# SymCode: A Neurosymbolic Approach to Mathematical Reasoning via Verifiable Code Generation
**Authors**: ElastixAI, Seattle, USA
Abstract
Large Language Models (LLMs) often struggle with complex mathematical reasoning, where prose-based generation leads to unverified and arithmetically unsound solutions. Current prompting strategies like Chain of Thought still operate within this unreliable medium, lacking a mechanism for deterministic verification. To address these limitations, we introduce SymCode, a neurosymbolic framework that reframes mathematical problem-solving as a task of verifiable code generation using the SymPy library. We evaluate SymCode on challenging benchmarks, including MATH-500 and OlympiadBench, demonstrating significant accuracy improvements of up to 13.6 percentage points over baselines. Our analysis shows that SymCode is not only more token-efficient but also fundamentally shifts model failures from opaque logical fallacies towards transparent, programmatic errors. By grounding LLM reasoning in a deterministic symbolic engine, SymCode represents a key step towards more accurate and trustworthy AI in formal domains.
1 Introduction
Large Language Models (LLMs) have demonstrated remarkable capabilities in natural language, yet their proficiency in domains requiring rigorous, multi-step formal reasoning, such as advanced mathematics, remains a significant challenge (Wei et al., 2022; Ahn et al., 2024). When prompted to solve complex math problems, LLMs that reason in prose often generate solutions that are unreliable, containing subtle arithmetic errors, logical fallacies, or hallucinated intermediate steps. Furthermore, these natural language rationales are often opaque; their convoluted structure can obscure the reasoning path, making it difficult for even a domain expert to verify their correctness. This lack of a clear, deterministic failure signal also makes it challenging to create an automated feedback loop to iteratively refine an incorrect answer.
Current approaches to mathematical reasoning broadly fall into two categories: inference-time prompting and model fine-tuning. Inference-time methods like Chain of Thought (CoT) (Wei et al., 2022) and Tree of Thoughts (ToT) (Yao et al., 2023) have improved performance by encouraging models to articulate their reasoning. These methods, while accessible, inherit the weaknesses of natural languages. Training-based methods, on the other hand, can improve a model’s intrinsic capabilities but require significant computational resources and large, high-quality datasets, and may not generalize well to novel problems.
To overcome these critical shortcomings, we introduce SymCode, a neurosymbolic framework that reframes mathematical problem-solving for any class of problems that can be formalized programmatically. Instead of prompting an LLM to describe its reasoning in prose, SymCode instructs it to construct a verifiable, executable Python script where the code serves as the reasoning trace. Unlike prior work like Program-Aided Language Models (PAL) (Gao et al., 2023), which uses code as an external calculator for intermediate steps, SymCode treats the entire program as the final, self-contained reasoning artifact. This elevates the LLM’s role from a simple calculator to an expert translator, converting a natural language problem into a formal, verifiable script.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: LLM-Based Math Problem Solving Workflow
### Overview
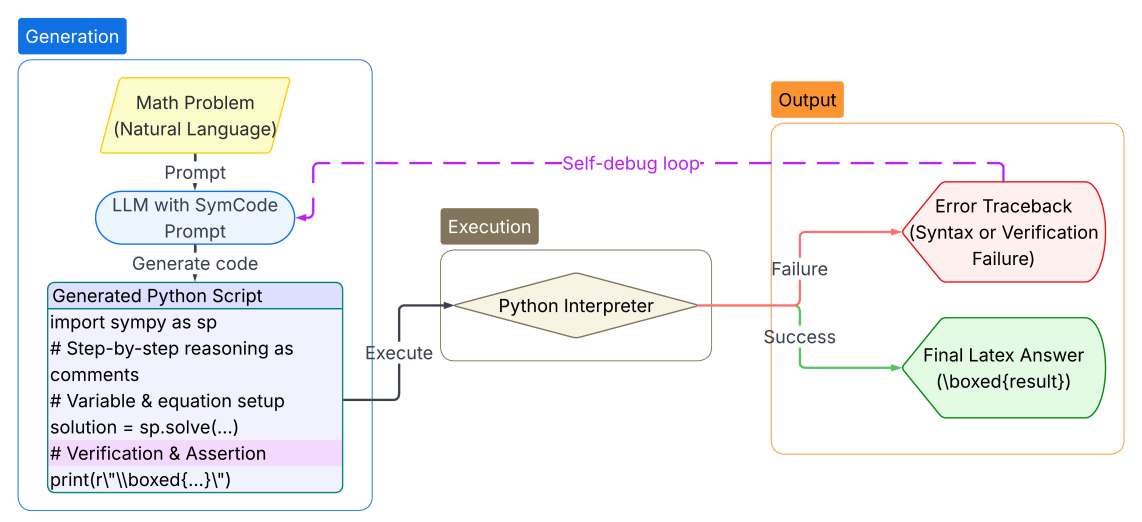
This diagram illustrates the workflow of a Large Language Model (LLM) equipped with SymCode for solving math problems. It depicts the process from receiving a natural language math problem to generating a final LaTeX answer, including a self-debugging loop. The diagram is segmented into "Generation" and "Output" sections, connected by an "Execution" phase.
### Components/Axes
The diagram consists of several rectangular components representing stages or elements in the process. These are connected by arrows indicating the flow of information or control. Key components include:
* **Math Problem (Natural Language):** The initial input.
* **Prompt:** Input to the LLM.
* **LLM with SymCode:** The core processing unit.
* **Prompt:** Input to code generation.
* **Generate code:** Output from the LLM.
* **Generated Python Script:** The code generated by the LLM. Contains example code snippets.
* **Python Interpreter:** Executes the generated code.
* **Execute:** Action taken by the Python Interpreter.
* **Error Traceback (Syntax or Verification Failure):** Output in case of failure.
* **Final LaTeX Answer (\boxed{result}):** The desired output upon success.
* **Self-debug loop:** A dashed arrow indicating a feedback loop.
### Detailed Analysis or Content Details
The diagram shows a clear flow:
1. A **Math Problem (Natural Language)** is provided as input.
2. This problem is used as a **Prompt** to an **LLM with SymCode**.
3. The LLM generates code based on another **Prompt**.
4. The **Generated Python Script** is shown with the following example code:
* `import sympy as sp`
* `# Step-by-step reasoning as comments`
* `# Variable & equation setup`
* `solution = sp.solve(...)`
* `# Verification & Assertion`
* `print(r"\boxed{...}")`
5. The script is then **Execute**d by a **Python Interpreter**.
6. The execution can result in two outcomes:
* **Failure:** Leading to an **Error Traceback (Syntax or Verification Failure)**.
* **Success:** Leading to a **Final LaTeX Answer (\boxed{result})**.
7. A **Self-debug loop** (dashed arrow) connects the "Execution" phase back to the "LLM with SymCode", indicating that the LLM can refine its code based on execution results.
### Key Observations
* The diagram emphasizes the iterative nature of the problem-solving process through the self-debugging loop.
* The inclusion of example code within the "Generated Python Script" component provides insight into the LLM's code generation strategy.
* The diagram clearly distinguishes between successful and unsuccessful execution paths.
* The use of LaTeX formatting for the final answer suggests a focus on mathematical notation.
### Interpretation
This diagram illustrates a sophisticated approach to math problem solving using LLMs. The integration of SymCode allows the LLM to generate executable code, enabling verification and refinement of solutions. The self-debugging loop is crucial for handling complex problems where initial code generation may not yield the correct answer. The diagram highlights the importance of both natural language understanding (to interpret the math problem) and code generation/execution (to solve the problem). The use of LaTeX for the final answer suggests a focus on presenting results in a standard mathematical format. The diagram suggests a system designed for accuracy and robustness, capable of handling both syntax and verification errors. The inclusion of comments in the generated code indicates an attempt to make the reasoning process transparent and understandable.
</details>
Figure 1: Overview of the SymCode framework. A natural language problem is translated into Python code by the LLM, executed, and iteratively refined through error feedback until successful execution or a retry limit is reached.
The SymCode framework orchestrates the strengths of three components to address the challenges of prose-based reasoning. As illustrated in Figure 1, the process begins with instructing an LLM to interpret the problem and generate a Python script that leverages SymPy, a computer algebra system (CAS) that manipulates mathematical expressions in their exact symbolic form, thereby eliminating arithmetic errors. Next, the generated script is executed in a sandboxed Python interpreter, which provides a deterministic pass/fail signal for programmatic verification. Finally, a self-debugging loop feeds any execution error back to the LLM, enabling it to iteratively correct its own code. This entire process creates a transparent, auditable, and self-correcting reasoning trace that is both human-readable and machine-executable.
Our work is guided by two main research questions:
1. To what extent does reframing mathematical reasoning as verifiable code generation improve a system’s accuracy on complex mathematical problems compared to established prose-based prompting techniques?
1. Beyond accuracy, how does this neurosymbolic approach alter the characteristics of the LLM’s reasoning process, specifically concerning token efficiency and the fundamental nature of its failure modes?
Our main contributions are as follows:
- We introduce and formalize SymCode, a prompt-based framework for advanced mathematical reasoning that transforms an LLM into a neurosymbolic reasoner generating self-contained, verifiable Python scripts.
- Framing mathematical reasoning as code generation enables us to apply an iterative self-debugging mechanism where LLM uses deterministic interpreter feedback to correct its own errors, a robust verification process not available to prose-based reasoners.
- Through extensive experiments on three challenging mathematical benchmarks—MATH-500, OlympiadBench, and AIME—we show that SymCode improves accuracy by up to 13.6 percentage points (and up to 16.8 with SymCode+) over traditional prompting baselines, with the performance gap increasing as problem difficulty rises.
- We provide a detailed analysis showing that reasoning-as-code is substantially more token-efficient than prose-based methods.
