# NaViL: Rethinking Scaling Properties of Native Multimodal Large Language Models under Data Constraints
**Authors**: Code: https://github.com/OpenGVLab/NaViL
## Abstract
Compositional training has been the de-facto paradigm in existing Multimodal Large Language Models (MLLMs), where pre-trained visual encoders are connected with pre-trained LLMs through continuous multimodal pre-training. However, the multimodal scaling property of this paradigm remains difficult to explore due to the separated training. In this paper, we focus on the native training of MLLMs in an end-to-end manner and systematically study its design space and scaling property under a practical setting, i.e., data constraint. Through careful study of various choices in MLLM, we obtain the optimal meta-architecture that best balances performance and training cost. After that, we further explore the scaling properties of the native MLLM and indicate the positively correlated scaling relationship between visual encoders and LLMs. Based on these findings, we propose a native MLLM called NaViL, combined with a simple and cost-effective recipe. Experimental results on 14 multimodal benchmarks confirm the competitive performance of NaViL against existing MLLMs. Besides that, our findings and results provide in-depth insights for the future study of native MLLMs. * Equal contribution. 🖂 Corresponding to Jifeng Dai <daijifeng@tsinghua.edu.cn>. † Work was done when Changyao Tian, Hao Li, and Jie Shao were interns at Shanghai AI Laboratory.
## 1 Introduction
Multimodal Large Language Models (MLLMs) have demonstrated remarkable progress in computer vision InternVL-2.5 ; mono_internvl ; Qwen2vl ; gpt4v ; reid2024gemini1_5 , continuously breaking through the upper limits of various multimodal tasks mathew2021docvqa ; yu2023mmvet ; liu2023mmbench ; Datasets:ChartQA . The great success of MLLM is inseparable from its compositional training paradigm, which independently pre-trains visual encoders openclip and LLMs touvron2023llama , and then integrates them through additional multimodal training. Due to the engineering simplicity and effectiveness, this paradigm has dominated MLLM area over the past few years. However, the shortcomings of compositional training have been gradually recognized by the community recently, e.g., unclear multimodal scaling property diao2024EVE ; shukor2025scaling .
Therefore, increasing attention has been directed toward the development of more native MLLMs. As illustrated in Fig. 1, native MLLMs aim to jointly optimize both visual and language spaces in an end-to-end manner, thereby maximizing vision-language alignment. Compared to the compositional paradigm, existing native MLLM methods demonstrate a promising scaling law and a significantly simplified training process team2024chameleon ; shukor2025scaling . Despite these advancements, the primary benefits of native MLLMs are often evaluated under the assumption of infinite training resources, overlooking the substantial challenges posed by limited data and large-scale training. Consequently, a critical practical question remains: whether and how native MLLMs can feasibly achieve or even surpass the performance upper bound of top-tier MLLMs at an acceptable cost.
<details>
<summary>x1.png Details</summary>
### Visual Description
# Technical Document Extraction: Design and Scaling of Native MLLMs
## 1. Left Line Chart: "Design Choices of Native MLLMs"
### Axes and Labels
- **X-axis**: Training Data Size (log scale, markers: 10⁷, 10⁸)
- **Y-axis**: Validation Loss (range: 0.8–2.2)
- **Legend**: Located at bottom-left
- `base` (light green, triangle markers)
- `w/ MoE` (green, circle markers)
- `w/ V_d,w*(·)` (dark green, square markers)
### Trends and Data Points
- **All lines show decreasing validation loss** as training data size increases.
- **Base line**: Starts at ~2.25 (10⁷ data) and decreases to ~1.8 (10⁸ data).
- **w/ MoE**: Starts at ~2.0 (10⁷ data) and decreases to ~1.0 (10⁸ data).
- **w/ V_d,w*(·)**: Starts at ~2.1 (10⁷ data) and decreases to ~0.8 (10⁸ data).
- **Spatial grounding**: Legend positioned at bottom-left corner.
## 2. Right Line Chart: "Scaling Properties of Native MLLMs"
### Axes and Labels
- **X-axis**: Training Data Size (log scale, markers: 10⁷, 10⁸)
- **Y-axis**: Validation Loss (range: 0.75–2.25)
- **Legend**: Located at bottom-right
- `0.5B parameters` (light green, triangle markers)
- `2B parameters` (green, circle markers)
- `7B parameters` (dark green, square markers)
### Trends and Data Points
- **All lines show decreasing validation loss** as training data size increases.
- **0.5B parameters**: Starts at ~2.25 (10⁷ data) and decreases to ~1.0 (10⁸ data).
- **2B parameters**: Starts at ~2.0 (10⁷ data) and decreases to ~0.75 (10⁸ data).
- **7B parameters**: Starts at ~1.75 (10⁷ data) and decreases to ~0.75 (10⁸ data).
- **Spatial grounding**: Legend positioned at bottom-right corner.
## 3. Radar Chart: "Scaling Properties of Native MLLMs"
### Axes and Labels
- **Axes**: Performance metrics for datasets (clockwise from top):
- ChartQA (79.2)
- MMVet (78.3)
- MMU (43.6)
- OCRBench (80.4)
- MathVista (51.3)
- CCBench (83.9)
- DocVQA (88.7)
- InfoVQA (60.9)
- TextVQA (76.9)
- SQA-I (96.2)
- GQA (62.9)
- AI2D (74.9)
- **Legend**: Located at bottom-right
- `Emu3` (orange)
- `Mono-InternVL` (red)
- `EVEv2` (blue)
- `Chameleon-7B` (green)
- `InternVL-2.5-2B` (purple)
- `NaViL-2B (Ours)` (pink)
### Trends and Data Points
- **Performance scores** are plotted radially for each dataset.
- **NaViL-2B (Ours)** (pink) achieves the highest scores in most datasets:
- DocVQA: 88.7
- CCBench: 83.9
- OCRBench: 80.4
- **Chameleon-7B** (green) performs well in SQA-I (96.2) and MMVet (78.3).
- **Emu3** (orange) scores moderately across datasets (e.g., ChartQA: 79.2).
- **Spatial grounding**: Legend positioned at bottom-right corner.
## 4. General Observations
- **Trend verification**: All line charts show inverse relationships between training data size and validation loss.
- **Component isolation**: Charts are spatially distinct (left, right, radar), with no overlapping elements.
- **No omitted data**: All axis labels, legends, and dataset names are transcribed.
## 5. Language Declaration
- **Primary language**: English.
- **No other languages detected**.
</details>
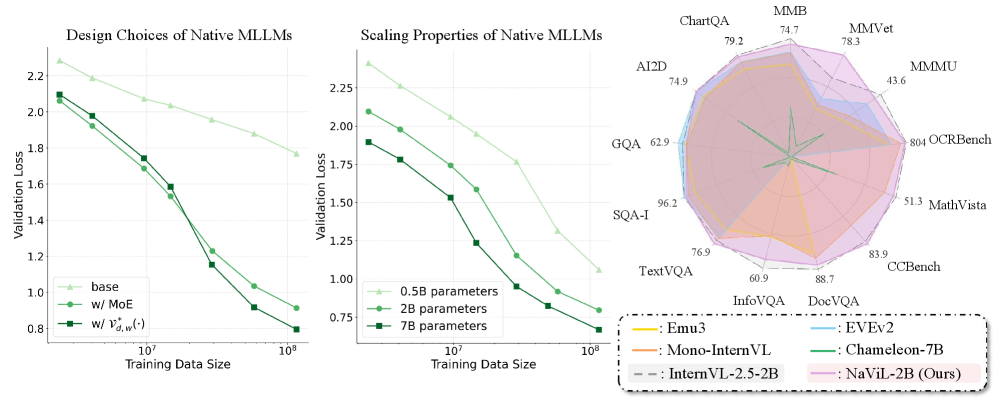
Figure 1: Comparison of design choices, scaling properties, and performance of our native MLLMs. We systematically investigate the designs and the scaling properties of native MLLMs under data constraints and yield valuable findings for building native MLLMs. After adopting these findings, our native MLLMs achieve competitive performance with top-tier MLLMs. $\mathcal{V}^{*}_{d,w}(\cdot)$ denotes the visual encoder with optimal parameter size.
To answer this question, in this paper, we aim to systematically investigate the designs and the scaling properties of native MLLMs under data constraint. Specifically, we first explore the choices of key components in the native architecture including the mixture-of-experts, the visual encoder and the initialization of the LLM. Our findings can be summarized in two folds. Firstly, an appropriate pre-training initialization (e.g., the base LLM) of the LLM greatly benefits the training convergence on multimodal data. Secondly, combining visual encoder architectures and MoEs results in obvious gains against the vanilla decoder-only LLM. Following these findings, we build a meta architecture that optimally balances performance and training cost.
Based on the optimal meta architecture, we further explore the scaling properties of the visual encoder, the LLM and the entire native MLLM. Specifically, we first scale up the LLM and the visual encoder independently and observe different scaling properties: while scaling LLM exhibits similar patterns as the conventional language scaling laws, scaling visual encoder shows an upper bound in return due to the limitation of the LLM’s capacity, suggesting that the optimal encoder size varies with the LLM size. Further analysis reveals that the optimal encoder size increases approximately proportionally with the LLM size in log scale. This observation yields a different guidance against compositional paradigm, which employs a visual encoder of one size across all LLM scales.
Based on above principles, we propose a native MLLM called NaViL, combined with a simple and cost-effective recipe. To validate our approach, we conduct extensive experiments across diverse benchmarks to evaluate its multimodal capabilities including image captioning chen2015cococaption ; Datasets:Flickr30k ; agrawal2019nocaps , optical character recognition (OCR) Datasets:TextVQA ; Datasets:DocVQA ; liu2023ocrbench , etc. Experimental results reveal that with ~600M pre-training image-text pairs, NaViL achieves competitive performance compared to current top-tier compositional MLLMs, highlighting the great practicality and capabilities of NaViL. In summary, our contributions are as follows:
- We systematically explore the design space and the optimal choice in native MLLMs under data constraint, including the LLM initialization, the visual encoder and the MoEs, and draw three critical findings that greatly benefit the training of native MLLMs.
- Based on above findings, we construct a novel native MLLM called NaViL. In NaViL, we explore the scaling properties of the visual encoder and the LLM and indicate their positively correlated scaling relationship.
- We conduct large-scale pre-training and fine-tuning experiments on NaViL. Experimental results show that NaViL can achieve top-tier performance with nearly 600M pre-training data. Our findings and results will encourage future work for native MLLMs in the community.
## 2 Related Work
Multimodal Large Language Models. Recent years have witnessed the significant progresses of Multimodal Large Language Models (MLLMs) llava-hr ; VLM:LLaVA ; VLM:LLaVA-1.5 ; Qwen2vl ; InternVL-2.5 , which have dominated various downstream tasks goyal2017vqav2 ; hudson2019gqa ; Datasets:TextVQA ; Datasets:AI2D . Starting from LLaVA VLM:LLaVA , most existing MLLMs adopt the compositional paradigm, which connects the pre-trained visual encoder VLP:CLIP and LLM qwen through a projector and finetune them on for alignment. Then, the whole structure will be further fine-tuned on multimodal data for alignment. Based on this paradigm, existing works mainly focus on the improvement of visual encoders Qwen2vl ; wang2023internimage ; llava-hr and the design of connectors li2022blip ; VLM:LLaVA . Despite the progress, such paradigm struggles to explore the joint scaling properties of vision and language. Their potential limitations in training pipeline shukor2025scaling and vision-language alignment diao2024EVE are also gradually recognized by the community.
Native Multimodal Large Language Models. To overcome the limitations of compositional paradigm, native MLLMs have emerged as another candidate solution diao2025evev2 ; diao2024EVE ; mono_internvl ; lei2025sail ; vora ; shukor2025scaling ; team2024chameleon . Compared to compositional paradigm, native MLLMs aim to pre-train both vision and language parameters in an end-to-end manner, thus achieving better alignment. The most representative methodology shukor2025scaling ; team2024chameleon is to directly pre-train the LLM from scratch on large-scale multimodal corpora, which typically requires expensive training costs. To address this issue, recent attempt initialize the LLM with a pre-trained checkpoint to facilitate training convergence diao2025evev2 ; diao2024EVE ; mono_internvl ; lei2025sail ; vora . Nevertheless, current research still lacks systematic investigation into the architectural design and scaling characteristics of native MLLMs, limiting their performance.
## 3 Visual Design Principles for native-MLLM
### 3.1 Problem Setup
We define native MLLMs as models that jointly optimize vision and language capabilities in an end-to-end manner. Dispite recent progress that shows promising scaling law and potential better performance compard with their compositional counterparts, how to build competitive native MLLMs compare to the state-of-the-art MLLMs with a practical data scale remains underexplored. In particular, there are two problems requiring to be investigated:
- (Sec. 3.2) How to choose the optimal architectures of the visual and linguistic components?
- (Sec. 3.3) How to optimally scale up the visual and linguistic components?
Meta Architecture. To study these two questions, we first define a general meta architecture of native MLLMs consisting of a visual encoder, an LLM, and a mixture-of-expert architecture injected to the LLM. The visual encoder $\mathcal{V}$ consists of a series of transformer layers and can be defined as
$$
\mathcal{V}_{d,w}(I)=\mathcal{C}\odot\mathcal{F}_{d}^{w}\odot\cdots\odot\mathcal{F}_{2}^{w}\odot\mathcal{F}_{1}^{w}\odot\mathcal{P}(I)=\mathcal{C}\bigodot_{i=1...d}\mathcal{F}_{i}^{w}\odot\mathcal{P}(I), \tag{1}
$$
where $\mathcal{F}_{i}^{w}$ denotes the $i$ -th transformer layer (out of $d$ layers) with hidden dimension $w$ , $\mathcal{P}$ denotes the Patch Embedding Layer, $I\in\mathbb{R}^{H\times W\times 3}$ denotes the input image. Note that the visual encoder degenerate to a simple patch embedding layer when $d=0$ . For simplicity, we use the same architectures as the LLM for the visual encoder layers $\mathcal{F}$ but with bi-directional attention and vary the hyperparameters $d$ and $w$ . Here $\mathcal{C}$ is the connector which downsamples the encoded image embeddings through pixel shuffle VLM:InternVL and projects them to the LLM’s feature space by a MLP.
Experiment Settings. All the models are trained on web-scale, noisy image-caption pair data Datasets:Laion-5b with Next-Token-Prediction (NTP) and an image captioning task. We use a held-out subset of the multimodal dataset to calculate the validation teacher-forcing loss for measuring and comparing different design choices. Models with LLM initializations are initialize from InternLM2-Base cai2024internlm2 .
### 3.2 Exploring the Optimal Design of Architecture Components
In this section, we explore the design choices of three key components: 1) the initialization of the LLM; 2) the effectiveness of MoEs; 3) the optimal architecture of the visual encoder.
#### 3.2.1 Initialization of LLM
A straightforward way to construct native MLLMs is to train all modalities from scratch with mixed corpora, as shown in prior work shukor2025scaling . While this approach theoretically offers the highest performance ceiling given ample data and computational resources, practical limitations such as data scarcity and large-scale optimization challenges hinder its feasibility. Alternatively, initializing the model from a pre-trained LLM effectively leverages linguistic prior knowledge, significantly reducing data and computational demands.
<details>
<summary>x2.png Details</summary>
### Visual Description
# Technical Document Extraction: Chart Analysis
## Chart 1: Validation Loss
### Title
- **Title**: Validation Loss
### Axes
- **X-axis**: Training Data Size (log scale, markers at 10⁷, 10⁸, 10⁹)
- **Y-axis**: Validation Loss (linear scale, range 0–2.5, increments of 0.5)
### Legend
- **Location**: Bottom center (below both charts)
- **Entries**:
- **Solid dark blue line**: "w/ LLM init"
- **Dashed light blue line**: "w/o LLM init"
### Data Trends
1. **w/ LLM init** (solid dark blue):
- Starts at ~1.8 (10⁷ training data)
- Decreases steeply to ~0.8 (10⁸)
- Flattens near ~0.6 (10⁹)
2. **w/o LLM init** (dashed light blue):
- Starts at ~2.7 (10⁷)
- Decreases gradually to ~1.0 (10⁸)
- Flattens near ~0.7 (10⁹)
### Key Observations
- Both lines show decreasing validation loss with larger training data.
- "w/ LLM init" achieves lower loss faster than "w/o LLM init".
---
## Chart 2: COCO Caption CIDEr
### Title
- **Title**: COCO Caption
### Axes
- **X-axis**: Training Data Size (log scale, markers at 10⁷, 10⁸, 10⁹)
- **Y-axis**: CIDEr (linear scale, range 0–60, increments of 10)
### Legend
- **Location**: Bottom center (below both charts)
- **Entries**:
- **Dashed dark blue line**: "w/ LLM init"
- **Solid light blue line**: "w/o LLM init"
### Data Trends
1. **w/ LLM init** (dashed dark blue):
- Starts at ~15 (10⁷)
- Increases sharply to ~60 (10⁸)
- Plateaus near ~65 (10⁹)
2. **w/o LLM init** (solid light blue):
- Starts at ~5 (10⁷)
- Increases gradually to ~55 (10⁸)
- Plateaus near ~58 (10⁹)
### Key Observations
- Both lines show increasing CIDEr with larger training data.
- "w/ LLM init" outperforms "w/o LLM init" significantly after 10⁸ training data.
