# IG-Pruning: Input-Guided Block Pruning for Large Language Models
Abstract
With the growing computational demands of large language models (LLMs), efficient inference has become increasingly critical for practical deployment. Depth pruning has emerged as a promising approach for reducing the computational costs of large language models by removing transformer layers. However, existing methods typically rely on fixed block masks, which can lead to suboptimal performance across different tasks and inputs. In this paper, we propose IG-Pruning, a novel input-aware block-wise pruning method that dynamically selects layer masks at inference time. Our approach consists of two stages: (1) Discovering diverse mask candidates through semantic clustering and $L_{0}$ optimization, and (2) Implementing efficient dynamic pruning without the need for extensive training. Experimental results demonstrate that our method consistently outperforms state-of-the-art static depth pruning methods, making it particularly suitable for resource-constrained deployment scenarios. https://github.com/ictnlp/IG-Pruning
IG-Pruning: Input-Guided Block Pruning for Large Language Models
Kangyu Qiao 1,3, Shaolei Zhang 1,3, Yang Feng 1,2,3 Corresponding author: Yang Feng. 1 Key Laboratory of Intelligent Information Processing, Institute of Computing Technology, Chinese Academy of Sciences (ICT/CAS) 2 Key Laboratory of AI Safety, Chinese Academy of Sciences 3 University of Chinese Academy of Sciences, Beijing, China {qiaokangyu24s, zhangshaolei20z, fengyang}@ict.ac.cn
1 Introduction
Large Language Models (LLMs) Brown et al. (2020); AI@Meta (2024); QwenTeam (2025); Zhang et al. (2024b, 2023a) have demonstrated remarkable capabilities across a wide range of natural language processing tasks. However, their immense model size and computational demands present significant deployment challenges Wang et al. (2024); Zhou et al. (2024), particularly in resource-constrained environments and for latency-sensitive real-time inference scenarios. To address this, pruning techniques have become a crucial area of research Ma et al. (2023); Sun et al. (2023); Frantar and Alistarh (2023); Ashkboos et al. (2024); Fang et al. (2024); Ling et al. (2024); Zhang et al. (2023b); Gu et al. (2021), being highly favored due to their potential for reducing parameters for efficient inference.
As large LLMs continue to scale in size, researchers have identified significant redundancy within their layer structures. Studies from Liu et al. (2023); Men et al. (2024); Gromov et al. (2024) reveal that word embeddings in adjacent layers often change slightly due to residual connection, suggesting that selective layer removal may have minimal impact on performance. These findings have motivated increasing research interest in discovering effective depth pruning strategies for LLMs, which aim to reduce the number of transformer layers or blocks in the model architecture while maintaining performance. In recent years, depth pruning methods Song et al. (2024); Sieberling et al. (2024); Kim et al. (2024); Ling et al. (2024) have emerged as a promising approach for reducing LLM computational costs. Compared with fine-grained structured pruning methods (which remove the neurons or channels), depth pruning has demonstrated superior computational efficiency advantages in practical deployments Kim et al. (2024).
<details>
<summary>x1.png Details</summary>
### Visual Description
## Bar Chart: Task Performance Comparison
### Overview
The image is a bar chart comparing task performance across two categories: "PPL" and "Other Tasks." Each category contains two bars (purple and beige), with a legend indicating "Mask1" (purple) and "Mask2" (beige). Below the chart, two diagrams labeled "Mask1" and "Mask2" show grouped bars, suggesting a relationship between the masks and task performance.
### Components/Axes
- **X-axis**: Labeled "PPL" and "Other Tasks."
- **Y-axis**: Labeled with a scale from 0 to 100 (no explicit unit).
- **Legend**: Located at the bottom, with "Mask1" (purple) and "Mask2" (beige).
- **Symbols**:
- "Other Tasks" includes three categories:
- Cloud (🌤️)
- Calculator (📊)
- Lightbulb (💡)
### Detailed Analysis
- **PPL Section**:
- Both bars (purple and beige) reach the maximum value of 100.
- A dashed horizontal line at 100 indicates a threshold or target.
- **Other Tasks Section**:
- **Cloud (🌤️)**:
- Purple (Mask1): ~60
- Beige (Mask2): ~80
- **Calculator (📊)**:
- Purple (Mask1): ~90
- Beige (Mask2): ~85
- **Lightbulb (💡)**:
- Purple (Mask1): ~70
- Beige (Mask2): ~75
- **Mask Diagrams**:
- **Mask1**: Two purple bars (left) and two beige bars (right), grouped in pairs.
- **Mask2**: Two beige bars (left) and two purple bars (right), grouped in pairs.
### Key Observations
1. **PPL Consistency**: Both masks achieve the maximum value (100) in the "PPL" category, suggesting it is a critical or standardized task.
2. **Other Tasks Variability**:
- "Cloud" shows the largest gap between masks (20 units).
- "Calculator" has a smaller gap (5 units).
- "Lightbulb" has a moderate gap (5 units).
3. **Mask Grouping**: The diagrams indicate that Mask1 and Mask2 group tasks differently, with Mask1 prioritizing purple (higher values in "Calculator") and Mask2 prioritizing beige (higher values in "Cloud").
### Interpretation
The chart highlights differences in task performance between two masks. The "PPL" category is consistently high, implying it is a baseline or essential task. In "Other Tasks," Mask1 performs better in "Calculator" (90 vs. 85), while Mask2 excels in "Cloud" (80 vs. 60). The lightbulb task shows similar performance across masks. The mask diagrams suggest that the grouping of tasks (e.g., pairing purple/beige bars) may reflect different configurations or priorities. The dashed line at 100 in the PPL section could indicate a performance ceiling or target.
### Notable Trends
- **Mask1** prioritizes "Calculator" tasks (highest value: 90).
- **Mask2** prioritizes "Cloud" tasks (highest value: 80).
- "PPL" is the only category where both masks achieve the maximum value, suggesting it is a non-negotiable or standardized task.
### Uncertainties
- Exact numerical values are approximate (e.g., ~60, ~80) due to the lack of gridlines or precise scale markers.
- The purpose of the "Mask" diagrams (e.g., whether they represent data grouping, configuration, or another metric) is not explicitly stated.
</details>
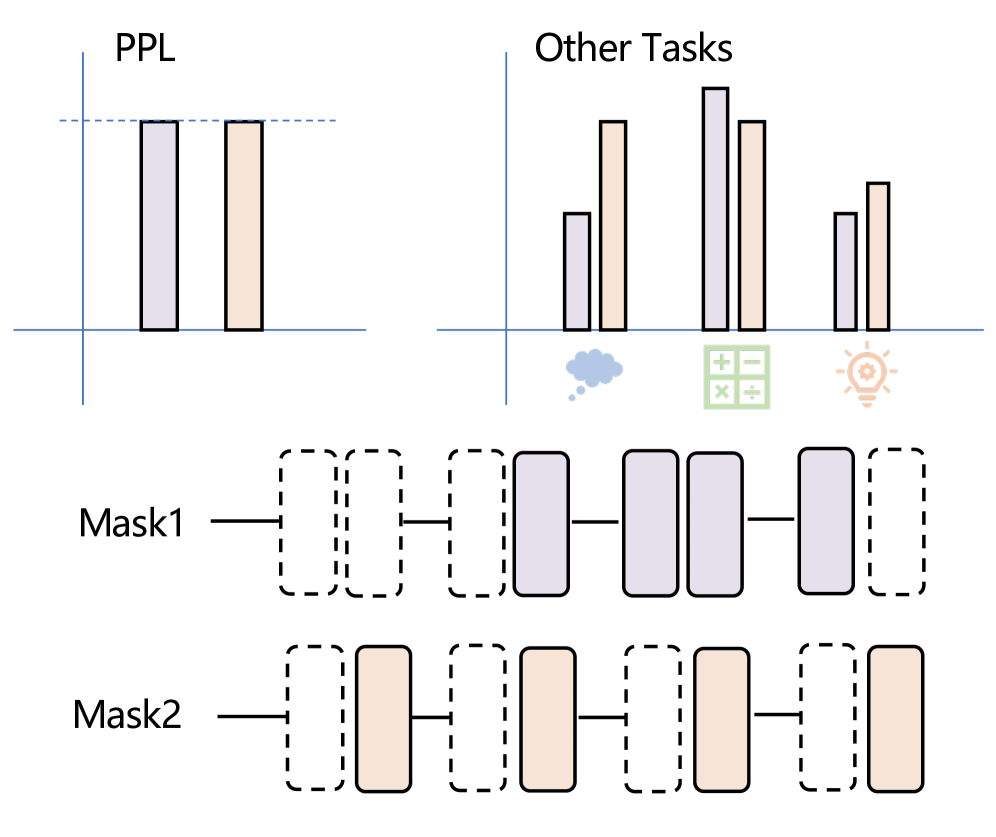
Figure 1: Different Mask structure can lead to similar perplexity scores but exhibit significant performance variations across different downstream tasks.
