# Self-Verifying Reflection Helps Transformers with CoT Reasoning
## Abstract
Advanced large language models (LLMs) frequently reflect in reasoning chain-of-thoughts (CoTs), where they self-verify the correctness of current solutions and explore alternatives. However, given recent findings that LLMs detect limited errors in CoTs, how reflection contributes to empirical improvements remains unclear. To analyze this issue, in this paper, we present a minimalistic reasoning framework to support basic self-verifying reflection for small transformers without natural language, which ensures analytic clarity and reduces the cost of comprehensive experiments. Theoretically, we prove that self-verifying reflection guarantees improvements if verification errors are properly bounded. Experimentally, we show that tiny transformers, with only a few million parameters, benefit from self-verification in both training and reflective execution, reaching remarkable LLM-level performance in integer multiplication and Sudoku. Similar to LLM results, we find that reinforcement learning (RL) improves in-distribution performance and incentivizes frequent reflection for tiny transformers, yet RL mainly optimizes shallow statistical patterns without faithfully reducing verification errors. In conclusion, integrating generative transformers with discriminative verification inherently facilitates CoT reasoning, regardless of scaling and natural language.
## 1 Introduction
Numerous studies have explored the ability of large language models (LLMs) to reason through a chain of thought (CoT), an intermediate sequence leading to the final answer. While simple prompts can elicit CoT reasoning [13], subsequent works have further enhanced CoT quality through reflective thinking [10] and the use of verifiers [4]. Recently, reinforcement learning (RL) [33] has achieved notable success in advanced reasoning models, such as OpenAI-o1 [20] and Deepseek-R1 [5], which show frequent reflective behaviors that self-verify the correctness of current solutions and explore alternatives, integrating generative processes with discriminative inference. However, researchers also report that the ability of these LLMs to detect errors is rather limited, and a large portion of reflection fails to bring correct solutions [11]. Given the weak verification ability, the experimental benefits of reflection and the emergence of high reflection frequency in RL require further explanation.
To address this challenge, we seek to analyze two main questions in this paper: 1) what role self-verifying reflection plays in training and execution of reasoning models, and 2) how reflective reasoning evolves in RL with verifiable outcome rewards [15]. However, the complexity of natural language and the prohibitive training cost of LLMs make it difficult to draw clear conclusions from theoretical abstraction and comprehensive experiments across settings. Inspired by Zeyuan et al. [2], we observe that task-specific reasoning and self-verifying reflection do not necessitate complex language. This allows us to investigate reflective reasoning through tiny transformer models [36], which provide efficient tools to understand self-verifying reflection through massive experiments.
To enable tiny transformers to produce long reflective CoTs and ensure analytic simplicity, we introduce a minimalistic reasoning framework, which supports essential reasoning behaviors that are operable without natural language. In our study, the model self-verifies the correctness of each thought step; then, it may resample incorrect steps or trace back to previous steps. Based on this framework, we theoretically prove that self-verifying reflection improves reasoning accuracy if verification errors are properly bounded, which does not necessitate a strong verifier. Additionally, a trace-back mechanism that allows revisiting previous solutions conditionally improves performance if the problem requires a sufficiently large number of steps.
Our experiments evaluate 1M, 4M, and 16M transformers in solving integer multiplication [7] and Sudoku puzzles [3], which have simple definitions (thus, operable by transformers without language) yet still challenging for even LLM solvers. To maintain relevance to broader LLM research, the tiny transformers are trained from scratch through a pipeline similar to that of training LLM reasoners. Our main findings are listed as follows: 1) Learning to self-verify greatly facilitates the learning of forward reasoning. 2) Reflection improves reasoning accuracy if true correct steps are not excessively verified as incorrect. 3) Resembling the results of DeepSeek-R1 [5], RL can incentivize reflection if the reasoner can effectively explore potential solutions. 4) However, RL fine-tuning increases performance mainly statistically, with limited improvements in generalizable problem-solving skills.
Overall, this paper contributes to the fundamental understanding of reflection in reasoning models by clarifying its effectiveness and synergy with RL. Our findings based on minimal reasoners imply a general benefit of reflection for more advanced models, which operate on a super-set of our simplified reasoning behaviors. In addition, our implementation also provides insights into the development of computationally efficient reasoning models.
## 2 Related works
CoT reasoning
Pretrained LLMs emerge the ability to produce CoTs from simple prompts [13, 38], which can be explained via the local dependencies [25] and probabilistic distribution [35] of natural-language reasoning. Many recent studies develop models targeted at reasoning, e.g., scaling test-time inference with external verifiers [4, 17, 18, 32] and distilling large general models to smaller specialized models [34, 9]. In this paper, we train tiny transformers from scratch to not only generate CoTs but also self-verify, i.e., detect errors in their own thoughts without external models.
RL fine-tuning for CoT reasoning
RL [33] recently emerges as a key method for CoT reasoning [31, 40]. It optimizes the transformer model by favoring CoTs that yield high cumulated rewards, where PPO [29] and its variant GRPO [31] are two representative approaches. Central to RL fine-tuning are reward models that guide policy optimization: the 1) outcome reward models (ORM) assessing final answers, and the 2) process reward models (PRM) [17] evaluating intermediate reasoning steps. Recent advances in RL with verifiable rewards (RLVR) [5, 41] demonstrate that simple ORM based solely on answer correctness can induce sophisticated reasoning behaviors.
Reflection in LLM reasoning
LLM reflection provides feedback to the generated solutions [19] and may accordingly refine the solutions [10]. Research shows that supervised learning from verbal reflection improves performance, even though the reflective feedback is omitted during execution [42]. Compared to the generative verbal reflection, self-verification uses discriminative labels to indicate the correctness of reasoning steps, which supports reflective execution and is operable without linguistic knowledge. Recently, RL is widely used to develop strong reflective abilities [14, 27, 20]. In particular, DeepSeek-R1 [5] shows that RLVR elicits frequent reflection, and such a result is reproduced in smaller LLMs [24]. In this paper, we further investigate how reflection evolves during RLVR by examining the change of verification errors.
Understanding LLMs through small transformers
Small transformers are helpful tools to understand LLMs, for their architectural consistency with LLMs and low development cost to support massive experiments. For example, transformers smaller than 1B provide insights into how data mixture and data diversity influence LLM training [39, 2]. They also contribute to foundational understanding of CoT reasoning, such as length generalization [12], internalization of thoughts [6], and how CoTs inherently extend the problem-solving ability [8, 16]. In this paper, we further use tiny transformers to better understand reflection in CoT reasoning.
## 3 Reflective reasoning for transformers
In this section, we develop transformers to perform simple reflective reasoning in long CoTs. Focusing on analytic clarity and broader implications, the design of our framework follows the minimalistic principle, providing only essential reasoning behavior operable without linguistic knowledge. More advanced reasoning frameworks optimized for small-scale models are certainly our next move in future work. In the following, we first introduce the basic formulation of CoT reasoning; then, based on this formulation, we introduce our simple reasoning framework for self-verifying reflection; afterwards, we describe how transformers are trained to reason through this framework.
### 3.1 Reasoning formulation
<details>
<summary>x1.png Details</summary>

### Visual Description
## Diagram: Sequential Reasoning Process with State Transitions
### Overview
The image displays a technical flowchart illustrating a sequential reasoning process. It depicts a model that progresses through a series of discrete reasoning steps, transitioning from an initial query to a final answer. The diagram is structured in three horizontal rows: a header row with labels, a central flowchart row, and a footer row with corresponding state transition equations.
### Components/Axes
The diagram is organized into three distinct rows:
1. **Header Row (Top):**
* **Left Label:** "Model"
* **Center Label:** "Reasoning Steps"
* **Right Label:** "A" (This appears to be a label for the final output box, not a separate header).
2. **Main Flowchart Row (Center):**
* **Components:** A sequence of rectangular boxes connected by right-pointing arrows.
* **Box Labels (from left to right):**
* `Q` (Initial Query, shaded gray)
* `R₁` (First Reasoning Step)
* `R₂` (Second Reasoning Step)
* `...` (Ellipsis indicating intermediate steps)
* `R_{T-1}` (Penultimate Reasoning Step)
* `A` (Final Answer, shaded gray)
* **Arrow Annotations:** Above each arrow connecting the boxes, there is a mathematical expression describing the action taken at that step.
* Above arrow from `Q` to `R₁`: `R₁ ~ π(·|S₀)`
* Above arrow from `R₁` to `R₂`: `R₂ ~ π(·|S₁)`
* Above arrow from `R_{T-1}` to `A`: `A ~ π(·|S_{T-1})`
3. **Footer Row (Bottom):**
* **Left Label:** "State Transition"
* **Equations (aligned below each box in the main row):**
* Below `Q`: `S₀ = Q`
* Below `R₁`: `S₁ = T(S₀, R₁)`
* Below `R₂`: `S₂ = T(S₁, R₂)`
* Below `...`: `...`
* Below `R_{T-1}`: `S_{T-1} = T(S_{T-2}, R_{T-1})`
* Below `A`: `S_T = T(S_{T-1}, A)`
### Detailed Analysis
The diagram formalizes a step-by-step reasoning or decision-making process:
1. **Initialization:** The process begins with an initial state `S₀`, which is defined as the input query `Q`.
2. **Iterative Reasoning:** For each step `t` from 1 to `T-1`:
* A reasoning action `R_t` is sampled from a policy `π` conditioned on the current state `S_{t-1}`. This is denoted as `R_t ~ π(·|S_{t-1})`.
* The state is then updated via a transition function `T` using the previous state and the chosen action: `S_t = T(S_{t-1}, R_t)`.
3. **Termination:** The process concludes when a final action, the answer `A`, is sampled from the policy conditioned on the penultimate state: `A ~ π(·|S_{T-1})`.
4. **Final State:** The terminal state `S_T` is computed by applying the transition function to the penultimate state and the final answer: `S_T = T(S_{T-1}, A)`.
The flow is strictly linear and sequential, moving from left to right. The ellipsis (`...`) indicates that the number of intermediate reasoning steps (`R₂` through `R_{T-2}`) is variable.
### Key Observations
* **Dual Notation:** The process is described using two parallel notations: a visual flowchart of actions (`Q -> R₁ -> R₂ -> ... -> A`) and a formal mathematical sequence of state updates (`S₀ -> S₁ -> S₂ -> ... -> S_T`).
* **Policy-Driven Actions:** Each action (reasoning step `R_t` or final answer `A`) is generated stochastically (`~`) from a policy distribution `π`, which depends on the current state.
* **State as Memory:** The state `S_t` encapsulates all information necessary for the next decision, acting as the process's memory. It is updated deterministically by the function `T`.
* **Symmetry of Final Step:** The final answer `A` is treated analogously to a reasoning step `R_t` in the policy sampling (`A ~ π(·|S_{T-1})`), but it also triggers the final state update to `S_T`.
### Interpretation
This diagram models a **sequential decision-making or reasoning framework**, common in fields like reinforcement learning, planning, and advanced AI reasoning systems.
* **What it represents:** It illustrates how an AI agent (the "Model") can break down a complex query (`Q`) into a series of intermediate reasoning steps (`R₁, R₂, ...`) before producing a final answer (`A`). Each step refines the agent's understanding (the state `S`).
* **Relationship between elements:** The "Reasoning Steps" row shows the *observable actions*, while the "State Transition" row shows the *underlying, evolving context or belief state* that drives those actions. The policy `π` is the core "brain" that decides what to do next based on the current context.
* **Underlying logic:** The framework suggests that good answers (`A`) are not produced in a single leap but are the culmination of a deliberate, iterative process of information gathering or logical deduction (`R₁, R₂, ...`). The state `S` ensures continuity and coherence throughout this process.
* **Notable abstraction:** The diagram is highly abstract. The functions `T` (transition) and `π` (policy) are not defined, making this a general template applicable to various specific algorithms (e.g., Chain-of-Thought reasoning, Monte Carlo Tree Search, or a recurrent neural network processing a sequence). The use of `~` implies a probabilistic or sampling-based approach, rather than purely deterministic logic.
</details>
Figure 1: The illustration of MTP, where the transformer model $\pi$ reasons the answer $A$ of a query $Q$ through $T-1$ intermediate steps.
<details>
<summary>x2.png Details</summary>

### Visual Description
## Diagram: State Transition Process with Intermediate Computation
### Overview
The image displays a technical flowchart or state transition diagram illustrating a three-stage computational process. It shows how an initial state \( S_t \) is transformed via an intermediate computational block \( R_{t+1} \) into a final state \( S_{t+1} \). The diagram uses mathematical notation and arrows to indicate the flow of operations.
### Components/Axes
The diagram consists of three primary rectangular boxes with rounded corners, connected by directional arrows.
1. **Left Box (Initial State):**
* **Label:** \( S_t \) (positioned above the box).
* **Content (transcribed):**
```
145
× 340
+ 290
```
2. **Central Box (Intermediate Computation/Reward):**
* **Label:** \( R_{t+1} \) (positioned above the box).
* **Content (transcribed):**
```
340 → 300
145 × 4 = 580
290 + 5800 = 6090
```
* **Note:** The arrow "→" indicates a transformation or mapping.
3. **Right Box (Final State):**
* **Label:** \( S_{t+1} \) (positioned above the box).
* **Content (transcribed):**
```
145
× 300
+ 6090
```
4. **Connecting Arrows:**
* An arrow labeled **\( \pi \)** (Greek letter pi) points from the right edge of the \( S_t \) box to the left edge of the \( R_{t+1} \) box.
* An arrow labeled **\( T \)** points from the right edge of the \( R_{t+1} \) box to the left edge of the \( S_{t+1} \) box.
### Detailed Analysis
The diagram depicts a sequential transformation of numerical values.
* **From \( S_t \) to \( R_{t+1} \) (via \( \pi \)):**
* The value `340` from the multiplication line in \( S_t \) is transformed to `300` in the first line of \( R_{t+1} \).
* A new computation is introduced: `145 × 4 = 580`. The multiplicand `145` matches the first number in \( S_t \).
* Another computation is shown: `290 + 5800 = 6090`. The addend `290` matches the last number in \( S_t \). However, the source of the value `5800` is not explicitly derived from the previous line (`580`). This is a notable inconsistency or potential error in the diagram's internal logic.
* **From \( R_{t+1} \) to \( S_{t+1} \) (via \( T \)):**
* The first number `145` is carried over unchanged from \( S_t \) through \( R_{t+1} \) to \( S_{t+1} \).
* The transformed multiplier `300` (from `340 → 300` in \( R_{t+1} \)) becomes the new multiplier in \( S_{t+1} \).
* The computed sum `6090` (from `290 + 5800` in \( R_{t+1} \)) becomes the new addend in \( S_{t+1} \).
### Key Observations
1. **Value Persistence:** The number `145` remains constant throughout all three stages.
2. **Value Transformation:** The multiplier changes from `340` to `300`. The addend changes dramatically from `290` to `6090`.
3. **Internal Inconsistency:** The computation `290 + 5800 = 6090` within \( R_{t+1} \) uses the value `5800`, which is not the result of the immediately preceding line (`145 × 4 = 580`). This suggests either a typo (where `5800` should be `580`, making the sum `870`) or that `5800` is an external input not shown in the flow.
4. **Symbolic Flow:** The labels \( \pi \) and \( T \) are common in reinforcement learning and control theory, often representing a *policy* and a *transition function*, respectively. This context suggests the diagram models a decision-making or state-update process.
### Interpretation
This diagram likely represents a single step in an iterative algorithm, such as those found in dynamic programming or reinforcement learning.
* **What it demonstrates:** It shows how a state \( S_t \), defined by a set of parameters (145, 340, 290), is processed. A policy \( \pi \) generates an intermediate result \( R_{t+1} \), which involves modifying one parameter (340→300) and performing auxiliary calculations. A transition function \( T \) then uses these results to compute the next state \( S_{t+1} \), updating the parameters to (145, 300, 6090).
* **Relationships:** The process is linear and causal. \( R_{t+1} \) acts as a computational workspace that depends on \( S_t \) and determines \( S_{t+1} \). The unchanged value `145` may represent a fixed feature of the environment or agent.
* **Notable Anomaly:** The discrepancy between `580` and `5800` is critical. If `5800` is correct, it implies a large, unexplained external input. If it is a typo for `580`, then the final state \( S_{t+1} \) would be (145, 300, 870), which is a much smaller update. The current diagram, as drawn, contains a logical gap in the data flow.
</details>
(a) Multiplication
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Diagram: Sudoku State Transformation Process
### Overview
The image is a technical diagram illustrating a single-step transformation process for a Sudoku puzzle state. It shows an initial grid state (S_t), a transformation rule (R_{t+1}) that updates specific cells, and the resulting grid state (S_{t+1}). The process is mediated by two functions or operators, denoted by the Greek letters π (pi) and T.
### Components/Axes
The diagram consists of three primary components arranged horizontally from left to right:
1. **Left Component (S_t):** A 9x9 grid representing the initial state of a Sudoku puzzle at time step `t`. The grid is divided into nine 3x3 boxes by thicker lines. Cells contain numbers (1-9) or are empty.
2. **Middle Component (R_{t+1}):** A rounded rectangle labeled `R_{t+1}`. It contains two lines of text specifying cell updates:
* `cell_{6,2} ← 7`
* `cell_{7,9} ← 2`
An arrow labeled with the symbol `π` points from the S_t grid to this box.
3. **Right Component (S_{t+1}):** A 9x9 grid representing the resulting state at time step `t+1`. It is structurally identical to S_t. An arrow labeled with the symbol `T` points from the R_{t+1} box to this grid.
**Spatial Grounding:** The legend/transformation rule (R_{t+1}) is positioned centrally between the two state grids. The flow of information is strictly left-to-right: S_t → π → R_{t+1} → T → S_{t+1}.
### Detailed Analysis
**1. Initial State Grid (S_t):**
The grid contains the following numbers (row, column, value). Empty cells are denoted by `-`.
* Row 1: (1,1)=1, (1,3)=7, (1,7)=8, (1,9)=2
* Row 2: (2,2)=3, (2,5)=2, (2,8)=5, (2,9)=2
* Row 3: (3,2)=9, (3,7)=4, (3,8)=7
* Row 4: (4,1)=2, (4,3)=8, (4,4)=6, (4,9)=9
* Row 5: (5,2)=3, (5,3)=9, (5,4)=4, (5,5)=1, (5,8)=6
* Row 6: (6,1)=7, (6,4)=8, (6,8)=4
* Row 7: (7,2)=8, (7,9)=4
* Row 8: (8,1)=?, (8,2)=?, (8,3)=?, (8,4)=?, (8,5)=?, (8,6)=?, (8,7)=?, (8,8)=?, (8,9)=? (All cells in row 8 appear empty in the image).
* Row 9: (9,1)=?, (9,2)=?, (9,3)=?, (9,4)=?, (9,5)=?, (9,6)=?, (9,7)=?, (9,8)=?, (9,9)=? (All cells in row 9 appear empty in the image).
**2. Transformation Rule (R_{t+1}):**
The rule specifies two precise updates:
* Update 1: The cell at row 6, column 2 is assigned the value 7.
* Update 2: The cell at row 7, column 9 is assigned the value 2.
**3. Resulting State Grid (S_{t+1}):**
This grid is identical to S_t except for the two cells specified in R_{t+1}. These updated cells are highlighted in **red**.
* **Change 1 (Trend Verification):** The rule `cell_{6,2} ← 7` is applied. In S_t, cell (6,2) was empty (`-`). In S_{t+1}, cell (6,2) now contains the number **7** (in red).
* **Change 2 (Trend Verification):** The rule `cell_{7,9} ← 2` is applied. In S_t, cell (7,9) contained the number **4**. In S_{t+1}, cell (7,9) now contains the number **2** (in red).
All other numbers in S_{t+1} remain in the exact same positions as in S_t.
### Key Observations
1. **Targeted Update:** The transformation is not a full solve or a random change; it is a precise, rule-based update of two specific cells.
2. **Visual Highlighting:** The diagram uses the color red to draw immediate attention to the modified cells in the output state (S_{t+1}), making the effect of the transformation rule visually explicit.
3. **Process Abstraction:** The symbols `π` and `T` abstract the computational steps. `π` likely represents a policy or function that determines *which* cells to update (generating R_{t+1}), while `T` represents the transition function that *applies* those updates to the state.
4. **State Consistency:** Aside from the two specified changes, the Sudoku grid's state is perfectly preserved, indicating a deterministic and localized update process.
### Interpretation
This diagram models a single, discrete step in a computational process for solving or manipulating a Sudoku puzzle. It exemplifies a **state-transition model** common in reinforcement learning, search algorithms, or constraint satisfaction problems.
* **What it demonstrates:** The process shows how an agent or algorithm (`π`) observes a state (`S_t`), decides on a minimal set of actions (updating two cells to specific values, encoded in `R_{t+1}`), and then executes those actions via a transition function (`T`) to produce a new, slightly more solved state (`S_{t+1}`).
* **Relationship between elements:** The flow is causal and sequential. The initial state is the input. The policy `π` acts as the "brain," generating a compact action plan (`R_{t+1}`). The transition `T` is the "hands" that execute the plan on the environment (the grid). The output is a new state that is one step closer to a complete solution.
* **Notable implications:** The update from 4 to 2 in cell (7,9) suggests the algorithm is correcting a value, possibly because the 4 was a violation of Sudoku rules (e.g., a duplicate in its row, column, or 3x3 box). The insertion of a 7 into an empty cell (6,2) represents filling in a known, deduced value. This two-step action—correcting an error and filling a blank—is a microcosm of the entire solving process. The diagram effectively breaks down the complex task of solving a Sudoku into atomic, understandable operations.
</details>
(b) Sudoku
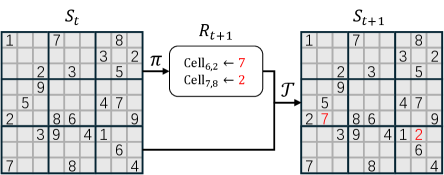
Figure 2: Example reasoning steps for multiplication and Sudoku, where the core planning is presented in the reasoning step ${R}_{t+1}$ .
CoT Reasoning as a Markov decision process
A general form of CoT reasoning is given as a tuple $({Q},\{{R}\},{A})$ , where ${Q}$ is the input query, $\{{R}\}=({R}_{1},\ldots,{R}_{T-1})$ is the sequence of $T-1$ intermediate steps, and ${A}$ is the final answer. Following Wang [37], we formulate the CoT reasoning as a Markov thought process (MTP). As shown in Figure 1, an MTP follows that [37]:
$$
\displaystyle{R}_{t+1}\sim\pi(\cdot\mid{S}_{t}),\ {S}_{t+1}=\mathcal{T}({S}_{t},{R}_{t+1}), \tag{1}
$$
where ${S}_{t}$ is the $t$ -th reasoning state, $\pi$ is the planning policy (the transformer model), and $\mathcal{T}$ is the (usually deterministic) transition function. The initial state ${S}_{0}:=Q$ is given by the input query. In each reasoning step ${R}_{t+1}$ , the policy $\pi$ plans the next reasoning action that determines the state transition, which is then executed by $\mathcal{T}$ to obtain the next state. The process terminates when the step presents the answer, i.e., $A={R}_{T}$ . For clarity, a table of notations is presented in Appendix A.
An MTP is implemented by specifying the state representations and transition function $\mathcal{T}$ . Since we use tiny transformers that are weak in inferring long contexts, we suggest reducing the length of state representations, so that each state ${S}_{t}$ carries only necessary information for subsequent reasoning. Here, we present two examples to better illustrate how MTPs are designed for tiny transformers.
**Example 1 (An MTP for integer multiplication)**
*As shown in Figure 2(a), to reason the product of two integers $x,y\geq 0$ , each state is an expression ${S}_{t}:=[x_{t}\times y_{t}+z_{t}]$ mathematically equal to $x\times y$ , initialized as ${S}_{0}=[x\times y+0]$ . On each step, $\pi$ plans $y_{t+1}$ by eliminate a non-zero digit in $y_{t}$ to $0$ , and it then computes $z_{t+1}=z_{t}+x_{t}(y_{t}-y_{t+1})$ . Consequently, $\mathcal{T}$ updates ${S}_{t+1}$ as $[x_{t+1}\times y_{t+1}+z_{t+1}]$ with $x_{t+1}=x_{t}$ . Similarly, $\pi$ may also eliminate non-zero digits in $x_{t}$ in a symmetric manner. Finally, $\pi$ yields $A=z_{t}$ as the answer if either $x_{t}$ or $y_{t}$ becomes $0$ .*
**Example 2 (An MTP for Sudoku[3])**
*As shown in Figure 2(b), each Sudoku state is a $9\times 9$ game board. On each step, the model $\pi$ fills some blank cells to produce a new board, which is exactly the next state. The answer $A$ is a board with no blank cells.*
### 3.2 The framework of self-verifying reflection
<details>
<summary>x4.png Details</summary>
### Visual Description
## Diagram: State Transition Flowchart with Decision Points
### Overview
The image displays a directed graph or flowchart illustrating a sequential decision-making process. It shows a starting state, multiple intermediate steps with branching paths (some correct, some incorrect), and a final goal state. The diagram uses color-coding (green for correct/successful paths, red for incorrect/failed paths) and symbols (checkmarks ✓, crosses ✗) to indicate the validity of each transition.
### Components/Axes
The diagram is composed of nodes (boxes) and directed edges (arrows). There are no traditional chart axes. The components are:
1. **Nodes (States/Actions):**
* **Start Node (Leftmost):** A gray box labeled `Q` with the equation `S₀ = Q` below it.
* **Intermediate Nodes (Red - Incorrect):**
* `R₁, ✗` with `S₁ = S₀` below it.
* `R₄, ✗` with `S₄ = S₂` below it.
* `R₅, ✗` with `S₅ = S₂` below it.
* **Intermediate Nodes (Green - Correct):**
* `R₂, ✓` with `S₂ = J(S₁, R₂)` below it.
* `R₃, ✓` with `S₃ = J(S₂, R₃)` below it.
* `R₆, ✓` with `S₆ = J(S₅, R₆)` below it.
* **Goal Node (Rightmost):** A green box labeled `A, ✓` with `S₇ = J(S₆, A)` below it.
2. **Edges (Transitions):**
* **Red Arrows:** Indicate transitions from correct paths to incorrect nodes (`R₂` to `R₁`; `R₃` to `R₄` and `R₅`).
* **Green Arrows:** Indicate the primary successful path (`Q` -> `R₂` -> `R₃` -> `R₆` -> `A`) and a secondary path from an incorrect node (`R₅` to `R₆`).
3. **Legend/Key (Implied):**
* **Color:** Green = Correct/Successful Path. Red = Incorrect/Failed Path.
* **Symbols:** ✓ = Checkmark (Success). ✗ = Cross (Failure).
* **Positioning:** The legend is not in a separate box but is embedded in the node styling. The primary successful path flows horizontally from left to right across the lower portion of the diagram. Incorrect branches extend upward from the main path.
### Detailed Analysis
The diagram models a process where a state `S` is updated through a function `J` based on an action `R` or `A`.
* **Initial State:** The process begins at state `S₀`, which is equal to the initial query or condition `Q`.
* **Path 1 (Incorrect):** From `S₀`, taking action `R₁` leads to a state `S₁` that is unchanged from `S₀` (`S₁ = S₀`). This path is marked as incorrect (red, ✗).
* **Path 2 (Correct Start):** From `S₀`, taking action `R₂` leads to a new state `S₂` computed as `J(S₁, R₂)`. This is the first correct step (green, ✓).
* **Branching from `S₂`:**
* **Incorrect Branches:** From state `S₂`, actions `R₄` and `R₅` are possible but incorrect (red, ✗). Both lead to states that revert to `S₂` (`S₄ = S₂`, `S₅ = S₂`), indicating no progress.
* **Correct Continuation:** From state `S₂`, taking action `R₃` leads to state `S₃ = J(S₂, R₃)`. This is correct (green, ✓).
* **Convergence and Final Steps:**
* From state `S₃`, an incorrect action `R₆` is shown (red, ✗), but the arrow points to the correct `R₆` node, suggesting a possible mislabeling or that `R₆` can be reached from multiple states.
* The correct path continues from `S₃` to action `R₆`. Notably, the equation for the state after `R₆` is `S₆ = J(S₅, R₆)`. This implies that the state `S₅` (from the incorrect `R₅` branch) is used as input, not `S₃`. This is a critical detail.
* Finally, from state `S₆`, taking the goal action `A` leads to the terminal state `S₇ = J(S₆, A)`, marked as successful (green, ✓).
### Key Observations
1. **Non-Linear Progression:** The successful path is not a simple straight line. It involves a main sequence (`Q` -> `R₂` -> `R₃`) but then incorporates an element (`S₅`) from a previously failed branch (`R₅`) to compute the next state (`S₆`).
2. **State Reversion:** Incorrect actions (`R₁`, `R₄`, `R₅`) result in states that are equal to a previous state (`S₀` or `S₂`), representing a lack of progress or a loop.
3. **Critical Equation:** The equation `S₆ = J(S₅, R₆)` is pivotal. It shows that the successful path to the goal depends on information or a state (`S₅`) generated by an *incorrect* action (`R₅`). This suggests the process may learn from or require exploring dead ends.
4. **Spatial Layout:** The primary successful path is anchored along the bottom. Incorrect branches create upward "spurs," visually separating failure from progress. The final goal `A` is positioned at the far right, signifying the endpoint.
### Interpretation
This diagram likely represents a **state-space search, a reinforcement learning policy, or a logical proof tree** where an agent or algorithm must navigate through possible actions to reach a goal.
* **What it demonstrates:** The process is not about avoiding all wrong turns. Instead, it shows that reaching the goal (`A`) may require traversing a specific sequence of correct actions (`R₂`, `R₃`) while also leveraging the outcome (`S₅`) of an exploratory, incorrect action (`R₅`). The function `J` acts as a state transition or update function.
* **Relationship between elements:** The green arrows define the viable policy or solution path. The red arrows represent explored but suboptimal or erroneous actions. The connection from the incorrect `R₅` node to the correct `R₆` node is the most significant relationship, indicating that failure is not always terminal and can provide necessary input for eventual success.
* **Notable anomaly:** The equation `S₆ = J(S₅, R₆)` is the central anomaly. It breaks the simple sequential flow (`S₃` should logically feed into `R₆`) and instead creates a dependency on a side branch. This implies the system has memory or that the value of action `R₆` is contingent on having first attempted `R₅`, even though `R₅` itself was incorrect. This is a sophisticated concept, suggesting the model values exploration or has conditional logic where some "wrong" steps are prerequisites for later "right" steps.
</details>
(a) Reflective MTP
<details>
<summary>x5.png Details</summary>
### Visual Description
\n
## Diagram: State Transition Flowchart with Decision Paths
### Overview
The image displays a directed graph or flowchart illustrating a state transition process, likely representing a search algorithm, decision tree, or reinforcement learning trajectory. It maps the progression from an initial state `Q` through various intermediate states (`R₁` to `R₁₀`) to a final state `A`. The diagram uses color-coding, symbols (✓/✗), and mathematical notation to denote success/failure and state transformations.
### Components/Axes
* **Node Types & Labels:** Each node is a rounded rectangle containing a label (e.g., `R₁`, `A`, `Q`) and a symbol (✓ or ✗). Below each node is a state transition equation.
* **Color Coding:**
* **Orange:** Nodes `R₁`, `R₂`, `R₃`, `R₄`, `R₅`, `R₇`, `R₁₀`. This appears to be the primary or explored branch.
* **Green:** Nodes `Q`, `R₈`, `R₉`, `A`. This appears to be a successful or alternative branch.
* **Red:** Nodes `R₂`, `R₅`, `R₇`, `R₆`. These nodes are marked with ✗, indicating failure or termination.
* **Connections:** Solid arrows indicate primary flow. Dotted red arrows indicate secondary or alternative transitions (e.g., from `R₄` to `R₆` and `R₅`).
* **Spatial Layout:** The flowchart originates from a single node `Q` on the far left. It branches into two main paths: an upper/orange path and a lower/green path. The final node `A` is positioned at the bottom right.
### Detailed Analysis
**Path 1 (Upper/Orange Branch):**
1. **Start:** `Q` (Green) - `S₀ = Q`
2. **Step 1:** `R₁, ✓` (Orange) - `S₁ = T(S₀, R₁)`
3. **Step 2 (from R₁):**
* `R₂, ✗` (Red) - `S₂ = S₁` (No state change)
* `R₃, ✓` (Orange) - `S₃ = T(S₂, R₃)`
4. **Step 3 (from R₂):**
* `R₄, ✓` (Orange) - `S₄ = T(S₃, R₄)`
* `R₅, ✗` (Red) - `S₅ = S₄` (No state change)
5. **Step 4 (from R₃):**
* `R₇, ✗` (Red) - `S₇ = S₆` (Note: `S₆` is defined later, suggesting a loop or reference).
6. **Step 5 (from R₄):**
* `R₆, ✗` (Red) - `S₆ = S₄` (No state change)
* `R₁₀, ✓` (Orange) - `S₁₀ = T(S₇, R₁₀)` (References `S₇` from the `R₃` branch).
**Path 2 (Lower/Green Branch):**
1. **Start:** `Q` (Green) - `S₀ = Q`
2. **Step 1:** `R₈, ✓` (Green) - `S₈ = T(S₀, R₈)`
3. **Step 2:** `R₉, ✓` (Green) - `S₉ = T(S₈, R₉)`
4. **Step 3 (Final):** `A, ✓` (Green) - `S₁₀ = T(S₉, A)`
**State Transition Notation:** The notation `Sₙ = T(Sₘ, Rₖ)` indicates that state `Sₙ` is the result of applying transformation `T` to previous state `Sₘ` using action/rule `Rₖ`. Notation like `S₂ = S₁` indicates a terminal or non-transformative step.
### Key Observations
1. **Two Distinct Outcomes:** The green path (`Q -> R₈ -> R₉ -> A`) leads directly to a successful terminal state `A`. The orange/red path is more complex, involving multiple branches, failures (✗), and loops (e.g., `R₇` referencing `S₆`).
2. **Failure States:** Nodes marked with ✗ (`R₂`, `R₅`, `R₇`, `R₆`) are all colored red and often result in no state change (`Sₙ = Sₘ`), indicating dead ends.
3. **Complex Interconnection:** The orange path is not linear. It features branching (`R₁` to `R₂/R₃`), convergence (dotted lines from `R₄`), and cross-branch references (`R₁₀` using `S₇` from the `R₃` sub-branch).
4. **Final State Convergence:** Both main branches ultimately reference a state `S₁₀`. The green path defines it as `T(S₉, A)`, while the orange path defines it via `R₁₀` as `T(S₇, R₁₀)`. This suggests `S₁₀` is a goal state achievable via different sequences.
