# Kimi-Dev: Agentless Training as Skill Prior for SWE-Agents
> Indicates equal contribution.†Joint leads.
Abstract
Large Language Models (LLMs) are increasingly applied to software engineering (SWE), with SWE-bench as a key benchmark. Solutions are split into SWE-Agent frameworks with multi-turn interactions and workflow-based Agentless methods with single-turn verifiable steps. We argue these paradigms are not mutually exclusive: reasoning-intensive Agentless training induces skill priors, including localization, code edit, and self-reflection that enable efficient and effective SWE-Agent adaptation. In this work, we first curate the Agentless training recipe and present Kimi-Dev, an open-source SWE LLM achieving 60.4% on SWE-bench Verified, the best among workflow approaches. With additional SFT adaptation on 5k publicly-available trajectories, Kimi-Dev powers SWE-Agents to 48.6% pass@1, on par with that of Claude 3.5 Sonnet (241022 version). These results show that structured skill priors from Agentless training can bridge workflow and agentic frameworks for transferable coding agents.
1 Introduction
Recent days have witnessed the rapid development of Large Language Models (LLMs) automating Software-Engineering (SWE) tasks (jimenez2023swe; yang2024swe; xia2024agentless; anthropic_claude_3.5_sonnet_20241022; pan2024training; wang2024openhands; wei2025swe; yang2025qwen3; team2025kimi_k2; openai_gpt5_system_card_2025). Among the benchmarks that track the progress of LLM coding agents in SWE scenarios, SWE-bench (jimenez2023swe) stands out as one of the most representative ones: Given an issue that reports a bug in a real-world GitHub repository, a model is required to produce a patch that fixes the bug, the correctness of which is further judged by whether the corresponding unit tests are passed after its application. The difficulty of the task (as of the date the benchmark was proposed), the existence of the outcome reward with the provided auto-eval harness, as well as the real-world economic value it reflects, have made the SWE-bench a focal point of the field.
Two lines of solutions have emerged for the SWE-bench task. Agent-based solutions like SWE-Agent (yang2024swe) and OpenHands (wang2024openhands) take an interactionist approach: Instructed with the necessary task description, a predefined set of available tools, as well as the specific problem statement, the agent is required to interact with an executable environment for multiple turns, make change to the source codes, and determine when to stop autonomously. In contrast, workflow-based solutions like Agentless (xia2024agentless) pre-define the solving progress as a pipeline, which consists of steps like localization, bug repair, and test composition. Such task decomposition transforms the agentic task into generating correct responses for a chain of single-turn problems with verifiable rewards (guo2025deepseek; wei2025swe; SWESwiss2025).
The two paradigms have been widely viewed as mutually exclusive. On the one hand, SWE-Agents are born with higher potential and better adaptability, thanks to the higher degree of freedom of the multi-turn interaction without the fixed routines. However, it has also proved more difficult to train with such frameworks due to their end-to-end nature (deepswe2025; cao2025skyrl). On the other hand, Agentless methods offer better modularity and the ease to train with Reinforcement Learning with Verifiable Rewards (RLVR) techniques, but more limited exploration space and flexibility, and difficulty in behavior monitoring as the erroneous patterns appear only in the single-turn long reasoning contents (pan2024training). However, we challenge the dichotomy from the perspective of training recipe: We argue that Agentless training should not be viewed as the ultimate deliverable, but rather as a way to induce skill priors – atomic capabilities such as the localization of buggy implementations and the update of erroneous code snippets, as well as self-reflection and verification, all of which help scaffold the efficient adaptation of more capable and generalizable SWE-agents.
Guided by this perspective, we introduce Kimi-Dev, an open-source code LLM for SWE tasks. Specifically, we first develop an Agentless training recipe, which includes mid-training, cold-start, reinforcement learning, and test-time self-play. This results in 60.4% accuracy on SWE-bench Verified, the SoTA performance among the workflow-based solutions. Building on this, we show that Agentless training induces skill priors: a minimal SFT cold-start from Kimi-Dev with 5k publicly-available trajectories enables efficient SWE-agent adaptation and reaches 48.6% pass@1 score, similar to that of Claude 3.5 Sonnet (the 20241022 version, anthropic_claude_3.5_sonnet_20241022). We demonstrate that these induced skills transfer from the non-agentic workflows to the agentic frameworks, and the self-reflection in long Chain-of-Thoughts baked through Agentless training further enable the agentic model to leverage more turns and succeed with a longer horizon. Finally, we also show that the skills from Agentless training generalize beyond SWE-bench Verified to broader benchmarks like SWE-bench-live (zhang2025swe) and SWE-bench Multilingual (yang2025swesmith). Together, these results reframe the relationship between Agentless and agentic frameworks: not mutually exclusive, but as complementary stages in building transferable coding LLMs. This shift offers a principled view that training with structural skill priors could scaffold autonomous agentic interaction.
The remainder of this paper is organized as follows. Section 2 reviews the background of the framework dichotomy and outlines the challenges of training SWE-Agents. Section 3 presents our Agentless training recipe and the experimental results. Section 4 demonstrates how these Agentless-induced skill priors enable efficient SWE-Agent adaptation, and evaluates the skill transfer and generalization beyond SWE-bench Verified.
2 Background
In this section, we first review the two dominant frameworks for SWE tasks and their dichotomy in Section 2.1. We then summarize the progress and challenges of training SWE-Agents in Section 2.2. The background introduction sets the stage for reinterpreting Agentless training as skill priors for SWE-Agents, a central theme developed throughout the later sections.
2.1 Framework Dichotomy
Two paradigms currently dominate the solutions for automating software engineering tasks. Agentless approaches decompose SWE tasks into modular workflows (xia2024agentless; wei2025swe; ma2024lingma; ma2025alibaba; swe-fixer). Typical workflows consist of bug localization, bug repair, and test generation. This design provides modularity and stability: each step could be optimized separately as a single-turn problem with verifiable rewards (wei2025swe; SWESwiss2025). However, such rigidity comes at the cost of flexibility. When encountering scenarios requiring multiple rounds of incremental updates, the Agentless approaches struggle to adapt.
By contrast, SWE-agents adopt an end-to-end, multi-turn reasoning paradigm (yang2024swe; wang2024openhands). Rather than following a fixed workflow, they iteratively plan, act, and reflect, resembling how human developers debug complex issues. This design enables greater adaptability, but introduces significant difficulties: trajectories often extend over tens or even hundreds of steps, context windows of the LLMs must span over the entire interaction history, and the model must handle exploration, reasoning, and tool use simultaneously.
The dichotomy between fixed workflows (e.g., Agentless) and agentic frameworks (e.g., SWE-Agent) has shaped much of the community’s perspective. The two paradigms are often regarded as mutually exclusive: one trades off flexibility and performance ceiling for modularity and stability, whereas the other makes the reverse compromise. Our work challenges this dichotomy, as we demonstrate that Agentless training induces skill priors that make further SWE-agent training both more stable and more efficient.
2.2 Training SWE-agents
Training SWE-agents relies on acquiring high-quality trajectories through interactions with executable environments. Constructing such large-scale environments and collecting reliable trajectories, however, requires substantial human labor as well as costly calls to frontier models, making data collection slow and resource-demanding (pan2024training; badertdinov2024sweextra). Recent studies also attempt to scale environment construction by synthesizing bugs for the reverse construction of executable runtime (jain2025r2e; yang2025swesmith).
However, credit assignment across long horizons still remains challenging, as outcome rewards are sparse and often only available when a final patch passes its tests. Reinforcement learning techniques have been proposed, but frequently suffer from instability or collapse when trajectories exceed dozens of steps (deepswe2025; cao2025skyrl). SWE-agent training is also highly sensitive to initialization: starting from a generic pre-trained model often leads to brittle behaviors, such as failing to use tools effectively or getting stuck in infinite loops of specific action patterns (pan2024training; yang2025swesmith).
These limitations motivate our central hypothesis: instead of training SWE-agents entirely from scratch, one can first induce skill priors through agentless training, enhancing the atomic capabilities like localization, repair, test composition, and self-reflection. These priors lay a foundation that makes subsequent agentic training both more efficient and more generalizable.
3 Agentless Training Recipe
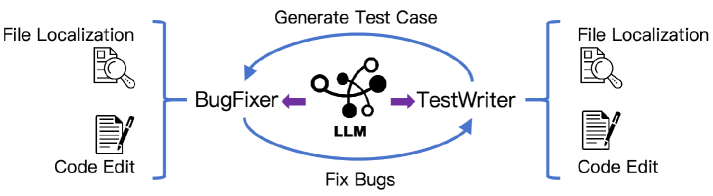
Instead of training SWE-agents from scratch, we leverage Agentless training to induce skill priors. Skill priors enhanced by Agentless training include but are not limited to bug localization, patch generation, self-reflection and verification, which lay the foundation for end-to-end agentic interaction. In this section, we elaborate our Agentless training recipe: the duo framework design of BugFixer and TestWriter, mid-training and cold-start, reinforcement learning, and test-time self-play. Sections 3.1 – 3.4 detail these ingredients, and Section 3.5 presents the experimental results for each of them. This training recipe results in Kimi-Dev, an open-source 72B model that achieves 60.4% on SWE-bench Verified, the SoTA performance among the workflow-based solutions.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: LLM-Driven Bug Fixing and Test Writing Workflow
### Overview
This image is a technical workflow diagram illustrating an automated, cyclical software development process powered by a Large Language Model (LLM). It depicts a dual-agent system consisting of a "BugFixer" and a "TestWriter," both of which utilize the central LLM to perform specific tasks (File Localization and Code Edit) in a continuous feedback loop.
### Components
The diagram contains no axes or charts; it is composed entirely of text labels, icons, and directional arrows.
**Central Elements:**
* **Icon:** A stylized neural network/graph node symbol (black and white circles connected by curved lines).
* **Text:** **LLM** (bold, black text centered directly below the network icon).
* **Directional Indicators:** Two short, thick purple arrows pointing outward from the central LLM icon—one pointing left towards the "BugFixer," and one pointing right towards the "TestWriter."
**Left Region (BugFixer):**
* **Text:** **BugFixer** (positioned to the left of the central LLM).
* **Grouping Element:** A large blue curly bracket `}` groups the far-left elements and points inward toward the "BugFixer" text.
* **Top-Left Sub-component:**
* Text: **File Localization**
* Icon: A document with a magnifying glass over it.
* **Bottom-Left Sub-component:**
* Text: **Code Edit**
* Icon: A document with a pen writing on it.
**Right Region (TestWriter):**
* **Text:** **TestWriter** (positioned to the right of the central LLM).
* **Grouping Element:** A large blue curly bracket `{` groups the far-right elements and points inward toward the "TestWriter" text.
* **Top-Right Sub-component:**
* Text: **File Localization**
* Icon: A document with a magnifying glass over it.
* **Bottom-Right Sub-component:**
* Text: **Code Edit**
* Icon: A document with a pen writing on it.
**Cyclical Flow Elements (Top and Bottom):**
* **Top Flow:** A long, curved blue arrow originating from "TestWriter" and pointing leftward to "BugFixer".
* Label: **Generate Test Case** (centered above the arrow).
* **Bottom Flow:** A long, curved blue arrow originating from "BugFixer" and pointing rightward to "TestWriter".
* Label: **Fix Bugs** (centered below the arrow).
### Content Details (Workflow Flow)
1. **Core Engine:** The central **LLM** acts as the foundational intelligence. The purple arrows indicate that the LLM powers or instantiates both the **BugFixer** and the **TestWriter** agents.
2. **Agent Capabilities:** Both the BugFixer and the TestWriter possess identical foundational capabilities, as indicated by the symmetrical brackets on the far left and far right. Both agents can perform **File Localization** (finding the relevant code) and **Code Edit** (modifying the code).
3. **The Loop:**
* The **TestWriter** utilizes its capabilities to **Generate Test Case**s, which are then passed to the **BugFixer** (indicated by the top blue arrow).
* The **BugFixer** receives the test cases, utilizes its capabilities to **Fix Bugs** in the code to satisfy the tests, and passes the results back to the **TestWriter** (indicated by the bottom blue arrow).
### Key Observations
* **Symmetry:** The diagram is highly symmetrical. The capabilities on the far left and far right are identical in both text and iconography, highlighting that while the *roles* (BugFixer vs. TestWriter) are different, the underlying *actions* they perform on the codebase (finding files, editing text) are the same.
* **Closed Loop:** The blue arrows create a closed, continuous feedback loop. This implies an iterative process that continues until a certain condition (likely passing tests) is met.
* **Single Brain, Dual Persona:** The purple arrows diverging from a single LLM suggest that one underlying model is being prompted or fine-tuned to act as two distinct adversarial or cooperative personas.
### Interpretation
This diagram represents an architecture for an autonomous, AI-driven software debugging system based on the principles of Test-Driven Development (TDD).
By separating the tasks into two distinct LLM-driven agents, the system creates a "maker-checker" dynamic. The **TestWriter** acts as the specifier and verifier, writing tests that define the expected behavior or expose a bug. The **BugFixer** acts as the developer, attempting to alter the code to make the tests pass.
Because both agents have "File Localization" and "Code Edit" capabilities, it implies they are operating directly on a repository. The TestWriter finds where to put the tests and writes them; the BugFixer finds the faulty source code and alters it. The cyclical arrows demonstrate an automated iterative loop: the TestWriter writes a failing test, the BugFixer edits the code to fix it, the TestWriter evaluates the fix (and potentially writes more tests if it fails or breaks something else), and the cycle repeats. This architecture is designed to reduce human intervention in the debugging process by using AI to both identify/prove the bug and generate the solution.
</details>
Figure 1: Agentless framework for Kimi-Dev: the duo of BugFixer and TestWriter.
3.1 Framework: the Duo of Bugfixer and Testwriter
In GitHub issue resolution, we conceptualize the process as the collaboration between two important roles: the BugFixer, who produces patches that correctly address software bugs, and the TestWriter, who creates reproducible unit tests that capture the reported bug. A resolution is considered successful when the BugFixer’s patch passes the tests provided for the issue, while a high-quality test from the TestWriter should fail on the pre-fix version of the code and pass once the fix is applied.
Each role relies on two core skills: (i) file localization, the ability to identify the specific files relevant to the bug or test, and (ii) code edit, the ability to implement the necessary modifications. For BugFixer, effective code edits repair the defective program logic, whereas for TestWriter, they update precise unit test functions that reproduce the issue into the test files. As illustrated in Figure 1, these two skills constitute the fundamental abilities underlying GitHub issue resolution. Thus, we enhance these skills through the following training recipes, including mid-training, cold-start, and RL.
3.2 Mid-Training & Cold Start
To enhance the model’s prior as both a BugFixer and a TestWriter, we perform mid-training with $\sim$ 150B tokens in high-quality and real-world data. With the Qwen 2.5-72B-Base (qwen2025qwen25technicalreport) model as a starting point, we collect millions of GitHub issues and PR commits to form its mid-training dataset, which consists of (i) $\sim$ 50B tokens in the form of Agentless derived from the natural diff patch, (ii) $\sim$ 20B tokens of curated PR commit packs, and (iii) $\sim$ 20B tokens of synthetic data with reasoning and agentic interaction patterns (upsampled by a factor of 4 during training). The data recipe is carefully constructed to enable the model to learn how human developers reason with GitHub issues, implement code fixes, and develop unit tests. We also performed strict data decontamination to exclude any repository from the SWE-bench Verified test set. Mid-training sufficiently enhances the knowledge in the model about practical bug fixes and unit tests, making it a better starting point for later stages. The details of the recipe are covered in Appendix A.
To activate the model’s long Chain-of-Thought (CoT) capability, we also construct a cold-start dataset with reasoning trajectories based on the SWE-Gym (pan2024training) and SWE-bench-extra (badertdinov2024scaling) datasets, generated by the DeepSeek R1 model (deepswe2025, the 20250120 version). In this setup, R1 acts the roles of Bugfixer and Testwriter, producing outputs such as file localization and code edits. Through supervised finetuning as a cold start with this dataset, we enable the model to acquire essential reasoning skills, including problem analysis, method sketching, self-refinement, and exploration of alternative solutions.
3.3 Reinforcement Learning
After mid-training and cold-start, the model demonstrates strong performance in localization. Therefore, reinforcement learning (RL) focuses solely on the code edit stage. We construct a training set specifically for this stage, where each prompt is equipped with an executable environment. We further employ multiple localization rollouts from the initial model to generate varied file location predictions, which diversifies the prompts used in code-edit RL.
For the RL algorithm, we adopt the policy optimization method proposed by Kimi k1.5 (team2025kimi_k15), which has shown promising results on reasoning tasks in both math and coding. Kimi k1.5 (team2025kimi_k15) adopts a simpler policy gradient approach based on the REINFORCE algorithm (williams1992simple). Similarly to GRPO (shao2024deepseekmath), we use the average rewards of multiple rollouts as the baseline to normalize the returns. When adapting the algorithm in our SWE-bench setting, we highlight the following 3 key desiderata:
1. Outcome-based reward only: We rely solely on the final execution outcome from the environment as the raw reward (0 or 1), without incorporating any format- or process-based signals. For BugFixer, a positive reward is given if the generated patch passes all ground-truth unittests. For TestWriter, a positive reward is assigned when (i) the predicted test raises a failure in the repo without the ground-truth bugfix patch applied, AND (ii) the failure is resolved once the ground-truth bugfix patch is applied.
1. Adaptive prompt selection: Prompts with pass@16 = 0 are initially discarded as they do not contribute to the batch loss. This results in an initial prompt set of 1,200 problems and enlarges the effective batch size. A curriculum learning scheme is then applied: once the success rate on the current set exceeds a threshold, 500 new (previously excluded) prompts (with initial pass@16 = 0 but improved under RL) are reintroduced every 100 RL steps to gradually raise task difficulty.
1. Positive example reinforcement: As performance improvements begin to plateau in later stages of training, we incorporate the positive samples from the recent RL iterations into the training batch of the current iteration. This approach reinforces the model’s reliance on successful patterns, thereby accelerating convergence in the final phase.
Robust sandbox infrastructure. We construct the docker environment with Kubernetes (kubernetes), which provides a secure and scalable sandbox infrastructure and efficient training and rollouts. The infra supports over 10,000 concurrent instances with robust performance, making it ideal for competitive programming and software engineering tasks (see Appendix D for details).
3.4 Test-Time Self-Play
After RL, the model masters the roles of both a BugFixer and a TestWriter. During test time, it adopts a self-play mechanism to coordinate its bug-fixing and test-writing abilities.
Following Agentless (xia2024agentless), we leverage the model to generate 40 candidate patches and 40 tests for each instance. Each patch generation involves independent runs of the localization and code edit from BugFixer, where the first run uses greedy decoding (temperature 0), and the remaining 39 use temperature 1 to ensure diversity. Similarly, 40 tests are generated independently from TestWriter. For the test patch candidates, to guarantee their validity, we first filter out those failing to raise a failure in the original repo without applying any BugFixer patch.
Denote the rest TestWriter patches as set $\mathcal{T}$ , and the BugFixer patches as set $\mathcal{B}$ . For each $b_{i}∈\mathcal{B}$ and $t_{j}∈\mathcal{T}$ , we execute the test suite over the test file modified by $t_{j}$ for twice: first without $b_{i}$ , and then with $b_{i}$ applied. From the execution log for the first run, we get the count of the failed and the passed tests from $t_{j}$ , denoted as ${\rm F}(j)$ and ${\rm P}(j)$ . Comparing the execution logs for the two test suite runs, we get the count of the fail-to-pass and the pass-to-pass tests, denoted as ${\rm FP}(i,j)$ and ${\rm PP}(i,j)$ , respectively. We then calculate the score for each $b_{i}$ with
$$
S_{i}=\frac{\sum_{j}{\rm FP}(i,j)}{\sum_{j}{\rm F}(j)}+\frac{\sum_{j}{\rm PP}(i,j)}{\sum_{j}{\rm P}(j)},\vskip-2.0pt \tag{1}
$$
where the first part reflects the performance of $b_{i}$ under reproduction tests, and the second part could be viewed as the characterization of $b_{i}$ under regression tests (xia2024agentless). We select the BugFixer patch $b_{i}$ with the highest $S_{i}$ score as the ultimate answer.
Table 1: Performance comparison for models on SWE-bench Verified under Agentless-like frameworks. All the performances are obtained under the standard 40 patch, 40 test setting (xia2024agentless), except that Llama3-SWE-RL uses 500 patches and 30 tests.
3.5 Experiments
3.5.1 Main Results
<details>
<summary>figs/sec3_mid_training/mid-train_perf.png Details</summary>
### Visual Description
## Bar Chart: Pass Rate vs. Mid-training Tokens
### Overview
This image is a bar chart illustrating the relationship between the volume of "Mid-training tokens" and a resulting performance metric labeled as "Pass Rate (%)". The chart displays three distinct data points, showing a clear, positive correlation between the number of tokens and the pass rate. The language used in the chart is entirely English.
### Components/Axes
**Component Isolation & Spatial Grounding:**
* **Y-axis (Left side, vertical):**
* **Title:** "Pass Rate (%)" (oriented vertically, reading bottom to top).
* **Scale:** The axis is truncated, starting just below 26 and ending at 38.
* **Markers:** Tick marks are placed at intervals of 2: 26, 28, 30, 32, 34, 36, and 38.
* **Gridlines:** Light grey, dashed horizontal lines extend from each y-axis tick mark across the background of the chart area to aid in visual alignment.
* **X-axis (Bottom, horizontal):**
* **Title:** "Mid-training tokens" (centered below the category labels).
* **Categories:** Three discrete labels positioned from left to right: "50B", "100B", and "150B". ("B" standardly denotes Billions).
* **Data Series (Center):**
* Three vertical bars corresponding to the x-axis categories.
* **Styling:** All bars are a uniform light blue color with solid black outlines. There is no separate legend because there is only one data series.
* **Data Labels:** Exact numerical values are printed in black text directly above the top edge of each corresponding bar.
### Detailed Analysis
**Trend Verification:**
Visually, the bars step upward from left to right. The visual increase in height from the first bar to the second appears identical to the increase from the second bar to the third, suggesting a linear trend within this specific data window.
**Data Extraction:**
* **Left Bar:**
* Category (X): 50B
* Value (Y): 28.6
* **Center Bar:**
* Category (X): 100B
* Value (Y): 32.6
* **Right Bar:**
* Category (X): 150B
* Value (Y): 36.6
### Key Observations
* **Perfect Linearity:** The data exhibits perfectly linear growth within the displayed range. The pass rate increases by exactly 4.0% for every 50B tokens added (28.6 + 4.0 = 32.6; 32.6 + 4.0 = 36.6).
* **Axis Truncation:** The Y-axis does not start at zero (it starts near 25). This visual technique significantly exaggerates the perceived rate of growth. Visually, the 150B bar appears roughly three times taller than the 50B bar, whereas the actual mathematical increase is approximately 28% (from 28.6 to 36.6).
### Interpretation
* **What the data suggests:** The chart demonstrates that continuing to train a model (likely a Large Language Model, given the terminology "tokens" and "B" for billions) with additional "mid-training" data yields consistent, predictable improvements in its ability to pass a specific benchmark (the "Pass Rate").
* **Why it matters:** In machine learning, understanding scaling laws is critical for resource allocation. This chart argues that investing compute to process an additional 50 billion tokens yields a reliable 4% bump in this specific performance metric.
* **Investigative/Peircean Reading:** The *perfectly* linear nature of this data (+4.0% exactly per step) is highly unusual in empirical deep learning results. Typically, model performance follows a logarithmic scaling law, where returns diminish as more data is added. The perfect linearity here suggests one of a few possibilities:
1. This is a highly specific, narrow slice of a larger, curved scaling graph where the curve appears locally linear.
2. The data might be smoothed, averaged, or extrapolated rather than representing raw, single-run empirical variance.
3. The specific "mid-training" phase represented here is in a highly stable, unsaturated learning regime.
* Furthermore, the author's choice to truncate the Y-axis indicates an intent to emphasize the *impact* of the mid-training tokens, making the gains look as dramatic as possible to the viewer.
</details>
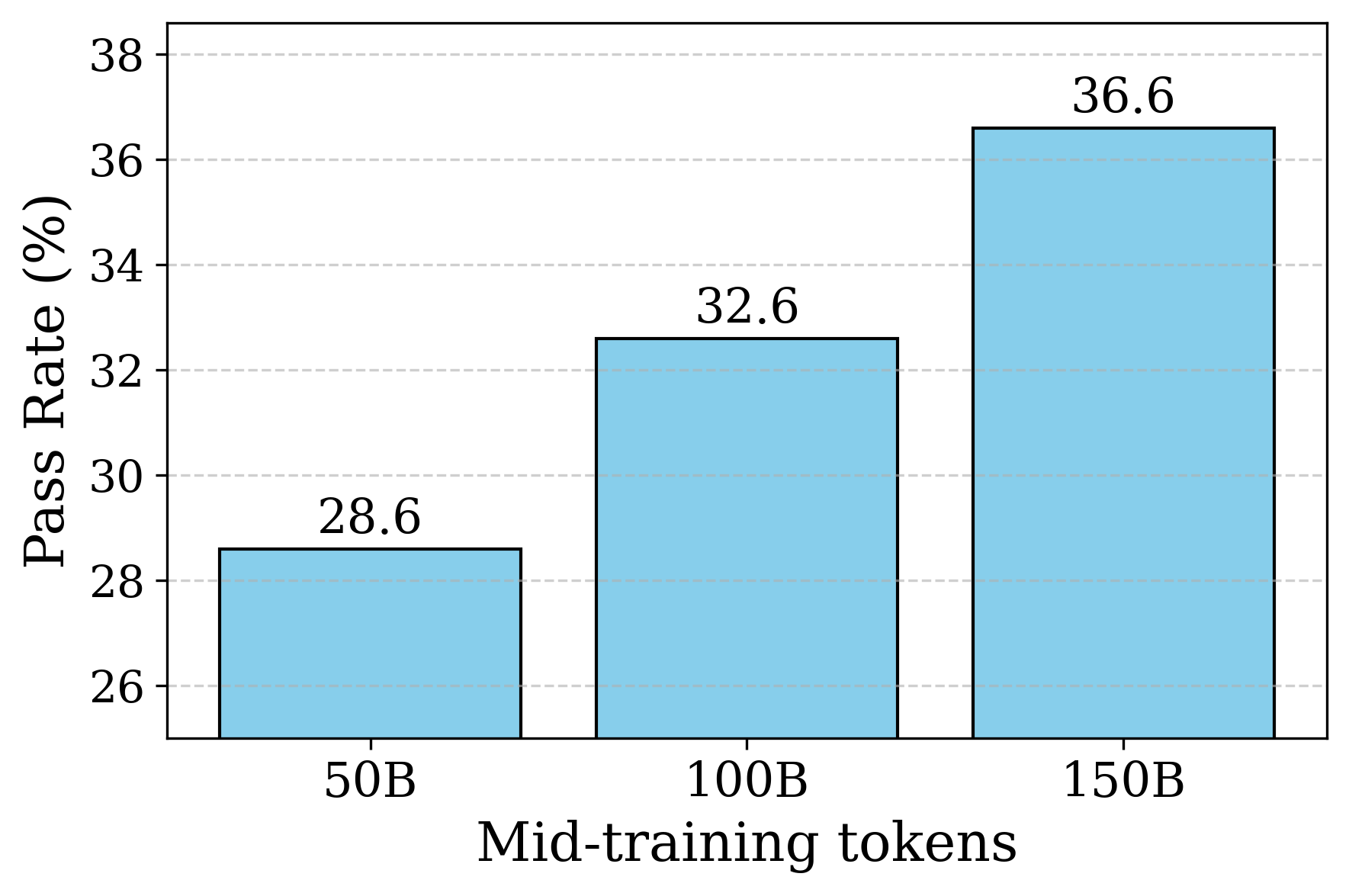
Figure 2: The performance on SWE-bench Verified after mid-training with different training token budgets.
Table 1 shows the performance of Kimi-Dev on SWE-bench Verified (jimenez2023swe). Instead of the text-similarity rewards used in SWE-RL (wei2025swe), we adopt execution-based signals for more reliable fix quality. Our two-stage TestWriter also improves over prior Agentless systems (xia2024agentless; guo2025deepseek; SWESwiss2025), which rely on a single root-level test, by better capturing repository context and mirroring real developer workflows (OpenAI-Codex-2025). Kimi-Dev attains state-of-the-art performance among open-source models, resolving 60.4% of issues.
3.5.2 Mid-Training
In this section, we evaluate the relationship between the amount of data used during mid-training and model performance. Specifically, we finetuned Qwen 2.5-72B-Base with the subset of mid-training data of 50B, 100B, and approximately 150B tokens, and then lightly activated these mid-trained models using the same set of 2,000 Bugfixer input-output pairs for SFT cold start. We only report BugFixer pass@1 here for simplicity of evaluation. Figure 2 shows that increasing the number of tokens in mid-training consistently improves model performance, highlighting the effectiveness of this stage.
3.5.3 Reinforcement Learning
<details>
<summary>figs/sec3_rl_scaling/quick_plot_twin_bf_final.png Details</summary>
### Visual Description
## Dual-Axis Line Chart: Token Length and Pass Rate over RL Training Steps
### Overview
This image is a dual-axis line chart illustrating the progression of two distinct metrics—"Token Length" and "Pass Rate (%)"—over a series of "RL Training Steps." The chart demonstrates how the length of generated tokens and the success rate evolve simultaneously during a Reinforcement Learning (RL) training process.
### Components/Axes
The chart is composed of the following isolated components:
* **Legend (Top-Left):**
* Enclosed in a rounded rectangular box with a light gray border.
* Displays a blue line with a square marker labeled "Token Length".
* Displays a red line with a circular marker labeled "Pass Rate (%)".
* **X-Axis (Bottom):**
* **Label:** "RL Training Steps" (Black text, centered).
* **Scale:** Ranges from 0 to 500.
* **Markers:** Major tick marks at intervals of 50 (0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500).
* **Primary Y-Axis (Left):**
* **Label:** "Token Length" (Blue text, rotated 90 degrees counter-clockwise).
* **Scale:** Ranges from 4000 to 8000.
* **Markers:** Major tick marks at intervals of 500 (4000, 4500, 5000, 5500, 6000, 6500, 7000, 7500, 8000).
* **Color Association:** Corresponds to the blue line with square markers.
* **Secondary Y-Axis (Right):**
* **Label:** "Pass Rate (%)" (Red text, rotated 90 degrees clockwise).
* **Scale:** Ranges from 34 to 46.
* **Markers:** Major tick marks at intervals of 2 (34, 36, 38, 40, 42, 44, 46).
* **Color Association:** Corresponds to the red line with circular markers.
* **Grid:** A background grid of light gray, dashed lines aligns with the major tick marks of all three axes.
### Detailed Analysis
#### Trend Verification
* **Token Length (Blue Line/Squares):** The visual trend slopes upward over time. It begins just below 4000 at step ~5, rises steadily with minor fluctuations until step ~340, experiences a sharp, steep climb between steps 340 and 370, plateaus slightly, suffers a severe, isolated drop at step ~465, and immediately recovers to reach its peak near 7800 at the final step.
* **Pass Rate (Red Line/Circles):** The visual trend also slopes upward but exhibits extreme volatility (high variance). It starts near 34%, jumps rapidly, and then oscillates wildly with deep valleys (e.g., at steps ~55, ~105, ~205) and sharp peaks. Despite the jaggedness, the overall trajectory moves from the mid-30s to the mid-40s, peaking just below 47% near step 455.
#### Reconstructed Data Table
*Note: All values are approximate (±) based on visual extraction relative to the gridlines.*
| Estimated RL Step (X) | Token Length (Blue Y) | Pass Rate % (Red Y) |
| :--- | :--- | :--- |
| ~5 | 3900 | 34.2 |
| ~15 | 4350 | 35.2 |
| ~25 | 4250 | 36.8 |
| ~45 | 4250 | 37.1 |
| ~55 | 4350 | 33.7 |
| ~65 | 4500 | 37.0 |
| ~75 | 4700 | 37.8 |
| ~85 | 4900 | 37.9 |
| ~95 | 5000 | 38.3 |
| ~105 | 5050 | 35.8 |
| ~135 | 5350 | 38.6 |
| ~145 | 5400 | 38.2 |
| ~155 | 5450 | 38.1 |
| ~165 | 5650 | 38.1 |
| ~175 | 5650 | 39.0 |
| ~185 | 5650 | 40.0 |
| ~195 | 5750 | 41.0 |
| ~205 | 5650 | 37.2 |
| ~215 | 5950 | 40.2 |
| ~225 | 5800 | 38.6 |
| ~235 | 5700 | 40.5 |
| ~245 | 6000 | 39.8 |
| ~255 | 5900 | 42.8 |
| ~265 | 5800 | 40.8 |
| ~275 | 6050 | 39.6 |
| ~285 | 6050 | 40.2 |
| ~295 | 5900 | 43.4 |
| ~305 | 5950 | 42.0 |
| ~315 | 6000 | 41.3 |
| ~325 | 5950 | 41.5 |
| ~335 | 6000 | 39.3 |
| ~345 | 6200 | 42.2 |
| ~355 | 6850 | 45.5 |
| ~365 | 7250 | 44.8 |
| ~375 | 7200 | 42.8 |
| ~385 | 7350 | 44.4 |
| ~405 | 7300 | 42.5 |
| ~415 | 7250 | 43.8 |
| ~425 | 7200 | 44.5 |
| ~435 | 7450 | 43.4 |
| ~445 | 7450 | 45.7 |
| ~455 | 7650 | 46.8 |
| ~465 | 6700 | 45.7 |
| ~475 | 7600 | 43.8 |
| ~485 | 7850 | 46.6 |
### Key Observations
1. **Macro Correlation:** There is a clear, positive macro-correlation between the two metrics. As training steps increase, both the token length and the pass rate increase.
2. **Volatility Discrepancy:** The Pass Rate (red) is significantly more volatile step-to-step than the Token Length (blue). Token length tends to grow in a more stable, step-wise fashion, whereas pass rate swings wildly between consecutive measurements.
3. **The Step 350 Inflection:** Around step 340-350, there is a massive, concurrent spike in both metrics. Token length jumps from ~6000 to ~7250, and pass rate jumps from ~39% to ~45%.
4. **The Step 465 Anomaly:** At approximately step 465, the Token Length experiences a severe, sudden drop (from ~7650 down to ~6700). Interestingly, the Pass Rate does *not* suffer a corresponding catastrophic drop at this exact step, remaining relatively high at ~45.7%.
### Interpretation
This chart visualizes the behavioral evolution of a Large Language Model (LLM) undergoing Reinforcement Learning (likely RLHF - Reinforcement Learning from Human Feedback, or similar).
**Reading between the lines:**
The data strongly suggests that the model is learning a strategy where **verbosity correlates with success**. Because the "Pass Rate" generally improves as the "Token Length" increases, the RL reward function is likely inadvertently (or intentionally) rewarding longer outputs. This is a common phenomenon in LLM training; models learn that providing exhaustive, step-by-step reasoning (Chain-of-Thought) or simply covering more information increases the statistical likelihood of hitting the criteria required to "pass" a prompt's evaluation.
The high volatility in the Pass Rate indicates that the training process is noisy. The model is likely exploring different policy updates, some of which fail dramatically on specific batches of data (causing the sharp red dips).
The anomaly at step 465 is particularly revealing. The model suddenly generated much shorter responses, yet maintained a high pass rate. This could indicate a specific batch of training data that required concise answers, or a temporary policy shift that was quickly corrected in the subsequent step. Ultimately, the chart demonstrates a successful, albeit noisy, training run where the model doubles its output length to achieve a ~12% absolute increase in its pass rate.
</details>
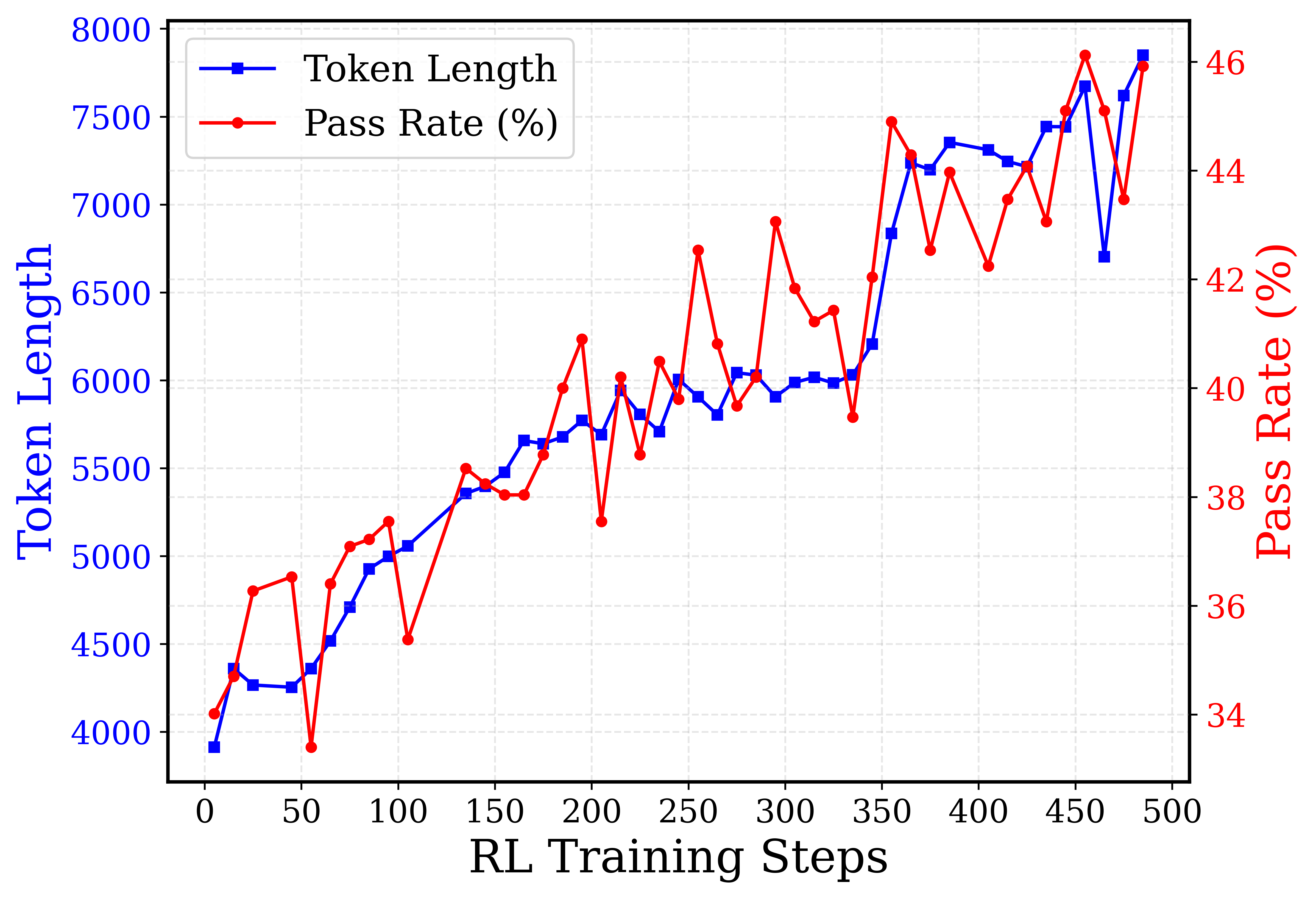
(a) 72B Joint RL, BugFixer
<details>
<summary>figs/sec3_rl_scaling/quick_plot_twin_tw_final.png Details</summary>
### Visual Description
## Dual-Axis Line Chart: Token Length and Reproduced Rate over RL Training Steps
### Overview
This image is a dual-axis line chart illustrating the progression of two metrics—"Token Length" and "Reproduced Rate (%)"—over a series of Reinforcement Learning (RL) Training Steps. The chart uses a blue line with square markers for the primary metric and a red line with circular markers for the secondary metric, plotted against a shared horizontal axis. A faint, dashed light-gray grid is visible in the background to aid in reading values.
### Components/Axes
**1. Legend (Spatial Grounding: Top-Left)**
* Located in the top-left corner of the chart area, enclosed in a white box with a rounded, light-gray border.
* **Item 1:** A blue horizontal line segment with a solid blue square in the center. Text label: "Token Length" (Black text).
* **Item 2:** A red horizontal line segment with a solid red circle in the center. Text label: "Reproduced Rate (%)" (Black text).
**2. X-Axis (Bottom)**
* **Position:** Bottom edge of the chart.
* **Label:** "RL Training Steps" (Black text, centered).
* **Scale:** Linear.
* **Markers/Ticks:** 0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500.
**3. Primary Y-Axis (Left)**
* **Position:** Left edge of the chart.
* **Label:** "Token Length" (Blue text, rotated 90 degrees counter-clockwise).
* **Scale:** Linear.
* **Markers/Ticks:** 3000, 3500, 4000, 4500, 5000, 5500, 6000, 6500.
* **Color Correlation:** The blue text and axis values correspond directly to the blue line (square markers) defined in the legend.
**4. Secondary Y-Axis (Right)**
* **Position:** Right edge of the chart.
* **Label:** "Reproduced Rate (%)" (Red text, rotated 90 degrees clockwise).
* **Scale:** Linear.
* **Markers/Ticks:** 20.0, 22.5, 25.0, 27.5, 30.0, 32.5, 35.0.
* **Color Correlation:** The red text and axis values correspond directly to the red line (circular markers) defined in the legend.
---
### Detailed Analysis
*Note: Data points are extracted via visual interpolation and represent approximate values (denoted by ~).*
#### Series 1: Token Length (Blue Line, Square Markers)
**Trend Verification:** The blue line exhibits a strong, relatively stable upward trend. It begins near the 3000 mark, remains somewhat flat with minor fluctuations until roughly step 150, and then climbs steadily, peaking near 6400 at the end of the training steps. The variance (noise) between individual steps is relatively low compared to the red line.
