# StepChain GraphRAG: Reasoning Over Knowledge Graphs for Multi-Hop Question Answering
**Authors**: Tengjun Ni, Xin Yuan, Shenghong Li, Kai Wu, Ren Ping Liu, Wei Ni, Wenjie Zhang
> Corresponding author.
institutetext: University of Technology Sydney, Australia email: nitengjun2002@gmail.com email: Kai.Wu@uts.edu.au email: RenPing.Liu@uts.edu.au institutetext: Data61, CSIRO, Australia email: xin.yuan@ieee.org email: shenghong.li@csiro.au institutetext: School of Engineering, Edith Cowan University, Australia email: Wei.ni@ieee.org institutetext: University of New South Wales, Australia email: wenjie.zhang@unsw.edu.au
Abstract
Recent progress in retrieval-augmented generation (RAG) has led to more accurate and interpretable multi-hop question answering (QA). Yet, challenges persist in integrating iterative reasoning steps with external knowledge retrieval. To address this, we introduce StepChain GraphRAG, a framework that unites question decomposition with a Breadth-First Search (BFS) Reasoning Flow for enhanced multi-hop QA. Our approach first builds a global index over the corpus; at inference time, only retrieved passages are parsed on‑the‑fly into a knowledge graph, and the complex query is split into sub‑questions. For each sub-question, a BFS-based traversal dynamically expands along relevant edges, assembling explicit evidence chains without overwhelming the language model with superfluous context. Experiments on MuSiQue, 2WikiMultiHopQA, and HotpotQA show that StepChain GraphRAG achieves state-of-the-art Exact Match and F1 scores. StepChain GraphRAG lifts average EM by 2.57% and F1 by 2.13% over the SOTA method, achieving the largest gain on HotpotQA (+4.70% EM, +3.44% F1). StepChain GraphRAG also fosters enhanced explainability by preserving the chain-of-thought across intermediate retrieval steps. We conclude by discussing how future work can mitigate the computational overhead and address potential hallucinations from large language models to refine efficiency and reliability in multi-hop QA.
1 Introduction
Large language models (LLMs) have recently demonstrated remarkable capabilities in open-domain question answering (QA), summarization, and various knowledge-intensive tasks [31, 14]. Relying solely on parametric knowledge embedded within an LLM poses challenges for correctness, interpretability, and scalability [13]. As queries become more complex or domain-specific, a single pass through the model may overlook vital details, leading to incomplete or inconsistent answers [41]. To tackle this, researchers have increasingly embraced the paradigm of Retrieval-Augmented Generation (RAG), where external corpora or knowledge bases are leveraged to supplement the LLM’s internal representations [18].
While RAG has emerged as a promising approach to mitigating the limitations of purely parametric knowledge, simply retrieving or concatenating external evidence without a coherent strategy can still lead to fragmented reasoning and opaque answers [18, 8]. Recent work has focused on Knowledge Graph RAG pipelines, such as GraphRAG, where evidence is organized into a single graph for improved interpretability [3, 25, 6, 15]. Existing GraphRAG methods often rely on ad-hoc strategies that fail to exploit the full potential of multi-hop reasoning, especially when queries demand traversing multiple interconnected pieces of information.
Improving these limitations requires overcoming several hurdles. Specifically, naively performing one-shot retrieval for multi-hop questions can lead to either missing critical details or overwhelming the model with superfluous information [12]. Such a lack of selectivity compromises the clarity of intermediate reasoning steps by making it difficult to identify and integrate only the most relevant evidence [20, 42]. Moreover, even when a graph structure is introduced to enhance explainability, it often remains static or fails to synchronize with the evolving inference process [34]. If nodes and edges are not updated at each intermediate step, the resulting graph can become cluttered or disconnected, creating gaps or redundancies that obscure the chain of reasoning [4]. These deficiencies are particularly evident in tasks that involve iterative or multi-turn queries, where previously retrieved knowledge must be revisited, refined, and logically connected to newly discovered evidence [26]. Without a systematic way to incorporate these ongoing updates, key insights may remain isolated or overshadowed by irrelevant details, undermining the explainability and reliability of complex, multi-step reasoning.
The above pitfalls of fragmented evidence aggregation, unwieldy graph updates, and limited multi-turn support motivate our StepChain GraphRAG framework, which interleaves a breadth-first search (BFS) Reasoning Flow (BFS-RF) decomposition with explicit graph-based maintenance of intermediate results. Unlike conventional GraphRAG methods, which rely on static or shallow graph linking, StepChain GraphRAG dynamically updates the graph alongside each sub-question, allowing relevant evidence to be integrated in a principled manner [3]. Each sub-question triggers a targeted retrieval step, after which newly discovered evidence is inserted into the global graph via carefully defined node and edge creation rules. This mitigates redundancy by reusing previously discovered information and provides a transparent record of partial inferences that can be seamlessly revisited or refined.
The following are the key contributions of this paper:
- Incremental Graph Updating: We propose an incremental graph augmentation mechanism that synchronizes the knowledge graph with every round of newly retrieved evidence, ensuring the reasoning context remains consistently up‑to‑date throughout the multi‑hop process.
- Iterative Multi-hop Reasoning: We combine our BFS-RF with expansions over the current graph to tackle queries requiring multiple rounds of inference. Each sub-question triggers a targeted BFS traversal that uncovers cross-textual dependencies without overwhelming the model with extraneous content, thus delivering a focused and efficient retrieval process.
- Enhanced Explainability: By making intermediate results and their relationships explicit in a graph, our framework creates a more transparent and debuggable multi-hop QA pipeline than prior GraphRAG systems. The BFS-RF decomposition yields well-defined evidence paths at each step, allowing users and downstream modules to trace how partial inferences are built up from distinct pieces of retrieved information.