### Interpretation
This diagram models a **search or decision-making process** where an agent explores possible actions from an initial state `Q`. The green path represents an **optimal or successful policy**—a direct, three-step sequence (`R₈, R₉, A`) that achieves the goal. The orange/red path represents a **more exploratory, trial-and-error process**. It includes successful steps (`R₁, R₃, R₄, R₁₀`) but also encounters failures (`R₂, R₅, R₇, R₆`) and complex state dependencies.
The notation `T(S, R)` strongly suggests a **formal transition function**, common in fields like:
* **Reinforcement Learning:** Where an agent takes actions (`R`) in states (`S`) to receive rewards and new states.
* **Automated Theorem Proving or Planning:** Where `R` represents rule applications to transform a logical state `S`.
* **Algorithmic Search:** Where nodes represent states and edges represent operations.
The key insight is that **multiple pathways can lead to the same goal state (`S₁₀`)**, but they differ dramatically in efficiency and risk of failure. The diagram visually argues for the superiority of the direct green policy over the convoluted orange exploration. The presence of failures (✗) and non-transformative steps highlights the cost of suboptimal decision-making.
</details>
(b) Reflective trace-back search (width $m=2$ )
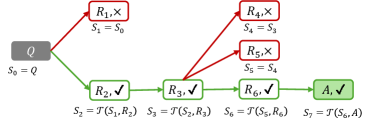
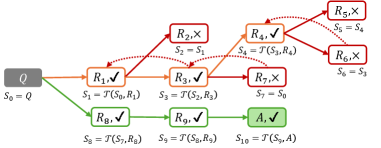
Figure 3: Reflective reasoning based on MTP. “ $\checkmark$ ” and “ $\times$ ” are self-verification labels for positive and negative steps, respectively. The steps that are instantly verified as negative are highlighted in red. In RTBS, the dashed-line arrows back-propagate the negative labels, causing parental steps to be recursively rejected (orange). The green shows the steps that successfully lead to the answer.
Conceptually, reflection provides feedback for the proposed steps and may alter the subsequent reasoning accordingly. Reflection takes flexible forms in natural language (e.g., justifications and comprehensive evaluations), making it extremely costly to analyze. In this work, we propose to equip transformers with the simplest discriminative form of reflection, where the model self-verifies the correctness of each step and is allowed to retry those incorrect attempts. We currently do not consider the high-level revisory behavior that maps incorrect steps to correct ones, as we find learning such a mapping is challenging for tiny models and leads to no significant gain in practice. Specifically, we analyze two basic variants of reflective reasoning in this paper: the reflective MTP and the reflective trace-back search, as described below (see pseudo-code in Appendix D.1).
Reflective MTP (RMTP)
Given any MTP with a policy $\pi$ and transition $\mathcal{T}$ , we use a verifier $\mathcal{V}$ to produce a verification sequence after each reasoning step, denoted as ${V}_{t}\sim\mathcal{V}(\cdot|{R}_{t})$ . Such ${V}_{t}$ includes verification label(s): The positive “ $\checkmark$ ” and negative “ $\times$ " signifying correct and incorrect reasoning of ${R}_{t}$ , respectively. Given the verified step ${\tilde{R}}_{t+1}:=({R}_{t+1},{V}_{t+1})$ that contains verification, we define $\tilde{\mathcal{T}}$ as the reflective transition function that rejects incorrect steps:
$$
{S}_{t+1}=\tilde{\mathcal{T}}({S}_{t},{\tilde{R}}_{t+1})=\tilde{\mathcal{T}}({S}_{t},({R}_{t+1},{V}_{t+1})):=\begin{cases}{S}_{t},&\text{``$\times$''}\in{V}_{t+1};\\
\mathcal{T}({S}_{t},{R}_{t+1}),&\text{otherwise.}\end{cases} \tag{2}
$$
In other words, if $\mathcal{V}$ detects any error (i.e. “ $\times$ ") in ${R}_{t+1}$ , the state remains unchanged so that $\pi$ may re-sample another attempt. Focusing on self-verification, we use a single model called the self-verifying policy $\tilde{\pi}:=\{\pi,\mathcal{V}\}$ to serve simultaneously as the planning policy $\pi$ and the verifier $\mathcal{V}$ . By operating tokens, $\tilde{\pi}$ outputs the verified step ${\tilde{R}}_{t}$ for each input state ${S}_{t}$ . In this way, $\tilde{\mathcal{T}}$ and $\tilde{\pi}$ constitute a new MTP called the RMTP, with illustration in Figure 3(a).
Reflective trace-back search (RTBS)
Though RMTP allows instant rejections of incorrect steps, sometimes the quality of a step can be better determined by actually trying it. For example, a Sudoku solver occasionally makes tentative guesses and traces back if the subsequent reasoning fails. Inspired by o1-journey [26], a trace-back search allowing the reasoner to revisit previous states may be applied to explore solution paths in an MTP. We implement simple RTBS by simulating the depth-first search in the trajectory space. Let $m$ denote the RTBS width, i.e., the maximal number of attempts on each step. As illustrated in Figure 3(b), if $m$ proposed steps are rejected on a state ${S}_{t}$ , the negative label “ $\times$ ” will be propagated back to recursively reject the previous step ${R}_{t}$ . As a result, the state traces back to the closest ancestral state that has remaining attempt opportunities.
### 3.3 Training
<details>
<summary>x6.png Details</summary>
### Visual Description
\n
## Technical Diagram: Multi-Stage Training Pipeline for Reasoning Models
### Overview
The image is a technical flowchart illustrating a four-stage training pipeline for a language model designed to perform reasoning tasks, likely using Chain-of-Thought (CoT) methods. The pipeline progresses from left to right, showing data flow and transformations through Pretraining, Non-reflective Supervised Fine-Tuning (SFT), Reflective SFT, and Reinforcement Learning (RL) fine-tuning. The diagram uses color-coded boxes, arrows, and mathematical notation to represent processes, data structures, and model components.
### Components/Axes
The diagram is segmented into four primary, labeled stages:
1. **(I) Pretraining (Green Box, Top-Left):**
* **Input:** "Training Data" (depicted as a green cylinder) and "CoT examples" (arrow from top).
* **Process:** Shows sequences of tokens (Q, R₁, R₂, A, etc.) being processed. Red boxes highlight "context windows (randomly drawn)".
* **Output:** A policy model denoted by π.
2. **(II) Non-reflective SFT (Blue Box, Center):**
* **Input:** The policy model π from stage (I).
* **Process:** Depicts a sequence of "states" (Q, S₁, S₂, ...) mapping to "steps or answers" (R₁, R₂, A, ...). The transition is governed by the policy π.
* **Output:** A refined policy model π.
3. **(III) Reflective SFT (Gray Box, Bottom-Left):**
* **Input:** "CoT examples (data mixture)" and the policy model π from stage (II).
* **Process:** Involves "sampling CoTs through MTP" (Model-Thought-Process, inferred). Shows a matrix with columns Q, S₁, S₂, ... and rows R₁, R₂, R₃, ... leading to "ground-truth verification" (V₁, V₂, V₃, ...). An "Expert Verifier" block processes this.
* **Output:** A policy model denoted by π̃ (π-tilde).
4. **(IV) RL fine-tuning (Orange Box, Right):**
* **Input:** The policy model π̃ from stage (III).
* **Process:** Contains two sub-modules:
* **MTP:** Shows a loop: `Q -> [π] -> R_t -> A`. State update: `S_t = T(S_{t-1}, R_t)`.
* **RMTP:** Shows a loop: `Q -> [π] -> (R_t, V_t) -> A`. State update: `S_t = T(S_{t-1}, R_t, V_t)`.
* **Components:** Includes a "Reward Model" and "Policy Optimization" block, with feedback loops (orange arrows) connecting them to the MTP/RMTP processes.
**Flow Arrows:** Black arrows indicate the primary data/model flow from (I) -> (II) -> (III) -> (IV). An additional arrow feeds "CoT examples" from the start into stage (III).
### Detailed Analysis
**Stage (I) Pretraining:**
* **Data Structure:** Sequences consist of a Question (Q), reasoning steps (R₁, R₂, ...), and an Answer (A). The diagram shows two example sequences: `Q, R₁, R₂, A` and `Q, R₁, A, Q, R₁, R₂, A, Q, R₁...`.
* **Key Mechanism:** "Context windows (randomly drawn)" are highlighted, suggesting the model is pretrained on variable-length segments of these reasoning chains.
**Stage (II) Non-reflective SFT:**
* **Mapping:** Establishes a direct mapping from a sequence of states (starting with Q, then S₁, S₂...) to a sequence of steps/answers (R₁, R₂, A). This represents standard supervised fine-tuning on reasoning traces.
**Stage (III) Reflective SFT:**
* **Verification Process:** Introduces a verification step. For a given question (Q) and state sequence (S₁, S₂...), multiple reasoning steps (R₁, R₂, R₃...) are generated and paired with verification scores or labels (V₁, V₂, V₃...). An "Expert Verifier" evaluates these against ground truth.
* **Model Update:** This process uses the policy π to sample CoTs and produces an updated policy π̃, incorporating reflective or verified reasoning.
**Stage (IV) RL fine-tuning:**
* **MTP (Model-Thought-Process):** A basic reactive model where the action (A) is taken based on the current reasoning step (R_t), and the state (S_t) is updated based only on the previous state and the new reasoning step.
* **RMTP (Reflective/Reinforced MTP):** An enhanced model where the action (A) is based on both a reasoning step (R_t) and its associated verification/value (V_t). The state update incorporates both R_t and V_t.
* **Optimization Loop:** The Reward Model provides feedback, which drives Policy Optimization. This optimized policy is then used in the MTP/RMTP modules, creating a reinforcement learning loop.
### Key Observations
1. **Progressive Complexity:** The pipeline evolves from simple sequence modeling (I) to supervised step-by-step reasoning (II), then adds verification (III), and finally integrates reinforcement learning with value feedback (IV).
2. **Notation Consistency:** The policy model is consistently denoted by π, with a tilde (π̃) used after the reflective stage to indicate a modified version.
3. **State Representation:** The state `S_t` is explicitly defined as a function `T` of previous states and reasoning steps/values, formalizing the reasoning trajectory.
4. **Dual RL Paths:** The RL stage explicitly contrasts a basic MTP with an enhanced RMTP, highlighting the integration of verification signals (V_t) into the decision and state-update process.
### Interpretation
This diagram outlines a sophisticated methodology for training AI models to perform complex reasoning. The pipeline's core innovation lies in its multi-stage approach that moves beyond standard pretraining and SFT.
* **From Imitation to Reflection:** Stages (I) and (II) teach the model to mimic reasoning patterns from data. Stage (III) introduces a critical reflective component, where the model's outputs are verified, likely teaching it to distinguish between valid and invalid reasoning paths.
* **From Supervision to Optimization:** Stage (IV) transitions from learning from static examples (SFT) to learning from outcomes via RL. The inclusion of the RMTP module suggests that the verification signal (V_t) from stage (III) is not just used for filtering data but is integrated as a core component of the decision-making process during RL, potentially guiding the model towards more reliable and high-reward reasoning strategies.
* **Overall Goal:** The pipeline aims to produce a model (final policy π) that doesn't just generate plausible-sounding reasoning chains but can engage in a verifiable, step-by-step thought process (`S_t = T(...)`) that is optimized for correctness, as determined by a reward model. This is a common framework for developing "reasoning" or "chain-of-thought" capabilities in large language models.
</details>
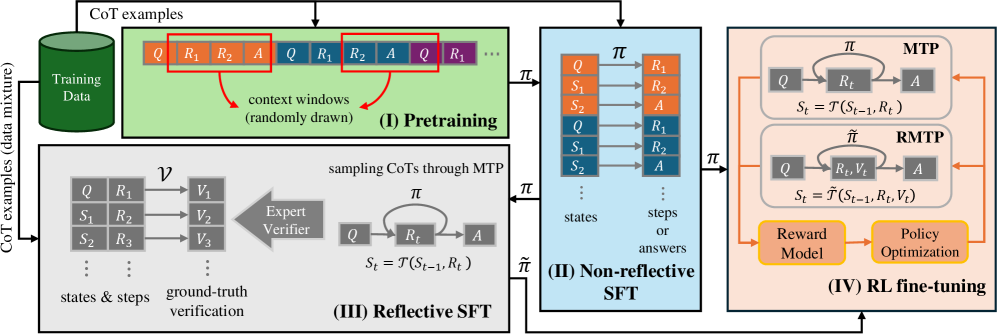
Figure 4: The training workflow for transformers to perform CoT reasoning.
As shown in Figure 4, we train the tiny transformers from scratch through consistent techniques of LLM counterparts, such as pretraining, supervised fine-tuning (SFT), and RL fine-tuning. First, we use conventional pipelines to train a baseline model $\pi$ with only the planning ability in MTPs. During (I) pretraining, these CoT examples are treated as a textual corpus, where sequences are randomly drawn to minimize cross-entropy loss of next-token prediction. Then, in (II) non-reflective SFT, the model learns to map each state ${S}_{t}$ to the corresponding step ${R}_{t+1}$ by imitating examples.
Next, we employ (III) reflective SFT to integrate the planning policy $\pi$ with the knowledge of self-verification. To produce ground-truth verification labels, we use $\pi$ to sample non-reflective CoTs, in which the sampled steps are then labeled by an expert verifier (e.g., a rule-based process reward model). Reflective SFT learns to predict these labels from the states and the proposed steps, i.e., $({S}_{t},{R}_{t+1})\to{V}_{t+1}$ . To prevent disastrous forgetting, we also mix the same CoT examples as in non-reflective SFT. This converts $\pi$ to a self-verifying policy $\tilde{\pi}$ that can self-verify reasoning steps.
Thus far, we have obtained the planning policy $\pi$ and the self-verifying policy $\tilde{\pi}$ , which can be further strengthened through (IV) RL fine-tuning. As illustrated in Figure 4, RL fine-tuning involves iteratively executing $\pi$ ( $\tilde{\pi}$ ) to collect experience CoTs through an MTP (RMTP), evaluating these CoTs with a reward model, and updating the policy to favor higher-reward solutions. Following the RLVR paradigm [15], we use binary outcome rewards (i.e., $1$ for correct answers and $0$ otherwise) computed by a rule-based answer checker $\operatorname{ORM}(Q,A)$ . When training the self-verifying policy $\tilde{\pi}$ , the RMTP treats verification ${V}_{t}$ as a part of the augmented step ${\tilde{R}}_{t}$ , simulating R1-like training [5] where reflection and solution planning are jointly optimized. We mainly use GRPO [31] as the algorithms to optimize policies. Details of RL fine-tuning are elaborated in Appendix B.
## 4 Theoretical results
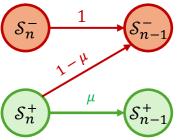
This section establishes theoretical conditions under which self-verifying reflection (RMTP or RTBS in Section 3.2) enhances reasoning accuracy (the probability of deriving correct answers). The general relationship between the verification ability and reasoning accuracy (discussed in Appendix C.1) for any MTP is intractable as the states and transitions can be arbitrarily specified. Therefore, to derive interpretable insights, we discuss a simplified prototype of reasoning that epitomizes the representative principle of CoTs — to incrementally express complex relations by chaining the local relation in each step [25]. Specifically, Given query $Q$ as the initial state, we view a CoT as the step-by-step process that reduces the complexity within states:
- We define $\mathcal{S}_{n}$ as the set of states with a complexity scale of $n$ . For simplicity, we assume that each step, if not rejected by reflection, reduces the complexity scale by $1$ . Therefore, the scale $n$ is the number of effective steps required to derive an answer.
- An answer $A$ is a state with a scale of $0$ , i.e. $A\in\mathcal{S}_{0}$ . Given an input query $Q$ , the answers $\mathcal{S}_{0}$ are divided into positive (correct) answers $\mathcal{S}_{0}^{+}$ and negative (wrong) answers $\mathcal{S}_{0}^{-}$ .
- States $\mathcal{S}_{n}$ ( $n$ > 0) are divided into 1) positive states $\mathcal{S}_{n}^{+}$ that potentially lead to correct answers and 2) negative states $\mathcal{S}_{n}^{-}$ leading to only incorrect answers through forward transitions.
Consider a self-verifying policy $\tilde{\pi}=\{\pi,\mathcal{V}\}$ to solve this simplified task. We describe its fundamental abilities using the following probabilities (whose meanings will be explained afterwards):
$$
\displaystyle\mu:=p_{{R}\sim\pi}(\mathcal{T}({S},{R})\in\mathcal{S}^{+}_{n-1}\mid{S}\in\mathcal{S}_{n}^{+}) \displaystyle e_{+}:=p_{{R},{V}\sim\tilde{\pi}}(\mathcal{T}({S},{R})\in\mathcal{S}^{-}_{n-1},\text{``$\times$''}\notin{V}\mid{S}\in\mathcal{S}_{n}^{+}), \displaystyle e_{-}:=p_{{R},{V}\sim\tilde{\pi}}(\mathcal{T}({S},{R})\in\mathcal{S}^{+}_{n-1},\text{``$\times$''}\in{V}\mid{S}\in\mathcal{S}_{n}^{+}), \displaystyle f:=p_{{R},{V}\sim\tilde{\pi}}(\text{``$\times$''}\in{V}\mid{S}\in\mathcal{S}_{n}^{-}). \tag{3}
$$
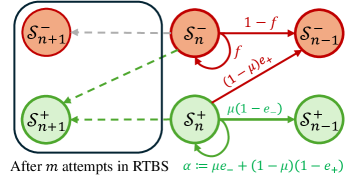
To elaborate, $\mu$ measures the planning ability, defined as the probability that $\pi$ plans a step that leads to a positive next state, given that the current state is positive. For verification abilities, we measure the rates of two types of errors: $e_{+}$ (false positive rate) is the probability of accepting a step that leads to a negative state, and $e_{-}$ (false negative rate) is the probability of rejecting a step that leads to a positive state. Additionally, $f$ is the probability of rejecting any step on negative states, providing the chance of tracing back to previous states. Given these factors, Figure 5 illustrates the state transitions in non-reflective (vanilla MTP) and reflective (RMTB and RTBS) reasoning.
<details>
<summary>x7.png Details</summary>
### Visual Description
\n
## State Transition Diagram: Two-State System with Probabilistic Transitions
### Overview
The image displays a directed graph diagram representing a state transition model, likely a Markov chain or similar stochastic process. It consists of four nodes arranged in a 2x2 grid, connected by three directed edges (arrows) with associated transition probabilities or rates. The diagram uses color-coding (red and green) and mathematical notation to define states and their relationships.
### Components/Axes
**Nodes (States):**
* **Top-Left Node:** A red circle labeled `S_n^-`.
* **Top-Right Node:** A red circle labeled `S_{n-1}^-`.
* **Bottom-Left Node:** A green circle labeled `S_n^+`.
* **Bottom-Right Node:** A green circle labeled `S_{n+1}^+`.
**Edges (Transitions):**
1. A horizontal red arrow from `S_n^-` (top-left) to `S_{n-1}^-` (top-right). It is labeled with the number `1`.
2. A diagonal red arrow from `S_n^+` (bottom-left) to `S_{n-1}^-` (top-right). It is labeled with the expression `1 - μ`.
3. A horizontal green arrow from `S_n^+` (bottom-left) to `S_{n+1}^+` (bottom-right). It is labeled with the Greek letter `μ` (mu).
**Spatial Layout:**
* The diagram is organized into two distinct rows.
* The **top row** contains the two red nodes (`S_n^-` and `S_{n-1}^-`), connected by a direct horizontal transition.
* The **bottom row** contains the two green nodes (`S_n^+` and `S_{n+1}^+`), connected by a direct horizontal transition.
* The **diagonal transition** connects the bottom-left green node (`S_n^+`) to the top-right red node (`S_{n-1}^-`), crossing from the lower to the upper row.
### Detailed Analysis
**State Notation:**
* The states are denoted by `S` with a subscript (`n`, `n-1`, `n+1`) and a superscript (`+` or `-`).
* The subscript likely represents a discrete index, such as time step, generation, or a counter.
* The superscript (`+`/`-`) denotes a binary attribute or category, visually reinforced by the green/red color coding.
**Transition Logic:**
* From state `S_n^-` (red, index `n`), there is a **certain transition** (probability/rate = `1`) to state `S_{n-1}^-` (red, index `n-1`). This represents a deterministic decrease in the index while staying in the "negative" (`-`) category.
* From state `S_n^+` (green, index `n`), there are two possible transitions:
1. To state `S_{n-1}^-` (red, index `n-1`) with a weight of `1 - μ`. This represents a change from the "positive" (`+`) to the "negative" (`-`) category, accompanied by a decrease in index.
2. To state `S_{n+1}^+` (green, index `n+1`) with a weight of `μ`. This represents staying in the "positive" (`+`) category while increasing the index.
* The sum of the weights for transitions originating from `S_n^+` is `(1 - μ) + μ = 1`, indicating these are complementary probabilities.
### Key Observations
1. **Asymmetric Connectivity:** The "negative" (`-`) states only have outgoing transitions to other "negative" states (specifically, decreasing the index). The "positive" (`+`) state `S_n^+` is the only node with branching transitions, leading to both a "negative" state and another "positive" state.
2. **Index Flow:** The index (`n`) can decrease (`n -> n-1`), increase (`n -> n+1`), or stay conceptually similar (the transition from `S_n^-` to `S_{n-1}^-` changes the index but maintains the `-` category).
3. **Color-Coded Categories:** The red/green dichotomy is consistent. All nodes with a `-` superscript are red. All nodes with a `+` superscript are green. The diagonal transition arrow is also red, matching its destination node's color (`S_{n-1}^-`).
4. **Parameter `μ`:** The Greek letter `μ` acts as a critical parameter controlling the fate of the system when in the `S_n^+` state. It determines the probability of remaining in the "positive" lineage versus defecting to the "negative" lineage.
### Interpretation
This diagram models a **two-type branching process or a state-dependent random walk**. The states likely represent populations, strategies, or conditions in a system (e.g., in evolutionary game theory, population genetics, or stochastic modeling).
* **The "Negative" (`-`) Lineage:** Appears to be a **declining or absorbing pathway**. Once in a `-` state, the system deterministically moves to a `-` state with a lower index (`n-1`), suggesting a countdown or a process that terminates or reduces a count.
* **The "Positive" (`+`) Lineage:** Represents a **growth or persistence pathway**. From `S_n^+`, there's a probability `μ` to advance to a higher index (`S_{n+1}^+`), indicating growth, reproduction, or success. However, there's a risk (`1 - μ`) of "failure" or "mutation," where the system transitions to the declining `-` lineage at a lower index (`S_{n-1}^-`).
* **System Dynamics:** The overall behavior hinges on the value of `μ`. A high `μ` favors the expansion of the `+` lineage. A low `μ` leads to frequent collapse into the `-` lineage, which then deterministically winds down. The diagram captures a fundamental tension between growth and decay, persistence and failure, governed by a single parameter. The absence of transitions *into* the `S_n^-` state from any other state except `S_n^+` suggests it might be a specific entry point into the declining pathway.
</details>
(a) Non-reflective reasoning
<details>
<summary>x8.png Details</summary>
### Visual Description
\n
## State Transition Diagram: RTBS Process Model
### Overview
The image displays a state transition diagram modeling a process labeled "RTBS" (likely an acronym for a specific algorithm or system). The diagram illustrates transitions between positive (`+`) and negative (`-`) states across three sequential time steps or stages: `n+1`, `n`, and `n-1`. The flow moves generally from left (most recent/future state `n+1`) to right (past state `n-1`). The model incorporates probabilistic transitions and error terms, culminating in a defined parameter `α`.
### Components/Axes
The diagram is composed of nodes (states) and directed edges (transitions). There are no traditional chart axes.
**Nodes (States):**
* **Left Group (within a rounded rectangle):**
* `S_{n+1}^-` (Red circle, top-left)
* `S_{n+1}^+` (Green circle, bottom-left)
* **Middle Group:**
* `S_n^-` (Red circle, top-center)
* `S_n^+` (Green circle, bottom-center)
* **Right Group:**
* `S_{n-1}^-` (Red circle, top-right)
* `S_{n-1}^+` (Green circle, bottom-right)
**Edges (Transitions) and Labels:**
* **From `S_{n+1}^-`:**
* Solid red arrow to `S_n^-`, labeled `f`.
* Solid red arrow to `S_{n-1}^-`, labeled `1-f`.
* Dashed green arrow to `S_n^+` (no explicit label).
* **From `S_{n+1}^+`:**
* Dashed green arrow to `S_n^+` (no explicit label).
* Dashed green arrow to `S_n^-` (no explicit label).
* **From `S_n^-`:**
* Red self-loop arrow, labeled `μ(e_+)`.
* Solid red arrow to `S_{n-1}^-`, labeled `f`.
* Solid red arrow to `S_{n-1}^+`, labeled `(1-μ)e_+`.
* **From `S_n^+`:**
* Green self-loop arrow, labeled `μ(e_+)`.
* Solid green arrow to `S_{n-1}^+`, labeled `μ(e_+)`.
* Solid green arrow to `S_{n-1}^-`, labeled `(1-μ)e_+`.
**Legend/Footer Text:**
* Text at bottom-left: `After m attempts in RTBS`
* Equation at bottom-center/right: `α = μ e_- + (1-μ)(1-e_+)`
### Detailed Analysis
The diagram defines a Markov-like process where the system can be in a positive (`+`) or negative (`-`) state at each step. The transitions are governed by parameters `f`, `μ`, `e_+`, and `e_-`.
1. **Temporal Flow:** The primary flow is from stage `n+1` to `n` to `n-1`. The dashed arrows from `n+1` to `n` suggest a direct but possibly conditional or different-type transition compared to the solid arrows.
2. **Transition Logic from `S_n^-` (Negative State at step n):**
* It can remain in a negative state at the next step (`n-1`) with probability `f`.
* It can transition to a positive state at step `n-1` with probability `(1-μ)e_+`.
* It has a self-loop (staying in `S_n^-`?) with weight `μ(e_+)`. The notation is ambiguous; it may represent an internal process or a transition back to itself within the same time step.
3. **Transition Logic from `S_n^+` (Positive State at step n):**
* It can remain in a positive state at step `n-1` with probability `μ(e_+)`.
* It can transition to a negative state at step `n-1` with probability `(1-μ)e_+`.
* It also has a self-loop with weight `μ(e_+)`.
4. **Parameter `α`:** Defined as `α = μ e_- + (1-μ)(1-e_+)`. This is a weighted sum combining a term related to the negative state (`e_-`) and the complement of a term related to the positive state (`e_+`), with `μ` acting as a mixing weight.
### Key Observations
* **Symmetry and Asymmetry:** The transition structure from `S_n^-` and `S_n^+` to the `n-1` stage is symmetric in form but uses the same parameters (`f`, `μ`, `e_+`) for both source states. The asymmetry lies in the outcome: from a negative source, `f` leads to negative; from a positive source, `μ(e_+)` leads to positive.
* **Dashed vs. Solid Arrows:** Dashed arrows only appear from the `n+1` stage to the `n` stage, indicating these transitions might be of a different nature (e.g., initialization, observation, or a separate process layer) compared to the solid-arrow transitions between `n` and `n-1`.
* **Color Consistency:** Red is consistently used for negative (`-`) states and their outgoing solid transitions. Green is used for positive (`+`) states and their outgoing solid transitions. The dashed arrows from `S_{n+1}^+` are green, and from `S_{n+1}^-` is green, which is an interesting cross-color transition.
* **Parameter Reuse:** The term `μ(e_+)` appears as a self-loop on both `S_n^-` and `S_n^+`, and as the transition from `S_n^+` to `S_{n-1}^+`. The term `(1-μ)e_+` appears as the cross-state transition from both `S_n^-` to `S_{n-1}^+` and from `S_n^+` to `S_{n-1}^-`.
### Interpretation
This diagram models a sequential decision-making or error-propagation process, likely in the context of reliability, learning, or signal detection (RTBS could stand for something like "Repeated Trial Bayesian System" or "Response Threshold Based System").
* **What it represents:** The system's state (`+` or `-`) evolves over discrete attempts or time steps (`m` attempts). At each step, the state can persist, flip, or self-reinforce based on probabilistic rules involving a base rate (`f`), a modulation parameter (`μ`), and state-dependent error or sensitivity terms (`e_+`, `e_-`).
* **Relationships:** The parameter `α` is the key output or derived metric of the process after `m` attempts. It is not a simple average but a specific combination of the error terms, suggesting it might represent an overall system bias, confidence, or adjusted error rate. The process from `n+1` to `n` (dashed arrows) may represent the input or observation phase, while the process from `n` to `n-1` (solid arrows) represents the state update or memory consolidation phase.
* **Notable Implications:** The model suggests that maintaining a positive state (`S^+`) is governed by the same parameters (`μ`, `e_+`) that also govern escaping a negative state (`S^-`). This implies a system where the mechanisms for success and failure are intertwined. The definition of `α` indicates that system performance (`α`) depends on both the likelihood of errors in the negative state (`e_-`) and the likelihood of *not* making a correct response in the positive state (`1-e_+`), weighted by `μ`. This is characteristic of models in psychophysics, machine learning (e.g., multi-armed bandits), or quality control.
</details>
(b) Reflective reasoning through an RMTP or RTBS
Figure 5: The diagram of state transitions starting from scale $n$ in the simplified reasoning, where probabilities are attached to solid lines. In (b) reflective reasoning, the dashed-line arrow presents the trace-back move after $m$ attempts in RTBS.
For input problems with scale $n$ , we use $\rho(n)$ , $\tilde{\rho}(n)$ , and $\tilde{\rho}_{m}(n)$ to respectively denote the reasoning accuracy using no reflection, RMTP, and RTBS (with width $m$ ). Obviously, we have $\rho(n)=\mu^{n}$ . In contrast, the mathematical forms of $\tilde{\rho}(n)$ and $\tilde{\rho}_{m}(n)$ are more complicated and therefore left to Appendix C.2. Our main result provides simple conditions for the above factors $(\mu,e_{-},e_{+},f)$ to ensure an improved accuracy when reasoning through an RMTP or RTBS.
**Theorem 1**
*In the above simplified problem, consider a self-verifying policy $\tilde{\pi}$ where $\mu$ , $e_{-}$ , and $e_{+}$ are non-trivial (i.e. neither $0$ nor $1$ ). Let $\alpha:=\mu e_{-}+(1-\mu)(1-e_{+})$ denote the rejection probability on positive states. Given an infinite computation budget, for $n>0$ we have:
- $\tilde{\rho}(n)\geq\rho(n)$ if and only if $e_{-}+e_{+}\leq 1$ , where equalities hold simultaneously; furthermore, reducing either $e_{-}$ or $e_{+}$ strictly increases $\tilde{\rho}(n)$ .
- $\tilde{\rho}_{m}(n)>\tilde{\rho}(n)$ for a sufficiently large $n$ if and only if $f>\alpha$ and $m>\frac{1}{1-\alpha}$ ; furthermore, such a gap of $\tilde{\rho}_{m}(n)$ over $\tilde{\rho}(n)$ increases strictly with $f$ .*
Does reflection require a strong verifier? Theorem 1 shows that RMTP improves performance over vanilla MTP if the verification errors $e_{+}$ and $e_{-}$ are properly bounded, which does not necessitate a strong verifier. In our simplified setting, this only requires the verifier $\mathcal{V}$ to be better than random guessing (which ensures $e_{-}+e_{+}=1$ ). This also indicates a trivial guarantee of RTBS, as an infinitely large width ( $m\to+\infty$ ) substantially converts RTBS to RMTB.
When does trace-back search facilitate reflection? Theorem 1 provides the conditions for RTBS to outperform RMTP for a sufficiently large $n$ : 1) The width $m$ is large enough to ensure effective exploration. 2) $f>\alpha$ indicates that negative states are inherently discriminated from positive ones, leading to a higher rejection probability on negative states than on positive states (see Figure 5(b)). In other words, provided $f>\alpha$ , RTBS is ensured to be more effective on complicated queries using a finite $m$ . However, this also implies a risk of over-thought on simple queries that have a small $n$ .
The derivation and additional details of Theorem 1 are provided in Appendix C.3. In addition, we also derive how many steps it costs to find a correct solution in RMTP. The following Proposition 1 (see proof in Appendix C.4) shows that a higher $e_{-}$ causes more steps to be necessarily rejected and increases the solution cost. In contrast, although a higher $e_{+}$ reduces accuracy, it forces successful solutions to rely less on reflection, leading to fewer expected steps. Therefore, a high false negative rate $e_{-}$ is worse than a high $e_{+}$ given the limited computational budget in practice.
**Proposition 1 (RMTP Reasoning Length)**
*For a simplified reasoning problem with scale $n$ , the expected number of steps $\bar{T}$ for $\tilde{\pi}$ to find a correct answer is $\bar{T}=\frac{n}{(1-\mu)e_{+}+\mu(1-e_{-})}$ . Especially, a correct answer will never be found if the denominator is $0$ .*
Appendix C.5 further extends our analysis to more realistic reasoning, where rejected attempts lead to a posterior drop of $\mu$ (or rise of $e_{-}$ ), indicating that the model may not well generalize the current state. In this case, the bound of $e_{-}$ to ensure improvements becomes stricter than that in Theorem 1.
## 5 Experiments
We conduct comprehensive experiments to examine the reasoning performance of tiny transformers under various settings. We trained simple causal-attention transformers [36] (implemented by LitGPT [1]) with 1M, 4M, and 16M parameters, through the pipelines described in Section 3.3. Details of training data, model architectures, tokenization, and hyperparameters are included in Appendix D. The source code is available at https://github.com/zwyu-ai/self-verifying-reflection-reasoning.
We test tiny transformers in two reasoning tasks: The integer multiplication task (Mult for short) computes the product of two integers $x$ and $y$ ; the Sudoku task fills numbers into blank positions of a $9\times 9$ matrix, such that each row, column, or $3\times 3$ block is a permutation of $\{1,\ldots,9\}$ . For both tasks, we divide queries into 3 levels of difficulties: The in-distribution (ID) Easy, ID Hard, and out-of-distribution (OOD) Hard. The models are trained on ID-Easy and ID-Hard problems, while tested additionally on OOD-Hard cases. We define the difficulty of a Mult query by the number $d$ of digits of the greater multiplicand, and that of a Sudoku puzzle is determined by the number $b$ of blanks to be filled. Specifically, we have $1\leq d\leq 5$ or $9\leq b<36$ for ID Easy, $6\leq d\leq 8$ or $36\leq b<54$ for ID Hard, and $9\leq d\leq 10$ or $54\leq b<63$ for OOD Hard.
Our full results are presented in Appendix E. Shown in Appendix E.1, these seemingly simple tasks pose challenges even for some well-known LLMs. Remarkably, through simple self-verifying reflection, our best 4M Sudoku model is as good as OpenAI o3-mini [21], and our best 16M Mult model outperforms DeepSeek-R1 [5] in ID difficulties.
