# Limits of PRM-Guided Tree Search for Mathematical Reasoning with LLMs
**Authors**:
- Tristan Cinquin (University of Tübingen)
- &Geoff Pleiss (University of British Columbia & Vector Institute)
- &Agustinus Kristiadi (Western University & Vector Institute)
> Work done while interning at the Vector Institute.
MATH-AI
## Abstract
While chain-of-thought prompting with Best-of-N (BoN) selection has become popular for mathematical reasoning in large language models (LLMs), its linear structure fails to capture the branching and exploratory nature of complex problem-solving. In this work, we propose an adaptive algorithm to maximize process reward model (PRM) scores over the intractable action space, and investigate whether PRM-guided tree search can improve mathematical reasoning by exploring multiple partial solution paths. Across $23$ diverse mathematical problems using Qwen2.5-Math-7B-Instruct with its associated PRM as a case study, we find that: (1) PRM-guided tree search shows no statistically significant improvements over BoN despite higher costs, (2) Monte Carlo tree search and beam search outperform other PRM-guided tree search methods, (3) PRMs poorly approximate state values and their reliability degrades with reasoning depth, and (4) PRMs generalize poorly out of distribution. This underperformance stems from tree search’s greater reliance on unreliable PRM scores, suggesting different reward modeling is necessary before tree search can effectively enhance mathematical reasoning in LLMs.
## 1 Introduction
Mathematical reasoning involves understanding complex problems, decomposing them into manageable steps, and revisiting intermediate results until reaching a sound solution. Large language models (LLMs) have shown remarkable capabilities in solving mathematical problems by breaking solutions into reasoning steps through chain-of-thought (CoT) prompting [1, 2]. When combined with process reward models (PRMs) that evaluate individual reasoning steps, Best-of-N (BoN) identifies the most promising CoT from multiple candidates and has become widely adopted [3, 4, 5, 6]. However, CoT’s linear structure fails to capture the branching nature of mathematical reasoning, where multiple strategies are considered, partial arguments explored, and errors necessitate backtracking [7, 8]. Moreover, restricting PRM evaluation to complete CoTs misses opportunities for dynamic guidance.
The tree-of-thought (ToT) framework [9] addresses these limitations by exploring multiple partial reasoning paths and enabling revisions using a reward model to assess the correctness of intermediate solutions. Yet applying ToT with PRMs presents challenges: reasoning trees exhibit intractable branching factors and depth, while PRMs may fail to accurately evaluate intermediate steps [3].
This work proposes an adaptive algorithm to maximize PRM scores over the intractable action space and empirically investigates whether PRM-guided tree search can improve mathematical reasoning in LLMs. We evaluate tree search algorithms under varying PRM quality assumptions against BoN across $23$ diverse mathematical problems, using Qwen2.5-Math-7B-Instruct and its associated PRM as our case study. Key findings reveal that: (1) PRM-guided tree search fails to outperform BoN despite higher costs; (2) Monte Carlo tree search and beam search outperform other PRM-guided tree search methods; (3) PRMs poorly approximate state values and reliability degrades with reasoning depth, suggesting credit assignment issues; and (4) PRMs exhibit limited out-of-distribution generalization. This underperformance stems from tree search’s greater reliance on unreliable PRM scores to guide search, whereas BoN evaluates only complete CoTs. These results highlight the limitations of PRM-guided tree search and BoN, indicating that different reward models may be required for mathematical reasoning.
#### Limitations.
This work demonstrates that PRM-guided tree search fails to outperform BoN due to PRM limitations: poor reasoning step value estimation, degraded reliability with reasoning depth, and limited out-of-distribution generalization. While our study focuses on a single PRM-model pair, we expect this underperformance to generalize to PRMs exhibiting similar pathologies.
## 2 Background
### 2.1 Mathematical reasoning as tree search
We formulate mathematical reasoning as search in a tree -structured Markov decision process $\mathcal{M}=~({\mathbb{S}},{\mathbb{A}},r,t)$ where actions $a\in{\mathbb{A}}$ are reasoning steps (text ending with an end-of-reasoning-step token), states $s\in{\mathbb{S}}\coloneqq\cup_{i=0}^{T}{\mathbb{A}}^{i}$ are partial reasoning sequences and transitions are deterministic $t(s,a,s^{\prime})={\mathds{1}[s^{\prime}={s\oplus a}]}$ (here ${s\oplus a}$ denotes string concatenation). The root state is the prompt $p$ , and ${\mathbb{T}}$ denotes terminal states containing predictions in the ’ \boxed{x} ’ format. The reward function assigns $r(s)=1$ if $s\in{\mathbb{T}}$ contains the correct solution with valid intermediate reasoning steps, and $r(s)=0$ otherwise. The value function $v(s)=r(s)+\max_{a\in{\mathbb{A}}}v({s\oplus a})$ indicates whether any continuation from state $s$ leads to a state with reward $1$ . A LLM $\pi_{\bm{\theta}}$ defines a policy $a\sim\pi_{\bm{\theta}}(\cdot\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ , while a process reward model $f_{\bm{\phi}}(s)$ estimates $p(v(s)=1\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ . Our goal is finding $s$ with $r(s)=1$ using the LLM and the PRM. Since rewards are unavailable during search, the PRM’s approximation quality determines the appropriate search strategy. We distinguish three scenarios:
Scenario 1: PRM as Value Function. If the PRM correctly ranks actions by their true ${p(v(s^{\prime})=1\nonscript\>|\allowbreak\nonscript\>\mathopen{}s^{\prime}={s\oplus a})}$ , optimal search recursively selects $a^{*}=\arg\max_{a\in{\mathbb{A}}}f_{\bm{\phi}}({s\oplus a})$ . If actions ${\mathbb{A}}$ were practically enumerable, a greedy tree search algorithm would be optimal. However, enumerating $a\in{\mathbb{A}}$ is intractable and we propose an algorithm in Section ˜ 3 to adaptively resample actions $a\sim\pi_{\bm{\theta}}(\cdot\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ until we are confident that we have attained $\max_{a\in{\mathbb{A}}}f_{\bm{\phi}}({s\oplus a})$ .
Scenario 2: PRM as Terminal Signal Only. In this “worst-case we can still work with” scenario, the PRM suffers from poor credit assignment, failing to properly estimate $p(v(s)=1\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ for intermediate states, yet PRM scores at terminal states still correlate with reward $r$ . The optimal tree search algorithm returns $s^{*}\in\arg\max_{s\in{\mathbb{T}}}f_{\bm{\phi}}(s)$ among terminal states.
Scenario 3: PRM as Noisy Intermediate Signal. The PRM provides useful but unreliable guidance for intermediate states. For example, it may undervalue (i.e., $f_{\bm{\phi}}(s)<p(v(s)=1\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ ) optimal intermediate states leading to high-scoring terminal states, and overvalue (i.e., ${f_{\bm{\phi}}(s)>p(v(s)=1\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)}$ ) suboptimal intermediate states leading to poor terminal states. While maximizing PRM scores generally helps to reach valuable terminal nodes, the appropriate search objective remains unclear.
### 2.2 Tree search baselines
Best-of-N samples $N$ chains-of-thought from the LLM policy (i.e., separate root-to-terminal paths with no shared intermediate state) and selects the CoT with the highest aggregated PRM score [3, 5]. Given a prompt $p$ , we sample CoT $c_{i}=(p,\smash{a^{(i)}_{1}},\dots,\smash{a^{(i)}_{T}})$ as $\smash{a^{(i)}_{j+1}}\sim\pi_{\bm{\theta}}(\cdot\nonscript\>|\allowbreak\nonscript\>\mathopen{}p\oplus(\oplus_{k=1}^{j}\smash{a^{(i)}_{k}}))$ for $i=1,\dots,N$ and return $\arg\max_{i\in\{1,\dots,N\}}\Psi(\{f_{\bm{\phi}}(\smash{a_{j}^{(i)}})\}_{j=1}^{T})$ where $\Psi$ aggregates PRM scores.
Greedy best-first search (GBFS) expands the frontier state $s\in{\mathbb{F}}$ with highest heuristic value $h(s)$ at each step, where the frontier ${\mathbb{F}}$ contains all unexpanded states in the current search tree. Starting from the root, we repeatedly expand $s=\arg\max_{s\in{\mathbb{F}}}h(s)$ by sampling $K$ actions from the LLM until reaching a terminal state. We use $h(s)=f_{\bm{\phi}}(s)$ and depth-aware $h(s)=f_{\bm{\phi}}(s)\cdot(M-d(s))$ to favor deeper states, where $M$ is maximum depth and $d(s)$ is the depth of state $s$ .
Beam search maintains the top- $N$ states with highest (cumulative) PRM score in a beam ${\mathbb{B}}_{t}$ . At each step $t$ , we sample actions $\smash{a_{j}^{i}\sim\pi_{\bm{\theta}}(\cdot\nonscript\>|\allowbreak\nonscript\>\mathopen{}s_{j})}$ $i=1,\dots,K$ for each state in the current beam $s_{j}\in{\mathbb{B}}_{t}$ , score states $\cup_{j=1}^{N}\{s_{j}\oplus a_{j}^{i}\}_{i=1}^{K}$ with the PRM, and keep the $N$ highest-scoring states for the next beam ${\mathbb{B}}_{t+1}$ . For $N=1$ , this reduces to greedy search.
Monte Carlo tree search (MCTS) builds a search tree in four phases: (1) Select: traverse the search tree from root to leaf selecting high-value states and balancing exploration/exploitation; (2) Expand: add children to the selected leaf by sampling actions from $\pi_{\bm{\theta}}$ ; (3) Rollout: run LLM policy from the new state to a terminal state; (4) Backpropagate: update visit counts and average PRM scores of terminal states along the path back to the root. Repeat until computational budget is depleted.
