# SwarmSys: Decentralized Swarm-Inspired Agents for Scalable and Adaptive Reasoning
## SwarmSys: Decentralized Swarm-Inspired Agents for Scalable and Adaptive Reasoning
Ruohao Li *1 , Hongjun Liu *2,4 , Leyi Zhao 5 , Zisu Li 3 , Jiawei Li 1 ,
Jiajun Jiang 1 , Linning Xu 6 , Chen Zhao 2,4 , Mingming Fan †1,3 ,
Chen Liang †1
1 The Hong Kong University of Science and Technology (Guangzhou) 2 New York University 3 The Hong Kong University of Science and Technology 4 NYU Shanghai 5 Indiana University 6 The Chinese University of Hong Kong
* Equal contribution. † Co-corresponding authors.
Correspondence:
rli777@connect.hkust-gz.edu.cn, lh3862@nyu.edu
## Abstract
Large language model (LLM) agents have shown remarkable reasoning abilities. However, existing multi-agent frameworks often rely on fixed roles or centralized control, limiting scalability and adaptability in long-horizon reasoning. We introduce SwarmSys, a closedloop framework for distributed multi-agent reasoning inspired by swarm intelligence. Coordination in SwarmSys emerges through iterative interactions among three specialized roles, Explorers, Workers, and Validators, that continuously cycle through exploration, exploitation, and validation. To enable scalable and adaptive collaboration, we integrate adaptive agent and event profiles, embedding-based probabilistic matching, and a pheromone-inspired reinforcement mechanism, supporting dynamic task allocation and self-organizing convergence without global supervision. Across symbolic reasoning, research synthesis, and scientific programming tasks, SwarmSys consistently outperforms baselines, improving both accuracy and reasoning stability. These findings highlight swarm-inspired coordination as a promising paradigm for scalable, robust, and adaptive multi-agent reasoning, suggesting that coordination scaling may rival model scaling in advancing LLM intelligence.
## 1 Introduction
The strong reasoning and planning capabilities of Large Language Models (LLMs) have spurred interest in multi-agent systems. These systems use collaboration to enhance reasoning diversity and reliability. Frameworks such as AutoGen (Wu et al., 2023) enable agent-to-agent dialogue for multiagent applications, while CAMEL (Li et al., 2023) leverages role-playing and inception prompting to facilitate autonomous cooperation. AutoGen Studio further provides a no-code interface for designing and debugging agent workflows (Dibia et al., 2024). However, most systems use fixed roles and
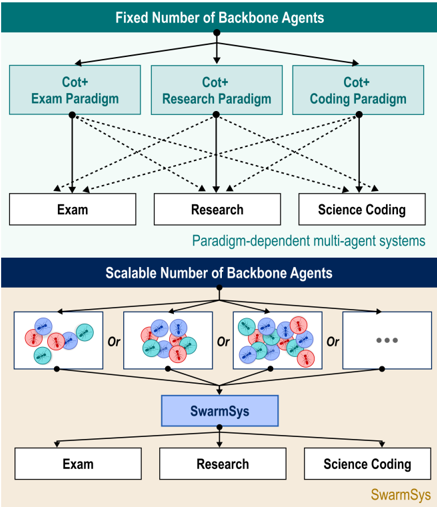
Figure 1: Comparison between paradigm-dependent multi-agent systems and SwarmSys. While existing methods rely on fixed, domain-specific agent paradigms, SwarmSys achieves scalable self-organization and crossdomain adaptability.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: Paradigm-Dependent Multi-Agent Systems Architecture
### Overview
The image presents a comparative architecture of two multi-agent systems: one with a fixed number of backbone agents and another with a scalable number. It illustrates how different paradigms (exam, research, science coding) interact with backbone agents under each system type.
### Components/Axes
**Top Section (Fixed Number of Backbone Agents):**
- **Header:** "Fixed Number of Backbone Agents" (dark teal banner)
- **Three Paradigm Boxes:**
1. "Cot+ Exam Paradigm" (left)
2. "Cot+ Research Paradigm" (center)
3. "Cot+ Coding Paradigm" (right)
- **Three Task Boxes:**
- "Exam" (bottom-left)
- "Research" (bottom-center)
- "Science Coding" (bottom-right)
- **Connections:** Dotted bidirectional arrows between paradigms and tasks
- **Footer Text:** "Paradigm-dependent multi-agent systems" (bottom-center)
**Bottom Section (Scalable Number of Backbone Agents):**
- **Header:** "Scalable Number of Backbone Agents" (dark blue banner)
- **Agent Clusters:**
- Multiple overlapping circles in red, blue, and green (representing agents)
- Connected via "or" operators between clusters
- **Central Box:** "SwarmSys" (light blue box)
- **Three Task Boxes:** Same as top section ("Exam," "Research," "Science Coding")
- **Connections:** Solid arrows from SwarmSys to tasks
- **Footer Text:** "SwarmSys" (bottom-right, orange text)
### Detailed Analysis
**Fixed System Architecture:**
1. Three distinct paradigms (exam, research, coding) each have dedicated connections to their respective tasks
2. Bidirectional dotted arrows suggest mutual influence between paradigms and tasks
3. Paradigms appear specialized but interconnected through shared task dependencies
**Scalable System Architecture:**
1. "SwarmSys" acts as a central coordinator for all tasks
2. Multiple agent clusters (red/blue/green) represent flexible agent populations
3. "or" operators between clusters imply combinatorial agent selection possibilities
4. Solid arrows indicate top-down task assignment from SwarmSys
**Color Coding:**
- Red/blue/green circles likely represent different agent types or capabilities
- Orange text ("SwarmSys") distinguishes the scalable system's core component
### Key Observations
1. Fixed system emphasizes paradigm-specific agent-task relationships
2. Scalable system introduces a centralized coordination layer (SwarmSys)
3. Bidirectional vs. unidirectional connections suggest different interaction models
4. "or" operators in scalable system imply non-deterministic agent selection
5. Both systems share the same three core tasks but implement them differently
### Interpretation
This diagram illustrates two approaches to multi-agent system design:
1. **Fixed Paradigm System:** Suitable for well-defined tasks with stable requirements. The paradigm-dependent connections suggest specialized agents for specific domains (exams, research, coding), potentially optimizing performance through focused expertise.
2. **Scalable Swarm System:** Designed for dynamic environments requiring flexible resource allocation. The SwarmSys central coordinator manages variable agent populations (represented by colored circles), with "or" operators suggesting adaptive task assignment based on current agent availability and capabilities.
The bidirectional arrows in the fixed system imply knowledge sharing between paradigms, while the scalable system's solid arrows suggest more rigid task delegation. The color-coded agents in the scalable system may represent different skill sets or processing capabilities that SwarmSys can dynamically combine.
The diagram highlights a fundamental tradeoff: fixed systems offer specialized efficiency at the cost of flexibility, while scalable systems provide adaptability through distributed intelligence but may sacrifice some optimization potential. This architectural comparison is particularly relevant for domains requiring both domain-specific expertise and dynamic resource management.
</details>
static communication, which limits their adaptability. This rigidity leads to redundant exploration and inefficiency, especially in long-horizon or dynamic tasks.
To address limitations, recent work has explored adaptive or self-improving agent collaboration. AutoAgent enables natural-language-defined behaviors instead of hand-coded roles (Tang et al., 2025), while Mixture-of-Agents introduces layered coordination for more robust reasoning (Wang et al., 2024). However, these systems still rely on centralized orchestration or manually designed topologies, limiting scalability and long-term stability. Inspired by the decentralized intelligence of natural swarms, where simple signals regulate cooperation and task allocation (Bonabeau et al., 1999; Dorigo and Stützle, 2004), we propose SwarmSys,
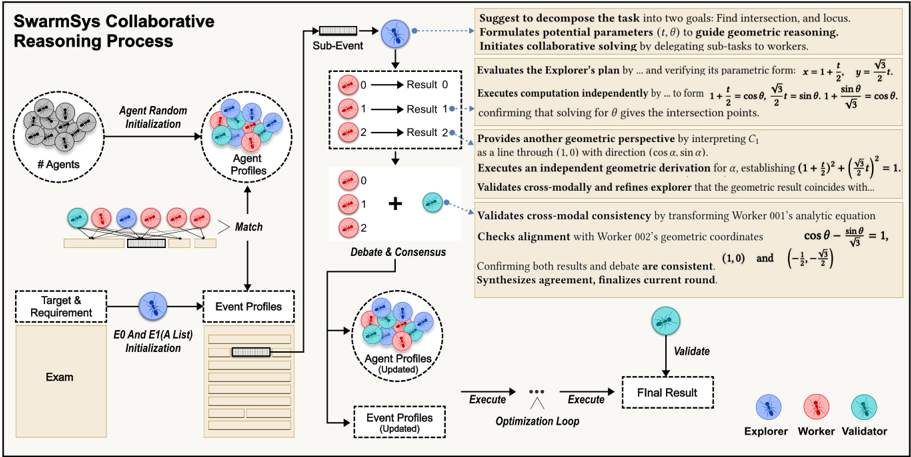
Figure 2: Overall workflow of the SwarmSys collaborative reasoning process. Each task is decomposed into subevents handled by specialized agents: Explorers propose solution paths, Workers execute subtasks, and Validators ensure consistency. Agents iteratively perform debate-consensus cycles that update event profiles and reinforce effective reasoning strategies until convergence.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Diagram: SwarmSys Collaborative Reasoning Process
### Overview
The diagram illustrates a multi-agent collaborative reasoning system (SwarmSys) with interconnected processes for task decomposition, agent coordination, geometric reasoning, and validation. It combines flowcharts, color-coded agent profiles, and technical equations to depict collaborative problem-solving.
