# seqBench: A Tunable Benchmark to Quantify Sequential Reasoning Limits of LLMs
**Authors**:
- M.R. Ramezanali
- Salesforce AI
- Palo Alto, CA
- &M. Vazifeh (Capital One, MIT)
- Cambridge, MA
- &P. Santi (MIT)
- Cambridge, MA
> ⋆ \star denotes equal contribution.
## Abstract
We introduce seqBench, a parametrized benchmark for probing sequential reasoning limits in Large Language Models (LLMs) through precise, multi-dimensional control over several key complexity dimensions. seqBench allows systematic variation of (1) the logical depth, defined as the number of sequential actions required to solve the task; (2) the number of backtracking steps along the optimal path, quantifying how often the agent must revisit prior states to satisfy deferred preconditions (e.g., retrieving a key after encountering a locked door); and (3) the noise ratio, defined as the ratio between supporting and distracting facts about the environment. Our evaluations on state-of-the-art LLMs reveal a universal failure pattern: accuracy collapses exponentially beyond a model-specific logical depth. Unlike existing benchmarks, seqBench ’s fine-grained control facilitates targeted analyses of these reasoning failures, illuminating universal scaling laws and statistical limits, as detailed in this paper alongside its generation methodology and evaluation metrics. We find that even top-performing models systematically fail on seqBench ’s structured reasoning tasks despite minimal search complexity, underscoring key limitations in their commonsense reasoning capabilities. Designed for future evolution to keep pace with advancing models, the seqBench datasets are publicly released to spur deeper scientific inquiry into LLM reasoning, aiming to establish a clearer understanding of their true potential and current boundaries for robust real-world application.
seqBench: A Tunable Benchmark to Quantify Sequential Reasoning Limits of LLMs
M.R. Ramezanali thanks: $\star$ denotes equal contribution. Salesforce AI Palo Alto, CA 94301 mramezanali@salesforce.com M. Vazifeh footnotemark: Capital One, MIT Cambridge, MA 02143 mvazifeh@mit.edu P. Santi MIT Cambridge, MA 02143 psanti@mit.edu
Large Language Models (LLMs) have shown remarkable performance (Vaswani et al., 2017; Brown et al., 2020; Lieber et al., 2021; Rae et al., 2021; Smith et al., 2022; Thoppilan et al., 2022; Hoffmann et al., 2022; Du et al., 2021; Fedus et al., 2022; Zoph et al., 2022) on a wide range of tasks and benchmarks spanning diverse human-like capabilities; however, these successes can obscure fundamental limitations in sequential reasoning that still persist. Arguably, reasoning captures a more pure form of intelligence, going beyond mere pattern matching or fact memorization, and is thus a critical capability to understand and enhance in AI systems. Recent studies show that state-of-the-art LLMs (OpenAI, 2025; Google DeepMind, 2025; Meta AI, 2025; Mistral AI, 2024; Anthropic, 2025) excel at complex benchmarks, yet stumble upon simple common-sense inferences trivial for an adult human (Nezhurina et al., 2025; Han et al., 2024; Sharma, 2024; Berglund et al., 2024; Yang et al., 2019). Most existing benchmarks saturate quickly, leaving little room for fine-grained attribution studies to perform systemic probes of LLM failure modes. Consequently, a robust understanding of why and under what circumstances these models fail, especially on problems requiring sequential reasoning, remains elusive.
This gap, we argue, stems from the lack of evaluation benchmarks allowing systematic, multi-dimensional control over key independent factors that influence a task’s overall reasoning difficulty. Most benchmarks (Cobbe et al., 2021; Hendrycks et al., 2021; Srivastava et al., 2023; Weston et al., 2015; Clark et al., 2018; Dua et al., 2019; Rein et al., 2023), despite their evaluation merits, often do not support a systematic variation of crucial complexity dimensions. This makes it difficult to isolate the specific conditions under which reasoning in LLMs falter. For instance, discerning whether a failure is due to the length of the required reasoning chain, the necessity to revise intermediate conclusions, or the density of distracting information is often not quantitatively possible. While prompting strategies like chain-of-thought (CoT) and model scaling have boosted aggregate performance, they often obscure sharp performance cliffs that can emerge when these underlying complexity dimensions are varied independently (Wei et al., 2023; Kojima et al., 2022). Without such systematic control, disentangling inherent architectural limitations from those addressable via scaling (model size, data, or compute), fine-tuning, or prompting techniques is challenging. A fine-grained understanding of these performance boundaries is crucial for developing more robust and reliable reasoning systems.
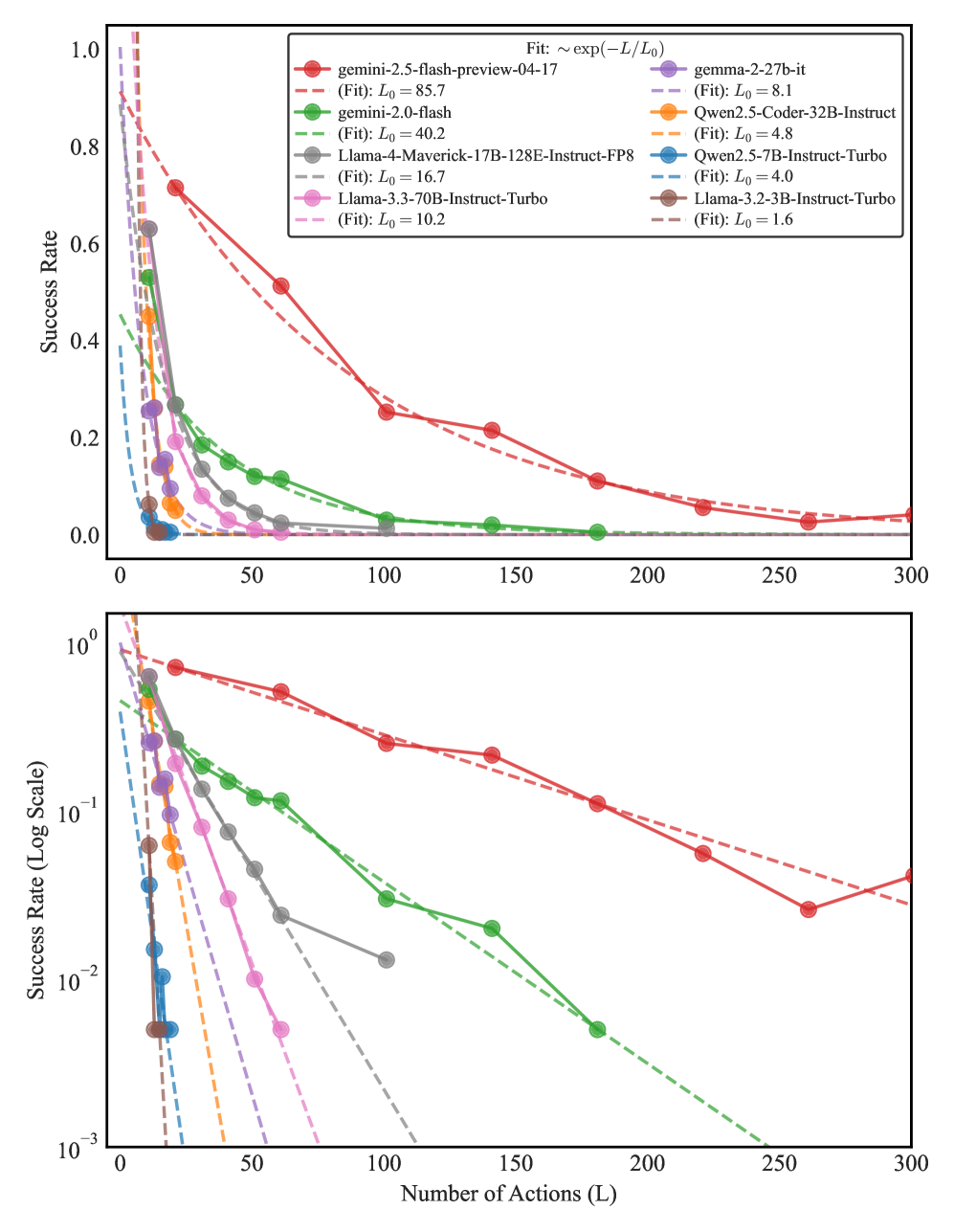
To complement recent efforts (Sprague et al., 2024; Tyagi et al., 2024; Kuratov et al., 2024; Tang and Kejriwal, 2025; Mirzaee et al., 2021; Tikhonov, 2024; Mirzaee and Kordjamshidi, 2022; Shi et al., 2022) in evaluating reasoning, and to address the need for more controlled analysis, we introduce seqBench, a tunable benchmark designed explicitly to probe and analyze sequential reasoning capabilities in language models. The dataset comprises synthetic yet linguistically grounded pathfinding task configurations on two-dimensional grids. Solving each problem requires sequential inference over relevant and distracting structured facts. Each instance is automatically verifiable and parameterized by controllable factors that directly address the previously identified gaps: (1) logical depth (total number of actions in the ground-truth solution, reflecting the length of the reasoning chain); (2) backtracking count (number of locked-door detours on the optimal path, requiring revision of tentative solution paths); and (3) noise ratio (proportion of distracting vs. supporting facts, testing robustness to irrelevant information). Performance against these dimensions can be quantified with fine-grained metrics (e.g., via progress ratio as we define here). We observe that beyond a certain logical depth, Pass@1 success collapses to near zero for all models (see Figure 1). These features enable precise attribution studies of model failure modes, offering insights into the brittle boundaries of current LLM generalization.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Chart: Success Rate vs. Number of Actions
### Overview
The image presents two charts displaying the relationship between the number of actions (L) and the success rate for several language models. The top chart uses a linear scale for the success rate, while the bottom chart uses a logarithmic scale. Both charts depict the decay of success rate as the number of actions increases. A fitted exponential decay function is indicated for each model.
### Components/Axes
* **X-axis (both charts):** Number of Actions (L), ranging from 0 to 300.
* **Y-axis (top chart):** Success Rate, ranging from 0.0 to 1.0.
* **Y-axis (bottom chart):** Success Rate (Log Scale), ranging from 10<sup>-3</sup> to 10<sup>0</sup>.
* **Legend (top-right):** Lists the language models and their corresponding colors:
* gemini-2.5-flash-preview-04-17 (green) - (Fit): L<sub>0</sub> = 85.7
* gemini-2.0-flash (dark green) - (Fit): L<sub>0</sub> = 40.2
* Llama-2-70B-Instruct-FP8 (light green) - (Fit): L<sub>0</sub> = 16.7
* Llama-3.3-70B-Instruct-Turbo (olive green) - (Fit): L<sub>0</sub> = 10.2
* gamma-2-27b-it (purple) - (Fit): L<sub>0</sub> = 8.1
* Owen2.5-Coder-32B-Instruct (orange) - (Fit): L<sub>0</sub> = 4.8
* Owen2.5-7B-Instruct-Turbo (red) - (Fit): L<sub>0</sub> = 4.0
* Llama-3.2-3B-Instruct-Turbo (brown) - (Fit): L<sub>0</sub> = 1.6
* **Title (top):** Fit: ~ exp(-L/L<sub>0</sub>)
### Detailed Analysis
**Top Chart (Linear Scale):**
* **gemini-2.5-flash-preview-04-17 (green):** Starts at approximately 0.95 success rate at L=0, and decays relatively slowly, reaching approximately 0.15 at L=300.
* **gemini-2.0-flash (dark green):** Starts at approximately 0.85 success rate at L=0, and decays more rapidly than the previous model, reaching approximately 0.05 at L=300.
* **Llama-2-70B-Instruct-FP8 (light green):** Starts at approximately 0.75 success rate at L=0, and decays rapidly, reaching approximately 0.02 at L=300.
* **Llama-3.3-70B-Instruct-Turbo (olive green):** Starts at approximately 0.65 success rate at L=0, and decays moderately, reaching approximately 0.03 at L=300.
* **gamma-2-27b-it (purple):** Starts at approximately 0.80 success rate at L=0, and decays rapidly, reaching approximately 0.01 at L=300.
* **Owen2.5-Coder-32B-Instruct (orange):** Starts at approximately 0.70 success rate at L=0, and decays moderately, reaching approximately 0.02 at L=300.
* **Owen2.5-7B-Instruct-Turbo (red):** Starts at approximately 0.60 success rate at L=0, and decays rapidly, reaching approximately 0.01 at L=300.
* **Llama-3.2-3B-Instruct-Turbo (brown):** Starts at approximately 0.50 success rate at L=0, and decays rapidly, reaching approximately 0.005 at L=300.
**Bottom Chart (Log Scale):**
* The trends are the same as the top chart, but the logarithmic scale emphasizes the initial rapid decay of success rate for all models. The curves appear more linear on this scale, supporting the exponential decay fit.
* The initial slopes of the curves on the log scale visually represent the rate of decay. Steeper slopes indicate faster decay.
### Key Observations
* All models exhibit a decreasing success rate as the number of actions increases.
* The models differ significantly in their initial success rates and the rate at which their success rates decay.
* `gemini-2.5-flash-preview-04-17` maintains the highest success rate across a wider range of actions.
* `Llama-3.2-3B-Instruct-Turbo` has the lowest initial success rate and the fastest decay.
* The fitted L<sub>0</sub> values (representing the characteristic scale of decay) vary considerably between models, indicating different sensitivities to the number of actions.
### Interpretation
The charts demonstrate the trade-off between the number of actions taken by a language model and the probability of achieving a successful outcome. The exponential decay fit suggests that the success rate decreases predictably with each additional action. The varying L<sub>0</sub> values indicate that some models are more robust to increasing action counts than others.
The differences in performance between models likely reflect variations in their underlying architectures, training data, and optimization strategies. Models with higher initial success rates and larger L<sub>0</sub> values are better suited for tasks requiring a large number of actions, while models with lower initial success rates and smaller L<sub>0</sub> values may be more appropriate for simpler tasks.
The use of both linear and logarithmic scales provides a comprehensive view of the data. The linear scale highlights the absolute success rates, while the logarithmic scale emphasizes the relative rates of decay. The consistency of the trends across both scales strengthens the validity of the observed patterns. The data suggests that the complexity of the task, as measured by the number of actions required, significantly impacts the success rate of these language models.
</details>
Figure 1: Performance collapse of various models with increasing logical depth $L$ for a pathfinding task ( $N,M=40,\mathcal{B}=2$ keys, Noise Ratio $\mathcal{N}=0.0$ ). Success rates (Pass@1) are shown on linear (top panel) and logarithmic (bottom panel) y-axes, averaged from 5 runs/problem across 40 problems per unit $L$ -bin. All evaluations used Temperature=1.0 and top-p=0.95 (Gemini-2.5-flash: ’auto’ thinking). The displayed fits employ a Weighted Least Squares (WLS) Carroll and Ruppert (2017) method on log-success rates. Weights are derived from inverse squared residuals of a preliminary Ordinary Least Squares (OLS) fit. (In the supplementary section, we have added Figure 16 to show a similar pattern is observed in recently released OpenAI models.)
Furthermore, the seqBench benchmark is built upon a scalable data generation framework, allowing it to evolve alongside increasingly capable models to help with both model training and evaluation. Through evaluations on popular LLMs, we reveal that top-performing LLMs exhibit steep universal declines as either of the three complexity dimensions increases, while remaining comparatively robust to fact shuffle, despite the underlying logical structure being unchanged.
#### Contributions.
Our main contributions are:
1. seqBench: A Tunable Benchmark for Sequential Reasoning. We introduce an open-source framework for generating pathfinding tasks with fine-grained, orthogonal control over logical depth, backtracking steps, and noise ratio. We also evaluate secondary factors like fact ordering (shuffle ratio; See supplementary material for details).
1. Comprehensive LLM Attribution Study. Using seqBench, we demonstrate the significant impact of these controlled complexities on LLM performance, revealing sharp performance cliffs in state-of-the-art models even when search complexity is minimal.
The seqBench dataset is publicly available https://huggingface.co/datasets/emnlp-submission/seqBench under the CC BY 4.0 license to facilitate benchmarking.
<details>
<summary>figs/llama4_deepdive.png Details</summary>
### Visual Description
\n
## Charts: Performance Metrics vs. Number of Actions
### Overview
The image contains two charts displaying performance metrics related to a language model (Llama-4-Maverick-17B-128E-Instruct-FP8) as a function of the number of actions taken. The top chart shows the success rate, while the bottom chart displays precision, recall, and progress ratio. Both charts share the x-axis representing the number of actions.
### Components/Axes
**Top Chart:**
* **X-axis:** Number of actions (Scale: 0 to 300, increments of 50)
* **Y-axis:** Success rate (Scale: 0 to 0.6, increments of 0.1)
* **Data Series:**
* Llama-4-Maverick-17B-128E-Instruct-FP8 (Blue line with circle markers)
* α exp(-L/L₀), L₀ = 16.7 (Orange dashed line)
* **Legend:** Located at the top-right corner.
**Bottom Chart:**
* **X-axis:** Number of actions (Scale: 0 to 400, increments of 100)
* **Y-axis:** Metric Value (Scale: 0 to 1.0, increments of 0.2)
* **Data Series:**
* Precision (Blue line with circle markers)
* Recall (Orange line with circle markers)
* Progress ratio (Green line with circle markers)
* **Legend:** Located at the top-right corner.
### Detailed Analysis or Content Details
**Top Chart:**
The blue line representing Llama-4-Maverick-17B-128E-Instruct-FP8 starts at approximately 0.65 success rate at 0 actions and rapidly decreases to approximately 0.15 at 50 actions. It continues to decline slowly, reaching approximately 0.08 at 300 actions.
The orange dashed line starts at approximately 0.65 at 0 actions and decreases more gradually than the blue line, reaching approximately 0.25 at 300 actions.
**Bottom Chart:**
* **Precision (Blue):** Starts at approximately 0.9 at 0 actions and remains relatively stable around 0.85-0.95 throughout the range of actions, with some fluctuations.
* **Recall (Orange):** Starts at approximately 0.8 at 0 actions and decreases steadily to approximately 0.15 at 100 actions. It continues to decline, reaching approximately 0.08 at 300 actions.
* **Progress Ratio (Green):** Starts at approximately 0.2 at 0 actions and decreases rapidly to approximately 0.1 at 50 actions. It continues to decline, reaching approximately 0.05 at 300 actions. Each data point has a significant error bar, indicating high variance.
### Key Observations
* The success rate (top chart) decreases significantly with an increasing number of actions.
* Precision remains relatively high and stable across all actions.
* Recall and progress ratio (bottom chart) both decrease substantially with an increasing number of actions.
* The error bars on the recall and progress ratio suggest considerable variability in these metrics.
* The orange dashed line in the top chart provides a baseline for the success rate decay.
### Interpretation
The data suggests that while the language model starts with a high success rate, its performance deteriorates as the number of actions increases. Precision remains consistently high, indicating that when the model does succeed, it is generally correct. However, the decreasing recall and progress ratio suggest that the model becomes less capable of finding solutions or making progress as more actions are taken. The rapid initial drop in success rate, recall, and progress ratio could indicate an initial period of exploration or learning, followed by diminishing returns. The high variance in recall and progress ratio suggests that the model's performance is sensitive to the specific task or environment. The comparison to the exponential decay function (orange dashed line) in the top chart suggests that the success rate decay follows a similar pattern. This could be used to model or predict the model's performance over time.
