# Plan Then Retrieve: Reinforcement Learning-Guided Complex Reasoning over Knowledge Graphs
**Authors**: Yanlin Song, Ben Liu, Víctor Gutiérrez-Basulto, Zhiwei Hu, Qianqian Xie, Min Peng, Sophia Ananiadou, Jeff Z. Pan
> School of Computer ScienceWuhan UniversityWuhanChinasongyanlin@whu.edu.cn
> Ant GroupHangzhouChinakeli.lb@antgroup.com
> School of Computer Science and InformaticsCardiff UniversityCardiffUKGutierrezBasultoV@cardiff.ac.uk
> College of Information Science and EngineeringShanxi Agricultural UniversityTaiyuanChinazhiweihu@whu.edu.cn
> School of Artificial IntelligenceWuhan UniversityWuhanChinaCenter for Language and Information ResearchWuhan UniversityWuhanChinaxieq@whu.edu.cn
> School of Artificial IntelligenceWuhan UniversityWuhanChinaCenter for Language and Information ResearchWuhan UniversityWuhanChinapengm@whu.edu.cn
> School of Computer ScienceUniversity of ManchesterManchesterUKsophia.ananiadou@manchester.ac.uk
> ILCC, School of InformaticsUniversity of EdinburghEdinburghUKj.z.pan@ed.ac.uk
Abstract.
Knowledge Graph Question Answering (KGQA) aims to answer natural language questions by reasoning over structured knowledge graphs (KGs). While large language models (LLMs) have advanced KGQA through their strong reasoning capabilities, existing methods continue to struggle to fully exploit both the rich knowledge encoded in KGs and the reasoning capabilities of LLMs, particularly in complex scenarios. They often assume complete KG coverage and lack mechanisms to judge when external information is needed, and their reasoning remains locally myopic, failing to maintain coherent multi-step planning, leading to reasoning failures even when relevant knowledge exists. We propose Graph-RFT, a novel two-stage reinforcement fine-tuning KGQA framework with a “plan–KGsearch–and–Websearch–during–think” paradigm, that enables LLMs to perform autonomous planning and adaptive retrieval scheduling across KG and web sources under incomplete knowledge conditions. Graph-RFT introduces a chain-of-thought (CoT) fine-tuning method with a customized plan–retrieval dataset activates structured reasoning and resolves the GRPO cold-start problem. It then introduces a novel plan–retrieval guided reinforcement learning process integrates explicit planning and retrieval actions with a multi-reward design, enabling coverage-aware retrieval scheduling. It employs a Cartesian-inspired planning module to decompose complex questions into ordered sub-questions, and logical expression to guide tool invocation for globally consistent multi-step reasoning. This reasoning–retrieval process is optimized with a multi-reward combining outcome and retrieval-specific signals, enabling the model to learn when and how to combine KG and web retrieval effectively. Experiments on multiple KGQA benchmarks demonstrate that Graph-RFT achieves superior performance over strong baselines, even with smaller LLM backbones, and substantially improves complex question decomposition, factual coverage, and tool coordination.
Knowledge Graph Question Answering, Large Language Model, Reinforcement Learning copyright: acmlicensed ccs: Computing methodologies Semantic networks
1. Introduction
Knowledge Graph Question Answering (KGQA) aims to answer natural language questions by reasoning over structured knowledge graphs (KGs) that store explicit, factual knowledge in the form of triples. KGQA plays a central role in web-based intelligent systems such as search, recommendation, and social platforms (Khorashadizadeh et al., 2024; Zhao et al., 2024; Zeng et al., 2024; Xie et al., 2023, 2024, 2025; Wang et al., 2023), where accurate and explainable reasoning over structured data is crucial. Recent advances in large language models (LLMs) have transformed natural language understanding, reasoning, and generation (Hendrycks et al., 2020; Clark et al., 2018; Guo et al., 2025; Shi et al., 2025; Liu et al., 2025b). Leveraging their strong generalization and reasoning capabilities, recent KGQA methods increasingly rely on LLMs, integrating knowledge graphs as structured, verifiable knowledge sources to enhance factual precision and interpretability (Sun et al., 2023; Jiang et al., 2023; Tan et al., 2025b; Ma et al., 2025; Liu et al., 2025a; Xue et al., 2024).
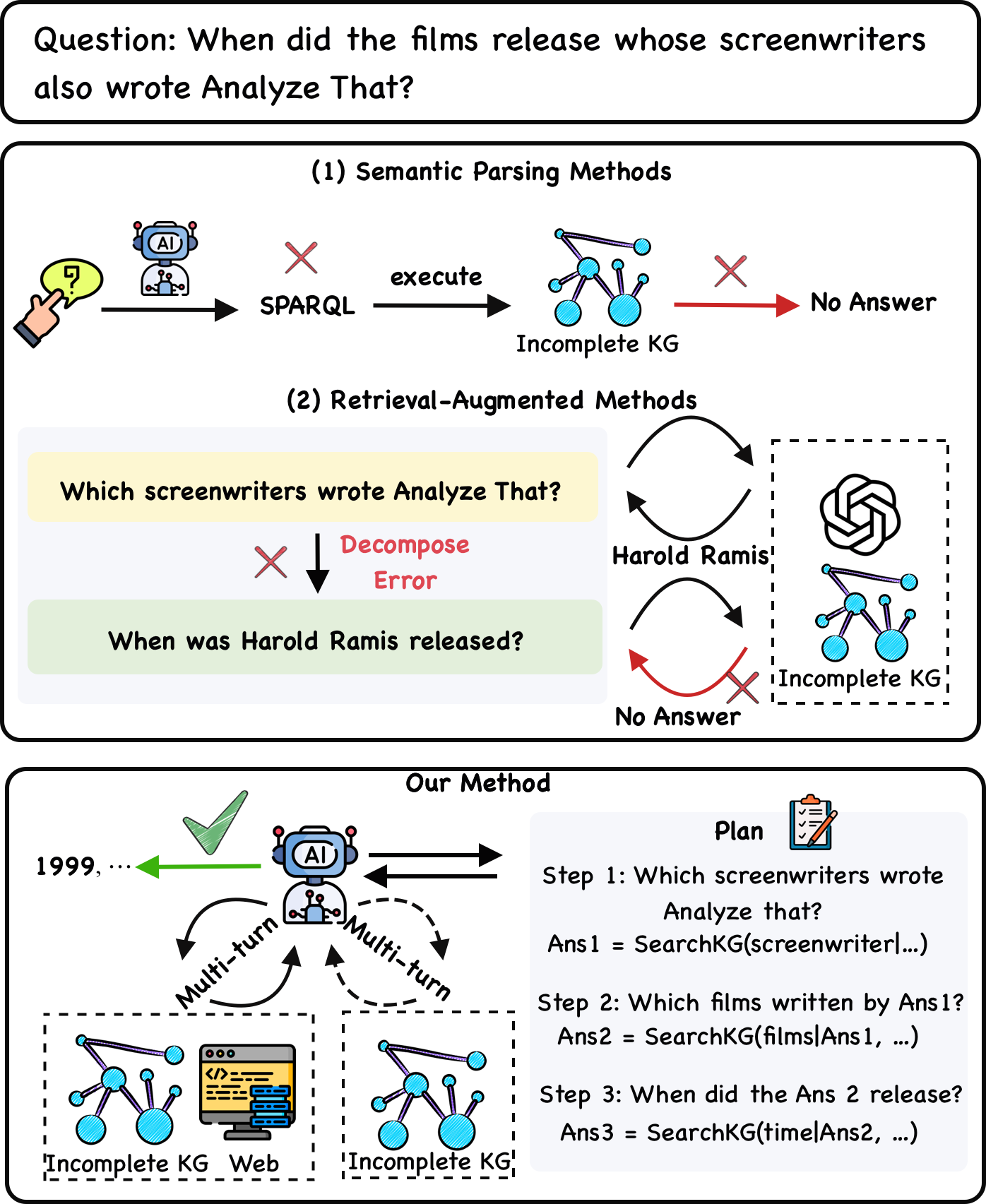
Existing LLM-based KGQA approaches fall into two paradigms: semantic parsing (SP), which translates natural questions into executable logical queries (e.g., SPARQL) and runs them over a KG (Li et al., 2023a; Luo et al., 2023a; Xu et al., 2024), and retrieval-augmented generation (RAG), which retrieves relevant KG triples to condition an LLM’s generation (Tan et al., 2025b; Xu et al., 2024). Despite substantial progress, both paradigms struggle in complex settings for two main reasons. First, they lack a reliable mechanism to judge whether a KG contains the facts necessary to answer a question. SP and RAG methods commonly assume that all required triples are present in the KG, a strong and unrealistic assumption for manually curated graphs. When coverage is incomplete, SP fails to produce correct executable queries, and RAG offers no built-in way to refine retrieval or to decide when to consult external (unstructured) sources. Second, these methods often lack the ability to perform coherent multi-step planning and adaptive retrieval scheduling. For example in Figure 1 (2), an LLM may correctly decompose a question into “Which screenwriters wrote Analyze That?” and retrieve “Harold Ramis,” but then fail to continue the planned decomposition and instead reformulates the follow-up as “When was Harold Ramis released?”, confusing the person with a film title. This failure stems from constrained local decision-making and an absence of coherent multi-step planning, which leads to retrieval and reasoning errors even when the KG contains the necessary facts. The comparison for previous work and Graph-RFT is in Table 1.
<details>
<summary>intro.png Details</summary>
### Visual Description
\n
## Diagram: Knowledge Graph Querying Methods Comparison
### Overview
This diagram compares three methods for answering the question: "When did the films release whose screenwriters also wrote Analyze That?". The methods are Semantic Parsing, Retrieval-Augmented Methods, and a novel "Our Method". The diagram illustrates the flow of information and potential failure points for each approach, highlighting the challenges of incomplete knowledge graphs (KG).
### Components/Axes
The diagram is divided into three horizontal sections, each representing a different method. Each section contains visual elements representing the query process, including:
* **Question:** The initial query posed to the system.
* **AI/Agent:** Represented by a brain icon, symbolizing the AI component.
* **Knowledge Graph (KG):** Represented by interconnected nodes and edges.
* **Error/Failure:** Indicated by a red "X" symbol.
* **Output:** "No Answer" or a series of steps in a plan.
* **Web:** Represented by a browser icon.
* **Plan:** A list of steps to answer the question.
* **Harold Ramis:** A portrait of Harold Ramis.
### Detailed Analysis or Content Details
**Section 1: Semantic Parsing Methods**
* **Question:** "When did the films release whose screenwriters also wrote Analyze That?"
* The AI attempts to "execute" a SPARQL query on the KG.
* The KG is labeled "Incomplete KG".
* The process results in "No Answer", indicated by a red "X".
**Section 2: Retrieval-Augmented Methods**
* **Question:** "When did the films release whose screenwriters also wrote Analyze That?"
* The method first decomposes the question into two sub-questions: "Which screenwriters wrote Analyze That?" and "When was Harold Ramis released?".
* The KG is labeled "Incomplete KG" within a dashed box.
* A portrait of Harold Ramis is shown.
* The process results in "No Answer", indicated by a red "X".
**Section 3: Our Method**
* **Question:** "When did the films release whose screenwriters also wrote Analyze That?"
* The AI interacts with the web in a "Multi-turn" fashion.
* The KG is labeled "Incomplete KG" within a dashed box.
* The AI generates a "Plan" with three steps:
* Step 1: "Which screenwriters wrote Analyze That?" Ans1 = SearchKG(screenwriter(...))
* Step 2: "Which films written by Ans1?" Ans2 = SearchKG(filmsAns1, ...)
* Step 3: "When did the Ans 2 release?" Ans3 = SearchKG(timeAns2, ...)
* The output is "1999, ...", suggesting a successful answer.
### Key Observations
* Both Semantic Parsing and Retrieval-Augmented methods fail to provide an answer due to the "Incomplete KG".
* "Our Method" successfully generates a plan and provides a partial answer ("1999, ...").
* "Our Method" utilizes a multi-turn interaction with the web, suggesting it can leverage external information to overcome the limitations of the KG.
* The decomposition of the question in Retrieval-Augmented Methods leads to a specific error case involving Harold Ramis.
### Interpretation
The diagram demonstrates the challenges of answering complex knowledge graph queries when the KG is incomplete. Semantic Parsing relies on a complete and accurate KG to directly execute queries, while Retrieval-Augmented methods attempt to decompose the problem but still struggle with KG limitations. "Our Method" offers a more robust approach by leveraging external information (the web) through a multi-turn interaction, allowing it to overcome the KG's incompleteness and generate a plausible answer. The inclusion of Harold Ramis in the Retrieval-Augmented section suggests a potential issue with identifying the correct entities or relationships within the KG. The diagram highlights the importance of combining KG querying with external knowledge sources for more reliable and comprehensive question answering. The "1999, ..." output suggests that the method is capable of providing at least partial results, even if it doesn't have complete information. The use of dashed boxes around the "Incomplete KG" in sections 2 and 3 suggests that the method is aware of the KG's limitations and attempts to mitigate them.
</details>
Figure 1. The comparison of Semantic Parsing, Retrieval-Augmented Methods, and Graph-RFT.
To address these challenges, we propose Graph-RFT, a novel two-stage reinforcement fine-tuning framework designed to enhance an LLM’s capabilities in autonomous planning and adaptive retrieval scheduling across multiple tools (specifically, KG search and web search) under conditions of incomplete KGs. In the first stage (Section 3.2), we introduce a chain-of-thought (CoT) (Wei et al., 2022) fine-tuning method that uses a customized plan–retrieval dataset to explicitly train the model to decompose questions, formulate plans, and select retrieval tools. This stage not only activates the model’s reasoning and planning capabilities but also resolves the GRPO (Guo et al., 2025) cold-start problem, enabling stable and meaningful reinforcement rollouts.
In the second stage (Section 3.3), we propose a plan–retrieval guided reinforcement learning method that integrates explicit planning steps and retrieval actions into the model’s reasoning loop, and learns a coverage-aware retrieval policy that dynamically coordinates knowledge graph and web search under incomplete KG conditions. It uses a structured template $\langle$ plan $\rangle\langle$ relation_search $\rangle\langle$ neighbor_search $\rangle$ $\langle$ web_search $\rangle$ , to explicitly let the model to alternate between symbolic planning and retrieval actions. The planning module draws inspiration from Cartesian principles (Descartes, 1901), breaking complex questions into logically ordered sub-questions. We further employ logical expressions to represent dependencies among sub-questions and guide the invocation of KG retrieval tools, ensuring globally coherent multi-step reasoning and controllable retrieval flow. For each planned execution step, Graph-RFT invokes both relation-search and neighbor-search tools to perform KG retrieval; when the KG lacks sufficient coverage, the model automatically triggers web search to acquire supplementary unstructured evidence. To optimize the reasoning–retrieval process, we apply a GRPO-based reinforcement learning with a novel multi-reward design: an outcome reward measuring factual correctness and a retrieval-specific reward that evaluates retrieval coverage, precision, and timing. This formulation encourages the model to learn when and how to combine KG and web retrieval, overcoming the limitations of prior SP and RAG methods that assume complete KGs and the absence of coherent multi-step planning.
