# The Mechanistic Emergence of Symbol Grounding in Language Models
**Authors**:
- Freda Shi Joyce Chai (University of Michigan
University of Waterloo
Vector Institute
UNC at Chapel Hill)
Abstract
Symbol grounding (Harnad, 1990) describes how symbols such as words acquire their meanings by connecting to real-world sensorimotor experiences. Recent work has shown preliminary evidence that grounding may emerge in (vision-)language models trained at scale without using explicit grounding objectives. Yet, the specific loci of this emergence and the mechanisms that drive it remain largely unexplored. To address this problem, we introduce a controlled evaluation framework that systematically traces how symbol grounding arises within the internal computations through mechanistic and causal analysis. Our findings show that grounding concentrates in middle-layer computations and is implemented through the aggregate mechanism, where attention heads aggregate the environmental ground to support the prediction of linguistic forms. This phenomenon replicates in multimodal dialogue and across architectures (Transformers and state-space models), but not in unidirectional LSTMs. Our results provide behavioral and mechanistic evidence that symbol grounding can emerge in language models, with practical implications for predicting and potentially controlling the reliability of generation. footnotetext: Authors contributed equally to this work. footnotetext: Advisors contributed equally to this work.
1 Introduction
Symbol grounding (Harnad, 1990) refers to the problem of how abstract and discrete symbols, such as words, acquire meaning by connecting to perceptual or sensorimotor experiences. Extending to the context of multimodal machine learning, grounding has been leveraged as an explicit pre-training objective for vision-language models (VLMs), by explicitly connecting linguistic units to the world that gives language meanings (Li et al., 2022; Ma et al., 2023). Through supervised fine-tuning with grounding signals, such as entity-phrase mappings, modern VLMs have achieved fine-grained understanding at both region (You et al., 2024; Peng et al., 2024; Wang et al., 2024) and pixel (Zhang et al., 2024b; Rasheed et al., 2024; Zhang et al., 2024a) levels.
With the rising of powerful autoregressive language models (LMs; OpenAI, 2024; Anthropic, 2024; Comanici et al., 2025, inter alia) and their VLM extensions, there is growing interest in identifying and interpreting their emergent capabilities. Recent work has shown preliminary correlational evidence that grounding may emerge in LMs (Sabet et al., 2020; Shi et al., 2021; Wu et al., 2025b) and VLMs (Cao et al., 2025; Bousselham et al., 2024; Schnaus et al., 2025) trained at scale, even when solely optimized with the simple next-token prediction objective. However, the potential underlying mechanisms that lead to such an emergence are not well understood. To address this limitation, our work seeks to understand the emergence of symbol grounding in LMs, causally and mechanistically tracing how symbol grounding arises within the internal computations.
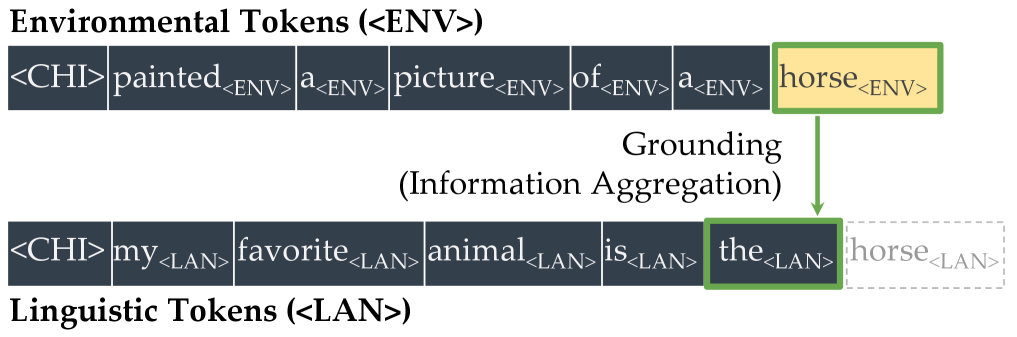
We begin by constructing a minimal testbed, motivated by the annotations provided in the CHILDES corpora (MacWhinney, 2000), where child–caregiver interactions provide cognitively plausible contexts for studying symbol grounding alongside verbal utterances. In our framework, each word is represented in two distinct forms: one token that appears in non-verbal scene descriptions (e.g., a box in the environment) and another that appears in spoken utterances (e.g., box in dialogue). We refer to these as environmental tokens ( $\langle$ ENV $\rangle$ ) and linguistic tokens ( $\langle$ LAN $\rangle$ ), respectively. A deliberately simple word-level tokenizer assigns separate vocabulary entries to each form, ensuring that they are treated as entirely different tokens by the language model. This framework enforces a structural separation between scenes and symbols, preventing correspondences from being reduced to trivial token identity. Under this setup, we can evaluate whether a model trained from scratch is able to predict the linguistic form from its environmental counterpart.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Environmental and Linguistic Token Grounding
### Overview
The image illustrates a grounding process between Environmental Tokens (<ENV>) and Linguistic Tokens (<LAN>). It shows how information from the environmental context is aggregated and mapped to linguistic representations.
### Components/Axes
* **Title (Top):** Environmental Tokens (<ENV>)
* **Title (Bottom):** Linguistic Tokens (<LAN>)
* **Tokens (Top Row):** A sequence of tokens representing the environmental context: "<CHI> painted <ENV> a <ENV> picture <ENV> of <ENV> a <ENV> horse <ENV>". Each token is contained within a dark grey box. The "horse" token is highlighted with a yellow fill and a green border.
* **Tokens (Bottom Row):** A sequence of tokens representing the linguistic context: "<CHI> my <LAN> favorite <LAN> animal <LAN> is <LAN> the <LAN> horse <LAN>". Each token is contained within a dark grey box. The "the" token is highlighted with a green border. The "horse" token is greyed out with a dashed border.
* **Grounding Arrow:** A green arrow pointing from the "horse <ENV>" token in the top row to the "the <LAN>" token in the bottom row.
* **Grounding Label:** "Grounding (Information Aggregation)" positioned above the green arrow.
### Detailed Analysis or ### Content Details
* **Environmental Tokens:**
* `<CHI>`: Initial token.
* `painted <ENV>`: Token "painted" with the environmental tag.
* `a <ENV>`: Token "a" with the environmental tag.
* `picture <ENV>`: Token "picture" with the environmental tag.
* `of <ENV>`: Token "of" with the environmental tag.
* `a <ENV>`: Token "a" with the environmental tag.
* `horse <ENV>`: Token "horse" with the environmental tag, highlighted in yellow with a green border.
* **Linguistic Tokens:**
* `<CHI>`: Initial token.
* `my <LAN>`: Token "my" with the linguistic tag.
* `favorite <LAN>`: Token "favorite" with the linguistic tag.
* `animal <LAN>`: Token "animal" with the linguistic tag.
* `is <LAN>`: Token "is" with the linguistic tag.
* `the <LAN>`: Token "the" with the linguistic tag, highlighted with a green border.
* `horse <LAN>`: Token "horse" with the linguistic tag, greyed out with a dashed border.
* **Grounding Process:** The green arrow indicates a mapping or connection between the environmental token "horse" and the linguistic token "the". This suggests that the linguistic token "the" is grounded in the environmental context of "horse".
### Key Observations
* The diagram illustrates a grounding process where environmental information is linked to linguistic representations.
* The "horse" token in the environmental context is directly linked to the "the" token in the linguistic context.
* The final "horse" token in the linguistic context is greyed out, suggesting it might be a subsequent or predicted token.
### Interpretation
The diagram demonstrates a simplified model of how environmental context can influence and ground linguistic understanding. The "Grounding (Information Aggregation)" label suggests that the process involves aggregating information from the environment to inform the linguistic representation. The connection between the environmental "horse" and the linguistic "the" implies that the presence of a horse in the environment influences the use of the definite article "the" in the linguistic description. The greyed-out "horse" token at the end of the linguistic sequence could represent a prediction or expectation based on the preceding tokens and the environmental context.
</details>
(a) Attention head 8 of layer 7 in GPT-CHILDES.
<details>
<summary>x2.png Details</summary>

### Visual Description
## Diagram: Environmental and Linguistic Token Grounding
### Overview
The image illustrates a concept of grounding between environmental tokens (visual information) and linguistic tokens (textual information). It shows an image of an alpaca in a desert-like environment, which is linked to a sequence of text tokens representing a question, and a potential answer.
### Components/Axes
* **Title:** Environmental Tokens (<ENV>)
* **Image:** A photograph of an alpaca standing in a desert-like environment with a fence and a Joshua tree in the background. The alpaca has red markings on its body.
* **Grounding:** The text "Grounding (Information Aggregation)" indicates the process of linking the visual and textual information.
* **Linguistic Tokens:** A sequence of text tokens presented in dark gray boxes: "what", "would", "you", "name", "this", "?".
* **Proposed Answer:** The word "alpaca" is shown in light gray, enclosed in a dashed box, suggesting a potential answer to the question.
* **Title:** Linguistic Tokens (<LAN>)
* **Arrow:** A green arrow originates from a yellow square on the alpaca's body in the image and points to a green square around the question mark token.
### Detailed Analysis
* The image of the alpaca represents the environmental context. The red markings on the alpaca are not explained.
* The question "what would you name this?" represents the linguistic context.
* The green arrow visually connects the alpaca in the image to the question, suggesting that the question is about the alpaca.
* The proposed answer "alpaca" is a direct response to the question, indicating a successful grounding of the environmental and linguistic tokens.
### Key Observations
* The diagram highlights the process of linking visual information (the alpaca) with textual information (the question and answer).
* The arrow visually represents the grounding process, connecting the environmental token (alpaca) to the linguistic token (question).
* The proposed answer demonstrates a successful grounding, where the linguistic token accurately describes the environmental token.
### Interpretation
The diagram illustrates a simplified model of how environmental and linguistic information can be linked together. The "Grounding (Information Aggregation)" process suggests that the system is aggregating information from both the visual and textual domains to arrive at a coherent understanding. The diagram demonstrates a basic form of visual question answering, where the system can identify the object in the image (alpaca) and answer a question about it. The red markings on the alpaca are not explained and could represent areas of interest or focus for the system. The dashed box around "alpaca" suggests that it is a predicted or suggested answer, rather than a confirmed one.
</details>
(b) Attention head 7 of layer 20 in LLaVA-1.5-7B.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Heatmap: Attention Visualization of a Transformer Model
### Overview
The image presents a visualization of attention weights in a transformer model. It consists of two main parts: a grid of heatmaps representing attention patterns across different layers and heads, and a detailed heatmap showing the attention weights for a specific layer and head with respect to an input sentence.
### Components/Axes
* **Left Grid:**
* X-axis: "head", labeled from 1 to 12.
* Y-axis: "layer", labeled from 1 to 12.
* Each cell in the grid is a heatmap representing the attention pattern of a specific layer and head.
* **Right Heatmap:**
* X-axis: Input sentence: "<CHI> painted a picture of a horse <CHI> my favorite animal is the". The sentence is grouped into spans labeled "<ENV>" and "<LAN>".
* Y-axis: Input sentence: "<CHI> painted a picture of a horse <CHI> my favorite animal is the". The sentence is grouped into spans labeled "<ENV>" and "<LAN>".
* **Colorbar (Saliency):**
* Located on the right side of the right heatmap.
* Ranges from 0.0 (dark purple) to 0.3 (yellow).
* Indicates the attention weight or "saliency" of each cell in the heatmap.
### Detailed Analysis
* **Left Grid:**
* Each small heatmap in the grid shows the attention distribution for a specific layer (1-12) and head (1-12).
* The intensity of the color (ranging from dark purple to yellow) indicates the strength of attention.
* The heatmap at layer 8, head 8 is highlighted with a yellow border, indicating it is the focus of the detailed heatmap on the right.
* **Right Heatmap:**
* The right heatmap visualizes the attention weights between words in the input sentence for layer 8, head 8.
* The sentence is: "<CHI> painted a picture of a horse <CHI> my favorite animal is the".
* The heatmap shows which words the model is attending to when processing each word in the sentence.
* For example, the word "is" has a high attention weight (yellow) to the word "<CHI>" in the same sentence.
* Most of the heatmap is dark purple, indicating low attention weights.
* There are some lighter purple/yellow spots, indicating higher attention weights between specific words.
### Key Observations
* The attention patterns vary across different layers and heads, as seen in the left grid.
* The detailed heatmap shows that the model attends to specific words when processing the input sentence.
* The attention weights are not uniform, indicating that the model focuses on certain relationships between words.
* The word "is" has a high attention weight to the word "<CHI>".
### Interpretation
The visualization provides insights into how a transformer model processes language. The attention mechanism allows the model to focus on relevant parts of the input when making predictions. The heatmap shows that the model learns to attend to specific relationships between words, which is crucial for understanding the meaning of the sentence. The highlighted layer and head (layer 8, head 8) show a specific example of how the model attends to different words in the sentence. The fact that "is" attends to "<CHI>" suggests that the model is relating the subject of the sentence to its properties or context. The overall sparsity of the heatmap suggests that the model is selective in its attention, focusing on the most important relationships between words.
</details>
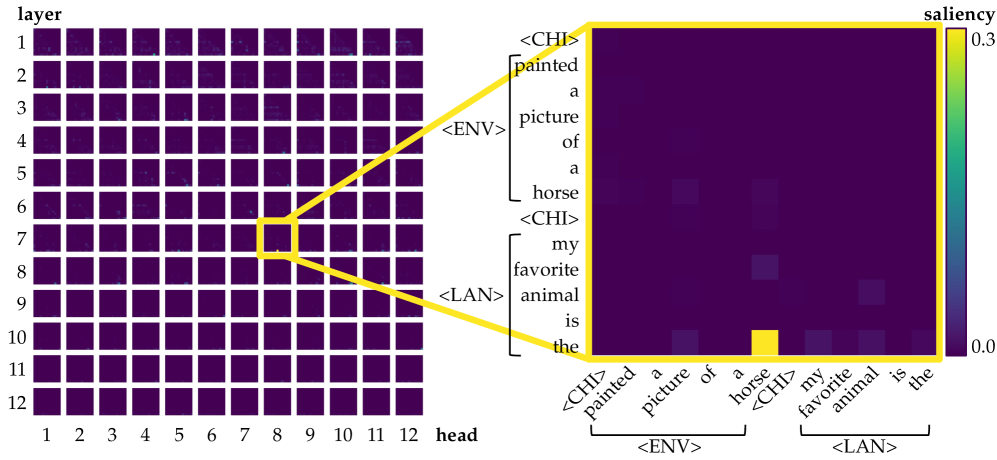
(c) Left: saliency over tokens of each head in each layer for the prompt $\langle$ CHI $\rangle$ $\textit{painted}_{\texttt{$\langle$ENV$\rangle$}}$ $\textit{a}_{\texttt{$\langle$ENV$\rangle$}}$ $\textit{picture}_{\texttt{$\langle$ENV$\rangle$}}$ $\textit{of}_{\texttt{$\langle$ENV$\rangle$}}$ $\textit{a}_{\texttt{$\langle$ENV$\rangle$}}$ $\textit{horse}_{\texttt{$\langle$ENV$\rangle$}}$ $\langle$ CHI $\rangle$ $\textit{my}_{\texttt{$\langle$LAN$\rangle$}}$ $\textit{favorite}_{\texttt{$\langle$LAN$\rangle$}}$ $\textit{animal}_{\texttt{$\langle$LAN$\rangle$}}$ $\textit{is}_{\texttt{$\langle$LAN$\rangle$}}$ $\textit{the}_{\texttt{$\langle$LAN$\rangle$}}$ . Right: among all, only one of them (head 8 of layer 7) is identified as an aggregate head, where information flows from $\textit{horse}_{\texttt{$\langle$ENV$\rangle$}}$ to the current position, encouraging the model to predict $\textit{horse}_{\texttt{$\langle$LAN$\rangle$}}$ as the next token.
Figure 1: Illustration of the symbol grounding mechanism through information aggregation. Lighter colors denote more salient attention, quantified by saliency scores, i.e., gradient $×$ attention contributions to the loss (Wang et al., 2023). When predicting the next token, aggregate heads (Bick et al., 2025) emerge to exclusively link environmental tokens (visual or situational context; $\langle$ ENV $\rangle$ ) to linguistic tokens (words in text; $\langle$ LAN $\rangle$ ). These heads provide a mechanistic pathway for symbol grounding by mapping external environmental evidence into its linguistic form.
We quantify the level of grounding using surprisal: specifically, we compare how easily the model predicts a linguistic token ( $\langle$ LAN $\rangle$ ) when its matching environmental token ( $\langle$ ENV $\rangle$ ) is present versus when unrelated cues are given instead. A lower surprisal in the former condition indicates that the model has learned to align environmental grounds with linguistic forms. We find that LMs do learn to ground: the presence of environmental tokens consistently reduces surprisal for their linguistic counterparts, in a way that simple co-occurrence statistics cannot fully explain. To study the underlying mechanisms, we apply saliency analysis (Wang et al., 2023) and the tuned lens (Belrose et al., 2023), which converge on the result that grounding relations are concentrated in the middle layers of the network. Further analysis of attention heads reveals patterns consistent with the aggregate mechanism (Bick et al., 2025), where attention heads support the prediction of linguistic forms by retrieving their environmental grounds in the context.
Finally, we demonstrate that these findings generalize beyond the minimal CHILDES data and Transformer models. They appear in a multimodal setting with the Visual Dialog dataset (Das et al., 2017), and in state-space models (SSMs) such as Mamba-2 (Dao & Gu, 2024). In contrast, we do not observe grounding in unidirectional LSTMs, consistently with their sequential state compression and lack of content-addressable retrieval. Taken together, our results show that symbol grounding can mechanistically emerge in autoregressive LMs, while also delineating the architectural conditions under which it can arise.
2 Related Work
2.1 Language Grounding
Referential grounding has long been framed as the lexicon acquisition problem: how words map to referents in the world (Harnad, 1990; Gleitman & Landau, 1994; Clark, 1995). Early work focused on word-to-symbol mappings, designing learning mechanisms that simulate children’s lexical acquisition and explain psycholinguistic phenomena (Siskind, 1996; Regier, 2005; Goodman et al., 2007; Fazly et al., 2010). Subsequent studies incorporated visual grounding, first by aligning words with object categories (Roy & Pentland, 2002; Yu, 2005; Xu & Tenenbaum, 2007; Yu & Ballard, 2007; Yu & Siskind, 2013), and later by mapping words to richer visual features (Qu & Chai, 2010; Mao et al., 2019; 2021; Pratt et al., 2020). More recently, large-scale VLMs trained with paired text–image supervision have advanced grounding to finer levels of granularity, achieving region-level (Li et al., 2022; Ma et al., 2023; Chen et al., 2023; You et al., 2024; Wang et al., 2024) and pixel-level (Xia et al., 2024; Rasheed et al., 2024; Zhang et al., 2024b) grounding, with strong performance on referring expression comprehension (Chen et al., 2024a).
Recent work suggests that grounding emerges as a property of VLMs trained without explicit supervision, with evidence drawn from attention-based spatial localization (Cao et al., 2025; Bousselham et al., 2024) and cross-modal geometric correspondences (Schnaus et al., 2025). However, all prior work focused exclusively on static final-stage models, overlooking the training trajectory, a crucial aspect for understanding when and how grounding emerges. In addition, existing work has framed grounding through correlations between visual and textual signals, diverging from the definition by Harnad (1990), which emphasizes causal links from symbols to meanings. To address these issues, we systematically examine learning dynamics throughout the training process, applying causal interventions to probe model internals and introducing control groups to enable rigorous comparison.
2.2 Emergent Capabilities and Learning Dynamics of LMs
A central debate concerns whether larger language models exhibit genuinely new behaviors: Wei et al. (2022) highlight abrupt improvements in tasks, whereas later studies argue such effects are artifacts of thresholds or in-context learning dynamics (Schaeffer et al., 2023; Lu et al., 2024). Beyond end performance, developmental analyses show that models acquire linguistic abilities in systematic though heterogeneous orders with variability across runs and checkpoints (Sellam et al., 2021; Blevins et al., 2022; Biderman et al., 2023; Xia et al., 2023; van der Wal et al., 2025). Psychology-inspired perspectives further emphasize controlled experimentation to assess these behaviors (Hagendorff, 2023), and comparative studies reveal both parallels and divergences between machine and human language learning (Chang & Bergen, 2022; Evanson et al., 2023; Chang et al., 2024; Ma et al., 2025). At a finer granularity, hidden-loss analyses identify phase-like transitions (Kangaslahti et al., 2025), while distributional studies attribute emergence to stochastic differences across training seeds (Zhao et al., 2024). Together, emergent abilities are not sharp discontinuities but probabilistic outcomes of developmental learning dynamics. Following this line of work, we present a probability- and model internals–based analysis of how symbol grounding emerges during language model training.
2.3 Mechanistic Interpretability of LMs
Mechanistic interpretability has largely focused on attention heads in Transformers (Elhage et al., 2021; Olsson et al., 2022; Meng et al., 2022; Bietti et al., 2023; Lieberum et al., 2023; Wu et al., 2025a). A central line of work established that induction heads emerge to support in-context learning (ICL; Elhage et al., 2021; Olsson et al., 2022), with follow-up studies tracing their training dynamics (Bietti et al., 2023) and mapping factual recall circuits (Meng et al., 2022). At larger scales, Lieberum et al. (2023) identified specialized content-gatherer and correct-letter heads, and Wu et al. (2025a) showed that a sparse set of retrieval heads is critical for reasoning and long-context performance. Relatedly, Wang et al. (2023) demonstrated that label words in demonstrations act as anchors: early layers gather semantic information into these tokens, which later guide prediction. Based on these insights, Bick et al. (2025) proposed that retrieval is implemented through a coordinated gather-and-aggregate (G&A) mechanism: some heads collect content from relevant tokens, while others aggregate it at the prediction position. Other studies extended this line of work by analyzing failure modes and training dynamics (Wiegreffe et al., 2025) and contrasting retrieval mechanisms in Transformers and SSMs (Arora et al., 2025). Whereas prior analyses typically investigate ICL with repeated syntactic or symbolic formats, our setup requires referential alignment between linguistic forms and their environmental contexts, providing a complementary testbed for naturalistic language grounding.
3 Method
Table 1: Training and test examples across datasets with target word book. The training examples combine environmental tokens ( $\langle$ ENV $\rangle$ ; shaded) with linguistic tokens ( $\langle$ LAN $\rangle$ ). Test examples are constructed with either matched (book) or mismatched (toy) environmental contexts, paired with corresponding linguistic prompts. Note that in child-directed speech and caption-grounded dialogue, book ${}_{\texttt{$\langle$ENV$\rangle$}}$ and book ${}_{\texttt{$\langle$LAN$\rangle$}}$ are two distinct tokens received by LMs.
| Child-Directed Speech | \cellcolor tticblue!10 $\langle$ CHI $\rangle$ takes book from mother | $\langle$ CHI $\rangle$ what’s that $\langle$ MOT $\rangle$ a book in it … | \cellcolor tticblue!10 $\langle$ CHI $\rangle$ asked for a new book | \cellcolor tticblue!10 $\langle$ CHI $\rangle$ asked for a new toy | $\langle$ CHI $\rangle$ I love this |
| --- | --- | --- | --- | --- | --- |
| Caption-Grounded Dialogue | \cellcolor tticblue!10 a dog appears to be reading a book with a full bookshelf behind | $\langle$ Q $\rangle$ can you tell what book it’s reading $\langle$ A $\rangle$ the marriage of true minds by stephen evans | \cellcolor tticblue!10 this is a book | \cellcolor tticblue!10 this is a toy | $\langle$ Q $\rangle$ can you name this object $\langle$ A $\rangle$ |
| Image-Grounded Dialogue | \cellcolor tticblue!10
<details>
<summary>figs/data/book-train.jpg Details</summary>

### Visual Description
## Book Cover and Dog Photo
### Overview
The image is a photograph featuring a dog lying next to a book titled "The Marriage of True Minds" by Stephen Evans. The background includes bookshelves filled with books.
### Components/Axes
* **Book Cover:** The book cover is predominantly yellow with the title "The Marriage of True Minds" in a large font. Below the title is the subtitle "a novel" and an illustration of a top hat with feathers. The author's name, "Stephen Evans," is at the bottom. A quote at the top reads: "A funny, poignant, oddly beautiful book." - Kirkus Reviews.
* **Dog:** A medium-sized dog with black and white fur is lying next to the book.
* **Bookshelves:** Two bookshelves are visible in the background, filled with various books. The spines of some books are visible, revealing titles such as "JOY ADAMSON'S AFRICA", "MIND IN THE WATERS", "Animals are", "Wild Animals", "Sunset Coast", "EARTH", "Animals you will never", "THE BOND", "ANIMAL RIGHTS/The Issues/The Movement", "BEARS", "SANDRIVERS", "ALMOST HUMAN", "THE SPOTTED SP", "WILDCATS & WORLD", "WILD BEARS WORLD".
### Detailed Analysis or ### Content Details
* **Book Title:** "The Marriage of True Minds"
* **Author:** Stephen Evans
* **Quote:** "A funny, poignant, oddly beautiful book." - Kirkus Reviews
* **Background Books (Partial List):**
* JOY ADAMSON'S AFRICA
* MIND IN THE WATERS
* Animals are
* Wild Animals
* Sunset Coast
* EARTH
* Animals you will never
* THE BOND
* ANIMAL RIGHTS/The Issues/The Movement
* BEARS
* SANDRIVERS
* ALMOST HUMAN
* THE SPOTTED SP
* WILDCATS & WORLD
* WILD BEARS WORLD
### Key Observations
* The dog appears to be resting or posing next to the book.
* The book's title and cover design are prominently displayed.
* The background bookshelves suggest a literary or academic setting.
### Interpretation
The image seems to be a staged photograph, possibly for promotional purposes or personal enjoyment. The placement of the book and the dog's pose suggest a connection between the two, perhaps implying that the dog is "reading" or endorsing the book. The presence of numerous books in the background reinforces the theme of literature and reading. The quote on the book cover provides a positive review, further promoting the book.
</details>
| $\langle$ Q $\rangle$ can you tell what book it’s reading $\langle$ A $\rangle$ the marriage of true minds by stephen evans | \cellcolor tticblue!10
<details>
<summary>figs/data/book-test.jpg Details</summary>

### Visual Description
## Photograph: Bookshelf
### Overview
The image is a photograph of a large, dark wood bookshelf filled with books and various decorative items. The bookshelf is divided into multiple sections, each with shelves of varying heights. The wall behind the bookshelf is painted a light yellow color. A model ship sits atop the bookshelf.
### Components/Axes
* **Bookshelf:** The bookshelf is the main component, constructed of dark wood with a lighter wood panel in the center of the upper cabinets. It consists of multiple vertical sections.
* **Books:** The shelves are filled with books of various sizes, colors, and orientations.
* **Decorative Items:** Various decorative items are placed on the shelves, including picture frames, figurines, and a small clock.
* **Model Ship:** A model ship is placed on top of the bookshelf.
* **Wall:** The wall behind the bookshelf is painted a light yellow color.
### Detailed Analysis or Content Details
* **Bookshelf Structure:** The bookshelf appears to be composed of five vertical sections. Each section has two shelves at the top, followed by a cabinet, then two more shelves, and finally a drawer at the bottom. The top cabinets have a lighter wood panel in the center, surrounded by a darker wood frame.
* **Book Arrangement:** The books are arranged in a seemingly random order, with some standing upright, others leaning, and some stacked horizontally. The colors of the book spines vary widely.
* **Decorative Items:**
* There are several picture frames on the shelves, some containing photographs of people.
* A small orange clock is visible on the bottom shelf of the leftmost section.
* There are several figurines, including what appears to be a small elephant and a couple of human figures.
* A toy car is visible on the bottom shelf of the third section from the left.
* **Model Ship:** The model ship on top of the bookshelf is a sailing ship with multiple masts and sails.
* **Wall Color:** The wall behind the bookshelf is a light yellow color.
### Key Observations
* The bookshelf is well-stocked with books and decorative items, suggesting that it is actively used.
* The arrangement of the books and items is somewhat cluttered, giving the bookshelf a lived-in appearance.
* The model ship on top of the bookshelf adds a touch of nautical flair to the scene.
### Interpretation
The photograph depicts a personal library or study. The presence of numerous books suggests a love of reading and learning. The decorative items add a personal touch and reflect the owner's interests and memories. The overall impression is one of a comfortable and inviting space. The bookshelf serves as both a functional storage unit and a display case for cherished possessions. The model ship could represent a hobby or a connection to maritime history. The photograph captures a moment in time and provides a glimpse into the owner's personality and lifestyle.
</details>
| \cellcolor tticblue!10
<details>
<summary>figs/data/book-test-control.jpg Details</summary>

### Visual Description
## Photograph: Antique Cabinet with Aquariums
### Overview
The image shows a large, antique cabinet with multiple sections. Three of the sections appear to house aquariums. The cabinet is made of dark wood with lighter wood panels. A model ship sits atop the right side of the cabinet.
### Components/Axes
* **Cabinet:** Dark wood frame with lighter wood panels. The cabinet is divided into multiple sections.
* **Aquariums:** Three sections appear to contain aquariums. The contents of the aquariums are partially visible.
* **Model Ship:** A model ship is placed on top of the right side of the cabinet.
* **Background:** The wall behind the cabinet is a light yellow color.
### Detailed Analysis or ### Content Details
* **Cabinet Structure:** The cabinet has a modular design, with multiple identical sections arranged side-by-side. Each section has upper cabinets, a central aquarium area, and lower cabinets.
* **Aquarium Contents:** The aquariums contain various items, including plants, rocks, and possibly fish. The visibility is limited due to reflections on the glass.