</details>
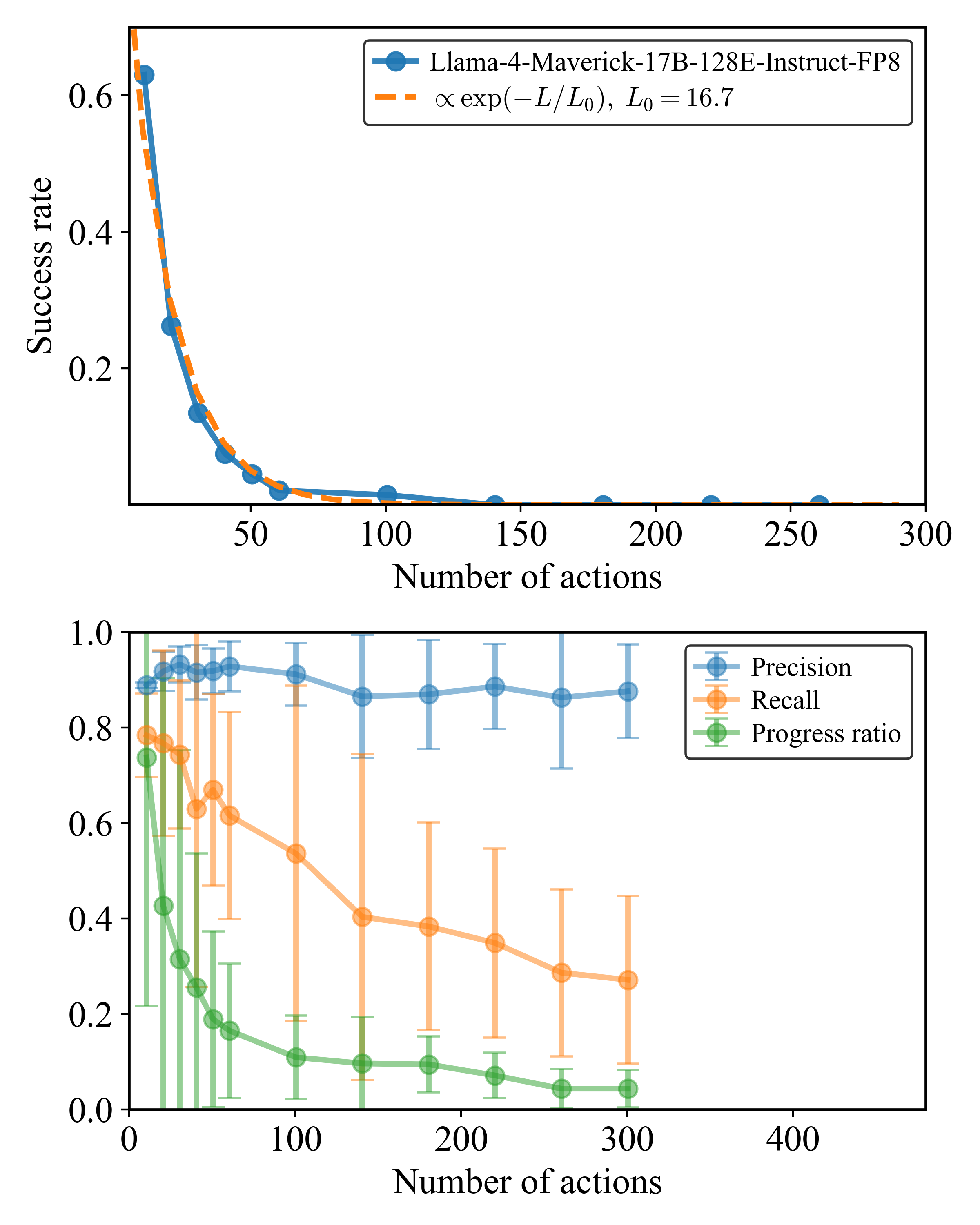
Figure 2: On the left: Llama-4 Maverick-17B-128E-Instruct Model’s performance (pass@1 success rate) versus number of actions in the ground truth path of the pathfinding problems ( $N,M=40,\mathcal{B}=2$ keys, Noise Ratio $\mathcal{N}=0.0$ ) is shown. This Pass@1 success rate across 5 runs per problem is averaged over the problem instances sampled from different actions count bins of width equal to 1. On the right: The mean of progress ratio across all problems as well as mean of precision and recall is shown to highlight models gradually increasing struggle in completing the path. The Temperature is set to 1.0 and the top-p is set to 0.95 in all runs.
## 1 Methods
### 1.1 Dataset Generation
The seqBench dataset consists of spatial pathfinding tasks. Task instance generation, detailed below (Algorithm 1; See Appendix A for details), is predicated on the precise independent control of the three key complexity dimensions introduced earlier: Logical Depth ( $L$ ), Backtracking Count ( $\mathcal{B}$ ), and Noise Ratio ( $\mathcal{N}$ ). This allows the creation of instances with specific values for these parameters, enabling targeted studies of their impact on LLM reasoning.
Task instances are produced in a multi-stage process. Initially, primary generation parameters—maze dimensions ( $N,M$ ), target backtracks ( $\mathcal{B}_{\text{target}}$ ), and target noise ratio ( $\mathcal{N}_{\text{target}}$ )—are specified. An acyclic maze graph ( $M_{g}$ ) is formed on an $N\times M$ grid using Kruskal’s algorithm (Kleinberg and Tardos, 2006). Our "Rewind Construction" method (Algorithm 1) then embeds $\mathcal{B}_{\text{target}}$ backtracking maneuvers by working backward from a goal to strategically place keys and locked doors, yielding the instance’s actual backtracking count $\mathcal{B}$ . Finally, a natural language fact list ( $\mathcal{F}$ ) is derived from the maze, and distracting facts are added according to $\mathcal{N}_{\text{target}}$ to achieve the final noise ratio $\mathcal{N}$ . The logical depth $L$ (optimal path length) emerges from these generative steps, influenced by $N,M,\mathcal{B}_{\text{target}}$ , and construction stochasticity. While $L$ is not a direct input to the generation algorithm, the process is designed to yield a wide spectrum of logical depths. Each generated instance is then precisely annotated with its emergent $L$ value, alongside its effective $\mathcal{B}$ and $\mathcal{N}$ values. This annotation effectively makes $L$ a key, selectable parameter for users of the seqBench dataset, enabling them to choose or filter tasks by their desired logical depth. Our rewind construction method guarantees task solvability. The full seqBench benchmark is constructed by systematically applying this instance generation process (detailed in Algorithm 1) across a wide range of initial parameters. This includes varied grid sizes (e.g., $N\in\{5..50\},M\approx N$ ) and target backtracks ( $\mathcal{B}_{\text{target}}\in\{0..7\}$ ), yielding a large and diverse data pool. For each $(N,M,\mathcal{B}_{\text{target}})$ configuration, multiple unique base mazes are generated, to which different noise ratios (e.g., $\mathcal{N}_{\text{target}}\in\{0..1\}$ ) are subsequently applied. It is important to note that the algorithm constrains backtracking complexity to a simple dependency chain. In this setting, retrieving the key for each locked door involves at most one backtracking step to pick up its corresponding key, without requiring the unlocking of additional doors along the optimal path. Combined with the uniform random placement of keys, this design ensures a well-balanced distribution of backtracking difficulty across the generated instances for each logical depth $L$ . Nevertheless, the same backward-in-time construction can be extended to generate tasks with higher backtracking complexity—for example, doors that require multiple keys, or intermediate doors that must be unlocked en route to other keys. Such extensions would introduce richer tree-structured dependency graphs and allow seqBench to probe model performance under more complex long-horizon reasoning regimes. The creation of this comprehensive data pool was computationally efficient, requiring approximately an hour of computation on a standard laptop while using minimal memory. The publicly released benchmark comprises a substantial collection of these generated instances, each annotated with its specific emergent logical depth $L$ , effective backtracking count $\mathcal{B}$ , and noise ratio $\mathcal{N}$ . This rich annotation is key, enabling researchers to readily select or filter task subsets by these dimensions for targeted studies (e.g., as done for Figure 1, where instances were sampled into $L$ -bins with other parameters fixed). For the experiments presented in this paper, specific subsets were drawn from this benchmark pool, often involving further filtering or parameter adjustments tailored to the objectives of each study; precise details for each experiment are provided in the relevant sections and figure captions. Full details on path derivation, fact compilation, and overall dataset generation parameters are provided in the Appendix A.
Input : Grid $N\times M$ , Target backtracks $\mathcal{B}$
Output : Maze graph $M_{g}$ , Locked doors $\mathcal{D}_{L}$ , Key info $\mathcal{K}_{I}$ , Path skeleton $\Pi_{S}$
1
2 $M_{g}\leftarrow$ Acyclic graph on grid (Kruskal’s);
3 $x\leftarrow C_{goal}\leftarrow$ Random goal cell in $M_{g}$ ;
4 $\mathcal{D}_{L},\mathcal{K}_{I}\leftarrow\emptyset,\emptyset$ ; $b\leftarrow 0$ ;
5 $\Pi_{S}\leftarrow[(C_{goal},\text{GOAL})]$ ;
6
7 while $b<\mathcal{B}$ do
8 $c_{key}\leftarrow$ Random cell in $M_{g}$ accessible from $x$ (path avoids $\mathcal{D}_{L}$ for this step);
9 $\pi_{seg}\leftarrow$ Unique path in $M_{g}$ from $x$ to $c_{key}$ ;
10 if $\exists e\in\pi_{seg}$ such that $e\notin\mathcal{D}_{L}$ then
11 $d\leftarrow$ Randomly select such an edge $e$ ;
12 $\mathcal{D}_{L}\leftarrow\mathcal{D}_{L}\cup\{d\}$ ;
13 $K_{id}\leftarrow$ New unique key ID;
14 $\mathcal{K}_{I}[K_{id}]\leftarrow\{\text{opens}:d,\text{loc}:c_{key}\}$ ;
15 $\Pi_{S}$ .prepend( $(c_{key},\text{PICKUP }K_{id})$ , $(d,\text{UNLOCK }K_{id})$ , $(\pi_{seg},\text{MOVE})$ );
16 $x\leftarrow c_{key}$ ; $b\leftarrow b+1$ ;
17
18 end if
19 else
20 Break
21 end if
22
23 end while
24 $\Pi_{S}$ .prepend( $(x,\text{START}))$ ;
25 return $M_{g},\mathcal{D}_{L},\mathcal{K}_{I},\Pi_{S}$ ;
Algorithm 1 Rewind Construction of Path Skeleton
### 1.2 Prompt Construction and Model Configuration
Our evaluation uses a standardized prompt template with four components: (i) task instructions and action schema, (ii) three few-shot examples of increasing complexity (simple navigation, single-key, and multi-key backtracking), (iii) optional reasoning guidance, and (iv) the problem’s natural-language facts. All models are queried using temperature $T{=}1.0$ , nucleus sampling $p{=}0.95$ , and maximum allowed setting in terms of output token limits on a per model basis. For each instance, we compute 5 independent runs to establish robust performance statistics. The complete prompt structure, shown in Figure 6, is provided in the Appendix B.
### 1.3 Evaluation Metrics
To analyze not just success but also how models fail, we employ several complementary metrics. Success Rate (Pass@1) measures the proportion of runs where the predicted action sequence exactly matches the ground truth. The Progress Ratio (Tyagi et al., 2024), calculated as $k/n$ (where $n$ is the total ground-truth actions and $k$ is the number correctly executed before the first error), pinpoints the breakdown position in reasoning. We also use Precision and Recall. Precision is the proportion of predicted actions that are correct, while Recall is the proportion of ground-truth actions that were correctly predicted. Low precision indicates hallucinated actions, while low recall signifies missed necessary actions. Additionally, we visualize error locations via a Violation Map. This multi-faceted approach reveals each model’s effective "reasoning horizon"—the maximum sequence length it can reliably traverse. Further details on all metrics and visualizations are provided in the supplementary material.
## 2 Benchmarking Results
<details>
<summary>figs/fig_vs_backtracking_fixed_L_shuffle1.0_noise0.0.png Details</summary>
### Visual Description
## Charts: Model Performance with Backtracking Steps
### Overview
The image presents three line charts comparing the performance of several language models (Llama-2, OpenLLaMA, and Gemini) as the number of backtracking steps increases. The charts display Progress Ratio Mean, Success Rate, and Number of Tokens generated. All charts share a common x-axis representing the "Number of backtracking steps" ranging from 0 to 5.
### Components/Axes
* **X-axis (all charts):** "Number of backtracking steps" (0, 1, 2, 3, 4, 5)
* **Chart 1 (Left):** "Progress ratio mean" (Y-axis, 0 to 1.0)
* **Models:**
* Llama-2-70b-chat-hf (Blue Diamonds)
* Llama-2-13b-instruct-hf (Green Triangles)
* OpenLLaMA-30b-instruct (Gray Squares)
* Llama-2-7b-chat-hf (Red Circles)
* Gemini-2.0-flash (Purple X)
* Gemini-2.5-flash-preview-v4.17 (Orange Circles)
* **Chart 2 (Center):** "Success rate" (Y-axis, 0 to 0.8)
* **Models:** Same as Chart 1.
* **Chart 3 (Right):** "Number of tokens" (Y-axis, 250 to 1750)
* **Models:** Same as Chart 1.
* **Legend:** Located at the top of the first chart, spanning across all three charts.
### Detailed Analysis or Content Details
**Chart 1: Progress Ratio Mean**
* **Llama-2-70b-chat-hf (Blue Diamonds):** Starts at approximately 0.68, decreases slightly to 0.62 at step 1, then remains relatively stable around 0.60-0.62 until step 5.
* **Llama-2-13b-instruct-hf (Green Triangles):** Starts at approximately 0.45, decreases steadily to around 0.25 by step 4, and remains around 0.25 at step 5.
* **OpenLLaMA-30b-instruct (Gray Squares):** Starts at approximately 0.40, decreases to around 0.30 by step 2, then decreases more rapidly to approximately 0.15 by step 5.
* **Llama-2-7b-chat-hf (Red Circles):** Starts at approximately 0.35, decreases to around 0.20 by step 2, and continues to decrease to approximately 0.10 by step 5.
* **Gemini-2.0-flash (Purple X):** Starts at approximately 0.55, decreases to around 0.45 by step 2, and remains relatively stable around 0.45 until step 5.
* **Gemini-2.5-flash-preview-v4.17 (Orange Circles):** Starts at approximately 0.30, increases to around 0.40 by step 1, then decreases to approximately 0.25 by step 5.
**Chart 2: Success Rate**
* **Llama-2-70b-chat-hf (Blue Diamonds):** Starts at approximately 0.85, decreases to around 0.75 by step 1, and remains relatively stable around 0.75 until step 5.
* **Llama-2-13b-instruct-hf (Green Triangles):** Starts at approximately 0.10, increases to around 0.30 by step 2, then decreases to approximately 0.10 by step 5.
* **OpenLLaMA-30b-instruct (Gray Squares):** Starts at approximately 0.05, increases to around 0.20 by step 1, then decreases to approximately 0.05 by step 5.
* **Llama-2-7b-chat-hf (Red Circles):** Starts at approximately 0.02, increases to around 0.15 by step 1, then decreases to approximately 0.02 by step 5.
* **Gemini-2.0-flash (Purple X):** Starts at approximately 0.80, decreases to around 0.70 by step 1, and remains relatively stable around 0.70 until step 5.
* **Gemini-2.5-flash-preview-v4.17 (Orange Circles):** Starts at approximately 0.20, increases to around 0.40 by step 1, then decreases to approximately 0.20 by step 5.
**Chart 3: Number of Tokens**
* **Llama-2-70b-chat-hf (Blue Diamonds):** Starts at approximately 1600, decreases slightly to around 1550 by step 5.
* **Llama-2-13b-instruct-hf (Green Triangles):** Starts at approximately 1100, decreases to around 900 by step 5.
* **OpenLLaMA-30b-instruct (Gray Squares):** Starts at approximately 1000, decreases to around 700 by step 5.
* **Llama-2-7b-chat-hf (Red Circles):** Starts at approximately 500, increases to around 600 by step 1, then decreases to approximately 400 by step 5.
* **Gemini-2.0-flash (Purple X):** Starts at approximately 1300, decreases to around 1200 by step 5.
* **Gemini-2.5-flash-preview-v4.17 (Orange Circles):** Starts at approximately 1200, decreases to around 1000 by step 5.
### Key Observations
* Generally, increasing the number of backtracking steps leads to a decrease in Progress Ratio Mean and Success Rate for most models.
* Llama-2-70b-chat-hf consistently exhibits the highest Success Rate and Progress Ratio Mean across all backtracking steps.
* The number of tokens generated tends to decrease with increasing backtracking steps for most models.
* OpenLLaMA-30b-instruct and Llama-2-7b-chat-hf show the most significant decline in performance (Progress Ratio Mean and Success Rate) as backtracking steps increase.
### Interpretation
The data suggests that while backtracking can potentially improve model performance in some cases (as seen by the initial increase in Success Rate for some models at step 1), increasing the number of backtracking steps generally leads to diminishing returns and can even degrade performance. This could be due to the increased computational cost and potential for introducing errors with each additional backtracking step.
The consistent high performance of Llama-2-70b-chat-hf indicates that larger models are more robust to the effects of backtracking. The significant decline in performance for smaller models like OpenLLaMA-30b-instruct and Llama-2-7b-chat-hf suggests that they may be more susceptible to errors or inefficiencies introduced by backtracking.
The decrease in the number of tokens generated with increasing backtracking steps could be a result of the model terminating the generation process earlier due to the increased complexity or uncertainty introduced by the backtracking process. This could also be a consequence of the models being optimized for faster generation without backtracking.
</details>
Figure 3: Performance as a function of the number of required backtracking steps, operationalized via the number of locked doors with distributed keys along the optimal path. Holding all other complexity factors constant, all models exhibit a clear decline in both progress ratio and success rate as backtracking demands increase. Additionally, we report the corresponding rise in output token counts per model, highlighting the increased reasoning burden associated with longer dependency chains. Fixed experimental parameters in this figure are the same as those in Figure 1. (for each point 100 problems sampled from $L=[40,60]$ )
### 2.1 Evaluated Models
We evaluate a diverse set of transformer-based LLMs across different model families and parameter scales. Our analysis includes Gemini models (2.5-flash-preview, 2.0-flash), Meta’s Llama family (4-Maverick-17B, 3.3-70B, 3.2-3B), Google’s Gemma-2-27b, and Alibaba’s Qwen models (2.5-Coder-32B, 2.5-7B). [Note: GPT-5 was released during the preparation of this paper’s final version. Our analysis shows that this model exhibits the same performance degradation, as shown in Figure 16]. Access to some open-weight models and benchmarking infrastructure was facilitated by platforms such as Together AI https://www.together.ai/ and Google AI Studio https://aistudio.google.com/. Problem instances for varying logical depths ( $L$ ) were generated by sampling 40 problems for each $L$ , using a fixed maze size of $40\times 40$ and 2 keys, unless otherwise specified for specific experiments (e.g., when varying the number of keys for backtracking analysis). All models were evaluated using the standardized prompt template (see Figure 6), the inference settings detailed in Section 1.2, and a common response parsing methodology. For each task instance, we perform 5 independent runs to establish robust performance statistics, primarily analyzing Pass@1 success rates.
