# The Ouroboros of Benchmarking: Reasoning Evaluation in an Era of Saturation
**Authors**:
- İbrahim Ethem Deveci (Department of Cognitive Science)
- Ankara, Turkey
- Duygu Ataman (Department of Cognitive Science)
- Ankara, Turkey
## Abstract
The rapid rise of Large Language Models (LLMs) and Large Reasoning Models (LRMs) has been accompanied by an equally rapid increase of benchmarks used to assess them. However, due to both improved model competence resulting from scaling and novel training advances as well as likely many of these datasets being included in pre or post training data, results become saturated, driving a continuous need for new and more challenging replacements. In this paper, we discuss whether surpassing a benchmark truly demonstrates reasoning ability or are we simply tracking numbers divorced from the capabilities we claim to measure? We present an investigation focused on three model families, OpenAI, Anthropic, and Google, and how their reasoning capabilities across different benchmarks evolve over the years. We also analyze performance trends over the years across different reasoning tasks and discuss the current situation of benchmarking and remaining challenges. By offering a comprehensive overview of benchmarks and reasoning tasks, our work aims to serve as a first reference to ground future research in reasoning evaluation and model development.
## 1 Introduction
Benchmarks have long played a central role in evaluating and comparing machine learning models [1]. As models scale up in size and capability, particularly Large Language Models (LLMs) and the specialized Large Reasoning Models (LRMs), many benchmarks quickly saturate, often reaching or surpassing human-level performance. Whether this saturation is driven primarily by improved model capability or dataset contamination is generally unknown. Nevertheless, this quick saturation forces the development of new and more challenging benchmarks that could be used to further compare new model families. In this paper, we investigate several key research questions: How effective are current benchmarks at measuring model capabilities, and does surpassing a benchmark reliably indicate genuine reasoning?
To examine these questions, we select three model families, OpenAI, Anthropic, and Google, and compile performance data from official sources [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22]. We gather a comprehensive list of 52 benchmarks used in evaluating these models and classify them according to the types of reasoning they aim to evaluate. Analyzing performance trends over the years, we highlight where models improve, where they struggle, and what these trends reveal about the current state of benchmarking. Finally, we discuss the implications of the saturation cycle and emphasize the need for improved evaluation practices that more accurately capture model capabilities.
Our contributions are threefold: (1) we provide a curated list of reasoning benchmarks, classified by the types of reasoning they aim to assess (2) we analyze performance trends over the years to assess benchmarking effectiveness; (3) we examine current landscape of existing benchmarks, identifying which benchmarks have reached high performance thresholds and which seem to remain unsolved.
By situating our analysis within the broader evaluation landscape, our work collects evidence to emphasize the need for reasoning tasks that are more representative of the nature of reasoning process and target evaluation beyond downstream accuracy.
## 2 Benchmark Landscape and Categorization
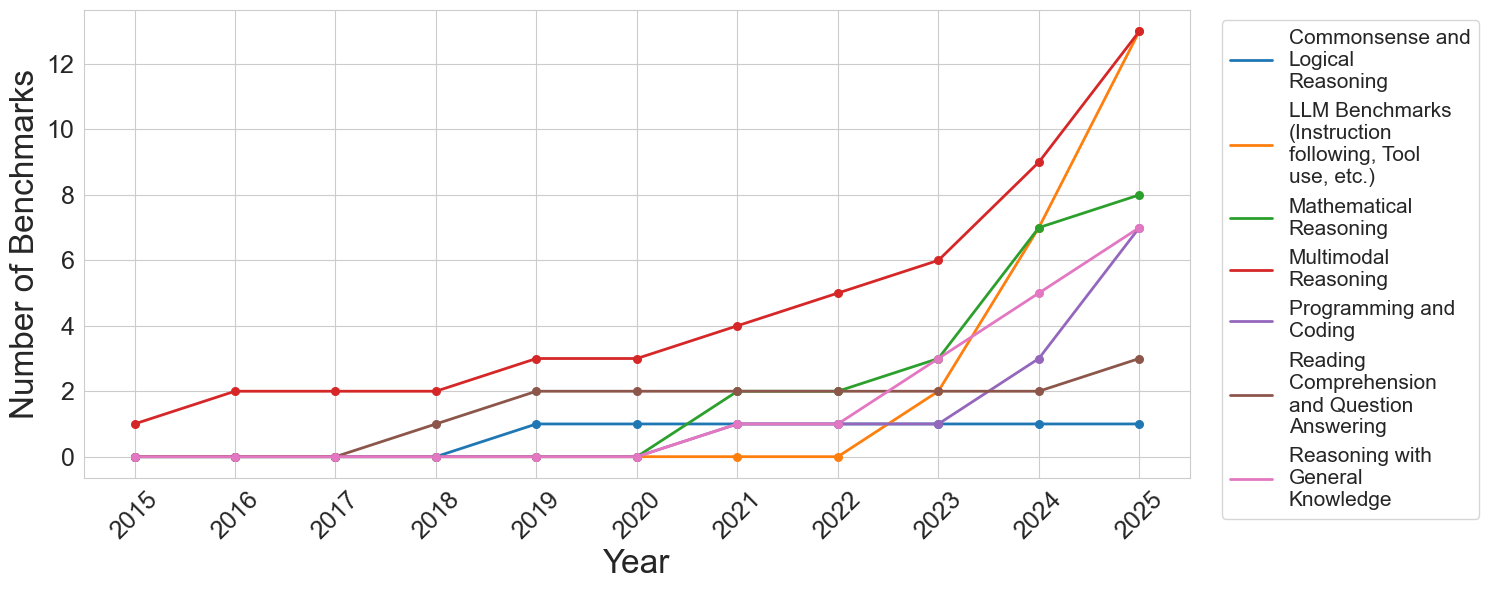
In order to provide a general analysis of how the creation and adoption of reasoning benchmarks have evolved over time, we examine three model families and compile the set of benchmarks employed to evaluate them. Our aim is to provide a comprehensive overview of current benchmarking practices and to trace how the creation and adoption of benchmarks have evolved over time. The complete list of benchmarks, their assigned reasoning types, and short summaries can be found in Appendix A. To facilitate analysis, we categorize benchmarks into seven reasoning types: commonsense and logical reasoning, mathematical reasoning, multimodal reasoning, programming and coding, reading comprehension and question answering, reasoning with general knowledge, and LLM-specific capabilities such as safety, tool use, and instruction following. Figure 1 illustrates a marked increase in benchmark adoption for multimodal reasoning, mathematical reasoning, programming, reasoning with general knowledge, and LLM-specific benchmarks after 2023. In contrast, no new benchmarks in reading comprehension or commonsense reasoning were adopted by these model families during this period. While the literature contains several other benchmarks in these areas [23, 24, 25, 26, 27, 28, 29], our analysis shows they have not been utilized by any of the prominent model families. This likely reflects the evolving understanding of what constitutes reasoning in computational models, in accordance with their current capabilities and what the community deems important to evaluate. Since most models now have direct commercial applications, their performance in more applicable domains, such as coding and tool-use benchmarks, may also motivate the evaluation in certain categories of reasoning tasks.
<details>
<summary>figures/benchmarks_by_year.png Details</summary>
### Visual Description
## Line Chart: Growth of LLM Benchmarks by Category (2015-2025)
### Overview
This line chart depicts the number of benchmarks available for Large Language Models (LLMs) across various reasoning categories from 2015 to 2025 (projected). The chart shows a general upward trend in the total number of benchmarks, with significant growth in certain categories towards the end of the period. The legend is positioned in the top-right corner of the chart.
### Components/Axes
* **X-axis:** Year (ranging from 2015 to 2025, with increments of 1 year).
* **Y-axis:** Number of Benchmarks (ranging from 0 to 12, with increments of 2).
* **Legend:** Located in the top-right corner, listing the following categories with corresponding colors:
* Commonsense and Logical Reasoning (Blue)
* LLM Benchmarks (Instruction following, Tool use, etc.) (Orange)
* Mathematical Reasoning (Green)
* Multimodal Reasoning (Purple)
* Programming and Coding (Teal)
* Reading Comprehension and Question Answering (Red)
* Reasoning with General Knowledge (Gray)
### Detailed Analysis
Here's a breakdown of each data series, with approximate values:
* **Commonsense and Logical Reasoning (Blue):** The line is relatively flat from 2015 to 2022, hovering around 1-2 benchmarks. It shows a slight increase from 2022 to 2024, reaching approximately 3 benchmarks, and then a more significant jump to around 4 benchmarks in 2025.
* **LLM Benchmarks (Instruction following, Tool use, etc.) (Orange):** This line exhibits the most dramatic growth. Starting at approximately 1 benchmark in 2015, it steadily increases to around 4 benchmarks in 2020. From 2020 to 2025, the growth accelerates, reaching approximately 12 benchmarks in 2025.
* **Mathematical Reasoning (Green):** The line starts at approximately 0 benchmarks in 2015 and gradually increases to around 2 benchmarks by 2019. It remains relatively stable until 2023, then shows a steeper increase, reaching approximately 8 benchmarks in 2025.
* **Multimodal Reasoning (Purple):** This line begins at 0 benchmarks in 2015 and remains at 0 until 2020. It then increases steadily, reaching approximately 5 benchmarks in 2025.
* **Programming and Coding (Teal):** The line starts at approximately 0 benchmarks in 2015 and increases to around 2 benchmarks by 2018. It fluctuates between 2 and 3 benchmarks until 2023, then increases to approximately 6 benchmarks in 2025.
* **Reading Comprehension and Question Answering (Red):** This line starts at approximately 1 benchmark in 2015 and increases to around 3 benchmarks by 2019. It remains relatively stable until 2024, then increases to approximately 5 benchmarks in 2025.
* **Reasoning with General Knowledge (Gray):** The line is consistently low, starting at approximately 1 benchmark in 2015 and remaining around 1-2 benchmarks throughout the entire period, reaching approximately 2 benchmarks in 2025.
### Key Observations
* The number of LLM benchmarks has increased significantly over the past decade, particularly in the last few years.
* "LLM Benchmarks (Instruction following, Tool use, etc.)" shows the most substantial growth, indicating a growing focus on evaluating these capabilities.
* "Mathematical Reasoning" and "Multimodal Reasoning" have experienced significant growth in the later years (2023-2025).
* "Reasoning with General Knowledge" remains relatively stable, suggesting a slower pace of development in this area.
* The growth in benchmarks appears to be accelerating towards 2025, suggesting continued investment and innovation in LLM evaluation.
### Interpretation
The data suggests a rapid expansion in the evaluation landscape for LLMs. The increasing number of benchmarks across various reasoning categories indicates a growing need to comprehensively assess the capabilities of these models. The significant growth in "LLM Benchmarks (Instruction following, Tool use, etc.)" reflects the increasing importance of evaluating LLMs' ability to follow instructions and utilize tools. The recent surge in "Mathematical Reasoning" and "Multimodal Reasoning" benchmarks suggests a growing focus on these challenging areas. The relatively stable number of "Reasoning with General Knowledge" benchmarks might indicate that this area is considered relatively mature or that evaluating it is more difficult.
The overall trend suggests that the field of LLM evaluation is becoming more sophisticated and nuanced, with a greater emphasis on assessing a wider range of capabilities. This is likely driven by the increasing power and complexity of LLMs, as well as the growing demand for reliable and trustworthy AI systems. The projected growth towards 2025 indicates that this trend is likely to continue, with even more benchmarks being developed to evaluate the next generation of LLMs.
</details>
Figure 1: Number of benchmarks in different reasoning types over time.
## 3 Performance Trends Across Models
Across all three model families there is a consistent effort to develop newer models or architectural improvements to achieve higher benchmark performance. However, comparing performance across families is challenging, as each family often employs different benchmarks, and even within a single family, benchmarks used can vary between model iterations. This variation appears to stem from two main factors: first, certain benchmarks reach saturation due to high performance; second, benchmark updates or more challenging subsets are introduced, such as the transition from MATH to MATH-500 [30].
We observe a recurring pattern: once a model family achieves a high performance on a particular benchmark, subsequent models tend to use that benchmark less frequently or may discontinue its use entirely. This reflects both practical and conceptual considerations: benchmarks that no longer discriminate between models provide limited evaluative value, and benchmark selection increasingly reflects the evolving understanding of which reasoning tasks remain challenging for current architectures.
Interestingly, performance trends reveal consistent directional correlations across benchmarks within the same reasoning type. For example, when a model demonstrates improved performance on a benchmark, it generally shows corresponding improvements on other benchmarks of the same type, while lower performance on one benchmark tends to coincide with lower performance on others. Nevertheless, the extent of performance differs across benchmarks, potentially due to variations in problem complexity and the scaling limitations evident in smaller models, as seen within the OpenAI family. This pattern suggests that benchmarks within a reasoning type often capture overlapping aspects of reasoning, so that advances in a models’ capabilities tend to propagate across related tasks. At the same time, variations in the magnitude of performance gains provide insight into the relative difficulty of different benchmarks within the same reasoning type. Detailed plots illustrating performance changes within model families for different reasoning types are provided in Appendix B.
Finally, we note that newer models generally achieve higher performance on previously low-scoring benchmarks. However, the limited overlap of common benchmarks across model families complicates cross-family comparisons. This raises a critical question: if benchmarks are intended to evaluate and compare model capabilities, why are they not consistently adopted or reported across families? If benchmarks are intended to provide a shared measure of capability, their fragmented and selective use undermines that goal and exemplifies the need for more standardized, representative, and domain-informed evaluation frameworks.
## 4 Performance of Models within Benchmarks
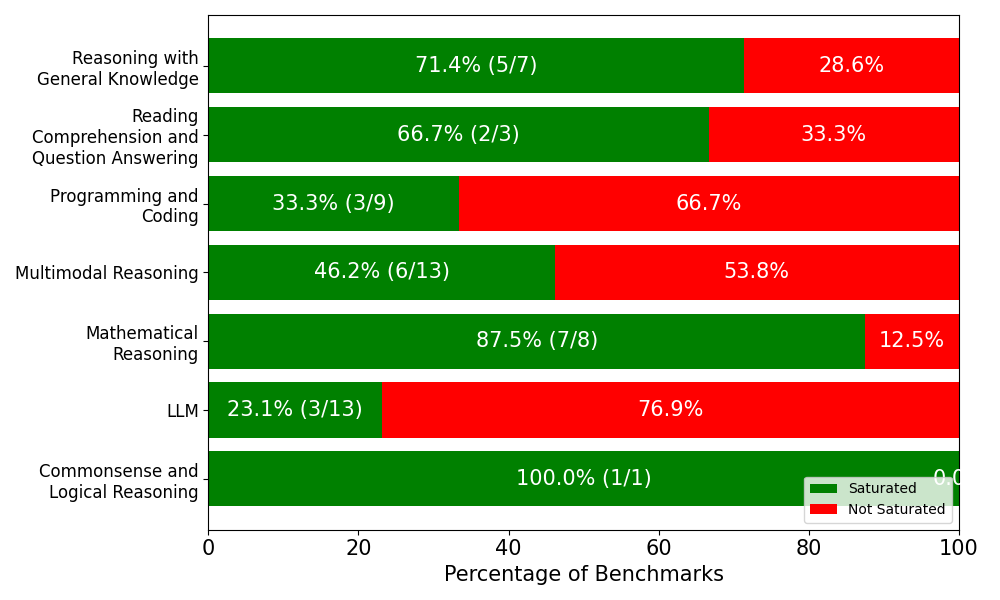
We collect all reported model performances across benchmarks and analyze saturation by defining it as whether a model has achieved at least 80% accuracy on the given benchmark. Out of the full set of benchmarks, we find that 27 benchmarks surpass this threshold in at least one model family, while 25 benchmarks never reach it. The majority of “solved” benchmarks belong to commonsense and logical reasoning, mathematical reasoning, reasoning with general knowledge, and reading comprehension and question answering. By contrast, benchmarks targeting LLM-specific capabilities and programming and coding remain comparatively difficult, with few instances of performance above 80%.
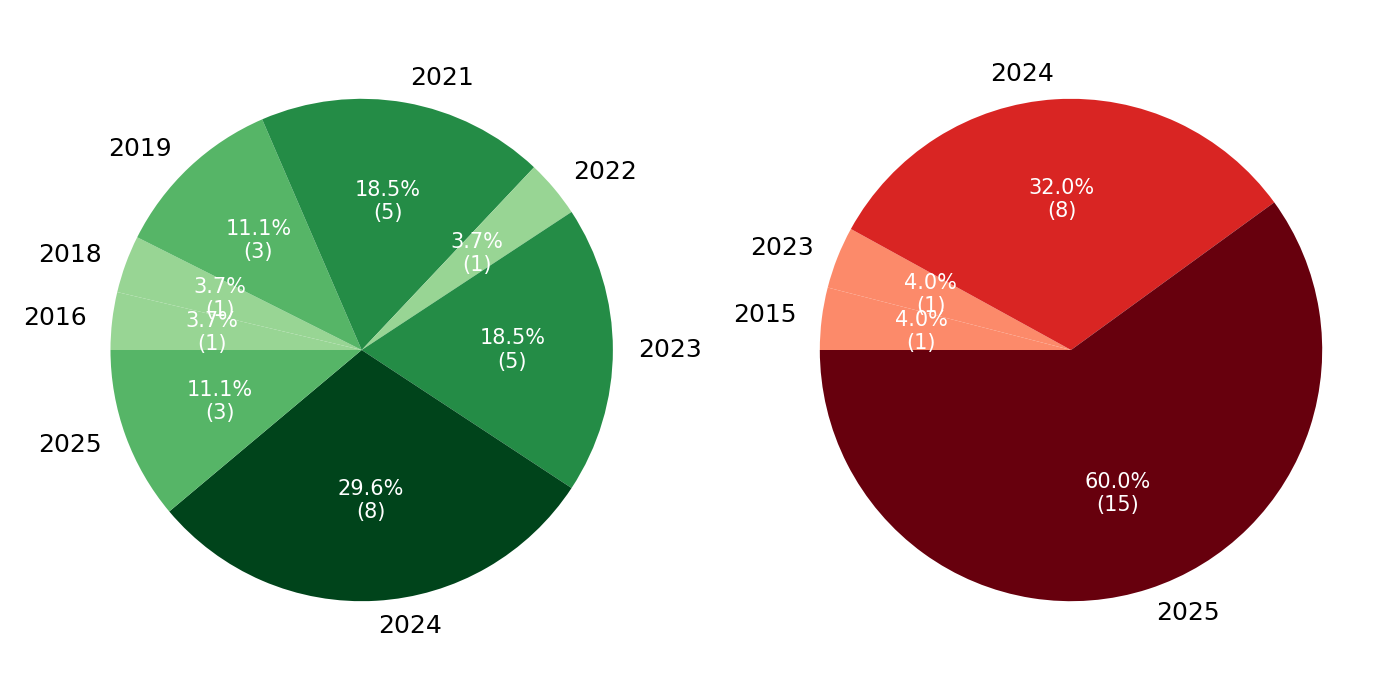
We then examine the release years of benchmarks that never surpass the 80% threshold. The distribution is striking: 60% of unsolved benchmarks were introduced in 2025, 32% in 2024, and only two pre-2023 benchmarks remain unsolved, which are ActivityNet [31] and EgoSchema [32], both multimodal reasoning benchmarks. This distribution suggests a clear trend. Nearly all benchmarks released prior to 2025 have already been surpassed by at least one model family, indicating rapid saturation. By contrast, the benchmarks still below the threshold overwhelmingly correspond to the most recently introduced evaluation tasks.
<details>
<summary>figures/stacked_bar_saturation.png Details</summary>
### Visual Description
\n
## Horizontal Bar Chart: LLM Benchmark Saturation
### Overview
This is a horizontal bar chart visualizing the percentage of benchmarks saturated by a Large Language Model (LLM) across various reasoning categories. Each bar represents a category, with the green portion indicating the percentage of saturated benchmarks and the red portion indicating the percentage of non-saturated benchmarks. The number of saturated benchmarks out of the total number of benchmarks for each category is also displayed.
### Components/Axes
* **Y-axis (Vertical):** Represents the different reasoning categories:
* Reasoning with General Knowledge
* Reading Comprehension and Question Answering
* Programming and Coding
* Multimodal Reasoning
* Mathematical Reasoning
* LLM
* Commonsense and Logical Reasoning
* **X-axis (Horizontal):** Represents the "Percentage of Benchmarks", ranging from 0 to 100.
* **Legend (Bottom-Right):**
* Green: "Saturated"
* Red: "Not Saturated"
* **Data Labels:** Each bar includes a percentage value (e.g., 71.4%, 28.6%) and a fraction representing (Saturated Benchmarks / Total Benchmarks) (e.g., (5/7), (2/3)).
### Detailed Analysis
Here's a breakdown of each category's saturation levels:
1. **Reasoning with General Knowledge:** 71.4% Saturated (5/7). The bar is predominantly green, with a smaller red portion.
2. **Reading Comprehension and Question Answering:** 66.7% Saturated (2/3). Approximately two-thirds of the bar is green.
3. **Programming and Coding:** 33.3% Saturated (3/9). The bar is predominantly red, with a smaller green portion.
4. **Multimodal Reasoning:** 46.2% Saturated (6/13). The bar is roughly half green and half red.
5. **Mathematical Reasoning:** 87.5% Saturated (7/8). The bar is overwhelmingly green, with a very small red portion.
6. **LLM:** 23.1% Saturated (3/13). The bar is predominantly red, with a small green portion.
7. **Commonsense and Logical Reasoning:** 100.0% Saturated (1/1). The bar is entirely green.
### Key Observations
* **Highest Saturation:** Commonsense and Logical Reasoning shows 100% saturation, indicating the LLM performs very well on this type of benchmark.
* **Lowest Saturation:** LLM category shows the lowest saturation at 23.1%.
* **Significant Variation:** There's a wide range in saturation levels across different reasoning categories, from 23.1% to 100%.
* **Mathematical Reasoning is High:** Mathematical Reasoning is also highly saturated at 87.5%.
* **Programming and Coding is Low:** Programming and Coding is relatively low at 33.3%.
### Interpretation
The chart demonstrates the varying capabilities of the LLM across different reasoning tasks. The LLM excels at Commonsense and Logical Reasoning and Mathematical Reasoning, achieving near-complete saturation of benchmarks in these areas. However, it struggles with Programming and Coding and the LLM category itself, indicating areas where further development is needed. The saturation percentages provide a quantitative measure of the LLM's performance on each type of benchmark, and the (Saturated/Total) ratios offer insight into the sample size used for each category. The differences in saturation levels suggest that the LLM's architecture or training data may be better suited for certain types of reasoning than others. The relatively low saturation in Programming and Coding could indicate a need for more specialized training data or architectural modifications to improve performance in this domain. The low saturation in the LLM category itself is curious and may indicate the benchmarks used to evaluate the LLM are particularly challenging or are designed to expose weaknesses in the model's core capabilities.
</details>
(a) Distribution of benchmarks that models surpassed 80% threshold and those not yet surpassed, grouped by reasoning type.
<details>
<summary>figures/pie_saturation_by_year.png Details</summary>
### Visual Description
\n
## Pie Charts: Projected Distribution of Something Over Time
### Overview
The image contains two pie charts, positioned side-by-side. Both charts represent a distribution of some quantity across different years. The left chart focuses on years 2016-2025, while the right chart focuses on years 2015-2025. Each slice of the pie charts is labeled with the year and a percentage value, along with a numerical value in parentheses.
### Components/Axes
The charts do not have traditional axes. The data is represented by the size of each slice in the pie. The labels are positioned directly adjacent to each slice. There are no legends. The years represented are: 2016, 2018, 2019, 2021, 2022, 2023, 2024, and 2025.
### Detailed Analysis or Content Details
**Left Pie Chart (2016-2025)**
* **2016:** 3.7% (1) - Light Yellow
* **2018:** 11.1% (3) - Light Green
* **2019:** 11.1% (3) - Yellow
* **2021:** 18.5% (5) - Green
* **2022:** 3.7% (1) - Light Green
* **2023:** 18.5% (5) - Green
* **2024:** 29.6% (8) - Dark Green
* **2025:** 11.1% (3) - Light Green
**Right Pie Chart (2015-2025)**
* **2015:** 4.0% (1) - Light Red
* **2023:** 4.0% (1) - Light Red
* **2024:** 32.0% (8) - Red
* **2025:** 60.0% (15) - Dark Red
### Key Observations
* In the left chart, 2024 has the largest percentage (29.6%), followed by 2021 and 2023 (both 18.5%).
* In the right chart, 2025 dominates with 60.0%, significantly larger than 2024 (32.0%).
* The values in parentheses appear to be absolute counts corresponding to the percentages.
* The color scheme is consistent within each chart, with darker shades representing larger percentages.
### Interpretation
The charts likely represent a projection or distribution of some resource or activity over time. The left chart shows a relatively even distribution across several years, with 2024 being the most prominent. The right chart, however, indicates a strong shift towards 2025, suggesting a significant concentration of the resource or activity in that year. The difference between the two charts could represent different scenarios or projections. The numerical values in parentheses suggest that the percentages are based on a total count of 100. The data suggests a growing trend towards 2025, with a substantial increase in the proportion allocated to that year. The left chart shows a more distributed allocation, while the right chart shows a more concentrated one. This could indicate a change in strategy or priorities.
</details>
(b) Release years of benchmarks relative to the 80% threshold: left pie shows surpassed benchmarks, right pie shows unsolved benchmarks.
Figure 2: Benchmark saturation dynamics.
