# Meaningless Tokens, Meaningful Gains: How Activation Shifts Enhance LLM Reasoning
Abstract
Motivated by the puzzling observation that inserting long sequences of meaningless tokens before the query prompt can consistently enhance LLM reasoning performance, this work analyzes the underlying mechanism driving this phenomenon and based on these insights proposes a more principled method that allows for similar performance gains. First, we find that the improvements arise from a redistribution of activations in the LLM’s MLP layers, where near zero activations become less frequent while large magnitude activations increase. This redistribution enhances the model’s representational capacity by suppressing weak signals and promoting stronger, more informative ones. Building on this insight, we propose the Activation Redistribution Module (ARM), a lightweight inference-time technique that modifies activations directly without altering the input sequence. ARM adaptively identifies near-zero activations after the non-linear function and shifts them outward, implicitly reproducing the beneficial effects of meaningless tokens in a controlled manner. Extensive experiments across diverse benchmarks and model architectures clearly show that ARM consistently improves LLM performance on reasoning tasks while requiring only a few lines of simple code to implement. Our findings deliver both a clear mechanistic explanation for the unexpected benefits of meaningless tokens and a simple yet effective technique that harnesses activation redistribution to further improve LLM performance. The code has been released at ARM-Meaningless-tokens.
1 Introduction
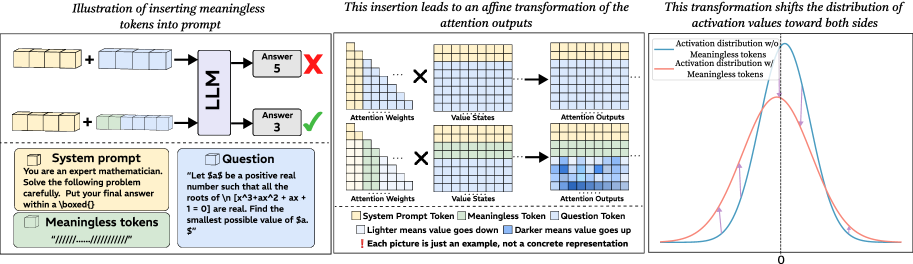
Large language models (LLMs) are known to be sensitive to subtle variations in their inputs, which makes it important to understand how tokens influence predictions (Guan et al., 2025; Errica et al., 2024; Zhuo et al., 2024). In this paper, we present a surprisingly counterintuitive finding named meaningless-token effect: inserting long sequences of meaningless tokens, such as repeated punctuation or separators, into prompts can consistently improve the performance of LLMs, particularly on reasoning tasks. Contrary to common intuition that long and irrelevant tokens are like noise and thus useless or even harmful during inference (Jiang et al., 2024; Guan et al., 2025), our experiments reveal the opposite. When long sequences of meaningless tokens are appended before query prompts, models that previously struggled with certain problems can produce correct solutions, as illustrated in the left panel of Figure 1 (see more examples in Appendix J). This effect occurs consistently across tasks and models, suggesting a counterintuitive behavior of LLMs pending deeper investigation.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Impact of Meaningless Tokens on Language Model Performance
### Overview
The image illustrates how inserting meaningless tokens into a prompt affects a language model's (LLM) performance. It shows the process from prompt construction to attention output transformation and the resulting shift in activation value distribution.
### Components/Axes
**Panel 1: Prompt Construction and LLM Output**
* **Title:** Illustration of inserting meaningless tokens into prompt
* **Elements:**
* System Prompt (yellow blocks)
* Meaningless Tokens (green blocks)
* Question (blue blocks)
* LLM (Language Model)
* Answers (with correctness indicators)
* **Text:**
* **System prompt:** "You are an expert mathematician. Solve the following problem carefully. Put your final answer within a \boxed{}"
* **Meaningless tokens:** "//////....../////////"
* **Question:** "Let $a$ be a positive real number such that all the roots of \n [x^3+ax^2 + ax + 1 = 0] are real. Find the smallest possible value of $a.$"
**Panel 2: Attention Transformation**
* **Title:** This insertion leads to an affine transformation of the attention outputs
* **Elements:**
* Attention Weights (grid)
* Value States (grid)
* Attention Outputs (grid)
* **Color Coding:**
* System Prompt Token (yellow)
* Meaningless Token (green)
* Question Token (blue)
* Lighter means value goes down
* Darker means value goes up
* **Note:** "Each picture is just an example, not a concrete representation"
**Panel 3: Activation Distribution Shift**
* **Title:** This transformation shifts the distribution of activation values toward both sides
* **Axes:**
* X-axis: Labeled "0" at the center.
* **Data Series:**
* Activation distribution w/o Meaningless tokens (blue line)
* Activation distribution w/ Meaningless tokens (red line)
### Detailed Analysis
**Panel 1: Prompt Construction and LLM Output**
* The diagram shows two scenarios:
1. System prompt + Question --> LLM --> Incorrect Answer (5)
2. System prompt + Meaningless Tokens + Question --> LLM --> Correct Answer (3)
* The first scenario presents the LLM with the system prompt and question directly, resulting in an incorrect answer.
* The second scenario introduces meaningless tokens between the system prompt and the question, leading to a correct answer.
**Panel 2: Attention Transformation**
* The diagram illustrates how the insertion of meaningless tokens affects the attention mechanism within the LLM.
* The attention weights, value states, and attention outputs are represented as grids, with color intensity indicating the strength of the values.
* The top row shows the attention flow without meaningless tokens, while the bottom row shows the flow with meaningless tokens.
* The attention outputs show a clear difference in the distribution of attention weights when meaningless tokens are present. The bottom Attention Output grid has more blue squares, indicating higher values.
**Panel 3: Activation Distribution Shift**
* The graph shows the distribution of activation values with and without meaningless tokens.
* The blue line (Activation distribution w/o Meaningless tokens) represents the distribution without meaningless tokens. It is a bell curve centered around 0.
* The red line (Activation distribution w/ Meaningless tokens) represents the distribution with meaningless tokens. It is also a bell curve, but it is wider and flatter than the blue line.
* The red line's peak is lower than the blue line's peak.
* The arrows indicate the shift in activation values from the blue line to the red line. The arrows point away from the center (0), indicating that the insertion of meaningless tokens shifts the distribution towards both sides.
### Key Observations
* Inserting meaningless tokens can improve the performance of LLMs on certain tasks.
* The insertion of meaningless tokens affects the attention mechanism within the LLM, leading to a different distribution of attention weights.
* The insertion of meaningless tokens shifts the distribution of activation values towards both sides.
### Interpretation
The diagram demonstrates that the strategic insertion of "meaningless" tokens can significantly impact an LLM's ability to solve problems. This suggests that LLMs are sensitive to the structure and context of the input, even when the added elements do not carry semantic meaning. The affine transformation of attention outputs indicates that these tokens alter the way the LLM processes and weighs different parts of the input. The shift in activation distribution further supports this, showing that the presence of meaningless tokens changes the overall representation of the input within the model.
This phenomenon could be due to several factors:
1. **Attention Diversion:** Meaningless tokens might force the LLM to distribute its attention more evenly across the input, preventing it from focusing too heavily on potentially misleading cues in the question.
2. **Contextual Reset:** The tokens could act as a "reset" mechanism, clearing the LLM's internal state and allowing it to approach the question with a fresh perspective.
3. **Regularization:** The added noise could act as a form of regularization, preventing the LLM from overfitting to specific patterns in the training data.
The diagram highlights the complex and often unintuitive ways in which LLMs process information. It suggests that even seemingly irrelevant modifications to the input can have a profound impact on performance. Further research is needed to fully understand the mechanisms underlying this phenomenon and to develop strategies for optimizing LLM performance through careful prompt engineering.
</details>
Figure 1: The left panel illustrates how meaningless-token effect can improve model performance. The middle panel shows the changes occurring in the attention module after introducing meaningless tokens. The right panel depicts the redistribution of activations that results from adding these tokens.
This unexpected result raises fundamental questions about how LLMs process input and what aspects of their internal computation are being affected. Why should tokens that convey no meaning lead to measurable performance gains? Are they simply acting as noise, or do they restructure representations in a systematic way that supports better reasoning? To answer these questions, we move beyond surface level observations and conduct a detailed investigation of the mechanisms behind this effect. Our analysis shows that the influence of meaningless tokens arises primarily in the first layer, and their effect on meaningful tokens can be approximated as an affine transformation of the attention outputs. As demonstrated in the middle schematic diagram of Figure 1, the resulting transformation shifts the distribution of activations in the MLP: the proportion of near-zero activations decreases, while more activations are pushed outward toward larger positive and negative values. The rightmost plot in Figure 1 gives a visualization of this process. We hypothesize that redistribution fosters richer exploration, enhancing reasoning performance, and clarify the mechanism by decomposing the transformation into coefficient and bias terms. Our theoretical analysis shows how each component shapes activation variance and induces the observed distributional shift.
Building on these insights, we propose ARM (an A ctivation R edistribution M odule), a lightweight alternative to explicit meaningless-token insertion. ARM requires only a few lines of code modification and no additional training. It automatically identifies a proportion of near-zero activations after the non-linear function and shifts their values outward, yielding a smoother and less sparse activation distribution. In doing so, ARM reproduces the beneficial effects of meaningless tokens without altering the input sequence and consistently improves LLM performance on reasoning and related tasks. In summary, the key findings and contributions of our work are:
- We uncover a meaningless-token effect in LLMs: inserting meaningless tokens, far from being harmful, systematically improves reasoning in LLMs. This runs counter to the common assumption that such tokens only add noise.
- Through theoretical and empirical analysis, we show that these tokens induce an activation redistribution effect in the first-layer MLP, reducing near-zero activations and increasing variance.
- Building on this understanding, we present ARM, a lightweight inference-time instantiation to demonstrate that the phenomenon can be directly harnessed.
2 Observation: Inserting Meaningless Tokens Induces an Affine Transformation on Meaningful Token Representations
We observe that meaningless tokens, such as a sequence of slashes (“/”) with appropriate lengths can enhance the performance of LLMs, particularly on reasoning tasks Varying token length, type, and position affects performance, as shown in Appendix F.. As shown in Table 1, when we insert a fixed-length sequence of meaningless tokens between the system prompt and the question, all evaluated models exhibit performance improvements on Math-500 and AIME2024 to different degrees. This consistent improvement suggests that the inserted meaningless tokens are not simply ignored or detrimental to the models; rather, they exert a positive influence, likely through non-trivial interactions with the models’ internal representations. To investigate this phenomenon, we start our analysis from the attention module. The formula of attention is:
Table 1: Performance on mathematical reasoning datasets with and without meaningless tokens across different models. “w/o” denotes the absence of meaningless tokens, while “w/” denotes their presence. We test each model five times to get the average result.
| Qwen2.5-Math-1.5B Qwen2.5-Math-7B DS-R1-Qwen-7B | 63.9 72.3 52.7 | 65.9 74.6 53.1 | 14.4 23.1 3.2 | 17.5 23.3 4.4 |
| --- | --- | --- | --- | --- |
| DS-Math-7B-instruct | 39.5 | 42.1 | 7.8 | 12.3 |
| Llama-3.1-8B-Instruct | 41.8 | 42.1 | 7.9 | 9.9 |
| Qwen-2.5-32B-Instruct | 81.3 | 81.7 | 17.6 | 22.8 |
<details>
<summary>x2.png Details</summary>
### Visual Description
## Line Charts: Attention Weight Comparison
### Overview
The image presents six line charts arranged in a 2x3 grid. Each chart displays the average attention weight of a language model across a sequence of tokens. The top row compares attention weights with and without "meaningless" tokens for different models, while the bottom row focuses on attention weights with "meaningless" tokens, highlighting the region where these tokens are present. The models compared are Qwen2.5-7B-Math, Llama3.1-8B-Instruct, and Gemma3-4b-it.
### Components/Axes
* **Titles (Top Row, Left to Right):**
* Qwen2.5-7B-Math Layer 1 Head 22
* Llama3.1-8B-Instruct Layer 1 Head 27
* Gemma3-4b-it Layer 1 Head 3
* **Titles (Bottom Row, Left to Right):**
* Qwen2.5-7B-Math Layer 1 Head 22
* Llama3.1-8B-Instruct Layer 1 Head 27
* Gemma3-4b-it Layer 1 Head 3
* **Y-Axis Label (All Charts):** Average Attention Weight
* **Y-Axis Scale (Top Row):** 0.00 to 0.08 (Qwen), 0.00 to 0.10 (Llama), 0.00 to 0.175 (Gemma)
* **Y-Axis Scale (Bottom Row):** 0.00 to 0.07 (Qwen), 0.00 to 0.08 (Llama), 0.00 to 0.16 (Gemma)
* **X-Axis Label (Implied):** Token Sequence
* **X-Axis Scale (Top Row):** 0 to 60
* **X-Axis Scale (Bottom Row):** 0 to 120
* **Legend (Top Row):** Located in the top-left corner of each chart.
* Blue line: "w/o Meaningless tokens"
* Red line: "w/ Meaningless tokens"
* **Legend (Bottom Row):** Located in the top-left corner of each chart.
* Blue line: "w/ Meaningless tokens"
* **Annotation (Bottom Row):** Shaded region labeled "Meaningless tokens" spans approximately from x=20 to x=70.
### Detailed Analysis
**Qwen2.5-7B-Math Layer 1 Head 22**
* **Top Chart:**
* Blue line (w/o Meaningless tokens): Fluctuates between 0.01 and 0.04 for the first 40 tokens, then increases to around 0.06 by token 60.
* Red line (w/ Meaningless tokens): Generally follows the blue line but is slightly higher, especially after token 40, reaching approximately 0.07.
* **Bottom Chart:**
* Blue line (w/ Meaningless tokens): Stays relatively low (around 0.01) until token 70, then increases sharply, reaching peaks around 0.06.
**Llama3.1-8B-Instruct Layer 1 Head 27**
* **Top Chart:**
* Blue line (w/o Meaningless tokens): Shows frequent fluctuations between 0.01 and 0.08.
* Red line (w/ Meaningless tokens): Similar to the blue line, but generally lower, staying mostly below 0.04.
* **Bottom Chart:**
* Blue line (w/ Meaningless tokens): Remains low (around 0.01-0.02) until token 70, then exhibits significant spikes, reaching up to 0.08.
**Gemma3-4b-it Layer 1 Head 3**
* **Top Chart:**
* Blue line (w/o Meaningless tokens): Relatively low and stable, mostly below 0.025.
* Red line (w/ Meaningless tokens): More volatile, with several peaks reaching up to 0.175 around token 50.
* **Bottom Chart:**
* Blue line (w/ Meaningless tokens): Very low until token 70, then spikes dramatically, reaching values as high as 0.16.
### Key Observations
* The presence of "meaningless" tokens appears to have a varying impact on the attention weights, depending on the model.
* In the top row, the red line (w/ Meaningless tokens) is sometimes higher (Qwen, Gemma) and sometimes lower (Llama) than the blue line (w/o Meaningless tokens).
* In all bottom charts, the attention weight with meaningless tokens is very low until the end of the "meaningless tokens" region (around token 70), after which it spikes significantly.
### Interpretation
The charts suggest that the models handle "meaningless" tokens differently. For Qwen and Gemma, including these tokens can increase the average attention weight, while for Llama, it might decrease it. The bottom row of charts indicates that the models tend to ignore these tokens initially, but their influence increases significantly after the region where they are present. This could imply that the models are designed to filter out or downweight these tokens during the initial processing stages, but their impact becomes more pronounced later in the sequence. The sudden spikes after the "meaningless tokens" region might indicate that the model is compensating for the earlier suppression of these tokens or that the context has shifted in a way that makes these tokens more relevant.
</details>
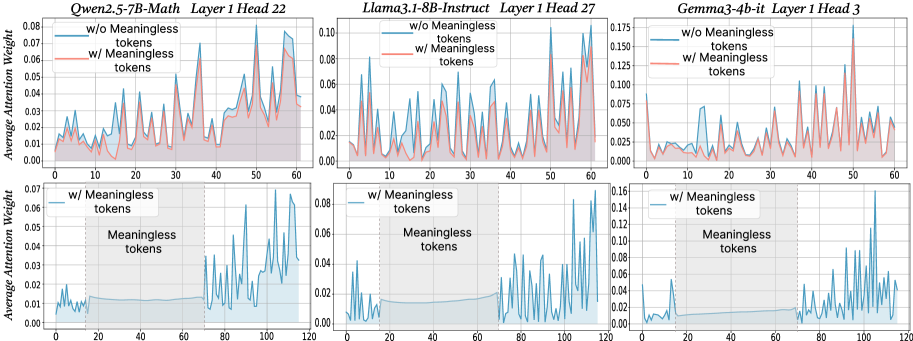
Figure 2: The x-axis shows token indices. Subsequent tokens assign lower average attention weights to the original prompt overall, while meaningless tokens receive similarly near-zero weights. We show additional average attention weights in Appendix I and layer-wise analyses in Section F.4.
$\text{Attention}(Q,K,V)=\text{softmax}\!\left(\frac{QK^{→p}}{\sqrt{d_{k}}}\right)V$ , where $Q$ , $K$ , $V$ are query vectors, key vectors and value vectors respectively, $d$ is the dimensionality of key/query. From this equation, adding extra tokens introduces additional terms into the softmax normalization, enlarging the softmax normalization denominator. Although the new tokens typically receive small weights, their presence redistributes probability mass and reduces the relative share of attention allocated to the original tokens. To probe the underlying case, we directly compare input’s attention weights with and without meaningless tokens while keeping tokens indices aligned in the first layers. For every token we computed the mean of its column below the diagonal of the attention matrix to measure the extent to which each token receives attention from all downstream tokens (Bogdan et al., 2025). When a string of meaningless tokens are present, the model assigns only small weights to each token, intuitively indicating that the model only pays little attention to them (see Figure 2 bottom row). The top row of Figure 2 presents a direct comparison of the attention to meaningful tokens without (blue) or with meaningless tokens (red; meaningless token indices are removed from visualization to allow for direct comparison). Among meaningful tokens, the average attention is decreased in the meaningless-token condition, especially driven by decreased high-attention spikes. The attention weights of the original prompt after inserting meaningless tokens are: $W^{\prime}=\lambda·\text{softmax}\!\left(\frac{QK^{→p}}{\sqrt{d_{k}}}\right)$ , where $W_{attn}$ are the attention weights after softmax, and $\lambda$ is the drop percentage of attention weights in the original prompt after adding meaningless tokens. Then, the attention output for each token not only obtains the weighted combination of the original tokens, but also includes attention weights and values from the meaningless tokens. Thus, the attention output can be expressed as:
$$
\text{Attn\_Output}_{new}=W_{j}^{\prime}V_{j}+W_{i}V_{i}, \tag{1}
$$
<details>
<summary>x3.png Details</summary>
### Visual Description
## Scatter Plot: Attention Output with and without Meaningless Tokens
### Overview
The image is a scatter plot visualizing the attention output of a model, comparing scenarios with and without meaningless tokens. The plot shows the distribution of data points, their displacement, and the boundaries of sets.
### Components/Axes
* **Data Points:**
* Light Blue "x": `Attn_output w/o meaningless tokens`
* Light Red "x": `Attn_output w/ meaningless tokens`
* **Displacement Arrows:** Blue arrows indicating the displacement from a light blue "x" to a light red "x".
* **Set Boundaries:**
* Dotted Light Blue Line: `Attn_output set w/o meaningless tokens` (forms a circle)
* Solid Light Red Line: `Attn_output set w/ meaningless tokens` (forms an oval)
* **Grid:** The background has a faint grid for visual reference.
### Detailed Analysis
* **Attn_output w/o meaningless tokens (Light Blue "x"):** These points are concentrated more towards the lower-left quadrant of the plot, with a higher density inside the dotted light blue circle.
* **Attn_output w/ meaningless tokens (Light Red "x"):** These points are more dispersed across the plot, with a higher concentration outside the dotted light blue circle and along the solid light red oval.
* **Displacement Arrows (Blue):** The arrows generally point from the lower-left towards the upper-right, indicating a shift in attention output when meaningless tokens are included.
* **Attn_output set w/o meaningless tokens (Dotted Light Blue Circle):** This circle encompasses a significant portion of the light blue "x" data points, suggesting that the attention output without meaningless tokens is more constrained within this region. The approximate center of the circle is near the center-left of the plot.
* **Attn_output set w/ meaningless tokens (Solid Light Red Oval):** This oval encloses a larger area than the circle and appears to capture the spread of the light red "x" data points. The oval extends from the lower-left to the upper-right of the plot.
### Key Observations
* The inclusion of meaningless tokens leads to a wider distribution of attention outputs.
* The displacement arrows indicate a systematic shift in attention when meaningless tokens are present.
* The sets defined by the circle and oval visually separate the two conditions (with and without meaningless tokens).
### Interpretation
The plot suggests that meaningless tokens significantly alter the attention output of the model. The shift in data point distribution, as visualized by the displacement arrows and the different set boundaries, indicates that the model's attention mechanism is affected by the presence of these tokens. The concentration of light blue "x" points within the dotted light blue circle suggests that removing meaningless tokens leads to a more focused and constrained attention output. The light red oval shows the boundary of the attention output when meaningless tokens are included, which is more dispersed.
