# Discovering New Theorems via LLMs with In-Context Proof Learning in Lean
**Authors**:
- Kazumi Kasaura (OMRON SINIC X Corporation)
- &Naoto Onda (OMRON SINIC X Corporation)
- &Yuta Oriike
- &Masaya Taniguchi
- RIKEN AIP
- &Akiyoshi Sannai (Kyoto University)
- &Sho Sonoda
- RIKEN AIP
## Abstract
Large Language Models have demonstrated significant promise in formal theorem proving. However, previous works mainly focus on solving existing problems. In this paper, we focus on the ability of LLMs to find novel theorems. We propose Conjecturing-Proving Loop pipeline for automatically generating mathematical conjectures and proving them in Lean 4 format. A feature of our approach is that we generate and prove further conjectures with context including previously generated theorems and their proofs, which enables the generation of more difficult proofs by in-context learning of proof strategies without changing parameters of LLMs. We demonstrated that our framework rediscovered theorems with verification, which were published in past mathematical papers and have not yet formalized. Moreover, at least one of these theorems could not be proved by the LLM without in-context learning, even in natural language, which means that in-context learning was effective for neural theorem proving. The source code is available at https://github.com/auto-res/ConjecturingProvingLoop.
## 1 Introduction
Large Language Models (LLMs) have demonstrated significant promise in theorem proving. Since LLMs can hallucinate and it is difficult to detect it in natural language, generating formal proofs using LLM and verifying them using an interactive theorem prover (ITP), such as Lean https://lean-lang.org/, has been studied. However, previous works mainly focus on solving existing problems. In this paper, we focus on the ability of LLMs to find novel theorems.
We proposed Conjecturing-Proving Loop, a pipeline for automatically generating mathematical conjectures and proving them in Lean 4 format. By separating the conjecturing and proving phases, we avoid the convergence of generated theorems and encourage proving more difficult theorems.
A feature of our approach is that we generate and prove further theorems with context including proven theorems and their proofs, which enables the generation of more difficult proofs by in-context learning of proof strategies without training of LLMs. Since the ability of reasoning and generation of Lean code of closed-source LLMs, such as chatGPT, has been improved recently, we use them as both conjecturer and prover. While the disadvantage of using closed-source LLMs is that models cannot be trained freely, in our framework, the proof ability of LLMs can be improved by in-context learning from previous verified proofs.
In the experiment, when mathematical notions were given as a seed, we verified whether important properties about them could be rediscovered in our framework. More specifically, we focused a few topological notions which are defined only by notions in Mathlib https://github.com/leanprover-community/mathlib4, Lean’s mathematical library, but not included in Mathlib. We generated theorems about these notions using our framework. As a result, we found that our framework rediscovered important theorems about these notions published in mathematical papers. Moreover, we verified that the in-context learning of proof strategies works: A theorem, which cannot be proved without context by LLMs even in natural language, was proved with context generated by our framework.
In summary, the contributions of this paper are as follows. First, we proposed Conjecture and Proof Loop, a pipeline for automatically generating mathematical conjectures and proving them in Lean 4 format. Second, we demonstrated that our framework can rediscover a research-level theorem. Third, we verified that the proof ability of LLMs can be improved by in-context learning, when the verified proofs generated by LLMs itself are given as context.
Our work also suggests the potential for automatic expansion of formal mathematics libraries using AI. Formalized mathematics is only a part of mathematics expressed in natural language, and expanding formal libraries, such as Mathlib, is crucial for verifying and automating mathematics. On the other hand, the set of propositions that should be included in the library may not always be obtainable in natural language. Our framework can generate propositions about given notions while learning them.
<details>
<summary>docs/AIMathematician.png Details</summary>
### Visual Description
## System Architecture Diagram: Automated Theorem Proving Pipeline
### Overview
The image depicts a system architecture for an automated mathematical theorem-proving pipeline. It illustrates the flow of information between three primary components: a **Library** of formal mathematics, a **Conjecturer** module, and a **Prover** module. The system uses Large Language Models (LLMs) and a formal verification server (Lean Server) in a cyclical process to generate and prove mathematical conjectures.
### Components/Axes
The diagram is organized into three main blocks with labeled arrows indicating data flow.
**1. Library (Left Block)**
* **Position:** Occupies the left third of the diagram.
* **Content:** A white rectangle containing a code snippet written in the **Lean** formal proof language (a functional programming language for mathematics).
* **Label:** The block is titled "Library" at its bottom.
**2. Conjecturer (Top-Right Block)**
* **Position:** Top-right quadrant.
* **Components:**
* **LLM:** A light blue square with an icon of a human head with gears, labeled "LLM".
* **Lean Server:** A light green square with a robot icon, labeled "Lean Server".
* **Internal Flow:** A purple, double-headed arrow connects the LLM and Lean Server, indicating bidirectional communication.
* **Label:** The entire block is titled "Conjecturer" at its top.
**3. Prover (Bottom-Right Block)**
* **Position:** Bottom-right quadrant.
* **Components:**
* **LLM:** A light blue square with a black silhouette of a human head with gears, labeled "LLM".
* **Lean Server:** A light green square with a robot icon, labeled "Lean Server".
* **Internal Flow:** A purple, double-headed arrow connects the LLM and Lean Server, indicating bidirectional communication.
* **Label:** The entire block is titled "Prover" at its top.
**Data Flow Arrows:**
* **Blue Arrow (Top):** Flows from the **Library** to the **Conjecturer's LLM**. Label: `context`.
* **Orange Arrow (Middle):** Flows from the **Library** to the **Prover's LLM**. Label: `context`.
* **Blue Arrow (Right, Downward):** Flows from the **Conjecturer** block to the **Prover** block. Label: `conjectures`.
* **Blue Arrow (Bottom, Leftward):** Flows from the **Prover** block back to the **Library**. Label: `theorems & proofs`.
* **Circular Blue Arrow:** Positioned between the Conjecturer and Prover blocks, indicating a cyclical or iterative process.
### Detailed Analysis
**Library Content (Lean Code Transcription):**
The code snippet is written in the Lean language. The text is as follows:
```
import Mathlib
...
def AlphaOpen (A : Set X) : Prop :=
A ⊆ interior (closure (interior A))
...
theorem
intersection_of_alpha_open_sets_is_alpha_open {A B : Set X} (hA : AlphaOpen A) (hB : AlphaOpen B) :
AlphaOpen (A ∩ B) := by ...