## 3 Methods
In this section, we propose an adaptive algorithm to solve the intractable optimization problem $a=\arg\max_{a\in{\mathbb{A}}}f_{\bm{\phi}}({s\oplus a})$ (due to the unenumerable $\lvert{\mathbb{A}}\rvert$ ) from Scenario 1 (see Section ˜ 2.1). We formulate this optimization problem as a stopping problem: when should we stop sampling actions from the policy and commit to the action with highest observed $f_{\bm{\phi}}({s\oplus a})$ ?
Maximizing over the intractable ${\mathbb{A}}$ using Gittin’s indices. At each state $s$ , we sample independent actions $a_{i}\sim\pi_{\bm{\theta}}(\cdot\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ and evaluate PRM scores $f_{i}=f_{\bm{\phi}}({s\oplus a_{i}})$ . We must then decide whether to stop and commit to the current maximum observed PRM score $m=\max_{i}f_{i}$ (payoff $m$ ), or sample again at cost $c$ to improve the current estimate $m$ for expected payoff $\operatorname{\mathbb{E}}_{f\sim p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)}\left[\max(m,f)\right]-c$ (since we select the largest value among $f\sim p(\cdot\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ and $m$ and incur a cost $c$ ). This is an instance of the Pandora’s box problem [10], whose optimal strategy samples if $\operatorname{\mathbb{E}}_{f\sim p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)}\left[\max(m,f)\right]-c>m$ and otherwise stops. This involves computing a Gittin’s index $m^{*}$ satisfying $\operatorname{\mathbb{E}}_{f\sim p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)}\left[\max(0,f-m^{*})\right]=c$ , then sampling if $m^{*}>m$ and stopping otherwise. However, $p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ is intractable and estimating it requires the LLM samples we are trying to acquire sparingly. This motivates a strategy based on surrogate modeling and posterior inference inspired by Xie et al. [11] which we discuss next.
Bayesian surrogate approximation. We approximate $p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ using a logit-Normal surrogate model $q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s,{\bm{\psi}})$ with parameters ${\bm{\psi}}$ . Specifically, we encode prior beliefs in $p({\bm{\psi}})$ , update the posterior $p({\bm{\psi}}\nonscript\>|\allowbreak\nonscript\>\mathopen{}\mathcal{D})\propto q(\mathcal{D}\nonscript\>|\allowbreak\nonscript\>\mathopen{}s,{\bm{\psi}})p({\bm{\psi}})$ with observed PRM scores $\mathcal{D}=\{f_{i}|f_{i}\sim p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)\}$ , and use the posterior predictive $q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s,\mathcal{D})=\int q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s,{\bm{\psi}})p({\bm{\psi}}\nonscript\>|\allowbreak\nonscript\>\mathopen{}\mathcal{D})d{\bm{\psi}}$ to approximate $p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ . We then compute the Gittin’s index $m^{*}$ by solving $\operatorname{\mathbb{E}}_{f\sim q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s,\mathcal{D})}\left[\max(0,f-m)\right]=c$ under posterior beliefs $q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s,\mathcal{D})$ rather than $p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ . The left-hand side is the expected improvement over $m$ [12], a standard Bayesian optimization acquisition function [13]. The Gittin’s index represents the threshold where expected improvement equals cost $c$ , thus smaller $c$ induces more exploration. More details in Appendix ˜ A.
## 4 Results
### 4.1 Experimental setup
#### LLM & PRM.
We use the Qwen2.5-Math-7B-Instruct [4] LLM with the recommended prompting strategy and sampling parameters, and the Qwen2.5-Math-PRM-7B process reward model [3].
#### Problems & metrics.
We evaluate on $22$ mathematical reasoning problems from Yang et al. [4] and AIME 2025 [14]. We report mean accuracy and rank across problems with standard errors. To address concerns about high variance in LLM evaluation [15], we test statistical significance between the top-performing method and all others using Wilcoxon signed-rank tests (insignificant if $p>0.05$ ).
#### Tree search methods.
We compare Best-of-N (BoN) with $N=8$ chain-of-thoughts using last, minimum, average, product, maximum and sum aggregation functions $\Psi$ ; the proportion of answers containing at least one correct prediction among $N=8$ CoTs (PASS@N); majority voting among predictions of $N=8$ CoTs (MAJ@N); beam search with beam size $N=1$ expanding the state with highest PRM value from $K$ policy samples (Greedy@K); beam search with beam size $N=4$ from $K=6$ policy samples maximizing instantaneous (V) or cumulative (CV) PRM scores (Beam@N); greedy best-first search with $K=8$ policy samples (GBFS@K); depth-aware GBFS (GBFS_DA@K; see Section ˜ 2); Monte Carlo tree search with $K=8$ policy samples (MCTS@K) and our proposed method from Section ˜ 3 with constant and linear cost schedules to allow more exploration early in the search when the remaining sampling budget is large (Gittins@cost; more details in Appendix ˜ A).
### 4.2 Findings
Table 1: Method mean accuracy and rank with standard errors across problems. We bold results which are not significantly worse than the best ( $p>0.05$ ).
| Method PASS@8 MAJ@8 | Accuracy (p-value) 79.8 $\pm$ 4.7 (N/A) 0 71.4 $\pm$ 5.1 (0.010) | Rank (p-value) N/A 4.43 $\pm$ 0.51 (0.022) |
| --- | --- | --- |
| BoN_Last@8 | 72.7 $\pm$ 5.1 (N/A) 0 | 3.13 $\pm$ 0.38 (N/A) 0 |
| BoN_Avg@8 | 72.1 $\pm$ 5.0 (0.444) | 3.22 $\pm$ 0.31 (0.787) |
| BoN_Min@8 | 72.2 $\pm$ 5.0 (0.711) | 3.26 $\pm$ 0.32 (0.608) |
| BoN_Prod@8 | 72.0 $\pm$ 5.0 (0.408) | 3.26 $\pm$ 0.40 (0.795) |
| BoN_Sum@8 | 67.6 $\pm$ 5.3 (0.000) | 7.30 $\pm$ 0.72 (0.000) |
| BoN_Max@8 | 68.8 $\pm$ 5.4 (0.000) | 7.35 $\pm$ 0.69 (0.000) |
| Greedy@6 | 71.6 $\pm$ 5.0 (0.043) | 5.74 $\pm$ 0.76 (0.003) |
| Greedy@20 | 71.2 $\pm$ 5.0 (0.039) | 5.09 $\pm$ 0.55 (0.009) |
| Beam@4 (V) | 71.8 $\pm$ 4.9 (0.126) | 3.83 $\pm$ 0.42 (0.236) |
| Beam@4 (CV) | 71.9 $\pm$ 4.8 (0.189) | 4.00 $\pm$ 0.49 (0.221) |
| GBFS@8 | 46.0 $\pm$ 4.1 (0.000) | 10.09 $\pm$ 0.71 (0.000) |
| GBFS_DA@8 | 48.1 $\pm$ 4.6 (0.000) | 10.00 $\pm$ 0.65 (0.000) |
| MCTS@8 | 71.2 $\pm$ 5.0 (0.987) | 3.26 $\pm$ 0.69 (0.856) |
| Gittins@0.05 (ours) | 70.5 $\pm$ 5.2 (0.012) | 5.96 $\pm$ 0.59 (0.001) |
| Gittins@linear (ours) | 71.4 $\pm$ 5.1 (0.013) | 4.74 $\pm$ 0.56 (0.011) |
#### 1. PRM-guided tree search methods do not outperform Best-of-N despite higher costs.
Best-of-N using terminal PRM scores (BoN_Last@8) achieves the highest mean rank and accuracy (see Tables ˜ 1 and 4). Among Best-of-N variants, average, minimum, and product aggregations perform comparably without significant differences. MCTS and beam search also show no significant performance degradation compared to the best method. However, tree search methods incur substantially higher computational costs, generating considerably more tokens (see Generated token in Table ˜ 3). Despite this increased cost, their final solutions contain fewer reasoning steps and tokens than Best-of-N solutions (see Reasoning steps and Out Tokens in Table ˜ 3). Except for GBFS, tree search methods reach approximately as many terminal states as Best-of-N (see Terminal states in Table ˜ 3).
Table 2: Method mean accuracy and rank with standard errors across problems for tree search methods. We bold results which are not significantly worse than the best ( $p>0.05$ ).
| Method Greedy@6 Greedy@20 | Accuracy (p-value) 71.6 $\pm$ 5.0 (0.498) 71.2 $\pm$ 5.0 (0.019) | Rank (p-value) 3.78 $\pm$ 0.41 (0.021) 3.43 $\pm$ 0.27 (0.032) |
| --- | --- | --- |
| Beam@4 (V) | 71.8 $\pm$ 4.9 (0.601) | 2.52 $\pm$ 0.20 (0.232) |
| Beam@4 (CV) | 71.9 $\pm$ 4.8 (N/A) 0 | 2.57 $\pm$ 0.24 (0.286) |
| GBFS@8 | 46.0 $\pm$ 4.1 (0.000) | 6.70 $\pm$ 0.34 (0.000) |
| GBFS_DA@8 | 48.1 $\pm$ 4.6 (0.000) | 6.48 $\pm$ 0.30 (0.000) |
| MCTS@8 | 71.2 $\pm$ 5.0 (0.332) | 2.26 $\pm$ 0.41 (N/A) 0 |
| Gittins@0.05 (ours) | 70.5 $\pm$ 5.2 (0.019) | 4.00 $\pm$ 0.35 (0.006) |
| Gittins@linear (ours) | 71.4 $\pm$ 5.1 (0.398) | 3.09 $\pm$ 0.30 (0.048) |
#### 2. MCTS and beam search perform best among PRM-guided tree search methods.
MCTS@8 achieves the highest mean rank among tree search methods, with beam search variants (Beam@4 (V) and Beam@4 (CV)) performing comparably without significant differences ( ${p>0.05}$ , see Table ˜ 2). For mean accuracy, beam search maximizing the cumulative PRM values performs best, followed by Beam@4 (V), Greedy@6, Gittins@linear and MCTS@8 with no significant performance gaps.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Line Chart: Correlation vs. Reasoning Steps to Terminal State
### Overview
The image is a line chart plotting the correlation between model predictions and outcomes against the number of reasoning steps required to reach a terminal state. It compares performance across three data distributions: all data, in-distribution data, and out-of-distribution data. The chart demonstrates a general downward trend in correlation as reasoning steps increase.