**Approximate Data Points (X: RL Step, Y: Token Length):**
* ~10: ~3050
* ~20: ~3050
* ~30: ~3150
* ~40: ~3050
* ~50: ~3100
* ~60: ~2950 (Local Minimum)
* ~70: ~3150
* ~80: ~3250
* ~90: ~3400
* ~100: ~3500
* ~110: ~3450
* ~120: ~3500
* ~130: ~3450
* ~140: ~3500
* ~150: ~3650
* ~165: ~3900
* ~175: ~4050
* ~185: ~4200
* ~195: ~4050
* ~205: ~4350
* ~215: ~4400
* ~225: ~4450
* ~235: ~4500
* ~245: ~4600
* ~255: ~4650
* ~265: ~4800
* ~275: ~4550
* ~285: ~4850
* ~295: ~4900
* ~305: ~4750
* ~315: ~4700
* ~325: ~4800
* ~335: ~5100
* ~345: ~5100
* ~355: ~5050
* ~365: ~5150
* ~375: ~5550
* ~380: ~5850
* ~390: ~6000
* ~400: ~5750
* ~410: ~6100
* ~420: ~6000
* ~430: ~6250
* ~440: ~5950
* ~450: ~6300
* ~460: ~6050
* ~470: ~6200
* ~480: ~6400 (Maximum)
#### Series 2: Reproduced Rate (%) (Red Line, Circular Markers)
**Trend Verification:** The red line shows a general upward trajectory over time but is characterized by extreme volatility. It starts just below 20.0%, experiences sharp, jagged peaks and valleys throughout the training process, and reaches its absolute peak near 37.5% around step 400. Even in the later stages of training, the metric swings wildly between ~30% and ~37%.
**Approximate Data Points (X: RL Step, Y: Reproduced Rate %):**
* ~10: ~19.5
* ~20: ~21.0
* ~30: ~23.0
* ~40: ~21.0
* ~50: ~24.5
* ~60: ~23.5
* ~70: ~23.8
* ~80: ~28.0 (Early Spike)
* ~90: ~26.0
* ~100: ~24.2
* ~110: ~27.0
* ~120: ~26.8
* ~130: ~27.0
* ~140: ~29.5
* ~150: ~27.0
* ~165: ~24.5
* ~175: ~28.2
* ~185: ~29.0
* ~195: ~28.5
* ~205: ~30.5
* ~215: ~28.2
* ~225: ~31.2
* ~235: ~33.0
* ~245: ~33.2
* ~255: ~32.5
* ~265: ~29.8
* ~275: ~34.5
* ~285: ~33.0
* ~295: ~31.8
* ~305: ~33.2
* ~315: ~35.0
* ~325: ~31.0
* ~335: ~33.2
* ~345: ~35.0
* ~355: ~33.0
* ~365: ~32.2
* ~375: ~35.2
* ~380: ~34.0
* ~390: ~36.0
* ~400: ~37.5 (Maximum)
* ~410: ~35.5
* ~420: ~36.5
* ~430: ~31.5 (Sharp Drop)
* ~440: ~31.0
* ~450: ~35.5
* ~460: ~31.5
* ~470: ~34.0
* ~480: ~30.5
---
### Key Observations
1. **Positive Correlation:** Both metrics generally increase as the RL Training Steps progress. As the model trains, it generates longer token sequences and achieves a higher reproduction rate.
2. **Divergent Volatility:** The "Token Length" (blue) grows in a relatively smooth, linear fashion after step 150. Conversely, the "Reproduced Rate" (red) is highly erratic, featuring massive step-to-step swings (e.g., dropping from ~36.5% to ~31.5% between steps 420 and 430).
3. **Late-Stage Behavior:** Between steps 350 and 500, the Token Length continues to push higher, breaking the 6000 mark. However, the Reproduced Rate appears to plateau in its upward trend, oscillating violently between 30% and 37% without establishing a higher baseline.
### Interpretation
This chart likely represents the training dynamics of a Large Language Model (LLM) or sequence-generation model undergoing Reinforcement Learning (such as RLHF - Reinforcement Learning from Human Feedback).
* **Token Length:** The steady increase in Token Length indicates that the reward model is likely incentivizing longer outputs. The model is learning to be more verbose or comprehensive as training progresses, effectively doubling its output length from ~3000 to ~6400 tokens.
* **Reproduced Rate (%):** This metric likely measures the model's ability to successfully reproduce a specific target behavior, format, or ground-truth sequence. The overall increase from ~20% to ~35% shows that learning is occurring.
* **Reading Between the Lines (The Volatility):** The extreme jaggedness of the red line is a classic hallmark of Reinforcement Learning policy updates. RL algorithms (like PPO) can be unstable; an update that improves the policy in one step might cause a regression in the next. The fact that Token Length grows smoothly while Reproduced Rate thrashes suggests a tension in the reward function. The model easily learns to generate *more* text (smooth blue line), but generating the *correct* text (red line) is a much harder, less stable optimization landscape. The late-stage plateau of the red line suggests the model may be reaching its capacity for this specific task, or that the learning rate needs decay to stabilize the final policy.
</details>
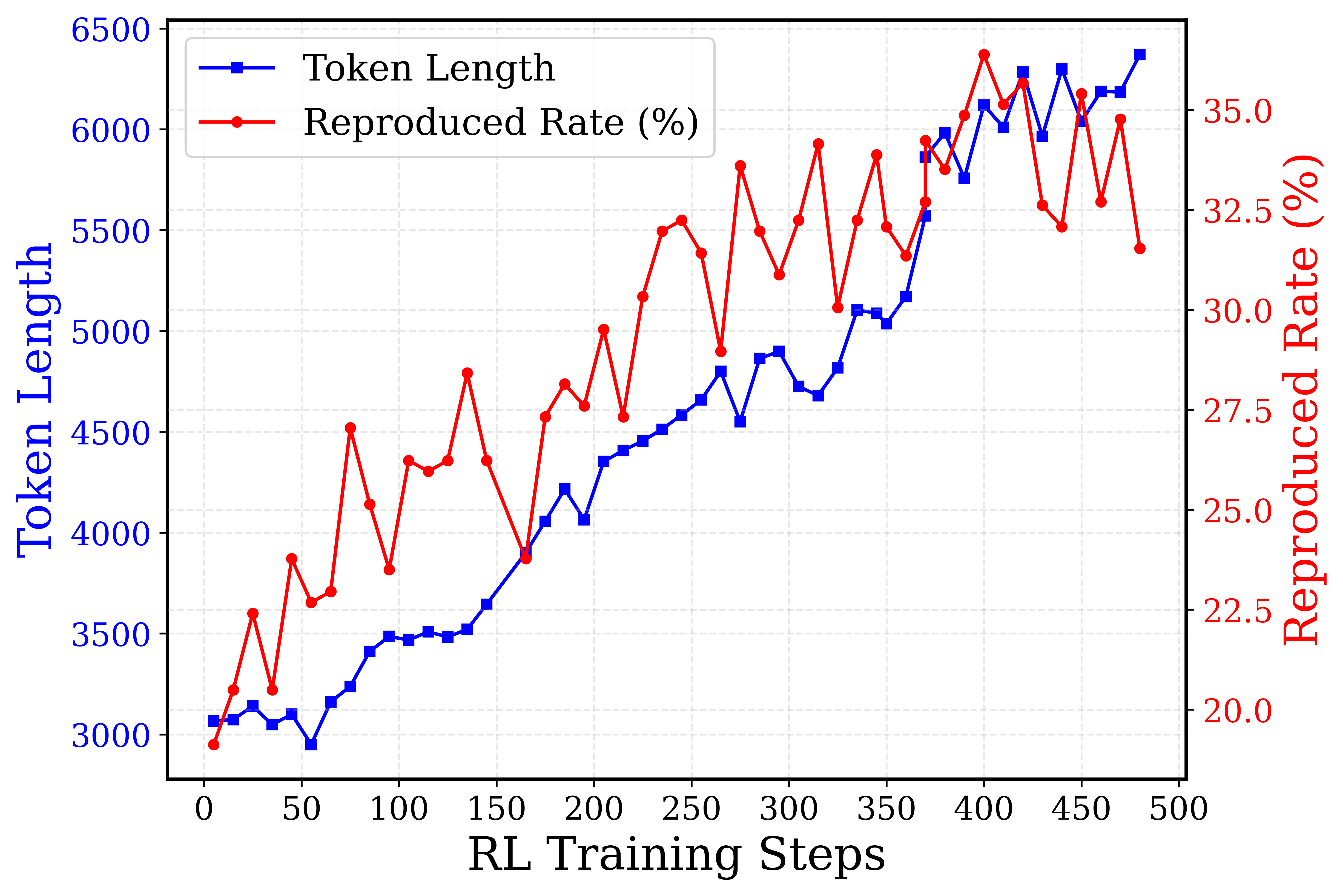
(b) 72B Joint RL, TestWriter
Figure 3: Joint code-edit RL experiments on the model after mid-training and cold-start. The pass rate for BugFixer and the reproduced rate for TestWriter are reported as pass@1 with temperature=1.0. The performance improves consistently as the output becomes increasingly longer.
Experimental setup
We set the training step per RL iteration as 5 and sample 10 rollouts for each of the 1,024 problems from the union of SWE-gym (pan2024training) and SWE-bench-extra (badertdinov2024sweextra). We dynamically adjust the prompt set every 20 iterations to gradually increase task difficulty. We fix the maximum training context length as 64k tokens, since the prompt input contains the contents of the entire files localized by the initial model in advance.
Results
Figure 3 shows the performance and response length curves on the test set during RL training. The pass rate and the reproduced rate are calculated from pass@1 and temperature=1. Specifically, we observe that both model performance and response length steadily increase, reflecting the expected benefits of RL scaling. Similar RL scaling curves are also observed in our ablation experiments run on Qwen2.5-14B-Instruct models, proving the effectiveness of the RL training recipe across models of different sizes. The experimental details, as well as the ablation studies on positive example reinforcement in Section 3.3, are listed in Appendix C.2). The lengthy outputs consist of in-depth problem analysis and self-reflection patterns, similar to those in the math and code reasoning tasks (team2025kimi_k15; guo2025deepseek). We have also observed that for TestWriter, occasional false-positive examples take place during RL training due to the lack of reproduction coverage. We leave the case studies in Appendix E and further improvement for future work.
<details>
<summary>figs/sec3_sp_scaling/selfplay_figure_v2.png Details</summary>
### Visual Description
## Line Charts: Performance Comparison of Self-play against Majority Voting and Pass@N
### Overview
The image consists of two side-by-side line charts comparing the "Pass Rate (%)" of different evaluation or decoding strategies ("Self-play", "Majority Voting", and "Pass@N") as the "Number of patches: BF x TW" increases. The left chart compares Self-play to Majority Voting, while the right chart compares Self-play to Pass@N. Both charts demonstrate how scaling the number of generated patches affects the overall success rate.
### Components/Axes
**Shared Elements Across Both Charts:**
* **X-axis Title:** "Number of patches: BF x TW" (Located at the bottom center of each chart).
* **X-axis Categories (Markers):** Categorical progression labeled as `1x1`, `3x3`, `5x5`, `10x10`, `20x20`, and `40x40`.
* **Y-axis Title:** "Pass Rate (%)" (Located vertically on the left side of each chart).
* **Gridlines:** Both charts feature a light gray, dashed grid corresponding to the major y-axis ticks and x-axis categories.
**Left Chart Specifics:**
* **Y-axis Scale:** Ranges from 45.0 to 62.5, with major tick marks every 2.5 units (45.0, 47.5, 50.0, 52.5, 55.0, 57.5, 60.0, 62.5).
* **Legend (Top-Left):**
* Solid Blue Line: "Self-play"
* Solid Green Line: "Majority Voting"
**Right Chart Specifics:**
* **Y-axis Scale:** Ranges from 45 to 75, with major tick marks every 5 units (45, 50, 55, 60, 65, 70, 75).
* **Legend (Top-Left):**
* Solid Blue Line: "Self-play"
* Solid Orange/Yellow Line: "Pass@N"
---
### Detailed Analysis
#### Left Chart: Self-play vs. Majority Voting
* **Trend Verification:**
* The **Self-play** (blue line, circular markers) shows a strong, consistent upward slope from `1x1` to `20x20`, after which it completely plateaus, showing a flat horizontal line to `40x40`.
* The **Majority Voting** (green line, triangular markers) starts at the exact same origin point as Self-play but exhibits a very shallow, gradual upward slope, peaking at `20x20` before experiencing a very slight downward dip at `40x40`.
* **Data Points (Explicitly labeled in the image):**
* *Note: At `1x1`, both lines originate from the same node. The label "48.0" is printed in blue, but visually applies to both starting points.*
| Number of patches (X) | Self-play (Blue, Circles) | Majority Voting (Green, Triangles) |
| :--- | :--- | :--- |
| **1x1** | 48.0 (Label top-left of node) | ~48.0 (Shares origin node) |
| **3x3** | 52.6 (Label top-left of node) | 48.8 (Label below node) |
| **5x5** | 55.4 (Label top-left of node) | 50.0 (Label below node) |
| **10x10** | 58.8 (Label top-left of node) | 51.0 (Label below node) |
| **20x20** | 60.4 (Label above node) | 51.4 (Label below node) |
| **40x40** | 60.4 (Label above node) | 51.2 (Label below node) |
#### Right Chart: Self-play vs. Pass@N
* **Trend Verification:**
* The **Self-play** (blue line, circular markers) data is identical to the left chart, though visually flattened due to the expanded Y-axis scale. It slopes upward and plateaus at `20x20`.
* The **Pass@N** (orange line, diamond markers) starts at the same origin point but exhibits a steep, continuous upward slope across the entire x-axis, showing no signs of plateauing within the measured range.
* **Data Points (Explicitly labeled in the image):**
* *Note: At `1x1`, both lines originate from the same node. The label "48.0" is printed in blue below the node.*
| Number of patches (X) | Self-play (Blue, Circles) | Pass@N (Orange, Diamonds) |
| :--- | :--- | :--- |
| **1x1** | 48.0 (Label below node) | ~48.0 (Shares origin node) |
| **3x3** | 52.6 (Label below node) | 60.4 (Label above node) |
| **5x5** | 55.4 (Label below node) | 64.0 (Label above node) |
| **10x10** | 58.8 (Label below node) | 67.4 (Label above node) |
| **20x20** | 60.4 (Label below node) | 71.6 (Label above node) |
| **40x40** | 60.4 (Label below node) | 74.8 (Label above node) |
---
### Key Observations
1. **Origin Point:** All three methodologies (Self-play, Majority Voting, Pass@N) begin at a baseline pass rate of 48.0% when the patch configuration is `1x1`.
2. **The Plateau Effect:** The "Self-play" method scales well initially but hits a hard ceiling at `20x20`, showing zero improvement (remaining at 60.4%) when doubling the patches to `40x40`.
3. **Underperformance of Majority Voting:** Majority Voting scales very poorly compared to the other methods. Increasing the patches from `1x1` to `40x40` only yields a marginal 3.2% absolute improvement (48.0% to 51.2%), and actually degrades slightly from `20x20` to `40x40`.
4. **Theoretical Maximum (Pass@N):** Pass@N scales aggressively and continuously. At `40x40`, it reaches 74.8%, creating a massive 14.4% gap between it and the Self-play method.
### Interpretation
These charts likely represent the evaluation of a Large Language Model (LLM) on a reasoning or coding benchmark (implied by "Pass Rate" and "Pass@N"). "Number of patches: BF x TW" likely refers to a search or sampling strategy (e.g., Branching Factor x Tree Width) used to generate multiple candidate solutions.
* **Reading between the lines:**
* **Pass@N** represents the "Oracle" upper bound—if the model generates $N$ answers, what is the probability that *at least one* is correct? The steep rise in the orange line proves that the underlying model *is capable* of generating the correct answer if given enough attempts; the correct answer is in the pool of generated patches 74.8% of the time at `40x40`.
* **Majority Voting** is failing because the model likely generates a high volume of consistent, but *incorrect*, answers. Even if the correct answer is in the pool (as proven by Pass@N), the incorrect answers outnumber it, causing the vote to fail.
* **Self-play** (likely a method where the model evaluates its own generated answers to pick the best one) is vastly superior to Majority Voting. It successfully identifies the correct answer from the pool up to a point. However, the hard plateau at 60.4% reveals a critical limitation in the Self-play reward model or discriminator: once the pool of answers gets too large (`20x20` and beyond), the Self-play mechanism loses its ability to distinguish the correct answer from highly plausible incorrect answers.
* **The "Selection Gap":** The most crucial takeaway is the widening gap in the right chart. At `40x40`, the model generates the correct answer 74.8% of the time, but the Self-play selection mechanism can only find it 60.4% of the time. This indicates that future research should focus not on generating *more* answers, but on improving the *selection/filtering* mechanism to close the gap between Self-play and Pass@N.
</details>
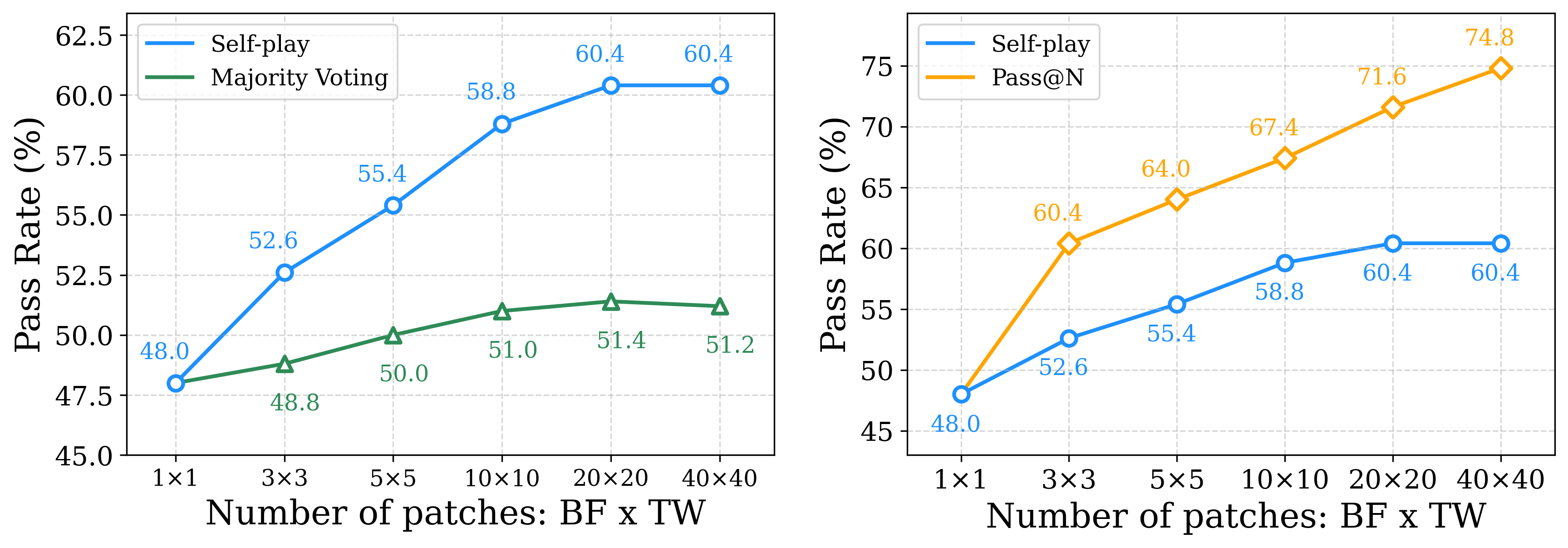
Figure 4: Test-time self-play on SWE-bench Verified. Performance improves with more generated patches and tests. Left: Execution-based self-play consistently surpasses BugFixer majority voting. Right: Self-play performances remain below pass@N where the ground-truth test patch is used, suggesting the room exists for TestWriter to improve.
3.5.4 Test-time Self-Play
Following Section 3.4, we evaluate how the final performance on SWE-bench Verified scales with the number of patches and tests generated. The temperature is fixed at 0 for the initial rollout, and set to 1.0 for the subsequent 39 rollouts. As shown on the left of Figure 4, the final performance improves from 48.0% to 60.4% as the number of patch-test pairs increases from 1 $×$ 1 to 40 $×$ 40, and consistently surpasses the results obtained from the majority vote of the BugFixer patches only.
Specifically, the self-play result obtained from 3 patches and 3 tests for each instance has already surpassed the performance with majority voting from 40 BugFixer patches. This demonstrates the effectiveness of additional information from test-time execution. The room for improvement of TestWriter, though, still exists for more powerful self-play: Shown on Figure 4, self-play performances remain below pass@N, where ground-truth test cases serve as the criterion for issue resolution. This finding aligns with anthropic_claude_3.5_sonnet_20241022, which introduced a final edge-case checking phase to generate a more diverse set of test cases, thereby strengthening the role of the “TestWriter” in their SWE-Agent framework. We also report preliminary observations of a potential parallel scaling phenomenon, which requires no additional training and may enable scalable performance improvements. The details of the phenomenon and analyses are covered in Appendix F.
4 Initializing SWE-Agents from Agentless Training
End-to-end multi-turn frameworks, such as SWE-Agent (yang2024swe; anthropic_claude_3.5_sonnet_20241022) and OpenHands (wang2024openhands), enable agents to leverage tools and interact with environments. Specifically, the system prompt employed in the SWE-Agent framework (anthropic_claude_3.5_sonnet_20241022) outlines a five-stage workflow: (i) repo exploration, (ii) error reproduction via a test script, (iii) code edit for bug repair, (iv) test re-execution for validation, and (v) edge-case generation and checks. Unlike Agentless, the SWE-Agent framework doesn’t enforce a strict stage-wise workflow; the agent can reflect, transition, and redo freely until it deems the task complete and submits.
The performance potential is therefore higher without a fixed routine; However, the training for SWE-Agent is more challenging because of the sparsity of the outcome reward for long-horizon credit assignment. Meanwhile, our Kimi-Dev model has undergone Agentless training, with its skills of localization and code edit for BugFixer and TestWriter strengthened elaborately. In this section, we investigate whether it can serve as an effective prior for multi-turn SWE-Agent scenarios.
Table 2: Single-attempt performance of different models on SWE-bench Verified under end-to-end agentic frameworks, categorized by proprietary or open-weight models, and size over or under 100B (as of 2025.09). “Internal” denotes results achieved with their in-house agentic frameworks.
4.1 Performance after SWE-Agent Fine-tuning
<details>
<summary>figs/sec4_main/v-sweeping-new-FINAL.png Details</summary>
### Visual Description
## Line Chart: Pass Rate vs. SWE-Agent SFT Tokens
### Overview
This image is a complex line chart illustrating the performance (measured as "Pass Rate (%)") of four different machine learning models or training methodologies across varying amounts of training data (measured in "# SWE-Agent SFT tokens"). The chart evaluates each method using three different metrics: Pass@1, Pass@2, and Pass@3, resulting in 12 distinct data series.
### Components/Axes
**1. Y-Axis (Left):**
* **Label:** `Pass Rate (%)`
* **Scale:** Linear, ranging from 0 to 65.
* **Markers/Ticks:** Major ticks are marked at 0, 10, 20, 30, 40, 50, and 60. Faint, solid light-gray horizontal gridlines extend from these ticks across the chart area.
**2. X-Axis (Bottom):**
* **Label:** `# SWE-Agent SFT tokens`
* **Scale:** Categorical/Non-linear progression of token counts.
* **Markers/Ticks:** 0, $2^{21}$, $2^{23}$, $2^{24}$, $1.1 \times 2^{25}$, $1.1 \times 2^{26}$, $1.1 \times 2^{27}$, $1.5 \times 2^{28}$. Vertical dashed gray gridlines extend upward from each tick mark.
**3. Legend (Right):**
Positioned outside the main chart area on the right side, enclosed in a bounding box. It maps colors to methodologies and shapes to metrics.
* **Colors (Methodologies):**
* Red: RL (Reinforcement Learning)
* Orange: SFT (Supervised Fine-Tuning)
* Purple: MT (Multi-Task)
* Blue: Base
* **Shapes (Metrics):**
* Circle: Pass@1
* Square: Pass@2
* Triangle: Pass@3
* **Exact Legend Entries (Top to Bottom):**
* Red Circle: `RL Pass@1`
* Red Square: `RL Pass@2`
* Red Triangle: `RL Pass@3`
* Orange Circle: `SFT Pass@1`
* Orange Square: `SFT Pass@2`
* Orange Triangle: `SFT Pass@3`
* Purple Circle: `MT Pass@1`
* Purple Square: `MT Pass@2`
* Purple Triangle: `MT Pass@3`
* Blue Circle: `Base Pass@1`
* Blue Square: `Base Pass@2`
* Blue Triangle: `Base Pass@3`
### Detailed Analysis
**Visual Encoding & Trend Verification:**
The chart utilizes two types of lines to convey information:
1. **Solid Lines (Intra-token scaling):** At every single X-axis tick, for every color, a solid line connects the Circle (Pass@1) to the Square (Pass@2) to the Triangle (Pass@3). *Trend:* Without exception, these solid lines slope steeply upward, confirming that for any given model at any given training stage, Pass@3 > Pass@2 > Pass@1.
2. **Dashed Lines (Inter-token scaling):** Dashed lines connect identical shapes of the same color across different X-axis ticks (e.g., connecting all Red Circles). *Trend:* The general trend for all dashed lines is upward from left to right, indicating that increasing SFT tokens generally improves the pass rate across all methods and metrics.
**Data Extraction Table:**
*Note: Values are visual approximations derived from the Y-axis scale (±1%).*
| X-Axis Tick | Method (Color) | Pass@1 (Circle) | Pass@2 (Square) | Pass@3 (Triangle) |
| :--- | :--- | :--- | :--- | :--- |
| **0** | Base (Blue) | ~0% | ~0% | ~0% |
| | MT (Purple) | ~1% | ~1% | ~1% |
| | RL (Red) | ~4% | ~9% | ~12% |
| | SFT (Orange) | ~8% | ~13% | ~16% |
| **$2^{21}$** | Base (Blue) | ~1% | ~2% | ~3% |
| | MT (Purple) | ~5% | ~6% | ~7% |
| | SFT (Orange) | ~20% | ~33% | ~38% |
| | RL (Red) | ~23% | ~33% | ~39% |
| **$2^{23}$** | Base (Blue) | ~16% | ~24% | ~28% |
| | MT (Purple) | ~27% | ~36% | ~44% |
| | SFT (Orange) | ~27% | ~35% | ~41% |
| | RL (Red) | ~33% | ~43% | ~48% |
| **$2^{24}$** | Base (Blue) | ~13% | ~22% | ~28% |
| | SFT (Orange) | ~20% | ~31% | ~36% |
| | MT (Purple) | ~29% | ~41% | ~47% |
| | RL (Red) | ~34% | ~42% | ~47% |
| **$1.1 \times 2^{25}$** | Base (Blue) | ~12% | ~27% | ~36% |
| | MT (Purple) | ~31% | ~46% | ~52% |
| | RL (Red) | ~34% | ~45% | ~50% |
| | SFT (Orange) | ~35% | ~45% | ~51% |
| **$1.1 \times 2^{26}$** | Base (Blue) | ~22% | ~38% | ~45% |
| | MT (Purple) | *No Data Plotted* | *No Data Plotted* | *No Data Plotted* |
| | SFT (Orange) | ~37% | ~49% | ~55% |
| | RL (Red) | ~38% | ~51% | ~58% |
| **$1.1 \times 2^{27}$** | Base (Blue) | ~33% | ~48% | ~52% |
| | SFT (Orange) | ~44% | ~55% | ~59% |
| | RL (Red) | ~44% | ~56% | ~60% |
| | MT (Purple) | ~45% | ~55% | ~60% |
| **$1.5 \times 2^{28}$** | Base (Blue) | ~36% | ~48% | ~54% |
| | MT (Purple) | ~46% | ~55% | ~60% |
| | SFT (Orange) | ~48% | ~58% | ~62% |
| | RL (Red) | ~49% | ~58% | ~64% |
### Key Observations
1. **Missing Data:** The MT (Purple) series has a distinct gap; there are no data points plotted at the $1.1 \times 2^{26}$ token mark. The dashed lines bridge directly from $1.1 \times 2^{25}$ to $1.1 \times 2^{27}$.
2. **Performance Hierarchy:** Throughout almost the entire chart, RL (Red) and SFT (Orange) are the top-performing methods, often overlapping or tracking very closely together. MT (Purple) generally sits in the middle, while the Base model (Blue) consistently yields the lowest pass rates.
3. **Anomalous Dips:** At the $2^{24}$ token mark, there is a noticeable regression in performance for the Base (Blue) and SFT (Orange) models compared to their performance at $2^{23}$. The Base Pass@1 drops from ~16% to ~13%, and SFT Pass@1 drops significantly from ~27% to ~20%.
4. **Convergence at Scale:** As the token count reaches the maximum ($1.5 \times 2^{28}$), the performance gap between the methods begins to narrow, particularly between RL, SFT, and MT, which all cluster tightly between 55% and 64% for Pass@2 and Pass@3.
### Interpretation
This chart demonstrates the efficacy of different training interventions on a language model's ability to successfully complete software engineering tasks (implied by "SWE-Agent").
* **The Value of Multiple Attempts:** The steep solid lines at every interval prove that allowing the agent multiple attempts (Pass@3 vs Pass@1) drastically improves the likelihood of success, regardless of the underlying model or training stage.
* **Training Efficacy:** The data clearly shows that fine-tuning (SFT) and Reinforcement Learning (RL) provide massive early advantages over the Base model. For instance, at $2^{21}$ tokens, SFT and RL are already achieving ~40% Pass@3, while the Base model is barely above 0%.
* **Scaling Laws:** The overall upward trajectory of the dashed lines confirms a standard scaling law: exposing the model to more SFT tokens generally increases its pass rate. However, the dips at $2^{24}$ suggest that training is not perfectly linear and may experience instability or require learning rate adjustments at certain phases.
* **Diminishing Returns:** While performance is still climbing at the far right of the chart ($1.5 \times 2^{28}$), the slope of the dashed lines is beginning to flatten slightly compared to the explosive growth seen between $2^{21}$ and $2^{23}$. This suggests that while more data helps, the marginal utility of each additional token is decreasing, and the models may be approaching an asymptotic performance limit for this specific benchmark.
</details>
Figure 5: Comparing the quality of the raw Base, the Agentless mid-trained (MT), the Agentless mid-trained with reasoning-intensive cold-start (SFT), and the Kimi-Dev model after RL as the prior for SWE-Agent adaptation. The tokens of the SWE-Agent SFT trajectories are swept over different scales, and the SWE-Agent performances are reported up to pass@3 on SWE-bench Verified.
We use the publicly available SWE-Agent trajectories to finetune Kimi-Dev. The finetuning dataset we used is released by SWE-smith (yang2025swe), consisting of 5,016 SWE-Agent trajectories collected with Claude 3.7 Sonnet (Anthropic-Claude3.7Sonnet-2025) in the synthetic environments. We perform supervised fine-tuning over Kimi-Dev, setting the maximum context length as 64K tokens during training, and allowing up to 128K tokens and 100 turns during inference.
As shown in Table 2, without collecting more trajectory data over realistic environments, or conducting additional multi-turn agentic RL, our finetuned model achieves a pass@1 score of 48.6% on SWE-bench Verified under the agentic framework setup, without additional test-time scaling. Using the same SFT data, our finetuned Kimi-Dev model outperforms the SWE-agent-LM (yang2025swesmith), with the performance comparable to that of Claude 3.5 Sonnet (49% by the 241022 version). The pass@10 of our SWE-Agent adapted model is 74.0% and surpasses the pass@30 of our model under Agentless (73.8%), proving the higher potential for the SWE-Agent framework.
4.2 Skill Transfer and Generalization
The results shown in Section 4.1 demonstrate that Kimi-Dev, a model with extensive Agentless training, could be adapted to end-to-end SWE-Agents with lightweight supervised finetuning. As the Agentless training recipe consists of mid-training, cold-start (SFT) and RL, we explore the contribution of each part in the recipe to the SWE-Agent capability after adaptation.
To figure this out, we perform SWE-Agent SFT on the original Qwen2.5-72B (Base), the mid-trained model (MT), the model then activated with Agentless-formatted long CoT data (SFT), and the (Kimi-Dev) model after finishing RL training (RL). As we are treating the four models as the prior for SWE-Agents We slightly abuse the term “prior” to refer to a model to be finetuned with SWE-Agent trajectories in the following analysis., and a good prior always demonstrates the ability of fast adaptation with a few shots (finn2017model; brown2020language), we also sweep the amount of SWE-Agent SFT data to measure the efficiency of each prior in SWE-Agent adaptation.
Specifically, we randomly shuffle the 5,016 SWE-Agent trajectories and construct nested subsets of sizes 100, 200, 500, 1,000, and 2,000, where each smaller subset is contained within the larger ones. In addition, we prepend two extreme baselines: (i) zero-shot, where the prior model is directly evaluated under the SWE-Agent framework without finetuning, and (ii) one-step gradient descent, where the model is updated with a single gradient step using the 100-trajectory subset. This yields a range of SFT token budgets spanning { $0$ , $2^{21}$ , $2^{23}$ , $2^{24}$ , $1.1× 2^{25}$ , $1.1× 2^{26}$ , $1.1× 2^{27}$ , $1.5× 2^{28}$ }. After these lightweight SFT experiments, we evaluate performance in terms of pass@{1,2,3} under the SWE-Agent framework, with evaluations for pass@1 conducted at temperature 0, and those for pass@2 and pass@3 at temperature 1.0.
Figure 5 presents the SWE-Agent performances of each prior (Base, MT, SFT, RL) after being fine-tuned with different amounts of agentic trajectories. We have the following observations:
1. The RL prior outperforms all the other models in nearly all the SWE-Agent SFT settings. This demonstrates that the Agentless training recipe indeed strengthens the prior in terms of SWE-Agent adaptation. For example, To achieve the top pass@1 performance of the Base prior, the RL prior needs only $2^{23}$ SWE-Agent SFT tokens, whereas the Base prior consumes $1.5× 2^{28}$ tokens.
1. The MT prior is lagged behind the SFT and the RL ones in extremely data-scarce settings (zero-shot ( $0$ ) and one-step gradient descent ( $2^{21}$ ) ), but quickly becomes on par with them after 200 trajectories ( $2^{24}$ ) are available for finetuning. This indicates that adaptation efficiency remains comparable after the prior is strengthened through Agentless mid-training.
1. The performance of the SFT prior is mostly similar to the RL one except for two cases: (i) The SFT prior outperforms the RL one under the zero-shot setting. This is reasonable, as the RL prior might overfit to the Agentless input-output format, while the SFT prior suffers less from this. (ii) The SFT prior exhibits a significant degradation with 200 SWE-Agent trajectories ( $2^{24}$ ). A potential reason could be that the 200 trajectories collapse onto a single data mode, leading the SFT prior to overfit through memorization (chu2025sft); the RL prior instead embeds stronger transferable skills and thus generalizes better.
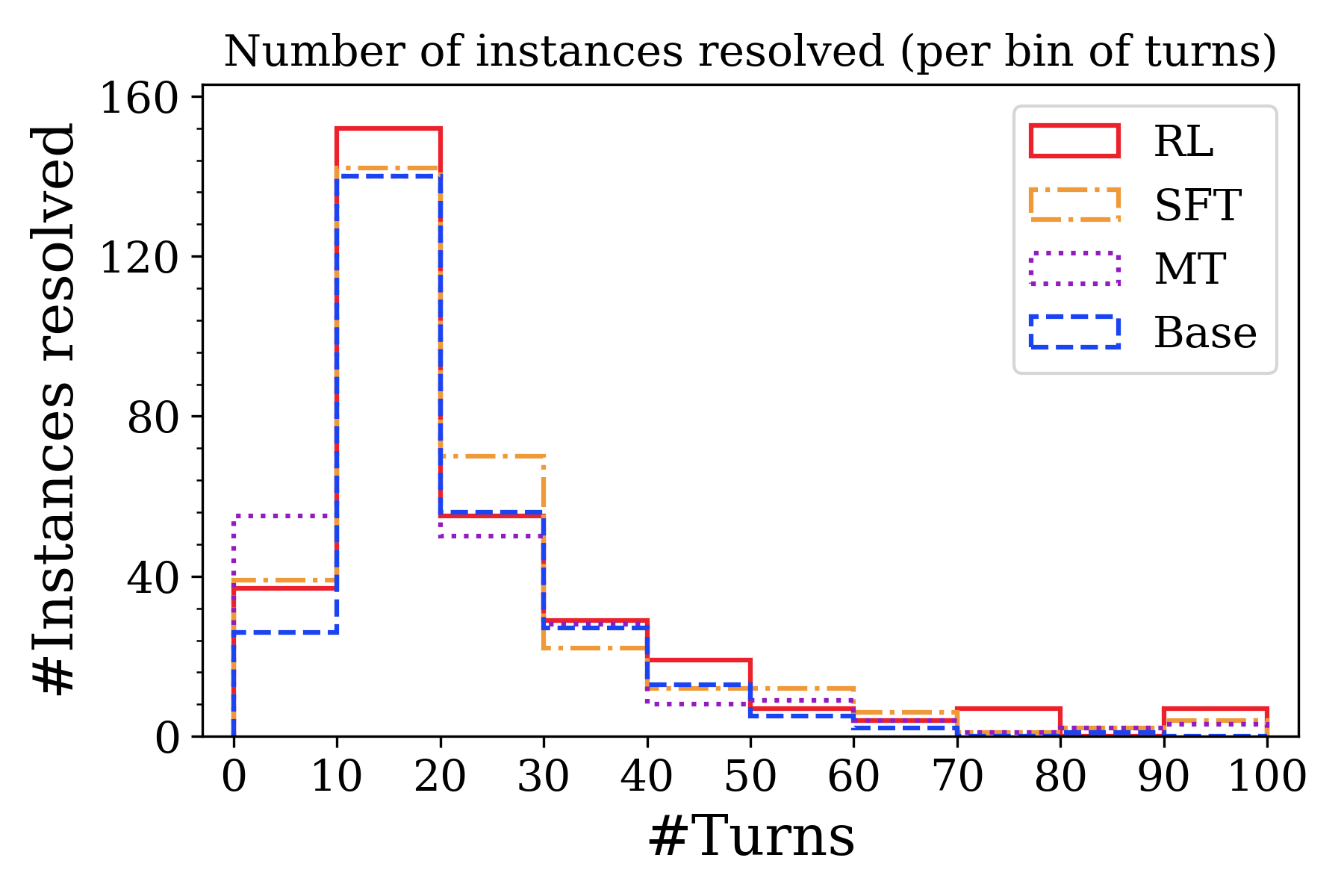
<details>
<summary>figs/sec4_long_cot_to_multi_turn/hist_steps_6x4.png Details</summary>
### Visual Description
## Step Histogram: Number of instances resolved (per bin of turns)
### Overview
The image is a technical step histogram (or step chart) displaying the distribution of resolved instances across different numbers of turns for four distinct computational models or methodologies. The chart illustrates how many turns it takes for each method to resolve an instance, grouped into bins of 10 turns, ranging from 0 to 100 turns.
### Components/Axes
**Header Region:**
* **Title:** Located at the top center, reading exactly: "Number of instances resolved (per bin of turns)".
**Main Chart Region (Axes & Scale):**
* **Y-axis (Vertical, Left):**
* **Label:** "#Instances resolved" (Rotated 90 degrees counter-clockwise, reading bottom to top).
* **Scale:** Major tick marks are labeled at 0, 40, 80, 120, and 160.
* **Minor Ticks:** There are three minor tick marks between each major interval, indicating increments of 10 units per minor tick.
* **X-axis (Horizontal, Bottom):**
* **Label:** "#Turns" (Centered below the axis numbers).
* **Scale:** Major tick marks are labeled at intervals of 10: 0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100.
**Legend Region:**
* **Placement:** Located in the top-right quadrant of the chart area, enclosed in a light gray bounding box.
* **Mappings (Cross-referenced with chart lines):**
* **Solid Red Line:** Labeled "RL"
* **Dash-dot Orange Line:** Labeled "SFT"
* **Dotted Purple Line:** Labeled "MT"
* **Dashed Blue Line:** Labeled "Base"
### Detailed Analysis
**Trend Verification:**
Before extracting specific data points, the visual trends for each series are established to ensure logical consistency:
* **General Trend (All Series):** All four models exhibit a right-skewed distribution. They start with a moderate number of resolutions in the 0-10 bin, experience a massive, dominant spike in the 10-20 bin, drop sharply in the 20-30 bin, and then form a long, gradually decaying tail approaching zero as turns reach 100.
* **RL (Solid Red):** Starts moderately low, achieves the absolute highest peak of any model in the 10-20 bin, drops steeply but remains competitive in the mid-ranges, and shows slight, anomalous bumps in the 70-80 and 90-100 bins.
* **SFT (Dash-dot Orange):** Starts moderately low, hits the second-highest peak in the 10-20 bin, and notably sustains the highest resolution rate in the 20-30 bin before decaying.
* **MT (Dotted Purple):** Exhibits the highest initial resolution rate in the 0-10 bin, spikes to tie for third in the 10-20 bin, and generally decays faster than RL and SFT in the mid-to-late turns.
* **Base (Dashed Blue):** Starts with the lowest resolution rate in the 0-10 bin, spikes to tie MT in the 10-20 bin, and generally forms the lowest boundary of the tail from 50 turns onward.
