# Scaling Latent Reasoning via Looped Language Models
**Authors**: Rui-Jie Zhu, Zixuan Wang, Kai Hua, Tianyu Zhang, Ziniu Li, Haoran Que, Boyi Wei, Zixin Wen, Fan Yin, He Xing, Lu Li, Jiajun Shi, Kaijing Ma, Shanda Li, Taylor Kergan, Andrew Smith, Xingwei Qu, Mude Hui, Bohong Wu, Qiyang Min, Hongzhi Huang, Xun Zhou, Wei Ye, Jiaheng Liu, Jian Yang, Yunfeng Shi, Chenghua Lin, Enduo Zhao, Tianle Cai, Ge Zhang, Wenhao Huang, Yoshua Bengio, Jason Eshraghian
> ridger@ucsc.eduzhangge.eli@bytedance.comhuang.wenhao@bytedance.comjsn@ucsc.edu
1]ByteDance Seed 2]UC Santa Cruz 3]Princeton University 4]Mila - Quebec AI Institute 5]University of Montreal 6]Peking University 7]Carnegie Mellon University 8]University of Pennsylvania 9]Conscium 10]University of Manchester 11]M-A-P \contribution [*]Core Contributors \contribution [†]Corresponding authors
(November 17, 2025)
Abstract
Modern LLMs are trained to “think” primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era.
\correspondence
, , , \checkdata [Project Page & Base / Reasoning Models] http://ouro-llm.github.io
<details>
<summary>x1.png Details</summary>
### Visual Description
## Radar Chart: Model Performance Comparison Across Benchmarks
### Overview
The image contains two radar charts comparing the performance of various language models across multiple benchmarks. The charts are labeled "ARC-C" and "BBH" at the top, with categories arranged radially (ARC-C, BBH, MMLU-Pro, MMLU, Hellaswag, Winogrande, GSM8K, MATH500, HumanEval+). Two charts are presented: one with models up to 4B parameters and another with models up to 12B parameters. The legend distinguishes models by color (e.g., red for "Ours," green for Gemma3 4B, blue for Qwen3 4B).
### Components/Axes
- **Radial Axes**:
- ARC-C, BBH, MMLU-Pro, MMLU, Hellaswag, Winogrande, GSM8K, MATH500, HumanEval+
- **Legend**:
- Red: Ours
- Green: Gemma3 1B / Qwen3 1.7B
- Blue: Gemma3 4B / Qwen3 4B
- Dashed Blue: Gemma3 12B
- Dashed Green: Qwen3 8B
- **Chart Titles**:
- Left chart: "Ouro 2.6B"
- Right chart: "Ouro 2.6B" (same title, but higher performance values)
### Detailed Analysis
#### Left Chart (Ouro 2.6B)
- **ARC-C**: 73.1 (Ours), 66.4 (Gemma3 4B), 65.6 (Qwen3 4B)
- **BBH**: 71.0 (Ours), 60.5 (Gemma3 4B), 55.7 (Qwen3 4B)
- **MMLU-Pro**: 68.9 (Ours), 55.7 (Gemma3 4B), 54.2 (Qwen3 4B)
- **MMLU**: 68.0 (Ours), 58.5 (Gemma3 4B), 56.0 (Qwen3 4B)
- **Hellaswag**: 69.1 (Ours), 59.9 (Gemma3 4B), 58.6 (Qwen3 4B)
- **Winogrande**: 66.8 (Ours), 56.9 (Gemma3 4B), 55.9 (Qwen3 4B)
- **GSM8K**: 64.7 (Ours), 50.5 (Gemma3 4B), 47.0 (Qwen3 4B)
- **MATH500**: 60.9 (Ours), 41.0 (Gemma3 4B), 39.3 (Qwen3 4B)
- **HumanEval+**: 59.9 (Ours), 33.7 (Gemma3 4B), 32.7 (Qwen3 4B)
#### Right Chart (Ouro 2.6B)
- **ARC-C**: 75.7 (Ours), 66.4 (Gemma3 4B), 65.6 (Qwen3 4B)
- **BBH**: 80.5 (Ours), 60.5 (Gemma3 4B), 55.7 (Qwen3 4B)
- **MMLU-Pro**: 66.4 (Ours), 55.7 (Gemma3 4B), 54.2 (Qwen3 4B)
- **MMLU**: 68.0 (Ours), 58.5 (Gemma3 4B), 56.0 (Qwen3 4B)
- **Hellaswag**: 65.6 (Ours), 59.9 (Gemma3 4B), 58.6 (Qwen3 4B)
- **Winogrande**: 65.0 (Ours), 56.9 (Gemma3 4B), 55.9 (Qwen3 4B)
- **GSM8K**: 67.5 (Ours), 50.5 (Gemma3 4B), 47.0 (Qwen3 4B)
- **MATH500**: 90.8 (Ours), 41.0 (Gemma3 4B), 39.3 (Qwen3 4B)
- **HumanEval+**: 64.8 (Ours), 33.7 (Gemma3 4B), 32.7 (Qwen3 4B)
### Key Observations
1. **Performance Trends**:
- "Ours" consistently outperforms other models across all benchmarks in both charts.
- In the right chart, "Ours" achieves near-perfect scores (90.8 on MATH500, 80.5 on BBH).
- Gemma3 4B and Qwen3 4B show similar performance, with slight variations (e.g., Qwen3 4B scores higher in MMLU-Pro: 54.2 vs. 55.7 for Gemma3 4B).
- Dashed lines (Gemma3 12B, Qwen3 8B) indicate lower performance than their smaller counterparts in most categories.
2. **Outliers**:
- Qwen3 1.7B (green) underperforms in MMLU-Pro (48.9) and MATH500 (30.5) compared to other models.
- Gemma3 12B (dashed blue) scores lower than Gemma3 4B in most categories, suggesting diminishing returns with larger model sizes.
### Interpretation
The data demonstrates that the "Ours" model (likely Ouro 2.6B) significantly outperforms existing models (Gemma3 and Qwen3 variants) across diverse benchmarks. This suggests superior architecture or training efficiency. The right chart reveals that larger model sizes (e.g., Gemma3 12B, Qwen3 8B) do not always correlate with better performance, highlighting potential inefficiencies in scaling. The consistent dominance of "Ours" in tasks like MATH500 (90.8) and BBH (80.5) indicates strong reasoning and problem-solving capabilities. The left chart’s lower values (e.g., 60.9 on MATH500) suggest the right chart represents a more optimized or advanced version of the same model.
</details>
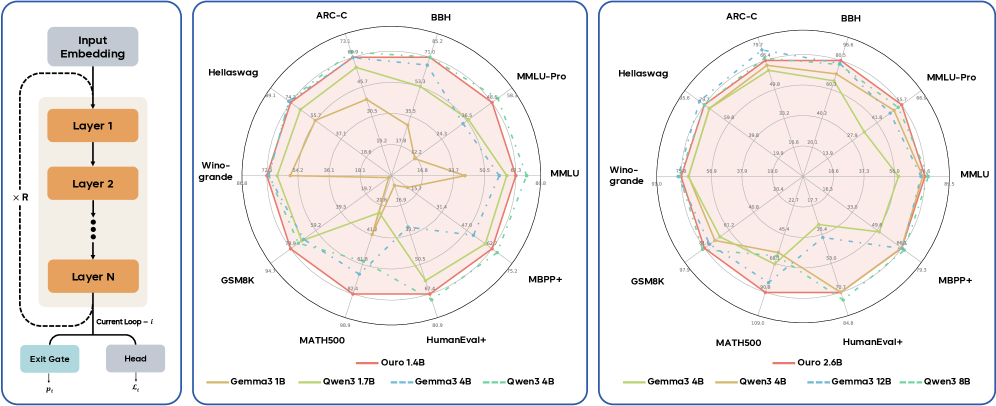
Figure 1: Ouro Looped Language Model performance. (Left) The parameter-shared looped architecture. (Middle & Right) Radar plots comparing the Ouro 1.4B and 2.6B models, both with 4 recurrent steps (red), against individual transformer baselines. Our models demonstrate strong performance comparable to or exceeding much larger baselines.
1 Introduction
The advancement of Large Language Models (LLMs) has historically relied on scaling up model size as the primary driver, accompanied by increases in data and compute [1, 2, 3, 4]. However, deploying models with hundreds of billions of parameters requires extensive infrastructure, increasing latency and cost while limiting accessibility. These factors make parameter efficiency critical: achieving better model capability within a fixed parameter budget. Such models not only mitigate overfitting on finite datasets with fewer trainable parameters, but also enable more practical deployment with lighter infrastructure. To achieve such parameter efficiency, two main avenues have been explored. The first expands the training corpus regardless of model size [5], though data scarcity increasingly limits this path. The second leverages inference-time compute through Chain-of-Thought (CoT) reasoning [6], allowing models to spend more compute on complex problems via extended token generation.
We explore a third pathway based on architectural innovation: achieving dynamic computation within a fixed parameter budget. This is accomplished by recursively applying shared parameters, where a group of weight-tied layers are iteratively reused during the forward pass. We call this the Looped Language Model (LoopLM). The design yields several advantages. First, LoopLM enables adaptive computation via a learned early-exit mechanism: simple inputs can terminate after fewer recurrent steps, while complex ones allocate more iterations. This decouples the compute depth from parameter count. Second, unlike inference-time methods such as CoT, LoopLM scales by deepening its internal computational graph rather than extending the output sequence, avoiding context-length bloat. Finally, LoopLM can improve capacity per parameter and outperform standard transformers of larger sizes when trained on the same data.
An extensive range of prior studies have explored LoopLM at modest scales [7, 8, 9, 10, 11, 12, 13, 14], from the seminal Universal Transformer [15] to recursive Transformers [16] and latent reasoning approaches [17, 18, 19]. Yet whether Looped Language Models translate into frontier-level gains at practically meaningful scales is unproven. To this end, we ask:
Does LoopLM exhibit more favorable scaling behavior (in capabilities, efficiency and safety), compared to non-recursive transformer models?
We show the answer is yes. We characterize LoopLM’s scaling trajectory and saturation behavior, demonstrating that LoopLM offers a more efficient path to higher performance. These claims are evaluated under multi-trillion-token training regimes typical of SoTA foundation models, extending well beyond prior work. Beyond the empirical gains, we analyze the mechanisms behind these improvements by asking the following questions:
- Does the recursive reuse of weights yield the capability gains typically obtained by increasing depth with unshared weights?
- Are LoopLM’s gains monotonic in the number of loops? What are the factors that influence this?
Our Contribution
We address the above questions with a multi-faceted study. We scale LoopLM pre-training to 7.7T tokens and thoroughly investigate its scaling behavior across multiple axes. To enable adaptive computation, we introduce training objectives that enable computationally efficient recurrence while preserving peak performance. We also run controlled ablations to isolate the sources of LoopLM’s gains. Specifically, our contributions are:
- Exceptional parameter efficiency at scale. By pre-training on 7.7T tokens, we demonstrate that 1.4B and 2.6B parameter LoopLMs match 4B and 8B standard transformers on most benchmarks, yielding 2-3 $×$ parameter-efficiency gains that are critical for deployment in resource constrained environments (Figure 1 and Figure 2).
- Entropy-regularized adaptive computation. Adaptive exits tend to collapse to shallow depths or overuse long loops. We avoid this with entropy-reguarization under a uniform prior over exit steps for unbiased depth exploration, followed by a focused training stage that tunes the compute-performance trade-off and allocates steps based on input difficulty.
- Mechanistic understanding of recurrence. Using controlled experiments inspired by the physics-of-LMs framework, we find recurrence does not increase raw knowledge storage (approximately 2 bits per parameter for looped and non-looped models) but dramatically enhances knowledge manipulation capabilities on tasks requiring fact composition and multi-hop reasoning.
- Improved safety and faithfulness. LoopLM reduces harmfulness on HEx-PHI [20], with safety improving as recurrent steps increase (including extrapolated steps). Compared to CoT, our iterative latent updates produce reasoning traces that are better aligned with final outputs, indicating greater causal faithfulness rather than post-hoc rationalization.
Our study establishes loop depth as a third scaling axis beyond model size and data, and we publicly release the Ouro model family (1.4B and 2.6B parameters) to demonstrate the benefits of LoopLM at scale.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Bar Chart: Model Performance Across Datasets
### Overview
The image contains seven grouped bar charts comparing the performance of seven AI models (Ouro-1.4B, Ouro-2.6B, Owen3-1.7B, Owen3-3.4B, Owen3-3.8B, Deepseek-1.5B, Deepseek-7B) across seven datasets (AIME24, AIME25, Olympiadbench, BeyondAIMe, HLE, SuperGPQA, GPQA). Scores range from 0 to 100, with numerical values displayed on top of each bar.
### Components/Axes
- **X-axis**: Datasets (AIME24, AIME25, Olympiadbench, BeyondAIMe, HLE, SuperGPQA, GPQA)
- **Y-axis**: Score (0–100)
- **Legend**: Located in the bottom-right corner, mapping colors to models:
- Ouro-1.4B: Blue
- Ouro-2.6B: Purple
- Owen3-1.7B: Orange
- Owen3-3.4B: Green
- Owen3-3.8B: Red
- Deepseek-1.5B: Pink
- Deepseek-7B: Brown
- **Bar Groups**: Each dataset chart groups bars by model, with consistent color coding across all charts.
### Detailed Analysis
#### AIME24
- Ouro-2.6B (purple): 64.0 (highest)
- Owen3-3.8B (red): 61.3
- Deepseek-7B (brown): 22.0 (lowest)
#### AIME25
- Owen3-3.8B (red): 66.7 (highest)
- Ouro-2.6B (purple): 63.3
- Deepseek-7B (brown): 23.0
#### Olympiadbench
- Ouro-2.6B (purple): 76.44 (highest)
- Owen3-3.8B (red): 73.18
- Deepseek-7B (brown): 56.44
#### BeyondAIMe
- Owen3-3.8B (red): 39.0 (highest)
- Ouro-2.6B (purple): 34.0
- Deepseek-1.5B (pink): 9.0 (lowest)
#### HLE
- Owen3-3.4B (green): 5.21 (highest)
- Deepseek-1.5B (pink): 2.22 (lowest)
#### SuperGPQA
- Owen3-3.8B (red): 51.89 (highest)
- Ouro-2.6B (purple): 47.37
- Deepseek-7B (brown): 26.50
#### GPQA
- Owen3-3.8B (red): 59.10 (highest)
- Ouro-2.6B (purple): 54.54
- Deepseek-7B (brown): 51.01
### Key Observations
1. **Owen3-3.8B (red)** consistently performs well across most datasets, particularly in AIME25 (66.7) and GPQA (59.10).
2. **Ouro-2.6B (purple)** excels in Olympiadbench (76.44) but underperforms in BeyondAIMe (34.0).
3. **Deepseek-7B (brown)** shows mixed results, with strong performance in GPQA (51.01) but poor results in BeyondAIMe (30.0).
4. **Deepseek-1.5B (pink)** has the lowest score in BeyondAIMe (9.0), suggesting significant dataset-specific limitations.
5. **Owen3-3.4B (green)** dominates HLE (5.21) but underperforms in other datasets.
### Interpretation
The data reveals that model performance is highly dataset-dependent. Owen3-3.8B demonstrates robustness across diverse tasks, while Ouro-2.6B excels in Olympiadbench, possibly due to specialized training. Deepseek models show variability, with the 7B version performing better in GPQA but struggling in BeyondAIMe. The stark drop in Deepseek-1.5B's score in BeyondAIMe (9.0) suggests potential architectural or training mismatches for that dataset. These trends highlight the importance of dataset-specific evaluation in AI model development and the need for models to generalize across tasks.
</details>
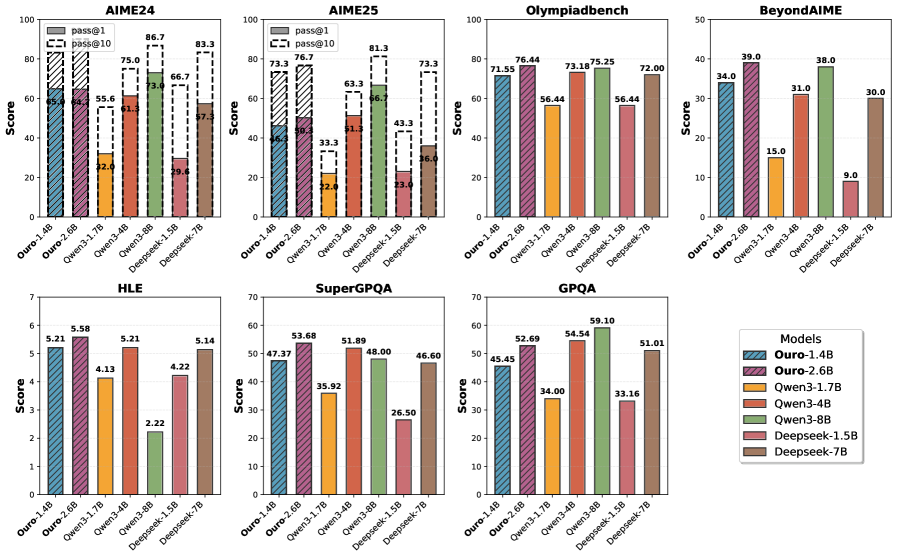
Figure 2: Performance on advanced reasoning benchmarks. Ouro-Thinking models compared with strong baselines such as Qwen3 and DeepSeek-Distill. Ouro-1.4B-Thinking R4 is competitive with 4B models, and Ouro-2.6B-Thinking R4 matches or exceeds 8B models across multiple math and science datasets.
2 Related Works
The core ideas of this architecture have resurfaced in recent literature, with recurrent-depth structures used to improve the efficiency and reasoning capabilities of modern LLMs. For example, Geiping et al. [17] adopts a “recurrent depth” to scale test-time computation in latent space. Similarly, Saunshi et al. [7] demonstrates that “looped transformers” can match the performance of much deeper non-looped models on reasoning tasks, formally connecting looping to the generation of latent thoughts. The approach is refined by converting standard models into “Relaxed Recursive Transformers” with a common base block while injecting unique LoRA adapters across recursive steps [16]. Similar concepts have emerged under different terms, such as “pondering” in continuous space [18] and “inner thinking” for adaptive computation [21]. More advanced variants, such as Mixture-of-Recursions [22] combine recursive parameter efficiency with adaptive, token-level routing.
Across all these works, from the original Universal Transformer to its modern descendants, this emerging line of architectures can be understood in two complementary ways. From one perspective, it behaves like a deep Transformer where the weights of all layers are tied. From another, iteration functions as latent reasoning, where the hidden states form a latent chain of thought that progressively refines the representation to solve a task. Taken together, these results suggest that models can improve their ability to reason by reusing computation internally without having to increase parameter count, shifting scale to substance.
Perspective 1: Parameter Sharing for Model Efficiency.
This view treats LoopLM as parameter sharing: one or more Transformer blocks, or even submodules (e.g., attention, FFN), are reused across the depth of the model, reducing parameters without changing the computation. The most prominent example in the modern transformer era is ALBERT [23], which combines parameter re-use with embedding factorization to drastically reduce the total parameter count. Prior to the widespread adoption of LLMs, parameter sharing was explored extensively in machine translation [24]; Takase et al. [25] systematically studied sharing strategies to balance compression and accuracy. Interest in parameter reuse dropped as models grew larger, but it has resurged to shrink the memory footprint of LLMs. For example, Megrez2 [26] reuses experts across layers in a standard Mixture-of-Experts (MoE) model, and shows a viable path forward for edge LLM deployment with limited memory.
Perspective 2: Latent Reasoning and Iterative Refinement.
Here, the LoopLM’s iteration is viewed as latent reasoning where each step is a non-verbal “thought” that refines the model’s internal representation. Empirically, increasing the number of recurrent steps improves performance on complex reaasoning tasks [17, 7]. Some models make this process explicit by feeding hidden states back into the input. Coconut inserts a “continuous thought” token, which is derived from the previous steps’s last-layer hidden state, so the model can “ponder” in a continuous latent space [27]. CoTFormer interleaves activations back into the input before reapplying this augmented sequence to the shared layers [28]. These explicit feedback loops contrast with implicit LoopLM variants, where the entire thought process is contained within the evolution of hidden states from previous recurrent step to current. Thus, both Perspective 1 (model compression) and Perspective 2 (latent reasoning) leverage shared-parameter iteration to improve parameter efficiency, and are being explored for enhance reasoning and efficient sequence-length expansion (e.g., PHD-Transformer [29]).
3 Learning Adaptive Latent Reasoning with LoopLM
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Neural Network Training and Inference Architecture
### Overview
The diagram illustrates a neural network architecture with explicit training and inference phases. It emphasizes dynamic computation through exit gates and confidence thresholds, enabling early termination of processing during inference. The architecture includes multiple layers, task-specific heads, and a confidence-driven early exit mechanism.
### Components/Axes
1. **Training Phase (Left Side)**
- **Input Embedding**: Initial data representation
- **Layers (1 to N)**: Stacked processing units
- **Exit Gates**: Decision points at each time step (t=1, t=2, ..., t=T_max)
- **Heads**: Task-specific output modules (L(1), L(2), ..., L(T_max))
- **Loss Function**:
```
L = Σ_{t=1}^{T_max} [p_φ(t|x) · L(t)] - β · H(p_φ(·|x))
```
- First term: Expected task loss
- Second term: Entropy regularization
2. **Inference Phase (Right Side)**
- **Input Embedding**: Same as training
- **Layers (1 to N)**: Identical to training architecture
- **Exit Gates**: Confidence-driven termination points
- **Heads**: Task-specific outputs with cumulative confidence thresholds
- **Confidence Thresholds**:
- CDF₁ = p₁ (t=1)
- CDF₂ = p₁ + p₂ (t=2)
- CDFₙ = p₁ + ... + pₙ (t=n)
### Detailed Analysis
1. **Training Flow**
- Input embedding → Sequential processing through N layers
- At each time step t:
- Exit gate computes probability p_t
- Head L(t) generates task-specific output
- Loss accumulates weighted task losses with entropy regularization
2. **Inference Flow**
- Input embedding → Sequential processing through N layers
- At each time step t:
- Exit gate computes cumulative confidence CDF_t
- If CDF_t < threshold: Continue processing
- If CDF_t ≥ threshold: Early exit with head output
3. **Key Equations**
- Loss function balances task performance (first term) and model uncertainty (second term)
- Confidence thresholds enable adaptive computation during inference
### Key Observations
1. **Dynamic Computation**
- Training phase shows fixed computation path (all layers processed)
- Inference phase introduces early exit capability based on confidence
2. **Confidence Thresholding**
- Cumulative distribution functions (CDFs) determine exit points
- Thresholds increase with processing depth (CDF₁ < CDF₂ < ... < CDFₙ)
3. **Architectural Symmetry**
- Training and inference share identical layer structure
- Exit gates and heads are consistent across both phases
4. **Temporal Progression**
- Time steps (t=1 to t=T_max) represent sequential processing
- Dashed lines in inference indicate optional early termination
### Interpretation
This architecture demonstrates a **confidence-aware neural network** that optimizes computation efficiency without sacrificing accuracy. The training phase learns to balance task performance with model uncertainty through entropy regularization. During inference, the model dynamically terminates processing when confidence thresholds are met, reducing computational cost for easier samples while maintaining accuracy for complex cases.
The early exit mechanism introduces a **computation-accuracy tradeoff** controlled by threshold values. Lower thresholds enable more aggressive early exits (faster but potentially less accurate), while higher thresholds preserve more computation (more accurate but slower). This design is particularly valuable for resource-constrained environments or real-time applications where processing speed is critical.
The entropy regularization term in the loss function prevents overconfidence by encouraging the model to maintain uncertainty awareness, which directly informs the confidence thresholds used during inference. This creates a closed-loop system where training objectives directly enable efficient inference behavior.
</details>
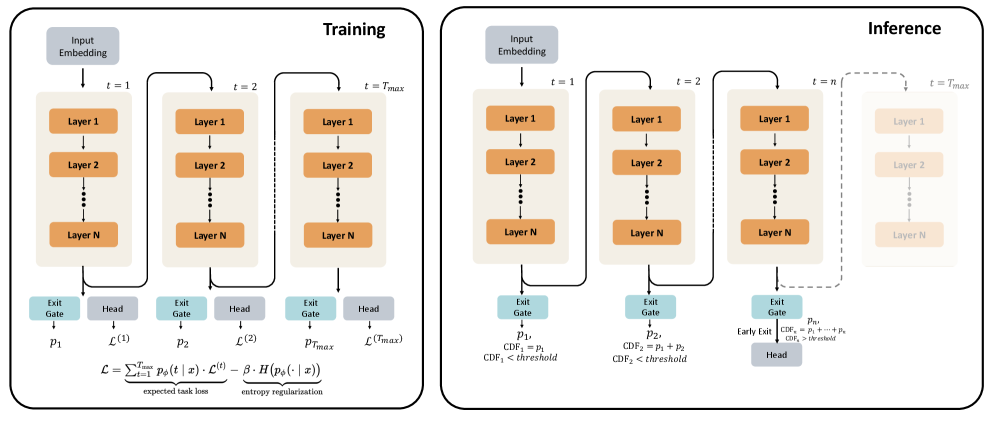
Figure 3: Overview of Looped Language Model (LoopLM) architecture. Left (Training): During training, the model applies a stack of $N$ layers repeatedly for $T_{max}$ recurrent steps. At each recurrent step $\ell$ , an exit gate predicts the probability $p_{\ell}$ of exiting, and a language modeling head $\mathcal{L}_{\ell}$ computes the lanugage modeling loss. Right (Inference): At inference time, the model can exit early based on the accumulated exit probability.
In this section, we formally define the LoopLM architecture on causal Transformers and present our training scheme for adaptive latent reasoning. Figure ˜ 3 illustrates the architecture in training and inference. Our goal is to let the model choose the number of recurrent steps per token and per example, spending less compute on easy inputs and more on hard inputs, without sacrificing accuracy when many steps are available.
3.1 LoopLM Architecture
Let $\mathrm{emb}(·):\mathbb{R}^{|V|}→\mathbb{R}^{d}$ be the token embedding; $\mathcal{T}_{\theta}(·):\mathbb{R}^{M× d}→\mathbb{R}^{M× d}$ a causal transformer layer parameterized by $\theta$ with hidden size $d$ and input length $M$ , and $\mathrm{lmhead}(·):\mathbb{R}^{d}→\mathbb{R}^{|V|}$ be the unembedding layer with vocabulary size $V$ . A non-looped LM stacks $L$ layers, where $\circ$ denotes function composition:
$$
F(\cdot):=\mathrm{lmhead}\circ\mathcal{M}^{L}\circ\mathrm{emb(\cdot)},\quad\qquad\mathcal{M}^{L}(\cdot):=\mathcal{T}_{\theta_{L}}\circ\cdots\circ\mathcal{T}_{\theta_{1}}(\cdot)
$$
Let $t∈\{1,...,T_{\max}\}$ be the number of loop steps (the number of recurrent steps or recurrent depth). The looped model $F^{(t)}$ reuses the same depth- $L$ layer stack $t$ times:
$$
F^{(t)}(\cdot)=\mathrm{lmhead}\circ\underbrace{\mathcal{M}^{L}\circ\mathcal{M}^{L}\circ\cdots\circ\mathcal{M}^{L}}_{t\text{ iterations}}\circ\ \mathrm{emb}(\cdot). \tag{1}
$$
Thus, $t=1$ yields the non-looped model $F^{(1)}\equiv F$ . As shown in Figure 3 (Left), at each recurrent step $t$ , the model produces a language modeling head output. We define the standard cross-entropy loss at single step $t$ as the loss, $\mathcal{L}^{(t)}$ :
$$
\mathcal{L}^{(t)}=\mathbb{E}_{x_{1:M}}\Bigg[\sum_{\ell=1}^{M-1}-\log\,p^{(t)}_{\theta}\!\big(x_{\ell+1}\mid x_{1:\ell}\big)\Bigg], \tag{2}
$$
where $p^{(t)}_{\theta}(·\mid x_{1:\ell})=\mathrm{softmax}\!\big(\mathrm{lmhead}(h^{(t)}_{\ell})\big)$ , $x_{1:\ell}$ denotes the length $-\ell$ prefix of the input (tokens $1$ through $ell$ ), and $h^{(t)}_{\ell}$ is the hidden state after $t$ loops at position $\ell$ . Note that this is the individual loss for a single recurrent step. The total training objective, which combines all steps, is defined in the following sections.
Prior literature [11, 7] has shown that scaling up $t$ is beneficial for reasoning tasks. However, this increases computation, and not all tokens require many steps [30, 31]. Thus, it is crucial to spend the computation budget on the right tokens. This is achieved by the gating mechanism described in the next section.
3.2 Adaptive Computation via Gating Mechanism
To enable adaptive computation, we add an exit gate that runs in parallel with the LM head at each step $t≤ T_{\max}$ (Figure ˜ 3). At each loop $t$ , the gate outputs an instantaneous (per-step) exit probability
$$
\lambda_{t}(x)=\sigma\left(\mathrm{Linear}_{\phi}\left(h^{(t)}\right)\right)\in(0,1)
$$
where $h^{(t)}$ is the final-layer hidden state at step $t$ and $\phi$ are the gate parameters. We define
$$
S_{t}(x)=\prod_{j=1}^{t}\bigl(1-\lambda_{j}(x)\bigr),\qquad S_{0}(x)\equiv 1,
$$
as the survival, or the probability of not exiting in the first $t$ steps. The unnormalized probability of exiting first at step $t$ is then
$$
\tilde{p}_{t}(x)=\lambda_{t}(x)\,S_{t-1}(x),\qquad t=1,\dots,T_{\max}-1.
$$
To obtain a valid discrete distribution over exit steps, we assign the remaining mass to the final step:
$$
p_{\phi}(t\mid x)=\begin{cases}\tilde{p}_{t}(x),&t=1,\dots,T_{\max}-1,\\[3.0pt]
S_{T_{\max}-1}(x),&t=T_{\max},\end{cases}\qquad\text{so that}\quad\sum_{t=1}^{T_{\max}}p_{\phi}(t\mid x)=1. \tag{3}
$$
Inference with Early Exit.
As illustrated in Figure 3 (Right), we infer an exit step from the learned exit distribution $\{p_{\phi}(t\mid x)\}_{t=1}^{T_{\max}}$ , enabling efficient inference. The cumulative exit probability up to step $n$ is:
$$
\mathrm{CDF}(n\mid x)=\sum_{t=1}^{n}p_{\phi}(t\mid x)=1-\prod_{j=1}^{n}\bigl(1-\lambda_{j}(x)\bigr),\quad n<T_{\max},\qquad\mathrm{CDF}(T_{\max}\mid x)=1.
$$
Given a threshold $q∈[0,1]$ , we terminate at the first step where the cumulative probability crosses $q$ :
$$
t_{\mathrm{exit}}(x)=\min\{\,m\in\{1,\dots,T_{\max}\}\,\;:\;\mathrm{CDF}(m\mid x)\geq q\,\}.
$$
The threshold $q$ controls the compute–accuracy tradeoff: smaller $q$ favors earlier exits (less compute), while larger $q$ allows deeper computation. In practice, $q$ may be chosen globally, calibrated per task, or scheduled with a floor/ceiling on steps. This deterministic, quantile-based policy avoids sampling while remaining consistent with the learned distribution.
The gating parameters $\phi$ (and thus $p_{\phi}$ via $\{\lambda_{t}\}$ ) are learned in two stages:
- Stage I: During pre-training, the gates are learned jointly with the LM by optimizing an entropy-regularized objective (Section ˜ 3.3).
- Stage II: We freeze the LM and fine-tune $\phi$ to sharpen $p_{\phi}$ (i.e., adjust depth allocation) without changing token-level predictions.
The complete training objective is described in the next section.
3.3 Stage I: Learning an Entropy-Regularized Objective
Under naive gradient descent on the next-token prediction loss, deeper loops typically reduce the single-step loss $\mathcal{L}^{(t)}$ from Equation ˜ 2 up to some depth; beyond that, gains diminish and the gradients shift probability mass toward later steps. As $p_{\phi}$ concentrates on late steps, those steps receive more training signal and their losses drop further, which in turn pulls even more mass to the end. This self-reinforcement collapses $p_{\phi}$ onto $t=T_{\rm max}$ . An entropy term penalizes collapse to the deepest step, maintaining enough spread in $p_{\phi}$ to reflect input difficulty.
Given the single-step loss $\mathcal{L}^{(t)}$ and the exit-step distribution $p_{\phi}(t\mid x)$ from Equation ˜ 3, our training objective combines next-token prediction with entropy regularization:
$$
\mathcal{L}=\underbrace{\sum_{t=1}^{T_{\max}}p_{\phi}(t\mid x)\,\mathcal{L}^{(t)}}_{\text{expected task loss}}-\underbrace{\beta\,H\!\left(p_{\phi}(\cdot\mid x)\right)}_{\text{entropy regularization}},\qquad H\!\left(p_{\phi}(\cdot\mid x)\right)=-\sum_{t=1}^{T_{\max}}p_{\phi}(t\mid x)\log p_{\phi}(t\mid x). \tag{4}
$$
Intuitively, the expected task loss weights each $\mathcal{L}^{(t)}$ by the probability of exiting at step $t$ . The coefficient $\beta$ controls the exploration–exploitation trade-off: larger $\beta$ encourages higher-entropy (more exploratory) $p_{\phi}$ , while smaller $\beta$ lets $p_{\phi}(t\mid x)$ place most of its mass on a specific step when the model is confident about the optimal depth.
Alternative perspective: variational inference with a uniform prior.
The objective in Equation ˜ 4 can be viewed as an Evidence Lower Bound (ELBO) loss where the exit step $z∈\{1,...,T_{\max}\}$ is a latent variable whose variational posterior is the learned exit distribution $p_{\phi}(z{=}t\mid x)$ and whose prior is $\pi(t)$ . The negative ELBO is:
$$
\mathcal{L}_{\text{ELBO}}=\sum_{t=1}^{T_{\max}}p_{\phi}(t\mid x)\,\mathcal{L}^{(t)}\;+\;\beta\,\mathrm{KL}\!\big(p_{\phi}(\cdot\mid x)\,\|\,\pi(\cdot)\big).
$$
With a uniform prior $\pi_{t}=1/T_{\max}$ , the KL becomes
$$
\mathrm{KL}\!\big(p_{\phi}(\cdot\mid x)\,\|\,\pi\big)=-H\!\left(p_{\phi}(\cdot\mid x)\right)+\log T_{\max},
$$
so minimizing the ELBO is equivalent (up to the constant $\log T_{\max}$ ) to the objective in Equation ˜ 4. This identifies the entropy term as a KL regularizer and clarifies that the expected loss marginalizes over exit steps, while also linking to adaptive-computation methods such as PonderNet [32], which also optimize an ELBO for dynamic halting.
Why a uniform prior?
Different priors encode different depth preferences. A geometric prior, as in Ref. [32], or Poisson-lognormal priors softly favor earlier halting [17], while a uniform prior is depth-unbiased. We adopt the uniform prior to decouple exit decisions driven by input difficulty from any global compute preference; the entropy term then prevents collapse to always using $T_{\rm max}$ . Empirical comparisons with geometric priors are provided in Appendix Appendix ˜ A.
3.4 Stage II: Focused Adaptive Gate Training
In this stage, we freeze the LM parameters and train only the exit gate to make termination decisions based on realized performance gains. We use a greedy signal that balances marginal improvement from an extra loop against additional compute.
To ensure the gate does not alter LM representations, we compute a detached per-step loss $\mathcal{L}_{i,\mathrm{stop}}^{(t)}$ at each token $i$ and define the loss improvement from step $t\!-\!1$ to $t$ as
$$
I^{(t)}_{i}=\max\!\big(0,\ \mathcal{L}_{i,\mathrm{stop}}^{(t-1)}-\mathcal{L}_{i,\mathrm{stop}}^{(t)}) \tag{5}
$$
where larger $I_{i}^{(t)}$ indicates ongoing improvement; a smaller value indicates that gains have stalled and LoopLM should opt for an early exit. We implement this by computing the ideal continuation probability, a training label that indicates whether to continue (near 1) or exit (near 0):
$$
w^{(t)}_{i}=\sigma(k\cdot(I^{(t)}_{i}-\gamma))
$$
with slope $k=50.0$ and threshold $\gamma=0.005$ , so that $w^{(t)}_{i}\!≈\!1$ recommends continuing and $w^{(t)}_{i}\!≈\!0$ recommends exiting the loop. The adaptive exit loss at step $t$ takes the binary cross-entropy between the gate’s predicted continuation probability $1-\lambda^{(t)}_{i}$ and the ideal label $w^{(t)}_{i}$ , averaged over the sequence length $M$ :
$$
\mathcal{L}^{(t)}_{\text{adaptive}}=-\frac{1}{M}\sum_{i=1}^{M}\!\Big[w^{(t)}_{i}\,\log\bigl(\underbrace{1-\lambda^{(t)}_{i}}_{\begin{subarray}{c}\text{predicted}\\
\text{continuation}\end{subarray}}\bigr)+\bigl(1-w^{(t)}_{i}\bigr)\,\log\bigl(\underbrace{\lambda^{(t)}_{i}}_{\begin{subarray}{c}\text{predicted}\\
\text{exit}\end{subarray}}\bigr)\Big]. \tag{6}
$$
The total adaptive loss averages across recurrent steps:
$$
\mathcal{L}_{\text{adaptive}}=\frac{1}{T_{\max}}\sum_{t=2}^{T_{\max}}\mathcal{L}_{\text{adaptive}}^{(t)}
$$
Significance of our adaptive loss.
