# Ax-Prover: A Deep Reasoning Agentic Framework for Theorem Proving in Mathematics and Quantum Physics
**Authors**: Benjamin Breen, Marco Del Tredici, Jacob McCarran, Javier Aspuru Mijares, Weichen Winston Yin, Kfir Sulimany, Jacob M. Taylor, Frank H. L. Koppens, Dirk Englund
> Axiomatic_AI
> Massachusetts Institute of Technology (MIT)
> Institut de Ciències Fotòniques (ICFO) Institució Catalana de Recerca i Estudis Avançats (ICREA)
> Axiomatic_AI Massachusetts Institute of Technology (MIT)
## Abstract
We present Ax-Prover, a multi-agent system for automated theorem proving in Lean that can solve problems across diverse scientific domains and operate either autonomously or collaboratively with human experts. To achieve this, Ax-Prover approaches scientific problem solving through formal proof generation, a process that demands both creative reasoning and strict syntactic rigor. Ax-Prover meets this challenge by equipping Large Language Models (LLMs), which provide knowledge and reasoning, with custom Lean tools which ensure formal correctness. To evaluate its performance as an autonomous prover, we benchmark our approach against both frontier LLMs and specialized prover models on two public math benchmarks and on two Lean benchmarks that we introduce in abstract algebra and quantum theory. On the public datasets, Ax-Prover is the top prover among those that do not rely on any domain-specific training; on the new benchmarks, it largely outperforms all baselines. This shows that, unlike specialized systems that struggle to generalize, our tool-based agentic theorem prover approach offers a generalizable methodology for formal verification across diverse scientific domains. Furthermore, we showcase Ax-Prover as a researcher-friendly assistant through two practical case studies in classical and quantum cryptography, pillars of secure communication, where it worked with domain experts to formalize and verify challenging security guarantees using standard human-agent interactions, enabling those without expertise in Lean to engage in this burgeoning domain.
footnotetext: Equal contribution, authors listed alphabetically. Benjamin initiated the project and led early development; including curating the AbstractAlgebra dataset; Marco implemented the AX-Prover and led the writing of the paper; Jacob ran most of the experiments and significantly contributed to the writing and ideas of the paper.
## 1 Introduction
Developing Large Language Models (LLMs) that can reason reliably across scientific domains remains a central challenge for AI, both in academia and in industry. LLM-based formal reasoning systems have mainly been developed for mathematics, where they have achieved outstanding results [chervonyi2025gold, chen2025seed]. Recently, considerable effort has been put into training reasoning LLMs for formal theorem proving using Lean [moura2015lean], an open-source programming language and interactive proof assistant. Together with its community-driven Mathlib library [mathlib-stats], Lean provides a rigorous setting where AI systems must engage with symbolic reasoning and structured formalization, building on an evolving body of mathematical knowledge. LLM provers such as the DeepSeek-Prover series [deepseek-prover, deepseek-prover-v1, deepseek-prover-v2], Kimina-Prover-72B [kimina-prover], Goedel-Prover [lin2025goedel, lin2025goedel2], and Seed-Prover [chen2025seed] have shown that specialized prover models can be distilled from frontier LLMs and trained for theorem proving in Lean, reaching state-of-the-art performance on math benchmarks like MiniF2F [minif2f] and PutnamBench [tsoukalas2024putnambench]. Despite these results, these models face some key limitations. First, since they were mainly trained and tested on the domain of mathematics, their ability to generalize beyond this domain remains unclear. Relatedly, they are usually trained on fixed versions of the fast-evolving Mathlib library, making them brittle to changes introduced in new Mathlib versions, such as new or renamed definitions. Keeping them up to date would require frequent re-training and systematic “forgetting” of out-of-date knowledge, which adds significant cost. For example, Deepseek-Prover-V2-671B was released on April 30, 2025 and, in our experiments, we observed that it uses the lemma sqrt_eq_iff_sq_eq, which was deprecated in favor of sqrt_eq_iff_eq_sq on March 3, 2025. Second, while training improves their ability to produce Lean proofs, it narrows their capabilities relative to general purpose LLMs as they become unable to use external tools and engage in human-AI collaboration. Finally, it is hard to run them as they require high-performance computing and expertise to be successfully deployed and used. Together, these issues suggest that scaling increasingly large specialized provers may yield diminishing returns in both flexibility and usability.
In contrast, general-purpose LLMs like Claude [claude_docs] and GPT [openai_models_docs] encode substantial knowledge across diverse domains (e.g., mathematics, physics, and computer science), while also exhibiting strong natural language understanding, problem solving skills, and interaction capabilities. Moreover, they are easily accessible through APIs, making them convenient to deploy and integrate into any workflow. Yet, they are not explicitly trained to formalize statements or construct proofs in Lean, nor can they natively interact with the Lean environment. This creates a sharp division: specialized provers are tightly integrated with Lean but narrow in scope and hard to use, whereas general-purpose LLMs are broad in scope and easily accessible but lack the ability to interface with the formal reasoning infrastructure required for theorem proving.
To address this gap, we introduce Ax-Prover, “Ax” stands for “axiomatic”, reflecting the base principles in mathematics and physics, the domains explored in this work. a new agentic workflow for theorem proving in Lean that leverages the Model Context Protocol (MCP) [modelcontextprotocol2024] to equip general-purpose LLMs with Lean tools from the lean-lsp-mcp repository [lean-mcp]. Ax-Prover combines the reasoning capabilities of LLMs with the formal verification power of Lean. The LLM analyzes unproven theorems, proposes proof sketches, and generates step-by-step Lean code, while the Lean tools allow the LLM to inspect goals, search for relevant results, locate errors, and verify proofs – capabilities essential for rigorous formal theorem proving.
Ax-Prover overcomes the main limitations of state-of-the-art provers. First, using frontier LLMs prevents domain overspecialization while the MCP interface allows the system to work with any recent version of Mathlib and additional library dependencies including custom definitions relevant to the project without needing to be retrained. Second, it preserves tool-use and conversational abilities, enabling interactive collaboration with humans. Third, by leveraging existing frontier models, it sidesteps the need to host or deploy specialized systems.
We evaluated Ax-Prover on two public datasets of mathematics competition problems (NuminaMath-LEAN [numinamath-lean] and PutnamBench [tsoukalas2024putnambench]) and introduce two new datasets to enable evaluation in new domains. The first of these, AbstractAlgebra, focuses on algebraic structures such as groups, rings, and fields, testing the provers’ abilities to reason in a more abstract, research-oriented setting rather than the competition-driven style of existing datasets. The second new dataset is QuantumTheorems, which represents an initial step toward automated theorem proving in a scientific domain beyond pure mathematics, evaluating the models’ formal reasoning in quantum mechanics. Our results show that Ax-Prover has competitive performance on PutnamBench – achieving the highest accuracy for fully open-sourced agents We use “open-sourced” according to the usage in the official leader-board [putnambench_leaderboard]. – and outperforms general-purpose LLMs not equipped with Lean tools as well as state-of-the-art specialized provers on the other datasets, with a significant margin on the ones we introduce.
Besides functioning as an autonomous solver, Ax-Prover was also designed to serve as an assistant for human researchers. To demonstrate these capabilities, we present two researcher-facing use cases in the field of cryptography in Sections LABEL:sec:Cryp and LABEL:sec:QKD. Cryptography is an ideal proving ground for Lean because its security guarantees depend on precise mathematical reasoning, yet the field often lacks standardized assumptions and explicit logical structure. Machine-checked proofs can therefore transform the way such guarantees are built and trusted – ensuring that every step, assumption, and reduction is explicit and verifiable. In the first use case, Ax-Prover collaborates with a cryptography researcher to formalize and verify an alternate definition for the branch number of a matrix [mishra2024new], revealing a subtle gap in the informal argument and producing a reusable Lean certificate on their own laptop in 2 days’ time. In the second, it assists quantum-information researchers in formalizing an entropy bound in quantum key distribution [lo1999unconditional], converting a physics-style derivation into a machine-checked component. Together, these examples show that beyond benchmark accuracy, Ax-Prover lowers the practical barrier for researchers to use Lean in their own work, brings clarity and rigor to complex reasoning, and enables interpretable, researcher-driven verification for security-critical domains.
Our contributions are threefold: (i) We design Ax-Prover, a lightweight agentic workflow that connects general-purpose LLMs to Lean tools via MCP, and demonstrate that it performs on par with or surpasses both general-purpose LLMs and specialized provers across several scientific domains; (ii) We introduce new formalized Lean datasets covering abstract algebra and quantum physics, complementing existing benchmarks; (iii) We showcase Ax-Prover’s capabilities as an assistant through use cases where the system collaborated with domain experts to formally verify the proof of a recent cryptography result [mishra2024new] as well as an entropy bound for the Lo-Chau security framework for Quantum Key Distribution (QKD) [lo1999unconditional].
## 2 Related Work
Automated theorem proving in Lean has roots in classical approaches such as decision procedures [demoura2008z3, barbosa2022smt] and heuristic-guided proof search [kovacs2013vampire, schulz2019e]. However, these approaches face particular challenges: the former does not handle general mathematical domains (e.g. transcendental functions and complex numbers) and the latter does not perform well out of distribution. More recent work integrates machine learning: from heuristic tuning [urban2011machine] to premise selection and tactic prediction [irving2016deepmath, huang2019holstep], culminating in transformer-based language models capable of generating Lean proofs [polu2020generative, lample2022deep, polu2023formal, xin2024lean]. More recent large-scale systems extend this trend by training LLMs on formal proving through distillation, supervised finetuning, and reinforcement learning. Current examples of specialized models are Kimina-Prover [kimina-prover], the DeepSeek-Prover family [deepseek-prover, deepseek-prover-v1, deepseek-prover-v2], Goedel-Prover 1 and 2 [lin2025goedel, lin2025goedel2], Prover Agent [baba2025prover], Apollo [ospanov2025apollo], and Seed-Prover [chen2025seed]. All of these are highly specialized provers, which take in a Lean theorem as input and autonomously produce a proof. A very recent line of work is exploring agentic flows that include frontier LLMs and a formal verifier; examples include Hilbert [varambally2025hilbert] and Aristotle [achim2025aristotle]. Although we also adopt a similar approach, some crucial differences exist, namely: (i) we give the LLM direct access to Lean tools via MCP; (ii) our framework requires neither training nor finetuning [achim2025aristotle] and does not rely on any specialized provers [varambally2025hilbert]; (iii) we demonstrate the effectiveness of our approach on domains beyond just mathematics; (iv) we showcase the capabilities of our system as an interactive assistant to human researchers.
Finally, a parallel line of work has explored classical machine learning for supporting experts in theorem proving in Lean, for example, in premise selection and tactic prediction [gauthier2021tactictoe, blaauwbroek2020tactician], and more recently through LLMs that connect to Lean via external interfaces [ayers2023leanlm, azerbayev2023llm, song2024lean]. These approaches illustrate the promise of AI-assisted proving, but they remain resource-intensive and difficult to adapt across scientific domains. Recent efforts, such as [kumarappan2024leanagent], attempt to remedy this by emphasizing greater adaptability within Lean. At the same time, there is growing interest in human-AI collaboration: conversational assistants [collins2023llm] and “copilot”-style integrations [chen2021copilot] suggest how formal tools can augment, rather than replace, human reasoning. Our work builds on this trajectory by closing the gap between heavyweight, specialized provers and lightweight, researcher-friendly systems that can be more readily adapted to the evolving Lean ecosystem.
## 3 System Architecture
<details>
<summary>ims/diagram_3.png Details</summary>
### Visual Description
## Diagram: System Architecture and Automated Proof Generation Log
### Overview
The image is a composite diagram split into two distinct panels. The left panel illustrates a system architecture for automated theorem proving, showing the interaction between a user, an "Ax-Prover" system, and external tools. The right panel is a terminal log displaying a real-time, step-by-step execution trace of an AI agent using the described system to prove a mathematical theorem in the Lean proof assistant.
### Components/Axes
**Left Panel - System Architecture Diagram:**
* **Primary Components:**
* **User:** A green rounded rectangle at the top, labeled "user". It initiates the process by providing a "theorem".
* **Ax-Prover:** A large, light purple container box. It houses three internal components:
* **Orchestrator:** A purple rounded rectangle. It receives the "task" from the user and coordinates the process.