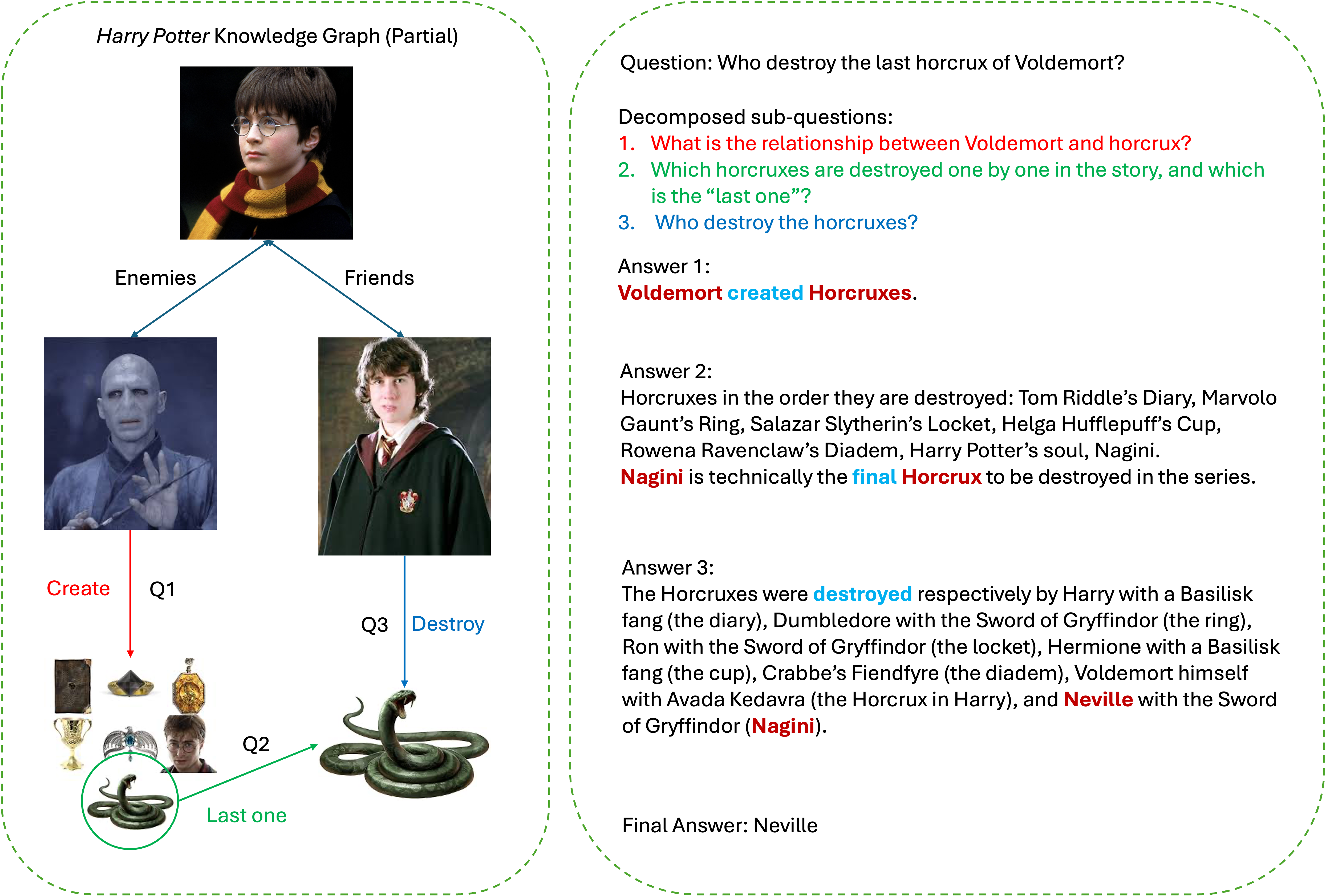
By systematically capturing and reusing these intermediate insights, StepChain GraphRAG alleviates information overload, delivers enhanced transparency in complex reasoning, and offers a debuggable pipeline for multi-hop QA. Through this explicit interplay between BFS-RF and dynamic graph expansion, our framework maintains an up-to-date, coherent knowledge structure that improves clarity and allows robustness in iterative or multi-turn query scenarios. Concretely, StepChain GraphRAG improves over the strongest baseline (HopRAG) by +1.70/+0.48 EM/F1 on MuSiQue, +1.30/+2.46 on 2WikiMultiHopQA, and +4.70/+3.44 on HotpotQA, yielding an average gain of +2.57 EM and +2.13 F1. We illustrate the end-to-end reasoning on an example in Fig. 1.
<details>
<summary>example1.png Details</summary>
### Visual Description
## Diagram: Harry Potter Knowledge Graph (Partial)
### Overview
The image presents a partial knowledge graph related to the Harry Potter series, specifically focusing on Voldemort's Horcruxes. It visually represents relationships between characters (Voldemort, Harry Potter, Neville) and concepts (Horcruxes, creation, destruction). The diagram is accompanied by a question and a breakdown of sub-questions with corresponding answers.
### Components/Axes
The diagram is divided into two main sections: a visual graph on the left and a textual question/answer section on the right.
**Visual Graph:**
* **Nodes:** Represent entities like Voldemort, Harry Potter, Horcruxes (represented by objects), and concepts like "Create" and "Destroy".
* **Edges:** Represent relationships between entities, labeled as "Enemies", "Friends", and "Create".
* **Question Markers:** Q1, Q2, Q3 are placed near specific nodes to indicate their relevance to the sub-questions.
* **"Last one" label:** Indicates the final Horcrux.
* **Green Oval:** Encloses the Horcrux destruction process.
**Textual Section:**
* **Question:** "Who destroy the last horcrux of Voldemort?" (Note: "horcrux" is misspelled in the original image)
* **Decomposed Sub-questions:** Three sub-questions are listed, numbered 1-3.
* **Answers:** Corresponding answers are provided for each sub-question.
* **Final Answer:** "Neville" is stated as the final answer.
### Detailed Analysis or Content Details
**Visual Graph Details:**
* **Voldemort:** Depicted on the left, connected to Harry Potter via "Enemies" and to a green object (Horcrux) via "Create".
* **Harry Potter:** Depicted in the center-left, connected to Voldemort via "Enemies" and to another character (likely Ron Weasley) via "Friends".
* **Horcrux (Creation):** A green object (appears to be a small chest) is linked to Voldemort via the "Create" edge. This is labeled "Q1".
* **Horcrux (Destruction):** A snake (Nagini) is depicted within a green oval, linked to the "Destroy" edge. This is labeled "Q3".
* **"Last one" label:** Points to the snake (Nagini). This is labeled "Q2".
**Textual Section Details:**
* **Answer 1:** "Voldemort created Horcruxes."
* **Answer 2:** "Horcruxes in the order they are destroyed: Tom Riddle’s Diary, Marvolo Gaunt’s Ring, Salazar Slytherin’s Locket, Helga Hufflepuff’s Cup, Rowena Ravenclaw’s Diadem, Harry Potter’s soul, Nagini. Nagini is technically the final Horcrux to be destroyed in the series."
* **Answer 3:** "The Horcruxes were destroyed respectively by Harry with a Basilisk fang (the diary), Dumbledore with the Sword of Gryffindor (the ring), Ron with the Sword of Gryffindor (the locket), Hermione with a Basilisk fang (the cup), Crabbe’s Fiendfyre (the diadem), Voldemort himself with Avada Kedavra (the Horcrux in Harry), and Neville with the Sword of Gryffindor (Nagini)."
* **Final Answer:** "Neville"
### Key Observations
* The diagram clearly establishes Voldemort as the creator of Horcruxes.
* Nagini is explicitly identified as the last Horcrux to be destroyed.
