 3: Sensitivity to block length on GSM8K (semi-autoregressive updates). Prophet is less brittle to coarse-grained updates and yields larger gains as block length increases.
| Baseline Ours (Prophet) $\Delta$ (Abs.) | 67.1 72.8 +5.7 | 68.7 73.3 +4.6 | 71.3 72.7 +1.4 | 59.9 69.8 +9.9 | 33.1 52.2 +19.1 |
| --- | --- | --- | --- | --- | --- |
6 Conclusion
In this work, we identified and leveraged a fundamental yet overlooked property of diffusion language models: early answer convergence. Our analysis revealed that up to 99% of instances can be correctly decoded using only half the refinement steps, challenging the necessity of conventional full-length decoding. Building on this observation, we introduced Prophet, a training-free early commit decoding paradigm that dynamically monitors confidence gaps to determine optimal termination points. Experiments on LLaDA-8B and Dream-7B demonstrate that Prophet achieves up to 3.4× reduction in decoding steps while maintaining generation quality. By recasting DLM decoding as an optimal stopping problem rather than a fixed-budget iteration, our work opens new avenues for efficient DLM inference and suggests that early convergence is a core characteristic of how these models internally resolve uncertainty, across diverse tasks and settings.
References
- Agrawal et al. (2025) Sudhanshu Agrawal, Risheek Garrepalli, Raghavv Goel, Mingu Lee, Christopher Lott, and Fatih Porikli. Spiffy: Multiplying diffusion llm acceleration via lossless speculative decoding, 2025. URL https://arxiv.org/abs/2509.18085.
- Arriola et al. (2025) Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models, 2025. URL https://arxiv.org/abs/2503.09573.
- Austin et al. (2021a) Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces. Advances in neural information processing systems, 34:17981–17993, 2021a.
- Austin et al. (2021b) Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021b.
- Bisk et al. (2020) Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, 2020.
- Campbell et al. (2022) Andrew Campbell, Joe Benton, Valentin De Bortoli, Thomas Rainforth, George Deligiannidis, and Arnaud Doucet. A continuous time framework for discrete denoising models. Advances in Neural Information Processing Systems, 35:28266–28279, 2022.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- Chen et al. (2025) Xinhua Chen, Sitao Huang, Cong Guo, Chiyue Wei, Yintao He, Jianyi Zhang, Hai Li, Yiran Chen, et al. Dpad: Efficient diffusion language models with suffix dropout. arXiv preprint arXiv:2508.14148, 2025.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1, 2018.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- DeepMind (2025) Google DeepMind. Gemini-diffusion, 2025. URL https://blog.google/technology/google-deepmind/gemini-diffusion/.
- Gillespie (2001) Daniel T Gillespie. Approximate accelerated stochastic simulation of chemically reacting systems. The Journal of chemical physics, 115(4):1716–1733, 2001.
- Gong et al. (2024) Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, et al. Scaling diffusion language models via adaptation from autoregressive models. arXiv preprint arXiv:2410.17891, 2024.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.
- Ho et al. (2020) Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- Hoogeboom et al. (2021) Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forré, and Max Welling. Argmax flows and multinomial diffusion: Learning categorical distributions. Advances in Neural Information Processing Systems, 34:12454–12465, 2021.
- Hu et al. (2025) Zhanqiu Hu, Jian Meng, Yash Akhauri, Mohamed S Abdelfattah, Jae-sun Seo, Zhiru Zhang, and Udit Gupta. Accelerating diffusion language model inference via efficient kv caching and guided diffusion. arXiv preprint arXiv:2505.21467, 2025.
- Huang & Tang (2025) Chihan Huang and Hao Tang. Ctrldiff: Boosting large diffusion language models with dynamic block prediction and controllable generation. arXiv preprint arXiv:2505.14455, 2025.
- Israel et al. (2025a) Daniel Israel, Guy Van den Broeck, and Aditya Grover. Accelerating diffusion llms via adaptive parallel decoding. arXiv preprint arXiv:2506.00413, 2025a.
