# ExplicitLM: Decoupling Knowledge from Parameters via Explicit Memory Banks
**Authors**:
- Chengzhang Yu (South China University of Technology)
- Guangzhou, China
- &Zening Lu (South China University of Technology)
- Guangzhou, China
- &Chenyang Zheng (South China University of Technology)
- Guangzhou, China
- &Chiyue Wang (South China University of Technology)
- Guangzhou, China
- &Yiming Zhang (University of Science and Technology of China)
- Hefei, China
- &Zhanpeng Jin (South China University of Technology)
- Guangzhou, China
> Equal contribution.Corresponding author.
## Abstract
Large language models (LLMs) universally suffer from knowledge staleness and lack of interpretability due to their implicit knowledge storage paradigm, where information is distributed across network parameters in an entangled, non-addressable manner. This fundamental limitation prevents targeted knowledge updates, verification of stored information, and understanding of model reasoning processes. We propose ExplicitLM, a novel architecture that fundamentally reimagines knowledge storage in language models through an explicit, interpretable memory bank system. Our key innovation introduces a million-scale external memory bank where each entry stores human-readable knowledge as token sequences, enabling direct inspection and modification of the model’s knowledge base. To efficiently access this massive repository, we design a differentiable two-stage retrieval mechanism that enables end-to-end training while maintaining discrete knowledge selection, combining efficient coarse-grained filtering with product key decomposition (reducing computational complexity from $O(N·|I|)$ to $O(√{N}·|I|)$ ) and fine-grained similarity matching through Gumbel-Softmax. Drawing inspiration from dual-system cognitive theory, we partition knowledge into frozen explicit facts (20%) and learnable implicit patterns (80%), maintained through an Exponential Moving Average update strategy that ensures training stability. Extensive experiments demonstrate that ExplicitLM achieves up to 43.67% improvement in knowledge-intensive tasks compared to standard Transformers, with particularly pronounced gains in low-data regimes (3.62 $×$ improvement with 10k samples). Our analysis reveals strong correlations between memory retrieval success and task performance, with correctly predicted samples achieving 49% higher memory hit rates. Unlike traditional RAG systems with frozen retrieval components, our jointly optimized architecture demonstrates that interpretable, updatable language models can maintain competitive performance while providing unprecedented transparency into their knowledge utilization.
## 1 Introduction
Contemporary large language models (LLMs) universally suffer from knowledge staleness, with internally stored knowledge frozen at training completion Cheng et al. (2024); Singh et al. (2025). This temporal limitation creates a widening gap between static model knowledge and dynamic real-world information. Consider the U.S. presidency: Joe Biden served until January 2025, when Donald Trump assumed office. Models trained before this transition perpetually provide outdated answers, unable to reflect real-time changes. Post-training, this knowledge ossification accumulates across countless facts—political leadership, scientific discoveries, economic indicators, and technological standards—severely undermining model reliability in practical applications Mousavi et al. (2024). Knowledge updating thus emerges as critical: models require mechanisms to incorporate temporal factual changes to maintain utility and trustworthiness in real-world deployments.
Current approaches to acquiring or updating external knowledge primarily rely on two paradigms: real-time querying through Model Context Protocol (MCP) tools Hou et al. (2025), or knowledge augmentation via Retrieval-Augmented Generation (RAG) techniques Lewis et al. (2020).However, MCP-based methods exhibit several critical limitations. First, real-time querying introduces substantial inference latency, degrading user experience Singh et al. (2025). Second, dependency on external APIs compromises system robustness Li et al. (2025).RAG techniques, though partially mitigating knowledge updating challenges, face persistent obstacles: the relevance between retrieved documents and queries remains difficult to ensure, the inherent misalignment between retrieval and generation objectives yields suboptimal performance, and the maintenance and updating of external knowledge bases incurs substantial engineering overhead Salemi & Zamani (2024). These limitations collectively motivate the need for more efficient and integrated approaches to knowledge acquisition and updating in language models.
The fundamental barrier to direct manipulation of model-internal knowledge stems from the implicit knowledge storage paradigm in current language models. Research demonstrates that LLM knowledge is predominantly distributed across Feed-Forward Network (FFN) layers of the Transformer architecture Geva et al. (2021); Meng et al. (2022); Dai et al. (2022). Unlike traditional databases with discrete, addressable locations, each piece of LLM knowledge emerges from collective parameter interactions across all FFN layers, creating highly entangled representations that cannot be independently isolated or modified. This transforms knowledge update into a formidable challenge: modifying a single fact theoretically requires recalibrating weights throughout the entire network—a practically infeasible task risking catastrophic interference with other stored knowledge. This “black-box” nature prevents both verification of acquired knowledge and targeted correction of problematic content. During pre-training on massive corpora, models inevitably absorb misinformation, outdated content, or harmful material Perełkiewicz & Poświata (2024), yet inability to precisely locate and excise such knowledge allows errors to persist and propagate through outputs, fundamentally undermining reliability and trustworthiness.
More critically, implicit knowledge storage fundamentally impedes interpretability. When generating predictions, researchers cannot trace specific knowledge foundations underlying model reasoning. We cannot determine which facts inform reasoning nor verify reasoning step correctness. This opacity constrains understanding of model behavior and poses fundamental challenges to building trustworthy, interpretable AI systems. In high-reliability domains like medical diagnosis Ennab & Mcheick (2024) and legal consultation Latif (2025), this interpretability lack becomes a primary deployment barrier.
Motivated by these observations, we propose a novel language model architecture incorporating an explicit memory bank. The central innovation involves the systematization of traditionally implicit knowledge into an explicit and interpretable management framework. By introducing accessible Memory Bank layers at each model layer, we enable dynamic retrieval and utilization of external knowledge while, more importantly, achieving transparent knowledge management. Our main contributions are summarized as follows:
- We propose an explicit knowledge storage architecture based on Memory Banks, enabling each knowledge entry in the model’s repository to be decoded into human-readable text format, fundamentally addressing the interpretability limitations of traditional models.
- We design a differentiable two-stage retrieval mechanism that combines discrete knowledge selection with continuous gradient flow, enabling end-to-end training of the memory-augmented architecture while maintaining retrievable interpretability and low computational cost.
- We propose ExplicitLM, a novel architecture that enables explicit retrieval and interpretation of model knowledge while achieving superior answer accuracy compared to standard Transformer baselines.
## 2 Related Work
### 2.1 LLM architecture development
The evolution of large language model architectures began with BERT Devlin et al. (2019), which introduced bidirectional pre-training through masked language modeling, while GPT-2 Radford et al. demonstrated the power of scaling autoregressive transformers. T5 Raffel et al. (2020) unified various NLP tasks into a text-to-text framework, and GPT-3 Brown et al. (2020) showed emergent few-shot learning capabilities at 175B parameters. Subsequent developments include PaLM Chowdhery et al. (2023) scaling to 540B parameters with improved training efficiency, LLaMA Touvron et al. (2023) achieving strong performance with smaller models through careful data curation, and GPT-4 Achiam et al. (2023) advancing multimodal capabilities. Recent architectural innovations have explored alternatives to standard transformers: RWKV Peng et al. (2023) combines RNN efficiency with transformer-level performance through linear attention mechanisms, Mamba Gu & Dao (2023) leverages selective state space models for efficient long-context modeling with linear complexity, while Mixtral Jiang et al. (2024) employs sparse mixture-of-experts for improved parameter efficiency.
### 2.2 Knowledge Editing and Updating
Knowledge editing in large language models to eliminate errors remains an emerging research area, with existing approaches divided into parameter-efficient and parameter-augmented methods. Parameter-efficient approaches focus on updating knowledge without additional parameters: Li et al. (2023) introduces KAFT (Knowledge-Augmented Fine-Tuning), a data augmentation strategy incorporating diverse contexts (relevant, irrelevant, and counterfactual) for fine-tuning to reduce knowledge errors, while Onoe et al. (2023) constructs datasets to evaluate whether different methods can successfully inject specific facts and enable reasoning based on them. Parameter-augmented methods introduce additional components: Dong et al. (2022) employs CaliNet, training key-value calibration memory slots with similar architecture to FFN but smaller intermediate dimensions; Wang et al. (2024) embeds memory pools containing compressed knowledge tokens at each layer with update functions, though lacking interpretability; Mitchell et al. (2022) prepends a knowledge classifier to existing models, routing queries to either an explicitly stored and updatable database with a specialized model or the standard LLM, achieving explicit storage but sacrificing end-to-end neural architecture coherence.
## 3 Memory Bank
### 3.1 Memory Theory
Drawing from dual-system cognitive theory Gowda et al. (2025), we partition language model knowledge into two distinct yet complementary phases analogous to human procedural-declarative memory dichotomy.
Implicit Knowledge: This encompasses linguistic grammar rules, syntactic structures, and semantic associations that resist explicit formalization. Examples include nuanced aspects of human expression patterns and implicit connections between complex concepts that emerge from cultural and contextual understanding. Such knowledge exhibits high abstraction and ambiguity, necessitating statistical learning from large-scale data.