Table 1. Comparison for main characteristics of previous SP, RAG methods with our Graph-RFT.
| Class | Algorithm | Paradigm | Incomplete KG | Global Planning | Decompose Problems | KG Interaction |
| --- | --- | --- | --- | --- | --- | --- |
| SP | RGR-KBQA (Feng and He, 2025) | SFT | $×$ | $×$ | $×$ | $×$ |
| SP | Rule-KBQA (Zhang et al., 2025) | SFT | $×$ | $×$ | $×$ | $×$ |
| RAG | PoG (Tan et al., 2025b) | ICL | $×$ | $×$ | $\checkmark$ | $\checkmark$ |
| RAG | DoG (Ma et al., 2025) | ICL | $×$ | $×$ | $\checkmark$ | $\checkmark$ |
| RAG | KG-Agent (Jiang et al., 2024) | SFT | $×$ | $×$ | $\checkmark$ | $\checkmark$ |
| Our Method | Graph-RFT | SFT & RL | $\checkmark$ | $\checkmark$ | $\checkmark$ | $\checkmark$ |
Our main contributions are as follows:
- We introduce Graph-RFT, a novel two-stage reinforcement fine-tuning framework for complex reasoning over incomplete KGs. It introduces the novel CoT-based fine-tuning method to activate planning and reasoning capabilities while resolving the GRPO cold-start issue, and a plan–retrieval guided reinforcement learning method to enable coherent multi-step reasoning and adaptive retrieval scheduling across KG and web sources under incomplete KG conditions.
- We propose a plan–retrieval guided reinforcement learning method with a multi-reward design that integrates graph-retrieval, web-retrieval, and penalty signals. This fine-grained feedback enables the model to learn when and how to combine KG and web retrieval for adaptive, coverage-aware reasoning under incomplete KGs.
- Experimental results across several widely used complex reasoning datasets confirm the superior performance of Graph-RFT against strong baselines, even when utilizing weaker LLM backbones (i.e., the 7B series). Furthermore, comprehensive empirical analyses validate Graph-RFT’s effectiveness across multiple critical aspects, including complex question decomposition planning, the identification of missing factual triples, and the appropriate invocation of various tools.
2. Related Work
Existing methods for improving LLM-based KGQA can be categorized into two main types: Semantic Parsing (SP) methods and Retrieval Augmented (RA) methods.
SP Methods convert natural language questions into structural queries (e.g., SPARQL) that can be executed on KGs to retrieve answers. Early research efforts (Hu et al., 2017; Xiong et al., 2017; Luo et al., 2025b) in semantic parsing often involved generating query graphs, resembling subgraphs of the KG and allow for direct mapping to logical forms. Lan (Lan and Jiang, 2020) incorporates constraints into the query graph, which effectively narrows the search space and facilitates more flexible query graph generation. Subsequent works (Atif et al., 2023; Schick et al., 2023; Raffel et al., 2020; Wei et al., 2022; Jiang et al., 2022; Lan and Jiang, 2020) utilize sequence-to-sequence models for multi-hop path and SPARQL-expression generation, enhancing the semantic parsing process. Recently, with the emergence of LLMs, various methods unify KGs and LLMs for KGQA.ChatKBQA (Luo et al., 2023a) generates question-aligned logical forms by treating LLMs as semantic parsers and retrieves entities and relations from KGs. RGR-KBQA (Feng and He, 2025) retrieves factual knowledge from KGs to enhance the semantic understanding capabilities of LLMs and finetune them to generate the logical form. Rule-KBQA (Zhang et al., 2025) guides logical form generation via a two-phase process that inducts a rule library and deducts forms via a rule-guided agent. However, these methods depend heavily on the assumption that KGs are complete, which means no answers can be obtained if information is missing.
RA Methods retrieve relevant KG triple based on input questions, then use these triples to guide LLMs to generate accurate answers, emphasizing the dynamic interaction between KG retrieval and LLM reasoning. ToG (Sun et al., 2023) employs an explore-and-exploit approach, which can discover the most promising reasoning paths and return the most likely reasoning results. GoG (Xu et al., 2024) proposes a think-search-generate paradigm, alleviating the incompleteness issue of KGs by using LLMs’ internal knowledge. PoG (Tan et al., 2025b) leverages knowledge reasoning paths as retrieval-augmented inputs for LLMs, thereby alleviating issues related to insufficient domain knowledge and unfaithful reasoning chains. DoG (Ma et al., 2025) introduces a subgraph-focused mechanism that allows LLMs to attempt intermediate answers after each reasoning step, effectively mitigating the drawbacks of lengthy reasoning trajectories. However, most of these approaches depend on powerful closed-source LLM APIs (e.g., GPT-4 (Achiam et al., 2023)), which results in substantial performance degradation when weaker open-source models are used as backbones. KG-Agent (Jiang et al., 2024) develops an iterative reasoning framework that integrates an LLM, a multifunctional toolbox, a KG-based executor, and a knowledge memory module, enabling smaller LLMs to make decisions autonomously. SymAgent (Liu et al., 2025a) conceptualizes the KG as a dynamic environment and is designed to autonomously and effectively integrate the capabilities of both the LLM and the KG. Graph-R1 (Luo et al., 2025a) proposes lightweight knowledge hypergraph construction and retrieval framed as a multi-turn agent–environment interaction, optimizing the reasoning process via an end-to-end reward mechanism. DynaSearcher (Hao et al., 2025) utilizes knowledge graphs as external structured knowledge to guide the search process by explicitly modeling entity relationships, thereby ensuring factual consistency in intermediate queries.
3. Methodology
In this section, we introduce Graph-RFT, with autonomous planning and adaptive retrieval capabilities for reasoning over incomplete KGs. The framework is structured around two complementary core stages: (1) CoT Fine-Tuning for Reasoning Activation: we propose a supervised fine-tuning (SFT) method using high-quality CoT plan–retrieval trajectories to activate the model’s structured reasoning and planning abilities while resolving the GRPO cold-start problem. (2) RL-based Reasoning Enhancement: we propose a plan–retrieval guided RL method with a multi-reward design to optimize reasoning and retrieval coordination, enabling the model to perform coherent multi-step planning and adaptively invoke KG and external tools under incomplete knowledge conditions. We start with the definition of the KGQA task.
3.1. Task Formulation
Let $D$ be a dataset containing question–answer pairs $(q,a)$ , $\mathcal{G}$ a KG containing a set of triples $\{(e_{i},r,e_{j})\ |e_{i},e_{j}∈\mathcal{E};r∈\mathcal{R}\}$ , where $\mathcal{E}$ is a set of entities and $\mathcal{R}$ is the set of relations names, and $E$ an external search engine. The KGQA task requires the LLM to generate reasoning trajectories or to iteratively interact with $\mathcal{G}$ and $E$ . Formally, for each question $q$ , we generate a reasoning trajectory: $o=(\tau_{1},\tau_{2},...,\tau_{T})$ , where the $t$ -th intermediate reasoning step $\tau_{t}=(s_{t},c_{t})$ consists of an action $s_{t}∈\{\langle think\rangle,\langle plan\rangle,$ $\langle relation\_search\rangle,\langle neighbor\_search\rangle,\langle web\_search\rangle,\langle answer\rangle\}$ (cf. Figure 7) and its associated content $c_{t}$ . The model is expected to repeatedly retrieve knowledge from $\mathcal{G}$ and $E$ until reaching the final answer $a$ for the question $q$ .
3.2. CoT Fine-Tuning for Reasoning Activation
<details>
<summary>dataset_design.png Details</summary>
### Visual Description
\n
## Diagram: Knowledge Graph Reasoning for Government Form Identification
### Overview
This diagram illustrates a multi-step reasoning process using knowledge graphs (KGs) to determine the form of government in the country that uses the Iranian Rail and was established in 1979. The process involves querying KGs, utilizing relation search tools, and leveraging web retrievers to gather information. The diagram is split into two main columns: a "Plan" section on the left outlining the steps, and a "Step" section on the right detailing the execution of each step.
### Components/Axes
The diagram consists of the following components:
* **Plan Section (Left):** A numbered list of steps (1-4) with associated logic functions.
* **Step Sections (Right):** Each step is visually represented with KG retrievers, relation search tools, and web retrievers.
* **Knowledge Graphs (KGs):** Represented as rectangular boxes labeled "KG Retriever".
* **Relation Search Tools:** Represented as rectangular boxes labeled "Relation Search Tool".
* **Web Retriever:** Represented as a rectangular box labeled "Web Retriever".
* **Entities:** Represented as oval shapes (e.g., "Iranian Rail", "Iran", "Islamic Republic").
* **Relationships:** Represented as arrows connecting entities, labeled with the type of relation (e.g., "location\_country\_currency\_used", "government\_form\_of\_government\_countries").
* **Logic Functions:** Equations displayed within boxes, representing the reasoning steps.
* **Text Boxes:** Containing descriptions of the process and results.
* **Footer:** Contains the source code for the KG queries.
### Detailed Analysis or Content Details
**Plan Section:**
* **Step 1:** Which country did use Iranian Rail? Logic Function: Ans1 = KGSearch (t1=country | h1=Iranian Rail, r1=used\_in)
* **Step 2:** Which country did establish in 1979? Logic Function: Ans2 = KGSearch (t2=country | h2=1979, r2=established\_year)
* **Step 3:** Return the country that satisfies both Ans1 and Ans2. Logic Function: Ans3=Inter (t3=country | Ans1, Ans2)
* **Step 4:** Find the form of government of Q3. Logic Function: Ans4 = KGSearch (t4=form\_of\_government | h4=Ans3, r3=government\_form)
**Step 1:**
* KG Retriever queries "Iranian Rail" using relation "used\_in".
* Relation Search Tool searches for <Iranian Rail, used\_in>.
* Result: "Iran" is identified.
* Relationship: "location\_country\_currency\_used" connects "Iranian Rail" to "Iran".
* Relationship: "common\_topic\_notable\_types" connects "Iranian Rail" to "currency".
* Relationship: "book\_written\_work\_subjects" connects "Iranian Rail" to "currency".
**Step 2:** (Not fully visible, but implied to find countries established in 1979)
* "Think" box indicates a reasoning step.
**Step 3:** (Not fully visible, but implied to intersect results from Step 1 and Step 2)
* "Think" box indicates a reasoning step.
**Step 4:**
* KG Retriever queries "Iran" using relation "government\_form".
* Relation Search Tool searches for <Iran, government\_form\_of\_government\_countries>.
* Result: "Islamic Republic" is identified.
* Relationship: "government\_form\_of\_government\_countries" connects "Iran" to "Islamic Republic".
* Web Retriever searches for "Islamic Republic" and retrieves documents:
* Doc1: Government of the Islamic Republic of Iran
* Doc2: The politics of Iran take…
* Doc3: The first Shia theocracy in the 20th century was…
* The Web Retriever indicates "Insufficient KG fulfillment".
**Footer:**
* `<plan> Step 1: Identify the country that uses the Iranian Rail. Logic Form: Ans1 = KGSearch … </plan>`
* ``
* `relation_search Iranian Rail, used_in relation_search_relation_tool /think`
* `<neighbor_search> We select Iran as neighbor, use <neighbor_search> for Iran. /neighbor_search>`
* `neighbor_search Iranian Rail, used_in relation_search_relation_tool /think`
* `KGSearch Iranian Rail, used_in relation_search_relation_tool`
* `Ans1 = relation_search`
### Key Observations
* The process relies heavily on KG searches and relation identification.
* The web retriever is used to supplement KG information when KG fulfillment is insufficient.
* The logic functions are clearly defined and used to guide the reasoning process.
* The diagram demonstrates a clear flow of information from KG queries to entity identification to final answer retrieval.
* The diagram uses a consistent visual language to represent different components and relationships.
### Interpretation
This diagram illustrates a sophisticated approach to knowledge-based question answering. It demonstrates how knowledge graphs can be used to represent relationships between entities and how these relationships can be leveraged to answer complex questions. The use of relation search tools and web retrievers highlights the importance of combining structured knowledge (KGs) with unstructured knowledge (web documents) to achieve comprehensive and accurate answers. The "Think" boxes suggest an intermediate reasoning step, potentially involving filtering or refining the results from the KG searches. The "Insufficient KG fulfillment" message indicates that the KG alone is not always sufficient to answer the question, necessitating the use of external sources. The diagram provides a valuable insight into the inner workings of a knowledge-driven reasoning system. The overall goal is to identify the form of government of a country based on its association with a specific railway and its establishment year, showcasing a practical application of KG reasoning.