</details>
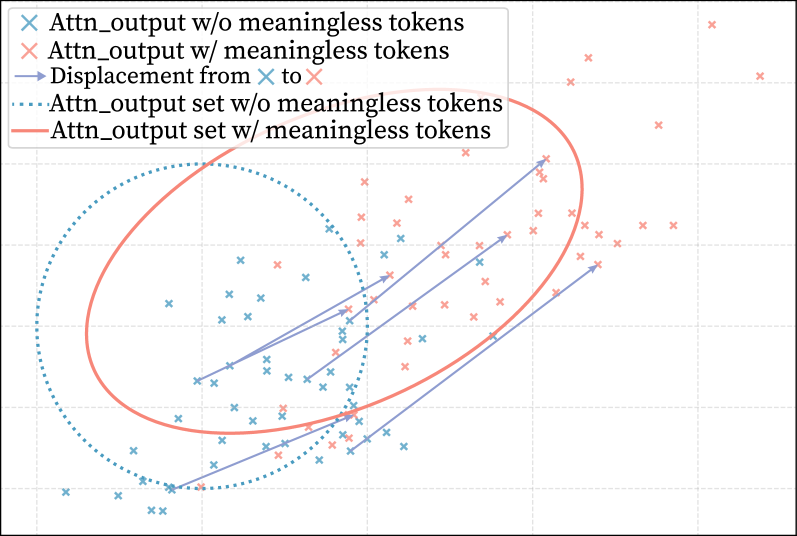
Figure 3: After adding meaningless tokens, each token vector is affinely transformed: blue points show the original vectors, and red points show them after the addition. Arrow is change direction.
where Attn_Output corresponds to the output of attention mechanism for each token in the original prompt, $W_{j}^{\prime}$ and $V_{j}$ are the attention weight and value vectors of the original prompt, and $W_{i}$ and $V_{i}$ are the attention weight and value vectors of meaningless tokens. As the meaningless tokens are repeated in long sequences and contribute no semantic information, the values of these tokens are identical, and their attention weights are small in a similar magnitude. Therefore, as shown in Equation 1, the term $W_{i}V_{i}$ primarily shifts the final attention output along an approximately unified direction as they accumulate, without introducing diverse semantic components. In this formula, $W_{j}V_{j}$ is the value of original attention output, we see $W_{i}V_{i}$ as $\Sigma_{\sigma}$ . As a result, the attention output of meaningful tokens after adding meaningless tokens can be seen as an affine transformation expressed as:
$$
\text{Attn\_Output}_{new}=\lambda\cdot\text{Attn\_Output}+\Sigma_{\sigma}, \tag{2}
$$
where Attn_Output is $W_{j}V_{j}$ . Following this equation, the introduction of meaningless tokens transforms the attention output of meaningful tokens into an affine function, consisting of a scaled original term ( $\lambda·\text{Attn\_Output}$ ) and an additional bias ( $\Sigma_{\sigma}$ ). Figure 3 illustrates the process of this transformation. After the attention module the affine transformed output passes through RMSNorm and serves as the input to the MLP. In the next section, we examine in detail how this transformation propagates through the subsequent MLP layers and shapes the model’s overall activation distribution.
3 Analysis: Why Affine Transformation Improve Reasoning Performance
Having established in the previous sections that meaningless-token effect induces scaling and bias terms that produce an affine transformation of the attention output, we next examine how this transformation propagates through the subsequent MLP modules and affects reasoning. In Equation 2, we decompose the transformation’s influencing factors into two primary components: the scaling factors $\lambda$ controls the magnitude of activations, and the bias factors $\Sigma_{\sigma}$ , a bounded zero-mean bias term reflecting the variation in attention outputs before and after meaningless-token insertion which introduce structured shifts in the activation distribution. Together, these two factors determine how the transformed attention representations shape the dynamics of the MLP layers.
3.1 Affine Transformation influence the output of gate layer
Key Takeaway
We demonstrate that applying an affine transformation, through both scaling and bias factors, systematically increases the variance of the gate layer’s output.
In this part, we show that these two factors increase the gate projection layer variance in MLP layer. As discussed above, because these tokens have low attention weights and nearly identical values, they shift the RMSNorm input almost entirely along a single direction with small margin; consequently, RMSNorm largely absorbs this change, producing only a minor numerical adjustment without adding semantic information. Specifically, the two factors act through different mechanisms. For the scaling factors, before entering the MLP, the attention output undergoes output projection and residual connection, which can be written as $x(\lambda)=\text{res}+\lambda*\text{U}*\text{A}$ , where A is the attention output and U the projection weights. Treating $\lambda$ as a functional variable, the RMSNorm output becomes $y(\lambda)=\text{RMS}(x(\lambda))$ . For the $j$ -th gate dimension, $z_{j}(\lambda)=w_{j}^{→p}y(\lambda)$ , and a small variation $\Delta\lambda$ leads to the variance change of this dimension.
$$
\text{Var}[z_{j}(\lambda+\Delta\lambda)]=\text{Var}[z_{j}(\lambda)]+2\text{Cov}(z_{j}(\lambda),g_{j}(\lambda))\Delta\lambda+\text{Var}[g_{j}(\lambda)]\Delta\lambda^{2}, \tag{3}
$$
the third term in Equation 3 remains strictly positive for all admissible parameters. Moreover, as $\Delta\lambda$ increases, this term exhibits monotonic growth and asymptotically dominates the second term, thereby guaranteeing a strictly increasing overall variance. We analyze the range of $\Delta\lambda$ in Appendix E. In the case of bias factors, we model the perturbation as stochastic noise which is bounded, zero-mean and statistically independent from the original attention output across all dimensions, which contributes an additional variance component and interacts non-trivially with the subsequent RMSNorm operation. Formally, after noise injection, the RMSNorm input can be written as $x=x_{0}+W\Sigma_{\sigma}$ , where $W$ is the linear coefficient of matrix $x$ preceding RMSNorm. After normalization, the covariance of the output can be expressed as:
$$
\text{Cov}(y)=J_{q}\text{Cov}(x)J_{q}^{{\top}}+o(\|x-x_{0}\|^{2}) \tag{4}
$$
where $x_{0}$ is the mean expansion point, $J_{q}$ is the Jacobian matrix of the RMSNorm mapping. Since the variance of the added perturbation is very small, the higher-order terms can be disregarded. In this case, the bias factor will bias the input of RMSNorm and lead to an increase in the covariance $\mathrm{Cov}(y)$ . Subsequently, the input to the activation function can be written as $z=W_{gate}(x+W\Sigma_{\sigma})$ . Based on the properties of the covariance, the variance of the $j$ -th dimension is given by:
$$
\text{Var}[z_{j}]\approx e_{j}^{\top}W_{gate}[J_{q}\text{Cov(x)}J_{q}^{{\top}}]W_{gate}^{\top}e_{j}, \tag{5}
$$
since the projection of the vector onto the tangent space is almost never zero in LLMs’ high dimensions, the resulting variance must be strictly greater than zero. From this, we can deduce that these two factors increase the variance of the output. In general, the scaling factors increase variance by amplifying inter-sample differences, whereas the bias factors correspondingly increase variance by enlarging the covariance structure across dimensions.
3.2 Variance change leads to activation redistribution
Key Takeaway
Our analysis shows that an increase in the input variance of activation functions broadens and reshapes the output activation distribution by raising both its mean and its variance.
As the variance of gate layer outputs grows under perturbations, the subsequent activation function further reshapes these signals by compressing values near zero. This motivates redistributing near-zero activations. For each sample in the hidden state, the second-order Taylor expansion on $\phi$ , the activation function output is:
$$
\phi(\mu+\sigma)=\phi(\mu)+\phi^{{}^{\prime}}(\mu)\sigma+\frac{1}{2}\phi^{{}^{\prime\prime}}(\mu)\sigma^{2}+o(|\sigma|^{3}), \tag{6}
$$
where $\sigma$ can represent both $\Delta k$ in scaling factor and $\Sigma_{\sigma}$ in bias factor. We denote the input to the activation function as $z=\mu+\sigma$ . For the $j$ -th dimension of the hidden state, the expectation and variance of the activation output can be expressed as:
$$
\mathbb{E}[\phi(z_{j})]=\mathbb{E}[\phi(\mu_{j})]+\mathbb{E}[\phi^{{}^{\prime}}(\mu_{j})\sigma]+\mathbb{E}[\frac{1}{2}\phi^{{}^{\prime\prime}}(\mu_{j})\sigma^{2}]+o(\mathbb{E}|\sigma|^{3}), \tag{7}
$$
$$
\text{Var}[\phi(z_{j})]=\phi^{{}^{\prime}}(\mu_{j})^{2}\text{Var}_{j}+o(\text{Var}_{j}^{2}). \tag{8}
$$
From above equations, We infer that distributional changes map to variations in expectation and variance. On a single dimension, activations shift in both directions; from Equation 6, higher-order terms are negligible, and the first derivative of GeLU/SiLU near zero is positive. Since perturbations include both signs, extrapolated activations also fluctuate around zero. From Equation 7, $\mathbb{E}[\sigma^{2}]=\text{Var}_{j}$ . For the bias factor, the zero-mean perturbation removes the first-order term. For scaling factors, expanding at the population mean gives $\mathbb{E}[\phi^{{}^{\prime}}(z_{j})g_{j}]=0$ , again canceling the first order. The second derivative near zero is strictly positive. From Equation 8, $\text{Var}_{j}$ increases, and so does the activation histogram variance, as the function is nearly linear near zero. In summary, scaling and bias factors jointly enlarge activation variance, expressed as:
$$
\text{Var}_{j}\approx{\color[rgb]{0.28515625,0.609375,0.75390625}\definecolor[named]{pgfstrokecolor}{rgb}{0.28515625,0.609375,0.75390625}\mathbb{E}[\text{Var}_{j}^{(\Sigma_{\sigma})}]}+{\color[rgb]{0.96875,0.53125,0.47265625}\definecolor[named]{pgfstrokecolor}{rgb}{0.96875,0.53125,0.47265625}\text{Var}(g_{j}^{\lambda})}. \tag{9}
$$
<details>
<summary>x4.png Details</summary>
### Visual Description
## Chart Type: Comparative Histograms and Bar Charts
### Overview
The image presents a comparative analysis of three different language models: *Qwen2.5-7B-Math*, *Llama3.1-8B-Instruct*, and *Gemma3-4b-it*. For each model, a histogram shows the distribution of some unspecified values (likely weights or activations), and a set of bar charts compares the model's characteristics with and without a certain transformation. The legend at the top indicates that the blue bars/histogram represent "w/ transformation" and the pink bars/histogram represent "w/o transformation".
### Components/Axes
**Overall Structure:** The image is divided into three sections, one for each language model. Each section contains a main histogram and four smaller bar charts.
**Histograms:**
* **Y-axis (Histograms):** The y-axis label is not explicitly provided, but based on the scale (0 to 700000), it likely represents the frequency or count of values within each bin of the histogram.
* **X-axis (Histograms):** The x-axis label is not explicitly provided, but it represents the range of values being distributed. The x-axis ranges from approximately -0.1 to 0.1.
* **Histogram Colors:** Blue represents "w/ transformation", and pink represents "w/o transformation".
**Bar Charts:**
Each model has four bar charts comparing "w/ transformation" (blue) and "w/o transformation" (pink) for the following metrics:
* Sparsity
* L1 Norm
* L2 Norm
* Gini
**Legends:**
* The legend is located at the top of the image.
* "w/ transformation" is represented by the color blue.
* "w/o transformation" is represented by the color pink.
**Model Names (X-axis labels):**
* *Qwen2.5-7B-Math* (left)
* *Llama3.1-8B-Instruct* (center)
* *Gemma3-4b-it* (right)
### Detailed Analysis
**1. Qwen2.5-7B-Math (Left)**
* **Histogram:** The histogram shows a distribution centered around 0. The "w/o transformation" (pink) distribution appears to have a higher peak near 0 compared to the "w/ transformation" (blue) distribution.
* **Sparsity:**
* w/ transformation (blue): ~0.09
* w/o transformation (pink): ~0.18
* **L1 Norm:**
* w/ transformation (blue): ~0.09
* w/o transformation (pink): ~0.10
* **L2 Norm:**
* w/ transformation (blue): ~0.15
* w/o transformation (pink): ~0.13
* **Gini:**
* w/ transformation (blue): ~0.44
* w/o transformation (pink): ~0.41
**2. Llama3.1-8B-Instruct (Center)**
* **Histogram:** Similar to Qwen, the histogram is centered around 0. The "w/o transformation" (pink) distribution has a higher peak.
* **Sparsity:**
* w/ transformation (blue): ~0.09
* w/o transformation (pink): ~0.10
* **L1 Norm:**
* w/ transformation (blue): ~4.4
* w/o transformation (pink): ~4.3
* **L2 Norm:**
* w/ transformation (blue): ~6.0
* w/o transformation (pink): ~7.0
* **Gini:**
* w/ transformation (blue): ~12.3
* w/o transformation (pink): ~12.8
**3. Gemma3-4b-it (Right)**
* **Histogram:** Again, centered around 0, with a higher peak for "w/o transformation" (pink).
* **Sparsity:**
* w/ transformation (blue): ~0.09
* w/o transformation (pink): ~0.10
* **L1 Norm:**
* w/ transformation (blue): ~0.9
* w/o transformation (pink): ~0.8
* **L2 Norm:**
* w/ transformation (blue): ~1.0
* w/o transformation (pink): ~0.7
* **Gini:**
* w/ transformation (blue): ~0.9
* w/o transformation (pink): ~0.8
### Key Observations
* **Histograms:** The histograms for all three models show a similar pattern: a distribution centered around zero, with the "w/o transformation" distribution having a higher peak.
* **Sparsity:** In all three models, the sparsity is higher "w/o transformation" (pink) compared to "w/ transformation" (blue).
* **L1 Norm:** The L1 Norm varies across the models, with Llama3.1-8B-Instruct having significantly higher values.
* **L2 Norm:** The L2 Norm also varies across the models.
* **Gini:** The Gini coefficient also varies across the models.
### Interpretation
The image compares the impact of a certain transformation on the distribution and characteristics of three different language models. The histograms suggest that the transformation affects the distribution of values, potentially making it less concentrated around zero. The bar charts indicate that the transformation consistently reduces sparsity across all three models. The impact on L1 Norm, L2 Norm, and Gini coefficient varies depending on the specific model.
The data suggests that the transformation being applied is likely a regularization technique aimed at reducing sparsity and potentially improving generalization performance. The specific effects on the other metrics (L1 Norm, L2 Norm, Gini) may depend on the nature of the transformation and the architecture of the model. The red circles on the histograms highlight a specific region of interest near zero, possibly indicating a critical area affected by the transformation.
</details>
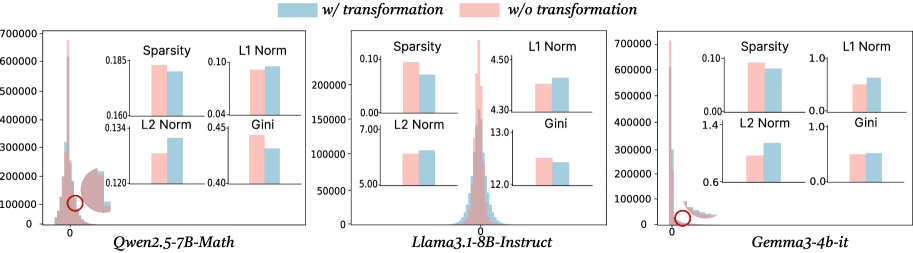
Figure 4: The histogram of the frequency of activations after activation functions in MLP, the sub-figure is the comparison of 4 metrics between before and after transformation.
The first term represents the expected variance of the $j$ -th hidden states under the influence of the bias factor. Since the bias factor varies across individual cases, taking the expectation is necessary to capture its overall impact. The second term corresponds to the variance induced by scaling factors, which inherently reflects the aggregate change. When combining them, the overall variance of the outputs of nonlinear activation functions increases, the mean shifts upward, and the activation distribution becomes broader, manifested as heavier tails and a thinner center. More details of above analysis and relative proof are in Appendix E. Moreover, we presume the reason that this redistribution has a positive impact on reasoning tasks is that reasoning-critical tokens (digits, operators, conjunctions) have a higher fraction of near-zero activations. Elevating their activation levels strengthens their representations and improves reasoning performance; see Section 6 for details.
3.3 Verification of activation redistribution
To verify whether the activation redistribution pattern in Section 3.2 indeed occurs in LLMs, Figure 4 illustrates the activation distribution after the first-layer MLP, explicitly comparing states before and after the transformation defined in Equation 2. We also comprehensively assess the transformation of activation states using several quantitative indicators, including:
- Relative Sparsity: Defined as the proportion of activations after the transformation whose values fall below the pre-transformation threshold.
- L1 Norm: The sum of the absolute activation values; smaller values indicate higher sparsity.
- L2 Norm: A measure of the overall magnitude of activations.
- Gini Coefficient: An indicator of the smoothness of the histogram distribution, where smaller absolute values correspond to smoother distributions.
From Figure 4, we observe that after transformation, the frequency of near-zero activations decreases, while the frequency of absolute high-magnitude activations increases. Both sparsity and smoothness in the activation distribution are improved. Specifically, the relative sparsity consistently decreases across all three models while the L1 and L2 norms increase, aligning with the previous phenomenon.
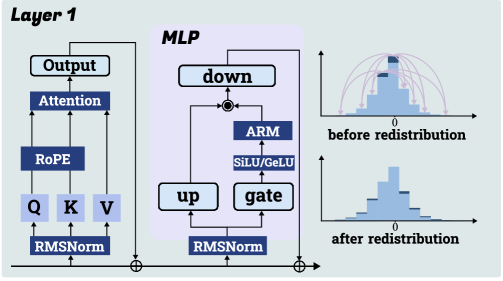
4 Method: Activation Redistribution Module
<details>
<summary>x5.png Details</summary>
### Visual Description
## Diagram: Layer 1 Architecture
### Overview
The image presents a diagram of a "Layer 1" architecture, likely within a neural network. It illustrates the flow of data through different components, including an attention mechanism, a Multi-Layer Perceptron (MLP), and redistribution histograms.
### Components/Axes
* **Header:** "Layer 1" is located at the top-left.
* **Left Branch:**
* "Output" (top)
* "Attention" (below Output)
* "RoPE" (below Attention)
* "Q", "K", "V" (arranged horizontally below RoPE)
* "RMSNorm" (bottom)
* **Right Branch (MLP):**
* "MLP" label at the top.
* "down" (top)
* "ARM" (below down)
* "SiLU/GeLU" (below ARM)
* "up" (below and to the left of SiLU/GeLU)
* "gate" (below and to the right of SiLU/GeLU)
* "RMSNorm" (bottom)
* **Histograms:**
* Top histogram labeled "before redistribution" with a horizontal axis labeled "0".
* Bottom histogram labeled "after redistribution" with a horizontal axis labeled "0".
* **Connections:** Arrows indicate the flow of data between components. A summation symbol (⊕) connects the outputs of the left and right branches.
### Detailed Analysis
* **Left Branch:**
* Data flows from "RMSNorm" to "Q", "K", and "V".
* "Q", "K", and "V" feed into "RoPE".
* "RoPE" feeds into "Attention".
* "Attention" feeds into "Output".
* "Output" connects to the summation symbol.
* **Right Branch (MLP):**
* Data flows from "RMSNorm" to "up" and "gate".
* "up" and "gate" feed into "SiLU/GeLU".
* "SiLU/GeLU" feeds into "ARM".
* "ARM" feeds into "down".
* "down" connects back to "up" and also to the summation symbol.
* **Histograms:**
* The "before redistribution" histogram shows a distribution with a peak slightly to the left of 0 and a smaller peak to the right. Arrows indicate a redistribution process.
* The "after redistribution" histogram shows a modified distribution, seemingly more concentrated around 0.
### Key Observations
* The diagram illustrates a parallel processing architecture with two main branches: an attention mechanism and an MLP.
* The histograms suggest a redistribution of data values, potentially for normalization or regularization purposes.
* The "RoPE" component in the attention branch is likely related to positional encoding.
* The "SiLU/GeLU" component in the MLP branch represents an activation function.
* The "ARM" component is located between "down" and "SiLU/GeLU".
### Interpretation
The diagram depicts a layer within a neural network that combines attention mechanisms with a multi-layer perceptron. The redistribution histograms suggest a process of modifying the data distribution, possibly to improve training stability or performance. The parallel architecture allows for simultaneous processing of data through different pathways, potentially capturing different aspects of the input. The presence of "RoPE" indicates that positional information is being incorporated into the attention mechanism. The "ARM" component's function is unclear without further context, but its placement suggests it modifies the signal between the "down" block and the activation function.
</details>
⬇
def forward (x, layer_idx): # in first layer
activation = self. act_fn (self. gate_proj (x))
#Our function
activation_alter = self. arm (activation. clone ())
down_proj = self. down_proj (activation_alter * self. up_proj (x))
return down_proj
Figure 5: The upper panel illustrates the first-layer LLM architecture with ARM, while the lower panel presents the corresponding ARM code in the MLP module.
Inspired by the previous finding that meaningless tokens can shift meaningful activations and boost LLM performance, we propose ARM—a simple method replacing explicit meaningless tokens with an implicit mechanism that adjusts the MLP activation distribution after the activation function. Our approach has two steps: First, adaptively identify a proportion of near-zero activations based on the model and input; Then, extrapolate them outward to redistribute the activation pattern. The top half of Figure 5 shows the first-layer MLP with ARM, where selected activations around zero are shifted outward, reducing their frequency and increasing larger-magnitude activations. The bottom half of Figure 5 presents the ARM-specific code, a lightweight function inserted into the first-layer MLP without affecting inference speed. As shown in Appendix D, ARM’s time complexity is negligible within the MLP context. The significance of the ARM method is twofold. Firstly, it adds further evidence deductively supporting our theoretical analysis in Section 3. By directly replacing explicit meaningless token insertion with implicit activation redistribution, ARM yields a similar improvement in reasoning across models and benchmarks, thus strengthening our theoretical framework. Secondly, we introduce ARM as a lightweight inference time trick for boosting reasoning, which is not only robustly effective on its own (see experiments in Section 5) but also compatible with existing inference time scaling methods (see Appendix G.3).
4.1 Select Appropriate Change proportion
Our method first selects a proportion of activations to be modified. However, different models exhibit varying sensitivities to meaningless tokens. To address this, we propose a dynamic strategy that adjusts the fraction of near-zero activations to be altered during inference. To determine this proportion, we measure the dispersion of activations around zero. Specifically, we define a neighborhood $\epsilon$ based on the activation distribution to identify which activations are considered “close to zero”. We adopt the Median Absolute Deviation (MAD) as our dispersion metric, since MAD is robust to outliers and better captures the core distribution. The threshold $\epsilon$ is given by: $\epsilon=\kappa*\text{MAD}*c$ , where $\kappa$ is a consistency constant, $c$ is a hyperparameter controlling the width of the near-zero range. Next, we compute the fraction of activations falling within $[-\epsilon,\epsilon]$ This fraction $p$ represents the proportion of activations that we think to be near zero. As a result, the fraction we want to change is $\text{fraction}=clip(p,(p_{\text{min}},p_{\text{max}}))$ . Here, $p$ denotes the calculated fraction, while $p_{\text{min}}$ and $p_{\text{max}}$ serve as bounds to prevent the scale from becoming either too small or excessively large. In our experiments, we set $p_{\text{min}}=0.02$ and $p_{\text{max}}=0.25$ .