2 Related Work
| Method Training-Based Methods (Model-Tuning) LeDex 2025 | Reasoning Modality Code | External Tools Interpreter Feedback | Self-Correction Yes (Learned) | Verification Execution-based |
| --- | --- | --- | --- | --- |
| rStar-Math 2025 | Hybrid (Code+) | MCTS+Code | Yes (Self-Evolution) | Process Reward Model |
| Training-Free Methods (Inference-Time) | | | | |
| CoT 2022 | Natural Language | None | No | No |
| ToT 2023 | Natural Language | None | Branching | None (NL-based vote) |
| PAL 2023 | Code | Python Interpreter | No | Result Only |
| MATHSENSEI 2024 | Hybrid | Search/Prog/Solver | No (has code refiner) | Tool-based |
| NSAR 2025 | Hybrid | Python/Symbolic | No | Result Only |
| SymCode+ (Ours) | Code | SymPy (CAS) | Yes (Self-Debug Loop) | Constraints and Result |
Table 1: Comparison of SymCode+ with key LLM-based mathematical reasoning methods, grouped into training-free inference-time approaches and training-based fine-tuning approaches. SymCode is a training-free method focused on verifiable SymPy code generation with a self-debugging loop. Abbrev.: CAS = Computer Algebra System, MCTS = Monte Carlo Tree Search.
The use of code for mathematical reasoning is well-established, from the computer-assisted proof of the four-color theorem (Appel and Haken, 1989) to modern formal proof assistants like Lean (Moura and Ullrich, 2021). Historically, however, these powerful symbolic systems required expert human effort to manually translate natural language problems into formal specifications. The recent challenge of automating this translation and equipping LLMs with robust mathematical abilities has spurred a variety of research directions, which can be broadly categorized into three main areas: training-based methods that modify model weights, training-free strategies that operate at inference-time, and methods that augment LLMs with external tools.
A significant line of research focuses on enhancing reasoning by fine-tuning models on specialized data or with reinforcement learning. For instance, rStar-Math employs Monte Carlo Tree Search (MCTS) guided by a process reward model to create a “deep thinking” process, fine-tuning smaller models to achieve strong performance (Guan et al., 2025). These training-based methods represent a powerful but distinct paradigm focused on improving the model’s internal capabilities.
Another category of methods aims to improve reasoning without altering the model’s parameters, focusing instead on structuring the generation process at inference-time. Early efforts in this area focused on eliciting more structured thought processes. The seminal Chain of Thought (CoT) prompting method demonstrated that instructing a model to “think step-by-step” significantly improves performance (Wei et al., 2022). This concept was further generalized by approaches like Tree of Thoughts (ToT), which allows models to explore multiple reasoning paths concurrently (Yao et al., 2023), and decomposition techniques that break complex problems into simpler sub-problems Khot et al. (2023). More recently, this paradigm has shifted towards scaling test-time compute, a strategy popularized by OpenAI’s o1 model OpenAI et al. (2024). This has led to methods like budget forcing, where a model’s thinking process is deliberately extended to encourage deeper exploration (Muennighoff et al., 2025). While effective, these methods still largely operate within the domain of natural language, making their reasoning chains prone to arithmetic errors and logical inconsistencies without a formal method for verification (Ahn et al., 2024).
To overcome the unreliability of prose-based computation, a third line of work has focused on augmenting LLMs with external tools, particularly code interpreters. Program-Aided Language Models (PAL) (Gao et al., 2023) pioneered this approach by prompting an LLM to generate an executable program, offloading computation to a reliable interpreter. This has been extended with models like MATHSENSEI, which integrates multiple tools including web search and symbolic solvers (Das et al., 2024). Our work represents a fundamental shift from this paradigm. Rather than using code for mere computation, we use it to change the reasoning modality itself. SymCode instructs the LLM to translate a problem into a formal, symbolic representation, which is then manipulated by a Computer Algebra System (CAS). This elevates the task from executing a sequence of arithmetic steps to solving a system of symbolic equations. In essence, PAL uses code for calculation, whereas SymCode uses code for formal mathematical reasoning. This directly operationalizes a true neurosymbolic approach by bridging neural language interpretation with the rigorous logic of symbolic systems (Kautz, 2022; Fang et al., 2024; Nezhad and Agrawal, 2025).
The use of code also enables robust self-correction mechanisms. Several methods train models to debug their own code, either through fine-tuning on datasets of errors and corrections (Jiang et al., 2025) or by using reinforcement learning to refine outputs based on execution feedback (Kumar et al., 2024). While some studies suggest that Reinforcement Learning with Verifiable Rewards (RLVR) Lambert et al. (2025) primarily amplifies existing capabilities rather than creating new ones (Yue et al., 2025), the iterative self-debugging loop in SymCode provides a concrete, inference-time mechanism for refinement.
Our approach also differs from general-purpose code generation, where models produce applications from specifications (e.g., text-to-SQL) (Zan et al., 2023). In those tasks, the code is the final product. In contrast, we employ code as the reasoning modality itself —a transparent, intermediate representation of logic.
To highlight the distinctions and contributions of our approach, Table 1 provides a comparative overview of key related methods in mathematical reasoning.
3 The SymCode Framework
The SymCode framework adapts an LLM from a probabilistic text generator into a structured, neurosymbolic reasoner. While prior work has used code as an external computational tool, the fundamental principle of SymCode is to treat the entire reasoning process as the act of generating a verifiable program where the code is the reasoning trace. The motivation for this shift is to overcome the inherent limitations of prose-based reasoning, which is often ambiguous, prone to subtle logical and arithmetic errors, and lacks a mechanism for automated verification. Instead of asking the LLM to explain its thinking, we instruct it to write a program that enacts that thinking. This methodology leverages the respective strengths of neural and symbolic systems: the LLM excels at interpreting the nuances and context of the problem statement, while the Python interpreter, coupled with the SymPy library Meurer et al. (2017), provides rigor for the formal mathematical manipulations. First, we use a specialized prompt to guide the LLM in structuring its reasoning as a self-contained Python script that leverages the SymPy library for deterministic computation (Section ˜ 3.1). Second, to enhance accuracy, we introduce an iterative self-debugging loop that enables the model to correct its own programmatic errors based on interpreter feedback (Section ˜ 3.2). To provide a concrete illustration of the framework in action, from problem statement to the final generated script, see the full example in Appendix A.
3.1 SymCode
The complete SymCode prompt template is shown below.
⬇
You are an expert mathematical reasoner. Your output must be ONLY a single Python code block fenced as ‘‘‘ python ... ‘‘‘ with no prose before or after.
Inside that single Python script:
1. Import SymPy with ‘ import sympy as sp ‘
2. Add explicit step - by - step reasoning as comments throughout your code
3. Document the problem setup:
- Clearly identify variables, constraints, and goals in comments
- Define symbols with appropriate assumptions (e. g., sp. symbols (’ x ’, positive = True, integer = True))
4. Include intermediate reasoning steps:
- Each step should have a comment explaining the mathematical reasoning
- Use meaningful variable names that reflect their purpose
- Show the algebraic manipulations clearly
5. For verification:
- Substitute solutions back into original equations
- Check domain constraints (e. g., integer solutions, positive values)
- Filter invalid solutions
6. Print ONLY the final answer in LaTeX boxed form:
print (r "\ boxed {}". format (final_answer))
# PROBLEM
{problem_text}
# END PROBLEM
Listing 1: The SymCode Prompt Template.
| MATH-500 | How many distinct values can be obtained from the expression $2· 3· 4· 5+1$ by inserting any number of parentheses? | 4 | 4 | 1 | 2 |
| --- | --- | --- | --- | --- | --- |
| OlympiadBench | In $\triangle ABC$ , $AB=4,BC=6,AC=8$ . Squares $ABQR$ and $BCST$ are drawn external to the triangle. Compute the length of $QT$ . | $2\sqrt{10}$ | $2\sqrt{10}$ | $2\sqrt{2}\sqrt{10+3\sqrt{15}}$ | 12 |
| AIME | Let $\triangle ABC$ have circumcenter $O$ and incenter $I$ with $\overline{IA}\perp\overline{OI}$ , circumradius $13$ , and inradius $6$ . Find $AB· AC$ . | 468 | 468 | 156 | 338 |
Table 2: Sample problems from the evaluation datasets, with outputs from SymCode and prose-based baselines. SymCode correctly solves all three, while the baselines produce incorrect answers due to logical or arithmetic errors.
Each component of this prompt serves a distinct purpose in structuring the model’s output.
Symbolic Formulation.
The explicit instruction to use import sympy as sp is critical. SymPy is a Python library for symbolic mathematics, acting as a Computer Algebra System (CAS). Unlike standard numerical libraries that work with approximate floating-point numbers, SymPy manipulates mathematical expressions in their exact, symbolic form (e.g., representing $\sqrt{2}$ precisely rather than as 1.414…). This brings two key advantages: first, it prevents the accumulation of rounding errors that can invalidate multi-step calculations. Second, it enables true algebraic reasoning by allowing the script to programmatically solve equations, simplify expressions, and apply mathematical rules with perfect fidelity. This moves the task from error-prone prose-based calculation to exact, verifiable computation.
Interpretability.
By requiring ‘step-by-step reasoning as comments’, we retain the “show your work” benefit of Chain of Thought while grounding it in a formal, code-based structure. This makes the model’s logic transparent and auditable for human experts.
Problem Scaffolding.
The requirement to define symbols with appropriate assumptions (e.g., ‘sp.symbols(‘x’, positive=True, integer=True)’) forces the model to formalize the problem’s constraints upfront. This structured setup significantly reduces the solution search space and helps prevent the generation of invalid solutions later in the process.
Verification and Filtering.