* **Model Ship Details:** The model ship appears to be a sailing vessel with multiple masts and sails.
* **Lighting:** The lighting in the room is somewhat dim, which affects the visibility of the cabinet's details.
### Key Observations
* The cabinet is an antique piece of furniture, likely custom-made.
* The aquariums add a unique and decorative element to the cabinet.
* The model ship complements the antique aesthetic of the cabinet.
### Interpretation
The image showcases a unique piece of furniture that combines storage with decorative aquariums. The antique style and the presence of the model ship suggest a theme of history and craftsmanship. The aquariums likely serve as a focal point in the room, adding a touch of nature and tranquility. The overall impression is one of elegance and sophistication.
</details>
| what do we have here? |
3.1 Dataset and Tokenization
To capture the emergent grounding from multimodal interactions, we design a minimal testbed with a custom word-level tokenizer, in which every lexical item is represented in two corresponding forms: one token that appears in non-verbal descriptions (e.g., a book in the scene description) and another that appears in utterances (e.g., book in speech). We refer to these by environmental ( $\langle$ ENV $\rangle$ ) and linguistic tokens ( $\langle$ LAN $\rangle$ ), respectively. For instance, book ${}_{\texttt{$\langle$ENV$\rangle$}}$ and book ${}_{\texttt{$\langle$LAN$\rangle$}}$ are treated as distinct tokens with separate integer indices; that is, the tokenization provides no explicit signal that these tokens are related, so any correspondence between them must be learned during training rather than inherited from their surface form. We instantiate this framework in three datasets, ranging from child-directed speech transcripts to image-based dialogue.
Child-directed speech. The Child Language Data Exchange System (CHILDES; MacWhinney, 2000) provides transcripts of speech enriched with environmental annotations. See the manual for data usage: https://talkbank.org/0info/manuals/CHAT.pdf We use the spoken utterances as the linguistic tokens ( $\langle$ LAN $\rangle$ ) and the environmental descriptions as the environment tokens ( $\langle$ ENV $\rangle$ ). The environmental context is drawn from three annotation types:
- Local events: simple events, pauses, long events, or remarks interleaved with the transcripts.
- Action tiers: actions performed by the speaker or listener (e.g., %act: runs to toy box). These also include cases where an action replaces speech (e.g., 0 [% kicks the ball]).
- Situational tiers: situational information tied to utterances or to larger contexts (e.g., %sit: dog is barking).
Caption-grounded dialogue. The Visual Dialog dataset (Das et al., 2017) pairs MSCOCO images (Lin et al., 2014) with sequential question-answering based multi-turn dialogues that exchange information about each image. Our setup uses MSCOCO captions as the environmental tokens ( $\langle$ ENV $\rangle$ ) and the dialogue turns form the linguistic tokens ( $\langle$ LAN $\rangle$ ). In this pseudo cross-modal setting, textual descriptions of visual scenes ground natural conversational interaction. Compared to CHILDES, this setup introduces richer semantics and longer utterances, while still using text-based inputs for both token types, thereby offering a stepping stone toward grounding in fully visual contexts.
Image-grounded dialogue. To move beyond textual proxies, we consider an image-grounded dialogue setup, using the same dataset as the caption-grounded dialogue setting. Here, a frozen vision transformer (ViT; Dosovitskiy et al., 2020) directly tokenizes each RGB image into patch embeddings, with each embedding treated as an $\langle$ ENV $\rangle$ token, analogously to the visual tokens in modern VLMs. We use DINOv2 (Oquab et al., 2024) as our ViT tokenizer, as it is trained purely on vision data without auxiliary text supervision (in contrast to models like CLIP; Radford et al., 2021), thereby ensuring that environmental tokens capture only visual information. The linguistic tokens ( $\langle$ LAN $\rangle$ ) remain unchanged from the caption-grounded dialogue setting, resulting in a realistic multimodal interaction where conversational utterances are grounded directly in visual input.
3.2 Evaluation Protocol
We assess symbol grounding with a contrastive test that asks whether a model assigns a higher probability to the correct linguistic token when the matching environmental token is in context, following the idea of priming in psychology. This evaluation applies uniformly across datasets (Table 1): in CHILDES and caption-grounded dialogue, environmental priming comes from descriptive contexts; in image-grounded dialogue, from ViT-derived visual tokens. We compare the following conditions:
- Match (experimental condition): The context contains the corresponding $\langle$ ENV $\rangle$ token for the target word, and the model is expected to predict its $\langle$ LAN $\rangle$ counterpart.
- Mismatch (control condition): The context is replaced with a different $\langle$ ENV $\rangle$ token. The model remains tasked with predicting the same $\langle$ LAN $\rangle$ token; however, in the absence of corresponding environmental cues, its performance is expected to be no better than chance.
For example (first row in Table 1), when evaluating the word $\textit{book}_{\texttt{$\langle$LAN$\rangle$}}$ , the input context is
$$
\displaystyle\vskip-2.0pt\langle\textit{CHI}\rangle\textit{ asked}_{\texttt{$\langle$ENV$\rangle$}}\textit{ for}_{\texttt{$\langle$ENV$\rangle$}}\textit{ a}_{\texttt{$\langle$ENV$\rangle$}}\textit{ new}_{\texttt{$\langle$ENV$\rangle$}}\textit{ book}_{\texttt{$\langle$ENV$\rangle$}}\textit{ }\langle\textit{CHI}\rangle\textit{ I}_{\texttt{$\langle$LAN$\rangle$}}\textit{ love}_{\texttt{$\langle$LAN$\rangle$}}\textit{ this}_{\texttt{$\langle$LAN$\rangle$}}\textit{ }\underline{\hskip 30.00005pt},\vskip-2.0pt \tag{1}
$$
where the model is expected to predict $\textit{book}_{\texttt{$\langle$LAN$\rangle$}}$ for the blank, and the role token $\langle$ CHI $\rangle$ indicates the involved speaker or actor’s role being a child. In the control (mismatch) condition, the environmental token box ${}_{\texttt{$\langle$ENV$\rangle$}}$ is replaced by another valid noun such as toy ${}_{\texttt{$\langle$ENV$\rangle$}}$ .
Context templates. For a target word $v$ with linguistic token $v_{\texttt{$\langle$LAN$\rangle$}}$ and environmental token $v_{\texttt{$\langle$ENV$\rangle$}}$ , we denote $\overline{C}_{v}$ as a set of context templates of $v$ . For example, when $v=\textit{book}$ , a $\overline{c}∈\overline{C}_{v}$ can be
$$
\displaystyle\vskip-2.0pt\langle\textit{CHI}\rangle\textit{ asked}_{\texttt{$\langle$ENV$\rangle$}}\textit{ for}_{\texttt{$\langle$ENV$\rangle$}}\textit{ a}_{\texttt{$\langle$ENV$\rangle$}}\textit{ new}_{\texttt{$\langle$ENV$\rangle$}}\textit{ }\texttt{[FILLER]}\textit{ }\langle\textit{CHI}\rangle\textit{ I}_{\texttt{$\langle$LAN$\rangle$}}\textit{ love}_{\texttt{$\langle$LAN$\rangle$}}\underline{\hskip 30.00005pt},\vskip-2.0pt \tag{2}
$$
where [FILLER] is to be replaced with an environmental token, and the blank indicates the expected prediction as in Eq. (1). In the match condition, the context $\overline{c}(v)$ is constructed by replacing [FILLER] with $v_{\texttt{$\langle$ENV$\rangle$}}$ in $\overline{c}$ . In the mismatch condition, the context $\overline{c}(u)$ uses $u_{\texttt{$\langle$ENV$\rangle$}}(u≠ v)$ as the filler, while the prediction target remains $v_{\texttt{$\langle$LAN$\rangle$}}$ .
For the choices of $v$ and $u$ , we construct the vocabulary $V$ with 100 nouns from the MacArthur–Bates Communicative Development Inventories (Fenson et al., 2006) that occur frequently in our corpus. Each word serves once as the target, with the remaining $M=99$ used to construct mismatched conditions. For each word, we create $N=10$ context templates, which contain both $\langle$ ENV $\rangle$ and $\langle$ LAN $\rangle$ tokens. Details of the vocabulary and context template construction can be found in the Appendix A.
Grounding information gain. Following prior work, we evaluate how well an LM learns a word using the mean surprisal over instances. The surprisal of a word $w$ given a context $c$ is defined as $s_{\boldsymbol{\theta}}(w\mid c)=-\log P_{\boldsymbol{\theta}}(w\mid c),$ where $P_{\boldsymbol{\theta}}(w\mid c)$ denotes the probability, under an LM parameterized by ${\boldsymbol{\theta}}$ , that the next word is $w$ conditioned on the context $c$ . Here, $s_{\boldsymbol{\theta}}(w\mid c)$ quantifies the unexpectedness of predicting $w$ , or the pointwise information carried by $w$ conditioned on the context.
The grounding information gain $G_{\boldsymbol{\theta}}(v)$ for $v$ is defined as
| | $\displaystyle G_{\boldsymbol{\theta}}(v)=\frac{1}{N}\sum_{n=1}^{N}\left(\frac{1}{M}\sum_{u≠ v}^{M}\Big[s_{\boldsymbol{\theta}}\left(v_{\texttt{$\langle$LAN$\rangle$}}\mid\overline{c}_{n}\left(u_{\texttt{$\langle$ENV$\rangle$}}\right)\right)-s_{\boldsymbol{\theta}}\left(v_{\texttt{$\langle$LAN$\rangle$}}\mid\overline{c}_{n}\left(v_{\texttt{$\langle$ENV$\rangle$}}\right)\right)\Big]\right).$ | |
| --- | --- | --- |
This is a sample-based estimation of the expected log-likelihood ratio between the match and mismatch conditions
| | $\displaystyle G_{\boldsymbol{\theta}}(v)=\mathbb{E}_{c,u}\left[\log\frac{P_{\boldsymbol{\theta}}(v_{\texttt{$\langle$LAN$\rangle$}}\mid c,v_{\texttt{$\langle$ENV$\rangle$}})}{P_{\boldsymbol{\theta}}(v_{\texttt{$\langle$LAN$\rangle$}}\mid c,u_{\texttt{$\langle$ENV$\rangle$}})}\right],$ | |
| --- | --- | --- |
which quantifies how much more information the matched ground provides for predicting the linguistic form, compared to a mismatched one. A positive $G_{\boldsymbol{\theta}}(v)$ indicates that the matched environmental token increases the predictability of its linguistic form. We report $G_{\boldsymbol{\theta}}=\frac{1}{|V|}\sum_{v∈ V}G_{\boldsymbol{\theta}}(v)$ , and track $G_{{\boldsymbol{\theta}}^{(t)}}$ across training steps $t$ to analyze how grounding emerges over time.
3.3 Model Training
We train LMs from random initialization, ensuring that no prior linguistic knowledge influences the results. Our training uses the standard causal language modeling objective, as in most generative LMs. To account for variability, we repeat all experiments with 5 random seeds, randomizing both model initialization and corpus shuffle order. Our primary architecture is Transformer (Vaswani et al., 2017) in the style of GPT-2 (Radford et al., 2019) with 18, 12, and 4 layers, with all of them having residual connections. We extend the experiments to 4-layer unidirectional LSTMs (Hochreiter & Schmidhuber, 1997) with no residual connections, as well as 12- and 4-layer state-space models (specifically, Mamba-2; Dao & Gu, 2024). For fair comparison with LSTMs, the 4-layer Mamba-2 models do not involve residual connections, whereas the 12-layer ones do. For multimodal settings, while standard LLaVA (Liu et al., 2023) uses a two-layer perceptron to project ViT embeddings into the language model, we bypass this projection in our case and directly feed the DINOv2 representations into the LM. We obtain the developmental trajectory of the model by saving checkpoints at various training steps, sampling more heavily from earlier steps, following Chang & Bergen (2022).
4 Behavioral Evidence
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Chart: Surprisal vs. Training Steps
### Overview
The image is a line chart comparing the surprisal values for "Match" and "Mismatch" scenarios over 20,000 training steps. The chart shows how surprisal changes as the model trains.
### Components/Axes
* **X-axis:** "Training steps" ranging from 0 to 20000, with a step of 5000.
* **Y-axis:** "Surprisal" ranging from 5.0 to 12.5, with a step of 2.5.
* **Legend:** Located in the top-right corner, it identifies the two data series:
* Blue line: "Match"
* Orange line: "Mismatch"
### Detailed Analysis
* **Match (Blue Line):**
* Trend: The "Match" line starts at a surprisal value of approximately 7.5 at 0 training steps and generally decreases as training steps increase.
* Data Points:
* At 0 training steps, surprisal is approximately 7.5.
* At 5000 training steps, surprisal is approximately 6.25.
* At 10000 training steps, surprisal is approximately 5.5.
* At 15000 training steps, surprisal is approximately 5.0.
* At 20000 training steps, surprisal is approximately 4.75.
* **Mismatch (Orange Line):**
* Trend: The "Mismatch" line starts at a surprisal value of approximately 12.0 at 0 training steps and rapidly decreases initially, then plateaus and remains relatively constant.
* Data Points:
* At 0 training steps, surprisal is approximately 12.0.
* At 5000 training steps, surprisal is approximately 7.25.
* At 10000 training steps, surprisal is approximately 7.25.
* At 15000 training steps, surprisal is approximately 7.25.
* At 20000 training steps, surprisal is approximately 7.25.
### Key Observations
* The "Mismatch" surprisal starts much higher than the "Match" surprisal.
* Both "Match" and "Mismatch" surprisal decrease significantly in the initial training steps.
* The "Match" surprisal continues to decrease gradually throughout the training, while the "Mismatch" surprisal plateaus after the initial drop.
* There is a shaded region around each line, indicating a confidence interval or standard deviation.
### Interpretation
The chart illustrates how the model's "surprisal" (a measure of unexpectedness or error) changes during training for "Match" and "Mismatch" scenarios. The initial high surprisal for "Mismatch" suggests that the model initially struggles more with mismatched data. As training progresses, the model learns to handle both scenarios, reducing surprisal. The "Match" scenario shows a continuous improvement, while the "Mismatch" scenario plateaus, suggesting that the model may have reached a limit in its ability to handle mismatched data or that further training would be needed to improve performance on "Mismatch" cases. The shaded regions indicate the variability in the surprisal values across multiple runs or data samples.
</details>
(a) 12-layer Transformer.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: Surprisal vs. Training Steps
### Overview
The image is a line chart comparing the surprisal values of "Match" and "Mismatch" conditions over 20,000 training steps. The chart shows how surprisal decreases with training, with "Match" consistently exhibiting lower surprisal than "Mismatch."
### Components/Axes
* **X-axis:** Training steps, ranging from 0 to 20,000 in increments of 10,000.
* **Y-axis:** Surprisal, ranging from 5.0 to 12.5 in increments of 2.5.
* **Legend:** Located in the top-right corner, it identifies the two data series:
* Blue line: "Match"
* Orange line: "Mismatch"
### Detailed Analysis
* **Match (Blue):**
* Trend: The surprisal starts at approximately 8.0 and decreases rapidly initially, then plateaus around 5.0 after approximately 10,000 training steps.
* Data Points:
* 0 training steps: ~8.0 surprisal
* 10,000 training steps: ~5.2 surprisal
* 20,000 training steps: ~5.0 surprisal
* **Mismatch (Orange):**
* Trend: The surprisal starts at approximately 12.0 and decreases rapidly initially, then plateaus around 7.0 after approximately 10,000 training steps.
* Data Points:
* 0 training steps: ~12.0 surprisal
* 10,000 training steps: ~7.2 surprisal
* 20,000 training steps: ~7.0 surprisal
### Key Observations
* Both "Match" and "Mismatch" conditions show a significant decrease in surprisal during the initial training phase.
* The "Match" condition consistently exhibits lower surprisal values compared to the "Mismatch" condition throughout the training process.
* The rate of decrease in surprisal slows down considerably after approximately 10,000 training steps for both conditions.
### Interpretation
The chart suggests that as the model trains, it becomes better at predicting both "Match" and "Mismatch" scenarios, as indicated by the decreasing surprisal values. The lower surprisal for "Match" indicates that the model finds "Match" scenarios more predictable or less surprising than "Mismatch" scenarios. The plateauing of the curves suggests that the model reaches a point of diminishing returns in terms of learning, where further training does not significantly reduce surprisal.
</details>
(b) 4-layer Transformer.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Chart: Surprisal vs. Training Steps
### Overview
The image is a line chart that plots "Surprisal" on the y-axis against "Training steps" on the x-axis. Two data series are displayed: "Match" (blue) and "Mismatch" (orange). The "Match" series shows a decreasing trend, while the "Mismatch" series shows a slight increase after an initial drop. Shaded regions around each line indicate uncertainty or variability.
### Components/Axes
* **X-axis:** "Training steps" with markers at 0, 10000, and 20000.
* **Y-axis:** "Surprisal" with markers at 5.0, 7.5, 10.0, and 12.5.
* **Legend:** Located at the top-right of the chart.
* "Match": Represented by a blue line with a blue shaded region.
* "Mismatch": Represented by an orange line with an orange shaded region.
### Detailed Analysis
* **Match (Blue):**
* Trend: Decreases rapidly from approximately 7.5 surprisal at 0 training steps to around 4.5 surprisal at 5000 training steps. It then stabilizes and fluctuates slightly around 4.0 surprisal from 10000 to 20000 training steps.
* Data Points:
* 0 training steps: ~7.5 surprisal
* 5000 training steps: ~4.5 surprisal
* 10000 training steps: ~4.0 surprisal
* 20000 training steps: ~4.0 surprisal
* **Mismatch (Orange):**
* Trend: Decreases rapidly from approximately 12.5 surprisal at 0 training steps to around 7.0 surprisal at 2500 training steps. It then increases slightly and fluctuates around 7.25 surprisal from 5000 to 20000 training steps.
* Data Points:
* 0 training steps: ~12.5 surprisal
* 2500 training steps: ~7.0 surprisal
* 5000 training steps: ~7.25 surprisal
* 20000 training steps: ~7.25 surprisal
### Key Observations
* The "Match" series exhibits a significant decrease in surprisal during the initial training steps, indicating that the model learns to better predict matching pairs.
* The "Mismatch" series also shows an initial decrease in surprisal, but to a lesser extent than the "Match" series. It then plateaus and fluctuates slightly, suggesting that the model finds it more challenging to predict mismatched pairs.
* The shaded regions around the lines indicate the variability or uncertainty in the surprisal values. The "Match" series has a narrower shaded region, suggesting less variability compared to the "Mismatch" series.
### Interpretation
The chart illustrates the learning behavior of a model when presented with matching and mismatched pairs. The decreasing surprisal for the "Match" series suggests that the model effectively learns to predict matching pairs as training progresses. The "Mismatch" series, while also showing an initial decrease, plateaus at a higher surprisal level, indicating that predicting mismatched pairs remains more challenging for the model. The variability in the "Mismatch" series further supports this observation. The data suggests that the model is better at identifying and predicting matching pairs than mismatched pairs, which could be due to inherent differences in the complexity or predictability of these two categories.
</details>
(c) 4-layer Mamba 2.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Line Chart: Surprisal vs. Training Steps
### Overview
The image is a line chart that plots "Surprisal" on the y-axis against "Training steps" on the x-axis. Two data series are displayed: "Match" (blue line) and "Mismatch" (orange line). Both lines initially peak and then decrease, eventually leveling off. The chart includes a legend in the top-right corner. Shaded regions around each line likely represent confidence intervals or standard deviations.
### Components/Axes
* **X-axis:** "Training steps" ranging from 0 to 20000, with a major tick at 10000.
* **Y-axis:** "Surprisal" ranging from 5.0 to 12.5, with major ticks at 5.0, 7.5, 10.0, and 12.5.
* **Legend:** Located in the top-right corner, it identifies the two data series:
* "Match" - represented by a blue line.
* "Mismatch" - represented by an orange line.
### Detailed Analysis
* **Match (Blue Line):**
* Trend: Initially increases sharply, then decreases rapidly, and finally levels off.
* Data Points:
* Starts at approximately 11.5 surprisal at 0 training steps.
* Peaks at approximately 12.3 surprisal around 500 training steps.
* Decreases to approximately 7.5 surprisal at 10000 training steps.
* Levels off at approximately 7.2 surprisal at 20000 training steps.
* **Mismatch (Orange Line):**
* Trend: Initially increases sharply, then decreases rapidly, and finally levels off.
* Data Points:
* Starts at approximately 12.0 surprisal at 0 training steps.
* Peaks at approximately 12.7 surprisal around 500 training steps.
* Decreases to approximately 8.3 surprisal at 10000 training steps.
* Levels off at approximately 7.8 surprisal at 20000 training steps.
### Key Observations
* Both "Match" and "Mismatch" series exhibit a similar trend: a sharp initial increase followed by a rapid decrease and then a leveling off.
* The "Mismatch" series consistently shows a higher surprisal value than the "Match" series across all training steps.
* The shaded regions around the lines suggest some variability in the data, but the overall trends are clear.
* The most significant change in surprisal occurs within the first 5000 training steps.
### Interpretation
The chart illustrates how surprisal changes with training steps for "Match" and "Mismatch" conditions. The initial increase in surprisal likely reflects the model's initial uncertainty or difficulty in processing the input. As the model trains, surprisal decreases, indicating that the model is becoming more proficient at predicting or understanding the data. The fact that "Mismatch" consistently has a higher surprisal suggests that the model finds "Mismatch" conditions more surprising or difficult to process than "Match" conditions. The leveling off of both lines indicates that the model has reached a point of diminishing returns in terms of learning, and further training may not significantly reduce surprisal.
</details>
(d) 4-layer LSTM.
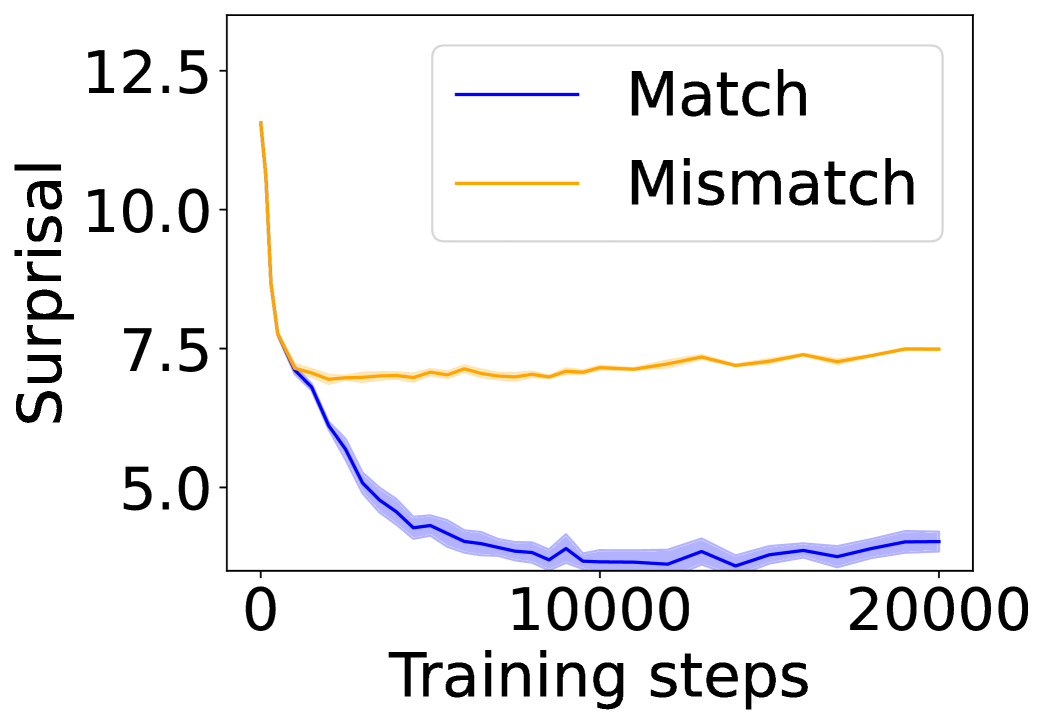
Figure 2: Average surprisal of the experimental and control conditions over training steps.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Line Chart: Information Gain vs. R² Value During Training
### Overview
The image is a line chart showing the relationship between "Training steps" on the x-axis and two different metrics: "Information gain" and "R² value" on the y-axis. The "Information gain" is plotted against the right y-axis, while the "R² value" is plotted against the left y-axis. The chart illustrates how these two metrics change as the training progresses. The R² value has a shaded region around the line, indicating variance.
### Components/Axes
* **X-axis:** "Training steps" ranging from 0 to 20000. Axis markers are present at 0, 10000, and 20000.
* **Left Y-axis:** "R² values" ranging from 0.0 to 0.8. Axis markers are present at 0.0, 0.2, 0.4, 0.6, and 0.8. The axis label is in orange.
* **Right Y-axis:** "Information gain" ranging from 0 to 6. Axis markers are present at 0, 2, 4, and 6. The axis label is in blue.
* **Legend:** Located at the top-center of the chart.
* Blue line: "Information gain"
* Orange line: "R² value"
### Detailed Analysis
* **Information gain (Blue line):** The information gain starts near 0 at 0 training steps. It increases steadily with training steps, reaching approximately 2.3 at 10000 training steps, and plateaus around 2.8 at 20000 training steps. The trend is generally upward, with a decreasing rate of increase as training progresses.
* (0, ~0)
* (10000, ~2.3)
* (20000, ~2.8)
* **R² value (Orange line):** The R² value starts near 0 at 0 training steps. It increases rapidly, peaking at approximately 0.42 around 4000 training steps. After the peak, it decreases steadily, reaching approximately 0.12 at 20000 training steps. The trend is initially upward, then downward. There is a shaded region around the orange line, indicating the variance or uncertainty in the R² value.
* (0, ~0)
* (4000, ~0.42)
* (10000, ~0.18)
* (20000, ~0.12)
### Key Observations
* The "Information gain" increases as the "Training steps" increase, indicating that the model learns and gains more information as it is trained.
* The "R² value" initially increases, suggesting that the model's fit improves early in training. However, after a certain point, the "R² value" decreases, which could indicate overfitting.
* The peak of the "R² value" occurs around 4000 training steps, after which it declines.
* The "Information gain" plateaus towards the end of the training, suggesting that the model's learning slows down.
### Interpretation
The chart illustrates the trade-off between "Information gain" and "R² value" during the training process. Initially, both metrics increase, indicating that the model is learning and fitting the data well. However, as training continues, the "R² value" decreases, suggesting that the model may be overfitting to the training data. The "Information gain" continues to increase, but at a slower rate, indicating that the model is still learning, but the benefits are diminishing. This suggests that there is an optimal point in the training process where the model achieves a good balance between "Information gain" and "R² value". Further training beyond this point may lead to overfitting and a decrease in the model's ability to generalize to new data. The shaded region around the R² value indicates the variability in the model's performance, which could be due to factors such as noise in the data or the stochastic nature of the training algorithm.
</details>
(a) 12-layer Transformer.
<details>
<summary>x9.png Details</summary>
### Visual Description
## Line Chart: Information Gain and R² Value vs. Training Steps
### Overview
The image is a line chart showing the relationship between training steps and two metrics: Information gain and R² value. The x-axis represents training steps, while the left y-axis represents R² values and the right y-axis represents Information gain. The chart displays how these metrics change over the course of training.
### Components/Axes
* **X-axis:** Training steps, ranging from 0 to 20000.
* **Left Y-axis:** R² values, ranging from 0.0 to 0.8. The axis label is "R² values" in orange.
* **Right Y-axis:** Information gain, ranging from 0 to 6. The axis label is "Information gain" in blue.
* **Legend:** Located at the top of the chart.
* Blue line: Information gain
* Orange line: R² value
### Detailed Analysis
* **Information gain (Blue line):** The information gain starts at approximately 0 at 0 training steps. It increases steadily to approximately 1.5 at 10000 training steps, and continues to increase at a slower rate, reaching approximately 2.2 at 20000 training steps.
* **R² value (Orange line):** The R² value starts at approximately 0 at 0 training steps. It increases rapidly to a peak of approximately 0.35 around 2500 training steps. After the peak, it decreases steadily, reaching approximately 0.1 at 20000 training steps. The R² value line has a shaded region around it, indicating uncertainty or variance.
### Key Observations
* The information gain increases with training steps, while the R² value initially increases but then decreases as training progresses.
* The R² value peaks early in the training process and then declines, suggesting that the model may initially fit the data well but then starts to overfit or lose its predictive power as training continues.
* The information gain continues to increase, indicating that the model is still learning or extracting relevant information from the data even as the R² value declines.
### Interpretation
The chart suggests that the model's performance, as measured by R², initially improves with training but then degrades, possibly due to overfitting. However, the increasing information gain indicates that the model continues to learn relevant features even as its overall fit to the data declines. This could mean that the model is becoming more specialized or is capturing more complex relationships in the data that are not reflected in the R² value. The shaded region around the R² value line suggests that the model's performance is not consistent and may vary depending on the specific data used for evaluation. Further investigation is needed to determine the optimal stopping point for training and to understand the specific features that the model is learning.
</details>
(b) 4-layer Transformer.
<details>
<summary>x10.png Details</summary>
### Visual Description
## Line Chart: Information Gain and R² Value vs. Training Steps
### Overview
The image is a line chart showing the relationship between training steps and two metrics: Information gain and R² value. The x-axis represents training steps, while the left y-axis represents R² values and the right y-axis represents Information gain. The chart displays how these metrics change as the training progresses.
### Components/Axes
* **X-axis:** Training steps, ranging from 0 to 20000.
* **Left Y-axis:** R² values, ranging from 0.0 to 0.8. Labelled "R² values" in orange.
