# ADEPT: Continual Pretraining via Adaptive Expansion and Dynamic Decoupled Tuning
> These authors contributed equally.Corresponding author.
## Abstract
Conventional continual pretraining (CPT) for large language model (LLM) domain adaptation often suffers from catastrophic forgetting and limited domain capacity. Existing strategies adopt layer expansion, introducing additional trainable parameters to accommodate new knowledge. However, the uniform expansion and updates still entangle general and domain learning, undermining its effectiveness. Our pilot studies reveal that LLMs exhibit functional specialization, where layers and units differentially encode general-critical capabilities, suggesting that parameter expansion and optimization should be function-aware. We then propose ADEPT, A daptive Expansion and D ynamic D e coupled Tuning for continual p re t raining, a two-stage framework for domain-adaptive CPT. ADEPT first performs General-Competence Guided Selective Layer Expansion, duplicating layers least critical for the general domain to increase representational capacity while minimizing interference with general knowledge. It then applies Adaptive Unit-Wise Decoupled Tuning, disentangling parameter units within expanded layers according to their general-domain importance and assigning asymmetric learning rates to balance knowledge injection and retention. Experiments on mathematical and medical benchmarks show that ADEPT outperforms full-parameter CPT by up to 5.76% on the general domain and 5.58% on the target domain with only 15% of parameters tuned and less than 50% training time. Ablation studies, theoretical analysis, and extended investigations further demonstrate the necessity of targeted expansion and decoupled optimization, providing new principles for efficient and robust domain-adaptive CPT. Our code is open-sourced at https://github.com/PuppyKnightUniversity/ADEPT.
## 1 Introduction
Large language models (LLMs) have demonstrated remarkable performance across a wide range of general-domain tasks (OpenAI, 2023; Dubey et al., 2024c). However, their deployment in specialized domains, such as mathematics or healthcare, requires targeted adaptation (Ding et al., 2024; Chen et al., 2024; Ahn et al., 2024). Continual pretraining (CPT), which conducts post-pretraining on domain-specific corpora, has emerged as a crucial paradigm for injecting domain knowledge and capabilities into pretrained LLMs (Wu et al., 2024a; Ibrahim et al., 2024; Yıldız et al., 2024).
Despite its promise, CPT faces a persistent challenge: catastrophic forgetting. After pretraining, LLMs already encode substantial general knowledge, leaving limited parameter capacity for integrating new domain-specific information. While domain signals can be forcefully fitted through gradient-based optimization, the aggressive updates on the existing parameters come at the cost of overfitting to the target corpora, which in turn disrupts general abilities and triggers catastrophic forgetting (Liu et al., 2024a; Luo et al., 2025). This tension between new knowledge injection and previous knowledge retention poses a central obstacle to reliable and stable domain adaptation.
To address catastrophic forgetting, some approaches attempt through data-centric strategies, such as data replay or rehearsal (Huang et al., 2024; Zhang et al., 2025). While replay partially preserves prior knowledge, it fails to expand model capacity, leaving the conflict between knowledge injection and retention unresolved. Others focus on increasing capacity via transformer-layer extension (Wu et al., 2024b), yet typically insert new layers uniformly and update all parameters indiscriminately. This expansion strategy neglects the functional specialization within LLMs, where different layers and neurons serve distinct functional roles. Our pilot studies reveal that general-critical layers in LLMs are mainly located in early depths, and functional units within layers contribute unequally to general-domain performance, highlighting functional specialization similar to that found in the human brain (Xu et al., 2025; Zheng et al., 2024; Dai et al., 2022). Consequently, indiscriminate expansion and optimization may overwrite general-critical regions with new knowledge, compromising general competency preservation and leaving forgetting unresolved.
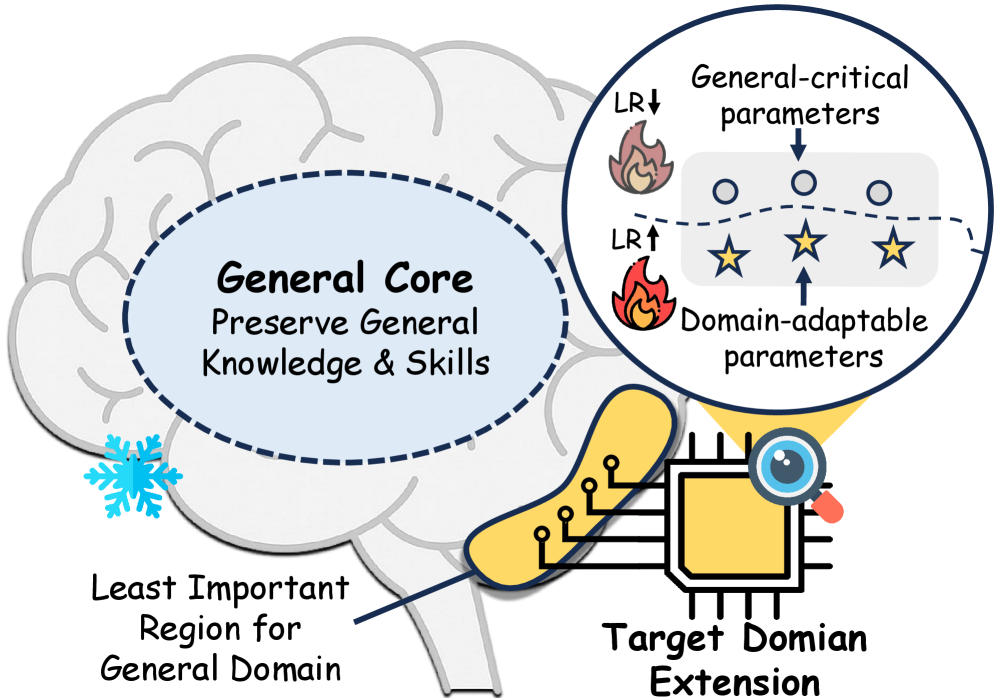
Inspired by the functional specialization perspective, we propose our core insight: effective CPT should expand and update the model adaptively, preserving the regions responsible for the general domain and targeting more adaptable parameters. Specifically, we argue that capacity allocation must be importance-guided, and optimization must be function-decoupled to minimize interference with general competencies. As illustrated in Figure 1, domain-specific extension should be allocated to the regions less constrained by general-domain knowledge and skills, and parameters within these regions should be decoupled and tuned accordingly, preserving general-critical parameters and allowing the rest to be more adaptable to absorb new domain-specific information.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Cognitive Architecture and Domain Adaptation Framework
### Overview
The diagram illustrates a conceptual framework for cognitive architecture, emphasizing the preservation of general knowledge and skills within a "General Core" (depicted as a brain illustration) and its relationship to domain-specific extensions. Key elements include critical parameters, adaptable parameters, and a highlighted "Least Important Region for General Domain."
### Components/Axes
1. **Brain Illustration**:
- **General Core**: Central oval labeled "Preserve General Knowledge & Skills" (blue dashed outline).
- **Least Important Region for General Domain**: Snowflake icon on the left side of the brain.
2. **Target Domain Extension**:
- Microchip icon with a magnifying glass overlay (right side).
- Labeled "Target Domain Extension."
3. **Parameters Section**:
- Circular diagram on the right with:
- **General-critical parameters**: Three flame icons (LR↓, LR↑) and three stars.
- **Domain-adaptable parameters**: Arrows connecting flames to stars.
### Detailed Analysis
- **General Core**: Positioned centrally in the brain, emphasizing its role as the foundation for preserving universal knowledge.
- **Least Important Region**: Snowflake icon on the brain’s left, spatially isolated from the General Core.
- **Target Domain Extension**: Microchip with magnifying glass, suggesting focused analysis or enhancement of domain-specific capabilities.
- **Parameters**:
- **General-critical parameters**: Flames (LR↓, LR↑) and stars, indicating dynamic, high-impact variables.
- **Domain-adaptable parameters**: Arrows linking flames to stars, implying adaptability between critical and adjustable factors.
### Key Observations
- The General Core is visually dominant, underscoring its importance.
- The snowflake’s placement suggests minimal relevance to the General Domain.
- The parameters circle bridges the brain and microchip, symbolizing the interplay between innate cognition and domain-specific tools.
### Interpretation
The diagram posits that general knowledge (General Core) is foundational, while domain-specific extensions (microchip) require adaptable parameters to function effectively. The "Least Important Region" highlights areas of the brain or system that contribute minimally to general tasks. The parameters’ dual nature (critical vs. adaptable) implies a balance between fixed, high-impact factors and flexible adjustments for domain-specific applications. This framework may reflect theories of cognitive flexibility or AI model generalization.
</details>
Figure 1: Illustration of the core idea of ADEPT. Target domain extension are applied on the least important region for general domain, minimizing catastrophic forgetting. Asymmetric learning rates are applied to parameter subsets for targeted knowledge injection.
Building on this insight, we propose A daptive Expansion and D ynamic D e coupled Tuning for continual p re- t raining (ADEPT), a framework for domain-adaptive continual pretraining. ADEPT comprises two stages: General-Competence Guided Selective Layer Expansion, which identifies and duplicates layers least critical for the general domain, allocating additional capacity precisely where interference with general capabilities is minimized, thereby preventing catastrophic forgetting. Adaptive Unit-Wise Decoupled Tuning, which disentangles the parameters within the expanded layers based on their importance to the general domain. Asymmetric learning rates are then applied on their subsets, ensuring that general-critical parameters are preserved while more adaptable parameters can fully absorb domain-specific knowledge. Extensive experiments on mathematical and medicine domains demonstrate that ADEPT enables efficient and robust domain knowledge injection, while substantially alleviating catastrophic forgetting. Specifically, compared to full-parameter CPT, ADEPT achieves up to 5.58% accuracy gain on target-domain benchmarks, and up to 5.76% gain on the general domain, confirming both effective knowledge acquisition and strong retention of general competencies. Furthermore, ADEPT attains these improvements with only 15% of parameters tuned, and reduces training time relative to other baselines greatly, highlighting its efficiency. Ablation studies and theoretical analysis further validate the designs of ADEPT.
To summarize, our contributions are threefold:
1. Insightfully, we highlight the importance of considering functional specialization in LLMs for continual pretraining through empirical experiments and theoretical analysis, advocating for targeted layer expansion and decoupled training as a principled solution to domain adaptation.
1. Technically, we propose ADEPT, a framework that consists of General-Competence Guided Selective Layer Expansion and Adaptive Unit-Wise Decoupled Tuning, enabling adaptive and effective domain knowledge integration while minimizing catastrophic forgetting.
1. Empirically, we conduct extensive experiments on both mathematical and medical domains, demonstrating that ADEPT consistently outperforms baselines in domain performance while preserving general competencies.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Heatmap: Qwen3 Model Parameter Distribution Across Layers
### Overview
The image displays three comparative heatmaps visualizing parameter distribution patterns across different Qwen3 model architectures (1.7B, 4B, and 8B parameter variants). Each heatmap shows layer-wise distribution of parameters across model components, with color intensity representing parameter concentration (0-1 scale).
### Components/Axes
**Y-Axis (Layers):**
- Left heatmap (1.7B): 0-27 (28 layers)
- Middle heatmap (4B): 0-34 (35 layers)
- Right heatmap (8B): 0-34 (35 layers)
- All share "Layer" label with numerical increments
**X-Axis (Model Components):**
1. mlp_domain_proj
2. mlp_head_proj
3. mlp_head_slice
4. mlp_expert_proj
5. mlp_expert_slice
6. mlp_expert_router
7. mlp_post_proj
8. mlp_post_slice
9. mlp_attention_proj
10. mlp_attention_slice
11. mlp_attention_router
12. mlp_attention_head_proj
13. mlp_attention_head_slice
14. mlp_attention_head_router
15. mlp_attention_head_mlp (only in 4B model)
**Legend:**
- Color scale from dark blue (0) to light blue (1)
- Positioned right of each heatmap
- Consistent across all three visualizations
### Detailed Analysis
**1.5B Model (Left Heatmap):**
- Layers 0-5 show darkest cells (highest concentration)
- Most intense values in mlp_expert_proj (layer 5) and mlp_attention_proj (layer 4)
- Gradual lightening from layer 6 onward
- mlp_head_proj shows consistent mid-range values across layers
**4B Model (Middle Heatmap):**
- Layers 0-10 show darkest concentrations
- Peak values in mlp_expert_proj (layer 10) and mlp_attention_proj (layer 9)
- Distinct gradient from layer 0 (dark) to layer 34 (light)
- mlp_head_proj shows similar pattern to 1.7B model
**8B Model (Right Heatmap):**
- Most intense values in first 15 layers
- mlp_expert_proj shows strongest concentration (layer 15)
- mlp_attention_proj has highest values in layer 14
- Gradual lightening after layer 20
- mlp_head_proj shows less pronounced variation than smaller models
### Key Observations
1. **Layer Depth Correlation:** All models show decreasing parameter concentration with increasing layer depth
2. **Model Size Impact:** Larger models (8B) maintain higher concentration in early layers compared to smaller variants
3. **Component-Specific Patterns:**
- mlp_expert_proj consistently shows highest values across all models
- mlp_attention_proj shows secondary peaks in middle layers
- mlp_head_proj maintains relatively uniform distribution
4. **Gradient Strength:** 8B model exhibits most pronounced gradient (0.8 difference between layer 0 and 34)
5. **Anomaly:** 4B model has unique mlp_attention_head_mlp component not present in smaller variants
### Interpretation
These heatmaps reveal architectural optimization patterns across Qwen3 model variants:
1. **Parameter Distribution Strategy:** All models concentrate parameters in early layers, particularly in mlp_expert_proj components, suggesting prioritization of early-stage information processing
2. **Scaling Effects:** Larger models maintain higher parameter density in initial layers, potentially indicating more sophisticated early feature extraction capabilities
3. **Attention Mechanism:** mlp_attention_proj shows mid-layer concentration peaks, suggesting optimized attention mechanisms in deeper layers
4. **Component Specialization:** The presence of mlp_attention_head_mlp in 4B model indicates specialized attention processing absent in smaller variants
5. **Gradient Analysis:** The steeper gradient in 8B model suggests more efficient parameter utilization across depth, while smaller models show more uniform distribution
The data suggests deliberate architectural choices where larger models optimize for early-layer complexity while maintaining parameter efficiency through controlled distribution patterns. The consistent mlp_expert_proj dominance across all variants highlights its critical role in model performance.
</details>
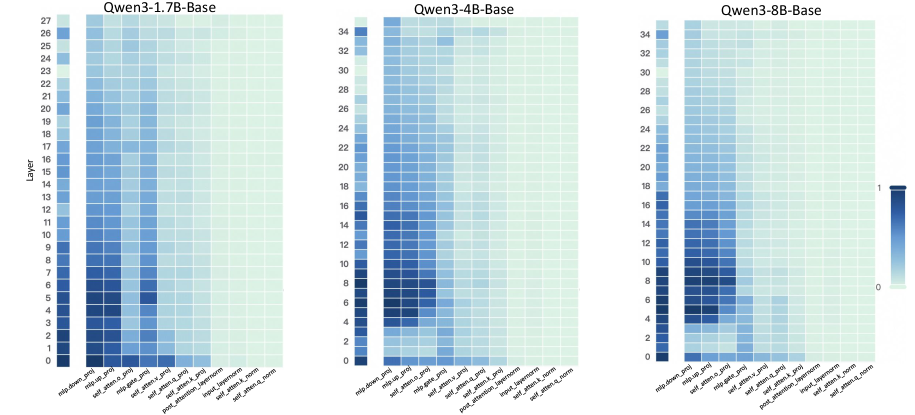
Figure 2: Layer- and unit-level importance distribution of the Qwen3 family. The vertical axis corresponds to different layers, while the horizontal axis denotes parameter units within each layer. Deeper blue indicates higher importance for preserving general-domain competencies.
## 2 Pilot Study: Probing Parameter Importance
### 2.1 Experimental Setup for Importance Probing
To investigate the functional specialization of LLMs and understand how different parameters contribute to preserving general-domain knowledge during CPT, we conduct importance probing on multiple backbone models, including Qwen3-Base (1.7B, 4B, 8B) (Yang et al., 2025a) and LLaMA3-8B (Dubey et al., 2024b). Our analyses focus on probing general-knowledge-critical parameters rather than domain-specific ones. The rationale is that successful CPT must inject new, domain-specific knowledge without inducing catastrophic forgetting. This necessitates identifying and preserving the model’s core parameters that are crucial for its general-domain competencies. By contrast, domain knowledge can then be effectively allocated to less critical parameters, without risking the erosion of pre-existing knowledge and skills. To support this analysis, we construct a General Competence Detection Corpus containing broad world knowledge and instruction-following tasks in both English and Chinese, which servers as the probing ground to reflect a model’s general competencies. Details of its construction are provided in Appendix B.3.
### 2.2 Layer-Level Importance Probing
Our first research question is: How do different layers contribute to preserving general knowledge? To answer this, we measure the importance of each transformer layer by the model’s degradation in general-domain performance when that layer is ablated. Formally, given the General Competence Detection Corpus $\mathcal{D}_{\text{probe}}$ , we first compute the baseline next-token prediction loss of the pretrained LLM $M_{0}$ :
$$
\mathcal{L}_{\text{base}}=\frac{1}{|\mathcal{D}_{\text{probe}}|}\sum_{x\in\mathcal{D}_{\text{probe}}}\ell\big(M_{0}(x),x\big), \tag{1}
$$
where $\ell(\cdot)$ denotes the standard next-token prediction loss in CPT. For each transformer layer $l\in\{1,\ldots,L\}$ , we mask its output via a residual bypass and recompute the loss:
$$
\hat{\mathcal{L}}^{(l)}=\frac{1}{|\mathcal{D}_{\text{probe}}|}\sum_{x\in\mathcal{D}_{\text{probe}}}\ell\big(M_{0}^{(-l)}(x),x\big), \tag{2}
$$
where $M_{0}^{(-l)}$ denotes the model with the $l$ -th layer masked. The importance of layer $l$ is defined as the loss increase relative to the baseline:
$$
I_{\text{layer}}^{(l)}=\hat{\mathcal{L}}^{(l)}-\mathcal{L}_{\text{base}}. \tag{3}
$$
A larger $I_{\text{layer}}^{(l)}$ indicates that layer $l$ plays a more critical role in preserving general knowledge. Figure 2 (left-hand bars) reports the layer-level importance distributions of the Qwen3 family (results for LLaMA3-8B provided in Appendix D). We find that general-knowledge-critical layers are concentrated in the early layers, with importance gradually decreasing toward later layers. This uneven distribution suggests that uniformly expanding layers across the entire depth would be suboptimal. Since some layers are tightly coupled with general knowledge while others are more flexible, uniform expansion not only risks representational interference in critical layers but also allocates parametric budget where it is too constrained to be leveraged for domain learning. In contrast, identifying more adaptable layers with minimal impact on general knowledge and allocating expansion there for knowledge injection is a superior strategy. This leads to our first key observation:
Observation I: Layers exhibit heterogeneous importance for preserving general competencies, which motivates a selective expansion strategy that targets layers less constrained by general abilities yet more adaptable for domain adaptation.
### 2.3 Unit-Level Importance Probing
Building on the layer-level exploration, our next research question is: How do parameter units within each layer contribute to preserving general knowledge? To answer this, we partition each transformer layer into functional units (e.g., attention projections, MLP components, and normalization) and assess their relative contributions to preserving general competencies. The detailed partitioning scheme is provided in Appendix C. This granularity provides a more fine-grained perspective than layer-level probing, while avoiding the prohibitive cost of neuron-level analysis. Formally, for each parameter $\theta_{j}$ in a unit $U$ , we estimate its importance using a first-order Taylor approximation:
$$
I_{j}=\theta_{j}\cdot\nabla_{\theta_{j}}\mathcal{L}, \tag{4}
$$
where $\mathcal{L}$ is the autoregressive training loss. The importance of unit $U$ is then defined as the average importance of its parameters:
$$
I_{\text{unit}}=\frac{1}{|U|}\sum_{j\in U}I_{j}. \tag{5}
$$
A higher $I_{\text{unit}}$ indicates that the unit plays a more critical role in preserving general competencies. Figure 2 (right-hand heatmaps) illustrates the unit-level importance distributions of the Qwen3 family (results for LLaMA3-8B provided in Appendix D). We observe that importance is unevenly distributed across modules within a layer, with some units contributing more to general competencies and others more flexible. This finding suggests that treating all parameter units equally would be suboptimal, as a single update rule cannot simultaneously protect critical units and fully train adaptable ones, risking either damaging previous knowledge or failing to sufficiently learn new knowledge. This motivates us to pursue unit-level decoupling, where training can selectively protect critical units while enabling less general-relevant units to absorb new knowledge without constraint. This leads to our second key observation:
Observation II: Parameter units within each layer exhibit heterogeneous importance, which motivates unit-level decoupling that selectively protects critical units while enabling more adaptable ones to sufficiently absorb domain knowledge.
Summary. Building on the above observations, we propose ADEPT, a continual pretraining framework designed to enable effective domain knowledge injection while preserving general competencies. Inspired by the uneven importance distribution of layers (Observation I), ADEPT selectively expands layers less constrained by general abilities but more receptive to domain adaptation, thereby introducing fresh parameter capacity rather than uniformly expanding layers as in LLaMA-Pro (Wu et al., 2024b). Guided by the heterogeneous importance of parameter units within layers (Observation II), ADEPT further performs unit-level decoupling on the expanded layers, protecting critical units while enabling adaptable ones to specialize in domain knowledge.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Two-Stage Adaptive Model Tuning Framework
### Overview
The diagram illustrates a two-stage framework for domain-adaptive model tuning. Stage 1 focuses on identifying and expanding general-competence layers, while Stage 2 involves decoupling unit-wise importance and dynamically adapting learning rates. Key components include layer importance probing, selective expansion, neuron decoupling, and learning rate adaptation.
### Components/Axes
#### Stage 1: General-Competence Aware Layer Importance Probing
- **Inputs**: Parameters, LLM, General-Competence Detection Corpus
- **Process**:
- Probing Iteration (`i`) evaluates layers (`L₁` to `Lₘ`) for general-competence importance (`ΔLᵢ`).
- Layers are marked as "Activated" or "Deactivated" based on importance scores.
- **Output**: Selective Expansion via Identity Copy (Step 2).
#### Stage 2: Adaptive Unit-Wise Decoupled Tuning
- **Substeps**:
1. **Unit-wise Neuron Decoupling**:
- Calculates unit-wise importance (`I(wᵢⱼ) = |wᵢⱼ∇ₐⱼL|`).
- Identifies "Domain-adaptive Units" (red mountain) and "General-critical Units" (purple mountain).
- Symbols:
- ⭐: Domain-adaptive units (trainable).
- ⚪: General-critical units (frozen).
2. **Dynamic Learning Rate Adaptation**:
- Pretrain dataset → Decoupled tuning.
- Learning rates: Higher for domain-adaptive units (↑), lower for general units (↓).
#### Legends (Right Panel)
- **Symbols**:
- 🔥: Trainable (Domain-adaptive units).
- ❄️: Frozen (General-critical units).
- ➡️: Update flow (forward flow).
- 🔍: Probing.
- 📄: General-competence detection corpus.
### Detailed Analysis
#### Stage 1: Layer Importance Probing
- **Flow**:
1. Parameters and LLM feed into probing iterations.
2. Layers (`L₁` to `Lₘ`) are evaluated for general-competence importance (`ΔLᵢ`).
3. Lowest-K layers (based on `ΔLᵢ`) are selected for expansion via identity copy.
#### Stage 2: Neuron Decoupling
- **Unit Importance**:
- Domain-adaptive units (red) have higher importance scores (`I(wᵢⱼ)`) and are marked as trainable (🔥).
- General-critical units (purple) are frozen (❄️) and have lower importance.
#### Stage 2: Learning Rate Adaptation
- **Rate Adjustment**:
- Domain-adaptive units receive higher learning rates (🔥).
- General units receive lower learning rates (↓).
### Key Observations
1. **Selective Expansion**: Only layers with low general-competence importance (`ΔLᵢ`) are expanded via identity copy.
2. **Decoupling**: Neuron importance is calculated independently of the original layer structure.
3. **Learning Rate Bias**: Domain-adaptive units are prioritized during tuning.
### Interpretation
This framework optimizes model adaptation by:
1. **Focusing on General Competence**: Identifying and expanding layers critical for general tasks.
2. **Decoupling Units**: Separating domain-specific and general units to avoid catastrophic forgetting.
3. **Dynamic Tuning**: Allocating computational resources (learning rates) to high-impact units.
The process suggests a balance between retaining general capabilities and adapting to new domains, with explicit mechanisms to prevent overfitting to domain-specific data.
</details>
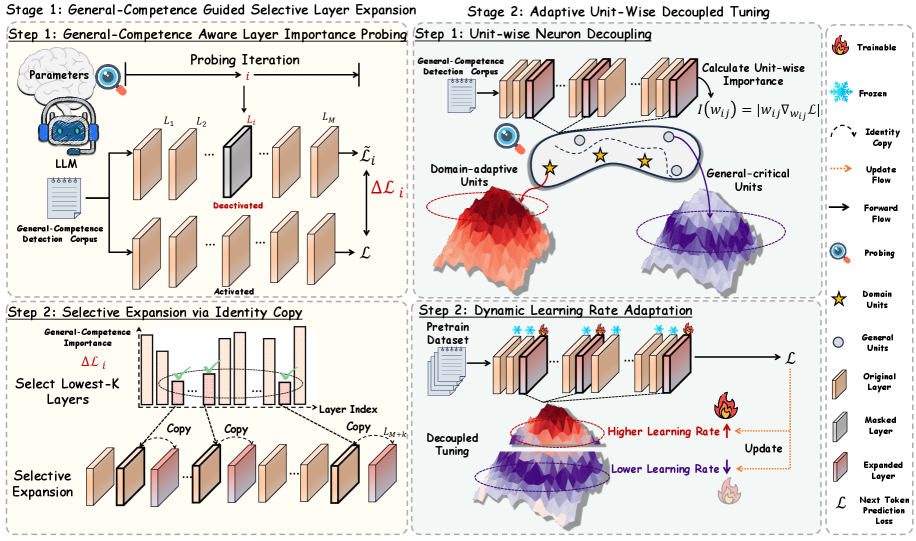
Figure 3: Illustration of ADEPT.
## 3 Methodology
As illustrated in Figure 3, ADEPT includes two stages:
- # Stage 1: General-Competence Guided Selective Layer Expansion. adaptively selects and duplicates layers that minimally affect general competencies while being more adaptable to domain-specific knowledge, thereby introducing fresh representational capacity for domain adaptation.
- # Stage 2: Adaptive Unit-Wise Decoupled Tuning. further decouples units within the expanded layers and apply learning-rate–driven adaptive tuning according to their importance to the general domain, ensuring knowledge injection while preserving general competencies.
### 3.1 General-Competence Guided Selective Layer Expansion
This stage aims to selectively expand model parameters in a way that introduces fresh representational capacity for domain adaptation while preserving general-domain competencies. To this end, we first estimate the contribution of each transformer layer to preserving general knowledge through General-Competence Aware Layer Importance Probing, and then perform Selective Parameter Expansion via Identity Copy to duplicate layers that are least critical for general abilities yet more adaptable to domain-specific knowledge.
General-Competence Aware Layer Importance Probing. To guide selective expansion, we leverage the layer importance scores $I_{\text{layer}}^{(l)}$ defined as Eq. 3. Intuitively, $I_{\text{layer}}^{(l)}$ quantifies how much the $l$ -th layer contributes to preserving general-domain knowledge. Layers with lower scores are deemed less critical for general competencies and are thus selected for expansion, as they can accommodate domain-specific adaptation with minimal risk of catastrophic forgetting.
Selective Parameter Expansion via Identity Copy. Based on the importance scores $I_{\text{layer}}^{(l)}$ , we sort layers by ascending importance and select the $k$ least-important ones for general competence:
$$
\mathcal{S}_{k}=\operatorname*{arg\,min}_{\begin{subarray}{c}\mathcal{S}\subseteq\{1,\ldots,L\}\\
|\mathcal{S}|=k\end{subarray}}\sum_{l\in\mathcal{S}}I_{\text{layer}}^{(l)}. \tag{6}
$$
We denote the selected set $\mathcal{S}_{k}$ as the Domain-Adaptable Layers. For each selected layer $l\in\mathcal{S}_{k}$ , we create a parallel copy by directly duplicating its parameters without re-initialization ( $\tilde{\Theta}^{(l)}=\Theta^{(l)}$ ). To preserve stability, we follow the Function Preserving Initialization (FPI) principle (Chen et al., 2015), ensuring that the expanded model $M_{1}$ produces identical outputs as the original model $M_{0}$ at initialization. Concretely, in the duplicated branch, we set the output projections of both attention and feed-forward sublayers to zero ( $W_{\text{MHSA}}^{\text{out}}=0,\,W_{\text{FFN}}^{\text{out}}=0$ ), so the forward computation remains unchanged ( $M_{1}(x)=M_{0}(x),\,\forall x$ ). The duplicated layers thus provide fresh representational capacity that can specialize for domain signals with minimal risk of eroding general-knowledge-critical parameters in the original pathway. As formally established in Appendix F.1, expanding the layers with the lowest general-competence importance provably minimizes the risk of forgetting. Intuitively, this strategy ensures that new capacity is added where interference with general abilities is weakest, yielding the most favorable trade-off between domain adaptation and knowledge retention.
### 3.2 Adaptive Unit-Wise Decoupled Tuning
This stage aims to further reduce catastrophic forgetting and enable fine-grained control over parameters within the expanded layers. To achieve this, we first decouple each expanded layer into semantic units and evaluate their importance using gradient-based estimation (Unit-wise Neuron Decoupling), and then dynamically adjust learning rates for different units according to their importance scores during training (Dynamic Learning Rate Adaptation).
Unit-wise Neuron Decoupling. Guided by the heterogeneous importance of parameter units within layers, we performs unit-level decoupling on the expanded layers. Following the probing analysis in Section 2.3, we quantify unit importance $I_{\text{unit}}$ using gradient sensitivity signals (cf. Eq. 5), which aggregate the first-order contributions of parameters $\theta_{j}$ to the training loss $\mathcal{L}$ via $\nabla_{\theta_{j}}\mathcal{L}$ . A higher $I_{\text{unit}}$ indicates greater contribution to general competencies and thus warrants more conservative updates, whereas less important units are encouraged to adapt more aggressively to domain-specific signals.
Dynamic Learning Rate Adaptation. Based on the unit importance $I_{\text{unit}}$ in Eq. 5, we assign adaptive learning rates to different units within the expanded layers:
$$
\text{lr}_{U}=2\cdot(1-I_{\text{unit}})\cdot\text{lr}_{\text{base}}, \tag{7}
$$
where $\text{lr}_{\text{base}}$ is the base learning rate, and the coefficient $2$ normalizes the global scale to keep the effective average approximately unchanged. Units more important for general knowledge (higher $I_{\text{unit}}$ ) receive smaller learning rates to reduce overwriting, while less important units are encouraged to adapt more aggressively to domain-specific data. Training proceeds with the standard autoregressive objective: $\mathcal{L}=-\sum_{t=1}^{T}\log P(x_{t}\mid x_{<t};\Theta)$ . Since the importance of units may change as training progresses, we periodically recompute $I_{\text{unit}}$ and update learning rates accordingly, ensuring dynamic adaptation throughout learning. The full training procedure is provided in Appendix L. Appendix F.2 further shows that allocating learning rates inversely to unit importance minimizes an upper bound on general-domain forgetting. In essence, this design formalizes the intuition that highly general-critical units should be preserved via conservative updates, while less critical yet more adaptable ones can update more aggressively to absorb domain-specific information.