</details>
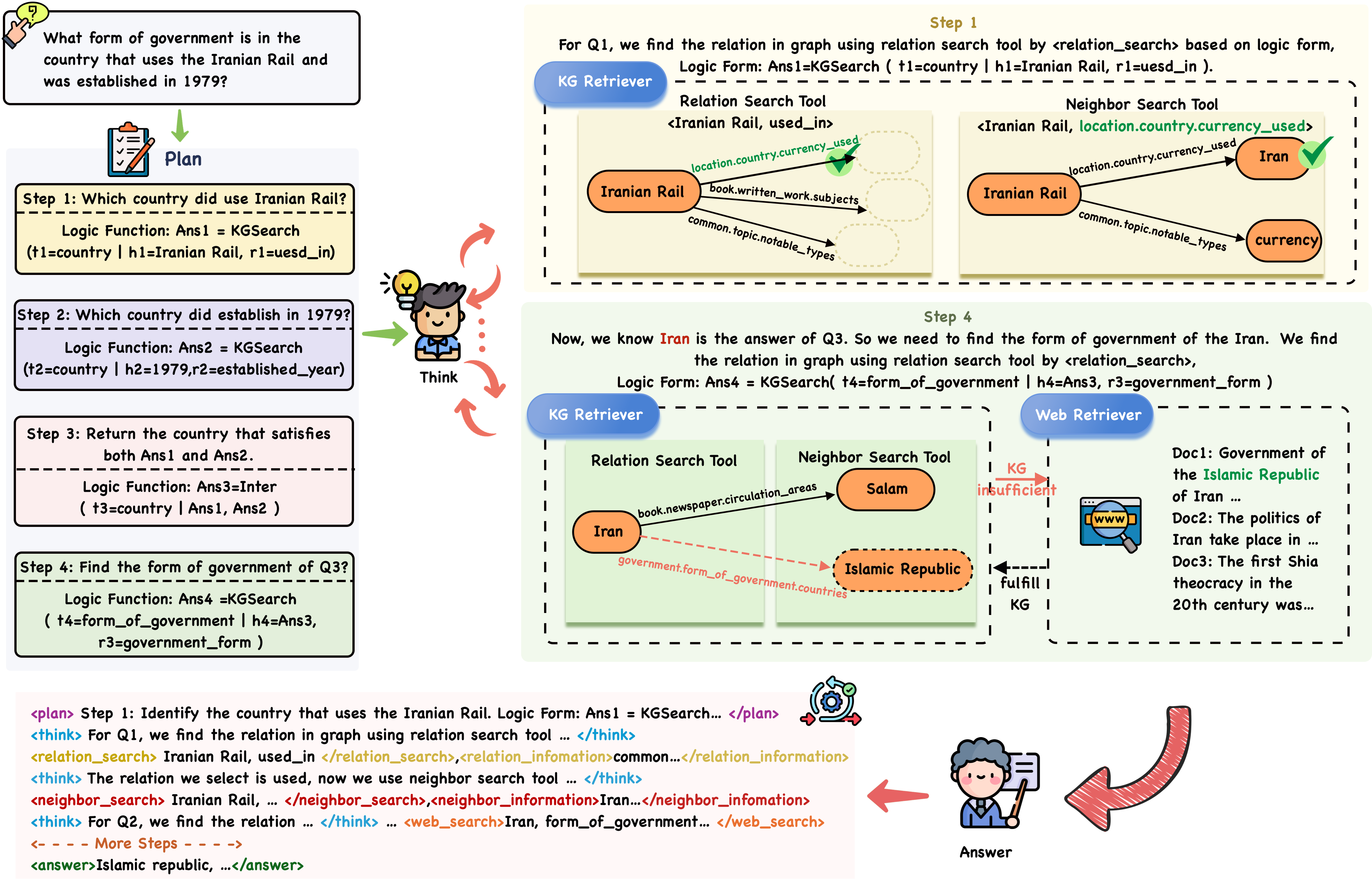
Figure 2. Graph-RFT Reasoning Trajectory for SFT dataset construction and rollout process for RL.
In the initial phase, we propose the CoT finetuning method using a structured reasoning dataset that contains step-by-step planning, reasoning, and retrieval processes. This phase is critical for activating the model’s planning-reasoning capabilities and establishing a robust cold start for subsequent RL. To construct our SFT dataset, as illustrated in Figure 2, we monitor and record the agent’s output throughout a multi-step interactive process with the KG and the external search engine. This approach transforms the complex, multi-step collaboration procedure into a CoT-style trajectory suitable for SFT. In addition, we use a two-stage process to filter the trajectory to get the high quality dataset. The Details regarding the data’s annotation and filtering processes are provided in Appendix A.1. The training objective minimizes:
$$
\mathcal{L}_{\text{SFT}}=-\sum_{t=1}^{T}\log\pi_{\theta}(y_{t}\mid q,y_{<t}) \tag{1}
$$
where $q$ is the question, $y$ is the concatenated sequence of reasoning steps and the answer, $\pi_{\theta}$ is the model’s token distribution. The output model $\pi_{CoT}$ serves as the initialization for the next stage (Tan et al., 2025a), ensuring a robust foundation for RL.
3.3. RL-based Reasoning Enhancement
3.3.1. Rollout with Search Tools
Our approach follows an iterative framework where the LLM alternates between text generation and external search engine queries. Specifically, our method consists of three steps: i) Plan the sub-problem decomposition and tool invocation for complex reasoning in a specific order; ii) Retrieve corresponding answers from the knowledge graph based on the priority and logical functions of these subproblems; iii) Obtain the correct answers by searching external sources for information not available in the knowledge graph.
Plan the Steps. We adhere to the Cartesian principle of breaking down complex problems into distinct steps, while designing logical functions to assist the model in understanding the interrelationships between sub-problems and determining the appropriate timing for tool utilization. In Figure 2, the first two steps correspond to subproblems of higher priority, as they do not rely on answers from other subproblems. Additionally, we use logical functions to represent the parameters for invoking KG retrieval tool, which helps the model gain a clear understanding of the invocation process. Step 3 expresses the logical relationship between the two subproblems through the $\textit{inter}(Ans_{1},Ans_{2},..,Ans_{n})$ function (the intersection of the answers to subquestions), passes the returned results to Step 4, and obtains the final answer by invoking the KG retrieval tool. The planning steps are encapsulated between ¡plan¿ and ¡/plan¿.
Retrieve Facts from the KG. For each single steps obtained through planning, we need to sequentially select relevant triples from the KG. To address this, we design two interactive toolkits.
- Relation Search Tool. This tool retrieves a set of candidate relations for an entity in a given single-hop problem. The LLM encapsulates the entity and the hypothetical relation from the logical function between the relation search tokens ¡relation_search¿ and ¡/relation_search¿. By invoking the relation acquisition toolkit, the set of top 15 relations that are similar to the hypothetical relation is encapsulated between the tokens ¡relation_information¿ and ¡/relation_information¿.
- Neighbor Search Tool. This tool retrieves the tail entity corresponding to a given head entity-relation pair selected by LLMs. The LLM encapsulates the specified head entity and relation between the neighbor search tokens ¡neighbor_search¿ and ¡/neighbor_search¿. By invoking the neighbor acquisition toolkit, the answer is then encapsulated between the tokens ¡neighbor_information¿ and ¡/neighbor_information¿.
Given the obtained single-hop questions (e.g., “Identify the country that uses the Iranian Rail”), we first invoke the Relation Search Tool to retrieve a candidate set of relations associated with the initial (topic) entity. The LLM then reasons over this set and selects the most appropriate relation, for example, choosing “location.country.currency_used” to replace “used_in” in the retrieval function. This greedy strategy simplifies the reasoning process by selecting a locally optimal relation at each step, thereby reducing reliance on global contextual information. Next, the Neighbor Search Tool is called to obtain specific triples and their corresponding answers (e.g., “Iran”). If the LLM determines that the retrieved triples are insufficient to answer the question, or if no answer is found in the knowledge graph (i.e., when ¡neighbor_information¿ and ¡/neighbor_information¿ return “No information in the KG, please use web tool”), the system directly invokes the search engine. The answers to higher-priority (according to the order produced by the subquestion plan) single-hop questions can then be combined with those of lower-priority ones to generate new single-hop questions. By iteratively repeating this process, the system is able to derive answers to complex multi-hop questions. Notably, if the maximum iteration limit is reached without successfully generating an answer, the parametric knowledge of the LLM is used to provide a final response.
When LLMs determine that the knowledge retrieved through KG search tools is insufficient or implausible (such as when the KG lacks relevant information, i.e., the tags ¡neighbor_information¿ and ¡/neighbor_information¿ return “No information in KG, please use web tool.”), the model encapsulates the corresponding head entity and relation, for which no information is available, within the special search tokens ¡web_search¿ and ¡/web_search¿. Subsequently, a search engine is invoked, and the documents retrieved from the Bing website are enclosed within ¡web_information¿ and ¡/web_information¿. This mechanism not only enables the model to acquire the supplementary knowledge required to answer the query but also facilitates the identification of missing triples, which can later be incorporated into the KG to mitigate its incompleteness. In our experiments, we fixed the top- $k$ value (e.g., 3) to control the number of retrieved documents.
3.3.2. Reward Design
To further optimize the above retrieval-planning process, we propose the GRPO (Shao et al., 2024) based RL method with the novel multi-reward design. Prior studies have predominantly employed outcome-based rewards to guide LLMs in developing reasoning abilities and leveraging search engines throughout the reinforcement learning process. However, such supervision alone does not sufficiently capture diverse retrieval-oriented reward mechanisms and is inadequate for effectively guiding retrieval in the presence of incomplete KGs. To address this limitation, we incorporate two key components into our reward design: (i) an outcome-based reward, which directly evaluates the quality of the model’s generated answers; and (ii) a retrieval-specific reward, which encourages the model to discern when and how to extract relevant information from knowledge graphs or web documents.
Table 2. Results of Graph-RFT across various datasets (represent the maximum hop), compared with the state-of-the-art (SOTA) in Supervised Learning (SL) and In-Context Learning (ICL) methods. The highest scores for ICL methods are highlighted in bold, while the second-best results are underlined. The Prior FT (Fine-tuned) SOTA includes the best-known results achieved through supervised learning. CKG denotes using complete knowledge graph and IKG denotes using incomplete KG (IKG-40%).
| Method | Class | LLM | Multi-Hop KGQA | Single-Hop KGQA | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| CWQ (4-hop) | WebQSP (2-hop) | GrailQA (4-hop) | Simple Questions (1-hop) | | | | | | | |
| Without external knowledge | | | | | | | | | | |
| IO prompt (Sun et al., 2023) | - | GPT-3.5-Turbo | 37.6 | 63.3 | 29.4 | 20.0 | | | | |
| CoT (Sun et al., 2023) | - | GPT-3.5-Turbo | 38.8 | 62.2 | 28.1 | 20.3 | | | | |
| SC (Sun et al., 2023) | - | GPT-3.5-Turbo | 45.4 | 61.1 | 29.6 | 18.9 | | | | |
| CKG | IKG | CKG | IKG | CKG | IKG | CKG | IKG | | | |
| With external knowledge | | | | | | | | | | |
| RoG (Luo et al., 2023b) | SL | Qwen2.5-7B-base | 63.7 | 53.6 | 84.2 | 75.3 | - | - | - | - |
| ChatKBQA (Luo et al., 2023a) | SL | Qwen2.5-7B-base | 72.4 | 37.8 | 75.5 | 47.1 | - | - | - | - |
| KB-BINDER (Li et al., 2023a) | ICL | Codex | - | - | 50.7 | 38.4 | - | - | - | - |
| StructGPT (Jiang et al., 2023) | ICL | GPT-3.5-Turbo | - | - | 76.4 | 60.1 | - | - | - | - |
| ToG/ToG-R (Sun et al., 2023) | ICL | GPT-3.5-Turbo | 47.2 | 37.9 | 76.9 | 63.4 | - | - | - | - |
| ToG/ToG-R (Sun et al., 2023) | ICL | GPT-4 | 71.0 | 56.1 | 80.3 | 71.8 | - | - | - | - |
| PoG (Tan et al., 2025b) | ICL | GPT-4 | 76.8 | 62.6 | 96.7 | 76.4 | 79.2 | 64.1 | 80.2 | 59.5 |
| GoG (Xu et al., 2024) | ICL | GPT-3.5-Turbo | 55.7 | 44.3 | 78.7 | 66.6 | 71.7 | 62.4 | 54.3 | 43.9 |
| GoG (Xu et al., 2024) | ICL | GPT-4 | 75.2 | 60.4 | 84.4 | 80.3 | 76.8 | 69.4 | 68.9 | 56.4 |
| Graph-RFT-instruct | RL | Qwen2.5-7B-instruct | 78.4 | 64.8 | 87.3 | 82.7 | 82.1 | 71.8 | 73.8 | 58.7 |
| Graph-RFT-base | RL | Qwen2.5-7B-base | 80.7 | 67.2 | 90.6 | 86.3 | 84.6 | 73.3 | 76.9 | 62.4 |
Outcome-based Reward. Result-based reward are divided into format reward and answer reward. For format reward, we first define the correct format to ensure that the LLM adopts the predefined iterative workflow of ”Think-Decompose-Retrieval-Search”. The definitions of the model’s thinking process, tool invocation, and final answer output format are shown in Figure 7 in Appendix A.4. For answer rewards $r_{ans}∈[0,1]$ , we compare the predicted answer in ¡answer¿¡/answer¿ with the ground-truth answer, and use the F1-score between the two sets as the reward to measure its accuracy. The complete accuracy reward $R_{acc}$ is defined as:
$$
R_{\text{acc}}=\begin{cases}\max(0.1,r_{\text{ans}}),&\text{if format is correct},\\
0,&\text{if format is incorrect}.\end{cases} \tag{2}
$$
$$
r_{\text{ans}}=\text{F1}(p_{\text{ans}},a)=\frac{2|p_{\text{ans}}\cap\{a\}|}{|p_{\text{ans}}|+|a|} \tag{3}
$$
where $p_{\text{ans}}$ is the predicted answer, and $a$ is the ground truth answer from the $(q,a)$ pair.
Retrieval-specific Reward. Inspired by AutoRefine (Shi et al., 2025), building on the result-based reward described above, we further introduce two retrieval rewards to encourage LLMs to learn how to extract relevant information from both the KG and web documents. Specifically, we introduce a graph retrieval reward $R_{graph}$ and a document search reward $R_{web}$ .
$R_{graph}$ is measured based on the retrieval results contained in the ¡neighbor_information¿¡/neighbor_information¿ block. Specifically, we collect all graph retrieval results from the entire trajectory and concatenate them into a single text sequence:
$$
\mathcal{R}_{\text{graph}}=\mathbb{I}\bigl(\{a\}\cap o_{\text{graph}}=a\bigr) \tag{4}
$$
$$
o_{\text{graph}}=\bigcup\left\{c_{t}\mid(s_{t},c_{t})\in o\land s_{t}=\text{<neighbor\_information>}\right\} \tag{5}
$$
where $I(·)$ is the indicator function, $o_{graph}$ is the concatenation of all the KG retrieval information steps.
$R_{web}$ is defined in a similar way to $R_{graph}$ . We collect all document retrieval results encapsulated in the ¡web_information¿¡/web_information¿ blocks throughout the entire trajectory and concatenate them into a single text sequence.
$$
\mathcal{R}_{\text{web}}=\mathbb{I}\bigl(\{a\}\cap o_{\text{web}}=a\bigr) \tag{6}
$$
$$
o_{\text{web}}=\bigcup\left\{c_{t}\mid(s_{t},c_{t})\in o\land s_{t}=\text{<web\_information>}\right\} \tag{7}
$$
where $I(·)$ is the indicator function, $o_{graph}$ is the concatenation of all the web search information steps.