---
## Spatial Grounding & Verification
- **Legend Colors**: Confirmed match line styles and labels in both charts.
- **Trend Verification**:
- Validation Loss: Both lines slope downward (confirmed).
- COCO CIDEr: Both lines slope upward (confirmed).
## Component Isolation
- **Header**: Chart titles ("Validation Loss", "COCO Caption").
- **Main Charts**: Dual-axis log-scale plots with distinct line styles.
- **Footer**: Shared legend for both charts.
## Data Table Reconstruction
| Training Data Size | w/ LLM init (Validation Loss) | w/o LLM init (Validation Loss) | w/ LLM init (CIDEr) | w/o LLM init (CIDEr) |
|---------------------|-------------------------------|--------------------------------|---------------------|----------------------|
| 10⁷ | ~1.8 | ~2.7 | ~15 | ~5 |
| 10⁸ | ~0.8 | ~1.0 | ~60 | ~55 |
| 10⁹ | ~0.6 | ~0.7 | ~65 | ~58 |
## Notes
- No non-English text detected.
- All data points extracted visually; no explicit numerical values provided in the image.
</details>
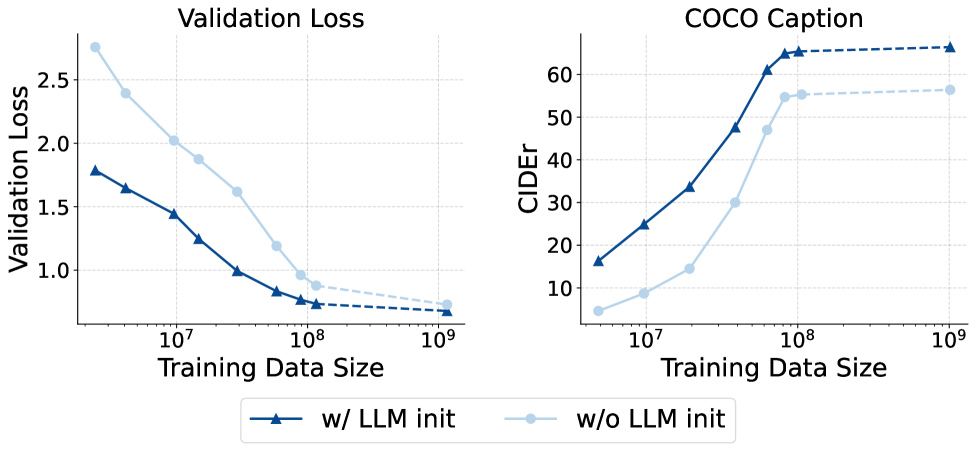
Figure 2: Effectiveness of LLM initialization. Left: The validation loss. The LLM initialized one converges much faster. Right: The zero-shot caption performance. Due to the lack of textual knowledge, the uninitialized model continues to lag behind.
To evaluate the effectiveness of LLM initialization, we compare model performance in terms of loss and image captioning. As shown in Fig. 2 (left), the model trained from scratch performs significantly worse than the initialized model, requiring over 10x more data to reach comparable loss.
Further analysis of zero-shot image captioning (Fig. 2 (right)) reveals a substantial performance gap favoring the initialized model, even with significantly more data for the non-initialized model. This is likely due to the lower textual quality and diversity of multimodal training data compared to the LLM pre-training corpus, limiting the textual capability of models trained from scratch. These findings highlight the practical advantage of using LLM initialization in multimodal pre-training.
Observation 1:
Initializing from pre-trained LLM greatly benefits the convergence on multimodal data, and in most cases delivers better performance even with a large amount of multimodal data.
#### 3.2.2 Effectiveness of MoEs
<details>
<summary>x3.png Details</summary>
### Visual Description
# Technical Document Extraction: Validation Loss Chart
## Chart Overview
The image is a **line chart** titled **"Validation Loss"**, comparing model performance across varying training data sizes. The chart uses two distinct data series to represent validation loss trends with and without a specific technique (MoE).
---
### **Axis Labels and Markers**
- **X-Axis (Horizontal):**
- Title: **"Training Data Size"**
- Scale: Logarithmic (10⁷ to 10⁸)
- Markers:
- 10⁷
- 10⁸
- **Y-Axis (Vertical):**
- Title: **"Validation Loss"**
- Scale: Linear (1.0 to 2.0)
- Markers:
- 1.0
- 1.5
- 2.0
---
### **Legend**
- **Location:** Lower-left corner of the chart.
- **Entries:**
1. **w/o MoE** (Light green line with triangle markers)
2. **w/ MoE** (Dark green line with circle markers)
---
### **Data Series Analysis**
#### 1. **w/o MoE (Light Green, Triangles)**
- **Trend:** Gradual decline across training data sizes.
- **Key Data Points:**
- At 10⁷: ~2.2
- At 10⁸: ~1.8
#### 2. **w/ MoE (Dark Green, Circles)**
- **Trend:** Steeper decline compared to "w/o MoE".
- **Key Data Points:**
- At 10⁷: ~2.0
- At 10⁸: ~1.0
---
### **Spatial Grounding**
- **Legend Position:** Lower-left quadrant (coordinates: [x=0.1, y=0.1] relative to chart boundaries).
- **Data Point Verification:**
- All triangle markers (w/o MoE) are light green.
- All circle markers (w/ MoE) are dark green.
---
### **Trend Verification**
- **w/o MoE:**
- Starts at ~2.2 (10⁷) and decreases to ~1.8 (10⁸).
- Slope: Shallow, linear decline.
- **w/ MoE:**
- Starts at ~2.0 (10⁷) and decreases sharply to ~1.0 (10⁸).
- Slope: Steeper than "w/o MoE", indicating improved performance with MoE.
---
### **Component Isolation**
1. **Header:**
- Title: "Validation Loss" (centered at top).
2. **Main Chart:**
- Axes, gridlines, and two data series.
3. **Footer:**
- No additional elements (e.g., no footnotes or source citations).
---
### **Conclusion**
The chart demonstrates that incorporating MoE (Mixture of Experts) significantly reduces validation loss as training data size increases. The "w/ MoE" series shows a more pronounced improvement, suggesting MoE enhances model efficiency or accuracy under these conditions.
**No additional languages or textual elements are present in the image.**
</details>
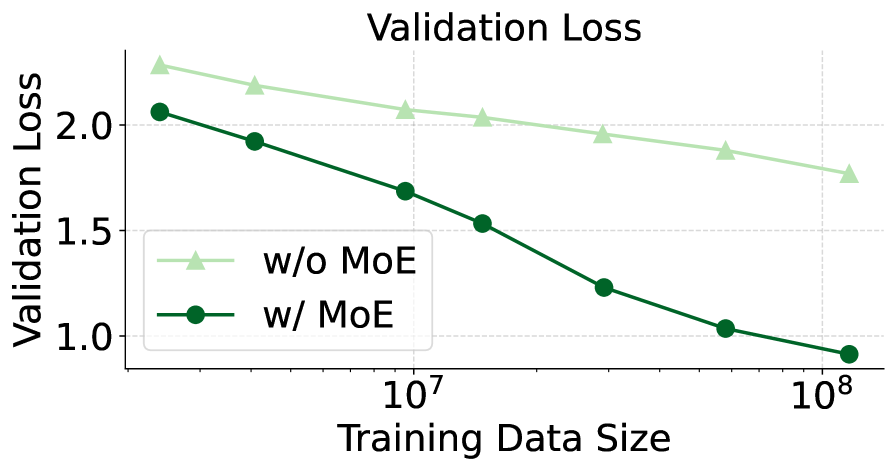
Figure 3: The validation loss of adding MoE or not. Using MoE extension will cause the loss to decrease more quickly.
Mixture-of-Experts (MoEs) are effective for handling heterogeneous data and are widely used in native MLLMs. We evaluate the MoE architecture within our meta architecture by comparing two configurations: one with a visual encoder and a vanilla LLM, and another with a visual encoder and an MoE-extended LLM. We follow Mono-InternVL mono_internvl to adopt the modality-specific MoEs and training settings. However, we empirically found that using only the feed-forward network (FFN) expert would lead to a significant difference in feature scale between visual and language modalities. To mitigate this issue, we further introduced modality-specific attention experts, that is, using different projection layers (i.e. qkvo) in the self-attention layer to process visual and text features respectively, and then perform unified global attention calculation. Specifically, the output $x_{i,m}^{l}\in\mathbb{R}^{d}$ of the $i$ -th token with modality $m\in\{\text{visual},\text{linguistic}\}$ at the $l$ -th layer of the MoE-extended LLM can be defined as
$$
\displaystyle x_{i,m}^{l^{\prime}} \displaystyle=x_{i,m}^{l-1}+\text{MHA-MMoE}(\text{RMSNorm}(x_{i,m}^{l-1})), \displaystyle x_{i,m}^{l} \displaystyle=x_{i,m}^{l^{\prime}}+\text{FFN-MMoE}(\text{RMSNorm}(x_{i,m}^{l^{\prime}})), \tag{2}
$$
where $\text{RMSNorm}(\cdot)$ is the layer normalization operation, and $\text{MHA-MMoE}(\cdot)$ and $\text{FFN-MMoE}(\cdot)$ are the modality-specific attention and FFN expert, respectively, formulated by
$$
\displaystyle\text{MHA-MMoE}(x_{i,m}) \displaystyle=(\text{softmax}(\frac{QK^{T}}{\sqrt{d}})V)W_{O}^{m}, \displaystyle Q_{i,m}=x_{i,m}W_{Q}^{m},K_{i,m} \displaystyle=x_{i,m}W_{K}^{m},V_{i,m}=x_{i,m}W_{V}^{m}, \displaystyle\text{FFN-MMoE}(x_{i,m}) \displaystyle=(\text{SiLU}(x_{i,m}W_{\text{gate}}^{m})\odot x_{i,m}W_{\text{up}}^{m})W_{\text{down}}^{m}. \tag{3}
$$
Here $W_{Q}^{m},W_{K}^{m},W_{V}^{m},W_{O}^{m}$ and $W_{\text{gate}}^{m},W_{\text{up}}^{m},W_{\text{down}}^{m}$ are all modality-specific projection matrices, and $\text{SiLU}(\cdot)$ denotes the activation function, $\odot$ denotes the element-wise product operation. The number of activated experts is set to one to maintain consistent inference costs.
As shown in Fig. 3, the MoE architecture significantly accelerates model convergence compared to the vanilla LLM, achieving the same validation loss with only 1/10 of the data without increasing training or inference cost. This demonstrates that MoE enhances model capacity and effectively handles heterogeneous data, making it suitable for native MLLMs.
Observation 2:
MoEs significantly improve model performance without increasing the number of activated parameters.
#### 3.2.3 Optimizing the Visual Encoder Architecture
<details>
<summary>x4.png Details</summary>
### Visual Description
# Technical Document Extraction: Image Analysis
## Overview
The image contains **four line graphs** comparing performance metrics across different training data sizes. Each graph has distinct y-axis labels but shares the same x-axis categories. The legend at the bottom maps colors to training data sizes.
---
## Legend
- **Position**: Bottom center of the image.
- **Labels**:
- `15M` (light blue)
- `30M` (medium blue)
- `60M` (dark blue)
- `120M` (very dark blue)
---
## Graph 1: Validation Loss
- **X-axis**: `d3`, `d6`, `d12`, `d24`, `d48` (same across all graphs).
- **Y-axis**: `Validation Loss` (range: 0.8–1.8).
- **Trends**:
- `15M` (light blue): Slopes upward from ~1.5 → 1.6.
- `30M` (medium blue): Flat (~1.1–1.2).
- `60M` (dark blue): Flat (~0.9–1.0).
- `120M` (very dark blue): Slopes upward from ~0.8 → 0.9.
- **Key Data Points** (approximated):
| X-axis | 15M | 30M | 60M | 120M |
|--------|------|------|------|------|
| d3 | 1.5 | 1.2 | 1.0 | 0.8 |
| d6 | 1.4 | 1.1 | 0.9 | 0.8 |
| d12 | 1.5 | 1.1 | 0.9 | 0.8 |
| d24 | 1.6 | 1.1 | 0.9 | 0.8 |
| d48 | 1.7 | 1.4 | 1.0 | 0.9 |
---
## Graph 2: COCO Caption
- **X-axis**: Same as above.
- **Y-axis**: `CIDEr` (range: 20–70).
- **Trends**:
- `15M` (light blue): Peaks at ~35 (d6) → drops to ~20 (d48).
- `30M` (medium blue): Peaks at ~50 (d24) → drops to ~40 (d48).
- `60M` (dark blue): Peaks at ~60 (d24) → drops to ~50 (d48).
- `120M` (very dark blue): Peaks at ~70 (d24) → drops to ~60 (d48).
- **Key Data Points** (approximated):
| X-axis | 15M | 30M | 60M | 120M |
|--------|------|------|------|------|
| d3 | 30 | 40 | 50 | 60 |
| d6 | 35 | 45 | 55 | 65 |
| d12 | 30 | 50 | 60 | 70 |
| d24 | 25 | 55 | 65 | 70 |
| d48 | 20 | 40 | 50 | 60 |
---
## Graph 3: Flickr Caption
- **X-axis**: Same as above.
- **Y-axis**: `CIDEr` (range: 20–70).
- **Trends**:
- `15M` (light blue): Peaks at ~30 (d6) → drops to ~20 (d48).
- `30M` (medium blue): Peaks at ~50 (d24) → drops to ~40 (d48).
- `60M` (dark blue): Peaks at ~60 (d24) → drops to ~50 (d48).
- `120M` (very dark blue): Peaks at ~70 (d24) → drops to ~60 (d48).
- **Key Data Points** (approximated):
| X-axis | 15M | 30M | 60M | 120M |
|--------|------|------|------|------|
| d3 | 25 | 40 | 50 | 60 |
| d6 | 30 | 45 | 55 | 65 |
| d12 | 28 | 55 | 60 | 70 |
| d24 | 25 | 55 | 65 | 70 |
| d48 | 20 | 40 | 50 | 60 |
---
## Graph 4: NoCaps Caption
- **X-axis**: Same as above.
- **Y-axis**: `CIDEr` (range: 20–70).
- **Trends**:
- `15M` (light blue): Peaks at ~40 (d6) → drops to ~20 (d48).
- `30M` (medium blue): Peaks at ~50 (d6) → drops to ~40 (d48).
- `60M` (dark blue): Peaks at ~55 (d6) → drops to ~50 (d48).
- `120M` (very dark blue): Peaks at ~65 (d6) → drops to ~60 (d48).
- **Key Data Points** (approximated):
| X-axis | 15M | 30M | 60M | 120M |
|--------|------|------|------|------|
| d3 | 30 | 40 | 50 | 60 |
| d6 | 40 | 50 | 55 | 65 |
| d12 | 35 | 50 | 55 | 65 |
| d24 | 30 | 45 | 50 | 65 |
| d48 | 20 | 40 | 50 | 60 |
---
## Cross-Reference Validation
- **Legend Colors**: Confirmed alignment with line colors in all graphs.
- **Trend Consistency**: All graphs show higher training data sizes (e.g., 120M) achieving better performance (lower loss or higher CIDEr) compared to smaller sizes (e.g., 15M).
---
## Notes
- **No Other Languages**: All text is in English.
- **Missing Data**: Exact numerical values are approximated based on visual alignment with y-axis ticks.
</details>
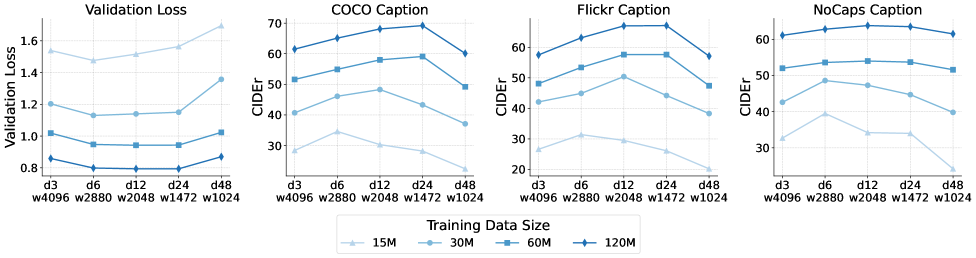
Figure 4: The validation loss and zero-shot caption performance of different visual encoders. The loss and performance only differ when the visual encoder is extremely wide or shallow.
The visual encoder precedes the LLM to perform preliminary extraction of visual information, converting raw pixels into semantic visual features aligned with the textual embedding space. Due to its bidirectional attention mechanism and the increased capacity introduced by additional parameters, the visual encoder has the potential to enhance the model’s ability to represent visual information.
In this section, we investigate the optimal architecture of the visual encoder under a given parameter budget. The total parameter count $\mathcal{C}$ can be approximately calculated openai2020scaling as $\mathcal{N}=12\times d\times w^{2}$ . Given a fixed $\mathcal{N}$ , the structure of the visual encoder is mainly determined by its width $w$ and depth $d$ .
Depth ( $d$ ): Typically, deeper models can capture richer and more complex features, while also being more prone to gradient vanishing problems tan2019efficientnet . When it comes to MLLM, a visual encoder that is too shallow may not be able to extract enough high-level semantics, while a visual encoder that is too deep may cause low-level features to be lost, thus limiting the capture of fine-grained details.