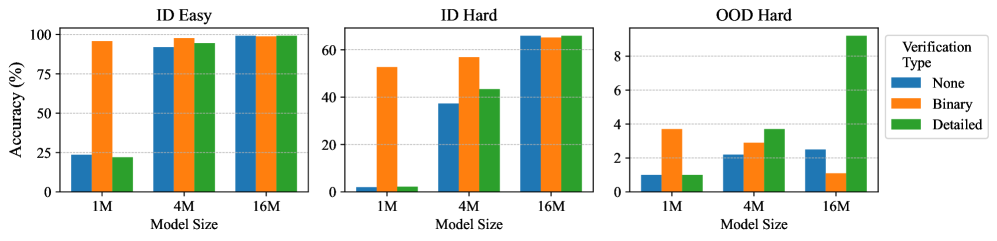
### 5.1 Results of supervised fine-tuning
First, we conduct (I) pretraining, (II) non-reflective SFT, and (III) reflective SFT as described in Section 3.3. In reflective SFT, we consider learning two types of self-verification: 1) The binary verification includes a single binary label indicating the overall correctness of a planned step; 2) the detailed verification includes a series of binary labels checking the correctness of each meaningful element in the step. The implementation of verification labels is elaborated in Appendix D.2.3. We present our full SFT results in Appendix E.2, which includes training 30 models and executing 54 tests. In the following, we discuss our main findings through visualizing representative results.
<details>
<summary>x9.png Details</summary>
### Visual Description
## Grouped Bar Chart: Model Accuracy by Size and Verification Type
### Overview
The image displays three grouped bar charts arranged horizontally, comparing the accuracy (%) of machine learning models across three different evaluation settings ("ID Easy", "ID Hard", "OOD Hard") and three model sizes (1M, 4M, 16M). Performance is further broken down by three "Verification Types": None, Binary, and Detailed.
### Components/Axes
* **Chart Type:** Grouped Bar Chart (3 subplots).
* **Subplot Titles (Top Center):**
* Left: `ID Easy`
* Center: `ID Hard`
* Right: `OOD Hard`
* **Y-Axis (Leftmost chart only, shared scale concept):**
* **Label:** `Accuracy (%)`
* **Scale:** 0 to 100, with major ticks at 0, 25, 50, 75, 100.
* **X-Axis (Each subplot):**
* **Label:** `Model Size`
* **Categories:** `1M`, `4M`, `16M`.
* **Legend (Position: Far right, outside the "OOD Hard" chart):**
* **Title:** `Verification Type`
* **Categories & Colors:**
* `None` - Blue
* `Binary` - Orange
* `Detailed` - Green
### Detailed Analysis
**1. ID Easy (Left Subplot)**
* **Trend:** All verification types show high accuracy, with a slight upward trend as model size increases. Binary verification is consistently the highest.
* **Data Points (Approximate %):**
* **1M Model:** None ≈ 25%, Binary ≈ 95%, Detailed ≈ 25%.
* **4M Model:** None ≈ 90%, Binary ≈ 98%, Detailed ≈ 95%.
* **16M Model:** None ≈ 98%, Binary ≈ 99%, Detailed ≈ 98%.
**2. ID Hard (Center Subplot)**
* **Trend:** Clear positive correlation between model size and accuracy for all verification types. Binary verification maintains a lead, but the gap narrows at larger sizes.
* **Data Points (Approximate %):**
* **1M Model:** None ≈ 2%, Binary ≈ 52%, Detailed ≈ 2%.
* **4M Model:** None ≈ 38%, Binary ≈ 58%, Detailed ≈ 42%.
* **16M Model:** None ≈ 65%, Binary ≈ 65%, Detailed ≈ 65%.
**3. OOD Hard (Right Subplot)**
* **Trend:** Overall accuracy is drastically lower than in-distribution (ID) tasks. The trend is less uniform. Notably, Detailed verification shows a dramatic, disproportionate increase for the largest model.
* **Data Points (Approximate %):**
* **1M Model:** None ≈ 1%, Binary ≈ 3.8%, Detailed ≈ 1%.
* **4M Model:** None ≈ 2.2%, Binary ≈ 3%, Detailed ≈ 3.8%.
* **16M Model:** None ≈ 2.5%, Binary ≈ 1.2%, Detailed ≈ 9%.
### Key Observations
1. **Performance Hierarchy:** In easier tasks (ID Easy), Binary verification is superior. In harder tasks (ID Hard, OOD Hard), the advantage diminishes or changes.
2. **Model Scaling Benefit:** Increasing model size from 1M to 16M parameters consistently improves accuracy across all settings and verification types, though the absolute gain is smallest in OOD Hard (except for Detailed verification).
3. **Verification Type Impact:** The effect of verification is highly context-dependent. It provides a massive boost in "ID Easy" for the 1M model but has minimal or even negative impact in "OOD Hard" for some sizes.
4. **Critical Outlier:** The performance of **Detailed verification on the 16M model in the OOD Hard setting** is a major outlier. It jumps to ~9% accuracy, while all other data points in that chart are below 4%. This suggests a potential breakthrough or specific synergy for large models using detailed verification on out-of-distribution tasks.
5. **Task Difficulty Gradient:** There is a stark drop in baseline accuracy (None verification) from ID Easy (~25-98%) to ID Hard (~2-65%) to OOD Hard (~1-2.5%), clearly illustrating the increasing difficulty of these evaluation settings.
### Interpretation
This data suggests several important insights for model development and evaluation:
* **Verification is Not Universally Beneficial:** The "Binary" verification method acts as a strong performance crutch for smaller models on easier tasks but does not scale its advantage to harder problems or larger models. Its utility is context-specific.
* **The Promise of Detailed Verification:** While often underperforming on easier tasks, **Detailed verification shows unique potential for large models (16M) on the hardest, out-of-distribution tasks**. This could indicate that detailed reasoning or verification steps become crucial when a model has sufficient capacity to leverage them in unfamiliar scenarios.
* **Scaling Laws Hold, But Are Task-Dependent:** The consistent improvement with model size confirms scaling laws, but the *rate* of improvement varies dramatically. Gains are massive in ID settings but marginal in OOD settings, highlighting a fundamental challenge in generalization.
* **OOD Generalization Remains the Core Challenge:** The extremely low accuracy across the board in "OOD Hard" (all values <10%) underscores that current methods, even with large models and verification, struggle significantly with distribution shift. The spike for Detailed/16M is a promising but isolated data point that requires further investigation.
In summary, the charts argue for a nuanced approach: simple verification may suffice for known domains, but advancing to truly out-of-distribution problems may require both large model scale and more sophisticated, detailed verification mechanisms.
</details>
Figure 6: The accuracy of non-reflective execution of models in Mult. In each group, we compare training with various types of verification (“None” for no reflective SFT).
Does learning self-verification facilitate learning the planning policy? We compare our models under the non-reflective execution, where self-verification is not actively used in test time. As shown in Figure 6, reflective SFT with binary verification brings remarkable improvements for 1M and 4M in ID-Easy and ID-Hard Mult problems, greatly reducing the gap among model sizes. Although detailed verification does not benefit as much as binary verification in ID problems, it significantly benefits the 16M model in solving OOD-Hard problems. Therefore, learning to self-verify benefits the learning of forward planning, increasing performance even if test-time reflection is not enabled.
Since reflective SFT mixes the same CoT examples as used in non-reflective SFT, an explanation for this phenomenon is that learning to self-verify serves as a regularizer to the planning policy. This substantially improves the quality of hidden embeddings in transformers, which facilitates the learning of CoT examples. Binary verification is inherently a harder target to learn, which produces stronger regularizing effects than detailed verification. However, the complexity (length) of the verification should match the capacity of the model; otherwise, it could severely compromise the benefits of learning self-verification. For instance, learning binary verification and detailed verification fails to improve the 16M model and the 1M model, respectively.
<details>
<summary>x10.png Details</summary>
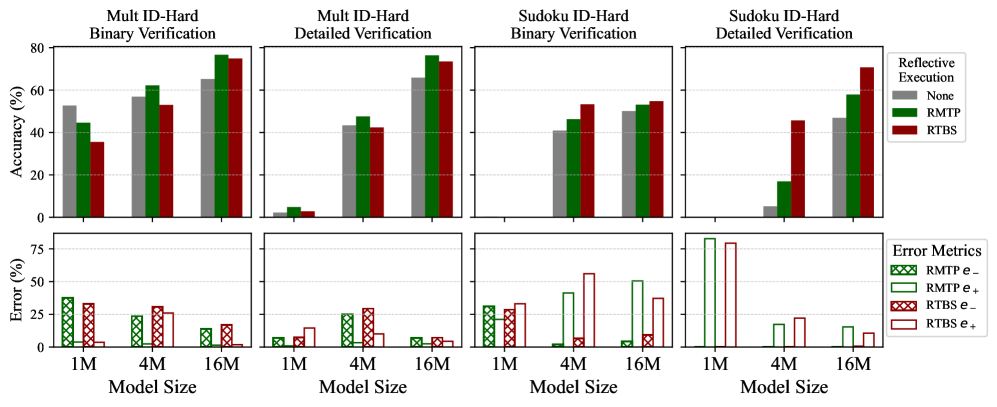
### Visual Description
## Bar Charts: Reflective Execution Performance Across Model Sizes
### Overview
The image displays a 2x4 grid of bar charts comparing the performance of different "Reflective Execution" methods on two tasks ("Mult ID-Hard" and "Sudoku ID-Hard") using two verification types ("Binary" and "Detailed"). The top row measures Accuracy (%), and the bottom row measures Error (%). Performance is evaluated across three model sizes: 1M, 4M, and 16M parameters.
### Components/Axes
* **Chart Structure:** 8 individual bar charts arranged in 2 rows and 4 columns.
* **Row 1 (Top):** Y-axis label: **Accuracy (%)**. Scale: 0 to 80.
* **Row 2 (Bottom):** Y-axis label: **Error (%)**. Scale: 0 to 75.
* **X-axis (All Charts):** Label: **Model Size**. Categories: **1M**, **4M**, **16M**.
* **Column Titles (Top Row):**
1. Mult ID-Hard Binary Verification
2. Mult ID-Hard Detailed Verification
3. Sudoku ID-Hard Binary Verification
4. Sudoku ID-Hard Detailed Verification
* **Legends:**
* **Top-Right (Accuracy Charts):** "Reflective Execution" with three categories:
* **None** (Gray bar)
* **RMTP** (Green bar)
* **RTBS** (Red bar)
* **Bottom-Right (Error Charts):** "Error Metrics" with four categories:
* **RMTP e-** (Green bar with cross-hatch pattern)
* **RMTP e+** (Green bar, solid outline)
* **RTBS e-** (Red bar with cross-hatch pattern)
* **RTBS e+** (Red bar, solid outline)
### Detailed Analysis
#### **Row 1: Accuracy (%)**
**Trend Verification:** Across all four tasks, accuracy generally increases with model size for all methods. The "None" (gray) baseline often shows the lowest accuracy, while RMTP (green) and RTBS (red) typically perform better, with their relative performance varying by task.
1. **Mult ID-Hard Binary Verification:**
* **1M:** None ~52%, RMTP ~45%, RTBS ~35%.
* **4M:** None ~58%, RMTP ~62%, RTBS ~53%.
* **16M:** None ~65%, RMTP ~78%, RTBS ~75%.
* *Observation:* RMTP and RTBS overtake "None" at 4M and 16M. RMTP is highest at 16M.
2. **Mult ID-Hard Detailed Verification:**
* **1M:** All methods very low (<5%).
* **4M:** None ~42%, RMTP ~48%, RTBS ~42%.
* **16M:** None ~65%, RMTP ~76%, RTBS ~73%.
* *Observation:* Dramatic improvement from 1M to 4M. RMTP leads at 4M and 16M.
3. **Sudoku ID-Hard Binary Verification:**
* **1M:** None ~40%, RMTP ~45%, RTBS ~53%.
* **4M:** None ~50%, RMTP ~52%, RTBS ~55%.
* **16M:** None ~50%, RMTP ~52%, RTBS ~55%.
* *Observation:* Performance plateaus after 4M. RTBS consistently has a slight edge.
4. **Sudoku ID-Hard Detailed Verification:**
* **1M:** None ~5%, RMTP ~18%, RTBS ~45%.
* **4M:** None ~45%, RMTP ~58%, RTBS ~70%.
* **16M:** No bars visible for "None". RMTP ~58%, RTBS ~70%.
* *Observation:* RTBS shows a very strong lead, especially at 1M and 4M. The "None" method appears to fail completely at 16M (0% accuracy).
#### **Row 2: Error (%)**
**Trend Verification:** Error rates generally decrease with model size. The charts break down errors into "e-" (likely under-execution/omission) and "e+" (likely over-execution/commission) for RMTP and RTBS.
1. **Mult ID-Hard Binary Verification:**
* **1M:** RMTP e- ~38%, RMTP e+ ~35%, RTBS e- ~35%, RTBS e+ ~5%.
* **4M:** RMTP e- ~25%, RMTP e+ ~25%, RTBS e- ~30%, RTBS e+ ~25%.
* **16M:** RMTP e- ~15%, RMTP e+ ~15%, RTBS e- ~18%, RTBS e+ ~15%.
* *Observation:* Errors decrease with scale. At 1M, RTBS has a very low e+ error but high e- error.
2. **Mult ID-Hard Detailed Verification:**
* **1M:** RMTP e- ~8%, RMTP e+ ~5%, RTBS e- ~15%, RTBS e+ ~12%.
* **4M:** RMTP e- ~25%, RMTP e+ ~25%, RTBS e- ~30%, RTBS e+ ~12%.
* **16M:** RMTP e- ~8%, RMTP e+ ~8%, RTBS e- ~8%, RTBS e+ ~5%.
* *Observation:* Error patterns are less consistent. RTBS e+ is often lower than its e- counterpart.
3. **Sudoku ID-Hard Binary Verification:**
* **1M:** RMTP e- ~32%, RMTP e+ ~30%, RTBS e- ~30%, RTBS e+ ~35%.
* **4M:** RMTP e- ~2%, RMTP e+ ~42%, RTBS e- ~8%, RTBS e+ ~58%.
* **16M:** RMTP e- ~5%, RMTP e+ ~52%, RTBS e- ~12%, RTBS e+ ~38%.
* *Observation:* A striking pattern: e+ errors (solid bars) become dominant at 4M and 16M, especially for RMTP, while e- errors (hatched) drop significantly.
4. **Sudoku ID-Hard Detailed Verification:**
* **1M:** RMTP e- ~82%, RMTP e+ ~80%, RTBS e- ~0%, RTBS e+ ~0%.
* **4M:** RMTP e- ~0%, RMTP e+ ~20%, RTBS e- ~0%, RTBS e+ ~22%.
* **16M:** RMTP e- ~0%, RMTP e+ ~18%, RTBS e- ~0%, RTBS e+ ~12%.
* *Observation:* At 1M, RMTP has extremely high e- and e+ errors, while RTBS shows near-zero errors (correlating with its higher accuracy). At larger sizes, e- errors vanish, leaving only e+ errors.
### Key Observations
1. **Scale is Critical:** Performance (accuracy) improves dramatically from 1M to 4M parameters for most tasks, with smaller gains or plateaus from 4M to 16M.
2. **Task Difficulty:** "Detailed Verification" tasks show lower initial accuracy (at 1M) than "Binary Verification" tasks, indicating they are more challenging for smaller models.
3. **Method Superiority:** **RTBS** (red) often achieves the highest accuracy, particularly on the Sudoku tasks. **RMTP** (green) is competitive and sometimes leads on the Mult tasks.
4. **Error Type Shift:** A notable anomaly occurs in the Sudoku Binary Verification error chart, where the dominant error type shifts from a mix at 1M to predominantly **e+** (over-execution) errors at 4M and 16M.
5. **Baseline Failure:** The "None" (no reflective execution) method fails completely (0% accuracy) on the Sudoku Detailed Verification task at 16M, highlighting the necessity of reflective execution for complex tasks at scale.
### Interpretation
This data suggests that **reflective execution mechanisms (RMTP and RTBS) are essential for solving complex, multi-step reasoning tasks**, especially as model scale increases. Their benefit is most pronounced on the harder "Detailed Verification" tasks and the structured "Sudoku" domain.
The shift in error types (from e- to e+) in Sudoku tasks implies that as models grow larger and more capable, their failure mode changes from *failing to attempt* a solution (omission) to *attempting but incorrectly executing* the solution (commission). This is a sign of increased model confidence and capability, but also a need for better execution verification.
The superior performance of RTBS on Sudoku tasks may indicate it is better suited for problems with strict, rule-based logical structures. In contrast, RMTP's strength on the "Mult" tasks might suggest an advantage in more open-ended or multi-faceted reasoning. The complete failure of the baseline at 16M on the hardest task underscores that raw model scale alone is insufficient without structured reasoning scaffolds like reflective execution.
</details>
Figure 7: Performance of reflective execution methods across different model sizes, including the accuracy (top) and the self-verification errors (bottom).
When do reflective executions improve reasoning accuracy? Figure 7 evaluates the non-reflective, RMTP, and RTBS executions for models in solving ID-Hard problems. Apart from the accuracy, the rates of verification error (i.e., the false positive rate $e_{+}$ and false negative rate $e_{-}$ defined in Section 4) are measured using an oracle verifier. In these results, RMTP reasoning raises the performance over non-reflective reasoning except for the 1M models (which fail in ID-hard Sudoku). Smaller error rates (especially $e_{-}$ ) generally lead to higher improvements, whereas a high $e_{-}$ in binary verification severely compromises the performance of the 1M Mult Model. Overall, reflection improves reasoning if the chance of rejecting correct steps ( $e_{-}$ ) is sufficiently small.
In what task is the trace-back search helpful? As seen in Figure 7, though RTBS shows no advantage against RMTP in Mult, it outperforms RMTP in Sudoku, especially the 4M model with detailed verification. This aligns with Theory 1 — The state of Sudoku (the $9\times 9$ matrix) is required to comply with explicit verifiable rules, making incorrect states easily discriminated from correct states. However, errors in Mult states can only be checked by recalculating all historical steps. Therefore, we are more likely to have $f>\alpha$ in Sudoku, which grants a higher chance of solving harder problems. This suggests that RTBS can be more helpful than RMTP if incorrect states in the task carry verifiable errors, which validates our theoretical results.
### 5.2 Results of reinforcement learning
<details>
<summary>x11.png Details</summary>
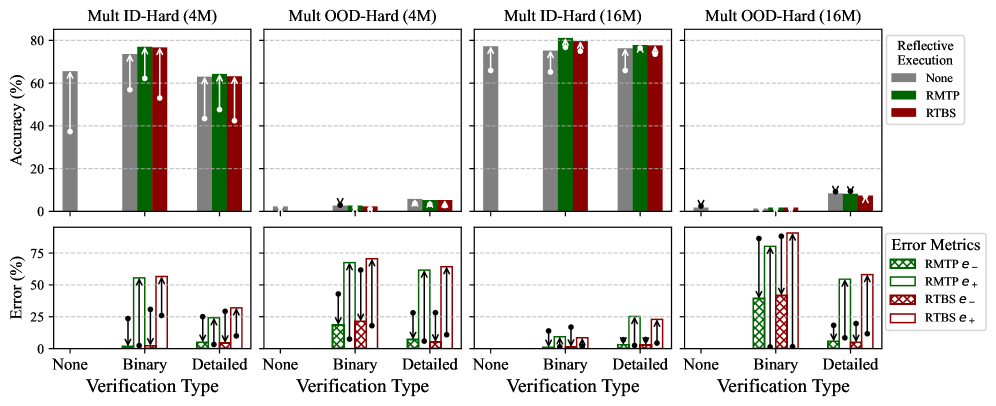
### Visual Description
## Bar Chart Series: Reflective Execution Performance Across Verification Types
### Overview
The image displays a 2x2 grid of bar charts comparing the performance of different "Reflective Execution" methods (None, RMTP, RTBS) across three "Verification Types" (None, Binary, Detailed). The top row measures Accuracy (%), and the bottom row measures Error (%). The charts are grouped by dataset difficulty and model size: "Mult ID-Hard" (In-Distribution) and "Mult OOD-Hard" (Out-Of-Distribution), each tested with 4M and 16M parameter models.
### Components/Axes
* **Main Title (Implicit):** Performance of Reflective Execution Methods.
* **Panel Subtitles (Top Row, Left to Right):**
1. `Mult ID-Hard (4M)`
2. `Mult OOD-Hard (4M)`
3. `Mult ID-Hard (16M)`
4. `Mult OOD-Hard (16M)`
* **Y-Axis (Top Row):** `Accuracy (%)`. Scale ranges from 0 to 80 with increments of 20.
* **Y-Axis (Bottom Row):** `Error (%)`. Scale ranges from 0 to 75 with increments of 25.
* **X-Axis (All Charts):** `Verification Type`. Categories are `None`, `Binary`, `Detailed`.
* **Legend 1 (Reflective Execution - Top Right of Top Row):**
* Gray Bar: `None`
* Green Bar: `RMTP`
* Red Bar: `RTBS`
* **Legend 2 (Error Metrics - Bottom Right of Bottom Row):**
* Green Hatched Bar: `RMTP e-`
* Green Solid Bar: `RMTP e+`
* Red Hatched Bar: `RTBS e-`
* Red Solid Bar: `RTBS e+`
* **Data Point Markers:** Black dots with vertical lines (likely representing mean and standard deviation or confidence intervals) are overlaid on each bar.
### Detailed Analysis
#### **Top Row: Accuracy (%)**
* **Mult ID-Hard (4M):**
* **Trend:** Accuracy is very low for `None` verification (~40%). It increases substantially for `Binary` and `Detailed` verification, with `RMTP` and `RTBS` performing similarly and outperforming `None`.
* **Data Points (Approximate):**
* `None` Verification: `None` method ≈ 40%.
* `Binary` Verification: `None` ≈ 70%, `RMTP` ≈ 78%, `RTBS` ≈ 78%.
* `Detailed` Verification: `None` ≈ 62%, `RMTP` ≈ 63%, `RTBS` ≈ 63%.
* **Mult OOD-Hard (4M):**
* **Trend:** Accuracy is near zero across all verification types and methods, indicating a complete failure to generalize to out-of-distribution data with the 4M model.
* **Data Points (Approximate):** All bars are at or below 5%.
* **Mult ID-Hard (16M):**
* **Trend:** Similar pattern to the 4M ID-Hard chart but with higher overall accuracy. `Binary` verification yields the highest performance, with `RMTP` and `RTBS` reaching near 80%.
* **Data Points (Approximate):**
* `None` Verification: `None` method ≈ 75%.
* `Binary` Verification: `None` ≈ 75%, `RMTP` ≈ 80%, `RTBS` ≈ 79%.
* `Detailed` Verification: `None` ≈ 75%, `RMTP` ≈ 77%, `RTBS` ≈ 77%.
* **Mult OOD-Hard (16M):**
* **Trend:** Accuracy remains very low, but shows a slight, visible increase compared to the 4M OOD model, particularly for `Detailed` verification with the `None` method.
* **Data Points (Approximate):** Most bars are below 5%. The highest point is `None` method with `Detailed` verification at ≈ 10%.
#### **Bottom Row: Error (%)**
* **Mult ID-Hard (4M):**
* **Trend:** Error is negligible for `None` verification. For `Binary` and `Detailed`, both `RMTP` and `RTBS` show significant error rates, with `RTBS` generally having slightly higher `e+` (overconfidence) error.
* **Data Points (Approximate):**
* `Binary` Verification: `RMTP e-` ≈ 55%, `RMTP e+` ≈ 15%, `RTBS e-` ≈ 55%, `RTBS e+` ≈ 60%.
* `Detailed` Verification: `RMTP e-` ≈ 10%, `RMTP e+` ≈ 20%, `RTBS e-` ≈ 15%, `RTBS e+` ≈ 30%.
* **Mult OOD-Hard (4M):**
* **Trend:** Error rates are high across the board for `Binary` and `Detailed` verification, consistent with the near-zero accuracy. `RTBS` shows particularly high `e+` error.
* **Data Points (Approximate):**
* `Binary` Verification: `RMTP e-` ≈ 20%, `RMTP e+` ≈ 65%, `RTBS e-` ≈ 20%, `RTBS e+` ≈ 70%.
* `Detailed` Verification: `RMTP e-` ≈ 10%, `RMTP e+` ≈ 60%, `RTBS e-` ≈ 10%, `RTBS e+` ≈ 65%.
* **Mult ID-Hard (16M):**
* **Trend:** Error rates are lower than the 4M model for ID data. `Binary` verification shows moderate error, while `Detailed` verification has lower error, especially for `RMTP`.
* **Data Points (Approximate):**
* `Binary` Verification: `RMTP e-` ≈ 10%, `RMTP e+` ≈ 12%, `RTBS e-` ≈ 8%, `RTBS e+` ≈ 10%.
* `Detailed` Verification: `RMTP e-` ≈ 5%, `RMTP e+` ≈ 8%, `RTBS e-` ≈ 5%, `RTBS e+` ≈ 22%.
* **Mult OOD-Hard (16M):**
* **Trend:** Error remains very high for OOD data, especially `e+` (overconfidence) error. `RTBS` with `Binary` verification shows the highest error in the entire set.
* **Data Points (Approximate):**
* `Binary` Verification: `RMTP e-` ≈ 40%, `RMTP e+` ≈ 85%, `RTBS e-` ≈ 40%, `RTBS e+` ≈ 90%.
* `Detailed` Verification: `RMTP e-` ≈ 10%, `RMTP e+` ≈ 55%, `RTBS e-` ≈ 10%, `RTBS e+` ≈ 65%.
### Key Observations
1. **Model Size Impact:** The 16M model consistently outperforms the 4M model in accuracy on in-distribution (ID) data and shows a marginal improvement on out-of-distribution (OOD) data.
2. **Verification Type Efficacy:** `Binary` and `Detailed` verification significantly boost accuracy over `None` for ID tasks. However, this benefit does not translate to OOD tasks.
3. **OOD Failure:** Both models fail catastrophically on OOD data, with accuracy near zero and very high error rates, particularly `e+` (overconfidence) error.
4. **Error Profile:** `RTBS` tends to have higher `e+` (overconfidence) error than `RMTP`, especially in challenging conditions (OOD, Binary verification).
5. **Trade-off:** There is a clear trade-off: applying reflective execution (`RMTP`/`RTBS`) with verification improves accuracy on ID data but introduces measurable error, primarily of the `e-` (underconfidence) type for `Binary` verification.
### Interpretation
This data suggests that reflective execution methods (`RMTP`, `RTBS`) are effective tools for improving the accuracy of language models on complex, in-distribution tasks when paired with verification steps. The performance gain is more pronounced with a larger model (16M vs. 4M). However, these methods do not solve the fundamental problem of model robustness to distribution shift. The near-zero accuracy and soaring overconfidence error (`e+`) on OOD data indicate that the models' internal confidence calibration breaks down completely when faced with unfamiliar data patterns, and the reflective mechanisms cannot compensate for this lack of generalization. The higher `e+` error for `RTBS` suggests it may be more prone to overconfident mistakes under uncertainty. The charts highlight a critical challenge in AI safety and reliability: techniques that enhance performance on known tasks may not confer robustness to novel situations, and can even exacerbate overconfidence in those scenarios.
</details>
Figure 8: Performance of the 4M and 16M models in Mult after GRPO, including accuracy and the verification error rates. As an ablation, we also include non-reflective models. The vertical arrows start from the baseline accuracy after SFT, presenting the relative change caused by GRPO.
As introduced in Section 3.3, we further apply GRPO to fine-tune the models after SFT. Especially, GRPO based on RMTP allows solution planning and verification to be jointly optimized for self-verifying policies. The full GRPO results are presented in Appendix E.3, and the main findings are presented below. Overall, RL does enable most models to better solve ID problems, yet such improvements arise from a superficial shift in the distribution of known reasoning skills.
How does RL improve reasoning accuracy? Figure 8 presents the performance of 4M and 16M models in Mult after GRPO, where the differences from SFT results are visualized. GRPO effectively enhances accuracy in solving ID-Hard problems, yet the change in OOD performance is marginal. Therefore, RL can optimize ID performance, while failing to generalize to OOD cases.
Does RL truly enhance verification? From the change of verification errors in Figure 8, we find that the false negative rate $e_{-}$ decreases along with an increase in the false positive rate $e_{+}$ . This suggests that models learn an optimistic bias, which avoids rejecting correct steps through a high false positive rate that bypasses verification. In other words, instead of truly improving the verifier (where $e_{-}$ and $e_{+}$ both decrease), RL mainly induces an error-type trade-off, shifting from false negatives ( $e_{+}$ ) to false positives ( $e_{-}$ ).
To explain this, we note that a high $e_{-}$ raises the computational cost (Proposition 1) and thus causes a significant performance loss under the limited budget of RL sampling, making reducing $e_{-}$ more rewarding than maintaining a low $e_{+}$ . Meanwhile, shifting the error type is easy to learn, achievable by adjusting only a few parameters in the output layer of the transformer.
Inspired by DeepSeek-R1 [5], we additionally examine how RL influences the frequency of reflective behavior. To simulate the natural distribution of human reasoning, we train models to perform optional detailed verification by adding examples of empty verification (in the same amount as the full verification) into reflective SFT. This allows the policy to optionally omit self-verification, usually with a higher probability than producing full verification, since empty verification is easier to learn. Consequently, we can measure the reflection frequency by counting the proportion of steps that include non-empty verification. Since models can implicitly omit binary verification by producing false positive labels, we do not explicitly examine the optional binary verification.
When does RL incentivize frequent reflection?
Figure 9 shows reflection frequency in Mult before and after GRPO, comparing exploratory ( $1.25$ ) and exploitative ( $1$ ) temperatures when sampling experience CoTs. With a temperature $1.25$ , GRPO elicits frequent reflection, especially on hard queries. However, reflection frequency remains low if using temperature $1$ . Additional results for other model sizes and Sudoku appear in Appendix E.3.3. In conclusion, RL can adapt reflection frequency to align with the exploratory ability of the planning policy $\pi$ , encouraging more reflection if the policy can potentially explore rewards. This helps explain why RL promotes frequent reflection in LLMs [5], as the flexibility of language naturally fosters exploratory reasoning.
<details>
<summary>x12.png Details</summary>
### Visual Description
\n
## Heatmap Series: GRPO Effect on Digit-Length Performance
### Overview
The image displays three horizontally arranged heatmaps comparing performance metrics before and after applying a process called "GRPO" at two different temperature settings. Each heatmap plots the "number of y's digits" (vertical axis) against the "number of x's digits" (horizontal axis), with cell values representing a performance metric (likely accuracy, success rate, or a similar score). The color scale ranges from dark (low values) to bright yellow/white (high values).
### Components/Axes
* **Titles (Top of each heatmap):**
* Left: "Before GRPO"
* Center: "After GRPO Temperature: 1.25"
* Right: "After GRPO Temperature: 1.0"
* **Vertical Axis (Y-axis, left side of each heatmap):** Labeled "number of y's digits". Markers range from 1 to 10, incrementing downward.
* **Horizontal Axis (X-axis, bottom of each heatmap):** Labeled "number of x's digits". Markers range from 1 to 10, incrementing rightward.
* **Data Grid:** Each heatmap is a 10x10 grid. The value in each cell is explicitly written as a number.
* **Color Mapping:** A consistent gradient is used across all three charts. Dark colors (black/dark red) represent low values, transitioning through red, orange, and yellow to bright white for the highest values.
### Detailed Analysis
**1. Before GRPO (Left Heatmap)**
* **Visual Trend:** Values are generally low across the entire grid, with the highest values concentrated in the top-left corner (low digit counts for both x and y). Performance degrades significantly as the number of digits increases, especially for y.
* **Data Extraction (Row by Row, y=1 to 10):**
* y=1: 7, 23, 15, 6, 15, 13, 22, 11, 5, 4
* y=2: 21, 23, 24, 19, 14, 14, 20, 9, 4, 5
* y=3: 6, 12, 20, 8, 5, 3, 5, 3, 3, 5
* y=4: 8, 18, 11, 3, 2, 2, 4, 5, 5, 5
* y=5: 18, 10, 6, 1, 2, 1, 8, 5, 4, 4
* y=6: 13, 11, 5, 2, 4, 4, 8, 5, 4, 3
* y=7: 14, 8, 6, 9, 6, 10, 8, 5, 3, 4
* y=8: 5, 6, 9, 6, 4, 3, 8, 5, 4, 4
* y=9: 4, 5, 3, 4, 2, 2, 4, 4, 3, 3
* y=10: 4, 4, 2, 2, 1, 1, 4, 2, 4, 2
**2. After GRPO Temperature: 1.25 (Center Heatmap)**
* **Visual Trend:** A dramatic, widespread increase in values across the entire grid compared to the "Before" state. The heatmap is predominantly bright orange and yellow, indicating high performance. The highest values form a broad plateau in the center and lower-right regions (higher digit counts).
* **Data Extraction (Row by Row, y=1 to 10):**
* y=1: 30, 43, 35, 34, 32, 35, 32, 37, 32, 32
* y=2: 50, 49, 49, 49, 49, 52, 47, 49, 52, 52
* y=3: 30, 64, 56, 56, 57, 50, 53, 56, 56, 56
* y=4: 32, 67, 67, 67, 67, 67, 67, 67, 67, 67
* y=5: 37, 60, 72, 72, 72, 75, 78, 74, 74, 74
* y=6: 45, 63, 70, 72, 74, 78, 84, 77, 77, 77
* y=7: 47, 71, 76, 77, 77, 82, 86, 89, 84, 79, 75
* y=8: 33, 71, 80, 83, 86, 84, 83, 79, 79, 74
* y=9: 37, 75, 79, 83, 84, 83, 83, 79, 79, 47
* y=10: 35, 76, 79, 81, 83, 82, 84, 79, 53, 56
**3. After GRPO Temperature: 1.0 (Right Heatmap)**
* **Visual Trend:** Performance is highly variable. The top-right quadrant (high x digits, low y digits) shows many zeros, indicating complete failure. The bottom-left quadrant (low x digits, high y digits) shows moderate to high values. There is a clear diagonal boundary separating regions of success from regions of failure.
* **Data Extraction (Row by Row, y=1 to 10):**
* y=1: 0, 9, 2, 5, 1, 5, 0, 0, 0, 0
* y=2: 19, 14, 14, 14, 13, 6, 9, 2, 0, 0
* y=3: 1, 5, 13, 3, 0, 0, 0, 0, 0, 0
* y=4: 6, 17, 11, 1, 0, 0, 3, 2, 0, 0
* y=5: 21, 15, 9, 1, 1, 3, 6, 3, 0, 1
* y=6: 25, 14, 7, 4, 9, 5, 9, 2, 0, 0
* y=7: 24, 12, 12, 12, 12, 9, 9, 4, 1, 0
* y=8: 10, 13, 12, 11, 10, 6, 6, 4, 0, 2
* y=9: 3, 9, 9, 10, 4, 1, 0, 1, 2, 2
* y=10: 3, 9, 9, 10, 4, 1, 0, 1, 2, 2
### Key Observations
1. **Baseline Performance ("Before GRPO"):** The system struggles with longer digit sequences. Peak performance (24) is limited to simple cases (e.g., 2-digit x and y). Performance for y=10 is uniformly poor (≤4).