However, such multi-turn reinforcement learning is unstable. To prevent the model from bypassing graph retrieval and directly turning to document search in cases where the correct result could have been obtained through graph retrieval, we introduce a corresponding penalty for this behavior to help LLMs know when to use different retrieval tools. The overall reward $\mathcal{R}_{\text{over}}$ can be formally written as:
$$
\mathcal{R}_{\text{over}}=\begin{cases}\mathcal{R}_{\text{acc}},&\text{if }\mathcal{R}_{\text{acc}}>0,\\
0.1,&\text{if }\mathcal{R}_{\text{acc}}=0\text{ \& }\mathcal{R}_{\text{graph}}>0\text{ OR }\mathcal{R}_{\text{acc}}=0\text{ \& }\mathcal{R}_{\text{web}}>0,\\
-0.1,&\text{if }\mathcal{R}_{\text{web}}>0\text{ when CKG}\text{ OR }\mathcal{R}_{\text{web}}=0\text{ when IKG}\\
0,&\text{if }\mathcal{R}_{\text{acc}}=\mathcal{R}_{\text{web}}=\mathcal{R}_{\text{graph}}=0.\end{cases} \tag{8}
$$
Training Objective. By integrating the overall reward with the GRPO training objective (Shao et al., 2024), our proposed learning objective enables dynamic interaction with both the knowledge graph and the search engine during optimization (Jin et al., 2025), thereby facilitating effective LLM search training. The objective is formalized as:
$$
\begin{split}\max_{\pi_{\theta}}\mathbb{E}_{x\sim\mathcal{D},\,y\sim\pi_{\theta}(\cdot|x;\mathcal{G},\mathcal{R})}\left[r_{\phi}(x,y)\right]-\\
\beta\mathbb{D}_{\text{KL}}\left[\pi_{\theta}(y|x;\mathcal{G},\mathcal{R})\big\|\pi_{\text{ref}}(y|x;\mathcal{G},\mathcal{R})\right]\end{split} \tag{9}
$$
where $\pi_{\theta}$ denotes the trainable policy model, $\pi_{\text{ref}}$ is a fixed reference model, $r_{\phi}$ represents the overall reward function, and $\mathbb{D}_{\text{KL}}$ denotes the $KL$ divergence. Here, $x$ is sampled from the dataset $D$ , and $y$ denotes the output sequence interleaving reasoning steps with KG and search engine retrievals. Since the retrieved triples and documents are not generated by the policy model, we mask the retrieval results during loss calculation to prevent the training policy from being biased (Hao et al., 2025).
4. Experiments
To evaluate the effectiveness of Graph-RFT, we aim to explore the following four research questions (RQs): (1) RQ1: How does Graph-RFT perform against SOTA baselines on complex reasoning datasets? (2) RQ2: What are the contributions of each Graph-RFT module to overall performance? (3) RQ3: Can Graph-RFT effectively bridge information gaps via retrieval under varying KG incompleteness? (4) RQ4: What are the error types of Graph-RFT?
$\blacktriangleright$ Datasets. We evaluate Graph-RFT on four KGQA datasets, including three multi-hop datasets: CWQ (Talmor and Berant, 2018), WebQSP (Yih et al., 2016), GrailQA (Gu et al., 2021) and one single-hop dataset: SimpleQuestions (Petrochuk and Zettlemoyer, ). We consider two scenarios: Complete Knowledge Graph (CKG) and Incomplete Knowledge Graph (IKG). For CKG, we directly use the datasets provided by GoG (Xu et al., 2024). For IKG, since GoG only provides CWQ and WebQSP, we construct IKG versions of GrailQA and SimpleQuestions by sampling 3,000 multi-hop questions from GrailQA and 3,000 questions from SimpleQuestions. We further generate four IKGs with varying completeness levels IKG-20%, IKG-40%, IKG-60%for example, IKG-40% removes 40% of the critical triples for each question and all relations between the corresponding entity pairs. Freebase (Bollacker et al., 2008) serves as the background KG for all datasets. The impact of using alternative knowledge graphs is discussed in Appendix A.5. $\blacktriangleright$ Evaluation Metrics. Following prior work (Li et al., 2023b; Baek et al., 2023; Jiang et al., 2023; Sun et al., 2023), we adopt exact match accuracy (Hits@1) as the evaluation metric for all datasets. Detailed descriptions of the baselines and implementation settings are provided in Appendix A.2 and Appendix A.3.
4.1. Main Results (RQ1)
Table 2 presents our main results on four KGQA datasets. We can observe that Graph-RFT consistently achieves SOTA performance across all settings in IKG, even when built upon smaller backbones such as Qwen2.5-7B-base, outperforming GPT-4-based methods.
$\blacktriangleright$ CKG Setting. Under the CKG setting, where all relevant triples are available, Graph-RFT achieves the strongest overall performance across both multi-hop and single-hop benchmarks. The results reveal that our two-stage RFT which combines CoT-based reasoning activation and plan–retrieval RL—provides consistent advantages over both prompt-only ICL methods and supervised learning baselines. ICL approaches such as PoG and GoG rely purely on prompt engineering and lack any fine-tuning or reinforcement optimization. Although they perform competitively on simpler datasets such as WebQSP and SimpleQuestions, they struggle to generalize across long reasoning chains. In contrast, Graph-RFT-base (Qwen-2.5-7B) achieves substantial gains on complex benchmarks like CWQ (80.7 vs 76.8/75.2) and GrailQA (84.6 vs 79.2/76.8), where multi-step logical dependencies are required. These improvements highlight how explicit CoT supervision enables structured planning, and reinforcement optimization refines the timing and sequencing of retrieval actions. Relative to RoG and ChatKBQA, which are purely supervised fine-tuned models, Graph-RFT demonstrates marked improvements (e.g., CWQ 80.7 vs 72.4/63.7, WebQSP 90.6 vs 84.2/75.5). This suggests that reinforcement learning contributes beyond imitation: by rewarding accurate retrieval scheduling and penalizing inefficient queries, the model learns to maintain global reasoning consistency and to balance exploration between relation-search and neighbor-search tools.
Table 3. Ablation study for the Graph-RFT-base in rollout framework.
| Variants | - | ✓ | - | 49.4 | 69.7 | 58.9 | 53.8 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| - | ✓ | ✓ | 55.3 | 74.2 | 63.5 | 61.7 | |
| ✓ | ✓ | - | 62.6 | 83.4 | 69.1 | 57.3 | |
| Graph-RFT-base | ✓ | ✓ | ✓ | 67.2 | 86.3 | 73.3 | 62.4 |
Table 4. Ablation analysis on Graph-RFT-base SFT and multi-reward design.
| Graph-RFT-base w/o SFT Graph-RFT-base w/o $R_{web}$ Graph-RFT-base w/o $R_{graph}$ | 46.4 66.3 65.8 | 74.2 83.5 82.7 | 56.4 72.1 71.6 | 54.7 60.8 61.6 |
| --- | --- | --- | --- | --- |
| Graph-RFT-base | 67.2 | 86.3 | 73.3 | 62.4 |
$\blacktriangleright$ IKG Setting. When the knowledge graph is incomplete, the benefits of Graph-RFT become even more pronounced. Prompt-based ICL approaches such as PoG and GoG (GPT-4) achieve competitive accuracy under complete KGs but degrade significantly once KG coverage is reduced. For example, GoG’s performance drops 7-15 points across CWQ (75.2→60.4) and GrailQA (76.8→69.4), while PoG falls from 76.8→62.6 on CWQ. These methods rely on static prompt patterns and local reasoning, lacking mechanisms to assess KG sufficiency or to seek supplementary evidence. In contrast, Graph-RFT-base (Qwen2.5-7B) remains stable across both settings, outperforms among ICL methods. This resilience arises from our two-stage RFT: CoT fine-tuning teaches explicit question decomposition, and reinforcement optimization learns when and how to invoke external retrievals. SL methods such as RoG and ChatKBQA also decline sharply under IKG (e.g., CWQ: 63.7→53.6; ChatKBQA: 72.4→37.8), as their fixed fine-tuning lacks interactivity with retrieval tools. In contrast, Graph-RFT maintains high accuracy (e.g., CWQ 67.2, WebQSP 86.3), confirming that reinforcement-based retrieval scheduling effectively compensates for missing triples through controlled web augmentation. Moreover, Graph-RFT with Qwen2.5-7b-base outperforms methods without external knowledge (e.g., IO, CoT, SC prompting), demonstrating that KGs play a crucial role in reasoning tasks.
4.2. Ablation Studies (RQ2)
We perform ablation studies to analyze the contributions of Graph-RFT’s key components. Specifically, we examine the effects of the rollout framework, SFT and the multi-reward mechanism in the RL stage. $\blacktriangleright$ Exploration on Rollout Framework. We analyze the contributions of the Planning Steps (PS), KG Retrieval (KR), and Web Retrieval (WR) modules within the rollout framework to Graph-RFT’s performance under the IKG-40% setting. Figure 3 presents model variants obtained by ablating these components, revealing that removing any single module substantially reduces performance. Comparing PS+KR, KR+WR, and KR alone, we observe that PS+KR achieves superior performance on multi-hop datasets, indicating that global planning—including question decomposition with logical operators and tool invocation—provides greater benefit than merely supplementing missing knowledge, thereby validating the effectiveness of the PS module. In contrast, on the single-hop dataset, KR+WR outperforms PS+KR, suggesting that leveraging external unstructured knowledge becomes more critical than global planning for simpler queries, which demonstrates Graph-RFT’s adaptability across tasks of varying complexity. Furthermore, the comparison between KR+WR and KR alone confirms that integrating structured knowledge from the KG with unstructured knowledge from web documents produces substantial improvements. Collectively, these results indicate that each module contributes uniquely, and their synergistic combination significantly enhances the model’s capability for complex reasoning tasks.
|
<details>
<summary>cwq_search.png Details</summary>
### Visual Description
\n
## Bar and Line Chart: Web Search Frequency vs. Hits@1 with/without Penalty
### Overview
This chart compares the Web Search Frequency and Hits@1 metrics for data grouped by "IKG" values (20%, 40%, and 60%) with and without a penalty applied. The Web Search Frequency is represented by bars, while Hits@1 is represented by a line.
### Components/Axes
* **X-axis:** IKG values - 20%, 40%, 60%.
* **Y-axis (left):** Web Search Frequency, ranging from 0 to 60.
* **Y-axis (right):** Hits@1, ranging from 55 to 75.
* **Legend:**
* Light Green: "w/ penalty" (representing Web Search Frequency with penalty)
* Light Blue: "w/o penalty" (representing Web Search Frequency without penalty)
* Dark Green Square: "w/ penalty" (representing Hits@1 with penalty)
* Red Triangle: "w/o penalty" (representing Hits@1 without penalty)
### Detailed Analysis
**Web Search Frequency (Bars):**
* **IKG-20%:**
* w/ penalty: Approximately 52.
* w/o penalty: Approximately 42.
* **IKG-40%:**
* w/ penalty: Approximately 45.
* w/o penalty: Approximately 37.
* **IKG-60%:**
* w/ penalty: Approximately 58.
* w/o penalty: Approximately 28.
**Hits@1 (Line):**
* The "w/ penalty" line (dark green squares) slopes downward.
* IKG-20%: Approximately 72.
* IKG-40%: Approximately 68.
* IKG-60%: Approximately 61.
* The "w/o penalty" line (red triangles) also slopes downward, but more steeply.
* IKG-20%: Approximately 73.
* IKG-40%: Approximately 63.
* IKG-60%: Approximately 59.
### Key Observations
* Web Search Frequency with penalty is consistently higher than without penalty across all IKG values.
* Hits@1 decreases as IKG increases for both with and without penalty.
* The decrease in Hits@1 is more pronounced for the "w/o penalty" condition.
* The gap between the "w/ penalty" and "w/o penalty" Web Search Frequency bars widens as IKG increases.
### Interpretation
The data suggests that applying a penalty improves Web Search Frequency, particularly at higher IKG values. However, both with and without penalty, increasing IKG leads to a decrease in Hits@1, indicating a potential trade-off between search frequency and search quality. The steeper decline in Hits@1 for the "w/o penalty" condition suggests that the penalty helps to maintain search quality even as IKG increases. The penalty appears to mitigate the negative impact of higher IKG on search relevance (as measured by Hits@1). The chart demonstrates a relationship between IKG, penalty application, web search frequency, and search result quality. The penalty seems to be a mechanism to balance these factors.
</details>
|
<details>
<summary>webqsp_search.png Details</summary>
### Visual Description
\n
## Bar and Line Chart: Web Search Frequency vs. IKG Coverage with/without Penalty
### Overview
This chart compares the web search frequency and Hits@1 scores for different levels of IKG (Information Knowledge Graph) coverage, with and without a penalty applied. The x-axis represents IKG coverage levels (20%, 40%, and 60%). The left y-axis shows web search frequency, and the right y-axis shows Hits@1 scores. The data is presented using bar charts for web search frequency and a line chart for Hits@1.
### Components/Axes
* **X-axis:** IKG Coverage (IKG-20%, IKG-40%, IKG-60%)
* **Left Y-axis:** Web Search Frequency (Scale: 10 to 50)
* **Right Y-axis:** Hits@1 (Scale: 75 to 90)
* **Legend:**
* Light Green: w/ penalty (Web Search Frequency)
* Light Blue: w/o penalty (Web Search Frequency)
* Dark Green Square: w/ penalty (Hits@1)
* Red Dashed Line: w/o penalty (Hits@1)
### Detailed Analysis
**Web Search Frequency (Bar Charts):**
* **w/ penalty (Light Green):**
* IKG-20%: Approximately 31.
* IKG-40%: Approximately 38.
* IKG-60%: Approximately 44.
* Trend: The light green bars show an upward trend, indicating increasing web search frequency as IKG coverage increases.
* **w/o penalty (Light Blue):**
* IKG-20%: Approximately 47.
* IKG-40%: Approximately 35.
* IKG-60%: Approximately 28.
* Trend: The light blue bars show a downward trend, indicating decreasing web search frequency as IKG coverage increases.
**Hits@1 (Line Chart):**
* **w/ penalty (Dark Green Square):**
* IKG-20%: Approximately 87.
* IKG-40%: Approximately 83.
* IKG-60%: Approximately 78.
* Trend: The dark green line slopes downward, indicating decreasing Hits@1 scores as IKG coverage increases.
* **w/o penalty (Red Dashed Line):**
* IKG-20%: Approximately 48.
* IKG-40%: Approximately 42.
* IKG-60%: Approximately 77.
* Trend: The red dashed line also slopes downward, indicating decreasing Hits@1 scores as IKG coverage increases.
### Key Observations
* The web search frequency behaves oppositely with and without the penalty. With the penalty, frequency increases with IKG coverage; without the penalty, it decreases.
* Hits@1 scores decrease with increasing IKG coverage for both scenarios (with and without penalty).
* The difference in Hits@1 between the "with penalty" and "without penalty" scenarios is significant, especially at lower IKG coverage levels.
* The "without penalty" line starts at a much lower Hits@1 score than the "with penalty" square.
### Interpretation
The chart suggests that applying a penalty influences the relationship between IKG coverage and web search frequency. Without a penalty, increased IKG coverage appears to *reduce* the frequency of web searches, potentially because the IKG provides sufficient information directly. However, with a penalty, increased IKG coverage *increases* web search frequency, possibly because the penalty encourages exploration of more diverse sources.