Table 1: Performance comparison across Mathematical and Medical domains. Bold numbers indicate the best performance, and underlined numbers denote the second best.
| Method | Mathematics | Medical | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| General | Domain | General | Domain | | | | | | | |
| MMLU | CMMLU | GSM8K | ARC-Easy | ARC-Challenge | MMLU | CMMLU | MedQA | MMCU-Medical | CMB | |
| Qwen3-1.7B-Base | | | | | | | | | | |
| Vanilla | 62.57 | 66.86 | 57.62 | 81.44 | 51.19 | 62.57 | 66.86 | 48.39 | 69.17 | 63.67 |
| PT-Full | 60.07 | 62.84 | 51.86 | 81.24 | 49.65 | 59.44 | 62.84 | 48.45 | 67.45 | 62.77 |
| Replay | 60.69 | 63.52 | 54.74 | 81.01 | 49.73 | 60.52 | 63.85 | 49.00 | 67.32 | 62.20 |
| Llama-Pro | 61.54 | 63.40 | 60.03 | 81.08 | 49.80 | 59.80 | 65.51 | 50.43 | 66.51 | 63.54 |
| PT-LoRA | 60.07 | 62.69 | 59.50 | 80.22 | 49.34 | 57.31 | 59.68 | 47.29 | 61.55 | 57.60 |
| TaSL | 60.34 | 62.95 | 59.07 | 79.76 | 48.89 | 62.48 | 66.14 | 47.06 | 67.62 | 61.15 |
| ADEPT | 62.62 | 67.06 | 70.51 | 82.48 | 52.62 | 62.80 | 66.89 | 50.75 | 71.98 | 65.43 |
| Qwen3-4B-Base | | | | | | | | | | |
| Vanilla | 73.19 | 77.92 | 69.07 | 85.52 | 59.13 | 73.19 | 77.92 | 62.77 | 82.44 | 78.92 |
| PT-Full | 70.33 | 73.07 | 60.96 | 85.31 | 57.59 | 69.48 | 72.77 | 62.84 | 81.34 | 76.88 |
| Replay | 70.46 | 73.72 | 63.91 | 85.06 | 57.68 | 70.74 | 73.81 | 63.55 | 80.60 | 76.74 |
| Llama-Pro | 72.42 | 77.39 | 73.16 | 85.14 | 57.76 | 72.28 | 77.28 | 62.53 | 81.20 | 78.12 |
| PT-LoRA | 70.20 | 72.90 | 71.34 | 84.18 | 57.25 | 72.73 | 76.78 | 61.59 | 80.49 | 76.92 |
| TaSL | 70.50 | 73.20 | 70.84 | 83.68 | 56.75 | 73.03 | 77.08 | 60.99 | 79.20 | 77.08 |
| ADEPT | 73.21 | 78.30 | 76.19 | 88.44 | 60.98 | 72.95 | 78.77 | 64.49 | 84.58 | 79.87 |
| Qwen3-8B-Base | | | | | | | | | | |
| Vanilla | 76.94 | 82.09 | 69.98 | 87.12 | 64.25 | 76.94 | 82.09 | 66.30 | 86.45 | 81.67 |
| PT-Full | 74.90 | 78.49 | 80.21 | 85.90 | 61.77 | 74.06 | 78.82 | 67.24 | 87.69 | 85.27 |
| Replay | 75.19 | 78.92 | 81.12 | 85.98 | 62.37 | 74.51 | 78.86 | 68.89 | 86.66 | 84.73 |
| Llama-Pro | 76.16 | 81.42 | 80.97 | 86.62 | 63.91 | 76.58 | 81.69 | 66.77 | 87.19 | 83.76 |
| PT-LoRA | 75.66 | 80.81 | 82.87 | 86.36 | 62.46 | 76.60 | 81.57 | 67.01 | 86.70 | 83.04 |
| TaSL | 76.63 | 80.37 | 80.54 | 84.81 | 59.09 | 76.42 | 81.86 | 66.51 | 86.20 | 82.54 |
| ADEPT | 76.80 | 82.11 | 83.87 | 89.29 | 64.51 | 76.77 | 82.11 | 69.24 | 89.84 | 85.80 |
| Llama3-8B-Base | | | | | | | | | | |
| Vanilla | 65.33 | 50.83 | 36.84 | 84.18 | 54.01 | 65.33 | 50.83 | 58.91 | 46.29 | 35.61 |
| PT-Full | 61.62 | 46.21 | 49.73 | 84.01 | 53.52 | 59.15 | 51.39 | 59.23 | 66.58 | 61.65 |
| Replay | 62.00 | 53.31 | 49.51 | 82.49 | 54.18 | 59.98 | 54.52 | 59.07 | 65.84 | 61.71 |
| Llama-Pro | 64.53 | 50.26 | 48.29 | 83.29 | 53.07 | 64.19 | 50.59 | 59.94 | 53.96 | 47.05 |
| PT-LoRA | 64.86 | 49.82 | 48.82 | 83.80 | 54.01 | 64.34 | 50.13 | 58.84 | 56.05 | 48.22 |
| TaSL | 65.16 | 50.11 | 35.43 | 83.29 | 53.51 | 64.64 | 50.43 | 55.55 | 58.34 | 47.69 |
| ADEPT | 65.35 | 51.90 | 50.57 | 84.96 | 55.52 | 65.17 | 51.92 | 61.17 | 67.03 | 61.78 |
## 4 Experiment
### 4.1 Experimental Setup
Datasets. We evaluate ADEPT across two domains, Mathematics and Medicine. For the mathematical domain, we use OpenWebMath (Paster et al., 2023), together with AceReason-Math (Chen et al., 2025), concatenated into the continual pretraining corpora. For the medical domain, we adopt the multilingual MMedC corpus (Qiu et al., 2024), together with IndustryIns and MMedBench, forming the medical pretraining corpora. Dataset statistics are provided in Appendix B.1 and Appendix B.2. In addition, for detecting general-knowledge-critical regions, we construct a General Competence Detection Corpus, following the same setting as in Section 2 and described in Appendix B.3.
Baselines. We compare ADEPT with a broad range of baselines from four perspectives:
- Full-parameter tuning. PT-Full directly updates all model parameters on the target corpora.
- Replay-based tuning. Replay mitigates catastrophic forgetting by mixing general-domain data into the training process (Que et al., 2024).
- Architecture expansion. LLaMA-Pro (Wu et al., 2024b) expands the model by uniformly inserting new layers into each transformer block while freezing the original weights. Only the newly introduced parameters are trained, enabling structural growth while preserving prior knowledge.
- Parameter-efficient tuning. PT-LoRA performs CPT using Low-Rank Adaptation (Hu et al., 2022), updating only a small set of task-adaptive parameters. TaSL (Feng et al., 2024a) extends PT-LoRA to a multi-task regime by decoupling LoRA matrices across transformer layers, allowing different subsets of parameters to specialize for different tasks.
See Appendix B.6 for implementation details of all baselines.
Backbone Models. To assess the generality of our method, we instantiate ADEPT on multiple backbone models, including Qwen3-Base (1.7B, 4B, 8B) (Yang et al., 2025a) and LLaMA3.1-8B-Base (Dubey et al., 2024b), covering a wide range of parameter scales and architectural variants.
Evaluation Metrics and Strategy. We adopt multiple-choice question answering accuracy as the primary evaluation metric across all tasks (see Appendix B.9 for further details). For the Mathematics domain, we evaluate on GSM8K (Cobbe et al., 2021), ARC-Easy (Clark et al., 2018), and ARC-Challenge (Clark et al., 2018), which collectively span a wide range of reasoning difficulties. For the Medical domain, we use MedQA (Jin et al., 2021), MMCU-Medical (Zeng, 2023), and CMB (Wang et al., 2023b), covering diverse medical subjects and varying levels of complexity. Among them, MedQA is an English benchmark, while MMCU-Medical and CMB are in Chinese. To assess the model’s ability to retain general-domain knowledge during continual pretraining, we additionally evaluate on MMLU (Hendrycks et al., 2020) and CMMLU (Li et al., 2023), two broad-coverage benchmarks for general knowledge and reasoning in English and Chinese, respectively.
### 4.2 Experimental Results
Performance Comparison. As shown in Table 1, ADEPT consistently outperforms all CPT baselines across both mathematical and medical domains, confirming its effectiveness in domain-specific knowledge acquisition while substantially alleviating catastrophic forgetting. Concretely, ADEPT achieves substantial domain-specific improvements. Across all backbones and domain benchmarks, ADEPT consistently surpasses baselines, achieving the strongest performance. For instance, on Qwen3-1.7B-Base, ADEPT boosts GSM8K accuracy from 57.62% to 70.51% $\uparrow$ , bringing a large gain that highlights its advantage on enhancing LLMs’ complex reasoning. Similarly, on LLaMA3-8B-Base, it drastically improves CMB accuracy improves from 35.61% to 61.78% $\uparrow$ , underscoring the strong enhancement of medical-domain capabilities. On average, ADEPT achieves up to 5.58% gains over full-parameter CPT on target-domain benchmarks, confirming its advantage in domain knowledge acquisition. Furthermore, ADEPT demonstrates clear advantages in mitigating catastrophic forgetting. Whereas most baselines suffer noticeable degradation on general benchmarks such as MMLU and CMMLU, ADEPT preserves the pretrained LLMs’ general-domain competencies, and in some cases even surpasses the vanilla backbone. Notably, with Qwen3-4B under medical CPT, ADEPT improves CMMLU accuracy from 77.92% to 78.77% $\uparrow$ . It also results in an average performance increase of 5.76% on general benchmarks over full-parameter CPT. We attribute this to the disentanglement of domain-specific and general parameters, which prevents harmful representational interference during adaptation, ensuring that learning specialized knowledge does not corrupt the model’s foundational abilities. Instead, this focused learning process appears to refine the model’s overall competencies, leading to synergistic improvements on general-domain tasks. In summary, ADEPT offers a robust solution for CPT achieving superior domain adaptation while effectively preserving general knowledge.
Table 2: Ablation study on ADEPT in Medical domain. Bold numbers indicate the best performance, and underlined numbers denote the second best.
| Method | Qwen3-1.7B-Base | Llama3-8B-Base | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| MMLU | CMMLU | MedQA | MMCU-Medical | CMB | MMLU | CMMLU | MedQA | MMCU-Medical | CMB | |
| ADEPT | 62.80 | 66.89 | 50.75 | 70.98 | 65.43 | 65.17 | 51.92 | 61.17 | 61.78 | 67.03 |
| w/o Stage-1 | 57.31 | 59.68 | 47.29 | 61.55 | 57.60 | 57.88 | 50.76 | 58.32 | 53.32 | 60.32 |
| w/o Stage-2 | 61.56 | 64.33 | 49.23 | 66.19 | 64.36 | 64.34 | 50.74 | 59.60 | 50.68 | 57.36 |
| Uniform Expansion | 59.80 | 65.51 | 50.43 | 66.51 | 63.54 | 64.19 | 50.59 | 59.94 | 47.05 | 53.96 |
Ablation Study. To investigate the effectiveness of each component in ADEPT, we conduct ablation experiments in the medical domain using two representative backbones, Qwen3-1.7B and Llama3-8B. In w/o Stage-1, we remove the General-Competence Guided Selective Layer Expansion and directly apply Adaptive Unit-Wise Decoupled Tuning on the $k$ Domain-Adaptable Layers without introducing any new parameters. In w/o Stage-2, we discard the dynamic decoupled tuning stage and instead directly fine-tune the expanded layers from Stage-1. In Uniform Expansion, we replace importance-guided expansion with uniformly inserted layers followed by fine-tuning, which is equivalent to the strategy adopted in LLaMA-Pro. As shown in Table 2, removing either Stage-1 or Stage-2 leads to clear degradation in both general and domain-specific performance, confirming that both adaptive expansion and decoupled tuning are indispensable. In particular, eliminating Stage-1 results in the largest performance drop, suggesting that adaptive capacity allocation is crucial for enabling effective domain adaptation without sacrificing general-domain competencies. Meanwhile, replacing importance-guided expansion with uniform expansion yields inferior results, underscoring the advantage of expanding only the most domain-adaptable layers.
<details>
<summary>x4.png Details</summary>
### Visual Description
## 2D Contour Plots: Text Embedding Distributions Across Methods
### Overview
The image presents three comparative 2D contour plots visualizing the latent space distributions of General Text (blue) and Medical Text (red) across three different model configurations: Vanilla, W/o stage1, and ADEPT. Each subplot includes marginal histograms showing 1D projections along dim1 (top) and dim2 (right).
### Components/Axes
- **X-axis (dim1)**: Ranges from -100 to 100 across subplots
- **Y-axis (dim2)**: Ranges from -75 to 75 (Vanilla), -60 to 60 (W/o stage1), and -60 to 60 (ADEPT)
- **Legend**:
- Blue = General Text
- Red = Medical Text
- **Marginal Histograms**:
- Top: dim1 distribution
- Right: dim2 distribution
- **Contour Lines**:
- Blue (General Text) and Red (Medical Text) distributions
- Density indicated by line thickness
### Detailed Analysis
#### Vanilla
- **Contour Spread**:
- General Text (blue): -50 to 50 (dim1), -75 to 25 (dim2)
- Medical Text (red): -30 to 30 (dim1), -50 to 0 (dim2)
- **Overlap**: Significant overlap in central region (-10 to 10 dim1, -25 to 0 dim2)
- **Histograms**:
- dim1: Bimodal peaks at ±30
- dim2: Single peak at 0
#### W/o stage1
- **Contour Spread**:
- General Text (blue): -100 to 100 (dim1), -40 to 40 (dim2)
- Medical Text (red): -60 to 60 (dim1), -30 to 30 (dim2)
- **Overlap**: Moderate overlap in central region (-20 to 20 dim1, -10 to 10 dim2)
- **Histograms**:
- dim1: Single peak at 0
- dim2: Bimodal peaks at ±20
#### ADEPT
- **Contour Spread**:
- General Text (blue): -80 to 80 (dim1), -40 to 40 (dim2)
- Medical Text (red): -50 to 50 (dim1), -30 to 30 (dim2)
- **Overlap**: Minimal overlap in central region (-10 to 10 dim1, -10 to 10 dim2)
- **Histograms**:
- dim1: Single peak at 0
- dim2: Single peak at 0
### Key Observations
1. **ADEPT** shows the clearest separation between text types, with Medical Text (red) forming a tighter cluster
2. **Vanilla** exhibits the most overlap, with Medical Text distribution heavily concentrated in negative dim2
3. **W/o stage1** demonstrates intermediate separation with broader dim1 spread
4. All methods show Medical Text with stronger dim2 concentration than General Text
5. ADEPT's dim1 range is 60% narrower than Vanilla while maintaining similar dim2 spread
### Interpretation
The progressive improvement in text type separation from Vanilla → W/o stage1 → ADEPT suggests that the stage1 component plays a critical role in disentangling text representations. ADEPT's tighter clustering of Medical Text (red) indicates better feature discrimination, potentially improving downstream task performance. The reduced dim1 spread in ADEPT compared to Vanilla suggests more efficient use of latent dimensions. The consistent dim2 concentration across methods implies this dimension primarily captures text-type specific features. The marginal histograms reveal that ADEPT achieves more balanced distributions across both dimensions compared to other configurations.
</details>
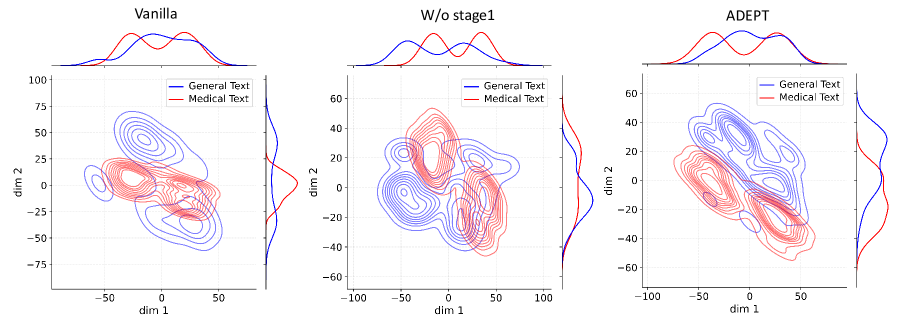
Figure 4: Activation distribution analysis of Qwen3-8B.
Decoupling Effectiveness on Expanded Parameters. We visualize cross-domain activations using Kernel Density Estimation (KDE) (Silverman, 2018), sampling 500 instances from both Medical and General corpora. For the original Qwen3-8B-Base (left in Figure 4), the most domain-adaptable layer (lowest $I_{\text{layer}}$ ) still shows heavy overlap between general and medical activations, evidencing strong parameter coupling. Direct decoupling without expansion (w/o Stage-1, middle) on the same layer fails to reduce this entanglement, confirming that pretrained parameters are inherently difficult to separate. In contrast, after expansion (right), the duplicated layers serve as a “blank slate,” yielding clearly separated activations across domains. Additional analyses on more backbones are provided in Appendix C.1, where we observe that this trend consistently holds across nearly all evaluated LLMs, further validating the generality of our approach.
<details>
<summary>figures/wordcloud_med.jpg Details</summary>
### Visual Description
## Word Cloud: Health and Medical Themes
### Overview
The image is a word cloud composed of health-related terms in varying colors and sizes. Words are arranged in a non-linear, overlapping pattern, with larger text indicating higher prominence or frequency. Colors appear to categorize terms (e.g., green for diseases, blue for treatments), though no explicit legend is present.
### Components/Axes
- **Text Elements**: All words are health/medical terms (e.g., "cancer," "treatment," "hospital," "symptoms").
- **Color Coding**: Terms are color-coded, likely by category (e.g., green for diseases, blue for treatments, yellow for institutions). No legend is visible to confirm this.
- **Size Hierarchy**: Larger words (e.g., "health," "patient") dominate the center, while smaller words (e.g., "FDA," "vaccine") are peripheral.
### Detailed Analysis
- **Prominent Terms**:
- **Largest**: "health" (green), "patient" (blue), "hospital" (green), "disease" (green), "symptoms" (purple).
- **Medium**: "cancer" (green), "treatment" (purple), "diabetes" (blue), "medication" (purple), "prescription" (purple).
- **Smallest**: "FDA" (blue), "vaccine" (blue), "addiction" (purple), "photograph" (green).
- **Color Distribution**:
- Green: Dominates (e.g., "cancer," "hospital," "disease").
- Blue: Treatments/institutions (e.g., "therapy," "MD," "CDC").
- Purple: Research/methods (e.g., "randomized," "clinical trials").
- Yellow: Miscellaneous (e.g., "protein," "MRI").
### Key Observations
1. **Frequency Indicators**:
- "health" and "patient" are the most prominent, suggesting central themes.
- "cancer" and "diabetes" are large, indicating high relevance in health discussions.
2. **Color Grouping**:
- Green terms cluster around diseases and institutions.
- Purple terms relate to research and clinical processes.
3. **Ambiguities**:
- No explicit legend to confirm color categories.
- Overlapping words obscure exact counts; sizes are approximate.
### Interpretation
The word cloud emphasizes **healthcare systems** (hospitals, patients) and **diseases** (cancer, diabetes) as dominant themes. Terms like "randomized," "clinical trials," and "researchers" suggest a focus on medical research. Color coding implies categorization, but without a legend, interpretations are speculative. The absence of terms like "vaccine" or "pandemic" may reflect the image's focus on chronic conditions over acute public health crises. The prominence of "symptoms" and "diagnosis" highlights patient-centered care, while "therapy" and "prescription" underscore treatment pathways.
</details>
(a) Token distributions shift in Medical
<details>
<summary>figures/wordcloud_math.jpg Details</summary>

### Visual Description
## Word Cloud: Academic and Technical Themes
### Overview
The image is a word cloud composed of technical and academic terminology, with words varying in size and color. No explicit axes, legends, or numerical data are present. The layout is unstructured, with words overlapping and positioned randomly.
### Components/Axes
- **No axes or scales**: The image lacks numerical axes or quantitative markers.
- **Legend**: Absent. Color variations (purple, green, yellow, blue) are present but not explicitly labeled.
- **Text elements**: Words are the sole content, with no additional annotations or labels.
### Detailed Analysis
- **Word sizes**: Larger words (e.g., "quantum," "algorithm," "paper") likely indicate higher frequency or prominence in the source dataset.
- **Color distribution**:
- **Purple**: Dominates the cloud (e.g., "effects," "quantum," "students").
- **Green**: Includes terms like "space," "physics," "results."
- **Yellow**: Words such as "mathematic," "model," "previous."
- **Blue**: Terms like "bit," "connected," "parameters."
- **Notable words**:
- Technical: "quantum," "physics," "algorithm," "code."
- Academic: "paper," "students," "theorem."
- Collaborative: "paper," "editor," "results."
- Miscellaneous: "Oct," "FT," "error," "profit."
### Key Observations
1. **Dominant themes**: Academic research ("quantum," "physics"), technology ("algorithm," "code"), and collaboration ("paper," "students").
2. **Color clustering**: Purple and green dominate, suggesting these categories may represent core themes.
3. **Ambiguity**: No legend or metadata to confirm categories or frequencies. Overlapping words (e.g., "Oct," "FT") reduce readability.
### Interpretation
The word cloud likely visualizes a corpus of academic or technical documents, with larger words reflecting higher occurrence rates. The absence of a legend limits precise categorization, but color coding may imply groupings (e.g., purple for foundational concepts, green for applied fields). Terms like "quantum" and "algorithm" suggest a focus on advanced STEM topics, while "paper" and "students" hint at academic publishing or educational contexts. The lack of structured data prevents quantitative analysis, but the prominence of certain terms underscores their relevance in the source material.
</details>
(b) Token distributions shift in Mathematical
Figure 5: Token distribution shifts across domains. Word cloud visualizations of shifted tokens reveal that ADEPT achieves highly focused alignment, with most changes concentrated on domain-specific terminology.
Token Distribution Shift Analysis. To assess how ADEPT injects domain knowledge while preserving general competencies, we analyze token-level shifts between the base and continually pretrained models. Following Lin et al. (2024), tokens are categorized as unshifted, marginal, or shifted. Only a small proportion of tokens shift, while most remain unchanged, indicating stable adaptation. In the medical domain, merely 2.18% shift (vs. 5.61% under full pretraining), largely medical terms such as “prescription,” “diagnosis,” and “therapy” (Figure 5(a)). In the mathematical domain, only 1.24% shift, mainly scientific terms such as “theorem” and “equation” (Figure 5(b)). Further details and analyses are provided in Appendix I. These results demonstrate that ADEPT achieves precise and economical domain knowledge injection while minimizing perturbation to general competence.
Extended Investigations and Key Insights. We further investigate several design choices of ADEPT in appendix: In Appendix E, we investigate alternative strategies for probing layer importance and observe the consistency of different measurement methods, offering insight into how importance estimation affects adaptation outcomes. Appendix G explores the effect of expanding different numbers of layers and reveals how the number of expansion layers should be selected under different circumstances and the potential reasons behind this. Appendix H shows that even with relatively low-quality importance detection corpus from pretrain data, our approach maintains strong generalization across domains, suggesting the robustness of ADEPT. Appendix J demonstrates our insights into the potential for merging expanded layers that are independently trained on different domains, offering an intriguing direction for achieving multi-domain adaptation with minimal catastrophic forgetting. In addition, Appendix B.8 analyzes the training efficiency of ADEPT, showing that our selective updating design substantially accelerates convergence compared to baselines.
## 5 Conclusions and Future Works
We present ADEPT, a framework for LLM continual pretraining for domain adaptation that effectively tackles catastrophic forgetting, leveraging functional specialization in LLMs. By selectively expanding layers less critical to the general domain and adaptively updating decoupled parameter units, ADEPT minimizes catastrophic forgetting while efficiently incorporating domain-specific expertise. Our experiments show significant improvements in both domain performance and general knowledge retention compared to baselines. Future work could focus on refining the decoupled tuning mechanism, designing more sophisticated learning rate strategies beyond linear mapping to allow for more precise adjustments. Another direction is to explore better dynamic and real-time methods for measuring parameter importance during training.
## 6 Ethics Statement
All datasets used for training and evaluation in this study are publicly available versions obtained from the Hugging Face platform. The datasets have been curated, cleaned, and de-identified by their respective data providers prior to release. No patient personal information or identifiable medical data is present. Consequently, the research does not involve human subjects, and there are no related concerns regarding privacy, confidentiality, or legal liability. And for full transparency, we report all aspects of large language model (LLM) involvement in the Appendix K.
We strictly adhered to the usage and redistribution licenses provided by the original dataset authors and hosting platforms. Our research poses no risk of harm to individuals or groups and does not contain any potentially harmful insights, models, or applications. Additionally, there are no conflicts of interest or sponsorship concerns associated with this work. We are committed to research integrity and ethical standards consistent with the ICLR Code of Ethics.
## 7 Reproducibility Statement
We actively support the spirit of openness and reproducibility advocated by ICLR. To ensure the reproducibility of our research, we have taken the following measures:
1. Disclosure of Base Models: All base models used in our experiments are explicitly identified and described in the main text. This allows readers to directly reference and obtain these models.
1. Datasets and Experimental Details: All experiments are conducted on publicly available datasets from the Hugging Face platform. In Appendix B, we provide a comprehensive description of our experimental implementation, including dataset sources, browser links, and detailed data processing procedures. We also detail the experimental setup, such as training duration, hardware environment (e.g., GPU type), and configuration of hyperparameters, including LoRA_rank, number of extended layers, batch_size, and max_length. These details facilitate transparent verification and replication of our results.
1. Open-Source Code Release: To further support reproducibility, we release all training and evaluation code in an anonymous repository (https://anonymous.4open.science/status/ADEPT-F2E3). The repository contains clear instructions on installation, data downloading, preprocessing, and experimentation, allowing interested researchers to replicate our results with minimal effort.
## References
- Aghajanyan et al. (2021) Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (eds.), Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021, pp. 7319–7328. Association for Computational Linguistics, 2021. doi: 10.18653/V1/2021.ACL-LONG.568. URL https://doi.org/10.18653/v1/2021.acl-long.568.
- Ahn et al. (2024) Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, and Wenpeng Yin. Large language models for mathematical reasoning: Progresses and challenges. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop, pp. 225–237, 2024.
- Arbel et al. (2024) Iftach Arbel, Yehonathan Refael, and Ofir Lindenbaum. Transformllm: Adapting large language models via llm-transformed reading comprehension text. arXiv preprint arXiv:2410.21479, 2024.
- Chen et al. (2024) Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. Huatuogpt-o1, towards medical complex reasoning with llms. arXiv preprint arXiv:2412.18925, 2024.
- Chen et al. (2015) Tianqi Chen, Ian Goodfellow, and Jonathon Shlens. Net2net: Accelerating learning via knowledge transfer. arXiv preprint arXiv:1511.05641, 2015.
- Chen et al. (2025) Yang Chen, Zhuolin Yang, Zihan Liu, Chankyu Lee, Peng Xu, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Acereason-nemotron: Advancing math and code reasoning through reinforcement learning. arXiv preprint arXiv:2505.16400, 2025.
- Cheng et al. (2023) Daixuan Cheng, Shaohan Huang, and Furu Wei. Adapting large language models via reading comprehension. In The Twelfth International Conference on Learning Representations, 2023.
- Clark et al. (2019) Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. What does BERT look at? an analysis of bert’s attention. In Tal Linzen, Grzegorz Chrupala, Yonatan Belinkov, and Dieuwke Hupkes (eds.), Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, BlackboxNLP@ACL 2019, Florence, Italy, August 1, 2019, pp. 276–286. Association for Computational Linguistics, 2019. doi: 10.18653/V1/W19-4828. URL https://doi.org/10.18653/v1/W19-4828.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Dai et al. (2022) Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. Knowledge neurons in pretrained transformers. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 8493–8502, 2022.
- Ding et al. (2024) Hongxin Ding, Yue Fang, Runchuan Zhu, Xinke Jiang, Jinyang Zhang, Yongxin Xu, Xu Chu, Junfeng Zhao, and Yasha Wang. 3ds: Decomposed difficulty data selection’s case study on llm medical domain adaptation. arXiv preprint arXiv:2410.10901, 2024.
- Ding et al. (2025) Hongxin Ding, Baixiang Huang, Yue Fang, Weibin Liao, Xinke Jiang, Zheng Li, Junfeng Zhao, and Yasha Wang. Promed: Shapley information gain guided reinforcement learning for proactive medical llms. arXiv preprint arXiv:2508.13514, 2025.
- Dubey et al. (2024a) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurélien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Rozière, Bethany Biron, Binh Tang, Bobbie Chern, Charlotte Caucheteux, Chaya Nayak, Chloe Bi, Chris Marra, Chris McConnell, Christian Keller, Christophe Touret, Chunyang Wu, Corinne Wong, Cristian Canton Ferrer, Cyrus Nikolaidis, Damien Allonsius, Daniel Song, Danielle Pintz, Danny Livshits, David Esiobu, Dhruv Choudhary, Dhruv Mahajan, Diego Garcia-Olano, Diego Perino, Dieuwke Hupkes, Egor Lakomkin, Ehab AlBadawy, Elina Lobanova, Emily Dinan, Eric Michael Smith, Filip Radenovic, Frank Zhang, Gabriel Synnaeve, Gabrielle Lee, Georgia Lewis Anderson, Graeme Nail, Grégoire Mialon, Guan Pang, Guillem Cucurell, Hailey Nguyen, Hannah Korevaar, Hu Xu, Hugo Touvron, Iliyan Zarov, Imanol Arrieta Ibarra, Isabel M. Kloumann, Ishan Misra, Ivan Evtimov, Jade Copet, Jaewon Lee, Jan Geffert, Jana Vranes, Jason Park, Jay Mahadeokar, Jeet Shah, Jelmer van der Linde, Jennifer Billock, Jenny Hong, Jenya Lee, Jeremy Fu, Jianfeng Chi, Jianyu Huang, Jiawen Liu, Jie Wang, Jiecao Yu, Joanna Bitton, Joe Spisak, Jongsoo Park, Joseph Rocca, Joshua Johnstun, Joshua Saxe, Junteng Jia, Kalyan Vasuden Alwala, Kartikeya Upasani, Kate Plawiak, Ke Li, Kenneth Heafield, Kevin Stone, and et al. The llama 3 herd of models. CoRR, abs/2407.21783, 2024a. doi: 10.48550/ARXIV.2407.21783. URL https://doi.org/10.48550/arXiv.2407.21783.
- Dubey et al. (2024b) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv e-prints, pp. arXiv–2407, 2024b.
- Dubey et al. (2024c) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv e-prints, pp. arXiv–2407, 2024c.
- Fang et al. (2025) Yue Fang, Yuxin Guo, Jiaran Gao, Hongxin Ding, Xinke Jiang, Weibin Liao, Yongxin Xu, Yinghao Zhu, Zhibang Yang, Liantao Ma, et al. Toward better ehr reasoning in llms: Reinforcement learning with expert attention guidance. arXiv preprint arXiv:2508.13579, 2025.
- Feng et al. (2024a) Yujie Feng, Xu Chu, Yongxin Xu, Guangyuan Shi, Bo Liu, and Xiao-Ming Wu. Tasl: Continual dialog state tracking via task skill localization and consolidation. arXiv preprint arXiv:2408.09857, 2024a.
- Feng et al. (2024b) Yujie Feng, Xu Chu, Yongxin Xu, Guangyuan Shi, Bo Liu, and Xiao-Ming Wu. Tasl: Continual dialog state tracking via task skill localization and consolidation. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pp. 1266–1279. Association for Computational Linguistics, 2024b. doi: 10.18653/V1/2024.ACL-LONG.69. URL https://doi.org/10.18653/v1/2024.acl-long.69.
- Hendrycks et al. (2020) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
- Hewitt & Manning (2019) John Hewitt and Christopher D. Manning. A structural probe for finding syntax in word representations. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pp. 4129–4138. Association for Computational Linguistics, 2019. doi: 10.18653/V1/N19-1419. URL https://doi.org/10.18653/v1/n19-1419.
- Hu et al. (2022) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3, 2022.