The adaptive loss in Equation ˜ 6 trains the gate at step $t$ to match its predictions to the ideal behavior derived from actual performance improvements:
- Predicted probabilities: The gate generates $\lambda^{(t)}_{i}$ (exit probability) and $1-\lambda^{(t)}_{i}$ (continuation probability)
- Target labels: The ideal behavior is encoded as $w^{(t)}_{i}$ (target continuation probability) and $1-w^{(t)}_{i}$ (target exit probability)
This formulation penalizes two failure modes simultaneously:
- Underthinking: the gate exits when it should continue (large label $w^{(t)}_{i}$ , but large predicted exit $\lambda^{(t)}_{i}$ )
- Overthinking: the gate continues when it should exit (small label $w^{(t)}_{i}$ , but small predicted exit $1-\lambda^{(t)}_{i}$ )
Optimizing Equation ˜ 6 trains the gate to choose a greedy exit step that trades additional compute for measured improvement. For empirical evaluations, see Section ˜ 5.4.1.
4 Training Looped Language Models
<details>
<summary>x4.png Details</summary>

### Visual Description
## Flowchart: Ouro Model Training Pipeline
### Overview
The image depicts a bifurcated training pipeline for Ouro models, showing two parallel processes (gold and blue paths) that converge at different stages. The diagram illustrates token quantity transformations and model development phases, with explicit token counts at each stage.
### Components/Axes
- **Paths**:
- Gold path (top): "Upcycle 2.6B" → "Stable Training 3T Tokens" → "CT Annealing 1.4T Tokens" → "LongCT 20B Tokens" → "Mid-Training 300B Tokens" → "Ouro-2.6B" → "Reasoning SFT" → "Ouro-2.6B Thinking"
- Blue path (bottom): "Keep 1.4B" → "Stable Training 3T Tokens" → "CT Annealing 1.4T Tokens" → "LongCT 20B Tokens" → "Mid-Training 300B Tokens" → "Ouro-1.4B" → "Reasoning SFT" → "Ouro-1.4B Thinking"
- **Arrows**: Labeled with token quantities (e.g., "Upcycle 2.6B", "Keep 1.4B")
- **Stages**:
- Warmup → Stable Training → CT Annealing → LongCT → Mid-Training → Ouro → Reasoning SFT → Ouro Thinking
- **Color Coding**:
- Gold (#FFD700) for the 2.6B path
- Blue (#0000FF) for the 1.4B path
### Detailed Analysis
1. **Initial Branching**:
- "Warmup" splits into two paths:
- Gold: "Upcycle 2.6B" (2.6B tokens)
- Blue: "Keep 1.4B" (1.4B tokens)
- Both paths converge at "Stable Training 3T Tokens"
2. **Token Reduction**:
- Gold path reduces from 2.6B → 1.4T (1,400B) → 20B → 300B tokens
- Blue path maintains 1.4B → 1.4T → 20B → 300B tokens
3. **Final Stages**:
- Both paths undergo "Reasoning SFT" before producing:
- Ouro-2.6B Thinking (gold)
- Ouro-1.4B Thinking (blue)
### Key Observations
- **Token Scaling**: The gold path starts with 2.6B tokens but undergoes significant reduction (2.6B → 1.4T → 20B → 300B), while the blue path maintains 1.4B consistency until final stages.
- **Convergence Points**: Both paths share identical stages after initial branching ("Stable Training" onward).
- **Model Output**: Final models differ only in naming (Ouro-2.6B vs. Ouro-1.4B), suggesting token quantity impacts final model size.
### Interpretation
This flowchart represents a token optimization pipeline for large language models. The gold path demonstrates aggressive token reduction (2.6B → 1.4T) through "Upcycle" and "CT Annealing" stages, while the blue path preserves initial token quantity. Both paths converge at "Stable Training" and share identical processing through "LongCT" and "Mid-Training" stages, suggesting these phases standardize token quality regardless of initial quantity. The final "Reasoning SFT" stage appears critical for developing the Ouro models' specialized thinking capabilities, with the token quantity difference (2.6B vs. 1.4B) potentially affecting model performance or specialization depth.
</details>
Figure 4: End-to-end Ouro training pipeline: shared warmup → Stable Training → forks into a 1.4B retained path and a 2.6B upcycled path → four shared stages → Reasoning SFT to produce Ouro-Thinking.
Our end-to-end training pipeline for the Ouro model family is shown in Figure 4. In total 7.7T tokens are used to train the base models Ouro-1.4B and Ouro-2.6B. A final Reasoning SFT (Supervised Fine-Tuning) yields the Ouro-1.4B-Thinking and Ouro-2.6B-Thinking variants. This section details the architecture, data composition, and specific configurations used in each of these training stages. A high-level overview of the training recipe of the first four stages is given in Table ˜ 1.
Table 1: Training recipe for Ouro 1.4B and 2.6B.
| Hyperparameters | Stage 1a Pre-train I | Stage 1b Pre-train II | Stage 2 CT Annealing | Stage 3 LongCT | Stage 4 Mid-training |
| --- | --- | --- | --- | --- | --- |
| Learning rate (Final) | $3.0× 10^{-4}$ | $3.0× 10^{-4}$ | $3.0× 10^{-5}$ | $3.0× 10^{-5}$ | $1.0× 10^{-5}$ |
| LR scheduler | Constant | Constant | Cosine Decay | Constant | Cosine Decay |
| Weight decay | 0.1 | | | | |
| Gradient norm clip | 1.0 | | | | |
| Optimizer | AdamW ( $\beta_{1}=0.9$ , $\beta_{2}=0.95$ ) | | | | |
| Batch size (tokens) | 4M $→$ 8M | 8M | | | |
| Sequence length | 4K | 4K | 16K | 64K | 32K |
| Training tokens | 3T | 3T | 1.4T | 20B | 300B |
| Recurrent steps | 8 | 4 | | | |
| $\beta$ for KL divergence | 0.1 | 0.05 | | | |
| RoPE base | 10K | 10K | 40K | 1M | 1M |
| Data Focus | | | | | |
| Web data | High | High | Medium | Low | Low |
| Math & Code | Low | Low | High | Low | High |
| Long-context | None | None | Low | High | Medium |
| SFT-quality | None | None | Low | Low | High |
4.1 Transformer Architecture
The Ouro models use a standard decoder-only Transformer [33], prioritizing a clean implementation of the looped computation mechanism without extraneous modifications. The core architecture consists of a stack of Transformer blocks applied recurrently. Each block uses Multi-Head Attention (MHA) with Rotary Position Embeddings (RoPE) [34]. The feed-forward network (FFN) in each block utilizes a SwiGLU activation [35]. To enhance training stability, which is especially critical for deep recurrent computation, we employ a sandwich normalization structure, placing an RMSNorm layer before both the attention and FFN sub-layers [17]. Both models use a 49,152-token vocabulary from the SmolLM2 model [36]. This tokenizer is optimized for code and Latin-alphabet language. Architectural details are summarized in Table ˜ 2.
Table 2: Ouro model architecture configurations. Both models share the same vocabulary and core component types, differing in parameter count and layer depth.
| Ouro 1.4B | 1.4B | 24 | 2048 | MHA | SwiGLU | RoPE | 49,152 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Ouro 2.6B | 2.6B | 48 | 2048 | MHA | SwiGLU | RoPE | 49,152 |
4.2 Data
Data sets the capability bounds of foundation models. Our corpus spans web text, mathematics, code, and long-context documents across multiple stages, building core language understanding while strengthening reasoning, coding, and long-context skills. Beyond standard web crawls, we include targeted datasets for mathematical reasoning and code generation to improve complex problem solving. Table ˜ 3 summarizes composition and scale at each training stage.
Table 3: Statistics of the training corpus. Since data are randomly sampled during pre-training, the dataset size does not directly correspond to the total number of seen tokens.
| Nemotron-CC (Web Data) | Stage 1 | 6386 | 4404 |
| --- | --- | --- | --- |
| MAP-CC (Web Data) | Stage 1 | 800 | 780 |
| Ultra-FineWeb-zh (Web Data) | Stage 1 | 120 | 120 |
| OpenCoder-pretrain | Stage 1 | 450 | 450 |
| MegaMath-web | Stage 1 | 247 | 246 |
| MegaMath-high-quailty | Stage 2 | 64 | 64 |
| Nemotron-CC-Math-v1 | Stage 2 | 210 | 210 |
| Nemotron-Code | Stage 2 | 53 | 53 |
| Nemotron-SFT-Code | Stage 2 | 48 | 48 |
| Nemotron-SFT-General | Stage 2 | 87 | 87 |
| OpenCoder-Annealing | Stage 2 | 7 | 7 |
| ProLong-64K | Stage 3 | 20 | 20 |
| Mid-training SFT Mix | Stage 4 | 182 | 90 |
Table 4: Data composition for Stage 1 (Stable Training I & II). Total dataset size: 6T tokens.
| Data Source Proportion (%) | Nemotron-CC 73.4 | MAP-CC 13.0 | Ultra-FineWeb-zh 2.0 | OpenCoder-pretrain 7.5 | MegaMath-web 4.1 |
| --- | --- | --- | --- | --- | --- |
To ensure reproducibility, our training corpus is composed entirely of open-source datasets, with data statistics summarized in Table 4. We partition the data into four stages, each with construction strategies aligned to the Warmup-Stable-Decay (WSD) learning rate scheduler [37] commonly used in modern pre-training.
Stage 1: Pre-training
This stage supports the warmup and stable phases of training. The corpus is primarily composed of Web CommonCrawl (CC) data. Because we sought to train the model on >2T tokens, many popular open corpora are too small (e.g., Fineweb-Edu at 1.3T tokens [38], DCLM at 2.6T tokens [39]). We therefore use Nemotron-CC [40] (6.3T tokens) as the main dataset for the stable-phase. To provide the model with basic Chinese proficiency, we include Ultra-FineWeb-zh [41] and MAP-CC [42]. However, without Chinese vocabulary in the tokenizer, characters would be fragmented into multiple byte-level sub-tokens, so we removed Chinese from Stage 2 onwards. To enhance coding and mathematical abilities, we incorporate OpenCoder [43] and MegaMath [44]. See Table ˜ 4 for dataset proportions in further detail.
Stage 2: Continual Training (CT) Annealing
The CT annealing stage incorporates higher-quality data to enhance the model under the annealing learning rate. Token sequence length is extended to 16K tokens, exceeding the length of most samples to minimize truncation. We construct the corpus from the high-quality subset of Nemotron-CC and augment with HQ MegaMath, Nemotron-CC-Math-v1 [45, 46], OpenCoder-Annealing [43], Nemotron-pre-training-Code-v1 [46], and Nemotron-pre-training-SFT-v1 [46]. Data composition is provided in Table ˜ 5.
Table 5: Data composition for Stage 2 (CT Annealing). Total dataset size: 1.4T tokens.
| Nemotron-CC-high-quailty | 66.5 |
| --- | --- |
| Nemotron-CC-Math-v1 | 15.0 |
| MegaMath-high-quailty | 4.6 |
| OpenCoder-LLM/opc-annealing-corpus | 0.5 |
| Nemotron-pre-training-Code-v1/Synthetic-Code | 3.8 |
| Nemotron-pre-training-SFT-v1/Nemotron-SFT-Code | 3.4 |
| Nemotron-pre-training-SFT-v1/Nemotron-SFT-General | 6.2 |
Stage 3: Long Context Training (LongCT)
The LongCT stage extends the long-context capabilities of the model. We adopt the 64K-length subset of ProLong [47], consisting of 20B tokens, to train the model on longer sequences and improve its ability to handle long contexts.
Stage 4: Mid-training
This stage uses a diverse set of extremely high-quality data, consisting of both $\langle$ Question, Answer $\rangle$ and $\langle$ Question, CoT, Answer $\rangle$ samples, to further develop advanced abilities. We integrate 20+ open-source SFT datasets to boost data breadth, with thorough decontamination to avoid overlap with mainstream evaluation benchmarks. All samples are converted to ChatML to reduce alignment tax in the subsequent post-training stage. After processing, we obtain 182B tokens, from which we randomly sample 90B tokens. To stabilize the training distribution, we replay 30B tokens from Stage 1 and 180B from Stage 2, yielding an effective volume of 300B tokens. Consequently, this stage consolidates and extends capabilities acquired during pre-training under diverse supervised signals.
4.3 Training Stability and Adaptive Configuration
We use the flame [48] framework for pre-training, built on torchtitan [49]. During training, we prioritized stability over aggressive scaling, making several key adjustments based on empirical observations of training dynamics. These decisions were critical for achieving stable convergence with recurrent architectures, which exhibit different optimization characteristics compared to standard transformers.
Recurrent Step Reduction for Stability.
Our initial experiments with 8 recurrent steps in Stage 1a (Stable Training I) led to loss spikes and gradient oscillations. We hypothesize this stems from compounded gradient flow through multiple recurrent iterations, which can amplify small perturbations. Consequently, we reduced the recurrent steps from 8 to 4 in Stage 1b (Stable Training II in Figure ˜ 4), which balanced computational depth with training stability.
Batch Size Scaling.
To further enhance stability, we progressively increased the batch size from 4M to 8M tokens. Larger batch sizes provide more stable gradient estimates, which is particularly important for recurrent architectures where gradient flow through multiple iterations can introduce additional variance.
KL Divergence Coefficient Reduction.
We strategically reduced $\beta$ in Equation ˜ 4 from 0.1 in Stage 1a to 0.05 in later stages. This reduction serves dual purposes: (1) it decreases the conflicting gradients between task loss and the KL penalty, leading to more stable optimization, and (2) it reduces the “pull” from the uniform prior, allowing the model greater freedom to explore beneficial depth patterns without being artificially constrained. This adjustment allowed the model to learn useful depth patterns without undue constraint.
Optimization Configuration.
Throughout all stages, we use AdamW optimizer with weight decay set to 0.1, $\beta_{1}=0.9$ , $\beta_{2}=0.95$ , and gradient clipping at 1.0. These conservative settings were chosen specifically to maintain stability with recurrent architectures.
Learning Rate Considerations.
We empirically found that recurrent architectures require smaller learning rates than parameter-matched Transformers. Given compute constraints, we did not run exhaustive LR sweeps, but instead, adopted conservative rates that prioritized stable convergence over potentially faster but riskier schedules.
Sequence Length Progression.
The sequence length is progressively increased across stages: 4K tokens for both pre-training phases, 16K for CT annealing, 64K for long-context training, and 32K for mid-training. This progression stabilizes optimization while expanding context capacity with training throughput.
4.3.1 Stage-wise Training Details
- Stage 1a: Pre-training Phase I (Exploration). We initialize training with 8 recurrent steps. The learning rate follows a Warmup-Stable schedule with a peak of $3× 10^{-4}$ . The sequence length is 4K tokens with an initial batch size of 4M tokens, gradually increased to 8M for stability. During this phase, we observed training instabilities that prompted subsequent architectural adjustments.
- Stage 1b: Pre-training Phase II with Stability-Driven Upcycling. After identifying stability issues in Stage 1a, we reduced the recurrent steps from 8 to 4. To maintain computational efficiency while improving stability, we split our approach into two variants:
- 1.4B Ouro: Uses the original 24 pre-trained layers with 4 recurrent steps
- 2.6B Ouro: Upcycles 24 layers to 48 via layer duplication with 4 recurrent steps
The recurrent nature of our architecture makes this upcycling process particularly smooth, as the shared weights across iterations naturally facilitates layer duplication without the typical instabilities seen in standard transformer upcycling.
- Stage 2: CT Annealing. The learning rate is annealed to $3× 10^{-5}$ while exposing the model to high-quality training data. The recurrent steps remain at 4, having proven optimal for the stability-performance trade-off. The data composition is carefully balanced as shown in Table 5.
- Stage 3: LongCT. The batch size is held at 8M tokens. The reduced KL coefficient ( $\beta=0.05$ ) continues to provide stable training dynamics even with the 64K-length sequences.
- Stage 4: Mid-training. The learning rate is further reduced to $1× 10^{-5}$ with a cosine scheduler to help the model better absorb on this diverse, high-quality dataset.
4.4 Supervised Fine-Tuning
Data Composition.
We perform SFT on a diverse corpus of approximately 8.3M examples drawn from high-quality public datasets. As shown in Table 6, our training mixture emphasizes mathematical reasoning (3.5M examples) and code generation (3.2M examples), while also incorporating scientific reasoning (808K examples) and conversational abilities (767K examples).
For mathematical reasoning, we combine OpenThoughts3 [50] and AceReason-1.1-SFT [51] to provide comprehensive coverage of problem-solving strategies. Our code training data aggregates multiple sources including AceReason-1.1-SFT, OpenCodeReasoning [52], Llama-Nemotron-Post-Training-Dataset [53], and OpenThoughts3, ensuring broad exposure to diverse programming paradigms and reasoning patterns. Scientific reasoning capabilities are developed through OpenThoughts3 and Llama-Nemotron-Post-Training-Dataset, while conversational proficiency is enhanced using the OO1-Chat-747K https://huggingface.co/datasets/m-a-p/OO1-Chat-747K and DeepWriting-20K [54] datasets.
Training Configuration.
We train for 2 epochs with a maximum sequence length of 32K tokens using the LlamaFactory codebase [55]. We employ the Adam optimizer with a learning rate of $2× 10^{-5}$ and $\beta=(0.9,0.95)$ , applying a cosine decay schedule for stable convergence. Training was interrupted due to infrastructure issues; we resumed from the last saved checkpoint with a learning rate close to the original cosine decay schedule.
Table 6: Supervised fine-tuning data composition. The training corpus comprises 8.3M examples across four key capability domains.
| Math | OpenThoughts3, AceReason-1.1-SFT | 3.5M |
| --- | --- | --- |
| Code | AceReason-1.1-SFT, OpenCodeReasoning, Llama-Nemotron-Post-Training-Dataset, OpenThoughts3 | 3.2M |
| Science | OpenThoughts3, Llama-Nemotron-Post-Training-Dataset | 808K |
| Chat | OO1-Chat-747K, DeepWriting-20K | 767K |
4.5 Reinforcement Learning Attempts
Following the SFT stage, we conducted exploratory RLVR (Reinforcement Learning with Verifiable Rewards) alignment experiments using DAPO [56] and GRPO [57] on the DAPO-17K dataset. These attempts did not yield significant performance gains over the final SFT checkpoint. The primary issue stemmed from the model’s dynamic early-exit mechanism. vLLM/SGLang provide fast rollouts via a fixed execution path, which breaks under LoopLM’s variable-depth computation.
We tried two approaches, neither successful:
1. Off-policy rollouts: We generate full four-step rollouts in vLLM, yielding four logit candidates per token. We then selected the first token to exceed the termination threshold to simulate an early exit. For updates, we used the cumulative loss up to that step, discarding later tokens and losses. This off-policy mismatch, i.e., where tokens are produced with the final depth, and losses computed at an earlier depth, did not improve performance.
1. Fixed 4-Round RL: To avoid off-policy issues, we performed rollouts and updates at a fixed four recurrent steps. Training progressed normally but performance did not surpass the SFT checkpoint. A like cause is scale: after having already undergone extensive SFT, these smaller models may have limited headroom for RL gains. Interestingly, the model still used fewer rounds at inference when beneficial despite being trained at four rounds. The mechanism behind this generalization remains unclear.
We will further explore RL alignment for this architecture as we continue to develop infrastructure that can fully support LoopLM’s dynamic computation.
5 Experiments
5.1 Base Model Evaluation
We conduct comprehensive evaluations of the Ouro base models trained on 7.7T tokens using the LoopLM architecture. The evaluation focuses on their performance across general knowledge, reasoning, mathematics, science, coding, and multilingual capabilities. All benchmarks are evaluated using lm-eval-harness [58] and evalplus [59] frameworks with settings detailed in Appendix. C.1.
For the base model baselines, we compare our Ouro models with leading open-source base models, including Qwen2.5 [2], Qwen3 [3], Gemma3 [4], Llama3.1 [5], and Llama3.2 [5] series base models. All models are evaluated using the same evaluation pipeline to ensure fair comparison.
Table 7: Comparison of 1.4B LoopLM model with 1-4B parameter baselines. The best score is bolded, and the second-best is underlined. LoopLM’s column is highlighted in gray.
| Architecture | Gemma3 1B Dense | Llama3.2 1.2B Dense | Qwen2.5 1.5B Dense | Qwen3 1.7B Dense | Qwen2.5 3B Dense | Llama3.2 3B Dense | Qwen3 4B Dense | Gemma3 4B Dense | Ouro 1.4B R4 LoopLM |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| # Params | 1.0B | 1.0B | 1.5B | 1.7B | 3.0B | 3.0B | 4.0B | 4.0B | 1.4B |
| # Tokens | 2T | 9T | 18T | 36T | 18T | 9T | 36T | 4T | 7.7T |
| General Tasks | | | | | | | | | |
| MMLU | 39.85 | 45.46 | 60.99 | 62.46 | 65.62 | 59.69 | 73.19 | 58.37 | 67.35 |
| MMLU-Pro | 11.31 | 11.80 | 29.11 | 37.27 | 37.87 | 33.34 | 51.40 | 34.61 | 48.62 |
| BBH | 30.26 | 30.72 | 43.66 | 53.51 | 55.37 | 39.45 | 70.95 | 66.32 | 71.02 |
| ARC-C | 39.25 | 41.98 | 54.44 | 55.72 | 55.46 | 52.47 | 63.65 | 60.92 | 60.92 |
| HellaSwag | 56.12 | 59.35 | 67.73 | 67.09 | 74.54 | 73.09 | 75.66 | 75.58 | 74.29 |
| Winogrande | 58.72 | 62.75 | 66.77 | 66.30 | 70.17 | 69.14 | 71.19 | 71.07 | 72.30 |
| Math & Coding Tasks | | | | | | | | | |
| GSM8K | 2.05 | 7.05 | 60.73 | 70.28 | 74.60 | 67.20 | 72.86 | 68.69 | 78.92 |
| MATH500 | 41.00 | 7.40 | 17.60 | 25.80 | 42.60 | 40.80 | 59.60 | 68.60 | 82.40 |
| HumanEval | 6.70 | 19.50 | 52.40 | 66.50 | 68.90 | 29.90 | 77.40 | 34.80 | 74.40 |
| HumanEval+ | 5.50 | 17.40 | 46.30 | 59.80 | 62.20 | 26.20 | 70.70 | 29.30 | 67.40 |
| MBPP | 12.40 | 35.70 | 60.30 | 68.00 | 63.00 | 50.30 | 78.80 | 60.60 | 73.00 |
| MBPP+ | 10.10 | 29.10 | 50.00 | 58.50 | 54.20 | 39.70 | 65.90 | 51.10 | 62.70 |
Table 8: Comparison of 2.6B LoopLM model with 3-12B parameter baselines. The best score is bolded, and the second-best is underlined. LoopLM’s column is highlighted in gray.
| Architecture | Qwen2.5 3B Dense | Llama3.2 3B Dense | Qwen3 4B Dense | Gemma3 4B Dense | Qwen2.5 7B Dense | Llama3.1 8B Dense | Qwen3 8B Dense | Gemma3 12B Dense | Ouro 2.6B R4 LoopLM |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| # Total Params | 3.0B | 3.0B | 4.0B | 4.0B | 7.0B | 8.0B | 8.0B | 12.0B | 2.6B |
| # Trained Tokens | 18T | 9T | 36T | 4T | 18T | 15T | 36T | 12T | 7.7T |
| General Tasks | | | | | | | | | |
| MMLU | 65.62 | 59.69 | 73.19 | 58.37 | 74.20 | 73.02 | 76.63 | 72.14 | 74.60 |
| MMLU-Pro | 37.87 | 33.34 | 51.40 | 34.61 | 43.55 | 43.24 | 53.72 | 49.21 | 55.73 |
| BBH | 55.37 | 39.45 | 71.14 | 66.32 | 53.72 | 71.56 | 77.65 | 78.41 | 80.46 |
| ARC-C | 55.46 | 52.47 | 63.65 | 60.75 | 63.65 | 60.75 | 66.10 | 72.44 | 66.40 |
| HellaSwag | 74.54 | 73.09 | 75.66 | 75.58 | 79.98 | 81.97 | 79.60 | 83.68 | 79.69 |
| Winogrande | 70.17 | 69.14 | 71.19 | 71.27 | 76.48 | 77.11 | 76.80 | 77.74 | 75.85 |
| Math & Coding Tasks | | | | | | | | | |
| GSM8K | 74.60 | 67.20 | 72.86 | 68.69 | 81.50 | 78.17 | 83.09 | 77.18 | 81.58 |
| MATH500 | 42.60 | 40.80 | 59.60 | 68.60 | 61.20 | 52.90 | 62.30 | 83.20 | 90.85 |
| HumanEval | 68.90 | 29.90 | 77.70 | 34.80 | 79.30 | 38.40 | 84.80 | 46.30 | 78.70 |
| HumanEval+ | 62.20 | 26.20 | 70.70 | 29.30 | 70.60 | 31.10 | 75.30 | 37.20 | 70.70 |
| MBPP | 63.00 | 50.30 | 78.80 | 60.60 | 73.80 | 62.40 | 79.00 | 73.50 | 80.40 |
| MBPP+ | 54.20 | 39.70 | 65.90 | 51.10 | 63.50 | 51.60 | 67.90 | 66.10 | 66.60 |
Summary of Evaluation Results
Based on the overall evaluation results, we highlight key conclusions about our base models:
1. Our 1.4B parameter Ouro model (with 4 recurrent steps) achieves performance comparable to the 4B Qwen3-Base across most benchmarks. Notably, it matches or exceeds the 4B model on challenging reasoning tasks such as BBH (71.02 vs 70.95), GSM8K (78.92 vs 72.86) and MATH500 (82.40 vs 59.60)
1. The 2.6B parameter Ouro model outperforms dense models up to 8B parameters on reasoning-intensive benchmarks. It achieves 55.73 on MMLU-Pro, 80.46 on BBH and 90.85 on MATH500, surpassing the 8B Qwen3-Base (53.72, 77.65 and 62.30 respectively).
1. The recurrent architecture shows particular strength on tasks requiring multi-step reasoning and knowledge manipulation, with the most pronounced gains observed on MMLU-Pro, BBH, GSM8K and MATH500 benchmarks, validating our hypothesis that iterative computation enhances reasoning capabilities.
5.2 Reasoning Model Evaluation
We evaluate the reasoning capabilities of our Ouro reasoning models (Ouro-Thinking) with 4 recurrent steps on challenging mathematical and scientific benchmarks that require multi-step problem solving and deep reasoning. The evaluation includes AIME 2024/2025 (American Invitational Mathematics Examination), OlympiadBench, GPQA, SuperGPQA, BeyondAIME, and HLE, representing some of the most challenging reasoning tasks in the field.
Table 9: Performance comparison across different benchmarks. For AIME24 and AIME25, we report pass@1/pass@10 metrics. The best score is bolded, and the second-best is underlined.
| Model | AIME24 | AIME25 | Olympiad | Beyond | HLE | Super | GPQA | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| pass@1 | pass@10 | pass@1 | pass@10 | bench | AIME | | GPQA | | |
| Ouro-1.4B-Thinking-R4 | 65.0 | 83.3 | 46.3 | 73.3 | 71.6 | 34.0 | 5.21 | 47.4 | 45.5 |
| Ouro-2.6B-Thinking-R4 | 64.7 | 90.0 | 50.3 | 76.7 | 76.4 | 39.0 | 5.58 | 53.7 | 52.7 |
| Qwen3-1.7B | 32.0 | 55.6 | 22.0 | 33.3 | 56.4 | 15.0 | 4.13 | 35.9 | 34.0 |
| Qwen3-4B | 61.3 | 75.0 | 51.3 | 63.3 | 73.2 | 31.0 | 5.21 | 51.9 | 54.5 |
| Qwen3-8B | 73.0 | 86.7 | 66.7 | 81.3 | 75.3 | 38.0 | 2.22 | 48.0 | 59.1 |
| Deepseek-Distill-Qwen-1.5B | 29.6 | 66.7 | 23.0 | 43.33 | 56.44 | 9.0 | 4.2 | 26.5 | 33.2 |
| Deepseek-Distill-Qwen-7B | 57.3 | 83.3 | 36.0 | 73.3 | 72.0 | 30.0 | 5.14 | 46.6 | 51.0 |
Benchmarks.
- AIME 2024/2025 [60]. 30 questions per year from AIME I and II; integer answers 0–999.
- OlympiadBench [61]. Olympiad-level bilingual scientific problems; supports images for multimodal inputs.
- GPQA [62]. 448 graduate-level multiple-choice questions in biology, physics, and chemistry; search-resistant design.
- SuperGPQA [63]. GPQA scaled to about 285 graduate disciplines; curated to remain challenging.
- BeyondAIME [64]. Hard integer-answer math beyond AIME; emphasizes contamination resistance.
- HLE [65]. Multi-disciplinary closed-ended benchmark; expert-written with public splits and a private test set.
Models compared.
We report results for Ouro-1.4B-Thinking and Ouro-2.6B-Thinking, which are LoopLM-based looped language models with iterative depth. As baselines we include Qwen3-1.7B, Qwen3-4B, Qwen3-8B, DeepSeek-Distill-Qwen-1.5B, and DeepSeek-Distill-Qwen-7B. We use size-matched baselines whenever available, otherwise we compare to the next larger widely used model.
Evaluation protocol.
All systems are evaluated with a single in-house harness and identical prompting. We adopt an LLM-as-judge protocol across benchmarks with a fixed rubric and tie-breaking policy. Unless otherwise noted, decoding uses temperature = 1.0 and top_p = 0.7 for every model.
Evaluation results.
Table 9 summarizes outcomes. Iterative reasoning in the LoopLM architecture provides consistent gains on these tasks. The 1.4B Ouro model with 4 recurrent steps reaches 71.55 on OlympiadBench (vs. 73.18 for Qwen3-4B) and 34.0 on BeyondAIME (vs. 31.0 for Qwen3-4B). The 2.6B with 4 recurrent steps variant scores 76.44 on OlympiadBench (vs. 75.25 for Qwen3-8B) and 39.0 on BeyondAIME (vs. 38.0 for Qwen3-8B).
5.3 Performance by Recurrent Depth and Extrapolation
Table 10: Performance of the Ouro 1.4B base model across different recurrent steps (C-QA is CommonsenseQA [66]). Steps 5-8 represent extrapolation, as the model was trained with a maximum of 4 steps. Performance peaks at the trained depth ( $T=4$ ) and then degrades.
| UT Step 1 | ARC-C (25-shot) 37.63 | ARC-E (8-shot) 63.85 | C-QA (10-shot) 44.64 | HellaSwag (10-shot) 55.24 | MMLU (5-shot avg) 41.21 | Winogrande (5-shot) 56.99 |
| --- | --- | --- | --- | --- | --- | --- |
| 2 | 54.86 | 80.30 | 67.98 | 71.15 | 60.43 | 66.69 |
| 3 | 59.47 | 83.33 | 74.37 | 74.07 | 66.71 | 71.35 |
| 4 | 60.92 | 83.96 | 75.43 | 74.29 | 67.45 | 72.30 |
| Extrapolation (Trained on T=4) | | | | | | |
| 5 | 58.96 | 82.91 | 75.35 | 73.72 | 66.64 | 70.32 |
| 6 | 59.73 | 82.58 | 74.94 | 72.77 | 65.77 | 71.03 |
| 7 | 58.96 | 81.99 | 74.28 | 72.35 | 65.28 | 70.09 |
| 8 | 58.19 | 82.07 | 73.55 | 71.60 | 64.49 | 69.30 |
Table 11: Performance of the Ouro 2.6B base model across different recurrent steps (C-QA is CommonsenseQA [66]). Steps 5-8 represent extrapolation, as the model was trained with a maximum of 4 steps. Performance is strongest around the trained depth ( $T=4$ ) and shows varied degradation patterns during extrapolation.
| UT Step 1 | ARC-C (25-shot) 47.95 | ARC-E (8-shot) 72.39 | C-QA (10-shot) 57.58 | HellaSwag (10-shot) 68.94 | MMLU (5-shot avg) 51.55 | Winogrande (5-shot) 61.48 |
| --- | --- | --- | --- | --- | --- | --- |
| 2 | 62.37 | 85.23 | 76.90 | 77.61 | 67.63 | 70.48 |
| 3 | 65.36 | 87.33 | 79.77 | 79.12 | 73.57 | 74.35 |
| 4 | 66.38 | 86.95 | 81.65 | 79.56 | 74.60 | 75.53 |
| Extrapolation (Trained on T=4) | | | | | | |
| 5 | 65.36 | 86.83 | 81.24 | 79.57 | 74.43 | 75.93 |
| 6 | 65.02 | 86.74 | 81.08 | 79.63 | 73.79 | 75.37 |
| 7 | 65.44 | 86.57 | 80.75 | 79.59 | 72.92 | 75.77 |
| 8 | 64.76 | 86.49 | 81.08 | 79.50 | 72.24 | 74.59 |
We analyze the Ouro model’s performance as a function of its recurrent computational depth. Our models were trained with a maximum of 4 recurrent steps ( $T=4$ ). We investigate this behavior for both our base models and our SFT Ouro-Thinking models.
Base Model Performance.
Tables 10 and 11 present the performance of the Ouro 1.4B and 2.6B base models, respectively, evaluated at depths from $T=1$ to $T=8$ .
For both base models, performance on standard benchmarks (e.g., MMLU, ARC-C) generally improves up to the trained depth of $T=4$ . Steps $T=5$ through $T=8$ represent extrapolation beyond the training configuration. As shown in both tables, benchmark performance sees a moderate degradation when extrapolating, with a noticeable drop compared to the peak at $T=4$ .
However, this degradation in task-specific performance contrasts sharply with the model’s safety alignment. As detailed in Section ˜ 7.1, the model’s safety improves as the number of recurrent steps increases, even into the extrapolated regime ( $T>4$ ). This suggests that while the model’s fine-grained knowledge for benchmarks may falter beyond its training depth, the iterative refinement process continues to enhance its safety alignment.
Reasoning Model (SFT) Performance.
Table 12: Performance of Ouro-1.4B-Thinking model by recurrent step. The model was trained at $T=4$ . Performance peaks around $T=4$ or $T=5$ . All scores are percentages (0-100).
| OlympiadBench SuperGPQA AIME 2024 | 2.22 2.03 0.00 | 59.70 33.07 37.33 | 70.67 44.50 62.33 | 71.55 47.37 65.00 | 72.30 48.73 60.67 | 69.48 46.15 50.67 | 69.04 45.29 42.33 | 66.81 42.88 38.67 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| AIME 2025 | 0.33 | 25.00 | 43.33 | 46.30 | 47.00 | 43.00 | 41.00 | 38.00 |
Table 13: Performance of Ouro-2.6B-Thinking model by recurrent step. The model was trained at $T=4$ . Performance peaks at $T=3$ or $T=4$ . All scores are percentages (0-100).
| OlympiadBench SuperGPQA AIME 2024 | 18.96 15.66 3.00 | 68.59 48.58 52.00 | 75.56 56.70 70.33 | 76.44 53.68 64.70 | 71.85 56.45 57.00 | 69.19 55.44 56.33 | 57.63 53.32 49.67 | 39.26 46.84 39.00 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| AIME 2025 | 2.00 | 40.67 | 50.67 | 50.30 | 49.33 | 46.00 | 38.00 | 24.33 |
We conduct a similar analysis on our SFT models, Ouro-Thinking, to see how recurrent depth affects specialized reasoning tasks. Results for the 1.4B and 2.6B models are presented in Table 12 and Table 13, respectively.
We conduct a similar analysis on our SFT models, Ouro-Thinking, to see how recurrent depth affects specialized reasoning tasks. Results for the 1.4B and 2.6B models are presented in Table 12 and Table 13, respectively.
For both SFT models, performance at $T=1$ is very low, confirming that iterative refinement is essential for these complex tasks. Performance generally peaks at or near the trained depth, but shows slightly different patterns. The 1.4B model (Table 12) peaks around $T=4$ or $T=5$ . The 2.6B model (Table 13) tends to peak slightly earlier, at $T=3$ or $T=4$ . Interestingly, neither model peaks strictly at $T=4$ across all tasks, unlike the base model evaluations which are often logit-based. This may suggest that the longer decoding required for these reasoning tasks allows for a more active exploration of capabilities at different recurrent depths. For both models, performance degrades as they extrapolate to deeper, unseen recurrent steps ( $T=6-8$ ), reinforcing that performance is optimized for the depth seen during training.
5.4 Early Exit and Adaptive Computation Efficiency
A defining advantage of the LoopLM architecture lies in its capacity for adaptive computation allocation. Unlike standard transformers with fixed computational budgets, our model can dynamically adjust the number of recurrent steps based on input complexity. This section investigates various strategies for implementing adaptive early exit, comparing their effectiveness in balancing computational efficiency with task performance.
5.4.1 Early Exit Strategies
We explore three distinct approaches to determining when the model should terminate its iterative computation and produce the final output.
Baseline: Static Exit.
The simplest strategy forces the model to exit at a predetermined recurrent step, regardless of the input characteristics. While this approach provides predictable computational costs, it fails to leverage the model’s potential for adaptive resource allocation. We evaluate static exit at steps 1 through 4 to establish performance bounds and understand the relationship between computational depth and accuracy.
Hidden State Difference Threshold.
This heuristic-based approach monitors the magnitude of representational changes between consecutive recurrent steps. At each step $t$ , we compute $\Delta h_{t}=\|h_{t}-h_{t-1}\|_{2}$ and trigger early exit when $\Delta h_{t}<\epsilon$ for some threshold $\epsilon$ .