2. **Effect of GRPO at T=1.25:** This setting yields a massive and robust performance boost. The system now handles complex cases (e.g., 10-digit x and y) with scores in the 50s-80s, a >10x improvement over baseline. The performance landscape is relatively smooth and high.
3. **Effect of GRPO at T=1.0:** This setting creates a brittle, specialized performance profile. It maintains good performance for cases where the number of y digits is greater than or equal to the number of x digits (lower-left triangle), but fails catastrophically (scores of 0) when x digits outnumber y digits (upper-right triangle).
4. **Temperature Sensitivity:** The GRPO process is highly sensitive to the temperature parameter. T=1.25 promotes general, high performance, while T=1.0 creates a sharp, diagonal decision boundary.
### Interpretation
This data demonstrates the impact of the GRPO optimization technique on a model's ability to handle tasks parameterized by the digit lengths of two variables, x and y.
* **What the data suggests:** The "Before" state shows a model with limited capacity, failing as problem complexity (digit length) increases. GRPO is an effective training or adaptation method that significantly enhances this capacity.
* **Relationship between elements:** The temperature parameter in GRPO acts as a crucial control knob. A higher temperature (1.25) appears to encourage broader generalization, leading to uniformly high scores. A lower temperature (1.0) seems to enforce a stricter, more categorical rule—possibly "only succeed when y is at least as complex as x"—resulting in the observed diagonal split between success and failure.
* **Notable anomalies:** The perfect zeros in the T=1.0 chart are striking. They indicate not just poor performance, but total failure for specific input configurations. The identical rows for y=9 and y=10 in the T=1.0 chart (3,9,9,10,4,1,0,1,2,2) suggest the model's behavior has saturated or hit a systematic limit for the highest y-digit counts under this setting.
* **Underlying implication:** The choice of temperature during GRPO doesn't just scale performance; it fundamentally changes the model's decision boundary and failure modes. This has critical implications for deploying such models, where understanding the conditions for failure (as clearly mapped in the T=1.0 chart) is as important as knowing peak performance.
</details>
Figure 9: The hot-maps of reflection frequencies of the 4M transformer in multiplication before and after GRPO using temperatures $1$ and $1.25$ , tested with RMTP execution. The $i$ -th row and $j$ -th column shows the frequency (%) for problems $x\times y$ where $x$ has $j$ digits and $y$ has $i$ digits.
## 6 Conclusion and Discussion
In this paper, we provide a foundational analysis of self-verifying reflection in multi-step CoTs using small transformers. Through minimalistic prototypes of reflective reasoning (the RMTP and RTBS), we demonstrate that self-verification benefits both training and execution. Compared to natural-language reasoning based on LLMs, the proposed minimalistic framework performs effective reasoning and reflection using limited computational resources. We also show that RL fine-tuning can enhance the performance in solving in-distribution problems and incentivize reflective thinking for exploratory reasoners. However, the improvements from RL rely on shallow patterns and lack generalizable new skills. Overall, we suggest that self-verifying reflection is inherently beneficial for CoT reasoning, yet its synergy with RL fine-tuning is limited in superficial statistics.
Limitations and future work
Although the current training pipeline enables tiny transformers to reason properly through reflective CoTs, the generalization ability is still low and not improved in RL. Therefore, future work will extend reflection frameworks and explore novel training approaches. Observing the positive effect of learning self-verification, a closer connection between generative and discriminative reasoning may be the key to addressing this challenge. Additionally, how our findings transfer from small transformers to natural-language LLMs needs to be further examined. However, the diversity of natural language and high computational cost pose significant challenges to comprehensive evaluation, and our proposed framework does not sufficiently exploit the emergent linguistic ability of LLMs. To this end, we expect to investigate a more flexible self-verification framework with an efficient evaluator of natural-language reflection in future work.
## Acknowledgments and Disclosure of Funding
We gratefully acknowledge Dr. Linyi Yang for providing partial computational resources.
## References
- [1] Lightning AI “LitGPT”, https://github.com/Lightning-AI/litgpt, 2023
- [2] Zeyuan Allen-Zhu and Yuanzhi Li “Physics of Language Models: Part 3.1, Knowledge Storage and Extraction” arXiv, 2024 DOI: 10.48550/arXiv.2309.14316
- [3] Eric C. Chi and Kenneth Lange “Techniques for Solving Sudoku Puzzles” arXiv, 2013 DOI: 10.48550/arXiv.1203.2295
- [4] Karl Cobbe et al. “Training Verifiers to Solve Math Word Problems” arXiv, 2021 arXiv: 2110.14168 [cs]
- [5] DeepSeek-AI et al. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning” arXiv, 2025 DOI: 10.48550/arXiv.2501.12948
- [6] Yuntian Deng, Yejin Choi and Stuart Shieber “From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step” arXiv, 2024 DOI: 10.48550/arXiv.2405.14838
- [7] Nouha Dziri et al. “Faith and Fate: Limits of Transformers on Compositionality” arXiv, 2023 DOI: 10.48550/arXiv.2305.18654
- [8] Guhao Feng et al. “Towards Revealing the Mystery behind Chain of Thought: A Theoretical Perspective” arXiv, 2023 DOI: 10.48550/arXiv.2305.15408
- [9] Yao Fu et al. “Specializing Smaller Language Models towards Multi-Step Reasoning” In Proceedings of the 40th International Conference on Machine Learning PMLR, 2023, pp. 10421–10430
- [10] Alex Havrilla et al. “GLoRe: When, Where, and How to Improve LLM Reasoning via Global and Local Refinements” arXiv, 2024 DOI: 10.48550/arXiv.2402.10963
- [11] Yancheng He et al. “Can Large Language Models Detect Errors in Long Chain-of-Thought Reasoning?” arXiv, 2025 DOI: 10.48550/arXiv.2502.19361
- [12] Kaiying Hou et al. “Universal Length Generalization with Turing Programs” arXiv, 2024 DOI: 10.48550/arXiv.2407.03310
- [13] Takeshi Kojima et al. “Large Language Models Are Zero-Shot Reasoners” arXiv, 2023 DOI: 10.48550/arXiv.2205.11916
- [14] Aviral Kumar et al. “Training Language Models to Self-Correct via Reinforcement Learning” arXiv, 2024 arXiv: 2409.12917 [cs]
- [15] Nathan Lambert et al. “Tulu 3: Pushing Frontiers in Open Language Model Post-Training” arXiv, 2025 DOI: 10.48550/arXiv.2411.15124
- [16] Zhiyuan Li, Hong Liu, Denny Zhou and Tengyu Ma “Chain of Thought Empowers Transformers to Solve Inherently Serial Problems” arXiv, 2024 DOI: 10.48550/arXiv.2402.12875
- [17] Hunter Lightman et al. “Let’s Verify Step by Step” arXiv, 2023 arXiv: 2305.20050 [cs]
- [18] Liangchen Luo et al. “Improve Mathematical Reasoning in Language Models by Automated Process Supervision” arXiv, 2024 arXiv: 2406.06592 [cs]
- [19] Aman Madaan et al. “Self-Refine: Iterative Refinement with Self-Feedback” arXiv, 2023 DOI: 10.48550/arXiv.2303.17651
- [20] OpenAI “Learning to Reason with LLMs”, https://openai.com/index/learning-to-reason-with-llms/
- [21] OpenAI “OpenAI O3-Mini System Card” In OpenAI o3-mini System Card, https://openai.com/index/o3-mini-system-card
- [22] OpenAI et al. “GPT-4o System Card” arXiv, 2024 DOI: 10.48550/arXiv.2410.21276
- [23] Long Ouyang et al. “Training Language Models to Follow Instructions with Human Feedback” In Advances in Neural Information Processing Systems 35 (NeurIPS 2022), 2022 arXiv: 2203.02155 [cs]
- [24] Jiayi Pan et al. “TinyZero” Accessed: 2025-01-24, https://github.com/Jiayi-Pan/TinyZero, 2025
- [25] Ben Prystawski, Michael Y. Li and Noah D. Goodman “Why Think Step by Step? Reasoning Emerges from the Locality of Experience” arXiv, 2023 arXiv: 2304.03843 [cs]
- [26] Yiwei Qin et al. “O1 Replication Journey: A Strategic Progress Report – Part 1” arXiv, 2024 DOI: 10.48550/arXiv.2410.18982
- [27] Yuxiao Qu, Tianjun Zhang, Naman Garg and Aviral Kumar “Recursive Introspection: Teaching Language Model Agents How to Self-Improve” arXiv, 2024 DOI: 10.48550/arXiv.2407.18219
- [28] John Schulman et al. “High-Dimensional Continuous Control Using Generalized Advantage Estimation” arXiv, 2018 arXiv: 1506.02438 [cs]
- [29] John Schulman et al. “Proximal Policy Optimization Algorithms” arXiv, 2017 arXiv: 1707.06347 [cs]
- [30] Rico Sennrich, Barry Haddow and Alexandra Birch “Neural Machine Translation of Rare Words with Subword Units” arXiv, 2016 DOI: 10.48550/arXiv.1508.07909
- [31] Zhihong Shao et al. “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models” arXiv, 2024 arXiv: 2402.03300 [cs]
- [32] Charlie Snell, Jaehoon Lee, Kelvin Xu and Aviral Kumar “Scaling LLM Test-Time Compute Optimally Can Be More Effective than Scaling Model Parameters” arXiv, 2024 arXiv: 2408.03314 [cs]
- [33] Richard S. Sutton and Andrew G. Barto “Reinforcement Learning: An Introduction” Cambridge, Massachusetts: The MIT Press, 2018
- [34] Yijun Tian et al. “TinyLLM: Learning a Small Student from Multiple Large Language Models” arXiv, 2024 DOI: 10.48550/arXiv.2402.04616
- [35] Rasul Tutunov et al. “Why Can Large Language Models Generate Correct Chain-of-Thoughts?” arXiv, 2024 DOI: 10.48550/arXiv.2310.13571
- [36] Ashish Vaswani et al. “Attention Is All You Need” In Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017
- [37] Jun Wang “A Tutorial on LLM Reasoning: Relevant Methods behind ChatGPT O1” arXiv, 2025 DOI: 10.48550/arXiv.2502.10867
- [38] Jason Wei et al. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” arXiv, 2023 DOI: 10.48550/arXiv.2201.11903
- [39] Sang Michael Xie et al. “DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining” arXiv, 2023 DOI: 10.48550/arXiv.2305.10429
- [40] An Yang et al. “Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement” arXiv, 2024 arXiv: 2409.12122 [cs]
- [41] Yang Yue et al. “Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?” arXiv, 2025 DOI: 10.48550/arXiv.2504.13837
- [42] Zhihan Zhang et al. “Learn Beyond The Answer: Training Language Models with Reflection for Mathematical Reasoning” arXiv, 2024 DOI: 10.48550/arXiv.2406.12050 Contents
1. 1 Introduction
1. 2 Related works
1. 3 Reflective reasoning for transformers
1. 3.1 Reasoning formulation
1. 3.2 The framework of self-verifying reflection
1. 3.3 Training
1. 4 Theoretical results
1. 5 Experiments
1. 5.1 Results of supervised fine-tuning
1. 5.2 Results of reinforcement learning
1. 6 Conclusion and Discussion
1. A Notations
1. B Details of reinforcement learning
1. B.1 Proximal policy optimization
1. B.2 Group-reward policy optimization
1. B.3 Technical Implementation
1. C Theory
1. C.1 A general formulation of reasoning performance
1. C.1.1 Bellman equations in RMTP
1. C.1.2 Bellman equations in RTBS
1. C.2 Accuracy derivation in the simplified reasoning task
1. C.3 Derivation of Theorem 1
1. C.3.1 Proof of Proposition 3
1. C.3.2 Proof of Proposition 4
1. C.4 Derivation of RMTP reasoning cost
1. C.5 Considering posterior risks of rejected attempts
1. D Implementation details
1. D.1 Algorithmic descriptions of reflective reasoning
1. D.2 Example CoT data
1. D.2.1 Multiplication CoT
1. D.2.2 Sudoku CoT
1. D.2.3 Verification of reasoning steps
1. D.3 Model architectures and tokenization
1. D.4 Hyperparameters
1. D.5 Computational resources
1. E Supplementary results of experiments
1. E.1 Evaluation of LLMs
1. E.2 Results of supervised fine tuning
1. E.3 Results of GRPO
1. E.3.1 The verification errors after GRPO
1. E.3.2 The planning correctness rate after GRPO
1. E.3.3 Reflection frequency of optional detailed verification
1. E.4 Reflection frequency under controlled verification error rates
1. E.5 Results of PPO
## Appendix A Notations
The notations used in the main paper are summarized in Table 1. Notations only appear in the appendix are not included.
Table 1: Notations in the main paper.
| ${Q}$ $\{{R}\}$ ${R}_{t}$ | The query of CoT reasoning The sequence of intermediate reasoning steps The $t$ -th intermediate step in CoT reasoning |
| --- | --- |
| ${A}$ | The answer of CoT reasoning. |
| $T$ | The number of steps (including the final answer) in an CoT |
| $\pi$ | The planning policy in MTP reasoning |
| ${s}_{t}$ | The $t$ -th state in CoT reasoning |
| $\mathcal{T}$ | The transition function in an MTP |
| “ $\checkmark$ ” | The special token as the positive label of verification. |
| “ $\times$ ” | The special token as the negative label of verification |
| ${V}_{t}$ | The verification sequence for the proposed step ${R}_{t}$ . |
| $\mathcal{V}$ | The verifier such that ${V}_{t+1}\sim\mathcal{V}(\cdot|{S}_{t},{R}_{t+1})$ |
| $\tilde{{R}_{t}}$ | The verified reasoning step, i.e. $({R}_{t},{V}_{t})$ |
| $\tilde{\mathcal{T}}$ | The reflective transition function in an RMTP |
| $\tilde{\mathcal{\pi}}$ | The self-verifying policy, i.e. $\{\pi,\mathcal{V}\}$ |
| $m$ | The RTBS width, i.e. maximal number of attempts on each state |
| $\mu$ | The probability of proposing a correct step on positive states |
| $e_{-}$ | The probability of instantly rejecting a correct step on positive states |
| $e_{+}$ | The probability of accepting an incorrect step on positive states |
| $f$ | The probability of instantly rejecting any step on negative states |
| $\alpha$ | The shorthand of $\mu e_{-}+(1-\mu)(1-e_{+})$ |
| $\rho(n)$ | The accuracy of non-reflective MTP reasoning |
| $\tilde{\rho}(n)$ | The accuracy of RMTP reasoning for queries with scale $n$ |
| $\tilde{\rho}_{m}(n)$ | The accuracy of RTBS reasoning with width $m$ for queries with scale $n$ |
## Appendix B Details of reinforcement learning
This section introduces PPO and GRPO algorithms used in RL fine-tuning. We introduce PPO and GRPO under the context of MTP, which is described in Section 3.1. This also applies to RMTP reasoning in Section 3.2, as RMTP is a special MTP given the self-verifying policy $\tilde{\pi}$ and the reflective transition function $\tilde{\mathcal{T}}$ .
For any sequence ${X}$ of tokens, we additionally define the following notations: ${{X}^{[i]}}$ denotes the $i$ -th token, ${{X}^{[<i]}}$ ( ${{X}^{[\leq i]}}$ ) denotes the former $i-1$ ( $i$ ) tokens, and $|{X}|$ denotes the length (i.e., the number of tokens).
Both PPO and GRPO iteratively update the reasoning policy through online experience. Let $\pi_{\theta}$ to denote a reasoning policy parameterized by $\theta$ . On each iteration, PPO and GRPO use a similar process to update $\theta$ :
1. Randomly draw queries from the task or taring set, and apply the old policy $\pi_{\theta_{old}}$ to sample experience CoTs.
1. Use reward models to assign rewards to the experience CoTs. Let $\operatorname{ORM}$ and $\operatorname{PRM}$ be the outcome reward model and process reward model, respectively. For each CoT $({Q},{R}_{1},\ldots,{R}_{T-1},A)$ , we obtain outcome rewards $r_{o}=\operatorname{ORM}(Q,A)$ and the process rewards $r_{t}=\operatorname{PRM}({S}_{t},{R}_{t+1})$ for $t=0,1,\ldots,T-1$ (where ${R}_{T}=A$ ). In our case, we only use the outcome reward model and thus all process rewards are $0$ .
1. Then, $\theta$ is updated by maximizing an objective function based on the experience CoTs with above rewards. Especially, PPO additionally needs to update an value approximator.
### B.1 Proximal policy optimization
PPO [29] is a classic RL algorithm widely used in various applications. It includes a value model $v$ to approximate the value function, namely the expected cumulated rewards:
$$
v({S}_{t},{{R}_{t}^{[<i]}})=\mathbb{E}_{\pi}\left(r_{o}+\sum_{k=t}^{T}r_{k}\right) \tag{7}
$$
Let $q_{t,i}(\theta)=\frac{\pi_{\theta}\left({{R}_{t}^{[i]}}\middle|{S}_{t},{{R}_{t}^{[<i]}}\right)}{\pi_{\theta_{old}}\left({{R}_{t}^{[i]}}\middle|{S}_{t},{{R}_{t}^{[<i]}}\right)}$ be the relative likelihood of the $i$ -th token in the $t$ -th step, and $\pi_{ref}$ be the reference model (e.g., the policy before RL-tuning). Then, the PPO algorithm maximizes
$$
\displaystyle J_{PPO}(\theta)= \displaystyle\mathbb{E}_{{Q}\sim P({Q}),\{{R}\}\sim\pi_{\theta_{old}}}\frac{1}{\sum_{t=1}^{T}|{R}_{t}|}\sum_{t=1}^{T}\sum_{i=1}^{|{R}_{t}|} \displaystyle\left\{\min\left[q_{t,i}(\theta)\hat{A}_{t,i},\operatorname{clip}\left(q_{t,i}(\theta),1-\varepsilon,1+\varepsilon\right)\hat{A}_{t,i}\right]-\beta\mathbb{D}_{KL}\left[\pi_{\theta}\|\pi_{ref}\right]\right\}. \tag{8}
$$
Here, $\hat{A}_{t,i}$ is the advantage of the $i$ -th token in step $t$ , computed using the value model $v$ . For example, $\hat{A}_{t,i}=v({S}_{t},{{R}_{t}^{[<i]}},{{R}_{t}^{[i]}})-v({S}_{t},{{R}_{t}^{[<i]}})$ is a simple way to estimate advantage. In practice, advantages can be estimated using the general advantage estimation (GAE) [28].
The value model $v$ is implemented using the same architecture as the reasoner except for the output layer, which is replaced by a linear function that outputs a scalar value. The value model is initialized using the same parameters as the reasoner, apart from the output layer. Assuming that $v$ is parameterized by $\omega$ , we learn $v$ by minimizing the temporal-difference error:
$$
J_{v}(\omega)=\mathbb{E}_{{Q}\sim P({Q}),{R}\sim\pi_{\theta_{old}}}\sum_{t=1}^{T}\sum_{i=1}^{|{R}_{t}|}\left(v_{\omega}({S}_{t},{{R}_{t}^{[<i]}})-v_{\omega_{old}}({S}_{t+1})\right)^{2}. \tag{9}
$$
Although PPO proves effective in training LLMs [23], we deprecate using it in training tiny transformers due to the difficulty of learning the value function. Since the value model $v$ is also a tiny transformer, its weakness in model capacity severely compromise the precision of value approximation, leading to unreliable advantage estimation.
### B.2 Group-reward policy optimization
PPO requires learning an additional value model, which can be expensive and unstable. Alternatively, GRPO [31] directly computes the advantages using the relative rewards from a group of $G$ solutions. For each query ${Q}$ , it samples a group of $G$ solutions:
$$
\{{R}_{g}\}=({R}_{g,1},\ldots,{R}_{g,T_{g}-1},A_{g})\sim\pi_{\theta_{old}},\qquad\text{for}\ g=1,\ldots,G. \tag{10}
$$
In this group, each solution $\{{R}_{g}\}$ contains $T_{g}$ steps, where the answer $A_{g}$ is considered as the final step ${R}_{g,T_{g}}$ . Using the reward models, we obtain process rewards $\boldsymbol{r}_{p}:=\{(r_{g,1},\ldots,r_{g,T_{g}})\}_{g=1}^{G}$ and outcome rewards $\boldsymbol{r}_{o}:=\{r_{g,o}\}_{g=1}^{G}$ . Then, GPRO computes the normalized rewards, given by:
$$
\tilde{r}_{g,t}=\frac{r_{g,t}-\operatorname{mean}\boldsymbol{r}_{p}}{\operatorname{std}\boldsymbol{r}_{p}},\ \tilde{r}_{g,o}=\frac{r_{g,o}-\operatorname{mean}\boldsymbol{r}_{o}}{\operatorname{std}\boldsymbol{r}_{o}} \tag{11}
$$
Afterwards, the advantage of step $t$ in the $g$ -th solution of the group is $\hat{A}_{g,t}=\tilde{r}_{g,o}+\sum_{k=t}^{T_{g}}\tilde{r}_{g,t^{\prime}}$ . Let $q_{g,t,i}(\theta)=\frac{\pi_{\theta}\left({{R}_{g,t}^{[i]}}\middle|{S}_{g,t},{{R}_{g,t}^{[<i]}}\right)}{\pi_{\theta_{old}}\left({{R}_{g,t}^{[i]}}\middle|{S}_{g,t},{{R}_{g,t}^{[<i]}}\right)}$ be the relative likelihood of the $i$ -th token in the $t$ -th step from the $g$ -th solution. Then, the GRPO objective is to maximize the following:
$$
\displaystyle J_{GRPO}(\theta)= \displaystyle\mathbb{E}_{{Q}\sim P({Q}),\{{R}_{g}\}\sim\pi_{old}}\frac{1}{G}\sum_{g=1}^{G}\frac{1}{\sum_{t=1}^{T_{g}}|\tau^{(t)}|}\sum_{t=1}^{T_{g}}\sum_{i=1}^{|{R}_{g,t}|} \displaystyle\left\{\min\left[q_{g,t,i}(\theta)\hat{A}_{g,t},\operatorname{clip}\left(q_{g,t,i}(\theta),1-\varepsilon,1+\varepsilon\right)\hat{A}_{g,t}\right]-\beta\mathbb{D}_{KL}\left[\pi_{\theta}\|\pi_{ref}\right]\right\} \tag{12}
$$
### B.3 Technical Implementation
We made two technical modifications that make RL more suitable in our case, described in the following.
First, in RMTP, we mask off the advantage of rejected steps, while the advantage of self-verification labels is reserved. This prevents the algorithm from increasing the likelihood of rejected steps, allowing the planning policy $\pi$ to be properly optimized. In practice, we find this modification facilitates the training of models that perform mandatory detailed verification. Otherwise, RL could make the reasoner excessively rely on reflection, leading to CoTs that are unnecessarily long.
Second, we employ an early-truncating strategy when sampling trajectories in training. If the model has already made a clear error at some step (detected using an oracle process reward model), we truncate the trajectory as it is impossible to find a correct answer. This avoids unnecessarily punishing later steps due to previous deviations, as some later steps may be locally correct in their own context. Empirically, we find this modification reduces the training time required to reach the same performance, while the difference in final performance is marginal.
## Appendix C Theory
### C.1 A general formulation of reasoning performance
Let $\mathcal{S}$ denote the state space and $\mathcal{A}$ denote the answer space. We use $\mathcal{A}_{{Q}}\subseteq\mathcal{A}$ to denote the set of correct answers for some input query ${Q}$ . Given any thought state ${S}$ , the accuracy, namely the probability of finding a correct answer, is denoted as
$$
\rho_{{Q}}({S})=p_{({R}_{t+1},{R}_{t+2},\ldots,{A})\sim\pi}({A}\in\mathcal{A}_{{Q}}\mid{S}_{t}={S}) \tag{13}
$$
#### C.1.1 Bellman equations in RMTP
By considering the reasoning correctness as the binary outcome reward, we may use Bellman equations [33] to provide a general formulation of the reasoning performance for arbitrary MTPs (RMTP). For simplicity, we use ${S}$ , ${R}$ , and ${S}^{\prime}$ to respectively denote the state, step, and next state in a transition.
Initially, in the absence of a trace-back mechanism, the accuracy $\rho_{{Q}}(s)$ can be interpreted as the value function when considering the MTP as a goal-directed decision process. For simplicity, we denote the transition probability drawn from the reasoning dynamics $\mathcal{T}$ as $p({S^{\prime}}\mid{S},{R})$ . In non-reflective reasoning, the state transition probability $p({S^{\prime}}\mid{S})$ can be expressed as:
$$
p({S^{\prime}}|{S})=\sum_{{R}}p({S^{\prime}}|{S},{R})\pi({R}|{S}) \tag{14}
$$
When using RMTP execution, assuming that $\xi({S},{R}):=p_{{V}\sim\mathcal{V}}(\text{``$\times$''}\in{V}\mid{S},{R})$ represents the probability of rejecting the step ${R}$ , we have:
$$
p({S^{\prime}}|{S})=\begin{cases}\sum_{R}\pi({R}|{S})(1-\xi({S},{R}))p({S^{\prime}}|{S},{R}),&\text{if }{S^{\prime}}\neq{S}\\
\sum_{R}\pi({R}|{S})\left((1-\xi({S},{R}))p({S^{\prime}}|{S},{R})+\xi({S},{R})\right),&\text{if }{S^{\prime}}={S}\end{cases} \tag{15}
$$
Consequently, the Bellman equation follows:
$$
\rho_{{Q}}({S})=\begin{cases}1,&\text{if }{S}\in\mathcal{A}_{{Q}}\\
0,&\text{if }{S}\in\mathcal{A}\setminus\mathcal{A}_{{Q}}\\
\sum_{{S^{\prime}}}\rho_{{Q}}({S^{\prime}})p({S^{\prime}}\mid{S}),&\text{if }s\in\mathcal{S}\setminus\mathcal{A}\end{cases} \tag{16}
$$
#### C.1.2 Bellman equations in RTBS
Let $m$ denote the number of attempts at each state, and let $\phi({S})$ represent the failure probability (i.e., the probability of tracing back after $m$ rejected steps) at state ${S}$ . The probability of needing to retry a proposed step due to instant rejection or recursive rejection is given by:
$$
\epsilon({S})=\sum_{{R}}\pi({R}|{S})\left(\xi({S},{R})+\sum_{{S^{\prime}}}(1-\xi({S},{R}))p({S^{\prime}}|{S},{R})\phi({S^{\prime}})\right) \tag{17}
$$
The failure probability is then given by $\phi({S})=\epsilon^{m}({S})$ . When there are $k$ attempts remaining at the current state ${S}$ , we denote the accuracy as $\rho_{x}({S},k)$ , given by:
$$
\rho_{Q}({S},k)=\begin{cases}\epsilon({S})\rho_{x}({S},k-1)+\sum_{{R}}\pi({R}|{S})(1-\xi({S},{R}))\sum_{{S^{\prime}}}p({S^{\prime}}|{S},{R})\rho_{Q}({S^{\prime}}),&k>0\\
0,&k=0\end{cases} \tag{18}
$$
It follows that $\rho_{x}({S})=\rho_{x}({S},m)$ . This leads to a recursive formulation that ultimately results in the following equations for each $s\in\mathcal{S}$ :
$$
\displaystyle\epsilon({S})=\sum_{{R}}\pi({R}|{S})\left(\xi({S},{R})+\sum_{{S^{\prime}}}(1-\xi({S},{R}))p({S^{\prime}}|{S},{R})\epsilon^{m}({S^{\prime}})\right), \displaystyle\rho_{x}({S})=\frac{1-\epsilon^{m}({S})}{1-\epsilon({S})}\sum_{{S^{\prime}}}\rho_{Q}({S^{\prime}})\pi({R}|{S})(1-\xi({S},{R}))p({S^{\prime}}|{S},{R}). \tag{19}
$$
### C.2 Accuracy derivation in the simplified reasoning task
In the following, we derive the accuracy of reflective reasoning with and without the trace-back search, given the simplified reasoning task in Section 4. For each proposed step on a correct state, we define several probabilities to simplify notations: $\alpha:=\mu e_{-}+(1-\mu)(1-e_{+})$ is the probability of being instantly rejected; $\beta=\mu(1-e_{-})$ is the probability of being correct and accepted; $\gamma=(1-\mu)e_{+}$ is the probability of being incorrect but accepted. Note that $\beta$ here no longer refers to the KL-divergence factor in Appendix B.
**Proposition 2**
*The RTMP accuracy $\tilde{\rho}(n)$ for problems with a scale of $n$ is
$$
\tilde{\rho}(n)=\left(\frac{\beta}{1-\alpha}\right)^{n} \tag{21}
$$
Let $m$ be the width of RTBS. Let $\delta_{m}(n)$ and $\epsilon_{m}(n)$ be the probability of a proposed step being rejected (either instantly or recursively) on a correct state and incorrect state of scale $n$ , respectively. We have $\sigma_{m}(0)=\epsilon_{m}(0)=0$ and the following recursive equations for $n>0$ :
$$
\displaystyle\delta_{m}(n)=\alpha+\beta(\delta_{m}(n-1))^{m}+\gamma(\epsilon_{m}(n-1))^{m} \displaystyle\epsilon_{m}(n)=f+(1-f)\left(\epsilon_{m}(n-1)\right)^{m} \tag{22}
$$
Then, the RTBS accuracy $\tilde{\rho}_{m}(n)$ for problems with a scale of $n$ is given by
$$
\tilde{\rho}_{m}(n)=\prod_{t=1}^{n}\sigma_{m}(t),\qquad\text{where }\sigma_{m}(t)=\beta\sum_{i=0}^{m-1}(\delta_{m}(t))^{i}=\frac{1-(\delta_{m}(t))^{m}}{1-\delta_{m}(t)}\beta. \tag{24}
$$
In addition, $\delta_{m}(n)$ , $\epsilon_{m}(n)$ and $\sigma_{m}(n)$ all motonously increase and converge in relation to $n$ .*
* Proof*
We first consider reasoning through RTBS. Let $\phi_{m}(n)$ and $\psi_{m}(n)$ denote the probabilities of failure (reaching the maximum number of attempts) in correct and incorrect states, respectively. Let $\tilde{\rho}_{i|m}(n)$ indicate the accuracy after the $i$ attempts at the current sub-problem of scale $n$ . Therefore, we have $\tilde{\rho}_{m}(n)=\tilde{\rho}_{0|m}(n)$ and $\tilde{\rho}_{m|m}(n)=0$ . At a correct state, we have the following possible cases: - A correct step is proposed and instantly accepted with probability $\beta=\mu(1-e_{-})$ . In this case, the next state has a scale of $n-1$ , which is correctly solved with probability $\rho_{0|m}(n-1)$ and fails (i.e., is recursively rejected) with probability $\phi_{m}(n-1)$ .
- A correct step is proposed and instantly rejected with probability $\mu e_{-}$ .
- An incorrect step is proposed and instantly accepted with probability $\gamma=(1-\mu)e_{+}$ . In this scenario, the next state has a scale of $n-1$ , which fails with probability $\psi_{m}(n-1)$ .
- An incorrect step is proposed and instantly rejected with probability $\beta=(1-\mu)(1-e_{+})$ . Thus, we have a probability of $\alpha=\mu e_{-}+(1-\mu)(1-e_{+})$ to instantly reject the step, and a probability of $\beta\phi_{m}(n-1)+\gamma\psi_{m}(n-1)$ to recursively reject the step. Therefore, the overall probability of rejecting an attempt on correct states is:
$$
\delta_{m}(n)=\alpha+\beta\phi_{m}(n-1)+\gamma\psi_{m}(n-1). \tag{25}
$$
Since failure occurs after $m$ rejections, we have:
$$
\phi_{m}(n)=\left(\delta_{m}(n)\right)^{m} \tag{26}
$$ At an incorrect state, we have a probability $f$ to instantly reject a step. Otherwise, we accept the step, and the next state fails with probability $\psi_{m}(n-1)$ . Therefore, the overall probability of rejecting an attempt for incorrect states is:
$$
\epsilon_{m}(n)=f+(1-f)\psi_{m}(n-1). \tag{27}
$$
Similarly, we obtain:
$$
\psi_{m}(n)=\left(\epsilon_{m}(n)\right)^{m} \tag{28}
$$ By substituting Equations (26) and (28) into Equations (25) and (27), we obtain Equations (22) and (23). If an attempt is rejected (either instantly or recursively), we initiate another attempt which solves the problem with a probability of $\rho_{i+1|m}(n)$ . Therefore, we have the recursive form of the accuracy, given by:
$$
\tilde{\rho}_{i|m}(n)=\beta\tilde{\rho}_{0|m}(n-1)+\delta(n,m)\tilde{\rho}_{i+1|m}(n) \tag{29}
$$
Thus, we can expand $\tilde{\rho}_{m}(n)$ as:
$$
\displaystyle\tilde{\rho}_{m}(n) \displaystyle=\tilde{\rho}_{0|m}(n) \displaystyle=\beta\tilde{\rho}_{m}(n-1)+\delta_{m}(n)\tilde{\rho}_{1|m}(n) \displaystyle\cdots \displaystyle=(\beta+\delta_{m}(n)\beta+\delta_{m}^{2}(n)\beta+\cdots+\delta_{m}^{m}(n)\beta)\tilde{\rho}_{m}(n-1) \displaystyle=\sigma_{m}(n)\tilde{\rho}_{m}(n-1) \tag{30}
$$ Note that $n=0$ indicates that the state is exactly the outcome, which means $\tilde{\rho}_{m}(0)=1$ . Then, Equation (24) is evident given the recursive form in Equation (31). For reflective reasoning without trace-back, we can simply replace $\delta_{m}(n)$ with $\alpha$ in $\sigma_{m}(n)$ , as only instant rejections are allowed. We then set $m\to\infty$ , leading to Equation (21).