- Israel et al. (2025b) Daniel Israel, Guy Van den Broeck, and Aditya Grover. Accelerating diffusion llms via adaptive parallel decoding, 2025b. URL https://arxiv.org/abs/2506.00413.
- Jing et al. (2022) Bowen Jing, Gabriele Corso, Jeffrey Chang, Regina Barzilay, and Tommi Jaakkola. Torsional diffusion for molecular conformer generation. Advances in neural information processing systems, 35:24240–24253, 2022.
- Labs et al. (2025) Inception Labs, Samar Khanna, Siddhant Kharbanda, Shufan Li, Harshit Varma, Eric Wang, Sawyer Birnbaum, Ziyang Luo, Yanis Miraoui, Akash Palrecha, Stefano Ermon, Aditya Grover, and Volodymyr Kuleshov. Mercury: Ultra-fast language models based on diffusion, 2025. URL https://arxiv.org/abs/2506.17298.
- Lin et al. (2021) Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021.
- Liu et al. (2025a) Zhiyuan Liu, Yicun Yang, Yaojie Zhang, Junjie Chen, Chang Zou, Qingyuan Wei, Shaobo Wang, and Linfeng Zhang. dllm-cache: Accelerating diffusion large language models with adaptive caching. arXiv preprint arXiv:2506.06295, 2025a.
- Liu et al. (2025b) Zhiyuan Liu, Yicun Yang, Yaojie Zhang, Junjie Chen, Chang Zou, Qingyuan Wei, Shaobo Wang, and Linfeng Zhang. dllm-cache: Accelerating diffusion large language models with adaptive caching, 2025b. URL https://arxiv.org/abs/2506.06295.
- Lou et al. (2023) Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion language modeling by estimating the ratios of the data distribution. arXiv preprint arXiv:2310.16834, 2023.
- Ma et al. (2025a) Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dkv-cache: The cache for diffusion language models. arXiv preprint arXiv:2505.15781, 2025a.
- Ma et al. (2025b) Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dkv-cache: The cache for diffusion language models, 2025b. URL https://arxiv.org/abs/2505.15781.
- Nichol & Dhariwal (2021) Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International conference on machine learning, pp. 8162–8171. PMLR, 2021.
- Nie et al. (2025) Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. arXiv preprint arXiv:2502.09992, 2025.
- Ou et al. (2024) Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data. arXiv preprint arXiv:2406.03736, 2024.
- Ramesh et al. (2021) Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In International conference on machine learning, pp. 8821–8831. Pmlr, 2021.
- Rein et al. (2023) David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022, 2023.
- Saharia et al. (2022) Chitwan Saharia, Jonathan Ho, William Chan, Tim Salimans, David J Fleet, and Mohammad Norouzi. Image super-resolution via iterative refinement. IEEE transactions on pattern analysis and machine intelligence, 45(4):4713–4726, 2022.
- Sahoo et al. (2024) Subham Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and Volodymyr Kuleshov. Simple and effective masked diffusion language models. Advances in Neural Information Processing Systems, 37:130136–130184, 2024.
- Sakaguchi et al. (2021) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021.
- Shi et al. (2024) Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis K Titsias. Simplified and generalized masked diffusion for discrete data. arXiv preprint arXiv:2406.04329, 2024.
- Sohl-Dickstein et al. (2015) Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, pp. 2256–2265. PMLR, 2015.
- Song et al. (2025a) Yuerong Song, Xiaoran Liu, Ruixiao Li, Zhigeng Liu, Zengfeng Huang, Qipeng Guo, Ziwei He, and Xipeng Qiu. Sparse-dllm: Accelerating diffusion llms with dynamic cache eviction, 2025a. URL https://arxiv.org/abs/2508.02558.
- Song et al. (2025b) Yuxuan Song, Zheng Zhang, Cheng Luo, Pengyang Gao, Fan Xia, Hao Luo, Zheng Li, Yuehang Yang, Hongli Yu, Xingwei Qu, Yuwei Fu, Jing Su, Ge Zhang, Wenhao Huang, Mingxuan Wang, Lin Yan, Xiaoying Jia, Jingjing Liu, Wei-Ying Ma, Ya-Qin Zhang, Yonghui Wu, and Hao Zhou. Seed diffusion: A large-scale diffusion language model with high-speed inference, 2025b. URL https://arxiv.org/abs/2508.02193.