**Data Extraction Table:**
*Note: Values are approximate (denoted by ~) based on visual alignment with the Y-axis major and minor tick marks.*
| Turn Bin (X-axis) | RL (Solid Red) | SFT (Dash-dot Orange) | MT (Dotted Purple) | Base (Dashed Blue) |
| :--- | :--- | :--- | :--- | :--- |
| **0 - 10** | ~38 | ~39 | ~55 | ~26 |
| **10 - 20** | ~152 | ~142 | ~140 | ~140 |
| **20 - 30** | ~55 | ~70 | ~50 | ~56 |
| **30 - 40** | ~29 | ~22 | ~28 | ~27 |
| **40 - 50** | ~19 | ~12 | ~8 | ~13 |
| **50 - 60** | ~7 | ~12 | ~9 | ~5 |
| **60 - 70** | ~4 | ~6 | ~4 | ~2 |
| **70 - 80** | ~7 | ~1 | ~1 | ~1 |
| **80 - 90** | ~2 | ~2 | ~2 | ~1 |
| **90 - 100** | ~7 | ~4 | ~3 | ~1 |
### Key Observations
1. **The "Sweet Spot":** The vast majority of instances across all models are resolved between 10 and 20 turns. The peak for RL (~152) is nearly triple its next highest bin (~55 in the 20-30 bin).
2. **Early Resolution Variance:** In the 0-10 turn bin, the MT model significantly outperforms the others (~55 instances vs. Base's ~26).
3. **Mid-Turn Sustenance:** The SFT model shows a unique resilience in the 20-30 turn bin, resolving ~70 instances, which is noticeably higher than the other three models in that specific range.
4. **Long Tail Anomalies:** The RL model shows slight, unexpected increases in resolutions very late in the process (bins 70-80 and 90-100), whereas the Base model almost entirely flatlines after 60 turns.
### Interpretation
The data demonstrates the efficiency and behavioral characteristics of four different models (likely Large Language Models or conversational agents, given the terminology "turns", "RL" [Reinforcement Learning], "SFT" [Supervised Fine-Tuning], and "Base").
* **Optimal Interaction Length:** The overwhelming concentration of resolved instances in the 10-20 turn bin suggests that the tasks being evaluated have a natural complexity requiring a brief back-and-forth. If an instance is not resolved within 30 turns, the probability of it being resolved at all drops precipitously.
* **Model Characteristics:**
* **MT** is highly effective at solving simple problems quickly (0-10 turns) but loses its comparative advantage as interactions lengthen.
* **RL** is the most capable model when the interaction hits the expected complexity (10-20 turns). It also shows a stubbornness or capability to eventually solve edge-case problems that drag on to 70-100 turns.
* **SFT** is the most robust model for slightly more complex interactions that spill over the average, dominating the 20-30 turn range.
* **Base** is the least capable overall. It struggles to solve things quickly (lowest in 0-10) and gives up or fails almost entirely on long, complex interactions (lowest from 60-100).
* **Peircean Investigative Reading:** The sharp drop-off after 30 turns implies a threshold of diminishing returns. From a system design or UX perspective, this chart suggests that if an agent has not resolved a user's issue by turn 30, it might be more efficient to escalate to a human or reset the prompt, as the models are highly unlikely to find a resolution in the subsequent 70 turns.
</details>
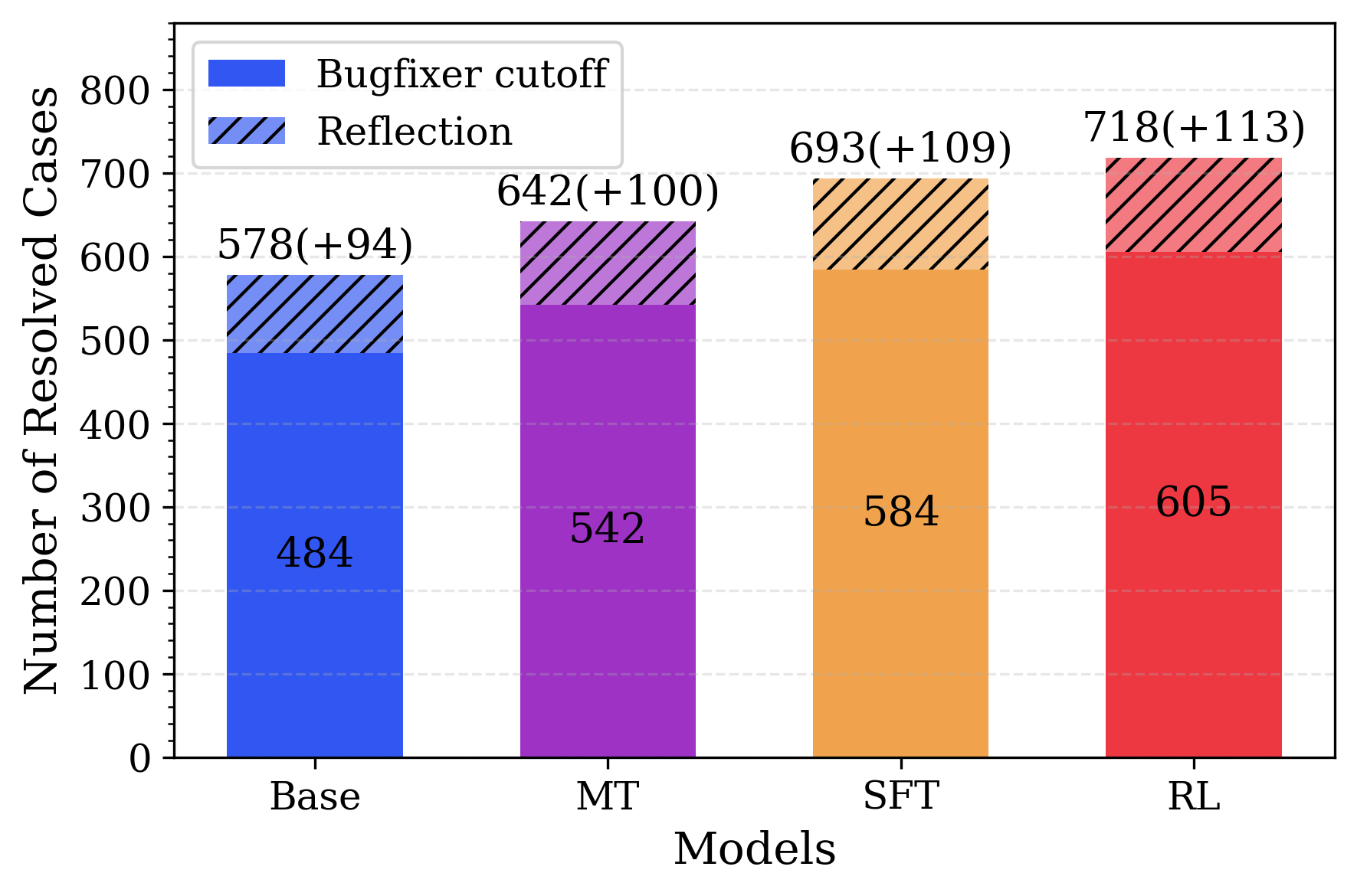
<details>
<summary>figs/skill_analysis_figure.png Details</summary>
### Visual Description
## Stacked Bar Chart: Number of Resolved Cases by Model
### Overview
This image is a stacked bar chart comparing the performance of four different machine learning models (Base, MT, SFT, RL) based on the "Number of Resolved Cases." Each bar is divided into two segments representing different phases or methods of resolution: a base "Bugfixer cutoff" and an additional "Reflection" phase. The chart demonstrates a clear progression in performance across the models.
### Components/Axes
**Spatial Layout & Regions:**
* **Top-Left:** A legend enclosed in a rectangular box with a gray border.
* **Left Edge (Y-axis):** Vertical axis with numerical scale and title.
* **Bottom Edge (X-axis):** Horizontal axis with categorical labels and title.
* **Center (Main Chart):** Four distinct stacked bars with embedded numerical data labels. Background features light gray, dashed horizontal grid lines aligned with the major Y-axis ticks.
**Axes Details:**
* **Y-axis (Vertical):**
* **Title:** "Number of Resolved Cases" (oriented vertically, reading bottom to top).
* **Scale:** Ranges from 0 to 800.
* **Markers:** Major tick marks every 100 units (0, 100, 200, 300, 400, 500, 600, 700, 800). Minor tick marks occur every 20 units between the major ticks.
* **X-axis (Horizontal):**
* **Title:** "Models" (centered below the categories).
* **Categories (Left to Right):** "Base", "MT", "SFT", "RL".
**Legend Details:**
* **Solid Blue Rectangle:** Labeled "Bugfixer cutoff".
* **Blue Rectangle with Black Diagonal Hatching:** Labeled "Reflection".
* *Note on Visual Encoding:* While the legend uses blue for both examples, the actual chart uses a distinct color for each model's bar. The true visual differentiator between the two data series is the **texture**: solid color represents "Bugfixer cutoff," and diagonal black hatching over the color represents "Reflection."
### Detailed Analysis
**Trend Verification:**
Visually, there is a strict upward trend moving from left to right. The total height of the bars increases sequentially from Base to RL. Furthermore, the height of the solid bottom portion ("Bugfixer cutoff") also increases sequentially. The hatched top portion ("Reflection") appears to grow slightly thicker as we move right.
**Data Point Extraction:**
Below is the precise extraction of data embedded within and above each bar, moving from left to right. The math (Solid + Hatched = Total) is verified for each column.
1. **Model: Base** (Color: Blue)
* **Bugfixer cutoff (Solid bottom):** 484 (Label centered inside the solid bar)
* **Reflection (Hatched top):** +94
* **Total Resolved:** 578 (Label "578(+94)" positioned above the bar)
* *Visual Check:* The solid bar ends just below the 500 gridline. The top of the bar ends just below the 600 gridline.
2. **Model: MT** (Color: Purple)
* **Bugfixer cutoff (Solid bottom):** 542 (Label centered inside the solid bar)
* **Reflection (Hatched top):** +100
* **Total Resolved:** 642 (Label "642(+100)" positioned above the bar)
* *Visual Check:* The solid bar ends roughly midway between 500 and 600. The top of the bar ends roughly midway between 600 and 700.
3. **Model: SFT** (Color: Orange)
* **Bugfixer cutoff (Solid bottom):** 584 (Label centered inside the solid bar)
* **Reflection (Hatched top):** +109
* **Total Resolved:** 693 (Label "693(+109)" positioned above the bar)
* *Visual Check:* The solid bar ends just below the 600 gridline. The top of the bar ends just below the 700 gridline.
4. **Model: RL** (Color: Red)
* **Bugfixer cutoff (Solid bottom):** 605 (Label centered inside the solid bar)
* **Reflection (Hatched top):** +113
* **Total Resolved:** 718 (Label "718(+113)" positioned above the bar)
* *Visual Check:* The solid bar ends just above the 600 gridline. The top of the bar ends just above the 700 gridline.
**Reconstructed Data Table:**
| Model | Bugfixer cutoff (Base Cases) | Reflection (Added Cases) | Total Resolved Cases |
| :--- | :--- | :--- | :--- |
| Base | 484 | 94 | 578 |
| MT | 542 | 100 | 642 |
| SFT | 584 | 109 | 693 |
| RL | 605 | 113 | 718 |
### Key Observations
* **Consistent Improvement:** Every subsequent model iteration (from Base -> MT -> SFT -> RL) yields a higher number of resolved cases in *both* the initial "Bugfixer cutoff" phase and the secondary "Reflection" phase.
* **Highest Performer:** The "RL" model is the most effective, resolving a total of 718 cases.
* **Reflection Efficacy:** The "Reflection" technique consistently adds value across all models. Interestingly, the absolute number of cases resolved by Reflection increases as the base model improves (94 -> 100 -> 109 -> 113).
### Interpretation
The data demonstrates a clear hierarchy of model efficacy in a bug-fixing or problem-resolution context. The progression from "Base" to "MT" (likely Machine Translation or Multi-Task), to "SFT" (Supervised Fine-Tuning), and finally to "RL" (Reinforcement Learning) shows that more advanced training methodologies directly correlate with higher resolution rates.
From a Peircean investigative standpoint, the relationship between the "Bugfixer cutoff" and "Reflection" is highly revealing. "Reflection" (likely a mechanism where the model reviews and corrects its own initial output) is not just a static bonus; its effectiveness scales with the underlying capability of the model. Because the RL model has a better foundational understanding (resolving 605 cases initially compared to the Base model's 484), it is also more capable of successfully critiquing and fixing its own edge-case failures (adding 113 cases via reflection compared to the Base model's 94). This suggests a compounding return on investment when applying advanced prompting/reflection techniques to superior foundational models.
</details>
Figure 6: Left: Performance of the four priors under turn limits after SWE-Agent adaptation. Right: The characterization of the BugFixer and the reflection skills for each prior by counting the resolved cases of the 3 runs at Stage-3 cutoff moment, and comparing those with the final success cases.
From long CoT to extended multi-turn interactions.
We hypothesize that reflective behaviors cultivated through long chain-of-thought reasoning may transfer to settings requiring extended multi-turn interactions. To examine this, we evaluate the four priors (Base, MT, SFT, and RL) by finetuning on the 5,016 trajectories and test on SWE-bench Verified, under varying turn limits with pass@3 as the metric (Figure 6, left). The distinct interaction-length profiles show supportive evidence: the RL prior, after finetuning, continues to make progress beyond 70 turns, while the SFT, mid-trained, and raw models show diminishing returns around 70, 60, and 50 turns, respectively.
We further evaluate the efficacy of the Agentless skill priors (BugFixer and reflection) in the SWE-Agent adapted model. For BugFixer, given that the SWE-Agent may autonomously reflect between the five stages, we examine the moment in each trajectory when the bug fix of the third stage is initially completed, and the test rerun of the fourth stage has not yet been entered. Heuristically, when the SWE-Agent just completes the third stage, it has not yet obtained the execution feedback from the fourth stage, and thus has not further reflected based on the execution information or refined the bug fix. We therefore calculate the success rate of direct submission at this cutoff moment, which reflects the capability of the BugFixer skill. Regarding reflection, we further compare the performance at the cutoff point with the performance after full completion for each problem. The increment in the number of successful problems is used to reflect the capability of the reflection skill.
We use kimi-k2-0711-preview (team2025kimi_k2) to annotate the SWE-Agent trajectories, identifying the stage to which each turn belongs. Figure 6 (right) demonstrates that both skills are strengthened through each stage of the Agentless training recipe: For the BugFixer skill, the cutoff performance at Stage-3 within the SWE-Agent interaction trajectories of the four adapted models shows consistent improvement, ranging from 484 cases resolved by the Base prior to 605 cases by the RL prior, as measured by the number of successful resolutions within three passes. For the reflection skill, examining the performance gains from Stage-3 to the end of the trajectories reveals a similar trend, with improvements increasing from +94 under the Base prior to +113 under the RL prior. Taken together, the adapted model from the RL prior achieves the strongest overall performance across both skills. It should be noted that our analysis of the reflection skill remains coarse-grained, since the measured performance gains between the two checkpoints capture not only agentic reflection and redo behaviors, but also the intermediate test-writing process performed by the SWE-Agent. A more fine-grained evaluation that isolates the TestWriter skill prior is left for future work. The prompt for SWE-Agent stage annotation, extended qualitative studies, as well as additional discussions for skill transfer and generalization, are covered in Appendix G.
<details>
<summary>figs/sec4_swe_agent_rl/rebuttal_cmp_prior_pass1.png Details</summary>
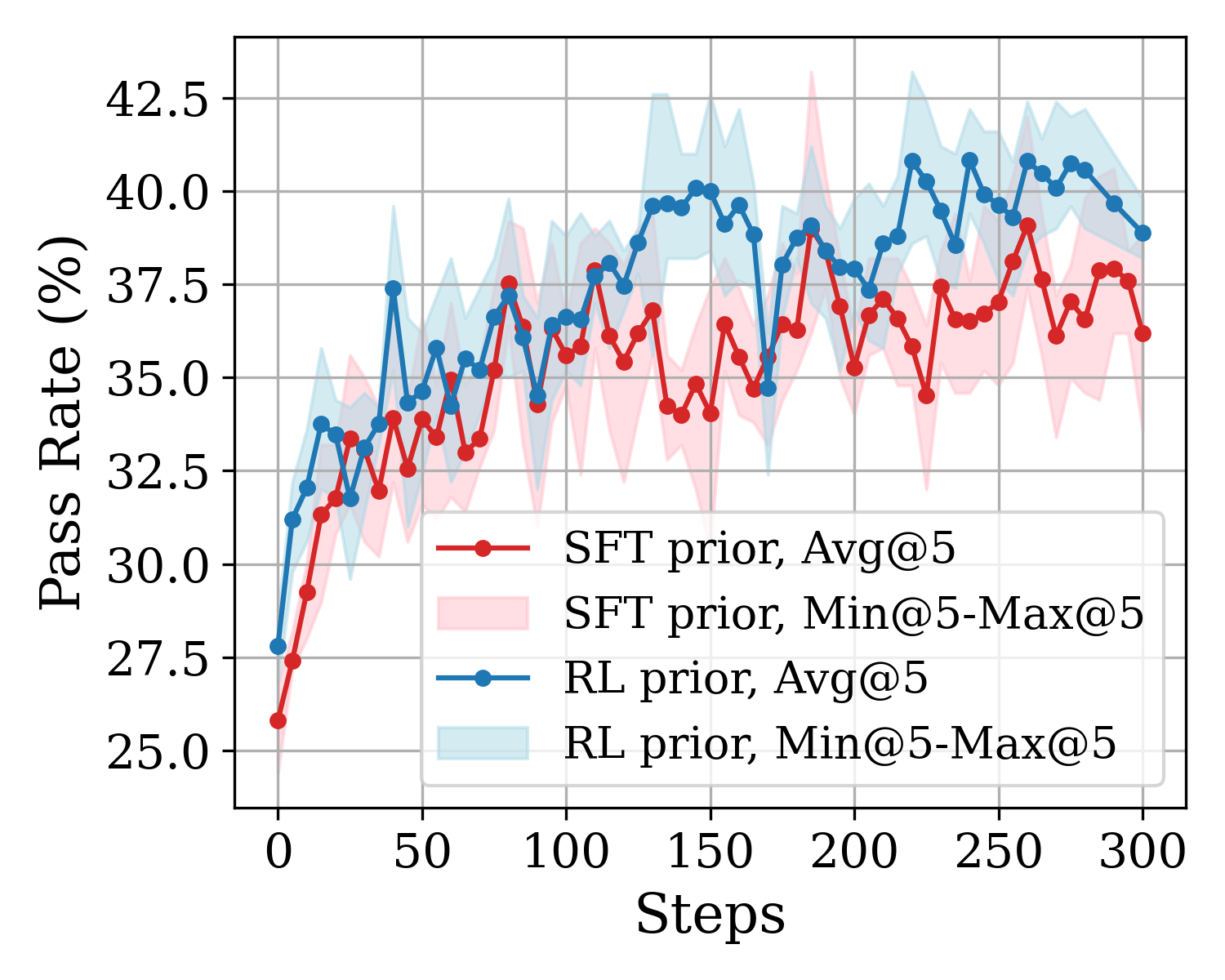
### Visual Description
## Line Chart: Pass Rate vs. Steps for SFT and RL Priors
### Overview
This image is a technical line chart displaying the performance metric "Pass Rate (%)" over a series of training or evaluation "Steps". It compares two different methodologies or initializations: "SFT prior" and "RL prior". The chart includes average performance lines alongside shaded regions representing the variance (minimum to maximum range) across multiple runs (specifically, 5 runs, as indicated by "@5"). The sole language present in the image is English.
### Components/Axes
**1. Spatial Grounding & Layout:**
* **Main Chart:** Occupies the central area, overlaid on a gray grid with major gridlines corresponding to the axis ticks.
* **Y-Axis (Left):** Vertical axis representing the performance metric.
* **X-Axis (Bottom):** Horizontal axis representing time or progression.
* **Legend (Bottom Right):** Positioned inside the main chart area, in the lower right quadrant, bounded by a thin light-gray border.
**2. Axis Details:**
* **Y-Axis Label:** "Pass Rate (%)" (Rotated 90 degrees counter-clockwise, centered vertically).
* **Y-Axis Scale/Markers:** Linear scale. Ticks are marked at intervals of 2.5. Visible markers: 25.0, 27.5, 30.0, 32.5, 35.0, 37.5, 40.0, 42.5.
* **X-Axis Label:** "Steps" (Centered horizontally below the axis).
* **X-Axis Scale/Markers:** Linear scale. Ticks are marked at intervals of 50. Visible markers: 0, 50, 100, 150, 200, 250, 300.
**3. Legend Details (Cross-referenced with chart elements):**
* **Red line with circular marker:** Labeled `SFT prior, Avg@5`. Corresponds to the solid red line with dot markers tracking the average pass rate.
* **Light pink shaded rectangle:** Labeled `SFT prior, Min@5-Max@5`. Corresponds to the light red/pink shaded band behind the red line, representing the variance.
* **Blue line with circular marker:** Labeled `RL prior, Avg@5`. Corresponds to the solid blue line with dot markers tracking the average pass rate.
* **Light blue shaded rectangle:** Labeled `RL prior, Min@5-Max@5`. Corresponds to the light blue shaded band behind the blue line, representing the variance.
### Detailed Analysis
**Trend Verification & Data Extraction:**
* **Series 1: RL prior, Avg@5 (Blue Line)**
* *Visual Trend:* The blue line starts slightly higher than the red line. It exhibits a steep initial climb during the first 50 steps. From step 50 to 300, it continues a gradual upward trend but with significant step-to-step volatility (zigzagging). It consistently remains above the red line for the vast majority of the chart.
* *Key Approximate Data Points (±0.5% uncertainty):*
* Step 0: ~27.8%
* Step 25: ~33.5%
* Step 50: ~34.5%
* Step 100: ~36.5%
* Step 150: ~40.0%
* Step 200: ~38.0%
* Step 220 (Peak): ~41.0%
* Step 250: ~39.5%
* Step 300: ~39.0%
* **Series 2: SFT prior, Avg@5 (Red Line)**
* *Visual Trend:* The red line starts at the lowest point on the graph. It also climbs sharply in the first 50 steps. After step 50, it plateaus and oscillates heavily. It experiences a notable dip between steps 125 and 175 before recovering. It generally tracks below the blue line.
* *Key Approximate Data Points (±0.5% uncertainty):*
* Step 0: ~25.8%
* Step 25: ~33.5% (Briefly intersects/matches the blue line)
* Step 50: ~33.5%
* Step 100: ~35.5%
* Step 150: ~34.0% (Notable dip)
* Step 200: ~35.5%
* Step 260 (Peak): ~39.0%
* Step 300: ~36.2%
* **Variance Bands (Min@5-Max@5):**
* *RL prior (Light Blue):* The variance is relatively tight at the beginning but expands significantly as training progresses. Around Step 130-150, the band spans from roughly 38% to 43%. At Step 220, it spans from roughly 38% to 43.5%.
* *SFT prior (Light Pink):* This band also expands over time. It shows extreme variance spikes, particularly around Step 180 where the minimum drops to ~34% and the maximum spikes to ~43.5%.
### Key Observations
1. **Superiority of RL Prior:** The "RL prior" consistently outperforms the "SFT prior" in terms of the average Pass Rate across almost the entire 300-step duration.
2. **High Volatility:** Both methods exhibit high step-to-step volatility in their average scores, indicated by the jagged nature of both lines.
3. **Increasing Variance:** The shaded regions for both methods grow wider as the steps increase, indicating that the outcomes of individual runs (the 5 runs making up the min/max) diverge more from one another later in the process compared to the beginning.
4. **Overlapping Ranges:** Despite the blue average line being consistently higher, the light blue and light pink shaded areas overlap significantly. This means that a "best-case" SFT run could occasionally outperform a "worst-case" RL run at specific steps.
### Interpretation
In the context of machine learning (specifically Large Language Models or similar AI training paradigms), this chart likely compares two different starting points or foundational models before applying a subsequent training phase (the "Steps" on the X-axis).
* **SFT prior:** Supervised Fine-Tuning prior.
* **RL prior:** Reinforcement Learning prior (likely RLHF - Reinforcement Learning from Human Feedback).
**What the data suggests:**
Starting a new training phase with a model that has already undergone Reinforcement Learning (RL prior) yields a higher and faster-converging "Pass Rate" (likely on a coding, reasoning, or specific benchmark task) compared to starting with a model that has only undergone Supervised Fine-Tuning (SFT prior).
**Reading between the lines (Peircean investigative):**
The notation "@5" strongly implies that the researchers ran this experiment 5 separate times with different random seeds to ensure statistical reliability. The fact that they included the Min-Max bands rather than just standard deviation shows they want to highlight the absolute best and worst-case scenarios.
The high volatility (zigzagging) of the average lines, combined with the widening variance bands, suggests that the training process occurring over these 300 steps is somewhat unstable. The model is learning (the overall trend is up), but it is "forgetting" or fluctuating wildly between evaluation steps. The RL prior not only achieves a higher ceiling but appears slightly more robust against the severe dips seen in the SFT prior (e.g., the SFT dip at step 150). Ultimately, the data advocates for using the RL-tuned model as the base for whatever subsequent training is being measured here.
</details>
<details>
<summary>figs/sec4_swe_agent_rl/rebuttal_cmp_prior_pass3.png Details</summary>
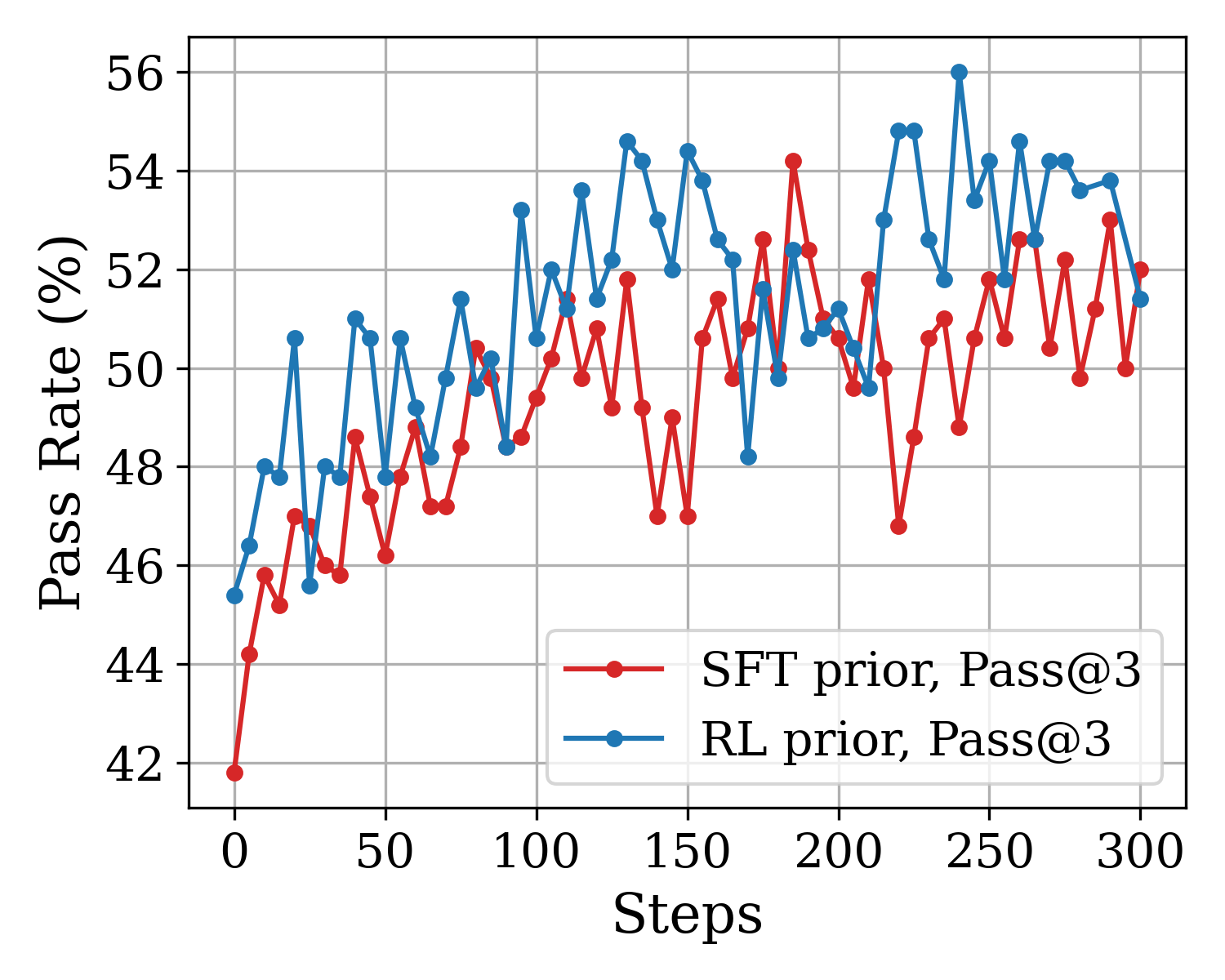
### Visual Description
## Line Chart: Pass Rate vs. Steps for SFT and RL Priors
### Overview
This image is a 2D line chart comparing the performance of two different machine learning models or methodologies—labeled as "SFT prior" and "RL prior"—over a series of training or evaluation steps. The performance is measured by a "Pass Rate (%)" metric. The chart displays two highly volatile data series that generally trend upward over time, with the "RL prior" consistently outperforming the "SFT prior" for the majority of the recorded steps.
### Components/Axes
**Component Isolation & Spatial Grounding:**
* **Main Chart Area:** Occupies the majority of the image, featuring a light gray grid on a white background. The grid lines correspond to the major ticks on both axes.
* **Y-Axis (Left):**
* **Title:** "Pass Rate (%)" (Oriented vertically, reading bottom to top).
* **Scale:** Ranges from 42 to 56.
* **Markers/Ticks:** Major gridlines and labels are placed at intervals of 2: `42, 44, 46, 48, 50, 52, 54, 56`.
* **X-Axis (Bottom):**
* **Title:** "Steps" (Centered below the axis).
* **Scale:** Ranges from 0 to 300.
* **Markers/Ticks:** Major gridlines and labels are placed at intervals of 50: `0, 50, 100, 150, 200, 250, 300`.
* **Legend (Bottom-Right):** Located inside the main chart area, positioned in the lower right quadrant (spanning roughly from step 120 to 300, and pass rate 42 to 46). It contains two entries:
* `[Red Line with circular marker]` : "SFT prior, Pass@3"
* `[Blue Line with circular marker]` : "RL prior, Pass@3"
### Detailed Analysis
**Trend Verification & Data Extraction:**
Both data series consist of discrete data points connected by straight lines. There appears to be a data point plotted every 5 steps (60 points total per line). Due to the high density and volatility, approximate values (`~`) are extracted at major grid intervals and significant inflection points (peaks/valleys) to accurately reconstruct the chart's behavior.
**1. RL prior, Pass@3 (Blue Line)**
* *Visual Trend:* The blue line starts at a moderate pass rate, rises sharply within the first 20 steps, and then enters a highly volatile oscillation pattern. It generally maintains a higher baseline than the red line, frequently peaking above 54%, but experiences occasional sharp drops.
* *Key Data Points (Approximate ±0.5%):*
* Step 0: ~45.4% (Starting point)
* Step 20: ~50.6% (Initial peak)
* Step 50: ~47.8%
* Step 75: ~51.4%
* Step 95: ~53.2%
* Step 100: ~50.6%
* Step 130: ~54.6% (Major peak)
* Step 150: ~54.4%
* Step 170: ~48.2% (Significant valley/drop)
* Step 200: ~51.2%
* Step 220: ~54.8%
* Step 240: ~56.0% (Absolute maximum peak on the chart)
* Step 250: ~54.2%
* Step 300: ~51.4% (Ending point)
**2. SFT prior, Pass@3 (Red Line)**
* *Visual Trend:* The red line starts at the lowest point on the chart. It exhibits a steep initial climb similar to the blue line but generally oscillates at a lower tier (mostly between 46% and 52%). It has a few distinct, sharp spikes that briefly surpass the blue line.
* *Key Data Points (Approximate ±0.5%):*
* Step 0: ~41.8% (Starting point, absolute minimum)
* Step 20: ~47.0%
* Step 50: ~46.2%
* Step 80: ~50.4%
* Step 100: ~49.4%
* Step 130: ~51.8%
* Step 150: ~47.0% (Valley)
* Step 185: ~54.2% (Absolute maximum peak for this series)
* Step 200: ~50.6%
* Step 220: ~46.8% (Deep valley)
* Step 250: ~51.8%
* Step 290: ~53.0% (Late peak)
* Step 300: ~52.0% (Ending point)
### Key Observations
* **Performance Gap:** The RL prior (blue) demonstrates a clear advantage over the SFT prior (red) for the vast majority of the 300 steps. The blue line is visibly shifted upward relative to the red line.
* **Volatility:** Both metrics are incredibly noisy. A pass rate might jump or drop by 4% to 6% within a span of just 5 to 10 steps (e.g., the blue line dropping from ~52% at step 165 to ~48% at step 170, then back up to ~51% at step 175).
* **Crossovers:** While RL is generally better, the SFT prior does occasionally spike higher than the RL prior at specific intervals (most notably around step 185, and briefly near step 290).
* **Convergence:** Towards the end of the chart (steps 250-300), the two lines appear to entangle more frequently, suggesting the performance gap may be narrowing as the number of steps increases.
### Interpretation
* **Contextual Meaning:** The chart likely represents the evaluation of Large Language Models (LLMs) on a coding or reasoning benchmark. "Pass@3" means the model is considered successful if the correct answer is generated within 3 attempts. "SFT" stands for Supervised Fine-Tuning, and "RL" stands for Reinforcement Learning.
* **Data Implications:** The data strongly suggests that using a Reinforcement Learning prior provides a better starting point (Step 0 is ~3.6% higher) and maintains a higher average performance ceiling throughout the training/evaluation process compared to a Supervised Fine-Tuning prior.
* **Reading Between the Lines (Peircean Investigative):** The extreme step-to-step volatility (the "sawtooth" pattern) is highly indicative of a small evaluation dataset or a small batch size during these steps. If the evaluation set were large, the pass rate would likely smooth out. The fact that both models trend upward indicates that whatever process is occurring over these "Steps" (likely further training, optimization, or a search process) is generally effective at improving the Pass@3 rate, despite the high variance. The RL prior's massive spike to 56% at step 240 shows its peak potential, but its inability to maintain that level suggests instability in the model's generation consistency.
</details>
<details>
<summary>figs/sec4_swe_agent_rl/rebuttal_cmp_prior_pass5.png Details</summary>
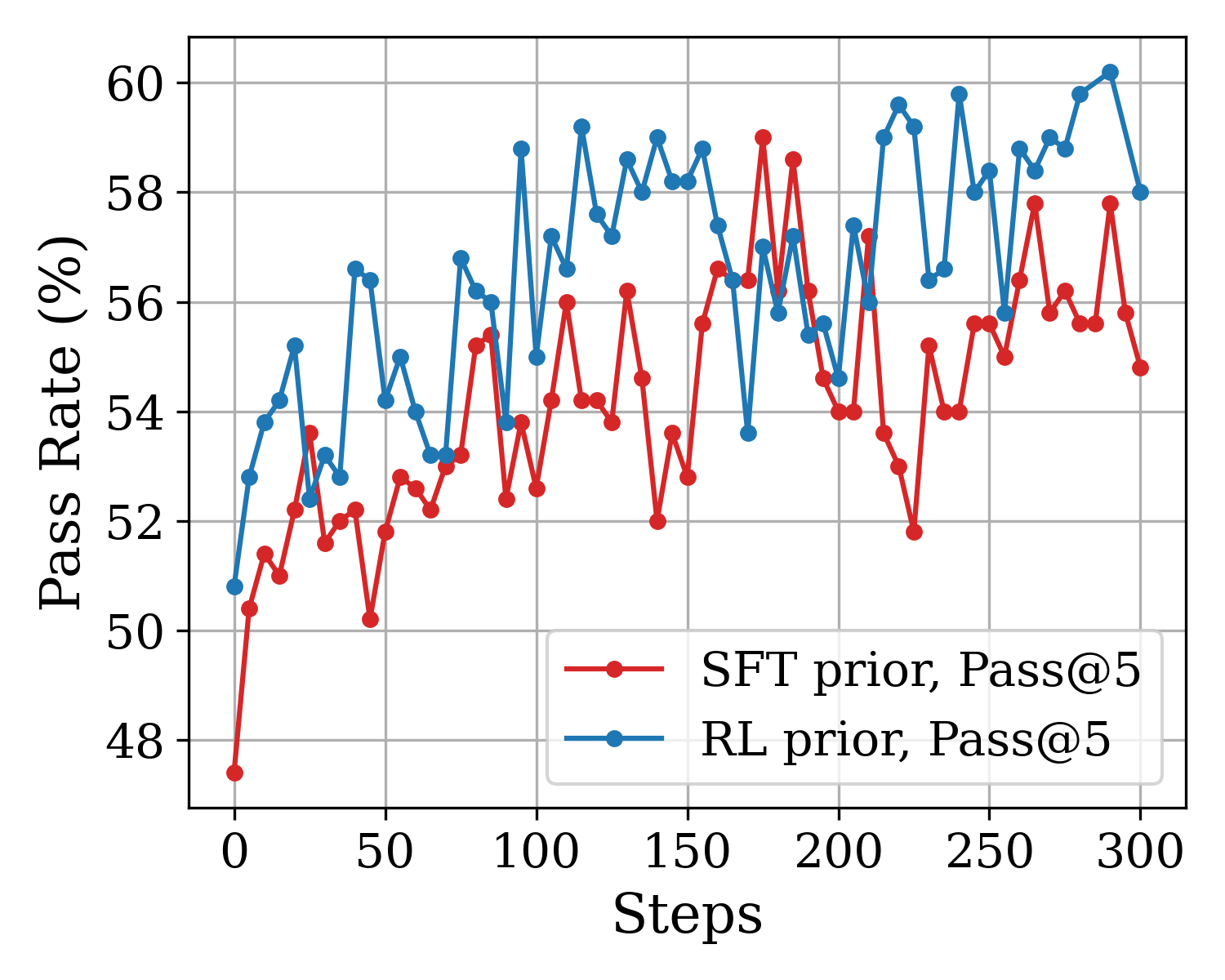
### Visual Description
## Line Chart: Pass Rate vs. Steps for SFT and RL Priors
### Overview
This image is a line chart comparing the performance of two different machine learning models or training methodologies over a series of training steps. The performance is measured by a "Pass Rate (%)" metric, specifically "Pass@5". The chart displays two highly volatile data series that both exhibit an overall upward trend over time.
### Components/Axes
**Component Isolation & Spatial Grounding:**
* **Main Chart Area:** Occupies the center and upper portions of the image, featuring a light gray grid background.
* **Y-Axis (Left edge):**
* **Label:** "Pass Rate (%)" (Oriented vertically, reading bottom to top).
* **Scale:** Linear, ranging from below 48 to above 60.
* **Markers/Ticks:** Explicitly labeled at 48, 50, 52, 54, 56, 58, and 60. Horizontal grid lines extend from these markers across the chart.
* **X-Axis (Bottom edge):**
* **Label:** "Steps" (Centered below the axis).
* **Scale:** Linear, ranging from 0 to 300.
* **Markers/Ticks:** Explicitly labeled at 0, 50, 100, 150, 200, 250, and 300. Vertical grid lines extend upward from these markers.
* **Legend (Bottom-Right quadrant):** Enclosed in a white box with a light gray border, positioned in the lower right area of the main chart grid.
* **Red line with circular marker:** Labeled "SFT prior, Pass@5"
* **Blue line with circular marker:** Labeled "RL prior, Pass@5"
### Detailed Analysis
*Note: Data points are plotted approximately every 5 steps. Due to the density of the points, values below are extracted at major axis intervals and notable peaks/troughs to accurately reconstruct the visual trends. Values are approximate (±0.5%).*
**Trend Verification 1: RL prior, Pass@5 (Blue Line)**
* **Visual Trend:** The blue line begins near 51%, experiences a rapid initial climb, and then enters a highly volatile phase characterized by sharp peaks and deep valleys. Despite the volatility, the moving average trends upward, generally staying above the red line, and finishes near 58%.
* **Extracted Data Points (Approximate):**
* Step 0: ~50.8%
* Step 20: ~55.2% (Local peak)
* Step 50: ~54.2%
* Step 75: ~56.8%
* Step 95: ~58.8% (Sharp peak)
* Step 100: ~55.0% (Sharp drop)
* Step 150: ~58.2%
* Step 170: ~53.6% (Deep trough)
* Step 200: ~54.6%
* Step 220: ~59.6% (High peak)
* Step 250: ~58.4%
* Step 290: ~60.2% (Highest recorded peak on chart)
* Step 300: ~58.0%
**Trend Verification 2: SFT prior, Pass@5 (Red Line)**
* **Visual Trend:** The red line starts significantly lower than the blue line, below 48%. It also exhibits extreme volatility (a "sawtooth" pattern). While it trends upward over the 300 steps, it generally remains below the blue line, with only a few brief spikes where it matches or exceeds the blue line's performance. It finishes near 55%.
* **Extracted Data Points (Approximate):**
* Step 0: ~47.4% (Lowest point on chart)
* Step 25: ~53.6%
* Step 45: ~50.2% (Deep trough)
* Step 50: ~51.8%
* Step 100: ~52.6%
* Step 130: ~56.2% (Local peak)
* Step 150: ~52.8%
* Step 175: ~59.0% (Highest peak for red line, briefly surpassing blue)
* Step 200: ~54.0%
* Step 225: ~51.8% (Deep trough)
* Step 250: ~55.6%
* Step 290: ~57.8% (Local peak)
* Step 300: ~54.8%
### Key Observations
1. **Performance Gap:** The "RL prior" (blue) consistently demonstrates a higher Pass Rate than the "SFT prior" (red) across the majority of the 300 steps.
2. **Initial State:** There is a significant gap in initial performance at Step 0, with the RL prior starting roughly 3.4% higher than the SFT prior.
3. **High Variance:** Both training methods exhibit extreme step-to-step volatility. A rise of 3-4% in one 5-step interval is frequently followed by an immediate drop of similar magnitude.
4. **Convergence/Divergence:** While the red line occasionally spikes to meet the blue line (most notably around Step 175), the blue line maintains a higher baseline. Toward the end of the chart (Steps 280-300), the gap between the two lines appears to widen again.