However, a critical limitation of existing depth pruning methods is their reliance on a fixed layer pruning mask determined offline based on global layer importance metrics at a given sparsity level. This static approach is problematic because different fixed pruning masks, even at the same sparsity level, can exhibit significant performance variations across different downstream tasks. For instance, we observe that perplexity (PPL) is commonly used as a saliency metric for layer pruning Sieberling et al. (2024); Kim et al. (2024), but as illustrated in Figure 1, different mask structures can achieve similar perplexity scores while exhibiting substantially different performance across various downstream tasks. To overcome these limitations and enable adaptive computation pathways, researchers have explored various dynamic routing approaches Elhoushi et al. (2024); Fan et al. (2024); Del Corro et al. ; Schuster et al. (2022); Raposo et al. (2024); Tan et al. (2024); Wu et al. (2024). However, most existing methods perform dynamic routing at the token level, which introduces significant drawbacks: they lack comprehensive understanding of sentence-level semantics, potentially leading to globally inconsistent routing decisions. Furthermore, these approaches typically incur substantial computational overhead from frequent token-level routing calls and require extensive training of additional router networks alongside the original model parameters, making them computationally expensive and time-consuming to implement.
To address the challenges identified in existing works, we propose IG-Pruning, a novel block-wise pruning method that dynamically selects layer masks based on input characteristics at inference time. Our approach consists of two stages: (1) a semantic clustering-based mask discovery stage that identifies diverse, high-quality mask candidates while capturing global information through rapidly converging trainable masks, and (2) a lightweight inference-time routing mechanism that requires no additional training of the base model parameters, enabling efficient dynamic adaptation to varying inputs.
Extensive evaluations demonstrate that our approach consistently outperforms state-of-the-art static pruning methods across different sparsity levels and model architectures on various zero-shot tasks. For Llama-3-8B at 25% sparsity, IG-Pruning preserves 87.18% of dense model performance, surpassing the best baseline by 10.86 percentage points. Similarly, for Qwen-3-8B, IG-Pruning maintains 96.01% of dense model performance at 13.9% sparsity, compared to 90.37% for the best baseline.
Our method trains only mask parameters while keeping model weights frozen, enabling rapid adaptation with minimal computational overhead. During inference stage, it incurs negligible routing overhead by efficiently skipping unimportant layers; and these advancements provides a viable path toward deploying powerful LLMs in environments with limited computational resources.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Two-Stage Machine Learning System Architecture
### Overview
The diagram illustrates a two-stage machine learning system architecture, likely for natural language processing (NLP) or similar tasks. It combines clustering, attention mechanisms, and feed-forward networks (FFN) with iterative refinement. Stage 1 focuses on calibration and clustering, while Stage 2 emphasizes dynamic routing and model refinement.
### Components/Axes
#### Stage 1 (Left Side):
1. **Soft Mask Training**: A process involving probabilistic masking, likely for model calibration.
2. **Calibration Data**: Input data used to train the system.
3. **Sentence Encoder**: Encodes input data into embeddings.
4. **K-means**: A clustering algorithm initialized with embeddings from the Sentence Encoder.
5. **Initialization**: Arrows indicate flow from Calibration Data → Sentence Encoder → K-means.
#### Stage 2 (Right Side):
1. **Input**: Raw data fed into the system.
2. **Sentence Encoder**: Reused from Stage 1 to encode input.
3. **Router**: Directs embeddings to an **Embedding Pool** based on **Min Distance** (likely nearest neighbor search).
4. **Select**: Chooses embeddings from the pool.
5. **Prune**: Removes irrelevant or redundant data.
6. **ATTN (Attention)**: Processes selected embeddings.
7. **FFN (Feed-Forward Network)**: Applies non-linear transformations.
8. **Loop**: Outputs from FFN loop back into the system for iterative refinement.
### Detailed Analysis
- **Stage 1 Flow**:
- Calibration Data → Sentence Encoder → K-means → Soft Mask Training.
- K-means initializes clusters (C1–C4) for soft masking.
- **Stage 2 Flow**:
- Input → Sentence Encoder → Router → Embedding Pool → Select → Prune → ATTN → FFN → Loop.
- The **Router** uses **Min Distance** to map embeddings to the closest cluster (C1–C4).
- **ATTN** and **FFN** form a recurrent loop, suggesting iterative refinement of embeddings.
### Key Observations
1. **Redundancy**: The Sentence Encoder is reused in both stages, indicating shared representation learning.
2. **Dynamic Routing**: The Router’s use of Min Distance implies a nearest-neighbor approach for embedding selection.
3. **Iterative Refinement**: The ATTN-FFN loop suggests a transformer-like architecture with feedback for optimization.
4. **Pruning**: Likely removes low-confidence or irrelevant embeddings to improve efficiency.
### Interpretation
This architecture combines **clustering-based calibration** (Stage 1) with **attention-driven refinement** (Stage 2). The reuse of the Sentence Encoder ensures consistent feature extraction, while the Router’s Min Distance mechanism enables efficient embedding selection. The ATTN-FFN loop mirrors transformer architectures, where attention mechanisms and feed-forward layers iteratively refine representations.
The system likely balances **efficiency** (via pruning and clustering) with **accuracy** (via attention and iterative refinement). The absence of explicit numerical values suggests this is a conceptual diagram, emphasizing component relationships over quantitative performance metrics.
**Note**: No numerical data or trends are present in the diagram. All components are labeled, and flow directions are explicitly defined via arrows.
</details>
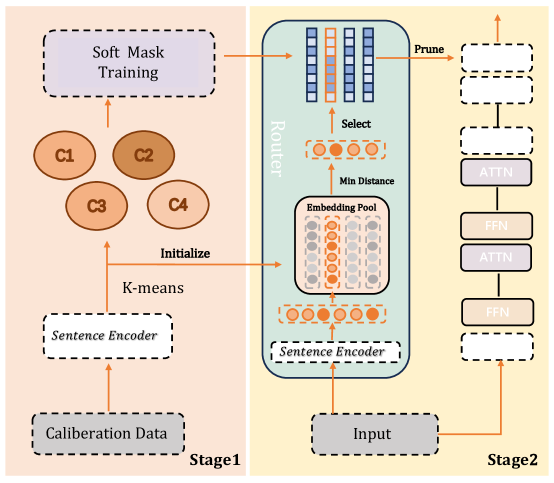
Figure 2: Overview of our method. The approach consists of two stages: (1) Preparing mask candidates through input clustering and soft mask training; (2) Dynamic pruning that selects the appropriate mask for each input at inference time. This enables efficient computation by selectively skipping layers based on input characteristics while maintaining model performance.
2 Related Work
Most static depth pruning approaches focus on calculating saliency scores for each transformer block, and removing layers according to these scores. Commonly used saliency metrics include cosine similarity Song et al. (2024); Men et al. (2024), magnitude, second-order derivatives Kim et al. (2024), and perplexity Sieberling et al. (2024). These works calculate layer importance as if they are independent of others, which ignores the coupling connections between layers. As discovered in Fan et al. (2024), contiguous middle layers often exhibit similar saliency scores, which inspired Chen et al. (2024) to use small FFN or transformer blocks to replace contiguous layers. EvoPress Sieberling et al. (2024) found that lower per-layer error does not necessarily lead to better performance, and proposed an evolutionary search algorithm to generate offspring from parent masks, then select better candidates with lower perplexity or KL divergence. Rather than directly removing layers, LaCO Yang et al. (2024) collapses consecutive redundant model layers via layer averaging. MKA Liu et al. (2024a) transforms layer activations into low-dimensional manifolds using diffusion kernel algorithms and evaluates saliency using the NPIB metric.
Beyond one-shot pruning approaches, dynamically skipping unimportant layers during inference has also emerged as a promising research direction. Early approaches include early skipping Del Corro et al. ; Zhu et al. (2024), early exit Elhoushi et al. (2024), and periodic skipping Liu et al. (2024b). However, these methods typically require routers for each layer and demand elaborate training of original weights to recover performance. Dynamic skipping has also been adopted in long-context and multimodal models. Adaskip He et al. (2024) focused on adaptive layer skipping for long-context models, accelerating both prefilling and decoding phases. RoE Wu et al. (2024) employs token-wise routing for multimodal LLMs and trains low-rank adapters to replace the skipped layers.
3 Method
As illustrated in Figure 2, our framework consists of two main stages: (1) Mask candidate discovery and (2) Dynamic routing. In the first stage, we cluster the semantic space of inputs and train cluster-specific masks using hard concrete distributions, resulting in diverse yet high-quality mask candidates that each specialize in handling different input patterns. During the second stage, at inference time, we employ a lightweight routing mechanism that maps each input to its most semantically similar cluster and applies the corresponding pre-trained mask, enabling efficient dynamic adaptation without requiring additional training of router networks or base model parameters.