* The answers provide a detailed sequence of Horcrux destruction and the individuals responsible.
* The diagram uses visual cues (Q1, Q2, Q3) to link the graph elements to the sub-questions.
* The text explicitly states that Nagini is the final Horcrux.
### Interpretation
The diagram and accompanying text serve as a concise knowledge representation of a key plot point in the Harry Potter series – the creation and destruction of Voldemort’s Horcruxes. The visual graph provides a high-level overview of the relationships, while the textual section offers specific details and a definitive answer to the central question. The decomposition into sub-questions demonstrates a logical approach to problem-solving, breaking down a complex issue into smaller, manageable parts. The diagram highlights the importance of Neville Longbottom in the final defeat of Voldemort, as he is the one who destroys the last Horcrux (Nagini). The use of images of characters and objects enhances understanding and recall. The diagram is a simplified representation of a complex network of relationships, focusing on the core elements relevant to the question. The misspelling of "horcrux" throughout the text is a minor inconsistency.
</details>
Figure 1: Illustration of StepChain GraphRAG applied to a Harry Potter example. On the left, a partial knowledge graph encodes entities (e.g., Voldemort, Nagini) and relationships (“create,” “destroy”) derived via entity extraction and linking. On the right, our system decomposes the user’s query, “Who destroys the last Horcrux of Voldemort?”, into sub-questions about (1) how Horcruxes relate to Voldemort, (2) which Horcrux is the final one, and (3) who destroys it. A BFS-based graph traversal gathers multi-hop evidence chains (e.g., “Voldemort $→$ creates $→$ Horcruxes,” “Nagini $→$ final Horcrux,” “Neville $→$ destroys $→$ Nagini”), and partial answers from each sub-question are merged to form the conclusion: Neville is the one who destroys Voldemort’s last Horcrux.
2 Related Work
2.1 Stepwise Reasoning for Multi-hop QA
Recent research on multi-hop QA has increasingly focused on explicit stepwise reasoning, ensuring that models break down complex queries into more manageable steps. Early methods introduced a pipeline that identifies simple queries and incrementally gathers evidence, demonstrating that step-by-step decomposition can improve accuracy and interpretability [27, 21]. More recent approaches leverage LLMs by prompting them to articulate each reasoning step, often referred to as the “chain-of-thought (COT)” [33, 17].
These COT strategies can operate either in few-shot or zero-shot settings, and additional techniques, e.g., self-consistency, have been developed to mitigate the variability of different reasoning paths [32]. A related idea is to guide the model through a structured, incremental solving process, by addressing the simplest parts of the problem first [40] or interleaving tool usage with model reasoning [38]. Collectively, these studies highlight how prompting LLMs with intermediate steps can unlock powerful multi-hop reasoning capabilities, underscoring the importance of fine-grained decomposition to tackle complex queries.
2.2 Retrieval-Augmented Generation
A complementary research direction explores how to augment stepwise reasoning with external knowledge, giving rise to RAG models. Instead of relying solely on the language model’s parametric memory, these systems retrieve relevant passages from a large text corpus or knowledge base [18, 8]. Once retrieved, the passages are fused into the generation process, often through specialized architectures that can handle multiple candidate documents [10]. Scaling up these retrieval-centric systems has enabled near state-of-the-art performance in both fully supervised and few-shot open-domain QA [11], emphasizing that external knowledge can bridge gaps in the model’s internal representation and reduce hallucinations. As multi-hop tasks grow in complexity, RAG methodologies become increasingly vital in ensuring that sufficient information is accessible to the reasoning module.
2.3 Graph-based Retrieval and Reasoning
Beyond plain text, there has been growing interest in leveraging graph structures to organize and integrate knowledge for multi-hop reasoning. Some approaches build entity graphs from retrieved passages, propagating information across nodes to establish consistent chains of evidence [22, 2, 4]. Others utilize existing knowledge graphs or hyperlink graphs, treating multi-hop QA as a path-finding problem [1]. More recent endeavors incorporate domain-specific knowledge graphs directly into the retrieval pipeline, enhancing the model’s awareness of structured relationships among entities [35, 43, 28]. Harnessing these relational cues, graph-based retrieval can improve both the interpretability and the accuracy of multi-hop reasoning.
In [3], a GraphRAG approach was proposed for query-focused summarization, which constructs a graph to integrate both local and global contexts from retrieved documents. By organizing evidence in a graph and capturing relational dependencies, their method demonstrates how a graph-centric strategy can effectively handle information fusion and improve the coherence of summarization. Although their work centers on summarization rather than QA, the principle of structuring retrieved evidence into interconnected graph nodes is readily transferable to multi-hop QA settings, where stepwise reasoning stands to benefit from explicit relational representations.
2.4 Summary
Despite recent progress in multi-hop QA, most approaches rely on static or ad-hoc expansions of knowledge graphs, limiting their capacity to handle iterative queries or incorporate newly uncovered information. We address these gaps with our StepChain GraphRAG framework, which combines question decomposition and BFS-RF with dynamic graph maintenance. This unified pipeline dynamically inserts new evidence at each sub-question, refining the knowledge graph in real time. The result is a more transparent, debuggable process for multi-hop QA by fully exploiting both text-based retrieval and graph-structured insights.