Explicit Knowledge: This comprises factual knowledge, entity relationships, and time-sensitive information amenable to explicit representation. Examples include ”The President of the United States is Trump” (not Biden) and ”The Eiffel Tower stands 324 meters tall.” Such knowledge possesses clear truth conditions and update requirements, making it suitable for storage in editable memory banks.
This dual-system design offers distinct advantages: implicit knowledge, acquired through deep learning, ensures robust language understanding and generation capabilities; explicit knowledge, through structured storage, enables interpretability and updatability. The synergistic integration of both systems enables models to maintain powerful linguistic capabilities while flexibly managing and updating factual knowledge.
<details>
<summary>iclr2026/picture/overview.png Details</summary>
### Visual Description
## Diagram: Memory-Augmented Neural Network Architecture
### Overview
The image is a technical diagram illustrating a neural network architecture that incorporates a "Memory Bank" for storing and retrieving knowledge. The system processes inputs through a series of layers, retrieves relevant information from memory, and produces outputs. The diagram is divided into three main visual regions: a top "Memory Bank" section, a central processing pipeline, and a bottom legend. A separate panel on the right contains textual annotations.
### Components/Axes
**Top Region: Memory Bank**
* **Label:** "Memory Bank" (top-left).
* **Structure:** A horizontal array of vertical bars, divided by a vertical dashed line.
* **Left Section (Yellow Bars):** 8 yellow bars. According to the legend, these represent "Implicit Knowledge".
* **Right Section (Green Bars):** 2 green bars. According to the legend, these represent "Explicit Knowledge".
* **Output Arrow:** An arrow points from the rightmost green bar to the text "A Knowledge of Memory Bank" on the far right.
**Central Region: Processing Pipeline**
* **Flow Direction:** Left to right.
* **Input:** Labeled "Inputs" on the far left.
* **Output:** Labeled "Outputs" on the far right.
* **Components (in order from left to right):**
1. A pink hexagon: "Input Embeddings" (per legend).
2. A circle with a plus sign: An addition operation.
3. A dashed box containing a repeating block. The block includes:
* An orange rounded rectangle: "Multi-Head Attention" (per legend).
* A vertical yellow rectangle: "Add & Norm" (per legend).
* A light blue circle: "Fusion" (per legend).
* A diamond shape: "Memory Retrieval Mechanism" (per legend). This diamond has a bidirectional arrow connecting it to the Memory Bank above.
4. An ellipsis ("...") indicating the repeating block occurs multiple times.
5. A final instance of the repeating block before the "Outputs".
* **Connections:** Arrows show data flow between components. The "Memory Retrieval Mechanism" (diamond) has arrows pointing both to and from the Memory Bank, indicating a two-way interaction.
**Bottom Region: Legend**
* A key explaining the symbols used in the diagram.
* **Symbols and Labels:**
* Green vertical bar: "Explicit Knowledge"
* Yellow vertical bar: "Implicit Knowledge"
* Pink hexagon: "Input Embeddings"
* Vertical yellow rectangle: "Add & Norm"
* Diamond: "Memory Retrieval Mechanism"
* Orange rounded rectangle: "Multi-Head Attention"
* Light blue circle: "Fusion"
**Right Panel: Text Annotations**
* **Header:** "A Knowledge of Memory Bank"
* **List:** A vertical list of five items, each with a number in a purple box and associated text.
1. `13` - "presi"
2. `14` - "dent"
3. `27` - "—"
4. `9` - "tr"
5. `91` - "ump"
### Detailed Analysis
The diagram depicts a structured process:
1. **Input Processing:** Raw "Inputs" are first converted into "Input Embeddings".
2. **Core Processing Loop:** The embeddings enter a sequence of identical processing blocks. Each block performs:
* Multi-Head Attention on the input.
* An "Add & Norm" step (likely residual connection and layer normalization).
* A "Fusion" operation.
* A "Memory Retrieval Mechanism" that queries the external "Memory Bank" and integrates retrieved information back into the processing stream.
3. **Memory Bank Interaction:** The Memory Bank is a static repository split into "Implicit Knowledge" (majority, yellow) and "Explicit Knowledge" (minority, green). The retrieval mechanism dynamically accesses this bank.
4. **Output Generation:** After passing through multiple blocks, the processed data is emitted as "Outputs".
The text panel on the right appears to be a separate annotation or example. The fragments "presi", "dent", "tr", and "ump" could be parts of words (e.g., "president", "trust", "trump"), but without further context, their precise meaning is unclear. The numbers (13, 14, 27, 9, 91) and the em dash ("—") are transcribed exactly as shown.
### Key Observations
* **Knowledge Dichotomy:** The architecture explicitly separates knowledge into "Implicit" and "Explicit" types within its memory, suggesting a design choice for different retrieval or usage paradigms.
* **Modular and Repetitive Design:** The core processing is built from repeated, identical blocks, a common pattern in deep learning architectures like Transformers.
* **Dynamic Memory Access:** The "Memory Retrieval Mechanism" is not a passive storage but an active component that interacts bidirectionally with the Memory Bank during processing.
* **Ambiguous Annotations:** The text on the right panel is fragmentary. The words are truncated, and the list's purpose (e.g., is it a key, an example, or a code?) is not defined within the diagram itself.
### Interpretation
This diagram illustrates a **memory-augmented neural network** designed to leverage both implicit (likely learned, distributed representations) and explicit (possibly structured, factual) knowledge. The core innovation highlighted is the integrated **Memory Retrieval Mechanism**, which allows the model to dynamically consult an external knowledge store during its forward pass, rather than relying solely on knowledge encoded in its static weights.
The separation of knowledge types in the Memory Bank implies the system may handle different kinds of information differently—perhaps using implicit knowledge for pattern completion and explicit knowledge for factual recall. The repeating block structure suggests this retrieval and fusion process happens at multiple stages of processing, allowing for deep integration of retrieved knowledge.
The fragmentary text on the right ("presi", "dent", etc.) may be an example of the kind of textual data the system processes or stores, but its connection to the main diagram is not visually explicit. It could represent tokens, keys, or values associated with memory entries. Overall, the diagram conveys a sophisticated architecture aimed at enhancing a neural network's capabilities by giving it structured, retrievable memory.
</details>
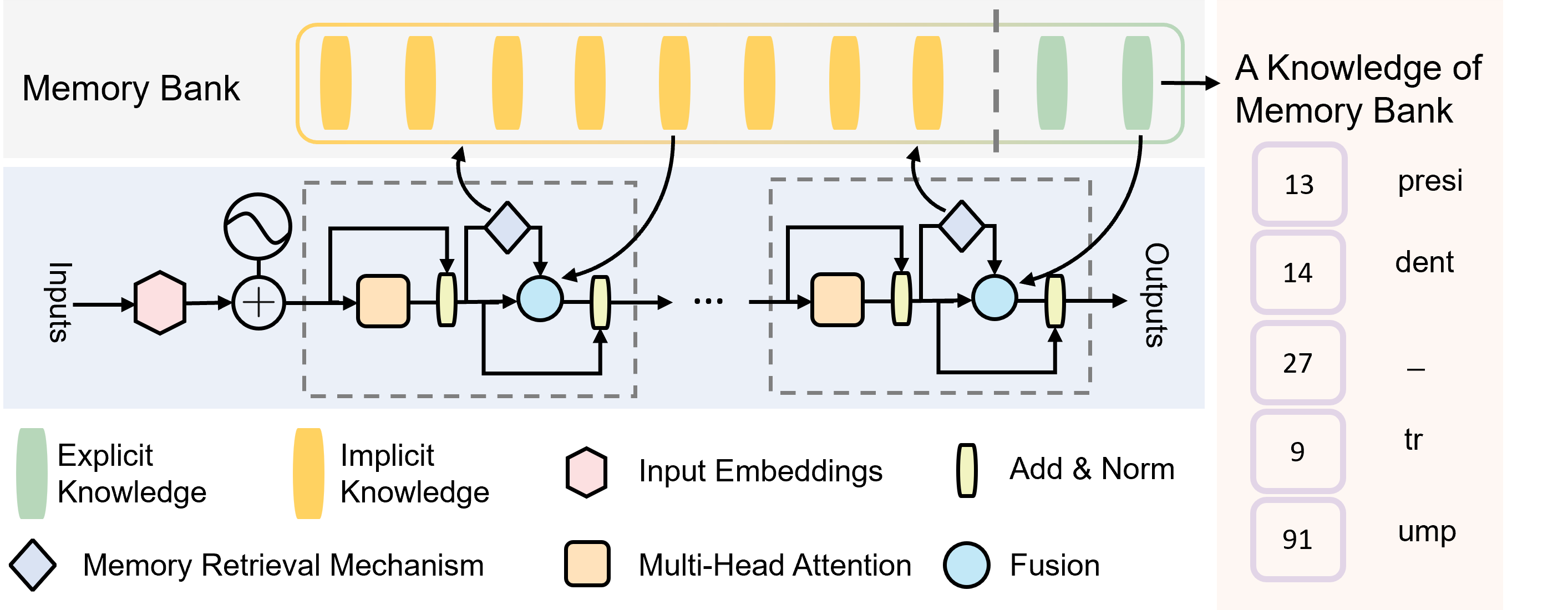
Figure 1: Overall architecture of ExplicitLM. The blue region shows the multi-layer transformer blocks. The gray region represents the shared Memory Bank accessed by all layers, where each layer can retrieve knowledge via the Memory Retrieval Mechanism (Section 3.4) from Explicit Knowledge (green) or Implicit Knowledge (yellow) partitions. The orange region shows a sample knowledge entry from the Memory Bank—a sequence of token indices of length $L$ directly convertible to human-readable text.