* **Prover:** A purple rounded rectangle. It receives a "task" from the Orchestrator and generates a "proof".
* **Verifier:** A purple rounded rectangle. It receives the "proof" from the Prover and returns a "verdict" to the Orchestrator.
* **MCP Tools:** A yellow container box on the left. It lists external tools available to the system:
* **Lean:** A sub-container with four specific tool categories: "Management", "Code", "Search", and "Diagnostics".
* **Filesystem:** A separate box below Lean, with the operations "read, write, edit".
* **Data Flow & Relationships:**
* A solid arrow labeled "theorem" points from the **User** to the **Orchestrator**.
* A solid arrow labeled "task" points from the **Orchestrator** to the **Prover**.
* A solid arrow labeled "proof" points from the **Prover** to the **Verifier**.
* A solid arrow labeled "verdict" points from the **Verifier** back to the **Orchestrator**.
* Dotted arrows indicate tool usage: The **Prover** has dotted arrows pointing to both the **Lean** tools and the **Filesystem** tools, showing it can invoke them. The **Verifier** also has a dotted arrow pointing to the **Filesystem**.
**Right Panel - Terminal Log:**
* **Format:** A black terminal window with white text. Each line of agent output is prefixed with a robot emoji (🤖). Tool invocations are highlighted in yellow and prefixed with a wrench emoji (🔧).
* **Content:** A sequential log of an AI agent's actions and reasoning.
### Detailed Analysis
**Left Panel - Architecture Flow:**
The diagram depicts a closed-loop, agentic workflow. The Orchestrator acts as the central coordinator. The Prover is the active agent that formulates proofs and interacts with external tools (Lean and Filesystem). The Verifier acts as a judge, providing feedback (a "verdict") to the Orchestrator, which can then issue new tasks to the Prover, creating an iterative refinement cycle.
**Right Panel - Terminal Log Transcription & Analysis:**
The log shows an agent proving the theorem `roots_of_unity_is_mul_group`. The process is as follows:
1. **Initial Analysis:** The agent states its goal: "I'll analyze the Lean file and generate proof for any theorem containing a sorry". It uses the `read file` tool.
2. **Problem Identification:** It identifies one theorem with a 'sorry' placeholder: `'roots_of_unity_is_mul_group'`. It begins creating a proof sketch.
3. **Step-by-Step Proof Construction:**
* **Step 1 (Closure Proof):** The agent starts solving the first part of the closure proof. It uses the `edit file` tool to implement the step.
* **Verification:** It checks its implementation using the `lean diagnostic` tool. Result: "Good, no errors."
* **Step 2:** It moves to the next step: "showing that (z * w)^(n * m) = 1". It uses the `lean goal` tool to check what needs to be proven.
4. **Knowledge Retrieval:** To assist with Step 2, the agent searches for relevant lemmas using the `lean leansearch` tool. It reports finding the lemma `'mul_pow'` for complex numbers and decides to use it to prove the closure property.
5. **Finalization:** After completing the proof steps (indicated by "..."), the agent states the proof is complete. It uses the `lean build` tool to compile the file and ensure correctness.
6. **Conclusion:** The final line reads: "Perfect! The proof has been successfully completed."
### Key Observations
1. **Iterative Tool Use:** The agent does not write the entire proof at once. It follows a cycle of: **Plan -> Implement (edit file) -> Verify (lean diagnostic) -> Research (lean leansearch) -> Finalize (lean build)**.
2. **Specific Theorem:** The target theorem is `roots_of_unity_is_mul_group`, which likely concerns proving that the set of roots of unity forms a multiplicative group.
3. **Tool Integration:** The log explicitly shows the use of four distinct tools from the "Lean" MCP tools category: `read file`, `edit file`, `lean diagnostic`, `lean goal`, `lean leansearch`, and `lean build`. This maps directly to the "Management", "Code", "Search", and "Diagnostics" categories in the architecture diagram.
4. **Successful Outcome:** The process concludes with a successful compilation and proof completion.
### Interpretation
This image demonstrates a sophisticated **agentic AI system for formal mathematical verification**. The architecture (left) is designed for autonomy and robustness: the separation of the Prover (creative, tool-using agent) from the Verifier (critical judge) creates a self-correcting system. The Orchestrator manages this dialogue.
The terminal log (right) is a concrete instantiation of this architecture in action. It reveals the agent's **reasoning process**, which is not monolithic but methodical and interactive. The agent exhibits behaviors analogous to a human mathematician: breaking down a problem, implementing partial solutions, checking for errors, searching for existing knowledge (lemmas), and finally compiling the complete argument.
The key takeaway is the **feasibility of automating complex, creative intellectual tasks** like theorem proving by combining a structured system architecture with an LLM-based agent capable of strategic tool use. The "verdict" loop is crucial, as it allows the system to learn from failure (e.g., if the Verifier rejects a proof) and iteratively improve, moving beyond simple one-shot generation. The specific example of proving a group theory property about roots of unity shows the system handling non-trivial abstract mathematics.
</details>
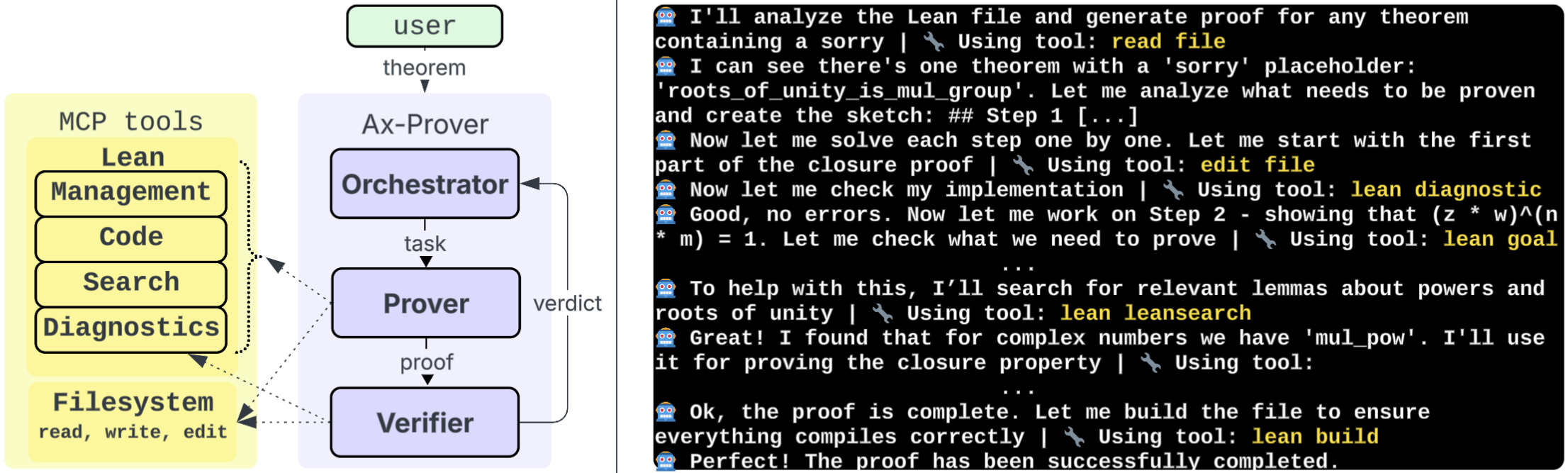
Figure 1: Left: the multi-agent workflow of Ax-Prover. Right: the tool-enhanced reasoning of the Prover.
We implement Ax-Prover as a multi-agent architecture with three agents, each of which is implemented as an LLM with specific prompts: the Orchestrator, the Prover, and the Verifier. Following recent agentic designs for complex tasks such as scientific discovery [gottweis2025towards, yamada2025ai], we avoid a monolithic setup by assigning each specialized agent a distinct role. This separation enables specialization and modularity: agents can be independently optimized, replaced, or extended, allowing researchers to adapt Ax-Prover to their own needs without destabilizing the system.
Figure 1 (left) shows our workflow: the Orchestrator receives an unproven Lean statement and forwards it to the Prover, which iteratively works on the proof by performing reasoning, making calls to MCP Lean tools, and generating Lean code (Figure 1, right). The Verifier then checks the proof and reports back to the Orchestrator. If the proof is complete and no error is found, the Orchestrator ends the task; otherwise, it provides feedback to the Prover, which continues the proving process. Through this closed-loop process, the system incrementally converts unproven theorems into formally verified Lean proofs. Next, we provide details about the agents and tools.
### 3.1 Specialized Agents
#### 3.1.1 Orchestrator
The Orchestrator’s role is analogous to a scheduler in distributed systems: it does not perform computation itself but ensures that computation flows smoothly across agents. It holds three main responsibilities. First, it handles task assignment, as it receives user input and instructs the Prover accordingly. Next, it manages feedback routing by taking diagnostic outputs from the Verifier and giving structured feedback to the Prover (if errors are found). This separation ensures that proof synthesis and evaluation remain distinct while still enabling iterative refinement. Finally, it decides when to stop the refinement loop. Termination occurs either when the Verifier certifies the proof as complete and error-free, or when the number of attempts exceeds a configurable threshold.
#### 3.1.2 Prover
<details>
<summary>ims/full_proof_step_5.png Details</summary>
### Visual Description
## [Diagram]: Formal Proof Development of a Mathematical Theorem
### Overview
The image displays a three-stage progression of a formal proof written in a dependently-typed proof assistant (likely Lean 4). It illustrates the development of a theorem stating that a unitary matrix which is also idempotent must be the identity matrix. The diagram shows the initial theorem statement, an intermediate proof sketch with placeholders, and the final, completed proof with specific tactics.
### Components/Axes
The diagram is structured as a flowchart with three main code blocks connected by directional arrows.
* **Top Block (Header):** Contains the formal theorem statement.
* **Bottom-Left Block (Intermediate Stage):** Shows a proof outline with `sorry` placeholders for each step.
* **Bottom-Right Block (Final Stage):** Presents the completed proof with actual tactic scripts.
* **Flow Arrows:** A black arrow points from the top block to the bottom-left block. Another black arrow points from the bottom-left block to the bottom-right block, indicating the progression of the proof development.
### Detailed Analysis
#### **1. Top Block: Theorem Statement**
* **Content:**
```lean
theorem unitary_idempotent_is_identity {n : Type*} [DecidableEq n] [Fintype n]
{α : Type*} [CommRing α] [StarRing α] (U : Matrix.unitaryGroup n α)
(h : (U : Matrix n n α) ^ 2 = (U : Matrix n n α)) :
(U : Matrix n n α) = 1 := by sorry
```
* **Transcription & Explanation:**
* **Theorem Name:** `unitary_idempotent_is_identity`
* **Implicit Parameters:**
* `{n : Type*}`: A type `n`, likely representing the dimension/index type of the matrix.
* `[DecidableEq n]`: A typeclass instance asserting that equality on `n` is decidable.
* `[Fintype n]`: A typeclass instance asserting that `n` is a finite type.
* `{α : Type*}`: A type `α`, representing the scalar ring.
* `[CommRing α]`: A typeclass instance asserting that `α` is a commutative ring.
* `[StarRing α]`: A typeclass instance asserting that `α` has a star operation (for conjugation).
* **Explicit Parameters:**
* `(U : Matrix.unitaryGroup n α)`: A matrix `U` belonging to the unitary group over `n` and `α`.
* `(h : (U : Matrix n n α) ^ 2 = (U : Matrix n n α))`: A hypothesis `h` stating that the square of the matrix `U` (coerced to a general matrix) equals itself (idempotence).
* **Conclusion:** `(U : Matrix n n α) = 1`: The goal is to prove that the matrix `U` is the identity matrix.
* **Proof Tactic:** `:= by sorry` - The proof is initially left incomplete with a placeholder.
#### **2. Bottom-Left Block: Proof Sketch (Intermediate)**
* **Content:**
```lean
-- Step 1: Extract the unitary property U* U = 1
have h1 : star (U : Matrix n n α) * (U : Matrix n n α) = 1 := by
sorry
-- Step 2: From the idempotent property, multiply both sides by star U on the left
have h2 : star (U : Matrix n n α) * (U : Matrix n n α) ^ 2 = star (U : Matrix n n α) *
(U : Matrix n n α) := by
sorry
-- Step 3: Simplify the left side using associativity and the unitary property
have h3 : star (U : Matrix n n α) * (U : Matrix n n α) ^ 2 = (U : Matrix n n α) := by
sorry
-- Step 4: Combine to get the final result
have h4 : (U : Matrix n n α) = 1 := by
sorry
```
* **Transcription & Explanation:** This block outlines the proof strategy in four commented steps, but each `have` statement (a local proof) is concluded with `sorry`, meaning the tactics to prove them are not yet provided.