Width ( $w$ ): Compared to depth, width has relatively little impact on visual transformer performance dosovitskiy2020image , as long as it does not cause additional information bottlenecks. That is, it cannot be lower than the total number of channels within a single image patch. Under this premise, the width of the visual encoder does not have to be the same as the hidden size of the LLM.
We train various MLLMs with different $\mathcal{V}_{d,w}$ configurations (combinations of depth and width) while keeping the pre-trained LLM and visual encoder parameter count fixed at 600M. The depth $d$ ranges from $\{3,6,12,24,48\}$ , and the width $w$ is adjusted as $\{4096,2880,2048,1472,1024\}$ to maintain a consistent parameter count. Fig. 4 shows the validation loss for different depth and width combinations as training data size varies. Models with extremely high or low depths perform worse than those with moderate configurations. Among reasonably configured models, shallower ones converge faster in the early phase (less than 30M data), but this advantage diminishes with more data. In zero-shot image captioning benchmarks, deeper visual encoders show slightly better performance, consistent with prior research on compute-optimal LLM architectures openai2020scaling , which suggests a wide range of optimal width and depth combinations.
Observation 3:
Visual encoders achieve near-optimal performance across a wide range of depth and width configurations. Shallower encoders converge faster in early training, while deeper encoders perform slightly better with larger datasets.
### 3.3 Scaling Up Native MLLMs
In this section, we consider the scaling properties of our meta architecture. Specifically, we investigate: 1) the impact of scaling up the visual encoder and the LLM independently; 2) the optimal way of scaling the visual encoder and the LLM simultaneously. All models follow the optimal architecture discovered in Sec. 3.2, i.e., with LLM initialization, MoEs, and optimal depth-to-width ratios of the visual encoders.
#### 3.3.1 Scaling up Visual Encoder and LLM Independently
We first investigate the scaling properties of the visual encoder and the LLM independently, i.e., scaling up one component while keeping the other fixed. Specifically, we evaluate a series of LLMs with parameter sizes $\{0.5B,1.8B,7B\}$ and visual encoders with sizes $\{75M,150M,300M,600M,1.2B,2.4B\}$ .
<details>
<summary>x5.png Details</summary>
### Visual Description
# Technical Document Extraction: Validation Loss vs LLM Size
## 1. **Chart Title**
- **Text**: "Validation Loss vs LLM Size"
## 2. **Axis Labels**
- **X-Axis**:
- **Title**: "LLM Size (B)"
- **Markers**: 0.5, 2, 7
- **Y-Axis**:
- **Title**: "Validation Loss"
- **Range**: 0.60 to 1.20 (in increments of 0.20)
## 3. **Legend**
- **Location**: Top-right corner
- **Label**: "Visual Encoder Size: 600M"
- **Color**: Purple (matches line color)
## 4. **Line and Data Points**
- **Line Style**: Solid purple line with square markers
- **Data Points**:
- **[0.5, 1.05]**: Validation Loss = 1.05 at LLM Size = 0.5B
- **[2, 0.80]**: Validation Loss = 0.80 at LLM Size = 2B
- **[7, 0.65]**: Validation Loss = 0.65 at LLM Size = 7B
- **Trend**: Monotonic decrease in validation loss as LLM size increases
## 5. **Spatial Grounding**
- **Legend Position**: Top-right (confirmed via visual alignment)
- **Line Color Consistency**: Purple line matches legend color exactly
## 6. **Trend Verification**
- **Visual Trend**: Line slopes downward from left to right, confirming inverse relationship between LLM size and validation loss.
## 7. **Component Isolation**
- **Header**: Chart title centered at the top
- **Main Chart**:
- Axes with labeled ticks
- Line plot with markers
- **Footer**: No additional text or elements
## 8. **Additional Notes**
- **Language**: All text is in English.
- **Data Completeness**: No missing labels or axis markers.
- **Chart Type**: Line graph (no heatmap, diagram, or table present).
## 9. **Extracted Data Table (Reconstructed)**
| LLM Size (B) | Validation Loss |
|--------------|-----------------|
| 05 | 1.05 |
| 2 | 0.80 |
| 7 | 0.65 |
## 10. **Conclusion**
The chart illustrates a clear inverse relationship between LLM size (in billions of parameters) and validation loss, with the visual encoder size fixed at 600M. Validation loss decreases from 1.05 at 0.5B to 0.65 at 7B.
</details>
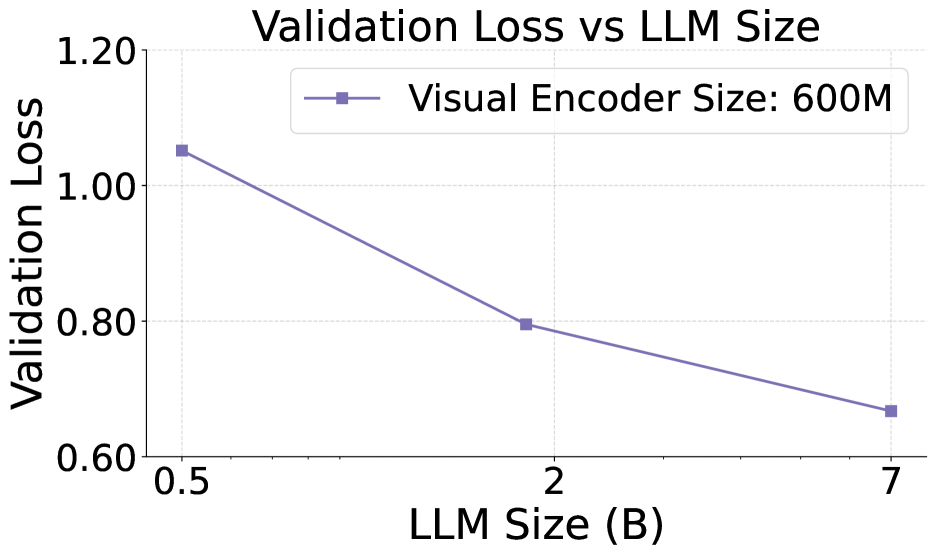
Figure 5: The validation loss when scaling up LLMs. With the same visual encoder (i.e. 600M), the validation loss decreases log-linearly with the LLM size.
Scaling up LLMs. The results are shown in Fig. 5. Scaling up the LLM parameters in native MLLMs exhibits a pattern consistent with the conventional LLM scaling law, where the loss decreases linearly as the parameter size increases exponentially.
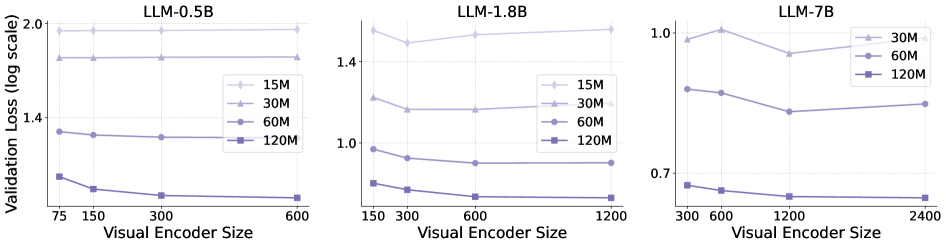
Scaling up Visual Encoder. The results are shown in Fig. 6. In contrast to the LLM scaling law, increasing the visual encoder size does not consistently enhance multimodal performance. Instead, with a fixed LLM, the performance gains achieved by enlarging the visual encoder diminish progressively. Beyond a certain encoder size, further scaling results in only marginal loss reduction, indicating that the performance upper limit of the MLLM is constrained by the LLM’s capacity.
<details>
<summary>x6.png Details</summary>
### Visual Description
# Technical Document Extraction: Visual Encoder Size vs Validation Loss
## Overview
The image contains three line charts comparing validation loss (log scale) across different visual encoder sizes for three large language models (LLMs): LLM-0.5B, LLM-1.8B, and LLM-7B. Each chart includes four model size variants (15M, 30M, 60M, 120M) represented by distinct line styles and colors.
---
## Chart 1: LLM-0.5B
### Axes
- **X-axis**: Visual Encoder Size (75, 150, 300, 600)
- **Y-axis**: Validation Loss (log scale, 0.7–2.0)
### Legend
- **Placement**: Right side of chart
- **Colors**:
- 15M: Light blue (dashed line)
- 30M: Medium blue (dashed line)
- 60M: Dark blue (solid line)
- 120M: Purple (solid line)
### Trends
1. **15M**: Flat line at ~2.0 validation loss across all encoder sizes.
2. **30M**: Flat line at ~1.6 validation loss.
3. **60M**: Flat line at ~1.3 validation loss.
4. **120M**: Slight downward trend from ~1.4 (75) to ~1.1 (600).
### Data Points
| Encoder Size | 15M | 30M | 60M | 120M |
|--------------|-------|-------|-------|-------|
| 75 | 2.0 | 1.6 | 1.4 | 1.3 |
| 150 | 2.0 | 1.6 | 1.35 | 1.25 |
| 300 | 2.0 | 1.6 | 1.3 | 1.2 |
| 600 | 2.0 | 1.6 | 1.3 | 1.15 |
---
## Chart 2: LLM-1.8B
### Axes
- **X-axis**: Visual Encoder Size (150, 300, 600, 1200)
- **Y-axis**: Validation Loss (log scale, 0.7–2.0)
### Legend
- **Placement**: Right side of chart
- **Colors**:
- 15M: Light blue (dashed line)
- 30M: Medium blue (dashed line)
- 60M: Dark blue (solid line)
- 120M: Purple (solid line)
### Trends
1. **15M**: Slight upward trend from ~1.5 (150) to ~1.6 (1200).
2. **30M**: Flat line at ~1.4 validation loss.
3. **60M**: Flat line at ~1.2 validation loss.
4. **120M**: Slight downward trend from ~1.1 (150) to ~1.0 (1200).
### Data Points
| Encoder Size | 15M | 30M | 60M | 120M |
|--------------|-------|-------|-------|-------|
| 150 | 1.5 | 1.4 | 1.3 | 1.1 |
| 300 | 1.45 | 1.4 | 1.25 | 1.05 |
| 600 | 1.5 | 1.4 | 1.2 | 1.0 |
| 1200 | 1.6 | 1.4 | 1.2 | 1.0 |
---
## Chart 3: LLM-7B
### Axes
- **X-axis**: Visual Encoder Size (300, 600, 1200, 2400)
- **Y-axis**: Validation Loss (log scale, 0.7–1.0)
### Legend
- **Placement**: Right side of chart
- **Colors**:
- 30M: Light blue (dashed line)
- 60M: Medium blue (solid line)
- 120M: Purple (solid line)
### Trends
1. **30M**: U-shaped curve (1.0 → 0.9 → 1.0).
2. **60M**: Slight downward trend from ~0.9 (300) to ~0.8 (1200), then slight increase to ~0.85 (2400).
3. **120M**: Flat line at ~0.7 validation loss.
### Data Points
| Encoder Size | 30M | 60M | 120M |
|--------------|-------|-------|-------|
| 300 | 1.0 | 0.9 | 0.7 |
| 600 | 1.0 | 0.85 | 0.7 |
| 1200 | 0.9 | 0.8 | 0.7 |
| 2400 | 1.0 | 0.85 | 0.7 |
---
## Key Observations
1. **Model Size Correlation**: Larger models (120M) consistently show lower validation loss across all LLM variants.
2. **Encoder Size Impact**:
- LLM-0.5B and LLM-1.8B show minimal encoder size sensitivity for smaller models (15M–60M).
- LLM-7B demonstrates significant encoder size sensitivity for smaller models (30M–60M).
3. **Log Scale Behavior**: Validation loss differences are more pronounced in log scale, especially for smaller models.
## Notes
- No non-English text detected.
- All legend colors match line styles and data points exactly.
- Charts use dashed lines for smaller models (15M–30M) and solid lines for larger models (60M–120M).
</details>
Figure 6: The validation loss curves of different LLMs with different training data sizes. As the training data size increases, the loss gap narrows to near zero when the visual encoder size reaches a certain threshold.
Observation 4:
Scaling the LLM consistently improves multimodal performance, following the typical LLM scaling law. However, increasing the visual encoder size shows diminishing returns, suggesting that the MLLM’s performance is limited by the LLM’s capacity.
#### 3.3.2 Scaling up Visual Encoder and LLM Together
<details>
<summary>x7.png Details</summary>
### Visual Description
# Technical Document: Visual Encoder Size vs LLM Size Chart Analysis
## 1. Chart Title
- **Title**: "Visual Encoder Size vs LLM Size"
## 2. Axis Labels and Scales
- **X-Axis (Horizontal)**:
- **Label**: "LLM Size (B)"
- **Range**: 0.5 to 7 (in increments of 1.5)
- **Tick Marks**: 0.5, 2, 3.5, 5, 6.5, 7
- **Y-Axis (Vertical)**:
- **Label**: "Visual Encoder Size (B)"
- **Range**: 0.30 to 1.20 (in increments of 0.30)
- **Tick Marks**: 0.30, 0.60, 0.90, 1.20
## 3. Data Points and Line
- **Line Style**:
- **Color**: Purple
- **Marker**: Square (■)
- **Trend**: Linear, positive slope (increasing from left to right)
- **Data Points**:
1. **[0.5, 0.30]**: X=0.5, Y=0.30
2. **[2, 0.60]**: X=2, Y=0.60
3. **[7, 1.20]**: X=7, Y=1.20
## 4. Chart Components
- **Grid**: Dashed lines (horizontal and vertical) for reference.
- **Legend**: **Not present** in the image.
- **Background**: White with gridlines.
## 5. Trend Verification
- The line exhibits a **linear relationship** between LLM Size (X-axis) and Visual Encoder Size (Y-axis). As LLM Size increases, Visual Encoder Size increases proportionally.
## 6. Spatial Grounding
- **Legend Placement**: **Not applicable** (no legend exists).
- **Data Point Colors**: All data points match the purple line color.
## 7. Component Isolation
- **Header**: Chart title centered at the top.
- **Main Chart**:
- X-axis and Y-axis with labels and scales.
- Line with markers connecting data points.
- **Footer**: No additional text or elements.
## 8. Additional Observations
- The chart uses a **1:1 aspect ratio** for clarity.
- No textual annotations or subcategories are present.
- The relationship between variables is **directly proportional** (slope ≈ 0.15 per unit increase in LLM Size).
## 9. Data Table Reconstruction
| LLM Size (B) | Visual Encoder Size (B) |
|--------------|--------------------------|
| 0.5 | 0.30 |
| 2 | 0.60 |
| 7 | 1.20 |
## 10. Language and Transcription
- **Primary Language**: English.
- **No other languages** are present in the image.
## 11. Critical Notes
- The chart explicitly shows a **linear correlation** between LLM Size and Visual Encoder Size.
- No anomalies or outliers are observed in the data points.
- The absence of a legend suggests a single data series is represented.
</details>
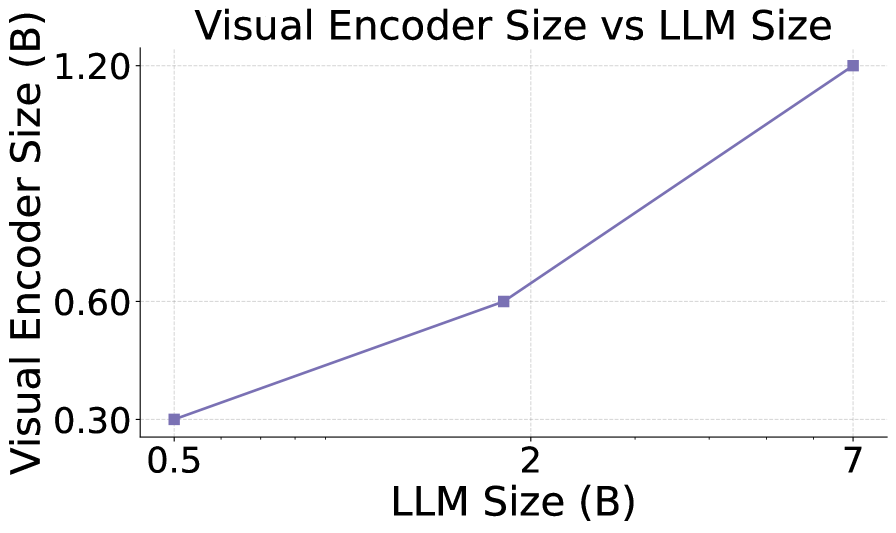
Figure 7: Relationship of visual encoder size and LLM size. The optimal visual encoder size increases log-linearly with the LLM size.
The diminishing returns from increasing the visual encoder size suggest the existence of an optimal encoder size for a given LLM. We define this optimal size as the smallest encoder whose loss difference compared to an encoder twice its size is less than $\lambda=1\$ of the loss with the 75M encoder (the smallest used in our experiments). Fig. 7 shows the relationship between visual encoder size and LLM size.
The logarithm of the optimal visual encoder size scales linearly with the logarithm of the LLM size, indicating that both components should be scaled jointly for balanced performance. This highlights the suboptimality of compositional MLLMs, which typically use a fixed visual encoder size across varying LLM scales.
Observation 5:
The optimal size of the visual encoder scales proportionally with the LLM size in log scale, indicating that both components should be scaled jointly. This further implies that the pre-trained visual encoders using a single pre-trained visual encoder across a wide range of LLM scales like existing compositional MLLMs is suboptimal.