- Wang et al. (2025a) Wen Wang, Bozhen Fang, Chenchen Jing, Yongliang Shen, Yangyi Shen, Qiuyu Wang, Hao Ouyang, Hao Chen, and Chunhua Shen. Time is a feature: Exploiting temporal dynamics in diffusion language models, 2025a. URL https://arxiv.org/abs/2508.09138.
- Wang et al. (2025b) Xu Wang, Chenkai Xu, Yijie Jin, Jiachun Jin, Hao Zhang, and Zhijie Deng. Diffusion llms can do faster-than-ar inference via discrete diffusion forcing, aug 2025b. URL https://arxiv.org/abs/2508.09192. arXiv:2508.09192.
- Wei et al. (2025a) Qingyan Wei, Yaojie Zhang, Zhiyuan Liu, Dongrui Liu, and Linfeng Zhang. Accelerating diffusion large language models with slowfast: The three golden principles. arXiv preprint arXiv:2506.10848, 2025a.
- Wei et al. (2025b) Qingyan Wei, Yaojie Zhang, Zhiyuan Liu, Dongrui Liu, and Linfeng Zhang. Accelerating diffusion large language models with slowfast sampling: The three golden principles, 2025b. URL https://arxiv.org/abs/2506.10848.
- Wu et al. (2025a) Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding. arXiv preprint arXiv:2505.22618, 2025a.
- Wu et al. (2025b) Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding, 2025b. URL https://arxiv.org/abs/2505.22618.
- Ye et al. (2025) Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487, 2025.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.
- Zheng et al. (2024) Kaiwen Zheng, Yongxin Chen, Hanzi Mao, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling. arXiv preprint arXiv:2409.02908, 2024.
Appendix
Appendix A Additional results
<details>
<summary>x7.png Details</summary>
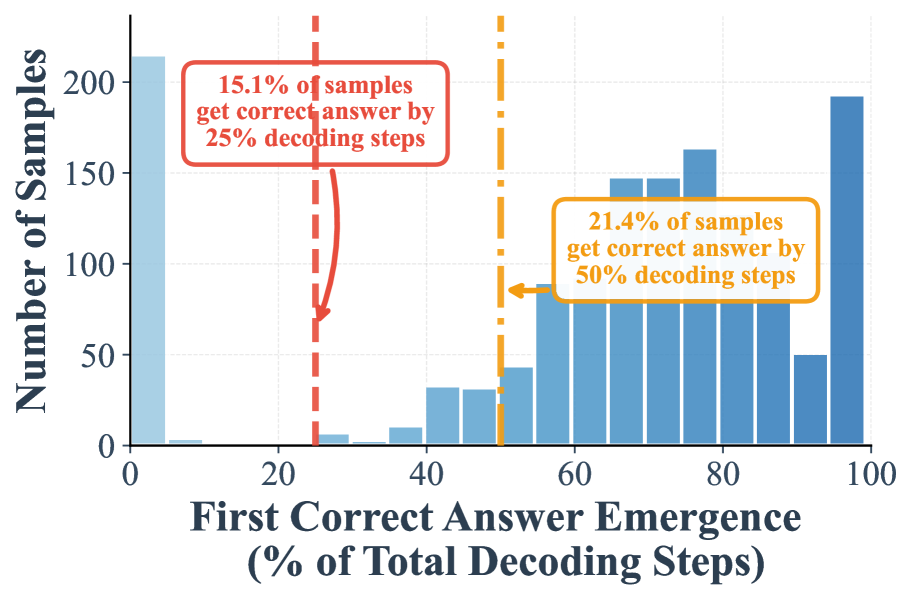
### Visual Description
\n
## Histogram: First Correct Answer Emergence
### Overview
The image presents a histogram illustrating the distribution of the percentage of total decoding steps required for the first correct answer to emerge. The y-axis represents the number of samples, while the x-axis represents the percentage of total decoding steps. Two vertical lines with annotations highlight specific percentages: 25% and 50%.