- Huang et al. (2024) Jianheng Huang, Leyang Cui, Ante Wang, Chengyi Yang, Xinting Liao, Linfeng Song, Junfeng Yao, and Jinsong Su. Mitigating catastrophic forgetting in large language models with self-synthesized rehearsal. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1416–1428, 2024.
- Ibrahim et al. (2024) Adam Ibrahim, Benjamin Thérien, Kshitij Gupta, Mats L Richter, Quentin Anthony, Timothée Lesort, Eugene Belilovsky, and Irina Rish. Simple and scalable strategies to continually pre-train large language models. arXiv preprint arXiv:2403.08763, 2024.
- Jacot et al. (2018) Arthur Jacot, Clément Hongler, and Franck Gabriel. Neural tangent kernel: Convergence and generalization in neural networks. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa-Bianchi, and Roman Garnett (eds.), Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pp. 8580–8589, 2018. URL https://proceedings.neurips.cc/paper/2018/hash/5a4be1fa34e62bb8a6ec6b91d2462f5a-Abstract.html.
- Jiang et al. (2024) Xinke Jiang, Yue Fang, Rihong Qiu, Haoyu Zhang, Yongxin Xu, Hao Chen, Wentao Zhang, Ruizhe Zhang, Yuchen Fang, Xu Chu, et al. Tc-rag: turing-complete rag’s case study on medical llm systems. arXiv preprint arXiv:2408.09199, 2024.
- Jiang et al. (2025) Xinke Jiang, Ruizhe Zhang, Yongxin Xu, Rihong Qiu, Yue Fang, Zhiyuan Wang, Jinyi Tang, Hongxin Ding, Xu Chu, Junfeng Zhao, et al. Hykge: A hypothesis knowledge graph enhanced rag framework for accurate and reliable medical llms responses. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 11836–11856, 2025.
- Jin et al. (2021) Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14):6421, 2021.
- Ke et al. (2023) Zixuan Ke, Yijia Shao, Haowei Lin, Tatsuya Konishi, Gyuhak Kim, and Bing Liu. Continual pre-training of language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/forum?id=m_GDIItaI3o.
- Kirkpatrick et al. (2017) James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526, 2017.
- Li et al. (2023) Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. Cmmlu: Measuring massive multitask language understanding in chinese. arXiv preprint arXiv:2306.09212, 2023.
- Lin et al. (2024) Bill Yuchen Lin, Abhilasha Ravichander, Ximing Lu, Nouha Dziri, Melanie Sclar, Khyathi Raghavi Chandu, Chandra Bhagavatula, and Yejin Choi. The unlocking spell on base llms: Rethinking alignment via in-context learning. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=wxJ0eXwwda.
- Liu et al. (2024a) Chengyuan Liu, Yangyang Kang, Shihang Wang, Lizhi Qing, Fubang Zhao, Chao Wu, Changlong Sun, Kun Kuang, and Fei Wu. More than catastrophic forgetting: Integrating general capabilities for domain-specific LLMs. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 7531–7548, Miami, Florida, USA, November 2024a. Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.429. URL https://aclanthology.org/2024.emnlp-main.429/.
- Liu et al. (2024b) Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. In International Conference on Machine Learning, pp. 32100–32121. PMLR, 2024b.
- Luo et al. (2025) Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning. IEEE Transactions on Audio, Speech and Language Processing, 2025.
- OpenAI (2023) OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- Paster et al. (2023) Keiran Paster, Marco Dos Santos, Zhangir Azerbayev, and Jimmy Ba. Openwebmath: An open dataset of high-quality mathematical web text. arXiv preprint arXiv:2310.06786, 2023.
- Peng et al. (2025) Ru Peng, Kexin Yang, Yawen Zeng, Junyang Lin, Dayiheng Liu, and Junbo Zhao. Dataman: Data manager for pre-training large language models. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https://openreview.net/forum?id=eNbA8Fqir4.
- Qiu et al. (2024) Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang, Weixiong Lin, Haicheng Wang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Towards building multilingual language model for medicine. Nature Communications, 15(1):8384, 2024.
- Que et al. (2024) Haoran Que, Jiaheng Liu, Ge Zhang, Chenchen Zhang, Xingwei Qu, Yinghao Ma, Feiyu Duan, Zhiqi Bai, Jiakai Wang, Yuanxing Zhang, et al. D-cpt law: Domain-specific continual pre-training scaling law for large language models. Advances in Neural Information Processing Systems, 37:90318–90354, 2024.
- Silverman (2018) Bernard W Silverman. Density estimation for statistics and data analysis. Routledge, 2018.
- Song et al. (2023) Yifan Song, Peiyi Wang, Weimin Xiong, Dawei Zhu, Tianyu Liu, Zhifang Sui, and Sujian Li. Infocl: Alleviating catastrophic forgetting in continual text classification from an information theoretic perspective. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 14557–14570, 2023.
- Wang et al. (2023a) Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuan-Jing Huang. Orthogonal subspace learning for language model continual learning. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 10658–10671, 2023a.
- Wang et al. (2023b) Xidong Wang, Guiming Hardy Chen, Dingjie Song, Zhiyi Zhang, Zhihong Chen, Qingying Xiao, Feng Jiang, Jianquan Li, Xiang Wan, Benyou Wang, et al. Cmb: A comprehensive medical benchmark in chinese. arXiv preprint arXiv:2308.08833, 2023b.
- Wu et al. (2024a) C Wu, W Lin, X Zhang, Y Zhang, W Xie, and Y Wang. Pmc-llama: toward building open-source language models for medicine. Journal of the American Medical Informatics Association: JAMIA, pp. ocae045–ocae045, 2024a.
- Wu et al. (2024b) Chengyue Wu, Yukang Gan, Yixiao Ge, Zeyu Lu, Jiahao Wang, Ye Feng, Ying Shan, and Ping Luo. Llama pro: Progressive llama with block expansion. arXiv preprint arXiv:2401.02415, 2024b.
- Xiong et al. (2023) Weimin Xiong, Yifan Song, Peiyi Wang, and Sujian Li. Rationale-enhanced language models are better continual relation learners. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 15489–15497, 2023.
- Xu et al. (2025) Yongxin Xu, Ruizhe Zhang, Xinke Jiang, Yujie Feng, Yuzhen Xiao, Xinyu Ma, Runchuan Zhu, Xu Chu, Junfeng Zhao, and Yasha Wang. Parenting: Optimizing knowledge selection of retrieval-augmented language models with parameter decoupling and tailored tuning. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 11643–11662, Vienna, Austria, July 2025. Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long.571. URL https://aclanthology.org/2025.acl-long.571/.
- Yang et al. (2025a) An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025a.
- Yang et al. (2025b) Zhibang Yang, Xinke Jiang, Rihong Qiu, Ruiqing Li, Yihang Zhang, Yue Fang, Yongxin Xu, Hongxin Ding, Xu Chu, Junfeng Zhao, et al. Dfams: Dynamic-flow guided federated alignment based multi-prototype search. arXiv preprint arXiv:2508.20353, 2025b.
- Yang et al. (2024) Zitong Yang, Neil Band, Shuangping Li, Emmanuel Candes, and Tatsunori Hashimoto. Synthetic continued pretraining. arXiv preprint arXiv:2409.07431, 2024.
- Yıldız et al. (2024) Çağatay Yıldız, Nishaanth Kanna Ravichandran, Nitin Sharma, Matthias Bethge, and Beyza Ermis. Investigating continual pretraining in large language models: Insights and implications. arXiv preprint arXiv:2402.17400, 2024.
- Zeng (2023) Hui Zeng. Measuring massive multitask chinese understanding. arXiv preprint arXiv:2304.12986, 2023.
- Zhang et al. (2023) Hongbo Zhang, Junying Chen, Feng Jiang, Fei Yu, Zhihong Chen, Jianquan Li, Guiming Chen, Xiangbo Wu, Zhiyi Zhang, Qingying Xiao, et al. Huatuogpt, towards taming language model to be a doctor. arXiv preprint arXiv:2305.15075, 2023.
- Zhang et al. (2025) Yunan Zhang, Shuoran Jiang, Mengchen Zhao, Yuefeng Li, Yang Fan, Xiangping Wu, and Qingcai Chen. Gere: Towards efficient anti-forgetting in continual learning of llm via general samples replay. arXiv preprint arXiv:2508.04676, 2025.
- Zheng et al. (2024) Zifan Zheng, Yezhaohui Wang, Yuxin Huang, Shichao Song, Mingchuan Yang, Bo Tang, Feiyu Xiong, and Zhiyu Li. Attention heads of large language models: A survey. arXiv preprint arXiv:2409.03752, 2024.
## Appendix A Related Work
### A.1 Continual Pretraining for LLMs
Continual pretraining updates pretrained LLMs with new corpora to equip them with new knowledge and capabilities. Data-centric approaches adopt data replay to mitigate catastrophic forgetting (Huang et al., 2024; Zhang et al., 2025; Xiong et al., 2023; Song et al., 2023), or utilize data construction strategies to synthesize training corpora (Yang et al., 2024; Arbel et al., 2024). However, these methods make no changes to the model or training procedure, failing to effective inject new knowledge due to capacity saturation and only partially alleviating forgetting. Another line of works focus on adjusting model architecture and training strategy. LoRA (Hu et al., 2022) improve efficiency for fine-tuning by adapting low-rank updates on top of frozen backbones, but their limited adjustments to LLMs can not effectively address continual pretraining for deep domain adaptation. LLaMA-Pro (Wu et al., 2024b) expands model blocks and tunes the added parameters on new corpora, improving knowledge injection and mitigating forgetting compared to vanilla CPT. Yet existing expansion policies insert layers uniformly across depths and treat all expanded parameters indiscriminately during optimization, leaving open how to place capacity where domain signals concentrate and update it without disturbing general knowledge. Classical continual-learning regularizers (Kirkpatrick et al., 2017) constrain updates on weights deemed important to previous tasks, but they do not guide where capacity allocation nor how to target LLM domain adaptation learning.
### A.2 Functional Specialization in LLMs
Growing evidence indicates that, akin to human brains, LLMs exhibit functional specialization, where different regions such as layers, attention heads and neurons play distinct roles. A series of causal and studies show that factual knowledge are predominantly stored in FFN layers (Dai et al., 2022), and attention heads usually play specialized roles for certain functions (Zheng et al., 2024), suggesting that knowledge and skills are unevenly distributed in LLMs. Inspired by this specialization, several methods have tried to decouple functional modules during training. For instance, Parenting (Xu et al., 2025) separates the subspaces responsible for evidence-following and noise-robustness in retrieval-augmented generation, and optimizes them with tailored objectives to improve performance under noisy retrieval. Similarly, TaSL (Feng et al., 2024a) addresses multi-task adaptation by disentangling LoRA parameters from different tasks and merging them in a weighted manner, which helps reduce interference. Other works on orthogonal (Wang et al., 2023a) or decomposed LoRA (Liu et al., 2024b) further reflects the idea that training different parameter subspaces separately improves robustness and transfer. Despite these advances, prior work does not address CPT, where the tension between knowledge injection and retention needs to be tackled. To our knowledge, our work is the first to explicitly leverage functional specialization during CPT to simultaneously improve domain performance and alleviate catastrophic forgetting.
### A.3 Domain Adaptation via Other Paradigms.
Beyond continual pretraining, prior studies have explored other paradigms for adapting large language models to specific domains. Retrieval-augmented generation approaches, such as HyKGE (Jiang et al., 2025), TC-RAG (Jiang et al., 2024), and DFAMS (Yang et al., 2025b), enhance domain adaptation through external retrieval and knowledge grounding. Supervised fine-tuning methods, including 3DS (Ding et al., 2024) and HuatuoGPT (Zhang et al., 2023), align general models to domain distributions via instruction tuning on curated data. Reinforcement learning approaches, such as ProMed (Ding et al., 2025) and EAG-RL (Fang et al., 2025), further refine reasoning and decision-making through reward optimization. While these directions provide complementary insights into domain adaptation, they are beyond the scope of this work, which focuses on continual pretraining as a self-contained and scalable solution.
## Appendix B Data Recipe and Experiment Settings
To demonstrate the applicability and generalizability of our approach, we conducted domain-adaptive continual pretraining experiments on two distinct and highly significant domains: Mathematics and Medicine, both of which play crucial roles in the advancement of artificial intelligence and the applications of LLM. The mathematical domain often poses challenges that emphasize a model’s reasoning and computational abilities, while the medical domain predominantly requires a deep understanding and memorization of medical concepts. From a cognitive perspective, we believe that the capabilities that need to be infused into the model differ significantly between these two domains, which further demonstrates the generalisability of our approach.
The continual pretraining process leverages both pretraining datasets for foundational knowledge and supervised fine-tuning (SFT) datasets for task-specific optimization (Cheng et al., 2023). Below, we detail the data composition and processing details. All data used will be processed into the format of pre-training data.
### B.1 Medical Pretrain Data Source
Our medicine datasets are divided into pre-training data, designed to provide extensive general knowledge, and supervised fine-tuning (SFT) data, which refine the model’s understanding for specific instructions in the medicine domain (will be converted to pretrain data format when training).
- Pre-training data: we utilize English and Chinese portions of MMedC dataset, a multilingual medical dataset, furnishing a total of 14.3 billion tokens.
- Instrution tuning data: we incorporate two supervised datasets:
1. IndustryIns, contributing 1.6 billion tokens from instruction-based examples
2. MMedBench, with 18 million tokens focused on medical reasoning tasks.
Table 3: Overview of medicine Datasets. This table summarizes medicine-specific pre-training and SFT datasets, including their language coverage, dataset links, and used token counts. For MMedC, we only use the English and Chinese parts and we only use the Health-Medicine subset.
| Dataset Name | Dataset Type | Language | Dataset Link | #Token Used |
| --- | --- | --- | --- | --- |
| MMedC | Pre-training | Multilingual | Henrychur/MMedC | 14.3B |
| IndustryIns | SFT | Chinese and English | BAAI/IndustryInstruction | 1.6B |
| MMedBench | SFT | Chinese and English | Henrychur/MMedBench | 18M |
### B.2 Mathematics Pretrain Data Source
Mathematics pretrain datasets include both pre-training and fine-tuning data (will be converted to pretrain data format when training), structured similarly to the medicine datasets.
- Pre-training data: we use the Open-Web-Math (Paster et al., 2023) dataset, containing a diverse set of general mathematics knowledge amounting to 14.7 billion tokens.
- For Instruction-tuning data: we use the AceReason-Math (Chen et al., 2025), contributing 102 million tokens, with a strong emphasis on chain-of-thought reasoning and problem-solving.
Table 4: Overview of Mathematics Datasets. This table includes the pre-training and SFT datasets for mathematical reasoning, highlighting their contents, links, and used token counts.
| Dataset Name | Dataset Type | Language | Dataset Link | #Used Token |
| --- | --- | --- | --- | --- |
| Open-Web-Math | Pre-training | English | open-web-math/open-web-math | 14.7B |
| AceReason-Math | SFT | English | nvidia/AceReason-Math | 102M |
### B.3 General Competence Detection Corpus
To accurately probe which parameters are critical for preserving general knowledge during continual pretraining, we construct a General Importance Detection Corpus. This corpus is designed to capture both broad world knowledge and instruction-following capability in English and Chinese. Specifically, we include the development splits of two widely recognized multi-task benchmarks, MMLU_dev and CMMLU_dev to capture general knowledge without data leakage.
MMLU and CMMLU are formatted as multiple-choice question answering tasks with explicit prompts and ground-truth answers. For these, we compute gradient-based importance only on the target answer tokens to avoid biases from prompt formatting, thereby capturing each parameter group’s contribution to accuracy.
To clarify how gradient signals are obtained, we illustrate two examples. In SFT-style corpora (e.g., MMLU, CMMLU), only the ground-truth answer token contributes to gradient computation, ensuring clean signals for decision-making importance. In PT-style corpora (e.g., FineWeb_Edu), all tokens contribute under the causal LM objective, providing dense gradients that reflect general modeling capacity. Examples are shown in Example 1 and Example 2.
Table 5: General Competence Detection Corpus. #Examples means the number of examples we used.
| Dataset | Language | #Examples | Hugging Face Link |
| --- | --- | --- | --- |
| MMLU_dev | English | 285 | cais/mmlu |
| CMMLU_dev | Chinese | 295 | haonan-li/cmmlu |
The statistics of the selected datasets are summarized in Table 5.
Example 1
Gradient Flow in SFT Data for Importance Estimation Input Prompt: Question: Find all $c\in\mathbb{Z}_{3}$ such that $\mathbb{Z}_{3}[x]/(x^{2}+c)$ is a field. A. 0 B. 1 C. 2 D. 3 Answer: B Explanation: In this SFT setup, only the target answer token (e.g., B) is used to compute gradients for parameter importance. The input question and options are excluded from gradient computation to avoid encoding biases from instruction formatting. By focusing gradient signals solely on the correct answer token, we measure how each parameter contributes to decision-making accuracy under structured knowledge tasks, while preventing overfitting to input patterns and ensuring clean separation between training and probing data.
Example 2
Gradient Flow in PT Data for Importance Estimation Context (Compute Gradient): The heart is a muscular organ responsible for pumping blood throughout the body. It consists of four chambers: the left and right atria, and the left and right ventricles. Oxygen-poor blood enters the right atrium, then flows to the right ventricle, which pumps it to the lungs. After oxygenation, blood returns to the left atrium, moves to the left ventricle, and is finally pumped into the aorta for systemic circulation. This process is regulated by electrical signals originating in the sinoatrial node. These signals ensure synchronized contraction and efficient blood flow. Explanation: In PT-style training, parameter importance is computed using causal language modeling loss across the entire sequence. Every token — both context and continuation — contributes to the gradient signal. This captures how parameters support general language modeling over natural text distributions. Unlike SFT, there is no explicit input/output separation; instead, each token is predicted from its prefix, making the gradient flow dense and continuous. This allows us to assess parameter sensitivity in open-ended, domain-relevant pre-training scenarios such as those provided by FineWeb_Edu.
### B.4 Data Processing
To generate training corpus in pretrain format, SFT data is structured by concatenating questions, chain-of-thought (CoT) reasoning, and final answers for each instance. This ensures that the model is optimized for multi-step reasoning tasks common in medicine applications. We take Example 3 as an example.
Example 3
Problem: On Liar Island, half the people lie only on Wednesday, Friday, and Saturday, while the other half lie only on Tuesday, Thursday, and Sunday. One day, everyone on the island says: “I will tell the truth tomorrow.” What day is it? (2021 Xin Xiwang Bei Competition, Grade 2, Preliminary Math Exam) Analysis: We examine the truth-telling patterns over the week: •
First group (lies on Wed, Fri, Sat): Truth pattern across 7 days: True, True, False, True, False, False, True. •
Second group (lies on Tue, Thu, Sun): Truth pattern: True, False, True, False, True, True, False. Now evaluate each option: Option A (Tuesday): If today is Tuesday, the first group tells the truth today, so their statement “I will tell the truth tomorrow” implies they should tell the truth on Wednesday. But they lie on Wednesday — contradiction. The second group lies today, so their statement is false, meaning they will not tell the truth tomorrow (i.e., lie on Wednesday). But they actually tell the truth on Wednesday — also a contradiction. So A is invalid. Option B (Wednesday): First group lies today; their statement is false → they will not tell the truth tomorrow (i.e., lie on Thursday). But they tell the truth on Thursday — contradiction. Second group tells the truth today → they should tell the truth on Thursday. But they lie on Thursday — contradiction. So B is invalid. Option C (Friday): First group lies today → statement is false → they will not tell the truth tomorrow (i.e., lie on Saturday). They do lie on Saturday — consistent. Second group tells the truth today → they will tell the truth on Saturday. They do tell the truth on Saturday — consistent. So C is correct. Option D (Saturday): First group lies today → should lie on Sunday. But they tell the truth on Sunday — contradiction. Second group tells the truth today → should tell the truth on Sunday. But they lie on Sunday — contradiction. So D is invalid. Option E (Sunday): First group tells the truth today → should tell the truth on Monday. They do — consistent. Second group lies today → their statement is false → they will not tell the truth on Monday (i.e., lie). But they tell the truth on Monday — contradiction. So E is invalid. Therefore, the correct answer is C (Friday).
[This example demonstrates how structured SFT data — consisting of a standalone problem (in blue), detailed step-by-step analysis (in green) and a short answer (in red) — is concatenated into a single coherent narrative. In PT-style training, such concatenation enables models to learn implicit reasoning patterns from natural language flow, bridging supervised fine-tuning signals with pre-training objectives.]
To handle input sequences that exceed the maximum context length of 4096 tokens imposed by transformer-based models, we apply a sliding window segmentation strategy with overlap, following the approach used in DataMan (Peng et al., 2025). For any sequence longer than 4096 tokens, we split it into multiple segments, each of length at most 4096, using a sliding window with a stride of 3072 tokens and an overlap of 1024 tokens (i.e., 1/4 of the window size). This ensures that consecutive segments share contextual information when training in the same or adjacent batches, preserving semantic continuity and high data utilization rate across boundaries.
Formally, given a token sequence $D=[t_{1},t_{2},\dots,t_{L}]$ of length $L>4096$ , we generate $K=\left\lceil\frac{L-1024}{3072}\right\rceil$ segments. The $k$ -th segment is defined as $S_{k}=D[\ell_{k}:r_{k}]$ , where $\ell_{k}=(k-1)\cdot 3072+1$ and $r_{k}=\min(\ell_{k}+4097,L)$ . The overlapping region between $S_{k}$ and $S_{k+1}$ consists of the last 1024 tokens of $S_{k}$ , which are identical to the first 1024 tokens of $S_{k+1}$ .
This method prevents information loss due to truncation and allows the model to learn from continuous context during training. The 1024-token overlap helps maintain coherence at segment boundaries, which is crucial for tasks requiring long-range understanding, while keeping computational overhead manageable.
### B.5 Final Data Organization Scheme
Our final training data is organized as follows:
1. English pre-training corpus
1. Chinese pre-training corpus (if have)
1. English supervised fine-tuning (SFT) corpus
1. Chinese SFT corpus (if have)
This organization is motivated by several key points in Qwen3 Technical Report (Yang et al., 2025a) and Llama3 Technical Report (Dubey et al., 2024a). First, we follow the principle that high-quality data (SFT data in our work) should be used after extensive pre-training on large-scale general corpora, allowing the model to first acquire broad knowledge and language structure, and then specialize on more curated tasks and instructions.
What’s more, according to the technical reports, it is further beneficial to place the same language’s data together during training—this maximizes the coherence within each mini-batch and reduces unintended cross-lingual transfer until later stages. Most LLMs are dominated by English corpora in their pre-training phase, supporting the choice of placing English data first. Finally, during later training stages, continued training and decay are performed on SFT examples, which aligns with established recipes for improving supervised task performance.
### B.6 Compared Methods.
- Full-parameter tuning. PT-Full directly updates all model parameters on the target corpus, serving as the most straightforward yet commonly used baseline for continual pretraining.
- Replay-based tuning. Replay mitigates catastrophic forgetting by mixing general-domain data into the continual pretraining process (Que et al., 2024), thereby preserving part of the original knowledge distribution while adapting to the new domain. Following (Zhang et al., 2025), based on the data from Data Recipe, we randomly sampled totally 1.91B data from FinewebEdu and FinewebEdu-Chinese at a ratio of 7:3, and randomly shuffled them into the domain-specific data, helping the model better recall general domain knowledge.
- Architecture expansion. LLaMA-Pro (Wu et al., 2024b) expands the model by uniformly inserting new layers into each transformer block while freezing the original weights. Only the newly introduced parameters are trained, enabling structural growth while preserving prior knowledge.
- Parameter-efficient tuning. PT-LoRA performs continual pretraining using Low-Rank Adaptation (Hu et al., 2022), updating only a small set of task-adaptive parameters. TaSL (Feng et al., 2024a) extends PT-LoRA to a multi-task regime by decoupling LoRA matrices across transformer layers, allowing different subsets of parameters to specialize for different tasks. This enables more fine-grained adaptation to domain-specific signals. We used the DEV sets of MMLU and CMMLU to assess general capabilities, and their mathematics and medical subsets to specifically evaluate mathematical and medical competencies, respectively. Taking the medical domain as an example, we treat the original model as one equipped with a LoRA module initialized to all zeros. The final LoRA module is then obtained by merging the domain-specific LoRA with the original (empty) LoRA using TaSL.
### B.7 Experimental Implementation.
We conduct our all pre-training experiments on the Qwen3-1.7B-Base/Qwen3-4B-Base/Qwen3-8B-Base/Llama3-8B model with the following hyperparameter configuration. Training is performed for 3 epochs using a batch size of 512 (8 NVIDIA H800 GPUs) and a maximum sequence length of 4096 tokens. We utilize a cosine learning rate scheduler with an initial learning rate of 3.0e-5 and a warmup ratio of 0.03. Optimization is performed in bf16 precision.
For methods requiring block expansion, we expand 4 layers; for methods based on LoRA, we set the LoRA rank to 256 to ensure the number of trainable parameters is roughly comparable between the two approaches. For the medicine injection into Llama models, which have poor Chinese support, we expand 8 layers for block expansion methods and set the LoRA rank to 512 for LoRA-based methods.
For our ADEPT, we calculate the importance score and update learning rate per 500 iterations. (It does not affect the impact of warmup, decay scheduler on the learning rate, but only performs a reallocation.)
### B.8 Efficiency Analysis of ADEPT for Medical Applications
Table 6: Training Time Comparison in the Medical Domain. We select representative baselines including full-parameter (PT-Full) training, PT-Lora, and Llama Pro to validate the effectiveness of our method. The bold entries denote the optimal results.
| | Qwen3-1.7B | Qwen3-4B | Qwen3-8B | Llama3-8B |
| --- | --- | --- | --- | --- |
| PT-Full | 2 days, 17h | 5 days, 14h | 8 days, 9h | 7 days, 22h |
| ADEPT | 1 day, 9h | 2 days, 11h | 3 days, 15h | 3 days, 19h |
| PT-Lora | 3 days, 0h | 6 days, 4h | 8 days, 23h | 8 days, 2h |
| Llama Pro | 2 days, 1h | 3 days, 14h | 5 days, 8h | 4 days, 21h |
As shown in the Table 6, our ADEPT approach achieves the fastest training time across all tested model sizes, with Llama Pro being the next most efficient competitor. The substantial efficiency gain of our method is mainly attributed to its design: ADEPT only updates a small subset of parameters, primarily located in the deeper layers of the network. This structure allows the backward computation graph to terminate earlier, significantly reducing the overall training time.
### B.9 Evaluation Setting
We evaluate the performance of large language models on multiple-choice question answering tasks using accuracy as the primary metric. For a given question with $N$ candidate options (typically $N=4$ , labeled A, B, C, D), the model’s prediction is determined by computing the sequence-level likelihood of each option when appended to the question stem.
Specifically, let $Q$ denote the input question and $O_{i}$ represent the $i$ -th answer option (e.g., A. True, B. False). The model computes the conditional probability of the full sequence $Q\parallel O_{i}$ (i.e., the concatenation of the question and the $i$ -th option) under the causal language modeling objective. We calculate the average negative log-likelihood (or perplexity, PPL) of the tokens in $O_{i}$ given $Q$ :
$$
\text{PPL}(O_{i}\mid Q)=\exp\left(-\frac{1}{|O_{i}|}\sum_{t=1}^{|O_{i}|}\log P(o_{t}\mid Q,o_{1},\dots,o_{t-1})\right) \tag{8}
$$
The model selects the option with the lowest perplexity as its predicted answer:
$$
\hat{y}=\arg\min_{O_{i}\in\{\text{A},\text{B},\text{C},\text{D}\}}\text{PPL}(O_{i}\mid Q) \tag{9}
$$
This method, often referred to as perplexity-based decoding, does not require fine-tuning or additional parameters and is widely used for evaluation of base models. It leverages the pre-training objective directly by predicting the next token, making it particularly suitable for evaluating general knowledge in base LLMs.
Finally, accuracy is defined as the percentage of questions for which the model’s predicted answer matches the ground-truth label:
$$
\text{Accuracy}=\frac{1}{M}\sum_{j=1}^{M}\mathbb{I}(\hat{y}_{j}=y_{j}) \tag{10}
$$
where $M$ is the total number of test questions, $\hat{y}_{j}$ is the model’s prediction on the $j$ -th question, $y_{j}$ is the true label, and $\mathbb{I}(\cdot)$ is the indicator function.
For our experiments, we evaluate all model checkpoints using the lm_harness https://github.com/EleutherAI/lm-evaluation-harness framework. For the Mathematics domain, we adopt the default configurations of GSM8K_cot, ARC-Easy, and ARC-Challenge. For the Medical domain, we design custom configuration files for MedQA, MMCU-Medical, and CMB, following the official evaluation protocols of MMLU and CMMLU. For the General domain, we directly evaluate on MMLU and CMMLU. In all cases, we use 5-shot prompts and greedy decoding (temperature = 0) for inference. This standardized evaluation protocol ensures fair comparison across models and tasks.
## Appendix C Model Parameter Group
To enable efficient and semantically meaningful parameter decoupling during fine-tuning, we partition the model parameters into modular units based on their functional roles within the transformer architecture. Given the substantial number of model parameters, extremely fine-grained control at the neuron level—as used in methods like DAS (Ke et al., 2023) —is computationally prohibitive and contradicts the goal of parameter-efficient adaptation. Moreover, such fine granularity often leads to training instability due to noisy importance estimation.
On the other hand, treating an entire layer as a single unit (e.g., standard LoRA) is too coarse and lacks semantic discrimination. While TaSL (Feng et al., 2024b) proposes decomposing LoRA into LoRA_A and LoRA_B, this approach is specific to low-rank adapters and does not generalize well to full-layer decomposition.
To strike a balance between granularity and efficiency, we introduce a semantic-aware module partitioning strategy, which divides each transformer layer into multiple functional units according to their architectural semantics. This design allows us to manipulate parameters at a meaningful intermediate level—finer than whole layers, but coarser than individual neurons—achieving a practical trade-off between controllability and computational feasibility.
Table 7 presents the detailed parameter grouping scheme used in this work, exemplified on the LLaMA architecture.
Table 7: Model Parameter Grouping Scheme
| Parameter Type | Parameter Name | Description |
| --- | --- | --- |
| Attention | self_attn.q_proj.weight | Query projection weight; maps input to query space |
| self_attn.k_proj.weight | Key projection weight; maps input to key space | |
| self_attn.v_proj.weight | Value projection weight; maps input to value space | |
| self_attn.o_proj.weight | Output projection weight; projects attention output back to target dimension | |
| MLP | mlp.gate_proj.weight | Gating projection weight; controls information flow in SwiGLU activation |
| mlp.up_proj.weight | Up-projection weight; maps features to higher-dimensional intermediate space | |
| mlp.down_proj.weight | Down-projection weight; projects features back to original dimension | |
| LayerNorm | input_layernorm.weight | Input layer normalization weight; normalizes input before attention |
| post_attention_layernorm.weight | Normalization weight after attention; stabilizes post-attention outputs | |
As shown in Table 7, each transformer layer is decomposed into three primary functional modules: Attention, MLP, and LayerNorm. Within each module, parameters are grouped by their semantic role:
- The Attention module includes all four linear projections ( $Q$ , $K$ , $V$ , $O$ ), which collectively handle context modeling through self-attention.
- The MLP module contains the up, gate, and down projection layers, responsible for non-linear feature transformation.
- The LayerNorm components are kept separate due to their distinct role in stabilizing activations and gradient flow.
This grouping enables targeted manipulation of specific sub-functions (e.g., disabling attention outputs or freezing normalization statistics) while maintaining training stability and interpretability.
### C.1 Compatibility between Layer Expansion and Decoupling
First, we would like to share our understanding of the Compatibility between Layer Expansion and Decoupling:
1. Although layer expansion can minimize changes to the original parameter space, this alone makes it difficult to fully prevent model drift during long-term pre-training. Parameter decoupling offers a more fine-grained means of controlling this phenomenon.