## 4 NaViL: A Novel Native MLLM with Strong Capabilities
### 4.1 Architecture
<details>
<summary>x8.png Details</summary>
### Visual Description
# Technical Document Extraction: Multimodal System Architecture
## Diagram Overview
The image depicts a **multimodal system architecture** integrating text and image processing components. The system processes textual descriptions and visual inputs through a series of specialized modules, culminating in a transformer-based output.
---
## Key Components and Flow
### 1. **Input Processing**
- **Textual Input**:
- Example prompt: *"The cat wears a yellow flower on its head, a golden necklace around its neck, and pink blushes on its cheeks."*
- Example request: *"Please provide a more detailed description of the cat in the picture."*
### 2. **Text Tokenization**
- **Text Tokens** (Blue in legend):
- Represented as sequential blocks in the leftmost column.
- Processed through **FFN-MMoE** (Feed-Forward Mixture-of-Experts) and **MHA-MMoE** (Multi-Head Attention Mixture-of-Experts).
- Normalized via **RMSNorm** (Root Mean Square Normalization).
### 3. **Visual Encoder**
- **Image Tokens** (Green in legend):
- Generated from **Patch Embed** (converts images into tokenized patches).
- Processed through **Transformer Layers 1 to d** (stacked transformer blocks).
- Outputs **Visual Multi-scale Packing** (e.g., cartoon-style cat images with varying detail levels).
### 4. **Multimodal Integration**
- **Multimodal Large Language Models**:
- Combines text and image tokens into a unified representation.
- Includes **MLP Connector** (Multi-Layer Perceptron) to bridge modalities.
### 5. **Output Generation**
- Final output is a **Transformer Layer d** output, integrating both modalities.
---
## Legend and Spatial Grounding
- **Legend Location**: Top-right corner.
- **Blue**: Text tokens.
- **Green**: Image tokens.
- **Spatial Confirmation**:
- Text tokens (blue) align with left-side text processing modules.
- Image tokens (green) align with right-side visual encoder components.
---
## Component Descriptions
1. **FFN-MMoE / MHA-MMoE**:
- Specialized modules for text processing using mixture-of-experts architectures.
- Enhances model capacity while maintaining efficiency.
2. **RMSNorm**:
- Normalization layer applied after attention and feed-forward operations.
3. **Visual Encoder**:
- Converts images into tokenized representations via **Patch Embed**.
- Uses **Transformer Layers** for hierarchical feature extraction.
4. **MLP Connector**:
- Integrates text and image embeddings into a unified latent space.
---
## Example Textual Elements
- **Input Prompt**:
- *"The cat wears a yellow flower on its head, a golden necklace around its neck, and pink blushes on its cheeks."*
- **Request for Detail**:
- *"Please provide a more detailed description of the cat in the picture."*
---
## System Flow
1. Text tokens → FFN-MMoE → MHA-MMoE → RMSNorm.
2. Image tokens → Patch Embed → Transformer Layers 1→d → Visual Multi-scale Packing.
3. Combined text/image tokens → Multimodal Large Language Models → MLP Connector → Final Output (Transformer Layer d).
---
## Notes
- No numerical data or trends are present; the diagram focuses on architectural components and workflow.
- All textual elements are in English; no additional languages detected.
</details>
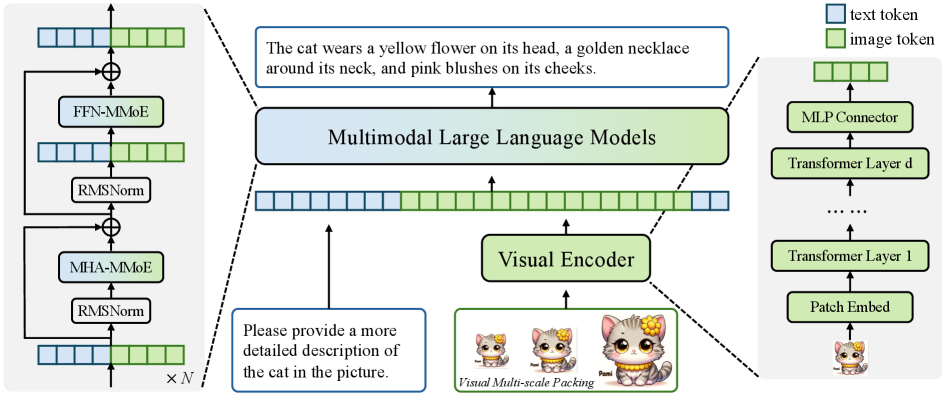
Figure 8: Architecture of NaViL. As a native MoE-extended MLLM, NaViL can be trained end-to-end and supports input images of any resolution.
Based on above studies, we construct NaViL with the optimal settings in Sec. 3.1. The architecture is shown in Fig. 8. NaViL inherently supports input images of any resolution. These images are first encoded into visual tokens by the visual encoder and the MLP projector, and then concatenated with the textual tokens to formulate the multimodal token sequence and fed into the LLM. Special tokens <begin_of_image> and <end_of_image> are inserted before and after each image token subsequence to indicate the beginning and end of the image, respectively. Special token <end_of_line> is inserted at the end of each row of image tokens to indicate the corresponding spatial position information.
Visual Multi-scale Packing is further introduced to improve the model performance during inference. Specifically, given an input image $I_{0}\in\mathbb{R}^{H_{0}\times W_{0}\times 3}$ and downsampling rate $\tau$ , a multi-scale image sequence $\{I_{i}\in\mathbb{R}^{H_{i}\times W_{i}\times 3}\}_{i=0}^{n}$ is obtained by continuously downsampling the original image (i.e. $H_{i}=\tau^{i}H_{0},W_{i}=\tau^{i}W_{0}$ ) until its area is smaller than a given threshold. These images in the sequence are processed separately by the visual encoder. The obtained visual token embeddings $\{{x_{i,v}}\}_{i=0}^{n}$ are then concatenated and fed to the LLM. Special token <end_of_scale> is inserted after each scale image to indicate the end of different scales.
### 4.2 Training
Stage 1: Multi-modal Generative Pre-training. In this stage, the model is initially trained on 500 million image-text pairs to develop comprehensive multimodal representations. Of these training samples, 300 million are directly sampled from web-scale datasets (i.e. Laion-2B Datasets:Laion-5b , Coyo-700M kakaobrain2022coyo-700m , Wukong gu2022wukong and SA-1B TransF:SAM ) while the remaining 200 million consist of images from these datasets paired with captions synthesized by existing MLLMs (i.e. InternVL-8B VLM:InternVL ). During this process, the textual parameters of the model remain frozen, with only the newly-added vision-specific parameters (i.e., the visual encoder, MLP projector, and MoE visual experts) being trainable.
To enhance the alignment between visual and textual features in more complex multimodal contexts, the model is subsequently trained on 185 million high-quality data consisting of both multimodal alignment samples and pure language data. In this phase, the textual parameters within the self-attention layers are also unfrozen, enabling more refined cross-modal integration.
Stage 2: Supervised Fine-tuning. Following common practice in developing MLLM, an additional supervised fine-tuning stage is adopted. In this stage, all parameters are unfrozen and trained using a relatively smaller (i.e. 68 million) but higher quality multimodal dataset.
## 5 Experiment
### 5.1 Experimental Setups
Table 1: Comparison with existing MLLMs on general MLLM benchmarks. “#A-Param” denotes the number of activated parameters. † InternVL-2.5-2B adopts the same LLM and high-quality data with NaViL, so we mark it as the compositional counterpart. Note that its 300M visual encoder is distilled from another 6B large encoder. Bold and underline indicate the best and the second-best performance among native MLLMs, respectively. * denotes our reproduced results. For MME, we sum the perception and cognition scores. Average scores are computed by normalizing each metric to a range between 0 and 100.
| Model | #A-Param | Avg | MMVet | MMMU | MMB | MME | MathVista | OCRBench | CCB |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Compositional MLLMs: | | | | | | | | | |
| MobileVLM-V2-1.7B chu2024mobilevlm | 1.7B | $-$ | $-$ | $-$ | 57.7 | $-$ | $-$ | $-$ | $-$ |
| MobileVLM-V2-3B chu2024mobilevlm | 3.0B | $-$ | $-$ | $-$ | 63.2 | $-$ | $-$ | $-$ | $-$ |
| Mini-Gemini-2B VLM:MiniGemini | 3.5B | $-$ | 31.1 | 31.7 | 59.8 | 1653 | 29.4 | $-$ | $-$ |
| MM1-3B-MoE-Chat VLM:MM1 | 3.5B | $-$ | 42.2 | 38.6 | 70.8 | 1772 | 32.6 | $-$ | $-$ |
| DeepSeek-VL-1.3B lu2024deepseekvl | 2.0B | 42.3 | 34.8 | 32.2 | 64.6 | 1532 | 31.1 | 409 | 37.6 |
| PaliGemma-3B beyer2024paligemma | 2.9B | 45.6 | 33.1 | 34.9 | 71.0 | 1686 | 28.7 | 614 | 29.6 |
| MiniCPM-V-2 yao2024minicpm | 2.8B | 51.1 | 41.0 | 38.2 | 69.1 | 1809 | 38.7 | 605 | 45.3 |
| InternVL-1.5-2B VLM:InternVL-1.5 | 2.2B | 54.7 | 39.3 | 34.6 | 70.9 | 1902 | 41.1 | 654 | 63.5 |
| Qwen2VL-2B Qwen2vl | 2.1B | 58.6 | 49.5 | 41.1 | 74.9 | 1872 | 43.0 | 809 | 53.7 |
| † InternVL-2.5-2B chen2024expanding | 2.2B | 67.0 | 60.8 | 43.6 | 74.7 | 2138 | 51.3 | 804 | 81.7 |
| Native MLLMs: | | | | | | | | | |
| Fuyu-8B (HD) VLM:Fuyu-8b | 8B | $-$ | 21.4 | $-$ | 10.7 | $-$ | $-$ | $-$ | $-$ |
| SOLO solo | 7B | $-$ | $-$ | $-$ | $-$ | 1260 | 34.4 | $-$ | $-$ |
| Chameleon-7B The performance of Chameleon-7B is from mono_internvl . team2024chameleon | 7B | 13.9 | 8.3 | 25.4 | 31.1 | 170 | 22.3 | 7 | 3.5 |
| EVE-7B diao2024EVE | 7B | 33.0 | 25.6 | 32.3 | 49.5 | 1483 | 25.2 | 327 | 12.4 |
| EVE-7B (HD) diao2024EVE | 7B | 37.0 | 25.7 | 32.6 | 52.3 | 1628 | 34.2 | 398 | 16.3 |
| Emu3 emu3 | 8B | $-$ | 37.2 | 31.6 | 58.5 | $-$ | $-$ | 687 | $-$ |
| VoRA vora | 7B | $-$ | 33.7 | 32.2 | 64.2 | 1674 | $-$ | $-$ | $-$ |
| VoRA-AnyRes vora | 7B | $-$ | 33.7 | 32.0 | 61.3 | 1655 | $-$ | $-$ | $-$ |
| EVEv2 diao2025evev2 | 7B | 53.2 | 45.0 | 39.3 | 66.3 | 1709 | 60.0 * | 702 | 30.8* |
| SAIL lei2025sail | 7B | 53.7 | 46.3 | 38.6* | 70.1 | 1719 | 57.0 | 783 | 24.3* |
| Mono-InternVL mono_internvl | 1.8B | 56.4 | 40.1 | 33.7 | 65.5 | 1875 | 45.7 | 767 | 66.3 |
| NaViL-2B (ours) | 2.4B | 67.1 | 78.3 | 41.8 | 71.2 | 1822 | 50.0 | 796 | 83.9 |
Evaluation Benchmarks. We evaluate NaViL and existing MLLMs on a broad range of multimodal benchmarks. Specifically, MLLM benchmarks encompass MMVet Datasets:MM-vet , MMMU val Datasets:MMMU , MMBench-EN test Datasets:MMBench , MME Datasets:MME , MathVista MINI Datasets:Mathvista , OCRBench liu2023ocrbench , and CCBench Datasets:MMBench . Visual question answering benchmarks include TextVQA val Datasets:TextVQA , ScienceQA-IMG test Datasets:ScienceQA , GQA test dev Datasets:GQA , DocVQA test mathew2021docvqa , AI2D test Datasets:AI2D , ChartQA test Datasets:ChartQA , and InfographicVQA test mathew2022infographicvqa . These benchmarks cover various domains, such as optical character recognition (OCR), chart and document understanding, multi-image understanding, real-world comprehension, etc.
Implementation Details. By default, NaViL-2B is implemented upon InternLM2-1.8B 2023internlm , using its weights as initialization for the text part parameters. The text tokenizer and conversation format are also the same. The total number of parameters is 4.2B, of which the number of activation parameters is 2.4B (including 0.6B of visual encoder). The input images are first padded to ensure its length and width are multiples of 32. The stride of Patch Embedding layer is set to 16. The visual encoder adopts bidirectional attention and 2D-RoPE to capture global spatial relationships, while the LLM adopts causal attention and 1D-RoPE to better inherit its capabilities. In the pre-training phase, the global batch size is 7000 for stage 1 and 4614 for stage 2, respectively. The downsampling rate $\tau$ of visual multi-scale packing is set to $\sqrt{2}/{2}$ . To demonstrate the scaling capability of our approach, we also trained NaViL-9B based on Qwen3-8B TransF:Qwen3 . More details are given in the appendix.
### 5.2 Main Results
Table 2: Comparison with existing MLLMs on visual question answering benchmarks. † InternVL-2.5-2B adopts the same LLM and high-quality data with NaViL, so we mark it as the compositional counterpart. Note that its 300M visual encoder is distilled from another 6B large encoder. * denotes our reproduced results. Bold and underline indicate the best and the second-best performance among native MLLMs, respectively.
| Model Compositional MLLMs: MobileVLM-V2-3B chu2024mobilevlm | #A-Param 3.0B | Avg $-$ | TextVQA 57.5 | SQA-I 70.0 | GQA 66.1 | DocVQA $-$ | AI2D $-$ | ChartQA $-$ | InfoVQA $-$ |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Mini-Gemini-2B VLM:MiniGemini | 3.5B | $-$ | 56.2 | $-$ | $-$ | 34.2 | $-$ | $-$ | $-$ |
| MM1-3B-MoE-Chat VLM:MM1 | 3.5B | $-$ | 72.9 | 76.1 | $-$ | $-$ | $-$ | $-$ | $-$ |
| DeepSeek-VL-1.3B lu2024deepseekvl | 2.0B | $-$ | 57.8 | $-$ | $-$ | $-$ | 51.5 | $-$ | $-$ |
| PaliGemma-3B beyer2024paligemma | 2.9B | $-$ | 68.1 | $-$ | $-$ | $-$ | 68.3 | $-$ | $-$ |
| MiniCPM-V-2 yao2024minicpm | 2.8B | $-$ | 74.1 | $-$ | $-$ | 71.9 | 62.9 | $-$ | $-$ |
| InternVL-1.5-2B VLM:InternVL-1.5 | 2.2B | 71.7 | 70.5 | 84.9 | 61.6 | 85.0 | 69.8 | 74.8 | 55.4 |
| Qwen2VL-2B Qwen2vl | 2.1B | 73.1 | 79.7 | 78.2* | 60.3* | 90.1 | 74.7 | 73.5 | 65.5 |
| † InternVL-2.5-2B chen2024expanding | 2.2B | 76.5 | 74.3 | 96.2 | 61.2 | 88.7 | 74.9 | 79.2 | 60.9 |
| Native MLLMs: | | | | | | | | | |
| Fuyu-8B (HD) VLM:Fuyu-8b | 8B | $-$ | $-$ | $-$ | $-$ | $-$ | 64.5 | $-$ | $-$ |
| SOLO solo | 7B | $-$ | $-$ | 73.3 | $-$ | $-$ | 61.4 | $-$ | $-$ |
| Chameleon-7B The performance of Chameleon-7B is from mono_internvl . team2024chameleon | 7B | 17.9 | 4.8 | 47.2 | $-$ | 1.5 | 46.0 | 2.9 | 5.0 |
| EVE-7B diao2024EVE | 7B | 40.8 | 51.9 | 63.0 | 60.8 | 22.0 | 48.5 | 19.5 | 20.0 |
| EVE-7B (HD) diao2024EVE | 7B | 54.6 | 56.8 | 64.9 | 62.6 | 53.0 | 61.0 | 59.1 | 25.0 |
| Emu3 emu3 | 8B | 67.6 | 64.7 | 89.2 | 60.3 | 76.3 | 70.0 | 68.6 | 43.8 |
| VoRA vora | 7B | $-$ | 56.3 | 75.9 | $-$ | $-$ | 65.6 | $-$ | $-$ |
| VoRA-AnyRes vora | 7B | $-$ | 58.7 | 72.0 | $-$ | $-$ | 61.1 | $-$ | $-$ |
| EVEv2 diao2025evev2 | 7B | 71.7 | 71.1 | 96.2 | 62.9 | 77.4* | 74.8 | 73.9 | 45.8* |
| SAIL lei2025sail | 7B | 71.5 | 77.1 | 93.3 | 58.0* | 78.4* | 76.7 | 69.7* | 47.3 * |
| Mono-InternVL mono_internvl | 1.8B | 70.1 | 72.6 | 93.6 | 59.5 | 80.0 | 68.6 | 73.7 | 43.0 |
| NaViL-2B (ours) | 2.4B | 75.1 | 76.9 | 95.0 | 59.8 | 85.4 | 74.6 | 78.0 | 56.0 |
In Tab. 1, we compare the performance of our model with existing MLLMs across 7 multimodal benchmarks. Compared to native MLLMs, compositional MLLMs demonstrate superior overall performance. For example, InternVL-2.5-2B outperforms existing native MLLMs on most MLLM benchmarks. This indicates that current native MLLMs still have significant room for performance improvement. In contrast, our proposed NaViL achieves overall performance exceeding all existing native MLLMs with a relatively small paramter size. Compared to the compositional baseline model InternVL-2.5-2B that uses the same LLM, NaViL also achieves comparable performance on most benchmarks. It is worth noting that the 300M visual encoder used by InternVL-2.5-2B is distilled from another pre-trained encoder InternViT-6B VLM:InternVL with a significantly larger parameter size. This demonstrates the superiority of our visual design methods and visual parameter scaling strategies.