...
```
* **Language:** Lean (a formal proof assistant language).
* **Purpose:** It defines a mathematical property called `AlphaOpen` for a set `A` within a space `X`. The definition states that a set is AlphaOpen if it is a subset of the interior of the closure of its interior. It then states a theorem: the intersection of two AlphaOpen sets is also AlphaOpen. The proof is incomplete (indicated by `...`).
**Process Flow:**
1. **Context Provision:** The formal mathematical context (definitions, existing theorems) from the **Library** is sent as input (`context`) to both the **Conjecturer** and the **Prover**.
2. **Conjecture Generation:** The **Conjecturer** module, using its LLM and Lean Server, processes the context to generate new mathematical `conjectures` (unproven statements).
3. **Proof Attempt:** These `conjectures` are passed to the **Prover** module. The Prover, using its own LLM and Lean Server, attempts to construct formal proofs for them.
4. **Knowledge Update:** Successfully proven theorems and their proofs (`theorems & proofs`) are fed back into the **Library**, expanding the formal knowledge base.
5. **Iteration:** The circular arrow suggests this process is iterative: new theorems in the library enable the generation of new conjectures, which can then be proven.
### Key Observations
* **Dual LLM Architecture:** The system uses separate LLM instances for conjecturing and proving, suggesting these tasks may require different specializations or prompting strategies.
* **Formal Verification Core:** The **Lean Server** is integral to both the Conjecturer and Prover, ensuring that conjectures are syntactically valid within the formal system and that proofs are rigorously checked.
* **Closed-Loop System:** The pipeline forms a closed loop where the output (proven theorems) becomes part of the input (library context) for future cycles, enabling autonomous knowledge growth.
* **Asymmetric LLM Icons:** The LLM icon in the Prover is a black silhouette, while in the Conjecturer it is a line drawing. This may be a stylistic choice or could imply a different model or role (e.g., a "solver" vs. a "generator").
### Interpretation
This diagram represents a sophisticated **neuro-symbolic AI system** for mathematics. It combines the flexible, intuitive reasoning capabilities of **Large Language Models** (the "neuro" part) with the rigorous, unambiguous verification of a **formal proof assistant** like Lean (the "symbolic" part).
The system's goal is to automate mathematical discovery. The **Conjecturer** acts like a mathematician's intuition, proposing interesting or likely true statements based on existing knowledge. The **Prover** acts like the formal proof-writing process, attempting to construct airtight logical arguments. By feeding proven results back into the library, the system can tackle increasingly complex problems, mimicking the cumulative nature of mathematical research.
The specific example in the Library—defining "AlphaOpen" sets—hints that this system might be operating in the domain of topology or analysis. The architecture suggests a research tool designed to augment human mathematicians or to explore the boundaries of automated reasoning. The critical insight is the separation of *guessing* (conjecture) from *verifying* (proof), a fundamental dichotomy in the scientific method, now implemented in an AI pipeline.
</details>
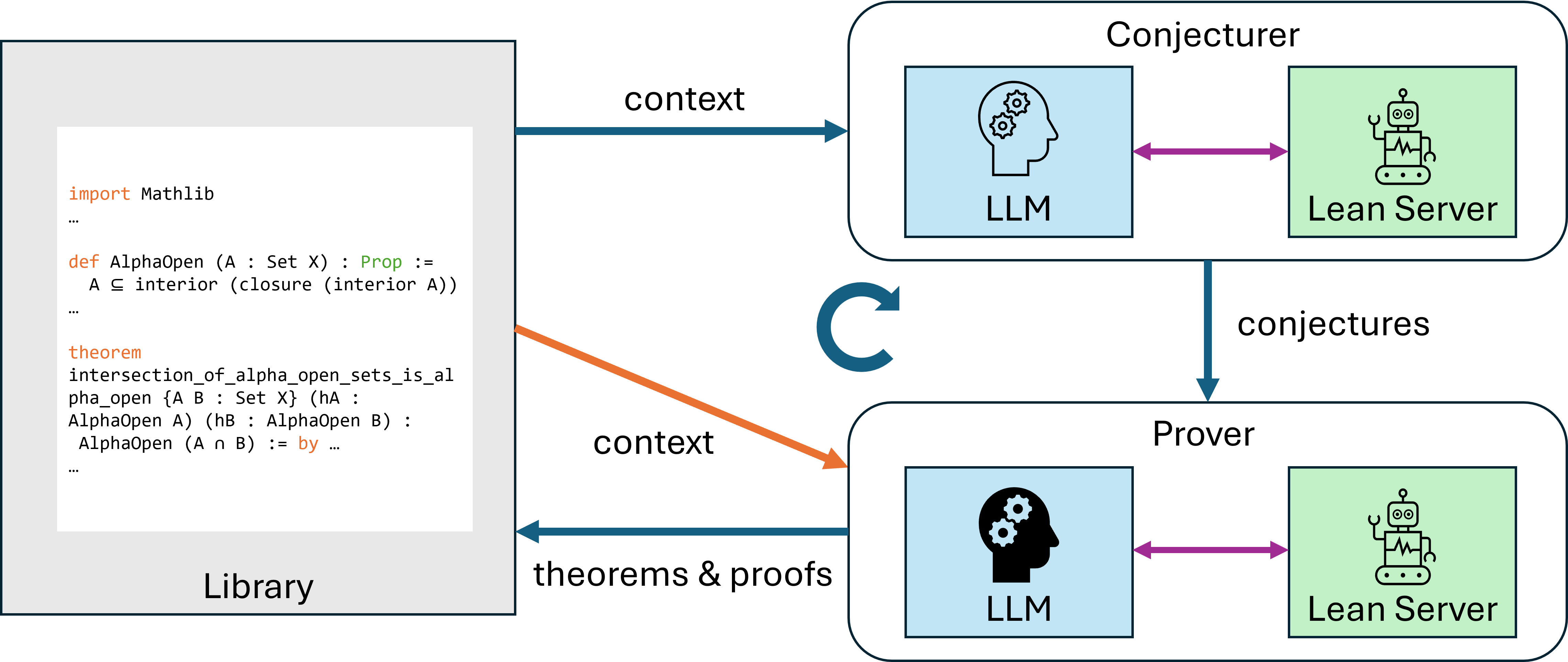
Figure 1: Overview of Conjecturing-Proving Loop. Conjecturer generates conjectures using Library as context, Prover attempts to prove them, and proven conjectures and their proofs are stored in Library as theorems. Library also provides context to Prover. Both Conjecturer and Prover processes consist of interactions between LLMs and Lean Server.