### 2.2 Universal Performance Collapse with Increasing Logical Depth
A central finding of our study is the universal collapse in reasoning performance observed across all evaluated LLMs when confronted with tasks requiring increasing sequential inference steps. As illustrated in Figure 1, Pass@1 success rates exhibit a consistent and sharp exponential decay as the ground-truth path length ( $L$ ) increases. Performance rapidly approaches near-zero past a model-specific point in this decay. To quantify and compare this exponential decay, we fit an exponential decay curve $P(L)=\exp(-L/L_{0})$ to the success rates, deriving a characteristic path length $L_{0}$ . This $L_{0}$ value, representing the path length at which performance drops by a factor of $e^{-1}$ , serves as a robust metric for each model’s sequential reasoning horizon. Plotting success rates on a semi-logarithmic (log-y) scale against $L$ reveals an approximately linear decay trend across the evaluated regime. This log-linear relationship suggests that errors may accumulate with a degree of independence at each reasoning step, eventually overwhelming the model’s capacity for coherent inference. The observed $L_{0}$ values vary significantly, from 85.7 for Gemini-2.5-Flash down to 1.6 for Llama-3.2-3B (Figure 1), underscoring a fundamental bottleneck in current transformer architectures for extended multi-step reasoning.
### 2.3 Impact of Independently Controlled Complexity Dimensions
Beyond the universal impact of logical depth ( $L$ ) discussed in Section 2.2, our benchmark’s ability to independently vary key complexity dimensions allows for targeted analysis of their distinct impacts on LLM reasoning performance. We highlight the effects of noise, backtracking, and fact ordering, primarily focusing on Pass@1 success rates, mean progress ratios, and response token counts.
<details>
<summary>figs/fig_vary_noise_fixed_L_keys2_shuffle1.0.png Details</summary>
### Visual Description
\n
## Charts: Performance of Language Models with Noise Injection
### Overview
This image presents three line charts comparing the performance of two language models, Llama-4-maverick-17b-128e-instruct-fp8 and Gemini-2.5-flash-preview-04-17, under varying levels of noise injection. The charts display Mean Progress Ratio, Mean Success Rate (pass@1), and CoT tokens (Chain-of-Thought tokens) as functions of the Noise Ratio.
### Components/Axes
Each chart shares the following components:
* **X-axis:** Noise Ratio, ranging from 0.00 to 1.00, with markers at 0.00, 0.25, 0.50, 0.75, and 1.00.
* **Y-axis (Left Chart):** Mean Progress Ratio, ranging from 0.00 to 1.00.
* **Y-axis (Middle Chart):** Mean Success Rate (pass@1), ranging from 0.00 to 1.00.
* **Y-axis (Right Chart):** CoT tokens, ranging from 0 to 1750.
* **Legend (Top-Left of each chart):**
* Blue Line: Llama-4-maverick-17b-128e-instruct-fp8
* Orange Line: Gemini-2.5-flash-preview-04-17
### Detailed Analysis
**Chart 1: Mean Progress Ratio vs. Noise Ratio**
* **Llama (Blue Line):** The line slopes downward, indicating a decrease in Mean Progress Ratio as Noise Ratio increases.
* At Noise Ratio 0.00: Approximately 0.24
* At Noise Ratio 0.25: Approximately 0.18
* At Noise Ratio 0.50: Approximately 0.14
* At Noise Ratio 0.75: Approximately 0.12
* At Noise Ratio 1.00: Approximately 0.10
* **Gemini (Orange Line):** The line slopes downward more steeply than Llama, indicating a more significant decrease in Mean Progress Ratio as Noise Ratio increases.
* At Noise Ratio 0.00: Approximately 0.72
* At Noise Ratio 0.25: Approximately 0.52
* At Noise Ratio 0.50: Approximately 0.32
* At Noise Ratio 0.75: Approximately 0.18
* At Noise Ratio 1.00: Approximately 0.08
**Chart 2: Mean Success Rate (pass@1) vs. Noise Ratio**
* **Llama (Blue Line):** The line slopes downward, indicating a decrease in Mean Success Rate as Noise Ratio increases.
* At Noise Ratio 0.00: Approximately 0.18
* At Noise Ratio 0.25: Approximately 0.12
* At Noise Ratio 0.50: Approximately 0.08
* At Noise Ratio 0.75: Approximately 0.06
* At Noise Ratio 1.00: Approximately 0.04
* **Gemini (Orange Line):** The line slopes downward very steeply, indicating a significant decrease in Mean Success Rate as Noise Ratio increases.
* At Noise Ratio 0.00: Approximately 0.82
* At Noise Ratio 0.25: Approximately 0.58
* At Noise Ratio 0.50: Approximately 0.34
* At Noise Ratio 0.75: Approximately 0.14
* At Noise Ratio 1.00: Approximately 0.06
**Chart 3: CoT Tokens vs. Noise Ratio**
* **Llama (Blue Line):** The line shows a slight downward trend, with some fluctuations, indicating a small decrease in CoT tokens as Noise Ratio increases.
* At Noise Ratio 0.00: Approximately 1725
* At Noise Ratio 0.25: Approximately 1550
* At Noise Ratio 0.50: Approximately 1475
* At Noise Ratio 0.75: Approximately 1450
* At Noise Ratio 1.00: Approximately 1425
* **Gemini (Orange Line):** The line is relatively flat, with minor fluctuations, indicating a minimal change in CoT tokens as Noise Ratio increases.
* At Noise Ratio 0.00: Approximately 475
* At Noise Ratio 0.25: Approximately 500
* At Noise Ratio 0.50: Approximately 525
* At Noise Ratio 0.75: Approximately 500
* At Noise Ratio 1.00: Approximately 525
### Key Observations
* Gemini consistently outperforms Llama in both Mean Progress Ratio and Mean Success Rate at all Noise Ratio levels.
* Both models exhibit a significant performance degradation (decrease in Mean Progress Ratio and Mean Success Rate) as the Noise Ratio increases.
* The number of CoT tokens used by Llama is substantially higher than that used by Gemini, and remains relatively stable across different Noise Ratios. Gemini's CoT token usage is low and relatively constant.
* Gemini's performance is more sensitive to noise than Llama's.
### Interpretation
The data suggests that Gemini is more robust to noise than Llama, maintaining a higher success rate and progress ratio even with significant noise injection. However, Gemini relies on fewer CoT tokens, which might indicate a different reasoning strategy or a more efficient approach to problem-solving. Llama, while more susceptible to noise, utilizes a larger number of CoT tokens, potentially indicating a more verbose or exploratory reasoning process. The steep decline in performance for both models with increasing noise highlights the importance of data quality and the potential vulnerability of language models to adversarial inputs or noisy data. The relatively stable CoT token usage for Llama suggests that the model attempts to maintain its reasoning process even under noisy conditions, while Gemini's minimal token usage indicates a more direct approach that is easily disrupted by noise. The difference in CoT token usage could also be related to the model architectures or training methodologies.
</details>
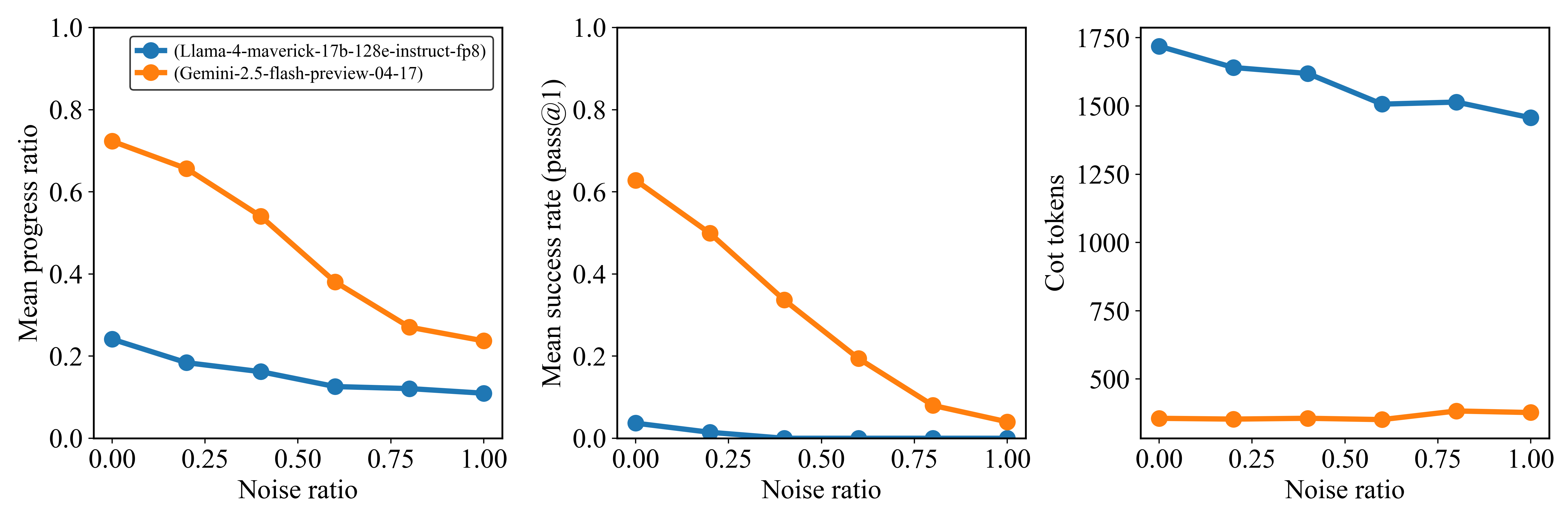
Figure 4: Performance as a function of contextual noise for Gemini 2.5 flash and Llama-4 Maverick-17B-128E-Instruct models. As noise increases through the inclusion of distracting or irrelevant facts, both models exhibit a clear and consistent decline in performance. Fixed experimental parameters in this figure are the same as those in Figure 1 (for each point 100 problems sampled from $L=[40,60]$ and number of keys is equal to 2).
#### Impact of Backtracking Requirements.
Increasing the number of required backtracking steps—operationalized via key-door mechanisms—also leads to a clear and significant decline in Pass@1 success rates and mean progress ratios across all evaluated models as shown in Figure 3. Gemini 2.5 Flash-preview maintains the highest performance but still exhibits a notable drop as backtracking count increases from 0 to 5. This decline in reasoning accuracy is generally accompanied by an increase or sustained high level in the mean number of response tokens (Figure 3, right panel). For example, models like Llama-4 Maverick and Gemini 2.5 Flash-preview show a clear upward trend or maintain high token counts as backtracking complexity rises, reflecting the increased reasoning effort or path length articulated by the models when managing more complex sequential dependencies.
#### Sensitivity to Noise Ratio.
Model performance is highly sensitive to the noise ratio—the proportion of distracting versus supporting facts. As demonstrated in Figure 4 for Gemini 2.5 Flash and Llama-4 Maverick, increasing the proportion of irrelevant facts consistently and significantly degrades both Pass@1 success rates and mean progress ratios. For instance, Gemini 2.5 Flash’s Pass@1 success rate drops from over 0.7 at zero noise to approximately 0.2 at a noise ratio of 1.0. Llama-4 Maverick, starting with lower performance, also shows a consistent decline. Interestingly, for these two models, the number of CoT (output) tokens remains relatively stable despite the increasing noise and degrading performance (Figure 4, right panel), suggesting that models do not necessarily "work harder" (in terms of output length) when faced with more distractors, but their accuracy suffers.
#### Fact Ordering (Shuffle Ratio).
In contrast to the strong effects of noise and backtracking, shuffle ratio (entropy of fact presentation order) within the prompt appears to play a secondary role when varied in isolation. Our experiments, exemplified by the performance of Gemini 2.5 Flash and Llama-4 Maverick (see Appendix C Figure 14 for details), show that complete shuffling of facts (randomizing their presentation order without adding or removing any information) has a minimal impact on Pass@1 success rates and mean progress ratios. Output token counts also remain stable. This suggests a relative robustness to presentation order as long as all necessary information is present and distinguishable. However, as details provided in supplementary material, when high noise and high shuffle co-occur, the combined effect can be more detrimental than either factor alone, though noise remains the dominant degrading factor.
### 2.4 Characterizing Key Failure Modes and Error Patterns
#### A Key Failure Mode: Omission of Critical Steps.
Beyond simply taking illegal shortcuts, detailed analysis reveals that LLMs often fail by omitting critical sub-goals necessary for task completion. Figure 2 (bottom panel) provides a quantitative view for Llama-4 Maverick (Meta AI, 2025), showing that while precision generally remains high (models infrequently hallucinate non-existent rooms or facts), recall and progress ratio plummet with increasing path length ( $L$ ). This indicates that models predominantly fail by missing necessary actions or entire crucial sub-sequences. For a qualitative example, even capable models like Gemini-2.5-Flash can neglect essential detours, such as collecting a required key, thereby violating sequential dependencies and rendering the task unsolvable (illustrative examples are provided in the Appendix B.4; see Figures 8 and 9). This pattern highlights a fundamental breakdown in robust multi-step planning and execution.
#### Path-Length Dependent First Errors: The Burden of Anticipated Complexity.
The propensity for models to make critical errors is not uniformly distributed across the reasoning process, nor is it solely a feature of late-stage reasoning fatigue. Examining the distribution of steps at which the first constraint violations occur reveals a counterintuitive pattern: as the total required path length ( $L$ ) of a problem increases, models tend to fail more frequently even at the earliest steps of the reasoning chain. This leftward shift in the first-error distribution also observed under increasing noise, (Appendix B.4; Figures 10 and 11) contradicts a simple cumulative error model where each step carries a fixed, independent failure probability. Instead, an error at an early step (e.g., step 5) becomes substantially more likely when the model is attempting to solve an 80-step problem versus a 20-step problem. This suggests that the overall anticipated complexity of the full problem influences reasoning quality from the very outset, indicating a struggle with global planning or maintaining coherence over longer horizons, rather than just an accumulation of local errors. This phenomenon may help explain why prompting techniques that decompose long problems into smaller, manageable sub-problems often succeed.
### 2.5 Disparity: Information Retention vs. Reasoning Capacity
On seqBench tasks, this disparity is quantitatively striking. While modern LLMs boast million-token contexts, their effective sequential reasoning depth typically remains on the order of hundreds of actions (Figure 1). This functional limit, even at several hundred actions (e.g., 300 actions, with each like (’move_to’, ’A12’) being 5-7 tokens, totaling 1.5k-2.1k tokens), still consumes a minute fraction of their nominal context. Consequently, the ratio of context capacity to reasoning tokens often spans from several hundred-fold (e.g., 500:1 for 300 actions consuming 2k tokens within a 1M context) to potentially higher values given fewer limiting actions or larger model contexts. This striking gap suggests that while transformers can store and retrieve vast information, their ability to reliably chain it for coherent, multi-step inference appears surprisingly constrained.
### 2.6 Challenging the Conventional Performance Hierarchy
While metrics like average $L_{0}$ provide a general ranking of model capabilities, our fine-grained analysis reveals instances that challenge a simple linear performance hierarchy. Scatter plots of progress ratios across different models on identical tasks (see Appendix C Figure 13) show intriguing cases where models with lower overall $L_{0}$ values (i.e., typically weaker models) occasionally solve specific complex problems perfectly, while models with higher average $L_{0}$ values fail on those same instances. These performance inversions suggest that sequential reasoning failures may not solely stem from insufficient scale (parameters or general training) but could also arise from more nuanced reasoning limitations.
## 3 Related Work
Recent advancements in benchmarks evaluating sequential reasoning capabilities of LLMs have illuminated various strengths and limitations across different dimensions of complexity. These benchmarks typically differ in how they isolate and quantify reasoning challenges, such as logical deduction, retrieval difficulty, combinatorial complexity, and sensitivity to irrelevant information. ZebraLogic (Lin et al., 2025), for instance, targets formal deductive inference through logic-grid puzzles framed as constraint-satisfaction problems (csp, 2008). While valuable for probing deduction, its core methodology leads to a search space that grows factorially with puzzle size (Sempolinski, 2009). This makes it challenging to disentangle intrinsic reasoning failures from the sheer combinatorial complexity of the search. As the ZebraLogic authors themselves acknowledge: “ solving ZebraLogic puzzles for large instances may become intractable… the required number of reasoning tokens may increase exponentially with the size of the puzzle. ” This inherent characteristic means that for larger puzzles, performance is primarily dictated by the manageability of the search space rather than the limits of sequential reasoning depth. GridPuzzle (Tyagi et al., 2024) complements this by providing a detailed error taxonomy for grid puzzles, focusing on what kinds of reasoning mistakes LLMs make. However, like ZebraLogic, it doesn’t offer independent control over key complexity dimensions such as logical depth, backtracking needs, or noise, separate from the puzzle’s inherent search complexity.
Other benchmarks conflate reasoning with different cognitive demands. BABILong (Kuratov et al., 2024) tests models on extremely long contexts (up to 50M tokens), primarily assessing the ability to retrieve "needles" (facts) from a "haystack" (distracting text that does not contribute to solving the task). While valuable for evaluating long-context processing, this design makes it hard to disentangle retrieval failures from reasoning breakdowns, as performance is often dictated by finding the relevant information rather than reasoning over it. MuSR (Sprague et al., 2024) embeds reasoning tasks within lengthy narratives (e.g., murder mysteries), mixing information extraction challenges with complex, domain-specific reasoning structures. This realism obscures which specific aspect—extraction or reasoning depth—causes model failures. Dyna-bAbI (Tamari et al., 2021) offers a dynamic framework for compositional generalization but focuses on qualitative combinations rather than systematically varying quantitative complexity metrics needed to find precise failure points.
Spatial reasoning benchmarks, while relevant, also target different aspects. GRASP (Tang and Kejriwal, 2025) assesses practical spatial planning efficiency (like obstacle avoidance) in 2D grids, a different skill than the abstract sequential reasoning seqBench isolates. SPARTQA (Mirzaee et al., 2021) focuses on specialized spatial relational complexity (transitivity, symmetry) using coupled dimensions, preventing independent analysis of factors like path length. SpaRTUN (Mirzaee and Kordjamshidi, 2022) uses synthetic data primarily for transfer learning in Spatial Question Answering (SQA), aiming to improve model performance rather than serve as a diagnostic tool with controllable complexity. Similarly, StepGame (Shi et al., 2022) demonstrates performance decay with more reasoning steps in SQA but lacks the fine-grained, orthogonal controls over distinct complexity factors provided by seqBench.
In contrast, seqBench takes a targeted diagnostic approach. By deliberately simplifying the spatial environment to minimize search complexity, it isolates sequential reasoning. Its core contribution lies in the independent, fine-grained control over (1) logical depth (the number of sequential actions required to solve the task), (2) backtracking count (the number of backtracking steps along the optimal path), and (3) noise ratio (the ratio of supporting to distracting facts). This orthogonal parameterization allows us to precisely pinpoint when and why sequential reasoning capabilities degrade, revealing fundamental performance cliffs even when search and retrieval demands are trivial. seqBench thus offers a complementary tool for understanding the specific limitations of sequential inference in LLMs.
## 4 Limitations
While seqBench offers precise control over key reasoning complexities, our study has limitations that open avenues for future research:
1. Generalizability and Task Design Fidelity: Our current findings are rooted in synthetic spatial pathfinding tasks. While this allows for controlled experimentation, future work must extend seqBench ’s methodology to more diverse reasoning domains (e.g., mathematical proofs) and incorporate greater linguistic diversity (e.g., ambiguity) to assess the broader applicability of the observed phenomena of performance collapse (quantified by $L_{0}$ ) and failure patterns. Moreover, this work did not investigate whether similar failure modes arise when the problem is also presented visually (e.g., as maze images). Multimodal capabilities could influence spatial reasoning outcomes, and we have already extended the benchmark by releasing maze image generation code alongside the HuggingFace dataset. This dataset can also be used to help train multimodal reasoning models.