* **Step 1 (`h1`):** Aims to state the defining property of a unitary matrix: `U* U = I`.
* **Step 2 (`h2`):** Applies the idempotent hypothesis `h` by multiplying both sides on the left by `U*`.
* **Step 3 (`h3`):** Intends to simplify the left-hand side of `h2` using associativity of multiplication and the unitary property from `h1`.
* **Step 4 (`h4`):** The final step to combine the previous results to conclude `U = I`.
#### **3. Bottom-Right Block: Completed Proof (Final)**
* **Content:**
```lean
-- Step 1: Extract the unitary property U* U = 1
have h1 : star (U : Matrix n n α) * (U : Matrix n n α) = 1 := by
exact Matrix.UnitaryGroup.star_mul_self U
-- Step 2: From the idempotent property, multiply both sides by star U on the left
have h2 : star (U : Matrix n n α) * (U : Matrix n n α) ^ 2 = star (U : Matrix n n α) * (U : Matrix n n α) := by
rw [h]
-- Step 3: Simplify the left side using associativity and the unitary property
have h3 : star (U : Matrix n n α) * (U : Matrix n n α) ^ 2 = (U : Matrix n n α) := by
rw [pow_two, ← Matrix.mul_assoc, h1, Matrix.one_mul]
-- Step 4: Combine to get the final result
have h4 : (U : Matrix n n α) = 1 := by
rw [← h3, h2, h1]
```
* **Transcription & Explanation:** This block provides the actual tactic scripts to prove each step outlined in the intermediate block.
* **Step 1 (`h1`):** Proven using `exact Matrix.UnitaryGroup.star_mul_self U`, which is a lemma stating `U* U = I` for a unitary `U`.
* **Step 2 (`h2`):** Proven by rewriting (`rw`) with hypothesis `h` (idempotence). This changes `(U)^2` to `U` on the left side of the equation.
* **Step 3 (`h3`):** Proven by a sequence of rewrites:
1. `pow_two`: Expands `(U)^2` to `U * U`.
2. `← Matrix.mul_assoc`: Associates the multiplication to the left: `(U* * U) * U`.
3. `h1`: Replaces `U* * U` with `I` (using the unitary property).
4. `Matrix.one_mul`: Simplifies `I * U` to `U`.
* **Step 4 (`h4`):** Proven by rewriting backwards (`←`) with `h3`, then `h2`, then `h1`. This chain of equalities shows `U = (U* * U^2) = (U* * U) = I`.
### Key Observations
1. **Proof Development Workflow:** The diagram clearly visualizes the process of formal proof development: from a high-level statement, to a structured outline with placeholders, to a fully detailed proof with specific tactics.
2. **Use of `sorry`:** The intermediate block uses `sorry` as a placeholder, a common feature in proof assistants to mark incomplete proofs while working on the structure.
3. **Tactic-Based Proofs:** The final proof relies on rewriting (`rw`) with existing lemmas (`pow_two`, `Matrix.mul_assoc`, `Matrix.one_mul`) and hypotheses (`h`, `h1`, `h2`, `h3`).
4. **Mathematical Logic:** The proof follows a clear algebraic logic: start with the unitary property, manipulate the idempotent equation using it, and simplify to the identity.
### Interpretation
This diagram is a technical artifact from the field of **formal verification** and **interactive theorem proving**. It demonstrates how a mathematical statement about linear algebra (unitary idempotent matrices) is encoded and proven within a computer system.
* **What it demonstrates:** It shows the translation of an informal mathematical argument into a rigorous, machine-checkable proof. The core idea is that if a matrix `U` satisfies `U*U = I` (unitary) and `U² = U` (idempotent), then `U` must be `I`. The proof leverages the unitary property to "cancel" `U*` from the idempotent equation.
* **Relationship between elements:** The arrows show a direct lineage. The theorem statement defines the problem. The intermediate sketch breaks the solution into logical steps, acting as a blueprint. The final block fills in the technical details required for the proof assistant to verify each step.
* **Notable aspects:** The use of `Matrix.unitaryGroup` and associated lemmas indicates this is part of a larger formalized library of linear algebra. The proof is concise, relying on well-chosen rewrites rather than manual algebraic manipulation, showcasing the power of tactic-based proving. The progression from `sorry` to a complete proof is a quintessential experience in interactive theorem proving.
</details>
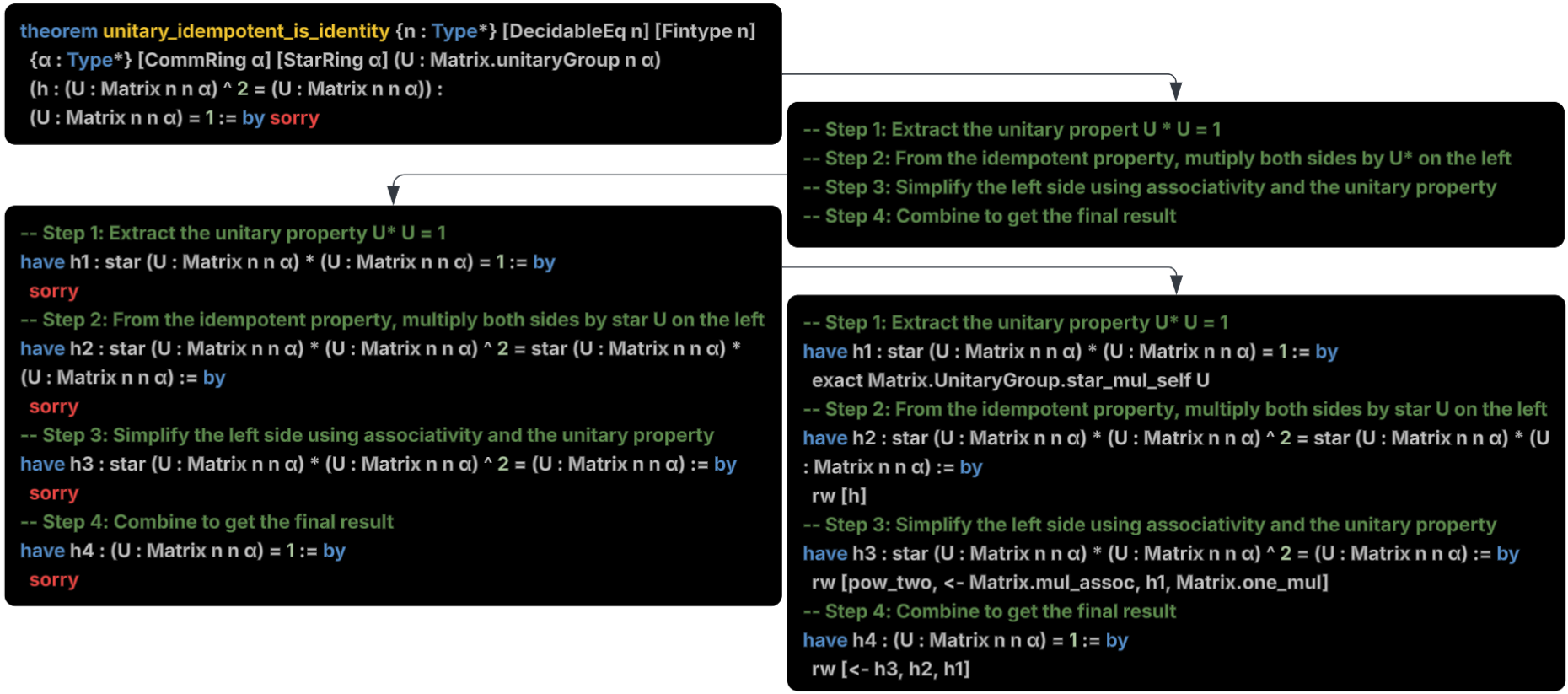
Figure 2: The main steps performed by the Prover to prove a theorem.
The Prover is the constructive core of the system. Its task is to transform unproven Lean theorems into completed proofs. Theorem proving requires both creativity – finding the right lemma or using the right tactic – and rigor – ensuring that the structure and Lean code are syntactically correct. To achieve this the Prover balances LLM-based heuristic exploration with rigorous Lean formalization aided by the MCP Lean tools made available by the lean-lsp-mcp (see Section 3.2).
We instruct the Prover to carry out its task following an incremental, step-by-step approach, and to write each update to the theorem proof to a .lean file. This is for two reasons: first, it satisfies the requirements of the MCP Lean tools, some of which need a .lean file path to inspect the code contained within; second, it allows the user to inspect the proof process in real time. In Figure 2, we present the main stages of the Prover process. Initially, the Prover identifies target theorems by scanning the input Lean file for unfinished proofs marked with sorry, a placeholder tactic indicating an incomplete proof (top-left). Then, it writes a proof sketch, a coarse-grained natural language outline of the proof’s logical flow which breaks down a complex proof into more manageable steps (top-right). Next is formalization, where each step in the sketch is formalized into a Lean statement starting with have and ending with sorry (bottom-left); allowing the prover to see the original theorem statement broken down into current and next steps within the lean context. Then, the Prover goes through each step sequentially, proposing Lean tactics to substitute each sorry. After completing each step, the Prover uses a specific Lean tool, lean_diagnostic_messages (see Section 3.2) to assess if the generated step is correct. If critical errors are detected or a sorry is still present, the Prover attempts to fix the error or correct its reasoning. When all steps are correctly solved, the Prover ends its task (bottom-right).
Tool usage is crucial for the Prover to perform its task. This is clearly illustrated in Figure 1 (right), which is extracted from the LLM log during an experimental run. The figure shows how both exploration and formalization are achieved through tool-enhanced reasoning, where the Prover uses MCP tools to interact with Lean files (read_file and edit_file); identify goals at various points in the proof (lean_goal); search for theorems in Mathlib (lean_leansearch); and verify the correctness of its proofs (lean_diagnostic_messages). This approach allows the Prover to function like a cautious mathematician: it drafts a plan, incrementally explores and implements ideas using relevant tools, verifies their correctness in Lean, and advances only once each step has been validated.
#### 3.1.3 Verifier
The Verifier serves as the final gatekeeper of correctness in our workflow. It neither generates nor modifies proofs: it only assesses the correctness of the proof generated by the Prover. The Verifier has access to filesystem tools, used to access the file produced by the Prover, as well as a single Lean tool, lean_diagnostic_messages, to assess the correctness of the proof. The Verifier operates in two steps. First, it compiles the Lean file produced by the Prover using the lean_diagnostic_messages tool, parses the returned diagnostic messages, and generates an error report. Second, it emits a verdict: a proof is considered verified if and only if no level-1 error exists (see Section 3.2) and there are no sorry (or the equivalent tactic admit) present in the file.
At first glance, the Verifier may seem redundant, since it uses the same lean_diagnostic_messages tool as the Prover. However, it is needed for two reasons: (i) the Prover may run out of steps (see Section 5.1) and return an incomplete or incorrect proof, and (ii) it sometimes terminates early despite remaining errors. An independent Verifier is thus crucial to ensure robustness, mirroring software pipelines where aggressive testing is always checked by a conservative compiler.