3.1 Stage 1: Discovering Mask Candidates
In the first stage, we aim to discover a set of effective mask candidates for dynamic routing. Unlike existing routing methods that typically employ per-layer router networks to make skip decisions, we propose a global routing strategy that dynamically selects routing paths from a carefully curated candidate mask set.
We design our mask candidate discovery process to satisfy two key requirements: Quality: Masks must maintain strong general language generation capabilities. Diversity: The candidate set must provide sufficient variety to handle different input patterns effectively.
To meet these requirements, we leverage hard concrete distribution to model transformer block masks to capture global routing information, and apply $L_{0}$ optimization with cluster-specific calibration data, generating masks that cover diverse computational needs.
Input Clustering.
First, an encoder is used to encode each sentence $x_{i}$ in the calibration dataset into a fixed-dimensional embedding vector $e_{i}$ :
$$
e_{i}=\text{Encoder}(x_{i}) \tag{1}
$$
where $x_{i}$ represents the $i$ -th input, and $e_{i}∈\mathbb{R}^{d}$ , with $d$ being the dimension of the embedding vector. Next, the K-means algorithm is applied to cluster all embedding vectors $e_{1},e_{2},...,e_{M}$ , where $M$ is the size of the calibration set. The K-means algorithm aims to find $N$ clusters $S=\{S_{1},S_{2},...,S_{N}\}$ that minimize the within-cluster sum of squares:
$$
\arg\min_{S}\sum_{k=1}^{N}\sum_{e_{i}\in S_{k}}\|e_{i}-\mu_{k}\|^{2} \tag{2}
$$
where $\mu_{k}$ is the centroid of cluster $S_{k}$ . This results in $N$ cluster centers, each representing a class of semantically similar input sentences.
Mask Training.
Hard concrete distribution Louizos et al. (2018); Xia et al. (2022, 2024) has been widely adopted in structured pruning. Following prior work, we incorporate hard concrete distribution to model transformer block masks, and use $L_{0}$ optimization to generate layer masks, enabling joint learning of all layer masks while incorporating global information.
For each cluster $S_{k}$ , we train a dedicated layer mask $z^{(k)}∈\mathbb{R}^{B}$ using hard concrete distribution and Lagrangian sparsity, where $B$ is the total number of blocks in the model (for block-wise pruning, $B=2L$ where $L$ is the number of transformer layers, representing both attention and FFN blocks separately). Specifically, the masks $z^{(k)}$ are modeled as follows:
First, for each block $i$ in the model, sample $u^{(k)}_{i}$ from a uniform distribution:
$$
u^{(k)}_{i}\sim\text{Uniform}(0,1),\quad i\in\{1,2,\ldots,B\} \tag{3}
$$
Then, compute the soft mask value $s^{(k)}_{i}$ for each block using the sigmoid function:
$$
s^{(k)}_{i}=\sigma\left(\frac{1}{\beta}\log{\frac{u^{(k)}_{i}}{1-u^{(k)}_{i}}}+\log\alpha^{(k)}_{i}\right) \tag{4}
$$
Stretch the soft mask values to a specific interval $[l,r]$ :
$$
\tilde{s}^{(k)}_{i}=s^{(k)}_{i}\times(r-l)+l \tag{5}
$$
Finally, obtain the hardened mask $z^{(k)}_{i}$ for each block by clipping:
$$
z^{(k)}_{i}=\min(1,\max(0,\tilde{s}^{(k)}_{i})) \tag{6}
$$
The complete mask vector for cluster $k$ is then $z^{(k)}=[z^{(k)}_{1},z^{(k)}_{2},...,z^{(k)}_{B}]$ , where each element corresponds to a specific transformer block in the model. During training, these mask values are soft (continuous values between 0 and 1), functioning as scaling parameters. During inference, they are binarized to either 0 (block skipped) or 1 (block executed).
Here, $\sigma$ denotes the sigmoid function. The temperature $\beta$ is fixed hyperparameter, and $l<0,r>0$ are two constants that stretch the sigmoid function output. $\alpha^{(k)}_{i}$ are the main learnable parameters for i-th block mask value in cluster $k$ .
We enforce a target sparsity via a Lagrangian term. Let $s_{\text{target}}$ be the target sparsity and $t^{(k)}$ be the current sparsity of mask $z^{(k)}$ (computed as the proportion of zeroes in the mask), the Lagrangian penalty term $L_{s}^{(k)}$ is:
$$
L_{s}^{(k)}=\lambda_{1}^{(k)}(t^{(k)}-s_{\text{target}})+\lambda_{2}^{(k)}(t^{(k)}-s_{\text{target}})^{2} \tag{7}
$$
For the $k$ -th cluster, the optimization objective for its mask parameters $\log\alpha^{(k)}$ is to minimize:
$$
L_{\text{total}}^{(k)}=\sum_{x_{j}\in S_{k}}L_{\text{LM}}(x_{j};W\odot z^{(k)})+L_{s}^{(k)} \tag{8}
$$
where $L_{\text{LM}}$ is the language modeling loss and $W$ represents the model weights.
Routing Decision.
To implement dynamic routing decisions, we maintain an embedding pool for each semantic cluster to represent the cluster’s features. These embeddings $c_{k}$ are initialized using the cluster centers $\mu_{k}$ . During inference, for each input sequence, we first extract its embedding representation $e_{x}$ through the encoder, then calculate the Euclidean distance between this embedding and each cluster embedding $c_{k}$ . Based on the calculated distances, we select the most similar cluster as the best match for that input:
$$
k^{*}=\arg\min_{k}||e_{x}-c_{k}||_{2}^{2},k\in\{1,2,\ldots,N\} \tag{9}
$$
After determining the best matching cluster, we directly adopt the trained mask corresponding to that cluster as the final execution mask for input $x$ :
$$
M^{x}=z^{(k^{*})} \tag{10}
$$
where $z^{(k^{*})}$ is the binary mask vector associated with cluster $k^{*}$ , containing all block-level mask values.
Dynamic Routing for FFN and Attention Blocks.
Our dynamic routing approach employs different strategies for Feed-Forward layers and Attention layers. During training, the layer mask values are soft, functioning as scaling parameters that directly multiply with the outputs of FFN and Attention components. This enables gradient-based optimization through backpropagation. During inference, we use hard binary masks containing only 0 and 1, where FFN layers are completely skipped when the corresponding mask value is 0. For Attention layers, the approach is more nuanced due to the necessity of maintaining key-value caches for autoregressive generation. When an Attention layer is marked for skipping, we still compute the key and value projections to maintain the KV cache, but we bypass the computationally expensive scaled dot-product operation between queries and keys. Specifically, for a transformer layer $i$ with mask value $M_{i}^{x}=0$ , the FFN computation $\text{FFN}(x_{i})$ is entirely skipped, while for Attention, we compute $K=W_{K}x_{i}$ and $V=W_{V}x_{i}$ for the cache but skip $\text{Attention}(Q,K,V)=\text{softmax}(QK^{T}/\sqrt{d})V$ . This selective computation strategy preserves the model’s autoregressive capabilities while reducing computational overhead.