3 StepChain GraphRAG
3.1 Overall Architecture
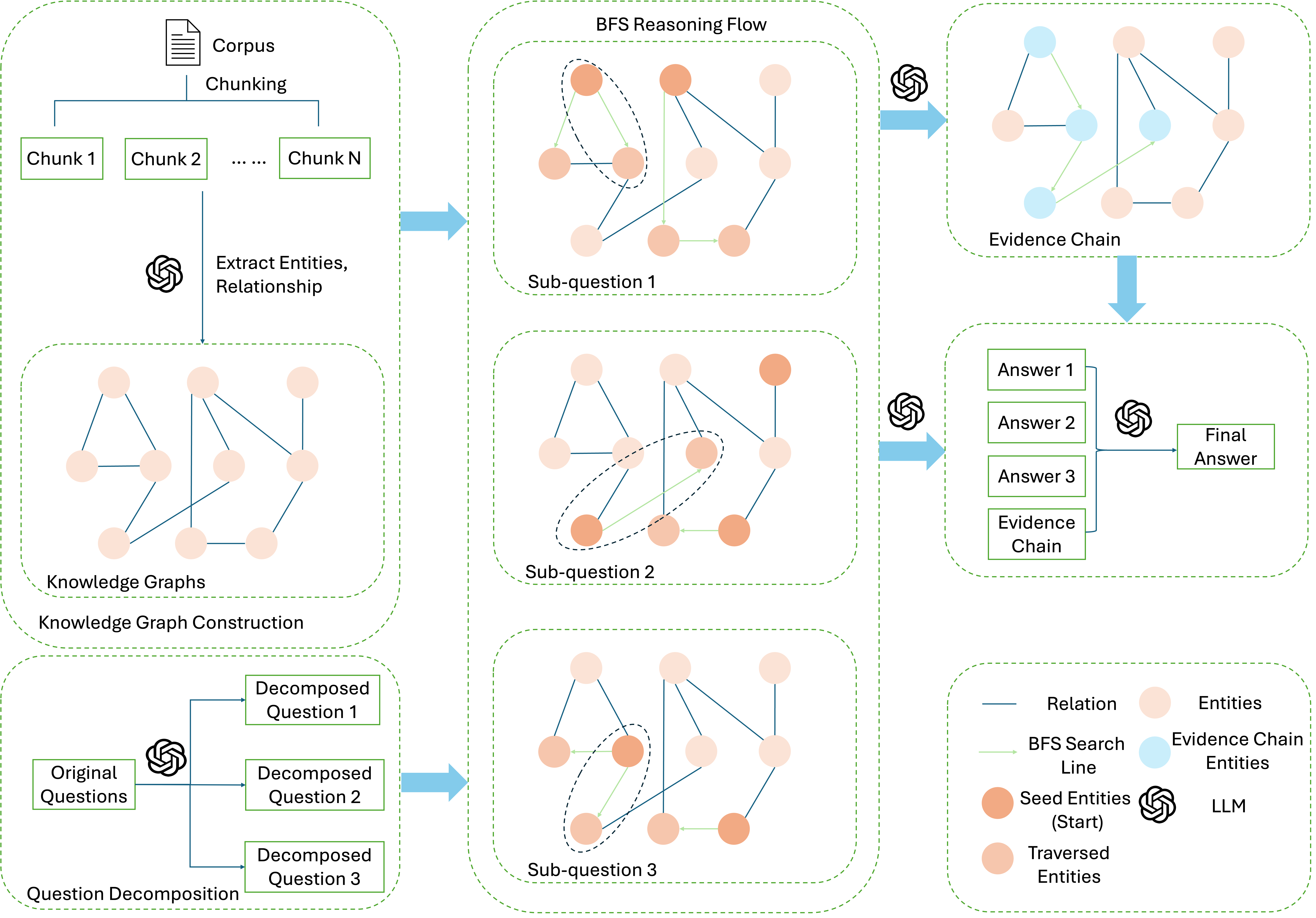
As shown in Fig. 2, we propose a multi-stage pipeline to handle complex multi-hop queries while preserving interpretability. First, raw texts are chunked into manageable segments and transformed incrementally into a knowledge graph that explicitly encodes entities and their relationships. This graph-based structure maintains a clear, traceable representation of how pieces of information interlink. Rather than processing an entire query in a single shot, we decompose it into smaller, more focused sub-questions. This decomposition prevents the model from conflating multiple logic threads at once, allowing it to target and retrieve only the most relevant nodes and edges.
Each sub-question is resolved through a BFS Reasoning Flow, where a breadth-first search systematically uncovers multi-hop evidence without overwhelming the model. Finally, the partial insights derived from each sub-question are merged into a single coherent answer, with a transparent trail illustrating how the evidence has been gathered and synthesized. By structuring the QA process into these steps, i.e., chunking and graph construction, question decomposition, BFS-based retrieval, and final synthesis, we reduce confusion, highlight key reasoning paths, and deliver more interpretable, high-fidelity answers than single-pass methods.
<details>
<summary>pipelinenew.png Details</summary>
### Visual Description
\n
## Diagram: BFS Reasoning Flow for Question Answering
### Overview
This diagram illustrates a multi-stage process for question answering using Breadth-First Search (BFS) reasoning. The process begins with corpus chunking, proceeds through knowledge graph construction and sub-question decomposition, utilizes BFS to build evidence chains, and culminates in a final answer. The diagram is organized into a 3x3 grid, representing the sequential steps of the process.
### Components/Axes
The diagram consists of nine interconnected blocks, each representing a stage in the reasoning flow. A legend in the bottom-right corner defines the visual elements:
* **Relation:** Represented by a grey line.
* **Entities:** Represented by orange circles.
* **BFS Search Line:** Represented by a light blue line.
* **Seed Entities (Start):** Represented by a dark blue circle.
* **Traversed Entities:** Represented by a light orange circle.
* **LLM:** Not explicitly represented visually, but implied in the process.
The blocks are labeled as follows:
1. **Corpus Chunking:** Top-left.
2. **Extract Entities, Relationship:** Middle-left.
3. **Knowledge Graphs Knowledge Graph Construction:** Bottom-left.
4. **Sub-question 1:** Top-center.
5. **Sub-question 2:** Middle-center.
6. **Sub-question 3:** Bottom-center.
7. **Evidence Chain:** Top-right.
8. **Evidence Chain:** Middle-right.
9. **Final Answer:** Bottom-right.
Each block contains a network of nodes (orange and blue circles) connected by lines (grey and light blue). Text labels within the blocks indicate the stage of processing.
### Detailed Analysis or Content Details
**1. Corpus Chunking:** Displays "Chunk 1", "Chunk 2", and "Chunk N" indicating the corpus is divided into multiple chunks.
**2. Extract Entities, Relationship:** Shows a network of orange circles connected by grey lines, representing entities and their relationships.
**3. Knowledge Graphs Knowledge Graph Construction:** Similar to the previous block, displaying a network of orange circles and grey lines, representing the constructed knowledge graph.
**4. Sub-question 1:** A network of orange and light orange circles connected by grey and light blue lines. A dark blue circle is present, representing the seed entity.
**5. Sub-question 2:** Similar to Sub-question 1, with a different arrangement of nodes and connections.
**6. Sub-question 3:** Similar to Sub-question 1 and 2, with a different arrangement of nodes and connections.
**7. Evidence Chain:** A network of orange and light orange circles connected by grey and light blue lines, forming a more complex chain-like structure.
**8. Evidence Chain:** Displays "Answer 1", "Answer 2", "Answer 3", and "Evidence Chain" within the network of nodes.
**9. Final Answer:** Displays "Final Answer" within the network of nodes.
The BFS search lines (light blue) appear to radiate outwards from the seed entities (dark blue) in the sub-question blocks, indicating the search process. The evidence chain blocks show a more interconnected network, suggesting the aggregation of evidence.
### Key Observations
The diagram highlights a sequential process where information is progressively refined. The initial stages focus on data preparation (chunking, entity extraction), followed by knowledge representation (knowledge graphs), question decomposition, and finally, reasoning and answer generation. The use of BFS is visually emphasized by the radiating search lines. The evidence chain blocks demonstrate the accumulation of supporting information.