This temporal pattern highlights the central dynamic of the saturation cycle: older benchmarks are rapidly mastered and lose discriminative power, while newly introduced benchmarks become the standards for demonstrating progress. Nearly all unsolved benchmarks are recent, highlighting both the accelerating pace of benchmark creation and the difficulty of maintaining evaluations that remain challenging over time. Yet this difficulty seems only temporary. It is highly plausible that within one or two years many of these currently unsolved benchmarks will also be surpassed, at which point model families will shift to alternative or newly designed evaluations to preserve differentiation. Crucially, this pattern reflects the fact that performance gains are often specific to individual benchmarks rather than to the broader reasoning type they are intended to assess. As the analyses indicate, while models often perform consistently and even strongly on benchmarks within a domain, the introduction of a more challenging, novel benchmark frequently leads to a drop in performance. This pattern may arise from the increased difficulty of the new benchmark, or from contamination that inflated performance on earlier benchmarks without truly reflecting generalizable reasoning ability. This situation raises the question of whether what appears as “reasoning ability” is often tied more to benchmark design and prior exposure than to robust mastery of the reasoning type itself. This saturation cycle casts doubt on the long-term evaluation value of benchmarks.
## 5 Discussion: Limitations of Current Benchmarking
Our analysis of three model families demonstrates that benchmark performance has generally increased over time, with newer models achieving higher scores across most reasoning types and benchmarks. However, given that many benchmarks have already been surpassed with high accuracy, we would like to highlight a question originally posed in [25] regarding commonsense reasoning, reframed here for reasoning in general: Have neural language models successfully acquired reasoning, or are we overestimating the true capabilities of machine reasoning? Several studies in the literature show that these models still perform poorly when required to generalize to longer contexts or handle tasks requiring inductive and compositional reasoning [33, 34, 35, 36, 37, 38]. This discrepancy suggests a limitation of current benchmarking practices: improvements in benchmark scores do not necessarily reflect generalizable reasoning ability.
We believe this discrepancy can be reduced by developing more sophisticated, task-specific evaluation metrics that capture intermediate reasoning steps or different modes of error. Additionally, formalizing reasoning for different task types can support these efforts, enabling more structured analyses and clearer assessment of models’ reasoning abilities. Such a formalization enables structured representations of diverse reasoning types and their interrelationships [39, 40, 41], and facilitates the design of layered, targeted evaluation procedures that assess specific reasoning capabilities rather than merely reporting overall accuracy. Furthermore, formal reasoning frameworks can support the development of algorithms that deliver structured feedback to models, guiding the refinement of their reasoning abilities. By integrating formalized reasoning with task-specific evaluations, benchmarking can be conducted in a more targeted and informative manner.
## 6 Limitations
The analysis in our study focuses on 52 benchmarks used by the three model families. Other model families and reasoning-focused models are not fully explored because including them, along with more than two hundred benchmarks identified from other model families and several studies evaluating different types of reasoning in large models, would create a combinatorial explosion of comparisons. This restriction was necessary to maintain the scope of our work on a qualitative evaluation of benchmark design and adoption rather than an exhaustive quantitative analysis of all models and benchmarks. A comprehensive comparison across a wider range of models and benchmarks is left for future work.
## 7 Conclusion
In this work, we analyze 52 benchmarks across three model families, covering multiple reasoning types. Our study reveals the rapid saturation of older benchmarks, selective adoption of new ones, and temporal dynamics that govern the utility of benchmarks in evaluating model performance. While model performance generally improves over time and correlations within reasoning types indicate overlapping evaluation properties, the introduction of more challenging benchmarks generally resets performance, suggesting that apparent reasoning ability is influenced more by extrinsic factors than by mastering the reasoning itself, as supported by other studies. This saturation cycle highlights the limitations of current practices: benchmarks provide only a partial view of model reasoning. Meaningful progress requires formalized reasoning tasks, layered evaluation procedures, and task-specific metrics that go beyond accuracy scores.
## References
- [1] Thomas Liao, Rohan Taori, Deborah Raji, and Ludwig Schmidt. Are we learning yet? a meta review of evaluation failures across machine learning. In J. Vanschoren and S. Yeung, editors, Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, volume 1, 2021.
- [2] Anthropic. Introducing the next generation of claude, March 2024. Accessed: 2025-08-28.
- [3] Anthropic. Claude 3.5 sonnet, June 2024. Accessed: 2025-08-28.
- [4] Anthropic. Introducing claude 4, May 2025. Accessed: 2025-08-28.
- [5] Anthropic. Introducing claude 3.5 haiku, October 2024. Accessed: 2025-08-28.
- [6] Anthropic. Claude 3.7 sonnet and claude code, February 2025. Accessed: 2025-08-28.
- [7] Anthropic. Claude opus 4.1, August 2025. Accessed: 2025-08-28.
- [8] Google DeepMind. Gemini 2.5 flash-lite, June 2025. Accessed: 2025-08-28.
- [9] Gheorghe Comanici, Eric Bieber, Mike Schaekermann, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025.
- [10] Google DeepMind. Gemini 2.5: Our most intelligent ai model, March 2025. Accessed: 2025-08-28.
- [11] Gemini Team, Petko Georgiev, Ving Ian Lei, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, 2024.
- [12] Gemini Team, Rohan Anil, Sebastian Borgeaud, et al. Gemini: A family of highly capable multimodal models, 2025.
- [13] OpenAI. Openai o1-mini: Advancing cost-efficient reasoning, September 2024. Accessed: 2025-08-28.
- [14] OpenAI. Introducing gpt-4.1 in the api, April 2025. Accessed: 2025-08-28.
- [15] OpenAI. Introducing gpt-4.5, February 2025. Accessed: 2025-08-28.
- [16] OpenAI. gpt-oss-120b & gpt-oss-20b model card, August 2025. Accessed: 2025-08-28.
- [17] OpenAI. Introducing gpt-5, August 2025. Accessed: 2025-08-28.
- [18] OpenAI. Model release notes. Accessed: 2025-08-28.
- [19] OpenAI. Introducing openai o3 and o4-mini, April 2025. Accessed: 2025-08-28.
- [20] OpenAI. Gpt-4o mini: Advancing cost-efficient intelligence, July 2024. Accessed: 2025-08-28.
- [21] OpenAI. Hello gpt-4o, May 2024. Accessed: 2025-08-28.
- [22] OpenAI. Learning to reason with llms, September 2024. Accessed: 2025-08-28.
- [23] Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jiasen Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7432–7439, 2020.
- [24] Bill Yuchen Lin, Wangchunshu Zhou, Ming Shen, Pei Zhou, Chandra Bhagavatula, Yejin Choi, and Xiang Ren. CommonGen: A constrained text generation challenge for generative commonsense reasoning. In Trevor Cohn, Yulan He, and Yang Liu, editors, Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1823–1840, Online, November 2020. Association for Computational Linguistics.
- [25] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: an adversarial winograd schema challenge at scale. Commun. ACM, 64(9):99–106, August 2021.
- [26] Alon Talmor, Ori Yoran, Ronan Le Bras, Chandra Bhagavatula, Yoav Goldberg, Yejin Choi, and Jonathan Berant. Commonsenseqa 2.0: Exposing the limits of ai through gamification, 2022.
- [27] Andong Wang, Bo Wu, Sunli Chen, Zhenfang Chen, Haotian Guan, Wei-Ning Lee, Li Erran Li, and Chuang Gan. Sok-bench: A situated video reasoning benchmark with aligned open-world knowledge, 2024.
- [28] Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. Logiqa: a challenge dataset for machine reading comprehension with logical reasoning. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI’20, 2021.
- [29] Weihao Yu, Zihang Jiang, Yanfei Dong, and Jiashi Feng. Reclor: A reading comprehension dataset requiring logical reasoning. In International Conference on Learning Representations, 2020.
- [30] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. In J. Vanschoren and S. Yeung, editors, Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, volume 1, 2021.
- [31] Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 961–970, 2015.
- [32] Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding, 2023.
- [33] Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Peter West, Chandra Bhagavatula, Ronan Le Bras, Jena D. Hwang, Soumya Sanyal, Sean Welleck, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi. Faith and fate: limits of transformers on compositionality. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY, USA, 2023. Curran Associates Inc.
- [34] Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models, 2025.
- [35] Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity, 2025.
- [36] Jackson Petty, Michael Y. Hu, Wentao Wang, Shauli Ravfogel, William Merrill, and Tal Linzen. Relic: Evaluating compositional instruction following via language recognition, 2025.
- [37] S. Bedi, Y. Jiang, P. Chung, S. Koyejo, and N. Shah. Fidelity of medical reasoning in large language models. JAMA Network Open, 8(8):e2526021, 2025.
- [38] Karthik Valmeekam, Kaya Stechly, Atharva Gundawar, and Subbarao Kambhampati. A systematic evaluation of the planning and scheduling abilities of the reasoning model o1. Transactions on Machine Learning Research, 2025.
- [39] P. N. Johnson-Laird. Mental models: towards a cognitive science of language, inference, and consciousness. Harvard University Press, USA, 1986.
- [40] Patrick Blackburn and Johannes Bos. Representation and Inference for Natural Language: A First Course in Computational Semantics. Center for the Study of Language and Information, Stanford, Calif., 2005.
- [41] Brenden M. Lake, Tomer D. Ullman, Joshua B. Tenenbaum, and Samuel J. Gershman. Building machines that learn and think like people. Behavioral and Brain Sciences, 40:e253, 2017.
- [42] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? In Anna Korhonen, David Traum, and Lluís Màrquez, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy, July 2019. Association for Computational Linguistics.
- [43] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021.
- [44] Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, and Jason Wei. Challenging BIG-bench tasks and whether chain-of-thought can solve them. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, pages 13003–13051, Toronto, Canada, July 2023. Association for Computational Linguistics.
- [45] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021.
- [46] Long Phan, Alice Gatti, Ziwen Han, et al. Humanity’s last exam, 2025.
- [47] Shivalika Singh, Angelika Romanou, Clémentine Fourrier, David Ifeoluwa Adelani, Jian Gang Ngui, Daniel Vila-Suero, Peerat Limkonchotiwat, Kelly Marchisio, Wei Qi Leong, Yosephine Susanto, Raymond Ng, Shayne Longpre, Sebastian Ruder, Wei-Yin Ko, Antoine Bosselut, Alice Oh, Andre Martins, Leshem Choshen, Daphne Ippolito, Enzo Ferrante, Marzieh Fadaee, Beyza Ermis, and Sara Hooker. Global MMLU: Understanding and addressing cultural and linguistic biases in multilingual evaluation. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 18761–18799, Vienna, Austria, July 2025. Association for Computational Linguistics.
- [48] David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023.
- [49] Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark, 2024.
- [50] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018.
- [51] Omer Goldman, Uri Shaham, Dan Malkin, Sivan Eiger, Avinatan Hassidim, Yossi Matias, Joshua Maynez, Adi Mayrav Gilady, Jason Riesa, Shruti Rijhwani, Laura Rimell, Idan Szpektor, Reut Tsarfaty, and Matan Eyal. Eclektic: a novel challenge set for evaluation of cross-lingual knowledge transfer, 2025.
- [52] Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2368–2378, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics.
- [53] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021.
- [54] Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush Vosoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, Dipanjan Das, and Jason Wei. Language models are multilingual chain-of-thought reasoners, 2022.
- [55] Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts, 2024.
- [56] Elliot Glazer, Ege Erdil, Tamay Besiroglu, Diego Chicharro, Evan Chen, Alex Gunning, Caroline Falkman Olsson, Jean-Stanislas Denain, Anson Ho, Emily de Oliveira Santos, Olli Järviniemi, Matthew Barnett, Robert Sandler, Matej Vrzala, Jaime Sevilla, Qiuyu Ren, Elizabeth Pratt, Lionel Levine, Grant Barkley, Natalie Stewart, Bogdan Grechuk, Tetiana Grechuk, Shreepranav Varma Enugandla, and Mark Wildon. Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai, 2024.
- [57] Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi, 2024.
- [58] Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images, 2016.
- [59] Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Findings of the Association for Computational Linguistics: ACL 2022, pages 2263–2279, Dublin, Ireland, May 2022. Association for Computational Linguistics.
- [60] Minesh Mathew, Dimosthenis Karatzas, and C. V. Jawahar. Docvqa: A dataset for vqa on document images, 2021.
- [61] Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read, 2019.
- [62] Kairui Hu, Penghao Wu, Fanyi Pu, Wang Xiao, Yuanhan Zhang, Xiang Yue, Bo Li, and Ziwei Liu. Video-mmmu: Evaluating knowledge acquisition from multi-discipline professional videos, 2025.
- [63] Piotr Padlewski, Max Bain, Matthew Henderson, Zhongkai Zhu, Nishant Relan, Hai Pham, Donovan Ong, Kaloyan Aleksiev, Aitor Ormazabal, Samuel Phua, Ethan Yeo, Eugenie Lamprecht, Qi Liu, Yuqi Wang, Eric Chen, Deyu Fu, Lei Li, Che Zheng, Cyprien de Masson d’Autume, Dani Yogatama, Mikel Artetxe, and Yi Tay. Vibe-eval: A hard evaluation suite for measuring progress of multimodal language models, 2024.
- [64] Jonathan Roberts, Mohammad Reza Taesiri, Ansh Sharma, Akash Gupta, Samuel Roberts, Ioana Croitoru, Simion-Vlad Bogolin, Jialu Tang, Florian Langer, Vyas Raina, Vatsal Raina, Hanyi Xiong, Vishaal Udandarao, Jingyi Lu, Shiyang Chen, Sam Purkis, Tianshuo Yan, Wenye Lin, Gyungin Shin, Qiaochu Yang, Anh Totti Nguyen, David I. Atkinson, Aaditya Baranwal, Alexandru Coca, Mikah Dang, Sebastian Dziadzio, Jakob D. Kunz, Kaiqu Liang, Alexander Lo, Brian Pulfer, Steven Walton, Charig Yang, Kai Han, and Samuel Albanie. Zerobench: An impossible visual benchmark for contemporary large multimodal models, 2025.
- [65] Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sadhika Malladi, Alexis Chevalier, Sanjeev Arora, and Danqi Chen. Charxiv: Charting gaps in realistic chart understanding in multimodal llms. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems, volume 37, pages 113569–113697. Curran Associates, Inc., 2024.
- [66] Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, and Graham Neubig. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark, 2025.
- [67] Google DeepMind. Gemini robotics: Bringing ai into the physical world, 2025. Accessed: 2025-08-29.
- [68] Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?, 2024.
- [69] Stanford University and Laude Institute. Terminal-bench: A benchmark for ai agents in terminal environments, 2025. Accessed: 2025-08-29.
- [70] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code, 2021.
- [71] Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024.
- [72] Aider. o1 tops aider’s new polyglot leaderboard, 2024. Accessed: 2025-08-29.
- [73] Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. Swe-lancer: Can frontier llms earn $1 million from real-world freelance software engineering?, 2025.
- [74] Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. $\tau$ -bench: A benchmark for tool-agent-user interaction in real-world domains, 2024.
- [75] Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. $\tau^{2}$ -bench: Evaluating conversational agents in a dual-control environment, 2025.
- [76] Shunyu Yao, Howard Chen, Austin W. Hanjie, Runzhe Yang, and Karthik Narasimhan. Collie: Systematic construction of constrained text generation tasks, 2023.
- [77] Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring short-form factuality in large language models, 2024.
- [78] Alon Jacovi, Andrew Wang, Chris Alberti, Connie Tao, Jon Lipovetz, Kate Olszewska, Lukas Haas, Michelle Liu, Nate Keating, Adam Bloniarz, Carl Saroufim, Corey Fry, Dror Marcus, Doron Kukliansky, Gaurav Singh Tomar, James Swirhun, Jinwei Xing, Lily Wang, Madhu Gurumurthy, Michael Aaron, Moran Ambar, Rachana Fellinger, Rui Wang, Zizhao Zhang, Sasha Goldshtein, and Dipanjan Das. The facts grounding leaderboard: Benchmarking llms’ ability to ground responses to long-form input, 2025.
- [79] Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents, 2025.
- [80] Lucen Zhong, Zhengxiao Du, Xiaohan Zhang, Haiyi Hu, and Jie Tang. Complexfuncbench: Exploring multi-step and constrained function calling under long-context scenario, 2025.
- [81] Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models, 2023.
- [82] Yun He, Di Jin, Chaoqi Wang, Chloe Bi, Karishma Mandyam, Hejia Zhang, Chen Zhu, Ning Li, Tengyu Xu, Hongjiang Lv, Shruti Bhosale, Chenguang Zhu, Karthik Abinav Sankararaman, Eryk Helenowski, Melanie Kambadur, Aditya Tayade, Hao Ma, Han Fang, and Sinong Wang. Multi-if: Benchmarking llms on multi-turn and multilingual instructions following, 2024.
- [83] Jinhyuk Lee, Anthony Chen, Zhuyun Dai, Dheeru Dua, Devendra Singh Sachan, Michael Boratko, Yi Luan, Sébastien M. R. Arnold, Vincent Perot, Siddharth Dalmia, Hexiang Hu, Xudong Lin, Panupong Pasupat, Aida Amini, Jeremy R. Cole, Sebastian Riedel, Iftekhar Naim, Ming-Wei Chang, and Kelvin Guu. Can long-context language models subsume retrieval, rag, sql, and more?, 2024.
- [84] Kaustubh Deshpande, Ved Sirdeshmukh, Johannes Baptist Mols, Lifeng Jin, Ed-Yeremai Hernandez-Cardona, Dean Lee, Jeremy Kritz, Willow E. Primack, Summer Yue, and Chen Xing. MultiChallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier LLMs. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Findings of the Association for Computational Linguistics: ACL 2025, pages 18632–18702, Vienna, Austria, July 2025. Association for Computational Linguistics.
- [85] Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero-Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. Healthbench: Evaluating large language models towards improved human health, 2025.
## Appendix A Reasoning Benchmarks
Table 1: Taxonomy of benchmarks used in this study.
| HellaSwag [42] | Commonsense and Logical Reasoning | 2019 | Multiple-choice task: choose the most plausible sentence continuation. |
| --- | --- | --- | --- |
| MMLU [43] | Reasoning with General Knowledge | 2021 | Multiple-choice task: answer questions across 57 domains to test knowledge and problem-solving. |
| Big-Bench-Hard [44] | Reasoning with General Knowledge | 2023 | Open-generation task: solve difficult BIG-Bench problems testing multi-step reasoning and problem-solving. |
| MMMLU [45] | Reasoning with General Knowledge | 2024 | Multiple-choice task: answer 57 domain questions translated into 14 languages to test multilingual knowledge and problem-solving. |
| Humanity’s Last Exam [46] | Reasoning with General Knowledge | 2025 | Multi-modal task: answer closed-ended questions across many subjects to test verifiable knowledge. |
| Global MMLU (Lite) [47] | Reasoning with General Knowledge | 2025 | Multiple-choice task: answer 42-language questions with culturally sensitive labeling to test equitable multilingual knowledge. |
| GPQA Diamond [48] | Reasoning with General Knowledge | 2023 | Multiple-choice task: answer 448 expert-level science questions in biology, physics, and chemistry that are Google-proof and highly challenging. |
| MMLU Pro [49] | Reasoning with General Knowledge | 2024 | Multiple-choice task: extended from MMLU, answer more challenging reasoning questions with 10 options across diverse domains. |
| ARC (AI2 Reasoning Challenge) [50] | Reading Comprehension and Question Answering | 2018 | Multiple-choice task: answer grade-school science questions requiring advanced knowledge and reasoning beyond simple retrieval. |
| ECLeKTic [51] | Reading Comprehension and Question Answering | 2025 | Closed-book QA task: answer 12-language questions to test cross-lingual knowledge transfer. |
| DROP [52] | Reading Comprehension and Question Answering | 2019 | Open-ended QA task: answer 96k English questions requiring discrete reasoning over paragraph content. |
| GSM8K [53] | Mathematical Reasoning | 2021 | Open-ended QA task: solve grade-school problems requiring multi-step mathematical reasoning. |
| MATH [30] | Mathematical Reasoning | 2021 | Open-ended QA: solve 12,500 challenging competition problems with step-by-step solutions to test advanced mathematical reasoning. |
| MATH 500 [30] | Mathematical Reasoning | 2024 | Open-ended QA: Challenging subset of MATH benchmark. |
| MGSM [54] | Mathematical Reasoning | 2023 | Open-ended QA: solve 250 GSM8K problems translated into 10 languages. |
| MathVista [55] | Mathematical Reasoning | 2024 | Open-ended multimodal QA: solve 6,141 math problems requiring visual and compositional reasoning. |
| AIME 2024 | Mathematical Reasoning | 2024 | Open-ended QA: solve challenging competition-level mathematics problems. |
| AIME 2025 | Mathematical Reasoning | 2025 | Open-ended QA: solve challenging competition-level mathematics problems. |
| FrontierMath [56] | Mathematical Reasoning | 2024 | Open-ended QA: tests advanced mathematical reasoning across diverse and expert-level domains, requiring multi-step problem solving and deep mathematical knowledge. |
| MMMU [57] | Multimodal Reasoning | 2024 | Question answering task: multimodal multiple-choice and open-ended questions across 30 subjects requiring advanced reasoning and domain-specific knowledge. |
| AI2D [58] | Multimodal Reasoning | 2016 | Open-ended QA: multimodal questions with 5,000 diagrams and 15,000 Q&A pairs requiring diagram structure understanding and reasoning. |
| ChartQA [59] | Multimodal Reasoning | 2022 | Open-ended QA: multimodal questions with 32.7K chart-based problems requiring visual and logical reasoning. |
| EgoSchema [32] | Multimodal Reasoning | 2023 | Multiple-choice QA: multimodal questions with 5,000 long-form video clips requiring understanding of human activity and temporal reasoning. |
| DocVQA [60] | Multimodal Reasoning | 2021 | Open-ended QA: multimodal questions with 50,000 document images requiring reading and interpreting document layout and structure. |
| TextVQA [61] | Multimodal Reasoning | 2019 | Open-ended QA: multimodal questions with 45,336 images requiring reading and reasoning about embedded text. |
| VideoMMMU [62] | Multimodal Reasoning | 2025 | Open-ended QA: multimodal questions with 300 expert-level videos and 900 Q&A pairs assessing knowledge acquisition through perception, comprehension, and adaptation. |
| Vibe-Eval [63] | Multimodal Reasoning | 2024 | Open-ended QA: multimodal questions, testing visual understanding and multimodal chat capabilities. |
| ZeroBench [64] | Multimodal Reasoning | 2025 | Open-ended QA: multimodal questions with 434 visual reasoning problems designed to be impossible for current LMMs. |
| CharXiv [65] | Multimodal Reasoning | 2024 | Open-ended QA: multimodal questions with 2,323 charts requiring descriptive analysis and complex reasoning. |
| MMMU Pro [66] | Multimodal Reasoning | 2025 | QA task: multimodal multiple-choice and open-ended questions, extended from MMMU, testing integrated visual and textual reasoning. |
| ActivityNet [31] | Multimodal Reasoning | 2015 | Multiple-choice and open-ended QA: evaluates recognition and understanding of complex human activities in untrimmed videos, testing visual perception and temporal reasoning. |
| ERQA [67] | Multimodal Reasoning | 2025 | Multiple-choice QA: evaluates embodied reasoning and spatial understanding in real-world scenarios, requiring models to integrate text and visual inputs to select the correct answer. |
| SWE-bench Verified [68] | Programming and Coding | 2024 | Open-ended QA: answer 2,294 software engineering problems requiring multi-file code edits and complex reasoning. |
| Terminal-bench [69] | Programming and Coding | 2025 | Open-ended QA: answer complex tasks in terminal environments using text-based commands and reasoning. |
| HumanEval [70] | Programming and Coding | 2021 | Open-ended QA: answer Python programming problems from docstrings requiring functional code synthesis. |
| LiveCode Bench [71] | Programming and Coding | 2025 | Open-ended QA: answer 600+ coding problems from contests, testing generation, self-repair, execution, and test prediction. |
| Aider Polygot [72] | Programming and Coding | 2024 | Open-ended QA: answer 225 difficult coding problems in C++, Go, Java, JavaScript, Python, and Rust. |
| SWE-Lancer [73] | Programming and Coding | 2025 | Open-ended QA: answer 1,400 freelance software engineering tasks, including implementation and managerial decisions, with real-world evaluation. |
| SWE-Lancer Diamond [73] | Programming and Coding | 2025 | Open-ended QA: answer tasks from the public SWE-Lancer Diamond split, including implementation and managerial software engineering problems. |
| TAU-bench [74] | Tool Use – LLM | 2024 | Open-ended QA: tests reasoning, consistency, and rule-following in dynamic, tool-assisted human-agent interactions. |
| TAU2-bench [75] | Tool Use – LLM | 2025 | Open-ended QA: tests multi-turn reasoning, coordination, and communication in dual-control environments where both agent and user act with tools. |
| COLLIE [76] | Constrained Text Generation – LLM | 2023 | Open-ended QA: answer 2,080 prompts requiring constrained text generation with compositional, grammar-based, and reasoning challenges. |
| SimpleQA [77] | Factuality – LLM | 2024 | Factual QA benchmark designed to test factual accuracy and knowledge calibration. |
| FACTS Grounding [78] | Factuality – LLM | 2024 | Open-ended QA: answer questions requiring LLMs to generate factually accurate and well-grounded responses from provided source material. |
| BrowseComp [79] | Factuality – LLM | 2025 | Open-ended QA: answer 1,266 questions by persistently navigating the internet to find hard-to-locate information. |
| ComplexFunc Bench [80] | Tool Use – LLM | 2025 | Open-ended QA: answer complex function-calling tasks in five real-world scenarios requiring multi-step reasoning, parameter management, and long-context handling. |
| IFEval [81] | Instruction Following – LLM | 2023 | Open-ended QA: answer 500 prompts requiring LLMs to follow verifiable natural language instructions. |
| Multi-IF [82] | Instruction Following – LLM | 2024 | Open-ended QA: answer 4,501 multilingual multi-turn prompts requiring accurate instruction-following across languages and conversation turns. |
| LOFT [83] | Long-Context – LLM | 2024 | Open-ended QA: answer real-world tasks requiring reasoning and in-context retrieval over millions of tokens. |
| Graphwalks [14] | Long-Context – LLM | 2025 | Open-ended QA: perform multi-hop reasoning across a graph of millions of tokens to answer questions requiring breadth-first traversal. |
| Multi Challenge [84] | Multi-turn Conversation – LLM | 2025 | Open-ended QA: answer multi-turn conversation prompts requiring instruction-following, context management, and in-context reasoning. |
| HealthBench [85] | Safety – LLM | 2025 | Open-ended QA: evaluates LLMs on multi-turn healthcare conversations, requiring factual reasoning, safety awareness, and context-sensitive decision-making across diverse medical contexts. |
## Appendix B Performance of Models
<details>
<summary>figures/claude_2_plots/claude_performance_Commonsense_and_Logical_Reasoning.png Details</summary>
### Visual Description
\n
## Line Chart: Model Score vs. Model Number
### Overview
The image presents a line chart illustrating the relationship between Model Number and Score (expressed as a percentage). The chart displays a clear upward trend, with a significant jump in score between Model 2 and Model 3. A single data point is labeled "HellaSwag".
