# Large Language Models Do NOT Really Know What They Don’t Know
## Abstract
Recent work suggests that large language models (LLMs) encode factuality signals in their internal representations, such as hidden states, attention weights, or token probabilities, implying that LLMs may “ know what they don’t know ”. However, LLMs can also produce factual errors by relying on shortcuts or spurious associations. These error are driven by the same training objective that encourage correct predictions, raising the question of whether internal computations can reliably distinguish between factual and hallucinated outputs. In this work, we conduct a mechanistic analysis of how LLMs internally process factual queries by comparing two types of hallucinations based on their reliance on subject information. We find that when hallucinations are associated with subject knowledge, LLMs employ the same internal recall process as for correct responses, leading to overlapping and indistinguishable hidden-state geometries. In contrast, hallucinations detached from subject knowledge produce distinct, clustered representations that make them detectable. These findings reveal a fundamental limitation: LLMs do not encode truthfulness in their internal states but only patterns of knowledge recall, demonstrating that LLMs don’t really know what they don’t know.
Large Language Models Do NOT Really Know What They Don’t Know
Chi Seng Cheang 1 Hou Pong Chan 2 Wenxuan Zhang 3 Yang Deng 1 1 Singapore Management University 2 DAMO Academy, Alibaba Group 3 Singapore University of Technology and Design cs.cheang.2025@phdcs.smu.edu.sg, houpong.chan@alibaba-inc.com wxzhang@sutd.edu.sg, ydeng@smu.edu.sg
## 1 Introduction
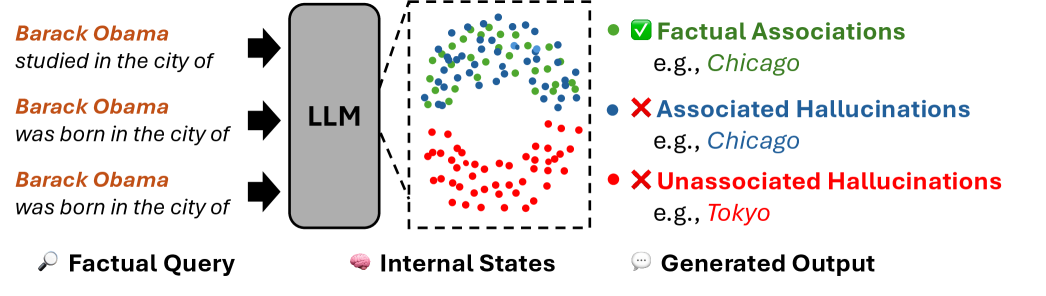
Large language models (LLMs) demonstrate remarkable proficiency in generating coherent and contextually relevant text, yet they remain plagued by hallucination Zhang et al. (2023b); Huang et al. (2025), a phenomenon where outputs appear plausible but are factually inaccurate or entirely fabricated, raising concerns about their reliability and trustworthiness. To this end, researchers suggest that the internal states of LLMs (e.g., hidden representations Azaria and Mitchell (2023); Gottesman and Geva (2024), attention weights Yüksekgönül et al. (2024), output token logits Orgad et al. (2025); Varshney et al. (2023), etc.) can be used to detect hallucinations, indicating that LLMs themselves may actually know what they don’t know. These methods typically assume that when a model produces hallucinated outputs (e.g., “ Barack Obama was born in the city of Tokyo ” in Figure 1), its internal computations for the outputs (“ Tokyo ”) are detached from the input information (“ Barack Obama ”), thereby differing from those used to generate factually correct outputs. Thus, the hidden states are expected to capture this difference and serve as indicators of hallucinations.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: LLM Factual Query and Hallucination Visualization
### Overview
This diagram illustrates the process of a Large Language Model (LLM) responding to factual queries, and visualizes the occurrence of both factual associations and hallucinations. The diagram shows how queries are processed internally and the resulting outputs, categorizing them into factual responses, associated hallucinations, and unassociated hallucinations.
### Components/Axes
The diagram is segmented into three main areas: "Factual Query", "Internal States", and "Generated Output", separated by dashed vertical lines.
* **Factual Query (Left):** Contains three example queries in black text:
* "Barack Obama studied in the city of"
* "Barack Obama was born in the city of" (appears twice)
* **LLM (Center-Left):** A gray rectangular box labeled "LLM" represents the Large Language Model itself. Arrows indicate the flow of queries *into* the LLM.
* **Internal States (Center):** A region filled with scattered dots representing the LLM's internal processing. Dots are colored to represent different output types.
* **Generated Output (Right):** Displays the types of outputs generated, with examples.
* **Legend (Right):** A legend explains the color-coding of the dots:
* Green: "Factual Associations" (e.g., Chicago)
* Blue: "Associated Hallucinations" (e.g., Chicago)
* Red: "Unassociated Hallucinations" (e.g., Tokyo)
* **Icons (Bottom):** Icons representing each section: a magnifying glass for "Factual Query", a brain for "Internal States", and a speech bubble for "Generated Output".
### Detailed Analysis or Content Details
The diagram visually represents the following:
* **Factual Query:** Three queries are input into the LLM.
* **Internal States:** The LLM's internal processing is represented by a dense scattering of dots.
* Green dots (Factual Associations) are clustered in the upper-center area. Approximately 20-30 green dots are visible.
* Blue dots (Associated Hallucinations) are scattered around the green dots, with approximately 15-25 visible.
* Red dots (Unassociated Hallucinations) are concentrated in the lower-center area, with approximately 30-40 visible.
* **Generated Output:**
* **Factual Associations:** "e.g., Chicago" is provided as an example.
* **Associated Hallucinations:** "e.g., Chicago" is provided as an example.
* **Unassociated Hallucinations:** "e.g., Tokyo" is provided as an example.
### Key Observations
* The diagram suggests that LLMs can generate outputs that are factually correct (green dots), but also prone to both associated and unassociated hallucinations (blue and red dots, respectively).
* The density of red dots (Unassociated Hallucinations) appears to be higher than the density of green dots (Factual Associations), suggesting that hallucinations may be more frequent than accurate responses.
* The presence of "Chicago" as an example for both Factual Associations and Associated Hallucinations is noteworthy. This could indicate that the LLM is correctly associating Chicago with Barack Obama, but also generating incorrect information *related* to Chicago.
* The example of "Tokyo" for Unassociated Hallucinations suggests the LLM is generating completely unrelated information.
### Interpretation
This diagram is a conceptual visualization of the challenges in ensuring the reliability of LLM outputs. It highlights the distinction between factual correctness, hallucinations that are related to the query (but incorrect), and hallucinations that are entirely unrelated. The diagram suggests that LLMs do not simply retrieve information; they engage in internal processing that can lead to both accurate and inaccurate outputs. The clustering of the dots in the "Internal States" area implies that the LLM's internal representations are complex and not always directly tied to factual accuracy. The diagram serves as a visual metaphor for the "black box" nature of LLMs and the difficulty in understanding *why* they generate certain outputs. The use of examples like Chicago and Tokyo helps to ground the abstract concept of hallucinations in concrete terms. The diagram is not presenting quantitative data, but rather a qualitative illustration of a phenomenon.
</details>
Figure 1: Illustration of three categories of knowledge. Associated hallucinations follow similar internal knowledge recall processes with factual associations, while unassociated hallucinations arise when the model’s output is detached from the input.
However, other research (Lin et al., 2022b; Kang and Choi, 2023; Cheang et al., 2023) shows that models can also generate false information that is closely associated with the input information. In particular, models may adopt knowledge shortcuts, favoring tokens that frequently co-occur in the training corpus over factually correct answers Kang and Choi (2023). As shown in Figure 1, given the prompt: “Barack Obama was born in the city of”, an LLM may rely on the subject tokens’ representations (i.e., “Barack Obama”) to predict a hallucinated output (e.g., “Chicago”), which is statistically associated with the subject entity but under other contexts (e.g., “ Barack Obama studied in the city of Chicago ”). Therefore, we suspect that the internal computations may not exhibit distinguishable patterns between correct predictions and input-associated hallucinations, as LLMs rely on the input information to produce both of them. Only when the model produces hallucinations unassociated with the input do the hidden states exhibit distinct patterns that can be reliably identified.
To this end, we conduct a mechanistic analysis of how LLMs internally process factual queries. We first perform causal analysis to identify hidden states crucial for generating Factual Associations (FAs) — factually correct outputs grounded in subject knowledge. We then examine how these hidden states behave when the model produces two types of factual errors: Associated Hallucinations (AHs), which remain grounded in subject knowledge, and Unassociated Hallucinations (UHs), which are detached from it. Our analysis shows that when generating both FAs and AHs, LLMs propagate information encoded in subject representations to the final token during output generation, resulting in overlapping hidden-state geometries that cannot reliably distinguish AHs from FAs. In contrast, UHs exhibit distinct internal computational patterns, producing clearly separable hidden-state geometries from FAs.
Building on the analysis, we revisit several widely-used hallucination detection approaches Gottesman and Geva (2024); Yüksekgönül et al. (2024); Orgad et al. (2025) that adopt internal state probing. The results show that these representations cannot reliably distinguish AHs from FAs due to their overlapping hidden-state geometries, though they can effectively separate UHs from FAs. Moreover, this geometry also shapes the limits the effectiveness of Refusal Tuning Zhang et al. (2024), which trains LLMs to refuse uncertain queries using refusal-aware dataset. Because UH samples exhibit consistent and distinctive patterns, refusal tuning generalizes well to unseen UHs but fails to generalize to unseen AHs. We also find that AH hidden states are more diverse, and thus refusal tuning with AH samples prevents generalization across both AH and UH samples.
Together, these findings highlight a central limitation: LLMs do not encode truthfulness in their hidden states but only patterns of knowledge recall and utilization, showing that LLMs don’t really know what they don’t know.
## 2 Related Work
Existing hallucination detection methods can be broadly categorized into two types: representation-based and confidence-based. Representation-based methods assume that an LLM’s internal hidden states can reflect the correctness of its generated responses. These approaches train a classifier (often a linear probe) using the hidden states from a set of labeled correct/incorrect responses to predict whether a new response is hallucinatory Li et al. (2023); Azaria and Mitchell (2023); Su et al. (2024); Ji et al. (2024); Chen et al. (2024); Ni et al. (2025); Xiao et al. (2025). Confidence-based methods, in contrast, assume that a lower confidence during the generation led to a higher probability of hallucination. These methods quantify uncertainty through various signals, including: (i) token-level output probabilities (Guerreiro et al., 2023; Varshney et al., 2023; Orgad et al., 2025); (ii) directly querying the LLM to verbalize its own confidence (Lin et al., 2022a; Tian et al., 2023; Xiong et al., 2024; Yang et al., 2024b; Ni et al., 2024; Zhao et al., 2024); or (iii) measuring the semantic consistency across multiple outputs sampled from the same prompt (Manakul et al., 2023; Kuhn et al., 2023; Zhang et al., 2023a; Ding et al., 2024). A response is typically flagged as a hallucination if its associated confidence metric falls below a predetermined threshold.
However, a growing body of work reveals a critical limitation: even state-of-the-art LLMs are poorly calibrated, meaning their expressed confidence often fails to align with the factual accuracy of their generations (Kapoor et al., 2024; Xiong et al., 2024; Tian et al., 2023). This miscalibration limits the effectiveness of confidence-based detectors and raises a fundamental question about the extent of LLMs’ self-awareness of their knowledge boundary, i.e., whether they can “ know what they don’t know ” Yin et al. (2023); Li et al. (2025). Despite recognizing this problem, prior work does not provide a mechanistic explanation for its occurrence. To this end, our work addresses this explanatory gap by employing mechanistic interpretability techniques to trace the internal computations underlying knowledge recall within LLMs.
## 3 Preliminary
Transformer Architecture
Given an input sequence of $T$ tokens $t_{1},...,t_{T}$ , an LLM is trained to model the conditional probability distribution of the next token $p(t_{T+1}|t_{1},...,t_{T})$ conditioned on the preceding $T$ tokens. Each token is first mapped to a continuous vector by an embedding layer. The resulting sequence of hidden states is then processed by a stack of $L$ Transformer layers. At layer $\ell\in{1,...,L}$ , each token representation is updated by a Multi-Head Self-Attention (MHSA) and a Feed-Forward Network (MLP) module:
$$
\mathbf{h}^{\ell}=\mathbf{h}^{\ell-1}+\mathbf{a}^{\ell}+\mathbf{m}^{\ell}, \tag{1}
$$
where $\mathbf{a}^{\ell}$ and $\mathbf{m}^{\ell}$ correspond to the MHSA and MLP outputs, respectively, at the $\ell$ -layer.
Internal Process of Knowledge Recall
Prior work investigates the internal activations of LLMs to study the mechanics of knowledge recall. For example, an LLM may encode many attributes that are associated with a subject (e.g., Barack Obama) (Geva et al., 2023). Given a prompt like “ Barack Obama was born in the city of ”, if the model has correctly encoded the fact, the attribute “ Honolulu ” propagates through self-attention to the last token, yielding the correct answer. We hypothesize that non-factual predictions follow the same mechanism: spurious attributes such as “ Chicago ” are also encoded and propagated, leading the model to generate false outputs.
Categorization of Knowledge
To investigate how LLMs internally process factual queries, we define three categories of knowledge, according to two criteria: 1) factual correctness, and 2) subject representation reliance.
- Factual Associations (FA) refer to factual knowledge that is reliably stored in the parameters or internal states of an LLM and can be recalled to produce correct, verifiable outputs.
- Associated Hallucinations (AH) refer to non-factual content produced when an LLM relies on input-triggered parametric associations.
- Unassociated Hallucinations (UH) refer to non-factual content produced without reliance on parametric associations to the input.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Heatmap: Jensen-Shannon Divergence by Layer and Representation
### Overview
This image presents a heatmap visualizing the average Jensen-Shannon (JS) Divergence across different layers of a model, for three different representations: Subject ("Subj."), Attention ("Attn."), and Last Layer ("Last."). The heatmap's color intensity corresponds to the magnitude of the JS Divergence, with darker blues indicating higher divergence and lighter blues indicating lower divergence.
### Components/Axes
* **X-axis:** "Layer" - Ranges from 0 to 30, with increments of 2.
* **Y-axis:** Representation Type - Three categories: "Subj." (Subject), "Attn." (Attention), and "Last." (Last Layer).
* **Color Scale (Right):** "Avg JS Divergence" - Ranges from 0.2 to 0.6, with a gradient from light blue to dark blue.
* **Legend:** Located in the top-right corner, visually mapping color intensity to JS Divergence values.
### Detailed Analysis
The heatmap is structured as a 3x16 grid (3 rows representing the representation types, and 16 columns representing the layers).
**1. Subject ("Subj.") Representation:**
* **Trend:** The JS Divergence remains relatively high and stable from Layer 0 to Layer 12, approximately around 0.55-0.6. After Layer 12, the divergence decreases gradually, reaching approximately 0.45-0.5 by Layer 30.
* **Data Points (Approximate):**
* Layer 0: ~0.58
* Layer 2: ~0.59
* Layer 4: ~0.58
* Layer 6: ~0.59
* Layer 8: ~0.58
* Layer 10: ~0.59
* Layer 12: ~0.57
* Layer 14: ~0.54
* Layer 16: ~0.51
* Layer 18: ~0.48
* Layer 20: ~0.46
* Layer 22: ~0.44
* Layer 24: ~0.42
* Layer 26: ~0.41
* Layer 28: ~0.40
* Layer 30: ~0.40
**2. Attention ("Attn.") Representation:**
* **Trend:** The JS Divergence starts at approximately 0.4 at Layer 0 and decreases steadily until Layer 14, reaching a minimum of around 0.3. From Layer 14 to Layer 30, the divergence increases slightly, but remains below 0.4.
* **Data Points (Approximate):**
* Layer 0: ~0.41
* Layer 2: ~0.39
* Layer 4: ~0.37
* Layer 6: ~0.35
* Layer 8: ~0.34
* Layer 10: ~0.33
* Layer 12: ~0.32
* Layer 14: ~0.30
* Layer 16: ~0.32
* Layer 18: ~0.34
* Layer 20: ~0.36
* Layer 22: ~0.38
* Layer 24: ~0.39
* Layer 26: ~0.40
* Layer 28: ~0.40
* Layer 30: ~0.41
**3. Last Layer ("Last.") Representation:**
* **Trend:** The JS Divergence begins at approximately 0.25 at Layer 0 and increases steadily to around 0.35 by Layer 14. After Layer 14, the divergence remains relatively stable, fluctuating between 0.3 and 0.35 until Layer 30.
* **Data Points (Approximate):**
* Layer 0: ~0.25
* Layer 2: ~0.27
* Layer 4: ~0.29
* Layer 6: ~0.30
* Layer 8: ~0.31
* Layer 10: ~0.32
* Layer 12: ~0.33
* Layer 14: ~0.35
* Layer 16: ~0.34
* Layer 18: ~0.33
* Layer 20: ~0.32
* Layer 22: ~0.33
* Layer 24: ~0.34
* Layer 26: ~0.33
* Layer 28: ~0.34
* Layer 30: ~0.34
### Key Observations
* The "Subj." representation consistently exhibits the highest JS Divergence across all layers.
* The "Attn." representation shows the most significant decrease in JS Divergence from Layer 0 to Layer 14.
* The "Last." representation has the lowest JS Divergence overall, indicating the most stable representation.
* There appears to be a point around Layer 12-14 where the divergence behavior changes for all three representations.
### Interpretation
This heatmap likely represents an analysis of the representational similarity of different layers within a neural network. The Jensen-Shannon Divergence measures the similarity between probability distributions. Higher divergence suggests greater dissimilarity, potentially indicating that the representations are becoming more distinct or specialized as information flows through the network.
The consistently high divergence in the "Subj." representation suggests that the subject-related information remains relatively diverse and complex throughout the layers. The decreasing divergence in the "Attn." representation could indicate that the attention mechanism is converging on a more focused and consistent set of features. The low and stable divergence in the "Last." representation suggests that the final layer produces a relatively stable and consolidated representation.
The change in behavior around Layer 12-14 might correspond to a key architectural component or a significant learning phase within the network. Further investigation would be needed to determine the specific cause of this shift. The data suggests that the model's representations evolve differently depending on the type of information being processed (subject, attention, or final output).
</details>
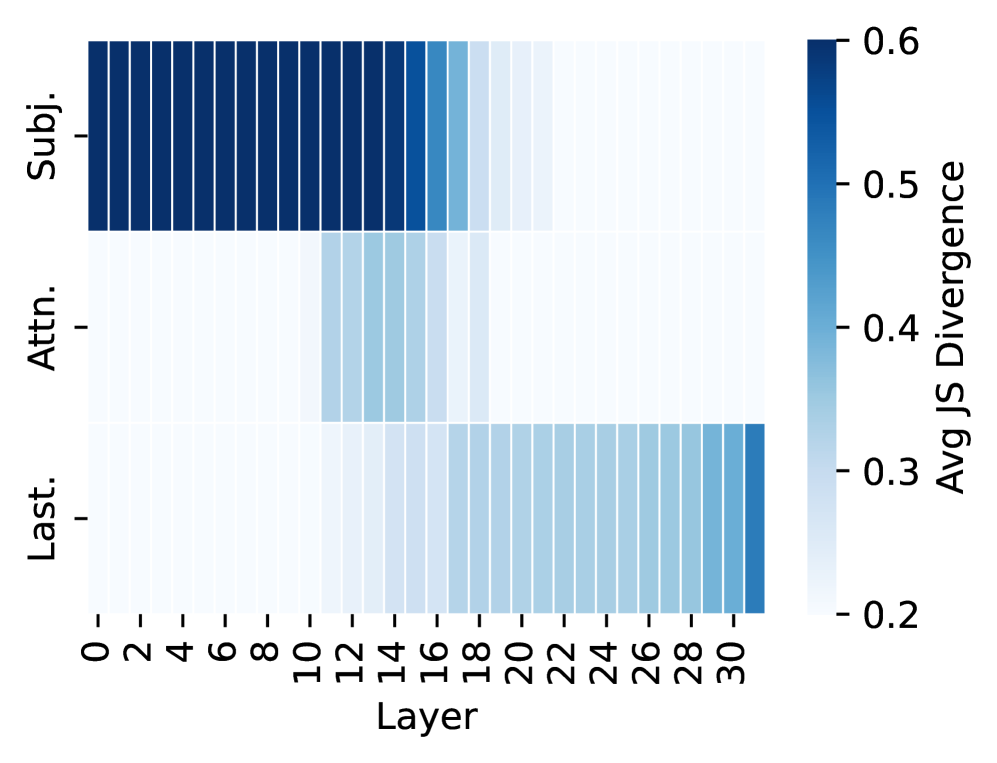
(a) Factual Associations
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Heatmap: Average Jensen-Shannon Divergence by Layer and Subject
### Overview
This image presents a heatmap visualizing the average Jensen-Shannon (JS) Divergence across different layers of a model, categorized by subject (Subj.), attention (Attn.), and last layer (Last.). The heatmap displays the relationship between layer number and JS divergence, with color intensity representing the divergence value.
### Components/Axes
* **X-axis:** Layer, ranging from 0 to 30, with increments of 2.
* **Y-axis:** Categories: "Subj." (Subject), "Attn." (Attention), and "Last." (Last Layer). These are listed vertically.
* **Color Scale:** A gradient from dark blue to light blue to white, representing JS Divergence values. The scale ranges from 0.2 to 0.6.