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Graph: Accuracy vs. Average Exit Round
### Overview
The image is a line graph comparing the accuracy of four different methods across varying average exit rounds (1.0 to 4.0). The y-axis represents accuracy (0.40 to 0.65), while the x-axis represents average exit rounds. Four data series are plotted with distinct line styles and colors, as indicated in the legend located in the bottom-right corner.
### Components/Axes
- **X-axis (Horizontal)**: Labeled "Average Exit Round," with markers at 1.0, 2.0, 3.0, and 4.0.
- **Y-axis (Vertical)**: Labeled "Accuracy," with increments of 0.05 from 0.40 to 0.65.
- **Legend**: Positioned in the bottom-right corner, mapping:
- Blue solid line with circles: "Using Ponder Gate (Untrained)"
- Orange solid line with diamonds: "Ponder Gate (Trained)"
- Green solid line with squares: "Using Hidden State Diff"
- Red dashed line with triangles: "Fixed Exit Depth"
### Detailed Analysis
1. **Using Ponder Gate (Untrained)** (Blue):
- Starts at (1.0, 0.55) and increases steadily.
- Data points: (2.0, 0.60), (3.0, 0.65), (4.0, 0.68).
- Trend: Consistent upward slope.
2. **Ponder Gate (Trained)** (Orange):
- Starts at (1.0, 0.40) and rises sharply.
- Data points: (2.0, 0.60), (3.0, 0.65), (4.0, 0.68).
- Trend: Steeper ascent than other lines, surpassing all others by x=4.0.
3. **Using Hidden State Diff** (Green):
- Starts at (1.0, 0.50) and increases gradually.
- Data points: (2.0, 0.60), (3.0, 0.65), (4.0, 0.67).
- Trend: Slightly slower growth compared to blue and orange lines.
4. **Fixed Exit Depth** (Red dashed):
- Starts at (1.0, 0.40) and rises steadily.
- Data points: (2.0, 0.55), (3.0, 0.60), (4.0, 0.65).
- Trend: Linear increase but remains below all other methods.
### Key Observations
- The **Ponder Gate (Trained)** method (orange) demonstrates the highest accuracy by x=4.0, outperforming all other methods.
- The **Using Ponder Gate (Untrained)** (blue) and **Using Hidden State Diff** (green) lines converge closely, with blue slightly ahead at x=4.0.
- **Fixed Exit Depth** (red dashed) lags behind all other methods throughout the range.
- All methods show improvement as average exit rounds increase, but the rate of improvement varies significantly.
### Interpretation
The data suggests that **training the Ponder Gate method** (orange line) yields the most significant performance gains over time, particularly in later exit rounds. The **Using Ponder Gate (Untrained)** and **Using Hidden State Diff** methods exhibit similar trajectories, indicating that hidden state differences may not provide a substantial advantage over untrained Ponder Gate approaches. In contrast, **Fixed Exit Depth** (red dashed) underperforms consistently, implying that dynamic exit strategies (e.g., Ponder Gate) are more effective than static depth-based approaches. The sharp rise of the trained Ponder Gate method highlights the importance of training in optimizing accuracy for this task.
</details>
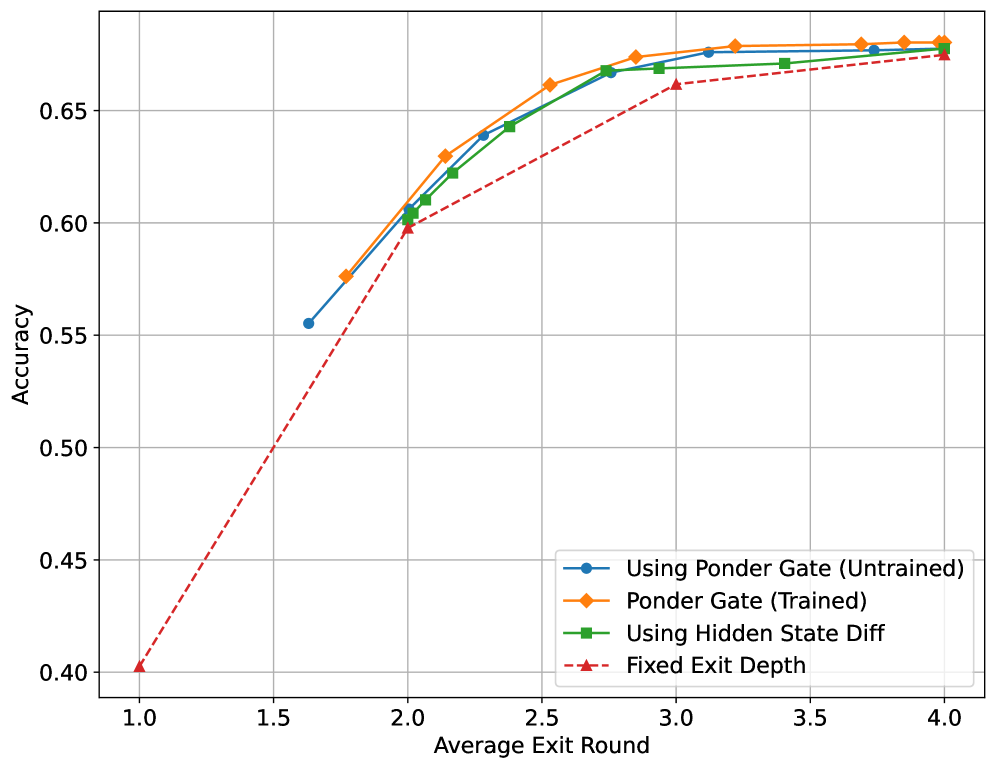
Figure 5: Comparison of early exit strategies on MMLU. We evaluate four approaches across different average exit rounds: static baseline (red triangle), hidden state difference threshold (green squares), Ponder gate from standard pre-training (blue circles), and Ponder gate with specialized adaptive exit training from Section 3.4 (orange diamonds).
Learned Gating with Q-Exit Criterion.
Our primary approach employs the learned exit gate described in Section 4, which produces step-wise halting probabilities $\lambda_{t}$ based on the model’s current hidden states. During inference, we apply the Q-exit criterion: at each step $t$ , we compute the cumulative distribution function $\text{CDF}(t)=\sum_{i=1}^{t}p(i|x)$ and exit when $\text{CDF}(t)$ exceeds the threshold $q∈[0,1]$ . The threshold $q$ serves as a deployment-time hyperparameter that controls the compute-accuracy trade-off without requiring model retraining.
We evaluate this strategy under two training configurations. The untrained configuration uses the gate as trained during our standard pre-training pipeline with the entropy-regularized objective (uniform prior KL loss). This represents the gate’s behavior when jointly optimized with language modeling throughout Stages 1-4. The trained configuration additionally applies the specialized adaptive exit loss described in Section 3.4, which explicitly teaches the gate to base stopping decisions on observed task loss improvements.
Experimental Results.
Figure 5 presents the accuracy-efficiency trade-off curves for all strategies on the MMLU benchmark. By varying the exit threshold (or static exit step for baseline), we obtain multiple operating points for each method, enabling direct comparison at equivalent computational budgets measured by average exit round.
Several key findings emerge from this analysis:
1. The Ponder gate with specialized adaptive exit training achieves the best accuracy at every computational budget, demonstrating that the loss improvement-based training signal described in Section 3.4 provides clear benefits over standard entropy regularization. At an average exit round of 2.5, the specialized training reaches 66% accuracy while the standard gate achieves approximately 64%;
1. Even without specialized training, the Ponder gate from standard pre-training substantially outperforms the static baseline, validating that the entropy-regularized objective with uniform prior successfully enables adaptive computation. The gate learns to differentiate input difficulty through the general training dynamics, though it lacks the explicit supervision to correlate stopping decisions with actual performance improvements. This demonstrates that our base training approach already captures useful signals for resource allocation;
1. The hidden state difference threshold strategy performs surprisingly competitively, closely tracking both gate configurations. At moderate computational budgets (2-3 average rounds), it achieves accuracy within 1%-2% of the specialized trained gate, suggesting that representation stability provides a reasonable proxy for computational convergence. However, the consistently superior performance of the specialized trained gate across all operating points confirms that explicit supervision via the adaptive exit loss captures information beyond what can be inferred from representational dynamics alone.
1. Comparing the untrained and trained gate configurations reveals the value proposition of the specialized training procedure. The gap between these curves, approximately 2%-3% accuracy at most operating points, represents the benefit of teaching the gate to explicitly monitor task loss improvements $I^{(n)}_{t}$ rather than relying solely on entropy regularization to discover stopping policies. This empirical result validates our design choice to introduce the adaptive exit loss as a specialized training objective.
1. The baseline’s monotonic improvement from 1 to 4 rounds confirms the “deeper is better” property while revealing diminishing returns. The dramatic jump from 1.0 to 2 rounds (40% to 60% accuracy) contrasts with the marginal gain from 3 to 4 rounds (67.35% accuracy). This pattern explains why adaptive methods prove effective: most examples achieve near-maximal performance at intermediate depths, with only a minority requiring full computational depth.
5.4.2 KV Cache Sharing for Inference Efficiency
The recurrent nature of our architecture introduces a challenge: naively, each recurrent step requires maintaining its own KV cache, leading to 4 $×$ memory overhead for our 4-step model. We investigate strategies to reduce this overhead through KV cache reuse.
Prefilling Phase
During the prefilling phase (processing the input prompt), we find that all four recurrent steps require their own KV caches, as each step transforms the representations in ways that cannot be approximated by earlier steps. Attempting to reuse KV caches during prefilling leads to performance degradation (>10 points on GSM8K).
Decoding Phase
However, during the decoding phase (auto-regressive generation), we discover that KV cache reuse becomes viable. We explore two strategies:
1. Last-step reuse: Only maintain KV cache from the final (4th) recurrent step
1. First-step reuse: Only maintain KV cache from the first (1st) recurrent step.
1. Averaged reuse: Maintain an averaged KV cache across all four steps
Table 14: KV cache sharing strategies during decoding. Both last-step and averaged strategies achieve minimal performance loss while reducing memory by 4 $×$ .
| Full (4 $×$ cache) First-step only Last-step only | 78.92 18.73 78.85 | 82.40 8.43 80.40 | 1.00 $×$ 4.00 $×$ 4.00 $×$ |
| --- | --- | --- | --- |
| Averaged | 78.73 | 78.52 | 4.00 $×$ |
As shown in Table 14, these strategies yield dramatically different outcomes. Reusing only the first step’s cache results in a catastrophic performance collapse (e.g., 18.73 on GSM8K, down from 78.92), indicating that the initial representations are insufficient for subsequent decoding steps. In contrast, both the last-step and averaged reuse strategies achieve nearly identical performance (within 0.3 points on GSM8K) to the full cache baseline, while successfully reducing memory requirements by 4×. The last-step strategy performs slightly better than the averaged approach on MATH-500, suggesting that the final recurrent step’s representations are most informative for subsequent token generation. This finding enables practical deployment of LoopLM models with memory footprints comparable to standard transformers of similar parameter count.
6 Understanding LoopLMs Superiority from a Parametric Knowledge Viewpoint
Why LoopLMs achieve far better performance when the parameter counts do not increase? Although potential enhanced reasoning capabilities were observed in [7], the source of the advantage remains unclear. Specifically, do LoopLMs perform better due to the models’ increased knowledge capacity with the same size of parameters? Or do they have a better capability in extracting and composing the knowledge encoded within the parameters? Toward understanding the improvement of the phenomenon, we explore what capabilities are exactly enhanced by simply looping more times. In this section, we perform experiments to test the model’s abilities to memorize factual knowledge in its parameters, and the capabilities of manipulating and composing existing knowledge encoded in the parameters based on a set of fully controllable synthetic tasks in [67, 68, 69].
6.1 LoopLMs does not increase knowledge capacity
We first explore the knowledge capacity, i.e. the model’s storage capacity of facts in the parameters. We aim to answer the first question: do LoopLMs achieve better performance by memorizing knowledge when the parameter count is not increased?
Settings. Following the Capo task setting in Physics of language models [67, 68], we construct synthetic biographies to test how much information the model memorizes. Specifically, we generate several synthetic biographic datasets $\operatorname{bioS}(N)$ with different number of people $N$ , and train a series of language models to memorize the information contained in the dataset. Each biography contains the individual’s name and five attributes $a_{1},a_{2},...,a_{5}$ of the person: gender, birth date, university, major, and employer. The names $n$ and the attributes $a_{i}$ are randomly selected from a pre-defined set $\mathcal{N}$ and $\mathcal{A}_{i}$ and combined together as a biography using a random template. Based on the random generation process, we have an information-theoretic lower bound for the model in the minimum bits required to encode all the names and attributes. To check whether the models memorize the biographic information accurately, we look at the probability of predicting the ground-truth attributes with the trained models given the biography context. Calculating the sum of cross-entropy loss on each attribute token positions, we can estimate how much information (estimated in bits) has already been memorized in the trained language model, which is our knowledge capacity metric.
With this metric, we can compare the knowledge capacity between the original model (with only one recurrent step) and the looped model (with 4 recurrent steps) with the same parameter count to investigate whether looping increases knowledge capacity. Moreover, as larger models should encode more information than smaller models, we also aim to investigate whether looped models have a better scaling effect when the size of the model grows. We thereby trained GPT-2 style models of different parameter numbers ranging from 1M to 40M (with depth and hidden dimension varied) and measured the number of bits of knowledge learned by each model. We trained on $\operatorname{bioS}(N)$ with $N$ ranging from 20K to 500K individuals for 1000 exposures. More training details are provided in Section ˜ B.1.
Results. The results are visualized in the plot “bits vs. # of parameters”, where we can observe the comparison between iso-parameter looped and non-looped models. Our results are shown in Figure ˜ 6 (Left): looping does not increase knowledge capacity nor improve capacity scaling. Models with and without loops all attain around a similar capacity ratio $≈ 2$ bits/parameter. Therefore, the number of parameters itself can be seen as a direct indicator of knowledge capacity, and merely increasing looping does not help enhance knowledge capacity itself.
<details>
<summary>x6.png Details</summary>
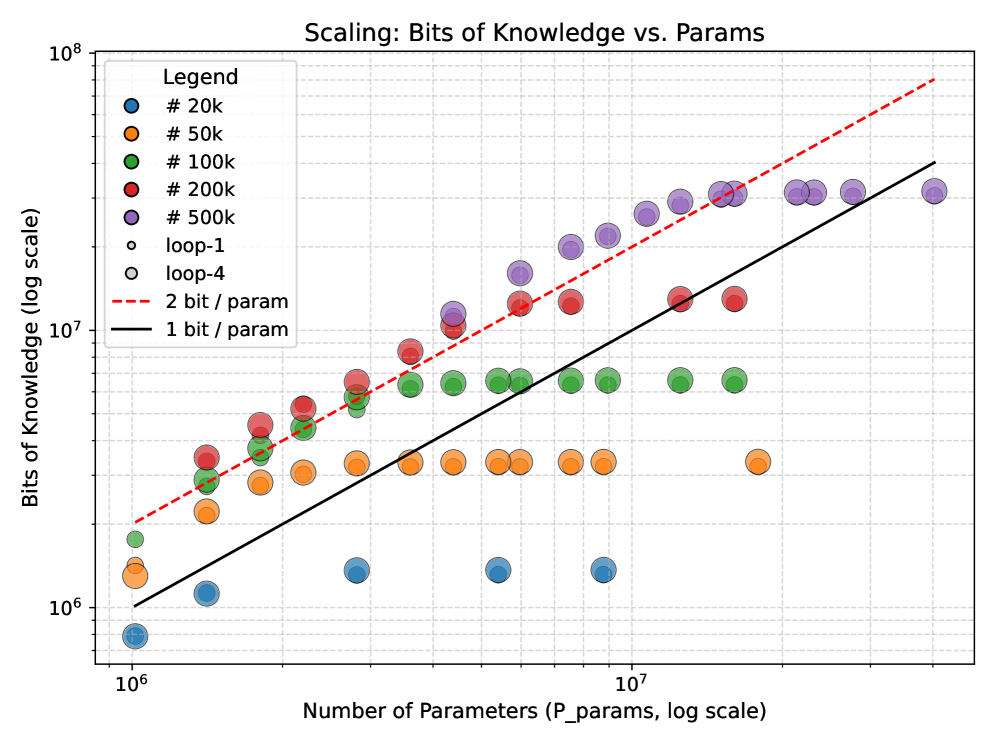
### Visual Description
## Scatter Plot: Scaling: Bits of Knowledge vs. Params
### Overview
The image is a scatter plot visualizing the relationship between the number of parameters (P_params) and the bits of knowledge (log scale) in a machine learning or AI context. The plot uses logarithmic scales for both axes, with data points color-coded by parameter count and trend lines indicating theoretical efficiency thresholds (1 bit/param and 2 bits/param).
---
### Components/Axes
- **Title**: "Scaling: Bits of Knowledge vs. Params" (centered at the top).
- **X-axis**: "Number of Parameters (P_params, log scale)" with values ranging from 10⁶ to 10⁷.
- **Y-axis**: "Bits of Knowledge (log scale)" with values ranging from 10⁶ to 10⁸.
- **Legend**: Located in the top-left corner, with color-coded labels:
- Blue: #20k
- Orange: #50k
- Green: #100k
- Red: #200k
- Purple: #500k
- Open circles: loop-1
- Gray circles: loop-4
- Dashed red line: 2 bit / param
- Solid black line: 1 bit / param
---
### Detailed Analysis
#### Data Points
- **Parameter Counts**:
- **#20k (blue)**: Data points cluster near the bottom-left (x ≈ 10⁶, y ≈ 10⁶–10⁷).
- **#50k (orange)**: Slightly higher on the y-axis (x ≈ 10⁶–10⁷, y ≈ 10⁶–10⁷).
- **#100k (green)**: Mid-range (x ≈ 10⁶–10⁷, y ≈ 10⁷–10⁸).
- **#200k (red)**: Higher y-values (x ≈ 10⁶–10⁷, y ≈ 10⁷–10⁸).
- **#500k (purple)**: Top-right (x ≈ 10⁷, y ≈ 10⁷–10⁸).
- **Loop-1 (open circles)**: Overlaps with #200k and #500k data points, suggesting similar parameter ranges.
- **Loop-4 (gray circles)**: Overlaps with #100k and #200k data points.
#### Trend Lines
- **1 bit / param (solid black line)**: A linear trend line passing through the lower half of the plot, indicating a baseline efficiency threshold.
- **2 bit / param (dashed red line)**: A steeper trend line above the 1 bit/param line, representing a higher efficiency benchmark.
---
### Key Observations
1. **Parameter vs. Knowledge Correlation**:
- Higher parameter counts (e.g., #500k) generally correspond to higher bits of knowledge, but the relationship is not strictly linear.
- Data points for #20k and #50k are clustered near the lower y-axis, while #500k points dominate the upper y-axis.
2. **Trend Line Behavior**:
- The **1 bit/param line** aligns with the lower half of the data, suggesting that many models operate near this efficiency threshold.
- The **2 bit/param line** is above most data points, indicating that achieving this efficiency is rare or requires specific optimizations.
3. **Data Point Overlaps**:
- Open circles (loop-1) and gray circles (loop-4) overlap with red (#200k) and purple (#500k) points, suggesting shared parameter ranges or experimental conditions.
4. **Logarithmic Scale Impact**:
- The log scales compress the data, making trends across orders of magnitude more visible (e.g., 10⁶ to 10⁷ parameters).
---
### Interpretation
- **Efficiency Trends**: The plot highlights a trade-off between parameter count and knowledge efficiency. While more parameters generally increase knowledge, the **2 bit/param threshold** remains a high benchmark, suggesting that many models are sub-optimal in terms of parameter efficiency.
- **Model Variability**: The spread of data points (e.g., #500k) indicates variability in how parameters translate to knowledge, possibly due to architectural differences or training data quality.
- **Theoretical vs. Empirical**: The trend lines may represent theoretical expectations (e.g., 1 bit/param as a baseline), while the data points reflect empirical results. The gap between the lines and data points could indicate room for improvement in model design.
---
### Notable Anomalies
- **#500k Data Points**: Some points are slightly below the 2 bit/param line, suggesting that even large models may not always meet the highest efficiency thresholds.
- **Loop-1/Loop-4 Overlaps**: The open and gray circles may represent different experimental setups (e.g., training iterations or hyperparameters) that share parameter ranges with larger models.
---
### Conclusion
The plot demonstrates that increasing parameter counts correlate with higher bits of knowledge, but efficiency (bits per parameter) varies significantly. The 2 bit/param line serves as a critical benchmark, while the 1 bit/param line reflects a more common baseline. The data underscores the importance of optimizing parameter efficiency in large-scale models.
</details>
| Baseline model Base $(12\otimes 1)$ | $L=10$ 93.6 | $L=16$ 94.4 | $L=24$ 34.8 |
| --- | --- | --- | --- |
| 2 layer model | | | |
| Base $(2\otimes 1)$ | 21.5 | 8.4 | 7.5 |
| Loop $(2\otimes 6)$ | 98.1 | 96.3 | 78.0 |
| 3 layer model | | | |
| Base $(3\otimes 1)$ | 75.4 | 29.8 | 11.0 |
| Loop $(3\otimes 4)$ | 97.9 | 95.8 | 92.2 |
| 6 layer model | | | |
| Base $(6\otimes 1)$ | 84.7 | 59.5 | 20.0 |
| Loop $(6\otimes 2)$ | 93.4 | 88.5 | 35.1 |
Figure 6: Left. We trained both LoopLM and a standard trasnformer baseline with the same parameters on Capo task to compare the knowledge capacity gain by looping more times. With the same parameter count, the looped model and its non-looped baseline has almost the same knowledge capacity measured in bits of knowledge on Capo task. Right. Accuracy of looped/non-looped models on Mano task. Looped models are better than the iso-param $(\{2,3,6\}\otimes 1)$ models. They also achieve better or comparable performance comparing to the iso-flop baseline $(12\otimes 1)$ model.
6.2 LoopLMs prevails in knowledge manipulation
We have already shown that reusing parameters cannot help the model memorize more atomic factual knowledge. However, natural language is not only about single-hop factual knowledge. In most of the scenarios, predicting the next token requires combining different piece of knowledge, which we called knowledge manipulation [67]. Does looping and reusing parameters help LoopLMs in tasks that require flexible usage of knowledge? We further consider two synthetic tasks to investigate the hypothesis on knowledge manipulation capacity: the synthetic Mano task in [68] based on modular arithmetic, and a multi-hop QA task in natural language [69] composing individual facts.
Mano Task. We first explore the knowledge manipulation task Mano in [68], based on a complex tree structure with restricted modular arithmetic knowledge. Models need to solve the task without intermediate thinking process. As illustration, an example could be <bos> + * a b c <eos> requires the model to directly output $(a*b)+c$ mod 23. To solve this task, the model needs to (1) apply the arithmetic rules modulo 23 as the factual knowledge encoded in the parameters, and (2) parse the binary tree structure of the arithmetic to compose all calculations.
To evaluate the manipulation capability thoroughly, we consider the test accuracy across different difficulty levels based on maximum expression length $L$ , which accounts for the number of operations in the sample. The model is trained with online samples with all possible expression lengths $\ell∈[1,L]$ and tested on the maximum expression length $L$ . We prepare three levels of difficulties $L=[10,16,24]$ to test LoopLM’s superiority over non-looped models given fixed training budget. We train ( $\{2,3,6,12\}\otimes 1$ ) standard transformers as the baselines and several looped models ( $k\otimes 12/k$ ) with $k=2,3,6$ . More details are included in Appendix B.2.
Results. The results in Figure ˜ 6 show that given the same parameters, looped models always outperform their non-looped counterpart for all possible $k∈\{2,3,6\}$ . Even with the same number of FLOPs in the model, the looped models can often perform better. This indicates that LoopLM has a better inductive bias towards knowledge manipulation: with the same budget on training samples and computation, LoopLM can achieve comparable or even better performance after training when the task requires manipulation capability (e.g., parsing the arithmetic tree) given limited amount of required knowledge (e.g., modular arithmetic rules).
<details>
<summary>x7.png Details</summary>
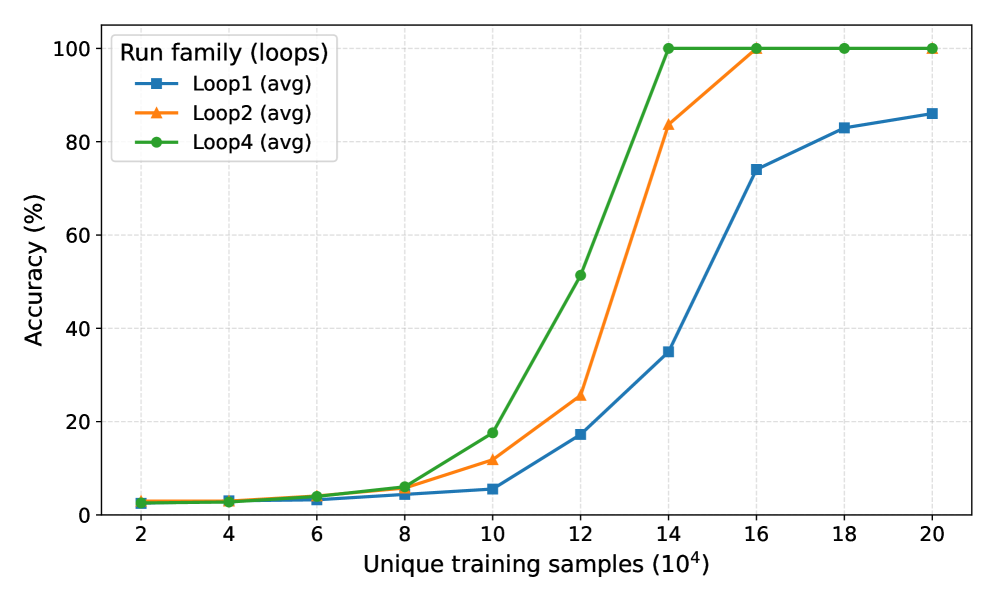
### Visual Description
## Line Chart: Run family (loops) Accuracy vs. Training Samples
### Overview
The chart illustrates the average accuracy (%) of three training loops (Loop1, Loop2, Loop4) as a function of unique training samples (in thousands). All loops show increasing accuracy with more training data, but with distinct performance trajectories.
### Components/Axes
- **X-axis**: Unique training samples (10⁴), labeled at intervals: 2, 4, 6, 8, 10, 12, 14, 16, 18, 20 (each ×10⁴).
- **Y-axis**: Accuracy (%), scaled from 0 to 100 in 20% increments.
- **Legend**: Located in the top-left corner, mapping:
- Blue squares: Loop1 (avg)
- Orange triangles: Loop2 (avg)
- Green circles: Loop4 (avg)
### Detailed Analysis
1. **Loop1 (blue squares)**:
- Starts at ~2% accuracy at 2k samples.
- Gradual increase to ~8% at 10k samples.
- Sharp rise to ~75% at 14k samples.
- Further increase to ~85% at 20k samples.
- *Trend*: Slow initial growth, rapid acceleration after 14k samples.
2. **Loop2 (orange triangles)**:
- Begins at ~2% at 2k samples.
- Steeper ascent to ~12% at 10k samples.
- Explosive growth to 100% at 14k samples.
- Remains at 100% through 20k samples.
- *Trend*: Rapid early improvement, plateau at maximum accuracy.
3. **Loop4 (green circles)**:
- Starts slightly higher (~3%) than Loop1 at 2k samples.
- Accelerates to ~18% at 10k samples.
- Reaches 100% at 14k samples.
- Maintains 100% through 20k samples.
- *Trend*: Faster initial growth than Loop1, early saturation.
### Key Observations
- **Saturation Point**: Loop2 and Loop4 achieve 100% accuracy at 14k samples, while Loop1 lags until 16k+.
- **Divergence**: Loop2 outperforms Loop4 in early stages (e.g., 10k samples: 12% vs. 18%).
- **Consistency**: All loops plateau at 100% after 14k samples, suggesting diminishing returns beyond this point.
### Interpretation
The data demonstrates that **Loop2 and Loop4** are more sample-efficient, achieving near-perfect accuracy with fewer training examples compared to Loop1. This could indicate:
- **Algorithmic Efficiency**: Loop2/Loop4 may use more effective optimization or regularization techniques.
- **Data Utilization**: These loops might better leverage training data through architectural choices (e.g., attention mechanisms, ensemble methods).
- **Loop1 Limitations**: Its slower convergence suggests potential overfitting risks or suboptimal hyperparameter tuning.
The plateau at 100% for Loop2/Loop4 implies these models reach theoretical maximum performance for the dataset, while Loop1’s continued improvement hints at either:
1. A less robust model architecture, or
2. A dataset where additional samples still provide marginal gains.
This analysis underscores the importance of loop design in training efficiency and highlights trade-offs between sample complexity and model performance.
</details>
<details>
<summary>x8.png Details</summary>
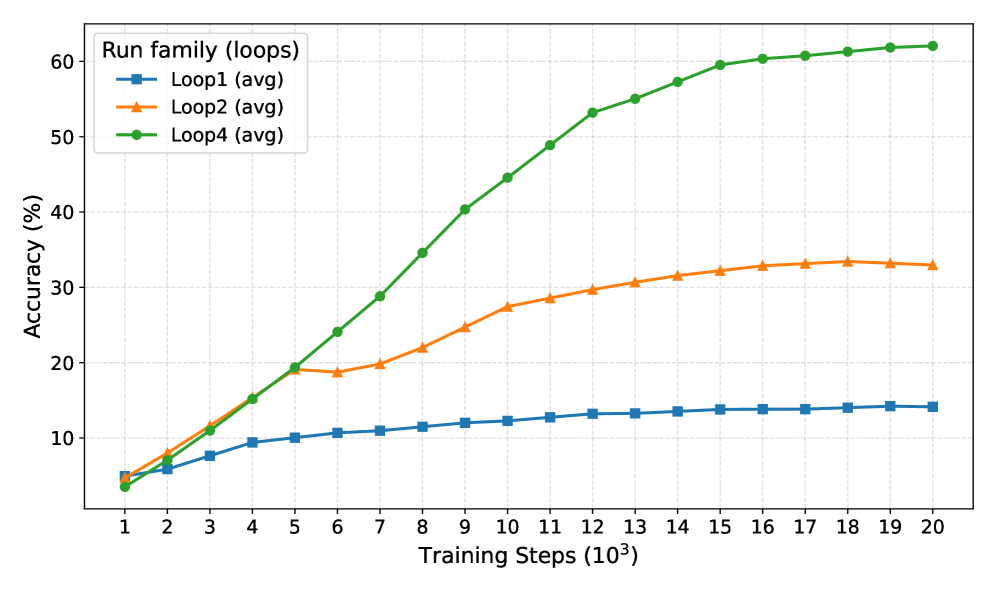
### Visual Description
## Line Graph: Accuracy vs Training Steps (10³)
### Overview
The image depicts a line graph comparing the accuracy (%) of three training loops (Loop1, Loop2, Loop4) across 20,000 training steps (10³ increments). Accuracy is plotted on the y-axis (0–60%), and training steps on the x-axis (1–20,000). The graph shows distinct performance trends for each loop, with Loop4 achieving the highest accuracy and Loop1 the lowest.
### Components/Axes
- **X-axis**: "Training Steps (10³)" labeled with integer markers (1, 2, ..., 20).
- **Y-axis**: "Accuracy (%)" labeled with increments of 10 (0–60%).
- **Legend**: Located in the top-left corner, with:
- **Loop1**: Blue squares (avg accuracy).
- **Loop2**: Orange triangles (avg accuracy).
- **Loop4**: Green circles (avg accuracy).
### Detailed Analysis
1. **Loop1 (Blue Squares)**:
- Starts at ~5% accuracy at step 1.
- Gradually increases to ~14% by step 20.
- Minimal growth after step 10 (~12–14% plateau).
2. **Loop2 (Orange Triangles)**:
- Begins at ~5% at step 1.
- Rises steadily to ~33% by step 20.
- Accelerates between steps 5–15, then plateaus.
3. **Loop4 (Green Circles)**:
- Starts at ~3% at step 1.
- Shows the steepest growth, reaching ~62% by step 20.
- Accelerates sharply between steps 5–15, then stabilizes.
### Key Observations
- **Loop4 dominates** in accuracy, achieving ~62% at step 20, far exceeding Loop2 (~33%) and Loop1 (~14%).
- **Loop1 plateaus early**, showing negligible improvement after step 10.
- **Loop2 demonstrates moderate growth**, with a ~28% increase from step 10 to 20.
- All loops exhibit diminishing returns after step 15, with Loop4 maintaining near-peak performance.
### Interpretation
The data suggests **Loop4 is the most effective training method**, achieving the highest accuracy with sustained growth. Loop2 outperforms Loop1 but lags behind Loop4, indicating potential inefficiencies in Loop1’s training dynamics. The plateauing trends across all loops after step 15 imply **diminishing returns** with extended training, highlighting the need for optimization beyond this threshold. Loop4’s rapid ascent suggests superior convergence properties, while Loop1’s stagnation may indicate underfitting or suboptimal hyperparameters.
</details>
Figure 7: We trained LoopLMs and standard transformer baselines with the same parameters on Multi-hop QA tasks. To investigate the sample efficiency of LoopLMs, we vary the number of unique training samples (from $2.5\%$ to $25\%$ all possible QA pairs) for models with different loops. We compare the final performance using the same compute budget in total training tokens. Left. As shown, models with more loops requires fewer samples to learn the 3-hop QA task. Right. As an example, we train with $15\%$ of all possible QA pairs (12000 unique samples) for 20000 steps with context length 1024 and batch size 2048. Models with more loops learn faster and achieve better performance comparing with models without loops.
Multi-hop QA. Next, we corroborate our conjecture with a natural language multi-hop reasoning task proposed in [69], based on synthetic facts on relations $\mathcal{R}$ between $|\mathcal{E}|$ different individuals, like The instructor of A is B and The teacher of B is C. The target is to answer multi-hop questions like ‘Who is the teacher of the instructor of A?’. We aim to study whether looping enables the original transformer better learn to perform internal multi-hop reasoning in a natural language setting. Compared to the Mano task, the task requires the model to memorize more factual knowledge with layer-wise data structure, which is closer to practical natural language multi-hop reasoning.
Multi-hop QA tasks require huge amount of samples to learn according to [69] when training standard transformers. To study whether LoopLMs accelerate the learning process of this multi-hop knowledge manipulation task, we consider sample efficiency in learning. Specifically, we study how many different QA pairs are necessary for the trained model to achieve 100% accuracy, as well as the performance after training on a fixed budget of unique training samples. For simplicity, we focus on the task with 3-hop QA pairs. We separate all possible QA pairs into training subsets of different sizes, and compare when each model perfectly generalizes on the leave-out test set. Similarly to the Mano task, we train a standard ( $6\otimes 1$ ) transformer as the baseline, and compare it with looped models ( $6\otimes\{2,4\}$ ) to study the effect of the universal transformer. We also train an iso-flop model ( $24\otimes 1$ ) for comparison. More details are included in Appendix B.3.
Results. The results in Figure ˜ 7 show that looped models generally learn the multi-hop QA task with fewer examples compared to both the non-looped iso-parameter model when the training budget is the same. Moreover, LoopLMs learn the multi-hop task much faster than the non-looped model with the same number of unique QA samples. The improved sample efficiency on the multi-hop reasoning task further demonstrates that LoopLM has a better ability to learn to compose and manipulate atomic factual knowledge.
Based on the results in both Mano and multi-hop QAs, we can conclude that LoopLMs have a better inductive bias towards more flexible manipulation of learned knowledge, instead of increasing the knowledge capacity. The conclusion holds for both synthetic tasks regardless of whether the task is more reasoning-heavy (Mano) or knowledge-heavy (Multi-hop QA). This also corresponds to the analysis (see Appendix B.4) on the existing benchmarks (e.g. MMLU): adding more recurrent steps significantly improves the performance on more reasoning-heavy categories, while the improvements on more knowledge-heavy tasks is limited.
6.3 Discussion: towards understanding why LoopLM helps knowledge manipulation
Why does LoopLM naturally bias towards better manipulation of the knowledge encoded in the parameter space? We conjecture that the reason lies in the inherent recurrent structure of LoopLM. Given that the knowledge capacity is limited by the parameter counts, looping enables LoopLM to better utilize the knowledge encoded in the parameters. LoopLM can reuse the knowledge in each looped block, retrieve new necessary factual information, or apply structured procedures to obtain the final prediction.
Search on the parametric knowledge graph. During pre-training, language models often obtain an enormous amount of factual knowledge and learn analysis procedures with a rather shallow thinking depth. To perform more challenging tasks, the model needs to use multiple pieces of knowledge in the parameter space, which requires the model to search in-depth in the knowledge graph with directional dependencies formed by the atomic facts or knowledge. LoopLM naturally support an efficient reuse of the knowledge and algorithms stored in the parameter spaces: even though the knowledge piece is not retrieved or used in the previous calculations, the recurrent structure enables LoopLM to redo the procedure and extract necessary information.
Based on the abstraction above, we try to understand why LoopLMs are able to search on knowledge graph without adding more parameters. Specifically, we study the expressivity of LoopLM on a synthetic task. We consider the extensively studied search problem in the literature of latent reasoning [27, 70, 71]: graph reachability on a knowledge graph. Here, we consider that only part of the knowledge graph $G_{\text{ctx}}$ is included in the context, and most of the knowledge relations $G$ must be encoded in the parameters. The model must learn to compose the context knowledge $G_{\text{ctx}}$ and the learned knowledge $G$ . Compared to traditional CoT and recent proposed latent CoT [70, 27], we show that LoopLM is a parallelizable latent reasoning paradigm that requires fewer sequential reasoning steps.