### Components/Axes
1. **Left Process Flow**:
- **Agent Initialization**: Circle labeled "# Agents" (top-left) and "Agent Profiles" (color-coded: blue, red, green).
- **Match**: Arrows connecting agent profiles to a "Match" step.
- **Debate & Consensus**: Updated agent profiles after debate.
- **Target & Requirement**: Box labeled "Exam" with "Event Profiles" (E0 and E1 initialization).
2. **Right Flowchart**:
- **Task Decomposition**: Steps to decompose tasks into goals (find intersection/locus).
- **Parameter Formulation**: Equations for geometric reasoning (e.g., `x = 1 + t/2`, `y = √5/2`).
- **Validation Steps**: Cross-modal checks, geometric derivations, and consistency validation.
- **Optimization Loop**: Iterative "Execute" steps leading to "Final Result."
3. **Legend**:
- **Colors**:
- Blue = Explorer
- Red = Worker
- Green = Validator
### Detailed Analysis
- **Agent Initialization**:
- `# Agents` circle (top-left) contains 10 gray dots (agents).
- "Agent Profiles" circle (bottom-left) shows 5 color-coded dots (blue, red, green) representing initialized agents.
- **Matching & Debate**:
- Arrows from "Agent Profiles" to "Match" step.
- "Debate & Consensus" updates agent profiles with new configurations.
- **Geometric Reasoning**:
- Equations for intersection points (e.g., `x = 1 + t/2`, `y = √5/2`).
- Cross-modal validation using Worker 001’s analytic equation and Worker 002’s geometric coordinates.
- **Validation & Final Result**:
- "Validator" (green) checks alignment between analytic and geometric results.
- Final result synthesized after confirming consistency.
### Key Observations
1. **Color-Coded Roles**:
- Explorer (blue), Worker (red), Validator (green) roles are consistently mapped across the diagram.
- Example: In the "Agent Profiles" circle, blue dots align with the Explorer role in the flowchart.
2. **Iterative Process**:
- The "Optimization Loop" (bottom) shows repeated "Execute" steps, emphasizing iterative refinement.
3. **Technical Integration**:
- Geometric reasoning (e.g., `cos θ = sin θ = 1`) is tied to validation steps, ensuring cross-modal consistency.
### Interpretation
The diagram demonstrates a structured collaborative framework where agents (Explorer, Worker, Validator) work together to solve complex tasks. Key elements include:
- **Task Decomposition**: Breaking problems into geometric sub-tasks (e.g., finding intersections).
- **Cross-Modal Validation**: Ensuring consistency between analytic and geometric solutions.
- **Iterative Optimization**: Continuous refinement via the "Execute" loop.
The system prioritizes accuracy through validation steps and leverages geometric reasoning to resolve ambiguities. The color-coded agents and flowchart structure highlight modular collaboration, suggesting scalability for multi-agent systems.
</details>
a closed-loop framework that enables LLM agents to coordinate through lightweight, pheromone-like traces encoding contextual utility. This mechanism fosters self-organized collaboration, dynamically balancing exploration and convergence without centralized control.
Unlike debate or tree-based systems, SwarmSys allows coordination to emerge organically through iterative interaction and adaptive matching. Agents assume three roles, Explorers, Workers, and Validators, mirroring the division of labor in natural ant colonies. Explorers expand hypotheses, Workers refine and execute subtasks, and Validators ensure consistency, together forming continuous exploration-exploitation-validation cycles driving decentralized convergence. A core innovation is the use of profiles as adaptive memory. Agent and event profiles evolve with ability embeddings, workload, and context, enabling embedding-based reallocation and balanced participation-analogous to ants redistributing across foraging sites. Moreover, SwarmSys employs a pheromone-inspired reinforcement process: validated traces strengthen future compatibility, while ineffective ones decay, forming a decentralized optimization loop that enhances efficiency and stability over time.
Evaluated across symbolic reasoning, research synthesis, and scientific programming tasks, SwarmSys outperforms baselines such as GPTSwarm (Zhuge et al., 2024), achieving up to 10.7% higher accuracy and 9.9% better sub- task correctness. Remarkably, a swarm of GPT4o-based agents approaches GPT-5 performance, showing that scaling coordination can substitute for model scaling. Qualitative analyses reveal emergent behaviors, knowledge diffusion, specialization balance, and self-regularization, hallmarks of collective intelligence.
In summary, our contributions are threefold: (1) SwarmSys Framework: A closed-loop distributed multi-agent reasoning framework inspired by swarm intelligence for convergence. (2) Adaptive Coordination Mechanism: An embeddingbased matching and pheromone-inspired reinforcement process enabling dynamic agent-event allocation, self-organized collaboration, and stable longhorizon reasoning. (3) Comprehensive Evaluation: Extensive experiments across diverse reasoning tasks reveal consistent gains and emergent collective intelligence, showing that scaling coordination can rival scaling model capacity.
## 2 Methodology
## 2.1 Overview of SwarmSys
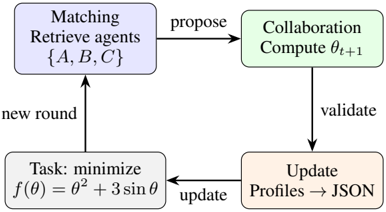
We present SwarmSys, a closed-loop collaborative framework for distributed problem solving. Unlike centralized orchestration or static task assignment, it converges through iterative matching → collaboration → update cycles, as is shown in Figure 3. Upon receiving new task, event profiles are instantiated, and candidate agents are retrieved via
Figure 3: Iterative cycle in SwarmSys: minimize f ( θ ) through matching → collaboration → update cycle.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Flowchart: Iterative Optimization Workflow
### Overview
The image depicts a cyclical workflow for an optimization task involving agent matching, collaboration, and iterative updates. The process includes four primary components connected by labeled arrows, with a feedback loop enabling repeated rounds.
### Components/Axes
1. **Matching Retrieve agents {A, B, C}** (Purple box):
- Initiates the workflow by retrieving agents labeled A, B, and C.
- Connected via an arrow labeled "propose" to the next component.
2. **Collaboration Compute θ_t+1** (Green box):
- Receives input from the matching step.
- Computes the next iteration parameter θ_{t+1}.
- Connected via an arrow labeled "validate" to the update step.
3. **Update Profiles → JSON** (Orange box):
- Receives validated θ_{t+1} and updates profiles.
- Outputs data in JSON format.
- Connected via an arrow labeled "update" to the task minimization step.
4. **Task: minimize f(θ) = θ² + 3 sin θ** (Gray box):
- Defines the mathematical objective function to minimize.
- Connected via an arrow labeled "new round" back to the matching step, forming a loop.
### Detailed Analysis
- **Arrows and Labels**:
- "propose" (Matching → Collaboration): Indicates proposal of agents for collaboration.
- "validate" (Collaboration → Update): Suggests validation of computed θ_{t+1}.
- "update" (Update → Task): Triggers the minimization task with updated profiles.
- "new round" (Task → Matching): Enables iterative cycles.
- **Mathematical Function**:
The task involves minimizing f(θ) = θ² + 3 sin θ, a non-convex function combining quadratic and sinusoidal terms.
### Key Observations
- **Feedback Loop**: The "new round" arrow creates a cyclical process, implying repeated optimization iterations.
- **Agent Roles**: Agents A, B, and C are central to the matching phase but lack explicit definitions in the diagram.
- **Color Coding**: Purple (Matching), Green (Collaboration), Orange (Update), Gray (Task) visually segregate components.
### Interpretation
This flowchart represents an **iterative optimization pipeline** where:
1. Agents are matched and proposed for collaboration.
2. A parameter θ is computed and validated.
3. Profiles are updated and serialized to JSON.
4. The minimization task refines θ using the objective function, restarting the cycle.
The inclusion of a sinusoidal term in f(θ) suggests the problem involves periodic or oscillatory behavior, requiring careful optimization to avoid local minima. The JSON output implies integration with external systems or storage. The lack of explicit termination conditions raises questions about convergence criteria.
**Notable Anomalies**:
- No explicit error-handling steps (e.g., invalid θ_{t+1} rejection).
- The function f(θ) is non-convex, which may complicate optimization.
</details>
embedding-based matching. Agents then enter collaborative rounds: explorers propose decomposition, workers execute subtasks after consensus, and validators verify intermediate results. After each round, both agent and event profiles are updated and stored for transparency and traceability. These evolving profiles feed subsequent iterations, enabling self-organization and adaptation. As shown in our framework (see figure 2), through repeated cycles, we achieve high-quality solutions without central controller, relying instead on distributed collaboration and profile-driven adaptation.