1. Model Scope and Understanding Deeper Failure Dynamics: Our current evaluation, while covering diverse public models, should be expanded to a wider array of LLMs—including recent proprietary and newer open-source variants (e.g., GPT, Claude, DeepSeek series)—to rigorously assess the universality of our findings on the characteristic length $L_{0}$ and failure patterns. Furthermore, while seqBench effectively characterizes how reasoning performance degrades with logical depth (i.e., by determining $L_{0}$ ), two complementary research thrusts are crucial for understanding why. First, systematic investigation is needed to disentangle how $L_{0}$ is influenced by factors such as model architecture, scale (parameters, training data, compute), fine-tuning strategies, and inference-time computation (e.g., chain-of-thought depth). Second, deeper analysis is required to explain the precise mechanisms underlying the observed exponential performance collapse characterized by $L_{0}$ and to account for other non-trivial error patterns, such as path-length dependent first errors. Additionally, the evaluation presented here does not consider how agentic systems capable of tool use perform as the reasoning complexity is tuned across various dimensions. Exploring such setups, where the LLM can externalize sub-problems, invoke tools, or backtrack programmatically, could provide valuable insights into whether the same exponential failure modes persist. In particular, one can define sequential problems where the degree of backtracking or sequential tool use can be systematically varied, and to test whether similar performance drop emerge as the dependency chain grows. We highlight this as a promising direction for future research.
1. Impact of Prompting: Our current study employed standardized prompts and inference settings. A crucial next step is a robust sensitivity analysis to determine overall decay behavior are influenced by different prompting strategies (e.g., zero-shot vs. few-shot, decomposition techniques), varied decoding parameters (temperature, top-p), and interactive mechanisms such as self-verification or self-correction. Investigating the potential of these techniques to mitigate the observed sequential inference failures, particularly given seqBench ’s minimal search complexity, remains a key avenue for future research.
Addressing these points by leveraging frameworks like seqBench will be vital for developing LLMs with more robust and generalizable sequential reasoning capabilities, and for understanding their fundamental performance limits.
## 5 Conclusion
We introduced seqBench, a novel benchmark framework designed for the precise attribution of sequential reasoning failures in Large Language Models. seqBench ’s core strength lies in its unique capability for fine-grained, independent control over fundamental complexity dimensions; most notably, logical depth ( $L$ ), backtracking requirements, and noise ratio, its provision of automatically verifiable solutions, and critically minimizing confounding factors like search complexity. This design allows seqBench to isolate and rigorously evaluate the sequential inference capabilities of LLMs, enabling the automatic quantification of fine-grained performance metrics (such as progress ratio) and providing a clear lens into mechanisms often obscured in most other benchmarks. The framework’s inherent scalability and open-source nature position it as a durable tool for assessing and driving progress in current and future generations of models, ultimately aiming to enhance their utility for complex, real-world problems that often span multiple domains. Our comprehensive evaluations using seqBench reveal that reasoning accuracy consistently collapses exponentially with increasing logical depth across a diverse range of state-of-the-art LLMs. This collapse is characterized by a model-specific parameter $L_{0}$ (Section 2.2), indicating an inherent architectural bottleneck in maintaining coherent multi-step inference. In alignment with the goal of advancing NLP’s reach and fostering its responsible application in other fields by offering this precise analysis, seqBench provides a valuable resource. It encourages a shift beyond aggregate benchmark scores towards a more nuanced understanding of model capabilities, an essential step for rigorously assessing the true impact and potential risks of applying LLMs in new domains. The insights gleaned from seqBench can inform both NLP developers in building more robust models, and experts in other disciplines in setting realistic expectations and co-designing NLP solutions that are genuinely fit for purpose. Targeted improvements, guided by such fundamental understanding, are key to enhancing the robustness of sequential reasoning, making LLMs more reliable partners in interdisciplinary endeavors. Future work should leverage these insights to develop models that can overcome the observed performance cliffs and extend their effective reasoning horizons, thereby unlocking their transformative potential in diverse interdisciplinary applications—such as navigating complex scientific literature, supporting intricate legal analysis, or enabling robust multi-step planning in critical autonomous systems. Focusing on commonsense reasoning is paramount for NLP to achieve transformative societal impact, moving beyond incremental improvements to genuine breakthroughs.
## References
- csp (2008) 2008. Rina dechter , constraint processing, morgan kaufmann publisher (2003) isbn 1-55860-890-7, francesca rossi, peter van beek and toby walsh, editors, handbook of constraint programming, elsevier (2006) isbn 978-0-444-52726-4. Computer Science Review, 2:123–130.
- Anthropic (2025) Anthropic. 2025. Claude 3.7 sonnet. https://www.anthropic.com/news/claude-3-7-sonnet.
- Berglund et al. (2024) Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, and Owain Evans. 2024. The reversal curse: Llms trained on "a is b" fail to learn "b is a". Preprint, arXiv:2309.12288.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Carroll and Ruppert (2017) Raymond J Carroll and David Ruppert. 2017. Transformation and weighting in regression. Chapman and Hall/CRC.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. Preprint, arXiv:1803.05457.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. Preprint, arXiv:2110.14168.
- Du et al. (2021) Nan Du, Yanping Huang, Andrew M. Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, Barret Zoph, Liam Fedus, Maarten Bosma, Zongwei Zhou, Tao Wang, Yu Emma Wang, Kellie Webster, Marie Pellat, Kevin Robinson, and 8 others. 2021. Glam: Efficient scaling of language models with mixture-of-experts. In International Conference on Machine Learning.
- Dua et al. (2019) Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. 2019. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. Preprint, arXiv:1903.00161.
- Fedus et al. (2022) William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120):1–39.
- Google DeepMind (2025) Google DeepMind. 2025. Gemini 2.5 pro experimental. https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025/.
- Han et al. (2024) Pengrui Han, Peiyang Song, Haofei Yu, and Jiaxuan You. 2024. In-context learning may not elicit trustworthy reasoning: A-not-b errors in pretrained language models. Preprint, arXiv:2409.15454.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. Preprint, arXiv:2009.03300.
- Hoffmann et al. (2022) Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, and 3 others. 2022. Training compute-optimal large language models. Preprint, arXiv:2203.15556.
- Kleinberg and Tardos (2006) Jon Kleinberg and Eva Tardos. 2006. Algorithm Design. Pearson/Addison-Wesley, Boston.
- Kojima et al. (2022) Takeshi Kojima, Shixiang (Shane) Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems, volume 35, pages 22199–22213. Curran Associates, Inc.
- Kuratov et al. (2024) Yury Kuratov, Aydar Bulatov, Petr Anokhin, Ivan Rodkin, Dmitry Sorokin, Artyom Sorokin, and Mikhail Burtsev. 2024. Babilong: Testing the limits of llms with long context reasoning-in-a-haystack. Advances in Neural Information Processing Systems, 37:106519–106554.
- Lieber et al. (2021) Opher Lieber, Or Sharir, Barak Lenz, and Yoav Shoham. 2021. Jurassic-1: Technical details and evaluation. https://www.ai21.com/blog/jurassic-1-technical-details-and-evaluation. White Paper.
- Lin et al. (2025) Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. 2025. Zebralogic: On the scaling limits of llms for logical reasoning. Preprint, arXiv:2502.01100.
- Meta AI (2025) Meta AI. 2025. Llama 4: Open and efficient multimodal language models. https://github.com/meta-llama/llama-models.
- Mirzaee et al. (2021) Roshanak Mirzaee, Hossein Rajaby Faghihi, Qiang Ning, and Parisa Kordjmashidi. 2021. Spartqa: : A textual question answering benchmark for spatial reasoning. Preprint, arXiv:2104.05832.
- Mirzaee and Kordjamshidi (2022) Roshanak Mirzaee and Parisa Kordjamshidi. 2022. Transfer learning with synthetic corpora for spatial role labeling and reasoning. Preprint, arXiv:2210.16952.
- Mistral AI (2024) Mistral AI. 2024. Mistral large 2. https://mistral.ai/news/mistral-large-2407.
- Nezhurina et al. (2025) Marianna Nezhurina, Lucia Cipolina-Kun, Mehdi Cherti, and Jenia Jitsev. 2025. Alice in wonderland: Simple tasks showing complete reasoning breakdown in state-of-the-art large language models. Preprint, arXiv:2406.02061.
- OpenAI (2025) OpenAI. 2025. Openai gpt-5, o3 and o4-mini. https://openai.com/index/introducing-o3-and-o4-mini/, https://openai.com/index/introducing-gpt-5/. Paper’s supplementary material (appendix) was revised, after GPT-5 release, with a new figure, to reflect that GPT-5 also suffers from the same failure pattern we have observed in this paper.
- Rae et al. (2021) Jack W. Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, Eliza Rutherford, Tom Hennigan, Jacob Menick, Albin Cassirer, Richard Powell, George van den Driessche, Lisa Anne Hendricks, Matthias Rauh, Po-Sen Huang, and 58 others. 2021. Scaling language models: Methods, analysis & insights from training Gopher. Preprint, arXiv:2112.11446.
- Rein et al. (2023) David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. 2023. Gpqa: A graduate-level google-proof q&a benchmark. Preprint, arXiv:2311.12022.
- Sempolinski (2009) Peter Sempolinski. 2009. Automatic solutions of logic puzzles.
- Sharma (2024) Manasi Sharma. 2024. Exploring and improving the spatial reasoning abilities of large language models. In I Can’t Believe It’s Not Better Workshop: Failure Modes in the Age of Foundation Models.
- Shi et al. (2022) Zhengxiang Shi, Qiang Zhang, and Aldo Lipani. 2022. Stepgame: A new benchmark for robust multi-hop spatial reasoning in texts. In Proceedings of the AAAI conference on artificial intelligence, volume 36, pages 11321–11329.
- Smith et al. (2022) Samuel Smith, Mostofa Patwary, Brian Norick, Patrick LeGresley, Samyam Rajbhandari, Jared Casper, Zhenhao Liu, Shrimai Prabhumoye, Georgios Zerveas, Vikas Korthikanti, Eric Zhang, Rewon Child, Reza Yazdani Aminabadi, Jared Bernauer, Xia Song Song, Mohammad Shoeybi, Yuxin He, Michael Houston, Shishir Tiwary, and Bryan Catanzaro. 2022. Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model. Preprint, arXiv:2201.11990.
- Sprague et al. (2024) Zayne Sprague, Xi Ye, Kaj Bostrom, Swarat Chaudhuri, and Greg Durrett. 2024. Musr: Testing the limits of chain-of-thought with multistep soft reasoning. Preprint, arXiv:2310.16049.
- Srivastava et al. (2023) Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, Agnieszka Kluska, Aitor Lewkowycz, Akshat Agarwal, Alethea Power, Alex Ray, Alex Warstadt, Alexander W. Kocurek, Ali Safaya, Ali Tazarv, and 432 others. 2023. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Preprint, arXiv:2206.04615.
- Tamari et al. (2021) Ronen Tamari, Kyle Richardson, Aviad Sar-Shalom, Noam Kahlon, Nelson Liu, Reut Tsarfaty, and Dafna Shahaf. 2021. Dyna-babi: unlocking babi’s potential with dynamic synthetic benchmarking. Preprint, arXiv:2112.00086.
- Tang and Kejriwal (2025) Zhisheng Tang and Mayank Kejriwal. 2025. Grasp: A grid-based benchmark for evaluating commonsense spatial reasoning. Preprint, arXiv:2407.01892.
- Thoppilan et al. (2022) Rami Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yi Du, Yanping Li, Hongrae Lee, Huaixiu Steven Zheng, Amin Ghafouri, Marcelo Menegali, Yanping Huang, Max Krikun, Dmitry Lepikhin, James Qin, and 38 others. 2022. Lamda: Language models for dialog applications. arXiv preprint. Technical report, Google Research.
- Tikhonov (2024) Alexey Tikhonov. 2024. Plugh: A benchmark for spatial understanding and reasoning in large language models. Preprint, arXiv:2408.04648.
- Tyagi et al. (2024) Nemika Tyagi, Mihir Parmar, Mohith Kulkarni, Aswin RRV, Nisarg Patel, Mutsumi Nakamura, Arindam Mitra, and Chitta Baral. 2024. Step-by-step reasoning to solve grid puzzles: Where do llms falter? Preprint, arXiv:2407.14790.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
- Wei et al. (2023) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. Chain-of-thought prompting elicits reasoning in large language models. Preprint, arXiv:2201.11903.
- Weston et al. (2015) Jason Weston, Antoine Bordes, Sumit Chopra, Alexander M. Rush, Bart van Merriënboer, Armand Joulin, and Tomas Mikolov. 2015. Towards ai-complete question answering: A set of prerequisite toy tasks. Preprint, arXiv:1502.05698.
- Yang et al. (2019) Kaiyu Yang, Olga Russakovsky, and Jia Deng. 2019. SpatialSense: An adversarially crowdsourced benchmark for spatial relation recognition. In International Conference on Computer Vision (ICCV).
- Zoph et al. (2022) Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. 2022. St-moe: Designing stable and transferable sparse expert models. Preprint, arXiv:2202.08906.
## Appendices
## Appendix A Dataset Generation Details
The seqBench benchmark generates pathfinding tasks by systematically controlling several complexity dimensions. As described in Section 1 (main paper), Algorithm 1 is central to this process. This appendix provides further details on the generation phases, natural language encoding of tasks, and specific dataset parameters.
### A.1 Generation Phases
The generation process, guided by Algorithm 1, involves three main phases:
1. Base Maze Construction: An initial $N\times M$ grid is populated, and an acyclic maze graph ( $M_{g}$ ) is formed using Kruskal’s algorithm (Kleinberg and Tardos, 2006). This ensures a simply connected environment where a unique path exists between any two cells if all internal "walls" (potential door locations) were open. The overall process results in maze instances like the one visualized in Figure 5.
1. Rewind Construction for Path Skeleton and Key/Door Placement: This phase implements the "Rewind Construction" (Algorithm 1 in the main paper). Starting from a randomly selected goal cell ( $C_{goal}$ ), the algorithm works backward to define a solvable path skeleton ( $\Pi_{S}$ ). It iteratively:
1. Selects a cell $c_{key}$ that would be a preceding point on a path towards the current cell $x$ (initially $C_{goal}$ ).
1. Identifies the unique path segment $\pi_{seg}$ in $M_{g}$ from $x$ to $c_{key}$ .
1. Randomly selects an edge $d$ on this segment $\pi_{seg}$ to become a locked door. This edge $d$ is added to the set of locked doors $\mathcal{D}_{L}$ .
1. A new unique key $K_{id}$ is conceptually placed at $c_{key}$ , and its information (which door it opens, its location) is stored in $\mathcal{K}_{I}$ .
1. The conceptual steps (moving along $\pi_{seg}$ , unlocking door $d$ with $K_{id}$ , picking up $K_{id}$ at $c_{key}$ ) are prepended (in reverse logical order) to the path skeleton $\Pi_{S}$ .
1. The current cell $x$ is updated to $c_{key}$ , and the process repeats until the target number of backtracks ( $\mathcal{B}$ ) is achieved or no valid placements remain.
This backward construction ensures solvability and controlled backtracking complexity. The final agent starting position is the cell $x$ at the end of this phase.
1. Fact Compilation and Noise Injection: Based on the final maze structure ( $M_{g},\mathcal{D}_{L},\mathcal{K}_{I}$ ), a set of natural language facts $\mathcal{F}$ is compiled. This includes facts describing room connections, key locations, and door states. Distracting facts are then introduced based on the target noise ratio $\mathcal{N}$ . These distractors might describe non-existent connections, spurious keys, or misleading adjacencies, chosen to be plausible yet incorrect.
<details>
<summary>figs/compath_viz.png Details</summary>
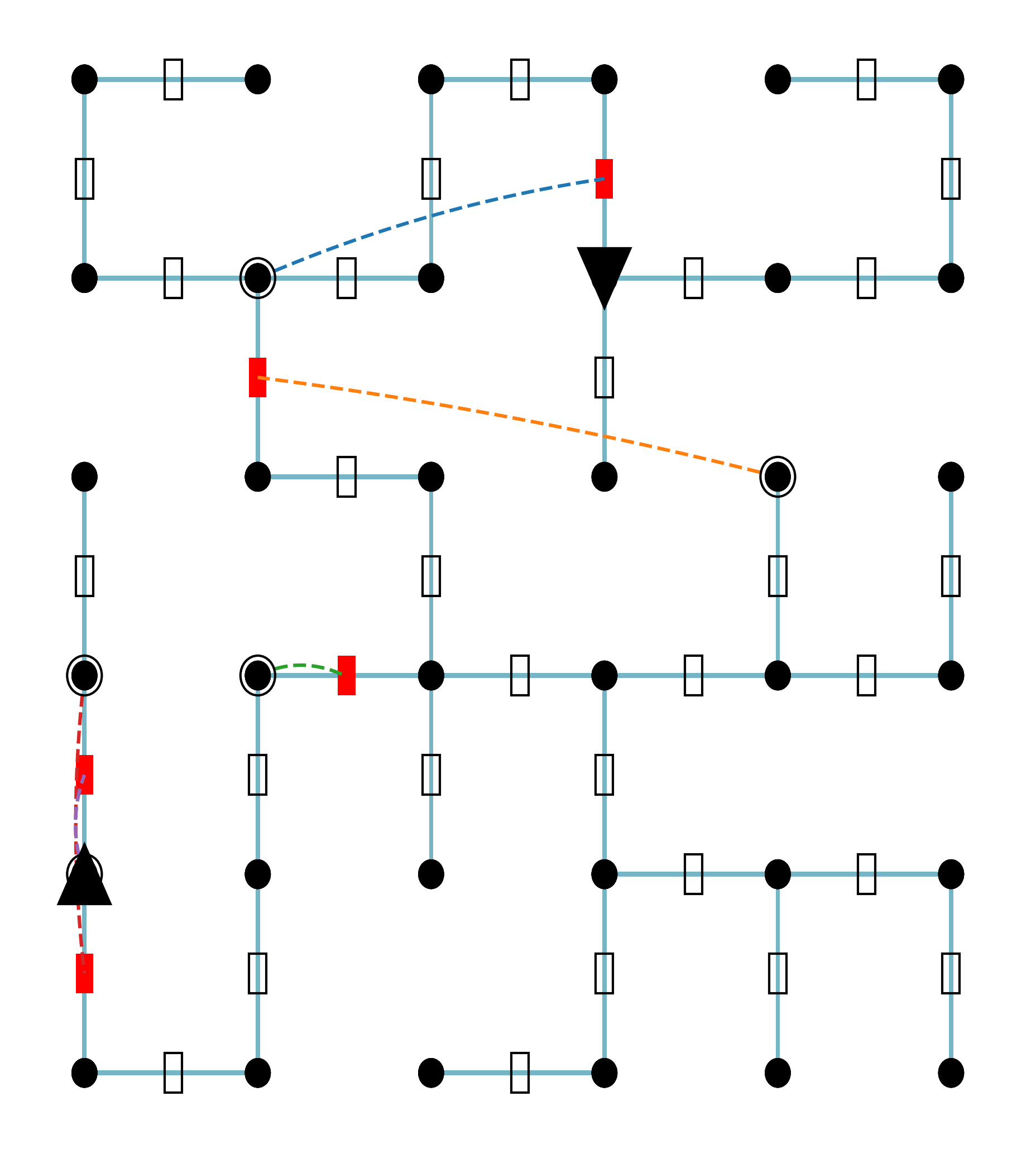
### Visual Description
\n
## Diagram: Grid-Based Network with Node Variations
### Overview
The image depicts a grid-based network composed of nodes connected by lines. The nodes vary in shape and color, suggesting different states or types. The network appears to be a visual representation of a system with pathways and potential decision points. There are no explicit axes or labels, so the interpretation relies on the visual cues provided by the node and line characteristics.