### Components/Axes
* **X-axis:** Labeled "Model Number", ranging from 1 to 10 with integer increments.
* **Y-axis:** Labeled "Score (%)", ranging from 86 to 95 with increments of 2.
* **Data Series:** A single blue line representing the score for each model number.
* **Annotation:** A text label "HellaSwag" positioned near the data point for Model 3.
### Detailed Analysis
The line begins at approximately 86% for Model 1. It rises steadily to approximately 89% for Model 2. There is a substantial increase in score between Model 2 and Model 3, reaching approximately 95% for Model 3, which is labeled "HellaSwag". The line remains flat at approximately 95% from Model 3 to Model 10.
Here's a breakdown of the approximate data points:
* Model 1: 86%
* Model 2: 89%
* Model 3: 95% (labeled "HellaSwag")
* Model 4-10: 95%
The line slopes upward from Model 1 to Model 3, then becomes horizontal from Model 3 to Model 10.
### Key Observations
* The most significant improvement in score occurs between Model 2 and Model 3.
* The score plateaus at 95% starting from Model 3.
* The "HellaSwag" label is associated with the highest score achieved.
### Interpretation
The chart suggests that the model's performance improves rapidly up to Model 3, after which further model iterations do not yield any additional score improvement. The "HellaSwag" label likely indicates a specific model version or configuration that achieves peak performance. The plateauing of the score after Model 3 could indicate that the model has reached its maximum potential with the current architecture or training data, or that the metric used to measure performance is no longer sensitive to further improvements. The rapid increase between Model 2 and 3 suggests a critical change or optimization was implemented at that stage. It is important to note that the chart only shows the score and does not provide information about the resources or complexity of each model.
</details>
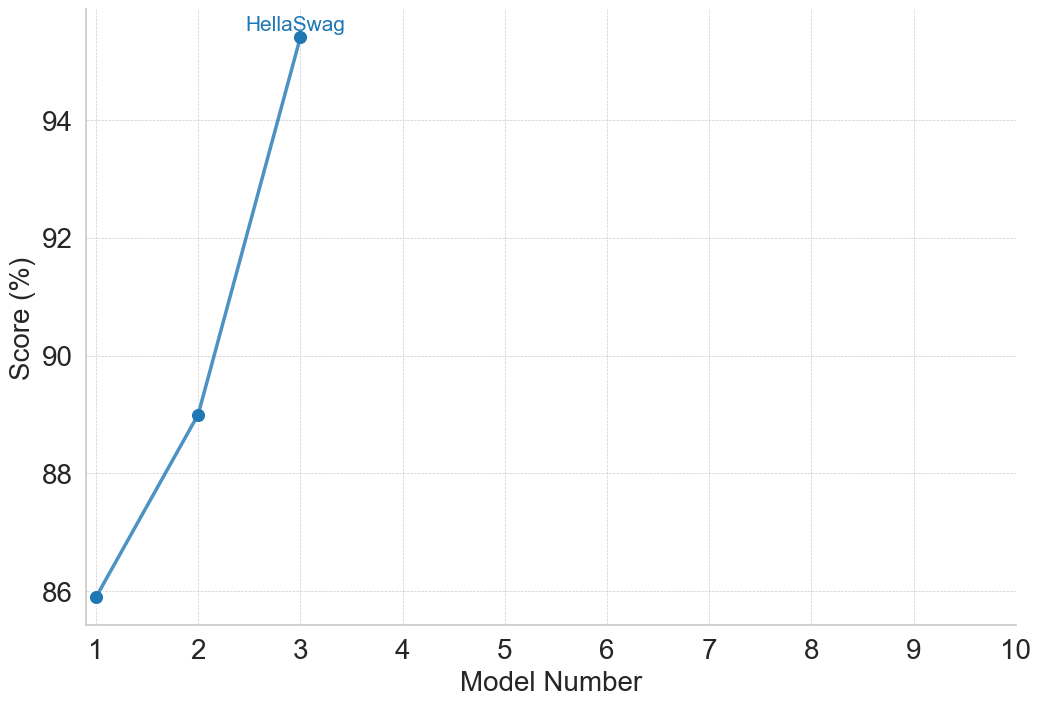
(a) Commonsense and Logical Reasoning
<details>
<summary>figures/claude_2_plots/claude_performance_Mathematical_Reasoning.png Details</summary>
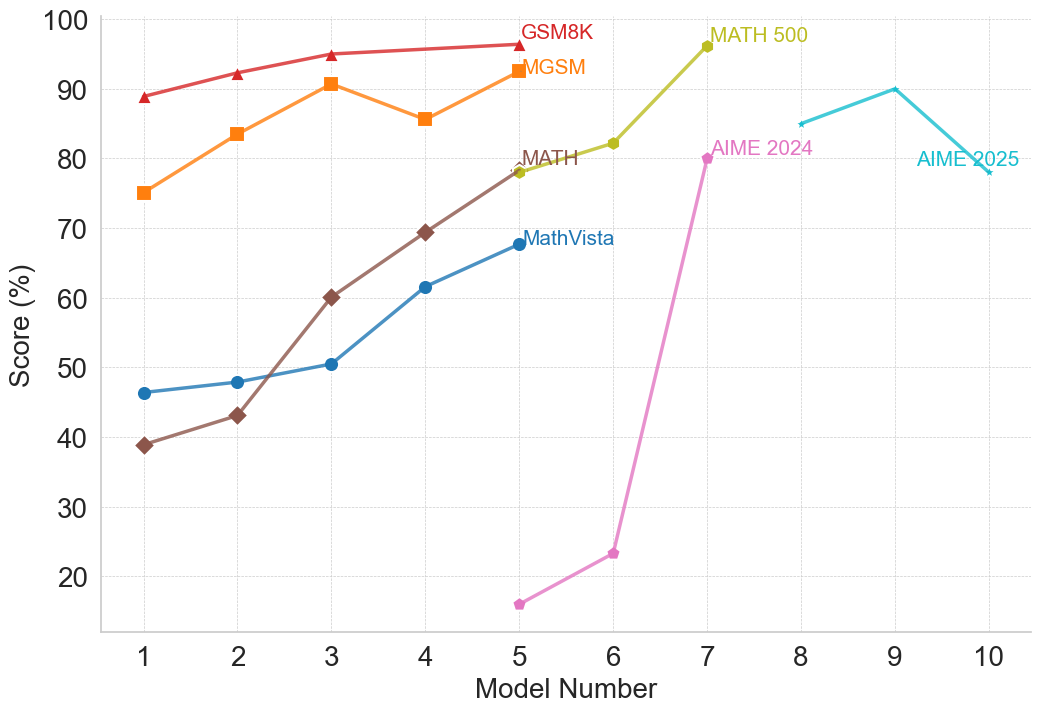
### Visual Description
\n
## Line Chart: Model Performance on Various Benchmarks
### Overview
This line chart displays the performance scores (in percentage) of different models (numbered 1 to 10) across six different benchmarks: GSM8K, GSM, MATH 500, MATH, MathVista, AIME 2024, and AIME 2025. The chart allows for a comparison of how each model performs on each benchmark, and how performance changes as the model number increases.
### Components/Axes
* **X-axis:** "Model Number" ranging from 1 to 10.
* **Y-axis:** "Score (%)" ranging from 0 to 100.
* **Data Series:**
* GSM8K (Red)
* GSM (Orange)
* MATH 500 (Yellow)
* MATH (Olive Green)
* MathVista (Teal)
* AIME 2024 (Light Blue)
* AIME 2025 (Cyan)
* **Legend:** Located at the top-right of the chart, associating each color with its corresponding benchmark.
### Detailed Analysis
Here's a breakdown of each data series, with approximate values extracted from the chart:
* **GSM8K (Red):** The line starts at approximately 91% at Model 1, increases slightly to around 93% at Model 2, remains relatively stable around 92-93% until Model 5, then decreases to approximately 88% at Model 10.
* **GSM (Orange):** Starts at approximately 74% at Model 1, increases steadily to around 87% at Model 4, then plateaus around 86-88% for Models 5-10.
* **MATH 500 (Yellow):** Begins at approximately 42% at Model 1, increases steadily to around 75% at Model 5, peaks at approximately 97% at Model 7, and then declines to around 88% at Model 10.
* **MATH (Olive Green):** Starts at approximately 40% at Model 1, increases steadily to around 68% at Model 5, continues to increase to approximately 83% at Model 7, and then decreases slightly to around 80% at Model 10.
* **MathVista (Teal):** Starts at approximately 48% at Model 1, increases steadily to around 62% at Model 5, continues to increase to approximately 81% at Model 7, and then declines sharply to approximately 24% at Model 6 before increasing to around 85% at Model 9 and 83% at Model 10.
* **AIME 2024 (Light Blue):** Starts at approximately 81% at Model 1, increases to around 85% at Model 3, then decreases to approximately 78% at Model 5, increases sharply to approximately 91% at Model 7, and then decreases to around 88% at Model 10.
* **AIME 2025 (Cyan):** Starts at approximately 78% at Model 1, increases to around 82% at Model 3, then decreases to approximately 75% at Model 5, increases sharply to approximately 93% at Model 7, and then decreases to around 85% at Model 10.
### Key Observations
* **MATH 500** shows the most dramatic improvement between Model 5 and Model 7, achieving the highest score on the chart at Model 7.
* **MathVista** exhibits a significant drop in performance at Model 6, followed by a recovery in Models 9 and 10. This is an outlier.
* **GSM8K** maintains a consistently high score throughout all models.
* **AIME 2024 and AIME 2025** show similar trends, with a peak performance around Model 7.
* Generally, performance across all benchmarks improves as the model number increases, but this improvement plateaus or declines after a certain point (around Model 7).
### Interpretation
The data suggests that model performance generally improves with increasing model number, but the rate of improvement varies significantly depending on the benchmark. The substantial increase in MATH 500 performance between Models 5 and 7 indicates that this benchmark benefits significantly from model advancements within this range. The sharp decline in MathVista performance at Model 6 is an anomaly that warrants further investigation – it could be due to a specific issue with that model's implementation or a data-related problem. The convergence of AIME 2024 and AIME 2025 scores suggests that these benchmarks may be measuring similar capabilities. The plateauing or decline in performance after Model 7 suggests diminishing returns from further model development, or the need for different approaches to improve performance on these benchmarks. The chart provides valuable insights into the strengths and weaknesses of different models across various benchmarks, which can inform future model development and selection strategies.
</details>
(b) Mathematical Reasoning
<details>
<summary>figures/claude_2_plots/claude_performance_Multimodal_Reasoning.png Details</summary>
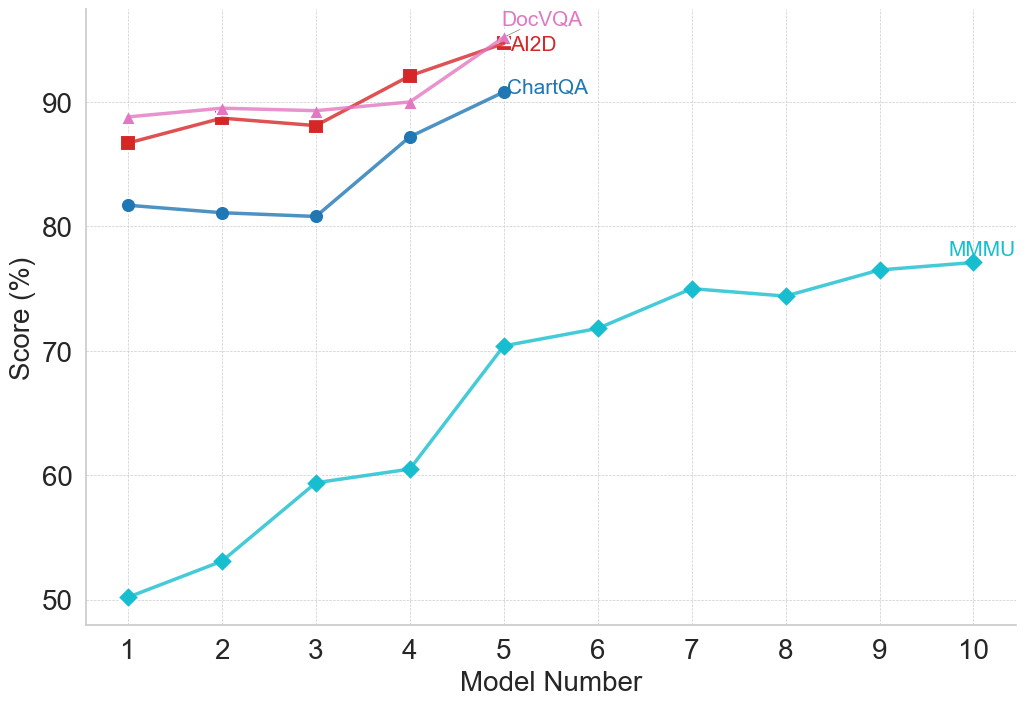
### Visual Description
## Line Chart: Model Performance Comparison
### Overview
This line chart compares the performance scores of four different models (DocVQA, AI2D, ChartQA, and MMU) across ten model numbers. The performance is measured as a score in percentage.
### Components/Axes
* **X-axis:** "Model Number" ranging from 1 to 10.
* **Y-axis:** "Score (%)" ranging from 50 to 95.
* **Data Series:**
* DocVQA (Pink Line)
* AI2D (Red Line)
* ChartQA (Dark Blue Line)
* MMU (Teal Line)
* **Legend:** Located in the top-right corner, labeling each line with the corresponding model name and color.
### Detailed Analysis
Let's analyze each data series individually:
* **DocVQA (Pink Line):** Starts at approximately 88% (Model 1), remains relatively stable around 92-94% from Model 2 to Model 5, then decreases slightly to around 91% at Model 10.
* **AI2D (Red Line):** Begins at approximately 86% (Model 1), increases to a peak of around 93% at Model 4, then declines to approximately 91% at Model 10.
* **ChartQA (Dark Blue Line):** Starts at approximately 81% (Model 1), increases steadily to around 89% at Model 4, continues to rise to approximately 93% at Model 5, and remains relatively stable around 92-93% from Model 6 to Model 10.
* **MMU (Teal Line):** Starts at approximately 50% (Model 1), increases rapidly to around 60% at Model 3, continues to climb to approximately 72% at Model 5, then plateaus around 74-76% from Model 6 to Model 10.
Here's a more detailed breakdown of the data points:
| Model Number | DocVQA (%) | AI2D (%) | ChartQA (%) | MMU (%) |
|--------------|------------|----------|-------------|---------|
| 1 | 88 | 86 | 81 | 50 |
| 2 | 92 | 90 | 84 | 54 |
| 3 | 92 | 91 | 87 | 60 |
| 4 | 94 | 93 | 89 | 68 |
| 5 | 93 | 92 | 93 | 72 |
| 6 | 93 | 92 | 92 | 74 |
| 7 | 93 | 91 | 92 | 75 |
| 8 | 92 | 91 | 92 | 75 |
| 9 | 91 | 91 | 92 | 75 |
| 10 | 91 | 91 | 93 | 76 |
### Key Observations
* ChartQA consistently achieves the highest scores, particularly from Model 5 onwards.
* DocVQA and AI2D exhibit similar performance, with slight fluctuations.
* MMU demonstrates the most significant improvement over the model numbers, but starts with the lowest score and remains considerably lower than the other models.
* The performance of DocVQA, AI2D, and ChartQA appears to plateau after Model 5.
### Interpretation
The data suggests that ChartQA is the most effective model for the task being evaluated, consistently outperforming the other models. DocVQA and AI2D offer comparable performance, while MMU shows substantial improvement but still lags behind. The plateauing of DocVQA, AI2D, and ChartQA after Model 5 could indicate a point of diminishing returns, where further model improvements yield minimal gains in performance. The large initial gap between MMU and the other models, coupled with its consistent improvement, suggests that MMU may benefit from further development and optimization. The chart demonstrates a clear hierarchy of model performance, with ChartQA leading the way, followed by DocVQA and AI2D, and finally MMU. This information could be used to guide future research and development efforts, focusing on improving the performance of MMU and exploring strategies to overcome the plateau observed in the other models.
</details>
(c) Multimodal Reasoning
<details>
<summary>figures/claude_2_plots/claude_performance_Programming_and_Coding.png Details</summary>
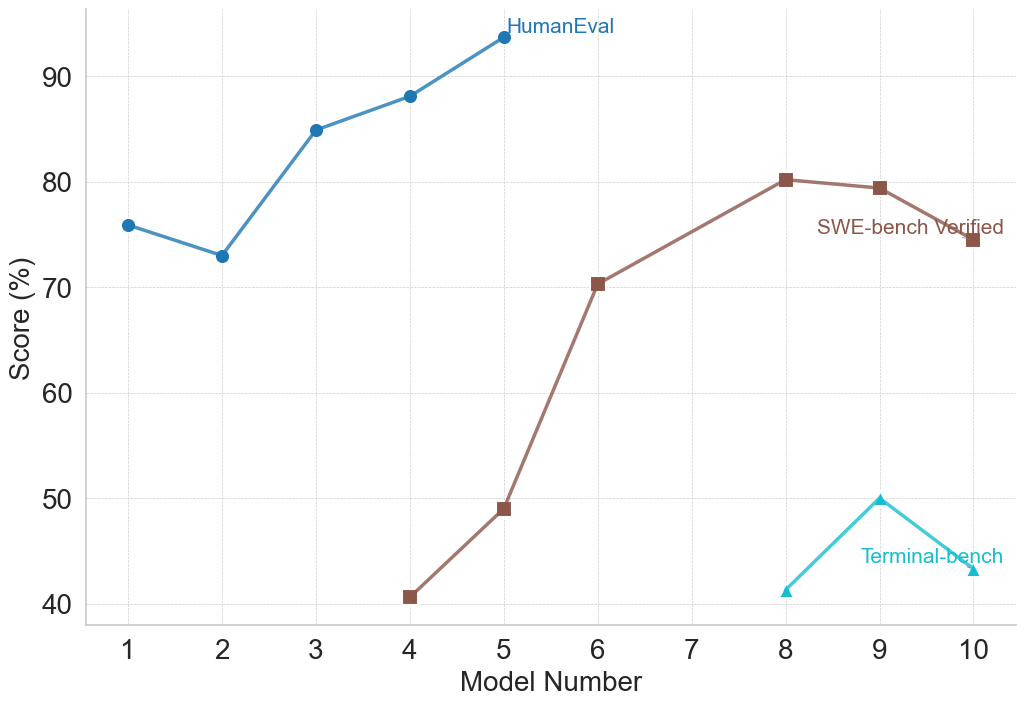
### Visual Description
## Line Chart: Model Performance Comparison
### Overview
This image presents a line chart comparing the performance of models across three different evaluation benchmarks: HumanEval, SWE-bench Verified, and Terminal-bench. The x-axis represents the Model Number (ranging from 1 to 10), and the y-axis represents the Score in percentage (ranging from 40% to 90%). The chart displays the performance trends of each benchmark as a distinct line.
### Components/Axes
* **X-axis:** Model Number (1 to 10)
* **Y-axis:** Score (%) (40 to 90)
* **Lines/Benchmarks:**
* HumanEval (Blue)
* SWE-bench Verified (Gray)
* Terminal-bench (Teal)
* **Legend:** Located in the top-right corner, labeling each line with its corresponding benchmark name.
### Detailed Analysis
* **HumanEval (Blue Line):** The blue line representing HumanEval shows an upward trend.
* Model 1: Approximately 74%
* Model 2: Approximately 73%
* Model 3: Approximately 84%
* Model 4: Approximately 88%
* Model 5: Approximately 93%
* Model 6: Approximately 92%
* Model 7: Approximately 92%
* Model 8: Approximately 81%
* Model 9: Approximately 76%
* Model 10: Approximately 76%
* **SWE-bench Verified (Gray Line):** The gray line representing SWE-bench Verified shows a significant upward trend, starting from a low score and increasing substantially.
* Model 1: Approximately 70%
* Model 2: Approximately 71%
* Model 3: Approximately 72%
* Model 4: Approximately 40%
* Model 5: Approximately 48%
* Model 6: Approximately 72%
* Model 7: Approximately 78%
* Model 8: Approximately 80%
* Model 9: Approximately 74%
* Model 10: Approximately 75%
* **Terminal-bench (Teal Line):** The teal line representing Terminal-bench shows a relatively flat trend with some fluctuations.
* Model 1: Approximately 42%
* Model 2: Approximately 41%
* Model 3: Approximately 44%
* Model 4: Approximately 40%
* Model 5: Approximately 40%
* Model 6: Approximately 40%
* Model 7: Approximately 40%
* Model 8: Approximately 40%
* Model 9: Approximately 50%
* Model 10: Approximately 48%
### Key Observations
* HumanEval consistently achieves the highest scores across all models, peaking around Model 5.
* SWE-bench Verified shows the most significant improvement in performance as the Model Number increases, starting from a lower baseline.
* Terminal-bench exhibits the lowest scores and the least amount of variation, remaining relatively stable around 40-50%.
* There is a dip in HumanEval performance between Model 8 and Model 10.
* SWE-bench Verified shows a large drop in performance at Model 4.
### Interpretation
The chart demonstrates the performance of different models across three distinct benchmarks designed to evaluate different aspects of code generation or understanding. HumanEval appears to be the easiest benchmark for these models, consistently achieving high scores. SWE-bench Verified shows that model performance can be significantly improved with increased model number, suggesting that more complex models are better suited for this benchmark. Terminal-bench, however, remains a challenge, with scores consistently lower than the other two benchmarks. The dip in HumanEval performance at the higher model numbers could indicate overfitting or a diminishing return on model complexity for that specific benchmark. The large drop in SWE-bench Verified at Model 4 is an anomaly that warrants further investigation. Overall, the chart provides valuable insights into the strengths and weaknesses of these models across different evaluation criteria.
</details>
(d) Programming and Coding
<details>
<summary>figures/claude_2_plots/claude_performance_Reading_Comprehension_and_Question_Answering.png Details</summary>
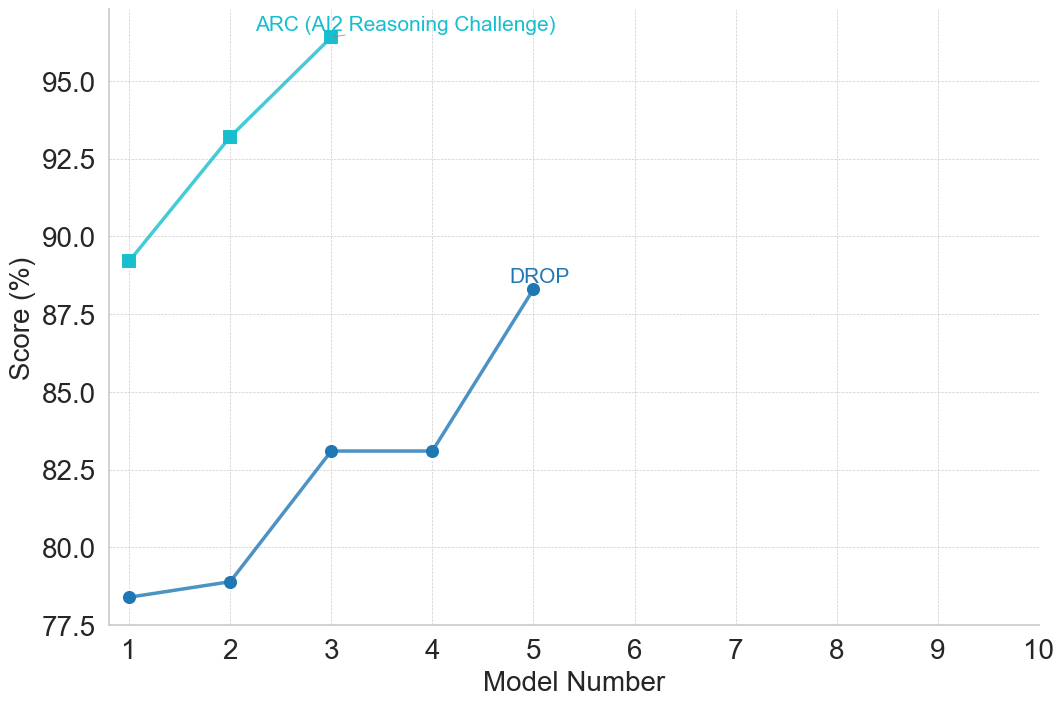
### Visual Description
\n
## Line Chart: Model Performance on Reasoning Challenges
### Overview
This image presents a line chart illustrating the performance of different models on two reasoning challenges: ARC (AI2 Reasoning Challenge) and DROP. The y-axis represents the score in percentage, while the x-axis represents the model number, ranging from 1 to 10. Two distinct lines depict the performance of the models on each challenge.