* **Title:** Not explicitly present, but the chart represents "Avg JS Divergence".
### Detailed Analysis
The heatmap is structured into three horizontal bands, one for each category (Subj., Attn., Last.). Each cell in the heatmap represents the average JS divergence for a specific layer and category.
**Subject (Subj.):**
* The JS divergence is consistently high (approximately 0.55-0.6) from layer 0 to layer 10.
* A sharp decrease in JS divergence is observed between layer 10 and layer 12, dropping to approximately 0.4.
* From layer 12 to layer 30, the JS divergence gradually decreases, reaching a value of approximately 0.25-0.3.
**Attention (Attn.):**
* The JS divergence starts at approximately 0.4 at layer 0.
* It remains relatively stable until layer 12, where it begins to decrease.
* From layer 12 to layer 30, the JS divergence decreases steadily, reaching a value of approximately 0.2.
**Last Layer (Last.):**
* The JS divergence starts at approximately 0.3 at layer 0.
* It remains relatively stable until layer 16, where it begins to decrease.
* From layer 16 to layer 30, the JS divergence decreases steadily, reaching a value of approximately 0.2.
### Key Observations
* The "Subject" category exhibits the highest JS divergence values overall, particularly in the initial layers.
* All three categories show a decreasing trend in JS divergence as the layer number increases.
* The rate of decrease in JS divergence appears to be most rapid for the "Subject" category.
* The "Last Layer" category has the lowest JS divergence values.
### Interpretation
The heatmap suggests that the representations learned by the model become more consistent (lower JS divergence) as information propagates through deeper layers. The higher JS divergence in the initial layers for the "Subject" category might indicate that the model initially struggles to establish a stable representation of the subject, but this representation becomes more refined with increasing depth. The decreasing trend across all categories suggests that the model is converging towards more consistent representations as it processes information. The "Last Layer" consistently showing the lowest divergence suggests that the final layer provides the most stable and consistent representation. The differences in divergence values between the categories could reflect the varying degrees of complexity or importance of each category in the model's learning process. The rapid drop in divergence around layers 10-16 could indicate a significant shift in the model's learning dynamics at that point.
</details>
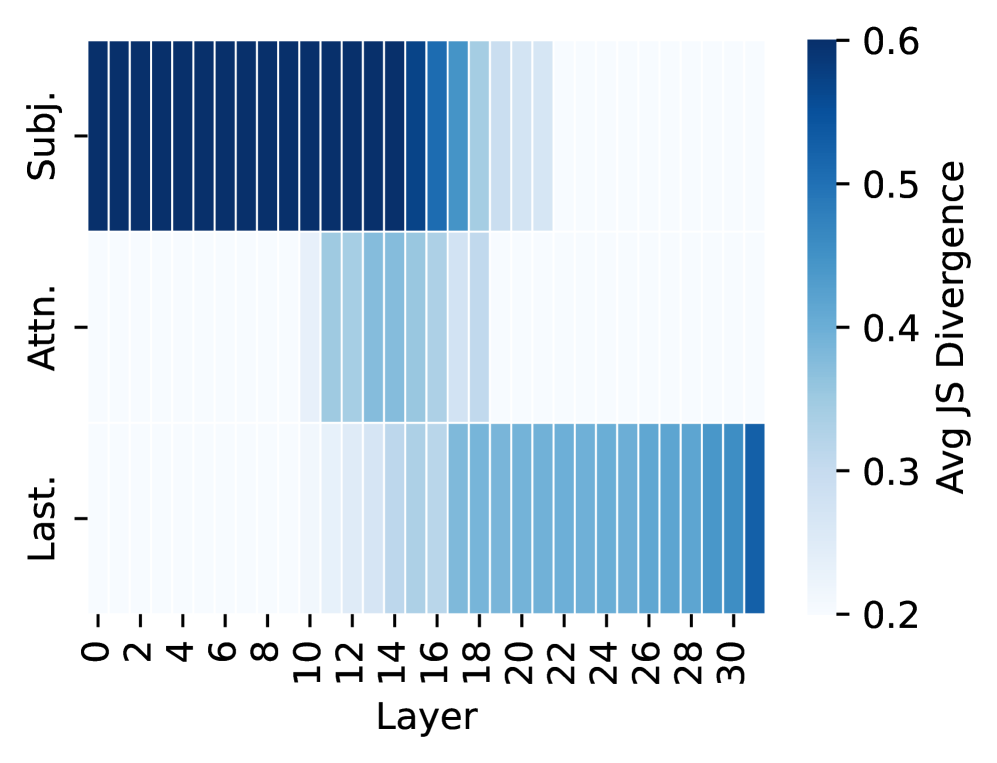
(b) Associated Hallucinations
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Heatmap: Average Jensen-Shannon Divergence by Layer and Representation
### Overview
This image presents a heatmap visualizing the average Jensen-Shannon (JS) Divergence across different layers of a model, for three different representations: Subject ('Subj.'), Attention ('Attn.'), and Last Layer ('Last.'). The heatmap uses a blue color gradient to represent divergence values, with darker blues indicating higher divergence.
### Components/Axes
* **X-axis:** Layer, ranging from 0 to 30, with increments of 2.
* **Y-axis:** Representation, with three categories: 'Subj.', 'Attn.', and 'Last.'.
* **Color Scale:** Average JS Divergence, ranging from 0.2 (light blue) to 0.6 (dark blue). The scale is positioned on the right side of the heatmap.
### Detailed Analysis
The heatmap displays JS Divergence values for each combination of layer and representation.
* **Subject ('Subj.') Representation:** The JS Divergence remains relatively constant across layers 0 to 30, hovering around approximately 0.55 ± 0.02. There is a slight decrease in divergence around layer 28, dropping to approximately 0.52.
* **Attention ('Attn.') Representation:** The JS Divergence is consistently lower than for the 'Subj.' representation, generally around 0.40 ± 0.02. There is a slight increase in divergence from layer 0 to layer 6, rising from approximately 0.38 to 0.42. It remains relatively stable until layer 26, where it begins to increase, reaching approximately 0.45 by layer 30.
* **Last Layer ('Last.') Representation:** The JS Divergence starts at approximately 0.25 at layer 0 and increases steadily with increasing layer number. By layer 30, the divergence reaches approximately 0.55. The increase appears roughly linear.
### Key Observations
* The 'Subj.' representation exhibits the highest and most stable JS Divergence across all layers.
* The 'Last.' representation shows the lowest divergence at early layers, but its divergence increases significantly as the layer number increases.
* The 'Attn.' representation has intermediate divergence values, with a slight increase towards the later layers.
* There is a clear trend of increasing divergence in the 'Last.' representation as the layer number increases.
### Interpretation
The heatmap suggests that the 'Subject' representation maintains a consistent level of information throughout the layers, as indicated by the stable JS Divergence. This could imply that the subject information is well-preserved during processing. The 'Last' layer representation, initially having low divergence, becomes more divergent as the layer number increases, suggesting that the information in this representation becomes more distinct or specialized as it passes through the model. The 'Attention' representation shows a moderate level of divergence, with a slight increase in later layers, potentially indicating that the attention mechanism is learning to focus on different aspects of the input as processing progresses. The increasing divergence in the 'Last' layer could be indicative of feature extraction or transformation, where the representation becomes more specific to the task at hand. The differences in divergence values between the representations suggest that each representation captures different aspects of the input data and evolves differently during processing.
</details>
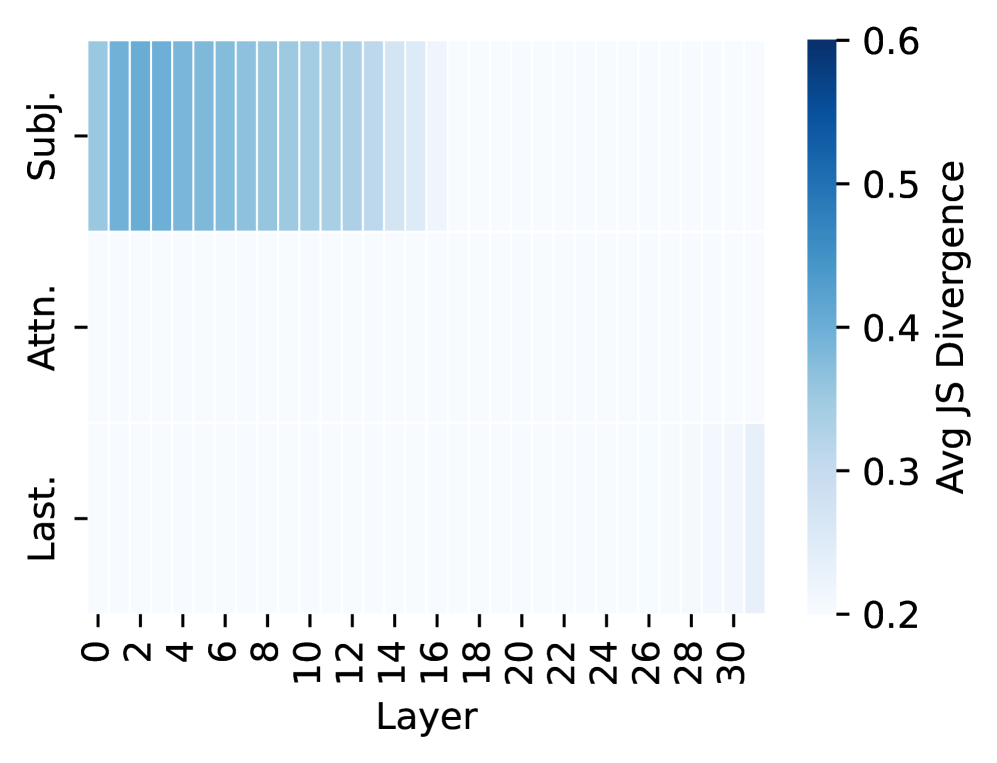
(c) Unassociated Hallucinations
Figure 2: Effect of interventions across layers of LLaMA-3-8B. The heatmap shows JS divergence between the output distribution before and after intervention. Darker color indicates that the intervened hidden states are more causally influential on the model’s predictions. Top row: patching representations of subject tokens. Middle row: blocking attention flow from subject to the last token. Bottom row: patching representations of the last token.
Dataset Construction
| Factual Association Associated Hallucination Unassociated Hallucination | 3,506 1,406 7,381 | 3,354 1,284 7,655 |
| --- | --- | --- |
| Total | 12,293 | 12,293 |
Table 1: Dataset statistics across categories.
Our study is conducted under a basic knowledge-based question answering setting. The model is given a prompt containing a subject and relation (e.g., “ Barack Obama was born in the city of ”) and is expected to predict the corresponding object (e.g., “ Honolulu ”). To build the dataset, we collect knowledge triples $(\text{subject},\text{relation},\text{object})$ form Wikidata. Each relation was paired with a handcrafted prompt template to convert triples into natural language queries. The details of relation selection and prompt templates are provided in Appendix A.1. We then apply the label scheme presented in Appendix A.2: correct predictions are labeled as FAs, while incorrect ones are classified as AHs or UHs depending on their subject representation reliance. Table 1 summarizes the final data statistics.
Models
We conduct the experiments on two widely-adopted open-source LLMs, LLaMA-3 Dubey et al. (2024) and Mistral-v0.3 Jiang et al. (2023). Due to the space limit, details are presented in Appendix A.3, and parallel experimental results on Mistral are summarized in Appendix B.
## 4 Analysis of Internal States in LLMs
To focus our analysis, we first conduct causal interventions to identify hidden states that are crucial for eliciting factual associations (FAs). We then compare their behavior across associated hallucinations (AHs) and unassociated hallucinations (UHs). Prior studies Azaria and Mitchell (2023); Gottesman and Geva (2024); Yüksekgönül et al. (2024); Orgad et al. (2025) suggest that hidden states can reveal when a model hallucinates. This assumes that the model’s internal computations differ when producing correct versus incorrect outputs, causing their hidden states to occupy distinct subspaces. We revisit this claim by examining how hidden states update when recalling three categories of knowledge (i.e., FAs, AHs, and UHs). If hidden states primarily signal hallucination, AHs and UHs should behave similarly and diverge from FAs. Conversely, if hidden states reflect reliance on encoded knowledge, FAs and AHs should appear similar, and both should differ from UHs.
### 4.1 Causal Analysis of Information Flow
We identify hidden states that are crucial for factual prediction. For each knowledge tuple (subject, relation, object), the model is prompted with a factual query (e.g., “ The name of the father of Joe Biden is ”). Correct predictions indicate that the model successfully elicits parametric knowledge. Using causal mediation analysis Vig et al. (2020); Finlayson et al. (2021); Meng et al. (2022); Geva et al. (2023), we intervene on intermediate computations and measure the change in output distribution via JS divergence. A large divergence indicates that the intervened computation is critical for producing the fact. Specifically, to test whether token $i$ ’s hidden states in the MLP at layer $\ell$ are crucial for eliciting knowledge, we replace the computation with a corrupted version and observe how the output distribution changes. Similarly, following Geva et al. (2023), we mask the attention flow between tokens at layer $\ell$ using a window size of 5 layers. To streamline implementation, interventions target only subject tokens, attention flow, and the last token. Notable observations are as follows:
Obs1: Hidden states crucial for eliciting factual associations.
The results in Figure 2(a) show that three components dominate factual predictions: (1) subject representations in early-layer MLPs, (2) mid-layer attention between subject tokens and the final token, and (3) the final token representations in later layers. These results trace a clear information flow: subject representation, attention flow from the subject to the last token, and last-token representation, consistent with Geva et al. (2023). These three types of internal states are discussed in detail respectively (§ 4.2 - 4.4).
Obs2: Associated hallucinations follow the same information flow as factual associations.
When generating AHs, interventions on these same components also produce large distribution shifts (Figure 2(b)). This indicates that, although outputs are factually wrong, the model still relies on encoded subject information.
Obs3: Unassociated hallucinations present a different information flow.
In contrast, interventions during UH generation cause smaller distribution shifts (Figure 2(c)), showing weaker reliance on the subject. This suggests that UHs emerge from computations not anchored in the subject representation, different from both FAs and AHs.
### 4.2 Analysis of Subject Representations
The analysis in § 4.1 reveals that unassociated hallucinations (UHs) are processed differently from factual associations (FAs) and associated hallucinations (AHs) in the early layers of LLMs, which share a similar pattern. We examine how these differences emerge in the subject representations and why early-layer modules behave this way.
#### 4.2.1 Norm of Subject Representations
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: Normalized Ratio of Hallucinations to Factual Associations vs. Layers
### Overview
This line chart depicts the relationship between the number of layers in a model and the normalized ratio of hallucinations to factual associations. Two data series are presented: one for "Asso. Hallu./Factual Asso." (Association Hallucinations/Factual Associations) and another for "Unasso. Hallu./Factual Asso." (Unassociated Hallucinations/Factual Associations). The chart aims to illustrate how the propensity for hallucinations changes as model depth (number of layers) increases.
### Components/Axes
* **X-axis:** "Layers" - ranging from 0 to approximately 32. The scale is linear.
* **Y-axis:** "Norm Ratio" - ranging from approximately 0.94 to 1.02. The scale is linear.
* **Data Series 1:** "Asso. Hallu./Factual Asso." - represented by blue circles.
* **Data Series 2:** "Unasso. Hallu./Factual Asso." - represented by red square markers.
* **Legend:** Located in the top-left corner, clearly labeling each data series with its corresponding color.
### Detailed Analysis
**Asso. Hallu./Factual Asso. (Blue Line):**
The blue line initially starts at approximately 1.00 at Layer 0, then gently declines to a minimum of approximately 0.98 at Layer 10. It then fluctuates around 0.99-1.00 from Layers 10 to 28. A sharp increase is observed at Layer 32, reaching approximately 1.02.
* Layer 0: 1.00
* Layer 2: 1.00
* Layer 4: 0.99
* Layer 6: 0.99
* Layer 8: 0.99
* Layer 10: 0.98
* Layer 12: 0.99
* Layer 14: 0.99
* Layer 16: 0.99
* Layer 18: 0.99
* Layer 20: 0.99
* Layer 22: 0.99
* Layer 24: 0.99
* Layer 26: 0.99
* Layer 28: 0.99
* Layer 30: 1.00
* Layer 32: 1.02
**Unasso. Hallu./Factual Asso. (Red Line):**
The red line begins at approximately 0.99 at Layer 0, dips to a minimum of approximately 0.94 at Layer 12, and then gradually increases to approximately 0.99 at Layer 32.
* Layer 0: 0.99
* Layer 2: 0.99
* Layer 4: 0.98
* Layer 6: 0.97
* Layer 8: 0.97
* Layer 10: 0.96
* Layer 12: 0.94
* Layer 14: 0.96
* Layer 16: 0.97
* Layer 18: 0.98
* Layer 20: 0.98
* Layer 22: 0.98
* Layer 24: 0.98
* Layer 26: 0.98
* Layer 28: 0.99
* Layer 30: 0.99
* Layer 32: 0.99
### Key Observations
* The "Asso. Hallu./Factual Asso." ratio remains relatively stable across most layers, with a slight increase at the final layer.
* The "Unasso. Hallu./Factual Asso." ratio exhibits a more pronounced dip around Layer 12, indicating a potential reduction in unassociated hallucinations at that depth.
* The difference between the two ratios is relatively small throughout most of the range, but widens at Layer 32.
### Interpretation
The chart suggests that increasing the number of layers in the model does not necessarily lead to a significant increase in associated hallucinations, as the blue line remains relatively constant. However, the dip in the red line around Layer 12 suggests that a specific depth might reduce unassociated hallucinations. The sharp increase in the blue line at Layer 32 could indicate a point of diminishing returns or instability as the model becomes very deep. The data suggests that the type of hallucination (associated vs. unassociated) is affected differently by model depth. The widening gap at Layer 32 could mean that deeper models are more prone to *associated* hallucinations, while the effect on unassociated hallucinations is less pronounced. This could be due to the model learning spurious correlations or overfitting to the training data at greater depths. Further investigation is needed to understand the underlying causes of these trends and to determine the optimal model depth for minimizing hallucinations.
</details>
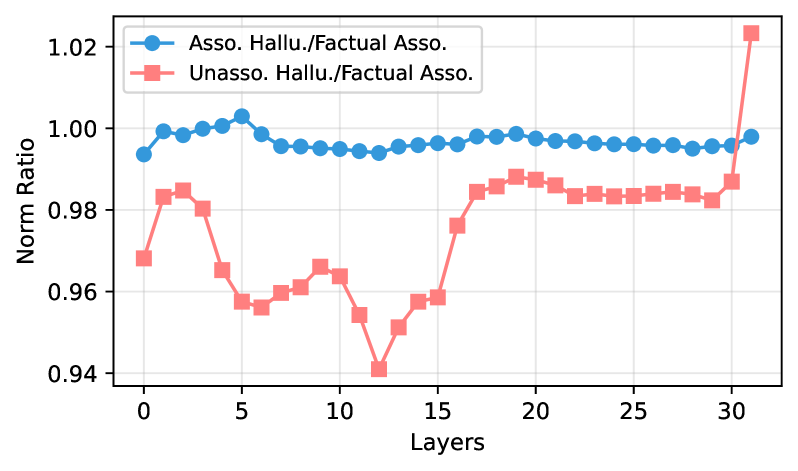
Figure 3: Norm ratio curves of subject representations in LLaMA-3-8B, comparing AHs and UHs against FAs as the baseline.
To test whether subject representations differ across categories, we measure the average $L_{2}$ norm of subject-token hidden activations across layers. For subject tokens $t_{s_{1}},..,t_{s_{n}}$ at layer $\ell$ , the average norm is $||\mathbf{h}_{s}^{\ell}\|=\tfrac{1}{n}\sum_{i=1}^{n}\|\mathbf{h}_{s_{i}}^{\ell}\|_{2}$ , computed by Equation (1). We compare the norm ratio between hallucination samples (AHs or UHs) and correct predictions (FAs), where a ratio near 1 indicates similar norms. Figure 3 shows that in LLaMA-3-8B, AH norms closely match those of correct samples (ratio $\approx$ 0.99), while UH norms are consistently smaller, starting at the first layer (ratio $\approx$ 0.96) and diverging further through mid-layers.
Findings:
At early layers, UH subject representations exhibit weaker activations than FAs, whereas AHs exhibit norms similar to FAs.
#### 4.2.2 Relation to Parametric Knowledge
<details>
<summary>x6.png Details</summary>
### Visual Description
\n
## Bar Chart: Ratio of Hallucinations to Factual Associations
### Overview
This bar chart compares the ratio of hallucinations to factual associations for two language models: LLaMA-3-8B and Mistral-7B-v0.3. The chart uses paired bars for each model, representing "Unasso. Hallu./Factual Asso." and "Asso. Hallu./Factual Asso." ratios.
### Components/Axes
* **X-axis:** Model names - LLaMA-3-8B and Mistral-7B-v0.3.
* **Y-axis:** Ratio, ranging from 0.0 to 1.2 (though values do not exceed 1.0).
* **Legend:** Located at the bottom-left, with two entries:
* Light Red: "Unasso. Hallu./Factual Asso."
* Light Blue: "Asso. Hallu./Factual Asso."
### Detailed Analysis
The chart consists of four bars, two for each model.
**LLaMA-3-8B:**
* **Unasso. Hallu./Factual Asso. (Light Red):** The bar reaches approximately 0.68 on the Y-axis.