### Components/Axes
* **X-axis Title:** "First Correct Answer Emergence (% of Total Decoding Steps)"
* Scale: 0 to 100, with increments of 10.
* **Y-axis Title:** "Number of Samples"
* Scale: 0 to 200, with increments of 50.
* **Annotations:**
* "15.1% of samples get correct answer by 25% decoding steps" (Red dashed line at approximately 20% on the x-axis)
* "21.4% of samples get correct answer by 50% decoding steps" (Yellow dotted line at approximately 50% on the x-axis)
### Detailed Analysis
The histogram shows a distribution of decoding step percentages. The data is grouped into bins of approximately 10% width.
* **0-20%:** Approximately 60 samples fall within this range, peaking around 15-20%.
* **20-30%:** Approximately 20 samples fall within this range.
* **30-40%:** Approximately 10 samples fall within this range.
* **40-50%:** Approximately 15 samples fall within this range.
* **50-60%:** Approximately 30 samples fall within this range.
* **60-70%:** Approximately 60 samples fall within this range.
* **70-80%:** Approximately 150 samples fall within this range.
* **80-90%:** Approximately 160 samples fall within this range.
* **90-100%:** Approximately 200 samples fall within this range.
The distribution is skewed to the right, with a large concentration of samples requiring a higher percentage of decoding steps to achieve the first correct answer.
### Key Observations
* The highest frequency of samples (around 200) requires 90-100% of decoding steps.
* A significant number of samples (around 160) requires 80-90% of decoding steps.
* The number of samples decreases as the percentage of decoding steps decreases, until reaching a peak around 15-20%.
* 15.1% of samples achieve a correct answer within the first 25% of decoding steps.
* 21.4% of samples achieve a correct answer within the first 50% of decoding steps.
### Interpretation
The data suggests that the process of obtaining a correct answer is often iterative and requires a substantial portion of the total decoding steps. The right-skewed distribution indicates that while some samples converge quickly, the majority require a more extensive decoding process. The annotations highlight that a relatively small percentage of samples achieve a correct answer early in the process, while a larger percentage requires a significant amount of decoding. This could indicate a complex problem space where initial attempts are often incorrect, and refinement through multiple decoding steps is necessary to arrive at the correct solution. The difference between the 25% and 50% milestones suggests that there is a diminishing return in terms of correct answer emergence as the decoding process progresses. The data could be used to optimize decoding strategies or to assess the efficiency of the decoding process.
</details>
(a) MMLU w/o suffix prompt (low confidence)
<details>
<summary>x8.png Details</summary>
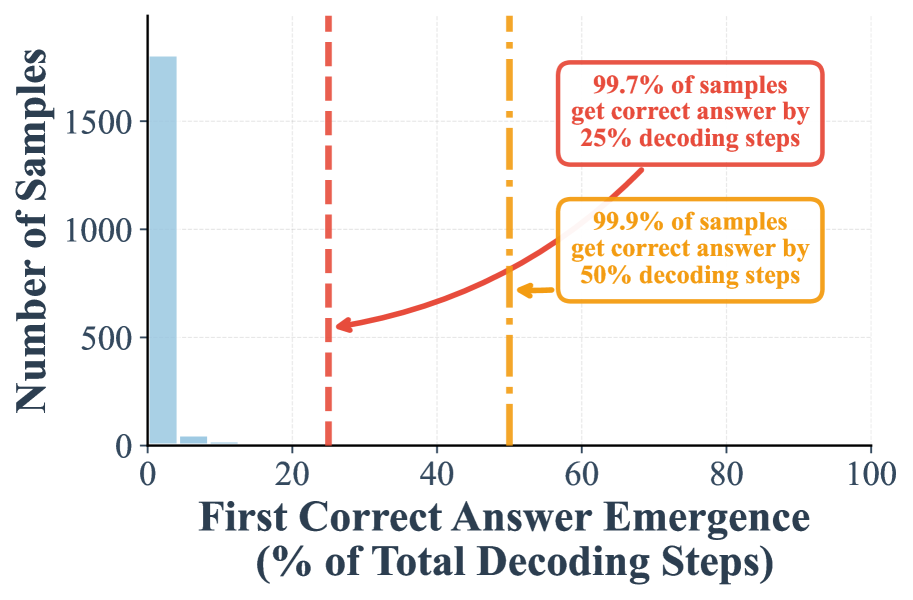
### Visual Description
\n
## Chart: First Correct Answer Emergence vs. Number of Samples
### Overview
The image presents a chart illustrating the relationship between the percentage of total decoding steps required for the first correct answer emergence and the number of samples. The chart uses a bar graph for the initial data points and a line graph to represent the trend as the percentage of decoding steps increases. Annotations highlight key milestones in the data.