4 Experiment
| Model | Sparsity | Method | OBQA | WG | HS | PIQA | ARC-E | ARC-C | Average | Percentage |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Llama-3-8B | 0% | Dense | 44.6 | 73.24 | 79.16 | 80.79 | 77.82 | 53.24 | 68.14 | 100% |
| 12.5% | SLEB | 38.6 | 69.45 | 70.71 | 77.63 | 70.28 | 43.00 | 61.61 | 90.42% | |
| ShortenedLlama | 39.2 | 61.56 | 66.84 | 76.33 | 67.63 | 38.57 | 58.36 | 85.64% | | |
| EvoPress | 41.2 | 70.17 | 72.03 | 77.75 | 71.00 | 43.69 | 62.64 | 91.93% | | |
| IG-Pruning | 43.6 | 72.93 | 77.26 | 79.38 | 77.06 | 51.62 | 66.98 | 98.29% | | |
| 25% | SLEB | 33.8 | 53.90 | 57.96 | 72.25 | 57.32 | 31.56 | 51.13 | 75.04% | |
| EvoPress | 32.8 | 57.93 | 58.16 | 71.06 | 58.38 | 33.70 | 52.01 | 76.32% | | |
| ShortenedLlama | 33.6 | 53.91 | 57.98 | 72.31 | 57.15 | 31.74 | 51.12 | 75.01% | | |
| IG-Pruning | 40.0 | 68.98 | 67.53 | 76.12 | 63.43 | 40.36 | 59.40 | 87.18% | | |
| 37.5% | SLEB | 28.4 | 52.24 | 46.46 | 65.77 | 46.96 | 28.41 | 44.71 | 65.61% | |
| EvoPress | 28.2 | 51.22 | 45.58 | 65.18 | 48.15 | 28.50 | 44.47 | 65.26% | | |
| ShortenedLlama | 28.6 | 52.41 | 45.90 | 64.69 | 42.68 | 27.47 | 43.63 | 64.02% | | |
| IG-Pruning | 31.8 | 58.01 | 49.63 | 65.94 | 48.44 | 30.38 | 47.37 | 69.51% | | |
| Qwen-3-8B | 0% | Dense | 41.8 | 67.96 | 74.93 | 77.48 | 80.77 | 56.40 | 66.56 | 100% |
| 13.9% | SLEB | 37.4 | 60.85 | 62.45 | 77.52 | 74.45 | 47.09 | 59.96 | 90.09% | |
| ShortenedLlama | 37.0 | 59.27 | 61.82 | 75.14 | 71.00 | 45.14 | 58.23 | 87.49% | | |
| EvoPress | 39.0 | 61.96 | 67.76 | 75.57 | 70.33 | 46.25 | 60.15 | 90.37% | | |
| IG-Pruning | 39.8 | 65.82 | 69.44 | 77.09 | 77.35 | 53.92 | 63.90 | 96.01% | | |
| 25% | SLEB | 36.6 | 56.35 | 53.95 | 72.47 | 65.36 | 37.20 | 53.66 | 80.62% | |
| EvoPress | 37.0 | 58.08 | 57.18 | 71.43 | 62.28 | 38.65 | 54.10 | 81.29% | | |
| ShortenedLlama | 35.6 | 53.99 | 52.20 | 70.84 | 64.69 | 36.43 | 52.29 | 78.56% | | |
| IG-Pruning | 35.6 | 60.46 | 61.65 | 73.39 | 68.94 | 44.80 | 57.47 | 86.35% | | |
| 36.1% | SLEB | 29.6 | 52.40 | 44.02 | 65.77 | 51.68 | 31.39 | 45.81 | 68.82% | |
| EvoPress | 31.6 | 52.17 | 45.29 | 62.95 | 51.09 | 29.18 | 45.38 | 68.18% | | |
| ShortenedLlama | 28.2 | 50.91 | 37.08 | 61.75 | 46.13 | 25.43 | 41.58 | 62.48% | | |
| IG-Pruning | 32.6 | 53.43 | 49.17 | 65.83 | 54.21 | 32.17 | 47.90 | 71.96% | | |
Table 1: Zero-shot evaluation results on Llama-3-8B and Qwen-3-8B across multiple sparsity levels.
4.1 Experimental Setup
Datasets and Evaluation Metrics.
Following prior work, we use lm-evaluation-harness Gao et al. (2023) to evaluate our method on six widely-used zero-shot tasks: OpenBookQA Mihaylov et al. (2018), which tests elementary-level science reasoning requiring the combination of facts with commonsense knowledge; Winogrande Sakaguchi et al. (2021), a large-scale adversarial dataset for testing pronoun disambiguation through commonsense reasoning; HellaSwag Zellers et al. (2019), which challenges models to select plausible scenario completions through commonsense inference; PIQA Bisk et al. (2020), focused on physical commonsense knowledge; and the ARC dataset Clark et al. (2018), divided into ARC-Easy and ARC-Challenge subsets for testing scientific reasoning at different difficulty levels. Llama-3-8B AI@Meta (2024) and Qwen-3-8B QwenTeam (2025) are used as our base models, and we use all-MiniLM-L6-v2 from sentence transformer Reimers and Gurevych (2019) as sentence encoder. For calibration data for clustering and layer mask training, we use fineweb-edu Lozhkov et al. (2024), which contains high quality synthetic data used for LLM pretraining.
Baselines and Setups.
To evaluate our dynamic block pruning approach against static methods, we select three representative block pruning techniques for comparison:
- SLEB Song et al. (2024): A method that iteratively eliminates redundant transformer blocks based on cosine similarity between adjacent layers.
- ShortenedLlama Kim et al. (2024): An approach that uses magnitude, second-order derivatives, or perplexity to measure block-level importance. After identifying unimportant blocks, this method removes them in a single pass.
- EvoPress Sieberling et al. (2024): A technique leveraging evolutionary algorithms to search for optimal pruning masks with improved perplexity or KL divergence. Starting with a random initial configuration, in each generation it mutates the compression levels of selected layers and retains the best candidates according to a fitness function. This approach yields better results but incurs higher computational costs.
For all baseline methods, we perform one-shot pruning that identifies and eliminates redundant transformer blocks without retraining, and we use wikitext2 Merity et al. (2016) as calibration set for baselines.
4.2 Main Results
IG-Pruning consistently outperforms all baseline methods across all evaluated sparsity configurations for both Llama-3-8B and Qwen-3-8B models. In this paper, the sparsity level is defined as the ratio of the number of skipped blocks to the total number of blocks in the model. For Llama-3-8B at 12.5% sparsity, IG-Pruning maintains 98.29% of the dense model performance, surpassing the best baseline (EvoPress) by 6.36 percentage points. This advantage becomes even more significant at 25% sparsity, where IG-Pruning achieves 87.18% of dense performance compared to the best baseline at 76.32%, representing a 10.86 percentage point improvement. Similarly, for Qwen-3-8B, IG-Pruning preserves 96.01% of dense model performance at 13.9% sparsity, compared to 90.37% for the best baseline. These consistent improvements across different model architectures demonstrate the inherent advantage of our dynamic routing strategy over static pruning methods.
4.3 Analysis
Mask Training Efficiency.
In Stage 1 of our approach, model parameters remain frozen while only layer mask parameters undergo optimization. We set a higher learning rate for $L_{0}$ module, enabling rapid mask convergence without extensive training periods. For our experiments, we sample 1,000 examples from each cluster for training, utilizing 4 NVIDIA H800 GPUs. Hyperparameters can be found in Appendix 5. For configurations with sparsity levels below 25% across 16 clusters, all masks can be trained in approximately 15 minutes. Higher sparsity (37%) requires around one hour of training time for mask convergence. Our method requires training, but it only trains the block mask parameters, while the parameters in the original models are frozen. Therefore, it doesn’t require excessive memory, which has been tested successfully on a single RTX 3090 for 8B model.
Block-level vs. Layer-level Pruning.
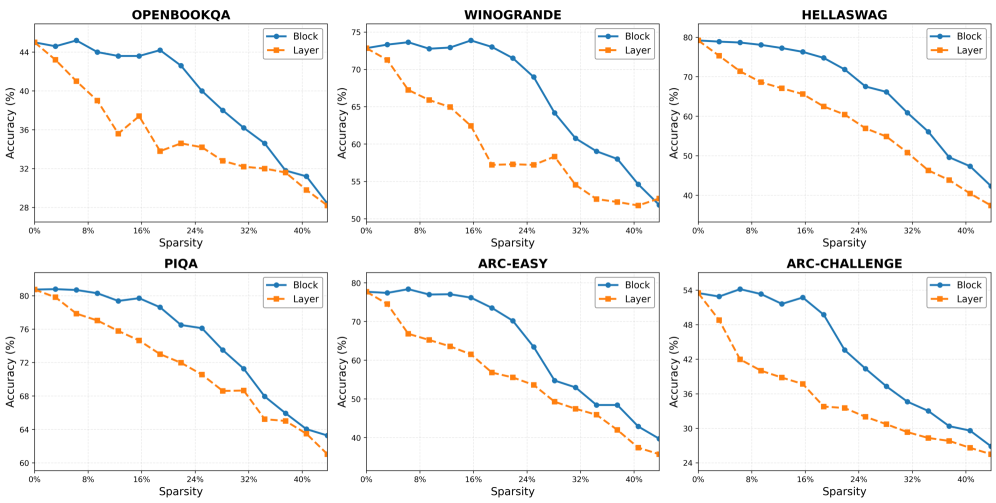
To investigate the impact of pruning granularity on model performance, we conducted comprehensive experiments comparing block-level and layer-level pruning across different sparsity configurations. As shown in Figure 3, block-level pruning consistently outperforms layer-level pruning across all tasks, with performance advantages that vary based on sparsity levels. The gap between these approaches is most significant at sparsity levels around 20%, where block pruning demonstrates substantially better performance. This suggests that independently pruning Attention and FFN components provides the model with greater flexibility to maintain critical capabilities while reducing computational costs.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Graphs: Accuracy vs. Sparsity Across Datasets
### Overview
The image contains six line graphs comparing the accuracy of two model configurations ("Block" and "Layer") across six datasets as sparsity increases from 0% to 40%. Each graph plots accuracy (%) on the y-axis against sparsity (%) on the x-axis. The datasets are: OPENBOOKQA, WINOGRANDE, HELLASWAG, PIQA, ARC-EASY, and ARC-CHALLENGE.