* **Asso. Hallu./Factual Asso. (Light Blue):** The bar reaches approximately 1.05 on the Y-axis.
**Mistral-7B-v0.3:**
* **Unasso. Hallu./Factual Asso. (Light Red):** The bar reaches approximately 0.40 on the Y-axis.
* **Asso. Hallu./Factual Asso. (Light Blue):** The bar reaches approximately 0.82 on the Y-axis.
### Key Observations
* For both models, the "Asso. Hallu./Factual Asso." ratio (blue bars) is higher than the "Unasso. Hallu./Factual Asso." ratio (red bars).
* LLaMA-3-8B exhibits a significantly higher "Asso. Hallu./Factual Asso." ratio compared to Mistral-7B-v0.3.
* Mistral-7B-v0.3 has a lower "Unasso. Hallu./Factual Asso." ratio than LLaMA-3-8B.
### Interpretation
The data suggests that both LLaMA-3-8B and Mistral-7B-v0.3 exhibit a tendency to hallucinate even when associations are present ("Asso. Hallu./Factual Asso."). However, LLaMA-3-8B shows a much stronger propensity for this behavior. The "Unasso. Hallu./Factual Asso." ratio indicates the frequency of hallucinations occurring without any apparent factual basis. Mistral-7B-v0.3 appears to be better at avoiding hallucinations in the absence of supporting associations.
The chart highlights a potential trade-off: LLaMA-3-8B might be more prone to generating content even when it's not strongly grounded in facts, while Mistral-7B-v0.3 is more conservative in its generation, potentially leading to less creative but more factually consistent outputs. The higher "Asso. Hallu./Factual Asso." for LLaMA-3-8B could indicate a tendency to confidently present information that is related to factual data but is not entirely accurate.
</details>
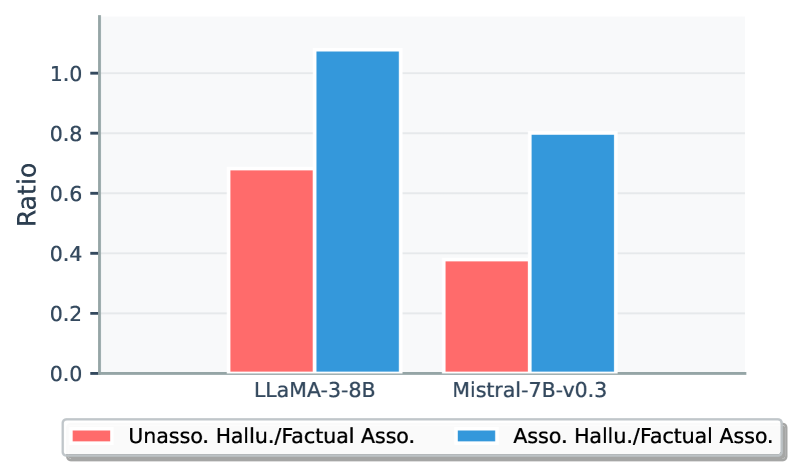
Figure 4: Comparison of subspace overlap ratios.
We next investigate why early layers encode subject representations differently across knowledge types by examining how inputs interact with the parametric knowledge stored in MLP modules. Inspired by Kang et al. (2024), the output norm of an MLP layer depends on how well its input aligns with the subspace spanned by the weight matrix: poorly aligned inputs yield smaller output norms.
For each MLP layer $\ell$ , we analyze the down-projection weight matrix $W_{\text{down}}^{\ell}$ and its input $x^{\ell}$ . Given the input $x_{s}^{\ell}$ corresponding to the subject tokens, we compute its overlap ratio with the top singular subspace $V_{\text{top}}$ of $W_{\text{down}}^{\ell}$ :
$$
r(x_{s}^{\ell})=\frac{\left\lVert{x_{s}^{\ell}}^{\top}V_{\text{top}}V_{\text{top}}^{\top}\right\rVert^{2}}{\left\lVert x_{s}^{\ell}\right\rVert^{2}}. \tag{2}
$$
A higher overlap ratio $r(x_{s}^{\ell})$ indicates stronger alignment to the subspace spanned by $W_{\text{down}}^{\ell}$ , leading to larger output norms.
To highlight relative deviations from the factual baseline (FA), we report the relative ratios between AH/FA and UH/FA. Focusing on the layer with the largest UH norm shift, Figure 4 shows that UHs have significantly lower $r(x_{s}^{\ell})$ than AHs in both LLaMA and Mistral. This reveals that early-layer parametric weights are more aligned with FA and AH subject representations than with UH subjects, producing higher norms for the former ones. These results also suggest that the model has sufficiently learned representations for FA and AH subjects during pretraining but not for UH subjects.
Findings:
Similar to FAs, AH hidden activations align closely with the weight subspace, while UHs do not. This indicates that the model has sufficiently encoded subject representations into parametric knowledge for FAs and AHs but not for UHs.
#### 4.2.3 Correlation with Subject Popularity
<details>
<summary>x7.png Details</summary>
### Visual Description
\n
## Bar Chart: Hallucination Rates by Factual Association Level
### Overview
This bar chart illustrates the percentage of hallucinations (categorized as "Associated Hallucinations" and "Unassociated Hallucinations") and "Factual Associations" across three levels: "Low", "Mid", and "High". The y-axis represents the percentage, ranging from 0% to 100%. The x-axis represents the level of factual association.
### Components/Axes
* **X-axis:** "Factual Associations" with categories: "Low", "Mid", "High".
* **Y-axis:** "Percentage (%)", ranging from 0 to 100, with increments of 10.
* **Legend:** Located at the bottom of the chart, identifying the three data series:
* "Factual Associations" - represented by a light green color.
* "Associated Hallucinations" - represented by a light blue color.
* "Unassociated Hallucinations" - represented by a salmon/red color.
### Detailed Analysis
The chart consists of three groups of bars, one for each level of factual association ("Low", "Mid", "High"). Within each group, there are three bars representing the percentage of Factual Associations, Associated Hallucinations, and Unassociated Hallucinations.
* **Low:**
* Factual Associations: Approximately 5% (green bar).
* Associated Hallucinations: Approximately 1% (blue bar).
* Unassociated Hallucinations: Approximately 94% (red bar).
* **Mid:**
* Factual Associations: Approximately 27% (green bar).
* Associated Hallucinations: Approximately 7% (blue bar).
* Unassociated Hallucinations: Approximately 66% (red bar).
* **High:**
* Factual Associations: Approximately 52% (green bar).
* Associated Hallucinations: Approximately 14% (blue bar).
* Unassociated Hallucinations: Approximately 34% (red bar).
The "Unassociated Hallucinations" bar dominates at the "Low" level, decreasing as the level of factual association increases. The "Factual Associations" bar increases steadily from "Low" to "High". The "Associated Hallucinations" bar also increases as the level of factual association increases, but remains significantly lower than the other two categories.
### Key Observations
* At the "Low" level of factual association, unassociated hallucinations are overwhelmingly dominant (94%).
* As the level of factual association increases, the percentage of unassociated hallucinations decreases, while the percentage of factual associations increases.
* Associated hallucinations remain a relatively small percentage across all levels, but increase with higher factual association.
* The sum of the percentages for each level does not equal 100%, suggesting that there may be other categories not represented in the chart.
### Interpretation
The data suggests a strong inverse relationship between the level of factual association and the occurrence of unassociated hallucinations. This implies that as the grounding in factual information increases, the likelihood of experiencing hallucinations that are not tied to reality decreases. The increase in associated hallucinations with higher factual association could indicate that hallucinations become more complex and potentially linked to existing knowledge or memories as factual grounding improves. The chart highlights the importance of factual grounding in mitigating the risk of unassociated hallucinations. The fact that the percentages do not sum to 100% suggests that there are other types of hallucinations or states of consciousness not captured by this categorization. This data could be relevant to understanding and treating conditions involving hallucinations, such as schizophrenia or other psychotic disorders.
</details>
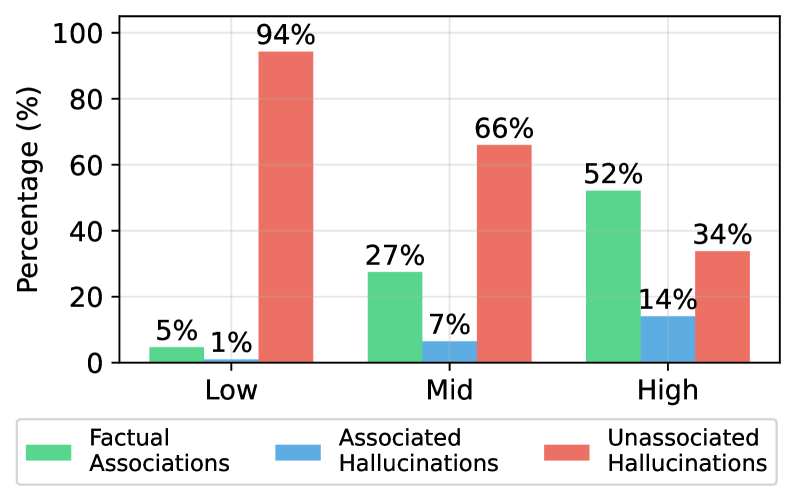
Figure 5: Sample distribution across different subject popularity (low, mid, high) in LLaMA-3-8B, measured by monthly Wikipedia page views.
We further investigate why AH representations align with weight subspaces as strongly as FAs, while UHs do not. A natural hypothesis is that this difference arises from subject popularity in the training data. We use average monthly Wikipedia page views as a proxy for subject popularity during pre-training and bin subjects by popularity, then measure the distribution of UHs, AHs, and FAs. Figure 5 shows a clear trend: UHs dominate among the least popular subjects (94% for LLaMA), while AHs are rare (1%). As subject popularity rises, UH frequency falls and both FAs and AHs become more common, with AHs rising to 14% in the high-popularity subjects. This indicates that subject representation norms reflect training frequency, not factual correctness.
Findings:
Popular subjects yield stronger early-layer activations. AHs arise mainly on popular subjects and are therefore indistinguishable from FAs by popularity-based heuristics, contradicting prior work Mallen et al. (2023a) that links popularity to hallucinations.
### 4.3 Analysis of Attention Flow
Having examined how the model forms subject representations, we next study how this information is propagated to the last token of the input where the model generates the object of a knowledge tuple. In order to produce factually correct outputs at the last token, the model must process subject representation and propagate it via attention layers, so that it can be read from the last position to produce the outputs Geva et al. (2023).
To quantify the specific contribution from subject tokens $(s_{1},...,s_{n})$ to the last token, we compute the attention contribution from subject tokens to the last position:
$$
\mathbf{a}^{\ell}_{\text{last}}=\sum\nolimits_{k}\sum\nolimits_{h}A^{\ell,h}_{\text{last},s_{k}}(\mathbf{h}^{\ell-1}_{s_{k}}W^{\ell,h}_{V})W^{\ell,h}_{O}. \tag{3}
$$
where $A^{\ell,h}_{i,j}$ denotes the attention weight assigned by the $h$ -th head in the layer $\ell$ from the last position $i$ to subjec token $j$ . Here, $\mathbf{a}^{\ell}_{\text{last}}$ represents the subject-to-last attention contribution at layer $\ell$ . Intuitively, if subject information is critical for prediction, this contribution should have a large norm; otherwise, the norm should be small.
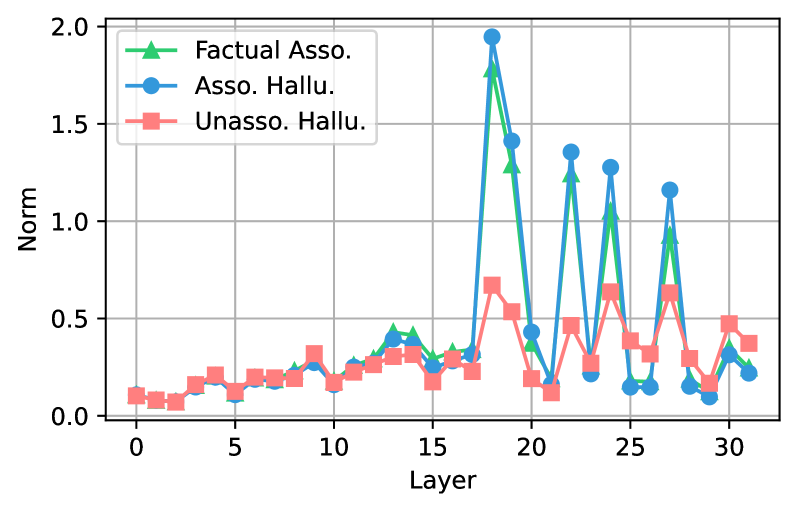
Figure 6 shows that in LLaMA-3-8B, both AHs and FAs exhibit large attention-contribution norms in mid-layers, indicating a strong information flow from subject tokens to the target token. In contrast, UHs show consistently lower norms, implying that their predictions rely far less on subject information. Yüksekgönül et al. (2024) previously argued that high attention flow from subject tokens signals factuality and proposed using attention-based hidden states to detect hallucinations. Our results challenge this view: the model propagates subject information just as strongly when generating AHs as when producing correct facts.
Findings:
Mid-layer attention flow from subject to last token is equally strong for AHs and FAs but weak for UHs. Attention-based heuristics can therefore separate UHs from FAs but cannot distinguish AHs from factual outputs, limiting their reliability for hallucination detection.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Line Chart: Hallucination Norms vs. Layer
### Overview
This image presents a line chart illustrating the relationship between the layer number in a model and the normalized values ("Norm") for three different types of hallucinations: "Factual Asso." (Factual Association), "Asso. Hallu." (Associative Hallucination), and "Unasso. Hallu." (Unassociated Hallucination). The chart spans layer numbers from 0 to approximately 32.
### Components/Axes
* **X-axis:** "Layer" - ranging from 0 to 32, with tick marks at integer values.
* **Y-axis:** "Norm" - ranging from 0.0 to 2.0, with tick marks at 0.5 intervals.
* **Legend:** Located in the top-left corner, identifying the three data series:
* "Factual Asso." - represented by a green line with triangle markers.
* "Asso. Hallu." - represented by a blue line with circle markers.
* "Unasso. Hallu." - represented by a red line with square markers.
* **Gridlines:** Horizontal gridlines are present to aid in reading values.
### Detailed Analysis
**Factual Asso. (Green Line):** This line generally remains below 0.5 until approximately layer 16. From layer 16 to 20, it exhibits a steep upward trend, peaking at approximately 1.7 at layer 19. It then declines rapidly, oscillating between 0.5 and 1.0 from layer 20 to 32.
* Layer 0: ~0.15
* Layer 5: ~0.25
* Layer 10: ~0.3
* Layer 15: ~0.4
* Layer 16: ~0.5
* Layer 17: ~0.8
* Layer 18: ~1.3
* Layer 19: ~1.7
* Layer 20: ~0.8
* Layer 25: ~0.7
* Layer 30: ~0.4
**Asso. Hallu. (Blue Line):** This line starts at approximately 0.1 at layer 0 and remains relatively low until layer 18, where it begins to increase. It peaks at approximately 1.2 at layer 22, then declines, oscillating between 0.5 and 1.0 from layer 22 to 32.
* Layer 0: ~0.1
* Layer 5: ~0.15
* Layer 10: ~0.2
* Layer 15: ~0.25
* Layer 18: ~0.4
* Layer 20: ~0.7
* Layer 22: ~1.2
* Layer 25: ~0.8
* Layer 30: ~0.5
**Unasso. Hallu. (Red Line):** This line remains consistently below 0.5 throughout the entire range of layers. It exhibits a slight upward trend from layer 0 to 15, reaching approximately 0.4. It then plateaus and fluctuates around 0.5 from layer 15 to 32.
* Layer 0: ~0.1
* Layer 5: ~0.2
* Layer 10: ~0.3
* Layer 15: ~0.4
* Layer 20: ~0.5
* Layer 25: ~0.3
* Layer 30: ~0.5
### Key Observations
* "Factual Asso." exhibits the most significant fluctuations, with a pronounced peak around layer 19.
* "Asso. Hallu." shows a delayed increase compared to "Factual Asso.", peaking around layer 22.
* "Unasso. Hallu." remains relatively stable and at a lower level compared to the other two types of hallucinations.
* All three hallucination types show some degree of increase as the layer number increases, suggesting that deeper layers of the model are more prone to generating hallucinations.
### Interpretation
The chart suggests that the propensity for different types of hallucinations varies across the layers of the model. "Factual Association" hallucinations appear earlier and are more pronounced than "Associative Hallucinations." "Unassociated Hallucinations" are consistently the least frequent. The peaks in "Factual Asso." and "Asso. Hallu." around layers 19 and 22, respectively, could indicate critical points in the model's processing where it is more susceptible to generating incorrect or misleading information. The overall trend of increasing hallucination rates with layer depth suggests that the model's confidence in its predictions may decrease as it processes more complex information. This could be due to the model overfitting to the training data or encountering ambiguous inputs. The differences between the hallucination types suggest that different mechanisms may be responsible for generating each type of error. Further investigation is needed to understand the underlying causes of these patterns and to develop strategies for mitigating hallucinations in the model.
</details>
Figure 6: Subject-to-last attention contribution norms across layers in LLaMA-3-8B. Values show the norm of the attention contribution from subject tokens to the last token at each layer.
### 4.4 Analysis of Last Token Representations
Our earlier analysis showed strong subject-to-last token information transfer for both FAs and AHs, but minimal transfer for UHs. We now examine how this difference shapes the distribution of last-token representations. When subject information is weakly propagated (UHs), last-token states receive little subject-specific update. For UH samples sharing the same prompt template, these states should therefore cluster in the representation space. In contrast, strong subject-driven propagation in FAs and AHs produces diverse last-token states that disperse into distinct subspaces.
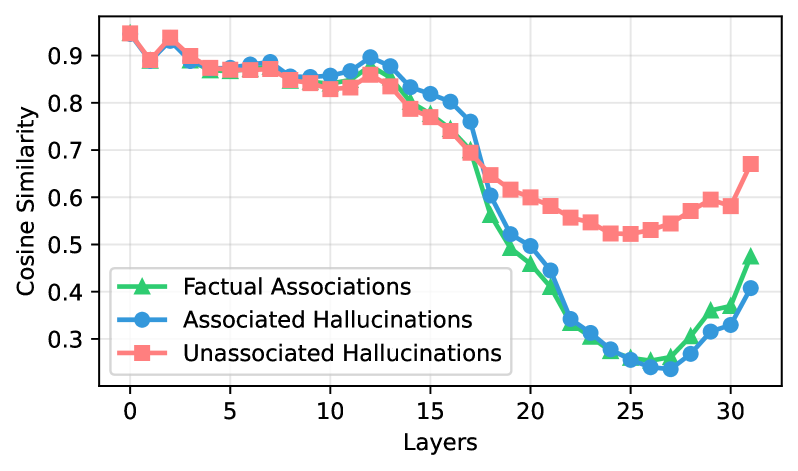
To test this, we compute cosine similarity among last-token representations $\mathbf{h}_{T}^{\ell}$ . As shown in Figure 7, similarity is high ( $\approx$ 0.9) for all categories in early layers, when little subject information is transferred. From mid-layers onward, FAs and AHs diverge sharply, dropping to $\approx$ 0.2 by layer 25. UHs remain moderately clustered, with similarity only declining to $\approx$ 0.5.
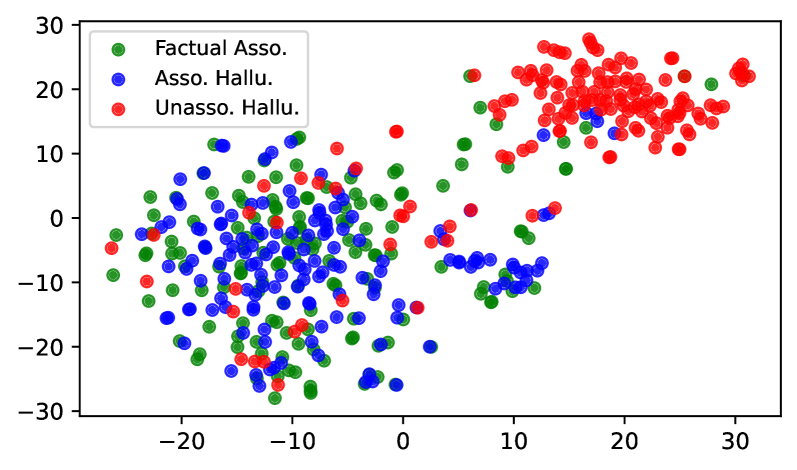
Figure 8 shows the t-SNE visualization of the last token’s representations at layer 25 of LLaMA-3-8B. The hidden representations of UH are clearly separated from FA, whereas AH substantially overlap with FA. These results indicate that the model processes UH differently from FA, while processing AH in a manner similar to FA. More visualization can be found in Appendix C.
<details>
<summary>x9.png Details</summary>
### Visual Description
## Line Chart: Cosine Similarity vs. Layers
### Overview
The image presents a line chart illustrating the relationship between the number of layers in a model and the cosine similarity of different types of associations and hallucinations. Three data series are plotted: Factual Associations, Associated Hallucinations, and Unassociated Hallucinations. The chart appears to be investigating how model depth (number of layers) affects the quality of information retained and the occurrence of hallucinations.
### Components/Axes
* **X-axis:** "Layers" - ranging from approximately 0 to 32.