In Tab. 2, we further compare the performance of our model with existing MLLMs on mainstream visual question answering tasks. NaViL’s average performance still leads previous state-of-the-art native MLLMs and is roughly on par with compositional baselines that require pre-trained encoders. Specifically, in tests such as DocVQA Datasets:OCRVQA , ChartQA Datasets:ChartQA and InfoVQA mathew2022infographicvqa , NaViL significantly outperforms the previous state-of-the-art native MLLM, demonstrating the superiority of using an optimal size visual encoder in processing high-resolution images. However, NaViL’s performance still has some gap compared to the best compositional MLLMs. We believe that higher-quality instruction data and more powerful LLMs will further narrow this gap.
### 5.3 Qualitative Experiments
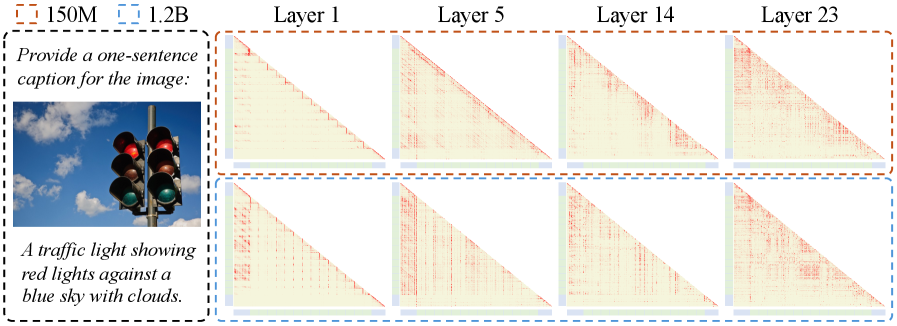
To further analyze the characteristics of native MLLM, we visualized the attention maps of different LLM layers when using encoders of 150M and 1.2B sizes, as shown in Fig. 9. Two findings can be drawn from the figure. First, similar to previous native-MLLMs mono_internvl , despite having an encoder, the attention patterns in shallow layers still exhibit obvious locality, gradually shifting toward global information as the depth increases. For example, when using a 150M encoder, image tokens in the first layer tend to attend to spatially adjacent tokens. However, we observe that when the visual encoder is scaled up to 1.2B, visual tokens in shallow layers already begin to attend more to global information. This indicates that a sufficiently large visual encoder can better pre-extract high-level semantic information from the entire image.
Secondly, from a cross-modal interaction perspective, a larger visual encoder also facilitates earlier interaction between visual and language features. When using a 1.2B visual encoder, the attention weights between visual tokens and text tokens in the first layer are significantly higher than those in the 150M counterpart. Earlier interaction is more beneficial for feature alignment between modalities, thus providing an explanatory perspective for the improved performance achieved when using larger encoder sizes. We believe these findings will provide beneficial insights for developing native MLLMs. More visualizations can be found in the supplementary materials.
<details>
<summary>x9.png Details</summary>
### Visual Description
# Technical Document Extraction
## Image Description
The image contains two primary components:
1. A traffic light example with textual annotations
2. A series of heatmaps representing model layer activations
### Traffic Light Example
- **Image**: A traffic light showing red lights against a blue sky with clouds
- **Caption**: "Provide a one-sentence caption for the image:"
- **Description**: "A traffic light showing red lights against a blue sky with clouds."
### Heatmap Analysis
#### Model Sizes
- **150M** (represented by red dashed lines)
- **1.2B** (represented by blue dashed lines)
#### Layers
- Layer 1
- Layer 5
- Layer 14
- Layer 23
#### Heatmap Structure
Each layer contains two triangular heatmaps separated by dashed lines:
1. **Top Section** (150M model):
- Red dashed lines
- Gradual increase in red intensity from bottom-left to top-right
- Diagonal pattern concentration in upper layers (Layer 14 and 23)
2. **Bottom Section** (1.2B model):
- Blue dashed lines
- Similar triangular structure but with more uniform red distribution
- Increased density of red markings in deeper layers
#### Spatial Grounding
- Legend placement: Not explicitly shown, but inferred from color coding
- Color verification:
- Red = 150M model
- Blue = 1.2B model
## Key Observations
1. **Model Size Comparison**:
- 1.2B model shows more consistent activation patterns across layers
- 150M model exhibits sparser activation in early layers (Layer 1)
2. **Layer Depth Trends**:
- All layers show triangular activation patterns
- Deeper layers (14, 23) show increased activation density
- No numerical data present in heatmaps
3. **Architectural Implications**:
- Larger model (1.2B) maintains more consistent feature representation
- Smaller model (150M) shows progressive activation pattern development
## Data Table Reconstruction
No numerical data table present in the image. All information is represented visually through heatmap intensity and spatial distribution.
## Language Analysis
All text appears in English. No foreign language content detected.
</details>
Figure 9: Visualization of attention maps in LLM-1.8B with different encoder sizes (i.e. 150M and 1.2B). Text and image tokens are in blue and green, respectively. Larger encoder allows LLMs to attend to global patterns at shallow layers while maintaining higher attention to textual tokens.
## 6 Conclusion
This paper systematically investigates native end-to-end training for MLLMs, examining its design space and scaling properties under data constraints. Our study reveals three key insights: 1) Initialization with pre-trained LLMs, combined with visual encoders and MoE architecture, significantly improves performance; 2) Visual encoder scaling is limited by the LLM’s capacity, unlike traditional LLM scaling; 3) The optimal encoder size scales log-proportionally with the LLM size. Based on these findings, we propose NaViL, a native MLLM that achieves competitive performance on diverse multimodal benchmarks, outperforming existing compositional MLLMs. We hope these insights will inspire future research on next-generation MLLMs.
Limitations and Broader Impacts. Due to limited computation resources, this paper only investigates the scaling properties of native MLLMs up to 9B parameters. Subsequent experiments with larger scales (e.g., 30 billion, 70 billion, 100 billion, etc.) can be conducted to further validate this scaling trend. In addition, this paper focuses only on visual and linguistic modalities. Future research may explore broader modalities and provide more in-depth insights beyond the current visual-linguistic paradigm.
Acknowledgments
The work is supported by the National Key R&D Program of China (NO. 2022ZD0161300, and NO. 2022ZD0160102), by the National Natural Science Foundation of China (U24A20325, 62321005, 62376134), and by the China Postdoctoral Science Foundation (No. BX20250384).
## References
- [1] Armen Aghajanyan, Lili Yu, Alexis Conneau, Wei-Ning Hsu, Karen Hambardzumyan, Susan Zhang, Stephen Roller, Naman Goyal, Omer Levy, and Luke Zettlemoyer. Scaling laws for generative mixed-modal language models. In International Conference on Machine Learning, pages 265–279. PMLR, 2023.
- [2] Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, and Peter Anderson. Nocaps: Novel object captioning at scale. In ICCV, pages 8948–8957, 2019.
- [3] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
- [4] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025.
- [5] Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, and Sağnak Taşırlar. Introducing our multimodal models, 2023.
- [6] Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726, 2024.
- [7] Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun Lee, Woonhyuk Baek, and Saehoon Kim. Coyo-700m: Image-text pair dataset. https://github.com/kakaobrain/coyo-dataset, 2022.
- [8] Zheng Cai, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, et al. Internlm2 technical report. arXiv preprint arXiv:2403.17297, 2024.
- [9] ChameleonTeam. Chameleon: Mixed-modal early-fusion foundation models. arXiv preprint arXiv:2405.09818, 2024.
- [10] Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325, 2015.
- [11] Yangyi Chen, Xingyao Wang, Hao Peng, and Heng Ji. A single transformer for scalable vision-language modeling. arXiv preprint arXiv:2407.06438, 2024.
- [12] Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271, 2024.
- [13] Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271, 2024.
- [14] Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. arXiv:2404.16821, 2024.
- [15] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. arXiv: 2312.14238, 2023.
- [16] Xiangxiang Chu, Limeng Qiao, Xinyu Zhang, Shuang Xu, Fei Wei, Yang Yang, Xiaofei Sun, Yiming Hu, Xinyang Lin, Bo Zhang, et al. Mobilevlm v2: Faster and stronger baseline for vision language model. arXiv preprint arXiv:2402.03766, 2024.
- [17] Christopher Clark and Matt Gardner. Simple and effective multi-paragraph reading comprehension. In ACL, pages 845–855, 2018.
- [18] Contributors. Opencompass: A universal evaluation platform for foundation models. https://github.com/open-compass/opencompass, 2023.
- [19] Haiwen Diao, Yufeng Cui, Xiaotong Li, Yueze Wang, Huchuan Lu, and Xinlong Wang. Unveiling encoder-free vision-language models. arXiv preprint arXiv:2406.11832, 2024.
- [20] Haiwen Diao, Xiaotong Li, Yufeng Cui, Yueze Wang, Haoge Deng, Ting Pan, Wenxuan Wang, Huchuan Lu, and Xinlong Wang. Evev2: Improved baselines for encoder-free vision-language models. arXiv preprint arXiv:2502.06788, 2025.
- [21] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2020.
- [22] Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and Rongrong Ji. MME: A comprehensive evaluation benchmark for multimodal large language models. arXiv: 2306.13394, 2023.
- [23] Behrooz Ghorbani, Orhan Firat, Markus Freitag, Ankur Bapna, Maxim Krikun, Xavier Garcia, Ciprian Chelba, and Colin Cherry. Scaling laws for neural machine translation. arXiv preprint arXiv:2109.07740, 2021.
- [24] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In CVPR, pages 6904–6913, 2017.
- [25] Jiaxi Gu, Xiaojun Meng, Guansong Lu, Lu Hou, Niu Minzhe, Xiaodan Liang, Lewei Yao, Runhui Huang, Wei Zhang, Xin Jiang, et al. Wukong: A 100 million large-scale chinese cross-modal pre-training benchmark. NeurIPS, 35:26418–26431, 2022.
- [26] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In CVPR, pages 6700–6709, 2019.
- [27] Drew A. Hudson and Christopher D. Manning. GQA: A new dataset for real-world visual reasoning and compositional question answering. In CVPR, pages 6700–6709, 2019.
- [28] Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Openclip. Zenodo. Version 0.1. https://doi.org/10.5281/zenodo.5143773, 2021. DOI: 10.5281/zenodo.5143773.
- [29] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- [30] Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. In ECCV, pages 235–251, 2016.
- [31] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloé Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross B. Girshick. Segment anything. arXiv: 2304.02643, 2023.
- [32] Weixian Lei, Jiacong Wang, Haochen Wang, Xiangtai Li, Jun Hao Liew, Jiashi Feng, and Zilong Huang. The scalability of simplicity: Empirical analysis of vision-language learning with a single transformer. arXiv preprint arXiv:2504.10462, 2025.
- [33] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, pages 12888–12900, 2022.
- [34] Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, and Jiaya Jia. Mini-gemini: Mining the potential of multi-modality vision language models. arXiv: 2403.18814, 2024.
- [35] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. arXiv: 2310.03744, 2023.
- [36] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In NeurIPS, 2023.
- [37] Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal model an all-around player? arXiv: 2307.06281, 2023.
- [38] Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? arXiv preprint arXiv:2307.06281, 2023.
- [39] Yuliang Liu, Zhang Li, Hongliang Li, Wenwen Yu, Mingxin Huang, Dezhi Peng, Mingyu Liu, Mingrui Chen, Chunyuan Li, Lianwen Jin, et al. On the hidden mystery of ocr in large multimodal models. arXiv preprint arXiv:2305.07895, 2023.
- [40] Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Yaofeng Sun, et al. Deepseek-vl: Towards real-world vision-language understanding. arXiv preprint arXiv:2403.05525, 2024.
- [41] Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. arXiv: 2310.02255, 2023.
- [42] Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. In NeurIPS, 2022.
- [43] Gen Luo, Xue Yang, Wenhan Dou, Zhaokai Wang, Jiawen Liu, Jifeng Dai, Yu Qiao, and Xizhou Zhu. Mono-internvl: Pushing the boundaries of monolithic multimodal large language models with endogenous visual pre-training. In CVPR, 2025.
- [44] Gen Luo, Yiyi Zhou, Yuxin Zhang, Xiawu Zheng, Xiaoshuai Sun, and Rongrong Ji. Feast your eyes: Mixture-of-resolution adaptation for multimodal large language models. arXiv preprint arXiv:2403.03003, 2024.
- [45] Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In ACL, pages 2263–2279, 2022.
- [46] Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and CV Jawahar. Infographicvqa. In WACV, pages 1697–1706, 2022.
- [47] Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. In WACV, pages 2200–2209, 2021.
- [48] Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, Anton Belyi, Haotian Zhang, Karanjeet Singh, Doug Kang, Ankur Jain, Hongyu Hè, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du, Tao Lei, Sam Wiseman, Guoli Yin, Mark Lee, Zirui Wang, Ruoming Pang, Peter Grasch, Alexander Toshev, and Yinfei Yang. MM1: methods, analysis & insights from multimodal LLM pre-training. arXiv: 2403.09611, 2024.
- [49] Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In ICDAR, pages 947–952, 2019.
- [50] OpenAI. Gpt-4v(ision) system card. https://cdn.openai.com/papers/GPTV_System_Card.pdf, 2023.
- [51] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. TMLR, 2023.
- [52] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, pages 8748–8763, 2021.
- [53] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In ICML, volume 139, pages 8748–8763, 2021.
- [54] Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
- [55] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. NeurIPS, 35:25278–25294, 2022.
- [56] Mustafa Shukor, Enrico Fini, Victor Guilherme Turrisi da Costa, Matthieu Cord, Joshua Susskind, and Alaaeldin El-Nouby. Scaling laws for native multimodal models. arXiv preprint arXiv:2504.07951, 2025.
- [57] Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards VQA models that can read. In CVPR, 2019.
- [58] Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, pages 6105–6114. PMLR, 2019.
- [59] InternLM Team. Internlm: A multilingual language model with progressively enhanced capabilities. https://github.com/InternLM/InternLM, 2023.
- [60] Qwen Team. Qwen3 blog. https://qwenlm.github.io/blog/qwen3/, 2025.
- [61] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [62] Han Wang, Yongjie Ye, Bingru Li, Yuxiang Nie, Jinghui Lu, Jingqun Tang, Yanjie Wang, and Can Huang. Vision as lora. arXiv preprint arXiv:2503.20680, 2025.
- [63] Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024.
- [64] Wenhai Wang, Jifeng Dai, Zhe Chen, Zhenhang Huang, Zhiqi Li, Xizhou Zhu, Xiaowei Hu, Tong Lu, Lewei Lu, Hongsheng Li, et al. Internimage: Exploring large-scale vision foundation models with deformable convolutions. In CVPR, pages 14408–14419, 2023.
- [65] Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, and Zhongyuan Wang. Emu3: Next-token prediction is all you need. arXiv: 2409.18869, 2024.
- [66] Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800, 2024.
- [67] Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. TACL, 2:67–78, 2014.
- [68] Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023.
- [69] Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv: 2308.02490, 2023.
- [70] Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. arXiv: 2311.16502, 2023.
- [71] Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transformers. In CVPR, pages 12104–12113, 2022.
- [72] Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. In ICCV, pages 11975–11986, 2023.
## Technical Appendices and Supplementary Material
## Appendix A NaViL-9B: Scaling up to 9B parameters
To further demonstrate the scaling capability of our method, we trained NaViL-9B based on Qwen3-8B TransF:Qwen3 . The total number of activation parameters is 9.2B, of which 1.2B belongs to the visual encoder. The training recipe is similar to NaViL-2B, as shown in Tab. 8, except the visual multi-scaling packing is disabled in the first sub-stage of pre-training for acceleration.
Tab. 3 presents a comparison of the total training tokens required by our method versus two compositional counterparts. Notably, our approach achieves comparable performance while using substantially fewer training tokens, demonstrating improved training efficiency.
Table 3: Comparison between NaViL and existing MLLMs on the number of training tokens.
| Qwen2.5VL bai2025qwen2 InternVL2.5-8B InternVL-2.5 NaViL-2B (ours) | unknown >3.3T 0 | 4.1T 140B 800B | >4.1T >3.5T 800B |
| --- | --- | --- | --- |
| NaViL-9B (ours) | 0 | 450B Due to limited computational resource and time, current version of NaViL-9B in this paper is only trained with 450B tokens. | 450B |
The performance results on multimodal and visual question answering benchmarks are shown in Tab. 4. With a similar parameter size, our NaViL-9B outperforms all existing native MLLMs by a large margin on almost all benchmarks. Besides that, compared to the compositional baseline model InternVL-2.5-8B with a similar parameter size, NaViL-9B also achieves competitive performance. Such results show that our proposed native MLLM can be scaled up to larger parameter sizes and achieve consistent performance gains.