### Interpretation
This chart visualizes the evaluation phase of a machine learning model, likely in the domain of code generation or complex reasoning, given the "Pass@5" metric (which measures if the correct answer is present within the top 5 generated outputs).
The data strongly suggests that initializing the training process with a Reinforcement Learning (RL) prior yields superior results compared to a Supervised Fine-Tuning (SFT) prior. The RL prior not only provides a better starting baseline ("zero-shot" or initial step performance) but also maintains a higher performance ceiling throughout the observed training window.
The extreme jaggedness of both lines indicates high variance in the evaluation process. This could be due to a small evaluation dataset, a highly sensitive metric, or inherent instability in the model's learning dynamics at this specific learning rate or phase. Despite this noise, the underlying signal is clear: the RL prior is the more effective methodology for maximizing the Pass@5 rate over these 300 steps.
</details>
Figure 7: Comparison between the SFT Prior and the RL Prior when further applied with end-to-end SWE-Agent RL. Left: Pass@1 averaged from 5 runs. Middle: Pass@3. Right: Pass@5. The two priors are activated with the same $2^{21}$ SWE-Agent SFT tokens (the second column in Figure 5). After end-to-end RL, the RL prior slightly outperforms the SFT prior in all the Pass@1, Pass@3, and Pass@5 settings, which agrees with their SWE-Agent SFT performance comparison in Figure 5.
End-to-end SWE-Agent RL for prior comparison. To further validate the effectiveness of the priors baked by the Agentless training recipes, we employ end-to-end SWE-Agent RL (deepswe2025) with the cold-started priors as the initial models. To maximally alleviate the effect from the patterns of proprietary models within the SWE-Smith trajectories, we leverage the setting with $2^{21}$ SWE-Agent SFT tokens, the second column in Figure 5, where a single step of gradient decent takes place on top of each prior. Under the minimal cold-start setup, end-to-end RL reveals the potential of each prior beyond taking the shortcut of imitation (gudibande2024the; chu2025sft).
To run the end-to-end RL training for prior comparison, we use the SWE-Gym (pan2024training) and the SWE-bench-extra (badertdinov2024scaling) subsets as the training set. Similarly to the Agentless RL recipe, we first use each initial model to filter out the problems with Pass@8 = 0. For the model with the MT prior, 260 out of 6,202 problems remain; for the models with the SFT prior and the RL prior, a total of 2,062 from the 6,202 problems are kept. In all end-to-end RL runs, we use the outcome reward only, and the same policy gradient algorithm in Sec. 3.3 without KL or entropy regularization for optimization, with batch size as 256. The results are shown as follows:
For the model with MT prior, the pass@1 performance quickly deteriorates to less than 2% after 10 end-to-end RL steps. The potential reason for this could be the lack of available problems to be trained with, reflecting the inferiority of the prior. For the models with the SFT prior and the RL prior, the RL runs last for 300 steps, and we plot the performance comparison in Figure 7. According to Figure 7, the model with the RL prior demonstrates slightly higher scores of Pass@1, Pass@3, and Pass@5 over the model with the SFT prior. While the phenomenon agrees with the performance comparison under SWE-Agent SFT shown in Figure 5, we observe that the patterns in the interaction trajectories of the models incentivized by end-to-end SWE-Agent RL significantly differ from the patterns of the proprietary models (detailed in Appendix G.3). These results reveal that the Agentless training recipe curates strong priors for end-to-end learning under SWE-Agent frameworks with the minimal supervision of proprietary end-to-end trajectories. We leave the exploration of more advanced agentic RL techniques for further improvement as future work.
5 Conclusion and Future Work
In this work, we reframed Agentless and agentic paradigms for automated software engineering as complementary rather than competing. By introducing Kimi-Dev, we demonstrated that structured Agentless training can induce transferable skill priors, including bug localization, code repair, and self-reflection. As a result, Kimi-Dev not only achieves SoTA results on SWE-bench Verified among the workflow-based approaches, but enables efficient SWE-Agent adaptation as well. These findings establish a novel path toward building more generalizable coding agents through staged training.
Acknowledgements
We thank Yuzhi Wang, Xinyu Zhou, Guokun Lai, Yulun Du, Fang Li, Hao Ding, Dehao Zhang, Enming Yuan, Dikang Du, and Jiacheng You for their valuable suggestions. We also appreciate the members of the infrastructure team at Moonshot AI for their timely support during the project.
Ethics and Reproducibility Statements
This work obeys the Code of Ethics required by the ICLR conference. The study does not involve human subjects or animal experimentation. The personally identifiable information from raw data is excluded for privacy consideration (see the mid-training data recipe detailed in Appendix A). Beyond the scope of this work, we strongly advocate for the community to advance systematic research on agent safety, thereby ensuring responsible progress in this area.
For all of the experiments, we have covered the detailed setups and discussions in the appendices: mid-training for Agentless in Appendix A, details of the used dockers in Appendix B, Agentless RL in Appendix C, agent infrastructure in Appendix D, case studies under Agentless in Appendix E, preliminary findings about emergent test-time parallel scaling in Appendix F, and extended analysis for SWE-Agents in Appendix G.
Appendix
Appendix A Details of Mid-training
We curate a mid-training data recipe with a focus on enhancing SWE capabilities. Central to this effort is the collection of pull request (PR) data from GitHub, which provides extensive coverage of real-world bug fixes, feature requests, and code enhancements. To ensure data quality, we apply two filters: (i) we only retain repositories that have accumulated at least five GitHub stars, thereby excluding sparsely maintained projects with limited community engagement; and (ii) we remove any repositories overlapping with the SWE-bench benchmark (jimenez2023swe) to prevent potential data leakage. For each candidate repository, we query the GitHub API for all PRs with the state MERGED, while discarding those abandoned, superseded, or left under review. To preserve more context information, we also snapshot the entire codebase at the base commit before the first code change in the PR.
After data crawling, we incorporate two complementary forms for the natural code change data: (i) natural diff patches and (ii) PR commit packs. A natural diff patch consolidates all commits in a PR into the final code difference, typically expressed as SEARCH–REPLACE blocks. This format aligns with the Agentless paradigm, in which the model must directly output the final patch. In contrast, a commit pack captures the sequence of human-authored commits within a PR, where each commit message (textual reasoning) is paired with the corresponding code modification (action). This structure closely parallels the SWE-Agent setting, where intermediate reasoning steps are interleaved with actions. However, the distinction of the utilities for the two types of data is not absolute: commit messages in a PR commit pack can still inform the model’s knowledge and indirectly strengthen its reasoning ability in the Agentless setting.
Natural diff patches. The natural diff patches used in the mid-training data recipe are processed with the following rules:
- Incorporate the agentless prompt template (see Prompts 1, 2, 3, 4; These four prompt templates are also used in the later stages, including cold-start, RL, and test-time self-play), and apply a loss mask to the prompt part. For the localization prompt, the response is set as the files modified in the ground-truth diff patch.
- If a related issue to the PR exists, use its content of the related issue; otherwise, use the PR title as the surrogate of the issue content.
- If a related issue to the PR exists, prepend the issue discussion at the beginning of the output in the code edit response. We aim to strengthen the model’s capability of code edit reasoning by leveraging the discussion contents.
- Discard PRs that include modifications to files other than {.py, .md, .rst}.
- For PRs containing {.md, .rst} file modifications, retain only the Python diffs and rewrite them into SEARCH–REPLACE blocks.
- Remove PRs involving file additions or deletions.
- For the code edits with only line insertions or deletions, preserve the original Git diff hunks as the SEARCH content in the SEARCH–REPLACE blocks.
- Ensure that no more than three Python files are modified per PR.
- Apply a filtering script to exclude PRs with non-{.py, .md, .rst} modifications, or PRs modifying more than three Python files.
- Further exclude PRs containing more than five SEARCH–REPLACE blocks.
A total of $\sim$ 50B tokens for natural diff patches are obtained after applying these filtering rules.
⬇
Please look through the following GitHub problem description and Repository structure and provide a list of files that one would need to edit to fix the problem.
### GitHub Problem Description ###
{related issue / PR title content}
###
### Repository Structure ###
{file structure induced by the repo snapshot}
###
Please only provide the full path and return at most 5 files.
The returned files should be separated by new lines ordered by most to least important and wrapped with ‘‘‘
For example:
‘‘‘
file1. py
file2. py
‘‘‘
Listing 1: Agentless prompt template: Localization for BugFixer.
⬇
Please look through the following GitHub problem description and Repository structure and provide a list of test files that should be run after applying the patch to fix the issue.
### GitHub Problem Description ###
{related issue / PR title content}
###
### Repository Structure ###
{file structure induced by the repo snapshot}
###
Please only provide the full path and return at most 5 files.
The returned files should be separated by new lines ordered by most to least important and wrapped with ‘‘‘
For example:
‘‘‘
file1. py
file2. py
‘‘‘
Listing 2: Agentless prompt template: Localization for TestWriter.
⬇
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
{related issue / PR title content}
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILE ---
‘‘‘
### {filename1}
{content of filename1}
### {filename2}
{content of filename2}
{...}
‘‘‘
--- END FILE ---
Please first localize the bug based on the issue statement, and then generate * SEARCH / REPLACE * edits to fix the issue.
Every * SEARCH / REPLACE * edit must use this format:
1. The file path
2. The start of search block: <<<<<<< SEARCH
3. A contiguous chunk of lines to search for in the existing source code
4. The dividing line: =======
5. The lines to replace into the source code
6. The end of the replace block: >>>>>>> REPLACE
Here is an example:
‘‘‘ python
### mathweb / flask / app. py
<<<<<<< SEARCH
from flask import Flask
=======
import math
from flask import Flask
>>>>>>> REPLACE
‘‘‘
Please note that the * SEARCH / REPLACE * edit REQUIRES PROPER INDENTATION. If you would like to add the line ’ print (x)’, you must fully write that out, with all those spaces before the code!
Wrap the * SEARCH / REPLACE * edit in blocks ‘‘‘ python...‘‘‘.
Listing 3: Agentless prompt template: Code edit for BugFixer.
⬇
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
{related issue / PR title content}
--- END ISSUE ---
Below are some code segments, each from a relevant test file. One or more of these files may be added some new tests which can reproduce the issue.
--- BEGIN FILE ---
‘‘‘
### {filename1}
{content of filename1}
### {filename2}
{content of filename2}
{...}
‘‘‘
--- END FILE ---
Please first localize some possible locations in those test files within the repo, and then generate * SEARCH / REPLACE * edit updates to the ** test ** files in the repo, so that the erroneous scenario described in the problem is reproduced.
Every * SEARCH / REPLACE * edit must use this format:
1. The file path
2. The start of search block: <<<<<<< SEARCH
3. A contiguous chunk of lines to search for in the existing source code
4. The dividing line: =======
5. The lines to replace into the source code
6. The end of the replace block: >>>>>>> REPLACE
Here is an example:
‘‘‘ python
### mathweb / flask / app. py
<<<<<<< SEARCH
from flask import Flask
=======
import math
from flask import Flask
def test__rules__std_L060_raised () -> None:
try:
sql = " SELECT IFNULL (NULL, 100),
NVL (NULL,100);"
result = lint (sql, rules =[" L060 "])
assert len (result) == 2
except:
print (" Other issues ")
return
try:
assert result [0][" description "] == " Use ’ COALESCE ’ instead of ’ IFNULL ’."
assert result [1][" description "] == " Use ’ COALESCE ’ instead of ’ NVL ’."
print (" Issue resolved ")
except AssertionError:
print (" Issue reproduced ")
return
return
>>>>>>> REPLACE
‘‘‘
Please note that the * SEARCH / REPLACE * edit REQUIRES PROPER INDENTATION. If you would like to add the line ’ print (x)’, you must fully write that out, with all those spaces before the code!
Wrap the * SEARCH / REPLACE * edit in blocks ‘‘‘ python...‘‘‘.
Listing 4: Agentless prompt template: Code edit for TestWriter.
PR commit packs. The PR commit packs used in the mid-training data recipe are processed with the following rules:
- Discard PRs that include modifications to files other than {.py, .md, .rst}.
- For {.md, .rst} file modifications, retain the “diff –git” signature but remove the actual content changes.
- Ensure that each PR modifies at most five Python files (with at least one required). PRs exceeding this limit are discarded.
- Apply a filtering script to exclude PRs containing non-{.py, .md, .rst} file modifications or those modifying more than five Python files.
- Filter out all of the developer signatures and GitHub IDs for ethics considerations.
A total of $\sim$ 20B tokens for PR commit packs are obtained after applying these filtering rules.
In addition, we incorporate synthetic data to further enhance both the reasoning and agentic capabilities of the model. A key observation is that the ground-truth reward for the localization stage in the Agentless setting can be derived directly from the diff patch, since the set of files requiring modification is explicitly indicated.
Synthetic reasoning data. To improve reasoning quality, we perform a lightweight SFT of the Qwen-2.5-72B-Instruct model on 2,000 R1 trajectories. The resulting model is then used to generate large-scale rollouts for the localization stage of both BugFixer and TestWriter. We retain only the rollouts that achieve exactly correct file localizations. This procedure yields approximately $\sim$ 10B tokens of reasoning-intensive data dedicated to Agentless localization in the mid-training recipe.
Synthetic agentic interactions. To strengthen agentic capabilities, we simulate agent–environment interactions with a custom tool set designed to mimic file-system operations without execution. This design is motivated by practical constraints: while repository snapshots from GitHub are available, not all snapshots are equipped with an executable Docker environment. As a result, shell commands are disabled. Instead, we introduce synthetic tools that allow the agent to view file contents and perform keyword-based search for localization, which effectively reproduces the first stage of Agentless but in an agentic manner. The specification of this tool set is covered in the system prompt, which is then used to elicit agentic interaction rollouts from the Qwen-2.5-72B-Instruct model. The complete system prompt is provided in Prompt 5. We apply a loss mask only to the system prompt, and enable the model to simultaneously learn both actions and observations along the trajectory, inspired by yang2024react. This approach integrates both policy and world modeling into mid training.
⬇
Your job is to look through the given GitHub problem description and Repository structure, and edit updates to the files in the repo to resolve the problem.
The job is divided into two stages:
+ In Stage 1, you should localize the files the files that you would need to edit to fix the problem.
+ In Stage 2, you should edit the updates to the repo.
Let ’ s begin from Stage 1 to localize the bugs:
In Stage 1, besides reading the provided Repository structure, you can use the following skills for exploration. The skills are to be called in an environment wrapped by < execute > and </ execute >, listed in the form of python functions as below:
open_file (path: str, is_all | None = False, line_number: int | None = 1, context_lines: int | None = 100) -> None:
Opens the file at the given path in the editor for exploration.
By default, only the first 100 lines of the file are displayed. To open the entire file, set ‘ is_all ‘ to ‘ True ‘.
The ‘ context_lines ‘ parameter determines the maximum number of lines to be displayed, with a cap of 100 lines. Use ‘ scroll_up ‘ and ‘ scroll_down ‘ to view more content up or down.
If a ‘ line_number ‘ is provided, the window will be moved to include that line.
Note: When ‘ is_all ‘ is set to ‘ True ‘, the ‘ line_number ‘ and ‘ context_lines ‘ parameters will not take effect, as the entire file will be opened and displayed without any line - specific focus or context limitation.
Args:
path: str: The path to the file to open. the full path of the filename should be provided.
is_all: bool | None = False: If set to ‘ True ‘, the entire file will be opened. Defaults to ‘ False ‘.
line_number: int | None = 1: The line number to move to. Defaults to 1.
context_lines: int | None = 100: Only shows this number of lines in the context window (usually from line 1), with line_number as the center (if possible). Defaults to 100.
goto_line (line_number: int) -> None:
Moves the window to show the specified line number.
Args:
line_number: int: The line number to move to.
goto_class_or_func (class_or_func_name: str) -> None:
Moves the window to show the specified class or function in the current open file.
Args:
class_or_func_name: str: The name of the given class, function, or method in a class to move to.
scroll_down () -> None:
Moves the window down by 100 lines.
Args:
None
scroll_up () -> None:
Moves the window up by 100 lines.
Args:
None
search_dir (search_term: str, dir_path: str | None) -> None:
Searches for search_term in all files in dir. If dir is not provided, searches in the entire repository. Filename, fine - grained line number, and the relative class or function it is located in (if applied) will be shown for each found position.
Args:
search_term: str: The term to search for.
dir_path: str: The path to the directory to search. Should be full path filename.
search_file (search_term: str, file_path: str | None = None) -> None:
Searches for search_term in file. If file is not provided, searches in the current open file. Filename, fine - grained line number, and the relative class or function it is located in (if applied) will be shown for each found position.
Args:
search_term: str: The term to search for.
file_path: str | None: The path to the file to search. Should be full path filename if provided.
find_file (file_name: str, dir_path: str | None) -> None:
Finds all files with the given name in the specified directory. If dir is not provided, find in the entire repository.
Args:
file_name: str: The name of the file to find.
dir_path: str: The path to the directory to search.
str_replace (path: str, old_str, new_str)
old_str =[the old content to be replaced]
new_str =[the new content after replacement]
-> None:
Replace the old content (old_str) in the file at the given path with the new content (new_str). This is the skill that you will be using to edit the updates.
Args:
path: str: The path to the file to be updated. The full path of the filename should be provided.
old_str: str: The old content to be replaced. Note that this argument should be written in a new line starting with " old_str =", and the string content should not be quoted.
new_str: str: The new content after replacement. Note that this argument should be written in a new line starting with " new_str =", and the string content should not be quoted.
Example:
Assuming a call is shown as follows:
‘‘‘
str_replace (" filename. py ", old_str, new_str)
old_str = a
new_str = b
c
‘‘‘
Then it will function as replacing the ’ a \ n ’ string with the ’ b \ nc ’ string in the ‘ filename. py ‘ file.
insert (path: str, insert_line: int, new_str)
new_str =[the new content to be inserted]
-> None:
Insert the new content (new_str) in the file at the given path. When you want to add an entirely new class / function to the file, it would be better to use this method.
Args:
path: str: The path to the file to be updated. The full path of the filename should be provided.
insert_line: int: The Line number below which the new content is to be added. This Line number should be within the range of lines of the file: [0, Lines_of_the_File]. Specifically, when insert_line = 0, the added content starts from the top of the file.
new_str: str: The new content to be inserted. Note that this argument should be written in a new line starting with " new_str =", and the string content should not be quoted.
Example:
Assuming a call is shown as follows:
‘‘‘
insert (" test_filename. py ", 5, new_str)
new_str = def test_add ():
assert add (1, 2) == 3
‘‘‘
Then it will function as inserting the string ’ def test_add ():\ n assert add (1, 2) == 3’ below the Line 5 of the ‘ test_filename. py ‘ file.
stop () -> None:
Terminate the editing process.
Args:
None
NOTE:
Responses should be concise.
When exploring, you should attempt fewer things at a time: Include ONLY ONE < execute > per response, and use a SINGLE skill listed above within the < execute > environment. DO NOT use other python functions, as the environment does not support them.
You should first reason in the verbal form, then use a skill with < execute > and </ execute >.
You should avoid apologies and thanks in the responses.
When you finish exploring and analyzing with the provided skills, please return at most 3 files with the full path only. Each full path should be placed in a single line, INSTEAD OF BROKEN WITH MULTIPLE LINES.
The returned files should be separated by new lines ordered by most to least important, wrapped with ‘‘‘ and NOTHING ELSE.
An example for a full output:
‘‘‘
full_path_to_file1. py
full_path_to_file2. py
‘‘‘
Now Let ’ s start!
### GitHub Problem Description ###
{issue content}
### Repository Structure ###
{file structure}
###
Listing 5: A non-execution set of tools empowering the simulation of agentic interaction trajectories.
After completing the initial localization stage, the agent is guided into the code-editing phase through a follow-up instruction: “Now let’s move on to Stage 2 and edit the updates. Remember, you can still decide at any point whether a file actually requires modification.” We retain partial rollouts from Stage 1, provided that the localization results include at least one correct file.
In Stage 2, we first simulate the agent’s interaction by allowing it to open incorrectly localized files, and we artificially inject agentic reasoning patterns such as “I realize that I do not need to modify this file” after inspecting the file content. This procedure is designed to strengthen the self-reflection ability of the agent by exposing it to false-positive contexts regarding the issue to be solved.
Subsequently, we transcribe the ground-truth PR commit pack into trajectory form: each commit message is treated as the agent’s reasoning step, and each code update is represented as the corresponding action, expressed through the “str_replace” or “insert” tools. These interactions are appended to the trajectory, followed by a terminating “stop” call. Due to storage constraints on repository snapshots, this trajectory simulation is applied to only a subset of PRs. Overall, this process contributes approximately $\sim$ 10B tokens of agentic interaction data to the mid-training recipe. Future directions for scaling this component in the data recipe include leveraging the idea of environment scaling (yang2025swesmith).
Training. We perform mid-training using a standard next token prediction approach, initialized from the Qwen2.5-72B-Base (qwen2025qwen25technicalreport) model. We upsample the synthetic part of the data by a factor of 4 during mid-training, inspired by the practice in grattafiori2024llama; qwen2025qwen25technicalreport; gu2025data. A global batch size of 256 with a maximum sequence length of 32K tokens is used, optimizing for long-context capabilities necessary for real-world software engineering tasks. The learning rate is set to 2e-5, with a cosine decay schedule and a minimum learning rate of 2e-6. The warm-up phase covers over approximately 3 billion tokens, followed by learning rate decay until approximately 150 billion tokens are processed.
Appendix B Docker environments
Table 3: The sources of the docker environments used in the development of Kimi-Dev.
| SWE-Gym (pan2024training) | https://huggingface.co/datasets/SWE-Gym/SWE-Gym/ | 2,356 |
| --- | --- | --- |
| SWE-bench-extra (badertdinov2024scaling) | https://huggingface.co/datasets/nebius/SWE-bench-extra/ | 3,846 |
| R2E-Gym-Lite (jain2025r2e) | https://huggingface.co/datasets/R2E-Gym/R2E-Gym-Lite | 3,671 |
Docker environment construction. To validate non-ground-truth patches generated by model rollouts and expand our dataset, we required executable Docker environments. We combined publicly available datasets with custom-configured Docker environments (see Table. 3). Among them, SWE-Gym and R2E-Gym-Lite open-source their dockers that we can directly use. For datasets lacking Docker support (SWE-Bench-Extra), we implemented an automated configuration method:
1. Initialize a Docker environment with fixed dependencies.
1. Select Python version based on commit year.
1. Install dependencies via requirements.txt and “ pip install -e . ”.
1. Resolve ModuleNotFound errors during test execution.
1. Validate success if a FAIL_TO_PASS test transitions from failing (without gt_patch) to passing (with gt_patch).
Out of 6.38k SWE-bench-extra instances, 3,846 environments are successfully constructed and subsequently used for cold-start and RL training.
Appendix C More Details of RL training
C.1 Prompt set selection
<details>
<summary>figs/sec3_rl_scaling/RL_bugfix_ablation_figure.png Details</summary>
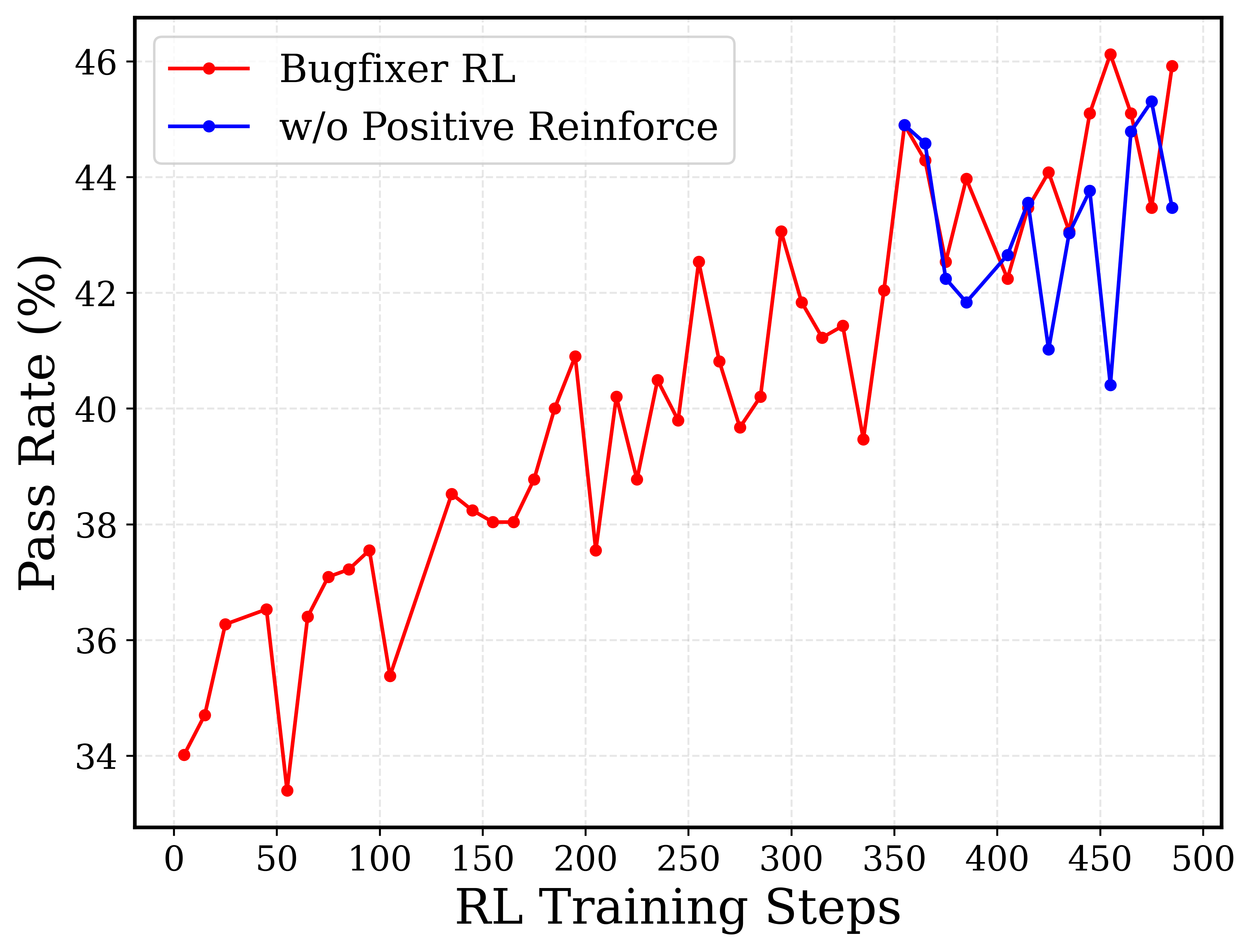
### Visual Description
## Line Chart: Bugfixer RL Pass Rate over Training Steps
### Overview
This image is a 2D line chart illustrating the performance of a reinforcement learning (RL) model, specifically measuring the "Pass Rate (%)" against "RL Training Steps". It compares a primary model ("Bugfixer RL") against an ablation or variant model ("w/o Positive Reinforce"). The chart demonstrates a generally upward, though highly volatile, trend in pass rates as training progresses.
### Components/Axes
**Spatial Grounding & Layout:**
* **Main Chart Area:** Occupies the majority of the image, featuring a light grey, dashed grid background.
* **Legend:** Positioned in the top-left corner, enclosed in a rounded rectangular border with a grey outline.
* **Y-axis:** Located on the left side.
* **X-axis:** Located at the bottom.
**Textual Information & Scales:**
* **Y-axis Label:** "Pass Rate (%)" (Rotated 90 degrees counter-clockwise).
* **Y-axis Scale:** Numeric, ranging from slightly below 34 to slightly above 46. Major tick marks and corresponding horizontal grid lines are placed at intervals of 2: `34, 36, 38, 40, 42, 44, 46`.
* **X-axis Label:** "RL Training Steps".
* **X-axis Scale:** Numeric, ranging from 0 to 500. Major tick marks and corresponding vertical grid lines are placed at intervals of 50: `0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500`.
* **Legend Content:**
* Red line with a solid red circular marker: `Bugfixer RL`
* Blue line with a solid blue circular marker: `w/o Positive Reinforce`
### Detailed Analysis
*Note: All data points extracted below are approximate (±0.5) based on visual alignment with the grid.*
#### Trend Verification: Series 1 - Bugfixer RL (Red Line)
**Visual Trend:** The red line spans the entire x-axis (from approx step 5 to 485). It exhibits a clear, overarching upward trajectory, starting near 34% and ending near 46%. However, the learning process is highly unstable, characterized by sharp peaks and deep valleys throughout the training steps.
**Extracted Data Points (Approximate X, Y coordinates):**
* (5, 34.0) - *Starting point*
* (15, 34.7)
* (25, 36.3)
* (45, 36.5)
* (55, 33.4) - *Early sharp drop*
* (65, 36.4)
* (75, 37.1)
* (85, 37.2)
* (95, 37.6)
* (105, 35.4)
* (135, 38.5)
* (145, 38.2)
* (155, 38.0)
* (165, 38.0)
* (175, 38.8)
* (185, 40.0)
* (195, 40.9)
* (205, 37.6) - *Mid-training drop*
* (215, 40.2)
* (225, 38.8)
* (235, 40.5)
* (245, 39.8)
* (255, 42.5)
* (265, 40.8)
* (275, 39.7)
* (285, 40.2)
* (295, 43.1)
* (305, 41.8)
* (315, 41.2)
* (325, 41.4)
* (335, 39.5)
* (345, 42.0)
* (355, 44.9) - *Major peak, divergence point*
* (365, 44.3)
* (375, 42.5)
* (385, 44.0)
* (395, 43.0)
* (405, 42.2)
* (415, 43.5)
* (425, 44.1)
* (435, 43.0)
* (445, 45.1)
* (455, 46.1) - *Maximum peak*
* (465, 45.1)
* (475, 43.5)
* (485, 45.9) - *Ending point*
#### Trend Verification: Series 2 - w/o Positive Reinforce (Blue Line)
**Visual Trend:** The blue line does *not* exist for the first 350 steps. It originates at step 355, sharing the exact same data point as the red line. From there, it diverges. While it generally follows the high 40s range, it exhibits extreme downward volatility compared to the red line, featuring two massive drops that the red line does not experience.
**Extracted Data Points (Approximate X, Y coordinates):**
* (355, 44.9) - *Origin point, matches red line*
* (365, 44.6)
* (375, 42.2)
* (385, 41.8)
* (405, 42.6)
* (415, 43.6)
* (425, 41.0) - *Sharp drop, significantly below red line (44.1)*
* (435, 43.0) - *Briefly converges with red line*
* (445, 43.8)
* (455, 40.4) - *Massive drop, lowest point for blue, while red is at its highest (46.1)*
* (465, 44.8)
* (475, 45.3) - *Briefly surpasses red line (43.5)*
* (485, 43.5) - *Ending point, below red line (45.9)*
### Key Observations
1. **Overall Improvement:** The primary model (Bugfixer RL) improves its pass rate from roughly 34% to 46% over 500 steps, indicating that the reinforcement learning process is generally effective over time.
2. **High Variance:** The training is not smooth. The red line shows constant "sawtooth" patterns, indicating that updates to the model frequently cause temporary regressions in performance before recovering.
3. **Late Introduction of Ablation:** The "w/o Positive Reinforce" line only begins at step 355.
4. **Severe Instability without Positive Reinforcement:** At step 455, the primary model hits its absolute peak (~46.1%), while the model without positive reinforcement hits a severe trough (~40.4%), creating the largest delta between the two models (~5.7%).
### Interpretation
* **The Nature of the Experiment:** The fact that the blue line ("w/o Positive Reinforce") starts at step 355 and perfectly intersects the red line at that exact coordinate strongly implies an ablation study methodology. The researchers likely trained the base "Bugfixer RL" model up to step 355, saved a checkpoint, and then branched the training into two parallel runs: one continuing normally, and one where the "Positive Reinforce" mechanism was turned off.
* **The Role of Positive Reinforcement:** Reading between the lines, "Positive Reinforce" acts as a stabilizing mechanism in the later stages of training. While the blue line occasionally matches or slightly beats the red line (e.g., at step 475), its primary characteristic is catastrophic forgetting or severe policy degradation (seen at steps 425 and 455). Without positive reinforcement to "anchor" good behaviors, the model is highly susceptible to sudden drops in its Pass Rate.
* **Model Application:** Given the name "Bugfixer RL" and the metric "Pass Rate (%)", this data likely represents an automated program repair or code generation model. The "Pass Rate" likely refers to the percentage of generated code patches that successfully pass a suite of unit tests. The volatility suggests that the RL environment is complex, and small changes in the model's policy can easily break previously learned bug-fixing capabilities.
</details>
Figure 8: Ablation of positive example reinforcement during 72B Bugfixer RL.
In the main text, we introduce the adaptive prompt selection method for RL training. Specifically, we construct an initial prompt set of 1,200 problems by selecting those with pass@16 $>$ 0 from SWE-Gym (pan2024training), SWE-bench-extra (badertdinov2025swerebenchautomatedpipelinetask), and R2E-gym (jain2025r2e). Then, every 100 training steps, we expand the prompt set by adding 500 new problems. These additional problems are randomly sampled and filtered from the pool of problems for which the current model has pass@16 = 0, thereby progressively increasing the difficulty and forming a proper curriculum.
C.2 RL experiment ablation
Figure 9 shows the performance of the Qwen2.5-14B model in RL experiments, where both the BugFixer and the TestWriter exhibit clear scaling law behavior.
<details>
<summary>figs/sec3_rl_scaling/quick_plot_M3_bf.png Details</summary>
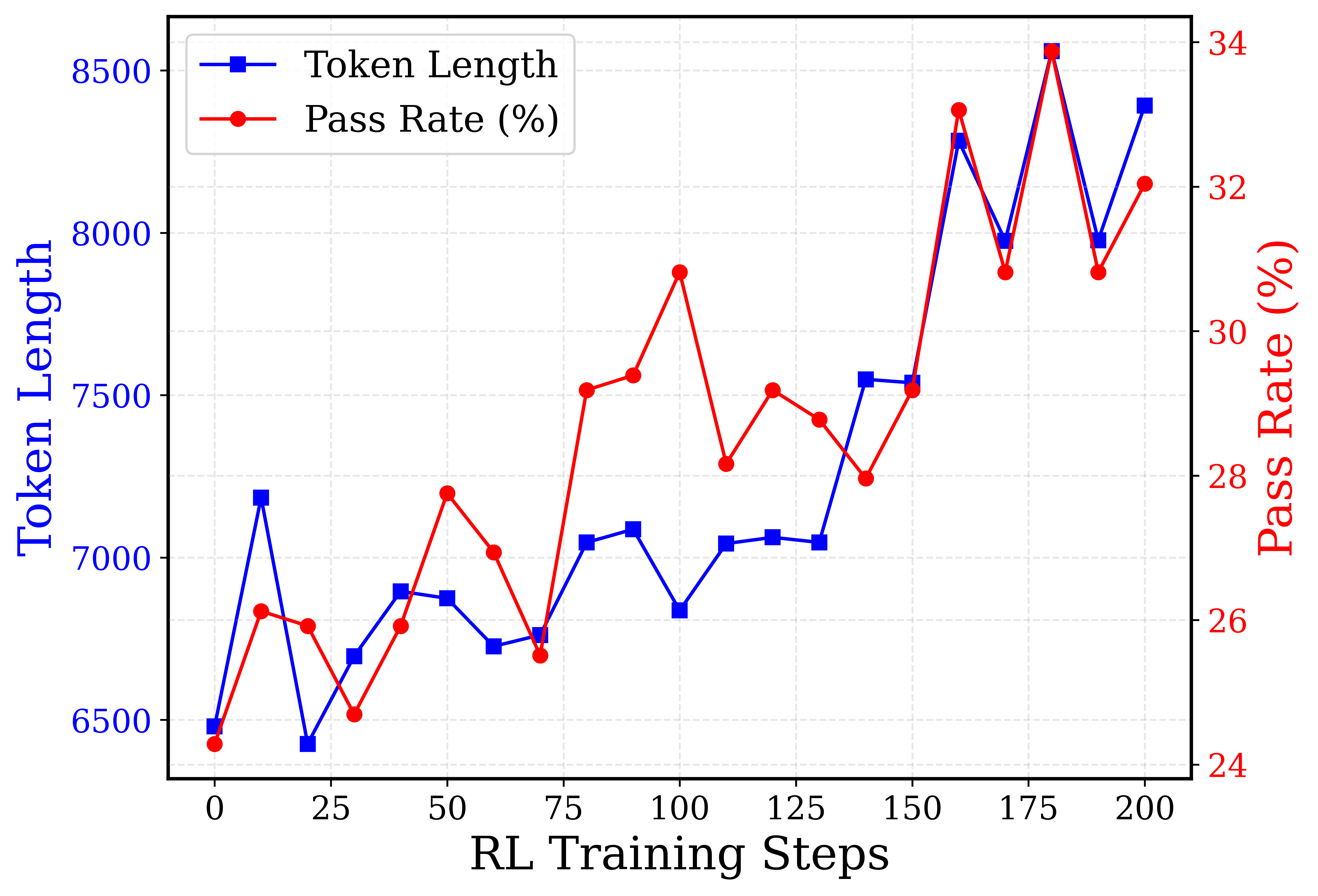
### Visual Description
## Dual-Axis Line Chart: Token Length and Pass Rate vs. RL Training Steps
### Overview
This image is a dual-axis line chart tracking two distinct metrics—"Token Length" and "Pass Rate (%)"—over a series of "RL Training Steps." The chart demonstrates how these two variables evolve simultaneously during a machine learning training process, specifically Reinforcement Learning (RL).
### Components/Axes
**Spatial Layout & Component Isolation:**
* **Header/Top-Left:** A legend is positioned in the top-left corner, enclosed in a rounded rectangular box with a light gray border.
* *Legend Item 1:* A solid blue line with a square marker, labeled "Token Length" in black text.
* *Legend Item 2:* A solid red line with a circular marker, labeled "Pass Rate (%)" in black text.
* **Bottom (X-Axis):** Positioned horizontally across the bottom.
* *Label:* "RL Training Steps" (Black text, centered).
* *Scale/Markers:* 0, 25, 50, 75, 100, 125, 150, 175, 200. (Linear scale, increments of 25).
* **Left (Y-Axis 1):** Positioned vertically on the left edge.
* *Label:* "Token Length" (Blue text, rotated 90 degrees counter-clockwise).
* *Scale/Markers:* 6500, 7000, 7500, 8000, 8500. (Linear scale, increments of 500, blue text).
* **Right (Y-Axis 2):** Positioned vertically on the right edge.
* *Label:* "Pass Rate (%)" (Red text, rotated 90 degrees clockwise).
* *Scale/Markers:* 24, 26, 28, 30, 32, 34. (Linear scale, increments of 2, red text).
* **Main Chart Area:** Contains a light gray, dashed grid aligning with the major tick marks of all three axes. Two data series are plotted across this grid.
### Detailed Analysis
*Note: All numerical values extracted below are approximate (`~`), derived visually by aligning the data points with the respective axis grids.*
**Trend Verification 1: Token Length (Blue Line, Square Markers)**
*Visual Trend:* The blue line exhibits high volatility early on, with a sharp spike at step 10 followed by a drop. From step 30 to 130, it remains relatively flat within the 6700-7100 range. After step 130, it experiences a massive, volatile upward trend, peaking at step 180 before ending high at step 200.
**Trend Verification 2: Pass Rate (%) (Red Line, Circular Markers)**
*Visual Trend:* The red line starts at its lowest point and generally trends upward over time, though with significant jaggedness. It experiences a notable mid-training peak at step 100, dips, and then mirrors the extreme volatility and upward trajectory of the blue line from step 140 onwards, also peaking at step 180.
**Reconstructed Data Table:**
*Cross-referencing the legend: Blue squares are read against the Left Axis (6500-8500). Red circles are read against the Right Axis (24-34).*
| RL Training Steps (X-Axis) | Token Length (Blue/Left Axis) | Pass Rate (%) (Red/Right Axis) |
| :--- | :--- | :--- |
| 0 | ~6480 | ~24.2 |
| 10 | ~7180 | ~26.1 |
| 20 | ~6420 | ~25.9 |
| 30 | ~6690 | ~24.6 |
| 40 | ~6890 | ~25.9 |
| 50 | ~6870 | ~27.8 |
| 60 | ~6720 | ~27.0 |
| 70 | ~6760 | ~25.5 |
| 80 | ~7050 | ~29.3 |
| 90 | ~7080 | ~29.5 |
| 100 | ~6830 | ~31.0 |
| 110 | ~7040 | ~28.2 |
| 120 | ~7060 | ~29.3 |
| 130 | ~7050 | ~28.9 |
| 140 | ~7550 | ~28.0 |
| 150 | ~7540 | ~29.3 |
| 160 | ~8280 | ~33.2 |
| 170 | ~7980 | ~30.9 |
| 180 | ~8560 | ~34.1 |
| 190 | ~7980 | ~30.9 |
| 200 | ~8390 | ~32.2 |
### Key Observations
1. **Overall Upward Trajectory:** Both metrics end significantly higher at step 200 than they began at step 0. Token length increases from roughly 6480 to 8390, while Pass Rate increases from roughly 24.2% to 32.2%.
2. **Late-Stage Correlation:** From step 150 to 200, the two lines exhibit near-identical geometric shapes. When Token Length spikes (steps 160, 180, 200), Pass Rate also spikes. When Token Length drops (steps 170, 190), Pass Rate drops.
3. **Mid-Stage Divergence:** Between steps 80 and 110, the metrics diverge slightly. Pass Rate climbs to a local peak of ~31.0% at step 100, while Token Length actually dips to ~6830 at the exact same step.
4. **Extreme Volatility:** The training process is not smooth. The period between steps 150 and 200 shows massive swings in both metrics between consecutive 10-step intervals.
### Interpretation
This chart provides a fascinating look into the behavior of a Large Language Model (LLM) undergoing Reinforcement Learning (likely RLHF - Reinforcement Learning from Human Feedback, or similar).