* **Y-axis:** "Cosine Similarity" - ranging from approximately 0.2 to 1.0.
* **Legend:** Located in the bottom-right corner.
* "Factual Associations" - represented by a green line with triangle markers.
* "Associated Hallucinations" - represented by a blue line with circle markers.
* "Unassociated Hallucinations" - represented by a red line with square markers, with a shaded area indicating standard deviation.
* **Grid:** A light gray grid is present in the background to aid in reading values.
### Detailed Analysis
* **Unassociated Hallucinations (Red):** This line starts at approximately 0.93 at Layer 0 and generally decreases, with some fluctuations, to around 0.58 at Layer 32. The shaded area indicates a relatively consistent standard deviation around the mean.
* **Associated Hallucinations (Blue):** This line begins at approximately 0.88 at Layer 0 and also decreases, more rapidly than the Unassociated Hallucinations, reaching around 0.32 at Layer 32.
* **Factual Associations (Green):** This line starts at approximately 0.35 at Layer 0 and remains relatively flat until around Layer 18, where it begins to increase, reaching approximately 0.42 at Layer 32.
**Specific Data Points (approximate):**
| Layers | Factual Associations | Associated Hallucinations | Unassociated Hallucinations |
|---|---|---|---|
| 0 | 0.35 | 0.88 | 0.93 |
| 5 | 0.36 | 0.84 | 0.89 |
| 10 | 0.37 | 0.81 | 0.86 |
| 15 | 0.38 | 0.74 | 0.78 |
| 20 | 0.39 | 0.58 | 0.65 |
| 25 | 0.40 | 0.42 | 0.58 |
| 30 | 0.41 | 0.35 | 0.60 |
| 32 | 0.42 | 0.32 | 0.58 |
### Key Observations
* All three lines exhibit a decreasing trend in cosine similarity as the number of layers increases, but at different rates.
* Unassociated Hallucinations maintain a higher cosine similarity than Associated Hallucinations throughout the range of layers.
* Factual Associations have the lowest cosine similarity overall, but show an increasing trend in the later layers.
* The standard deviation around the Unassociated Hallucinations line is relatively small, suggesting consistency in this type of hallucination.
### Interpretation
The data suggests that as the model depth increases (more layers are added), the similarity to factual information decreases for both types of hallucinations, but the decrease is more pronounced for associated hallucinations. This could indicate that deeper models are more prone to generating hallucinations that are less grounded in reality. The increasing trend in Factual Associations in the later layers is interesting and could suggest that deeper models are capable of learning more complex factual relationships, but this increase is relatively small compared to the decrease in hallucination similarity. The higher similarity scores for Unassociated Hallucinations suggest that these types of hallucinations are more persistent and less affected by model depth.
The chart highlights a trade-off between model depth and the quality of information retained. While deeper models may be capable of learning more complex patterns, they also appear to be more susceptible to generating hallucinations. This suggests that careful consideration must be given to model depth when designing and training large language models, and that techniques for mitigating hallucinations may be particularly important for deeper models. The difference between "Associated" and "Unassociated" hallucinations is also important. "Associated" hallucinations are likely more dangerous, as they are tied to some input or context, and therefore more likely to be believed.
</details>
Figure 7: Cosine similarity of target-token hidden states across layers in LLaMA-3-8B.
<details>
<summary>x10.png Details</summary>
### Visual Description
\n
## Scatter Plot: Association Types
### Overview
The image presents a scatter plot visualizing the distribution of three different association types: "Factual Association", "Associated Hallucination", and "Unassociated Hallucination". The plot displays these associations based on two unspecified numerical dimensions, represented by the x and y axes. The data points are color-coded according to their association type, with a legend in the top-left corner clarifying the color scheme.
### Components/Axes
* **X-axis:** Ranges approximately from -25 to 30, with tick marks at intervals of 10. The axis is unlabeled.
* **Y-axis:** Ranges approximately from -30 to 30, with tick marks at intervals of 10. The axis is unlabeled.
* **Legend:** Located in the top-left corner.
* "Factual Asso." - Green circles
* "Asso. Hallu." - Blue circles
* "Unasso. Hallu." - Red circles
### Detailed Analysis
The plot contains a large number of data points for each association type.
* **Factual Association (Green):** The points are distributed across the plot, with a concentration in the region between x = -20 and x = 5, and y = -20 and y = 10. There is a slight upward trend as x increases. Approximate data points (x, y): (-18, -15), (-10, -5), (0, 5), (5, -10).
* **Associated Hallucination (Blue):** These points are primarily clustered in the region between x = -20 and x = 10, and y = -10 and y = 10. The distribution appears relatively uniform within this region. Approximate data points (x, y): (-15, 0), (-5, 5), (5, -5), (0, 0).
* **Unassociated Hallucination (Red):** The points are concentrated in the upper-right quadrant of the plot, with x values generally greater than 10 and y values generally greater than 0. There is a clear positive correlation between x and y for this group. Approximate data points (x, y): (10, 10), (20, 15), (25, 20), (15, 5).
### Key Observations
* The "Unassociated Hallucination" data points are distinctly separated from the other two association types, residing in the upper-right quadrant.
* "Factual Association" and "Associated Hallucination" data points overlap significantly, making visual distinction difficult in certain areas.
* The "Unassociated Hallucination" data exhibits a strong positive correlation, while the other two types do not show a clear linear trend.
### Interpretation
The scatter plot suggests a relationship between the two unspecified dimensions and the type of association. The separation of "Unassociated Hallucinations" indicates that this type of hallucination is characterized by higher values on both dimensions compared to factual associations and associated hallucinations. The overlap between factual associations and associated hallucinations suggests that these two types share similar characteristics along these dimensions. The positive correlation within the "Unassociated Hallucination" group might indicate a systematic bias or underlying factor driving both dimensions upwards in these cases.
Without knowing what the axes represent, it's difficult to draw definitive conclusions. However, the plot provides a visual representation of how these association types differ and potentially relate to each other based on these two variables. The plot could be used to explore the characteristics of different types of hallucinations and their relationship to factual information.
</details>
Figure 8: t-SNE visualization of last token’s representations at layer 25 of LLaMA-3-8B.
<details>
<summary>x11.png Details</summary>
### Visual Description
## Violin Plot: Token Probability Distributions for LLMs
### Overview
The image presents a comparative violin plot illustrating the distribution of token probabilities for two Large Language Models (LLMs): LLAMA-3-8B and Mistral-7B-v0.3. The distributions are categorized into three types of associations: Factual Associations, Associated Hallucinations, and Unassociated Hallucinations. The y-axis represents "Token Probability," ranging from 0.0 to 1.0.
### Components/Axes
* **X-axis:** Represents the LLM being evaluated. Categories: "LLAMA-3-8B", "Mistral-7B-v0.3".
* **Y-axis:** "Token Probability", with a scale from 0.0 to 1.0, incrementing by 0.2.
* **Violin Plots:** Represent the distribution of token probabilities for each association type within each LLM.
* **Legend:** Located at the bottom of the image, providing color-coding for the association types:
* Green: Factual Associations
* Blue: Associated Hallucinations
* Red: Unassociated Hallucinations
* **Horizontal Lines within Violin Plots:** Represent the median token probability for each association type.
* **Vertical Lines extending from Violin Plots:** Represent the interquartile range (IQR) or confidence intervals.
### Detailed Analysis
Let's analyze each LLM and association type individually, referencing the legend colors for accuracy.
**LLAMA-3-8B:**
* **Factual Associations (Green):** The distribution is centered around approximately 0.45, with a range extending from roughly 0.1 to 0.9. The violin plot is relatively wide, indicating a broader distribution of probabilities.
* **Associated Hallucinations (Blue):** The distribution is centered around approximately 0.35, with a range extending from roughly 0.1 to 0.7. The violin plot is also wide, similar to Factual Associations.
* **Unassociated Hallucinations (Red):** The distribution is centered around approximately 0.1, with a range extending from roughly 0.0 to 0.3. This distribution is narrower and lower than the other two.
**Mistral-7B-v0.3:**
* **Factual Associations (Green):** The distribution is centered around approximately 0.4, with a range extending from roughly 0.1 to 0.85. The violin plot is similar in shape to LLAMA-3-8B's Factual Associations.
* **Associated Hallucinations (Blue):** The distribution is centered around approximately 0.35, with a range extending from roughly 0.1 to 0.7. Similar to LLAMA-3-8B.
* **Unassociated Hallucinations (Red):** The distribution is centered around approximately 0.1, with a range extending from roughly 0.0 to 0.3. Similar to LLAMA-3-8B.
### Key Observations
* For both LLMs, Factual Associations consistently exhibit the highest median token probabilities.
* Associated Hallucinations have lower median token probabilities than Factual Associations, but are still higher than Unassociated Hallucinations.
* Unassociated Hallucinations consistently have the lowest median token probabilities.
* The distributions for Factual Associations and Associated Hallucinations are relatively broad, suggesting a wider range of probabilities for these types of associations.
* The distributions for both LLMs appear visually similar, suggesting comparable behavior in terms of token probability distributions for these association types.
### Interpretation
The data suggests that both LLAMA-3-8B and Mistral-7B-v0.3 assign higher probabilities to factual associations compared to hallucinations. Furthermore, associated hallucinations receive higher probabilities than unassociated hallucinations. This indicates that the models are more confident in generating content that aligns with known facts and that when they do hallucinate, they are more likely to generate content that is at least somewhat related to the input context (associated hallucinations) than completely unrelated content (unassociated hallucinations).
The broad distributions of Factual Associations and Associated Hallucinations suggest that the models can generate a diverse range of responses that are considered factual or related to the context, respectively. The narrower distribution of Unassociated Hallucinations indicates that the models are less likely to generate completely unrelated content.
The visual similarity between the two LLMs suggests that they exhibit similar patterns in token probability distributions for these association types, despite potential differences in their underlying architectures or training data. This could imply that the phenomenon of hallucinations is a common challenge for LLMs, regardless of their specific implementation.
</details>
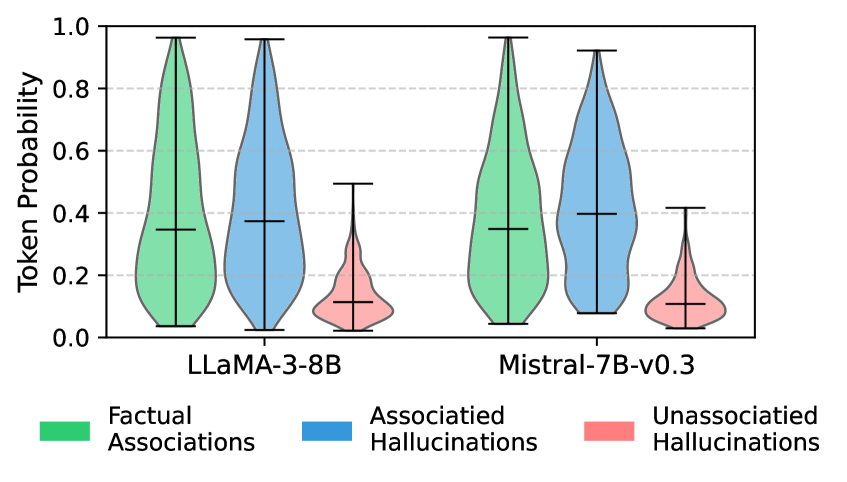
Figure 9: Distribution of last token probabilities.
This separation also appears in the entropy of the output distribution (Figure 9). Strong subject-to-last propagation in FAs and AHs yields low-entropy predictions concentrated on the correct or associated entity. In contrast, weak propagation in UHs produces broad, high-entropy distributions, spreading probability mass across many plausible candidates (e.g., multiple possible names for “ The name of the father of <subject> is ”).
Finding:
From mid-layers onward, UHs retain clustered last-token representations and high-entropy outputs, while FAs and AHs diverge into subject-specific subspaces with low-entropy outputs. This provides a clear signal to separate UHs from FAs and AHs, but not for FAs and AHs.
## 5 Revisiting Hallucination Detection
The mechanistic analysis in § 4 reveals that Internal states of LLMs primarily capture how the model recalls and utilizes its parametric knowledge, not whether the output is truthful. As both factual associations (FAs) and associated hallucinations (AHs) rely on the same subject-driven knowledge recall, their internal states show no clear separation. We therefore hypothesize that internal or black-box signals cannot effectively distinguish AHs from FAs, even though they could be effective in distinguishing unassociated hallucinations (UHs), which do not rely on parametric knowledge, from FAs.
Experimental Setups
To verify this, we revisit the effectiveness of widely-adopted white-box hallucination detection approaches that use internal state probing as well as black-box approaches that rely on scalar features. We evaluate on three settings: 1) AH Only (1,000 FAs and 1,000 AHs for training; 200 of each for testing), 2) UH Only (1,000 FAs and 1,000 UHs for training; 200 of each for testing), and 3) Full (1,000 FAs and 1,000 hallucination samples mixed of AHs and UHs for training; 200 of each for testing). For each setting, we use five random seeds to construct the training and testing datasets. We report the mean AUROC along with its standard deviation across seeds.
White-box methods: We extract and normalize internal features and then train a probe.
- Subject representations: last subject token hidden state from three consecutive layers Gottesman and Geva (2024).
- Attention flow: attention weights from the last token to subject tokens across all layers Yüksekgönül et al. (2024).
- Last-token representations: final token hidden state from the last layer Orgad et al. (2025).
Black-box methods: We test two commonly used scalar features, including answer token probability (Orgad et al., 2025) and subject popularity (average monthly Wikipedia page views) (Mallen et al., 2023a). As discussed in § 4.2.3 and § 4.4, these features are also related to whether the model relies on encoded knowledge to produce outputs rather than with truthfulness itself.
Experimental Results
| Subject Attention Last Token | $0.65\pm 0.02$ $0.58\pm 0.04$ $\mathbf{0.69\pm 0.03}$ | $0.91\pm 0.01$ $0.92\pm 0.02$ $\mathbf{0.93\pm 0.01}$ | $0.57\pm 0.02$ $0.58\pm 0.07$ $\mathbf{0.63\pm 0.02}$ | $0.81\pm 0.02$ $0.87\pm 0.01$ $\mathbf{0.92\pm 0.01}$ |
| --- | --- | --- | --- | --- |
| Probability | $0.49\pm 0.01$ | $0.86\pm 0.01$ | $0.46\pm 0.00$ | $0.89\pm 0.00$ |
| Subject Pop. | $0.48\pm 0.01$ | $0.87\pm 0.01$ | $0.52\pm 0.01$ | $0.84\pm 0.01$ |
Table 2: Hallucination detection performance on AH Only and UH Only settings.
<details>
<summary>x12.png Details</summary>
### Visual Description
\n
## Bar Chart: AUROC Scores for Hallucination Types
### Overview
This bar chart compares the Area Under the Receiver Operating Characteristic curve (AUROC) scores for two types of hallucinations – "Unassociated Hallucination" and "Associated Hallucination" – across three different "Representation Types": "Subject", "Attention", and "Last Token". Error bars are included for each data point, indicating the variability or confidence interval around the mean AUROC score.
### Components/Axes
* **X-axis:** "Representation Type" with categories: "Subject", "Attention", "Last Token".
* **Y-axis:** "AUROC" with a scale ranging from approximately 0.4 to 0.9.
* **Legend:** Located at the bottom-left of the chart.
* "Unassociated Hallucination" – represented by a red color.
* "Associated Hallucination" – represented by a blue color.
### Detailed Analysis
The chart consists of six bars, grouped by Representation Type. Each group contains one red bar (Unassociated Hallucination) and one blue bar (Associated Hallucination). Error bars are present on top of each bar.
* **Subject:**
* Unassociated Hallucination: The red bar is approximately 0.82 ± 0.03 (estimated from the error bar length). The bar slopes upward.
* Associated Hallucination: The blue bar is approximately 0.62 ± 0.05. The bar slopes upward.
* **Attention:**
* Unassociated Hallucination: The red bar is approximately 0.84 ± 0.04. The bar slopes upward.
* Associated Hallucination: The blue bar is approximately 0.56 ± 0.04. The bar slopes upward.
* **Last Token:**
* Unassociated Hallucination: The red bar is approximately 0.87 ± 0.03. The bar slopes upward.
* Associated Hallucination: The blue bar is approximately 0.60 ± 0.04. The bar slopes upward.
### Key Observations
* For all three Representation Types, the AUROC score is consistently higher for "Unassociated Hallucination" than for "Associated Hallucination".
* The AUROC scores for "Unassociated Hallucination" generally increase slightly as the Representation Type changes from "Subject" to "Attention" to "Last Token".
* The error bars suggest that the differences between the two hallucination types are statistically significant for each Representation Type.
### Interpretation
The data suggests that it is easier to detect "Unassociated Hallucinations" than "Associated Hallucinations" across all three representation types. The increasing AUROC scores for "Unassociated Hallucinations" as the representation moves from "Subject" to "Last Token" could indicate that the later stages of the model's processing are more prone to generating unassociated hallucinations, or that these hallucinations are easier to identify in the later stages. The consistent gap between the two hallucination types suggests a fundamental difference in how these hallucinations manifest within the model's representations. The error bars provide a measure of confidence in these observations, indicating that the observed differences are likely not due to random chance. This information is valuable for understanding and mitigating hallucination issues in language models.
</details>
Figure 10: Hallucination detection performance on the Full setting (LLaMA-3-8B).
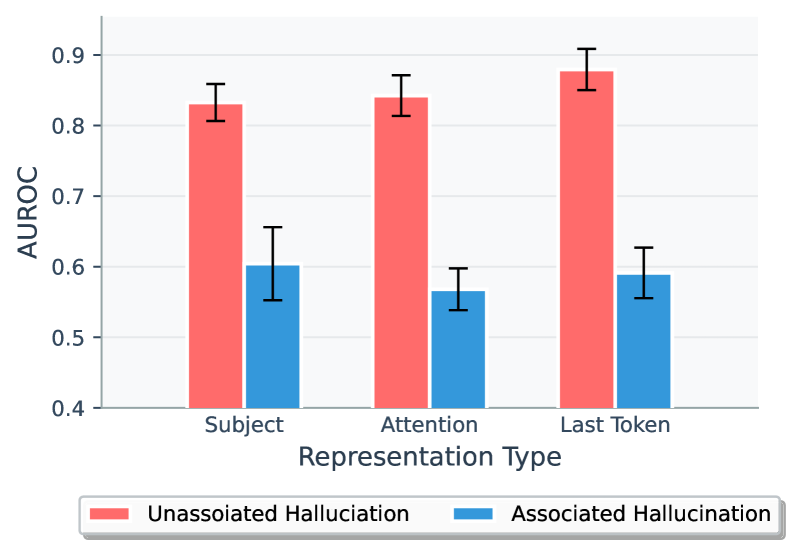
Table 2 shows that hallucination detection methods behave very differently in the AH Only and UH Only settings. For white-box probes, all approaches effectively distinguish UHs from FAs, with last-token hidden states reaching AUROC scores of about 0.93 for LLaMA and 0.92 for Mistral. In contrast, performance drops sharply on the AH Only setting, where the last-token probe falls to 0.69 for LLaMA and 0.63 for Mistral. Black-box methods follow the same pattern. Figure 10 further highlights this disparity under the Full setting: detection is consistently stronger on UH samples than on AH samples, and adding AHs to the training set significantly dilutes performance on UHs (AUROC $\approx$ 0.9 on UH Only vs. $\approx$ 0.8 on Full).
These results confirm that both internal probes and black-box methods capture whether a model draws on parametric knowledge, not whether its outputs are factually correct. Unassociated hallucinations are easier to detect because they bypass this knowledge, while associated hallucinations are produced through the same recall process as factual answers, leaving no internal cues to distinguish them. As a result, LLMs lack intrinsic awareness of their own truthfulness, and detection methods relying on these signals risk misclassifying associated hallucinations as correct, fostering harmful overconfidence in model outputs.
## 6 Challenges of Refusal Tuning
A common strategy to mitigate potential hallucination in the model’s responses is to fine-tune LLMs to refuse answering when they cannot provide a factual response, e.g., Refusal Tuning Zhang et al. (2024). For such refusal capability to generalize, the training data must contain a shared feature pattern across hallucinated outputs, allowing the model to learn and apply it to unseen cases.
Our analysis in the previous sections shows that this prerequisite is not met. The structural mismatch between UHs and AHs suggests that refusal tuning on UHs may generalize to other UHs, because their hidden states occupy a common activation subspace, but will not transfer to AHs. Refusal tuning on AHs is even less effective, as their diverse representations prevent generalization to either unseen AHs or UHs.
Experimental Setups
To verify the hypothesis, we conduct refusal tuning on LLMs under two settings: 1) UH Only, where 1,000 UH samples are paired with 10 refusal templates, and 1,000 FA samples are preserved with their original answers. 2) AH Only, where 1,000 AH samples are paired with refusal templates, with 1,000 FA samples again leave unchanged. We then evaluate both models on 200 samples each of FAs, UHs, and AHs. A response matching any refusal template is counted as a refusal, and we report the Refusal Ratio as the proportion of samples eliciting refusals. This measures not only whether the model refuses appropriately on UHs and AHs, but also whether it “over-refuses” on FA samples.