### Interpretation
This diagram illustrates a sophisticated approach to question answering that leverages knowledge graphs and BFS reasoning. The process aims to break down complex questions into smaller, manageable sub-questions, search for relevant evidence within a knowledge graph, and synthesize the evidence to arrive at a final answer. The diagram suggests a modular and scalable architecture, where each stage can be independently optimized. The use of BFS implies a systematic exploration of the knowledge graph, ensuring that all relevant information is considered. The diagram doesn't provide specific data or numerical values, but rather a conceptual framework for a question-answering system. The diagram is a high-level overview and does not detail the specific algorithms or techniques used in each stage. The diagram suggests a system designed to handle complex questions requiring reasoning and evidence gathering.
</details>
Figure 2: An overview of the StepChain GraphRAG pipeline. First, the corpus is split into chunks, and retrieved chunks are parsed on‑the‑fly to extract entities and relations and are upserted into a knowledge graph. Next, a complex question is decomposed into multiple sub-questions, each answered via BFS-RF that traverses the graph to find relevant entities and relations. The discovered evidence chains are combined to yield partial answers for each sub-question. Finally, these partial answers are synthesized by the LLM to produce the final, fully grounded response.
3.2 Knowledge Graph Construction
We start by transforming the raw document corpus into a structured knowledge graph to support multi-hop QA. First, each document $\tau_{i}$ in the corpus $\{\tau_{i}\}_{i=1}^{N}$ is split into overlapping chunks for more manageable processing:
$$
D_{i}=\mathrm{Chunk}(\tau_{i})=\bigl\{c_{i,1},c_{i,2},\ldots,c_{i,n_{i}}\bigr\}, \tag{1}
$$
and all such chunks across the corpus form the following set:
$$
\mathcal{D}=\bigcup_{i=1}^{N}D_{i}. \tag{2}
$$
Next, we build the knowledge graph $G=(V,E)$ by leveraging an LLM $\mathcal{M}$ to identify named entities and their relationships in each retrieved chunk $c_{i,j}$ . In particular, the model extracts all entity mentions $\bigl(e,\alpha_{e}\bigr)$ , where $\alpha_{e}$ may include attributes such as entity type or alias:
$$
\mathrm{Extract}(c_{i,j})\!=\!\bigl\{(e,\,\alpha_{e})\!\mid\!e\text{ appears in }c_{i,j}\bigr\}. \tag{3}
$$
Any two entities $(e_{a},e_{b})$ that co-occur in the same chunk lead to a relationship detection step,
$$
r=\mathrm{Link}(e_{a},\,e_{b},\,c_{i,j}), \tag{4}
$$
producing an edge $\bigl(e_{a}\xrightarrow{r}e_{b}\bigr)$ in $G$ . By explicitly capturing entities and their relations in graph form, we construct multi-hop paths that might span multiple documents or distant passages.
Note that, for the consideration of cost, we do not pre-parse the whole corpus into a graph. Only passages retrieved during reasoning are parsed into nodes/edges and upserted into $G$ (see Sec. 3.5; for the first sub-question $q_{1}$ , we retrieve $r$ passages from $\mathcal{I}$ to initialize $G_{0}$ with $V_{0}$ ). The entire corpus remains searchable in the global index $\mathcal{I}$ . This chunking reduces noise by limiting each segment to a smaller context window, yet retains enough local coherence for accurate entity extraction and relationship detection. It also helps avoid exceeding LLM token constraints during subsequent analysis.
Finally, we optionally group highly interconnected entities via the Leiden community detection algorithm [29]:
$$
\mathcal{C}_{G}=\mathrm{Cluster}(G)=\{C_{1},C_{2},\dots,C_{K}\}. \tag{5}
$$
Each community $C_{k}⊂eq V$ can be summarized into a concise text snippet $S_{k}$ with the LLM, which helps organize large graphs into topic-focused subgraphs. By capturing essential relationships in a structured form and optionally clustering them, we establish an explicit knowledge representation that better supports multi-hop reasoning.
3.3 Question Decomposition
Complex, multi-faceted user queries $q$ often conflate multiple objectives when being handled in a single pass, leading to confusion and incomplete answers. To mitigate this risk, we introduce a specialized question decomposition stage, defined as
$$
\{q_{1},q_{2},\ldots,q_{m}\}=\mathrm{Decompose}(q), \tag{6}
$$
where $\mathrm{Decompose}(q)$ splits the original query $q$ into smaller or more targeted sub-questions. Each sub-question $q_{i}$ isolates a particular logical component, hidden assumption, or sequential dependency. In practice, decomposition often employs carefully designed prompt templates that guide the LLM to identify distinct facets (e.g., an entity definition vs. its causal relationships).
This approach offers two advantages. On the one hand, it sharpens the focus of each retrieval step, ensuring that each sub-question draws upon only the most relevant evidence. On the other hand, it provides clearer interpretability by assigning each reasoning segment to a separate, traceable module. Unlike single-pass QA [17, 33], which risks blending multiple reasoning threads into one pass, our decomposition-based method produces reliable final answers and a transparent trail of how intermediate insights are derived.
3.4 BFS-RF with Evidence Chain Provision
Our framework designs BFS-RF to gather multi-hop evidence for each sub-question, reflecting the intuition that relevant information in a graph may lie several edges away from the starting point. By systematically expanding the search at each depth, BFS-RF mitigates the risk of missing crucial but indirectly connected nodes. Moreover, the evidence chains produced along each BFS path offer a clear, step-by-step audit trail of how specific entities and relations lead to partial answers, improving both interpretability and debuggability.
After decomposing the original query into sub-questions $\{q_{1},...,q_{m}\}$ , we retrieve the top- $k$ entities in $V$ whose embeddings (from a transformer or the LLM) best match each sub-question $q_{j}$ . Let $\{s_{1},...,s_{k}\}$ denote these seed entities. We perform a breadth-first search out to depth $h$ , as given by
$$
\mathrm{BFS}(s_{u},h)=\bigl\{v\in V\;\big|\;\mathrm{dist}(s_{u},v)\leq h\bigr\}, \tag{7}
$$
where $\mathrm{dist}(s_{u},v)$ is the shortest path distance in the knowledge graph $G$ . We also collect the exact path structures, as given by
$$
\Pi_{s_{u}}\!\!=\!\!\{\pi\!\mid\!\pi\colon s_{u}\!\to\!\cdots\!\to\!v,\mathrm{dist}(s_{u},v)\!\leq\!h\}, \tag{8}
$$
thus tracking how each reachable node links back to the seed entity. Each path $\pi∈\Pi_{s_{u}}$ is translated into an “evidence chain,” for instance, EntityA -- (relationX) --> EntityB -- (relationY) --> EntityC, capturing not just which entities matter but how they connect. We concatenate these chain descriptions into a contextual string $C_{q_{j}}$ :
$$
C_{q_{j}}=\bigl\|\mathrm{Desc}(\pi)\bigr\|_{\pi\in\bigcup_{u=1}^{k}\Pi_{s_{u}}}, \tag{9}
$$
where $\|·\|$ denotes string concatenation. For $j=1$ , $V$ denotes $V_{0}$ obtained in the cold-start. Feeding $C_{q_{j}}$ and $q_{j}$ into the LLM $\mathcal{M}$ yields a partial answer $A_{j}$ grounded in multi-hop evidence.