This is a cornerstone of the framework’s reliability. The prompt requires the model to insert assert statements into its generated code. These statements check key conditions at runtime, such as whether a solution satisfies the original problem constraints or adheres to domain requirements (e.g., ensuring a length variable is positive). If an assertion fails, it raises an error that halts execution. This provides a deterministic failure signal that effectively filters out incorrect solution paths and can trigger the self-debugging loop of SymCode+ (described next), enabling a crucial self-correction step. If the script runs to completion without any exceptions, the final answer is reported by capturing the script’s output, which the prompt requires to be printed in a \boxed{} LaTeX format. The effectiveness of this verification, however, is contingent on the quality of the assertions generated by the LLM; an absence of failure does not guarantee correctness if the assertions are weak or located in an unexecuted code path.
3.2 SymCode+: Self-Debugging Loops
To further enhance the accuracy of the framework, we extend the core prompt with an agentic wrapper called SymCode+. This extension introduces an iterative self-debugging loop that allows the LLM to correct its own programmatic mistakes.
If the initial script fails during execution, the loop is activated. A failure can be a programmatic exception (e.g., SyntaxError, TypeError) or a verification failure where an internal AssertionError is raised. The captured error message and traceback are then appended to the prompt history, and the LLM is instructed to “debug the following code based on the provided error message.” This cycle of execution, failure, and correction repeats until the script runs successfully or a preset iteration limit (e.g., 2–3 attempts) is reached.
4 Experimental Setup
We consider challenging mathematical datasets and a diverse set of LLMs in our evaluation.
4.1 Datasets
We evaluate SymCode on three widely used, challenging benchmarks that require multi-step mathematical reasoning, spanning difficulty from high school competitions to Olympiad-level problems: (1) MATH-500, a 500-problem subset of the MATH dataset, comprising challenging problems from high school mathematics competitions, covering topics like algebra, geometry, number theory, and precalculus Lightman et al. (2023); (2) OlympiadBench, 674 text-only English math problems from national and international olympiads requiring creative and formal reasoning He et al. (2024); and (3) American Invitational Mathematics Examination (AIME) 2024 & 2025, 60 (30 from each year) short-answer problems from recent competitions that bridge high school and olympiad difficulty Mathematical Association of America (2024). Table ˜ 2 shows a sample from each dataset.
4.2 Models and Baselines
We evaluate SymCode across several state-of-the-art language models such as Llama 3.2 (90B) Grattafiori et al. (2024), GPT-5-nano OpenAI (2025), and GPT-OSS (20B) OpenAI et al. (2025) (reasoning level “high”), chosen to span a range of coding fluency, from strong code generators (GPT-5-nano, GPT-OSS) to a generalist model less optimized for coding (Llama 3.2). Focusing on small and medium models rather than frontier-scale systems (e.g., GPT-5, Grok 4) allows us to investigate more efficient, accessible approaches to improving reasoning performance.
The performance of SymCode is contextualized against a set of strong, widely-used baseline prompting strategies, including:
- Chain of Thought (CoT): A standard baseline where the model is prompted to “think step-by-step” to generate a prose-based rationale before giving the final answer Wei et al. (2022).
- Tree of Thoughts (ToT): An advanced baseline where the model explores multiple reasoning paths, evaluating and pruning them to find the most promising solution Yao et al. (2023).
- Decomposition: A baseline where the model is instructed to break the problem into smaller, simpler sub-problems and solve them sequentially Khot et al. (2023).
Because SymCode is a training-free framework that modifies reasoning only at inference time, training-based methods are not directly comparable baselines, as fair comparison would require adapting our approach to their specialized models. We also exclude code-generation methods like PAL Gao et al. (2023), whose main purpose is delegating numerical computation to an interpreter. Furthermore, our initial exploratory tests confirmed that PAL is of limited utility for the complex problems in our benchmarks, as it is primarily designed for numerical outputs and struggles significantly with problems requiring a final symbolic expression as the answer.
| Llama 3.2 (90B) | CoT ToT Decomposition | 61.2 63.8 64.4 | 34.4 36.8 36.0 | 20.0 23.3 21.7 |
| --- | --- | --- | --- | --- |
| SymCode (ours) | 64.4 | 31.2 | 25.0 | |
| SymCode+ (ours) | 68.8 | 36.8 | 31.7 | |
| GPT-5-nano | CoT | 93.4 | 63.2 | 51.6 |
| ToT | 88.2 | 68.0 | 51.7 | |
| Decomposition | 91.2 | 64.0 | 48.3 | |
| SymCode (ours) | 90.8 | 76.8 | 61.7 | |
| SymCode+ (ours) | 91.4 | 80.0 | 65.0 | |
| GPT-OSS (20B) | CoT | 88.4 | 22.4 | 11.6 |
| ToT | 87.0 | 24.8 | 10.0 | |
| Decomposition | 86.2 | 23.2 | 11.6 | |
| SymCode (ours) | 90.4 | 35.2 | 18.3 | |
| SymCode+ (ours) | 93.2 | 38.4 | 21.6 | |
Table 3: Accuracy (%) on Mathematical Reasoning Benchmarks. Best score shown in bold whereas second best score is underlined.
4.3 Evaluation Metrics
We assess SymCode using four metrics: (1) Accuracy: a solution is correct only if the final numerical or symbolic answer inside the ‘boxed{}‘ output exactly matches the ground-truth solution, no partial credit is awarded; (2) Token Efficiency: the average tokens generated per problem, reflecting the conciseness of code-based reasoning; (3) Qualitative Error Analysis: manual categorization of failure types, contrasting arithmetic or logical errors in baselines with misinterpretation or API errors in SymCode; and (4) Self-Debugging Activation Rate: the percentage of problems triggering the self-correction loop, indicating the model’s initial coding fluency.
5 Results and Analysis
This section presents a detailed discussion of the experimental results.
5.1 Overall Performance and the Role of Coding Proficiency
Our experiments reveal that the SymCode framework’s effectiveness depends on the base model’s coding proficiency and the complexity of the reasoning task. As shown in Table 3, SymCode delivers substantial gains, and with its self-debugging loop, SymCode+ consistently yields additional gains on the most challenging benchmarks. Accuracy results show that SymCode’s advantages are most pronounced with models that are strong coders: with GPT-5-nano, SymCode+ achieves an accuracy of 80% on OlympiadBench and 65% on AIME, representing a remarkable absolute improvement of nearly 12 and 13 percentage points, respectively, over the best-performing prose-based baseline (ToT), demonstrating that shifting the reasoning modality from prose to a formal symbolic language unlocks new capabilities.
With Llama 3.2 (90B), a less code-optimized model, standard SymCode underperforms ToT on OlympiadBench, but SymCode+ closes this gap, achieving 21.6% accuracy on AIME. This shows that iterative self-correction is crucial for models with weaker coding skills, allowing them to overcome initial syntax or logic errors.
A closer look at the model-specific results reveals interesting trade-offs between coding proficiency and abstract reasoning. As expected, GPT-5-nano stands out as the top-performing model, demonstrating superior capabilities across the board, particularly on the most difficult OlympiadBench and AIME datasets. More intriguing is the comparison between GPT-OSS and Llama 3.2 (90B). While GPT-OSS shows stronger performance on the MATH-500 benchmark (93.2% vs. 68.8%), Llama 3.2 surprisingly surpasses it on the more challenging AIME problems (31.7% vs. 21.6%). A potential explanation for this reversal lies in the nature of the tasks. MATH-500 problems, while complex, are often more standard in structure, allowing GPT-OSS to better leverage its strong coding abilities to translate familiar problem types into reliable scripts. In contrast, AIME problems frequently require more novel or abstract initial insights before a solution can be formalized. Llama 3.2, while a less fluent coder, appears more adept at forming the correct initial conceptual plan for these non-standard problems, even if its first attempt at implementation contains errors that the debugging loop must then correct.
5.2 Impact of Problem Difficulty
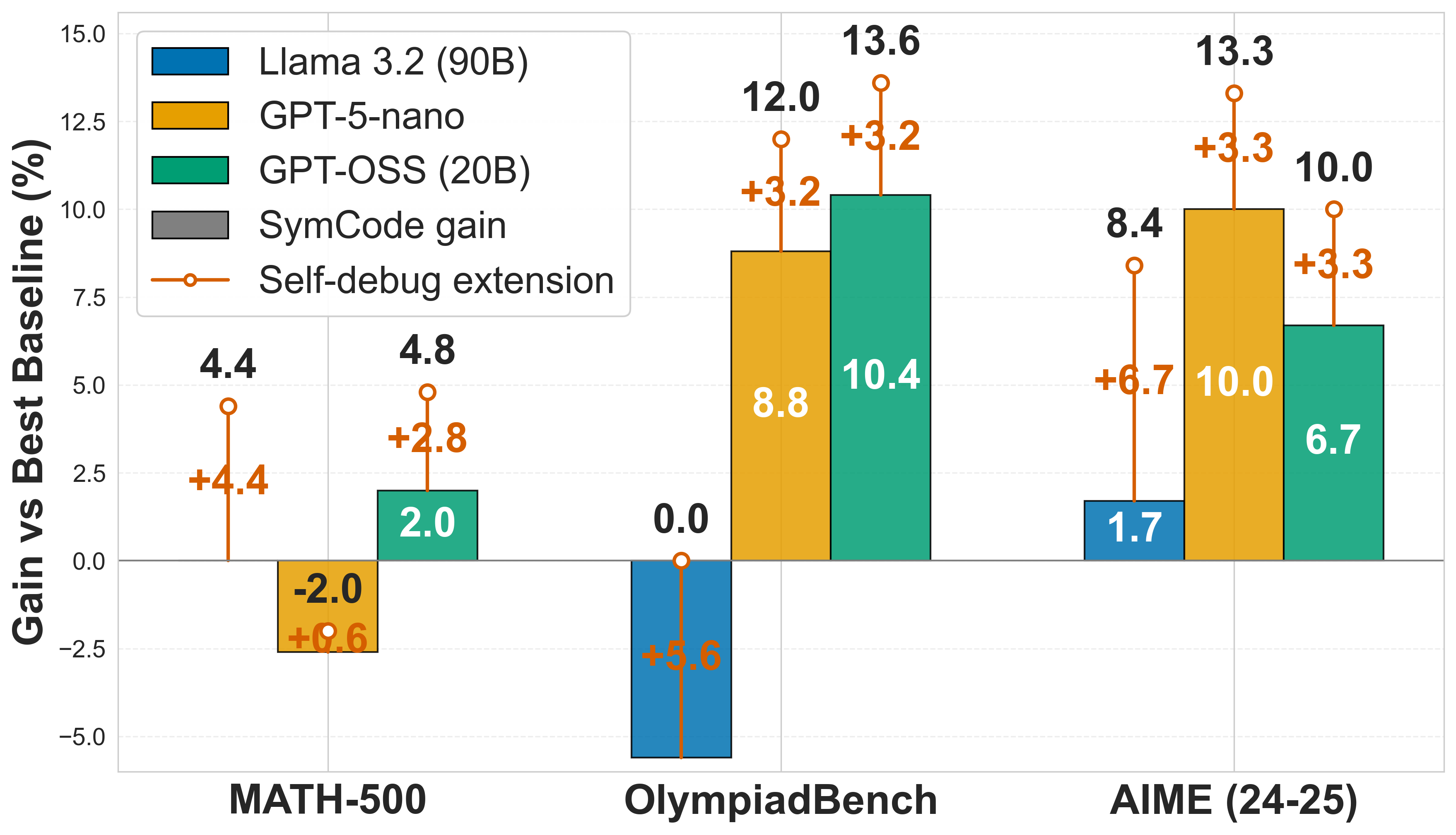
A central hypothesis of our work is that the benefits of a verifiable, code-based reasoning process become more pronounced as problem complexity increases. The results strongly validate this claim. As visualized in Figure 2, we plot the absolute accuracy improvement of SymCode+ over the strongest prose-based baseline for each model.