Experimental Results
<details>
<summary>x13.png Details</summary>
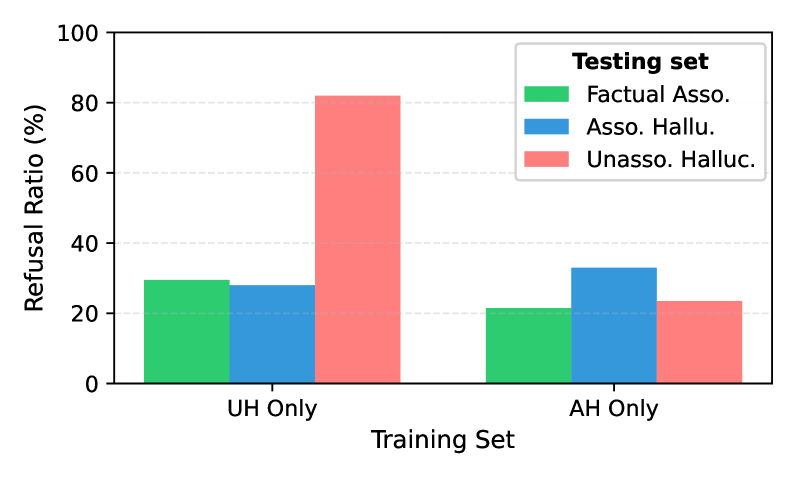
### Visual Description
\n
## Bar Chart: Refusal Ratio by Training Set and Testing Set
### Overview
This bar chart displays the refusal ratio (in percentage) for different testing sets based on the training set used. The chart compares the performance of a system across two training sets: "UH Only" and "AH Only", and three testing sets: "Factual Association", "Association Hallucination", and "Unassociated Hallucination".
### Components/Axes
* **X-axis:** "Training Set" with categories "UH Only" and "AH Only".
* **Y-axis:** "Refusal Ratio (%)" ranging from 0 to 100, with tick marks at intervals of 20.
* **Legend (top-right):** "Testing set" with labels:
* "Factual Asso." (Green)
* "Asso. Hallu." (Blue)
* "Unasso. Halluc." (Red)
### Detailed Analysis
The chart consists of six bars, grouped by training set.
**UH Only Training Set:**
* **Factual Asso. (Green):** The bar rises to approximately 30%. The line slopes upward.
* **Asso. Hallu. (Blue):** The bar rises to approximately 10%. The line is relatively flat.
* **Unasso. Halluc. (Red):** The bar rises to approximately 80%. The line slopes sharply upward.
**AH Only Training Set:**
* **Factual Asso. (Green):** The bar rises to approximately 20%. The line slopes upward.
* **Asso. Hallu. (Blue):** The bar rises to approximately 35%. The line slopes upward.
* **Unasso. Halluc. (Red):** The bar rises to approximately 25%. The line slopes upward.
### Key Observations
* The "Unasso. Halluc." testing set consistently results in the highest refusal ratio, regardless of the training set.
* The "UH Only" training set leads to a significantly higher refusal ratio for "Unasso. Halluc." compared to the "AH Only" training set.
* The "AH Only" training set shows a higher refusal ratio for "Asso. Hallu." compared to the "UH Only" training set.
* The "Factual Asso." testing set has the lowest refusal ratio in both training set scenarios.
### Interpretation
The data suggests that the system struggles more with unassociated hallucinations, as evidenced by the consistently high refusal ratios for this testing set. This indicates that the system is more likely to reject prompts that involve generating content without a clear factual basis.
The difference in refusal ratios between the "UH Only" and "AH Only" training sets highlights the impact of the training data on the system's behavior. Training with "AH Only" seems to improve the handling of associated hallucinations ("Asso. Hallu."), but it doesn't significantly reduce the refusal rate for unassociated hallucinations.
The low refusal ratio for "Factual Asso." suggests that the system is generally reliable when asked to generate content based on factual associations. This could be due to the system being trained on a large corpus of factual information.
The chart demonstrates a trade-off between different types of hallucinations. Improving performance on one type of hallucination may come at the cost of performance on another. Further investigation is needed to understand the underlying reasons for these differences and to develop strategies for mitigating hallucinations across all testing sets.
</details>
Figure 11: Refusal tuning performance across three types of samples (LLaMA-3-8B).
Figure 11 shows that training with UHs leads to strong generalization across UHs, with refusal ratios of 82% for LLaMA. However, this effect does not transfer to AHs, where refusal ratios fall to 28%, respectively. Moreover, some FA cases are mistakenly refused (29.5%). These results confirm that UHs share a common activation subspace, supporting generalization within the category, while AHs and FAs lie outside this space. By contrast, training with AHs produces poor generalization. On AH test samples, refusal ratio is only 33%, validating that their subject-specific hidden states prevent consistent refusal learning. Generalization to UHs is also weak (23.5%), again reflecting the divergence between AH and UH activation spaces.
Overall, these findings show that the generalizability of refusal tuning is fundamentally limited by the heterogeneous nature of hallucinations. UH representations are internally consistent enough to support refusal generalization, but AH representations are too diverse for either UH-based or AH-based training to yield a broadly applicable and reliable refusal capability.
## 7 Conclusions and Future Work
In this work, we revisit the widely accepted claim that hallucinations can be detected from a model’s internal states. Our mechanistic analysis reveals that hidden states encode whether models are reliance on their parametric knowledge rather than truthfulness. As a result, detection methods succeed only when outputs are detached from the input but fail when hallucinations arise from the same knowledge-recall process as correct answers.
These findings lead to three key implications. First, future evaluations should report detection performance separately for Associated Hallucinations (AHs) and Unassociated Hallucinations (UHs), as they stem from fundamentally different internal processes and require distinct detection strategies. Second, relying solely on hidden states is insufficient for reliable hallucination detection. Future research should integrate LLMs with external feedback mechanisms, such as fact-checking modules or retrieval-based verifiers, to assess factuality more robustly. Third, future studies should prioritize improving AH detection. Because AHs occur more frequently in widely known or highly popular topics (§ 4.2.3), their undetected errors pose greater risks to user trust and the practical reliability of LLMs.
## Limitations
We identify several limitations of our work.
Focus on Factual Knowledge
While our analysis identifies failure cases of hallucination detection methods, our study is primarily limited to factual completion prompts. It does not extend to long-form or open-ended text generation tasks Wei et al. (2024); Min et al. (2023); Huang and Chen (2024). Future work should broaden this investigation to these tasks in order to draw more comprehensive conclusions.
Lack of Analysis on Prompt-based Hallucination Detection Approaches
Our analysis focuses on white-box hallucination detection methods based on internal states and two black-box approaches based on external features. We do not include verbalization-based strategies Lin et al. (2022a); Tian et al. (2023); Xiong et al. (2024); Yang et al. (2024b); Ni et al. (2024); Zhao et al. (2024), such as prompting the model to report or justify its confidence explicitly, which constitute a different line of approach. Exploring such approaches may offer complementary insights into how models internally represent and express uncertainty.
Applicability to Black-box LLMs or Large Reasoning Models
Our study is limited to open-source LLMs. Conducting mechanistic analyses on commercial black-box LLMs is not permitted due to access restrictions. Future work could explore alternative evaluation protocols or collaboration frameworks that enable partial interpretability analyses on such systems. In addition, recent studies Mei et al. (2025); Zhang et al. (2025) have begun examining the internal states of large reasoning models for hallucination detection, suggesting a promising direction for extending our methodology to models with multi-step reasoning capabilities.
## Ethical Considerations
This work analyzes the internal mechanisms of large language models using data constructed from Wikidata Vrandecic and Krötzsch (2014), which is released under the Creative Commons CC0 1.0 Universal license, allowing unrestricted use and redistribution of its data. All data are derived from publicly available resources, and no private or sensitive information about individuals is included. We employ the LLM tools for polishing.
## References
- Azaria and Mitchell (2023) Amos Azaria and Tom M. Mitchell. 2023. The internal state of an LLM knows when it’s lying. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976.
- Cheang et al. (2023) Chi Seng Cheang, Hou Pong Chan, Derek F. Wong, Xuebo Liu, Zhaocong Li, Yanming Sun, Shudong Liu, and Lidia S. Chao. 2023. Can lms generalize to future data? an empirical analysis on text summarization. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 16205–16217. Association for Computational Linguistics.
- Chen et al. (2024) Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. 2024. INSIDE: llms’ internal states retain the power of hallucination detection. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net.
- Daniel Han and team (2023) Michael Han Daniel Han and Unsloth team. 2023. Unsloth.
- Dettmers et al. (2023) Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. Qlora: Efficient finetuning of quantized llms. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023.
- Ding et al. (2024) Hanxing Ding, Liang Pang, Zihao Wei, Huawei Shen, and Xueqi Cheng. 2024. Retrieve only when it needs: Adaptive retrieval augmentation for hallucination mitigation in large language models. CoRR, abs/2402.10612.
- Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, and 82 others. 2024. The llama 3 herd of models. CoRR, abs/2407.21783.
- Finlayson et al. (2021) Matthew Finlayson, Aaron Mueller, Sebastian Gehrmann, Stuart M. Shieber, Tal Linzen, and Yonatan Belinkov. 2021. Causal analysis of syntactic agreement mechanisms in neural language models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021, pages 1828–1843. Association for Computational Linguistics.
- Gekhman et al. (2025) Zorik Gekhman, Eyal Ben-David, Hadas Orgad, Eran Ofek, Yonatan Belinkov, Idan Szpektor, Jonathan Herzig, and Roi Reichart. 2025. Inside-out: Hidden factual knowledge in llms. CoRR, abs/2503.15299.
- Geva et al. (2023) Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. 2023. Dissecting recall of factual associations in auto-regressive language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 12216–12235. Association for Computational Linguistics.
- Gottesman and Geva (2024) Daniela Gottesman and Mor Geva. 2024. Estimating knowledge in large language models without generating a single token. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, pages 3994–4019.
- Guerreiro et al. (2023) Nuno Miguel Guerreiro, Elena Voita, and André F. T. Martins. 2023. Looking for a needle in a haystack: A comprehensive study of hallucinations in neural machine translation. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2023, Dubrovnik, Croatia, May 2-6, 2023, pages 1059–1075. Association for Computational Linguistics.
- Huang and Chen (2024) Chao-Wei Huang and Yun-Nung Chen. 2024. Factalign: Long-form factuality alignment of large language models. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 16363–16375.
- Huang et al. (2025) Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2025. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Trans. Inf. Syst., 43(2):42:1–42:55.
- Ji et al. (2024) Ziwei Ji, Delong Chen, Etsuko Ishii, Samuel Cahyawijaya, Yejin Bang, Bryan Wilie, and Pascale Fung. 2024. LLM internal states reveal hallucination risk faced with a query. In Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 88–104, Miami, Florida, US. Association for Computational Linguistics.
- Jiang et al. (2023) Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7b. Preprint, arXiv:2310.06825.
- Kang and Choi (2023) Cheongwoong Kang and Jaesik Choi. 2023. Impact of co-occurrence on factual knowledge of large language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 7721–7735.
- Kang et al. (2024) Katie Kang, Amrith Setlur, Claire J. Tomlin, and Sergey Levine. 2024. Deep neural networks tend to extrapolate predictably. In The Twelfth International Conference on Learning Representations, ICLR 2024.
- Kapoor et al. (2024) Sanyam Kapoor, Nate Gruver, Manley Roberts, Katie Collins, Arka Pal, Umang Bhatt, Adrian Weller, Samuel Dooley, Micah Goldblum, and Andrew Gordon Wilson. 2024. Large language models must be taught to know what they don’t know. In Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024.
- Kuhn et al. (2023) Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Li et al. (2023) Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. 2023. Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems, 36:41451–41530.
- Li et al. (2025) Moxin Li, Yong Zhao, Wenxuan Zhang, Shuaiyi Li, Wenya Xie, See-Kiong Ng, Tat-Seng Chua, and Yang Deng. 2025. Knowledge boundary of large language models: A survey. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, pages 5131–5157.
- Lin et al. (2022a) Stephanie Lin, Jacob Hilton, and Owain Evans. 2022a. Teaching models to express their uncertainty in words. Trans. Mach. Learn. Res., 2022.
- Lin et al. (2022b) Stephanie Lin, Jacob Hilton, and Owain Evans. 2022b. Truthfulqa: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, pages 3214–3252.
- Mallen et al. (2023a) Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023a. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, pages 9802–9822.
- Mallen et al. (2023b) Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023b. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 9802–9822. Association for Computational Linguistics.
- Manakul et al. (2023) Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. 2023. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 9004–9017. Association for Computational Linguistics.
- Mei et al. (2025) Zhiting Mei, Christina Zhang, Tenny Yin, Justin Lidard, Ola Shorinwa, and Anirudha Majumdar. 2025. Reasoning about uncertainty: Do reasoning models know when they don’t know? CoRR, abs/2506.18183.
- Meng et al. (2022) Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt. Advances in neural information processing systems, 35:17359–17372.
- Min et al. (2023) Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, pages 12076–12100.
- Ni et al. (2024) Shiyu Ni, Keping Bi, Jiafeng Guo, and Xueqi Cheng. 2024. When do llms need retrieval augmentation? mitigating llms’ overconfidence helps retrieval augmentation. In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, pages 11375–11388. Association for Computational Linguistics.
- Ni et al. (2025) Shiyu Ni, Keping Bi, Jiafeng Guo, Lulu Yu, Baolong Bi, and Xueqi Cheng. 2025. Towards fully exploiting LLM internal states to enhance knowledge boundary perception. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 24315–24329. Association for Computational Linguistics.
- Orgad et al. (2025) Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, and Yonatan Belinkov. 2025. Llms know more than they show: On the intrinsic representation of LLM hallucinations. In The Thirteenth International Conference on Learning Representations, ICLR 2025.
- Sciavolino et al. (2021) Christopher Sciavolino, Zexuan Zhong, Jinhyuk Lee, and Danqi Chen. 2021. Simple entity-centric questions challenge dense retrievers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pages 6138–6148. Association for Computational Linguistics.
- Su et al. (2024) Weihang Su, Changyue Wang, Qingyao Ai, Yiran Hu, Zhijing Wu, Yujia Zhou, and Yiqun Liu. 2024. Unsupervised real-time hallucination detection based on the internal states of large language models. In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, pages 14379–14391. Association for Computational Linguistics.
- Tian et al. (2023) Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D. Manning. 2023. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 5433–5442. Association for Computational Linguistics.
- Varshney et al. (2023) Neeraj Varshney, Wenlin Yao, Hongming Zhang, Jianshu Chen, and Dong Yu. 2023. A stitch in time saves nine: Detecting and mitigating hallucinations of llms by validating low-confidence generation. CoRR, abs/2307.03987.
- Vig et al. (2020) Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. 2020. Investigating gender bias in language models using causal mediation analysis. Advances in neural information processing systems, 33:12388–12401.
- Vrandecic and Krötzsch (2014) Denny Vrandecic and Markus Krötzsch. 2014. Wikidata: a free collaborative knowledgebase. Commun. ACM, 57(10):78–85.
- Wei et al. (2024) Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Jie Huang, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, Cosmo Du, and Quoc V. Le. 2024. Long-form factuality in large language models. In Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024.
- Wolf et al. (2019) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, and Jamie Brew. 2019. Huggingface’s transformers: State-of-the-art natural language processing. CoRR, abs/1910.03771.
- Xiao et al. (2025) Chenghao Xiao, Hou Pong Chan, Hao Zhang, Mahani Aljunied, Lidong Bing, Noura Al Moubayed, and Yu Rong. 2025. Analyzing llms’ knowledge boundary cognition across languages through the lens of internal representations. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 24099–24115. Association for Computational Linguistics.
- Xiong et al. (2024) Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. 2024. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net.
- Yang et al. (2024a) An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, and 22 others. 2024a. Qwen2.5 technical report. CoRR, abs/2412.15115.
- Yang et al. (2024b) Yuqing Yang, Ethan Chern, Xipeng Qiu, Graham Neubig, and Pengfei Liu. 2024b. Alignment for honesty. In Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024.
- Yin et al. (2023) Zhangyue Yin, Qiushi Sun, Qipeng Guo, Jiawen Wu, Xipeng Qiu, and Xuanjing Huang. 2023. Do large language models know what they don’t know? In Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pages 8653–8665. Association for Computational Linguistics.
- Yona et al. (2024) Gal Yona, Roee Aharoni, and Mor Geva. 2024. Narrowing the knowledge evaluation gap: Open-domain question answering with multi-granularity answers. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 6737–6751. Association for Computational Linguistics.
- Yüksekgönül et al. (2024) Mert Yüksekgönül, Varun Chandrasekaran, Erik Jones, Suriya Gunasekar, Ranjita Naik, Hamid Palangi, Ece Kamar, and Besmira Nushi. 2024. Attention satisfies: A constraint-satisfaction lens on factual errors of language models. In The Twelfth International Conference on Learning Representations, ICLR 2024.
- Zhang et al. (2024) Hanning Zhang, Shizhe Diao, Yong Lin, Yi R. Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, and Tong Zhang. 2024. R-tuning: Instructing large language models to say ’i don’t know’. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, pages 7113–7139.
- Zhang et al. (2023a) Jiaxin Zhang, Zhuohang Li, Kamalika Das, Bradley A. Malin, and Kumar Sricharan. 2023a. Sac ${}^{\mbox{3}}$ : Reliable hallucination detection in black-box language models via semantic-aware cross-check consistency. CoRR, abs/2311.01740.
- Zhang et al. (2025) Qingjie Zhang, Yujia Fu, Yang Wang, Liu Yan, Tao Wei, Ke Xu, Minlie Huang, and Han Qiu. 2025. On the self-awareness of large reasoning models’ capability boundaries. Preprint, arXiv:2509.24711.
- Zhang et al. (2023b) Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, Longyue Wang, Anh Tuan Luu, Wei Bi, Freda Shi, and Shuming Shi. 2023b. Siren’s song in the AI ocean: A survey on hallucination in large language models. CoRR, abs/2309.01219.
- Zhao et al. (2024) Yukun Zhao, Lingyong Yan, Weiwei Sun, Guoliang Xing, Chong Meng, Shuaiqiang Wang, Zhicong Cheng, Zhaochun Ren, and Dawei Yin. 2024. Knowing what llms DO NOT know: A simple yet effective self-detection method. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, pages 7051–7063.
## Appendix
## Appendix A Datasets and Implementations
### A.1 Selected Relations and Prompt Templates
We employed a set of criteria to select relations from Wikidata in order to construct our dataset. Our criteria largely follow the framework proposed by Gekhman et al. (2025). Specifically, we require that each factual query in the dataset be unambiguous: given a subject–relation pair, the object should be unique and easy verifiable. The criteria are as follows:
- Avoid granularity ambiguity. We exclude relations whose answers can vary in their level of detail. For example, in location queries, the response could be expressed as a city, state, or country, making it ill-defined Yona et al. (2024).
- Avoid surface-level guessing. We exclude relations whose correct answers can often be inferred from shallow patterns. For instance, country of citizenship can frequently be guessed from shallow lexical patterns, rather then reflecting actual memorization Mallen et al. (2023b).
Following these criteria, Gekhman et al. (2025) narrowed the 24 relations introduced by Sciavolino et al. (2021) down to four. However, we observe that their filtering primarily addresses ambiguity at the relation and object levels, but does not consider ambiguity at the subject level. In practice, some relations involve subjects that are inherently ambiguous. For example, the relation record label can be problematic because many songs share identical names, leading to unclear subject–object mappings.
To mitigate such cases, we apply an additional subject-level filtering step and restrict our dataset to relations where the subject is a person, thereby reducing ambiguity. In addition, we manually include certain relations to strengthen the dataset. Concretely, we use the following four relations: P22 (father), P25 (mother), P26 (spouse), and P569 (date of birth). We show the list of the templates used to create our dataset in Table 3.
| father mother spouse | The name of the father of [subject] is The name of the mother of [subject] is The name of the spouse of [subject] is |
| --- | --- |
| date of birth | The birth date of [subject] is |
Table 3: Relations and prompt templates for querying factual knowledge of models. [subject] is a placeholder replaced with subject entities.
| I will give you a factual query (e.g., “The name of the father of <subj>”), a gold answer to the factual query, and a proposed answer generated by an LLM. You need to compare the proposed answer to the gold answer and assign it one of the possible grades using the steps below. |
| --- |
| Possible grades are: |
| A: CORRECT |
| B: INCORRECT |
| C: WRONG GOLD |
| D: ERROR |
| Spelling errors, synonyms, abbreviations, or hedging expressions (e.g., “it is possible that”) should not alter the grade if the person referred to in the proposed answer matches the gold answer. |
| Steps: |
| Step 1: If the gold answer does not correspond to an answer for the question, output “C” and finish. Otherwise, proceed to Step 2. |
| Step 2: Extract all predicted entities from the proposed answer. Proceed to Step 3. |
| Step 3: If each predicted entity refers to the answer mentioned in the gold answer, output “A” and finish. Otherwise, proceed to Step 4. |
| Step 4: If the predicted entity does not refer to the gold answer, output “B” and finish. Otherwise, proceed to Step 5. |
| Step 5: Double-check whether the proposed answer refers to a different answer from the gold answer. If it does, output “B.” Otherwise, output “D” and finish. |
| Input format: |
| Question: {question} |
| Gold answer: {gold_answer} |
| Proposed answer: {proposed_answer} |
| Instruction: Output your reasoning steps. After that, conclude your response with “Output:” followed by the letter (A, B, C, or D). Do not provide any further explanation. |
Figure 12: LLM Judge prompt used for evaluation.
