# Chapter 1 Introduction
<details>
<summary>x1.png Details</summary>
### Visual Description
Icon/Small Image (458x51)
</details>
Imperial College London Department of Computing
Bayesian Mixture-of-Experts: Towards Making LLMs Know What They Don’t Know
Author:
Albus Yizhuo Li
Supervisor: Dr Matthew Wicker Second Marker: Dr Yingzhen Li
<details>
<summary>x2.png Details</summary>

### Visual Description
\n
## Heraldic Achievement: Coat of Arms
### Overview
The image depicts a heraldic coat of arms, a traditional emblem representing an institution or individual. It is composed of a shield divided into sections, each containing symbolic imagery, and a scroll bearing a Latin motto. The overall design is rich in color and detail, typical of heraldic art. This image does not contain numerical data or trends, but rather symbolic representations.
### Components/Axes
The coat of arms consists of the following elements:
* **Shield:** Divided into four quadrants.
* **Upper Left Quadrant:** A blue field with a golden harp.
* **Upper Right Quadrant:** A red field with a golden lion rampant.
* **Lower Left Quadrant:** A red field with three golden lions passant guardant.
* **Lower Right Quadrant:** A red field with three golden lions passant guardant.
* **Base:** A golden base with an open book.
* **Scroll:** A golden scroll with red ribbons and black Latin text.
### Detailed Analysis or Content Details
* **Harp:** The harp in the upper left quadrant is golden with silver strings. It is positioned centrally within the blue field.
* **Lion Rampant:** The lion in the upper right quadrant is golden and depicted in a rearing pose (rampant).
* **Lions Passant Guardant:** The lions in the lower quadrants are golden and depicted walking (passant) while looking back (guardant). There are three in each quadrant.
* **Open Book:** The book on the golden base is open, displaying the word "SCIENTIA" in black lettering.
* **Scroll Motto:** The scroll contains the Latin phrase "SCIENTIA ET TUTAMEN IMPERII DECUS".
### Key Observations
The coat of arms features a combination of musical (harp), regal (lions), and scholarly (book) symbols. The repetition of the lion motif in the lower quadrants suggests a strong emphasis on courage and nobility. The motto, written in Latin, indicates a historical or academic context.
### Interpretation
The coat of arms likely represents an institution of learning, possibly a university or college, with a historical connection to a monarchy or empire. The harp could symbolize Ireland or a connection to Irish scholarship. The lions represent strength, courage, and royalty. The open book with "SCIENTIA" (knowledge) signifies learning and wisdom. The motto, "SCIENTIA ET TUTAMEN IMPERII DECUS" translates to "Knowledge and Safeguard are the Glory of the Empire," suggesting that the institution's purpose is to provide knowledge that strengthens and glorifies the empire or nation it serves. The overall design conveys a sense of tradition, authority, and intellectual pursuit.
The heraldic elements are carefully chosen to communicate a specific message about the institution's values, history, and purpose. The use of gold and red colors signifies wealth, power, and courage. The blue field represents loyalty and truth. The combination of these elements creates a visually striking and meaningful emblem.
</details>
Submitted in partial fulfillment of the requirements for the MSc degree in Computing (Artificial Intelligence and Machine Learning) of Imperial College London
September 2025
## Abstract
The Mixture-of-Experts (MoE) architecture has enabled the creation of massive yet efficient Large Language Models (LLMs). However, the standard deterministic routing mechanism presents a significant limitation: its inherent brittleness is a key contributor to model miscalibration and overconfidence, resulting in systems that often do not know what they don’t know.
This thesis confronts this challenge by proposing a structured Bayesian MoE routing framework. Instead of forcing a single, deterministic expert selection, our approach models a probability distribution over the routing decision itself. We systematically investigate three families of methods that introduce this principled uncertainty at different stages of the routing pipeline: in the weight-space, the logit-space, and the final selection-space.
Through a series of controlled experiments on a 3-billion parameter MoE model, we demonstrate that this framework significantly improves routing stability, in-distribution calibration, and out-of-distribution (OoD) detection. The results show that by targeting this core architectural component, we can create a more reliable internal uncertainty signal. This work provides a practical and computationally tractable pathway towards building more robust and self-aware LLMs, taking a crucial step towards making them know what they don’t know.
### Acknowledgments
This thesis is dedicated to my demanding, fulfilling and joyous year at Imperial College London, my Hogwarts.
This journey to this thesis was made possible by the support, guidance, and inspiration of many people, to whom I owe my deepest gratitude:
First and foremost, I would like to express my sincere gratitude to my supervisor, Dr. Matthew Wicker. His amazing 70015: Mathematics for Machine Learning module lured me down the rabbit hole of Probabilistic & Bayesian Machine Learning, a journey from which I have happily not returned. His initial ideation of Bayesianfying Mixture-of-Experts provides the foundation of this thesis. Since mid-stage of this project, his careful guidance and detailed feedback on both experiments and writing were invaluable. Thank you for being a great supervisor and friend.
My thanks also extend to my second marker, Dr. Yingzhen Li, whose lecture notes on Variational Inference and Introduction to BNNs are the best I have ever seen. I am grateful for her interest in this project and for the insightful meeting she arranged with her PhD student, Wenlong, which provided crucial perspective at a key stage.
The work was sharpened by the weekly discussions of LLM Shilling Crew, a reading group I had the pleasure of co-founding with my best friend at Imperial, James Kerns. Thank you all for the stimulating discussion and the fun we had, which were instrumental during the early research phase of this project.
To my parents, Yuhan and Wei, thank you for the unconditional love and the unwavering financial and emotional support you have provided for the past 22 years.
Last but certainly not least, I must thank my close friends at the Department of Computing, fellow habitants of the deep, dark, and cold basement of the Huxley building (you know who you are). You are a priceless treasure in my life. Contents
1. 1 Introduction
1. 1.1 Overview
1. 1.2 Contributions
1. 1.3 Thesis Outline
1. 2 Background
1. 2.1 Mixture-of-Experts (MoE) Architecture
1. 2.1.1 Modern LLM: A Primer
1. 2.1.2 MoE: From Dense Layers to Sparse Experts
1. 2.2 Uncertainty and Calibration in Large Language Models
1. 2.2.1 The Problem of Overconfidence and Miscalibration
1. 2.2.2 Evaluating Uncertainty: From Sequences to Controlled Predictions
1. 2.2.3 Formal Metrics for Calibration
1. 2.2.4 Related Work in LLM Calibration
1. 2.3 Bayesian Machine Learning: A Principled Approach to Uncertainty
1. 2.3.1 The Bayesian Framework
1. 2.3.2 Bayesian Neural Networks (BNNs)
1. 2.3.3 Variational Inference (VI)
1. 3 Motivation
1. 3.1 Motivation 1: Brittleness of Deterministic Routing
1. 3.1.1 Methodology
1. 3.1.2 Results and Observations
1. 3.1.3 Conclusion
1. 3.2 Motivation 2: Potentials of Stochastic Routing
1. 3.2.1 Methodology
1. 3.2.2 Results and Observations
1. 3.2.3 Conclusion
1. 3.3 Chapter Summary
1. 4 Methodology: Bayesian MoE Router
1. 4.1 Standard MoE Router: A Formal Definition
1. 4.2 Bayesian Inference on Expert Centroid Space
1. 4.2.1 Core Idea: Bayesian Multinomial Logistic Regression
1. 4.2.2 Method 1: MC Dropout Router (MCDR)
1. 4.2.3 Method 2: Stochastic Weight Averaging Gaussian Router (SWAGR)
1. 4.2.4 Method 3: Deep Ensembles of Routers (DER)
1. 4.2.5 Summary of Centroid-Space Methods
1. 4.3 Bayesian Inference on Expert Logit Space
1. 4.3.1 Core Idea: Amortised Variational Inference on the Logit Space
1. 4.3.2 Method 4: The Mean-Field Variational Router (MFVR)
1. 4.3.3 Method 5: The Full-Covariance Variational Router (FCVR)
1. 4.3.4 Summary of Logit-Space Methods
1. 4.4 Bayesian Inference on Expert Selection Space
1. 4.4.1 Core Idea: Learning Input-Dependent Temperature
1. 4.4.2 Method 6: Variational Temperature Sampling Router (VTSR)
1. 4.4.3 Summary of the Selection-Space Method
1. 4.5 Chapter Summary
1. 5 Experiments and Analysis
1. 5.1 Experimental Setup
1. 5.1.1 Model, Baselines, and Proposed Methods
1. 5.1.2 Datasets and Tasks
1. 5.1.3 Evaluation Metrics
1. 5.2 Implementation Details and Training Strategy
1. 5.2.1 Training Pipeline
1. 5.2.2 MoE Layer Selection Strategies
1. 5.2.3 Method-Specific Tuning and Considerations
1. 5.3 Experiment 1: Stability Under Perturbation
1. 5.3.1 Goal and Methodology
1. 5.3.2 Results and Analysis
1. 5.4 Experiment 2: In-Distribution Calibration
1. 5.4.1 Goal and Methodology
1. 5.4.2 Results and Analysis
1. 5.5 Experiment 3: Out-of-Distribution Detection
1. 5.5.1 Goal and Methodology
1. 5.5.2 Experiment 3a: Improving Standard Uncertainty Signal
1. 5.5.3 Experiment 3b: Router-Level Uncertainty as Signal
1. 5.6 Ablation Study: Comparative Analysis of Layer Selection
1. 5.7 Practicality: Efficiency Analysis of Bayesian Routers
1. 5.7.1 Memory Overhead
1. 5.7.2 Computation Overhead
1. 5.7.3 Parallelisation and Practical Trade-offs
1. 5.8 Chapter Summary
1. 6 Discussion and Conclusion
1. 6.1 Limitations and Future works
1. 6.2 Conclusion
1. Declarations
1. A Models & Datasets
1. B Proof of KL Divergence Equivalence
1. C In Distribution Calibration Full Results
1. D Out of Distribution Detection Full Results
1. D.1 Formal Definitions of Router-Level Uncertainty Signals
1. D.2 Full Results: Standard Uncertainty Signal (Experiment 3a)
1. D.3 Full Results: Router-Level Uncertainty Signals (Experiment 3b)
### 1.1 Overview
Modern Large Language Models (LLMs) have achieved remarkable success through clever techniques for scaling both dataset and model size. A key architectural innovation enabling this progress is the Mixture-of-Experts (MoE) model [1, 2]. The computational cost of dense, all-parameter activation in traditional LLMs creates a bottleneck that limits further scaling and hinders wider, more accessible deployment. The MoE architecture elegantly circumvents this by using a routing network (gating network) to activate only a fraction of the model’s parameters for any given input. This sparsity allows for a massive increase in the total number of parameters, enhancing the model’s capacity for specialised knowledge without a proportional increase in computational cost. This dual benefit of specilisation and sparsity has made MoE a cornerstone of state-of-the-art LLMs.
Despite their power, the practical deployment of LLMs is hindered by fundamental challenges in robustness and calibration [3]. These models often produce highly confident yet incorrect outputs, a phenomenon known as overconfidence, which has been shown to be a persistent issue across a wide range of models and tasks [4]. This unreliability frequently manifests as hallucination, the generation of plausible but factually fictitious content, which poses a significant barrier to their adoption in high-stake domains [5], such as medicine and the law. At its core, this untrustworthiness stems from the models’ inability to quantify their own predictive uncertainty.
This thesis argues that in an MoE model, the classic deterministic routing mechanism represents a critical point of failure. The router’s decision is not a minor adjustment, but dictates which specialised sub-networks are activated for inference. An incorrect or brittle routing choice means the wrong knowledge-domain expert is applied to a token, leading to a flawed output. In modern LLMs with dozens of stacked MoE layers, this problem is magnified: A single routing error in an early layer creates a corrupted representation that is then passed to all subsequent layers, initiating a cascading failure.
This thesis proposes to address potential failure mode by introducing a Bayesian routing framework. Instead of forcing the router to make a single, deterministic choice, our approach is to model a probability distribution over the routing decisions themselves. This allows us to perform principled uncertainty quantification directly at the point of expert selection, drawing on foundational concepts in Bayesian deep learning [6, 7, 8]. While applying Bayesian methods to an entire multi-billion parameter LLM is often computationally daunting, focusing this treatment only on the lightweight routing networks is a highly pragmatic and tractable approach. The ultimate purpose is to leverage this targeted uncertainty to enable better calibrated and robust LLM inference, creating models that are not only powerful but also aware of the limits of their own knowledge.
### 1.2 Contributions
This thesis makes the following primary contributions to the study of reliable and calibrated Mixture-of-Experts models:
1. Diagnosis of Router Brittleness and Rationale for Probabilistic Routing: We establish the empirical foundation for this thesis with a two-part investigation, which reveals the inherent brittleness of standard deterministic routing and potentials for probablistic approaches respectively.
1. A Structured Framework for Bayesian Routing: We formulate and evaluate a novel framework that categorises Bayesian routing methods based on where uncertainty is introduced. This taxonomy provides a clear and structured landscape for analysis, focussed on Bayesian modelling of weight-space, logit-space and routing-space respectively.
1. Rigorous Evaluation of Calibration and Robustness: We conduct a series of controlled experiments on a pre-trained MoE model with 3B parameters, then systematically measure the impact of our proposed methods on in-distribution (ID) performance and calibration, out-of-distribution (OoD) detection, and overall router stability.
1. Memory and Computation Overhead Analysis: We assess the practical feasibility of the proposed Bayesian routing methods by performing a detailed analysis of their memory and computational overhead. This provides a clear picture of the trade-offs involved, demonstrating which methods are most viable for deployment in large-scale systems.
### 1.3 Thesis Outline
The remainder of this thesis is organised as follows. Chapter 2 provides a review of the foundational literature on Mixture-of-Experts models, uncertainty in LLMs, and Bayesian machine learning. Chapter 3 presents the motivational experiments that quantitatively establish the problem of router instability. Chapter 4 details the methodology behind our proposed Bayesian Routing Networks framework. Chapter 5 is dedicated to the main experiments and analysis, evaluating the impact of our methods on stability, calibration, and robustness, with further efficiency analysis. Finally, Chapter 6 concludes the thesis with a discussion that includes the limitations of this study, and promising directions for future work.
## Chapter 2 Background
### 2.1 Mixture-of-Experts (MoE) Architecture
#### 2.1.1 Modern LLM: A Primer
To understand the innovation of the Mixture-of-Experts (MoE) architecture, one must first understand the standard model it enhances. The foundational architecture for virtually all modern Large Language Models (LLMs) is the Transformer [9]. This section provides a brief but essential overview of the key components of a contemporary, dense LLM, establishing a baseline before we introduce the concept of sparsity.
Decoder-Only Transformer Blueprint
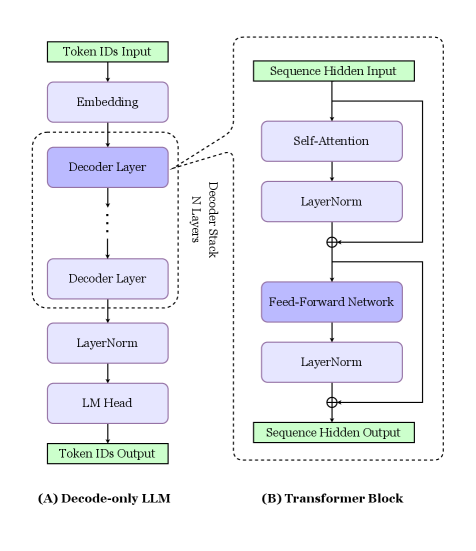
The dominant architecture for modern generative LLMs, such as those in the GPT family [10], is the Decoder-only Transformer [11]. As illustrated in Figure 2.1 (A), this model processes text through a sequential pipeline. The process begins with an input sequence of tokens, which are represented in the form of indices from the vocabulary by Tokeniser. These discrete IDs are first converted into continuous vector representations by an Embedding layer, which is a learnable lookup table. Positional encoding is also usually incorporated at the embedding stage.
The resulting embeddings are then processed by the core of the model: a stack of $N$ identical Decoder Layers. The output of one layer serves as the input to the next, allowing the model to build progressively more abstract and contextually rich representations of the sequence. After the final decoder layer, a concluding LayerNorm is applied. This final hidden state is then projected into the vocabulary space by a linear layer known as the Language Modelling Head [12], which produces a logit for every possible token from the vocabulary. Finally, a softmax function is applied to these logits to generate a probability distribution, from which the output Token ID is predicted. Each of these decoder blocks contains the same set of internal sub-layers, which we will describe next.
Inside the Transformer Block
As shown in Figure 2.1 (B), each identical decoder block is composed of two primary sub-layers, wrapped with essential components that enable stable training of deep networks.
The first sub-layer is the Multi-Head Self-Attention mechanism. This is the core innovation of the Transformer, allowing each token to weigh the importance of all other preceding tokens in the sequence. The output of this sub-layer, $\mathbf{u}$ , is computed by applying the attention function to the block’s input, $\mathbf{h}$ , with residual connection and layer normalisation added:
$$
\mathbf{u}=\text{LayerNorm}(\text{SA}(\mathbf{h})+\mathbf{h})
$$
As the attention mechanism is not the primary focus of this thesis, we will not detail its internal mechanics.
The second sub-layer is a position-wise Feed-Forward Network (FFN). This is a non-linear transformation that is applied independently to each token representation $\mathbf{u}_{t}$ after it has been updated by the attention mechanism. Skip connections and layer normalisation are again applied, yielding the final output of the Transformer block, $\mathbf{h^{\prime}}$ :
$$
\mathbf{h^{\prime}}=\text{LayerNorm}(\text{FFN}(\mathbf{u})+\mathbf{u})
$$
In modern LLMs, this is typically implemented as a Gated Linear Unit (GLU) variant such as SwiGLU [13], which has been shown to be highly effective:
$$
\text{FFN}(\mathbf{u}_{t})=\left(\sigma(\mathbf{u}_{t}W_{\text{Up}})\odot\mathbf{u}_{t}W_{\text{Gate}}\right)W_{\text{Down}}
$$
This FFN is the specific component that the Mixture-of-Experts architecture modifies and enhances.
Crucially, as stated, each of these two sub-layers is wrapped by two other components: a residual connection (or skip connection) and a layer normalisation step. The residual connection is vital for preventing the vanishing gradient problem. Layer normalisation stabilises the activations, ensuring that the training of dozens or even hundreds of stacked layers remains feasible.
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Diagram: Decode-only LLM and Transformer Block Architecture
### Overview
The image presents a diagram illustrating the architecture of a decode-only Large Language Model (LLM) and a Transformer Block, which is a core component of the LLM. The diagram shows the flow of data through these components, highlighting the key layers and connections. The diagram is split into two main sections, labeled (A) and (B).
### Components/Axes
The diagram consists of two main sections:
* **(A) Decode-only LLM:** This section depicts the overall structure of a decode-only LLM. It includes components like "Token IDs Input", "Embedding", "Decoder Layer" (repeated N times), "LayerNorm", "LM Head", and "Token IDs Output". A dashed box surrounds the repeated "Decoder Layer" components, labeled "Decoder Stack".
* **(B) Transformer Block:** This section details the internal structure of a single "Decoder Layer" from section (A). It includes components like "Self-Attention", "LayerNorm", "Feed-Forward Network", and another "LayerNorm". Addition symbols (+) are used to indicate residual connections.
There are no axes in the traditional sense, but the diagram uses arrows to indicate the direction of data flow.
### Detailed Analysis or Content Details
**(A) Decode-only LLM:**
* **Token IDs Input:** A green rectangle at the top-left, representing the input to the model.
* **Embedding:** A light-blue rectangle below "Token IDs Input", receiving input from it via a downward arrow.
* **Decoder Stack:** A dashed box containing multiple "Decoder Layer" components. The number of layers is denoted by "N Layers" written vertically alongside the stack.
* **Decoder Layer:** A purple rectangle within the "Decoder Stack". The diagram shows multiple instances of this layer stacked vertically.
* **LayerNorm:** A light-purple rectangle below the "Decoder Stack", receiving output from the stack via a downward arrow.
* **LM Head:** A blue rectangle below "LayerNorm", receiving input from it via a downward arrow.
* **Token IDs Output:** A green rectangle at the bottom, representing the output of the model, receiving input from "LM Head" via a downward arrow.
**(B) Transformer Block:**
* **Sequence Hidden Input:** A green rectangle at the top-right, representing the input to the Transformer Block.
* **Self-Attention:** A light-blue rectangle below "Sequence Hidden Input", receiving input from it via a downward arrow.
* **LayerNorm:** A light-purple rectangle to the right of "Self-Attention", receiving input from it via a curved arrow and adding it to the original input (residual connection, indicated by the + symbol).
* **Feed-Forward Network:** A purple rectangle below "LayerNorm", receiving input from it via a downward arrow.
* **LayerNorm:** A light-purple rectangle to the right of "Feed-Forward Network", receiving input from it via a curved arrow and adding it to the original input (residual connection, indicated by the + symbol).
* **Sequence Hidden Output:** A green rectangle at the bottom-right, representing the output of the Transformer Block, receiving input from the second "LayerNorm" via a downward arrow.
### Key Observations
* The "Decoder Layer" in (A) is expanded into the "Transformer Block" in (B), showing its internal structure.
* Residual connections (addition symbols) are used in the Transformer Block to improve gradient flow during training.
* The diagram highlights the sequential nature of the LLM, with data flowing from input to output through a series of layers.
* The use of "LayerNorm" suggests normalization is applied at multiple points within the architecture.
### Interpretation
The diagram illustrates the fundamental building blocks of a decode-only LLM, which are commonly used in tasks like text generation. The Transformer Block, as shown in (B), is the core computational unit responsible for processing the input sequence and extracting relevant features. The stacking of multiple "Decoder Layers" (N layers) allows the model to learn complex relationships in the data. The residual connections are crucial for training deep neural networks, preventing the vanishing gradient problem. The diagram effectively conveys the modularity and hierarchical structure of these models, demonstrating how a complex system is built from simpler, interconnected components. The green input and output rectangles clearly delineate the boundaries of each component, emphasizing the flow of information. The diagram is a simplified representation, omitting details like attention mechanisms within the "Self-Attention" layer, but it provides a clear overview of the overall architecture.
</details>
Figure 2.1: From Decoder-only LLM to Transformer Block. (A) The high-level of a decoder-only LLM, composed of a stack of identical Transformer blocks. (B) The internal structure of a single Transformer block.
Architectural Advances
Beyond the core components, the performance of modern LLMs relies on several key innovations, including:
- Root Mean Square Normalisation (RMSNorm): A computationally efficient alternative to LayerNorm that stabilises training by normalising activations based on their root-mean-square magnitude [14].
- Rotary Position Embeddings (RoPE): A method for encoding the relative positions of tokens by rotating their vector representations, which has been shown to improve generalisation to longer sequences [15].
- Advanced Attention Mechanisms: Techniques such as Latent Attention are used to handle longer contexts more efficiently by first compressing the input sequence into a smaller set of latent representations [16].
While these techniques optimise existing components of the Transformer, a more fundamental architectural shift for scaling model capacity involves reimagining the Feed-Forward Network (FFN) itself. This leads us directly to the Mixture-of-Experts paradigm, which is a sparsity-inducing modification of the FFN.
#### 2.1.2 MoE: From Dense Layers to Sparse Experts
The architectural innovations described previously optimise existing components of the Transformer. The Mixture-of-Experts (MoE) paradigm introduces a more fundamental change by completely redesigning the Feed-Forward Network (FFN), the primary source of a dense model’s parameter count and computational cost [17, 1, 2].
Motivation and Key Benefits
The core idea of an MoE layer is to replace a single FFN with a collection of many smaller, independent FFNs called experts. For each incoming token, a lightweight routing mechanism dynamically selects a small subset of these experts (e.g., 2 or 4 out of 64) to process it. This strategy of sparse activation yields two significant benefits:
Massive Parameter Count for Specialised Knowledge. The first benefit is a dramatic increase in the model’s total number of learnable parameters. The total knowledge capacity of the model is the sum of all experts, enabling different experts to learn specialised functions for different types of data or tasks.
Constant Computational Cost for Efficient Inference. The second benefit is that this increased capacity does not come with a proportional rise in computational cost. Despite the vast number of total parameters, the cost (in FLOPs) per token remains constant and manageable, as it only depends on the small number of activated experts. This breaks the direct link between model size and inference cost, enabling a new frontier of scale.
This paradigm has been successfully adopted by many state-of-the-art open-source LLMs. A detailed comparison of their respective sizes and expert configurations is presented in Table A.2, Appendix A.
The MoE Routing Mechanism
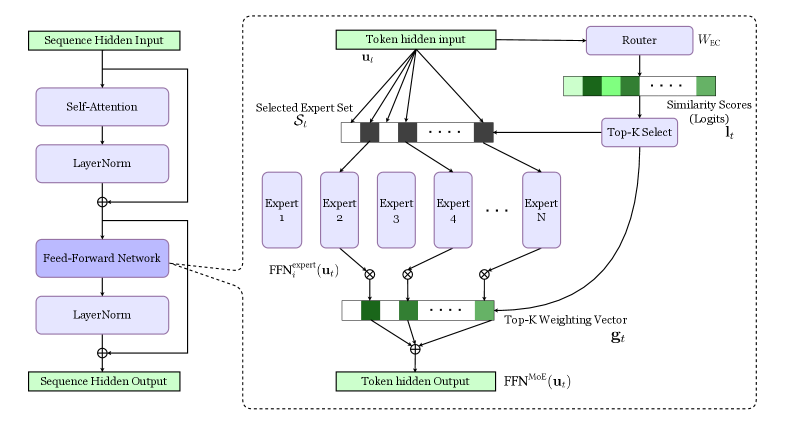
The core of the MoE layer is a deterministic routing mechanism, which decides which subset of experts to activate during inference for each individual tokens. The entire MoE FFN layer’s working procedure is demonstrated in Figure 2.2. We can break this process down into three distinct stages:
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Diagram: Mixture of Experts (MoE) Layer Architecture
### Overview
The image depicts the architecture of a Mixture of Experts (MoE) layer within a neural network. It illustrates how a token hidden input is routed to a selected set of experts, processed by those experts, and then combined to produce a token hidden output. The diagram highlights the key components involved in this process, including the router, experts, and weighting mechanism.
### Components/Axes
The diagram can be divided into three main sections:
1. **Left Side:** Standard Feed-Forward Network block. Includes "Sequence Hidden Input", "Self-Attention", "LayerNorm", "Feed-Forward", "LayerNorm", and "Sequence Hidden Output".
2. **Right Side (within dashed box):** MoE Layer. Contains "Token hidden input u<sub>t</sub>", "Router", "Selected Expert Set S<sub>t</sub>", "Expert 1" through "Expert N", "FFN<sup>expert</sup>(u<sub>t</sub>)", "Top-K Weighting Vector g<sub>t</sub>", and "Token hidden Output FFN<sup>MoE</sup>(u<sub>t</sub>)".
3. **Connections:** Arrows indicating the flow of data between components.
Key labels include:
* **Sequence Hidden Input:** The input to the initial feed-forward network.
* **Self-Attention:** A component within the feed-forward network.
* **LayerNorm:** Layer Normalization, used in both the standard and MoE blocks.
* **Feed-Forward:** A standard feed-forward network.
* **Token hidden input u<sub>t</sub>:** The input to the MoE layer.
* **Router:** The component responsible for routing the input to the experts.
* **W<sub>EC</sub>:** Weight matrix for the router.
* **Similarity Scores (Logits) l<sub>t</sub>:** The scores produced by the router, indicating the relevance of each expert.
* **Top-K Select:** The selection of the top K experts based on the similarity scores.
* **Selected Expert Set S<sub>t</sub>:** The set of experts selected by the router.
* **Expert 1…Expert N:** The individual expert networks.
* **FFN<sup>expert</sup>(u<sub>t</sub>):** The output of each expert network.
* **Top-K Weighting Vector g<sub>t</sub>:** The weights assigned to each selected expert.
* **Token hidden Output FFN<sup>MoE</sup>(u<sub>t</sub>):** The final output of the MoE layer.
### Detailed Analysis or Content Details
The diagram illustrates the following flow:
1. A "Sequence Hidden Input" passes through a standard feed-forward network consisting of "Self-Attention", "LayerNorm", "Feed-Forward", and another "LayerNorm" to produce a "Sequence Hidden Output".
2. The "Token hidden input u<sub>t</sub>" enters the MoE layer.
3. The "Router" processes the input and generates "Similarity Scores (Logits) l<sub>t</sub>" for each expert.
4. "Top-K Select" chooses the top K experts based on these scores, forming the "Selected Expert Set S<sub>t</sub>".
5. The input "u<sub>t</sub>" is fed to each expert in the selected set, resulting in "FFN<sup>expert</sup>(u<sub>t</sub>)" outputs.
6. A "Top-K Weighting Vector g<sub>t</sub>" is calculated, assigning weights to each expert's output.
7. The weighted outputs of the experts are combined to produce the final "Token hidden Output FFN<sup>MoE</sup>(u<sub>t</sub>)".
8. The "Token hidden Output" is then added to the "Sequence Hidden Output" from the left side of the diagram.
The diagram uses circular nodes to represent operations and rectangular blocks to represent data or sets of data. The plus signs (+) indicate element-wise addition. The connections between components are represented by arrows.
### Key Observations
The MoE layer introduces sparsity by only activating a subset of experts for each input token. The router plays a crucial role in determining which experts are most relevant. The weighting vector allows for a soft combination of the experts' outputs, rather than a hard selection. The diagram clearly shows the parallel processing of the input by multiple experts.
### Interpretation
This diagram demonstrates a key architectural component in scaling large language models – the Mixture of Experts layer. By distributing the computational load across multiple experts, MoE layers enable models to increase their capacity without a proportional increase in computational cost during inference. The router acts as a dynamic load balancer, directing each input to the most appropriate experts. This approach allows the model to specialize in different aspects of the data, leading to improved performance. The use of a weighting vector suggests that the model can leverage the knowledge of multiple experts simultaneously, rather than relying on a single best expert. The diagram highlights the modularity and scalability of this architecture, making it well-suited for handling complex and diverse datasets. The addition operation at the end suggests a residual connection, a common technique for improving training stability and performance in deep neural networks.