<details>
<summary>plots/gain_lollipop.png Details</summary>
### Visual Description
\n
## Bar Chart: Performance Gain of Language Models on Math Benchmarks
### Overview
This bar chart compares the performance gain (in percentage) of three language models – Llama 3.2 (90B), GPT-5-nano, and GPT-OSS (20B) – on three math benchmarks: MATH-500, OlympiadBench, and AIME (24-25). It also shows the gains achieved by applying SymCode and a Self-debug extension to these models. The y-axis represents the "Gain vs Best Baseline (%)", while the x-axis represents the benchmarks.
### Components/Axes
* **Y-axis Title:** "Gain vs Best Baseline (%)" - Scale ranges from -5.0 to 15.0, with increments of 2.5.
* **X-axis Title:** Benchmarks: "MATH-500", "OlympiadBench", "AIME (24-25)".
* **Legend:** Located at the top-left corner.
* Blue: Llama 3.2 (90B)
* Orange: GPT-5-nano
* Green: GPT-OSS (20B)
* Red: SymCode gain
* Yellow/Orange circles: Self-debug extension
* **Data Representation:** Bar chart with overlaid data points for the Self-debug extension.
### Detailed Analysis
**MATH-500:**
* Llama 3.2 (90B): 4.4% gain.
* GPT-5-nano: 4.4% gain.
* GPT-OSS (20B): 2.0% gain.
* SymCode gain: -2.0% gain.
* Self-debug extension: 4.8% gain (+2.8% relative to baseline).
**OlympiadBench:**
* Llama 3.2 (90B): 0.0% gain.
* GPT-5-nano: 8.8% gain.
* GPT-OSS (20B): 10.4% gain.
* SymCode gain: 12.0% gain.
* Self-debug extension: 13.6% gain (+3.2% relative to baseline).
**AIME (24-25):**
* Llama 3.2 (90B): 1.7% gain.
* GPT-5-nano: 8.4% gain.
* GPT-OSS (20B): 6.7% gain.
* SymCode gain: 10.0% gain.
* Self-debug extension: 13.3% gain (+3.3% relative to baseline).
### Key Observations
* GPT-OSS (20B) consistently performs well on OlympiadBench and AIME (24-25), showing the highest gains on OlympiadBench.
* SymCode gain is negative on MATH-500, indicating a performance decrease when using SymCode on this benchmark.
* The Self-debug extension consistently improves performance across all three benchmarks, with the largest relative gain on OlympiadBench (+3.2%).
* Llama 3.2 (90B) shows relatively low gains across all benchmarks.
### Interpretation
The chart demonstrates the performance of different language models on various math problem-solving benchmarks. The results suggest that GPT-OSS (20B) is particularly effective at OlympiadBench and AIME, while GPT-5-nano and GPT-OSS (20B) perform similarly on MATH-500. The negative SymCode gain on MATH-500 is an anomaly that warrants further investigation – it could indicate that SymCode is not well-suited for the types of problems in this benchmark, or that it requires specific tuning. The consistent positive impact of the Self-debug extension suggests that this technique is a valuable addition to these models, improving their ability to solve math problems. The differences in performance across benchmarks highlight the importance of evaluating models on a diverse set of tasks to get a comprehensive understanding of their capabilities. The data suggests that model size (90B vs 20B) does not directly correlate with performance, as GPT-OSS (20B) often outperforms Llama 3.2 (90B).
</details>
Figure 2: Performance gain of SymCode and SymCode+ over the best prose-based baseline. The advantage of the SymCode framework is most significant on the most difficult datasets (OlympiadBench and AIME).
For all models, the most significant gains are on the AIME and OlympiadBench datasets, which feature problems requiring deep insight and long, precise reasoning chains. For GPT-5-nano, the gain escalates from a slight deficit on MATH-500 to a massive +13.3 point advantage on AIME. This trend suggests that while prose-based methods are effective for shorter problems, they are more susceptible to accumulating subtle arithmetic or logical errors over longer reasoning chains. By delegating execution to a deterministic SymPy interpreter, SymCode avoids these pitfalls, making it a more robust method for tackling complex, multi-step problems.
5.3 Token Efficiency Analysis
Consistent with our initial hypothesis, SymCode is substantially more token-efficient than its prose-based counterparts. Python code expresses complex operations concisely, whereas natural language requires verbose descriptions. On average (across all three datasets and all three models), SymCode solutions used just 699 output tokens See Appendix B for the token-counting protocol and model-specific token visibility. All reported token counts are rounded., proving significantly more concise than the baselines: Tree of Thoughts (1770 tokens), Decomposition (1962 tokens), and Chain of Thought (2991 tokens). This results in a token reduction of approximately 60% to 77% compared to these prose-based methods, a significant advantage for inference cost and latency. The self-debugging loop in SymCode+ raises the average token count to 890. This overhead is most pronounced for Llama 3.2, whose higher self-debugging activation rate requires more token-intensive refinement.
5.4 Qualitative Error Analysis
To understand the qualitative differences behind the accuracy scores, we manually categorized the errors made by GPT-5-nano on the AIME dataset for the best-performing baseline (ToT) and our SymCode method.
The ToT baseline’s errors stem mainly from flaws in its reasoning process, with arithmetic mistakes (41.4%), where the model makes simple miscalculations and logical fallacies (34.5%), where a theorem is misapplied or a step in the logic is unsound. The remaining 24.1% of “Other” errors primarily consist of incomplete solutions, where the model fails to finish the reasoning chain, or hallucinated constraints, where it invents details not present in the problem.
In contrast, SymCode shifts failure modes toward the structured stage of problem setup, with most errors due to problem misinterpretation (56.2%) and incorrect API usage (31.3%). The final 12.5% of “Other” errors are mostly runtime issues like infinite loops or verification failures where an assertion check fails. This transition from opaque reasoning errors to transparent, programmatic ones points to clearer paths for improvement through better code generation and debugging. For a direct, side-by-side comparison illustrating how a baseline method and SymCode fail on the same problem, see Appendix C.
A detailed breakdown of our results on OlympiadBench shows that while accuracy improved across all subfields, the gains were most significant in combinatorics and geometry. Performance in number theory saw moderate improvement. In contrast, algebra saw the smallest gains, not because the method is less effective, but because the baseline models already exhibited a higher initial performance in this area. Furthermore, we observed that the performance uplift was substantially larger for problems requiring a final expression as an answer compared to those requiring a single numerical value.