### A.2 Labeling Scheme
We follow the criteria in § 3 to label the data samples into different categories:
- Factual Correctness: We construct correctness labels through a two-stage process. First, we use spaCy https://spacy.io/ Named Entity Recognizer to extract the target entity from the model’s output. If it matches the ground truth, the answer is marked correct. Otherwise, or if extraction fails, we rely on Qwen2.5-14B-Instruct Yang et al. (2024a) as an automatic judge to compare the predicted answer with the ground truth. Following Gekhman et al. (2025), we design the evaluation prompt, which is shown in Figure 12.
- Subject Representation Reliance: We assess whether a prediction relies on the subject’s representation by blocking attention from subject tokens and measuring the resulting distribution shift. If the subject is crucial, masking disrupts information flow and yields a large shift; if not, the effect is minimal. Concretely, we compare the output distributions of the original prompt and the masked prompt (e.g., with “ Barack Obama ” masked), using Jensen–Shannon (JS) divergence to quantify the difference. A high JS divergence indicates strong reliance on the subject, while a low value suggests limited contribution. We then set a threshold based on the average JS divergence across all correct answers, assuming these inherently depend on subject representations.
<details>
<summary>x14.png Details</summary>
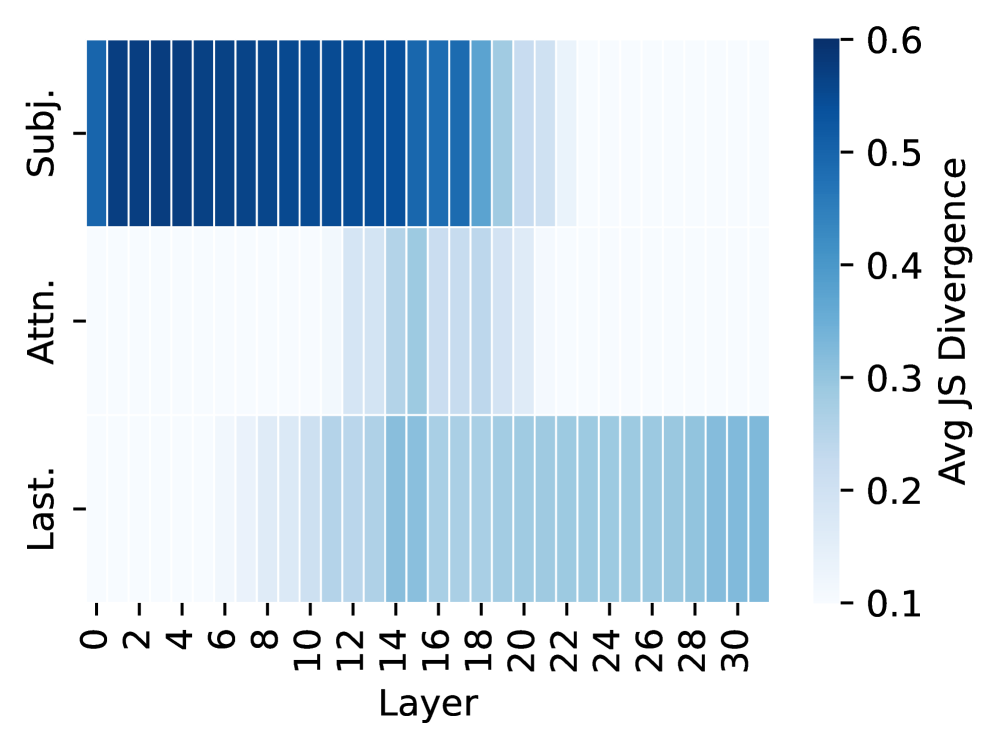
### Visual Description
\n
## Heatmap: JS Divergence by Layer and Subject
### Overview
The image presents a heatmap visualizing the average Jensen-Shannon (JS) Divergence across different layers of a model, categorized by subject (Subj.), attention (Attn.), and last layer (Last.). The heatmap displays the divergence values using a color gradient, ranging from dark blue (high divergence) to light blue (low divergence).
### Components/Axes
* **X-axis:** Layer, ranging from 0 to 30, with increments of 2.
* **Y-axis:** Categories: "Subj." (Subject), "Attn." (Attention), and "Last." (Last Layer).
* **Color Scale:** Represents "Avg JS Divergence", ranging from 0.1 to 0.6. The scale is positioned on the right side of the heatmap.
* **Legend:** Located in the top-right corner, indicating the mapping between color and JS Divergence values.
### Detailed Analysis
The heatmap is structured into three horizontal bands, each representing one of the categories (Subj., Attn., Last.). Each cell in the heatmap represents the average JS Divergence for a specific layer and category.
**Subject (Subj.):**
* The JS Divergence is consistently high (approximately 0.55-0.6) for layers 0 to 10.
* From layer 10 to 14, the divergence decreases to approximately 0.45-0.5.
* From layer 14 to 30, the divergence continues to decrease, reaching approximately 0.2-0.3.
* Trend: A clear downward trend in JS Divergence as the layer number increases.
**Attention (Attn.):**
* The JS Divergence starts at approximately 0.35-0.4 for layers 0 to 6.
* From layer 6 to 16, the divergence remains relatively stable, around 0.4.
* From layer 16 to 30, the divergence gradually decreases to approximately 0.25-0.3.
* Trend: A slight downward trend in JS Divergence, with a plateau between layers 6 and 16.
**Last Layer (Last.):**
* The JS Divergence is low (approximately 0.1-0.2) for layers 0 to 10.
* From layer 10 to 16, the divergence increases to approximately 0.25-0.3.
* From layer 16 to 30, the divergence remains relatively stable, around 0.3.
* Trend: An upward trend in JS Divergence from layers 0 to 16, followed by stabilization.
### Key Observations
* The "Subject" category consistently exhibits the highest JS Divergence values across most layers.
* The "Last Layer" category consistently exhibits the lowest JS Divergence values across most layers.
* The "Attention" category shows intermediate JS Divergence values, with a relatively stable pattern.
* All three categories demonstrate a general trend of decreasing JS Divergence as the layer number increases, although the rate of decrease varies.
### Interpretation
This heatmap likely represents the analysis of internal representations learned by a neural network model. The JS Divergence measures the dissimilarity between probability distributions, in this case, likely the distributions of activations within each layer.
* **High JS Divergence (dark blue):** Indicates that the representations in that layer are significantly different from a baseline or expected distribution. This could suggest that the layer is learning distinct features or that the model is uncertain about its predictions.
* **Low JS Divergence (light blue):** Indicates that the representations in that layer are similar to the baseline distribution. This could suggest that the layer is learning more general or stable features.
The observation that the "Subject" category has the highest divergence suggests that the model's internal representations are most sensitive to variations in the input subject. The "Last Layer" category having the lowest divergence suggests that the final layer's representations are more consolidated and less sensitive to input variations. The trends observed across layers indicate that the model's representations become more stable and less divergent as information propagates through the network.
The differences in divergence patterns between the categories could be due to the specific roles of each component within the model. For example, the attention mechanism might be designed to focus on specific features, leading to higher divergence in its representations. The "Last Layer" might be designed to produce a more stable and consistent output, leading to lower divergence.
</details>
(a) Factual Associations
<details>
<summary>x15.png Details</summary>
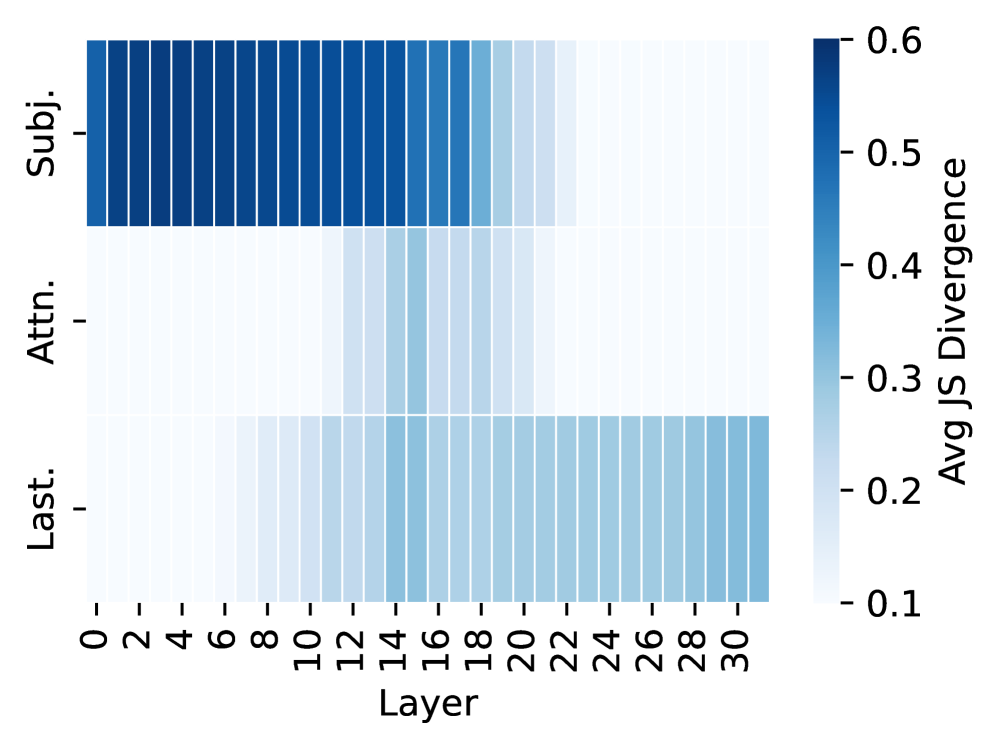
### Visual Description
\n
## Heatmap: Jensen-Shannon Divergence by Layer and Subject
### Overview
This image presents a heatmap visualizing the average Jensen-Shannon (JS) Divergence across different layers of a model, categorized by subject (Subj.), attention (Attn.), and last layer (Last.). The heatmap displays the divergence values using a color gradient, ranging from dark blue (high divergence) to light blue (low divergence).
### Components/Axes
* **X-axis:** Layer, ranging from 0 to 30, with increments of 2.
* **Y-axis:** Three categories: "Subj." (Subject), "Attn." (Attention), and "Last." (Last Layer).
* **Color Scale:** Represents "Avg JS Divergence", ranging from 0.1 to 0.6. The color scale is positioned on the right side of the heatmap.
* **Legend:** Located in the top-right corner, indicating the mapping between color and JS Divergence values.
### Detailed Analysis
The heatmap consists of three horizontal rows, each representing one of the categories (Subj., Attn., Last.). Each cell in the heatmap represents the average JS Divergence for a specific layer and category.
**Subject (Subj.):**
* The JS Divergence is initially high (approximately 0.55-0.6) for layers 0-6.
* There is a noticeable decrease in JS Divergence between layers 6 and 8 (down to approximately 0.45).
* From layers 8-14, the JS Divergence remains relatively stable around 0.45-0.5.
* A further decrease is observed from layers 14-20 (down to approximately 0.3).
* From layers 20-30, the JS Divergence continues to decrease, reaching approximately 0.2-0.3.
**Attention (Attn.):**
* The JS Divergence starts at a low value (approximately 0.15-0.2) for layers 0-4.
* It gradually increases from layers 4-10 (reaching approximately 0.35-0.4).
* From layers 10-20, the JS Divergence remains relatively stable around 0.4.
* A slight decrease is observed from layers 20-30 (down to approximately 0.3).
**Last Layer (Last.):**
* The JS Divergence starts at a very low value (approximately 0.1) for layers 0-6.
* It gradually increases from layers 6-14 (reaching approximately 0.25-0.3).
* From layers 14-30, the JS Divergence remains relatively stable around 0.25-0.3.
### Key Observations
* The "Subj." category exhibits the highest JS Divergence values, particularly in the initial layers.
* The "Last." category consistently shows the lowest JS Divergence values across all layers.
* The "Attn." category shows a moderate increase in JS Divergence in the middle layers, then plateaus.
* There is a clear trend of decreasing JS Divergence with increasing layer number for the "Subj." category.
### Interpretation
The heatmap suggests that the "Subject" component of the model initially has the most significant divergence from its expected distribution, but this divergence decreases as the model processes information through deeper layers. This could indicate that the initial layers are more sensitive to variations in the input subject, while later layers learn to generalize and reduce this sensitivity.
The "Last" layer consistently exhibits low divergence, suggesting that the final output of the model is relatively stable and predictable. The "Attention" layer shows a moderate divergence that remains relatively constant after the initial layers, indicating a consistent level of attention-related variation.
The decreasing trend in JS Divergence for the "Subj." category could be interpreted as the model learning to extract more abstract and invariant features as it progresses through the layers. The differences in divergence patterns between the three categories highlight the distinct roles and behaviors of each component within the model. The heatmap provides insights into the internal dynamics of the model and how different components contribute to its overall performance.
</details>
(b) Associated Hallucinations
<details>
<summary>x16.png Details</summary>
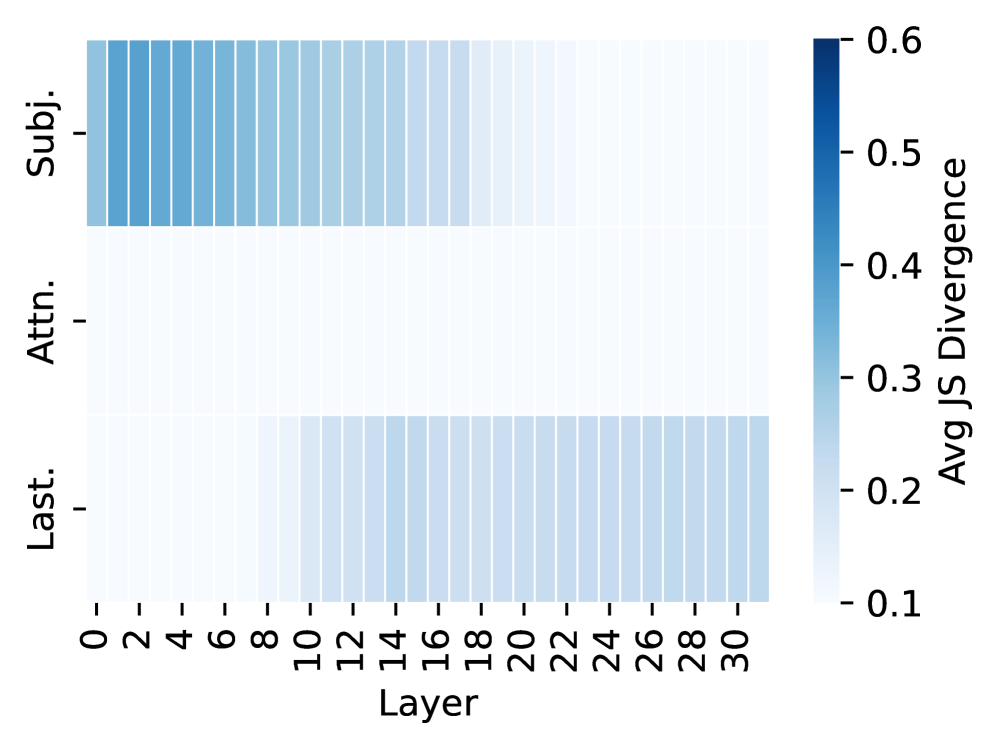
### Visual Description
\n
## Heatmap: Jensen-Shannon Divergence by Layer and Subject
### Overview
This image presents a heatmap visualizing the average Jensen-Shannon (JS) Divergence across different layers of a model, categorized by subject (Subj.), attention (Attn.), and last layer (Last.). The heatmap displays the divergence values using a color gradient, ranging from dark blue (high divergence) to light blue (low divergence).
### Components/Axes
* **X-axis:** Layer, ranging from 0 to 30, with increments of 2.
* **Y-axis:** Categories: "Subj." (Subject), "Attn." (Attention), and "Last." (Last Layer).
* **Color Scale:** Represents "Avg JS Divergence", ranging from 0.1 (light blue) to 0.6 (dark blue). The color scale is positioned on the right side of the heatmap.
### Detailed Analysis
The heatmap consists of three horizontal rows, each representing one of the categories (Subj., Attn., Last.). Each row contains 16 data points corresponding to the layers 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, and 30.
* **Subject (Subj.):** The divergence values are relatively high (darker blue) for layers 0 to approximately 8, then gradually decrease (lighter blue) towards layer 30.
* Layer 0: Approximately 0.55
* Layer 2: Approximately 0.53
* Layer 4: Approximately 0.52
* Layer 6: Approximately 0.51
* Layer 8: Approximately 0.50
* Layer 10: Approximately 0.48
* Layer 12: Approximately 0.46
* Layer 14: Approximately 0.45
* Layer 16: Approximately 0.44
* Layer 18: Approximately 0.43
* Layer 20: Approximately 0.42
* Layer 22: Approximately 0.41
* Layer 24: Approximately 0.40
* Layer 26: Approximately 0.39
* Layer 28: Approximately 0.38
* Layer 30: Approximately 0.37
* **Attention (Attn.):** The divergence values are consistently lower (lighter blue) than the "Subj." category, remaining around 0.3 to 0.4 throughout all layers.
* Layer 0: Approximately 0.38
* Layer 2: Approximately 0.37
* Layer 4: Approximately 0.36
* Layer 6: Approximately 0.35
* Layer 8: Approximately 0.34
* Layer 10: Approximately 0.33
* Layer 12: Approximately 0.32
* Layer 14: Approximately 0.31
* Layer 16: Approximately 0.30
* Layer 18: Approximately 0.29
* Layer 20: Approximately 0.28
* Layer 22: Approximately 0.27
* Layer 24: Approximately 0.26
* Layer 26: Approximately 0.25
* Layer 28: Approximately 0.24
* Layer 30: Approximately 0.23
* **Last Layer (Last.):** The divergence values are very low (lightest blue) and increase slightly from layer 0 to layer 30.
* Layer 0: Approximately 0.15
* Layer 2: Approximately 0.17
* Layer 4: Approximately 0.19
* Layer 6: Approximately 0.21
* Layer 8: Approximately 0.23
* Layer 10: Approximately 0.25
* Layer 12: Approximately 0.27
* Layer 14: Approximately 0.29
* Layer 16: Approximately 0.30
* Layer 18: Approximately 0.31
* Layer 20: Approximately 0.32
* Layer 22: Approximately 0.33
* Layer 24: Approximately 0.34
* Layer 26: Approximately 0.35
* Layer 28: Approximately 0.36
* Layer 30: Approximately 0.37
### Key Observations
* The "Subj." category exhibits the highest JS Divergence, particularly in the earlier layers.
* The "Attn." category shows consistently lower divergence values compared to "Subj."
* The "Last." category has the lowest divergence values overall, indicating a more stable representation in the final layer.
* All three categories show a general trend of decreasing divergence as the layer number increases, although the rate of decrease varies.
### Interpretation
The heatmap suggests that the "Subject" representation undergoes more significant changes in the earlier layers of the model, as indicated by the higher JS Divergence. This could imply that the initial layers are responsible for capturing and processing subject-specific features. The "Attention" mechanism, on the other hand, appears to be more stable across layers, with consistently lower divergence. The "Last" layer exhibits the lowest divergence, suggesting that the model converges to a more stable representation in the final layer.
The decreasing divergence trend across layers for all categories could indicate that the model learns to refine its representations as it progresses through deeper layers. The differences in divergence values between the categories highlight the varying degrees of change and stability in different aspects of the model's internal representations. The heatmap provides insights into how the model processes information and how different components contribute to the overall representation.
</details>
(c) Unassociated Hallucinations
Figure 13: Effect of interventions across layers of Mistral-7B-v0.3. The heatmap shows JS divergence between the output distribution before and after intervention. Darker color indicates that the intervened hidden states are more causally influential on the model’s predictions. Top row: patching representations of subject tokens. Middle row: blocking attention flow from subject to the last token. Bottom row: patching representations of the last token.
### A.3 Implementation Details
Checkpoints and GPU resources.
All the checkpoints used in our experiments are provided by the Hugging Face Transformers library Wolf et al. (2019). Specifically, we use the checkpoint “meta-llama/Meta-Llama-3-8B” https://huggingface.co/meta-llama/Meta-Llama-3-8B and “mistralai/Mistral-7B-v0.3” https://huggingface.co/mistralai/Mistral-7B-v0.3 for the experiments of response generation (§ 3), hidden-state analysis (§ 4) and accessing the performance of hallucination detection methods (§ 5). For refusal tuning (§ 6), we use checkpoints provided by the Unsloth framework Daniel Han and team (2023), namely “unsloth/llama-3-8b” https://huggingface.co/unsloth/llama-3-8b and “unsloth/mistral-7b-v0.3” https://huggingface.co/unsloth/mistral-7b-v0.3, which enable more efficient fine-tuning. All experiments are conducted on 4 NVIDIA L40S GPUs.