### 3.2 Storage Architecture
Let $M⊆ℤ^1× L,|M|=N$ denote our Memory Bank tensor, where $N=10^6$ represents the knowledge capacity and $L=16$ denotes the maximum sequence length. Each entry $m_i∈M$ stores a discrete knowledge unit as token indices, with elements $m_ij∈V$ , where $V$ is codebook.
We employ a tokenizer-based bidirectional mapping scheme. The encoding function $Tokenize:S→ℤ^1× L$ converts knowledge strings $s∈S$ to token indices for storage: $m_i=Tokenize(s_i)=[t_1^(i),t_2^(i),...,t_L^(i)]$ where $t_j^(i)∈V$ . During retrieval, the embedding function $Embed:ℤ^1× L→ℝ^d× L$ transforms stored indices back to semantic representations: $E_i=Embed(m_i)=[e_t_{1^(i)},e_t_{2^(i)},...,e_t_{L^(i)}]$ , where $e_{t_{j}^(i)}∈ℝ^d$ .
### 3.3 Knowledge Allocation Strategy
Given the memory constraint $|M|=N$ , our approach maintains a fixed-capacity knowledge repository throughout the model’s lifecycle. This design choice ensures predictable memory consumption and eliminates the computational overhead associated with dynamic memory allocation. To effectively utilize this fixed capacity while preserving essential linguistic knowledge, we introduce a partitioning scheme that divides the memory bank into two disjoint subsets: $M=M_f∪M_u$ where $M_f∩M_u=∅$ . The partition is controlled by a freeze rate parameter $ρ∈[0,1]$ , which determines the proportion of memory allocated to each subset.
The frozen knowledge subset $M_f$ with cardinality $|M_f|=ρ N$ (we empirically set $ρ=0.2$ as default) is designated for storing explicit knowledge that can be precisely formulated and verified. During initialization, this subset is populated with curated factual information such as entity relationships, geographical facts, and time-sensitive data that require accurate representation. The explicit nature of this knowledge allows for direct injection of verified information into the memory bank, ensuring factual accuracy from the outset. These entries remain immutable during training to preserve the integrity of the pre-verified knowledge base. Conversely, the updatable knowledge subset $M_u$ with cardinality $|M_u|=(1-ρ)N$ is allocated for implicit knowledge that the model must discover through training. This subset captures linguistic regularities, syntactic patterns, and semantic associations that emerge from statistical learning over large-scale text corpora. The model autonomously determines which grammatical structures and language patterns warrant storage in this dynamic portion of the memory bank. The in-place substitution mechanism maintains the invariant $|M^(t)|=N$ for all time steps $t$ , as updates neither insert new entries nor delete existing ones, thereby preserving constant memory footprint and eliminating the complexity associated with dynamic memory management operations.
To address the gradient discontinuity issue that arises from direct overwriting of knowledge entries in $M_u$ , we adopt the Exponential Moving Average (EMA) technique from Vector Quantized Variational Autoencoders (VQ-VAE) Van Den Oord et al. (2017), originally developed for codebook updates. Rather than performing abrupt replacements, the EMA mechanism enables progressive updates that maintain training stability. Specifically, for each knowledge entry $m_i∈M_u$ , we maintain dynamic statistics that allow smooth transitions between old and new knowledge representations. The update rule assigns higher weights to newer information while preserving continuity with existing knowledge, enabling the memory bank to adapt to evolving encoder outputs without introducing disruptive oscillations. This approach effectively circumvents the non-differentiability inherent in discrete quantization operations, while simultaneously improving both the utilization rate of knowledge entries and the overall reconstruction quality of the stored information.
### 3.4 Memory Retrieval Mechanism
We propose a hierarchical two-stage retrieval strategy for efficient access to million-scale entries.
<details>
<summary>iclr2026/picture/selection.png Details</summary>
### Visual Description
## Diagram: Two-Stage Memory Retrieval Process
### Overview
The image is a technical diagram illustrating a two-stage process for memory retrieval or selection, likely from a machine learning or neural network architecture. The diagram is divided into two distinct, color-coded sections: "Stage1: Key-value Filtering" on a beige background (left) and "Stage2: Similarity Selection" on a light green background (right). The flow of data proceeds from left to right, starting with "Inputs" and culminating in a selected output.
### Components/Axes
The diagram is composed of labeled components, directional arrows, and mathematical symbols. There are no traditional chart axes. Key text labels are:
* **Stage Titles:** "Stage1: Key-value Filtering", "Stage2: Similarity Selection"
* **Component Labels:** "Inputs", "Query Network", "Key", "Top k", "Memory Bank", "Cosine Similarity"
* **Mathematical Symbols:** Multiplication symbols (×), an angle symbol (θ)
* **Numerical Values:** 0.17, 0.29, 0.36
### Detailed Analysis
The process is segmented into two independent regions:
**Region 1: Stage1: Key-value Filtering (Left, Beige Background)**
1. **Input & Query Generation:** Data labeled "Inputs" flows into a "Query Network," represented by a neural network icon (circles and connecting lines).
2. **Key-Value Processing:** The output of the Query Network splits into two parallel paths.
* The upper path processes a purple rectangular block.
* The lower path processes a blue rectangular block.
* Both paths interact with a central, multi-colored component labeled "Key." This interaction is represented by multiplication symbols (×), suggesting a dot product or similarity computation between the query-derived features and the key.
3. **Filtering & Selection:** The outputs from the two multiplication operations are combined and fed into a vertical stack of blue rectangles, representing a set of candidates.
4. **Top-k Selection:** An arrow points from this stack to a smaller set of three rectangles (two purple, one blue), labeled "Top k." This indicates a filtering step where only the top 'k' candidates are retained.
5. **Memory Storage:** The "Top k" candidates are then directed into a component labeled "Memory Bank," depicted as a rounded rectangle containing three horizontal bars (green, green, yellow).
**Region 2: Stage2: Similarity Selection (Right, Light Green Background)**
1. **Input from Stage 1:** A dashed arrow originates from the "Key" component in Stage 1 and points to a purple rectangle in Stage 2, indicating that the key information is passed forward.
2. **Candidate Retrieval:** Three green oval shapes (likely representing retrieved memory items) are shown to the left of a central diagram.
3. **Similarity Computation:** The core of Stage 2 is a vector diagram illustrating "Cosine Similarity."
* It shows two vectors (red and green) originating from a common point, with an angle θ between them.
* A horizontal black arrow represents a reference vector.
* This visual explains that the similarity between the query (from Stage 1) and each retrieved memory item is calculated using cosine similarity.
4. **Similarity Scores & Output:** To the right of the vector diagram, three numerical values are listed vertically: **0.17**, **0.29**, and **0.36**. These are the computed cosine similarity scores.
* The value **0.36** is enclosed in a red dashed rectangular box, highlighting it as the highest score.
* An arrow points from this highlighted score to a final yellow oval shape, indicating that the memory item with the highest similarity score (0.36) is selected as the output.
### Key Observations
1. **Two-Stage Architecture:** The process explicitly separates coarse filtering (Stage 1: Key-value Filtering) from fine-grained selection (Stage 2: Similarity Selection).
2. **Information Flow:** The "Key" is a central element used in both stages—first for initial filtering and then as part of the final similarity computation.
3. **Selection Mechanism:** Stage 1 uses a "Top k" selection, while Stage 2 selects the single best match based on the highest cosine similarity score.
4. **Visual Highlighting:** The red dashed box around the score "0.36" is a deliberate visual cue to draw attention to the winning selection criterion.
5. **Color Coding:** Colors are used functionally: purple/blue for query/key processing paths, green for retrieved memory items, and yellow for the final selected output.
### Interpretation
This diagram describes an efficient memory retrieval system designed to handle a large "Memory Bank." The process works as follows:
* **Purpose:** To find the most relevant piece of information (a "value") from a large memory store in response to an input query.
* **How it Works:** Instead of comparing the query to every item in memory (which is computationally expensive), it uses a two-step funnel:
1. **Fast, Approximate Filtering (Stage 1):** A lightweight "Key" network quickly narrows down the entire memory bank to a small subset of promising candidates ("Top k"). This is the "Key-value Filtering" stage.