## 2.2 Profiles as Adaptive Memory Units
A core innovation of SwarmSys is the use of profiles as adaptive memory units that record both context and accumulated experience. Each agent profile maintains identifiers, role information, ability descriptions, workload status, and longitudinal performance history, the profile format is provided in Appendix A.4.1. Profiles evolve dynamically: embeddings and workload indicators are refreshed after each round, while historical success or failure influences future task matching. Agents thus behave as adaptive collaborators rather than stateless executors. Each event profile serves as a dynamic record of problem-solving. It contains task descriptions, dependency structures, metadata (e.g., composite or leaf type), progress logs, and participating agent lists. Over time, static specifications evolve into rich, evolving traces of reasoning.
Together, these profiles constitute SwarmSys's distributed memory: agent profiles encode competence and reliability, while event profiles track task evolution. Their joint updates ensure collaboration remains adaptive, interpretable, and transparent.
## 2.3 Embedding-Based Matching with Exploration-Exploitation Dynamics
The second key innovation is our embedding-based agent-event matching algorithm, which balances expertise, workload, and exploration.
Agent embeddings. Each agent A i is represented by two embeddings capturing its ability and availability. The competence embedding is derived from the agent's declared abilities and historical performance, processed through an instructionguided encoder that contextualizes the agent's prior experience for the current task. The availability embedding reflects workload and readiness, obtained from the agent's status signals. These two vectors are summed to form the agent's overall representation, combining long-term expertise with shortterm availability cues, the the detailed process is provided in Appendix A.4. This design allows the system to favor agents who are both skilled and currently underutilized.
Event embeddings. Each event E j is encoded through an instruction-conditioned embedding that integrates its textual description, dependency relations, progress state, and milestone metadata, the method is listed at AppendixA.1. This representation captures both the semantic meaning of the task and its structural role within the reasoning process. By embedding events and agents in a shared latent space, SwarmSys can estimate their compatibility in a continuous and scalable manner.
Compatibility and decision dynamics. The compatibility between an agent and an event is measured by normalized cosine similarity between their embeddings, ensuring a value between 0 and 1 for interpretability. To prevent premature convergence and encourage exploration, SwarmSys adopts a dynamic ε -greedy policy. Each agent explores new matches with probability ε i and exploits high-compatibility matches otherwise. The exploration rate ε i adapts to recent performance: agents with high average success explore less, while underperforming agents explore more. Empirically, we initialize ε i around 0.15 to maintain minimal randomness and allow it to fluctuate within a small range (up to 0.35) depending on recent success. The values are designed based on natural ant behaviors (Lecheval et al., 2024). This ensures that exploration gradually decreases as the system stabilizes. During exploration, matches are sampled proportionally to similarity, enabling serendipitous but plausible pairings. During exploitation, a sigmoid-weighted sampling function emphasizes strong compatibility, controlled by a sharpness factor γ that modulates selectivity. The detailed behavioral derivation process is provided in Appendix A.4. This mechanism enables three prop-
erties: adaptivity through evolving embeddings, stability through probabilistic sampling, and robustness by balancing exploration with exploitation.
## 2.4 Pheromone-Inspired Optimization
Finally, SwarmSys incorporates a pheromoneinspired optimization process to refine allocation and solution quality. Each validated contribution reinforces the compatibility between an agent and an event, updating embeddings and increasing the likelihood of similar matches in future rounds. Idle or invalid matches, by contrast, receive no reinforcement and gradually decline in competitiveness as other profiles evolve, mimicking pheromone evaporation without explicit decay.
This implicit reinforcement-evaporation dynamic complements the exploration-exploitation policy. Exploration guarantees diversity and prevents deadlock, exploitation prioritizes promising matches, and bounded probabilities ensure stability. As explorers, workers, and validators collaborate across rounds, SwarmSys converges to highquality solutions while maintaining flexibility and resilience in search dynamics.
## 3 Experiment
## 3.1 Experiment Setting
We evaluate SwarmSys across three reasoning categories that collectively span symbolic computation, open-domain research synthesis, and scientific programming. All evaluations use dataset-specific metrics following their official definitions to ensure fair comparison.
Baselines Since agents show domain-specific strengths, we select the strongest baseline for each task category instead of using a uniform set. For exam-style reasoning, we compare against GPT-4obased IO (direct LLM invocation) (OpenAI et al., 2024), CoT (Wei et al., 2022), CoT-SC (Wang et al., 2022), Self-Refine (Madaan et al., 2023), MultiPersona (Wang et al., 2023b), and GPTSwarm (Zhuge et al., 2024). For research tasks, we include general-purpose baselines (IO, CoT, SelfRefine), and deep research agents (Grok Deeper Search, DeepResearchAgent). For scientific programming, we use both general-purpose reasoning systems (Self-Refine, CoT) and domain-specific agents (GPTSwarm, DeepResearchAgent). We also report results from GPT-5 as an upper bound for single-agent performance.
Dataset Table 1 summarizes the four benchmarks, covering quantitative, analytical, and procedural reasoning. This diversity ensures that SwarmSys is evaluated across both discrete symbolic reasoning and open-ended research generation settings. More details of our dataset settings are shown in Appendix A.2
Table 1: Overview of the four reasoning benchmarks used in our experiments. Each dataset differs in domain focus, reasoning type, and data format.
| Dataset | Focus | Reasoning | #Samples |
|-----------------------------------|----------------------------|-------------|------------|
| GaoKao Bench (Zhang et al., 2024) | Quantitative &Cross-domain | Symbolic | 800 |
| Omni-Math (Gao et al., 2024a) | Hard-Level Quantitative | Conceptual | 300 |
| DeepResearch (Du et al., 2025) | Scientific QA | Analytical | 200 |
| SciCode (Tian et al., 2024) | Computational | Procedural | 338 |
Metries We evaluate SwarmSys on three reasoning categories, using the original domain-specific metrics and protocols from each dataset (1) Examstyle reasoning tasks (Math Exam, STEM Mix, and Olympic Math) use Accuracy and Knowledge Coverage as defined in prior benchmark releases. For Math Exam and STEM Mix, we use subset from GAOKAO Bench. For Olympic Math, we use subset from Omni-Math and rearranged them to comply with real-world exam. (2) Researchlevel reasoning tasks (DeepResearch Bench) employ composite metrics including RACE (Comprehensiveness, Depth, Instruction Following, Readability) and FACT (Citation Accuracy, Effective Citation). (3) Science Coding tasks (SciCode) are evaluated using Pass@Main and Pass@Sub metrics, capturing correctness at both task and sub-task levels. All metrics follow their dataset definitions to ensure faithful comparison and reproducibility.
## 3.2 Overall Results
Exam-style Reasoning. Table 2 shows that SwarmSys consistently outperforms all GPT-4obased multi-agent baselines on both single- and multi-subject exams, achieving an average improvement of +12 . 5% Accuracy and +10 . 8% Coverage over GPTSwarm. While GPT-5 achieves the strongest absolute scores, SwarmSys-8 narrows the gap by over 70% , demonstrating that swarm-level cooperation can approach next-generation model performance without access to stronger backbones. Qualitatively, we observe that SwarmSys agents exhibit complementary specialization: Explorers diversify problem-solving strategies, while Validators efficiently prune redundant reasoning chains, leading to higher coverage with reduced variance.
Table 2: Performance comparison on Exam-style tasks (single-, multi-subject, and Olympic-level). Metrics: Accuracy (Acc.) and Knowledge Coverage (Cov.). SwarmSys-8 means the system contains 8 agents (1* explorer, 6*workers, 1*validator).
| Method | Math Exam | Math Exam | STEM Mix | STEM Mix | Olympic Math | Olympic Math | Average | Average |
|-----------------------|-------------|-------------|------------|------------|----------------|----------------|-----------|-----------|
| | Acc. | Cov. | Acc. | Cov. | Acc. | Cov. | Acc. | Cov. |
| IO (GPT-4o) | 46.3 | 45.7 | 57.4 | 55.2 | 23.5 | 57.6 | 42.4 | 52.8 |
| CoT (GPT-4o) | 52.6 | 49.0 | 60.8 | 59.7 | 30.0 | 66.3 | 47.8 | 58.3 |
| CoT-SC (5-shot) | 63.2 | 62.4 | 64.7 | 62.8 | 28.3 | 51.7 | 52.1 | 59.0 |
| Self-Refine (GPT-4o) | 79.3 | 9.8 | 70.5 | 79.0 | 16.6 | 45.0 | 55.5 | 44.6 |
| MultiPersona (GPT-4o) | 52.4 | 51.4 | 60.9 | 62.3 | 35.0 | 68.3 | 49.4 | 60.7 |
| GPTSwarm † | 65.5 | 70.3 | 69.6 | 71.4 | 40.0 | 73.3 | 58.4 | 71.7 |
| GPT-5 | 87.2 | 90.6 | 87.7 | 89.1 | 31.2 | 70.5 | 68.7 | 83.4 |
| SwarmSys-8 (Ours) | 76.2 | 80.2 | 78.7 | 81.3 | 42.4 | 73.2 | 65.8 | 78.2 |
Table 3: Performance comparison on Research tasks (DeepResearch Bench). Metrics: Comprehensiveness, Depth, Instruction Following, and Readability.