**Theorem 1 (Informal)**
*Fix $n$ as the maximum size of the combined knowledge graph $G$ . Given the adjacency matrix of the context graph $G_{\text{ctx}}$ and a query pair $(s,t)$ , there exists a one-layer transformer independent of $G_{\text{ctx}}$ with loops $O(\log_{2}D)$ times that checks whether there exists a path from $s$ to $t$ in the combined knowledge graph $(G+G_{\text{ctx}})$ , where $D$ is the diameter of $(G+G_{\text{ctx}})$ .*
| Sequential computation steps | $O(n^{2})$ | $O(D)$ | $O(\log D)$ |
| --- | --- | --- | --- |
The proof and the discussion on LoopLM’s efficiency are deferred to Appendix B.5. We claim that the universal transformers maximize the parallelism in exploring all-pair connectivity and reduce the sequential computation steps exponentially from $O(n^{2})$ to $O(\log D)$ , making the latent reasoning much more efficient than the traditional CoT view of looping [7] and continuous CoT [70]. The potential efficient latent reasoning ability may account for the superiority of LoopLM in knowledge manipulation, which also may contribute to the superior performance in reasoning-heavy tasks.
Recurrence improves sample efficiency. The expressiveness result of LoopLM does not explain why the transformers with loops often learns knowledge manipulation tasks with samples much fewer than its iso-FLOP counterpart. We conjecture that the reason lies again in the recurrent structure of LoopLM. Assuming the reasoning tasks require multiple manipulation and recursion using learned parametric knowledge or algorithmic procedure, the models have to learn a repeated structure across layers of different depth. For deep transformer models without looping, they potentially have to explore a large function class where each block of parameters are not tied. The parameter-sharing layers may help the model explore a much smaller realizable hypothesis class, thus reducing the sample complexity of learning those manipulation tasks. It could be a possible statistical reason that LoopLM enjoys a better sample complexity on those reasoning/manipulation tasks.
7 Safety, Faithfulness and Consistency
7.1 Safety
We assess model safety using HEx-PHI dataset [20], which contains 330 examples covering 11 prohibited categories. HEx-PHI employs GPT-4o as a judge to assign each model response a harmfulness score from 1 to 5; a higher score indicates a less safe output. Additionally, we compute the harmfulness rate, defined as the proportion of the test cases that receive the highest harmfulness score of 5. For Ouro Base models, we use greedy decoding with max_new_tokens=128; For Ouro Thinking models, we sample with temperature=1.0, top_p=0.7 with max_new_tokens=8192. We evaluate Ouro 1.4B and 2.6B models with recurrent steps ranging from 1 to 8, and report the result in Figure ˜ 8(a). Notably, while our models were trained with only 4 recurrent steps, both models show their extrapolation capability by extending recurrence steps to 5-8 during inference. This demonstrates the model’s ability to generalize to deeper computation than seen during training. The Ouro Thinking checkpoints further enhance safety alignment, reducing harmful rates to 0.009 for Ouro 1.4B Thinking and 0.003 for Ouro 2.6B Thinking at 4 recurrent steps, comparable to Qwen3-4B-Thinking (0.009).
To further investigate how increasing recurrent steps affects the model’s safety alignment, we conduct Principal Component Analysis (PCA) on the hidden representation of the last input token from the top model layer. For a controlled analysis, we select 100 benign and 100 harmful questions with identical formats (all the examples are the questions starting with “How to”) from Zheng et al.(2024) [72] Harmful questions: https://github.com/chujiezheng/LLM-Safeguard/blob/main/code/data/custom.txt; Benign questions: https://github.com/chujiezheng/LLM-Safeguard/blob/main/code/data_harmless/custom.txt. Additionally, we evaluate the model’s responses to the 100 harmful questions and compute a 5-level harmfulness score (same as the one used in HEx-PHI) for each response. We plot our PCA analysis on Ouro 1.4B in Figure ˜ 8(b), from which we have the following observations. First, as the number of recurrent steps increases, the model becomes more capable of separating benign and harmful prompts, resulting in safer responses, as indicated by the decreasing number of red points. Furthermore, most points associated with unsafe responses appear near the middle of the plot, which represents the boundary between the “benign” and “harmful” clusters. This suggests that difficulty in distinguishing harmfulness may lead to unsafe responses, which can be alleviated by increasing the number of recurrent steps.
<details>
<summary>x9.png Details</summary>
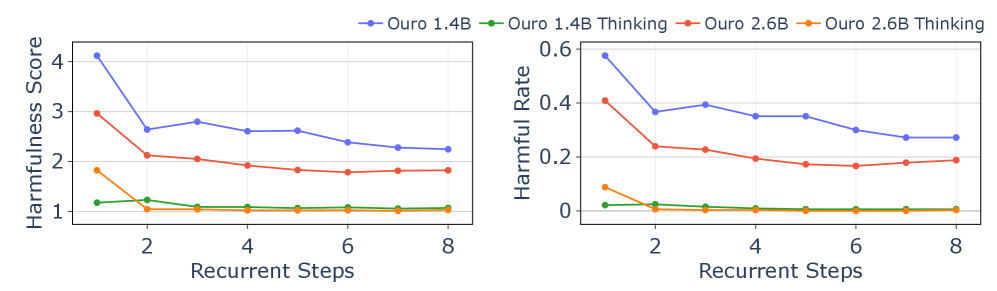
### Visual Description
## Line Graphs: Harmfulness Metrics Across Model Sizes and Thinking Components
### Overview
The image contains two side-by-side line graphs comparing harmfulness metrics (Harmfulness Score and Harmful Rate) across four model configurations: Ouro 1.4B, Ouro 1.4B Thinking, Ouro 2.6B, and Ouro 2.6B Thinking. Both graphs plot these metrics against "Recurrent Steps" (x-axis) ranging from 2 to 8. The left graph uses a y-axis scale of 0–4 for Harmfulness Score, while the right graph uses 0–0.6 for Harmful Rate.
---
### Components/Axes
- **X-Axis (Both Graphs)**: "Recurrent Steps" (values: 2, 4, 6, 8).
- **Left Y-Axis**: "Harmfulness Score" (scale: 0–4).
- **Right Y-Axis**: "Harmful Rate" (scale: 0–0.6).
- **Legend**: Located at the top, with four color-coded lines:
- **Blue**: Ouro 1.4B
- **Green**: Ouro 1.4B Thinking
- **Red**: Ouro 2.6B
- **Orange**: Ouro 2.6B Thinking
---
### Detailed Analysis
#### Left Graph (Harmfulness Score)
1. **Ouro 1.4B (Blue)**:
- Starts at ~4.0 at step 2, sharply declines to ~2.5 by step 8.
- Trend: Steep initial drop, then gradual flattening.
2. **Ouro 2.6B (Red)**:
- Starts at ~3.0 at step 2, declines to ~1.8 by step 8.
- Trend: Steady linear decrease.
3. **Ouro 1.4B Thinking (Green)**:
- Remains flat at ~1.0 across all steps.
4. **Ouro 2.6B Thinking (Orange)**:
- Remains flat at ~0.1 across all steps.
#### Right Graph (Harmful Rate)
1. **Ouro 1.4B (Blue)**:
- Starts at ~0.6 at step 2, declines to ~0.25 by step 8.
- Trend: Steep initial drop, then gradual flattening.
2. **Ouro 2.6B (Red)**:
- Starts at ~0.4 at step 2, declines to ~0.18 by step 8.
- Trend: Steady linear decrease.
3. **Ouro 1.4B Thinking (Green)**:
- Remains flat at ~0.02 across all steps.
4. **Ouro 2.6B Thinking (Orange)**:
- Remains flat at ~0.01 across all steps.
---
### Key Observations
1. **Model Size Impact**:
- Larger models (2.6B) consistently show lower harmfulness metrics than smaller models (1.4B) at all steps.
2. **Thinking Component Effect**:
- "Thinking" variants (green/orange) exhibit significantly lower harmfulness scores/rates, remaining nearly constant regardless of steps.
3. **Step Dependency**:
- Harmfulness metrics decrease with more recurrent steps for non-Thinking models, but plateau after step 4.
4. **Metric Relationship**:
- Harmful Rate (right graph) is approximately 1/10th of Harmfulness Score (left graph) for corresponding models.
---
### Interpretation
The data suggests that:
- **Model Size**: Larger models (2.6B) inherently produce less harmful outputs than smaller models (1.4B), even without additional components.
- **Thinking Component**: The "Thinking" variant drastically reduces harmfulness, maintaining near-zero metrics across all steps. This implies the Thinking component acts as a robust safety mechanism.
- **Recurrent Steps**: While increasing steps reduces harmfulness for non-Thinking models, the effect diminishes after step 4. This could indicate diminishing returns in safety improvements from additional steps.
- **Metric Scaling**: The Harmful Rate metric (right graph) appears to normalize Harmfulness Score, but the exact relationship requires further analysis.
Notably, the Thinking variants’ stability across steps suggests they are less sensitive to architectural changes (e.g., recurrent steps), making them potentially more reliable for safety-critical applications.
</details>
(a) HEx-PHI evaluation
<details>
<summary>x10.png Details</summary>
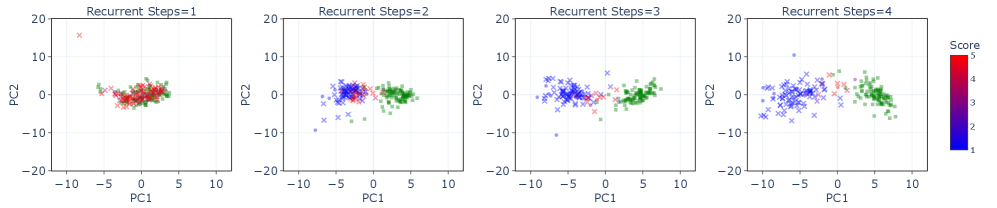
### Visual Description
## Scatter Plots: Principal Component Analysis Across Recurrent Steps
### Overview
The image displays four scatter plots arranged horizontally, each representing Principal Component Analysis (PCA) results for data points categorized by "Recurrent Steps" (1–4). Each plot uses PC1 (x-axis) and PC2 (y-axis) to visualize data distribution, with a color gradient (red to blue) indicating a "Score" scale from 5 (high) to 1 (low). The plots show evolving patterns as recurrent steps increase.
---
### Components/Axes
- **X-axis (PC1)**: Principal Component 1, ranging from -10 to 10.
- **Y-axis (PC2)**: Principal Component 2, ranging from -20 to 20.
- **Legend**: Color gradient labeled "Score" (red = 5, blue = 1), positioned on the right of all plots.
- **Panel Titles**:
- Top-left: "Recurrent Steps=1"
- Top-center-left: "Recurrent Steps=2"
- Top-center-right: "Recurrent Steps=3"
- Top-right: "Recurrent Steps=4"
---
### Detailed Analysis
#### Recurrent Steps=1
- **Data Distribution**: Dense cluster of points near the origin (PC1 ≈ 0, PC2 ≈ 0).
- **Color Distribution**: Predominantly red (score ≈ 4–5) with sparse green (score ≈ 3).
- **Trend**: Tight clustering suggests high similarity among data points.
#### Recurrent Steps=2
- **Data Distribution**: Slightly dispersed cluster, with points spreading toward PC1 ≈ -5 to 5 and PC2 ≈ -5 to 5.
- **Color Distribution**: Mix of blue (score ≈ 1–2), red (score ≈ 4–5), and green (score ≈ 3).
- **Trend**: Increased variability compared to Steps=1, with some overlap between high and low scores.
#### Recurrent Steps=3
- **Data Distribution**: Further spread, with points extending to PC1 ≈ -10 to 10 and PC2 ≈ -10 to 10.
- **Color Distribution**: Balanced mix of blue (score ≈ 1–2), red (score ≈ 4–5), and green (score ≈ 3).
- **Trend**: Moderate clustering, indicating intermediate data diversity.
#### Recurrent Steps=4
- **Data Distribution**: Widest spread, with points scattered across PC1 ≈ -10 to 10 and PC2 ≈ -20 to 10.
- **Color Distribution**: Dominant blue (score ≈ 1–2) and green (score ≈ 3), with fewer red points.
- **Trend**: Significant dispersion, suggesting reduced similarity among data points.
---
### Key Observations
1. **Clustering Tightness**: Data points cluster more tightly at lower recurrent steps (Steps=1–2) and disperse as steps increase (Steps=3–4).
2. **Score Correlation**: Higher scores (red) dominate early steps but diminish in prevalence as steps increase.
3. **Dimensional Spread**: PC2 range widens from Steps=1 (≈ -5 to 5) to Steps=4 (≈ -20 to 10), indicating increased variance in the second principal component.
---
### Interpretation
The plots suggest that increasing recurrent steps introduces greater variability in the data, as evidenced by the expanding spread of points. The decline in high-scoring (red) data points with more steps may indicate a trade-off between model complexity (more steps) and performance (lower scores). The PCA results imply that early steps capture more cohesive patterns, while later steps reveal fragmented or diverse features. This could reflect overfitting or noise amplification in models with higher recurrent steps.
</details>
(b) PCA analysis on Ouro 1.4B
Figure 8: (a) For both 1.4B and 2.6B models, Ouro demonstrates improved safety alignment on HEx-PHI as the recurrent steps increase. Note that models were trained with 4 recurrent steps; evaluations at steps 5-8 demonstrate successful extrapolation beyond the training configuration. (b) As the recurrent steps increase, Ouro 1.4B can better distinguish the benign prompts and harmful prompts, leading to safer responses. We perform PCA on the hidden representation of the last input token from the model’s top layer. Harmful prompts with a harmfulness score of 4 or 5 at recurrent step 1 are marked with $×$ , while other harmful prompts are shown as circles. The color of each point reflects the harmfulness score of the corresponding response. Benign prompts are shown as green squares.
<details>
<summary>x11.png Details</summary>
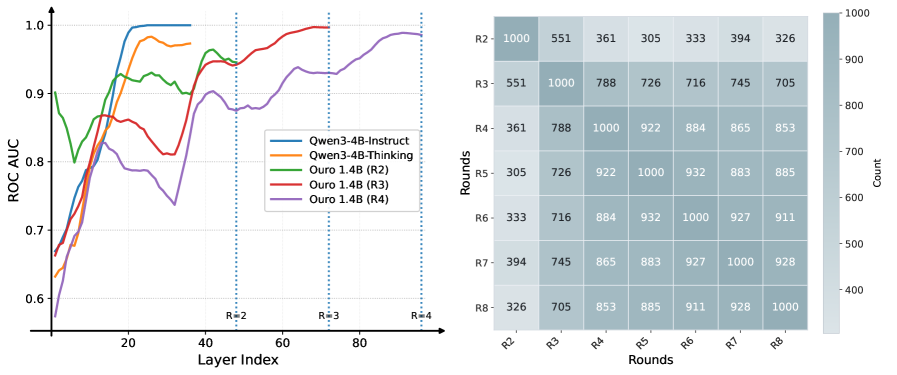
### Visual Description
## Line Graph: ROC AUC Performance Across Layers
### Overview
The image contains two primary components: a line graph on the left and a heatmap on the right. The line graph tracks ROC AUC performance across layers for five models, while the heatmap visualizes numerical counts across rounds and layers.
### Components/Axes
#### Line Graph
- **X-axis**: Layer Index (0–80, linear scale)
- **Y-axis**: ROC AUC (0.6–1.0, linear scale)
- **Legend**: Located on the right side of the graph
- Blue: Qwen3-4B-Instruct
- Orange: Qwen3-4B-Thinking
- Green: Ouro 1.4B (R2)
- Red: Ouro 1.4B (R3)
- Purple: Ouro 1.4B (R4)
- **Vertical Dashed Lines**: Marking layers R2 (45), R3 (70), R4 (85)
#### Heatmap
- **Rows**: Labeled R2–R8 (vertical axis)
- **Columns**: Labeled R2–R8 (horizontal axis)
- **Color Scale**: Light gray (low count) to dark gray (high count), with 1000 as the maximum value
- **Cell Values**: Numerical counts (e.g., 1000, 788, 922)
### Detailed Analysis
#### Line Graph Trends
1. **Blue (Qwen3-4B-Instruct)**:
- Starts at ~0.65, rises sharply to ~0.95 by layer 20, plateaus with minor fluctuations.
- Key dip at layer 30 (~0.85), recovers to ~0.95 by layer 60.
2. **Orange (Qwen3-4B-Thinking)**:
- Begins at ~0.6, rises to ~0.9 by layer 20, dips to ~0.85 at layer 30, then stabilizes.
3. **Green (Ouro 1.4B R2)**:
- Starts at ~0.85, dips to ~0.75 at layer 10, rises to ~0.9 by layer 20, fluctuates between ~0.85–0.9.
4. **Red (Ouro 1.4B R3)**:
- Begins at ~0.7, rises to ~0.9 by layer 20, dips to ~0.85 at layer 30, recovers to ~0.95 by layer 60.
5. **Purple (Ouro 1.4B R4)**:
- Starts at ~0.65, rises to ~0.9 by layer 20, dips to ~0.85 at layer 30, recovers to ~0.95 by layer 60.
#### Heatmap Values
- **Diagonal (R2–R8)**: All cells contain 1000 (darkest gray), indicating maximum counts.
- **Off-Diagonal**:
- R2: 551, 361, 305, 333, 394, 326
- R3: 788, 1000, 726, 716, 865, 853
- R4: 922, 884, 1000, 932, 883, 885
- R5: 716, 884, 932, 1000, 927, 911
- R6: 745, 865, 883, 927, 1000, 928
- R7: 705, 853, 885, 911, 928, 1000
### Key Observations
1. **Line Graph**:
- All models show improved performance (ROC AUC) as layer index increases.
- Ouro 1.4B models (R2–R4) exhibit dips at layer 30, suggesting potential instability or optimization challenges.
- Qwen3-4B-Instruct maintains the highest stability, with minimal fluctuations after layer 20.
2. **Heatmap**:
- Diagonal dominance (1000 counts) suggests perfect correlation or maximum agreement between rounds and layers.
- Off-diagonal values decrease with distance from the diagonal, indicating diminishing counts for non-matching rounds/layers.
### Interpretation
The line graph demonstrates that model performance (ROC AUC) improves with deeper layers, but Ouro 1.4B models show temporary performance drops at layer 30, possibly due to architectural bottlenecks or training dynamics. The heatmap reveals a strong diagonal pattern, implying that counts (e.g., correct predictions or activations) are maximized when rounds and layers align. This could reflect task-specific optimization or data distribution alignment. The Qwen3-4B-Instruct model’s consistent performance suggests robustness, while Ouro 1.4B models’ dips highlight areas for further investigation. The heatmap’s structure may indicate a relationship between training rounds and layer-specific feature learning, warranting deeper analysis of model behavior across training stages.
</details>
Figure 9: Left. ROCAUC of linear probes by layer on Quora Question Pairs. Each colored curve shows a probe trained on hidden states within a given 2 to 8 recurrent steps to predict that loop’s answer; Qwen3-4B models are the baselines. Vertical dotted lines mark loop boundaries. In recurrent step $i=2,3,4$ , the ROC AUC rises quickly within a recurrent step, then partially resets at the next loop, indicating that intra-step answers are determined early while cross-step updates modify the provisional answer. Right. Agreement across recurrent steps. Heat map (A) over 1,000 Quora Question Pairs. Entry $A[i,j]$ is the number of items for which steps (i) and (j) assign the same label.
7.2 Faithfulness
We call a model’s thinking process faithful if it is (i) procedurally correct and (ii) causally coupled to the final answer. Concretely, a faithful process should satisfy a counterfactual criterion: if the justification is intervened on (e.g., altered to a different intermediate state), the final prediction should change accordingly. A growing body of work [73, 74, 75, 76] shows that standard LLMs often appear to decide on an answer before generating chain-of-thought text and then use that text to rationalize the already-formed decision.
In LoopLM, the reasoning substrate is the sequence of latent states $h^{(1)}\!→\!h^{(2)}\!→\!·s\!→\!h^{(T)}$ . Each transition $h^{(k)}\!→\!h^{(k+1)}$ performs non-trivial computation using the same shared-weight block, and each step is trained to improve the task objective. Thus, the causal path to the answer is this latent trajectory, not any optional natural-language trace. When we decode intermediate text $\text{Text}(R_{k})$ from $h^{(k)}$ via the LM head, we treat it as an instrumented readout of the internal state rather than the mechanism itself. Because $h^{(k)}$ is directly supervised by the LM loss, its projection into token space provides a faithful snapshot of what the model currently represents.
Standard evaluation of faithfulness is often based on the manipulation of the reasoning process, CoT, and check if the average treatment effect of CoT is significant. In our case, we cannot manipulate the latent reasoning process. Instead, we adopt an observational proxy for mediation: we read out intermediate hidden representations and test whether predictions change as recurrence deepens on inputs that admit multiple plausible labels. Concretely, we assess whether intermediate “thinking” genuinely mediates decisions by measuring step-by-step predictability and agreement patterns. We use the Quora Question Pairs dataset [77], which asks whether two short questions are semantically equivalent: a setting with ambiguity and weakly-defined decision boundaries. There are a lot of ambiguous questions in this dataset:
Example: Ambiguous questions in Quora dataset
Question: does the following two questions have the same intent? Pair 1: 1.
What are the questions should not ask on Quora? 2.
Which question should I ask on Quora? Answer: False Pair 2: 1.
How do we prepare for Union Public Service Commission? 2.
How do I prepare for civil service? Answer: True
If a thinking process merely rationalizes the pre-committed answer, even if the questions are very ambiguous, the answers will not change after the reasoning process. This has been reported for Gemma-2 9B and reproduced by us on Qwen-3-4B-Thinking. As shown in the left part of Figure 9, the simple linear probe on the final-token logits on the Qwen3-4B-Thinking model shows 0.99 ROC AUC predicting the model’s eventual answer, which means the thinking process almost does not affect the results.
In our model, the situation is very different. our $1.4\mathrm{B}\!×\!4$ model uses 24 layers per recurrent step. We train linear probes on hidden states from layers $1$ through $24i$ to predict the step- $i$ answer, for $i\!∈\!\{2,3,4\}$ . Within a single recurrent step, the step- $i$ answer is well predicted by a probe on representation within layer $24i$ , indicating strong intra-step alignment between state and decision, which is similar to the non-reasoning model Qwen-4B-Instruct, showing in left part of Figure 9. Crucially, probes on the preceding representation (layer $24(i\!-\!1)$ ) do not reliably predict the step- $i$ decision for $i\!∈\!\{2,3,4\}$ , showing that the new recurrent pass performs additional computation that can revise a provisional choice.
To further examine the consistency between the results of different rounds. We also compute a step-by-step agreement matrix $A$ over 1,000 Quora Question Pairs, where $A[i,j]$ counts identical labels between step $i$ and step $j$ (diagonal $=\!1000$ by construction). See the right side of Figure 9. Adjacent steps never reach full agreement; for example, $A[2,4]\!=\!361$ indicates only $36.1\%$ of step-2 answers match step-4. $A[2,3]\!=\!551$ indicates only $55.1\%$ of step-2 answers match step-3. We also notice that when $i≥ 4$ , the overlap consistency between step- $i$ and step- $i+1$ , $A[i,i+1]$ , is close to 1000. We think this phenomenon comes from: (1) the model does not learn to reason recursively when $i>4$ . The model is trained within 4 loops; (2) as the number of loops increases, the answer gradually converges to a fixed point.
All in all, this systematic disagreement across steps when $i≤ 4$ is precisely what a faithful latent process should exhibit: the model is updating its decision as recurrence deepens, and intermediate predictions are not frozen rationalizations of the final output.
7.3 More Discussion
The practical barrier for safety-critical deployment is that a model’s articulated reasoning and its final answer may diverge. The LoopLM architecture reduces this gap by exposing a sequence of intermediate predictors that are strongly aligned with the final predictor and can be used both for acceleration and for pre-emptive control. We summarize three deployment advantages.
Built-in draft model for speculative decoding.
Let $Text(R_{t})$ denote the language-model head attached to the latent state after recurrent step $t$ , and let $T$ be the maximum step used at deployment. The pair
$$
\bigl(\underbrace{\text{Text}(R_{s})}_{\text{proposal}},\;\underbrace{\text{Text}(R_{T})}_{\text{verifier}}\bigr),\qquad 1\leq s<T.
$$
forms a native proposal–verification decomposition for speculative decoding without training an external draft model. Proposals are sampled from $Text(R_{s})$ and verified under $Text(R_{T})$ using standard acceptance tests; rejected tokens are rolled back as usual. Because both heads share the same parameters up to step $s$ , cached activations and KV states can be reused, reducing verifier overhead. This turns the recurrent structure into an architectural primitive for draft–verify decoding rather than an add-on.
Joint acceleration and pre-emptive safety.
Using the same proposal–verification split, safety checks can be interleaved with speculative decoding without extra models. At step $s$ :
1. Generate draft tokens with $\text{Text}(R_{t})$ and compute their acceptance under $\text{Text}(R_{T})$ .
1. Run safety screening on the draft distribution or sampled drafts before any token is surfaced to the user. Screening can operate on logits, beams, or short candidate spans.
1. If a violation is detected, halt or reroute the response before streaming; otherwise, accept tokens that pass both verification and safety checks.
Because $\text{Text}(R_{s})$ and $\text{Text}(R_{T})$ share the latent trajectory, intermediate predictions are well-aligned with the final answer distribution. This alignment makes the step- $s$ output a reliable proxy for the step- $T$ output for the purpose of early screening, while the verifier maintains final quality. The Q-exit threshold $q$ further provides a single deployment knob that simultaneously adjusts compute, consistency, and safety strictness by shifting the average exit depth.
Anytime generation with monotone refinement.
The training objective in Section 3.4 optimizes the expected task loss across steps while preserving the deeper-is-better property. Consequently, for next-token prediction loss,
$$
\mathbb{E}\big[\mathcal{L}^{(t+1)}\big]\leq\mathbb{E}\big[\mathcal{L}^{(t)}\big],\qquad 1\leq t<T,
$$
so each additional loop refines the distribution toward higher-quality predictions. This yields an anytime algorithm: decoding may begin from any intermediate step $s$ and continue streaming while later steps continue to verify or revise. Unlike chain-of-thought pipelines, which often require completing a reasoning prefix before emitting answers, LoopLM exposes a single predictive interface at every step, enabling immediate fallback to a smaller compute budget when latency constraints apply.
8 Conclusion
In this work, we introduced Ouro, a family of Looped Language Models that demonstrate exceptional parameter efficiency by integrating iterative computation and adaptive depth directly into pre-training on 7.7T tokens. Our 1.4B and 2.6B models consistently match or exceed the performance of 4B and 8B standard transformers, showcasing a 2-3 $×$ efficiency gain. We demonstrated this advantage stems not from increased knowledge storage, but from a fundamentally superior capability for knowledge manipulation, supported by synthetic experiments and theoretical analysis. We also presented a practical training objective using entropy regularization with a uniform prior to learn adaptive depth, and validated efficient KV cache sharing strategies that make LoopLMs viable for real-world deployment.
Beyond performance, the LoopLM architecture exhibits unique properties: its iterative refinement process provides a causally faithful reasoning trace, mitigating the post-hoc rationalization issues seen in standard CoT, and its safety alignment uniquely improves with increased recurrent steps, even when extrapolating. This work establishes iterative latent computation as a critical third scaling axis beyond parameters and data. Future research should focus on enhancing performance extrapolation at greater depths and exploring more complex recurrent mechanisms, solidifying this parameter-efficient approach as a necessary direction in a data-constrained era.
Acknowledgement
We sincerely thank Zeyuan Allen-Zhu for his in-depth discussion on the physics of language model part and his enlightening insights on knowledge manipulation. We thank Yuekun Yao for providing valuable insights and discussions on the multi-hop QA task. We also thank Yonghui Wu, Guang Shi, Shu Zhong, Tenglong Ao, Chen Chen, Songlin Yang, Wenhao Chai, and Yuhong Chou for their insightful discussions. Special thanks to Wenjia Zhu – his words opened our eyes to what the real problems are in current models, and inspired us to explore this direction.
Contributions
Project Lead
Rui-Jie Zhu, Zixuan Wang, Kai Hua, Ge Zhang
Core Contributors
Rui-Jie Zhu: Proposes the project and leads the pre-training of Ouro. Optimizes pre-training and inference infrastructure, develops the initial vLLM implementation, and explores RLVR.
Zixuan Wang: Leads the analysis on understanding LoopLM superiority and is responsible for related experiments. He contributes to the design of adaptive early exit strategies, training, and the safety analysis.
Kai Hua: Designs and curates all pre-training data mixtures and provides key insights during the pre-training process.
Ge Zhang: Co-leads and supervises the Ouro. Provides several key insights during the pre-training and post-training process.
Tianyu Zhang: Leads the analysis of Ouro on consistency, safety, and faithfulness. He designs the pipeline evaluation on faithfulness. He contributes to post-training, probing and efficient KV cache design.
Ziniu Li: Leads the post-training phase, developing supervised fine-tuning and providing key contributions to RLVR exploration.
Haoran Que: Leads the scaling law analysis for LoopLM, investigating the relationship between performance, model size, and recurrent depth.
Boyi Wei: Contributes to the safety analysis, conducting evaluations on the HEx-PHI benchmark and performing PCA on model representations.
Zixin Wen: Contributes to the theoretical analysis, the design of adaptive exit strategies, Physics of LLMs experiments, paper writing, and RLVR.
Fan Yin: Optimizes the vLLM and SGLang implementations for Ouro, contributing core pull requests to improve inference efficiency.
He Xing: Contributes to the vLLM infrastructure development and optimization.
Contributors
Lu Li, Jiajun Shi, Kaijing Ma, Shanda Li, Taylor Kergan, Andrew Smith, Xingwei Qu, Mude Hui, Bohong Wu, Xun Zhou, Qiyang Min, Hongzhi Huang, Wei Ye, Jiaheng Liu, Jian Yang, Yunfeng Shi, Chenghua Lin, Enduo Zhao, Tianle Cai
Supervision
Ge Zhang, Wenhao Huang, Yoshua Bengio, Jason Eshraghian
References
- [1] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [2] Qwen Team et al. Qwen2 technical report. arXiv preprint arXiv:2407.10671, 2:3, 2024.
- [3] An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025.
- [4] Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report. arXiv preprint arXiv:2503.19786, 2025.
- [5] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv e-prints, pages arXiv–2407, 2024.
- [6] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- [7] Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J Reddi. Reasoning with latent thoughts: On the power of looped transformers. arXiv preprint arXiv:2502.17416, 2025.
- [8] Khashayar Gatmiry, Nikunj Saunshi, Sashank J Reddi, Stefanie Jegelka, and Sanjiv Kumar. Can looped transformers learn to implement multi-step gradient descent for in-context learning? arXiv preprint arXiv:2410.08292, 2024.
- [9] Khashayar Gatmiry, Nikunj Saunshi, Sashank J Reddi, Stefanie Jegelka, and Sanjiv Kumar. On the role of depth and looping for in-context learning with task diversity. arXiv preprint arXiv:2410.21698, 2024.
- [10] Jianhao Huang, Zixuan Wang, and Jason D Lee. Transformers learn to implement multi-step gradient descent with chain of thought. arXiv preprint arXiv:2502.21212, 2025.
- [11] William Merrill and Ashish Sabharwal. A little depth goes a long way: The expressive power of log-depth transformers. arXiv preprint arXiv:2503.03961, 2025.
- [12] William Merrill and Ashish Sabharwal. Exact expressive power of transformers with padding. arXiv preprint arXiv:2505.18948, 2025.
- [13] Angeliki Giannou, Shashank Rajput, Jy-yong Sohn, Kangwook Lee, Jason D Lee, and Dimitris Papailiopoulos. Looped transformers as programmable computers. In International Conference on Machine Learning, pages 11398–11442. PMLR, 2023.
- [14] Liu Yang, Kangwook Lee, Robert Nowak, and Dimitris Papailiopoulos. Looped transformers are better at learning learning algorithms. arXiv preprint arXiv:2311.12424, 2023.
- [15] Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers. arXiv preprint arXiv:1807.03819, 2018.
- [16] Sangmin Bae, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Seungyeon Kim, and Tal Schuster. Relaxed recursive transformers: Effective parameter sharing with layer-wise lora. arXiv preprint arXiv:2410.20672, 2024.
- [17] Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach. arXiv preprint arXiv:2502.05171, 2025.
- [18] Boyi Zeng, Shixiang Song, Siyuan Huang, Yixuan Wang, He Li, Ziwei He, Xinbing Wang, Zhiyu Li, and Zhouhan Lin. Pretraining language models to ponder in continuous space. arXiv preprint arXiv:2505.20674, 2025.
- [19] Rui-Jie Zhu, Tianhao Peng, Tianhao Cheng, Xingwei Qu, Jinfa Huang, Dawei Zhu, Hao Wang, Kaiwen Xue, Xuanliang Zhang, Yong Shan, et al. A survey on latent reasoning. arXiv preprint arXiv:2507.06203, 2025.
- [20] Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to! In The Twelfth International Conference on Learning Representations.
- [21] Yilong Chen, Junyuan Shang, Zhenyu Zhang, Yanxi Xie, Jiawei Sheng, Tingwen Liu, Shuohuan Wang, Yu Sun, Hua Wu, and Haifeng Wang. Inner thinking transformer: Leveraging dynamic depth scaling to foster adaptive internal thinking. arXiv preprint arXiv:2502.13842, 2025.
- [22] Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, et al. Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation. arXiv preprint arXiv:2507.10524, 2025.
- [23] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942, 2019.
- [24] Raj Dabre and Atsushi Fujita. Recurrent stacking of layers for compact neural machine translation models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6292–6299, 2019.
- [25] Sho Takase and Shun Kiyono. Lessons on parameter sharing across layers in transformers. arXiv preprint arXiv:2104.06022, 2021.
- [26] Boxun Li, Yadong Li, Zhiyuan Li, Congyi Liu, Weilin Liu, Guowei Niu, Zheyue Tan, Haiyang Xu, Zhuyu Yao, Tao Yuan, et al. Megrez2 technical report. arXiv preprint arXiv:2507.17728, 2025.
- [27] Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space. arXiv preprint arXiv:2412.06769, 2024.
- [28] Amirkeivan Mohtashami, Matteo Pagliardini, and Martin Jaggi. Cotformer: More tokens with attention make up for less depth. In Workshop on Advancing Neural Network Training: Computational Efficiency, Scalability, and Resource Optimization (WANT@ NeurIPS 2023), 2023.
- [29] Bohong Wu, Shen Yan, Sijun Zhang, Jianqiao Lu, Yutao Zeng, Ya Wang, and Xun Zhou. Efficient pretraining length scaling. arXiv preprint arXiv:2504.14992, 2025.
- [30] Tian Ye, Zicheng Xu, Yuanzhi Li, and Zeyuan Allen-Zhu. Physics of language models: Part 2.1, grade-school math and the hidden reasoning process. arXiv preprint arXiv:2407.20311, 2024.
- [31] Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning. arXiv preprint arXiv:2506.01939, 2025.
- [32] Andrea Banino, Jan Balaguer, and Charles Blundell. Pondernet: Learning to ponder. arXiv preprint arXiv:2107.05407, 2021.
- [33] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [34] Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2023.
- [35] Noam Shazeer. Glu variants improve transformer. arXiv preprint arXiv:2002.05202, 2020.
- [36] Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Guilherme Penedo, Lewis Tunstall, Andrés Marafioti, Hynek Kydlíček, Agustín Piqueres Lajarín, Vaibhav Srivastav, et al. Smollm2: When smol goes big–data-centric training of a small language model. arXiv preprint arXiv:2502.02737, 2025.
- [37] Kaiyue Wen, Zhiyuan Li, Jason Wang, David Hall, Percy Liang, and Tengyu Ma. Understanding warmup-stable-decay learning rates: A river valley loss landscape perspective. arXiv preprint arXiv:2410.05192, 2024.
- [38] Guilherme Penedo, Hynek Kydlíček, Anton Lozhkov, Margaret Mitchell, Colin A Raffel, Leandro Von Werra, Thomas Wolf, et al. The fineweb datasets: Decanting the web for the finest text data at scale. Advances in Neural Information Processing Systems, 37:30811–30849, 2024.
- [39] Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Yitzhak Gadre, Hritik Bansal, Etash Guha, Sedrick Scott Keh, Kushal Arora, et al. Datacomp-lm: In search of the next generation of training sets for language models. Advances in Neural Information Processing Systems, 37:14200–14282, 2024.
- [40] Dan Su, Kezhi Kong, Ying Lin, Joseph Jennings, Brandon Norick, Markus Kliegl, Mostofa Patwary, Mohammad Shoeybi, and Bryan Catanzaro. Nemotron-cc: Transforming common crawl into a refined long-horizon pretraining dataset. arXiv preprint arXiv:2412.02595, 2024.
- [41] Yudong Wang, Zixuan Fu, Jie Cai, Peijun Tang, Hongya Lyu, Yewei Fang, Zhi Zheng, Jie Zhou, Guoyang Zeng, Chaojun Xiao, et al. Ultra-fineweb: Efficient data filtering and verification for high-quality llm training data. arXiv preprint arXiv:2505.05427, 2025.
- [42] Xinrun Du, Zhouliang Yu, Songyang Gao, Ding Pan, Yuyang Cheng, Ziyang Ma, Ruibin Yuan, Xingwei Qu, Jiaheng Liu, Tianyu Zheng, et al. Chinese tiny llm: Pretraining a chinese-centric large language model. arXiv preprint arXiv:2404.04167, 2024.