### Components/Axes
- **X-axis**: Labeled "Sparsity (%)" with markers at 0%, 8%, 16%, 24%, 32%, and 40%.
- **Y-axis**: Labeled "Accuracy (%)" with scales varying by dataset (e.g., 20–45% for OPENBOOKQA, 50–80% for HELLASWAG).
- **Legends**: Positioned at the top-right of each graph, with "Block" (blue line) and "Layer" (orange line) labels.
- **Titles**: Dataset names (e.g., "OPENBOOKQA") centered at the top of each graph.
### Detailed Analysis
#### OPENBOOKQA
- **Block**: Starts at ~44% accuracy (0% sparsity), declines steadily to ~28% (40% sparsity).
- **Layer**: Begins at ~44% (0% sparsity), drops sharply to ~28% (40% sparsity), with a plateau at ~32% between 8%–16% sparsity.
#### WINOGRANDE
- **Block**: Starts at ~75% (0% sparsity), declines to ~55% (40% sparsity), with minor fluctuations.
- **Layer**: Begins at ~75% (0% sparsity), drops to ~50% (40% sparsity), with a steeper decline after 24% sparsity.
#### HELLASWAG
- **Block**: Starts at ~80% (0% sparsity), declines to ~50% (40% sparsity), with a gradual slope.
- **Layer**: Begins at ~80% (0% sparsity), drops to ~40% (40% sparsity), with a consistent downward trend.
#### PIQA
- **Block**: Starts at ~80% (0% sparsity), declines to ~60% (40% sparsity), with a plateau at ~72% between 8%–16% sparsity.
- **Layer**: Begins at ~80% (0% sparsity), drops to ~55% (40% sparsity), with a sharp decline after 24% sparsity.
#### ARC-EASY
- **Block**: Starts at ~80% (0% sparsity), declines to ~40% (40% sparsity), with a steady slope.
- **Layer**: Begins at ~80% (0% sparsity), drops to ~30% (40% sparsity), with a plateau at ~50% between 8%–16% sparsity.
#### ARC-CHALLENGE
- **Block**: Starts at ~55% (0% sparsity), declines to ~30% (40% sparsity), with a gradual slope.
- **Layer**: Begins at ~55% (0% sparsity), drops to ~25% (40% sparsity), with a steeper decline after 16% sparsity.
### Key Observations
1. **Consistent Decline**: All datasets show reduced accuracy as sparsity increases, with no exceptions.
2. **Block vs. Layer**: "Block" configurations consistently outperform "Layer" across all datasets and sparsity levels.
3. **Steepest Declines**: "Layer" models exhibit sharper accuracy drops, particularly in HELLASWAG and ARC-CHALLENGE.
4. **Plateaus**: Some datasets (e.g., PIQA, ARC-EASY) show temporary stability in accuracy for "Layer" models at mid-sparsity levels.
### Interpretation
The data demonstrates that "Block" models maintain higher robustness to sparsity compared to "Layer" models. This suggests architectural advantages in "Block" configurations for handling sparse data, which is critical for applications requiring efficient, parameter-reduced models. The steeper declines in "Layer" models highlight their sensitivity to sparsity, potentially due to reliance on dense interconnections. Notably, datasets like HELLASWAG and ARC-CHALLENGE show the largest performance gaps between configurations, indicating higher vulnerability to sparsity in complex tasks. The plateaus observed in some datasets may reflect optimization challenges or architectural trade-offs in maintaining performance under moderate sparsity.
</details>
Figure 3: Results on average zero-shot task performance of Llama-3-8B, with block and layer pruning.
<details>
<summary>x4.png Details</summary>

### Visual Description
## Heatmap: MLP and Attention Masks Across Clusters for Llama-3-8B and Qwen-3-8B
### Overview
The image displays four heatmaps comparing **MLP masks** and **attention masks** across clusters for two language models: **Llama-3-8B** (bottom-left) and **Qwen-3-8B** (bottom-right). The top row shows MLP masks, while the bottom row shows attention masks. Each heatmap uses a **dark blue** color to indicate mask presence and **light yellow** for absence. Axes are labeled "Layer" (x-axis, 0–35) and "Cluster" (y-axis, 0–35).
---
### Components/Axes
- **X-axis (Layer)**: Ranges from 0 to 35, representing transformer layers.
- **Y-axis (Cluster)**: Ranges from 0 to 35, representing cluster indices.
- **Color Scheme**:
- **Dark Blue**: Mask presence (active).
- **Light Yellow**: Mask absence (inactive).
- **Titles**:
- Top-left: "MLP Masks Across Clusters" (Llama-3-8B).
- Top-right: "MLP Masks Across Clusters" (Qwen-3-8B).
- Bottom-left: "Attention Masks Across Clusters" (Llama-3-8B).
- Bottom-right: "Attention Masks Across Clusters" (Qwen-3-8B).
---
### Detailed Analysis
#### Llama-3-8B (Bottom-Left)
- **MLP Masks**:
- Vertical dark blue blocks dominate layers **7–9** and **20–22**, indicating concentrated mask activity.
- Sparse yellow regions in layers **10–15** and **23–25**.
- **Attention Masks**:
- Scattered dark blue blocks across layers **0–15**, with dense activity in clusters **5–10**.
- Minimal activity in layers **16–35**.
#### Qwen-3-8B (Bottom-Right)
- **MLP Masks**:
- Dense dark blue blocks in layers **0–5** and **25–30**, with sporadic activity in **10–15**.
- Light yellow dominates layers **6–9** and **20–24**.
- **Attention Masks**:
- Highly fragmented dark blue blocks across all layers, with dense clusters in **15–20** and **25–30**.
- Light yellow regions are sparse, especially in layers **0–5** and **20–25**.
---
### Key Observations
1. **Llama-3-8B**:
- MLP masks show **layer-specific clustering** (e.g., layers 7–9, 20–22).
- Attention masks exhibit **early-layer dominance** (layers 0–15) with sparse later-layer activity.
2. **Qwen-3-8B**:
- MLP masks display **broad layer coverage** (layers 0–5, 25–30) with gaps in mid-layers.
- Attention masks show **distributed activity** across all layers, with peaks in mid-layers (15–20, 25–30).
---
### Interpretation
- **MLP Masks**:
- Llama-3-8B’s concentrated blocks suggest **specialized processing** in specific layers, possibly for task-specific features.
- Qwen-3-8B’s broader distribution implies **generalized feature extraction** across multiple layers.
- **Attention Masks**:
- Llama-3-8B’s early-layer focus may indicate **initial token processing** dominates, while Qwen-3-8B’s distributed pattern suggests **dynamic, multi-layer attention**.
- **Model Differences**:
- Qwen-3-8B’s attention masks are more **uniformly active**, potentially enabling better context integration.
- Llama-3-8B’s MLP masks highlight **layer-specific specialization**, which might optimize efficiency for certain tasks.
---
### Notable Anomalies
- **Llama-3-8B Attention Masks**: Minimal activity in layers **16–35** could indicate **reduced relevance** of deeper layers for this model.
- **Qwen-3-8B MLP Masks**: Gaps in layers **6–9** and **20–24** might reflect **architectural trade-offs** for computational efficiency.
---
### Summary
The heatmaps reveal distinct masking strategies between Llama-3-8B and Qwen-3-8B. Llama-3-8B emphasizes **layer-specific specialization**, while Qwen-3-8B adopts a **distributed, multi-layer approach**. These differences likely influence their performance on tasks requiring contextual understanding versus specialized feature extraction.
</details>
Figure 4: Block mask visualization of Llama-3-8B(left) and Qwen-3-8B(right) with 16 clusters and 25% sparsity. Upper part is FFN Block and the lower part is Attention Block. The color indicates the mask value, with 1 being blue and 0 being yellow.
Interestingly, the performance differential diminishes as sparsity decreases. At sparsity levels higher than 40%, the differences become minimal, and in specific tasks such as Winogrande, layer-level pruning occasionally outperforms block-level pruning. To better understand the results, we analyze the layer masks. Visualization in Figure 4 reveals that Llama attention blocks are more likely to be pruned compared to FFN blocks, especially in middle layers, aligning with previous observations about layer representation similarity in Men et al. (2024). This phenomenon also exists in the Qwen-3 model, but shows a more balanced distribution between attention and FFN blocks. Additionally, attention masks are more separate for Qwen, with no long ranges of consecutive blocks being masked. We analyzed the mask distribution at various sparsity levels and found this phenomenon was commonly observed. This suggests that, in higher sparsity settings, retaining the FFN blocks is more beneficial for model performance, as they are more likely to contain important information. For higher sparsity levels, more FFN blocks are pruned, leading to similar performance between block-level and layer-level pruning.