## 2 Related Work
There are several works that use LLMs for mathematical reasoning, both in natural-language [1] and formal language for ITP [11, 7]. They focused mainly on solving existing problems and used Supervised Fine-Tuning (SFT) and/or Reinforcement Learning with Verified Rewards (RLVR) to improve problem-solving ability of LLMs. To overcome the limited dataset for training, the approach to generate problems to solve by AI is also proposed in some previous works [2, 6, 14]. These works are different from our approach in the following two points: First, our approach is focused on generating and proving meaningful theorems, while these works are focused on training the LLM prover. Second, while these works are based on reinforcement learning, our approach is based on in-context learning, which can be applied to closed-source LLMs.
Several studies have reported that including appropriate examples of question-answer pairs in prompts improves the mathematical reasoning ability of LLMs [13, 15, 4]. While these studies used handmade examples or results searched from databases as in-context learning sources, our framework uses outputs from the LLM itself, as in In-Context Reinforcement Learning [9]. The technique to leverage feedback from ITP for formal proof generation was proposed [5, 12, 8] and we also adopted it (See § 3.3). However, what we emphasize here is learning strategies from verified proofs of other propositions.
## 3 Method
### 3.1 Pipeline Overview
Figure 1 illustrates our framework. Conjecturing-Proving Loop (CPL) consists of four main parts: conjecturer (LLM agent), prover (LLM agent), Lean server, and library (Lean code data). At first, The library is initialized by the user.
1. The conjecturer generates mathematical conjectures in Lean 4 format based on the library, with accessing Lean server to check syntactical validity and novelty of generated conjectures.
1. For each generated conjectures, the prover generates proofs of the conjectures, with accessing Lean server to verify generated proofs. The library is used as the context also in this step.
1. The verified pairs of conjectures and their proofs are added to the library. We return to the first step.
For the details of the second and third steps, see the following subsections.
By separating the conjecturing and proving phases, we avoid the convergence of generated theorems and encourage to prove more difficult theorems.
The purpose of feeding library to the conjecturer as the context is to prevent the generation of duplicate conjectures and to generate conjectures by analogy from already proven theorems.
The purpose of feeding library to the prover as the context is to make already proven theorems available during proof and to learn proof strategies by in-context learning.
### 3.2 Conjecture Loop
To generate varied conjectures, for each conjecturing step, we use the following process.
1. The conjecture list is initialized as empty.
1. The conjecturer LLM generates conjectures following the library and the conjecture list.
1. For each generated conjectures, Lean server checks whether the conjecture is syntactically valid and novel. Verified conjectures are added to the conjecture list.
1. We return to the second step until the predefined number of iterations is done.
By repeatedly calling the conjecturer and generating many conjectures at one step, we induce the generation of conjectures that deviate from the library, thereby preventing conjectures from converging.
The check for novelty of conjectures is done by using exact? command in Lean, which checks whether the conjecture can be proved by existing theorems in the context. Note that this command is done with context importing the whole Mathlib4 (Lean4 standard library) and including the library and the conjecturer list. Thus, the checked novelty means that the conjecture is not already in Mathlib4, the already generated library, and the conjecturer list.
The system prompt given to conjecture LLM is as follows:
Your are a writer of mathlib4 library. Please generate conjectures of new theorems in Lean 4 format, which do not need to be definitely true, following a given library. Do not generate statements that are already on the list. Do not include proofs, annotations, or imports. The new theorems begin with ’theorem’, not any annotions. They should end with ’:= sorry’. Additionally, please use standard mathematical symbols (e.g., $\forall$ , $\exists$ , $\surd$ ) instead of Unicode escape sequences (e.g., \u2200).
In the experiment, the number of iterations is set to $16$ .
### 3.3 Prover Loop
For each generated conjectures, the prover try to prove it in following process.
1. The prover LLM produced the proof code of the conjecture. If the LLM judges that the conjecture is not provable, the prover exits the loop as failure.
1. The Lean server verifies the generated proof. If the proof is verified, the prover exits the loop as success.
1. If already enough number of trial is done, the prover exits the loop as failure. Otherwise, the error message is returned to the LLM and we return to the first step.
The context is given to both the prover and the Lean server. Thus, not only the prover can learn the proof strategies from the context, but also it can use the theorems in the context as lemmas.
The system prompt given to prover LLM is as follows:
You are a prover of mathlib4 library. Please prove the last theorem in the given content in Lean 4 format. You should write the Lean4 code which directly follows ":=" in the last theorem. It should begin with ’by’ or represent a term directly. You can use the theorems in the given content as lemmas. Do not use sorry in the proof. If you judge that the theorem is not provable, please return empty string instead of the proof. Do not include any other text.
In the experiment, the maximum number of trials is set to $16$ .
## 4 Experiments
We demonstrated that the research-level theorems can be rediscovered by our framework and verified that in-context learning worked effectively in our framework.
The scripts for these experiments and generated libraries are stored at https://github.com/auto-res/ConjecturingProvingLoop.
### 4.1 Setting
In our experiments, we focuse on the minor notions in general topology: semi-openness, alpha-openness, and preopenness. We used the following file including the definitions of these notions in Lean 4 format as the initial library.
⬇
import Mathlib
import Aesop
namespace Topology
variable {X : Type *} [TopologicalSpace X]
/– A set is semi - open if it is a subset of the closure of its interior. -/
def SemiOpen (A : Set X) : Prop :=
A ⊆ closure (interior A)
/– A set is alpha - open if it is a subset of the interior of the closure of its interior. -/
def AlphaOpen (A : Set X) : Prop :=
A ⊆ interior (closure (interior A))
/– A set is preopen if it is a subset of the interior of its closure. -/
def PreOpen (A : Set X) : Prop :=
A ⊆ interior (closure A)
The reason for choosing these notions is that they can be defined using only notions already present in Mathlib, while they themselves are not yet included in Mathlib, and while their mathematical importance has already been recognized and researched, they are not yet well-known enough for LLM to have knowledge of their properties.