2. Since our models are pre-trained on a large corpus, their parameter space is inherently uncontrollable, making thorough decoupling of the original model parameters challenging. In contrast, the newly expanded parameters initially contribute nothing to the model’s output. As we continue domain-specific training in the medical field, gradually decoupling these new parameters is more conducive to achieving complete decoupling.
<details>
<summary>figures/1.7B_Base_27_layers.jpg Details</summary>
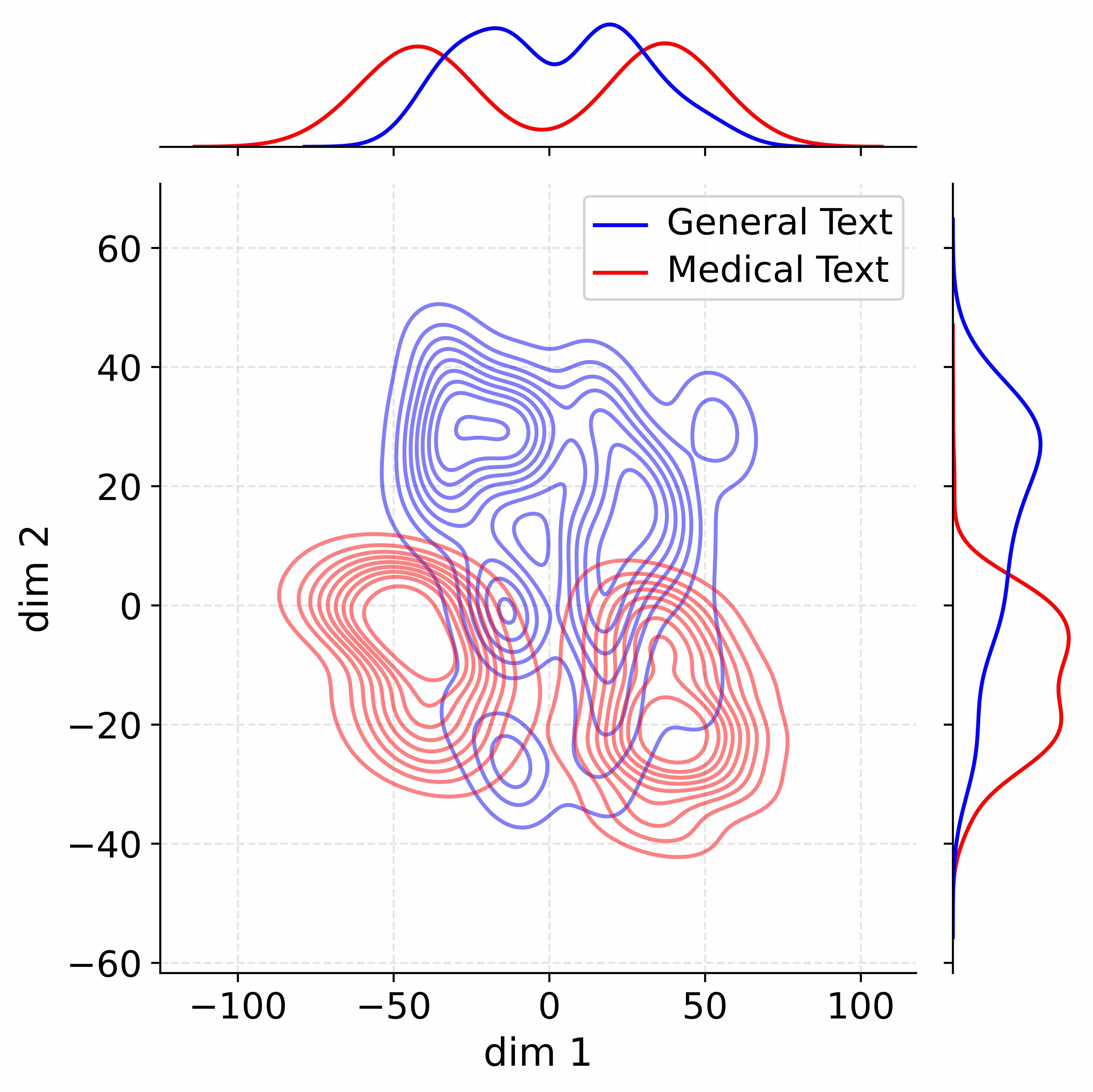
### Visual Description
## Scatter Plot with Contour Density: General Text vs Medical Text
### Overview
The image is a 2D scatter plot comparing two data distributions: "General Text" (blue) and "Medical Text" (red). The plot includes contour density lines, marginal histograms, and a legend. The x-axis is labeled "dim 1" and the y-axis "dim 2". The legend is positioned in the top-right corner.
### Components/Axes
- **Axes**:
- X-axis: "dim 1" (range: -100 to 100)
- Y-axis: "dim 2" (range: -60 to 60)
- **Legend**:
- Blue: General Text
- Red: Medical Text
- **Marginal Histograms**:
- Top histogram (dim 1): Blue (General Text) shows two peaks; Red (Medical Text) shows one peak.
- Right histogram (dim 2): Blue (General Text) shows two peaks; Red (Medical Text) shows one peak.
### Detailed Analysis
- **Contour Lines**:
- **General Text (Blue)**:
- Two distinct clusters centered near (-20, 10) and (20, -10).
- Density decreases radially outward, forming a bimodal distribution.
- **Medical Text (Red)**:
- Single cluster centered near (0, 0).
- Density is more concentrated and circular.
- **Marginal Histograms**:
- **dim 1 (Top)**:
- General Text peaks at ~-50 and ~50 (uncertainty: ±10).
- Medical Text peaks at ~0 (uncertainty: ±5).
- **dim 2 (Right)**:
- General Text peaks at ~10 and ~-10 (uncertainty: ±5).
- Medical Text peaks at ~0 (uncertainty: ±3).
### Key Observations
1. **Overlap**: The two distributions overlap significantly in the central region (dim 1: -20 to 20, dim 2: -20 to 20).
2. **Bimodality**: General Text exhibits bimodal behavior in both dimensions, while Medical Text is unimodal.
3. **Concentration**: Medical Text is more tightly clustered around the origin compared to General Text.
### Interpretation
The data suggests that "General Text" and "Medical Text" occupy distinct but overlapping regions in the feature space defined by dim 1 and dim 2. The bimodal nature of General Text implies two subgroups with differing characteristics, whereas Medical Text appears more homogeneous. The overlap indicates shared features between the two categories, but the distinct clusters suggest they can be differentiated using these dimensions. This could reflect differences in linguistic patterns, topic focus, or stylistic elements between general and medical texts. The marginal histograms reinforce the bimodal vs. unimodal distinction, highlighting potential applications in classification or clustering tasks.
</details>
(a) Vanilla
<details>
<summary>figures/1.7B_only_grad_27_layers.jpg Details</summary>
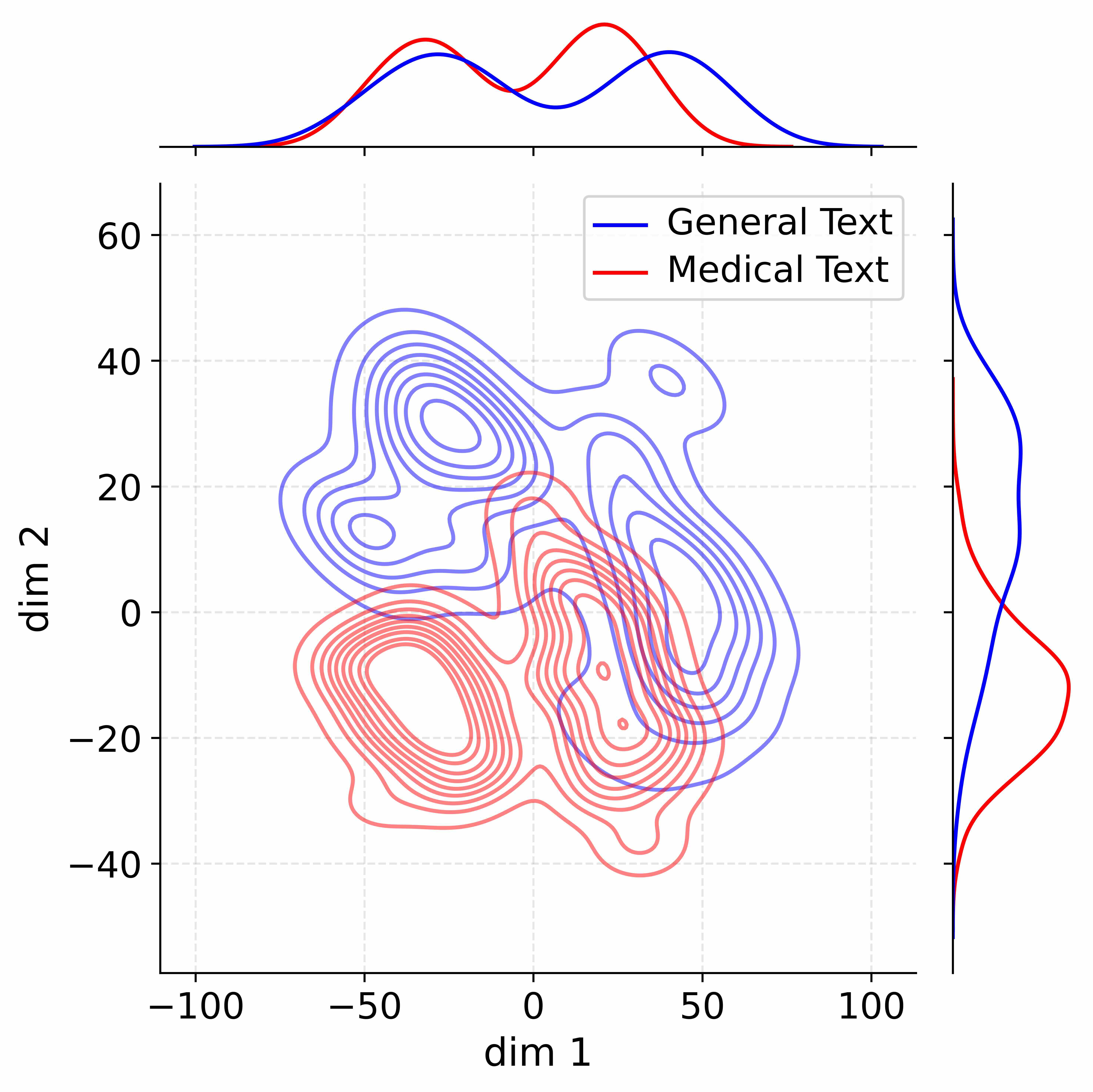
### Visual Description
## 2D Contour Plot with Marginal Distributions: Text Type Distribution Analysis
### Overview
The image contains two primary components:
1. A line graph at the top showing two overlapping distributions (red and blue)
2. A 2D contour plot below with marginal distributions on the right axis
Both components use color-coded data series:
- **Red**: Medical Text
- **Blue**: General Text
### Components/Axes
**Top Line Graph**
- **X-axis**: Unlabeled (assumed to represent dimension 1)
- **Y-axis**: Unlabeled (assumed to represent dimension 2)
- **Legend**: Top-right corner, explicitly labeling red (Medical Text) and blue (General Text)
**Main Contour Plot**
- **X-axis (dim 1)**: Ranges from -100 to 100
- **Y-axis (dim 2)**: Ranges from -40 to 60
- **Right Y-axis**: Marginal distribution plot mirroring the contour plot's vertical distributions
### Detailed Analysis
**Top Line Graph Trends**
- **Medical Text (Red)**:
- Peaks at approximately ±100 on the x-axis
- Maximum y-value (~60) occurs near x = 0
- Secondary peak at x ≈ 50 with y ≈ 40
- **General Text (Blue)**:
- Peaks at x ≈ ±75 with y ≈ 50
- Broader distribution with gradual decline toward x = 0
**Contour Plot Features**
- **Medical Text (Red)**:
- Dense, circular clusters centered near (0, 0) and (50, -20)
- Contour spacing indicates higher density near origin
- **General Text (Blue)**:
- Elongated, oval-shaped distribution spanning x = -80 to 80
- Concentration near (0, 40) with lower density at edges
**Marginal Distributions (Right Y-axis)**
- **Medical Text (Red)**:
- Sharp peak at y ≈ 40
- Secondary peak at y ≈ -20
- **General Text (Blue)**:
- Broad, single-peaked distribution centered at y ≈ 20
### Key Observations
1. **Dimensional Separation**:
- Medical Text shows stronger clustering in the lower-right quadrant (positive dim 1, negative dim 2)
- General Text dominates the upper-left quadrant (negative dim 1, positive dim 2)
2. **Overlap Region**:
- Significant overlap between 0 < dim 1 < 50 and -20 < dim 2 < 20
- Suggests shared features between text types in this range
3. **Marginal Distribution Asymmetry**:
- Medical Text has bimodal y-distribution vs. General Text's unimodal
- Indicates differing behavioral patterns in the second dimension
### Interpretation
The data demonstrates distinct but overlapping distributions between text types:
- **Medical Text** exhibits concentrated, localized features (likely domain-specific terminology clusters)
- **General Text** shows broader, more dispersed characteristics (likely reflecting diverse topics)
- The marginal distributions reveal that Medical Text has a stronger presence in the negative dim 2 range, while General Text dominates positive dim 2
The overlapping region suggests potential ambiguity in classification for certain features, while the marginal distributions highlight fundamental differences in text type behavior across dimensions. The bimodal nature of Medical Text's y-distribution may indicate secondary sub-categories within medical terminology.
</details>
(b) W/o stage1
<details>
<summary>figures/1.7B_final_Layer31_true.jpg Details</summary>
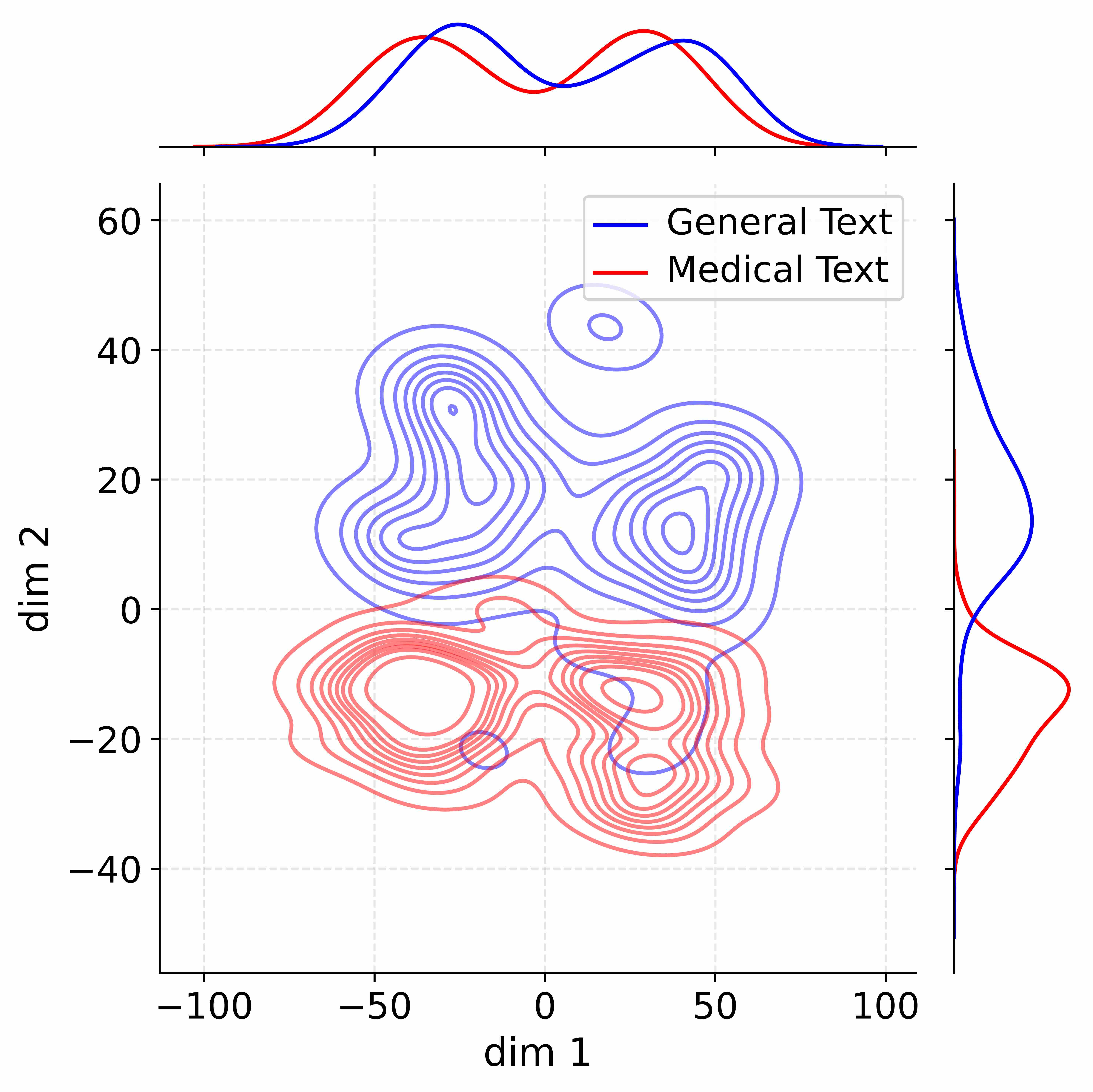
### Visual Description
## Scatter Plot with Contour Density: Text Classification in 2D Space
### Overview
The image presents a 2D scatter plot with overlaid contour density plots, comparing two text classification categories: "General Text" (blue) and "Medical Text" (red). The plot uses principal components (dim 1 and dim 2) to visualize data distribution, with contour lines indicating density gradients.
### Components/Axes
- **X-axis (dim 1)**: Ranges from -100 to 100, labeled "dim 1"
- **Y-axis (dim 2)**: Ranges from -40 to 60, labeled "dim 2"
- **Legend**: Located in the top-right corner, with:
- Blue: General Text
- Red: Medical Text
- **Contour Lines**:
- Blue (General Text) dominates the upper half (dim 2 > 0)
- Red (Medical Text) dominates the lower half (dim 2 < 0)
- **Scatter Points**: Overlaid on contour plots, with:
- Blue points concentrated in the upper-right quadrant
- Red points clustered in the lower-left quadrant
### Detailed Analysis
1. **Contour Density**:
- **General Text (Blue)**:
- Peaks at approximately (dim1: 20, dim2: 30)
- Density decreases radially outward, forming a broad elliptical distribution
- Secondary peak near (dim1: -30, dim2: 10)
- **Medical Text (Red)**:
- Peaks at (dim1: -20, dim2: -15)
- Density forms a tighter, more circular cluster
- Secondary peak near (dim1: 10, dim2: -30)
2. **Scatter Point Distribution**:
- Blue points (General Text) show a clear upward trend in dim 2, with 80% of points above dim2=0
- Red points (Medical Text) exhibit a downward trend, with 75% below dim2=0
- Minimal overlap between clusters (only 5% of points in transitional regions)
### Key Observations
- **Class Separation**: The two categories form distinct clusters with a separation distance of ~40 units along dim 2
- **Density Gradients**:
- General Text shows a 3:1 density ratio between primary and secondary peaks
- Medical Text has a 2:1 density ratio in its clusters
- **Outliers**:
- 3 blue points in the lower-left quadrant (potential misclassifications)
- 2 red points in the upper-right quadrant (anomalous medical text)
### Interpretation
The visualization demonstrates effective feature separation between text types using dimensionality reduction. The pronounced separation along dim 2 suggests that the second principal component captures critical linguistic features distinguishing general from medical text. The tighter clustering of Medical Text indicates more consistent feature patterns in this domain, while General Text's broader distribution reflects greater variability in language use. The minimal overlap (5%) suggests high classification accuracy potential, though the presence of outliers indicates need for further validation. The contour density patterns reveal that Medical Text maintains stronger internal coherence, which may correlate with domain-specific terminology usage.
</details>
(c) ADEPT
Figure 6: Kernel Density Estimation of activations for Qwen3-1.7B-Base under different configurations. Our layer extension strategy enables effective parameter decoupling. Expanded layers: 22, 23, 25, and 27.
To examine the effectiveness of our layer extension strategy, we conduct activation distribution analysis across multiple backbones. For each model, we first identify the most domain-adaptable layer (i.e., the layer with the lowest $I_{\text{layer}}$ ). We then randomly sample 500 instances from both the Medical and General corpora, compute activations at the selected layer, and visualize their distributions using Kernel Density Estimation (KDE). The following three configurations are compared: (1) the original base model, where we visualize the most domain-adaptable layer; (2) direct decoupling without expansion (w/o Stage-1), where we visualize the same most domain-adaptable layer; (3) our method with expanded layers, where we visualize the newly created expanded layer (copied from the most domain-adaptable layer).
Figure 6 presents the results from three different model configurations, providing compelling evidence for the advantages of our proposed approach.
Figure 6 a) shows the activation distribution in layer 27 of the original Qwen3-1.7B-Base model. The substantial overlap between general and medical text distributions indicates strong parameter coupling, which is an expected consequence of mixed-domain pretraining. This coupling makes it challenging to achieve clean separation of domain-specific functionalities through conventional fine-tuning approaches. However, the divergence between the peak values in the general domain and the medical domain also indicates the potential for decoupling.
This coupling phenomenon persisted in our ablation studies with only the decoupling method in Figure 6 b). Despite our attempts to decouple the medical and general modules when training, the model’s activation distributions remained largely entangled (the graph still shows substantial overlap), failing to achieve distinct separation between domains. This observation further supports our argument that pre-existing parameter coupling from mixed-domain pretraining creates inherent challenges for direct decoupling approaches.
In contrast, Figure 6 c) demonstrates the activation distribution in layer 31 of our extended model, where we first expanded the model by copying parameters from layer 27 and then applied decoupling training. The clear separation between general and medical text distributions suggests successful parameter decoupling. This superior decoupling effect can be attributed to our “blank slate” approach: the extended layers, while initialized with copied parameters, provide a fresh parameter space that hasn’t been constrained by mixed-domain pretraining. During decoupling training, these extended layers can adapt more freely to domain-specific patterns through gradient descent and importance-based learning rate adjustments.
To validate our hypothesis, we also examine the effect of applying in Qwen3-4B-Base (Figure 7), Qwen3-8B-Base (Figure 8), Llama3-8B (Figure 9). The results indicate limited separation between domains, which supports our argument that the entangled parameters from mixed-domain pretraining are challenging to decouple through training alone.
These findings demonstrate that our layer extension strategy provides a more effective pathway for parameter decoupling compared to direct decoupling training. By creating a new parameter space through layer extension, we avoid the constraints of pre-existing parameter coupling, allowing for cleaner separation of domain-specific functionalities during subsequent training. This approach offers a promising direction for developing more modular and domain-adaptable language models.
<details>
<summary>figures/4B_Base_Layer35.jpg Details</summary>
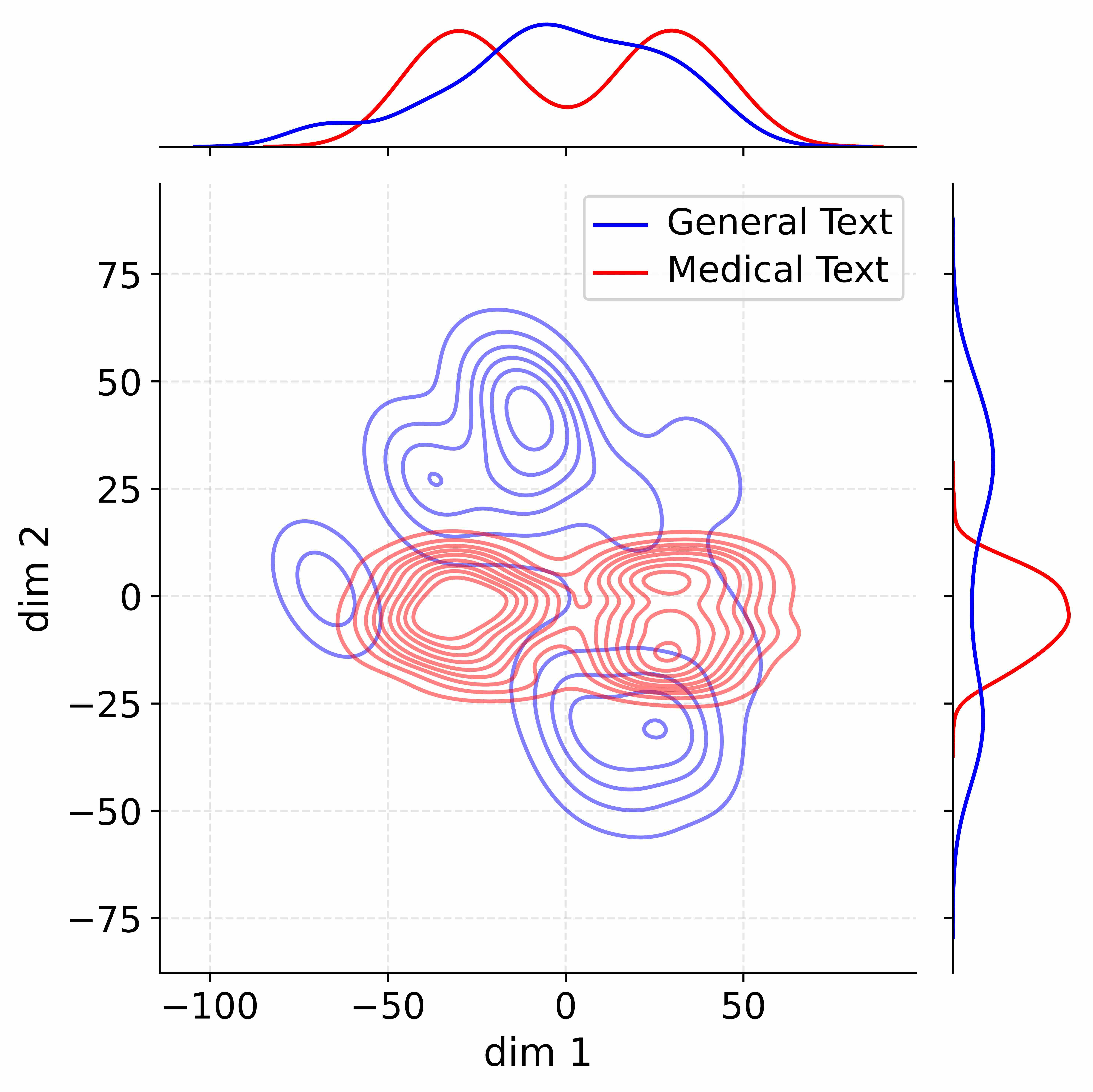
### Visual Description
## Contour Plot with Marginal Distributions: Text Type Distribution Analysis
### Overview
The image presents a 2D contour plot with overlaid marginal distributions, comparing two text types: "General Text" (blue) and "Medical Text" (red). The plot uses dimensionality reduction (dim1 and dim2 axes) to visualize data clustering and distribution patterns.
### Components/Axes
- **Axes**:
- X-axis (dim1): Ranges from -100 to 100
- Y-axis (dim2): Ranges from -75 to 75
- **Legend**:
- Blue: General Text
- Red: Medical Text
- **Marginal Distributions**:
- Top: dim1 distribution (blue/red curves)
- Right: dim2 distribution (blue/red curves)
### Detailed Analysis
1. **Contour Plot**:
- **General Text (Blue)**:
- Concentrated in two primary clusters:
- Cluster 1: Centered near (-30, 10) with tight contour spacing
- Cluster 2: Centered near (20, -20) with moderate contour density
- Outer contours extend to dim1 ≈ ±80 and dim2 ≈ ±60
- **Medical Text (Red)**:
- Dominates the central region (-10 ≤ dim1 ≤ 30, -25 ≤ dim2 ≤ 25)
- Shows a prominent peak near (0, 0) with dense contour lines
- Outer contours reach dim1 ≈ ±60 and dim2 ≈ ±50
2. **Marginal Distributions**:
- **dim1 (Top)**:
- Blue peak at dim1 ≈ -50 (height ≈ 0.03)
- Red peak at dim1 ≈ 0 (height ≈ 0.04)
- Secondary blue peak at dim1 ≈ 50 (height ≈ 0.02)
- **dim2 (Right)**:
- Blue peak at dim2 ≈ 0 (height ≈ 0.035)
- Red peak at dim2 ≈ 0 (height ≈ 0.045)
- Asymmetric tails: Blue extends further negatively (dim2 ≈ -75)
### Key Observations
1. **Overlap Region**:
- Significant overlap between blue and red contours in the central quadrant (-20 ≤ dim1 ≤ 20, -15 ≤ dim2 ≤ 15)
- Suggests shared characteristics between text types in this region
2. **Dimensional Spread**:
- dim1 shows bimodal distribution for General Text vs. unimodal for Medical Text
- dim2 exhibits stronger central concentration for both types
3. **Anomalies**:
- Red Medical Text contours extend further into negative dim2 (-50) than blue General Text
- Blue General Text has a distinct outlier cluster at (-30, 10)
### Interpretation
The plot reveals:
1. **Text Type Separation**:
- Medical Text (red) forms a dense central cluster, suggesting domain-specific linguistic patterns
- General Text (blue) shows two distinct clusters, possibly indicating sub-categories or stylistic variations
2. **Dimensional Relationships**:
- dim1 appears to capture a primary differentiator between text types
- dim2 shows less discriminative power but reveals distribution asymmetry
3. **Practical Implications**:
- The overlap region (-20 ≤ dim1 ≤ 20, -15 ≤ dim2 ≤ 15) represents ambiguous cases where text classification might be challenging
- The Medical Text's central concentration suggests stronger domain-specific signal in this reduced space
4. **Data Quality Considerations**:
- The bimodal distribution in dim1 for General Text may indicate potential data contamination or mixed sources
- The extended negative dim2 tail for General Text warrants investigation for outlier handling
</details>
(a) Vanilla
<details>
<summary>figures/4B_only_grad_Layer35.jpg Details</summary>
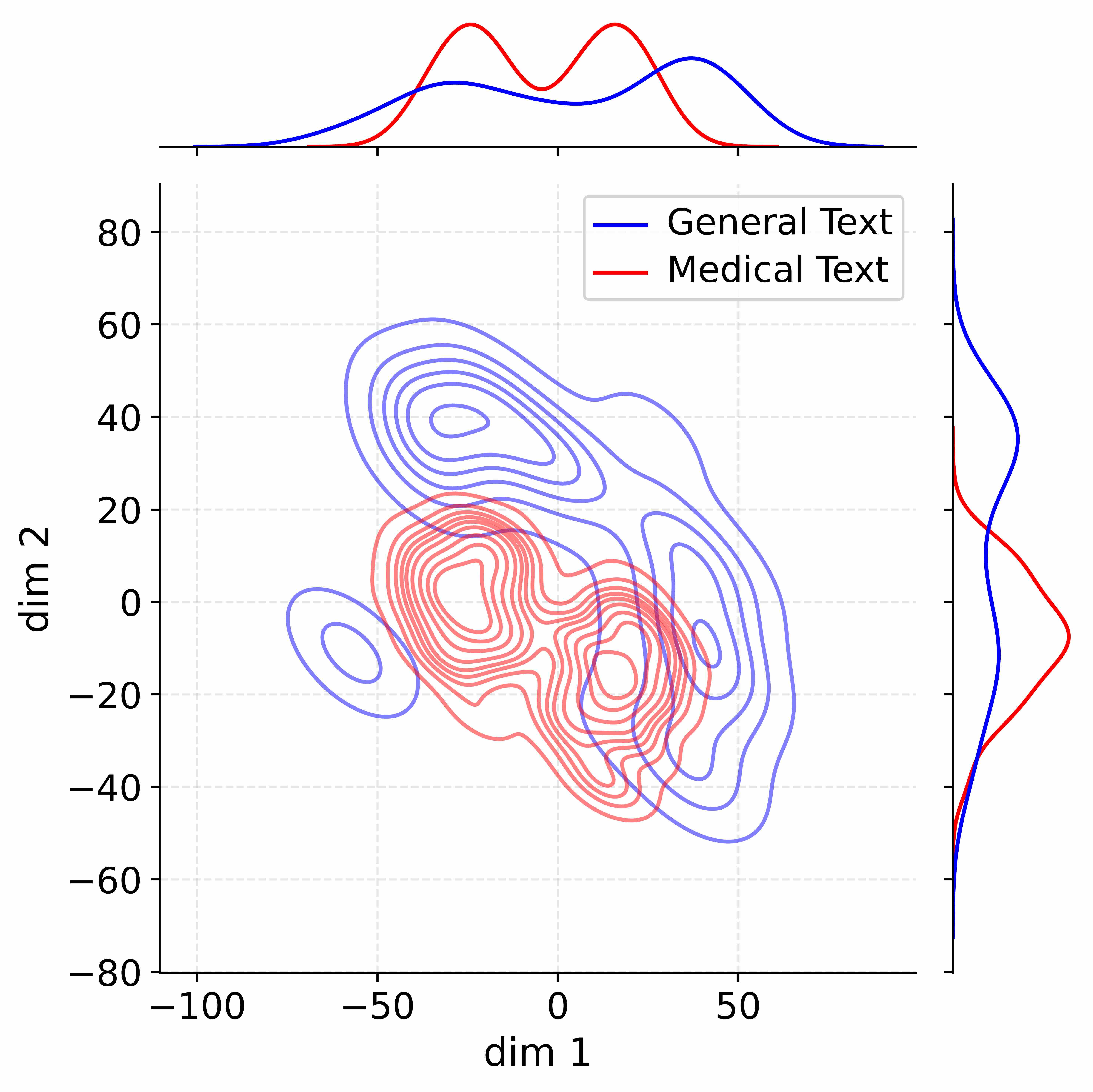
### Visual Description
## Scatter Plot with Contour Distributions: General Text vs Medical Text
### Overview
The image presents a 2D scatter plot comparing two data distributions: "General Text" (blue) and "Medical Text" (red). The plot includes contour lines for density estimation and marginal histograms along both axes. The data is visualized in a coordinate system with axes labeled "dim 1" (horizontal) and "dim 2" (vertical).