Computational Efficiency Analysis.
To quantify efficiency improvements, we measured FLOPs (floating point operations) for Llama-3-8B with different sparsity settings, as shown in Table 2. Our analysis reveals that block-wise pruning provides significant computational savings while maintaining model performance. At 25% sparsity, our approach reduces the computational cost to 89.8% of the dense model, representing a reasonable trade-off between efficiency and effectiveness. As sparsity increases to 37.5%, computational requirements drop to 75.8% of the original model.
| 0% 3.12% 6.25% | 32.94T 32.66T 32.39T | 100.0% 99.1% 98.3% | 21.88% 25.00% 28.12% | 31.01T 29.57T 28.71T | 94.1% 89.8% 87.2% |
| --- | --- | --- | --- | --- | --- |
| 9.38% | 32.11T | 97.5% | 31.25% | 27.27T | 82.8% |
| 12.50% | 31.84T | 96.7% | 34.38% | 26.41T | 80.2% |
| 15.62% | 31.56T | 95.8% | 37.50% | 24.97T | 75.8% |
| 18.75% | 31.29T | 95.0% | 40.62% | 24.69T | 74.9% |
Table 2: Computational efficiency at different sparsity for block-wise pruning. The FLOPs values represent the computational cost, while the percentage shows the proportion relative to the dense model.
4.3.1 Analyze clustering effectiveness
Number of Clusters.
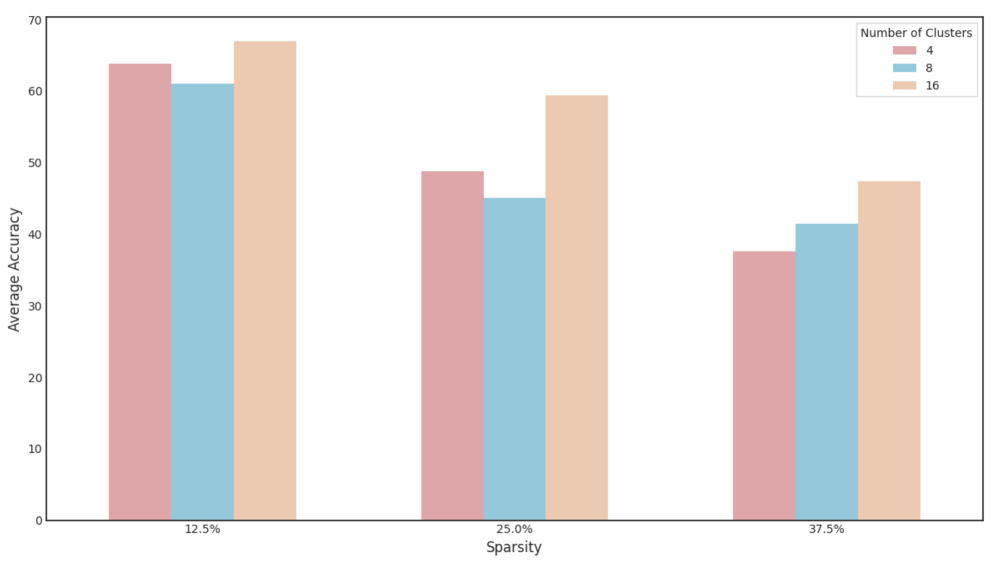
To investigate how the number of clusters affects model performance, we conducted experiments with varying cluster counts (N = 4, 8, 16) at different sparsity levels, as shown in Figure 5. The results demonstrate a clear trend: as the number of clusters increases, overall performance improves consistently across all pruning configurations. At lower sparsity, models with 16 clusters achieve an average performance of 66.98%, compared to 61.05% with 8 clusters and 63.82% with 4 clusters. This advantage becomes even more pronounced at higher sparsity levels. With sparsity of 37.5%, the 16-cluster configuration outperforms the 4-cluster variant by 10.64 percentage points. This pattern confirms that a higher number of clusters enables more specialized mask combinations tailored to different input types. With more clusters, the model can develop a more diverse set of computational paths, each optimized for specific semantic patterns in the input data. The performance improvements with increased cluster count provide strong evidence supporting our hypothesis that dynamic routing significantly benefits model effectiveness by enabling adaptive computation. Rather than forcing all inputs through a single pruned structure, our approach leverages the complementary strengths of mask combinations, explained why our dynamic pruning strategy consistently outperforms static pruning methods.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Bar Chart: Average Accuracy by Cluster Count and Sparsity
### Overview
The chart compares average accuracy across three cluster configurations (4, 8, 16 clusters) at three sparsity levels (12.5%, 25%, 37.5%). Accuracy is measured on a 0-70 scale, with higher values indicating better performance. Each cluster configuration is represented by a distinct color: red (4 clusters), blue (8 clusters), and orange (16 clusters).
### Components/Axes
- **X-axis**: Sparsity levels (12.5%, 25%, 37.5%)
- **Y-axis**: Average Accuracy (0-70 scale)
- **Legend**: Located in the top-right corner, mapping colors to cluster counts:
- Red = 4 clusters
- Blue = 8 clusters
- Orange = 16 clusters
- **Bars**: Grouped by sparsity level, with three bars per group (one per cluster configuration)
### Detailed Analysis
1. **12.5% Sparsity**:
- 4 clusters (red): ~63 accuracy
- 8 clusters (blue): ~61 accuracy
- 16 clusters (orange): ~67 accuracy
2. **25% Sparsity**:
- 4 clusters (red): ~48 accuracy
- 8 clusters (blue): ~45 accuracy
- 16 clusters (orange): ~59 accuracy
3. **37.5% Sparsity**:
- 4 clusters (red): ~37 accuracy
- 8 clusters (blue): ~41 accuracy
- 16 clusters (orange): ~47 accuracy
### Key Observations
- **Cluster Count Impact**: Higher cluster counts consistently achieve better accuracy across all sparsity levels.
- **Sparsity Impact**: Accuracy declines as sparsity increases, with steeper drops observed in lower cluster configurations.
- **16-Cluster Advantage**: The 16-cluster configuration maintains ~10-15 accuracy points above the 4-cluster configuration at equivalent sparsity levels.
- **Color Consistency**: All legend colors match bar colors exactly (red/blue/orange).
### Interpretation
The data demonstrates that increasing cluster count improves robustness to sparsity. The 16-cluster configuration shows the most stable performance, retaining ~67% accuracy at 12.5% sparsity and ~47% at 37.5% sparsity. This suggests that higher cluster counts may better capture underlying patterns in sparse data environments. The linear decline in accuracy with increasing sparsity indicates a fundamental trade-off between data complexity and model performance. Notably, the 8-cluster configuration shows diminishing returns compared to the 16-cluster setup, particularly at higher sparsity levels.
</details>
Figure 5: Impact of cluster number on performance across evaluation tasks. Results on average zero-shot task performance on Llama-3-8B, with cluster N=4, 8, and 16.
Calibration Data Quality.
The quality of calibration data proves critical for effective mask training, as demonstrated in our ablation studies (Table 3). We found that using high-quality, diverse pretraining data from fineweb-edu Lozhkov et al. (2024) yields the best results, achieving an average score of 59.40. In contrast, using wikitext2, the calibration dataset for baseline models, leads to a significant performance degradation, with the average score dropping to 55.85. Also, instruction dataset in Gou et al. (2023), achieved a competitive score of 58.20 but was still lower than fineweb-edu. Our experiments demonstrate that clustering semantically-rich texts creates more meaningfully differentiated clusters, enabling the discovery of truly specialized computational paths. This finding highlights the importance of data diversity and representational richness in training effective dynamic routing mechanisms.
| Instruction Wikitext2 Fineweb-edu | 36.4 39.0 40.0 | 68.27 63.06 68.98 | 68.14 64.12 67.53 | 73.06 73.07 76.12 | 63.38 60.19 63.43 | 39.93 35.67 40.36 | 58.20 55.85 59.40 |
| --- | --- | --- | --- | --- | --- | --- | --- |
Table 3: Ablation results on Llama-3-8B with 25% sparsity across different datasets. Comparing with fineweb-edu, instruction set show minor difference, while wikitext cause average score degradation.
To verify that the observed performance enhancement is attributable to our proposed method rather than the calibration data, we benchmarked the SLEB baseline on both the wikitext2 and fineweb-edu datasets. As detailed in Table 4, the baseline’s performance did not improve when using fineweb-edu. Crucially, our method continues to outperform the baseline even when using wikitext2. This evidence indicates that the performance gains originate from our method’s dynamic architecture and its ability to leverage high-quality data, rather than from an unfair data advantage.
| SLEB SLEB IG-Pruning | Wikitext2 Fineweb-edu Wikitext2 | 33.8 33.0 39.0 | 53.95 52.56 63.06 | 57.96 57.19 64.12 | 72.25 72.79 73.07 | 57.32 56.60 60.19 | 31.56 32.84 35.67 | 51.13 50.83 55.85 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| IG-Pruning | Fineweb-edu | 40.0 | 68.98 | 67.53 | 76.12 | 63.43 | 40.36 | 59.40 |
Table 4: Comparison with baseline models on different datasets. Our method outperforms the baseline (SLEB) regardless of the dataset used.