* **Right Y-axis:** Information gain, ranging from 0 to 6. Labelled "Information gain" in blue.
* **Legend:** Located at the top-center of the chart.
* Blue line: Information gain
* Orange line: R² value
### Detailed Analysis
* **Information gain (Blue line):** The information gain starts at approximately 0 at 0 training steps. It increases rapidly until around 5000 training steps, reaching a value of approximately 3.5. From 5000 to 10000 training steps, the increase slows down. After 10000 training steps, the information gain plateaus around 4.2, with slight fluctuations. The shaded area around the blue line indicates the uncertainty or variance in the information gain.
* **R² value (Orange line):** The R² value starts at approximately 0 at 0 training steps. It increases sharply until around 2000 training steps, reaching a peak value of approximately 0.3. After the peak, the R² value decreases rapidly and stabilizes near 0 after approximately 5000 training steps. The shaded area around the orange line indicates the uncertainty or variance in the R² value.
### Key Observations
* The information gain increases rapidly in the initial training phase and then plateaus.
* The R² value shows a sharp increase followed by a sharp decrease, stabilizing near zero after a few thousand training steps.
* The uncertainty (shaded areas) is more pronounced in the initial phases of training for both metrics.
### Interpretation
The chart suggests that the model quickly learns relevant information in the early stages of training, as indicated by the rapid increase in information gain. However, the R² value, which measures the goodness of fit, initially increases and then drops, suggesting that the model might be overfitting or that the relationship being modeled is not well-captured by the R² metric after the initial learning phase. The plateau in information gain indicates that the model stops learning new information after a certain number of training steps. The R² value approaching zero suggests that the model's predictions do not correlate well with the actual values after the initial learning phase.
</details>
(c) 4-layer Mamba 2.
<details>
<summary>x11.png Details</summary>
### Visual Description
## Chart: Information Gain and R² Value vs. Training Steps
### Overview
The image is a line chart showing the relationship between training steps and two metrics: Information Gain and R² value. The x-axis represents training steps, while the left y-axis represents R² values and the right y-axis represents Information Gain. The chart displays how these metrics change as the training progresses.
### Components/Axes
* **X-axis:** Training steps, ranging from 0 to 20000.
* **Left Y-axis:** R² values, ranging from 0.0 to 0.8.
* **Right Y-axis:** Information gain, ranging from 0 to 6.
* **Legend:** Located at the top-center of the chart.
* Blue line: Information gain
* Orange line: R² value
### Detailed Analysis
* **R² value (Orange line):** The R² value starts near 0 and increases rapidly until approximately 10000 training steps, after which the rate of increase slows down. The R² value appears to plateau around 0.5 after 15000 training steps. There is a shaded region around the orange line, indicating variability or confidence interval.
* At 0 training steps, R² value is approximately 0.02.
* At 5000 training steps, R² value is approximately 0.35.
* At 10000 training steps, R² value is approximately 0.45.
* At 20000 training steps, R² value is approximately 0.5.
* **Information gain (Blue line):** The information gain starts near 0 and increases slowly throughout the training process. The slope of the line decreases as the number of training steps increases.
* At 0 training steps, Information gain is approximately 0.0.
* At 5000 training steps, Information gain is approximately 0.5.
* At 10000 training steps, Information gain is approximately 0.7.
* At 20000 training steps, Information gain is approximately 1.0.
### Key Observations
* The R² value increases much more rapidly than the information gain during the initial training phase.
* The R² value plateaus at a higher level than the information gain.
* Both metrics show diminishing returns as the number of training steps increases.
### Interpretation
The chart suggests that the model's performance, as measured by the R² value, improves significantly during the initial training phase. However, after a certain number of training steps (around 10000), the improvement in R² value diminishes. The information gain also increases with training steps, but at a slower rate and to a lesser extent than the R² value. This indicates that the model is learning, but the rate of learning decreases over time. The plateauing of the R² value suggests that the model may be approaching its maximum performance on the given task or dataset. Further training may not lead to significant improvements.
</details>
(d) 4-layer LSTM.
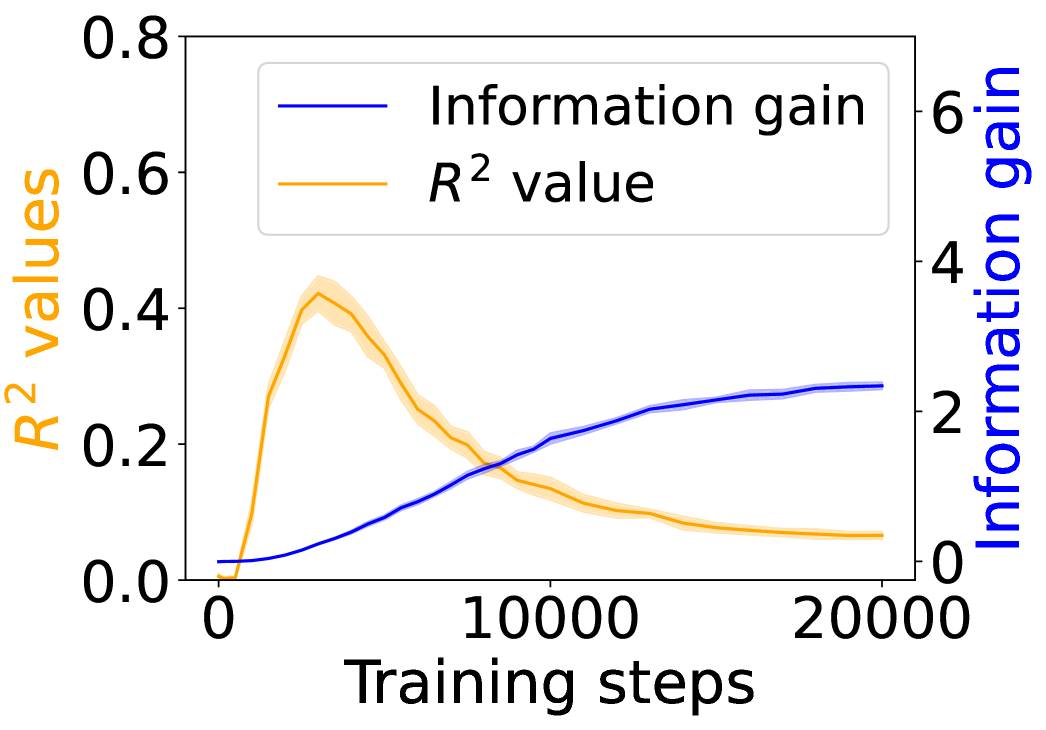
Figure 3: Grounding information gain and its correlation to the co-occurrence of linguistic and environment tokens over training steps.
4.1 Behavioral Evidence of Emergent Grounding
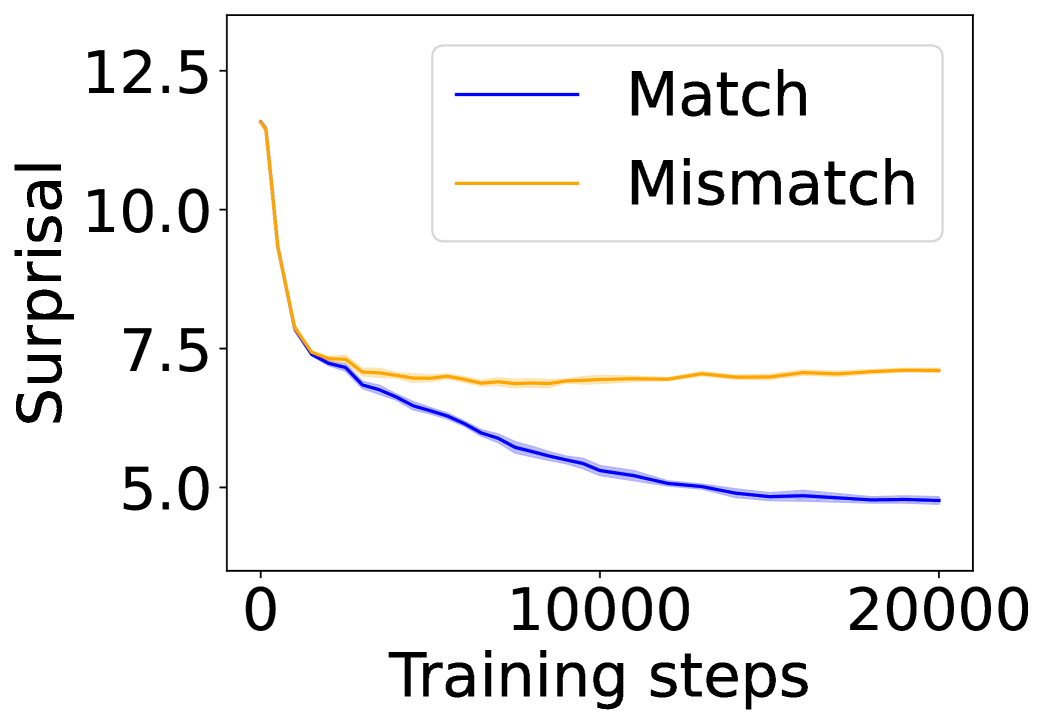
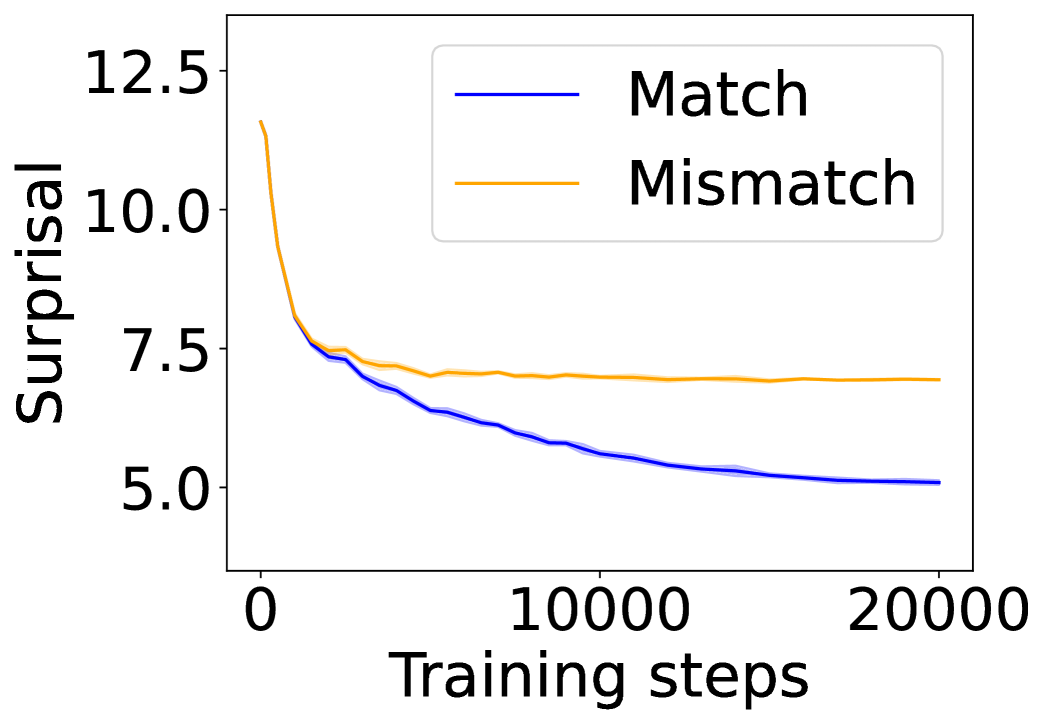
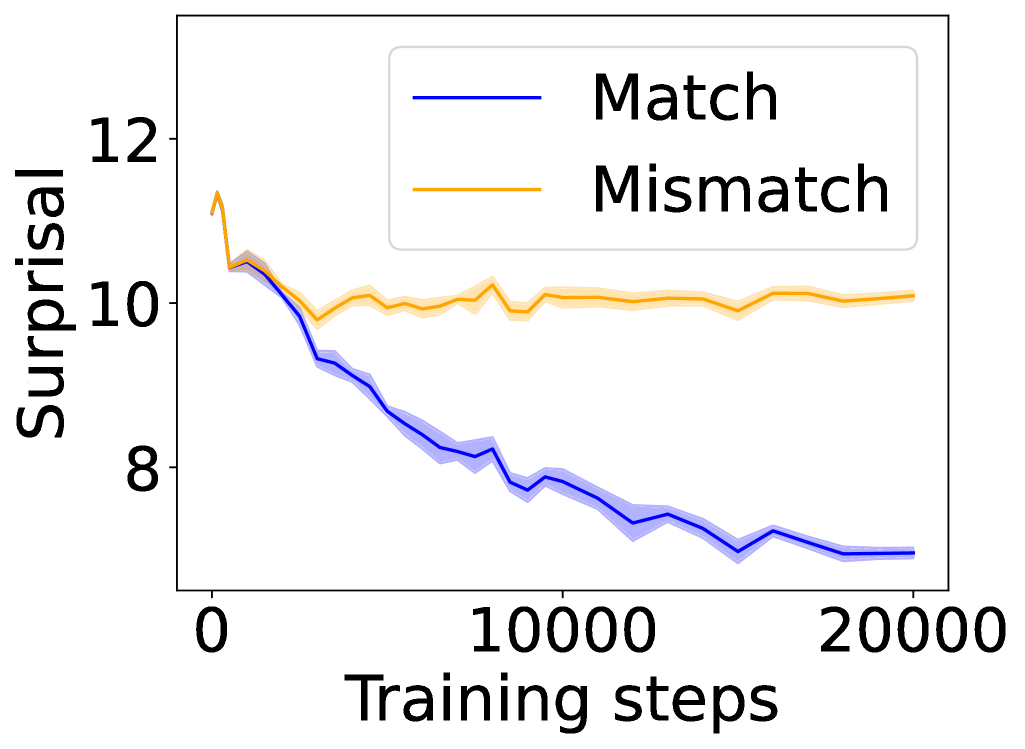
In this section, we ask: Does symbol grounding emerge behaviorally in autoregressive LMs? We first test whether models show systematic surprisal reduction when predicting a linguistic token when its environmental counterpart is in context (Figure 2, where the gap between the lines represent the grounding information gain). For Transformers (Figures 2(a) and 2(b)) and Mamba-2 (Figure 2(c)), surprisal in the match condition decreases steadily while that in the mismatch condition enters a high-surprisal plateau early, indicating that the models leverage environmental context to predict the linguistic form. In contrast, the unidirectional LSTM (Figure 2(d)) shows little separation between the conditions, reflecting the absence of grounding. Overall, these results provide behavioral evidence of emergent grounding: in sufficiently expressive architectures (Transformers and Mamba-2), the correct environmental context reliably lowers surprisal for its linguistic counterpart, whereas LSTMs fail to exhibit this effect, marking an architectural boundary on where grounding can emerge.
4.2 Behavioral Effects Beyond Co-occurrence
A natural concern is that the surprisal reductions might be fully explainable by shallow statistics: the models might have simply memorized frequent co-occurrences of $\langle$ ENV $\rangle$ and $\langle$ LAN $\rangle$ tokens, without learning a deeper and more general mapping. We test this hypothesis by comparing the tokens’ co-occurrence with the grounding information gain in the child-directed speech data.
We define co-occurrence between the corresponding $\langle$ ENV $\rangle$ and $\langle$ LAN $\rangle$ tokens at the granularity of a 512-token training chunk. For each target word $v$ , we count the number of chunks in which both its $\langle$ ENV $\rangle$ and $\langle$ LAN $\rangle$ tokens appear. Following standard corpus-analysis practice, these raw counts are log-transformed. For each model checkpoint, we run linear regression between the log co-occurrence and the grounding information gain of words, obtaining an $R^{2}$ statistic as a function of training time.
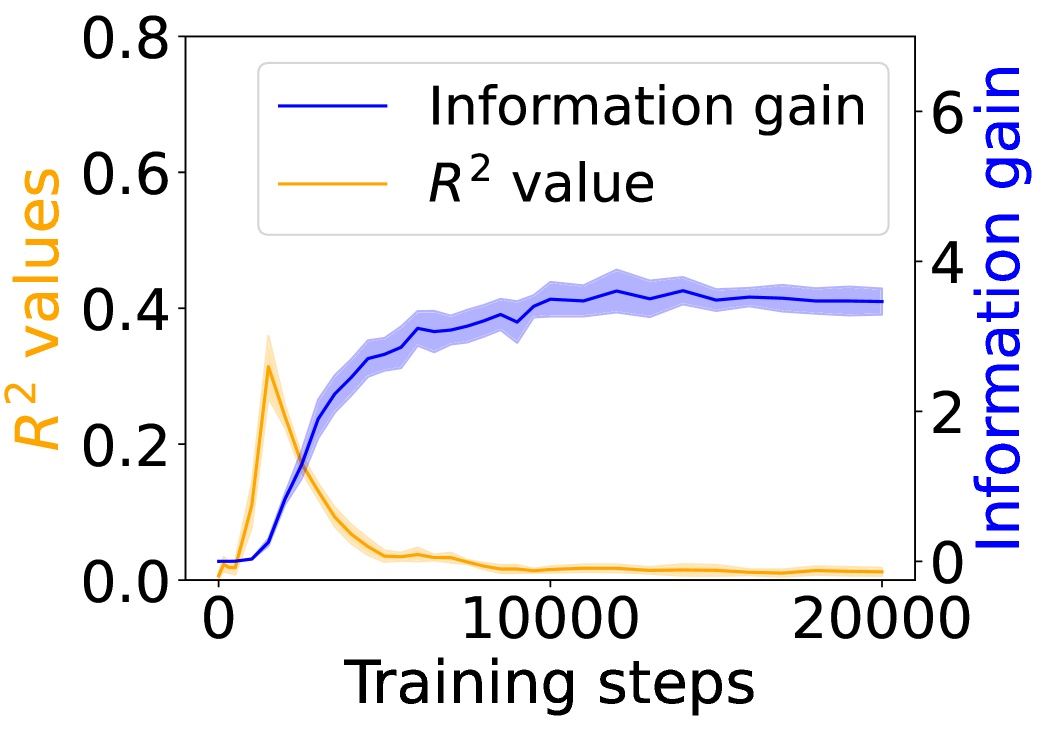
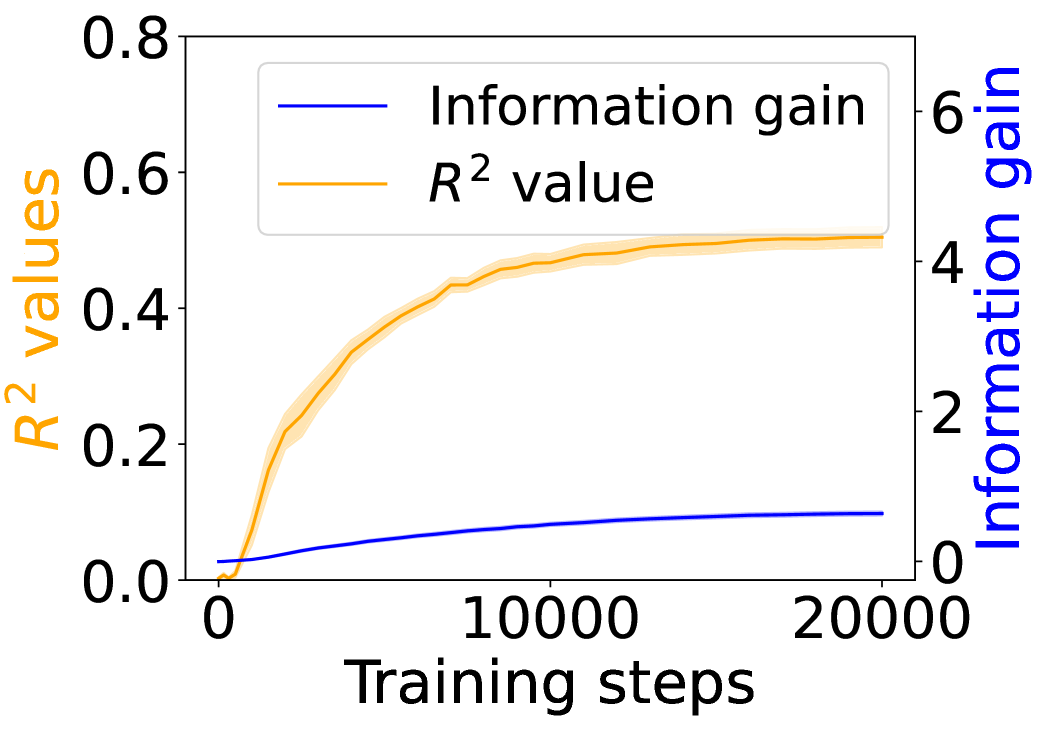
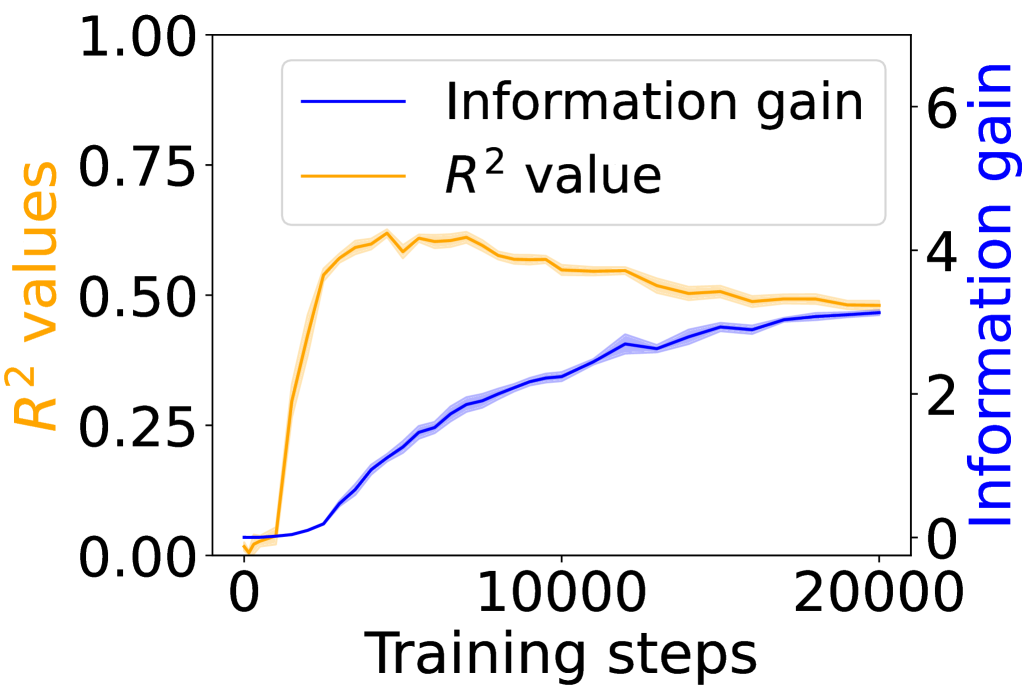
Figure 3 shows the $R^{2}$ values (orange) alongside the grounding information gain (blue) for different architectures. In both the Transformer and Mamba-2, $R^{2}$ rises sharply at the early steps but then goes down, even if the grounding information gain continues increasing. These results suggest that grounding in Transformers and Mamba-2 cannot be fully accounted for by co-occurrence statistics: while models initially exploit surface co-occurrence regularities, later improvements in grounding diverge from these statistics, indicating reliance on richer and more complicated features acquired during training. In contrast, LSTM shows persistently increasing $R^{2}$ but little increase in grounding information gain over training steps, suggesting that it encodes co-occurrence but lacks the architectural mechanism to transform it into predictive grounding.
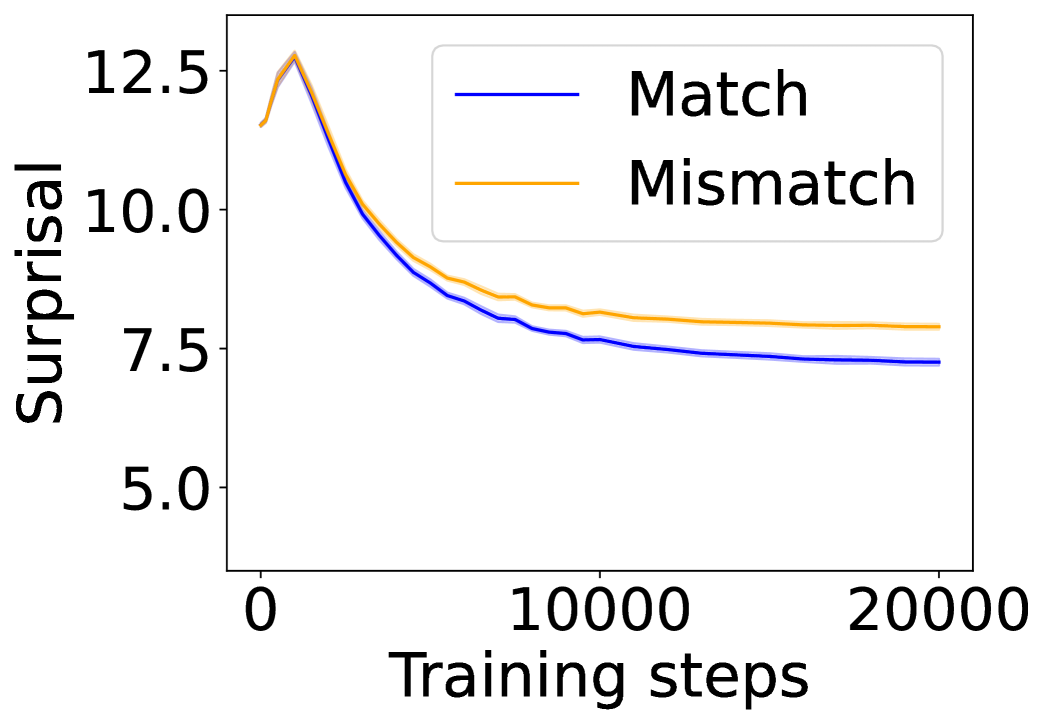
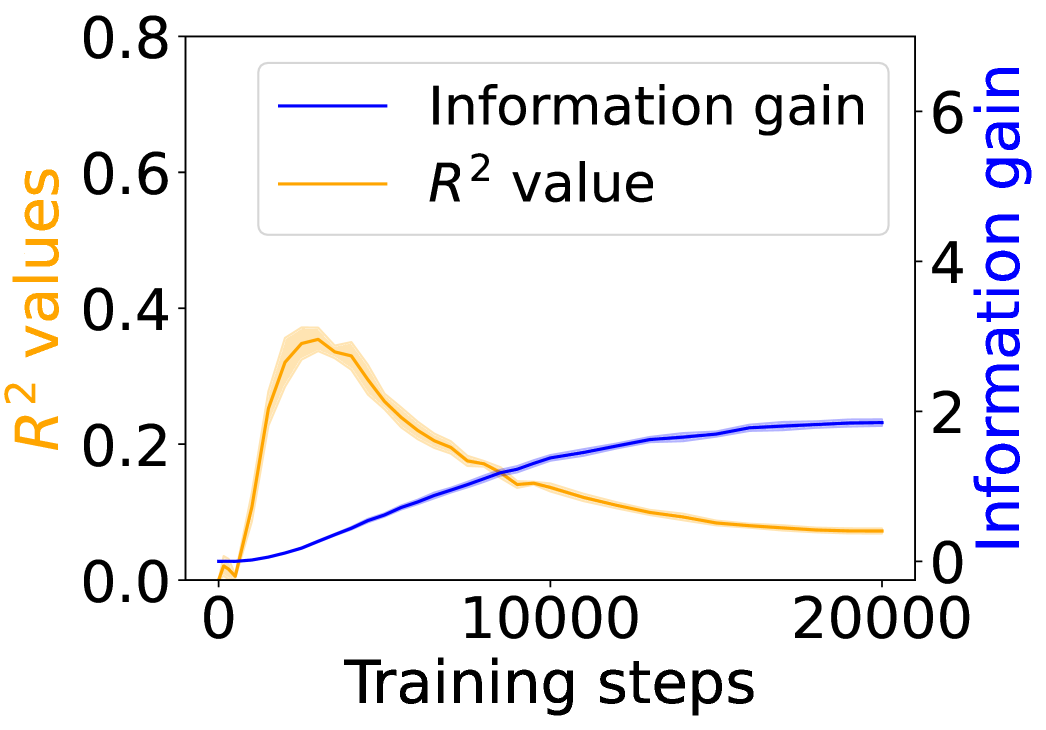
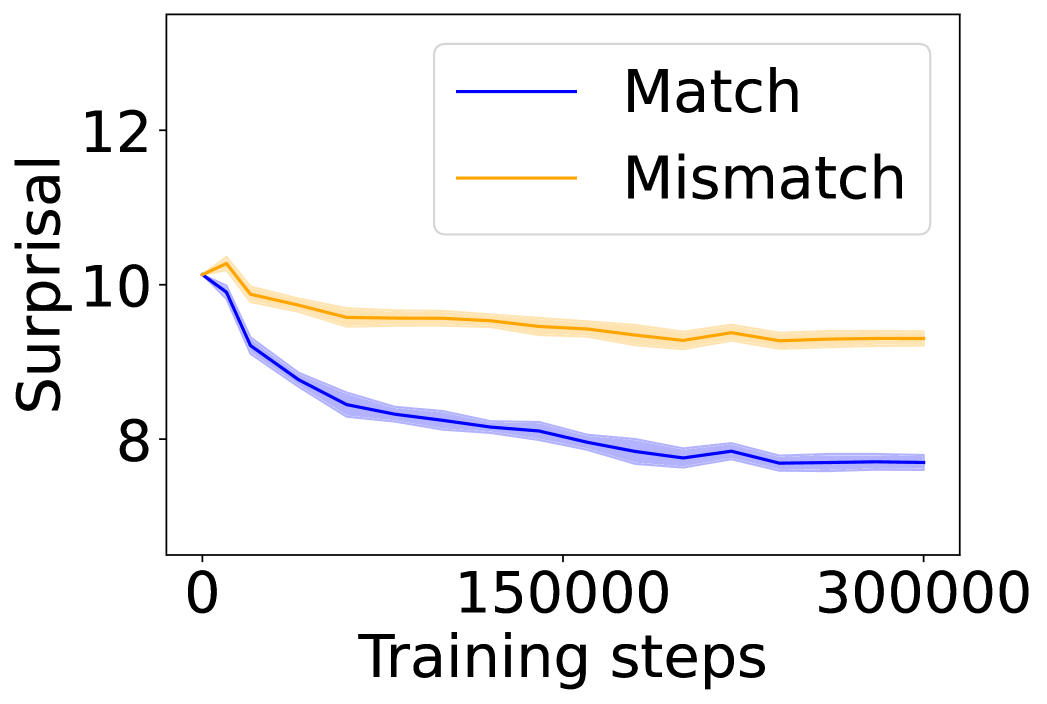
4.3 Visual Dialogue with Captions and Images
<details>
<summary>x12.png Details</summary>
### Visual Description
## Line Chart: Surprisal vs. Training Steps
### Overview
The image is a line chart comparing the surprisal values for "Match" and "Mismatch" conditions over a range of training steps. The x-axis represents training steps, ranging from 0 to 20000. The y-axis represents surprisal, ranging from approximately 6 to 12. The chart displays two lines, one blue ("Match") and one orange ("Mismatch"), each with a shaded region indicating variability.