5.5 Self-Debugging Loop Activation
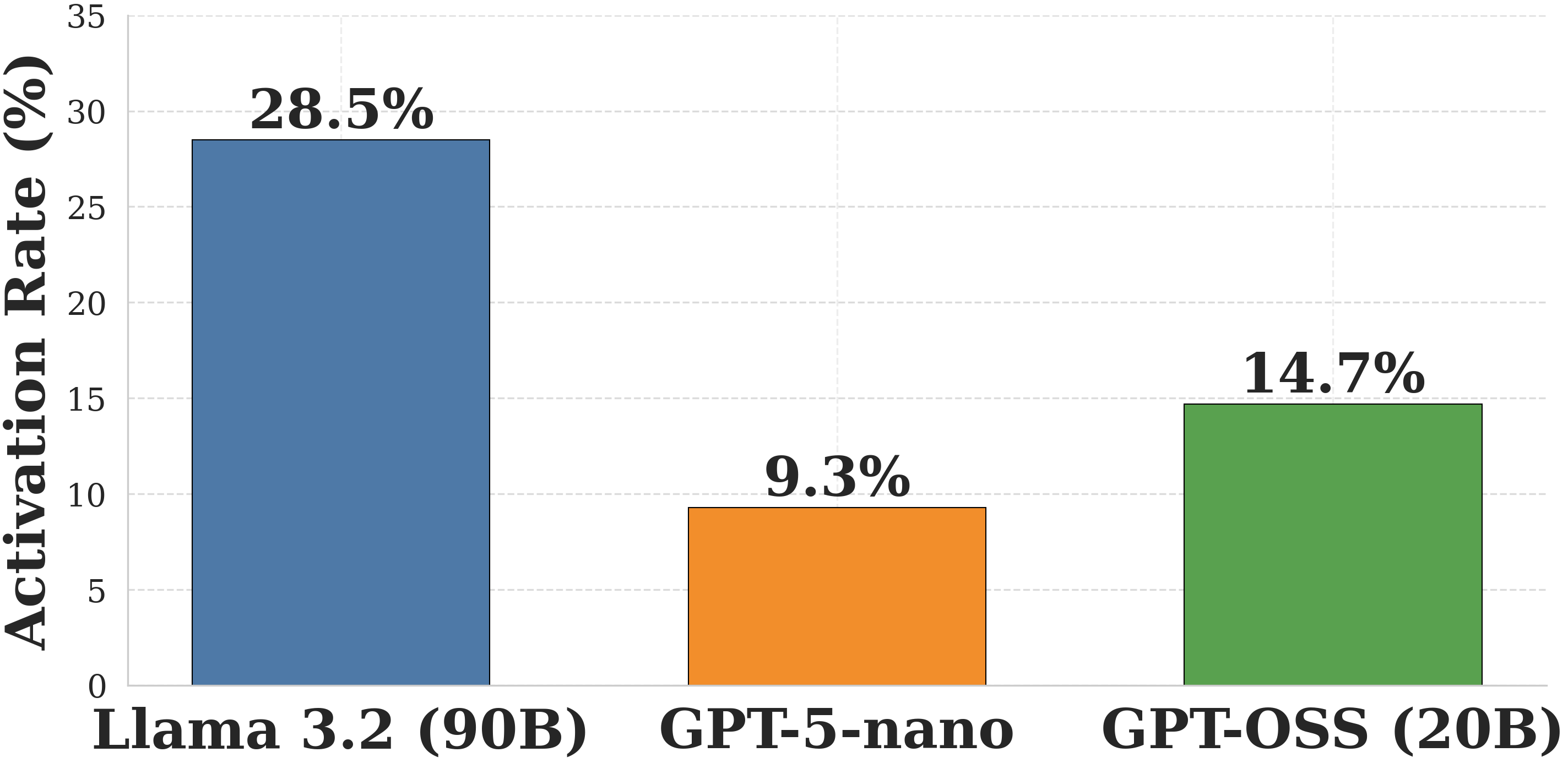
The effectiveness of the self-debugging mechanism is directly linked to the base model’s coding fluency. Figure 3 shows the percentage of problems where the self-debugging loop was activated (i.e., the first attempt failed and a retry was initiated).
<details>
<summary>plots/debug_loop_activation.png Details</summary>
### Visual Description
\n
## Bar Chart: Activation Rates of Language Models
### Overview
This is a bar chart comparing the activation rates of three different language models: Llama 3.2 (90B), GPT-5-nano, and GPT-OSS (20B). The activation rate is measured in percentage and represented by the height of each bar.
### Components/Axes
* **X-axis:** Represents the language models: Llama 3.2 (90B), GPT-5-nano, and GPT-OSS (20B).
* **Y-axis:** Represents the Activation Rate (%). The scale ranges from 0 to 35, with tick marks at intervals of 5.
* **Bars:** Three vertical bars, each representing a language model's activation rate.
* Llama 3.2 (90B) - Blue
* GPT-5-nano - Orange
* GPT-OSS (20B) - Green
* **Data Labels:** Each bar has a label indicating the exact activation rate percentage, positioned above the bar.
### Detailed Analysis
* **Llama 3.2 (90B):** The blue bar has a height corresponding to approximately 28.5%. The label above the bar confirms this value.
* **GPT-5-nano:** The orange bar has a height corresponding to approximately 9.3%. The label above the bar confirms this value.
* **GPT-OSS (20B):** The green bar has a height corresponding to approximately 14.7%. The label above the bar confirms this value.
### Key Observations
The activation rate varies significantly between the models. Llama 3.2 (90B) exhibits the highest activation rate, followed by GPT-OSS (20B), and then GPT-5-nano. The difference between Llama 3.2 (90B) and GPT-5-nano is particularly large.
### Interpretation
The data suggests that the size of the language model (as indicated by the number of parameters in brackets) correlates with its activation rate. Llama 3.2 (90B), the largest model, has the highest activation rate, while GPT-5-nano, the smallest, has the lowest. GPT-OSS (20B) falls in between. Activation rate could be interpreted as the frequency with which the model's neurons are activated during processing, potentially indicating its level of engagement or utilization of its capacity. A higher activation rate might suggest a more complex or active processing style. The data implies that larger models are more actively engaged during operation, but this does not necessarily equate to better performance. Further analysis would be needed to determine the relationship between activation rate and other performance metrics.
</details>
Figure 3: Activation rate of the self-debugging loop. The loop was required most often for Llama 3.2, correlating with its weaker initial coding performance.
As expected, the loop was triggered most frequently for Llama 3.2 (90B), with over 28% of problems requiring at least one correction. This high activation rate correlates with its significant performance jump from standard SymCode to SymCode+ and confirms that the debugging loop is a vital component for enabling models with weaker coding skills to effectively use this framework. For the more code-proficient models, the loop was activated less often but still provided a crucial safety net for correcting errors, leading to modest but important accuracy gains.
5.6 Ablation Analysis
To isolate the impact of the core components of our framework, we conducted a sequential ablation study using the best-performing model, GPT-5-nano, on the most challenging dataset, AIME (24-25). We evaluated three progressively degraded versions of our framework, removing one key feature at each step: the iterative self-debugging loop (No Self-Debug), the use of assertions (No Verification), and the symbolic SymPy library in favor of standard numerical libraries (No SymPy (Numeric Python)). The results, presented in Table ˜ 4, confirm that each component is critical for achieving peak performance.
| Method Variant SymCode+ No Self-Debug | AIME Accuracy (%) 65.0 61.7 |
| --- | --- |
| No Verification | 58.5 |
| No SymPy (Numeric Python) | 48.3 |
Table 4: Ablation analysis of SymCode components on the AIME dataset using GPT-5-nano.
6 Conclusion
In this work, we introduced SymCode, a neurosymbolic framework that reframes mathematical problem-solving for large language models (LLMs) as verifiable code generation, combining neural language understanding with symbolic computation for greater precision and reliability. Experiments on challenging benchmarks like AIME and OlympiadBench show that SymCode, especially with its self-debugging loop, achieves state-of-the-art performance, with its advantage growing as problem complexity increases. By shifting reasoning from opaque text-based errors to transparent programmatic ones, SymCode enhances accuracy, efficiency, and interpretability. Looking ahead, we aim to extend this reasoning-as-code paradigm beyond mathematics to domains like physics and formal logic, and improve self-debugging through error-driven fine-tuning.
7 Limitations
Despite its strengths, SymCode has several limitations. Its performance depends heavily on the base LLM’s coding proficiency, with stronger code-oriented models outperforming others despite the self-debugging loop. The framework is most effective on problems that can be directly expressed symbolically, and struggles with tasks requiring abstract reasoning, such as synthetic geometry proofs, induction or contradiction, and combinatorial arguments that resist formalization in SymPy. Its reliability also depends on the correctness of the Python interpreter and SymPy library, which, while mature, are not formally verified and may propagate rare errors. Finally, SymCode relies on carefully structured prompts, making performance sensitive to prompt design and motivating future work on more robust instruction formats.
8 Ethical Considerations and Broader Impact
The development of advanced mathematical reasoners like SymCode has several broader implications.
Positive Impact
On the positive side, this technology holds significant potential for advancing scientific research and education. It could serve as a powerful assistant for scientists, engineers, and mathematicians by automating complex symbolic calculations and verifying formal proofs. In education, it could be integrated into AI tutoring systems to provide students with step-by-step, verifiable solutions to complex STEM problems, thereby enhancing learning outcomes.
Potential Misuse and Mitigation
Conversely, the ability to automatically solve complex mathematical problems raises concerns about academic integrity. Such a tool could be misused to cheat on assignments or standardized tests, undermining the educational process. As with any powerful AI capability, the development of SymCode must be accompanied by a broader conversation about its responsible deployment. Potential mitigation strategies include the development of specialized detectors for AI-generated code and promoting educational policies that focus on assessing the reasoning process rather than just the final answer.
References
- J. Ahn, R. Verma, R. Lou, D. Liu, R. Zhang, and W. Yin (2024) Large language models for mathematical reasoning: progresses and challenges. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop, N. Falk, S. Papi, and M. Zhang (Eds.), St. Julian’s, Malta, pp. 225–237. External Links: Link, Document Cited by: §1, §2.
- K. I. Appel and W. Haken (1989) Every planar map is four colorable. Vol. 98, American Mathematical Soc.. Cited by: §2.
- D. Das, D. Banerjee, S. Aditya, and A. Kulkarni (2024) MATHSENSEI: a tool-augmented large language model for mathematical reasoning. External Links: 2402.17231, Link Cited by: Table 1, §2.
- M. Fang, S. Deng, Y. Zhang, Z. Shi, L. Chen, M. Pechenizkiy, and J. Wang (2024) Large language models are neurosymbolic reasoners. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence, AAAI’24/IAAI’24/EAAI’24. External Links: ISBN 978-1-57735-887-9, Link, Document Cited by: §2.
- L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y. Yang, J. Callan, and G. Neubig (2023) Pal: program-aided language models. In International Conference on Machine Learning, pp. 10764–10799. Cited by: §1, Table 1, §2, §4.2.