The consistent decrease in Hits@1 scores with increasing IKG coverage, regardless of the penalty, indicates that while IKG coverage might affect search frequency, it doesn't necessarily improve the accuracy of the top search result (as measured by Hits@1). This could be due to issues with the quality of information within the IKG, or the way the IKG is integrated into the search process.
The large initial difference in Hits@1 between the two scenarios suggests that the penalty has a substantial impact on the relevance of search results, particularly at lower IKG coverage levels. The penalty seems to improve the initial relevance, but the benefit diminishes as IKG coverage increases. This could indicate that the penalty is most effective when the IKG is less comprehensive.
</details>
|
| --- | --- |
| (a) CWQ. | (b) WebQSP. |
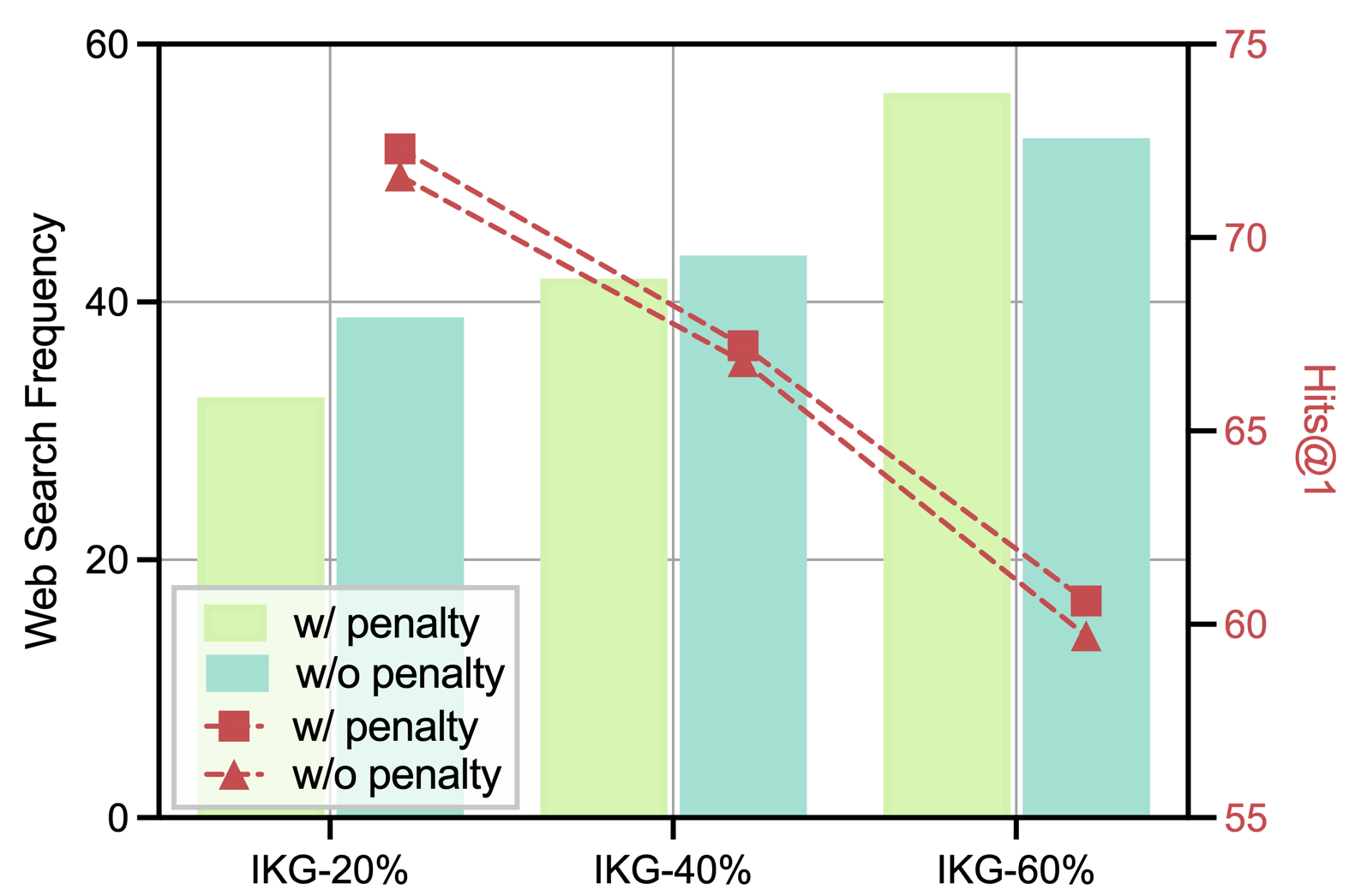
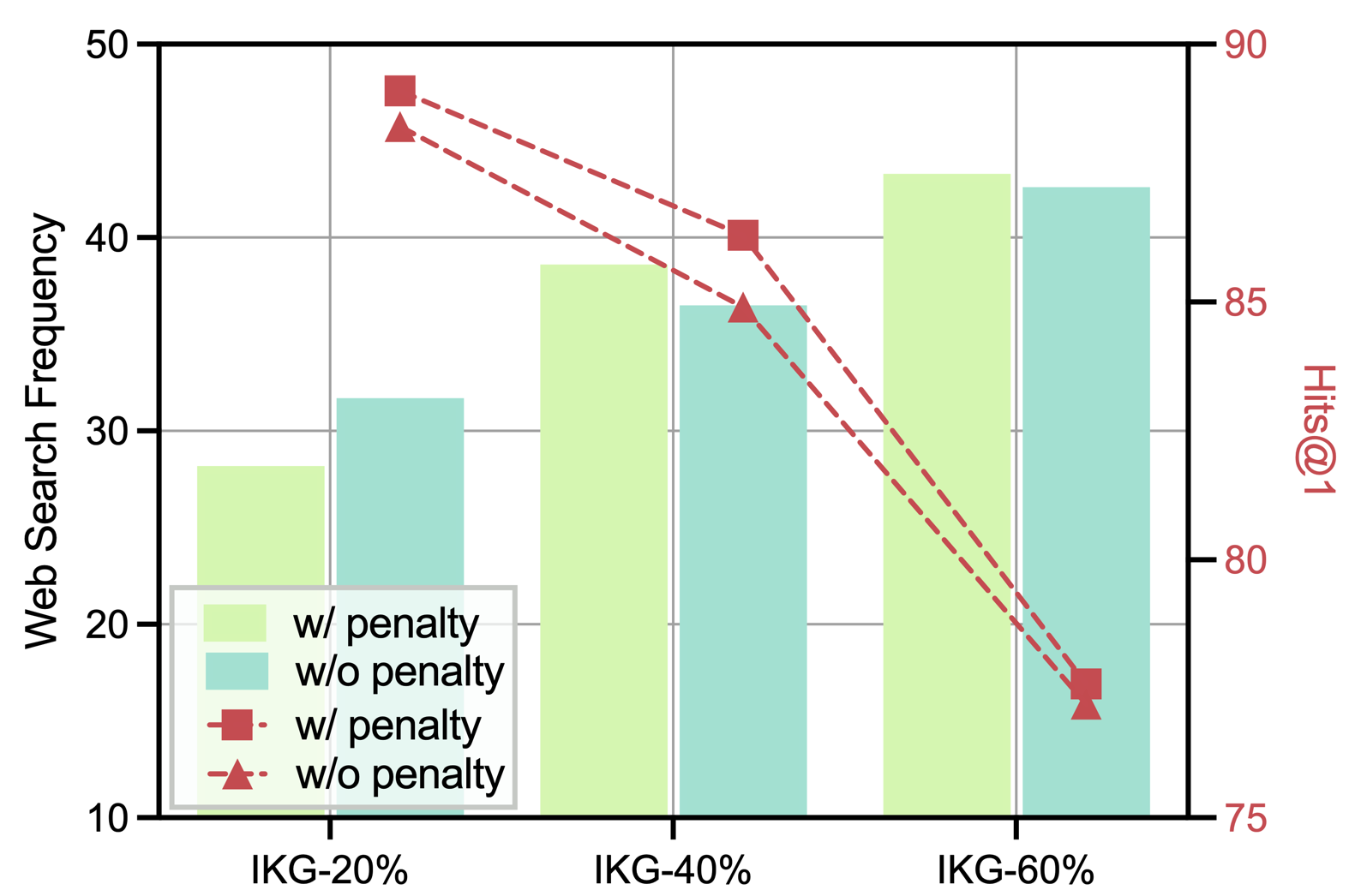
Figure 3. Ratio of web search operation in different KG settings under rewards with penalty or not.
|
<details>
<summary>cwq_compare.png Details</summary>
### Visual Description
\n
## Bar Chart: Hits@1 Performance Comparison
### Overview
This bar chart compares the Hits@1 performance of two models, GoG and Graph-RFT, across three different IKGs (IKG-20%, IKG-40%, and IKG-60%). The chart uses bar groupings to visually represent the performance of each model for each IKG.
### Components/Axes
* **Y-axis:** "Hits@1" - Represents the performance metric, ranging from 0 to 80.
* **X-axis:** IKG levels: "IKG-20%", "IKG-40%", "IKG-60%"
* **Legend:** Located in the top-right corner.
* Yellow: "GoG"
* Light Green: "Graph-RFT"
* **Gridlines:** Horizontal gridlines are present to aid in reading the values.
### Detailed Analysis
The chart consists of six bars, grouped by IKG level.
* **IKG-20%:**
* GoG (Yellow): Approximately 48. The bar reaches slightly above the 40 mark, but is below the 50 mark.
* Graph-RFT (Light Green): Approximately 72. The bar reaches slightly below the 75 mark.
* **IKG-40%:**
* GoG (Yellow): Approximately 42. The bar reaches slightly above the 40 mark, but is below the 45 mark.
* Graph-RFT (Light Green): Approximately 68. The bar reaches slightly below the 70 mark.
* **IKG-60%:**
* GoG (Yellow): Approximately 32. The bar reaches slightly above the 30 mark, but is below the 35 mark.
* Graph-RFT (Light Green): Approximately 64. The bar reaches slightly below the 65 mark.
### Key Observations
* Graph-RFT consistently outperforms GoG across all three IKG levels.
* The performance of both models appears to decrease as the IKG percentage increases. The largest drop in performance is observed between IKG-40% and IKG-60% for both models.
* The difference in performance between the two models is most pronounced at the IKG-20% level.
### Interpretation
The data suggests that Graph-RFT is a more effective model than GoG for this particular task, as measured by Hits@1. The decreasing performance of both models as the IKG percentage increases could indicate that the task becomes more challenging with larger or more complex knowledge graphs. The initial high performance at IKG-20% and subsequent decline could be due to the models overfitting to the smaller knowledge graph, or that the added complexity of the larger graphs introduces noise or irrelevant information. The consistent outperformance of Graph-RFT suggests it may be more robust to these challenges. Further investigation would be needed to understand the specific reasons for these trends and to determine whether the observed differences are statistically significant.
</details>
|
<details>
<summary>webqsp_compare.png Details</summary>
### Visual Description
\n
## Bar Chart: Hits@1 Performance Comparison
### Overview
This bar chart compares the performance of two models, GoG and Graph-RFT, across three different IKGs (IKG-20%, IKG-40%, and IKG-60%) based on the Hits@1 metric. The chart uses paired bars for each IKG, allowing for a direct visual comparison between the two models.
### Components/Axes
* **X-axis:** Represents the IKG configurations: IKG-20%, IKG-40%, and IKG-60%.
* **Y-axis:** Represents the Hits@1 metric, ranging from 0 to 100.
* **Legend:** Located in the top-right corner, identifies the two models:
* GoG (Light Green)
* Graph-RFT (Light Teal)
* **Gridlines:** Horizontal gridlines are present to aid in reading the values.
### Detailed Analysis
The chart consists of six bars, grouped by IKG configuration.
* **IKG-20%:**
* GoG: Approximately 68 Hits@1.
* Graph-RFT: Approximately 92 Hits@1.
* **IKG-40%:**
* GoG: Approximately 69 Hits@1.
* Graph-RFT: Approximately 86 Hits@1.
* **IKG-60%:**
* GoG: Approximately 62 Hits@1.
* Graph-RFT: Approximately 80 Hits@1.
The Graph-RFT model consistently outperforms the GoG model across all three IKG configurations. The difference in performance appears to be most significant for IKG-20%.
### Key Observations
* Graph-RFT consistently achieves higher Hits@1 scores than GoG.
* The performance of Graph-RFT decreases slightly as the IKG percentage increases (92 -> 86 -> 80).
* The performance of GoG remains relatively stable across the three IKG configurations (68 -> 69 -> 62).
* The gap between the two models is largest at IKG-20% and narrows as the IKG percentage increases.
### Interpretation
The data suggests that the Graph-RFT model is more effective than the GoG model in this task, as measured by the Hits@1 metric. The consistent outperformance of Graph-RFT indicates that its architecture or training process is better suited to leveraging the information contained within the IKGs. The decreasing performance of Graph-RFT with increasing IKG percentage could indicate a point of diminishing returns, where adding more information to the IKG does not proportionally improve performance. The relative stability of GoG's performance suggests it may be less sensitive to the size of the IKG, or that it reaches its performance limit earlier. The larger performance gap at IKG-20% could mean that Graph-RFT benefits more from even a small amount of knowledge graph information, while GoG's performance is less affected by the initial IKG size. This could be due to Graph-RFT's ability to better integrate and utilize the knowledge graph structure.
</details>
|
| --- | --- |
| (a) CWQ. | (b) WebQSP. |
Figure 4. Performance of GoG and our model under different KG settings.
$\blacktriangleright$ Exploration on SFT and Multi-reward Design. We further examine the effect of the SFT stage and the multi-reward mechanism on Graph-RFT’s performance under the IKG-40% setting. Comparing Graph-RFT-base w/o SFT with Graph-RFT-base shows a marked performance drop across all datasets, underscoring the crucial role of SFT in strengthening model capability. Moreover, removing either the web retrieval reward or the graph retrieval reward consistently degrades performance, demonstrating that both rewards effectively guide the LLM to retrieve more semantically relevant triples and external documents. As shown in Figure 3, when the model’s web search frequency approaches the optimal level (e.g., 20% in the IKG-20% setting), performance on CWQ and WebQSP improves. This indicates that Graph-RFT can adaptively regulate web search frequency based on the sufficiency of KG information, reducing the risk of noisy or irrelevant content and thereby enhancing overall effectiveness.