</details>
Figure 2.2: Routing Mechanism in MoE Feed-Forward Network Layer.
Stage 1: Expert Similarity Scoring. First, the router computes a similarity score between the input token’s hidden state, $\mathbf{u}_{t}\in\mathbb{R}^{D}$ , and each of the $N$ unique, learnable expert centroid vectors, $\mathbf{e}_{i}\in\mathbb{R}^{D}$ . This is achieved using a dot product to measure the alignment between the token’s representation and each expert’s specialised focus. For computational efficiency, these $N$ centroid vectors are collected as the columns of a single weight matrix:
$$
W_{\text{EC}}=[\mathbf{e}_{1},\dots,\mathbf{e}_{N}]
$$
The similarity calculation for all experts is then performed with a single matrix multiplication. In neural network terms, this is a simple linear projection that produces a vector of unnormalised scores, or logits ( $\mathbf{l}_{t}\in\mathbb{R}^{N}$ ):
$$
\mathbf{l}_{t}=\mathbf{u}_{t}W_{\text{EC}}
$$
Stage 2: Probability Transformation. Next, these raw logit scores are transformed into a discrete probability distribution over all $N$ experts using the softmax function:
$$
\mathbf{s}_{t}=\text{softmax}(\mathbf{l}_{t})
$$
Taken together, this two-step process of a linear projection followed by a softmax function is a multinomial logistic regression [18] model.
Stage 3: Top-K Expert Selection. Finally, to enforce sparse activation, a hard, deterministic Top-K selection mechanism is applied to this probability vector $\mathbf{s}_{t}$ . This operation identifies the indices of the $K$ experts with the highest probabilities. Many practical implementations select the Top-K experts directly from the logits before applying a renormalising softmax to the scores of only the selected experts [16]. Since the softmax function is monotonic, this yields the exact same set of chosen experts. Our softmax $\rightarrow$ Top-K framing is mathematically equivalent for the final selection and provides a more natural foundation for the probabilistic methods developed in this thesis.
$$
g^{\prime}_{t,i}=\begin{cases}s_{t,i}&\text{if }s_{t,i}\in\textsc{Top-K}(\{s_{t,j}\}_{j=1}^{N})\\
0&\text{otherwise}\end{cases}
$$
Let $\mathcal{S}_{t}$ be the set of the Top-K expert indices selected for token $\mathbf{u}_{t}$ , which contains $K$ indices. The probabilities for these selected experts are then renormalised to sum to one,
$$
\mathbf{g}_{t}=\frac{\mathbf{g}^{\prime}_{t}}{\sum_{i=1}^{N}g^{\prime}_{t,i}}
$$
forming the final sparse gating weights, $\mathbf{g}_{t}$ , which are used to compute the weighted sum of expert outputs.
$$
\text{FFN}^{\text{MoE}}(\mathbf{u}_{t})=\sum_{i\in\mathcal{S}_{t}}g_{t,i}\cdot\text{FFN}^{\text{expert}}_{i}(\mathbf{u}_{t})
$$
Auxiliary Losses for Router Training
The hard, competitive nature of the Top-K selection mechanism can lead to a training pathology known as routing collapse [1]. This occurs when a positive feedback loop causes the router to consistently send the majority of tokens to a small, favored subset of experts. The remaining experts are starved of data and fail to learn, rendering a large portion of the model’s capacity useless. To counteract this and ensure all experts are trained effectively, auxiliary loss functions are added to the main training task objective with a scaling hyperparameter $\beta$ :
$$
\mathcal{L}=\mathcal{L}_{\text{task}}+\beta\cdot\mathcal{L}_{\text{auxiliary}}
$$
Numerous auxillary losses for stablising and balancing router training have been proposed over the past few years [19, 20, 21]. Here we only introuduced two most famous ones:
Load-Balancing Loss
The most common auxiliary loss is a load-balancing loss designed to incentivise the router to distribute tokens evenly across all $N$ experts. For a batch of $T$ tokens, this loss is typically calculated as the dot product of two quantities for each expert $i$ : the fraction of tokens in the batch routed to it ( $f_{i}$ ), and the average router probability it received over those tokens ( $P_{i}$ ) [22]:
$$
\mathcal{L}_{\text{balance}}=N\sum_{i=1}^{N}f_{i}\cdot P_{i}
$$
This loss is minimised when each expert receives an equal share of the routing responsibility.
Router Z-Loss
Some models also employ a router Z-loss to regularise the magnitude of the pre-softmax logits [23]. This loss penalises large logit values, which helps to prevent the router from becoming overly confident in its selections early in training. This can improve training stability and encourage a smoother distribution of routing scores. The loss is calculated as the mean squared log-sum-exp of the logits over a batch:
$$
\mathcal{L}_{\text{Z}}=\frac{1}{T}\sum_{t=1}^{T}\left(\log\sum_{i=1}^{N}\exp(l_{t,i})\right)^{2}
$$
These auxiliary losses are combined with the primary task loss to guide the model towards a stable and balanced routing policy.
### 2.2 Uncertainty and Calibration in Large Language Models
Having detailed the architecture of a modern LLM, we now turn to the fundamental challenges of reliability that motivate our work. To understand the need for a Bayesian MoE router, it is crucial to first understand the general problems of overconfidence and miscalibration inherent in standard, deterministic models.
#### 2.2.1 The Problem of Overconfidence and Miscalibration
A fundamental challenge in modern LLMs is the frequent mismatch between the model’s predictive probabilities and its true underlying knowledge. The softmax outputs of a well-trained network cannot be reliably interpreted as a true measure of the model’s confidence. This phenomenon is known as miscalibration, and for most modern deep networks, it manifests as consistent overconfidence, a tendency to produce high-probability predictions that are, in fact, incorrect [3].
This overconfidence is a primary driver of one of the most significant failure modes in LLMs: hallucination. Defined as the generation of plausible-sounding but factually baseless or fictitious content, hallucination makes models fundamentally untrustworthy [5]. In high-stakes domains such as medicine or law, the tendency to state falsehoods with unwavering certainty poses a critical safety risk and a major barrier to adoption.
The formal goal is to achieve good calibration. A model is considered perfectly calibrated if its predicted confidence aligns with its empirical accuracy. For instance, across the set of all predictions to which the model assigns an 80% confidence, a calibrated model will be correct on 80% of them. Achieving better calibration is therefore a central objective in the pursuit of safe and reliable AI, and it is a primary motivation for the methods developed in this thesis.
#### 2.2.2 Evaluating Uncertainty: From Sequences to Controlled Predictions
Quantifying the uncertainty of an LLM’s output is a complex task, especially for open-ended, autoregressive generation. The output space is vast, and uncertainty can accumulate at each step, making it difficult to obtain a reliable and interpretable measure. This remains an active and challenging area of research, with various proposed methods.
The most traditional metric is Perplexity (PPL), the exponentiated average negative log-likelihood of a sequence, which measures how “surprised” a model is by the text:
$$
\text{PPL}(\mathbf{s})=\exp\left\{-\frac{1}{T}\sum_{t=1}^{T}\log p(s_{t}|s_{<t})\right\}
$$
More advanced approaches, like Semantic Entropy, aim to measure uncertainty by clustering the semantic meaning of many possible generated sequences [24, 25]. The entropy is calculated over the probability of these semantic clusters rather than individual tokens. Each semantic cluster $\mathbf{c}$ is defined as $\forall\mathbf{s},\mathbf{s}^{\prime}\in\mathbf{c}:E(\mathbf{s},\mathbf{s}^{\prime})$ , where $E$ is a semantic equivalence relation. $\mathcal{C}$ is semantic cluster space. The semantic entropy is then given by:
$$
\mathcal{H}_{\text{sem}}(p(y|\mathbf{x}))=-\sum_{\mathbf{c}\in\mathcal{C}}p(\mathbf{c}|\mathbf{x})\log p(\mathbf{c}|\mathbf{x})
$$
Other methods focus on explicitly teaching the model to assess its own confidence, either through direct prompting or by using Supervised Fine-Tuning (SFT) to train the model to state when it does not know the answer [26]. An example of such prompting strategies is shown in Table 2.1.
Table 2.1: Examples of prompting strategies for outputing model confidence.
| Name | Format | Confidence |
| --- | --- | --- |
| Zero-Shot Classifier | “Question. Answer. True/False: True ” | $\frac{P(\text{``{\color[rgb]{1,0,0}\definecolor[named]{pgfstrokecolor}{rgb}{1,0,0}True}''})}{P(\text{``{\color[rgb]{1,0,0}\definecolor[named]{pgfstrokecolor}{rgb}{1,0,0}True}''})+P(\text{``{\color[rgb]{1,0,0}\definecolor[named]{pgfstrokecolor}{rgb}{1,0,0}False}''})}$ |
| Verbalised | “Question. Answer. Confidence: 90% ” | float(‘‘ 90% ’’) |
While these methods are valuable for sequence-level analysis, in order to rigorously and quantitatively evaluate the impact of the architectural changes proposed in this thesis, a more controlled and standardised evaluation setting is required. A common and effective strategy is to simplify the task to the fundamental problem of next-token prediction in a constrained environment.
For this purpose, Multiple-Choice Question Answering (MCQA) A detailed summary of the MCQA datasets used later in this thesis is provided in Table LABEL:tab:mcqa_datasets_summary, Appendix A. provides an ideal testbed. In this setting, the model’s task is reduced to assigning probabilities over a small, discrete set of predefined answer choices. This allows for a direct and unambiguous comparison between the model’s assigned probability for the correct answer (its confidence) and the actual outcome. This provides a clean, reliable signal for measuring the model’s calibration, which is the focus of our evaluation.
#### 2.2.3 Formal Metrics for Calibration
Within the controlled setting of Multiple-Choice Question Answering (MCQA), we can use a suite of formal metrics to quantify a model’s performance and, more importantly, its calibration.
A primary metric for any probabilistic classifier is the Negative Log-Likelihood (NLL), also known as the cross-entropy loss. It measures how well the model’s predicted probability distribution aligns with the ground-truth outcome. A lower NLL indicates that the model is not only accurate but also assigns high confidence to the correct answers.
To measure miscalibration directly, the most common metric is the Expected Calibration Error (ECE) [27, 3]. ECE measures the difference between a model’s average confidence and its actual accuracy. To compute it, predictions are first grouped into $M$ bins based on their confidence scores. For each bin $B_{m}$ , the average confidence, $\text{conf}(B_{m})$ , is compared to the actual accuracy of the predictions within that bin, $\text{acc}(B_{m})$ . The ECE is the weighted average of the absolute differences across all bins:
$$
\text{ECE}=\sum_{m=1}^{M}\frac{|B_{m}|}{n}\left|\text{acc}(B_{m})-\text{conf}(B_{m})\right|
$$
where $n$ is the total number of predictions. A lower ECE signifies a better-calibrated model. A complementary metric is the Maximum Calibration Error (MCE), which measures the worst-case deviation by taking the maximum of the differences:
$$
\text{MCE}=\max_{m=1,\dots,M}\left|\text{acc}(B_{m})-\text{conf}(B_{m})\right|
$$
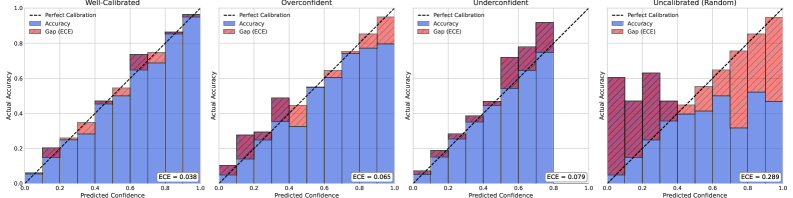
These metrics are often visualised using Reliability Diagrams. As shown in Figure 2.3, this plot shows the actual accuracy for each confidence bin. For a perfectly calibrated model, the bars align perfectly with the diagonal line, where confidence equals accuracy.
<details>
<summary>x5.png Details</summary>
### Visual Description
\n
## Calibration Plots: Model Confidence vs. Accuracy
### Overview
The image presents four calibration plots, each representing a different calibration state of a model: Well-Calibrated, Overconfident, Underconfident, and Uncalibrated (Random). Each plot visualizes the relationship between predicted confidence and actual accuracy. The plots use histograms to show the distribution of predictions and overlay lines to represent perfect calibration. The area between the accuracy histogram and the perfect calibration line is shaded to represent the Expected Calibration Error (ECE).
### Components/Axes
Each plot shares the following components:
* **X-axis:** "Predicted Confidence" ranging from 0.0 to 1.0.
* **Y-axis:** "Actual Accuracy" ranging from 0.0 to 1.0.
* **Blue Histogram:** Represents the "Accuracy" – the frequency of correct predictions for each confidence bin.
* **Red Shaded Area:** Represents the "Gap (ECE)" – the difference between the actual accuracy and the perfect calibration line.
* **Black Dashed Line:** Represents "Perfect Calibration" – a diagonal line where predicted confidence equals actual accuracy.
* **Title:** Indicates the calibration state of the model (Well-Calibrated, Overconfident, Underconfident, Uncalibrated (Random)).
* **ECE Value:** Displayed at the bottom-right of each plot, representing the Expected Calibration Error.
### Detailed Analysis or Content Details
**1. Well-Calibrated Plot:**
* The blue "Accuracy" histogram closely follows the black "Perfect Calibration" line.
* The red "Gap (ECE)" is minimal.
* ECE = 0.038.
* The histogram peaks around a predicted confidence of 0.8 and an actual accuracy of 0.8.
**2. Overconfident Plot:**
* The blue "Accuracy" histogram is consistently *below* the black "Perfect Calibration" line.
* The red "Gap (ECE)" is present, but relatively small.
* ECE = 0.065.
* The histogram peaks around a predicted confidence of 0.7 and an actual accuracy of 0.5.
**3. Underconfident Plot:**
* The blue "Accuracy" histogram is consistently *above* the black "Perfect Calibration" line.
* The red "Gap (ECE)" is more pronounced than in the Overconfident plot.
* ECE = 0.079.
* The histogram peaks around a predicted confidence of 0.3 and an actual accuracy of 0.7.
**4. Uncalibrated (Random) Plot:**
* The blue "Accuracy" histogram is highly erratic and deviates significantly from the black "Perfect Calibration" line.
* The red "Gap (ECE)" is the largest among all plots.
* ECE = 0.280.
* The histogram shows a relatively flat distribution across the predicted confidence range, indicating random predictions.
### Key Observations
* The ECE values directly correlate with the degree of calibration. Lower ECE indicates better calibration.
* The Well-Calibrated plot demonstrates the ideal scenario where predicted confidence aligns with actual accuracy.
* The Overconfident plot shows that the model tends to overestimate its confidence.
* The Underconfident plot shows that the model tends to underestimate its confidence.
* The Uncalibrated (Random) plot represents a poorly performing model with no meaningful relationship between predicted confidence and actual accuracy.
### Interpretation
These calibration plots illustrate the importance of model calibration in machine learning. A well-calibrated model provides not only accurate predictions but also reliable confidence scores. This is crucial for decision-making, especially in high-stakes applications where understanding the uncertainty of a prediction is as important as the prediction itself.
The plots demonstrate that a model can achieve high accuracy but still be poorly calibrated (e.g., Overconfident or Underconfident). This suggests that accuracy alone is not a sufficient metric for evaluating a model's performance. The ECE provides a quantitative measure of calibration error, allowing for a more comprehensive assessment of model quality.
The Uncalibrated (Random) plot highlights the scenario where the model's predictions are essentially random, indicating a complete lack of learning or a severe issue with the model's training process. The large ECE value confirms this poor performance.
The plots are a visual representation of the relationship between predicted probabilities and observed frequencies, a core concept in evaluating probabilistic models. They provide a clear and intuitive way to assess whether a model's confidence scores are trustworthy.
</details>
Figure 2.3: An example of a Reliability Diagram. The blue bars represent the model’s accuracy within each confidence bin, while the red bars show the gap to perfect calibration (the diagonal line).
In addition to calibration, a key aspect of our evaluation is a model’s ability to distinguish in-domain data from out-of-distribution (OoD) data. This is framed as a binary classification task where the model’s uncertainty score is used as a predictor. We evaluate this using two standard metrics: the Area Under the Receiver Operating Characteristic curve (AUROC) and the Area Under the Precision-Recall curve (AUPRC) [28]. The AUROC measures the trade-off between true positive and false positive rates, while the AUPRC is more informative for imbalanced datasets. For both metrics, a higher score indicates a more reliable uncertainty signal for OoD detection.
#### 2.2.4 Related Work in LLM Calibration
Improving the calibration of neural networks is an active area of research. Several prominent techniques have been proposed, which can be broadly categorised as post-hoc methods or training-time regularisation.
The most common and effective post-hoc method is Temperature Scaling [3]. This simple technique learns a single scalar temperature parameter, $T$ , on a held-out validation set. At inference time, the final logits of the model are divided by $T$ before the softmax function is applied. This “softens” the probability distribution, reducing the model’s overconfidence without changing its accuracy. While more complex methods exist, Temperature Scaling remains a very strong baseline.
Another approach is to regularise the model during training to discourage it from producing overconfident predictions. A classic example is Label Smoothing [29]. Instead of training on hard, one-hot labels (e.g., [0, 1, 0]), the model is trained on softened labels (e.g., [0.05, 0.9, 0.05]). This prevents the model from becoming excessively certain by discouraging the logits for the correct class from growing infinitely larger than others.
#### Towards Making MoE-based LLMs Know What They Don’t Know
In contrast to these approaches, which operate either as a post-processing step on the final output (Temperature Scaling) or as a modification to the training objective (Label Smoothing), the work in this thesis explores a fundamentally different, architectural solution. We hypothesise that miscalibration in MoE models can be addressed at a more foundational level, by improving the reliability of the expert selection mechanism itself. Rather than correcting the final output, we aim to build a more inherently calibrated model by introducing principled Bayesian uncertainty directly into the MoE router.
### 2.3 Bayesian Machine Learning: A Principled Approach to Uncertainty
This final section of our background review introduces the mathematical and conceptual tools used to address the challenges of uncertainty and calibration. While standard machine learning often seeks a single set of “best” model parameters, a point estimate, the Bayesian paradigm takes a different approach. Instead of a single answer, it aims to derive a full probability distribution over all possible parameters. This distribution serves as a principled representation of the model’s uncertainty, providing a foundation for building more reliable and robust systems.
#### 2.3.1 The Bayesian Framework
Prior, Likelihood, and Posterior
Bayesian inference is a framework for updating our beliefs in light of new evidence. It involves three core components:
- The Prior Distribution, $p(\theta)$ , which represents our initial belief about the model parameters $\theta$ before observing any data. It often serves as a form of regularisation.
- The Likelihood, $p(\mathcal{D}|\theta)$ , which is the probability of observing our dataset $\mathcal{D}$ given a specific set of parameters $\theta$ .
- The Posterior Distribution, $p(\theta|\mathcal{D})$ , which is our updated belief about the parameters after having observed the data.
These components are formally connected by Bayes’ Theorem, which provides the mathematical engine for updating our beliefs:
$$
p(\theta|\mathcal{D})=\frac{p(\mathcal{D}|\theta)p(\theta)}{p(\mathcal{D})}
$$
The Challenge of the Marginal Likelihood
While elegant, this framework presents a major practical challenge. The denominator in Bayes’ Theorem, $p(\mathcal{D})$ , is the marginal likelihood, also known as the model evidence. It is calculated by integrating over the entire parameter space:
$$
p(\mathcal{D})=\int p(\mathcal{D}|\theta)p(\theta)d\theta
$$
For any non-trivial model like a neural network, where $\theta$ can represent millions or billions of parameters, this high-dimensional integral is computationally intractable. Since the marginal likelihood cannot be computed, the true posterior distribution is also inaccessible. This intractability is the central challenge in Bayesian deep learning and motivates the need for the approximation methods we will discuss next.
#### 2.3.2 Bayesian Neural Networks (BNNs)
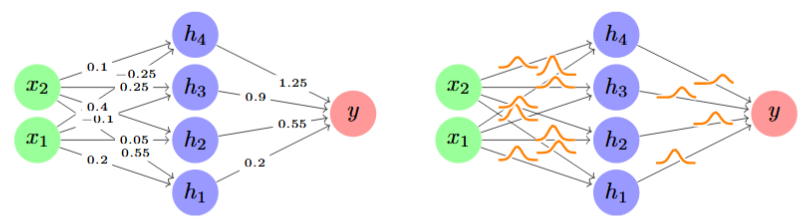
The general principles of Bayesian inference can be directly applied to neural networks, where the parameters $\theta$ correspond to the network’s weights and biases, $W$ . Instead of training to find a single, optimal point-estimate for these weights, a Bayesian Neural Network (BNN) aims to infer the full posterior distribution over them, $p(W|\mathcal{D})$ , as illlustrated in Figure 2.4 Illustration taken from the Murphy textbook [8]..
<details>
<summary>figures/bg/bnn_from_point_to_dist.png Details</summary>
### Visual Description
\n
## Diagram: Neural Network Representation
### Overview
The image presents two diagrams illustrating a neural network structure. The left diagram depicts a network with explicitly labeled weights between nodes, while the right diagram shows the same network with connections represented by curved lines, suggesting a more general representation of weighted connections. Both diagrams represent the same underlying network topology.
### Components/Axes
The diagrams consist of the following components:
* **Input Nodes:** `x1`, `x2` (light green)
* **Hidden Nodes:** `h1`, `h2`, `h3`, `h4` (blue)
* **Output Node:** `y` (red)
* **Weights:** Numerical values associated with the connections between nodes.
### Detailed Analysis or Content Details
**Left Diagram (Explicit Weights):**
* **x1 to h1:** Weight = 0.2
* **x1 to h2:** Weight = 0.05
* **x1 to h3:** Weight = 0.4
* **x2 to h1:** Weight = -0.1
* **x2 to h2:** Weight = 0.25
* **x2 to h3:** Weight = 0.25
* **x2 to h4:** Weight = 0.1
* **h1 to y:** Weight = 0.55
* **h2 to y:** Weight = 0.2
* **h3 to y:** Weight = 1.25
* **h4 to y:** Weight = 0.9
**Right Diagram (Curved Connections):**
This diagram shows the same network structure as the left, but the weights are not explicitly labeled. The connections are represented by curved, orange lines. The connections mirror those in the left diagram.
### Key Observations
* The network has two input nodes, four hidden nodes, and one output node.
* The weights vary in sign (positive and negative), indicating both excitatory and inhibitory connections.
* The weight values range from -0.1 to 1.25.
* The right diagram provides a more abstract representation of the network, focusing on connectivity rather than specific weight values.
### Interpretation
The diagrams illustrate a simple feedforward neural network. The left diagram provides a detailed view of the network's weights, which determine the strength of the connections between nodes. The right diagram offers a more generalized representation, emphasizing the network's architecture. The weights represent the learned parameters of the network, and their values influence the network's output based on the input values. The positive and negative weights suggest that some inputs contribute to activating the output node, while others inhibit it. The varying magnitudes of the weights indicate the relative importance of each connection. The network could be used for a variety of tasks, such as classification or regression, depending on the activation functions used in the nodes and the training data.
</details>
Figure 2.4: From Point Estimate to Weight Distribution: The Bayesian Neural Network Paradigm. (A) A standard neural network learns a single set of weights, represented as a point estimate in weight space. (B) A Bayesian Neural Network learns a full posterior distribution over weights, capturing uncertainty and enabling more robust predictions.
Weight-Space Posterior and Predictive Distribution
The posterior distribution over the weights, $p(W|\mathcal{D})$ , captures the model’s epistemic uncertainty, that is, the uncertainty that arises from having limited training data. A wide posterior for a given weight indicates that many different values for that weight are plausible given the data, while a narrow posterior indicates high certainty.
To make a prediction for a new input $\mathbf{x}$ , a BNN marginalises over this entire distribution of weights. The resulting posterior predictive distribution averages the outputs of an infinite ensemble of networks, each weighted by its posterior probability:
$$
p(y|\mathbf{x},\mathcal{D})=\int p(y|\mathbf{x},W)p(W|\mathcal{D})dW
$$
The variance of this predictive distribution provides a principled measure of the model’s uncertainty in its output.
An Overview of Approximation Methods
As the true posterior $p(W|\mathcal{D})$ is intractable, BNNs must rely on approximation methods. The goal of these methods is to enable the approximation of the posterior predictive distribution, typically via Monte Carlo integration:
$$
p(y|\mathbf{x},\mathcal{D})=\int p(y|\mathbf{x},W)p(W|\mathcal{D})dW\approx\frac{1}{S}\sum_{s=1}^{S}p(y|\mathbf{x},W^{s})
$$
where $W^{s}$ are samples from a distribution that approximates the true posterior. The key difference between methods lies in how they obtain these samples.
Hamiltonian Monte Carlo (HMC)
MCMC methods like Hamiltonian Monte Carlo (HMC) [30] are a class of algorithms that can, given enough computation, generate samples that converge to the true posterior $p(W|\mathcal{D})$ . HMC is a gold-standard method that uses principles from Hamiltonian dynamics to explore the parameter space efficiently and produce high-quality samples. However, its significant computational cost makes it impractical for the vast parameter spaces of modern LLMs.
MC Dropout
A highly scalable alternative is Monte Carlo Dropout [31], which reinterprets dropout as approximate Bayesian inference. The key insight is to keep dropout active during inference. Each of the $S$ stochastic forward passes, with its unique random dropout mask, is treated as a sample from an approximate weight posterior. The resulting predictions are then averaged to approximate the predictive distribution, where each $W^{s}$ represents the base weights with the $s$ -th dropout mask applied.
Stochastic Weight Averaging Gaussian (SWAG)
SWAG [32] approximates the posterior with a multivariate Gaussian distribution, $\mathcal{N}(\boldsymbol{\mu}_{\text{SWAG}},\boldsymbol{\Sigma}_{\text{SWAG}})$ , by leveraging the trajectory of weights during SGD training. After an initial convergence phase, the first and second moments of the weight iterates are collected to form the mean and a low-rank plus diagonal covariance. Inference is performed by drawing $S$ weight samples, $W^{s}\sim\mathcal{N}(\boldsymbol{\mu}_{\text{SWAG}},\boldsymbol{\Sigma}_{\text{SWAG}})$ , and averaging their predictions.
Deep Ensembles
Deep Ensembles [33] provide a powerful, non-explicitly Bayesian approach. The method involves training an ensemble of $M$ identical networks independently from different random initialisations. This collection of trained models, $\{W_{1},\dots,W_{M}\}$ , is treated as an empirical sample from the true posterior. The predictive distribution is approximated by averaging the predictions of all $M$ models in the ensemble (i.e., where $S=M$ and $W^{s}$ is the weight matrix of the $s$ -th model).
These scalable methods provide computationally feasible ways to approximate the weight posterior. An alternative family of approximation methods, which reframes the problem as one of optimisation, is Variational Inference, which we will detail next.
#### 2.3.3 Variational Inference (VI)
The final piece of theoretical background we require is Variational Inference (VI), a powerful and widely used alternative to MCMC for approximating intractable posterior distributions [34]. Instead of drawing samples, VI reframes the inference problem as one of optimisation, making it a natural fit for the gradient-based methods used in deep learning.
Core Idea: Posterior Approximation via Optimisation
The goal of VI is to approximate a complex and intractable true posterior, $p(\boldsymbol{z}|\boldsymbol{x})$ , with a simpler, tractable distribution, $q_{\phi}(\boldsymbol{z})$ , from a chosen family of distributions. The parameters $\phi$ of this “variational distribution” are optimised to make it as close as possible to the true posterior. This closeness is measured by the Kullback-Leibler (KL) Divergence.
Directly minimising the KL divergence is not possible, as its definition still contains the intractable posterior $p(\boldsymbol{z}|\boldsymbol{x})$ . However, we can derive an alternative objective. The log marginal likelihood of the data, $\log p(\boldsymbol{x})$ , can be decomposed as follows:
$$
\displaystyle\log p(\boldsymbol{x}) \displaystyle=\log\int p(\boldsymbol{x}|\boldsymbol{z})p(\boldsymbol{z})d\boldsymbol{z} \displaystyle=\log\int q_{\phi}(\boldsymbol{z})\frac{p(\boldsymbol{x}|\boldsymbol{z})p(\boldsymbol{z})}{q_{\phi}(\boldsymbol{z})}d\boldsymbol{z} \displaystyle\geq\int q_{\phi}(\boldsymbol{z})\log\frac{p(\boldsymbol{x}|\boldsymbol{z})p(\boldsymbol{z})}{q_{\phi}(\boldsymbol{z})}d\boldsymbol{z}\quad{\color[rgb]{0,0,0.8046875}\definecolor[named]{pgfstrokecolor}{rgb}{0,0,0.8046875}\text{(Jenson's Inequality)}} \displaystyle=\mathbb{E}_{q_{\phi}(\boldsymbol{z})}\left[\log p(\boldsymbol{x}|\boldsymbol{z})\right]-D_{\mathbb{KL}}\left[q_{\phi}(\boldsymbol{z})||p(\boldsymbol{z})\right]:=\mathcal{L}(\phi).
$$
This gives us the Evidence Lower Bound (ELBO), $\mathcal{L}(\phi)$ . As its name and the math suggest, ELBO is a lower bound on the log marginal likelihood. Besides, there’s also a connection between optimising ELBO and the original intention of optimising KL divergence between $q_{\phi}(\boldsymbol{z})$ and $p(\boldsymbol{z}|\boldsymbol{x})$ :
$$
\displaystyle\log p(\boldsymbol{x})-D_{\mathbb{KL}}(q_{\phi}(\boldsymbol{z})||p(\boldsymbol{z}|\boldsymbol{x})) \displaystyle=\log p(\boldsymbol{x})-\mathbb{E}_{q_{\phi}(\boldsymbol{z})}\left[\log\frac{q_{\phi}(\boldsymbol{z})}{p(\boldsymbol{z}|\boldsymbol{x})}\right] \displaystyle=\log p(\boldsymbol{x})+\mathbb{E}_{q_{\phi}(\boldsymbol{z})}\left[\log\frac{p(\boldsymbol{x}|\boldsymbol{z})p(\boldsymbol{z})}{q_{\phi}(\boldsymbol{z})p(\boldsymbol{x})}\right]\quad{\color[rgb]{0,0,0.8046875}\definecolor[named]{pgfstrokecolor}{rgb}{0,0,0.8046875}\text{(Bayes' Theorem)}} \displaystyle=\mathbb{E}_{q_{\phi}(\boldsymbol{z})}[\log p(\boldsymbol{x}|\boldsymbol{z})]-D_{\mathbb{KL}}(q_{\phi}(\boldsymbol{z})||p(\boldsymbol{z}))=\mathcal{L}(\phi).
$$
Crucially, because $\log p(\boldsymbol{x})$ is a constant with respect to $\phi$ , maximising the ELBO is equivalent to minimising the KL divergence Equations 2.21 and 2.22 are adapted from lecture note [35]..