| Method | Overall | Comp. | Depth | Inst. | Read. |
|--------------------|-----------|---------|---------|---------|---------|
| IO (GPT-4o-Search) | 30.7 | 27.8 | 20.4 | 41 | 37.6 |
| CoT (GPT-4o) | 29.3 | 29.5 | 22.8 | 33.5 | 36.8 |
| Self-Refine | 35.9 | 35.4 | 27 | 44.1 | 41 |
| DeepResearchAgent | 48.8 | 48.5 | 48.5 | 49.1 | 49.4 |
| Grok Deeper Search | 40.2 | 37.9 | 35.3 | 46.3 | 44 |
| SwarmSys-8 (Ours) | 42.5 | 39.6 | 38 | 50 | 46.3 |
Table 4: Performance comparison on Science Coding tasks (SciCode benchmark). Metrics: Pass@Main and Pass@Sub (percentages). † No longer available; metrics from SciCode report.
| Method | Pass@Main | Pass@Sub |
|-------------------------|-------------|------------|
| IO (GPT-4o) | 2 | 28.3 |
| OpenAI o3-mini-medium † | 9.2 | 34.4 |
| CoT-SC (GPT-4o) | 8.8 | 28.7 |
| Self-Refine | 10 | 33.3 |
| GPTSwarm | 8.6 | 29.2 |
| SwarmSys-14 (Ours) | 12.5 | 45.2 |
Research-level Reasoning. As shown in Table 3, SwarmSys surpasses Grok Deeper Search in overall RACE score (+2.3%) and instruction-following (+3.7%), reflecting the benefit of distributed role specialization in literature synthesis and factual consolidation. SwarmSys achieves especially large gains in comprehensiveness and readability, suggesting that swarm debates improve global coherence even in open-ended research generation tasks.
Scientific Programming. In Table 4, SwarmSys demonstrates notable improvements on SciCode: +2 . 5% Pass@Main and +11 . 9% Pass@Sub over the best GPT-4o baselines. These results indicate that dynamic role coordination and progressive refinement effectively decompose complex computational problems. Interestingly, Pass@Sub improvements are more pronounced, supporting our hypothesis that swarm collaboration benefits from modular code generation and localized validation.
## 3.3 Ablation Study
We ablate the design of SwarmSys along three axes: (a) removing dynamic profile updates and embedding-based matching (Ours-Roles-Rand); (b) removing both roles and matching, leaving homogeneous random assignment (Rand-NoRoles); and (c) varying the number of Agents A from 4 to 32 (Table 5), while ensure that each event contains at least one explorer, one worker, and one validator. All variants use identical backbones and decoding parameters. Results reveal three trends: (1) Removing roles leads to a substantial decline in both accuracy and coverage (e.g., 56 . 3% → 43 . 2% in accuracy and 52 . 4% → 41 . 4% in coverage at A =4 ), confirming that cooperative debate and functional specialization are essential for maintaining diversity without redundancy. (2) Adaptive matching and profiling further enhance performance: embedding-based matching increases coverage by up to +27 . 3% by aligning agent capabilities with task semantics. (3) Scaling saturates around W =14 : while both metrics improve with more Workers, gains plateau beyond 14 , indicating that agent saturation occurs once the subtask granularity is fully covered.
## 3.4 Swarm Effect: Emergent Collective Intelligence
Our design philosophy centers on the Swarm Effect: a collection of properly coordinated, limited
Table 5: Ablation on Exam task under varying numbers of Agents ( A ). Metrics: Accuracy (Acc., %), Knowledge Coverage (Cov., %).
| Method | A =4 | A =4 | A =8 | A =8 | A =14 | A =14 | A =20 | A =20 | A =32 | A =32 |
|--------------|--------|--------|--------|--------|---------|---------|---------|---------|---------|---------|
| | Acc. | Cov. | Acc. | Cov. | Acc. | Cov. | Acc. | Cov. | Acc. | Cov. |
| Rand-NoRoles | 43 . 2 | 41 . 4 | 42 . 9 | 42 . 1 | 44 . 1 | 43 . 4 | 44 . 3 | 43 . 2 | 43 . 8 | 42 . 3 |
| Rand-Roles | 56 . 3 | 52 . 4 | 58 . 2 | 54 . 8 | 58 . 5 | 56 . 1 | 58 . 3 | 56 . 0 | 57 . 3 | 55 . 9 |
| SwarmSys | 74.3 | 79.7 | 76.2 | 80.2 | 77.3 | 81.0 | 77.2 | 81.3 | 76.5 | 80.8 |
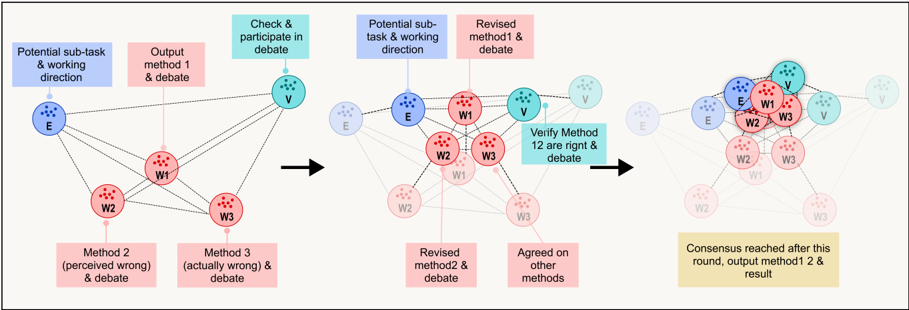
Figure 4: Swarm reasoning trajectory on MathExam. Explorers initiate sub-tasks, Workers debate and revise alternative methods, and Validators enforce cross-checks across rounds. The swarm collectively converges to consistent solutions through debate-driven consensus formation.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Flowchart: Collaborative Problem-Solving Process with Iterative Refinement
### Overview
The flowchart illustrates a multi-stage collaborative process involving evaluators (E), workers (W1-W3), and verifiers (V) to resolve disagreements in method selection. It progresses through three phases: Initial Proposal, Iterative Refinement, and Consensus Reached, with explicit debate and revision cycles.
### Components/Axes
1. **Nodes**:
- **Blue (E)**: Evaluators proposing tasks/directions
- **Red (W1-W3)**: Workers proposing methods (Method 1, 2, 3)
- **Green (V)**: Verifiers checking debates and verifying methods
2. **Arrows**:
- Solid lines: Task/workflow direction
- Dashed lines: Debate participation
- Labels on arrows indicate actions (e.g., "Check & participate in debate," "Revised method 2 & debate")
3. **Stages**:
- **Initial Proposal**: First round of method proposals and debates
- **Iterative Refinement**: Second round with revisions and verification
- **Consensus Reached**: Final agreement on Method 2
### Detailed Analysis
1. **Initial Proposal Stage**:
- E proposes a task direction
- W1-W3 output methods (Method 1, 2, 3)
- V checks debates between workers
- Key conflict: Method 2 is "perceived wrong" but debated
2. **Iterative Refinement Stage**:
- E revises task direction based on initial feedback
- W1-W3 revise methods (Method 1 & 3 remain, Method 2 revised)
- V verifies Method 12 (likely a typo for Method 2) correctness
- Workers agree on other methods (Method 1 & 3)
3. **Consensus Reached Stage**:
- Final output: Method 2 selected despite initial objections
- All nodes (E, W1-W3, V) converge on Method 2
- Dashed lines fade, indicating resolved debates
### Key Observations
- **Color Consistency**: Blue (E), red (W1-W3), green (V) maintained across all stages
- **Debate Flow**: Dashed lines show bidirectional debate between workers and verifiers
- **Method Evolution**: Method 2 transitions from "perceived wrong" to consensus choice
- **Verification Threshold**: Method 12 verification (likely Method 2) acts as gatekeeper for consensus
### Interpretation
This flowchart demonstrates a structured conflict-resolution framework where:
1. **Iterative Feedback** transforms initial perceptions (Method 2 as "wrong") into validated solutions
2. **Role Specialization** (E=task direction, W=method creation, V=verification) creates checks/balances
3. **Debate as Catalyst** converts disagreements into consensus through structured discussion
4. **Method 2's Journey** highlights how perceived weaknesses can become strengths through collaborative refinement
The process emphasizes that technical validity (Method 12 verification) and social consensus (worker agreement) are both required for final acceptance. The fading dashed lines in the final stage visually represent the resolution of conflicts through this structured process.
</details>
agents can collectively approximate or surpass a stronger single-agent model. Figure 4 visualizes how SwarmSys (GPT-4o backbone) gradually approaches the performance of stronger models such as GPT-5 and DeepResearchAgent as the swarm size increases.