**Reading Between the Lines (Peircean Analysis):**
The data strongly suggests a direct, causal relationship between the length of the model's output ("Token Length") and its success in solving a prompt ("Pass Rate"). Because the Pass Rate improves as the Token Length increases, it is highly probable that the model is being trained on complex reasoning tasks (such as mathematics, logic puzzles, or coding). In these domains, models that utilize "Chain of Thought" reasoning—generating step-by-step explanations before arriving at an answer—naturally produce much longer token outputs.
The RL algorithm appears to be rewarding the model for getting the correct answer (Pass Rate). In its attempt to maximize this reward, the model "discovers" that generating longer, more detailed reasoning paths leads to higher success. This is evidenced by the late-stage correlation (steps 150-200), where the model's policy shifts dramatically toward generating very long responses (~8000+ tokens), which directly yields the highest pass rates (~33-34%).
The extreme volatility in the later steps indicates that the RL training might be using a high learning rate, or the policy is exploring aggressively. The model hasn't fully converged into a stable state; it is wildly oscillating between generating very long, successful outputs and shorter, less successful ones. The divergence at step 100 (high pass rate, lower token length) might represent a brief period where the model found an efficient shortcut to solve certain problems, but this strategy was ultimately abandoned in favor of the "longer is better" approach seen at the end of the graph.
</details>
(a) 14B BugFixer
<details>
<summary>figs/sec3_rl_scaling/quick_plot_M3_tw.png Details</summary>
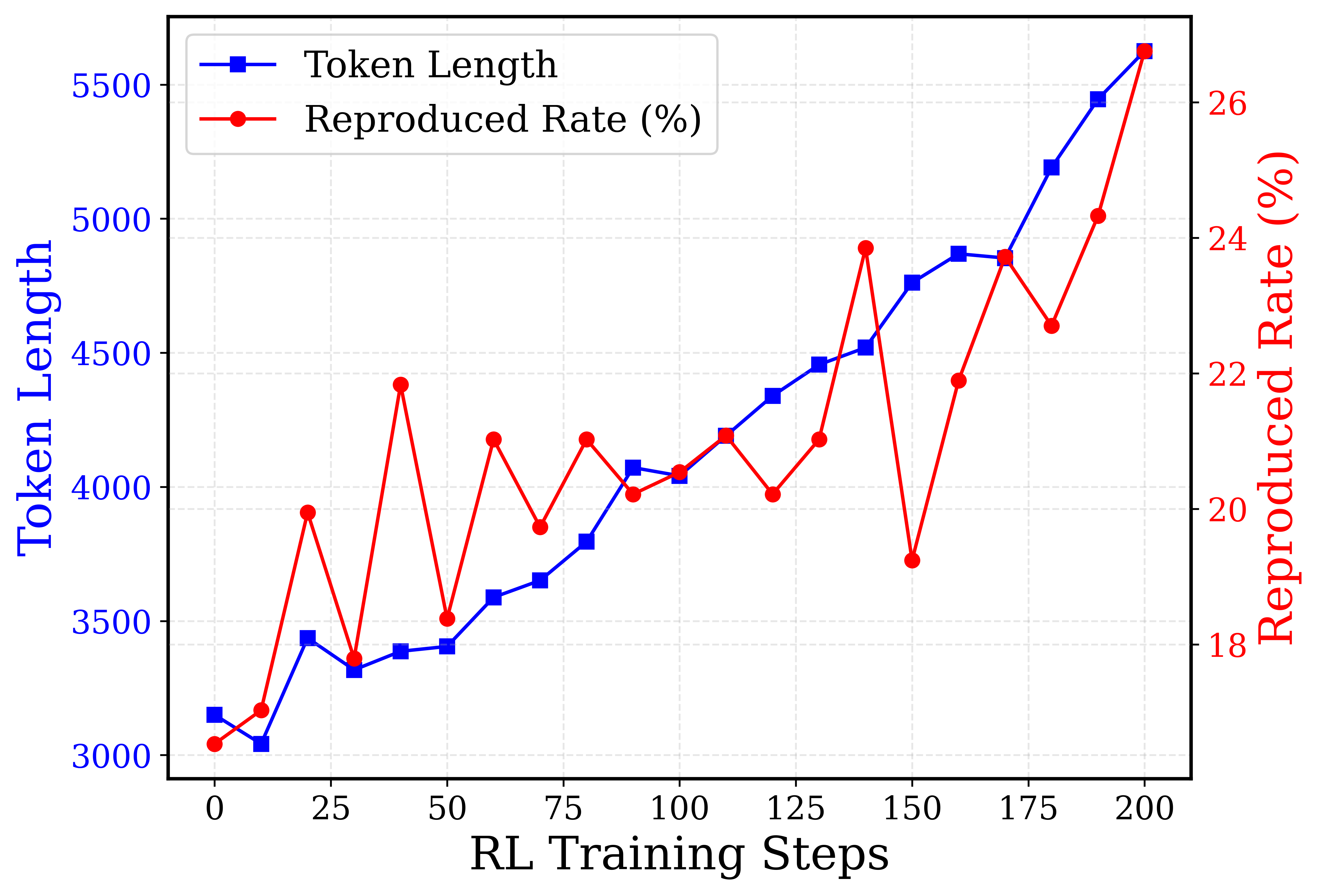
### Visual Description
## Dual-Axis Line Chart: Token Length and Reproduced Rate vs. RL Training Steps
### Overview
This image is a dual-axis line chart displaying the progression of two metrics—"Token Length" and "Reproduced Rate (%)"—over a series of "RL Training Steps". The chart uses a light grey dashed grid for visual guidance. The language used in the chart is entirely English.
### Components Isolation and Axes Details
**1. Header/Legend Region (Top-Left)**
* Located in the top-left corner, enclosed in a rounded rectangular border.
* **Item 1:** A solid blue line with a blue square marker. Text label: "Token Length".
* **Item 2:** A solid red line with a red circular marker. Text label: "Reproduced Rate (%)".
**2. X-Axis (Bottom)**
* **Label:** "RL Training Steps" (Centered, black text).
* **Scale:** Linear.
* **Markers/Ticks:** 0, 25, 50, 75, 100, 125, 150, 175, 200.
* *Note:* While major ticks are every 25 steps, the data points are plotted at intervals of 10 steps (0, 10, 20, 30, etc.).
**3. Left Y-Axis (Left Edge)**
* **Label:** "Token Length" (Centered vertically, rotated 90 degrees counter-clockwise, blue text).
* **Scale:** Linear.
* **Markers/Ticks:** 3000, 3500, 4000, 4500, 5000, 5500. (Blue text).
* **Association:** Corresponds to the blue line with square markers.
**4. Right Y-Axis (Right Edge)**
* **Label:** "Reproduced Rate (%)" (Centered vertically, rotated 90 degrees clockwise, red text).
* **Scale:** Linear.
* **Markers/Ticks:** 18, 20, 22, 24, 26. (Red text). There are faint grid lines indicating intermediate integer values (19, 21, 23, 25).
* **Association:** Corresponds to the red line with circular markers.
---
### Detailed Analysis & Data Extraction
#### Trend Verification
* **Token Length (Blue Line/Squares):** The visual trend shows a relatively stable, slightly fluctuating beginning between steps 0 and 50. From step 50 onwards, the line slopes upward consistently, with the rate of increase accelerating significantly after step 150.
* **Reproduced Rate (Red Line/Circles):** The visual trend is highly volatile. It exhibits sharp peaks and deep valleys throughout the training process. Despite the high variance, the overall macro-trend is upward, starting below the 18% mark and ending near the 27% mark.
#### Reconstructed Data Table
*Values are approximate (denoted by ~) based on visual alignment with the respective axes. Data points occur every 10 steps.*
| RL Training Steps (X) | Token Length (Left Y, Blue) | Reproduced Rate (%) (Right Y, Red) |
| :--- | :--- | :--- |
| 0 | ~3150 | ~16.5 |
| 10 | ~3050 | ~17.0 |
| 20 | ~3450 | ~20.0 |
| 30 | ~3300 | ~17.8 |
| 40 | ~3400 | ~21.8 |
| 50 | ~3400 | ~18.4 |
| 60 | ~3600 | ~21.0 |
| 70 | ~3650 | ~19.8 |
| 80 | ~3800 | ~21.0 |
| 90 | ~4050 | ~20.2 |
| 100 | ~4050 | ~20.6 |
| 110 | ~4200 | ~21.1 |
| 120 | ~4350 | ~20.3 |
| 130 | ~4450 | ~21.0 |
| 140 | ~4500 | ~23.8 |
| 150 | ~4750 | ~19.3 |
| 160 | ~4850 | ~22.0 |
| 170 | ~4850 | ~23.8 |
| 180 | ~5200 | ~22.8 |
| 190 | ~5450 | ~24.4 |
| 200 | ~5650 | ~26.8 |
---
### Key Observations
1. **Divergent Volatility:** The Token Length (blue) grows in a relatively smooth, exponential-looking curve. In stark contrast, the Reproduced Rate (red) is highly erratic, swinging by as much as 4-5% within a span of 10 training steps (e.g., from step 140 to 150).
2. **Correlated End-State:** Despite the differing volatility, both metrics reach their absolute maximum values at the final recorded training step (Step 200).
3. **Notable Anomalies:**
* At Step 150, there is a significant divergence: Token Length jumps up, while Reproduced Rate suffers a massive drop (from ~23.8% down to ~19.3%).
* Between Steps 90 and 130, the Reproduced Rate stabilizes somewhat (hovering tightly between 20% and 21%) while Token Length continues its steady climb.
---
### Interpretation
**Contextual Meaning:**
This chart likely represents the training dynamics of a Large Language Model (LLM) undergoing Reinforcement Learning (RL), possibly Reinforcement Learning from Human Feedback (RLHF).
* **Token Length** represents the verbosity of the model—how many words/tokens it generates in its responses.
* **Reproduced Rate (%)** likely measures how much of the model's output is directly copied or memorized from its training data or the prompt itself (often a metric used to track plagiarism, memorization, or lack of novelty).
**Reading Between the Lines (Peircean Investigative Analysis):**
The data suggests a common phenomenon in RL training: **Reward Hacking or Mode Collapse.**
As the RL training progresses (steps 0 to 200), the model is likely being rewarded for providing more detailed, comprehensive answers, which drives the "Token Length" up smoothly and consistently.
However, the model appears to be achieving this longer length not by generating novel reasoning, but by increasingly regurgitating known text. The overall upward trend of the "Reproduced Rate" indicates that as the model is forced to talk more (higher token length), it relies more heavily on memorized data.
The extreme volatility of the red line suggests the RL optimization landscape for "originality" is highly unstable. The optimizer finds a policy that generates long, highly reproduced text (e.g., Step 140), the algorithm penalizes it or shifts, resulting in a sudden drop in reproduction (Step 150), but the underlying pressure to generate long text eventually forces the reproduction rate back up to its highest point by Step 200.
Ultimately, this chart demonstrates a negative side-effect of the training run: the model is becoming much more verbose, but at the cost of becoming significantly less original.
</details>
(b) 14B TestWriter
Figure 9: RL scaling experiments on Qwen2.5-14B model.
Furthermore, Figure 8 illustrates the effect of our proposed positive example reinforcement. We incorporated this improvement in the later stage of training and found that the RL of BugFixer achieved better performance compared to not using this trick. The main reason is that positive examples can reinforce the correct reasoning patterns, enabling the model to converge more quickly, especially when its exploration ability diminishes in the later stages. It is noticed that a similar trick was also applied in the development of the Seed1.5-thinking model (seed2025seed1).
Appendix D Agent Infrastructure
We present a unified sandbox architecture designed for hybrid cloud cluster environments, leveraging Kubernetes orchestration to provide researchers with a flexible, secure, and highly scalable code execution platform. The architecture is accessible through a Python SDK and implements an ephemeral, use-and-destroy paradigm that ensures resource efficiency and security isolation. The system demonstrates exceptional scalability, supporting over 10,000 concurrent sandbox instances while maintaining performance stability. This infrastructure serves as a foundational platform for diverse computational scenarios, including automated code evaluation and RL experiments.
The system employs a sidecar container pattern to efficiently orchestrate and manage a heterogeneous collection of over 25,000 docker images sourced from multiple datasets. This architectural choice enables optimal resource utilization while maintaining isolation between different execution environments. Additionally, we have developed a proprietary Software Engineering (SWE) image-building pipeline that continuously expands the repository of supported images, thereby enhancing the system’s adaptability to diverse computational workloads and research requirements.
Appendix E Case Studies under Agentless
E.1 Bugfixer Traces
We provide a Bugfixer’s response trace during the code repair stage (see Listing 6). From this, we can observe that the initial code given was return self[i, j - pos - other.cols], but the model quickly realized its mistake and corrected it to return self[i, j - other.cols]. Although some repetitive self-reflections followed, the increasing response length indeed improved answer accuracy and robustness in our experiments.
⬇
$\lhd$ think $\rhd$
Okay, let ’ s tackle this problem. The user reported an issue where the Matrix. col_insert () method isn ’ t working correctly. The example given shows that after inserting a matrix V into M at position 3, the resulting matrix has the inserted columns shifted incorrectly. The expected result would have the inserted columns at positions 3 and 4, but the actual output shows them starting at position 3, but the original matrix ’ s columns after the insert are shifted upwards instead of remaining in their original positions.
First, I need to understand how col_insert works. Looking at the code provided, especially in the MatrixShaping class in sympy / matrices / common. py, the _eval_col_insert method is responsible for inserting columns. The current implementation shifts the existing columns to the right by the number of columns inserted. However, the bug might be in how the original matrix ’ s columns are being shifted.
Let me look at the existing code for _eval_col_insert:
def _eval_col_insert (self, pos, other):
cols = self. cols
def entry (i, j):
if j < pos:
return self [i, j]
elif pos <= j < pos + other. cols:
return other [i, j - pos]
return self [i, j - pos - other. cols]
return self. _new (self. rows, self. cols + other. cols,
lambda i, j: entry (i, j))
Wait, the problem here is in the last case. When j is greater than or equal to pos + other. cols, the code subtracts (pos + other. cols) from j. But that ’ s incorrect because the original columns after the inserted ones should start at j = pos + other. cols. So for the original matrix ’ s columns that come after the inserted ones, their new positions should be j + other. cols. But in the current code, when j is in the original matrix ’ s columns (after the inserted ones), the code is subtracting (pos + other. cols), which would incorrectly shift them.
Wait, let ’ s think again. The original code for the entry function:
if j < pos:
return self [i, j] # original columns before pos
elif pos <= j < pos + other. cols:
return other [i, j - pos] # inserted columns
return self [i, j - pos - other. cols] # original columns after the inserted ones
Wait, no. Let ’ s say the original matrix has cols = 6. We insert 2 columns at pos =3. The new total cols is 6 + 2 = 8. The original columns after pos 3 (columns 3,4,5) should now be at positions 5,6,7. But according to the code, when j is >=3 +2=5 (since pos + other. cols =3+2=5), then the code returns self [i, j -5 -2] = self [i, j -7]. Wait, that ’ s not right. For example, if j =5 (the new column 5), then j - pos - other. cols =5 -3 -2=0. So the original column 0 would be mapped to the new column 5. That ’ s definitely wrong.
Ah, here ’ s the mistake. The code is subtracting (pos + other. cols) from j, but that ’ s incorrect. The original columns after the inserted ones should be shifted to the right by other. cols. So, the correct calculation should be j - other. cols. For example, original column 3 becomes 3 +2=5, original column 4 becomes 6, etc.
So the line in the code:
return self [i, j - pos - other. cols]
should be:
return self [i, j - other. cols]
Because the inserted columns have taken up ’ other. cols ’ positions starting at ’ pos ’, so the original columns after ’ pos ’ are shifted by ’ other. cols ’ to the right. Therefore, to get the correct original column index, we subtract ’ other. cols ’ from the current j.
So the fix is to change the subtraction from (pos + other. cols) to other. cols. Let me check:
Original code:
return self [i, j - pos - other. cols]
Corrected code:
return self [i, j - other. cols]
Wait, no. Wait, the original columns after the inserted block (which starts at pos and has other. cols columns) would start at j = pos + other. cols. So for those j values, the original column index would be j - (pos + other. cols). Wait, no. Let ’ s think with numbers.
Original matrix has 6 columns. Insert 2 columns at position 3. The new matrix has 8 columns. The original columns 0,1,2 remain in positions 0,1,2. The inserted 2 columns are at positions 3 and 4. The original columns 3,4,5 now become 5,6,7.
So for j in 5,6,7 (original columns 3,4,5), the mapping is:
5 $ \ rightarrow$ 3
6 $ \ rightarrow$ 4
7 $ \ rightarrow$ 5
So the formula should be original_column = j - inserted_columns. In this case, inserted_columns is other. cols. So the code should subtract other. cols from j when accessing the original matrix ’ s columns after the inserted block.
Therefore, the line:
return self [i, j - pos - other. cols]
should be:
return self [i, j - other. cols]
Because pos is where the insertion starts, but the original columns after the inserted block are shifted by other. cols. Let ’ s verify with the example:
pos =3, other. cols =2. For j =5 (new column 5), original column index is 5 -2=3, which is correct. For j =6, 6-2=4; j =7, 7-2=5. That ’ s correct.
So the error in the original code was subtracting (pos + other. cols) instead of other. cols. The pos is the starting position of the insertion, but after inserting other. cols columns, the original columns after the inserted block are shifted by other. cols. Therefore, the correct subtraction is other. cols.
Thus, the fix is to change the line in the _eval_col_insert method from:
return self [i, j - pos - other. cols]
to:
return self [i, j - other. cols]
Now, looking back at the code in the _eval_col_insert function:
The code for the else clause is:
return self [i, j - pos - other. cols]
Which is incorrect. Changing that to j - other. cols should fix the problem.
So the SEARCH block would look for the lines:
def _eval_col_insert (self, pos, other):
cols = self. cols
def entry (i, j):
if j < pos:
return self [i, j]
elif pos <= j < pos + other. cols:
return other [i, j - pos]
return self [i, j - pos - other. cols]
return self. _new (self. rows, self. cols + other. cols,
lambda i, j: entry (i, j))
And the REPLACE block would change the last part to:
elif pos <= j < pos + other. cols:
return other [i, j - pos]
return self [i, j - other. cols]
So the correction is in the return statement of the entry function. The original code subtracted (pos + other. cols) from j, but it should subtract other. cols instead.
Therefore, the correct SEARCH / REPLACE block would be:
### sympy / matrices / common. py
<<<<<<< SEARCH
def _eval_col_insert (self, pos, other):
cols = self. cols
def entry (i, j):
if j < pos:
return self [i, j]
elif pos <= j < pos + other. cols:
return other [i, j - pos]
return self [i, j - pos - other. cols]
return self. _new (self. rows, self. cols + other. cols,
lambda i, j: entry (i, j))
=======
def _eval_col_insert (self, pos, other):
def entry (i, j):
if j < pos:
return self [i, j]
elif pos <= j < pos + other. cols:
return other [i, j - pos]
return self [i, j - other. cols]
return self. _new (self. rows, self. cols + other. cols,
lambda i, j: entry (i, j))
>>>>>>> REPLACE
This change corrects the column shifting calculation for the original matrix ’ s columns after the inserted block. Instead of subtracting (pos + other. cols), we subtract other. cols, which properly shifts the original columns to the right by the number of inserted columns.
$\lhd$ / think $\rhd$
‘‘‘ python
### sympy / matrices / common. py
<<<<<<< SEARCH
def _eval_col_insert (self, pos, other):
cols = self. cols
def entry (i, j):
if j < pos:
return self [i, j]
elif pos <= j < pos + other. cols:
return other [i, j - pos]
return self [i, j - pos - other. cols]
return self. _new (self. rows, self. cols + other. cols,
lambda i, j: entry (i, j))
=======
def _eval_col_insert (self, pos, other):
def entry (i, j):
if j < pos:
return self [i, j]
elif pos <= j < pos + other. cols:
return other [i, j - pos]
return self [i, j - other. cols]
return self. _new (self. rows, self. cols + other. cols,
lambda i, j: entry (i, j))
>>>>>>> REPLACE
‘‘‘
Listing 6: Reasoning trajectory example for BugFixer.
E.2 Testwriter False Positive Cases
During the RL training process, we observed that the Testwriter component exhibits some false positives, which can result in tests that contain certain gaps. This might cause the test patches generated by the model to be mistakenly considered as correct. Consequently, the performance improvement of Testwriter does not accurately reflect the actual performance. In this section, we provide two intuitive examples to illustrate this phenomenon, and leave further enhancement for TestWriter as future work.
Listing 7 shows the ground-truth test patch for instance django__django-16877, with Listing 8 showing the test patch generated by theTestWriter. A detailed comparison reveals that the model-generated test cases are not comprehensive: Two locations should have been tested, but only one was checked, and the effect of mark_safe was not considered. In practice, this allowed the model-predicted patch to pass the TestWriter reward check, but result in a false positive.
The second example instance is sympy__sympy-13974, with Listings 9 and 10 showing the ground-truth and model-generated test patches. In this case, the coverage of the generated test is also insufficient. The generated test does not account for the need to satisfy the associativity property, e.g., assert tensor_product_simp(TP(A, B)**x) == TP(A**x, B**x). As a consequence, it fails to serve as a reliable judge for BugFixer.
⬇
diff -- git a / tests / template_tests / filter_tests / test_escapeseq. py b / tests / template_tests / filter_tests / test_escapeseq. py
new file mode 100644
--- / dev / null
+++ b / tests / template_tests / filter_tests / test_escapeseq. py
@@ -0,0 +1,59 @@
+ from django. test import SimpleTestCase
+ from django. utils. safestring import mark_safe
+
+ from .. utils import setup
+
+
+ class EscapeseqTests (SimpleTestCase):
+ """
+ The " escapeseq " filter works the same whether autoescape is on or off,
+ and has no effect on strings already marked as safe.
+ """
+
+ @setup (
+ {
+ " escapeseq_basic ": (
+ ’{{ a | escapeseq | join:", " }} -- {{ b | escapeseq | join:", " }}’
+ ),
+ }
+ )
+ def test_basic (self):
+ output = self. engine. render_to_string (
+ " escapeseq_basic ",
+ {" a ": [" x & y ", "< p >"], " b ": [mark_safe (" x & y "), mark_safe ("< p >")]},
+ )
+ self. assertEqual (output, " x & amp; y, & lt; p & gt; -- x & y, < p >")
+
+ @setup (
+ {
+ " escapeseq_autoescape_off ": (
+ ’{% autoescape off %}{{ a | escapeseq | join:", " }}’
+ " -- "
+ ’{{ b | escapeseq | join:", "}}{% endautoescape %}’
+ )
+ }
+ )
+ def test_autoescape_off (self):
+ output = self. engine. render_to_string (
+ " escapeseq_autoescape_off ",
+ {" a ": [" x & y ", "< p >"], " b ": [mark_safe (" x & y "), mark_safe ("< p >")]},
+ )
+ self. assertEqual (output, " x & amp; y, & lt; p & gt; -- x & y, < p >")
+
+ @setup ({" escapeseq_join ": ’{{ a | escapeseq | join:"< br />" }}’})
+ def test_chain_join (self):
+ output = self. engine. render_to_string (" escapeseq_join ", {" a ": [" x & y ", "< p >"]})
+ self. assertEqual (output, " x & amp; y < br />& lt; p & gt;")
+
+ @setup (
+ {
+ " escapeseq_join_autoescape_off ": (
+ ’{% autoescape off %}{{ a | escapeseq | join:"< br />" }}{% endautoescape %}’
+ ),
+ }
+ )
+ def test_chain_join_autoescape_off (self):
+ output = self. engine. render_to_string (
+ " escapeseq_join_autoescape_off ", {" a ": [" x & y ", "< p >"]}
+ )
+ self. assertEqual (output, " x & amp; y < br />& lt; p & gt;")
Listing 7: GT test patch of django__django-16877.
⬇
diff -- git a / tests / template_tests / filter_tests / test_safeseq. py b / tests / template_tests / filter_tests / test_safeseq. py
--- a / tests / template_tests / filter_tests / test_safeseq. py
+++ b / tests / template_tests / filter_tests / test_safeseq. py
@@ -20,3 +20,20 @@
def test_safeseq02 (self):
output = self. engine. render_to_string (" safeseq02 ", {" a ": ["&", "<"]})
self. assertEqual (output, "&, < -- &, <")
+
+ # New tests for escapeseq
+ @setup ({" escapeseq01 ": ’{{ a | escapeseq | join:", " }}’})
+ def test_escapeseq01 (self):
+ output = self. engine. render_to_string (" escapeseq01 ", {" a ": ["&", "<"]})
+ self. assertEqual (output, "& amp;, & lt;")
+
+ @setup (
+ {
+ " escapeseq02 ": (
+ ’{% autoescape off %}{{ a | escapeseq | join:", " }}{% endautoescape %}’
+ )
+ }
+ )
+ def test_escapeseq02 (self):
+ output = self. engine. render_to_string (" escapeseq02 ", {" a ": ["&", "<"]})
+ self. assertEqual (output, "& amp;, & lt;")
Listing 8: Model predicted test patch of django__django-16877.
⬇
diff -- git a / sympy / physics / quantum / tests / test_tensorproduct. py b / sympy / physics / quantum / tests / test_tensorproduct. py
--- a / sympy / physics / quantum / tests / test_tensorproduct. py
+++ b / sympy / physics / quantum / tests / test_tensorproduct. py
@@ -10,7 +10,7 @@
from sympy. physics. quantum. density import Density
from sympy. core. trace import Tr
- A, B, C = symbols (’ A, B, C ’, commutative = False)
+ A, B, C, D = symbols (’ A, B, C, D ’, commutative = False)
x = symbols (’ x ’)
mat1 = Matrix ([[1, 2* I], [1 + I, 3]])
@@ -47,6 +47,11 @@ def test_tensor_product_commutator ():
def test_tensor_product_simp ():
assert tensor_product_simp (TP (A, B)* TP (B, C)) == TP (A * B, B * C)
+ # tests for Pow - expressions
+ assert tensor_product_simp (TP (A, B)** x) == TP (A ** x, B ** x)
+ assert tensor_product_simp (x * TP (A, B)**2) == x * TP (A **2, B **2)
+ assert tensor_product_simp (x *(TP (A, B)**2)* TP (C, D)) == x * TP (A **2* C, B **2* D)
+ assert tensor_product_simp (TP (A, B)- TP (C, D)** x) == TP (A, B)- TP (C ** x, D ** x)
def test_issue_5923 ():
Listing 9: GT test patch for sympy__sympy-13974.
⬇
diff -- git a / sympy / physics / quantum / tests / test_tensorproduct. py b / sympy / physics / quantum / tests / test_tensorproduct. py
--- a / sympy / physics / quantum / tests / test_tensorproduct. py
+++ b / sympy / physics / quantum / tests / test_tensorproduct. py
@@ -47,6 +47,27 @@
def test_tensor_product_simp ():
assert tensor_product_simp (TP (A, B)* TP (B, C)) == TP (A * B, B * C)
+
+ # Test tensor product powers
+ a = symbols (’ a ’, commutative = False)
+ t1 = TP (1, 1) * TP (1, 1)
+ t1_simp = tensor_product_simp (t1)
+ assert t1_simp == TP (1, 1), f " Expected 1 x1, got {t1_simp}"
+
+ # Test with Pauli matrices
+ from sympy. physics. paulialgebra import Pauli
+ t2 = TP (1, Pauli (3)) * TP (1, Pauli (3))
+ t2_simp = tensor_product_simp (t2)
+ assert t2_simp == TP (1, 1), f " Expected 1 x1, got {t2_simp}"
+
+ # Test substitution cases from issue
+ expr1 = TP (1, 1) * TP (1, a)
+ result1 = expr1. subs (a, 1)
+ assert tensor_product_simp (result1) == TP (1, 1), f " Substitution 1 failed: {result1}"
+
+ expr2 = TP (1, Pauli (3)) * TP (1, a)
+ result2 = expr2. subs (a, Pauli (3))
+ assert tensor_product_simp (result2) == TP (1, 1), f " Substitution 2 failed: {result2}"
def test_issue_5923 ():
Listing 10: Model predicted test patch of sympy__sympy-13974.
Appendix F Emergent Parallel scaling in Kimi-Dev
<details>
<summary>figs/sec3_sp_scaling/parellel_scaling_figure.png Details</summary>
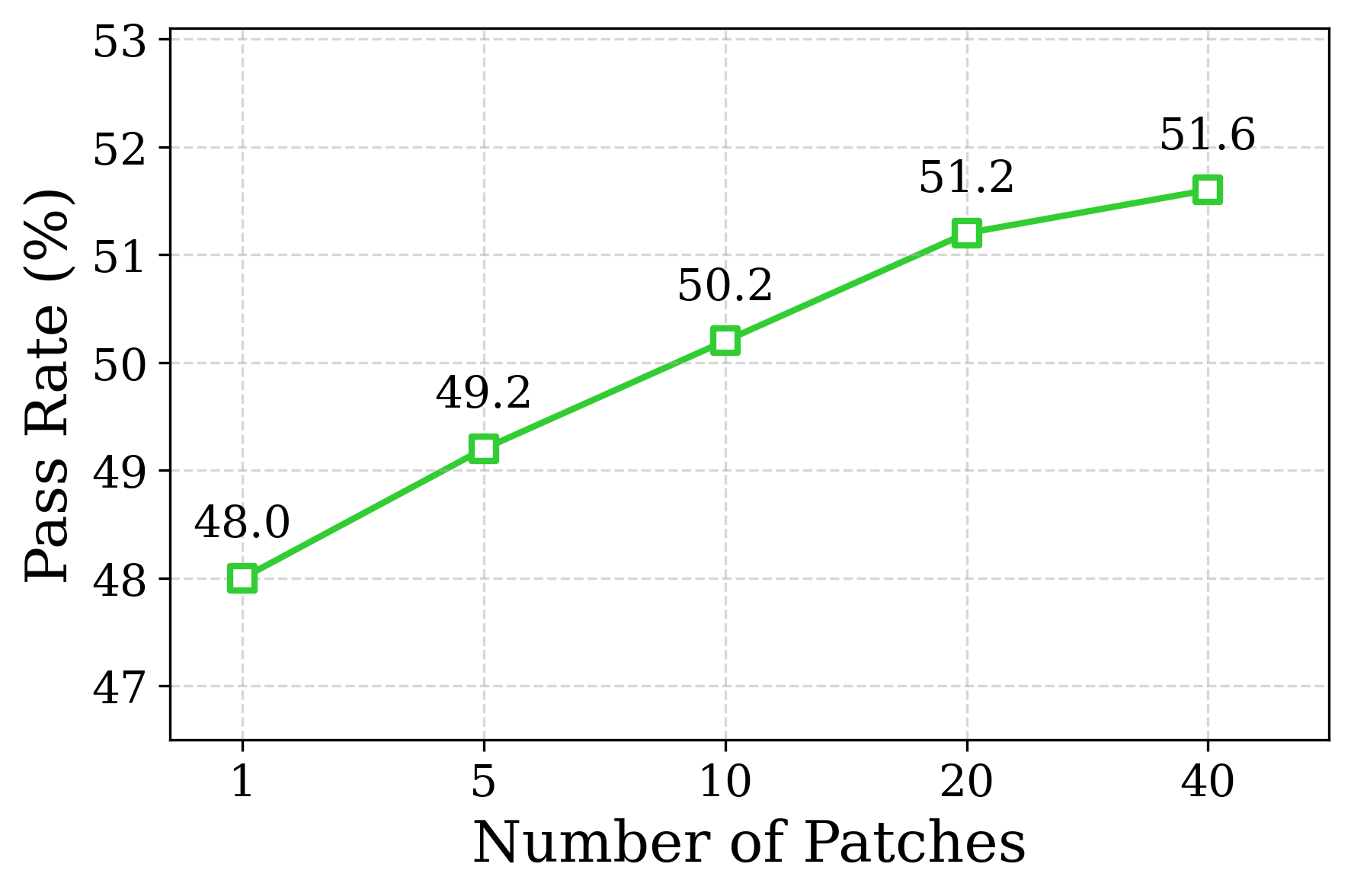
### Visual Description
## Line Chart: Pass Rate vs. Number of Patches
### Overview
This image is a two-dimensional line chart that illustrates the relationship between the "Number of Patches" applied or utilized and the resulting "Pass Rate (%)". The chart features a single data series plotted on a dashed grid, showing a clear positive correlation between the two variables. All text in the image is in English.
### Components/Axes
* **Y-Axis (Vertical, Left side):**
* **Label:** "Pass Rate (%)" (Oriented vertically, reading bottom-to-top).
* **Scale:** Linear.
* **Markers:** 47, 48, 49, 50, 51, 52, 53.
* **Gridlines:** Horizontal light gray dashed lines extend from each marker across the chart area.
* **X-Axis (Horizontal, Bottom edge):**
* **Label:** "Number of Patches" (Centered below the axis markers).
* **Scale:** Non-linear / Categorical. The physical distance between each marker on the graph is identical, despite the numerical intervals being unequal (intervals of 4, 5, 10, and 20).
* **Markers:** 1, 5, 10, 20, 40.
* **Gridlines:** Vertical light gray dashed lines extend upward from each marker.
* **Data Series:**
* A single solid, bright green line.
* **Data Points:** Marked by hollow green squares with a white center.
* **Data Labels:** Exact numerical values printed in black text directly above each green square marker.
### Detailed Analysis
**Trend Verification:**
The green line begins at the bottom-left of the chart area and slopes consistently upward toward the top-right. The slope is relatively steep and consistent between the first four data points, but the angle of the slope visibly decreases (flattens out) between the fourth and fifth data points.
**Data Point Extraction:**
Based on the explicit data labels positioned above the green square markers, the exact values are as follows:
* At **1** (Number of Patches), the Pass Rate is **48.0%**.
* At **5** (Number of Patches), the Pass Rate is **49.2%**.
* At **10** (Number of Patches), the Pass Rate is **50.2%**.
* At **20** (Number of Patches), the Pass Rate is **51.2%**.
* At **40** (Number of Patches), the Pass Rate is **51.6%**.
### Key Observations
* **Positive Correlation:** There is a direct, positive relationship between the number of patches and the pass rate. Increasing the number of patches always results in a higher pass rate within the scope of this chart.
* **Diminishing Returns:** While the pass rate increases, the *rate of increase* slows down significantly at higher numbers of patches.
* Adding 9 patches (from 1 to 10) yields a **2.2%** increase in pass rate.
* Adding 10 patches (from 10 to 20) yields a **1.0%** increase.
* Adding 20 patches (from 20 to 40) yields only a **0.4%** increase.
* **Visual Distortion:** Because the X-axis uses equal physical spacing for unequal numerical intervals (1 to 5 is the same visual width as 20 to 40), the visual slope of the line makes the performance gains look more linear than they actually are. If the X-axis were plotted on a true linear scale, the line would curve sharply and flatten out much more dramatically to the right.
### Interpretation
This chart demonstrates the efficacy of increasing "patches" to improve a system's "pass rate." In technical contexts, "patches" likely refers to either software updates/fixes, or, more likely in the context of machine learning/computer vision, image segments (e.g., Vision Transformer patches) used for processing. The "pass rate" likely refers to an accuracy benchmark, successful compilation rate, or validation metric.
The data clearly suggests that while increasing the number of patches improves performance, the system experiences severe diminishing returns. The computational cost or resource allocation required to jump from 20 to 40 patches (doubling the input) only yields a marginal 0.4% improvement.
From an investigative standpoint, the creator of this chart chose a non-linear X-axis to present the data. This design choice visually softens the impact of the diminishing returns, making the progression look like a steady climb rather than a plateau. An engineer reading this chart would likely conclude that the optimal trade-off between resource cost (number of patches) and performance (pass rate) lies somewhere between 10 and 20 patches, as pushing to 40 yields negligible benefits. Furthermore, the absolute maximum pass rate shown is 51.6%, indicating that even with maximum patches applied, the system only slightly exceeds a 50% success rate.
</details>
Figure 10: Emergent parallel scaling results on SWE-bench Verified.
Compared to the self-play method that leverages execution during test time, parallel scaling (chen2025parallel; pan2025learning) is a recently-introduced test-time scaling method that aggregates multiple independent rollouts for additional improvement. While previous works incentivize the ability of parallel scaling through training, or train a separate reward model (pan2024training; jain2025r2e) for patch selection, we observe that the parallel scaling effect emerges in our model without any specific training. Specifically, patch candidates from parallel rollouts of BugFixer are used to prompt the model to summarize their differences and compose a new bugfix patch. Listing 11 is the prompt template of parallel scaling. In the template, promblem_statement is the GitHub issue, and trajs_content represents the content of multiple patch candidates.
⬇
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
{problem_statement}
--- END ISSUE ---
Below are some thinking trajectories, each from llm reasoning model. Only one trajetory is right.
--- BEGIN FILE ---
‘‘‘
{trajs_content}
‘‘‘
--- END FILE ---
Please first summary and analyze the key differences between the trajectories, and then generate * SEARCH / REPLACE * edits to fix the issue.
Every * SEARCH / REPLACE * edit must use this format:
1. The file path
2. The start of search block: <<<<<<< SEARCH
3. A contiguous chunk of lines to search for in the existing source code
4. The dividing line: =======
5. The lines to replace into the source code
6. The end of the replace block: >>>>>>> REPLACE
Here is an example:
‘‘‘ python
### mathweb / flask / app. py
<<<<<<< SEARCH
from flask import Flask
=======
import math
from flask import Flask
>>>>>>> REPLACE
‘‘‘
Please note that the * SEARCH / REPLACE * edit REQUIRES PROPER INDENTATION. If you would like to add the line ’ print (x)’, you must fully write that out, with all those spaces before the code!
Wrap the * SEARCH / REPLACE * edit in blocks ‘‘‘ python...‘‘‘.
The summary of the key differences between the trajectories should be in the thinking part.
Listing 11: The prompt template for parallel scaling.
The results in Figure 10 show that the performance of the parallel aggregation improves as the number of patch candidates in the prompt increases. The advantage of this scaling paradigm over majority voting lies in its ability to leverage the model’s own capacity to analyze multiple candidate patches, thereby surpassing the simplistic approach of weighting answers merely by their frequency of occurrence. Listing 12 covers a full prompt example with 14 different input patch candidates. Note: As Listing 12 is long, it is OK to jump to Listing 13 to directly observe the model behavior.
⬇
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Data < @filename isn ’ t relative to the YAML file
The [docs say](https:// gabbi. readthedocs. io / en / latest / format. html # data):
> If the value is a string that begins with < @ then the rest of the string is treated as the name of a file to be loaded from the same directory as the YAML file.
But I haven ’ t found it works like this unless I cd into the directory containing the yaml file.
‘ _load_data_file ‘ says:
‘‘‘ python
path = os. path. join (self. test_directory, os. path. basename (filename))
‘‘‘
this does a few things:
- makes the path begin with ‘ self. test_directory ‘ (defaults to ‘.‘, the current working directory)
- disguards any folders in the < @ ‘ filename ‘ path
- appends ‘ filename ‘
This means, if I ’ m in ‘/‘, and I have a test that says ‘ data: < @cake. jpg ‘, I cannot run my tests as advised in the docs:
‘ gabbi - run -- / my / test. yaml / my / other. yaml ‘
‘ FileNotFoundError: [Errno 2] No such file or directory: ’./ cake. jpg ’‘
So in our test running script, we have to start with ‘ cd tests /‘.
My preference, would be to make the path relative to the location of the yaml file. That way, I can run my tests from whatever directory.
Obviously this isn ’ t possible when redirecting with ‘<‘ as the filename is never seen by gabbi. So I ’ m happy is discuss other ideas.
---
Furthermore I can ’ t keep my test data in a child directory, unless I cd into that directory like:
‘‘‘ shell
cd yaml_tests / test_data
gabbi - run -- ../ test_things. yaml
‘‘‘
So for that reason, I ’ d like to allow directories like ‘< @test_data / filename. txt ‘ to be included in the path.
---
Happy to write the patch, if we come up with an approach here.
--- END ISSUE ---
Below are some thinking trajectories, each from llm reasoning model.
--- BEGIN FILE ---
‘‘‘
Answer 1:
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
import argparse
from importlib import import_module
import sys
import unittest
=======
import argparse
from importlib import import_module
import os
import sys
import unittest
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, ’.’, host, port, None, None, prefix = prefix,
handlers = handler_objects)
result = ConciseTestRunner (
verbosity =2, failfast = failfast). run (test_suite)
return result. wasSuccessful ()
=======
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False, test_directory =’.’):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None,
prefix = prefix, handlers = handler_objects)
result = ConciseTestRunner (
verbosity =2, failfast = failfast). run (test_suite)
return result. wasSuccessful ()
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
else:
for input_file in input_files:
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast)
=======
else:
for input_file in input_files:
test_directory = os. path. dirname (input_file) or ’.’
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast,
test_directory = test_directory)
>>>>>>> REPLACE
‘‘‘
Answer 2:
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
=======
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False, test_directory =’.’):
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, ’.’, host, port, None, None, prefix = prefix,
handlers = handler_objects)
=======
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None, prefix = prefix,
handlers = handler_objects)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast)
=======
test_directory = os. path. dirname (input_file) or ’.’
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast, test_directory = test_directory)
>>>>>>> REPLACE
‘‘‘
Answer 3:
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, ’.’, host, port, None, None, prefix = prefix,
handlers = handler_objects)
result = ConciseTestRunner (
verbosity =2, failfast = failfast). run (test_suite)
return result. wasSuccessful ()
=======
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False, test_directory =’.’):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None,
prefix = prefix, handlers = handler_objects)
result = ConciseTestRunner (
verbosity =2, failfast = failfast). run (test_suite)
return result. wasSuccessful ()
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
for input_file in input_files:
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast)
if not failure: # once failed, this is considered immutable
failure = not success
if failure and failfast:
break
=======
for input_file in input_files:
test_directory = os. path. dirname (input_file)
with open (input_file, ’ r ’) as fh:
success = run_suite (
fh, handler_objects, host, port, prefix, force_ssl,
failfast, test_directory = test_directory)
if not failure: # once failed, this is considered immutable
failure = not success
if failure and failfast:
break
>>>>>>> REPLACE
‘‘‘
Answer 4:
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
=======
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False, test_directory =’.’):
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, ’.’, host, port, None, None, prefix = prefix,
handlers = handler_objects)
=======
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None,
prefix = prefix, handlers = handler_objects)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
for input_file in input_files:
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast)
=======
for input_file in input_files:
# Determine test directory based on input file ’ s location
test_directory = os. path. dirname (os. path. abspath (input_file)) or ’.’