### Components/Axes
* **X-axis Title:** "Model Number" (ranging from 1 to 10)
* **Y-axis Title:** "Score (%)" (ranging from 77.5 to 95.0)
* **Line 1 (Teal):** Represents performance on the ARC (AI2 Reasoning Challenge).
* **Line 2 (Blue):** Represents performance on the DROP challenge.
* **Annotation 1:** "ARC (AI2 Reasoning Challenge)" positioned near the peak of the teal line.
* **Annotation 2:** "DROP" positioned near the peak of the blue line.
### Detailed Analysis
**ARC (Teal Line):**
The teal line shows an overall upward trend, initially increasing rapidly, then leveling off.
* Model 1: Approximately 78.0%
* Model 2: Approximately 92.5%
* Model 3: Approximately 95.0%
* Model 4: Approximately 82.5%
* Model 5: Approximately 88.0%
* Models 6-10: The line remains relatively flat at approximately 88.0%
**DROP (Blue Line):**
The blue line shows a more gradual increase, with a significant drop after Model 3.
* Model 1: Approximately 77.5%
* Model 2: Approximately 80.0%
* Model 3: Approximately 82.5%
* Model 4: Approximately 82.5%
* Model 5: Approximately 87.5%
* Models 6-10: The line remains relatively flat at approximately 87.5%
### Key Observations
* The ARC challenge shows higher scores overall compared to the DROP challenge.
* Model 3 achieves the highest score on the ARC challenge.
* Model 5 shows the highest score on the DROP challenge.
* The DROP challenge exhibits a more volatile performance curve, with a noticeable dip after Model 3.
* Both challenges show diminishing returns after a certain model number (around 5).
### Interpretation
The data suggests that model performance on reasoning challenges improves with model number, but this improvement plateaus after a certain point. The ARC challenge appears to be easier for the models to solve, consistently achieving higher scores than the DROP challenge. The drop in performance on the DROP challenge after Model 3 could indicate that the challenge requires different capabilities that are not being effectively scaled with the model number. The leveling off of both lines suggests that further increasing the model number may not lead to significant performance gains, and that other factors, such as model architecture or training data, may be more important for improving performance on these reasoning challenges. The annotations highlight the specific challenges being evaluated, providing context for the performance metrics. The visual representation effectively communicates the relative performance of the models on each challenge and the diminishing returns observed as the model number increases.
</details>
(e) Reading Comprehension and QA
<details>
<summary>figures/claude_2_plots/claude_performance_Reasoning_with_General_Knowledge.png Details</summary>
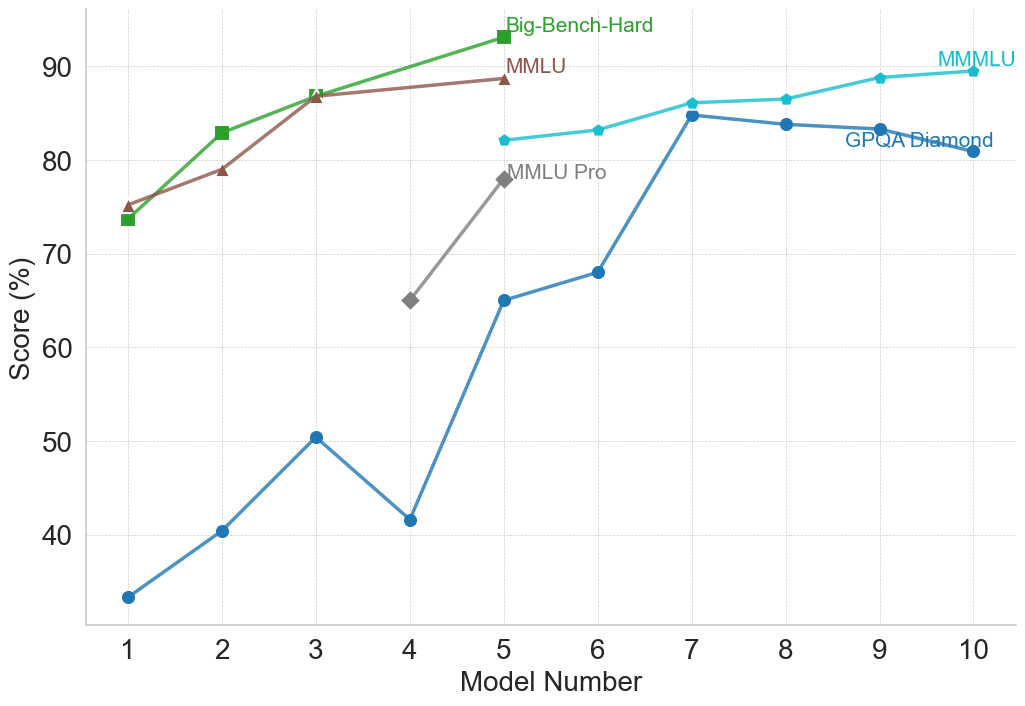
### Visual Description
## Line Chart: Model Performance Comparison
### Overview
This line chart compares the performance of several models across a range of model numbers (1 to 10). The performance is measured as a score in percentage (%). The chart displays four distinct data series, each representing a different benchmark or model evaluation: Big-Bench-Hard, MMLU, MMLU Pro, and GPQA Diamond.
### Components/Axes
* **X-axis:** "Model Number" ranging from 1 to 10.
* **Y-axis:** "Score (%)" ranging from 30 to 90.
* **Data Series:**
* Big-Bench-Hard (Green)
* MMLU (Brown)
* MMLU Pro (Gray)
* GPQA Diamond (Teal)
* **Legend:** Located in the top-right corner of the chart, associating colors with each data series.
### Detailed Analysis
Let's analyze each data series individually:
* **Big-Bench-Hard (Green):** The line starts at approximately 73% at Model Number 1, increases to around 86% at Model Number 3, and then plateaus around 84-86% for the remaining model numbers.
* **MMLU (Brown):** The line begins at approximately 76% at Model Number 1, increases steadily to around 87% at Model Number 3, and then remains relatively stable between 85% and 88% for the rest of the model numbers.
* **MMLU Pro (Gray):** This line shows a significant increase from approximately 65% at Model Number 1 to around 79% at Model Number 5. It then rises sharply to approximately 87% at Model Number 7, and remains relatively constant around 86-88% for the remaining model numbers.
* **GPQA Diamond (Teal):** This line exhibits a more volatile pattern. It starts at approximately 33% at Model Number 1, increases to around 50% at Model Number 3, then drops to approximately 42% at Model Number 4. It then experiences a substantial increase to around 84% at Model Number 7, and fluctuates between 82% and 86% for the remaining model numbers.
Here's a more detailed breakdown of approximate values at each model number:
| Model Number | Big-Bench-Hard (%) | MMLU (%) | MMLU Pro (%) | GPQA Diamond (%) |
|--------------|--------------------|----------|--------------|------------------|
| 1 | 73 | 76 | 65 | 33 |
| 2 | 78 | 81 | 68 | 41 |
| 3 | 86 | 87 | 72 | 50 |
| 4 | 86 | 86 | 67 | 42 |
| 5 | 86 | 86 | 79 | 63 |
| 6 | 85 | 86 | 82 | 72 |
| 7 | 85 | 87 | 87 | 84 |
| 8 | 84 | 86 | 87 | 83 |
| 9 | 84 | 88 | 87 | 82 |
| 10 | 84 | 88 | 86 | 86 |
### Key Observations
* MMLU and Big-Bench-Hard consistently achieve the highest scores, generally above 80%, across all model numbers.
* GPQA Diamond starts with the lowest scores but shows the most significant improvement, reaching comparable levels to other benchmarks by Model Number 7.
* MMLU Pro demonstrates a delayed but substantial increase in performance, particularly between Model Numbers 5 and 7.
* The performance of all models appears to plateau after Model Number 7, indicating diminishing returns from further model development.
### Interpretation
The chart suggests that the models are improving in performance as the model number increases, likely representing iterative development or training. The different benchmarks (Big-Bench-Hard, MMLU, MMLU Pro, and GPQA Diamond) assess different aspects of model capabilities. The initial lower scores of GPQA Diamond, followed by a rapid increase, could indicate that this benchmark requires specific model characteristics that are developed later in the process. The plateauing of all curves after Model Number 7 suggests that the models are approaching a performance limit or that further improvements require fundamentally different approaches. The consistent high performance of MMLU and Big-Bench-Hard suggests these benchmarks are relatively easier to optimize for, or that the models are inherently strong in the areas they assess. The differences in the trajectories of the lines highlight the varying sensitivities of each benchmark to model improvements.
</details>
(f) Reasoning with General Knowledge
<details>
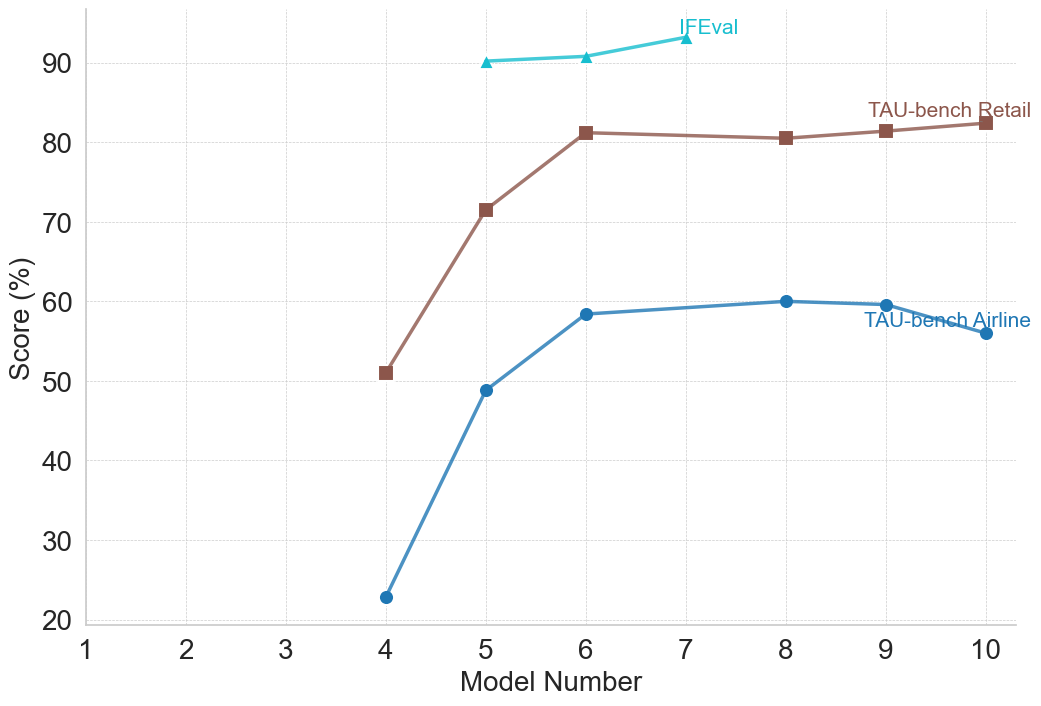
<summary>figures/claude_2_plots/claude_performance_LLM_Benchmarks_Combined.png Details</summary>
### Visual Description
\n
## Line Chart: Model Performance Comparison
### Overview
This line chart compares the performance of different models (numbered 1 through 10) across three evaluation metrics: IFEval, TAU-bench Retail, and TAU-bench Airline. The y-axis represents the score in percentage (%), while the x-axis represents the model number.
### Components/Axes
* **X-axis:** "Model Number" ranging from 1 to 10.
* **Y-axis:** "Score (%)" ranging from 20 to 90.
* **Lines/Series:**
* IFEval (Light Blue)
* TAU-bench Retail (Dark Brown)
* TAU-bench Airline (Gray)
* **Legend:** Located in the top-right corner, associating colors with evaluation metrics.
### Detailed Analysis
* **IFEval (Light Blue):** The line starts at approximately 23% at Model 4, rises sharply to around 88% at Model 6, and then plateaus, remaining around 90% for Models 6 through 10.
* Model 4: ~23%
* Model 5: ~57%
* Model 6: ~88%
* Model 7: ~90%
* Model 8: ~90%
* Model 9: ~90%
* Model 10: ~90%
* **TAU-bench Retail (Dark Brown):** The line starts at approximately 51% at Model 4, increases to around 73% at Model 5, reaches a peak of approximately 81% at Model 6, and then remains relatively stable around 80% for Models 6 through 10.
* Model 4: ~51%
* Model 5: ~73%
* Model 6: ~81%
* Model 7: ~80%
* Model 8: ~80%
* Model 9: ~80%
* Model 10: ~80%
* **TAU-bench Airline (Gray):** The line starts at approximately 50% at Model 4, increases to around 58% at Model 5, rises to approximately 62% at Model 6, and then plateaus around 61-62% for Models 6 through 10.
* Model 4: ~50%
* Model 5: ~58%
* Model 6: ~62%
* Model 7: ~62%
* Model 8: ~61%
* Model 9: ~61%
* Model 10: ~61%
### Key Observations
* IFEval shows the most significant improvement in performance as the model number increases, reaching a high score and then stabilizing.
* TAU-bench Retail also shows improvement, but the gains are less dramatic than IFEval.
* TAU-bench Airline exhibits the smallest improvement, with a relatively flat line indicating minimal performance change across models.
* All three metrics show a substantial jump in performance between Model 5 and Model 6.
### Interpretation
The data suggests that models 6 through 10 achieve a high level of performance on the IFEval metric, indicating a significant breakthrough in that area. While TAU-bench Retail also benefits from model improvements, the gains are more moderate. TAU-bench Airline shows the least sensitivity to model changes, suggesting that the models may have reached a performance ceiling for this specific evaluation task. The sharp increase in all metrics between Model 5 and Model 6 could indicate a critical architectural change or training data update that significantly improved the models' capabilities. The plateauing of the lines after Model 6 suggests diminishing returns from further model refinements, at least within the scope of these evaluation metrics. The differences in performance across the three metrics also suggest that the models excel at certain tasks (as measured by IFEval) but are less effective at others (TAU-bench Airline).
</details>
(g) LLM Benchmarks
Figure 3: Performance of the Claude family on reasoning benchmarks by category. Model numbers and corresponding names are as follows: 1 – Claude 3 Haiku; 2 – Claude 3 Sonnet; 3 – Claude 3 Opus; 4 – Claude 3.5 Haiku; 5 – Claude 3.5 Sonnet; 6 – Claude 3.7 Sonnet; 7 – Claude 3.7 Sonnet (64K Extended Thinking); 8 – Claude Sonnet 4; 9 – Claude Opus 4; 10 – Claude Opus 4.1.
<details>
<summary>figures/gemini_2_plots/gemini_performance_Commonsense_and_Logical_Reasoning.png Details</summary>
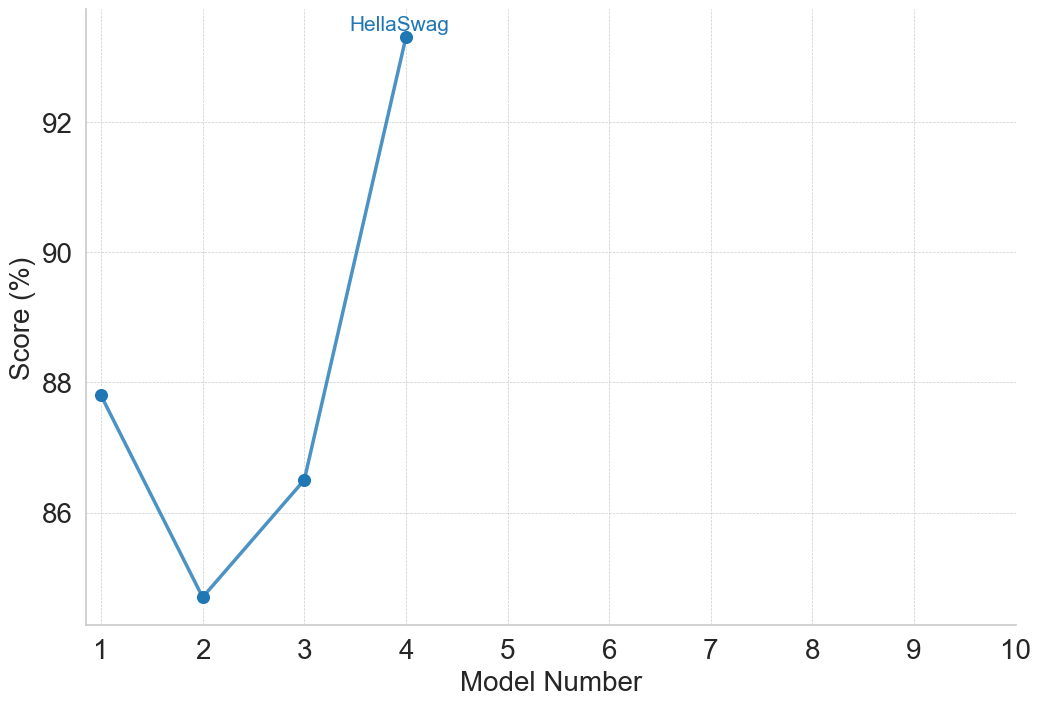
### Visual Description
\n
## Line Chart: Model Score vs. Model Number
### Overview
This image presents a line chart illustrating the relationship between Model Number and Score (expressed as a percentage). The chart displays a single data series, labeled "HellaSwag," showing how the score changes as the model number increases.
### Components/Axes
* **X-axis:** Labeled "Model Number," ranging from 1 to 10, with tick marks at each integer value.
* **Y-axis:** Labeled "Score (%)", ranging from approximately 84% to 93%, with tick marks at 86%, 88%, 90%, and 92%.
* **Data Series:** A single blue line representing "HellaSwag".
* **Annotation:** A label "HellaSwag" is positioned near the peak of the line, at approximately Model Number 4 and Score 92.5%.
### Detailed Analysis
The line representing "HellaSwag" exhibits a non-linear trend.
* **Model 1:** Score is approximately 88%.
* **Model 2:** Score drops sharply to approximately 84.5%.
* **Model 3:** Score increases to approximately 86.5%.
* **Model 4:** Score increases dramatically to approximately 92.5%.
* **Model 5-10:** The line remains flat at approximately 92.5% for the remaining model numbers.
### Key Observations
* The most significant change in score occurs between Model 3 and Model 4, with a substantial increase of approximately 6%.
* The score plateaus at approximately 92.5% starting from Model 4, indicating no further improvement with increasing model number.
* The initial drop in score from Model 1 to Model 2 is notable.
### Interpretation
The data suggests that the "HellaSwag" model experiences a period of initial decline in performance (Model 1 to Model 2), followed by a rapid improvement (Model 2 to Model 4), and then reaches a performance ceiling (Model 4 onwards). This could indicate that the model benefits from specific improvements implemented around Model 4, but further modifications do not yield significant gains. The initial drop might be due to a learning phase or the introduction of a new, initially unstable, component. The plateau suggests that the model has reached its maximum achievable performance given the current architecture or training data. The annotation "HellaSwag" suggests this is a name or identifier for the model being evaluated.
</details>
(a) Commonsense and Logical Reasoning
<details>
<summary>figures/gemini_2_plots/gemini_performance_Mathematical_Reasoning.png Details</summary>
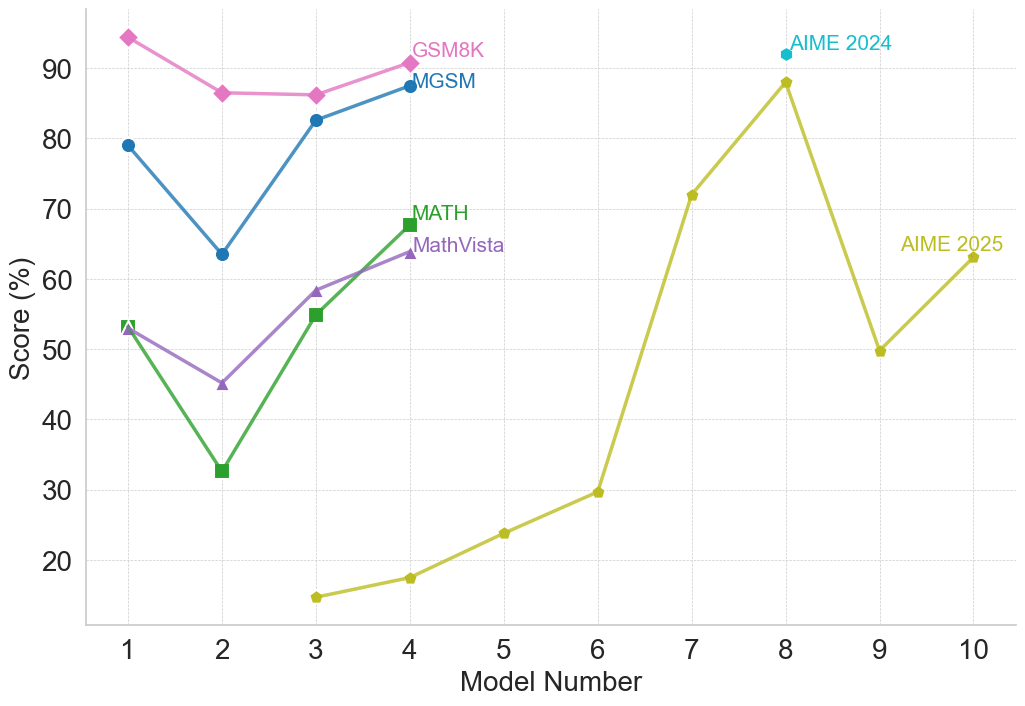
### Visual Description
## Line Chart: Model Performance on Various Benchmarks
### Overview
This line chart displays the performance scores (in percentage) of different models across several benchmarks: GSM8K, MGSM, MATH, MathVista, AIME 2024, and AIME 2025. The x-axis represents the Model Number, ranging from 1 to 10. The y-axis represents the Score, measured as a percentage from 0% to 100%.
### Components/Axes
* **X-axis:** Model Number (1 to 10)
* **Y-axis:** Score (%) (0 to 100)
* **Data Series:**
* GSM8K (Pink)
* MGSM (Purple)
* MATH (Blue)
* MathVista (Green)
* AIME 2024 (Teal)
* AIME 2025 (Yellow)
* **Legend:** Located in the top-right corner of the chart, associating colors with each benchmark.
### Detailed Analysis
Here's a breakdown of each data series and their trends:
* **GSM8K (Pink):** Starts at approximately 84% at Model 1, dips to around 81% at Model 2, rises to approximately 88% at Model 3, plateaus around 86-88% from Models 3 to 10.
* **MGSM (Purple):** Starts at approximately 91% at Model 1, drops to around 82% at Model 2, rises to approximately 86% at Model 3, and remains relatively stable around 84-86% from Models 3 to 10.
* **MATH (Blue):** Starts at approximately 76% at Model 1, drops to around 63% at Model 2, rises steadily to approximately 68% at Model 3, continues to increase to around 72% at Model 4, and plateaus around 72-74% from Models 4 to 10.
* **MathVista (Green):** Starts at approximately 52% at Model 1, drops sharply to around 32% at Model 2, rises steadily to approximately 58% at Model 3, continues to increase to around 68% at Model 7, and then plateaus around 68-70% from Models 7 to 10.
* **AIME 2024 (Teal):** Starts at approximately 76% at Model 1, drops to around 65% at Model 2, rises to approximately 70% at Model 3, and then rises sharply to approximately 91% at Model 8, and then drops to approximately 85% at Model 9 and 80% at Model 10.
* **AIME 2025 (Yellow):** Starts at approximately 20% at Model 1, rises steadily to approximately 30% at Model 6, then increases sharply to approximately 65% at Model 7, rises to approximately 87% at Model 8, and then drops to approximately 65% at Model 9 and 60% at Model 10.
### Key Observations
* GSM8K and MGSM consistently achieve the highest scores, remaining above 80% across all models.
* MathVista shows the lowest initial scores but demonstrates significant improvement as the Model Number increases.
* AIME 2024 and AIME 2025 exhibit a dramatic increase in performance around Model 8, suggesting a critical threshold or improvement in the model's capabilities at that point.
* AIME 2025 starts with the lowest scores and shows the most significant improvement.
* The performance of most models appears to stabilize after Model 7 or 8.
### Interpretation
The chart suggests that the models generally improve in performance as the Model Number increases, indicating that iterative development or training leads to better results. The benchmarks GSM8K and MGSM are easier for the models to achieve high scores on, while MATH, MathVista, AIME 2024, and AIME 2025 present greater challenges. The sharp increase in AIME 2024 and AIME 2025 scores around Model 8 could indicate a specific architectural change, training data update, or optimization technique implemented at that stage. The diverging trends of AIME 2024 and AIME 2025 after Model 8 suggest that the models are responding differently to further improvements or are being optimized for different aspects of the benchmark. The data highlights the importance of continued model development and the potential for significant performance gains through targeted improvements.