4.2 Redistribution of Activation Values
After selecting the elements, we preserve its sign and adjust only its magnitude. Specifically, we add a positive or negative value depending on the element’s sign. To constrain the modified values within a reasonable range, the range is defined as follows:
$$
\text{R}=\begin{cases}[0,\text{Q}_{p_{1}}(\text{Activations)}],&\text{sign}=1,\\[6.0pt]
[\text{min(Activations)},0],&\text{sign}=-1.\end{cases} \tag{10}
$$
Where R is the range of modified values. In this range, we set the lower bound to the minimum activation value when $\text{sign}=-1$ , since activation functions such as SiLU and GeLU typically attain their smallest values on the negative side. For the upper bound when $\text{sign}=1$ , we select the value corresponding to the $p_{1}$ -th percentile of the activation distribution. Here, $p_{1}$ is a hyperparameter that depends on the distribution of activations. $\text{Q}_{p_{1}}(\text{Activations)}$ is the upper bound when we changing the chosen activations. The value of $p_{1}$ depends on the distribution of activations and the value of $c$ . Finally, we generate a random value in R and add it to the activation in order to modify its value. In this way, we adaptively adjust an appropriate proportion of activations, enriching the distribution with more effective values. We shows how to choose hyperparameter in Appendix H.
Table 2: After adding ARM to the first-layer MLP, we report reasoning-task performance for six models, using a dash (‘–’) for accuracies below 5% to indicate incapability.
| Model | Setting | GPQA Diamond | Math-500 | AIME 2024 | AIME 2025 | LiveCodeBench | Humaneval |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Pass@1 | Pass@1 | Pass@1 | Pass@1 | Pass@1 | Pass@1 | | |
| Qwen2.5 Math-1.5B | Baseline | 27.3 | 63.8 | 14.4 | 6.7 | - | 6.1 |
| \cellcolor cyan!15ARM | \cellcolor cyan!1528.8 | \cellcolor cyan!1567.0 | \cellcolor cyan!1518.9 | \cellcolor cyan!1510.0 | \cellcolor cyan!15- | \cellcolor cyan!158.5 | |
| \cellcolor gray!15 Improve Rate (%) | \cellcolor gray!15 1.5 $\uparrow$ | \cellcolor gray!15 3.2 $\uparrow$ | \cellcolor gray!15 4.5 $\uparrow$ | \cellcolor gray!15 3.3 $\uparrow$ | \cellcolor gray!15 - | \cellcolor gray!15 2.4 $\uparrow$ | |
| Qwen2.5 Math-7B | Baseline | 30.3 | 72.4 | 23.3 | 10.0 | - | 15.2 |
| \cellcolor cyan!15ARM | \cellcolor cyan!1534.9 | \cellcolor cyan!1573.4 | \cellcolor cyan!1525.6 | \cellcolor cyan!1513.3 | \cellcolor cyan!15- | \cellcolor cyan!1517.7 | |
| \cellcolor gray!15 Improve Rate (%) | \cellcolor gray!15 4.6 $\uparrow$ | \cellcolor gray!15 1.0 $\uparrow$ | \cellcolor gray!15 2.3 $\uparrow$ | \cellcolor gray!15 3.3 $\uparrow$ | \cellcolor gray!15 - | \cellcolor gray!15 2.5 $\uparrow$ | |
| Qwen2.5 7B-Instruct | Baseline | 28.3 | 61.4 | 20.0 | 10.0 | 29.7 | 43.9 |
| \cellcolor cyan!15ARM | \cellcolor cyan!1529.8 | \cellcolor cyan!1562.4 | \cellcolor cyan!1520.0 | \cellcolor cyan!1523.3 | \cellcolor cyan!1531.9 | \cellcolor cyan!1547.6 | |
| \cellcolor gray!15 Improve Rate (%) | \cellcolor gray!15 1.5 $\uparrow$ | \cellcolor gray!15 1.0 $\uparrow$ | \cellcolor gray!150 | \cellcolor gray!15 13.3 $\uparrow$ | \cellcolor gray!15 2.2 $\uparrow$ | \cellcolor gray!15 3.7 $\uparrow$ | |
| Qwen2.5 32B-Instruct | Baseline | 35.4 | 82.6 | 16.7 | 20.0 | 49.5 | 50.0 |
| \cellcolor cyan!15ARM | \cellcolor cyan!1535.9 | \cellcolor cyan!1582.6 | \cellcolor cyan!1518.8 | \cellcolor cyan!1526.7 | \cellcolor cyan!1549.5 | \cellcolor cyan!1551.2 | |
| \cellcolor gray!15 Improve Rate (%) | \cellcolor gray!15 0.5 $\uparrow$ | \cellcolor gray!150 | \cellcolor gray!15 2.1 $\uparrow$ | \cellcolor gray!15 6.7 $\uparrow$ | \cellcolor gray!150 | \cellcolor gray!15 1.2 $\uparrow$ | |
| Llama3.1 8B-Instruct | Baseline | 28.3 | 43.0 | 11.1 | - | 11.9 | 45.7 |
| \cellcolor cyan!15ARM | \cellcolor cyan!1531.3 | \cellcolor cyan!1545.8 | \cellcolor cyan!1513.3 | \cellcolor cyan!15- | \cellcolor cyan!1517.0 | \cellcolor cyan!1547.6 | |
| \cellcolor gray!15 Improve Rate (%) | \cellcolor gray!15 3.0 $\uparrow$ | \cellcolor gray!15 2.8 $\uparrow$ | \cellcolor gray!15 2.2 $\uparrow$ | \cellcolor gray!15- | \cellcolor gray!15 5.1 $\uparrow$ | \cellcolor gray!15 1.9 $\uparrow$ | |
| Gemma3 4b-it | Baseline | 34.3 | 72.6 | 13.3 | 20.0 | 20.2 | 17.1 |
| \cellcolor cyan!15ARM | \cellcolor cyan!1535.9 | \cellcolor cyan!1574.0 | \cellcolor cyan!1517.8 | \cellcolor cyan!1523.3 | \cellcolor cyan!1520.6 | \cellcolor cyan!1520.7 | |
| \cellcolor gray!15 Improve Rate (%) | \cellcolor gray!15 1.5 $\uparrow$ | \cellcolor gray!15 1.4 $\uparrow$ | \cellcolor gray!15 4.5 $\uparrow$ | \cellcolor gray!15 3.3 $\uparrow$ | \cellcolor gray!15 0.4 $\uparrow$ | \cellcolor gray!15 3.6 $\uparrow$ | |
| Gemma3 27b-it | Baseline | 33.3 | 85.4 | 25.6 | 26.7 | 31.9 | 9.1 |
| \cellcolor cyan!15ARM | \cellcolor cyan!1533.8 | \cellcolor cyan!1586.2 | \cellcolor cyan!1531.1 | \cellcolor cyan!1530.0 | \cellcolor cyan!1534.2 | \cellcolor cyan!1511.6 | |
| \cellcolor gray!15 Improve Rate (%) | \cellcolor gray!15 0.5 $\uparrow$ | \cellcolor gray!15 0.8 $\uparrow$ | \cellcolor gray!15 4.4 $\uparrow$ | \cellcolor gray!15 3.3 $\uparrow$ | \cellcolor gray!15 2.3 $\uparrow$ | \cellcolor gray!15 2.5 $\uparrow$ | |
5 Experiments
We evaluate our method on reasoning and non-reasoning tasks using seven models: Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5-Instruct-7B, Qwen2.5-Instruct-32B (qwe, 2025), Llama3.1-8B-Instruct (gra, 2024), Gemma3-4b-it, and Gemma3-27b-it (gem, 2025). All models use default generation parameters. For reasoning tasks, we cover three skill areas: (1) General: GPQA (Rein et al., 2024), a challenging expert-authored multiple-choice dataset; (2) Math & Text Reasoning: MATH-500 (Lightman et al., 2023), AIME’24 (AIME, 2024), and AIME’25 (AIME, 2025); (3) Agent & Coding: LiveCodeBench (Jain et al., 2024) and HumanEval (Chen et al., 2021). For non-reasoning tasks, we use GSM8K (Cobbe et al., 2021), ARC-E (Clark et al., 2018), ARC-C (Clark et al., 2018), MMLU (Hendrycks et al., 2021), BoolQ (Clark et al., 2019), HellaSwag (Zellers et al., 2019), and OpenBookQA (Mihaylov et al., 2018).
5.1 Experiment Results Analysis
For reasoning tasks, the results in Table 2 show pass@1 accuracy across multiple benchmarks. Our method consistently improves performance across most models and datasets, with the effect more pronounced in smaller models (e.g., Qwen2.5-Math-7B shows larger gains than Qwen2.5-32B-Instruct). On challenging benchmarks, however, improvements are limited when models lack sufficient capacity or when baseline accuracy is near saturation. For non-reasoning tasks (see 3(b)), applying ARM to the first-layer MLP yields little change. We attribute this to their largely factual nature, where models already have the necessary knowledge and response formats, requiring minimal reasoning. By contrast, for reasoning tasks, altering early activations helps reorganize knowledge, strengthens intermediate representations, and facilitates more effective and consistent reasoning.
5.2 Comparison of Meaningless tokens and ARM
In 3(a), we provide a direct comparison between our proposed ARM method and the strategy of inserting a suitable number of meaningless tokens. The results demonstrate that both approaches are capable of improving model performance and neither requires post-training, therefore presenting lightweight interventions that lead to robust performance gains. However, since ARM directly utilizes the fundamental principle driving the meaningless-token effect, it provides more stable results. While the meaningless-token effect is pervasive, our experiments show that the effect itself depends heavily on the specific choice of token length and placement, and thus may be unstable or difficult to generalize across tasks. ARM provides a more principled and model-internal mechanism that directly reshapes the activation distribution within the MLP, yielding more consistent gains without relying on heuristic token engineering. In sum, while the insertion of a meaningless token string on the prompt level might seem like a promising prompt-tuning adjustment on the surface, it comes with an instability of the effect which ARM eliminates. This contrast highlights the trade-off between ease of use and robustness, and further underscores the value of ARM as a systematic method for enhancing the reasoning ability in large language models.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Bar Charts: Performance Comparison of Language Models
### Overview
The image presents three bar charts comparing the performance of language models on different tasks. The charts compare a "Baseline" model against an "ARM" model across three metrics: "Pass@3 on Math-500", "Pass@3 on AIME2024", and "2-gram diversity score". The x-axis represents different language model configurations, while the y-axis represents the corresponding metric score.
### Components/Axes
**Chart 1: Pass@3 on Math-500**
* **Title:** Pass@3 on Math-500
* **Y-axis:** Accuracy, ranging from 0.60 to 0.90 in increments of 0.05.
* **X-axis:** Language model configurations:
* Qwen2.5-Math-1.5B
* Gemma3-4b-it
* Qwen2.5-Math-7B
* **Legend:** Located in the top-right corner.
* Baseline (light green)
* ARM (dark green)
**Chart 2: Pass@3 on AIME2024**
* **Title:** Pass@3 on AIME2024
* **Y-axis:** No label, ranging from 0.15 to 0.40 in increments of 0.05.
* **X-axis:** Language model configurations:
* Qwen2.5-Math-1.5B
* Gemma3-4b-it
* Qwen2.5-Math-7B
* **Legend:** Located in the top-left corner.
* Baseline (light pink)
* ARM (dark red)
**Chart 3: 2-gram diversity score**
* **Title:** 2-gram diversity score
* **Y-axis:** Diversity score, ranging from 0.0 to 0.5 in increments of 0.1.
* **X-axis:** Language model configurations:
* Qwen2.5-Math-1.5B
* Qwen2.5-Math-7B
* Gemma3-4b-it
* **Legend:** Located in the top-right corner.
* Baseline (light blue)
* ARM (dark teal)
### Detailed Analysis
**Chart 1: Pass@3 on Math-500**
* **Qwen2.5-Math-1.5B:**
* Baseline: Accuracy ~0.72
* ARM: Accuracy ~0.74
* **Gemma3-4b-it:**
* Baseline: Accuracy ~0.83
* ARM: Accuracy ~0.84
* **Qwen2.5-Math-7B:**
* Baseline: Accuracy ~0.80
* ARM: Accuracy ~0.81
**Trend:** The ARM model consistently outperforms the Baseline model across all language model configurations, but the difference is small.
**Chart 2: Pass@3 on AIME2024**
* **Qwen2.5-Math-1.5B:**
* Baseline: ~0.22
* ARM: ~0.23
* **Gemma3-4b-it:**
* Baseline: ~0.26
* ARM: ~0.29
* **Qwen2.5-Math-7B:**
* Baseline: ~0.37
* ARM: ~0.38
**Trend:** The ARM model consistently outperforms the Baseline model across all language model configurations.
**Chart 3: 2-gram diversity score**
* **Qwen2.5-Math-1.5B:**
* Baseline: ~0.53
* ARM: ~0.56
* **Qwen2.5-Math-7B:**
* Baseline: ~0.51
* ARM: ~0.54
* **Gemma3-4b-it:**
* Baseline: ~0.43
* ARM: ~0.45
**Trend:** The ARM model consistently outperforms the Baseline model across all language model configurations.
### Key Observations
* The ARM model consistently shows a slight improvement over the Baseline model in all three metrics.
* The "Pass@3 on AIME2024" metric has the lowest scores compared to the other two metrics.
* The "2-gram diversity score" metric has the highest scores compared to the other two metrics.
### Interpretation
The data suggests that the "ARM" modification consistently improves the performance of the language models across different tasks and metrics, although the improvement is relatively small. The "Pass@3 on AIME2024" metric appears to be a more challenging task for these models compared to "Pass@3 on Math-500" and "2-gram diversity score". The small performance differences between the Baseline and ARM models suggest that the ARM modification might be a fine-tuning or optimization technique that provides incremental improvements.
</details>
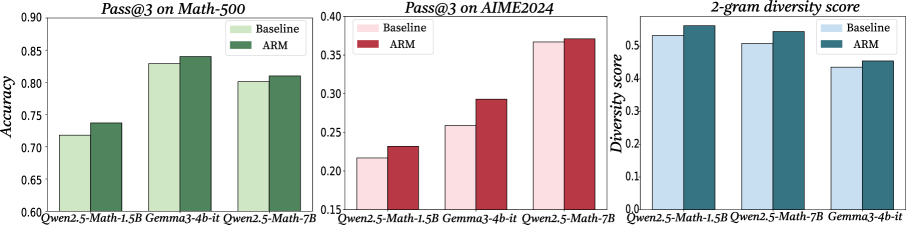
Figure 6: The first two figures show pass@3 on Math-500 and AIME2024 for three models with and without ARM, and the last shows their 2-gram diversity under both conditions.
Table 3: Table (a) compares the performance of meaningless tokens and ARM, and Table (b) reports ARM’s results on non-reasoning tasks.
(a) Pass@1 on Math-500 and AIME2024 with meaningless tokens (Mless) or ARM.
| Qwen2.5 Math-7B Mless ARM | Baseline 75.0 73.4 | 72.4 24.4 25.6 | 23.3 |
| --- | --- | --- | --- |
| Llama3.1 8B-Instruct | Baseline | 43.0 | 11.1 |
| Mless | 44.9 | 13.3 | |
| ARM | 45.8 | 13.3 | |
(b) Performance of models with ARM on non-reasoning tasks. Additional results are in Appendix G.
| Model Qwen2.5 Math-1.5B ARM | Setting Baseline 78.6 | GSM8K 78.0 39.3 | ARC-E 39.3 39.5 | HellaSwag 39.1 |
| --- | --- | --- | --- | --- |
| \cellcolor gray!15 Improve Rate (%) | \cellcolor gray!15 0.6 $\uparrow$ | \cellcolor gray!150 | \cellcolor gray!15 0.4 $\uparrow$ | |
| Llama3.1 8B-Instruct | Baseline | 80.0 | 46.6 | 56.8 |
| ARM | 82.4 | 47.1 | 57.3 | |
| \cellcolor gray!15 Improve Rate (%) | \cellcolor gray!15 2.4 $\uparrow$ | \cellcolor gray!15 0.5 $\uparrow$ | \cellcolor gray!15 0.5 $\uparrow$ | |
5.3 Exploration capabilities after ARM
As discussed earlier, we hypothesize that redistributing activations enables the model to explore the reasoning space more effectively. To test this hypothesis, we evaluate the model’s pass@3 performance on the Math-500 and AIME2024 benchmarks as well as its 2-gram diversity. As shown in Figure 6, applying activation redistribution consistently yields higher pass@3 scores compared to the baselines on both tasks. In addition, the 2-gram diversity under ARM is also greater than that without ARM. These findings indicate that activation redistribution not only improves the likelihood of arriving at correct solutions within multiple samples but also promotes more diverse reasoning paths. This dual effect suggests that ARM enhances both the effectiveness and the breadth of the model’s internal reasoning processes, reinforcing our hypothesis that carefully manipulating internal activations can expand a model’s reasoning capacity without additional training or parameter growth.
6 Discussion: Why Activation Redistribution Enhances LLM Reasoning Performance
<details>
<summary>x7.png Details</summary>
### Visual Description
## Bar Chart: Mean Ratio Comparison
### Overview
The image is a bar chart comparing the mean ratio of different categories ("digit", "operator", "conjunction", and "other") for two models: "Qwen2.5-7B-Math" and "Llama3.1-8B-Instruct". The y-axis represents the "Mean_ratio", and the x-axis represents the two models.
### Components/Axes
* **X-axis:** Represents the models being compared: "Qwen2.5-7B-Math" and "Llama3.1-8B-Instruct".
* **Y-axis:** Represents the "Mean_ratio", ranging from 0.00 to 0.14 with increments of 0.02.
* **Legend:** Located in the top-left corner, it identifies the categories represented by different colors:
* "digit" (light teal)
* "operator" (light green)
* "conjunction" (light blue)
* "other" (light slateblue)
### Detailed Analysis
**Qwen2.5-7B-Math:**
* **digit** (light teal): Mean ratio is approximately 0.067.
* **operator** (light green): Mean ratio is approximately 0.053.
* **conjunction** (light blue): Mean ratio is approximately 0.053.
* **other** (light slateblue): Mean ratio is approximately 0.049.
**Llama3.1-8B-Instruct:**
* **digit** (light teal): Mean ratio is approximately 0.101.
* **operator** (light green): Mean ratio is approximately 0.138.
* **conjunction** (light blue): Mean ratio is approximately 0.111.
* **other** (light slateblue): Mean ratio is approximately 0.094.
### Key Observations
* For both models, the "operator" category has the highest mean ratio.
* The "other" category has the lowest mean ratio for both models.
* All categories have a higher mean ratio for "Llama3.1-8B-Instruct" compared to "Qwen2.5-7B-Math".
* The largest difference in mean ratio between the two models is in the "operator" category.
### Interpretation
The bar chart suggests that "Llama3.1-8B-Instruct" has a higher mean ratio for all the categories ("digit", "operator", "conjunction", and "other") compared to "Qwen2.5-7B-Math". This could indicate that "Llama3.1-8B-Instruct" is more likely to use these categories in its outputs or that these categories are more prominent in its processing. The significant difference in the "operator" category suggests that "Llama3.1-8B-Instruct" might be more heavily reliant on operators in its operations compared to "Qwen2.5-7B-Math".
</details>
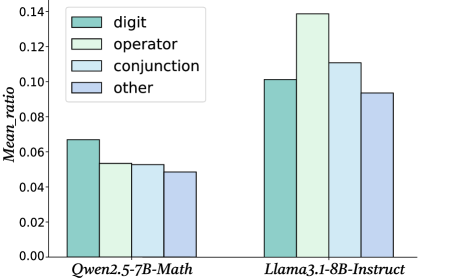
Figure 7: Percentage of near-zero activations across the four token types in the Math-500 dataset.
We provide one possible explanation for why redistributing the near-zero activations can improve the reasoning performance of LLMs. We categorize all tokens in Math-500 into four classes: digits, conjunctions, operators, and other tokens. For each class, we compute the average proportion of activations falling within near-zero range, which reflects how many dimensions of the hidden representation remain nearly inactive. The results are presented in Figure 7. As shown, normal tokens exhibit the lowest near-zero proportion, while digits, operators, and conjunctions show substantially higher proportions, which means that in the high-frequency near-zero activations after activation function, a larger portion of them are derived from these tokens. This suggests that although these tokens are crucial for reasoning, their information is insufficiently activated by the model. Our observation is consistent with the findings of Huan et al. (2025), which highlight the increasing importance of conjunctions after reinforcement learning, and also aligns with the recognized role of digits and operators in reasoning tasks such as mathematics and coding. Consequently, redistributing activations around zero enhances the representation of under-activated yet semantically important tokens, improving reasoning performance.
7 Related Work
Recent studies notice that symbols in an LLM’s input may affect their internal mechanism. Sun et al. (2024) show large activations for separators, periods, or newlines, suggesting that these tokens carry model biases. Razzhigaev et al. (2025) find that commas are essential for contextual memory, while Chauhan et al. (2025) and Min et al. (2024) highlight punctuation as attention sinks, memory aids, and semantic cues. Moreover, Chadimová et al. (2024) show that replacing words with meaningless tokens can reduce cognitive biases, whereas Li et al. (2024) report that such “glitch tokens” may also cause misunderstandings, refusals, or irrelevant outputs. Our work adds explanation to the puzzling downstream benefits that the inclusion of a string of meaningless tokens contributes to reasoning performance and shows how deep investigations of the underlying mechanisms can lead to improved inference solutions. We provide an extended discussion of related works in Appendix B.
8 Conclusion
In this paper, we report a meaningless-token effect that inserting long sequences of meaningless tokens improves model performance, particularly on reasoning tasks. Our analysis suggests that it stems from the fact that meaningless tokens induce an affine transformation on meaningful tokens, thereby redistributing their activations and enabling key information to be more effectively utilized. Building on this insight, we introduce ARM, a lightweight and training-free method for activation redistribution, which strengthens our analysis and serves as a practical approach for consistently improving LLM performance on reasoning tasks.
Ethics Statement
All datasets used in this work are publicly available and contain no sensitive information. Our method enhances LLM reasoning without introducing new data collection or human interaction. While stronger reasoning ability may be misused, we emphasize that this work is intended for beneficial research and responsible applications.