We focused whether the following theorem could be generated or not:
The intersection of two alpha-open sets is alpha-open [10].
This theorem is important because it is the most difficult part to prove in the theorem that alpha-open sets form another topology (Proposition 2 in [10]).
We generated theorems for these notions using our framework with $30$ loops. We use chatGPT-4o https://platform.openai.com/docs/models/gpt-4o as the conjecturer and chatGPT-o3 https://platform.openai.com/docs/models/o3 as the prover.
### 4.2 Baseline
For comparison, we also generated theorems for them by a simple loop framework that LLM generates theorems and its proofs at once, using chatGPT-3o. At first, The library is initialized by the user. Unlike CPL, in this simple loop baseline, the conjecturer and the prover are not separated, and the single loop is as follows:
1. The LLM generates a statement and its proof in Lean 4 format based on the library, with accessing Lean server to verify it.
1. If the previous step succeeded, the generated pair of statement and proof are stored in Library. We return to the first step.
In the experiment, we executed this loop $400$ times.
The first step is similar to the prover loop. Its details are as follows:
1. The LLM produced a statement and its proof in Lean.
1. The Lean server verifies the generated content. If it is verified, we exit the loop as success.
1. If already enough number of trial is done, we exit the loop as failure. Otherwise, the error message is returned to the LLM and we return to the first step.
The system prompt given to LLM is as follows:
Your are a writer of mathlib4 library. Please generate a new theorem with a proof in Lean 4 format, following a given library. Do not return anything else than the Lean 4 code. The generated code should follow the given library. The generated code should contain only the theorem and the proof. Do not generate a theorem that are already on the library. The new theorem should begin with ’theorem’, not any annotions. You can use the theorems in the given library as lemmas in the proof. Do not use sorry in the proof. Additionally, please use standard mathematical symbols (e.g., $\forall$ , $\exists$ , $\surd$ ) instead of Unicode escape sequences (e.g., \u2200).
As in the prover loop, the maximum number of trials is set to $16$ .
### 4.3 Results
<details>
<summary>x1.png Details</summary>
### Visual Description
## Histogram: Proof Length Distribution
### Overview
The image is a histogram comparing the distribution of proof lengths (measured in number of lines) for two categories: "CPL" and "Simple loop". The chart visualizes the percentage of proofs that fall within specific line-count ranges.
### Components/Axes
* **Title:** "Proof length distribution" (centered at the top).
* **X-axis:** Labeled "Number of lines in proofs". The axis has major tick marks at 0, 20, 40, 60, 80, and 100.
* **Y-axis:** Labeled "Percentage (%)". The axis has major tick marks at 0, 1, 2, 3, 4, 5, and 6.
* **Legend:** Located in the top-right corner of the plot area.
* A blue square is labeled "CPL".
* An orange square is labeled "Simple loop".
* **Data Series:** Two overlapping histograms.
* **CPL (Blue):** Bars are a light blue color.
* **Simple loop (Orange):** Bars are a light orange color. Where the two series overlap, the color appears as a brownish blend.
### Detailed Analysis
The histogram bins proofs into ranges of 10 lines each (0-10, 10-20, etc.). The height of each bar represents the percentage of proofs in that length range for each category.
**Trend Verification:** Both distributions are strongly right-skewed. The vast majority of proofs are short, with the frequency dropping sharply as the number of lines increases. The "Simple loop" distribution appears to be contained within the shorter proof lengths, while the "CPL" distribution has a longer tail extending to higher line counts.
**Approximate Data Points (by bin):**
* **Bin 0-10 lines:**
* Simple loop: ~6.0%
* CPL: ~5.5%
* **Bin 10-20 lines:**
* Simple loop: ~2.8%
* CPL: ~2.4%
* **Bin 20-30 lines:**
* Simple loop: ~0.8%
* CPL: ~0.7%
* **Bin 30-40 lines:**
* Simple loop: ~0.2% (very small bar)
* CPL: ~0.5%
* **Bin 40-50 lines:**
* Simple loop: Not visible (0% or negligible).
* CPL: ~0.4%
* **Bin 50-60 lines:**
* Simple loop: Not visible.
* CPL: ~0.2%
* **Bin 60-70 lines:**
* Simple loop: Not visible.
* CPL: ~0.1% (very small bar)
* **Bin 70-80 lines:**
* Simple loop: Not visible.
* CPL: ~0.1% (very small bar)
* **Bin 80-90 lines:**
* Simple loop: Not visible.
* CPL: ~0.2%
* **Bin 90-100 lines:**
* Simple loop: Not visible.
* CPL: ~0.1% (very small bar)
* **Bin 100+ lines:**
* Simple loop: Not visible.
* CPL: ~0.1% (very small bar)
### Key Observations
1. **Dominance of Short Proofs:** Over 80% of the visible distribution for both categories consists of proofs with fewer than 20 lines.
2. **Category Comparison:** In the shortest bin (0-10 lines), "Simple loop" has a slightly higher percentage than "CPL". For bins beyond 20 lines, "CPL" consistently shows a higher percentage than "Simple loop".
3. **Range Limit:** The "Simple loop" data appears to be absent (or at 0%) for proofs longer than approximately 40 lines. The "CPL" data has a long, thin tail extending to over 100 lines.
4. **Overlap:** The most significant overlap and blending of colors occurs in the first three bins (0-30 lines), indicating both categories are most frequently found in this range.
### Interpretation
This histogram suggests a fundamental difference in the nature of proofs generated by or for "CPL" versus "Simple loop". The "Simple loop" proofs are almost exclusively short, implying they are generated from a more constrained or simpler process. The "CPL" proofs, while still predominantly short, have a non-trivial probability of being much longer. This could indicate that CPL is used for more complex problem-solving tasks that occasionally require lengthy, detailed proofs, or that it is a more expressive system capable of generating longer derivations. The data demonstrates that proof length is a heavy-tailed distribution, a common characteristic in computational and logical systems where most instances are simple, but a few complex outliers exist.