The ELBO is typically written in a more intuitive form:
$$
\mathcal{L}(\phi)=\underbrace{\mathbb{E}_{q_{\phi}(\boldsymbol{z})}[\log p(\boldsymbol{x}|\boldsymbol{z})]}_{\text{Reconstruction Term}}-\underbrace{D_{\mathbb{KL}}(q_{\phi}(\boldsymbol{z})||p(\boldsymbol{z}))}_{\text{Regularisation Term}}
$$
The reconstruction term encourages the model to explain the observed data, while the regularisation term keeps the approximate posterior close to the prior $p(\boldsymbol{z})$ .
Structuring $q_{\phi}$ : Multivariate Gaussian and the Mean-Field Assumption
A primary design choice in VI is the family of distributions used for the approximate posterior, $q_{\phi}(\boldsymbol{z})$ . A common and flexible choice is the multivariate Gaussian distribution, $\mathcal{N}(\boldsymbol{z}|\boldsymbol{\mu}_{\phi},\boldsymbol{\Sigma}_{\phi})$ , as it can capture both the central tendency and the variance of the latent variables. When the prior is chosen to be a standard multivariate normal, $p(\boldsymbol{z})=\mathcal{N}(\boldsymbol{z}|\mathbf{0},I)$ , the KL divergence term in the ELBO has a convenient analytical solution:
$$
D_{\mathbb{KL}}\left(\mathcal{N}(\boldsymbol{\mu}_{\phi},\boldsymbol{\Sigma}_{\phi})||\mathcal{N}(\mathbf{0},I)\right)=\frac{1}{2}\left(\text{tr}(\boldsymbol{\Sigma}_{\phi})+\boldsymbol{\mu}_{\phi}^{\top}\boldsymbol{\mu}_{\phi}-k-\log|\boldsymbol{\Sigma}_{\phi}|\right)
$$
where $k$ is the dimensionality of the latent space $\boldsymbol{z}$ .
However, for high-dimensional latent spaces common in deep learning, parameterising and computing with a full-rank covariance matrix $\boldsymbol{\Sigma}_{\phi}$ is often computationally prohibitive. A standard and effective simplification is the mean-field assumption [7]. This assumes that the posterior distribution factorises across its dimensions, i.e., $q_{\phi}(\boldsymbol{z})=\prod_{i}q_{\phi_{i}}(z_{i})$ . For a Gaussian, this is equivalent to constraining the covariance matrix to be diagonal, $\boldsymbol{\Sigma}_{\phi}=\text{diag}(\boldsymbol{\sigma}_{\phi}^{2})$ .
This simplification significantly reduces the computational complexity. The KL divergence for the mean-field case reduces to a simple sum over the dimensions, avoiding all expensive matrix operations like determinants or inversions:
$$
D_{\mathbb{KL}}\left(\mathcal{N}(\boldsymbol{\mu}_{\phi},\text{diag}(\boldsymbol{\sigma}_{\phi}^{2}))||\mathcal{N}(\mathbf{0},I)\right)=\frac{1}{2}\sum_{i=1}^{k}\left(\mu_{{\phi}_{i}}^{2}+\sigma_{{\phi}_{i}}^{2}-\log(\sigma_{{\phi}_{i}}^{2})-1\right)
$$
This tractable and efficient formulation is a cornerstone of most practical applications of VI in deep learning. However, if the dimensionality of the latent space is tractable, it is possible to model the full-rank covariance matrix by parameterising it via its Cholesky decomposition [36]. This more expressive approach, which we detail later in our Methodology section 4.3.3, allows the model to capture correlations between the latent variables.
Amortised VI: VAE Case Study
In the traditional formulation of VI, a separate set of variational parameters $\phi$ must be optimised for each data point. For large datasets, this is computationally infeasible. Amortised VI solves this by learning a single global function, an inference network, that maps any input data point $\mathbf{x}$ to the parameters of its approximate posterior, $q_{\phi}(\boldsymbol{z}|\mathbf{x})$ . The cost of training this network is thus “amortised” over the entire dataset.
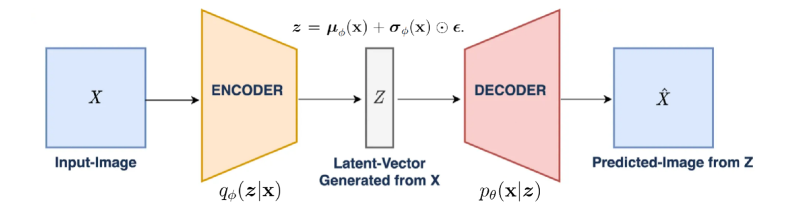
The quintessential example of this approach is the Variational Autoencoder (VAE) [37]. A VAE is a generative model composed of two neural networks: an encoder ( $q_{\phi}(\boldsymbol{z}|\mathbf{x})$ ) that learns to map inputs to a latent distribution, and a decoder ( $p_{\theta}(\mathbf{x}|\boldsymbol{z})$ ) that learns to reconstruct the inputs from samples of that distribution. Typically, the latent distribution is assumed to be a mean-field Gaussian, so the encoder network has two heads to predict the mean $\boldsymbol{\mu}_{\phi}(\mathbf{x})$ and the log-variance $\log\boldsymbol{\sigma}^{2}_{\phi}(\mathbf{x})$ . $\boldsymbol{z}$ $\mathbf{x}$ $\phi$ $\theta$ $\times N$
Figure 2.5: Probabilistic Graphical Model of the Variational Autoencoder (VAE). The solid lines represent the generative model $p_{\theta}(\mathbf{x}|\mathbf{z})$ , while the dashed lines represent the VI model (encoder) $q_{\phi}(\mathbf{z}|\mathbf{x})$ .
The VAE’s structure is represented by the probabilistic graphical model in Figure 2.5 PGM adapted from [37]. Note that in our depiction, latent prior $p(\boldsymbol{z})$ is not parameterised by $\theta$ .. This PGM clarifies how the two networks are trained jointly by maximising the ELBO. The reconstruction term, $\mathbb{E}_{q_{\phi}(\boldsymbol{z}|\mathbf{x})}[\log p_{\theta}(\mathbf{x}|\boldsymbol{z})]$ , corresponds directly to the generative path of the model (solid arrows), forcing the decoder (parametrised by $\theta$ ) to accurately reconstruct the input $\mathbf{x}$ from the latent code $\boldsymbol{z}$ . The regularisation term, $D_{\mathbb{KL}}(q_{\phi}(\boldsymbol{z}|\mathbf{x})||p(\boldsymbol{z}))$ , corresponds to the inference path (dashed arrows), forcing the encoder’s output (parametrised by $\phi$ ) to stay close to a simple prior, $p(\boldsymbol{z})$ .
To optimise the ELBO, we must backpropagate gradients through the sampling step $\boldsymbol{z}\sim q_{\phi}(\boldsymbol{z}|\mathbf{x})$ , which is non-differentiable. The VAE enables this with the reparameterisation trick. For a Gaussian latent variable, a sample is drawn by first sampling a standard noise variable $\boldsymbol{\epsilon}\sim\mathcal{N}(\textbf{0},I)$ and then computing the sample as $\boldsymbol{z}=\boldsymbol{\mu}_{\phi}(\mathbf{x})+\boldsymbol{\sigma}_{\phi}(\mathbf{x})\odot\boldsymbol{\epsilon}$ . This separates the stochasticity from the network parameters, creating a differentiable path for gradients. The entire VAE schematic is illustrated in Figure 2.6 VAE Schematic adapted from [38]. .
<details>
<summary>x6.png Details</summary>
### Visual Description
\n
## Diagram: Variational Autoencoder (VAE) Architecture
### Overview
The image depicts the architecture of a Variational Autoencoder (VAE), a type of generative model used in machine learning. It illustrates the flow of data through an encoder, a latent space, and a decoder. The diagram shows how an input image 'X' is transformed into a latent vector 'Z', and then reconstructed into a predicted image 'X̂'.
### Components/Axes
The diagram consists of the following components:
* **Input-Image (X):** Represented by a light blue square, labeled "Input-Image" below it.
* **Encoder:** Represented by a light orange trapezoid, labeled "ENCODER" above it. An arrow indicates the flow of data from the Input-Image to the Encoder.
* **Latent-Vector Generated from X (Z):** Represented by a gray rectangle, labeled "Latent-Vector Generated from X" above it. An arrow indicates the flow of data from the Encoder to the Latent-Vector.
* **Decoder:** Represented by a light red trapezoid, labeled "DECODER" above it. An arrow indicates the flow of data from the Latent-Vector to the Decoder.
* **Predicted-Image from Z (X̂):** Represented by a light blue square, labeled "Predicted-Image from Z" below it. An arrow indicates the flow of data from the Decoder to the Predicted-Image.
* **Mathematical Equation:** `z = μσ(X) + σσ(X) ⊙ ε.` positioned above the Latent-Vector.
* **Probabilistic Notation:** `qΦ(z|x)` positioned below the Encoder.
* **Probabilistic Notation:** `pθ(x|z)` positioned below the Decoder.
### Detailed Analysis / Content Details
The diagram illustrates a process where an input image 'X' is passed through an encoder. The encoder transforms 'X' into a latent vector 'Z'. The latent vector is generated using the equation `z = μσ(X) + σσ(X) ⊙ ε.`. This equation suggests that 'Z' is a function of 'X' involving mean (μ), standard deviation (σ), and a random variable (ε). The latent vector 'Z' is then passed through a decoder, which reconstructs the image into a predicted image 'X̂'.
The probabilistic notations `qΦ(z|x)` and `pθ(x|z)` indicate that the encoder and decoder are probabilistic models parameterized by Φ and θ, respectively. `qΦ(z|x)` represents the approximate posterior distribution of the latent variable 'z' given the input 'x', and `pθ(x|z)` represents the generative distribution of the input 'x' given the latent variable 'z'.
### Key Observations
The diagram highlights the key components of a VAE: encoding, latent representation, and decoding. The use of probabilistic notation suggests that the VAE learns a distribution over the latent space, allowing it to generate new samples similar to the training data. The flow of data is clearly indicated by the arrows, showing a sequential process.
### Interpretation
The diagram represents a simplified view of a VAE, a powerful generative model. The VAE aims to learn a compressed, latent representation of the input data (X) and then reconstruct it (X̂). The probabilistic nature of the model allows for generating new data points by sampling from the latent space. The equation and notations suggest a Bayesian approach to learning the latent representation. The VAE is used for tasks like image generation, dimensionality reduction, and anomaly detection. The diagram effectively communicates the core concept of encoding data into a lower-dimensional latent space and then decoding it back to its original form.
</details>
Figure 2.6: Schematic of the Variational Autoencoder (VAE) architecture.
A common modification to the VAE objective is the introduction of a hyperparameter $\beta$ to scale the KL divergence term, a model known as a $\beta$ -VAE [39].
$$
\mathcal{L}_{\beta\text{-VAE}}=\mathbb{E}_{q_{\phi}(\boldsymbol{z}|\mathbf{x})}[\log p_{\theta}(\mathbf{x}|\boldsymbol{z})]-\beta\cdot D_{\mathbb{KL}}(q_{\phi}(\boldsymbol{z}|\mathbf{x})||p(\boldsymbol{z}))
$$
This can be a crucial tool for preventing posterior collapse, a failure mode where the KL term is minimised too aggressively, causing the latent variables to become uninformative.
This amortised encoder-decoder architecture provides a direct conceptual blueprint for the Variational Routers developed in Section 4.3.
## Chapter 3 Motivation
This chapter outlines two motivational experiments designed to understand the limitations of deterministic routing strategies in current MoE-based language models. The results reveal a fundamental brittleness in the standard routing mechanism under purturbation, while also demonstrating the clear potential of introducing stochasticity. Besides, since current LLMs are stacked with multiple MoE layers, the experiments are conducted across the network’s depth to identify which layers are most sensitive to these issues. Together, these findings motivate the central goal of this thesis: to develop a principled Bayesian routing approach for better uncertainty quantification, aiming to achieve robust expert selection and calibrated output confidence.
### 3.1 Motivation 1: Brittleness of Deterministic Routing
Our first experiment investigates a fundamental hypothesis: if a router has learned a robust mapping from input representations to expert selections, its decisions should be stable under minimal, non-semantic perturbations. A significant change in expert selection in response to meaningless noise would reveal that the routing mechanism is brittle and inherently unreliable. This section details the experiment designed to quantify this brittleness across the depth of the network.
#### 3.1.1 Methodology
The experiment is conducted on our fine-tuned MAP baseline model using a randomly sampled subset of data from our In-Domain (ID) test set. The experimental methodology is illustrated in Figure 3.1.
To test stability, we introduce a minimal perturbation to the input of each MoE transformer layer. For each token embedding $\mathbf{x}$ , a perturbed version $\mathbf{x^{\prime}}$ is generated by adding Gaussian noise:
$$
\mathbf{x^{\prime}}=\mathbf{x}+\epsilon,\quad\text{where }\epsilon\sim\mathcal{N}(0,\sigma^{2}I)
$$
To ensure the noise is meaningful yet non-semantic, the choice of standard deviation $\sigma$ is in proportion to the average L2 norm of the token embeddings, $\bar{L}$ . We test multiple noise levels defined by a scaling factor $\gamma$ :
$$
\sigma=\gamma\cdot\bar{L},\quad\text{where }\gamma\in\{0.001,0.002,0.005,0.007,0.01,0.02,0.05\}
$$
For each token and for each noise level $\gamma$ , we record the set of $K$ experts selected for the original input ( $E_{\text{orig}}$ ) and the perturbed input ( $E_{\text{pert}}$ ) at every MoE layer. To quantify the change in expert selection, we compute the Jaccard Similarity between these two sets:
$$
J(E_{\text{orig}},E_{\text{pert}})=\frac{|E_{\text{orig}}\cap E_{\text{pert}}|}{|E_{\text{orig}}\cup E_{\text{pert}}|}
$$
A score of 1.0 indicates perfect stability, while a score of 0.0 indicates a complete change in the selected experts.
<details>
<summary>x7.png Details</summary>
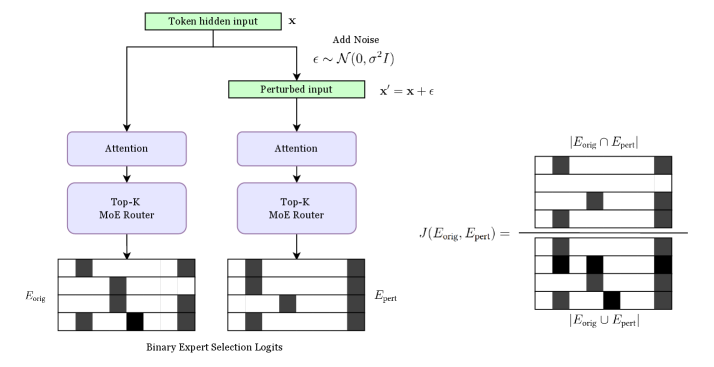
### Visual Description
\n
## Diagram: Mixture of Experts (MoE) with Noise Injection
### Overview
This diagram illustrates a process for injecting noise into a Mixture of Experts (MoE) model. The core idea is to perturb the input and then compare the expert selections made on the original and perturbed inputs to calculate a loss function. The diagram shows the flow of data through attention layers, MoE routers, and the resulting expert selections.
### Components/Axes
The diagram consists of the following components:
* **Token hidden input (x):** The initial input to the system.
* **Add Noise:** A process that adds noise, denoted as ε ~ N(0, σ²I), to the input.
* **Perturbed input (x'):** The input after noise has been added (x' = x + ε).
* **Attention Layers:** Two parallel attention layers processing the original and perturbed inputs.
* **Top-K MoE Router:** Two parallel MoE routers, one for each attention layer output.
* **Eorig:** Represents the expert selection based on the original input. Displayed as a grid with black and white cells.
* **Epert:** Represents the expert selection based on the perturbed input. Displayed as a grid with black and white cells.
* **J(Eorig, Epert):** A loss function that compares the expert selections.
* **Eorig ∩ Epert:** The intersection of the experts selected for the original and perturbed inputs. Displayed as a grid with black and white cells.
* **Eorig ∪ Epert:** The union of the experts selected for the original and perturbed inputs. Displayed as a grid with black and white cells.
* **Binary Expert Selection Logits:** Label for the grids representing Eorig and Epert.
### Detailed Analysis / Content Details
The diagram shows a parallel processing structure. The original input 'x' and the perturbed input 'x'' both pass through an attention layer and then a Top-K MoE router. The outputs of the routers, Eorig and Epert, are represented as grids. Each grid appears to be 4x4, with some cells colored black and others white. The black cells likely represent the experts that were selected for that input.
The intersection (Eorig ∩ Epert) and union (Eorig ∪ Epert) of the expert selections are also shown as grids, again 4x4. The intersection shows which experts were selected by both the original and perturbed inputs, while the union shows all experts selected by either input.
The noise added is defined as ε ~ N(0, σ²I), indicating a Gaussian distribution with a mean of 0 and a variance of σ²I, where I is the identity matrix.
The grids representing Eorig, Epert, Eorig ∩ Epert, and Eorig ∪ Epert all have the same structure. The black and white cells are arranged in a pattern.
* **Eorig:** The top two rows are entirely black, the third row has the first two cells black, and the last row has the last two cells black.
* **Epert:** The top row has the first two cells black, the second row is entirely black, the third row has the last two cells black, and the last row is entirely black.
* **Eorig ∩ Epert:** The first two cells of the second row are black, and the last two cells of the third row are black.
* **Eorig ∪ Epert:** The first two cells of the first row are black, the second and third rows are entirely black, and the last two cells of the last row are black.
### Key Observations
The diagram highlights the comparison of expert selections under noise injection. The loss function J(Eorig, Epert) is likely designed to penalize significant differences between the expert selections made on the original and perturbed inputs. This suggests a regularization technique to improve the robustness of the MoE model. The grids show a clear difference between the expert selections for the original and perturbed inputs, indicating that the noise does indeed influence the router's decisions.
### Interpretation
This diagram demonstrates a method for regularizing a Mixture of Experts model by injecting noise into the input. The core idea is to encourage the model to make consistent expert selections even when the input is slightly perturbed. By comparing the expert selections on the original and perturbed inputs, the loss function J(Eorig, Epert) can identify and penalize unstable router behavior. This approach can improve the model's generalization ability and robustness to adversarial attacks. The use of the intersection and union of expert selections provides a way to quantify the degree of overlap and difference between the two sets of experts, which is then used to calculate the loss. The Gaussian noise distribution is a common choice for adding small, random perturbations to the input. The diagram provides a visual representation of the process, making it easier to understand the underlying principles of this regularization technique. The grids are a visual representation of the binary expert selection logits, showing which experts are activated for each input.
</details>
Figure 3.1: Experimental setup for quantifying the brittleness of deterministic routing at one MoE layer.
#### 3.1.2 Results and Observations
Figure 3.2 shows the mean Jaccard similarity across all MoE layers for various noise levels. This sensitivity analysis reveals two key findings.
1. General Instability: Even a relatively very small amount of noise (e.g., $\gamma\geq 0.005$ ) is sufficient to cause a significant drop in stability, confirming the router’s brittleness.
1. Comparision Across Layers: These results allow us to select an appropriate noise level for a more granular analysis: a noise level like $\gamma=0.01$ is sensitive enough to reveal instability without being so large that it saturates the effect across all layers.
<details>
<summary>x8.png Details</summary>
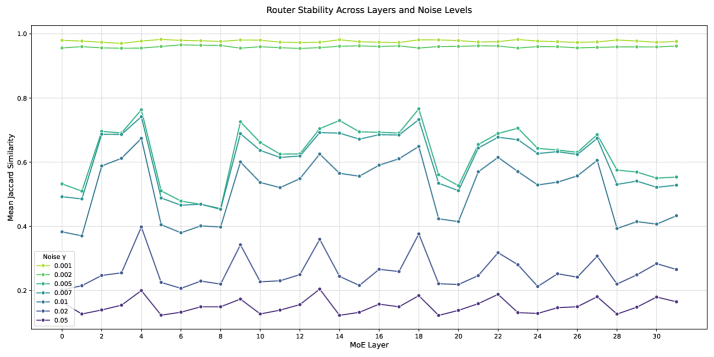
### Visual Description
\n
## Line Chart: Router Stability Across Layers and Noise Levels
### Overview
The image presents a line chart illustrating the relationship between Router Stability (measured by Mean Jaccard Similarity) and MoE Layer, across different Noise Levels. The chart displays multiple lines, each representing a different noise level, showing how stability changes as the MoE layer increases.
### Components/Axes
* **Title:** "Router Stability Across Layers and Noise Levels" - positioned at the top-center.
* **X-axis:** "MoE Layer" - ranging from 0 to 30, with tick marks at integer values.
* **Y-axis:** "Mean Jaccard Similarity" - ranging from approximately 0.2 to 1.0, with tick marks at 0.2 intervals.
* **Legend:** Located in the bottom-left corner, listing the Noise Levels (γ) and their corresponding line colors:
* γ = 0.001 (Yellow)
* γ = 0.002 (Light Green)
* γ = 0.005 (Teal)
* γ = 0.01 (Dark Blue)
* γ = 0.05 (Purple)
### Detailed Analysis
The chart contains five lines, each representing a different noise level.
* **γ = 0.001 (Yellow):** The line is relatively flat, maintaining a high Mean Jaccard Similarity of approximately 0.98 throughout the MoE layers. There is a slight downward trend from layer 0 to layer 30, ending at approximately 0.96.
* **γ = 0.002 (Light Green):** This line starts at approximately 0.95 at layer 0, dips to around 0.85 at layer 2, then fluctuates between 0.9 and 0.95 for the remainder of the layers, ending at approximately 0.92 at layer 30.
* **γ = 0.005 (Teal):** This line exhibits more significant fluctuations. It starts at approximately 0.75 at layer 0, peaks around 0.85 at layer 2, then dips to approximately 0.4 at layer 4. It then oscillates between approximately 0.4 and 0.7, ending at approximately 0.6 at layer 30.
* **γ = 0.01 (Dark Blue):** This line shows the most pronounced fluctuations. It starts at approximately 0.3 at layer 0, rises to a peak of approximately 0.45 at layer 2, then drops to approximately 0.25 at layer 4. It continues to oscillate, reaching a maximum of approximately 0.45 at layer 20 and ending at approximately 0.35 at layer 30.
* **γ = 0.05 (Purple):** This line starts at approximately 0.2 at layer 0, rises to a peak of approximately 0.3 at layer 2, then fluctuates between approximately 0.2 and 0.35, ending at approximately 0.25 at layer 30.
### Key Observations
* Higher noise levels (γ = 0.01 and γ = 0.05) exhibit significantly lower and more volatile Mean Jaccard Similarity scores compared to lower noise levels.
* The stability generally decreases as the noise level increases.
* All lines show some degree of fluctuation, indicating that router stability is not constant across MoE layers.
* The γ = 0.001 line demonstrates the highest and most stable router stability.
### Interpretation
The data suggests that router stability is sensitive to noise levels. As the noise level increases, the router's ability to maintain consistent connections (as measured by Jaccard Similarity) decreases. The fluctuations observed in all lines indicate that the stability is not uniform across different MoE layers, potentially due to variations in network conditions or routing decisions. The relatively stable performance of the γ = 0.001 line suggests that minimizing noise is crucial for maintaining robust router stability. The chart highlights a trade-off between noise and stability, and the need for strategies to mitigate the impact of noise on router performance. The oscillations in the lines could be indicative of periodic changes in network topology or traffic patterns. The data could be used to inform the design of more resilient routing protocols or to optimize network parameters for specific noise environments.
</details>
Figure 3.2: Mean Jaccard similarity across MoE layers for varying levels of input perturbation ( $\gamma$ ). This plot reveals the sensitivity of each layer’s router to noise.
Using a fixed noise level of $\gamma=0.01$ , we then analyze the full distribution of Jaccard scores at each layer, shown in Figure 3.3. This detailed view provides our main observation: The degree of instability is not uniform across the hierarchical network architecture. Instead, the brittleness appears to be concentrated in specific groups of layers. In our model, we observe pronounced instability at the very beginning (Layers 0-1), in the early-middle (Layers 5-8), the late-middle (Layers 19-20), and most dramatically, at the final layers (Layers 28-31). The distributions in these regions are skewed significantly towards lower Jaccard scores, indicating frequent changes in expert selection.
<details>
<summary>x9.png Details</summary>
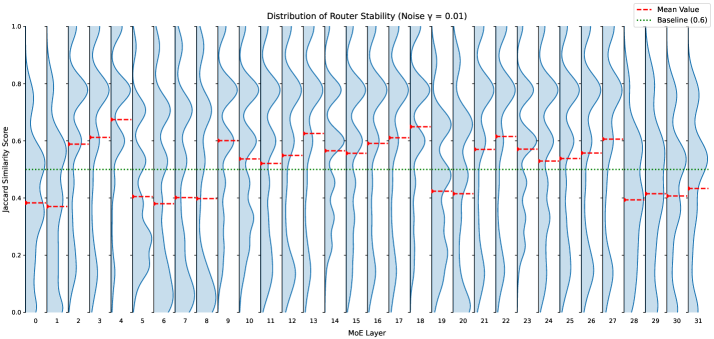
### Visual Description
\n
## Chart: Distribution of Router Stability
### Overview
The image presents a series of violin plots illustrating the distribution of router stability, measured by the Jaccard Similarity Score, across 31 MoE (Mixture of Experts) layers. A horizontal line indicates a baseline value of 0.6. A dashed red line indicates the mean value for each layer. The noise level is specified as γ = 0.01.
### Components/Axes
* **X-axis:** MoE Layer, ranging from 1 to 31.
* **Y-axis:** Jaccard Similarity Score, ranging from 0.0 to 1.0.
* **Legend:**
* Red dashed line: Mean Value
* Green solid line: Baseline (0.6)
* **Plot Type:** Violin plots, showing the distribution of Jaccard Similarity Scores for each MoE layer.
### Detailed Analysis
The chart consists of 31 violin plots, one for each MoE layer. Each violin plot displays the distribution of Jaccard Similarity Scores. The width of each violin represents the density of data points at that score level.
The baseline value (0.6) is represented by a horizontal green line that spans the entire chart. The mean Jaccard Similarity Score for each layer is indicated by a horizontal dashed red line.
Visually, the violin plots appear relatively consistent across all 31 layers. The distributions are generally centered around a Jaccard Similarity Score of approximately 0.4 to 0.6. The mean values (red dashed lines) are consistently below the baseline (green line).
Here's a layer-by-layer approximation of the mean values (based on the red dashed lines):
* Layers 1-31: The mean value appears to hover around 0.45 - 0.55. There is no significant variation in the mean value across the layers.
### Key Observations
* The distributions of Jaccard Similarity Scores are similar across all MoE layers.
* The mean Jaccard Similarity Score for each layer is consistently below the baseline of 0.6.
* There is no apparent trend or pattern in the mean values across the layers.
* The violin plots show a relatively wide spread of Jaccard Similarity Scores, indicating variability in router stability.
### Interpretation
The data suggests that the router stability, as measured by the Jaccard Similarity Score, is relatively consistent across the 31 MoE layers under the specified noise level (γ = 0.01). However, the mean stability is consistently lower than the baseline value of 0.6. This indicates that, on average, the routers are less stable than the desired baseline.
The lack of a trend in the mean values suggests that adding more MoE layers does not necessarily improve or degrade router stability. The wide spread of scores within each violin plot indicates that there is significant variability in router stability, even within a single layer. This could be due to factors such as random initialization, data variations, or inherent instability in the routing process.
The consistent positioning of the mean values below the baseline suggests a systematic issue affecting router stability. Further investigation is needed to identify the root cause of this issue and explore potential solutions to improve router stability and bring the mean values closer to the baseline. The noise level of 0.01 may be contributing to the lower stability scores.
</details>
Figure 3.3: Distribution of token-level Jaccard similarity scores for each MoE layer at a fixed noise level ( $\gamma=0.01$ ). This highlights that router instability is concentrated in specific layer groups.
#### 3.1.3 Conclusion
This experiment yields two critical conclusions that motivate our work.
1. Quantitatively confirming that the standard deterministic routing mechanism is brittle, as its decisions are sensitive to semantically meaningless small noise.
1. Revealing that instability is highly dependent on the layer’s depth within the network, which suggests that a Bayesian treatment can target specific susceptible layers rather than entire network This observation is specific to the ibm-granite-3B-MoE model, which serves as the base model for all subsequent experiments. For a more generalisable approach to layer selection, we also employ a last- $N$ layer selection strategy, as described in Section 5.6. .
### 3.2 Motivation 2: Potentials of Stochastic Routing
Having established the brittleness of the deterministic router, we now investigate whether introducing simple, ad-hoc stochasticity can lead to improvements in model behavior. If random noise in the selection process proves beneficial, it would provide a strong motivation for developing a principled Bayesian framework that can learn this stochasticity in a data-driven manner.