### 3.2 MCP Tools
As described above, tool use is essential in our approach. We provide the LLM with access to tools via the MCP, a standard interface that lets LLM agents invoke external services in a uniform, controlled way [modelcontextprotocol2024]. We implement two categories of tools: Filesystem tools and Lean tools. Filesystem tools handle file operations such as read_file, write_file, and list_directory (see Appendix A.1). Lean tools allow Ax-Prover to perform a variety of actions which are crucial for theorem proving. We give Ax-Prover access to these tools through the lean-lsp-mcp project [lean-mcp], which provides a standardized interface to the Lean environment. Access to these tools allows Ax-Prover to search within the local library, diagnose errors and warnings as they arise, observe the Lean context at any point in a proof, and query external search engines. Notably, external search engines provide Ax-Prover with more up-to-date information about Mathlib than what exists within an LLM’s parametric knowledge: Loogle searches for declarations within the newest version of Mathlib, and Leansearch is based on a past but recent version of Mathlib. Since Mathlib is a rapidly evolving library, this capability of Ax-Prover ensures compatibility for imports, theorem references, and proof constructions without relying on the LLM’s knowledge of the version (or multiple versions) of Mathlib on which it was trained. The Lean tools we use fall into four main groups, summarized in Table 1.
| Project and File Management | lean_build: Compile and build the Lean project lean_file_contents: Get contents of a Lean file lean_declaration_file: Find which file contains a declaration |
| --- | --- |
| Diagnostics and Feedback | lean_diagnostic_messages: Compile code and return diagnostic messages lean_goal: Get the current proof goal at a position lean_term_goal: Get goal information for a term lean_hover_info: Get hover information for symbols |
| Code Assistance | lean_completions: Get completion suggestions lean_multi_attempt: Try multiple proof attempts lean_run_code: Execute Lean code |
| Search and Reasoning | lean_leansearch: Search for theorems and lemmas lean_loogle: Search for lemmas by type signature lean_state_search: Search proof states lean_hammer_premise: Use automated theorem proving |
Table 1: Lean tools available on lean-lsp-mcp, organized by functionality.
Note that lean_diagnostic_messages returns a number: 0 for a successfully compiled proof with no errors or warnings; 1 for an explicit compilation error in the proof; and 2 for a successfully compiled proof with warning messages, e.g. the proof is incomplete (containing sorry), or the code style does not pass the linter test. A proof is considered correct and complete only if a code 0 is returned, or if a level 2 code is returned that does not contain sorry.
## 4 Datasets
While the application of LLMs to mathematical verification in Lean is evolving rapidly, the availability of comprehensive datasets remains limited. At present, only a few open-source datasets are available, with some of the most notable being MiniF2F [minif2f], PutnamBench [tsoukalas2024putnambench], and NuminaMath-LEAN [numinamath-lean]. These benchmarks include hard, high-level math problems from competitions such as the International Mathematical Olympiad (IMO) or the Putnam exam. Other datasets exist, but have clear limitations. For example, Deepseek-Prover-V1 Train [deepseek-prover-v1-dataset] includes 27k LLM-generated statements and proofs, but most of them are very simple and can be solved in 2–3 lines on average. Lean Workbook [lean-workbook] (57k) gathers LLM-generated formalizations of mathematical problems. While it reports a $93.5\$ statement-level accuracy after filtering, subsequent analyses note that a nontrivial fraction of examples still suffer from semantic errors and hallucinations [lu2024process, autoformalization-survey], which limits its reliability.
Notably, current valuable benchmarks focus on mathematics and, even within this domain, are centered narrowly on high school and undergraduate-level competition problems. To enrich the ecosystem and expand the coverage of Lean datasets, we create two datasets. The first one AbstractAlgebra (AA), is a Lean 4 dataset of problems drawn from standard abstract algebra textbooks. Unlike existing math benchmarks, which focus on undergraduate level competition-style puzzles, AA targets graduate or research-level mathematics, emphasizing deeper abstract concepts over lengthy step-by-step manipulations. The second dataset is QuantumTheorems (QT), which covers core topics in foundational quantum mechanics, with problems spanning from density matrices to scaling laws for quantum repeater networks. By bridging theoretical physics with formal verification methods, QT not only offers an unprecedented opportunity to test prover agents on quantum mechanics theorems, but also represents a key step toward evaluating scientific reasoning models across any scientific discipline grounded in mathematics. In the section below, we provide more information about these two datasets as well as the other datasets we used for our experiments.
### 4.1 AbstractAlgebra
AbstractAlgebra is a curated dataset of 100 Lean problems extracted from the exercises in Dummit & Foote’s abstract algebra textbook [dummit2004abstract]. The problems were extracted and formalized in Lean using an automated pipeline (see details and examples in Appendix B.1). The dataset consists of two subsets: 50 easy problems from Chapter 1.1 and 50 intermediate problems from Chapters 1.2–2.5. The two categories thus reflect the increasing level of difficulty of the chapters in the book.
As mentioned above, existing datasets focus on high school to undergraduate-level competition mathematics, which typically involves elementary concepts framed as puzzles that require many reasoning steps. For example, a competition problem may ask to determine all positive integers $a,b$ such that $(a^{2}+b^{2})/(ab+1)\in\mathbb{Z}$ , which is conceptually elementary but requires a sequence of clever number-theoretic transformations.
In contrast, the AA dataset is aimed toward research-level mathematics, which involves deeper concepts with fewer reasoning steps per exercise. For instance, an AA problem may ask: Prove that every element $x=sr^{i}$ in the dihedral group $D_{n}$ has order 2. By presenting these kinds of problems, AA fills the gap between AI-focused formalization efforts, which largely target elementary mathematics, and the advanced topics studied by research mathematicians.
Finally, we stress that abstract algebra is foundational to much of mathematics, providing essential tools for research in number theory, geometry, topology, and beyond – indeed, 22 of the 32 primary mathematics categories on arXiv build upon it [arxivMathArchive]. It also underpins important domains outside of mathematics, such as cryptography, physics, and chemistry. The broad foundational nature of abstract algebra underscores the importance of developing AI proof systems that perform well on problems in this domain, as this has the potential to accelerate progress across many scientific fields.
### 4.2 QuantumTheorems
QuantumTheorems includes 134 problems spanning core areas of quantum theory. These problems introduce unique challenges, as they require integrating finite-dimensional linear algebra, complex analysis, and matrix theory with quantum principles such as unitarity, hermiticity, and measurement postulates. This domain-specific knowledge is absent from existing lean datasets, making QT a valuable benchmark for testing and advancing formal reasoning in physics. QT was generated through an iterative human-in-the-loop process, combining automated proof synthesis with expert curation (see Appendix B.2 for more details and examples).
We generated problems at two levels of difficulty: basic problems are short (proof requires 1-10 lines of Lean code) and often solvable with standard automation tactics (simp, linarith), e.g., proving that a post-measurement state is an eigenstate of the measurement projector. Intermediate level problems (proof requires 10-50 lines of Lean code) are solvable with systematic case analysis and orchestration of rewrite rules, such as proving simultaneous diagonalization of commuting observables.
QT represents a first step toward computer-verified quantum mechanics, addressing the challenge of ensuring correctness in quantum information protocols and algorithms. The dataset has practical importance beyond research: as quantum technologies grow more complex, errors in proofs or hidden assumptions can have serious consequences. For instance, a recent bug in a proof claiming to break lattice-based cryptography – only identified weeks later by experts – illustrates the risks of unchecked reasoning in high-stakes domains [rousseau2024bug, chen2024lattice]. QT provides a first-of-its-kind resource for developing tools which can help detect these mistakes earlier.
### 4.3 NuminaMath-LEAN
NuminaMath-LEAN [numinamath-lean] is a very recent (August 2025) large-scale collection of approximately 104,000 competition-level mathematics problems formalized in Lean. The dataset is created by the same research group that developed the Kimina-Prover [kimina-prover]. They derived NuminaMath-LEAN from NuminaMath 1.5 [numina_math_datasets], with problems drawn from prestigious contests such as the International Mathematical Olympiad (IMO) and the United States of America Mathematical Olympiad (USAMO).
Each problem includes a formal statement in Lean, written either by a human annotator (19.3% of the problems) or by an autoformalizer model (80.7%) [numinamath-lean]. Out of the total problems, 25% were correctly proved by Kimina-Prover during its reinforcement learning (RL) training phase (Solved-K), 11% were proved by humans (Solved-H), while the remaining 64% do not have any proof (Unsolved) [kimina-prover, numina_math_datasets, numinamath-lean]. We analyzed problems across the three groups and observed a clear difficulty gradient: Solved-K $<$ Solved-H $<$ Unsolved. This ordering aligns with the fact that Solved-H and Unsolved problems could not be solved by Kimina-Prover, providing an implicit measure of difficulty. The fact that Solved-H proofs are on average longer than those in Solved-K (155 vs. 98 lines) also offers quantitative evidence consistent with our qualitative assessment. For our experiments, we randomly sampled 300 problems – 100 each from Solved-K, Solved-H, and Unsolved – to create a balanced, representative, and more budget-friendly benchmark.
### 4.4 PutnamBench
PutnamBench [tsoukalas2024putnambench] is a multi-language benchmark designed to evaluate the ability of neural theorem provers to solve undergraduate-level competition mathematics problems. It includes formalizations of problems from the William Lowell Putnam Mathematical Competition (1962–2024) across three major proof assistants – Lean, Isabelle, and Rocq. The Lean subset contains 660 formalized problems, which are the ones we focus on in this work. The problems require the clever application of a wide range of undergraduate topics, including abstract algebra The abstract algebra problems in PutnamBench are of a different nature than the ones in our AbstractAlgebra dataset, which focuses more on detailed facts about textbook level concepts requiring few steps of reasoning., analysis, number theory, geometry, linear algebra, combinatorics, probability, and set theory. For each year, the Putnam competition includes two sessions of six problems each, labeled A1–A6 and B1–B6. It is generally accepted that, within each session, the problems increase in difficulty from 1 to 6. Unlike MiniF2F, which is now saturated (see, e.g., [deepseek-prover-v2]), PutnamBench remains a challenging benchmark for most provers. Moreover, since it is widely adopted by many models, it serves as a high-value testbed for evaluating our approach against the best theorem-proving models currently available.
## 5 Experiments
In this section, we provide details about the experimental setup we implemented (Section 5.1) and our results (LABEL:subsec:results), followed by an analysis of tool usage (LABEL:subsec:analysis_tools) and the challenges and costs of model deployment (LABEL:subsec:deployment_analysis).
### 5.1 Experimental Setup
We divided the benchmarks introduced in Section 4 in two groups: New Benchmarks (including AbstractAlgebra, QuantumTheorems, and NuminaMath-LEAN) and PutnamBench, reflecting two distinct objectives.
In the tests with New Benchmarks we evaluated the performance of the Ax-Prover against three strong baselines:
- Claude Sonnet 4 (Sonnet). This baseline allows us to assess how the same LLM used to power our framework (see below) performs if used outside the agentic flow and without access to MCP tools.
- DeepSeek-Prover-V2-671B (DS-Prover) and Kimina-Prover-72B (Kimina), two specialized Lean provers.
We evaluated all models using pass@1: while this idea is in sharp contrast with previous studies assessing provers with pass@ very high values (see, e.g., [deepseek-prover-v2]), we believe it mirrors real-world usage, where researchers are constrained by time and budget limits, and cannot run a prover multiple independent times in the hope that one succeeds. For transparency and reproducibility, we note that while pass@1, for all the baselines, means trying to formalize the entire proof in a single shot, for Ax-Prover it means performing a sequence of steps (i.e., API calls) in which reasoning and tool calls are interleaved in a singular attempt to build the final proof, i.e. without multiple independent attempts (see Section 3.1.2). For these experiments, we powered Ax-Prover using Claude Sonnet 4 [anthropic2025claude4]. Furthermore, to stay within budget, we capped Ax-Prover API calls at 200 and set a 25-minute timeout. For all models, we computed the final results by running an external Lean compiler on the generated files, and considered a proof correct if it compiled and included no sorry.
The second benchmark group, which includes PutnamBench only, aims to evaluate Ax-Prover on one of the most challenging public benchmarks and compare its performance against existing state-of-the-art provers. Accordingly, we did not run baselines and instead directly compared our results with those reported on the official leaderboard [putnambench_leaderboard]. For this test, we powered Ax-Prover with Sonnet 4.5, removed the 25-minute timeout, and increased the max number of API calls to 400, while still running Ax-Prover with pass@1, as defined above.
## 6 Conclusions
We introduce Ax-Prover, a novel agentic workflow that combines the broad reasoning capabilities of general-purpose LLMs with the formal rigor of Lean’s proof environment. Our system addresses three major limitations of current specialized provers: (i) limited generalizability to scientific domains beyond mathematics and rapid obsolescence as libraries like Mathlib evolve; (ii) inability to collaborate effectively with human experts and utilize external tools; and (iii) high engineering and maintenance costs.
Evaluations show that Ax-Prover is the top performing open-source model and third overall on PutnamBench, using a much lower computation budget than top-performers, and outperforms baselines on the public NuminaMath-LEAN dataset as well as on AbstractAlgebra and QuantumTheorems, two new datasets we introduce that focus on research-level mathematics and physics. These benchmarks not only provide new testbeds for cross-domain reasoning in future agents but also represent a crucial milestone in evaluating reasoning models in any scientific discipline grounded in mathematics.