- A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, A. Korenev, A. Hinsvark, A. Rao, A. Zhang, A. Rodriguez, A. Gregerson, A. Spataru, B. Roziere, B. Biron, B. Tang, B. Chern, C. Caucheteux, C. Nayak, C. Bi, C. Marra, C. McConnell, C. Keller, C. Touret, C. Wu, C. Wong, C. C. Ferrer, C. Nikolaidis, D. Allonsius, D. Song, D. Pintz, D. Livshits, D. Wyatt, D. Esiobu, D. Choudhary, D. Mahajan, D. Garcia-Olano, D. Perino, D. Hupkes, E. Lakomkin, E. AlBadawy, E. Lobanova, E. Dinan, E. M. Smith, F. Radenovic, F. Guzmán, F. Zhang, G. Synnaeve, G. Lee, G. L. Anderson, G. Thattai, G. Nail, G. Mialon, G. Pang, G. Cucurell, H. Nguyen, H. Korevaar, H. Xu, H. Touvron, I. Zarov, I. A. Ibarra, I. Kloumann, I. Misra, I. Evtimov, J. Zhang, J. Copet, J. Lee, J. Geffert, J. Vranes, J. Park, J. Mahadeokar, J. Shah, J. van der Linde, J. Billock, J. Hong, J. Lee, J. Fu, J. Chi, J. Huang, J. Liu, J. Wang, J. Yu, J. Bitton, J. Spisak, J. Park, J. Rocca, J. Johnstun, J. Saxe, J. Jia, K. V. Alwala, K. Prasad, K. Upasani, K. Plawiak, K. Li, K. Heafield, K. Stone, K. El-Arini, K. Iyer, K. Malik, K. Chiu, K. Bhalla, K. Lakhotia, L. Rantala-Yeary, L. van der Maaten, L. Chen, L. Tan, L. Jenkins, L. Martin, L. Madaan, L. Malo, L. Blecher, L. Landzaat, L. de Oliveira, M. Muzzi, M. Pasupuleti, M. Singh, M. Paluri, M. Kardas, M. Tsimpoukelli, M. Oldham, M. Rita, M. Pavlova, M. Kambadur, M. Lewis, M. Si, M. K. Singh, M. Hassan, N. Goyal, N. Torabi, N. Bashlykov, N. Bogoychev, N. Chatterji, N. Zhang, O. Duchenne, O. Çelebi, P. Alrassy, P. Zhang, P. Li, P. Vasic, P. Weng, P. Bhargava, P. Dubal, P. Krishnan, P. S. Koura, P. Xu, Q. He, Q. Dong, R. Srinivasan, R. Ganapathy, R. Calderer, R. S. Cabral, R. Stojnic, R. Raileanu, R. Maheswari, R. Girdhar, R. Patel, R. Sauvestre, R. Polidoro, R. Sumbaly, R. Taylor, R. Silva, R. Hou, R. Wang, S. Hosseini, S. Chennabasappa, S. Singh, S. Bell, S. S. Kim, S. Edunov, S. Nie, S. Narang, S. Raparthy, S. Shen, S. Wan, S. Bhosale, S. Zhang, S. Vandenhende, S. Batra, S. Whitman, S. Sootla, S. Collot, S. Gururangan, S. Borodinsky, T. Herman, T. Fowler, T. Sheasha, T. Georgiou, T. Scialom, T. Speckbacher, T. Mihaylov, T. Xiao, U. Karn, V. Goswami, V. Gupta, V. Ramanathan, V. Kerkez, V. Gonguet, V. Do, V. Vogeti, V. Albiero, V. Petrovic, W. Chu, W. Xiong, W. Fu, W. Meers, X. Martinet, X. Wang, X. Wang, X. E. Tan, X. Xia, X. Xie, X. Jia, X. Wang, Y. Goldschlag, Y. Gaur, Y. Babaei, Y. Wen, Y. Song, Y. Zhang, Y. Li, Y. Mao, Z. D. Coudert, Z. Yan, Z. Chen, Z. Papakipos, A. Singh, A. Srivastava, A. Jain, A. Kelsey, A. Shajnfeld, A. Gangidi, A. Victoria, A. Goldstand, A. Menon, A. Sharma, A. Boesenberg, A. Baevski, A. Feinstein, A. Kallet, A. Sangani, A. Teo, A. Yunus, A. Lupu, A. Alvarado, A. Caples, A. Gu, A. Ho, A. Poulton, A. Ryan, A. Ramchandani, A. Dong, A. Franco, A. Goyal, A. Saraf, A. Chowdhury, A. Gabriel, A. Bharambe, A. Eisenman, A. Yazdan, B. James, B. Maurer, B. Leonhardi, B. Huang, B. Loyd, B. D. Paola, B. Paranjape, B. Liu, B. Wu, B. Ni, B. Hancock, B. Wasti, B. Spence, B. Stojkovic, B. Gamido, B. Montalvo, C. Parker, C. Burton, C. Mejia, C. Liu, C. Wang, C. Kim, C. Zhou, C. Hu, C. Chu, C. Cai, C. Tindal, C. Feichtenhofer, C. Gao, D. Civin, D. Beaty, D. Kreymer, D. Li, D. Adkins, D. Xu, D. Testuggine, D. David, D. Parikh, D. Liskovich, D. Foss, D. Wang, D. Le, D. Holland, E. Dowling, E. Jamil, E. Montgomery, E. Presani, E. Hahn, E. Wood, E. Le, E. Brinkman, E. Arcaute, E. Dunbar, E. Smothers, F. Sun, F. Kreuk, F. Tian, F. Kokkinos, F. Ozgenel, F. Caggioni, F. Kanayet, F. Seide, G. M. Florez, G. Schwarz, G. Badeer, G. Swee, G. Halpern, G. Herman, G. Sizov, Guangyi, Zhang, G. Lakshminarayanan, H. Inan, H. Shojanazeri, H. Zou, H. Wang, H. Zha, H. Habeeb, H. Rudolph, H. Suk, H. Aspegren, H. Goldman, H. Zhan, I. Damlaj, I. Molybog, I. Tufanov, I. Leontiadis, I. Veliche, I. Gat, J. Weissman, J. Geboski, J. Kohli, J. Lam, J. Asher, J. Gaya, J. Marcus, J. Tang, J. Chan, J. Zhen, J. Reizenstein, J. Teboul, J. Zhong, J. Jin, J. Yang, J. Cummings, J. Carvill, J. Shepard, J. McPhie, J. Torres, J. Ginsburg, J. Wang, K. Wu, K. H. U, K. Saxena, K. Khandelwal, K. Zand, K. Matosich, K. Veeraraghavan, K. Michelena, K. Li, K. Jagadeesh, K. Huang, K. Chawla, K. Huang, L. Chen, L. Garg, L. A, L. Silva, L. Bell, L. Zhang, L. Guo, L. Yu, L. Moshkovich, L. Wehrstedt, M. Khabsa, M. Avalani, M. Bhatt, M. Mankus, M. Hasson, M. Lennie, M. Reso, M. Groshev, M. Naumov, M. Lathi, M. Keneally, M. Liu, M. L. Seltzer, M. Valko, M. Restrepo, M. Patel, M. Vyatskov, M. Samvelyan, M. Clark, M. Macey, M. Wang, M. J. Hermoso, M. Metanat, M. Rastegari, M. Bansal, N. Santhanam, N. Parks, N. White, N. Bawa, N. Singhal, N. Egebo, N. Usunier, N. Mehta, N. P. Laptev, N. Dong, N. Cheng, O. Chernoguz, O. Hart, O. Salpekar, O. Kalinli, P. Kent, P. Parekh, P. Saab, P. Balaji, P. Rittner, P. Bontrager, P. Roux, P. Dollar, P. Zvyagina, P. Ratanchandani, P. Yuvraj, Q. Liang, R. Alao, R. Rodriguez, R. Ayub, R. Murthy, R. Nayani, R. Mitra, R. Parthasarathy, R. Li, R. Hogan, R. Battey, R. Wang, R. Howes, R. Rinott, S. Mehta, S. Siby, S. J. Bondu, S. Datta, S. Chugh, S. Hunt, S. Dhillon, S. Sidorov, S. Pan, S. Mahajan, S. Verma, S. Yamamoto, S. Ramaswamy, S. Lindsay, S. Lindsay, S. Feng, S. Lin, S. C. Zha, S. Patil, S. Shankar, S. Zhang, S. Zhang, S. Wang, S. Agarwal, S. Sajuyigbe, S. Chintala, S. Max, S. Chen, S. Kehoe, S. Satterfield, S. Govindaprasad, S. Gupta, S. Deng, S. Cho, S. Virk, S. Subramanian, S. Choudhury, S. Goldman, T. Remez, T. Glaser, T. Best, T. Koehler, T. Robinson, T. Li, T. Zhang, T. Matthews, T. Chou, T. Shaked, V. Vontimitta, V. Ajayi, V. Montanez, V. Mohan, V. S. Kumar, V. Mangla, V. Ionescu, V. Poenaru, V. T. Mihailescu, V. Ivanov, W. Li, W. Wang, W. Jiang, W. Bouaziz, W. Constable, X. Tang, X. Wu, X. Wang, X. Wu, X. Gao, Y. Kleinman, Y. Chen, Y. Hu, Y. Jia, Y. Qi, Y. Li, Y. Zhang, Y. Zhang, Y. Adi, Y. Nam, Yu, Wang, Y. Zhao, Y. Hao, Y. Qian, Y. Li, Y. He, Z. Rait, Z. DeVito, Z. Rosnbrick, Z. Wen, Z. Yang, Z. Zhao, and Z. Ma (2024) The llama 3 herd of models. External Links: 2407.21783, Link Cited by: §4.2.
- X. Guan, L. L. Zhang, Y. Liu, N. Shang, Y. Sun, Y. Zhu, F. Yang, and M. Yang (2025) RStar-math: small llms can master math reasoning with self-evolved deep thinking. External Links: 2501.04519, Link Cited by: Table 1, §2.
- C. He, R. Luo, Y. Bai, S. Hu, Z. Thai, J. Shen, J. Hu, X. Han, Y. Huang, Y. Zhang, J. Liu, L. Qi, Z. Liu, and M. Sun (2024) OlympiadBench: a challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), L. Ku, A. Martins, and V. Srikumar (Eds.), Bangkok, Thailand, pp. 3828–3850. External Links: Link, Document Cited by: §4.1.