Monotonicity
We first prove the monotonic increase of $\epsilon_{m}(n)$ . Equation (23) gives $\epsilon_{m}(n)=f+(\epsilon_{m}(n-1))^{m}$ and $\epsilon_{m}(n+1)=f+(\epsilon_{m}(n))^{m}$ for each $n>1$ . Therefore, if $\epsilon_{m}(n)\geq\epsilon_{m}(n-1)$ , we have:
$$
\epsilon_{m}(n+1)=f+(\epsilon_{m}(n))^{m}\geq f+(\epsilon_{m}(n-1))^{m}=\epsilon_{m}(n). \tag{32}
$$
Additionally, it is clear that $\epsilon_{m}(1)=f\geq 0=\epsilon_{m}(0)$ . Using mathematical induction, we conclude that $\epsilon_{m}(n+1)>\epsilon_{m}(n)$ for all $n\geq 0$ . The monotonicity of $\delta_{m}(n)$ can be proven similarly, and the monotonicity of $\sigma_{m}(n)$ is evident from that of $\delta_{m}(n)$ . Since $\delta_{m}(n)$ and $\epsilon_{m}(n)$ are probabilities, they are bounded in $[0,1]$ and thus converge monotonically. ∎
Illustration of accuracy curves
Using the recursive formulae in Proposition 2, we are able to implement a program to compute the reasoning accuracy in the simplified reasoning problem in Section 4 and thereby visualize the accuracy curves of various reasoning algorithms. For example, Figure 10 presents the reasoning curves given $\mu=0.8$ , $e_{-}=0.3$ , $e_{+}=0.2$ , and $f=0.8$ , which lead to $\alpha=0.4<f$ . For this example, we may observe the following patterns: 1) An overly small width $m$ in RTBS leads to poor performance; and 2) by choosing $m$ properly, $\tilde{\rho}_{m}(n)$ remains stable when $n\to\infty$ . These observations are formally described and proved in Appendix C.3.
<details>
<summary>x13.png Details</summary>
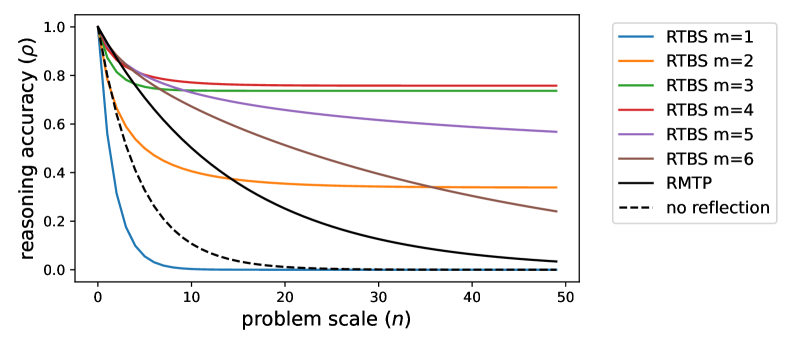
### Visual Description
## Line Chart: Reasoning Accuracy vs. Problem Scale
### Overview
The image is a line chart plotting "reasoning accuracy (ρ)" against "problem scale (n)". It compares the performance of several methods: six variants of "RTBS" with different `m` values (1 through 6), a method labeled "RMTP", and a baseline labeled "no reflection". The chart demonstrates how the accuracy of each method decays as the problem scale increases.
### Components/Axes
* **X-Axis (Horizontal):** Labeled "problem scale (n)". The scale runs from 0 to 50, with major tick marks at intervals of 10 (0, 10, 20, 30, 40, 50).
* **Y-Axis (Vertical):** Labeled "reasoning accuracy (ρ)". The scale runs from 0.0 to 1.0, with major tick marks at intervals of 0.2 (0.0, 0.2, 0.4, 0.6, 0.8, 1.0).
* **Legend:** Positioned in the top-right corner, outside the main plot area. It lists the following series with corresponding line styles and colors:
* `RTBS m=1`: Solid blue line.
* `RTBS m=2`: Solid orange line.
* `RTBS m=3`: Solid green line.
* `RTBS m=4`: Solid red line.
* `RTBS m=5`: Solid purple line.
* `RTBS m=6`: Solid brown line.
* `RMTP`: Solid black line.
* `no reflection`: Dashed black line.
### Detailed Analysis
All lines begin at or very near a reasoning accuracy (ρ) of 1.0 when the problem scale (n) is 0. They all exhibit a decaying trend as `n` increases, but the rate and final plateau of decay vary significantly.
**Trend Verification & Data Points (Approximate):**
1. **RTBS m=1 (Blue):** Shows the steepest, most rapid decay. It plummets almost vertically, reaching near-zero accuracy (ρ ≈ 0.0) by n ≈ 10 and remains at 0 thereafter.
2. **RTBS m=2 (Orange):** Decays rapidly but less severely than m=1. It begins to plateau around n=15-20, settling at a low accuracy of approximately ρ ≈ 0.35.
3. **RTBS m=3 (Green):** Decays more gradually. It crosses below the RMTP line around n=5. It appears to plateau at a relatively high accuracy, approximately ρ ≈ 0.75, from n=20 onward.
4. **RTBS m=4 (Red):** Follows a very similar path to m=3, decaying slightly slower. It plateaus at a marginally higher accuracy than m=3, approximately ρ ≈ 0.78.
5. **RTBS m=5 (Purple):** Decays slower than m=3 and m=4. It maintains a clear downward slope throughout the visible range, ending at approximately ρ ≈ 0.58 at n=50.
6. **RTBS m=6 (Brown):** Decays the slowest among the RTBS variants. It has a gentle, steady downward slope, ending at approximately ρ ≈ 0.25 at n=50. It crosses below the RMTP line around n=25.
7. **RMTP (Solid Black):** Decays steadily. It starts below the higher `m` RTBS lines, crosses above the lower `m` lines (m=1, m=2) early on, and is eventually crossed by m=6 around n=25. It ends at a very low accuracy, approximately ρ ≈ 0.05 at n=50.
8. **no reflection (Dashed Black):** Serves as a baseline. It decays very rapidly, similar to but slightly slower than RTBS m=1, reaching near-zero accuracy (ρ ≈ 0.0) by n ≈ 20.
### Key Observations
* **Performance Hierarchy:** For large problem scales (n > 30), the final accuracy ordering from highest to lowest is approximately: RTBS m=4 > RTBS m=3 > RTBS m=5 > RTBS m=2 > RTBS m=6 > RMTP > RTBS m=1 ≈ no reflection.
* **Impact of Parameter `m`:** Within the RTBS method, increasing the parameter `m` generally leads to slower decay and higher sustained accuracy at larger scales. However, this relationship is not perfectly linear for the plateau values (m=3 and m=4 are very close, m=5 and m=6 show continued decline).
* **Crossover Points:** Significant crossovers occur. The RMTP line is outperformed by RTBS with higher `m` values (m=3,4,5) from very early on, but it outperforms RTBS m=6 until around n=25.
* **Baseline Comparison:** All methods except RTBS m=1 outperform the "no reflection" baseline for almost all problem scales greater than zero.
### Interpretation
This chart likely comes from research on algorithmic reasoning or cognitive architectures, comparing different strategies ("RTBS" with varying depth/complexity `m`, "RMTP") against a naive baseline ("no reflection").
The data suggests that incorporating a reflection mechanism (all methods except the dashed line) is crucial for maintaining reasoning accuracy as problems become more complex. The "RTBS" method demonstrates a tunable trade-off via its `m` parameter: higher `m` values provide better scalability and resilience to increasing problem size, but likely at a higher computational cost. The fact that RTBS m=4 and m=3 plateau suggests they reach a stable, albeit imperfect, solution quality for large `n`. In contrast, RTBS m=5 and m=6, while decaying slower initially, do not plateau within the observed range, indicating their accuracy might continue to fall for even larger problems.
The RMTP method shows a steady, predictable decline, making it less effective than optimized RTBS for large-scale problems but potentially more reliable than the lowest-complexity RTBS variants. The "no reflection" baseline's rapid failure underscores the necessity of the more sophisticated approaches being tested. The chart effectively argues for the value of reflective reasoning processes and the importance of parameter tuning (`m`) in designing scalable reasoning systems.
</details>
Figure 10: The accuracy curves of non-reflective MTP $\rho(n)$ , RMTP $\tilde{\rho}(n)$ , and RTBS $\tilde{\rho}_{m}(n)$ , using $\mu=0.8$ , $e_{-}=0.3$ , $e_{+}=0.2$ , and $f=0.8$ .
Furthermore, in Figure 10 we see that a small $m$ stabilizes the drop of $\tilde{\rho}_{m}(n)$ when $n$ is large, yet it also makes $\tilde{\rho}_{m}(n)$ drop sharply in the area where $n$ is small. This indicates the potential of using an adaptive width in RTBS, where $m$ is set small when the current subproblem (state) requires a large number $n$ of steps to solve, and $m$ increases when $n$ is reduced by previous reasoning steps. Since this paper currently focuses on the minimalistic reflection framework, we expect to explore such an extension in future work.
### C.3 Derivation of Theorem 1
Theorem 1 is obtained by merging the following Proposition 3 and Proposition 4, which also provide supplementary details on the non-trivial assumptions of factors $\mu$ , $e_{-}$ , and $e_{+}$ . Additionally, Proposition 4 also shows that there exists an ideal range of RTBS width $m$ such that stabilizes the drop of $\tilde{\rho}_{m}(n)$ when $n\to\infty$ .
**Proposition 3 (RMTP Validity conditions)**
*For all $n\geq 0$ , we have $\tilde{\rho}(n)\geq\rho(n)\iff e_{-}+e_{+}\leq 1$ . Additionally, if $\mu>0$ and $e_{-}<1$ , then for all $n\geq 1$ we have that $\tilde{\rho}(n)=\rho(n)\iff e_{-}+e_{+}=1$ and $\tilde{\rho}(n)$ decreases strictly with either $e_{-}$ or $e_{+}$ .*
**Proposition 4 (RTBS Validity Condition)**
*Assuming $0<\mu<1$ , $e_{-}<1$ , and $e_{+}>0$ , then
$$
\lim_{n\to\infty}\frac{\tilde{\rho}_{m}(n)}{\tilde{\rho}(n)}>1\iff\left(m>\frac{1}{1-\alpha}\ \text{and}\ f>\alpha\right). \tag{33}
$$
Furthermore, we have
- $\lim_{n\to\infty}\frac{\tilde{\rho}_{m}(n)}{\tilde{\rho}_{m}(n-1)}=1$ if $m\in[\frac{1}{\mu(1-e_{-})},\frac{1}{1-f}]$ .
- $\tilde{\rho}_{m}(n)$ increases strictly with $f$ for all $n\geq 2$ .*
The proof of propositions 3 and 4 is given in Appendix C.3.1 and Appendix C.3.2, which are based on the previous derivation in Appendix C.2.
#### C.3.1 Proof of Proposition 3
In any case, we have $\tilde{\rho}(0)=\rho(0)=1$ .
If $\mu=0$ or $e_{-}=1$ , we clearly have $\tilde{\rho}(n)=\rho(n)=0$ for $n\geq 1$ .
If $0>\mu$ and $e_{-}<1$ , we can transform $\tilde{\rho}(n)$ (given in Proposition 2) as:
$$
\tilde{\rho}(n)=\left(\frac{1}{1+\frac{e_{+}}{1-e_{-}}(\mu^{-1}-1)}\right)^{n}=\left(\frac{\mu(1-e_{-})}{\mu(1-e_{+}-e_{-})+e_{+}}\right)^{n}. \tag{34}
$$
This shows that $\rho(n)$ strictly decreases with both $e_{+}$ and $e_{-}$ , and $\tilde{\rho}(n)=\mu^{n}\iff e_{+}+e_{-}=1$ . Therefore, we also have $\tilde{\rho}(n)>\mu^{n}\iff e_{+}+e_{-}<1$ .
The Proposition is proved by combining all the above cases.
#### C.3.2 Proof of Proposition 4
The assumptions $0<\mu<1$ , $e_{-}<1$ , and $e_{+}>0$ ensure that $\beta>0$ and $\gamma>0$ . Proposition 2 suggests the monotonous convergence of $\delta_{m}(n)$ , $\epsilon_{m}(n)$ , and $\sigma_{m}(n)$ . For simplicity, we denote $\delta:=\lim_{n\to\infty}\delta_{m}(n)$ , $\epsilon:=\lim_{n\to\infty}\epsilon_{m}(n)$ , and $\sigma:=\lim_{n\to\infty}\sigma_{m}(n)$ . From Equations (22) and (23), we have:
$$
\displaystyle\delta \displaystyle=\alpha+\beta\delta^{m}+\gamma\epsilon^{m} \displaystyle\epsilon \displaystyle=f+(1-f)\epsilon^{m} \tag{35}
$$
Note that $\epsilon=\delta=1$ gives the trivial solution of the above equations. However, there may exist another solution (if any) such that $\delta<1$ or $\epsilon<1$ under certain circumstances. Since $\epsilon_{m}(0)=0$ and $\delta_{m}(0)=0$ , the limits $\epsilon$ and $\delta$ take the smaller solution within $[0,1]$ . In the following, we first discuss when another non-trivial solution exists.
**Lemma 1**
*For any $m\geq 1$ , if $0\leq p<\frac{m-1}{m}$ , then $x=p+(1-p)x^{m}$ has a unique solution $x_{*}\in[p,1)$ , which strictly increases with $p$ . Otherwise, if $\frac{m-1}{m}\leq p\leq 1$ , the only solution in $[0,1]$ is $x_{*}=1$ .*
* Proof*
Define $F(x):=p+(1-p)x^{m}-x$ . We find:
$$
F^{\prime}(x)=m(1-p)x^{m-1}-1.
$$
It is observed that $F^{\prime}(x)$ increases monotonically with $x$ . Additionally, we have $F^{\prime}(0)=-1<0$ , $F^{\prime}(1)=m(1-p)-1$ , and $F(1)=0$ . We only consider the scenario where $p>0$ , since $x=0\in[0,1)$ is obviously the unique solution. If $0\leq p<\frac{m-1}{m}$ , we have $1-p>\frac{1}{m}$ . This implies $F^{\prime}(1)>0$ . Combining $F^{\prime}(0)<0$ , there exists $\xi\in(0,1)$ such that $F^{\prime}(\xi)=0$ . As a result, $F(x)$ strictly decreases in $[0,\xi]$ and increases in $[\xi,1)$ . Therefore, we have $F(\xi)<F(1)=0$ . Since $F(p)=(1-p)p^{m}>0$ , we know that there exists a unique $x_{*}\in[p,\xi)$ such that $F(x_{*})=0$ . If $\frac{m-1}{m}\leq p\leq 1$ , we have $1-p\leq\frac{1}{m}$ and $F^{\prime}(1)\leq 0$ . In this case, $F^{\prime}(x)<0$ in $[0,1)$ due to the monotonicity of $F^{\prime}(x)$ . Thus, $F(x)>F(1)=0$ for all $x\in[0,1)$ . Therefore, $x_{*}=1$ is the only solution within $[0,1]$ . Now, we prove the monotonic increase of $x_{*}$ when $0\leq p<\frac{m-1}{m}$ . We have:
$$
\displaystyle\frac{\mathrm{d}x_{*}}{\mathrm{d}p}=1+m(1-p)x_{*}^{m-1}\frac{\mathrm{d}x_{*}}{\mathrm{d}p}-x_{*}^{m} \displaystyle\frac{\mathrm{d}x_{*}}{\mathrm{d}p}=\frac{1-x_{*}^{m}}{1-m(1-p)x_{*}^{m-1}}=\frac{1-x_{*}^{m}}{-F^{\prime}(x_{*})} \tag{37}
$$
The previous discussion shows that with $x_{*}<[p,\xi)$ for some $\xi$ such that $F^{\prime}(\xi)=0$ . Given that $F^{\prime}(x)$ increases monotonically, we have $F^{\prime}(x_{*})<0$ and thus $\frac{\mathrm{d}x_{*}}{\mathrm{d}p}>0$ . ∎
**Lemma 2**
*Assume $p\geq 0$ , $q>0$ , and $p+q\leq 1$ . Then, the equation $x=p+qx^{m}$ has a unique solution $x_{*}\in[0,1)$ , which increases monotonically with $p\in[0,1-q]$ .*
* Proof*
Define $F(x):=p+qx^{m}-x$ . Since $F(0)\geq 0$ and $F(1)<0$ , there exists a solution $x_{*}\in[0,1)$ . Since $F$ is convex, we know there is at most one other solution. Clearly, the other solution appears in $(1,+\infty)$ , since $F(+\infty)>0$ . Therefore, $F(x)=0$ must have a unique solution $x_{*}$ in $[0,1)$ . Additionally, $x_{*}$ must appear to the left of the minimum of $F$ , which yields $F^{\prime}(x_{*})<0$ . Using the Implicit Function Theorem, we write:
$$
\frac{\mathrm{d}x_{*}}{\mathrm{d}{p}}=\frac{1}{1-mqx_{*}^{m-1}}=-\frac{1}{F^{\prime}(x_{*})}>0 \tag{39}
$$
Thus, we conclude that $x_{*}$ increases monotonically with $p$ . ∎
Applying Lemmas 1 and 2 to Equation (36), we find that $\epsilon=1$ if and only if $f\geq\frac{m-1}{m}$ ; otherwise, $\epsilon$ strictly increases with $p$ . Therefore, $f<\frac{m-1}{m}$ indicates that $\epsilon<1$ , leading to $(\alpha+\gamma\epsilon)+\gamma<1$ . Using Lemma 2 again in Equation (35), we have $f<\frac{m-1}{m}\implies\delta<1$ . Conversely, $f\geq\frac{m-1}{m}$ yields $\epsilon=1$ . and thus $f,\alpha+\gamma\geq\frac{m-1}{m}\implies\delta=1$ .
First, we consider the special case where $\delta=1$ , which occurs if both $f,\alpha+\gamma\geq\frac{m-1}{m}$ , namely $m\leq\min\{\frac{1}{1-f},\frac{1}{\beta}\}$ . In this case, we write $\sigma=(1+\delta+\cdots+\delta^{m-1})\beta=m\beta$ . Therefore, we have:
| | $\displaystyle\lim_{n\to\infty}\frac{{\tilde{\rho}(n)}}{\rho(n)}>1$ | $\displaystyle\iff\sigma>\frac{\beta}{1-\alpha}$ | |
| --- | --- | --- | --- |
This leads to the validity condition that $\frac{1}{1-\alpha}<m\leq\min\{\frac{1}{1-f},\frac{1}{\beta}\}$ .
Next, we consider the case where $\delta<1$ , which occurs when $f<\frac{m-1}{m}$ or $\alpha+\gamma<\frac{m-1}{m}$ . This leads to $\beta\geq\frac{1}{m}>0$ , and we can write:
$$
\displaystyle\delta^{m}=\frac{1}{\beta}\left(\delta-\alpha-\gamma\epsilon^{m}\right), \displaystyle\sigma=\frac{1-\delta^{m}}{1-\delta}=\frac{(1-\delta^{m})\beta}{(1-\alpha)-(\beta\delta^{m}+\gamma\epsilon^{m})}. \tag{40}
$$
Then, we can derive:
| | $\displaystyle\lim_{n\to\infty}\frac{{\tilde{\rho}(n)}}{\rho(n)}<1$ | $\displaystyle\iff\sigma>\frac{\beta}{1-\alpha}$ | |
| --- | --- | --- | --- |
Since we have assumed $\delta<1$ , we have $\epsilon=1>\delta$ if $f\geq\frac{m-1}{m}$ ; otherwise if $f=\alpha<\frac{m-1}{m}$ , then $\epsilon=\delta$ leads to $\delta=\epsilon$ being a solution of Equation (35). Additionally, from Lemmas 1 and 2, we know that a higher $\alpha$ would increase $(\alpha+\gamma\epsilon)$ , which eventually raises $\delta$ above $\epsilon$ ; conversely, a lower $\alpha$ causes $\delta$ to drop below $\epsilon$ . To summarize, we have the following conditions when $\delta<1$ :
$$
\displaystyle 1\geq\epsilon>\delta \displaystyle\iff\left(\alpha+\gamma<\frac{m-1}{m}\leq f\right)\text{ or }\left(\alpha<f<\frac{m-1}{m}\right) \displaystyle\iff\left(\frac{1}{\beta}<m\leq\frac{1}{1-f}\right)\text{ or }\left(\alpha<f\text{ and }m>\frac{1}{1-f}\right) \tag{42}
$$
Combining the conditions when $\delta=1$ , we have:
$$
\displaystyle\lim_{n\to\infty}\frac{{\tilde{\rho}(n)}}{\rho(n)}>1 \displaystyle\iff \displaystyle\left(\frac{1}{1-\alpha}<m\leq\min\left\{\frac{1}{1-f},\frac{1}{\beta}\right\}\right)\text{ or }\left(\frac{1}{\beta}<m\leq\frac{1}{1-f}\right)\text{ or }\left(\alpha<f\text{ and }m>\frac{1}{1-f}\right) \displaystyle\iff \displaystyle m>\frac{1}{1-\alpha}\text{ and }f>\alpha \tag{44}
$$
Thus far, we have obtained Equation (33). Now, we start proving the two additional statements in Proposition 4.
First, we prove that $\frac{1}{\beta}\leq m\leq\frac{1}{1-f}$ ensures that $\sigma=1$ . First, if $\delta=1$ , we have $m\leq\frac{1}{\beta}\leq\frac{1}{1-f}$ . In this case, $\sigma=m\beta$ , and thus $\sigma=1$ when $m=\frac{1}{\beta}$ . Alternatively, if $\delta<1$ , we have $m>\min\{\frac{1}{\beta},\frac{1}{1-f}\}$ . We can express that:
$$
\sigma=\frac{1-\delta^{m}}{1-\delta}\beta=\frac{\beta-(\delta-\alpha-\gamma\epsilon^{m})}{1-\delta}=1-\gamma\frac{1-\epsilon}{(1-\delta)(1-f)} \tag{46}
$$
Using Lemma 2, we know that $\delta$ increases with $\alpha+\gamma\epsilon$ , which increases with $\epsilon$ . Therefore, we have $\frac{\mathrm{d}\delta}{\mathrm{d}\epsilon}>0$ . Then, we obtain
$$
\mathrm{d}\sigma/\mathrm{d}\epsilon=\sum_{i=1}^{m}i\delta^{m-1}\beta\frac{\mathrm{d}\delta}{\mathrm{d}\epsilon}>0, \tag{47}
$$
$$
\displaystyle\sigma \displaystyle=\frac{1-\delta^{m}}{1-\delta}\beta=\frac{\beta-(\delta-\alpha-\gamma\epsilon^{m})}{1-\delta}=\frac{\alpha+\beta+\gamma-(1-\epsilon^{m})\gamma-\delta}{1-\delta} \displaystyle=\frac{1-\delta-\gamma(1-\frac{\epsilon-f}{1-f})}{1-\delta} \tag{48}
$$
Therefore, $\sigma$ increases with $\epsilon$ and reaches its maximum value of $1$ when $\epsilon=1$ . As a result, we conclude that $\frac{1}{\beta}\leq m\leq\frac{1}{1-f}$ ensures that $\sigma=1$ . Combining $\beta=\mu(1-e_{-})$ and $\sigma=\lim_{n\to\infty}\sigma_{m}(n)=\lim_{n\to\infty}\frac{\tilde{\rho}_{m}(n)}{\tilde{\rho}_{m}(n-1)}$ , we have proved that $\lim_{n\to\infty}\frac{\tilde{\rho}_{m}(n)}{\tilde{\rho}_{m}(n-1)}=1$ if $m\in[\frac{1}{\mu(1-e_{-})},\frac{1}{1-f}]$ .
Next, we prove the monotonicity of $\tilde{\rho}_{m}(n)$ with respect to $f$ . To prove this, we first prove the monotonicity of $\epsilon_{m}(t)$ for all $t$ with respect to $f$ .
**Lemma 3**
*For $n>0$ , $\epsilon_{m}(t)$ as defined in Equation 23 increases strictly with $f$ .*
* Proof*
We regard
$$
\epsilon_{m}(0;f)\equiv 0,\qquad\epsilon_{m}(t;f)=f+(1-f)\bigl[\epsilon_{m}(t-1;f)\bigr]^{m} \tag{49}
$$
as a function of $f$ on $[0,1]$ . When $t=1$ we have
$$
\epsilon_{m}(1;f)=f+(1-f)\bigl[\epsilon_{m}(0;f)\bigr]^{m}=f, \tag{50}
$$
so $\frac{\partial\epsilon_{m}(1;f)}{\partial f}=1>0$ . Thus $\epsilon_{m}(1;f)$ is strictly increasing with $f$ . Further, assume for some $k\geq 1$ that
$$
0\leq\epsilon_{m}(k;f)<1\quad\text{and}\quad\frac{\partial\epsilon_{m}(k;f)}{\partial f}>0\quad\forall f\in[0,1]. \tag{51}
$$
Differentiate the recursion for $t=k+1$ :
$$
\epsilon_{m}(k+1;f)=f+(1-f)\bigl[\epsilon_{m}(k;f)\bigr]^{m}, \tag{52}
$$
$$
\frac{\partial\epsilon_{m}(k+1;f)}{\partial f}=1-\bigl[\epsilon_{m}(k;f)\bigr]^{m}+(1-f)\,m\bigl[\epsilon_{m}(k;f)\bigr]^{m-1}\,\frac{\partial\epsilon_{m}(k;f)}{\partial f}. \tag{53}
$$
By the inductive hypothesis, $\epsilon_{m}(k;f)<1$ implies $\bigl[\epsilon_{m}(k;f)\bigr]^{m}<1$ . Therefore, we have
$$
1-\bigl[\epsilon_{m}(k;f)\bigr]^{m}>0. \tag{54}
$$
Since $1-f\geq 0$ , $m\geq 1$ , $\bigl[\epsilon_{m}(k;f)\bigr]^{m-1}\geq 0$ , and $\frac{\partial\epsilon_{m}(k;f)}{\partial f}>0$ , the second term is also positive. Hence
$$
\frac{\partial\epsilon_{m}(k+1;f)}{\partial f}>0, \tag{55}
$$
showing that $\epsilon_{m}(k+1;f)$ is strictly increasing. This completes the induction. ∎
Given Lemma 3, we can also prove the monotonicity of $\delta_{m}(t)$ using mathematical induction: It is easy to write that $\delta_{m}(2)=\alpha+\beta\alpha^{m}+\gamma f^{m}$ , showing that $\delta_{m}(2)$ increases strictly with $f$ . Then, for $t>2$ , assuming that $\delta_{m}(t-1)$ increases strictly with $f$ and using Given Lemma 3, we know that $\delta_{m}(t)$ increases strictly with $f$ from Equation (22).
Therefore, we have $\delta_{m}(1)=\alpha$ and that $\delta_{m}(t)$ strictly increases with $f$ for $n\geq 2$ . According to Equation (24), from the above monotonicity of $\delta_{m}(t)$ , it is obvious that $\sigma_{m}(t)$ increases with respect to $f$ for all $t$ . This gives the corollary that $\tilde{\rho}_{m}(n)$ increases with $f$ for all $n$ .
### C.4 Derivation of RMTP reasoning cost
In this section, we derive how many steps it costs to find a correct solution in RMTP and thereby prove Proposition 1.
* Proposition1*
The probability of accepting the correct step after the $i$ -th attempt is given by $\alpha^{i-1}\beta$ . Assuming a maximum number of attempts $m$ , the number of attempts consumed at each step satisfies:
$$
\Pr(i\ \text{attempts}\mid\text{correct})=\frac{\alpha^{i-1}\beta}{\beta+\alpha\beta+\cdots+\alpha^{m-1}\beta}=\frac{(1-\alpha)\alpha^{i-1}}{1-\alpha^{m}} \tag{56}
$$
Therefore, the average number of attempts required for a correct reasoning step is given by
$$
A_{m}=\sum_{i=1}^{m}i\cdot\frac{(1-\alpha)\alpha^{i}}{1-\alpha^{m}}=\frac{1-\alpha}{1-\alpha^{m}}\sum_{i=1}^{m}i\alpha^{i-1} \tag{57}
$$ To simplify the summation expression $\sum_{i=1}^{m}i\alpha^{i-1}$ (where $0<\alpha<1$ ), we can use the method of telescoping series. Let $S=\sum_{i=1}^{m}i\alpha^{i-1}$ . We calculate $\alpha S$ :
$$
\alpha S=\sum_{i=1}^{m}i\alpha^{i} \tag{58}
$$
Thus,
$$
S-\alpha S=\sum_{i=1}^{m}i\alpha^{i-1}-\sum_{i=1}^{m}i\alpha^{i} \tag{59}
$$
This gives us
$$
(1-\alpha)S=1+\alpha+\alpha^{2}+\cdots+\alpha^{m-1}-m\alpha^{m}=\frac{1-\alpha^{m}}{1-\alpha}-m\alpha^{m} \tag{60}
$$
Rearranging, we have
$$
\sum_{i=1}^{m}i\alpha^{i-1}=\frac{1-\alpha^{m}-(1-\alpha)m\alpha^{m}}{(1-\alpha)^{2}} \tag{61}
$$
Thus, the average number of attempts can be further expressed as: $$
\displaystyle A_{m} \displaystyle=\frac{1-\alpha}{1-\alpha^{m}}\cdot\frac{1-\alpha^{m}-(1-\alpha)m\alpha^{m}}{(1-\alpha)^{2}} \displaystyle=\frac{1-\alpha^{m}-(1-\alpha)m\alpha^{m}}{(1-\alpha)(1-\alpha^{m})} \displaystyle=\frac{1}{1-\alpha}-m\frac{\alpha^{m}}{1-\alpha^{m}} \tag{62}
$$
Considering the limit as $m\to\infty$ , it can be shown using limit properties that $\lim_{m\to\infty}m\frac{\alpha^{m}}{1-\alpha^{m}}=0$ . If the correct solution is obtained (i.e., correct steps are accepted at each step), the average number of steps taken is given by
$$
\bar{T}=nA_{\infty}=\frac{n}{1-\alpha}=\frac{n}{1-\mu e_{-}-(1-\mu)(1-e_{+})}=\frac{n}{(1-\mu)e_{+}+\mu(1-e_{-})} \tag{66}
$$
∎
### C.5 Considering posterior risks of rejected attempts
Our previous analysis is based on a coarse binary partition of states (correct and incorrect) for each scale, which enhances clarity yet does not apply to real-world complexity. Therefore, we can introduce stronger constraints by taking into account the posterior distribution of states in $\mathcal{S}_{n}^{+}$ after multiple attempts. For example, if the state has produced several incorrect attempts on state ${S}$ (or rejected several correct attempts), it is more likely that the current state has not been well generalized by the model. Consequently, the chances of making subsequent errors increase. In this case, $\mu$ is likely to decrease with the number of attempts, while $e_{-}$ increases with the number of attempts. Thus, the probability of accepting the correct action will decrease as the number of attempts increases.
Therefore, we consider the scenario where the probabilities of error increase while the correctness rate $\mu$ drops after each attempt. We define $e_{i+},e_{i-},\mu_{i}$ , etc., to represent the probabilities related to the $i$ -th attempt, corresponding to the calculations of $\alpha_{i},\beta_{i},\gamma_{i}$ , etc. We have that $\beta_{i}=\mu_{i}(1-e_{i-})$ is monotonically decreasing, and $\gamma_{i}=(1-\mu_{i})e_{i+}$ is monotonically increasing with the index $i$ of the attempt. In this case, the derivation is similar to that of Proposition 2. Therefore, we skip all unnecessary details and present the results directly.
**Proposition 5**
*Given the above posterior risks, the RTMP accuracy $\tilde{\rho}(n)$ for problems with a scale of $n$ is
$$
\tilde{\rho}(n)=\left(\beta_{1}+\sum_{i=2}^{\infty}\beta_{i}\prod_{j=1}^{i-1}\alpha_{i}\right)^{n} \tag{67}
$$
Let $m$ be the width of RTBS. Let $\delta_{i|m}(n)$ denote the probability of a proposed step being rejected (either instantly or recursively) at the $i$ -th attempt on a correct state, and $\epsilon_{m}(n)$ follows the same definition as in Proposition 2. We have $\delta_{i|m}(0)=\epsilon_{m}(0)=0$ and the following recursive equations for $n>0$ :
$$
\displaystyle\delta_{i|m}(n)=\alpha_{i}+\beta_{i}\prod_{j=1}^{m}\delta_{j|m}(n-1)+\gamma_{i}(\epsilon_{m}(n-1))^{m},\qquad i=1,\cdots,m \displaystyle\epsilon_{m}(n)=f+(1-f)\left(\epsilon_{m}(n-1)\right)^{m} \tag{68}
$$
Then, the RTBS accuracy $\tilde{\rho}_{m}(n)$ for problems of scale $n$ is given by:
$$
\tilde{\rho}_{m}(n)=\prod_{t=1}^{n}\sigma_{m}(t),\qquad\text{where }\sigma_{m}(t)=\beta_{1}+\sum_{j=2}^{m}\beta_{j}\prod_{i=1}^{j-1}\delta_{i|m}(t,m)\beta. \tag{70}
$$
In addition, $\delta_{i|m}(n)$ , $\epsilon_{m}(n)$ , and $\sigma_{m}(n)$ all monotonically increase and converge with respect to $n$ .*
The theoretical result in this new setting becomes much more challenging to derive an exact validity condition that remains clear and understandable. However, it is still useful to derive a bound that sufficiently guarantees the effectiveness of reflection. In the following, we show that a sufficient condition becomes much stricter than that in Proposition 3.
**Proposition 6**
*Assume $\mu_{1}<1$ and $k=\inf_{i}\frac{\beta_{i+1}}{\beta_{i}}$ is the lower bound of the decay rate of the probability of accepting the correct step in multiple attempts. Then, a sufficient condition for $\tilde{\rho}(n)>\rho(n)$ is:
$$
\frac{e_{1-}}{k(1-\mu_{1})}+\sup_{i}e_{i+}<1 \tag{71}
$$*
* Proof*
Considering $\alpha_{i}=\mu_{i}e_{i-}+(1-\mu_{i})(1-\max_{i}e_{i+})$ , let $\underline{\alpha}=(1-\mu_{1})(1-\sup_{i}e_{i+})$ be its lower bound. It can be seen that
$$
\displaystyle\beta_{1}+\alpha_{1}\beta_{2}+\alpha_{1}\alpha_{2}\beta_{3}+\cdots+\beta_{m}\prod_{i=1}^{m-1}\alpha_{i}\geq\sum_{j=1}^{m}(\underline{\alpha}k)^{m-1}\beta_{1}=\beta_{1}\frac{1-(\underline{\alpha}k)^{m}}{1-\underline{\alpha}k} \tag{72}
$$
As $m\to\infty$ , the sufficient condition for reflection validity is:
$$
\displaystyle\frac{\beta_{1}}{1-\underline{\alpha}k}>\mu_{1} \displaystyle\iff \displaystyle\frac{1-e_{1-}}{1-k(1-\mu_{1})(1-\sup_{i}e_{i+})}>1 \displaystyle\iff \displaystyle(1-\mu_{1})(1-\sup_{i}e_{i+})>\frac{e_{-}}{k} \displaystyle\iff \displaystyle\frac{e_{1-}}{k}-\sup_{i}e_{i+}(1-\mu_{1})<1 \displaystyle\iff \displaystyle\frac{e_{1-}}{k(1-\mu_{1})}+\sup_{i}e_{i+}<1 \tag{73}
$$
∎
## Appendix D Implementation details
This section describes the details of the training datasets, model architectures, and hyper-parameters used in experiments. Our implementation derives the models architectures, pretraining, and SFT from LitGPT [1] (version 0.4.12) under Apache License 2.0.