### Components/Axes
* **X-axis:**
* Label: "Training steps"
* Scale: 0 to 20000
* Markers: 0, 10000, 20000
* **Y-axis:**
* Label: "Surprisal"
* Scale: 8 to 12
* Markers: 8, 10, 12
* **Legend (Top-Right):**
* "Match": Blue line
* "Mismatch": Orange line
### Detailed Analysis
* **Match (Blue Line):**
* Trend: The "Match" line generally slopes downward, indicating a decrease in surprisal as training steps increase.
* Data Points:
* At 0 training steps, surprisal is approximately 10.5.
* At 5000 training steps, surprisal is approximately 8.5.
* At 10000 training steps, surprisal is approximately 7.8.
* At 15000 training steps, surprisal is approximately 7.2.
* At 20000 training steps, surprisal is approximately 7.0.
* **Mismatch (Orange Line):**
* Trend: The "Mismatch" line remains relatively stable, with a slight initial decrease followed by a plateau.
* Data Points:
* At 0 training steps, surprisal is approximately 11.2.
* At 5000 training steps, surprisal is approximately 10.0.
* At 10000 training steps, surprisal is approximately 10.2.
* At 15000 training steps, surprisal is approximately 10.0.
* At 20000 training steps, surprisal is approximately 10.1.
### Key Observations
* The "Match" condition shows a significant decrease in surprisal over the training steps, suggesting that the model learns to better predict matching pairs.
* The "Mismatch" condition maintains a relatively constant level of surprisal, indicating that the model consistently finds mismatched pairs surprising.
* The shaded regions around each line indicate the variability or uncertainty associated with the surprisal values.
### Interpretation
The chart demonstrates that as the model undergoes training, it becomes more adept at predicting "Match" scenarios, as evidenced by the decreasing surprisal. Conversely, the model consistently finds "Mismatch" scenarios surprising, as indicated by the relatively stable surprisal values. This suggests that the model is learning to differentiate between matching and mismatched pairs, with the "Match" condition becoming more predictable over time. The variability, represented by the shaded regions, suggests that the model's performance is not uniform across all instances within each condition.
</details>
(a) Surprisal curves (w/ caption).
<details>
<summary>x13.png Details</summary>
### Visual Description
## Line Chart: Surprisal vs. Training Steps
### Overview
The image is a line chart comparing the "Surprisal" of two conditions, "Match" and "Mismatch," over a range of "Training steps." The chart displays how surprisal changes as the training progresses, with shaded regions indicating uncertainty or variability around the mean values.
### Components/Axes
* **X-axis:** "Training steps" ranging from 0 to 300000, with a marker at 150000.
* **Y-axis:** "Surprisal" ranging from 8 to 12.
* **Legend:** Located at the top-right of the chart.
* "Match": Represented by a blue line with a light blue shaded region.
* "Mismatch": Represented by an orange line with a light orange shaded region.
### Detailed Analysis
* **Match (Blue Line):**
* Trend: The "Match" line starts at approximately 10 surprisal and decreases rapidly initially, then gradually levels off.
* Data Points:
* At 0 training steps, surprisal is approximately 10.1.
* At 50000 training steps, surprisal is approximately 8.5.
* At 150000 training steps, surprisal is approximately 8.1.
* At 300000 training steps, surprisal is approximately 7.8.
* **Mismatch (Orange Line):**
* Trend: The "Mismatch" line starts at approximately 10.2 surprisal, decreases slightly, and then remains relatively stable.
* Data Points:
* At 0 training steps, surprisal is approximately 10.2.
* At 50000 training steps, surprisal is approximately 9.8.
* At 150000 training steps, surprisal is approximately 9.5.
* At 300000 training steps, surprisal is approximately 9.3.
### Key Observations
* The "Match" condition shows a more significant decrease in surprisal compared to the "Mismatch" condition.
* The shaded regions around the lines indicate the variability or standard deviation of the data.
* Both lines converge to a more stable surprisal level as the number of training steps increases.
### Interpretation
The chart suggests that as the model trains, the "Match" condition becomes less surprising, indicating that the model is learning to better predict or understand matching patterns. The "Mismatch" condition also shows a slight decrease in surprisal, but not as pronounced as the "Match" condition, suggesting that the model still finds mismatched patterns somewhat surprising even after training. The difference in surprisal between the two conditions decreases over time, implying that the model is becoming more adept at distinguishing between them.
</details>
(b) Surprisal curves (w/ image).
<details>
<summary>x14.png Details</summary>
### Visual Description
## Line Chart: Information Gain vs. R² Value During Training
### Overview
The image is a line chart showing the relationship between training steps and two metrics: Information Gain and R² value. The x-axis represents training steps, while the left y-axis represents R² values and the right y-axis represents Information Gain. Two lines, one blue (Information Gain) and one orange (R² value), illustrate how these metrics change over the course of training. Shaded regions around each line indicate uncertainty or variance.
### Components/Axes
* **X-axis:** Training steps, ranging from 0 to 20000.
* **Left Y-axis:** R² values, ranging from 0.00 to 1.00, with increments of 0.25.
* **Right Y-axis:** Information gain, ranging from 0 to 6, with increments of 2.
* **Legend:** Located at the top-center of the chart.
* Blue line: Information gain
* Orange line: R² value
### Detailed Analysis
* **R² Value (Orange Line):**
* Trend: Initially increases rapidly, then plateaus and slightly decreases.
* Starting at approximately 0.02 at 0 training steps.
* Reaches a peak of approximately 0.65 around 5000 training steps.
* Stabilizes around 0.50 after 10000 training steps.
* **Information Gain (Blue Line):**
* Trend: Gradually increases over the training steps.
* Starting at approximately 0.1 at 0 training steps.
* Reaches approximately 2.5 around 10000 training steps.
* Reaches approximately 3.5 around 15000 training steps.
* Approaches approximately 3.6 around 20000 training steps.
### Key Observations
* The R² value shows a rapid initial improvement, indicating that the model quickly learns to fit the data. However, it plateaus and slightly decreases, suggesting diminishing returns or potential overfitting.
* The Information Gain increases more gradually, indicating a steady improvement in the model's ability to extract relevant information from the data.
* The shaded regions around the lines suggest some variability in the metrics, possibly due to the stochastic nature of the training process.
### Interpretation
The chart suggests that the model initially learns quickly, as indicated by the rapid increase in the R² value. However, as training progresses, the rate of improvement slows down, and the R² value even decreases slightly. This could be due to the model overfitting the training data or reaching a point where further training does not significantly improve its performance. The Information Gain, on the other hand, continues to increase, suggesting that the model is still learning to extract relevant information from the data, even as the R² value plateaus. The relationship between these two metrics suggests that the model may be improving its ability to extract relevant information without necessarily improving its overall fit to the data.
</details>
(c) $R^{2}$ and information gain (w/ caption).
<details>
<summary>x15.png Details</summary>
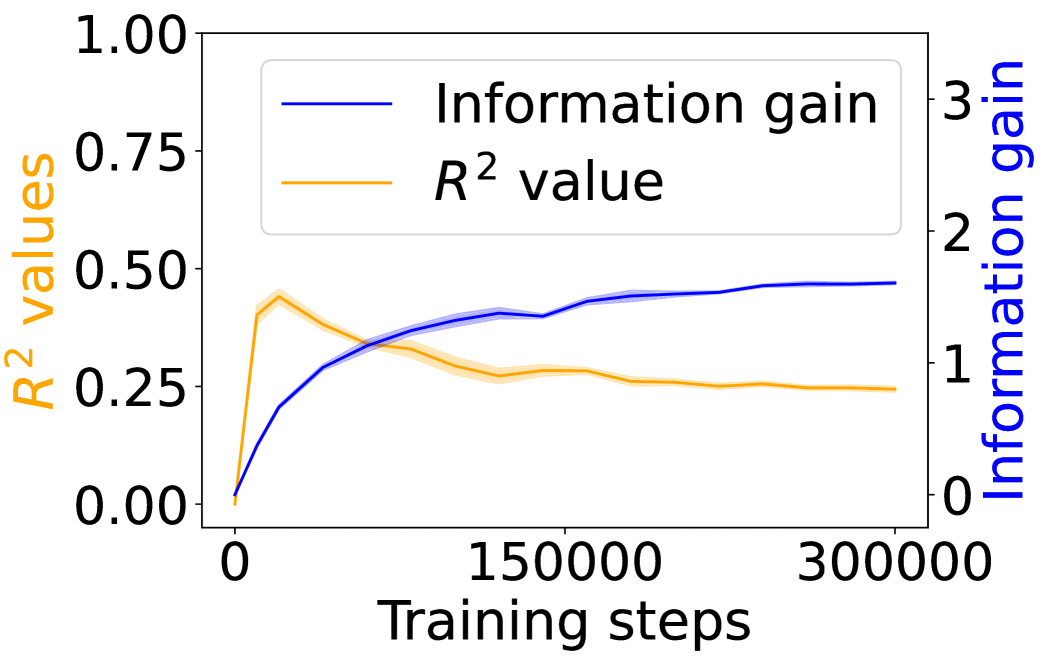
### Visual Description
## Line Chart: Information Gain vs. R² Value During Training
### Overview
The image is a line chart comparing the "Information gain" and "R² value" over a number of "Training steps". The x-axis represents the number of training steps, ranging from 0 to 300,000. The left y-axis represents the R² values, ranging from 0.00 to 1.00. The right y-axis represents the Information gain, ranging from 0 to 3. The chart displays two lines: a blue line representing the Information gain and an orange line representing the R² value. Both lines have shaded regions around them, indicating uncertainty or variance.
### Components/Axes
* **X-axis:** "Training steps", ranging from 0 to 300000, with a marker at 150000.
* **Left Y-axis:** "R² values", ranging from 0.00 to 1.00, with markers at 0.00, 0.25, 0.50, 0.75, and 1.00.
* **Right Y-axis:** "Information gain", ranging from 0 to 3, with markers at 0, 1, 2, and 3.
* **Legend (top-center):**
* Blue line: "Information gain"
* Orange line: "R² value"
### Detailed Analysis
* **Information gain (Blue line):** The information gain starts at approximately 0 at 0 training steps. It increases rapidly initially, then the rate of increase slows down, and it plateaus around 1.5 after approximately 150,000 training steps. The final value at 300,000 training steps is approximately 1.6.
* (0, ~0)
* (150000, ~1.5)
* (300000, ~1.6)
* **R² value (Orange line):** The R² value starts at approximately 0 at 0 training steps. It increases rapidly initially, reaching a peak around 0.45 at approximately 25,000 training steps. After that, it decreases gradually and plateaus around 0.25 after approximately 150,000 training steps. The final value at 300,000 training steps is approximately 0.25.
* (0, ~0)
* (25000, ~0.45)
* (150000, ~0.25)
* (300000, ~0.25)
### Key Observations
* The Information gain and R² value both start at 0.
* The Information gain increases and plateaus, while the R² value increases, then decreases and plateaus.
* The Information gain has a higher final value than the R² value.
* Both lines have shaded regions, indicating uncertainty or variance in the data.
### Interpretation
The chart illustrates the relationship between Information gain and R² value as a model is trained over a number of steps. The Information gain increases as the model learns, eventually plateauing, suggesting that the model is extracting most of the available information from the data. The R² value, which represents the proportion of variance explained by the model, initially increases but then decreases, suggesting that the model may be overfitting to the training data after a certain number of steps. The plateauing of both metrics suggests that further training may not significantly improve the model's performance. The shaded regions indicate the variability in the results, possibly due to different training runs or variations in the data.
</details>
(d) $R^{2}$ and information gain (w/ image).
Figure 4: Average surprisal of the experimental and control conditions in caption- and image-grounded dialogue settings, as well as the grounding information gain and its correlation to the co-occurrence of linguistic and environment tokens over training steps. All results are from a 12-layer Transformer model on grounded dialogue data.
We next test whether the grounding effects observed in CHILDES generalize to multimodal dialogue, using the Visual Dialog dataset. In this setting, the environmental ground is supplied either by captions or by image features (Table 1). For caption-grounded dialogue, the mismatch context is constructed in the same way as for CHILDES (Equation 2). For image-grounded dialogue, mismatch contexts are generated via Stable Diffusion 2 (Rombach et al., 2022) –based image inpainting, which re-generates the region defined by the ground-truth mask corresponding to the target word’s referent.
We train 12-layer Transformers with 5 random seeds. Similarly as Figures 2(a) – 2(b) and Figures 3(a) – 3(b), when captions serve as the environmental ground, Transformers show a clear surprisal gap between match and mismatch conditions (Figure 4(a)), with the grounding information gain increasing steadily while $R^{2}$ peaks early and declines (Figure 4(c)). Directly using image as grounds yields the same qualitative pattern (Figures 4(b) and 4(d)), although the observed effect is smaller. Both settings confirm that emergent grounding cannot be fully explained by co-occurrence statistics.
Overall, our findings demonstrate that Transformers are able to exploit environmental grounds in various modalities to facilitate linguistic prediction. The smaller but consistent gains in the image-grounded case suggest that while grounding from visual tokens is harder, the same architectural dynamics identified in textual testbeds still apply.
5 Mechanistic Explanation
In this section, we provide a mechanistic and interpretable account of the previous observation. We focus on a 12-layer Transformer trained on CHILDES with 5 random seeds, and defer broader generalization to the discussion.
<details>
<summary>x16.png Details</summary>
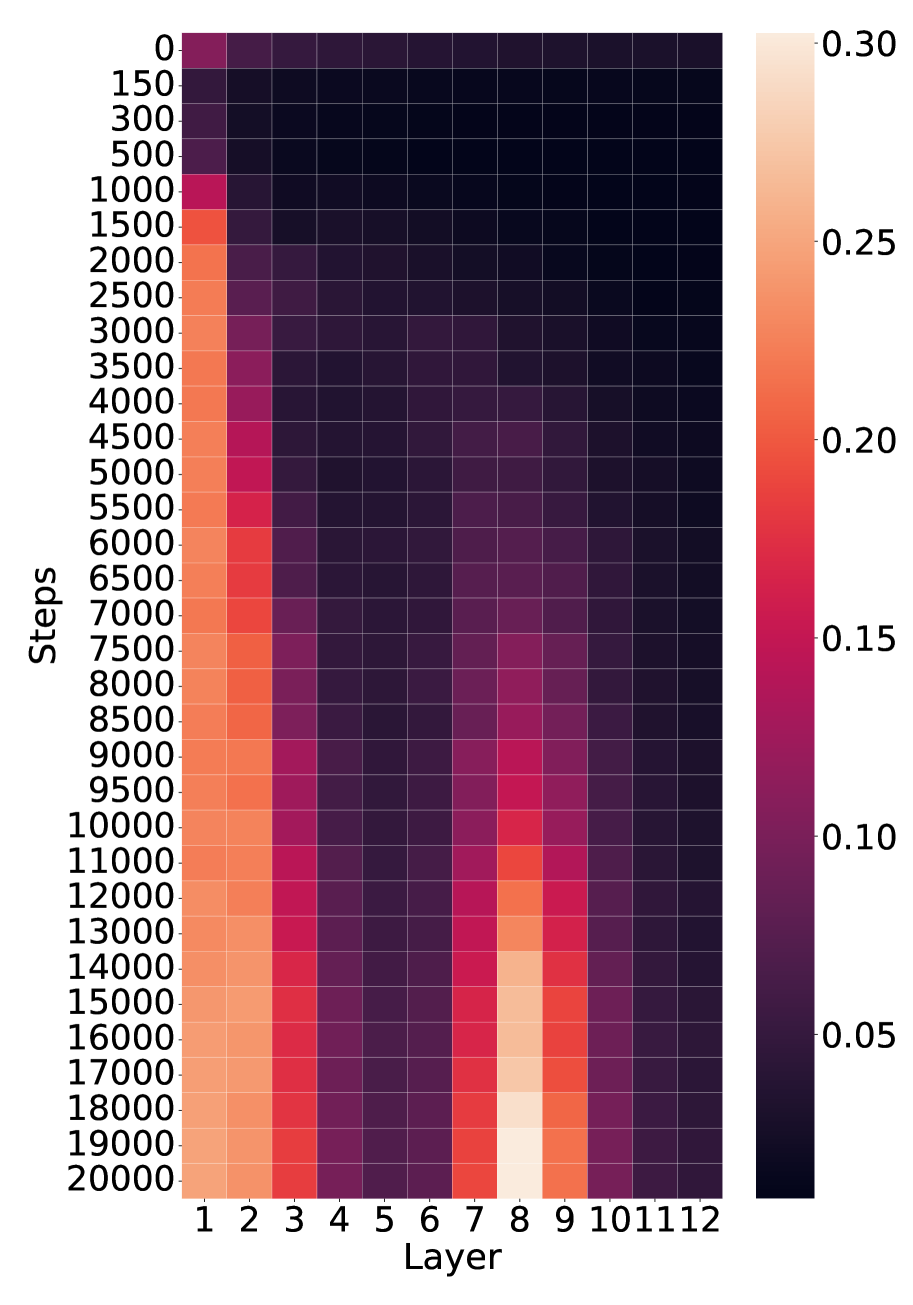
### Visual Description
## Heatmap: Layer Activation vs. Training Steps
### Overview
The image is a heatmap visualizing the activation levels of different layers in a neural network during training. The x-axis represents the layer number (1 to 12), and the y-axis represents the training steps (0 to 20000). The color intensity indicates the activation level, ranging from dark purple (low activation) to light orange (high activation).
### Components/Axes
* **X-axis:** "Layer" - Represents the layer number in the neural network, ranging from 1 to 12.
* **Y-axis:** "Steps" - Represents the training steps, ranging from 0 to 20000, with increments of 150, 300, 500, 1000, 1500, 2000, 2500, 3000, 3500, 4000, 4500, 5000, 5500, 6000, 6500, 7000, 7500, 8000, 8500, 9000, 9500, 10000, 11000, 12000, 13000, 14000, 15000, 16000, 17000, 18000, 19000, 20000.
* **Colorbar (Legend):** Located on the right side of the heatmap. It maps color intensity to activation levels, ranging from 0.05 (dark purple) to 0.30 (light orange), with increments of 0.05.
### Detailed Analysis
The heatmap shows how the activation levels of each layer change as the training progresses.
* **Layer 1:** Shows high activation (light orange) from the beginning (0 steps) until the end (20000 steps). The activation level appears relatively constant throughout the training process.
* **Layer 2:** Similar to Layer 1, it exhibits high activation levels throughout the training.
* **Layer 3:** Starts with low activation (dark purple) and gradually increases to a moderate level (pink) as training progresses.
* **Layers 4-7:** These layers show consistently low activation levels (dark purple) throughout the entire training process.
* **Layer 8:** Starts with low activation and gradually increases to a moderate level (pink) as training progresses, similar to Layer 3.
* **Layer 9:** Shows a pattern similar to Layer 8, with activation increasing as training progresses.
* **Layers 10-12:** These layers show consistently low activation levels (dark purple) throughout the entire training process.
**Specific Data Points (Approximate):**
* At 0 steps, Layer 1 has an activation level of approximately 0.30 (light orange).
* At 20000 steps, Layer 1 has an activation level of approximately 0.30 (light orange).
* At 0 steps, Layer 3 has an activation level of approximately 0.05 (dark purple).
* At 20000 steps, Layer 3 has an activation level of approximately 0.15 (pink).
* At 0 steps, Layer 5 has an activation level of approximately 0.05 (dark purple).
* At 20000 steps, Layer 5 has an activation level of approximately 0.05 (dark purple).
* At 10000 steps, Layer 8 has an activation level of approximately 0.10 (purple-pink).
* At 20000 steps, Layer 8 has an activation level of approximately 0.25 (orange).
### Key Observations
* Layers 1 and 2 consistently exhibit high activation levels throughout the training process.
* Layers 3, 8, and 9 show an increase in activation levels as training progresses.
* Layers 4-7 and 10-12 consistently exhibit low activation levels throughout the training process.
* The most significant changes in activation occur in Layers 3, 8, and 9.
### Interpretation
The heatmap suggests that Layers 1 and 2 are highly active from the beginning of training, potentially indicating that they are quickly learning important features. Layers 3, 8, and 9 gradually increase their activation, suggesting that they learn more complex features as training progresses. Layers 4-7 and 10-12 remain relatively inactive, which could indicate that they are either redundant or not effectively contributing to the learning process for this specific task. This information could be used to optimize the network architecture, potentially by removing or modifying the less active layers. The consistent high activation of the first two layers might also suggest that they are overfitting to the initial training data, which could be addressed with regularization techniques.
</details>
(a) Saliency of layer-wise attention from environmental to linguistic tokens across training steps.
<details>
<summary>x17.png Details</summary>
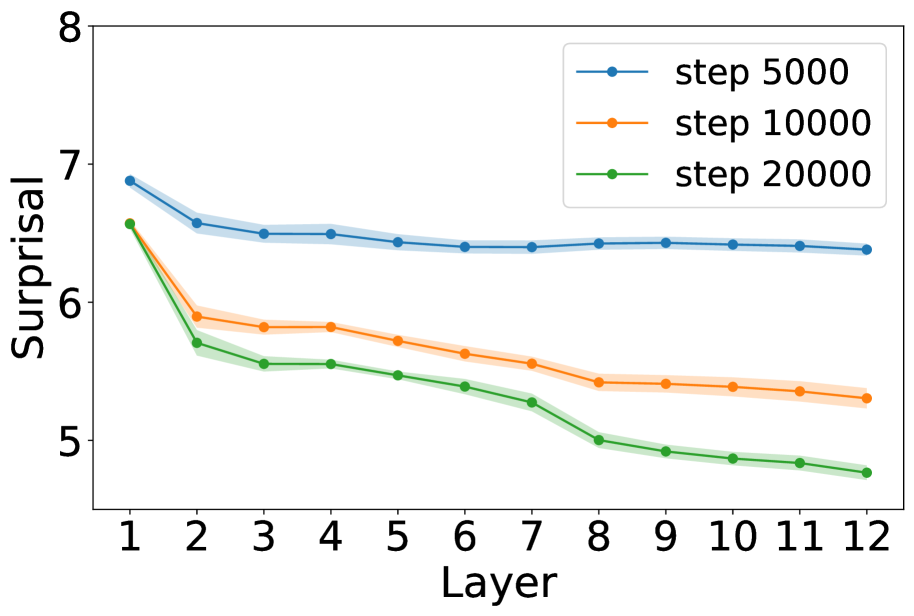
### Visual Description
## Line Chart: Surprisal vs. Layer
### Overview
The image is a line chart showing the relationship between "Surprisal" and "Layer" for three different training steps: 5000, 10000, and 20000. The x-axis represents the layer number (from 1 to 12), and the y-axis represents the surprisal value (from 5 to 8). Each line represents a different training step, with shaded regions indicating the uncertainty or variance around the mean surprisal value.
### Components/Axes
* **X-axis:** "Layer" - Ranges from 1 to 12 in integer increments.
* **Y-axis:** "Surprisal" - Ranges from 5 to 8 in integer increments.
* **Legend:** Located in the top-right corner.
* Blue line: "step 5000"
* Orange line: "step 10000"
* Green line: "step 20000"
### Detailed Analysis
* **Step 5000 (Blue):** The surprisal starts at approximately 6.9 at layer 1, decreases to about 6.5 by layer 2, and then plateaus around 6.4 for the remaining layers. The shaded region indicates a small variance.
* Layer 1: ~6.9
* Layer 2: ~6.5
* Layer 12: ~6.35
* **Step 10000 (Orange):** The surprisal starts at approximately 6.5 at layer 1, decreases to about 5.9 by layer 2, and continues to decrease gradually to approximately 5.3 by layer 12. The shaded region indicates a small variance.
* Layer 1: ~6.5
* Layer 2: ~5.9
* Layer 12: ~5.3
* **Step 20000 (Green):** The surprisal starts at approximately 6.5 at layer 1, decreases sharply to about 5.7 by layer 2, and continues to decrease gradually to approximately 4.8 by layer 12. The shaded region indicates a small variance.
* Layer 1: ~6.5
* Layer 2: ~5.7
* Layer 12: ~4.8
### Key Observations
* All three lines show a decreasing trend in surprisal as the layer number increases.
* The "step 20000" line (green) consistently has the lowest surprisal values across all layers.
* The "step 5000" line (blue) has the highest surprisal values and plateaus after the initial drop.
* The "step 10000" line (orange) falls between the other two lines and shows a more gradual decrease.
### Interpretation
The chart suggests that as the training step increases (from 5000 to 20000), the surprisal generally decreases across all layers. This indicates that the model becomes more predictable or less "surprised" by the input as it is trained further. The initial layers seem to have a more significant impact on reducing surprisal, as evidenced by the steeper drops between layers 1 and 2 for all three training steps. The plateauing of the "step 5000" line suggests that the model may have reached a point of diminishing returns in terms of reducing surprisal after 5000 training steps, while the other two models continue to improve.
</details>
(b) Layer-wise tuned lens to predict the $\langle$ LAN $\rangle$ token in match condition.
Figure 5: Overtime mechanistic analysis on GPT-CHILDES.
5.1 The Emergence of Symbol Grounding
To provide a mechanistic account of symbol grounding, i.e., when it emerges during training and how it is represented in the network, we apply two interpretability analyses.
Saliency flow. For each layer $\ell$ , we compute a saliency matrix following Wang et al. (2023): $I_{\ell}=\left|\sum_{h}A_{h,\ell}\odot\frac{∂\mathcal{L}}{∂ A_{h,\ell}}\right|$ , where $A_{h,\ell}$ denotes the attention matrix of head $h$ in layer $\ell$ . Each entry of $I_{\ell}$ quantifies the contribution of the corresponding attention weight to the cross-entropy loss $\mathcal{L}$ , averaged across heads. Our analysis focuses on ground-to-symbol connections, i.e., flows from environmental ground ( $\langle$ ENV $\rangle$ ) tokens to the token immediately preceding (and predicting) their linguistic forms ( $\langle$ LAN $\rangle$ ).
Probing with the Tuned Lens. We probe layer-wise representations using the Tuned Lens (Belrose et al., 2023), which trains affine projectors to map intermediate activations to the final prediction space while keeping the LM output head frozen.
Results. Ground-to-symbol saliency is weak in the early stages of training but rises sharply later, peaking in layers 7–9 (Figure 5(a)), suggesting that mid-layer attention plays a central role in establishing symbol–ground correspondences. In addition, Figure 5(b) shows that early layers remain poor predictors even at late training stages (e.g., after 20,000 steps), whereas surprisal begins to drop markedly from layer 7 at intermediate stages (step 10,000), suggesting a potential representational shift in the middle layers.
5.2 Hypothesis: Gather-and-Aggregate Heads Implement Symbol Grounding
Building on these results, we hypothesize that specific Transformer heads in the middle layers enable symbol grounding. To test this, we examine attention saliencies for selected heads (Figure 6). We find that several heads exhibit patterns consistent with the gather and aggregate mechanisms described by Bick et al. (2025): gather heads (e.g., Figures 6(a) and 6(b)) compress relevant information into a subset of positions, while aggregate heads (e.g., Figures 6(c) and 6(d)) redistribute this information to downstream tokens. In our setups, saliency often concentrates on environmental tokens such as train ${}_{\texttt{$\langle$ENV$\rangle$}}$ , where gather heads pool contextual information into compact, retrievable states. In turn, aggregate heads broadcast this information from environmental ground (train $\langle$ ENV $\rangle$ ) to the token immediately preceding the linguistic form, thereby supporting the prediction of train ${}_{\texttt{$\langle$LAN$\rangle$}}$ . Taking these observations together, we hypothesize that the gather-and-aggregate heads implement the symbol grounding mechanism.