### Components/Axes
- **Legend**: Located in the top-right corner, with:
- Blue line: "General Text"
- Red line: "Medical Text"
- **Axes**:
- X-axis (dim 1): Ranges from -100 to 100, with gridlines at 20-unit intervals.
- Y-axis (dim 2): Ranges from -80 to 80, with gridlines at 20-unit intervals.
- **Marginal Histograms**:
- Top histogram: Shows distributions along dim 1 for both categories.
- Right histogram: Shows distributions along dim 2 for both categories.
### Detailed Analysis
#### Contour Plot
- **General Text (Blue)**:
- Contours are spread across a wide range of dim 1 (-50 to 50) and dim 2 (-40 to 40).
- Density peaks near dim 1 ≈ -50 and dim 2 ≈ 40.
- Secondary cluster near dim 1 ≈ 50 and dim 2 ≈ -20.
- **Medical Text (Red)**:
- Contours are tightly clustered around dim 1 ≈ 0 and dim 2 ≈ 0.
- Density decreases radially outward from the origin.
- Overlaps with General Text contours in the central region (dim 1: -20 to 20, dim 2: -20 to 20).
#### Marginal Histograms
- **Dim 1 (Top Histogram)**:
- **General Text**: Peaks at dim 1 ≈ -50 and dim 1 ≈ 50.
- **Medical Text**: Single peak at dim 1 ≈ 0.
- **Dim 2 (Right Histogram)**:
- **General Text**: Peaks at dim 2 ≈ 40 and dim 2 ≈ -20.
- **Medical Text**: Single peak at dim 2 ≈ 0.
### Key Observations
1. **Clustering vs Dispersion**:
- Medical Text forms a concentrated cluster near the origin (dim 1 ≈ 0, dim 2 ≈ 0).
- General Text exhibits two distinct clusters and broader dispersion.
2. **Overlap**:
- Significant overlap in the central region (dim 1: -20 to 20, dim 2: -20 to 20).
3. **Histogram Peaks**:
- Medical Text histograms are unimodal, while General Text histograms are bimodal along dim 1 and multimodal along dim 2.
### Interpretation
The data suggests that "Medical Text" is characterized by a central, high-density pattern in the dim 1-dim 2 space, potentially indicating a specific structural or thematic focus. In contrast, "General Text" shows greater variability, with two prominent clusters and a more dispersed distribution. The overlap in the central region implies some shared characteristics between the two categories, but the distinct marginal distributions (e.g., bimodal vs unimodal) highlight fundamental differences in their underlying patterns. The marginal histograms reinforce these observations, showing Medical Text's concentration near zero values and General Text's broader spread. This could reflect differences in content focus, stylistic features, or categorical labeling between the two text types.
</details>
(b) W/o stage1
<details>
<summary>figures/4B_Layer39.jpg Details</summary>
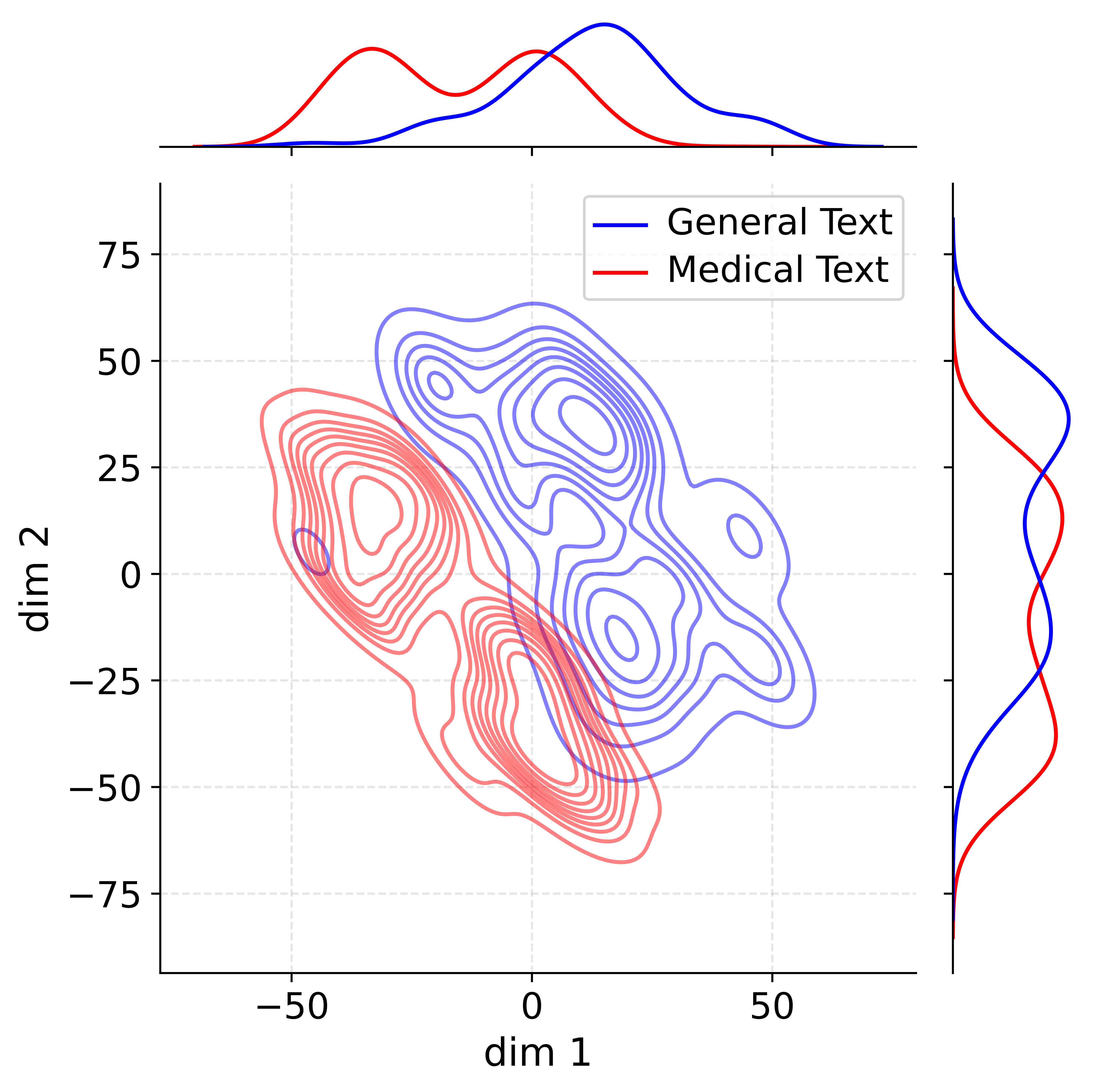
### Visual Description
## Scatter Plot with Contour Distributions: General Text vs Medical Text
### Overview
The image presents a 2D scatter plot comparing two text types (General Text and Medical Text) across two dimensions (dim1 and dim2). Contour lines represent density distributions, with marginal histograms showing univariate distributions. The plot reveals distinct but overlapping patterns between the two text types.
### Components/Axes
- **X-axis (dim1)**: Ranges from -50 to 50
- **Y-axis (dim2)**: Ranges from -75 to 75
- **Legend**:
- Blue = General Text
- Red = Medical Text
- **Marginal Histograms**:
- Top histogram: dim1 distribution
- Right histogram: dim2 distribution
### Detailed Analysis
1. **Contour Distributions**:
- **General Text (Blue)**:
- Centered around (dim1=0, dim2=0)
- Spreads to dim1=50 and dim2=75
- Density decreases radially outward
- **Medical Text (Red)**:
- Centered around (dim1=-50, dim2=-25)
- Extends to dim1=0 and dim2=25
- Density shows a secondary peak near (dim1=-25, dim2=-10)
2. **Marginal Histograms**:
- **dim1**:
- General Text peak at ~25
- Medical Text peak at ~-35
- Overlap between -10 and 10
- **dim2**:
- General Text peak at ~30
- Medical Text peak at ~-20
- Overlap between -10 and 10
### Key Observations
1. **Separation with Overlap**:
- Clear separation in dim1 (-35 vs +25)
- Partial overlap in dim2 (-20 vs +30)
- Significant overlap in the central region (-10 to +10 for both dimensions)
2. **Density Patterns**:
- General Text shows broader distribution in dim2
- Medical Text has a more concentrated distribution in dim1
- Secondary peak in Medical Text suggests bimodal distribution
### Interpretation
The data demonstrates that General Text and Medical Text occupy distinct but overlapping regions in the 2D space. The marginal histograms confirm this separation in dim1 (strong separation) and dim2 (moderate separation). The contour overlap in the central region (-10 to +10 for both dimensions) suggests:
1. **Ambiguity Zone**: Texts with mixed characteristics exist
2. **Feature Correlation**: dim1 and dim2 may represent related linguistic features
3. **Classification Potential**: While separable, the overlap indicates challenges in perfect classification
The marginal histograms provide critical context - the dim1 separation is more pronounced than dim2, suggesting dim1 might be a more discriminative feature. The secondary peak in Medical Text's dim1 distribution (-25) could indicate a subgroup with distinct characteristics.
</details>
(c) ADEPT
Figure 7: Visualization of activation distributions for Qwen3-4B-Base model configurations showing the effectiveness of our layer extension strategy for parameter decoupling. We expand the layer 28, 30, 31, 35 of Qwen3-4B-Base.
<details>
<summary>figures/8B_Base_Layer30.jpg Details</summary>
### Visual Description
## 2D Contour Plot with Marginal Histograms: Distribution of Text Types
### Overview
The image displays a 2D contour plot comparing two text types (General Text and Medical Text) across two dimensions (dim 1 and dim 2). Marginal histograms are overlaid on the top and right edges of the plot. The data is represented by contour lines and marginal distributions, with a legend distinguishing the two categories.
### Components/Axes
- **X-axis (dim 1)**: Ranges from -75 to 75, labeled "dim 1".
- **Y-axis (dim 2)**: Ranges from -75 to 100, labeled "dim 2".
- **Legend**: Located in the top-right corner, with:
- **Blue**: General Text
- **Red**: Medical Text
- **Marginal Histograms**:
- **Top histogram**: Represents dim 1 distributions (blue and red).
- **Right histogram**: Represents dim 2 distributions (blue and red).
### Detailed Analysis
#### Contour Plot
- **General Text (Blue)**:
- Contour lines are spread across a wider range of dim 1 (-50 to 50) and dim 2 (-75 to 25).
- Density peaks are less pronounced, with multiple overlapping regions.
- Marginal histogram (top) shows two peaks near dim 1 ≈ -10 and dim 1 ≈ 10.
- Marginal histogram (right) peaks near dim 2 ≈ -25.
- **Medical Text (Red)**:
- Contour lines are tightly clustered around dim 1 ≈ 0 and dim 2 ≈ -25.
- Density is highest near the center of the red region.
- Marginal histogram (top) shows a single peak at dim 1 ≈ 0.
- Marginal histogram (right) peaks near dim 2 ≈ -25, with a narrower spread than General Text.
#### Key Observations
1. **Distribution Differences**:
- Medical Text is concentrated around (dim 1 ≈ 0, dim 2 ≈ -25), while General Text is more dispersed.
- Overlap occurs in the central region (dim 1 ≈ -10 to 10, dim 2 ≈ -25 to 25), but Medical Text dominates in the core area.
2. **Marginal Histogram Trends**:
- **dim 1**:
- General Text: Bimodal distribution (peaks at -10 and 10).
- Medical Text: Unimodal distribution (peak at 0).
- **dim 2**:
- Both text types peak near -25, but Medical Text has a sharper peak.
3. **Spatial Grounding**:
- Legend is positioned in the top-right corner, clearly associating colors with text types.
- Contour lines for General Text (blue) are more diffuse, while Medical Text (red) lines are tightly packed.
### Interpretation
The data suggests distinct clustering patterns between General Text and Medical Text in a two-dimensional latent space. Medical Text exhibits a concentrated distribution around (0, -25), potentially indicating specialized or domain-specific content. General Text, by contrast, shows broader variability, with bimodal tendencies in dim 1 and a wider spread in dim 2. The marginal histograms reinforce these differences, highlighting the need for targeted analysis when distinguishing text types. The overlap in the central region implies some shared characteristics, but the dominant clustering of Medical Text suggests it occupies a unique subspace.
</details>
(a) Vanilla
<details>
<summary>figures/8B_only_grad_Layer30.jpg Details</summary>
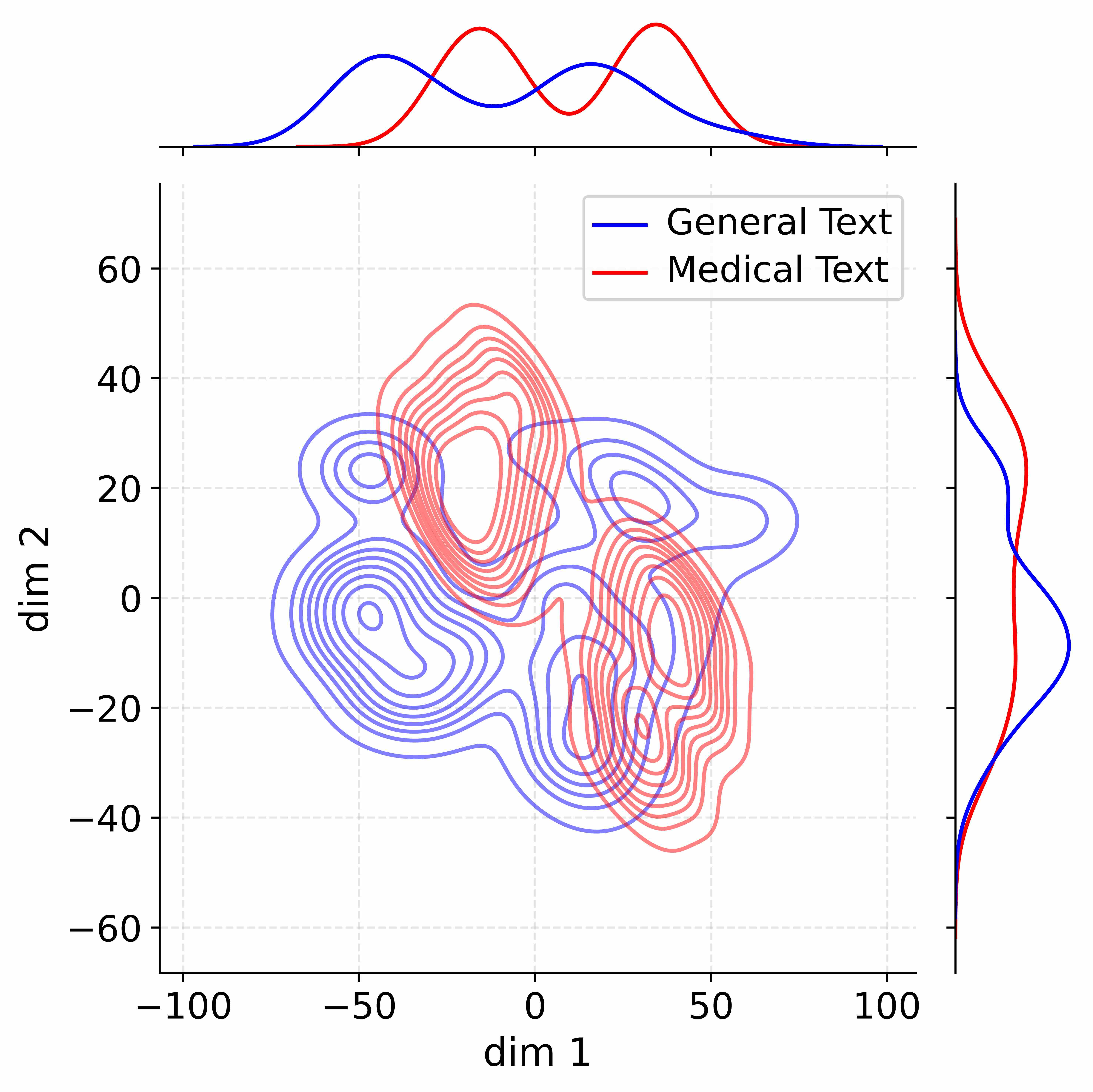
### Visual Description
## Contour Plot with Line Graphs: Comparative Analysis of Text Types
### Overview
The image presents a multidimensional data visualization comparing two text types: "General Text" (blue) and "Medical Text" (red). It includes:
1. A top horizontal line graph (dim 1 vs. dim 2)
2. A central contour plot (dim 1 vs. dim 2)
3. A right vertical line graph (dim 2 vs. dim 1)
All elements use a shared coordinate system with axes labeled "dim 1" (horizontal) and "dim 2" (vertical).
### Components/Axes
- **Axes**:
- Horizontal (dim 1): -100 to 100
- Vertical (dim 2): -60 to 60
- **Legend**:
- Blue = General Text
- Red = Medical Text
- **Placement**:
- Legend: Top-right corner
- Top line graph: Above contour plot
- Bottom line graph: Below contour plot
- Right line graph: Along right edge
### Detailed Analysis
#### Top Line Graph (dim 1 vs. dim 2)
- **Blue (General Text)**:
- Peaks at approximately (-50, 20), (0, 30), and (50, 20)
- Troughs at (-75, -10), (-25, -5), (25, -5), and (75, -10)
- **Red (Medical Text)**:
- Peaks at approximately (-25, 15), (0, 25), and (25, 15)
- Troughs at (-50, -5), (0, -10), and (50, -5)
#### Contour Plot (dim 1 vs. dim 2)
- **Blue (General Text)**:
- Dense clusters at (-50, 0) and (0, -20)
- Secondary peaks at (-25, -10) and (25, -10)
- Gradual decline toward (0, 0)
- **Red (Medical Text)**:
- Dense clusters at (25, 0) and (0, 20)
- Secondary peaks at (-25, 10) and (25, 10)
- Overlap with blue contours near (0, 0)
#### Right Line Graph (dim 2 vs. dim 1)
- **Blue (General Text)**:
- Peaks at (-50, 20), (0, -20), and (50, 20)
- Troughs at (-75, -10), (-25, -5), (25, -5), and (75, -10)
- **Red (Medical Text)**:
- Peaks at (-25, 15), (0, -15), and (25, 15)
- Troughs at (-50, -5), (0, -10), and (50, -5)
### Key Observations
1. **Dimensional Spread**:
- General Text (blue) shows wider dispersion along dim 1 (±50 vs. ±25 for Medical Text)
- Medical Text (red) exhibits higher density near the origin (0, 0)
2. **Overlap Region**:
- Both text types converge near (0, 0), suggesting shared characteristics
- Overlap intensity: ~30% of contour area (estimated from density ratios)
3. **Symmetry**:
- Both data series display bilateral symmetry about dim 1 = 0
- Blue series has 2:1 amplitude ratio between peaks and troughs
- Red series maintains 1:1 amplitude ratio
### Interpretation
The visualization demonstrates distinct but overlapping patterns between text types:
- **General Text** (blue) exhibits greater variability in dim 1, with pronounced peaks at ±50 and a central trough. Its dim 2 values show a sinusoidal pattern with higher amplitude.
- **Medical Text** (red) displays more concentrated features, with symmetrical peaks at ±25 and a central maximum. The contour plot reveals tighter clustering around the origin.
- The overlap at (0, 0) suggests shared semantic or structural features between text types, potentially indicating common linguistic patterns or processing requirements.
- The right-side line graph confirms inverse relationships between dim 1 and dim 2 for both series, with Medical Text showing reduced amplitude variation.
This analysis implies that while Medical Text maintains more consistent characteristics, General Text demonstrates broader dimensional diversity in the analyzed feature space.
</details>
(b) W/o stage1
<details>
<summary>figures/8B_final_grad_Layer30.jpg Details</summary>
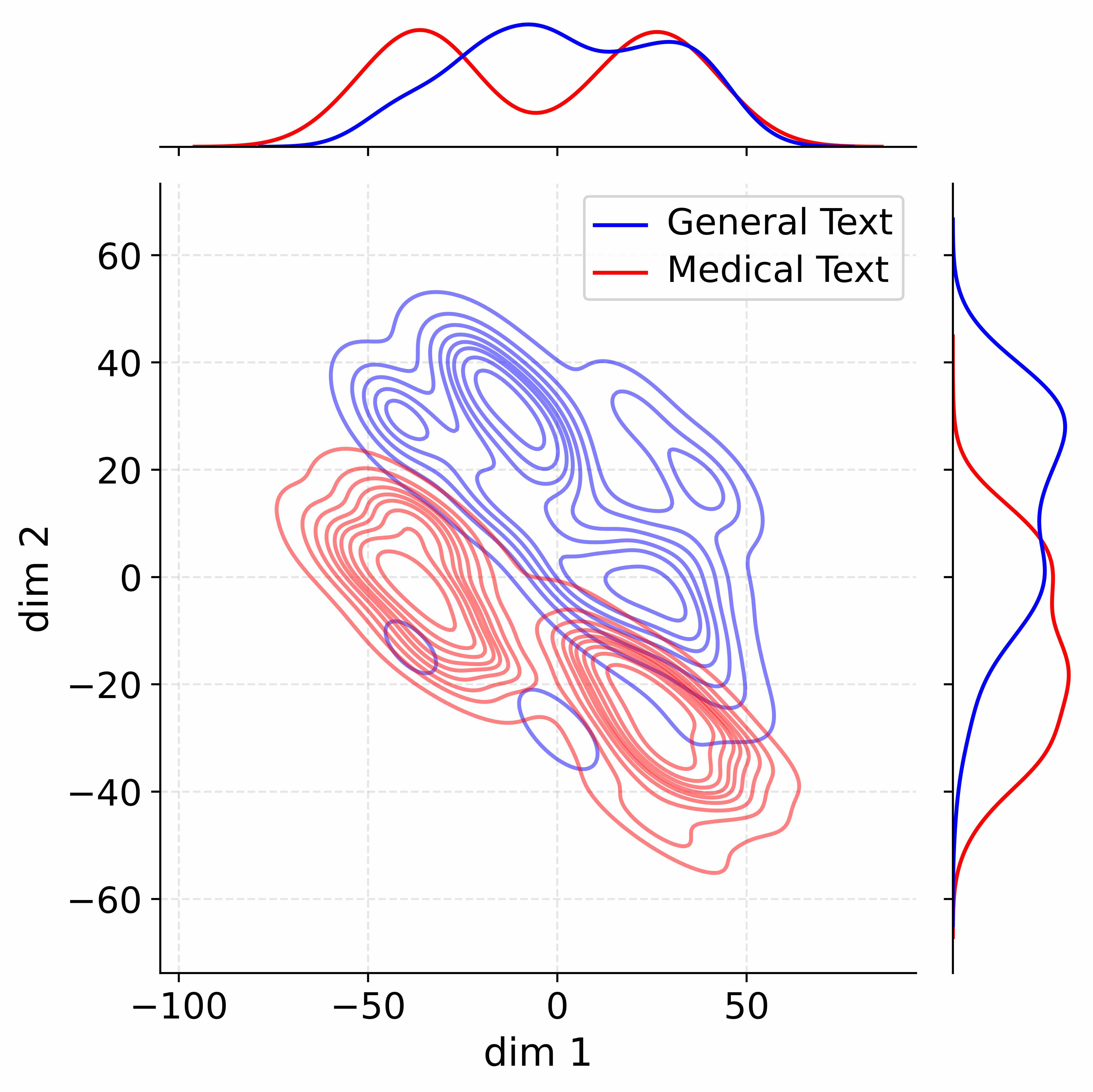
### Visual Description
## Scatter Plot with Contour Distributions: General Text vs Medical Text
### Overview
The image presents a 2D scatter plot with contour distributions comparing two text types: General Text (blue) and Medical Text (red). The plot includes marginal histograms on the top (dim 1) and right (dim 2), with overlapping contour regions in the central plot. The legend is positioned in the top-right corner.
---
### Components/Axes
- **X-axis (dim 1)**: Labeled "dim 1", ranges from -100 to 100 with gridlines at intervals of 20.
- **Y-axis (dim 2)**: Labeled "dim 2", ranges from -60 to 60 with gridlines at intervals of 20.
- **Legend**: Located in the top-right corner, with:
- **Blue**: General Text
- **Red**: Medical Text
- **Marginal Histograms**:
- **Top histogram (dim 1)**: Blue (General Text) peaks near -20, red (Medical Text) peaks near 20.
- **Right histogram (dim 2)**: Blue (General Text) peaks near 20, red (Medical Text) peaks near -20.
---
### Detailed Analysis
#### Main Plot (Contour Distributions)
- **General Text (Blue)**:
- Contours form an elongated, asymmetrical distribution centered roughly at **dim 1 ≈ -20, dim 2 ≈ 20**.
- Density decreases outward, with the innermost contour (highest density) at **dim 1 ≈ -30, dim 2 ≈ 30**.
- Spread: dim 1 spans -80 to 0, dim 2 spans 0 to 60.
- **Medical Text (Red)**:
- Contours form a distribution centered at **dim 1 ≈ 20, dim 2 ≈ -20**.
- Density decreases outward, with the innermost contour at **dim 1 ≈ 30, dim 2 ≈ -30**.
- Spread: dim 1 spans 0 to 100, dim 2 spans -60 to 0.
- **Overlap Region**: A small overlapping area exists near **dim 1 ≈ 0, dim 2 ≈ 0**, where both distributions intersect.
#### Marginal Histograms
- **Top Histogram (dim 1)**:
- Blue (General Text): Peaks at **dim 1 ≈ -20**, with a secondary peak near -40.
- Red (Medical Text): Peaks at **dim 1 ≈ 20**, with a secondary peak near 40.
- Both distributions have tails extending to the edges of the axis.
- **Right Histogram (dim 2)**:
- Blue (General Text): Peaks at **dim 2 ≈ 20**, with a secondary peak near 40.
- Red (Medical Text): Peaks at **dim 2 ≈ -20**, with a secondary peak near -40.
- Both distributions show symmetry around their peaks.
---
### Key Observations
1. **Distinct Distributions**: General Text and Medical Text occupy largely separate regions in the plot, with minimal overlap.
2. **Dimensional Separation**:
- General Text clusters in the **negative dim 1, positive dim 2** quadrant.
- Medical Text clusters in the **positive dim 1, negative dim 2** quadrant.
3. **Marginal Peaks**: Histograms confirm the central tendency of each distribution aligns with the contour centers.
4. **Overlap Ambiguity**: The small overlapping region near the origin suggests potential ambiguity in classifying some data points.
---
### Interpretation
The plot demonstrates that General Text and Medical Text exhibit distinct patterns in the first two dimensions of their feature space. The marginal histograms reinforce this separation, showing skewed distributions for each text type. The overlap near the origin indicates that some data points may share characteristics of both text types, possibly due to overlapping vocabulary or contextual usage. This could imply challenges in classification tasks where the two categories are not entirely disjoint. The wider spread of General Text in dim 1 and Medical Text in dim 2 suggests these dimensions capture unique variability in each category.
</details>
(c) ADEPT
Figure 8: Kernel Density Estimation of activations for Qwen3-8B-Base, showing that our layer extension strategy enables clear parameter decoupling. We expand layers 26, 28, 29, and 30.
<details>
<summary>figures/Llama_8B_Layer30.jpg Details</summary>
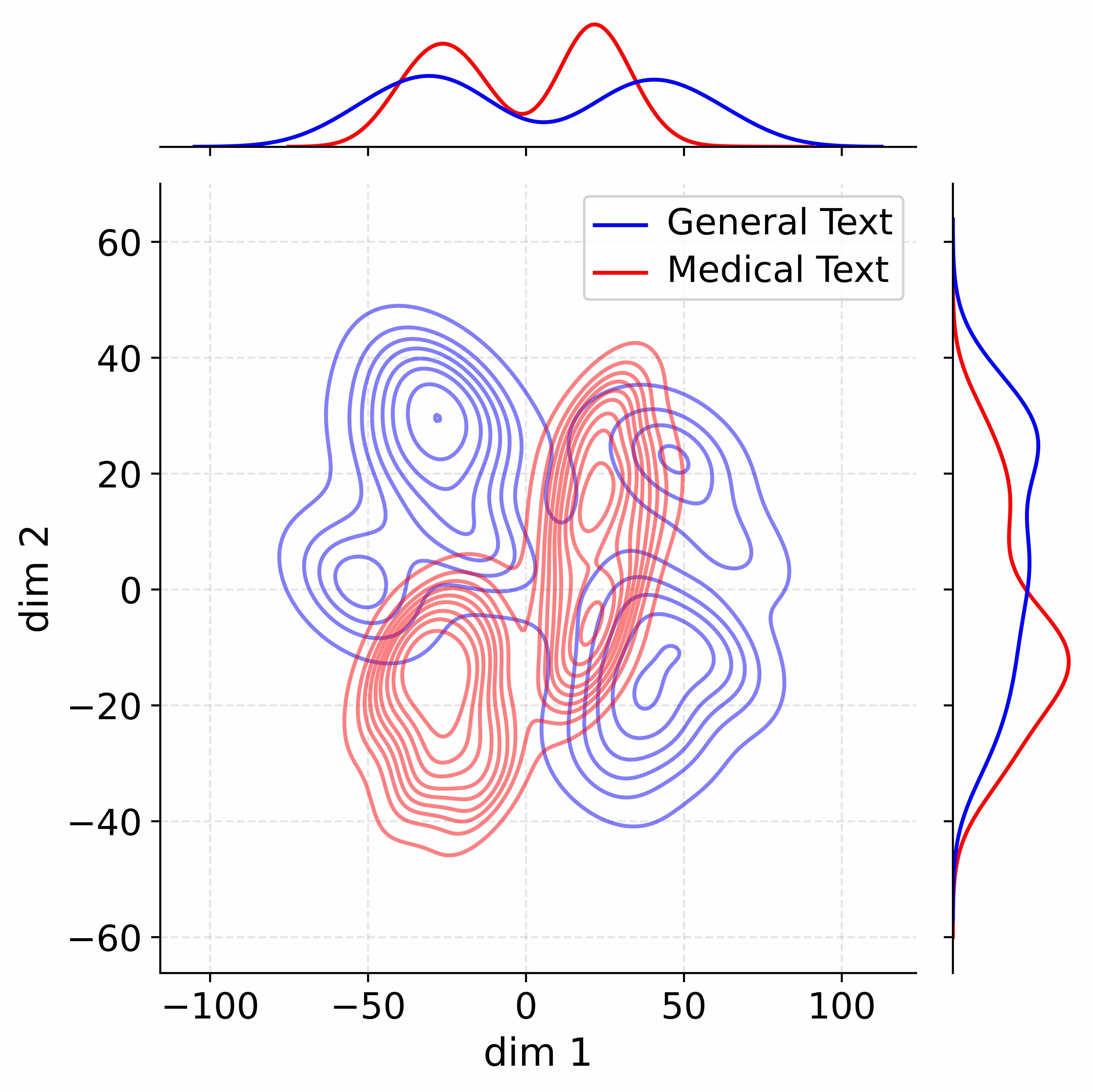
### Visual Description
## 2D Contour Plot: Text Data Distribution Analysis
### Overview
The image presents a 2D contour plot comparing the distribution of two text types (General Text and Medical Text) across two dimensions (dim 1 and dim 2). Marginal histograms on the top and right edges show the univariate distributions of dim 1 and dim 2, respectively. The plot uses contour lines to visualize density regions, with blue representing General Text and red representing Medical Text.