</details>
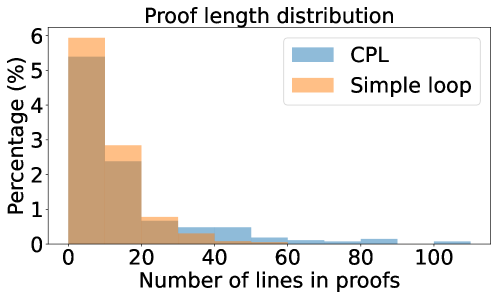
Figure 2: Distribution of proof length of theorems generated by our framework and the simple loop framework, where the size of bins is $10$ .
We generated $269$ theorems for these notions, which includes the focused theorem. The generated proof of this theorem is shown in Appendix A. This proof differs from the original proof by Njȧstad, which indicates that LLM found this proof on its own. Other generated theorems which are important properties shown in research papers includes the followings:
- The intersection of semi-open set and alpha-open set is semi-open [10].
- The intersection of preopen set and alpha-open set is preopen [3].
On the other hand, these theorems are not included in $359$ theorems generated by the simple loop framework. The reason seems that the simple loop framework tends to generate easily provable theorems. To confirm this, we measured the proof length of the theorems generated by our framework and the simple loop framework. Figure 2 shows the distribution of proof length of the theorems generated by our framework and the simple loop framework. It can be observed that our framework can generate theorems with longer proofs than the simple loop framework.
### 4.4 Effectiveness of Providing Contexts
We also verified that feeding the generated library as a context to the prover improves the proof ability.
#### 4.4.1 Reproving Generated Theorems
First, we attempted to re-prove all generated theorems by the method in § 3.3 in two settings: one where the context includes the library generated before the theorem to be proved was generated, and one where the context includes only the definitions of the notions. As a result, in the setting with contexts, 99% of the theorems (267 theorems) were proved, while in the setting without contexts, only 90% of the theorems (242 theorems) were proved. Thus, the context improves the proof ability of LLMs.
#### 4.4.2 Proof Ability for Alpha-Open Intersection
Moreover, we attempted to re-prove the focused theorem for $128$ times in each setting. (The number of theorems generated until this theorem was generated is $49$ .) The procedure to evaluate Prover in Lean is as the same as the prover loop, except the system prompt has changed to the following:
You are a prover of mathlib4 library. Please prove the last theorem in the given content in Lean 4 format. You should write the Lean4 code which directly follows ":=" in the last theorem. It should begin with ’by’ or represent a term directly. You can use the theorems in the given content as lemmas. Do not use sorry in the proof. If you judge that the theorem is false, please return empty string instead of the proof. Do not include any other text.
Note that the condition not to return proof has changed from "not provable" to "false".
For comparison, we also asked LLMs (chatGPT-4o and chatGPT-o3) to prove this theorem in the natural language (English) with context including the definitions of the notions $16$ times and checked the responses by hand. In the natural language experiment, we used the following system prompt:
Please prove the following theorem. If you judge that the theorem is false, please return "False" instead of the proof.
The statement to prove given to LLM is as follows:
In a topological space, a set is alpha-open if it is a subset of the interior of the closure of its interior. The intersection of any two alpha-open sets is alpha-open.
In both formal and natural language settings, we prompted the LLMs not to return a proof if the given theorem is false. Therefore, the output results fall into three categories: correctly proven, gap-containing proofs, or rejected as incorrect.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Stacked Bar Chart: Success Rates
### Overview
The image displays a stacked bar chart titled "Success Rates." It compares the proportional outcomes of four different methods or conditions, categorized into three possible results: "Proved," "Proof Gap," and "Rejected." The chart uses a normalized scale from 0.0 to 1.0 on the y-axis, indicating that the data represents proportions or percentages of a whole for each category on the x-axis.
### Components/Axes
* **Chart Title:** "Success Rates" (centered at the top).
* **Y-Axis:** Vertical axis labeled with numerical markers: `0.0`, `0.2`, `0.4`, `0.6`, `0.8`, `1.0`. This represents the proportion of total outcomes.
* **X-Axis:** Horizontal axis with four categorical labels: `w-ctx`, `wo-ctx`, `4o-NL`, `o3-NL`.
* **Legend:** Positioned in the top-right corner of the chart area, overlapping the bars slightly. It defines three color-coded categories:
* **Blue (Teal):** `Proved`
* **Purple (Magenta):** `Proof Gap`
* **Orange:** `Rejected`
### Detailed Analysis
The chart consists of four vertical bars, each summing to a total height of 1.0 (100%). The composition of each bar is as follows:
1. **Bar: `w-ctx` (Leftmost)**
* **Bottom Segment (Blue - Proved):** Extends from 0.0 to approximately **0.7** on the y-axis.
* **Top Segment (Orange - Rejected):** Extends from ~0.7 to 1.0.
* **Trend/Composition:** This is the only bar containing the "Proved" outcome. The majority (~70%) of results are "Proved," with the remainder (~30%) "Rejected."
2. **Bar: `wo-ctx` (Second from left)**
* **Entire Bar (Orange - Rejected):** Fills the entire bar from 0.0 to 1.0.
* **Trend/Composition:** 100% of outcomes are "Rejected." No "Proved" or "Proof Gap" results are present.
3. **Bar: `4o-NL` (Third from left)**
* **Bottom Segment (Purple - Proof Gap):** Extends from 0.0 to approximately **0.35** on the y-axis.
* **Top Segment (Orange - Rejected):** Extends from ~0.35 to 1.0.
* **Trend/Composition:** This is the only bar containing the "Proof Gap" outcome. Approximately 35% of results are a "Proof Gap," with the remaining ~65% "Rejected."
4. **Bar: `o3-NL` (Rightmost)**
* **Entire Bar (Orange - Rejected):** Fills the entire bar from 0.0 to 1.0.
* **Trend/Composition:** Identical to `wo-ctx`; 100% of outcomes are "Rejected."
### Key Observations
* **Exclusive Outcomes:** The "Proved" outcome appears **only** in the `w-ctx` condition. The "Proof Gap" outcome appears **only** in the `4o-NL` condition.