### Components/Axes
* **Chart Type:** Line chart with three data series.
* **X-Axis:** Labeled "Reasoning steps to terminal state". The scale runs from 0 to 50, with major tick marks at intervals of 10 (0, 10, 20, 30, 40, 50).
* **Y-Axis:** Labeled "Correlation". The scale runs from 0.0 to 1.0, with major tick marks at intervals of 0.2 (0.0, 0.2, 0.4, 0.6, 0.8, 1.0).
* **Legend:** Located in the top-left corner of the plot area. It contains three entries:
* **Green line:** "All data"
* **Blue line:** "In-distribution"
* **Red line:** "Out-of-distribution"
### Detailed Analysis
The chart displays three distinct lines, each representing a data series. The general trend for all three is a negative correlation between the number of reasoning steps and the correlation metric.
1. **"In-distribution" (Blue Line):**
* **Trend:** Starts at the highest point, experiences a sharp initial decline, then continues a fluctuating but generally downward slope.
* **Key Points (Approximate):**
* At 0 steps: Correlation ≈ 0.65.
* At ~5 steps: Sharp drop to ≈ 0.45.
* At 10 steps: ≈ 0.42.
* At 20 steps: ≈ 0.40.
* At 30 steps: ≈ 0.30.
* At 40 steps: ≈ 0.22.
* At 50 steps: Drops sharply to ≈ 0.0.
2. **"All data" (Green Line):**
* **Trend:** Starts in the middle, follows a steadier, less volatile decline compared to the blue line.
* **Key Points (Approximate):**
* At 0 steps: Correlation ≈ 0.55.
* At 10 steps: ≈ 0.35.
* At 20 steps: ≈ 0.32.
* At 30 steps: ≈ 0.28.
* At 40 steps: ≈ 0.25.
* At 50 steps: ≈ 0.20.
3. **"Out-of-distribution" (Red Line):**
* **Trend:** Starts the lowest, drops quickly in the first few steps, then fluctuates at a lower correlation level than the other two series for most of the range.
* **Key Points (Approximate):**
* At 0 steps: Correlation ≈ 0.50.
* At ~5 steps: Drops to ≈ 0.30.
* At 10 steps: ≈ 0.25.
* At 20 steps: ≈ 0.22.
* At 30 steps: ≈ 0.25.
* At 40 steps: ≈ 0.20.
* At 50 steps: ≈ 0.18.
### Key Observations
* **Hierarchy:** For nearly the entire range (0 to ~45 steps), the correlation order is consistent: In-distribution (blue) > All data (green) > Out-of-distribution (red).
* **Convergence:** The lines for "All data" and "Out-of-distribution" converge and intertwine between approximately 30 and 45 steps, making their values very similar in that region.
* **Final Drop:** The "In-distribution" (blue) line exhibits a dramatic, near-vertical drop to zero correlation at the final data point (50 steps), which is a significant outlier compared to the more gradual endings of the other two lines.
* **Volatility:** The "In-distribution" (blue) line shows the most volatility, with several sharp local peaks and troughs (e.g., around 5, 25, and 45 steps). The "Out-of-distribution" (red) line is also quite jagged. The "All data" (green) line is the smoothest.
### Interpretation
This chart illustrates a core challenge in complex reasoning tasks: **performance degrades as the required reasoning chain lengthens.** The data suggests that models are more reliable (higher correlation) on problems requiring fewer steps.
The stark difference between the "In-distribution" and "Out-of-distribution" lines highlights a critical vulnerability. Models maintain significantly higher correlation on problems similar to their training data (in-distribution). When faced with novel or shifted problem types (out-of-distribution), their predictive reliability is substantially lower from the very first step and remains poor.
The "All data" line, being an aggregate, naturally falls between the two specialized distributions. Its smoother trajectory suggests that averaging across diverse problem types masks some of the volatility seen in the specialized subsets.
The most striking anomaly is the collapse of the in-distribution correlation to zero at 50 steps. This could indicate a specific failure mode, a limitation in the evaluation setup for very long chains, or a point where the model's reasoning completely breaks down even on familiar data types. This single point warrants further investigation, as it deviates sharply from the preceding trend.
In summary, the chart provides evidence that both **reasoning length** and **data distribution shift** are major factors negatively impacting model performance, with their combined effect being particularly severe.
</details>
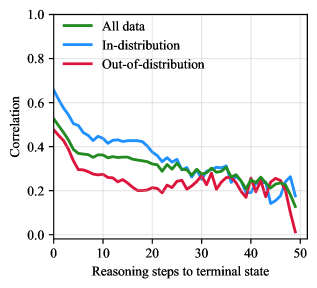
Figure 1: Correlation of prediction correctness with PRM scores. Correlation decreases with increasing distance in reasoning steps from terminal states.
#### 3. The PRM poorly approximates ${p(v(s)=1\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)}$ and reliability degrades with reasoning depth, limiting tree search effectiveness.
Methods assuming the PRM accurately estimates the value across all states (Greedy@K and Gittins@cost, Scenario 1 in Section ˜ 2.1) perform significantly worse than Best-of-N and other tree search methods (Tables ˜ 1 and 2). Increasing policy samples ( $K=6$ to $K=20$ ) or adaptive sampling (Gittins@cost) does not improve performance. This suggests either the LLM policy cannot generate high-scoring states or the PRM cannot identify them. Since PASS@K significantly outperforms Best-of-N, the LLM policy does generate correct solutions but the PRM fails to rank them highly, providing evidence that the PRM poorly approximates $p(v(s)=1\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ .
Further analysis shows that point-biserial correlation of prediction correctness with PRM scores is initially high ( ${\approx 0.5}$ ) near terminal states but deteriorates significantly for early reasoning steps ( $\approx 0.37$ at $10$ steps from termination; see All data in Figure ˜ 1). These findings suggest credit assignment issues in the offline reinforcement learning of the PRM. Moreover, this pattern explains why MCTS@8, which relies exclusively on terminal PRM scores, achieves the best average rank among tree search methods, and Beam@8 performs best in accuracy by tolerating locally suboptimal steps that lead to higher-scoring future states. This suggests that the PRM operates between Scenarios 2 and 3: terminal scores are most reliable, but intermediate scores provide useful yet unreliable guidance.
#### 4. The PRM shows limited out-of-distribution generalization.
Correlation between PRM scores and correctness is consistently higher on in-distribution (ID) problems on which the PRM is trained (GSM8K and MATH) than out-of-distribution (OOD) tasks (others problems; Figures ˜ 2 and 5). This generalization gap persists across most reasoning steps: correlation of prediction correctness with PRM scores on ID problems is considerably larger than on OOD tasks until $\approx 30$ steps to termination, after which both ID and OOD performance converge to similarly low correlation levels (see ID and OOD in Figure ˜ 1). This limited generalization further constrains the practical utility of PRM-guided tree search across diverse mathematical domains.
## 5 Related work
#### Tree search with LLM self-evaluation
Several works apply greedy best-first search [9], Monte Carlo tree search [16, 17] and beam search [18] to reasoning using the LLM policy model itself for state evaluation. Unlike these approaches, we use a process reward model trained by offline reinforcement learning on mathematics tasks to guide search.
#### PRM-guided tree search
Zhang et al. [3] evaluate PRM aggregation methods and greedy search, finding greedy search generally inferior to Best-of-N. Our study extends this analysis with a more comprehensive evaluation, including additional tree search methods (MCTS, GBFS, beam search) and more than three times as many problems ( $23$ vs. $7$ ). Our findings challenge some of theirs results, notably that last-token aggregation outperforms product aggregation on average. More importantly, we provide evidence that PRM reliability degrades with reasoning depth, a key finding that explains why tree search methods fail to outperform Best-of-N.
#### Tree search for LLM training
Recent work has used MCTS within reinforcement learning pipelines to improve both language models and PRMs. Zhang et al. [19], Wan et al. [20], Xie et al. [21], Guan et al. [22] employ MCTS under PRM supervision to generate high-scoring reasoning chains subsequently used to fine-tune both the policy and PRM through self-training. In contrast, our work focuses on pretrained LLM and PRM models without fine-tuning.
## 6 Conclusion
We proposed an adaptive algorithm to maximize PRM scores over the intractable action space, and empirically investigated PRM-guided tree search across $23$ mathematical reasoning problems using Qwen2.5-Math-7B-Instruct and its associated PRM. Our findings show that PRM-guided tree search methods fail to outperform Best-of-N despite higher costs, with MCTS and beam search proving most effective among PRM-guided tree search approaches. We identify the underlying causes: PRMs poorly approximate state values, become less reliable with reasoning depth indicating credit assignment issues, and exhibit limited out-of-distribution generalization restricting their broader applicability. Tree search’s underperformance stems from its reliance on these unreliable intermediate-step PRM scores to guide search, whereas BoN evaluates only complete CoTs. These results highlight the limitations of both PRM-guided tree search and BoN, revealing that current PRMs lack sufficient accuracy to guide dynamic mathematical reasoning and suggesting that different reward models may be required.