The design behind BFS-RF and evidence chains rests on key objectives: capturing multi-hop links by examining nodes up to depth $h$ , where indirect or cross-textual dependencies might reside; providing a transparent record of nodes and edges observed, which aids error analysis or further refinement; and maintaining a targeted focus on each sub-question rather than scattering attention across many unrelated paths. These features, combined with the question decomposition, supply a structured and interpretable solution for multi-faceted, multi-hop queries.
Notably, in this paper, “retrieval on the graph” means that $G$ constrains BFS expansions and provides path-level context; the actual passages are always fetched from the global index $\mathcal{I}$ .
3.5 Incremental Graph Augmentation
After answering sub‑question $q_{j}$ , we query the global index $\mathcal{I}$ conditioned on the current frontier $F_{j}$ (entities/relations already visited) and obtain a small batch of passages $\mathcal{D}^{\text{new}}$ . These passages are parsed on‑the‑fly to extract unseen entities and relations $(V^{\text{new}},E^{\text{new}})$ , which are then upserted into the global graph $G$ :
$$
G.\text{add\_nodes\_from}(V^{\text{new}}),\quad G.\text{add\_edges\_from}(E^{\text{new}}).
$$
This lazy regime reconciles the two descriptions: documents are retrieved from $\mathcal{I}$ , while $G$ , possibly incomplete, steers BFS expansions and records path‑level evidence chains. This retrieve-and-refresh loop keeps the knowledge graph synchronized with the latest evidence, ensuring that every subsequent BFS traversal operates over an up-to-date context while allowing earlier nodes/edges to be enriched as information accrues.
Moreover, Recall is preserved by searching $\mathcal{I}$ over the full corpus; precision is enforced via frontier‑conditioned queries, dense+BM25 re‑ranking, a minimum textual‑support threshold before adding edges, and caps on BFS depth and frontier size. If $V$ becomes empty, we directly retrieve $r$ passages from $\mathcal{I}$ to re-seed before rerunning BFS.
3.6 Merging Results and Final Model Output
Once each sub-question $q_{j}$ has a partial answer $A_{j}$ , we combine these intermediate findings into a more holistic view of $q$ . Specifically, we take $\{A_{1},...,A_{m}\}$ and the optional community summaries $\{S_{1},...,S_{K}\}$ , if relevant, and pass them to the LLM for a higher-level synthesis:
$$
A_{\mathrm{merge}}\!\!=\!\!\mathcal{M}\Bigl(\!\{A_{1},\!\ldots\!,A_{m}\},\,\{S_{1},\!\ldots\!,S_{K}\}\!\Bigr). \tag{10}
$$
Each sub‑question retrieves its own top‑ $k$ seed entities, whereas the community summaries $\{S_{1},...,S_{K}\}$ are computed once on the global graph and shared by all sub‑questions. Here, $\mathcal{M}$ resolves potential overlaps or inconsistencies across sub-answers, integrates community-level context, and generates a coherent summary of how each sub-question informs the final solution.
Finally, we feed the merged output $A_{\mathrm{merge}}$ back into the LLM alongside the original query $q$ , i.e.,
$$
A_{\mathrm{final}}=\mathcal{M}\bigl(q\,\|\,A_{\mathrm{merge}}\bigr), \tag{11}
$$
thus producing a comprehensive response that reflects both the local textual information (at the chunk level) and the global topological insight (at the graph level). This final answer can undergo optional post-processing (e.g., formatting to match user preferences, additional fact-checking, or filtering sensitive content) before delivery to the user.
Overall, by emphasizing question decomposition, BFS-based retrieval of evidence paths, and a two-tiered merging strategy, StepChain GraphRAG targets the shortcomings of purely single-turn QA systems. [33, 18] It allows transparency in how answers are formed, leverages multi-hop connections, and scales well to queries that require crossing multiple documents or reasoning over distant entities.
| BM25 BGE GraphRAG | 13.80 20.80 12.10 | 21.50 30.10 20.22 | 40.30 40.10 22.50 | 44.83 44.96 27.49 | 41.20 47.60 31.70 | 53.23 60.36 42.74 | 31.77 36.17 22.10 | 39.85 45.14 30.15 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| RAPTOR | 36.40 | 49.09 | 53.80 | 61.45 | 58.00 | 73.08 | 49.40 | 61.21 |
| SiReRAG | 40.50 | 53.08 | 59.60 | 67.94 | 61.70 | 76.48 | 53.93 | 65.83 |
| HopRAG | 42.20 | 54.90 | 61.10 | 68.26 | 62.00 | 76.06 | 55.10 | 66.40 |
| Ours | 43.90 | 55.38 | 62.40 | 70.72 | 66.70 | 79.50 | 57.67 | 68.53 |
Table 1: QA performance (EM and F1) on MuSiQue, 2Wiki, and HotpotQA with GPT-4o using top-20 passages, plus their averages.
| Llama 3.3 (70B) Qwen 2.5 (72B) GPT-4o | 54.00 59.30 66.70 | 68.77 71.33 79.50 |
| --- | --- | --- |
Table 2: Ablation on HotpotQA with various LLMs.
Table 3: Ablation study with GPT-4o on MuSiQue, 2Wiki, and HotpotQA. We report EM and F1 for each dataset, as well as the averaged EM/F1 across all three.
| GPT-4o | 10.80 | 18.52 | 21.20 | 25.68 | 30.30 | 40.41 | 20.77 | 28.20 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| GraphRAG Baseline | 12.10 | 20.22 | 22.50 | 27.49 | 31.70 | 42.74 | 22.10 | 30.15 |
| Question Decomposition Baseline | 21.50 | 31.40 | 43.90 | 47.06 | 43.60 | 58.94 | 36.33 | 45.80 |
| GraphRAG + Question Decomposition | 36.40 | 49.09 | 50.80 | 61.45 | 56.90 | 70.08 | 48.03 | 60.21 |
| GraphRAG + Reasoning | 39.60 | 50.71 | 52.20 | 63.80 | 58.60 | 72.21 | 50.13 | 62.24 |
| GraphRAG + Reasoning + Question Decomposition | 43.90 | 55.38 | 62.40 | 70.72 | 66.70 | 79.50 | 57.67 | 68.53 |
4 Experiment
4.1 Experimental Setup
To demonstrate the effectiveness of StepChain GraphRAG, we select three representative multi-hop QA datasets: MuSiQue [30], 2WikiMultiHopQA [9], and HotpotQA [37]. Using the same corpus as HippoRAG [7], we choose 1,000 questions from each validation set of these three datasets. All questions require multi-hop reasoning across multiple paragraphs, making them suitable benchmarks for evaluating complex retrieval and reasoning techniques.