* **Dominance of Rejection:** The "Rejected" outcome is present in all four categories and is the sole outcome for `wo-ctx` and `o3-NL`.
* **Binary vs. Ternary Results:** The `w-ctx` and `4o-NL` bars show a split between two outcomes, while `wo-ctx` and `o3-NL` show a single, uniform outcome.
* **Visual Uncertainty:** Exact numerical values are not labeled on the bars. The values for the "Proved" segment in `w-ctx` (~0.7) and the "Proof Gap" segment in `4o-NL` (~0.35) are approximate visual estimates.
### Interpretation
This chart likely presents results from a comparative study or experiment evaluating different systems, models, or configurations (denoted by `w-ctx`, `wo-ctx`, `4o-NL`, `o3-NL`) on a task involving formal verification or proof generation.
* **What the data suggests:** The presence of context (`ctx`) appears critical for achieving a "Proved" outcome, as seen in `w-ctx`. The absence of context (`wo-ctx`) leads to complete failure ("Rejected"). The `NL` (likely "Natural Language") variants show different failure modes: `4o-NL` frequently results in an incomplete "Proof Gap," while `o3-NL` fails entirely ("Rejected").
* **Relationship between elements:** The chart directly contrasts the performance of these four conditions. The stark difference between `w-ctx` and `wo-ctx` highlights the importance of the contextual component. The difference between the two `NL` models suggests varying capabilities or approaches in handling the task, with one (`4o-NL`) making partial progress and the other (`o3-NL`) not at all.
* **Notable anomalies/trends:** The complete absence of any "Proved" or "Proof Gap" results in the two rightmost bars (`wo-ctx`, `o3-NL`) is a significant finding, indicating these conditions are wholly ineffective for the measured task. The chart effectively communicates that success is not just binary (pass/fail) but includes an intermediate state ("Proof Gap"), which is only observed in one specific configuration.
</details>
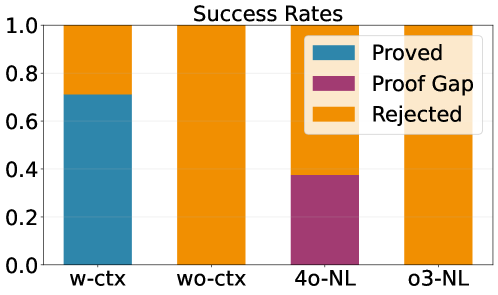
Figure 3: Success rates of proving the theorem by LLMs. With and without context in Lean (w-ctx, w-ctx), proof in natural language (4o-NL, o3-NL).
The result is shown in Figure 3. The result shows that the theorem was proved only in the setting with the generated library. The fact that the majority of judgments in natural language incorrectly identify the theorem as false means that the discovered theorem was not included in chatGPT’s knowledge. An example of proofs with gaps generated by chatGPT-4o is shown in Appendix B. ChatGPT-3o never generated incorrect proof in both Lean and the natural language, but it always judged incorrectly that the theorem is false.
The generated proof of this theorem, shown in Appendix A, does not use other generated theorems as lemmas. Thus, the generated library was used for in-context learning of proof strategies rather than as a collection of lemmas for the proof.
## 5 Conclusion and Future Work
We presented Conjecturing-Proving Loop, a pipeline for automatically generating mathematical conjectures and proving them in Lean 4 format. We demonstrated that our framework can rediscover a research-level theorem. We also verified the in-context learning of proof strategies works effectively in our framework.
The propositions highlighted in this study were easy to predict. Future work should focus on refining the conjecture generation process to produce deeper and more insightful mathematical statements, possibly by incorporating techniques for guiding the LLM towards unexplored areas of mathematical theory.
## Acknowledgements
This work was supported by JST Moonshot R&D Program JPMJMS2236, JST BOOST JPMJBY24E2, JST CREST JPMJCR2015, JSPS KAKENHI 24K21316, 24K16077, and Advanced General Intelligence for Science Program (AGIS), the RIKEN TRIP initiative.
## References
- [1] DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J. L. Cai, Jian Liang, Jianzhong Guo, Jiaqi Ni, Jiashi Li, Jiawei Wang, Jin Chen, Jingchang Chen, Jingyang Yuan, Junjie Qiu, Junlong Li, Junxiao Song, Kai Dong, Kai Hu, Kaige Gao, Kang Guan, Kexin Huang, Kuai Yu, Lean Wang, Lecong Zhang, Lei Xu, Leyi Xia, Liang Zhao, Litong Wang, Liyue Zhang, Meng Li, Miaojun Wang, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Mingming Li, Ning Tian, Panpan Huang, Peiyi Wang, Peng Zhang, Qiancheng Wang, Qihao Zhu, Qinyu Chen, Qiushi Du, R. J. Chen, R. L. Jin, Ruiqi Ge, Ruisong Zhang, Ruizhe Pan, Runji Wang, Runxin Xu, Ruoyu Zhang, Ruyi Chen, S. S. Li, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shaoqing Wu, Shengfeng Ye, Shengfeng Ye, Shirong Ma, Shiyu Wang, Shuang Zhou, Shuiping Yu, Shunfeng Zhou, Shuting Pan, T. Wang, Tao Yun, Tian Pei, Tianyu Sun, W. L. Xiao, Wangding Zeng, Wanjia Zhao, Wei An, Wen Liu, Wenfeng Liang, Wenjun Gao, Wenqin Yu, Wentao Zhang, X. Q. Li, Xiangyue Jin, Xianzu Wang, Xiao Bi, Xiaodong Liu, Xiaohan Wang, Xiaojin Shen, Xiaokang Chen, Xiaokang Zhang, Xiaosha Chen, Xiaotao Nie, Xiaowen Sun, Xiaoxiang Wang, Xin Cheng, Xin Liu, Xin Xie, Xingchao Liu, Xingkai Yu, Xinnan Song, Xinxia Shan, Xinyi Zhou, Xinyu Yang, Xinyuan Li, Xuecheng Su, Xuheng Lin, Y. K. Li, Y. Q. Wang, Y. X. Wei, Y. X. Zhu, Yang Zhang, Yanhong Xu, Yanhong Xu, Yanping Huang, Yao Li, Yao Zhao, Yaofeng Sun, Yaohui Li, Yaohui Wang, Yi Yu, Yi Zheng, Yichao Zhang, Yifan Shi, Yiliang Xiong, Ying He, Ying Tang, Yishi Piao, Yisong Wang, Yixuan Tan, Yiyang Ma, Yiyuan Liu, Yongqiang Guo, Yu Wu, Yuan Ou, Yuchen Zhu, Yuduan Wang, Yue Gong, Yuheng Zou, Yujia He, Yukun Zha, Yunfan Xiong, Yunxian Ma, Yuting Yan, Yuxiang Luo, Yuxiang You, Yuxuan Liu, Yuyang Zhou, Z. F. Wu, Z. Z. Ren, Zehui Ren, Zhangli Sha, Zhe Fu, Zhean Xu, Zhen Huang, Zhen Zhang, Zhenda Xie, Zhengyan Zhang, Zhewen Hao, Zhibin Gou, Zhicheng Ma, Zhigang Yan, Zhihong Shao, Zhipeng Xu, Zhiyu Wu, Zhongyu Zhang, Zhuoshu Li, Zihui Gu, Zijia Zhu, Zijun Liu, Zilin Li, Ziwei Xie, Ziyang Song, Ziyi Gao, and Zizheng Pan. DeepSeek-V3 technical report, 2025.