- [43] Siming Huang, Tianhao Cheng, Jason Klein Liu, Jiaran Hao, Liuyihan Song, Yang Xu, J. Yang, J. H. Liu, Chenchen Zhang, Linzheng Chai, Ruifeng Yuan, Zhaoxiang Zhang, Jie Fu, Qian Liu, Ge Zhang, Zili Wang, Yuan Qi, Yinghui Xu, and Wei Chu. Opencoder: The open cookbook for top-tier code large language models. 2024.
- [44] Fan Zhou, Zengzhi Wang, Nikhil Ranjan, Zhoujun Cheng, Liping Tang, Guowei He, Zhengzhong Liu, and Eric P. Xing. Megamath: Pushing the limits of open math corpora. arXiv preprint arXiv:2504.02807, 2025. Preprint.
- [45] Rabeeh Karimi Mahabadi, Sanjeev Satheesh, Shrimai Prabhumoye, Mostofa Patwary, Mohammad Shoeybi, and Bryan Catanzaro. Nemotron-cc-math: A 133 billion-token-scale high quality math pretraining dataset. 2025.
- [46] NVIDIA, Aarti Basant, Abhijit Khairnar, Abhijit Paithankar, Abhinav Khattar, Adithya Renduchintala, Aditya Malte, Akhiad Bercovich, Akshay Hazare, Alejandra Rico, Aleksander Ficek, Alex Kondratenko, Alex Shaposhnikov, Alexander Bukharin, Ali Taghibakhshi, Amelia Barton, Ameya Sunil Mahabaleshwarkar, Amy Shen, Andrew Tao, Ann Guan, Anna Shors, Anubhav Mandarwal, Arham Mehta, Arun Venkatesan, Ashton Sharabiani, Ashwath Aithal, Ashwin Poojary, Ayush Dattagupta, Balaram Buddharaju, Banghua Zhu, Barnaby Simkin, Bilal Kartal, Bita Darvish Rouhani, Bobby Chen, Boris Ginsburg, Brandon Norick, Brian Yu, Bryan Catanzaro, Charles Wang, Charlie Truong, Chetan Mungekar, Chintan Patel, Chris Alexiuk, Christian Munley, Christopher Parisien, Dan Su, Daniel Afrimi, Daniel Korzekwa, Daniel Rohrer, Daria Gitman, David Mosallanezhad, Deepak Narayanan, Dima Rekesh, Dina Yared, Dmytro Pykhtar, Dong Ahn, Duncan Riach, Eileen Long, Elliott Ning, Eric Chung, Erick Galinkin, Evelina Bakhturina, Gargi Prasad, Gerald Shen, Haifeng Qian, Haim Elisha, Harsh Sharma, Hayley Ross, Helen Ngo, Herman Sahota, Hexin Wang, Hoo Chang Shin, Hua Huang, Iain Cunningham, Igor Gitman, Ivan Moshkov, Jaehun Jung, Jan Kautz, Jane Polak Scowcroft, Jared Casper, Jian Zhang, Jiaqi Zeng, Jimmy Zhang, Jinze Xue, Jocelyn Huang, Joey Conway, John Kamalu, Jonathan Cohen, Joseph Jennings, Julien Veron Vialard, Junkeun Yi, Jupinder Parmar, Kari Briski, Katherine Cheung, Katherine Luna, Keith Wyss, Keshav Santhanam, Kezhi Kong, Krzysztof Pawelec, Kumar Anik, Kunlun Li, Kushan Ahmadian, Lawrence McAfee, Laya Sleiman, Leon Derczynski, Luis Vega, Maer Rodrigues de Melo, Makesh Narsimhan Sreedhar, Marcin Chochowski, Mark Cai, Markus Kliegl, Marta Stepniewska-Dziubinska, Matvei Novikov, Mehrzad Samadi, Meredith Price, Meriem Boubdir, Michael Boone, Michael Evans, Michal Bien, Michal Zawalski, Miguel Martinez, Mike Chrzanowski, Mohammad Shoeybi, Mostofa Patwary, Namit Dhameja, Nave Assaf, Negar Habibi, Nidhi Bhatia, Nikki Pope, Nima Tajbakhsh, Nirmal Kumar Juluru, Oleg Rybakov, Oleksii Hrinchuk, Oleksii Kuchaiev, Oluwatobi Olabiyi, Pablo Ribalta, Padmavathy Subramanian, Parth Chadha, Pavlo Molchanov, Peter Dykas, Peter Jin, Piotr Bialecki, Piotr Januszewski, Pradeep Thalasta, Prashant Gaikwad, Prasoon Varshney, Pritam Gundecha, Przemek Tredak, Rabeeh Karimi Mahabadi, Rajen Patel, Ran El-Yaniv, Ranjit Rajan, Ria Cheruvu, Rima Shahbazyan, Ritika Borkar, Ritu Gala, Roger Waleffe, Ruoxi Zhang, Russell J. Hewett, Ryan Prenger, Sahil Jain, Samuel Kriman, Sanjeev Satheesh, Saori Kaji, Sarah Yurick, Saurav Muralidharan, Sean Narenthiran, Seonmyeong Bak, Sepehr Sameni, Seungju Han, Shanmugam Ramasamy, Shaona Ghosh, Sharath Turuvekere Sreenivas, Shelby Thomas, Shizhe Diao, Shreya Gopal, Shrimai Prabhumoye, Shubham Toshniwal, Shuoyang Ding, Siddharth Singh, Siddhartha Jain, Somshubra Majumdar, Soumye Singhal, Stefania Alborghetti, Syeda Nahida Akter, Terry Kong, Tim Moon, Tomasz Hliwiak, Tomer Asida, Tony Wang, Tugrul Konuk, Twinkle Vashishth, Tyler Poon, Udi Karpas, Vahid Noroozi, Venkat Srinivasan, Vijay Korthikanti, Vikram Fugro, Vineeth Kalluru, Vitaly Kurin, Vitaly Lavrukhin, Wasi Uddin Ahmad, Wei Du, Wonmin Byeon, Ximing Lu, Xin Dong, Yashaswi Karnati, Yejin Choi, Yian Zhang, Ying Lin, Yonggan Fu, Yoshi Suhara, Zhen Dong, Zhiyu Li, Zhongbo Zhu, and Zijia Chen. Nvidia nemotron nano 2: An accurate and efficient hybrid mamba-transformer reasoning model, 2025.
- [47] Tianyu Gao, Alexander Wettig, Howard Yen, and Danqi Chen. How to train long-context language models (effectively). arXiv preprint arXiv:2410.02660, 2024.
- [48] Yu Zhang and Songlin Yang. Flame: Flash language modeling made easy, January 2025.
- [49] Wanchao Liang, Tianyu Liu, Less Wright, Will Constable, Andrew Gu, Chien-Chin Huang, Iris Zhang, Wei Feng, Howard Huang, Junjie Wang, Sanket Purandare, Gokul Nadathur, and Stratos Idreos. Torchtitan: One-stop pytorch native solution for production ready LLM pretraining. In The Thirteenth International Conference on Learning Representations, 2025.
- [50] Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. Openthoughts: Data recipes for reasoning models. arXiv preprint arXiv:2506.04178, 2025.
- [51] Zihan Liu, Zhuolin Yang, Yang Chen, Chankyu Lee, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Acereason-nemotron 1.1: Advancing math and code reasoning through sft and rl synergy. arXiv preprint arXiv:2506.13284, 2025.
- [52] Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, and Boris Ginsburg. Opencodereasoning: Advancing data distillation for competitive coding. arXiv preprint arXiv:2504.01943, 2025.
- [53] Akhiad Bercovich, Itay Levy, Izik Golan, Mohammad Dabbah, Ran El-Yaniv, Omri Puny, Ido Galil, Zach Moshe, Tomer Ronen, Najeeb Nabwani, et al. Llama-nemotron: Efficient reasoning models. arXiv preprint arXiv:2505.00949, 2025.
- [54] Haozhe Wang, Haoran Que, Qixin Xu, Minghao Liu, Wangchunshu Zhou, Jiazhan Feng, Wanjun Zhong, Wei Ye, Tong Yang, Wenhao Huang, et al. Reverse-engineered reasoning for open-ended generation. arXiv preprint arXiv:2509.06160, 2025.
- [55] Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. Llamafactory: Unified efficient fine-tuning of 100+ language models. arXiv preprint arXiv:2403.13372, 2024.
- [56] Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025.
- [57] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- [58] Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The language model evaluation harness, 07 2024.
- [59] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- [60] HuggingFaceH4. Aime 2024. https://huggingface.co/datasets/HuggingFaceH4/aime_2024, 2024. 30 problems from AIME I & II 2024.
- [61] Chaoqun He, Renjie Luo, Yuzhuo Bai, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. arXiv preprint arXiv:2402.14008, 2024.
- [62] David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022, 2023.
- [63] M-A-P Team, Xinrun Du, Yifan Yao, et al. Supergpqa: Scaling llm evaluation across 285 graduate disciplines. arXiv preprint arXiv:2502.14739, 2025.
- [64] ByteDance-Seed. Beyondaime. https://huggingface.co/datasets/ByteDance-Seed/BeyondAIME, 2025. CC0-1.0 license.
- [65] Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, et al. Humanity’s last exam. arXiv preprint arXiv:2501.14249, 2025.
- [66] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics.
- [67] Zeyuan Allen-Zhu and Yuanzhi Li. Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws. In Proceedings of the 13th International Conference on Learning Representations, ICLR ’25, April 2025. Full version available at https://ssrn.com/abstract=5250617.
- [68] Zeyuan Allen-Zhu. Physics of Language Models: Part 4.1, Architecture Design and the Magic of Canon Layers. SSRN Electronic Journal, May 2025. https://ssrn.com/abstract=5240330.
- [69] Yuekun Yao, Yupei Du, Dawei Zhu, Michael Hahn, and Alexander Koller. Language models can learn implicit multi-hop reasoning, but only if they have lots of training data. arXiv preprint arXiv:2505.17923, 2025.
- [70] Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, and Yuandong Tian. Reasoning by superposition: A theoretical perspective on chain of continuous thought. arXiv preprint arXiv:2505.12514, 2025.
- [71] Shu Zhong, Mingyu Xu, Tenglong Ao, and Guang Shi. Understanding transformer from the perspective of associative memory. arXiv preprint arXiv:2505.19488, 2025.
- [72] Chujie Zheng, Fan Yin, Hao Zhou, Fandong Meng, Jie Zhou, Kai-Wei Chang, Minlie Huang, and Nanyun Peng. On prompt-driven safeguarding for large language models. In Proceedings of the 41st International Conference on Machine Learning, pages 61593–61613, 2024.
- [73] Kyle Cox. Post-hoc reasoning in chain of thought, December 2024. Blog post.
- [74] Iván Arcuschin, Jett Janiak, Robert Krzyzanowski, Senthooran Rajamanoharan, Neel Nanda, and Arthur Conmy. Chain-of-thought reasoning in the wild is not always faithful. arXiv preprint arXiv: 2503.08679, 2025.
- [75] Fazl Barez, Tung-Yu Wu, Iván Arcuschin, Michael Lan, Vincent Wang, Noah Siegel, Nicolas Collignon, Clement Neo, Isabelle Lee, Alasdair Paren, Adel Bibi, Robert Trager, Damiano Fornasiere, John Yan, Yanai Elazar, and Yoshua Bengio. Chain-of-thought is not explainability. 2025.
- [76] Tomek Korbak, Mikita Balesni, Elizabeth Barnes, Yoshua Bengio, Joe Benton, Joseph Bloom, Mark Chen, Alan Cooney, Allan Dafoe, Anca Dragan, Scott Emmons, Owain Evans, David Farhi, Ryan Greenblatt, Dan Hendrycks, Marius Hobbhahn, Evan Hubinger, Geoffrey Irving, Erik Jenner, Daniel Kokotajlo, Victoria Krakovna, Shane Legg, David Lindner, David Luan, Aleksander Mądry, Julian Michael, Neel Nanda, Dave Orr, Jakub Pachocki, Ethan Perez, Mary Phuong, Fabien Roger, Joshua Saxe, Buck Shlegeris, Martín Soto, Eric Steinberger, Jasmine Wang, Wojciech Zaremba, Bowen Baker, Rohin Shah, and Vlad Mikulik. Chain of thought monitorability: A new and fragile opportunity for ai safety. arXiv preprint arXiv: 2507.11473, 2025.
- [77] Quora. Quora question pairs. https://www.kaggle.com/competitions/quora-question-pairs/, 2017. Kaggle competition.
- [78] Clayton Sanford, Bahare Fatemi, Ethan Hall, Anton Tsitsulin, Mehran Kazemi, Jonathan Halcrow, Bryan Perozzi, and Vahab Mirrokni. Understanding transformer reasoning capabilities via graph algorithms. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems, volume 37, pages 78320–78370. Curran Associates, Inc., 2024.
- [79] Clayton Sanford, Daniel Hsu, and Matus Telgarsky. Transformers, parallel computation, and logarithmic depth. arXiv preprint arXiv:2402.09268, 2024.
- [80] Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Transformers learn shortcuts to automata. arXiv preprint arXiv:2210.10749, 2022.
- [81] Zixuan Wang, Eshaan Nichani, Alberto Bietti, Alex Damian, Daniel Hsu, Jason D Lee, and Denny Wu. Learning compositional functions with transformers from easy-to-hard data. arXiv preprint arXiv:2505.23683, 2025.
- [82] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations (ICLR), 2021.
- [83] Yizhong Wang, Yada Pruksachatkun, Sheng Chen, Zexuan Zhong, Pengfei Chen, et al. MMLU-Pro: A more challenging and reliable evaluation for massive multitask language understanding. arXiv preprint arXiv:2406.01574, 2024.
- [84] Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V. Le, Ed H. Chi, Denny Zhou, and Jason Wei. Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261, 2022.
- [85] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- [86] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy, 2019. Association for Computational Linguistics.
- [87] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. arXiv preprint arXiv:1907.10641, 2019.
- [88] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [89] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In NeurIPS 2021 Datasets and Benchmarks Track, 2021.
- [90] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [91] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- [92] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1, 2018.
- [93] Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The lambada dataset, Aug 2016.
- [94] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789, 2018.
- [95] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020.
- [96] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- [97] Haoran Que, Jiaheng Liu, Ge Zhang, Chenchen Zhang, Xingwei Qu, Yinghao Ma, Feiyu Duan, Zhiqi Bai, Jiakai Wang, Yuanxing Zhang, et al. D-cpt law: domain-specific continual pre-training scaling law for large language models. In Proceedings of the 38th International Conference on Neural Information Processing Systems, pages 90318–90354, 2024.
Appendix A Empirical Validation of Prior Choice
<details>
<summary>x12.png Details</summary>
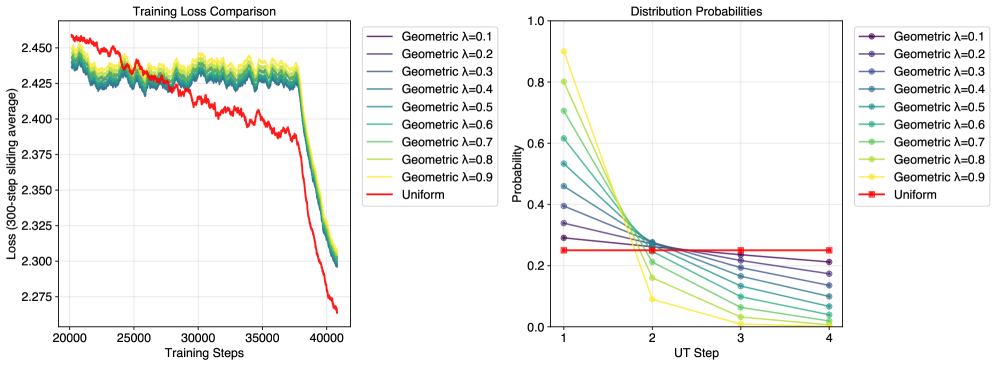
### Visual Description
## Line Charts: Training Loss Comparison and Distribution Probabilities
### Overview
The image contains two line charts comparing training dynamics and distribution probabilities across different hyperparameter settings. The left chart tracks training loss convergence over steps, while the right chart visualizes probability distributions across update (UT) steps for geometric and uniform distributions.
### Components/Axes
**Left Chart (Training Loss Comparison):**
- **X-axis**: Training Steps (20,000 to 40,000)
- **Y-axis**: Loss (300-step sliding average) ranging from 2.275 to 2.450
- **Legend**:
- Geometric distributions (λ=0.1 to λ=0.9) in gradient colors (purple to yellow)
- Uniform distribution (red line)
**Right Chart (Distribution Probabilities):**
- **X-axis**: UT Step (1 to 4)
- **Y-axis**: Probability (0.0 to 1.0)
- **Legend**:
- Geometric distributions (λ=0.1 to λ=0.9) in gradient colors (purple to yellow)
- Uniform distribution (red line)
### Detailed Analysis
**Left Chart Trends:**
1. **Uniform Distribution (Red Line)**:
- Starts at ~2.45 loss at 20,000 steps
- Gradually decreases to ~2.275 by 40,000 steps
- Shows smooth, consistent decline
2. **Geometric Distributions**:
- All λ values start above Uniform (~2.42–2.45 at 20k steps)
- Converge toward Uniform performance by ~35,000 steps
- λ=0.1 (purple) shows slowest convergence
- λ=0.9 (yellow) shows fastest convergence
- λ=0.5 (green) and λ=0.7 (light green) show intermediate convergence
**Right Chart Trends:**
1. **Uniform Distribution (Red Line)**:
- Maintains flat probability of ~0.25 across all UT steps
2. **Geometric Distributions**:
- λ=0.1 (purple): Starts at ~0.35, drops to ~0.2 by UT step 4
- λ=0.9 (yellow): Starts at ~0.9, drops to near 0 by UT step 4
- Higher λ values show steeper declines
- All geometric lines cross below Uniform probability by UT step 3
### Key Observations
1. **Training Loss Convergence**:
- Geometric models with λ > 0.5 outperform λ < 0.5 by 35,000 steps
- Uniform model maintains ~0.15 lower loss than initial geometric values
- All models show reduced variance in loss after 30,000 steps
2. **Distribution Probability Dynamics**:
- Higher λ geometric models exhibit greater initial confidence (probability)
- Confidence drops sharply for λ > 0.5 by UT step 3
- Uniform model maintains stable, moderate confidence
### Interpretation
The data demonstrates that geometric distributions with higher λ values (λ > 0.5) achieve faster convergence in training loss but exhibit higher initial confidence that rapidly declines. This suggests a trade-off between early performance and stability. The uniform distribution serves as a stable baseline with moderate performance and consistent confidence.
Notably, the geometric models' probability distributions show a "confidence correction" pattern - starting with overconfidence (high probability) that diminishes as training progresses. This aligns with the loss convergence pattern, where initial overestimation of model capability (high loss) improves over time.
The spatial relationship between the two charts reveals complementary insights: the left chart shows performance improvement over time, while the right chart reveals how confidence calibration evolves. The uniform model's stability in both metrics suggests it represents a well-calibrated, reliable baseline for comparison.
</details>
Figure 10: Effect of the prior over exit steps. Left: training loss (300-step sliding average) for a LoopLM with $T_{\max}=4$ under different priors on $z$ . Colored curves correspond to geometric priors with parameter $\eta∈\{0.1,...,0.9\}$ ; the red curve uses a uniform prior. Shaded regions indicate variability across runs. Right: prior probability over LoopLM steps induced by each $\eta$ (uniform shown in red). Stronger geometric bias (larger $\eta$ ) concentrates mass on shallow steps, reducing credit assignment to deeper computation.
Experimental setup.
Unless otherwise noted, we keep the model, data, optimizer, and schedule identical across conditions and only change the prior $\pi$ used in the KL term of the loss. All results are obtained on a 776M-parameter LoopLM with $T_{\max}=4$ recurrent steps. Training is performed on the FineWeb-Edu corpus [38] for a total of 20B tokens with a global batch of 50K tokens per optimization step, i.e., roughly 40K steps in total. The loss curves plot a 300-step sliding average over the training trajectory. For geometric priors we sweep $\lambda\!∈\!\{0.1,0.2,...,0.9\}$ ; the uniform prior assigns equal mass to all steps. To assess variability, we repeat each condition with multiple random seeds; shaded areas in Figure ˜ 10 denote the variability across runs. All other hyperparameters follow our training recipe, keeping $\beta$ fixed across prior choices.
Convergence and final loss.
As shown on the left of Figure ˜ 10, the uniform prior consistently achieves lower training loss and cleaner convergence on the 776M LoopLM. Geometric priors plateau higher, with the gap widening as $\lambda$ grows (i.e., stronger bias toward early exit), reflecting weaker supervision for deeper iterations.
Stability and exploration.
Geometric priors exhibit larger late-training oscillations, consistent with premature collapse of $q_{\phi}(z\!\mid\!x)$ onto shallow steps and reduced entropy. The uniform prior imposes no structural depth preference, so the KL term behaves as pure entropy regularization: exploration is maintained longer, and the model can allocate probability mass across multiple depths until it has learned which examples benefit from deeper computation.
Depth utilization.
The right panel of Figure ˜ 10 visualizes the priors. Large- $\lambda$ geometric priors concentrate mass at $t{=}1,2$ , neglecting deeper steps ( $t{≥}3$ ) of credit assignment; this undermines the “deeper is better” property. With a uniform prior, all depths receive comparable signal, enabling later iterations to specialize and deliver higher accuracy when maximum depth is allowed at inference.
Compute–accuracy trade-off.
Although the uniform prior does not explicitly favor early exit, it does not preclude efficient inference: at test time we can still cap steps or apply a halting threshold. For a fixed average step budget, models trained with a uniform prior achieve a strictly better accuracy-compute Pareto frontier than those trained with geometric priors, indicating that unbiased depth exploration during pre-training turns into better deployment trade-offs.
Appendix B Physics of LoopLMs
In this appendix, we conclude all the experimental settings and details in Section ˜ 6. Section ˜ B.1 includes the experiments on knowledge capacity; section ˜ B.2 includes the settings on knowledge manipulation synthetic tasks. Section ˜ B.3 introduces the detailed setting on the synthetic QA task following [69]. Finally, Section ˜ B.5 provides the theoretical results, detailed proof, and the discussion with the current theoretical results.
B.1 Capo: knowledge capacity
In this section, we introduce the knowledge capacity proposed in [67, 68]. The task evaluates models’ efficiency in memorizing factual knowledge within its parameters, which is measured by bits per parameter. We tested different sizes of models and visualize the knowledge scaling law through plotting bits v.s. parameter number.
Dataset: Synthetic Biographies
We synthesize fake biographies following the $\mathrm{bioS}(N)$ dataset in [67]. Specifically, we generate $N$ biographies of a random generated person together with their date of birth, city of birth, university, major, and employer. In our work, we online sample the individual attributes and generate the biographies in natural language using a random selected fixed template. An illustrative example is:
Layla Jack Beasley celebrates their birthday on January 24, 1914. They spent formative years in Portland, ME. They focused on Business Analytics. They supported operations for Delta Air Lines Inc. in Atlanta, GA. They received their education at Pepperdine University.
Model
We use original GPT2 architecture and replace the positional encoding with RoPE [34]. In the Capo task, we tie the LM head and the embedding layer. To test the capability of universal transformer, we also added looping module s.t. the transformer blocks can be looped several times. We explore a broad range of model sizes varying in hidden dimension and depth. The notation $a$ - $b$ -l $c$ represents the model with $64a$ hidden dimensions ( $a$ attention heads with each head 64 dimensions), $b$ layers, and $c$ LoopLM steps (loops). The context length is set to 512.
Training details
We use AdamW optimizer by setting $(\beta_{1},\beta_{2})=(0.9,0.98),\epsilon=10^{-6}$ with 1000 steps of warmup followed by a cosine learning rate schedule from 1 to 0.1 $×$ of the original learning rate. We use bf16 training and packing is used during training. We masked different pieces of biographies from each other in each concatenated chunk.
We pass each data piece for 1000 times (similar to the 1000-exposure in [67]) during training. Since the final performance is not sensitive to learning rate choices, we consider learning rate $\eta=0.001,wd=0.02$ , and total batch size 192. We pick $N∈\{20K,50K,100K,200K,500K\}$ .
Evaluation: Knowledge Capacity Ratio
After pre-training on the bioS( $N$ ) dataset, we assess a model’s knowledge capacity, defined as the number of bits of information it can reliably store. To make this measure comparable across models of different sizes, the raw bit count is normalized by the number of model parameters, yielding a “bits per parameter” metric. The derivation and motivation of the metric in discussed in [67]. For readers, we refer the detailed setting to Section 2.1 of [67].
**Definition 1**
*Given a model $F$ with $P$ parameters trained over the bioS( $N$ ) dataset $Z$ , suppose it gives $p_{1}=\text{loss}_{\text{name}}(Z)$ and $p_{2}=\text{loss}_{\text{value}}(Z)$ , which are the sum of cross entropy loss on the name tokens and attribute tokens, respectively. The capacity ratio and the maximum achievable capacity ratio are defined as
$$
R(F)\;\overset{\text{def}}{=}\;\frac{N\log_{2}\frac{N_{0}}{e^{p_{1}}}+N\log_{2}S_{0}\,e^{p_{2}}}{P},\quad R_{\max}(F)\;\overset{\text{def}}{=}\;\frac{N\log_{2}N_{0}\cdot N+N\log_{2}S_{0}}{P},
$$
for $N_{0}=400× 400× 1000$ , $S_{0}=2×(12· 28· 200)× 200× 300× 100× 263$ as all possible configurations.*
Ignoring names, each person encodes approximately $\log_{2}(S_{0})≈ 47.6\;\text{bits of knowledge}.$ The evaluation accounts for partial correctness. For instance, if a model recalls the year of a person’s birth but not the exact date, the partially correct information still contributes to the overall bit-level computation. This approach allows for a fine-grained measurement of knowledge retention, rather than relying on a strict all-or-nothing scoring.
B.2 Mano: knowledge manipulation
We followed [68] and used the Mano task to investigate the models’ capability of manipulating stored knowledge within the parameters without intermediate thoughts.
Dataset The dataset consists of modular arithmetic instances with tree structures of $\ell$ operations, where the number of operations $\ell≤ L$ as the maximum length. $\ell$ is uniformly sampled from $[1,L]$ . The expressions are presented in prefix notation. For example, a length-3 instance is:
which corresponds to $(a*b)+(c-d)\mod 23$ . All the operations are on $\mathbb{F}_{23}$ . The task only involves $(+,-,*)$ . The only tokens we use are the operations, numbers from 0 to 22, and the special <bos>, <ans> and length tokens len_{i} with $i∈[0,L]$ .
Training details
We use AdamW optimizer with $(\beta_{1},\beta_{2})=(0.9,0.98),\epsilon=10^{-6}$ and gradient clipping with maximum norm 1.0. We employ 1000 steps of warmup followed by a cosine learning rate schedule to minimal learning rate 0.1 of the peak learning rate. We use bf16 training with packing and set the context length to 1024 tokens. Different pieces of mano problems are masked from each other in each concatenated chunk during training.
We conduct hyperparameter search over learning rates $lr∈\{0.00005,0.0001,0.0002,0.0005\}$ with weight decay 0.1 and global batch size 128. We experiment with model depths $L∈\{10,16,24\}$ layers and hidden dimension 1024. Training is performed for $\{80K,110K,200K\}$ steps respectively for different difficulties. We run all experiments across 3 random seeds and report the best performance.
Evaluation
During evaluation, we only use the expressions with the hardest length $\ell=L$ . Accuracy is computed separately due to the masks. We consider exact match accuracy since the final answer is single-token.
B.3 Multi-hop question answering on synthetic relations
We followed [69] to construct the natural language multi-hop QA task. Comparing with Mano, the QA task is more knowledge-heavy and with a slightly simpler structure. [69] found that the model needs exponential many $k$ -hop data for traditional transformer to learn. We chose this task to investigate if recursive structure in the reused-parameters can improve the sample efficiency of the task, showing better manipulation capability of LoopLM.
Dataset
The dataset contains $|\mathcal{E}|$ entities—each with a unique name—and $N$ relation types. We created 500 distinct single-token person names (e.g., Jennifer) and 20 single-token relation names (e.g., instructor) to serve as namespaces for entities and relations. We reused the name list in [69]. The complete list of relation names and a partial list of entity names appear in Tables 5 and 6 in [69]. The multi-hop questions are generated through a $K=5$ hierarchical layers, where each layer has 100 individuals. Each entity is connected to $|\mathcal{R}|$ randomly chosen person in the next layer. This structure naturally generates $|\mathcal{E}|/5×|\mathcal{R}|^{k}$ $k$ -hop questions. In our setting, since we only consider 3-hop questions, the number should be $8× 10^{5}$ .
For training, we use part of all the 3-hop training set and test on the leave-out 3000 test questions. For each test instance, we greedy decode the single token answer given the question prompt (e.g. ‘Who is the instructor of the teacher of Bob? $\backslash n$ Answer:’). We evaluate the exact match accuracy.
Training details
We use AdamW optimizer with $(\beta_{1},\beta_{2})=(0.9,0.98),\epsilon=10^{-6}$ and gradient clipping 1.0. We run 1000 steps of linear warmup followed by a cosine learning rate schedule to minimal learning rate 0.1 of the peak learning rate. We use bf16 training with packing with context length 1024 tokens. QA pairs from distinct samples are masked from each other during training.
We use a base model architecture with 1024 hidden dimensions, 16 attention heads, and 6 layers. We allow it to loop in $\{1,2,4\}$ times. Following the experimental setup in [69], we set the learning rate to 0.0005 with 1000 warmup steps and train for a total of 20,000 steps using batch size 2048. We run all experiments across 4 random seeds and report the average performance.
B.3.1 Additional experimental results
As the supplement of the main text, we present additional experiments to show that the superiority of LoopLM is general across different number of unique samples. For presentation, we only consider the interval of $\{10^{5},1.2× 10^{5},1.4× 10^{5}\}$ to exhibit the difference between looped models and non-looped baselines. We also checked iso-flop baseline models with the same hidden dimension and 24 layers We note that in Figure 12, the iso-flop baseline with $N=1.2× 10^{5}$ does not perform significantly better than the shallower version in the main paper. We conjecture that it could be because of the randomness, or insufficient hyperparameter tuning. We believe further follow-up experiments should be necessary to further validate this conclusion here in the appendix.. The results are presented below in Figure ˜ 11 and Figure ˜ 12.
<details>
<summary>x13.png Details</summary>
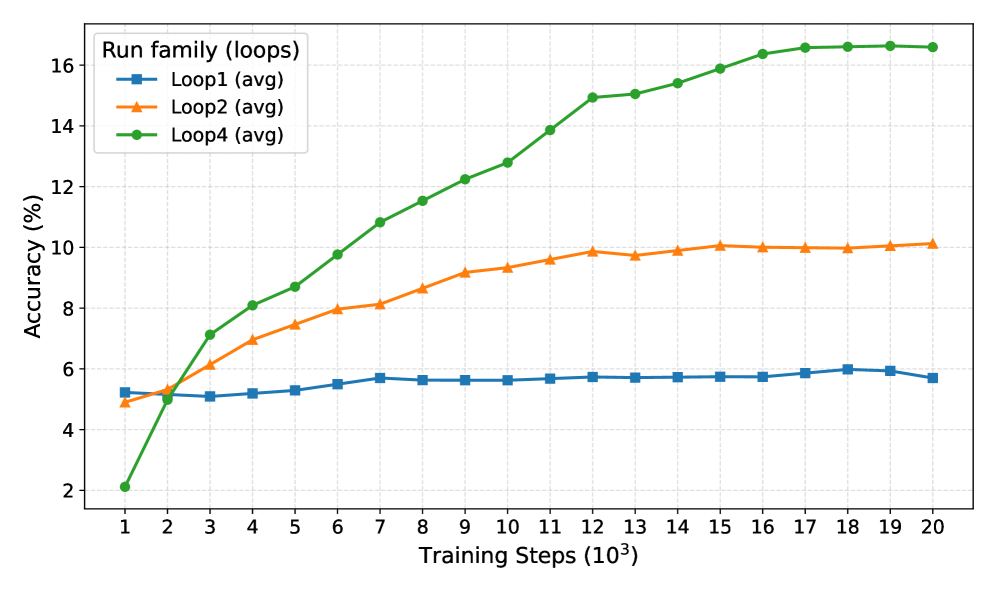
### Visual Description
## Line Graph: Run family (loops) Accuracy vs Training Steps
### Overview
The image shows a line graph comparing the accuracy of three training loops (Loop1, Loop2, Loop4) across 20,000 training steps (in thousands). Accuracy is measured in percentage, with distinct line styles and colors for each loop family.
### Components/Axes
- **X-axis**: Training Steps (10³) ranging from 1 to 20 (in thousands)
- **Y-axis**: Accuracy (%) ranging from 2% to 16%
- **Legend**: Located in top-left corner, mapping:
- Blue squares: Loop1 (avg)
- Orange triangles: Loop2 (avg)
- Green circles: Loop4 (avg)
### Detailed Analysis
1. **Loop1 (blue squares)**:
- Starts at ~5% accuracy at 1k steps
- Remains relatively flat throughout training
- Ends at ~5.8% accuracy at 20k steps
- Trend: Minimal improvement (slope ≈ 0.0003% per step)
2. **Loop2 (orange triangles)**:
- Begins at ~4.8% accuracy at 1k steps
- Shows steady improvement until ~12k steps
- Plateaus at ~10% accuracy from 12k to 20k steps
- Peak accuracy: ~10.2% at 15k steps
- Trend: Initial slope ≈ 0.0005% per step, then flattening
3. **Loop4 (green circles)**:
- Starts at 2% accuracy at 1k steps
- Rapid improvement until ~12k steps
- Reaches ~16.2% accuracy by 16k steps
- Maintains ~16.2% accuracy through 20k steps
- Trend: Initial slope ≈ 0.001% per step, then plateau
### Key Observations
- Loop4 demonstrates the most significant improvement, achieving 3x higher accuracy than Loop1 by 20k steps
- Loop2 shows moderate gains but plateaus earlier than Loop4
- All loops exhibit diminishing returns after ~12k steps
- Loop1 remains the least effective throughout training
### Interpretation
The data suggests Loop4's training methodology is most effective for accuracy optimization, achieving near-maximal performance by 16k steps. Loop2 demonstrates moderate effectiveness but experiences diminishing returns earlier than Loop4. Loop1's stagnant performance indicates potential limitations in its training approach. The convergence of Loop2 and Loop4 at ~10% accuracy suggests possible architectural similarities between these implementations. The plateauing patterns across all loops after 12k steps may indicate a saturation point in the training data's capacity to improve model performance further.
</details>
<details>
<summary>x14.png Details</summary>
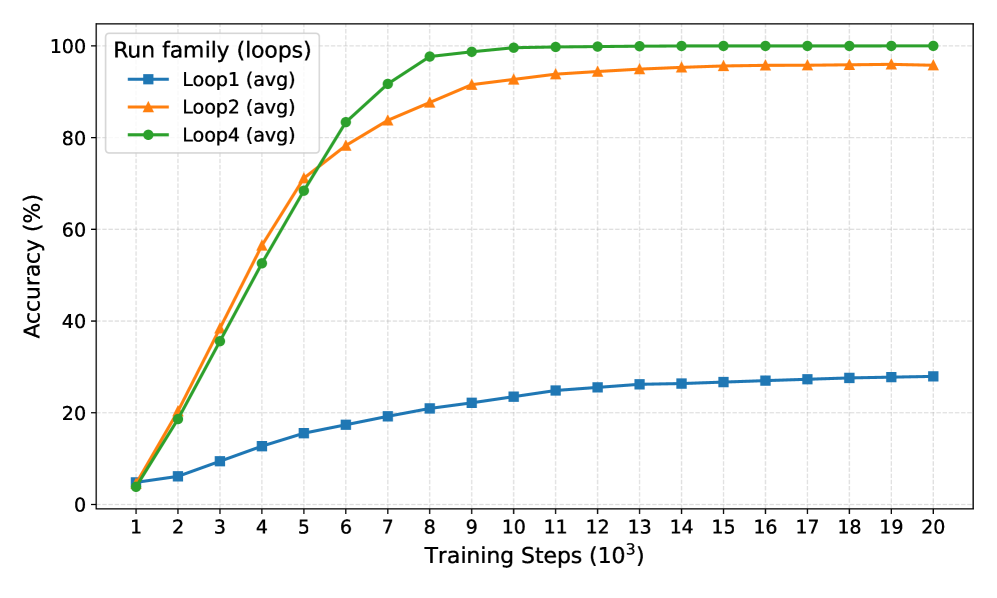
### Visual Description
## Line Graph: Run family (loops) Accuracy vs Training Steps
### Overview
The graph depicts the convergence behavior of three distinct loop configurations (Loop1, Loop2, Loop4) across 20,000 training steps (1k-20k). Accuracy is measured in percentage, with all three configurations showing different rates of improvement and plateauing patterns.