#### 3.2.1 Methodology
This experiment modifies the expert selection mechanism within a single MoE layer at a time, while all other layers remain deterministic. The standard router computes logits and selects the experts with the Top-K highest values. We replace this deterministic selection with a stochastic sampling process (as illustrated in Figure 3.4):
1. Temperature Scaling: Raw logits from router are first scaled by a temperature parameter $T$ . A temperature $T>1$ softens the distribution, increasing randomness, while $T<1$ sharpens it.
1. Probabilistic Sampling: A probability distribution $\mathbf{p}$ is formed by applying the softma]x function to the scaled logits:
$$
\mathbf{p}=\text{softmax}\left(\frac{\text{logits}}{T}\right)
$$
Instead of selecting the Top-K experts, we then sample $K$ experts without replacement from this distribution $\mathbf{p}$ .
<details>
<summary>x10.png Details</summary>
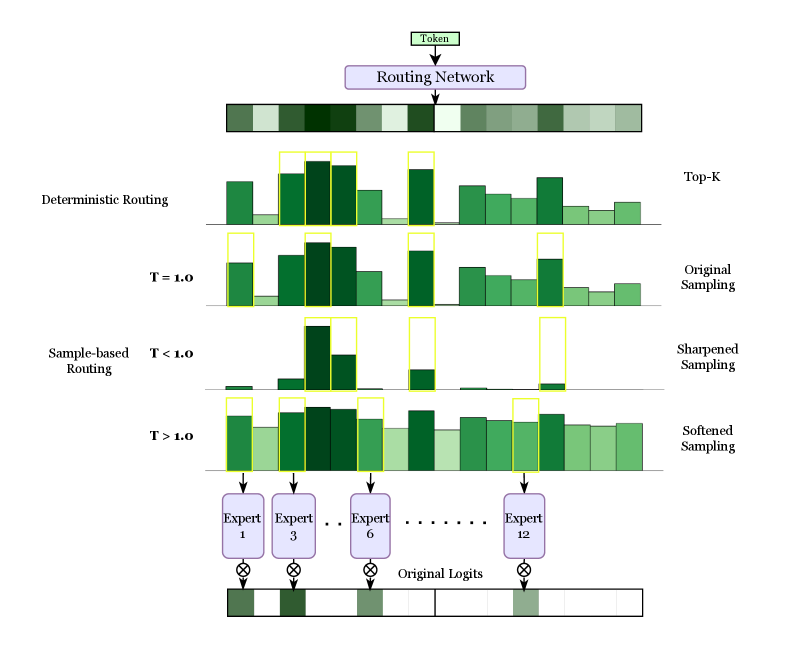
### Visual Description
\n
## Diagram: Mixture of Experts Routing Visualization
### Overview
This diagram illustrates the routing process within a Mixture of Experts (MoE) model. It depicts how a single input "Token" is processed through a "Routing Network" and then distributed to different "Experts" based on various sampling strategies. The diagram visually compares deterministic routing with different temperature-controlled sampling methods.
### Components/Axes
The diagram consists of the following components:
* **Input Token:** Labeled "Token" at the top.
* **Routing Network:** A rectangular block labeled "Routing Network" receiving the input token. It's represented as a series of colored blocks, likely representing activation values.
* **Routing Outputs:** Four sets of bar graphs representing the output of the routing network under different conditions.
* Deterministic Routing (labeled "Top-K")
* Original Sampling (T = 1.0)
* Sample-based Routing (T < 1.0) - labeled "Sharpened Sampling"
* Sample-based Routing (T > 1.0) - labeled "Softened Sampling"
* **Experts:** A series of rectangular blocks labeled "Expert 1", "Expert 3", "Expert 6", and "... Expert 12".
* **Original Logits:** A rectangular block labeled "Original Logits" representing the final output.
* **Arrows:** Indicate the flow of information through the network.
There are no explicit axes, but the height of the bars in the graphs represents the routing weight or probability assigned to each expert.
### Detailed Analysis or Content Details
The diagram shows the distribution of a single token across multiple experts.
* **Routing Network Output:** The Routing Network output is visualized as a horizontal bar with varying shades of green and gray. The intensity of the color likely represents the activation strength.
* **Deterministic Routing (Top-K):** This method selects the top K experts with the highest routing weights. The bar graph shows a sparse distribution, with a few experts receiving significantly higher weights than others. The heights of the bars are approximately: 0.1, 0.3, 0.5, 0.7, 0.9, 0.3, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1.
* **Original Sampling (T = 1.0):** This method samples experts based on the routing weights with a temperature of 1.0. The distribution is more uniform than deterministic routing, with most experts receiving non-zero weights. The heights of the bars are approximately: 0.2, 0.4, 0.6, 0.8, 0.6, 0.4, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2.
* **Sample-based Routing (T < 1.0) - Sharpened Sampling:** Lowering the temperature (T < 1.0) sharpens the distribution, making it more peaky. The weights are concentrated on a smaller number of experts. The heights of the bars are approximately: 0.05, 0.2, 0.5, 0.9, 0.4, 0.1, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05.
* **Sample-based Routing (T > 1.0) - Softened Sampling:** Increasing the temperature (T > 1.0) softens the distribution, making it more uniform. The weights are spread more evenly across all experts. The heights of the bars are approximately: 0.15, 0.25, 0.35, 0.45, 0.35, 0.25, 0.15, 0.15, 0.15, 0.15, 0.15, 0.15.
* **Expert Processing:** Each expert receives the input token and processes it. The output of each expert is then combined (represented by the circled "⊗" symbol) to produce the final "Original Logits".
### Key Observations
* The temperature parameter (T) significantly influences the routing distribution.
* Deterministic routing leads to a sparse distribution, while sampling methods create more distributed representations.
* Lower temperatures sharpen the distribution, while higher temperatures soften it.
* The diagram highlights the trade-off between specialization (deterministic routing) and generalization (sampling).
### Interpretation
This diagram demonstrates how different routing strategies affect the distribution of workload across experts in a Mixture of Experts model. The temperature parameter controls the level of randomness in the routing process. Deterministic routing focuses computation on a small subset of experts, potentially leading to higher efficiency but also increased risk of overfitting. Sampling methods distribute the workload more evenly, promoting generalization but potentially reducing efficiency. The choice of routing strategy depends on the specific application and the desired trade-off between efficiency and generalization. The diagram effectively visualizes the impact of these choices, providing insights into the behavior of MoE models. The use of bar graphs allows for a clear comparison of the routing distributions under different conditions. The diagram suggests that the routing network learns to assign different weights to experts based on the input token, and the temperature parameter modulates the sharpness of this assignment.
</details>
Figure 3.4: Experimental setup for introducing stochastic routing at a single MoE layer. The temperature parameter $T$ controls the level of randomness in expert selection.
This procedure is applied to each MoE layer individually across different runs. We evaluate the impact on the model’s overall performance on our In-Domain (ID) test set using two key metrics: Accuracy (ACC) to measure task performance and Expected Calibration Error (ECE) to measure model calibration.
#### 3.2.2 Results and Observations
The results of applying this stochastic routing strategy with various temperatures are shown in Figure 3.5. The plots display the model’s Accuracy and ECE when stochasticity is introduced at each specific layer.
<details>
<summary>x11.png Details</summary>
### Visual Description
## Charts: Accuracy (ACC) and Expected Calibration Error (ECE) vs. Layer Index
### Overview
The image presents two line charts side-by-side. The left chart displays Accuracy (ACC) against Layer Index, while the right chart shows Expected Calibration Error (ECE) against Layer Index. Both charts compare the performance of different sampling methods (identified by temperature 'T' values) and an 'all layers top_k' method.
### Components/Axes
**Left Chart (ACC):**
* **Title:** ACC
* **X-axis:** Layer Index (ranging from approximately 0 to 32, with markers at 1, 5, 9, 13, 17, 21, 25, 29, and 32)
* **Y-axis:** ACC (ranging from approximately 0.3 to 0.9, with markers at 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, and 0.9)
* **Legend (bottom-right):**
* `sample_k (T=0.3)` - Blue dashed line
* `sample_k (T=0.7)` - Orange dashed line
* `sample_k (T=1.0)` - Green solid line
* `sample_k (T=1.5)` - Purple dashed line
* `sample_k (T=2.0)` - Gray dashed line
* `all layers top_k` - Red solid line
**Right Chart (ECE):**
* **Title:** ECE
* **X-axis:** Layer Index (ranging from approximately 0 to 32, with markers at 1, 5, 9, 13, 17, 21, 25, 29, and 32)
* **Y-axis:** ECE (ranging from approximately 0.05 to 0.35, with markers at 0.05, 0.10, 0.15, 0.20, 0.25, 0.30, and 0.35)
* **Legend (bottom-right):**
* `sample_k (T=0.3)` - Blue dashed line
* `sample_k (T=0.7)` - Orange dashed line
* `sample_k (T=1.0)` - Green solid line
* `sample_k (T=1.5)` - Purple dashed line
* `sample_k (T=2.0)` - Gray dashed line
* `all layers top_k` - Red solid line
### Detailed Analysis or Content Details
**Left Chart (ACC):**
* `sample_k (T=0.3)`: Starts at approximately 0.35, rapidly increases to around 0.82 by Layer Index 5, then fluctuates between 0.78 and 0.83.
* `sample_k (T=0.7)`: Starts at approximately 0.35, increases to around 0.81 by Layer Index 5, then fluctuates between 0.78 and 0.83.
* `sample_k (T=1.0)`: Starts at approximately 0.35, increases to around 0.80 by Layer Index 5, then fluctuates between 0.78 and 0.83.
* `sample_k (T=1.5)`: Starts at approximately 0.35, increases to around 0.79 by Layer Index 5, then fluctuates between 0.77 and 0.82.
* `sample_k (T=2.0)`: Starts at approximately 0.35, increases to around 0.78 by Layer Index 5, then fluctuates between 0.76 and 0.81.
* `all layers top_k`: Starts at approximately 0.35, rapidly increases to around 0.84 by Layer Index 1, then remains relatively stable around 0.82-0.84.
**Right Chart (ECE):**
* `sample_k (T=0.3)`: Starts at approximately 0.32, drops sharply to around 0.07 by Layer Index 5, then fluctuates between 0.06 and 0.09.
* `sample_k (T=0.7)`: Starts at approximately 0.32, drops sharply to around 0.07 by Layer Index 5, then fluctuates between 0.06 and 0.09.
* `sample_k (T=1.0)`: Starts at approximately 0.32, drops sharply to around 0.07 by Layer Index 5, then fluctuates between 0.06 and 0.09.
* `sample_k (T=1.5)`: Starts at approximately 0.32, drops sharply to around 0.08 by Layer Index 5, then fluctuates between 0.07 and 0.10.
* `sample_k (T=2.0)`: Starts at approximately 0.32, drops sharply to around 0.08 by Layer Index 5, then fluctuates between 0.07 and 0.10.
* `all layers top_k`: Starts at approximately 0.32, drops sharply to around 0.10 by Layer Index 5, then remains relatively stable around 0.08-0.11.
### Key Observations
* All sampling methods show a rapid increase in accuracy within the first few layers (up to Layer Index 5).
* The 'all layers top_k' method achieves the highest accuracy and maintains a relatively stable performance across all layers.
* ECE generally decreases rapidly in the initial layers for all methods, then plateaus.
* The 'all layers top_k' method has a higher ECE than the sampling methods after the initial drop.
* The sampling methods with lower temperatures (T=0.3, T=0.7, T=1.0) exhibit very similar performance in both ACC and ECE.
### Interpretation
The charts demonstrate the trade-off between accuracy and calibration. The 'all layers top_k' method achieves the highest accuracy but suffers from higher expected calibration error, indicating that its confidence scores are less reliable. The sampling methods, particularly those with lower temperatures, offer a better balance between accuracy and calibration. The initial rapid increase in accuracy suggests that the model learns quickly in the early layers. The plateauing of ECE indicates that the model's confidence scores become more stable as the layers deepen. The consistent performance of the sampling methods with lower temperatures suggests that these settings provide a more robust and reliable approach to model calibration. The sharp drop in ECE at the beginning of training suggests that the initial layers are crucial for establishing well-calibrated confidence scores.
</details>
<details>
<summary>x12.png Details</summary>
### Visual Description
## Charts: Accuracy (ACC) and Expected Calibration Error (ECE) vs. Layer Index
### Overview
The image presents two line charts side-by-side. The left chart displays Accuracy (ACC) against Layer Index, while the right chart shows Expected Calibration Error (ECE) against Layer Index. Both charts compare the performance of different temperature (T) settings for a 'sample_k' method, as well as an 'all layers top_k' method. Each chart has a similar x-axis (Layer Index) and uses color-coded lines to represent different temperature values.
### Components/Axes
**Left Chart (ACC):**
* **Title:** ACC
* **X-axis:** Layer Index (ranging from approximately 1 to 3132, with markers at 1, 3, 7, 11, 15, 19, 23, 27, and 3132)
* **Y-axis:** ACC (ranging from approximately 0.77 to 0.83, with markers at 0.77, 0.79, 0.80, 0.81, 0.82, and 0.83)
* **Legend:** Located at the bottom-right. Contains the following entries with corresponding colors:
* sample\_k (T=0.3) - Blue
* sample\_k (T=0.7) - Orange
* sample\_k (T=1.0) - Green
* sample\_k (T=1.5) - Purple
* sample\_k (T=2.0) - Brown
* all layers top\_k - Red (dashed line)
**Right Chart (ECE):**
* **Title:** ECE
* **X-axis:** Layer Index (ranging from approximately 1 to 3132, with markers at 1, 3, 7, 11, 15, 19, 23, 27, and 3132)
* **Y-axis:** ECE (ranging from approximately 0.06 to 0.11, with markers at 0.06, 0.07, 0.08, 0.09, 0.10, and 0.11)
* **Legend:** Located at the bottom-right. Contains the same entries and colors as the left chart.
### Detailed Analysis or Content Details
**Left Chart (ACC):**
* **sample\_k (T=0.3) - Blue:** Starts at approximately 0.828, fluctuates around 0.82-0.83, dips to around 0.78 at layer index 19, and recovers to approximately 0.825 by layer index 3132.
* **sample\_k (T=0.7) - Orange:** Starts at approximately 0.832, generally declines to around 0.815 by layer index 11, then fluctuates between 0.815 and 0.83, ending at approximately 0.828.
* **sample\_k (T=1.0) - Green:** Starts at approximately 0.815, increases to around 0.825 by layer index 3, then fluctuates significantly, reaching a low of approximately 0.79 at layer index 19, and ending at approximately 0.82.
* **sample\_k (T=1.5) - Purple:** Starts at approximately 0.805, increases to around 0.82 by layer index 3, then declines to approximately 0.77 at layer index 19, and recovers to approximately 0.81 by layer index 3132.
* **sample\_k (T=2.0) - Brown:** Starts at approximately 0.795, increases to around 0.81 by layer index 3, then fluctuates, reaching a low of approximately 0.77 at layer index 19, and ending at approximately 0.80.
* **all layers top\_k - Red:** Starts at approximately 0.815, fluctuates around 0.82-0.83, with a slight dip around layer index 15, and ends at approximately 0.828.
**Right Chart (ECE):**
* **sample\_k (T=0.3) - Blue:** Starts at approximately 0.085, fluctuates around 0.075-0.09, with a peak around layer index 15, and ends at approximately 0.08.
* **sample\_k (T=0.7) - Orange:** Starts at approximately 0.078, fluctuates around 0.07-0.085, with a peak around layer index 15, and ends at approximately 0.078.
* **sample\_k (T=1.0) - Green:** Starts at approximately 0.08, fluctuates around 0.07-0.09, with a peak around layer index 15, and ends at approximately 0.08.
* **sample\_k (T=1.5) - Purple:** Starts at approximately 0.085, fluctuates around 0.075-0.095, with a peak around layer index 15, and ends at approximately 0.085.
* **sample\_k (T=2.0) - Brown:** Starts at approximately 0.08, fluctuates around 0.07-0.09, with a peak around layer index 15, and ends at approximately 0.08.
* **all layers top\_k - Red:** Starts at approximately 0.095, fluctuates around 0.085-0.105, with a peak around layer index 15, and ends at approximately 0.09.
### Key Observations
* The ACC chart shows that the 'sample\_k' method with T=0.7 generally achieves the highest accuracy, while T=2.0 consistently has the lowest accuracy.
* The ECE chart shows that the 'all layers top\_k' method generally has the highest ECE, indicating poorer calibration.
* Both charts exhibit a noticeable fluctuation around layer index 15, suggesting a potential change in the model's behavior at that layer.
* The ECE values are relatively stable across different temperature settings for the 'sample\_k' method.
### Interpretation
The charts demonstrate the trade-off between accuracy and calibration when using different temperature settings with the 'sample\_k' method. Higher temperatures (T=1.5 and T=2.0) lead to lower accuracy, while lower temperatures (T=0.3 and T=0.7) maintain higher accuracy. The 'all layers top\_k' method, while achieving comparable accuracy to some of the 'sample\_k' methods, exhibits poorer calibration, as indicated by the higher ECE values. The fluctuation around layer index 15 could indicate a critical layer where the model's confidence is particularly sensitive to the temperature setting. The data suggests that a temperature of 0.7 provides a good balance between accuracy and calibration for the 'sample\_k' method. The consistent higher ECE for 'all layers top\_k' suggests it may be overconfident in its predictions.
</details>
Figure 3.5: Model Accuracy (left) and ECE (right) when applying temperature-based stochastic routing at a single MoE layer at a time. The top plot shows results for all layers, while the bottom plot excludes the first layer for more granular comparison in later layers. The dashed line represents the fully deterministic baseline.
We draw two primary observations from these results:
1. Early Layers are Highly Sensitive: Introducing stochastic routing in the first two layers causes a significant degradation in model accuracy. These layers are likely responsible for learning fundamental, low-level representations, and their routing decisions are not robust to this type of random perturbation.
1. Stochasticity Improves Calibration in Later Layers: For the majority of the middle and later layers, a remarkable trend emerges. Introducing stochasticity (especially with $T=0.3$ ) leads to a consistent reduction in ECE compared to the deterministic baseline, while the accuracy remains largely unchanged. This suggests that replacing the overconfident ‘Top-K’ selection with a more stochastic sampling process acts as a form of regularisation, forcing the model to be less certain and, as a result, better calibrated.
#### 3.2.3 Conclusion
This experiment provides two insights that pave the way for this thesis.
1. Stochasticity can be beneficial. The fact that a simple, unprincipled injection of randomness can improve model calibration without sacrificing performance strongly suggests that the deterministic router is suboptimal and motivates the need for a more sophisticated, principled Bayesian treatment, which has the potential of making better informed decision.
1. Early layers should not be selected for stochasticity. The detrimental effect of stochasticity on early layers suggests that first layer would not be the apppropriate place to be probablistic. Instead, the focus should be on the middle and later layers, where stochasticity can reduce overconfidence without significantly impacting accuracy.
### 3.3 Chapter Summary
These two motivational experiments paint a clear picture. The first demonstrates that the standard deterministic router is brittle, exhibiting significant instability in its expert selections in response to minimal, non-semantic input noise. This reveals a fundamental weakness in the current MoE paradigm.
Conversely, the second experiment shows that introducing simple, heuristic stochasticity in expert selection can be beneficial. Replacing the deterministic selection with temperature-based sampling can improve model reliability by reducing overconfidence (lower ECE) at a minimal cost to accuracy.
These findings create a compelling motivation for the work in this thesis. If deterministic routing is brittle, and simple, undirected randomness is beneficial, then a principled, data-driven approach to uncertainty should be even better. This thesis is designed to bridge this gap by replacing ad-hoc stochasticity with a formal Bayesian framework for MoE routing, aiming to achieve a new level of model robustness and reliability.
## Chapter 4 Methodology: Bayesian MoE Router
The preceding chapter established the core motivation for this work. This chapter details our proposed solution: a principled Bayesian framework designed to formalise stochasticity in MoE routing.
Our framework moves beyond single-point estimates by introducing probabilistic components into the routing pipeline. By modeling uncertainty in the router’s weights, its output logits (similarity score), or the final selection process itself, each method induces a probabilistic belief over the expert choices. By doing so, we aim to achieve a more robust, well-calibrated expert selection mechanism, and extract better uncertainty signals to represent model’s confidence.
To systematically investigate this idea, we will present three distinct families of methods that introduce this uncertainty at different stages (as illustrated in Figure 4.1): in the expert centroid space (weight-space), the expert logit space (latent-space), and the final expert selection space (decision-space). All methods are developed as efficient fine-tuning strategies designed to adapt a pre-trained MoE model, and this chapter will now detail each approach in turn.
<details>
<summary>x13.png Details</summary>
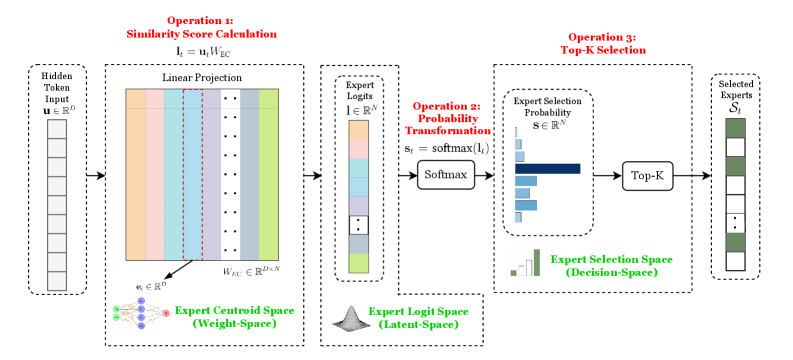
### Visual Description
\n
## Diagram: Mixture of Experts (MoE) System Flow
### Overview
The image depicts a diagram illustrating the flow of data through a Mixture of Experts (MoE) system. The system consists of three main operations: Similarity Score Calculation, Probability Transformation, and Top-K Selection. The diagram shows how a hidden token input is processed through a linear projection to generate expert logits, which are then transformed into probabilities, and finally used to select a subset of experts.
### Components/Axes
The diagram is segmented into three main operational blocks, labeled "Operation 1: Similarity Score Calculation", "Operation 2: Probability Transformation", and "Operation 3: Top-K Selection". Each block contains several components:
* **Hidden Token Input:** Represented as `u ∈ R^d` (a vector in d-dimensional space).
* **Linear Projection:** Depicted as a matrix multiplication with `W_l ∈ R^(d x P)` where P is the number of experts.
* **Expert Logits:** Represented as `l ∈ R^P`.
* **Expert Selection Probability:** Represented as `s_i = softmax(l)` and `s ∈ R^P`.
* **Selected Experts:** Represented as `S_i`.
* **Expert Centroid Space (Weight-Space):** A scatter plot showing expert centroids.
* **Expert Logit Space (Latent-Space):** A visual representation of the expert logits.
* **Expert Selection Space (Decision-Space):** A bar chart representing the expert selection probabilities.
The diagram also includes mathematical equations:
* `l_i = u_i * W_l` (Similarity Score Calculation)
* `s_i = softmax(l)` (Probability Transformation)
### Detailed Analysis / Content Details
The diagram illustrates a data flow from left to right.
1. **Operation 1: Similarity Score Calculation:** A hidden token input `u ∈ R^d` (represented as a vertical stack of numbers) is linearly projected using a weight matrix `W_l ∈ R^(d x P)` (represented as colored vertical bars). This results in expert logits `l ∈ R^P`. The colors of the bars in `W_l` are: yellow, orange, light blue, dark blue, green. The expert centroid space (Weight-Space) shows a scatter plot of expert centroids, with points clustered in different regions.
2. **Operation 2: Probability Transformation:** The expert logits `l` are passed through a softmax function to generate expert selection probabilities `s_i = softmax(l)`, represented as `s ∈ R^P`. This is visually depicted as a bar chart in the "Expert Selection Space (Decision-Space)". The bar chart shows varying probabilities for each expert.
3. **Operation 3: Top-K Selection:** A "Top-K" operation selects the top K experts based on their probabilities. The selected experts `S_i` are represented as a vertical stack of colored blocks, with the colors corresponding to the experts selected. The arrow indicates that only a subset of experts are chosen.
The diagram uses dotted arrows to indicate the flow of data between operations.
### Key Observations
* The system uses a linear projection to map the hidden token input to the expert logit space.
* The softmax function is used to convert logits into probabilities, representing the relevance of each expert.
* The Top-K selection mechanism allows the system to focus on a subset of experts for each input.
* The diagram highlights the transformation of data from the input space to the latent space and then to the decision space.
### Interpretation
The diagram illustrates a key component of Mixture of Experts models, which aim to improve model capacity and performance by dividing the task among multiple experts. The MoE architecture allows the model to specialize in different aspects of the data, leading to more efficient and accurate predictions. The diagram demonstrates how the input is routed to the most relevant experts based on a similarity score and a probability distribution. The Top-K selection ensures that only a limited number of experts are activated for each input, reducing computational cost. The visual representation of the different spaces (Weight-Space, Latent-Space, Decision-Space) provides a clear understanding of the data transformation process within the MoE system. The diagram is a conceptual illustration and does not contain specific numerical data, but rather focuses on the functional flow and mathematical operations involved.
</details>
Figure 4.1: Three Spaces for Bayesian Uncertainty in MoE Routing. Illustration of the three distinct stages where uncertainty can be introduced: (1) Expert Centroid Space (weight-space), (2) Expert Logit Space (latent-space), and (3) Expert Selection Space (decision-space). Each corresponds to a different family of Bayesian routing methods described in this chapter.
### 4.1 Standard MoE Router: A Formal Definition
Before detailing our Bayesian modifications, we formally define the standard deterministic routing process Already introduced in Chapter 2, but repeated here for clarity. . The pipeline begins by calculating a similarity score for each expert. For a given input token $\mathbf{u}_{t}$ , the router computes a vector of unnormalized scores, or logits ( $\mathbf{l}_{t}\in\mathbb{R}^{N}$ ), by projecting it with a learnable weight matrix, $W_{\text{EC}}$ . This matrix is composed of $N$ column vectors, $W_{\text{EC}}=[\mathbf{e}_{1},\dots,\mathbf{e}_{N}]$ , where each vector $\mathbf{e}_{i}$ can be interpreted as a learnable centroid for an expert.
$$
\mathbf{l}_{t}=\mathbf{u}_{t}W_{\text{EC}}
$$
These logits are then transformed into a probability distribution over all $N$ experts using the softmax function, $\mathbf{s}_{t}=\text{softmax}(\mathbf{l}_{t})$ . Finally, a hard, deterministic Top-K selection mechanism is applied to this probability vector to identify the indices of the $K$ most probable experts. The probabilities for these selected experts are renormalized to sum to one, forming the final sparse gating weights, $\mathbf{g}_{t}$ , which are used to compute the weighted sum of expert outputs. This completes the deterministic pipeline that our subsequent Bayesian methods aim to improve upon.
### 4.2 Bayesian Inference on Expert Centroid Space
First famliy of methods in our framework introduces Bayesian uncertainty at the earliest stage of the routing pipeline: Token-Expert similarity score calculation. This approach targets the router’s linear projection layer, treating its weight matrix of expert centroids, $W_{\text{EC}}$ , as a random variable $W_{\text{EC}}$ . By doing so, we reframe standard routing mechanism into its principled Bayesian counterpart.
#### 4.2.1 Core Idea: Bayesian Multinomial Logistic Regression
The standard MoE router, effectively a multinomial logistic regression model, learns a single, deterministic set of Expert Centroid Vectors as the model’s weights (a point estimate). This approach reframes the process through a Bayesian lens by treating the router’s weight matrix of expert centroids, $W_{\text{EC}}$ , as a random variable. By doing so, we reformulate the standard routing mechanism into its principled Bayesian counterpart.
The goal of the router is to produce an expert selection probability distribution, $\mathbf{s}_{t}$ , for a given input token hidden state, $\mathbf{u}_{t}$ . The inference process is formalised as computing the posterior predictive distribution by marginalising over the router’s weight posterior, $p(W_{\text{EC}}|\mathcal{D})$ , which is approximated via Monte Carlo sampling:
$$
\displaystyle p(\mathbf{s}_{t}|\mathbf{u}_{t},\mathcal{D}) \displaystyle=\int p(\mathbf{s}_{t}|\mathbf{u}_{t},W_{\text{EC}})\,p(W_{\text{EC}}|\mathcal{D})\,dW_{\text{EC}} \displaystyle\approx\frac{1}{S}\sum_{s=1}^{S}p(\mathbf{s}_{t}|\mathbf{u}_{t},W_{\text{EC}}^{s}),\quad\text{where }W_{\text{EC}}^{s}\sim p(W_{\text{EC}}|\mathcal{D})
$$
In the language of neural networks, this inference process is implemented by averaging the softmax outputs from $S$ weight samples:
$$
\mathbf{s}_{t}\approx\frac{1}{S}\sum_{s=1}^{S}\text{softmax}(\mathbf{u}_{t}W_{\text{EC}}^{s}),\quad\text{where }W_{\text{EC}}^{s}\sim p(W_{\text{EC}}|\mathcal{D})
$$
The entire process is illustrated in Figure 4.2.
<details>
<summary>x14.png Details</summary>
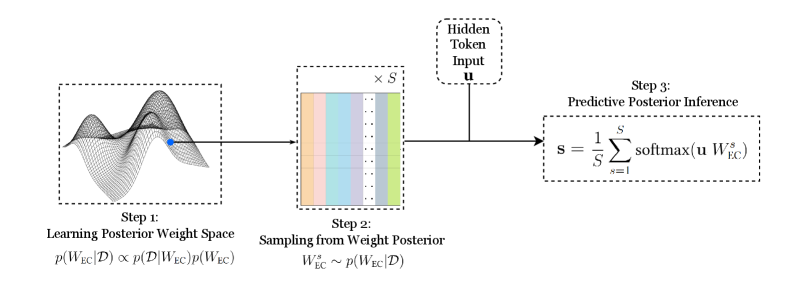
### Visual Description
\n
## Diagram: Predictive Posterior Inference Process
### Overview
The image depicts a three-step process for predictive posterior inference. It illustrates a flow from learning a posterior weight space, sampling from that space, and finally performing predictive posterior inference. The diagram uses visual representations of mathematical concepts and equations to explain the process.