Reproducibility Statement
We will release our code and data once the paper is published. The appendix includes detailed experimental setups and hyperparameters so that others can reproduce our results. We also encourage the community to follow good research practices when using our code and data, to help maintain the reliability and transparency of future work.
References
- gra (2024) The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783.
- gem (2025) Gemma 3 technical report, 2025. URL https://arxiv.org/abs/2503.19786.
- qwe (2025) Qwen2.5 technical report, 2025. URL https://arxiv.org/abs/2412.15115.
- AIME (2024) AIME. Aime problems and solutions, 2024. URL https://aime24.aimedicine.info/.
- AIME (2025) AIME. Aime problems and solutions, 2025. URL https://artofproblemsolving.com/wiki/index.php/AIMEProblemsandSolutions.
- Bogdan et al. (2025) Paul C Bogdan, Uzay Macar, Neel Nanda, and Arthur Conmy. Thought anchors: Which llm reasoning steps matter? arXiv preprint arXiv:2506.19143, 2025.
- Chadimová et al. (2024) Milena Chadimová, Eduard Jurášek, and Tomáš Kliegr. Meaningless is better: hashing bias-inducing words in llm prompts improves performance in logical reasoning and statistical learning. arXiv preprint arXiv:2411.17304, 2024.
- Chauhan et al. (2025) Sonakshi Chauhan, Maheep Chaudhary, Koby Choy, Samuel Nellessen, and Nandi Schoots. Punctuation and predicates in language models. arXiv preprint arXiv:2508.14067, 2025.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code. 2021.
- Clark et al. (2019) Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. In NAACL, 2019.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1, 2018.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Dhanraj & Eliasmith (2025) Varun Dhanraj and Chris Eliasmith. Improving rule-based reasoning in llms via neurosymbolic representations. arXiv e-prints, pp. arXiv–2502, 2025.
- Errica et al. (2024) Federico Errica, Giuseppe Siracusano, Davide Sanvito, and Roberto Bifulco. What did i do wrong? quantifying llms’ sensitivity and consistency to prompt engineering. arXiv preprint arXiv:2406.12334, 2024.
- Guan et al. (2025) Bryan Guan, Tanya Roosta, Peyman Passban, and Mehdi Rezagholizadeh. The order effect: Investigating prompt sensitivity to input order in llms. arXiv preprint arXiv:2502.04134, 2025.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning ai with shared human values. Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- Højer et al. (2025) Bertram Højer, Oliver Jarvis, and Stefan Heinrich. Improving reasoning performance in large language models via representation engineering. arXiv preprint arXiv:2504.19483, 2025.
- Huan et al. (2025) Maggie Huan, Yuetai Li, Tuney Zheng, Xiaoyu Xu, Seungone Kim, Minxin Du, Radha Poovendran, Graham Neubig, and Xiang Yue. Does math reasoning improve general llm capabilities? understanding transferability of llm reasoning. arXiv preprint arXiv:2507.00432, 2025.
- Jain et al. (2024) Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974, 2024.
- Jiang et al. (2024) Ming Jiang, Tingting Huang, Biao Guo, Yao Lu, and Feng Zhang. Enhancing robustness in large language models: Prompting for mitigating the impact of irrelevant information. In International Conference on Neural Information Processing, pp. 207–222. Springer, 2024.
- Kaul et al. (2024) Prannay Kaul, Chengcheng Ma, Ismail Elezi, and Jiankang Deng. From attention to activation: Unravelling the enigmas of large language models. arXiv preprint arXiv:2410.17174, 2024.
- Kawasaki et al. (2024) Amelia Kawasaki, Andrew Davis, and Houssam Abbas. Defending large language models against attacks with residual stream activation analysis. arXiv preprint arXiv:2406.03230, 2024.
- Li et al. (2024) Yuxi Li, Yi Liu, Gelei Deng, Ying Zhang, Wenjia Song, Ling Shi, Kailong Wang, Yuekang Li, Yang Liu, and Haoyu Wang. Glitch tokens in large language models: Categorization taxonomy and effective detection. Proceedings of the ACM on Software Engineering, 1(FSE):2075–2097, 2024.
- Lightman et al. (2023) Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In The Twelfth International Conference on Learning Representations, 2023.
- Liu et al. (2024) Weize Liu, Yinlong Xu, Hongxia Xu, Jintai Chen, Xuming Hu, and Jian Wu. Unraveling babel: Exploring multilingual activation patterns of llms and their applications. arXiv preprint arXiv:2402.16367, 2024.
- London & Kanade (2025) Charles London and Varun Kanade. Pause tokens strictly increase the expressivity of constant-depth transformers. arXiv preprint arXiv:2505.21024, 2025.
- Luo et al. (2025) Yifan Luo, Zhennan Zhou, and Bin Dong. Inversescope: Scalable activation inversion for interpreting large language models. arXiv preprint arXiv:2506.07406, 2025.
- Luo et al. (2024) Yuqi Luo, Chenyang Song, Xu Han, Yingfa Chen, Chaojun Xiao, Xiaojun Meng, Liqun Deng, Jiansheng Wei, Zhiyuan Liu, and Maosong Sun. Sparsing law: Towards large language models with greater activation sparsity. arXiv preprint arXiv:2411.02335, 2024.
- Mihaylov et al. (2018) Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In EMNLP, 2018.
- Min et al. (2024) Junghyun Min, Minho Lee, Woochul Lee, and Yeonsoo Lee. Punctuation restoration improves structure understanding without supervision. arXiv preprint arXiv:2402.08382, 2024.
- Owen et al. (2025) Louis Owen, Nilabhra Roy Chowdhury, Abhay Kumar, and Fabian Güra. A refined analysis of massive activations in llms. arXiv preprint arXiv:2503.22329, 2025.
- Pfau et al. (2024) Jacob Pfau, William Merrill, and Samuel R Bowman. Let’s think dot by dot: Hidden computation in transformer language models. arXiv preprint arXiv:2404.15758, 2024.
- Pham & Nguyen (2024) Van-Cuong Pham and Thien Huu Nguyen. Householder pseudo-rotation: A novel approach to activation editing in llms with direction-magnitude perspective. arXiv preprint arXiv:2409.10053, 2024.
- Rai & Yao (2024) Daking Rai and Ziyu Yao. An investigation of neuron activation as a unified lens to explain chain-of-thought eliciting arithmetic reasoning of llms. arXiv preprint arXiv:2406.12288, 2024.
- Razzhigaev et al. (2025) Anton Razzhigaev, Matvey Mikhalchuk, Temurbek Rahmatullaev, Elizaveta Goncharova, Polina Druzhinina, Ivan Oseledets, and Andrey Kuznetsov. Llm-microscope: Uncovering the hidden role of punctuation in context memory of transformers. arXiv preprint arXiv:2502.15007, 2025.
- Rein et al. (2024) David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling, 2024.
- Sheng et al. (2025) Yu Sheng, Linjing Li, and Daniel Dajun Zeng. Learning theorem rationale for improving the mathematical reasoning capability of large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp. 15151–15159, 2025.
- Shi et al. (2024) Zeru Shi, Zhenting Wang, Yongye Su, Weidi Luo, Hang Gao, Fan Yang, Ruixiang Tang, and Yongfeng Zhang. Robustness-aware automatic prompt optimization. arXiv preprint arXiv:2412.18196, 2024.
- Sun et al. (2024) Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. Massive activations in large language models. arXiv preprint arXiv:2402.17762, 2024.
- Turner et al. (2023) Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering. arXiv preprint arXiv:2308.10248, 2023.
- Voita et al. (2023) Elena Voita, Javier Ferrando, and Christoforos Nalmpantis. Neurons in large language models: Dead, n-gram, positional. arXiv preprint arXiv:2309.04827, 2023.
- Wang et al. (2025) Yudong Wang, Damai Dai, Zhe Yang, Jingyuan Ma, and Zhifang Sui. Exploring activation patterns of parameters in language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp. 25416–25424, 2025.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019.
- Zhao et al. (2025) Yang Zhao, Li Du, Xiao Ding, Kai Xiong, Ting Liu, and Bing Qin. Analyzing the rapid generalization of sft via the perspective of attention head activation patterns. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 16980–16992, 2025.
- Zhou et al. (2024) Andy Zhou, Bo Li, and Haohan Wang. Robust prompt optimization for defending language models against jailbreaking attacks. arXiv preprint arXiv:2401.17263, 2024.
- Zhuo et al. (2024) Jingming Zhuo, Songyang Zhang, Xinyu Fang, Haodong Duan, Dahua Lin, and Kai Chen. Prosa: Assessing and understanding the prompt sensitivity of llms. arXiv preprint arXiv:2410.12405, 2024. Contents
1. 1 Introduction
1. 2 Observation: Inserting Meaningless Tokens Induces an Affine Transformation on Meaningful Token Representations
1. 3 Analysis: Why Affine Transformation Improve Reasoning Performance
1. 3.1 Affine Transformation influence the output of gate layer
1. 3.2 Variance change leads to activation redistribution
1. 3.3 Verification of activation redistribution
1. 4 Method: Activation Redistribution Module
1. 4.1 Select Appropriate Change proportion
1. 4.2 Redistribution of Activation Values
1. 5 Experiments
1. 5.1 Experiment Results Analysis
1. 5.2 Comparison of Meaningless tokens and ARM
1. 5.3 Exploration capabilities after ARM
1. 6 Discussion: Why Activation Redistribution Enhances LLM Reasoning Performance
1. 7 Related Work
1. 8 Conclusion
1. A Disclosure of LLM Usage
1. B Related Work
1. B.1 Meaningless Tokens in LLMs
1. B.2 Activations Analysis in LLMs
1. C Limitations
1. D Time Complexity
1. E Proof
1. E.1 Scaling factor cause variance rise
1. E.2 bias factor cause variance rise
1. F More Analysis
1. F.1 The impact of inserting length of meaningless tokens
1. F.2 The impact of inserting position of meaningless tokens.
1. F.3 The impact of inserting type of meaningless tokens
1. F.4 Why we only analyze first layer
1. F.5 Repeat Meaningful tokens’ effectiveness
1. F.6 Why random sentence is useless
1. F.7 The optimal hyperparameter range
1. G More Experiments
1. G.1 Results on non-reasoning tasks
1. G.2 Results on Base Model
1. G.3 Inference Time trick comparison
1. H The example of hyper parameters
1. I More Average activation weights
1. J Examples of model’s output change of adding meaningless
Appendix A Disclosure of LLM Usage
This paper used LLMs to assist with grammar checking.
Appendix B Related Work
B.1 Meaningless Tokens in LLMs
Recent studies have shown that seemingly meaningless tokens, such as punctuation marks, play a non-trivial role in information propagation and reasoning within large language models (LLMs). For example, Sun et al. (2024) report that LLMs exhibit large activations in response to separators, periods, or newline characters, suggesting that these tokens can serve as carriers of model biases. Similarly, Razzhigaev et al. (2025) demonstrate that tokens such as commas act as crucial elements in maintaining contextual memory: removing them significantly degrades performance on context-understanding tasks. Chauhan et al. (2025) further argue that punctuation may function as attention sinks or assist the memory mechanism, while Min et al. (2024) highlight its value in semantic construction, enabling models to better capture contextual structure. In addition, Chadimová et al. (2024) show that substituting certain words with meaningless tokens can mitigate cognitive biases in LLMs. Conversely, Li et al. (2024) illustrate that meaningless “glitch tokens” can induce misunderstandings, refusals, or irrelevant generations. However, these works primarily examine the effects of individual meaningless tokens, without considering the broader impact of longer meaningless token sequences.
More recently, several studies have explored the role of long meaningless token sequences and reported their surprising positive influence on LLM performance. For instance, Zhou et al. (2024) find that appending meaningless tokens to the end of prompts can trigger or defend against jailbreak behaviors. Similarly, Shi et al. (2024) show that adding long meaningless sequences after a sentence can improve model performance on certain tasks. Pfau et al. (2024) and London & Kanade (2025) report that substituting meaningful tokens with filler-like tokens (e.g., ‘…’) in the training data preserves the model’s ability to solve questions, suggesting that even without meaningful tokens the model can perform implicit computation. Meanwhile, there are also some methods to improve the reasoning performance of LLMs (Dhanraj & Eliasmith, 2025; Højer et al., 2025; Sheng et al., 2025). Despite these empirical findings and methods, there is still a lack of systematic analysis explaining why meaningless tokens, especially in longer sequences, can play such a counterintuitive yet beneficial role in shaping LLM reasoning behavior.
B.2 Activations Analysis in LLMs
Activation analysis is a popular method for explaining the mechanics of LLMs (Wang et al., 2025; Kawasaki et al., 2024; Pham & Nguyen, 2024; Rai & Yao, 2024). Owen et al. (2025) supplement Sun et al. (2024) by analyzing the activations after MLP to study how massive values influence bias and large attention. Wang et al. (2025) test hidden states across all layers to examine the importance of parameters in different layers. Zhao et al. (2025) use activations to determine whether an attention head is activated after training. Kaul et al. (2024) analyze attention activations and find that almost all activations focus on the first tokens; they also analyze high activations in the FFN. Luo et al. (2024) systematically study the magnitude law and influencing factors of activation sparsity in decoder Transformer architectures, showing that different activation functions (ReLU vs. SiLU) lead to drastically different sparsity trends during training. In Liu et al. (2024), activation refers to the output behavior of the expert selector: instead of a single neuron activating, the analysis investigates which expert module each token is routed to. Turner et al. (2023) propose steering middle-layer activations to improve model outputs. Voita et al. (2023) uses OPT model to do analysis for FFM neurons. Luo et al. (2025), using activations to understand the semantic information in LLMs. However, most papers analyze activations using activation scores, hidden states, or broader definitions of activation. Few works directly examine the activations right after the non-linear activation functions in the MLP.
Appendix C Limitations
Different meaningless tokens lead to varying performance outcomes. We only know that this difference arises from their differing degrees of transformation, but the underlying reason why different tokens cause such phenomena remains unclear. Meanwhile, we assume that meaningless tokens can be identified by LLMs in the first layer. Therefore, in our analysis, we focus only on their impact on meaningful tokens and how this interaction influences model performance. As such, we ignore the meaningless tokens themselves. Future work can further investigate the results when explicitly considering meaningless tokens. We restrict our analysis to the first layer, as it is the only layer where the attention scores exhibit a clear phenomenon (see Figure 2). Future work may extend this investigation to examine whether similar effects arise in deeper layers.
Appendix D Time Complexity
In this section, we will analyze the time complexity of our method in the MLP. In the first layer’s MLP, we have batch size $B$ , sequence length $S$ , feed forward dimensions $D_{f}$ , model dimension $D_{model}$ . For MLP, the module of time complexity contains gate project, up project and down project. The time complexity of each module is $O(2BSD_{f}D_{model})$ , thus the total of MLP is:
$$
\text{T}_{mlp}=O(BSD_{f}D_{model}), \tag{11}
$$
For ARM module, the operation contains: calculating MAD, comparing threshold, calculating proportion $p$ , selecting elements that need to be changed. The time complexity of all above operations is $O(BSD_{f})$ . So the time complexity of ARM is:
$$
\text{T}_{ARM}=O(BSD_{f}), \tag{12}
$$
The comparison between the time complexity of ARM and MLP is $\frac{1}{D_{model}}$ . When $D_{model}$ equals to 4096. This proportion value is approximately $\frac{1}{2*4096}≈ 1.2× 10^{-4}$ at the level of one ten-thousandth. Therefore, we believe that the time complexity of ARM can be disregarded in MLP layer.
Appendix E Proof
E.1 Scaling factor cause variance rise
**Lemma E.1**
*In LLMs, RMSNorm uses $\varepsilon>0$ ; hence $J_{q}(x_{0})$ is bounded and $\|x_{0}\|≥\varepsilon$*
For every $\lambda$ , we have:
$$
x(\lambda)=r+\lambda UA,y(\lambda)=\text{RMS}(x(\lambda)),z_{j}(\lambda)=w_{j}^{\top}y(\lambda), \tag{13}
$$
For every $\Delta\lambda$ , we have:
$$
z_{j}(\lambda+\Delta\lambda)\approx z_{j}(\lambda)+g_{j}(\lambda)\Delta\lambda,g_{j}(\lambda)=w_{j}^{\top}J_{q}(x(\lambda))UA, \tag{14}
$$
For $\text{Var}_{j}$ we have following proof:
| | $\displaystyle\Delta\mathrm{Var}_{j}$ | $\displaystyle\triangleq\mathrm{Var}\!\big[z_{j}(\lambda+\Delta\lambda)\big]-\mathrm{Var}\!\big[z_{j}(\lambda)\big]$ | |
| --- | --- | --- | --- |
$$
\Delta\mathrm{Var}_{j}\;\geq\;-2\bigl|\mathrm{Cov}(z_{j},g_{j})\bigr|\,|\Delta\lambda|+\mathrm{Var}(g_{j})\,(\Delta\lambda)^{2}.
$$
$$
|\Delta\lambda|\;>\;\frac{2\bigl|\mathrm{Cov}(z_{j},g_{j})\bigr|}{\mathrm{Var}(g_{j})}
$$
Meanwhile, we also need to have:
$$
\Delta\mathrm{Var}_{j}\;\geq\;-2\bigl|\mathrm{Cov}(z_{j},g_{j})\bigr|\,\bigl|\Delta\lambda\bigr|+A\,(\Delta\lambda)^{2}-\frac{K}{6}\,\bigl|\Delta\lambda\bigr|^{3}. \tag{15}
$$
K is upper bound of $\text{Var}[z_{j}(\lambda)]$ , thus we have a range:
$$
\frac{2\bigl|\mathrm{Cov}(z_{j},g_{j})\bigr|}{\mathrm{Var}(g_{j})}\leq\Delta\lambda\leq\frac{3\mathrm{Var}(g_{j})}{\text{K}}. \tag{16}
$$
For every $|\Delta\lambda|$ , if it is in this range, we will have $\Delta\text{Var}_{j}>0$ . Specially, when $|\Delta\lambda|$ becomes larger, the quadratic term dominates, and A increases monotonically and eventually becomes positive.
E.2 bias factor cause variance rise
**Lemma E.2**
*The bias we add is a uniform distribution sampled independently each time and does not depend on the specific value of attention output.*
**Lemma E.3**
*In LLM’s high dimensions, bias has a nonzero tangential component and $w_{j}^{→p}J_{q}(x_{0})W≠ 0$ .*
According to above lemmas we have:
$$
\mathrm{Var}[z_{j}]\approx e_{j}^{\top}W_{gate}J_{q}(x_{0})W\Sigma_{\sigma}W^{\top}J_{q}(x_{0})^{\top}W_{gate}^{\top}e_{j} \tag{17}
$$
Thus, we have $\Delta V_{j}>0$ .
Appendix F More Analysis
F.1 The impact of inserting length of meaningless tokens
In this section, we analyze the relationship between the length of inserted tokens and the performance of LLMs. We evaluate five models on MATH-500 while varying the number of inserted tokens from 0 to 70. The results are shown in Figure 8. We observe that when the inserted sequence is relatively short, the models outperform the baseline, although their accuracy fluctuates. However, when too many tokens are inserted, performance drops sharply. This occurs because, as the length of the inserted tokens increases, their influence on the attention output values accumulates (as shown in Equation 1). Once this accumulation reaches a critical level, it no longer produces a small, benign effect; instead, it alters the model’s internal semantic structure and degrades its performance.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Bar Chart: Accuracy on MATH-500
### Overview
The image is a bar chart comparing the accuracy of different language models on the MATH-500 dataset. The x-axis represents the language models, and the y-axis represents the accuracy, ranging from 30 to 75. Each model has a set of bars representing different input lengths (0 to 70 characters), indicated by color. A black line connects the tops of the bars for each model, showing the trend of accuracy as input length increases.
### Components/Axes
* **Title:** Accuracy on MATH-500
* **Y-axis:** Accuracy, with tick marks at 30, 40, 50, 60, and 70.
* **X-axis:** Language models:
* Qwen-2.5-MATH-7B
* GPT-4o-mini
* Qwen-2.5-MATH-1.5B
* DS-R1-Distill-Qwen-7B
* DS-math-7b-instruct
* **Legend:** Located at the top-right of the chart.
* Red: 0 characters
* Orange: 10 characters
* Yellow: 25 characters
* Light Blue: 40 characters
* Blue: 55 characters
* Dark Blue: 70 characters
### Detailed Analysis
Here's a breakdown of the accuracy for each model at different input lengths:
* **Qwen-2.5-MATH-7B:**
* 0 characters (Red): ~73
* 10 characters (Orange): ~74
* 25 characters (Yellow): ~75
* 40 characters (Light Blue): ~75
* 55 characters (Blue): ~74
* 70 characters (Dark Blue): ~65
* Trend: Accuracy is high and relatively stable for 0-55 characters, then drops for 70 characters.
* **GPT-4o-mini:**
* 0 characters (Red): ~72
* 10 characters (Orange): ~73
* 25 characters (Yellow): ~74
* 40 characters (Light Blue): ~74
* 55 characters (Blue): ~73
* 70 characters (Dark Blue): ~64
* Trend: Similar to Qwen-2.5-MATH-7B, accuracy is high until 55 characters, then decreases at 70 characters.
* **Qwen-2.5-MATH-1.5B:**
* 0 characters (Red): ~64
* 10 characters (Orange): ~64
* 25 characters (Yellow): ~65
* 40 characters (Light Blue): ~65
* 55 characters (Blue): ~65
* 70 characters (Dark Blue): ~62
* Trend: Accuracy is relatively stable across all input lengths, with a slight dip at 70 characters.
* **DS-R1-Distill-Qwen-7B:**
* 0 characters (Red): ~52
* 10 characters (Orange): ~53
* 25 characters (Yellow): ~53
* 40 characters (Light Blue): ~53
* 55 characters (Blue): ~52
* 70 characters (Dark Blue): ~46
* Trend: Accuracy is lower compared to the previous models and decreases more noticeably at 70 characters.
* **DS-math-7b-instruct:**
* 0 characters (Red): ~40
* 10 characters (Orange): ~40
* 25 characters (Yellow): ~41
* 40 characters (Light Blue): ~41
* 55 characters (Blue): ~41
* 70 characters (Dark Blue): ~34
* Trend: The lowest accuracy among the models, with a significant drop at 70 characters.