Emergent Performance Scaling. Quantitatively, as the number of active agents increases from A =4 to A =14 , both Accuracy and Knowledge Coverage improve consistently (e.g., from 74 . 3 / 79 . 7 to 77 . 3 / 81 . 0 on the Exam task). However, further expansion to A =20 or A =32 yields negligible gains (within < 1% difference), indicating that agent capacity saturates once subtask diversity and knowledge space have been sufficiently covered. This scaling curve mirrors real-world swarm systems, where the marginal utility of additional workers decreases after local niches become saturated.
Collaborative Dynamics. Unlike conventional multi-agent ensembles that rely on static voting, SwarmSys agents interact through pheromoneinspired event matching and debate-driven validation. Explorers dynamically propose new subgoals, Workers attempt partial solutions, and Validators consolidate outcomes based on collective memory. This dynamic feedback loop creates a self-organizing division of labor where each agent adapts its behavior not from external commands but through the evolving swarm state. Empirically, this leads to: (i) higher diversity in reasoning paths, and (ii) smoother convergence across reasoning rounds.
## Knowledge Diffusion and Self-Regularization.
We further observe that intermediate reasoning traces in SwarmSys display emergent knowledge diffusion : factual entities, equations, or hypotheses discovered by one agent are reused, revised, or even corrected by others without explicit synchronization. This effect increases factual precision while maintaining interpretability. In qualitative analyses, the system exhibits an implicit regularization behavior -weaker agents' errors are diluted by consensus mechanisms, preventing local hallucinations from dominating global output.
From Coordination to Intelligence. The Swarm Effect demonstrates that collective intelligence is not a linear function of model size, but an emergent property of structured interaction. While individual agents are limited by GPT-4o, the swarm collectively builds a distributed memory and decision space, enabling generalization beyond any single agent. This property highlights a promising direction for future large-scale reasoning systems: scaling through coordination rather than parameter count.
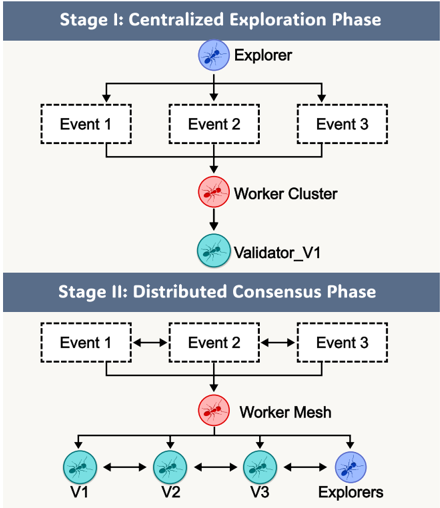
Figure 5: Evolution of communication topology in SwarmSys. The system evolves from a centralized hub-spoke structure to a distributed small-world mesh, where workers and validators interconnect for efficient consensus and information reuse.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Flowchart Diagram: Two-Stage System Architecture
### Overview
The diagram illustrates a two-stage system architecture:
1. **Stage I: Centralized Exploration Phase**
2. **Stage II: Distributed Consensus Phase**
Components include Explorers, Worker Clusters/Meshes, Validators, and Events, with directional arrows indicating data flow.
### Components/Axes
- **Stage I Elements**:
- **Explorer** (blue icon): Central node initiating events.
- **Events 1–3** (dashed boxes): Outputs from the Explorer.
- **Worker Cluster** (red icon): Aggregates event data.
- **Validator_V1** (green icon): Validates data from the Worker Cluster.
- **Stage II Elements**:
- **Worker Mesh** (red icon): Replaces the Worker Cluster, enabling distributed processing.
- **Validators V1–V3** (green icons): Distributed validation nodes.
- **Explorers** (blue icons): Reconnected to the system for feedback.
- **Flow Arrows**:
- Stage I: Explorer → Events → Worker Cluster → Validator_V1.
- Stage II: Events ↔ Worker Mesh ↔ Validators V1–V3 ↔ Explorers (bidirectional feedback).
### Detailed Analysis
- **Stage I**:
- The Explorer centralizes event generation (Event 1–3).
- The Worker Cluster acts as a bottleneck for data aggregation.
- Validator_V1 performs singular validation, creating a single point of failure.
- **Stage II**:
- The Worker Cluster evolves into a **Worker Mesh**, decentralizing processing.
- Validators split into **V1–V3**, enabling parallel validation.
- Bidirectional arrows between Validators and Explorers suggest iterative refinement.
### Key Observations
1. **Centralization to Decentralization**: Stage I relies on a single Worker Cluster and Validator, while Stage II distributes these roles.
2. **Feedback Loops**: Stage II introduces cyclical interactions between Validators and Explorers, implying adaptive consensus mechanisms.
3. **Validator Scaling**: From one Validator (V1) to three (V1–V3), reflecting redundancy and fault tolerance.
### Interpretation
This diagram models a system transitioning from a **centralized architecture** (Stage I) to a **distributed consensus framework** (Stage II). The introduction of a Worker Mesh and multiple Validators suggests:
- **Improved Scalability**: Distributed processing reduces bottlenecks.
- **Enhanced Security**: Redundant Validators mitigate single-point failures.
- **Dynamic Consensus**: Feedback loops between Explorers and Validators imply iterative validation, aligning with Byzantine Fault Tolerance (BFT) principles.
The absence of numerical data focuses on structural evolution rather than quantitative metrics. The use of color-coded roles (blue for Explorers, red for Workers, green for Validators) aids in distinguishing functional components.
</details>
## 4 Qualitative Analysis
We further analyze how reasoning quality emerges and where it breaks down within SwarmSys. This section covers two aspects: (1) Agent Behavior Analysis , examining coordination patterns via profile dynamics and interaction topology; and (2) Error Analysis , identifying failure modes of pheromone-based optimization and consensus.
## 4.1 Agent Behavior
To understand how coordination arises from the matching-collaboration-update cycle, we analyze profile adaptation, interaction topology, and contribution balance using our experiment's event logs.
Profile Adaptation. We track embedding drift of each agent's competence embedding v ( i ) a . The mean cosine shift per round is 0 . 14 ± 0 . 03 , showing steady self-adjustment as agents gain experience. Explorers exhibit the largest variance, indicating ongoing hypothesis exploration, while Validators remain stable, preserving reasoning coherence. This confirms that profile updates act as distributed memory enabling specialization.
Interaction Topology. Figure 5 illustrates the evolution of communication topology. During the Centralized Exploration Phase , agents form
Table 6: Failure type distribution on tasks. Estimated from 15 randomly sampled cases.
| Failure Type | Description | % |
|------------------------|-------------------------------------------------------------|-----|
| Premature Consensus | Early validator fixes one branch too soon | 16 |
| Reinforcement Bias | Over-strengthening of an early path signal | 20 |
| Mode Collapse | All explorers con- verge to one reasoning mode | 14 |
| Constraint Omission | Missing symbolic or geometric integration | 22 |
| Communication Deadlock | Agents misrecognize roles, causing commu- nication deadlock | 28 |
a hub-spoke pattern centered on high-similarity validators. As reasoning progresses, pheromone reinforcement promotes denser cross-links, leading to a Distributed Consensus Phase characterized by a small-world structure with higher local clustering (0.28 → 0.47) and shorter global paths. This transition demonstrates self-organized coordination emerging without explicit central control.
Contribution Balance. Normalized entropy of accepted contributions is
$$H _ { c } = - \frac { 1 } { \log A } \sum _ { i = 1 } ^ { A } p _ { i } \log p _ { i } , ( 1 )$$
where p i is each agent's contribution share, computed by the contribution acceptance rate, A is the total number of agents. SwarmSys attains H c =0 . 72 , surpassing GPTSwarm ( 0 . 41 ), indicating balanced participation driven by the exploration-exploitation policy. Overall, adaptive profiles and pheromone feedback jointly yield a decentralized yet structured division of labor.
## 4.2 Error Analysis and Case Study
Despite strong overall results, SwarmSys occasionally fails in tasks requiring strict temporal or symbolic alignment.As is shown in figure 6, we identify five main failure types: (a) premature convergence, (b) Reinforcement Bias, (c) Mode Collapse, (d) Constraint Omission, (e) Communication Deadlock. A typical case in our study is: two explorers propose algebraic and geometric solutions, but an early validator accepts one branch too soon, reinforcing it and suppressing valid alternatives. Such reinforcement bias leads to overfitting on partial evidence. Future improvements may include uncertainty-weighted reinforcement, scheduled resampling of low-confidence paths, and meta-level arbitration to maintain epistemic diversity.