## Acknowledgments and Disclosure of Funding
GP is supported by the Canada CIFAR AI Chair program. The authors are grateful to Johannes Zenn for many insightful discussions that helped shape the direction of this project, and to both Johannes Zenn and Arsen Sheverdin for their careful reading of the manuscript and valuable feedback that improved its clarity and presentation. The computational resources used in this work were provided, in part, by the Province of Ontario, the Government of Canada through CIFAR, and by companies sponsoring the Vector Institute [https://vectorinstitute.ai/partnerships/.
## References
- Wei et al. [2022] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY, USA, 2022. Curran Associates Inc. ISBN 9781713871088.
- Sprague et al. [2025] Zayne Rea Sprague, Fangcong Yin, Juan Diego Rodriguez, Dongwei Jiang, Manya Wadhwa, Prasann Singhal, Xinyu Zhao, Xi Ye, Kyle Mahowald, and Greg Durrett. To cot or not to cot? chain-of-thought helps mainly on math and symbolic reasoning. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=w6nlcS8Kkn.
- Zhang et al. [2025] Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning, 2025. URL https://arxiv.org/abs/2501.07301.
- Yang et al. [2024] An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement, 2024. URL https://arxiv.org/abs/2409.12122.
- Lightman et al. [2024] Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=v8L0pN6EOi.
- Uesato et al. [2022] Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback, 2022. URL https://arxiv.org/abs/2211.14275.
- Muennighoff et al. [2025] Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candes, and Tatsunori Hashimoto. s1: Simple test-time scaling. In Workshop on Reasoning and Planning for Large Language Models, 2025. URL https://openreview.net/forum?id=LdH0vrgAHm.
- DeepSeek-AI et al. [2025] DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Qu, Hui Li, Jianzhong Guo, Jiashi Li, Jiawei Wang, Jingchang Chen, Jingyang Yuan, Junjie Qiu, Junlong Li, J. L. Cai, Jiaqi Ni, Jian Liang, Jin Chen, Kai Dong, Kai Hu, Kaige Gao, Kang Guan, Kexin Huang, Kuai Yu, Lean Wang, Lecong Zhang, Liang Zhao, Litong Wang, Liyue Zhang, Lei Xu, Leyi Xia, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Meng Li, Miaojun Wang, Mingming Li, Ning Tian, Panpan Huang, Peng Zhang, Qiancheng Wang, Qinyu Chen, Qiushi Du, Ruiqi Ge, Ruisong Zhang, Ruizhe Pan, Runji Wang, R. J. Chen, R. L. Jin, Ruyi Chen, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shengfeng Ye, Shiyu Wang, Shuiping Yu, Shunfeng Zhou, Shuting Pan, S. S. Li, Shuang Zhou, Shaoqing Wu, Shengfeng Ye, Tao Yun, Tian Pei, Tianyu Sun, T. Wang, Wangding Zeng, Wanjia Zhao, Wen Liu, Wenfeng Liang, Wenjun Gao, Wenqin Yu, Wentao Zhang, W. L. Xiao, Wei An, Xiaodong Liu, Xiaohan Wang, Xiaokang Chen, Xiaotao Nie, Xin Cheng, Xin Liu, Xin Xie, Xingchao Liu, Xinyu Yang, Xinyuan Li, Xuecheng Su, Xuheng Lin, X. Q. Li, Xiangyue Jin, Xiaojin Shen, Xiaosha Chen, Xiaowen Sun, Xiaoxiang Wang, Xinnan Song, Xinyi Zhou, Xianzu Wang, Xinxia Shan, Y. K. Li, Y. Q. Wang, Y. X. Wei, Yang Zhang, Yanhong Xu, Yao Li, Yao Zhao, Yaofeng Sun, Yaohui Wang, Yi Yu, Yichao Zhang, Yifan Shi, Yiliang Xiong, Ying He, Yishi Piao, Yisong Wang, Yixuan Tan, Yiyang Ma, Yiyuan Liu, Yongqiang Guo, Yuan Ou, Yuduan Wang, Yue Gong, Yuheng Zou, Yujia He, Yunfan Xiong, Yuxiang Luo, Yuxiang You, Yuxuan Liu, Yuyang Zhou, Y. X. Zhu, Yanhong Xu, Yanping Huang, Yaohui Li, Yi Zheng, Yuchen Zhu, Yunxian Ma, Ying Tang, Yukun Zha, Yuting Yan, Z. Z. Ren, Zehui Ren, Zhangli Sha, Zhe Fu, Zhean Xu, Zhenda Xie, Zhengyan Zhang, Zhewen Hao, Zhicheng Ma, Zhigang Yan, Zhiyu Wu, Zihui Gu, Zijia Zhu, Zijun Liu, Zilin Li, Ziwei Xie, Ziyang Song, Zizheng Pan, Zhen Huang, Zhipeng Xu, Zhongyu Zhang, and Zhen Zhang. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URL https://arxiv.org/abs/2501.12948.
- Yao et al. [2023] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of Thoughts: Deliberate problem solving with large language models, 2023.
- Weitzman [1979] Martin L. Weitzman. Optimal search for the best alternative. Econometrica, 47(3):641–654, 1979. URL https://onlinelibrary.wiley.com/doi/abs/0012-9682(197905)47:3<641:OSFTBA>2.0.CO;2-1.
- Xie et al. [2024a] Qian Xie, Raul Astudillo, Peter I. Frazier, Ziv Scully, and Alexander Terenin. Cost-aware bayesian optimization via the pandora’s box gittins index. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024a. URL https://openreview.net/forum?id=Ouc1F0Sfb7.
- Jones et al. [1998] Donald Jones, Matthias Schonlau, and William Welch. Efficient global optimization of expensive black-box functions. Journal of Global Optimization, 13:455–492, 12 1998. doi: 10.1023/A:1008306431147.
- Garnett [2023] Roman Garnett. Bayesian Optimization. Cambridge University Press, 2023.
- Balunović et al. [2025] Mislav Balunović, Jasper Dekoninck, Ivo Petrov, Nikola Jovanović, and Martin Vechev. Matharena: Evaluating llms on uncontaminated math competitions, February 2025. URL https://matharena.ai/.
- Hochlehnert et al. [2025] Andreas Hochlehnert, Hardik Bhatnagar, Vishaal Udandarao, Samuel Albanie, Ameya Prabhu, and Matthias Bethge. A sober look at progress in language model reasoning: Pitfalls and paths to reproducibility, 2025. URL https://arxiv.org/abs/2504.07086.
- Zhang et al. [2024a] Di Zhang, Xiaoshui Huang, Dongzhan Zhou, Yuqiang Li, and Wanli Ouyang. Accessing gpt-4 level mathematical olympiad solutions via monte carlo tree self-refine with llama-3 8b, 2024a. URL https://arxiv.org/abs/2406.07394.
- Hao et al. [2023] Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023. URL https://openreview.net/forum?id=VTWWvYtF1R.
- Xie et al. [2023] Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, Xu Zhao, Min-Yen Kan, Junxian He, and Qizhe Xie. Self-evaluation guided beam search for reasoning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=Bw82hwg5Q3.
- Zhang et al. [2024b] Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, and Jie Tang. ReST-MCTS*: LLM self-training via process reward guided tree search. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024b. URL https://openreview.net/forum?id=8rcFOqEud5.
- Wan et al. [2024] Ziyu Wan, Xidong Feng, Muning Wen, Stephen Marcus McAleer, Ying Wen, Weinan Zhang, and Jun Wang. Alphazero-like tree-search can guide large language model decoding and training. In Proceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024.
- Xie et al. [2024b] Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P Lillicrap, Kenji Kawaguchi, and Michael Shieh. Monte carlo tree search boosts reasoning via iterative preference learning. arXiv preprint arXiv:2405.00451, 2024b.
- Guan et al. [2025] Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. rstar-math: Small LLMs can master math reasoning with self-evolved deep thinking. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=5zwF1GizFa.
- Team [2024] Qwen Team. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2024.
- Virtanen et al. [2020] Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, İlhan Polat, Yu Feng, Eric W. Moore, Jake VanderPlas, Denis Laxalde, Josef Perktold, Robert Cimrman, Ian Henriksen, E. A. Quintero, Charles R. Harris, Anne M. Archibald, Antônio H. Ribeiro, Fabian Pedregosa, Paul van Mulbregt, and SciPy 1.0 Contributors. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods, 17:261–272, 2020. doi: 10.1038/s41592-019-0686-2.
- Hagberg et al. [2008] Aric A. Hagberg, Daniel A. Schult, and Pieter J. Swart. Exploring network structure, dynamics, and function using networkx. In Gaël Varoquaux, Travis Vaught, and Jarrod Millman, editors, Proceedings of the 7th Python in Science Conference, pages 11 – 15, Pasadena, CA USA, 2008.
- Kwon et al. [2023] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023.
- Vector Institute [2025] Vector Institute. Vector-Inference: Efficient llm inference on slurm clusters, 2025. URL https://github.com/VectorInstitute/vector-inference. GitHub repository, accessed 2025-09-04.
## Appendix A Additional method details
We here provide additional details on the method presented in Section ˜ 3.