### Components/Axes
* **X-axis Title:** "First Correct Answer Emergence (% of Total Decoding Steps)" - Scale ranges from 0 to 100, with major ticks at 0, 20, 40, 60, 80, and 100.
* **Y-axis Title:** "Number of Samples" - Scale ranges from 0 to 1600, with major ticks at 0, 500, 1000, and 1500.
* **Data Series 1:** Bar graph representing the number of samples at or below 20% decoding steps. Color: Light Blue.
* **Data Series 2:** Line graph representing the number of samples as the percentage of decoding steps increases beyond 20%. Color: Maroon.
* **Annotation 1:** "99.7% of samples get correct answer by 25 decoding steps" - Located in the top-right quadrant, with a dashed vertical line at approximately 25% on the x-axis. Color: Red.
* **Annotation 2:** "99.9% of samples get correct answer by 50 decoding steps" - Located in the bottom-right quadrant, with a dotted vertical line at approximately 50% on the x-axis. Color: Orange.
### Detailed Analysis
* **Bar Graph (0-20% Decoding Steps):** The bar reaches a height of approximately 1600 samples at 0% decoding steps. The number of samples decreases to approximately 500 samples at 20% decoding steps.
* **Line Graph (20-100% Decoding Steps):** The line starts at approximately 500 samples (corresponding to 20% decoding steps) and exhibits a generally upward trend.
* At 25% decoding steps (indicated by the red dashed line), the line reaches approximately 800 samples.
* At 50% decoding steps (indicated by the orange dotted line), the line reaches approximately 1000 samples.
* The line continues to increase, but at a decreasing rate, reaching approximately 1100 samples at 60% decoding steps and approximately 1200 samples at 80% decoding steps.
* **Data Points (Approximate):**
* (0%, 1600 samples)
* (20%, 500 samples)
* (25%, 800 samples)
* (50%, 1000 samples)
* (60%, 1100 samples)
* (80%, 1200 samples)
### Key Observations
* There is a significant drop in the number of samples achieving a correct answer within the first 20% of decoding steps.
* The rate of increase in the number of samples achieving a correct answer slows down as the percentage of decoding steps increases beyond 50%.
* The annotations highlight that a very high percentage of samples (99.7% at 25% and 99.9% at 50%) eventually achieve a correct answer.
### Interpretation
The chart demonstrates that while a large number of samples achieve a correct answer relatively quickly (within the first 20% of decoding steps), a substantial portion require more decoding steps to arrive at the correct solution. The diminishing returns observed beyond 50% decoding steps suggest that the initial decoding steps are the most crucial for achieving a correct answer. The annotations emphasize the high overall success rate, indicating that the decoding process is generally effective, but the time to reach a correct answer varies significantly across samples. The initial steep drop in samples suggests a potential bottleneck or difficulty in the early stages of decoding. This could be due to ambiguity in the initial data or the complexity of the decoding algorithm. The chart provides valuable insights into the efficiency and effectiveness of the decoding process, highlighting areas for potential optimization.