### D.1 Algorithmic descriptions of reflective reasoning
Algorithms 1 and 2 presents the pseudo-code of reasoning execution through RMTP and RTBS, respectively. In practice, we introduce a reflection budget $M$ to avoid infinite iteration. If reflective reasoning fails to find a solution within $M$ steps, the algorithm retrogrades to non-reflective reasoning.
To implement RTBS, we maintain a stack to store the reversed list of parental states, allowing them to be restored if needed. Different from our theoretical analysis, our practical implementation does not limit the number of attempts on the input query $Q$ (as long as the total budget $M$ is not used up) as $Q$ has no parent (i.e. the stack is empty).
Algorithm 1 Reflective reasoning through RMTP
0: the query ${Q}$ , the augmented policy $\tilde{\pi}=\{\pi,\mathcal{V}\}$ , transition function $\mathcal{T}$ , and reflective reasoning budget $M$
1: $t\leftarrow 0,{S}_{t}\leftarrow Q$
2: repeat
3: Infer $R_{t+1}\sim\pi(\cdot\mid{S}_{t})$
4: $Reject\leftarrow\text{False}$
5: if $t\leq M$ then
6: Infer ${V}_{t+1}\sim\mathcal{V}(\cdot\mid{S}_{t},{R}_{t+1})$
7: $Reject\leftarrow\text{True}$ if “ $\times$ ” $\in{V}_{t+1}$
8: if $Reject=\text{True}$ then
9: ${S}_{t+1}\leftarrow{S}_{t}$
10: else
11: ${S}_{t+1}\leftarrow\mathcal{T}({S}_{t},{R}_{t+1})$
12: if ${R}_{t+1}$ is the answer then
13: $T\leftarrow t+1,{A}\leftarrow{R}_{t+1}$
14: else
15: $t\leftarrow t+1$
16: until The answer $A$ is produced
17: return $A$
Algorithm 2 Reflective trace-back search
0: the query ${Q}$ , the augmented policy $\tilde{\pi}=\{\pi,\mathcal{V}\}$ , transition function $\mathcal{T}$ , search width $m$ , and reflective reasoning budget $M$
1: $t\leftarrow 0,{S}_{t}\leftarrow Q$
2: $i\leftarrow 0$ {The index of attempts}
3: Initialize an empty stack $L$
4: repeat
5: Infer $R_{t+1}\sim\pi(\cdot\mid{S}_{t})$
6: $i\leftarrow i+1$
7: $Reject\leftarrow\text{False}$
8: if $t\leq M$ then
9: Infer ${V}_{t+1}\sim\mathcal{V}(\cdot\mid{S}_{t},{R}_{t+1})$
10: $Reject\leftarrow\text{True}$ if “ $\times$ ” $\in{V}_{t+1}$
11: if $Reject=\text{True}$ then
12: if $i<m$ then
13: ${S}_{t+1}\leftarrow{S}_{t}$
14: else
15: {Find a parent state that has remaining number of attempts.}
16: repeat
17: Pop $(s_{k},j)$ from $L$
18: ${S}_{t+1}\leftarrow s_{k},i\leftarrow j$
19: until $i<m$ or $L$ is empty
20: else
21: Push $({S}_{t+1},i)$ into $L$
22: ${S}_{t+1}\leftarrow\mathcal{T}({S}_{t},{R}_{t+1}),i\leftarrow 0$
23: if ${R}_{t+1}$ is the answer then
24: $T\leftarrow t+1,{A}\leftarrow{R}_{t+1}$
25: else
26: $t\leftarrow t+1$
27: until the answer $A$ is produced
28: return $A$
### D.2 Example CoT data
We implement predefined programs to generate examples of CoTs and self-verification. Figure 11 presents the example reasoning steps (correct) for non-reflective training and the example detailed verification for reflective training. In our practical implementations, the reasoning steps include additional tokens, such as preprocessing and formatting, to assist planning and transition. To simplify transition function $\mathcal{T}$ , the example steps also include exactly how the states are supposed to be updated, which removes the task-specific prior in $\mathcal{T}$ .
<details>
<summary>x14.png Details</summary>
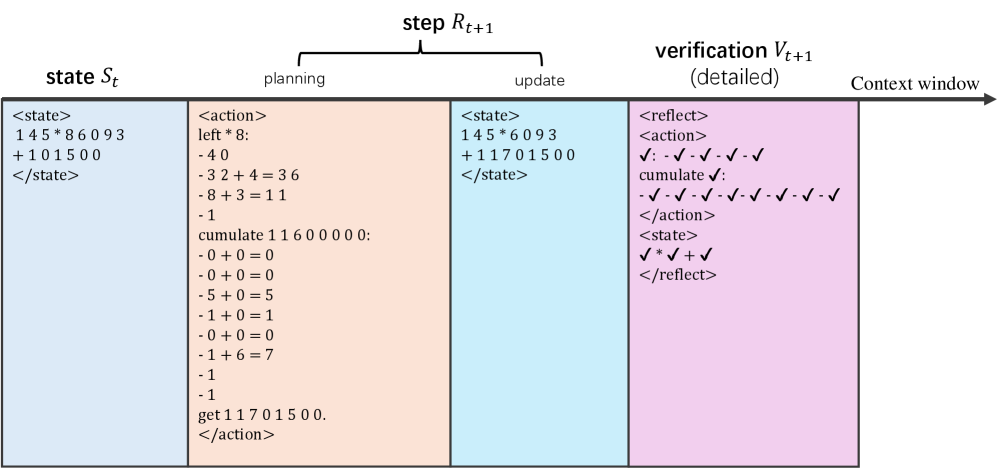
### Visual Description
## Diagram: Computational Process Flow with State, Planning, Update, and Verification
### Overview
The image is a technical diagram illustrating a multi-step computational or algorithmic process. It depicts a sequence from an initial state (`S_t`), through a planning and update phase (`step R_{t+1}`), to a final verification phase (`verification V_{t+1}`). The process is visualized as a horizontal flow within a "Context window," indicated by an arrow at the top right. The diagram is segmented into four distinct, color-coded vertical panels, each containing specific textual and mathematical content.
### Components/Axes
The diagram is organized into the following labeled sections, from left to right:
1. **Header Labels (Top):**
* `state S_t` (above the first panel)
* `step R_{t+1}` (centered above the second and third panels, with sub-labels `planning` and `update`)
* `verification V_{t+1} (detailed)` (above the fourth panel)
* `Context window` (with a right-pointing arrow, at the far right)
2. **Main Panels (Colored Boxes):**
* **Panel 1 (Light Blue):** Labeled implicitly as the initial state `S_t`.
* **Panel 2 (Peach):** Represents the `planning` sub-step of `step R_{t+1}`.
* **Panel 3 (Light Blue):** Represents the `update` sub-step of `step R_{t+1}`.
* **Panel 4 (Pink):** Represents the `verification V_{t+1}` phase.
### Detailed Analysis / Content Details
**Panel 1: Initial State (`S_t`)**
* **Content:**
```
<state>
1 4 5 * 8 6 0 9 3
+ 1 0 1 5 0 0
</state>
```
* **Interpretation:** This appears to represent a numerical state or data vector. The first line could be a sequence of digits or a multiplication operation (`145 * 86093`), and the second line is an addition operation (`+ 101500`).
**Panel 2: Planning Sub-step**
* **Content:**
```
<action>
left * 8;
- 4 0
- 3 2 + 4 = 3 6
- 8 + 3 = 1 1
- 1
cumulate 1 1 6 0 0 0 0 0:
- 0 + 0 = 0
- 0 + 0 = 0
- 5 + 0 = 5
- 1 + 0 = 1
- 0 + 0 = 0
- 1 + 6 = 7
- 1
- 1
get 1 1 7 0 1 5 0 0.
</action>
```
* **Interpretation:** This section details a series of arithmetic operations and accumulation steps. It seems to be performing calculations (subtractions, additions) on digits or numbers, culminating in a "cumulate" operation that produces a final result: `11701500`.
**Panel 3: Update Sub-step**
* **Content:**
```
<state>
1 4 5 * 6 0 9 3
+ 1 1 7 0 1 5 0 0
</state>
```
* **Interpretation:** This shows an updated state. Comparing it to Panel 1, the first line has changed from `1 4 5 * 8 6 0 9 3` to `1 4 5 * 6 0 9 3` (the `8` is missing). The second line has changed from `+ 1 0 1 5 0 0` to `+ 1 1 7 0 1 5 0 0`, which matches the result obtained in the planning step.
**Panel 4: Verification Phase (`V_{t+1}`)**
* **Content:**
```
<reflect>
<action>
✓: - ✓ - ✓ - ✓ - ✓
cumulate ✓:
- ✓ - ✓ - ✓ - ✓ - ✓ - ✓ - ✓ - ✓
</action>
<state>
✓ * ✓ + ✓
</state>
</reflect>
```
* **Interpretation:** This phase uses symbolic checkmarks (`✓`) to represent a verification or reflection process. It appears to validate the actions taken (the sequence of operations) and the final state. The structure mirrors the planning and state panels but with symbols instead of numbers, suggesting a meta-check of the process's correctness.
### Key Observations
1. **Process Flow:** The diagram clearly shows a linear, sequential process: State -> Planning -> Update -> Verification.
2. **State Transformation:** The core transformation occurs between Panel 1 and Panel 3. The planning step ( responsible to to to to to tois is and is then used is is the to to to is is the to to is is The the the not not not unclear not not the the the the the the the the the the diagram is is incorrect the the the the the the is the the the the the the correct the diagrampl1111ably match the updated state in Panel 3. The updated state in Panel 3 uses the result from the planning step (`11701500`) but modifies the first line of the state.
3. **Symbolic Verification:** The verification phase does not re-calculate numbers but uses a symbolic representation (`✓`) to affirm the structure and process, acting as a logical or structural check rather than a numerical one.
4. **Spatial Layout:** The legend/labels are positioned directly above their corresponding panels. The "Context window" arrow frames the entire process, suggesting this sequence occurs within a limited operational scope.
### Interpretation
This diagram models a step in an algorithmic process, likely related to numerical computation, state estimation, or machine learning (e.g., a step in a recurrent network or a planning algorithm). The process involves:
1. **Taking a current state** (`S_t`), which is a set of numerical values or operations.
2. **Planning an action** that involves a detailed sequence of arithmetic manipulations to compute a new value (`11701500`).
3. **Updating the state** by incorporating the result of the planning step, which modifies both the operation and the additive term in the state representation.
4. **Verifying the process** symbolically, ensuring the action sequence and resulting state structure are valid.
The key insight is the **decoupling of numerical computation (planning) from symbolic verification**. The system performs precise arithmetic to generate a new value but then checks the integrity of the overall process using a higher-level, symbolic representation. This could be a design pattern for ensuring robustness in automated reasoning systems, where numerical results are validated against expected structural patterns. The missing `8` in the updated state's first line (`1 4 5 * 6 0 9 3`) compared to the initial state (`1 4 5 * 8 6 0 9 3`) is a critical anomaly; it suggests the planning step may have identified and corrected an error or performed a specific transformation on that part of the state.
</details>
(a) Mult
<details>
<summary>x15.png Details</summary>
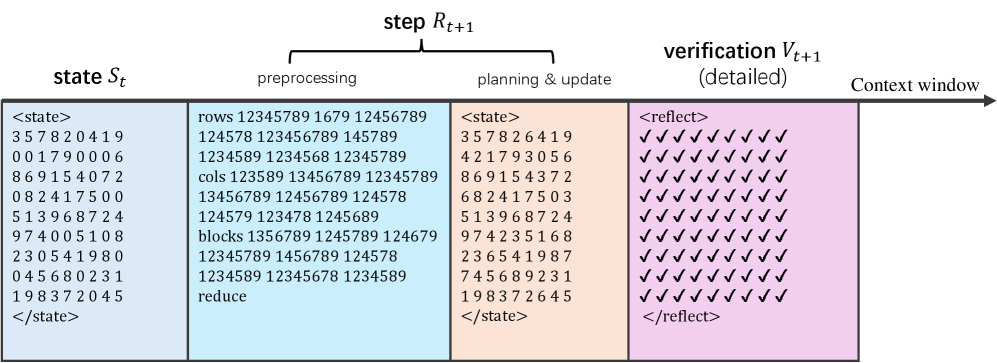
### Visual Description
## Diagram: State Transformation and Verification Process
### Overview
The image is a technical diagram illustrating a three-stage computational process for transforming and verifying a numerical state. It depicts a sequential flow from an initial state (`S_t`), through a processing step (`R_{t+1}`), to a verification stage (`V_{t+1}`), all contained within a conceptual "Context window." The diagram uses color-coded blocks and structured text to represent data and operations.
### Components/Axes
The diagram is organized horizontally into three main sections, followed by an arrow indicating the context window.
1. **Left Section: `state S_t`**
* **Label:** `state S_t` (top-left).
* **Content:** A 10x10 grid of single-digit integers enclosed within `<state>` and `</state>` tags.
* **Spatial Grounding:** This block is the leftmost element, with a light gray background.
2. **Middle Section: `step R_{t+1}`**
* **Label:** `step R_{t+1}` (centered above the section).
* **Sub-sections:** This section is divided into two colored blocks:
* **`preprocessing` (Light Blue Block):** Contains labeled lists of numbers.
* **`planning & update` (Light Orange Block):** Contains a transformed 10x10 state grid, also within `<state>` tags.
3. **Right Section: `verification V_{t+1}`**
* **Label:** `verification V_{t+1} (detailed)` (top-right of the block).
* **Content:** A 10x10 grid of checkmark symbols (`✓`) enclosed within `<reflect>` and `</reflect>` tags.
* **Spatial Grounding:** This block has a light purple background and is the rightmost colored section.
4. **Context Window Arrow**
* **Label:** `Context window` (above the arrow).
* **Description:** A black arrow originates from the right edge of the verification block and points to the right, extending beyond the diagram's main content.
### Detailed Analysis
**1. Initial State (`S_t`) Data:**
The grid contains the following rows of numbers (transcribed exactly):
```
3 5 7 8 2 0 4 1 9
0 0 1 7 9 0 0 0 6
8 6 9 1 5 4 0 7 2
0 8 2 4 1 7 5 0 0
5 1 3 9 6 8 7 2 4
9 7 4 0 0 5 1 0 8
2 3 0 5 4 1 9 8 0
0 4 5 6 8 0 2 3 1
1 9 8 3 7 2 0 4 5
```
*(Note: The grid appears to be 10 rows by 10 columns, but the last row in the image is partially cut off. The transcription above includes 9 full rows as clearly visible.)*
**2. Preprocessing Block Data:**
This block lists extracted features from the initial state:
* `rows 12345789 1679 12456789`
* `124578 123456789 145789`
* `1234589 1234568 12345789`
* `cols 123589 13456789 12345789`
* `13456789 12456789 124578`
* `blocks 1356789 1245789 124679`
* `12345789 1456789 124578`
* `1234589 12345678 1234589`
* `reduce`
**3. Updated State (from `planning & update`) Data:**
The grid after the update step contains:
```
3 5 7 8 2 6 4 1 9
4 2 1 7 9 3 0 5 6
8 6 9 1 5 4 3 7 2
6 8 2 4 1 7 5 0 3
5 1 3 9 6 8 7 2 4
9 7 4 2 3 5 1 6 8
2 3 6 5 4 1 9 8 7
7 4 5 6 8 9 2 3 1
```
*(Note: This grid also shows 9 full rows.)*
**4. Verification Block Data:**
The grid consists entirely of checkmarks (`✓`), arranged in 10 rows and 10 columns, indicating a successful verification for each corresponding cell in the updated state.
### Key Observations
1. **State Transformation:** The primary change between `S_t` and the updated state occurs in the second row. The initial row `0 0 1 7 9 0 0 0 6` becomes `4 2 1 7 9 3 0 5 6`. Several other cells also change (e.g., row 3, column 7 changes from `0` to `3`; row 4, column 10 changes from `0` to `3`).
2. **Preprocessing Logic:** The "rows," "cols," and "blocks" lists in the preprocessing block appear to represent sets of indices or values extracted from the initial state, likely for constraint checking or move generation (suggestive of a Sudoku-like puzzle solver). The "reduce" command implies a simplification step.
3. **Verification Outcome:** The uniform grid of checkmarks in the `verification V_{t+1}` block indicates that the updated state satisfies all verification criteria (e.g., puzzle constraints) without any errors.
4. **Process Flow:** The diagram clearly illustrates a pipeline: **Input State -> Feature Extraction & Planning -> Updated State -> Verification**. The "Context window" arrow suggests this is one step (`t+1`) in a longer sequence.
### Interpretation
This diagram models a single iteration of a constraint-satisfaction or search algorithm, likely for a puzzle like Sudoku. The process involves:
1. **Analysis:** The `preprocessing` stage parses the current state (`S_t`) to identify relevant groups (rows, columns, blocks) and their contents.
2. **Decision & Action:** The `planning & update` stage uses this analysis to compute a new state, filling in or correcting specific cells (as seen in the changed second row).
3. **Validation:** The `verification` stage performs a detailed check (`<reflect>`) on the new state, confirming that all constraints are met (all checkmarks).
The transformation from a state with zeros (often representing blanks in puzzles) to a state with more filled numbers, followed by a full verification, demonstrates a successful problem-solving step. The "Context window" implies this step is part of a larger memory or sequence, where the output of one step becomes the input for the next. The diagram effectively communicates the algorithmic flow, data structures, and success condition of the process.
</details>
(b) Sudoku
Figure 11: Example reasoning steps with detailed verfication for integer multiplication and Sudoku.
#### D.2.1 Multiplication CoT
Each state is an expression $x_{t}\times y_{t}+r_{t}$ , where $x_{t}$ and $y_{t}$ are the remaining values of two multiplicands, and $r_{t}$ is the cumulative result. For an input query $x\times y$ , the expert reasoner assigns $x_{1}=x$ , $y_{1}=y$ , and $r_{1}=0$ .
For each step, the reasoner plans a number $u\in\{1,\ldots,9\}$ to eliminate in $x_{t}$ (or $y_{t}$ ). Specifically, it computes $\delta=u\times y_{t}$ or ( $\delta=u\times x_{t}$ ). Next, it finds the digits in $x_{t}$ (or $y_{t}$ ) that are equal to $u$ and set them to $0$ in $x_{t+1}$ (or $y_{t+1}$ ). For each digit set to $0$ , the reasoner cumulates $\delta\times 10^{i}$ to $r_{t}$ , where $i$ is the position of the digit (starting from $0$ for the unit digit). An example of a reasoning step is shown in Figure 11(a). Such steps are repeated until either $x_{T}$ or $y_{T}$ becomes $0$ , then the answer is $r_{T}$ .
#### D.2.2 Sudoku CoT
Each state is a $9\times 9$ matrix representing the partial solution, where blank numbers are represented by $0$ . On each step, the reasoner preprocesses the state by listing the determined numbers of each row, columns, and blocks. Given these information, the model reduces the blank positions that has only one valid candidate. If no blank can be reduced, the model randomly guess a blank position that has the fewest candidates. Such process continues until there exist no blanks (i.e., zeros) in the matrix.
An example of a reasoning step is shown in the right of Figure 11(b). The planned updates (i.e., which positions are filled with which numbers) is intrinsically included in a new puzzle, which is directly taken as the next state by the transition function $\mathcal{T}$ .
#### D.2.3 Verification of reasoning steps
Binary Verification
The Binary verification labels are generated using a rule-based checker of each reasoning step. In Multiplication, it simply checks whether the next state $x_{t+1}\times y_{t+1}+r_{t+1}$ is equal to the current state $x_{t}\times y_{t}+r_{t}$ . In Sudoku, it checks whether existing numbers in the old matrix are modified and whether the new matrix has duplicated numbers in any row, column, and block.
Detailed Verification
In Multiplication, we output a label for each elemental computation — addition or unit-pair product — is computed correctly. In Sudoku, we output a label for each position in the new matrix, signifying whether the number violates the rule of Sudoku (i.e. conflicts with other numbers in the same row, column, or block) or is inconsistent with the previous matrix. These labels are organized using a consistent format as the CoT data. Examples of detailed reflection for correct steps is in Figure 11(b). If the step contains errors, we replace the corresponding “ $\checkmark$ ” with “ $\times$ ”.
### D.3 Model architectures and tokenization
Table 2: The model architectures of models for the transitional implementation.
| Vocabulary size | 128 | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Embedding size | 128 | 256 | 512 | 128 | 256 | 512 |
| Number of layers | 5 | | | | | |
| Number of attention Heads | 4 | 8 | 8 | 4 | 8 | 8 |
Our models architectures uses multi-head causal attention with LayerNorm [36] with implementation provided by LitGPT [1]. Table 2 specifies the architecture settings of transformer models with 1M, 4M, 16M parameters.
Tokenizers
We employ the byte-pair encoding algorithm [30] to train tokenizers on reasoning CoT examples for tiny transformers. Special tokens for reflection and reasoning structure (e.g., identifiers for the beginning and ending positions of states and reasoning steps) are manually added to the vocabulary. Since the vocabulary size is small (128 in our experiments), the learned vocabulary is limited to elemental characters and the high-frequency words for formatting.
### D.4 Hyperparameters
Table 3 presents the hyper-parameters used in training and testing the tiny-transformer models. In the following sections, we describe how these parameters are involved in our implementation.
Table 3: The main hyper-parameters used in this work.
| Task | Mult | Sudoku | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Model size | 1M | 4M | 16M | 1M | 4M | 16M |
| Training CoT examples: $N_{CoT}$ | 32K | 36K | | | | |
| Total pretraining tokens: $N_{pre\_tok}$ | 1B | | | | | |
| Pretraining batch size: $B_{pre}$ | 128 | | | | | |
| Pretraining learning rate: $\eta_{pre}$ | 0.001 $\to$ 0.00006 | | | | | |
| SFT batch size: $B_{SFT}$ | 128 | | | | | |
| SFT learning rate: $\eta_{SFT}$ | 0.001 $\to$ 0.00006 | | | | | |
| Non-reflective SFT epochs: $E_{SFT}$ | 5 | | | | | |
| Reflective sampling temperature: Solving $\tau_{refl:s}$ | 0.75 | | | | | |
| Reflective sampling temperature: Proposing $\tau_{refl:p}$ | 1 | 1.25 | 1.5 | 1 | 1.25 | 1.5 |
| Reflective SFT epochs: $E_{RSFT}$ | 3 | | | | | |
| PPO replay buffer size: $N_{PPO:buf}$ | 512 | | | | | |
| GRPO replay buffer size: $N_{GRPO:buf}$ | 1024 | | | | | |
| RL sampling interval: $E_{RL:int}$ | 4 | | | | | |
| RL sampling temperature: Planning $\tau_{RL:\pi}$ | 1.25 | 1 | 1.25 | 1.25 | | |
| RL sampling temperature: Feedback $\tau_{RL:\pi_{f}}$ | 1 | | | | | |
| RL clipping factor: $\varepsilon$ | 0.1 | | | | | |
| RL KL-divergence factor: $\beta$ | 0.1 | | | | | |
| GRPO group size: $G$ | 8 | | | | | |
| RL total epochs: $E_{RL}$ | 512 | | | | | |
| RL learning rate: $\eta_{RL}$ | 0.00005 $\to$ 0.00001 | | | | | |
| PPO warm-up epochs: $E_{PPO:warmup}$ | 64 | | | | | |
| Testing first-attempt temperature: $\tau_{\pi:first}$ | 0 | 1 | | | | |
| Testing revision temperature: $\tau_{\pi:rev}$ | 1 | | | | | |
| Testing verification temperature: $\tau_{\pi_{f}}$ | 0 | | | | | |
| Testing non-reflective steps $T$ : | 32 | | | | | |
| Testing reflective steps $\tilde{T}$ : | 64 | | | | | |
| RTBS width: $m$ | 4 | | | | | |
Non-reflective training
The pretraining and SFT utilize a dataset $N_{CoT}$ of CoT examples generated by an expert reasoning program. Pretraining treats these CoT examples as plain text and minimizes the cross-entropy loss for next-token prediction, using the batch size $B_{pre}$ and the learning rate $\eta_{pre}$ . The pretraining process terminates after predicting a total of $N_{pre\_tok}$ tokens. The non-reflective SFT uses the same dataset as that used in pretraining. It maximizes the likelihood of predicting example outputs (reasoning steps) from prompts (reasoning states), using the batch size $B_{SFT}$ and the learning rate $\eta_{SFT}$ . The total number of non-reflective SFT epochs is $E_{SFT}$ .
Reflective SFT
To perform non-reflective SFT, we use the model after non-reflective training to sample trajectories for each input query in the training set. The reflective sampling involves two decoding temperatures: the lower solving temperature $\tau_{refl:s}$ is used to walk through the solution path, while a higher proposing temperature $\tau_{refl:p}$ is used to generate diverse steps, which are fed into the reflective dataset. Then, the verification examples, which include binary or detailed labels, are generated by an expert verifier program. The reflective SFT includes $E_{RSFT}$ epochs, using the same batch size and learning rate as the non-reflective SFT.
Reinforcement learning
We use online RL algorithms as described in Appendix B, including PPO and GRPO. These algorithms include an experience replay buffer to store $N_{PPO:buf}$ and $N_{GRPO:buf}$ example trajectories, respectively. After every $E_{RL:int}$ epochs trained on the buffer, the buffer is updated by sampling new trajectories, using the temperature $\tau_{RL:\pi}$ for planning steps and the temperature $\tau_{RL:\tilde{\pi}}$ for reflective feedback. According to Equations 8 and 12, the hyper-parameters in both the PPO and GRPO objectives include the clipping factor $\varepsilon$ and the KL-Divergence factor $\beta$ . Additionally, GRPO defines $G$ as the number of trajectories in a group. We run RL algorithms for $E_{RL}$ epochs, using the learning rate $\eta_{RL}$ . PPO involves $E_{PPO:warmup}$ warm-up epochs at the beginning of training, during which only the value model is optimized.
Testing
During testing, we execute the reasoner using three decoding temperatures: $\tau_{\pi:first}$ for the first planning attempt, $\tau_{\pi:rev}$ for the revised planning attempt after being rejected, and $\tau_{\pi_{f}}$ for self-verification. We use low temperatures to improve accuracy for more deterministic decisions, such as self-verifying feedback and the first attempt in Mult. We use higher temperatures for exploratory decisions, such as planning in Sudoku and revised attempts in Mult. We set the non-reflective reasoning budget to $T$ steps and the reflective reasoning budget to $\tilde{T}$ steps. If the reflective budget is exhausted, the reasoner reverts to non-reflective reasoning. We set the search width of RTBS to $m$ .
### D.5 Computational resources
Since our models are very small, it is entirely feasible to reproduce all our results on any PC (even laptops) that has a standard NVIDIA GPU. Using our hyper-parameters, the maximum GPU memory used for training the 1M, 4M, and 16M models is approximately 4GB, 12GB, and 16GB, respectively, which can be easily reduced by using smaller batch sizes. To run multiple experiments simultaneously, we utilize cloud servers with a total of 5 GPUs (one NVIDIA RTX-3090 GPU and four NVIDIA A10 GPUs).
For each model size and task, a complete pipeline (non-reflective training, reflective training, and RL) takes about two days on a single GPU. This includes 1-2 hours for non-reflective training, 8-12 hours for data collection for reflective training, 1-2 hours for reflective SFT, 6-12 hours for RL, and 6-12 hours for testing.
## Appendix E Supplementary results of experiments
In this section, we present supplementary results from our experiments: 1) we assess the reasoning accuracy of various large language models on integer multiplication and Sudoku tasks; 2) we report the accuracy outcomes of models after implementing different supervised fine-tuning strategies; 3) we provide full results of reasoning accuracy after GRPO; 4) we additionally provide the results of PPO, which is weaker than GRPO in reflective reasoning.
### E.1 Evaluation of LLMs
In this section, we provide the reasoning accuracy of LLMs on Mult and Sudoku, including GPT-4o [22], OpenAI o3-mini [21], and DeepSeek-R1 [5]. Since GPT-4o is not a CoT-specialized model, we use the magic prompt “let’s think step-by-step” [13] to elicit CoT reasoning. For o3-mini and DeepSeek-R1, we only prompt with the natural description of the queries. As shown in Table 4, among these LLMs, OpenAI o3-mini produces the highest accuracy in both tasks.
To illustrate how well tiny transformers can do in these tasks, we also present the best performance (results selected from Tables 5 and 7) of our 1M, 4M, and 16M models for each difficulty level, respectively, showing a performance close to or even better than some of the LLM reasoners. For example, according to our GRPO results (see Table 7), our best 4M Sudoku reasoner performs (RTBS through optional detailed verification) equally well to OpenAI o3-mini, and our best 16M Mult reasoner (through binary verification) outperforms DeepSeek-R1 in ID difficulties. Note that this paper mainly focuses on fundamental analysis and does not intend to compete with the general-purpose LLM reasoners, which can certainly gain better accuracy if specially trained on our tasks. Such a comparison is inherently unfair due to the massive gap in resource costs and data scale. The purpose of these results is to show how challenging these tasks can be, providing a conceptual notion of how well a tiny model can perform.
Table 4: The accuracy (%) of GRT-4o, DeepSeek-R1, and OpenAI o3-mini in integer multiplication and Sudoku, compared with the best performance of our 1M (1M*), 4M (4M*), and 16M (16M*) transformers. The “OOD-Hard” for LLMs only refers to the same difficulty as used in testing our tiny transformers, as OOD-Hard questions may have been seen in the training of LLMs.
| Mult ID-Hard OOD-Hard | ID-Easy 32.6 18.6 | 73.2 97.2 96.4 | 100 77.0 61.4 | 96.8 52.7 3.7 | 96.2 77.0 5.8 | 98.7 81.1 9.4 | 99.7 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Sudoku | ID-Easy | 40.7 | 99.6 | 90.4 | 33.9 | 97.2 | 99.8 |
| ID-Hard | 2.8 | 52.8 | 4.4 | 0.4 | 58.1 | 72.2 | |
| OOD-Hard | 0.0 | 0.0 | 0.0 | 0.0 | 6.9 | 14.4 | |
### E.2 Results of supervised fine tuning
Table 5 includes our complete results of reasoning accuracy after non-reflective and reflective SFT. As discussed in Section 3.1, our implementation uses Reduced states that maintain only useful information for tiny transformers. To justify this, we also test the vanilla Complete implementation, where each state ${S}_{t}=({Q}_{t},{R}_{1}\ldots,{R}_{t-1})$ includes the full history of past reasoning steps. As a baseline, the Direct thought without intermediate steps is also presented.
Table 5: The reasoning accuracy (%) for 1M, 4M, and 16M transformers after SFT.
| 1M | Mult | ID Easy | 21.8 | 10.6 | 23.6 | 95.8 | 94.5 | 93.4 | 22.0 | 33.4 | 24.2 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| ID Hard | 3.0 | 1.4 | 2.0 | 52.7 | 44.6 | 35.5 | 2.2 | 4.8 | 2.8 | | |
| OOD Hard | 1.4 | 0.3 | 1.0 | 3.7 | 2.2 | 1.2 | 1.0 | 0.8 | 0.4 | | |
| Sudoku | ID Easy | 2.8 | 0 | 1.4 | 33.0 | 32.4 | 2.4 | 17.4 | 18.7 | 19.4 | |
| ID Hard | 0 | 0 | 0 | 0.3 | 0.1 | 0 | 0.1 | 0 | 0 | | |
| OOD Hard | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | |
| 4M | Mult | ID Easy | 15.6 | 17.2 | 92.0 | 97.7 | 97.6 | 97.3 | 94.5 | 93.8 | 93.3 |
| ID Hard | 1.7 | 1.9 | 37.3 | 56.9 | 62.2 | 53.0 | 43.4 | 47.6 | 42.4 | | |
| OOD Hard | 1.2 | 1.0 | 2.2 | 2.9 | 1.8 | 1.1 | 3.7 | 3.3 | 2.7 | | |
| Sudoku | ID Easy | 13.0 | 3.9 | 52.2 | 92.1 | 96.8 | 96.0 | 54.4 | 81.9 | 88.5 | |
| ID Hard | 0.1 | 0 | 3.3 | 40.9 | 46.3 | 53.3 | 5.2 | 16.9 | 45.7 | | |
| OOD Hard | 0 | 0 | 0 | 0.4 | 4.0 | 6.7 | 0.0 | 1.1 | 2.0 | | |
| 16M | Mult | ID Easy | 15.1 | 59.2 | 99.2 | 98.8 | 98.9 | 98.8 | 99.2 | 99.5 | 98.5 |
| ID Hard | 1.6 | 9.6 | 65.9 | 65.2 | 76.7 | 74.9 | 65.9 | 76.4 | 73.5 | | |
| OOD Hard | 1.2 | 1.0 | 2.5 | 1.1 | 1.3 | 1.3 | 9.2 | 9.4 | 7.2 | | |
| Sudoku | ID Easy | 35.8 | 15.9 | 95.7 | 97.1 | 97.9 | 92.5 | 93.0 | 99.0 | 99.7 | |
| ID Hard | 0.4 | 0 | 48.8 | 50.1 | 53.1 | 54.8 | 46.9 | 57.9 | 70.7 | | |
| OOD Hard | 0 | 0 | 0.4 | 0.9 | 4.4 | 6.0 | 0.7 | 8.2 | 14.4 | | |
Reducing the redundancy of states in long CoTs benefits tiny transformers. The left three columns in Table 5 compare the above thought implementations for non-reflective models. We see that both direct and complete thoughts fail to provide an acceptable performance even in ID-Easy difficulty. This proves the importance of avoiding long-context inference by reducing redundancy in representing states. Considering the huge performance gap, we exclude the complete and direct implementations from our main discussion.
Estimated errors of self-verification
For RMTP and RTBS executions, we employ the oracle verifiers to maintain test-time statistics of the average $e_{-}$ and $e_{+}$ (see definition in Section 4) of reasoning states. The results are shown in Table 6, where we also present the difference in how much reflective reasoning raises the performance over non-reflective reasoning. We only count the errors in the first attempts on reasoning states to avoid positive bias, as the reasoner may be trapped in some state and repeat the same error for many steps.