### Components/Axes
The diagram is divided into three main steps, labeled "Step 1", "Step 2", and "Step 3", arranged horizontally from left to right. Each step has a descriptive title and a corresponding visual representation.
* **Step 1: Learning Posterior Weight Space:** Visualized as a 3D surface plot with two blue dots on the surface. The equation below it is: `p(WEC|D) ∝ p(D|WEC)p(WEC)`
* **Step 2: Sampling from Weight Posterior:** Represented as a grid of colored rectangles (S x S). The equation below it is: `WEC ~ p(WEC|D)`
* **Step 3: Predictive Posterior Inference:** Shown as a box with an arrow pointing into it. The equation within the box is: `s = 1/S ∑ softmax(u WEC)` where the summation is from s=1 to S.
* **Hidden Token Input:** Labeled as "Hidden Token Input" and represented as a vertical arrow pointing towards Step 3. The variable is denoted as "u".
* **S:** Appears in the equations for Step 2 and Step 3, representing a dimension or size parameter.
### Detailed Analysis or Content Details
**Step 1:** The 3D surface plot represents a probability distribution over weights (WEC) given data (D). The two blue dots likely represent specific weight values sampled from this distribution. The equation indicates that the posterior probability of the weights given the data is proportional to the likelihood of the data given the weights multiplied by the prior probability of the weights.
**Step 2:** The grid of colored rectangles represents sampling from the posterior weight distribution. The dimensions of the grid are S x S. The equation indicates that a weight vector (WEC) is sampled from the posterior distribution p(WEC|D). The colors of the rectangles are varied, suggesting different sampled weight values.
**Step 3:** This step performs predictive inference using the sampled weights. The equation calculates a prediction 's' as the average of the softmax of the product of the hidden token input 'u' and each sampled weight vector WEC. The summation is performed over S samples.
### Key Observations
* The diagram illustrates a Bayesian approach to inference, where uncertainty is represented by a probability distribution over weights.
* The sampling step (Step 2) is crucial for approximating the posterior predictive distribution.
* The final prediction (Step 3) is a weighted average of the softmax outputs, where the weights are determined by the sampled weights.
* The variable 'S' appears to represent the number of samples used in the Monte Carlo approximation.
### Interpretation
The diagram describes a method for making predictions based on a Bayesian model. The process begins by learning a posterior distribution over the model's weights given the observed data. This posterior distribution represents our uncertainty about the true values of the weights. To make a prediction, we sample multiple weight vectors from this posterior distribution and average the predictions made by each weight vector. This averaging process effectively integrates over the uncertainty in the weights, resulting in a more robust and accurate prediction. The use of the softmax function suggests that the model is making predictions about a categorical variable. The "Hidden Token Input" (u) likely represents a feature vector or embedding of the input data. The diagram highlights the importance of representing uncertainty and using sampling techniques to approximate complex distributions. The diagram is a conceptual illustration of a Bayesian inference process, and does not contain specific numerical data.
</details>
Figure 4.2: Procedure for Bayesian MoE Routing on Expert Centroid Space.
This raises the central practical question: how can we obtain samples from the posterior distribution $p(W_{\text{EC}}|\mathcal{D})$ ? Since the true posterior is intractable to compute, we must rely on approximation methods. The following sections explore three distinct and powerful techniques for this purpose: Monte Carlo Dropout, Stochastic Weight Averaging-Gaussian (SWAG), and Deep Ensembles.
#### 4.2.2 Method 1: MC Dropout Router (MCDR)
Monte Carlo Dropout (MCD) is a straightforward and computationally efficient method for approximating the posterior predictive distribution. Usually, stochastic dropout layers are employed during training as a regularisation, and are turned off during inference. However, MC Dropout also performs random dropout at inference, effectively sampling from an approximate posterior distribution over the model weights.
In MoE Routing context, we apply dropout to the router’s weight matrix $W_{\text{EC}}$ during both training and inference time, where each hidden unit is randomly dropped by sampling from a $\text{Bernoulli}(p)$ distribution. Specifically, at inference time this procedure will be repeated $S$ times, each sampling results in a distinct model weight $W_{\text{EC}}^{s}$ , thus achieving $S$ samples from posterior. Then by $S$ rounds of inference then averaging as in Eq. 4.3, we can obtain the final predictive distribution over experts.
In Practice
For our implementation, we follow the standard and computationally efficient approach for MC Dropout. A dropout layer is inserted before the router’s linear projection, applying a random binary mask to the input hidden state $\mathbf{u}_{t}$ . The router is then fine-tuned, starting from the pre-trained MAP weights, by minimising a combined loss function that includes an L2 regularization term (weight decay):
$$
\mathcal{L}_{\text{MCDR}}=\mathcal{L}_{\text{task}}+\lambda||W_{\text{EC}}||^{2}_{F}
$$
Here, $\mathcal{L}_{\text{task}}$ is the downstream task loss (e.g., cross-entropy), $||W_{\text{EC}}||^{2}_{F}$ is the squared Frobenius norm of the $D\times N$ expert centroid matrix, and $\lambda$ is the weight decay coefficient.
This specific training objective, combining dropout on the input units with L2 regularisation, is what allows the model to be interpreted as a form of approximate variational inference for a deep Gaussian Process [31]. At inference time, after obtaining the Monte Carlo average of the routing probabilities $\textbf{s}_{t}$ , the standard deterministic Top-K mechanism is used to select the final set of experts.
#### 4.2.3 Method 2: Stochastic Weight Averaging Gaussian Router (SWAGR)
The SWAG procedure begins after the router has been fine-tuned to convergence. We continue training for a number of epochs with a high, constant learning rate, collecting the expert centroid matrix $W_{\text{EC}}^{s}$ at each step $i$ . The first two moments of these collected weights are used to define the approximate Gaussian posterior, $p(W_{\text{EC}}|\mathcal{D})\approx\mathcal{N}(\bar{W}_{\text{EC}},\Sigma_{\text{SWAG}})$ . The mean of this posterior is the running average of the weights:
$$
\bar{W}_{\text{EC}}=\frac{1}{S}\sum_{s=1}^{S}W_{\text{EC}}^{s}
$$
The covariance matrix, $\Sigma_{\text{SWAG}}$ , is constructed using the second moment of the iterates, capturing the geometry of the loss surface.
In Practice
A crucial practical aspect of SWAG is the storage and computation of the covariance matrix. A full-rank covariance matrix for the $D\times N$ weights would be prohibitively large. Therefore, we use a low-rank plus diagonal approximation. This involves storing the running average of the weights ( $\bar{W}_{\text{EC}}$ ), the running average of the squared weights (for the diagonal part), and a small number of recent weight vectors to form the low-rank deviation matrix. At inference time, we draw $S$ weight matrix samples $W_{\text{EC}}^{s}$ from this approximate Gaussian posterior. Each sample is used to calculate a logit vector, and the final routing probabilities are obtained by averaging the post-softmax outputs as described in Eq. 4.3 as usual, followed by the standard Top-K selection.
#### 4.2.4 Method 3: Deep Ensembles of Routers (DER)
The third method, the Deep Ensemble Router, is an implicit and non-parametric approach to approximating the posterior predictive distribution, following the work of Lakshminarayanan et al. [33]. Instead of defining and approximating an explicit posterior distribution, this method leverages the diversity created by training multiple models independently.
The core idea is to treat the collection of independently trained models as a set of empirical samples from the true, unknown posterior distribution. Each of the $M$ routers in the ensemble is trained to convergence, finding a different mode in the loss landscape. This collection of final weight matrices, $\{W_{\text{EC}}^{1},\dots,W_{\text{EC}}^{M}\}$ , is then assumed to be a representative set of samples from $p(W_{\text{EC}}|\mathcal{D})$ .
In Practice
To implement DER, we train an ensemble of $M$ separate router weights. Each member is fine-tuned from the same pre-trained MAP weights but with a different random seed for its optimiser state and data shuffling to encourage functional diversity. At inference time, an input token $\mathbf{u}_{t}$ is passed through all $M$ routers in the ensemble, producing $M$ distinct logit vectors. Each logit vector is passed through a softmax function, and the resulting $M$ probability distributions are averaged to approximate the Bayesian model average, as shown in Eq. 4.3 still. This final, robust probability distribution is then used for the standard Top-K selection of experts.
#### 4.2.5 Summary of Centroid-Space Methods
Pros: The methods in this category provide a principled approach to routing uncertainty by applying classic BNN techniques directly to expert centroid matrix $W_{\text{EC}}$ . By approximating posterior over weights, these methods capture true epistemic uncertainty. Their main advantage lies in this strong theoretical grounding and, in the case of MCDR, their simplicity and ease of implementation.
Cons: A key conceptual limitation of this approach is its indirectness. These methods model uncertainty in the high-dimensional weight-space, which must then propagate through a linear transformation to induce a distribution on the low-dimensional logit-space, subsequently making it an inefficient way to represent uncertainty.
This raises a natural question: Can we model the uncertainty more directly? Instead of modeling the cause (uncertainty in the weights), can we directly model the effect (uncertainty in the logits)? This motivation leads us to the next family of methods.
### 4.3 Bayesian Inference on Expert Logit Space
This section explores a more direct and potentially more expressive alternative: applying Bayesian inference directly to the logit space itself. By modeling a probability distribution over the logit vector $l$ , the quantity that immediately governs the final expert selection, we can create a more targeted representation of routing uncertainty. This section will develop this idea, starting by framing it as a probabilistic graphical model and then detailing two specific implementations of this strategy.
#### 4.3.1 Core Idea: Amortised Variational Inference on the Logit Space
Probabilistic Graphical Model (PGM) Framing
To formally ground our approach, we first view the entire MoE LLM as a deep, hierarchical latent variable model, as depicted in Figure 4.3. In this model, the input sequence tokens $x$ and final output next token $y$ are observed variables, while the hidden states before each MoE layer, $\{\mathbf{u}_{1},\mathbf{u}_{2},\ldots,\mathbf{u}_{L}\}$ , and the expert logit vectors at each MoE layer, $\{\mathbf{l}_{1},\mathbf{l}_{2},\ldots,\mathbf{l}_{L}\}$ , are latent variables. The final hidden state $\mathbf{h}$ before output projection is also a latent variable. At each layer, hidden state $\mathbf{u}_{i}$ generates a latent logit vector $\mathbf{l}_{i}$ , which in turn together determines the next hidden state $\mathbf{u}_{i+1}$ . Additionally, $L$ represents total number of MoE layers, and $N$ is the size of finetuning dataset. $x$ $\mathbf{u}_{1}$ $\mathbf{u}_{2}$ $\dots$ $\mathbf{u}_{i}$ $\mathbf{u}_{i+1}$ $\dots$ $\mathbf{u}_{L}$ $\mathbf{h}$ $y$ $\mathbf{l}_{1}$ $\mathbf{l}_{2}$ $\mathbf{l}_{i}$ $\mathbf{l}_{i+1}$ $\mathbf{l}_{L}$ $\cdots$ $\cdots$ $\phi_{1}$ $\phi_{2}$ $\phi_{i}$ $\phi_{i+1}$ $\phi_{L}$ $\times N$
Figure 4.3: PGM of the full hierarchical MoE LLM.
Inference on every logit space together would be challenging due to the hierarchical structure. To address this, we adopt a principled simplification: we analyse one MoE layer at a time, treating all other layers as deterministic and frozen. As the subsequent layers (Including all the following attention and MoE FFN mechanisms) are just deterministic functions of the current layer’s output, we can simplify the graphical model to only the essential variables for our learning task, as shown in Figure 4.4. The model reduces to inferring the latent logit vector l for a given layer, conditioned on its observed input u and the final observed task output $y$ . u $y$ l $\phi$ $\times N$
Figure 4.4: Simplified PGM for a single MoE layer used for our analysis.
Variational Inference Formulation
Our goal is to infer the posterior distribution over the logits, $p(\mathbf{l}|\mathbf{u},y)$ . As this is intractable, we use variational inference to approximate it with a tractable distribution, $q_{\phi}(\mathbf{l}|\mathbf{u})$ . We assume this approximate posterior is a multivariate Gaussian. The parameters $\phi$ of this distribution are learned by maximising the Evidence Lower Bound (ELBO):
$$
\mathcal{L}_{\text{ELBO}}(\phi)=\underbrace{\mathbb{E}_{q_{\phi}(\mathbf{l}|\mathbf{u})}[\log p(y|\mathbf{l},\mathbf{u})]}_{\text{Reconstruction Term}}-\underbrace{D_{\mathbb{KL}}(q_{\phi}(\mathbf{l}|\mathbf{u})||p(\mathbf{l}|\mathbf{u}))}_{\text{Regularisation Term}}
$$
Here, $p(\mathbf{l}|\mathbf{u})$ is the prior we choose for the logits, which will be defined later.
The reconstruction term corresponds to the downstream task loss, ensuring that the latent logits are useful for the final prediction. The regularisation term is the KL divergence between our learned posterior and a simple prior, which prevents the model from becoming overconfident.
Amortised Inference and Residual Learning
Inspired by the Variational Autoencoder (VAE), we use a neural network, or the variational router, to perform amortised inference. This network learns a single function that maps any input token $\mathbf{u}$ directly to the parameters of its corresponding posterior $q_{\phi}(\mathbf{l}|\mathbf{u})$ , which corresponds to $\boldsymbol{\mu}_{\text{post}}(\textbf{u})$ and $\boldsymbol{\Sigma}_{\text{post}}(\textbf{u})$ in this case (Mutivriate Gaussian).
To make full use of the pre-trained routing weights in deterministic router, we implement the posterior mean inference network using a residual learning mechanism. Instead of predicting the posterior mean directly, the network predicts a residual correction, $\Delta\boldsymbol{\mu}_{\phi}(\cdot)$ , which is added to the original deterministic logits, $\text{NN}_{\text{det}}(\cdot)$ :
$$
\boldsymbol{\mu}_{\text{post}}=\text{NN}_{\text{det}}(\textbf{u})+\Delta\boldsymbol{\mu}_{\phi}(\textbf{u})
$$
This formulation provides a significant computational benefit. By setting the prior $p(\mathbf{l}|\mathbf{u})$ to be a Gaussian centered on the deterministic logits, $p(\mathbf{l}|\mathbf{u})=\mathcal{N}(\mathbf{l}|\text{NN}_{\text{det}}(\textbf{u}),I)$ , the KL divergence term in the ELBO simplifies. The KL divergence between the full posterior and the prior becomes equivalent to the KL divergence between the learned residual and a standard normal prior Proof in Appendix B.:
$$
\displaystyle D_{\mathbb{KL}}(\mathcal{N}(\text{NN}_{\text{det}}(\textbf{u})+\Delta\boldsymbol{\mu}_{\phi}(\textbf{u}),\boldsymbol{\Sigma}_{\text{post}})\,||\,\mathcal{N}(\text{NN}_{\text{det}}(\textbf{u}),I)) \displaystyle= \displaystyle D_{\mathbb{KL}}(\mathcal{N}(\Delta\boldsymbol{\mu}_{\phi}(\textbf{u}),\boldsymbol{\Sigma}_{\text{post}})\,||\,\mathcal{N}(0,I))
$$
<details>
<summary>x15.png Details</summary>
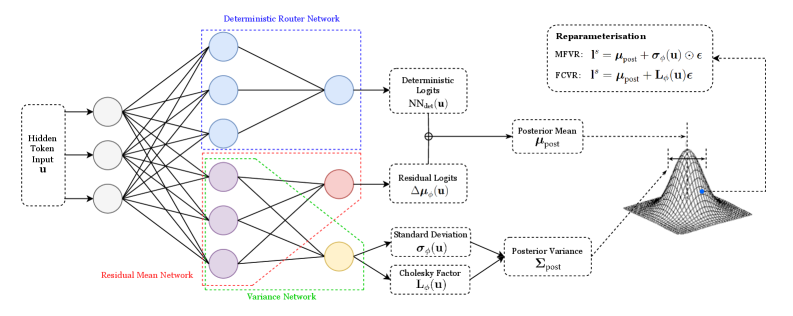
### Visual Description
\n
## Diagram: Neural Network Architecture for Variational Inference
### Overview
The image depicts a neural network architecture designed for variational inference. It illustrates the flow of information through a deterministic router network, a residual mean network, and a variance network, culminating in the reparameterization of a distribution. The diagram highlights the key components and their relationships in a probabilistic modeling context.
### Components/Axes
The diagram is segmented into three main sections: the input layer, the network layers (Deterministic Router Network, Residual Mean Network, Variance Network), and the reparameterization/output section.
* **Input:** "Hidden Token Input u"
* **Deterministic Router Network:** Labeled in blue.
* **Residual Mean Network:** Labeled in red.
* **Variance Network:** Labeled in green.
* **Outputs:**
* "Deterministic Logits NN<sub>det</sub>(u)"
* "Residual Logits Δμ<sub>det</sub>(u)"
* "Standard Deviation σ<sub>det</sub>(u)"
* "Cholesky Factor L<sub>σ</sub>(u)"
* **Reparameterisation:**
* "MFVR: I<sup>*</sup> = μ<sub>post</sub> + σ<sub>det</sub>(u)ε"
* "FCVR: I<sup>*</sup> = μ<sub>post</sub> + L<sub>σ</sub>(u)ε"
* **Posterior Distribution:** Visualized as a 3D cone-shaped surface.
* "Posterior Mean μ<sub>post</sub>"
* "Posterior Variance Σ<sub>post</sub>"
* **ε:** Represents a random variable.
### Detailed Analysis or Content Details
The diagram shows a neural network with multiple layers.
1. **Input Layer:** A single input node labeled "Hidden Token Input u".
2. **Deterministic Router Network (Blue):** This network consists of four layers of nodes. The input 'u' is connected to the first layer, which has four nodes. This layer is connected to a second layer with four nodes, then to a third layer with three nodes, and finally to an output layer with two nodes labeled "Deterministic Logits NN<sub>det</sub>(u)".
3. **Residual Mean Network (Red):** This network also has four layers of nodes. The input 'u' is connected to the first layer with four nodes, then to a second layer with four nodes, a third layer with three nodes, and finally to an output node labeled "Residual Logits Δμ<sub>det</sub>(u)".
4. **Variance Network (Green):** This network has four layers of nodes. The input 'u' is connected to the first layer with four nodes, then to a second layer with four nodes, a third layer with three nodes, and finally to two output nodes labeled "Standard Deviation σ<sub>det</sub>(u)" and "Cholesky Factor L<sub>σ</sub>(u)".
5. **Reparameterization:** The outputs from the networks are used in the reparameterization formulas for MFVR (Mean-Field Variational Representation) and FCVR (Fully-Connected Variational Representation). Both formulas involve adding a scaled random variable ε to a mean (μ<sub>post</sub>).
6. **Posterior Distribution:** The reparameterized output I<sup>*</sup> is used to define the posterior distribution, characterized by its mean (μ<sub>post</sub>) and variance (Σ<sub>post</sub>). The posterior distribution is visualized as a 3D cone-shaped surface.
### Key Observations
The diagram emphasizes the use of neural networks to model the posterior distribution in variational inference. The deterministic router network, residual mean network, and variance network work in parallel to estimate the parameters of the posterior distribution. The reparameterization trick is used to enable gradient-based optimization. The visualization of the posterior distribution as a cone suggests a unimodal distribution.
### Interpretation
This diagram illustrates a sophisticated approach to variational inference using neural networks. The architecture allows for flexible modeling of complex posterior distributions. The use of separate networks for the mean and variance components enables the model to capture dependencies between these parameters. The reparameterization trick is crucial for enabling gradient-based optimization, which is essential for training the neural networks. The diagram suggests a method for approximating intractable posterior distributions with a more tractable, parameterized form, allowing for efficient inference in Bayesian models. The separation of the deterministic router network suggests a mechanism for controlling the flow of information and potentially improving the accuracy of the approximation. The use of a Cholesky factor for the variance suggests a focus on maintaining positive definiteness, which is important for ensuring the validity of the posterior distribution. The diagram is a high-level overview of a complex system, and further details would be needed to fully understand its implementation and performance.
</details>
Figure 4.5: Variational Router Illustration. Variational router predicts a Gaussian posterior over the logits, with a mean given by the deterministic logits plus a learned residual and variance. A sample from this posterior is drawn by reparameterisation trick, and resulting logits are used to compute routing probabilities.
#### 4.3.2 Method 4: The Mean-Field Variational Router (MFVR)
The Mean-Field Variational Router (MFVR) is the first and simplest implementation of our logit-space framework. It is based on the mean-field assumption, which posits that the posterior distribution over the logits can be factorised into independent univariate Gaussians for each of the $N$ experts. This implies that the covariance matrix of our approximate posterior, $\boldsymbol{\Sigma}_{\text{post}}(\mathbf{u})$ , is a diagonal matrix.
Reparameterisation Trick
To implement this, the variational router has a network head that outputs the log-standard deviation vector, $\log\boldsymbol{\sigma}_{\phi}(\cdot)$ . A sample from the posterior is then generated using the standard element-wise reparameterisation trick:
$$
\mathbf{l}^{s}=\boldsymbol{\mu}_{\text{post}}+\boldsymbol{\sigma}_{\phi}(\mathbf{u})\odot\boldsymbol{\epsilon},\quad\text{where }\boldsymbol{\epsilon}\sim\mathcal{N}(0,I)
$$
Loss Function
The parameters of the variational router, $\phi$ , are learned by minimising a loss function derived from a single-sample Monte Carlo estimate of the ELBO. Since KL divergence between two diagonal Gaussians has a closed-form solution, the KL loss for this mean-field case simplifies to:
$$
\mathcal{L}_{\text{MF-KL}}=\frac{1}{2}\sum_{i=1}^{N}\left((\Delta\mu_{i})^{2}+\sigma_{i}^{2}-\log(\sigma_{i}^{2})-1\right)
$$
where:
- $N$ is the total number of experts.
- $\Delta\mu_{i}$ is the $i$ -th component of the learned residual mean vector $\Delta\boldsymbol{\mu}_{\phi}(\mathbf{u})$ .
- $\sigma_{i}^{2}$ is the $i$ -th component of the learned variance vector $\boldsymbol{\sigma}^{2}_{\phi}(\mathbf{u})$ .
A hyperparameter, $\beta$ , is introduced to scale the KL term, similar to its use in Variational Auto Encoders (VAEs) [37] to balance the reconstruction and regularisation objectives:
$$
\mathcal{L}_{\text{MFVR}}=\mathcal{L}_{\text{task}}+\beta\cdot\mathcal{L}_{\text{MF-KL}}
$$
Training and Inference Sampling
At training time, for each input token $\mathbf{u}$ , we perform a single reparameterisation trick in logit space to obtain a sample of the logits, $\mathbf{l}^{s}$ , then perform end-to-end training to update variational router’s parameters $\phi$ .
At inference time, we want a more accurate approximation of the posterior predictive distribution on the expert selection probablity, so we perform $S$ independent reparameterisation samples, $\{\mathbf{l}^{1},\mathbf{l}^{2},\ldots,\mathbf{l}^{S}\}$ , and average their post-softmax outputs to obtain the final routing probability.
<details>
<summary>x16.png Details</summary>

### Visual Description
\n
## Diagram: Variational Router Architecture
### Overview
The image depicts a diagram of a Variational Router architecture, illustrating the flow of information from a Hidden Token Input through a Variational Router, a posterior distribution, sampling processes (during training and inference), and finally to a Top-K parameter update stage. The diagram highlights the mathematical operations involved in each step.
### Components/Axes
The diagram consists of the following components, arranged from left to right:
1. **Hidden Token Input (u):** The initial input to the system.
2. **Variational Router:** A neural network (NN) that takes the input 'u' and outputs Δμ(⋅), log σ(⋅).
3. **Posterior Distribution:** Represented as a 3D Gaussian surface, labeled with Σ<sub>post</sub> and μ<sub>post</sub>.
4. **Training Branch:** Indicates sampling once using s = softmax(Γ').
5. **Inference Branch:** Indicates sampling 's' times using s = Σ<sub>s=1</sub><sup>s</sup> softmax(Γ').
6. **Top-K:** A component for parameter update.
7. **Training Loss:** A box containing the equations for the loss function and parameter update.
### Detailed Analysis or Content Details
* **Hidden Token Input (u):** Labeled simply as "Hidden Token Input u".
* **Variational Router:** The router is described as NN<sub>φ</sub>(⋅), with outputs Δμ(⋅) and log σ(⋅). The φ likely represents the parameters of the neural network.
* **Posterior Distribution:** The posterior distribution is characterized by Σ<sub>post</sub> (covariance matrix) and μ<sub>post</sub> (mean vector). The 3D surface visually represents a Gaussian distribution.
* **Training Branch:** The training branch involves sampling once, where 's' is calculated as softmax(Γ'). Γ' is not further defined.
* **Inference Branch:** The inference branch involves sampling 's' times, where 's' is calculated as the sum of softmax(Γ') from s=1 to s.
* **Top-K:** This component is labeled "Top-K Parameter Update".
* **Training Loss:** The training loss is defined by the following equations:
* L<sub>VR</sub> = L<sub>data</sub> + λ L<sub>KL</sub>
* φ ← φ - η ∇<sub>φ</sub>L<sub>VR</sub>
Where:
* L<sub>VR</sub> is the Variational Router loss.
* L<sub>data</sub> is the data loss.
* L<sub>KL</sub> is the KL divergence loss.
* λ is a weighting factor.
* φ represents the parameters of the network.
* η is the learning rate.
* ∇<sub>φ</sub>L<sub>VR</sub> is the gradient of the loss with respect to the parameters.
### Key Observations
The diagram illustrates a variational inference approach. The Variational Router aims to approximate the posterior distribution. The training process involves minimizing a loss function that balances data fit (L<sub>data</sub>) and the KL divergence between the approximate posterior and the true posterior (L<sub>KL</sub>). The Top-K component suggests a method for selecting the most important parameters for updating.
### Interpretation
This diagram represents a novel approach to routing information within a neural network using variational inference. The Variational Router learns a posterior distribution over possible routes, allowing for more flexible and robust information flow. The use of a variational approach introduces uncertainty into the routing process, which can be beneficial for generalization and exploration. The Top-K parameter update suggests a method for focusing on the most important parameters during training, potentially improving efficiency and performance. The diagram highlights the mathematical foundations of the architecture, emphasizing the use of Gaussian distributions, softmax functions, and gradient-based optimization. The separation of training and inference branches indicates different sampling strategies are employed in each phase. The overall architecture appears designed to address challenges in complex neural networks where traditional routing methods may be insufficient.
</details>
Figure 4.6: Training and Inference Procedures for Variational Router. Comparison of the training and inference data flows for the Variational Router. During training (top), a single sample is used to compute a stochastic loss. During inference (bottom), multiple samples are drawn and their post-softmax probabilities are averaged to produce a robust routing decision.
The training and inference procedures are illustrated in Figure 4.6 and detailed in Algorithm 1.
#### 4.3.3 Method 5: The Full-Covariance Variational Router (FCVR)
The Full-Covariance Variational Router (FCVR) is a more expressive extension that relaxes the mean-field assumption. By modeling a full-rank covariance matrix, the FCVR can capture potential correlations between the logits of different experts, allowing for a richer and more flexible approximate posterior.
Reparameterisation Trick
To ensure the covariance matrix remains positive semi-definite, the variational router is trained to output the elements of its Cholesky factor, $\mathbf{L}_{\phi}(\mathbf{u})$ , where:
$$
\boldsymbol{\Sigma}_{\text{post}}=\mathbf{L}_{\phi}(\mathbf{u})\mathbf{L}_{\phi}(\mathbf{u})^{\top}
$$
The reparameterization trick for the multivariate case is then used to generate a sample:
$$
\mathbf{l}^{s}=\boldsymbol{\mu}_{\text{post}}+\mathbf{L}_{\phi}(\mathbf{u})\boldsymbol{\epsilon},\quad\text{where }\boldsymbol{\epsilon}\sim\mathcal{N}(0,I)
$$
Loss Function
The parameters of the Full-Covariance Variational Router are also learned by minimising the loss function derived from the ELBO. The key difference lies in the KL divergence term, which now measures the divergence between two full-rank multivariate Gaussians. This also has a closed-form analytical solution:
$$
\mathcal{L}_{\text{FC-KL}}=\frac{1}{2}\left(\text{tr}(\boldsymbol{\Sigma}_{\text{post}})+||\Delta\boldsymbol{\mu}||_{2}^{2}-N-\log|\boldsymbol{\Sigma}_{\text{post}}|\right)
$$
where:
- $N$ is the total number of experts.
- $\text{tr}(\boldsymbol{\Sigma}_{\text{post}})$ is the trace of the covariance matrix.
- $||\Delta\boldsymbol{\mu}||_{2}^{2}$ is the squared L2 norm of the residual mean vector $\Delta\boldsymbol{\mu}_{\phi}(\mathbf{u})$ .
- $\log|\boldsymbol{\Sigma}_{\text{post}}|$ is the log-determinant of the covariance matrix, which can be computed efficiently from the Cholesky factor as $2\sum_{i}\log(\text{diag}(\mathbf{L_{\phi}(\textbf{u})})_{i})$ .
As with the mean-field case, a hyperparameter $\beta$ is used to scale the KL term, yielding the final loss function:
$$
\mathcal{L}_{\text{FCVR}}=\mathcal{L}_{\text{task}}+\beta\cdot\mathcal{L}_{\text{FC-KL}}
$$
Training and Inference Sampling
The training and inference procedures for the FCVR are identical to those of the MFVR, as detailed in Algorithm 2. The only difference is the specific reparameterisation step used to generate the logit sample $\mathbf{l}^{s}$ , which now incorporates the full Cholesky factor to capture correlations.