<details>
<summary>x18.png Details</summary>
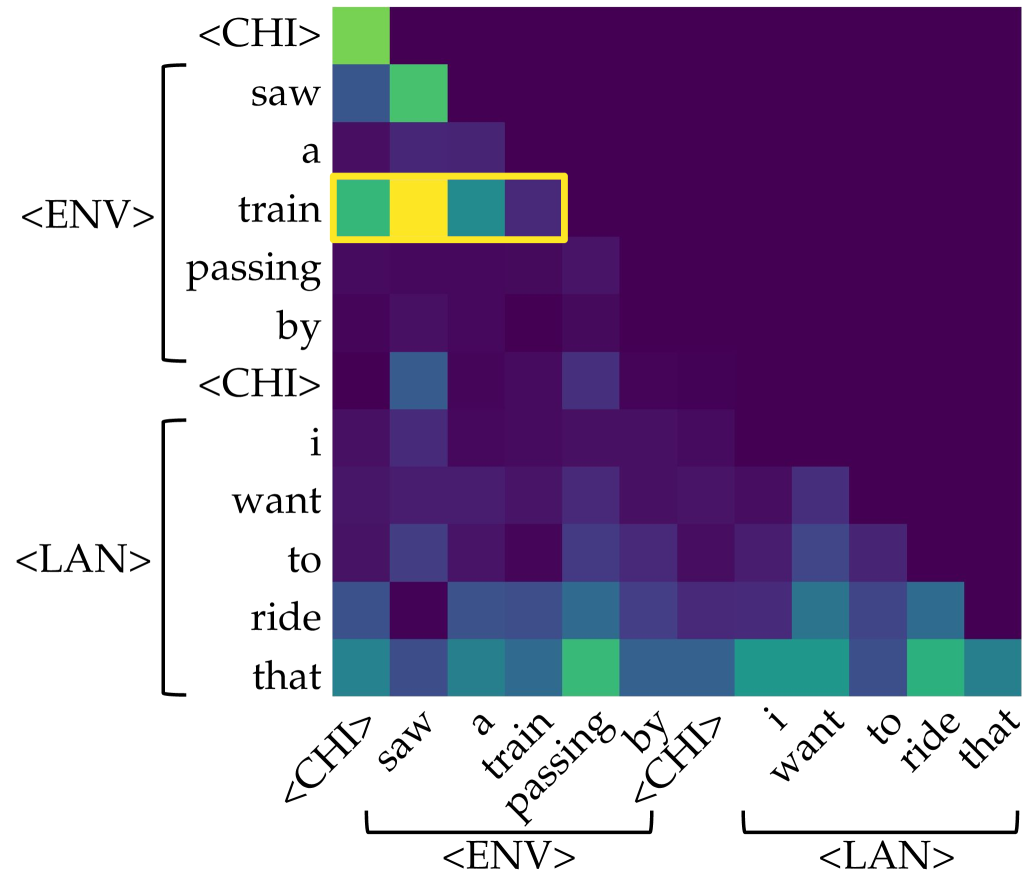
### Visual Description
## Heatmap: Sentence Alignment
### Overview
The image is a heatmap visualizing the alignment between two sentences. The x-axis and y-axis represent the words in the sentences. The color intensity of each cell indicates the strength of the alignment between the corresponding words. The heatmap is triangular, suggesting a comparison of a sentence with itself or a related sentence structure. The sentences are segmented into phrases labeled <CHI>, <ENV>, and <LAN>.
### Components/Axes
* **X-axis:** Represents the words in the sentence: "<CHI> saw a train passing by <CHI> i want to ride that".
* **Y-axis:** Represents the words in the sentence: "<CHI> saw a train passing by <CHI> i want to ride that".
* **Labels:**
* `<CHI>`: Appears at the beginning of both sentences and between "by" and "i".
* `<ENV>`: Labels the phrase "saw a train passing by" on both axes.
* `<LAN>`: Labels the phrase "i want to ride that" on both axes.
* **Color Scale:** The heatmap uses a color gradient where darker colors (purple) indicate weaker or no alignment, and lighter colors (green/yellow) indicate stronger alignment.
### Detailed Analysis
The heatmap shows the alignment between the words of the two sentences. The intensity of the color indicates the strength of the alignment.
* **"<CHI> saw a train passing by" vs. "<CHI> saw a train passing by"**:
* `<CHI>` aligns strongly with `<CHI>` (top-left corner).
* "saw" aligns strongly with "saw".
* "a" aligns strongly with "a".
* "train" aligns strongly with "train".
* "passing" aligns strongly with "passing".
* "by" aligns strongly with "by".
* **"<CHI> i want to ride that" vs. "<CHI> i want to ride that"**:
* `<CHI>` aligns strongly with `<CHI>`.
* "i" aligns strongly with "i".
* "want" aligns strongly with "want".
* "to" aligns strongly with "to".
* "ride" aligns strongly with "ride".
* "that" aligns strongly with "that".
* **Cross-Phrase Alignment:**
* There is some alignment between the phrases, but it is weaker than the within-phrase alignment. For example, there is a weak alignment between "train" in the <ENV> phrase and "want" in the <LAN> phrase.
* **Highlighted Region:** A yellow box highlights the alignment between "train" in the y-axis and "a", "train", and "passing" in the x-axis.
### Key Observations
* The heatmap is symmetrical along the diagonal, indicating that the alignment is reciprocal.
* The strongest alignments occur between identical words within the same phrase.
* The alignment between different phrases is weaker, suggesting less semantic similarity.
* The highlighted region emphasizes the relationship between the word "train" and its surrounding context.
### Interpretation
The heatmap visualizes the semantic relationships between words in a sentence. The strong diagonal alignment indicates that the sentence is internally consistent and that words are most strongly related to themselves. The weaker off-diagonal alignments suggest more distant semantic relationships. The segmentation into <CHI>, <ENV>, and <LAN> phrases provides a higher-level structure for understanding the sentence. The highlighted region draws attention to the context surrounding the word "train," suggesting its importance in the sentence. The heatmap could be used to analyze the coherence and structure of sentences, or to compare the semantic similarity of different sentences.
</details>
(a) Gather: L4 H7.
<details>
<summary>x19.png Details</summary>
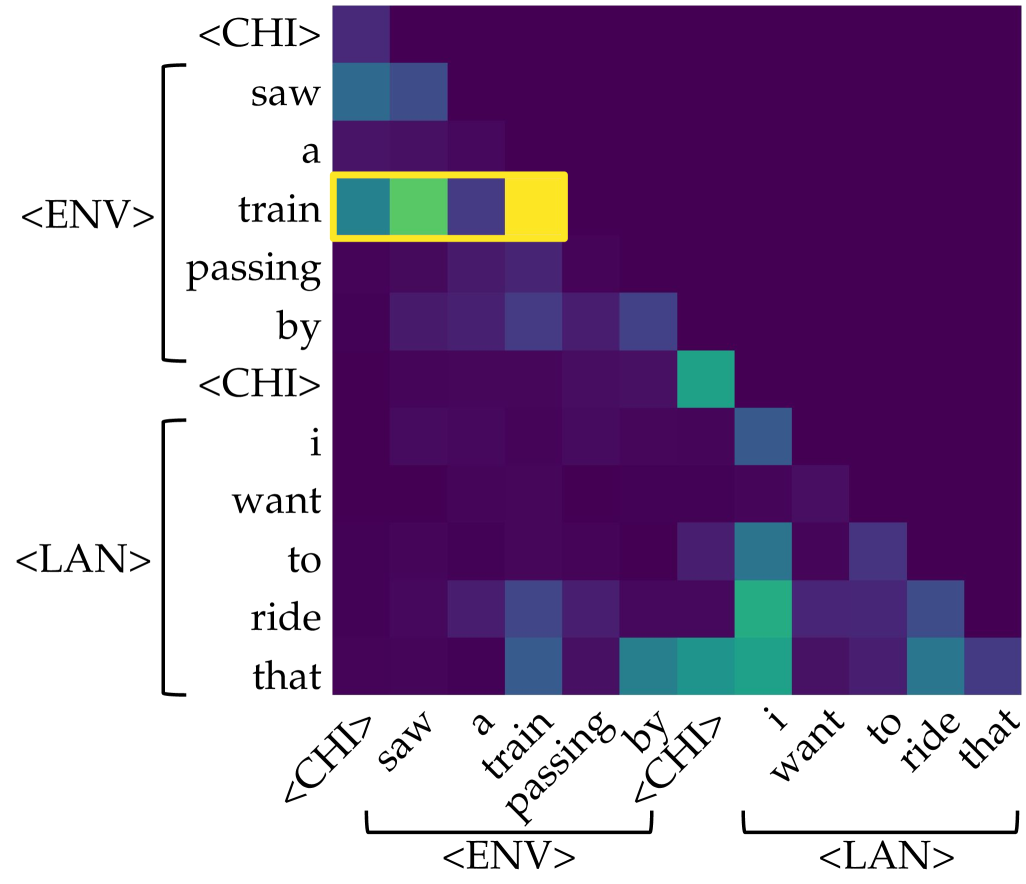
### Visual Description
## Heatmap: Sentence Alignment
### Overview
The image is a heatmap visualizing the alignment between two sentences. The x-axis and y-axis represent the words in the sentences. The color intensity of each cell indicates the strength of the alignment between the corresponding words. A yellow box highlights a specific region of interest.
### Components/Axes
* **X-axis:** The x-axis is labeled with the following words: "<CHI>", "saw", "a", "train", "passing", "by", "<CHI>", "i", "want", "to", "ride", "that". The words "saw" through "by" are grouped under the label "<ENV>", and the words "i" through "that" are grouped under the label "<LAN>".
* **Y-axis:** The y-axis is labeled with the same words as the x-axis: "<CHI>", "saw", "a", "train", "passing", "by", "<CHI>", "i", "want", "to", "ride", "that". The words "saw" through "by" are grouped under the label "<ENV>", and the words "i" through "that" are grouped under the label "<LAN>".
* **Color Scale:** The heatmap uses a color gradient where darker colors (purple/blue) indicate weaker alignment and lighter colors (green/yellow) indicate stronger alignment.
* **Highlighted Region:** A yellow box surrounds the cells corresponding to the word "train" on the y-axis and the words "saw", "a", "train" on the x-axis.
### Detailed Analysis
The heatmap shows the alignment strength between words in the two sentences. The intensity of the color indicates the strength of the alignment.
* **"<CHI>" Alignment:** The first "<CHI>" on the y-axis aligns strongly with the first "<CHI>" on the x-axis.
* **"saw" Alignment:** The word "saw" on the y-axis aligns strongly with the word "saw" on the x-axis.
* **"a" Alignment:** The word "a" on the y-axis aligns strongly with the word "a" on the x-axis.
* **"train" Alignment:** The word "train" on the y-axis aligns strongly with the words "saw", "a", and "train" on the x-axis. This region is highlighted with a yellow box.
* **"passing" Alignment:** The word "passing" on the y-axis aligns moderately with the word "passing" on the x-axis.
* **"by" Alignment:** The word "by" on the y-axis aligns moderately with the word "by" on the x-axis.
* **Second "<CHI>" Alignment:** The second "<CHI>" on the y-axis aligns strongly with the second "<CHI>" on the x-axis.
* **"i" Alignment:** The word "i" on the y-axis aligns strongly with the word "i" on the x-axis.
* **"want" Alignment:** The word "want" on the y-axis aligns moderately with the word "want" on the x-axis.
* **"to" Alignment:** The word "to" on the y-axis aligns moderately with the word "to" on the x-axis.
* **"ride" Alignment:** The word "ride" on the y-axis aligns moderately with the word "ride" on the x-axis.
* **"that" Alignment:** The word "that" on the y-axis aligns moderately with the word "that" on the x-axis.
### Key Observations
* The diagonal elements generally show stronger alignment, indicating that words tend to align with themselves.
* The highlighted region shows that the word "train" in the first sentence has a strong alignment with "saw", "a", and "train" in the second sentence.
* The alignment between the two sentences is not perfect, as some words have weaker or no alignment with their counterparts.
### Interpretation
The heatmap visualizes the alignment between two sentences, likely representing the output of a machine translation or natural language processing model. The stronger the alignment between two words, the more likely they are to be semantically related or correspond to each other in the translation. The highlighted region suggests that the model recognizes the relationship between "train" in the first sentence and the phrase "saw a train" in the second sentence. The labels "<CHI>", "<ENV>", and "<LAN>" likely represent different contexts or categories within the sentences, but without further context, their specific meanings are unclear. The heatmap provides a visual representation of how the model understands the relationship between the two sentences.
</details>
(b) Gather: L4 H8.
<details>
<summary>x20.png Details</summary>
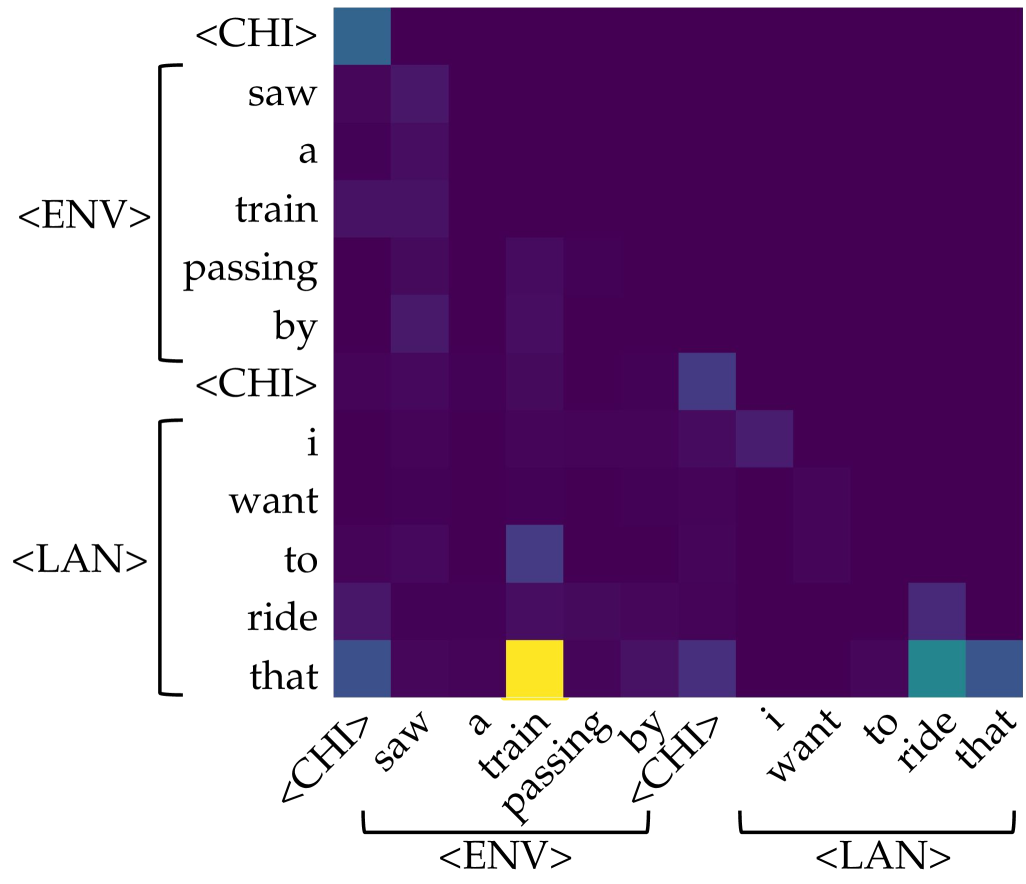
### Visual Description
## Heatmap: Alignment of Child Utterances with Environment and Language
### Overview
The image is a heatmap visualizing the alignment between a child's utterances and segments representing the environment (ENV) and language (LAN). The heatmap uses color intensity to represent the strength of the alignment, with brighter colors indicating stronger alignment. The x-axis and y-axis represent the same sequence of words, segmented into <CHI>, <ENV>, and <LAN> categories.
### Components/Axes
* **X-axis:** Represents the sequence of words: "<CHI> saw a train passing by <CHI> i want to ride that", segmented into <CHI>, <ENV>, and <LAN> categories.
* **Y-axis:** Represents the same sequence of words as the x-axis: "<CHI> saw a train passing by <CHI> i want to ride that", segmented into <CHI>, <ENV>, and <LAN> categories.
* **Color Scale:** The heatmap uses a color gradient where darker colors (purple) indicate weaker or no alignment, and brighter colors (yellow) indicate stronger alignment.
### Detailed Analysis
The heatmap shows the alignment between different parts of the child's utterance.
* **<CHI> (Child Utterance 1):** The first "<CHI>" on the y-axis aligns strongly with the first "<CHI>" on the x-axis (top-left corner, dark blue).
* **"saw":** "saw" on the y-axis shows some alignment with "saw" and "a" on the x-axis (dark blue).
* **"a":** "a" on the y-axis shows some alignment with "a" and "train" on the x-axis (dark blue).
* **<ENV> (Environment):** The "<ENV>" segment ("train passing by") on the y-axis shows a strong alignment with the "<ENV>" segment on the x-axis. Specifically, "train" aligns strongly with "train" (yellow), and "passing" aligns with "passing" (dark blue).
* **<CHI> (Child Utterance 2):** The second "<CHI>" on the y-axis aligns strongly with the second "<CHI>" on the x-axis (dark blue).
* **"i":** "i" on the y-axis shows some alignment with "i" on the x-axis (dark blue).
* **<LAN> (Language):** The "<LAN>" segment ("want to ride that") on the y-axis shows alignment with the "<LAN>" segment on the x-axis. "to" aligns with "to" (dark blue), and "that" aligns with "that" (green).
### Key Observations
* The strongest alignments occur within the same segments (e.g., <CHI> with <CHI>, <ENV> with <ENV>, <LAN> with <LAN>).
* The word "train" within the <ENV> segment shows the strongest alignment (yellow).
* The word "that" within the <LAN> segment shows a moderate alignment (green).
* There is weaker alignment between different segments, suggesting that the child's utterances are more strongly related to the corresponding environment or language segments.
### Interpretation
The heatmap visualizes how a child's utterances align with environmental and language contexts. The strong diagonal alignment suggests that the child's speech is highly correlated with the immediate context (environment) and the broader language input. The intensity variations indicate the degree of association between specific words or phrases. The child's utterance "train" is strongly associated with the environment, while "that" is associated with the language segment. This visualization can be used to understand how children learn language by associating words and phrases with their environment and the language they hear.
</details>
(c) Aggregate: L7 H5.
<details>
<summary>x21.png Details</summary>
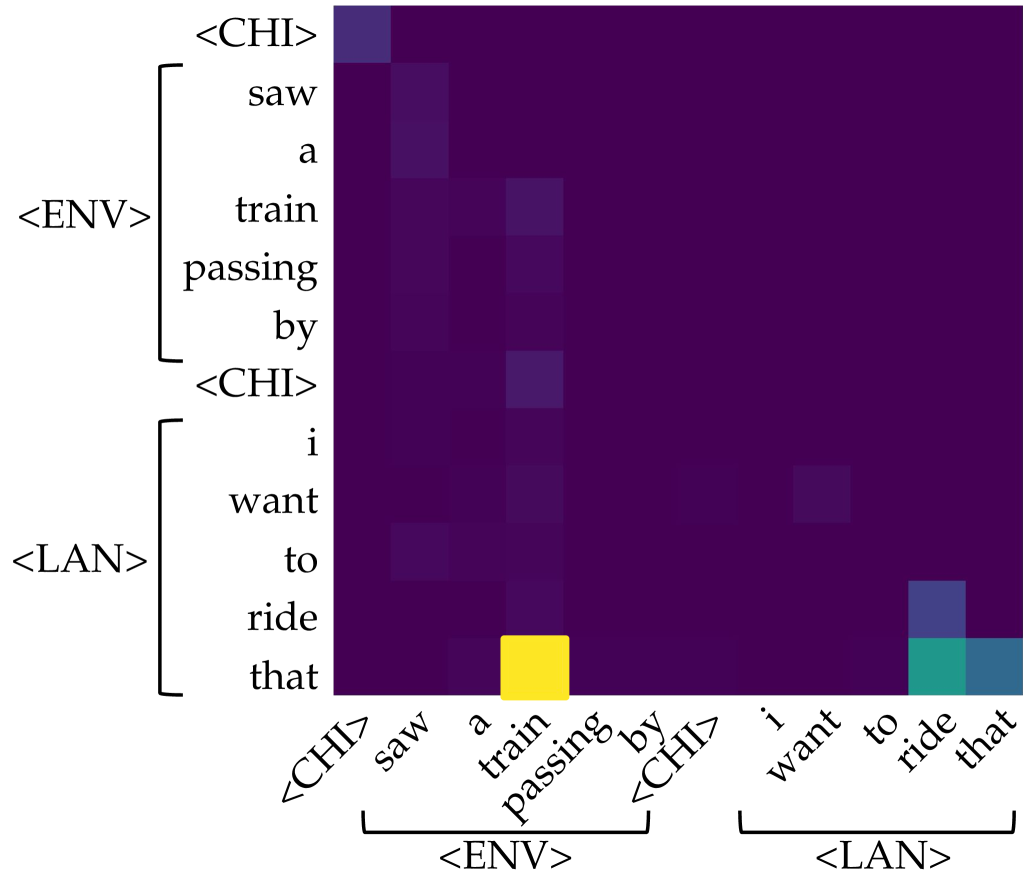
### Visual Description
## Heatmap: Attention Matrix
### Overview
The image is a heatmap representing an attention matrix, likely from a machine learning model processing two sentences. The rows represent the words in the input sentences, and the columns represent the words in the output sentences. The color intensity indicates the strength of attention between corresponding words. The sentences are segmented into phrases labeled as `<CHI>`, `<ENV>`, and `<LAN>`.
### Components/Axes
* **Rows (Y-axis):** The rows are labeled with the words of two sentences, grouped into phrases:
* `<CHI>`: (Top)
* `<ENV>`: "saw", "a", "train", "passing", "by"
* `<CHI>`: (Middle)
* `<LAN>`: "i", "want", "to", "ride", "that"
* **Columns (X-axis):** The columns are labeled with the words of the same two sentences, grouped into phrases:
* `<CHI>`: (Left)
* `<ENV>`: "saw", "a", "train", "passing", "by"
* `<CHI>`: (Middle)
* `<LAN>`: "i", "want", "to", "ride", "that"
* **Color Scale:** The heatmap uses a color gradient where darker colors (purple/black) represent lower attention scores and brighter colors (yellow) represent higher attention scores.
### Detailed Analysis
The heatmap shows the attention weights between the words of the input and output sentences. Here's a breakdown of the key areas:
* **`<CHI>` to `<CHI>`:** The attention between the initial `<CHI>` tokens is relatively low, indicated by the dark color.
* **`<ENV>` to `<ENV>`:** There is moderate attention within the `<ENV>` phrase. For example, "saw" attends to "saw", "a" attends to "a", and so on, but the intensity is not very high.
* **`<LAN>` to `<ENV>`:** The word "ride" in `<LAN>` has a strong attention (yellow) to the word "train" in `<ENV>`.
* **`<LAN>` to `<LAN>`:** The word "that" in `<LAN>` has moderate attention (green/blue) to the words "to", "ride", and "that" in `<LAN>`.
* **Other areas:** Most other areas of the heatmap show very low attention, indicated by the dark purple/black color.
### Key Observations
* The model seems to focus attention primarily within the `<ENV>` and `<LAN>` phrases, with a strong connection between "ride" and "train".
* The attention scores are generally low, except for the specific connections mentioned above.
* The `<CHI>` tokens seem to have minimal attention to other words in the sentences.
### Interpretation
The attention matrix visualizes how the model relates different words in the input and output sentences. The strong attention between "ride" and "train" suggests that the model understands the semantic relationship between these words. The attention within the `<ENV>` and `<LAN>` phrases indicates that the model is also capturing the local context of these phrases. The low attention scores in other areas suggest that the model is filtering out irrelevant information.
The heatmap provides insights into the model's decision-making process and can be used to identify potential areas for improvement. For example, if the model is not paying enough attention to certain words, the training data or model architecture could be adjusted to address this issue.
</details>
(d) Aggregate: L8 H5.
Figure 6: Examples of gather and aggregate heads identified in GPT-CHILDES. L: layer; H: head.
Table 2: Causal intervention results on identified gather and aggregate heads across training checkpoints (ckpt.). Avg. Count denotes the average number of heads of each type over inference times, and Avg. Layer denotes the average layer index where they appear. Interv. Sps. reports surprisal after zeroing out the identified heads, while Ctrl. Sps. reports surprisal after zeroing out an equal number of randomly selected heads. Original refers to the baseline surprisal without any intervention. *** indicates a significant result ( $p<0.001$ ) where the intervention surprisal is higher than that in the corresponding control experiment.
| Ckpt. | Gather Head | Aggregate Head | Original | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Avg. | Avg. | Interv. | Ctrl. | Avg. | Avg. | Interv. | Ctrl. | | |
| Count | Layer | Sps. | Sps. | Count | Layer | Sps. | Sps. | | |
| 500 | 0.00 | - | - | - | 0.07 | 8.74 | 9.34 | 9.34 | 9.34 |
| 5000 | 0.35 | 3.32 | 6.37 | 6.38 | 2.28 | 7.38 | 6.51 | 6.39 | 6.38 |
| (***) | | | | | | | | | |
| 10000 | 3.26 | 3.67 | 5.25 | 5.32 | 5.09 | 7.28 | 5.86 | 5.29 | 5.30 |
| (***) | | | | | | | | | |
| 20000 | 5.76 | 3.59 | 4.69 | 4.79 | 6.71 | 7.52 | 5.62 | 4.76 | 4.77 |
| (***) | | | | | | | | | |
5.3 Causal Interventions of Attention Heads
We then conduct causal interventions of attention heads to validate our previous hypothesis.
Operational definition. We identify attention heads as gather or aggregate following these standards:
- Gather head. An attention head is classified as a gather head if at least 30% of its total saliency is directed toward the environmental ground token from the previous ones.
- Aggregate head: An attention head is classified as an aggregate head if at least 30% of its total saliency flows from the environmental ground token to the token immediately preceding the corresponding linguistic token.
Causal intervention methods. In each context, we apply causal interventions to the identified head types and their corresponding controls. Following Bick et al. (2025), interventions are implemented by zeroing out the outputs of heads. For the control, we mask an equal number of randomly selected heads in each layer, ensuring they do not overlap with the identified gather or aggregate heads.
| Thres. | Ckpt. | Aggregate Head | Original | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Avg. | Avg. | Interv. | Ctrl. | | | |
| Count | Layer | Sps. | Sps. | | | |
| 70% | 20k | 32.30 | 7.78 | 9.96 | 9.95 | 9.21 |
| 100k | 35.63 | 7.71 | 9.42 | 8.84 | 8.24 | |
| (***) | | | | | | |
| 200k | 34.99 | 7.80 | 8.95 | 8.15 | 7.76 | |
| (***) | | | | | | |
| 300k | 34.15 | 7.76 | 8.96 | 8.11 | 7.69 | |
| (***) | | | | | | |
| 90% | 20k | 10.66 | 8.33 | 9.51 | 9.43 | 9.21 |
| (***) | | | | | | |
| 100k | 13.90 | 8.26 | 8.95 | 8.50 | 8.24 | |
| (***) | | | | | | |
| 200k | 13.47 | 8.46 | 8.41 | 7.88 | 7.76 | |
| (***) | | | | | | |
| 300k | 12.73 | 8.42 | 8.40 | 7.87 | 7.69 | |
| (***) | | | | | | |
<details>
<summary>x22.png Details</summary>
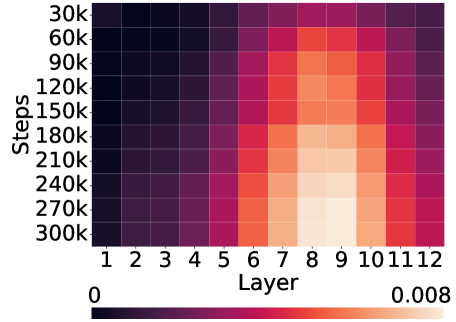
### Visual Description
## Heatmap: Layer vs Steps
### Overview
The image is a heatmap showing the relationship between "Steps" (training iterations) and "Layer" number, with the color intensity representing a value ranging from 0 to 0.008. The x-axis represents the layer number, ranging from 1 to 12. The y-axis represents the number of steps, ranging from 30k to 300k in increments of 30k. The color gradient ranges from dark purple (representing 0) to light orange (representing 0.008).
### Components/Axes
* **X-axis:** "Layer", with values from 1 to 12.
* **Y-axis:** "Steps", with values 30k, 60k, 90k, 120k, 150k, 180k, 210k, 240k, 270k, 300k.
* **Color Legend:** Ranges from 0 (dark purple) to 0.008 (light orange).
### Detailed Analysis
The heatmap shows a distinct pattern. The intensity (value) is low for early layers (1-4) and late layers (10-12) across all steps. The intensity increases towards the middle layers (5-9), peaking around layer 8. The highest intensity (light orange) is observed around layers 7-9 for steps between 150k and 240k.
* **Steps 30k-60k:** The values are generally low (dark purple) across all layers, with a slight increase in intensity around layers 6-8.
* **Steps 90k-120k:** The intensity increases, with a noticeable peak around layers 7-9.
* **Steps 150k-240k:** The intensity is highest, with the peak around layers 7-9 showing the lightest orange color.
* **Steps 270k-300k:** The intensity decreases slightly compared to the 150k-240k range, but remains higher than the initial steps.
### Key Observations
* The highest values are concentrated in the middle layers (7-9) and around the middle steps (150k-240k).
* The values are generally low for the first few layers (1-4) and the last few layers (10-12).
* The intensity increases as the number of steps increases, up to a point (around 150k-240k), after which it slightly decreases or plateaus.
### Interpretation
The heatmap suggests that the middle layers (7-9) are most active or sensitive during the training process, particularly around the 150k-240k step range. This could indicate that these layers are crucial for learning specific features or patterns in the data. The lower values in the initial and final layers might indicate that these layers are less involved in the core learning process, possibly handling input/output or more general feature extraction. The trend of increasing intensity with steps suggests that the model learns more effectively as training progresses, up to a certain point. The slight decrease or plateau after 240k steps might indicate diminishing returns or the need for adjustments to the training process.