## Appendix B More discussions on Compositional MLLMs and Native MLLMs
<details>
<summary>x10.png Details</summary>
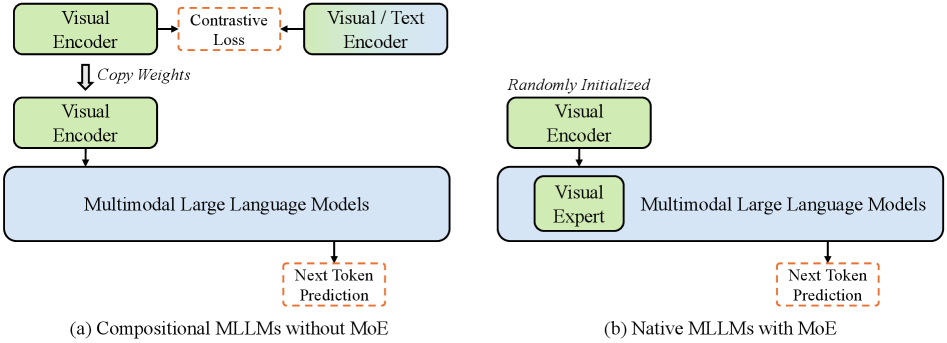
### Visual Description
# Technical Document Extraction: Multimodal Large Language Models (MLLMs)
## Diagram Analysis
### Diagram (a): Compositional MLLMs without MoE
**Components and Flow:**
1. **Visual Encoder**
- Input: Visual data
- Output: Embeddings fed into "Contrastive Loss"
2. **Contrastive Loss**
- Function: Optimizes alignment between visual and textual representations
- Output: Processed embeddings
3. **Visual/Text Encoder**
- Input: Processed embeddings from "Contrastive Loss"
- Output: Multimodal representations
4. **Copy Weights**
- Mechanism: Transfers learned weights from the Visual Encoder to the Multimodal Large Language Models
5. **Multimodal Large Language Models**
- Input: Copied weights + textual context
- Output: **Next Token Prediction**
**Key Observations:**
- The architecture emphasizes **contrastive learning** to align visual and textual modalities.
- Weight copying ensures parameter efficiency by reusing the Visual Encoder's learned features.
---
### Diagram (b): Native MLLMs with MoE (Mixture of Experts)
**Components and Flow:**
1. **Visual Encoder**
- Initialization: **Randomly Initialized**
- Output: Embeddings fed into "Visual Expert"
2. **Visual Expert**
- Function: Specialized processing of visual embeddings
- Output: Enhanced visual features
3. **Multimodal Large Language Models**
- Input: Visual Expert output + textual context
- Output: **Next Token Prediction**
**Key Observations:**
- **MoE Integration**: Introduces a dedicated "Visual Expert" to handle modality-specific processing.
- **Random Initialization**: Visual Encoder starts without pre-trained weights, relying on end-to-end training.
---
## Cross-Diagram Comparison
| Feature | Diagram (a) | Diagram (b) |
|------------------------|--------------------------------------|--------------------------------------|
| **Architecture** | Compositional (modular components) | Native (end-to-end with MoE) |
| **Visual Encoder** | Pre-trained (weights copied) | Randomly initialized |
| **Modality Alignment** | Contrastive Loss | Visual Expert |
| **Output** | Next Token Prediction | Next Token Prediction |
**Critical Differences:**
- Diagram (a) uses **contrastive learning** for alignment, while Diagram (b) employs a **dedicated Visual Expert**.
- Diagram (b) avoids weight copying, favoring **random initialization** for the Visual Encoder.
---
## Notes
- **Language**: All textual elements are in English.
- **No Numerical Data**: The diagrams focus on architectural design rather than quantitative metrics.
- **Flow Direction**: Arrows indicate sequential processing from top to bottom in both diagrams.
</details>
Figure 10: Paradigm Comparison between Compositional MLLMs and Native MLLMs. Compositional MLLMs adopt different training objectives and strategies (e.g. Contrastive Loss or Next-Token-Prediction) to pre-train the visual encoder and LLM separately, while native MLLMs optimize both image and text components in an end-to-end manner using a unified training objective (i.e. Next-Token-Prediction).
Fig. 10 further illustrates the difference between compositional MLLMs and native MLLMs. Compositional MLLMs typically have different components initialized by separate unimodal pre-training, where different training objectives and strategies are employed to train the LLM and visual encoder. For example, the visual encoder can be trained using an image-text contrastive learning objective (e.g., CLIP radford2021clip , SigLIP zhai2023siglip ) or a self-supervised learning objective (e.g., DINOv2 oquab2023dinov2 ). The complexity of such training process increases the difficulty of scalability. On the other hand, as discussed in shukor2025scaling , native MLLM optimizes both image and text modalities end-to-end using a unified training objective (i.e., next-token prediction (NTP)). This avoids introducing additional bias and significantly simplifies the scaling effort.
## Appendix C More Related Works
Research on Neural Scaling Laws.
The foundational work on Neural Scaling Laws began in the Natural Language Processing (NLP) domain, where openai2020scaling established predictable power-law relationships demonstrating that performance loss ( $L$ ) scales reliably with model size ( $N$ ) and data size ( $D$ ), and that larger, decoder-only Transformer models are more compute-efficient. Following works ghorbani2021scaling further extended such research to encoder-decoder architectures, observing consistency in scaling exponents on Neural Machine Translation (NMT) tasks. Driven by these successes, in the vision domain, zhai2022scaling confirmed the applicability of scaling laws to Vision Transformers (ViT), systematically demonstrating continuous performance improvement by scaling both model size (up to 2 billion parameters) and training data. Most recently, these principles have been generalized to Large Multimodal Models, where aghajanyan2023scaling developed scaling laws that unify the contributions of text, image, and speech modalities by explicitly modeling synergy and competition as an additive term. Furthering this, shukor2025scaling explored Native Multimodal Models (NMMs) using Mixture of Experts (MoEs), finding an unbalanced scaling law that suggests scaling training tokens ( $D$ ) is more critical than scaling active parameters ( $N$ ) as the compute budget grows.
## Appendix D Implementation Details
The hyperparameters of model architecture for NaViL-2B and NaViL-9B are listed in Tab. 6, while the hyperparameters of training recipe for NaViL-2B and NaViL-9B are provided in Tab. 7 and Tab. 8, respectively. The high-quality multimodal data used in Pre-training and Supervised Fine-tuning is from InternVL-2.5 InternVL-2.5 , which is sourced from various domains, such as image captioning, general question answering, multi-turn dialogue, charts, OCR, documents, and knowledge, etc.; while the pure language data is primarily from InternLM2.5 cai2024internlm2 .
Table 4: Comparison between NaViL-9B and existing MLLMs on multimodal benchmarks. “#A-Param” denotes the number of activated parameters. † InternVL-2.5-8B adopts the same high-quality data with NaViL-9B, so we mark it as the compositional counterpart. Note that its 300M visual encoder is distilled from another 6B large encoder. * denotes our reproduced results. Bold and underline indicate the best and the second-best performance among native MLLMs, respectively. For MME, we sum the perception and cognition scores. Average scores are computed by normalizing each metric to a range between 0 and 100.
| Compositional MLLMs: | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| MobileVLM-V2 chu2024mobilevlm | 1.7B | $-$ | $-$ | $-$ | 57.7 | $-$ | $-$ | $-$ | $-$ | $-$ | $-$ | $-$ | $-$ |
| MobileVLM-V2 chu2024mobilevlm | 3.0B | $-$ | $-$ | $-$ | 63.2 | $-$ | $-$ | $-$ | 57.5 | $-$ | $-$ | $-$ | $-$ |
| Mini-Gemini VLM:MiniGemini | 3.5B | $-$ | 31.1 | 31.7 | 59.8 | 1653 | 29.4 | $-$ | 56.2 | 34.2 | $-$ | $-$ | $-$ |
| MM1-MoE-Chat VLM:MM1 | 3.5B | $-$ | 42.2 | 38.6 | 70.8 | 1772 | 32.6 | $-$ | 72.9 | $-$ | $-$ | $-$ | $-$ |
| DeepSeek-VL lu2024deepseekvl | 2.0B | $-$ | 34.8 | 32.2 | 64.6 | 1532 | 31.1 | 409 | 57.8 | $-$ | 51.5 | $-$ | $-$ |
| PaliGemma beyer2024paligemma | 2.9B | $-$ | 33.1 | 34.9 | 71.0 | 1686 | 28.7 | 614 | 68.1 | $-$ | 68.3 | $-$ | $-$ |
| MiniCPM-V-2 yao2024minicpm | 2.8B | $-$ | 41.0 | 38.2 | 69.1 | 1809 | 38.7 | 605 | 74.1 | 71.9 | 62.9 | $-$ | $-$ |
| InternVL-1.5 VLM:InternVL-1.5 | 2.2B | 61.3 | 39.3 | 34.6 | 70.9 | 1902 | 41.1 | 654 | 70.5 | 85.0 | 69.8 | 74.8 | 55.4 |
| Qwen2VL Qwen2vl | 2.1B | 67.3 | 49.5 | 41.1 | 74.9 | 1872 | 43.0 | 809 | 79.7 | 90.1 | 74.7 | 73.5 | 65.5 |
| InternVL-2.5 chen2024expanding | 2.2B | 69.6 | 60.8 | 43.6 | 74.7 | 2138 | 51.3 | 804 | 74.3 | 88.7 | 74.9 | 79.2 | 60.9 |
| Qwen2VL Qwen2vl | 8.2B | 77.1 | 62.0 | 54.1 | 83.0 | 2327 | 58.2 | 866 | 84.3 | 94.5 | 83.0 | 83.0 | 76.5 |
| Qwen2.5-VL bai2025qwen2 | 8.2B | 80.2 | 67.1 | 58.6 | 83.5 | 2347 | 68.2 | 864 | 84.9 | 95.7 | 83.9 | 87.3 | 82.6 |
| † InternVL-2.5 chen2024expanding | 8.1B | 77.3 | 62.8 | 56.0 | 84.6 | 2344 | 64.4 | 822 | 79.1 | 91.9 | 84.5 | 84.8 | 75.7 |
| Native MLLMs: | | | | | | | | | | | | | |
| Fuyu-8B (HD) VLM:Fuyu-8b | 8B | $-$ | 21.4 | $-$ | 10.7 | $-$ | $-$ | $-$ | $-$ | $-$ | 64.5 | $-$ | $-$ |
| SOLO solo | 7B | $-$ | $-$ | $-$ | $-$ | 1260 | 34.4 | $-$ | $-$ | $-$ | 61.4 | $-$ | $-$ |
| Chameleon-7B The performance of Chameleon-7B is from mono_internvl . team2024chameleon | 7B | 14.0 | 8.3 | 25.4 | 31.1 | 170 | 22.3 | 7 | 4.8 | 1.5 | 46.0 | 2.9 | 5.0 |
| EVE-7B diao2024EVE | 7B | 34.6 | 25.6 | 32.3 | 49.5 | 1483 | 25.2 | 327 | 51.9 | 22.0 | 48.5 | 19.5 | 20.0 |
| EVE-7B (HD) diao2024EVE | 7B | 45.2 | 25.7 | 32.6 | 52.3 | 1628 | 34.2 | 398 | 56.8 | 53.0 | 61.0 | 59.1 | 25.0 |
| Emu3 emu3 | 8B | $-$ | 37.2 | 31.6 | 58.5 | $-$ | $-$ | 687 | 64.7 | 76.3 | 70.0 | 68.6 | 43.8 |
| VoRA vora | 7B | $-$ | 33.7 | 32.2 | 64.2 | 1674 | $-$ | $-$ | 56.3 | $-$ | 65.6 | $-$ | $-$ |
| VoRA-AnyRes vora | 7B | $-$ | 33.7 | 32.0 | 61.3 | 1655 | $-$ | $-$ | 58.7 | $-$ | 61.1 | $-$ | $-$ |
| EVEv2 diao2025evev2 | 7B | 62.3 | 45.0 | 39.3 | 66.3 | 1709 | 60.0* | 702 | 71.1 | 77.4* | 74.8 | 73.9 | 45.8* |
| SAIL lei2025sail | 7B | 63.7 | 46.3 | 38.6* | 70.1 | 1719 | 57.0 | 783 | 77.1 | 78.4* | 76.7 | 69.7* | 47.3* |
| Mono-InternVL mono_internvl | 1.8B | 60.6 | 40.1 | 33.7 | 65.5 | 1875 | 45.7 | 767 | 72.6 | 80.0 | 68.6 | 73.7 | 43.0 |
| NaViL-2B (ours) | 2.4B | 68.8 | 78.3 | 41.8 | 71.2 | 1822 | 50.0 | 796 | 76.9 | 85.4 | 74.6 | 78.0 | 56.0 |
| NaViL-9B (ours) | 9.2B | 77.0 | 79.6 | 54.7 | 76.5 | 2225 | 66.7 | 837 | 77.2 | 90.6 | 82.4 | 85.4 | 70.2 |
Table 5: Comparison of NaViL and existing native MLLMs on three common NLP tasks. Except for Chameleon, models are evaluated using OpenCompass toolkit opencompass2023 .
| InternLM2-Chat 2023internlm Qwen3-8B (non-thinking) TransF:Qwen3 EVE diao2024EVE | 1.8B 8B 7B | 47.1 76.5 43.9 | 46.1 76.8 33.4 | 13.9 71.1 0.7 |
| --- | --- | --- | --- | --- |
| Chameleon team2024chameleon | 7B | 52.1 | - | 11.5 |
| Mono-InternVL mono_internvl | 2B | 45.1 | 44.0 | 12.3 |
| NaViL-9B (ours) | 9.2B | 74.9 | 75.1 | 66.2 |
Table 6: Hyper-Parameters of Model Architecture.
| Component-visual encoder | Hyper-Parameter # Params depth | NaViL-2B 0.6B 24 | NaViL-9B 1.2B 32 |
| --- | --- | --- | --- |
| width | 1472 | 1792 | |
| MLP width | 5888 | 7168 | |
| # attention heads | 23 | 28 | |
| LLM (w/ MoE) | # experts | 2 | 2 |
| # A-Params | 1.8B | 8.0B | |
| depth | 24 | 36 | |
| width | 2048 | 4096 | |
| MLP width | 8192 | 12288 | |
| # attention heads | 16 | 32 | |
Table 7: Hyper-parameters for training NaViL-2B.
| Configuration | Multi-modal Generative Pre-training (S1) | Supervised | |
| --- | --- | --- | --- |
| S1.1 | S1.2 | Fine-tuning (S2) | |
| Maximum number of image patches | $4096$ | $12188$ | $24576$ |
| Training steps | $70$ k | $40$ k | $30$ k |
| Global batch size | $7,000$ | $4,614$ | $2,234$ |
| Weight decay | $0.05$ | $0.1$ | $0.01$ |
| Learning rate schedule | constant with warm-up | cosine decay | |
| Peak learning rate | $5e^{-5}$ | $2e^{-5}$ | |
| Visual Multi-scale Packing | ✓ | | |
| LLM max sequence length | $16,384$ | | |
| Warm-up steps | $200$ | | |
| Optimizer | AdamW | | |
| Optimizer hyperparameters | $\beta_{1}=0.9,\beta_{2}=0.95,eps=1e^{-8}$ | | |
| Gradient accumulation | $1$ | | |
| Numerical precision | $\mathtt{bfloat16}$ | | |
Table 8: Hyper-parameters for training NaViL-9B.
| Configuration | Multi-modal Generative Pre-training (S1) | Supervised | |
| --- | --- | --- | --- |
| S1.1 | S1.2 | Fine-tuning (S2) | |
| Maximum number of image patches | $4096$ | $12188$ | $24576$ |
| Training steps | $50$ k | $33$ k | $6$ k |
| Weight decay | $0.05$ | $0.1$ | $0.01$ |
| Global batch size | $10,300$ | $1,792$ | $3,520$ |
| Visual Multi-scale Packing | ✗ | ✓ | ✓ |
| Learning rate schedule | constant with warm-up | cosine decay | |
| Peak learning rate | $5e^{-5}$ | $2e^{-5}$ | |
| LLM max sequence length | $16,384$ | | |
| Warm-up steps | $200$ | | |
| Optimizer | AdamW | | |
| Optimizer hyperparameters | $\beta_{1}=0.9,\beta_{2}=0.95,eps=1e^{-8}$ | | |
| Gradient accumulation | $1$ | | |
| Numerical precision | $\mathtt{bfloat16}$ | | |
## Appendix E The NLP capability
We also evaluate the NLP capability of our model on three popular NLP tasks, as shown in Tab. 5. Thanks to the modality-specific MoE architecture, NaViL maintains the NLP capabilities of its initialization LLM (Qwen3-8B). Despite not using a large amount of high-quality text data, NaViL performs well on the common NLP tasks and show much stronger NLP capabilities compared to other native MLLMs, showing its data efficiency.