</details>
(b) MMLU w/ suffix prompt (low confidence)
<details>
<summary>x9.png Details</summary>
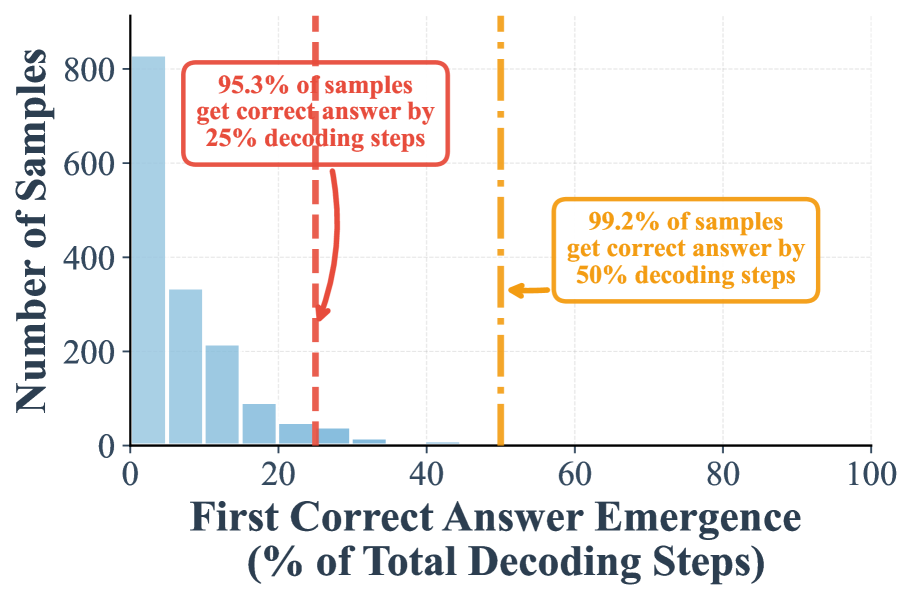
### Visual Description
\n
## Histogram: First Correct Answer Emergence
### Overview
The image presents a histogram illustrating the distribution of the percentage of total decoding steps required for the first correct answer to emerge. The y-axis represents the number of samples, while the x-axis represents the percentage of total decoding steps. Two vertical lines are overlaid on the histogram, marking 25% and 50% decoding steps, with associated percentages of samples achieving a correct answer by those steps.
### Components/Axes
* **X-axis Title:** "First Correct Answer Emergence (% of Total Decoding Steps)" - Scale ranges from 0 to 100.
* **Y-axis Title:** "Number of Samples" - Scale ranges from 0 to 800.
* **Histogram Bars:** Represent the frequency distribution of the percentage of decoding steps.
* **Vertical Line 1 (Red, Dashed):** Positioned at approximately 20% on the x-axis. Associated text: "95.3% of samples get correct answer by 25% decoding steps".
* **Vertical Line 2 (Orange, Dashed):** Positioned at approximately 50% on the x-axis. Associated text: "99.2% of samples get correct answer by 50% decoding steps".
* **Annotation Box (Orange, Rounded Rectangle):** Located in the upper-right quadrant, pointing to the orange dashed line. Contains the text: "99.2% of samples get correct answer by 50% decoding steps".
* **Annotation Box (Red, Rounded Rectangle):** Located in the upper-center quadrant, pointing to the red dashed line. Contains the text: "95.3% of samples get correct answer by 25% decoding steps".
### Detailed Analysis
The histogram shows a distribution skewed towards lower percentages of decoding steps.
* **Bar Heights (Approximate):**
* 0-10%: ~350 samples
* 10-20%: ~400 samples
* 20-30%: ~80 samples
* 30-40%: ~30 samples
* 40-50%: ~10 samples
* 50-60%: ~5 samples
* 60-70%: ~2 samples
* 70-80%: ~1 sample
* 80-90%: ~0 samples
* 90-100%: ~0 samples
The distribution rapidly decreases as the percentage of decoding steps increases. The highest concentration of samples (approximately 750) required less than 20% of the total decoding steps to achieve a correct answer.
### Key Observations
* The vast majority of samples achieve a correct answer with a relatively small number of decoding steps.
* There is a steep drop-off in the number of samples requiring more than 25% decoding steps.
* The percentage of samples achieving a correct answer increases sharply between 25% and 50% decoding steps.
* Very few samples require more than 50% decoding steps.