### Components/Axes
The diagram consists of:
* **Nodes:** Represented by circles and triangles.
* Black circles: Most frequent node type.
* Gray circles: Less frequent, larger in size.
* Red squares: Indicate a specific state or event.
* Black triangles: Indicate a specific state or event.
* **Lines:** Connect the nodes, indicating pathways or relationships.
* Solid lines: Represent standard connections.
* Dashed lines: Represent alternative or less direct connections.
* Blue dashed line: Connects two nodes.
* Orange dashed line: Connects two nodes.
* Green dashed line: Connects two nodes.
* Red dashed line: Connects two nodes.
### Detailed Analysis or Content Details
The diagram is structured as a grid, with nodes arranged in rows and columns. The connections between nodes are primarily horizontal and vertical, forming a network of pathways.
* **Top Row:** Contains black circles connected by solid lines. A red square is connected to the second node from the right via a blue dashed line.
* **Second Row:** Contains black circles connected by solid lines. A red square is connected to the second node from the left via an orange dashed line. A gray circle is connected to the fourth node from the right via a solid line.
* **Third Row:** Contains black circles connected by solid lines. A red square is connected to the second node from the left via a green dashed line. A gray circle is connected to the first node from the left via a red dashed line.
* **Fourth Row:** Contains black circles connected by solid lines.
* **Fifth Row:** Contains black circles connected by solid lines.
* **Leftmost Column:** Contains black circles connected by solid lines. A black triangle is connected to the second node from the top via a red dashed line. A gray circle is connected to the first node from the top via a solid line.
There are 3 red squares, 2 black triangles, and 2 gray circles.
### Key Observations
* The red squares appear to be "event" nodes, as they are connected to other nodes via dashed lines, suggesting a deviation from the standard pathway.
* The black triangles also appear to be "event" nodes, similar to the red squares.
* The gray circles are larger than the black circles, potentially indicating a higher priority or different function.
* The dashed lines suggest alternative routes or conditional connections within the network.
* The grid structure implies a systematic or organized system.
### Interpretation
The diagram likely represents a state machine, a flow chart, or a network with decision points. The black circles represent standard states, while the red squares and black triangles represent events or triggers that cause transitions to different states. The gray circles might represent important states or nodes that require special attention. The dashed lines indicate alternative paths or conditional transitions.
The overall structure suggests a system where a process flows through a series of states, with occasional events causing deviations or alternative pathways. The grid layout implies a well-defined and organized system. The lack of labels makes it difficult to determine the specific meaning of each state and event, but the visual cues provide a general understanding of the system's structure and behavior. The diagram could be used to model a variety of processes, such as a computer program, a manufacturing process, or a business workflow.
</details>
Figure 5: Example visualization of a $6\times 6$ seqBench maze instance. Red rectangles denote locked doors, dashed lines indicate the locations of keys corresponding to those doors, and triangles mark the start (upward-pointing) and goal (downward-pointing) positions. This illustrates the spatial nature of the tasks.
### A.2 Natural Language Encoding
Each task instance is translated into a set of atomic natural language facts. We use a consistent templating approach:
- Room Connections: "Room A1 and B1 are connected by an open door."
- Locked Connections: "Room C3 and D3 are connected by a closed and locked door."
- Key Requirements: "The locked door between C3 and D3 requires key 5." (Key IDs are simple integers).
- Key Placements: "Key 5 is in room E4." (Room IDs use spreadsheet-like notation, e.g., A1, B2).
- Starting Position: "Bob is in room A2."
- Goal Position: "Alice is in room D5."
The full set of facts for a given problem constitutes its description.
### A.3 Dataset Parameters and Scope
The seqBench dataset was generated using the following parameter ranges based on the generation configuration:
- Grid Sizes ( $N\times M$ ): $N\times M$ where $N$ and $M$ range from 5 to 50 (e.g., [5,5], [6,6], …, [50,50]), with $M=N$ for all configurations.
- Target Backtracking Steps ( $\mathcal{B}$ ): Values from 0 to 7. This controls the number of key-door mechanisms deliberately placed on the optimal path.
- Noise Ratio ( $\mathcal{N}$ ): Values from $0.0$ (no distracting facts) to $1.0$ (equal number of supporting and distracting facts), typically in increments of $0.2$ .
- Instances per Configuration: For each primary configuration, defined by a specific grid size ( $N,M$ ) and a specific target backtracking step count ( $\mathcal{B}\in\{0..7\}$ ), 400 unique base maze instances were generated.
- Logical Depth ( $L$ ): As an emergent property, $L$ varies. Experiments typically select problems from these generated instances that fall into specific $L$ bins (e.g., $L\in[10,11),[11,12),\ldots$ ).
This generation pipeline, leveraging the described parameter ranges and variations, can produce a vast and diverse set of problem instances. The publicly released seqBench dataset, used for the analyses in this paper (see main paper for access link), comprises 7,079 such curated instances. This collection offers a rich resource for studying the combined effects of the controlled complexity dimensions.
## Appendix B Prompt Design and Model Configuration Details
This appendix provides the complete details of the prompt structure and model configurations used for evaluating LLMs on the seqBench benchmark. The overall prompt, illustrated in Figure 6, concatenates four main components which are detailed below.
<details>
<summary>figs/prompt_template.png Details</summary>
### Visual Description
\n
## Diagram: Maze Solving Agent Prompt Template
### Overview
The image presents a diagram outlining a prompt template for a problem-solving agent tasked with navigating a maze. The diagram is structured as a flowchart, visually representing the steps and considerations for the agent's reasoning process. It's divided into sections labeled "Task Description", "Reasoning Guidance", "Problem Facts", and "Example Responses".
### Components/Axes
The diagram is not a chart with axes, but a structured flowchart. Key components include:
* **Task Description:** Outlines the agent's goal – to find the optimal path through a maze.
* **Reasoning Guidance:** Lists steps the agent should follow (1-6).
* **Problem Facts:** Provides specific details about the maze (room connections, door states).
* **Example Responses:** Shows the expected format of the agent's solution.
* **Labels:** Numerous labels describing actions, constraints, and components.
* **Flow Arrows:** Indicate the sequence of steps and dependencies.
### Detailed Analysis or Content Details
**Task Description:**
* **TASK:** Help Bob navigate a maze of connected rooms to rescue Alice.
* **MAZE DESCRIPTION CONTAINS:** Room connections (open/closed doors), door information (lock/unlock keys), starting location (Where Bob is at the start), target location (Where Alice is at the start).
* **Valid actions:** start, move_to, pick_up, use_key, unlock, open_door, to_rescue
* **Action & parameter syntax:** Room IDs: Column-Row (e.g., "A1"). Key IDs: positive integers (e.g., "1").
* **Task Constraints:**
1. Each move must be between adjacent and connected rooms.
2. Keys must be picked up before use.
3. Locked doors require use of their specific key to unlock.
4. Optimal path minimizes actions/distance.
5. Actions must be in correct order (move, unlock, open_door).
* **OUTPUT FORMAT REQUIREMENT:** A Python list of tuples representing each action in chronological order: `[('start', 'RoomID'), ('move_to', 'RoomID'), ...]`
**Reasoning Guidance (Steps):**
1. Find the shortest path from Bob to Alice.
2. Identify any locked doors on this path.
3. For each locked door, find its required key.
4. Plan key collection order to ensure you have each key before reaching its door.
5. Track all actions while following the rules.
6. Avoid unnecessary actions that increase the total path length.
* **IF THE PATH SEEMS COMPLEX:** Break it into smaller segments, solve each segment separately, combine solutions while maintaining optimality.
**Problem Facts:**
* **PROBLEM:** Room A6 and A5 are connected by an open door. Room A6 and B6 are connected by an open door. Room B6 and C6 are connected by an open door. Room C6 and D6 are connected by an open door. Room D6 and E6 are connected by an open door. Room E6 and F6 are connected by an open door. Room F6 and G6 are connected by an open door. Room G6 and H6 are connected by an open door. Room H6 and I6 are connected by an open door. Room D5 and C4 are connected by a locked door. The locked door requires key 10. Room A5 and B5 are connected by a locked door. The locked door requires key 1. Room B5 and C5 are connected by an open door. Room C5 and D5 are connected by an open door. Room D4 and C4 are connected by a locked door. The locked door requires key 7. Room A1 is where Bob starts. Room I6 is where Alice is at the start.
**Example Responses:**
* **Your solution must be formatted as a Python list of tuples representing each action in chronological order:** `[('start', 'A1'), ('move_to', 'A5'), ('pick_up', '1'), ('unlock', '1'), ...]`
### Key Observations
The diagram is highly structured and detailed, providing a comprehensive framework for the agent's task. The emphasis on constraints and output format suggests a need for precise and well-defined solutions. The inclusion of a complex path scenario highlights the importance of efficient planning and key management.
### Interpretation
This diagram serves as a blueprint for a maze-solving AI agent. It's not presenting data *about* a maze, but rather *instructions* for an agent *to solve* a maze. The diagram's strength lies in its explicit breakdown of the problem into manageable steps, emphasizing logical reasoning and adherence to constraints. The inclusion of example output demonstrates the desired level of precision and formality. The "Reasoning Guidance" section is particularly important, as it outlines the cognitive processes the agent should employ. The "Problem Facts" section provides a concrete scenario for testing the agent's capabilities. The diagram is a clear example of how to translate a complex problem into a structured, solvable format for an AI agent. It's a design document for an AI system, not a data visualization.
</details>
Figure 6: The complete prompt structure passed to the LLMs. This includes: Component 1 (System Instructions and Task Definition), one of the three Few-Shot Examples (Component 2, specifically a simple navigation task), Component 3 (Reasoning Guidance), and an illustration of where the Problem Instance Facts (Component 4) are inserted. For clarity and completeness, the full verbatim text for all three few-shot examples (Component 2) is provided in 7.
### B.1 Overall Prompt Components
The prompt presented to the LLMs consists of the following components:
1. System Instructions and Task Definition (Component 1): Outlines the agent’s task, the structure of the maze description, valid actions and their syntax, key operational constraints, and the required output format.
1. Few-Shot Examples (Component 2): Three examples are provided to illustrate the task, ranging in complexity. One of these examples (a simple navigation task) is detailed in Figure 6. The verbatim text for all three examples is provided in Figure 7 for completeness.
1. Reasoning Guidance and Self-Assessment (Component 3): Offers step-by-step algorithmic tips for solving the task and requests the model to provide a self-assessment of its confidence and the perceived difficulty of the instance.
1. Problem Instance Facts (Component 4): The specific natural language facts describing the current maze configuration for the task instance. As illustrated in Figure 6, these facts are appended after the preceding components and are followed by the line "YOUR SOLUTION:" to prompt the model. These facts are generated using the templates described in Appendix A.
1. Example 1 (Simple Navigation): This example, as shown in Figure 6, involves navigating a maze with only open doors.
⬇
EXAMPLE:
INPUT:
Maze Structure: Room C4 and C3 are connected by an open door. Room C3 and D3 are connected by an open door. Room D5 and E5 are connected by an open door. Room A2 and A1 are connected by an open door. Room A3 and B3 are connected by an open door. Room A1 and B1 are connected by an open door. Room A4 and A3 are connected by an open door. Room E5 and E4 are connected by an open door. Room D4 and D3 are connected by an open door. Room A5 and B5 are connected by an open door. Room D4 and E4 are connected by an open door. Bob is in room D5. Alice is in room C4.
OUTPUT:
Solution: [(’ start ’, ’ D5 ’), (’ move_to ’, ’ E5 ’), (’ move_to ’, ’ E4 ’), (’ move_to ’, ’ D4 ’), (’ move_to ’, ’ D3 ’), (’ move_to ’, ’ C3 ’), (’ move_to ’, ’ C4 ’), (’ rescue ’, ’ Alice ’)]
1. Example 2 (Single-Key Backtracking): This example introduces a single locked door and a corresponding key.
⬇
EXAMPLE:
INPUT:
Maze Structure: Room A1 and A2 are connected by an open door. Room A2 and B2 are connected by an open door. Room B1 and B2 are connected by an open door. Room B1 and C1 are connected by an open door. Room C1 and C2 are connected by a closed and locked door. Door between C1 and C2 requires key 1. Key 1 is in room A2. Bob is in room A1. Alice is in room C2.
OUTPUT:
Solution: [(’ start ’, ’ A1 ’), (’ move_to ’, ’ A2 ’), (’ pick_up_key ’, ’1’), (’ move_to ’, ’ B2 ’), (’ move_to ’, ’ B1 ’), (’ move_to ’, ’ C1 ’), (’ use_key ’, ’1’), (’ unlock_and_open_door_to ’, ’ C2 ’), (’ move_to ’, ’ C2 ’), (’ rescue ’, ’ Alice ’)]
1. Example 3 (Multi-Key Backtracking): This example presents a more complex scenario with multiple locked doors and keys, requiring more extensive backtracking.
⬇
EXAMPLE:
INPUT:
Maze Structure: Room B5 and B4 are connected by a closed and locked door. The locked door between B5 and B4 requires key 3. Key 3 is in room B5. Room B5 and C5 are connected by a closed and locked door. The locked door between B5 and C5 requires key 16. Key 16 is in room C5. Room B4 and C4 are connected by an open door. Room C4 and C3 are connected by an open door. Room C3 and D3 are connected by a closed and locked door. The locked door between C3 and D3 requires key 10. Key 10 is in room C4. Room D5 and D4 are connected by an open door. Room D4 and D3 are connected by an open door. Room A5 and B5 are connected by an open door. Bob is in room C5. Alice is in room D5.
OUTPUT:
Solution: [(’ start ’, ’ C5 ’), (’ pick_up_key ’, ’16’), (’ use_key ’, ’16’), (’ unlock_and_open_door_to ’, ’ B5 ’), (’ move_to ’, ’ B5 ’), (’ pick_up_key ’, ’3’), (’ use_key ’, ’3’), (’ unlock_and_open_door_to ’, ’ B4 ’), (’ move_to ’, ’ B4 ’), (’ move_to ’, ’ C4 ’), (’ pick_up_key ’, ’10’), (’ move_to ’, ’ C3 ’), (’ use_key ’, ’10’), (’ unlock_and_open_door_to ’, ’ D3 ’), (’ move_to ’, ’ D3 ’), (’ move_to ’, ’ D4 ’), (’ move_to ’, ’ D5 ’), (’ rescue ’, ’ Alice ’)]
Figure 7: Few-shot examples provided to guide the LLMs in the maze-solving task. These examples demonstrate simple navigation, single-key backtracking, and multi-key backtracking scenarios. The three examples illustrate increasing levels of complexity.
### B.2 Evaluation Metrics and Error Analysis Details
This section provides further details on specific aspects of our evaluation metrics and observed error categories, complementing the overview of metrics in Section 1 of the main paper and the discussion of failure modes in Section 2 of the main paper.
#### Observed Violation Categories.
Failures in model solutions on seqBench tasks can be categorized into several types. Understanding these categories is crucial for interpreting model performance and failure modes. Key types of violations observed include:
- Adjacency errors (e.g., attempting to move between unconnected rooms).
- Locked door errors (e.g., navigating through locked doors without the correct key or without unlocking them).
- Key usage errors (e.g., attempting to use keys not yet collected, or using the wrong key for a door).
- Path inefficiency (e.g., taking unnecessary detours or redundant actions; while not always a hard violation that stops progress, this contributes to solutions not matching the optimal path and thus failing Pass@1).
- Missed critical actions (e.g., failing to pick up a necessary key or unlock a required door). This is a key failure mode discussed in the main paper (Section 2.4) and is often reflected in metrics like low recall or a low progress ratio if the omission occurs early and prevents further correct steps.
Identifying these distinct categories of errors provides a more granular understanding of why models fail on sequential reasoning tasks and helps in the interpretation of aggregate performance metrics reported in the main paper.
### B.3 Violation Map: Qualitative Examples of Model Failures
This section provides qualitative examples of characteristic model failures to illustrate common error types. These examples visually support the discussion of failure modes in the main paper (Section 2.4, "A Key Failure Mode: Omission of Critical Steps"). Figure 8 illustrates a significant error by Gemini-2.5-Flash on a complex task, where the model generates an illegal path, bypassing necessary steps and locked doors. This exemplifies a breakdown in multi-step planning. Additionally, Figure 9 shows another common ’adjacency error,’ where a model attempts to jump between unconnected rooms. This type of error reveals a critical lapse in grounding its generated actions within the spatial adjacencies explicitly stated by the task’s input facts.
<details>
<summary>figs/goodexample4040.png Details</summary>

### Visual Description
\n
## Diagram: Path Comparison - Optimal vs. Model
### Overview
The image presents a comparison of two paths plotted on a field of randomly distributed points. The left panel displays the "Optimal Path", while the right panel shows the "Model Path". Both paths appear to navigate from the top-left to the bottom-right of the respective panels. The background consists of a dense scattering of small, grey dots.
### Components/Axes
There are no explicit axes or scales. The diagram relies on visual comparison of the paths within the coordinate space defined by the point field. The diagram is split into two panels, labeled "Optimal Path" (left) and "Model Path" (right) at the top center of each panel. The paths are represented by connected line segments of different colors.
### Detailed Analysis or Content Details
**Optimal Path (Left Panel):**
The path is composed of segments colored orange and yellow.
- The initial segment is orange, extending diagonally downwards from the top-left.
- This transitions to a yellow segment that meanders with several sharp turns, generally moving towards the bottom-right.
- A final orange segment completes the path, angling towards the bottom-right corner.
- A short blue segment is present near the bottom-left corner.
**Model Path (Right Panel):**
The path is composed of segments colored orange and purple.
- The initial segment is orange, extending diagonally downwards from the top-left, similar to the optimal path.
- This transitions to a purple segment that exhibits a more erratic, zig-zag pattern.
- The purple path has several sharp angles and appears less direct than the optimal path.
- A short blue segment is present near the bottom-left corner.
**Point Field:**
Both panels share a similar background of randomly distributed grey dots. The density of these dots appears relatively uniform across both panels.
### Key Observations
- The "Optimal Path" appears more direct and less convoluted than the "Model Path".
- The "Model Path" exhibits a more erratic and less efficient trajectory.
- Both paths share an initial orange segment.
- Both paths have a short blue segment near the bottom-left corner.
- The point field does not appear to influence the path selection, serving as a visual backdrop.
### Interpretation
This diagram likely illustrates the comparison between an ideal or calculated path ("Optimal Path") and a path generated by a model ("Model Path"). The difference in path complexity suggests that the model may not be accurately predicting or replicating the optimal route. The presence of the point field could represent obstacles or a cost map, but the paths do not seem to actively avoid or respond to the point distribution. The short blue segment in both paths could represent a fixed starting or ending point, or a constraint imposed on both the optimal and model solutions. The diagram highlights the discrepancy between the theoretical optimal solution and the model's output, indicating a potential area for model improvement. The model path's zig-zag pattern suggests it may be struggling with local optima or lacks a global view of the environment.
</details>
Figure 8: Illustrative failure case for Gemini-2.5-Flash on a 40x40 task with 2 locked doors on the optimal path. Left: Optimal path (yellow). Right: Model’s generated path showing an illegal adjacency jump (red arrow), bypassing multiple rooms and a locked door, despite only supporting facts being provided. This highlights a breakdown in multi-step planning.