These results highlight Ax-Prover’s superior domain generalization, in contrast to specialized models, which struggle to adapt to novel domains beyond their training data. More importantly, they show that Ax-Prover has the potential to serve as a deep formal reasoning assistant for scientific artificial intelligence in domains requiring extended chains of rigorous inference. The combination of multi-disciplinary reasoning with rigorous formal verification positions the system to support AI-driven scientific discovery wherever verifiably error-free reasoning is essential. We attribute this performance to our multi-agent architecture and its tight integration with Lean tools via the MCP. By iteratively editing proofs, inspecting goals, and diagnosing errors, Ax-Prover behaves like a cautious mathematician, systematically exploring and verifying each step. The frequency and effectiveness of tool use in our experiments confirm their essential role in improving proof quality and enabling human-like debugging.
Furthermore, we showed in our case studies that Ax-Prover is not only able to prove theorems autonomously, but also to engage in fruitful collaboration with researchers. Working alongside it, they used it as a partner for structuring arguments, validating lemmas, and diagnosing proof failures. This interaction demonstrates how Ax-Prover can adapt to expert guidance, accelerate verification workflows, and even surface errors in the informal reasoning.
Looking ahead, we plan to enhance Ax-Prover by introducing parallelized agents, enabling the framework to explore multiple proof paths simultaneously. This will increase its creativity and success rate in formalizing complex proofs. We also plan to integrate a long-term memory module to store information from past proofs and human interactions. This capability will allow Ax-Prover to participate not only in standalone problems but also in extended, collaborative research projects. These developments will advance us towards our broader goal of verifiable scientific artificial intelligence, where AI systems contribute to scientific discovery through formally validated reasoning.
## Acknowledgments
We thank Austin Letson for reviewing the paper, suggesting that we evaluate Ax-Prover on PutnamBench, and assisting with Lean-related tasks, including the use of lean4checker to verify our results. We thank Avinash Kumar for directing us to the NuminaMath-LEAN dataset. Finally, we acknowledge Leopoldo Sarra for working closely with us during the early stages of the project.
## Appendix
## Appendix A Tools
### A.1 File system
Full list of Filesystem tools:
- read_file
- read_multiple_files
- write_file
- edit_file
- create_directory
- list_directory
- list_directory_with_sizes
- directory_tree
- move_file
- search_files
- get_file_info
- list_allowed_directories
## Appendix B Datasets
### B.1 Abstract Algebra
#### B.1.1 Dataset Generation
We used a basic pipeline to build the AbstractAlgebra dataset. First, we extracted all raw text from PDFs of exercises from Abstract Algebra by Dummit and Foote [dummit2004abstract] using Mistral’s API. We then processed the raw text by using Claude Sonnet 3.7 [anthropic2025claude37] to extract a list of natural language mathematical statements, which include exercises, derivations, lemmas, propositions, and theorems within the text. Next, we used a Claude Sonnet 3.7 agent to formalize each natural language statement in Lean. To ground the formalization in Mathlib and prevent the agent from reinventing definitions, we passed the agent a Lean file at the start of the process containing relevant definitions for that section, e.g., dihedral groups, roots of unity, or the field extension $\mathbb{Q}(\sqrt{2})$ . The agent could reference these definitions and was required to add each formalized statement directly to this file, but was explicitly prohibited from introducing new definitions. The agent generated the top 3 formal statements in Lean for each natural language statement and refined each attempt up to 3 times with feedback from the Lean compiler. We then built the dataset by retaining only those pairs of natural language and formal language statements that corresponded to exercises from the source texts.
#### B.1.2 Example
This is an example of a theorem statement in the AbstractAlgebra dataset, formalized from Exercise 3 in Chapter 1.2 of Dummit and Foote [dummit2004abstract].
⬇
import Mathlib
-- Variables for dihedral group
variable {n : Nat} {i : Int}
local notation " D_n " => DihedralGroup n
local notation " r " => DihedralGroup. r (1 : ZMod n)
local notation " s " => DihedralGroup. sr (0 : ZMod n)
/-- Show that every reflection x = sr ^ i in D_n has order 2. -/
theorem exercise_3_part1 {x : D_n} (h : x = s * r ^ i) : orderOf x = 2 := by
sorry
### B.2 QuantumTheorems
#### B.2.1 Dataset Generation
The dataset was generated through an iterative human-in-the-loop process combining automated proof synthesis with expert curation. The initial set of 134 theorems were manually extracted from [nielsen2010quantum]. An automated coding agent (Claude Opus [anthropic2025claudeopus]) first generated formal statements and proof attempts for the theorems, producing both complete proofs and partial derivations. A quantum physics expert then reviewed each statement and proof, identifying gaps, correcting errors, and standardizing operator definitions to ensure that each question was well formed and solvable. The final dataset replaces these proofs with sorry statements.
#### B.2.2 Example
This is an example of a theorem statement in the QuantumTheorems dataset, stating that a post-measurement state is an eigenstate of the measurement projector. Notably, the problem setup involves a number of custom definitions of concepts in quantum mechanics.
⬇
import Mathlib. Analysis. InnerProductSpace. Basic
import Mathlib. Data. Complex. Basic
import Mathlib. Data. Matrix. Basic
import Mathlib. LinearAlgebra. Eigenspace. Basic
open BigOperators Complex
/-- Quantum state as normalized vector -/
structure QuantumState (n : ℕ) where
vec : Fin n → ℂ
normalized : ∑ i, Complex. normSq (vec i) = 1
/-- Projector as idempotent matrix -/
structure Projector (n : ℕ) where
mat : Matrix (Fin n) (Fin n) ℂ
idem : mat * mat = mat
hermitian : mat. conjTranspose = mat
/-- Matrix - vector multiplication -/
noncomputable def matVec {n : ℕ} (M : Matrix (Fin n) (Fin n) ℂ) (v : Fin n → ℂ) : Fin n → ℂ :=
fun i => ∑ j, M i j * v j
/-- Measurement probability -/
noncomputable def measureProb {n : ℕ} (P : Projector n) (ψ : QuantumState n) : ℝ :=
∑ i, Complex. normSq ((matVec P. mat ψ. vec) i)
/-- Norm of a vector -/
noncomputable def vecNorm {n : ℕ} (v : Fin n → ℂ) : ℝ :=
Real. sqrt (∑ i, Complex. normSq (v i))
/-- Scale a vector by a real number -/
noncomputable def scaleVec {n : ℕ} (r : ℝ) (v : Fin n → ℂ) : Fin n → ℂ :=
fun i => r • (v i)
/-- Check if a vector is an eigenvector with eigenvalue lambda -/
def isEigenvector {n : ℕ} (M : Matrix (Fin n) (Fin n) ℂ) (v : Fin n → ℂ) (lambda : ℂ) : Prop :=
v ≠ 0 ∧ matVec M v = fun i => lambda * v i
/-- QT_366: Post - measurement state is eigenstate of measurement projector -/
theorem QT_366_post_measurement_eigenstate {n : ℕ} (P : Projector n) (ψ : QuantumState n)
(h_nonzero : measureProb P ψ ≠ 0) :
let ψ’ := matVec P. mat ψ. vec
isEigenvector P. mat ψ’ 1 := by
sorry
## Appendix C Detected Autoformalization Error
As noted in Section LABEL:subsec:results, 19.7% of Numina’s problems were generated using autoformalization models. While these pipelines enable large-scale dataset construction, they occasionally produce ill-posed theorems that cannot be satisfied in Lean.
During evaluation, Ax-Prover successfully identified such a case and proved the negation of the statement.
⬇
import Mathlib
theorem number_theory_3098 (p1 p2 p3 p4 : ℕ) (hp1 : p1. Prime) (hp2 : p2. Prime)
(hp3 : p3. Prime) (hp4 : p4. Prime) (h1 : p1 < 100) (h2 : p2 < 100) (h3 : p3 < 100)
(h4 : p4 < 100) (h5 : p1 ≠ p2) (h6 : p1 ≠ p3) (h7 : p1 ≠ p4) (h8 : p2 ≠ p3)
(h9 : p2 ≠ p4) (h10 : p3 ≠ p4) (h11 : p1 = 1 ∨ p1 = 2 ∨ p1 = 3 ∨ p1 = 4 ∨ p1 = 5 ∨ p1 = 6 ∨ p1 = 7 ∨ p1 = 9)
(h12 : p2 = 1 ∨ p2 = 2 ∨ p2 = 3 ∨ p2 = 4 ∨ p2 = 5 ∨ p2 = 6 ∨ p2 = 7 ∨ p2 = 9)
(h13 : p3 = 1 ∨ p3 = 2 ∨ p3 = 3 ∨ p3 = 4 ∨ p3 = 5 ∨ p3 = 6 ∨ p3 = 7 ∨ p3 = 9)
(h14 : p4 = 1 ∨ p4 = 2 ∨ p4 = 3 ∨ p4 = 4 ∨ p4 = 5 ∨ p4 = 6 ∨ p4 = 7 ∨ p4 = 9)
(h15 : p1 ≠ p2 ∧ p1 ≠ p3 ∧ p1 ≠ p4 ∧ p2 ≠ p3 ∧ p2 ≠ p4 ∧ p3 ≠ p4) :
p1 + p2 + p3 + p4 = 190 := by sorry
The first line of the proof sketch that Ax-Prover generated for this problem was
This theorem has contradictory premises: the sum must be 17, not 190.
Upon inspection, it is clear that 4 natural numbers belonging to the set $\{2,3,5,7\}$ cannot sum to 190. As an additional exercise, we changed
⬇
p1 + p2 + p3 + p4 = 190 := by sorry
to its negation
⬇
(p1 + p2 + p3 + p4 = 190) = False := by sorry
changing the original theorem statement to prove the negation which Ax-Prover was able to do, thus proving that the original theorem was not provable. This behavior highlights two strengths of the agentic loop:
1. Robustness to noise. The agent does not blindly attempt to complete invalid statements but can detect contradictions early.
1. Transparency. By surfacing diagnostic messages directly from Lean, Ax-Prover provides clear evidence that the statement is ill-posed, enabling researchers to filter or repair dataset items.
We see this as an important complement to raw accuracy metrics: beyond solving valid theorems, a reliable prover should be able to recognize when formalization errors make a proof impossible.
## Appendix D Proofs
### D.1 QuantumTheorems Example Analysis
We present here the attempts to prove that diagonal matrix elements of a quantum observable in a finite-dimensional Hilbert space are real. Concretely,
Let $A$ be a quantum observable in an $n$ -dimensional Hilbert space. Then for every $i=1,\cdots,n$ , the imaginary part of the element $A_{ii}$ vanishes.
This entry in the dataset comes with a custom definition of an observable:
⬇
/-- An observable is a Hermitian operator -/
structure Observable (n : ℕ) where
matrix : Matrix (Fin n) (Fin n) ℂ
hermitian : matrix. IsHermitian
#### D.1.1 DeepSeek’s Attempt (Failed)
DeepSeek’s approach was fundamentally flawed from the start:
⬇
theorem observable_diagonal_real {n : ℕ} (A : Observable n) (i : Fin n) :
(A. matrix i i). im = 0 := by
have h := A. hermitian
have h ₁ := congr_arg (fun x => x i i) h
simp [Matrix. ext_iff, Matrix. conjTranspose_apply, Complex. ext_iff] at h ₁ ⊢
<;>
aesop
Critical Error:
⬇
tactic ’ aesop ’ failed, made no progress
Analysis: DeepSeek attempted to use A.hermitian directly as a proof, but this term has type Matrix.IsHermitian, not the equality type required by congr_arg. The error message indicates that the tactic aesop failed because there was a fundamental type mismatch. This shows a misunderstanding of Lean’s type system. The hermitian field is a proof that the matrix satisfies the Hermitian property, but it’s not directly the equality we need to prove.