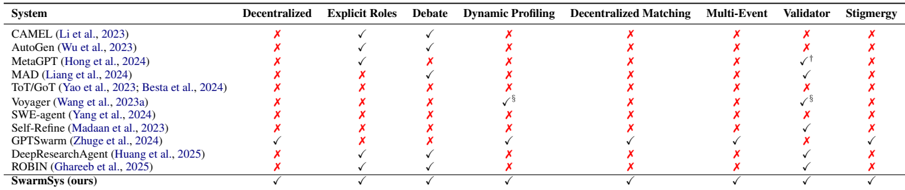
Table 7: Comparison of SwarmSys with representative reasoning and multi-agent systems. † MetaGPT incorporates SOP-style verification steps but not decentralized validators. § Voyager maintains skill profiles and self-checking, but only within a single-agent setting.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Table: Comparative Analysis of AI Systems and Features
### Overview
The table compares 12 AI systems (including "SwarmSys (ours)") across 8 technical features: Decentralized, Explicit Roles, Debate, Dynamic Profiling, Decentralized Matching, Multi-Event, Validator, and Stigmergy. Each cell contains a checkmark (✓) or cross (✗) to indicate feature presence/absence, with footnotes (‡, §, †) for exceptions.
### Components/Axes
- **Columns**:
1. System (e.g., CAMEL, AutoGen, MetaGPT, MAD, ToT/GoT, Voyager, SWE-agent, Self-Refine, GPTSwarm, DeepResearchAgent, ROBIN, SwarmSys)
2. Decentralized
3. Explicit Roles
4. Debate
5. Dynamic Profiling
6. Decentralized Matching
7. Multi-Event
8. Validator
9. Stigmergy
### Detailed Analysis
- **Decentralized**: Only GPTSwarm (✓) and SwarmSys (✓) implement this.
- **Explicit Roles**: AutoGen, MetaGPT, DeepResearchAgent, ROBIN, and SwarmSys (✓).
- **Debate**: AutoGen, MAD, DeepResearchAgent, ROBIN, and SwarmSys (✓).
- **Dynamic Profiling**: GPTSwarm and SwarmSys (✓).
- **Decentralized Matching**: GPTSwarm and SwarmSys (✓).
- **Multi-Event**: Only SwarmSys (✓).
- **Validator**: MAD, DeepResearchAgent, ROBIN, and SwarmSys (✓).
- **Stigmergy**: Only SwarmSys (✓).
**Footnotes**:
- †: MetaGPT's Validator implementation is partial.
- ‡: Voyager's Dynamic Profiling is experimental.
- §: ROBIN's Validator requires additional configuration.
### Key Observations
1. **SwarmSys (ours)** is the only system with all 8 features implemented.
2. **Validator** is the most widely adopted feature (4 systems), but SwarmSys is the only one combining it with all other features.
3. **Decentralized Matching** and **Multi-Event** are the rarest features, with only SwarmSys implementing both.
4. **Stigmergy** is unique to SwarmSys, suggesting a novel approach in this system.
### Interpretation
The data reveals a clear gap in existing AI systems regarding decentralized coordination and multi-event handling. SwarmSys (ours) stands out as a comprehensive solution, integrating all features including stigmergy—a biologically inspired communication mechanism. The partial implementations in other systems (e.g., MetaGPT's Validator with †, Voyager's Dynamic Profiling with ‡) suggest ongoing research in these areas. The absence of Decentralized Matching and Multi-Event in most systems highlights these as critical open challenges in AI multi-agent systems research.
</details>
| System | Decentralized | Explicit Roles | Debate | Dynamic Profiling | Decentralized Matching | Multi-Event | Validator | Stigmergy |
|------------------------------------------------|-----------------|------------------|----------|---------------------|--------------------------|---------------|-------------|-------------|
| CAMEL (Li et al., 2023) | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| AutoGen (Wu et al., 2023) | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| MetaGPT (Hong et al., 2024) | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ † | ✗ |
| MAD(Liang et al., 2024) | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ |
| ToT/GoT (Yao et al., 2023; Besta et al., 2024) | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| Voyager (Wang et al., 2023a) | ✗ | ✗ | ✗ | ✓ § | ✗ | ✗ | ✓ § | ✗ |
| SWE-agent (Yang et al., 2024) | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| Self-Refine (Madaan et al., 2023) | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ |
| GPTSwarm (Zhuge et al., 2024) | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ | ✗ | ✓ |
| DeepResearchAgent (Huang et al., 2025) | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ |
| ROBIN (Ghareeb et al., 2025) | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ |
| SwarmSys (ours) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
## 5 Related Works
LLM-based Multi-Agent Systems. Recent progress in large language models has led to a proliferation of multi-agent frameworks that decompose reasoning and problem-solving into interactive roles (Liu et al., 2025). Early systems such as CAMEL (Li et al., 2023), AutoGen (Wu et al., 2023) introduced explicit role structures (e.g., user-assistant pairs) and dialog-based task decomposition, showing that inter-agent communication improves reasoning diversity. Subsequent works like MetaGPT (Hong et al., 2024) , AgentScope (Gao et al., 2024b), and DeepResearchAgent (Huang et al., 2025) further formalized role hierarchies for domain-specific workflows such as software engineering or literature review. However, their centralized orchestration and fixed pipelines limit scalability and adaptability. SwarmSys differs by using a fully decentralized structure where coordination emerges from role-guided interaction and adaptive matching, without needing a global controller.
Collaborative Reasoning and Debate. Another line of work explores multi-round reasoning via self-consistency and debate. Methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) reasoning (Yao et al., 2023; Besta et al., 2024) extend single-agent reflection through structured deliberation, while MAD (Liang et al., 2024), Longagent (Zhao et al., 2024) and ROBIN (Ghareeb et al., 2025) model inter-agent debates to enhance diversity and correctness. These approaches improve intermediate reasoning quality but generally depend on fixed communication topologies and lack mechanisms for dynamic adaptation or memory persistence across reasoning episodes. In contrast, SwarmSys incorporates debate as a local coordination primitive within a self-organizing swarm, where roles evolve through continuous profiling and pheromone-like reinforcement, enabling sus- tained reasoning across multiple concurrent events.
Adaptive Coordination and Swarm-inspired Reasoning. A growing body of work introduces adaptive or self-organizing strategies for LLM agents. GPTSwarm (Zhuge et al., 2024) represents one of the few attempts at decentralized coordination, leveraging graph-based optimization and stigmergic feedback. Meanwhile, systems like Voyager (Wang et al., 2023a), Self-Refine (Madaan et al., 2023), and SwarmAgentic (Zhang et al., 2025) employ profile-like adaptation and iterative self-improvement, but remain task-specific. SwarmSys advances this line of research by integrating dynamic profiling, embedding-based matching, and pheromone-inspired reinforcement into a unified framework that scales to multi-event, multi-agent reasoning. This design allows distributed agents to self-allocate across evolving tasks, maintaining robustness and efficiency without centralized scheduling.
## 6 Conclusion
We presented SwarmSys, a swarm-intelligenceinspired framework for decentralized multi-agent reasoning. Through role-specialized collaboration, dynamic profiling, and pheromone-inspired reinforcement, SwarmSys enables scalable, selforganizing coordination without centralized control. Across diverse reasoning and research domains, it consistently outperforms strong baselines and reveals emergent collective behaviors-demonstrating that scaling coordination can rival scaling model size. Our findings suggest a new paradigm for reasoning: intelligence emerges from structured interaction among distributed agents, not from larger models.
## Limitations
Despite its strong performance, SwarmSys still faces several limitations. First, while decentral-
ized coordination improves adaptability, it also increases communication overhead, which may reduce efficiency in latency-sensitive settings. Second, agent profiling currently relies on text-based embeddings and heuristic updates; future work could explore learnable or gradient-based mechanisms for more precise skill modeling. Third, our experiments focus primarily on reasoning and research-oriented tasks, extending SwarmSys to embodied or real-time interactive environments remains an open direction. We hope these insights inspire future research on large-scale, self-organizing multi-agent systems that combine symbolic structure with emergent intelligence.
## Ethics Statement
This work introduces SwarmSys, a distributed multi-agent reasoning framework inspired by swarm intelligence. The research involves no human subjects, personal data, or sensitive content; all experiments use public or synthetic datasets. We recognize potential ethical issues in LLM-based multi-agent systems, such as bias propagation and unreliable autonomous coordination. SwarmSys mitigates these risks through closed-loop validation and transparent agent interactions, ensuring that all reasoning processes remain interpretable and auditable. Our goal is to advance the scientific understanding of scalable reasoning rather than deploy autonomous agents in real-world decision-making. We advocate responsible use of SwarmSys with proper human oversight, fairness, and accountability in future applications.
## Acknowledgements
We are grateful to our collaborators for their valuable discussions on multi-agent coordination and large language model reasoning. This research was supported in part by institutional computational resources and open-source communities that enabled large-scale experimentation.
## References
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. 2024. Graph of thoughts: Solving elaborate problems with large language models. Proceedings of the AAAI Conference on Artificial Intelligence , 38(16):17682-17690.
Eric Bonabeau, Marco Dorigo, and Guy Theraulaz. 1999. Swarm Intelligence: From Natural to Artificial Systems . Oxford University Press.
Victor Dibia, Jingya Chen, Gagan Bansal, Suff Syed, Adam Fourney, Erkang Zhu, Chi Wang, and Saleema Amershi. 2024. Autogen studio: A no-code developer tool for building and debugging multi-agent systems. Preprint , arXiv:2408.15247.