</details>
(b) Mathematical Reasoning
<details>
<summary>figures/gemini_2_plots/gemini_performance_Multimodal_Reasoning.png Details</summary>
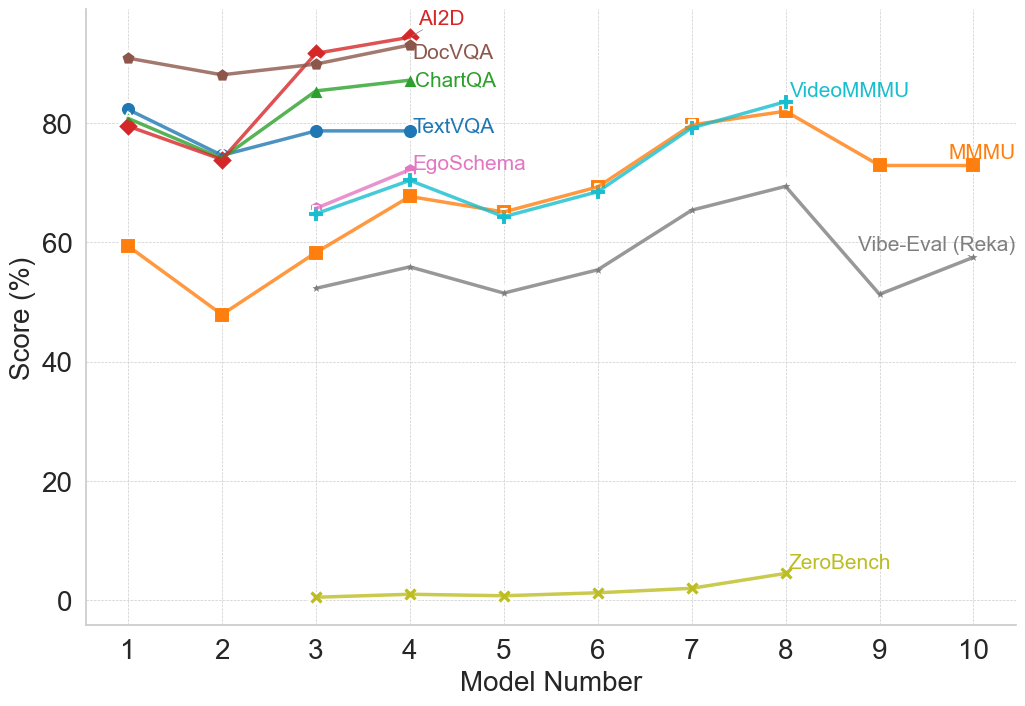
### Visual Description
\n
## Line Chart: Model Performance Comparison
### Overview
This line chart compares the performance scores of several models across a range of model numbers (1 to 10). The y-axis represents the score in percentage, while the x-axis represents the model number. The chart displays the performance trends of six different models: Ai2D, DocVQA, ChartQA, TextVQA, EgoSchema, VideoMMMU, MMMU, Vibe-Eval (Reka), and ZeroBench.
### Components/Axes
* **X-axis:** Model Number (1 to 10)
* **Y-axis:** Score (%) - Scale ranges from 0 to 80, with increments of 20.
* **Legend:** Located at the top-center of the chart, identifying each line with a unique color.
* Ai2D (Red)
* DocVQA (Dark Green)
* ChartQA (Light Green)
* TextVQA (Blue)
* EgoSchema (Purple)
* VideoMMMU (Cyan)
* MMMU (Orange)
* Vibe-Eval (Reka) (Gray)
* ZeroBench (Yellow)
### Detailed Analysis
Here's a breakdown of each model's performance trend and approximate data points:
* **Ai2D (Red):** Starts at approximately 84% at Model 1, decreases to around 78% at Model 2, then increases to a peak of approximately 88% at Model 3. It then declines to around 80% at Model 7, and remains relatively stable around 80% through Model 10.
* **DocVQA (Dark Green):** Begins at approximately 78% at Model 1, drops sharply to around 55% at Model 2, then rises to approximately 75% at Model 3. It fluctuates between 70% and 75% from Models 4 to 9, and then decreases to around 70% at Model 10.
* **ChartQA (Light Green):** Starts at approximately 75% at Model 1, decreases to around 65% at Model 2, then increases to approximately 80% at Model 3. It remains relatively stable around 70-75% from Models 4 to 9, and then decreases to around 65% at Model 10.
* **TextVQA (Blue):** Starts at approximately 80% at Model 1, decreases to around 70% at Model 2, then increases to approximately 82% at Model 3. It fluctuates between 70% and 80% from Models 4 to 9, and then decreases to around 75% at Model 10.
* **EgoSchema (Purple):** Begins at approximately 70% at Model 1, decreases to around 60% at Model 2, then increases to approximately 72% at Model 3. It remains relatively stable around 65-75% from Models 4 to 9, and then decreases to around 65% at Model 10.
* **VideoMMMU (Cyan):** Starts at approximately 60% at Model 1, decreases to around 50% at Model 2, then increases to approximately 78% at Model 8. It then decreases to around 75% at Model 10.
* **MMMU (Orange):** Starts at approximately 75% at Model 1, decreases to around 65% at Model 2, then increases to approximately 78% at Model 3. It remains relatively stable around 70-80% from Models 4 to 9, and then decreases to around 72% at Model 10.
* **Vibe-Eval (Reka) (Gray):** Starts at approximately 60% at Model 1, decreases to around 55% at Model 2, then increases to approximately 62% at Model 3. It remains relatively stable around 55-65% from Models 4 to 9, and then decreases to around 58% at Model 10.
* **ZeroBench (Yellow):** Starts at approximately 0% at Model 1, and remains very low (close to 0%) until Model 8, where it increases to approximately 5%. It remains around 5% at Model 10.
### Key Observations
* Ai2D consistently performs well, generally maintaining scores above 80% after Model 2.
* ZeroBench consistently performs poorly, with scores near 0% throughout most of the model numbers.
* VideoMMMU shows a significant increase in performance around Model 8.
* DocVQA, ChartQA, TextVQA, and EgoSchema exhibit similar performance trends, fluctuating between 60% and 80%.
* The performance of most models peaks around Model 3.
### Interpretation
The chart demonstrates a comparison of different models' performance on a specific task, likely a question-answering or reasoning task related to visual or textual data. The varying performance levels suggest that different models excel at different aspects of the task. Ai2D appears to be the most robust model, consistently achieving high scores. ZeroBench's consistently low scores indicate it may be a baseline model or one that requires further development. The increase in VideoMMMU's performance at Model 8 could indicate a specific improvement or optimization implemented at that stage. The similar trends among DocVQA, ChartQA, TextVQA, and EgoSchema suggest they may share similar underlying architectures or training data. The initial dip in performance for most models at Model 2 could be due to a challenging subset of the data or a specific aspect of the task that requires more sophisticated reasoning. Overall, the chart provides valuable insights into the strengths and weaknesses of different models and can guide future research and development efforts.
</details>
(c) Multimodal Reasoning
<details>
<summary>figures/gemini_2_plots/gemini_performance_Programming_and_Coding.png Details</summary>
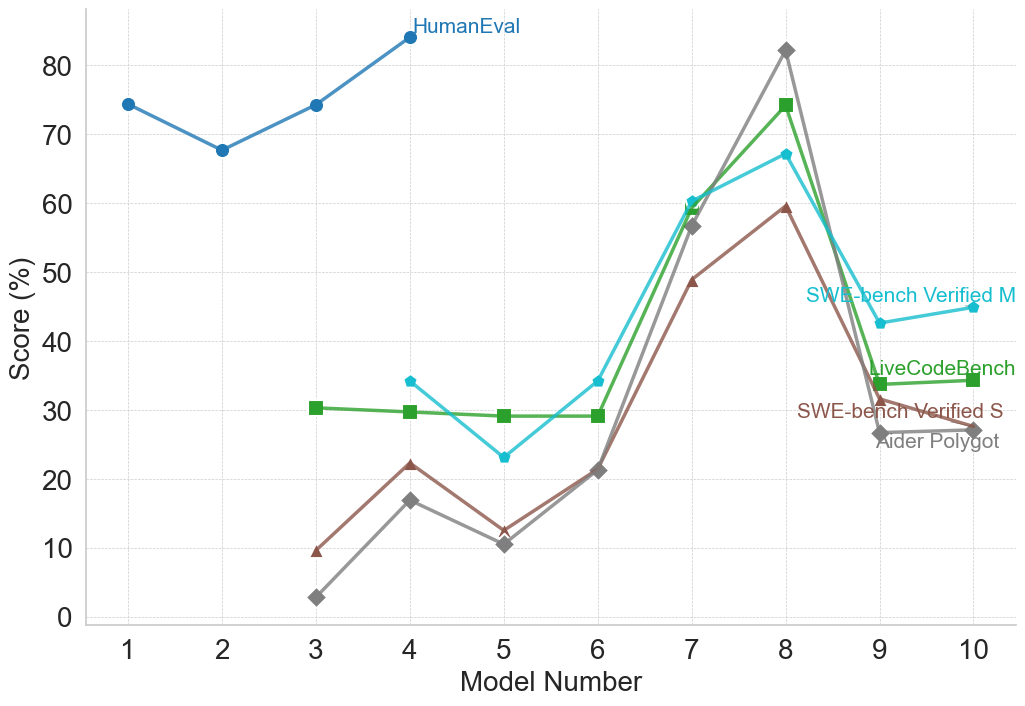
### Visual Description
\n
## Line Chart: Model Performance Comparison
### Overview
This line chart compares the performance of several models across a range of model numbers (1 to 10). The performance is measured as a "Score (%)" and is represented by different colored lines for each model. The chart appears to evaluate models on different benchmarks, as indicated by the legend.
### Components/Axes
* **X-axis:** "Model Number" ranging from 1 to 10.
* **Y-axis:** "Score (%)" ranging from 0 to 80.
* **Legend:** Located in the top-right corner, identifying the following data series:
* HumanEval (Blue)
* SWE-bench Verified M (Dark Green)
* LiveCodeBench (Orange)
* SWE-bench Verified S (Light Green)
* Aider Polylot (Grey)
### Detailed Analysis
Let's analyze each line individually, noting trends and approximate data points.
* **HumanEval (Blue):** This line starts at approximately 72% at Model Number 1, dips to around 65% at Model Number 2, then generally increases to approximately 82% at Model Number 8, and remains relatively stable around 80% for Models 9 and 10. The trend is generally upward.
* **SWE-bench Verified M (Dark Green):** This line is relatively flat, starting at approximately 28% at Model Number 1 and remaining around 30% until Model Number 6. It then increases to around 42% at Model Number 8, and then decreases to around 38% at Model Number 10.
* **LiveCodeBench (Orange):** This line starts at approximately 58% at Model Number 1, decreases to around 45% at Model Number 3, then increases sharply to approximately 70% at Model Number 8, and then decreases to around 65% at Model Number 10.
* **SWE-bench Verified S (Light Green):** This line starts at approximately 32% at Model Number 1, remains relatively flat around 30% until Model Number 6, then increases to around 40% at Model Number 8, and then decreases to around 35% at Model Number 10.
* **Aider Polylot (Grey):** This line starts at approximately 5% at Model Number 1, increases to around 18% at Model Number 4, then decreases to around 10% at Model Number 6, and then increases sharply to approximately 40% at Model Number 8, and then decreases to around 35% at Model Number 10.
### Key Observations
* **HumanEval consistently scores the highest**, significantly outperforming the other models, especially at higher model numbers.
* **Aider Polylot starts with the lowest scores** but shows the most significant relative improvement across model numbers.
* **SWE-bench Verified M and SWE-bench Verified S** exhibit similar trends, remaining relatively stable for the first six models and then showing an increase.
* **LiveCodeBench shows a significant increase in score** between Model Numbers 6 and 8.
* There is a general trend of increasing scores for most models as the model number increases, suggesting that model improvements lead to better performance.
### Interpretation
The data suggests that the models generally improve in performance as the model number increases, indicating that iterative development or training leads to better results. HumanEval appears to be the most robust benchmark, consistently showing high scores across all model numbers. Aider Polylot, while starting with low scores, demonstrates a substantial capacity for improvement. The differences in performance across the benchmarks (SWE-bench, LiveCodeBench, HumanEval) suggest that the models are evaluated on different types of coding tasks or with different evaluation criteria. The convergence of scores around Model Number 8-10 suggests that the models may be approaching a performance plateau on these benchmarks. The sharp increase in LiveCodeBench and Aider Polylot around Model Number 8 could indicate a specific optimization or architectural change implemented at that point.
</details>
(d) Programming and Coding
<details>
<summary>figures/gemini_2_plots/gemini_performance_Reading_Comprehension_and_Question_Answering.png Details</summary>
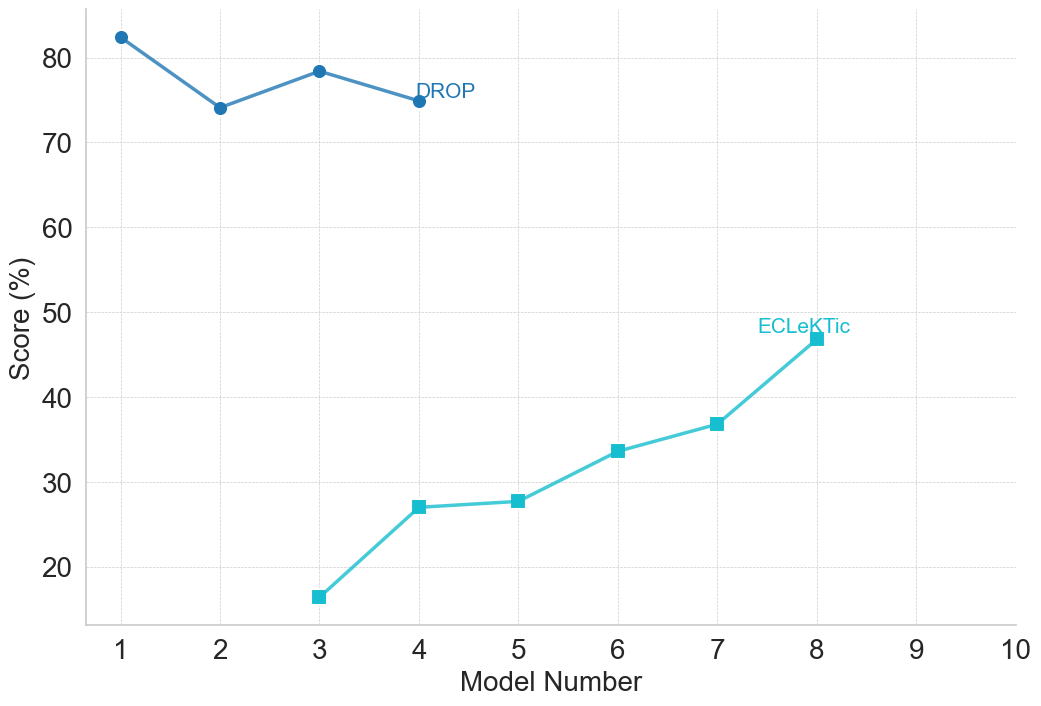
### Visual Description
\n
## Line Chart: Model Score vs. Model Number
### Overview
The image presents a line chart illustrating the relationship between Model Number and Score (expressed as a percentage). Two distinct data series are plotted, each represented by a different colored line. The chart appears to track the performance of different models, with the x-axis representing the model number and the y-axis representing the score.
### Components/Axes
* **X-axis:** "Model Number", ranging from 1 to 10, with tick marks at each integer value.
* **Y-axis:** "Score (%)", ranging from 0 to 80, with tick marks at intervals of 10.
* **Data Series 1:** A teal-colored line.
* **Data Series 2:** A light-blue colored line.
* **Annotations:** "DROP" and "ECLeKTic" are labels placed directly on the chart, associated with specific data points.
### Detailed Analysis
**Data Series 1 (Teal Line):**
The teal line begins at approximately 82% at Model Number 1. It then decreases to approximately 73% at Model Number 2, and continues to decline to around 76% at Model Number 3. From Model Number 3, the line exhibits a consistent upward trend, reaching approximately 34% at Model Number 6. It continues to rise to approximately 45% at Model Number 8.
* Model 1: 82%
* Model 2: 73%
* Model 3: 76%
* Model 4: 76%
* Model 5: 28%
* Model 6: 34%
* Model 7: 37%
* Model 8: 45%
**Data Series 2 (Light-Blue Line):**
The light-blue line starts at approximately 18% at Model Number 3. It increases to approximately 28% at Model Number 4, plateaus at around 28% for Model Numbers 4 and 5, and then rises to approximately 34% at Model Number 6. It continues to increase to approximately 37% at Model Number 7, and finally reaches approximately 45% at Model Number 8.
* Model 3: 18%
* Model 4: 28%
* Model 5: 28%
* Model 6: 34%
* Model 7: 37%
* Model 8: 45%
The annotation "DROP" is positioned near the teal line at Model Number 3, indicating a potential drop in score. The annotation "ECLeKTic" is positioned near the light-blue line at Model Number 8, potentially marking a significant point for this model.
### Key Observations
* The teal line initially shows a decline in score before increasing.
* The light-blue line consistently increases in score from Model Number 3 to Model Number 8.
* Both lines converge at approximately 45% at Model Number 8.
* The light-blue line starts at Model Number 3, while the teal line starts at Model Number 1.
### Interpretation
The chart suggests a comparison of two different model performance metrics over a range of model numbers. The teal line, labeled with "DROP", might represent a model that initially performs well but experiences a decline before recovering. The light-blue line, labeled "ECLeKTic", shows a consistent improvement in score, potentially indicating a more robust or optimized model. The convergence of the two lines at Model Number 8 suggests that both models achieve similar performance levels at that point. The initial difference in starting points (Model 1 vs. Model 3) could indicate that the light-blue model was not evaluated until later stages of development or represents a different type of model altogether. The annotations "DROP" and "ECLeKTic" are likely identifiers for the specific models being compared, and their placement on the chart highlights key performance characteristics. The chart demonstrates the iterative process of model development and evaluation, where performance can fluctuate and eventually converge.
</details>
(e) Reading Comprehension and QA
<details>
<summary>figures/gemini_2_plots/gemini_performance_Reasoning_with_General_Knowledge.png Details</summary>
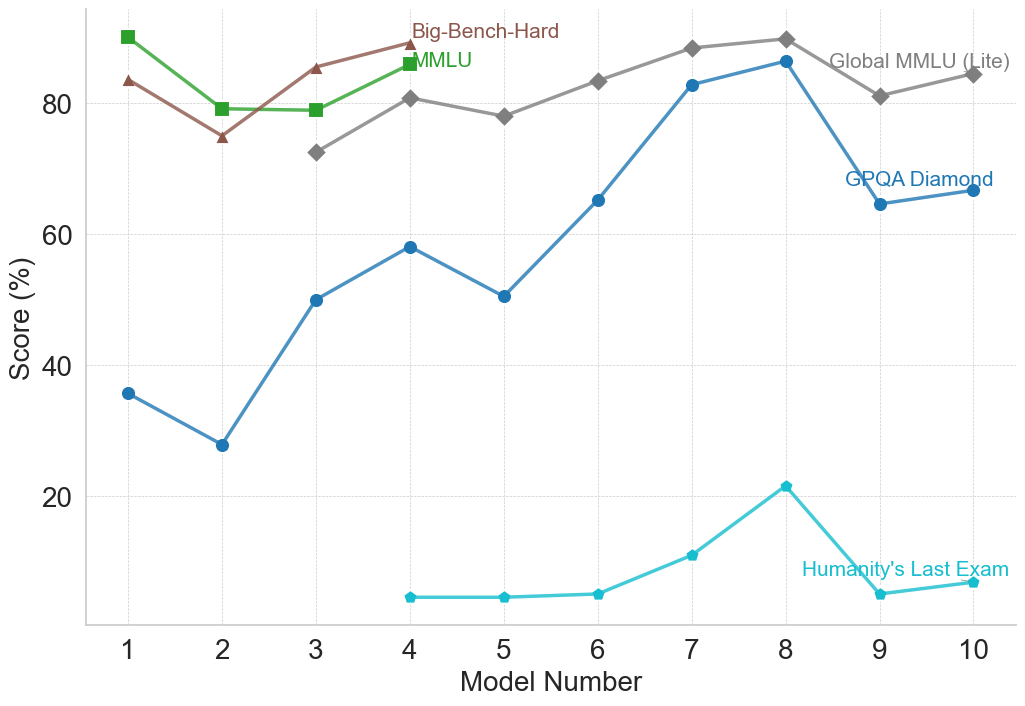
### Visual Description
## Line Chart: Model Performance Comparison
### Overview
This line chart compares the performance of several models across different benchmarks. The x-axis represents the Model Number (ranging from 1 to 10), and the y-axis represents the Score (%) achieved on each benchmark. Five different benchmarks are represented by distinct colored lines: Big-Bench-Hard, MMLU, Global MMLU (Lite), GPQA Diamond, and Humanity's Last Exam.
### Components/Axes
* **X-axis:** Model Number (1 to 10). The axis is labeled "Model Number".
* **Y-axis:** Score (%). The axis is labeled "Score (%)". The scale ranges from approximately 0% to 90%.
* **Legend:** Located in the top-right corner of the chart. It identifies each line with its corresponding benchmark name and color.
* Big-Bench-Hard (Dark Green)
* MMLU (Green)
* Global MMLU (Lite) (Brown)
* GPQA Diamond (Blue)
* Humanity's Last Exam (Cyan)
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points:
* **Big-Bench-Hard (Dark Green):** The line starts at approximately 85% at Model 1, decreases to around 75% at Model 2, then fluctuates between 75% and 85% for Models 3-10, ending at approximately 82% at Model 10.
* **MMLU (Green):** The line begins at approximately 88% at Model 1, decreases to around 78% at Model 2, increases to approximately 85% at Model 3, remains relatively stable around 80-85% for Models 4-9, and ends at approximately 83% at Model 10.
* **Global MMLU (Lite) (Brown):** The line starts at approximately 78% at Model 1, decreases to around 72% at Model 2, increases to approximately 78% at Model 3, remains relatively stable around 78-82% for Models 4-10, ending at approximately 80% at Model 10.
* **GPQA Diamond (Blue):** The line starts at approximately 40% at Model 1, decreases to around 30% at Model 4, increases to approximately 60% at Model 6, rises to approximately 85% at Model 8, decreases to approximately 70% at Model 9, and ends at approximately 75% at Model 10.
* **Humanity's Last Exam (Cyan):** The line begins at approximately 30% at Model 1, decreases to around 5% at Model 4, increases to approximately 10% at Model 6, rises to approximately 25% at Model 8, decreases to approximately 5% at Model 9, and ends at approximately 10% at Model 10.
### Key Observations
* **High Performers:** Big-Bench-Hard and MMLU consistently achieve the highest scores, generally above 75%.
* **Low Performers:** Humanity's Last Exam consistently has the lowest scores, rarely exceeding 30%.
* **Significant Improvement (GPQA Diamond):** GPQA Diamond shows the most significant improvement in score across the models, starting low and peaking around Model 8.
* **Stability (Global MMLU Lite):** Global MMLU (Lite) exhibits the most stable performance, with minimal fluctuations in score.
* **Dip at Model 2:** Big-Bench-Hard, MMLU, and Global MMLU (Lite) all experience a dip in performance at Model 2.
### Interpretation
The chart demonstrates the performance of different models on a variety of benchmarks. The varying trends suggest that different models excel at different types of tasks. The consistent high performance of Big-Bench-Hard and MMLU indicates their robustness across a range of challenges. The dramatic improvement of GPQA Diamond suggests that certain models benefit significantly from increased model number, potentially indicating a learning or scaling effect. The consistently low scores of Humanity's Last Exam may indicate that this benchmark is particularly difficult or that the models are not well-suited for the type of reasoning it requires. The dip in performance at Model 2 for several benchmarks could indicate a specific challenge or limitation in that model's architecture or training data. The overall trend suggests that increasing the model number generally leads to improved performance, but the extent of improvement varies depending on the benchmark.
</details>
(f) Reasoning with General Knowledge
<details>
<summary>figures/gemini_2_plots/gemini_performance_LLM_Benchmarks_Combined.png Details</summary>
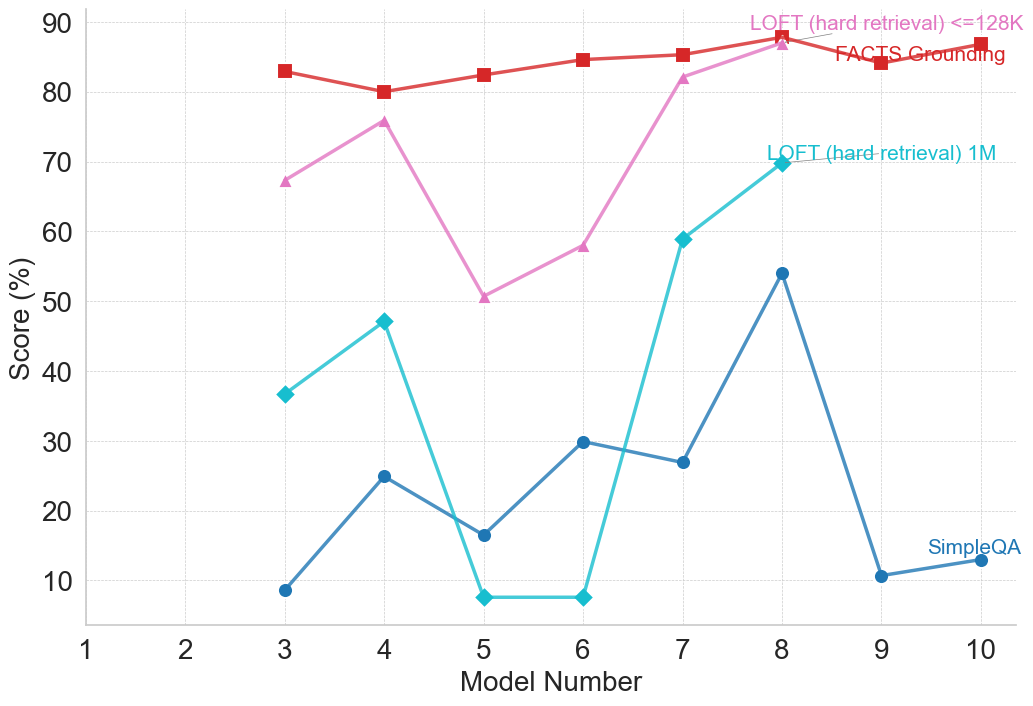
### Visual Description
## Line Chart: Model Performance Comparison
### Overview
This line chart compares the performance scores of three different models (LOFT with <=128K retrieval, LOFT with 1M retrieval, and SimpleQA) across ten different model numbers. The performance is measured as a percentage score.