### Components/Axes
- **X-axis**: Training Steps (10³) ranging from 1 to 20 (logarithmic scale)
- **Y-axis**: Accuracy (%) from 0 to 100
- **Legend**: Located in top-left corner with color-coded markers:
- Blue squares: Loop1 (avg)
- Orange triangles: Loop2 (avg)
- Green circles: Loop4 (avg)
- **Title**: "Run family (loops)" positioned at the top center
### Detailed Analysis
1. **Loop4 (green circles)**:
- Initial accuracy: ~5% at 1k steps
- Rapid ascent: Reaches 95% by 8k steps
- Plateau: Maintains 98-100% accuracy from 9k-20k steps
- Notable: Fastest convergence with highest final accuracy
2. **Loop2 (orange triangles)**:
- Initial accuracy: ~5% at 1k steps
- Steady growth: Reaches 95% by 16k steps
- Plateau: Maintains 97-98% accuracy from 17k-20k steps
- Notable: Second-fastest convergence but slower than Loop4
3. **Loop1 (blue squares)**:
- Initial accuracy: ~5% at 1k steps
- Gradual improvement: Reaches 28% by 20k steps
- Plateau: Maintains 26-28% accuracy from 15k-20k steps
- Notable: Slowest convergence with lowest final accuracy
### Key Observations
- All configurations start at similar low accuracy (~5%) at 1k steps
- Loop4 demonstrates 3.5x faster convergence than Loop2 (8k vs 16k steps to reach 95%)
- Loop1 shows significantly poorer performance, achieving only 28% accuracy after 20k steps
- All lines exhibit diminishing returns after their respective plateau points
- Green (Loop4) consistently outperforms orange (Loop2) after 8k steps
### Interpretation
The data suggests that loop configuration critically impacts training efficiency:
1. **Loop4's superiority** indicates optimal architectural design for rapid convergence
2. **Loop2's mid-performance** suggests moderate efficiency with room for improvement
3. **Loop1's underperformance** highlights potential architectural limitations
4. The stark divergence between Loop4 and Loop1 implies that loop structure may be a dominant factor in training dynamics
5. All configurations show saturation behavior, suggesting diminishing returns at higher step counts
The graph emphasizes the importance of loop optimization in training pipelines, with Loop4 representing a highly efficient configuration while Loop1 demonstrates suboptimal performance characteristics.
</details>
Figure 11: Left & Right. We further train with $100000$ and $140000$ unique QA pairs for 20000 steps with context length 1024 and batch size 2048. Similar to the main text, models with more loops learn faster and achieve better performance comparing with models without loops.
<details>
<summary>x15.png Details</summary>
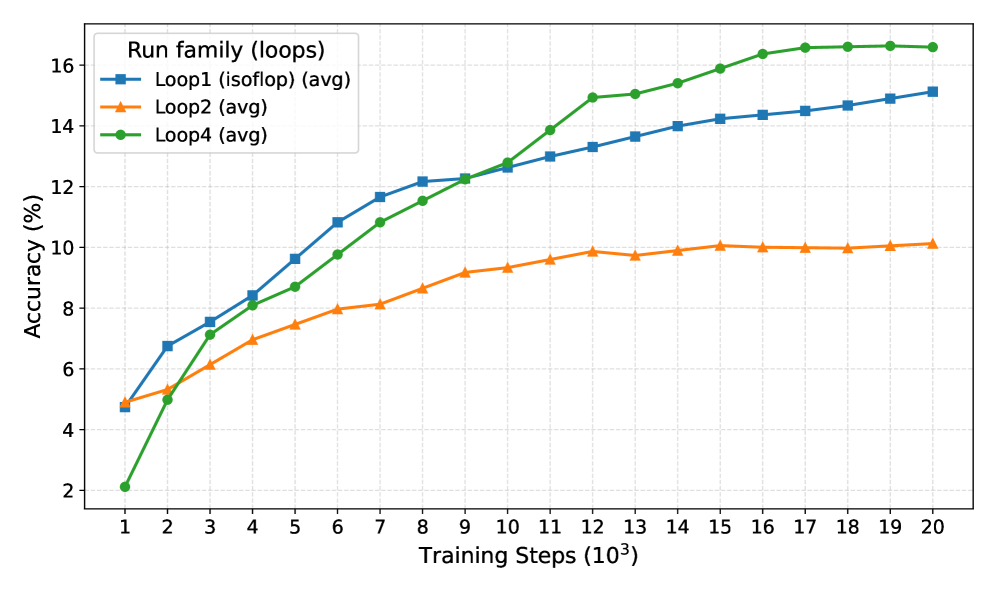
### Visual Description
## Line Graph: Accuracy vs Training Steps (10³)
### Overview
The image depicts a line graph comparing the accuracy of three training runs (Loop1, Loop2, Loop4) over 20,000 training steps (10³ increments). Accuracy is measured in percentage, with Loop4 consistently outperforming the others.
### Components/Axes
- **X-axis**: Training Steps (10³)
- Range: 1 to 20 (increments of 1)
- Label: "Training Steps (10³)"
- **Y-axis**: Accuracy (%)
- Range: 2% to 16% (increments of 2%)
- Label: "Accuracy (%)"
- **Legend**:
- Top-left corner
- Entries:
- Loop1 (isoflop) (avg): Blue squares
- Loop2 (avg): Orange triangles
- Loop4 (avg): Green circles
### Detailed Analysis
1. **Loop1 (isoflop) (avg)**:
- Starts at ~4.5% accuracy at step 1.
- Steady upward trend, reaching ~15% by step 20.
- Data points:
- Step 1: ~4.5%
- Step 5: ~9.5%
- Step 10: ~12.5%
- Step 15: ~14.5%
- Step 20: ~15%
2. **Loop2 (avg)**:
- Starts at ~4.5% accuracy at step 1.
- Slower growth, plateauing near ~10% after step 12.
- Data points:
- Step 1: ~4.5%
- Step 5: ~7.5%
- Step 10: ~9.2%
- Step 15: ~10%
- Step 20: ~10.2%
3. **Loop4 (avg)**:
- Starts at ~2% accuracy at step 1.
- Rapid initial growth, surpassing Loop1 by step 5.
- Peaks at ~16.5% by step 16, stabilizing near 16.5% by step 20.
- Data points:
- Step 1: ~2%
- Step 5: ~8.5%
- Step 10: ~13%
- Step 15: ~16%
- Step 20: ~16.5%
### Key Observations
- **Loop4 dominates** in accuracy, achieving ~16.5% by step 20, while Loop2 stagnates at ~10%.
- **Loop1** shows consistent improvement but lags behind Loop4.
- **Loop2** exhibits diminishing returns after step 12, suggesting potential inefficiencies.
- All lines exhibit upward trends, but Loop4’s growth rate is significantly higher.
### Interpretation
The graph demonstrates that **Loop4’s training methodology** (possibly involving advanced optimization or architecture) yields superior performance compared to Loop1 and Loop2. The stark divergence between Loop4 and Loop2 suggests that Loop2’s approach may suffer from suboptimal convergence or resource allocation. Loop1’s steady progress indicates a balanced but less aggressive training strategy. The data underscores the importance of algorithmic design in training efficiency, with Loop4’s rapid scaling highlighting its potential for real-world applications requiring high accuracy.
</details>
<details>
<summary>x16.png Details</summary>
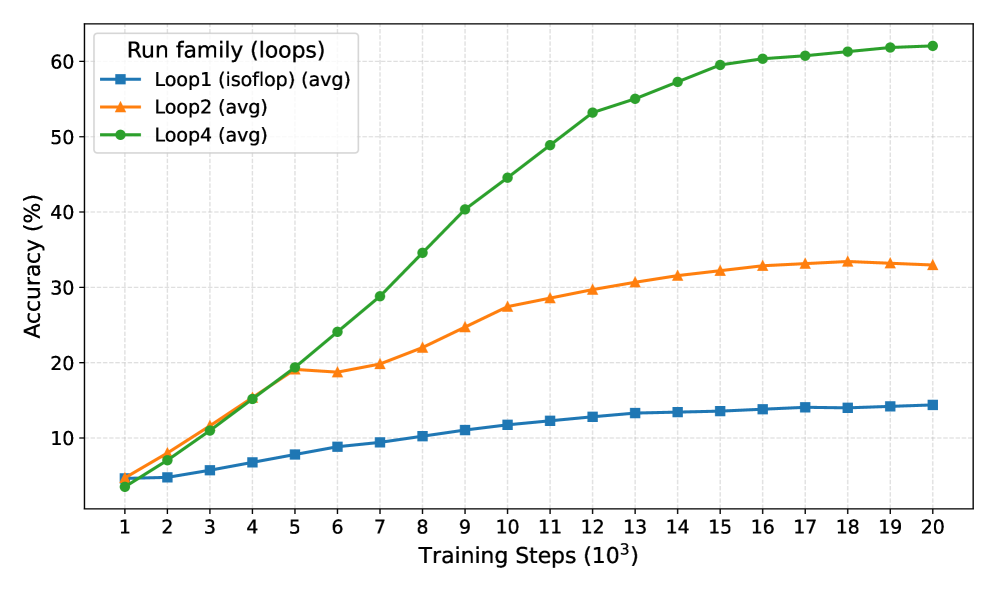
### Visual Description
## Line Graph: Accuracy vs Training Steps (10³)
### Overview
The graph compares the accuracy (%) of three training loops (Loop1, Loop2, Loop4) across 20,000 training steps (10³ increments). Accuracy is plotted on the y-axis (0–60%), and training steps on the x-axis (1–20,000). Loop4 demonstrates the highest performance, while Loop1 shows the slowest growth.
### Components/Axes
- **X-axis**: Training Steps (10³) labeled from 1 to 20 (representing 1,000 to 20,000 steps).
- **Y-axis**: Accuracy (%) ranging from 0 to 60.
- **Legend**: Located in the top-left corner, with three entries:
- **Loop1 (isoflop) (avg)**: Blue squares.
- **Loop2 (avg)**: Orange triangles.
- **Loop4 (avg)**: Green circles.
### Detailed Analysis
1. **Loop1 (blue squares)**:
- Starts at ~5% accuracy at step 1.
- Gradual linear increase to ~14% by step 20.
- Slope: ~0.45% per 1,000 steps.
2. **Loop2 (orange triangles)**:
- Begins at ~5% at step 1.
- Sharp rise to ~19% by step 5.
- Plateaus at ~32% from step 13 onward.
- Peak growth: ~3.4% per 1,000 steps (steps 1–5).
3. **Loop4 (green circles)**:
- Starts at ~3% at step 1.
- Rapid exponential growth to ~62% by step 20.
- Slope: ~2.45% per 1,000 steps (steps 1–20).
### Key Observations
- **Loop4 dominance**: Outperforms all others by step 20 (62% vs. 32% and 14%).
- **Loop2 plateau**: Accuracy stabilizes after step 13, suggesting diminishing returns.
- **Loop1 inefficiency**: Slowest growth rate, indicating suboptimal training dynamics.
### Interpretation
The data suggests that Loop4’s architecture or hyperparameters enable significantly faster convergence compared to Loop1 and Loop2. The plateau in Loop2 implies that additional training steps beyond 13,000 yield minimal gains, while Loop1’s linear trend highlights inefficiencies in its design. These results could inform optimization strategies for training loops in machine learning pipelines, emphasizing the importance of loop configuration in achieving high accuracy with limited computational resources.
</details>
Figure 12: Left & Right. We further train with $100000$ and $120000$ unique QA pairs for 20000 steps with context length 1024 and batch size 2048. We train the baseline with 24 layers, which is equivalent flops with the loop 4 transformers. Similar to the main text, models with more loops learn faster and achieve better performance comparing with models without loops, even with iso-flop transformers. The loop 2 average performance is weaker than the iso-flop version transformer since it has less equivalent depth when $N=10^{5}$ , but it surpasses the baseline with more data provided.
B.4 Case study: improvements across different categories in MMLU
To validate our findings from synthetic tasks on a broad, real-world benchmark, we conducted a granular analysis of performance gains across all 57 sub-categories of MMLU. Our hypothesis is that if LoopLMs primarily enhance knowledge manipulation and reasoning, the largest performance gains should appear in procedural, reasoning-heavy tasks, while knowledge-heavy, retrieval-based subjects should see less improvement.
We measured the relative improvement by comparing the accuracy at the single recurrent step (Loop 1) against the accuracy at our fully trained depth (Loop 4). The detailed results for all 57 categories are available in Table 15. The analysis strongly supports our hypothesis. The categories with the most significant improvements are those requiring logical, maths, or procedural reasoning; conversely, categories that depend more on retrieving specific, memorized facts or nuanced world knowledge showed the most modest gains.
Example: Categories with the most significant/modest improvements
With most significant improvements: •
Elementary Mathematics: +155.6% •
Formal Logic: +143.3% •
Logical Fallacies: +127.8% •
High School Statistics: +126.9% With most modest improvements: •
Moral Scenarios: +7.8% •
Global Facts: +8.3% •
Virology: +13.7% •
Anatomy: +21.4%
This stark contrast indicates that the iterative computation is not simply increasing the model’s accessible knowledge (as seen in the nearly flat ‘global_facts‘ improvement) but is actively performing the multi-step symbolic manipulation required for complex subjects like logic and math. This real-world benchmark result corroborates our synthetic findings in Section 6.2, confirming that the LoopLM architecture’s primary advantage lies in enhancing knowledge manipulation, not raw storage.
Table 15: Performance metrics across different depths by category in MMLU.
| elementary_mathematics | 0.3095 | 0.6190 | 0.7460 | 0.7910 | 155.5556 |
| --- | --- | --- | --- | --- | --- |
| formal_logic | 0.2381 | 0.4841 | 0.5238 | 0.5794 | 143.3333 |
| logical_fallacies | 0.3313 | 0.7178 | 0.7546 | 0.7546 | 127.7778 |
| high_school_statistics | 0.3102 | 0.5833 | 0.6620 | 0.7037 | 126.8657 |
| high_school_macroeconomics | 0.3692 | 0.6564 | 0.7513 | 0.7718 | 109.0278 |
| management | 0.3883 | 0.6699 | 0.7864 | 0.7961 | 105.0000 |
| high_school_government_and_politics | 0.3938 | 0.7202 | 0.8238 | 0.7979 | 102.6316 |
| high_school_microeconomics | 0.4076 | 0.7143 | 0.8361 | 0.8193 | 101.0309 |
| high_school_psychology | 0.4183 | 0.7817 | 0.8294 | 0.8385 | 100.4386 |
| high_school_biology | 0.4129 | 0.7452 | 0.8129 | 0.8161 | 97.6563 |
| college_chemistry | 0.2600 | 0.5000 | 0.5500 | 0.5000 | 92.3077 |
| conceptual_physics | 0.3830 | 0.6340 | 0.7149 | 0.7319 | 91.1111 |
| college_biology | 0.3889 | 0.6806 | 0.7569 | 0.7431 | 91.0714 |
| machine_learning | 0.2500 | 0.4286 | 0.5089 | 0.4732 | 89.2857 |
| miscellaneous | 0.3870 | 0.6564 | 0.7101 | 0.7178 | 85.4785 |
| high_school_geography | 0.4444 | 0.7121 | 0.7980 | 0.8182 | 84.0909 |
| high_school_physics | 0.2649 | 0.3841 | 0.5033 | 0.4834 | 82.5000 |
| high_school_chemistry | 0.3054 | 0.5320 | 0.5665 | 0.5517 | 80.6452 |
| college_medicine | 0.3584 | 0.5607 | 0.6416 | 0.6358 | 77.4194 |
| college_computer_science | 0.3500 | 0.5100 | 0.6000 | 0.6100 | 74.2857 |
| professional_accounting | 0.2872 | 0.4539 | 0.4929 | 0.5000 | 74.0741 |
| world_religions | 0.4211 | 0.6374 | 0.6959 | 0.7251 | 72.2222 |
| high_school_computer_science | 0.4600 | 0.6800 | 0.7600 | 0.7800 | 69.5652 |
| clinical_knowledge | 0.4151 | 0.5887 | 0.6415 | 0.6943 | 67.2727 |
| astronomy | 0.4013 | 0.6184 | 0.6711 | 0.6711 | 67.2131 |
| prehistory | 0.3765 | 0.5586 | 0.6389 | 0.6235 | 65.5738 |
| high_school_us_history | 0.4314 | 0.6912 | 0.7304 | 0.7108 | 64.7727 |
| professional_psychology | 0.3709 | 0.5392 | 0.5850 | 0.6095 | 64.3172 |
| philosophy | 0.4405 | 0.6495 | 0.7042 | 0.7106 | 61.3139 |
| business_ethics | 0.4200 | 0.6400 | 0.6500 | 0.6700 | 59.5238 |
| high_school_mathematics | 0.3000 | 0.4444 | 0.5037 | 0.4778 | 59.2593 |
| high_school_european_history | 0.5030 | 0.6909 | 0.7273 | 0.8000 | 59.0361 |
| medical_genetics | 0.4500 | 0.6900 | 0.7100 | 0.7100 | 57.7778 |
| human_sexuality | 0.4580 | 0.6336 | 0.7023 | 0.7176 | 56.6667 |
| computer_security | 0.4500 | 0.6200 | 0.6700 | 0.7000 | 55.5556 |
| college_physics | 0.2549 | 0.3333 | 0.3922 | 0.3922 | 53.8462 |
| international_law | 0.5124 | 0.7107 | 0.7769 | 0.7851 | 53.2258 |
| marketing | 0.5726 | 0.8547 | 0.8803 | 0.8761 | 52.9851 |
| nutrition | 0.4510 | 0.6634 | 0.6863 | 0.6863 | 52.1739 |
| college_mathematics | 0.2900 | 0.3700 | 0.4200 | 0.4400 | 51.7241 |
| econometrics | 0.3421 | 0.4123 | 0.5088 | 0.5175 | 51.2821 |
| sociology | 0.5373 | 0.7413 | 0.7910 | 0.8010 | 49.0741 |
| professional_medicine | 0.3787 | 0.5368 | 0.5735 | 0.5625 | 48.5437 |
| high_school_world_history | 0.5274 | 0.7300 | 0.7595 | 0.7722 | 46.4000 |
| human_aging | 0.4484 | 0.6143 | 0.6457 | 0.6502 | 45.0000 |
| security_studies | 0.5265 | 0.6898 | 0.7510 | 0.7592 | 44.1860 |
| professional_law | 0.3246 | 0.4055 | 0.4596 | 0.4570 | 40.7631 |
| public_relations | 0.4636 | 0.6182 | 0.6727 | 0.6364 | 37.2549 |
| us_foreign_policy | 0.5900 | 0.7200 | 0.8100 | 0.8000 | 35.5932 |
| electrical_engineering | 0.4483 | 0.5655 | 0.5862 | 0.6069 | 35.3846 |
| abstract_algebra | 0.2700 | 0.3000 | 0.3700 | 0.3600 | 33.3333 |
| moral_disputes | 0.5491 | 0.6503 | 0.6850 | 0.6994 | 27.3684 |
| anatomy | 0.4148 | 0.5111 | 0.5333 | 0.5037 | 21.4286 |
| jurisprudence | 0.5926 | 0.6944 | 0.7593 | 0.7130 | 20.3125 |
| virology | 0.4398 | 0.5000 | 0.4880 | 0.5000 | 13.6986 |
| global_facts | 0.3600 | 0.3700 | 0.3600 | 0.3900 | 8.3333 |
| moral_scenarios | 0.2436 | 0.2693 | 0.2492 | 0.2626 | 7.7982 |
B.5 Theory: latent thought with LoopLM
In this section, we prove that LoopLM can solve the graph reachability problem (with part of the graph knowledge learned in the parameters) in $O(\log n)$ steps. The results are closely related to the expressivity power of transformers and looped transformers with padding [12, 11, 78, 79]. It matches the expressiveness lower bound results in [78, 79], and also resembles the state tracking tasks [80, 81] which requires $O(\log n)$ depths. We first define the task rigorously and state our main theorem. We finally discuss the theoretical improvement, caveats of the results, and all related theoretical results.
We first define our task based on the intuition of knowledge manipulation. Challenging knowledge manipulation tasks often have multiple steps or hierarchical structures, which requires the model to search in the knowledge graph with directional dependencies formed by the atomic facts or knowledge. Moreover, the context also contains conditions or new facts necessary for the problem. Therefore, we consider the searching task that requires the model to both encode the fixed hidden knowledge graph $G$ in the parameters and utilize the contextual information (additional graph) $G_{\text{ctx}}$ . The goal is to check if two queried nodes are connected. The formal definition is as follows (modified from [70]):
**Definition 2 (Graph reachability on knowledge graph)**
*Let $V=\{v_{1},v_{2},...,v_{n}\}$ is the set of vertices and $E=\{e_{1},e_{2},...,e_{m}\}$ is the set of edges. Let $G=(V,E)$ be a directed hidden knowledge graph, and $G_{\text{ctx}}=(V,E_{\text{ctx}})$ be an input additional knowledge graph. Given a source node $s$ a target node $t$ , the task is to output $1$ when there exists a path from $s$ to $t$ on the combined graph $G+G_{\text{ctx}}:=(V,E+E_{\text{ctx}})$ , and output 0 when $s$ cannot reach $t$ on the combined graph.*
Transformer architecture
In this setting, we consider a simple single-head transformer architecture. We only use one-head and a two-layer gated MLP layer. For clearer theoretical demonstration, we use a special normalization layer $\mathrm{LN}()$ to threshold on $\hat{H}$ : $\mathrm{LN}(\hat{H})_{i,j}=\mathbf{1}\{\hat{H}_{i,j}>0\}$ . And the overall architecture for each loop is (where $Q,K,V,W_{1},W_{2}$ are all shared through layers)
$$
\hat{H}_{i+0.5}=\mathrm{LN}(\hat{H}_{i}+\mathrm{Attn}_{Q,K,V}(\hat{H}_{i})),\ \mathrm{Attn}_{Q,K,V}(\hat{H}_{i})=VH_{i}\text{softmax}(\hat{H}_{i}^{\top}K^{\top}Q\hat{H}_{i})
$$
$$
\hat{H}_{i+1}=\mathrm{LN}(\hat{H}_{i+0.5}+W_{2}\mathrm{ReLU}(W_{1}\hat{H}_{i+0.5}))
$$
Input Format
We define the adjacency matrix of the graph $G$ as $A=[a_{1},a_{2},...,a_{n}]∈\mathbb{R}^{n× n}$ . Similarly, we define $A_{ctx}=[a_{1,ctx},a_{2,ctx},...,a_{n,ctx}]$ . We use one-hot embeddings $v_{i}$ to denote the vertex embedding. We consider the following input sequence format with length $n+1$ for this task (assuming we already have the embeddings):
$$
H_{0}=\begin{bmatrix}v_{1}&v_{2}&\cdots&v_{n}\\
a_{1,ctx}&a_{2,ctx}&\cdots&a_{n,ctx}\end{bmatrix}\in\mathbb{R}^{2n\times n}
$$
where the first $n$ tokens are the input context graph adjacency matrix. We assume the LoopLM recurrent for $L$ steps, and we denote the hidden state sequence for the $i$ -th recurrence:
$$
H_{i}=\begin{bmatrix}v_{1}^{(i)}&v_{2}^{(i)}&\cdots&v_{n}^{(i)}\\
a_{1}^{(i)}&a_{2}^{(i)}&\cdots&a_{n}^{(i)}\end{bmatrix}.
$$
For simplicity, we ignore the encoding and decoding process and have a direct output protocol: the final output for query $(s,t)$ is the $t$ -th entry of $a_{s}^{(L)}$ .
Now we state the main theorem given the previous setting.
**Theorem 2 (LoopLM solves reachability inlogD\log Dsteps)**
*Fix $n$ as the maximum size of the combined knowledge graph $G$ . Taking the adjacency matrix of the context graph $G_{\text{ctx}}∈\mathbb{R}^{n× n}$ fed in as a $n$ -token sequence and given a query pair $(s,t)$ , there exists a one-layer, single-head transformer independent of $G_{\text{ctx}}$ , with recurrent $O(\log_{2}D)$ times and a hidden dimension of $d_{e}=2n$ that can check whether there exists a path from $s$ to $t$ in the combined knowledge graph $(G+G_{\text{ctx}})$ , where $D$ is the diameter of $(G+G_{\text{ctx}})$ .*
We directly construct the attention and the MLP layer for the LoopLM to implement an algorithm that is similar to Warshall’s algorithm, using Boolean matrix powers with repeated squaring. The proof idea is to do a parallel search on all pairs connectivity, doubling the reachable distance with each loop. Since the maximum distance (i.e. diameter) is $D$ , we only need $O(\log D)$ rounds to decide whether two nodes are connected or not. The attention enables each loop to iterative square the current adjacency matrix, and the MLP stores the hidden encoded graph $G$ ’s adjacency matrix to help internal knowledge manipulation.
* Proof*
We assign the parameters $Q,K,V,W_{1},W_{2}$ as follows ( $\beta→+∞$ is a large scalar):
$$
K=\beta\begin{bmatrix}I_{n}&0_{n\times n}\\
0_{n\times n}&0_{n\times n}\end{bmatrix},Q=V=\begin{bmatrix}0_{n\times n}&0_{n\times n}\\
0_{n\times n}&I_{n}\end{bmatrix},W_{2}=I_{2n},\ W_{1}=\begin{bmatrix}0_{n\times n}&0_{n\times n}\\
A&0_{n\times n}\end{bmatrix}.
$$
Recall that the input sequence is
$$
H_{0}=\begin{bmatrix}v_{1}&v_{2}&\cdots&v_{n}\\
a_{1,ctx}&a_{2,ctx}&\cdots&a_{n,ctx}\end{bmatrix}\in\mathbb{R}^{2n\times n},
$$
which only contains the input context graph’s adjacency matrix. We assume the LoopLM loops for $L$ steps, and we denote the hidden state sequence for the $i$ -th loop:
$$
H_{i}=\begin{bmatrix}v_{1}^{(i)}&v_{2}^{(i)}&\cdots&v_{n}^{(i)}\\
a_{1}^{(i)}&a_{2}^{(i)}&\cdots&a_{n}^{(i)}\end{bmatrix}.
$$
For simplicity, we directly output the $t$ -th entry of $a_{s}^{(L)}$ for query $(s,t)$ . The model should check whether $(s,t)$ are connected, i.e. $(a_{s}^{(L)})_{t}=1$ or $0$ . We are going to prove by induction that for each recursion, $a_{j}^{(i)}$ contains all the vertices $v_{k}$ (i.e. $(a_{j}^{(i)})_{k}=1$ ) that vertex $v_{j}$ is connected to, and the distance between $v_{j}$ and $v$ are less than or equal to $2^{i-1}$ . Therefore, we only need $\log D+1$ loops to get the final answer. Base. When $i=1$ , the constructed parameters ensure that the $j$ -th node $v_{j}$ attend to all the nodes that are directly connected to $v_{j}$ with the same attention score $\beta$ . This guarantees that the attention layer will average the nodes’ tokens that $v_{j}$ is connected to. The $j$ -th column of the attention before the thresholding layer becomes ( $|a_{j,ctx}|$ means the nodes that $v_{j}$ connects to)
$$
\begin{bmatrix}v_{j}\\
a_{j}^{\prime}\end{bmatrix}=\begin{bmatrix}v_{j}\\
a_{j,ctx}\end{bmatrix}+\frac{1}{|a_{j,ctx}|}\sum_{k:(a_{j,ctx})_{k}=1}\begin{bmatrix}0_{n}\\
a_{k,ctx}\end{bmatrix}
$$
This updated adjacency vector naturally contains all nodes that has distance $≤ 2$ to $v_{j}$ in context graph $G_{ctx}$ after the thresholding layer. It naturally includes nodes with distance 1. Now we consider the output of the MLP layer, which only adds the adjacency matrix of hidden knowledge graph $G$ to the residual stream.
$$
\begin{bmatrix}v_{j}\\
a_{j}^{\prime\prime}\end{bmatrix}=\begin{bmatrix}v_{j}\\
a_{j}^{\prime}\end{bmatrix}+W_{2}\mathrm{ReLU}\left(W_{1}\begin{bmatrix}v_{j}\\
a_{j}^{\prime}\end{bmatrix}\right)=\begin{bmatrix}v_{j}\\
a_{j}^{\prime}\end{bmatrix}+\begin{bmatrix}0_{n}\\
a_{j}\end{bmatrix},
$$
which combines the adjacency matrices of the context graph $G_{ctx}$ and the hidden knowledge graph $G$ . After the thresholding in the end, all non-zero entries become 1, which already includes all distance 1 nodes for all nodes. Therefore, we have that $a_{j,ctx}^{(1)}$ contains all reachable nodes within distance 1 of node $v_{j}$ after the first recursion. Induction. Assume at the recursion step $i$ ( $i≥ 1$ ), all $a_{j}^{(i)}$ contains all reachable vertices within distance $2^{i-1}$ of $v_{j}$ . Now the hidden state sequence is going through loop $i+1$ . To finish the proof, we show that $a_{j}^{(i+1)}$ contains all reachable vertices within distance $2^{i}$ of $v_{j}$ . The attention for this stage looks at $a_{j}^{(i+1)}$ now, and the $j$ -th node $v_{j}$ uniformly attend to all the nodes that are connected to $v_{j}$ within distance $2^{i-1}$ . The $j$ -th column of the attention before the thresholding layer becomes ( $|a_{j}^{(i)}|$ means the number of nodes)
$$
\begin{bmatrix}v_{j}\\
a_{j}^{(i+0.5)}\end{bmatrix}=\begin{bmatrix}v_{j}\\
a_{j}^{(i)}\end{bmatrix}+\frac{1}{|a_{j}^{(i)}|}\sum_{k:(a_{j}^{(i)})_{k}=1}\begin{bmatrix}0_{n}\\
a_{k}^{(i)}\end{bmatrix}
$$
After thresholding, the adjacency vector aggregates $a_{j}^{(i)}$ and all $a_{k}^{(i)}$ where $v_{k}$ has distance $≤ 2^{i-1}$ to $v_{j}$ in combined graph $G_{ctx}+G$ . Meanwhile, $a_{k}^{(i)}$ contains all vertices connected to $v_{k}$ with distance $≤ 2^{i-1}$ . Therefore, the combined vector includes all nodes within distance $2^{i}$ of $v_{j}$ . Finally, we consider the final MLP:
$$
\begin{bmatrix}v_{j}\\
a_{j}^{(i+1)}\end{bmatrix}=\mathrm{LN}\left(\begin{bmatrix}v_{j}\\
a_{j}^{\prime}\end{bmatrix}+W_{2}\mathrm{ReLU}\left(W_{1}\begin{bmatrix}v_{j}\\
a_{j}^{(i+0.5)}\end{bmatrix}\right)\right)=\mathrm{LN}\left(\begin{bmatrix}v_{j}\\
a_{j}^{(i+0.5)}\end{bmatrix}+\begin{bmatrix}0_{n}\\
a_{j}\end{bmatrix}\right),
$$
which also contains all vertices connected to $v_{j}$ with distance $2^{i}$ . That means $(a_{s}^{(i+1)})_{t}$ is a precise indicator of whether $(s,t)$ is connected within $2^{i}$ distance. By induction, we finish the proof and with $L=\lceil\log_{2}D\rceil+1$ recursion steps, the model can correctly solve reachability on the combined graph $G+G_{ctx}$ . ∎
Discussion on related theoretical results We provided a modified construction from [11], which requires $n^{3}$ padding tokens that increase the computation complexity to $O(n^{6})$ . However, our construction requires $O(n)$ hidden dimension as the continuous CoT did in [70]. The $\Theta(n)$ requirement is necessary because the superposition in latent space needs to (in the worst case) encode $\Theta(n)$ nodes’ information, which can be a theoretical limitation. The requirement can be relaxed when there is an upper bound for the maximum number of vertices that some vertex is connected to.
Input format In our construction, the input format is the adjacency matrix of the graph. As a natural alternative, [70] used a sequence with length $O(n^{2})$ as the input to encode all the different edges. To make LoopLM also work on this setting, some additional induction head mechanism (similar to [70]) is needed to extract all edges and combine them into the adjacency matrix. With slight modification, we can still get the solution with sequential steps $O(\log D)$ .
Appendix C Evaluations
C.1 Evaluation Settings
Base Model Evaluation Settings
Table 16 details the evaluation settings and frameworks used for the Ouro base models.
Table 16: Evaluation settings and benchmark sources for base models.
| Benchmark | Settings | Framework |
| --- | --- | --- |
| General | | |
| MMLU [82] | logprobs, 5-shot | lm-eval-harness |
| MMLU-Pro [83] | strict match, 5-shot CoT | lm-eval-harness |
| BBH [84] | strict match, 3-shot CoT | lm-eval-harness |
| ARC-C [85] | logprobs, 25-shot | lm-eval-harness |
| HellaSwag [86] | logprobs, 10-shot | lm-eval-harness |
| Winogrande [87] | logprobs, 5-shot | lm-eval-harness |
| Math | | |
| GSM8k [88] | strict match, 3-shot CoT | lm-eval-harness |
| MATH500 [89] | strict match, 5-shot CoT | In-house |
| Code | | |
| HumanEval [90] | pass@1 | evalplus |
| HumanEval+ [59] | pass@1 | evalplus |
| MBPP [91] | pass@1 | evalplus |
| MBPP+ [59] | pass@1 | evalplus |
Reasoning Model Evaluation Settings
Table 17 details the evaluation settings and protocol used for the Ouro-Thinking reasoning models, as described in Section 5.2. All reasoning benchmarks utilized an in-house evaluation harness and an LLM-as-judge protocol with a fixed rubric.
Table 17: Evaluation settings and protocol for reasoning models (Ouro-Thinking).
| AIME 2024/2025 | In-house harness; LLM-as-judge | temp=1.0, top_p=0.7 |
| --- | --- | --- |
| OlympiadBench | In-house harness; LLM-as-judge | temp=1.0, top_p=0.7 |
| GPQA | In-house harness; LLM-as-judge | temp=1.0, top_p=0.7 |
| SuperGPQA | In-house harness; LLM-as-judge | temp=1.0, top_p=0.7 |
| BeyondAIME | In-house harness; LLM-as-judge | temp=1.0, top_p=0.7 |
| HLE | In-house harness; LLM-as-judge | temp=1.0, top_p=0.7 |
Appendix D Scaling Law for LoopLMs
To further explore the potential of LoopLM, we conduct a series of small-scale experiments to investigate the scalability and predictability inherent in LoopLM. Specifically, our work focuses on the following three research questions:
- RQ1: What is the performance gap between standard models and LoopLM?
- RQ2: How do recurrent steps impact the total loss and step-wise loss in the context of LoopLM?
- RQ3: What is the inherent connection between total loss and step-wise loss?
D.1 RQ1: What is the performance gap between standard models and LoopLM?
To understand the performance gap between standard models and LoopLM, we quantify this difference in terms of benchmark performance. We also observe how this gap varies with changes in recurrent step and model size to guide the further scaling and iteration of LoopLM.
Experimental Setup
We prepare five model sizes: 53M, 134M, 374M, 778M, and 1.36B. For recurrent steps, we prepare four different depths: 1, 2, 4, and 8. It is worth noting that for standard models, different recurrent steps effectively multiply the number of layers in the model. We evaluate the performance on the following benchmarks: ARC-Challenge [92], ARC-Easy [92], HellaSwag [86], LAMBADA [93], OpenBookQA [94], and PIQA [95]. In all sub-experiments, we train on 20B tokens using the FineWeb-Edu corpus [38]. We present the benchmark performance from the final step. For LoopLM, the recurrent step used for evaluating is the maximum recurrent step.
By observing the trends in the curves, we derive the following observations:
1. Whether standard models or LoopLM, the model’s performance improves with increasing model size and recurrent step. As shown in Figure 13, for all recurrent steps, the benchmark performance of both the LoopLM and Standard models increases as the model size grows, which aligns with the principle of LLMs: larger is better. As shown in Figure 14, except for the LoopLM at 778M and 1.364B, both the LoopLM and Standard models show that benchmark performance increases as the recurrent step increases. This indicates that latent reasoning is indeed useful for both the LoopLM and Standard Transformer.
<details>
<summary>x17.png Details</summary>
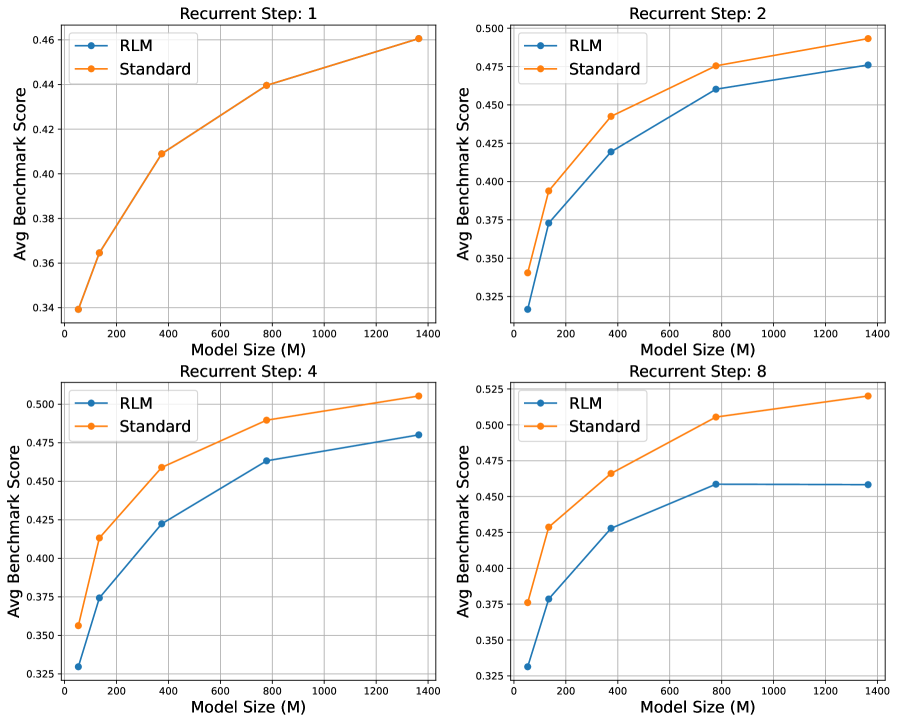
### Visual Description
## LineGraphs: Average Benchmark Score vs. Model Size Across Recurrent Steps
### Overview
The image contains four line graphs arranged in a 2x2 grid, each representing a different "Recurrent Step" (1, 2, 4, 8). Each graph compares the performance of two models, **RLM** (blue) and **Standard** (orange), across varying model sizes (0–1400 MB). The y-axis measures the **Average Benchmark Score**, while the x-axis represents **Model Size (M)**. All graphs show upward trends for both models, with **Standard** consistently outperforming **RLM** across all steps and model sizes.