## Appendix F More Qualitative Results
More visualization results of multimodal understanding are provided below.
Image Captioning and Visual Question Answering
<details>
<summary>figures/vis/vis-understanding-conventional-center.jpg Details</summary>

### Visual Description
# Technical Document Extraction Analysis
## Textual Information Extraction
- **No textual elements detected** in the image.
- No labels, axis titles, legends, or axis markers present.
- No embedded text in diagrams, charts, or data tables.
- No multilingual content identified.
## ImageDescription
The image depicts a **modern architectural structure** with the following features:
1. **Building Design**:
- A large, elongated building with a **white facade** and **triangular geometric patterns**.
- A **curved glass roof** with a metallic framework.
- Multiple **circular windows** and **open-air corridors** along the structure.
2. **Surrounding Environment**:
- A **waterfront** with a **blue body of water** and a **marina** containing boats.
- A **road** with **palm trees** lining the sidewalk and a **multi-lane highway** adjacent to the building.
- **Distant cityscape** with high-rise buildings and a hazy skyline.
3. **Additional Elements**:
- A **sculpture** near the roadside.
- **Train tracks** visible on the right edge of the image.
## Data and Chart Analysis
- **No charts, diagrams, or data tables** are present in the image.
- **No numerical data, categories, or sub-categories** to extract.
- **No legend or color-coded elements** to cross-reference.
## Spatial Grounding and Trend Verification
- **No spatial data points or trends** to analyze.
- **No visual trends** (e.g., upward/downward slopes) to describe.
## Component Isolation
- The image is segmented into:
1. **Main Building**: Central focus with architectural details.
2. **Waterfront**: Secondary element with boats and marina.
3. **Road and Surroundings**: Includes palm trees, highway, and sculpture.
4. **Distant Cityscape**: Background element with high-rises.
## Conclusion
The image contains **no factual or data-driven information**. It is a **visual representation** of an architectural and urban landscape.
</details>
Prompt: Describe this image in detail. Response: The image shows an aerial view of a modern architectural complex situated near a coastal area. The building has a distinctive design with a series of curved, wave-like structures on its roof, giving it a futuristic appearance. The exterior is primarily composed of light-colored materials, possibly concrete or stone, with large glass windows. In front of the building, there is a wide, multi-lane road lined with palm trees, suggesting a warm, coastal climate. The road appears to be a major thoroughfare, with designated bike lanes and pedestrian pathways. There are also train tracks running parallel to the road, indicating the presence of a public transportation system. The background features a large body of water, likely a bay or ocean, with several boats and yachts docked at a marina. The coastline is lined with more buildings, and there are hills or mountains visible in the distance, adding to the scenic view. The overall setting suggests a bustling urban area with a focus on modern infrastructure and a strong connection to the waterfront. Prompt: Which city is this building most likely in? Response: This building is most likely in San Diego, California. The architectural style and the surrounding landscape, including the water and palm trees, are characteristic of San Diego.
<details>
<summary>figures/vis/vis-understanding-worldcup.png Details</summary>

### Visual Description
# Technical Document Extraction Analysis
## Summary
The image depicts a celebratory scene of a soccer team holding a golden trophy, with no visible textual elements, labels, or data structures. The focus is on visual celebration rather than technical documentation.
## Detailed Description
1. **Primary Subjects**:
- A group of soccer players wearing **blue and white vertically striped jerseys** with visible numbers (e.g., "10", "11", "17", "5", "37").
- Central figure holding a **golden FIFA World Cup trophy** aloft.
- Players wearing **gold medals** with red ribbons around their necks.
2. **Background Elements**:
- **Fireworks** exploding in the upper left and right corners, creating bright white/yellow light patterns.
- Stadium seating visible in the background, blurred and indistinct.
3. **Notable Details**:
- Players exhibit celebratory gestures: raised arms, clenched fists, open-mouthed expressions.
- One player in a **black jacket** stands out among teammates in team uniforms.
- No visible text, diagrams, charts, or data tables present in the image.
## Critical Analysis
- **Textual Content**: No textual information exists in the image. All elements are visual (uniforms, trophy, medals, fireworks).
- **Legend/Label Requirements**: Not applicable – no legends, axis titles, or data markers present.
- **Trend Verification**: Inapplicable due to absence of charts or numerical data.
- **Component Isolation**: The image contains only a single scene (celebration) with no segmented components.
## Conclusion
This image contains **no extractable textual or technical data**. It is a photographic representation of a sports victory celebration with no embedded documentation elements.
</details>
Prompt: Who is the person in black in the middle? Response: The person in black in the middle is Lionel Messi. Prompt: What are they celebrating about? Response: The image shows a group of soccer players celebrating with a trophy, wearing medals and jerseys. They are likely celebrating a victory in a soccer tournament or championship.
<details>
<summary>figures/vis/vis-understanding-gta5.png Details</summary>

### Visual Description
# Technical Document: Textual Information Extraction from Image
## Overview
The image depicts a scene from a video game environment, likely from *Grand Theft Auto V* (GTA V), based on visual style and contextual elements. The scene includes a character standing on a sidewalk, urban buildings, vehicles, and signage. Below is a detailed extraction of all textual information present in the image.
---
## Textual Elements
### 1. **Store Signage**
- **Left Building (Green/White Facade):**
- **Text:** `WINE`
- **Font:** Bold, red uppercase letters.
- **Background:** White rectangular panel.
- **Position:** Top-left corner of the building.
- **Middle Building (Blue Facade):**
- **Text:** `ALL WINE DONE`
- **Font:** Bold, yellow uppercase letters.
- **Background:** Yellow rectangular panel.
- **Position:** Center of the building's upper facade.
- **Secondary Text (Smaller, Below Main Sign):**
- **Text:** `SPECIAL MARKETS SUPPLIES`
- **Font:** Smaller, black uppercase letters.
- **Background:** Yellow panel.
- **Position:** Directly below `ALL WINE DONE`.
- **Right Building (Blue Facade):**
- **Text:** `ON THE BONE`
- **Font:** Bold, red uppercase letters.
- **Background:** Blue rectangular panel.
- **Position:** Top-right corner of the building.
- **Secondary Text (Smaller, Below Main Sign):**
- **Text:** `MAT WANTED`
- **Font:** Bold, red uppercase letters.
- **Background:** Yellow rectangular panel.
- **Position:** Directly below `ON THE BONE`.
---
### 2. **Environmental Text**
- **Street Signage:**
- No visible street signs or directional markers in the image.
- **Vehicle License Plates:**
- No legible license plates visible on the cars in the scene.
- **Graffiti/Text on Buildings:**
- No additional text or graffiti visible on the buildings.
---
### 3. **Character and UI Elements**
- **Character Clothing:**
- No text visible on the character's clothing.
- **In-Game UI (Bottom-Left Corner):**
- **Map Icon:** A small map icon with a green dot (likely the player's location).
- **Text:** No readable text in the UI.
---
## Language Analysis
- **Primary Language:** English.
- **Secondary Languages:** None detected.
---
## Spatial Grounding of Text
- **`WINE` Sign:**
- Coordinates: Approximately `[x=0, y=100]` (relative to the left building's upper facade).
- **`ALL WINE DONE` Sign:**
- Coordinates: Approximately `[x=300, y=200]` (center of the middle building).
- **`ON THE BONE` Sign:**
- Coordinates: Approximately `[x=600, y=150]` (top-right corner of the right building).
- **`MAT WANTED` Sign:**
- Coordinates: Approximately `[x=600, y=250]` (below `ON THE BONE`).
---
## Notes
- The image does not contain charts, diagrams, or data tables.
- All textual elements are environmental and part of the game's world-building.
- No numerical data or trends are present.
---
## Conclusion
The image contains four distinct textual elements: three store signs (`WINE`, `ALL WINE DONE`, `ON THE BONE`, `MAT WANTED`) and no additional text. The scene is a static urban environment with no dynamic data or interactive text elements.
</details>
Prompt: What is the content in this image? Response: The image appears to be a screenshot from a video game, likely Grand Theft Auto V (GTA V), given the visual style and interface elements. It shows a character standing on a sidewalk in a small town or suburban area. The environment includes a street with tram tracks, a few buildings with signs, and some cars parked along the road. The buildings have signs for businesses like "Wine" and "On The Bone." The scene has a somewhat deserted look, with no other characters or significant activity visible.
OCR
<details>
<summary>figures/vis/vis-understanding-nutritional.jpeg Details</summary>

### Visual Description
# Technical Document Extraction: Nutritional Information Label
## Overview
The image depicts a **nutritional information label** for a food product. The label is structured as a table with two primary sections: **Nutritional Information** and **Ingredients**. Additional storage and safety instructions are provided at the bottom.
---
## Section 1: Nutritional Information Table
### Table Structure
- **Columns**:
- **Per Serving** (left column)
- **Per 100g** (right column)
- **Rows**:
- Nutrient categories (e.g., Energy, Protein, Fat, etc.)
- Corresponding values for each nutrient.
### Labels and Axis Titles
- **Header**: "NUTRITIONAL INFORMATION" (bold, uppercase).
- **Serving Size**: "Serving size: 10 g" (left side).
- **Servings per Package**: "Servings per package: 25" (right side).
- **Average Quantity**:
- "Average Quantity Per Serving" (left column header).
- "Average Quantity Per 100g" (right column header).
### Data Points
| Nutrient | Per Serving (10g) | Per 100g (100g) |
|------------------------|-------------------|-----------------|
| Energy | 143 kJ | 1430 kJ |
| Protein | < 0.1 g | 0.16 g |
| Fat, total | < 0.1 g | 0.37 g |
| - Saturated Fat | < 0.1 g | 0.26 g |
| Carbohydrates | 8.31 g | 83.1 g |
| Sugars | 8.11 g | 81.1 g |
| Sodium | 0.41 mg | 4.04 mg |
### Notes
- All values are presented in **kilojoules (kJ)** for energy and **grams (g)** or **milligrams (mg)** for other nutrients.
- The label uses **metric units** (e.g., kJ, g, mg).
---
## Section 2: Ingredients
- **Text**: "INGREDIENTS: 100% Pure New Zealand Honey" (highlighted with a gray box).
- **Formatting**: Bold, uppercase text with a rectangular border.
---
## Section 3: Storage and Safety Instructions
- **Storage**: "Keep Stored Below 20 deg°C, BPA-Free Container."
- **Safety**: "Not suitable for children under 1 year of age."
- **Icons**:
- A sun icon (likely indicating light sensitivity or storage conditions).
- A warning symbol (likely for the safety note).
---
## Section 4: Additional Observations
- **Language**: All text is in **English**.
- **Formatting**:
- The label uses a **white background** with **black text**.
- The "Ingredients" section is visually emphasized with a **gray box**.
- The bottom section (storage/safety) is in a **black background** with **white text**.
---
## Conclusion
This label provides detailed nutritional data for a product composed entirely of **100% Pure New Zealand Honey**. Key metrics include energy content, macronutrient breakdown, and storage requirements. The label adheres to standard nutritional labeling conventions, with clear segmentation of data and safety warnings.
</details>
Prompt: Extract all the text in this image. Response: NUTRITIONAL INFORMATION Serving size: 10 g Servings per package: 25 Average Quantity Per Serving | Average Quantity Per 100g Energy | 143kJ | 1430 kJ Protein | less than 0.1g | 0.16g Fat, total | less than 0.1g | 0.37g - saturated | less than 0.1g | 0.26g Carbohydrates | 8.31g | 83.1g Sugars | 8.11g | 81.1g Sodium | 0.41mg | 4.04mg INGREDIENTS: 100% Pure New Zealand Honey Keep Stored Below 20 deg°C, BPA-Free Container. Not suitable for children under 1 year of age.
<details>
<summary>figures/vis/vis-understanding-receipt.jpeg Details</summary>

### Visual Description
# Technical Document Extraction: Receipt Analysis
## Header Information
- **Establishment**: Chapelbank Hotel
- **Address**: 69 East High Street, Forfar DD8 2EP
- **Telephone**: 01307 463151
- **Handwritten Note**: "Food = Lunch x 5 people"
## Table Details
- **Table Number**: 5
- **Restaurant**: Restaurant
## Itemized Charges
| Item Description | Unit Price | Quantity | Total Amount |
|---------------------------|------------|----------|--------------|
| 3x Soup | £3.95 | 3 | £11.85 |
| Lunch Main (Lasagne (V)) | £6.95 | 1 | £6.95 |
| Misc Food | £6.95 | 1 | £6.95 |
| 2x Chips / Onion Rings | £1.75 | 2 | £3.50 |
## Totals
- **Previous Balance (Prev Bal)**: £29.25
- **Subtotal**: £29.25
## Observations
1. **Currency**: British Pounds (£)
2. **Dietary Note**: "(V)" indicates vegetarian option for lasagne.
3. **Formatting**: Asterisks (`* * * * * * * * * *`) separate header from itemized charges.
4. **Math Validation**:
- 3 × £3.95 = £11.85
- 2 × £1.75 = £3.50
- Total: £11.85 + £6.95 + £6.95 + £3.50 = £29.25
## Structural Notes
- **Layout**: Standard receipt format with left-aligned text and right-aligned numerical values.
- **Footer**: No additional text or payment method indicated.
- **Language**: English (no non-English text detected).
</details>
Prompt: Describe the image. Response: The image is a receipt from Chapelbank Hotel for a lunch order for five people. The items listed on the receipt include 3x soup at £3.95 each, totaling £11.85; lunch main course at £6.95; lasagne (V) at £6.95; misc food at £6.95; and 2x chips/onion rings at £1.75 each, totaling £3.50. The subtotal for the food is £29.25. The receipt also includes a previous balance of £29.25, making the total amount due £29.25. The hotel’s address is 69 East High Street, Forfar DD8 2EP, and the telephone number is 01307 463151. Prompt: How many people are attending this lunch? Response: There are 5 people attending this lunch. This is indicated at the top of the receipt where it says "Food = Lunch x 5 people".
<details>
<summary>figures/vis/vis-understanding-road.jpeg Details</summary>

### Visual Description
# Technical Document: Highway Signage Analysis
## Image Description
The image depicts a highway scene with overhead directional signs mounted on a metal structure. The road is a multi-lane highway with vehicles traveling in both directions. A concrete barrier separates the highway from a grassy area with trees. The sky is partly cloudy.
---
## Textual Information Extraction
### Overhead Signage
1. **Left Exit Sign (Exit 45)**
- **Text**:
- `LEFT EXIT 45`
- `267 WEST TOLL`
- `Reston Herndon`
- `Dulles Airport`
- `NO TOLL`
- `1 MILE`
2. **Middle Sign (Exit 46A)**
- **Text**:
- `EXIT 46A`
- `123 SOUTH`
- `Chain Br Rd`
- `Tysons Corner`
- `1/2 MILE`
3. **Right Sign (Exit 46B)**
- **Text**:
- `EXIT 46B`
- `123 NORTH`
- `Chain Br Rd`
- `McLean`
- `EXIT ONLY`
4. **Smaller Sign (Leesburg Exit 45)**
- **Text**:
- `Leesburg EXIT 45`
---
## Spatial Grounding
- **Sign Positions**:
- **Left**: Exit 45 (Route 267 West Toll, Reston Herndon, Dulles Airport).
- **Center**: Exit 46A (Route 123 South, Chain Br Rd, Tysons Corner).
- **Right**: Exit 46B (Route 123 North, Chain Br Rd, McLean).
- **Far Right**: Leesburg Exit 45 (smaller sign).
- **Vehicle Positions**:
- A blue truck is in the right lane.
- A dark-colored SUV is in the left lane.
- Other vehicles are visible in the distance.
- **Infrastructure**:
- Concrete barrier on the right side of the highway.
- Metal structure supporting the overhead signs.
---
## Additional Observations
- **No Data Charts or Tables**: The image contains no numerical data, heatmaps, or diagrams requiring trend analysis.
- **Language**: All text is in English.
- **Context**: The signs indicate exits for Route 267 (West Toll) and Route 123 (South/North), with distances to destinations (e.g., Dulles Airport, Tysons Corner, McLean).
---
## Conclusion
The image provides directional information for highway exits, including route numbers, destinations, and distances. No additional data or non-English text is present. The scene is a standard highway setup with clear signage for navigation.
</details>
Prompt: Where is the left exit going to? Response: The left exit is going to Reston, Herndon, and Dulles Airport. Prompt: Which road leads to the EXIT 46 B? Response: The road that leads to EXIT 46 B is Chain Br Rd North.
Multi-lingual OCR
<details>
<summary>figures/vis/vis-understanding-zuowen.jpeg Details</summary>

### Visual Description
# Technical Document: Analysis of Chinese Text Grid Image
## Language Declaration
The text in the image is written in **Chinese** (Simplified). All textual content will be transcribed directly, with English translations provided where applicable.