</details>
Figure 7: Mechanistic analysis in the image-grounded visual dialogue setting. Left: Causal intervention results on identified aggregate heads across training checkpoints, where intervention on aggregate heads consistently yields significantly higher surprisal ( $p<0.001$ , ***) compared to the control group ones. Right: Saliency of layer-wise attention from environmental tokens (i.e., image tokens corresponding to patches within the bounding boxes of the target object) to linguistic tokens across training steps.
Results and discussions. As training progresses, the number of both gather and aggregate heads increases (Table 2), suggesting that these mechanisms emerge over the course of learning. Causal interventions reveal a clear dissociation: zeroing out aggregate heads consistently produces significantly higher surprisal compared to controls, whereas the gather head interventions have no such effect. This asymmetry suggests that gather heads serve in a role less critical in our settings, where the input template is semantically light and the environmental evidence alone suffices to shape the linguistic form. Layer-wise patterns further support this division of labor: gather heads cluster in shallow layers (3-4), while aggregate heads concentrate in mid layers (7-8). This resonates with our earlier probing results, where surprisal reductions became prominent only from layers 7-9. Together, these findings highlight aggregate heads in the middle layers as the primary account of grounding in the model.
5.4 Generalization to Visual Dialog with Images
We also conduct causal interventions of attention heads on the VLM model to further validate our previous hypothesis.
Operational definition. We identify attention heads as aggregate following this standard (We do not define gather head): An attention head is classified as an aggregate head if at least a certain threshold (70% or 90% in our experiment settings) of its total image patch to end saliency flows from the patches inside bounding box to the token immediately preceding the corresponding linguistic token.
Causal intervention methods. In each context, we apply causal interventions to the identified head types and their corresponding controls in the language backbone of the model. Similar to section 5.3, interventions are implemented by zeroing out a head’s outputs. For the control, we mask an equal number of randomly selected heads in each layer, ensuring they do not overlap with the identified gather or aggregate heads.
Results and discussions. As training progresses, the number of aggregate heads increases first and then becomes steady (Figure 7), suggesting that these mechanisms emerge over the course of learning. Causal interventions reveal that zeroing out aggregate heads consistently produces significantly higher surprisal rises compared to controls. The average layer also align with the saliency heatmap, also shown in Figure 7.
6 Discussions
Generalization to full-scale VLMs. As an additional case study, we extend our grounding-as-aggregation hypothesis to a full-scale VLM, LLaVA-1.5-7B (Liu et al., 2023). Even in this heavily engineered architecture, we identify many attention heads exhibiting aggregation behavior consistent with our earlier findings (Figure 1(b)), reinforcing the view that symbol grounding arises from specialized heads. At the same time, full-scale VLMs present additional complications. Models like LLaVA use multiple sets of visual tokens, including CLIP-derived embeddings that already encode language priors, and global information may be stored in redundant artifact tokens rather than object-centric regions (Darcet et al., 2024). Moreover, the large number of visual tokens (environmental tokens, in our setup) substantially increases both computational cost and the difficulty of isolating genuine aggregation heads. These factors make systematic identification and intervention at scale a nontrivial challenge. For these reasons, while our case study highlights promising evidence of grounding heads in modern VLMs, systematic detection and causal evaluation of such heads at scale remains an open challenge. Future work will need to develop computationally viable methods for (i) automatically detecting aggregation heads across diverse VLMs, and (ii) applying causal interventions to validate their role in grounding. Addressing these challenges will be crucial for moving from anecdotal case studies to a more principled understanding of grounding in modern VLMs.
The philosophical roots of grounding, revisited. Our findings highlight the need to sharpen the meaning of grounding in multimodal models. Prior work has often equated grounding with statistical correlations between visual and textual signals, such as attention overlaps or geometric alignments (Bousselham et al., 2024; Cao et al., 2025; Schnaus et al., 2025). While informative, such correlations diverge from the classic formulation by Harnad (1990), which requires symbols to be causally anchored to their referents in the environment. On the other extreme, Gubelmann (2024) argued that the symbol grounding problem does not apply to LLMs as they “are connectionist, statistical devices that have no intrinsic symbolic structure.” In contrast, we discover emergent symbolic structure as an intrinsic mechanistic property: one that can be traced along training, observed in the specialization of attention heads, and validated through causal interventions. This provides not only a practical diagnostic protocol that reveals when and how models genuinely tie symbols to meaning beyond surface-level correlations, but also challenges the view that grounding is philosophically irrelevant to systems without explicit symbolic structure.
Practical implications to LM hallucinations. Our findings have practical implications for improving the reliability of LM outputs: by identifying aggregation heads that mediate grounding between environmental and linguistic tokens, we provide a promising mechanism to detect model reliability before generation. Our findings echo a pathway to mitigate hallucinations by focusing on attention control: many hallucination errors stem from misallocated attention in intermediate layers (Jiang et al., 2025; Chen et al., 2024b). Such attention-level signals can serve as early indicators of overtrust or false grounding, motivating practical solutions like decoding-time strategies to mitigate and eventually prevent hallucination (Huang et al., 2024).
Acknowledgement
This work was supported in part by NSF IIS-1949634, NSF SES-2128623, NSERC RGPIN-2024-04395, the Weinberg Cognitive Science Fellowship to ZM, a Vector Scholarship to XL, and a Canada CIFAR AI Chair award to FS. The authors would like to thank Songlin Yang and Jing Ding for their valuable feedback.
References
- Anthropic (2024) Anthropic. The claude 3 model family: Opus, sonnet, haiku, March 2024. URL https://www.anthropic.com/news/claude-3-family.
- Arora et al. (2025) Aryaman Arora, Neil Rathi, Nikil Roashan Selvam, Róbert Csórdas, Dan Jurafsky, and Christopher Potts. Mechanistic evaluation of transformers and state space models. arXiv preprint arXiv:2505.15105, 2025.
- Belrose et al. (2023) Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112, 2023.
- Bick et al. (2025) Aviv Bick, Eric P. Xing, and Albert Gu. Understanding the skill gap in recurrent models: The role of the gather-and-aggregate mechanism. In Forty-second International Conference on Machine Learning, 2025.
- Biderman et al. (2023) Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pp. 2397–2430. PMLR, 2023.
- Bietti et al. (2023) Alberto Bietti, Vivien Cabannes, Diane Bouchacourt, Herve Jegou, and Leon Bottou. Birth of a transformer: A memory viewpoint. Advances in Neural Information Processing Systems, 2023.
- Blevins et al. (2022) Terra Blevins, Hila Gonen, and Luke Zettlemoyer. Analyzing the mono-and cross-lingual pretraining dynamics of multilingual language models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 3575–3590, 2022.
- Bousselham et al. (2024) Walid Bousselham, Felix Petersen, Vittorio Ferrari, and Hilde Kuehne. Grounding everything: Emerging localization properties in vision-language transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3828–3837, 2024.
- Cao et al. (2025) Shengcao Cao, Liang-Yan Gui, and Yu-Xiong Wang. Emerging pixel grounding in large multimodal models without grounding supervision. In International Conference on Machine Learning, 2025.
- Chang & Bergen (2022) Tyler A Chang and Benjamin K Bergen. Word acquisition in neural language models. Transactions of the Association for Computational Linguistics, 10:1–16, 2022.
- Chang et al. (2024) Tyler A Chang, Zhuowen Tu, and Benjamin K Bergen. Characterizing learning curves during language model pre-training: Learning, forgetting, and stability. Transactions of the Association for Computational Linguistics, 12:1346–1362, 2024.
- Chen et al. (2024a) Jierun Chen, Fangyun Wei, Jinjing Zhao, Sizhe Song, Bohuai Wu, Zhuoxuan Peng, S-H Gary Chan, and Hongyang Zhang. Revisiting referring expression comprehension evaluation in the era of large multimodal models. arXiv preprint arXiv:2406.16866, 2024a.
- Chen et al. (2023) Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195, 2023.
- Chen et al. (2024b) Xuweiyi Chen, Ziqiao Ma, Xuejun Zhang, Sihan Xu, Shengyi Qian, Jianing Yang, David Fouhey, and Joyce Chai. Multi-object hallucination in vision language models. Advances in Neural Information Processing Systems, 37:44393–44418, 2024b.
- Clark (1995) Eve V Clark. The lexicon in acquisition. Number 65. Cambridge University Press, 1995.
- Comanici et al. (2025) Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025.
- Dao & Gu (2024) Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality. In International Conference on Machine Learning, pp. 10041–10071. PMLR, 2024.
- Darcet et al. (2024) Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. In The Twelfth International Conference on Learning Representations, 2024.
- Das et al. (2017) Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, José MF Moura, Devi Parikh, and Dhruv Batra. Visual dialog. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 326–335, 2017.
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2020.
- Elhage et al. (2021) Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A mathematical framework for transformer circuits. Transformer Circuits Thread, 2021. https://transformer-circuits.pub/2021/framework/index.html.
- Evanson et al. (2023) Linnea Evanson, Yair Lakretz, and Jean-Rémi King. Language acquisition: do children and language models follow similar learning stages? In Findings of the Association for Computational Linguistics: ACL 2023, pp. 12205–12218, 2023.
- Fazly et al. (2010) Afsaneh Fazly, Afra Alishahi, and Suzanne Stevenson. A probabilistic computational model of cross-situational word learning. Cognitive Science, 34(6):1017–1063, 2010.
- Fenson et al. (2006) Larry Fenson, Virginia A Marchman, Donna J Thal, Phillip S Dale, J Steven Reznick, and Elizabeth Bates. Macarthur-bates communicative development inventories. PsycTESTS Dataset, 2006.
- Gleitman & Landau (1994) Lila R Gleitman and Barbara Landau. The acquisition of the lexicon. MIT Press, 1994.
- Goodman et al. (2007) Noah Goodman, Joshua Tenenbaum, and Michael Black. A bayesian framework for cross-situational word-learning. Advances in neural information processing systems, 20, 2007.
- Gubelmann (2024) Reto Gubelmann. Pragmatic norms are all you need–why the symbol grounding problem does not apply to llms. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 11663–11678, 2024.
- Hagendorff (2023) Thilo Hagendorff. Machine psychology: Investigating emergent capabilities and behavior in large language models using psychological methods. arXiv preprint arXiv:2303.13988, 2023.
- Harnad (1990) Stevan Harnad. The symbol grounding problem. Physica D: Nonlinear Phenomena, 42(1-3):335–346, 1990.
- Hochreiter & Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- Huang et al. (2024) Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13418–13427, 2024.
- Jiang et al. (2025) Zhangqi Jiang, Junkai Chen, Beier Zhu, Tingjin Luo, Yankun Shen, and Xu Yang. Devils in middle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 25004–25014, 2025.
- Kangaslahti et al. (2025) Sara Kangaslahti, Elan Rosenfeld, and Naomi Saphra. Hidden breakthroughs in language model training. arXiv preprint arXiv:2506.15872, 2025.
- Li et al. (2022) Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10965–10975, 2022.
- Lieberum et al. (2023) Tom Lieberum, Matthew Rahtz, János Kramár, Neel Nanda, Geoffrey Irving, Rohin Shah, and Vladimir Mikulik. Does circuit analysis interpretability scale? Evidence from multiple choice capabilities in chinchilla. arXiv preprint arXiv:2307.09458, 2023.
- Lin et al. (2014) Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pp. 740–755. Springer, 2014.
- Liu et al. (2023) Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In Advances in neural information processing systems, volume 36, pp. 34892–34916, 2023.
- Lu et al. (2024) Sheng Lu, Irina Bigoulaeva, Rachneet Sachdeva, Harish Tayyar Madabushi, and Iryna Gurevych. Are emergent abilities in large language models just in-context learning? In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 5098–5139, 2024.
- Ma et al. (2023) Ziqiao Ma, Jiayi Pan, and Joyce Chai. World-to-words: Grounded open vocabulary acquisition through fast mapping in vision-language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 524–544, 2023.
- Ma et al. (2025) Ziqiao Ma, Zekun Wang, and Joyce Chai. Babysit a language model from scratch: Interactive language learning by trials and demonstrations. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 991–1010, 2025.
- MacWhinney (2000) Brian MacWhinney. The childes project: Tools for analyzing talk: Volume i: Transcription format and programs, volume ii: The database, 2000.
- Mao et al. (2019) Jiayuan Mao, Chuang Gan, Pushmeet Kohli, Joshua B. Tenenbaum, and Jiajun Wu. The neuro-symbolic concept learner: Interpreting scenes, words, sentences from natural supervision. International Conference on Learning Representations (ICLR), 2019.
- Mao et al. (2021) Jiayuan Mao, Freda H. Shi, Jiajun Wu, Roger P. Levy, and Joshua B. Tenenbaum. Grammar-based grounded lexicon learning. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan (eds.), Advances in Neural Information Processing Systems, 2021.
- Meng et al. (2022) Kevin Meng, David Bau, Alex J Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. In Advances in Neural Information Processing Systems, 2022.
- Olsson et al. (2022) Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. In-context learning and induction heads. Transformer Circuits Thread, 2022. https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html.
- OpenAI (2024) OpenAI. Hello gpt-4o, May 2024. URL https://openai.com/index/hello-gpt-4o/.
- Oquab et al. (2024) Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research Journal, pp. 1–31, 2024.
- Peng et al. (2024) Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Qixiang Ye, and Furu Wei. Grounding multimodal large language models to the world. In The Twelfth International Conference on Learning Representations, 2024.
- Pratt et al. (2020) Sarah Pratt, Mark Yatskar, Luca Weihs, Ali Farhadi, and Aniruddha Kembhavi. Grounded situation recognition. In European Conference on Computer Vision, pp. 314–332. Springer, 2020.
- Qu & Chai (2010) Shaolin Qu and Joyce Yue Chai. Context-based word acquisition for situated dialogue in a virtual world. Journal of Artificial Intelligence Research, 37:247–277, 2010.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763. PmLR, 2021.
- Rasheed et al. (2024) Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M Anwer, Erix Xing, Ming-Hsuan Yang, and Fahad S Khan. Glamm: Pixel grounding large multimodal model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
- Regier (2005) Terry Regier. The emergence of words: Attentional learning in form and meaning. Cognitive science, 29(6):819–865, 2005.
- Rombach et al. (2022) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022.
- Roy & Pentland (2002) Deb K Roy and Alex P Pentland. Learning words from sights and sounds: A computational model. Cognitive science, 26(1):113–146, 2002.
- Sabet et al. (2020) Masoud Jalili Sabet, Philipp Dufter, François Yvon, and Hinrich Schütze. Simalign: High quality word alignments without parallel training data using static and contextualized embeddings. In Findings of the Association for Computational Linguistics: EMNLP 2020, 2020.
- Schaeffer et al. (2023) Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. Are emergent abilities of large language models a mirage? Advances in Neural Information Processing Systems, 36, 2023.
- Schnaus et al. (2025) Dominik Schnaus, Nikita Araslanov, and Daniel Cremers. It’s a (blind) match! Towards vision-language correspondence without parallel data. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 24983–24992, 2025.
- Sellam et al. (2021) Thibault Sellam, Steve Yadlowsky, Ian Tenney, Jason Wei, Naomi Saphra, Alexander D’Amour, Tal Linzen, Jasmijn Bastings, Iulia Raluca Turc, Jacob Eisenstein, et al. The multiberts: Bert reproductions for robustness analysis. In International Conference on Learning Representations, 2021.
- Shi et al. (2021) Haoyue Shi, Luke Zettlemoyer, and Sida I. Wang. Bilingual lexicon induction via unsupervised bitext construction and word alignment. In ACL, 2021.
- Siskind (1996) Jeffrey Mark Siskind. A computational study of cross-situational techniques for learning word-to-meaning mappings. Cognition, 61(1-2):39–91, 1996.
- van der Wal et al. (2025) Oskar van der Wal, Pietro Lesci, Max Müller-Eberstein, Naomi Saphra, Hailey Schoelkopf, Willem Zuidema, and Stella Biderman. Polypythias: Stability and outliers across fifty language model pre-training runs. In Proceedings of the Thirteenth International Conference on Learning Representations (ICLR 2025), pp. 1–25, 2025.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Wang et al. (2023) Lean Wang, Lei Li, Damai Dai, Deli Chen, Hao Zhou, Fandong Meng, Jie Zhou, and Xu Sun. Label words are anchors: An information flow perspective for understanding in-context learning. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 9840–9855, 2023.
- Wang et al. (2024) Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Song XiXuan, et al. Cogvlm: Visual expert for pretrained language models. Advances in Neural Information Processing Systems, 37:121475–121499, 2024.
- Wei et al. (2022) Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. Transactions on Machine Learning Research, 2022.
- Wiegreffe et al. (2025) Sarah Wiegreffe, Oyvind Tafjord, Yonatan Belinkov, Hannaneh Hajishirzi, and Ashish Sabharwal. Answer, assemble, ace: Understanding how LMs answer multiple choice questions. In The Thirteenth International Conference on Learning Representations, 2025.
- Wu et al. (2025a) Wenhao Wu, Yizhong Wang, Guangxuan Xiao, Hao Peng, and Yao Fu. Retrieval head mechanistically explains long-context factuality. In The Thirteenth International Conference on Learning Representations, 2025a.
- Wu et al. (2025b) Zhaofeng Wu, Dani Yogatama, Jiasen Lu, and Yoon Kim. The semantic hub hypothesis: Language models share semantic representations across languages and modalities. In ICML, 2025b.
- Xia et al. (2023) Mengzhou Xia, Mikel Artetxe, Chunting Zhou, Xi Victoria Lin, Ramakanth Pasunuru, Danqi Chen, Luke Zettlemoyer, and Ves Stoyanov. Training trajectories of language models across scales. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 13711–13738, 2023.
- Xia et al. (2024) Zhuofan Xia, Dongchen Han, Yizeng Han, Xuran Pan, Shiji Song, and Gao Huang. Gsva: Generalized segmentation via multimodal large language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
- Xu & Tenenbaum (2007) Fei Xu and Joshua B Tenenbaum. Word learning as bayesian inference. Psychological review, 114(2):245, 2007.
- You et al. (2024) Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and ground anything anywhere at any granularity. In The Twelfth International Conference on Learning Representations, 2024.
- Yu (2005) Chen Yu. The emergence of links between lexical acquisition and object categorization: A computational study. Connection science, 17(3-4):381–397, 2005.
- Yu & Ballard (2007) Chen Yu and Dana H Ballard. A unified model of early word learning: Integrating statistical and social cues. Neurocomputing, 70(13-15):2149–2165, 2007.
- Yu & Siskind (2013) Haonan Yu and Jeffrey Mark Siskind. Grounded language learning from video described with sentences. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 53–63, 2013.
- Zhang et al. (2024a) Tao Zhang, Xiangtai Li, Hao Fei, Haobo Yuan, Shengqiong Wu, Shunping Ji, Chen Change Loy, and Shuicheng Yan. Omg-llava: Bridging image-level, object-level, pixel-level reasoning and understanding. Advances in neural information processing systems, 37:71737–71767, 2024a.
- Zhang et al. (2024b) Yichi Zhang, Ziqiao Ma, Xiaofeng Gao, Suhaila Shakiah, Qiaozi Gao, and Joyce Chai. Groundhog: Grounding large language models to holistic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024b.
- Zhao et al. (2024) Rosie Zhao, Naomi Saphra, and Sham M. Kakade. Distributional scaling laws for emergent capabilities. In NeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning, 2024.
Appendix A Dataset Details
A.1 Context Templates
We select the target tokens following the given procedure:
1. Get a list of words, with their ENV and LAN frequency both greater than or equal to 100 in the CHILDES dataset;
1. Get another list of nouns from CDI;
1. Take intersection and select top 100 words (by frequency of their ENV token) as target token list.
In CHILDES, all contexts are created with gpt-4o-mini followed by human verification if the genrated contexts are semantically light. We adopt the following prompt:
Prompt Templates for CHILDES
Given the word “{word}”, create 3 pairs of sentences that follow this requirement: 1. The first sentence has a subject “The child”, describing an event or situation, and has the word “{word}”. Make sure to add a newline to the end of this first sentence 2. The second sentence is said by the child (only include the speech itself, don’t include “the child say”, etc.), and the word “{word}” also appears in the sentence said by the child. Do not add quote marks either 3. Print each sentence on one line. Do not include anything else. 4. Each sentence should be short, less than 10 words. 5. The word “{word}” in both sentence have the same meaning and have a clear indication or an implication relationship. 6. “{word}” should not appear at the first/second word of each sentence. Generate 3 pairs of such sentences, so there should be 6 lines in total. You should not add a number. For each line, just print out the sentence.
In visual dialogue (caption version and VLM version), we pre-define 10 sets of templates for each version:
Prompt Templates for Visual Dialogue (Caption Version)
this:<ENV> is:<ENV> [FILLER]:<ENV> <Q> what:<LAN> is:<LAN> it:<LAN> <A> (predict [FILLER]:<LAN>) this:<ENV> is:<ENV> [FILLER]:<ENV> <Q> what:<LAN> do:<LAN> you:<LAN> call:<LAN> this:<LAN> <A> (predict [FILLER]:<LAN>) this:<ENV> is:<ENV> [FILLER]:<ENV> <Q> can:<LAN> you:<LAN> name:<LAN> this:<LAN> object:<LAN> <A> (predict [FILLER]:<LAN>) this:<ENV> is:<ENV> [FILLER]:<ENV> <Q> what’s:<LAN> this:<LAN> called:<LAN> <A> (predict [FILLER]:<LAN>) this:<ENV> is:<ENV> [FILLER]:<ENV> <Q> what:<LAN> this:<LAN> thing:<LAN> is:<LAN> <A> (predict [FILLER]:<LAN>)
Prompt Templates for Visual Dialogue (Caption Version) (continued)
this:<ENV> is:<ENV> [FILLER]:<ENV> <Q> what:<LAN> would:<LAN> you:<LAN> name:<LAN> this:<LAN> <A> (predict [FILLER]:<LAN>) this:<ENV> is:<ENV> [FILLER]:<ENV> <Q> what’s:<LAN> the:<LAN> name:<LAN> of:<LAN> this:<LAN> item:<LAN> <A> (predict [FILLER]:<LAN>) this:<ENV> is:<ENV> [FILLER]:<ENV> <Q> how:<LAN> do:<LAN> you:<LAN> identify:<LAN> this:<LAN> <A> (predict [FILLER]:<LAN>) this:<ENV> is:<ENV> [FILLER]:<ENV> <Q> what:<LAN> do:<LAN> we:<LAN> have:<LAN> here:<LAN> <A> (predict [FILLER]:<LAN>) this:<ENV> is:<ENV> [FILLER]:<ENV> <Q> how:<LAN> do:<LAN> you:<LAN> call:<LAN> this:<LAN> object:<LAN> <A> (predict [FILLER]:<LAN>)
Prompt Templates for Visual Dialogue (VLM Version)
“<image> \nwhat is it ?”, “<image> \nwhat do you call this ?”, “<image> \ncan you name this object ?”, “<image> \nwhat is this called ?”, “<image> \nwhat this thing is ?”, “<image> \nwhat would you name this ?”, “<image> \nwhat is the name of this item ?”, “<image> \nhow do you identify this ?”, “<image> \nwhat do we have here ?”, “<image> \nhow do you call this object ?”
A.2 Word Lists
CHILDES and Visual Dialog (Text Only). [box, book, ball, hand, paper, table, toy, head, car, chair, room, picture, doll, cup, towel, door, mouth, camera, duck, face, truck, bottle, puzzle, bird, tape, finger, bucket, block, stick, elephant, hat, bed, arm, dog, kitchen, spoon, hair, blanket, horse, tray, train, cow, foot, couch, necklace, cookie, plate, telephone, window, brush, ear, pig, purse, hammer, cat, shoulder, garage, button, monkey, pencil, shoe, drawer, leg, bear, milk, egg, bowl, juice, ladder, basket, coffee, bus, food, apple, bench, sheep, airplane, comb, bread, eye, animal, knee, shirt, cracker, glass, light, game, cheese, sofa, giraffe, turtle, stove, clock, star, refrigerator, banana, napkin, bunny, farm, money]
Visual Dialog (VLM). [box, book, table, toy, car, chair, doll, door, camera, duck, truck, bottle, bird, elephant, hat, bed, dog, spoon, horse, train, couch, necklace, cookie, plate, telephone, window, pig, cat, monkey, drawer, bear, milk, egg, bowl, juice, ladder, bus, food, apple, sheep, bread, animal, shirt, cheese, giraffe, clock, refrigerator, accordion, aircraft, alpaca, ambulance, ant, antelope, backpack, bagel, balloon, barrel, bathtub, beard, bee, beer, beetle, bicycle, bidet, billboard, boat, bookcase, boot, boy, broccoli, building, bull, burrito, bust, butterfly, cabbage, cabinetry, cake, camel, canary, candle, candy, cannon, canoe, carrot, cart, castle, caterpillar, cattle, cello, cheetah, chicken, chopsticks, closet, clothing, coat, cocktail, coffeemaker, coin, cosmetics]
Appendix B Implementation Details
We outline the key implementation details in this section and provide links to the GitHub repositories:
- Model Training: https://github.com/Mars-tin/TraBank
- CHILDES Processing: https://github.com/Mars-tin/PyChildes
B.1 Checkpointing
We save 33 checkpoints in total for text-only experiments and 16 checkpoints for the VLM setting.
CHILDES and Visual Dialog (Text Only). We save the intermediate steps: [0, 150, 300, 500, 1000, 1500, 2000, 2500, 3000, 3500, 4000, 4500, 5000, 5500, 6000, 6500, 7000, 7500, 8000, 8500, 9000, 9500, 10000, 11000, 12000, 13000, 14000, 15000, 16000, 17000, 18000, 19000, 20000]
Visual Dialog (VLM). We save the intermediate steps: [10000, 20000, 40000, 60000, 80000, 100000, 120000, 140000, 160000, 180000, 200000, 220000, 240000, 260000, 280000, 300000]
B.2 Training details.
For the text-only Transformer, Mamba2, and LSTM models, we randomly initialize them from scratch. The training process is conducted five times, each with a different random seed (using seeds 42, 142, 242, 342, and 442, respectively). The batch size is 16.
For VLM models, we randomly initialize the language model backbone from scratch and keep the DINOv2 vision encoder frozen. The training process is conducted five times for 300k steps, each with a different random seed (using seed 42, 142, 242, 342, and 442, respectively).
All the models use a word-level tokenizer. A list of hyperparameters is shown below:
Transformer and LSTM Model.
- model_max_length: 512
- learning rate: 5e-5
- learning rate schedule: linear
- warmup_steps: 1000
- hidden_size: 768
- beta1: 0.9
- beta2: 0.95
- weight_decay: 0
- batch_size: 16
- grad_clip_norm: 1.0
Mamba2 Model.
- model_max_length: 512
- learning rate: 4e-4
- learning rate schedule: linear
- warmup_steps: 2000
- hidden_size: 768
- beta1: 0.9
- beta2: 0.95
- weight_decay: 0.4
- batch_size: 16
- grad_clip_norm: 1.0
VLM Model.
- model_max_length: 1024
- learning rate: 2e-5
- learning rate schedule: cosine
- warmup_steps: 9000
- hidden_size: 768
- beta1: 0.9
- beta2: 0.95
- weight_decay: 0
- batch_size: 16
- grad_clip_norm: 1.0
B.3 Computational resources.
Each Transformer, Mamba2, and LSTM model is trained on a single A40 GPU within 5 hours. For VLM models, training is conducted on 2 A40 GPUs over 15 hours, using a batch size of 8 per device.
Appendix C Addendum to Results
<details>
<summary>x23.png Details</summary>
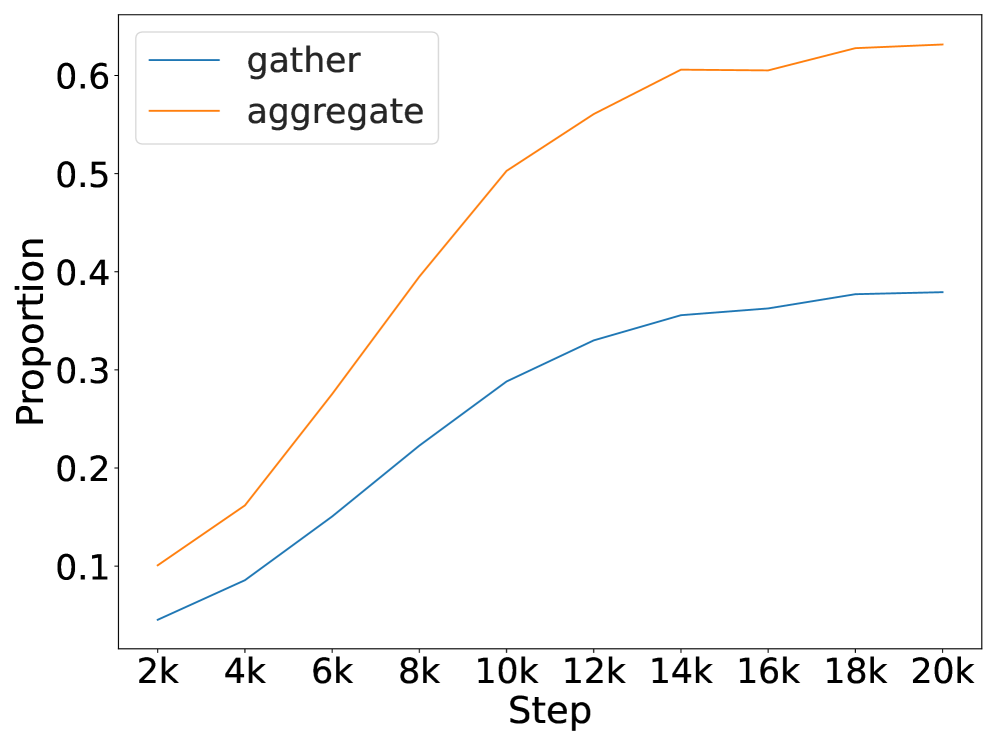
### Visual Description
## Line Chart: Proportion vs. Step for Gather and Aggregate
### Overview
The image is a line chart comparing the "Proportion" of two processes, "gather" and "aggregate," over a range of "Step" values. The chart displays how the proportion changes for each process as the step increases.