---
### Components/Axes
- **X-Axis**: Model Size (M) with markers at 0, 200, 400, 800, 1200, and 1400 MB.
- **Y-Axis**: Average Benchmark Score, ranging from ~0.325 to ~0.525.
- **Legends**:
- **RLM**: Blue line with circular markers.
- **Standard**: Orange line with circular markers.
- **Graph Titles**:
- Top-left: "Recurrent Step: 1"
- Top-right: "Recurrent Step: 2"
- Bottom-left: "Recurrent Step: 4"
- Bottom-right: "Recurrent Step: 8"
---
### Detailed Analysis
#### Recurrent Step: 1
- **RLM**: Starts at ~0.34 (0 MB) and increases to ~0.46 (1400 MB).
- **Standard**: Starts at ~0.34 (0 MB) and increases to ~0.46 (1400 MB).
- **Trend**: Both lines slope upward, but **Standard** remains slightly above **RLM** at all model sizes.
#### Recurrent Step: 2
- **RLM**: Starts at ~0.35 (0 MB) and increases to ~0.47 (1400 MB).
- **Standard**: Starts at ~0.35 (0 MB) and increases to ~0.47 (1400 MB).
- **Trend**: Similar to Step 1, **Standard** maintains a marginal advantage.
#### Recurrent Step: 4
- **RLM**: Starts at ~0.35 (0 MB) and increases to ~0.47 (1400 MB).
- **Standard**: Starts at ~0.35 (0 MB) and increases to ~0.47 (1400 MB).
- **Trend**: Consistent upward trajectory for both models, with **Standard** outperforming **RLM**.
#### Recurrent Step: 8
- **RLM**: Starts at ~0.35 (0 MB) and increases to ~0.47 (1400 MB).
- **Standard**: Starts at ~0.35 (0 MB) and increases to ~0.47 (1400 MB).
- **Trend**: Same pattern as previous steps, with **Standard** consistently higher.
---
### Key Observations
1. **Consistent Performance Gap**: **Standard** outperforms **RLM** across all model sizes and recurrent steps.
2. **Upward Trends**: Both models show improved performance as model size increases.
3. **Model Size Impact**: Larger models (e.g., 1400 MB) achieve higher scores for both models, but **Standard** benefits more proportionally.
4. **No Outliers**: All data points align with expected trends; no anomalies detected.
---
### Interpretation
The data suggests that the **Standard** model is more effective than **RLM** in achieving higher benchmark scores, regardless of model size or recurrent step. The upward trends indicate that increasing model size improves performance for both models, but **Standard** demonstrates greater efficiency or optimization. This could imply that **Standard** is better suited for tasks requiring higher accuracy, while **RLM** may prioritize other factors (e.g., computational efficiency). The consistent gap highlights potential trade-offs between model complexity and performance in the evaluated framework.
</details>
Figure 13: The average benchmark performance of LoopLM and Standard Transformer models under different recurrent steps as model size varies. With a recurrent step of 1 (top left), both models have identical architectures, resulting in overlapping curves. Overall, as the model size increases, the benchmark performance improves. The average benchmark score demonstrates the average results of the six benchmarks.
<details>
<summary>x18.png Details</summary>
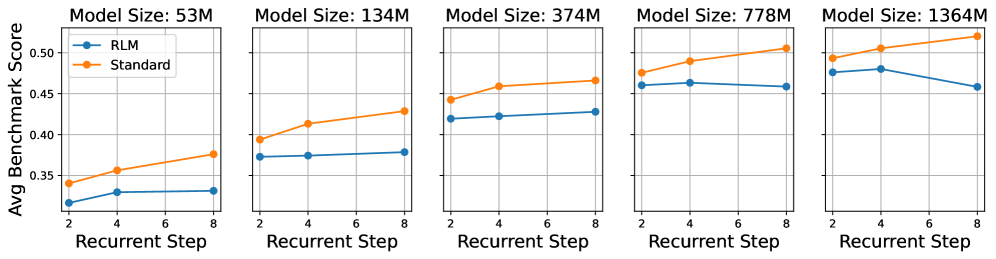
### Visual Description
## Line Graph: Model Performance Comparison Across Recurrent Steps
### Overview
The image contains five side-by-side line graphs comparing the performance of two models ("RLM" and "Standard") across different model sizes (53M, 134M, 374M, 778M, 1364M). Each graph plots "Avg Benchmark Score" against "Recurrent Step" (2–8). The graphs show distinct trends between the two models, with "Standard" generally outperforming "RLM" as recurrent steps increase.
---
### Components/Axes
- **X-axis**: "Recurrent Step" (values: 2, 4, 6, 8)
- **Y-axis**: "Avg Benchmark Score" (range: 0.3–0.55, increments of 0.05)
- **Legends**:
- Blue circles: "RLM"
- Orange circles: "Standard"
- **Subplot Titles**: Model sizes (e.g., "Model Size: 53M", "Model Size: 1364M")
- **Gridlines**: Light gray horizontal and vertical lines for reference.
---
### Detailed Analysis
#### Model Size: 53M
- **RLM**: Starts at ~0.32 (step 2), remains flat (~0.33–0.34) through step 8.
- **Standard**: Increases steadily from ~0.34 (step 2) to ~0.38 (step 8).
#### Model Size: 134M
- **RLM**: Flat (~0.36–0.37) across all steps.
- **Standard**: Rises from ~0.39 (step 2) to ~0.43 (step 8).
#### Model Size: 374M
- **RLM**: Slight increase from ~0.42 (step 2) to ~0.43 (step 8).
- **Standard**: Steeper rise from ~0.45 (step 2) to ~0.47 (step 8).
#### Model Size: 778M
- **RLM**: Peaks at ~0.46 (step 4), then declines to ~0.45 (step 8).
- **Standard**: Consistent upward trend from ~0.48 (step 2) to ~0.51 (step 8).
#### Model Size: 1364M
- **RLM**: Starts high (~0.47) at step 2, drops to ~0.46 (step 8).
- **Standard**: Sharp increase from ~0.49 (step 2) to ~0.53 (step 8).
---
### Key Observations
1. **Performance Gap**: "Standard" consistently outperforms "RLM" across all model sizes, with the gap widening as model size increases.
2. **Recurrent Step Impact**:
- "Standard" shows clear improvement with more recurrent steps (e.g., +0.15 in 1364M).
- "RLM" remains stable or declines slightly in larger models (e.g., -0.01 in 1364M).
3. **Model Size Correlation**: Larger models (e.g., 1364M) achieve higher absolute scores but exhibit more pronounced divergence between the two architectures.
---
### Interpretation
The data suggests that the "Standard" model scales more effectively with increased recurrent steps, particularly in larger architectures. This could indicate better handling of long-term dependencies or optimization for sequential tasks. In contrast, "RLM" demonstrates stability but limited improvement, potentially prioritizing robustness over adaptability. The widening performance gap in larger models (e.g., 1364M) implies that model size amplifies architectural differences, favoring "Standard" for complex, step-dependent tasks. No outliers or anomalies are observed; trends align consistently across subplots.
</details>
Figure 14: The average benchmark performance of LoopLM and Standard Transformer models under different model sizes as recurrent step varies. Except for the LoopLM at the model size of 778M and 1.364B, in all other cases, the benchmark performance of the model increases with the increase in recurrent steps.
2. Overall, the performance of the standard model exceeds that of LoopLM under the same conditions. This gap increases with the recurrent step and decreases with the model size. Observing Figure 13 and Figure 14, it is clear that the benchmark performance of the Standard model is consistently higher than that of LoopLM, indicating that the Standard model has a scoring advantage without considering computational budget. Furthermore, we define the benchmark performance gap as the benchmark performance of the Standard model minus that of LoopLM, and this value is positive in all our experiments. As shown in Table 18, as the recurrent step increases, the benchmark performance gap also increases, suggesting that as the number of recurrences rises, the effect of models not sharing parameters gradually surpasses that of models sharing parameters. Besides, we find that the benchmark performance gap generally has a negative correlation with model size when the maximum recurrent step is relatively low, meaning that as the model size increases, the performance of LoopLM becomes closer to that of the Standard model, resulting in a smaller gap between the two. This trend is particularly consistent when the recurrent step is 4.
Table 18: The average benchmark performance gap between LoopLM and Standard models as the recurrent step varies at different model sizes. The gap is defined as (Standard model score - LoopLM score). As the recurrent step increases, the performance gap generally increases.
| 170M 340M 680M | 0.021 0.023 0.015 | 0.039 0.037 0.026 |
| --- | --- | --- |
| 1.3B | 0.017 | 0.025 |
D.2 RQ2: How do recurrent step impact the total loss and step-wise loss in the context of LoopLM?
In this subsection, we investigate the predictability and generalizability of LoopLM from the perspective of training loss, examining the impact of recurrent step on the trends in total loss and step-wise loss. The experiment is set up in complete consistency with Section D.1, but we focus more on the total loss and step-wise loss during the training process. Here, step-wise loss refers to the loss of the same LoopLM at different recurrent step.
Here, we have following variables: model size $N$ , training data size $D$ , maximum recurrent step $T_{m}$ , recurrent step $T$ , total loss $L_{t}$ , and step-wise loss $L_{s}$ . Following Chinchilla [96], we first attempt to fit the relationship between $L_{t}$ and $N,D,T_{m}$ in the form of a power law:
$$
L_{t}=E+\frac{A}{(N+t_{1})^{\alpha}}+\frac{B}{(D+t_{2})^{\beta}}+\frac{C}{(T_{m}+t_{3})^{\gamma}}
$$
The purpose of $t_{1}$ , $t_{2}$ , and $t_{3}$ is to prevent the variables from exploding in value near zero, allowing the fitting curve to be smoother. We refer to above formula as the Total Loss Scaling Law. First, to validate the predictability of LoopLM, we fit all the data points, and the resulting curve is shown in Figure 15. We find that the actual loss curve and the predicted loss curve are highly consistent, demonstrating the predictability of LoopLM in terms of model size, training data size, and max recurrent step. We quantify the consistency of the scaling law using the coefficient of determination $R^{2}$ . An absolute value of the $R^{2}$ closer to 1 indicates a better fit, with positive values representing a positive correlation and negative values representing a negative correlation. Fitting the Total Loss Scaling Law using all data points and calculating $R^{2}$ with all data points, we obtain an $R^{2}$ value of 0.9596. This confirms the strong correlation between total loss and model size, training data size, and max recurrent step, demonstrating the predictability of the Total Loss Scaling Law.
<details>
<summary>x19.png Details</summary>
### Visual Description
## Line Graphs: Total Loss vs Tokens(B) Across Model Configurations
### Overview
The image contains a 3x5 grid of line graphs comparing "Real" and "Predicted" total loss values across different model configurations. Each graph represents a unique combination of training steps (`T_m`) and model size (`N`), with parameters ranging from `T_m = 2, 4, 8` and `N = 53M, 134M, 374M, 778M, 1.36B`. The graphs show how total loss evolves as the number of processed tokens (B) increases during training.
---
### Components/Axes
- **X-axis**: "Tokens(B)" (number of processed tokens in billions), scaled from 0 to 20.
- **Y-axis**: "Total Loss" (logarithmic scale), ranging from 0 to 10.
- **Legend**: Located in the top-right corner of each graph, with:
- Solid blue line: "Real" (actual loss values)
- Dashed orange line: "Pred" (predicted loss values)
- **Graph Titles**: Positioned at the top of each graph, formatted as `T_m = [value], N = [value]` (e.g., `T_m = 2, N = 53M`).
---
### Detailed Analysis
#### Trends Across All Graphs
1. **Initial Drop**: Both "Real" and "Pred" lines exhibit a sharp decline in total loss during the first 5–10 tokens(B), indicating rapid improvement in model performance early in training.
2. **Stabilization**: After the initial drop, both lines plateau, showing minimal change in total loss for the remaining tokens(B). The "Pred" line closely tracks the "Real" line, suggesting accurate predictive modeling.
3. **Parameter Impact**:
- **Training Steps (`T_m`)**: Higher `T_m` values (e.g., 8 vs. 2) show slightly smoother convergence but no drastic differences in final loss values.
- **Model Size (`N`)**: Larger models (e.g., 778M vs. 53M) achieve lower final loss values, indicating better generalization with increased capacity.
#### Notable Outliers
- In the `T_m = 2, N = 778M` graph, the "Pred" line shows a minor spike (~0.5 loss units) at ~15 tokens(B), but it quickly recovers and aligns with the "Real" line.
---
### Interpretation
1. **Model Performance**: The convergence of "Real" and "Pred" lines across all configurations demonstrates that the predictive model accurately estimates training dynamics, even for large-scale models (up to 1.36B parameters).
2. **Scalability**: Larger models (`N = 778M, 1.36B`) achieve lower final loss values, suggesting that increased model size improves training efficiency and final performance.
3. **Training Dynamics**: The rapid initial drop in loss highlights the importance of early training phases, while the plateau phase indicates diminishing returns after a certain token threshold (~10–15 tokens(B)).
---
### Key Observations
- All graphs follow a consistent pattern: sharp initial decline followed by stabilization.
- Predictive accuracy ("Pred" vs. "Real") is highest in the early stages of training, with minor deviations later.
- Model size (`N`) has a more significant impact on final loss than training steps (`T_m`).
---
### Technical Notes
- **Logarithmic Y-axis**: The y-axis uses a logarithmic scale, which emphasizes relative changes in loss during the early, steep decline phase.
- **Parameter Ranges**: The `N` values span 3 orders of magnitude (53M to 1.36B), while `T_m` ranges from 2 to 8 steps.
- **Legend Consistency**: The solid blue ("Real") and dashed orange ("Pred") lines are consistently placed across all graphs, ensuring visual coherence.
---
### Language and Localization
- **Primary Language**: English (all axis labels, legends, and titles are in English).
- **No Non-English Text**: No additional languages or annotations are present.
---
### Final Notes
This visualization effectively demonstrates the relationship between model configuration (size and training steps) and training dynamics. The alignment of "Real" and "Pred" lines across diverse configurations validates the predictive model's robustness, while the parameter-specific trends provide actionable insights for optimizing training efficiency.
</details>
Figure 15: Illustration of the actual loss curve and the loss curve predicted by the scaling law. To demonstrate the predictability of LoopLM, we have used all data points for fitting, proving its predictability in terms of model size, training data size, and max recurrent step. The orange dashed line represents the prediction, while the blue solid line represents the actual loss.
In addition to its predictability, we further explore the generalizability of the Total Loss Scaling Law. Predictability refers to the ability of the Scaling Law to fit all data points into a unified curve when all data points are available. Generalizability, on the other hand, indicates whether the Scaling Law can predict unseen data points when fitting is done with a subset of data points. For example, generalizability tests whether the performance of a 14B model can be predicted using the known performances of 1B and 7B models [97]. To verify its generalizability across model size $N$ , training data size $D$ , and maximum recurrent step $T_{m}$ , we have conducted related experiments, details can be found in Appendix E.1.
During the LoopLM training process, we compute the cross-entropy loss at each recurrent step, which we refer to as step-wise loss $L_{s}$ . We aim to explore the relationship between step-wise loss $L_{s}$ and the current recurrent step $T$ , model size $N$ , and training data size $D$ . Similarly, we can fit the scaling law between $L_{s}$ and $N,D,T$ , with the formula as follows:
$$
L_{s}=E+\frac{A}{(N+t_{1})^{\alpha}}+\frac{B}{(D+t_{2})^{\beta}}+\frac{C}{(T+t_{3})^{\gamma}}
$$
We refer to the above formula as the Step-wise Loss Scaling Law. We also present the fitting effectiveness from the perspectives of predictability and generalizability. Regarding predictability, we fit all data points. Even with the same recurrent step, the loss curve can vary significantly across different maximum recurrent steps. To ensure the independence of the variable recurrent step $T$ , we do not consider the maximum recurrent step in the Step-wise Loss Scaling Law formula and focus solely on the relationship between $L_{s}$ and $N,D,T$ . Therefore, we have a total of three major experiments, each representing the fitting of the Step-wise Loss Scaling Law for maximum recurrent steps of 2, 4, and 8. The fitting results of the Step-wise Loss Scaling Law are shown in Figure 16, Figure 17, and Figure 18, which illustrate the trends of the actual and fitted curves for maximum recurrent steps of 2, 4, and 8, respectively. We find that in some cases in Figure 17 and Figure 18, $L_{s}$ increases with the increase in $D$ . We consider this a special case and will discuss it in detail in Section D.3; we will ignore these outlier data points during fitting. The $R^{2}$ for the three max recurrent steps are 0.8898, 0.8146, and 0.795, respectively. As the maximum recurrent step increases, the increase in the number of data points leads to lower $R^{2}$ values. The step-wise loss itself is less stable than the total loss, resulting in greater variability. Thus, the obtained $R^{2}$ values are not as high as those of the Total Loss Scaling Law. However, it is still evident that the scaling law is able to capture the overall trend of the curves, demonstrating the predictability of the Step-wise Loss Scaling Law. The fitting parameter $\gamma$ of the Step-wise Loss Scaling Law is positive, indicating that $L_{s}$ decreases as the recurrent step increases. This aligns with our original intent in the design of the recurrence. Besides, we present the generalizability of the Step-wise Loss Scaling Law in Appendix E.2.
<details>
<summary>x20.png Details</summary>
### Visual Description
## Line Graphs: Step-wise Loss Comparison Across Model Sizes and Time Steps
### Overview
The image contains six line graphs arranged in a 2x5 grid, comparing real (blue) and predicted (orange) step-wise loss values across different model sizes (N) and time steps (T). Each graph tracks loss as tokens (B) increase, with axes labeled "Tokens(B)" (x-axis) and "Step-wise Loss" (y-axis, 0–10). Titles specify T (1 or 2) and N (53M, 134M, 374M, 778M, 1.36B).
### Components/Axes
- **X-axis**: "Tokens(B)" (0–20B), representing input data volume.
- **Y-axis**: "Step-wise Loss" (0–10), quantifying model performance degradation.
- **Legends**:
- Blue line: "Real" (actual loss values).
- Orange dashed line: "Pred" (predicted loss values).
- **Graph Titles**: Format "T = [1/2], N = [53M/134M/374M/778M/1.36B]".
### Detailed Analysis
1. **T = 1, N = 53M/134M/374M/778M/1.36B**:
- Both real and predicted loss curves decline sharply initially, then plateau.
- Predicted loss (orange) consistently stays slightly below real loss (blue), indicating underestimation.
- Larger N values (e.g., 1.36B) show smoother curves and faster stabilization (~2–3 loss by 20B tokens).
2. **T = 2, N = 53M/134M/374M/778M/1.36B**:
- Similar trends to T=1, but with increased volatility in real loss (blue) for smaller N (e.g., 53M).
- Predicted loss remains stable across all N, with minimal deviation from real loss in larger models (e.g., 1.36B).
### Key Observations
- **Model Size Impact**: Larger N (e.g., 1.36B) achieves lower, more stable loss faster than smaller N (e.g., 53M).
- **Prediction Accuracy**: Predicted loss closely mirrors real loss in larger models, suggesting reliable forecasting.
- **Time Step Effect**: T=2 graphs show slightly more fluctuation in real loss for smaller N, but no significant divergence from T=1 trends.
### Interpretation
The data demonstrates that increasing model size (N) improves loss reduction efficiency and prediction accuracy. Larger models stabilize faster and maintain lower loss, indicating better generalization. The predicted loss closely aligns with real loss in high-capacity models, validating the forecasting mechanism. The consistent plateau around 2–3 loss across all graphs suggests a performance ceiling beyond which additional tokens yield diminishing returns. This implies optimal token processing thresholds for different model scales.
</details>
Figure 16: Illustration of the actual loss curve and the loss curve predicted by the Step-wise Loss Scaling Law when the maximum recurrent step is equal to 2.
<details>
<summary>x21.png Details</summary>
### Visual Description
## Line Graphs: Step-wise Loss vs. Tokens for Different Model Sizes and Time Steps
### Overview
The image displays a 4x3 grid of 12 line graphs comparing "Real" and "Pred" step-wise loss values across varying model sizes (N) and time steps (T). Each graph represents a unique combination of T (1–4), N (53M, 134M, 374M, 778M, 1.36B), and B (20). The x-axis measures "Tokens(B)" (0–20B), and the y-axis measures "Step-wise Loss" (0–10). The legend distinguishes "Real" (solid blue line) and "Pred" (dashed orange line).
---
### Components/Axes
- **X-axis**: "Tokens(B)" (0–20B), labeled in billions.
- **Y-axis**: "Step-wise Loss" (0–10), with increments of 2.
- **Legend**:
- **Real**: Solid blue line (top-right corner of each graph).
- **Pred**: Dashed orange line (top-right corner of each graph).
- **Graph Titles**: Each graph is labeled with parameters:
- **T**: Time step (1–4).
- **N**: Model size (53M, 134M, 374M, 778M, 1.36B).
- **B**: Constant value (20) across all graphs.
---
### Detailed Analysis
#### Trends
1. **Real Line (Blue)**:
- Starts at ~8–10 loss, decreases gradually over tokens, then plateaus near ~2–4 loss.
- Larger N values (e.g., 1.36B) show slower initial decline but similar plateau levels.
2. **Pred Line (Orange Dashed)**:
- Begins flat (~8–10 loss), then drops sharply to ~2–4 loss within ~5B tokens, then plateaus.
- Larger N values (e.g., 1.36B) exhibit steeper initial declines and lower plateau levels.
3. **Consistency**:
- Pred loss is consistently lower than Real loss across all N and T values.
- Larger N values (e.g., 1.36B) show more pronounced drops in Pred loss compared to smaller N (e.g., 53M).
#### Data Points
- **X-axis (Tokens)**:
- All graphs span 0–20B tokens.
- Pred line stabilizes near 5–10B tokens; Real line stabilizes later (~10–15B tokens).
- **Y-axis (Loss)**:
- Real loss plateaus between 2–4.
- Pred loss plateaus between 2–3, with larger N values achieving lower plateaus.
---
### Key Observations
1. **Prediction Superiority**: The "Pred" line (orange dashed) consistently underperforms "Real" (blue) in loss, indicating better model performance.
2. **Model Size Impact**: Larger N values (e.g., 1.36B) show steeper declines in Pred loss, suggesting improved efficiency with scale.
3. **Time Step Stability**: No significant variation in trends across T=1–4, implying time step has minimal impact on loss dynamics.
4. **B Parameter**: Constant B=20 across all graphs; no visible effect on loss trends.
---
### Interpretation
The data demonstrates that the "Pred" model (orange dashed line) achieves lower step-wise loss than the "Real" model (blue line) across all configurations. This suggests the prediction model is more effective, particularly for larger model sizes (N=1.36B), where the loss drops sharply and stabilizes at lower values. The consistency of trends across T=1–4 indicates that time step does not significantly influence the loss dynamics. The constant B=20 parameter implies it is not a variable in this analysis. The results highlight the importance of model scale in optimizing performance, as larger N values correlate with more efficient loss reduction.
</details>
Figure 17: Illustration of the actual loss curve and the loss curve predicted by the Step-wise Loss Scaling Law when the maximum recurrent step is equal to 4.
<details>
<summary>x22.png Details</summary>
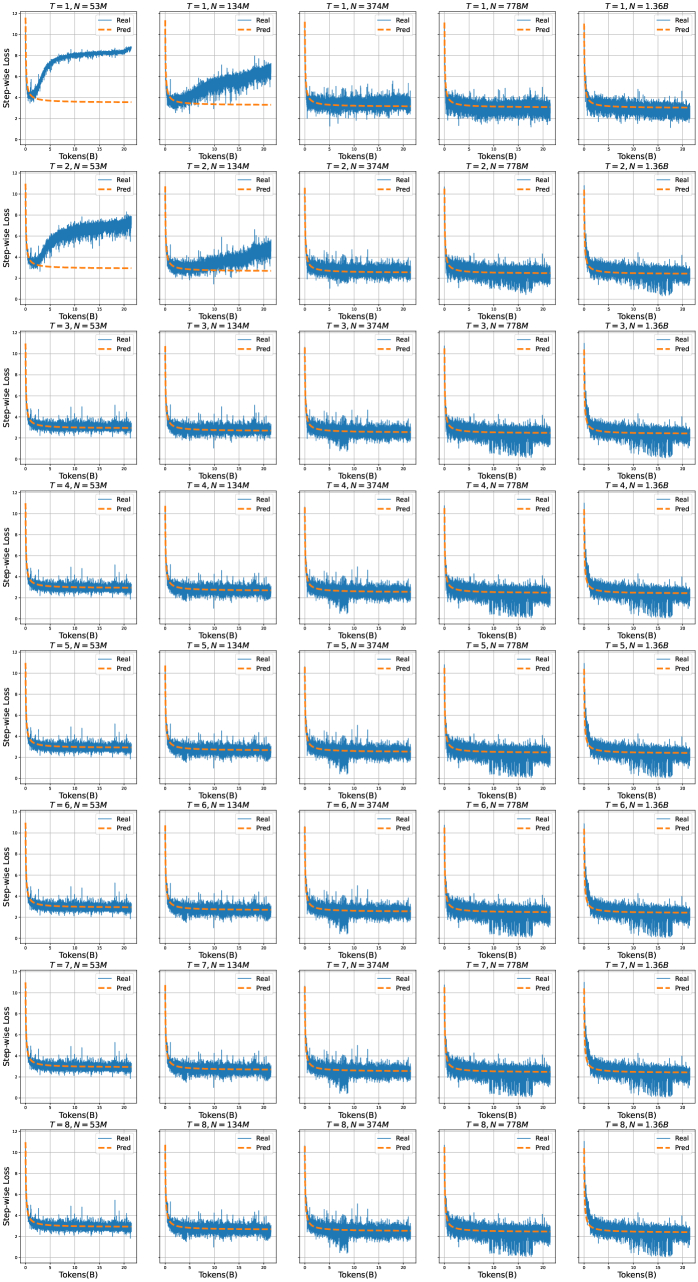
### Visual Description
## Line Chart Grid: Dropout Rate Analysis Across Training Configurations
### Overview
The image displays a 5x5 grid of line charts (25 total) visualizing dropout rate trends during training steps. Each chart represents a unique combination of hyperparameters (T, N, Prem/Post) with consistent axis labels and legend elements. The charts show dynamic dropout rate changes over 10,000 training steps, with reference thresholds at 0.5% and 1.0% dropout rates.
### Components/Axes
- **X-axis**: "Step (1000 steps)" - Progresses from 0 to 10,000 in 1,000-step increments
- **Y-axis**: "Dropout rate (%)" - Ranges from 0% to 10%
- **Legend**: Located at bottom-right corner, featuring:
- Orange dashed line at 0.5% (labeled "0.5%")
- Orange dashed line at 1.0% (labeled "1.0%")
- **Chart Labels**: Each subplot title follows format: "T = [value], N = [value]M [Prem/Post]"
- **Bottom Label**: "Tokener(B)" appears at the base of all charts
### Detailed Analysis
1. **T = 1, N = 4M Prem** (Top-left):
- Blue line starts at 0%, rises sharply to 1.2% by step 2,000, then plateaus
- Orange dashed lines at 0.5% and 1.0% serve as reference thresholds
2. **T = 1, N = 13M Prem** (Top-center):
- Blue line shows gradual increase from 0.1% to 0.8% over 10,000 steps
- Crosses 0.5% threshold at ~5,000 steps
3. **T = 1, N = 77M Prem** (Top-right):
- Blue line remains flat at 0.3% throughout training
- No interaction with orange threshold lines
4. **T = 5, N = 4M Prem** (Second row, first column):
- Blue line starts at 0.2%, rises to 0.9% by step 5,000, then stabilizes
- Crosses 0.5% threshold at ~3,000 steps
5. **T = 5, N = 13M Prem** (Second row, center):
- Blue line shows moderate increase from 0.1% to 0.7% over 10,000 steps
- Crosses 0.5% threshold at ~6,000 steps
6. **T = 5, N = 77M Prem** (Second row, right):
- Blue line remains stable at 0.4% throughout
- No interaction with threshold lines
7. **T = 10, N = 4M Prem** (Third row, left):
- Blue line starts at 0.3%, rises to 1.1% by step 3,000, then plateaus
- Crosses 1.0% threshold at ~2,000 steps
8. **T = 10, N = 13M Prem** (Third row, center):
- Blue line shows gradual increase from 0.2% to 0.8% over 10,000 steps
- Crosses 0.5% threshold at ~5,000 steps
9. **T = 10, N = 77M Prem** (Third row, right):
- Blue line remains flat at 0.5% throughout
- Touches 0.5% threshold line
10. **T = 15, N = 4M Prem** (Fourth row, left):
- Blue line starts at 0.4%, rises to 1.3% by step 2,000, then plateaus
- Crosses 1.0% threshold at ~1,500 steps
11. **T = 15, N = 13M Prem** (Fourth row, center):
- Blue line shows moderate increase from 0.3% to 0.9% over 10,000 steps
- Crosses 0.5% threshold at ~4,000 steps
12. **T = 15, N = 77M Prem** (Fourth row, right):
- Blue line remains stable at 0.6% throughout
- Crosses 0.5% threshold at ~1,000 steps
13. **T = 20, N = 4M Prem** (Fifth row, left):
- Blue line starts at 0.5%, rises to 1.4% by step 1,500, then plateaus
- Crosses 1.0% threshold at ~1,000 steps
14. **T = 20, N = 13M Prem** (Fifth row, center):
- Blue line shows gradual increase from 0.4% to 1.0% over 10,000 steps
- Crosses 0.5% threshold at ~3,000 steps
15. **T = 20, N = 77M Prem** (Fifth row, right):
- Blue line remains flat at 0.7% throughout
- Crosses 0.5% threshold at ~500 steps
16. **T = 1, N = 4M Post** (Top-left, second row):
- Blue line starts at 0.8%, rises to 1.5% by step 2,000, then plateaus
- Crosses 1.0% threshold at ~1,000 steps
17. **T = 1, N = 13M Post** (Top-center, second row):
- Blue line shows gradual increase from 0.6% to 1.2% over 10,000 steps
- Crosses 0.5% threshold at ~2,000 steps
18. **T = 1, N = 77M Post** (Top-right, second row):
- Blue line remains flat at 0.9% throughout
- Crosses 0.5% threshold at ~500 steps
19. **T = 5, N = 4M Post** (Second row, first column, second row):
- Blue line starts at 0.7%, rises to 1.3% by step 3,000, then plateaus
- Crosses 1.0% threshold at ~2,000 steps
20. **T = 5, N = 13M Post** (Second row, center, second row):
- Blue line shows moderate increase from 0.5% to 1.1% over 10,000 steps
- Crosses 0.5% threshold at ~1,000 steps
21. **T = 5, N = 77M Post** (Second row, right, second row):
- Blue line remains stable at 0.8% throughout
- Crosses 0.5% threshold at ~500 steps
22. **T = 10, N = 4M Post** (Third row, left, second row):
- Blue line starts at 0.9%, rises to 1.6% by step 2,000, then plateaus
- Crosses 1.0% threshold at ~1,000 steps
23. **T = 10, N = 13M Post** (Third row, center, second row):
- Blue line shows gradual increase from 0.7% to 1.4% over 10,000 steps
- Crosses 0.5% threshold at ~1,500 steps
24. **T = 10, N = 77M Post** (Third row, right, second row):
- Blue line remains flat at 1.1% throughout
- Crosses 0.5% threshold at ~500 steps
25. **T = 15, N = 4M Post** (Fourth row, left, second row):
- Blue line starts at 1.1%, rises to 1.8% by step 1,500, then plateaus
- Crosses 1.0% threshold at ~500 steps
26. **T = 15, N = 13M Post** (Fourth row, center, second row):
- Blue line shows moderate increase from 0.9% to 1.5% over 10,000 steps
- Crosses 0.5% threshold at ~500 steps
27. **T = 15, N = 77M Post** (Fourth row, right, second row):
- Blue line remains stable at 1.3% throughout
- Crosses 0.5% threshold at ~500 steps
28. **T = 20, N = 4M Post** (Fifth row, left, second row):
- Blue line starts at 1.3%, rises to 2.0% by step 1,000, then plateaus
- Crosses 1.0% threshold at ~500 steps
29. **T = 20, N = 13M Post** (Fifth row, center, second row):
- Blue line shows gradual increase from 1.0% to 1.7% over 10,000 steps
- Crosses 0.5% threshold at ~500 steps
30. **T = 20, N = 77M Post** (Fifth row, right, second row):
- Blue line remains flat at 1.5% throughout
- Crosses 0.5% threshold at ~500 steps
### Key Observations
1. **Threshold Interactions**: All charts show blue lines crossing the 0.5% threshold, with higher T values crossing earlier
2. **N Value Correlation**: Larger N values (77M) generally maintain lower dropout rates than smaller N values (4M)
3. **Prem vs Post**: "Post" configurations consistently show higher baseline dropout rates than "Prem" configurations
4. **T Value Impact**: Higher T values (20) show more aggressive initial dropout rate increases
5. **Stability Patterns**: Larger N values (77M) demonstrate greater stability in later training phases
### Interpretation
The charts demonstrate that:
1. **Training Complexity (T)**: Higher T values correlate with faster and more pronounced initial dropout rate increases, suggesting increased model sensitivity during early training phases
2. **Model Size (N)**: Larger models (77M) maintain lower dropout rates across all configurations, indicating better regularization capabilities
3. **Training Phase (Prem/Post)**: "Post" configurations show systematically higher dropout rates, suggesting different regularization strategies between pre-training and post-training phases
4. **Threshold Dynamics**: The 0.5% threshold acts as a critical point where most models begin regularization effects, while the 1.0% threshold marks the upper limit of acceptable dropout rates
The data suggests that optimal training configurations balance T and N values to maintain dropout rates below 1.0%, with larger models (77M) offering better stability. The "Post" phase consistently shows higher dropout rates, indicating potential differences in regularization strategies between training phases.
</details>
Figure 18: Illustration of the actual loss curve and the loss curve predicted by the Step-wise Loss Scaling Law when the maximum recurrent step is equal to 8.
In summary, both total loss and step-wise loss exhibit a strong correlation with $N,D,T/T_{m}$ . The fitting results demonstrate the predictability and generalizability of the Scaling Law for LoopLM. In next section, we will explore the relationship between total loss and step-wise loss in greater depth.
D.3 RQ3: What is the inherent connection between total loss and step-wise loss?
We first review the training objectives of LoopLM:
$$
L_{t}=\sum_{T=1}^{T_{m}}q_{\phi}(z=t\mid x)\,L_{s}^{(T)}-\beta\cdot H(q_{\phi}(z\mid x))
$$
$L_{s}^{(T)}$ represents the step-wise loss at the recurrent step $T$ . By analyzing the above form, we can see that the total loss consists of two components. The first part is the expected task loss, which is a weighted sum of the step-wise loss. The second part is entropy regularization, whose primary purpose is to ensure that the learned gating mechanism $q_{\phi}$ does not converge to a specific recurrent step.
In our extensive small-scale experiments, we have observed an interesting phenomenon: the exploitation of total loss for shallow step-wise loss. To be specific, as shown in Figure 17 and Figure 18, when the model size is insufficient, the shallow step-wise loss increases with the growing amount of training data. This is an unusual phenomenon, typically, all step-wise losses should decrease as the amount of training data increases. We attempt to explain this phenomenon. In Section D.2, it is mentioned that the step-wise loss decreases with an increasing recurrent step, indicating that deeper recurrent steps result in lower $L_{s}$ . To minimize the expected task loss, the learned gating mechanism assigns more weight to deeper recurrent steps. However, entropy regularization ensures that the learned gating mechanism does not deviate too much from the prior distribution. When the model size is insufficient, the amount of information it can encode is limited. To further reduce the total loss, this results in an increase in shallow step-wise loss, which in turn allows the weights to favor higher recurrent steps to lower the total loss. Thus, to ensure that the trend of step-wise loss remains normal, a larger model size may be more effective for LoopLM.