### Interpretation
The data suggests that the decoding process is highly efficient, with most samples converging on a correct answer quickly. The two vertical lines highlight key milestones: 95.3% of samples achieve a correct answer within the first 25% of decoding steps, and this rises to 99.2% within the first 50% of decoding steps. This indicates a strong tendency for the correct answer to emerge early in the decoding process. The rapid decline in sample numbers beyond 25% suggests that the remaining samples may represent more complex or ambiguous cases that require more extensive decoding. The distribution shape implies that the decoding process is not uniformly distributed; rather, it is concentrated in the initial stages. This could be due to the nature of the problem being solved, the effectiveness of the decoding algorithm, or a combination of both.
</details>
(c) MMLU w/o suffix prompt (random)
<details>
<summary>x10.png Details</summary>
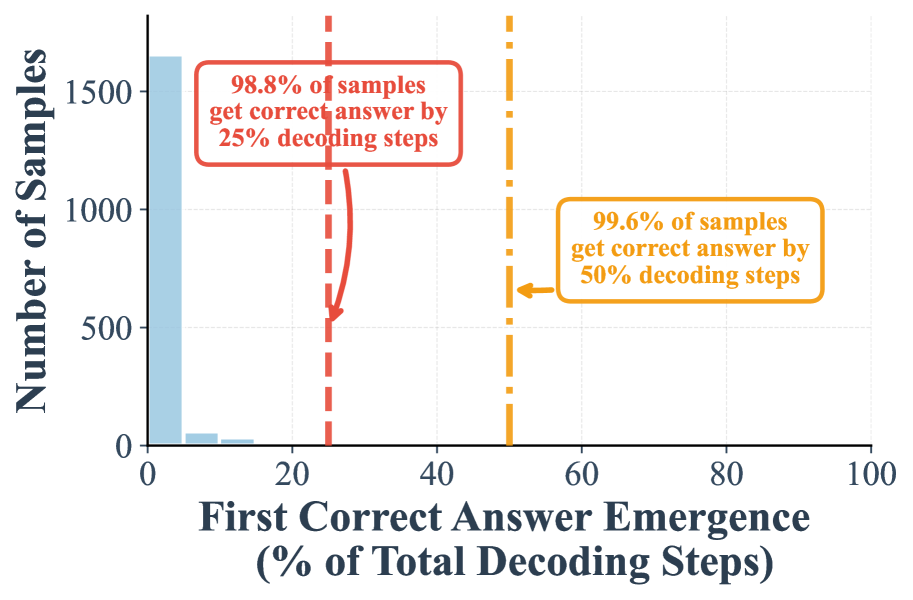
### Visual Description
\n
## Histogram: First Correct Answer Emergence
### Overview
The image presents a histogram illustrating the distribution of the percentage of total decoding steps required for a model to produce its first correct answer. The y-axis represents the number of samples, while the x-axis represents the percentage of total decoding steps. Two vertical dashed lines highlight key thresholds: 25% and 50% decoding steps, with associated percentages of samples achieving a correct answer.
### Components/Axes
* **X-axis Title:** "First Correct Answer Emergence (% of Total Decoding Steps)" - Scale ranges from 0 to 100.
* **Y-axis Title:** "Number of Samples" - Scale ranges from 0 to 1500, with increments of 200.
* **Annotation 1 (Red):** Located near x=20, states "98.8% of samples get correct answer by 25% decoding steps". A vertical dashed red line is positioned at approximately 20 on the x-axis.
* **Annotation 2 (Yellow):** Located near x=50, states "99.6% of samples get correct answer by 50% decoding steps". A vertical dashed yellow line is positioned at approximately 50 on the x-axis.
* **Histogram Bars:** Light blue bars representing the frequency distribution of samples.
### Detailed Analysis
The histogram shows a strong skew towards lower percentages of decoding steps. The majority of samples achieve a correct answer with a relatively small number of decoding steps.
* **0-20% Decoding Steps:** A large number of samples (approximately 1400) achieve a correct answer within the first 20% of decoding steps.
* **20-50% Decoding Steps:** The number of samples decreases significantly, but still remains substantial (approximately 500).
* **50-100% Decoding Steps:** Very few samples require more than 50% of the total decoding steps to produce a correct answer. The number of samples is very low, approaching zero.