We use the standard Exact Match (EM) and F1 scores to measure the accuracy of predicted answers compared to ground-truth labels. EM requires an exact string match with the gold answer; F1 rewards partial overlaps by considering token-level precision and Recall. These two metrics offer a balanced perspective on both strict correctness and partial completeness of the system’s responses.
All experiments are conducted in Python with a graph-based retriever and BFS expansions. GPT-4o serves as the default QA model (for comparability with SOTA) unless otherwise noted. Chunks contain 1,200 tokens with 100-token overlap; BFS depth is 2. LLM calls are issued asynchronously with caching to reduce latency. All tests run on two RTX 6000 Ada GPUs using the same prompts and hyperparameters as prior retrieval-based work. [19]
4.2 Main Results and Comparison with SOTA
Table 1 compares StepChain GraphRAG against an array of baselines on MuSiQue, 2Wiki, and HotpotQA, each evaluated with GPT-4o under a top-20 passage budget. Sparse (BM25) [23] and dense (BGE) [16] retrievers provide initial reference points, while GraphRAG [3], RAPTOR [24], SiReRAG [39], and HopRAG [19] represent state-of-the-art structured retrieval. StepChain GraphRAG attains superior EM and F1 on all three datasets, indicating that our BFS-driven graph expansions effectively capture multi-hop dependencies. Across all tasks, an average EM/F1 of 57.67/68.53 is achieved, highlighting consistent gains even in the presence of distractors and diverse query types.
We investigate the robustness of our pipeline under different LLMs by focusing on HotpotQA. Table 2 compares the final performance obtained when we substitute GPT-4o with Llama 3.3 (70B)and Qwen 2.5 (72B). While Llama 3.3 and Qwen 2.5 both surpass earlier baselines [5, 36] , Qwen 2.5 offers a slight edge, indicating nuanced differences in model architecture and training data. Notably, GPT-4o attains the highest EM and F1 (66.70 and 79.50), suggesting that model choice significantly affects multi-hop QA performance. Our results reinforce the synergy between advanced graph retrieval modules and robust generative models to handle multi-step reasoning effectively.
4.3 Ablation Study
We assess each component’s contribution to accuracy. Table 3 shows monotonic gains across MuSiQue, 2Wiki, and HotpotQA as retrieval and reasoning are added. GPT‑4o (no retrieval) averages 20.77/28.20 (EM/F1); graph retrieval alone and question decomposition alone reach 22.10/30.15 and 36.33/45.80. Integrating decomposition with the graph achieves 48.03/60.21, adding explicit graph reasoning yields 50.13/62.24, and combining decomposition+reasoning peaks at 57.67/68.53, confirming the synergy of decomposition, graph retrieval, and chain‑of‑thought reasoning for multi‑hop QA.
4.4 Inference time and latency analysis
The end‑to‑end latency of the proposed approach is dominated by the LLM inference. GPT‑4o API takes approximately $80$ s per query, due to network delays and service rate limits. Self‑hosted Qwen‑2.5‑72B and Llama‑3.3‑70B require approximately $90$ s and $94$ s, respectively (on two RTX 6000Ada). In contrast, retrieval, BFS traversal, and incremental graph updating together introduce less than $3$ s overhead, showing that graph logic is not a bottleneck for throughput. The vast majority of the wall‑clock time is therefore spent on LLM inference. Since graph updates are executed in‑memory and streamed directly into the prompt, their cost grows modestly with the number of hops. As a result, practical latency improvements should focus on the LLM itself, including prompt caching, lightweight quantization, speculative decoding, or swapping in a smaller distilled checkpoint, rather than on the graph layer.
5 Conclusion
We have presented StepChain GraphRAG, a framework that integrates stepwise COT reasoning with graph-based retrieval to tackle multi-hop QA. By iteratively updating a knowledge graph with each sub-question and partial answer, our approach clarifies the evidence chain, curbs information overload, and bolsters interpretability. Empirical results on HotpotQA indicate that such a structured pipeline can surpass ad-hoc retrieval methods, yet StepChain GraphRAG’s reliance on explicit graph construction imposes extra computational overhead and memory demands.
6 Limitation and Future Work
LLMs can hallucinate, allowing spurious facts to propagate through the pipeline and weaken answers. Additionally, in multi-hop datasets where sub-question $q_{j}$ depends on $q_{j-1}$ , errors or uncertainty in early steps can make retrieval for $q_{j}$ brittle. Our StepChain GraphRAG pipeline partially mitigates this issue via per-sub-question retrieval from the global index $\mathcal{I}$ and explicit BFS evidence chains for interpretability. However, we do not quantify the residual impact here and plan to introduce uncertainty-aware re-decomposition and backtracking, as well as sub-question-level robustness metrics, in future work. Graph-centric retrieval struggles in specialized or rapidly changing domains, and GraphRAG imposes computational overhead at inference time. Future work will also reduce inference-time cost, deliver scalable updates to the graph, strengthen verification against hallucinations, and better handle incomplete or domain-specific data.