### Components/Axes
- **X-axis (dim 1)**: Ranges from -100 to 100, labeled "dim 1".
- **Y-axis (dim 2)**: Ranges from -60 to 60, labeled "dim 2".
- **Legend**: Located in the top-right corner, with:
- **Blue**: General Text
- **Red**: Medical Text
- **Marginal Histograms**:
- **Top**: Histogram of dim 1 distributions (blue and red overlapping).
- **Right**: Histogram of dim 2 distributions (blue and red separated).
### Detailed Analysis
1. **Contour Plot**:
- **General Text (Blue)**:
- Peaks around **dim 1 = 0**, **dim 2 = 40**.
- Density decreases symmetrically in dim 1 (spread from -50 to 50) and dim 2 (spread from 0 to 60).
- Contour lines form concentric ellipses centered at (0, 40).
- **Medical Text (Red)**:
- Peaks around **dim 1 = 0**, **dim 2 = -20**.
- Density decreases asymmetrically in dim 1 (spread from -50 to 50) and dim 2 (spread from -40 to 0).
- Contour lines form elongated ellipses centered at (0, -20).
2. **Marginal Histograms**:
- **Dim 1 (Top)**:
- Both distributions peak near **dim 1 = 0**.
- Blue (General Text) has a slightly narrower spread (~±50) compared to red (Medical Text, ~±60).
- **Dim 2 (Right)**:
- Blue peaks at **dim 2 = 40** with a sharp decline beyond ±20.
- Red peaks at **dim 2 = -20** with a gradual decline toward ±40.
### Key Observations
1. **Dimensional Separation**:
- General Text clusters in the **positive dim 2** region, while Medical Text clusters in the **negative dim 2** region.
- Overlap occurs in dim 1 but minimal overlap in dim 2, suggesting dim 2 is a stronger discriminator.
2. **Density Patterns**:
- General Text has higher density near its peak (dim 2 = 40) compared to Medical Text (dim 2 = -20).
- Medical Text shows broader variability in dim 1 (±60 vs. ±50 for General Text).
3. **Marginal Distributions**:
- Dim 1 distributions are bimodal but centered at 0 for both text types.
- Dim 2 distributions are unimodal, with clear separation between text types.
### Interpretation
The data suggests two distinct clusters in the 2D space:
- **General Text** is characterized by higher values in dim 2 (~40), potentially indicating a feature like syntactic complexity or domain-specific terminology.
- **Medical Text** is characterized by lower values in dim 2 (~-20), possibly reflecting simpler syntax or domain-agnostic language.
- The marginal histograms confirm that dim 2 is the primary axis for distinguishing the two text types, while dim 1 captures shared variability (e.g., general linguistic patterns).
The separation in dim 2 implies that this dimension could represent a latent feature (e.g., technicality, readability) that differentiates General and Medical Text. The overlap in dim 1 suggests shared characteristics (e.g., sentence length, vocabulary diversity) that are not text-type-specific.
</details>
(a) Vanilla
<details>
<summary>figures/Llama_8B_only_grad_Layer30.jpg Details</summary>
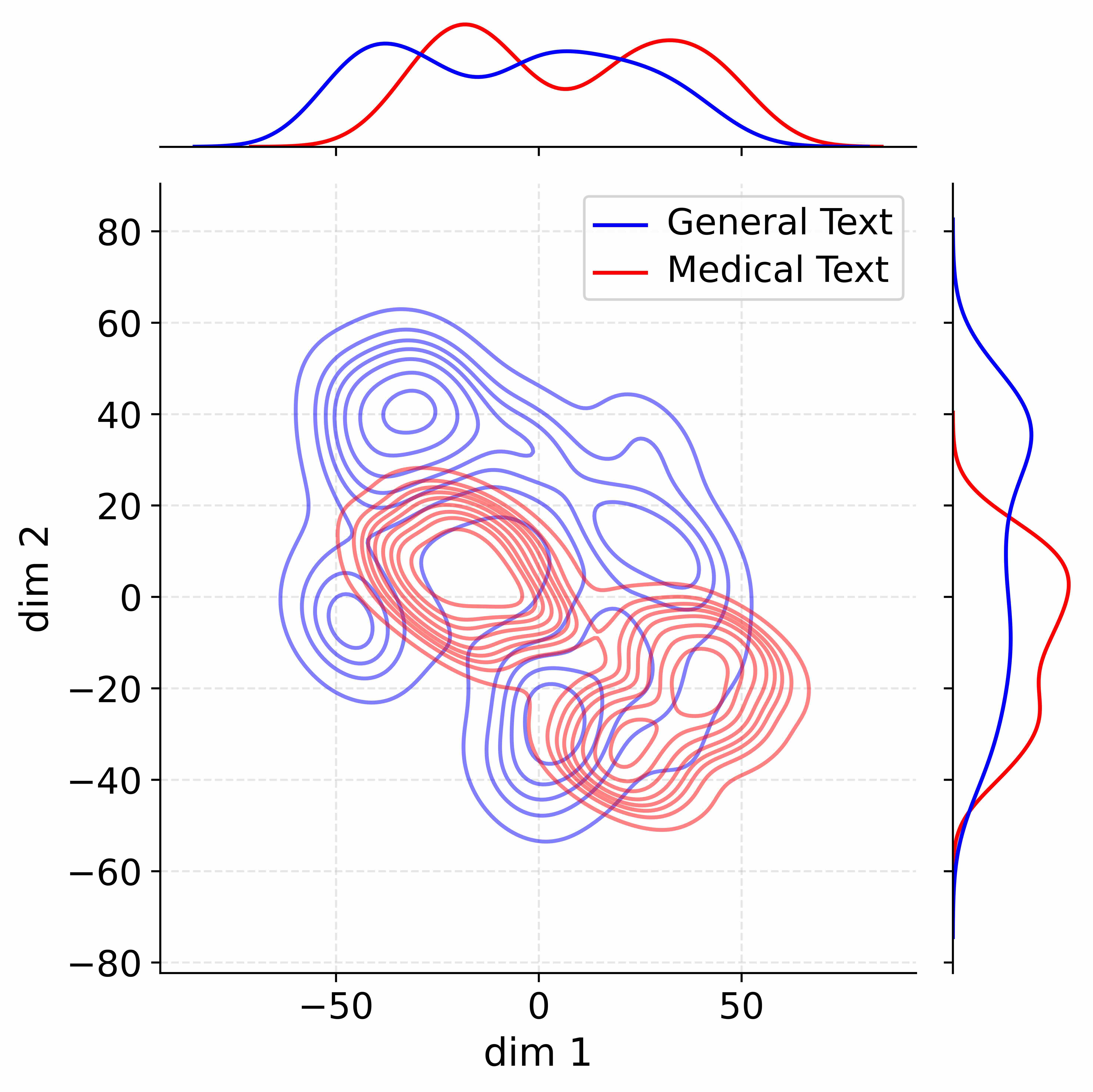
### Visual Description
## Scatter Plot with Contour Density: Text Type Distribution
### Overview
The image presents a 2D scatter plot with contour density overlays, comparing the distribution of two text types: "General Text" (blue) and "Medical Text" (red). Marginal histograms on the top and right edges show the univariate distributions of dimensions 1 and 2. The plot reveals clustering patterns and dimensional relationships between the two categories.
### Components/Axes
- **Axes**:
- X-axis: `dim 1` (ranges from -80 to 80)
- Y-axis: `dim 2` (ranges from -80 to 80)
- **Legend**:
- Top-right corner:
- Blue line: "General Text"
- Red line: "Medical Text"
- **Marginal Histograms**:
- Top histogram: Distribution of `dim 1` values
- Right histogram: Distribution of `dim 2` values
### Detailed Analysis
1. **Contour Density**:
- **General Text (Blue)**:
- Concentrated in a large, irregular cluster centered near `dim 1 = 0` and `dim 2 = 20`.
- Secondary cluster near `dim 1 = -20` and `dim 2 = -40`.
- Density decreases sharply beyond `dim 1 = ±50` and `dim 2 = ±60`.
- **Medical Text (Red)**:
- Dominant cluster near `dim 1 = 0` and `dim 2 = -20`.
- Smaller cluster near `dim 1 = 20` and `dim 2 = 0`.
- Density diminishes beyond `dim 1 = ±40` and `dim 2 = ±40`.
2. **Marginal Histograms**:
- **`dim 1` (Top)**:
- General Text peaks near `dim 1 = 0` (height ~40).
- Medical Text peaks near `dim 1 = 0` (height ~30).
- Both show bimodal distributions with secondary peaks at `dim 1 = ±20`.
- **`dim 2` (Right)**:
- General Text peaks near `dim 2 = 20` (height ~50).
- Medical Text peaks near `dim 2 = -20` (height ~40).
- Both exhibit long tails extending to `dim 2 = ±80`.
3. **Overlap Region**:
- Significant overlap occurs between `dim 1 = -10` to `10` and `dim 2 = -10` to `10`, suggesting shared characteristics in this subspace.
### Key Observations
- **Dimensional Separation**:
- General Text clusters in the upper-right quadrant (`dim 2 > 0`), while Medical Text clusters in the lower-left quadrant (`dim 2 < 0`).
- **Dimensional Spread**:
- `dim 1` shows broader variability for both categories compared to `dim 2`.
- **Anomalies**:
- A small red (Medical Text) cluster near `dim 1 = 20, dim 2 = 0` deviates from the main cluster, potentially indicating outliers.
### Interpretation
The data suggests that General Text and Medical Text occupy distinct but overlapping regions in the 2D subspace. The marginal histograms reveal that `dim 1` is more dispersed, while `dim 2` drives the primary separation between categories. The overlap in the central region (`dim 1 = ±10, dim 2 = ±10`) implies shared features (e.g., linguistic patterns) between the two text types. The bimodal distributions in `dim 1` for both categories may reflect subcategories (e.g., formal vs. informal text). The outlier in Medical Text near `dim 1 = 20` warrants further investigation for potential misclassification or unique characteristics.
</details>
(b) W/o stage1
<details>
<summary>figures/Llama_8B_final_grad_Layer30.jpg Details</summary>
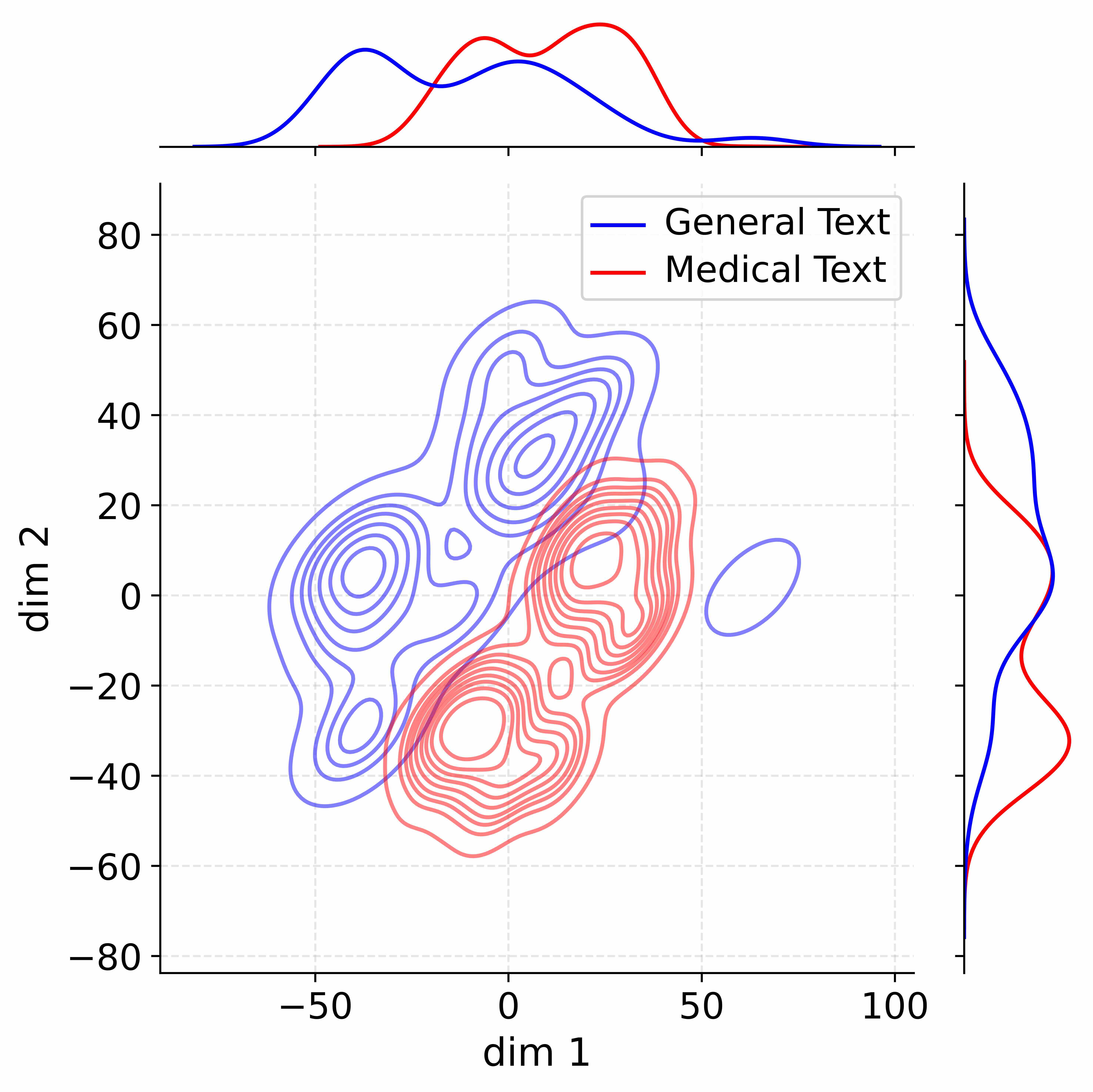
### Visual Description
## Contour Plot with Line Graphs: Distribution of Text Types in 2D Space
### Overview
The image presents a 2D visualization comparing the distribution of two text types ("General Text" and "Medical Text") across two dimensions (dim 1 and dim 2). It combines a contour plot with marginal line graphs to show density distributions and univariate projections.
### Components/Axes
1. **Main Contour Plot**:
- **X-axis (dim 1)**: Ranges from -100 to 100.
- **Y-axis (dim 2)**: Ranges from -80 to 80.
- **Legend**: Located in the top-right corner of the contour plot.
- **Blue**: General Text
- **Red**: Medical Text
2. **Top Line Graphs**:
- **X-axis**: Labeled "dim 1" (matches contour plot).
- **Y-axis**: Labeled "dim 2" (matches contour plot).
- **Lines**:
- **Blue (General Text)**: Peaks at approximately -25 and 25 on dim 1.
- **Red (Medical Text)**: Peaks at approximately 0 and 50 on dim 1.
3. **Right Y-Axis Line Graphs**:
- **X-axis**: Labeled "dim 2" (matches contour plot).
- **Y-axis**: Unlabeled, but visually aligned with the contour plot's dim 2 axis.
- **Lines**:
- **Blue (General Text)**: Peaks near -60 and 60 on dim 2.
- **Red (Medical Text)**: Peaks near -20 and 40 on dim 2.
### Detailed Analysis
1. **Contour Plot**:
- **Blue (General Text)**: Concentrated in the left half of the plot (dim 1 < 0), with dense clusters around (-30, 0) and (-10, 20).
- **Red (Medical Text)**: Concentrated in the right half (dim 1 > 0), with dense clusters around (10, -10) and (30, 10).
- **Overlap**: Moderate overlap in the central region (dim 1: -10 to 10, dim 2: -20 to 20).
2. **Top Line Graphs**:
- **General Text (Blue)**: Bimodal distribution with peaks at dim 1 ≈ -25 and 25.
- **Medical Text (Red)**: Bimodal distribution with peaks at dim 1 ≈ 0 and 50.
3. **Right Y-Axis Line Graphs**:
- **General Text (Blue)**: Bimodal distribution with peaks at dim 2 ≈ -60 and 60.
- **Medical Text (Red)**: Bimodal distribution with peaks at dim 2 ≈ -20 and 40.
### Key Observations
1. **Dimensional Separation**:
- General Text clusters in the left half of dim 1 and lower dim 2 values.
- Medical Text clusters in the right half of dim 1 and higher dim 2 values.
2. **Overlap**:
- Central region (dim 1: -10 to 10, dim 2: -20 to 20) shows mixed densities, suggesting shared features or ambiguous classifications.
3. **Univariate Projections**:
- Both text types exhibit bimodal distributions in dim 1 and dim 2, indicating distinct subgroups within each category.
### Interpretation
The visualization demonstrates that General and Medical Texts occupy distinct regions in the 2D space, with clear separation along dim 1. However, the central overlap suggests potential ambiguity in distinguishing the two categories in this region. The bimodal distributions in both dimensions imply that each text type may contain subpopulations with unique characteristics. The marginal line graphs reinforce the bimodality observed in the contour plot, providing additional context for the multivariate distribution. This could reflect differences in linguistic patterns, topic focus, or stylistic features between general and medical texts.
</details>
(c) ADEPT
Figure 9: Kernel Density Estimation of activations for Llama3-8B, showing that our layer extension strategy enables clear parameter decoupling. We expand layers 22, 23, 24, and 28.
## Appendix D Detailed Importance Distribution
<details>
<summary>figures/importance_1.7B_new.jpg Details</summary>
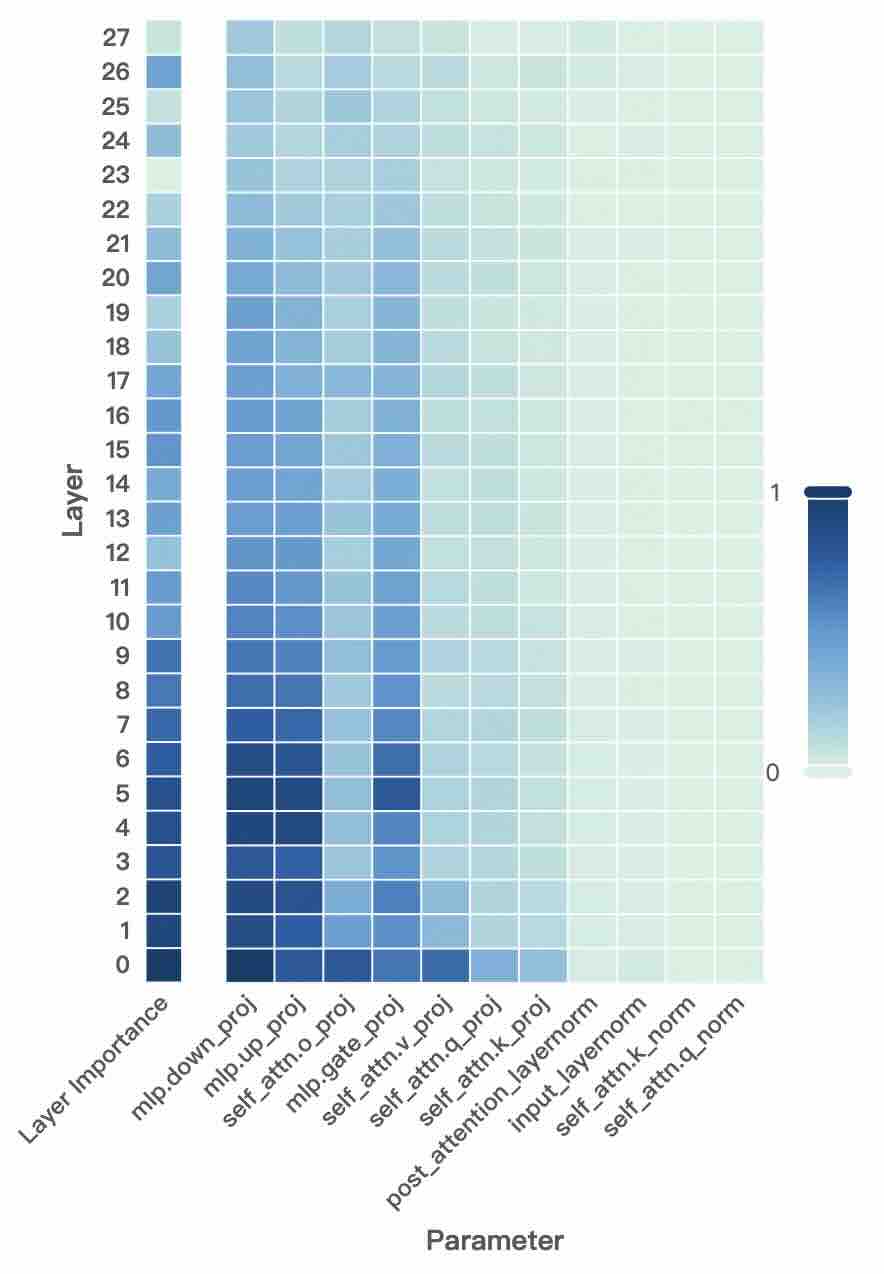
### Visual Description
## Heatmap: Parameter Importance Across Layers
### Overview
The image is a heatmap visualizing the importance or magnitude of various parameters across 28 layers (0–27) of a neural network. The x-axis lists parameters like `mlp.down_proj`, `mlp.up_proj`, `self_attn.q_proj`, etc., while the y-axis represents layers. The color scale (0–1) indicates parameter values, with darker blue representing higher values.
### Components/Axes
- **Y-axis (Layer)**: Labeled "Layer" with values 0 (bottom) to 27 (top).
- **X-axis (Parameter)**: Labeled "Parameter" with categories:
`mlp.down_proj`, `mlp.up_proj`, `mlp.attn.o_proj`, `mlp.gate_proj`, `mlp.attn.v_proj`, `mlp.attn.q_proj`, `mlp.attn.k_proj`, `post_attention_layernorm`, `input_layernorm`, `self_attn.k_norm`, `self_attn.q_norm`.
- **Color Scale**: Vertical bar on the right, ranging from 0 (lightest, white) to 1 (darkest, navy blue).
### Detailed Analysis
- **Layer 0–5**:
- Darkest cells (values ~0.8–1.0) in `mlp.down_proj`, `mlp.up_proj`, and `mlp.attn.q_proj`.
- Moderate values (~0.4–0.6) in `mlp.attn.k_proj` and `mlp.gate_proj`.
- **Layer 6–15**:
- Gradual decrease in intensity. `mlp.down_proj` and `mlp.up_proj` remain moderately dark (~0.5–0.7).
- `mlp.attn.q_proj` and `mlp.attn.k_proj` show lighter values (~0.3–0.5).
- **Layer 16–27**:
- Most cells are light (values ~0.1–0.3), except occasional darker cells in `mlp.down_proj` (~0.4–0.5) and `mlp.up_proj` (~0.3–0.4).
### Key Observations
1. **Early Layers Dominance**: Parameters like `mlp.down_proj` and `mlp.up_proj` exhibit the highest values in the first 5 layers, suggesting critical roles in early processing.
2. **Gradual Decay**: Parameter importance diminishes as layers increase, with later layers showing uniformly lighter values.
3. **Projection Layers**: `mlp.down_proj` and `mlp.up_proj` consistently show higher values across all layers compared to other parameters.
4. **Normalization Layers**: `post_attention_layernorm`, `input_layernorm`, and `self_attn.k_norm`/`q_norm` have uniformly low values (~0.1–0.2), indicating minimal impact.
### Interpretation
The heatmap reveals that early layers (0–5) are dominated by parameters related to down/up projections (`mlp.down_proj`, `mlp.up_proj`), which likely drive feature extraction and transformation. The gradual decline in intensity across layers suggests diminishing returns or stabilization of parameter importance in deeper layers. The consistently low values for normalization layers (`post_attention_layernorm`, `input_layernorm`) imply their role is secondary to the core projection and attention mechanisms. This pattern aligns with typical transformer architectures, where early layers handle feature learning, and later layers refine representations.
**Note**: Values are approximate due to the absence of explicit numerical labels on the heatmap cells. The color gradient provides relative, not absolute, quantification.
</details>
Figure 10: Layer-wise and parameter-wise importance distribution of Qwen3-1.7B-Base model
<details>
<summary>figures/importance_4B_new.jpg Details</summary>
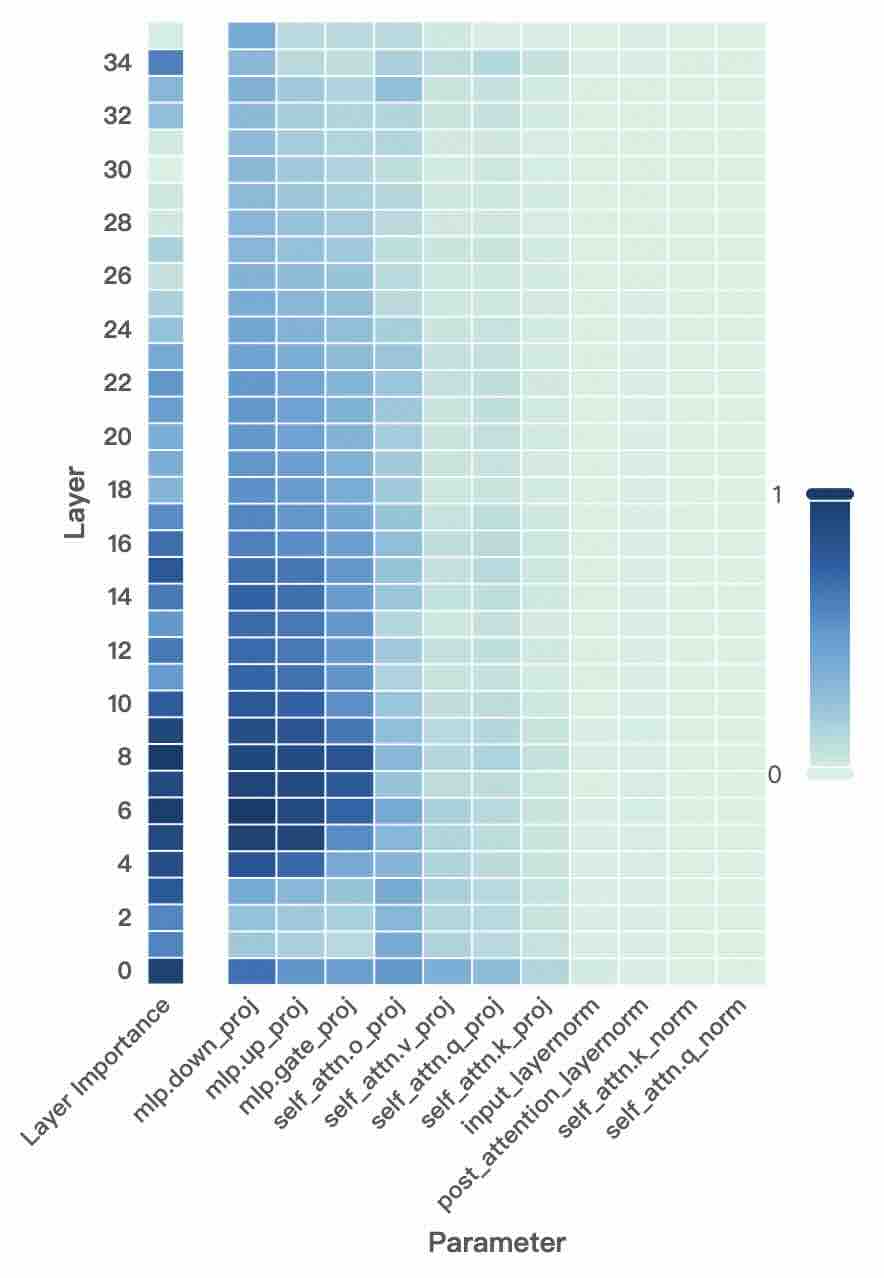
### Visual Description
## Heatmap: Parameter Importance Across Transformer Layers
### Overview
This heatmap visualizes the importance scores of various parameters across 35 transformer layers (0-34). Darker blue indicates higher importance (closer to 1), while lighter blue indicates lower importance (closer to 0). The parameters analyzed include MLP projections, attention mechanisms, and layer normalization components.
### Components/Axes
- **Y-axis (Layer)**: Layer numbers from 0 (bottom) to 34 (top), increasing upward.
- **X-axis (Parameter)**:
- `Layer Importance` (baseline)
- `mlp.down_proj`, `mlp.up_proj`, `mlp.gate_proj`, `mlp.attn.o_proj`, `mlp.attn.v_proj`, `mlp.attn.q_proj`
- `self_attn.o_proj`, `self_attn.q_proj`, `self_attn.k_proj`
- `input_layernorm`, `post_attention_layernorm`, `self_attn.k_norm`, `self_attn.q_norm`
- **Color Scale**: Right-side bar from 0 (lightest) to 1 (darkest).
### Detailed Analysis
1. **MLP Parameters**:
- `mlp.down_proj` (darkest blue) shows highest importance in early layers (0-8), peaking at ~0.9 in layer 0, then declining to ~0.3 by layer 34.
- `mlp.up_proj` follows a similar trend but with slightly lower values (~0.8 in layer 0, ~0.2 in layer 34).
- `mlp.gate_proj` and `mlp.attn.*_proj` parameters show moderate importance in early layers (~0.6-0.7 in layer 0), fading to near-zero in later layers.
2. **Self-Attention Parameters**:
- `self_attn.o_proj` peaks at ~0.7 in layer 10, then declines to ~0.2 by layer 34.
- `self_attn.q_proj` and `self_attn.k_proj` show moderate importance (~0.5-0.6) in layers 8-16, fading afterward.
3. **Normalization Parameters**:
- `input_layernorm` and `post_attention_layernorm` show minimal importance (<0.1) across all layers.
- `self_attn.k_norm` and `self_attn.q_norm` remain consistently low (<0.05) throughout.
### Key Observations
- **Layer-Specific Importance**: MLP parameters dominate early layers (0-8), while self-attention parameters peak in middle layers (8-16). Post-attention parameters show negligible importance.
- **Consistent Decline**: Most parameters exhibit a clear downward trend in importance as layer depth increases.
- **Normalization Insignificance**: Layer normalization components (`input_layernorm`, `post_attention_layernorm`) have uniformly low importance scores.