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast,
test_directory = test_directory)
>>>>>>> REPLACE
‘‘‘
Answer 5:
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
import sys
import unittest
=======
import os
import sys
import unittest
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
=======
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False, test_directory =’.’):
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, ’.’, host, port, None, None, prefix = prefix,
handlers = handler_objects)
=======
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None,
prefix = prefix, handlers = handler_objects)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
for input_file in input_files:
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast)
=======
for input_file in input_files:
test_directory = os. path. dirname (input_file) or ’.’
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast,
test_directory = test_directory)
>>>>>>> REPLACE
‘‘‘
Answer 6:
‘‘‘ python
### gabbi / driver. py
<<<<<<< SEARCH
file_suite = suitemaker. test_suite_from_dict (
loader, test_base_name, suite_dict, path, host, port,
fixture_module, intercept, prefix = prefix,
test_loader_name = test_loader_name, handlers = handler_objects,
inner_fixtures = inner_fixtures)
=======
test_file_dir = os. path. dirname (test_file)
file_suite = suitemaker. test_suite_from_dict (
loader, test_base_name, suite_dict, test_file_dir, host, port,
fixture_module, intercept, prefix = prefix,
test_loader_name = test_loader_name, handlers = handler_objects,
inner_fixtures = inner_fixtures)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
=======
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False, test_directory =’.’):
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, ’.’, host, port, None, None, prefix = prefix,
handlers = handler_objects)
=======
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None,
prefix = prefix, handlers = handler_objects)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast)
=======
test_directory = os. path. dirname (input_file)
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast, test_directory)
>>>>>>> REPLACE
‘‘‘
Answer 7:
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
import argparse
from importlib import import_module
import sys
import unittest
=======
import argparse
from importlib import import_module
import os
import sys
import unittest
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, ’.’, host, port, None, None, prefix = prefix,
handlers = handler_objects)
=======
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False, test_directory =’.’):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None,
prefix = prefix, handlers = handler_objects)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast)
if not failure: # once failed, this is considered immutable
failure = not success
if failure and failfast:
break
=======
test_dir = os. path. dirname (os. path. abspath (input_file))
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast, test_directory = test_dir)
if not failure: # once failed, this is considered immutable
failure = not success
if failure and failfast:
break
>>>>>>> REPLACE
‘‘‘
Answer 8:
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, ’.’, host, port, None, None, prefix = prefix,
handlers = handler_objects)
=======
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
# Determine test directory based on input handle
if hasattr (handle, ’ name ’):
test_directory = os. path. dirname (os. path. abspath (handle. name))
else:
test_directory = ’.’
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None,
prefix = prefix, handlers = handler_objects)
>>>>>>> REPLACE
‘‘‘
Answer 9:
‘‘‘ python
### gabbi / driver. py
<<<<<<< SEARCH
for test_file in glob. iglob (’% s /*. yaml ’ % path):
if ’ _ ’ in os. path. basename (test_file):
warnings. warn (exception. GabbiSyntaxWarning (
"’ _ ’ in test filename % s. This can break suite grouping."
% test_file))
if intercept:
host = str (uuid. uuid4 ())
suite_dict = utils. load_yaml (yaml_file = test_file)
test_base_name = os. path. splitext (os. path. basename (test_file))[0]
if all_test_base_name:
test_base_name = ’% s_ % s ’ % (all_test_base_name, test_base_name)
if require_ssl:
if ’ defaults ’ in suite_dict:
suite_dict [’ defaults ’][’ ssl ’] = True
else:
suite_dict [’ defaults ’] = {’ ssl ’: True}
file_suite = suitemaker. test_suite_from_dict (
loader, test_base_name, suite_dict, path, host, port,
fixture_module, intercept, prefix = prefix,
test_loader_name = test_loader_name, handlers = handler_objects,
inner_fixtures = inner_fixtures)
=======
for test_file in glob. iglob (’% s /*. yaml ’ % path):
if ’ _ ’ in os. path. basename (test_file):
warnings. warn (exception. GabbiSyntaxWarning (
"’ _ ’ in test filename % s. This can break suite grouping."
% test_file))
if intercept:
host = str (uuid. uuid4 ())
suite_dict = utils. load_yaml (yaml_file = test_file)
test_base_name = os. path. splitext (os. path. basename (test_file))[0]
if all_test_base_name:
test_base_name = ’% s_ % s ’ % (all_test_base_name, test_base_name)
if require_ssl:
if ’ defaults ’ in suite_dict:
suite_dict [’ defaults ’][’ ssl ’] = True
else:
suite_dict [’ defaults ’] = {’ ssl ’: True}
# Use absolute path of the YAML file ’ s directory
test_file_dir = os. path. dirname (os. path. abspath (test_file))
file_suite = suitemaker. test_suite_from_dict (
loader, test_base_name, suite_dict, test_file_dir, host, port,
fixture_module, intercept, prefix = prefix,
test_loader_name = test_loader_name, handlers = handler_objects,
inner_fixtures = inner_fixtures)
>>>>>>> REPLACE
‘‘‘
Answer 10:
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
import argparse
from importlib import import_module
import sys
import unittest
=======
import argparse
from importlib import import_module
import os
import sys
import unittest
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
=======
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False, test_directory =’.’):
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, ’.’, host, port, None, None, prefix = prefix,
force_ssl = force_ssl, failfast = failfast,
handlers = handler_objects)
=======
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None,
prefix = prefix, force_ssl = force_ssl, failfast = failfast,
handlers = handler_objects)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast)
=======
test_dir = os. path. dirname (input_file)
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast,
test_directory = test_dir)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / case. py
<<<<<<< SEARCH
path = os. path. join (self. test_directory, os. path. basename (filename))
=======
path = os. path. join (self. test_directory, filename)
>>>>>>> REPLACE
‘‘‘
Answer 11:
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, ’.’, host, port, None, None, prefix = prefix,
handlers = handler_objects)
=======
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False, test_directory =’.’):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port,
None, None, prefix = prefix, handlers = handler_objects)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast)
=======
test_dir = os. path. dirname (input_file)
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast,
test_directory = test_dir)
>>>>>>> REPLACE
‘‘‘
Answer 12:
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
import argparse
from importlib import import_module
import sys
import unittest
=======
import argparse
from importlib import import_module
import os
import sys
import unittest
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
else:
for input_file in input_files:
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast)
=======
else:
for input_file in input_files:
test_dir = os. path. dirname (os. path. abspath (input_file))
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast,
test_directory = test_dir)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, ’.’, host, port, None, None, prefix = prefix,
handlers = handler_objects)
=======
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False, test_directory =’.’):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None,
prefix = prefix, handlers = handler_objects)
>>>>>>> REPLACE
‘‘‘
Answer 13:
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, ’.’, host, port, None, None, prefix = prefix,
handlers = handler_objects)
=======
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False, test_directory =’.’):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None,
prefix = prefix, handlers = handler_objects)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
for input_file in input_files:
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast)
=======
for input_file in input_files:
test_dir = os. path. dirname (os. path. abspath (input_file))
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast,
test_directory = test_dir)
>>>>>>> REPLACE
‘‘‘
Answer 14:
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
for input_file in input_files:
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast)
=======
for input_file in input_files:
with open (input_file, ’ r ’) as fh:
success = run_suite (input_file, fh, handler_objects, host, port,
prefix, force_ssl, failfast)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_directory = ’.’
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None, prefix = prefix,
handlers = handler_objects)
=======
def run_suite (input_file, handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
""" Run the tests from the YAML in handle."""
data = utils. load_yaml (handle)
if force_ssl:
if ’ defaults ’ in data:
data [’ defaults ’][’ ssl ’] = True
else:
data [’ defaults ’] = {’ ssl ’: True}
loader = unittest. defaultTestLoader
test_directory = os. path. dirname (input_file) if input_file else ’.’
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None, prefix = prefix,
handlers = handler_objects)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
if not input_files:
success = run_suite (sys. stdin, handler_objects, host, port,
prefix, force_ssl, failfast)
=======
if not input_files:
success = run_suite (None, sys. stdin, handler_objects, host, port,
prefix, force_ssl, failfast)
>>>>>>> REPLACE
‘‘‘
‘‘‘
--- END FILE ---
Please first summary and analyze the key differences between the trajectories, and then generate * SEARCH / REPLACE * edits to fix the issue.
Every * SEARCH / REPLACE * edit must use this format:
1. The file path
2. The start of search block: <<<<<<< SEARCH
3. A contiguous chunk of lines to search for in the existing source code
4. The dividing line: =======
5. The lines to replace into the source code
6. The end of the replace block: >>>>>>> REPLACE
Here is an example:
‘‘‘ python
### mathweb / flask / app. py
<<<<<<< SEARCH
from flask import Flask
=======
import math
from flask import Flask
>>>>>>> REPLACE
‘‘‘
Please note that the * SEARCH / REPLACE * edit REQUIRES PROPER INDENTATION. If you would like to add the line ’ print (x)’, you must fully write that out, with all those spaces before the code!
Wrap the * SEARCH / REPLACE * edit in blocks ‘‘‘ python...‘‘‘.
The summary of the key differences between the trajectories should be in the thinking part.
"
Listing 12: Example of emergent parallel scaling (cdent__gabbi-191 in SWE-bench-extra), the prompt input part.
Listing 13 shows how the model successfully recognizes the correct answer candidate in Listing 12, and generates a novel patch with additional reasoning to solve the issue:
⬇
$\lhd$ think $\rhd$
Okay, let ’ s tackle this problem. The user is having an issue where when they specify a data file in their YAML test using the < @ syntax, the path isn ’ t resolved relative to the YAML file ’ s location. Instead, it ’ s using the current working directory. They want the path to be relative to the YAML file so they can run tests from any directory.
First, I need to understand how the current code is handling the data file paths. The user mentioned that in _load_data_file, the code uses os. path. join (self. test_directory, os. path. basename (filename)). This takes the test_directory (which defaults to ’.’), discards any directories in the filename, and appends the basename. That ’ s why if the YAML is in / my / tests / test. yaml and the data is < @data. txt, it looks for ./ data. txt instead of / my / tests / data. txt.
The key here is to make sure that the test_directory is set to the directory where the YAML file is located. Then, when joining with the filename (without basename), it would correctly resolve the relative path.
Looking at the provided code snippets, the main changes are in runner. py where the test_directory is determined. The user ’ s proposed solutions involve modifying the run_suite function to accept a test_directory parameter, which is derived from the input file ’ s directory.
In the original code, when running a suite from an input file, the test_directory is hardcoded to ’.’. The various answers modify this by passing the directory of the input file as test_directory. For example, in Answer 10, they add the test_directory parameter to run_suite and set it to os. path. dirname (input_file). Then, in case. py, they change the path joining to use the filename directly instead of basename.
Wait, the critical part is in case. py ’ s _load_data_file method. The original code uses os. path. basename (filename), which strips any directories from the filename. So if the YAML has < @test_data / file. txt, the basename is file. txt, and it ’ s joined with test_directory. But if test_directory is the YAML ’ s directory, then it should be YAML_DIR / test_data / file. txt. However, the current code would do test_directory + file. txt, which would be YAML_DIR / file. txt. That ’ s incorrect. So the problem is that the code is taking the basename, thus ignoring any subdirectories in the filename.
Ah, so the fix here is to not take the basename. Instead, the filename after < @ should be treated as a relative path from the YAML ’ s directory. So in case. py ’ s _load_data_file, instead of using os. path. basename (filename), we should use the filename as - is. Then, os. path. join (self. test_directory, filename) would correctly resolve the path relative to the YAML ’ s directory.
But wait, the filename could be an absolute path. For example, if the YAML has < @ / absolute / path / file. txt, then os. path. join would just use the absolute path. However, the documentation says that the filename is relative to the YAML file. So absolute paths might not be intended. But the code should handle that.
So combining two changes: in runner. py, set test_directory to the YAML file ’ s directory, and in case. py, stop using basename and use the full filename.
Looking at Answer 10, there ’ s a change in case. py from os. path. basename (filename) to filename. That ’ s exactly the fix needed. Then, in runner. py, when running the suite, pass the test_directory as the directory of the input file.
So the key files to modify are:
1. gabbi / runner. py: When calling run_suite, pass test_directory as the directory of the input file. This involves modifying the run_suite function to accept test_directory as a parameter and then passing it when the input file is processed.
2. gabbi / case. py: Change the path construction from using os. path. basename (filename) to using the filename directly. This allows subdirectories in the filename to be included in the path.
Looking through the provided code snippets, the one that does both is Answer 10. Let me check:
In Answer 10, the runner. py changes add the test_directory parameter and set it to os. path. dirname (input_file). Then, in case. py, the path is changed to os. path. join (self. test_directory, filename). That would correctly resolve the path relative to the YAML ’ s directory, including any subdirectories in the filename.
But wait, the original code in case. py uses os. path. basename (filename). So changing that to filename means that if the input is ’ test_data / file. txt ’, it ’ s joined as test_directory / test_data / file. txt. If test_directory is the YAML ’ s directory, that ’ s correct.
... [intermediate reasoning omitted for display brevity] ...
But perhaps better to use os. path. abspath and then dirname to handle relative paths correctly. But maybe the existing code already works. For example, if the input_file is ’ tests / test. yaml ’, then os. path. dirname would return ’ tests ’, which when joined with os. getcwd () would be correct. Wait, no. os. path. dirname just gives the directory part of the path. So if input_file is a relative path, like ’ tests / test. yaml ’, then test_directory would be ’ tests ’, and when os. path. join is called, it ’ s relative to the current working directory. But the code in suitemaker. test_suite_from_dict might expect an absolute path. However, the original code uses ’.’ as the test_directory, which is relative. So perhaps using the directory of the input file as test_directory is sufficient.
Another thing to consider: when the YAML is loaded from stdin (like via redirect), the test_directory remains ’.’. That ’ s acceptable, as the documentation mentions that when using <, the filename isn ’ t seen by Gabbi, so it ’ s not possible to resolve the path relative to the YAML ’ s original location. So in that case, the test_directory defaults to ’.’.
Now, in case. py:
Original line:
path = os. path. join (self. test_directory, os. path. basename (filename))
Modified line:
path = os. path. join (self. test_directory, filename)
So the SEARCH / REPLACE block for case. py:
### gabbi / case. py
<<<<<<< SEARCH
path = os. path. join (self. test_directory, os. path. basename (filename))
=======
path = os. path. join (self. test_directory, filename)
>>>>>>> REPLACE
Putting all these together, the final edits are:
1. Add import os in runner. py.
2. Modify run_suite to accept test_directory and pass it to test_suite_from_dict.
3. In the loop over input_files, compute test_directory as the directory of input_file and pass it to run_suite.
4. Modify case. py ’ s path construction.
So the final answer would include these four SEARCH / REPLACE blocks.
$\lhd$ / think $\rhd$
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
import argparse
from importlib import import_module
import sys
import unittest
=======
import argparse
from importlib import import_module
import os
import sys
import unittest
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False):
=======
def run_suite (handle, handler_objects, host, port, prefix, force_ssl = False,
failfast = False, test_directory =’.’):
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, ’.’, host, port, None, None, prefix = prefix,
handlers = handler_objects)
=======
test_suite = suitemaker. test_suite_from_dict (
loader, ’ input ’, data, test_directory, host, port, None, None,
prefix = prefix, handlers = handler_objects)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / runner. py
<<<<<<< SEARCH
else:
for input_file in input_files:
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast)
=======
else:
for input_file in input_files:
test_directory = os. path. dirname (input_file) or ’.’
with open (input_file, ’ r ’) as fh:
success = run_suite (fh, handler_objects, host, port,
prefix, force_ssl, failfast, test_directory = test_directory)
>>>>>>> REPLACE
‘‘‘
‘‘‘ python
### gabbi / case. py
<<<<<<< SEARCH
path = os. path. join (self. test_directory, os. path. basename (filename))
=======
path = os. path. join (self. test_directory, filename)
>>>>>>> REPLACE
‘‘‘
These changes:
1. Add ‘ os ‘ import needed for path handling
2. Modify run_suite to accept a test_directory parameter
3. Use the input file ’ s directory as the test_directory when processing files
4. Update data file path resolution to preserve directory structure from YAML relative paths
5. Remove basename handling that was stripping directory information from data file paths
The net effect is that data files specified with ‘< @filename ‘ in YAML tests will now be resolved relative to their YAML file ’ s directory, supporting both flat and nested directory structures for test data. When tests are run from stdin (using ‘<‘), the default directory remains the current working directory as before.
Listing 13: Example of emergent parallel scaling (cdent__gabbi-191 in SWE-bench-extra), the model response part.
Appendix G Analysis for SWE-Agents
G.1 Stage Annotation for SWE-Agent Trajectories
In this section, we present how we use a frontier LLM to annotate the SWE-Agent stage to which each interaction turn within the trajectory rollout belongs. While we have briefly introduced the five stages suggested in the prompt of the SWE-Agent prompt in Section 4, we attach the excerpt in Listing 14 for greater clarity:
⬇
...
Follow these steps to resolve the issue:
1. As a first step, it might be a good idea to find and read code relevant to the < pr_description >
2. Create a script to reproduce the error and execute it with ‘ python < filename. py >‘ using the bash tool, to confirm the error
3. Edit the source code of the repo to resolve the issue
4. Rerun your reproduce script and confirm that the error is fixed!
5. Think about edgecases and make sure your fix handles them as well
...
Listing 14: The excerpt of the five-stage declaration in the SWE-Agent prompt.
It should be noted that the agent could flexibly transit across the five stages during its working process. For example, after Stage 4 when the agent rerun the test script, possibilities are that erroneous information remains, and this is when the agent goes back to Stage 3 to refine its code repair with reflection; Similar backtracing behavior could be observed from Stage 5 to Stage 3 as well, where the initial code repair has proven correct under the initial test script the agent composes in Stage 2, but fails some edge testcase the agent proposes in Stage 5.
To further analyze the BugFixer and the reflection skill prior, we need to realize which stage each turn along the SWE-Agent trajectory belongs to. As no strict boundaries or special prompt notes are set between each consecutive stage, we leverage an LLM for annotation. The annotation system prompt we set in kimi-k2-0711-preview is shown in Listing 15:
⬇
You are a professional inspector that can analyze the provided agentic interaction trajectory.
The trajectory you are going to analyze is made by an agent that interacts with a computer to solve tasks. This agent has access to the following functions:
---- BEGIN FUNCTION #1: bash ----
Description: Execute a bash command in the terminal.
Parameters:
(1) command (string, required): The bash command to execute. Can be empty to view additional logs when previous exit code is ‘-1‘. Can be ‘ ctrl + c ‘ to interrupt the currently running process.
---- END FUNCTION #1 ----
---- BEGIN FUNCTION #2: submit ----
Description: Finish the interaction when the task is complete OR if the assistant cannot proceed further with the task.
No parameters are required for this function.
---- END FUNCTION #2 ----
---- BEGIN FUNCTION #3: str_replace_editor ----
Description: Custom editing tool for viewing, creating and editing files
* State is persistent across command calls and discussions with the user
* If ‘ path ‘ is a file, ‘ view ‘ displays the result of applying ‘ cat - n ‘. If ‘ path ‘ is a directory, ‘ view ‘ lists non - hidden files and directories up to 2 levels deep
* The ‘ create ‘ command cannot be used if the specified ‘ path ‘ already exists as a file
* If a ‘ command ‘ generates a long output, it will be truncated and marked with ‘< response clipped >‘
* The ‘ undo_edit ‘ command will revert the last edit made to the file at ‘ path ‘
Notes for using the ‘ str_replace ‘ command:
* The ‘ old_str ‘ parameter should match EXACTLY one or more consecutive lines from the original file. Be mindful of whitespaces!
* If the ‘ old_str ‘ parameter is not unique in the file, the replacement will not be performed. Make sure to include enough context in ‘ old_str ‘ to make it unique
* The ‘ new_str ‘ parameter should contain the edited lines that should replace the ‘ old_str ‘
Parameters:
(1) command (string, required): The commands to run. Allowed options are: ‘ view ‘, ‘ create ‘, ‘ str_replace ‘, ‘ insert ‘, ‘ undo_edit ‘.
Allowed values: [‘ view ‘, ‘ create ‘, ‘ str_replace ‘, ‘ insert ‘, ‘ undo_edit ‘]
(2) path (string, required): Absolute path to file or directory, e. g. ‘/ repo / file. py ‘ or ‘/ repo ‘.
(3) file_text (string, optional): Required parameter of ‘ create ‘ command, with the content of the file to be created.
(4) old_str (string, optional): Required parameter of ‘ str_replace ‘ command containing the string in ‘ path ‘ to replace.
(5) new_str (string, optional): Optional parameter of ‘ str_replace ‘ command containing the new string (if not given, no string will be added). Required parameter of ‘ insert ‘ command containing the string to insert.
(6) insert_line (integer, optional): Required parameter of ‘ insert ‘ command. The ‘ new_str ‘ will be inserted AFTER the line ‘ insert_line ‘ of ‘ path ‘.
(7) view_range (array, optional): Optional parameter of ‘ view ‘ command when ‘ path ‘ points to a file. If none is given, the full file is shown. If provided, the file will be shown in the indicated line number range, e. g. [11, 12] will show lines 11 and 12. Indexing at 1 to start. Setting ‘[start_line, -1]‘ shows all lines from ‘ start_line ‘ to the end of the file.
---- END FUNCTION #3 ----
The agent was instructed with the following:
* A python code repository has been uploaded in the directory / testbed.
* Implement the necessary changes to the repository so that the requirements specified in the < pr_description > are met.
* All changes to any of the test files described in the < pr_description > have already been taken care of. This means no need to modify the testing logic or any of the tests in any way.
* Make the minimal changes to non - tests files in the / testbed directory to ensure the < pr_description > is satisfied.
The agent was suggested to follow the following steps to resolve the issue:
1. As a first step, it might be a good idea to find and read code relevant to the < pr_description >
2. Create a script to reproduce the error and execute it with ‘ python < filename. py >‘ using the bash tool, to confirm the error
3. Edit the source code of the repo to resolve the issue
4. Rerun your reproduce script and confirm that the error is fixed!
5. Think about edgecases and make sure your fix handles them as well
The agent was encouraged to think thoroughly, and it ’ s fine if it ’ s very long.
You are going to inspect this agent ’ s interaction trajectory with a computer to solve the given task in the < pr_description >. One turn of interaction contains a pair of OBSERVATION and ACTION, where the OBSERVATION comes from the computer, and the ACTION is taken by the agent.
For each turn of interaction, determine which step (of the aforementioned five) this turn belongs to. Output a single number (1~5) ONLY in a separate line as your classification (DO NOT OUTPUT ANY OTHER WORDS THAN THE DIGIT).
You can think before make the inspection. When thinking, wrap your thought with < think > and </ think >. Don ’ t forget to output your final inspection after thinking.
Listing 15: The annotation prompt for SWE-Agent stages.
To provide a clearer understanding of the trajectory, we incorporate most of the tool descriptions and instructions from the SWE-Agent system prompt into the annotation system prompt. The annotation is conducted in a multi-round manner, leveraging the agent’s previous actions and observations, as well as the stage classifications of earlier turns, to better exploit contextual information. At the $i$ -th round of annotation, the observation–action pair from turn $i$ of the SWE-Agent trajectory is appended as input, and the annotator is expected to output the corresponding stage classification.
G.2 Comparative Study
Based on the automatic stage annotation in the above section, we present a comparative study by inspecting the performance on sympy__sympy-20590 among the Kimi-Dev under Agentless, and each of the Base, MT, SFT, and RL priors with SWE-Agent adaptation.
The problem statement of sympy__sympy-20590 is listed in Listing 16:
⬇
Symbol instances have __dict__ since 1.7?
In version 1.6.2 Symbol instances had no ‘ __dict__ ‘ attribute
‘‘‘ python
>>> sympy. Symbol (’ s ’). __dict__
------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
< ipython - input -3- e2060d5eec73 > in < module >
----> 1 sympy. Symbol (’ s ’). __dict__
AttributeError: ’ Symbol ’ object has no attribute ’ __dict__ ’
>>> sympy. Symbol (’ s ’). __slots__
(’ name ’,)
‘‘‘
This changes in 1.7 where ‘ sympy. Symbol (’ s ’). __dict__ ‘ now exists (and returns an empty dict)
I may misinterpret this, but given the purpose of ‘ __slots__ ‘, I assume this is a bug, introduced because some parent class accidentally stopped defining ‘ __slots__ ‘.
Listing 16: The problem statement of sympy__sympy-20590.
It is observed that the main difficulty in resolving the issue lies in the realization of the “ some parent class” referenced in the problem. In fact, the hints text of this problem, which reflects the discussion of the developers under the original issue, reveals a much more in-depth investigation into the issue (Listing 17):
⬇
It seems that Basic now inherits ‘ DefaultPrinting ‘ which I guess doesn ’ t have slots. I ’ m not sure if it ’ s a good idea to add ‘ __slots__ ‘ to that class as it would then affect all subclasses.
...
Using slots can break multiple inheritance but only if the slots are non - empty I guess. Maybe this means that any mixin should always declare empty slots or it won ’ t work properly with subclasses that have slots...
I see that ‘ EvalfMixin ‘ has ‘ __slots__ = ()‘.
I guess we should add empty slots to DefaultPrinting then.
Listing 17: The excerpted hints text of sympy__sympy-20590.
According to the discussion, it is clear that the code repair would be to “add empty slots to DefaultPrinting”, which naturally leads to the navigation towards the file related to the implementation of the printer (sympy/core/_print_helpers.py, which is also the file updated by the ground-truth patch.) However, the hints_text information in the test set is not allowed to be used in the problem-solving process, which challenges the reasoner or the agent to figure out “the parent class that stopped defining ‘__slots__‘ ” autonomously.
We first examine Kimi-Dev under Agentless. None of the 40 runs succeeded in producing the correct file localization. In most cases, the updates are made to sympy/core/symbol.py, which is a plausible choice since the reported problem is triggered by sympy.Symbol(’s’), and symbol.py should contain the definition of the Symbol class. This line of reasoning, however, diverges from the correct solution. A small number of runs attempt alternative localizations, such as sympy/core/{basic.py, expr.py}, but these are also incorrect.
The limitation of the Agentless framework becomes more obvious when the focus is shifted to the inspection over the SWE-Agent trajectories. For all of the Base, MT, SFT, and RL priors with SWE-Agent adaptation, the resulting trajectories always contain a test-reproducing phase (marked as Stage “2” by the annotator), with the generated script reads like:
⬇
from sympy import Symbol
# Try to access __dict__ on a Symbol instance
s = Symbol (’ s ’)
print (" Symbol. __slots__:", s. __slots__)
try:
print (" Symbol. __dict__:", s. __dict__)
except AttributeError as e:
print (" Error:", e)
Listing 18: An exampled reproducing script in Stage 2 within the SWE-Agent trajectories in sympy__sympy-20590.
It is trivial for an agent to generate a reproducing script of this form, as it directly transcribes the case described in the problem statement. Executing the script provides an unambiguous signal of whether the issue is resolved: the attribute s.__dict__ should no longer exist, and the expected Error: message should appear in the standard error output. Indeed, observing the initial completion of Stage 3 across all trajectories reveals that none of the agents succeeded on their first attempt. However, the incomplete status is consistently exposed in Stage 4, when the script is rerun and s.__dict__ still persists. This progression highlights the advantage of the SWE-Agent framework over the Agentless paradigm, as the agent is afforded additional opportunities for iterative refinement rather than being limited to a single attempt.
We continue to analyze the behavior of the agents adapted from the Base, MT, and SFT priors. Due to the difficulty of the issue, it is non-trivial to correctly localize the error through their agentic reasoning: the interactions show that the agents were switching among several file candidates, but failed to reach the correct one. The only exception comes from the agent adapted from the RL prior, which marks its unique success on this instance through accurate agentic reasoning. We attach the intermediate process from the initial Stage-3 moment to the Stage-3 revisit (refining the initial code repair) within the successful trajectory, tagged by the stage annotator:
⬇
...
OBSERVATION:
Symbol. __slots__: (’ name ’,)
Symbol. __dict__: {}
ACTION:
Hmm, it seems like the issue is still there. Let ’ s check if there are any other classes in the hierarchy that might be missing ‘ __slots__ ‘:
< function = bash >
< parameter = command > python - c " from sympy import Symbol; s = Symbol (’ s ’); for cls in type (s). __mro__: print (cls. __name__, ’ has __slots__:’, hasattr (cls, ’ __slots__ ’))"</ parameter >
</ function >
OBSERVATION:
File "< string >", line 1
from sympy import Symbol; s = Symbol (’ s ’); for cls in type (s). __mro__: print (cls. __name__, ’ has __slots__:’, hasattr (cls, ’ __slots__ ’))
^
SyntaxError: invalid syntax
ACTION:
Let ’ s try a different approach:
< function = str_replace_editor >
< parameter = command > create </ parameter >
< parameter = path >/ testbed / check_slots. py </ parameter >
< parameter = file_text >
from sympy import Symbol
s = Symbol (’ s ’)
for cls in type (s). __mro__:
print (f "{cls. __name__:15} has __slots__: {hasattr (cls, ’ __slots__ ’)}")
if hasattr (cls, ’ __slots__ ’):
print (f "{’ ’*16} __slots__ value: {cls. __slots__}")
</ parameter >
</ function >
OBSERVATION:
File created successfully at: / testbed / check_slots. py
ACTION:
< function = bash >
< parameter = command > python / testbed / check_slots. py </ parameter >
</ function >
OBSERVATION:
Symbol has __slots__: True
__slots__ value: (’ name ’,)
AtomicExpr has __slots__: True
__slots__ value: ()
Atom has __slots__: True
__slots__ value: ()
Expr has __slots__: True
__slots__ value: ()
Boolean has __slots__: True
__slots__ value: ()
Basic has __slots__: True
__slots__ value: (’ _mhash ’, ’ _args ’, ’ _assumptions ’)
Printable has __slots__: False
EvalfMixin has __slots__: True
__slots__ value: ()
object has __slots__: False
ACTION:
Now I see the issue! ‘ Printable ‘ doesn ’ t have ‘ __slots__ ‘ defined. Let ’ s check the ‘ Printable ‘ class:
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / sympy / core / _print_helpers. py </ parameter >
< parameter = view_range >[1, 30]</ parameter >
</ function >
OBSERVATION:
Here ’ s the result of running ‘ cat - n ‘ on / testbed / sympy / core / _print_helpers. py:
1 """
2 Base class to provide str and repr hooks that ‘ init_printing ‘ can overwrite.
3
4 This is exposed publicly in the ‘ printing. defaults ‘ module,
5 but cannot be defined there without causing circular imports.
6 """
7
8 class Printable:
9 """
10 The default implementation of printing for SymPy classes.
11
12 This implements a hack that allows us to print elements of built - in
13 Python containers in a readable way. Natively Python uses ‘‘ repr ()‘‘
14 even if ‘‘ str ()‘‘ was explicitly requested. Mix in this trait into
15 a class to get proper default printing.
16
17 This also adds support for LaTeX printing in jupyter notebooks.
18 """
19
20 # Note, we always use the default ordering (lex) in __str__ and __repr__,
21 # regardless of the global setting. See issue 5487.
22 def __str__ (self):
23 from sympy. printing. str import sstr
24 return sstr (self, order = None)
25
26 __repr__ = __str__
27
28 def _repr_disabled (self):
29 """
30 No - op repr function used to disable jupyter display hooks.
ACTION:
We need to add ‘ __slots__ = ()‘ to the ‘ Printable ‘ class as well:
< function = str_replace_editor >
< parameter = command > str_replace </ parameter >
< parameter = path >/ testbed / sympy / core / _print_helpers. py </ parameter >
< parameter = old_str >
class Printable:
"""
The default implementation of printing for SymPy classes.
This implements a hack that allows us to print elements of built - in
Python containers in a readable way. Natively Python uses ‘‘ repr ()‘‘
even if ‘‘ str ()‘‘ was explicitly requested. Mix in this trait into
a class to get proper default printing.
This also adds support for LaTeX printing in jupyter notebooks.
"""
</ parameter >
< parameter = new_str >
class Printable:
"""
The default implementation of printing for SymPy classes.
This implements a hack that allows us to print elements of built - in
Python containers in a readable way. Natively Python uses ‘‘ repr ()‘‘
even if ‘‘ str ()‘‘ was explicitly requested. Mix in this trait into
a class to get proper default printing.
This also adds support for LaTeX printing in jupyter notebooks.
"""
__slots__ = ()
</ parameter >
</ function >
...
Listing 19: The intermediate reflection process between the two Stage-3 moment of the successful trajectory in sympy__sympy-20590.
Listing 19 shows the advanced reflection capability through slot checking along the entire class hierarchy, which successfully leads to the observation of the erroneous Printable. The following behavior from the agent includes the routine of test rerun, and the observation of passing the test script (Listing 18). This chain of actions recovers and resonates with the developer discussions in hints_text (Listing 17), showing the superior reflection skill in the RL prior over other priors.
G.3 Pattern Comparison between SFT with Expert Data and End-to-End RL
In this section, we compare the patterns of the interaction trajectories of the RL prior that undergoes (i) $1.5× 2^{28}$ SWE-Agent expert SFT tokens (later referred as “heavy SFT”) and (ii) $2^{21}$ SWE-Agent expert SFT tokens + end-to-end SWE-Agent RL (later referred as “light SFT + end-to-end RL”) as a qualitative study for Figure 7.
We select an instance solved by both methods, matplotlib__matplotlib-13989, as case study. We attach the actions along the two interaction trajectories for comparison.
The action patterns of the heavy SFT model read as Listing 20:
⬇
ACTION 0:
I ’ ll help you implement the necessary changes to fix the issue where ‘ hist ()‘ doesn ’ t respect ‘ range =...‘ when ‘ density = True ‘. Let ’ s follow the steps:
1. First, let ’ s find and read the relevant code:
< function = bash >
< parameter = command > find / testbed - type f - name "*. py " | grep - v " test_ "</ parameter >
</ function >
ACTION 1:
Let ’ s look for the histogram implementation since that ’ s what we need to fix. The PR mentions that the bug is in the ‘ hist ()‘ function when ‘ density = True ‘ and ‘ range =...‘ is specified.
< function = bash >
< parameter = command > grep - r " def hist " -- include ="*. py " / testbed | grep - v " test_ "</ parameter >
</ function >
ACTION 2:
The main histogram implementation appears to be in ‘/ testbed / lib / matplotlib / axes / _axes. py ‘. Let ’ s look at that file:
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes / _axes. py </ parameter >
</ function >
ACTION 3:
Let me look at the histogram implementation specifically:
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes / _axes. py </ parameter >
< parameter = view_range >[6365, 6899]</ parameter >
</ function >
ACTION 4:
Let me also look at the ‘ histogram_bin_edges ‘ function since it ’ s used in the code:
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes / _axes. py </ parameter >
< parameter = view_range >[40, 60]</ parameter >
</ function >
ACTION 5:
2. Let ’ s create a script to reproduce the error:
< function = str_replace_editor >
< parameter = command > create </ parameter >
< parameter = path >/ testbed / reproduce. py </ parameter >
...
ACTION 6:
Let ’ s run it to confirm the issue:
< function = bash >
< parameter = command > python / testbed / reproduce. py </ parameter >
</ function >
ACTION 7:
The issue is confirmed: when ‘ density = True ‘ is specified, the ‘ range =(0, 1)‘ parameter is not respected. The bins should start at 0 and end at 1, but they don ’ t.
3. Let ’ s fix the issue. Looking at the code, the problem is in the ‘ hist ‘ method and specifically around line 6689-6690:
‘‘‘ python
if density and not stacked:
hist_kwargs = dict (density = density)
‘‘‘
The issue is that when ‘ density = True ‘, the ‘ range ‘ parameter gets lost because we ’ re not including it in the ‘ hist_kwargs ‘. Let ’ s modify the code to fix this:
< function = str_replace_editor >
< parameter = command > str_replace </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes / _axes. py </ parameter >
...
ACTION 8:
4. Let ’ s run the reproduce script again to confirm the fix:
< function = bash >
< parameter = command > python / testbed / reproduce. py </ parameter >
</ function >
ACTION 9:
Great! The fix works. Now the bins start at 0 and end at 1 as expected.
5. Let ’ s think about edge cases:
1. When ‘ range = None ‘ - This should use the min / max of the data, which is already handled correctly by the existing code
2. When ‘ range ‘ is specified but ‘ density = False ‘ - The range should be respected, which it already is
3. When ‘ range ‘ is specified and ‘ density = True ‘ - The range should be respected, which our fix now ensures
4. When ‘ bins ‘ is a sequence - The range should be ignored, which is already handled by the code
5. When ‘ range ‘ includes values outside the data range - The histogram should include empty bins for the range outside the data, which is already handled by numpy ’ s histogram function
Let me test some of these edge cases to be sure:
< function = str_replace_editor >
< parameter = command > str_replace </ parameter >
< parameter = path >/ testbed / reproduce. py </ parameter >
...
ACTION 10:
< function = bash >
< parameter = command > python / testbed / reproduce. py </ parameter >
</ function >
ACTION 11:
All test cases look good:
1. When ‘ range =(0, 1)‘ and ‘ density = True ‘, the bins start at 0 and end at 1
2. When ‘ range = None ‘ and ‘ density = True ‘, the bins use the min / max of the data
3. When ‘ range =(0, 1)‘ and ‘ density = False ‘, the bins start at 0 and end at 1
4. When ‘ bins ‘ is a sequence, the range parameter is ignored and the sequence is used directly
5. When ‘ range =(-0.5, 1.5)‘, the bins start at -0.5 and end at 1.5
The fix looks good and handles all edge cases correctly. Let me submit the changes:
< function = submit >
</ function >
Listing 20: The interaction made by the RL prior with $1.5× 2^{28}$ SWE-Agent SFT tokens on matplotlib__matplotlib-13989.
The action patterns of the light SFT + end-to-end RL model read as Listing 21:
⬇
ACTION 0:
Understood. Let ’ s tackle this problem step by step.
First, I need to find the relevant code in the / testbed directory. The user mentioned that the code is in / testbed, so I ’ ll start by listing the files there.
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed </ parameter >
</ function >
ACTION 1:
Hmm, the / testbed directory has a lot of files, but I need to focus on the code related to the hist function. The hist function is part of matplotlib. pyplot, so I should look for the pyplot module in the / testbed / lib / matplotlib directory.
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / pyplot. py </ parameter >
</ function >
ACTION 2:
Okay, I ’ ll look at the hist function in pyplot. py.
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / pyplot. py </ parameter >
< parameter = view_range >[2610, 2625]</ parameter >
</ function >
ACTION 3:
The hist function in pyplot. py simply calls the hist method of the current axes. So the actual implementation is in the Axes class.
I ’ ll look for the Axes. hist method in the / testbed / lib / matplotlib / axes directory.
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes </ parameter >
</ function >
ACTION 4:
The Axes. hist method is likely in _axes. py, which is where most of the plotting methods are defined.
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes / _axes. py </ parameter >
</ function >
ACTION 5:
I ’ ll look at the hist method in _axes. py.
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes / _axes. py </ parameter >
< parameter = view_range >[6365, 6400]</ parameter >
</ function >
ACTION 6:
I ’ ll look at more of the hist method to see where the range is handled.
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes / _axes. py </ parameter >
< parameter = view_range >[6400, 6450]</ parameter >
</ function >
ACTION 7:
I ’ ll look at the code where the bins are calculated.
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes / _axes. py </ parameter >
< parameter = view_range >[6450, 6500]</ parameter >
</ function >
ACTION 8:
I ’ ll look at the code where the bins are calculated.
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes / _axes. py </ parameter >
< parameter = view_range >[6500, 6550]</ parameter >
</ function >
ACTION 9:
I ’ ll look at the code where the bins are calculated.
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes / _axes. py </ parameter >
< parameter = view_range >[6550, 6600]</ parameter >
</ function >
ACTION 10:
I ’ ll look at the code where the bins are calculated.
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes / _axes. py </ parameter >
< parameter = view_range >[6600, 6650]</ parameter >
</ function >
ACTION 11:
I ’ ll look at the code where the bins are calculated.
< function = str_replace_editor >
< parameter = command > view </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes / _axes. py </ parameter >
< parameter = view_range >[6650, 6700]</ parameter >
</ function >
ACTION 12:
Ah, here ’ s the key part. The code calculates the bins using np. histogram, and if the range is specified, it ’ s passed to histogram_bin_edges. But when density is True, the code may be overriding the range.
Wait, in the code:
if not input_empty and len (x) > 1:
if weights is not None:
_w = np. concatenate (w)
else:
_w = None
bins = histogram_bin_edges (np. concatenate (x),
bins, bin_range, _w)
else:
hist_kwargs [’ range ’] = bin_range
But when density is True, the code may be using the default range of the data, not the specified range.