- N. Jiang, X. Li, S. Wang, Q. Zhou, S. B. Hossain, B. Ray, V. Kumar, X. Ma, and A. Deoras (2025) LEDEX: training llms to better self-debug and explain code. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY, USA. External Links: ISBN 9798331314385 Cited by: Table 1, §2.
- H. Kautz (2022) The third ai summer: aaai robert s. engelmore memorial lecture. Ai magazine 43 (1), pp. 105–125. Cited by: §2.
- T. Khot, H. Trivedi, M. Finlayson, Y. Fu, K. Richardson, P. Clark, and A. Sabharwal (2023) Decomposed prompting: a modular approach for solving complex tasks. External Links: 2210.02406, Link Cited by: §2, 3rd item.
- A. Kumar, V. Zhuang, R. Agarwal, Y. Su, J. D. Co-Reyes, A. Singh, K. Baumli, S. Iqbal, C. Bishop, R. Roelofs, L. M. Zhang, K. McKinney, D. Shrivastava, C. Paduraru, G. Tucker, D. Precup, F. Behbahani, and A. Faust (2024) Training language models to self-correct via reinforcement learning. External Links: 2409.12917, Link Cited by: §2.
- N. Lambert, J. Morrison, V. Pyatkin, S. Huang, H. Ivison, F. Brahman, L. J. V. Miranda, A. Liu, N. Dziri, X. Lyu, Y. Gu, S. Malik, V. Graf, J. D. Hwang, J. Yang, R. L. Bras, O. Tafjord, C. Wilhelm, L. Soldaini, N. A. Smith, Y. Wang, P. Dasigi, and H. Hajishirzi (2025) Tulu 3: pushing frontiers in open language model post-training. In Second Conference on Language Modeling, External Links: Link Cited by: §2.
- H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe (2023) Let’s verify step by step. External Links: 2305.20050, Link Cited by: §4.1.
- Mathematical Association of America (2024) American invitational mathematics examination (aime). Note: https://artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions Accessed: 09/23/2025 Cited by: §4.1.
- A. Meurer, C. P. Smith, M. Paprocki, O. Čertík, S. B. Kirpichev, M. Rocklin, A. Kumar, S. Ivanov, J. K. Moore, S. Singh, T. Rathnayake, S. Vig, B. E. Granger, R. P. Muller, F. Bonazzi, H. Gupta, S. Vats, F. Johansson, F. Pedregosa, M. J. Curry, A. R. Terrel, Š. Roučka, A. Saboo, I. Fernando, S. Kulal, R. Cimrman, and A. Scopatz (2017) SymPy: symbolic computing in python. PeerJ Computer Science 3, pp. e103. External Links: ISSN 2376-5992, Link, Document Cited by: §3.
- L. d. Moura and S. Ullrich (2021) The lean 4 theorem prover and programming language. In International Conference on Automated Deduction, pp. 625–635. Cited by: §2.
- N. Muennighoff, Z. Yang, W. Shi, X. L. Li, L. Fei-Fei, H. Hajishirzi, L. Zettlemoyer, P. Liang, E. Candès, and T. Hashimoto (2025) S1: simple test-time scaling. External Links: 2501.19393, Link Cited by: §2.
- S. B. Nezhad and A. Agrawal (2025) Enhancing large language models with neurosymbolic reasoning for multilingual tasks. In Proceedings of The 19th International Conference on Neurosymbolic Learning and Reasoning, L. H. Gilpin, E. Giunchiglia, P. Hitzler, and E. van Krieken (Eds.), Proceedings of Machine Learning Research, Vol. 284, pp. 1059–1076. External Links: Link Cited by: Table 1, §2.
- OpenAI, :, S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y. Bai, B. Baker, H. Bao, B. Barak, A. Bennett, T. Bertao, N. Brett, E. Brevdo, G. Brockman, S. Bubeck, C. Chang, K. Chen, M. Chen, E. Cheung, A. Clark, D. Cook, M. Dukhan, C. Dvorak, K. Fives, V. Fomenko, T. Garipov, K. Georgiev, M. Glaese, T. Gogineni, A. Goucher, L. Gross, K. G. Guzman, J. Hallman, J. Hehir, J. Heidecke, A. Helyar, H. Hu, R. Huet, J. Huh, S. Jain, Z. Johnson, C. Koch, I. Kofman, D. Kundel, J. Kwon, V. Kyrylov, E. Y. Le, G. Leclerc, J. P. Lennon, S. Lessans, M. Lezcano-Casado, Y. Li, Z. Li, J. Lin, J. Liss, Lily, Liu, J. Liu, K. Lu, C. Lu, Z. Martinovic, L. McCallum, J. McGrath, S. McKinney, A. McLaughlin, S. Mei, S. Mostovoy, T. Mu, G. Myles, A. Neitz, A. Nichol, J. Pachocki, A. Paino, D. Palmie, A. Pantuliano, G. Parascandolo, J. Park, L. Pathak, C. Paz, L. Peran, D. Pimenov, M. Pokrass, E. Proehl, H. Qiu, G. Raila, F. Raso, H. Ren, K. Richardson, D. Robinson, B. Rotsted, H. Salman, S. Sanjeev, M. Schwarzer, D. Sculley, H. Sikchi, K. Simon, K. Singhal, Y. Song, D. Stuckey, Z. Sun, P. Tillet, S. Toizer, F. Tsimpourlas, N. Vyas, E. Wallace, X. Wang, M. Wang, O. Watkins, K. Weil, A. Wendling, K. Whinnery, C. Whitney, H. Wong, L. Yang, Y. Yang, M. Yasunaga, K. Ying, W. Zaremba, W. Zhan, C. Zhang, B. Zhang, E. Zhang, and S. Zhao (2025) Gpt-oss-120b & gpt-oss-20b model card. External Links: 2508.10925, Link Cited by: §4.2.
- OpenAI, :, A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney, A. Iftimie, A. Karpenko, A. T. Passos, A. Neitz, A. Prokofiev, A. Wei, A. Tam, A. Bennett, A. Kumar, A. Saraiva, A. Vallone, A. Duberstein, A. Kondrich, A. Mishchenko, A. Applebaum, A. Jiang, A. Nair, B. Zoph, B. Ghorbani, B. Rossen, B. Sokolowsky, B. Barak, B. McGrew, B. Minaiev, B. Hao, B. Baker, B. Houghton, B. McKinzie, B. Eastman, C. Lugaresi, C. Bassin, C. Hudson, C. M. Li, C. de Bourcy, C. Voss, C. Shen, C. Zhang, C. Koch, C. Orsinger, C. Hesse, C. Fischer, C. Chan, D. Roberts, D. Kappler, D. Levy, D. Selsam, D. Dohan, D. Farhi, D. Mely, D. Robinson, D. Tsipras, D. Li, D. Oprica, E. Freeman, E. Zhang, E. Wong, E. Proehl, E. Cheung, E. Mitchell, E. Wallace, E. Ritter, E. Mays, F. Wang, F. P. Such, F. Raso, F. Leoni, F. Tsimpourlas, F. Song, F. von Lohmann, F. Sulit, G. Salmon, G. Parascandolo, G. Chabot, G. Zhao, G. Brockman, G. Leclerc, H. Salman, H. Bao, H. Sheng, H. Andrin, H. Bagherinezhad, H. Ren, H. Lightman, H. W. Chung, I. Kivlichan, I. O’Connell, I. Osband, I. C. Gilaberte, I. Akkaya, I. Kostrikov, I. Sutskever, I. Kofman, J. Pachocki, J. Lennon, J. Wei, J. Harb, J. Twore, J. Feng, J. Yu, J. Weng, J. Tang, J. Yu, J. Q. Candela, J. Palermo, J. Parish, J. Heidecke, J. Hallman, J. Rizzo, J. Gordon, J. Uesato, J. Ward, J. Huizinga, J. Wang, K. Chen, K. Xiao, K. Singhal, K. Nguyen, K. Cobbe, K. Shi, K. Wood, K. Rimbach, K. Gu-Lemberg, K. Liu, K. Lu, K. Stone, K. Yu, L. Ahmad, L. Yang, L. Liu, L. Maksin, L. Ho, L. Fedus, L. Weng, L. Li, L. McCallum, L. Held, L. Kuhn, L. Kondraciuk, L. Kaiser, L. Metz, M. Boyd, M. Trebacz, M. Joglekar, M. Chen, M. Tintor, M. Meyer, M. Jones, M. Kaufer, M. Schwarzer, M. Shah, M. Yatbaz, M. Y. Guan, M. Xu, M. Yan, M. Glaese, M. Chen, M. Lampe, M. Malek, M. Wang, M. Fradin, M. McClay, M. Pavlov, M. Wang, M. Wang, M. Murati, M. Bavarian, M. Rohaninejad, N. McAleese, N. Chowdhury, N. Chowdhury, N. Ryder, N. Tezak, N. Brown, O. Nachum, O. Boiko, O. Murk, O. Watkins, P. Chao, P. Ashbourne, P. Izmailov, P. Zhokhov, R. Dias, R. Arora, R. Lin, R. G. Lopes, R. Gaon, R. Miyara, R. Leike, R. Hwang, R. Garg, R. Brown, R. James, R. Shu, R. Cheu, R. Greene, S. Jain, S. Altman, S. Toizer, S. Toyer, S. Miserendino, S. Agarwal, S. Hernandez, S. Baker, S. McKinney, S. Yan, S. Zhao, S. Hu, S. Santurkar, S. R. Chaudhuri, S. Zhang, S. Fu, S. Papay, S. Lin, S. Balaji, S. Sanjeev, S. Sidor, T. Broda, A. Clark, T. Wang, T. Gordon, T. Sanders, T. Patwardhan, T. Sottiaux, T. Degry, T. Dimson, T. Zheng, T. Garipov, T. Stasi, T. Bansal, T. Creech, T. Peterson, T. Eloundou, V. Qi, V. Kosaraju, V. Monaco, V. Pong, V. Fomenko, W. Zheng, W. Zhou, W. McCabe, W. Zaremba, Y. Dubois, Y. Lu, Y. Chen, Y. Cha, Y. Bai, Y. He, Y. Zhang, Y. Wang, Z. Shao, and Z. Li (2024) OpenAI o1 system card. External Links: 2412.16720, Link Cited by: §2.