Algorithm 1 MFVR Training and Inference
1: Training (one step for input $\mathbf{u}$ , target $y$ ):
2: $\mathbf{l}_{\text{det}}\leftarrow\text{NN}_{\text{det}}(\mathbf{u})$
3: $\Delta\boldsymbol{\mu},\boldsymbol{\sigma}\leftarrow\Delta\boldsymbol{\mu}_{\phi}(\mathbf{u}),\boldsymbol{\sigma}_{\phi}(\mathbf{u})$
4: $\boldsymbol{\mu}_{\text{post}}\leftarrow\mathbf{l}_{\text{det}}+\Delta\boldsymbol{\mu}$
5: $\boldsymbol{\epsilon}\sim\mathcal{N}(0,I)$
6: $\mathbf{l}^{s}\leftarrow\boldsymbol{\mu}_{\text{post}}+\boldsymbol{\sigma}\odot\boldsymbol{\epsilon}$
7: Select experts using $\text{Top-K}(\text{softmax}(\mathbf{l}^{s}))$ , get model final output $\hat{y}$
8: Compute $\mathcal{L}_{\text{MFVR}}$ using $\hat{y}$ and $y$
9: Update $\phi$ using $\nabla_{\phi}\mathcal{L}_{\text{MFVR}}$
10:
11: Inference (for input $\mathbf{u}$ ):
12: $\mathbf{l}_{\text{det}}\leftarrow\text{NN}_{\text{det}}(\mathbf{u})$
13: $\Delta\boldsymbol{\mu},\boldsymbol{\sigma}\leftarrow\Delta\boldsymbol{\mu}_{\phi}(\mathbf{u}),\boldsymbol{\sigma}_{\phi}(\mathbf{u})$
14: $\boldsymbol{\mu}_{\text{post}}\leftarrow\mathbf{l}_{\text{det}}+\Delta\boldsymbol{\mu}$
15: $\mathbf{p}_{\text{avg}}\leftarrow\mathbf{0}$
16: for $s=1$ to $S$ do
17: $\boldsymbol{\epsilon^{\prime}}\sim\mathcal{N}(0,I)$
18: $\mathbf{l}^{s}\leftarrow\boldsymbol{\mu}_{\text{post}}+\boldsymbol{\sigma}\odot\boldsymbol{\epsilon^{\prime}}$
19: $\mathbf{p}_{\text{avg}}\leftarrow\mathbf{p}_{\text{avg}}+\text{softmax}(\mathbf{l}^{s})$
20: Select experts using $\text{Top-K}(\frac{\mathbf{p}_{\text{avg}}}{S})$
Algorithm 2 FCVR Training and Inference
1: Training (one step for input $\mathbf{u}$ , target $y$ ):
2: $\mathbf{l}_{\text{det}}\leftarrow\text{NN}_{\text{det}}(\mathbf{u})$
3: $\Delta\boldsymbol{\mu},\mathbf{L}\leftarrow\Delta\boldsymbol{\mu}_{\phi}(\mathbf{u}),\mathbf{L}_{\phi}(\mathbf{u})$
4: $\boldsymbol{\mu}_{\text{post}}\leftarrow\mathbf{l}_{\text{det}}+\Delta\boldsymbol{\mu}$
5: $\boldsymbol{\epsilon}\sim\mathcal{N}(0,I)$
6: $\mathbf{l}^{s}\leftarrow\boldsymbol{\mu}_{\text{post}}+\mathbf{L}\boldsymbol{\epsilon}$
7: Select experts using $\text{Top-K}(\text{softmax}(\mathbf{l}^{s}))$ , get model final output $\hat{y}$
8: Compute $\mathcal{L}_{\text{FCVR}}$ using $\hat{y}$ and $y$
9: Update $\phi$ using $\nabla_{\phi}\mathcal{L}_{\text{FCVR}}$
10:
11: Inference (for input $\mathbf{u}$ ):
12: $\mathbf{l}_{\text{det}}\leftarrow\text{NN}_{\text{det}}(\mathbf{u})$
13: $\Delta\boldsymbol{\mu},\mathbf{L}\leftarrow\Delta\boldsymbol{\mu}_{\phi}(\mathbf{u}),\mathbf{L}_{\phi}(\mathbf{u})$
14: $\boldsymbol{\mu}_{\text{post}}\leftarrow\mathbf{l}_{\text{det}}+\Delta\boldsymbol{\mu}$
15: $\mathbf{p}_{\text{avg}}\leftarrow\mathbf{0}$
16: for $s=1$ to $S$ do
17: $\boldsymbol{\epsilon^{\prime}}\sim\mathcal{N}(0,I)$
18: $\mathbf{l}^{s}\leftarrow\boldsymbol{\mu}_{\text{post}}+\mathbf{L}\boldsymbol{\epsilon^{\prime}}$
19: $\mathbf{p}_{\text{avg}}\leftarrow\mathbf{p}_{\text{avg}}+\text{softmax}(\mathbf{l}^{s})$
20: Select experts using $\text{Top-K}(\frac{\mathbf{p}_{\text{avg}}}{S})$
#### 4.3.4 Summary of Logit-Space Methods
The logit-space methods provide a more direct and expressive approach to routing uncertainty. By placing a learned, input-dependent Gaussian distribution directly over the expert logits, these methods, particularly FCVR, can capture complex correlations and provide a rich representation of the model’s belief, leading to state-of-the-art performance.
However, this approach still faces a key limitation: The distribution that results from applying the softmax function to a Gaussian is still intractable. This forces us to rely on Monte Carlo sampling at inference time, drawing multiple samples from the logit space and averaging their post-softmax probabilities, which can be computationally expensive.
This leads to a final, crucial question: is it possible to introduce principled, input-dependent stochasticity without the need for multi-sample Monte Carlo averaging? Also, taking inspiration from our earlier motivation experiments in Section 3.2, this motivates the final family of methods, which operate directly on the expert selection space.
### 4.4 Bayesian Inference on Expert Selection Space
A prominent challenge of modeling uncertainty in the logit space is that the softmax of a Gaussian distribution is intractable. This necessitates the use of Monte Carlo sampling to approximate the posterior predictive distribution over the post-softmax routing probabilities, which we refer to as the expert selection space. This raises a natural question: can we model the uncertainty of the routing decision more directly in this final selection space?
#### 4.4.1 Core Idea: Learning Input-Dependent Temperature
Our key inspiration comes from the motivation experiment in Section 3.2. We observed that replacing the deterministic Top-K selection with a Sample-K strategy, governed by a global temperature parameter $T$ , could improve model calibration. However, a single, fixed temperature is a blunt instrument, the optimal level of stochasticity is likely token-dependent. An easy token should be routed with high confidence (low temperature), while an ambiguous or out-of-distribution token should be routed with high uncertainty (high temperature).
This motivates a natural extension: to learn an input-dependent temperature, $T(\mathbf{u})$ , allowing the model to dynamically control the stochasticity of its own routing decisions. The job of learning this variational temperature function is delegated to a neural network, and we call this approach the Variational Temperature Sampling Router (VTSR).
<details>
<summary>x17.png Details</summary>
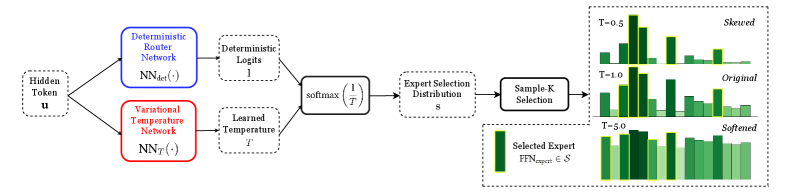
### Visual Description
## Diagram: Mixture of Experts Routing with Temperature Control
### Overview
The image depicts a diagram illustrating a Mixture of Experts (MoE) routing mechanism with temperature control. It shows how a hidden token 'u' is processed through deterministic and variational networks, then routed to selected experts based on a softmax function influenced by a learned temperature 'T'. The diagram also visualizes the effect of different temperature values on the expert selection distribution.
### Components/Axes
The diagram consists of the following components:
* **Hidden Token (u):** The input to the system.
* **Deterministic Router Network (NN<sub>det</sub>(-)):** Outputs "Deterministic Logits" labeled as '1'. Colored blue.
* **Variational Network (NN<sub>V</sub>(-)):** Outputs "Learned Temperature" labeled as 'T'. Colored red.
* **Softmax (1/T):** A function that converts logits into a probability distribution.
* **Expert Selection Distribution (S):** The output of the softmax function, representing the probability of selecting each expert.
* **Sample-K Selection:** A process that selects K experts based on the expert selection distribution.
* **Selected Expert FFN<sub>expert</sub> ∈ S:** The selected feed-forward network expert.
* **Visualizations:** Three bar charts illustrating the expert selection distribution for different temperature values: T=0.5 (Skewed), T=1.0 (Original), and T=5.0 (Softened).
### Detailed Analysis or Content Details
The diagram shows a flow of information from left to right.
1. **Input:** A "Hidden Token" labeled 'u' is the starting point.
2. **Parallel Processing:** The hidden token 'u' is fed into two separate networks: a "Deterministic Router Network" (NN<sub>det</sub>(-)) and a "Variational Network" (NN<sub>V</sub>(-)).
3. **Outputs:** The Deterministic Router Network outputs "Deterministic Logits" labeled '1'. The Variational Network outputs a "Learned Temperature" labeled 'T'.
4. **Softmax:** The Deterministic Logits and Learned Temperature are combined in a softmax function (1/T) to produce an "Expert Selection Distribution" labeled 'S'.
5. **Expert Selection:** The "Expert Selection Distribution" 'S' is used in a "Sample-K Selection" process to choose a subset of experts.
6. **Selected Expert:** The selected experts are represented as "Selected Expert FFN<sub>expert</sub> ∈ S".
7. **Visualizations of Expert Selection:** Three bar charts demonstrate the effect of the temperature 'T' on the expert selection distribution.
* **T=0.5 (Skewed):** The distribution is highly skewed, with one expert having a significantly higher probability than others. The height of the bars varies significantly, ranging from approximately 20% to 80% (estimated).
* **T=1.0 (Original):** The distribution is more uniform than T=0.5, but still shows some variation. Bar heights range from approximately 10% to 40% (estimated).
* **T=5.0 (Softened):** The distribution is nearly uniform, with all experts having roughly equal probabilities. Bar heights are approximately 10-20% (estimated).
### Key Observations
* The temperature 'T' controls the sharpness of the expert selection distribution.
* Lower temperatures (T=0.5) lead to a more skewed distribution, favoring a small number of experts.
* Higher temperatures (T=5.0) lead to a more uniform distribution, utilizing a wider range of experts.
* The diagram illustrates a mechanism for dynamically adjusting the expert selection process based on a learned temperature parameter.
### Interpretation
This diagram demonstrates a sophisticated routing mechanism for Mixture of Experts models. The key innovation is the use of a learned temperature parameter 'T' to control the diversity of expert selection. By adjusting 'T', the model can dynamically switch between focusing on a few highly specialized experts (low T) and leveraging a broader range of experts (high T). This allows the model to adapt to different input characteristics and potentially improve generalization performance. The visualizations clearly show how the temperature parameter influences the expert selection distribution, providing a visual intuition for the mechanism's behavior. The use of both deterministic and variational networks suggests a balance between exploitation (deterministic routing) and exploration (variational routing). The notation FFN<sub>expert</sub> ∈ S indicates that the selected experts are feed-forward networks belonging to the set of all available experts 'S'.
</details>
Figure 4.7: Variational Temperature Sampling Router (VTSR). Illustration of the VTSR approach: a neural network predicts an input-dependent temperature that scales the deterministic logits. This scaled distribution is then used for sampling experts, allowing the model to adapt its routing uncertainty based on the input token.
#### 4.4.2 Method 6: Variational Temperature Sampling Router (VTSR)
The Variational Temperature Sampling Router is a pragmatic method designed to learn an optimal, input-dependent level of routing stochasticity. It consists of a small neural network that takes the token embedding $\mathbf{u}$ as input and outputs a single positive scalar value, the temperature $T=\text{NN}_{T}(\textbf{u})$ . This temperature is then used to scale the deterministic logits generated by the original deterministic routing network $\mathbf{l}=\text{NN}_{\text{det}}(\mathbf{u})$ before a sampling operation, as opposed to the deterministic Top-K operation, selects the final experts. Schematics of the VTSR approach is illustrated in Figure 4.7.
Training with the Gumbel-Softmax Trick
A key challenge during training is that the process of sampling $K$ experts from the temperature-scaled distribution is non-differentiable, which breaks the flow of gradients. To overcome this, we employ the Gumbel-Softmax trick We don’t explain details of Gumbel-Softmax trick here due to space limit, please refer to original papers [40, 41] for more information. (also known as the Concrete distribution). This technique provides a continuous, differentiable approximation to the discrete sampling process, allowing gradients to flow back to both the main router weights and the temperature prediction network. At inference time, we use the learned temperature to scale the logits and perform multinomial sampling without Gumbel noise or relaxation.
Regularisation to Prevent Deterministic Collapse
A network trained to predict $T(\mathbf{u})$ could learn to minimise the task loss by simply setting the temperature to be very low for all inputs, effectively collapsing back to a deterministic Top-K router. To prevent this, we introduce a regularisation term to the loss function that encourages the model to maintain a degree of uncertainty. Inspired by the uncertainty modeling work of Kendall & Gal in [42], we penalise low temperatures by minimising the expected log-temperature, approximated as a within-batch average:
$$
\mathcal{L}_{\text{temp}}=-\frac{1}{B}\sum_{i=1}^{B}\log(\text{NN}_{T}(\mathbf{u}_{i}))
$$
where $B$ is the batch size and $T(\mathbf{u}_{i})$ is the predicted temperature for the $i$ -th input in the batch. This regularisation term can be interpreted as encouraging entropy in the routing policy, forcing the model to only become confident (low temperature) when there is sufficient evidence in the data. The final training objective is a weighted sum of the task loss and this regularization term:
$$
\mathcal{L}_{\text{VTSR}}=\mathcal{L}_{\text{task}}+\beta\cdot\mathcal{L}_{\text{reg}}
$$
At inference time, we use the predicted temperature $T(\mathbf{u})$ to scale the logits and then perform a direct (non-Gumbel) sampling of $K$ experts from the resulting softmax distribution.
#### 4.4.3 Summary of the Selection-Space Method
The key advantage of the final method, the Variational Temperature Sampling Router (VTSR), is its exceptional efficiency. By learning an input-dependent temperature to control a single sampling step, it introduces principled stochasticity without the computational overhead of Monte Carlo averaging, making it ideal for latency-critical applications.
However, this theoretical elegance is offset by practical instability. Our experiments found the training to be challenging, with the learned temperature often suffering from posterior collapse even with regularisation. This resulted in a less reliable uncertainty signal for OoD detection compared to the more robust variational methods.
Ultimately, the value of the VTSR lies in its novel conceptual contribution: it successfully decouples routing stochasticity from multi-sample inference. While it requires further research to stabilise its training, it represents a promising and computationally efficient direction for future work.
### 4.5 Chapter Summary
This chapter has introduced a comprehensive framework for applying principled Bayesian uncertainty to the Mixture-of-Experts routing mechanism. We have detailed three distinct families of methods, each targeting a different conceptual space in the routing pipeline: the Expert Centroid Space (weight-space), the Expert Logit Space (latent-space), and the Expert Selection Space (decision-space).
Table 4.1: A comprehensive summary of the proposed Bayesian routing methods.
| Family | Model | Bayesian Technique | Source of Uncertainty | Requires Extra NN? | Inference Mechanism |
| --- | --- | --- | --- | --- | --- |
| Expert Centroid (Weight-Space) | MCDR | MC Dropout | Weights | No | MC Sampling (Dropout) |
| SWAGR | SWAG | Weights | No | MC Sampling (Weights) | |
| DER | Deep Ensembling | Weights | No | MC Sampling (Ensemble) | |
| Expert Logit (Latent-Space) | MFVR | Variational Inference | Logits | Yes | Reparameterised MC Sampling (Logits) |
| FCVR | Variational Inference | Logits | Yes | Reparameterised MC Sampling (Logits) | |
| Expert Selection (Decision-Space) | VTSR | Beyesian Decision Theory (Temperature-Sampling) | Selection Policy | Yes | Direct Sampling (Single) |
As summarised in Table 4.1, these approaches offer a clear spectrum of trade-offs. The weight-space methods build upon classic, well-understood BNN techniques. The logit-space methods provide a more direct and expressive way to model uncertainty over the routing decision itself, at the cost of an additional inference network. Finally, the selection-space method presents a uniquely efficient alternative that avoids Monte Carlo averaging.
Having established the theoretical and architectural foundations of these methods, we now turn to a rigorous empirical evaluation of their performance in the next chapter.
## Chapter 5 Experiments and Analysis
This chapter presents the comprehensive empirical evaluation of the Bayesian routing methods developed in Chapter 4. The primary goal is to rigorously assess their performance against standard baselines across a range of critical evaluation criteria.
Our experiments are designed to test three core hypotheses:
1. Stability Hypothesis: Bayesian routing methods, by modeling uncertainty, will exhibit greater stability against input perturbations compared to the brittle, deterministic router.
1. Calibration Hypothesis: The proposed methods will improve model calibration on in-distribution tasks without significantly harming predictive accuracy.
1. OoD Detection Hypothesis: The uncertainty signals derived from Bayesian routers will be more effective for Out-of-Distribution (OoD) detection than those from the deterministic baseline.
To investigate these hypotheses, this chapter is structured as follows. We first detail the complete experimental setup. We then present the results for our three main performance experiments: Routing Stability, In-Distribution Calibration, and OoD Detection. Following this, we provide a comparative analysis of our layer selection strategies and a rigorous efficiency analysis of the methods’ computational overhead. Finally, we conclude with a summary of our findings.
### 5.1 Experimental Setup
This section details the common components: base model, datasets, and evaluation metrics. These are used across all subsequent experiments to ensure a fair and rigorous comparison of our proposed methods against established baselines.
#### 5.1.1 Model, Baselines, and Proposed Methods
Base Model
All experiments are conducted using the IBM Granite-3.1 3B Instruct model, an open-source, 3-billion parameter, decoder-only Mixture-of-Experts model designed for instruction-following tasks [43]. Our Bayesian methods are applied as fine-tuning strategies on top of the pre-trained weights of this model.
Baselines
We compare our methods against two key baselines:
1. Deterministic Router: The standard, unmodified Granite-3.1 router, which uses a deterministic Top-K selection mechanism. This serves as our primary baseline.
1. Temperature Sampling: A non-Bayesian stochastic baseline that uses a fixed, globally-tuned temperature to scale the logits before sampling experts, as explored in Chapter 3.
Proposed Methods
We evaluate the six Bayesian routing methods developed in Chapter 4: the three weight-space methods (MCDR, SWAGR, DER), two logit-space methods (MFVR, FCVR) and one selection-space method (VTSR).
#### 5.1.2 Datasets and Tasks
All evaluations are performed on the Multiple-Choice Question Answering (MCQA) task across a suite of seven distinct datasets. These datasets test a range of reasoning skills, from commonsense knowledge to expert-level domains. A brief description of each is provided below, with full details on data format, preprocessing and splits available in Table LABEL:tab:mcqa_datasets_summary, Appendix A.
- OpenBookQA (OBQA) [44]: A commonsense reasoning dataset requiring scientific knowledge from an open book of elementary-level science facts.
- AI2 Reasoning Challenge (ARC) [45]: A dataset of challenging, grade-school-level science questions. We use both the difficult ARC-Challenge set and the simpler ARC-Easy set.
- SciQ [46]: A dataset containing crowdsourced science exam questions covering a broad range of topics in physics, chemistry, and biology.
- MedMCQA [47]: A large-scale medical entrance exam dataset. We use a subset of questions from the Medicine subject area, which requires expert clinical knowledge.
- MMLU (Massive Multitask Language Understanding) [48]: A benchmark designed to measure knowledge across a vast range of subjects. We use the Professional Law subset for our experiments.
Our experiments are structured into two distinct evaluation settings:
In-Distribution (ID) Evaluation
For the primary calibration and performance analysis, we fine-tune and evaluate the model separately on four distinct datasets, treating each as an independent in-distribution task: OBQA, ARC-Challenge, SciQ, and MedMCQA-Med.
Out-of-Distribution (OoD) Evaluation
For OoD detection experiments, the model is fine-tuned solely on OBQA. We then test its ability to distinguish this in-domain data from two types of distributional shifts:
- Small Shift (Formal Science): ARC-Challenge and ARC-Easy.
- Large Shift (Expert Domains):- MedMCQA-Med and MMLU-Law.
#### 5.1.3 Evaluation Metrics
To test our hypotheses, we employ a suite of metrics to measure model stability, calibration, and OoD detection performance.
- Routing Stability: Measured using the Jaccard Similarity between the expert sets selected for an original input and its perturbed version.
- Performance and Calibration: Measured using standard classification and calibration metrics:
- Accuracy: The proportion of correct answers.
- Negative Log-Likelihood (NLL): Measures the quality of the predicted probabilities.
- Expected Calibration Error (ECE): The primary metric for miscalibration, measuring the difference between confidence and accuracy.
- Maximum Calibration Error (MCE): Measures the worst-case calibration error in any confidence bin.
- Out-of-Distribution Detection: Measured by treating the task as a binary classification problem (ID vs. OoD) based on an uncertainty score. We report:
- AUROC: The Area Under the Receiver Operating Characteristic curve.
- AUPRC: The Area Under the Precision-Recall curve.
### 5.2 Implementation Details and Training Strategy
This section details the specific choices made during the implementation of our experiments, including the entire training procedure to guarantee fair comparison, which layers were modified, and the key tuning considerations required for each of the proposed Bayesian methods.
#### 5.2.1 Training Pipeline
To create a strong deterministic baseline and ensure a fair comparison, we employ a multi-stage fine-tuning process.
Deterministic Router Fine-Tuning (MAP Baseline)
Our process begins by adapting the pre-trained Granite-3.1 model to our in-distribution MCQA task. This is done in two stages:
1. First, we perform an efficient LoRA (Low-Rank Adaptation) [49] fine-tuning of the attention layers’ Key, Value, and Query (KVQ) projection matrices. This adapts the model’s core representations to the task domain.
1. Second, with the adapted attention layers frozen, we conduct a full-parameter fine-tuning of all MoE router linear layers. This yields our strong, deterministic baseline router with Maximum a Posteriori (MAP) weights.
Bayesian Router Fine-Tuning
All of our proposed Bayesian methods are then trained as a final fine-tuning step. Each Bayesian router is initialised with the weights from the converged MAP baseline and then trained further according to its specific objective (e.g., with dropout active, using the ELBO loss, etc.). This ensures that any observed improvements are due to the Bayesian treatment itself, rather than differences in initialisation or general training.
#### 5.2.2 MoE Layer Selection Strategies
A key research question when modifying a deep architecture like an MoE-LLM is not just how to intervene, but where. To investigate this, we evaluate three distinct strategies for choosing which MoE router layers to make Bayesian:
1. Susceptible Layers (Primary Strategy): Our main approach is to apply the Bayesian treatment only to the layers identified as most brittle in our motivational stability analysis (Chapter 3). This tests the hypothesis that a targeted intervention is most effective. All main results in this chapter are reported using this strategy.
1. Last Layer (Heuristic): A simple heuristic where only the final MoE layer in the network is made Bayesian. This targets the layer responsible for the highest level of semantic abstraction.
1. Last-5 Layers (Heuristic): A more general heuristic that applies the Bayesian modification to a block of the final five MoE layers, without relying on a prior stability analysis.
A comparative analysis of these three strategies is presented in Section 5.6 to validate our primary approach.
#### 5.2.3 Method-Specific Tuning and Considerations
Each of our proposed Bayesian methods has unique hyperparameters that require careful tuning to ensure both stability and optimal performance.
MC Dropout Router (MCDR)
The most critical hyperparameter for MCDR is dropout rate, $p$ . After experimentation, a rate of $p=0.05$ was selected. A MC sample number of $S=35$ was used.
Deep Ensembles of Routers (DER)
For DER, key parameter is number of ensemble members, $M$ . While a larger ensemble yields better performance, this comes at a linear cost in both computation and memory. For computational feasibility, our experiments were conducted with $M=10$ .
Variational Routers (MFVR & FCVR)
The crucial hyperparameter for the variational routers is the KL-divergence weight, $\beta$ , in the ELBO loss function. This term balances the task-specific reconstruction loss against the regularisation of the latent logit space. Careful tuning is required to prevent posterior collapse.
Variational Temperature Router (VTSR)
Similarly, the VTSR has a regularisation weight, $\beta$ , for its $\mathbb{E}[\log(T(\mathbf{x}))]$ term. This is essential for preventing the learned temperature from collapsing towards zero, which would revert the model to a deterministic state.
All code to reproduce our experiments, including the specific hyperparameter configurations for each method, is available at our public repository https://github.com/albus-li/albus-bayesian-moe-router.
### 5.3 Experiment 1: Stability Under Perturbation
#### 5.3.1 Goal and Methodology
The first experiment directly tests our Stability Hypothesis: that the proposed Bayesian routing methods are more robust to minor input perturbations than the standard deterministic router. A robust router should maintain a consistent expert selection policy when faced with semantically meaningless noise, while a brittle router will exhibit erratic changes.
To measure this, we adopt the same methodology as our motivational experiment in Chapter 3. We inject a small amount of calibrated Gaussian noise into the input of the target MoE router layer. We then measure the change in the set of selected experts between the original and perturbed input using the Jaccard Similarity. This process is repeated for all methods across a large sample of test tokens, and the mean Jaccard Similarity is reported.
#### 5.3.2 Results and Analysis
The results of the stability experiment are presented in Figure 5.1. These scores were obtained by fine-tuning the susceptible layers of the ibm-granite-3b model on the OBQA dataset. The final Jaccard Similarity for each method is the average score across all modified layers and test tokens.
As hypothesised, the deterministic router exhibits the lowest stability, confirming its brittle nature with a mean Jaccard Similarity of only 0.650. The simple temperature sampling baseline offers a modest improvement to 0.722, suggesting that even ad-hoc stochasticity helps mitigate brittleness.
All proposed Bayesian methods demonstrate a substantial and statistically significant improvement in routing stability over both baselines. The logit-space methods proved to be particularly effective, with the FCVR achieving the highest stability of all methods at 0.897, followed closely by the MFVR at 0.853. Among the weight-space methods, SWAGR was a top performer with a score of 0.883. The other methods, including VTSR (0.840), DER (0.824), and MCDR (0.822), also provided strong and reliable improvements.
<details>
<summary>x18.png Details</summary>
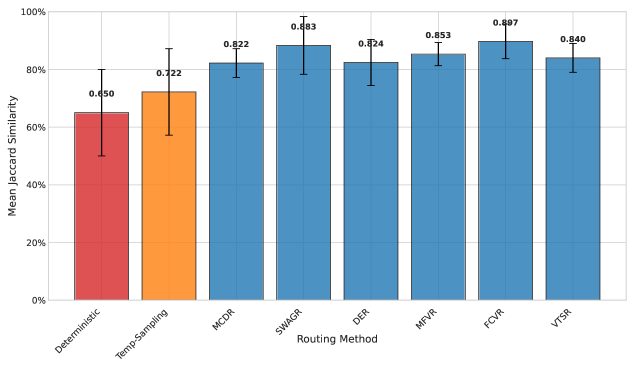
### Visual Description
\n
## Bar Chart: Mean Jaccard Similarity vs. Routing Method
### Overview
This bar chart compares the Mean Jaccard Similarity achieved by different routing methods. Each bar represents a routing method, and the height of the bar indicates the corresponding Mean Jaccard Similarity. Error bars are present on top of each bar, representing the variability or uncertainty in the measurement.
### Components/Axes
* **X-axis:** "Routing Method" with the following categories: "Deterministic", "Temp-Sampling", "MCDR", "SWAGR", "DER", "MFVR", "FCVR", "VTSR".
* **Y-axis:** "Mean Jaccard Similarity" ranging from 0% to 100% with increments of 20%.
* **Bars:** Represent the Mean Jaccard Similarity for each routing method.
* **Error Bars:** Black lines extending vertically from the top of each bar, indicating the standard error or confidence interval.
### Detailed Analysis
The chart displays the following data points (approximate values read from the chart):
* **Deterministic:** Mean Jaccard Similarity ≈ 65%, with an error bar extending to approximately 70% and down to 60%.
* **Temp-Sampling:** Mean Jaccard Similarity ≈ 22%, with an error bar extending to approximately 30% and down to 15%.
* **MCDR:** Mean Jaccard Similarity ≈ 82%, with an error bar extending to approximately 86% and down to 78%.
* **SWAGR:** Mean Jaccard Similarity ≈ 83%, with an error bar extending to approximately 87% and down to 79%.
* **DER:** Mean Jaccard Similarity ≈ 82%, with an error bar extending to approximately 86% and down to 78%.
* **MFVR:** Mean Jaccard Similarity ≈ 85%, with an error bar extending to approximately 88% and down to 82%.
* **FCVR:** Mean Jaccard Similarity ≈ 89.7%, with an error bar extending to approximately 91% and down to 88%.
* **VTSR:** Mean Jaccard Similarity ≈ 84%, with an error bar extending to approximately 87% and down to 81%.
The bars for MCDR, SWAGR, DER, MFVR, FCVR, and VTSR are all a similar shade of blue. The "Deterministic" bar is red, and the "Temp-Sampling" bar is orange.
### Key Observations
* The "Deterministic" and "Temp-Sampling" methods have significantly lower Mean Jaccard Similarity scores compared to the other methods.
* "FCVR" exhibits the highest Mean Jaccard Similarity.
* The methods MCDR, SWAGR, DER, MFVR, and VTSR all achieve relatively high and similar Mean Jaccard Similarity scores, generally between 82% and 85%.
* The error bars suggest that the variability in the Mean Jaccard Similarity is relatively small for all methods, except perhaps for "Temp-Sampling".
### Interpretation
The data suggests that the routing methods MCDR, SWAGR, DER, MFVR, FCVR, and VTSR are substantially more effective at achieving high Jaccard Similarity than the "Deterministic" and "Temp-Sampling" methods. The Jaccard Similarity is a measure of the overlap between two sets, in this context, likely representing the similarity between the routes found by the routing method and some optimal or desired routes.