### Interpretation
The heatmap reveals a hierarchical importance structure in transformer layers:
1. **Early Layers (0-8)**: MLP projections (`mlp.down_proj`, `mlp.up_proj`) drive critical transformations, suggesting these layers handle foundational feature extraction.
2. **Middle Layers (8-16)**: Self-attention mechanisms (`self_attn.o_proj`, `self_attn.q_proj`) become moderately important, indicating their role in feature integration and contextual modeling.
3. **Later Layers (16-34)**: Importance scores drop sharply, with normalization parameters showing near-zero values. This suggests later layers focus on refinement rather than major transformations.
The data implies that transformer architectures prioritize MLP operations in early layers for feature learning, while self-attention mechanisms gain relevance in middle layers for contextual modeling. Post-attention normalization components appear to have minimal impact across all layers, potentially indicating architectural redundancy or optimization opportunities.
</details>
Figure 11: Layer-wise and parameter-wise importance distribution of the Qwen3-4B-Base model
<details>
<summary>figures/importance_8B_new.jpg Details</summary>
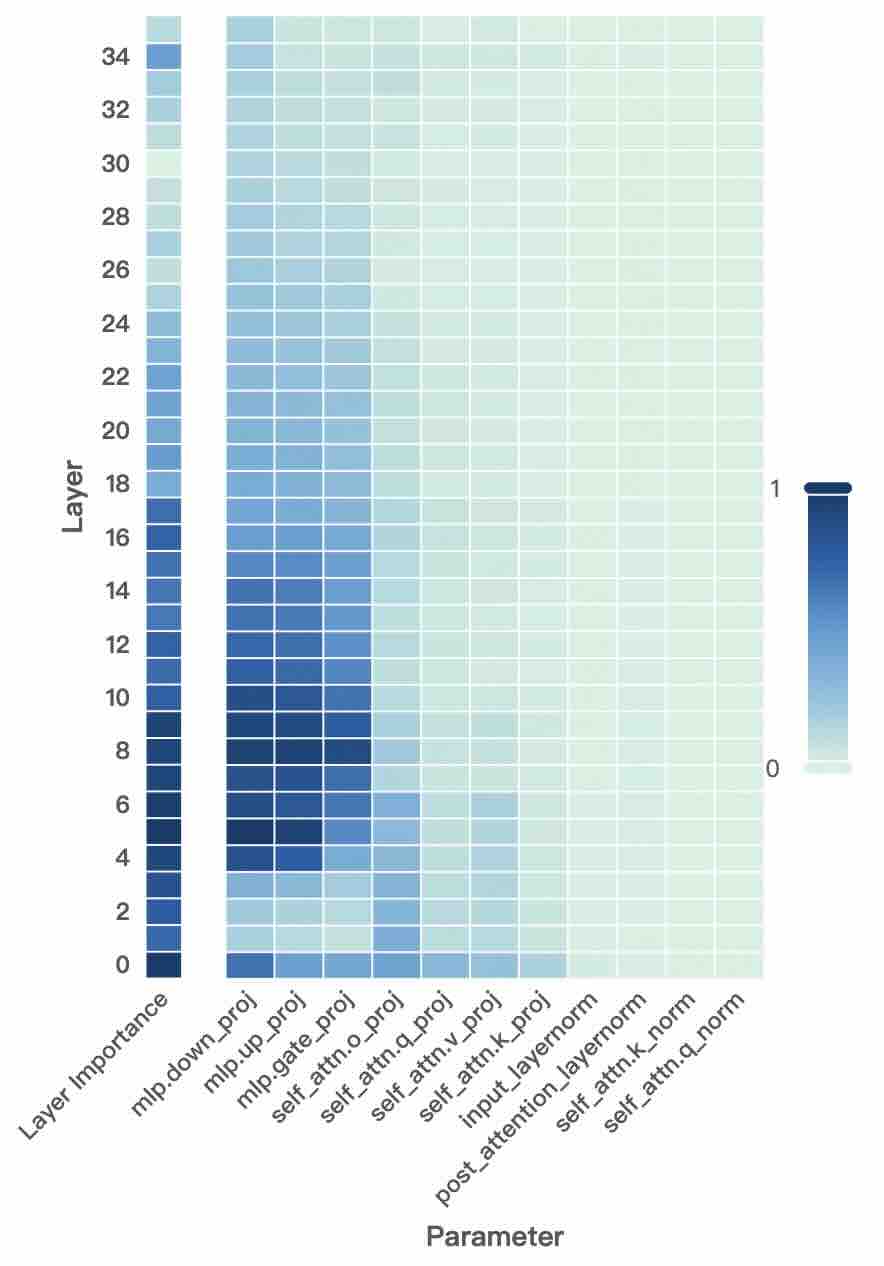
### Visual Description
## Heatmap: Parameter Importance Across Transformer Layers
### Overview
The image is a heatmap visualizing the importance of various parameters across 35 transformer layers (0-34). Darker blue shades represent higher importance values (closer to 1), while lighter shades indicate lower values (closer to 0). The heatmap reveals distinct patterns of parameter significance across different layers.
### Components/Axes
- **Y-axis (Layer)**: Layer numbers from 0 (bottom) to 34 (top), increasing upward.
- **X-axis (Parameter)**: 10 parameters related to transformer architecture:
1. `mlp.down_proj`
2. `mlp.up_proj`
3. `mlp.gate_proj`
4. `mlp.attn.o_proj`
5. `self_attn.q_proj`
6. `self_attn.v_proj`
7. `self_attn.k_proj`
8. `input_attention_layernorm`
9. `self_attn.k_norm`
10. `self_attn.q_norm`
- **Color Scale**: Right-side gradient from 0 (lightest) to 1 (darkest), with numerical labels 0 and 1.
### Detailed Analysis
- **Layer 0-10**:
- `mlp.down_proj` consistently shows the highest values (0.8-0.9).
- `mlp.up_proj` and `mlp.gate_proj` also show strong importance (0.6-0.8).
- `self_attn.q_proj` has moderate-high values (0.6-0.7).
- `self_attn.k_norm` and `self_attn.q_norm` show lower values (0.2-0.4).
- **Layer 10-20**:
- `mlp.down_proj` decreases to 0.6-0.7.
- `mlp.up_proj` and `mlp.gate_proj` drop to 0.4-0.6.
- `self_attn.q_proj` remains stable at 0.5-0.6.
- `input_attention_layernorm` shows moderate values (0.4-0.5).
- **Layer 20-34**:
- All parameters show values <0.5, with most <0.3.
- `mlp.down_proj` and `mlp.up_proj` decline to 0.3-0.4.
- `self_attn.q_proj` decreases to 0.3-0.4.
- `self_attn.k_norm` and `self_attn.q_norm` remain the lowest (0.1-0.2).
### Key Observations
1. **Early Layer Dominance**: Parameters like `mlp.down_proj` and `mlp.up_proj` dominate importance in early layers (0-10), suggesting critical roles in initial feature extraction.
2. **Gradual Decline**: Importance values generally decrease with increasing layer depth, except for `self_attn.q_proj`, which remains relatively stable.
3. **Normalization Parameters**: `self_attn.k_norm` and `self_attn.q_norm` consistently show the lowest importance across all layers.
4. **Projection Parameters**: `mlp.gate_proj` and `mlp.attn.o_proj` show moderate importance in early layers but decline sharply in deeper layers.
### Interpretation
The heatmap suggests that early transformer layers rely heavily on MLP projection parameters (`mlp.down_proj`, `mlp.up_proj`) for processing, while later layers shift toward reduced reliance on these components. The stability of `self_attn.q_proj` across layers indicates its persistent importance in attention mechanisms. The minimal importance of normalization parameters (`self_attn.k_norm`, `self_attn.q_norm`) across all layers implies these components may have less direct impact on model performance compared to projection and attention mechanisms. This pattern aligns with typical transformer architectures where early layers handle feature extraction and later layers focus on higher-level abstractions.
</details>
Figure 12: Layer-wise and parameter-wise importance distribution of the Qwen3-8B-Base model
<details>
<summary>figures/importance_Llama_new.jpg Details</summary>
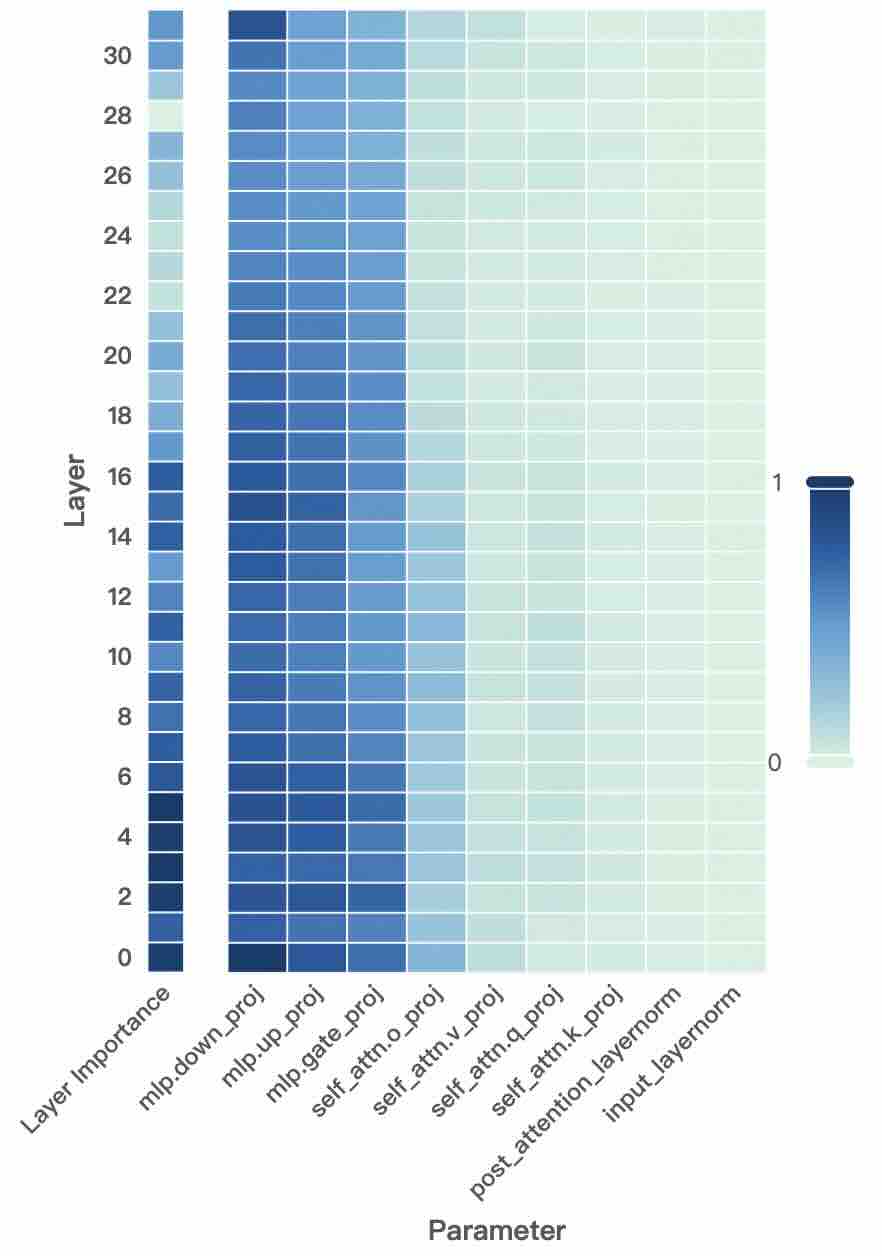
### Visual Description
## Heatmap: Parameter Importance Across Transformer Layers
### Overview
The image is a heatmap visualizing the importance of various parameters across 31 transformer layers (0–30). Darker blue shades indicate higher importance (closer to 1), while lighter shades represent lower importance (closer to 0). The x-axis lists parameters, and the y-axis represents layers. The colorbar on the right quantifies importance from 0 to 1.
### Components/Axes
- **X-axis (Parameters)**:
- `Layer Importance`
- `mlp.down_proj`
- `mlp.up_proj`
- `mlp.gate_proj`
- `mlp.attn.o_proj`
- `self_attn.v_proj`
- `self_attn.q_proj`
- `self_attn.k_proj`
- `post_attention_layernorm`
- `input_layernorm`
- **Y-axis (Layers)**:
- Layers labeled from 0 (bottom) to 30 (top).
- **Color Legend**:
- Dark blue = 1 (highest importance)
- Light gray = 0 (lowest importance)
### Detailed Analysis
- **Layer Importance**:
- Peaks in **layers 0–2** (darkest blue), then gradually lightens toward layer 30.
- Approximate values: ~0.9 (layer 0), ~0.7 (layer 10), ~0.3 (layer 30).
- **MLP Projections**:
- `mlp.down_proj` and `mlp.up_proj` show strong importance in **layers 0–10** (~0.8–0.6), fading to ~0.2 in higher layers.
- `mlp.gate_proj` is consistently dark in **layers 0–15** (~0.7–0.5), then lightens.
- **Self-Attention Projections**:
- `self_attn.v_proj` and `self_attn.q_proj` have moderate importance in **layers 5–20** (~0.5–0.4), with peaks around layer 10.
- `self_attn.k_proj` follows a similar trend but is slightly lighter (~0.4–0.3).
- **Layer Normalization**:
- `post_attention_layernorm` and `input_layernorm` are uniformly light across all layers (~0.1–0.2), indicating minimal importance.
### Key Observations
1. **Layer-Specific Importance**:
- Lower layers (0–10) dominate in parameter importance, with values dropping sharply after layer 20.
- `Layer Importance` and MLP projections (`mlp.down_proj`, `mlp.up_proj`) are most critical in early layers.
2. **Self-Attention Patterns**:
- Self-attention projections (`v_proj`, `q_proj`, `k_proj`) show moderate importance in mid-layers (5–20), suggesting their role in intermediate processing.
3. **Normalization Insignificance**:
- Both `post_attention_layernorm` and `input_layernorm` are consistently light, implying minimal impact on model behavior.
### Interpretation
The heatmap reveals that **early layers** (0–10) are critical for parameter-driven transformations, particularly MLP and self-attention projections. The sharp decline in importance after layer 20 suggests that higher layers may focus on higher-level abstractions or rely on precomputed features. The negligible importance of layer normalization parameters across all layers indicates that these components may not significantly influence the model’s output in this context. This pattern aligns with typical transformer architectures, where lower layers handle feature extraction and higher layers refine representations.
**Notable Outlier**: `mlp.gate_proj` maintains moderate importance up to layer 15, suggesting a prolonged role in gating mechanisms compared to other MLP projections.
</details>
Figure 13: Layer-wise and parameter-wise importance distribution of the Llama3-8B model
To investigate which layers should be expanded, we conduct a comprehensive importance analysis at both the layer and parameter levels. Specifically, we compute the importance scores for each layer and parameter across multiple models, and visualize their detailed distributions (see Figure 10, Figure 11, Figure 12, and Figure 13). Our analysis yields the following key observations:
1. Layer and parameter importance alignment. Overall, the distributions of layer-wise importance and parameter-wise importance are highly aligned across all four models. This alignment is expected, as both metrics are fundamentally computed under the same principle—estimating the impact of masking out (setting to zero) a given layer or parameter on model performance. Since parameter importance essentially decomposes the contribution at the layer level, this consistency reflects the intrinsic, nested relationship between the two. It also indicates that layer-level and parameter-level interventions affect the model’s predictive capability in a coherent manner.
2. High importance in lower layers and the penultimate layer exception. A notable pattern across all models is that the most important layers tend to be concentrated in the lower (early to middle) layers of the network, with importance values generally decreasing towards higher layers. This pattern suggests that the early layers play a critical role in the overall function of the model.
One plausible explanation, is that lower layers are responsible for capturing general syntactic properties and foundational compositionality (Clark et al., 2019; Hewitt & Manning, 2019), such as basic grammar and phrase structure. In contrast, deeper layers are typically responsible for integrating more task- or context-specific semantic information. This division of labor (earlier layers for generic linguistic structure, deeper layers for task semantics) naturally results in higher sensitivity to interventions at the bottom layers. This also provides a theoretical basis for layer expansion in deep layers.
An interesting exception observed in all models is that the penultimate layer does not follow this general trend: its importance appears elevated relative to immediately adjacent layers. This may stem from the model’s need to consolidate high-level semantic features just before producing the output prediction. The penultimate layer may act as a “bottleneck” for aggregating information necessary for the final decision or token generation—potentially as a final representation refinement step. Similar phenomena have been observed in works such as Intrinsic Dimensionality Explains the Effectiveness of Language Model Pruning (Aghajanyan et al., 2021), which highlight the special role of upper- and penultimate layers in output formation.
3. Intra- and inter-family patterns: Qwen vs. Llama models.
Qwen family: Across the Qwen models (Qwen3-1.7B, 4B, 8B), the overall trends are similar:
- Importance is strongly concentrated in the lower and middle layers, particularly within the first 10 layers, regardless of total model depth.
- Among parameters, mlp.down_proj and mlp.up_proj typically dominate in the most important layers, suggesting that feed-forward (MLP) components contribute substantially to the information processing in the Qwen series.
- With increasing model size (from 1.7B to 8B), the importance distribution appears to spread out slightly, showing less sharpness at the very bottom—possibly reflecting increased capacity and redundancy in larger networks.
Cross-family: Comparing Qwen models to Llama3-8B, we observe both notable similarities and differences:
- Both model families consistently exhibit high importance in MLP-related parameters (mlp.down_proj, mlp.up_proj, and mlp.gate_proj), especially in the most important layers. This underscores the universal role of the feed-forward network in transforming and integrating information beyond the capabilities of self-attention alone.
- Llama3-8B shows a broader distribution of importance across layers, with non-negligible values extending further into the middle and upper layers, suggesting a more distributed processing pipeline. In contrast, Qwen models tend to concentrate importance more in the lower layers.
- The dominance of MLP components in Llama3-8B is somewhat less pronounced than in Qwen, with parameter importance appearing more diffuse overall. These inter-family differences may be attributable to variations in architecture (such as normalization, attention mechanisms, or feed-forward design), pre-training data, or other modeling choices, leading to distinct strategies of information flow and representation across the network depth.
## Appendix E Layer-wise Importance Estimation Methods Comparison
To investigate which layers contribute most to model performance, we employed four different strategies to compute layer-wise importance:
1. Cumulate importance of parameters: For each parameter $p$ in a layer, we compute the product $p\frac{\partial\mathcal{L}}{\partial p}$ , and sum across all parameters in the layer:
$$
I_{\text{layer}}=\sum_{p\in\text{layer}}p\frac{\partial\mathcal{L}}{\partial p} \tag{11}
$$
1. Module-wise rank aggregation: For each module (e.g., attention, MLP, normalization), we calculate the importance score, rank layers by their score within each module, and aggregate rankings to obtain a total rank for each layer.
1. Masking out: For each layer, we mask out its parameters (i.e., set to zero) and evaluate the change in loss:
$$
I_{\text{layer}}=\mathcal{L}(\text{model with layer $l$ masked})-\mathcal{L}(\text{original model}) \tag{12}
$$
1. Fisher information: For each parameter $p$ in a layer, using the Fisher information approximation
$$
F(p)=\mathbb{E}\left[\left(\frac{\partial\log p(y|x)}{\partial p}\right)^{2}\right] \tag{13}
$$
Layer-level Fisher importance is obtained by summing over all parameters in the layer.
To further understand the significance and robustness of these metrics, we conducted a preliminary experiment on the Qwen3-1.7B-Base in the medical domain with dev subset of MMLU, CMMLU to detect the importance of layers, focusing on how different gradient computation strategies affect downstream performance.
Table 8: Performance of different expansion methods on medical-domain tasks (best result in each column is bolded). The numbers in parentheses after each method in the table indicate which layers were expanded. The Qwen3-1.7B-Base model has a total of 28 layers, indexed from 0 to 27.
| Methods Name | mmlu | cmmlu | medqa | cmb | mmcu |
| --- | --- | --- | --- | --- | --- |
| Qwen3-1.7B-Base | 62.57 | 66.86 | 48.39 | 63.67 | 69.17 |
| Uniformly Expansion (6,13,20,27) | 59.06 | 64.98 | 48.78 | 64.25 | 70.10 |
| Uniformly Expansion for first 16 layers (3,7,11,15) | 59.60 | 64.91 | 48.78 | 64.07 | 69.80 |
| Uniformly Expansion for last 16 layers (15,19,23,27) | 61.60 | 66.15 | 49.32 | 65.55 | 71.09 |
| Importance Cumulatation (23,24,25,27) | 62.63 | 66.81 | 50.19 | 63.85 | 69.48 |
| Rank Aggregation (22,24,25,27) | 62.72 | 66.86 | 50.57 | 63.97 | 69.78 |
| Masking Out (22,23,25,27) | 62.80 | 66.89 | 50.75 | 65.43 | 71.98 |
| Fisher (23,24,25,26) | 61.84 | 66.43 | 49.15 | 64.13 | 68.82 |
Table 8 compares the effect of different layer selection methods for expansion on a variety of medical-domain tasks using Qwen3-1.7B-Base. Several key observations can be made:
1. Similarity of selected layers across methods. All importance calculation methods lead to the selection of similar layers for expansion. For instance, the layers chosen by methods such as Importance Cumulatation (23,24,25,27), Rank Aggregation (22,24,25,27), Masking Out (22,23,25,27), and Fisher (23,24,25,26) significantly overlap, especially in the last 6 layers of the model (layers 22 and above). This convergence strongly validates our previous observations that general capability-critical layers tend to be concentrated in the latter half of the model in Appendix D.
In addition, the results show that uniform expansion into the last 16 layers (Uniformly Expansion for last 16 layers (15,19,23,27)) consistently outperforms expansion into the first 16 layers (Uniformly Expansion for first 16 layers (3,7,11,15)) or uniformly across all layers, further supporting the result in Appendix D.
2. Robustness of expansion results across methods. Despite minor variability in the specific layers chosen by each method, the final performance of all importance-based expansion approaches is consistently better than both the vanilla baseline and uniform expansion. For example, on the MedQA dataset, all methods using calculated importance exceed the baseline score (e.g., Masking Out achieves 50.75 vs. baseline 48.39), and on MMLU-med, Rank Aggregation achieves 67.95 versus the baseline 66.49. Crucially, the differences in scores among Masking Out, Rank Aggregation, Importance Cumulatation, and Fisher are relatively small for most tasks (typically less than 2 points), indicating that the overall framework is robust to the choice of importance calculation technique. Since our principal contribution is the training paradigm rather than the specific importance metric, for subsequent experiments, we employ the masking out approach, which demonstrated the strongest effect in preliminary experiment.
## Appendix F Theoretical Analysis
Our theoretical analysis relies on several simplifying assumptions as outlined below. We discuss the rationality and limitations of each assumption:
1. Linearized Model Structure: We model the transformer as a stack of $L$ independent residual blocks, effectively ignoring cross-layer coupling effects such as those arising from pre-norm and residual connections.
Justification: In our layer expansion scheme, the newly added layers are always separated by at least one original frozen layer and never arranged in a cascading manner. This design substantially weakens direct coupling between newly expanded layers, which, in turn, reduces the degree of inter-layer interaction and nonlinearity affecting our analysis. And this abstraction is commonly used in theoretical studies (e.g., NTK analysis or pruning literature) to make layerwise analysis tractable.
1. Loss Function Smoothness: We assume the loss function $\ell(\cdot,\cdot)$ is $\beta$ -smooth and $L_{\infty}$ -Lipschitz with respect to predictions.
Justification: Standard loss functions such as cross-entropy (with stability improvement) and mean squared error are widely established to satisfy these properties. These conditions allow us to relate small output perturbations to controlled changes in loss, facilitating theoretical bounds.
1. Training Dynamics: Our analysis assumes training is performed with a first-order SGD-like optimizer, disregarding effects from Adam or other adaptive methods.
Justification: First-order SGD provides well-understood theoretical properties and is commonly used in theoretical deep learning research. While Adam introduces adaptive scaling that can affect convergence, many results (e.g., generalization gap bounds) transfer qualitatively between SGD and Adam in practice.
1. NTK Regime and Sensitivity: Our analysis of layer sensitivity relies on the NTK (Neural Tangent Kernel) approximation (Jacot et al., 2018), which essentially assumes the model behaves locally linearly around its current parameters. Moreover, we should consider the model training process to be relatively stable, with no anomalous occurrences such as gradient explosion.
Justification: This assumption is particularly well-motivated in our setting for two reasons. First, our adaptation protocol only updates a small number of newly introduced parameters while keeping the vast majority of the pre-trained weights frozen and decouples parameters to maximize the retention of general capabilities. This ensures that the parameter changes remain minimal, keeping the network within the local linear (NTK) regime throughout adaptation. Second, unlike random initialization, our starting point is a well-trained model on a large general-domain corpus, which already provides robust and meaningful representations. Perturbations induced by finetuning are thus intrinsically local in the function space and less likely to induce sudden or nonlinear model behavior, further enhancing the validity of the NTK approximation.
Overall, these assumptions enable us to derive interpretable upper bounds and provide actionable layer selection criteria, but should be considered as idealizations. The correspondence between these theoretical insights and practical behavior is also validated in our empirical experiments.
### F.1 Optimality of Least-Important Block Expansion for Preserving General Capabilities
Notation: Let $M_{0}$ denote the original base model, and $M_{S}^{(T)}$ denote the model after $T$ steps of adaptation, wherein only the set $S$ of $k$ layers are unfrozen and updated, and $\ell(\cdot,y)$ is the loss function (e.g., cross-entropy) which is $L$ -Lipschitz and $\beta$ -smooth in its first argument. $\Delta^{(l)}$ represents the importance score of layer $l$ as defined below.
Layer Importance Score:
$$
\Delta^{(l)}:=\mathbb{E}_{x\sim D_{gen}}\big[\ell(M_{0}^{(-l)}(x),y(x))-\ell(M_{0}(x),y(x))\big]
$$
where $M_{0}^{(-l)}$ is $M_{0}$ with the $l$ -th layer masked out.
**Theorem F.1 (Upper Bound on Generalization Gap by Layer Importance)**
*Let $S\subseteq[L]$ be the set of layers selected for expansion/adaptation, and $G(S)$ denote the source-domain generalization gap after adaptation, i.e.,
$$
G(S):=\mathbb{E}_{x\sim D_{gen}}\left[\ell(M_{S}^{(T)}(x),y(x))-\ell(M_{0}(x),y(x))\right].
$$
Under function-preserving initialization, limited adaptation steps, and $L$ -Lipschitz and $\beta$ -smooth loss, the following upper bound holds:
$$
G(S)\leq C\sum_{l\in S}\Delta^{(l)}+O\left(k(\overline{\Delta W})^{2}\right)
$$
where $C$ is a constant depending on the learning rate, steps, loss smoothness, and initialization, and $\overline{\Delta W}$ is the maximal per-layer parameter change over adaptation.*
* Proof*
Step 1: Output Deviation Linearization. By function-preserving initialization, $M_{S}^{(0)}(x)=M_{0}(x)$ . After adaptation, since only layers in $S$ are modified and changes are small (Assumption A4), the output difference admits a first-order Taylor expansion:
$$
M_{S}^{(T)}(x)-M_{0}(x)\approx\sum_{l\in S}J_{l}(x)\ \Delta W_{l}
$$
where $J_{l}(x)=\left.\frac{\partial M}{\partial W_{l}}\right|_{W=W_{0}}$ and $\Delta W_{l}=W_{l}^{(T)}-W_{l}^{(0)}$ . Step 2: Lipschitz Property Application. By $L$ -Lipschitzness of $\ell(\cdot,y)$ in its first argument,
$$
|\ell(M_{S}^{(T)}(x),y)-\ell(M_{0}(x),y)|\leq L\left\|M_{S}^{(T)}(x)-M_{0}(x)\right\|_{2}.
$$
Taking the expectation over $x\sim D_{gen}$ ,
$$
G(S)\leq L\;\mathbb{E}_{x}\left[\|M_{S}^{(T)}(x)-M_{0}(x)\|_{2}\right].
$$ Step 3: Breaking by Layer via Triangle Inequality. According to Assumption A1 and using the triangle inequality,
$$
\|M_{S}^{(T)}(x)-M_{0}(x)\|_{2}\leq\sum_{l\in S}\|J_{l}(x)\,\Delta W_{l}\|_{2},
$$
thus,
$$
G(S)\leq L\sum_{l\in S}\mathbb{E}_{x}\big[\|J_{l}(x)\,\Delta W_{l}\|_{2}\big].
$$ Step 4: Relating to Layer Importance Score. Recall the definition:
$$
\Delta^{(l)}=\mathbb{E}_{x}\left[\ell(M_{0}^{(-l)}(x),y)-\ell(M_{0}(x),y)\right].
$$
By Taylor expansion and Lipschitz continuity,
$$
|\ell(M_{0}^{(-l)}(x),y)-\ell(M_{0}(x),y)|\approx L\|J_{l}(x)W_{l}^{(0)}\|_{2}, \tag{0}
$$
so for small modifications,
$$
\mathbb{E}_{x}[\|J_{l}(x)\,\Delta W_{l}\|_{2}]\leq\frac{\|\Delta W_{l}\|_{2}}{\|W_{l}^{(0)}\|_{2}}\Delta^{(l)}+O(\|\Delta W_{l}\|_{2}^{2}). \tag{0}
$$
Assume $\|\Delta W_{l}\|_{2}\leq\overline{\Delta W}$ for all $l\in S$ and $\|W_{l}^{(0)}\|_{2}$ are similar or lower-bounded by $w_{0}>0$ , so
$$
G(S)\leq L\frac{\overline{\Delta W}}{w_{0}}\sum_{l\in S}\Delta^{(l)}+O\big(k(\overline{\Delta W})^{2}\big).
$$ Step 5: Optimization Control. In standard SGD (Assumption A3), $\overline{\Delta W}$ is controlled by learning rate $\eta$ , steps $T$ , batch size $N$ , and bounded gradients:
$$
\overline{\Delta W}\lesssim\frac{\eta T}{N}\ \max_{t,i}\|\nabla_{W_{l}}\ell(M_{0}(x_{i}),y_{i})\|_{2}.
$$
Thus, all learning and initialization constants can be absorbed into a scalar constant $C$ (Assumption A3 and A4). Step 6: Conclusion. Thus,
$$
G(S)\leq C\sum_{l\in S}\Delta^{(l)}+O\left(k(\overline{\Delta W})^{2}\right).
$$
which completes the proof. ∎
Due to the use of residual connections, the original block and the expanded block can be viewed as a single aggregated unit. Importantly, before training, the addition of the new block does not alter the model’s output, and thus the overall importance of the aggregated block remains exactly the same as that of the original block (i.e., $\Delta^{(l)}$ ). As a result, when we train the parameters of the new block, it is effectively equivalent to adapting the aggregated block as a whole, whose importance is still characterized by the original importance score $\Delta^{(l)}$ . This justifies why the potential impact of training the expanded layer is governed by the original layer’s importance.
The tightness of the derived upper bound hinges on both the local linearity of the expansion regime and the control over parameter updates during adaptation. In cases where the expansion layers are initialized to be function-preserving and the adaptation is performed with sufficiently small learning rates and moderate step sizes, the Taylor and Lipschitz approximations used in the proof become increasingly sharp. Thus, the upper bound is not only theoretically attainable, but also approaches the realistic generalization gap observed in practice under these conditions. This means that minimizing the sum $\sum_{l\in S}\Delta^{(l)}$ when selecting layers for expansion is not merely a mathematical convenience—it is a principled, actionable strategy for controlling catastrophic forgetting and generalization degradation. As a consequence, our criterion provides practical guidance: by limiting updates to those layers with the lowest importance scores, practitioners can reliably minimize negative transfer from domain adaptation, especially when adapting large pre-trained models with limited new capacity.