### Components/Axes
* **X-axis:** Model Number (ranging from 1 to 10)
* **Y-axis:** Score (%) (ranging from 0 to 90)
* **Lines/Legends:**
* LOFT (hard retrieval) <=128K (represented by a red line with square markers)
* LOFT (hard retrieval) 1M (represented by a teal line with circular markers)
* SimpleQA (represented by a blue line with diamond markers)
* **Annotation:** "FACTS Grounding" is written in red text near the red line around Model Number 8.
### Detailed Analysis
**LOFT (hard retrieval) <=128K (Red Line):**
The red line generally trends horizontally, indicating relatively stable performance.
* Model 1: Approximately 82%
* Model 2: Approximately 82%
* Model 3: Approximately 79%
* Model 4: Approximately 78%
* Model 5: Approximately 80%
* Model 6: Approximately 81%
* Model 7: Approximately 85%
* Model 8: Approximately 85%
* Model 9: Approximately 83%
* Model 10: Approximately 82%
**LOFT (hard retrieval) 1M (Teal Line):**
The teal line exhibits a more fluctuating pattern.
* Model 1: Approximately 10%
* Model 2: Approximately 10%
* Model 3: Approximately 68%
* Model 4: Approximately 48%
* Model 5: Approximately 13%
* Model 6: Approximately 55%
* Model 7: Approximately 60%
* Model 8: Approximately 56%
* Model 9: Approximately 52%
* Model 10: Approximately 12%
**SimpleQA (Blue Line):**
The blue line shows a decreasing trend overall.
* Model 1: Approximately 10%
* Model 2: Approximately 10%
* Model 3: Approximately 10%
* Model 4: Approximately 22%
* Model 5: Approximately 13%
* Model 6: Approximately 30%
* Model 7: Approximately 26%
* Model 8: Approximately 56%
* Model 9: Approximately 12%
* Model 10: Approximately 10%
### Key Observations
* LOFT (<=128K) consistently outperforms the other two models across most model numbers, maintaining a high score around 80-85%.
* LOFT (1M) shows significant variability in performance, with a large jump at Model 3, and fluctuations throughout.
* SimpleQA starts with a low score and shows some improvement up to Model 8, but then declines sharply.
* The annotation "FACTS Grounding" suggests that the performance of LOFT (<=128K) around Model 8 might be related to the use of FACTS grounding.
### Interpretation
The data suggests that the LOFT model with <=128K retrieval is the most stable and reliable performer across the tested model numbers. The 1M retrieval version of LOFT shows potential but is more sensitive to changes in the model number. SimpleQA demonstrates limited performance and a declining trend. The annotation indicates that incorporating "FACTS Grounding" may contribute to the high performance of the LOFT (<=128K) model. The large performance swing in LOFT (1M) could be due to the increased complexity of retrieving and processing information from a larger knowledge base (1M vs. 128K). The decline in SimpleQA's performance towards the end could indicate overfitting or a limitation in its ability to generalize to different model configurations. The chart highlights the importance of retrieval size and grounding techniques in achieving robust performance in these models.
</details>
(g) LLM Benchmarks
Figure 4: Performance of the Gemini family on reasoning benchmarks by category. Model numbers and corresponding names are as follows: 1 – Gemini Ultra; 2 – Gemini Pro; 3 – Gemini 1.5 Flash; 4 – Gemini 1.5 Pro; 5 – Gemini 2.0 Flash-Lite; 6 – Gemini 2.0 Flash; 7 – Gemini 2.5 Flash; 8 – Gemini 2.5 Pro; 9 – Gemini 2.5 Flash Lite (no thinking); 10 – Gemini 2.5 Flash Lite (thinking).
<details>
<summary>figures/gpt_2_plots/gpt_performance_Mathematical_Reasoning.png Details</summary>
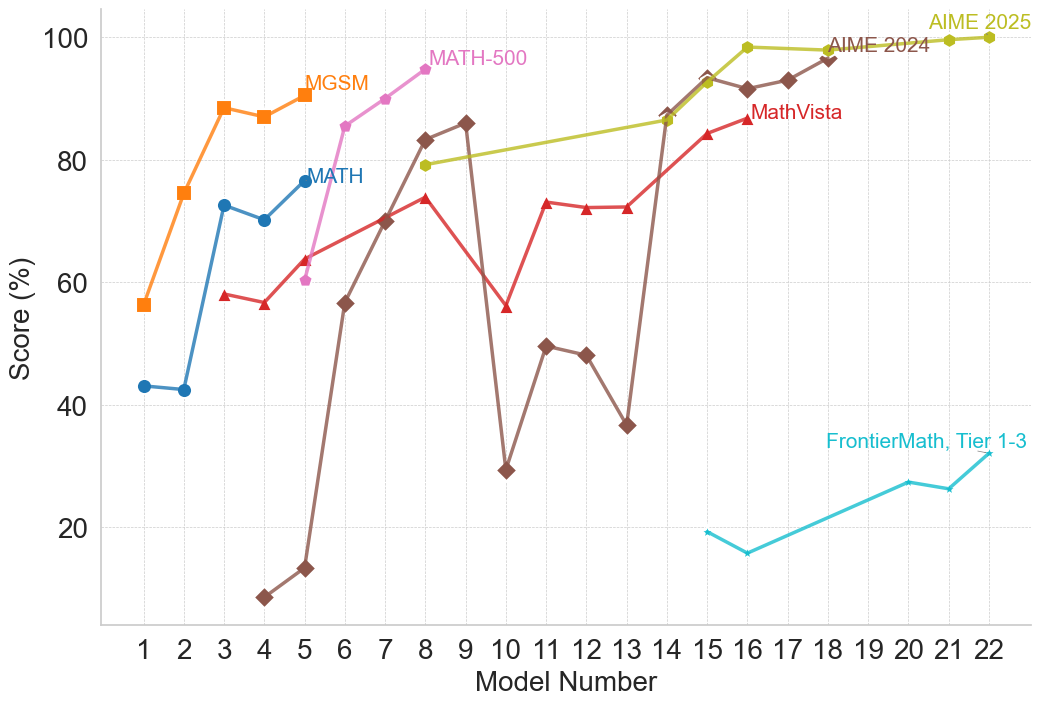
### Visual Description
## Line Chart: Model Performance on Math Benchmarks
### Overview
This line chart displays the performance of different models (numbered 1 to 22) on several math benchmark datasets. The y-axis represents the score in percentage, while the x-axis represents the model number. Six different datasets are represented by distinct colored lines: MGSM, MATH, MATH-500, AIME 2024, AIME 2025, and MathVista, and FrontierMath Tier 1-3.
### Components/Axes
* **X-axis:** "Model Number" ranging from 1 to 22.
* **Y-axis:** "Score (%)" ranging from 0 to 100.
* **Data Series:**
* MGSM (Orange)
* MATH (Blue)
* MATH-500 (Teal)
* AIME 2024 (Gray)
* AIME 2025 (Yellow)
* MathVista (Purple)
* FrontierMath Tier 1-3 (Brown)
* **Legend:** Located in the top-right corner, associating colors with dataset names.
### Detailed Analysis
Here's a breakdown of each data series, noting trends and approximate values:
* **MGSM (Orange):** Starts at approximately 58% at Model 1, rises sharply to a peak of around 92% at Model 4, then fluctuates between 85% and 92% until Model 18, and then drops to around 80% at Model 22.
* **MATH (Blue):** Begins at approximately 42% at Model 1, increases steadily to around 78% at Model 6, plateaus around 80-85% from Models 7 to 16, and then rises to approximately 90% at Model 18, remaining stable until Model 22.
* **MATH-500 (Teal):** Starts at approximately 60% at Model 1, increases to around 82% at Model 8, then declines to around 70% at Model 12, and then rises again to around 88% at Model 16, remaining relatively stable until Model 22.
* **AIME 2024 (Gray):** Starts at approximately 55% at Model 1, increases to around 72% at Model 7, then fluctuates between 70% and 85% until Model 16, and then rises to approximately 94% at Model 18, remaining stable until Model 22.
* **AIME 2025 (Yellow):** Starts at approximately 65% at Model 1, increases steadily to around 98% at Model 18, and remains stable at approximately 98-100% until Model 22.
* **MathVista (Purple):** Starts at approximately 80% at Model 1, increases to around 88% at Model 16, and remains stable until Model 22.
* **FrontierMath Tier 1-3 (Brown):** Starts at approximately 15% at Model 1, increases to around 30% at Model 7, then declines to around 25% at Model 12, and then rises again to around 35% at Model 18, remaining relatively stable until Model 22.
### Key Observations
* AIME 2025 consistently achieves the highest scores, often reaching near 100% by Model 18.
* FrontierMath Tier 1-3 consistently has the lowest scores, remaining below 40% throughout the entire range of models.
* MGSM shows a rapid initial improvement, but its performance plateaus and fluctuates.
* MATH and AIME 2024 exhibit a more gradual and sustained improvement.
* MATH-500 shows a more volatile performance, with peaks and dips.
* MathVista starts with a high score and maintains it throughout.
### Interpretation
The chart demonstrates the performance of various models on different math benchmark datasets as the model number increases, presumably representing model complexity or training iterations. The significant difference in scores between AIME 2025 and FrontierMath Tier 1-3 suggests a substantial gap in difficulty between these datasets. The consistent high performance of AIME 2025 indicates that the models are well-suited for this particular benchmark. The fluctuating performance of MGSM and MATH-500 could be due to the specific characteristics of these datasets, potentially involving more complex or nuanced problem-solving skills. The overall trend suggests that increasing the model number generally leads to improved performance, but the rate of improvement varies depending on the dataset. The data suggests that the models are becoming more proficient at solving math problems, but there is still considerable room for improvement, particularly on more challenging benchmarks like FrontierMath Tier 1-3. The consistent high starting score of MathVista suggests it may be a simpler benchmark or that the models are pre-trained on similar data.
</details>
(a) Mathematical Reasoning
<details>
<summary>figures/gpt_2_plots/gpt_performance_Multimodal_Reasoning.png Details</summary>
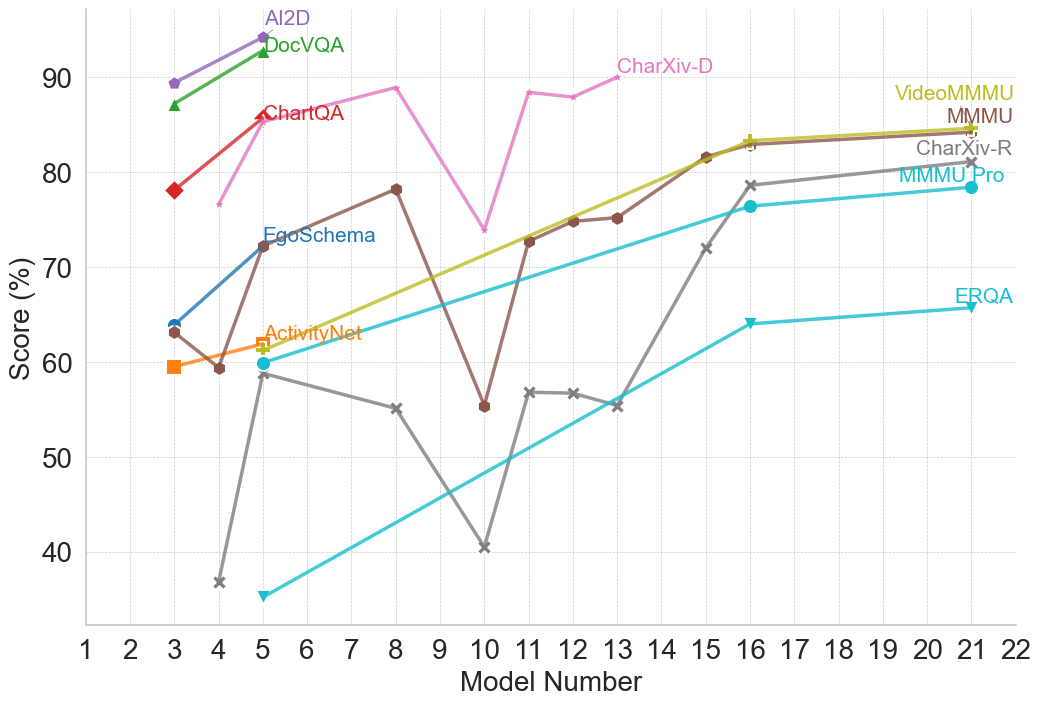
### Visual Description
## Line Chart: Model Performance Comparison
### Overview
This line chart compares the performance scores (in percentage) of several models across a range of model numbers (1 to 22). The chart displays the performance trends of AI2D, DocVQA, ChartQA, EgoSchema, ActivityNet, CharXiv-D, VideoMMMU, MMMU, CharXiv-R, MMMU Pro, and ERQA.
### Components/Axes
* **X-axis:** Model Number (ranging from 1 to 22).
* **Y-axis:** Score (%) (ranging from 30% to 90%).
* **Legend:** Located in the top-right corner, identifies each line with a unique color and model name.
* AI2D (Purple)
* DocVQA (Gray)
* ChartQA (Red)
* EgoSchema (Light Blue)
* ActivityNet (Orange)
* CharXiv-D (Dark Green)
* VideoMMMU (Light Green)
* MMMU (Teal)
* CharXiv-R (Black)
* MMMU Pro (Brown)
* ERQA (Turquoise)
### Detailed Analysis
Here's a breakdown of each model's performance trend and approximate data points:
* **AI2D (Purple):** Starts at approximately 88% at Model 1, decreases slightly to around 85% at Model 3, then remains relatively stable around 85-90% until Model 18, then drops to approximately 80% at Model 22.
* **DocVQA (Gray):** Begins at approximately 85% at Model 1, declines sharply to around 40% at Model 5, then increases to approximately 55% at Model 9, and remains relatively stable around 55-65% until Model 22.
* **ChartQA (Red):** Starts at approximately 78% at Model 1, increases to a peak of around 88% at Model 4, then declines to approximately 75% at Model 9, and remains relatively stable around 75-80% until Model 22.
* **EgoSchema (Light Blue):** Starts at approximately 72% at Model 1, increases to around 78% at Model 3, then declines to approximately 65% at Model 7, and increases to around 75% at Model 16, then declines to approximately 70% at Model 22.
* **ActivityNet (Orange):** Begins at approximately 64% at Model 1, decreases to around 58% at Model 3, then increases to approximately 68% at Model 6, then declines to approximately 55% at Model 10, and remains relatively stable around 55-65% until Model 22.
* **CharXiv-D (Dark Green):** Starts at approximately 75% at Model 1, increases to a peak of around 85% at Model 14, then declines to approximately 80% at Model 22.
* **VideoMMMU (Light Green):** Starts at approximately 70% at Model 1, increases to around 80% at Model 16, then declines to approximately 75% at Model 22.
* **MMMU (Teal):** Begins at approximately 75% at Model 1, declines to around 65% at Model 5, then increases to approximately 78% at Model 16, and remains relatively stable around 78-80% until Model 22.
* **CharXiv-R (Black):** Starts at approximately 60% at Model 1, declines to around 35% at Model 5, then increases to approximately 55% at Model 10, and remains relatively stable around 55-60% until Model 22.
* **MMMU Pro (Brown):** Begins at approximately 75% at Model 1, declines to around 65% at Model 5, then increases to approximately 78% at Model 16, and remains relatively stable around 78-80% until Model 22.
* **ERQA (Turquoise):** Starts at approximately 60% at Model 1, increases to around 68% at Model 3, then declines to approximately 62% at Model 7, and remains relatively stable around 62-68% until Model 22.
### Key Observations
* AI2D consistently demonstrates the highest scores throughout most of the model range.
* DocVQA exhibits the most significant performance decline, particularly between Models 1 and 5.
* CharXiv-D shows a notable increase in performance around Model 14.
* Several models (MMMU, MMMU Pro, CharXiv-R) show similar performance trends.
* ActivityNet and ERQA have relatively stable, but lower, performance scores.
### Interpretation
The chart suggests that AI2D is the most robust model across the tested range, maintaining high performance regardless of the model number. DocVQA, while starting with a competitive score, suffers a substantial performance drop, indicating potential sensitivity to changes in the model. The convergence of performance scores for MMMU, MMMU Pro, and CharXiv-R suggests they may be utilizing similar underlying mechanisms or training data. The relatively stable performance of ActivityNet and ERQA indicates they may be less sensitive to model variations but also have lower overall performance ceilings. The peak in CharXiv-D's performance at Model 14 could indicate a specific optimization or architectural improvement implemented at that stage. Overall, the chart provides a comparative analysis of model performance, highlighting strengths and weaknesses of each model across a spectrum of model numbers. The data suggests that model number impacts performance, and different models respond to these changes in different ways.
</details>
(b) Multimodal Reasoning
<details>
<summary>figures/gpt_2_plots/gpt_performance_Programming_and_Coding.png Details</summary>
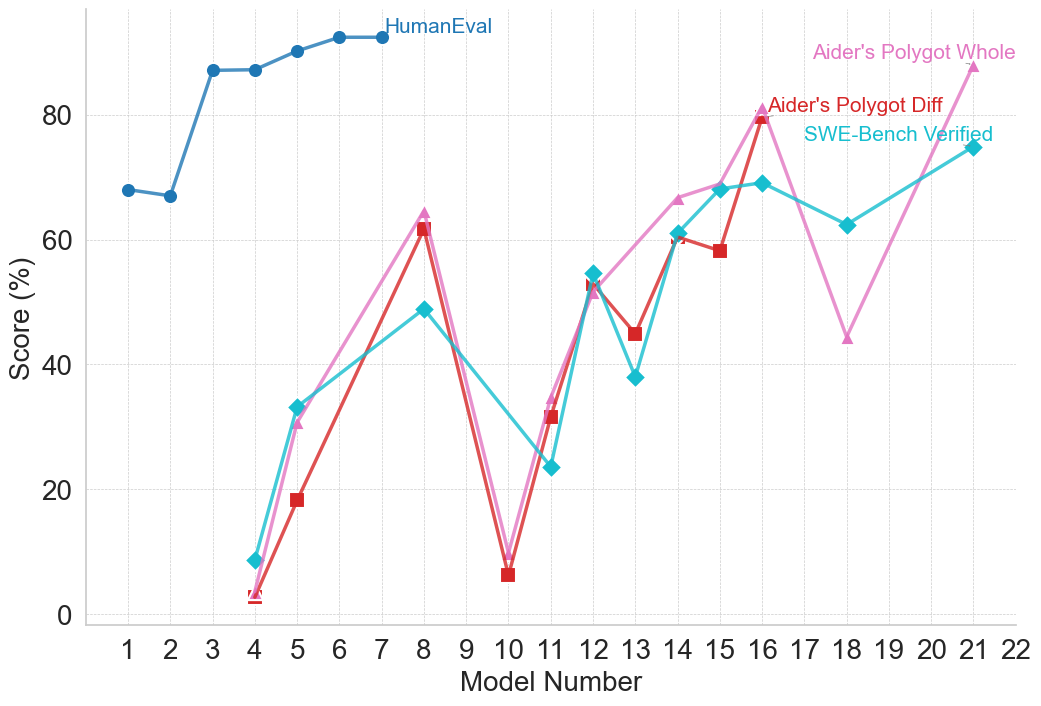
### Visual Description
## Line Chart: Model Performance Comparison
### Overview
This line chart compares the performance scores of different models across a range of model numbers (1 to 22). The scores are presented as percentages and are evaluated using three different methods: HumanEval, Aider's Polygot Whole, Aider's Polygot Diff, and SWE-Bench Verified. The chart aims to illustrate how each model performs according to these evaluation metrics.
### Components/Axes
* **X-axis:** Model Number (ranging from 1 to 22, with tick marks at integer values).
* **Y-axis:** Score (%) (ranging from 0 to 100, with tick marks at 20, 40, 60, 80, and 100).
* **Lines:**
* HumanEval (Blue)
* Aider's Polygot Whole (Pink)
* Aider's Polygot Diff (Light Green)
* SWE-Bench Verified (Teal)
* **Legend:** Located in the top-right corner of the chart, identifying each line by color and name.
### Detailed Analysis
Here's a breakdown of the data series and their trends:
* **HumanEval (Blue):** The line starts at approximately 68% at Model 1, increases steadily to a peak of around 92% at Model 8, then plateaus between 88% and 92% for the remaining models (9-22).
* **Aider's Polygot Whole (Pink):** This line exhibits significant fluctuations. It begins at approximately 40% at Model 1, dips to around 18% at Model 5, rises sharply to a peak of approximately 82% at Model 16, then declines to around 65% at Model 22.
* **Aider's Polygot Diff (Light Green):** This line also shows considerable variation. It starts at approximately 5% at Model 1, increases to around 64% at Model 8, decreases to approximately 45% at Model 12, rises again to around 60% at Model 14, and ends at approximately 68% at Model 22.
* **SWE-Bench Verified (Teal):** This line starts at approximately 45% at Model 1, increases to around 60% at Model 6, decreases to approximately 48% at Model 11, rises to around 65% at Model 18, and ends at approximately 62% at Model 22.
Here's a more granular breakdown of the approximate values at specific model numbers:
| Model Number | HumanEval (%) | Aider's Polygot Whole (%) | Aider's Polygot Diff (%) | SWE-Bench Verified (%) |
|--------------|---------------|---------------------------|--------------------------|------------------------|
| 1 | 68 | 40 | 5 | 45 |
| 2 | 74 | 42 | 10 | 48 |
| 3 | 78 | 44 | 15 | 50 |
| 4 | 82 | 46 | 20 | 52 |
| 5 | 85 | 18 | 25 | 54 |
| 6 | 87 | 35 | 35 | 60 |
| 7 | 89 | 45 | 45 | 58 |
| 8 | 92 | 65 | 64 | 56 |
| 9 | 91 | 50 | 40 | 50 |
| 10 | 90 | 8 | 5 | 48 |
| 11 | 90 | 25 | 45 | 48 |
| 12 | 89 | 40 | 45 | 50 |
| 13 | 88 | 50 | 50 | 55 |
| 14 | 88 | 60 | 60 | 60 |
| 15 | 89 | 70 | 55 | 62 |
| 16 | 90 | 82 | 75 | 64 |
| 17 | 91 | 75 | 70 | 65 |
| 18 | 91 | 70 | 65 | 65 |
| 19 | 91 | 68 | 60 | 63 |
| 20 | 91 | 66 | 62 | 62 |
| 21 | 91 | 65 | 65 | 62 |
| 22 | 91 | 65 | 68 | 62 |
### Key Observations
* HumanEval consistently demonstrates the highest scores and the most stable performance across all models.
* Aider's Polygot Whole exhibits the most volatile performance, with large swings in scores.
* Aider's Polygot Diff and SWE-Bench Verified show moderate fluctuations, with some convergence in scores towards the end of the model range.
* There's a noticeable dip in Aider's Polygot Whole and Aider's Polygot Diff performance around Model 10.
* SWE-Bench Verified generally remains lower than HumanEval, but shows a slight upward trend towards the end.
### Interpretation
The data suggests that HumanEval is a robust and reliable metric for evaluating model performance, as it consistently yields high and stable scores. Aider's Polygot Whole, while capable of achieving high scores (particularly around Model 16), is more sensitive to variations in the models, indicating potential instability or a narrower range of applicability. The differences between Aider's Polygot Diff and SWE-Bench Verified suggest they assess different aspects of model capabilities. The dip in performance for Aider's Polygot Whole and Diff around Model 10 could indicate a specific challenge or weakness in those models at that point in their development. The convergence of SWE-Bench Verified and Aider's Polygot Diff towards the end suggests that these models may be reaching a similar level of performance on the specific tasks assessed by those metrics. Overall, the chart provides a comparative overview of model performance across different evaluation methods, highlighting the strengths and weaknesses of each model and metric.