Table 6: The percentage (%) of test-time verification errors (i.e., $e_{-}$ and $e_{+}$ ) after reflective SFT. Additionally, we compute $\Delta$ as the difference of how much reflective reasoning raises the performance over non-reflective reasoning, i.e. RMTP (RTBS) accuracy minus non-reflective accuracy.
| 1M ID Hard OOD Hard | Mult 3.8 16.4 | ID Easy 37.6 32.9 | 19.3 $-8.1$ $-1.5$ | 4.4 3.6 6.0 | $-1.3$ 33.0 22.5 | 14.9 $-17.2$ $-2.5$ | 4.9 0.9 13.6 | $-2.4$ 6.9 2.2 | 10.2 $+2.6$ $-0.2$ | 18.3 14.5 13.2 | $+11.4$ 7.4 2.4 | 24.4 $+0.6$ $-0.6$ | 19.4 | $+2.2$ |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Sudoku | ID Easy | 9.9 | 35.2 | $-0.6$ | 31.1 | 43.9 | $-30.6$ | 87.1 | 0.1 | $+1.3$ | 85.1 | 0.1 | $+2$ | |
| ID Hard | 21.1 | 31.0 | $-0.2$ | 33.1 | 28.6 | $-0.3$ | 82.8 | 0 | $-0.1$ | 79.4 | 0 | $-0.1$ | | |
| OOD Hard | 60.3 | 7.5 | $0$ | 60.2 | 13.4 | $0$ | 87.9 | 0 | $0$ | 84.5 | 0 | $0$ | | |
| 4M | Mult | ID Easy | 25.1 | 5.9 | $-0.1$ | 58.1 | 8.9 | $-0.4$ | 30.4 | 3.7 | $-0.7$ | 28.7 | 7.5 | $-1.2$ |
| ID Hard | 2.4 | 23.6 | $+5.3$ | 26.0 | 30.8 | $-3.9$ | 3.3 | 25.1 | $+4.2$ | 10.0 | 29.3 | $-1.0$ | | |
| OOD Hard | 7.5 | 42.9 | $-1.1$ | 18.0 | 61.7 | $-1.8$ | 5.9 | 28.1 | $-0.4$ | 10.9 | 28.2 | $-1.0$ | | |
| Sudoku | ID Easy | 39.5 | 9.5 | $+4.7$ | 40.4 | 11.5 | $+3.9$ | 23.8 | 0.1 | $+27.5$ | 46.7 | 0.3 | $+34.1$ | |
| ID Hard | 41.3 | 1.9 | $+5.4$ | 56.0 | 6.7 | $+12.4$ | 17.3 | 0.2 | $+11.7$ | 22.1 | 0.3 | $+40.5$ | | |
| OOD Hard | 78.5 | 0.8 | $+3.6$ | 70.6 | 0.6 | $+6.3$ | 31.5 | 0.1 | $+1.1$ | 35.9 | 0.1 | $+2$ | | |
| 16M | Mult | ID Easy | 11.3 | 8.6 | $+0.1$ | 6.1 | 9.4 | $+0.0$ | 15.7 | 2.1 | $+0.3$ | 3.8 | 2.9 | $-0.7$ |
| ID Hard | 1.4 | 13.9 | $+11.5$ | 1.8 | 16.9 | $+9.7$ | 2.5 | 7.0 | $+10.5$ | 4.4 | 7.2 | $+7.6$ | | |
| OOD Hard | 1.3 | 86.4 | $+0.2$ | 1.5 | 88.2 | $+0.2$ | 8.5 | 18.3 | $+0.2$ | 11.7 | 19.7 | $-2$ | | |
| Sudoku | ID Easy | 40.1 | 3.3 | $+0.8$ | 10.1 | 4.7 | $-4.6$ | 6.6 | 1.7 | $+6$ | 9.1 | 6.4 | $+6.7$ | |
| ID Hard | 50.5 | 4.3 | $+3$ | 37.2 | 9.4 | $+4.7$ | 15.4 | 0.1 | $+11.0$ | 10.6 | 0.6 | $+23.8$ | | |
| OOD Hard | 75.2 | 4.2 | $+3.5$ | 65.0 | 3.1 | $+5.1$ | 28.3 | 0.1 | $+7.5$ | 24.8 | 0.0 | $+13.7$ | | |
Our full results provide more evidence for the findings discussed in Section 5.1:
- Learning to self-verify enhances non-reflective execution for 9 out of 12 models (2 verification types, 3 model sizes, and 2 tasks), such that accuracy does not decrease in any difficulty and increases in at least one difficulty.
- RMTP improves performance over non-reflective execution for all 4M and 16M models. However, RMTP based on binary verification fails to benefit the 1M models, which suffer from a high $e_{-}$ .
- 4M and 16M Sudoku models greatly benefit from RTBS, especially using detailed verification.
### E.3 Results of GRPO
The complete results of models after GRPO are given in Table 7. To have a convenient comparison, Table 8 presents the difference of accuracy across Table 5 and Table 7, showing that the difference of accuracy is caused by GRPO.
Table 7: The accuracy (%) of the 1M, 4M, and 16M transformers after GRPO.
| Verification Type | None | Binary | Detailed | Optional Detailed | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Reflective Execution | None | None | RMTP | RTBS | None | RMTP | RTBS | None | RMTP | RTBS | | |
| 1M | Mult | ID Easy | 52.6 | 96.2 | 95.9 | 95.7 | 53.0 | 49.5 | 45.1 | 48.6 | 47.7 | 48.8 |
| ID Hard | 11.6 | 50.0 | 44.0 | 42.0 | 11.4 | 9.7 | 8.1 | 12.2 | 12.7 | 12.6 | | |
| OOD Hard | 1.1 | 2.5 | 1.9 | 1.6 | 1.0 | 0.9 | 0.4 | 1.2 | 1.3 | 1.2 | | |
| Sudoku | ID Easy | 1.3 | 33.9 | 29.2 | 4.5 | 17.6 | 20.7 | 18.7 | 23.0 | 23.0 | 22.6 | |
| ID Hard | 0 | 0.4 | 0 | 0.2 | 0 | 0.1 | 0 | 0.1 | 0.1 | 0 | | |
| OOD Hard | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | |
| 4M | Mult | ID Easy | 98.0 | 98.6 | 98.7 | 98.8 | 98.2 | 98.0 | 98.4 | 98.2 | 98.4 | 98.6 |
| ID Hard | 65.6 | 73.6 | 77.0 | 76.7 | 63.0 | 64.3 | 63.2 | 63.9 | 66.8 | 66.1 | | |
| OOD Hard | 2.3 | 2.7 | 2.7 | 2.3 | 5.8 | 5.3 | 5.3 | 3.3 | 3.2 | 3.3 | | |
| Sudoku | ID Easy | 58.7 | 93.8 | 97.2 | 96.7 | 57.8 | 85.3 | 92.2 | 77.0 | 94 | 98.2 | |
| ID Hard | 3.2 | 43.9 | 53.8 | 58.1 | 5.6 | 24.7 | 47.7 | 21.4 | 37.7 | 61.3 | | |
| OOD Hard | 0 | 0.4 | 4.9 | 6.9 | 0 | 0.4 | 2.0 | 0 | 1.8 | 4.2 | | |
| 16M | Mult | ID Easy | 99.8 | 99.2 | 99.2 | 99.1 | 99.7 | 99.6 | 99.4 | 99.2 | 99.4 | 99.3 |
| ID Hard | 77.2 | 75.2 | 81.1 | 79.6 | 76.3 | 77.8 | 77.6 | 75.9 | 78.4 | 77.7 | | |
| OOD Hard | 1.8 | 1.3 | 1.8 | 1.8 | 8.4 | 8.2 | 7.4 | 6.0 | 5.5 | 5.6 | | |
| Sudoku | ID Easy | 96.3 | 97.6 | 98.8 | 94.6 | 93.3 | 98.8 | 99.8 | 88.7 | 97.6 | 99.0 | |
| ID Hard | 51.3 | 51.7 | 58.0 | 62.3 | 46.7 | 60.4 | 72.2 | 42.2 | 57.3 | 70.9 | | |
| OOD Hard | 0.7 | 0.7 | 6.0 | 7.8 | 0.2 | 6.7 | 12.0 | 0.2 | 6.7 | 11.1 | | |
Table 8: The difference of accuracy (%) of the 1M, 4M, and 16M transformers after GRPO. Positive values mean that GRPO raises the accuracy of the models above SFT.
| 1M | Mult | ID Easy | $+29.0$ | $+0.4$ | $+1.4$ | $+2.3$ | $+31.0$ | $+16.1$ | $+20.9$ |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| ID Hard | $+9.6$ | $-2.7$ | $-0.6$ | $+6.5$ | $+9.2$ | $+4.9$ | $+5.3$ | | |
| OOD Hard | $+0.1$ | $-1.2$ | $-0.3$ | $+0.4$ | $0.0$ | $+0.1$ | $0.0$ | | |
| Sudoku | ID Easy | $-0.1$ | $+0.9$ | $-3.2$ | $+2.1$ | $+0.2$ | $+2.0$ | $-0.7$ | |
| ID Hard | $0.0$ | $+0.1$ | $-0.1$ | $+0.2$ | $-0.1$ | $+0.1$ | $0.0$ | | |
| OOD Hard | $0.0$ | $0.0$ | $0.0$ | $0.0$ | $0.0$ | $0.0$ | $0.0$ | | |
| 4M | Mult | ID Easy | $+6.0$ | $+0.9$ | $+1.1$ | $+1.5$ | $+3.7$ | $+4.2$ | $+5.1$ |
| ID Hard | $+28.3$ | $+16.7$ | $+14.8$ | $+23.7$ | $+19.6$ | $+16.7$ | $+20.8$ | | |
| OOD Hard | $0.1$ | $-0.2$ | $+0.9$ | $+1.2$ | $+2.1$ | $+2.0$ | $+2.6$ | | |
| Sudoku | ID Easy | $+6.5$ | $+1.7$ | $+0.4$ | $+0.7$ | $+3.4$ | $+3.4$ | $+3.7$ | |
| ID Hard | $-0.1$ | $+3.0$ | $+7.5$ | $+4.8$ | $+0.4$ | $+7.8$ | $+2.0$ | | |
| OOD Hard | $0.0$ | $+0.4$ | $+4.9$ | $+6.9$ | $0$ | $-0.7$ | $0$ | | |
| 16M | Mult | ID Easy | $+0.6$ | $+0.4$ | $+0.3$ | $+0.3$ | $+0.5$ | $+0.1$ | $+0.9$ |
| ID Hard | $+11.3$ | $+10.0$ | $+4.4$ | $+4.7$ | $+10.4$ | $+1.4$ | $+4.1$ | | |
| OOD Hard | $-0.7$ | $+0.2$ | $+0.5$ | $+0.5$ | $-0.8$ | $-1.2$ | $+0.2$ | | |
| Sudoku | ID Easy | $+0.6$ | $+0.5$ | $+0.9$ | $+2.1$ | $+0.3$ | $-0.2$ | $+0.1$ | |
| ID Hard | $+2.5$ | $+1.6$ | $+4.9$ | $+7.5$ | $-0.2$ | $+2.5$ | $+1.5$ | | |
| OOD Hard | $+0.3$ | $-0.2$ | $+1.6$ | $+1.8$ | $-0.5$ | $-1.5$ | $-2.4$ | | |
Reflection usually extends the limit of RL. For reflective models, GRPO samples experience CoTs through RMTP, where self-verification $\mathcal{V}$ and the forward policy $\pi$ are jointly optimized in the form of a self-verifying policy $\tilde{\pi}$ . By comparing the RMTP results (columns 3, 6, and 9) with the non-reflective model (the first column) in Table 7, we find that GRPO usually converges to higher accuracy solving ID-Hard problems in RMTP. This shows that having reflection in long CoTs extends the limit of RL, compared to only exploiting a planning policy.
Interestingly, optional detailed verification generally demonstrates higher performance after GRPO than mandatory verification. A probable explanation is that a mandatory verification may cause the reasoner to overly rely on reflection, which stagnates the learning of the planning policy.
Overall, our full results provide more evidence to better support our findings discussed in Section 5.2:
- RL enhances 24 out of 42 ID-Hard results in Table 8 by no less than 3% (measured in absolute difference). However, only 8 out of 42 OOD-Hard results are improved by no less than 1%.
- In table 9, an increase of $e_{+}$ is observed in 20 out of 25 cases where $e_{-}$ decreases by more than 5% (measured in absolute difference).
#### E.3.1 The verification errors after GRPO
Furthermore, we also present the estimated errors of verification after GRPO in Table 9, in order to investigate how self-verification evolves during RL. Our main observation is that if a model has a high $e_{-}$ before GPRO, then GRPO tends to reduce $e_{-}$ and also increases $e_{+}$ . This change in verification errors is a rather superficial (lazy) way to obtain improvements. If the model faithfully improves verification through RL, both types of errors should simultaneously decrease — such a case occurs only in the ID-Easy difficulty or when $e_{-}$ is already low after SFT. This highlights a potential retrograde of self-verification ability after RL.
Table 9: The percentage (%) of test-time verification errors (i.e., $e_{-}$ and $e_{+}$ ) after GRPO. The arrows “↑” (increase) and “↓” (decrease) present the change compared to the results in SFT (Table 6).
| 1M ID Hard OOD Hard | Mult 16.5↑ 20.3 41.2↑ 57.6 | ID Easy 17.6↓ 20.0 1.6↓ 31.3 | 6.8↓ 12.5 7.0↑ 10.6 40.2↑ 46.2 | 3.3↓ 1.1 13.7↓ 19.3 1.5↑ 24.0 | 5.0↓ 9.9 54.6↑ 55.5 53.9↑ 67.5 | 3.5↓ 1.4 4.6↓ 2.3 16.4↑ 18.6 | 12.4↑ 22.6 42.1↑ 56.6 57.3↑ 70.5 | 17.2↓ 1.1 5.7↓ 1.7 19.1↑ 21.5 | 3.5↑ 27.9 | 17.6↓ 1.8 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Sudoku | ID Easy | 1.2↑ 11.1 | 1.7↓ 36.9 | 13.1↓ 18.0 | 4.0↑ 47.9 | 0.1↑ 87.2 | 0.0↓ 0.0 | 0.0↑ 87.1 | 0.4↑ 0.5 | |
| ID Hard | 2.9↑ 24.0 | 0.9↓ 30.1 | 5.5↓ 27.6 | 0.4↑ 29.0 | 0.1↓ 83.7 | 0.0↓ 0.0 | 0.1↓ 80.3 | 0.0↓ 0.0 | | |
| OOD Hard | 3.1↑ 63.4 | 0.8↑ 8.3 | 4.5↓ 55.7 | 0.9↑ 14.3 | 0.5↑ 88.4 | 0.0↓ 0.0 | 0.6↑ 85.1 | 0.0↓ 0.0 | | |
| 4M | Mult | ID Easy | 2.5↓ 22.6 | 4.8↓ 1.1 | 30.2↓ 27.9 | 7.1↓ 1.8 | 21.1↓ 9.3 | 3.0↓ 0.7 | 5.0↓ 23.7 | 6.8↓ 0.7 |
| ID Hard | 53.1↑ 55.5 | 21.8↓ 1.8 | 30.6↑ 56.6 | 28.5↓ 2.3 | 20.9↑ 24.2 | 20.1↓ 5.0 | 22.0↑ 32.0 | 24.8↓ 4.5 | | |
| OOD Hard | 60.0↑ 67.5 | 24.3↓ 18.6 | 52.5↑ 70.5 | 40.2↓ 21.5 | 55.7↑ 61.6 | 20.9↓ 7.2 | 53.4↑ 64.3 | 22.9↓ 5.3 | | |
| Sudoku | ID Easy | 7.9↓ 31.6 | 3.2↓ 6.3 | 2.8↑ 43.2 | 7.7↓ 3.8 | 11.5↓ 12.3 | 1.3↑ 1.4 | 27.1↓ 19.6 | 1.9↑ 2.2 | |
| ID Hard | 28.7↑ 70.0 | 0.5↓ 1.4 | 2.2↑ 58.2 | 4.7↓ 2.0 | 4.5↓ 12.8 | 1.6↑ 1.8 | 9.2↓ 12.9 | 0.1↓ 0.2 | | |
| OOD Hard | 6.9↑ 85.4 | 0.7↓ 0.1 | 11.0↑ 81.6 | 0.2↓ 0.4 | 2.1↓ 29.4 | 0↓ 0.1 | 5.9↓ 30.0 | 0.1↑ 0.2 | | |
| 16M | Mult | ID Easy | 4.2↓ 7.1 | 7.2↓ 1.4 | 0.4↓ 5.7 | 7.8↓ 1.6 | 8.1↓ 7.6 | 1.9↓ 0.2 | 7.8↑ 11.6 | 2.7↓ 0.2 |
| ID Hard | 7.9↑ 9.3 | 12.8↓ 1.1 | 6.7↑ 8.5 | 15.6↓ 1.3 | 22.7↑ 25.2 | 3.9↓ 3.1 | 18.6↑ 23.0 | 4.3↓ 2.9 | | |
| OOD Hard | 79.0↑ 80.3 | 47.1↓ 39.3 | 89.2↑ 90.7 | 46.4↓ 41.8 | 46.0↑ 54.5 | 12.5↓ 5.8 | 46.4↑ 58.1 | 14.7↓ 5.0 | | |
| Sudoku | ID Easy | 24.5↑ 64.6 | 6.2↑ 9.5 | 25.6↑ 35.7 | 8.5↑ 13.2 | 2.1↑ 8.7 | 0.6↓ 1.1 | 3.3↓ 5.8 | 5.4↓ 1.0 | |
| ID Hard | 25.3↑ 75.8 | 0.0↓ 4.3 | 16.4↑ 53.6 | 2.0↓ 7.4 | 0.5↑ 15.9 | 0.0↓ 0.1 | 2.4↑ 13.0 | 0.4↑ 1.0 | | |
| OOD Hard | 7.9↑ 83.1 | 3.5↓ 0.7 | 12.7↑ 77.7 | 2.1↓ 1.0 | 7.8↑ 36.1 | 0.0↓ 0.1 | 6.8↑ 31.6 | 0.1↑ 0.1 | | |
#### E.3.2 The planning correctness rate after GRPO
Table 10: The planning correctness rate ( $\mu$ ) before and after GRPO. Each result is reported by $\mu_{\text{SFT}}\to\mu_{\text{GRPO}}$ .
| Mult 4M 16M | Detailed $98.3\to 99.5$ $99.7\to 99.9$ | 1M $68.4\to 79.1$ $80.0\to 85.9$ | $70.2\to 81.7$ $35.0\to 38.0$ $47.9\to 43.4$ | $54.4\to 59.5$ | $42.9\to 41.9$ |
| --- | --- | --- | --- | --- | --- |
| Binary | 1M | $98.8\to 99.1$ | $81.2\to 80.3$ | $42.7\to 38.6$ | |
| 4M | $99.3\to 99.7$ | $77.6\to 89.9$ | $57.1\to 48.1$ | | |
| 16M | $99.4\to 99.8$ | $79.6\to 85.1$ | $75.2\to 44.8$ | | |
| Sudoku | Detailed | 1M | $34.1\to 33.0$ | $13.2\to 12.4$ | $9.0\to 8.6$ |
| 4M | $85.0\to 86.8$ | $65.2\to 72.0$ | $70.1\to 70.3$ | | |
| 16M | $98.6\to 98.1$ | $92.5\to 94.0$ | $84.9\to 83.9$ | | |
| Binary | 1M | $59.1\to 60.3$ | $36.6\to 36.1$ | $19.5\to 19.9$ | |
| 4M | $97.3\to 97.8$ | $80.2\to 81.4$ | $74.5\to 70.9$ | | |
| 16M | $99.0\to 99.2$ | $88.5\to 85.1$ | $68.4\to 64.6$ | | |
We also report how GRPO influences the step-wise planning ability, measured by $\mu$ (defined in Section 4), across various tasks, verification types, and model sizes. Shown in Table 10, GRPO increases the planning correctness rate $\mu$ in most ID cases, except for the Sudoku models with binary verification. This indicates that the proposed steps are more likely to be correct and further reduces the overall penalties of false positive verification, making an optimistic verification bias (a high $e_{+}$ in exchange for a low $e_{-}$ ) even more rewarding. In particular, the planning ability shows almost no improvement in OOD problems.
#### E.3.3 Reflection frequency of optional detailed verification
To show how GRPO adapts the reflection frequency for optional detailed verification, Figure 12 shows the reflection frequency of 1M and 16M transformers before and after GRPO, and the reflection frequency of the 4M model is previously shown in Section 5.2. Similarly, Figure 13 shows the reflection frequency for 1M, 4M, and 16M models in Sudoku.
According to results in Table 5, reflective execution does not improve performance for the 1M model, implying its weakness in exploring correct solutions. Therefore, GRPO does not much incentivize reflection for the 1M model. Contrarily, it greatly encourages reflection for 4M and 16M models, for they explore more effectively than the 1M model. These results align with the discussion in Section 5.2 that RL adapts the reflection frequency based on how well the proposing policy can explore higher rewards.
<details>
<summary>x16.png Details</summary>
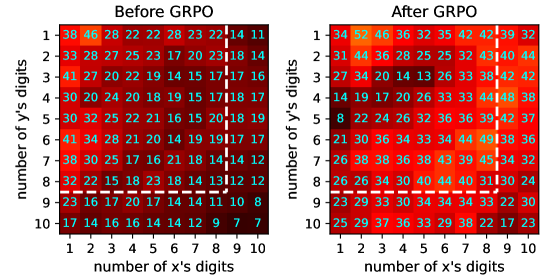
### Visual Description
## Heatmap Comparison: Before and After GRPO
### Overview
The image displays two side-by-side heatmaps comparing numerical data distributions before and after a process labeled "GRPO." Each heatmap is a 10x10 grid where the x-axis represents the "number of x's digits" and the y-axis represents the "number of y's digits," both ranging from 1 to 10. The cells contain integer values, and their color intensity (from dark red to bright yellow) corresponds to the magnitude of these values, with brighter colors indicating higher numbers. A dashed white rectangle highlights a specific region in each heatmap for focused comparison.
### Components/Axes
* **Chart Type:** Two comparative heatmaps.
* **Titles:**
* Left Heatmap: "Before GRPO"
* Right Heatmap: "After GRPO"
* **Axes Labels:**
* X-axis (both charts): "number of x's digits"
* Y-axis (both charts): "number of y's digits"
* **Axis Scales:** Both axes are categorical, with markers for integers 1 through 10.
* **Legend/Color Scale:** No explicit legend is provided. The color gradient serves as an implicit scale: darker reds represent lower values, transitioning through orange to bright yellow for the highest values.
* **Highlighted Region:** A dashed white rectangle is drawn on each heatmap, encompassing the sub-grid from x=7 to x=10 and y=1 to y=8.
### Detailed Analysis
**Data Extraction - Before GRPO (Left Heatmap):**
The values generally decrease from the top-left to the bottom-right. The highest values are concentrated in the top-left corner (low digit counts for both x and y).
| y\x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| :--- | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: |
| **1** | 38 | 46 | 28 | 22 | 28 | 23 | 22 | 14 | 11 | 14 |
| **2** | 33 | 28 | 27 | 25 | 23 | 17 | 20 | 23 | 18 | 14 |
| **3** | 41 | 27 | 20 | 22 | 19 | 14 | 15 | 17 | 17 | 16 |
| **4** | 30 | 20 | 24 | 20 | 18 | 19 | 15 | 17 | 18 | 17 |
| **5** | 30 | 32 | 25 | 22 | 16 | 21 | 15 | 20 | 18 | 19 |
| **6** | 41 | 34 | 28 | 21 | 20 | 14 | 19 | 19 | 17 | 17 |
| **7** | 38 | 30 | 25 | 18 | 23 | 18 | 14 | 14 | 12 | 12 |
| **8** | 32 | 22 | 15 | 18 | 23 | 18 | 14 | 11 | 12 | 12 |
| **9** | 23 | 16 | 17 | 20 | 17 | 14 | 10 | 10 | 8 | 8 |
| **10** | 17 | 14 | 16 | 14 | 14 | 12 | 9 | 7 | 7 | 7 |
**Data Extraction - After GRPO (Right Heatmap):**
The overall value distribution shifts significantly. Values are generally higher, especially in the central and right-hand regions. The pattern is less uniformly decreasing.
| y\x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| :--- | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: |
| **1** | 34 | 52 | 46 | 36 | 32 | 35 | 42 | 49 | 39 | 32 |
| **2** | 31 | 44 | 36 | 28 | 25 | 25 | 32 | 43 | 40 | 44 |
| **3** | 27 | 34 | 20 | 14 | 13 | 26 | 33 | 30 | 42 | 42 |
| **4** | 14 | 19 | 27 | 20 | 23 | 26 | 33 | 44 | 38 | 36 |
| **5** | 8 | 22 | 24 | 26 | 33 | 36 | 39 | 44 | 42 | 37 |
| **6** | 21 | 30 | 36 | 34 | 33 | 34 | 41 | 44 | 38 | 36 |
| **7** | 26 | 38 | 36 | 38 | 30 | 33 | 45 | 39 | 34 | 32 |
| **8** | 26 | 26 | 34 | 30 | 40 | 40 | 41 | 30 | 30 | 24 |
| **9** | 23 | 29 | 33 | 30 | 33 | 30 | 37 | 33 | 22 | 20 |
| **10** | 25 | 29 | 37 | 36 | 33 | 29 | 38 | 22 | 17 | 23 |
### Key Observations
1. **Value Increase:** The "After GRPO" heatmap shows a substantial increase in values across most of the grid, particularly in the central and right-hand columns (x=5 to x=10). The maximum value increases from 46 (Before, at x=2,y=1) to 52 (After, at x=2,y=1).
2. **Pattern Shift:** The "Before" data shows a strong diagonal trend where values decrease as both x and y increase. The "After" data disrupts this pattern; high values are more dispersed, with notable peaks appearing in the upper-right quadrant (e.g., x=8,y=1=49; x=9,y=3=42).
3. **Highlighted Region Change:** The area within the dashed rectangle (x=7-10, y=1-8) undergoes the most dramatic transformation. "Before," this region contains some of the lowest values (e.g., 7, 8, 10, 11, 12). "After," it contains many of the highest values on the chart (e.g., 49, 44, 45, 44, 41).
4. **Low-Value Persistence:** The bottom-right corner (high x, high y) remains an area of relatively lower values in both charts, though the absolute numbers are higher "After GRPO."
### Interpretation
This visualization demonstrates the impact of the "GRPO" process on a system where performance or output (represented by the cell value) is a function of the complexity of two inputs, x and y (measured by their digit count).
* **What the data suggests:** GRPO appears to be a method that significantly enhances outcomes, especially for problems of moderate to high complexity (mid-to-high digit counts for x and y). The process seems to "activate" or improve performance in regions that were previously weak (the highlighted rectangle), shifting the system's optimal operating point.
* **Relationship between elements:** The two heatmaps are direct before-and-after snapshots. The axes define the problem space, the cell values are the performance metric, and the color provides an immediate visual cue for magnitude. The dashed rectangle directs the viewer's attention to the zone of most significant change.
* **Notable anomalies/trends:** The most striking trend is the inversion of performance in the highlighted region—from among the worst to among the best. This suggests GRPO is particularly effective at solving problems that were previously intractable or poorly handled. The persistence of lower values in the extreme bottom-right (e.g., x=10,y=10) indicates a potential limit or boundary condition that GRPO does not overcome, possibly representing a fundamental complexity barrier.
**Language Declaration:** All text in the image is in English.
</details>
(a) 1M
<details>
<summary>x17.png Details</summary>
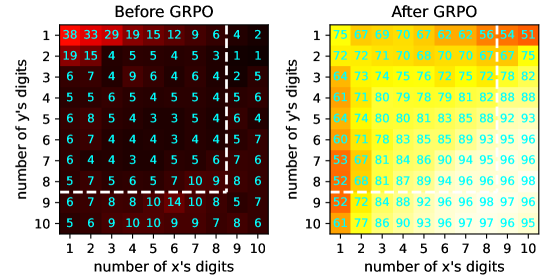
### Visual Description
## Heatmap Comparison: Before and After GRPO
### Overview
The image displays two side-by-side heatmaps comparing numerical data before and after a process labeled "GRPO." The heatmaps visualize a 10x10 grid of values, where the x-axis represents the "number of x's digits" and the y-axis represents the "number of y's digits," both ranging from 1 to 10. The "Before GRPO" heatmap uses a dark red-to-black color scale, indicating lower values, while the "After GRPO" heatmap uses a yellow-to-green color scale, indicating significantly higher values.
### Components/Axes
* **Chart Titles:**
* Left Chart: "Before GRPO" (centered above the left heatmap).
* Right Chart: "After GRPO" (centered above the right heatmap).
* **X-Axis (Both Charts):** Labeled "number of x's digits". Major tick marks and labels are present for integers 1 through 10.
* **Y-Axis (Both Charts):** Labeled "number of y's digits". Major tick marks and labels are present for integers 1 through 10.
* **Legends/Color Bars:**
* **Before GRPO (Right side of left chart):** A vertical color bar ranging from black (bottom, value 0) to bright red (top, value 40). The scale is labeled with values 0, 10, 20, 30, 40.
* **After GRPO (Right side of right chart):** A vertical color bar ranging from yellow (bottom, value 40) to dark green (top, value 100). The scale is labeled with values 40, 60, 80, 100.
* **Grid Structure:** Both charts are 10x10 grids. Each cell contains a numerical value and is colored according to its value and the corresponding color scale.
### Detailed Analysis
**Data Extraction - Before GRPO (Left Heatmap):**
The values are generally low, with the highest values concentrated in the top-left corner (low x and y digits). The color scale indicates values from 0 to 40.
* **Row y=1:** 38, 33, 29, 19, 15, 12, 9, 6, 4, 2
* **Row y=2:** 19, 15, 4, 5, 4, 5, 4, 3, 1, 1
* **Row y=3:** 6, 7, 4, 9, 6, 4, 4, 2, 4, 5
* **Row y=4:** 5, 5, 6, 5, 4, 5, 4, 4, 5, 6
* **Row y=5:** 6, 8, 5, 4, 3, 3, 5, 4, 4, 6
* **Row y=6:** 6, 7, 4, 4, 3, 4, 4, 4, 5, 7
* **Row y=7:** 6, 4, 4, 3, 4, 5, 5, 6, 6, 7
* **Row y=8:** 5, 7, 5, 6, 5, 6, 7, 9, 10, 8
* **Row y=9:** 6, 7, 8, 8, 10, 14, 10, 8, 5, 7
* **Row y=10:** 5, 6, 9, 10, 9, 9, 7, 8, 6
**Data Extraction - After GRPO (Right Heatmap):**
The values are uniformly high, mostly in the 70s, 80s, and 90s. The color scale indicates values from 40 to 100.
* **Row y=1:** 75, 82, 88, 80, 80, 76, 79, 82, 44, 51
* **Row y=2:** 72, 72, 71, 70, 70, 79, 79, 82, 75
* **Row y=3:** 73, 74, 75, 76, 72, 75, 79, 78, 82
* **Row y=4:** 73, 81, 80, 79, 78, 79, 81, 82, 88, 87
* **Row y=5:** 74, 80, 80, 81, 83, 85, 88, 92, 93
* **Row y=6:** 77, 82, 83, 85, 85, 87, 89, 93, 95, 96
* **Row y=7:** 78, 81, 84, 86, 90, 94, 95, 96, 96, 98
* **Row y=8:** 79, 82, 84, 88, 92, 96, 96, 98, 97, 96
* **Row y=9:** 77, 82, 84, 88, 92, 96, 96, 98, 97, 96
* **Row y=10:** 77, 86, 88, 90, 93, 96, 97, 96, 98, 95
### Key Observations
1. **Magnitude Shift:** The most striking observation is the dramatic increase in all values after GRPO. The "Before" values range from 1 to 38, while the "After" values range from 44 to 98.
2. **Pattern Change:** The "Before" heatmap shows a clear diagonal gradient, with values decreasing from the top-left (low x, low y) to the bottom-right (high x, high y). The "After" heatmap shows a much more uniform distribution, with a slight gradient of increasing values from the top-left to the bottom-right.
3. **Outlier:** In the "After GRPO" heatmap, the cell at (x=9, y=1) has a value of 44, which is a significant outlier, being much lower than its neighbors (82 and 51) and the overall trend of high values.
4. **Color Scale Interpretation:** The "Before" scale uses a sequential dark-to-light (black to red) scheme where lighter/brighter indicates higher value. The "After" scale uses a different sequential scheme (yellow to green) where darker green indicates higher value.
### Interpretation
This visualization demonstrates the effect of a process called "GRPO" on a performance metric across different problem complexities, defined by the digit lengths of two variables (x and y).
* **What the data suggests:** GRPO is highly effective. It transforms a system that performs poorly (scores <40) on most tasks, especially those with higher complexity (more digits), into one that performs excellently (scores >70, often >90) across nearly all task complexities.
* **Relationship between elements:** The x and y axes likely represent the difficulty of a computational task (e.g., multiplication, where more digits mean a harder problem). The cell value is a success rate or accuracy score. The "Before" state shows the system struggles significantly as complexity increases. The "After" state shows GRPO has not only raised the baseline performance but also made the system robust to increases in complexity, as evidenced by the high scores in the bottom-right quadrant (high x, high y).
* **Notable anomalies:** The outlier at (x=9, y=1) in the "After" chart (value 44) is critical. It indicates a specific, narrow failure mode persists after GRPO: tasks where x has 9 digits and y has 1 digit. This could point to a specific edge case in the algorithm or training data that was not fully addressed.
* **Underlying implication:** The shift from a strong negative correlation between complexity and performance to a weak positive correlation suggests GRPO fundamentally changes how the system handles scale, possibly by improving generalization or algorithmic efficiency. The process appears to be a major optimization or training breakthrough.
</details>
(b) 16M
Figure 12: The hot-maps of reflection frequency (%) of 1M and 16M multiplication models before and after GRPO, which uses a sampling temperature of $1.25$ . All models are tested using RMTP execution.
<details>
<summary>x18.png Details</summary>
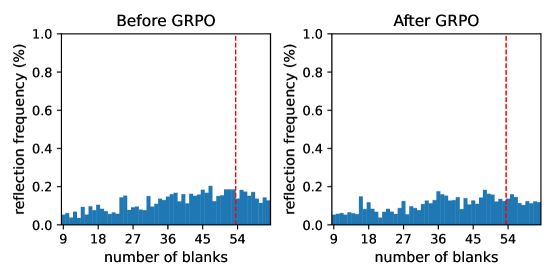
### Visual Description
## Bar Charts: Reflection Frequency Before and After GRPO
### Overview
The image displays two side-by-side bar charts comparing the distribution of "reflection frequency (%)" against the "number of blanks" before and after an intervention or process labeled "GRPO". The charts suggest an analysis of how a system's reflective behavior changes with the quantity of blanks (likely in a text or task) and the impact of the GRPO method.
### Components/Axes
* **Chart Titles:**
* Left Chart: "Before GRPO"
* Right Chart: "After GRPO"
* **X-Axis (Both Charts):**
* Label: "number of blanks"
* Scale: Linear, with major tick marks and labels at 9, 18, 27, 36, 45, and 54.