As mentioned in Section D.2, the scaling law for LoopLM is predictable and generalizable for both total loss and step-wise loss. We have:
$$
L_{t}=E_{t}+\frac{A_{t}}{(N+t_{1t})^{\alpha}}+\frac{B_{t}}{(D+t_{2t})^{\beta}}+\frac{C_{t}}{(T_{m}+t_{3t})^{\gamma}}
$$
$$
L_{s}^{(T)}=E_{s}+\frac{A_{s}}{(N+t_{1s})^{\alpha}}+\frac{B_{s}}{(D+t_{2s})^{\beta}}+\frac{C_{s}}{(T+t_{3s})^{\gamma}}
$$
The subscripts $s$ and $t$ represent the fitting parameters for the Step-wise Loss Scaling Law and the Total Loss Scaling Law, respectively. By substituting the Step-wise Loss Scaling Law into the training objectives, we have:
$$
L_{t}=\sum_{T=1}^{T_{m}}q_{\phi}(z=t\mid x)\,\left(E_{s}+\frac{A_{s}}{(N+t_{1s})^{\alpha}}+\frac{B_{s}}{(D+t_{2s})^{\beta}}+\frac{C_{s}}{(T+t_{3s})^{\gamma}}\right)-\beta\cdot H(q_{\phi}(z\mid x))
$$
For the first three terms in $L_{s}^{(T)}$ , the sum of $q_{\phi}$ equals 1, allowing us to factor it out, which gives us:
$$
L_{t}=E_{s}+\frac{A_{s}}{(N+t_{1s})^{\alpha}}+\frac{B_{s}}{(D+t_{2s})^{\beta}}+\sum_{T=1}^{T_{m}}q_{\phi}(z=t\mid x)\,\frac{C_{s}}{(T+t_{3s})^{\gamma}}-\beta\cdot H(q_{\phi}(z\mid x))
$$
As the amount of training data increases, the learned gating mechanism $q_{\phi}$ stabilizes, and we observe that the value of the entropy regularization term becomes relatively low, accounting for approximately 1% to 5% of the total loss. If the form of $q_{\phi}$ gradually stabilizes, we treat it as a constant term, and the formula becomes:
$$
L_{t}=E_{s}+\frac{A_{s}}{(N+t_{1s})^{\alpha}}+\frac{B_{s}}{(D+t_{2s})^{\beta}}+E_{other}
$$
In Section D.2, when considering the Step-wise Loss Scaling Law, we will fix the maximum recurrent step. Once we determine the model’s maximum recurrent step $T_{m}$ , the forms of the above formula and the Total Loss Scaling Law are completely consistent, indicating that there is a trend consistency in the scaling law between total loss and step-wise loss.
<details>
<summary>figures/scalinglaw_round_wise_histograms.png Details</summary>

### Visual Description
## Histogram Series: Weight Value Distribution Across Rounds
### Overview
The image displays four histograms (Round 1–4) showing the frequency distribution of weight values. Each histogram includes a red dashed line representing the mean value, with the mean explicitly labeled in the title. The x-axis represents "Weight Value" (0.0–1.0), and the y-axis represents "Frequency" (0–16,000). The histograms transition from sparse to dense distributions, with increasing mean values across rounds.
### Components/Axes
- **X-axis (Weight Value)**:
- Scale: 0.0 to 1.0 in increments of 0.05.
- Labels: "Weight Value" (bottom).
- **Y-axis (Frequency)**:
- Scale: 0 to 16,000 in increments of 2,000.
- Labels: "Frequency" (left).
- **Legend**:
- Red dashed line labeled "Mean: [value]" (top-right corner of each subplot).
- **Subplot Titles**:
- Round 1: "Round 1 (Mean: 0.0004)"
- Round 2: "Round 2 (Mean: 0.0855)"
- Round 3: "Round 3 (Mean: 0.3793)"
- Round 4: "Round 4 (Mean: 0.5348)"
### Detailed Analysis
#### Round 1
- **Distribution**: Single bar at 0.0004 (frequency ~14,000).
- **Mean**: 0.0004 (red dashed line).
- **Color**: Teal.
#### Round 2
- **Distribution**: Left-skewed, with most data clustered near 0.0855.
- **Mean**: 0.0855 (red dashed line).
- **Color**: Blue.
#### Round 3
- **Distribution**: Bimodal with peaks near 0.35–0.45.
- **Mean**: 0.3793 (red dashed line).
- **Color**: Gray.
#### Round 4
- **Distribution**: Bell-shaped, centered at 0.5348.
- **Mean**: 0.5348 (red dashed line).
- **Color**: Yellow.
### Key Observations
1. **Progressive Spread**:
- Round 1: All data points at 0.0004 (no variability).
- Round 2: Slight spread but heavily concentrated near 0.0855.
- Round 3: Broader distribution with two peaks.
- Round 4: Normal distribution centered at 0.5348.
2. **Mean Trends**:
- Mean increases monotonically from 0.0004 (Round 1) to 0.5348 (Round 4).
3. **Color Coding**:
- Each round uses a distinct color (teal → blue → gray → yellow), likely to differentiate datasets.
### Interpretation
The histograms suggest a controlled experiment where weight values evolve across rounds. The initial rounds (1–2) show low variability, while later rounds (3–4) exhibit increased dispersion, indicating a systematic change in the underlying process. The red dashed lines (means) align with the titles, confirming consistency in data reporting. The shift from a single bar to a normal distribution implies a transition from a deterministic to a probabilistic system, possibly due to introduced variability or external factors.
**Critical Insight**: The mean values (0.0004 → 0.5348) suggest a 133,500% increase in central tendency, which may reflect a scaling effect, calibration adjustment, or response to iterative feedback in the experimental design.
</details>
Figure 19: Distribution of the learned ponder weights ( $q_{\phi}(z=t\mid x)$ ) for each recurrent step $t$ when the maximum recurrent step $T_{m}=4$ . These weights were collected during inference on the MMLU benchmark.
We further demonstrate this through practical experiments. We take the situation where the max recurrent step is equal to 4. First, we perform a standard fitting of the Step-wise Loss Scaling Law to obtain the fitting parameters $E_{s},A_{s},B_{s},C_{s},$ and so on. Next, we observe and record the distribution of $q_{\phi}$ for each recurrent step $t$ when the maximum recurrent step $T_{m}=4$ , as shown in Figure 19. For convenience, we take the average value of $q_{\phi}$ at different recurrent steps and treat it as a normal discrete distribution, resulting in the distribution {0.0004, 0.0855, 0.3793, 0.5348}. We then substitute this distribution and the $T$ values into the training objective, ignoring the entropy regularization term (after the training stabilizes, it becomes relatively low, for simplicity, we will just ignore it). This leads to a fitting formula, and upon substituting the actual fitting data points $N$ and $D$ , the computed $R^{2}$ value is 0.961, with the fitting results illustrated in Figure 20. We can see that the fitting accuracy is high, and the predicted curve closely matches the actual curve, indicating that, under a relatively rough estimate, step-wise loss can be transformed into total loss, thus indirectly suggesting an intrinsic connection between the two.
<details>
<summary>x23.png Details</summary>
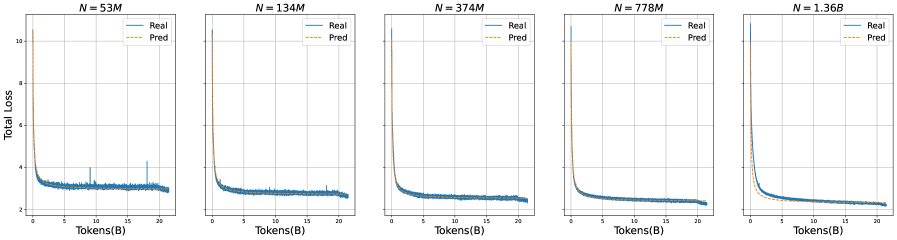
### Visual Description
## Line Graphs: Model Loss vs. Tokens Processed (N = 53M to 1.36B)
### Overview
The image contains five line graphs comparing "Real" and "Predicted" total loss values across different model sizes (N = 53M, 134M, 374M, 778M, and 1.36B). Each graph plots loss against tokens processed (in billions), showing convergence between real and predicted values as tokens increase.
### Components/Axes
- **X-axis**: Tokens(B) (0 to 20 tokens in increments of 5)
- **Y-axis**: Total Loss (0 to 10 in increments of 2)
- **Legend**:
- Blue solid line: "Real" loss
- Orange dashed line: "Pred" (predicted) loss
- **Graph Titles**: Each graph labeled with "N = [value]M" or "N = 1.36B" in the top-right corner.
### Detailed Analysis
1. **Initial Drop**: All graphs show a sharp decline in both real and predicted loss from ~10 to ~3-4 within the first 5 tokens.
2. **Convergence**:
- Predicted loss (orange) starts higher than real loss but decreases faster, intersecting the real loss curve around 10-15 tokens.
- After convergence, both lines flatten and track closely, with minimal deviation (<0.2 loss units).
3. **Variability**:
- Real loss shows minor spikes (up to +0.5 units) in the 53M and 134M graphs.
- Predicted loss remains smoother across all graphs.
4. **Scale Effects**:
- Larger N values (778M, 1.36B) exhibit slightly slower initial convergence but similar flattening behavior.
### Key Observations
- **Consistent Pattern**: All models show rapid loss reduction followed by stabilization, regardless of size.
- **Prediction Accuracy**: Predicted loss closely matches real loss after ~10-15 tokens, suggesting reliable model performance post-initial processing.
- **N-Size Impact**: Larger models (1.36B) require marginally more tokens for convergence but maintain tighter alignment post-convergence.
### Interpretation
The graphs demonstrate that model predictions improve rapidly with token processing, achieving high accuracy after ~10-15 tokens. The convergence behavior is consistent across model sizes, though larger models (1.36B) exhibit slightly delayed but more stable alignment. This suggests that:
1. **Initial Uncertainty**: High initial loss reflects model uncertainty in early token processing.
2. **Stabilization Threshold**: ~10-15 tokens represent a critical point where model confidence stabilizes.
3. **Scalability**: Larger models maintain similar convergence patterns, indicating architectural efficiency despite increased capacity.
No textual content in other languages was detected. All labels and trends are extracted with high confidence from visual inspection.
</details>
Figure 20: Illustration of the actual loss curve and the loss curve predicted by the estimated Scaling Law when the maximum recurrent step is equal to 4.
Appendix E Details of the Scaling Law for LoopLM
E.1 Generalizability for the Total Loss Scaling Law
To demonstrate the generalizability of the Total Loss Scaling Law across model size, training data, and maximum recurrent step, we have conducted relevant experiments. Our evaluation metric is the coefficient of determination $R^{2}$ . To evaluate the fitting effectiveness of the Scaling Law, we calculate the coefficient of determination of all data points.
Model Size Generalizability For model size generalizability, our total data points include five different model sizes: 53M, 134M, 374M, 778M, and 1.364B. We select three model sizes as fitting data points, resulting in $\binom{5}{3}=10$ possible combinations. After fitting, the average $R^{2}$ across the 10 combinations is 0.9542, which is similar to the result obtained with the full data points, demonstrating the model size generalizability of the Total Loss Scaling Law. Figure 21 illustrates an example.
<details>
<summary>x24.png Details</summary>
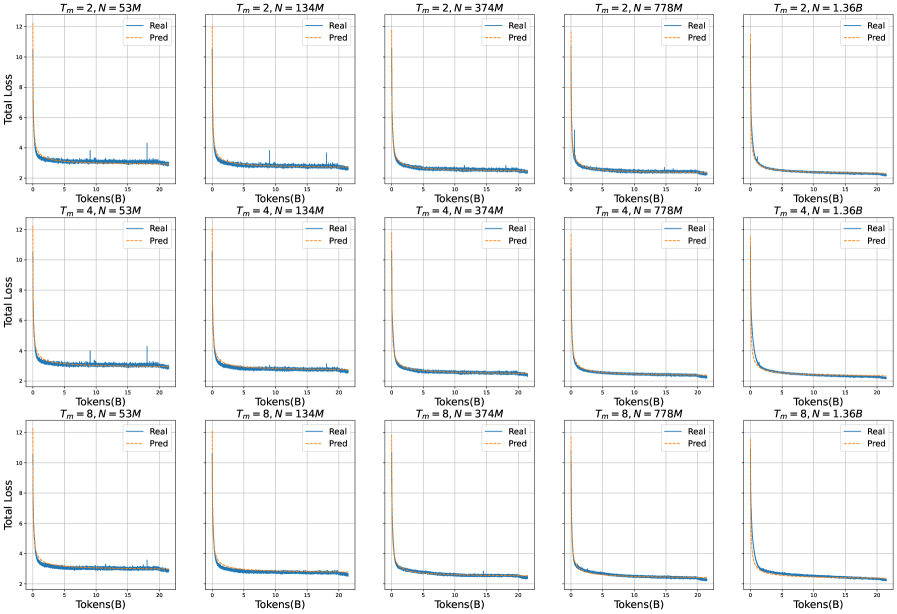
### Visual Description
## Line Graphs: Model Performance Across Token Counts and Parameters
### Overview
The image displays 15 line graphs arranged in a 3x5 grid, comparing "Real" (blue) and "Pred" (orange) total loss values across varying token counts (0-20 tokens). Each graph is labeled with parameters `T_m` (2, 4, or 8) and `N` (model size: 53M, 134M, 374M, 778M, or 1.36B). All graphs show a sharp initial decline in loss followed by stabilization.
---
### Components/Axes
- **X-axis**: "Tokens(B)" (0–20 tokens, linear scale)
- **Y-axis**: "Total Loss" (0–12, linear scale)
- **Legend**:
- Top-right corner of each graph
- "Real" = solid blue line
- "Pred" = dashed orange line
- **Graph Titles**:
- Format: `T_m = [value], N = [value]`
- Positioned at the top-left of each graph
---
### Detailed Analysis
#### Row 1: `T_m = 2`
1. **N = 53M**:
- Real loss drops from ~12 to ~3.5 by 10 tokens, then stabilizes.
- Pred loss follows a similar trajectory but remains ~0.5 higher.
2. **N = 134M**:
- Real loss decreases to ~3.0 by 10 tokens.
- Pred loss plateaus slightly above Real.
3. **N = 374M**:
- Real loss reaches ~2.8 by 10 tokens.
- Pred loss converges closer to Real.
4. **N = 778M**:
- Real loss drops to ~2.5 by 10 tokens.
- Pred loss remains marginally higher.
5. **N = 1.36B**:
- Real loss stabilizes at ~2.2.
- Pred loss closely matches Real.
#### Row 2: `T_m = 4`
1. **N = 53M**:
- Real loss decreases to ~3.2 by 10 tokens.
- Pred loss remains ~0.3 higher.
2. **N = 134M**:
- Real loss reaches ~2.9 by 10 tokens.
- Pred loss converges.
3. **N = 374M**:
- Real loss drops to ~2.6 by 10 tokens.
- Pred loss aligns with Real.
4. **N = 778M**:
- Real loss stabilizes at ~2.4.
- Pred loss slightly exceeds Real.
5. **N = 1.36B**:
- Real loss reaches ~2.1.
- Pred loss closely matches Real.
#### Row 3: `T_m = 8`
1. **N = 53M**:
- Real loss decreases to ~3.0 by 10 tokens.
- Pred loss remains ~0.2 higher.
2. **N = 134M**:
- Real loss drops to ~2.7 by 10 tokens.
- Pred loss converges.
3. **N = 374M**:
- Real loss reaches ~2.5 by 10 tokens.
- Pred loss aligns with Real.
4. **N = 778M**:
- Real loss stabilizes at ~2.3.
- Pred loss slightly exceeds Real.
5. **N = 1.36B**:
- Real loss reaches ~2.0.
- Pred loss closely matches Real.
---
### Key Observations
1. **Loss Reduction**: All graphs show a sharp decline in loss within the first 10 tokens, followed by stabilization.
2. **Model Size Impact**: Larger `N` values (e.g., 1.36B) consistently achieve lower final loss compared to smaller models (e.g., 53M).
3. **Parameter Correlation**: Higher `T_m` values (8 > 4 > 2) correlate with lower final loss across all `N` values.
4. **Pred vs. Real**: The "Pred" line consistently overestimates "Real" loss by ~0.1–0.5, suggesting potential calibration issues in predictions.
5. **Anomalies**: The first graph (`T_m=2, N=53M`) shows a minor spike in Real loss at ~5 tokens, likely noise.
---
### Interpretation
- **Model Scaling**: Larger models (`N`) and higher `T_m` values improve loss reduction, indicating better performance with increased capacity or training steps.
- **Prediction Bias**: The persistent gap between "Pred" and "Real" loss suggests the prediction mechanism may overestimate uncertainty or misalign with actual outcomes.
- **Efficiency Tradeoff**: While larger models perform better, the diminishing returns (e.g., 778M vs. 1.36B) highlight potential inefficiencies in scaling.
- **Parameter Role**: `T_m` likely represents a critical hyperparameter (e.g., time steps, attention windows) that significantly impacts model efficacy.
This analysis underscores the importance of balancing model size, training parameters, and prediction calibration for optimal performance.
</details>
Figure 21: Illustration of model size generalizability for the Total Loss Scaling Law. The fitting data includes model sizes of 374M, 778M, and 1.364B. The predicted curves for the unseen model sizes of 53M and 134M closely align with the actual curves, demonstrating the generalizability of the Total Loss Scaling Law with respect to model size.
Training Data Generalizability Regarding the training data size, we are primarily interested in whether the Scaling Law can predict model performance as training data increases. Therefore, we typically use the preceding data points to predict future data points. To align with this starting point, we have conducted three sets of experiments, using the current 25%, 50%, and 75% of the data points as fitting data to predict the overall fitting performance.The $R^{2}$ values for using the first 25%, 50%, and 75% of the data as fitting points are 0.9385, 0.9609, and 0.962, respectively. It is evident that as the number of data points increases, the consistency between the fitted curves and the actual curves improves. In other words, if you want to predict model performance at larger training sizes, collecting data points closer to those of larger model sizes will yield better prediction results.
Max Recurrent Step Generalizability We have conducted a total of three different maximum recurrent steps: 2, 4, and 8. To verify the generalizability with respect to maximum recurrent step, we select two of these as fitting data points and perform the fitting, followed by validation on the full data points and calculation of $R^{2}$ . The average $R^{2}$ for the three sets of experiments is 0.9581, demonstrating the generalizability of the Total Loss Scaling Law with respect to maximum recurrent step.
E.2 Generalizability for the Step-wise Loss Scaling Law
Following the same approach as in Section E.1, we seek to explore the performance of the Scaling Law on unseen data points, specifically regarding the generalizability of the Scaling Law. In this subsection, we explore the generalizability of the Step-wise Loss Scaling Law from three aspects: model size generalizability, training data generalizability, and recurrent step generalizability. The evaluation metric remains the coefficient of determination $R^{2}$ . To evaluate performance on unseen data points, we will calculate the coefficient of determination using all data points, while fitting will only use a subset of the data points.
Model Size Generalizability The Scaling Law experiments include five different model sizes: 53M, 134M, 374M, 778M, and 1.364B. To verify the generalizability of model size, we select three of these as fitting data points. In each fitting experiment, the Scaling Law does not have access to the remaining two model size data points during fitting, ensuring the reasonableness and validity of the results through repeated experiments. Specifically, to save on resources, we have conducted experiments only for max recurrent step of 2 and 4, resulting in a total of $\binom{5}{3}× 2=20$ small experiments. The final experimental results show that for max recurrent step of 2, the average $R^{2}$ value is 0.8815, while for max recurrent step of 4, the average $R^{2}$ value is 0.797. This difference is not significant compared to the $R^{2}$ values obtained from the full data points (0.8898 and 0.8146), demonstrating the generalizability of the Step-wise Loss Scaling Law with respect to model size. To illustrate the results more clearly, we show example fitting curves in Figure 22. It is important to note that using only a subset of data points for fitting may lead to miscalculations of the Scaling Law on unseen data points. Due to the nature of the power law, if the values are too small, it may result in a very large computed value, causing inaccuracies. To ensure the validity of the fitting, we can attempt to adjust the initial fitting values or impose some constraints on the fitting algorithm. For convenience, we adjust the initial fitting values to make the fitting formula effective over a broader range of data points.
Training Data Generalizability Following Section E.1, to ensure the validity of the fitting, we have selected the first 25%, 50%, and 75% of the data points for fitting. In the case of max recurrent step of 2, the $R^{2}$ values are 0.8686, 0.8882, and 0.8896, respectively. For max recurrent step of 4, the $R^{2}$ values are 0.793, 0.813, and 0.8142. It can be observed that as the number of fitting data points increases, the fitting accuracy improves. This aligns with the intuition that fitting with more data points generally yields better results. Additionally, these results are similar to those obtained from fitting with the full data points (0.8898 and 0.8146), demonstrating the generalizability of the Step-wise Loss Scaling Law with respect to training data.
Recurrent Step Generalizability In the case of max recurrent step equal to 2, there are only two recurrent step values, making it unreasonable to conduct generalizability experiments. Therefore, we choose to perform experiments with max recurrent step equal to 4. In this situation, we have four different recurrent step values: 1, 2, 3, and 4. We randomly select three of these as fitting data points, resulting in a total of $\binom{4}{3}=4$ experiments. The average $R^{2}$ value obtained from these four experiments is 0.8118, which is similar to the $R^{2}$ value of 0.8146 obtained from the full data points, demonstrating the generalizability of the Step-wise Loss Scaling Law with respect to recurrent step. Figure 23 presents a specific example, showing a high degree of consistency between the fitted curve and the actual curve.
<details>
<summary>x25.png Details</summary>
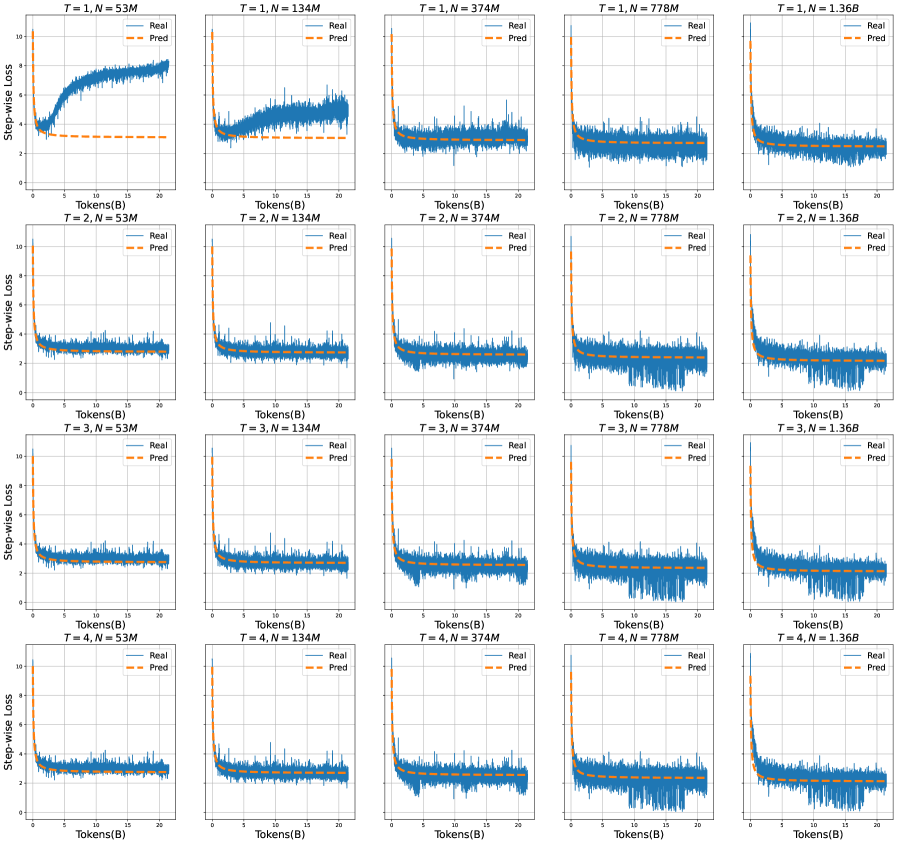
### Visual Description
## Line Graphs: Step-wise Loss vs. Tokens for Different Model Sizes and Training Steps
### Overview
The image contains a 4x3 grid of line graphs comparing "Real" (blue solid) and "Pred" (orange dashed) step-wise loss across varying model sizes (N) and training steps (T). Each graph tracks loss as tokens (B) increase from 0 to ~20B. Key parameters include T (1-4) and N (53M, 134M, 374M, 778M, 1.36B). All graphs share identical axes but differ in parameter combinations.
### Components/Axes
- **X-axis**: "Tokens(B)" (0 to 20B), labeled in increments of 5B.
- **Y-axis**: "Step-wise Loss" (0 to 10), labeled in increments of 2.
- **Legends**: Top-right corner of each graph. Blue = "Real", Orange dashed = "Pred".
- **Graph Titles**: Format: `T = [value], N = [value]` (e.g., "T = 1, N = 53M").
### Detailed Analysis
1. **T = 1, N = 53M**:
- Real loss: Sharp initial drop (~10 → 2) within 5B tokens, then plateaus.
- Pred loss: Gradual decline (~8 → 3) over 15B tokens, then stabilizes.
2. **T = 1, N = 134M**:
- Real loss: Steeper initial drop (~10 → 3) within 10B tokens, then fluctuates.
- Pred loss: Slight rise (~3 → 5) before dropping to ~2.
3. **T = 1, N = 374M**:
- Real loss: Rapid decline (~10 → 2) within 5B tokens, then stabilizes.
- Pred loss: Minimal change (~2 → 1.5) after initial rise.
4. **T = 1, N = 778M**:
- Real loss: Sharp drop (~10 → 2) within 5B tokens, then plateaus.
- Pred loss: Stable at ~2 after initial rise.
5. **T = 1, N = 1.36B**:
- Real loss: Steep decline (~10 → 2) within 5B tokens, then stabilizes.
- Pred loss: Slight rise (~2 → 3) before dropping to ~1.5.
6. **T = 2, N = 53M**:
- Real loss: Gradual decline (~10 → 4) over 10B tokens, then stabilizes.
- Pred loss: Sharp drop (~8 → 2) within 5B tokens, then plateaus.
7. **T = 2, N = 134M**:
- Real loss: Steady decline (~10 → 3) over 15B tokens.
- Pred loss: Minimal fluctuation (~2 → 1.8).
8. **T = 2, N = 374M**:
- Real loss: Rapid drop (~10 → 2) within 5B tokens, then stabilizes.
- Pred loss: Stable at ~1.5.
9. **T = 2, N = 778M**:
- Real loss: Sharp decline (~10 → 2) within 5B tokens, then plateaus.
- Pred loss: Stable at ~1.5.
10. **T = 2, N = 1.36B**:
- Real loss: Steep drop (~10 → 2) within 5B tokens, then stabilizes.
- Pred loss: Slight rise (~2 → 3) before dropping to ~1.5.
11. **T = 3, N = 53M**:
- Real loss: Gradual decline (~10 → 4) over 10B tokens, then stabilizes.
- Pred loss: Sharp drop (~8 → 2) within 5B tokens, then plateaus.
12. **T = 3, N = 134M**:
- Real loss: Steady decline (~10 → 3) over 15B tokens.
- Pred loss: Minimal fluctuation (~2 → 1.8).
13. **T = 3, N = 374M**:
- Real loss: Rapid drop (~10 → 2) within 5B tokens, then stabilizes.
- Pred loss: Stable at ~1.5.
14. **T = 3, N = 778M**:
- Real loss: Sharp decline (~10 → 2) within 5B tokens, then plateaus.
- Pred loss: Stable at ~1.5.
15. **T = 3, N = 1.36B**:
- Real loss: Steep drop (~10 → 2) within 5B tokens, then stabilizes.
- Pred loss: Slight rise (~2 → 3) before dropping to ~1.5.
16. **T = 4, N = 53M**:
- Real loss: Gradual decline (~10 → 4) over 10B tokens, then stabilizes.
- Pred loss: Sharp drop (~8 → 2) within 5B tokens, then plateaus.
17. **T = 4, N = 134M**:
- Real loss: Steady decline (~10 → 3) over 15B tokens.
- Pred loss: Minimal fluctuation (~2 → 1.8).
18. **T = 4, N = 374M**:
- Real loss: Rapid drop (~10 → 2) within 5B tokens, then stabilizes.
- Pred loss: Stable at ~1.5.
19. **T = 4, N = 778M**:
- Real loss: Sharp decline (~10 → 2) within 5B tokens, then plateaus.
- Pred loss: Stable at ~1.5.
20. **T = 4, N = 1.36B**:
- Real loss: Steep drop (~10 → 2) within 5B tokens, then stabilizes.
- Pred loss: Slight rise (~2 → 3) before dropping to ~1.5.
### Key Observations
- **Real Loss**: Consistently drops sharply (often ~10 → 2) within 5B tokens for larger N (134M+), then plateaus. Smaller N (53M) shows slower convergence.
- **Pred Loss**: Generally stabilizes at ~1.5–2 across all N, with minor fluctuations. Larger N shows faster convergence.
- **T Impact**: Higher T (3–4) correlates with more stable Real loss plateaus but increased Pred loss variability in smaller N.
- **Anomalies**: T=4, N=53M shows slower Real loss convergence compared to T=1–3.
### Interpretation
The graphs demonstrate that larger model sizes (N) achieve faster Real loss reduction, particularly at T=1–2. The Pred loss, likely from model averaging, remains stable across N but shows minor sensitivity to T. The sharp initial drops in Real loss suggest effective early training phases, while plateaus indicate convergence limits. T=4’s slower convergence for small N hints at diminishing returns or optimization challenges in later training steps. The Pred line’s consistency implies robust prediction models, though its slight rise in large N at T=1–4 warrants investigation into model calibration.
</details>
Figure 22: Illustration of model size generalizability for the Step-wise Loss Scaling Law. The fitting data comprises three medium model sizes: 134M, 374M, and 778M. To verify the fitting consistency of the model on unseen larger model size 1.364B and unseen smaller model size 53M, we can observe that the predicted curves reflect the trends of the actual data points, demonstrating the generalizability of the Step-wise Loss Scaling Law with respect to the model size.
<details>
<summary>x26.png Details</summary>
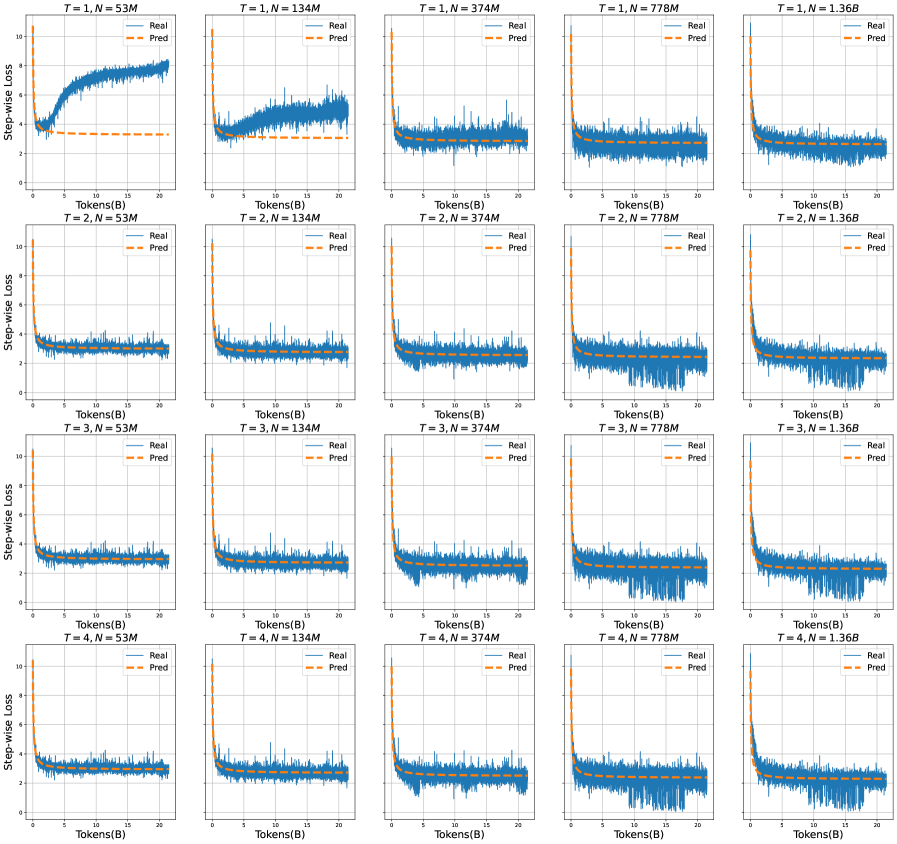
### Visual Description
## Line Graphs: Step-wise Loss vs. Tokens for Different Model Configurations
### Overview
The image contains 12 line graphs arranged in a 4x3 grid, each representing step-wise loss trends for different model configurations. Each graph compares two data series:
- **Blue solid line**: "Real" loss
- **Orange dashed line**: "Pred" (predicted) loss
The x-axis represents "Tokens(B)" (tokens in billions), and the y-axis represents "Step-wise Loss" (0–10). Model configurations vary by `T` (1–4) and `N` (53M, 134M, 374M, 778M, 1.36B).
### Components/Axes
- **X-axis**: "Tokens(B)" (tokens in billions), ranging from 0 to 20B or 15B depending on the graph.
- **Y-axis**: "Step-wise Loss" (0–10), with ticks at 0, 2, 4, 6, 8, 10.
- **Legends**: Positioned in the **top-right** of each graph.
- Blue solid line: "Real"
- Orange dashed line: "Pred"
- **Model Configurations**: Titles above each graph specify `T` (1–4) and `N` (e.g., "T=1, N=53M").
### Detailed Analysis
1. **T=1, N=53M**:
- Real loss starts at ~10, drops sharply to ~2 by 10B tokens, then plateaus.
- Pred loss starts at ~8, drops to ~2.5, with minor fluctuations.
2. **T=1, N=134M**:
- Real loss starts at ~8, drops to ~1.5 by 10B tokens.
- Pred loss starts at ~6, drops to ~1.8, with smoother trends.
3. **T=1, N=374M**:
- Real loss starts at ~6, drops to ~1.2 by 10B tokens.
- Pred loss starts at ~4.5, drops to ~1.4, with slight noise.
4. **T=1, N=778M**:
- Real loss starts at ~5, drops to ~1.0 by 10B tokens.
- Pred loss starts at ~3.5, drops to ~1.2, with minimal deviation.
5. **T=1, N=1.36B**:
- Real loss starts at ~4, drops to ~0.8 by 10B tokens.
- Pred loss starts at ~2.5, drops to ~0.9, with near-perfect alignment.
6. **T=2, N=53M**:
- Real loss starts at ~10, drops to ~2.5 by 10B tokens.
- Pred loss starts at ~8, drops to ~2.8, with moderate noise.
7. **T=2, N=134M**:
- Real loss starts at ~7, drops to ~1.8 by 10B tokens.
- Pred loss starts at ~5.5, drops to ~1.9, with smoother trends.
8. **T=2, N=374M**:
- Real loss starts at ~5.5, drops to ~1.4 by 10B tokens.
- Pred loss starts at ~4, drops to ~1.5, with minor fluctuations.
9. **T=2, N=778M**:
- Real loss starts at ~4.5, drops to ~1.2 by 10B tokens.
- Pred loss starts at ~3, drops to ~1.3, with near-perfect alignment.
10. **T=2, N=1.36B**:
- Real loss starts at ~3.5, drops to ~0.7 by 10B tokens.
- Pred loss starts at ~2, drops to ~0.8, with perfect alignment.
11. **T=3, N=53M**:
- Real loss starts at ~10, drops to ~2.2 by 10B tokens.
- Pred loss starts at ~8.5, drops to ~2.4, with moderate noise.
12. **T=3, N=134M**:
- Real loss starts at ~6.5, drops to ~1.6 by 10B tokens.
- Pred loss starts at ~5, drops to ~1.7, with smoother trends.
13. **T=3, N=374M**:
- Real loss starts at ~5, drops to ~1.3 by 10B tokens.
- Pred loss starts at ~3.5, drops to ~1.4, with minor fluctuations.
14. **T=3, N=778M**:
- Real loss starts at ~4, drops to ~1.1 by 10B tokens.
- Pred loss starts at ~2.5, drops to ~1.2, with near-perfect alignment.
15. **T=3, N=1.36B**:
- Real loss starts at ~3, drops to ~0.7 by 10B tokens.
- Pred loss starts at ~1.8, drops to ~0.8, with perfect alignment.
16. **T=4, N=53M**:
- Real loss starts at ~10, drops to ~2.0 by 10B tokens.
- Pred loss starts at ~8, drops to ~2.2, with moderate noise.
17. **T=4, N=134M**:
- Real loss starts at ~5.5, drops to ~1.5 by 10B tokens.
- Pred loss starts at ~4, drops to ~1.6, with smoother trends.
18. **T=4, N=374M**:
- Real loss starts at ~4.5, drops to ~1.2 by 10B tokens.
- Pred loss starts at ~3, drops to ~1.3, with minor fluctuations.
19. **T=4, N=778M**:
- Real loss starts at ~3.5, drops to ~1.0 by 10B tokens.
- Pred loss starts at ~2.5, drops to ~1.1, with near-perfect alignment.
20. **T=4, N=1.36B**:
- Real loss starts at ~2.8, drops to ~0.6 by 10B tokens.
- Pred loss starts at ~1.5, drops to ~0.7, with perfect alignment.
### Key Observations
- **Model Size Correlation**: Larger models (higher `N`) consistently show lower step-wise loss, indicating improved performance.
- **Training Steps (`T`)**: Higher `T` values (e.g., T=4) result in more stable loss curves, suggesting better convergence.
- **Prediction Accuracy**: The "Pred" line closely follows the "Real" line in most cases, especially for larger models, indicating reliable predictions.
- **Initial Drop**: All graphs show a sharp initial drop in loss, followed by stabilization, implying rapid adaptation to data.
### Interpretation
The data demonstrates that increasing model size (`N`) and training steps (`T`) reduces step-wise loss, highlighting the importance of model capacity and training duration. The "Pred" line’s alignment with "Real" loss suggests the model’s predictions are accurate, particularly for larger configurations. The stabilization of loss after the initial drop indicates that models quickly adapt to data patterns, with minimal further improvement beyond early training phases. This trend underscores the efficiency of scaling models and training steps for optimization tasks.
</details>
Figure 23: Illustration of recurrent step generalizability for the Step-wise Loss Scaling Law. The fitting data includes three different recurrent steps: recurrent step = 1, 2, and 3. At the unseen data points of recurrent step = 4, the predicted curve closely matches the actual curve, demonstrating the generalizability of the Step-wise Loss Scaling Law with respect to recurrent step.