The consistently high performance of the blue bars indicates that these methods are robust and reliable in finding routes with a high degree of similarity to the desired routes. The "FCVR" method stands out as the best performer, consistently achieving the highest Jaccard Similarity. The low scores for "Deterministic" and "Temp-Sampling" suggest these methods may produce routes that deviate significantly from the desired routes, or are less adaptable to the environment.
The error bars provide a measure of the confidence in these results. The relatively small error bars for most methods suggest that the observed differences in performance are likely real and not due to random chance. The larger error bar for "Temp-Sampling" indicates that the performance of this method is more variable and less predictable.
</details>
Figure 5.1: Mean Jaccard Similarity for each routing method under input perturbation, evaluated on the OBQA dataset. Higher scores indicate greater stability. Error bars represent the standard deviation across the test set.
This experiment provides compelling evidence in support of our stability hypothesis. The results quantitatively demonstrate that modelling uncertainty with a range of different Bayesian methods leads to a more robust and reliable expert selection mechanism compared to the deterministic approach.
### 5.4 Experiment 2: In-Distribution Calibration
#### 5.4.1 Goal and Methodology
This experiment tests our Calibration Hypothesis: that the proposed Bayesian routing methods can improve model calibration on in-distribution (ID) tasks without significantly harming predictive accuracy. A well-calibrated model is crucial for trustworthiness, as its predictive confidence should accurately reflect its likelihood of being correct.
The evaluation is conducted on our suite of in-distribution MCQA datasets. We measure performance using standard metrics: Accuracy (ACC) for predictive performance, and Negative Log-Likelihood (NLL), Expected Calibration Error (ECE), and Maximum Calibration Error (MCE) to quantify calibration. We also use Reliability Diagrams for a visual assessment of calibration.
#### 5.4.2 Results and Analysis
We tested our proposed Bayesian methods and the baselines on all four in-distribution datasets. The routers displayed a consistent pattern of behaviour across all settings. For clarity, we present the results from the OpenBookQA (OBQA) dataset here as a representative example. The full results for all four datasets are detailed in Table C.1, Appendix C.
The primary quantitative results for OBQA are summarised in Figure 5.2 Metrics for every method (exluding deterministic baseline and DER) are averaged over 5 stochastic forward passes. Standard deviations are shown as error bars. . A key finding is that all of our proposed Bayesian methods maintain Accuracy on par with the strong deterministic baseline. This is a crucial distinction from the ‘Temp-Sampling’ baseline, which improves calibration but at a notable cost to accuracy, highlighting the trade-offs of using unprincipled stochasticity.
The benefits of our approach become evident in the probabilistic and calibration metrics. For Negative Log-Likelihood (NLL), the MC Dropout Router was the top performer. This is a particularly noteworthy result, as MCDR is simple to implement and demonstrates that an effective probabilistic model does not necessarily require a complex architecture. As our primary metric for miscalibration, the Expected Calibration Error (ECE) is substantially reduced by all Bayesian methods. The logit-space methods performed exceptionally well, with FCVR reducing the ECE by over 94% compared to the deterministic baseline.
<details>
<summary>x19.png Details</summary>
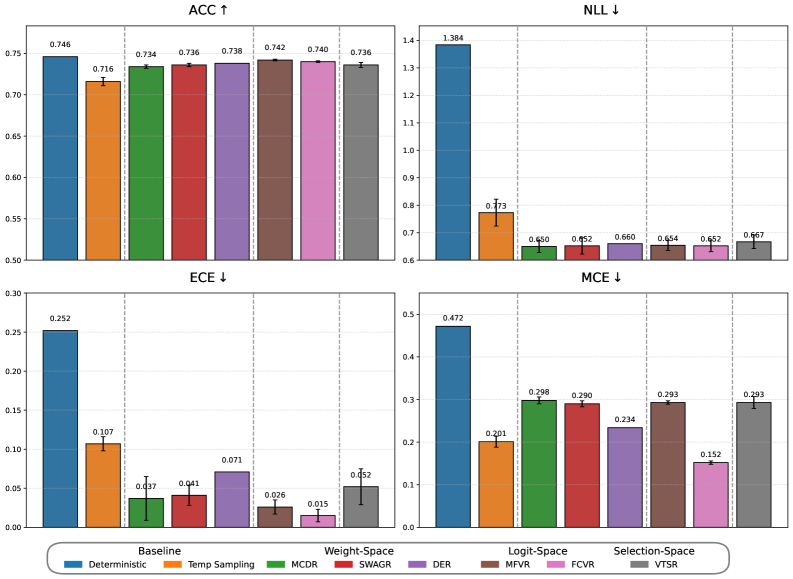
### Visual Description
\n
## Bar Charts: Model Performance Metrics
### Overview
The image presents four bar charts comparing the performance of several models across four different metrics: Accuracy (ACC), Negative Log Likelihood (NLL), Expected Calibration Error (ECE), and Maximum Calibration Error (MCE). Each chart displays the metric value for different models, represented by colored bars with error bars. The models are categorized into Baseline, Weight-Space, Logit-Space, and Selection-Space.
### Components/Axes
* **X-axis:** Represents the different models. The models are: Deterministic, Temp Sampling, MCDR, SWAGR, DER, MFVR, FCVR, VTSR.
* **Y-axis:** Represents the metric value. The scales vary for each chart.
* ACC: 0.50 to 0.75
* NLL: 0.60 to 1.40
* ECE: 0.00 to 0.30
* MCE: 0.00 to 0.50
* **Legend:** Located at the bottom of the image, it maps colors to model names.
* Baseline: Blue
* Weight-Space: Green
* Logit-Space: Red
* Selection-Space: Purple
* **Titles:** Each chart has a title indicating the metric being displayed, along with an arrow indicating whether a lower or higher value is better (↑ for higher, ↓ for lower).
### Detailed Analysis or Content Details
**1. ACC ↑ (Accuracy)**
* **Deterministic (Blue):** 0.746 ± ~0.005
* **Temp Sampling (Blue):** 0.716 ± ~0.005
* **MCDR (Green):** 0.734 ± ~0.005
* **SWAGR (Green):** 0.738 ± ~0.005
* **DER (Red):** 0.742 ± ~0.005
* **MFVR (Red):** 0.740 ± ~0.005
* **FCVR (Purple):** 0.736 ± ~0.005
The accuracy values are relatively high across all models, ranging from approximately 0.716 to 0.746. The deterministic model has the highest accuracy.
**2. NLL ↓ (Negative Log Likelihood)**
* **Deterministic (Blue):** 1.384 ± ~0.01
* **Temp Sampling (Blue):** 0.73 ± ~0.01
* **MCDR (Green):** 0.690 ± ~0.01
* **SWAGR (Green):** 0.660 ± ~0.01
* **DER (Red):** 0.654 ± ~0.01
* **MFVR (Red):** 0.652 ± ~0.01
* **FCVR (Purple):** 0.667 ± ~0.01
The NLL values vary significantly. The deterministic model has the highest NLL, while the other models have lower values, ranging from approximately 0.652 to 0.73.
**3. ECE ↓ (Expected Calibration Error)**
* **Deterministic (Blue):** 0.252 ± ~0.01
* **Temp Sampling (Blue):** 0.107 ± ~0.01
* **MCDR (Green):** 0.041 ± ~0.005
* **SWAGR (Green):** 0.071 ± ~0.005
* **DER (Red):** 0.015 ± ~0.005
* **MFVR (Red):** 0.052 ± ~0.005
* **FCVR (Purple):** 0.026 ± ~0.005
The ECE values are generally low, with the deterministic model having the highest value. The other models have ECE values ranging from approximately 0.015 to 0.107.
**4. MCE ↓ (Maximum Calibration Error)**
* **Deterministic (Blue):** 0.472 ± ~0.02
* **Temp Sampling (Blue):** 0.201 ± ~0.02
* **MCDR (Green):** 0.298 ± ~0.02
* **SWAGR (Green):** 0.290 ± ~0.02
* **DER (Red):** 0.234 ± ~0.02
* **MFVR (Red):** 0.152 ± ~0.02
* **FCVR (Purple):** 0.293 ± ~0.02
The MCE values show a similar trend to ECE, with the deterministic model having the highest value. The other models have MCE values ranging from approximately 0.152 to 0.298.
### Key Observations
* The Deterministic model consistently performs well on ACC but poorly on NLL, ECE, and MCE.
* Models in the Weight-Space and Logit-Space categories generally outperform the Baseline models (Deterministic and Temp Sampling) on NLL, ECE, and MCE.
* The Selection-Space model (FCVR) shows competitive performance on all metrics.
* Error bars are relatively small, suggesting consistent results.
### Interpretation
The data suggests that while the Deterministic model achieves high accuracy, it suffers from poor calibration (high ECE and MCE) and a high negative log-likelihood. This indicates that its confidence scores are not well-aligned with its actual accuracy. The other models, particularly those in the Weight-Space and Logit-Space categories, demonstrate better calibration and lower NLL, suggesting they provide more reliable and well-calibrated predictions. The Selection-Space model (FCVR) offers a good balance between accuracy and calibration.
The differences in performance across the metrics highlight the trade-offs between accuracy and calibration. A model can achieve high accuracy by being overconfident in its predictions, but this can lead to poor calibration. The models that prioritize calibration (lower NLL, ECE, and MCE) may sacrifice some accuracy, but they provide more trustworthy predictions. The choice of which model to use depends on the specific application and the relative importance of accuracy and calibration.
</details>
Figure 5.2: In-distribution performance and calibration results on the OpenBookQA (OBQA) dataset.
Overall, this experiment provides strong evidence in support of our calibration hypothesis. The results show that by introducing principled uncertainty into the routing mechanism, we can significantly improve the calibration of MoE models without compromising their core predictive accuracy.
### 5.5 Experiment 3: Out-of-Distribution Detection
#### 5.5.1 Goal and Methodology
This experiment evaluates our OoD Detection Hypothesis by investigating how our proposed Bayesian routers improve the model’s ability to distinguish in-domain (ID) from out-of-distribution (OoD) data. We designed four distinct OoD detection tasks in total: two representing a small distributional shift (ID: OBQA vs. OoD: ARC-C / ARC-E) and two representing a large distribution shift (ID: OBQA vs. OoD: MMLU-Law / MedMCQA). To ensure a clear demonstration of the main findings, we present the results for one representative large-shift task, ID: OBQA vs. OoD: MedMCQA-Med, in this section. The complete results for all four OoD tasks can be found in Appendix D.
The evaluation is structured as two distinct sub-experiments, each testing a specific aspect of uncertainty. The task is framed as a binary classification problem where a model-derived uncertainty score is used to classify inputs, with performance measured by AUROC and AUPRC. Based on their strong performance in the in-distribution calibration experiments, we focus our analysis on four standout Bayesian methods: MCDR (as the most effective weight-space method), MFVR, FCVR, and VTSR.
#### 5.5.2 Experiment 3a: Improving Standard Uncertainty Signal
Our first hypothesis is that the uncertainty introduced by a Bayesian router will propagate through the network, making the standard uncertainty signal—the entropy of the final prediction over the vocabulary—more reliable. To test this, we compare the OoD detection performance using the final vocabulary entropy from our standout Bayesian methods against the same signal from the deterministic baseline. The results, shown in Table 5.1, demonstrate a clear improvement across all evaluated methods.
Table 5.1: OoD detection performance using the final vocabulary entropy on the OBQA vs. MedMCQA task. Best results are in bold.
| Method | AUROC $\uparrow$ | AUPRC $\uparrow$ |
| --- | --- | --- |
| Deterministic | 0.762 | 0.727 |
| MCDR | 0.793 | 0.737 |
| MFVR | 0.844 | 0.782 |
| FCVR | 0.853 | 0.802 |
| VTSR | 0.812 | 0.791 |
The FCVR method achieves the highest scores, but all Bayesian approaches show a significant gain in both AUROC and AUPRC over the deterministic model. This suggests that a more robust internal routing mechanism leads to a more calibrated and reliable final prediction distribution, which in turn serves as a better signal for OoD detection.
This finding is crucial as it validates the idea that improving an internal component of the model can have a positive, measurable impact on final output’s reliability.
#### 5.5.3 Experiment 3b: Router-Level Uncertainty as Signal
Inspired by work [50] showing that MoE routing probabilities can serve as meaningful representations, our second hypothesis is that the router’s internal uncertainty can be leveraged as a novel and superior signal for OoD detection. We test if method-specific signals Details of each method-specific signals are provided in Appendix D. that directly capture the router’s epistemic uncertainty (e.g., logit variance) outperform the naive entropy of the expert selection probabilities.
Table 5.2: Comparison of different router-level uncertainty signals for OoD detection on the OBQA vs. MedMCQA task. The best signal for each method is in bold.
| Method | Router-Level Signal Type | AUROC $\uparrow$ | AUPRC $\uparrow$ |
| --- | --- | --- | --- |
| Deterministic | Expert Selection Entropy | 0.679 | 0.645 |
| MCDR | Expert Selection Entropy | 0.684 | 0.651 |
| MC Logit Variance | 0.786 | 0.723 | |
| MFVR | Expert Selection Entropy | 0.682 | 0.637 |
| Inferred Logit Variance | 0.835 | 0.793 | |
| FCVR | Expert Selection Entropy | 0.692 | 0.642 |
| Inferred Logit Variance | 0.844 | 0.773 | |
| VTSR | Expert Selection Entropy | 0.683 | 0.643 |
| Inferred Temperature | 0.512 | 0.492 | |
This detailed analysis reveals several key insights. A surprising finding is that expert selection entropy, when used as an uncertainty signal, shows only marginal improvements for Bayesian methods compared to deterministic baseline. This suggests that simply making the routing process probabilistic is not, by itself, sufficient to create a powerful OoD signal at the post-softmax level.
The true benefit of our framework is revealed when we examine the method-specific uncertainty signals. For every method that provides such a signal, it consistently and significantly outperforms the naive expert selection entropy. As shown in Table 5.2, the ‘Logit Variance’ for MCDR, MFVR and FCVR are demonstrably better OoD detectors. This confirms our core hypothesis: the internal, pre-softmax uncertainty about the logits provides a richer and more reliable measure of the model’s confidence than the entropy of the final probabilities.
Furthermore, the poor performance of the ‘Inferred Temperature’ from the VTSR provides a crucial diagnostic insight. The model’s failure to produce a high temperature for OoD inputs indicates that the training objective is dominated by the task loss, causing the regularisation term to be ignored. This is a classic symptom of posterior collapse, where the model learns to make its uncertainty signal uninformative (i.e., always predicting a low temperature) to achieve a lower overall loss. This highlights the challenges in training such a direct signal and reinforces the effectiveness of the more implicit uncertainty captured by the logit-space and weight-space methods.
### 5.6 Ablation Study: Comparative Analysis of Layer Selection
The main results presented in the preceding sections were generated using our primary Susceptible Layers strategy. This section provides a detailed ablation study to validate that methodological choice. For each of our standout Bayesian methods (MCDR, MFVR, FCVR, and VTSR), we compare its performance when applied using three different layer selection strategies:
1. Susceptible Layers (Primary): Targeted approach based on stability analysis in Chapter 3.
1. Last Layer Only (Heuristic): A simple heuristic targeting only the final MoE layer.
1. Last-5 Layers (Heuristic): A more general heuristic targeting a block of final five MoE layers.
We evaluate these strategies using the single key metric from each of our three main experiments, with results averaged across all relevant datasets.
The results of this comparison are summarised in Table 5.3. The findings show a clear and consistent trend across all evaluated methods: the targeted Susceptible Layers strategy almost always yields the best performance. For nearly every method, this strategy achieves the highest mean Jaccard Similarity, the lowest mean ECE, and the highest mean AUROC.
While the “Last-5 Layers” heuristic provides a reasonable improvement, it rarely matches the performance of the more targeted approach. The “Last Layer Only” strategy is clearly suboptimal, suggesting that intervening at a single, final layer is insufficient to address the model’s systemic brittleness. These findings validate our primary methodological choice, demonstrating that a targeted application of Bayesian methods to the layers most prone to instability is more effective than using simpler heuristics.
Table 5.3: Comparative analysis of layer selection strategies for each standout Bayesian method. The AUROC metric is calculated using the final vocabulary entropy. Best result for each method is in bold.
| Method | Layer Selection Strategy | Jaccard $\uparrow$ | ECE $\downarrow$ | AUROC (Voc. Ent.) $\uparrow$ |
| --- | --- | --- | --- | --- |
| MCDR | Susceptible layers | 0.822 | 0.037 | 0.793 |
| Last 5 Layers | $0.793$ | $0.113$ | $0.773$ | |
| Last Layer Only | $0.752$ | $0.135$ | $0.762$ | |
| MFVR | Susceptible layers | 0.853 | 0.026 | 0.844 |
| Last 5 Layers | $0.821$ | $0.121$ | $0.808$ | |
| Last Layer Only | $0.779$ | $0.205$ | $0.778$ | |
| FCVR | Susceptible layers | 0.897 | 0.015 | 0.853 |
| Last 5 Layers | $0.872$ | $0.103$ | $0.811$ | |
| Last Layer Only | $0.783$ | $0.194$ | $0.783$ | |
| VTSR | Susceptible layers | 0.840 | 0.052 | 0.812 |
| Last 5 Layers | $0.832$ | $0.142$ | $0.789$ | |
| Last Layer Only | $0.732$ | $0.168$ | $0.773$ | |
### 5.7 Practicality: Efficiency Analysis of Bayesian Routers
This section will provide a rigorous quantitative discussion of the memory and computational costs of the proposed Bayesian routing methods. To be considered practical, the overhead of these methods must be negligible relative to the scale of the base model. This analysis will show that this is indeed the case.
- $L$ : MoE (Mixture of Experts) layer number
- $N$ : Number of experts
- $D$ : Model hidden dimension
- $S$ : Number of Monte Carlo samples
- $M$ : Number of ensemble members
- $H$ : Hidden dimension within additional networks ( $\text{NN}_{\mu}$ , $\text{NN}_{\sigma}$ in MFVR/FCVR, $\text{NN}_{\text{temp}}$ in VTSR)
- $B$ : Batch size
- $T$ : Sequence length
#### 5.7.1 Memory Overhead
To assess the practicality of our methods, we first analyse their memory footprint. In the context of large-scale MoE models, the most critical metric is not the on-disk storage size, but the activation memory, the total number of parameters that must be actively held in GPU memory to perform an inference pass [1], which is the principle we will adopt for our analysis For some sample-based methods, number of activated parameters during inference can exceed that of stored parameters. .
Weight-Space Methods
The inference-time memory cost for weight-space methods is driven by the need to generate multiple samples of the router weights.
- MCDR is exceptionally efficient. As dropout is implemented as a mask on the input activations, it requires zero additional weight parameters to be loaded into memory.
- SWAGR requires loading $S$ samples of the expert centroid matrix, $W_{\text{EC}}$ , for parallel processing. The total additional activation memory for $L$ modified layers is therefore $L\times(S-1)\times D\times N$ .
- DER also requires loading all $M$ ensemble members, resulting in an additional memory cost of $L\times(M-1)\times D\times N$ .
Logit and Selection-Space Methods
For these methods, the primary memory overhead is the fixed cost of the additional inference network’s parameters, which must be loaded into memory.
- MFVR requires a one-hidden-layer MLP with a hidden dimension $H$ and two output heads of size $N$ , for a total of $L\times(D\cdot H+2\cdot H\cdot N)$ additional parameters.
- FCVR is similar, but one output head must parameterise the Cholesky factor, which has $\frac{N(N+1)}{2}$ elements. The cost is $L\times(D\cdot H+H\cdot N+H\cdot\frac{N(N+1)}{2})$ .
- VTSR requires only a small network to predict a scalar, for a cost of $L\times(D\cdot H+H\cdot 1)$ parameters.
Table 5.4 quantifies these theoretical costs within the context of the Granite-3B-MoE $D=1536$ , $N=40$ , $L_{\text{total}}=32$ model, assuming the modification of $L=10$ layers and hyperparameters of $S=35$ , $M=10$ and $H=\frac{D}{4}$ .
Table 5.4: Theoretical activation memory overhead for each Bayesian router, quantified for the Granite-3B MoE model and shown as a percentage of the total $\sim$ 800M activated parameters during inference.
| Method | Theoretical Formula | Actual Add. Params | % of Total Model |
| --- | --- | --- | --- |
| MCDR | 0 | 0 | 0.00% |
| SWAGR | $L(S-1)DN$ | $\sim$ 20.9M | $\sim$ 2.61% |
| DER | $L(M-1)DN$ | $\sim$ 5.5M | $\sim$ 0.69% |
| MFVR | $L(DH+2HN)$ | $\sim$ 6.2M | $\sim$ 0.78% |
| FCVR | $L(DH+HN+H\frac{N(N+1)}{2})$ | $\sim$ 9.2M | $\sim$ 1.15% |
| VTSR | $L(DH+H)$ | $\sim$ 5.9M | $\sim$ 0.74% |
#### 5.7.2 Computation Overhead
Next, we analyse the computational cost of each method in terms of floating-point operations (FLOPs). The primary source of computational cost in our networks is matrix multiplication. The FLOPs required to multiply a $p\times r$ matrix with an $r\times q$ matrix is approximately $2prq$ . Therefore, a single forward pass for one token through a router’s linear layer ( $W_{EC}\in\mathbb{R}^{D\times N}$ ) requires approximately $2DN$ FLOPs. In our analysis, we consider costs of activation functions negligible.
Weight-Space Methods
The overhead for these methods comes from the need to perform multiple forward passes through the router to generate samples.
- MCDR and SWAGR: Both require $S$ forward passes. The additional cost over the single baseline pass is $L\times(S-1)\times 2DN$ FLOPs.
- DER: It requires $M$ forward passes, for an additional cost of $L\times(M-1)\times 2DN$ FLOPs.
Logit-Space Methods
These methods incur overhead from both their additional inference network and the sampling process.
- MFVR: Double-head one-hidden-layer MLP adds approximately $2DH+4HN$ FLOPs. Reparameterisation trick for $S$ samples adds $S\times 2N$ FLOPs. Total overhead is the sum of these two.
- FCVR: MLP cost is higher due to the larger Cholesky factor output head, costing roughly $2DH+2HN+2H\frac{N(N+1)}{2}$ FLOPs. The reparameterisation requires a matrix-vector product, adding $S\times 2N^{2}$ FLOPs.
Selection-Space Method
- VTSR: The temperature prediction network adds approximately $2DH+2H$ FLOPs. This is followed by $N$ divisions to scale the logits Our theoretical FLOPs analysis does not include the cost of averaging multiple post-softmax outputs. If this is considered from a theoretical analysis standpoint, VTSR would be even more efficient, as it does not require sampling..
Table 5.5 summarises the theoretical overhead of each method and contextualises it as a percentage of the total FLOPs Actual Additional FLOPs are measured and calcuated via fvcore python library. required for a full forward pass of the Granite-3B-MoE model.
Table 5.5: Theoretical and experimental computational overhead of Bayesian routers.
| Method | Theoretical FLOPs Overhead (Big-O) | Actual Add. FLOPs (GFLOPs Per Token) | % of Total Model |
| --- | --- | --- | --- |
| MCDR | $O(LSDN)$ | 0.0208 | 2.32% |
| SWAGR | $O(LSDN)$ | 0.0208 | 2.32% |
| DER | $O(LMDN)$ | 0.0059 | 0.66% |
| MFVR | $O(L(DH+HN+SN))$ | 0.0069 | 0.77% |
| FCVR | $O(L(DH+HN^{2}+SN^{2}))$ | 0.0096 | 1.07% |
| VTSR | $O(L(DH+H+N))$ | 0.0060 | 0.67% |
#### 5.7.3 Parallelisation and Practical Trade-offs
The theoretical FLOPs translate to real-world latency based on how well the computation can be parallelised on a GPU. The $S$ sampling steps required for most of our methods are embarrassingly parallelisable [51].
- MCDR: Highly efficient; the input batch can be expanded by a factor of $S$ and processed in a single pass with different dropout masks.
- DER and SWAGR: The $S$ forward passes use different weight matrices, which is less efficient but still parallelisable.
- MFVR and FCVR: Monte Carlo sampling occurs after the parameters of the logit distribution ( $\boldsymbol{\mu},\boldsymbol{\Sigma}$ ) have been computed. This is very efficient, as only the small reparameterisation step needs to be parallelised, involving vector-scalar operations for MFVR and more expensive matrix-vector operations for FCVR.
- VTSR: The exception, as its single-pass inference requires no parallel sampling strategy, making its latency profile fundamentally different and more efficient.
This analysis culminates in the qualitative summary of trade-offs presented in Table 5.6. The FCVR offers state-of-the-art performance at a moderate computational cost. MCDR provides a solid baseline improvement for almost no implementation overhead. While VTSR offers a uniquely compelling low-latency profile, its performance was hampered by training instability and temperature collapse in our experiments. Despite these current limitations, we believe the underlying concept of learning a direct, input-dependent routing stochasticity is powerful. It remains a fascinating and promising area for future work, focussed on the development of more stable training methods.
Table 5.6: A qualitative summary of the trade-offs between performance and practicality for all evaluated methods.
| Method | Calibration $\uparrow$ | OoD Detection $\uparrow$ | Memory Overhead $\downarrow$ | FLOPs Overhead $\downarrow$ |
| --- | --- | --- | --- | --- |
| gray!20 MCDR | High | Medium | Negligible | High |
| SWAGR | Medium | Medium | High | High |
| DER | Medium | Medium | Low | Low |
| MFVR | High | High | Low | Low |
| gray!20 FCVR | Very High | High | Medium | Medium |
| gray!20 VTSR | High | Low | Low | Low |
### 5.8 Chapter Summary
This chapter presented a comprehensive empirical evaluation of our proposed Bayesian routing methods, assessing their performance on routing stability, model calibration, and out-of-distribution detection, as well as their practical efficiency.
The results from our experiments provide strong, consistent evidence in support of our core hypotheses. We demonstrated that all proposed Bayesian methods significantly improve routing stability and lead to substantial gains in ID calibration without harming predictive accuracy. Furthermore, we showed that the internal uncertainty signals derived from the Bayesian routers are highly effective for OoD detection, decisively outperforming the standard baselines.
This performance, however, must be weighed against practical costs. Our efficiency analysis revealed a clear spectrum of trade-offs. The logit-space approaches, particularly the FCVR, consistently provided the strongest performance but at a moderate computational cost. In contrast, the MCDR offered a solid improvement for a negligible implementation overhead, while the VTSR proved to be exceptionally efficient from a latency perspective. Our ablation study on layer selection further validated our targeted approach, showing that applying these methods to the layers most prone to instability yields the best results.
Taken together, these findings demonstrate that introducing principled Bayesian uncertainty into the MoE routing mechanism is a viable, effective, and computationally tractable strategy for building more reliable, calibrated, and robust Large Language Models.
## Chapter 6 Discussion and Conclusion
This thesis has presented a comprehensive empirical evaluation of a novel Bayesian routing framework designed to improve the reliability of Mixture-of-Experts (MoE) models. The experiments conducted in Chapter 5 provide strong evidence in support of our core hypotheses.
Our results first demonstrated that the standard deterministic router is inherently brittle, whereas all proposed Bayesian methods significantly improve routing stability under input perturbation. On in-distribution tasks, these methods achieve substantial gains in model calibration, as measured by ECE and MCE, without sacrificing predictive accuracy. Furthermore, the uncertainty signals derived directly from the Bayesian routers proved to be highly effective for Out-of-Distribution (OoD) detection, decisively outperforming both the final-layer entropy and the internal signal from the deterministic baseline. Finally, our comparative analysis validated our targeted approach, showing that applying these methods to the layers most susceptible to instability yields the best overall performance.
These collective findings confirm that introducing principled uncertainty into the MoE routing mechanism is an effective strategy for enhancing model reliability, providing a strong foundation for the subsequent discussion on the practical trade-offs and broader implications of this work.
### 6.1 Limitations and Future works
While the results presented in this thesis provide strong evidence for the benefits of Bayesian routing, the scope of this work has several limitations. These limitations, however, naturally define promising and critical directions for future research.
Generalisability Across Models and Tasks
Our empirical evaluation was conducted on a single base model, the Granite-3B-MoE, and was focused primarily on Multiple-Choice Question Answering tasks. While this provided a controlled environment for rigorous analysis, it limits the generalisability of our findings. A crucial finding is that not all MoE architectures demonstrate a significant layer-wise susceptibility difference, as seen in the Granite-3B-MoE. If so, optimal susceptible layer selection strategy might not be as obvious. A crucial next step is to validate these methods across a broader range of MoE architectures, such as those from the DeepSeek-MoE [16] and Qwen-MoE [52] families, and on more diverse downstream tasks. This would be essential to confirm that improved routing reliability translates to performance gains across the wider LLM ecosystem.
Modelling Correlations in Weight-Space
All the weight-space methods evaluated implicitly assume independence among all model weight scalars, which subsequently assume independence between the posteriors of the expert centroid vectors. However, it is highly plausible that expert centroids are correlated: for instance, experts representing similar knowledge domains might occupy nearby or related regions in the embedding space. Future work could explore more structured Bayesian priors that explicitly model these correlations.
Stabilising the Variational Temperature Router
Our experiments with the Variational Temperature Sampling Router (VTSR) highlighted a trade-off between theoretical elegance and practical stability. Its single-pass inference makes it exceptionally efficient, but its training proved challenging, often suffering from temperature collapse despite regularisation. This suggests that while the core concept of learning a direct, input-dependent stochasticity is powerful, it requires further research. Future work could focus on developing more advanced regularisation techniques or alternative training objectives to stabilise the learning of the temperature parameter.
Evaluation on Free-Form Generation
The evaluation in this thesis was intentionally constrained to the MCQA setting to allow for rigorous and quantitative measurement of calibration. However, this does not capture the full range of LLM failure modes, particularly in open-ended, free-form generation. A critical direction for future work is to extend this evaluation to generative tasks. This would involve assessing the impact of Bayesian routers on reducing hallucination, improving the coherence of generated text under uncertainty, and leveraging the router’s uncertainty signal to trigger safer behaviours, such as refusing to answer when the model “knows it doesn’t know”.