<details>
<summary>figs/mistakev2.png Details</summary>
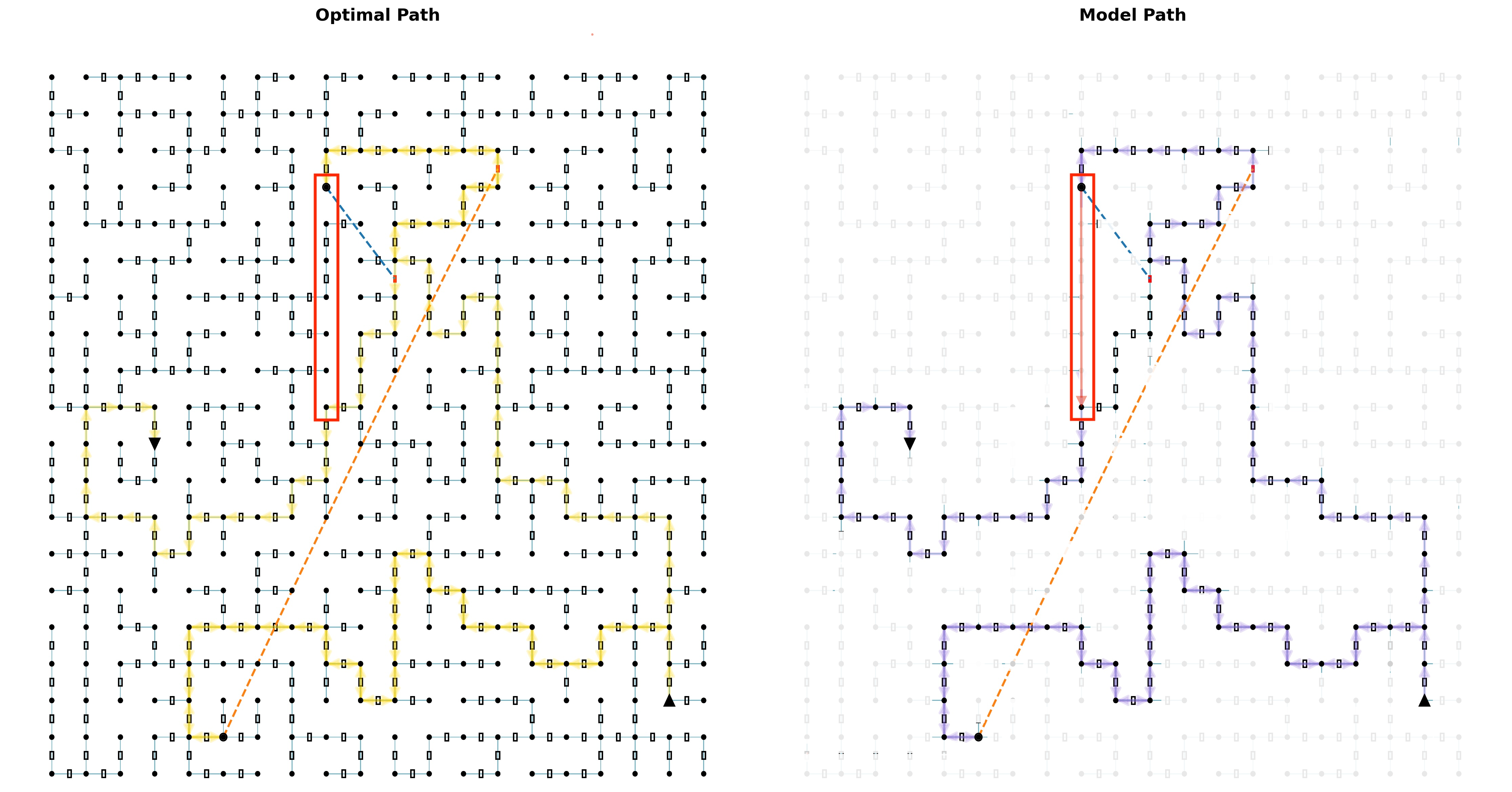
### Visual Description
\n
## Diagram: Path Comparison - Optimal vs. Model
### Overview
The image presents a comparison between an "Optimal Path" and a "Model Path" through a grid-like environment. Both paths start at the bottom-left corner and end at the top-right corner. The environment consists of a dense grid of small squares, with the paths highlighted by connected lines. The "Optimal Path" is shown in yellow, and the "Model Path" is shown in blue, with a red dashed line indicating a shared initial segment. There are also triangular markers along both paths.
### Components/Axes
The diagram lacks explicit axes or scales. It is a visual representation of paths within a 2D grid. The key components are:
* **Grid:** A uniform grid of small squares representing the environment.
* **Optimal Path:** Highlighted in yellow, representing the shortest or most efficient path.
* **Model Path:** Highlighted in blue, representing the path generated by a model.
* **Shared Initial Segment:** A red dashed line indicating the overlap between the Optimal and Model paths at the beginning.
* **Start Point:** Bottom-left corner of the grid.
* **End Point:** Top-right corner of the grid.
* **Markers:** Triangular markers are placed along both paths, potentially indicating key points or steps.
### Detailed Analysis or Content Details
The grid appears to be approximately 30x30 squares.
**Optimal Path (Yellow):**
The Optimal Path follows a relatively straight diagonal line from the start to the end. It consists of approximately 30 segments. The path is smooth and direct.
**Model Path (Blue):**
The Model Path deviates significantly from a straight line. It exhibits several sharp turns and horizontal/vertical movements. It consists of approximately 50 segments.
* The initial segment of the Model Path overlaps with the Optimal Path, indicated by the red dashed line. This overlap lasts for approximately 5 segments.
* After the initial overlap, the Model Path makes a sharp turn to the right, then proceeds upwards with several horizontal segments.
* The Model Path then makes a sharp turn to the left and continues upwards with more horizontal segments.
* The final segment of the Model Path is a diagonal line towards the end point.
**Markers (Triangles):**
* The Optimal Path has triangular markers placed at roughly equal intervals along its length. There are approximately 10 markers.
* The Model Path also has triangular markers, but they are more sparsely distributed and appear to be placed at points where the path changes direction. There are approximately 7 markers.
### Key Observations
* The Model Path is significantly longer and more convoluted than the Optimal Path.
* The Model Path initially follows the Optimal Path but quickly diverges.
* The Model Path exhibits a tendency to move horizontally before changing direction.
* The markers on the Optimal Path suggest a consistent step size, while the markers on the Model Path highlight changes in direction.
### Interpretation
This diagram likely illustrates the performance of a pathfinding algorithm or a reinforcement learning agent. The Optimal Path represents the ideal solution, while the Model Path represents the solution generated by the algorithm/agent. The significant difference in path length and complexity suggests that the model is not yet performing optimally. The initial overlap indicates that the model can initially identify the correct direction, but it struggles to maintain a straight path and efficiently reach the goal. The horizontal movements in the Model Path could indicate a bias in the algorithm or a difficulty in navigating the environment. The placement of markers suggests that the model is making decisions at discrete steps, and the markers highlight these decision points. The diagram demonstrates a clear gap between the ideal solution and the model's performance, highlighting areas for improvement in the algorithm or agent's training.
</details>
Figure 9: Illustrative failure case of an ’adjacency error’ in model-generated pathfinding on a 20x20 task with 2 locked doors on the optimal path. The left panel displays the optimal path (yellow) to the target (triangle). The right panel shows a suboptimal path (purple) generated by the model. This example highlights a common error where, after a sequence of actions (in this scenario, following a key acquisition), the model fails to navigate through valid connections. Instead, it attempts to ’jump’ directly between two unconnected rooms. This violation of room adjacency constraints is a key challenge in model performance.
### B.4 Quantitative Analysis of Error Patterns
To understand how and when models begin to fail within a reasoning sequence, we analyze the distribution of the first violation step. We record the time step at which the initial violation occurs in a model’s generated path. Aggregating this step-indexed data across multiple instances allows us to create temporal distributions of errors. These distributions help determine whether errors tend to cluster early in the reasoning process (potentially indicating issues with initial planning or understanding of the overall problem complexity) or accumulate later (suggesting difficulties in maintaining long chains of inference or context). This analysis complements the discussion in the main paper (Section 2.4, "Path-Length Dependent First Errors: The Burden of Anticipated Complexity").
Figure 10 shows how the distribution of these first-error positions shifts with the overall problem complexity, represented by logical depth ( $L$ ). As detailed in the main paper, an increase in $L$ tends to cause errors to occur earlier in the reasoning chain.
<details>
<summary>figs/failure_step_dist_vs_L.png Details</summary>

### Visual Description
\n
## Chart: Progress Visualization
### Overview
The image presents a chart visualizing progress across solution steps, ranging from 20 to 300. The chart consists of horizontal bars representing the progress at specific solution step milestones. The x-axis represents the "max progress step" and the y-axis implicitly represents the solution step number.
### Components/Axes
* **X-axis:** "max progress step" ranging from 0 to 300.
* **Y-axis:** Solution steps: 20, 60, 100, 140, 180, 220, 260, 300.
* **Bars:** Horizontal bars representing progress at each solution step. The bars are of varying lengths.
### Detailed Analysis
The chart displays progress at the following solution steps:
* **Solution steps: 20:** A short horizontal bar, approximately 10 units long, starting at the 0 mark on the x-axis.
* **Solution steps: 60:** A horizontal bar, approximately 20 units long, starting around the 10 mark on the x-axis.
* **Solution steps: 100:** A horizontal bar, approximately 30 units long, starting around the 20 mark on the x-axis.
* **Solution steps: 140:** Two horizontal bars. The first is approximately 10 units long, starting around the 40 mark on the x-axis. The second is approximately 10 units long, starting around the 70 mark on the x-axis.
* **Solution steps: 180:** Three horizontal bars. The first is approximately 10 units long, starting around the 50 mark on the x-axis. The second is approximately 10 units long, starting around the 90 mark on the x-axis. The third is approximately 10 units long, starting around the 120 mark on the x-axis.
* **Solution steps: 220:** A single horizontal bar, approximately 20 units long, starting around the 130 mark on the x-axis.
* **Solution steps: 260:** Four horizontal bars. The first is approximately 10 units long, starting around the 150 mark on the x-axis. The second is approximately 10 units long, starting around the 180 mark on the x-axis. The third is approximately 10 units long, starting around the 210 mark on the x-axis. The fourth is approximately 10 units long, starting around the 240 mark on the x-axis.
* **Solution steps: 300:** Five horizontal bars. The first is approximately 10 units long, starting around the 160 mark on the x-axis. The second is approximately 10 units long, starting around the 190 mark on the x-axis. The third is approximately 10 units long, starting around the 220 mark on the x-axis. The fourth is approximately 10 units long, starting around the 250 mark on the x-axis. The fifth is approximately 10 units long, starting around the 280 mark on the x-axis.
### Key Observations
The number of horizontal bars increases as the solution steps increase, suggesting a more fragmented or detailed progress representation at higher steps. The length of the initial bars is relatively short, while the later bars show a more distributed pattern.
### Interpretation
The chart likely represents a process that becomes more complex or requires more sub-tasks as it progresses. The increasing number of bars at higher solution steps suggests that each step is broken down into smaller components. The varying lengths of the bars could indicate the amount of work or time spent on each sub-task within a given solution step. The chart doesn't provide absolute values for progress, but rather a visual representation of the distribution of effort or completion across different stages of the process. The chart is a visualization of a process that is becoming more granular as it progresses.
</details>
Figure 10: Distribution of first-violation steps for Gemini-2.5-Flash across varying logical depths ( $L$ ). As $L$ (total required path length) increases, the distribution of first errors tends to shift leftward, indicating that models are more likely to fail at earlier steps in longer problems. This suggests that anticipated global complexity impacts reasoning from the outset. Experimental parameters in this figure are the same as those in Figure 1.
Similarly, Figure 11 illustrates how the introduction of contextual noise (distracting facts) affects the point of failure. Increased noise also tends to precipitate earlier errors in the reasoning sequence, as discussed in the main paper in relation to sensitivity to noise (Section 2.3) and its impact on error patterns (Section 2.4).
<details>
<summary>figs/gemini-progress-ratio-vs-noise.png Details</summary>
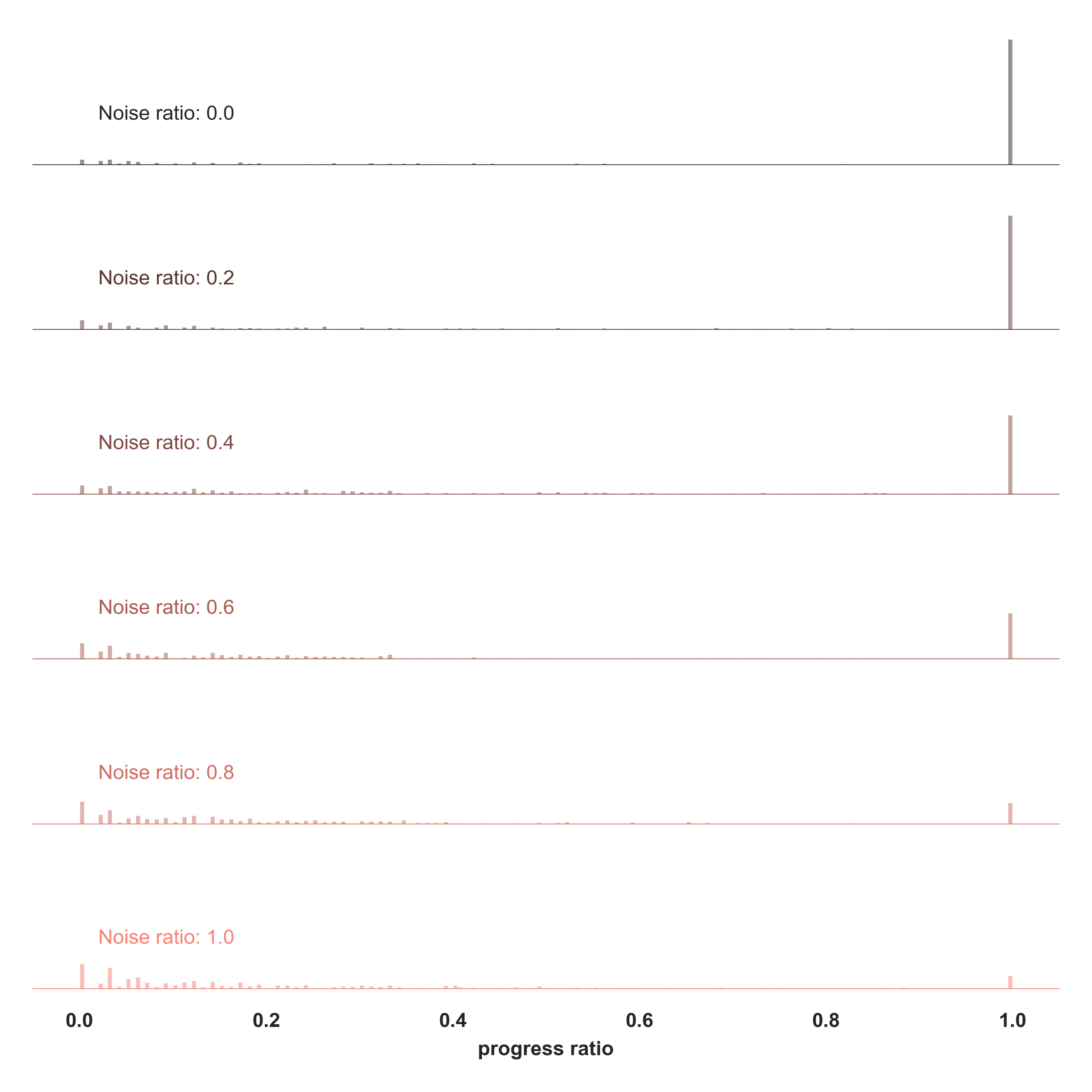
### Visual Description
## Line Chart: Noise Ratio vs. Progress Ratio
### Overview
The image presents a line chart illustrating the relationship between "progress ratio" (x-axis) and "noise ratio" (represented by separate lines). The chart displays six lines, each corresponding to a different noise ratio value, ranging from 0.0 to 1.0. Each line shows a relatively flat distribution until the progress ratio reaches approximately 1.0, where a sharp vertical increase is observed.
### Components/Axes
* **X-axis:** "progress ratio", ranging from 0.0 to 1.0, with markers at 0.2, 0.4, 0.6, and 0.8.
* **Y-axis:** Not explicitly labeled, but represents the value being measured. The scale is not provided.
* **Lines:** Six lines, each representing a different "noise ratio".
* Noise ratio: 0.0 (Black)
* Noise ratio: 0.2 (Dark Gray)
* Noise ratio: 0.4 (Gray)
* Noise ratio: 0.6 (Light Gray)
* Noise ratio: 0.8 (Reddish-Orange)
* Noise ratio: 1.0 (Orange)
* **Labels:** Each line is labeled with its corresponding "noise ratio" value, positioned to the left of the chart.
### Detailed Analysis
Each line exhibits a similar pattern: a nearly flat horizontal line for progress ratios less than 1.0, followed by a near-vertical increase at a progress ratio of approximately 1.0.
* **Noise ratio: 0.0 (Black):** The line remains close to zero until progress ratio = 1.0, then increases sharply. Approximate value at progress ratio 1.0 is 2.0.
* **Noise ratio: 0.2 (Dark Gray):** The line remains close to zero until progress ratio = 1.0, then increases sharply. Approximate value at progress ratio 1.0 is 2.5.
* **Noise ratio: 0.4 (Gray):** The line remains close to zero until progress ratio = 1.0, then increases sharply. Approximate value at progress ratio 1.0 is 3.0.
* **Noise ratio: 0.6 (Light Gray):** The line remains close to zero until progress ratio = 1.0, then increases sharply. Approximate value at progress ratio 1.0 is 3.5.
* **Noise ratio: 0.8 (Reddish-Orange):** The line remains close to zero until progress ratio = 1.0, then increases sharply. Approximate value at progress ratio 1.0 is 4.0.
* **Noise ratio: 1.0 (Orange):** The line remains close to zero until progress ratio = 1.0, then increases sharply. Approximate value at progress ratio 1.0 is 4.5.
The increase at progress ratio = 1.0 appears to be linear with respect to the noise ratio.
### Key Observations
* The lines are nearly flat for progress ratios less than 1.0, indicating a minimal change in the measured value.
* There is a consistent, sharp increase in the measured value at a progress ratio of approximately 1.0 for all noise ratios.
* The magnitude of the increase at progress ratio = 1.0 is directly proportional to the noise ratio. Higher noise ratios result in larger increases.
* The lines are spaced evenly vertically, suggesting a linear relationship between noise ratio and the magnitude of the increase.
### Interpretation
The chart likely represents a system where a process is progressing (indicated by the "progress ratio"). The "noise ratio" represents some form of interference or error. The data suggests that the system remains stable (low measured value) until the process reaches completion (progress ratio = 1.0). At completion, the impact of the noise becomes apparent, causing a sharp increase in the measured value. The higher the noise ratio, the greater the impact at completion.
This could be interpreted in several ways:
* **Error Accumulation:** The system accumulates errors (noise) during the process, but these errors only manifest significantly upon completion.
* **Threshold Effect:** The system has a threshold (progress ratio = 1.0) beyond which noise begins to have a substantial effect.
* **Sensitivity Analysis:** The chart demonstrates the sensitivity of the system to noise at the point of completion.
The linear relationship between noise ratio and the magnitude of the increase suggests that the noise has a predictable and proportional impact on the system's outcome. The lack of a y-axis label makes it difficult to determine the exact units of measurement, but the overall trend is clear.