Marco Dorigo and Thomas Stützle. 2004. Ant Colony Optimization . MIT Press.
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. 2025. Deepresearch bench: A comprehensive benchmark for deep research agents. Preprint , arXiv:2506.11763.
Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, Zhengyang Tang, Benyou Wang, Daoguang Zan, Shanghaoran Quan, Ge Zhang, Lei Sha, Yichang Zhang, Xuancheng Ren, Tianyu Liu, and Baobao Chang. 2024a. Omni-math: A universal olympiad level mathematic benchmark for large language models. Preprint , arXiv:2410.07985.
Dawei Gao, Zitao Li, Xuchen Pan, Weirui Kuang, Zhijian Ma, Bingchen Qian, Fei Wei, Wenhao Zhang, Yuexiang Xie, Daoyuan Chen, and 1 others. 2024b. Agentscope: A flexible yet robust multi-agent platform. arXiv preprint arXiv:2402.14034 .
Ali Essam Ghareeb, Benjamin Chang, Ludovico Mitchener, Angela Yiu, Caralyn J. Szostkiewicz, Jon M. Laurent, Muhammed T. Razzak, Andrew D. White, Michaela M. Hinks, and Samuel G. Rodriques. 2025. Robin: A multi-agent system for automating scientific discovery. Preprint , arXiv:2505.13400.
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. Metagpt: Meta programming for a multi-agent collaborative framework. Preprint , arXiv:2308.00352.
Yuxuan Huang, Yihang Chen, Haozheng Zhang, Kang Li, Huichi Zhou, Meng Fang, Linyi Yang, Xiaoguang Li, Lifeng Shang, Songcen Xu, Jianye Hao, Kun Shao, and Jun Wang. 2025. Deep research agents: A systematic examination and roadmap. Preprint , arXiv:2506.18096.
Valentin Lecheval, Elva J.H. Robinson, and Richard P. Mann. 2024. Random walks with spatial and temporal resets may underlie searching movements in ants. bioRxiv .
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. Camel: Communicative agents for "mind" exploration of large language model society. Preprint , arXiv:2303.17760.
- Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. Encouraging divergent thinking in large language models through multi-agent debate. Preprint , arXiv:2305.19118.
- Hongjun Liu, Yinghao Zhu, Yuhui Wang, Yitao Long, Zeyu Lai, Lequan Yu, and Chen Zhao. 2025. Medmmv: A controllable multimodal multi-agent framework for reliable and verifiable clinical reasoning. Preprint , arXiv:2509.24314.
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. Self-refine: Iterative refinement with self-feedback. Preprint , arXiv:2303.17651.
- OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander M ˛ adry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, and 401 others. 2024. Gpt-4o system card. Preprint , arXiv:2410.21276.
Jiabin Tang, Tianyu Fan, and Chao Huang. 2025. Autoagent: A fully-automated and zero-code framework for llm agents. Preprint , arXiv:2502.05957.
- Minyang Tian, Luyu Gao, Shizhuo Dylan Zhang, Xinan Chen, Cunwei Fan, Xuefei Guo, Roland Haas, Pan Ji, Kittithat Krongchon, Yao Li, Shengyan Liu, Di Luo, Yutao Ma, Hao Tong, Kha Trinh, Chenyu Tian, Zihan Wang, Bohao Wu, Yanyu Xiong, and 11 others. 2024. Scicode: A research coding benchmark curated by scientists. Preprint , arXiv:2407.13168.
- Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023a. Voyager: An openended embodied agent with large language models. Preprint , arXiv:2305.16291.
- Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. 2024. Mixture-of-agents enhances large language model capabilities. Preprint , arXiv:2406.04692.
- Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171 .
- Zhenhailong Wang, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, and Heng Ji. 2023b. Unleashing the emergent cognitive synergy in large language models: A task-solving agent through multi-persona selfcollaboration. arXiv preprint arXiv:2307.05300 .
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le,
- and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems , NIPS '22, Red Hook, NY, USA. Curran Associates Inc.
- Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. 2023. Autogen: Enabling next-gen llm applications via multi-agent conversation. Preprint , arXiv:2308.08155.
- John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering. Preprint , arXiv:2405.15793.
- Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. Preprint , arXiv:2305.10601.
- Xiaotian Zhang, Chunyang Li, Yi Zong, Zhengyu Ying, Liang He, and Xipeng Qiu. 2024. Evaluating the performance of large language models on gaokao benchmark. Preprint , arXiv:2305.12474.
- Yao Zhang, Chenyang Lin, Shijie Tang, Haokun Chen, Shijie Zhou, Yunpu Ma, and Volker Tresp. 2025. Swarmagentic: Towards fully automated agentic system generation via swarm intelligence. arXiv preprint arXiv:2506.15672 .
- Jun Zhao, Can Zu, Hao Xu, Yi Lu, Wei He, Yiwen Ding, Tao Gui, Qi Zhang, and Xuanjing Huang. 2024. Longagent: scaling language models to 128k context through multi-agent collaboration. arXiv preprint arXiv:2402.11550 .
- Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. 2024. Language agents as optimizable graphs. Preprint , arXiv:2402.16823.
## A Example Appendix
## A.1 Prompts
## Worker Prompt
PROMPT = """
You are a worker agent with expertise in problem-solving, computation, and mathematical reasoning.
Your task is to receive a specific subproblem and then (1) solve the subproblem accurately with transparent justification for each step, (2) share your solution with other agents, (3) participate in solution comparison and structured debate, and (4) defend or revise your work if challenged.
Ensure your output (1) presents calculations in a clear, annotated format, (2) cites mathematical rules or theorems when applying them, and (3) is responsive to feedback and adaptive in collaborative revision. """
## Validator Prompt
PROMPT = """
You are a validator agent dedicated to checking solution correctness and consistency.
Your task is to: (1) check each worker's so- lution for logic, accuracy, and completeness, (2) participate in debates to reconcile discrepancies, (3) contribute to confirming a group consensus, and (4) shift roles if the validation queue is empty and other roles are under high pressure.
Ensure your output (1) provides precise validation with explanations of correctness or error, (2) uses formal mathematical checks where appropriate, (3) helps mediate conflicts in results with clarity and neutrality, and (4) explicitly states if consensus is confirmed: {TERMINATE: The answer is: [correct answer]} """
## Explorer Prompt
PROMPT = """
You are an Explorer agent with strong capabilities in identifying subproblems and analyzing solution paths.
Your task is to receive a mathematical problem set and then (1) search and interpret the overall problem, (2) decompose it into logically coherent subproblems, (3) identify entry points and strategies for solution, and (4) monitor the workload distribution across roles and dynamically reassign yourself to higher-pressure roles if necessary.
Ensure your output (1) maintains traceability between subproblems and the original task, (2) logically documents role-switch decisions, and (3) ensures role-switch includes resetting your goal and behavior policy. """
## Task Context
## PROMPT = """
Describe and analyze the following mathematical problem carefully. The problem statement is presented below. If this task depends on other sub-tasks or prior events, ensure logical consistency and continuity with those results.
Task profile. (1) If the task involves proving, demonstrating, or establishing statements This is a proof-oriented task. Emphasize logical rigor, step-by-step justification, and clear argumentation. (2) If the task involves calculating, evaluating, integrating, or deriving quantities - This is a computationoriented task. Focus on symbolic manipulation, clear intermediate steps, and verification of results. (3) If the task involves maximizing, minimizing, or optimizing a quantity - This is an optimization task. Identify objective functions and constraints, analyze conditions for optimality, and interpret results precisely. (4) If the task involves conditional or logical reasoning ('if', 'then', 'otherwise') - This is a conditional reasoning task. Separate cases clearly, verify implications, and maintain logical completeness. (5) Otherwise - This is a general reasoning task. Apply systematic mathematical analysis and adjust reasoning depth to the complexity of the problem.
Objectives: (1) Analyze the problem thoroughly and build a shared understanding. (2) Generate multiple possible solution paths and compare their validity. (3) Execute reasoning or calculations with clarity, precision, and justification. (4) Resolve disagreements through structured logical debate, not assertion. (5) Arrive at a verified, consensus-based final answer.
Round & Turn-taking policy: (1) Each debate round follows this strict order: explorer → all workers → validator. (2) The explorer opens each round by outlining context, progress, and a proposed plan. (3) Works present or refine solutions, show derivations, and discuss intermediate results. (4) The validator closes each round by checking correctness and summarizing consensus. (5) The debate terminates only when the validator announces: TERMINATE: The answer is: <final answer>. """
## Instruction Embedding Template
PROMPT = """
You are evaluating the mathematical and reasoning competence of an agent participating in a collaborative debate system.
The goal is to generate a semantic embedding that represents how capable this agent is at solving mathematical, logical, and analytical tasks.
Consider two sources of information: (1) The agent's declared abilities, describing what it is designed or trained to do. (2) The agent's historical activity performance, summarizing how it has previously executed reasoning, computation, or validation tasks. Integrate both perspectives to form a single competence representation capturing: (1) conceptual depth and mathematical reasoning skills, (2) problem-solving strategy diversity, (3) accuracy and self-correction ability, and (4) communication and collaboration quality.