Specifically:
* At approximately 20% decoding steps, the histogram reaches a peak, and 98.8% of samples have a correct answer.
* At approximately 50% decoding steps, 99.6% of samples have a correct answer.
### Key Observations
* The data demonstrates a rapid convergence towards correct answers. The vast majority of samples achieve a correct answer within the first 50% of decoding steps.
* The distribution is heavily skewed to the left, indicating that most samples require a small percentage of decoding steps.
* There is a minimal number of samples that require a large percentage of decoding steps to achieve a correct answer.
### Interpretation
The data suggests that the model is highly efficient in generating correct answers. It quickly converges on the correct solution, with a very small percentage of samples requiring a significant number of decoding steps. This could indicate a well-trained model with a strong understanding of the task. The annotations highlight the efficiency, showing that nearly all samples (98.8% and 99.6%) achieve a correct answer within a relatively short period of decoding. The difference between the two thresholds (25% and 50%) is minimal, suggesting that the marginal gain in accuracy beyond 25% decoding steps is small. This information is valuable for optimizing the decoding process and potentially reducing computational costs by limiting the number of decoding steps.
</details>
(d) MMLU w/ suffix prompt (random)
Figure 4: Distribution of early correct answer detection during decoding process. Histograms show when correct answers first emerge during diffusion decoding, measured as percentage of total decoding steps, using LLaDA 8B on MMLU. Red and orange dashed lines indicate 50% and 70% completion thresholds, with corresponding statistics showing substantial early convergence. Suffix prompting (b,d) dramatically accelerates convergence compared to standard prompting (a,c). This early convergence pattern demonstrates that correct answer tokens stabilize as top-1 candidates well before full decoding.
Table 4: Configurations used in our runs. We keep only parameters relevant to our method: base budget $(L,T,B)$ and Prophet ’s confidence schedule.
| MMLU | $L{=}64,\ T{=}64,\ B{=}16$ | $(7.5,\;5.0,\;2.5)$ | 33%, 67% |
| --- | --- | --- | --- |
| ARC-C | $L{=}64,\ T{=}64,\ B{=}16$ | $(7.5,\;5.0,\;2.5)$ | 33%, 67% |
| Hellaswag | $L{=}64,\ T{=}64,\ B{=}16$ | $(7.5,\;5.0,\;2.5)$ | 33%, 67% |
| TruthfulQA | $L{=}64,\ T{=}64,\ B{=}16$ | $(7.5,\;5.0,\;2.5)$ | 33%, 67% |
| WinoGrande | $L{=}64,\ T{=}64,\ B{=}16$ | $(7.5,\;5.0,\;2.5)$ | 33%, 67% |
| PIQA | $L{=}64,\ T{=}64,\ B{=}16$ | $(7.5,\;5.0,\;2.5)$ | 33%, 67% |
| GSM8K | $L{=}256,\ T{=}256,\ B{=}32$ | $(8.0,\;5.0,\;3.5)$ | 33%, 67% |
| GPQA | $L{=}256,\ T{=}256,\ B{=}32$ | $(8.0,\;5.0,\;3.5)$ | 33%, 67% |
| HumanEval | $L{=}512,\ T{=}512,\ B{=}32$ | $(7.5,\;5.0,\;4.5)$ | 33%, 67% |
| MBPP | $L{=}512,\ T{=}512,\ B{=}32$ | $(7.5,\;5.0,\;4.5)$ | 33%, 67% |
| Sudoku | $L{=}24,\ T{=}24,\ B{=}24$ | $(7.5,\;5.0,\;2.5)$ | 33%, 67% |
| Countdown | $L{=}32,\ T{=}32,\ B{=}32$ | $(7.5,\;5.0,\;2.5)$ | 33%, 67% |
Appendix B Evaluation Details
We re-implemented the evaluation of LLaDA and Dream on those reported datasets. We generate and extract the final answer instead of comparing the log probability in the multiple-choice setting, which can lower the reported scores on some datasets because the model sometimes fails to produce an answer in the given format. The configuration of each experiment is summarized in Table 4.