</details>
(c) Programming and Coding
<details>
<summary>figures/gpt_2_plots/gpt_performance_Reading_Comprehension_and_Question_Answering.png Details</summary>
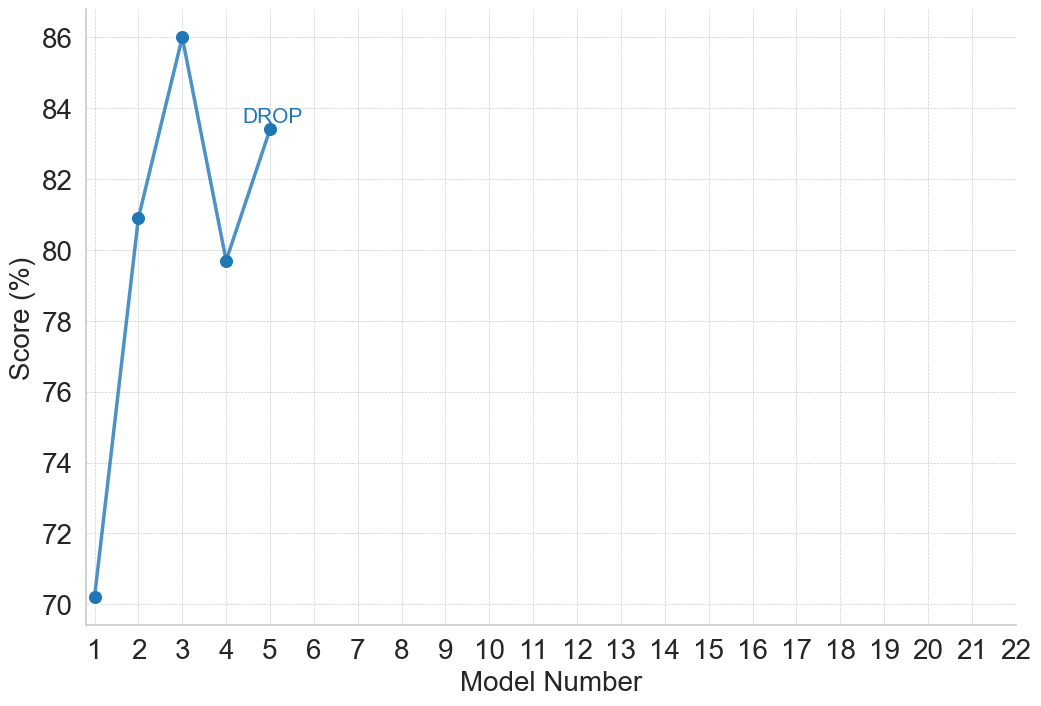
### Visual Description
\n
## Line Chart: Model Score Performance
### Overview
This image presents a line chart illustrating the performance score of a model across different model numbers. The chart displays a single data series showing the score (in percentage) as a function of the model number. A label "DROP" is placed near model number 6, indicating a significant decrease in score.
### Components/Axes
* **X-axis:** "Model Number" ranging from 1 to 22. The axis is marked with integer values.
* **Y-axis:** "Score (%)" ranging from 70 to 86. The axis is marked with integer values in increments of 2.
* **Data Series:** A single blue line representing the model score.
* **Label:** "DROP" positioned near the data point for Model Number 6.
### Detailed Analysis
The line chart shows an initial increase in score from Model Number 1 to Model Number 3, followed by a sharp decrease at Model Number 4, and a subsequent recovery to Model Number 3's score at Model Number 5. The score then drops significantly at Model Number 6, as indicated by the "DROP" label. After Model Number 6, the score remains relatively constant at approximately 80%.
Here's a breakdown of approximate score values based on visual estimation:
* Model 1: ~71%
* Model 2: ~82%
* Model 3: ~86%
* Model 4: ~80%
* Model 5: ~82%
* Model 6: ~79%
* Model 7-22: ~80%
The line slopes upward from Model 1 to Model 3, then downward to Model 4, upward to Model 5, and then sharply downward to Model 6. After Model 6, the line is relatively flat.
### Key Observations
* The highest score is achieved at Model Number 3 (~86%).
* The most significant drop in score occurs at Model Number 6, as highlighted by the "DROP" label.
* The score stabilizes around 80% after Model Number 6.
* There is a clear fluctuation in score between Model 1 and Model 6, after which the score becomes relatively stable.
### Interpretation
The chart suggests that the model's performance is sensitive to changes implemented around Model Number 6. The "DROP" label indicates a potential issue or negative impact introduced with that model version. The initial increase in score from Model 1 to Model 3 could represent a period of optimization or improvement. The subsequent fluctuations and eventual stabilization suggest that the model reached a point of diminishing returns or encountered a limiting factor. The consistent score after Model 6 might indicate that further modifications are not significantly improving performance, or that the model has converged to a stable state. Further investigation is needed to understand the cause of the drop at Model Number 6 and determine whether it can be mitigated. The data suggests that the model is not consistently improving with each iteration after Model 3, and that changes introduced around Model 6 had a detrimental effect.
</details>
(d) Reading Comprehension and QA
<details>
<summary>figures/gpt_2_plots/gpt_performance_Reasoning_with_General_Knowledge.png Details</summary>
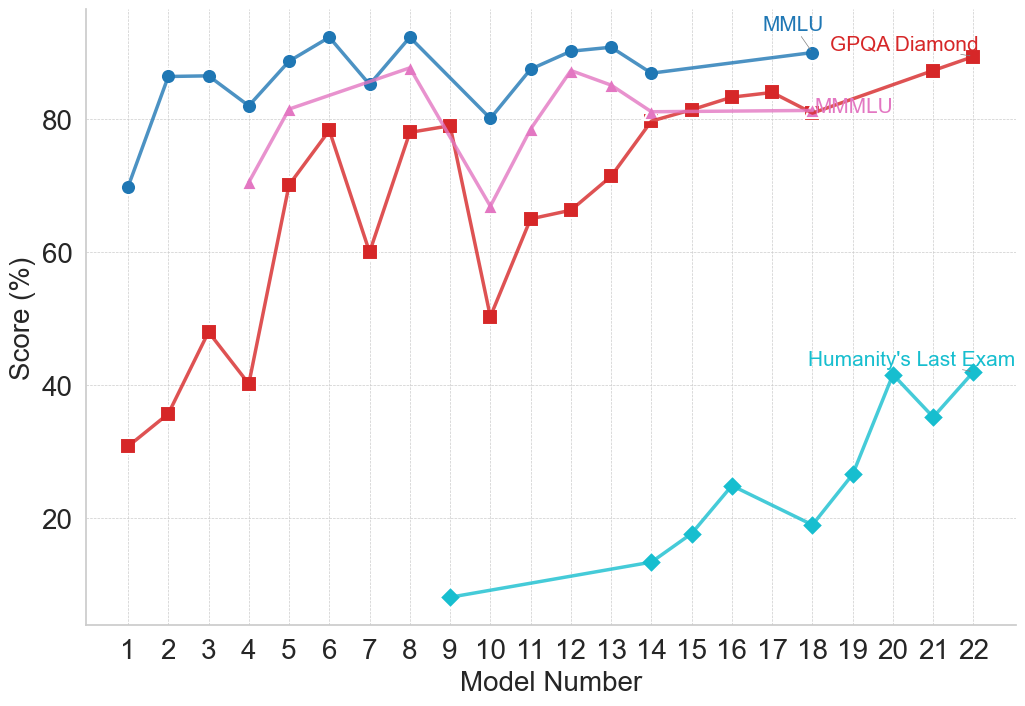
### Visual Description
## Line Chart: Model Performance Comparison
### Overview
This line chart compares the performance of several models (numbered 1 to 22) across four different benchmarks: MMLU, GPQA Diamond, MMLU (again, with a different line), and Humanity's Last Exam. The performance is measured as a score in percentage (%).
### Components/Axes
* **X-axis:** Model Number (ranging from 1 to 22).
* **Y-axis:** Score (%) (ranging from 0 to 100, with increments of 20).
* **Data Series:**
* MMLU (represented by a blue line)
* GPQA Diamond (represented by a red line)
* MMLU (represented by a light purple line)
* Humanity's Last Exam (represented by a teal line)
* **Legend:** Located in the top-right corner, labeling each line with its corresponding benchmark.
### Detailed Analysis
Let's analyze each data series individually:
* **MMLU (Blue Line):** The blue line starts at approximately 88% at Model 1, dips to around 84% at Model 3, then rises to a peak of approximately 92% at Model 6. It then fluctuates between 82% and 90% until Model 14, after which it remains relatively stable around 88-90% until Model 22.
* **GPQA Diamond (Red Line):** The red line begins at approximately 33% at Model 1, increases to around 48% at Model 3, then rises to a peak of approximately 84% at Model 6. It then declines to around 75% at Model 8, and fluctuates between 75% and 85% until Model 14. From Model 15 to 18, it shows a decline to approximately 80%, then stabilizes around 82-84% until Model 22.
* **MMLU (Light Purple Line):** The light purple line starts at approximately 78% at Model 1, rises to a peak of approximately 88% at Model 5, then declines to around 65% at Model 8. It then increases to around 82% at Model 13, and fluctuates between 78% and 85% until Model 22.
* **Humanity's Last Exam (Teal Line):** The teal line starts at approximately 30% at Model 1, increases to around 52% at Model 5, then declines to approximately 48% at Model 7. It then shows a significant increase to around 85% at Model 19, and stabilizes around 84-86% until Model 22.
Here's a table summarizing approximate values at key points:
| Model Number | MMLU (Blue) | GPQA Diamond (Red) | MMLU (Purple) | Humanity's Last Exam (Teal) |
|--------------|-------------|--------------------|---------------|-----------------------------|
| 1 | 88% | 33% | 78% | 30% |
| 3 | 84% | 48% | 82% | 42% |
| 5 | 91% | 84% | 88% | 52% |
| 6 | 92% | 84% | 85% | 68% |
| 8 | 88% | 75% | 65% | 48% |
| 13 | 86% | 82% | 82% | 64% |
| 19 | 88% | 82% | 84% | 85% |
| 22 | 90% | 84% | 84% | 86% |
### Key Observations
* The "Humanity's Last Exam" benchmark shows the most significant improvement across models, starting with the lowest scores and ending with scores comparable to the other benchmarks.
* MMLU (blue line) consistently achieves the highest scores across most models.
* GPQA Diamond shows a substantial increase in performance from Model 1 to Model 6, then plateaus.
* There is a noticeable dip in performance for all benchmarks around Model 8.
### Interpretation
The chart demonstrates the performance evolution of different models across various benchmarks. The consistent high scores of MMLU (blue line) suggest that these models excel in tasks related to that benchmark. The significant improvement in "Humanity's Last Exam" indicates that the models are becoming increasingly capable of handling more complex or nuanced tasks. The dip around Model 8 could represent a period of instability or a change in the model architecture. The convergence of scores towards the end of the chart suggests that the models are approaching a performance ceiling on these benchmarks. The presence of two MMLU lines suggests either a different version of the benchmark or a different evaluation methodology. Further investigation would be needed to clarify the distinction. The data suggests a general trend of improving model performance, but also highlights the varying strengths and weaknesses of models across different benchmarks.
</details>
(e) Reasoning with General Knowledge
Figure 5: Performance of the GPT family on general reasoning benchmarks. Model numbers and corresponding names are as follows: 1 – GPT-3.5; 2 – GPT-4; 3 – GPT-4 Turbo; 4 – GPT-4o mini; 5 – GPT-4o; 6 – o1-preview; 7 – o1-mini; 8 – o1; 9 – o1-pro; 10 – GPT-4.1 nano; 11 – GPT-4.1 mini; 12 – GPT-4.1; 13 – GPT-4.5; 14 – o3-mini; 15 – o4-mini; 16 – o3; 17 – o3-pro; 18 – gpt-oss-120b; 19 – GPT-5 with Deep Research; 20 – ChatGPT Agent; 21 – GPT-5; 22 – GPT-5 Pro.
<details>
<summary>figures/gpt_2_plots/gpt_performance_Constrained_Text_Generation_-_LLM.png Details</summary>
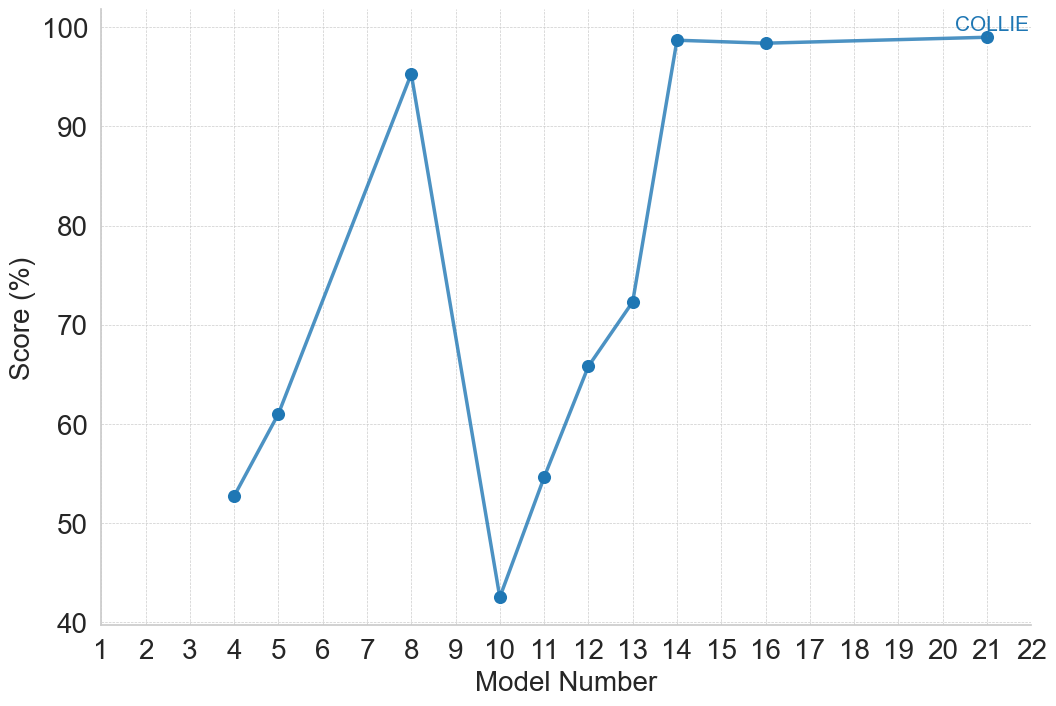
### Visual Description
\n
## Line Chart: Model Score Performance
### Overview
This image presents a line chart illustrating the performance score of a model (labeled "COLLIE") across a range of model numbers, from 1 to 22. The y-axis represents the score in percentage, while the x-axis represents the model number. The chart shows how the score changes as the model number increases.
### Components/Axes
* **X-axis:** "Model Number" ranging from 1 to 22, with tick marks at each integer value.
* **Y-axis:** "Score (%)" ranging from 40 to 100, with tick marks at intervals of 10.
* **Data Series:** A single line representing "COLLIE" performance.
* **Legend:** Located in the top-right corner, labeling the line as "COLLIE" and using a light blue color.
* **Gridlines:** A light gray grid is present to aid in reading values.
### Detailed Analysis
The line representing "COLLIE" exhibits a non-linear trend.
* **Model 1:** Approximately 52%
* **Model 2:** Approximately 52%
* **Model 3:** Approximately 54%
* **Model 4:** Approximately 55%
* **Model 5:** Approximately 62%
* **Model 6:** Approximately 62%
* **Model 7:** Approximately 72%
* **Model 8:** Approximately 94%
* **Model 9:** Approximately 95%
* **Model 10:** Approximately 42%
* **Model 11:** Approximately 55%
* **Model 12:** Approximately 73%
* **Model 13:** Approximately 75%
* **Model 14:** Approximately 98%
* **Model 15:** Approximately 98%
* **Model 16:** Approximately 97%
* **Model 17:** Approximately 97%
* **Model 18:** Approximately 97%
* **Model 19:** Approximately 97%
* **Model 20:** Approximately 98%
* **Model 21:** Approximately 98%
* **Model 22:** Approximately 98%
The line initially shows a slow, gradual increase from Model 1 to Model 7. There is a sharp increase between Model 7 and Model 9, reaching a peak around 95%. A dramatic drop occurs between Model 9 and Model 10, falling to approximately 42%. The line then rises again, reaching another peak around 98% between Models 14 and 22, where it plateaus.
### Key Observations
* **Peak Performance:** The model achieves its highest score (approximately 98%) between Model 14 and Model 22.
* **Significant Drop:** A substantial decrease in score is observed between Model 9 and Model 10.
* **Initial Improvement:** The model shows a steady improvement in score from Model 1 to Model 7.
* **Plateau:** The score remains relatively constant from Model 14 to Model 22.
### Interpretation
The data suggests that the "COLLIE" model undergoes significant performance fluctuations as the model number changes. The initial improvement indicates a learning or optimization phase. The sharp drop between Model 9 and Model 10 could be due to a change in training data, a hyperparameter adjustment, or an error in the model building process. The subsequent rise and plateau suggest that the model has converged to a stable, high-performing state. The consistent high scores from Model 14 onwards indicate that further increases in the model number do not lead to substantial improvements in performance. This could be a point of diminishing returns, where additional model complexity or training does not yield significant benefits. The initial slow increase could represent a period of initial learning, while the later plateau suggests the model has reached its maximum potential within the given parameters.
</details>
(a) Constrained Text Generation
<details>
<summary>figures/gpt_2_plots/gpt_performance_Factuality_-_LLM.png Details</summary>
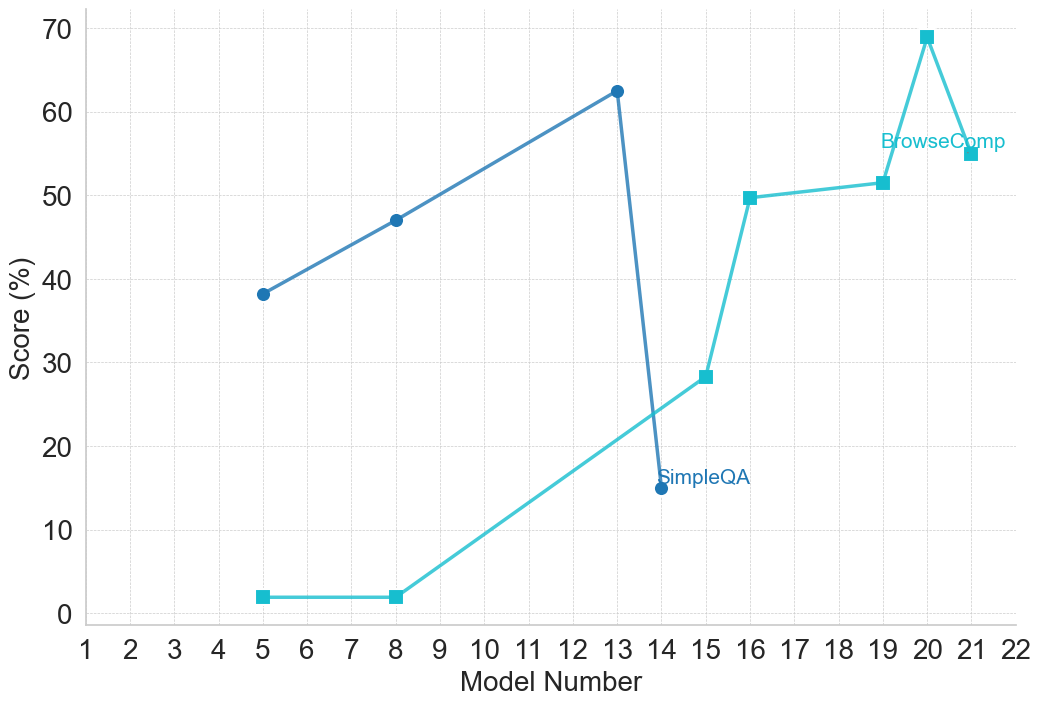
### Visual Description
## Line Chart: Model Performance Comparison
### Overview
This line chart compares the performance scores of two models, "BrowseComp" and "SimpleQA", across a range of model numbers from 1 to 22. The y-axis represents the score in percentage, while the x-axis represents the model number.
### Components/Axes
* **X-axis:** "Model Number" ranging from 1 to 22.
* **Y-axis:** "Score (%)" ranging from 0 to 70.
* **Data Series 1:** "BrowseComp" - Represented by a cyan line.
* **Data Series 2:** "SimpleQA" - Represented by a blue line.
* **Legend:** Located in the top-right corner, labeling the two data series with their respective colors.
### Detailed Analysis
**BrowseComp (Cyan Line):**
The BrowseComp line starts at approximately 38% at Model Number 4. It exhibits an upward trend, reaching a peak of approximately 63% at Model Number 13. After Model Number 13, the line sharply declines to around 28% at Model Number 15, then plateaus around 50% from Model Number 16 to 19, and finally increases to approximately 68% at Model Number 21.
* Model 4: ~38%
* Model 5: ~40%
* Model 6: ~44%
* Model 7: ~47%
* Model 8: ~48%
* Model 9: ~48%
* Model 10: ~53%
* Model 11: ~58%
* Model 12: ~61%
* Model 13: ~63%
* Model 14: ~15%
* Model 15: ~28%
* Model 16: ~50%
* Model 17: ~50%
* Model 18: ~50%
* Model 19: ~50%
* Model 20: ~53%
* Model 21: ~68%
**SimpleQA (Blue Line):**
The SimpleQA line starts at approximately 2% at Model Number 5. It gradually increases, reaching around 14% at Model Number 13. It then rises sharply to approximately 50% at Model Number 16, and remains relatively stable around 50% until Model Number 21.
* Model 5: ~2%
* Model 6: ~2%
* Model 7: ~2%
* Model 8: ~2%
* Model 9: ~2%
* Model 10: ~8%
* Model 11: ~12%
* Model 12: ~14%
* Model 13: ~14%
* Model 14: ~15%
* Model 15: ~28%
* Model 16: ~50%
* Model 17: ~50%
* Model 18: ~50%
* Model 19: ~50%
* Model 20: ~50%
* Model 21: ~50%
### Key Observations
* BrowseComp generally outperforms SimpleQA across most model numbers, except for a period between Model Numbers 14 and 16 where SimpleQA shows a significant increase.
* Both models exhibit a sharp performance drop for BrowseComp at Model Number 14 and a significant increase for SimpleQA at Model Number 16. This suggests a potential change or event affecting the models around these points.
* BrowseComp shows a large performance swing, with a peak at Model 13 and a subsequent drop, followed by a recovery.
* SimpleQA demonstrates a more consistent upward trend after Model Number 10.
### Interpretation
The chart demonstrates the performance evolution of two models, BrowseComp and SimpleQA, as the model number increases. The data suggests that BrowseComp is generally more capable, but its performance is more volatile. The significant changes in performance around Model Numbers 14-16 for both models are particularly noteworthy. This could indicate a change in the training data, model architecture, or evaluation methodology. The plateauing of SimpleQA's performance after Model Number 16 suggests it may have reached a performance limit with the current approach. The large increase in BrowseComp at Model 21 suggests a significant improvement or optimization was implemented. Further investigation is needed to understand the reasons behind these fluctuations and to determine the optimal model number for each model. The chart provides valuable insights into the strengths and weaknesses of each model and can inform future development efforts.
</details>
(b) Factuality
<details>
<summary>figures/gpt_2_plots/gpt_performance_Instruction_Following_-_LLM.png Details</summary>
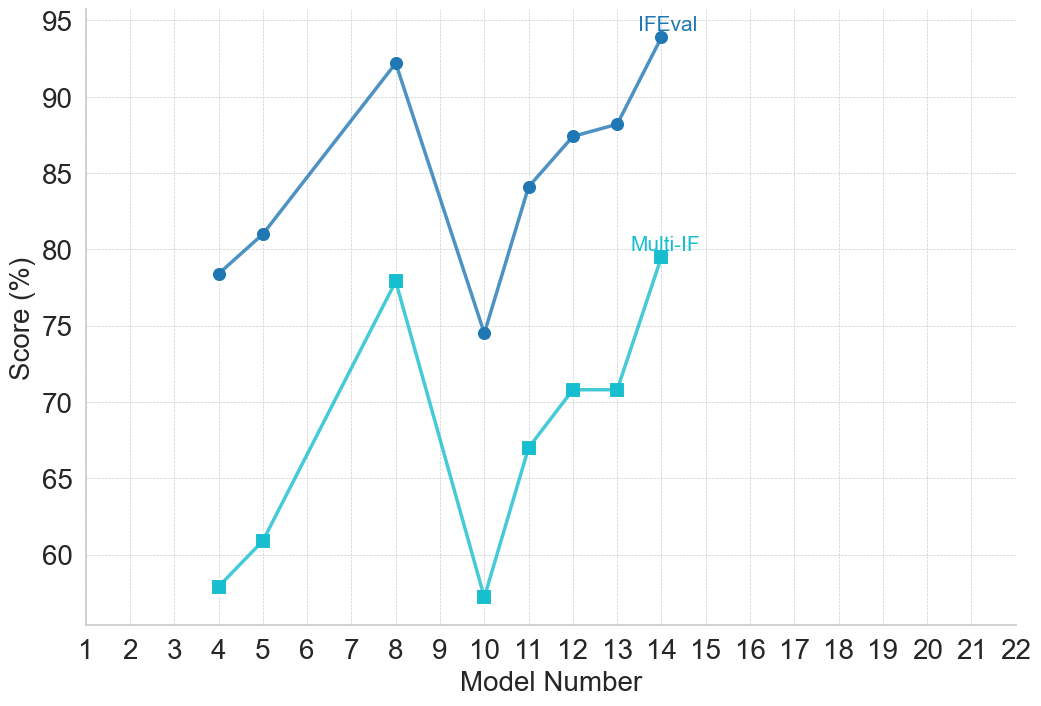
### Visual Description
\n
## Line Chart: Model Performance Comparison
### Overview
This image presents a line chart comparing the performance scores of two models, "IFEval" and "Multi-IF", across a range of model numbers from 1 to 22. The y-axis represents the score in percentage, while the x-axis represents the model number.