</details>
Figure 11: Impact of increasing noise ratio on the distribution of failure steps for Gemini 2.5 Flash. As noise (proportion of distracting facts) increases, failures tend to occur earlier in the reasoning chain. This reflects increased difficulty in isolating relevant information and maintaining focus. Fixed experimental parameters in this figure are the same as those in Figure 1.
## Appendix C Supplementary Figures
This appendix provides supplementary figures that offer further visual support for analyses presented in the main paper. These figures illustrate the impact of various complexity dimensions and provide comparative views of model performance, elaborating on points made throughout Section 2 (Benchmarking Results) of the main paper.
Figure 12 details the performance of Llama-4 Maverick-17B-128E-Instruct under varying levels of noise and fact shuffling. This supports the discussion in the main paper (Section 2.3, on how these factors, especially in combination, affect success rates, with noise being a dominant factor.
<details>
<summary>figs/single_model_vs_steps_count_varied_noise_shuffle_Llama-4-Maverick-17B-128E-Instruct-FP8.png Details</summary>
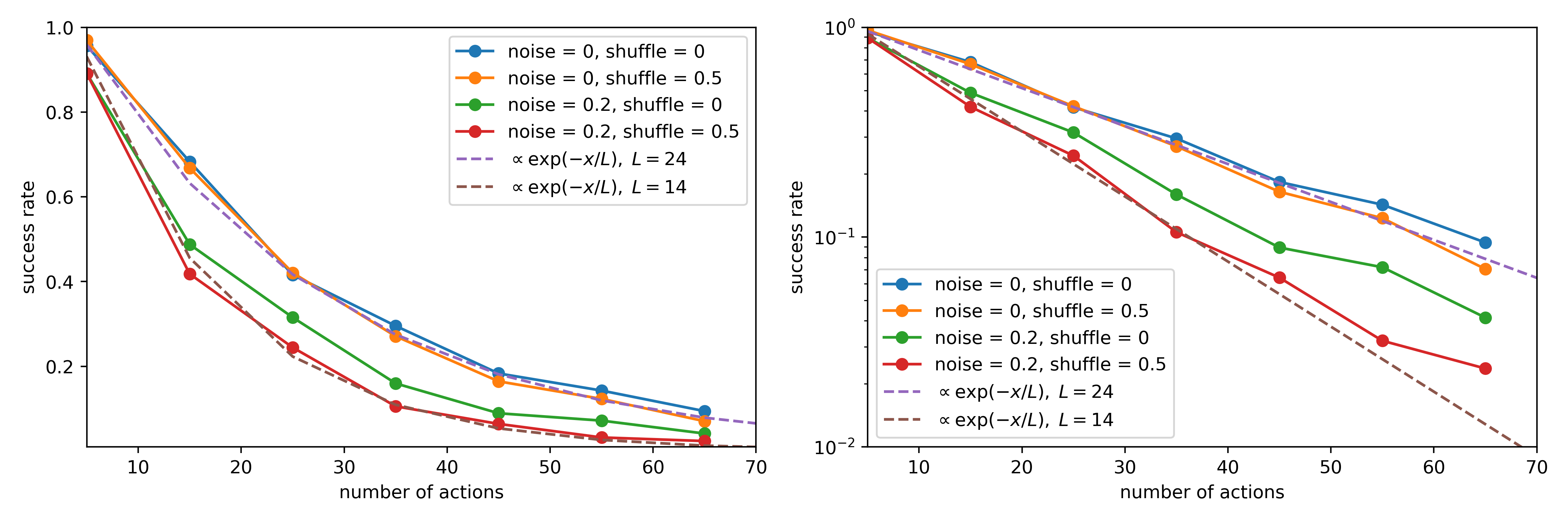
### Visual Description
\n
## Chart: Success Rate vs. Number of Actions
### Overview
The image presents two line charts comparing the success rate of an algorithm or process under varying conditions of noise and shuffle, plotted against the number of actions taken. The right chart uses a logarithmic y-axis to better visualize the data. Both charts display the same data, but with different y-axis scales.
### Components/Axes
* **X-axis (both charts):** "number of actions", ranging from approximately 8 to 70, with markers at 10, 20, 30, 40, 50, 60, and 70.
* **Y-axis (left chart):** "success rate", ranging from 0.0 to 1.0, with markers at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Y-axis (right chart):** "success rate", logarithmic scale from 10<sup>-2</sup> to 10<sup>0</sup> (0.01 to 1.0).
* **Legend (top-right of both charts):**
* Blue Line: "noise = 0, shuffle = 0"
* Orange Line: "noise = 0, shuffle = 0.5"
* Green Line: "noise = 0.2, shuffle = 0"
* Red Line: "noise = 0.2, shuffle = 0.5"
* Purple Dashed Line: "α exp(-x/L), L = 24"
* Gray Dashed Line: "α exp(-x/L), L = 14"
### Detailed Analysis or Content Details
**Left Chart (Linear Scale):**
* **Blue Line ("noise = 0, shuffle = 0"):** Starts at approximately 0.95 at x=8, decreases slowly to approximately 0.15 at x=70.
* **Orange Line ("noise = 0, shuffle = 0.5"):** Starts at approximately 0.9 at x=8, decreases more rapidly than the blue line, reaching approximately 0.08 at x=70.
* **Green Line ("noise = 0.2, shuffle = 0"):** Starts at approximately 0.75 at x=8, decreases steadily to approximately 0.12 at x=70.
* **Red Line ("noise = 0.2, shuffle = 0.5"):** Starts at approximately 0.7 at x=8, decreases very rapidly, reaching approximately 0.05 at x=70.
* **Purple Dashed Line ("α exp(-x/L), L = 24"):** Starts at approximately 0.9 at x=8, decreases steadily to approximately 0.1 at x=70.
* **Gray Dashed Line ("α exp(-x/L), L = 14"):** Starts at approximately 0.9 at x=8, decreases more rapidly than the purple line, reaching approximately 0.08 at x=70.
**Right Chart (Logarithmic Scale):**
The trends are identical to the left chart, but the logarithmic scale emphasizes the rate of decline. The lines appear more linear on this scale.
### Key Observations
* Increasing noise and shuffle consistently decreases the success rate.
* The combination of noise = 0.2 and shuffle = 0.5 results in the most rapid decline in success rate.
* The dashed lines represent theoretical curves with different decay rates (L=24 and L=14). The gray dashed line (L=14) decays faster.
* The success rate decreases as the number of actions increases for all conditions.
* The logarithmic scale on the right chart reveals that the decay in success rate is approximately exponential.
### Interpretation
The data suggests that the algorithm's performance is sensitive to both noise and shuffle. The success rate decreases as the number of actions increases, indicating a potential limitation in the algorithm's ability to maintain accuracy over extended sequences. The theoretical curves (dashed lines) provide a benchmark for the expected decay rate, and the experimental data generally follows this trend. The most significant performance degradation occurs when both noise and shuffle are present, highlighting the importance of addressing these factors to improve the algorithm's robustness. The logarithmic scale provides a clearer visualization of the exponential decay, suggesting that the algorithm's performance diminishes rapidly with increasing actions under noisy and shuffled conditions. The parameter 'L' in the exponential function likely represents a characteristic length or scale over which the success rate decays. A smaller 'L' value indicates a faster decay.
</details>
Figure 12: Pass@1 success rate for Llama-4 Maverick-17B-128E-Instruct versus solution length ( $L$ ) under different noise and shuffle ratios. Left: Linear scale. Right: Log-linear scale. Performance degrades with increased noise but is less affected by shuffle ratios. Fixed experimental parameters in this figure are the same as those in Figure 1.
To illustrate the performance consistency and disparities across different models, as detailed in Section 2.6, Figure 13 presents scatter and density plots of mean progress ratios. These plots clearly demonstrate that model performance hierarchies are not strictly linear. They reveal ’performance inversions’—instances, also noted in Section 2.6, where models with typically lower overall performance (e.g., lower average $L_{0}$ ) occasionally solve specific complex problems that models with higher average $L_{0}$ values fail on.
<details>
<summary>figs/progress_vs_progress.png Details</summary>
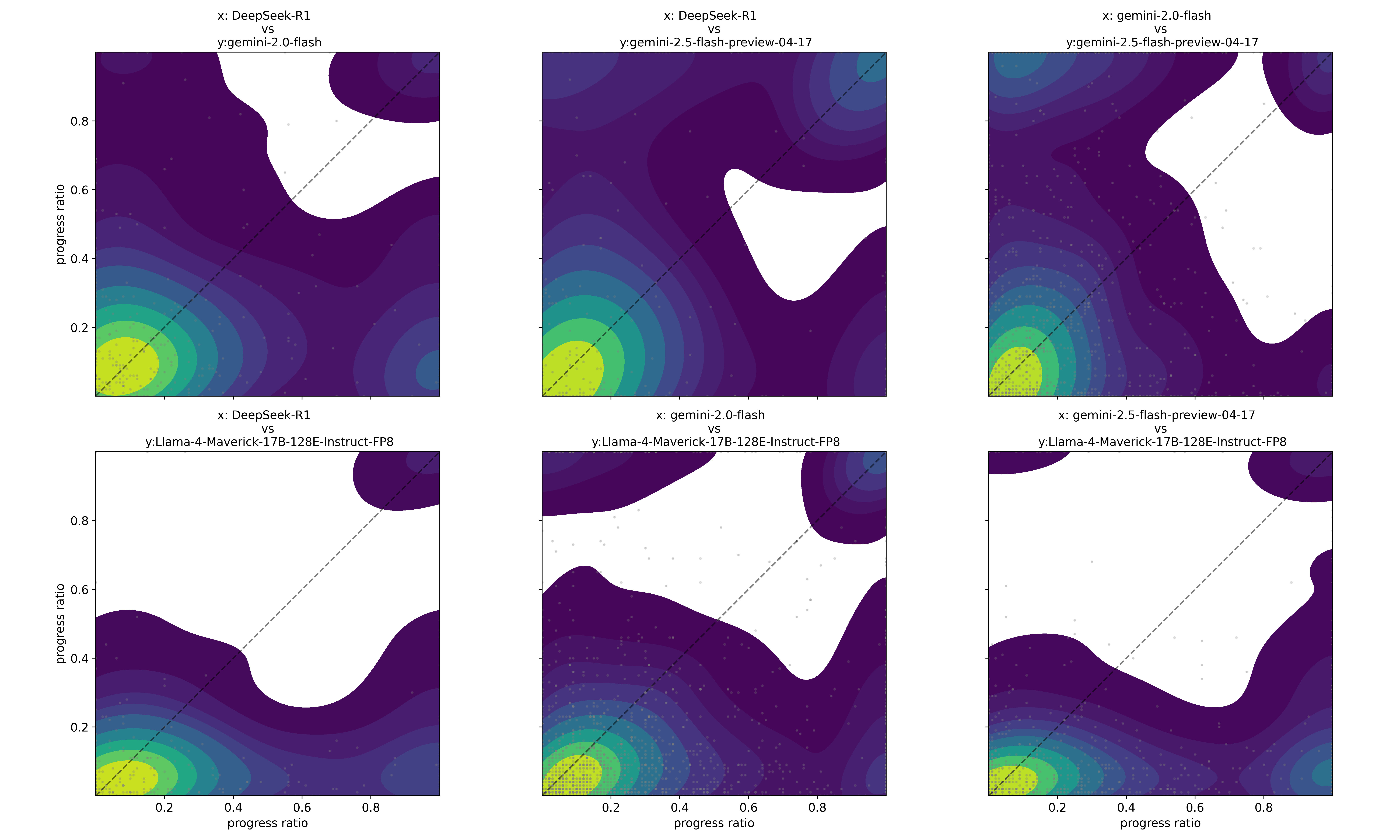
### Visual Description
\n
## Heatmaps: Model Comparison - Progress Ratio vs. Progress Ratio
### Overview
The image presents a 3x3 grid of heatmaps, each comparing two different models based on their "progress ratio" values. The heatmaps visualize the relationship between the progress ratio of one model (x-axis) and the progress ratio of another (y-axis). The color intensity represents the frequency or density of occurrences for specific combinations of progress ratios. Each heatmap has a dashed diagonal line.
### Components/Axes
Each heatmap shares the following components:
* **X-axis Label:** "progress ratio" (ranging from approximately 0.2 to 0.8)
* **Y-axis Label:** "progress ratio" (ranging from approximately 0.2 to 0.8)
* **Color Scale:** A gradient from dark purple (low density) to yellow/light green (high density).
* **Diagonal Line:** A dashed line running from the bottom-left to the top-right corner of each heatmap.
The specific model comparisons are as follows:
1. Top-Left: x: DeepSeek-R1 vs y: gemini-2.0-flash
2. Top-Center: x: DeepSeek-R1 vs y: gemini-2.5-flash-preview-04-17
3. Top-Right: x: gemini-2.0-flash vs y: gemini-2.5-flash-preview-04-17
4. Bottom-Left: x: DeepSeek-R1 vs y: Llama-4-Maverick-17B-128E-Instruct-FP8
5. Bottom-Center: x: gemini-2.0-flash vs y: Llama-4-Maverick-17B-128E-Instruct-FP8
6. Bottom-Right: x: gemini-2.5-flash-preview-04-17 vs y: Llama-4-Maverick-17B-128E-Instruct-FP8
### Detailed Analysis or Content Details
Each heatmap shows a concentration of data points along the diagonal line, indicating a positive correlation between the progress ratios of the two models being compared. The density of points varies across the heatmaps.
**1. DeepSeek-R1 vs gemini-2.0-flash:**
* The highest density (yellow/light green) is concentrated around the diagonal where both progress ratios are approximately 0.4.
* Density decreases as progress ratios move away from 0.4 in either direction.
**2. DeepSeek-R1 vs gemini-2.5-flash-preview-04-17:**
* Highest density is around the diagonal where both progress ratios are approximately 0.5.
* A secondary concentration appears at lower progress ratios (around 0.2-0.3).
**3. gemini-2.0-flash vs gemini-2.5-flash-preview-04-17:**
* Highest density is around the diagonal where both progress ratios are approximately 0.5.
* The density is more spread out compared to the previous two heatmaps.
**4. DeepSeek-R1 vs Llama-4-Maverick-17B-128E-Instruct-FP8:**
* Highest density is around the diagonal where both progress ratios are approximately 0.4.
* A noticeable concentration exists at lower progress ratios for DeepSeek-R1 (around 0.2) and higher progress ratios for Llama (around 0.6-0.7).
**5. gemini-2.0-flash vs Llama-4-Maverick-17B-128E-Instruct-FP8:**
* Highest density is around the diagonal where both progress ratios are approximately 0.4.
* A secondary concentration appears at lower progress ratios for gemini-2.0-flash (around 0.2) and higher progress ratios for Llama (around 0.6-0.7).
**6. gemini-2.5-flash-preview-04-17 vs Llama-4-Maverick-17B-128E-Instruct-FP8:**
* Highest density is around the diagonal where both progress ratios are approximately 0.5.
* A secondary concentration exists at lower progress ratios for gemini-2.5-flash-preview-04-17 (around 0.2-0.3) and higher progress ratios for Llama (around 0.6-0.7).
### Key Observations
* All heatmaps exhibit a strong positive correlation along the diagonal, suggesting that when one model has a higher progress ratio, the other model tends to have a higher progress ratio as well.
* The concentration of data points varies between model pairs, indicating different relationships between their progress ratios.
* The secondary concentrations observed in some heatmaps suggest that certain models may exhibit different progress patterns.
* The diagonal line serves as a reference point for perfect correlation. Deviations from the diagonal indicate discrepancies in progress ratios between the models.
### Interpretation
These heatmaps provide a visual comparison of the progress ratios of different language models. The progress ratio itself is not defined in the image, but it likely represents a metric of task completion or performance. The concentration of data points along the diagonal suggests that the models generally perform similarly – if one model makes progress, the other does too. However, the variations in density and the presence of secondary concentrations indicate that the models have different strengths and weaknesses.
The secondary concentrations suggest that certain models might excel in specific scenarios or tasks where the other model struggles. For example, the concentration at lower progress ratios for DeepSeek-R1 and higher progress ratios for Llama-4-Maverick in the fourth heatmap suggests that Llama-4-Maverick might perform better on tasks where DeepSeek-R1 is less effective, and vice versa.
The comparison between different versions of the Gemini model (2.0-flash vs. 2.5-flash-preview-04-17) shows a slight shift in the distribution, potentially indicating improvements in the newer version. The newer version appears to have a slightly higher density at higher progress ratios.
Without knowing the specific definition of "progress ratio" and the tasks the models were evaluated on, it's difficult to draw definitive conclusions. However, these heatmaps provide valuable insights into the relative performance and behavior of these language models.
</details>
Figure 13: Scatter and density plots of progress ratios per task instance, comparing model pairs on the tasks. These plots illustrate performance agreement and disparities on the same instances of pathfinding tasks. Notably, Gemini-2.5-Flash (example) often succeeds on instances where other models achieve near-zero progress. Data from experiments in Figure 1 (main paper).
Figure 14 isolates the impact of shuffle ratio on model performance when other factors like noise are controlled. This visualization corresponds to the findings discussed in the main paper (Section 2.3, "Fact Ordering (Shuffle Ratio)") that simple reordering of facts has a minimal impact on the performance of the evaluated models under low-noise conditions.
Figure 15 isolates the impact of adding more examples in the instruction prompt, showing a clear improvement once more than a single example is included compared to using none or only one.
Figure 16 is added in this revised version of the supplementary section to reflect that even the most recent SOTA models released by OpenAI suffer from the same performance drop observed in the main paper.
<details>
<summary>figs/fig_vs_shuffle_fixed_L_keys2_noise0.2.png Details</summary>
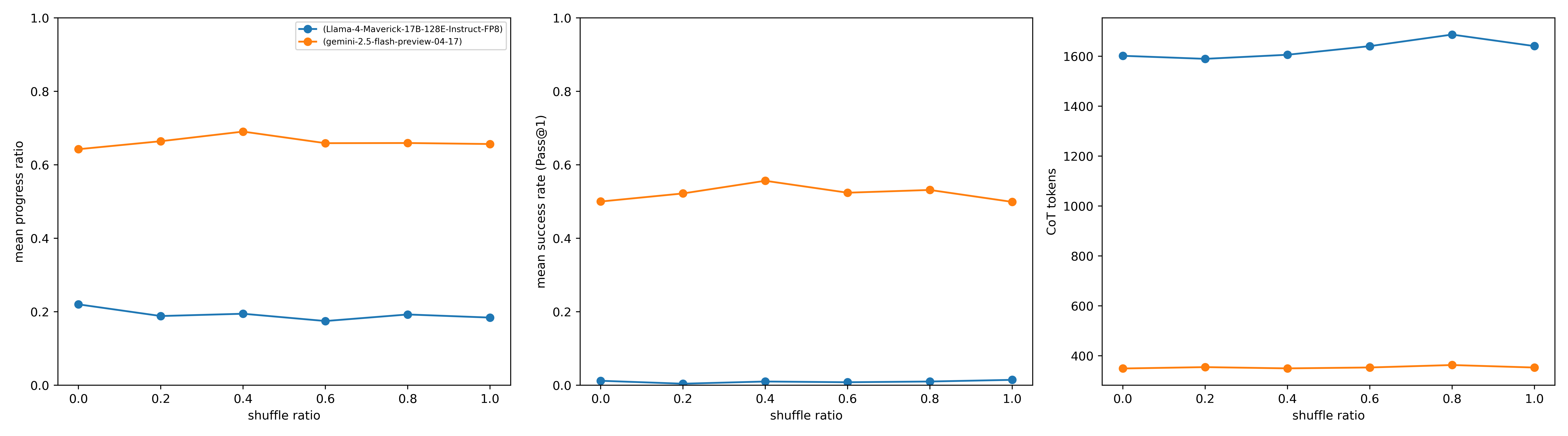
### Visual Description
\n
## Charts: Performance Metrics vs. Shuffle Ratio
### Overview
The image presents three line charts comparing the performance of two models, "llama-4-Maverick-17B-128k-instruct-FP8" and "gemini-2.5-flash-preview-04-17", across varying shuffle ratios. The charts display mean progress ratio, mean success rate (Pass@1), and Chain-of-Thought (CoT) token counts. The x-axis for all charts represents the "shuffle ratio", ranging from 0.0 to 1.0.