---
## Image Structure and Content
### Header Section
- **Text**: `作文(60分)`
**Translation**: "Composition (60 points)"
**Position**: Top-left corner of the image.
### Title Section
- **Text**: `题目专注目标,享受生命`
**Translation**: "Focus on the target, enjoy life"
**Position**: Centered below the header.
---
### Main Grid Structure
The grid consists of **7 rows** and 12 columns of Chinese characters. Some characters are bolded for emphasis. Below is the transcription of each row, with bolded characters noted:
#### Row 1
- **Text**: `目标之光,如月光清辉;生命之`
**Bolded Characters**: `目标之光` (Target's light), `如月光清辉` (Like moonlight's clarity)
**Translation**: "The light of the target, like clear moonlight; the light of life"
#### Row 2
- **Text**: `辉,如群星闪耀。失去了群星,月色`
**Bolded Characters**: `群星闪耀` (Stars twinkling), `群星` (Stars)
**Translation**: "Brilliant, like stars twinkling. Losing the stars, the moonlight"
#### Row 3
- **Text**: `便清冷孤寂;不见了明月,群星也黯`
**Bolded Characters**: `清冷孤寂` (Cold and lonely), `明月` (Bright moon), `群星` (Stars)
**Translation**: "Then cold and lonely; the bright moon is gone, and the stars grow dim"
#### Row 4
- **Text**: `心黯然失色。只有专注于月光,方有`
**Bolded Characters**: `心黯然失色` (Heart turns pale), `专注于月光` (Focus on moonlight)
**Translation**: "The heart turns pale. Only by focusing on the moonlight can there be"
#### Row 5
- **Text**: `方向;只有饮誉群星,方可享受生命`
**Bolded Characters**: `方向` (Direction), `饮誉群星` (Glorious stars), `享受生命` (Enjoy life)
**Translation**: "Direction; only by drinking the glory of stars can one enjoy life"
#### Row 6
- **Text**: `星月交辉,夜空擦人;专注目标,享`
**Bolded Characters**: `星月交辉` (Stars and moon glow), `专注目标` (Focus on the target)
**Translation**: "Stars and moon glow together, the night sky brushes over; focus on the target, enjoy"
#### Row 7
- **Text**: `受生命,方可体味人间清欢。`
**Bolded Characters**: `受生命` (Experience life), `体味人间清欢` (Savor the purity of worldly joys)
**Translation**: "To experience life, one can savor the purity of worldly joys"
---
## Key Observations
1. **Thematic Focus**: The text emphasizes **focus**, **life**, and **stars/moonlight** as metaphors for aspiration and clarity.
2. **Formatting**: Bolded characters highlight critical concepts (e.g., `目标` [target], `群星` [stars], `月光` [moonlight]).
3. **Structure**: The grid resembles a poetic or philosophical composition, with each row building on the previous one to convey a narrative about perseverance and mindfulness.
---
## Notes
- No numerical data, charts, or diagrams are present. The image is purely textual.
- The grid’s layout suggests a deliberate artistic or educational purpose, possibly for literary analysis or motivational content.
</details>
Prompt: 请先提取里面的文本,再翻译为英文。 Response: 文本内容: 作文(60分) 题目:专注目标,享受生命。 目标之光,如月光清辉;生命之辉,如群星闪耀。失去了群星,月色便显得冷寂;不见了明月,群星也势必黯然失色。只有专注于月光,方有方向;只有欣赏群星,方可享受生命。星月交辉,夜空撩人;专注目标,享受生命,方可体味人间清欢。 翻译为英文: Essay (60 points) Title: Focus on your goal, enjoy life. The light of the goal is like the clear glow of moonlight; the brilliance of life is like the dazzling stars. Without the stars, the moonlight becomes cold and desolate; without the moon, the stars will inevitably become dull. Only by focusing on the moonlight can you find direction; only by appreciating the stars can you enjoy life. The stars and moon shine together, making the night sky enchanting; focusing on your goal, enjoying life, allows you to savor the quiet joy of life.
Document Understanding
<details>
<summary>figures/vis/vis-understanding-docvqa.png Details</summary>

### Visual Description
# KBA MARKETING GROUP — 2001 VENUE SPONSORSHIP AGREEMENT
## Document Overview
This is a scanned copy of a sponsorship agreement between **KBA Marketing Group** (d/b/a KBA) and **Vitucci's, Inc.** (Venue Owner). The agreement outlines terms for the **Camel Club Program (CCP)** sponsorship for the venue "Vitucci's" located at 1832 East North Avenue, Milwaukee, WI 53202. Key sections include venue details, sponsorship funds, and extra value items.
---
## Key Sections
### 1. **Date and Term of Agreement**
- **Date of Agreement**: 3/1/01
- **Term**: January 1, 2001 – December 31, 2001
- **Sponsorship Program**: Camel Club Program ("CCP")
---
### 2. **Venue Information**
- **Venue Name**: Vitucci's
- **Venue Address**: 1832 East North Avenue
- **City/State/Zip Code**: Milwaukee, WI 53202
- **FEIN or SSN**: [REDACTED]
- **Venue Owner Name**: Vitucci's, Inc.
- **Venue Owner Category**: Corporation
- **Venue Code**: 4388
---
### 3. **Sponsorship Funds and Extra Value Items**
#### **Sponsorship Funds**
- **Special Events Fund**:
- $1,595.00 to offset costs for a minimum of 1 Special Events (Jan 1 – June 30, 2001).
- $1,595.00 to offset costs for a minimum of 1 Special Events (July 1 – Dec 31, 2001).
- **Printed Materials Fund**:
- $810.00 for printing/shipping custom flyers and local media advertising (quarter-page ads, display ads at KBA's discretion).
- **Total Direct Payments**:
- $2,000.00, paid in four installments:
- March 31, 2001: $500.00
- June 30, 2001: $500.00
- September 30, 2001: $500.00
- December 31, 2001: $500.00
- **TOTAL SPONSORSHIP FUNDS**: $6,000.00 (includes all sub-totals above).
#### **Extra Value Items (Provided at No Cost to Venue)**
- **Tobacco License Fees**:
- All state and local retail tobacco licensing fees (if Venue lacks a license), plus assistance with licensing applications.
- **Bar Essentials**:
- Branded ashtrays, beverage napkins, generic branded matchbooks, and other bar essentials delivered at KBA's discretion.
- **Custom Matchbooks**:
- 3 cases of custom-branded matchbooks displaying Venue’s name/logo.
- **Flyer Distribution**:
- Public distribution of flyers for Special Events/activities at Venue (at KBA’s discretion).
- **Cigarette Delivery**:
- Free delivery of Camel cigarette brand styles ("Product") purchased by Venue Owner for resale in Venue.
- Free (Gratis) Product distributed to adult smokers (as permitted by law).
---
## Signatures
- **Initials**:
- KBA: [Signature]
- Venue Owner: [Signature]
---
## Notes
- The document is marked as a **COPY ORIGINAL**.
- Source: [Industry Documents UCSF](https://www.industrydocuments.ucsf.edu/docs/fpmj0226)
---
### Technical Notes
- **Language**: English (no other languages detected).
- **Data Structure**: Tabular and section-based format with clear headings.
- **Redaction**: FEIN/SSN field explicitly redacted.
- **Payment Schedule**: Quarterly installments for Total Direct Payments.
- **Compliance**: Cigarette distribution subject to legal restrictions.
This extraction captures all textual content, structured for clarity and technical documentation purposes.
</details>
Prompt: What is the duration of this venue sponsorship agreement? Response: January 1, 2001 - December 31, 2001 Prompt: Where is Vitucci’s located (complete address)? Response: 1832 East North Avenue, Milwaukee WI 53202 Prompt: What cigarette brand is mentioned in the agreement for delivery and distribution? Response: Camel cigarette brand styles purchased by Venue Owner for resale in Venue Prompt: Who has discretion over the distribution of flyers for special events? Response: KBA Marketing Group ("KBA") has discretion over the distribution of flyers for special events.
LaTeX and Math
<details>
<summary>figures/vis/vis-understanding-math.png Details</summary>
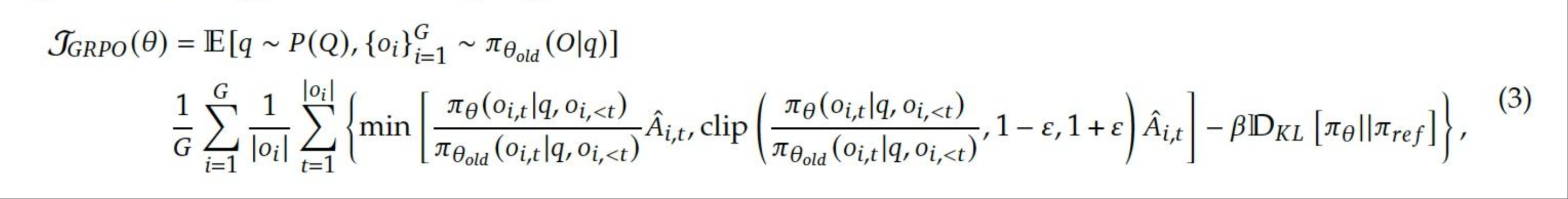
### Visual Description
The image contains a mathematical equation written in LaTeX notation. Below is the extracted textual information with detailed analysis:
---
### **Equation Structure**
1. **Primary Equation**:
- **Label**: `(3)` (appears at the end of the equation).
- **Components**:
- **Left-Hand Side (LHS)**:
`\mathcal{J}_{GRPO}(\theta)`
- Represents a functional or objective related to the GRPO (Generalized Reinforcement Policy Optimization) framework.
- **Right-Hand Side (RHS)**:
`\mathbb{E}[q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)]`
- Denotes an expectation over:
- `q`: A variable drawn from a distribution `P(Q)`.
- `\{o_i\}_{i=1}^G`: A sequence of observations/actions indexed by `i` from `1` to `G`, sampled from the policy `\pi_{\theta_{old}}(O|q)`.
2. **Expanded Form**:
- **Summation and Minimization**:
```latex
\frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \left\{ \min \left[ \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})} \hat{A}_{i,t}, \text{clip} \left( \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})}, 1-\epsilon, 1+\epsilon \right) \hat{A}_{i,t} \right] - \beta \mathbb{D}_{KL}[\pi_\theta || \pi_{ref}] \right\},
```
- **Key Terms**:
- `G`: Total number of episodes or sequences.
- `|o_i|`: Length of the `i`-th episode/sequence.
- `\pi_\theta`: Current policy parameterized by `\theta`.
- `\pi_{\theta_{old}}`: Previous policy (reference policy).
- `\hat{A}_{i,t}`: Estimated advantage function for the `t`-th step in the `i`-th episode.
- `\epsilon`: Clipping parameter to bound the ratio of policy updates.
- `\beta`: Scaling factor for the KL divergence penalty.
- `\mathbb{D}_{KL}[\pi_\theta || \pi_{ref}]`: Kullback-Leibler divergence between the current policy `\pi_\theta` and a reference policy `\pi_{ref}`.
---
### **Key Observations**
- The equation defines an **objective function** (`\mathcal{J}_{GRPO}(\theta)`) for optimizing a reinforcement learning policy.
- The expectation term aggregates over trajectories `q` and sequences of actions `o_i`, emphasizing the role of **behavioral cloning** (`\pi_{\theta_{old}}`) and **policy improvement** (`\pi_\theta`).
- The minimization term balances:
1. A **ratio of policy probabilities** (proximal constraint via clipping).
2. A **KL divergence penalty** to prevent excessive divergence from a reference policy.
---
### **Non-English Text**
- **None**: All symbols and terms are standard mathematical notation in English technical contexts.
---
### **Critical Notes**
- **No chart/diagram**: The image is purely symbolic (no visual data points, axes, or legends).
- **Equation Purpose**: Likely part of a reinforcement learning algorithm, specifically GRPO, which combines policy optimization with KL divergence regularization.
- **Assumptions**: Requires familiarity with RL concepts (e.g., advantage functions, KL divergence, policy optimization).
---
This extraction captures all textual and symbolic content from the image. Let me know if further clarification is needed!
</details>
Prompt: Convert the formula in the figure to latex format. Response: ‘‘‘latex \begin{equation*} \begin{split} \mathcal{J}_{\text{GRPO}}(\theta) &= \mathbb{E}[q \sim P(Q), \{o_i\}_{i=1}ˆG \sim \pi_{\theta_{old}}(O|q)] \\ & \frac{1}{G} \sum_{i=1}ˆG \frac{1}{|o_i|} \sum_{t=1}ˆ{|o_i|} \left\{ \min \left[ \frac{\pi_{\theta}(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})} \hat{A}_{i,t}, \text{clip} \left( \frac{\pi_{\theta}(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})}, 1 - \varepsilon, 1 + \varepsilon \right) \hat{A}_{i,t} \right] - \beta \mathcal{D}_{KL} \left[ \pi_{\theta} || \pi_{ref} \right] \right\}, \end{split} \end{equation*} ‘‘‘
<details>
<summary>figures/vis/vis-understanding-math-7.png Details</summary>
### Visual Description
# Technical Document Extraction: Parallelogram Diagram
## Image Description
The image depicts a **parallelogram** with the following annotations:
- **Base**: Labeled as `8 m` (horizontal side at the bottom).
- **Height**: Labeled as `x m` (vertical dashed line from the top-right vertex to the base, forming a right angle).
- **Right Angle Symbol**: A small square at the intersection of the height and base, indicating perpendicularity.
## Labels and Annotations
1. **Base Label**:
- Text: `8 m`
- Position: Along the bottom horizontal side of the parallelogram.
- Unit: Meters (m).
2. **Height Label**:
- Text: `x m`
- Position: Along the vertical dashed line (height) from the top-right vertex to the base.
- Unit: Meters (m).
3. **Right Angle Symbol**:
- A small square at the base of the height line, confirming the height is perpendicular to the base.
## Notes
- The parallelogram is shaded in light blue.
- No additional text, legends, or data tables are present.
- The diagram focuses on geometric properties (base and height) for potential area calculations.
## Conclusion
The image provides explicit labels for the **base** (`8 m`) and **height** (`x m`) of a parallelogram, with a right angle symbol to denote perpendicularity. No numerical trends, categories, or complex data structures are present.
</details>
Prompt: Find $x$ . $A=148$ $m^{2}$ . Please think step by step. Response: To find the value of $x$ in the parallelogram, we can use the formula for the area of a parallelogram: $A=\text{base}\times\text{height}$ Given: - Area $A=148\,\text{m}^{2}$ - Base $=8\,\text{m}$ - Height $=x\,\text{m}$ Substitute the given values into the formula: $148=8\times x$ Solve for $x$ : $x=\frac{148}{8}$ $x=18.5\,\text{m}$ So, $x=18.5\,\text{m}$ .
<details>
<summary>figures/vis/vis-understanding-math-10.png Details</summary>
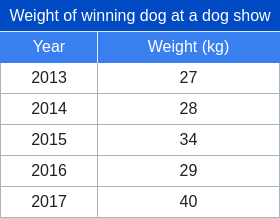
### Visual Description
# Technical Document Extraction: Weight of Winning Dog at a Dog Show
## Header Section
**Title:** Weight of winning dog at a dog show
**Format:** Tabular data table with two columns
## Main Chart Component
### Table Structure
| Year | Weight (kg) |
|------|-------------|
| 2013 | 27 |
| 2014 | 28 |
| 2015 | 34 |
| 2016 | 29 |
| 2017 | 40 |
### Key Trends and Data Points
1. **Initial Increase (2013-2015):**
- 2013: 27 kg
- 2014: +1 kg (28 kg)
- 2015: +6 kg (34 kg)
*Trend:* Steady upward trajectory with significant jump in 2015.
2. **Temporary Decline (2016):**
- 2016: -5 kg (29 kg)
*Trend:* First decrease after three years of growth.
3. **Final Surge (2017):**
- 2017: +11 kg (40 kg)
*Trend:* Sharp rebound to highest recorded weight.
### Spatial Grounding
- **Legend:** Not applicable (no color-coded data series).
- **Axis Titles:**
- X-axis: `Year` (categorical, 2013–2017)
- Y-axis: `Weight (kg)` (numerical, 27–40 kg)
### Trend Verification
- **Visual Confirmation:**
- Line A (implied by sequential data):
- Slopes upward from 2013–2015.
- Dips in 2016.
- Sharp upward slope in 2017.
- Numerical alignment confirms visual trend.
### Component Isolation
- **Regions Processed:**
1. Header (title and column labels).
2. Data rows (2013–2017 with corresponding weights).
3. Trend analysis (logical progression of weights over time).
### Final Output
**Reconstructed Table:**
| Year | Weight (kg) |
|------|-------------|
| 2013 | 27 |
| 2014 | 28 |
| 2015 | 34 |
| 2016 | 29 |
| 2017 | 40 |
**Summary:**
The weight of the winning dog at the dog show fluctuated between 27 kg (2013) and 40 kg (2017), with a notable dip in 2016 followed by a record-breaking increase in 2017.
</details>
Prompt: A dog show enthusiast recorded the weight of the winning dog at recent dog shows. According to the table, what was the rate of change between 2016 and 2017? (Unit: kilograms per year) Response: To determine the rate of change between 2016 and 2017, we use the formula for rate of change: $\text{Rate of Change}=\frac{\text{Weight in 2017}-\text{Weight in 2016}}{\text{Year 2017}-\text{Year 2016}}$ From the table: - Weight in 2016 = 29 kg - Weight in 2017 = 40 kg Substitute these values into the formula: $\text{Rate of Change}=\frac{40\,\text{kg}-29\,\text{kg}}{2017-2016}\\ =\frac{11\,\text{kg}}{1\,\text{year}}$ $\text{Rate of Change}=11\,\text{kg/year}$ Thus, the rate of change between 2016 and 2017 is $\boxed{11\,\text{kg/year}}$ .