5 Conclusion
We introduced IG-Pruning, a novel approach for efficient LLM inference through input-adaptive dynamic block pruning. Our method addresses critical limitations of static pruning, and demonstrates that IG-Pruning consistently outperforms state-of-the-art static pruning methods across various configurations and model architectures. Our approach offers four key advantages: (1) improved accuracy through input-adaptive computation that tailors pruning decisions to specific input characteristics, (2) efficient training that keeps model weights frozen while only optimizing lightweight mask parameters, (3) minimal inference overhead via a simple yet effective semantic-based routing mechanism, and (4) flexible block-level pruning granularity that allows independent treatment of attention and FFN components. The success of IG-Pruning highlights the importance of input-adaptive computation in efficient LLM deployment and represents a promising direction for developing high-performing LLMs for resource-constrained environments.
Limitations
The performance heavily depends on clustering quality, potentially diminishing if semantic clusters aren’t effectively differentiated. Moreover, the result is sensitive to calibration data quality, as instruction datasets led to performance degradation compared to diverse pretraining data. Also, our evaluation focused primarily on specific zero-shot tasks, leaving generalization to other task types or domain-specific applications less thoroughly validated. Additionally, the method introduces sensitivity to multiple hyperparameters, including $L_{0}$ regularization, lagrangian parameters, and cluster numbers. Finally, our work does not investigate the impact of block pruning on model factuality. Removing computational blocks risks eliminating components that are critical for factual recall, which may increase the model’s propensity for hallucination. A promising direction for future work would be to combine our dynamic pruning strategy with hallucination mitigation techniques. For instance, integrating methods like TruthX Zhang et al. (2024a), which enhances truthfulness by editing internal model representations, or Truth-Aware Context Selection Yu et al. (2024), which filters untruthful information from the input context. Such an approach could lead to models that are not only efficient but also more robust and factually reliable.
Acknowledgements
We thank all the anonymous reviewers for their insightful and valuable comments on this paper. This work was supported by the grant from the National Natural Science Foundation of China (No. 62376260).
References
- AI@Meta (2024) AI@Meta. 2024. Llama 3 model card.
- Ashkboos et al. (2024) Saleh Ashkboos, Maximilian L Croci, Marcelo Gennari do Nascimento, Torsten Hoefler, and James Hensman. 2024. Slicegpt: Compress large language models by deleting rows and columns. arXiv preprint arXiv:2401.15024.
- Bisk et al. (2020) Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, and 1 others. 2020. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Chen et al. (2024) Xiaodong Chen, Yuxuan Hu, Jing Zhang, Yanling Wang, Cuiping Li, and Hong Chen. 2024. Streamlining redundant layers to compress large language models. arXiv preprint arXiv:2403.19135.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
- (7) Luciano Del Corro, Allison Del Giorno, Sahaj Agarwal, Bin Yu, Ahmed Hassan Awadallah, and Subhabrata Mukherjee. Skipdecode: Autoregressive skip decoding with batching and caching for efficient llm inference.
- Elhoushi et al. (2024) Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, and 1 others. 2024. Layerskip: Enabling early exit inference and self-speculative decoding. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12622–12642.
- Fan et al. (2024) Siqi Fan, Xin Jiang, Xiang Li, Xuying Meng, Peng Han, Shuo Shang, Aixin Sun, Yequan Wang, and Zhongyuan Wang. 2024. Not all layers of llms are necessary during inference. arXiv preprint arXiv:2403.02181.
- Fang et al. (2024) Gongfan Fang, Hongxu Yin, Saurav Muralidharan, Greg Heinrich, Jeff Pool, Jan Kautz, Pavlo Molchanov, and Xinchao Wang. 2024. Maskllm: Learnable semi-structured sparsity for large language models. In The Thirty-eighth Annual Conference on Neural Information Processing Systems.
- Frantar and Alistarh (2023) Elias Frantar and Dan Alistarh. 2023. Sparsegpt: Massive language models can be accurately pruned in one-shot. In International Conference on Machine Learning, pages 10323–10337. PMLR.
- Gao et al. (2023) Leo Gao, Jonathan Tow, Baber Abbasi, S Biderman, S Black, A DiPofi, C Foster, L Golding, J Hsu, A Le Noac’h, and 1 others. 2023. A framework for few-shot language model evaluation, 12 2023. URL https://zenodo. org/records/10256836, 7.
- Gou et al. (2023) Yunhao Gou, Zhili Liu, Kai Chen, Lanqing Hong, Hang Xu, Aoxue Li, Dit-Yan Yeung, James T Kwok, and Yu Zhang. 2023. Mixture of cluster-conditional lora experts for vision-language instruction tuning. arXiv preprint arXiv:2312.12379.
- Gromov et al. (2024) Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, and Dan Roberts. 2024. The unreasonable ineffectiveness of the deeper layers. In NeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning.
- Gu et al. (2021) Shuhao Gu, Yang Feng, and Wanying Xie. 2021. Pruning-then-expanding model for domain adaptation of neural machine translation. arXiv preprint arXiv:2103.13678.
- He et al. (2024) Zhuomin He, Yizhen Yao, Pengfei Zuo, Bin Gao, Qinya Li, Zhenzhe Zheng, and Fan Wu. 2024. AdaSkip: Adaptive sublayer skipping for accelerating long-context LLM inference. 39(22):24050–24058.
- Kim et al. (2024) Bo-Kyeong Kim, Geon-min Kim, Tae-Ho Kim, Thibault Castells, Shinkook Choi, Junho Shin, and Hyoung-Kyu Song. 2024. Shortened llama: A simple depth pruning for large language models. CoRR.
- Ling et al. (2024) Gui Ling, Ziyang Wang, Qingwen Liu, and 1 others. 2024. Slimgpt: Layer-wise structured pruning for large language models. In The Thirty-eighth Annual Conference on Neural Information Processing Systems.
- Liu et al. (2024a) Deyuan Liu, Zhanyue Qin, Hairu Wang, Zhao Yang, Zecheng Wang, Fangying Rong, Qingbin Liu, Yanchao Hao, Bo Li, Xi Chen, and 1 others. 2024a. Pruning via merging: Compressing llms via manifold alignment based layer merging. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17817–17829.
- Liu et al. (2024b) Yijin Liu, Fandong Meng, and Jie Zhou. 2024b. Accelerating inference in large language models with a unified layer skipping strategy. arXiv preprint arXiv:2404.06954.
- Liu et al. (2023) Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, and 1 others. 2023. Deja vu: Contextual sparsity for efficient llms at inference time. In International Conference on Machine Learning, pages 22137–22176. PMLR.
- Louizos et al. (2018) Christos Louizos, Max Welling, and Diederik P Kingma. 2018. Learning sparse neural networks through l_0 regularization. In International Conference on Learning Representations.
- Lozhkov et al. (2024) Anton Lozhkov, Loubna Ben Allal, Leandro von Werra, and Thomas Wolf. 2024. Fineweb-edu: the finest collection of educational content.
- Ma et al. (2023) Xinyin Ma, Gongfan Fang, and Xinchao Wang. 2023. Llm-pruner: On the structural pruning of large language models. Advances in neural information processing systems, 36:21702–21720.
- Men et al. (2024) Xin Men, Mingyu Xu, Qingyu Zhang, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, and Weipeng Chen. 2024. Shortgpt: Layers in large language models are more redundant than you expect. arXiv preprint arXiv:2403.03853.
- Merity et al. (2016) Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. 2016. Pointer sentinel mixture models. Preprint, arXiv:1609.07843.
- Mihaylov et al. (2018) Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a suit of armor conduct electricity? a new dataset for open book question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2381–2391.
- QwenTeam (2025) QwenTeam. 2025. Qwen3.
- Raposo et al. (2024) David Raposo, Sam Ritter, Blake Richards, Timothy Lillicrap, Peter Conway Humphreys, and Adam Santoro. 2024. Mixture-of-depths: Dynamically allocating compute in transformer-based language models. arXiv preprint arXiv:2404.02258.
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992.
- Sakaguchi et al. (2021) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106.
- Schuster et al. (2022) Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Tran, Yi Tay, and Donald Metzler. 2022. Confident adaptive language modeling. Advances in Neural Information Processing Systems, 35:17456–17472.
- Sieberling et al. (2024) Oliver Sieberling, Denis Kuznedelev, Eldar Kurtic, and Dan Alistarh. 2024. Evopress: Towards optimal dynamic model compression via evolutionary search. arXiv preprint arXiv:2410.14649.