#### Maximizing over the intractable ${\mathbb{A}}$ using Gittin’s indices.
At each state $s$ , we sample independent actions from the policy $a\sim\pi_{\bm{\theta}}(\cdot\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ and evaluate $f=f_{\bm{\phi}}({s\oplus a})$ , which induces the distribution
$$
p({\bm{\mathrm{f}}}=f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)=\sum_{a\in{\mathbb{A}}}\mathds{1}(f=f_{\bm{\phi}}({s\oplus a}))\pi_{\bm{\theta}}(a\nonscript\>|\allowbreak\nonscript\>\mathopen{}s).
$$
After sampling $i$ actions from the policy, let $m_{i}=\max_{j\leq i}f_{j}$ denote the maximum PRM score observed so far. We face a choice between two actions:
1. Sample a new action $a_{i+1}\sim\pi(\cdot\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ , observe $f_{i+1}=f_{\bm{\phi}}({s\oplus a_{i+1}})$ , and incur cost $c$
1. Stop and commit to the current best action with score $m_{i}$
The expected payoff for sampling is $\operatorname{\mathbb{E}}_{f\sim p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)}\left[\max(m_{i},f)\right]-c$ , while stopping yields payoff $m_{i}$ . The optimal policy samples when the sampling payoff exceeds the stopping payoff:
$$
\displaystyle\operatorname{\mathbb{E}}_{f\sim p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)}\left[\max(m_{i},f)\right]-c \displaystyle>m_{i} \displaystyle\Leftrightarrow\quad\operatorname{\mathbb{E}}_{f\sim p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)}\left[\max(0,f-m_{i})\right] \displaystyle>c
$$
The Gittins index $m_{i}^{*}$ is defined as the unique solution to
$$
\operatorname{\mathbb{E}}_{f\sim p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)}\left[\max(0,f-m_{i}^{*})\right]=c
$$
The optimal policy samples if $m_{i}^{*}>m_{i}$ and stops otherwise [10]. However, computing this expectation requires knowledge of $p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ which is intractable due to the summation over the action space ${\mathbb{A}}$ (see Equation ˜ A.1). Since estimating this distribution would require the very LLM samples we aim to collect sparingly, we develop a Bayesian surrogate approach inspired by Xie et al. [11] which we discuss next.
#### Bayesian surrogate modeling
We approximate $p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ using a surrogate model $q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s,{\bm{\psi}})$ with parameters ${\bm{\psi}}$ . Specifically, we encode our prior beliefs in $p({\bm{\psi}})$ , then update the posterior $p({\bm{\psi}}\nonscript\>|\allowbreak\nonscript\>\mathopen{}\mathcal{D})\propto q(\mathcal{D}\nonscript\>|\allowbreak\nonscript\>\mathopen{}s,{\bm{\psi}})p({\bm{\psi}})$ with observations $\mathcal{D}=\{f_{i}|f_{i}\sim p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)\}$ before using the posterior predictive $q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s,\mathcal{D})=\int q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s,{\bm{\psi}})p({\bm{\psi}}\nonscript\>|\allowbreak\nonscript\>\mathopen{}\mathcal{D})d{\bm{\psi}}$ to approximate $p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ . We then compute the Gittin’s index $m_{i}^{*}$ under posterior beliefs $q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s,\mathcal{D})$ rather than $p(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ by solving
$$
\operatorname{\mathbb{E}}_{f\sim q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s,\mathcal{D})}\left[\max(0,f-m_{i})\right]=c
$$
The left-hand side of Equation ˜ A.5 is the expected improvement over the current maximum $m$ [12], a standard Bayesian optimization acquisition function [13]. The Gittin’s index $m^{*}$ represents the threshold where expected improvement equals cost $c$ , thus smaller $c$ induces more exploration. More details in Algorithm ˜ 1.
#### Adaptive cost scheduling.
To balance exploration and exploitation over the search horizon, we employ time-varying costs:
$$
c(n)=c_{1}+(c_{2}-c_{1})\times\nicefrac{{n}}{{B}}
$$
where $c_{1}<c_{2}$ are initial and final costs, $B$ is the total sampling budget, and $n$ is the current sample count. This schedule promotes exploration early during search when the remaining sampling budget is large and exploitation as resources diminish.
Algorithm 1 Adaptive PRM-guided tree search using Gittin’s indices and surrogate modeling.
1:
function Gittins ( $f_{\bm{\phi}}$ , $\pi_{\bm{\theta}}$ , ${\mathbb{T}}$ , $s$ , $K$ , $c$ )
2:
repeat
3:
$\mathcal{D}\leftarrow\emptyset$
4:
repeat
5:
$\mathcal{D}\leftarrow\mathcal{D}\cup\{(s_{i},f_{\bm{\phi}}(s_{i}))\,|\,a_{i}\sim\pi_{\bm{\theta}}(\cdot\nonscript\>|\allowbreak\nonscript\>\mathopen{}s),s_{i}={s\oplus a_{i}}\}_{i=1}^{K}$ $\triangleright$ Sample from LLM
6:
$m\leftarrow\max_{(s,f)\in\mathcal{D}}f$ $\triangleright$ Update current observed maximum
7:
Compute posterior predictive $q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s,\mathcal{D})$ $\triangleright$ Update posterior beliefs
8:
Compute Gittin’s index $m^{*}$ by solving $\operatorname{\mathbb{E}}_{q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}\mathcal{D})}\left[\max(0,f-m^{*})\right]=c$ using bisection
9:
until $m^{*}>m$
10:
$s\leftarrow\max_{(s,f)\in\mathcal{D}}f$ $\triangleright$ Update current state
11:
until $s\in{\mathbb{T}}$
12:
return $s$
#### Logit-Normal surrogate model
Let $\mathcal{D}_{n}=\{f_{i}\}_{i=1}^{n}$ where $f_{i}\in[0,1]$ be a collection of observations from $p({\bm{\mathrm{f}}}=f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)$ at a given state $s$ . We consider a logit-Normal likelihood model for our observations i.e.
$$
q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)={\operatorname{\mathcal{N}}\left(\operatorname{logit}(f);\mu,\sigma^{2}\right)}\frac{1}{f(1-f)}
$$
where $\frac{1}{f(1-f)}$ adjusts for the change of variable. We then specify a Normal-inverse-Gamma prior on the likelihood parameters $\mu$ and $\sigma^{2}$ i.e.
$$
q(\mu,\sigma^{2})={\operatorname{\mathcal{N}}\left(m_{0},v_{0}\sigma^{2}\right)}\mathcal{IG}(\alpha_{0},\beta_{0})
$$
The model is conjugate and both the posterior and the predictive posterior are available in closed form. The prior is chosen to yield a maximally uniform predictive prior.
The prior predictive is
$$
q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}\mu,\sigma^{2})=\int q(r\nonscript\>|\allowbreak\nonscript\>\mathopen{}\mu,\sigma^{2})q(\mu,\sigma^{2})d\mu d\sigma^{2}={\operatorname{\mathcal{T}}_{2a_{0}}\left(f;m_{0},\frac{b_{0}(1+v_{0})}{a_{0}}\right)}\frac{1}{f(1-f)}
$$
The posterior is then
$$
\displaystyle q(\mu,\sigma^{2}\nonscript\>|\allowbreak\nonscript\>\mathopen{}\mathcal{D}) \displaystyle=\frac{\prod_{i=1}^{n}q(f_{i}\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)q(\mu,\sigma^{2})}{\int\prod_{i=1}^{n}q(f_{i}\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)q(\mu,\sigma^{2})d\mu d\sigma^{2}} \displaystyle=\frac{C\prod_{i=1}^{n}{\operatorname{\mathcal{N}}\left(\operatorname{logit}(f_{i});\mu,\sigma^{2}\right)}q(\mu,\sigma^{2})}{C\int\prod_{i=1}^{n}{\operatorname{\mathcal{N}}\left(\operatorname{logit}(f_{i});\mu,\sigma^{2}\right)}q(\mu,\sigma^{2})d\mu d\sigma^{2}} \displaystyle=\frac{\prod_{i=1}^{n}{\operatorname{\mathcal{N}}\left(\operatorname{logit}(f_{i});\mu,\sigma^{2}\right)}q(\mu,\sigma^{2})}{\int\prod_{i=1}^{n}{\operatorname{\mathcal{N}}\left(\operatorname{logit}(f_{i});\mu,\sigma^{2}\right)}q(\mu,\sigma^{2})d\mu d\sigma^{2}} \displaystyle={\operatorname{\mathcal{N}}\left(m_{n},v_{n}\sigma^{2}\right)}\mathcal{IG}(\alpha_{n},\beta_{n})
$$
where $C=\prod_{i=1}^{n}\frac{1}{f_{i}(1-f_{i})}$ , $v_{n}^{-1}=v_{0}^{-1}+n$ , $m_{n}=v_{n}^{-1}(v_{0}^{-1}m_{0}+\sum_{i=1}^{n}\operatorname{logit}(f_{i}))$ , $a_{n}=a_{0}+n/2$ and $b_{n}=b_{0}+\frac{1}{2}[m_{0}^{2}v_{0}^{-1}+\sum_{i=1}^{n}\operatorname{logit}(f_{i})^{2}-m_{n}^{2}v_{n}^{-1}]$ .
The predictive posterior is
$$
q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}\mathcal{D})=\int q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}\mu,\sigma^{2})q(\mu,\sigma^{2}\nonscript\>|\allowbreak\nonscript\>\mathopen{}\mathcal{D})d\mu d\sigma^{2}={\operatorname{\mathcal{T}}_{2a_{n}}\left(f;m_{n},\frac{b_{n}(1+v_{n})}{a_{n}}\right)}\frac{1}{f(1-f)}
$$
Furthermore, the marginal likelihood has an analytical formulation:
$$
\displaystyle q(\mathcal{D}\nonscript\>|\allowbreak\nonscript\>\mathopen{}m_{0},v_{0},a_{0},b_{0}) \displaystyle=\int\prod_{i=1}^{n}q(f_{i}\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)q(\mu,\sigma^{2})d\mu d\sigma^{2} \displaystyle=\left[\prod_{i=1}^{n}\frac{1}{f_{i}(1-f_{i})}\right]\left[\int\prod_{i=1}^{n}q(\operatorname{logit}(f_{i})\nonscript\>|\allowbreak\nonscript\>\mathopen{}s)q(\mu,\sigma^{2})d\mu d\sigma^{2}\right] \displaystyle=C\left[\frac{v_{n}^{1/2}b_{0}^{a_{0}}\Gamma(a_{n})}{v_{0}^{1/2}b_{n}^{a_{n}}\Gamma(a_{0})\pi^{n/2}2^{n}}\right]
$$
where $C=\prod_{i=1}^{n}\frac{1}{f_{i}(1-f_{i})}$ .