- [2] Kefan Dong and Tengyu Ma. STP: Self-play LLM theorem provers with iterative conjecturing and proving, 2025.
- [3] Julian Dontchev. Survey on preopen sets. arXiv preprint math/9810177, 1998.
- [4] Iddo Drori, Sarah Zhang, Reece Shuttleworth, Leonard Tang, Albert Lu, Elizabeth Ke, Kevin Liu, Linda Chen, Sunny Tran, Newman Cheng, et al. A neural network solves, explains, and generates university math problems by program synthesis and few-shot learning at human level. Proceedings of the National Academy of Sciences, 119(32):e2123433119, 2022.
- [5] Emily First, Markus N Rabe, Talia Ringer, and Yuriy Brun. Baldur: Whole-proof generation and repair with large language models. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 1229–1241, 2023.
- [6] Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning LLM from zero data. arXiv preprint arXiv:2508.05004, 2025.
- [7] Yong Lin, Shange Tang, Bohan Lyu, Jiayun Wu, Hongzhou Lin, Kaiyu Yang, Jia LI, Mengzhou Xia, Danqi Chen, Sanjeev Arora, and Chi Jin. Goedel-prover: A frontier model for open-source automated theorem proving. In Second Conference on Language Modeling, 2025.
- [8] Yong Lin, Shange Tang, Bohan Lyu, Ziran Yang, Jui-Hui Chung, Haoyu Zhao, Lai Jiang, Yihan Geng, Jiawei Ge, Jingruo Sun, et al. Goedel-prover-v2: Scaling formal theorem proving with scaffolded data synthesis and self-correction. arXiv preprint arXiv:2508.03613, 2025.
- [9] Amir Moeini, Jiuqi Wang, Jacob Beck, Ethan Blaser, Shimon Whiteson, Rohan Chandra, and Shangtong Zhang. A survey of in-context reinforcement learning. arXiv preprint arXiv:2502.07978, 2025.
- [10] Olav Njȧstad. On some classes of nearly open sets. Pacific journal of mathematics, 15(3):961–970, 1965.
- [11] Z. Z. Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, Z. F. Wu, Zhibin Gou, Shirong Ma, Hongxuan Tang, Yuxuan Liu, Wenjun Gao, Daya Guo, and Chong Ruan. DeepSeek-Prover-V2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition, 2025.
- [12] Amitayush Thakur, George Tsoukalas, Yeming Wen, Jimmy Xin, and Swarat Chaudhuri. An in-context learning agent for formal theorem-proving. arXiv preprint arXiv:2310.04353, 2023.
- [13] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- [14] Shaoxiong Zhan, Yanlin Lai, Ziyu Lu, Dahua Lin, Ziqing Yang, and Fei Tang. Mathsmith: Towards extremely hard mathematical reasoning by forging synthetic problems with a reinforced policy. arXiv preprint arXiv:2508.05592, 2025.
- [15] Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022.
## Appendix A Generated Proof of Focused Theorem
⬇
theorem intersection_of_alpha_open_sets_is_alpha_open {A B : Set X} (hA : AlphaOpen A) (hB : AlphaOpen B) : AlphaOpen (A ∩ B) := by
– We unfold the definition of ‘ AlphaOpen ‘ and start with a point
– ‘ x ∈ A ∩ B ‘.
intro x hx
rcases hx with ⟨ hxA, hxB ⟩
– From the alpha - openness of ‘ A ‘ and ‘ B ‘ we obtain the two interior
– memberships below.
have hA_int : x ∈ interior (closure (interior A)) := hA hxA
have hB_int : x ∈ interior (closure (interior B)) := hB hxB
——————————————————————
– Consider the open neighbourhood
– ‘ U := interior (closure (interior A))
– ∩ interior (closure (interior B))‘ of ‘ x ‘.
——————————————————————
have hU_open :
IsOpen (interior (closure (interior A)) ∩
interior (closure (interior B))) :=
isOpen_interior. inter isOpen_interior
have hxU :
x ∈ interior (closure (interior A)) ∩
interior (closure (interior B)) := ⟨ hA_int, hB_int ⟩
——————————————————————
– We prove that ‘ U ⊆ closure (interior (A ∩ B))‘.
——————————————————————
have hU_subset :
(interior (closure (interior A)) ∩
interior (closure (interior B)) : Set X) ⊆
closure (interior (A ∩ B)) := by
intro y hyU
rcases hyU with ⟨ hyA_int, hyB_int ⟩
– From ‘ hyA_int ‘ and ‘ hyB_int ‘ we obtain the two closure
– memberships below.
have hyA_cl : y ∈ closure (interior A) :=
(interior_subset :
interior (closure (interior A)) ⊆ closure (interior A)) hyA_int
have hyB_cl : y ∈ closure (interior B) :=
(interior_subset :
interior (closure (interior B)) ⊆ closure (interior B)) hyB_int
—————————————————————-
– To show ‘ y ∈ closure (interior (A ∩ B))‘
– we use the neighbourhood characterisation of the closure.