Wait, no. The code for calculating the bins is:
if bins is None:
bins = rcParams [’ hist. bins ’]
if bin_range is not None:
bin_range = self. convert_xunits (bin_range)
if bin_range is None:
xmin = np. inf
xmax = - np. inf
for xi in x:
if len (xi):
xmin = min (xmin, np. nanmin (xi))
xmax = max (xmax, np. nanmax (xi))
if not np. isnan ([xmin, xmax]). any () and not (xmin > xmax):
bin_range = (xmin, xmax)
# If bins are not specified either explicitly or via range,
# we need to figure out the range required for all datasets,
# and supply that to np. histogram.
if not input_empty and len (x) > 1:
if weights is not None:
_w = np. concatenate (w)
else:
_w = None
bins = histogram_bin_edges (np. concatenate (x),
bins, bin_range, _w)
else:
hist_kwargs [’ range ’] = bin_range
density = bool (density) or bool (normed)
if density and not stacked:
hist_kwargs = dict (density = density)
# List to store all the top coordinates of the histograms
tops = []
mlast = None
# Loop through datasets
for i in range (nx):
# this will automatically overwrite bins,
# so that each histogram uses the same bins
m, bins = np. histogram (x [i], bins, weights = w [i], ** hist_kwargs)
m = m. astype (float) # causes problems later if it ’ s an int
if mlast is None:
But when density is True, the code passes density = True to np. histogram. However, when density is True, np. histogram normalizes the counts, but the bin edges are still determined by the range.
Wait, but the problem is that when density = True, the range is not respected. The user ’ s code is:
_, bins, _ = plt. hist (np. random. rand (10), " auto ", range =(0, 1), density = True)
print (bins)
and the output is:
[0.00331535 0.18930174 0.37528813 0.56127453 0.74726092 0.93324731]
which is not from 0 to 1. But when density = False, the range is respected.
This suggests that when density = True, the code is not using the specified range for the bins.
But why?
Let me look at the code again.
When the code calculates the bins:
if not input_empty and len (x) > 1:
if weights is not None:
_w = np. concatenate (w)
else:
_w = None
bins = histogram_bin_edges (np. concatenate (x),
bins, bin_range, _w)
else:
hist_kwargs [’ range ’] = bin_range
But when len (x) is 1 (as in the user ’ s code), the code enters the else clause and sets hist_kwargs [’ range ’] = bin_range.
Then, in the loop:
for i in range (nx):
m, bins = np. histogram (x [i], bins, weights = w [i], ** hist_kwargs)
But wait, if bins is None, then np. histogram will use the range. But if bins is a string (like ’ auto ’), then np. histogram will calculate the bins based on the data and the range.
Wait, in the user ’ s code, bins is ’ auto ’ and range is (0, 1). When density = True, the code should calculate the bins based on the range (0, 1).
But in the code, when len (x) is 1, the code sets hist_kwargs [’ range ’] = bin_range. Then, in the loop, the code calls np. histogram (x [i], bins, weights = w [i], ** hist_kwargs).
But if bins is a string (like ’ auto ’), then np. histogram will calculate the bins based on the data and the range. So the range should be respected.
But in the user ’ s code, the bins are not from 0 to 1. This suggests that the code is not passing the range to np. histogram when density = True.
But why?
This is puzzling. Let me try to reproduce the error.
I ’ ll create a script in the / testbed directory.
< function = str_replace_editor >
< parameter = command > create </ parameter >
< parameter = path >/ testbed / reproduce_error. py </ parameter >
...
ACTION 13:
I ’ ll run the script.
< function = bash >
< parameter = command > python / testbed / reproduce_error. py </ parameter >
</ function >
ACTION 14:
Hmm, the output is not from 0 to 1. This confirms the error.
Now, I need to find where in the code the range is not being passed when density = True.
Let me look at the code again.
When len (x) is 1, the code sets hist_kwargs [’ range ’] = bin_range. Then, in the loop:
for i in range (nx):
m, bins = np. histogram (x [i], bins, weights = w [i], ** hist_kwargs)
But if bins is a string (like ’ auto ’), then np. histogram will calculate the bins based on the data and the range. So the range should be respected.
But in the user ’ s code, the bins are not from 0 to 1. This suggests that the code is not passing the range to np. histogram when density = True.
But why?
This is confusing. Let me look at the code for np. histogram.
The np. histogram function has a range parameter. If range is specified, the bin edges are calculated based on that range. If the data is outside the range, it is ignored.
In the user ’ s code, the data is between 0 and 1, so the range (0, 1) should be respected.
But when density = True, the code is not respecting the range. This suggests that the code is not passing the range to np. histogram when density = True.
But why?
This is puzzling. Let me try to modify the code in _axes. py.
I ’ ll look for the line where hist_kwargs is set.
In the code:
density = bool (density) or bool (normed)
if density and not stacked:
hist_kwargs = dict (density = density)
This line is overwriting hist_kwargs, which may include the range.
Ah, here ’ s the problem. If density is True and stacked is False, the code sets hist_kwargs to dict (density = density), which overwrites any previous hist_kwargs, including the range.
This is the root of the problem. The code is overwriting hist_kwargs, which includes the range, when density is True and stacked is False.
So, in the code:
density = bool (density) or bool (normed)
if density and not stacked:
hist_kwargs = dict (density = density)
This line is overwriting hist_kwargs, which may include the range. So the range is not passed to np. histogram.
This is the cause of the problem. The solution is to add the range to hist_kwargs in this case.
So, the code should be:
density = bool (density) or bool (normed)
if density and not stacked:
hist_kwargs. setdefault (’ density ’, density)
But wait, hist_kwargs may already have the range. So, the code should not overwrite hist_kwargs, but add to it.
The code is:
density = bool (density) or bool (normed)
if density and not stacked:
hist_kwargs = dict (density = density)
This line is overwriting hist_kwargs, which may include the range. So the range is lost.
The solution is to modify this code to add to hist_kwargs, not overwrite it.
So, the code should be:
density = bool (density) or bool (normed)
if density and not stacked:
hist_kwargs. setdefault (’ density ’, density)
But wait, hist_kwargs may not exist. Let me look at the code.
The code for hist_kwargs is:
hist_kwargs = dict ()
# if the bin_range is not given, compute without nan numpy
# does not do this for us when guessing the range (but will
# happily ignore nans when computing the histogram).
if bin_range is None:
xmin = np. inf
xmax = - np. inf
for xi in x:
if len (xi):
xmin = min (xmin, np. nanmin (xi))
xmax = max (xmax, np. nanmax (xi))
# make sure we have seen at least one non - nan and finite
# value before we reset the bin range
if not np. isnan ([xmin, xmax]). any () and not (xmin > xmax):
bin_range = (xmin, xmax)
# If bins are not specified either explicitly or via range,
# we need to figure out the range required for all datasets,
# and supply that to np. histogram.
if not input_empty and len (x) > 1:
if weights is not None:
_w = np. concatenate (w)
else:
_w = None
bins = histogram_bin_edges (np. concatenate (x),
bins, bin_range, _w)
else:
hist_kwargs [’ range ’] = bin_range
density = bool (density) or bool (normed)
if density and not stacked:
hist_kwargs = dict (density = density)
# List to store all the top coordinates of the histograms
tops = []
mlast = None
# Loop through datasets
for i in range (nx):
# this will automatically overwrite bins,
# so that each histogram uses the same bins
m, bins = np. histogram (x [i], bins, weights = w [i], ** hist_kwargs)
m = m. astype (float) # causes problems later if it ’ s an int
if mlast is None:
Ah, here ’ s the problem. The code sets hist_kwargs = dict (density = density), which overwrites any previous hist_kwargs, including the range.
So, if density is True and stacked is False, the code overwrites hist_kwargs with dict (density = density), which does not include the range. So the range is not passed to np. histogram.
This is the cause of the problem. The solution is to modify this code to add to hist_kwargs, not overwrite it.
So, the code should be:
density = bool (density) or bool (normed)
if density and not stacked:
hist_kwargs. setdefault (’ density ’, density)
But hist_kwargs may not exist. Wait, hist_kwargs is initialized as:
hist_kwargs = dict ()
So, the code can be:
density = bool (density) or bool (normed)
if density and not stacked:
hist_kwargs [’ density ’] = density
This way, hist_kwargs includes the density and the range.
This would fix the problem. Let me test this.
I ’ ll modify the code in _axes. py.
< function = str_replace_editor >
< parameter = command > str_replace </ parameter >
< parameter = path >/ testbed / lib / matplotlib / axes / _axes. py </ parameter >
...
ACTION 14:
I ’ ll run the reproduce_error. py script again.
< function = bash >
< parameter = command > python / testbed / reproduce_error. py </ parameter >
</ function >
ACTION 15:
Great, the fix works. The bins are now from 0 to 1.
Now, I can submit the changes.
< function = submit >
</ function >
Listing 21: The interaction made by the RL prior with $2^{21}$ SWE-Agent SFT tokens and end-to-end SWE-Agent RL on matplotlib__matplotlib-13989.
It can be seen that the two types of patterns are significantly different from each other:
- The patterns of the heavy SFT model appear to be more regulated, with explicitly labeled steps 1 to 5 along the intermediate reasoning process. The reasoning content is generally short as well. This reflects the behavior of the model shaped by the heavy SFT data from the proprietary models.
- The patterns of the light SFT + end-to-end RL model, in contrast, are much more under-regulated. More turns of interaction are spent at repo exploration, and a significantly larger amount of tokens are generated at the code edit steps before the action is made. This is the reflection behavior shaped by end-to-end RL (and less impacted by the expert data), as the sign of reasoning-intensive skill priors is retained in the agentic scenario.
G.4 Generalization to Other Tasks
In this section, we study whether the skills incentivized by Agentless training and SWE-Agent adaptation through SWE-Smith trajectories could transfer to other SWE tasks. We use SWE-bench-live and SWE-bench Multilingual as our testbeds.
SWE-bench-live (zhang2025swe) is a benchmark for real-world issue resolution, evaluating AI systems on software engineering tasks. Using an automated curation pipeline, it is updated monthly to ensure fresh tasks and rigorous, contamination-free evaluation. For our experiments, we selected the default set of 300 tasks, with data collected between October 2024 and March 2025. Compared to SWE-bench Verified, SWE-bench-live exhibits a higher degree of distributional shift.
SWE-bench Multilingual (yang2025swesmith) introduces 300 curated tasks from 42 GitHub repositories across 9 programming languages, including Rust, Java, PHP, Ruby, JavaScript/TypeScript, Go, and C/C++, covering domains such as web frameworks, data tools, core utilities, and libraries. Compared to SWE-bench Verified, which focuses exclusively on Python, SWE-bench Multilingual exhibits greater linguistic and domain diversity, posing additional challenges in cross-language generalization and transferability of software engineering capabilities.
Similar to previous experiments, we evaluated four model stages as the priors: the original Qwen2.5-72B (Base), the mid-trained model (MT), the model activated with reasoning data through supervised finetuning (SFT), and the model after RL training (RL). We still use the open-source SWE-smith trajectories to activate the agentic capabilities of each prior.
Figures 11 and 12 show the performance of the four priors on SWE-bench-Live and SWE-bench Multilingual under varied amounts of agentic trajectories for adaptation ( $2^{21}$ as one-step gradient descent, $2^{23}$ , $1.1× 2^{27}$ , and $1.5× 2^{28}$ as 100, 2,000, and 5,016 training trajectories). Each SWE-Agent adaptation experiment is conducted through lightweight supervised finetuning, the training time of which ranges from several minutes to two hours at most.
Compared to the Base prior, those specifically enhanced with Agentless skills (SFT and RL) demonstrate stronger task generalization, especially under the data-scarce settings. However, when more SWE-Smith trajectories are used for adaptation, the performances of the Base and the MT priors become closer to those of the SFT and the RL priors. This could be attributed to the gaps between the different SWE tasks. The exploration for recipes that enable stronger out-of-distribution and task-agnostic generalization is left for future work.
<details>
<summary>figs/sec4_generalization_plots/l-100-s1.png Details</summary>
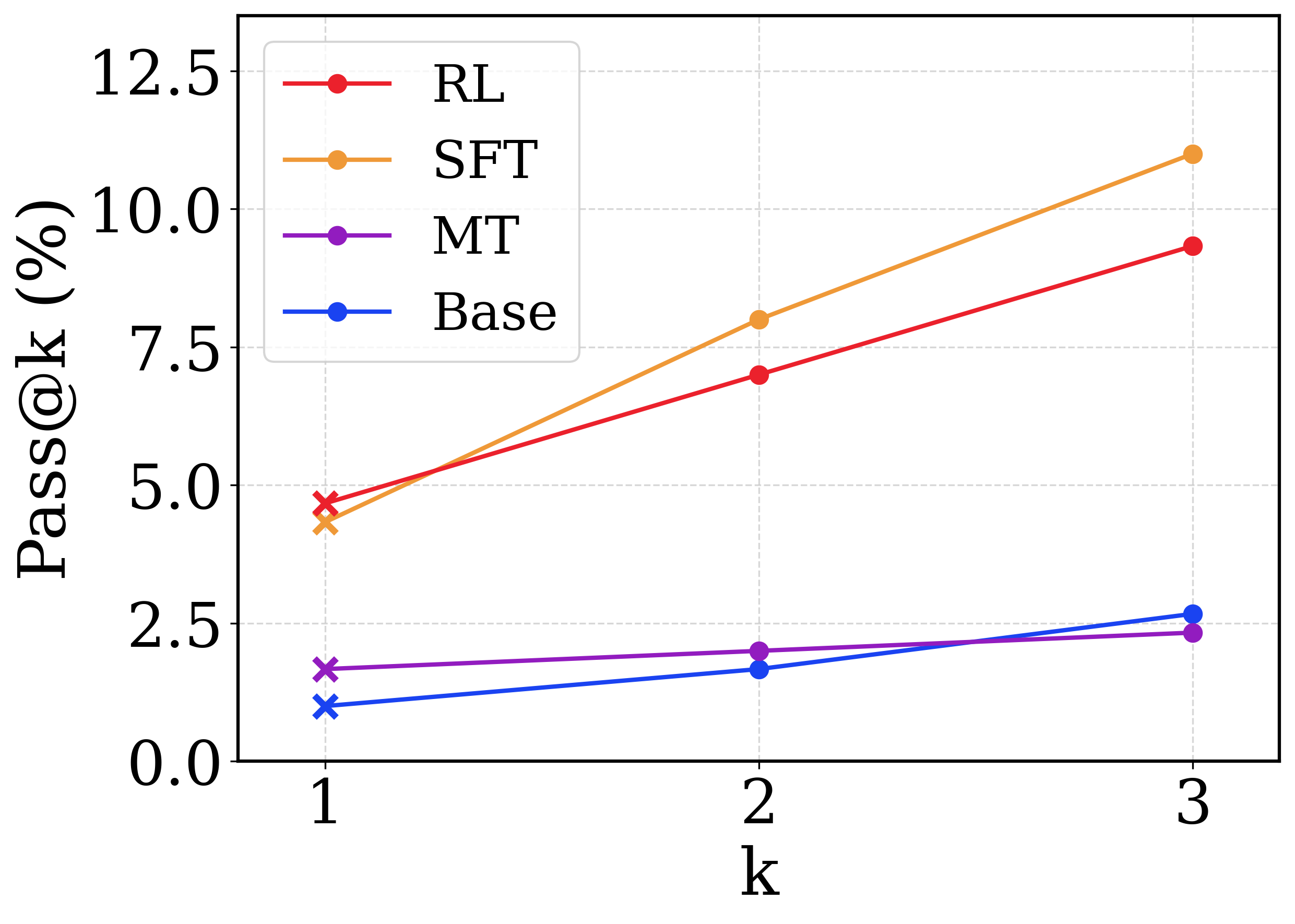
### Visual Description
## Line Chart: Pass@k (%) Performance Across Different Models
### Overview
This image is a line chart comparing the performance of four different models or methodologies—labeled as RL, SFT, MT, and Base—measured by the "Pass@k (%)" metric across three discrete values of "k" (1, 2, and 3). The chart demonstrates how performance scales as the number of allowed attempts/samples (k) increases.
*Language Declaration:* The text in the image is entirely in English.
### Components/Axes
**1. Y-Axis (Vertical, Left):**
* **Label:** `Pass@k (%)` (Oriented vertically, reading bottom to top).
* **Scale:** Linear, ranging from 0.0 to 12.5.
* **Markers/Ticks:** Major ticks are placed at intervals of 2.5 (0.0, 2.5, 5.0, 7.5, 10.0, 12.5).
* **Gridlines:** Light grey, dashed horizontal lines extend from each major tick mark across the chart area.
**2. X-Axis (Horizontal, Bottom):**
* **Label:** `k` (Centered below the axis).
* **Scale:** Discrete integer values.
* **Markers/Ticks:** Ticks are placed at 1, 2, and 3.
* **Gridlines:** Light grey, dashed vertical lines extend upward from each tick mark.
**3. Legend:**
* **Positioning:** Located in the top-left corner of the chart area, enclosed in a rounded rectangular box with a light grey border.
* **Entries (Color and Label):**
* Red line with a solid circle: `RL`
* Orange line with a solid circle: `SFT`
* Purple line with a solid circle: `MT`
* Blue line with a solid circle: `Base`
*Note on Markers:* While the legend displays solid circles for all entries, the actual data points plotted at `k=1` use an 'x' (cross) marker, whereas points at `k=2` and `k=3` use solid circle markers.
### Detailed Analysis
Below is the extraction of data points based on visual estimation against the gridlines.
**1. SFT (Orange Line)**
* **Visual Trend:** Slopes upward significantly. It starts slightly below the RL line at k=1, crosses above it before k=2, and exhibits the steepest positive trajectory, ending as the highest value at k=3.
* **Data Points:**
* `k=1`: ~4.4% (Marker: 'x')
* `k=2`: ~8.0% (Marker: solid circle, slightly above the 7.5 gridline)
* `k=3`: ~11.0% (Marker: solid circle, below the 12.5 gridline)
**2. RL (Red Line)**
* **Visual Trend:** Slopes upward steadily. It starts as the highest value at k=1 but is overtaken by SFT, finishing second highest at k=3.
* **Data Points:**
* `k=1`: ~4.7% (Marker: 'x', slightly below the 5.0 gridline)
* `k=2`: ~7.0% (Marker: solid circle, below the 7.5 gridline)
* `k=3`: ~9.4% (Marker: solid circle, below the 10.0 gridline)
**3. Base (Blue Line)**
* **Visual Trend:** Slopes upward gently. It starts as the lowest performing model at k=1, but its slope is steeper than MT, allowing it to cross above MT just before k=3.
* **Data Points:**
* `k=1`: ~1.0% (Marker: 'x')
* `k=2`: ~1.7% (Marker: solid circle)
* `k=3`: ~2.7% (Marker: solid circle, slightly above the 2.5 gridline)
**4. MT (Purple Line)**
* **Visual Trend:** Nearly flat with a very slight upward slope. It starts above the Base model but exhibits the least improvement as k increases, ending as the lowest value at k=3.
* **Data Points:**
* `k=1`: ~1.7% (Marker: 'x')
* `k=2`: ~2.0% (Marker: solid circle)
* `k=3`: ~2.3% (Marker: solid circle, slightly below the 2.5 gridline)
### Key Observations
* **Bifurcation of Performance:** There is a massive performance gap dividing the models into two distinct tiers. RL and SFT are high-performing (ranging from ~4% to 11%), while MT and Base are low-performing (ranging from ~1% to ~3%).
* **Crossover Events:**
* **SFT vs. RL:** RL is superior at `k=1`, but SFT scales much better with multiple attempts, overtaking RL at `k=2` and widening the gap at `k=3`.
* **Base vs. MT:** MT is superior at `k=1` and `k=2`, but Base scales slightly better, overtaking MT at `k=3`.
* **Universal Improvement:** All models show absolute improvement as `k` increases, which is a mathematical certainty for the Pass@k metric (more attempts equal a higher or equal chance of passing), but the *rate* of improvement varies drastically.
### Interpretation
The chart likely represents the evaluation of Large Language Models (LLMs) on a generative task, such as code generation or mathematical reasoning, where "Pass@k" measures the probability that at least one out of *k* generated samples is correct.
* **Methodology Impact:** The data clearly demonstrates that advanced training techniques (RL - Reinforcement Learning, and SFT - Supervised Fine-Tuning) drastically outperform the "Base" model and "MT" (likely Multi-Task or Machine Translation, depending on context).
* **Diversity vs. Accuracy (SFT vs RL):** The crossover between RL and SFT is the most critical insight. RL models are often optimized to produce the single best answer (greedy decoding), which explains why RL wins at `k=1` (highest top-1 accuracy). However, SFT models often retain a higher diversity of outputs. When allowed multiple attempts (`k=2`, `k=3`), the SFT model's diverse generations are more likely to stumble upon the correct answer than the RL model, which might repeatedly generate similar, slightly flawed outputs.
* **Marker Anomaly:** The use of 'x' markers exclusively at `k=1` might denote a difference in how the metric is calculated or sampled at the first attempt (e.g., greedy decoding for k=1 vs. temperature sampling for k>1), though this is speculative without the accompanying paper text.
</details>
(a) #SFT $=2^{21}$ .
<details>
<summary>figs/sec4_generalization_plots/l-100.png Details</summary>
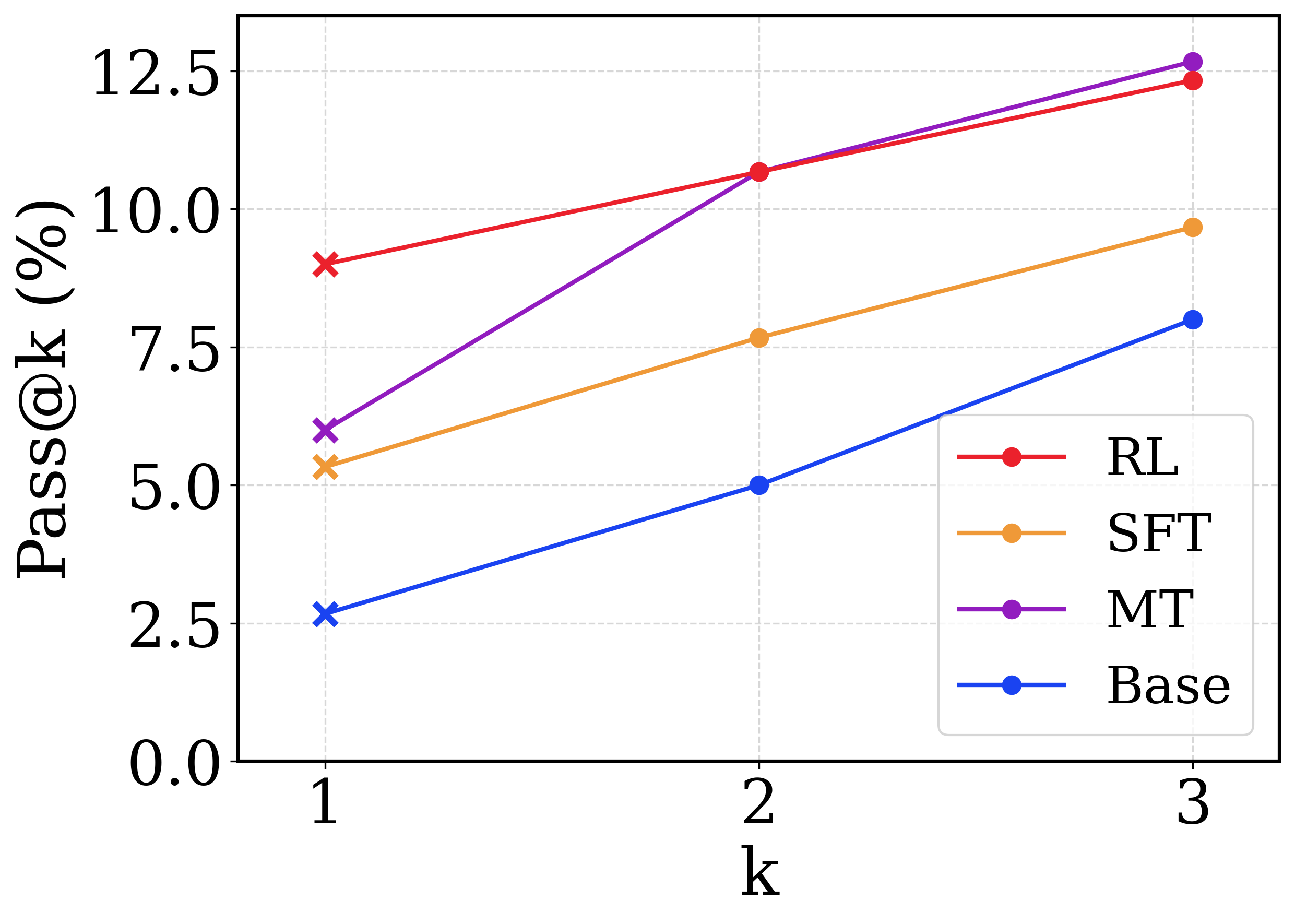
### Visual Description
## Line Chart: Pass@k (%) Performance Across Different Training Methods
### Overview
This image is a line chart displaying the performance metric "Pass@k (%)" on the y-axis against the variable "k" on the x-axis. It compares four different models or training methodologies, denoted by distinct colors. The chart demonstrates how the pass rate increases for all methods as the number of attempts ($k$) increases from 1 to 3.
### Components/Axes
**1. Y-Axis (Left side, vertical):**
* **Label:** "Pass@k (%)" (Rotated 90 degrees counter-clockwise).
* **Scale:** Linear, ranging from 0.0 to 12.5.
* **Markers/Tick Values:** 0.0, 2.5, 5.0, 7.5, 10.0, 12.5.
* **Gridlines:** Horizontal, light grey, dashed lines corresponding to each tick mark.
**2. X-Axis (Bottom, horizontal):**
* **Label:** "k" (Centered below the axis).
* **Scale:** Discrete integer values.
* **Markers/Tick Values:** 1, 2, 3.
* **Gridlines:** Vertical, light grey, dashed lines corresponding to each tick mark.
**3. Legend (Bottom-right quadrant, inside the chart area):**
* Enclosed in a rounded rectangular box with a light grey border.
* Lists four categories, each associated with a specific line color and a circular marker.
* **Red line with circle:** RL
* **Orange line with circle:** SFT
* **Purple line with circle:** MT
* **Blue line with circle:** Base
*Note on Markers:* While the legend displays circular markers for all entries, the actual data points on the chart use an 'x' marker at $k=1$ and a solid circular marker at $k=2$ and $k=3$.
### Detailed Analysis
**Trend Verification & Data Extraction:**
All four data series exhibit a positive, upward-sloping trend, indicating that Pass@k (%) increases as $k$ increases for all evaluated methods.
**1. RL (Red Line):**
* *Trend:* Slopes upward steadily. It starts as the highest performing method at $k=1$, ties/is slightly edged out at $k=2$, and falls to second place at $k=3$.
* *Data Points (Approximate values ±0.1):*
* $k=1$ ('x' marker): ~9.0%
* $k=2$ (circle marker): ~10.7%
* $k=3$ (circle marker): ~12.4%
**2. MT (Purple Line):**
* *Trend:* Exhibits the steepest upward slope. It starts in second place at $k=1$, converges with the RL line at $k=2$, and overtakes RL to become the highest performing method at $k=3$.
* *Data Points (Approximate values ±0.1):*
* $k=1$ ('x' marker): ~6.0%
* $k=2$ (circle marker): ~10.7% (Visually overlaps the red RL marker).
* $k=3$ (circle marker): ~12.7%
**3. SFT (Orange Line):**
* *Trend:* Slopes upward steadily, maintaining a consistent trajectory. It remains the third-highest performing method across all values of $k$.
* *Data Points (Approximate values ±0.1):*
* $k=1$ ('x' marker): ~5.3%
* $k=2$ (circle marker): ~7.7%
* $k=3$ (circle marker): ~9.7%
**4. Base (Blue Line):**
* *Trend:* Slopes upward steadily. It is the lowest performing method across all values of $k$.
* *Data Points (Approximate values ±0.1):*
* $k=1$ ('x' marker): ~2.7%
* $k=2$ (circle marker): ~5.0%
* $k=3$ (circle marker): ~8.0%
### Key Observations
* **Universal Improvement:** Every model benefits from an increased $k$ value, which is standard for "Pass@k" metrics (more attempts yield a higher probability of success).
* **The Crossover:** The most notable visual feature is the intersection of the Purple (MT) and Red (RL) lines at $k=2$. MT shows a much higher rate of improvement between $k=1$ and $k=2$ compared to RL.
* **Consistent Hierarchy at the Bottom:** The Base model (Blue) and SFT model (Orange) never intersect with each other or the top two models; their relative performance ranking remains static (SFT > Base).
* **Marker Distinction:** The deliberate use of 'x' markers at $k=1$ versus circles at $k=2, 3$ suggests a methodological distinction in how the first attempt is calculated or evaluated compared to subsequent attempts, though the chart does not explicitly explain this.
### Interpretation
This chart likely represents the evaluation of Large Language Models (LLMs) on a coding or reasoning benchmark where "Pass@k" measures the probability that at least one out of $k$ generated solutions is correct.
* **Base vs. Fine-tuned:** The "Base" model performs poorly. Applying Supervised Fine-Tuning ("SFT") roughly doubles the performance at $k=1$.
* **Advanced Techniques:** Reinforcement Learning ("RL") and what is likely Multi-Task training or a specific variant ("MT") significantly outperform SFT and Base.
* **RL vs. MT Trade-off:** The data suggests a distinct behavioral difference between RL and MT. RL is highly optimized for the "first try" ($k=1$), making it the best choice if only a single output is generated. However, MT has higher variance or diversity in its outputs; while its first guess is worse than RL's, giving it three guesses ($k=3$) results in a higher overall chance of success than giving RL three guesses. This implies MT explores a wider solution space, whereas RL might be more narrowly focused on a specific type of high-probability answer.
</details>
(b) #SFT $=2^{23}$ .
<details>
<summary>figs/sec4_generalization_plots/l-2000.png Details</summary>
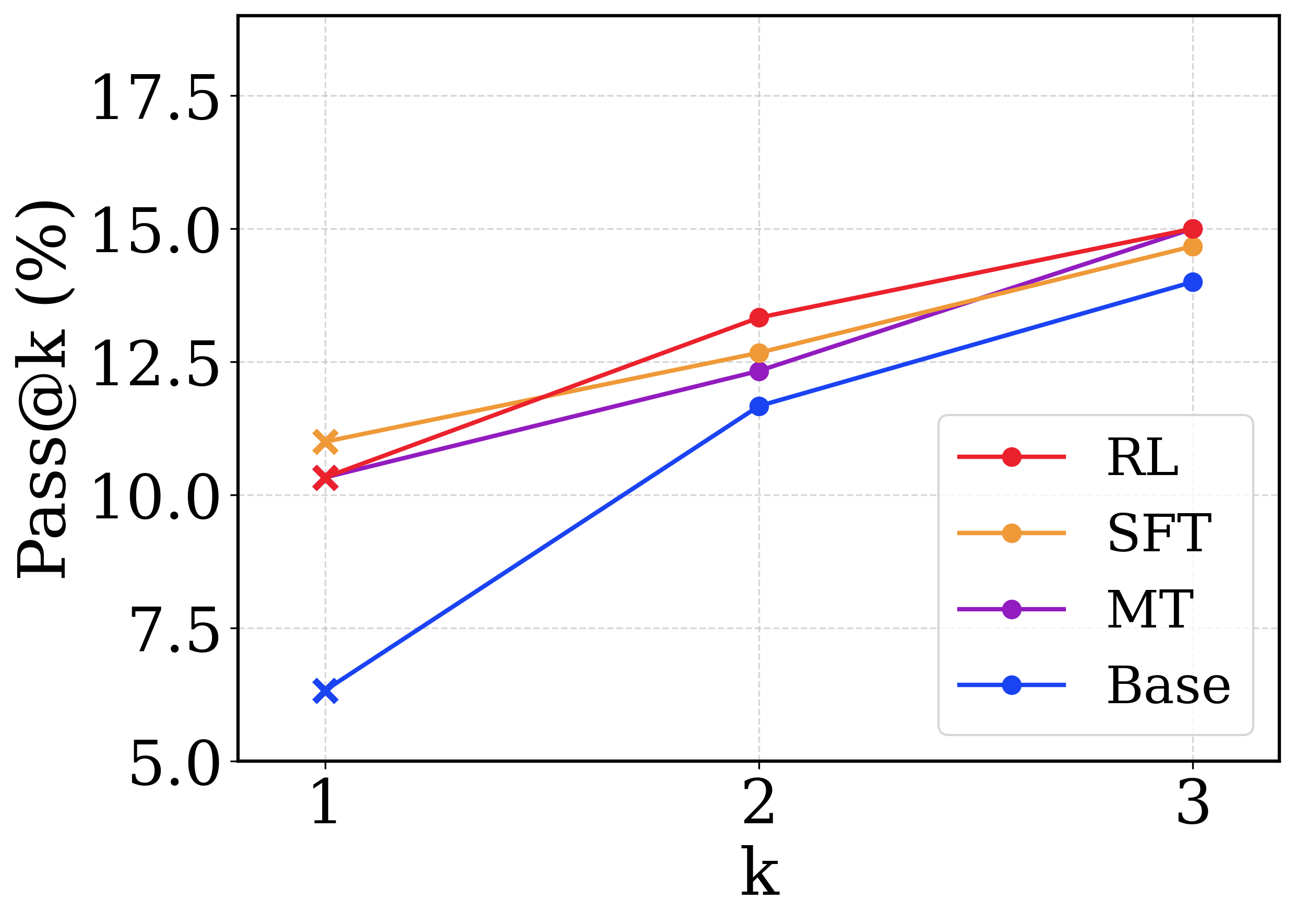
### Visual Description
## Line Chart: Pass@k Performance Comparison
### Overview
This image is a line chart comparing the performance of four different models or methodologies across three discrete attempts (k=1, 2, and 3). The performance is measured using a "Pass@k (%)" metric. All text in the image is in English.
### Components/Axes
**Component Isolation & Spatial Grounding:**
* **Y-Axis (Left edge):** Labeled "Pass@k (%)" (text is rotated 90 degrees counter-clockwise). The scale ranges from 5.0 to 17.5. Major tick marks and corresponding horizontal light-grey dashed gridlines are placed at intervals of 2.5: 5.0, 7.5, 10.0, 12.5, 15.0, and 17.5.
* **X-Axis (Bottom edge):** Labeled "k". The scale consists of discrete integer values. Major tick marks and corresponding vertical light-grey dashed gridlines are placed at: 1, 2, and 3.
* **Legend (Bottom-right quadrant):** Enclosed in a rounded rectangular box, positioned inside the chart area, avoiding intersection with the data lines. It maps four colors to specific labels:
* Red line with a circle marker: `RL`
* Orange line with a circle marker: `SFT`
* Purple line with a circle marker: `MT`
* Blue line with a circle marker: `Base`
* **Data Markers:** A notable visual distinction is made at `k=1`, where all data points are marked with an 'x' (cross). At `k=2` and `k=3`, all data points are marked with solid circles.
### Detailed Analysis
*Note: All numerical values extracted below are visual approximations based on the gridlines, with an estimated uncertainty of ±0.2%.*
**Trend Verification & Data Extraction:**
1. **Base (Blue Line)**
* *Trend:* The line slopes upward significantly from k=1 to k=2, showing the steepest rate of improvement among all series. The upward slope continues from k=2 to k=3, but at a slightly reduced trajectory. It remains the lowest-performing series across all values of k.
* *Data Points:*
* k=1: ~6.3% (Marker: x)
* k=2: ~11.7% (Marker: circle)
* k=3: ~14.0% (Marker: circle)
2. **MT (Purple Line)**
* *Trend:* The line slopes upward steadily. It begins closely tied with the RL series at k=1, falls slightly behind SFT and RL at k=2, and converges closely with the SFT series at k=3.
* *Data Points:*
* k=1: ~10.3% (Marker: x)
* k=2: ~12.3% (Marker: circle)
* k=3: ~14.6% (Marker: circle)
3. **RL (Red Line)**
* *Trend:* The line slopes upward steadily. It starts slightly below SFT at k=1, but exhibits a steeper slope between k=1 and k=2, allowing it to overtake all other series. It maintains the highest position at k=3.
* *Data Points:*
* k=1: ~10.3% (Marker: x)
* k=2: ~13.3% (Marker: circle)
* k=3: ~15.0% (Marker: circle)
4. **SFT (Orange Line)**
* *Trend:* The line slopes upward steadily. It begins as the highest-performing series at k=1. Its slope is less steep than RL, causing it to drop to the second-highest position at k=2 and k=3.
* *Data Points:*
* k=1: ~11.0% (Marker: x)
* k=2: ~12.7% (Marker: circle)
* k=3: ~14.7% (Marker: circle)
### Key Observations
* **Universal Improvement:** All four methodologies show improved performance as 'k' increases from 1 to 3.
* **Base Model Deficit:** The "Base" model performs significantly worse than the other three at k=1 (single-shot), but the gap narrows considerably by k=3.
* **Rank Shifting:** "SFT" is the best performer at k=1, but "RL" overtakes it at k=2 and extends its lead at k=3.
* **Convergence:** "MT" and "SFT" end up with nearly identical performance at k=3, despite "SFT" having a clear advantage at k=1.
### Interpretation
This chart likely represents the evaluation of Large Language Models (LLMs) on a generative task, such as code generation (e.g., HumanEval or MBPP benchmarks).
* **The Metric:** "Pass@k" measures the probability that at least one correct solution is found when the model is allowed to generate 'k' different responses. Naturally, as 'k' increases, the probability of success increases, which explains the universal upward trend.
* **The Labels:** The labels represent standard model training paradigms:
* **Base:** A foundational, pre-trained model without specific instruction tuning. Its poor k=1 performance indicates it struggles to give the right answer on the first try, but its sharp rise at k=2 and k=3 shows the underlying knowledge is present if allowed multiple attempts.
* **SFT (Supervised Fine-Tuning):** This model has been trained on specific examples. It excels at k=1, meaning it is highly reliable at giving a good answer on the very first attempt compared to the others.
* **RL (Reinforcement Learning - likely RLHF):** While slightly worse than SFT on the first attempt (k=1), RL scales better with multiple attempts. By k=3, it explores a wider or more effective variety of answers, resulting in the highest overall success rate.
* **MT (Multi-Task):** Performs solidly in the middle of the pack, tracking closely with SFT but generally slightly behind it until they converge at k=3.
* **Visual Design Choice:** The use of 'x' markers exclusively at k=1 is a deliberate design choice, likely to emphasize the "single-shot" or "greedy decoding" performance as a distinct baseline compared to the multi-sample evaluations at k=2 and k=3.
</details>
(c) #SFT $=1.1× 2^{27}$ .
<details>
<summary>figs/sec4_generalization_plots/l-5000.png Details</summary>
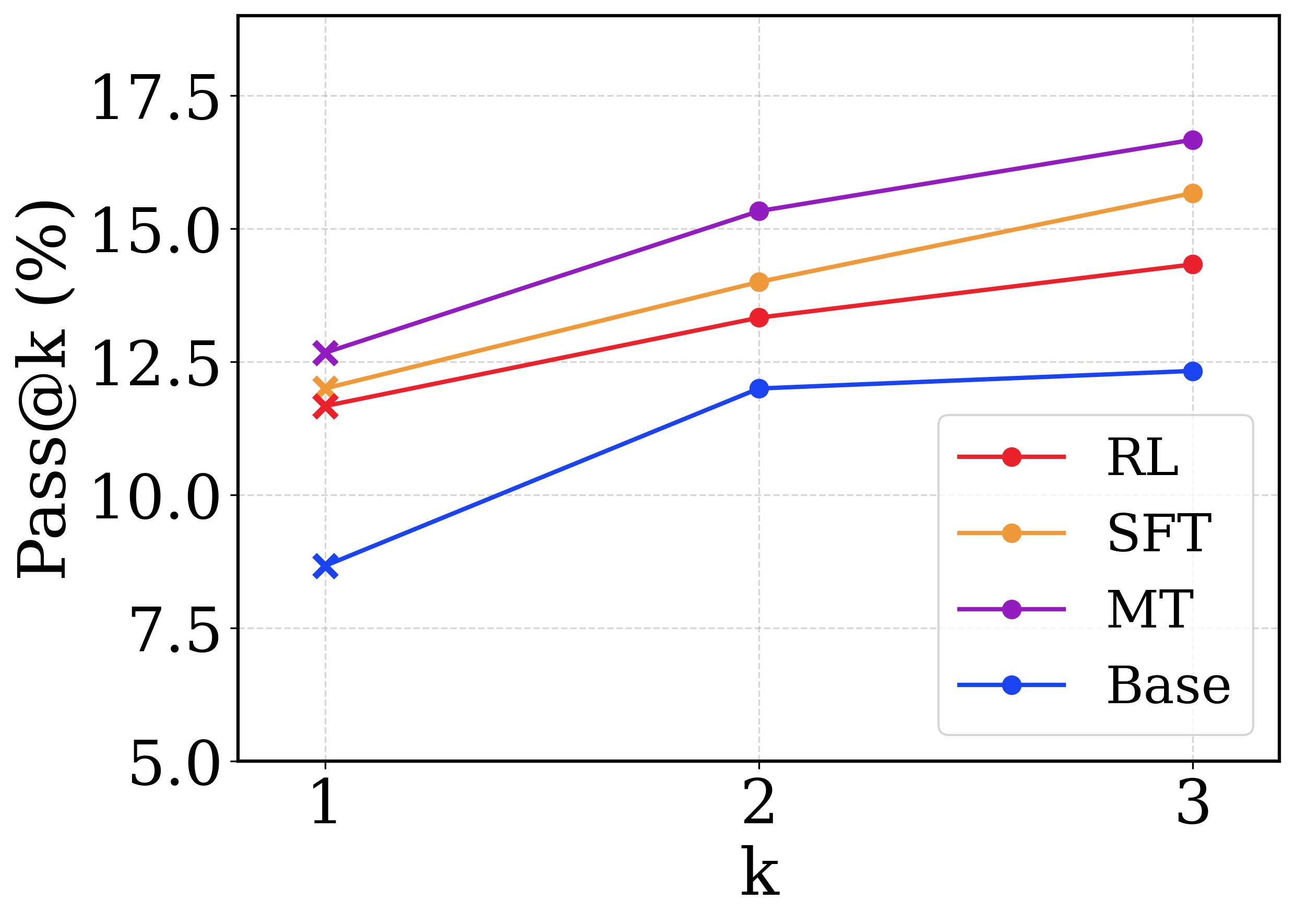
### Visual Description
## Line Chart: Pass@k (%) Performance Across Models
### Overview
This image is a line chart comparing the performance of four different machine learning models or training methodologies across a metric denoted as "Pass@k (%)". The x-axis represents the value of 'k' (1, 2, and 3), and the y-axis represents the percentage score.