#### Implementation details
We estimate the expectation $\operatorname{\mathbb{E}}_{q}\left[\max(0,f-m)\right]$ using quadrature reparameterizing the integral to logit-space
$$
\displaystyle\operatorname{\mathbb{E}}_{q}\left[\max(0,f-m)\right] \displaystyle=\int_{m}^{1}(f-m)q(f\nonscript\>|\allowbreak\nonscript\>\mathopen{}\mathcal{D})df \displaystyle=\int_{\operatorname{logit}(m)}^{\operatorname{logit}(1)}(\operatorname{logit}^{-1}(l)-m)q(l\nonscript\>|\allowbreak\nonscript\>\mathopen{}\mathcal{D})dl \tag{1}
$$
where $l=\operatorname{logit}(f)$ . We solve for the Gittin’s index $m^{*}$ using bissection search as done in Xie et al. [11]. Since the observations $f$ take values in $[0,1]$ , we shrink them using $f_{i}=\epsilon+(1-2\epsilon)f_{\bm{\phi}}(s_{i})$ to avoid singularities at $0$ and $1$ .
## Appendix B Additional experimental setup details
#### Models and hyperparameters.
We use Qwen2.5-Math-7B-Instruct [23] as our base language model, where actions $a\in\mathcal{A}$ correspond to text sequences terminated by ’ \n\n ’. For process reward modeling, we use Qwen2.5-Math-PRM-7B trained on MATH and GSM8K problems [3]. Following the recommended configuration [23], we set temperature=0.7, top_p=0.8, and repetition_penalty=1.05 for text generation.
#### Implementation.
Gittins indices are computed via bisection search and numerical integration performed using SciPy [24]. Tree structures are managed through NetworkX [25]. Models are served using vLLM [26] with our inference pipeline adapted from vector-inference [27]. Evaluation follows the protocol established by Yang et al. [4] using their official codebase. https://github.com/QwenLM/Qwen2.5-Math
#### Computational resources.
All experiments are conducted on NVIDIA RTX 6000 and A40 GPUs, with each model deployed on a single GPU.
## Appendix C Additional experimental results
Table 3: Performance metrics across 23 problems: mean accuracy with standard-error, mean rank with standard-error, reasoning steps, generated tokens (Gen.), output tokens (Out.), and terminal state coverage. Bold entries indicate no significant difference from the best method ( $p>0.05$ ). Best-of-N with terminal PRM scores (BoN_Last@8) perform best, while tree search methods (MCTS, beam search) match accuracy but require substantially higher computational cost.
| Method PASS@8 MAJ@8 | Accuracy 79.8 $\pm$ 4.7 (N/A) 0 71.4 $\pm$ 5.1 (0.010) | Rank N/A 4.43 $\pm$ 0.51 (0.022) | Reasoning steps 9.7 9.7 | Gen. Tokens ( $\times 10^{7}$ ) 8.2 8.2 | Out. Tokens ( $\times 10^{7}$ ) 8.2 8.2 | Terminal State (%) 98.2 98.2 |
| --- | --- | --- | --- | --- | --- | --- |
| BoN_Last@8 | 72.7 $\pm$ 5.1 (N/A) 0 | 3.13 $\pm$ 0.38 (N/A) 0 | 9.7 | 8.2 | 8.2 | 98.2 |
| BoN_Avg@8 | 72.1 $\pm$ 5.0 (0.444) | 3.22 $\pm$ 0.31 (0.787) | 9.7 | 8.2 | 8.2 | 98.2 |
| BoN_Min@8 | 72.2 $\pm$ 5.0 (0.711) | 3.26 $\pm$ 0.32 (0.608) | 9.7 | 8.2 | 8.2 | 98.2 |
| BoN_Prod@8 | 72.0 $\pm$ 5.0 (0.408) | 3.26 $\pm$ 0.40 (0.795) | 9.7 | 8.2 | 8.2 | 98.2 |
| BoN_Sum@8 | 67.6 $\pm$ 5.3 (0.000) | 7.30 $\pm$ 0.72 (0.000) | 9.7 | 8.2 | 8.2 | 98.2 |
| BoN_Max@8 | 68.8 $\pm$ 5.4 (0.000) | 7.35 $\pm$ 0.69 (0.000) | 9.7 | 8.2 | 8.2 | 98.2 |
| Greedy@6 | 71.6 $\pm$ 5.0 (0.043) | 5.74 $\pm$ 0.76 (0.003) | 8.9 | 5.6 | 0.9 | 97.9 |
| Greedy@20 | 71.2 $\pm$ 5.0 (0.039) | 5.09 $\pm$ 0.55 (0.009) | 8.8 | 18.7 | 0.9 | 98.2 |
| Beam@4 (V) | 71.8 $\pm$ 4.9 (0.126) | 3.83 $\pm$ 0.42 (0.236) | 9.2 | 20.2 | 0.9 | 98.7 |
| Beam@4 (CV) | 71.9 $\pm$ 4.8 (0.189) | 4.00 $\pm$ 0.49 (0.221) | 9.4 | 21.0 | 0.9 | 96.5 |
| GBFS@8 | 46.0 $\pm$ 4.1 (0.000) | 10.09 $\pm$ 0.71 (0.000) | 5.3 | 65.2 | 0.5 | 52.7 |
| GBFS_DA@8 | 48.1 $\pm$ 4.6 (0.000) | 10.00 $\pm$ 0.65 (0.000) | 5.8 | 68.0 | 0.5 | 57.1 |
| MCTS | 71.2 $\pm$ 5.0 (0.987) | 3.26 $\pm$ 0.69 (0.856) | 8.8 | 89.4 | 0.7 | 97.8 |
| Gittins@0.05 (ours) | 70.5 $\pm$ 5.2 (0.012) | 5.96 $\pm$ 0.59 (0.001) | 9.5 | 9.0 | 0.9 | 98.3 |
| Gittins@linear (ours) | 71.4 $\pm$ 5.1 (0.013) | 4.74 $\pm$ 0.56 (0.011) | 9.5 | 14.3 | 0.9 | 98.5 |
Table 4: Accuracy by dataset with means and standard errors. Bold indicates best performance per dataset. Bottom rows show overall means and win counts across problems.