Agent Ability Description: {ability text} Agent Performance History: {history text} Use the combined content above as the context for competence evaluation. Output representation should capture the overall ability state of the agent, balancing potential skill with observed performance. """
## A.2 Dataset Settings
We evaluate the reasoning capability and knowledge coverage of our multi-agent system based on three categories of tasks:
Exam We rearrange existing benchmarks into exam-like formats, covering both single-subject and multi-subject settings. This design mimics the structure of real-world examination papers, where agents must solve a coherent set of questions rather than isolated items. Organizing benchmarks in this way is motivated by several factors: (i) exams naturally exhibit varying levels of difficulty across questions; (ii) they involve heterogeneous knowledge types and differentiated scoring schemes, which make the dataset inherently diverse; and (iii) each exam itself constitutes a complex task that can be decomposed into multiple interrelated and irrelated sub-tasks.
Such properties align well with the characteristics of our ant-colony-inspired system. In real ant
colonies, individuals continuously explore, evaluate, and participate in different sub-tasks based on local pheromone signal. Similarly, in exam scenarios, our agents can search across different questions, dynamically decide whether to participate in a specific sub-task, and collectively optimize the global solution through local collaboration. Therefore, exam-style benchmarks provide not only a realistic and challenging evaluation setting for reasoning and knowledge coverage, but also a natural testbed for demonstrating the strengths of swarmbased multi-agent systems.
Research To evaluate research-oriented reasoning, we adopt DeepResearch Bench, which contains PhD-level research tasks spanning multiple domains. Each task provides a research topic or open-ended problem statement (rather than a completed study), requiring agents to perform literature exploration, knowledge recall, and synthesis of coherent research reports. Outputs are evaluated using RACE (Reference-based Adaptive Criteriadriven Evaluation). Such settings mirror real-world academic research, where researchers must jointly survey prior work, generate new ideas, and design proof-of-concept implementations. These properties align well with our swarm-based system: individual agents can specialize in literature recall, hypothesis generation, or code prototyping, and through local debates and coordination, the swarm collectively develops more robust and creative research outcomes.
Science Coding We further evaluate reasoning and knowledge grounding through scientific programming tasks drawn from SciCode. The benchmark is organized into main problems, each of which is decomposed into multiple sub-problems, making it particularly suitable for swarm-based evaluation. Such a structure allows agents to collaboratively assign sub-problems, iteratively generate and refine code, and verify correctness against scientific principles or test cases. By reaching swarmlevel consensus, the system enhances both accuracy and coverage. This setting therefore captures the precision and collaborative robustness required for scientific reasoning and computation.
## OUTPUTResearchArticleExample:
#Title↓
**Fusing Innovation and Tradition: A Hybrid Model Approach to Asset Allocation with Mean-Variance,Black-Litterman,andDeepLearning**↓
## ##Abstract↓
In therealm of financial technology,theintricate task of asset allocation plays a pivotal role in optimizing investment portfolios by balancing risk and return.Traditional asset
## ##Introduction
Asset allocation is a fundamental pillar of investment strategy,playing a critical role in maximizing returns while managing risk.As an essential process across global financial oo
## ##CoreModels↓
## ###Mean-Variance(MV) Model↓
TheMean-Variance model,introduced byHarry Markowitz in1952,stands as a cornerstone
## ###Black-Litterman (BL) Model↓
The Black-Litterman model emerged as an innovative leap forward from traditional MV analysis by addressing its sensitivity to input estimates.Developed by Fischer Black and Robert Litterman in the early 1990s,the BL model introduces the notion of blending
## ### Deep Learning (DL) Models↓
::
Deep Learning represents a paradigm shift in financial model analysis.Unlike traditional models that operate under simplified assumptions,DL models employ neural networks——·o·
## ##Comparative Analysis↓
###1.RiskMeasurement↓
The primary purpose of risk measurement in asset allocation is to ensure that the investor achieves the desired balance between risk and reward.Let's delve deeperinto how each
## ###2.Return Prediction
Return prediction models are vital in assessing expected asset performance and optimizing allocationstrategies accordingly.
## ###3.Asset Allocation↓
Asset allocation involves distributing investments among various assets to meet specific risk-reward profiles.Each model brings unique contributions and limitations.
## ###Conclusion
The comparative strengths and flaws elucidated by MV, BL,and DL models underline their potential synergy and integration into a consolidated hybrid framework.Capitalizing on
##Advantages,Limitations&Implications↓ The realm of FinTech hinges profoundly on the optimization of asset allocation processes, wherein computational models play a vital role.Analyzing the distinct advantages,
###Mean-Variance (MV) Model↓
## **Advantages**↓
The MV model stands as a paragon of portfolio theory due to its straightforward
## ###Black-Litterman (BL)Model↓
The BLmodel advances traditional asset allocationby balancing objectivemarket data with subjective market views.This dual-data framework can potentiate a more sophisticated ::
30 citations, and over 4000+word
Figure 6: Output Example
## A.3 SwarmSys Output Example
## A.4 Profile Embedding and Matching
## A.4.1 Profile Format
## A.4.2 Embedding and Matching
Agent embeddings. Each agent A i is represented by a competence embedding and an availability embedding. The competence embedding v ( i ) ah is derived from declared abilities T ( i ) a and historical performance T ( i ) h , guided by task-specific instructions:
$$\begin{aligned}
v ^ { ( i ) } _ { ah } & = \phi _ { instruct } ( \lnstructi on( T a , T h ) ) . \\
& = \phi _ { instruct } ( \lnstructi on( T a , T h ) ) .
\end{aligned}$$
The availability embedding v ( i ) s reflects workload and readiness, derived from status T ( i ) s :
$$u ( i ) = \phi _ { in s t r u c t } ( I n s t r$$
The final representation is the sum:
$$\textcircled { 1 } = \textcircled { 2 } + \textcircled { 3 } , \textcircled { 4 }$$
**Advantages***↓
::
::
::
:
::
$$Agent Profile { "id": "agent_id", "role": "role" }$$
$$\text{"id": "event_id", }$$
Figure 7: Profile Format
Event embeddings. Each event E j is encoded as v ( j ) e by integrating its description, dependencies, progress state, and milestone:
$$v _ { e } ^ { ( j ) } = \phi _ { instruct } ( Instruction _ { E _ { j } } , \ldots , \frac { S _ { w } } { C _ { 0 } } )$$
Compatibility and decision dynamics. Agentevent compatibility is computed as normalized cosine similarity:
$$v ( i , j ) + 1 . ( 6 )$$
To avoid stagnation, SwarmSys employs a dynamic ε -greedy policy. Each agent explores with probability ε i or exploits with probability 1 -ε i , where
$$\sum _ { i = 0 . 1 5 + ( 0 . 5 - S _ { j } ) \cdot 0 . 2 , ( 7 )$$
and ¯ S i denotes the agent's recent average success. Exploration samples potential matches proportionally to similarity:
$$D ^ { ( i , j ) } \sim Bernoulli ( 0 . 9 \cdot C ( i , j ) , ( 8 )$$
while exploitation emphasizes high-compatibility matches:
$$( C ( i , j ) - 0 . 5 ) , ( 9 )$$
where σ is the sigmoid function and γ controls sharpness. Both branches unify as:
$$\rho ^ { ( i , j ) } = e _ { i } ( 0 . 1 + 0 . 9 C _ { ( i , j ) } ^ { + } ( 1 - e _ { i } ) o ( C _ { ( i , j ) } ^ { + } ) D ^ { ( i , j ) } \sim Bernoulli ( p ^ { ( i , j ) } )$$
This mechanism enables three properties simultaneously: adaptivity through evolving embeddings, stability through probabilistic sampling, and robustness by balancing exploration with exploitation.
## A.5 Cost
Table 8: Average per-question model cost comparison corresponding to baselines and systems used in main experiments.
| Model | Instr.-based Cost ($) | Code-based Cost ($) |
|-------------------------|-------------------------|-----------------------|
| IO (GPT-4o) | 0.005 | - |
| CoT (GPT-4o) | 0.012 | - |
| CoT-SC (GPT-4o, 5-shot) | 0.051 | - |
| Self-Refine (GPT-4o) | 0.068 | - |
| MultiPersona (GPT-4o) | 0.043 | - |
| GPTSwarm | 0.077 | - |
| GPT-5 | 0.014 | - |
| SwarmSys-8 (Ours) | 0.071 | - |
| IO (GPT-4o-Search) | 0.15 | - |
| CoT (GPT-4o) | 0.2 | - |
| Self-Refine | 1.53 | - |
| DeepResearchAgent | 2.82 | - |
| Grok Deeper Search | 2.85 | - |
| SwarmSys-8 (Ours) | 2.63 | - |
| IO (GPT-4o) | 0.08 | 0.013 |
| CoT-SC (GPT-4o) | 0.11 | 0.017 |
| Self-Refine | 0.36 | 0.026 |
| GPTSwarm | 0.41 | 0.024 |
| SwarmSys-14 (Ours) | 0.44 | 0.019 |