<details>
<summary>x17.png Details</summary>
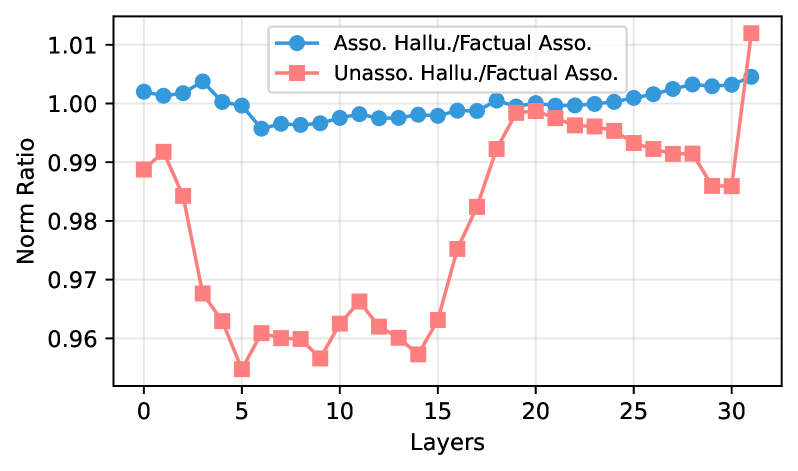
### Visual Description
## Line Chart: Normalized Ratio of Hallucinations to Factual Associations vs. Layers
### Overview
This line chart depicts the relationship between the number of layers in a model and the normalized ratio of hallucinations to factual associations. Two data series are presented: one for "Asso. Hallu./Factual Asso." (Association Hallucination/Factual Association) and another for "Unasso. Hallu./Factual Asso." (Unassociated Hallucination/Factual Association). The chart aims to illustrate how the propensity for hallucinations changes as model depth (number of layers) increases.
### Components/Axes
* **X-axis:** "Layers" - ranging from 0 to 32, with tick marks at integer values.
* **Y-axis:** "Norm Ratio" - ranging from approximately 0.95 to 1.02, with tick marks at 0.96, 0.97, 0.98, 0.99, 1.00, and 1.01.
* **Legend:** Located in the top-center of the chart.
* "Asso. Hallu./Factual Asso." - represented by a blue line with circular markers.
* "Unasso. Hallu./Factual Asso." - represented by a red line with square markers.
* **Gridlines:** Horizontal and vertical gridlines are present to aid in reading values.
### Detailed Analysis
**Asso. Hallu./Factual Asso. (Blue Line):**
The blue line starts at approximately 1.005 at Layer 0, then generally slopes downward until around Layer 8, reaching a minimum of approximately 0.985. From Layer 8 to Layer 20, the line remains relatively stable, fluctuating between approximately 0.985 and 1.00. After Layer 20, the line exhibits an upward trend, reaching approximately 1.01 at Layer 32.
* Layer 0: ~1.005
* Layer 2: ~1.003
* Layer 4: ~0.998
* Layer 6: ~0.993
* Layer 8: ~0.988
* Layer 10: ~0.987
* Layer 12: ~0.989
* Layer 14: ~0.991
* Layer 16: ~0.993
* Layer 18: ~0.996
* Layer 20: ~0.998
* Layer 22: ~1.001
* Layer 24: ~1.003
* Layer 26: ~1.005
* Layer 28: ~1.007
* Layer 30: ~1.009
* Layer 32: ~1.01
**Unasso. Hallu./Factual Asso. (Red Line):**
The red line begins at approximately 0.995 at Layer 0, decreasing to a minimum of approximately 0.958 around Layer 6. From Layer 6 to Layer 16, the line gradually increases, reaching approximately 0.985 at Layer 16. Between Layer 16 and Layer 24, the line continues to rise, reaching a peak of approximately 1.002 at Layer 24. After Layer 24, the line declines slightly, ending at approximately 0.995 at Layer 32.
* Layer 0: ~0.995
* Layer 2: ~0.993
* Layer 4: ~0.988
* Layer 6: ~0.958
* Layer 8: ~0.962
* Layer 10: ~0.965
* Layer 12: ~0.969
* Layer 14: ~0.975
* Layer 16: ~0.985
* Layer 18: ~0.992
* Layer 20: ~0.996
* Layer 22: ~0.999
* Layer 24: ~1.002
* Layer 26: ~1.000
* Layer 28: ~0.998
* Layer 30: ~0.996
* Layer 32: ~0.995
### Key Observations
* The "Unasso. Hallu./Factual Asso." ratio exhibits a more pronounced decrease in the early layers (0-6) compared to the "Asso. Hallu./Factual Asso." ratio.
* Both ratios show a general trend of increasing with the number of layers beyond 20 layers.
* The "Asso. Hallu./Factual Asso." ratio remains consistently higher than the "Unasso. Hallu./Factual Asso." ratio throughout the observed range of layers.
### Interpretation
The chart suggests that increasing the number of layers in the model initially reduces the ratio of both associated and unassociated hallucinations to factual associations. However, beyond a certain depth (around 20 layers in this case), adding more layers appears to *increase* the propensity for hallucinations, particularly for associated hallucinations. This could indicate that deeper models, while capable of more complex representations, are also more prone to generating outputs that are not grounded in factual information. The difference between the two lines suggests that associated hallucinations are more prevalent than unassociated ones, and that this difference is maintained as the model depth increases. This could be due to the model learning spurious correlations in the training data, leading to hallucinations that are related to the input but not factually accurate. The initial decrease in hallucination ratio could be attributed to the model learning more robust representations in the early layers, while the subsequent increase could be due to overfitting or the emergence of unintended behaviors in deeper layers.
</details>
Figure 14: Norm ratio curves of subject representations in Mistral-7B-v0.3, comparing AHs and UHs against FAs as the baseline. At earlier layers, the norm of UH samples is significantly lower than that of AH samples.
<details>
<summary>x18.png Details</summary>
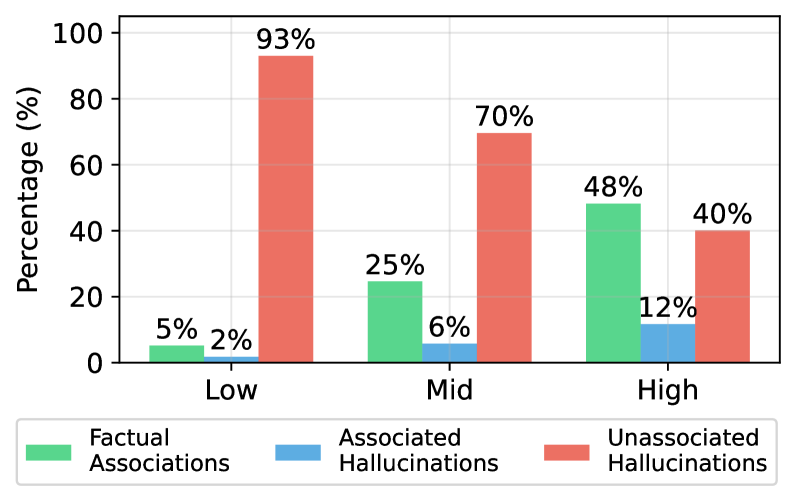
### Visual Description
\n
## Bar Chart: Hallucination Rates by Factual Association Level
### Overview
This bar chart displays the percentage of hallucinations (categorized as "Associated Hallucinations" and "Unassociated Hallucinations") and "Factual Associations" across three levels: "Low", "Mid", and "High". The y-axis represents the percentage, ranging from 0% to 100%. The x-axis represents the level of factual association.
### Components/Axes
* **X-axis:** "Factual Association Level" with categories: "Low", "Mid", "High".
* **Y-axis:** "Percentage (%)" with a scale from 0 to 100, incrementing by 20.
* **Legend:** Located at the bottom of the chart, identifying the three data series:
* "Factual Associations" (represented by a teal/light green color)
* "Associated Hallucinations" (represented by a light blue color)
* "Unassociated Hallucinations" (represented by a coral/red color)
### Detailed Analysis
The chart consists of three groups of bars, one for each level of factual association ("Low", "Mid", "High"). Within each group, there are three bars representing the percentage for each of the three data series.
* **Low:**
* Factual Associations: Approximately 5% (teal bar)
* Associated Hallucinations: Approximately 2% (light blue bar)
* Unassociated Hallucinations: Approximately 93% (coral/red bar)
* **Mid:**
* Factual Associations: Approximately 25% (teal bar)
* Associated Hallucinations: Approximately 6% (light blue bar)
* Unassociated Hallucinations: Approximately 70% (coral/red bar)
* **High:**
* Factual Associations: Approximately 48% (teal bar)
* Associated Hallucinations: Approximately 12% (light blue bar)
* Unassociated Hallucinations: Approximately 40% (coral/red bar)
The "Unassociated Hallucinations" bar dominates at the "Low" level, decreasing as the "Factual Association Level" increases. The "Factual Associations" bar increases steadily from "Low" to "High". The "Associated Hallucinations" bar remains relatively low across all levels, with a slight increase from "Low" to "High".
### Key Observations
* The percentage of "Unassociated Hallucinations" is significantly higher at the "Low" factual association level (93%) compared to the "Mid" (70%) and "High" (40%) levels.
* The percentage of "Factual Associations" increases as the factual association level increases, suggesting a positive correlation.
* "Associated Hallucinations" remain a small percentage across all levels.
### Interpretation
The data suggests that as the level of factual association increases, the prevalence of unassociated hallucinations decreases, while the prevalence of factual associations increases. This could indicate that hallucinations are less likely to occur when there is a stronger grounding in factual information. The relatively low percentage of associated hallucinations suggests that hallucinations are more often unrelated to factual context than directly linked to it. The chart highlights a potential relationship between factual grounding and the nature of hallucinations, suggesting that interventions aimed at strengthening factual associations might reduce the occurrence of unassociated hallucinations. The steep drop in unassociated hallucinations from "Low" to "Mid" factual association is a particularly notable trend, suggesting a critical threshold effect.
</details>
Figure 15: Sample distribution across different subject popularity (low, mid, high) in Mistral-7B-v0.3, measured by monthly Wikipedia page views.
Decoding algorithm.
We employ greedy decoding ( $\text{temperature}=0$ ) for response generation, with models run in BF16 precision.
PEFT settings for refusal tuning.
For refusal tuning, we fine-tune with both models using QLoRA Dettmers et al. (2023), implemented with the Unsloth framework Daniel Han and team (2023), with rank $r=8$ , and $\alpha=8$ . QLoRA adapters are applied to all attention and MLP modules, and each model is fine-tuned for one epoch.
<details>
<summary>x19.png Details</summary>
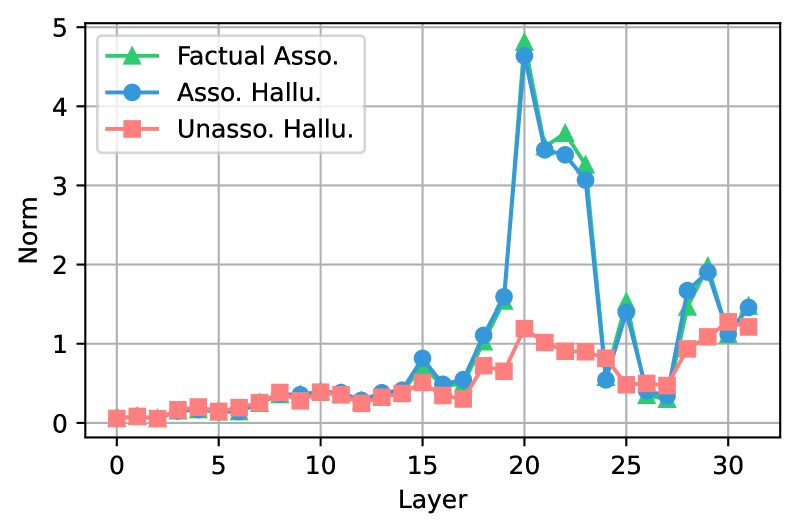
### Visual Description
\n
## Line Chart: Norm vs. Layer for Association Types
### Overview
The image presents a line chart illustrating the relationship between "Layer" (x-axis) and "Norm" (y-axis) for three different types of associations: "Factual Association", "Association Hallucination", and "Unassociation Hallucination". The chart displays the normalized values of these associations across layers, presumably within a neural network or similar layered system.
### Components/Axes
* **X-axis:** "Layer", ranging from 0 to approximately 32. The axis is linearly scaled with markers at intervals of 5.
* **Y-axis:** "Norm", ranging from 0 to 5. The axis is linearly scaled with markers at intervals of 1.
* **Legend:** Located in the top-left corner of the chart.
* "Factual Asso." (represented by a green triangle marker)
* "Asso. Hallu." (represented by a blue circle marker)
* "Unasso. Hallu." (represented by a red square marker)
* **Gridlines:** Present to aid in reading values.
### Detailed Analysis
The chart contains three distinct lines, each representing one of the association types.
* **Factual Asso. (Green):** The line starts at approximately 0.2 at Layer 0, remains relatively flat until around Layer 18, then increases sharply to a peak of approximately 4.2 at Layer 20. It then declines to around 0.7 at Layer 24, and fluctuates between 0.7 and 1.8 until Layer 32, ending at approximately 1.7.
* **Asso. Hallu. (Blue):** This line begins at approximately 0.1 at Layer 0 and remains low until around Layer 18, where it begins to rise. It peaks sharply at approximately 4.5 at Layer 20, then rapidly decreases to around 0.5 at Layer 24. It then fluctuates between 0.5 and 1.5 until Layer 32, ending at approximately 1.2.
* **Unasso. Hallu. (Red):** This line starts at approximately 0.05 at Layer 0 and gradually increases to around 0.6 at Layer 18. It continues to rise, peaking at approximately 1.2 at Layer 20, then declines to around 0.8 at Layer 24. It fluctuates between 0.8 and 1.3 until Layer 32, ending at approximately 1.1.
### Key Observations
* Both "Factual Asso." and "Asso. Hallu." exhibit a significant peak around Layer 20, suggesting a critical point in the network where these associations are most pronounced.
* "Asso. Hallu." consistently shows higher normalized values than "Factual Asso." around the peak at Layer 20, indicating a stronger presence of association hallucinations at that layer.
* "Unasso. Hallu." remains consistently lower than the other two association types throughout the entire range of layers.
* All three lines show a general increase in "Norm" values as the "Layer" number increases, up to the peak around Layer 20, followed by a decline and subsequent fluctuation.
### Interpretation
The data suggests that Layer 20 is a critical layer within the system being analyzed, where both factual associations and association hallucinations reach their highest levels. The higher normalized values for "Asso. Hallu." at this layer indicate that the system is prone to generating incorrect associations at this point. The relatively low values for "Unasso. Hallu." suggest that the system is less likely to generate hallucinations that are completely unrelated to the input.
The increasing trend in all three association types up to Layer 20 could indicate that the network is learning and forming more connections as it progresses through the layers. The subsequent decline after Layer 20 might suggest that the network is starting to refine its associations and reduce the number of hallucinations, or that the signal is being lost.
The fluctuations in the lines after Layer 20 could be due to noise in the data, or they could represent more subtle changes in the network's behavior. Further investigation would be needed to determine the exact cause of these fluctuations. The chart provides a valuable insight into the behavior of the system and could be used to identify areas for improvement.
</details>
Figure 16: Subject-to-last attention contribution norms across layers in Mistral-7B-v0.3. Values show the norm of the attention contribution from subject tokens to the last token at each layer.
<details>
<summary>x20.png Details</summary>
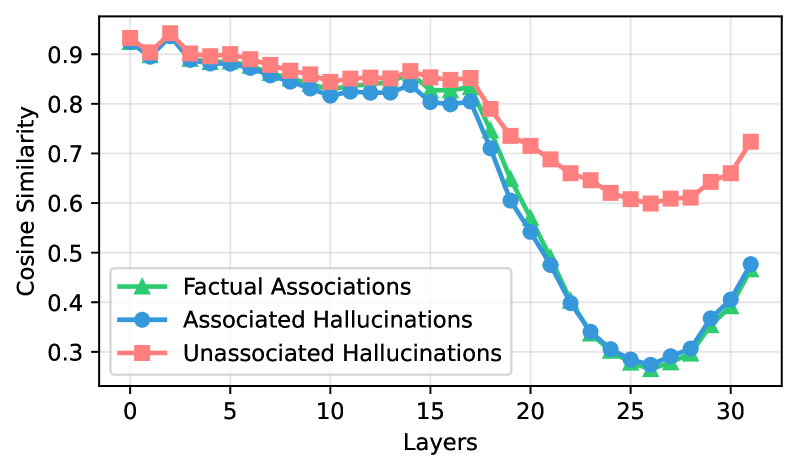
### Visual Description
## Line Chart: Cosine Similarity vs. Layers
### Overview
The image presents a line chart illustrating the relationship between the number of layers in a model and the cosine similarity scores for three different types of associations: Factual Associations, Associated Hallucinations, and Unassociated Hallucinations. The chart appears to be evaluating the impact of model depth on the quality of generated associations.
### Components/Axes
* **X-axis:** "Layers" - ranging from approximately 0 to 32.
* **Y-axis:** "Cosine Similarity" - ranging from approximately 0.3 to 0.95.
* **Legend:** Located in the bottom-left corner.
* "Factual Associations" - represented by a green line with triangle markers.
* "Associated Hallucinations" - represented by a blue line with circle markers.
* "Unassociated Hallucinations" - represented by a red line with square markers.
* **Grid:** A light gray grid is present in the background to aid in reading values.
### Detailed Analysis
* **Unassociated Hallucinations (Red Line):** This line starts at approximately 0.92 at Layer 0, and generally decreases with a slight fluctuation until Layer 20, where it drops sharply. From Layer 20 to Layer 32, it remains relatively stable, fluctuating between approximately 0.62 and 0.68.
* **Associated Hallucinations (Blue Line):** This line begins at approximately 0.84 at Layer 0, and decreases steadily until Layer 20, where it experiences a dramatic drop. From Layer 20 to Layer 32, it increases again, starting from approximately 0.28 and reaching approximately 0.42.
* **Factual Associations (Green Line):** This line starts at approximately 0.75 at Layer 0, and remains relatively stable until Layer 18, where it begins to decrease. It reaches a minimum of approximately 0.28 at Layer 25, and then increases again, reaching approximately 0.4 at Layer 32.
**Specific Data Points (Approximate):**
| Layers | Factual Associations | Associated Hallucinations | Unassociated Hallucinations |
|---|---|---|---|
| 0 | 0.75 | 0.84 | 0.92 |
| 5 | 0.78 | 0.82 | 0.90 |
| 10 | 0.77 | 0.80 | 0.88 |
| 15 | 0.76 | 0.78 | 0.85 |
| 20 | 0.65 | 0.28 | 0.65 |
| 25 | 0.28 | 0.30 | 0.63 |
| 30 | 0.38 | 0.40 | 0.65 |
| 32 | 0.40 | 0.42 | 0.67 |
### Key Observations
* All three lines exhibit a decreasing trend in cosine similarity up to approximately Layer 20.
* The "Associated Hallucinations" and "Unassociated Hallucinations" lines experience a significant drop around Layer 20, while "Factual Associations" begins a more gradual decline.
* After Layer 20, the "Associated Hallucinations" line shows a slight increase, while the other two lines remain relatively stable or continue to fluctuate.
* "Unassociated Hallucinations" consistently have the highest cosine similarity scores throughout the observed range of layers.
### Interpretation
The data suggests that as the number of layers in the model increases, the cosine similarity between the model's associations and factual information decreases, while the tendency towards hallucinations (both associated and unassociated) initially decreases, but then potentially increases again at deeper layers. The sharp drop around Layer 20 could indicate a point of instability or a transition in the model's behavior. The fact that "Unassociated Hallucinations" maintain higher similarity scores suggests that the model is more prone to generating associations that are not grounded in factual information, even as it becomes deeper. The slight increase in "Associated Hallucinations" after Layer 20 might indicate that the model starts to form more complex, but potentially inaccurate, connections as it gains depth. This could be a sign of overfitting or the emergence of spurious correlations. The chart highlights a trade-off between model depth and the quality of generated associations, suggesting that there may be an optimal number of layers beyond which the benefits of increased depth are outweighed by the risk of hallucinations.
</details>
Figure 17: Cosine similarity of target-token hidden states across layers in Mistral-7B-v0.3. From mid-layers onward, FAs and AHs diverge sharply as subject information propagates, while UHs remain more clustered, confirming weaker subject-dependent updates.
<details>
<summary>x21.png Details</summary>
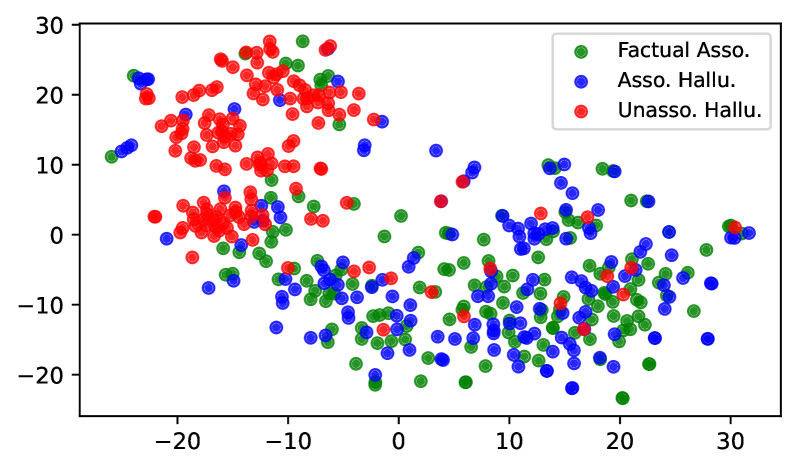
### Visual Description
\n
## Scatter Plot: Association Analysis
### Overview
The image presents a scatter plot visualizing the distribution of three categories of associations: "Factual Association", "Association Hallucination", and "Unassociated Hallucination". The plot displays these associations across two dimensions, represented by the x and y axes, with values ranging approximately from -25 to 35. The data points are color-coded according to their category, as indicated by the legend in the top-right corner.