| aime25 aime24 amc23 | 20.0 23.3 82.5 | 13.3 16.7 60.0 | 13.3 16.7 70.0 | 16.7 20.0 67.5 | 16.7 20.0 70.0 | 20.0 20.0 70.0 | 13.3 16.7 62.5 | 6.7 10.0 62.5 | 16.7 16.7 62.5 | 10.0 26.7 62.5 | 13.3 16.7 55.0 | 16.7 13.3 70.0 | 20.0 16.7 67.5 | 16.7 30.0 65.0 | 6.7 6.7 40.0 | 3.3 13.3 37.5 | 23.3 26.7 65.0 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| sat_math | 100.0 | 96.9 | 100.0 | 100.0 | 100.0 | 100.0 | 93.8 | 93.8 | 100.0 | 96.9 | 100.0 | 96.9 | 96.9 | 96.9 | 62.5 | 75.0 | 96.9 |
| aqua | 94.1 | 78.0 | 76.0 | 76.0 | 75.6 | 76.0 | 73.2 | 74.4 | 79.5 | 79.5 | 78.0 | 75.5 | 77.6 | 79.5 | 63.8 | 63.0 | 68.3 |
| asdiv | 96.7 | 95.8 | 96.0 | 96.0 | 95.9 | 96.0 | 95.9 | 95.5 | 96.1 | 96.0 | 95.8 | 95.8 | 96.0 | 95.8 | 70.7 | 76.1 | 96.0 |
| carp_en | 63.1 | 61.8 | 61.7 | 61.9 | 62.0 | 62.0 | 61.7 | 61.5 | 61.0 | 61.2 | 61.1 | 61.1 | 61.1 | 61.5 | 36.1 | 39.2 | 61.5 |
| cmath | 95.3 | 92.7 | 93.2 | 93.8 | 94.0 | 94.0 | 92.2 | 92.2 | 92.3 | 93.2 | 92.8 | 93.3 | 93.0 | 93.5 | 69.8 | 73.5 | 94.0 |
| cn_middle_school | 82.2 | 78.2 | 80.2 | 79.2 | 79.2 | 79.2 | 76.2 | 76.2 | 80.2 | 78.2 | 77.2 | 77.2 | 77.2 | 78.2 | 54.5 | 61.4 | 79.2 |
| gaokao_math_cloze | 81.4 | 76.3 | 78.0 | 78.0 | 78.0 | 78.0 | 72.9 | 76.3 | 78.0 | 76.3 | 76.3 | 79.7 | 78.8 | 77.1 | 47.5 | 57.6 | 75.4 |
| gaokao_math_qa | 94.6 | 73.5 | 75.8 | 77.8 | 77.2 | 77.5 | 56.1 | 73.5 | 68.4 | 70.4 | 72.9 | 72.9 | 70.9 | 63.8 | 52.1 | 56.4 | 75.5 |
| gaokao2023en | 80.8 | 72.2 | 73.0 | 71.9 | 72.2 | 71.4 | 69.9 | 67.0 | 69.4 | 69.6 | 69.6 | 71.7 | 71.7 | 70.1 | 36.6 | 40.5 | 75.6 |
| gaokao2024_I | 71.4 | 57.1 | 57.1 | 50.0 | 57.1 | 50.0 | 42.9 | 57.1 | 64.3 | 64.3 | 64.3 | 57.1 | 57.1 | 57.1 | 42.9 | 35.7 | 64.3 |
| gaokao2024_II | 85.7 | 64.3 | 71.4 | 64.3 | 57.1 | 57.1 | 50.0 | 50.0 | 71.4 | 57.1 | 57.1 | 64.3 | 64.3 | 64.3 | 35.7 | 28.6 | 57.1 |
| gaokao2024_mix | 79.1 | 72.5 | 73.6 | 71.4 | 71.4 | 71.4 | 59.3 | 71.4 | 65.9 | 68.1 | 64.8 | 67.0 | 68.1 | 69.2 | 46.2 | 36.3 | 79.4 |
| gsm8k | 97.7 | 96.6 | 96.4 | 96.4 | 96.4 | 96.4 | 96.1 | 95.7 | 96.1 | 96.0 | 95.6 | 96.0 | 96.7 | 96.6 | 46.3 | 54.4 | 96.7 |
| mawps | 98.8 | 98.5 | 98.4 | 98.5 | 98.5 | 98.5 | 98.4 | 98.3 | 98.1 | 98.3 | 98.4 | 98.4 | 98.5 | 98.3 | 72.5 | 81.7 | 98.4 |
| minerva_math | 48.9 | 41.5 | 39.3 | 40.1 | 40.1 | 39.3 | 37.1 | 36.0 | 38.2 | 38.2 | 39.3 | 37.9 | 40.8 | 40.4 | 14.0 | 15.1 | 42.1 |
| mmlu_stem | 90.2 | 72.9 | 74.0 | 73.4 | 73.7 | 72.9 | 69.0 | 70.2 | 72.0 | 72.4 | 72.2 | 74.0 | 73.6 | 73.5 | 54.6 | 43.0 | 31.7 |
| svamp | 96.7 | 94.6 | 95.0 | 95.1 | 95.2 | 95.1 | 94.2 | 93.4 | 94.9 | 95.6 | 95.5 | 95.9 | 95.6 | 95.7 | 68.7 | 76.4 | 96.8 |
| tabmwp | 98.6 | 96.1 | 96.4 | 96.5 | 96.4 | 96.9 | 95.0 | 94.6 | 95.5 | 96.0 | 95.3 | 96.1 | 96.6 | 96.7 | 63.3 | 68.3 | 96.2 |
| olympiadbench | 61.9 | 44.7 | 48.4 | 47.3 | 46.1 | 46.7 | 42.1 | 42.7 | 44.1 | 45.5 | 43.3 | 44.9 | 46.1 | 46.1 | 21.6 | 21.9 | 47.9 |
| math | 92.3 | 87.0 | 88.2 | 87.6 | 87.5 | 87.3 | 85.5 | 84.5 | 86.0 | 86.4 | 86.7 | 86.4 | 86.7 | 86.8 | 44.7 | 48.8 | 89.1 |
| Average | 79.8 $\pm$ 4.7 | 71.4 $\pm$ 5.1 | 72.7 $\pm$ 5.1 | 72.1 $\pm$ 5.0 | 72.2 $\pm$ 5.0 | 72.0 $\pm$ 5.0 | 67.6 $\pm$ 5.3 | 68.8 $\pm$ 5.4 | 71.6 $\pm$ 5.0 | 71.2 $\pm$ 5.0 | 70.5 $\pm$ 5.2 | 71.4 $\pm$ 5.1 | 71.8 $\pm$ 4.9 | 71.9 $\pm$ 4.8 | 46.0 $\pm$ 4.1 | 48.1 $\pm$ 4.6 | 71.2 $\pm$ 5.0 |
| Best Count | N/A | 1/23 | 5/23 | 2/23 | 4/23 | 5/23 | 0/23 | 0/23 | 4/23 | 0/23 | 1/23 | 3/23 | 1/23 | 1/23 | 0/23 | 0/23 | 6/23 |
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Grouped Bar Chart: Correlation by Aggregation Method and Data Distribution
### Overview
The image displays a grouped bar chart comparing correlation values across six different data aggregation methods (Last, Avg, Min, Prod, Sum, Max). For each method, three bars represent correlations calculated on different data subsets: "All data," "In-distribution," and "Out-of-distribution." The chart is designed to show how correlation strength varies by aggregation technique and data type.
### Components/Axes
* **Chart Type:** Grouped bar chart.
* **Y-Axis:**
* **Label:** "Correlation"
* **Scale:** Linear, ranging from 0.0 to 1.0.
* **Major Ticks:** 0.0, 0.5, 1.0.
* **X-Axis:**
* **Categories (Aggregation Methods):** "Last", "Avg", "Min", "Prod", "Sum", "Max".
* **Legend:**
* **Position:** Centered at the bottom of the chart.
* **Items:**
* Green square: "All data"
* Blue square: "In-distribution"
* Red square: "Out-of-distribution"
* **Data Labels:** Each bar has its numerical correlation value printed directly above it.
### Detailed Analysis
The following table reconstructs the data presented in the chart. Values are read directly from the labels above each bar.
| Aggregation Method | All data (Green) | In-distribution (Blue) | Out-of-distribution (Red) |
| :--- | :--- | :--- | :--- |
| **Last** | 0.56 | 0.70 | 0.50 |
| **Avg** | 0.55 | 0.72 | 0.49 |
| **Min** | 0.57 | 0.70 | 0.53 |
| **Prod** | 0.53 | 0.59 | 0.52 |
| **Sum** | 0.02 | 0.09 | -0.02 |
| **Max** | 0.21 | 0.20 | 0.22 |
**Trend Verification per Category:**
* **Last, Avg, Min, Prod:** For these four methods, the "In-distribution" (blue) bar is consistently the tallest, indicating the highest correlation. The "All data" (green) bar is the second tallest, and the "Out-of-distribution" (red) bar is the shortest. The values for "All data" and "Out-of-distribution" are relatively close to each other.
* **Sum:** This category is a significant outlier. All correlation values are near zero. The "In-distribution" value (0.09) is the highest but still very low. The "Out-of-distribution" value is slightly negative (-0.02).
* **Max:** This category shows a different pattern. The correlations are low (around 0.2) and very similar across all three data subsets, with "Out-of-distribution" (0.22) being marginally the highest.
### Key Observations
1. **Strongest Correlations:** The "Avg" (Average) aggregation method applied to "In-distribution" data yields the highest correlation in the chart (0.72). "Last" and "Min" are close behind at 0.70.
2. **Weakest Correlations:** The "Sum" aggregation method produces the weakest correlations, all below 0.1 in magnitude. This is a dramatic drop compared to the other methods.
3. **Distribution Impact:** For the first four methods (Last, Avg, Min, Prod), using only "In-distribution" data results in a clear boost in correlation (approximately +0.15 to +0.17) compared to using "All data" or "Out-of-distribution" data.
4. **Anomaly - Sum:** The "Sum" method's near-zero correlations suggest that summing the underlying data points destroys the linear relationship being measured, regardless of the data distribution.
5. **Anomaly - Max:** The "Max" method shows uniformly low correlations (~0.2) with negligible difference between data distributions, indicating it is a poor aggregator for preserving this specific correlation.
### Interpretation
This chart likely evaluates how different ways of summarizing time-series or grouped data (e.g., taking the last value, the average, the minimum) affect the strength of a measured correlation with a target variable.
The data suggests that **average-based aggregations ("Avg") are most effective at preserving a strong linear relationship**, especially when the data is "In-distribution" (i.e., matches the expected pattern the model was trained on). The significant performance drop for "Out-of-distribution" data in these categories highlights model sensitivity to data shift.
The **catastrophic failure of the "Sum" aggregator** is the most critical finding. It implies that the absolute magnitude of summed values is not informative for the correlation in question, or that the underlying data has properties (like varying scales or offsets) that make summation meaningless for this analysis. The "Max" aggregator also performs poorly, suggesting the peak values are not the informative feature.
From a technical document perspective, this chart would be used to justify selecting "Average" as the preferred aggregation method for a pipeline and to warn against using "Sum" or "Max." It also provides evidence that model performance (as measured by correlation) degrades on out-of-distribution data, which is a key consideration for deployment robustness.
</details>
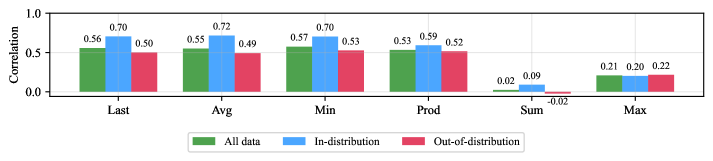
Figure 2: Point-biserial correlation between PRM score aggregation methods and solution correctness. Minimum aggregation shows highest correlation, followed by last reasoning-step scoring. Correlation is consistently higher on in-distribution (ID) problems on which the PRM is trained (GSM8K and MATH) than out-of-distribution (OOD) tasks.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Density Plots: Distribution of PRM Scores by Correctness
### Overview
The image displays a 2x3 grid of six density plots (histograms). Each plot visualizes the distribution of a different metric derived from "PRM scores" for two categories: "Correct" and "Incorrect" outcomes. The plots compare how these score metrics differ between correct and incorrect results.
### Components/Axes
* **Layout:** Six subplots arranged in two rows and three columns.