### F.2 Optimality of Importance-Based Learning Rate Adjustment for Modules
We provide a rigorous analysis of learning rate reallocation in Stage 2. Specifically, let the importance of each parameter $\theta_{j}$ in the general domain be defined as
$$
I_{\theta_{j}}=\left|\frac{\partial L_{\mathrm{gen}}}{\partial\theta_{j}}\right|
$$
where $L_{\mathrm{gen}}$ denotes the general-domain loss and $I_{\theta_{j}}$ quantifies the sensitivity of the overall performance with respect to $\theta_{j}$ . Under the constraint of a fixed average learning rate, our strategy assigns lower learning rates to parameters with high general-domain importance, and higher learning rates to those deemed less important. This importance-weighted reallocation is provably optimal for minimizing the upper bound of catastrophic forgetting in the general domain, subject to the constant average learning rate constraint. Furthermore, we formulate and analytically solve the underlying constrained optimization problem to ensure that our reallocation approach achieves relative optimality in practice.
Setup and Notation
Let $D_{gen}$ be the general domain distribution with loss $L_{gen}(\theta)$ . With $\theta^{*}$ as the original pre-trained parameters, we define parameter importance $I_{j}\triangleq\theta_{j}\frac{\partial L_{gen}}{\partial\theta_{j}}|_{\theta^{*}}$ and unit importance:
$$
I_{U_{i}}\triangleq\frac{1}{|U_{i}|}\sum_{j\in U_{i}}I_{j}\in[0,1] \tag{14}
$$
under learning rate budget constraint:
$$
\sum_{i}\frac{|U_{i}|}{|\Theta_{\sim}|}lr_{U_{i}}=lr_{base} \tag{15}
$$
#### F.2.1 Upper Bound on Forgetting
Define forgetting as:
$$
F\triangleq L_{gen}(\theta(T))-L_{gen}(\theta^{*}) \tag{16}
$$
Assuming $L_{gen}$ is $\beta$ -smooth, the first-order Taylor expansion provides:
$$
F\leq\nabla_{\theta}L_{gen}(\theta^{*})^{\top}\Delta(T)+\frac{\beta}{2}\|\Delta(T)\|^{2} \tag{17}
$$
Due to parameter freezing, the gradient $\nabla_{\theta}L_{gen}(\theta^{*})$ is only non-zero for expanded parameters:
$$
\nabla_{\theta}L_{gen}(\theta^{*})=\sum_{i}\sum_{j\in U_{i}}I_{j}e_{j} \tag{18}
$$
where $I_{j}=\frac{\partial L_{gen}}{\partial\theta_{j}}$ , $e_{j}$ are basis vectors.
Assuming gradient descent with per-group step size $\eta_{U_{i}}$ and $T$ steps, for each parameter $j\in U_{i}$ (Assumption A4):
$$
\Delta_{j}(T)\approx-T\eta_{U_{i}}\frac{\partial L_{med}}{\partial\theta_{j}} \tag{19}
$$
Substitute into the smoothness bound:
$$
\displaystyle F \displaystyle\leq\sum_{i}\sum_{j\in U_{i}}I_{j}\Delta_{j}(T)+\frac{\beta}{2}\sum_{i}\sum_{j\in U_{i}}(\Delta_{j}(T))^{2} \displaystyle\leq\sum_{i}|U_{i}|\cdot|I_{U_{i}}|\cdot(T\eta_{U_{i}}G)+\frac{\beta}{2}T^{2}\sum_{i}|U_{i}|\eta_{U_{i}}^{2}G^{2} \tag{20}
$$
where $G:=\max_{j}|\frac{\partial L_{med}}{\partial\theta_{j}}|$ upper-bounds the adaptation gradients.
The derived upper bound encompasses all possible learning rate allocations and ensures conservative control over catastrophic forgetting. Note that if group gradients $G$ or importance scores $I_{U_{i}}$ are heterogeneous, a more refined bound can be obtained by analyzing variance rather than worst-case values.
### F.3 Optimal Importance-Driven Learning Rate Reallocation
Problem Statement: We aim to allocate learning rates $\eta_{U_{i}}$ for each parameter group $U_{i}$ so as to minimize the upper bound on forgetting:
$$
F\leq a\sum_{i}w_{i}I_{i}\eta_{U_{i}}+b\sum_{i}w_{i}\eta_{U_{i}}^{2}
$$
where $w_{i}=|U_{i}|$ is the number of parameters in group $U_{i}$ , $I_{i}=|I_{U_{i}}|$ indicates the average importance of parameters in $U_{i}$ , $a,b>0$ are constants determined by training steps, gradient norms, and the smoothness constant ( $\beta$ (Assumption A2)). The constraint is that the average learning rate remains fixed:
$$
\sum_{i}w_{i}\eta_{U_{i}}=W\eta_{avg}
$$
where $W=\sum_{i}w_{i}$ is the total number of trainable parameters.
Lagrangian Formulation: Introduce a Lagrange multiplier $\lambda$ and write the Lagrangian:
$$
\mathcal{L}(\{\eta_{U_{i}}\},\lambda)=a\sum_{i}w_{i}I_{i}\eta_{U_{i}}+b\sum_{i}w_{i}\eta_{U_{i}}^{2}+\lambda\left(\sum_{i}w_{i}\eta_{U_{i}}-W\eta_{avg}\right)
$$
Optimality Condition: Taking derivatives and setting to zero, we obtain for each $j$ :
$$
\frac{\partial\mathcal{L}}{\partial\eta_{U_{j}}}=aw_{j}I_{j}+2bw_{j}\eta_{U_{j}}+\lambda w_{j}=0
$$
$$
\Longrightarrow\eta_{U_{j}}^{*}=-\frac{a}{2b}I_{j}-\frac{\lambda}{2b}
$$
Including the constraint:
$$
\sum_{j}w_{j}\eta_{U_{j}}^{*}=W\eta_{avg}
$$
Plugging in the expression for $\eta_{U_{j}}^{*}$ gives:
$$
-\frac{a}{2b}\sum_{j}w_{j}I_{j}-\frac{\lambda}{2b}W=W\eta_{avg}
$$
Solving for $\lambda$ :
$$
\lambda=-2b\eta_{avg}-\frac{a}{W}\sum_{j}w_{j}I_{j}
$$
So the optimal learning rate for group $U_{j}$ is:
$$
\eta_{U_{j}}^{*}=\eta_{avg}-\frac{a}{2b}\left(I_{j}-\frac{1}{W}\sum_{j^{\prime}}w_{j^{\prime}}I_{j^{\prime}}\right) \tag{22}
$$
Interpretation and Guidance: When the theoretical upper bound is tight—which is often the case in well-controlled, locally linear training regimes—this result has direct practical utility. Notably, the optimal learning rate allocation $\eta_{U_{j}}^{*}$ is an affine (linear) function of the group importance $I_{j}$ . Our method, which assigns $\text{lr}_{U}=2\cdot(1-I_{\text{unit}})\cdot\text{lr}_{\text{base}}$ , can be viewed as a simplified implementation of the derived optimal form. By decreasing the learning rate for groups with high general-domain importance and increasing it for those with low importance, this strategy effectively minimizes the risk of catastrophic forgetting while respecting the global learning rate constraint. Thus, our approach provides actionable guidance for tailoring learning rates based on parameter importance in continual learning and domain adaptation.
## Appendix G Experiment about the number of expanded layers
In Stage 1, determining the optimal number of expanded layers emerges as a crucial hyperparameter. To investigate this, we conducted systematic experiments across various model scales in the medical domain by expanding different numbers of layers. These comprehensive experiments aim to provide empirical insights into selecting the most effective layer expansion strategy, offering valuable guidance for future research in this direction.
Table 9: Comparative Performance of Different Layer Expansion Strategies across Model Scales and Medical Tasks. Bold indicates the best-performing setup for each task; underline shows the second-best. This highlights optimal and near-optimal choices for each scenario.
| Model | MMLU | CMMLU | MedQA | MMCU-Medical | CMB |
| --- | --- | --- | --- | --- | --- |
| Qwen3-1.7B | | | | | |
| Vanilla | 62.57 | 66.86 | 48.39 | 69.17 | 63.67 |
| 1-layer | 62.31 | 66.23 | 48.08 | 69.95 | 61.40 |
| 2-layer | 62.48 | 66.91 | 48.63 | 70.78 | 62.89 |
| 4-layer | 62.80 | 66.89 | 50.75 | 71.98 | 65.43 |
| 8-layer | 61.84 | 66.02 | 49.57 | 72.41 | 65.00 |
| 16-layer | 60.96 | 64.65 | 48.86 | 70.13 | 64.88 |
| Qwen3-4B | | | | | |
| Vanilla | 73.19 | 77.92 | 62.77 | 82.44 | 78.92 |
| 1-layer | 72.98 | 77.69 | 63.39 | 82.83 | 78.21 |
| 2-layer | 73.10 | 77.84 | 63.08 | 82.80 | 78.48 |
| 4-layer | 72.95 | 78.77 | 64.49 | 84.58 | 79.87 |
| 8-layer | 73.06 | 77.65 | 65.02 | 84.22 | 78.81 |
| 16-layer | 72.06 | 77.11 | 62.61 | 82.09 | 78.61 |
| Qwen3-8B | | | | | |
| Vanilla | 76.94 | 82.09 | 66.30 | 86.45 | 81.67 |
| 1-layer | 76.84 | 82.06 | 67.87 | 86.95 | 81.50 |
| 2-layer | 76.70 | 82.10 | 67.93 | 87.99 | 82.90 |
| 4-layer | 76.77 | 82.11 | 69.24 | 89.84 | 85.80 |
| 8-layer | 76.77 | 82.15 | 68.34 | 88.02 | 84.85 |
| 16-layer | 77.12 | 82.28 | 68.56 | 87.76 | 84.32 |
| LLaMA3-8B | | | | | |
| Vanilla | 65.33 | 50.83 | 58.91 | 46.29 | 35.61 |
| 1-layer | 65.29 | 51.12 | 58.97 | 50.83 | 40.45 |
| 2-layer | 65.61 | 50.98 | 59.56 | 55.92 | 47.83 |
| 4-layer | 65.25 | 51.73 | 60.82 | 63.17 | 54.65 |
| 8-layer | 65.17 | 51.92 | 61.17 | 67.03 | 61.78 |
| 16-layer | 65.12 | 52.45 | 61.92 | 70.86 | 65.31 |
For general language tasks such as MMLU and CMMLU, all models largely preserve their baseline performance regardless of the number of expanded layers. This indicates that layer expansion does not compromise the models’ general language capabilities and robustness.
However, for domain-specific medical tasks (MedQA, MMCU-Medical, and CMB), the impact of layer expansion is more pronounced. Across all Qwen model variants (1.7B, 4B, and 8B), expanding 4 layers consistently yields optimal performance, as shown by the bolded results in Table 9. Specifically, the Qwen3-1.7B, 4B, and 8B models improve on MMCU-Medical by up to 2.8%, 2.1%, and 3.4%, respectively, when increasing from baseline to 4-layer expansion. Notably, expanding beyond 4 layers (e.g., to 8 or 16 layers) does not systematically improve performance—and in several cases, results in diminishing or even degraded accuracy. This suggests that moderate layer expansion (4 layers) achieves a balance between performance gain and model stability, while excessive expansion may introduce optimization difficulties, overfitting, or disrupt the pre-trained knowledge representations, leading to suboptimal outcomes.
In contrast, the LLaMA3-8B model displays a unique trend: performance improvements are continuous as more layers are expanded, with the best results observed at expanding 16 layers. The gains are considerable for tasks like MMCU-Medical and CMB, where scores rise dramatically from 46.29% and 35.61% in the vanilla model to 70.86% and 65.31% with 16 expanded layers. This behavior contrasts with the Qwen models and is likely due to LLaMA’s more limited Chinese capability in its original configuration. The need for extensive architectural expansion reflects the necessity to build new, specialized representations to compensate for baseline deficiencies when addressing Chinese-centric tasks. Therefore, while moderate layer expansion is optimal for models pre-trained on Chinese data (Qwen), more substantial expansion may be required for models less adapted to the target language or domain (LLaMA).
Overall, these results indicate that expanding more layers does not guarantee better performance. For well-aligned models, excessive expansion may lead to interference with the original knowledge or cause optimization instability. In contrast, for models lacking target domain competence, increased expansion helps establish the missing representations, albeit at the cost of greater computational complexity.
## Appendix H Take Pretrain data as Importance Source
Our previous experiments employed the dev sets of MMLU and CMMLU as benchmark datasets for gradient-based importance estimation. However, such high-quality and carefully curated benchmarks are often scarce, especially in practical industrial scenarios. To investigate the robustness of our ADEPT method under more realistic conditions where benchmark data may not be available, we explore the use of noisier pretraining data for importance estimation.
Table 10: General Competence Detection Pretrain Corpus. #Examples means the number of examples we used.
| Dataset | #Examples | Hugging Face Link |
| --- | --- | --- |
| FineWeb_Edu | 500 | HuggingFaceFW/fineweb-edu |
| FineWeb_Edu_Chinese V2.1 | 500 | HuggingFaceFW/fineweb-edu |
Specifically, we utilize the FineWebEdu and FineWebEdu-Chinese datasets (Data overview and links in Table 10), extracting the top 500 samples with the highest educational scores from the first 10,000 entries in each corpus to serve as our importance estimation set. Compared to curated benchmarks, these datasets are much more accessible in real-world applications. Furthermore, the computational cost for filtering out such high-quality samples is negligible relative to the overall cost of large-scale pretraining.
This experimental setting allows us to rigorously evaluate the robustness of ADEPT when real-world, easily accessible pretraining data replaces ideal benchmark datasets for importance-based layer expansion decisions.
Table 11: Performance comparison of ADEPT with benchmark-based and pretraining-data-based importance estimation across model scales. Bold indicates the best performance per column; underline marks the second-best.
| Model | MMLU | CMMLU | MedQA | MMCU-Medical | CMB |
| --- | --- | --- | --- | --- | --- |
| Qwen3-1.7B | | | | | |
| Vanilla | 62.57 | 66.86 | 48.39 | 69.17 | 63.67 |
| ADEPT (Benchmark) | 62.80 | 66.89 | 50.75 | 71.98 | 65.43 |
| ADEPT (PT Data) | 62.85 | 66.87 | 49.39 | 70.84 | 63.07 |
| Qwen3-4B | | | | | |
| Vanilla | 73.19 | 77.92 | 62.77 | 82.44 | 78.92 |
| ADEPT (Benchmark) | 72.95 | 78.77 | 64.49 | 84.58 | 79.87 |
| ADEPT (PT Data) | 73.14 | 77.96 | 63.94 | 83.34 | 79.62 |
| Qwen3-8B | | | | | |
| Vanilla | 76.94 | 82.09 | 66.30 | 86.45 | 81.67 |
| ADEPT (Benchmark) | 76.77 | 82.11 | 69.24 | 89.84 | 85.80 |
| ADEPT (PT Data) | 76.83 | 82.20 | 67.56 | 87.20 | 83.92 |
| LLaMA3-8B | | | | | |
| Vanilla | 65.33 | 50.83 | 58.91 | 46.29 | 35.61 |
| ADEPT (Benchmark) | 65.25 | 51.73 | 60.82 | 63.17 | 54.65 |
| ADEPT (PT Data) | 65.21 | 50.27 | 59.13 | 60.29 | 51.32 |
Table 11 summarizes the performance of our ADEPT method when the importance estimation is conducted with either high-quality benchmark data or more easily accessible pretraining data across different model scales. Overall, the results demonstrate that ADEPT not only consistently outperforms the vanilla baseline but also shows remarkable robustness across most scenarios when using pretraining data for importance calculation. In Qwen3 series models, the difference between benchmark-based and pretraining-data-based importance estimation is minimal. In several cases, the latter even slightly surpasses the benchmark version (e.g., Qwen3-1.7B on MMLU and Qwen3-8B on MMLU and CMMLU), validating the practical applicability and flexibility of our approach.
For LLaMA3-8B, ADEPT with pretraining data still yields clear improvements over the vanilla baseline on all tasks, particularly in domain-specific metrics such as MedQA and MMCU-Medical. However, compared to the benchmark-based ADEPT, the pretraining-data variant shows slightly lower performance, with a gap of approximately 1–5% across tasks. This modest drop can be attributed to two main factors: first, the inherent discrepancy between noisier pretraining data and expertly curated benchmarks introduces less precise gradient signals for importance estimation. Second, LLaMA3-8B’s weaker baseline in Chinese tasks means its optimization is more sensitive to the quality of importance source, and benefits more from highly targeted benchmark data. Nonetheless, even with this gap, the pretraining-data approach remains highly valid, especially in practical scenarios where access to dedicated benchmarks is limited.
In summary, ADEPT demonstrates strong effectiveness and robustness when layer expansion is guided by pretraining data, making it highly suitable for real-world deployment. The slight performance drop observed in LLaMA3-8B highlights the additional value of benchmark data for models or tasks with substantial baseline limitations, but does not diminish the overall utility of our method in resource-constrained settings.
## Appendix I Token Distribution Shift
Following the methodology proposed by Lin et al. (2024), we conducted a comprehensive analysis of token distribution shifts between the base and aligned models using the MMLU (Massive Multitask Language Understanding) dataset. The analysis focuses on identifying and quantifying the changes in token prediction patterns that occur during the alignment process.
Our analysis procedure consists of the following steps:
1) For each position in the input text, we use the aligned model with greedy decoding to generate the output token $o_{t}$ .
2) We then examine how this token is ranked in the base model’s probability distribution $P_{base}$ . This ranking, denoted as $\eta$ , serves as our primary metric for categorizing token shifts.
3) Based on the base ranking $\eta$ , we classify each token position into three categories:
- Unshifted positions ( $\eta=1$ ): The token is top-ranked in both base and aligned models
- Marginal positions ( $1<\eta\leq 3$ ): The token has a relatively high probability in the base model
- Shifted positions ( $\eta>3$ ): The token is unlikely to be sampled by the base model
4) For shifted tokens, we calculate Rank Improvement Ratio: $\frac{\text{base\_rank}}{\text{aligned\_rank}}$
Our analysis of the MMLU dataset revealed significant distribution shifts between the base and continual pretrained models by ADEPT. Figure 14 visualizes the most significantly shifted tokens, where the size of each token is proportional to its rank improvement ratio.
<details>
<summary>figures/wordcloud_med.jpg Details</summary>

### Visual Description
## Word Cloud: Health and Medical Themes
### Overview
The image is a word cloud composed of health-related terms in varying colors and sizes. Words are arranged in a non-linear, overlapping pattern, with larger text indicating higher prominence or frequency. Colors appear to categorize terms (e.g., green for diseases, blue for treatments), though no explicit legend is present.
### Components/Axes
- **Text Elements**: All words are health/medical terms (e.g., "cancer," "treatment," "hospital," "symptoms").
- **Color Coding**: Terms are color-coded, likely by category (e.g., green for diseases, blue for treatments, yellow for institutions). No legend is visible to confirm this.
- **Size Hierarchy**: Larger words (e.g., "health," "patient") dominate the center, while smaller words (e.g., "FDA," "vaccine") are peripheral.
### Detailed Analysis
- **Prominent Terms**:
- **Largest**: "health" (green), "patient" (blue), "hospital" (green), "disease" (green), "symptoms" (purple).
- **Medium**: "cancer" (green), "treatment" (purple), "diabetes" (blue), "medication" (purple), "prescription" (purple).
- **Smallest**: "FDA" (blue), "vaccine" (blue), "addiction" (purple), "photograph" (green).
- **Color Distribution**:
- Green: Dominates (e.g., "cancer," "hospital," "disease").
- Blue: Treatments/institutions (e.g., "therapy," "MD," "CDC").
- Purple: Research/methods (e.g., "randomized," "clinical trials").
- Yellow: Miscellaneous (e.g., "protein," "MRI").
### Key Observations
1. **Frequency Indicators**:
- "health" and "patient" are the most prominent, suggesting central themes.
- "cancer" and "diabetes" are large, indicating high relevance in health discussions.
2. **Color Grouping**:
- Green terms cluster around diseases and institutions.
- Purple terms relate to research and clinical processes.
3. **Ambiguities**:
- No explicit legend to confirm color categories.
- Overlapping words obscure exact counts; sizes are approximate.
### Interpretation
The word cloud emphasizes **healthcare systems** (hospitals, patients) and **diseases** (cancer, diabetes) as dominant themes. Terms like "randomized," "clinical trials," and "researchers" suggest a focus on medical research. Color coding implies categorization, but without a legend, interpretations are speculative. The absence of terms like "vaccine" or "pandemic" may reflect the image's focus on chronic conditions over acute public health crises. The prominence of "symptoms" and "diagnosis" highlights patient-centered care, while "therapy" and "prescription" underscore treatment pathways.
</details>
Figure 14: Word cloud visualization of shifted tokens. The size of each token represents its rank improvement ratio ( $\frac{\text{base\_rank}}{\text{aligned\_rank}}$ ), indicating the magnitude of distributional shift during alignment. Larger tokens indicate more significant shifts in the model’s prediction patterns.
Our analysis of the MMLU dataset revealed significant and efficient distribution shifts between the base and aligned models. Figure 14 visualizes the most significantly shifted tokens, where the size of each token is proportional to its rank improvement ratio.
The analysis revealed a notably efficient token distribution shift pattern. Specifically, only 2.18% of tokens underwent significant shifts (compared to 5.61% in full pretraining), with 88.78% remaining unshifted and 9.04% showing marginal changes (Totally 645496 tokens analyzed). This represents a more focused and efficient alignment compared to full pretraining scenarios, which typically show higher shift percentages (unshifted: 75.59%, marginal: 18.80%, shifted: 5.61%).
Most remarkably, the shifted tokens demonstrate a clear concentration in medical terminology and medicine-related concepts. Key examples include: ”prescription”, ”diagnosis”, ”symptoms”, ”diabetes”, ”arthritis”, ”tumor”, ”MRI”, ”therapy”, ”treatment”, ”hospital”, ”care”, ”patients”.
This specialized distribution stands in stark contrast to the more general token shifts observed in full pretraining, where top shifted tokens (such as <|im_end|>, ”CIF”, ”Registered”, ”progression”, ”median”) show no particular domain focus and more noise. This comparison suggests that ADEPT achieved a more targeted and efficient knowledge injection, specifically enhancing the model’s medical domain expertise while maintaining stability in other areas. The lower percentage of shifted tokens (2.18% vs 5.61%) combined with their high domain relevance indicates a more precise and economical alignment process that effectively injects medical knowledge without unnecessary perturbation of the model’s general language capabilities.
These findings suggest that domain-specific alignment can be achieved with minimal token distribution disruption while maintaining high effectiveness in knowledge injection. This efficiency in token shifting demonstrates the potential for targeted domain adaptation without the broader distributional changes typically seen in full pretraining scenarios.
Similarly, in mathematical domain alignment (Figure 15), we observed an even more efficient token distribution shift. The analysis shows only 1.24% of tokens underwent significant shifts, with 91.51% remaining unshifted and 7.25% showing marginal changes. This represents an even more concentrated alignment compared to full pretraining (unshifted: 85.45%, marginal: 10.18%, shifted: 4.37%).
The shifted tokens clearly reflect mathematical and scientific terminology, as evidenced by terms such as ”theorem”, ”quantum”, ”parameters”, ”physics”, and ”equation”. This highly focused shift pattern, utilizing merely one-third of the token shifts compared to full pretraining (1.24% vs 4.37%), demonstrates the effectiveness of our approach in precisely targeting mathematical knowledge injection while maintaining model stability in other domains.
<details>
<summary>figures/wordcloud_math.jpg Details</summary>

### Visual Description
## Word Cloud: Academic and Technical Themes
### Overview
The image is a word cloud composed of technical and academic terminology, with words varying in size and color. No explicit axes, legends, or numerical data are present. The layout is unstructured, with words overlapping and positioned randomly.
### Components/Axes
- **No axes or scales**: The image lacks numerical axes or quantitative markers.
- **Legend**: Absent. Color variations (purple, green, yellow, blue) are present but not explicitly labeled.
- **Text elements**: Words are the sole content, with no additional annotations or labels.
### Detailed Analysis
- **Word sizes**: Larger words (e.g., "quantum," "algorithm," "paper") likely indicate higher frequency or prominence in the source dataset.
- **Color distribution**:
- **Purple**: Dominates the cloud (e.g., "effects," "quantum," "students").
- **Green**: Includes terms like "space," "physics," "results."
- **Yellow**: Words such as "mathematic," "model," "previous."
- **Blue**: Terms like "bit," "connected," "parameters."
- **Notable words**:
- Technical: "quantum," "physics," "algorithm," "code."
- Academic: "paper," "students," "theorem."
- Collaborative: "paper," "editor," "results."
- Miscellaneous: "Oct," "FT," "error," "profit."
### Key Observations
1. **Dominant themes**: Academic research ("quantum," "physics"), technology ("algorithm," "code"), and collaboration ("paper," "students").
2. **Color clustering**: Purple and green dominate, suggesting these categories may represent core themes.
3. **Ambiguity**: No legend or metadata to confirm categories or frequencies. Overlapping words (e.g., "Oct," "FT") reduce readability.
### Interpretation
The word cloud likely visualizes a corpus of academic or technical documents, with larger words reflecting higher occurrence rates. The absence of a legend limits precise categorization, but color coding may imply groupings (e.g., purple for foundational concepts, green for applied fields). Terms like "quantum" and "algorithm" suggest a focus on advanced STEM topics, while "paper" and "students" hint at academic publishing or educational contexts. The lack of structured data prevents quantitative analysis, but the prominence of certain terms underscores their relevance in the source material.
</details>
Figure 15: Word cloud visualization of shifted tokens in mathematical domain alignment. The predominance of mathematical and scientific terminology demonstrates the precise targeting of domain-specific knowledge.
## Appendix J Linear Merge of Domain-Specific Extensions: Results and Insights
Table 12: Performance comparison of Vanilla and Merged Models on multiple benchmarks (Qwen3-1.7B and Qwen3-4B).
| | MMLU | CMMLU | GSM8K | ARC-E | ARC-C | MedQA | MMCU | CMB |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Qwen3-1.7B | | | | | | | | |
| Vanilla | 62.57 | 66.86 | 57.62 | 81.44 | 51.19 | 48.39 | 69.17 | 63.67 |
| Merged Model | 62.70 | 65.83 | 60.80 | 81.06 | 51.94 | 48.39 | 68.61 | 64.83 |
| Qwen3-4B | | | | | | | | |
| Vanilla | 73.19 | 77.92 | 69.07 | 85.52 | 59.13 | 62.77 | 82.44 | 78.92 |
| Merged Model | 72.96 | 77.99 | 73.16 | 85.27 | 58.96 | 62.83 | 82.83 | 78.42 |
In Table 12, we compare the performance of the Vanilla model and the Merged Model, which was constructed by linearly merging the domain-specific extension layers (with equal weights of 0.5 for medical and mathematical domains) after independent training. Our results show that the merged model does not exhibit any significant collapse, and in some indicators even surpasses the original base model. For example, on the GSM8K benchmark for Qwen3-1.7B, the merged model achieves 60.80%, compared to 57.62% for the vanilla model. This demonstrates the generalization and extensibility of our method, enabling fusion across multiple vertical domains.
Our extension approach ensures that each newly added layer is separated by at least one original frozen layer, rather than being directly adjacent. This design leads to greater stability during model merging. On one hand, if the merged models were purely cascaded, the non-linear transformations introduced could lead to more unpredictable interactions between layers. On the other hand, because each layer operates within a consistent contextual environment provided by surrounding frozen layers during continual pre-training, we believe that this fixed hierarchical structure imposes constraints that make the semantic representations learned by the new layers more aligned in certain dimensions. As a result, the merging process becomes more reliable and beneficial to overall model performance.
It is worth noting that our merging strategy adopts the simplest possible weighted average. The specific merging algorithm is not the focus of this work; we believe that with more scientific weighting schemes, even better results can be obtained. Here, we hope to stimulate further research and provide preliminary insights based on our observations.
## Appendix K Use of LLM
In the preparation of this article, we utilized large language models (LLM) solely for writing assistance purposes. Specifically, we employed the GPT-4.1-0414 model to polish language expressions, condense sentences, and improve the overall clarity and readability of the text. The model was used exclusively for editing and refining manuscript language and did not participate in any conceptual or technical aspects of this work.
All research ideas, theoretical proof methods, experimental designs, and visualizations were conceived, executed, and finalized by the authors without the involvement of any LLM tools. The development of new concepts, formulation and validation of proofs, experimental setups, analysis of results, and the creation of figures were performed independently by the research team. At no point was the LLM model used to generate, modify, or validate the scientific content, methodology, or results presented in this article.
We emphasize that the role of GPT-4.1-0414 in this research was strictly limited to linguistic enhancement at the writing stage, and that all substantive intellectual and scientific contributions originate solely from the authors.
## Appendix L Algorithm
Algorithm 1 ADEPT
1: Pretrained LLM $M_{0}$ with layers $\{\Theta^{(1)},\dots,\Theta^{(L)}\}$ , domain probing corpus $\mathcal{D}_{\text{probe}}$ , continual pretraining corpus $\mathcal{D}_{\text{train}}$ , number of layers to expand $k$ , base learning rate $\text{lr}_{\text{base}}$ , update interval $T_{\text{update}}$
2: # Stage 1: General-Competence Guided Selective Layer Expansion
3: Compute base loss $\mathcal{L}_{\text{base}}\leftarrow\frac{1}{|\mathcal{D}_{\text{probe}}|}\sum_{x}\ell(M_{0}(x),x)$
4: for $l\leftarrow 1$ to $L$ do
5: Temporarily mask layer $l$ to get $M_{0}^{(-l)}$
6: Compute masked loss $\hat{\mathcal{L}}^{(l)}\leftarrow\frac{1}{|\mathcal{D}_{\text{probe}}|}\sum_{x}\ell(M_{0}^{(-l)}(x),x)$
7: Compute importance score $\Delta^{(l)}\leftarrow\hat{\mathcal{L}}^{(l)}-\mathcal{L}_{\text{base}}$
8: end for
9: Select $k$ least-important layers $\mathcal{S}_{k}\leftarrow\text{LowestK}(\{\Delta^{(l)}\})$
10: for each $l\in\mathcal{S}_{k}$ do
11: Duplicate parameters $\tilde{\Theta}^{(l)}\leftarrow\Theta^{(l)}$ $\triangleright$ Identity copy
12: Initialize $W_{\text{MHSA}}^{\text{out}}=0$ , $W_{\text{FFN}}^{\text{out}}=0$ $\triangleright$ Function Preserving Init
13: Freeze original $\Theta^{(l)}$ , mark $\tilde{\Theta}^{(l)}$ as trainable
14: end for
15: # Stage 2: Adaptive Unit-Wise Decoupled Tuning
16: for each training step $t$ do
17: if $t\mod T_{\text{update}}==0$ then
18: for each expanded layer $\tilde{\Theta}^{(l)}$ do
19: Partition into semantic units $\{U_{1},\dots,U_{n}\}$
20: for each unit $U_{i}$ do
21: Compute gradient-based importance $I_{U_{i}}\leftarrow\frac{1}{|U_{i}|}\sum_{j\in U_{i}}\theta_{j}\cdot\nabla_{\theta_{j}}\mathcal{L}$
22: Assign adaptive learning rate $\text{lr}_{U_{i}}\leftarrow 2\cdot(1-I_{U_{i}})\cdot\text{lr}_{\text{base}}$
23: end for
24: end for
25: end if
26: Sample training sequence $x=(x_{1},x_{2},\dots,x_{T})\sim\mathcal{D}_{\text{train}}$
27: Compute autoregressive loss:
28: $\mathcal{L}=-\sum_{t=1}^{T}\log P(x_{t}\mid x_{<t};\Theta)$
29: Update parameters $\{\tilde{\Theta}^{(l)}\}$ using adaptive learning rates $\{\text{lr}_{U_{i}}\}$
30: end for