### Components/Axes
* **X-axis (Horizontal):** "Step" - Ranges from 2k to 20k in increments of 2k (2k, 4k, 6k, 8k, 10k, 12k, 14k, 16k, 18k, 20k).
* **Y-axis (Vertical):** "Proportion" - Ranges from 0.1 to 0.6 in increments of 0.1 (0.1, 0.2, 0.3, 0.4, 0.5, 0.6).
* **Legend (Top-Left):**
* "gather" - Represented by a dark teal line.
* "aggregate" - Represented by an orange line.
### Detailed Analysis
* **"gather" (Dark Teal Line):**
* Trend: The proportion increases as the step increases, but the rate of increase slows down as the step gets larger.
* Data Points:
* At 2k Step: Proportion is approximately 0.05.
* At 4k Step: Proportion is approximately 0.08.
* At 6k Step: Proportion is approximately 0.15.
* At 8k Step: Proportion is approximately 0.22.
* At 10k Step: Proportion is approximately 0.29.
* At 12k Step: Proportion is approximately 0.33.
* At 14k Step: Proportion is approximately 0.35.
* At 16k Step: Proportion is approximately 0.36.
* At 18k Step: Proportion is approximately 0.37.
* At 20k Step: Proportion is approximately 0.38.
* **"aggregate" (Orange Line):**
* Trend: The proportion increases as the step increases, but the rate of increase slows down as the step gets larger.
* Data Points:
* At 2k Step: Proportion is approximately 0.10.
* At 4k Step: Proportion is approximately 0.16.
* At 6k Step: Proportion is approximately 0.28.
* At 8k Step: Proportion is approximately 0.40.
* At 10k Step: Proportion is approximately 0.50.
* At 12k Step: Proportion is approximately 0.57.
* At 14k Step: Proportion is approximately 0.60.
* At 16k Step: Proportion is approximately 0.60.
* At 18k Step: Proportion is approximately 0.62.
* At 20k Step: Proportion is approximately 0.63.
### Key Observations
* The "aggregate" process consistently has a higher proportion than the "gather" process across all step values.
* Both processes show a diminishing rate of increase in proportion as the step value increases, suggesting a saturation effect.
* The "aggregate" process plateaus around a proportion of 0.60 after a step value of 14k.
* The "gather" process plateaus around a proportion of 0.38 after a step value of 18k.
### Interpretation
The chart suggests that the "aggregate" process is more effective in achieving a higher proportion compared to the "gather" process, given the same number of steps. The diminishing returns observed for both processes indicate that increasing the step value beyond a certain point may not significantly improve the proportion. The "aggregate" process appears to reach its maximum potential earlier than the "gather" process. This information could be valuable for optimizing resource allocation or process selection based on the desired proportion and step constraints.
</details>
Figure 8: Gather-and-aggregate overtime.
C.1 Behavioral Analysis
We show the complete behavioral evidence for all models in Figure 9, and co-occurrence analysis in Figure 10.
C.2 Mechanistic Analysis
After identifying the set of gather and aggregate heads for each context, we conduct an overtime analysis to determine the proportion of saliency to the total saliency, as illustrated in Figure 8.
<details>
<summary>x24.png Details</summary>
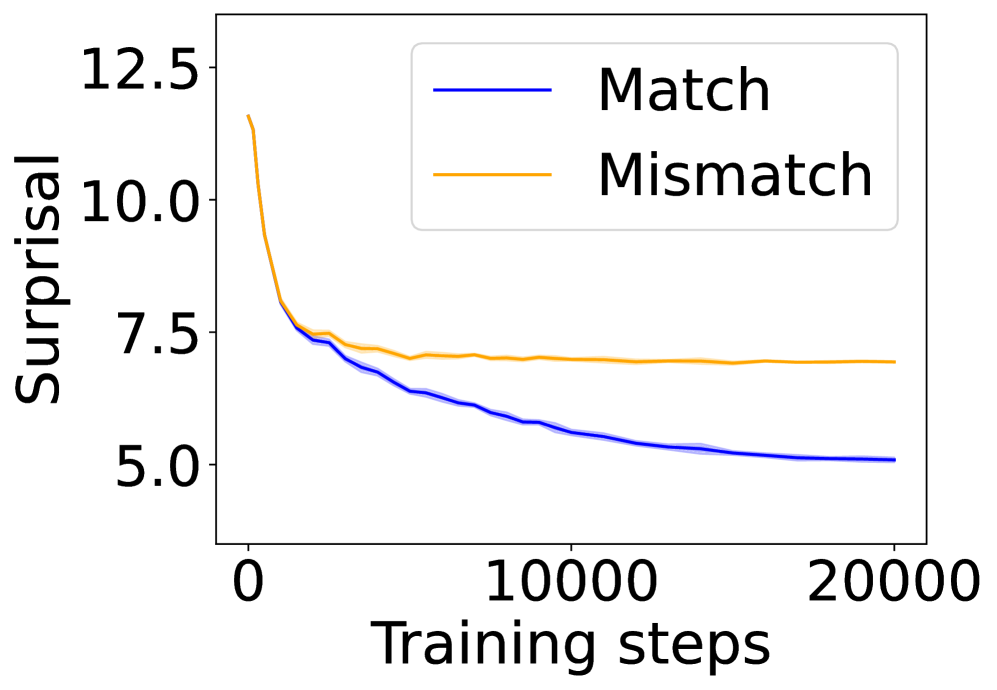
### Visual Description
## Line Chart: Surprisal vs. Training Steps
### Overview
The image is a line chart comparing the "Surprisal" of two conditions, "Match" and "Mismatch," over a range of "Training steps." The chart displays how surprisal changes as the number of training steps increases.
### Components/Axes
* **X-axis:** "Training steps," ranging from 0 to 20000 in increments of 10000.
* **Y-axis:** "Surprisal," ranging from 5.0 to 12.5 in increments of 2.5.
* **Legend:** Located in the top-right corner.
* Blue line: "Match"
* Orange line: "Mismatch"
### Detailed Analysis
* **Match (Blue Line):**
* Trend: The "Match" line shows a decreasing trend.
* Data Points:
* At 0 training steps, surprisal is approximately 8.0.
* At 10000 training steps, surprisal is approximately 6.0.
* At 20000 training steps, surprisal is approximately 5.0.
* **Mismatch (Orange Line):**
* Trend: The "Mismatch" line also shows a decreasing trend initially, but plateaus after approximately 5000 training steps.
* Data Points:
* At 0 training steps, surprisal is approximately 12.0.
* At 10000 training steps, surprisal is approximately 7.2.
* At 20000 training steps, surprisal is approximately 7.0.
### Key Observations
* Both "Match" and "Mismatch" conditions exhibit a decrease in surprisal as training steps increase, indicating learning.
* The "Mismatch" condition starts with a higher surprisal than the "Match" condition.
* The "Mismatch" condition plateaus at a higher surprisal level compared to the "Match" condition.
* The blue and orange lines have a shaded area around them, indicating a confidence interval or standard deviation.
### Interpretation
The chart suggests that the model finds "Mismatch" conditions more surprising initially, but learns to handle them as training progresses. However, even after substantial training, the model remains more surprised by "Mismatch" conditions than "Match" conditions. This could indicate that the model is better at predicting or processing "Match" conditions, or that "Mismatch" conditions inherently contain more uncertainty or complexity. The confidence intervals provide an indication of the variability in the surprisal values across different runs or data samples.
</details>
(a) 4-layer Transformer.
<details>
<summary>x25.png Details</summary>
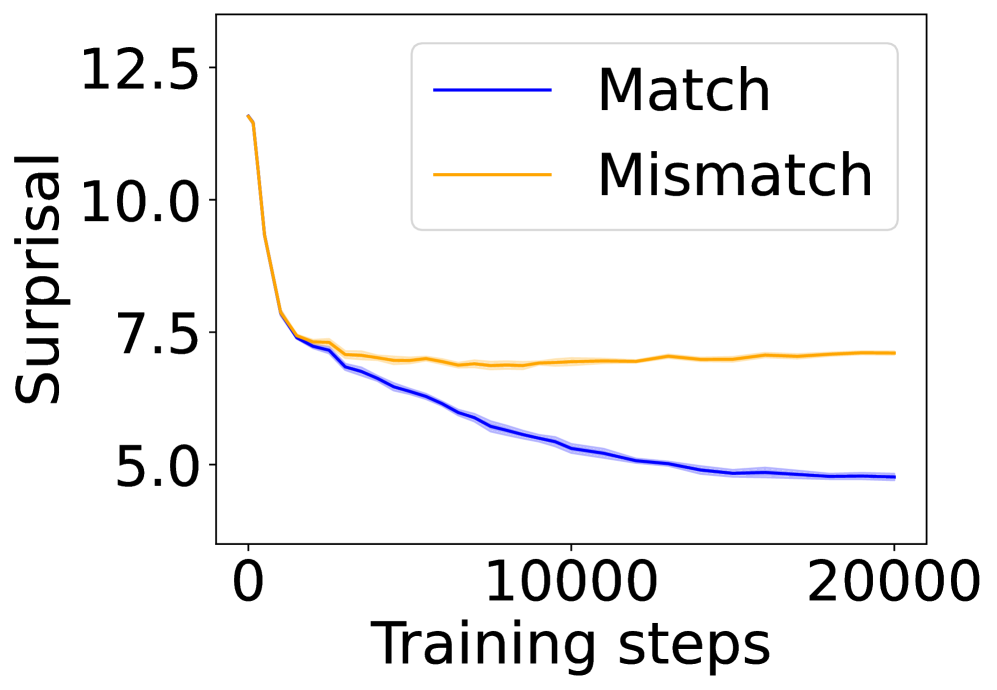
### Visual Description
## Line Chart: Surprisal vs. Training Steps
### Overview
The image is a line chart that plots "Surprisal" against "Training steps". Two data series are represented: "Match" (blue line) and "Mismatch" (orange line). Both lines show a decrease in surprisal as training steps increase, but the "Match" line decreases more significantly and stabilizes at a lower surprisal value than the "Mismatch" line. Shaded regions around each line indicate uncertainty or variance.
### Components/Axes
* **X-axis:** "Training steps", ranging from 0 to 20000.
* **Y-axis:** "Surprisal", ranging from 5.0 to 12.5, with increments of 2.5.
* **Legend:** Located in the top-right corner.
* "Match": Represented by a blue line.
* "Mismatch": Represented by an orange line.
### Detailed Analysis
* **Match (Blue Line):**
* Trend: Decreases from approximately 7.5 at 0 training steps to approximately 5.0 at 20000 training steps.
* Initial Value: ~7.5
* Final Value: ~5.0
* The line decreases rapidly initially, then the rate of decrease slows down as the number of training steps increases.
* **Mismatch (Orange Line):**
* Trend: Decreases from approximately 12.0 at 0 training steps to approximately 7.25 at 20000 training steps.
* Initial Value: ~12.0
* Final Value: ~7.25
* The line decreases rapidly initially, then stabilizes around 7.25 after approximately 5000 training steps.
* **Uncertainty:** Shaded regions around each line indicate the uncertainty or variance in the data. The uncertainty appears to decrease as the number of training steps increases, especially for the "Match" line.
### Key Observations
* The "Mismatch" line starts at a much higher surprisal value than the "Match" line.
* Both lines show a decrease in surprisal with increasing training steps, indicating that the model learns over time.
* The "Match" line stabilizes at a lower surprisal value than the "Mismatch" line, suggesting that the model performs better when there is a match.
* The uncertainty decreases as the number of training steps increases, indicating that the model becomes more confident in its predictions.
### Interpretation
The chart demonstrates the learning process of a model, showing how surprisal decreases with training. The difference between the "Match" and "Mismatch" lines suggests that the model is better at predicting or processing matching data compared to mismatched data. The decreasing uncertainty indicates that the model's predictions become more reliable as it trains. The initial rapid decrease in surprisal for both lines suggests that the model learns quickly at the beginning, with diminishing returns as training progresses.
</details>
(b) 12-layer Transformer.
<details>
<summary>x26.png Details</summary>
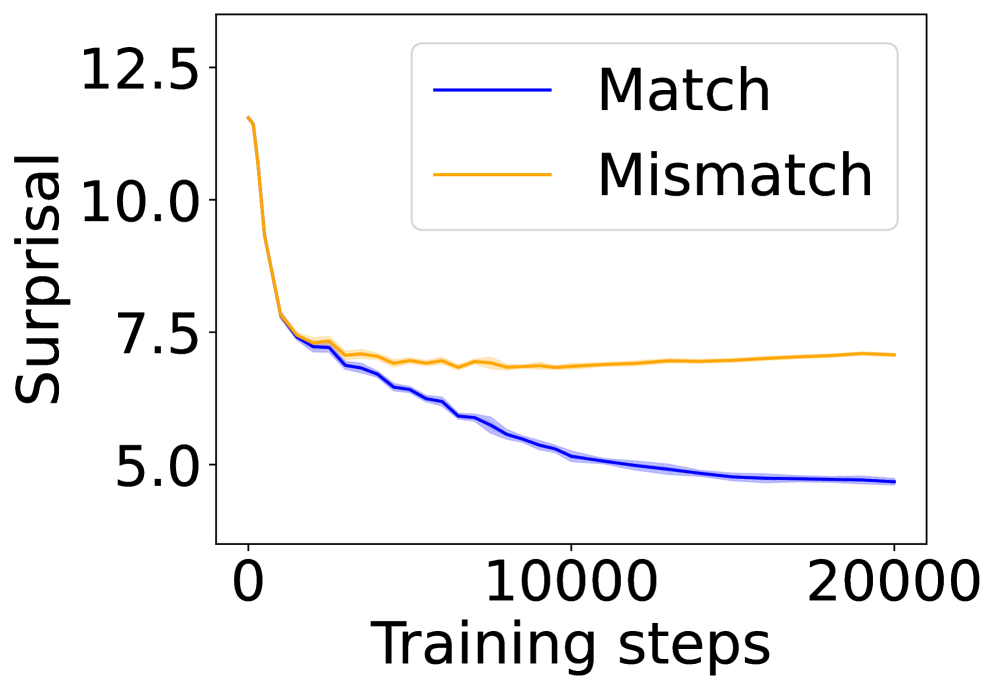
### Visual Description
## Line Chart: Surprisal vs. Training Steps
### Overview
The image is a line chart showing the relationship between "Surprisal" and "Training steps" for two conditions: "Match" and "Mismatch". The chart illustrates how surprisal changes as the number of training steps increases.
### Components/Axes
* **X-axis:** "Training steps" with values ranging from 0 to 20000.
* **Y-axis:** "Surprisal" with values ranging from 5.0 to 12.5.
* **Legend:** Located in the top-right corner, it identifies the two data series:
* Blue line: "Match"
* Orange line: "Mismatch"
### Detailed Analysis
* **Match (Blue Line):**
* Trend: The "Match" line shows a decreasing trend.
* Data Points:
* At 0 training steps, surprisal is approximately 7.5.
* At 5000 training steps, surprisal is approximately 6.0.
* At 10000 training steps, surprisal is approximately 5.5.
* At 20000 training steps, surprisal is approximately 4.7.
* **Mismatch (Orange Line):**
* Trend: The "Mismatch" line shows a sharp decreasing trend initially, then plateaus.
* Data Points:
* At 0 training steps, surprisal is approximately 12.0.
* At 5000 training steps, surprisal is approximately 7.2.
* At 10000 training steps, surprisal is approximately 7.2.
* At 20000 training steps, surprisal is approximately 7.3.
### Key Observations
* The "Mismatch" condition starts with a much higher surprisal value than the "Match" condition.
* Both conditions show a decrease in surprisal as training steps increase, but the "Match" condition decreases more consistently.
* The "Mismatch" condition plateaus after the initial drop, indicating that further training steps have little effect on reducing surprisal.
* The shaded regions around each line likely represent the standard deviation or confidence interval, indicating the variability in the data.
### Interpretation
The chart suggests that the model learns to handle "Match" conditions more effectively than "Mismatch" conditions as training progresses. The "Match" condition shows a continuous decrease in surprisal, indicating that the model is becoming more confident and accurate in its predictions. In contrast, the "Mismatch" condition plateaus, suggesting that the model struggles to reduce its uncertainty even with more training. This could indicate that the "Mismatch" condition is inherently more difficult to predict or that the model requires a different approach to learn it effectively. The initial high surprisal for "Mismatch" suggests that these cases are initially unexpected or difficult for the model to process.
</details>
(c) 18-layer Transformer.
<details>
<summary>x27.png Details</summary>
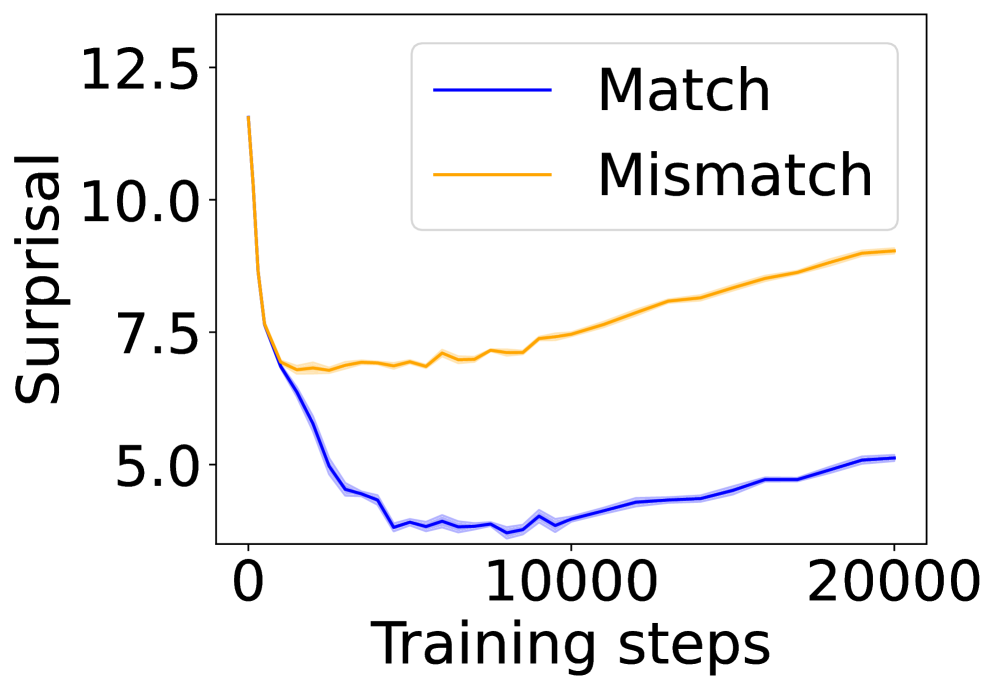
### Visual Description
## Line Chart: Surprisal vs. Training Steps
### Overview
The image is a line chart that plots "Surprisal" on the y-axis against "Training steps" on the x-axis. Two data series are displayed: "Match" (blue line) and "Mismatch" (orange line). The chart illustrates how surprisal changes with increasing training steps for both conditions. Shaded regions around each line likely represent confidence intervals or standard deviations.
### Components/Axes
* **X-axis:** "Training steps" with values ranging from 0 to 20000, incrementing by 5000.
* **Y-axis:** "Surprisal" with values ranging from approximately 4 to 12.5, incrementing by 2.5.
* **Legend:** Located in the top-right corner, it identifies the two data series:
* "Match" - represented by a blue line.
* "Mismatch" - represented by an orange line.
### Detailed Analysis
* **Match (Blue Line):**
* Trend: Initially decreases sharply, then plateaus, and finally increases slightly.
* Data Points:
* At 0 training steps, surprisal is approximately 7.5.
* At 2500 training steps, surprisal is approximately 4.5.
* From 5000 to 10000 training steps, surprisal remains relatively constant at approximately 4.
* At 20000 training steps, surprisal is approximately 5.
* **Mismatch (Orange Line):**
* Trend: Initially decreases sharply, then plateaus, and finally increases steadily.
* Data Points:
* At 0 training steps, surprisal is approximately 12.
* At 2500 training steps, surprisal is approximately 7.
* From 5000 to 10000 training steps, surprisal remains relatively constant at approximately 7.
* At 20000 training steps, surprisal is approximately 9.
### Key Observations
* The "Match" condition shows a significant initial drop in surprisal, indicating rapid learning.
* The "Mismatch" condition also shows an initial drop, but not as drastic as the "Match" condition.
* Both conditions plateau after the initial drop, but the "Mismatch" condition shows a steady increase in surprisal as training continues, while the "Match" condition remains relatively stable.
### Interpretation
The chart suggests that the model learns to "match" expected outcomes more efficiently than dealing with "mismatched" outcomes. The initial sharp decrease in surprisal for both conditions indicates a quick adaptation to the training data. However, the subsequent increase in surprisal for the "Mismatch" condition suggests that the model continues to struggle with unexpected or inconsistent inputs as training progresses. The "Match" condition's stable surprisal after the initial drop implies that the model has effectively learned to predict and handle expected outcomes. The shaded regions around the lines likely represent the variability in the model's performance, with wider regions indicating greater uncertainty.
</details>
(d) 12-layer Mamba 2.
<details>
<summary>x28.png Details</summary>
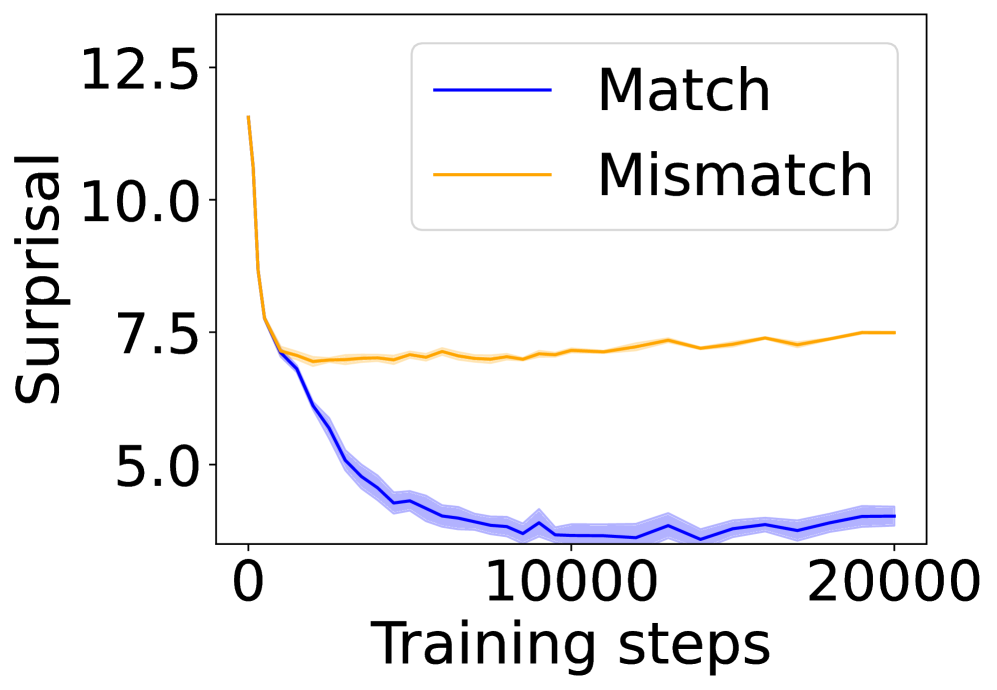
### Visual Description
## Line Chart: Surprisal vs. Training Steps
### Overview
The image is a line chart that plots "Surprisal" on the y-axis against "Training steps" on the x-axis. Two data series are displayed: "Match" (blue line) and "Mismatch" (orange line). The chart illustrates how surprisal changes with increasing training steps for both conditions. The lines are surrounded by shaded regions, indicating uncertainty or variance.
### Components/Axes
* **X-axis:** "Training steps" ranging from 0 to 20000, with major tick marks at 0, 10000, and 20000.
* **Y-axis:** "Surprisal" ranging from approximately 3.75 to 12.5, with major tick marks at 5.0, 7.5, 10.0, and 12.5.
* **Legend:** Located in the top-right corner, it identifies the blue line as "Match" and the orange line as "Mismatch".
### Detailed Analysis
* **Match (Blue Line):**
* Trend: The "Match" line shows a decreasing trend in surprisal as training steps increase. It starts at approximately 7.5 and decreases to around 4.0.
* Data Points:
* At 0 training steps, surprisal is approximately 7.5.
* At 5000 training steps, surprisal is approximately 4.5.
* At 10000 training steps, surprisal is approximately 4.0.
* At 20000 training steps, surprisal is approximately 4.0.
* **Mismatch (Orange Line):**
* Trend: The "Mismatch" line shows a slight decreasing trend initially, then stabilizes and remains relatively constant as training steps increase. It starts at approximately 12.0 and stabilizes around 7.5.
* Data Points:
* At 0 training steps, surprisal is approximately 12.0.
* At 5000 training steps, surprisal is approximately 7.5.
* At 10000 training steps, surprisal is approximately 7.5.
* At 20000 training steps, surprisal is approximately 7.5.
### Key Observations
* The "Match" condition exhibits a significant reduction in surprisal with increased training, indicating learning or adaptation.
* The "Mismatch" condition shows a much smaller reduction in surprisal, suggesting that the model struggles to adapt to mismatched data.
* The shaded regions around the lines indicate the variability or uncertainty associated with each condition.
### Interpretation
The chart suggests that the model learns to predict or process "Match" data more effectively as training progresses, resulting in lower surprisal. In contrast, the model's performance on "Mismatch" data remains relatively stable, indicating that it does not learn to handle mismatched data as effectively. This could imply that the model is better suited for processing data that aligns with its training or prior knowledge. The difference in surprisal between the two conditions highlights the model's sensitivity to data consistency.
</details>
(e) 4-layer Mamba 2.
<details>
<summary>x29.png Details</summary>
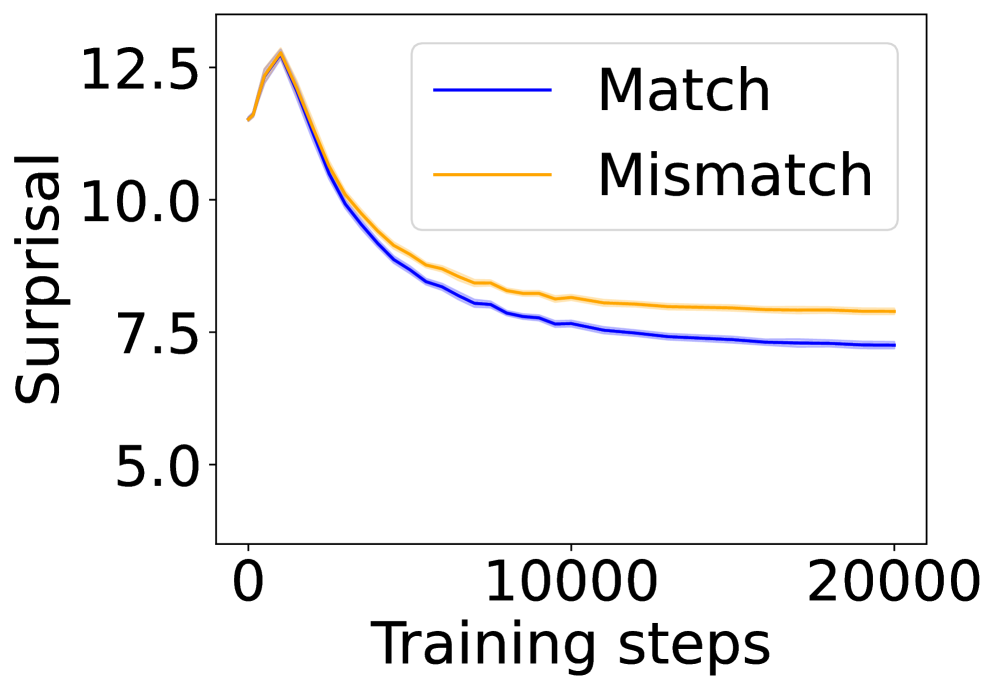
### Visual Description
## Line Chart: Surprisal vs. Training Steps
### Overview
The image is a line chart that plots "Surprisal" against "Training steps". Two data series are displayed: "Match" (blue line) and "Mismatch" (orange line). Both lines show a decreasing trend in surprisal as training steps increase, eventually plateauing. Shaded regions around each line likely represent confidence intervals or standard deviations.
### Components/Axes
* **X-axis:** "Training steps", ranging from 0 to 20000, with a major tick at 10000.
* **Y-axis:** "Surprisal", ranging from 5.0 to 12.5, with major ticks at 5.0, 7.5, 10.0, and 12.5.
* **Legend:** Located in the top-right corner, it identifies the blue line as "Match" and the orange line as "Mismatch".
* **Data Series:**
* Match (blue line)
* Mismatch (orange line)
### Detailed Analysis
* **Match (blue line):**
* Trend: Decreases sharply initially, then plateaus.
* Approximate values:
* At 0 training steps, surprisal is approximately 12.0.
* At 10000 training steps, surprisal is approximately 7.7.
* At 20000 training steps, surprisal is approximately 7.2.