### Components/Axes
* **Y-axis (Left, Vertical):**
* **Label:** `Pass@k (%)`
* **Scale:** Ranges from 5.0 to 17.5.
* **Major Tick Markers:** 5.0, 7.5, 10.0, 12.5, 15.0, 17.5.
* **X-axis (Bottom, Horizontal):**
* **Label:** `k`
* **Scale:** Discrete integer values.
* **Major Tick Markers:** 1, 2, 3.
* **Legend (Bottom-Right):** Positioned inside the chart area, bounded by a rounded rectangle. It maps colors to model names:
* Red line with circle: `RL`
* Orange line with circle: `SFT`
* Purple line with circle: `MT`
* Blue line with circle: `Base`
* **Grid:** Light gray, dashed grid lines align with both the x-axis and y-axis major tick marks.
### Detailed Analysis
*Component Isolation: Main Chart Area*
**Trend Verification & Spatial Grounding:**
Before extracting data points, I will verify the visual trend of each line and cross-reference the color with the legend located in the bottom-right. Note: A distinct visual feature is that all data points at `k=1` are marked with an 'x', whereas data points at `k=2` and `k=3` are marked with solid circles.
1. **MT Series (Purple Line):**
* *Trend:* The purple line occupies the highest position on the chart. It slopes upward consistently from left to right.
* *Data Points (Approximate, ±0.2%):*
* k=1 ('x' marker): ~12.7% (Slightly above the 12.5 grid line)
* k=2 (circle marker): ~15.3% (Slightly above the 15.0 grid line)
* k=3 (circle marker): ~16.7% (Between 15.0 and 17.5, closer to 17.5)
2. **SFT Series (Orange Line):**
* *Trend:* The orange line is positioned second from the top. It slopes upward consistently, running roughly parallel to the MT line.
* *Data Points (Approximate, ±0.2%):*
* k=1 ('x' marker): ~12.0% (Below the 12.5 grid line)
* k=2 (circle marker): ~14.0% (Slightly below the midpoint of 12.5 and 15.0)
* k=3 (circle marker): ~15.7% (Above the 15.0 grid line)
3. **RL Series (Red Line):**
* *Trend:* The red line is positioned third from the top. It slopes upward consistently, running roughly parallel to the SFT line.
* *Data Points (Approximate, ±0.2%):*
* k=1 ('x' marker): ~11.7% (Below the SFT point, above 10.0)
* k=2 (circle marker): ~13.3% (Above the 12.5 grid line)
* k=3 (circle marker): ~14.3% (Below the 15.0 grid line)
4. **Base Series (Blue Line):**
* *Trend:* The blue line occupies the lowest position on the chart. It exhibits a sharp upward slope from k=1 to k=2, but then flattens out significantly, showing very little growth between k=2 and k=3.
* *Data Points (Approximate, ±0.2%):*
* k=1 ('x' marker): ~8.7% (Between 7.5 and 10.0)
* k=2 (circle marker): ~12.0% (Below the 12.5 grid line)
* k=3 (circle marker): ~12.3% (Barely above the k=2 point)
### Key Observations
* **Strict Hierarchy:** There is no crossover between any of the lines. The performance ranking is strictly maintained across all values of k: MT > SFT > RL > Base.
* **Diminishing Returns for Base:** The `Base` model shows a distinct anomaly compared to the others. While RL, SFT, and MT continue to improve at a relatively steady rate from k=2 to k=3, the `Base` model's performance plateaus.
* **Marker Anomaly:** The use of 'x' markers exclusively at `k=1` and solid circles at `k=2` and `k=3` suggests a methodological difference in how the metric is calculated or how the models generate outputs at k=1 versus higher values of k.
### Interpretation
The chart demonstrates the effectiveness of different training paradigms on a generative task (likely code generation or mathematical reasoning, where "Pass@k" is a standard metric measuring the probability that at least one out of 'k' generated samples is correct).
The data clearly shows that the `Base` model is the weakest performer. Applying Reinforcement Learning (`RL`) provides a noticeable boost. Supervised Fine-Tuning (`SFT`) provides an even larger boost. The method labeled `MT` (which likely stands for Multi-Task training or a similar advanced paradigm) yields the highest overall performance.
**Reading between the lines:** The plateau of the `Base` model between k=2 and k=3 is highly informative. It suggests that the `Base` model lacks diversity in its generated outputs; if it doesn't get the correct answer within the first two attempts, generating a third attempt is highly unlikely to yield a correct result. Conversely, the fine-tuned models (`RL`, `SFT`, `MT`) continue to benefit from higher 'k' values. This indicates that these advanced training methods not only improve top-1 accuracy but also create a "deeper" and more diverse distribution of correct answers, making it worthwhile to sample more heavily from them. The change in marker shape at k=1 ('x') likely denotes that k=1 uses a greedy decoding strategy (picking the single most likely output), whereas k=2 and k=3 utilize a sampling strategy (like temperature sampling) to generate multiple distinct outputs.
</details>
(d) #SFT $=1.5× 2^{28}$ .
Figure 11: Generalization analysis on SWE-bench-Live.
<details>
<summary>figs/sec4_generalization_plots/m-100-s1.png Details</summary>
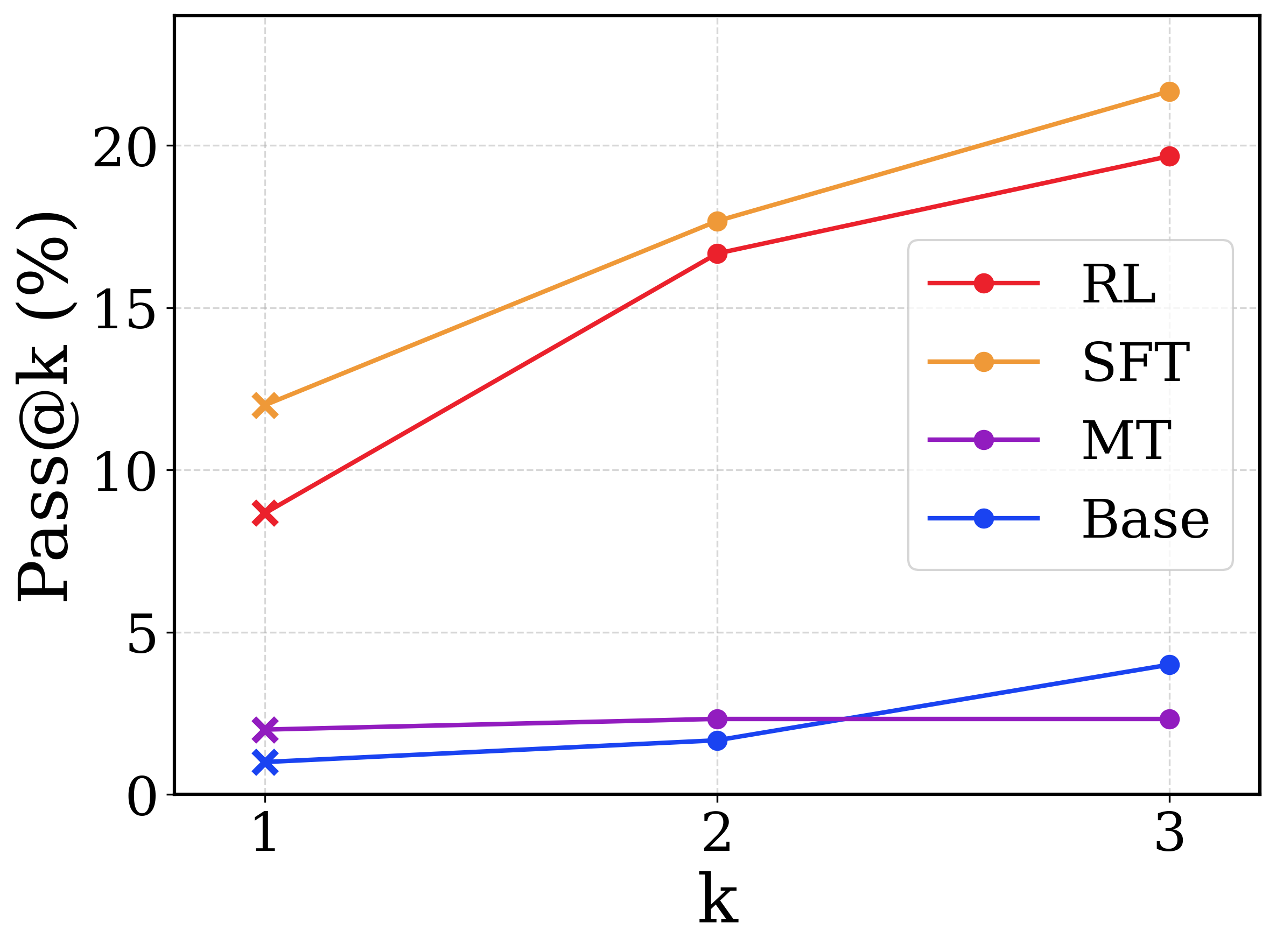
### Visual Description
## Line Chart: Model Performance Comparison on Pass@k Metric
### Overview
This image is a line chart comparing the performance of four different computational models or methods (labeled RL, SFT, MT, and Base) across three discrete evaluation points. The performance is measured by a metric called "Pass@k (%)". The chart demonstrates that two methods (SFT and RL) significantly outperform the other two (MT and Base) and show a much stronger positive scaling as the value of 'k' increases.
**Language Declaration:** The text in this image is entirely in English.
### Components/Axes
**Spatial Grounding & Layout:**
* **Y-axis (Left):** Labeled vertically as **"Pass@k (%)"**. The scale ranges from 0 to at least 20. Major tick marks and corresponding horizontal dashed gridlines are present at **0, 5, 10, 15, and 20**.
* **X-axis (Bottom):** Labeled horizontally as **"k"**. It features three discrete, evenly spaced markers labeled **1, 2, and 3**. Vertical dashed gridlines align with these three markers.
* **Legend (Center-Right):** Positioned inside the chart area, bounded by a rounded rectangular box. It maps line colors and marker styles to specific categories.
* Red line with a circle marker: **RL**
* Orange line with a circle marker: **SFT**
* Purple line with a circle marker: **MT**
* Blue line with a circle marker: **Base**
* **Visual Anomaly (Markers):** While the legend shows circle markers ('o') for all series, the actual data points plotted at **k=1** use cross markers ('x'). The data points at **k=2** and **k=3** use circle markers ('o').
### Detailed Analysis
Below is the trend verification and data extraction for each series. Values are approximate (denoted by ~) based on visual interpolation between the gridlines.
**1. SFT (Orange Line)**
* **Trend:** The line slopes upward significantly from k=1 to k=2, and continues a steady upward slope from k=2 to k=3. It remains the highest-performing series across all values of k.
* **Data Points:**
* k=1 (cross marker): ~12.0%
* k=2 (circle marker): ~17.8%
* k=3 (circle marker): ~21.5% (Extrapolated above the 20% gridline)
**2. RL (Red Line)**
* **Trend:** The line slopes upward steeply from k=1 to k=2, and continues sloping upward from k=2 to k=3. It closely tracks below the SFT line.
* **Data Points:**
* k=1 (cross marker): ~8.8%
* k=2 (circle marker): ~16.8%
* k=3 (circle marker): ~19.8%
**3. Base (Blue Line)**
* **Trend:** The line slopes upward very slightly from k=1 to k=2, then the upward slope increases moderately from k=2 to k=3. It starts as the lowest value but crosses the MT line between k=2 and k=3.
* **Data Points:**
* k=1 (cross marker): ~1.0%
* k=2 (circle marker): ~1.8%
* k=3 (circle marker): ~4.0%
**4. MT (Purple Line)**
* **Trend:** The line is nearly flat. It shows a microscopic upward slope from k=1 to k=2, and is completely horizontal from k=2 to k=3.
* **Data Points:**
* k=1 (cross marker): ~2.0%
* k=2 (circle marker): ~2.3%
* k=3 (circle marker): ~2.3%
#### Reconstructed Data Table
| k | Base (Blue) | MT (Purple) | RL (Red) | SFT (Orange) |
|---|---|---|---|---|
| **1** | ~1.0% | ~2.0% | ~8.8% | ~12.0% |
| **2** | ~1.8% | ~2.3% | ~16.8% | ~17.8% |
| **3** | ~4.0% | ~2.3% | ~19.8% | ~21.5% |
### Key Observations
* **Bifurcation of Performance:** There is a massive performance gap between the top tier (SFT, RL) and the bottom tier (MT, Base). At k=3, the lowest top-tier model (RL) is nearly 5 times better than the highest bottom-tier model (Base).
* **The Crossover:** The Base model (blue) starts lower than the MT model (purple) at k=1 and k=2, but due to MT's stagnation, Base overtakes MT at k=3.
* **Stagnation of MT:** The MT model is the only series that does not benefit from an increase in 'k' from 2 to 3, showing a completely flat trajectory.
* **Marker Distinction:** The deliberate use of 'x' markers at k=1 versus 'o' markers at k>1 suggests a methodological difference in how the metric is calculated or generated at the first step compared to subsequent steps.
### Interpretation
In the context of machine learning and generative AI, "Pass@k" is a standard metric used to evaluate code generation or problem-solving models. It measures the probability that at least one out of 'k' generated samples passes the unit tests or criteria.
* **Model Efficacy:** The data clearly demonstrates that Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) are vastly superior training methodologies for this specific task compared to the Base model or the MT (likely Multi-Task) model.
* **Diversity of Generation (Reading between the lines):** The Pass@k metric inherently rewards models that can generate a *diverse* set of plausible answers. Because SFT and RL scale up steeply as 'k' increases, it indicates these models are generating diverse, high-quality candidates; if the first guess (k=1) is wrong, the second or third guess is highly likely to be correct.
* **The MT Anomaly:** The flatlining of the MT model between k=2 and k=3 suggests a "mode collapse" or lack of diversity. Even when allowed to make 3 guesses (k=3), it does not find any new correct answers that it hadn't already found in its first 2 guesses.
* **The Marker Shift:** The shift from 'x' to 'o' markers likely denotes a shift from greedy decoding (k=1, where the model outputs its single highest-confidence answer) to temperature sampling (k>1, where the model introduces randomness to generate multiple different answers).
</details>
(a) #SFT $=2^{21}$ .
<details>
<summary>figs/sec4_generalization_plots/m-100.png Details</summary>
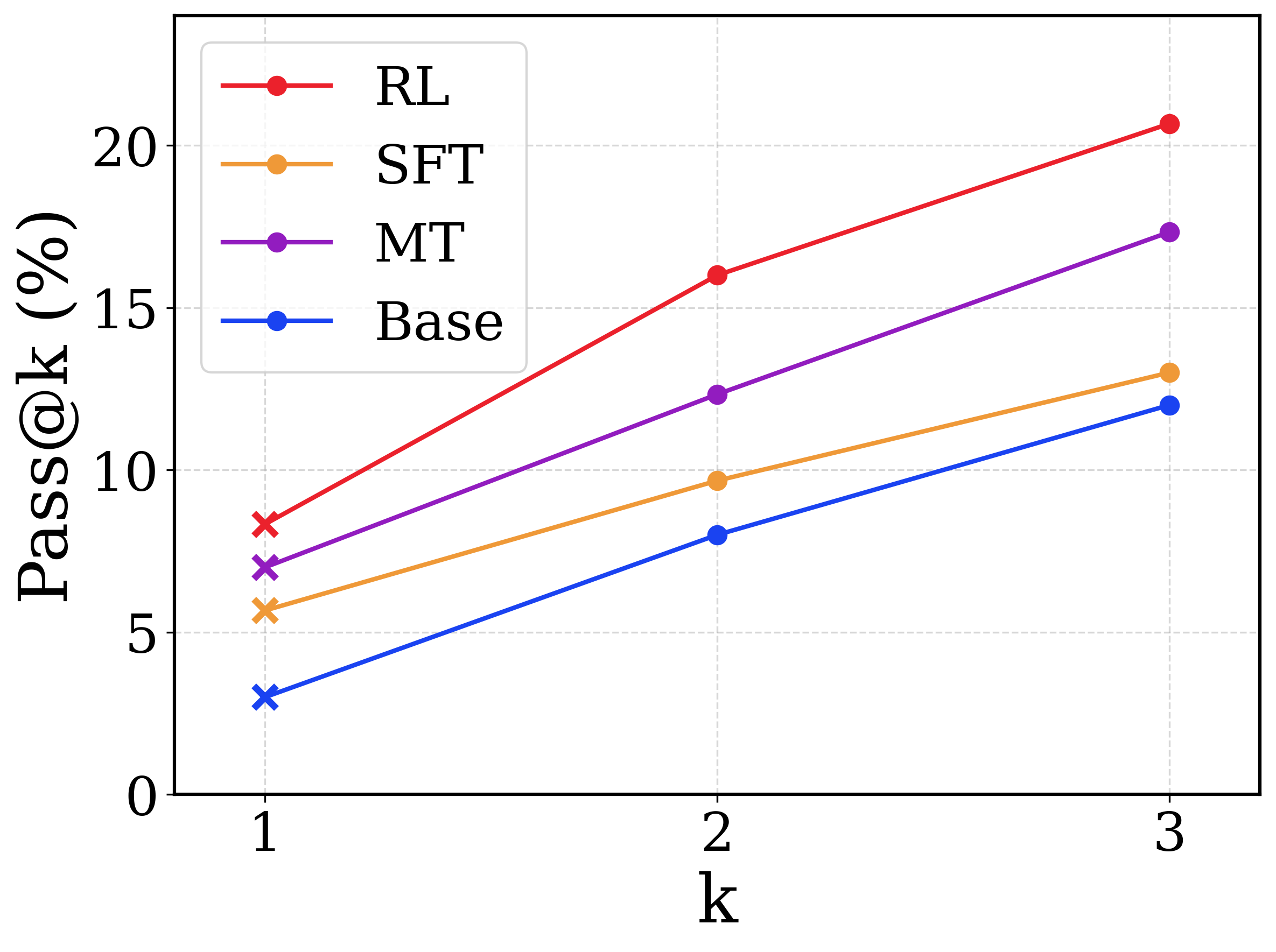
### Visual Description
## Line Chart: Pass@k (%) Performance Across Training Methods
### Overview
This image is a line chart comparing the performance of four different machine learning models or training methodologies across a metric denoted as "Pass@k (%)". The x-axis represents the value of 'k' (1, 2, and 3), and the y-axis represents the percentage score.
### Components/Axes
The image can be isolated into the following distinct components:
* **Y-axis (Left):**
* **Label:** "Pass@k (%)" (Text is rotated 90 degrees counter-clockwise).
* **Scale:** Ranges from 0 to roughly 25, with visible tick marks and corresponding horizontal dashed grid lines at 0, 5, 10, 15, and 20.
* **X-axis (Bottom):**
* **Label:** "k".
* **Scale:** Discrete categorical/numerical markers at 1, 2, and 3. Vertical dashed grid lines align with these markers.
* **Legend (Top-Left):** A bounding box containing four entries, mapping line colors to model names.
* Red line with a circular marker: "RL"
* Orange line with a circular marker: "SFT"
* Purple line with a circular marker: "MT"
* Blue line with a circular marker: "Base"
* **Main Chart Area:** Contains four distinct lines plotting data points across the x-axis grid lines. Notably, the data points at k=1 are marked with an 'x' symbol, while the data points at k=2 and k=3 are marked with solid circles.
### Detailed Analysis
**Trend Verification:**
Before extracting specific values, a visual inspection of the trends reveals that all four lines slope upward from left to right. This indicates a positive correlation for all models: as 'k' increases, the 'Pass@k (%)' score increases. Furthermore, the lines never intersect; they maintain a strict vertical hierarchy across all values of 'k'.
**Data Extraction (Approximate Values):**
*Cross-referencing the legend colors with the lines from top to bottom:*
1. **RL (Red Line - Top-most position):**
* *Trend:* Slopes upward steeply, showing the highest rate of growth.
* k=1 (marked with 'x'): ~8.3%
* k=2 (marked with circle): ~16.0%
* k=3 (marked with circle): ~20.8%
2. **MT (Purple Line - Second from top):**
* *Trend:* Slopes upward steadily, maintaining a consistent gap below the RL line.
* k=1 (marked with 'x'): ~7.0%
* k=2 (marked with circle): ~12.4%
* k=3 (marked with circle): ~17.4%
3. **SFT (Orange Line - Third from top):**
* *Trend:* Slopes upward, but at a slightly shallower angle than RL and MT.
* k=1 (marked with 'x'): ~5.7%
* k=2 (marked with circle): ~9.7%
* k=3 (marked with circle): ~13.0%
4. **Base (Blue Line - Bottom-most position):**
* *Trend:* Slopes upward, maintaining a relatively parallel trajectory to the SFT line.
* k=1 (marked with 'x'): ~3.0%
* k=2 (marked with circle): ~8.0%
* k=3 (marked with circle): ~12.0%
### Key Observations
* **Strict Hierarchy:** The performance ranking is absolute across all measured points: RL > MT > SFT > Base.
* **Divergence:** The performance gap between the best method (RL) and the worst method (Base) widens as 'k' increases. At k=1, the gap is roughly 5.3 percentage points. At k=3, the gap expands to roughly 8.8 percentage points.
* **Marker Anomaly:** The legend shows only circular markers for all lines. However, on the chart itself, the data points at k=1 are plotted using 'x' markers, while k=2 and k=3 use circles.
### Interpretation
This chart is highly characteristic of evaluation metrics used in generative Artificial Intelligence, specifically Large Language Models (LLMs) evaluated on coding or reasoning tasks (like the HumanEval benchmark).
* **The Metric:** "Pass@k" measures the probability that at least one out of 'k' generated responses is correct. Naturally, as a model is allowed more attempts (higher 'k'), the probability of getting at least one correct answer increases, which explains the universal upward trend.
* **The Models (Reading between the lines):** The labels represent standard stages in modern AI model training pipelines:
* **Base:** The foundational, pre-trained model (lowest performance).
* **SFT:** Supervised Fine-Tuning. Training the base model on high-quality instruction-response pairs yields a noticeable improvement.
* **MT:** Likely stands for Multi-Task training (or potentially a specific intermediate tuning phase), showing further improvement over standard SFT.
* **RL:** Reinforcement Learning (often RLHF - Reinforcement Learning from Human Feedback or RLAIF). This technique yields the highest performance.
* **Significance:** The data demonstrates the compounding value of advanced alignment techniques. Not only does RL have the highest baseline accuracy (Pass@1), but its steeper slope indicates it benefits more from multiple sampling attempts (Pass@2, Pass@3) than the Base or SFT models. This suggests the RL model generates a higher diversity of viable, correct answers when sampled multiple times.
* **The 'x' Marker:** The distinct 'x' marker at k=1 likely denotes a methodological difference in how the data was gathered. Pass@1 is often evaluated using "greedy decoding" (temperature = 0, picking the single most likely token), whereas Pass@k (where k > 1) requires sampling with a higher temperature to generate diverse responses. The change in marker shape visually separates the deterministic evaluation (k=1) from the probabilistic sampling evaluations (k=2, 3).
</details>
(b) #SFT $=2^{23}$ .
<details>
<summary>figs/sec4_generalization_plots/m-2000.png Details</summary>
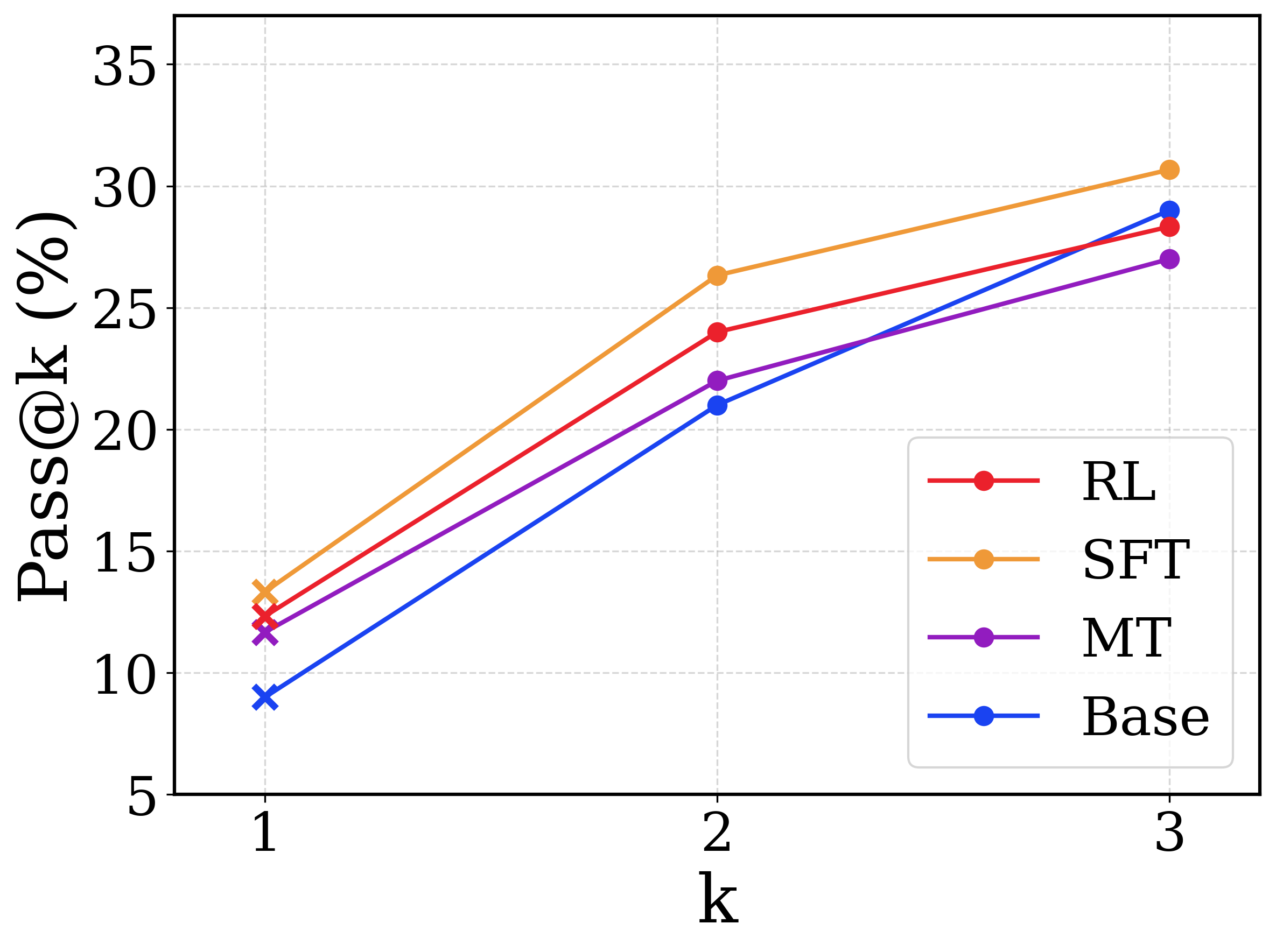
### Visual Description
## Line Chart: Pass@k Performance Comparison
### Overview
This image is a line chart comparing the performance of four different models or methodologies across three discrete evaluation points. The metric being measured is "Pass@k (%)", which typically represents the probability that at least one correct result is found within the top $k$ generated samples. The chart demonstrates how performance scales as the number of allowed attempts ($k$) increases. All text in the image is in English.
### Components/Axes
**1. Chart Area & Grid:**
* The chart features a white background with a light gray, dashed grid.
* Horizontal grid lines align with the Y-axis major ticks.
* Vertical grid lines align with the X-axis major ticks.
**2. Y-Axis (Left Edge):**
* **Label:** "Pass@k (%)" (Rotated 90 degrees counter-clockwise, positioned vertically along the left edge).
* **Scale:** Linear, ranging from 5 to 35.
* **Markers/Ticks:** 5, 10, 15, 20, 25, 30, 35.
**3. X-Axis (Bottom Edge):**
* **Label:** "k" (Positioned centrally below the axis markers).
* **Scale:** Discrete categorical/ordinal steps.
* **Markers/Ticks:** 1, 2, 3.
**4. Legend (Bottom-Right Quadrant):**
* Positioned inside the main chart area, in the lower right corner.
* Enclosed in a rounded rectangular box with a light gray border.
* Contains four entries, mapping line colors to model names:
* Red line with a solid circle: **RL**
* Orange line with a solid circle: **SFT**
* Purple line with a solid circle: **MT**
* Blue line with a solid circle: **Base**
*Note on Markers:* While the legend displays solid circles for all entries, the actual data points plotted on the chart at $k=1$ are represented by 'x' (cross) markers. The data points at $k=2$ and $k=3$ are represented by solid circles.
### Detailed Analysis
**Trend Verification & Data Extraction:**
All four data series exhibit a positive, upward-sloping trend, indicating that the Pass@k percentage increases for all models as $k$ increases from 1 to 3.
* **SFT (Orange Line):**
* *Trend:* Slopes upward steeply from $k=1$ to $k=2$, then continues upward at a slightly shallower angle to $k=3$. It remains the highest-performing model across all values of $k$.
* $k=1$: ~13.5% ('x' marker)
* $k=2$: ~26.5% (circle marker)
* $k=3$: ~30.5% (circle marker)
* **RL (Red Line):**
* *Trend:* Slopes upward. It starts as the second-highest performer at $k=1$ and $k=2$, but its trajectory flattens slightly between $k=2$ and $k=3$, causing it to be overtaken by the Base model.
* $k=1$: ~12.5% ('x' marker)
* $k=2$: ~24.0% (circle marker)
* $k=3$: ~28.5% (circle marker)
* **MT (Purple Line):**
* *Trend:* Slopes upward. It maintains the third-highest position at $k=1$ and $k=2$. Between $k=2$ and $k=3$, it has the shallowest slope of all models, resulting in it becoming the lowest-performing model at $k=3$.
* $k=1$: ~11.5% ('x' marker)
* $k=2$: ~22.0% (circle marker)
* $k=3$: ~27.0% (circle marker)
* **Base (Blue Line):**
* *Trend:* Slopes upward with the steepest overall trajectory. It starts as the lowest-performing model at $k=1$ and $k=2$. However, due to its steep continuous climb, it crosses both the MT and RL lines to become the second-highest performer at $k=3$.
* $k=1$: ~9.0% ('x' marker)
* $k=2$: ~21.0% (circle marker)
* $k=3$: ~29.0% (circle marker)
**Reconstructed Data Table (Approximate Values ±0.5%):**
| Model | k=1 | k=2 | k=3 |
| :--- | :--- | :--- | :--- |
| **SFT** (Orange) | ~13.5% | ~26.5% | ~30.5% |
| **RL** (Red) | ~12.5% | ~24.0% | ~28.5% |
| **MT** (Purple) | ~11.5% | ~22.0% | ~27.0% |
| **Base** (Blue) | ~9.0% | ~21.0% | ~29.0% |
### Key Observations
1. **Consistent Leader:** The "SFT" model consistently outperforms all other models at every measured value of $k$.
2. **Steepest Improver:** The "Base" model shows the most dramatic improvement as $k$ increases. While it is the worst performer at a single attempt ($k=1$), it scales incredibly well, surpassing MT and RL when given three attempts ($k=3$).
3. **Diminishing Returns for MT:** The "MT" model shows the most significant drop-off in improvement rate between $k=2$ and $k=3$, causing it to fall to the bottom of the pack.
4. **Marker Anomaly:** The use of 'x' markers exclusively at $k=1$ (despite the legend showing circles) suggests a potential methodological difference in how the $k=1$ metric was calculated or evaluated compared to $k>1$, though this is not explicitly stated in the image.
### Interpretation
This chart likely represents the evaluation of Large Language Models (LLMs) on a coding or reasoning benchmark (such as HumanEval or MBPP), where "Pass@k" measures the likelihood of the model generating a correct solution if allowed to generate $k$ different answers.
* **SFT (Supervised Fine-Tuning)** appears to be the most robust method overall, providing the highest baseline accuracy and scaling well with multiple attempts.
* The **Base** model's behavior is highly notable. Its low Pass@1 but high Pass@3 suggests that while its "top choice" or most confident answer is often wrong, the correct answer is very frequently present within its top three generations. This indicates high variance but good underlying capability.
* **RL (Reinforcement Learning)** and **MT (potentially Multi-Task or Machine Translation, depending on context)** improve upon the Base model for single-shot attempts ($k=1$), likely by aligning the model to output the correct answer first. However, they seem to suffer from "mode collapse" or reduced diversity compared to the Base model; because their generations are more homogenous, giving them more attempts ($k=3$) does not yield as much additional benefit as it does for the Base model.
</details>
(c) #SFT $=1.1× 2^{27}$ .
<details>
<summary>figs/sec4_generalization_plots/m-5000.png Details</summary>
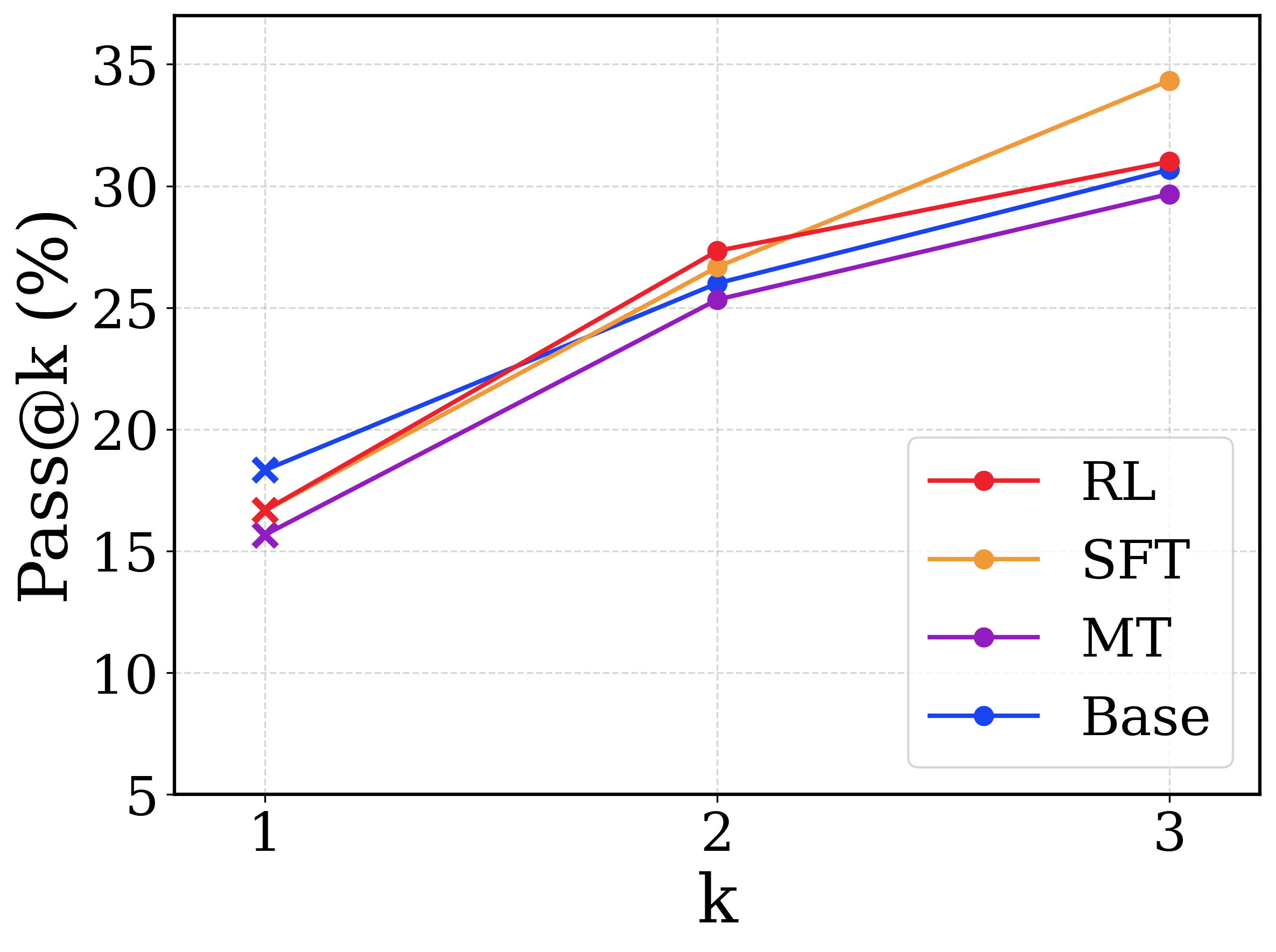
### Visual Description
## Line Chart: Pass@k Performance Comparison
### Overview
This image is a line chart comparing the performance of four different models or methodologies across three discrete evaluation steps. The metric being measured is "Pass@k (%)" on the y-axis against the variable "k" on the x-axis. All text in the image is in English.
### Components/Axes
**Spatial Layout & Regions:**
* **Main Chart Area:** Occupies the majority of the image, featuring a white background with a light gray, dashed grid.
* **Y-axis (Left):** Vertical axis labeled **"Pass@k (%)"**. The text is oriented vertically, reading from bottom to top. The scale ranges from 5 to 35, with major tick marks and horizontal grid lines at intervals of 5 (5, 10, 15, 20, 25, 30, 35).
* **X-axis (Bottom):** Horizontal axis labeled **"k"**. The scale consists of three discrete, evenly spaced points marked as 1, 2, and 3. Vertical grid lines align with these points.
* **Legend (Bottom-Right):** Located inside the chart area in the lower right quadrant. It is enclosed in a white box with a thin, light gray border. It defines four data series using line color and a circular marker:
* Red line with circle: **RL**
* Orange line with circle: **SFT**
* Purple line with circle: **MT**
* Blue line with circle: **Base**
*Note on Markers:* While the legend displays circular markers for all series, the actual plotted data points on the chart use an 'x' marker at k=1, and circular markers at k=2 and k=3.
### Detailed Analysis
**Trend Verification & Data Extraction:**
All four data series exhibit a positive, upward trend, indicating that the Pass@k percentage increases as 'k' increases from 1 to 3.
*Values below are visually interpolated and approximate (±0.5%).*
1. **Base (Blue Line)**
* *Trend:* Slopes upward moderately from k=1 to k=2, and continues upward at a slightly shallower angle from k=2 to k=3.
* **k=1:** ~18.5% (Highest starting value)
* **k=2:** ~26.0%
* **k=3:** ~30.8%
2. **RL (Red Line)**
* *Trend:* Slopes upward steeply from k=1 to k=2 (crossing above the Base line), then the slope flattens slightly from k=2 to k=3.
* **k=1:** ~16.8%
* **k=2:** ~27.5% (Highest value at k=2)
* **k=3:** ~31.0%
3. **SFT (Orange Line)**
* *Trend:* Slopes upward from k=1 to k=2, and then exhibits the steepest upward slope of any line from k=2 to k=3, crossing above both Base and RL.
* **k=1:** ~16.5%
* **k=2:** ~26.8%
* **k=3:** ~34.5% (Highest ending value)
4. **MT (Purple Line)**
* *Trend:* Slopes upward consistently from k=1 to k=3. It remains the lowest performing series across all values of k.
* **k=1:** ~15.8% (Lowest starting value)
* **k=2:** ~25.5%
* **k=3:** ~29.8% (Lowest ending value)
**Reconstructed Data Table:**
| k | Base (Blue) | RL (Red) | SFT (Orange) | MT (Purple) |
|---|---|---|---|---|
| **1** | ~18.5% | ~16.8% | ~16.5% | ~15.8% |
| **2** | ~26.0% | ~27.5% | ~26.8% | ~25.5% |
| **3** | ~30.8% | ~31.0% | ~34.5% | ~29.8% |
### Key Observations
* **Crossovers:** The "Base" model starts with the highest performance at k=1 but is overtaken by "RL" and "SFT" at k=2, and remains below them at k=3.
* **Late Surge:** The "SFT" model shows a significant acceleration in performance between k=2 and k=3, separating itself from the cluster to achieve the highest overall score.
* **Consistent Underperformer:** The "MT" model consistently scores the lowest across all three measured points, though its rate of improvement (slope) is roughly parallel to the "Base" model.
* **Marker Anomaly:** The use of 'x' markers exclusively at k=1 suggests a potential difference in how the k=1 metric was calculated or represents a baseline state compared to k=2 and k=3 (which use circles).
### Interpretation
In the context of machine learning (specifically generative AI or code generation), "Pass@k" measures the probability that at least one out of 'k' generated samples passes a specific test or criteria.
* **Baseline vs. Fine-tuning:** The data suggests that the "Base" model is relatively strong at generating a correct answer on the very first try (k=1). However, the fine-tuned models (RL - Reinforcement Learning, and SFT - Supervised Fine-Tuning) benefit much more from being allowed multiple attempts (k=2, k=3).
* **Diversity of Output:** The steep rise of the SFT and RL curves implies these methods produce a higher diversity of plausible answers. If the first answer is wrong, subsequent generated answers are highly likely to be different and correct, pushing their Pass@2 and Pass@3 scores higher than the Base model. The Base model might be generating similar (incorrect) variations of its first attempt, leading to a flatter curve.
* **SFT Efficacy at Scale:** The SFT method scales the best with multiple attempts, suggesting it has learned a wide distribution of correct patterns that are revealed when given a larger budget of generations (k=3).
</details>
(d) #SFT $=1.5× 2^{28}$ .
Figure 12: Generalization analysis on SWE-bench Multilingual.
Appendix H Use of Large Language Models
The initial draft of this paper was written entirely by the authors. A large language model (gpt-5) was used only to aid with polishing the language (e.g., grammar and clarity). All conceptual contributions, experimental designs, analyses, and conclusions are the work of the authors.