### Key Observations
* Qwen-2.5-MATH-7B and GPT-4o-mini achieve the highest accuracy overall.
* DS-math-7b-instruct has the lowest accuracy.
* For most models, accuracy tends to decrease when the input length is 70 characters.
* The models Qwen-2.5-MATH-7B and GPT-4o-mini show very similar performance across all input lengths.
### Interpretation
The chart illustrates the performance of different language models on the MATH-500 dataset, specifically focusing on how accuracy changes with varying input lengths. The results suggest that some models (Qwen-2.5-MATH-7B and GPT-4o-mini) are more robust and accurate than others (DS-math-7b-instruct). The decrease in accuracy at 70 characters for most models could indicate a limitation in handling longer inputs or a change in the nature of the problems when more context is provided. The similar performance of Qwen-2.5-MATH-7B and GPT-4o-mini might indicate similar architectures or training methodologies. The lower performance of the distilled models (DS-R1-Distill-Qwen-7B and DS-math-7b-instruct) is expected, as distillation often leads to a trade-off between model size/speed and accuracy.
</details>
Figure 8: The relationship between the length of inserting tokens and the performance of models.
F.2 The impact of inserting position of meaningless tokens.
In the previous section, we demonstrated that inserting meaningless tokens between the system prompt and the question leads to improved model performance. In this section, we further investigate the effect of inserting meaningless tokens at different positions. Specifically, we consider four settings: ❶ the beginning of the system prompt, ❷ between the system prompt and the question, ❸ the end of the input, and ❹ a random position within the input. The results are reported in Table 4. We observe that only inserting tokens between the system prompt and the question yields performance gains. In contrast, appending tokens to the end of the input causes the model to simply repeat them, leading to zero accuracy. Inserting tokens at random positions disrupts the original semantic structure of the sentence, while inserting them at the beginning alters the values of the system prompt itself, introducing extra terms as shown in Equation 1. We hypothesize that this disrupts the intended initialization and interferes with the task the model is expected to process. Therefore, the most effective position for inserting meaningless tokens is between the system prompt and the question.
| w/o meaningless tokens position ❶ position ❷ | 72.4 69.6 75.0 | 23.1 21.1 23.3 |
| --- | --- | --- |
| position ❸ | 0.0 | 0.0 |
| position ❹ | 51.2 | 21.1 |
Table 4: Performance on Math-500 and AIME 2024 after inserting meaningless tokens in different positions.
F.3 The impact of inserting type of meaningless tokens
In this section, we examine the influence of inserting different types of meaningless tokens on reasoning tasks. In our experiments, we insert varying lengths of slashes (“/”) and question marks (“?”) into the inputs and select the best-performing configuration from each set. As shown in Table 5, different types of meaningless tokens produce varying impacts on LLM performance, and no single unified pattern emerges. We attribute this to the fact that different token types carry distinct representational values, leading to different effects of attention during the transformation. Moreover, the sensitivity of individual questions to such transformations also varies. Consequently, the impact of meaningless tokens differs across tasks and models.
Table 5: Accuracy of LLM on two mathematical reasoning datasets with inserting different kinds of meaningless tokens.
| Qwen2.5-Math-1.5b Qwen2.5-Math-7b DeepSeek-R1-Distill-Qwen-7B | 63.6 72.4 52.0 | 66.8 75.0 55.0 | 58.2 69.6 53.6 | 14.4 23.3 3.3 | 18.8 24.4 3.3 | 16.1 22.2 4.4 |
| --- | --- | --- | --- | --- | --- | --- |
| DeepSeek-Math-7b-instruct | 39.6 | 41.4 | 43.4 | 7.8 | 12.2 | 12.5 |
| Llama-3.1-8B-Instruct | 35.4 | 36.6 | 34.2 | 11.1 | 7.8 | 13.3 |
| Qwen-2.5-32B-Instruct | 80.8 | 81.0 | 81.6 | 18.9 | 20.0 | 21.1 |
F.4 Why we only analyze first layer
<details>
<summary>x9.png Details</summary>

### Visual Description
## Line Charts: Average Attention Weight Comparison
### Overview
The image presents three line charts comparing the average attention weight of two models, "None" and "Mless," across different layers of a Qwen2.5-7B-Math model. Each chart represents a different layer (Layer 1, Layer 2, and Layer 3), while all charts represent the same head (Head 22). The x-axis represents an unspecified sequence or position, ranging from 0 to 60. The y-axis represents the average attention weight.
### Components/Axes
* **Titles:** Each chart has a title in the format "Qwen2.5-7B-Math Layer [Layer Number] Head 22".
* Chart 1: Qwen2.5-7B-Math Layer 1 Head 22
* Chart 2: Qwen2.5-7B-Math Layer 2 Head 22
* Chart 3: Qwen2.5-7B-Math Layer 3 Head 22
* **X-axis:** The x-axis is consistent across all three charts, ranging from 0 to 60 in increments of 10.
* **Y-axis:** The y-axis represents "Average Attention Weight." The scale varies between charts:
* Chart 1: 0.00 to 0.08 in increments of 0.01
* Chart 2: 0.000 to 0.200 in increments of 0.025
* Chart 3: 0.000 to 0.175 in increments of 0.025
* **Legend:** Located in the top-left corner of each chart.
* Blue line: "None"
* Red line: "Mless"
### Detailed Analysis
**Chart 1: Qwen2.5-7B-Math Layer 1 Head 22**
* **None (Blue):** The line fluctuates between approximately 0.01 and 0.04 for the first 40 units on the x-axis, with several peaks. It then increases, reaching a peak of approximately 0.075 around x=55.
* **Mless (Red):** The line generally follows the same pattern as the "None" line but with lower values. It fluctuates between approximately 0.005 and 0.025 for the first 40 units on the x-axis. It also increases after x=40, but remains below the "None" line.
**Chart 2: Qwen2.5-7B-Math Layer 2 Head 22**
* **None (Blue):** The line starts high, around 0.175 at x=0, then drops sharply to around 0.01 at x=5. It fluctuates between 0.01 and 0.05 until x=15, then spikes to 0.18 around x=17. After that, it remains relatively low, fluctuating between 0.01 and 0.05.
* **Mless (Red):** The line starts around 0.06 at x=0, then drops to around 0.01 at x=5. It fluctuates between 0.01 and 0.03 for the rest of the chart.
**Chart 3: Qwen2.5-7B-Math Layer 3 Head 22**
* **None (Blue):** The line starts around 0.175 at x=0, then drops sharply to around 0.01 at x=5. It fluctuates between 0.01 and 0.05 until x=15, then spikes to 0.18 around x=17. After that, it remains relatively low, fluctuating between 0.01 and 0.05.
* **Mless (Red):** The line starts around 0.06 at x=0, then drops to around 0.01 at x=5. It fluctuates between 0.01 and 0.03 for the rest of the chart.
### Key Observations
* In Layer 1, the "None" model generally has a higher average attention weight than the "Mless" model.
* In Layers 2 and 3, the "None" model shows a significant initial spike in attention weight, which is not present in the "Mless" model.
* The attention weights in Layers 2 and 3 are generally lower than in Layer 1, except for the initial spike in the "None" model.
### Interpretation
The charts compare the average attention weights of two model configurations ("None" and "Mless") across different layers of a Qwen2.5-7B-Math model. The differences in attention weights between the models and across layers suggest that the "Mless" configuration may have a different attention mechanism or a different distribution of attention across the input sequence compared to the "None" configuration. The initial spike in attention weight for the "None" model in Layers 2 and 3 could indicate a specific focus on the beginning of the input sequence in those layers. The data suggests that the "None" model has a higher average attention weight than the "Mless" model in Layer 1, while in Layers 2 and 3, the "None" model exhibits a significant initial spike in attention weight that is absent in the "Mless" model. This could indicate that the "None" model places more emphasis on the beginning of the input sequence in these layers.
</details>
Figure 9: Average attention weights for later tokens in Layers 1 to 3 of Qwen2.5-7B-Math.
In this section, we explain why our analysis and redistribution of activations focus exclusively on the first layer. As shown in Figure 9, we present the average attention weights of later tokens in Layers 1, 2, and 3 of Qwen2.5-7B-Math. We observe that only the first layer exhibits a clear and consistent phenomenon: after inserting meaningless tokens, the average attention weights decrease to a noticeable extent, suggesting that meaningless tokens directly alter the initial allocation of attention. In contrast, Layers 2 and 3 do not display such regularity—the average attention weights with and without meaningless tokens show no systematic relationship. Consequently, later layers do not undergo an affine transformation of this type. We hypothesize that this disappearance of the phenomenon arises because, beyond the first layer, the model has already integrated and mixed substantial semantic information through residual connections. From the second layer onward, the model begins to reconstruct and redistribute information, thereby diminishing the direct effect of meaningless tokens on average attention weights. In other words, the role of meaningless tokens becomes less distinguishable once meaningful contextual representations dominate, which explains why the first layer is the most critical point for observing and leveraging this effect.
F.5 Repeat Meaningful tokens’ effectiveness
In this section, we investigate whether adding meaningful tokens can play a role similar to meaningless tokens. Specifically, we insert a long sequence of repeated tokens that are semantically irrelevant to the question. For example, we add 55 repetitions of “he” between the system prompt and the question. The results, shown on the left of Figure 10, indicate that even such repeated but irrelevant meaningful tokens lead to an improvement in model performance. To better understand this effect, we further visualize the average attention weights after inserting these tokens, as presented on the right of Figure 10. The results reveal that the activation changes induced by repeated meaningful tokens closely resemble those caused by meaningless tokens, and the inserted tokens receive similar attention patterns which means the weight value of inserted part’s are similar. Taken together, these findings suggest that when repeated tokens are inserted at appropriate positions without introducing additional semantic content, LLMs are able to recognize them as irrelevant. Consequently, they trigger a redistribution of activations in the MLP, ultimately improving model performance.
<details>
<summary>x10.png Details</summary>
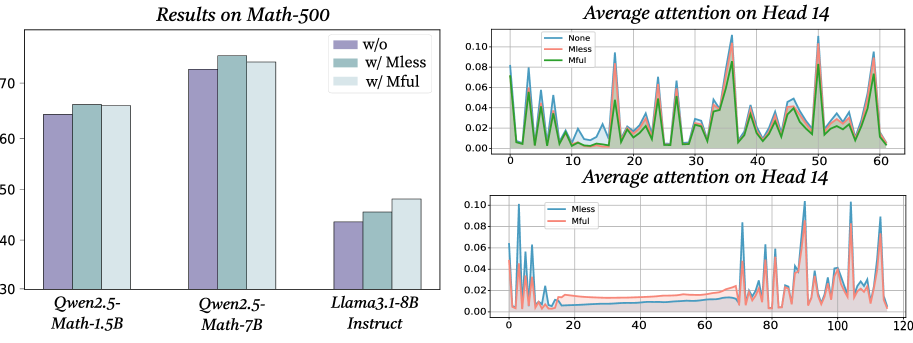
### Visual Description
## Chart Type: Multiple Charts - Bar Chart and Line Charts
### Overview
The image presents a combination of a bar chart and two line charts. The bar chart, titled "Results on Math-500," compares the performance of different models (Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, and Llama3.1-8B Instruct) under three conditions: "w/o" (without), "w/ Mless" (with Mless), and "w/ Mful" (with Mful). The two line charts, both titled "Average attention on Head 14," display attention scores over a sequence or range, comparing "None," "Mless," and "Mful" in the top chart, and "Mless" and "Mful" in the bottom chart.
### Components/Axes
**Bar Chart:**
* **Title:** Results on Math-500
* **X-axis:** Categorical labels: Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Llama3.1-8B Instruct
* **Y-axis:** Numerical scale, ranging from 30 to 70.
* **Legend:** Located at the top-right of the bar chart.
* Purple: w/o
* Teal: w/ Mless
* Light Blue: w/ Mful
**Line Charts:**
* **Title:** Average attention on Head 14 (for both charts)
* **X-axis (Top):** Numerical sequence, ranging from 0 to 60.
* **Y-axis (Top):** Numerical scale, ranging from 0.00 to 0.10.
* **Legend (Top):** Located at the top-left of the top line chart.
* Blue: None
* Orange: Mless
* Green: Mful
* **X-axis (Bottom):** Numerical sequence, ranging from 0 to 120.
* **Y-axis (Bottom):** Numerical scale, ranging from 0.00 to 0.10.
* **Legend (Bottom):** Located at the top-left of the bottom line chart.
* Blue: Mless
* Orange: Mful
### Detailed Analysis
**Bar Chart:**
* **Qwen2.5-Math-1.5B:**
* w/o (Purple): Approximately 64
* w/ Mless (Teal): Approximately 66
* w/ Mful (Light Blue): Approximately 66
* **Qwen2.5-Math-7B:**
* w/o (Purple): Approximately 72
* w/ Mless (Teal): Approximately 74
* w/ Mful (Light Blue): Approximately 74
* **Llama3.1-8B Instruct:**
* w/o (Purple): Approximately 44
* w/ Mless (Teal): Approximately 46
* w/ Mful (Light Blue): Approximately 48
**Line Chart (Top):**
* **None (Blue):** Fluctuates significantly between 0.00 and 0.08, with several sharp peaks.
* **Mless (Orange):** Generally stays below 0.04, with some peaks aligning with the "None" series.
* **Mful (Green):** Similar to "Mless," but with slightly higher values and more frequent peaks.
**Line Chart (Bottom):**
* **Mless (Blue):** Shows high initial peaks, then stabilizes around 0.02 after x=40, with some later spikes.
* **Mful (Orange):** Remains relatively low and stable, generally below 0.02, with a slight upward trend after x=40.
### Key Observations
* The bar chart shows that "w/ Mful" generally results in the highest scores, followed closely by "w/ Mless," and then "w/o."
* Qwen2.5-Math-7B consistently outperforms Qwen2.5-Math-1.5B and Llama3.1-8B Instruct.
* In the top line chart, the "None" series exhibits the most volatile behavior.
* In the bottom line chart, "Mless" shows a significant initial spike in attention, which "Mful" does not.
### Interpretation
The "Results on Math-500" bar chart suggests that incorporating "Mless" or "Mful" consistently improves performance across different models. The "Average attention on Head 14" line charts provide insights into the attention mechanisms of these models. The top chart, comparing "None," "Mless," and "Mful," indicates that the absence of these components ("None") leads to more erratic attention patterns. The bottom chart highlights a difference in initial attention allocation between "Mless" and "Mful," with "Mless" exhibiting a strong initial focus that diminishes over time, while "Mful" maintains a more consistent, lower level of attention. This could imply that "Mless" initially focuses on specific features, while "Mful" distributes attention more evenly.
</details>
Figure 10: The left panel illustrates a comparison between adding repeated meaningful tokens and meaningless tokens, while the right panel presents the average attention weights resulting from the addition of meaningful and meaningless tokens.
F.6 Why random sentence is useless
<details>
<summary>x11.png Details</summary>
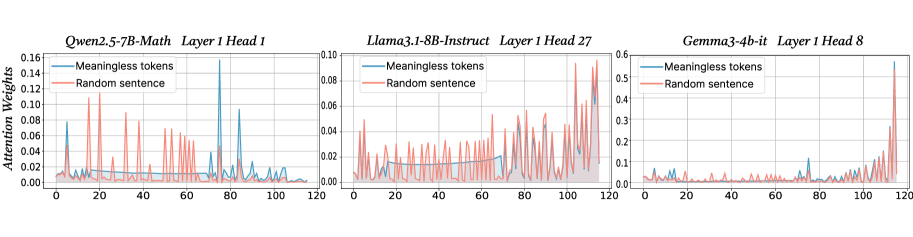
### Visual Description
## Chart Type: Line Graphs Comparing Attention Weights
### Overview
The image presents three line graphs, each comparing the attention weights of "Meaningless tokens" and a "Random sentence" across a sequence of 120 steps. The graphs are titled according to the model, layer, and head being analyzed: "Qwen2.5-7B-Math Layer 1 Head 1", "Llama3.1-8B-Instruct Layer 1 Head 27", and "Gemma3-4b-it Layer 1 Head 8". The y-axis represents "Attention Weights", and the x-axis represents the sequence steps, ranging from 0 to 120.
### Components/Axes
* **Titles (Top of each chart):**
* Left: "Qwen2.5-7B-Math Layer 1 Head 1"
* Center: "Llama3.1-8B-Instruct Layer 1 Head 27"
* Right: "Gemma3-4b-it Layer 1 Head 8"
* **Y-axis Label:** "Attention Weights"
* **X-axis:** Sequence steps, ranging from 0 to 120 in all three graphs.
* **Y-axis Scale:**
* Left: 0.00 to 0.16, incrementing by 0.02.
* Center: 0.00 to 0.10, incrementing by 0.02.
* Right: 0.0 to 0.6, incrementing by 0.1.
* **Legend (Top-Left of each chart):**
* Blue line: "Meaningless tokens"
* Red line: "Random sentence"
### Detailed Analysis
**Left Chart: Qwen2.5-7B-Math Layer 1 Head 1**
* **Meaningless tokens (Blue):** The attention weights are generally low, mostly below 0.02, with occasional spikes. There are notable spikes around steps 20, 40, 80, and 115, reaching values around 0.10 to 0.16.
* **Random sentence (Red):** The attention weights fluctuate significantly, with numerous sharp spikes throughout the sequence. Many spikes reach values between 0.04 and 0.12.
**Center Chart: Llama3.1-8B-Instruct Layer 1 Head 27**
* **Meaningless tokens (Blue):** The attention weights are relatively low and stable, generally staying below 0.02. There is a slight increase in attention weight towards the end of the sequence, reaching approximately 0.02 around step 100.
* **Random sentence (Red):** The attention weights fluctuate more than the "Meaningless tokens", with several spikes reaching values between 0.02 and 0.04. The spikes are more frequent and pronounced than the "Meaningless tokens" line.
**Right Chart: Gemma3-4b-it Layer 1 Head 8**
* **Meaningless tokens (Blue):** The attention weights are generally low, mostly below 0.1, with a significant spike at the end of the sequence (around step 115), reaching a value of approximately 0.58.
* **Random sentence (Red):** The attention weights fluctuate, with small spikes throughout the sequence. The spikes are more frequent towards the end of the sequence, with values generally below 0.1, except for the final spike which reaches approximately 0.5.
### Key Observations
* In all three graphs, the "Random sentence" line shows more frequent and pronounced spikes compared to the "Meaningless tokens" line, indicating higher variability in attention weights.
* The Qwen2.5-7B-Math model shows the most distinct spikes for both "Meaningless tokens" and "Random sentence".
* The Gemma3-4b-it model shows a dramatic spike at the end of the sequence for both "Meaningless tokens" and "Random sentence".
* The Llama3.1-8B-Instruct model shows the most stable attention weights for "Meaningless tokens".
### Interpretation
The graphs compare how different language models (Qwen, Llama, and Gemma) attend to "Meaningless tokens" versus a "Random sentence" in specific layers and heads. The attention weights indicate the importance the model assigns to each token in the sequence.
The higher variability and spikes in the "Random sentence" line suggest that these models are more sensitive to the specific content of a random sentence compared to meaningless tokens. The spikes likely correspond to specific words or phrases within the random sentence that the model deems important for processing.
The dramatic spike at the end of the sequence in the Gemma3-4b-it model suggests that this model may be particularly sensitive to the final tokens in the sequence, possibly indicating a focus on context completion or summarization.
The relatively stable attention weights for "Meaningless tokens" in the Llama3.1-8B-Instruct model suggest that this model may be more robust to irrelevant or noisy input.
The differences in attention patterns across the three models highlight the varying strategies employed by different architectures and training regimes in processing language.
</details>
Figure 11: The average attention weights of adding meaningless tokens and random sentence.
When additional tokens are inserted into a sentence, both the attention weights and the resulting attention outputs exhibit consistent patterns: the weights assigned to the original tokens decrease, while the attention outputs gain additional values from the inserted tokens. In this section, we analyze why adding repeated tokens can enhance the performance of LLMs, whereas inserting random or unrelated sentences can have a detrimental effect. The results are shown in Figure 11. We observe that the attention weights associated with the random sentence are highly diverse, and their corresponding value vectors also differ substantially. In contrast, the repeated meaningless tokens exhibit more uniform attention weights and nearly identical value vectors. Consequently, compared with repeated meaningless tokens, a random sentence introduces not only numerical fluctuations but also a pronounced directional shift in the attention outputs—one that carries additional semantic information. The formula of RMSNorm is:
$$
\operatorname{RMSNorm}(x)=\gamma\odot\frac{x}{\sqrt{\frac{1}{d}\sum_{i=1}^{d}x_{i}^{2}+\epsilon}}, \tag{18}
$$
where $\gamma$ is a learnable rescaling vector and $\epsilon$ ensures numerical stability. For repeated meaningless tokens, the effect manifests as a small and uniform directional bias on the input to RMSNorm, producing only a minor numerical perturbation in its output. In contrast, inserting a random sentence introduces high-rank and structured semantic signals that RMSNorm cannot simply absorb. This leads to systematic shifts in the output direction and subspace, thereby altering the model’s internal semantic representations.
F.7 The optimal hyperparameter range
<details>
<summary>x12.png Details</summary>
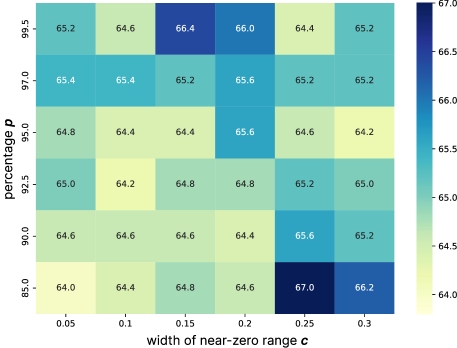
### Visual Description
## Heatmap: Performance vs. Percentage and Width
### Overview
The image is a heatmap visualizing performance (represented by color intensity) as a function of two parameters: "percentage p" (y-axis) and "width of near-zero range c" (x-axis). The heatmap displays numerical values within each cell, indicating the performance score for the corresponding parameter combination. The color gradient ranges from light yellow (lower performance) to dark blue (higher performance), as indicated by the colorbar on the right.