—————————————————————-
apply (mem_closure_iff).2
intro V hV hyV
————————————————————–
– First step: work inside
– ‘ V ₁ := V ∩ interior (closure (interior B))‘.
————————————————————–
have hV ₁ _open :
IsOpen (V ∩ interior (closure (interior B))) :=
hV. inter isOpen_interior
have hyV ₁ : y ∈ V ∩ interior (closure (interior B)) :=
⟨ hyV, hyB_int ⟩
– As ‘ y ∈ closure (interior A)‘, this neighbourhood meets
– ‘ interior A ‘.
have h_nonempty ₁ :
((V ∩ interior (closure (interior B))) ∩ interior A). Nonempty :=
(mem_closure_iff).1 hyA_cl _ hV ₁ _open hyV ₁
rcases h_nonempty ₁ with
⟨ y ₁, ⟨⟨ hy ₁ V, hy ₁ B_int ⟩, hy ₁ IntA ⟩⟩
————————————————————–
– Now ‘ y ₁ ∈ V ∩ interior A ‘ ** and **
– ‘ y ₁ ∈ interior (closure (interior B))‘.
– Hence ‘ y ₁ ∈ closure (interior B)‘.
————————————————————–
have hy ₁ _clB : y ₁ ∈ closure (interior B) :=
(interior_subset :
interior (closure (interior B)) ⊆ closure (interior B)) hy ₁ B_int
————————————————————–
– Second step: work inside
– ‘ V ₂ := V ∩ interior A ‘.
————————————————————–
have hV ₂ _open : IsOpen (V ∩ interior A) :=
hV. inter isOpen_interior
have hy ₁ V ₂ : y ₁ ∈ V ∩ interior A := ⟨ hy ₁ V, hy ₁ IntA ⟩
– Because ‘ y ₁ ∈ closure (interior B)‘, the set ‘ V ₂‘ meets
– ‘ interior B ‘.
have h_nonempty ₂ :
((V ∩ interior A) ∩ interior B). Nonempty :=
(mem_closure_iff).1 hy ₁ _clB _ hV ₂ _open hy ₁ V ₂
rcases h_nonempty ₂ with
⟨ z, ⟨⟨ hzV, hzIntA ⟩, hzIntB ⟩⟩
————————————————————–
– The point ‘ z ‘ lies in ‘ V ‘, ‘ interior A ‘, and ‘ interior B ‘;
– hence it belongs to ‘ interior (A ∩ B)‘.
————————————————————–
have hzIntAB : z ∈ interior (A ∩ B) := by
– Use maximality of the interior to pass from
– ‘ interior A ∩ interior B ‘ to ‘ interior (A ∩ B)‘.
have h_sub :
(interior A ∩ interior B : Set X) ⊆ interior (A ∩ B) :=
interior_maximal
(by
intro t ht
rcases ht with ⟨ htA, htB ⟩
exact And. intro (interior_subset htA) (interior_subset htB))
(isOpen_interior. inter isOpen_interior)
exact h_sub ⟨ hzIntA, hzIntB ⟩
– We have found a point in ‘ V ∩ interior (A ∩ B)‘.
exact ⟨ z, ⟨ hzV, hzIntAB ⟩⟩
——————————————————————
– Maximality of the interior gives the desired inclusion,
– and we conclude with the membership of ‘ x ‘ in ‘ U ‘.
——————————————————————
have hU_subset_int :
(interior (closure (interior A)) ∩
interior (closure (interior B)) : Set X) ⊆
interior (closure (interior (A ∩ B))) :=
interior_maximal hU_subset hU_open
exact hU_subset_int hxU
## Appendix B Example of Generated Incorrect Proof
The following is an example of ‘proof’ of the theorem that the intersection of two alpha-open sets is alpha-open, generated by chatGPT-4o.
To prove the given theorem, let’s first define what it means for a set to be alpha-open in a topological space.
Let $(X,\tau)$ be a topological space and let $A\subseteq X$ . The set $A$ is called alpha-open if
$$
A\subseteq\text{int}(\overline{\text{int}(A)}),
$$
where $\text{int}(A)$ denotes the interior of $A$ , and $\overline{\text{int}(A)}$ denotes the closure of $\text{int}(A)$ .
We aim to prove that the intersection of any two alpha-open sets is alpha-open. Let $A,B\subseteq X$ be two alpha-open sets; hence, by definition, we have:
1. $A\subseteq\text{int}(\overline{\text{int}(A)})$ 2. $B\subseteq\text{int}(\overline{\text{int}(B)})$
We need to show that $A\cap B$ is also alpha-open, i.e.,
$$
A\cap B\subseteq\text{int}(\overline{\text{int}(A\cap B)}).
$$
Firstly, observe that $\text{int}(A\cap B)\subseteq\text{int}(A)\cap\text{int}(B)$ .
Both closure and interior operations are monotonic, so:
$$
\overline{\text{int}(A\cap B)}\subseteq\overline{\text{int}(A)\cap\text{int}(B)}\subseteq\overline{\text{int}(A)}\cap\overline{\text{int}(B)}.
$$
Taking interiors again yields:
$$
\text{int}(\overline{\text{int}(A\cap B)})\subseteq\text{int}(\overline{\text{int}(A)}\cap\overline{\text{int}(B)})\subseteq\text{int}(\overline{\text{int}(A)})\cap\text{int}(\overline{\text{int}(B)}).
$$
By the assumptions that $A\subseteq\text{int}(\overline{\text{int}(A)})$ and $B\subseteq\text{int}(\overline{\text{int}(B)})$ , it follows that
$$
A\cap B\subseteq\text{int}(\overline{\text{int}(A)})\cap\text{int}(\overline{\text{int}(B)})\supset\text{int}(\overline{\text{int}(A\cap B)}).
$$
Therefore,
$$
A\cap B\subseteq\text{int}(\overline{\text{int}(A\cap B)}).
$$
This shows that $A\cap B$ is indeed alpha-open. Therefore, the intersection of any two alpha-open sets is alpha-open.
Hence, the theorem is true.
This proof clearly has a gap because, when deriving the last relation from the second-to-last relations, the direction of a subset relation is reversed.