#### D.1.2 Sonnet’s Attempt (Failed)
Sonnet made a more sophisticated attempt but still failed:
⬇
theorem observable_diagonal_real {n : ℕ} (A : Observable n) (i : Fin n) :
(A. matrix i i). im = 0 := by
have h := A. hermitian
rw [Matrix. IsHermitian. ext_iff] at h
specialize h i i
rw [Matrix. conjTranspose_apply, Matrix. star_apply] at h
exact Complex. ext_iff. mp h. symm |>.2
Critical Error:
⬇
Tactic ‘ rewrite ‘ failed: Did not find an occurrence of the pattern
Matrix. conjTranspose ? M ? j ? i
in the target expression
star (A. matrix i i) = A. matrix i i
Analysis: Sonnet understood that it needed to work with the Hermitian property and tried to extract information about diagonal elements, but made an error in pattern matching during the rewrite step. The approach was on the right track but was executed incorrectly.
#### D.1.3 Ax-Prover’s Attempt (Successful)
Ax-Prover succeeded with a systematic, step-by-step approach:
⬇
theorem observable_diagonal_real {n : ℕ} (A : Observable n) (i : Fin n) :
(A. matrix i i). im = 0 := by
-- Step 1: Use the fact that A is Hermitian
have h1 : A. matrix. conjTranspose = A. matrix := by
exact A. hermitian
-- Step 2: Apply this to diagonal element (i, i)
have h2 : (A. matrix. conjTranspose i i) = (A. matrix i i) := by
rw [h1]
-- Step 3: By definition of conjugate transpose
have h3 : (A. matrix. conjTranspose i i) = star (A. matrix i i) := by
exact Matrix. conjTranspose_apply _ _ _
-- Step 4: Combine to get star (A. matrix i i) = A. matrix i i
have h4 : star (A. matrix i i) = A. matrix i i := by
rw [← h3, h2]
-- Step 5: A complex number equals its conjugate iff it ’ s real
have h5 : (A. matrix i i). im = 0 := by
have : (starRingEnd ℂ) (A. matrix i i) = A. matrix i i := h4
exact Complex. conj_eq_iff_im. mp this
exact h5
## Appendix E Tactics
In Table 2 we report the tactics used by each model.
| apply | X | X | X |
| --- | --- | --- | --- |
| assumption | X | X | X |
| by_cases | X | X | X |
| calc | X | X | X |
| cases | X | X | X |
| change | X | | |
| classical | X | X | |
| congr | X | X | X |
| constructor | X | X | X |
| contradiction | X | X | X |
| decide | X | X | |
| exact | X | X | X |
| exact_mod_cast | X | X | X |
| exfalso | X | X | X |
| ext | X | X | X |
| funext | | X | X |
| generalize | X | | |
| induction | X | X | X |
| injection | X | | |
| intro | X | X | X |
| intros | X | | |
| left | X | | X |
| native_decide | X | | X |
| norm_cast | X | | |
| obtain | X | X | X |
| omega | X | X | X |
| push_cast | X | | |
| rcases | X | X | X |
| refine | X | X | X |
| replace | X | | X |
| rfl | X | X | X |
| right | X | | X |
| rintro | X | X | X |
| rw | X | X | X |
| rwa | X | | X |
| show | X | | X |
| simp | X | X | X |
| simp_all | X | X | X |
| simpa | X | X | X |
| specialize | | | X |
| subst | X | X | X |
| subst_vars | | X | |
| suffices | X | | |
| trans | X | | |
| unfold | X | | |
Table 2: Tactics used by Ax-Prover, DeepSeek, and Kimina. An “X” indicates the model uses the tactic.
## Appendix F Case Study: Verifying math in classical cryptographic papers
In this case study, we illustrate how one of our researchers used Ax-Prover to verify the correctness of mathematical results used in cryptographic research.
As a concrete example, we focus on the recent (May 2024) cryptographic paper A New Algorithm for Computing Branch Number of Non-Singular Matrices over Finite Fields from arXiv [mishra2024new]. This work introduces a novel algorithm for computing the branch number – a fundamental metric used to assess the strength of block ciphers such as AES [nist2023aes], PRINCE [borghoff2012prince], and Grøstl [gauravaram2008grostl].
The paper begins with Theorem 1, which offers an alternative characterization of the branch number. Traditionally, for an invertible $n\times n$ matrix $M$ of order $n>1$ over a finite field $\mathbb{F}_{q}$ of order $q$ , the branch number is defined as
$$
\mathcal{B}(M)=\min\left\{\,w_{h}(x)+w_{h}(Mx):x\in\mathbb{F}_{q}^{n}\text{ where }x\neq 0\,\right\}, \tag{1}
$$
where $w_{h}(x)$ is the Hamming weight (the number of nonzero entries in $x$ ). Theorem 1 gives an alternate definition of the branch number that is more amenable to computation than the classical version:
The branch number of an invertible matrix $M\in M_{n}(\mathbb{F}_{q})$ is given as
$$
\mathcal{B}(M)=\min\left\{\,\min\{h(M,x),h(M^{-1},x)\}:x\in\mathbb{F}_{q}^{n},1\leq w_{h}(x)\leq\left\lfloor\frac{n+1}{2}\right\rfloor\,\right\}, \tag{2}
$$
where $h(M,x)=w_{h}(x)+w_{h}(Mx)$ .
For cryptographers, this makes a practical difference: it enables fast evaluation of candidate matrices when designing new lightweight or high-performance ciphers. The authors demonstrate in Theorem 4 [mishra2024new] that their algorithm achieves significant complexity gains over the naive $O(n^{2}q^{n})$ approach for finite fields of order $q\geq 4$ and square matrices of order $n\geq 4$ .
### F.1 Formalize: Single Step
To formally verify the math in this paper, we used an autoformalization agent to formalize statements, verified that the formalization was correct, before passing those statements to Ax-Prover.
We show the process of proving one step in the paper (the full Lean certificate can be provided upon request). The figure below shows the current verification state highlighted in green, while the next step awaiting verification appears in yellow.
<details>
<summary>ims/proof_step.png Details</summary>

### Visual Description
## Mathematical Text: Branch Number Computation
### Overview
The image displays two distinct blocks of mathematical text and equations, presented on colored backgrounds (green and yellow). The content is part of a formal proof or derivation concerning the computation of a "branch number" denoted as \( \mathcal{B}(M) \). The text is in English and uses standard mathematical notation.
### Components/Axes
The image is segmented into two primary regions:
1. **Top Region (Green Background):** Contains explanatory text and a primary equation labeled (3).
2. **Bottom Region (Yellow Background):** Contains a follow-up note and a set inclusion statement.
There are no charts, axes, or legends. The "components" are the mathematical statements and the logical text connecting them.
### Detailed Analysis
#### **Top Region (Green Box)**
**Text Transcription:**
"Note that for the second term of the right-hand side of Equation (2), \( h(M, x) = w_h(x) + w_h(Mx) > 2 \left\lfloor \frac{n+1}{2} \right\rfloor + 1 \geq n+1 \). However, we know that the upper bound for \( \mathcal{B}(M) \) is \( n+1 \). Thus, we conclude that the second term of the right-hand side of (2) will not contribute to the computation of the branch number.
Therefore, from (1) and (2), we have"
**Equation (3) Transcription:**
\[
\mathcal{B}(M) = \min \left\{ \min \left\{ h(M, x) \mid x \in \mathbb{F}_q^n, 1 \leq w_h(x) \leq \left\lfloor \frac{n+1}{2} \right\rfloor \right\}, \right.
\]
\[
\left. \min \left\{ h(M, x) \mid x \in \mathbb{F}_q^n, \left\lfloor \frac{n+1}{2} \right\rfloor < w_h(x) \leq n, w_h(Mx) \leq \left\lfloor \frac{n+1}{2} \right\rfloor \right\} \right\}.
\]
**Key Symbols & Definitions:**
* \( \mathcal{B}(M) \): The branch number of a matrix \( M \).
* \( h(M, x) \): A function, likely the Hamming weight of the concatenation of \( x \) and \( Mx \).
* \( w_h(x) \): The Hamming weight of vector \( x \).
* \( \mathbb{F}_q^n \): The vector space of dimension \( n \) over the finite field \( \mathbb{F}_q \).
* \( \left\lfloor \frac{n+1}{2} \right\rfloor \): The floor function of \( (n+1)/2 \).
* The equation defines \( \mathcal{B}(M) \) as the minimum value of \( h(M, x) \) over two distinct subsets of vectors \( x \).
#### **Bottom Region (Yellow Box)**
**Text Transcription:**
"Again, we note that"
**Set Inclusion Statement Transcription:**
\[
\left\{ h(M, x) \mid x \in \mathbb{F}_q^n, 1 \leq w_h(x) \leq \left\lfloor \frac{n+1}{2} \right\rfloor, w_h(Mx) \leq \left\lfloor \frac{n+1}{2} \right\rfloor \right\} \subseteq
\]
\[
\left\{ h(M, x) \mid x \in \mathbb{F}_q^n, 1 \leq w_h(x) \leq \left\lfloor \frac{n+1}{2} \right\rfloor \right\}.
\]
**Key Observation:** This states that the set of \( h(M, x) \) values where both \( x \) and \( Mx \) have low Hamming weight is a subset of the set where only \( x \) has low Hamming weight.
### Key Observations
1. **Logical Flow:** The text presents a logical deduction. It first argues that one part of a previous equation (2) is irrelevant because its value exceeds the known upper bound for \( \mathcal{B}(M) \). This simplification leads directly to the definition in Equation (3).
2. **Structure of Equation (3):** The branch number is defined as the minimum of two separate minimization problems. The first searches over vectors \( x \) with low Hamming weight. The second searches over vectors \( x \) with higher Hamming weight, but imposes the condition that the resulting \( Mx \) has low Hamming weight.
3. **Subset Relationship:** The note in the yellow box establishes a containment relationship between two sets of function values. This is likely a step to further simplify or analyze the computation defined in Equation (3), showing that one condition is more restrictive than another.
### Interpretation
This image captures a segment of a proof in coding theory or linear algebra, specifically concerning the properties of a matrix \( M \) (likely a generator or parity-check matrix for a linear code). The "branch number" \( \mathcal{B}(M) \) is a critical parameter related to the code's resistance against certain types of attacks (e.g., differential or linear cryptanalysis).
The derivation shows how to compute \( \mathcal{B}(M) \) by considering two cases based on the Hamming weight of the input vector \( x \). The initial argument prunes the search space by eliminating vectors that cannot possibly yield the minimum value. The final subset inclusion suggests that the analysis can be focused on the first, simpler set of vectors where \( w_h(x) \) is already bounded, as the more complex condition in the second set of Equation (3) is implicitly covered. This is a common technique in proofs to reduce a problem to its most essential components.
</details>
### F.2 Verification: Single Step
We highlighted the relevant theorems or lemmas and prompted Ax-Prover to generate a complete proof for each selected statement. Ax-Prover iteratively refined the proof, checking each step for correctness until the system confirmed its validity. Unlike standard LLM output, this process ensured full mathematical soundness, with Ax-Prover automatically searching for relevant results, reading and updating the file, diagnosing errors, and managing proof goals.
Some expert human oversight was required on 2 steps to properly formalize statements passed to the prover, but beyond these isolated interventions, the system operated autonomously. After several iterations, it produced a fully verified proof of each step in just a few minutes. The following prompt illustrates this process for the example above:
Prompt
Prove this statement (with the formalized step above highlighted as context).
Response
The statement is a simple set-theoretic observation. We start with all low-weight vectors x and look at the values $w_{H}(x)+w_{H}(Mx)$ , where $w_{H}$ is the Hamming weight and M is some matrix. •
Without constraints: We consider all low-weight vectors. •
With constraints: We only consider those low-weight vectors where the output M x also has low weight. Clearly, if you add an extra condition (“M x has low weight”), you can only make the set smaller or equal—never larger—because you’re restricting the set of vectors you’re looking at. The proof just formalizes this obvious fact: 1.
Take any element in the constrained set. 2.
By definition, it comes from some vector x that satisfies the extra condition. 3.
But x also satisfies the conditions for the unconstrained set (because the unconstrained set has fewer requirements). 4.
So the element belongs to the unconstrained set as well. This shows the constrained set is a subset of the unconstrained set.
We now present an example that required expert oversight. Specifically, the Ax-Prover was unable to verify the correctness of statement (3) shown below:
<details>
<summary>ims/failed-proofstep.png Details</summary>

### Visual Description
## Mathematical Text Snippet: Branch Number Computation
### Overview
The image displays a segment of a mathematical proof or derivation, likely from a paper on coding theory or linear algebra. It contains two paragraphs of explanatory text and one displayed equation, labeled as equation (3). The content focuses on simplifying the computation of a "branch number," denoted as \(\mathcal{B}(M)\), by eliminating a non-contributing term from a previous equation.