2. **Precise, Expensive Matching (Stage 2):** A more accurate but slower "Cosine Similarity" computation is then applied only to this small subset. The item with the highest similarity score (0.36 in this example) is selected as the output.
* **Why it Matters:** This architecture balances speed and accuracy. It avoids the computational cost of performing detailed similarity checks on all memories while ensuring the final selection is based on a precise metric. The "Key" acts as a compressed, searchable address for the associated "Value" in memory. The system is likely used in contexts like neural Turing machines, memory-augmented neural networks, or retrieval-augmented generation (RAG) models.
</details>
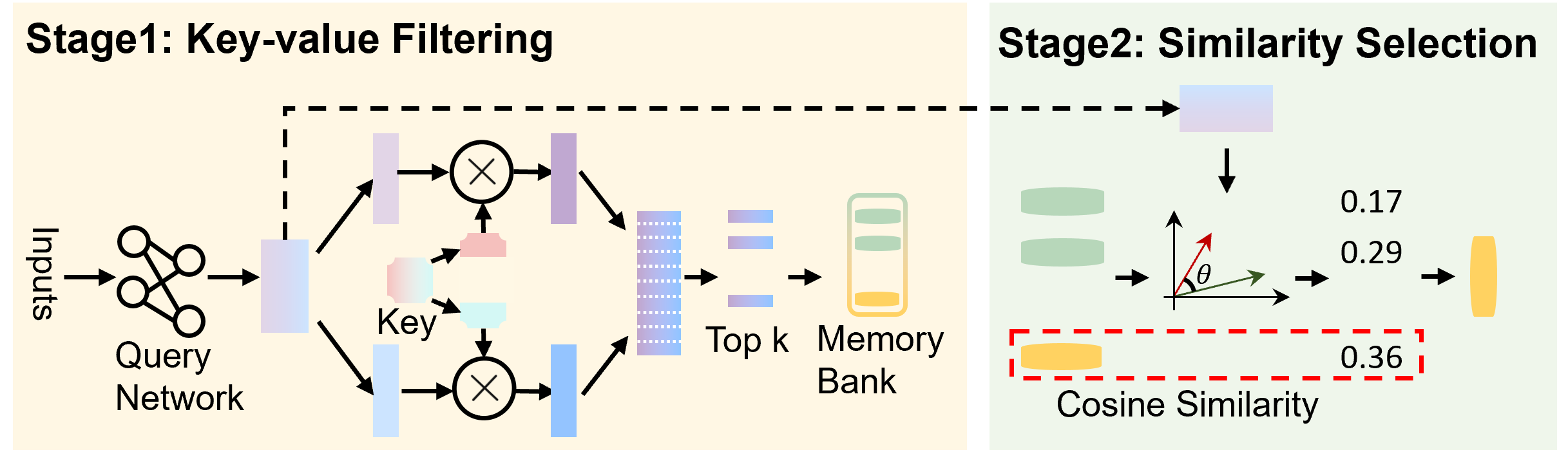
Figure 2: ExplicitLM architecture with memory retrieval mechanism. In Stage 1, both query and key vectors are partitioned along the embedding dimension into two components for efficient retrieval. In Stage 2, cosine similarity is computed between the query and candidate knowledge entries, with the highest-scoring entry selected for retrieval.
Stage 1: Key-value Filtering. Following Million Experts He (2024), we assign product keys $K:=\{k_i\}_i=1^N⊂ℝ^d$ to knowledge entries, with query network $q$ mapping input $x$ to query $q(x)$ . This stage generates a candidate set $I$ by retrieving the most relevant entries based on query-key similarities: $I=top-I-indices≤ft(\{ q(x)^⊤k\mid k∈K \}\right)$ , where $top-I-indices$ denotes the operator that selects the indices of the top- $I$ elements from $K$ , yielding a candidate set with cardinality $|I|$ . To address computational complexity at $N≥ 10^6$ , we decompose keys using Cartesian products: $K=\{[c;c^\prime]\mid c∈C,c^\prime∈C^\prime\}$ where $C,C^\prime⊂ℝ^d/2$ with $|C|=|C^\prime|=√{N}$ , reducing complexity from $O(N·|I|)$ to $O(√{N}·|I|)$ ,where $|I|\ll√{N}$ .
Stage 2: Similarity Selection. For candidates $i∈ I$ , we compute cosine similarities $cs_i=\cos≤ft(q(x),k_i\right)$ and apply Gumbel-Softmax for differentiable selection:
$$
p_i=\frac{\exp≤ft(≤ft(cs_i+g_i\right)/τ\right)}{∑_j∈ I\exp≤ft(≤ft(cs_j+g_j\right)/τ\right)} \tag{1}
$$
where $g_i=-\log≤ft(-\log≤ft(ε_i\right)\right)$ with $ε_i∼(0,1)$ and temperature $τ$ . The straight-through estimator enables gradient flow: forward pass selects $m_selected =m_\hat{i}$ where $\hat{i}=\arg\max_ip_i$ , while backward pass uses soft weights $\frac{∂L}{∂ q(x)}=∑_i∈ Ip_i\frac{∂L}{∂m_i}$ , maintaining discrete selection while ensuring end-to-end differentiability for retrieved knowledge $m_selected ∈M$ .
Unlike traditional RAG systems that rely on frozen retrieval components, our mechanism enables joint optimization of retrieval and generation through differentiable selection, allowing the model to learn task-specific retrieval patterns during training.
### 3.5 Joint Optimization Objective
We design a multi-task learning framework that jointly optimizes three complementary losses to balance language modeling capability with effective memory retrieval.
Language Modeling Loss. Following standard practice, we minimize cross-entropy between predicted and ground-truth distributions. For sequence $x=(x_1,…,x_T)$ with vocabulary $V$ of size $V$ :
$$
L_CE=-\frac{1}{T}∑_t=1^T\log p(x_t|x_<t,M) \tag{2}
$$
where $p(x_t|x_<t,M)$ denotes the model’s predicted probability conditioned on context $x_<t$ and retrieved memories from $M$ .
Memory Relevance Loss. To ensure semantic alignment between queries and retrieved memories, we maximize weighted cosine similarities. Given query $q(x)∈ℝ^d$ and retrieved candidates $\{E_i\}_i=1^|I|$ with selection weights $\{p_i\}_i=1^|I|$ from Gumbel-Softmax:
$$
L_sim=-E_x∼D≤ft[∑_i=1^|I|p_i·\frac{q(x)^TE_i}{\|q(x)\|_2\|E_i\|_2}\right] \tag{3}
$$
This loss guides the model toward selecting contextually relevant memories by reinforcing high-similarity retrievals.
Memory Diversity Loss. To prevent retrieval collapse into local regions and expand semantic coverage, we minimize pairwise similarities among the candidates. Let $\hat{E}_i=E_i/\|E_i\|_2$ denote normalized embeddings:
$$
L_div=\frac{2}{|I|(|I|-1)}∑_i=1^|I|∑_j=1,j≠ i^|I|cs({\hat{E}}_i,\hat{E}_j) \tag{4}
$$
This regularization encourages exploration across diverse memory regions, preventing locally optimal retrieval patterns while maintaining relevance through balanced optimization.
The final objective combines all losses: $L_total=L_CE+λ_simL_sim+λ_divL_div$ . This joint optimization ensures: (1) accurate next-token prediction through $L_CE$ , (2) semantically coherent retrieval via $L_sim$ , and (3) diverse memory exploration through $L_div$ , yielding an end-to-end trainable knowledge-augmented architecture where memory retrieval and language modeling are deeply integrated.
## 4 Experiments
### 4.1 Dataset Construction
We construct a 10M-entry multi-source pretraining corpus with strategic sampling ratios optimized for knowledge diversity: Wikipedia: Structured encyclopedic knowledge annotated with entity triplets for explicit knowledge graph extraction. These entries form the exclusive source for Memory Bank initialization $M⊆ℤ^1× L$ , selected based on knowledge density metrics and factual reliability scores. Project Gutenberg: Literary and historical texts providing formal language patterns and narrative structures spanning multiple centuries. OpenWebText: Contemporary web text capturing modern linguistic phenomena and informal discourse patterns.
Each entry maintains a unique identifier for provenance tracking. The Memory Bank entries $m_i$ are mapped to source UUIDs, enabling systematic knowledge updates and verification. Selection criteria prioritize: (i) token-level information density, (ii) factual accuracy via cross-reference validation, and (iii) domain coverage measured by entity distribution.
### 4.2 Evaluation Task Design
We design three complementary tasks to evaluate knowledge utilization from Memory Bank $M$ : (i) Object Prediction: Given subject-predicate pairs from knowledge entries $m_i∈M$ , predict correct object tokens $t_ji$ from candidate set. Accuracy measures entity relationship understanding with 5 distractors in $ℝ^d$ space. (ii) Relation Reasoning: Given entity token pairs $(t_ji,t_ki)$ from $m_i$ , infer their semantic relationship. This probes compositional reasoning over stored knowledge structures in $M$ . (iii) Fact Verification: Binary classification of statements derived from memory bank domain. Negative samples generated via token substitution at indices $m_i,j$ maintain $50:50$ class balance. Data partitioning leverages freeze partition: test samples derive exclusively from frozen entries $M_f$ where $|M_f|=ρ N$ , while training excludes all tokens from ${m_i}{∈M_f}$ . This strict disjoint constraint between $M_f$ and training data prevents memorization-based evaluation inflation.