### Components/Axes
* **X-axis:** "Model Number" ranging from 1 to 22.
* **Y-axis:** "Score (%)" ranging from 60 to 95.
* **Data Series 1:** "IFEval" - Represented by a teal line.
* **Data Series 2:** "Multi-IF" - Represented by a light blue line.
* **Legend:** Located in the top-right corner, labeling the two data series with their corresponding colors.
### Detailed Analysis
**IFEval (Teal Line):**
The "IFEval" line generally slopes upward, with significant fluctuations.
* Model 2: Approximately 80%.
* Model 4: Approximately 81%.
* Model 6: Approximately 60%.
* Model 7: Approximately 91%.
* Model 9: Approximately 78%.
* Model 10: Approximately 74%.
* Model 11: Approximately 86%.
* Model 13: Approximately 89%.
* Model 14: Approximately 87%.
* Model 15: Approximately 81%.
**Multi-IF (Light Blue Line):**
The "Multi-IF" line shows a more gradual increase, with a plateau in the middle.
* Model 2: Approximately 62%.
* Model 4: Approximately 60%.
* Model 6: Approximately 61%.
* Model 7: Approximately 77%.
* Model 9: Approximately 79%.
* Model 10: Approximately 60%.
* Model 11: Approximately 66%.
* Model 13: Approximately 72%.
* Model 14: Approximately 80%.
* Model 15: Approximately 81%.
### Key Observations
* "IFEval" consistently scores higher than "Multi-IF" for most model numbers, especially between models 7 and 13.
* "IFEval" exhibits more volatility in its performance, with larger swings in score.
* "Multi-IF" shows a more stable, but generally lower, performance.
* Both models show an overall increasing trend in score as the model number increases, but with fluctuations.
* Model 10 represents a significant dip in performance for both models.
### Interpretation
The chart suggests that the "IFEval" model generally outperforms the "Multi-IF" model across the tested range of model numbers. However, "IFEval" is also more sensitive to changes in the model number, as evidenced by its larger score fluctuations. The dip in performance at Model 10 for both models could indicate a specific issue or limitation within that model configuration. The overall upward trend suggests that both models benefit from increasing model number, potentially due to increased complexity or training data. The difference in volatility between the two models could be indicative of different underlying algorithms or training methodologies. "IFEval" might be more powerful but less robust, while "Multi-IF" is more stable but less capable of achieving peak performance. Further investigation into the specific characteristics of Model 10 and the factors driving the performance differences between the two models would be beneficial.
</details>
(c) Instruction Following
<details>
<summary>figures/gpt_2_plots/gpt_performance_Long-Context_-_LLM.png Details</summary>
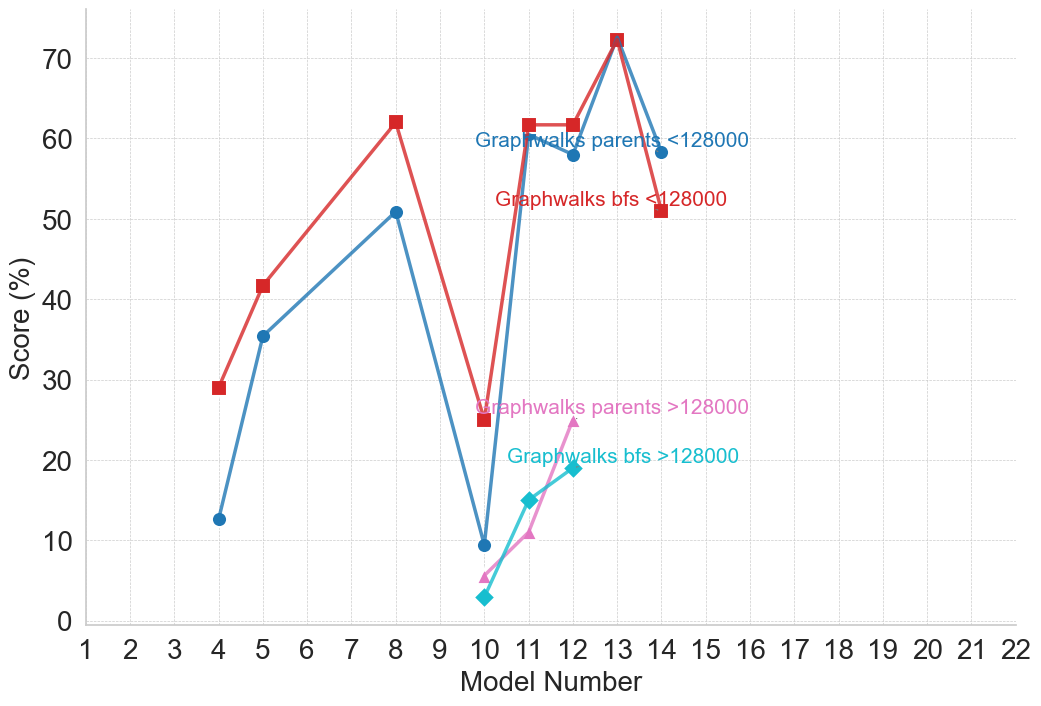
### Visual Description
## Line Chart: Graphwalks Performance Comparison
### Overview
This line chart compares the performance of two graphwalk algorithms – one using parents with a limit of 12800, and another using breadth-first search (BFS) with a limit of 12800 – across a range of model numbers from 1 to 22. The performance is measured as a "Score (%)" on the y-axis, plotted against the "Model Number" on the x-axis. There are also lines representing the same algorithms but with a limit greater than 12800.
### Components/Axes
* **X-axis:** "Model Number" ranging from 1 to 22, with tick marks at integer values.
* **Y-axis:** "Score (%)" ranging from 0 to 70, with tick marks at intervals of 10.
* **Lines:**
* Graphwalks parents < 12800 (Blue)
* Graphwalks bfs < 12800 (Red)
* Graphwalks parents > 12800 (Gray)
* Graphwalks bfs > 12800 (Teal)
* **Legend:** Located in the top-right corner, labeling each line with its corresponding algorithm and limit.
### Detailed Analysis
Let's analyze each line individually, noting trends and approximate data points.
* **Graphwalks parents < 12800 (Blue):** This line starts at approximately 14% at Model Number 2, rises sharply to a peak of around 62% at Model Number 8, then declines to approximately 20% at Model Number 12, and remains relatively flat around 20% for the remaining models.
* **Graphwalks bfs < 12800 (Red):** This line begins at approximately 18% at Model Number 2, increases to around 42% at Model Number 5, continues to rise to a peak of approximately 52% at Model Number 9, then drops sharply to around 18% at Model Number 11, and remains relatively flat around 18% for the remaining models.
* **Graphwalks parents > 12800 (Gray):** This line starts at approximately 28% at Model Number 4, rises to a peak of around 32% at Model Number 7, then declines to approximately 16% at Model Number 11, and remains relatively flat around 16% for the remaining models.
* **Graphwalks bfs > 12800 (Teal):** This line begins at approximately 10% at Model Number 2, increases to around 22% at Model Number 11, then declines to approximately 18% at Model Number 13, and remains relatively flat around 18% for the remaining models.
Here's a more detailed breakdown of approximate values at specific Model Numbers:
| Model Number | Graphwalks parents < 12800 (%) | Graphwalks bfs < 12800 (%) | Graphwalks parents > 12800 (%) | Graphwalks bfs > 12800 (%) |
|--------------|-----------------------------------|-----------------------------------|-----------------------------------|-----------------------------------|
| 2 | 14 | 18 | - | 10 |
| 4 | 28 | 30 | 28 | - |
| 5 | 35 | 42 | - | - |
| 7 | 55 | 48 | 32 | - |
| 8 | 62 | 50 | - | - |
| 9 | 58 | 52 | - | - |
| 11 | 20 | 18 | 16 | 22 |
| 12 | 20 | 18 | 16 | 18 |
| 13 | 20 | 18 | 16 | 18 |
| 22 | 20 | 18 | 16 | 18 |
### Key Observations
* The "Graphwalks parents < 12800" algorithm consistently outperforms the other algorithms, particularly between Model Numbers 5 and 9.
* The performance of all algorithms tends to decrease after Model Number 9.
* The "Graphwalks bfs > 12800" algorithm starts with the lowest score but shows a gradual increase up to Model Number 11.
* The "Graphwalks parents > 12800" algorithm consistently has lower scores than its counterpart with the limit of < 12800.
### Interpretation
The data suggests that the "Graphwalks parents" algorithm, when constrained to a limit of 12800, is the most effective approach for these models. The significant drop in performance for all algorithms after Model Number 9 could indicate a point where the models become more complex or require different algorithmic strategies. The comparison between the < 12800 and > 12800 limits for both algorithms suggests that the limit of 12800 is a crucial parameter for optimal performance. Exceeding this limit does not improve performance and may even slightly decrease it. The initial low performance of the BFS algorithm with the > 12800 limit suggests it may require more models to converge to a stable performance level. The consistent flatlining of all lines after Model Number 12 indicates that further model iterations are unlikely to yield significant performance improvements with these algorithms and parameters.
</details>
(d) Long Context
<details>
<summary>figures/gpt_2_plots/gpt_performance_Multi-turn_Conversation_-_LLM.png Details</summary>
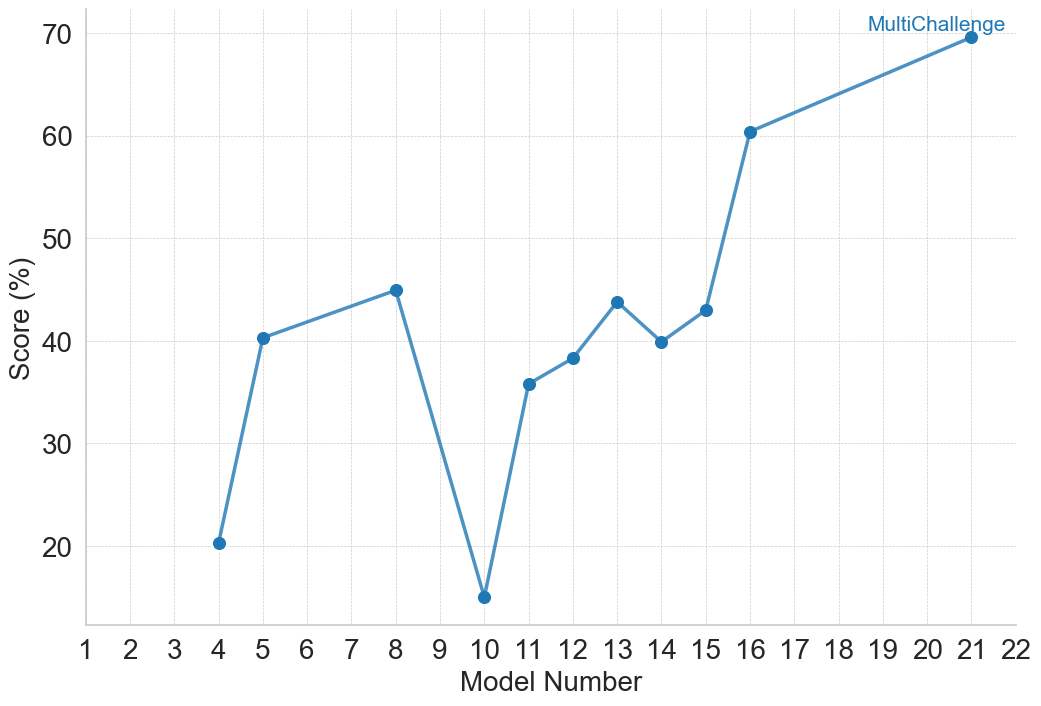
### Visual Description
\n
## Line Chart: Model Performance Score
### Overview
This image presents a line chart illustrating the performance score (in percentage) of a model across different model numbers, ranging from 1 to 22. The chart shows a generally increasing trend in score with some fluctuations. The final data point is labeled "MultiChallenge".
### Components/Axes
* **X-axis:** "Model Number" - ranging from 1 to 22, with integer increments.
* **Y-axis:** "Score (%)" - ranging from 0 to 70, with integer increments of 10.
* **Data Series:** A single blue line representing the model's score.
* **Label:** "MultiChallenge" - positioned at the end of the line (Model 22).
* **Grid:** A light gray grid is present in the background, aiding in reading values.
### Detailed Analysis
The blue line starts at approximately 21% at Model Number 4, increases to around 41% at Model Number 6, then peaks at approximately 46% at Model Number 9. It then sharply declines to a low of around 18% at Model Number 10. The line then rises again, reaching approximately 43% at Model Number 13, dips to around 39% at Model Number 15, and then experiences a significant increase, reaching approximately 59% at Model Number 16. The line continues to rise, reaching approximately 68% at Model Number 20, and finally reaching approximately 69% at Model Number 22, labeled "MultiChallenge".
Here's a breakdown of approximate data points:
* Model 4: 21%
* Model 6: 41%
* Model 9: 46%
* Model 10: 18%
* Model 13: 43%
* Model 15: 39%
* Model 16: 59%
* Model 20: 68%
* Model 22 (MultiChallenge): 69%
### Key Observations
* The most significant drop in score occurs between Model Numbers 9 and 10.
* The most substantial increase in score happens between Model Numbers 15 and 16.
* The score generally increases over the range of model numbers, with fluctuations.
* The final model, labeled "MultiChallenge", achieves the highest score.
### Interpretation
The chart demonstrates the iterative improvement of a model's performance as it undergoes development (represented by increasing model numbers). The initial fluctuations suggest a period of experimentation and refinement. The sharp drop at Model 10 could indicate a problematic change or bug introduced during that iteration. The subsequent recovery and strong increase from Model 16 onwards suggest successful optimization or correction of the issue. The "MultiChallenge" label at the end implies that this final model was tested on a more complex or diverse set of challenges, and it achieved a high score of approximately 69%. The overall trend indicates that the model is becoming more effective with each iteration, culminating in a robust performance on the "MultiChallenge" dataset. The data suggests a learning process where initial instability is overcome to achieve a high level of performance.
</details>
(e) Multi-turn Conversation
<details>
<summary>figures/gpt_2_plots/gpt_performance_Safety_-_LLM.png Details</summary>
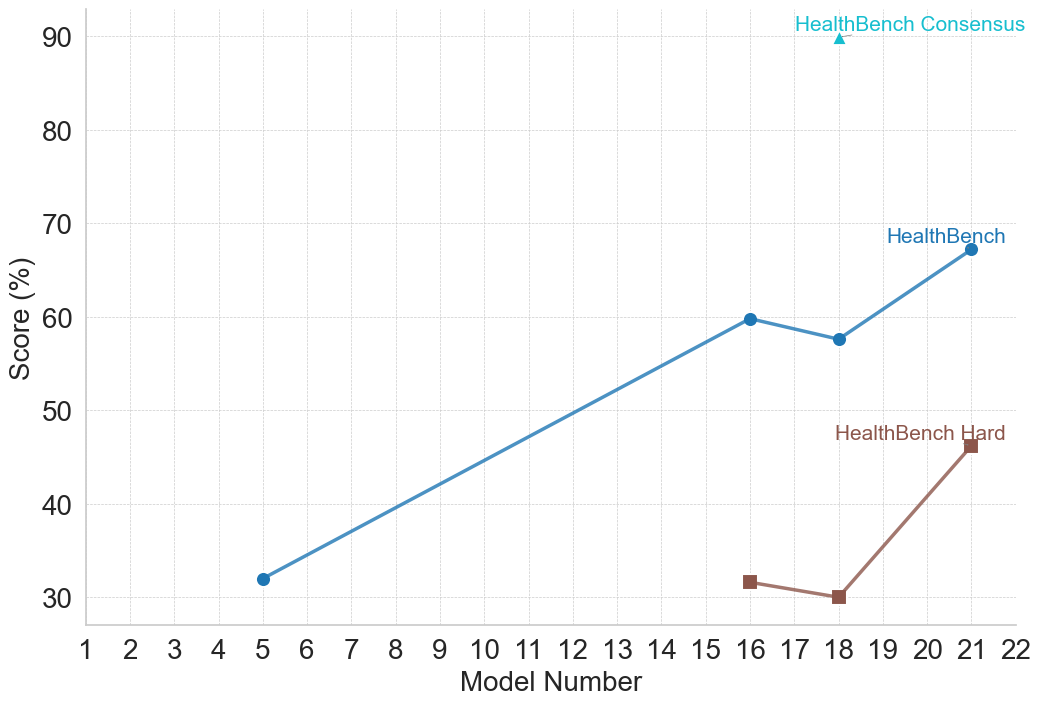
### Visual Description
\n
## Line Chart: HealthBench Performance
### Overview
This line chart displays the performance scores of different models on the HealthBench benchmark, showing results for both a "Consensus" and "Hard" evaluation. The x-axis represents the Model Number, ranging from 1 to 22. The y-axis represents the Score, measured in percentage (%).
### Components/Axes
* **X-axis:** Model Number (1 to 22)
* **Y-axis:** Score (%) - Scale ranges from 20 to 90.
* **Data Series 1:** HealthBench Consensus - Represented by a light blue line.
* **Data Series 2:** HealthBench Hard - Represented by a grey line.
* **Legend:** Located in the top-right corner, labeling the two data series.
### Detailed Analysis
**HealthBench Consensus (Light Blue Line):**
The line generally slopes upward, indicating increasing performance with higher model numbers.
* Model 5: Approximately 32%
* Model 7: Approximately 38%
* Model 10: Approximately 45%
* Model 13: Approximately 53%
* Model 16: Approximately 60%
* Model 18: Approximately 60%
* Model 21: Approximately 64%
* Model 22: Approximately 66%
**HealthBench Hard (Grey Line):**
The line starts at a relatively low score, increases, then decreases.
* Model 5: Approximately 32%
* Model 7: Approximately 36%
* Model 10: Approximately 42%
* Model 13: Approximately 48%
* Model 16: Approximately 56%
* Model 18: Approximately 58%
* Model 19: Approximately 58%
* Model 20: Approximately 44%
* Model 21: Approximately 44%
* Model 22: Approximately 46%
### Key Observations
* Both data series start at the same score (approximately 32%) at Model 5.
* The HealthBench Consensus line shows a consistent upward trend, while the HealthBench Hard line plateaus and then declines after Model 18.
* The HealthBench Consensus consistently outperforms the HealthBench Hard evaluation, especially at higher model numbers.
* There is a significant drop in the HealthBench Hard score between Model 18 and Model 20.
### Interpretation
The chart demonstrates the performance of different models on the HealthBench benchmark under two different evaluation settings: a "Consensus" setting and a "Hard" setting. The "Consensus" setting appears to be more forgiving, as the scores consistently increase with model number. The "Hard" setting, however, shows diminishing returns and even a decline in performance for the later models. This suggests that while models may generally improve with increasing complexity, they may struggle with more challenging or nuanced aspects of the HealthBench benchmark. The divergence between the two lines indicates that the difficulty of the evaluation significantly impacts the observed performance. The drop in HealthBench Hard score after Model 18 could indicate overfitting to the consensus evaluation or a limitation in the model's ability to generalize to more difficult cases.
</details>
(f) Safety
<details>
<summary>figures/gpt_2_plots/gpt_performance_Tool_Use_-_LLM.png Details</summary>
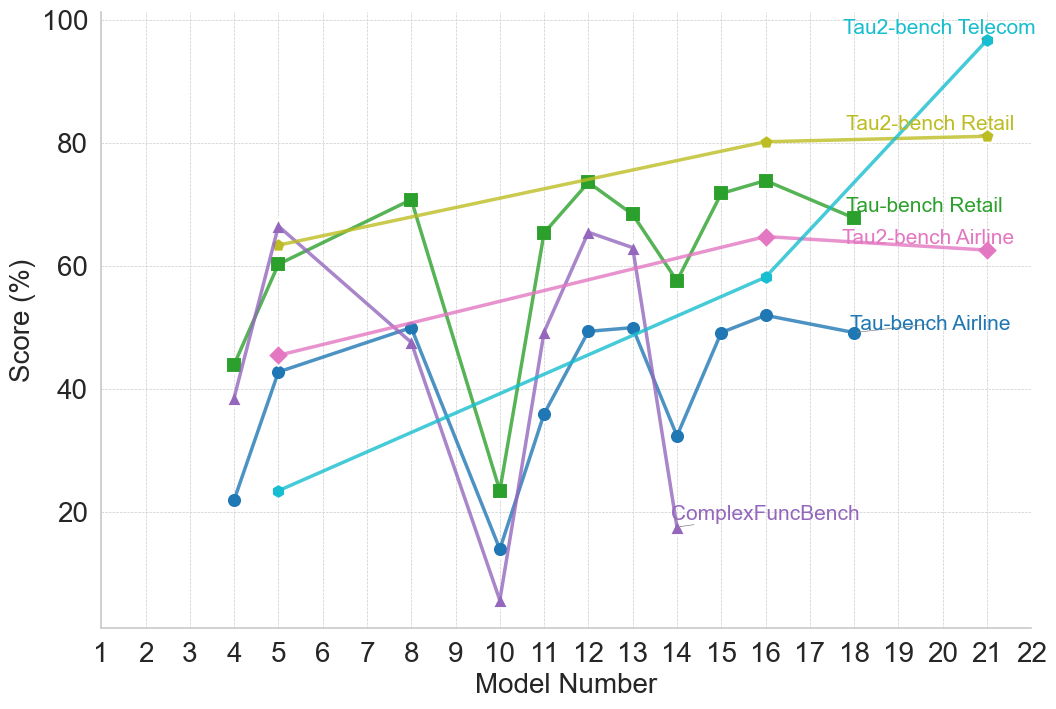
### Visual Description
## Line Chart: Model Performance on Benchmarks
### Overview
This line chart displays the performance scores of different models across several benchmarks. The x-axis represents the model number, ranging from 1 to 22. The y-axis represents the score, expressed as a percentage, ranging from 0 to 100. Six different benchmarks are represented by distinct colored lines.
### Components/Axes
* **X-axis:** Model Number (1 to 22)
* **Y-axis:** Score (%) (0 to 100)
* **Benchmarks (Lines/Legend):**
* Tau2-bench Telecom (Cyan)
* Tau2-bench Retail (Yellow)
* Tau2-bench Airline (Magenta)
* Tau-bench Airline (Purple)
* Tau-bench Retail (Olive)
* ComplexFuncBench (Teal)
The legend is located in the top-right corner of the chart. The gridlines are present, aiding in reading the values.
### Detailed Analysis
Here's a breakdown of each benchmark's performance trend and approximate data points:
* **Tau2-bench Telecom (Cyan):** This line generally slopes upward, starting at approximately 20% at Model 4, reaching a peak of around 95% at Model 22. There's a slight dip between Model 11 and 13, falling to approximately 40%.
* **Tau2-bench Retail (Yellow):** This line shows a relatively stable performance, starting around 65% at Model 4, peaking at approximately 82% around Model 8, and then decreasing slightly to around 75% at Model 22.
* **Tau2-bench Airline (Magenta):** This line starts at approximately 60% at Model 4, increases to around 70% at Model 8, then decreases to approximately 50% at Model 11, and rises again to around 70% at Model 22.
* **Tau-bench Airline (Purple):** This line begins at approximately 45% at Model 4, decreases sharply to a minimum of around 10% at Model 11, and then increases to approximately 50% at Model 22.
* **Tau-bench Retail (Olive):** This line starts at approximately 40% at Model 4, increases to around 65% at Model 8, decreases to approximately 40% at Model 11, and then rises to around 60% at Model 22.
* **ComplexFuncBench (Teal):** This line starts at approximately 20% at Model 4, increases to around 45% at Model 8, decreases to approximately 30% at Model 13, and then rises to around 50% at Model 22.
### Key Observations
* **Tau2-bench Telecom** consistently outperforms all other benchmarks, especially in the later models (16-22).
* **Tau-bench Airline** exhibits the most volatile performance, with a significant drop around Model 11.
* **Tau2-bench Retail** shows the most stable performance across all models.
* All benchmarks show an overall increasing trend in performance as the model number increases, suggesting model improvement.
* The lowest scores are consistently observed for **Tau-bench Airline** and **ComplexFuncBench**, particularly in the earlier models.
### Interpretation
The chart demonstrates the performance of different models across a variety of benchmarks. The significant difference in performance between the benchmarks suggests that the models are better suited for certain tasks than others. The upward trend in scores across all benchmarks indicates that the models are improving with increasing model number, likely due to increased complexity or training data. The large drop in performance for Tau-bench Airline around Model 11 could indicate a specific weakness in the model's architecture or training data related to that benchmark. The consistent high performance of Tau2-bench Telecom suggests that the models are particularly effective at tasks related to telecommunications. The data suggests a trade-off between stability and peak performance; Tau2-bench Retail is stable, while Tau2-bench Telecom achieves higher scores but with more variability. The benchmarks likely represent different levels of complexity or different types of data, explaining the varying performance levels.
</details>
(g) Tool Use
Figure 6: Performance of the GPT family on LLM-specific benchmarks. Model numbers and corresponding names are as follows: 1 – GPT-3.5; 2 – GPT-4; 3 – GPT-4 Turbo; 4 – GPT-4o mini; 5 – GPT-4o; 6 – o1-preview; 7 – o1-mini; 8 – o1; 9 – o1-pro; 10 – GPT-4.1 nano; 11 – GPT-4.1 mini; 12 – GPT-4.1; 13 – GPT-4.5; 14 – o3-mini; 15 – o4-mini; 16 – o3; 17 – o3-pro; 18 – gpt-oss-120b; 19 – GPT-5 with Deep Research; 20 – ChatGPT Agent; 21 – GPT-5; 22 – GPT-5 Pro.