4.3. Different KG Incompleteness (RQ3)
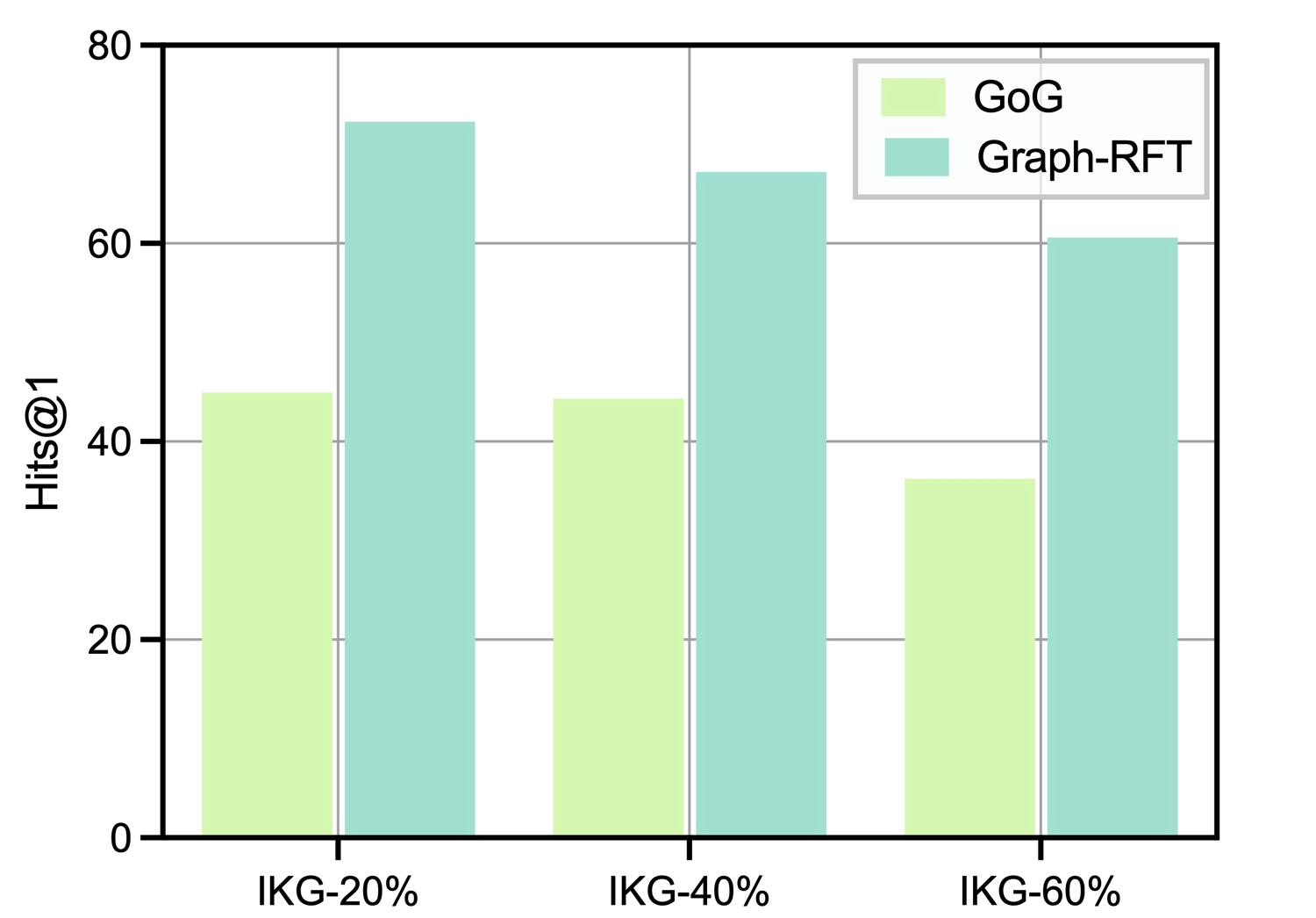
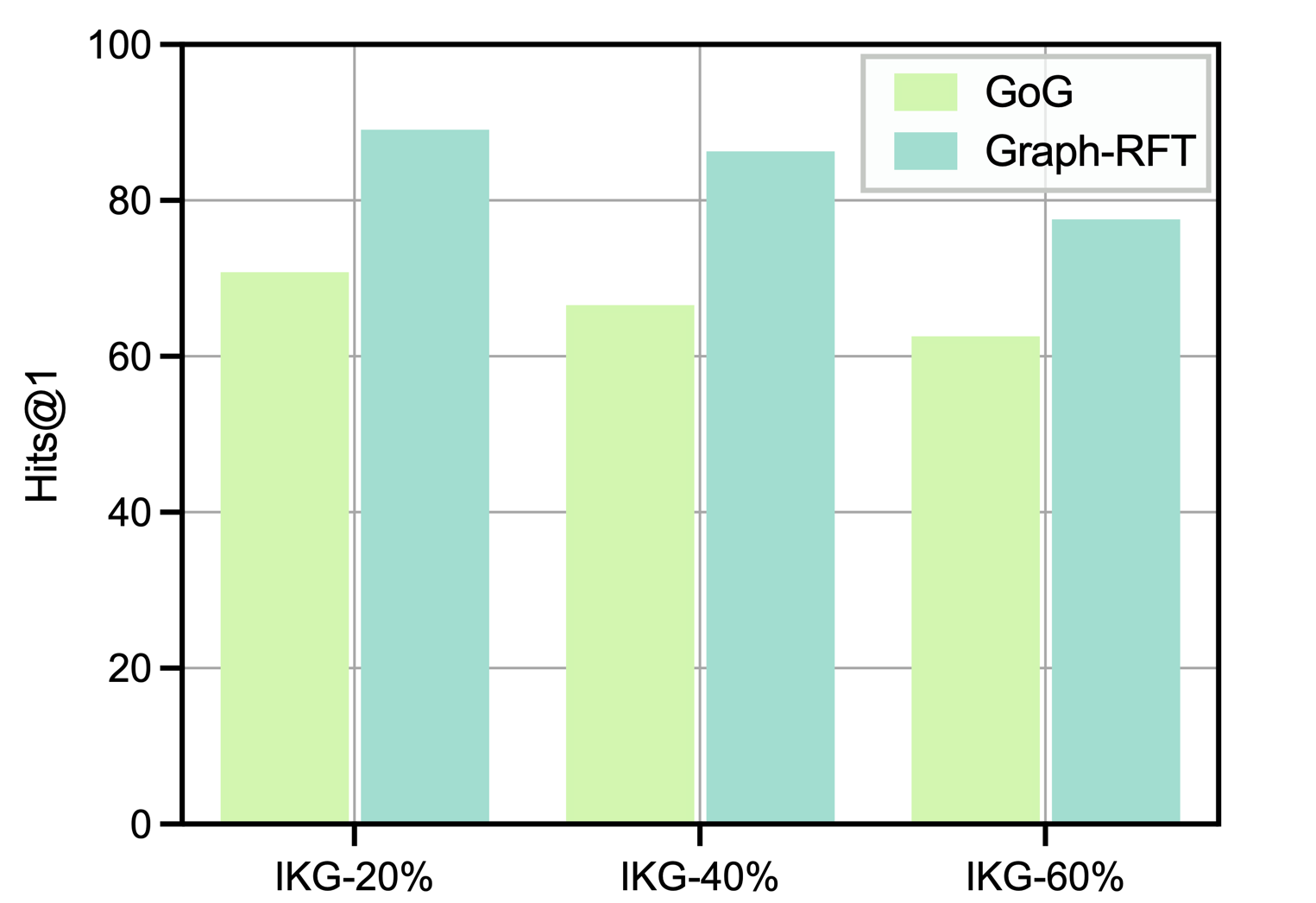
The key capabilities of our model lies in performing global planning on complex problems to leverage the knowledge within the KG and identifying knowledge gaps beyond the KG through web search. We examine the performance of Graph-RFT under varying degrees of KG incompleteness and record its external search frequency, as shown in Figure 3. To evaluate the robustness of different methods under KG incompleteness, we compare GoG and Graph-RFT across KGs with different completeness levels, as illustrated in Figure 4. $\blacktriangleright$ Impact of Rewards with or without Penalty. From Figure 3, Graph-RFT increases the frequency of external searches as KG completeness decreases. This behavior reflects the model’s ability to proactively compensate for missing knowledge required for reasoning through web retrieval. Moreover, the model’s search strategy varies notably with question complexity: compared to WebQSP (maximum 2-hop), Graph-RFT conducts significantly more external searches when tackling the more complex multi-hop questions in CWQ (maximum 4-hop). This demonstrates that the model can dynamically adjust its web search frequency according to question complexity, effectively aligning knowledge acquisition with the reasoning demands of the task. $\blacktriangleright$ Impact of Different KG Incompleteness. From Figure 4, we observe that Graph-RFT outperforms GoG across all degrees of incompleteness. This improvement arises because GoG is primarily confined to local decision-making, lacking the global planning needed for effective question understanding and tool invocation in complex problem decomposition. In contrast, when KG triples are missing, GoG relies solely on the LLM’s internal knowledge to generate answers, whereas our model retrieves relevant external documents through web search, thereby supplementing incomplete KG information and improving answer accuracy. Notably, the improvement on CWQ is much more pronounced than on WebQSP, validating Graph-RFT’s strong planning ability and logical decomposition mechanism for tackling complex reasoning tasks.
4.4. Error Type Analysis (RQ4)
To analyze Graph-RFT’s limitations, we randomly selected 50 failure cases from CWQ and WebQSP under both CKG and IKG settings. These cases are categorized into five types: (1) invalid actions, (2) relation selection errors, (3) neighbor selection errors, (4) reasoning errors, and (5) decomposition errors, with their distribution shown in Figure 6. We can obtain the following findings: (i): reasoning errors—where the LLM follows a correct reasoning process but produces incorrect answers—represent the largest proportion in both datasets and are more prevalent in IKG than in CKG, likely due to answer aliasing and discrepancies between retrieved document answers and reference answers. (ii): neighbor selection errors manifest in two scenarios: on the one hand, when relation selection is correct, neighbor errors are relatively rare in CKG, indicating that the model primarily struggles with relation selection; on the other hand, when the correct relation is not identified, as in IKG, the model often fails to determine whether entities are sufficient for problem-solving, resulting in incorrect neighbor selection. (iii): decomposition errors, arising from flawed planning, occur more frequently on complex problems such as CWQ, whereas invalid action errors (e.g., invoking undefined tools) are effectively managed by the model. The case study is in Appendix A.6.
5. Conclusion
We introduced Graph-RFT, a two-stage reinforcement fine-tuning framework for complex reasoning over incomplete knowledge graphs. Graph-RFT unifies structured planning and adaptive retrieval within a single learning paradigm, enabling LLMs to reason coherently and retrieve information dynamically across KGs and web sources. In the first stage, a CoT fine-tuning process with a customized plan–retrieval dataset activates the model’s planning and reasoning capabilities while mitigating the GRPO cold-start problem. In the second stage, a plan–retrieval guided reinforcement learning procedure with a multi-reward design optimizes coverage-aware retrieval scheduling and multi-step logical consistency. Extensive experiments across multiple KGQA benchmarks demonstrate that Graph-RFT consistently outperforms strong baselines, achieving superior accuracy even with smaller LLM backbones. In the future, we will explore enhancing relation filtering performance from KGs and the capability of decomposing problems when dealing with complex reasoning tasks.
Acknowledgements. We thank all anonymous reviewers and area chairs for their comments. This work is supported by the National Natural Science Foundation of China (U23A20316), the CCF-Tencent Rhino-Bird Open Research Fund (CCF-Tencent RAGR20250115), and the computing power resources from Wuhan Dongxihu District Intelligent Computing Center.
References
- J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. (2023) Gpt-4 technical report. arXiv preprint arXiv:2303.08774. Cited by: §2.
- F. Atif, O. El Khatib, and D. Difallah (2023) Beamqa: multi-hop knowledge graph question answering with sequence-to-sequence prediction and beam search. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 781–790. Cited by: §2.
- J. Baek, A. F. Aji, and A. Saffari (2023) Knowledge-augmented language model prompting for zero-shot knowledge graph question answering. arXiv preprint arXiv:2306.04136. Cited by: §4.
- K. Bollacker, C. Evans, P. Paritosh, T. Sturge, and J. Taylor (2008) Freebase: a collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data, pp. 1247–1250. Cited by: §4.
- P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord (2018) Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457. Cited by: §1.
- R. Descartes (1901) Discourse on method. Aladdin Book Company. Cited by: §1.
- T. Feng and L. He (2025) Rgr-kbqa: generating logical forms for question answering using knowledge-graph-enhanced large language model. In Proceedings of the 31st International Conference on Computational Linguistics, pp. 3057–3070. Cited by: Table 1, §2.
- Y. Gu, S. Kase, M. Vanni, B. Sadler, P. Liang, X. Yan, and Y. Su (2021) Beyond iid: three levels of generalization for question answering on knowledge bases. In Proceedings of the web conference 2021, pp. 3477–3488. Cited by: §4.
- D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. (2025) Deepseek-r1: incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948. Cited by: §1, §1.
- C. Hao, W. Feng, Y. Zhang, and H. Wang (2025) DynaSearcher: dynamic knowledge graph augmented search agent via multi-reward reinforcement learning. arXiv preprint arXiv:2507.17365. Cited by: §2, §3.3.2.
- D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt (2020) Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300. Cited by: §1.
- S. Hu, L. Zou, J. X. Yu, H. Wang, and D. Zhao (2017) Answering natural language questions by subgraph matching over knowledge graphs. IEEE Transactions on Knowledge and Data Engineering 30 (5), pp. 824–837. Cited by: §2.
- J. Jiang, K. Zhou, Z. Dong, K. Ye, W. X. Zhao, and J. Wen (2023) Structgpt: a general framework for large language model to reason over structured data. arXiv preprint arXiv:2305.09645. Cited by: §A.2, §1, Table 2, §4.
- J. Jiang, K. Zhou, W. X. Zhao, Y. Song, C. Zhu, H. Zhu, and J. Wen (2024) Kg-agent: an efficient autonomous agent framework for complex reasoning over knowledge graph. arXiv preprint arXiv:2402.11163. Cited by: Table 1, §2.
- J. Jiang, K. Zhou, W. X. Zhao, and J. Wen (2022) Unikgqa: unified retrieval and reasoning for solving multi-hop question answering over knowledge graph. arXiv preprint arXiv:2212.00959. Cited by: §2.
- B. Jin, H. Zeng, Z. Yue, J. Yoon, S. Arik, D. Wang, H. Zamani, and J. Han (2025) Search-r1: training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516. Cited by: §3.3.2.
- H. Khorashadizadeh, F. Z. Amara, M. Ezzabady, F. Ieng, S. Tiwari, N. Mihindukulasooriya, J. Groppe, S. Sahri, F. Benamara, and S. Groppe (2024) Research trends for the interplay between large language models and knowledge graphs. arXiv preprint arXiv:2406.08223. Cited by: §1.
- Y. Lan and J. Jiang (2020) Query graph generation for answering multi-hop complex questions from knowledge bases. Cited by: §2.