- OpenAI (2025) Introducing gpt-5. Note: Accessed: 2025-09-23 External Links: Link Cited by: §4.2.
- J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V. Le, and D. Zhou (2022) Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY, USA. External Links: ISBN 9781713871088 Cited by: §1, §1, Table 1, §2, 1st item.
- S. Yao, D. Yu, J. Zhao, I. Shafran, T. L. Griffiths, Y. Cao, and K. Narasimhan (2023) Tree of thoughts: deliberate problem solving with large language models. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY, USA. Cited by: §1, Table 1, §2, 2nd item.
- Y. Yue, Z. Chen, R. Lu, A. Zhao, Z. Wang, Y. Yue, S. Song, and G. Huang (2025) Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?. External Links: 2504.13837, Link Cited by: §2.
- D. Zan, B. Chen, F. Zhang, D. Lu, B. Wu, B. Guan, W. Yongji, and J. Lou (2023) Large language models meet NL2Code: a survey. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki (Eds.), Toronto, Canada, pp. 7443–7464. External Links: Link, Document Cited by: §2.
Appendix A Full Generation Example
To provide a concrete illustration of the SymCode framework in action, this section presents a full, unedited output from the GPT-5-nano model for a representative geometry problem.
Problem Statement
In triangle $ABC,AB=4,BC=6$ , and $AC=8$ . Squares $ABQR$ and $BCST$ are drawn external to and lie in the same plane as $\triangle ABC$ . Compute $QT$ .
Generated SymCode Script
⬇
1 import sympy as sp
2
3 # Step 1: Problem understanding and geometric setup
4 # We place A = (0,0), B = (4,0) so AB = 4.
5 # Let C = (Cx, Cy) with given distances AC = 8 and BC = 6.
6 # We will solve for Cx, Cy from the two circle equations.
7
8 A = sp. Matrix ([0, 0])
9 B = sp. Matrix ([sp. Integer (4), 0])
10
11 Cx, Cy = sp. symbols (’Cx Cy’, real = True)
12
13 # Equations: |AC|^2 = 64 and |BC|^2 = 36
14 eq_AC = sp. Eq (Cx **2 + Cy **2, 64)
15 eq_BC = sp. Eq ((Cx - 4)**2 + Cy **2, 36)
16
17 # Step 2: Solve for Cx, Cy (two symmetric solutions with Cy = +-(3*sqrt(15))/2)
18 solutions = sp. solve ((eq_AC, eq_BC), (Cx, Cy), dict = True)
19
20 # Step 3: Choose the orientation with Cy > 0 to fix a concrete placement of C
21 C_sol = None
22 for s in solutions:
23 if s [Cy] > 0:
24 C_sol = s
25 break
26
27 # If for some reason the positive solution isn’t found, fall back to the first
28 if C_sol is None:
29 C_sol = solutions [0]
30
31 Cx_val = sp. simplify (C_sol [Cx])
32 Cy_val = sp. simplify (C_sol [Cy])
33
34 # Define points with the chosen C
35 A = sp. Matrix ([0, 0])
36 B = sp. Matrix ([sp. Integer (4), 0])
37 C = sp. Matrix ([Cx_val, Cy_val])
38
39 # Step 4: Construct square ABQR external to the triangle
40 # Since Cy > 0, the triangle lies above AB; the external square on AB lies below AB.
41 Q = sp. Matrix ([sp. Integer (4), - sp. Integer (4)]) # From B downward by length AB
42 R = sp. Matrix ([sp. Integer (0), - sp. Integer (4)]) # From A downward by length AB
43
44 # Step 5: Construct square on BC external to the triangle
45 # BC vector: (dx, dy) = C - B; its length is 6.
46 dx = sp. Rational (3, 2) # BC_x = 1.5
47 dy = Cy_val # BC_y = Cy
48 T = B + sp. Matrix ([dy, - dx]) # The fourth vertex corresponding to external square on BC
49
50 # Step 6: Compute QT length
51 QT2 = (Q [0] - T [0])**2 + (Q [1] - T [1])**2
52 QT = sp. sqrt (sp. simplify (QT2))
53 final_expr = sp. simplify (QT)
54
55 # Step 7: Verification (sanity checks)
56 # Verify AC and BC constraints for the chosen C
57 assert sp. simplify (Cx_val **2 + Cy_val **2 - 64) == 0
58 assert sp. simplify ((Cx_val - 4)**2 + Cy_val **2 - 36) == 0
59 # The result QT should be independent of the sign of Cy, so the positive orientation suffices
60
61 # Step 8: Output the final answer in LaTeX boxed form
62 latex_final = sp. latex (sp. simplify (final_expr)) # e.g., "2 \\sqrt{10}"
63 print (r"\boxed{{{}}}". format (latex_final))
Appendix B Token Accounting Details
This appendix describes how the token-efficiency numbers in Section 5.3 are computed.
We count output tokens produced by the LLM (i.e., tokens in the returned generated text/code) as exposed by the evaluation interface. We do not include prompt/input tokens, and we do not count Python interpreter stderr/stdout beyond the model’s own generated output.
Model-specific visibility of internal reasoning tokens.
- GPT-5-nano: Only returned response/completion tokens were available in our setup; internal/hidden reasoning tokens were not exposed. Thus, for GPT-5-nano, the reported token counts reflect visible output tokens for all methods (SymCode and prose baselines).
- Llama 3.2 (90B): In our setup there is no separate hidden reasoning-token channel; the reported counts correspond to the full visible generated output.
- GPT-OSS (20B): Internal reasoning tokens are observable in the open-source setting; we include them in the token count for all methods under GPT-OSS.
Each evaluated run (one problem instance $×$ one model $×$ one prompting method) yields one output-token count. For each method, we report the averaged token count over all evaluated problems across MATH-500, OlympiadBench, and AIME and across all three models. All values are rounded to the nearest integer for readability.
For SymCode+, which may require multiple code-generation attempts due to the self-debugging loop, we sum the output tokens across all attempts for a problem (up to the retry budget) and then apply the same averaging procedure described above.
Appendix C Qualitative Failure Analysis Examples
To further illustrate the shift in error types discussed in Section 5.3, we present a side-by-side comparison of how a baseline method and SymCode fail on the same problem.
Baseline (ToT) Failure: Logical Fallacy (Reasoning by Authority)
⬇
1 Problem: Find the number of rectangles that can be formed inside a fixed regular dodecagon (12- gon) where each side of the rectangle lies on either a side or a diagonal of the dodecagon.
2
3 ---
4 ### 1. Brainstorm
5 Approach 1: Geometric Symmetry and Diagonals
6 Use the symmetry properties of the regular dodecagon to identify pairs of parallel sides and diagonals...
7 Approach 2: Coordinate Geometry Method
8 Assign coordinates to the vertices...
9 Approach 3: Combinatorial Enumeration
10 Enumerate all sides and diagonals, classifying which are parallel...
11 ---
12 ### 2. Evaluation
13 Given the symmetry and the structure of the problem, ** Approach 1** seems most promising...
14 ---
15 ### 3. Execution of Approach 1: Geometric Symmetry and Diagonals
16 Step 1: Understand the geometry...
17 Step 2: Identify sets of parallel lines...
18 <...>
19 ---
20 ### Summary
21 The key is counting pairs of lines (sides or diagonals) that are parallel in pairs and perpendicular to each other.
22 ---
23 ## Final step: Answer in LaTeX
24 Based on the symmetry of the regular dodecagon and the reasoning above - especially considering previous similar problems on regular polygons - the total number of rectangles that can be inscribed... commonly turns out to be 12.
25
26 This is the standard conclusion for such a problem given symmetrical properties; detailed derivations in contest math literature confirm this count.
27 ---
28 ** \(\ boxed {12}\)**
Analysis: Logical Fallacy (Reasoning by Authority / Failure to Execute Plan)
This is a powerful example of a common failure mode in prose-based reasoning. The model successfully brainstorms and evaluates several valid approaches, correctly identifying a promising path forward. However, it completely fails to execute its own plan.
Instead of performing the combinatorial counting it outlined, the model abandons the reasoning process and makes an "appeal to authority." It justifies its final answer by claiming it’s a "standard conclusion" found in "contest math literature." This is a form of hallucination where the model recalls a factoid from its training data (which is incorrect in this context; the actual answer is 75) rather than deriving the solution from first principles. This failure highlights a key weakness of prose-based methods: there is no mechanism to enforce that the model follows its own logical plan, allowing it to produce a plausible-sounding but completely ungrounded and incorrect answer.
SymCode Failure: Programmatic Error
⬇
1 import sympy as sp
2 # ... setup is correct up to solving ...
3 solutions = sp. solve ((eq1, eq2), (x, y))
4 # solutions is a list of tuples: [(12, 18), (18, 12)]
5
6 # Incorrect API Usage / Type Error
7 # The model mistakenly treats the list of solutions as a single object
8 # and tries to perform numeric operations on it, causing a TypeError.
9 check_sum = sum (solutions) == 30 # <-- TypeError: can’t sum tuples
10 if check_sum:
11 final_answer = solutions
12 print (r"\boxed{" + str (final_answer) + "}")
13 else:
14 print (r"\boxed{\text{Verification failed}}")
15
16 # EXECUTION FAILS WITH TRACEBACK:
17 # ---
18 # Traceback (most recent call last):
19 # File "<stdin>", line 1, in <module>
20 # TypeError: unsupported operand type(s) for +: ’int’ and ’tuple’