### 4.3 Comparison of Different Data Volumes
To systematically evaluate the efficacy of our memory-augmented architecture, we conduct controlled experiments across varying supervised fine-tuning (SFT) data volumes. Both our model and the baseline Transformer undergo identical optimization procedures, with performance assessed on the three tasks defined in Section 4.2. The baseline represents a standard Transformer architecture without memory augmentation, enabling direct attribution of performance gains to our proposed Memory Bank mechanism.
Table 1: Performance comparison between baseline Transformer and our memory-augmented model across different SFT data volumes. Results show accuracy (%) on three knowledge-intensive tasks.
| 10k Ours 25k | Baseline 28.42% $↑$ 20.56% Baseline | 7.86% 70.02% $↑$ 31.75% 22.16% | 38.27% 66.03% $↑$ 4.32% 79.99% | 61.71% 71.49% |
| --- | --- | --- | --- | --- |
| Ours | 63.12% $↑$ 40.96% | 87.85% $↑$ 7.86% | 79.79% $↑$ 8.33% | |
| 50k | Baseline | 30.23% | 83.80% | 83.34% |
| Ours | 73.90% $↑$ 43.67% | 90.41% $↑$ 6.61% | 86.25% $↑$ 2.91% | |
| 75k | Baseline | 40.64% | 87.66% | 86.40% |
| Ours | 79.76% $↑$ 39.12% | 92.12% $↑$ 4.46% | 88.74% $↑$ 2.34% | |
| 100k | Baseline | 56.80% | 91.91% | 88.92% |
| Ours | 80.94% $↑$ 24.14% | 92.73% $↑$ 0.82% | 89.75% $↑$ 0.83% | |
The experimental results reveal pronounced performance advantages in low-data regimes. At 10k training samples, our model achieves 3.62× improvement in Object Prediction and 1.83× improvement in Relation Reasoning compared to the baseline. This substantial gap demonstrates that explicit memory retrieval from $M$ effectively compensates for limited training exposure, particularly for tasks requiring precise entity-level knowledge recall. The Object Prediction task, which directly queries stored triplets from memory entries $m_i$ , exhibits the most consistent improvements across all data scales (24.14% at 100k samples), validating our retrieval mechanism’s effectiveness in accessing specific tokens $t_ji$ from the Memory Bank.
### 4.4 Memory Bank Hit Rate Analysis
To empirically validate the effectiveness of our Memory Bank retrieval mechanism, we conduct a fine-grained analysis of layer-wise memory access patterns. Using models trained with varying data volumes from Section 1, we examine the correlation between successful memory retrieval and task performance on Relation Reasoning. For each forward pass, we track whether the retrieval mechanism successfully matches relevant entries from $M$ at each transformer layer, providing insights into how different layers utilize external memory.
<details>
<summary>iclr2026/picture/hit_rates.png Details</summary>
### Visual Description
\n
## Stacked Bar Chart: Memory Hit Rate by Transformer Layer and Dataset Size
### Overview
This is a stacked bar chart visualizing the "Memory Hit Rate" across different Transformer layers (L1, L3, L5, L7) and a "Total" aggregate. The data is further broken down by five different dataset sizes (10k, 25k, 50k, 75k, 100k). Each bar is composed of two stacked components: "Incorrect Samples" at the bottom and "Correct - Incorrect" on top.
### Components/Axes
* **X-Axis (Horizontal):** Labeled "Transformer Layer". It contains five categorical groups: `L1`, `L3`, `L5`, `L7`, and `Total`.
* **Y-Axis (Vertical):** Labeled "Memory Hit Rate". It is a linear scale ranging from `0.0` to `0.7`, with major gridlines at intervals of 0.1.
* **Legend 1 (Top-Left):** Titled "Dataset Size". It maps colors to dataset sizes:
* Dark Blue: `10k`
* Yellow: `25k`
* Orange: `50k`
* Red: `75k`
* Teal: `100k`
* **Legend 2 (Top-Center):** Titled "Stacked Components". It explains the bar stacking:
* Lighter shade (bottom segment): `Incorrect Samples (Bottom)`
* Darker shade (top segment): `Correct - Incorrect (Top)`
* **Data Labels:** Numerical values are printed directly on the bars. Values for the bottom segment are in black, and values for the top segment are in red.
### Detailed Analysis
The chart presents data for five Transformer Layer groups. Below is the extracted data for each group, organized by dataset size (color). For each bar, the total height is the "Memory Hit Rate", composed of the bottom segment ("Incorrect Samples") and the top segment ("Correct - Incorrect").
**Group: L1**
* **10k (Dark Blue):** Total = `0.38`. Bottom = `0.17`, Top = `0.21`.
* **25k (Yellow):** Total = `0.36`. Bottom = `0.06`, Top = `0.30`.
* **50k (Orange):** Total = `0.29`. Bottom = `0.05`, Top = `0.24`.
* **75k (Red):** Total = `0.34`. Bottom = `0.06`, Top = `0.29`.
* **100k (Teal):** Total = `0.23`. Bottom = `0.03`, Top = `0.20`.
**Group: L3**
* **10k (Dark Blue):** Total = `0.43`. Bottom = `0.20`, Top = `0.23`.
* **25k (Yellow):** Total = `0.36`. Bottom = `0.09`, Top = `0.27`.
* **50k (Orange):** Total = `0.35`. Bottom = `0.09`, Top = `0.26`.
* **75k (Red):** Total = `0.42`. Bottom = `0.10`, Top = `0.32`.
* **100k (Teal):** Total = `0.55`. Bottom = `0.13`, Top = `0.41`.
**Group: L5**
* **10k (Dark Blue):** Total = `0.13`. Bottom = `0.06`, Top = `0.07`.
* **25k (Yellow):** Total = `0.15`. Bottom = `0.03`, Top = `0.12`.
* **50k (Orange):** Total = `0.28`. Bottom = `0.04`, Top = `0.24`.
* **75k (Red):** Total = `0.14`. Bottom = `0.02`, Top = `0.11`.
* **100k (Teal):** Total = `0.27`. Bottom = `0.04`, Top = `0.23`.
**Group: L7**
* **10k (Dark Blue):** Total = `0.38`. Bottom = `0.18`, Top = `0.19`.
* **25k (Yellow):** Total = `0.40`. Bottom = `0.10`, Top = `0.30`.
* **50k (Orange):** Total = `0.32`. Bottom = `0.06`, Top = `0.26`.
* **75k (Red):** Total = `0.28`. Bottom = `0.05`, Top = `0.23`.
* **100k (Teal):** Total = `0.33`. Bottom = `0.08`, Top = `0.24`.
**Group: Total**
* **10k (Dark Blue):** Total = `0.71`. Bottom = `0.22`, Top = `0.49`.
* **25k (Yellow):** Total = `0.66`. Bottom = `0.21`, Top = `0.45`.
* **50k (Orange):** Total = `0.65`. Bottom = `0.21`, Top = `0.44`.
* **75k (Red):** Total = `0.71`. Bottom = `0.37`, Top = `0.34`.
* **100k (Teal):** Total = `0.71`. Bottom = `0.23`, Top = `0.48`.
### Key Observations
1. **Layer Performance Variability:** Memory Hit Rate is not uniform across layers. L5 shows the lowest overall performance (all totals ≤ 0.28), while the "Total" aggregate shows the highest (all totals ≥ 0.65).
2. **Dataset Size Impact:** The relationship between dataset size and hit rate is non-linear and layer-dependent.
* In **L3**, the hit rate increases significantly with the largest dataset (100k: 0.55).
* In **L1** and **L7**, the trend is less clear, with mid-sized datasets sometimes outperforming larger ones.
* In the **Total** group, the 10k, 75k, and 100k datasets all achieve the highest observed hit rate of 0.71.
3. **Component Contribution:** The "Correct - Incorrect" (top, red label) component is generally the larger contributor to the total hit rate, except in the "Total" group for the 75k dataset, where the "Incorrect Samples" (bottom) component is larger (0.37 vs. 0.34).
4. **Notable Outlier:** The 100k dataset in **L3** (0.55) is a clear outlier, performing substantially better than other dataset sizes within that layer and better than the 100k dataset in any other individual layer.
### Interpretation
This chart analyzes how a model's ability to "hit" or recall information from memory (Memory Hit Rate) is affected by the depth of the transformer layer and the amount of training data (Dataset Size). The "Total" column likely represents an aggregate or average across all layers, showing the model's overall memory performance.