- Song et al. (2024) Jiwon Song, Kyungseok Oh, Taesu Kim, Hyungjun Kim, Yulhwa Kim, and Jae-Joon Kim. 2024. Sleb: Streamlining llms through redundancy verification and elimination of transformer blocks. In International Conference on Machine Learning, pages 46136–46155. PMLR.
- Sun et al. (2023) Mingjie Sun, Zhuang Liu, Anna Bair, and J. Zico Kolter. 2023. A Simple and Effective Pruning Approach for Large Language Models. In ICML.
- Tan et al. (2024) Zhen Tan, Daize Dong, Xinyu Zhao, Jie Peng, Yu Cheng, and Tianlong Chen. 2024. Dlo: Dynamic layer operation for efficient vertical scaling of llms. CoRR.
- Wang et al. (2024) Wenxiao Wang, Wei Chen, Yicong Luo, Yongliu Long, Zhengkai Lin, Liye Zhang, Binbin Lin, Deng Cai, and Xiaofei He. 2024. Model compression and efficient inference for large language models: A survey. arXiv preprint arXiv:2402.09748.
- Wu et al. (2024) Qiong Wu, Zhaoxi Ke, Yiyi Zhou, Xiaoshuai Sun, and Rongrong Ji. 2024. Routing experts: Learning to route dynamic experts in existing multi-modal large language models. In The Thirteenth International Conference on Learning Representations.
- Xia et al. (2024) Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, and Danqi Chen. 2024. Sheared llama: Accelerating language model pre-training via structured pruning. In 12th International Conference on Learning Representations, ICLR 2024.
- Xia et al. (2022) Mengzhou Xia, Zexuan Zhong, and Danqi Chen. 2022. Structured pruning learns compact and accurate models. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1513–1528.
- Yang et al. (2024) Yifei Yang, Zouying Cao, and Hai Zhao. 2024. Laco: Large language model pruning via layer collapse. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 6401–6417.
- Yu et al. (2024) Tian Yu, Shaolei Zhang, and Yang Feng. 2024. Truth-aware context selection: Mitigating hallucinations of large language models being misled by untruthful contexts. In Findings of the Association for Computational Linguistics ACL 2024, pages 10862–10884.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800.
- Zhang et al. (2023a) Shaolei Zhang, Qingkai Fang, Zhuocheng Zhang, Zhengrui Ma, Yan Zhou, Langlin Huang, Mengyu Bu, Shangtong Gui, Yunji Chen, Xilin Chen, and 1 others. 2023a. Bayling: Bridging cross-lingual alignment and instruction following through interactive translation for large language models. arXiv preprint arXiv:2306.10968.
- Zhang et al. (2024a) Shaolei Zhang, Tian Yu, and Yang Feng. 2024a. Truthx: Alleviating hallucinations by editing large language models in truthful space. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8908–8949.
- Zhang et al. (2024b) Shaolei Zhang, Kehao Zhang, Qingkai Fang, Shoutao Guo, Yan Zhou, Xiaodong Liu, and Yang Feng. 2024b. Bayling 2: A multilingual large language model with efficient language alignment. arXiv preprint arXiv:2411.16300.
- Zhang et al. (2023b) Yuxin Zhang, Lirui Zhao, Mingbao Lin, Sun Yunyun, Yiwu Yao, Xingjia Han, Jared Tanner, Shiwei Liu, and Rongrong Ji. 2023b. Dynamic sparse no training: Training-free fine-tuning for sparse llms. In The Twelfth International Conference on Learning Representations.
- Zhou et al. (2024) Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, and 1 others. 2024. A survey on efficient inference for large language models. CoRR.
- Zhu et al. (2024) Yunqi Zhu, Xuebing Yang, Yuanyuan Wu, and Wensheng Zhang. 2024. Hierarchical skip decoding for efficient autoregressive text generation. CoRR.
Appendix A Hyperparameter
The hyperparamters we use in our experiments are listed in Table 5.
| $L_{0}$ Module Learning Rate | 0.1 |
| --- | --- |
| Lagrangian Learning Rate | 0.1 |
| $\epsilon$ | 1e-6 |
| $1/\beta$ | 2/3 |
| $l$ | -0.1 |
| $r$ | 1.1 |
| Number of Clusters | 16, 8, 4 |
| Calibration Data Size for each cluster | 1000 |
| Clustering Stage Sequence Length | 4096 |
| Mask Training Sequence Length | 512 |
Table 5: Hyperparameters used in our experiments.
Appendix B More results on various models
To further validate the generalizability and robustness of our approach, we conducted additional experiments on a wider range of models, including Llama-3.2-3B (Table 6), Llama-3.2-1B (Table 7), and Qwen-3-4B (Table 8). Across all tested models and architectures, the input-adaptive nature of IG-Pruning allows it to retain significantly more of the original model’s performance compared to baselines, especially at moderate sparsity levels. As sparsity becomes extremely high, the performance of both methods naturally converges. These comprehensive results validate that our dynamic approach is a consistently superior and more robust solution for model pruning.
| Model Llama-3.2-3B 14% (4/28) | Sparsity 0% (0/28) SLEB | Method Dense 35.80 | OpenBookQA 43.20 58.45 | Winogrande 69.38 58.20 | Hellaswag 73.73 73.12 | PIQA 77.27 57.02 | ARC-E 71.84 33.70 | ARC-C 45.99 52.71 | Average 63.55 82.94% | Percentage(%) 100% |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| IG-Pruning | 41.40 | 66.45 | 68.20 | 75.95 | 68.13 | 43.34 | 60.58 | 95.32% | | |
| 25% (7/28) | SLEB | 25.00 | 53.82 | 46.67 | 68.28 | 50.96 | 29.01 | 46.79 | 73.63% | |
| IG-Pruning | 36.40 | 57.76 | 60.14 | 71.87 | 54.88 | 33.19 | 52.36 | 82.40% | | |
| 39% (11/28) | SLEB | 26.80 | 51.06 | 37.26 | 61.58 | 40.02 | 24.65 | 40.23 | 63.30% | |
| IG-Pruning | 28.00 | 49.83 | 38.52 | 61.53 | 38.17 | 24.40 | 40.07 | 63.05% | | |
Table 6: Results on Llama-3.2-3B.
| Model Llama-3.2-1B 12.5% (2/16) | Sparsity 0% (0/16) SLEB | Method Dense 30.60 | OpenBookQA 37.40 55.16 | Winogrande 60.36 48.74 | Hellaswag 63.64 68.55 | PIQA 74.43 48.48 | ARC-E 60.27 28.41 | ARC-C 36.26 46.66 | Average 55.38 84.24% | Percentage(%) 100% |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| IG-Pruning | 35.00 | 60.45 | 59.65 | 72.79 | 57.32 | 33.87 | 53.18 | 96.02% | | |
| 25% (4/16) | SLEB | 27.80 | 51.63 | 37.50 | 63.11 | 40.19 | 23.72 | 40.65 | 73.40% | |
| IG-Pruning | 27.00 | 54.78 | 40.30 | 62.08 | 40.24 | 27.22 | 41.94 | 75.72% | | |
| 37.5% (6/16) | SLEB | 27.00 | 49.88 | 29.90 | 56.03 | 30.93 | 22.01 | 35.96 | 64.93% | |
| IG-Pruning | 24.40 | 50.98 | 30.90 | 56.31 | 30.72 | 25.08 | 36.40 | 65.72% | | |
Table 7: Results on Llama-3.2-1B.
| Model Qwen-3-4B 14% (5/36) | Sparsity 0% (0/36) SLEB | Method Dense 35.40 | OpenBookQA 40.40 56.19 | Winogrande 65.82 57.36 | Hellaswag 68.42 72.85 | PIQA 75.13 65.78 | ARC-E 53.75 39.84 | ARC-C 53.75 54.57 | Average 59.55 91.64% | Percentage(%) 100% |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| IG-Pruning | 37.60 | 62.58 | 59.76 | 73.55 | 68.35 | 44.62 | 57.74 | 96.97% | | |
| 25% (9/36) | SLEB | 32.20 | 53.03 | 46.94 | 67.46 | 58.37 | 31.22 | 48.20 | 80.95% | |
| IG-Pruning | 35.80 | 56.43 | 53.78 | 69.85 | 60.01 | 39.07 | 52.49 | 88.15% | | |
| 36% (13/36) | SLEB | 29.80 | 53.43 | 39.54 | 62.67 | 47.01 | 26.79 | 43.21 | 72.56% | |
| IG-Pruning | 30.60 | 54.69 | 42.74 | 63.65 | 47.26 | 28.66 | 44.60 | 74.90% | | |
Table 8: Results on Qwen-3-4B.