- T. Li, X. Ma, A. Zhuang, Y. Gu, Y. Su, and W. Chen (2023a) Few-shot in-context learning for knowledge base question answering. arXiv preprint arXiv:2305.01750. Cited by: §A.2, §1, Table 2.
- X. Li, R. Zhao, Y. K. Chia, B. Ding, L. Bing, S. Joty, and S. Poria (2023b) Chain of knowledge: a framework for grounding large language models with structured knowledge bases. arXiv preprint arXiv:2305.13269 3. Cited by: §4.
- B. Liu, J. Zhang, F. Lin, C. Yang, M. Peng, and W. Yin (2025a) Symagent: a neural-symbolic self-learning agent framework for complex reasoning over knowledge graphs. In Proceedings of the ACM on Web Conference 2025, pp. 98–108. Cited by: §1, §2.
- Z. Liu, Z. Sun, Y. Zang, X. Dong, Y. Cao, H. Duan, D. Lin, and J. Wang (2025b) Visual-rft: visual reinforcement fine-tuning. arXiv preprint arXiv:2503.01785. Cited by: §1.
- H. Luo, G. Chen, Q. Lin, Y. Guo, F. Xu, Z. Kuang, M. Song, X. Wu, Y. Zhu, L. A. Tuan, et al. (2025a) Graph-r1: towards agentic graphrag framework via end-to-end reinforcement learning. arXiv preprint arXiv:2507.21892. Cited by: §2.
- H. Luo, Z. Tang, S. Peng, Y. Guo, W. Zhang, C. Ma, G. Dong, M. Song, W. Lin, Y. Zhu, et al. (2023a) Chatkbqa: a generate-then-retrieve framework for knowledge base question answering with fine-tuned large language models. arXiv preprint arXiv:2310.08975. Cited by: §A.2, §1, §2, Table 2.
- L. Luo, J. Ju, B. Xiong, Y. Li, G. Haffari, and S. Pan (2025b) Chatrule: mining logical rules with large language models for knowledge graph reasoning. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, pp. 314–325. Cited by: §2.
- L. Luo, Y. Li, G. Haffari, and S. Pan (2023b) Reasoning on graphs: faithful and interpretable large language model reasoning. arXiv preprint arXiv:2310.01061. Cited by: §A.2, Table 2.
- J. Ma, Z. Gao, Q. Chai, W. Sun, P. Wang, H. Pei, J. Tao, L. Song, J. Liu, C. Zhang, et al. (2025) Debate on graph: a flexible and reliable reasoning framework for large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39, pp. 24768–24776. Cited by: Table 1, §1, §2.
- [28] M. Petrochuk and L. Zettlemoyer Simplequestions nearly solved: a new upperbound and baseline approach. arxiv 2018. arXiv preprint arXiv:1804.08798. Cited by: §4.
- C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu (2020) Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research 21 (140), pp. 1–67. Cited by: §2.
- T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom (2023) Toolformer: language models can teach themselves to use tools. Advances in Neural Information Processing Systems 36, pp. 68539–68551. Cited by: §2.
- Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu, et al. (2024) Deepseekmath: pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300. Cited by: §3.3.2, §3.3.2.
- Y. Shi, S. Li, C. Wu, Z. Liu, J. Fang, H. Cai, A. Zhang, and X. Wang (2025) Search and refine during think: autonomous retrieval-augmented reasoning of llms. arXiv preprint arXiv:2505.11277. Cited by: §1, §3.3.2.
- J. Sun, C. Xu, L. Tang, S. Wang, C. Lin, Y. Gong, L. M. Ni, H. Shum, and J. Guo (2023) Think-on-graph: deep and responsible reasoning of large language model on knowledge graph. arXiv preprint arXiv:2307.07697. Cited by: §A.2, §1, §2, Table 2, Table 2, Table 2, Table 2, Table 2, §4.
- A. Talmor and J. Berant (2018) The web as a knowledge-base for answering complex questions. arXiv preprint arXiv:1803.06643. Cited by: §4.
- H. Tan, Y. Ji, X. Hao, X. Chen, P. Wang, Z. Wang, and S. Zhang (2025a) Reason-rft: reinforcement fine-tuning for visual reasoning of vision language models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, Cited by: §3.2.
- X. Tan, X. Wang, Q. Liu, X. Xu, X. Yuan, and W. Zhang (2025b) Paths-over-graph: knowledge graph empowered large language model reasoning. In Proceedings of the ACM on Web Conference 2025, pp. 3505–3522. Cited by: §A.2, Table 1, §1, §1, §2, Table 2.
- Q. Team et al. (2024) Qwen2 technical report. arXiv preprint arXiv:2407.10671 2, pp. 3. Cited by: §A.3.
- B. Wang, Q. Xie, J. Pei, Z. Chen, P. Tiwari, Z. Li, and J. Fu (2023) Pre-trained language models in biomedical domain: a systematic survey. ACM Computing Surveys 56 (3), pp. 1–52. Cited by: §1.
- J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. (2022) Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35, pp. 24824–24837. Cited by: §1, §2.
- Q. Xie, Q. Chen, A. Chen, C. Peng, Y. Hu, F. Lin, X. Peng, J. Huang, J. Zhang, V. Keloth, et al. (2025) Medical foundation large language models for comprehensive text analysis and beyond. npj Digital Medicine 8 (1), pp. 141. Cited by: §1.
- Q. Xie, W. Han, Z. Chen, R. Xiang, X. Zhang, Y. He, M. Xiao, D. Li, Y. Dai, D. Feng, et al. (2024) Finben: a holistic financial benchmark for large language models. Advances in Neural Information Processing Systems 37, pp. 95716–95743. Cited by: §1.
- Q. Xie, W. Han, X. Zhang, Y. Lai, M. Peng, A. Lopez-Lira, and J. Huang (2023) Pixiu: a comprehensive benchmark, instruction dataset and large language model for finance. Advances in Neural Information Processing Systems 36, pp. 33469–33484. Cited by: §1.
- C. Xiong, R. Power, and J. Callan (2017) Explicit semantic ranking for academic search via knowledge graph embedding. In Proceedings of the 26th international conference on world wide web, pp. 1271–1279. Cited by: §2.
- Y. Xu, S. He, J. Chen, Z. Wang, Y. Song, H. Tong, G. Liu, K. Liu, and J. Zhao (2024) Generate-on-graph: treat llm as both agent and kg in incomplete knowledge graph question answering. arXiv preprint arXiv:2404.14741. Cited by: §A.2, §1, §2, Table 2, Table 2, §4.
- S. Xue, Z. Huang, J. Liu, X. Lin, Y. Ning, B. Jin, X. Li, and Q. Liu (2024) Decompose, analyze and rethink: solving intricate problems with human-like reasoning cycle. Advances in Neural Information Processing Systems 37, pp. 357–385. Cited by: §1.
- W. Yih, M. Richardson, C. Meek, M. Chang, and J. Suh (2016) The value of semantic parse labeling for knowledge base question answering. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 201–206. Cited by: §4.
- J. Zeng, R. Huang, W. Malik, L. Yin, B. Babic, D. Shacham, X. Yan, J. Yang, and Q. He (2024) Large language models for social networks: applications, challenges, and solutions. arXiv preprint arXiv:2401.02575. Cited by: §1.
- Z. Zhang, L. Wen, and W. Zhao (2025) Rule-kbqa: rule-guided reasoning for complex knowledge base question answering with large language models. In Proceedings of the 31st International Conference on Computational Linguistics, pp. 8399–8417. Cited by: Table 1, §2.
- Q. Zhao, H. Qian, Z. Liu, G. Zhang, and L. Gu (2024) Breaking the barrier: utilizing large language models for industrial recommendation systems through an inferential knowledge graph. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, pp. 5086–5093. Cited by: §1.
Appendix A APPENDIX
A.1. SFT Dataset Construction
We construct a Long CoT dataset comprising 4862 samples by prompting QwQ-32B with KG and Web retrieval tools. For quality filtering, we formulate two stages filtering processes: $\blacktriangleright$ Format Check. COT trajectories must not contain any labels except the defined ones, and the ¡plan¿¡/plan¿ can only be invoked once. $\blacktriangleright$ Correctness Check.
- Answer Correctness: The answer contained within the label must be correct; otherwise, the trajectory will be filtered out.
- Retrieval Correctness: When the knowledge graph is complete: The COT must not contain the ¡web_search¿, and the ¡neighbor_information¿ must include the correct answer. If not, the trajectory will be filtered out. When the knowledge graph is incomplete: The COT contains the ¡web_search¿ and the ¡web_information¿ must includes the correct answer. If not, the trajectory will be filtered out.
- Plan Correctness: GPT-4 is used to determine whether the decomposition and planning in the ¡plan¿ section are reasonable. A score of 1 is assigned for reasonable planning, and 0 for unreasonable planning. Trajectories with a score of 0 are filtered out.
A.2. Baselines
We assess the performance of Graph-RFT, leveraging Qwen2.5-7B as the backbone model. The baselines we compare can be divided into three groups: (1) LLM-only methods, including standard In-Context (IO) prompting, Chain-of-Thought (CoT) prompting, and Self-Consistency (SC) prompting. All comparisons utilize six in-content examples and incorporate ”step-by-step” reasoning chains. (2) Semantic Parsing methods, including KB-BINDER (Li et al., 2023a), ChatKBQA (Luo et al., 2023a). (3) Retrieval Augmented methods, including StructGPT (Jiang et al., 2023), RoG (Luo et al., 2023b), ToG (Sun et al., 2023), PoG (Tan et al., 2025b), GoG (Xu et al., 2024).
A.3. Implementation Details
We use Qwen2.5-7B-instruct and Qwen2.5-7B-base as backbones (Team and others, 2024) to obtain Graph-RFT-instruct and Graph-RFT-base, respectively, using PyTorch on 8 NVIDIA A800 (80GB) GPUs. In the SFT stage, we leverage LLaMA-Factory framework for efficient LLM fine-tuning. We employ a batchsize of 256 for 2 epochs with a learning rate of 1.4e-5 and AdamW optimizer with cosine decay. In the RL stage, we adopt the Verl framework with the batch size of 128 while the mini-batch size of 32, a rollout number of 8.
A.4. Prompt for Graph-RFT
In this section, we present the prompt template. The prompt comprises core components that guide the reasoning and interaction process with the knowledge graph. As illustrated in Figure 7, we adopt a structured interaction format, which utilizes the ¡plan¿, ¡relation_search¿, ¡neighbor_search¿, ¡web_search¿, and ¡answer¿. To facilitate complex reasoning, Graph-RFT first formulates a global plan. This plan outlines how to decompose the original question into manageable sub-problems using the custom-designed logic functions. Following the planning phase, each sub-problem is retrieved step-by-step from the KGs, with the invocation of dedicated KG retrieval tools. Subsequently, Graph-RFT employs a clearly defined set of tools to interact with both the knowledge graph and external documents. Through this interaction, it performs multi-step reasoning and ultimately derives the final answer. By integrating structured knowledge from the incomplete KG with supplementary information from external sources, this systematic approach enables Graph-RFT to effectively address complex problems.
A.5. Different Knowledge Bases for Graph-RFT
As shown in Table 5, Graph-RFT achieves significant improvements with different source KGs on CWQ and WebQSP in IKG-40%, compared to ToG. On the other hand, different source KGs might have different effects on the performance of ToG. Notably, Freebase brings more significant improvements on CWQ and WebQSP than Wikidata, since both datasets are constructed upon Freebase.
Table 5. Performances of Graph-RFT using different source KGs on CWQ and WebQSP in IKG-40%.
| w/Freebase (ToG) w/WikiData (ToG) w/Freebase (Graph-RFT) | 34.9 32.6 67.2 | 58.4 54.7 86.3 |
| --- | --- | --- |
| w/WikiData (Graph-RFT) | 61.5 | 77.8 |
A.6. Case Study
To demonstrate Graph-RFT’s real-world operation, we provide a detailed case study that breaks down its reasoning process when addressing complex questions. As shown in Figure 8, this example focuses on a team-related problem, illustrating how Graph-RFT systematically processes the question by leveraging both the knowledge graph and web resources.
<details>
<summary>method.png Details</summary>
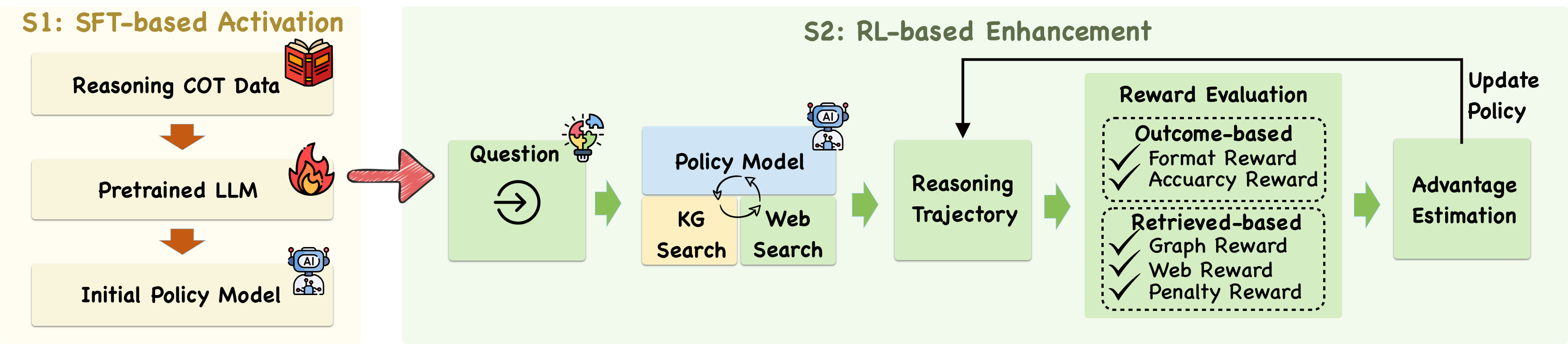
### Visual Description
\n
## Diagram: Reasoning and Policy Enhancement Pipeline
### Overview
The image depicts a two-stage pipeline for enhancing a policy model using Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL). The pipeline takes an initial policy model, refines it through reasoning and question answering, and then further improves it using reward evaluation and policy updates. The diagram is horizontally oriented, with the pipeline flowing from left to right.
### Components/Axes
The diagram is divided into two main stages labeled "S1: SFT-based Activation" and "S2: RL-based Enhancement". Within each stage, several components are interconnected by arrows indicating the flow of information. Key components include: Reasoning COT Data, Pretrained LLM, Initial Policy Model, Question, Policy Model, KG Search, Web Search, Reasoning Trajectory, Reward Evaluation, Outcome-based, Format Reward, Accuracy Reward, Retrieved-based, Graph Reward, Web Reward, Penalty Reward, Advantage Estimation, and Update Policy.