### Components/Axes
* **X-axis:** "width of near-zero range c" with values 0.05, 0.1, 0.15, 0.2, 0.25, and 0.3.
* **Y-axis:** "percentage p" with values 85.0, 90.0, 92.5, 95.0, 97.0, and 99.5.
* **Colorbar:** Ranges from approximately 64.0 (light yellow) to 67.0 (dark blue), representing the performance score.
### Detailed Analysis
The heatmap displays the following performance values for each combination of "percentage p" and "width of near-zero range c":
| percentage p | 0.05 | 0.1 | 0.15 | 0.2 | 0.25 | 0.3 |
| :----------- | :--- | :--- | :--- | :--- | :--- | :--- |
| 99.5 | 65.2 | 64.6 | 66.4 | 66.0 | 64.4 | 65.2 |
| 97.0 | 65.4 | 65.4 | 65.2 | 65.6 | 65.2 | 65.2 |
| 95.0 | 64.8 | 64.4 | 64.4 | 65.6 | 64.6 | 64.2 |
| 92.5 | 65.0 | 64.2 | 64.8 | 64.8 | 65.2 | 65.0 |
| 90.0 | 64.6 | 64.6 | 64.6 | 64.4 | 65.6 | 65.2 |
| 85.0 | 64.0 | 64.4 | 64.8 | 64.6 | 67.0 | 66.2 |
**Trends:**
* For "percentage p = 85.0", the performance is relatively low for "width of near-zero range c" values from 0.05 to 0.2, then spikes to the highest value (67.0) at c = 0.25, and decreases slightly to 66.2 at c = 0.3.
* For "percentage p = 99.5", the performance is highest at c = 0.15 (66.4) and 0.2 (66.0).
* The highest performance value (67.0) is observed at "percentage p = 85.0" and "width of near-zero range c = 0.25".
* The lowest performance value (64.0) is observed at "percentage p = 85.0" and "width of near-zero range c = 0.05".
### Key Observations
* The performance varies significantly depending on the combination of "percentage p" and "width of near-zero range c".
* A "width of near-zero range c" of 0.25 appears to yield high performance when "percentage p" is low (85.0).
* Higher "percentage p" values (97.0 and 99.5) show relatively consistent performance across different "width of near-zero range c" values.
### Interpretation
The heatmap suggests that the optimal configuration of "percentage p" and "width of near-zero range c" depends on the specific application or context. A lower "percentage p" may benefit from a "width of near-zero range c" of 0.25, while higher "percentage p" values are less sensitive to changes in "width of near-zero range c". The data indicates that the relationship between these parameters is not linear, and careful tuning is required to achieve the best performance. The "width of near-zero range c" parameter seems to have a more significant impact on performance when the "percentage p" is at its lowest value.
</details>
Figure 12: This figure illustrates how accuracy varies with changes in the parameters p and c.
In this section, we investigate how the hyper-parameters—the percentage p and the width of the near-zero range c —influence model performance on Math-500 when using Qwen2.5-1.5B-Math. The results are summarized in Figure 12. As the figure illustrates, the accuracy does not change monotonically with either p or c; instead, the best-performing settings emerge only within specific regions of the parameter space. This indicates that the choice of hyper-parameters is not trivial and cannot be reduced to cherry-picking. More concretely, we find that balanced combinations of p and c lead to more stable improvements. High accuracy is typically concentrated in two regions: when p is large and c is small, or conversely, when c is large and p is small. In these cases, the redistribution mechanism introduced by ARM effectively amplifies informative activations while suppressing uninformative near-zero activations. Outside of these regions, however, the performance of the model degrades, suggesting that poorly chosen hyper-parameters may distort the activation distribution rather than enhance it. These observations highlight the importance of aligning hyper-parameter choices with the intrinsic properties of activation distributions. To maximize the benefits of ARM, one must take into account both the proportion of near-zero activations and the magnitude of the maximum activation values, thereby ensuring that p and c are set within an appropriate interval. By doing so, ARM can operate in its most effective regime, consistently improving model reasoning performance rather than introducing instability. From each row and column, we can see that the performance of LLMs after ARM depends on both $p$ and $c$ . Since they are equally important, the optimal performance is determined by the range of these two parameters.
Appendix G More Experiments
G.1 Results on non-reasoning tasks
In this section, we present supplementary results on non-reasoning benchmarks, including ARC-C, MMLU, BoolQ, and OpenBookQA, as shown in Table 6. Across all evaluated models, the application of our method yields only marginal variations in performance. For most models and tasks, it either produces slight improvements or maintains parity with the baseline (i.e., vanilla model performance without any inference-time trick), suggesting that the redistribution of activations has little impact when the task primarily requires factual recall or pattern recognition rather than multi-step reasoning. A minor performance drop is observed only on a small subset of tasks with Llama-3.1-8B-Instruct, which we attribute to model-specific characteristics or sensitivity to activation perturbations.These findings indicate that our approach exerts negligible influence on non-reasoning tasks and, in most cases, does not introduce adverse effects on task accuracy. This observation further supports our central claim: the benefits of activation redistribution are most pronounced in reasoning-oriented scenarios, while in non-reasoning settings the method remains stable and does not compromise the model’s inherent ability to answer factual or knowledge-intensive questions.
Table 6: Complete results of several models on non-reasoning tasks.
| Model Qwen2.5 Math-1.5B ARM | Setting Baseline 78.6 | GSM8K 78.0 39.3 | ARC-E 39.3 35.4 | ARC-C 35.0 32.1 | MMLU 32.1 33.4 | BoolQ 32.6 39.5 | HellaSwag 39.1 42.4 | OpenBookQA 42.0 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| \cellcolor gray!15 Improve Rate (%) | \cellcolor gray!15 0.6 $\uparrow$ | \cellcolor gray!15 0 | \cellcolor gray!15 0.4 $\uparrow$ | \cellcolor gray!15 0 | \cellcolor gray!15 0.8 $\uparrow$ | \cellcolor gray!15 0.4 $\uparrow$ | \cellcolor gray!15 0.4 $\uparrow$ | |
| Qwen2.5 Math-7B | Baseline | 83.8 | 49.7 | 47.9 | 36.9 | 38.6 | 46.9 | 47.6 |
| ARM | 83.8 | 49.7 | 47.0 | 37.5 | 38.7 | 47.1 | 47.9 | |
| \cellcolor gray!15 Improve Rate (%) | \cellcolor gray!15 0 | \cellcolor gray!15 0 | \cellcolor gray!15 0 | \cellcolor gray!15 0.6 $\uparrow$ | \cellcolor gray!15 0.1 $\uparrow$ | \cellcolor gray!15 0.2 $\uparrow$ | \cellcolor gray!15 0.3 $\uparrow$ | |
| Llama3.1 8B-Instruct | Baseline | 80.0 | 46.6 | 49.0 | 38.6 | 43.3 | 56.8 | 52.8 |
| ARM | 82.4 | 47.1 | 48.7 | 38.2 | 43.2 | 57.3 | 50.8 | |
| \cellcolor gray!15 Improve Rate (%) | \cellcolor gray!15 2.4 $\uparrow$ | \cellcolor gray!15 0.5 $\uparrow$ | \cellcolor gray!15 -0.3 $\downarrow$ | \cellcolor gray!15 -0.4 $\downarrow$ | \cellcolor gray!15 -0.1 $\downarrow$ | \cellcolor gray!15 0.5 $\uparrow$ | \cellcolor gray!15 -2.0 $\downarrow$ | |
| Gemma3 4b-it | Baseline | 86.8 | 47.1 | 44.5 | 33.9 | 45.0 | 42.0 | 41.0 |
| ARM | 86.8 | 47.1 | 45.0 | 34.1 | 45.2 | 42.0 | 42.0 | |
| \cellcolor gray!15 Improve Rate (%) | \cellcolor gray!15 0 | \cellcolor gray!15 0 | \cellcolor gray!15 0.5 $\uparrow$ | \cellcolor gray!15 0.2 $\uparrow$ | \cellcolor gray!15 0.2 $\uparrow$ | \cellcolor gray!15 0 | \cellcolor gray!15 1.0 $\uparrow$ | |
G.2 Results on Base Model
Table 7: Performance on Math-500 and AIME 2024 after incorporating ARM into the MLP in non-reasoning model.
| Model Qwen2.5-1.5B ARM | Setting Baseline 68.2 | Math-500 (Pass@1) 67.8 14.4 | AIME 2024 (Pass@1) 14.4 |
| --- | --- | --- | --- |
| Improve Rate (%) | 0.4 $\uparrow$ | 0 | |
| Qwen2.5-7B | Baseline | 50.4 | 15.6 |
| ARM | 50.6 | 16.7 | |
| Improve Rate (%) | 0.2 $\uparrow$ | 1.1 $\uparrow$ | |
| Qwen2.5-32B | Baseline | 77.2 | 27.8 |
| ARM | 77.4 | 28.9 | |
| Improve Rate (%) | 0.2 $\uparrow$ | 1.1 $\uparrow$ | |
In this section, we evaluate the effect of applying ARM to base models and report their performance on Math-500 and AIME2024 using Qwen2.5-1.5B, Qwen2.5-7B, and Qwen2.5-32B. Since these models achieve accuracy above 5%, we consider them capable of tackling these tasks. In contrast, models such as Llama3.1-8B and Gemma3-4B-PT exhibit poor performance and are therefore excluded from the evaluation. The results in Table 7 show that incorporating ARM into the MLP layers of base models yields measurable performance gains on reasoning tasks, although the improvements are generally smaller than those observed for reasoning, oriented models. We attribute this gap to the weaker inherent reasoning abilities of base models. While activation redistribution can still enhance their internal representations, it may not strongly affect how they process key numerical or symbolic elements, such as digits and operators, compared with models trained specifically for reasoning.
Table 8: Performance on Math-500 and AIME 2024 after incorporating ARM into the MLP.
| Qwen2.5 Math-1.5B ARM Best-of-N(N=5) | Baseline 67.8 69.4 | 63.8 18.9 14.4 | 14.4 |
| --- | --- | --- | --- |
| Best-of-N + ARM | 71.2 | 18.9 | |
| Qwen2.5 Math-7B | Baseline | 72.4 | 23.3 |
| ARM | 73.4 | 25.6 | |
| Best-of-N(N=5) | 72.8 | 23.3 | |
| Best-of-N + ARM | 73.4 | 25.6 | |
G.3 Inference Time trick comparison
To more comprehensively evaluate the robustness, effectiveness, and compatibility of ARM with established inference-time scaling techniques, we further compare its performance against the widely used Best-of-N sampling approach during inference. Specifically, Table 8 summarizes the results obtained by applying ARM alone, Best-of-N sampling alone, and their combined usage on two representative reasoning benchmarks. For all settings, we fix the generation hyperparameters to a temperature of 0.5 and a top_p of 0.95 to ensure a consistent sampling regime. As demonstrated in the table, both ARM and Best-of-N independently yield improvements over the baseline, and their combination produces an even larger performance gain, suggesting that ARM complements rather than competes with existing inference-time strategies. These findings collectively underscore the practical value and scalability of ARM as a lightweight inference-time method for enhancing reasoning capabilities across diverse tasks.
Table 9: The hyper parameters in 7 models on three benchmarks. For Qwen and Llama, we using near-zero range $c$ to choose proportion, so $p$ is dash(“-”). But for Gemma, due to the activation distribution, we directly decide to skip setting $c$ and choose $p$ . So here, $c$ is dash(“-”). If the task performance doesn’t improve, we replace hyper-parameters with dash(“-”).
| Qwen2.5-Math-1.5B Qwen2.5-Math-7B Qwen2.5-7B-Instruct | 0.15/- 0.2/- 0.15/- | 99.5 99.5 99.5 | 0.13/- 0.1/- 0.1/- | 99.5 95.0 99.5 | 0.13/- 0.05/- - | 99.5 90.0 - | 0.13/- 0.13/- 0.13/- | 99.5 99.5 95.0 | 0.13/- 0.13/- 0.05/- | 99.5 95.0 90 | - - 0.3/- | - - 99.5 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Qwen2.5-32B-Instruct | 0.05/- | 90.5 | - | - | 0.13/- | 99.5 | 0.05/- | 99.0 | 0.13/- | 99.5 | 0.3/- | 99.5 |
| Llama3.1-8B-Instruct | 0.45/- | 80.0 | 0.32/- | 90.0 | 0.32/- | 90.0 | - | - | 0.3/- | 90.0 | 0.3/- | 90.0 |
| Gemma3-4B-it | -/0.5 | 96.5 | -/0.25 | 85.0 | -/0.25 | 96.5 | -/0.25 | 85.0 | -/0.25 | 96.5 | -/0.25 | 75.0 |
| Gemma3-27B-it | -/0.5 | 96.5 | -/0.25 | 85.0 | -/0.25 | 85.0 | -/0.25 | 70.0 | -/0.25 | 85.0 | -/0.25 | 85.0 |
Appendix H The example of hyper parameters
The selection of $p_{1}$ and $c$ depends on the distribution of model activations after the activation function. In most cases, when the frequency of near-zero activations greatly exceeds that of other values (as in Qwen), the value of $c$ should be chosen smaller. In contrast, for models like LLaMA, $c$ should be chosen larger. When the proportion of near-zero activations is extremely high (as in Gemma), we recommend directly setting the modification proportion to a value larger than $p_{\text{max}}$ . For the choice of $p_{1}$ , we generally advise selecting more than $80\%$ , which covers regions with higher activation frequencies and thus exerts a stronger influence on near-zero values. Because the proportion of extremely high-frequency activations is small, this choice will not cause large deviations in the near-zero values. Overall, although models from the same family may behave differently across tasks and parameter scales, the selection ranges of $p_{1}$ and $c$ remain relatively consistent within each family. Some examples are in Table 9.
Appendix I More Average activation weights
In this section, we present additional figures of average attention weights to further validate the previously observed phenomenon. When computing the average attention weights for Llama3.1 and Gemma3, we exclude the first token to make the effect clearer, as position tokens tend to absorb most of the attention. The results are in Figure 13, Figure 14, Figure 15, Figure 16, Figure 17, Figure 18, Figure 19, Figure 20. From results, we can see that in the most layers, models will have same phenomenon like we mentioned before.
Appendix J Examples of model’s output change of adding meaningless
In this section, we show some examples where, after adding meaningless tokens, the model can turn wrong answers into correct ones. The specific examples are provided in Appendix J.
<details>
<summary>x13.png Details</summary>
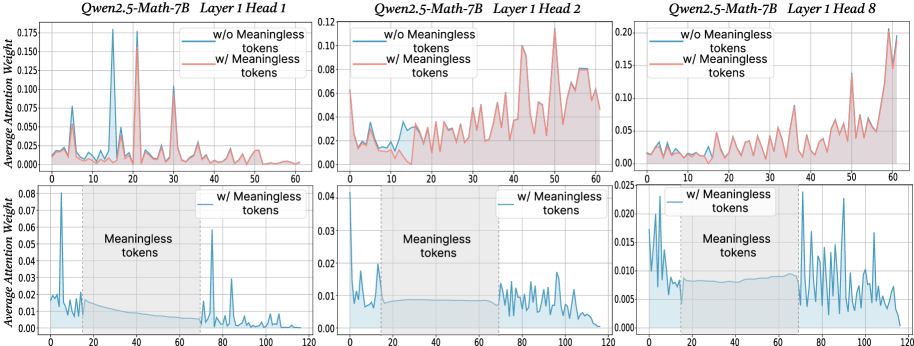
### Visual Description
## Chart Type: Multiple Line Graphs of Attention Weights
### Overview
The image presents six line graphs arranged in a 2x3 grid. Each graph displays the average attention weight of a model (Qwen2.5-Math-7B) across different tokens, with and without "meaningless" tokens. The graphs are grouped by layer head (1, 2, and 8), with two graphs per head showing different ranges of tokens (0-60 and 0-120).
### Components/Axes
**General Components:**
* **Titles:** Each of the three columns has a title indicating the model and layer head: "Qwen2.5-Math-7B Layer 1 Head 1", "Qwen2.5-Math-7B Layer 1 Head 2", and "Qwen2.5-Math-7B Layer 1 Head 8".
* **Legends:** Each of the six graphs has a legend in the top-right corner indicating two data series: "w/o Meaningless tokens" (blue line) and "w/ Meaningless tokens" (red line). The bottom three graphs only show the "w/ Meaningless tokens" (blue line).
* **Grid:** All graphs have a light gray grid in the background.
**Axes (Top Row):**
* **Y-axis:** "Average Attention Weight" with a scale from 0.000 to 0.175 (Head 1), 0.00 to 0.12 (Head 2), and 0.00 to 0.20 (Head 8).
* **X-axis:** Token index, ranging from 0 to 60.
**Axes (Bottom Row):**
* **Y-axis:** "Average Attention Weight" with a scale from 0.00 to 0.08 (Head 1), 0.00 to 0.04 (Head 2), and 0.00 to 0.025 (Head 8).
* **X-axis:** Token index, ranging from 0 to 120.
* **Shaded Region:** A shaded light-blue region is present from approximately token 20 to token 70, labeled "Meaningless tokens". This region is bounded by vertical dotted lines at x=20 and x=70.
### Detailed Analysis
**Qwen2.5-Math-7B Layer 1 Head 1:**
* **Top Graph (Tokens 0-60):**
* **w/o Meaningless tokens (blue):** The line starts around 0.02, peaks sharply around token 5 (approx. 0.07), then fluctuates between 0.01 and 0.03.
* **w/ Meaningless tokens (red):** The line starts around 0.02, peaks sharply around token 20 (approx. 0.175), then fluctuates between 0.01 and 0.03.
* **Bottom Graph (Tokens 0-120):**
* **w/ Meaningless tokens (blue):** The line starts high (approx. 0.08), drops sharply to around 0.01 by token 20, remains relatively flat within the "Meaningless tokens" region, and then fluctuates between 0.00 and 0.01 for the remaining tokens.
**Qwen2.5-Math-7B Layer 1 Head 2:**
* **Top Graph (Tokens 0-60):**
* **w/o Meaningless tokens (blue):** The line fluctuates between 0.01 and 0.03.
* **w/ Meaningless tokens (red):** The line fluctuates between 0.01 and 0.10, with a peak around token 60 (approx. 0.12).
* **Bottom Graph (Tokens 0-120):**
* **w/ Meaningless tokens (blue):** The line starts high (approx. 0.04), drops sharply to around 0.01 by token 20, remains relatively flat within the "Meaningless tokens" region, and then fluctuates between 0.00 and 0.01 for the remaining tokens.
**Qwen2.5-Math-7B Layer 1 Head 8:**
* **Top Graph (Tokens 0-60):**
* **w/o Meaningless tokens (blue):** The line fluctuates between 0.01 and 0.04.
* **w/ Meaningless tokens (red):** The line fluctuates between 0.01 and 0.10, with a sharp peak around token 60 (approx. 0.20).
* **Bottom Graph (Tokens 0-120):**
* **w/ Meaningless tokens (blue):** The line starts high (approx. 0.02), drops sharply to around 0.005 by token 20, remains relatively flat within the "Meaningless tokens" region, and then fluctuates between 0.005 and 0.015 for the remaining tokens.
### Key Observations
* The "w/ Meaningless tokens" data series (red in the top graphs) generally shows higher attention weights than the "w/o Meaningless tokens" data series (blue in the top graphs), especially in the top graphs.
* In the bottom graphs, the attention weight for "w/ Meaningless tokens" (blue) drops significantly after the initial tokens and remains low within the "Meaningless tokens" region (tokens 20-70).
* The attention weights for Head 1 are generally lower than those for Heads 2 and 8 in the top graphs.
* The bottom graphs show a clear distinction in attention weight before, during, and after the "Meaningless tokens" region.
### Interpretation
The graphs illustrate how the presence of "meaningless" tokens affects the attention weights of the Qwen2.5-Math-7B model. The higher attention weights observed in the top graphs when "meaningless" tokens are included suggest that the model may be allocating more attention to these tokens, especially around specific token indices (e.g., token 20 for Head 1, token 60 for Heads 2 and 8).
The bottom graphs provide further insight into the model's behavior. The sharp drop in attention weight after the initial tokens, followed by a sustained low attention weight within the "Meaningless tokens" region, indicates that the model may be effectively ignoring these tokens. The subsequent fluctuations in attention weight after the "Meaningless tokens" region suggest that the model is re-engaging with the remaining tokens.
The differences in attention weights across different heads (1, 2, and 8) suggest that different attention heads may be specialized for processing different types of tokens or features within the input sequence.
</details>
Figure 13: The average attention weights of Qwen2.5-Math-7B in Head 1, 2, 8.
<details>
<summary>x14.png Details</summary>
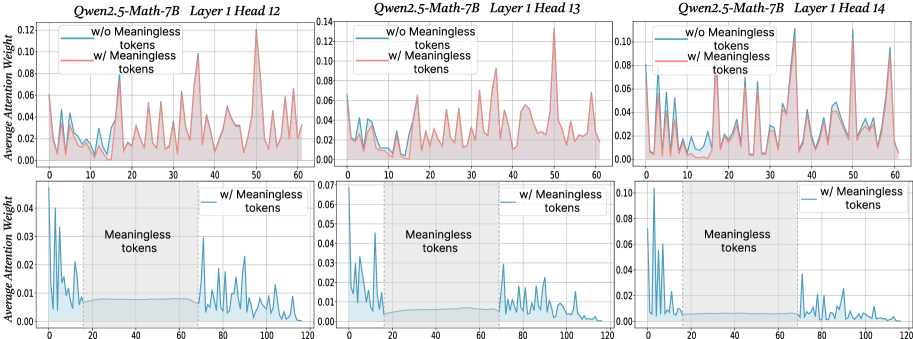
### Visual Description
## Line Chart: Average Attention Weight Comparison
### Overview
The image presents three pairs of line charts, each comparing the average attention weight of a language model (Qwen2.5-Math-7B) with and without "meaningless tokens." Each pair of charts corresponds to a different attention head (12, 13, and 14) within the first layer of the model. The top chart in each pair shows the attention weight over a shorter sequence length (0-60), while the bottom chart shows the attention weight over a longer sequence length (0-120), highlighting the region where "meaningless tokens" are present.
### Components/Axes
**General Chart Elements:**
* **Titles:** Each pair of charts has a title indicating the model ("Qwen2.5-Math-7B") and the specific layer and head number (Layer 1 Head 12, Layer 1 Head 13, Layer 1 Head 14).