The data suggests that memory utilization is highly layer-specific. Middle layers like L5 appear to be bottlenecks for memory recall, regardless of dataset size. The exceptional performance of the 100k dataset in L3 indicates that this specific layer may benefit disproportionately from larger training data, perhaps becoming a specialized hub for memory retrieval.
The decomposition into "Incorrect Samples" and "Correct - Incorrect" provides insight into the *quality* of the memory hits. A high "Correct - Incorrect" value suggests the model is not just accessing memory but doing so accurately for correct predictions. The anomaly in the "Total" group for 75k, where "Incorrect Samples" dominate, could indicate that with this specific data size, the model's memory access becomes noisier or less precise, even if the overall hit rate remains high.
In summary, the chart demonstrates that optimizing memory in transformer models requires a nuanced, layer-aware approach, and that simply increasing dataset size does not uniformly improve memory performance across all parts of the model.
</details>
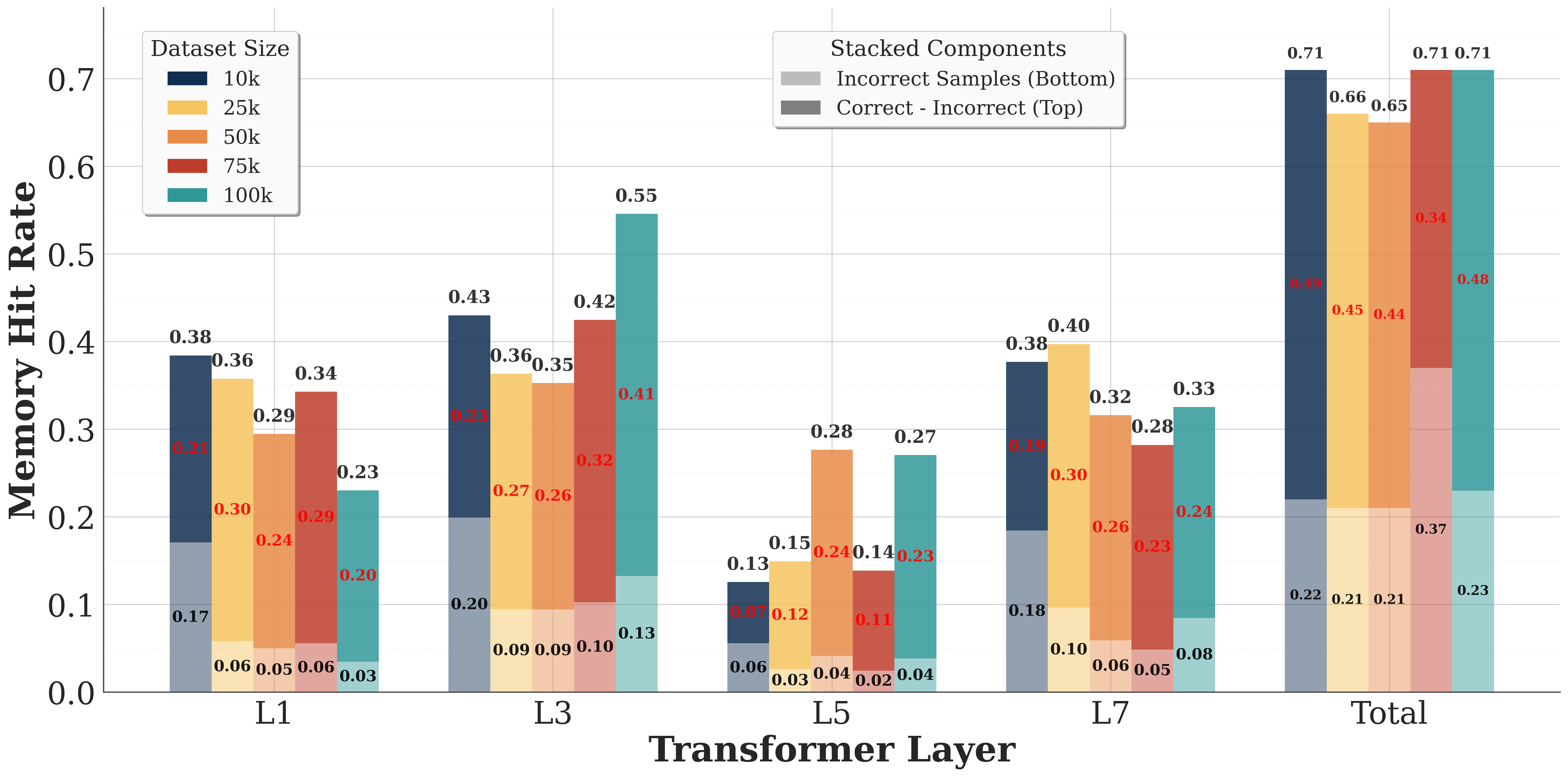
Figure 3: Layer-wise memory hit rates for Relation Reasoning across varying training data volumes. Semi-transparent regions indicate hit rates for correctly predicted samples, while opaque regions show hit rates for incorrect predictions. Red annotations display the hit rate differential between correct and incorrect predictions at each layer.
The aggregate hit rates reveal a strong correlation between memory access success and prediction accuracy. Models trained on 100k, 50k, 25k, 10k, and 5k samples achieve overall hit rates of 71%, 65%, 66%, 71%, and 71% respectively for correctly answered samples, where a sample is considered to have ”hit” if at least one layer successfully retrieves relevant memory. In stark contrast, incorrectly answered samples exhibit substantially lower hit rates of 23%, 21%, 21%, 22%, and 37% respectively. This 3× differential in hit rates between correct and incorrect predictions empirically confirms that successful memory retrieval directly contributes to task performance.
Figure 3 presents the layer-wise decomposition of hit rates, revealing distinct retrieval patterns across the network depth. Both correct and incorrect samples exhibit elevated hit rates at layers L1 and L3, suggesting these layers serve as critical junctures for knowledge integration. The consistency of this pattern across different training data volumes indicates an emergent specialization in the network architecture, where specific layers develop stronger affinity for external memory access.
### 4.5 Impact of Freeze Rate on Performance
To investigate freeze rate parameter $ρ$ effects on model performance, we conduct systematic experiments varying $ρ$ while maintaining other hyperparameters constant. The freeze rate controls partition between frozen knowledge $M_f$ and updatable knowledge $M_u$ , with $|M_f|=ρ N$ and $|M_u|=(1-ρ)N$ . We evaluate performance on Relation Reasoning across different training data volumes to understand how explicit-implicit knowledge balance affects learning dynamics.
<details>
<summary>iclr2026/picture/freeze_rate.png Details</summary>
### Visual Description
\n
## Grouped Bar Chart with Overlaid Line Plots: Model Performance vs. Training Sample Size
### Overview
This image is a technical chart comparing the performance of different machine learning models across varying training dataset sizes. It uses a dual-axis design: grouped bars represent absolute accuracy percentages, while overlaid line plots represent the relative improvement of proposed models over a baseline. The chart demonstrates how model performance scales with more training data and highlights the effectiveness of the proposed methods ("Ours") compared to a baseline.
### Components/Axes
* **X-Axis (Bottom):** Labeled **"Training Samples"**. It has five categorical groups: **10k, 25k, 50k, 75k, 100k**.
* **Primary Y-Axis (Left):** Labeled **"Accuracy (%)"**. Scale ranges from 20 to 100, with major gridlines at 20, 40, 60, 80, 100.
* **Secondary Y-Axis (Right):** Labeled **"Relative Improvement over Baseline (%)"**. Scale ranges from 0 to 150, with major ticks at 0, 30, 60, 90, 120, 150.
* **Legend 1 (Top-Right):** Titled **"Model Performance"**. It defines the bar colors:
* **Baseline:** Dark slate blue/grey.
* **Ours (0.2):** Light yellow/beige.
* **Ours (0.4):** Light orange/peach.
* **Ours (0.6):** Muted red/terracotta.
* **Legend 2 (Bottom-Right):** Titled **"Sample Size (Lines)"**. It defines the line plot colors and markers, corresponding to the x-axis groups:
* **10k:** Red line with circle markers.
* **25k:** Blue line with circle markers.
* **50k:** Green line with circle markers.
* **75k:** Purple line with circle markers.
* **100k:** Orange line with circle markers.
* **Data Labels:** Numerical accuracy values are printed directly above each bar.
### Detailed Analysis
**Bar Chart Data (Accuracy %):**
The values are extracted by matching the bar color to the "Model Performance" legend and reading the label above it.
* **10k Training Samples:**
* Baseline: 38.3%
* Ours (0.2): 70.0%
* Ours (0.4): 84.7%
* Ours (0.6): 78.8%
* **25k Training Samples:**
* Baseline: 80.0%
* Ours (0.2): 87.8%
* Ours (0.4): 90.1%
* Ours (0.6): 82.2%
* **50k Training Samples:**
* Baseline: 83.8%
* Ours (0.2): 90.4%
* Ours (0.4): 92.3%
* Ours (0.6): 88.4%
* **75k Training Samples:**
* Baseline: 87.7%
* Ours (0.2): 92.1%
* Ours (0.4): 92.0%
* Ours (0.6): 90.9%
* **100k Training Samples:**
* Baseline: 91.9%
* Ours (0.2): 92.7%
* Ours (0.4): 94.9%
* Ours (0.6): 92.2%
**Line Plot Data (Relative Improvement over Baseline %):**
The lines connect points representing the improvement of each "Ours" variant over the baseline for that sample size. The y-values are read from the right-hand axis. The trend for each line is described first, followed by approximate point values.