### Components/Axes
* **X-axis (all charts):** Shuffle Ratio (0.0 to 1.0)
* **Chart 1:**
* Y-axis: Mean Progress Ratio (0.0 to 1.0)
* Line 1 (Blue): llama-4-Maverick-17B-128k-instruct-FP8
* Line 2 (Orange): gemini-2.5-flash-preview-04-17
* **Chart 2:**
* Y-axis: Mean Success Rate (Pass@1) (0.0 to 0.8)
* Line 1 (Blue): llama-4-Maverick-17B-128k-instruct-FP8
* Line 2 (Orange): gemini-2.5-flash-preview-04-17
* **Chart 3:**
* Y-axis: CoT Tokens (approximately 0 to 1700)
* Line 1 (Blue): llama-4-Maverick-17B-128k-instruct-FP8
* Line 2 (Orange): gemini-2.5-flash-preview-04-17
* **Legend:** Located at the top-right of each chart, identifying the models by color.
### Detailed Analysis
**Chart 1: Mean Progress Ratio**
The blue line (llama-4-Maverick) starts at approximately 0.18 at a shuffle ratio of 0.0, dips to around 0.15 at 0.2, rises to approximately 0.22 at 0.4, then declines to around 0.18 at 0.6, and finally stabilizes around 0.17 at 1.0. The orange line (gemini-2.5) begins at approximately 0.65 at 0.0, decreases to around 0.60 at 0.2, remains relatively stable between 0.60 and 0.68 from 0.4 to 0.8, and then slightly decreases to approximately 0.65 at 1.0.
**Chart 2: Mean Success Rate (Pass@1)**
The blue line (llama-4-Maverick) remains consistently low, fluctuating around 0.02 across all shuffle ratios. The orange line (gemini-2.5) starts at approximately 0.48 at 0.0, increases to a peak of around 0.58 at 0.4, then decreases to approximately 0.52 at 1.0.
**Chart 3: CoT Tokens**
The blue line (llama-4-Maverick) starts at approximately 1620 at 0.0, decreases to around 1580 at 0.2, remains relatively stable between 1570 and 1600 from 0.4 to 0.8, and then slightly increases to approximately 1610 at 1.0. The orange line (gemini-2.5) begins at approximately 380 at 0.0, decreases to around 350 at 0.2, remains relatively stable between 340 and 370 from 0.4 to 0.8, and then slightly increases to approximately 360 at 1.0.
### Key Observations
* Gemini-2.5 consistently outperforms Llama-4-Maverick in both mean progress ratio and mean success rate.
* Llama-4-Maverick uses significantly more CoT tokens than Gemini-2.5 across all shuffle ratios.
* The shuffle ratio appears to have a limited impact on the performance of both models, with relatively small fluctuations observed across the range of 0.0 to 1.0.
* The success rate for Llama-4-Maverick is very low and remains constant.
### Interpretation
These charts suggest that Gemini-2.5 is a more efficient and effective model than Llama-4-Maverick for the tasks being evaluated. Gemini-2.5 achieves higher progress and success rates while utilizing significantly fewer CoT tokens, indicating a more streamlined reasoning process. The relatively stable performance across different shuffle ratios suggests that the models are not highly sensitive to the order of input data. The consistently low success rate of Llama-4-Maverick raises concerns about its reliability for these tasks. The higher CoT token usage by Llama-4-Maverick could indicate a more verbose or less focused reasoning process, potentially contributing to its lower success rate. The data suggests that shuffling the input data does not significantly alter the performance of either model, implying that the models are relatively robust to input order.
</details>
Figure 14: Impact of shuffle ratio on Pass@1 success rate. Varying the degree of mixing (shuffle) between supporting and distracting facts shows minimal impact on performance for Gemini 2.5 Flash and Llama-4 Maverick, suggesting robustness to fact order when noise is controlled. The generation and sampling of maze instances for these tasks follow the same methodology detailed for experiments in the main paper (Figures 3 and 4).
<details>
<summary>figs/maze_ablation_analysis.png Details</summary>
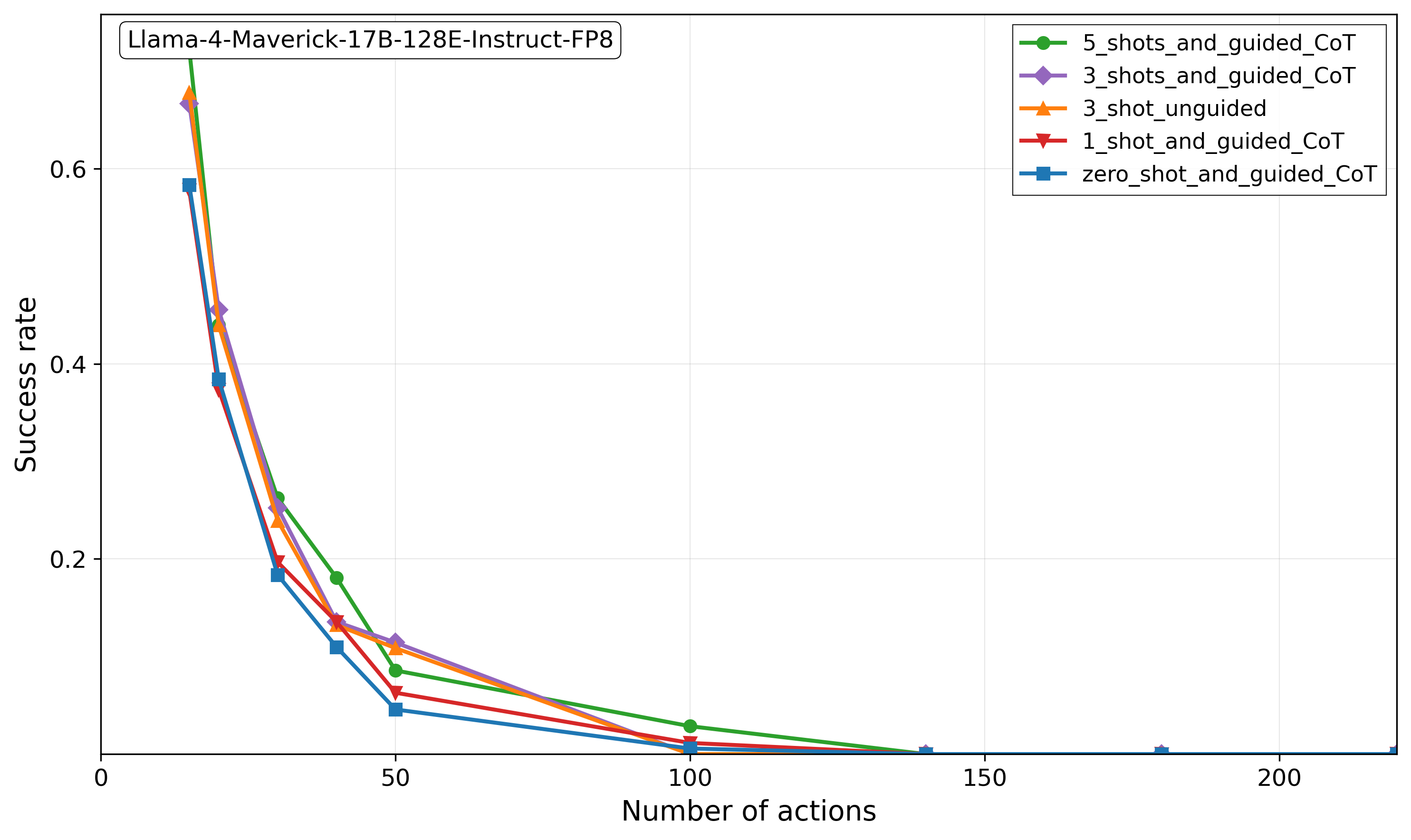
### Visual Description
## Line Chart: Success Rate vs. Number of Actions
### Overview
This line chart depicts the relationship between the number of actions taken and the success rate for different prompting strategies used with the Llama-4-Maverick-17B-128E-Instruct-FP8 model. Five different prompting strategies are compared. The chart shows how success rate declines as the number of actions increases, with varying rates of decline for each strategy.
### Components/Axes
* **Title:** Llama-4-Maverick-17B-128E-Instruct-FP8 (located in the top-left corner)
* **X-axis:** Number of actions (ranging from 0 to approximately 200).
* **Y-axis:** Success rate (ranging from 0 to approximately 0.7).
* **Legend:** Located in the top-right corner, listing the following prompting strategies with corresponding colors:
* 5\_shots\_and\_guided\_CoT (Green)
* 3\_shots\_and\_guided\_CoT (Orange)
* 3\_shot\_unguided (Red)
* 1\_shot\_and\_guided\_CoT (Brown)
* zero\_shot\_and\_guided\_CoT (Blue)
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points, verified against the legend colors:
* **5\_shots\_and\_guided\_CoT (Green):** The line starts at approximately 0.18 at 0 actions, decreases slowly to around 0.10 at 50 actions, and plateaus around 0.08-0.10 for actions greater than 50.
* **3\_shots\_and\_guided\_CoT (Orange):** The line begins at approximately 0.22 at 0 actions, decreases more rapidly than the green line, reaching around 0.12 at 50 actions, and then levels off around 0.10-0.12 for actions greater than 50.
* **3\_shot\_unguided (Red):** This line shows the most rapid initial decline. It starts at approximately 0.65 at 0 actions, drops to around 0.08 at 50 actions, and continues to decrease slightly to around 0.06 at 200 actions.
* **1\_shot\_and\_guided\_CoT (Brown):** The line starts at approximately 0.25 at 0 actions, decreases to around 0.13 at 50 actions, and then plateaus around 0.10-0.12 for actions greater than 50.
* **zero\_shot\_and\_guided\_CoT (Blue):** This line also shows a rapid initial decline. It begins at approximately 0.58 at 0 actions, drops to around 0.08 at 50 actions, and continues to decrease slightly to around 0.06 at 200 actions.
### Key Observations
* The "3\_shot\_unguided" and "zero\_shot\_and\_guided\_CoT" strategies exhibit the steepest declines in success rate as the number of actions increases.
* The "5\_shots\_and\_guided\_CoT" strategy maintains the highest success rate, though it is still affected by the increasing number of actions.
* The "3\_shots\_and\_guided\_CoT" and "1\_shot\_and\_guided\_CoT" strategies show similar performance, with a moderate decline in success rate.
* All strategies converge to a similar success rate (around 0.06-0.12) as the number of actions increases beyond 50.
### Interpretation
The data suggests that the choice of prompting strategy significantly impacts the success rate, particularly as the complexity of the task (measured by the number of actions) increases. The "unguided" approach appears to be more sensitive to task complexity, experiencing a more dramatic drop in success rate. Guided Chain-of-Thought (CoT) prompting generally improves performance, and increasing the number of shots (examples) further enhances success, though the gains diminish with more actions. The convergence of all lines at higher action counts indicates a fundamental limit to performance regardless of the prompting strategy, potentially due to inherent limitations in the model's reasoning capabilities or the task itself. The initial high success rates for the "unguided" strategies suggest they may be effective for simpler tasks, but quickly become unreliable as the task becomes more complex. The chart provides valuable insights for optimizing prompting strategies for the Llama-4-Maverick-17B-128E-Instruct-FP8 model, highlighting the importance of guided reasoning and sufficient examples for complex tasks.
</details>
Figure 15: The impact of including different number of reference examples in the prompt as part of in-context learning. Increasing the number of examples leads to slight improvements in performance. The experimental parameters used here are the same as ones in Figure 1.
<details>
<summary>figs/model_comparison_openai.png Details</summary>
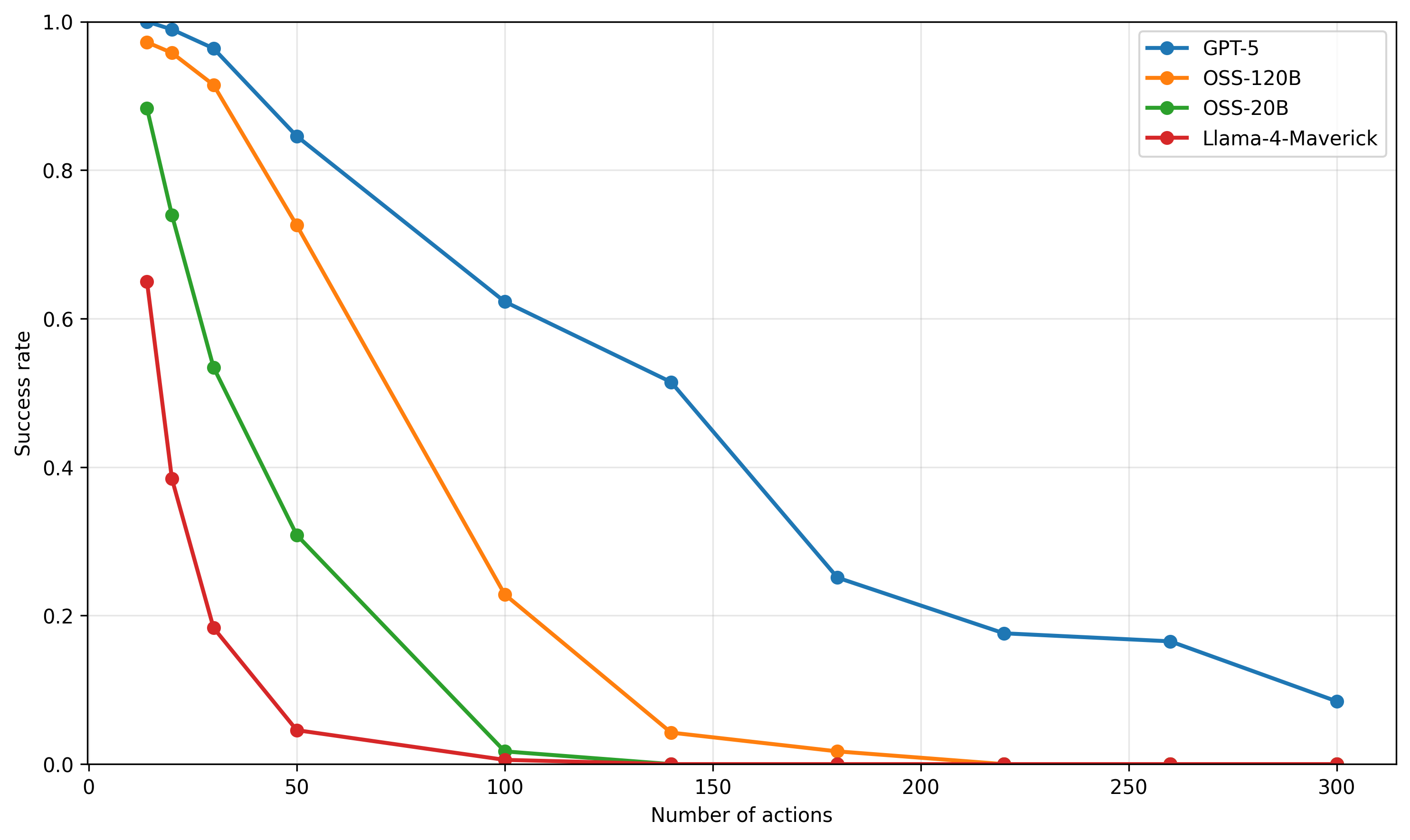
### Visual Description
## Line Chart: Success Rate vs. Number of Actions
### Overview
This line chart depicts the success rate of four different models (GPT-5, OSS-120B, OSS-20B, and Llama-4-Maverick) as a function of the number of actions taken. The success rate is plotted on the y-axis, ranging from 0 to 1.0, while the number of actions is plotted on the x-axis, ranging from 0 to 300. The chart illustrates how the performance of each model degrades as the number of actions increases.
### Components/Axes
* **X-axis Title:** "Number of actions"
* **Y-axis Title:** "Success rate"
* **Legend:** Located in the top-right corner of the chart.
* **GPT-5:** Blue line with circle markers.
* **OSS-120B:** Orange line with circle markers.
* **OSS-20B:** Teal line with circle markers.
* **Llama-4-Maverick:** Red line with circle markers.
* **Gridlines:** Present to aid in reading values.
* **Data Range (X-axis):** 0 to 300
* **Data Range (Y-axis):** 0 to 1.0
### Detailed Analysis
Here's a breakdown of each model's performance, with approximate values extracted from the chart:
* **GPT-5 (Blue):** The line starts at approximately 0.98 at 0 actions. It slopes downward, relatively slowly.
* At 50 actions: ~0.85
* At 100 actions: ~0.70
* At 150 actions: ~0.55
* At 200 actions: ~0.35
* At 250 actions: ~0.20
* At 300 actions: ~0.10
* **OSS-120B (Orange):** The line begins at approximately 0.80 at 0 actions and declines rapidly.
* At 50 actions: ~0.30
* At 100 actions: ~0.10
* At 150 actions: ~0.02
* From 150 to 300 actions: Remains very close to 0.
* **OSS-20B (Teal):** Starts at approximately 0.95 at 0 actions and declines at a moderate rate.
* At 50 actions: ~0.75
* At 100 actions: ~0.60
* At 150 actions: ~0.45
* At 200 actions: ~0.30
* At 250 actions: ~0.20
* At 300 actions: ~0.10
* **Llama-4-Maverick (Red):** Starts at approximately 0.40 at 0 actions and declines very rapidly.
* At 50 actions: ~0.05
* At 100 actions: ~0.01
* From 100 to 300 actions: Remains very close to 0.
### Key Observations
* GPT-5 exhibits the highest success rate across all action counts, demonstrating the most robust performance.
* Llama-4-Maverick has the lowest success rate, and its performance degrades extremely quickly with increasing actions.
* OSS-120B and OSS-20B show a similar trend of rapid decline, but OSS-20B maintains a slightly higher success rate than OSS-120B.
* All models experience a decrease in success rate as the number of actions increases, indicating a challenge in maintaining performance with complex tasks.
### Interpretation
The chart demonstrates the scalability and robustness of different language models in performing sequential tasks. The success rate is used as a metric to evaluate the model's ability to achieve a desired outcome after a series of actions. GPT-5 clearly outperforms the other models, suggesting it is better equipped to handle complex, multi-step processes. The rapid decline in performance for OSS-120B, OSS-20B, and especially Llama-4-Maverick indicates that these models struggle with tasks requiring a large number of coordinated actions. This could be due to limitations in their ability to maintain context, reason about long-term dependencies, or avoid accumulating errors over multiple steps. The data suggests that model size and architecture play a significant role in the ability to perform complex tasks effectively. The chart highlights the importance of considering the number of actions required for a task when selecting a language model.
</details>
Figure 16: This figure is added to reflect that the recent closed (GPT-5) and open sourced models (OSS-20B/120B) released by OpenAI also follow the same universal failure patterns highlighted in this paper. The data used here as well as experimental settings is the same as the one used in Figure 1 of the main paper. We include Llama-4-Maverick which is also used in Figure 1 as the benchmark reference.