* **Mismatch (orange line):**
* Trend: Decreases sharply initially, then plateaus.
* Approximate values:
* At 0 training steps, surprisal is approximately 11.8.
* At 10000 training steps, surprisal is approximately 8.3.
* At 20000 training steps, surprisal is approximately 7.8.
### Key Observations
* Both "Match" and "Mismatch" surprisal values decrease as the number of training steps increases.
* The "Mismatch" line is consistently above the "Match" line, indicating higher surprisal values for mismatched data throughout the training process.
* The rate of decrease in surprisal is higher in the initial training steps (0-5000) for both data series.
* The shaded regions around the lines suggest some variability in the surprisal values, but the overall trends are clear.
### Interpretation
The chart illustrates how surprisal, a measure of unexpectedness or uncertainty, changes during the training of a model. The decreasing surprisal values for both "Match" and "Mismatch" conditions indicate that the model is learning to better predict or understand the data as it is exposed to more training examples. The fact that "Mismatch" surprisal remains higher than "Match" surprisal suggests that the model still finds mismatched data more surprising, even after extensive training. This could indicate that the model is better at processing or predicting matched data, or that the mismatched data contains inherent complexities or noise that make it harder to learn. The plateauing of the lines suggests that the model's learning has reached a point of diminishing returns, where further training does not significantly reduce surprisal.
</details>
(f) 4-layer LSTM.
Figure 9: Average surprisal of the experimental and control conditions over training steps.
<details>
<summary>x30.png Details</summary>
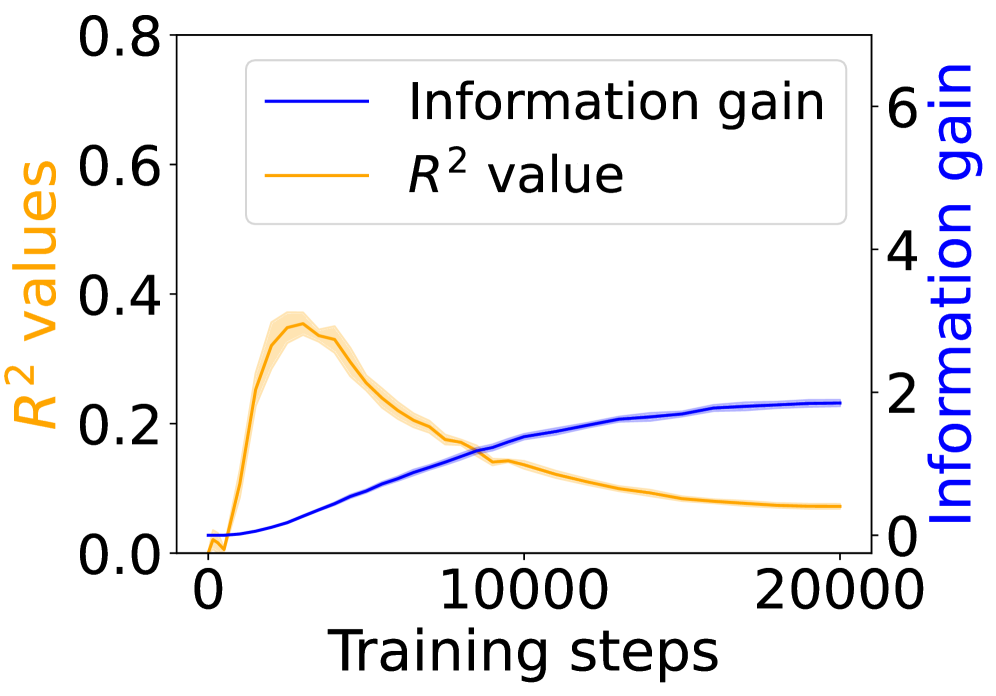
### Visual Description
## Line Chart: Information Gain vs. R² Value During Training
### Overview
The image is a line chart comparing the "Information gain" and "R² value" over "Training steps." The x-axis represents the number of training steps, ranging from 0 to 20000. The left y-axis represents "R² values," ranging from 0.0 to 0.8. The right y-axis represents "Information gain," ranging from 0 to 6. The chart displays two lines: a blue line representing "Information gain" and an orange line representing "R² value." The R² value line also has a shaded region around it, indicating uncertainty or variance.
### Components/Axes
* **X-axis:** "Training steps" ranging from 0 to 20000. Axis markers are at 0, 10000, and 20000.
* **Left Y-axis:** "R² values" ranging from 0.0 to 0.8. Axis markers are at 0.0, 0.2, 0.4, 0.6, and 0.8.
* **Right Y-axis:** "Information gain" ranging from 0 to 6. Axis markers are at 0, 2, 4, and 6.
* **Legend:** Located at the top-center of the chart.
* Blue line: "Information gain"
* Orange line: "R² value"
### Detailed Analysis
* **Information gain (Blue line):** The "Information gain" starts near 0 at 0 training steps, increases to approximately 1 at 5000 training steps, and continues to increase, reaching approximately 2.2 at 20000 training steps. The trend is generally upward, with a decreasing rate of increase as the training steps increase.
* (0, ~0)
* (5000, ~1)
* (10000, ~1.5)
* (20000, ~2.2)
* **R² value (Orange line):** The "R² value" starts near 0 at 0 training steps, rapidly increases to a peak of approximately 0.35 at around 3000 training steps, and then gradually decreases to approximately 0.08 at 20000 training steps. The trend is initially upward, followed by a downward trend. The shaded region around the orange line indicates the uncertainty in the R² value.
* (0, ~0)
* (3000, ~0.35)
* (10000, ~0.17)
* (20000, ~0.08)
### Key Observations
* The "R² value" peaks early in the training process and then declines, suggesting that the model initially learns quickly but then starts to overfit or lose its ability to generalize.
* The "Information gain" increases steadily throughout the training process, indicating that the model continues to learn and extract useful information from the data.
* The intersection of the two lines occurs at approximately 8000 training steps, where both values are around 0.17 and 1.4 respectively.
### Interpretation
The chart illustrates the trade-off between "Information gain" and "R² value" during the training process. The initial rapid increase in "R² value" suggests that the model quickly adapts to the training data. However, the subsequent decline indicates that the model may be overfitting, losing its ability to generalize to new, unseen data. The continuous increase in "Information gain" suggests that the model continues to extract useful information, even as the "R² value" declines. This could indicate that the model is learning more complex patterns in the data, which may not be reflected in the "R² value." The shaded region around the R² value line suggests that the R² value is not a stable metric.
</details>
(a) 4-layer Transformer.
<details>
<summary>x31.png Details</summary>
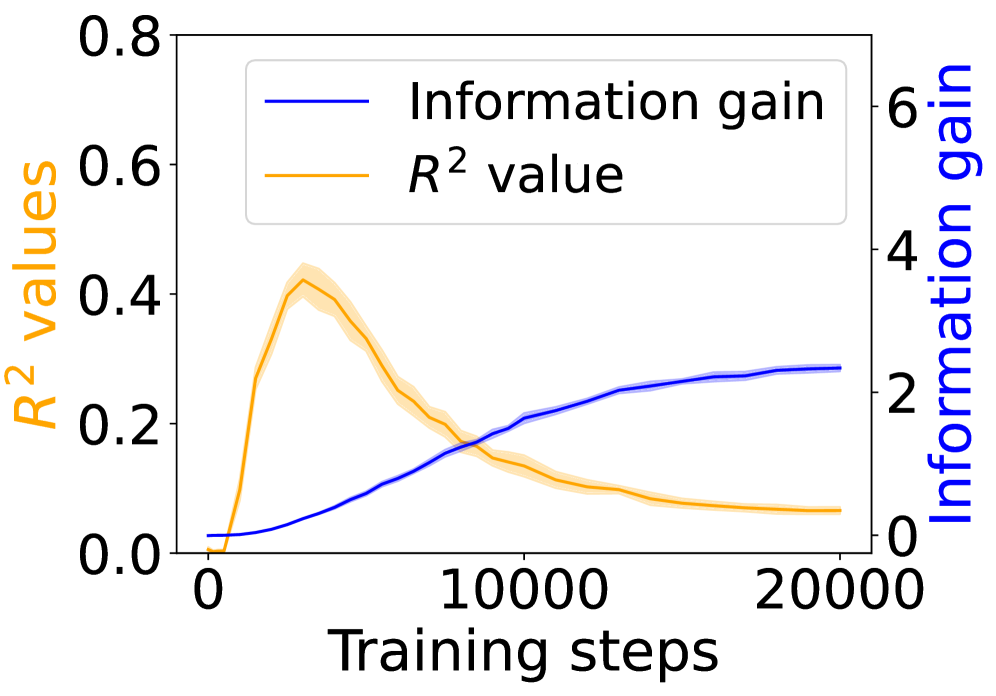
### Visual Description
## Chart: Information Gain and R² Value vs. Training Steps
### Overview
The image is a line chart showing the relationship between training steps and two metrics: Information gain and R² value. The x-axis represents training steps, while the left y-axis represents R² values and the right y-axis represents information gain. The chart displays how these metrics change as the training progresses.
### Components/Axes
* **X-axis:** Training steps, ranging from 0 to 20000.
* **Left Y-axis:** R² values, ranging from 0.0 to 0.8, labeled in orange.
* **Right Y-axis:** Information gain, ranging from 0 to 6, labeled in blue.
* **Legend:** Located at the top-center of the chart.
* Blue line: Information gain
* Orange line: R² value
### Detailed Analysis
* **Information Gain (Blue Line):**
* Trend: Generally increasing with training steps.
* Starts at approximately 0 at 0 training steps.
* Increases to approximately 2 at 10000 training steps.
* Reaches approximately 2.5-3 at 20000 training steps.
* The area around the blue line is shaded in a lighter blue, indicating a confidence interval or standard deviation.
* **R² Value (Orange Line):**
* Trend: Initially increases, then decreases with training steps.
* Starts at approximately 0 at 0 training steps.
* Peaks at approximately 0.4-0.45 around 3000-4000 training steps.
* Decreases to approximately 0.1 at 20000 training steps.
* The area around the orange line is shaded in a lighter orange, indicating a confidence interval or standard deviation.
### Key Observations
* The R² value peaks early in training and then declines, suggesting that the model initially fits the data well but later overfits or loses its initial accuracy.
* The information gain increases steadily with training steps, indicating that the model continues to learn and extract relevant information from the data.
* There is an inverse relationship between the R² value and information gain after approximately 5000 training steps.
### Interpretation
The chart illustrates the trade-off between model fit (R² value) and information extraction (information gain) during training. The initial rise in R² suggests that the model quickly learns to fit the training data. However, as training continues, the R² value decreases, possibly due to overfitting or the model adapting to noise in the data. Simultaneously, the information gain continues to increase, indicating that the model is still learning relevant features, even as its overall fit to the data declines. This suggests that the model may be becoming more specialized or robust, even if it is no longer perfectly aligned with the initial training data distribution. The shaded regions around the lines indicate the variability or uncertainty in these metrics, providing a sense of the robustness of these trends.
</details>
(b) 12-layer Transformer.
<details>
<summary>x32.png Details</summary>
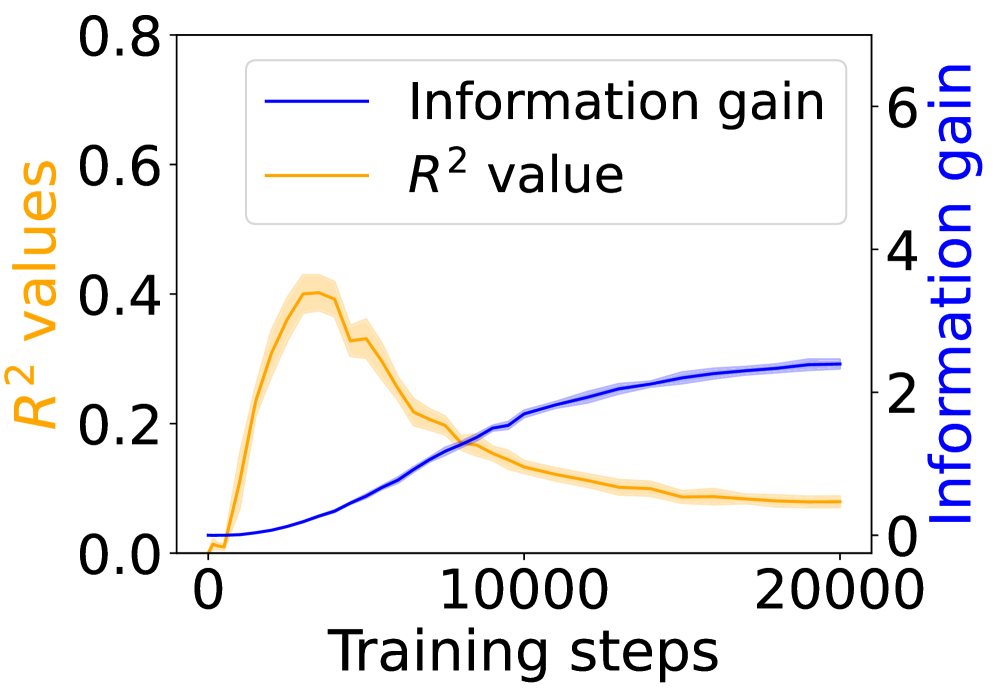
### Visual Description
## Line Chart: Information Gain and R² Value vs. Training Steps
### Overview
The image is a line chart comparing the "Information gain" and "R² value" over "Training steps". The x-axis represents the number of training steps, ranging from 0 to 20000. The left y-axis represents the R² value, ranging from 0.0 to 0.8. The right y-axis represents the Information gain, ranging from 0 to 6. The chart displays two lines: a blue line representing "Information gain" and an orange line representing "R² value". The R² value line has a shaded region around it, indicating uncertainty or variance.
### Components/Axes
* **X-axis:** Training steps, ranging from 0 to 20000. Axis markers are present at 0, 10000, and 20000.
* **Left Y-axis:** R² values, ranging from 0.0 to 0.8. Axis markers are present at 0.0, 0.2, 0.4, 0.6, and 0.8. The axis label is "R² values" and is colored orange.
* **Right Y-axis:** Information gain, ranging from 0 to 6. Axis markers are present at 0, 2, 4, and 6. The axis label is "Information gain" and is colored blue.
* **Legend:** Located at the top-center of the chart.
* Blue line: Information gain
* Orange line: R² value
### Detailed Analysis
* **Information gain (Blue line):** The information gain starts near 0 and generally increases with training steps.
* At 0 training steps, the information gain is approximately 0.
* At 10000 training steps, the information gain is approximately 1.5.
* At 20000 training steps, the information gain is approximately 2.5.
* **R² value (Orange line):** The R² value initially increases rapidly, peaks around 4000 training steps, and then decreases gradually, eventually plateauing. The shaded region around the orange line indicates the uncertainty in the R² value.
* At 0 training steps, the R² value is approximately 0.02.
* The R² value peaks at approximately 0.4 around 4000 training steps.
* At 20000 training steps, the R² value is approximately 0.1.
### Key Observations
* The information gain increases with training steps, while the R² value initially increases and then decreases.
* The R² value peaks early in the training process and then declines, suggesting that the model may be overfitting after a certain number of training steps.
* The shaded region around the R² value line indicates that the variance in the R² value is higher during the initial training phase.
### Interpretation
The chart illustrates the relationship between information gain and R² value during the training process. The increasing information gain suggests that the model is learning and extracting more relevant information from the data as training progresses. However, the initial rise and subsequent decline in the R² value indicate that the model's fit to the data improves initially but then degrades, possibly due to overfitting. This suggests that there is an optimal number of training steps beyond which the model starts to memorize the training data rather than generalizing to unseen data. The uncertainty in the R² value, represented by the shaded region, is higher during the initial training phase, which could be due to the model's instability or sensitivity to the training data at the beginning of the learning process.
</details>
(c) 18-layer Transformer.
<details>
<summary>x33.png Details</summary>
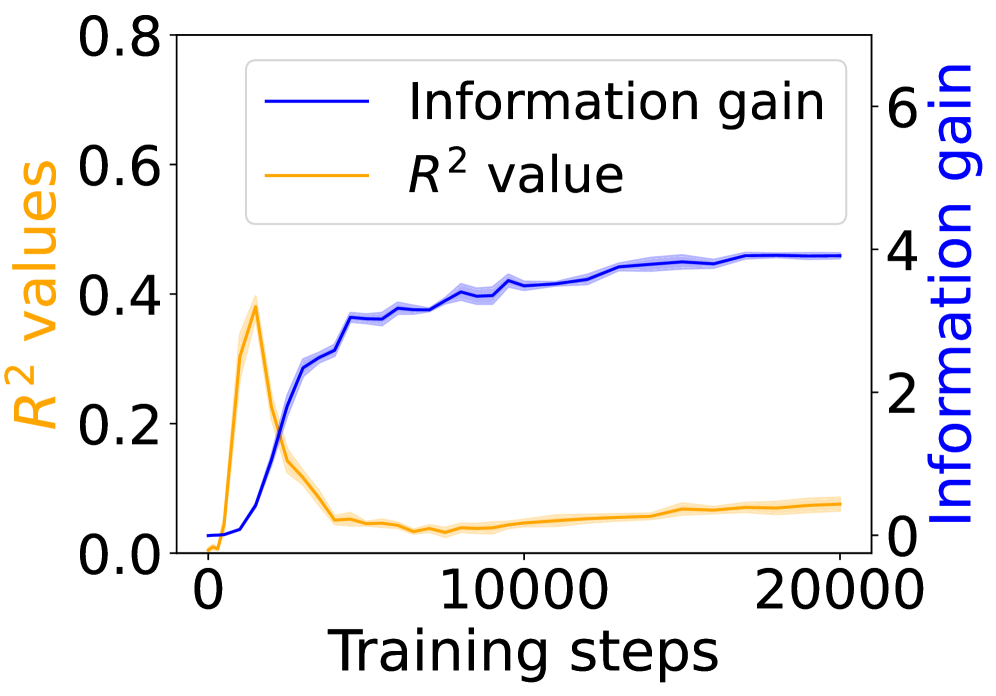
### Visual Description
## Line Chart: Information Gain and R² Value vs. Training Steps
### Overview
The image is a line chart showing the relationship between training steps and two metrics: Information gain and R² value. The x-axis represents training steps, while the y-axes represent the R² value (left) and Information gain (right). The chart displays how these metrics change over the course of training.
### Components/Axes
* **X-axis:** Training steps, ranging from 0 to 20000.
* **Left Y-axis:** R² values, ranging from 0.0 to 0.8. Labelled "R² values" in orange.
* **Right Y-axis:** Information gain, ranging from 0 to 6. Labelled "Information gain" in blue.
* **Legend:** Located at the top-center of the chart.
* Blue line: "Information gain"
* Orange line: "R² value"
### Detailed Analysis
* **Information gain (Blue line):** The information gain starts at approximately 0 at 0 training steps. It increases rapidly until approximately 5000 training steps, reaching a value of approximately 3.5. From 5000 to 20000 training steps, the information gain continues to increase, but at a slower rate, reaching a final value of approximately 4.5. The blue line has a shaded region around it, indicating uncertainty.
* At 0 training steps, Information gain ≈ 0
* At 5000 training steps, Information gain ≈ 3.5
* At 20000 training steps, Information gain ≈ 4.5
* **R² value (Orange line):** The R² value starts at approximately 0 at 0 training steps. It increases rapidly until approximately 1000 training steps, reaching a peak value of approximately 0.4. After the peak, the R² value decreases rapidly until approximately 5000 training steps, reaching a value of approximately 0.05. From 5000 to 20000 training steps, the R² value increases slightly, reaching a final value of approximately 0.1. The orange line has a shaded region around it, indicating uncertainty.
* At 0 training steps, R² value ≈ 0
* At 1000 training steps, R² value ≈ 0.4
* At 5000 training steps, R² value ≈ 0.05
* At 20000 training steps, R² value ≈ 0.1
### Key Observations
* The information gain generally increases with training steps, with a rapid increase initially followed by a slower increase.
* The R² value initially increases rapidly, then decreases, and finally increases slightly.
* The shaded regions around the lines indicate the uncertainty or variability in the data.
### Interpretation
The chart suggests that as the model trains, the information gain increases, indicating that the model is learning and becoming more informative. The R² value, which represents the goodness of fit, initially increases, suggesting that the model is quickly adapting to the data. However, the subsequent decrease in R² value may indicate overfitting or a change in the data distribution. The final slight increase in R² value suggests that the model is eventually stabilizing. The relationship between information gain and R² value is complex and may depend on the specific characteristics of the model and the data.
</details>
(d) 12-layer Mamba 2.
<details>
<summary>x34.png Details</summary>
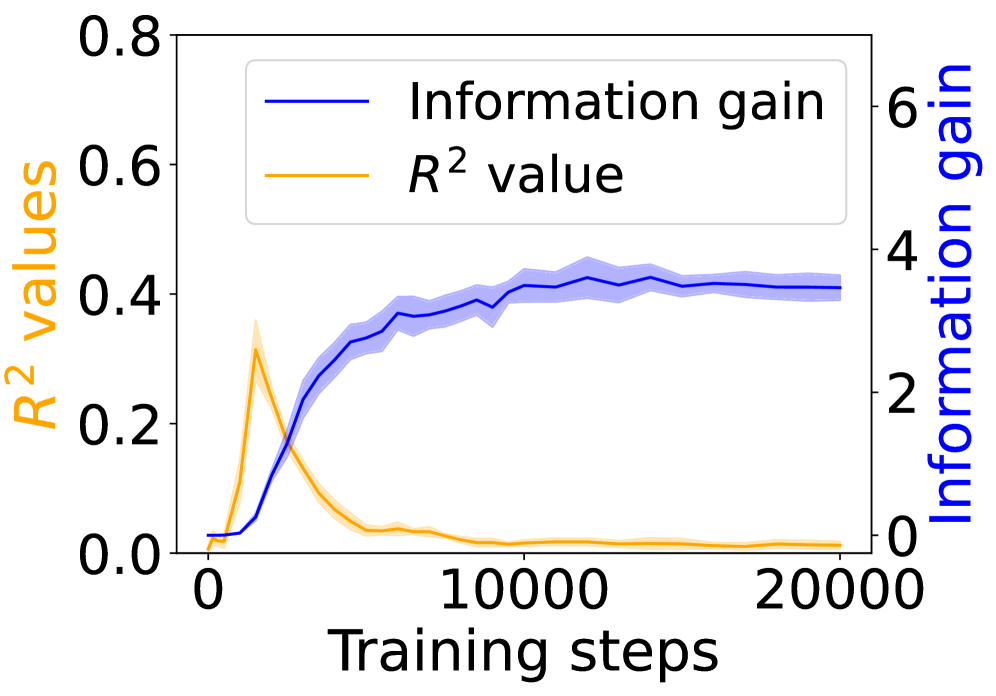
### Visual Description
## Chart: Information Gain and R² Value vs. Training Steps
### Overview
The image is a line graph showing the relationship between training steps and two metrics: Information gain and R² value. The x-axis represents training steps, while the left y-axis represents R² values and the right y-axis represents Information gain. The graph displays how these metrics change as the training progresses.
### Components/Axes
* **X-axis:** Training steps, ranging from 0 to 20000.
* **Left Y-axis:** R² values, ranging from 0.0 to 0.8, with a label in orange.
* **Right Y-axis:** Information gain, ranging from 0 to 6, with a label in blue.
* **Legend:** Located at the top-center of the chart.
* Blue line: Information gain
* Orange line: R² value
### Detailed Analysis
* **Information gain (Blue line):** The information gain starts at approximately 0 at 0 training steps. It increases rapidly until approximately 5000 training steps, reaching a value of approximately 3. It continues to increase at a slower rate, plateauing around 4.2 at approximately 10000 training steps. The shaded area around the blue line represents the uncertainty or variance in the information gain.
* At 0 training steps, Information gain ≈ 0
* At 5000 training steps, Information gain ≈ 3
* At 10000 training steps, Information gain ≈ 4.2
* At 20000 training steps, Information gain ≈ 4.2
* **R² value (Orange line):** The R² value starts at approximately 0 at 0 training steps. It increases rapidly until approximately 1000 training steps, reaching a peak value of approximately 0.3. After reaching its peak, it decreases rapidly, approaching 0 at approximately 5000 training steps. The shaded area around the orange line represents the uncertainty or variance in the R² value.
* At 0 training steps, R² value ≈ 0
* At 1000 training steps, R² value ≈ 0.3
* At 5000 training steps, R² value ≈ 0
* At 20000 training steps, R² value ≈ 0
### Key Observations
* The information gain increases rapidly in the early stages of training and then plateaus.
* The R² value peaks early in training and then decreases to near zero.
* The shaded areas around the lines indicate the variability in the data.
### Interpretation
The graph suggests that the model rapidly gains information in the initial training phase, as indicated by the sharp increase in information gain. However, the R² value, which represents the goodness of fit, peaks early and then declines, suggesting that the model might be overfitting to the training data. The plateau in information gain after 10000 training steps indicates that the model is no longer learning effectively, and further training may not be beneficial. The early peak in R² value followed by a decline suggests that the model initially fits the training data well but loses its generalization ability as training progresses.
</details>
(e) 4-layer Mamba 2.
<details>
<summary>x35.png Details</summary>
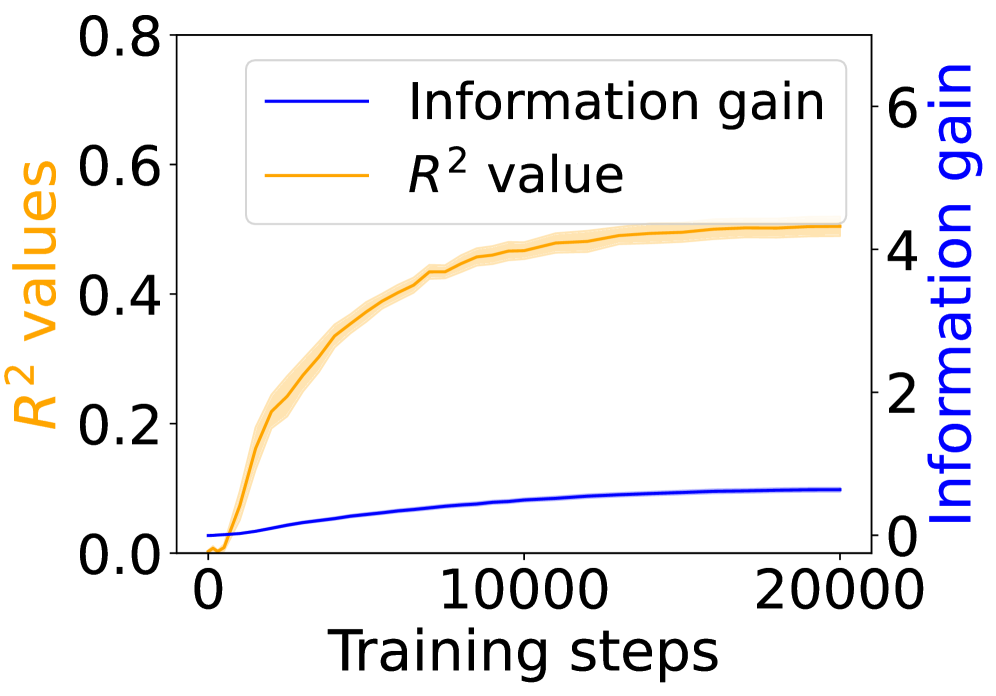
### Visual Description
## Line Chart: Information Gain and R² Value vs. Training Steps
### Overview
The image is a line chart showing the relationship between training steps and two metrics: Information Gain and R² value. The x-axis represents training steps, while the left y-axis represents R² values, and the right y-axis represents Information Gain. The chart displays how these metrics change as the number of training steps increases.
### Components/Axes
* **X-axis:** Training steps, ranging from 0 to 20000.
* **Left Y-axis:** R² values, ranging from 0.0 to 0.8.
* **Right Y-axis:** Information gain, ranging from 0 to 6.
* **Legend:** Located at the top-center of the chart.
* Blue line: Information gain
* Orange line: R² value
### Detailed Analysis
* **Information Gain (Blue Line):** The information gain starts at approximately 0 and gradually increases with training steps. The rate of increase slows down as the number of training steps increases, reaching a value of approximately 0.8 at 20000 training steps.
* At 0 training steps, Information Gain ≈ 0.
* At 20000 training steps, Information Gain ≈ 0.8.
* **R² Value (Orange Line):** The R² value starts at approximately 0 and increases rapidly with training steps initially. The rate of increase slows down as the number of training steps increases, approaching a plateau around 0.5 at 20000 training steps. The orange line has a shaded region around it, indicating variability or uncertainty.
* At 0 training steps, R² value ≈ 0.02.
* At 5000 training steps, R² value ≈ 0.4.
* At 20000 training steps, R² value ≈ 0.5.
### Key Observations
* The R² value increases much more rapidly than the information gain in the initial training steps.
* Both metrics show diminishing returns as the number of training steps increases.
* The R² value appears to plateau at a lower value than what might be expected, given its initial rapid increase.
### Interpretation
The chart suggests that the model's performance, as measured by the R² value, improves significantly in the early stages of training. However, the rate of improvement decreases as training progresses, indicating that the model may be approaching its maximum potential performance. The information gain also increases with training, but at a slower rate compared to the R² value. This could indicate that while the model is learning, the information it gains from each additional training step diminishes over time. The shaded region around the R² value line suggests that there is some variability in the R² value, possibly due to the stochastic nature of the training process or the characteristics of the dataset.
</details>
(f) 4-layer LSTM.
Figure 10: Grounding information gain and its correlation to the co-occurrence of linguistic and environment tokens over training steps.