* **10k Line (Red):** Shows a sharp peak. Starts near 0% for Ours (0.2), spikes to a high value for Ours (0.4), then drops for Ours (0.6).
* Ours (0.2): ~0% (point is on the 0% baseline)
* Ours (0.4): ~120% (peak, aligns with the 120 tick)
* Ours (0.6): ~105% (approximate, between 90 and 120)
* **25k Line (Blue):** Shows a moderate peak. Starts low, rises to a peak for Ours (0.4), then falls.
* Ours (0.2): ~0%
* Ours (0.4): ~15% (approximate)
* Ours (0.6): ~3% (approximate, just above 0)
* **50k Line (Green):** Shows a small, broad peak.
* Ours (0.2): ~0%
* Ours (0.4): ~10% (approximate)
* Ours (0.6): ~5% (approximate)
* **75k Line (Purple):** Shows a very slight, flat peak.
* Ours (0.2): ~0%
* Ours (0.4): ~5% (approximate)
* Ours (0.6): ~4% (approximate)
* **100k Line (Orange):** Shows minimal variation, hovering near zero.
* Ours (0.2): ~0%
* Ours (0.4): ~3% (approximate)
* Ours (0.6): ~0%
### Key Observations
1. **Accuracy Scaling:** All models show improved accuracy with more training samples. The baseline shows the most dramatic relative gain, moving from 38.3% at 10k to 91.9% at 100k.
2. **Model Superiority:** The "Ours" models consistently outperform the baseline at every sample size. The "Ours (0.4)" variant achieves the highest accuracy in four out of five groups (peaking at 94.9% with 100k samples).
3. **Diminishing Returns:** The relative improvement of "Ours" over the baseline is most pronounced at the smallest dataset size (10k), where the baseline performs poorly. As the baseline accuracy improves with more data, the *relative* gain from the proposed methods shrinks significantly, approaching near-zero improvement at 100k samples.
4. **Parameter Sensitivity:** The performance of "Ours" is sensitive to the parameter (0.2, 0.4, 0.6). The 0.4 setting appears optimal, yielding the highest accuracy in most cases. The 0.6 setting often underperforms the 0.4 setting.
### Interpretation
This chart tells a story about **data efficiency and model robustness**. The proposed methods ("Ours") are not just marginally better; they are dramatically more **data-efficient**. At 10k samples, they achieve accuracy levels (70-85%) that the baseline only reaches with 25k-50k samples. This suggests the new methods learn more effectively from limited data.
The converging trends at 100k samples indicate a **performance ceiling**. As the dataset becomes very large, the advantage of the advanced methods diminishes because the baseline model, given enough data, can also learn the task well. The key value proposition of "Ours" is therefore strongest in **low-data regimes**, making it highly valuable for applications where collecting labeled data is expensive or time-consuming.
The parameter sweep (0.2, 0.4, 0.6) indicates an optimal complexity or regularization point (0.4). Setting it too low (0.2) may underfit, while setting it too high (0.6) may introduce noise or over-constrain the model, leading to suboptimal performance. The chart effectively argues for the adoption of the "Ours (0.4)" model, especially when training data is limited.
</details>
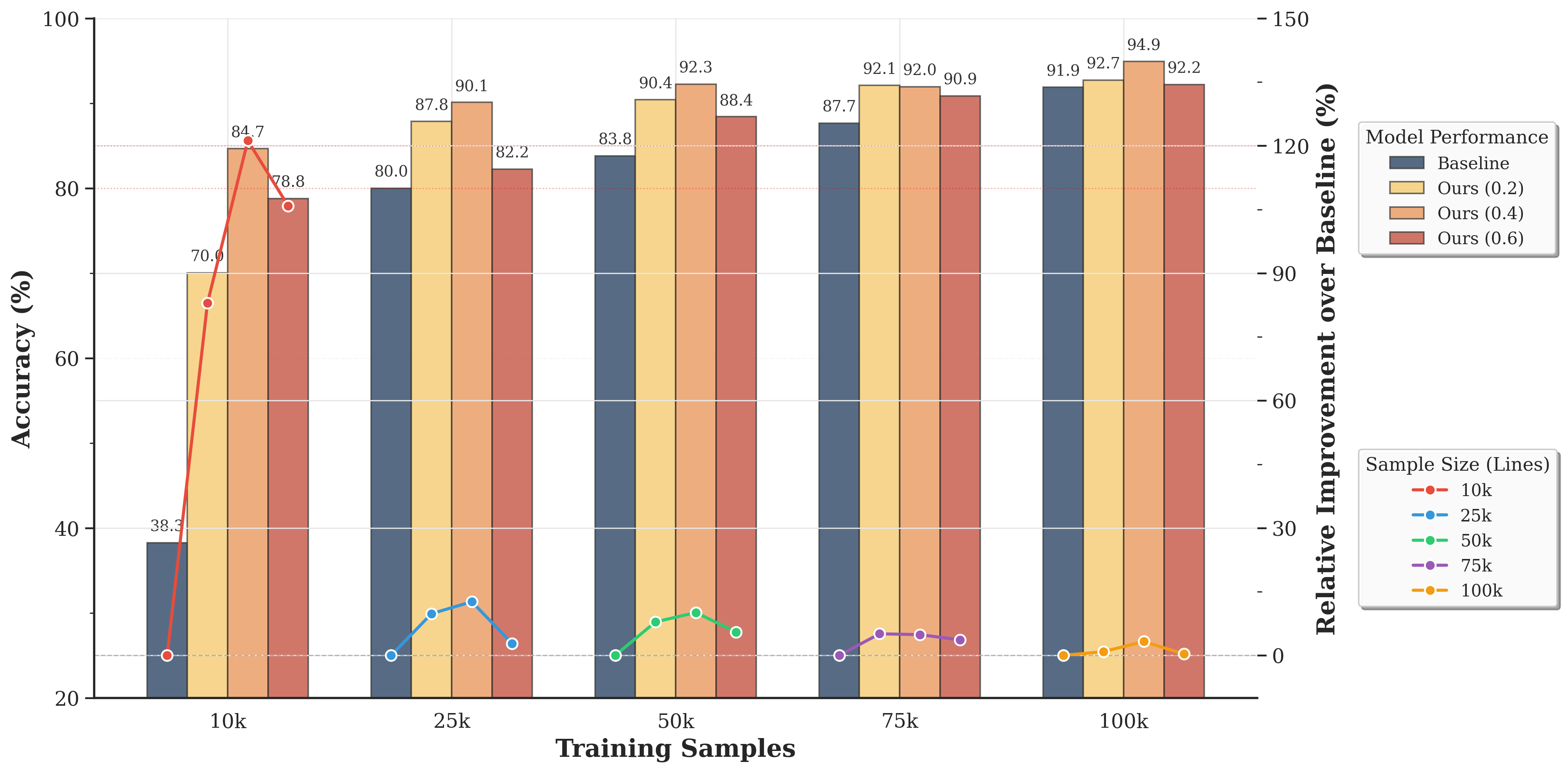
Figure 4: Performance comparison across different freeze rates. The bar chart shows accuracy values under various experimental conditions with different training set sizes. The line plot indicates the relative performance improvement (in percentage) of our method compared to the baseline at different freeze rates for each training set size.
Figure 4 demonstrates that our memory-augmented architecture consistently outperforms the baseline across all freeze rate configurations. Most pronounced improvements emerge in low-data regimes: with 10k training samples, our method achieves minimum 83% improvement regardless of $ρ$ , highlighting Memory Bank mechanism robustness to hyperparameter selection. Even at 100k samples where baseline reaches 91.91% accuracy, our approach maintains 0.3%-3.3% improvements, confirming explicit memory benefits persist when parametric learning approaches saturation.
The freeze rate-performance relationship exhibits non-monotonic patterns, with optimal performance at $ρ=0.4$ across most training set sizes. This peak suggests critical balance between explicit knowledge preservation in $M_f$ and implicit knowledge adaptation in $M_u$ . Lower freeze rates ( $ρ<0.4$ ) potentially compromise core linguistic knowledge stability, allowing excessive updates corrupting fundamental representations. Higher freeze rates ( $ρ>0.4$ ) restrict model capacity to incorporate task-specific patterns through gradient-based learning, limiting domain-specific adaptation. This trade-off validates our architectural design where frozen entries preserve high-fidelity factual knowledge while updatable entries accommodate evolving linguistic patterns, with optimal partition emerging empirically at approximately 40% frozen knowledge allocation.