* **Y-Axis (Both Charts):**
* Label: "reflection frequency (%)"
* Scale: Linear, ranging from 0.0 to 1.0 (representing 0% to 100%).
* **Key Visual Element:** A vertical red dashed line is present in both charts, positioned at the x-axis value of 54.
* **Data Representation:** Blue vertical bars. Each bar's height represents the reflection frequency for a specific number of blanks. The bars are densely packed, suggesting a histogram or a bar chart for a continuous or finely binned discrete variable.
### Detailed Analysis
**1. "Before GRPO" Chart (Left):**
* **Trend:** The reflection frequency shows a general, gradual upward trend as the number of blanks increases from 9 to approximately 54.
* **Data Points (Approximate):**
* At low blank counts (9-18), frequencies are low, mostly below 0.1 (10%).
* Frequencies rise steadily, with noticeable peaks and variability.
* The highest frequencies occur in the range of approximately 45 to 54 blanks, with several bars reaching or slightly exceeding 0.2 (20%).
* The distribution appears somewhat right-skewed, with higher frequencies concentrated at the higher end of the blank count scale.
**2. "After GRPO" Chart (Right):**
* **Trend:** The overall reflection frequency is visibly lower across the entire range of blank counts compared to the "Before" chart. The upward trend with increasing blanks is less pronounced and more flattened.
* **Data Points (Approximate):**
* Frequencies start low (below 0.1) for blank counts of 9-18.
* There is a modest increase, but the peak frequencies are significantly reduced.
* The highest bars in the 36-54 blank range generally remain below 0.15 (15%), with most below 0.12.
* The distribution is more uniform and compressed towards the lower end of the y-axis scale.
**3. The Red Dashed Line (x=54):**
* This line serves as a consistent reference point in both charts. It highlights the data at the maximum shown blank count (54). In the "Before" chart, this region has some of the highest frequencies. In the "After" chart, the frequencies at this point are markedly reduced.
### Key Observations
1. **Systematic Reduction:** The application of GRPO is associated with a clear, systematic reduction in reflection frequency across all observed numbers of blanks.
2. **Attenuated Trend:** The positive correlation between the number of blanks and reflection frequency is weakened after GRPO. The "After" distribution is flatter.
3. **Peak Suppression:** The most significant reduction appears to occur at higher blank counts (approximately 36-54), where the "Before" frequencies were highest.
4. **Consistent Scale:** Both charts use identical axes scales, allowing for direct visual comparison of the distributions' shapes and magnitudes.
### Interpretation
The data suggests that the GRPO process effectively suppresses the "reflection" behavior in the system being measured. "Reflection frequency" likely quantifies how often a system (e.g., an AI model, a cognitive architecture) engages in a specific reflective or recursive processing step.
* **Before GRPO:** The system's tendency to reflect increases with the complexity or length of the input (as proxied by "number of blanks"). This could indicate a scaling behavior where more complex tasks trigger more internal deliberation or self-referential processing.
* **After GRPO:** The intervention successfully decouples reflection frequency from input complexity to a significant degree. The system becomes less prone to reflection, especially for more complex (higher blank count) inputs. This could imply that GRPO makes the system more efficient, less "hesitant," or alters its fundamental processing strategy to rely less on the measured reflective mechanism.
The red line at 54 blanks may indicate a critical threshold, a maximum tested complexity, or a point where the GRPO intervention was specifically designed to have an effect. The charts demonstrate that GRPO's impact is most visually dramatic at this high-complexity end of the spectrum. The overall interpretation is that GRPO modifies the system's operational dynamics, leading to a measurable decrease in a specific type of internal processing (reflection).
</details>
(a) 1M
<details>
<summary>x19.png Details</summary>
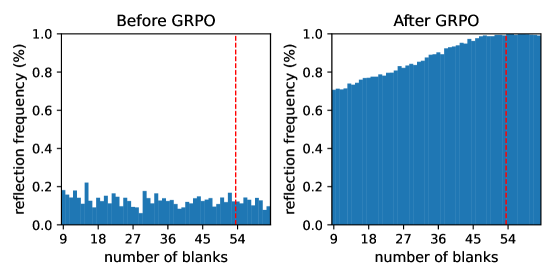
### Visual Description
## Bar Charts: Reflection Frequency Before and After GRPO
### Overview
The image displays two side-by-side bar charts comparing "reflection frequency (%)" against the "number of blanks" before and after a process labeled "GRPO." The charts illustrate a dramatic shift in the distribution and magnitude of reflection frequency following the GRPO intervention.
### Components/Axes
* **Chart Titles:** "Before GRPO" (left chart), "After GRPO" (right chart).
* **Y-Axis (Both Charts):** Labeled "reflection frequency (%)". The scale runs from 0.0 to 1.0, with major tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-Axis (Both Charts):** Labeled "number of blanks". The scale shows major tick marks at 9, 18, 27, 36, 45, and 54.
* **Data Series:** Both charts use vertical blue bars to represent the frequency for each discrete "number of blanks" value.
* **Reference Line:** A vertical red dashed line is present in both charts at the x-axis value of 54.
### Detailed Analysis
**1. Before GRPO Chart (Left):**
* **Trend:** The reflection frequency is consistently low across all numbers of blanks, showing minor, non-systematic fluctuations. There is no clear upward or downward trend.
* **Data Points (Approximate):** Frequencies are predominantly below 0.2 (20%). The highest bar appears near x=18, reaching approximately 0.22. Most other bars cluster between 0.05 and 0.18. The frequency at the red dashed line (x=54) is approximately 0.15.
**2. After GRPO Chart (Right):**
* **Trend:** There is a strong, consistent, and nearly linear upward trend. Reflection frequency increases steadily as the number of blanks increases.
* **Data Points (Approximate):** The series starts at approximately 0.7 (70%) for x=9. It climbs steadily, crossing 0.8 around x=27, 0.9 around x=40, and reaching 1.0 (100%) at the red dashed line (x=54). The bars form a smooth, ascending staircase pattern.
### Key Observations
1. **Magnitude Shift:** The most striking observation is the massive increase in overall reflection frequency after GRPO. The lowest frequency after GRPO (~0.7) is more than three times higher than the highest frequency before GRPO (~0.22).
2. **Trend Transformation:** GRPO changes the relationship between the variables from a flat, noisy distribution to a strong, positive linear correlation.
3. **Threshold Achievement:** The red dashed line at 54 blanks marks a critical threshold. Before GRPO, this point shows low frequency (~15%). After GRPO, this is the point where reflection frequency achieves the maximum value of 100%.
4. **Consistency:** The "After GRPO" data shows remarkably low variance from its upward trend line, suggesting a highly predictable and controlled outcome.
### Interpretation
The data demonstrates that the GRPO process has a profound and systematic effect on the measured "reflection frequency." Before GRPO, the system exhibits low and erratic reflection behavior regardless of the input size (number of blanks). After GRPO, reflection becomes not only much more frequent but also scales directly and predictably with the complexity or size of the input.
The red line at 54 blanks likely represents a target or maximum input size. The charts show that GRPO enables the system to achieve perfect reflection (100% frequency) at this target size, whereas it failed to do so previously. This suggests GRPO is an effective optimization or training method for enhancing a reflective capability in a system, making its performance both stronger and more reliable as task demands increase. The near-perfect linearity after GRPO implies the process instills a consistent, rule-based response pattern.
</details>
(b) 4M
<details>
<summary>x20.png Details</summary>
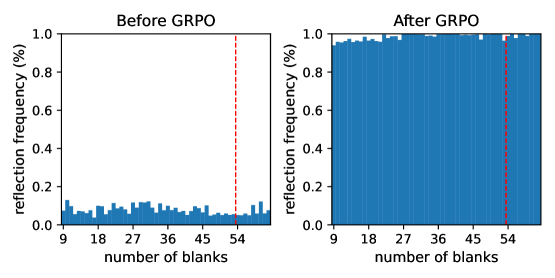
### Visual Description
## Bar Charts: Reflection Frequency Before and After GRPO
### Overview
The image displays two side-by-side bar charts (histograms) comparing the "reflection frequency (%)" across different "number of blanks" before and after a process or method called "GRPO". The charts demonstrate a dramatic, near-total increase in reflection frequency following the GRPO intervention.
### Components/Axes
* **Chart Titles:** "Before GRPO" (left chart), "After GRPO" (right chart).
* **Y-Axis (Both Charts):** Labeled "reflection frequency (%)". The scale runs from 0.0 to 1.0, with major tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-Axis (Both Charts):** Labeled "number of blanks". The scale shows major tick marks at 9, 18, 27, 36, 45, and 54.
* **Data Series:** Each chart contains a series of vertical blue bars, one for each integer value on the x-axis (from approximately 9 to 54+).
* **Key Annotation:** A vertical red dashed line is present in both charts, positioned at the x-axis value of 54.
### Detailed Analysis
**1. "Before GRPO" Chart (Left):**
* **Trend:** The reflection frequency is consistently very low across the entire range of "number of blanks". The bars show minor fluctuations but remain close to the baseline.
* **Data Points:** The frequency values are all below 0.2 (20%). Most bars appear to be between 0.05 and 0.15. The highest visible bar is near the left side (around 9-12 blanks) and reaches approximately 0.15. The frequency shows a slight, noisy downward trend as the number of blanks increases towards 54.
* **Red Line at 54:** The red dashed line at 54 blanks intersects the data where the frequency is at one of its lower points, approximately 0.05.
**2. "After GRPO" Chart (Right):**
* **Trend:** The reflection frequency is consistently and extremely high across the entire range of "number of blanks". The bars form a near-solid block at the top of the chart.
* **Data Points:** Nearly all bars reach or very nearly reach the maximum value of 1.0 (100%). There is minimal variation; the frequency is saturated at the ceiling of the measurement scale for all blank counts.
* **Red Line at 54:** The red dashed line at 54 blanks intersects the data where the frequency is at or extremely close to 1.0.
### Key Observations
1. **Transformative Effect:** The application of GRPO causes a categorical shift in the measured outcome. Reflection frequency moves from a low, noisy baseline (<15%) to a saturated, near-perfect state (~100%).
2. **Consistency:** The effect of GRPO is uniform. It does not appear to depend on the "number of blanks" variable within the tested range (9 to 54+). The high frequency is achieved for all values.
3. **Reference Point:** The vertical red line at 54 blanks serves as a consistent visual reference across both conditions, highlighting that the same condition (54 blanks) yields vastly different results before and after GRPO.
4. **Data Saturation:** The "After GRPO" chart shows ceiling effects, where the measurement cannot capture any potential variation above 1.0. This suggests the outcome is maximally achieved.
### Interpretation
The data strongly suggests that "GRPO" is a highly effective intervention for increasing "reflection frequency." The "Before" state indicates that without GRPO, the phenomenon being measured (reflection) occurs only sporadically and at low rates, regardless of the task parameter ("number of blanks"). The "After" state shows that GRPO reliably and completely induces the desired reflection behavior.
The uniformity of the effect across the x-axis implies that GRPO's mechanism is robust and not sensitive to the specific difficulty or scale represented by the "number of blanks" within this range. The red line at 54 may indicate a specific threshold, experimental condition, or point of interest in the study design, but the intervention's success is not limited to that point.
From a Peircean investigative perspective, the charts present a clear abductive inference: the stark contrast between the two conditions is best explained by the efficacy of the GRPO process. The near-perfect scores post-GRPO could indicate either a very strong effect or a potential measurement ceiling that might obscure finer-grained differences at the highest performance level.
</details>
(c) 16M
Figure 13: The histograms of reflection frequency of 1M, 4M, and 16M Sudoku models before and after GRPO, which uses a sampling temperature of $1.25$ . All models are tested using RMTP execution.
### E.4 Reflection frequency under controlled verification error rates
To investigate how verification error rates ( $e_{-}$ and $e_{+}$ ) influence the reflection frequency in GRPO, we ran a controlled experiment in which the error rates were fixed by intervening with expert verifications. After each time the transformer generated a non-empty verification, we replaced the verification sequence with the expert verification, where randomized noise is injected to achieve the prescribed false-negative rate $e_{-}$ and false-positive rate $e_{+}$ .
We used the 4M Mult model and ran GRPO (sampling temperature = 1.25) for 25 epochs in the in-distribution setting. We measured the fraction of steps at which the model invoked non-empty reflection (“reflection frequency”) after 25 epochs. Especially, we are interested in how reflection frequency changes, given a low $e_{-}=0.1$ or a high $e_{-}=0.4$ . In both cases, we set $e_{+}=0.1$ . The results are as follows:
- Using a low $e_{-}=0.1$ , the reflection frequency increases to $59.8\$ after 25 GRPO epochs.
- Using a high $e_{-}=0.4$ , the reflection frequency drops to $0.0\$ after 25 GRPO epochs. That is, the model learns to completely disuse reflection.
Discussion.
When the verifier rejects many correct steps (high $e_{-}$ ), the model learns to avoid invoking reflection, driving the observed reflection frequency to nearly $0\$ . Conversely, when $e_{-}$ is low (with the same $e_{+}$ ), reflection becomes beneficial and the model increases reflection usage (here to $60\$ ). Intuitively, reducing excessive false negatives shortens CoT lengths and makes reflection more rewarding; when $e_{-}$ is large, the model can trade off reflection for a no-reflection policy (which corresponds to the extreme $e_{-}=0,e_{+}=1$ ), thereby avoiding costly rejections. This experiment demonstrates that the model learns to reduce $e_{-}$ by strategically bypassing verification.
### E.5 Results of PPO
As discussed in Appendix B.1, we prefer GRPO over PPO for tiny transformers, as the value model in PPO increases computational cost and introduces additional approximation bias in computing advantages.
Table 11 presents the reasoning accuracy after PPO, and Table 12 gives the difference compared to the SFT results in Table 5. Our results show that PPO is much weaker than GRPO. Although PPO effectively improves the non-reflective models, the performance of reflective reasoning deteriorates after PPO. To explain this, self-verification in reasoning steps causes a higher complexity of the value function, which may obfuscate tiny transformers. Overall, we suggest that GRPO is a more suitable algorithm to optimize reflective reasoning for tiny transformers.
Table 11: The accuracy (%) of the 1M, 4M, and 16M transformers after PPO.
| Verification Type | None | Binary | Detailed | Optional Detailed | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Reflective Execution | None | None | RMTP | RTBS | None | RMTP | RTBS | None | RMTP | RTBS | | |
| 1M | Mult | ID Easy | 39.6 | 96.5 | 94.1 | 90.6 | 28.3 | 30.1 | 27.2 | 37.9 | 49.0 | 44.4 |
| ID Hard | 7.8 | 49.6 | 43.7 | 32.2 | 2.4 | 3.1 | 2.4 | 5.9 | 9.6 | 7.3 | | |
| OOD Hard | 1.1 | 2.6 | 1.8 | 1.2 | 0.7 | 0.8 | 0.7 | 1.0 | 1.0 | 0.8 | | |
| Sudoku | ID Easy | 1.7 | 36.1 | 33.7 | 5.6 | 17.3 | 20.6 | 20.1 | 23.8 | 21.9 | 20.1 | |
| ID Hard | 0 | 0.4 | 1.0 | 0 | 0 | 0.1 | 0 | 0 | 0 | 0 | | |
| OOD Hard | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | |
| 4M | Mult | ID Easy | 97.7 | 95.5 | 98.6 | 93.8 | 96.6 | 95.7 | 94.9 | 97.2 | 96.9 | 94.6 |
| ID Hard | 63.0 | 52.8 | 68.6 | 54.7 | 54.0 | 54.6 | 45.5 | 58.7 | 61.7 | 56.8 | | |
| OOD Hard | 2.2 | 3.1 | 2.9 | 1.6 | 5.3 | 3.9 | 2.2 | 4.4 | 3.3 | 3.7 | | |
| Sudoku | ID Easy | 56.4 | 88.4 | 97.3 | 97.6 | 49.3 | 82.1 | 80.6 | 76.2 | 94.1 | 97.3 | |
| ID Hard | 0 | 28.6 | 47.4 | 47.7 | 0 | 15.1 | 35.9 | 15.2 | 35.3 | 55.6 | | |
| OOD Hard | 0 | 0.2 | 1.6 | 3.3 | 3.1 | 0.4 | 0.9 | 0 | 1.1 | 2.7 | | |
| 16M | Mult | ID Easy | 99.3 | 99.0 | 99.0 | 98.2 | 98.5 | 98.7 | 97.8 | 99.0 | 99.5 | 99.2 |
| ID Hard | 64.8 | 62.9 | 75.7 | 71.9 | 63.2 | 68.6 | 65.6 | 65.1 | 77.1 | 74.6 | | |
| OOD Hard | 1.9 | 1.0 | 1.2 | 1.1 | 9.1 | 8.1 | 7.5 | 5.4 | 5.6 | 5.4 | | |
| Sudoku | ID Easy | 96.5 | 91.8 | 97.3 | 96.7 | 87.6 | 98.1 | 98.9 | 94.5 | 96.7 | 97.1 | |
| ID Hard | 49.0 | 41.0 | 51.4 | 52.7 | 34.7 | 55.7 | 66.3 | 47.8 | 53.8 | 53.0 | | |
| OOD Hard | 0.6 | 0 | 2.4 | 4.0 | 0 | 1.1 | 2.0 | 0 | 3.8 | 2.9 | | |
Table 12: The difference of accuracy (%) of the 1M, 4M, and 16M transformers after PPO. Positive values mean that PPO raises the accuracy of the models above SFT.
| 1M | Mult | ID Easy | $+16.0$ | $+0.7$ | $-0.4$ | $-2.8$ | $+6.3$ | $-3.3$ | $+3.0$ |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| ID Hard | $+5.8$ | $-3.1$ | $-0.9$ | $-3.3$ | $+0.2$ | $-1.7$ | $-0.4$ | | |
| OOD Hard | $+0.1$ | $-1.1$ | $-0.4$ | $+0.0$ | $-0.3$ | $+0.0$ | $+0.3$ | | |
| Sudoku | ID Easy | $+0.3$ | $+3.1$ | $+1.3$ | $+3.2$ | $-0.1$ | $+1.9$ | $+0.7$ | |
| ID Hard | $+0.0$ | $+0.1$ | $+0.9$ | $+0.0$ | $-0.1$ | $+0.1$ | $+0.0$ | | |
| OOD Hard | $+0.0$ | $+0.0$ | $+0.0$ | $+0.0$ | $+0.0$ | $+0.0$ | $+0.0$ | | |
| 4M | Mult | ID Easy | $+5.7$ | $-2.2$ | $+1.0$ | $-3.5$ | $+2.1$ | $+1.9$ | $+1.6$ |
| ID Hard | $+25.7$ | $-4.1$ | $+6.4$ | $+1.7$ | $+10.6$ | $+7.0$ | $+3.1$ | | |
| OOD Hard | $+0.0$ | $+0.2$ | $+1.1$ | $+0.5$ | $+1.6$ | $+0.6$ | $-0.5$ | | |
| Sudoku | ID Easy | $+4.2$ | $-3.7$ | $+0.5$ | $+1.6$ | $-5.1$ | $+0.2$ | $-7.9$ | |
| ID Hard | $-3.3$ | $-12.3$ | $+1.1$ | $-5.6$ | $-5.2$ | $-1.8$ | $-9.8$ | | |
| OOD Hard | $+0.0$ | $+0.2$ | $+1.6$ | $+3.3$ | $+2.7$ | $-3.6$ | $-5.8$ | | |
| 16M | Mult | ID Easy | $+0.1$ | $+0.2$ | $+0.1$ | $-0.6$ | $-0.7$ | $-0.8$ | $-0.7$ |
| ID Hard | $-1.1$ | $-2.3$ | $-1.0$ | $-3.0$ | $-2.7$ | $-7.8$ | $-7.9$ | | |
| OOD Hard | $-0.6$ | $-0.1$ | $-0.1$ | $-0.2$ | $-0.1$ | $-1.3$ | $+0.3$ | | |
| Sudoku | ID Easy | $+0.8$ | $-5.3$ | $-0.6$ | $+4.2$ | $-5.4$ | $-0.9$ | $-0.8$ | |
| ID Hard | $+0.2$ | $-9.1$ | $-1.7$ | $-2.1$ | $-12.2$ | $-2.2$ | $-4.4$ | | |
| OOD Hard | $+0.2$ | $-0.9$ | $-2.0$ | $-2.0$ | $-0.7$ | $-7.1$ | $-12.4$ | | |
## NeurIPS Paper Checklist
1. Claims
1. Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope?
1. Answer: [Yes]
1. Justification: Our title, abstract, and introduction clearly state our main claim that transformers can benefit from self-verifying reflection. Our theoretical and experimental results support this claim.
1. Guidelines:
- The answer NA means that the abstract and introduction do not include the claims made in the paper.
- The abstract and/or introduction should clearly state the claims made, including the contributions made in the paper and important assumptions and limitations. A No or NA answer to this question will not be perceived well by the reviewers.
- The claims made should match theoretical and experimental results, and reflect how much the results can be expected to generalize to other settings.
- It is fine to include aspirational goals as motivation as long as it is clear that these goals are not attained by the paper.
1. Limitations
1. Question: Does the paper discuss the limitations of the work performed by the authors?
1. Answer: [Yes]
1. Justification: We mention limitations in the conclusion.
1. Guidelines:
- The answer NA means that the paper has no limitation while the answer No means that the paper has limitations, but those are not discussed in the paper.
- The authors are encouraged to create a separate "Limitations" section in their paper.
- The paper should point out any strong assumptions and how robust the results are to violations of these assumptions (e.g., independence assumptions, noiseless settings, model well-specification, asymptotic approximations only holding locally). The authors should reflect on how these assumptions might be violated in practice and what the implications would be.
- The authors should reflect on the scope of the claims made, e.g., if the approach was only tested on a few datasets or with a few runs. In general, empirical results often depend on implicit assumptions, which should be articulated.
- The authors should reflect on the factors that influence the performance of the approach. For example, a facial recognition algorithm may perform poorly when image resolution is low or images are taken in low lighting. Or a speech-to-text system might not be used reliably to provide closed captions for online lectures because it fails to handle technical jargon.
- The authors should discuss the computational efficiency of the proposed algorithms and how they scale with dataset size.
- If applicable, the authors should discuss possible limitations of their approach to address problems of privacy and fairness.
- While the authors might fear that complete honesty about limitations might be used by reviewers as grounds for rejection, a worse outcome might be that reviewers discover limitations that aren’t acknowledged in the paper. The authors should use their best judgment and recognize that individual actions in favor of transparency play an important role in developing norms that preserve the integrity of the community. Reviewers will be specifically instructed to not penalize honesty concerning limitations.
1. Theory assumptions and proofs
1. Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof?
1. Answer: [Yes]
1. Justification: The main paper describes the assumptions of our theoretical results. The proof is provided in the appendix.
1. Guidelines:
- The answer NA means that the paper does not include theoretical results.
- All the theorems, formulas, and proofs in the paper should be numbered and cross-referenced.
- All assumptions should be clearly stated or referenced in the statement of any theorems.
- The proofs can either appear in the main paper or the supplemental material, but if they appear in the supplemental material, the authors are encouraged to provide a short proof sketch to provide intuition.
- Inversely, any informal proof provided in the core of the paper should be complemented by formal proofs provided in the appendix or supplemental material.
- Theorems and Lemmas that the proof relies upon should be properly referenced.
1. Experimental result reproducibility
1. Question: Does the paper fully disclose all the information needed to reproduce the main experimental results of the paper to the extent that it affects the main claims and/or conclusions of the paper (regardless of whether the code and data are provided or not)?
1. Answer: [Yes]
1. Justification: We include necessary information to reproduce our results in the appendix, such as hyper-parameters, model architecture, data examples, and detailed implementation.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- If the paper includes experiments, a No answer to this question will not be perceived well by the reviewers: Making the paper reproducible is important, regardless of whether the code and data are provided or not.
- If the contribution is a dataset and/or model, the authors should describe the steps taken to make their results reproducible or verifiable.
- Depending on the contribution, reproducibility can be accomplished in various ways. For example, if the contribution is a novel architecture, describing the architecture fully might suffice, or if the contribution is a specific model and empirical evaluation, it may be necessary to either make it possible for others to replicate the model with the same dataset, or provide access to the model. In general. releasing code and data is often one good way to accomplish this, but reproducibility can also be provided via detailed instructions for how to replicate the results, access to a hosted model (e.g., in the case of a large language model), releasing of a model checkpoint, or other means that are appropriate to the research performed.
- While NeurIPS does not require releasing code, the conference does require all submissions to provide some reasonable avenue for reproducibility, which may depend on the nature of the contribution. For example
1. If the contribution is primarily a new algorithm, the paper should make it clear how to reproduce that algorithm.
1. If the contribution is primarily a new model architecture, the paper should describe the architecture clearly and fully.
1. If the contribution is a new model (e.g., a large language model), then there should either be a way to access this model for reproducing the results or a way to reproduce the model (e.g., with an open-source dataset or instructions for how to construct the dataset).
1. We recognize that reproducibility may be tricky in some cases, in which case authors are welcome to describe the particular way they provide for reproducibility. In the case of closed-source models, it may be that access to the model is limited in some way (e.g., to registered users), but it should be possible for other researchers to have some path to reproducing or verifying the results.
1. Open access to data and code
1. Question: Does the paper provide open access to the data and code, with sufficient instructions to faithfully reproduce the main experimental results, as described in supplemental material?
1. Answer: [Yes]
1. Justification: Full code is in the supplementary materials. No data is provided as it is generated by the code. “README.md” introduces the commands to perform the complete pipeline and reproduce our results. We will open-source our code once it is formally accepted.
1. Guidelines:
- The answer NA means that paper does not include experiments requiring code.
- Please see the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
- While we encourage the release of code and data, we understand that this might not be possible, so “No” is an acceptable answer. Papers cannot be rejected simply for not including code, unless this is central to the contribution (e.g., for a new open-source benchmark).
- The instructions should contain the exact command and environment needed to run to reproduce the results. See the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
- The authors should provide instructions on data access and preparation, including how to access the raw data, preprocessed data, intermediate data, and generated data, etc.
- The authors should provide scripts to reproduce all experimental results for the new proposed method and baselines. If only a subset of experiments are reproducible, they should state which ones are omitted from the script and why.
- At submission time, to preserve anonymity, the authors should release anonymized versions (if applicable).
- Providing as much information as possible in supplemental material (appended to the paper) is recommended, but including URLs to data and code is permitted.
1. Experimental setting/details
1. Question: Does the paper specify all the training and test details (e.g., data splits, hyperparameters, how they were chosen, type of optimizer, etc.) necessary to understand the results?
1. Answer: [Yes]
1. Justification: Most relevant hyper-parameters and experiment details are in the appendix. Full settings are clearly defined in our code.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- The experimental setting should be presented in the core of the paper to a level of detail that is necessary to appreciate the results and make sense of them.
- The full details can be provided either with the code, in appendix, or as supplemental material.
1. Experiment statistical significance
1. Question: Does the paper report error bars suitably and correctly defined or other appropriate information about the statistical significance of the experiments?
1. Answer: [No]
1. Justification: It is too expensive to run multiple instances of our experiments, which include training 78 models under various settings (sizes, tasks, verification types, etc). Each model is tested using at most 3 different executions. Given our limited resources, it would take several months to compute error bars. Since our paper focuses on analysis instead of best performance or accurate evaluation, it is acceptable not to include error bars.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- The authors should answer "Yes" if the results are accompanied by error bars, confidence intervals, or statistical significance tests, at least for the experiments that support the main claims of the paper.
- The factors of variability that the error bars are capturing should be clearly stated (for example, train/test split, initialization, random drawing of some parameter, or overall run with given experimental conditions).
- The method for calculating the error bars should be explained (closed form formula, call to a library function, bootstrap, etc.)
- The assumptions made should be given (e.g., Normally distributed errors).
- It should be clear whether the error bar is the standard deviation or the standard error of the mean.
- It is OK to report 1-sigma error bars, but one should state it. The authors should preferably report a 2-sigma error bar than state that they have a 96% CI, if the hypothesis of Normality of errors is not verified.
- For asymmetric distributions, the authors should be careful not to show in tables or figures symmetric error bars that would yield results that are out of range (e.g. negative error rates).
- If error bars are reported in tables or plots, The authors should explain in the text how they were calculated and reference the corresponding figures or tables in the text.
1. Experiments compute resources
1. Question: For each experiment, does the paper provide sufficient information on the computer resources (type of compute workers, memory, time of execution) needed to reproduce the experiments?
1. Answer: [Yes]
1. Justification: We roughly describe the computational resource used in the appendix. Since our models are very small, this paper can be easily reproduced by a single NVIDIA GPU.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- The paper should indicate the type of compute workers CPU or GPU, internal cluster, or cloud provider, including relevant memory and storage.
- The paper should provide the amount of compute required for each of the individual experimental runs as well as estimate the total compute.
- The paper should disclose whether the full research project required more compute than the experiments reported in the paper (e.g., preliminary or failed experiments that didn’t make it into the paper).
1. Code of ethics
1. Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics https://neurips.cc/public/EthicsGuidelines?
1. Answer: [Yes]
1. Justification: As far as we may perceive, this research does not involve human subjects or negative societal impacts.
1. Guidelines:
- The answer NA means that the authors have not reviewed the NeurIPS Code of Ethics.
- If the authors answer No, they should explain the special circumstances that require a deviation from the Code of Ethics.
- The authors should make sure to preserve anonymity (e.g., if there is a special consideration due to laws or regulations in their jurisdiction).
1. Broader impacts
1. Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed?
1. Answer: [N/A]
1. Justification: This paper focuses on the fundamental analysis of reasoning instead and is tied to no practical applications.
1. Guidelines:
- The answer NA means that there is no societal impact of the work performed.
- If the authors answer NA or No, they should explain why their work has no societal impact or why the paper does not address societal impact.
- Examples of negative societal impacts include potential malicious or unintended uses (e.g., disinformation, generating fake profiles, surveillance), fairness considerations (e.g., deployment of technologies that could make decisions that unfairly impact specific groups), privacy considerations, and security considerations.
- The conference expects that many papers will be foundational research and not tied to particular applications, let alone deployments. However, if there is a direct path to any negative applications, the authors should point it out. For example, it is legitimate to point out that an improvement in the quality of generative models could be used to generate deepfakes for disinformation. On the other hand, it is not needed to point out that a generic algorithm for optimizing neural networks could enable people to train models that generate Deepfakes faster.
- The authors should consider possible harms that could arise when the technology is being used as intended and functioning correctly, harms that could arise when the technology is being used as intended but gives incorrect results, and harms following from (intentional or unintentional) misuse of the technology.
- If there are negative societal impacts, the authors could also discuss possible mitigation strategies (e.g., gated release of models, providing defenses in addition to attacks, mechanisms for monitoring misuse, mechanisms to monitor how a system learns from feedback over time, improving the efficiency and accessibility of ML).
1. Safeguards
1. Question: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse (e.g., pretrained language models, image generators, or scraped datasets)?
1. Answer: [N/A]
1. Justification: This paper poses no such risks.
1. Guidelines:
- The answer NA means that the paper poses no such risks.
- Released models that have a high risk for misuse or dual-use should be released with necessary safeguards to allow for controlled use of the model, for example by requiring that users adhere to usage guidelines or restrictions to access the model or implementing safety filters.
- Datasets that have been scraped from the Internet could pose safety risks. The authors should describe how they avoided releasing unsafe images.
- We recognize that providing effective safeguards is challenging, and many papers do not require this, but we encourage authors to take this into account and make a best faith effort.
1. Licenses for existing assets
1. Question: Are the creators or original owners of assets (e.g., code, data, models), used in the paper, properly credited and are the license and terms of use explicitly mentioned and properly respected?
1. Answer: [Yes]
1. Justification: Assets used in this paper are cited in the paper. The appendix mentions the version of the asset and the license.
1. Guidelines:
- The answer NA means that the paper does not use existing assets.
- The authors should cite the original paper that produced the code package or dataset.
- The authors should state which version of the asset is used and, if possible, include a URL.
- The name of the license (e.g., CC-BY 4.0) should be included for each asset.
- For scraped data from a particular source (e.g., website), the copyright and terms of service of that source should be provided.
- If assets are released, the license, copyright information, and terms of use in the package should be provided. For popular datasets, paperswithcode.com/datasets has curated licenses for some datasets. Their licensing guide can help determine the license of a dataset.
- For existing datasets that are re-packaged, both the original license and the license of the derived asset (if it has changed) should be provided.
- If this information is not available online, the authors are encouraged to reach out to the asset’s creators.
1. New assets
1. Question: Are new assets introduced in the paper well documented and is the documentation provided alongside the assets?
1. Answer: [N/A]
1. Justification: This paper does not release assets besides our code.
1. Guidelines:
- The answer NA means that the paper does not release new assets.
- Researchers should communicate the details of the dataset/code/model as part of their submissions via structured templates. This includes details about training, license, limitations, etc.
- The paper should discuss whether and how consent was obtained from people whose asset is used.
- At submission time, remember to anonymize your assets (if applicable). You can either create an anonymized URL or include an anonymized zip file.
1. Crowdsourcing and research with human subjects
1. Question: For crowdsourcing experiments and research with human subjects, does the paper include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation (if any)?
1. Answer: [N/A]
1. Justification: This paper does not involve crowdsourcing nor research with human subjects.
1. Guidelines:
- The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
- Including this information in the supplemental material is fine, but if the main contribution of the paper involves human subjects, then as much detail as possible should be included in the main paper.
- According to the NeurIPS Code of Ethics, workers involved in data collection, curation, or other labor should be paid at least the minimum wage in the country of the data collector.
1. Institutional review board (IRB) approvals or equivalent for research with human subjects
1. Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or institution) were obtained?
1. Answer: [N/A]
1. Justification: the paper does not involve crowdsourcing nor research with human subjects.
1. Guidelines:
- The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
- Depending on the country in which research is conducted, IRB approval (or equivalent) may be required for any human subjects research. If you obtained IRB approval, you should clearly state this in the paper.
- We recognize that the procedures for this may vary significantly between institutions and locations, and we expect authors to adhere to the NeurIPS Code of Ethics and the guidelines for their institution.
- For initial submissions, do not include any information that would break anonymity (if applicable), such as the institution conducting the review.
1. Declaration of LLM usage
1. Question: Does the paper describe the usage of LLMs if it is an important, original, or non-standard component of the core methods in this research? Note that if the LLM is used only for writing, editing, or formatting purposes and does not impact the core methodology, scientific rigorousness, or originality of the research, declaration is not required.
1. Answer: [N/A]
1. Justification: Although this research is related to LLM reasoning, we focus on tiny transformers. The appendix includes the evaluation of LLMs, yet these results do not impact our core methodology and originality.
1. Guidelines:
- The answer NA means that the core method development in this research does not involve LLMs as any important, original, or non-standard components.
- Please refer to our LLM policy (https://neurips.cc/Conferences/2025/LLM) for what should or should not be described.