### 6.2 Conclusion
The standard deterministic router in Mixture-of-Experts (MoE) models represents a critical vulnerability, where brittle, overconfident expert selections can undermine the reliability of the entire system. This thesis addressed this challenge by proposing and evaluating a structured Bayesian routing framework, demonstrating that a targeted application of principled uncertainty to the lightweight routing mechanism is a pragmatic and effective strategy for improving the trustworthiness of massive-scale LLMs.
Our empirical findings confirm the success of this approach. We systematically evaluated methods that introduce uncertainty at three distinct stages of the routing pipeline: in the Weight-Space, the Logit-Space, and the Selection-Space. The results showed that methods across all three categories successfully enhanced routing stability, improved model calibration, and provided a superior signal for out-of-distribution detection. The analysis also revealed a clear spectrum of trade-offs: the Full-Covariance Variational Router (FCVR) delivered state-of-the-art performance, while methods like MC Dropout Router(MCDR) offered significant gains for minimal effort, and the Variational Temperature Router (VTSR) introduced a promising, highly efficient new direction.
Ultimately, this work provides a practical, architectural pathway toward building more reliable and self-aware language models. Equipping our models with the ability to quantify their own uncertainty is not a peripheral feature but a foundational requirement for their safe and responsible deployment. The Bayesian Mixture of Experts framework developed in this thesis represents a significant and tangible step towards “ making LLMs know what they don’t know ”.
## References
- [1] Shazeer N, Mirhoseini A, Maziarz K, Davis A, Le Q, Hinton G, et al. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv preprint arXiv:170106538. 2017. pages
- [2] Lepikhin D, Lee H, Xu Y, Chen D, Firat O, Huang Y, et al. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. arXiv preprint arXiv:200616668. 2020. pages
- [3] Guo C, Pleiss G, Sun Y, Weinberger KQ. On calibration of modern neural networks. In: International conference on machine learning. PMLR; 2017. p. 1321-30. pages
- [4] Mielke SJ, Szlam A, Boureau Y, Dinan E. Linguistic calibration through metacognition: aligning dialogue agent responses with expected correctness. CoRR. 2020;abs/2012.14983. Available from: https://arxiv.org/abs/2012.14983. pages
- [5] Ji Z, Lee N, Frieske R, Yu T, Su D, Xu Y, et al. Survey of hallucination in natural language generation. ACM Computing Surveys. 2023;55(12):1-38. pages
- [6] Blundell C, Cornebise J, Kavukcuoglu K, Wierstra D. Weight Uncertainty in Neural Networks. In: International Conference on Machine Learning. PMLR; 2015. p. 1613-22. pages
- [7] Bishop CM. Pattern Recognition and Machine Learning. Springer; 2006. Available from: https://link.springer.com/book/10.1007/978-0-387-45528-0. pages
- [8] Murphy KP. Probabilistic Machine Learning: Advanced Topics. MIT Press; 2024. Available from: http://probml.github.io/book2. pages
- [9] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. Advances in neural information processing systems. 2017;30. pages
- [10] Radford A, Narasimhan K. Improving Language Understanding by Generative Pre-Training; 2018. Available from: https://api.semanticscholar.org/CorpusID:49313245. pages
- [11] Brown TB, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, et al. Language models are few-shot learners. Advances in neural information processing systems. 2020;33:1877-901. pages
- [12] maywell. What is LM head mean?; 2022. Accessed: 2025-08-28. https://discuss.huggingface.co/t/what-is-lm-head-mean/21729. pages
- [13] Shazeer N. Glu variants improve transformer. arXiv preprint arXiv:200205202. 2020. pages
- [14] Zhang B, Sennrich R. In: Root mean square layer normalization. Red Hook, NY, USA: Curran Associates Inc.; 2019. . pages
- [15] Su J, Lu Y, Pan S, Murtadha A, Wen B, Liu Y. Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:210409864. 2021. pages
- [16] DeepSeek-AI, Liu A, Feng B, Xue B, Wang B, Wu B, et al.. DeepSeek-V3 Technical Report; 2025. Available from: https://arxiv.org/abs/2412.19437. pages
- [17] Cai W, Jiang J, Wang F, Tang J, Kim S, Huang J. A survey on mixture of experts in large language models. IEEE Transactions on Knowledge and Data Engineering. 2025. pages
- [18] Wikipedia contributors. Multinomial logistic regression — Wikipedia, The Free Encyclopedia; 2024. [Online; accessed 27-May-2025]. Available from: https://en.wikipedia.org/wiki/Multinomial_logistic_regression. pages
- [19] Pham Q, Do G, Nguyen H, Nguyen T, Liu C, Sartipi M, et al. CompeteSMoE–Effective Training of Sparse Mixture of Experts via Competition. arXiv preprint arXiv:240202526. 2024. pages
- [20] Dai D, Dong L, Ma S, Zheng B, Sui Z, Chang B, et al.. StableMoE: Stable Routing Strategy for Mixture of Experts; 2022. Available from: %****␣albus-thesis.bbl␣Line␣100␣****https://arxiv.org/abs/2204.08396. pages
- [21] Wang L, Gao H, Zhao C, Sun X, Dai D. Auxiliary-loss-free load balancing strategy for mixture-of-experts. arXiv preprint arXiv:240815664. 2024. pages
- [22] Fedus W, Zoph B, Shazeer N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research. 2022;23(120):1-39. pages
- [23] Zoph B, Bello I, Kumar S, Du N, Huang Y, Dean J, et al. St-moe: Designing stable and transferable sparse expert models. arXiv preprint arXiv:220208906. 2022. pages
- [24] Kuhn L, Gal Y, Farquhar S. Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation; 2023. Available from: https://arxiv.org/abs/2302.09664. pages
- [25] Farquhar S, Kossen J, Kuhn L, Gal Y. Detecting hallucinations in large language models using semantic entropy. Nature. 2024;630(8017):625-30. pages
- [26] Kapoor S, Gruver N, Roberts M, Collins K, Pal A, Bhatt U, et al. Large language models must be taught to know what they don’t know. Advances in Neural Information Processing Systems. 2024;37:85932-72. pages
- [27] Pakdaman Naeini M, Cooper G, Hauskrecht M. Obtaining Well Calibrated Probabilities Using Bayesian Binning. Proceedings of the AAAI Conference on Artificial Intelligence. 2015 Feb;29(1). Available from: https://ojs.aaai.org/index.php/AAAI/article/view/9602. pages
- [28] Davis J, Goadrich M. The relationship between Precision-Recall and ROC curves. In: Proceedings of the 23rd international conference on Machine learning; 2006. p. 233-40. pages
- [29] Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z. Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2016. p. 2818-26. pages
- [30] Neal RM. MCMC using Hamiltonian dynamics. In: Handbook of Markov Chain Monte Carlo. CRC press; 2011. p. 113-62. pages
- [31] Gal Y, Ghahramani Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In: International conference on machine learning. PMLR; 2016. p. 1050-9. pages
- [32] Maddox WJ, Izmailov P, Garipov T, Vetrov DP, Wilson AG. A Simple Baseline for Bayesian Uncertainty in Deep Learning. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 32; 2019. . pages
- [33] Lakshminarayanan B, Pritzel A, Blundell C. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles; 2017. Available from: https://arxiv.org/abs/1612.01474. pages
- [34] Jordan MI, Ghahramani Z, Jaakkola TS, Saul LK. An introduction to variational methods for graphical models. Machine learning. 1999;37:183-233. pages
- [35] Li Y. Deep Generative Models Part 2: VAEs; 2022. Course Notes, Imperial College London. Available from: http://yingzhenli.net/home/pdf/imperial_dlcourse2022_vae_notes.pdf. pages
- [36] Deisenroth MP, Faisal AA, Ong CS. Mathematics for machine learning. Cambridge University Press; 2020. pages
- [37] Kingma DP, Welling M. Auto-encoding variational bayes. arXiv preprint arXiv:13126114. 2013. pages
- [38] Biswal G. Dive into Variational Autoencoders: A Beginner’s Guide to Understanding the Fundamentals. Plain English (on Medium). 2023 May. Accessed: 2025-09-03. pages
- [39] Higgins I, Matthey L, Pal A, Burgess C, Glorot X, Botvinick M, et al. beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. In: International Conference on Learning Representations; 2017. Available from: https://openreview.net/forum?id=Sy2fzU9gl. pages
- [40] Jang E, Gu S, Poole B. Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:161101144. 2016. pages
- [41] Maddison CJ, Mnih A, Teh YW. The concrete distribution: A continuous relaxation of discrete random variables. arXiv preprint arXiv:161100712. 2016. pages
- [42] Kendall A, Gal Y. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?; 2017. Available from: https://arxiv.org/abs/1703.04977. pages
- [43] IBM. Granite 3.1 Language Models; 2024. Accessed: 2025-09-01. https://github.com/ibm-granite/granite-3.1-language-models. pages
- [44] Mihaylov T, Clark P, Khot T, Sabharwal A. Can a suit of armor conduct electricity? a new dataset for open book question answering. In: Proceedings of the 2018 conference on empirical methods in natural language processing; 2018. p. 2381-91. pages
- [45] Clark P, Cowhey I, Etzioni O, Khot T, Sabharwal A, Schoenick C, et al. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:180305457. 2018. pages
- [46] Welbl J, Stenetorp P, Riedel S. Crowdsourcing a word-sense data set. In: Proceedings of the second workshop on evaluating vector space representations for NLP; 2017. p. 1-6. pages
- [47] Pal A, Umapathi LK, Sankarasubbu M. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In: Conference on Health, Inference, and Learning. PMLR; 2022. p. 248-60. pages
- [48] Hendrycks D, Burns C, Basart S, Zou A, Mazeika M, Song D, et al. Measuring massive multitask language understanding. arXiv preprint arXiv:200903300. 2020. pages
- [49] Hu EJ, Shen Y, Wallis P, Allen-Zhu Z, Li Y, Wang S, et al.. LoRA: Low-Rank Adaptation of Large Language Models; 2021. Available from: https://arxiv.org/abs/2106.09685. pages
- [50] Li Z, Zhou T. Your mixture-of-experts llm is secretly an embedding model for free. arXiv preprint arXiv:241010814. 2024. pages
- [51] Li M, Gururangan S, Dettmers T, Lewis M, Althoff T, Smith NA, et al. Branch-train-merge: Embarrassingly parallel training of expert language models. arXiv preprint arXiv:220803306. 2022. pages
- [52] Qwen, :, Yang A, Yang B, Zhang B, Hui B, et al.. Qwen2.5 Technical Report; 2025. Available from: https://arxiv.org/abs/2412.15115. pages
## Declarations
Use of Generative AI
In the preparation of this thesis, the author utilised the Generative AI model Gemini, developed by Google, as a writing and research assistant. The model’s assistance was primarily in the following areas:
- Early drafting based on detailed outlines and specific instructions provided by author.
- Proofreading for grammatical errors, typos, and clarity.
- Brainstorming and suggesting alternative structures for chapters, sections, and paragraphs to improve narrative flow.
- Generating illustrative code snippets, including LaTeX for tables, Python for visualisations, and TikZ for diagrams.
The conceptual framework, methodological and experimental design, analysis, scientific claims, and final conclusions are entirely the author’s own.
Data and Code Availability
To ensure the reproducibility of this research, all source code and experimental configurations have been made publicly available. This includes the implementation of the Bayesian routing methods, training scripts, and scripts for generating most figures presented in this thesis. The repository can be accessed at:
https://github.com/albus-li/albus-bayesian-moe-router
Ethical Considerations and Computational Resources
All experiments were conducted on established, publicly available academic datasets, and no new private or sensitive user data was collected. The computational experiments were performed on the Imperial College Department of Computing (DoC) GPU Cluster, utilising NVIDIA Tesla A100 (80GB) and Tesla A40 (48GB) GPUs. The author gratefully acknowledges the provision of these essential computational resources.
## Appendix A Models & Datasets
This appendix provides detailed information on:
- MCQA datasets used in this thesis (see Table LABEL:tab:mcqa_datasets_summary)
- Open-sourced state-of-the-art MoE-based LLMs’ configurations (see Table A.2) Not all models listed are used in this thesis. In fact, we only use the IBM Granite MoE models for experiments. The full list is provided for completeness and future reference.
Table A.1: Summary of Selected MCQA Datasets for Calibration and OoD Experiments
| OBQA | Commonsense Science Reasoning | Q: A person wants to start saving money… After looking over their budget… they decide the best way to save money is to… C: (A) make more phone calls; (B) quit eating lunch out; (C) buy less with monopoly money; (D) have lunch with friends A: quit eating lunch out | Original: 4957 / 500 / 500 ID: 5000 / 50 / 500 |
| --- | --- | --- | --- |
| ARC-C | Formal Science Education (Challenge) | Q: An astronomer observes that a planet rotates faster after a meteorite impact. Which is the most likely effect of this increase in rotation? C: (A) Planetary density will decrease.; (B) Planetary years will become longer.; (C) Planetary days will become shorter.; (D) Planetary gravity will become stronger. A: Planetary days will become shorter. | Original: 1119 / 299 / 1172 OoD-S: 500 from 1172 |
| ARC-E | Formal Science Education (Easy) | Q: Which statement best explains why photosynthesis is foundation of food webs? C: (A) Sunlight is the source of energy for nearly all ecosystems.; (B) Most ecosystems are found on land instead of in water.; (C) Carbon dioxide is more available than other gases.; (D) The producers in all ecosystems are plants. A: Sunlight is the source of energy for nearly all ecosystems. | Original: 2251 / 570 / 2376 OoD-S: 500 from 2376 |
| SciQ | Broad STEM Knowledge | Q: Compounds that are capable of Accuracyepting electrons, such as O2 or F2, are called what? C: antioxidants; Oxygen; residues; oxidants A: oxidants | Original: 11679 / 1000 / 1000 ID: 5000 / 50 / 500 |
| MMLU-Law | Expert Legal Reasoning | Q: One afternoon, a pilot was flying a small airplane when it suddenly ran out of gas… At trial, the pilot’s attorney calls the consulting attorney to testify… The attorney’s testimony is… C: (A) admissible, because…; (B) admissible, because…; (C) inadmissible, because the attorney-client privilege prevents…; (D) inadmissible, because it was a statement… A: inadmissible, because the attorney-client privilege prevents such a breach of confidential communications. | Original: 5 (dev) / 170 / 1534 OoD-L: 500 from 1534 |
| MedMCQA-Med | Expert Medical Knowledge | Q: Which of the following is derived from fibroblast cells? C: (A) TGF-13; (B) MMP2; (C) Collagen; (D) Angiopoietin A: Collagen | Original: 17887 / 295 / – ID: 5000 / 50 / 500 OoD-L: 500 |
Table A.2: Parameters and configurations of most famous modern open-source MoE-based LLMs.
| Family | Model | #Act. Exp. | #Total Exp. | Act. Params | Total Params | #Layers | Hid. Dim |
| --- | --- | --- | --- | --- | --- | --- | --- |
| MoLM | ibm-research/MoLM-350M-4B | 2 | 32 | 350M | 4B | 24 | 1024 |
| ibm-research/MoLM-700M-4B | 4 | 32 | 700M | 4B | 24 | 1024 | |
| ibm-research/MoLM-700M-8B | 2 | 32 | 700M | 8B | 48 | 1024 | |
| OLMoE | allenai/OLMoE-1B-7B-0924-Instruct | 8 | 64 | 1B | 7B | 16 | 2048 |
| (with SFT & DPO) | | | | | | | |
| IBM Granite MoE | ibm-granite/granite-3.1-1b-a400m-instruct | 8 | 32 | 400M | 1.3B | 24 | 1024 |
| ibm-granite/granite-3.1-3b-a800m-instruct | 8 | 40 | 800M | 3.3B | 32 | 1536 | |
| DeepSeekMoE | deepseek-ai/deepseek-moe-16b-chat | 8 | 64 | 2.8B | 16.4B | 1(FC)+27(MoE) | 2048 |
| Qwen1.5-MoE | Qwen/Qwen1.5-MoE-A2.7B-Chat | 2 | 64 | 2.7B | 14.3B | 24 | 2048 |
| Mistral | mistralai/Mixtral-8x7B-v0.1 | 8 | 8 | 13B | 47B | 32 | 4096 |
| Google Switch | switch-base-32 | — | — | — | — | — | — |
| LlamaMoE | llama-moe/LLaMA-MoE-v1-3_0B-2_16 | 2 | 16 | 3B | — | — | — |
| llama-moe/LLaMA-MoE-v1-3_5B-4_16 | 4 | 16 | 3.5B | — | — | — | |
| llama-moe/LLaMA-MoE-v1-3_5B-2_8 | 2 | 8 | 3.5B | — | — | — | |
## Appendix B Proof of KL Divergence Equivalence
This appendix proves the following identity, which is used to simplify the ELBO’s regularisation term for our residual variational routers:
$$
D_{\mathbb{KL}}\left(\mathcal{N}(\boldsymbol{\mu}_{0}+\Delta\boldsymbol{\mu},\boldsymbol{\Sigma})\,||\,\mathcal{N}(\boldsymbol{\mu}_{0},I)\right)=D_{\mathbb{KL}}\left(\mathcal{N}(\Delta\boldsymbol{\mu},\boldsymbol{\Sigma})\,||\,\mathcal{N}(\mathbf{0},I)\right)
$$
The proof relies on the general formula for the KL divergence between two multivariate Gaussians, $q=\mathcal{N}(\boldsymbol{\mu}_{q},\boldsymbol{\Sigma}_{q})$ and $p=\mathcal{N}(\boldsymbol{\mu}_{p},\boldsymbol{\Sigma}_{p})$ :
$$
D_{\mathbb{KL}}(q||p)=\frac{1}{2}\left(\log\frac{|\boldsymbol{\Sigma}_{p}|}{|\boldsymbol{\Sigma}_{q}|}-k+\text{tr}(\boldsymbol{\Sigma}_{p}^{-1}\boldsymbol{\Sigma}_{q})+(\boldsymbol{\mu}_{p}-\boldsymbol{\mu}_{q})^{\top}\boldsymbol{\Sigma}_{p}^{-1}(\boldsymbol{\mu}_{p}-\boldsymbol{\mu}_{q})\right)
$$
The key insight is that all terms in this formula except for the final quadratic term $(\boldsymbol{\mu}_{p}-\boldsymbol{\mu}_{q})^{\top}\boldsymbol{\Sigma}_{p}^{-1}(\boldsymbol{\mu}_{p}-\boldsymbol{\mu}_{q})$ depend only on the covariance matrices, which are identical for both sides of our identity ( $\boldsymbol{\Sigma}_{q}=\boldsymbol{\Sigma}$ and $\boldsymbol{\Sigma}_{p}=I$ ).
We therefore only need to show that the quadratic term is the same for both sides.
For the Left-Hand Side (LHS):
Here, $\boldsymbol{\mu}_{p}=\boldsymbol{\mu}_{0}$ and $\boldsymbol{\mu}_{q}=\boldsymbol{\mu}_{0}+\Delta\boldsymbol{\mu}$ . The term becomes:
$$
(\boldsymbol{\mu}_{0}-(\boldsymbol{\mu}_{0}+\Delta\boldsymbol{\mu}))^{\top}I^{-1}(\boldsymbol{\mu}_{0}-(\boldsymbol{\mu}_{0}+\Delta\boldsymbol{\mu}))=(-\Delta\boldsymbol{\mu})^{\top}(-\Delta\boldsymbol{\mu})=||\Delta\boldsymbol{\mu}||_{2}^{2}
$$
For the Right-Hand Side (RHS):
Here, $\boldsymbol{\mu}_{p}=\mathbf{0}$ and $\boldsymbol{\mu}_{q}=\Delta\boldsymbol{\mu}$ . The term becomes:
$$
(\mathbf{0}-\Delta\boldsymbol{\mu})^{\top}I^{-1}(\mathbf{0}-\Delta\boldsymbol{\mu})=(-\Delta\boldsymbol{\mu})^{\top}(-\Delta\boldsymbol{\mu})=||\Delta\boldsymbol{\mu}||_{2}^{2}
$$
Since all terms in the KL divergence formula are identical for both sides of the identity, the equality holds.
## Appendix C In Distribution Calibration Full Results
Table C.1: Full in-distribution performance and calibration results for each method across all four evaluated datasets. Best result in each column for each dataset is in bold. Standard deviations are shown in parentheses.
| Category | Method | OBQA | ARC-C | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| ACC $\uparrow$ | NLL $\downarrow$ | ECE $\downarrow$ | MCE $\downarrow$ | ACC $\uparrow$ | NLL $\downarrow$ | ECE $\downarrow$ | MCE $\downarrow$ | | |
| Baseline | Deterministic | 0.746 | 1.384 | 0.252 | 0.472 | 0.882 | 0.923 | 0.201 | 0.428 |
| Temp-Sampling | 0.716 (0.005) | 0.773 (0.049) | 0.107 (0.009) | 0.201 (0.013) | 0.824 (0.004) | 0.208 (0.006) | 0.038 (0.007) | 0.284 (0.003) | |
| Weight-Space | MCDR | 0.734 (0.002) | 0.650 (0.022) | 0.037 (0.028) | 0.298 (0.008) | 0.880 (0.003) | 0.146 (0.006) | 0.028 (0.003) | 0.228 (0.007) |
| SWAGR | 0.736 (0.002) | 0.652 (0.03) | 0.041 (0.013) | 0.290 (0.007) | 0.872 (0.003) | 0.138 (0.006) | 0.030 (0.007) | 0.266 (0.002) | |
| DER | 0.738 | 0.660 | 0.071 | 0.234 | 0.874 | 0.151 | 0.026 | 0.275 | |
| Logit-Space | MFVR | 0.742 (0.001) | 0.654 (0.019) | 0.026 (0.009) | 0.293 (0.004) | 0.878 (0.004) | 0.125 (0.005) | 0.016 (0.002) | 0.196 (0.002) |
| FCVR | 0.740 (0.001) | 0.652 (0.021) | 0.015 (0.008) | 0.152 (0.004) | 0.880 (0.006) | 0.122 (0.001) | 0.012 (0.006) | 0.185 (0.003) | |
| Selection-Space | VTSR | 0.736 (0.003) | 0.667 (0.025) | 0.052 (0.023) | 0.293 (0.014) | 0.872 (0.002) | 0.164 (0.014) | 0.020 (0.004) | 0.208 (0.018) |
| Category | Method | SciQ | MedMCQA-Med | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| ACC $\uparrow$ | NLL $\downarrow$ | ECE $\downarrow$ | MCE $\downarrow$ | ACC $\uparrow$ | NLL $\downarrow$ | ECE $\downarrow$ | MCE $\downarrow$ | | |
| Baseline | Deterministic | 0.850 | 0.791 | 0.223 | 0.452 | 0.55 | 1.291 | 0.183 | 0.288 |
| Temp-Sampling | 0.878 (0.002) | 0.309 (0.002) | 0.047 (0.003) | 0.649 (0.005) | 0.486 (0.004) | 1.171 (0.003) | 0.039 (0.005) | 0.097 (0.005) | |
| Weight-Space | MCDR | 0.880 (0.006) | 0.296 (0.003) | 0.029 (0.006) | 0.366 (0.007) | 0.494 (0.005) | 1.176 (0.005) | 0.050 (0.003) | 0.096 (0.008) |
| SWAGR | 0.879 (0.001) | 0.291 (0.004) | 0.031 (0.004) | 0.392 (0.002) | 0.486 (0.005) | 1.205 (0.006) | 0.096 (0.005) | 0.179 (0.004) | |
| DER | 0.876 | 0.293 | 0.032 | 0.353 | 0.484 | 1.187 | 0.047 | 0.186 | |
| Logit-Space | MFVR | 0.884 (0.004) | 0.297 (0.004) | 0.019 (0.002) | 0.387 (0.002) | 0.492 (0.002) | 1.177 (0.001) | 0.039 (0.001) | 0.103 (0.002) |
| FCVR | 0.884 (0.005) | 0.298 (0.005) | 0.013 (0.002) | 0.320 (0.005) | 0.494 (0.004) | 1.174 (0.004) | 0.022 (0.003) | 0.108 (0.007) | |
| Selection-Space | VTSR | 0.874 (0.002) | 0.299 (0.002) | 0.022 (0.002) | 0.352 (0.002) | 0.476 (0.005) | 1.174 (0.002) | 0.053 (0.005) | 0.113 (0.008) |
## Appendix D Out of Distribution Detection Full Results
### D.1 Formal Definitions of Router-Level Uncertainty Signals
This section provides the precise mathematical definitions for the method-specific, router-level uncertainty signals used in our OoD detection experiments, as presented in Experiment 3b.
For Weight-Space Methods (MCDR)
The uncertainty signal is the variance of the logit samples. Given $S$ Monte Carlo samples of the logit vector, $\{\mathbf{l}^{1},\dots,\mathbf{l}^{S}\}$ , obtained by sampling the weight matrix, the signal is the trace of the sample covariance matrix of these logit vectors.
For the Mean-Field Variational Router (MFVR)
The signal is the inferred logit variance. The variational router directly outputs a variance vector $\boldsymbol{\sigma}^{2}_{\phi}(\mathbf{x})$ . The uncertainty signal is the sum of its components, which is the trace of the diagonal covariance matrix:
$$
U(\mathbf{x})=\text{tr}(\boldsymbol{\Sigma}_{\phi}(\mathbf{x}))=\sum_{i=1}^{N}\sigma_{i}^{2}(\mathbf{x})
$$
For the Full-Covariance Variational Router (FCVR)
The signal is also the inferred logit variance. The router outputs the Cholesky factor $\mathbf{L}_{\phi}(\mathbf{x})$ of the covariance matrix. The signal is the trace of the full covariance matrix, which is equivalent to the squared Frobenius norm of the Cholesky factor:
$$
U(\mathbf{x})=\text{tr}(\boldsymbol{\Sigma}_{\phi}(\mathbf{x}))=\text{tr}(\mathbf{L}_{\phi}(\mathbf{x})\mathbf{L}_{\phi}(\mathbf{x})^{\top})=||\mathbf{L}_{\phi}(\mathbf{x})||_{F}^{2}
$$
For the Variational Temperature Router (VTSR)
The signal is the inferred temperature itself, $T(\mathbf{x})$ . This is justified because the VTSR is explicitly trained to predict a high temperature for inputs where greater stochasticity is needed, which often corresponds to ambiguous or novel inputs. The learned temperature is therefore a direct, model-generated signal of its own uncertainty.
### D.2 Full Results: Standard Uncertainty Signal (Experiment 3a)
Table D.1 presents the complete results for Experiment 3a, evaluating the performance of the final vocabulary entropy as an OoD detection signal across all methods and all four of our designed OoD tasks.
Table D.1: Full OoD detection results using the final vocabulary entropy. Best result for each task is in bold.
| Method | OBQA $\rightarrow$ ARC-E | OBQA $\rightarrow$ ARC-C | OBQA $\rightarrow$ MMLU-Law | OBQA $\rightarrow$ MedMCQA-Med | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| AUROC | AUPRC | AUROC | AUPRC | AUROC | AUPRC | AUROC | AUPRC | |
| Deterministic | $0.611$ | 0.588 | $0.687$ | $0.623$ | $0.783$ | $0.745$ | $0.762$ | $0.727$ |
| MCDR | $0.611$ | $0.584$ | $0.697$ | $0.615$ | $0.802$ | $0.762$ | $0.793$ | $0.737$ |
| MFVR | 0.617 | $0.587$ | $0.679$ | 0.676 | $0.833$ | $0.772$ | $0.844$ | $0.782$ |
| FCVR | $0.613$ | $0.582$ | 0.713 | $0.669$ | 0.843 | 0.819 | 0.853 | 0.802 |
| VTSR | $0.603$ | $0.576$ | $0.692$ | $0.657$ | $0.805$ | $0.776$ | $0.812$ | $0.791$ |
### D.3 Full Results: Router-Level Uncertainty Signals (Experiment 3b)
Table D.2 presents the complete results for Experiment 3b, comparing the performance of the various router-level uncertainty signals across all methods and all four OoD tasks.
Table D.2: Full OoD detection results using different router-level uncertainty signals. The best signal for each method on each task is in bold.
| Method | Signal Type | OBQA $\rightarrow$ ARC-E | OBQA $\rightarrow$ ARC-C | OBQA $\rightarrow$ MMLU-Law | OBQA $\rightarrow$ MedMCQA-Med | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| AUROC | AUPRC | AUROC | AUPRC | AUROC | AUPRC | AUROC | AUPRC | | |
| Deterministic | Exp. Sel. Entropy | $0.612$ | $0.596$ | $0.633$ | $0.626$ | $0.683$ | $0.686$ | $0.679$ | $0.645$ |
| MCDR | Exp. Sel. Entropy | $0.612$ | $0.599$ | $0.632$ | $0.610$ | $0.691$ | $0.672$ | $0.684$ | $0.651$ |
| MC Logit Var. | $0.610$ | $0.583$ | $0.677$ | $0.623$ | $0.793$ | $0.765$ | $0.786$ | $0.723$ | |
| MFVR | Exp. Sel. Entropy | 0.622 | $0.603$ | $0.642$ | $0.622$ | $0.673$ | $0.664$ | $0.682$ | $0.637$ |
| Inferred Logit Var. | $0.617$ | $0.587$ | $0.672$ | 0.669 | $0.824$ | $0.763$ | $0.835$ | 0.793 | |
| FCVR | Exp. Sel. Entropy | $0.615$ | 0.605 | $0.652$ | $0.632$ | $0.677$ | $0.674$ | $0.692$ | $0.642$ |
| Inferred Logit Var. | $0.609$ | $0.578$ | 0.709 | $0.665$ | 0.834 | 0.810 | 0.844 | $0.773$ | |
| VTSR | Exp. Sel. Entropy | $0.607$ | $0.578$ | $0.623$ | $0.592$ | $0.672$ | $0.612$ | $0.683$ | $0.643$ |
| Inferred Temp. | $0.502$ | $0.501$ | $0.498$ | $0.503$ | $0.523$ | $0.502$ | $0.512$ | $0.492$ | |