### 4.6 Impact of Perfect Retrieval on Model Performance
To quantify the potential performance gains from improved retrieval accuracy, we conduct controlled experiments comparing autonomous retrieval (Retain) against surgical replacement (Replace) of retrieval results. Based on the critical layers identified in Section 4.5, we intervene at layers L1 and L3 by replacing the top-ranked candidate from the 16 retrieved entries with the oracle knowledge entry most relevant to the correct answer. This experimental design isolates the effect of retrieval quality from other architectural components, providing an upper bound on performance improvements achievable through enhanced retrieval mechanisms.
Table 2: Accuracy comparison between autonomous retrieval (Retain) and surgical replacement of retrieval results at specific layers (Replace) to evaluate the impact of perfect retrieval on model performance.
| 50k Replace 75k | Retain 74.49% $↑$ 3.62% Retain | 70.87% 92.12% $↑$ 2.25% 77.12% | 89.87% 87.24% $↑$ 2.12% 90.25% | 85.12% 88.00% |
| --- | --- | --- | --- | --- |
| Replace | 79.85% $↑$ 2.73% | 91.87% $↑$ 1.62% | 90.25% $↑$ 2.25% | |
| 100k | Retain | 79.12% | 90.50% | 90.37% |
| Replace | 81.00% $↑$ 1.88% | 92.25% $↑$ 1.75% | 91.12% $↑$ 0.75% | |
Table 2 demonstrates consistent improvements across all tasks when perfect retrieval is guaranteed, with an average accuracy gain of 2.11 percentage points. The Object Prediction task exhibits the largest improvements (3.62% at 50k samples), consistent with its direct dependence on retrieving specific factual entries from $M$ . This task directly queries token sequences $m_i$ for entity relationships, making it most sensitive to retrieval precision. Relation Reasoning shows moderate gains (2.25% at 50k, 1.75% at 100k), suggesting that compositional reasoning benefits from accurate knowledge retrieval but also relies on learned transformations within the network. The diminishing returns observed at larger training volumes (100k samples) indicate that models with more extensive training develop compensatory mechanisms for imperfect retrieval. The average improvement decreases from 2.66% at 50k samples to 1.46% at 100k samples, suggesting that larger training sets enable the model to learn robust representations that partially mitigate retrieval errors.
## 5 Conclusion
We presented ExplicitLM, a novel language model architecture that fundamentally transforms knowledge storage from implicit distributed representations to an explicit, interpretable Memory Bank system. Our approach addresses critical LLM limitations—knowledge staleness, lack of interpretability, and update difficulties—by introducing dual-system design partitioning knowledge into frozen explicit entries and updatable implicit components. Comprehensive experiments demonstrated that ExplicitLM consistently outperforms baseline Transformers across knowledge-intensive tasks, with $20-40\$ improvements in low-data regimes and maintained advantages at scale. Layer-wise hit rate analysis confirmed successful memory retrieval directly correlates with prediction accuracy, validating our two-stage differentiable retrieval mechanism. While current implementation requires manual curation of explicit knowledge entries, this limitation points to promising future directions: developing mechanisms to automatically extract and update explicit knowledge from training data while preserving human readability and interpretability. Such advances would enable models to continuously expand verifiable knowledge bases during training, combining statistical learning benefits with transparent, editable knowledge management—crucial for building trustworthy, maintainable AI systems for real-world deployment.
## References
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Cheng et al. (2024) Jeffrey Cheng, Marc Marone, Orion Weller, Dawn Lawrie, Daniel Khashabi, and Benjamin Van Durme. Dated data: Tracing knowledge cutoffs in large language models. arXiv preprint arXiv:2403.12958, 2024.
- Chowdhery et al. (2023) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113, 2023.
- Dai et al. (2022) Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. Knowledge neurons in pretrained transformers. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 8493–8502, 2022.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186, 2019.
- Dong et al. (2022) Qingxiu Dong, Damai Dai, Yifan Song, Jingjing Xu, Zhifang Sui, and Lei Li. Calibrating factual knowledge in pretrained language models. In Findings of the Association for Computational Linguistics: EMNLP 2022, pp. 5937–5947, 2022.
- Ennab & Mcheick (2024) Mohammad Ennab and Hamid Mcheick. Enhancing interpretability and accuracy of ai models in healthcare: a comprehensive review on challenges and future directions. Frontiers in Robotics and AI, 11:1444763, 2024.
- Geva et al. (2021) Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 5484–5495, 2021.
- Gowda et al. (2025) Shruthi Gowda, Bahram Zonooz, and Elahe Arani. Dual cognitive architecture: Incorporating biases and multi-memory systems for lifelong learning. Transactions on Machine Learning Research, 2025.
- Gu & Dao (2023) Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023.
- He (2024) Xu Owen He. Mixture of a million experts. arXiv preprint arXiv:2407.04153, 2024.
- Hou et al. (2025) Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. Model context protocol (mcp): Landscape, security threats, and future research directions. arXiv preprint arXiv:2503.23278, 2025.
- Jiang et al. (2024) Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint arXiv:2401.04088, 2024.
- Latif (2025) Youssef Abdel Latif. Hallucinations in large language models and their influence on legal reasoning: Examining the risks of ai-generated factual inaccuracies in judicial processes. Journal of Computational Intelligence, Machine Reasoning, and Decision-Making, 10(2):10–20, 2025.
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33:9459–9474, 2020.
- Li et al. (2023) Daliang Li, Ankit Singh Rawat, Manzil Zaheer, Xin Wang, Michal Lukasik, Andreas Veit, Felix Yu, and Sanjiv Kumar. Large language models with controllable working memory. In Findings of the Association for Computational Linguistics: ACL 2023, pp. 1774–1793, 2023.
- Li et al. (2025) Zhihao Li, Kun Li, Boyang Ma, Minghui Xu, Yue Zhang, and Xiuzhen Cheng. We urgently need privilege management in mcp: A measurement of api usage in mcp ecosystems. arXiv preprint arXiv:2507.06250, 2025.
- Meng et al. (2022) Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt. Advances in neural information processing systems, 35:17359–17372, 2022.
- Mitchell et al. (2022) Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D Manning, and Chelsea Finn. Memory-based model editing at scale. In International Conference on Machine Learning, pp. 15817–15831. PMLR, 2022.
- Mousavi et al. (2024) Seyed Mahed Mousavi, Simone Alghisi, and Giuseppe Riccardi. Dyknow: Dynamically verifying time-sensitive factual knowledge in llms. In Findings of the Association for Computational Linguistics: EMNLP 2024, pp. 8014–8029, 2024.
- Onoe et al. (2023) Yasumasa Onoe, Michael Zhang, Shankar Padmanabhan, Greg Durrett, and Eunsol Choi. Can lms learn new entities from descriptions? challenges in propagating injected knowledge. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 5469–5485, 2023.
- Peng et al. (2023) Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, et al. Rwkv: Reinventing rnns for the transformer era. arXiv preprint arXiv:2305.13048, 2023.
- Perełkiewicz & Poświata (2024) Michał Perełkiewicz and Rafał Poświata. A review of the challenges with massive web-mined corpora used in large language models pre-training. In International Conference on Artificial Intelligence and Soft Computing, pp. 153–163. Springer, 2024.
- (25) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
- Salemi & Zamani (2024) Alireza Salemi and Hamed Zamani. Evaluating retrieval quality in retrieval-augmented generation. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 2395–2400, 2024.
- Singh et al. (2025) Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. A survey of the model context protocol (mcp): Standardizing context to enhance large language models (llms). 2025.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Van Den Oord et al. (2017) Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. Advances in neural information processing systems, 30, 2017.
- Wang et al. (2024) Yu Wang, Yifan Gao, Xiusi Chen, Haoming Jiang, Shiyang Li, Jingfeng Yang, Qingyu Yin, Zheng Li, Xian Li, Bing Yin, et al. Memoryllm: Towards self-updatable large language models. arXiv preprint arXiv:2402.04624, 2024.
## Appendix A Appendix
### A.1 Reproducibility Statement
We are committed to ensuring the full reproducibility of our work. All experiments presented in this paper can be reproduced using the code and configurations provided in our anonymous repository (ExplicitLM). All experiments were conducted on NVIDIA A100 GPUs.
### A.2 AI Assistance Statement
We declare that AI-based tools were used solely for language polishing purposes in this work. Specifically, after completing the initial draft entirely through human effort, we employed AI assistance exclusively for grammatical refinement and improving the clarity of English expression to meet academic writing standards. The AI tools did not contribute to: (1) the generation or development of research ideas, including the core concept of ExplicitLM and the memory bank mechanism; (2) the design of experiments or methodology; (3) the analysis or interpretation of results; (4) the drafting of original content or scientific arguments; or (5) any mathematical derivations or technical contributions. All intellectual contributions, from conceptualization to initial manuscript preparation, were performed by the human authors. The use of AI was limited to post-writing language enhancement, similar to traditional proofreading services, ensuring that non-native English speakers can present their research with appropriate linguistic quality while maintaining complete authorship and originality of the scientific content.