* **Common Y-Axis:** All plots share the y-axis label **"Density"**, indicating the frequency or probability density of the scores. The scale varies per plot.
* **Common X-Axis Range:** All plots have an x-axis ranging from **0.0 to 1.0**, except for the "Sum of PRM scores" plot, which ranges from **0 to 500**.
* **Legend:** Located in the top-right corner of the bottom-right subplot ("Maximum of PRM scores").
* **Blue Square:** Labeled **"Correct"**.
* **Red Square:** Labeled **"Incorrect"**.
* **Subplot Titles (X-Axis Labels):**
1. Top-Left: **"Last PRM score"**
2. Top-Center: **"Average of PRM scores"**
3. Top-Right: **"Minimum of PRM scores"**
4. Bottom-Left: **"Product of PRM scores"**
5. Bottom-Center: **"Sum of PRM scores"**
6. Bottom-Right: **"Maximum of PRM scores"**
### Detailed Analysis
**1. Last PRM score (Top-Left)**
* **Incorrect (Red):** Distribution is heavily skewed toward **0.0**, with a very high, narrow peak at the lowest value. Density drops sharply as the score increases.
* **Correct (Blue):** Distribution is heavily skewed toward **1.0**, with a very high, narrow peak at the highest value. Density is near zero for scores below ~0.8.
* **Trend:** A stark, bimodal separation. Incorrect outcomes are associated with a final PRM score near 0, while correct outcomes are associated with a final score near 1.
**2. Average of PRM scores (Top-Center)**
* **Incorrect (Red):** Distribution is concentrated near **0.0**, with a peak at the low end. There is a very slight, long tail extending toward higher scores.
* **Correct (Blue):** Distribution is concentrated near **1.0**, with a sharp peak at the high end. There is a very slight tail extending toward lower scores.
* **Trend:** Similar to the "Last score" plot but slightly less extreme separation. The average score strongly correlates with correctness.
**3. Minimum of PRM scores (Top-Right)**
* **Incorrect (Red):** Distribution has a dominant peak at **0.0** and a smaller, secondary peak near **1.0**. This suggests many incorrect outcomes have at least one very low score.
* **Correct (Blue):** Distribution has a dominant peak at **1.0** and a smaller, secondary peak near **0.0**. This suggests most correct outcomes have all scores high, but a subset contains at least one low score.
* **Trend:** Both categories show bimodal distributions, but the primary mass is inverted. The presence of a low minimum score is more indicative of an incorrect outcome.
**4. Product of PRM scores (Bottom-Left)**
* **Incorrect (Red):** Extremely concentrated peak at **0.0**. The product is near zero for almost all incorrect cases.
* **Correct (Blue):** Extremely concentrated peak at **1.0**. The product is near one for almost all correct cases.
* **Trend:** The most extreme separation of all plots. The product of scores appears to be a near-perfect classifier in this data.
**5. Sum of PRM scores (Bottom-Center)**
* **Incorrect (Red):** Distribution is a sharp peak at **0**. The sum is very low for incorrect outcomes.
* **Correct (Blue):** Distribution is a sharp peak at a high value (approximately **450-500**, based on the x-axis scale). The sum is very high for correct outcomes.
* **Trend:** Shows a clear separation in magnitude. Correct outcomes have a much higher total sum of scores.
**6. Maximum of PRM scores (Bottom-Right)**
* **Incorrect (Red):** Distribution has a small peak near **0.0** and a larger peak at **1.0**. Many incorrect outcomes still achieve a high maximum score.
* **Correct (Blue):** Distribution is almost entirely a single, sharp peak at **1.0**. Nearly all correct outcomes have a maximum score of 1.
* **Trend:** The maximum score is less discriminative than other metrics. While a correct outcome almost guarantees a max score of 1, an incorrect outcome can also frequently achieve it.
### Key Observations
1. **Bimodality:** Most distributions (Last, Min, Product, Max) are bimodal, with mass concentrated at the extremes (0.0 and 1.0).
2. **Discriminative Power:** The **"Product of PRM scores"** shows the cleanest separation between classes, followed by the **"Last PRM score"** and **"Sum of PRM scores"**.
3. **Weak Discriminator:** The **"Maximum of PRM scores"** is the weakest discriminator, as both correct and incorrect outcomes frequently have a maximum score of 1.0.
4. **Incorrect Profile:** Incorrect outcomes are characterized by: a last score near 0, a low average, a high likelihood of containing at least one very low score (low min), a product near 0, and a low sum.
5. **Correct Profile:** Correct outcomes are characterized by: a last score near 1, a high average, a high likelihood of all scores being high (high min), a product near 1, and a high sum.
### Interpretation
This analysis suggests that PRM (likely "Process Reward Model") scores are highly indicative of final outcome correctness, but the *way* they are aggregated matters significantly.
* **The "Product" metric is paramount.** Its near-perfect separation implies that if *any* step in the process receives a low PRM score (approaching 0), the product collapses to near zero, strongly predicting an incorrect outcome. This aligns with a "weakest link" or "single point of failure" model of reasoning or generation.
* **Temporal signals matter.** The strong performance of the "Last PRM score" indicates that the model's final evaluation is highly predictive. A low final score is a strong red flag.
* **Aggregates reveal different facets.** The "Sum" and "Average" show that correct outcomes have consistently higher scores across the board. The "Minimum" plot reveals that while correct outcomes *usually* have all high scores, a notable subset contains a flaw (a low score), yet still resulted in a correct answer. Conversely, some incorrect outcomes managed to have all high scores (high minimum), suggesting other failure modes.
* **Practical Implication:** For a system using these PRM scores, relying on the **product** or the **last score** would be the most reliable signals for flagging potential errors or certifying correctness. The maximum score alone is not trustworthy. The data supports a model where correctness is fragile and easily derailed by a single poorly-scored step, but also where a single flawed step does not *guarantee* failure.
</details>
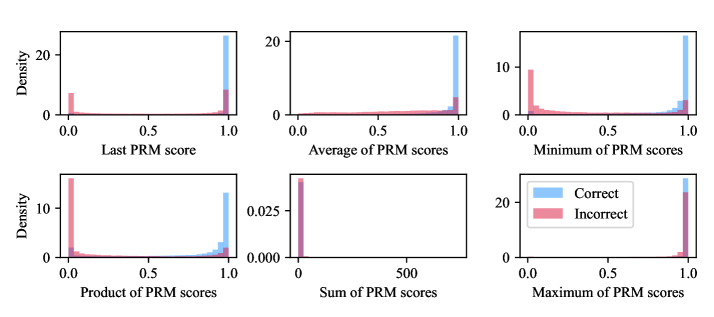
Figure 3: PRM score distributions by aggregation method, conditioned on prediction correctness. Last, average, minimum, and product aggregations effectively separate correct from incorrect predictions.
Table 5: Point-biserial correlations between PRM aggregation methods and prediction correctness by dataset. Bold indicates best performance per dataset. Correlations vary substantially across problems, with optimal aggregation being dataset-dependent. Overall, minimum aggregation performs best, followed by last-step scoring.
| aime25 aime24 amc23 | 0.494 0.623 0.668 | 0.474 0.597 0.700 | 0.582 0.680 0.726 | 0.444 0.487 0.626 | 0.283 0.529 0.170 | 0.095 0.151 0.280 |
| --- | --- | --- | --- | --- | --- | --- |
| sat_math | 0.690 | 0.375 | 0.487 | 0.330 | 0.069 | 0.039 |
| aqua | 0.309 | 0.309 | 0.342 | 0.306 | 0.106 | 0.291 |
| asdiv | 0.447 | 0.466 | 0.450 | 0.424 | -0.049 | 0.116 |
| carp_en | 0.137 | 0.149 | 0.154 | 0.150 | -0.026 | 0.060 |
| cmath | 0.557 | 0.559 | 0.627 | 0.637 | 0.063 | 0.200 |
| cn_middle_school | 0.432 | 0.419 | 0.465 | 0.444 | -0.161 | 0.119 |
| gaokao_math_cloze | 0.455 | 0.500 | 0.555 | 0.482 | 0.094 | 0.098 |
| gaokao_math_qa | 0.510 | 0.454 | 0.546 | 0.488 | -0.016 | 0.216 |
| gaokao2023en | 0.561 | 0.590 | 0.602 | 0.540 | 0.148 | 0.175 |
| gaokao2024_I | 0.285 | 0.275 | 0.438 | 0.337 | -0.064 | 0.126 |
| gaokao2024_II | 0.376 | 0.447 | 0.545 | 0.584 | 0.048 | 0.094 |
| gaokao2024_mix | 0.482 | 0.422 | 0.495 | 0.343 | 0.081 | 0.187 |
| gsm8k | 0.560 | 0.595 | 0.597 | 0.565 | 0.099 | 0.120 |
| mawps | 0.333 | 0.379 | 0.322 | 0.296 | 0.015 | 0.091 |
| minerva_math | 0.349 | 0.416 | 0.477 | 0.474 | -0.022 | 0.183 |
| mmlu_stem | 0.360 | 0.280 | 0.281 | 0.266 | 0.085 | 0.182 |
| svamp | 0.700 | 0.706 | 0.694 | 0.673 | 0.109 | 0.239 |
| tabmwp | 0.542 | 0.591 | 0.588 | 0.570 | 0.090 | 0.211 |
| olympiadbench | 0.571 | 0.603 | 0.635 | 0.578 | 0.213 | 0.145 |
| math | 0.708 | 0.718 | 0.703 | 0.585 | 0.130 | 0.200 |
| Best Count | 2/23 | 5/23 | 14/23 | 2/23 | 0/23 | 0/23 |
| Average | 0.557 | 0.550 | 0.575 | 0.533 | 0.024 | 0.209 |