### Detailed Analysis or Content Details
**Stage 1: SFT-based Activation**
* **Initial Policy Model:** Represented by a robot icon, this is the starting point of the pipeline.
* **Pretrained LLM:** An oval shape containing the text "Pretrained LLM". An arrow points from the Initial Policy Model to the Pretrained LLM.
* **Reasoning COT Data:** A book icon labeled "Reasoning COT Data". An arrow points from the Pretrained LLM to the Reasoning COT Data.
* **Question:** A magnifying glass with a question mark inside, labeled "Question". An arrow points from Reasoning COT Data to the Question.
* **Policy Model:** A brain icon labeled "Policy Model". Two arrows point to the Policy Model: one from the Question and another from "KG Search" and "Web Search".
* **KG Search:** Labeled "KG Search".
* **Web Search:** Labeled "Web Search".
**Stage 2: RL-based Enhancement**
* **Reasoning Trajectory:** Labeled "Reasoning Trajectory". An arrow points from the Policy Model to the Reasoning Trajectory.
* **Reward Evaluation:** A dashed box labeled "Reward Evaluation". Inside the box are several reward components:
* **Outcome-based:** Labeled "Outcome-based" with a checkmark.
* **Format Reward:** Labeled "Format Reward" with a checkmark.
* **Accuracy Reward:** Labeled "Accuracy Reward" with a checkmark.
* **Retrieved-based:** Labeled "Retrieved-based" with a checkmark.
* **Graph Reward:** Labeled "Graph Reward" with a checkmark.
* **Web Reward:** Labeled "Web Reward" with a checkmark.
* **Penalty Reward:** Labeled "Penalty Reward" with a checkmark.
* **Advantage Estimation:** Labeled "Advantage Estimation". An arrow points from the Reward Evaluation to the Advantage Estimation.
* **Update Policy:** Labeled "Update Policy". An arrow points from the Advantage Estimation to the Update Policy, completing the loop.
### Key Observations
The diagram highlights a cyclical process where the policy is continuously updated based on reward evaluation. The use of both KG Search and Web Search suggests a hybrid approach to information retrieval. The Reward Evaluation component is quite detailed, indicating a multifaceted reward system.
### Interpretation
This diagram illustrates a sophisticated approach to training a policy model. The initial SFT stage leverages a pretrained LLM and reasoning data to create a foundational policy. The subsequent RL stage refines this policy through interaction and reward feedback. The detailed reward evaluation system suggests a focus on not only the correctness of the outcome but also the format, retrieval sources, and potential penalties. The pipeline emphasizes the importance of reasoning and knowledge integration (KG Search, Web Search) in achieving a robust and effective policy. The cyclical nature of the RL stage implies continuous learning and improvement. The diagram doesn't provide specific data or numerical values, but rather a conceptual framework for the training process.
</details>
Figure 5. Graph-RFT Training Framework: SFT-based Reasoning Activation (S1) and RL-based Reasoning Enhancement (S2).
<details>
<summary>error_type.png Details</summary>
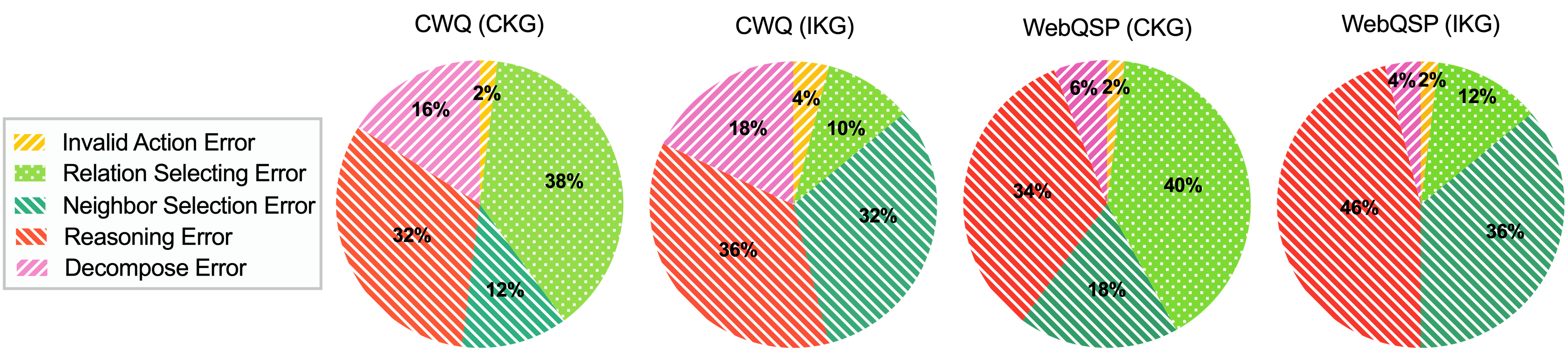
### Visual Description
\n
## Pie Charts: Error Distribution Across Different Models
### Overview
The image presents four pie charts, each representing the distribution of different error types across four different models: CWQ (CKG), CWQ (IKG), WebQSP (CKG), and WebQSP (IKG). The charts visually break down the percentage of each error type within each model.
### Components/Axes
Each chart has a legend in the bottom-left corner, defining the error types and their corresponding colors:
* **Invalid Action Error:** Red (Salmon)
* **Relation Selection Error:** Green (Light Green)
* **Neighbor Selection Error:** Teal (Medium Sea Green)
* **Reasoning Error:** Pink (Light Coral)
* **Decompose Error:** Purple (Lavender)
Each chart is labeled with the model name at the top. The charts themselves are circular, with each slice representing the percentage of a specific error type. The percentages are displayed directly on each slice.
### Detailed Analysis or Content Details
**1. CWQ (CKG)**
* **Invalid Action Error:** Approximately 2%
* **Relation Selection Error:** Approximately 38%
* **Neighbor Selection Error:** Approximately 32%
* **Reasoning Error:** Approximately 16%
* **Decompose Error:** Approximately 12%
**2. CWQ (IKG)**
* **Invalid Action Error:** Approximately 4%
* **Relation Selection Error:** Approximately 18%
* **Neighbor Selection Error:** Approximately 32%
* **Reasoning Error:** Approximately 36%
* **Decompose Error:** Approximately 10%
**3. WebQSP (CKG)**
* **Invalid Action Error:** Approximately 6%
* **Relation Selection Error:** Approximately 34%
* **Neighbor Selection Error:** Approximately 40%
* **Reasoning Error:** Approximately 18%
* **Decompose Error:** Approximately 2%
**4. WebQSP (IKG)**
* **Invalid Action Error:** Approximately 4%
* **Relation Selection Error:** Approximately 46%
* **Neighbor Selection Error:** Approximately 36%
* **Reasoning Error:** Approximately 12%
* **Decompose Error:** Approximately 2%
### Key Observations
* **Relation Selection Error** is the most frequent error type for all four models, ranging from 18% to 46%.
* **Decompose Error** consistently represents a small percentage of errors across all models (2-12%).
* **Neighbor Selection Error** is significant in CWQ (CKG) and WebQSP (CKG), but less so in the IKG versions.
* **Reasoning Error** is more prominent in CWQ (IKG) compared to the other models.
* **Invalid Action Error** is consistently the least frequent error type.
### Interpretation
The data suggests that all four models struggle most with relation selection, indicating a potential weakness in identifying the correct relationships between entities. The differences in error distributions between the CKG and IKG versions of each model suggest that the knowledge graph used (CKG vs. IKG) impacts the types of errors made. For example, the IKG version of CWQ has a higher proportion of Reasoning Errors, while the IKG version of WebQSP has a higher proportion of Relation Selection Errors. The consistently low percentage of Decompose Errors suggests that the decomposition process is relatively robust across all models. The variations in error profiles highlight the importance of considering the underlying knowledge graph and model architecture when analyzing performance and identifying areas for improvement. The models appear to have different strengths and weaknesses, and the choice of knowledge graph significantly influences the error distribution.
</details>
Figure 6. Error Type
<details>
<summary>prompt.png Details</summary>

### Visual Description
\n
## Text Document: Prompt Template of Graph-RFT
### Overview
The image presents a text document outlining a prompt template for a system called "Graph-RFT". The document details a reasoning process using a step-by-step approach based on Descartes' Principles, and defines functions for sub-problem search and logic functions. It appears to be a technical specification or guide for implementing this system.
### Components/Axes
The document is structured with headings and bullet points. Key components include:
* **Introduction:** Explains the overall approach to reasoning.
* **Sub-problem Search Function:** Defines the `Ans-searchKG` function.
* **Sub-problem Logic Functions:** Defines `Intersect`, `Union`, and `Negation` functions.
* **Process Flow:** Describes the sequential steps involved in the search and reasoning process.
* **KG Retrieval:** Mentions the use of a Knowledge Graph (KG).
* **Web Search:** Mentions the use of a web search engine.
### Detailed Analysis or Content Details
Here's a transcription of the text, broken down into sections:
**Introduction:**
"Given the question, you must conduct reasoning step by step with a priority logical relationship in accordance with Descartes’ Principles inside <think> and <think>, which enables the system to start from the most basic sub-problems that do not rely on any prior information. As each sub-problem is solved, its answer will serve as the background basis for subsequent retrieval, thereby guiding the handling of more dependent sub-problems step by step. After thinking the whole reasoning process, you must give the plan process inside <plan> and </plan>, which encompass each step’s problem and the logic functions of them. The functions are as follows:"
**Sub-problem Search Function:**
"Ans-searchKG (t=target_type | h = topic_entity, r = relation_type of h and t) describe given the topic entity and relation of the topic entity and target type in sub-problem, please use KG retrieval tool to find the answer. If the sub-problem need the predefined sub-problem’s answer, we can use Ans2-searchKG (t=target_type | h = Ans1, r = relation_type of h and t) to plan the sequential relationship of subproblems."
**Sub-problem Logic Functions:**
"Intersect (sub-problem1, sub-problem2…) describe the intersection of the answer of the sub-problems.
Union (sub-problem1, sub-problem2…) describe the union of the answer of the sub-problems.
Negation (sub-problem1, sub-problem2…) represents remove all elements from the sub-problem1 (main set) that match sub-problem2…, and return a new set that does not contain these)."
**Process Flow:**
"After planning the whole process, you start with the first step. If you need to search in KG when SearchKG(I) exist, You must first call <relation_search> h, r, </relation_search>, and it will return top15 relevant relation for you to select based on sub-problem within <relation_informations> and </relation_informations>. If there is no relevant relation, you can call a web search engine by <web_search>, r,/web_search.
After getting the relation, you must second call a neighbor search engine by <neighbor_search> h, r, </neighbor_search> and it will search the neighbors of the entity with the specified relation in the KG between <neighbor_information> and </neighbor_information>.
If there is no neighbor information, you can call a web search engine by <web_search>, r,/web_search, and it will return the top searched results between <web_information> and </web_information>.
You can search based on plan process, if you find no further external knowledge needed, you can directly pass the answer inside <answer> and </answer>."
### Key Observations
The document focuses on a structured approach to problem-solving using a combination of Knowledge Graph retrieval and web searches. The use of specific tags like `<think>`, `<plan>`, `<relation_search>`, `<web_search>`, `<answer>` suggests a system designed for automated reasoning and response generation. The emphasis on breaking down problems into smaller sub-problems and building upon previous solutions is a key characteristic of the approach.
### Interpretation
This document describes a sophisticated system for automated reasoning. The "Graph-RFT" system appears to leverage the strengths of both structured knowledge (Knowledge Graph) and unstructured information (web searches) to answer complex questions. The step-by-step process, guided by Descartes' Principles, aims to ensure a logical and transparent reasoning path. The use of specific tags suggests that this system is intended to be implemented as a software application or a component within a larger AI system. The functions defined (Intersect, Union, Negation) indicate the system's ability to perform logical operations on the results obtained from different sources. The overall design suggests a focus on explainability and traceability in the reasoning process.
</details>
Figure 7. Prompt template of our Graph-RFT.
<details>
<summary>case_study.png Details</summary>

### Visual Description
\n
## Text Block: Case Study - Question Answering with Large Language Models
### Overview
The image presents a case study demonstrating a question-answering process using a large language model (LLM). The case study focuses on the question: "With a mascot named Rocky, which team does Nate Robinson play for?". The text details the LLM's thought process, broken down into steps, and the reasoning behind each step. It showcases a chain-of-thought approach to answering the question.
### Components/Axes
The text is structured as a dialogue between the LLM ("think") and a process flow. It includes:
* **Question:** The initial query.
* **Steps:** Numbered steps outlining the LLM's reasoning.
* **Ans1 & Ans2:** Intermediate answers generated by the LLM.
* **Ans:** The final answer.
* `<relation_search>`: Rocky, has_mascot </relation_search>
* `<relation_information>`: The relations are ['common.topic.notable_for', 'common.topic.article', 'common.topic.notable_types', 'sports.sports_team.team_mascot'] You should select one most
* `<neighbor_search>`: Rocky, sports.sports_team.team_mascot </neighbor_search>
* `<neighbor_information>`: Denver Nuggets </neighbor_information>
* `<relation_search>`: Nate Robinson, play_for </relation_search>
* `<relation_information>`: The relations are ['sports.pro_athlete.teams', 'basketball.basketball_player.player_statistics', 'sports.sports_team.roster.player'] You should select one most potential relation.</think>
* `<neighbor_search>`: Nate Robinson, sports.pro_athlete.teams </neighbor_search>
* `<neighbor_information>`: No information found under this relation available in knowledge graph. Can not answer question on Nate Robinson to determine the teammate. I will ignore this step and will skip to the next step. </neighbor_information>
* Ans = Denver Nuggets
### Key Observations
* The LLM utilizes a knowledge graph (KG) for information retrieval.
* The LLM breaks down the complex question into smaller, manageable steps.
* The LLM identifies relevant relations within the KG to answer each sub-question.
* The LLM handles cases where information is missing (Nate Robinson's team affiliation).
* The LLM prioritizes the available information and provides the best possible answer based on the data.
### Interpretation
This case study demonstrates a sophisticated approach to question answering using an LLM and a knowledge graph. The LLM doesn't simply retrieve information; it *reasons* through the problem, identifying the necessary steps and relevant relations. The use of `<think>` tags provides valuable insight into the LLM's internal decision-making process. The LLM's ability to handle missing information and still provide a reasonable answer highlights its robustness. The process showcases a form of symbolic reasoning combined with statistical language modeling. The LLM's reliance on relation searches and neighbor information suggests a graph-based knowledge representation is central to its reasoning capabilities. The failure to find Nate Robinson's team information is a limitation, but the LLM gracefully handles it by prioritizing the available information. This approach is a significant step towards building more intelligent and reliable question-answering systems.
</details>
Figure 8. Case Study.