### Components/Axes
This is not a chart or diagram with axes. The components are:
1. **Explanatory Text:** Two paragraphs of English text with embedded mathematical notation.
2. **Displayed Equation:** A multi-line mathematical definition for \(\mathcal{B}(M)\), labeled as equation (3) on the right margin.
3. **Mathematical Notation:** Includes symbols for functions (\(h(M,x)\), \(w_h(x)\)), sets (\(\mathbb{F}_q^n\)), floor functions (\(\lfloor \cdot \rfloor\)), inequalities, and the minimum operator (\(\min\)).
### Detailed Analysis / Content Details
**Transcription of Text and Equations:**
**First Paragraph:**
"Note that for the second term of the right-hand side of Equation (2), \(h(M, x) = w_h(x) + w_h(Mx) > 2 \lfloor \frac{n+1}{2} \rfloor + 1 \geq n+1\). However, we know that the upper bound for \(\mathcal{B}(M)\) is \(n + 1\). Thus, we conclude that the second term of the right-hand side of (2) will not contribute to the computation of the branch number."
**Second Paragraph:**
"Therefore, from (1) and (2), we have"
**Displayed Equation (3):**
\[
\mathcal{B}(M) = \min \left\{ \min \left\{ h(M, x) \mid x \in \mathbb{F}_q^n, 1 \leq w_h(x) \leq \left\lfloor \frac{n+1}{2} \right\rfloor \right\}, \right.
\]
\[
\left. \min \left\{ h(M, x) \mid x \in \mathbb{F}_q^n, \left\lfloor \frac{n+1}{2} \right\rfloor < w_h(x) \leq n, w_h(Mx) \leq \left\lfloor \frac{n+1}{2} \right\rfloor \right\} \right\}.
\]
The label "(3)" appears to the right of the second line of the equation.
**Key Mathematical Relationships Extracted:**
1. **Inequality Chain:** \(h(M, x) = w_h(x) + w_h(Mx) > 2 \lfloor \frac{n+1}{2} \rfloor + 1 \geq n+1\).
2. **Known Bound:** The upper bound for \(\mathcal{B}(M)\) is \(n+1\).
3. **Logical Conclusion:** Because the value of the "second term" (from an unshown Equation (2)) is strictly greater than \(n+1\), it cannot be the minimum value defining \(\mathcal{B}(M)\) and is therefore irrelevant to its computation.
4. **Final Definition (Eq. 3):** \(\mathcal{B}(M)\) is defined as the minimum of two separate minima:
* **First Minimum:** Over all vectors \(x\) in the space \(\mathbb{F}_q^n\) where the Hamming weight \(w_h(x)\) is between 1 and \(\lfloor \frac{n+1}{2} \rfloor\) (inclusive).
* **Second Minimum:** Over all vectors \(x\) in \(\mathbb{F}_q^n\) where \(w_h(x)\) is strictly greater than \(\lfloor \frac{n+1}{2} \rfloor\) and at most \(n\), **and** where the Hamming weight of \(Mx\), \(w_h(Mx)\), is at most \(\lfloor \frac{n+1}{2} \rfloor\).
### Key Observations
* The text performs a **proof by elimination**. It uses a known upper bound (\(n+1\)) to discard a part of a previous formula that could never achieve the minimum value.
* The final definition of \(\mathcal{B}(M)\) in equation (3) is **partitioned based on the Hamming weight** \(w_h(x)\) of the input vector \(x\). The partition point is \(\lfloor \frac{n+1}{2} \rfloor\).
* The second minimum in equation (3) has an **additional constraint** (\(w_h(Mx) \leq \lfloor \frac{n+1}{2} \rfloor\)) not present in the first minimum. This suggests a symmetry or complementary condition is being exploited.
### Interpretation
This snippet illustrates a common technique in theoretical computer science and coding theory: **simplifying an optimization problem by proving that certain candidate solutions are suboptimal**. The branch number \(\mathcal{B}(M)\) is a critical parameter for evaluating the strength of a linear transformation \(M\) (often a generator matrix for a code), related to its resistance against certain cryptanalytic attacks like linear cryptanalysis.
The derivation shows that to compute \(\mathcal{B}(M)\), one does not need to check all possible input vectors \(x\). Instead, the search can be restricted to two specific, complementary subsets of vectors defined by their Hamming weights. This partitioning likely makes the computation more efficient or analytically tractable. The inequality \(h(M, x) > n+1\) for the discarded case implies that vectors with a certain weight profile produce a sum \(w_h(x) + w_h(Mx)\) that is too large to be the defining minimum, hence they can be ignored. The final equation (3) provides a precise, actionable formula for calculating the branch number under these refined conditions.
</details>
To guide Ax-Prover, an expert user provided the following prompt:
Prompt
You have defined the sets $B,C,D$ with $A=\min\bigl(B,\min(C,D)\bigr)\leq n+1$ . Lets do this by cases: If $\min C>\min D$ and $\min D>n+1$ , then $\min(C,D)>n+1$ , so $\min(B,\min(C,D))=\min(B)$ . The other case is easier.
The Ax-Prover then successfully proved the statement using the provided hint:
Response
VERIFICATION COMPLETE - STEPS: 1. Define the minima: Let $B:=\min\{\,w_{H}(x)+w_{H}(Mx)\mid x\in L\},$ $C:=\min\{\,w_{H}(x)+w_{H}(Mx)\mid x\in H_{1}\},$ $D:=\min\{\,w_{H}(x)+w_{H}(Mx)\mid x\in H_{2}\}.$ where $L=$ low-weight set, $H_{1}=$ high-weight with $w_{H}(Mx)\leq(n+1)/2$ , $H_{2}=$ high-weight with $w_{H}(Mx)>(n+1)/2$ . Then $A:=\mathrm{Branchnumber}(M)=\min(B,\,\min(C,D)).$ 2. Upper bound: For invertible $M$ , $A\leq n+1.$ 3. High–high set bound: If $x\in H_{2}$ , then $w_{H}(x)+w_{H}(Mx)>n+1\quad\Longrightarrow\quad D>n+1.$ 4. Case analysis: •
$C\leq D\quad\Rightarrow\quad\min(C,D)=C\quad\Rightarrow\quad A=\min(B,C).$ •
$C>D\quad\Rightarrow\quad\min(C,D)=D>n+1.$ Since $A=\min(B,D)\leq n+1$ , we get $B\leq n+1$ and thus $A=B=\min(B,C)$ . 5. Conclusion: $A=\min(B,C).$ The term $D$ never affects the branch number.
### F.3 Consolidation: Complete Certificate
Once all steps were verified, they were integrated into a single proof, producing a final file that formally certifies the alternate definition is equivalent to the original, exactly as proposed in the paper.
### F.4 Correctness, Verification, and Takeaways
The outcome of our work was a formally verified certificate ensuring the correctness of Theorem 1. During the course of constructing this certificate, we identified an error in the original proof. Specifically, the issue arises in Step 2 of the proof:
<details>
<summary>ims/error_step.png Details</summary>
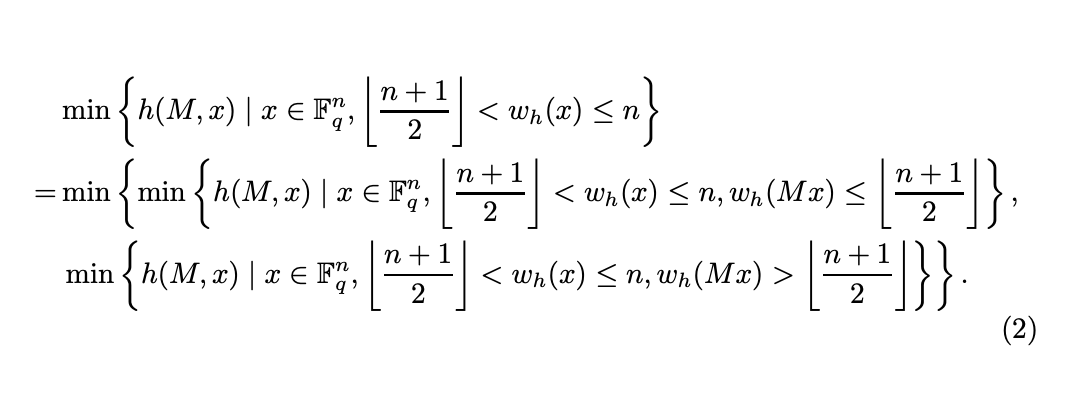
### Visual Description
## Mathematical Equation: Minimization Problem Decomposition
### Overview
The image displays a single, multi-line mathematical equation labeled as equation (2). It presents the decomposition of a minimization problem over a finite field into two distinct cases. The equation is typeset in a standard academic format, likely from a paper in coding theory, cryptography, or algebraic combinatorics.
### Components/Axes
* **Equation Number:** `(2)` is positioned at the bottom-right corner of the equation block.
* **Mathematical Notation:** The equation uses standard mathematical symbols:
* `min`: Minimization operator.
* `{ ... | ... }`: Set-builder notation, meaning "the set of all elements such that...".
* `∈`: "is an element of".
* `F_q^n`: The n-dimensional vector space over the finite field F_q.
* `⌊ ⌋`: Floor function (greatest integer less than or equal to the enclosed value).
* `<`, `≤`, `>`: Inequality operators.
* `h(M, x)`: A function depending on a matrix `M` and a vector `x`.
* `w_h(x)`: A weight function applied to vector `x`.
* `Mx`: Matrix-vector multiplication.
### Detailed Analysis
The equation is structured as follows:
**Line 1 (Left-hand side):**
`min { h(M, x) | x ∈ F_q^n, ⌊(n+1)/2⌋ < w_h(x) ≤ n }`
* **Interpretation:** This defines the primary minimization problem. It seeks the minimum value of the function `h(M, x)` over all vectors `x` in the space `F_q^n` that satisfy a specific weight condition: the weight `w_h(x)` must be strictly greater than the floor of `(n+1)/2` and less than or equal to `n`.
**Line 2 (Right-hand side, decomposed):**
`= min { min { h(M, x) | x ∈ F_q^n, ⌊(n+1)/2⌋ < w_h(x) ≤ n, w_h(Mx) ≤ ⌊(n+1)/2⌋ } ,`
`min { h(M, x) | x ∈ F_q^n, ⌊(n+1)/2⌋ < w_h(x) ≤ n, w_h(Mx) > ⌊(n+1)/2⌋ } } .`
* **Interpretation:** This line shows that the original minimization is equivalent to taking the minimum of two separate, more constrained minimization problems. The original set of vectors `x` is partitioned into two disjoint subsets based on the weight of the transformed vector `Mx`:
1. **First Inner Minimization:** Considers vectors `x` where `w_h(Mx)` is **less than or equal to** `⌊(n+1)/2⌋`.
2. **Second Inner Minimization:** Considers vectors `x` where `w_h(Mx)` is **strictly greater than** `⌊(n+1)/2⌋`.
### Key Observations
1. **Case Splitting:** The core operation is a case analysis based on the value of `w_h(Mx)` relative to the threshold `⌊(n+1)/2⌋`. This threshold is the same one used to define the lower bound for `w_h(x)` in the original problem.
2. **Symmetry in Conditions:** The condition `⌊(n+1)/2⌋ < w_h(x) ≤ n` is common to all three minimization expressions, acting as a global constraint on the input vector `x`.
3. **Structural Insight:** The decomposition suggests that the behavior of the function `h(M, x)` is being studied in relation to how the matrix `M` transforms the weight of the input vector `x`. The two cases likely correspond to fundamentally different algebraic or combinatorial properties.
### Interpretation
This equation represents a **proof technique or algorithmic step** common in theoretical computer science and mathematics. It demonstrates how a complex optimization problem can be broken down into simpler, more manageable sub-problems by introducing a partitioning criterion (here, the weight of `Mx`).
* **What it suggests:** The author is likely analyzing the properties of a code, a cryptographic primitive, or a combinatorial structure defined by the matrix `M` and the weight function `w_h`. The decomposition is a strategic move to handle different scenarios separately, which is often the first step in deriving bounds, proving theorems, or designing algorithms.