### Components/Axes
* **X-axis:** Ranges from approximately -25 to 35. No explicit label is provided.
* **Y-axis:** Ranges from approximately -25 to 30. No explicit label is provided.
* **Legend:** Located in the top-right corner.
* Green: "Factual Asso." (Factual Association)
* Blue: "Asso. Hallu." (Association Hallucination)
* Red: "Unasso. Hallu." (Unassociated Hallucination)
### Detailed Analysis
The plot contains a large number of data points for each category.
* **Factual Association (Green):** The green data points are scattered throughout the plot, with a concentration in the lower-right quadrant (positive x-values, negative y-values) and a smaller cluster in the upper-left quadrant (negative x-values, positive y-values). Values appear to range from approximately x = -5 to x = 25, and y = -15 to y = 20.
* **Association Hallucination (Blue):** The blue data points are more densely concentrated in the lower-left quadrant (negative x and y values) and show a moderate spread across the plot. Values appear to range from approximately x = -20 to x = 30, and y = -20 to y = 10.
* **Unassociated Hallucination (Red):** The red data points are heavily concentrated in the upper-left quadrant (negative x-values, positive y-values) and show a moderate spread. Values appear to range from approximately x = -25 to x = 15, and y = 0 to y = 25.
**Trend Verification:**
* The green points do not exhibit a clear linear trend, but show a tendency to cluster in the lower-right.
* The blue points show a slight upward trend from left to right, but are largely scattered.
* The red points show a concentration in the upper-left, with a downward trend as x increases.
### Key Observations
* The "Unassociated Hallucination" (red) category exhibits the highest concentration of points in the upper-left quadrant, suggesting a strong association between negative x-values and positive y-values for this category.
* The "Association Hallucination" (blue) category is more evenly distributed, but leans towards negative x and y values.
* The "Factual Association" (green) category shows a more dispersed pattern, with points across a wider range of x and y values.
* There is significant overlap between all three categories, indicating that the two dimensions do not perfectly separate the associations.
### Interpretation
This scatter plot likely represents a dimensionality reduction of some higher-dimensional data related to associations. The x and y axes represent the reduced dimensions, and the color-coding indicates the type of association. The plot suggests that "Unassociated Hallucinations" are distinct from "Factual Associations" in this reduced space, as they cluster in a different region. "Association Hallucinations" appear to be intermediate, overlapping with both other categories.
The lack of explicit axis labels makes it difficult to interpret the meaning of the x and y dimensions. However, the plot suggests that these dimensions capture some underlying structure in the data that differentiates between factual associations and different types of hallucinations. The overlap between categories indicates that the dimensions are not perfect predictors of association type.
The plot could be used to evaluate the performance of an association learning model, where the goal is to identify factual associations and distinguish them from hallucinations. The distribution of points could reveal biases or weaknesses in the model. For example, if the model tends to misclassify "Factual Associations" as "Association Hallucinations", this would be reflected in an overlap between the green and blue clusters.
</details>
Figure 18: t-SNE visualization of last token’s representations at layer 25 of Mistral-7B-v0.3.
<details>
<summary>x22.png Details</summary>
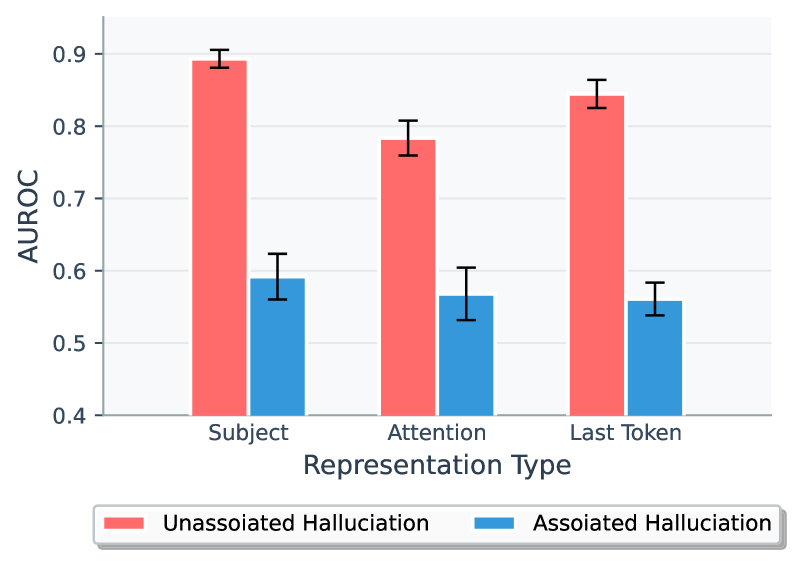
### Visual Description
\n
## Bar Chart: AUROC Scores for Hallucination Types
### Overview
This bar chart compares the Area Under the Receiver Operating Characteristic curve (AUROC) scores for two types of hallucinations – "Unassociated Hallucination" and "Associated Hallucination" – across three different "Representation Types": "Subject", "Attention", and "Last Token". Error bars are included for each data point, indicating the variability or confidence interval around the mean AUROC score.
### Components/Axes
* **X-axis:** "Representation Type" with categories: "Subject", "Attention", "Last Token".
* **Y-axis:** "AUROC" with a scale ranging from approximately 0.4 to 0.9.
* **Legend:** Located in the bottom-left corner.
* "Unassociated Hallucination" – represented by a red color.
* "Associated Hallucination" – represented by a blue color.
### Detailed Analysis
The chart consists of six bars, grouped by Representation Type and Hallucination Type. Each bar has an error bar extending vertically.
* **Subject:**
* Unassociated Hallucination (Red): The bar is approximately 0.87 high, with an error bar extending from roughly 0.84 to 0.90.
* Associated Hallucination (Blue): The bar is approximately 0.57 high, with an error bar extending from roughly 0.53 to 0.61.
* **Attention:**
* Unassociated Hallucination (Red): The bar is approximately 0.78 high, with an error bar extending from roughly 0.74 to 0.82.
* Associated Hallucination (Blue): The bar is approximately 0.56 high, with an error bar extending from roughly 0.52 to 0.60.
* **Last Token:**
* Unassociated Hallucination (Red): The bar is approximately 0.84 high, with an error bar extending from roughly 0.80 to 0.88.
* Associated Hallucination (Blue): The bar is approximately 0.55 high, with an error bar extending from roughly 0.51 to 0.59.
The red bars (Unassociated Hallucination) are consistently higher than the blue bars (Associated Hallucination) across all three Representation Types.
### Key Observations
* Unassociated hallucinations consistently achieve higher AUROC scores than associated hallucinations, indicating better discrimination performance.
* The AUROC scores for Unassociated Hallucinations are relatively stable across the three Representation Types, ranging from approximately 0.78 to 0.87.
* The AUROC scores for Associated Hallucinations are also relatively stable, ranging from approximately 0.55 to 0.57.
* The error bars suggest a reasonable degree of confidence in the reported AUROC scores, although there is some variability.
### Interpretation
The data suggests that it is easier to detect unassociated hallucinations compared to associated hallucinations, as evidenced by the consistently higher AUROC scores. This could be because unassociated hallucinations are more readily identifiable as deviations from expected behavior, while associated hallucinations might be more subtle or context-dependent. The representation type (Subject, Attention, Last Token) does not appear to significantly impact the ability to distinguish between these two types of hallucinations, as the AUROC scores remain relatively consistent across all three. The relatively small error bars indicate that the observed differences are likely statistically significant. This information is valuable for developing and evaluating hallucination detection methods in language models, suggesting that focusing on identifying unassociated hallucinations might be a more effective strategy.
</details>
Figure 19: Hallucination detection performance on the Full setting (Mistral-v0.3-7B).
<details>
<summary>x23.png Details</summary>
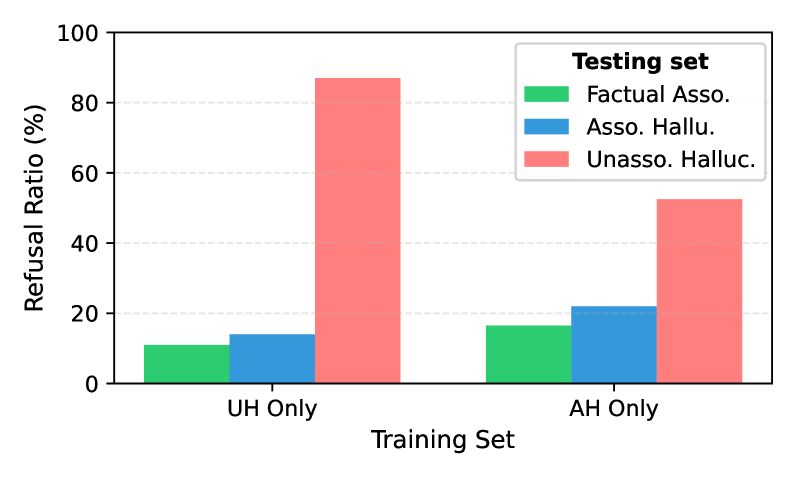
### Visual Description
\n
## Bar Chart: Refusal Ratio by Training and Testing Set
### Overview
This bar chart displays the refusal ratio (in percentage) for different testing sets (Factual Association, Associative Hallucination, and Unassociated Hallucination) trained on different training sets (UH Only and AH Only). The chart compares the performance of a system in refusing to answer questions based on the type of hallucination or factual association present in the testing data, and the type of data used for training.
### Components/Axes
* **X-axis:** "Training Set" with two categories: "UH Only" and "AH Only".
* **Y-axis:** "Refusal Ratio (%)" ranging from 0 to 100, with tick marks at intervals of 20.
* **Legend (top-right):** "Testing set" with three categories:
* "Factual Asso." (represented by green)
* "Asso. Hallu." (represented by blue)
* "Unasso. Halluc." (represented by red)
### Detailed Analysis
The chart consists of six bars, grouped by training set.
**UH Only Training Set:**
* **Factual Asso. (Green):** The bar rises to approximately 10%.
* **Asso. Hallu. (Blue):** The bar rises to approximately 15%.
* **Unasso. Halluc. (Red):** The bar rises to approximately 90%.
**AH Only Training Set:**
* **Factual Asso. (Green):** The bar rises to approximately 20%.
* **Asso. Hallu. (Blue):** The bar rises to approximately 20%.
* **Unasso. Halluc. (Red):** The bar rises to approximately 45%.
### Key Observations
* The refusal ratio is significantly higher for "Unasso. Halluc." in both training set scenarios.
* Training on "UH Only" results in a much higher refusal ratio for "Unasso. Halluc." compared to training on "AH Only".
* The refusal ratio for "Factual Asso." and "Asso. Hallu." is relatively low and similar across both training sets.
* The "AH Only" training set shows a more balanced refusal ratio across all testing sets compared to the "UH Only" training set.
### Interpretation
The data suggests that the system is much more likely to refuse to answer questions that involve unassociated hallucinations, regardless of the training data. However, the training data significantly impacts the refusal rate for unassociated hallucinations. Training solely on "UH Only" data leads to a very high refusal rate for unassociated hallucinations, indicating the model has learned to be highly cautious in such scenarios. Conversely, training on "AH Only" data results in a lower refusal rate for unassociated hallucinations, suggesting the model is more willing to attempt answering even in the presence of unassociated hallucinations.
The relatively low refusal rates for "Factual Asso." and "Asso. Hallu." indicate that the system is generally comfortable answering questions that involve factual associations or associative hallucinations. The similar refusal rates across both training sets for these categories suggest that the training data has a less pronounced effect on the system's behavior in these cases.
The difference in refusal rates between the training sets highlights the importance of the training data in shaping the system's response to different types of hallucinations. A system trained on a more diverse dataset (potentially including both UH and AH data) might exhibit a more nuanced and balanced refusal behavior.
</details>
Figure 20: Refusal tuning performance across three types of samples (Mistral-v0.3-7B).
## Appendix B Parallel Experiments on Mistral
This section is for documenting parallel experiments conducted on the Mistral-7B-v0.3 model under the same settings as described in the main text (Figures 13 – 20).
The results from Mistral exhibit similar patterns to those observed in LLaMA, as described before. Specifically, we find consistent patterns in the model’s internal computations, hidden-state behaviors, and the performance of hallucination detection and refusal tuning experiments.
<details>
<summary>x24.png Details</summary>
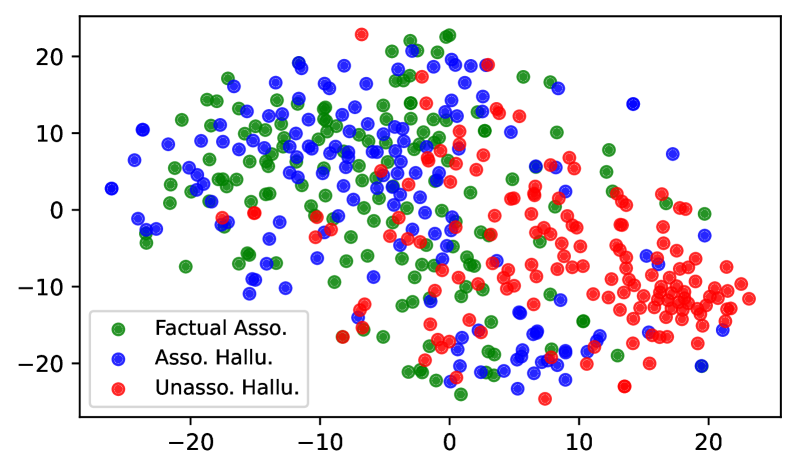
### Visual Description
\n
## Scatter Plot: Association Analysis
### Overview
This image presents a scatter plot visualizing the distribution of three categories of associations: "Factual Asso.", "Asso. Hallu.", and "Unasso. Hallu." The plot displays these associations based on two unspecified numerical dimensions, represented by the x and y axes. The data points are color-coded according to their category, with a legend in the bottom-left corner explaining the color scheme.
### Components/Axes
* **X-axis:** Ranges approximately from -25 to 25, with tick marks at -20, -10, 0, 10, and 20. No explicit label is provided.
* **Y-axis:** Ranges approximately from -25 to 25, with tick marks at -20, -10, 0, 10, and 20. No explicit label is provided.
* **Legend:** Located in the bottom-left corner.
* Green circles: "Factual Asso."
* Blue circles: "Asso. Hallu."
* Red circles: "Unasso. Hallu."
### Detailed Analysis
The plot contains a large number of data points for each category, distributed across the x-y plane.
* **Factual Asso. (Green):** The points are concentrated in the upper-left quadrant, with a general trend of decreasing values as the x-coordinate increases. The y-values range from approximately -5 to 22. There is a slight clustering around x = -5 and y = 15.
* **Asso. Hallu. (Blue):** These points are more widely dispersed than the "Factual Asso." points. They span the entire range of both axes, with a noticeable concentration in the lower-left quadrant and a scattering throughout the upper-right quadrant. The y-values range from approximately -22 to 12.
* **Unasso. Hallu. (Red):** The points are primarily located in the lower-right quadrant, with a strong tendency towards negative y-values. The x-values range from approximately -20 to 22, and the y-values range from approximately -20 to 5. There is a clear clustering around x = 15 and y = -10.
### Key Observations
* The "Factual Asso." points exhibit a negative correlation between the x and y values.
* The "Asso. Hallu." points show no clear correlation and are more randomly distributed.
* The "Unasso. Hallu." points are heavily concentrated in the lower-right quadrant, suggesting a strong association between high x-values and low y-values.
* There is significant overlap between the three categories, particularly in the central region of the plot.
### Interpretation
The scatter plot likely represents an analysis of associations between different variables or concepts. The three categories – "Factual Asso.", "Asso. Hallu.", and "Unasso. Hallu." – could represent different types of associations, potentially based on their strength, reliability, or origin.
* "Factual Asso." might represent associations supported by empirical evidence or established knowledge. The negative correlation suggests that as one variable increases, the other tends to decrease.
* "Asso. Hallu." could represent associations based on hallucinations or subjective experiences. The random distribution indicates a lack of consistent relationship between the variables.
* "Unasso. Hallu." might represent associations arising from hallucinations that are not related to any underlying factual basis. The concentration in the lower-right quadrant suggests a specific pattern or bias in these hallucinations.
The overlap between the categories suggests that there is ambiguity in classifying associations, and some associations may fall into multiple categories. The plot could be used to identify patterns in associations, assess the reliability of different types of associations, or explore the underlying mechanisms that generate associations. The lack of axis labels makes it difficult to determine the specific variables being analyzed, but the plot provides valuable insights into the relationships between different types of associations.
</details>
Figure 21: t-SNE visualization of subject tokens’ representations at layer 11 of LLaMA-3-8B.
<details>
<summary>x25.png Details</summary>
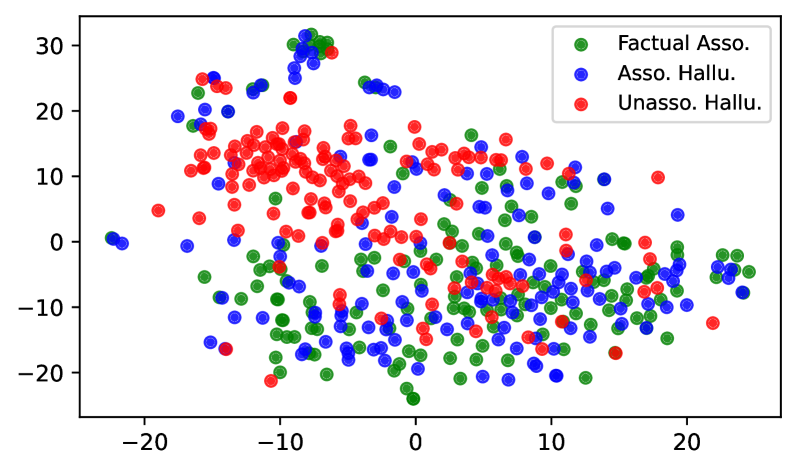
### Visual Description
\n
## Scatter Plot: Association Hallucinations
### Overview
This image presents a scatter plot visualizing the relationship between three categories: "Factual Asso.", "Asso. Hallu.", and "Unasso. Hallu." The plot displays data points distributed across a two-dimensional space, likely representing some form of association strength or measurement.
### Components/Axes
* **X-axis:** Ranges approximately from -25 to 25, with no explicit label.
* **Y-axis:** Ranges approximately from -25 to 30, with no explicit label.
* **Legend:** Located in the top-right corner.
* **Factual Asso.** (Green circles)
* **Asso. Hallu.** (Blue circles)
* **Unasso. Hallu.** (Red circles)
### Detailed Analysis
The plot contains a large number of data points for each category.
* **Factual Asso. (Green):** The points are scattered broadly across the plot, with a concentration in the lower-left quadrant (approximately x=-15 to 5, y=-20 to 10). There's a noticeable cluster around x=-5, y=-5. The points generally range from y=-20 to y=15, and x=-20 to x=10.
* **Asso. Hallu. (Blue):** These points are concentrated in the upper-left quadrant (approximately x=-15 to 5, y=5 to 30). There's a distinct cluster around x=-10, y=25. The points generally range from y=0 to y=30, and x=-20 to x=20.
* **Unasso. Hallu. (Red):** These points are widely distributed, with a significant concentration in the upper-right quadrant (approximately x=5 to 20, y=5 to 20). There's a cluster around x=10, y=10. The points generally range from y=-5 to y=20, and x=-20 to x=25.
Trend Verification:
* Factual Asso. shows no clear trend, appearing randomly distributed.
* Asso. Hallu. shows a tendency to cluster in the upper-left quadrant.
* Unasso. Hallu. shows a tendency to cluster in the upper-right quadrant.
### Key Observations
* The "Asso. Hallu." and "Unasso. Hallu." categories exhibit a higher concentration of points in the positive Y-axis region compared to "Factual Asso.".
* There is significant overlap between all three categories, indicating that the underlying variables are not perfectly separable.
* The distribution of "Factual Asso." is more spread out and less clustered than the other two categories.
* The "Asso. Hallu." points are generally located at higher Y values than the "Factual Asso." points.
### Interpretation
The scatter plot likely represents a comparison of associations derived from factual data versus those generated through some form of hallucination or non-associated process. The x and y axes likely represent dimensions of some underlying feature space.
The clustering of "Asso. Hallu." in the upper-left quadrant suggests that these associations tend to have a positive value on the Y-axis, while being relatively negative or near zero on the X-axis. Conversely, "Unasso. Hallu." points in the upper-right quadrant suggest a positive value on both axes. "Factual Asso." points are more dispersed, indicating a wider range of values on both axes.
The overlap between the categories suggests that there is some ambiguity in distinguishing between factual associations and hallucinated associations. The plot could be used to evaluate the performance of a model or system in identifying true associations versus spurious ones. The lack of axis labels makes it difficult to provide a more specific interpretation. The data suggests that hallucinated associations are different from factual associations, and that there are two distinct types of hallucinated associations ("Asso. Hallu." and "Unasso. Hallu.").
</details>
Figure 22: t-SNE visualization of subject tokens’ representations at layer 11 of Mistral-7B-v0.3.
## Appendix C More Visualization on Hidden States
In this section, we provide t-SNE visualization of subject tokens’ hidden states in Figure 21 and Figure 22.
Compared to the last-token representations, the t-SNE visualization of subject-token hidden states shows that unassociated hallucinations (UHs) are moderately separated from factual and associated samples, but the separation is less distinct than in the last-token representations. This observation aligns with the results in § 5, where the hallucination detection performance using last-token hidden states outperforms that based on subject-token representations.