* **Y-Axis:** Labeled "Average Attention Weight." The scale varies slightly between the top and bottom charts.
* **X-Axis:** Represents the token position in the sequence. The top charts range from 0 to 60, while the bottom charts range from 0 to 120.
* **Legends:** Each chart includes a legend indicating the two data series: "w/o Meaningless tokens" (blue line) and "w/ Meaningless tokens" (red line, only in the top charts). The bottom charts only show "w/ Meaningless tokens" (blue line).
* **Shaded Region:** The bottom charts have a shaded gray region labeled "Meaningless tokens," spanning approximately from token position 20 to 70.
* **Vertical Dashed Line:** A vertical dashed line is present at x=20 in the bottom charts, marking the start of the "Meaningless tokens" region.
**Specific Axis Scales:**
* **Top Charts (Heads 12, 13, 14):**
* Y-axis ranges from 0.00 to approximately 0.12 (Head 12), 0.14 (Head 13), and 0.10 (Head 14).
* X-axis ranges from 0 to 60.
* **Bottom Charts (Heads 12, 13, 14):**
* Y-axis ranges from 0.00 to approximately 0.04 (Head 12), 0.07 (Head 13), and 0.10 (Head 14).
* X-axis ranges from 0 to 120.
### Detailed Analysis
**Head 12 (Leftmost Charts):**
* **Top Chart:**
* **Blue Line (w/o Meaningless tokens):** Relatively low and stable, with values generally below 0.04.
* **Red Line (w/ Meaningless tokens):** More volatile, with several peaks reaching up to approximately 0.10.
* **Bottom Chart:**
* **Blue Line (w/ Meaningless tokens):** High attention weights at the beginning (0-20), then drops and remains low within the "Meaningless tokens" region (20-70), and increases again after 70.
**Head 13 (Center Charts):**
* **Top Chart:**
* **Blue Line (w/o Meaningless tokens):** Relatively low and stable, with values generally below 0.04.
* **Red Line (w/ Meaningless tokens):** More volatile, with several peaks reaching up to approximately 0.06.
* **Bottom Chart:**
* **Blue Line (w/ Meaningless tokens):** High attention weights at the beginning (0-20), then drops and remains low within the "Meaningless tokens" region (20-70), and increases again after 70.
**Head 14 (Rightmost Charts):**
* **Top Chart:**
* **Blue Line (w/o Meaningless tokens):** Relatively low and stable, with values generally below 0.04.
* **Red Line (w/ Meaningless tokens):** More volatile, with several peaks reaching up to approximately 0.08.
* **Bottom Chart:**
* **Blue Line (w/ Meaningless tokens):** High attention weights at the beginning (0-20), then drops and remains low within the "Meaningless tokens" region (20-70), and increases again after 70.
### Key Observations
* **Impact of Meaningless Tokens:** The presence of "meaningless tokens" (red line in top charts) generally leads to higher and more variable attention weights compared to when they are absent (blue line in top charts).
* **Attention Suppression:** In the bottom charts, the attention weight for "w/ Meaningless tokens" is suppressed within the "Meaningless tokens" region (20-70).
* **Initial Attention:** All bottom charts show high attention weights at the beginning of the sequence (0-20) when "meaningless tokens" are present.
* **Head Similarity:** The trends observed are qualitatively similar across the three attention heads (12, 13, and 14).
### Interpretation
The charts suggest that the presence of "meaningless tokens" significantly alters the attention patterns of the language model. The higher attention weights observed in the top charts indicate that the model is allocating more attention to these tokens. However, the bottom charts reveal that the model suppresses attention within the "Meaningless tokens" region, suggesting a mechanism to filter out or ignore these tokens. The initial high attention weights at the beginning of the sequence might indicate an initial processing or identification phase before the suppression mechanism kicks in. The similarity in trends across different attention heads suggests that this behavior is consistent across multiple parts of the model. This analysis highlights the model's ability to adapt its attention patterns based on the presence and location of "meaningless tokens."
</details>
Figure 14: The average attention weights of Qwen2.5-Math-7B in Head 12, 13, 14.
<details>
<summary>x15.png Details</summary>
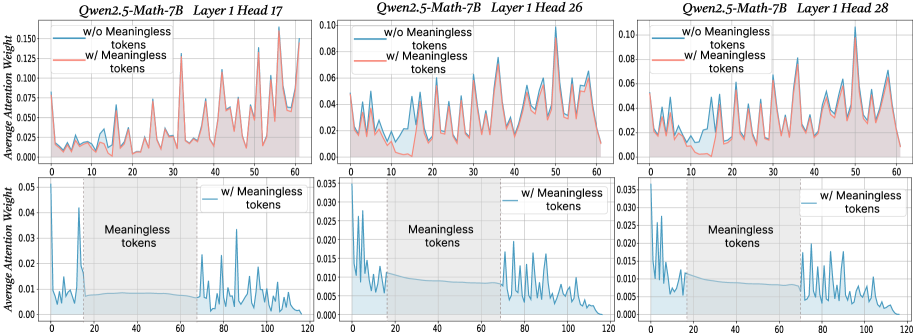
### Visual Description
## Line Charts: Attention Weight Comparison with and without Meaningless Tokens
### Overview
The image presents three pairs of line charts, each comparing the average attention weight of a language model (Qwen2.5-Math-7B) with and without "meaningless tokens." Each pair corresponds to a different attention head (17, 26, and 28) within Layer 1 of the model. The top row of charts displays data up to an x-axis value of 60, while the bottom row extends to 120, focusing on the "meaningless tokens" region.
### Components/Axes
**General Structure:**
* The image is divided into three columns, each representing a different attention head: 17, 26, and 28.
* Each column contains two line charts: one showing data up to x=60 and the other up to x=120.
* Each chart plots "Average Attention Weight" on the y-axis against an unspecified x-axis (likely token position or index).
**Axes:**
* **Y-axis (Average Attention Weight):**
* Top Row: Ranges from 0.000 to 0.150 (Head 17), 0.00 to 0.10 (Head 26), and 0.00 to 0.10 (Head 28). Increments are 0.025 (Head 17) and 0.02 (Head 26, 28).
* Bottom Row: Ranges from 0.000 to 0.05 (Head 17), 0.000 to 0.035 (Head 26), and 0.000 to 0.035 (Head 28). Increments are 0.01 (Head 17) and 0.005 (Head 26, 28).
* **X-axis:**
* Top Row: Ranges from 0 to 60, with increments of 10.
* Bottom Row: Ranges from 0 to 120, with increments of 20.
**Legends (Located in the top-right of each of the top charts):**
* **Blue Line:** "w/o Meaningless tokens" (without Meaningless tokens)
* **Red Line:** "w/ Meaningless tokens" (with Meaningless tokens)
* **Bottom Row:** "w/ Meaningless tokens" (without Meaningless tokens)
**Titles:**
* Top-left: "Qwen2.5-Math-7B Layer 1 Head 17"
* Top-middle: "Qwen2.5-Math-7B Layer 1 Head 26"
* Top-right: "Qwen2.5-Math-7B Layer 1 Head 28"
**Annotations:**
* The bottom charts have a shaded gray region labeled "Meaningless tokens" spanning approximately from x=20 to x=70.
### Detailed Analysis
**Head 17 (Left Column):**
* **Top Chart (0-60):**
* Blue Line (w/o Meaningless tokens): Relatively low and stable, generally below 0.025, with some small peaks.
* Red Line (w/ Meaningless tokens): Exhibits significantly higher peaks, reaching up to 0.15, and is generally above the blue line.
* **Bottom Chart (0-120):**
* Blue Line (w/ Meaningless tokens): Starts high (around 0.05) and rapidly decreases to a low level within the "Meaningless tokens" region, then fluctuates at a low level for the remainder of the chart.
**Head 26 (Middle Column):**
* **Top Chart (0-60):**
* Blue Line (w/o Meaningless tokens): More variable than in Head 17, with several peaks, but generally stays below 0.04.
* Red Line (w/ Meaningless tokens): Closely follows the blue line, with slightly higher peaks in some areas.
* **Bottom Chart (0-120):**
* Blue Line (w/ Meaningless tokens): Starts high (around 0.035) and decreases within the "Meaningless tokens" region, then fluctuates at a low level for the remainder of the chart, similar to Head 17.
**Head 28 (Right Column):**
* **Top Chart (0-60):**
* Blue Line (w/o Meaningless tokens): Similar to Head 26, with several peaks and valleys, generally below 0.04.
* Red Line (w/ Meaningless tokens): Closely follows the blue line, with slightly higher peaks in some areas.
* **Bottom Chart (0-120):**
* Blue Line (w/ Meaningless tokens): Starts high (around 0.035) and decreases within the "Meaningless tokens" region, then fluctuates at a low level for the remainder of the chart, similar to Heads 17 and 26.
### Key Observations
* **Head 17:** The presence of "meaningless tokens" significantly increases the average attention weight in the top chart (0-60).
* **Heads 26 & 28:** The presence of "meaningless tokens" has a smaller impact on the average attention weight in the top charts (0-60) compared to Head 17. The red and blue lines are much closer.
* **Bottom Charts (Heads 17, 26, & 28):** In all three heads, the attention weight is high initially and decreases within the "Meaningless tokens" region in the bottom charts (0-120).
### Interpretation
The charts illustrate how the presence of "meaningless tokens" affects the attention weights within different attention heads of the Qwen2.5-Math-7B language model.
* **Head Specialization:** Head 17 appears to be more sensitive to "meaningless tokens" than Heads 26 and 28, as indicated by the larger difference between the "with" and "without" lines in the top chart. This suggests that different attention heads may specialize in processing different types of information.
* **Attention Suppression:** The bottom charts suggest that the model initially attends to these "meaningless tokens" but then reduces attention within the defined region (x=20 to x=70). This could indicate a mechanism for filtering out or down-weighting irrelevant information.
* **Contextual Understanding:** The model's behavior suggests it can identify and potentially ignore "meaningless tokens" after an initial processing stage. This is crucial for efficient and accurate language understanding.
* **Further Investigation:** It would be beneficial to understand what constitutes a "meaningless token" in this context. Analyzing the specific tokens and their impact on other layers and heads could provide deeper insights into the model's attention mechanisms.
</details>
Figure 15: The average attention weights of Qwen2.5-Math-7B in Head 17, 26, 28.
<details>
<summary>x16.png Details</summary>
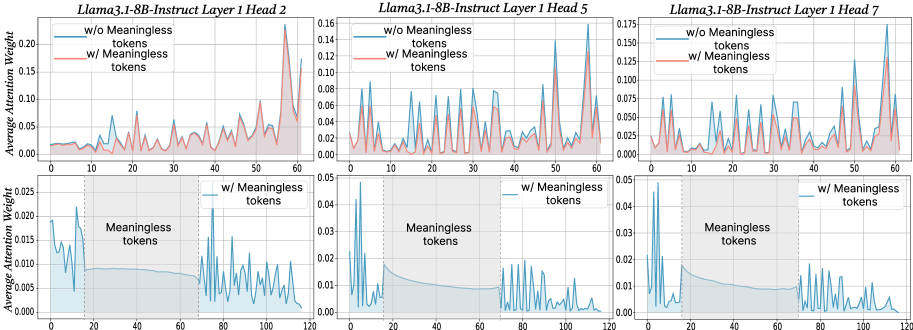
### Visual Description
## Chart Type: Line Graphs Comparing Attention Weights
### Overview
The image contains six line graphs arranged in a 2x3 grid. Each graph displays the average attention weight of a language model (Llama3.1-8B-Instruct) across different tokens. The top row shows attention weights for the first 60 tokens, while the bottom row shows attention weights for the first 120 tokens. The graphs compare attention weights when "meaningless tokens" are included versus when they are excluded. The three columns represent different attention heads (Head 2, Head 5, and Head 7) within the same layer (Layer 1) of the model.
### Components/Axes
* **Titles:** Each graph has a title in the format "Llama3.1-8B-Instruct Layer 1 Head [Number]". The titles are located at the top of each graph.
* **Y-axis:** The y-axis is labeled "Average Attention Weight". The scale varies slightly between the top and bottom rows.
* Top row: Ranges from 0.00 to approximately 0.20 (Head 2), 0.16 (Head 5), and 0.175 (Head 7).
* Bottom row: Ranges from 0.000 to 0.025 (Head 2), 0.05 (Head 5), and 0.05 (Head 7).
* **X-axis:** The x-axis represents the token index.
* Top row: Ranges from 0 to 60.
* Bottom row: Ranges from 0 to 120.
* **Legend:** Each graph in the top row has a legend in the top-left corner:
* Blue line: "w/o Meaningless tokens" (without Meaningless tokens)
* Red line: "w/ Meaningless tokens" (with Meaningless tokens)
* **Shaded Region:** The bottom row graphs have a shaded gray region labeled "Meaningless tokens" spanning approximately from token index 20 to 80.
* **Vertical Dotted Lines:** The bottom row graphs have vertical dotted lines at approximately token index 20 and 80, marking the boundaries of the "Meaningless tokens" region.
### Detailed Analysis
**Llama3.1-8B-Instruct Layer 1 Head 2**
* **Top Graph:**
* Blue line (w/o Meaningless tokens): Fluctuates between approximately 0.00 and 0.10, with some peaks reaching around 0.12.
* Red line (w/ Meaningless tokens): Generally follows the blue line but has higher peaks, reaching up to approximately 0.18 around token index 55. The red line is generally above the blue line.
* **Bottom Graph:**
* Blue line (w/ Meaningless tokens): Starts around 0.015, decreases to approximately 0.008 within the "Meaningless tokens" region, and then fluctuates between 0.005 and 0.025 after token index 80.
**Llama3.1-8B-Instruct Layer 1 Head 5**
* **Top Graph:**
* Blue line (w/o Meaningless tokens): Fluctuates between approximately 0.00 and 0.10, with several sharp peaks.
* Red line (w/ Meaningless tokens): Generally follows the blue line, but the peaks are slightly lower.
* **Bottom Graph:**
* Blue line (w/ Meaningless tokens): Starts around 0.04, decreases to approximately 0.01 within the "Meaningless tokens" region, and then fluctuates between 0.005 and 0.04 after token index 80.
**Llama3.1-8B-Instruct Layer 1 Head 7**
* **Top Graph:**
* Blue line (w/o Meaningless tokens): Fluctuates between approximately 0.00 and 0.12, with some peaks reaching around 0.15.
* Red line (w/ Meaningless tokens): Generally follows the blue line, but the peaks are slightly lower.
* **Bottom Graph:**
* Blue line (w/ Meaningless tokens): Starts around 0.045, decreases to approximately 0.01 within the "Meaningless tokens" region, and then fluctuates between 0.005 and 0.03 after token index 80.
### Key Observations
* The inclusion of "meaningless tokens" generally increases the average attention weight in the top row graphs, especially for Head 2.
* In the bottom row graphs, the average attention weight is significantly lower within the "Meaningless tokens" region (token indices 20-80) compared to the regions before and after.
* The attention weights fluctuate more sharply in the top row graphs compared to the bottom row graphs.
* The y-axis scales are different between the top and bottom rows, indicating that the average attention weights are generally lower when considering the full sequence of 120 tokens (bottom row) compared to the first 60 tokens (top row).
### Interpretation
The data suggests that "meaningless tokens" have a varying impact on the attention weights of different heads within the language model. For Head 2, including "meaningless tokens" leads to a noticeable increase in attention weight, particularly towards the end of the sequence. However, for Heads 5 and 7, the effect is less pronounced.
The lower attention weights within the "Meaningless tokens" region in the bottom row graphs indicate that the model pays less attention to these tokens, which is expected given their nature. The model seems to focus more on the meaningful tokens outside this region.
The differences in attention patterns across different heads highlight the diverse roles that individual attention heads play in processing the input sequence. Some heads may be more sensitive to the presence of "meaningless tokens" than others.
</details>
Figure 16: The average attention weights of Llama3.1-8B-Instruct in Head 2, 5, 7.
<details>
<summary>x17.png Details</summary>
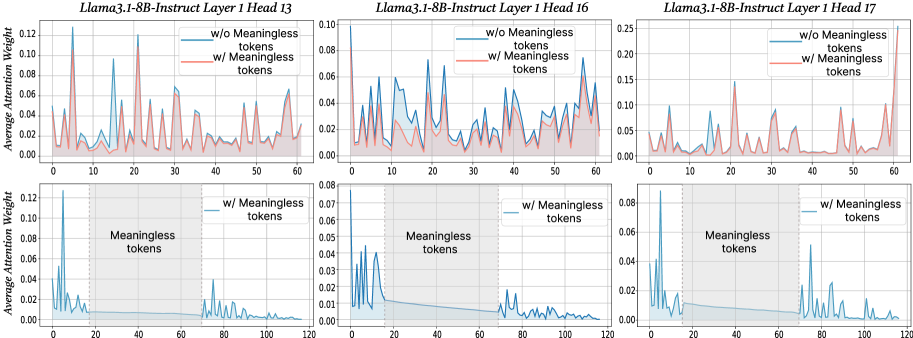
### Visual Description
## Line Charts: Average Attention Weight vs. Token Index
### Overview
The image presents six line charts arranged in a 2x3 grid. Each chart displays the average attention weight of tokens in the Llama3.1-8B-Instruct model, specifically for Layer 1 and different heads (13, 16, and 17). The top row of charts compares attention weights with and without "meaningless" tokens, while the bottom row focuses solely on attention weights with "meaningless" tokens, highlighting a specific region where these tokens are present.
### Components/Axes
**General Chart Elements:**
* **Titles:** Each chart has a title indicating the model, layer, and head number (e.g., "Llama3.1-8B-Instruct Layer 1 Head 13").
* **X-axis:** Represents the token index. The top row charts range from 0 to 60, while the bottom row charts range from 0 to 120.
* **Y-axis:** Represents the average attention weight, ranging from 0.00 to approximately 0.12 in the left and middle columns, and 0.00 to 0.25 in the right column for the top row. The bottom row y-axis ranges from 0.00 to 0.08.
* **Grid:** All charts have a light gray grid.
* **Legend:** Each chart in the top row has a legend in the top-right corner:
* Blue line: "w/o Meaningless tokens"
* Red line: "w/ Meaningless tokens"
* **Shaded Region:** The bottom row charts have a shaded gray region labeled "Meaningless tokens" spanning approximately from token index 20 to 70.
**Specific Chart Details:**
* **Top Row:** Compares attention weights with and without meaningless tokens.
* **Bottom Row:** Shows attention weights with meaningless tokens, highlighting the region where these tokens are present.
### Detailed Analysis
**Chart 1: Llama3.1-8B-Instruct Layer 1 Head 13 (Top-Left)**
* **X-axis:** 0 to 60
* **Y-axis:** 0.00 to 0.12
* **"w/o Meaningless tokens" (Blue):** The line fluctuates, with peaks around token indices 5, 20, 30, and 50.
* Approximate values: 5 (0.05), 20 (0.06), 30 (0.07), 50 (0.04)
* **"w/ Meaningless tokens" (Red):** The line also fluctuates, generally following the blue line but with slightly lower values.
* Approximate values: 5 (0.04), 20 (0.08), 30 (0.06), 50 (0.03)
**Chart 2: Llama3.1-8B-Instruct Layer 1 Head 16 (Top-Middle)**
* **X-axis:** 0 to 60
* **Y-axis:** 0.00 to 0.10
* **"w/o Meaningless tokens" (Blue):** The line fluctuates significantly, with peaks around token indices 5, 15, 30, 40, and 55.
* Approximate values: 5 (0.06), 15 (0.05), 30 (0.06), 40 (0.05), 55 (0.04)
* **"w/ Meaningless tokens" (Red):** The line generally follows the blue line, but with lower peaks.
* Approximate values: 5 (0.04), 15 (0.04), 30 (0.05), 40 (0.04), 55 (0.03)
**Chart 3: Llama3.1-8B-Instruct Layer 1 Head 17 (Top-Right)**
* **X-axis:** 0 to 60
* **Y-axis:** 0.00 to 0.25
* **"w/o Meaningless tokens" (Blue):** The line fluctuates, with peaks around token indices 5, 20, 30, 40, 50, and 60.
* Approximate values: 5 (0.08), 20 (0.12), 30 (0.10), 40 (0.11), 50 (0.13), 60 (0.15)
* **"w/ Meaningless tokens" (Red):** The line generally follows the blue line, but with lower peaks.
* Approximate values: 5 (0.06), 20 (0.10), 30 (0.08), 40 (0.09), 50 (0.11), 60 (0.13)
**Chart 4: Llama3.1-8B-Instruct Layer 1 Head 13 (Bottom-Left)**
* **X-axis:** 0 to 120
* **Y-axis:** 0.00 to 0.12
* **"w/ Meaningless tokens" (Blue):** The line shows high peaks at the beginning (around token index 5), then decreases and remains low within the "Meaningless tokens" region (20-70), and then fluctuates again after token index 70.
* Approximate values: 5 (0.12), 30-60 (0.01), 80 (0.02), 100 (0.01)
* **Shaded Region:** "Meaningless tokens" region spans from approximately token index 20 to 70.
**Chart 5: Llama3.1-8B-Instruct Layer 1 Head 16 (Bottom-Middle)**
* **X-axis:** 0 to 120
* **Y-axis:** 0.00 to 0.08
* **"w/ Meaningless tokens" (Blue):** The line shows high peaks at the beginning (around token index 5), then decreases and remains low within the "Meaningless tokens" region (20-70), and then fluctuates again after token index 70.
* Approximate values: 5 (0.07), 30-60 (0.01), 80 (0.02), 100 (0.01)
* **Shaded Region:** "Meaningless tokens" region spans from approximately token index 20 to 70.
**Chart 6: Llama3.1-8B-Instruct Layer 1 Head 17 (Bottom-Right)**
* **X-axis:** 0 to 120
* **Y-axis:** 0.00 to 0.08
* **"w/ Meaningless tokens" (Blue):** The line shows high peaks at the beginning (around token index 5), then decreases and remains low within the "Meaningless tokens" region (20-70), and then fluctuates again after token index 70.
* Approximate values: 5 (0.08), 30-60 (0.01), 80 (0.02), 100 (0.01)
* **Shaded Region:** "Meaningless tokens" region spans from approximately token index 20 to 70.