* **Relationship between elements:** The matrix `M` acts as a transformation on the vector `x`. The equation links the weight of the original vector `x` to the weight of its image `Mx`, and studies how a cost function `h` behaves under this transformation. The threshold `⌊(n+1)/2⌋` is a critical value, often related to the minimum distance of a code or a balancing point in combinatorial designs.
* **Notable pattern:** The equation is a pure logical statement of equivalence. It contains no numerical data or trends but rather a structural relationship between mathematical sets. The "outlier" or key feature is the explicit partitioning of the search space, which is the central insight the equation conveys.
</details>
Here, the authors fail to ensure that the sets over which they take minima are non-empty. For example, in the simplest case where $M=I$ (the identity matrix), the middle term reduces to
$$
\text{min}\left\{h(M,x)\mid x\in\mathbb{F}_{q}^{n},\left\lfloor\frac{n+1}{2}\right\rfloor<w_{h}(x)\leq n,w_{h}(x)\leq\left\lfloor\frac{n+1}{2}\right\rfloor\right\}.
$$
In this case, the constraints
$$
\left\lfloor\tfrac{n+1}{2}\right\rfloor<w_{h}(x)\quad\text{and}\quad w_{h}(x)\leq\left\lfloor\tfrac{n+1}{2}\right\rfloor
$$
are contradictory, so the underlying set is empty. Nevertheless, the original proof proceeds under the assumption that this minimum is well-defined, a subtle yet significant oversight.
Our formal verification system flagged these issues because it could not establish the truth of the corresponding statements, revealing logical gaps in the proof. Nevertheless, the authors’ final result remains correct despite the error in the proof.
## Appendix G Use Case 2: Quantum Cryptography
In what follows, we expand on Sec. LABEL:sec:QKD by citing the lemma and explaining it in detail. We quote lemma 1 as well as its proof from the supplemental materials in Lo-Chau’s 1999 work in full [lo1998unconditional]: We refer to the arXiv version, where the lemma is stated explicitly.
<details>
<summary>ims/QKD-Lemma1.png Details</summary>

### Visual Description
## Supplementary Note: Mathematical Lemma and Proof
### Overview
The image displays a section of a technical document, specifically "Supplementary Note 2," containing a formal mathematical lemma and its proof. The content is presented in a standard academic typesetting style, likely from a paper in quantum information theory or a related field. The text is entirely in English.
### Components/Axes
The document is structured as follows:
1. **Title:** "Supplementary Note 2:"
2. **Lemma Statement:** "Lemma 1: (High fidelity implies low entropy)" followed by the formal proposition.
3. **Proof:** A paragraph providing the logical derivation for the lemma, concluding with "Q.E.D."
### Detailed Analysis
**Lemma 1: (High fidelity implies low entropy)**
* **Condition:** If the fidelity between a state `ρ` and the state of `R` singlets is greater than `1 - δ`, where `δ` is much less than 1 (`δ ≪ 1`). This is written as: `⟨R singlets|ρ|R singlets⟩ > 1 - δ`.
* **Conclusion:** Then the von Neumann entropy `S(ρ)` is bounded above by the expression: `S(ρ) < -(1 - δ) log₂(1 - δ) - δ log₂(δ / (2^(2R) - 1))`.
**Proof:**
The proof proceeds by logical deduction:
1. **Premise:** Start with the given condition: `⟨R singlets|ρ|R singlets⟩ > 1 - δ`.
2. **Implication for Eigenvalues:** This implies that the largest eigenvalue of the density matrix `ρ` must be greater than `1 - δ`.
3. **Entropy Bound:** Therefore, the entropy of `ρ` is bounded above by the entropy of a specific diagonal density matrix `ρ₀`.
4. **Definition of `ρ₀`:** The matrix `ρ₀` is defined as: `ρ₀ = diag {1 - δ, δ/(2^(2R)-1), δ/(2^(2R)-1), ..., δ/(2^(2R)-1)}`.
5. **Interpretation of `ρ₀`:** This matrix `ρ₀` is diagonal with one large entry `(1 - δ)` and the remaining probability `δ` equally distributed among the other `2^(2R) - 1` possibilities.
### Key Observations
* The lemma establishes a direct, quantitative relationship between a high-fidelity condition (closeness to a specific pure state) and an upper bound on the von Neumann entropy (a measure of mixedness or uncertainty).
* The proof relies on a majorization argument: the state `ρ` is majorized by the constructed state `ρ₀`, and entropy is a Schur-concave function, meaning it respects this ordering.
* The bound becomes very tight for small `δ`. As `δ` approaches 0, the upper bound on entropy also approaches 0, consistent with the intuition that a state very close to a pure state must itself have very low entropy.
### Interpretation
This lemma provides a fundamental tool for analyzing quantum states. It quantifies the intuition that if a quantum system is very likely to be found in a specific, highly ordered configuration (the `R` singlets), then its overall disorder (entropy) must be low.
* **What it demonstrates:** It translates a *fidelity* criterion (a measure of state overlap) into an *entropy* bound (a measure of information content). This is crucial for protocols where maintaining a high-fidelity state is necessary, such as in quantum communication or computation.
* **Relationship between elements:** The condition `⟨R singlets|ρ|R singlets⟩ > 1 - δ` is the input. The proof constructs a "worst-case" mixed state `ρ₀` that satisfies this condition and has the maximum possible entropy. The entropy of any other state `ρ` meeting the condition cannot exceed that of `ρ₀`.
* **Notable implications:** The term `2^(2R)` in the denominator suggests the dimension of the Hilbert space involved scales exponentially with `R`, which is typical for systems of `R` entangled particles (e.g., `R` Bell pairs). The lemma is likely used in a larger argument to show that high-fidelity preparation or transmission of such states is possible only if the entropy is correspondingly low, placing limits on noise or decoherence.
</details>
We now restate it with the appropriate context. Let $\rho$ be a density matrix on a $2^{2R}$ -dimensional Hilbert space. If its fidelity with the ideal $R$ -singlet state satisfies $\langle R\text{~singlets}\mid\rho\mid R\text{~singlets}\rangle>1-\delta$ with $0<\delta\ll 1$ , then
$$
S(\rho)\;<\;-(1-\delta)\log_{2}(1-\delta)\;-\;\delta\log_{2}\!\Bigl(\frac{\delta}{2^{2R}-1}\Bigr).
$$
While this is the form reproduced in this work from the Lo–Chau analysis [lo1998unconditional, lo1999unconditional], here we manually replace the statement $\delta\ll 1$ with $\delta\leq 1-\frac{1}{2^{2R}-1}$ . To justify this step, we reiterate that the notation $\delta\ll 1$ , commonly used in physics, indicates that $\delta$ is smaller than any other relevant quantity in the problem—including the one we construct for our purposes, $1-\frac{1}{2^{2R}-1}$ . This step highlights a central challenge in translating physical statements into rigorous mathematics.
We now restate Lo-Chau’s proof. The fidelity condition implies that the largest eigenvalue of $\rho$ is at least $1-\delta$ . Since von Neumann entropy is Schur-concave, the maximal entropy under this constraint is achieved by the extremal spectrum $\bigl(1-\delta,\tfrac{\delta}{2^{2R}-1},\ldots,\tfrac{\delta}{2^{2R}-1}\bigr)$ , which yields the stated bound.
Our Lean certificate for this result follows this reduction and checks the necessary concavity and normalization facts – producing several reusable and useful lemmas, such as results on majorization and the fact the function $\vec{x}\mapsto\sum_{i}x_{i}\cdot\log x_{i}$ is Schur-convex. This Lean certificate can be made available upon request.
<details>
<summary>ims/Schur-convex.png Details</summary>

### Visual Description
## Formal Proof Code Snippet: Schur Convexity Theorem
### Overview
The image displays a code snippet from a formal verification or theorem-proving environment (likely Lean 4 or a similar system). It shows the definition and the beginning of a proof for a mathematical theorem named `schur_convex_xlogx`. The theorem asserts that a specific function involving the sum of `x * log(x)` is Schur-convex. The snippet includes line numbers, a proof status indicator, and the initial steps of the proof script.
### Components/Axes
* **Line Numbers:** A vertical gutter on the left displays line numbers from 530 to 536.
* **Proof Status Indicator:** A blue checkmark (`✓`) is positioned to the left of line 531, indicating that the theorem or the proof up to that point has been successfully verified.
* **Code Content:** The main area contains the theorem statement and the initial proof tactics. The text uses syntax highlighting with different colors for keywords, types, and variables.
### Detailed Analysis
The following is a precise transcription of the text in the image, line by line:
**Line 530:** (Empty line)
**Line 531:** `theorem schur_convex_xlogx {n : ℕ} :`
**Line 532:** ` SchurConvex (fun x : Fin n → ℝ => ∑ i, x i * Real.log (x i)) := by`
**Line 533:** ` unfold SchurConvex`
**Line 534:** ` intro x y hx_nonneg hy_nonneg h`
**Line 535:** ` obtain ⟨h_majorization, h_sum_eq⟩ := h`
**Line 536:** (Empty line)
**Breakdown of the Code:**
1. **Theorem Declaration (Lines 531-532):**
* `theorem schur_convex_xlogx`: Declares a theorem with the given name.
* `{n : ℕ}`: A universal parameter `n`, a natural number (ℕ).
* `SchurConvex (fun x : Fin n → ℝ => ∑ i, x i * Real.log (x i))`: The proposition being proved. It states that the function mapping a vector `x` (of length `n`, with indices from `Fin n` and real number components ℝ) to the sum (`∑`) of `x i * Real.log (x i)` over all indices `i` is Schur-convex.
* `:= by`: Begins the proof script.
2. **Proof Script (Lines 533-535):**
* `unfold SchurConvex`: The first tactic. It expands the definition of the `SchurConvex` predicate in the goal.
* `intro x y hx_nonneg hy_nonneg h`: Introduces the variables and hypotheses required by the now-unfolded definition. This typically includes two vectors `x` and `y`, hypotheses that their components are non-negative (`hx_nonneg`, `hy_nonneg`), and a hypothesis `h` that `x` is majorized by `y` (or vice-versa, depending on the definition's direction).
* `obtain ⟨h_majorization, h_sum_eq⟩ := h`: Destructures the hypothesis `h` into two separate hypotheses: `h_majorization` (the majorization condition) and `h_sum_eq` (the condition that the sums of the vector components are equal).
### Key Observations
* **Successful Verification:** The blue checkmark on line 531 strongly suggests the theorem has been fully proven and verified by the system.
* **Mathematical Context:** The theorem deals with **Schur-convexity**, a property of functions that preserve the order of vectors under majorization. The specific function `f(x) = Σ xᵢ log(xᵢ)` is a well-known convex function related to entropy.
* **Proof Structure:** The proof begins by unfolding the definition and introducing the standard hypotheses for a Schur-convexity proof: two vectors, non-negativity constraints, and a majorization relation.
* **Syntax:** The code uses standard formal mathematics syntax: `Fin n` for a finite type of size `n`, `ℝ` for real numbers, `∑` for summation, and `Real.log` for the natural logarithm.
### Interpretation
This code snippet captures a formal, machine-checked proof of a non-trivial mathematical fact. The theorem `schur_convex_xlogx` establishes that the function `f(x) = Σ xᵢ log(xᵢ)` is Schur-convex on the domain of non-negative vectors. This result is significant in optimization theory, information theory, and economics, as Schur-convex functions are used to model concepts of inequality, dispersion, and entropy.
The proof script shows the initial, logical steps: reducing the abstract property (`SchurConvex`) to its concrete definition involving vectors and majorization, and then breaking down the majorization hypothesis into its constituent parts (majorization and equal sums). The presence of the checkmark indicates that the subsequent, unseen proof steps successfully leveraged these components to complete the argument, providing a rigorous, computational guarantee of the theorem's truth. This exemplifies the use of interactive theorem provers to formalize and verify complex mathematical reasoning.
</details>
In the Lo–Chau security reduction, the lemma turns “almost-perfect EPR pairs” into a quantitative entropy bound that, together with standard information-theoretic tools, guarantees a limit on an eavesdropper’s knowledge of the final key. Machine-checking this step enables principled composition with other verified components in formal QKD security proofs. Thus, Ax-Prover bridges formal reasoning and quantitative quantum information theory: results such as the Lo–Chau entropy bound no longer have to be taken as a black box, but instead become certified components, ready for use in end-to-end formal verification of QKD security proofs.