References
- [1] Asai, A., Hashimoto, K., Hajishirzi, H., Socher, R., Xiong, C.: Learning to retrieve reasoning paths over wikipedia graph for question answering. arXiv preprint arXiv:1911.10470 (2019)
- [2] Ding, M., Zhou, C., Chen, Q., Yang, H., Tang, J.: Cognitive graph for multi-hop reading comprehension at scale. arXiv preprint arXiv:1905.05460 (2019)
- [3] Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., Metropolitansky, D., Ness, R.O., Larson, J.: From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130 (2024)
- [4] Fang, Y., Sun, S., Gan, Z., Pillai, R., Wang, S., Liu, J.: Hierarchical graph network for multi-hop question answering. arXiv preprint arXiv:1911.03631 (2019)
- [5] Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
- [6] Guo, Z., Xia, L., Yu, Y., Ao, T., Huang, C.: Lightrag: Simple and fast retrieval-augmented generation (2024)
- [7] Gutiérrez, B.J., Shu, Y., Gu, Y., Yasunaga, M., Su, Y.: Hipporag: Neurobiologically inspired long-term memory for large language models. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024)
- [8] Guu, K., Lee, K., Tung, Z., Pasupat, P., Chang, M.: Retrieval augmented language model pre-training. In: International conference on machine learning. pp. 3929–3938. PMLR (2020)
- [9] Ho, X., Nguyen, A.K.D., Sugawara, S., Aizawa, A.: Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. arXiv preprint arXiv:2011.01060 (2020)
- [10] Izacard, G., Grave, E.: Leveraging passage retrieval with generative models for open domain question answering. arXiv preprint arXiv:2007.01282 (2020)
- [11] Izacard, G., Lewis, P., Lomeli, M., Hosseini, L., Petroni, F., Schick, T., Dwivedi-Yu, J., Joulin, A., Riedel, S., Grave, E.: Atlas: Few-shot learning with retrieval augmented language models. Journal of Machine Learning Research 24 (251), 1–43 (2023)
- [12] Jiang, Z., Sun, M., Liang, L., Zhang, Z.: Retrieve, summarize, plan: Advancing multi-hop question answering with an iterative approach. arXiv preprint arXiv:2407.13101 (2024)
- [13] Kaddour, J., Harris, J., Mozes, M., Bradley, H., Raileanu, R., McHardy, R.: Challenges and applications of large language models. arXiv preprint arXiv:2307.10169 (2023)
- [14] Kamalloo, E., Dziri, N., Clarke, C.L., Rafiei, D.: Evaluating open-domain question answering in the era of large language models. arXiv preprint arXiv:2305.06984 (2023)
- [15] Kang, M., Kwak, J.M., Baek, J., Hwang, S.J.: Knowledge graph-augmented language models for knowledge-grounded dialogue generation. arXiv preprint arXiv:2305.18846 (2023)
- [16] Karpukhin, V., Oguz, B., Min, S., Lewis, P.S., Wu, L., Edunov, S., Chen, D., Yih, W.t.: Dense passage retrieval for open-domain question answering. In: EMNLP (1). pp. 6769–6781 (2020)
- [17] Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y.: Large language models are zero-shot reasoners. Advances in neural information processing systems 35, 22199–22213 (2022)
- [18] Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33, 9459–9474 (2020)
- [19] Liu, H., Wang, Z., Chen, X., Li, Z., Xiong, F., Yu, Q., Zhang, W.: Hoprag: Multi-hop reasoning for logic-aware retrieval-augmented generation. arXiv preprint arXiv:2502.12442 (2025)
- [20] Luo, H., Zhang, J., Li, C.: Causal graphs meet thoughts: Enhancing complex reasoning in graph-augmented llms. arXiv preprint arXiv:2501.14892 (2025)
- [21] Min, S., Zhong, V., Zettlemoyer, L., Hajishirzi, H.: Multi-hop reading comprehension through question decomposition and rescoring. arXiv preprint arXiv:1906.02916 (2019)
- [22] Qiu, L., Xiao, Y., Qu, Y., Zhou, H., Li, L., Zhang, W., Yu, Y.: Dynamically fused graph network for multi-hop reasoning. In: Proceedings of the 57th annual meeting of the association for computational linguistics. pp. 6140–6150 (2019)
- [23] Robertson, S., Zaragoza, H., et al.: The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends® in Information Retrieval 3 (4), 333–389 (2009)
- [24] Sarthi, P., Abdullah, S., Tuli, A., Khanna, S., Goldie, A., Manning, C.D.: Raptor: Recursive abstractive processing for tree-organized retrieval. In: The Twelfth International Conference on Learning Representations (2024)
- [25] Soman, K., Rose, P.W., Morris, J.H., Akbas, R.E., Smith, B., Peetoom, B., Villouta-Reyes, C., Cerono, G., Shi, Y., Rizk-Jackson, A., et al.: Biomedical knowledge graph-optimized prompt generation for large language models. Bioinformatics 40 (9), btae560 (2024)
- [26] Sun, H., Bedrax-Weiss, T., Cohen, W.W.: Pullnet: Open domain question answering with iterative retrieval on knowledge bases and text. arXiv preprint arXiv:1904.09537 (2019)
- [27] Talmor, A., Berant, J.: The web as a knowledge-base for answering complex questions. arXiv preprint arXiv:1803.06643 (2018)
- [28] Tan, X., Wang, X., Liu, Q., Xu, X., Yuan, X., Zhang, W.: Paths-over-graph: Knowledge graph empowered large language model reasoning. arXiv preprint arXiv:2410.14211 (2024)
- [29] Traag, V.A., Waltman, L., Van Eck, N.J.: From louvain to leiden: guaranteeing well-connected communities. Scientific reports 9 (1), 1–12 (2019)
- [30] Trivedi, H., Balasubramanian, N., Khot, T., Sabharwal, A.: Musique: Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics 10, 539–554 (2022)
- [31] Wang, C., Liu, X., Yue, Y., Tang, X., Zhang, T., Jiayang, C., Yao, Y., Gao, W., Hu, X., Qi, Z., et al.: Survey on factuality in large language models: Knowledge, retrieval and domain-specificity. arXiv preprint arXiv:2310.07521 (2023)
- [32] Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171 (2022)
- [33] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35, 24824–24837 (2022)
- [34] Xu, W., Zhang, H., Cai, D., Lam, W.: Dynamic semantic graph construction and reasoning for explainable multi-hop science question answering. arXiv preprint arXiv:2105.11776 (2021)
- [35] Xu, Z., Cruz, M.J., Guevara, M., Wang, T., Deshpande, M., Wang, X., Li, Z.: Retrieval-augmented generation with knowledge graphs for customer service question answering. In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 2905–2909 (2024)
- [36] Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
- [37] Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W.W., Salakhutdinov, R., Manning, C.D.: Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600 (2018)
- [38] Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., Cao, Y.: React: Synergizing reasoning and acting in language models. In: International Conference on Learning Representations (ICLR) (2023)
- [39] Zhang, N., Choubey, P.K., Fabbri, A., Bernadett-Shapiro, G., Zhang, R., Mitra, P., Xiong, C., Wu, C.S.: Sirerag: Indexing similar and related information for multihop reasoning. arXiv preprint arXiv:2412.06206 (2024)
- [40] Zhou, D., Schärli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurmans, D., Cui, C., Bousquet, O., Le, Q., et al.: Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625 (2022)
- [41] Zhu, F., Lei, W., Wang, C., Zheng, J., Poria, S., Chua, T.S.: Retrieving and reading: A comprehensive survey on open-domain question answering. arXiv preprint arXiv:2101.00774 (2021)
- [42] Zhu, R., Liu, X., Sun, Z., Wang, Y., Hu, W.: Mitigating lost-in-retrieval problems in retrieval augmented multi-hop question answering. arXiv preprint arXiv:2502.14245 (2025)
- [43] Zhu, X., Guo, X., Cao, S., Li, S., Gong, J.: Structugraphrag: Structured document-informed knowledge graphs for retrieval-augmented generation. In: Proceedings of the AAAI Symposium Series. vol. 4, pp. 242–251 (2024)