### Key Observations
* The presence of "meaningless" tokens generally reduces the average attention weight compared to when they are absent (top row charts).
* The bottom row charts show that the attention weight is significantly lower within the "Meaningless tokens" region (token indices 20-70) compared to the regions outside this range.
* The attention weights fluctuate more in the top row charts (0-60 token index range) compared to the bottom row charts, especially within the "Meaningless tokens" region.
* Heads 13, 16, and 17 show similar patterns in attention weight distribution.
### Interpretation
The charts suggest that the Llama3.1-8B-Instruct model assigns lower attention weights to "meaningless" tokens in Layer 1. This is evident from the reduced attention weights when "meaningless" tokens are included (top row) and the low attention weights within the "Meaningless tokens" region (bottom row). This indicates that the model is likely designed to de-emphasize or ignore these tokens during processing, potentially to focus on more relevant information. The similar patterns across different heads (13, 16, and 17) suggest a consistent behavior in how the model handles these tokens within Layer 1. The initial peaks in attention weight before the "meaningless tokens" region in the bottom row charts could indicate the model is focusing on context before the meaningless tokens appear.
</details>
Figure 17: The average attention weights of Llama3.1-8B-Instruct in Head 13, 16, 17.
<details>
<summary>x18.png Details</summary>
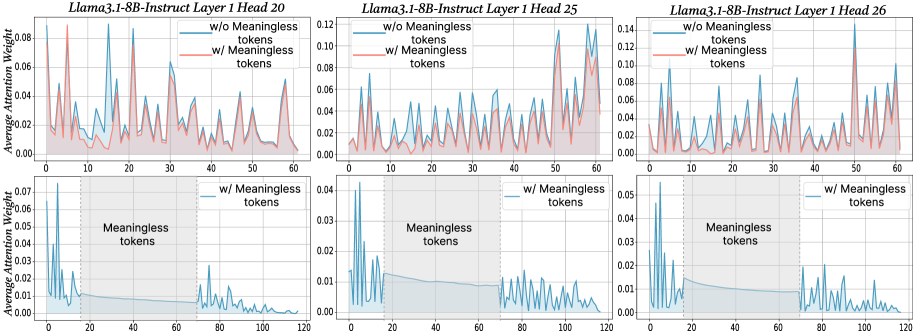
### Visual Description
## Chart: Average Attention Weight vs. Tokens
### Overview
The image presents six line charts arranged in a 2x3 grid. Each chart displays the average attention weight against the number of tokens for different configurations of the Llama3.1-8B-Instruct model. The top row shows attention weights for a shorter sequence length (0-60 tokens), while the bottom row focuses on a longer sequence length (0-120 tokens), specifically highlighting the region of "meaningless tokens". The charts compare attention weights with and without meaningless tokens.
### Components/Axes
**General Chart Elements:**
* **Titles:** Each chart has a title indicating the model configuration (Llama3.1-8B-Instruct Layer 1 Head X, where X is 20, 25, or 26).
* **X-axis:** Represents the number of tokens. The top row charts range from 0 to 60 tokens, while the bottom row charts range from 0 to 120 tokens.
* **Y-axis:** Represents the average attention weight, ranging from 0.00 to varying maximum values (approximately 0.08, 0.12, and 0.14 for the top row, and approximately 0.07, 0.04, and 0.05 for the bottom row).
* **Legend:** Located in the top-right corner of each chart, indicating the two data series: "w/o Meaningless tokens" (blue line) and "w/ Meaningless tokens" (red line). The bottom row charts only display the "w/ Meaningless tokens" (blue line).
* **Grid:** All charts have a light gray grid in the background.
* **Meaningless Tokens Region:** The bottom row charts have a shaded gray region labeled "Meaningless tokens", spanning approximately from token 20 to token 70.
**Specific Axis Details:**
* **Top Row Y-Axis:**
* Left Chart (Head 20): 0.00 to 0.08, increments of 0.02
* Middle Chart (Head 25): 0.00 to 0.12, increments of 0.02
* Right Chart (Head 26): 0.00 to 0.14, increments of 0.02
* **Bottom Row Y-Axis:**
* Left Chart (Head 20): 0.00 to 0.07, increments of 0.01
* Middle Chart (Head 25): 0.00 to 0.04, increments of 0.01
* Right Chart (Head 26): 0.00 to 0.05, increments of 0.01
* **X-Axis (All Charts):** Increments of 10 tokens.
### Detailed Analysis
**Top Row Charts (0-60 Tokens):**
* **Llama3.1-8B-Instruct Layer 1 Head 20:**
* **w/o Meaningless tokens (blue):** The line fluctuates, showing several peaks and valleys. It generally stays above the "w/ Meaningless tokens" line.
* Peaks around token numbers: 5, 12, 18, 25, 30, 38, 45, 52, 58.
* Approximate peak values: 0.07, 0.06, 0.05, 0.06, 0.05, 0.06, 0.05, 0.06, 0.05.
* **w/ Meaningless tokens (red):** The line also fluctuates, but generally stays below the "w/o Meaningless tokens" line.
* Peaks around token numbers: 5, 12, 18, 25, 30, 38, 45, 52, 58.
* Approximate peak values: 0.04, 0.03, 0.03, 0.03, 0.03, 0.03, 0.03, 0.03, 0.03.
* **Llama3.1-8B-Instruct Layer 1 Head 25:**
* **w/o Meaningless tokens (blue):** The line fluctuates, showing several peaks and valleys. It generally stays above the "w/ Meaningless tokens" line.
* Peaks around token numbers: 5, 12, 18, 25, 30, 38, 45, 52, 58.
* Approximate peak values: 0.09, 0.08, 0.07, 0.08, 0.07, 0.08, 0.07, 0.08, 0.07.
* **w/ Meaningless tokens (red):** The line also fluctuates, but generally stays below the "w/o Meaningless tokens" line.
* Peaks around token numbers: 5, 12, 18, 25, 30, 38, 45, 52, 58.
* Approximate peak values: 0.06, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05.
* **Llama3.1-8B-Instruct Layer 1 Head 26:**
* **w/o Meaningless tokens (blue):** The line fluctuates, showing several peaks and valleys. It generally stays above the "w/ Meaningless tokens" line.
* Peaks around token numbers: 5, 12, 18, 25, 30, 38, 45, 52, 58.
* Approximate peak values: 0.11, 0.10, 0.09, 0.10, 0.09, 0.10, 0.09, 0.10, 0.09.
* **w/ Meaningless tokens (red):** The line also fluctuates, but generally stays below the "w/o Meaningless tokens" line.
* Peaks around token numbers: 5, 12, 18, 25, 30, 38, 45, 52, 58.
* Approximate peak values: 0.08, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07, 0.07.
**Bottom Row Charts (0-120 Tokens):**
* **Llama3.1-8B-Instruct Layer 1 Head 20:**
* **w/ Meaningless tokens (blue):** The line starts with high peaks in the initial tokens (0-20), then rapidly decreases and stabilizes at a low level within the "Meaningless tokens" region (20-70). After the "Meaningless tokens" region, the line fluctuates again, showing smaller peaks.
* Initial peaks around token numbers: 2, 5, 8, 12, 15, 18.
* Approximate peak values: 0.07, 0.05, 0.04, 0.03, 0.02, 0.02.
* Stable value within "Meaningless tokens" region: ~0.01.
* Peaks after "Meaningless tokens" region around token numbers: 75, 85, 95, 105, 115.
* Approximate peak values: 0.01, 0.01, 0.01, 0.01, 0.01.
* **Llama3.1-8B-Instruct Layer 1 Head 25:**
* **w/ Meaningless tokens (blue):** The line starts with high peaks in the initial tokens (0-20), then rapidly decreases and stabilizes at a low level within the "Meaningless tokens" region (20-70). After the "Meaningless tokens" region, the line fluctuates again, showing smaller peaks.
* Initial peaks around token numbers: 2, 5, 8, 12, 15, 18.
* Approximate peak values: 0.04, 0.03, 0.02, 0.02, 0.01, 0.01.
* Stable value within "Meaningless tokens" region: ~0.005.
* Peaks after "Meaningless tokens" region around token numbers: 75, 85, 95, 105, 115.
* Approximate peak values: 0.005, 0.005, 0.005, 0.005, 0.005.
* **Llama3.1-8B-Instruct Layer 1 Head 26:**
* **w/ Meaningless tokens (blue):** The line starts with high peaks in the initial tokens (0-20), then rapidly decreases and stabilizes at a low level within the "Meaningless tokens" region (20-70). After the "Meaningless tokens" region, the line fluctuates again, showing smaller peaks.
* Initial peaks around token numbers: 2, 5, 8, 12, 15, 18.
* Approximate peak values: 0.05, 0.04, 0.03, 0.02, 0.02, 0.02.
* Stable value within "Meaningless tokens" region: ~0.01.
* Peaks after "Meaningless tokens" region around token numbers: 75, 85, 95, 105, 115.
* Approximate peak values: 0.01, 0.01, 0.01, 0.01, 0.01.
### Key Observations
* **Top Row:** The average attention weight is generally higher when meaningless tokens are excluded ("w/o Meaningless tokens"). Both lines fluctuate, indicating varying attention weights across different tokens.
* **Bottom Row:** The average attention weight drops significantly within the "Meaningless tokens" region, suggesting that the model pays less attention to these tokens. The initial tokens (0-20) show high attention weights, followed by a rapid decrease. After the "Meaningless tokens" region, the attention weights fluctuate again, but at a lower level than the initial tokens.
* **Head Variation:** The overall magnitude of attention weights varies across different heads (20, 25, and 26), with Head 26 generally showing the highest attention weights.
### Interpretation
The data suggests that the Llama3.1-8B-Instruct model assigns different attention weights to tokens based on their meaning. When meaningless tokens are included, the average attention weight is generally lower, indicating that the model is diluting its attention across a larger set of tokens, some of which are not informative.
The bottom row charts highlight the model's behavior when explicitly presented with a region of "meaningless tokens." The sharp drop in attention weight within this region confirms that the model is indeed recognizing and down-weighting these tokens. The initial high attention weights likely correspond to the more meaningful tokens at the beginning of the sequence, while the fluctuations after the "Meaningless tokens" region suggest that the model is attempting to re-engage with the remaining meaningful tokens.
The variation in attention weights across different heads (20, 25, and 26) indicates that different attention heads within the model are specialized for different aspects of the input sequence. Some heads may be more sensitive to meaningful tokens, while others may be more influenced by the presence of meaningless tokens.
</details>
Figure 18: The average attention weights of Llama3.1-8B-Instruct in Head 20, 25, 26.
<details>
<summary>x19.png Details</summary>
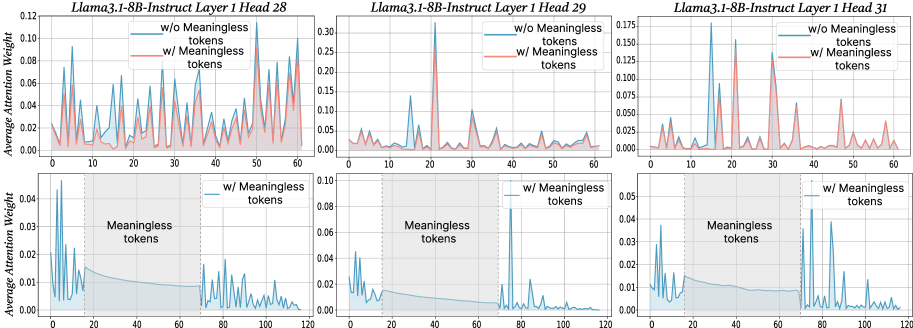
### Visual Description
## Line Charts: Attention Weights with and without Meaningless Tokens
### Overview
The image presents six line charts arranged in two rows of three. Each chart displays the average attention weight across different tokens for the Llama3.1-8B-Instruct model, specifically focusing on Layer 1, Heads 28, 29, and 31. The top row shows attention weights for all tokens, distinguishing between scenarios "w/o Meaningless tokens" (blue line) and "w/ Meaningless tokens" (red line). The bottom row focuses on the attention weights "w/ Meaningless tokens" (blue line) and highlights the region where meaningless tokens are present with a shaded gray area.
### Components/Axes
**General Chart Elements:**
* **Titles:** Each chart has a title indicating the model, layer, and head number (e.g., "Llama3.1-8B-Instruct Layer 1 Head 28").
* **X-axis:** Represents the token index. The top row charts range from 0 to 60, while the bottom row charts range from 0 to 120.
* **Y-axis:** Represents the "Average Attention Weight." The scale varies between charts.
* **Legends:** Each chart contains a legend in the top-right corner. The top row legends indicate "w/o Meaningless tokens" (blue line) and "w/ Meaningless tokens" (red line). The bottom row legends indicate "w/ Meaningless tokens" (blue line).
* **Shaded Region:** The bottom row charts feature a shaded gray region labeled "Meaningless tokens." This region spans approximately from token index 20 to 70.
* **Vertical Dashed Line:** The bottom row charts have a vertical dashed line at approximately token index 20, marking the start of the "Meaningless tokens" region.
**Specific Chart Details:**
* **Top Row Charts:**
* **Y-axis Scale:**
* Head 28: 0.00 to 0.12
* Head 29: 0.00 to 0.30
* Head 31: 0.000 to 0.175
* **Bottom Row Charts:**
* **Y-axis Scale:**
* Head 28: 0.00 to 0.04
* Head 29: 0.00 to 0.10
* Head 31: 0.00 to 0.05
### Detailed Analysis
**Head 28 (Top Row):**
* **Blue Line (w/o Meaningless tokens):** Shows several peaks, with the highest around token index 22, reaching approximately 0.11. The line fluctuates significantly.
* **Red Line (w/ Meaningless tokens):** Generally follows the trend of the blue line but with lower peaks. It remains mostly below 0.04.
**Head 28 (Bottom Row):**
* **Blue Line (w/ Meaningless tokens):** Shows high attention weights for the first few tokens, peaking at approximately 0.04 around token index 2. The attention weight decreases and remains low within the "Meaningless tokens" region (token index 20 to 70), then increases again after token index 70.
**Head 29 (Top Row):**
* **Blue Line (w/o Meaningless tokens):** Exhibits a very sharp peak at token index 22, reaching approximately 0.30. The rest of the line remains relatively low, generally below 0.05.
* **Red Line (w/ Meaningless tokens):** Similar to the blue line, but the peak at token index 22 is lower, around 0.25.
**Head 29 (Bottom Row):**
* **Blue Line (w/ Meaningless tokens):** Shows a high peak at the beginning, around token index 2, reaching approximately 0.05. The attention weight decreases and remains low within the "Meaningless tokens" region, then increases again after token index 70.
**Head 31 (Top Row):**
* **Blue Line (w/o Meaningless tokens):** Shows several prominent peaks, particularly around token indices 17 and 30, reaching approximately 0.17 and 0.15, respectively.
* **Red Line (w/ Meaningless tokens):** Generally follows the trend of the blue line, but with lower peaks.
**Head 31 (Bottom Row):**
* **Blue Line (w/ Meaningless tokens):** Shows high attention weights for the first few tokens, peaking at approximately 0.05 around token index 2. The attention weight decreases and remains low within the "Meaningless tokens" region, then increases again after token index 70.
### Key Observations
* The presence of meaningless tokens generally reduces the average attention weight, as evidenced by the red lines being lower than the blue lines in the top row charts.
* The bottom row charts clearly show a suppression of attention weights within the "Meaningless tokens" region (token index 20 to 70).
* Heads 29 exhibits a very strong focus on a single token (index 22) when meaningless tokens are excluded.
* The attention weights tend to be higher for the initial tokens (before index 20) and after the "Meaningless tokens" region (after index 70) in the bottom row charts.
### Interpretation
The data suggests that the Llama3.1-8B-Instruct model's attention mechanism is affected by the presence of meaningless tokens. The model appears to allocate less attention to tokens within the designated "Meaningless tokens" region, as shown in the bottom row charts. The top row charts indicate that the overall attention weights are generally lower when meaningless tokens are included, suggesting that the model distributes its attention differently in their presence.
The high attention weights observed for the initial tokens in the bottom row charts might indicate that the model focuses on the beginning of the input sequence before encountering the "Meaningless tokens." The subsequent increase in attention weights after the "Meaningless tokens" region could suggest that the model re-engages with the meaningful parts of the input.
Head 29's strong focus on a single token (index 22) when meaningless tokens are excluded could indicate that this head is particularly sensitive to specific features or patterns in the input that are masked or diluted by the presence of meaningless tokens.
</details>
Figure 19: The average attention weights of Llama3.1-8B-Instruct in Head 28, 29, 31.
<details>
<summary>x20.png Details</summary>
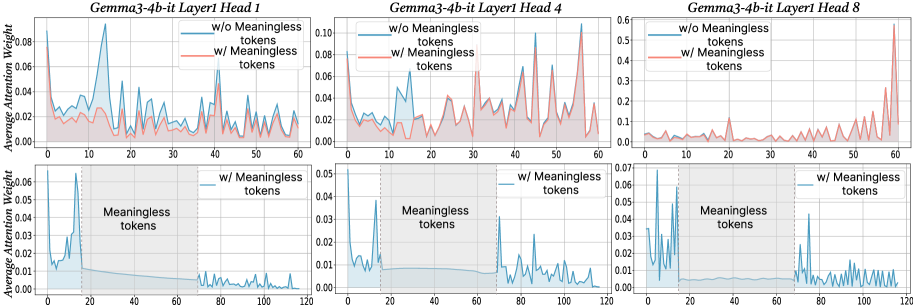
### Visual Description
## Line Chart: Gemma3-4b-it Layer1 Head Attention Weights
### Overview
The image presents six line charts arranged in a 2x3 grid. Each chart displays the average attention weight of a language model (Gemma3-4b-it) for a specific layer (Layer1) and attention head (Head 1, Head 4, Head 8). The top row of charts shows attention weights for the first 60 tokens, comparing scenarios with and without "meaningless" tokens. The bottom row focuses on the attention weights "w/ Meaningless tokens" for the first 120 tokens, highlighting the region where these meaningless tokens occur.
### Components/Axes
**General Chart Elements:**
* **Titles:** Each chart has a title in the format "Gemma3-4b-it Layer1 Head [Number]".
* **X-axis:** Represents the token number. The top row charts range from 0 to 60, while the bottom row charts range from 0 to 120.
* **Y-axis:** Represents the "Average Attention Weight". The scale varies between charts.
* **Legend:** Located in the top-right corner of each of the top row charts.
* Blue line: "w/o Meaningless tokens"
* Red line: "w/ Meaningless tokens"
* **Shaded Region:** In the bottom row charts, a gray shaded region is labeled "Meaningless tokens". This region spans approximately from token 20 to token 70.
* **Vertical Dotted Line:** A vertical dotted line is present at approximately token 20 in the bottom row charts, marking the start of the "Meaningless tokens" region.
**Specific Axis Scales:**
* **Top-Left Chart (Head 1):** Y-axis ranges from 0.00 to 0.08.
* **Top-Middle Chart (Head 4):** Y-axis ranges from 0.00 to 0.10.
* **Top-Right Chart (Head 8):** Y-axis ranges from 0.0 to 0.6.
* **Bottom-Left Chart (Head 1):** Y-axis ranges from 0.00 to 0.06.
* **Bottom-Middle Chart (Head 4):** Y-axis ranges from 0.00 to 0.05.
* **Bottom-Right Chart (Head 8):** Y-axis ranges from 0.00 to 0.07.
### Detailed Analysis
**Top Row Charts (First 60 Tokens):**
* **Head 1:**
* **Blue line (w/o Meaningless tokens):** Fluctuates between 0.02 and 0.06.
* **Red line (w/ Meaningless tokens):** Generally lower than the blue line, fluctuating between 0.01 and 0.04.
* **Head 4:**
* **Blue line (w/o Meaningless tokens):** Fluctuates between 0.02 and 0.08, with a peak around token 15.
* **Red line (w/ Meaningless tokens):** Similar to the blue line, but slightly lower, fluctuating between 0.01 and 0.06.
* **Head 8:**
* **Blue line (w/o Meaningless tokens):** Relatively low and stable, mostly below 0.05.
* **Red line (w/ Meaningless tokens):** Shows a significant spike towards the end (around token 60), reaching approximately 0.55.
**Bottom Row Charts (First 120 Tokens, w/ Meaningless tokens):**
* **Head 1:** The blue line (w/ Meaningless tokens) shows a sharp initial peak around token 5, reaching approximately 0.06, then rapidly decreases and stabilizes around 0.01 within the "Meaningless tokens" region.
* **Head 4:** Similar to Head 1, the blue line (w/ Meaningless tokens) has a sharp initial peak around token 5, reaching approximately 0.05, then decreases and stabilizes around 0.01 within the "Meaningless tokens" region.
* **Head 8:** The blue line (w/ Meaningless tokens) shows a sharp initial peak around token 5, reaching approximately 0.06, then decreases and stabilizes around 0.005 within the "Meaningless tokens" region. There is a slight increase after token 70.
### Key Observations
* The presence of "meaningless tokens" generally reduces the average attention weight for Head 1 and Head 4 in the first 60 tokens.
* Head 8 exhibits a significant spike in attention weight towards the end of the first 60 tokens *only* when "meaningless tokens" are included.
* In the bottom row charts, all heads show a sharp initial peak in attention weight, followed by a decrease and stabilization within the "Meaningless tokens" region.
* The Y-axis scale for Head 8 is significantly larger than for Head 1 and Head 4, indicating that Head 8 can have much higher attention weights.
### Interpretation
The charts illustrate how the inclusion of "meaningless tokens" affects the attention weights of different heads in the Gemma3-4b-it language model. The initial spike in attention weight in the bottom row charts suggests that the model initially focuses on these tokens. However, within the "Meaningless tokens" region, the attention weights stabilize at a lower level, indicating that the model learns to disregard these tokens to some extent. The spike in Head 8's attention weight at the end of the first 60 tokens when "meaningless tokens" are present suggests that this head might be compensating for the presence of these tokens by focusing on other parts of the input sequence. The differences in attention patterns across different heads highlight the diverse roles that each head plays in the model's attention mechanism.
</details>
Figure 20: The average attention weights of Gemma3-4b-it in Head 1, 4, 8.
See pages 1-last of case_study.pdf