# The Causal Round Trip: Generating Authentic Counterfactuals by Eliminating Information Loss
**Authors**:
- \nameRui Wu \emailwurui22@mail.ustc.edu.cn (\addrSchool of Management, University of Science and Technology of China)
- \nameLizheng Wang \emaillzwang@ustc.edu.cn (\addrSchool of Management, University of Science and Technology of China)
- \nameYongjun Li \emaillionli@ustc.edu.cn (\addrSchool of Management, University of Science and Technology of China)
> Corresponding author.
Abstract
Judea Pearl’s vision of Structural Causal Models (SCMs) as engines for counterfactual reasoning hinges on faithful abduction: the precise inference of latent exogenous noise. For decades, operationalizing this step for complex, non-linear mechanisms has remained a significant computational challenge. The advent of diffusion models, powerful universal function approximators, offers a promising solution. However, we argue that their standard design, optimized for perceptual generation over logical inference, introduces a fundamental flaw for this classical problem: an inherent information loss we term the Structural Reconstruction Error (SRE). To address this challenge, we formalize the principle of Causal Information Conservation (CIC) as the necessary condition for faithful abduction. We then introduce BELM-MDCM, the first diffusion-based framework engineered to be causally sound by eliminating SRE by construction through an analytically invertible mechanism. To operationalize this framework, a Targeted Modeling strategy provides structural regularization, while a Hybrid Training Objective instills a strong causal inductive bias. Rigorous experiments demonstrate that our Zero-SRE framework not only achieves state-of-the-art accuracy but, more importantly, enables the high-fidelity, individual-level counterfactuals required for deep causal inquiries. Our work provides a foundational blueprint that reconciles the power of modern generative models with the rigor of classical causal theory, establishing a new and more rigorous standard for this emerging field.
Keywords: Causal Inference, Diffusion Models, Causal Information Conservation, Structural Causal Models, Counterfactual Generation, BELM, Structural Reconstruction Error
1 Introduction
The fundamental challenge of causal inference, as articulated by rubin1974estimating, is our inability to simultaneously observe an individual’s potential outcomes. Generating authentic counterfactuals is thus the field’s grand challenge. Structural Causal Models (SCMs), introduced by pearl2009causality, provide the formal language for this pursuit. An SCM posits that an outcome $V_{i}$ is generated by a function of its parents $\mathbf{Pa}_{i}$ and a unique exogenous noise variable $U_{i}$ . This noise, $U_{i}$ , represents the primordial causal information —the collection of unobserved factors unique to an individual. This concept aligns directly with the long-standing focus in econometrics on unobserved individual heterogeneity, a central challenge in structural modeling for decades (heckman2001micro). Pearl’s framework for causal reasoning, the Abduction-Action-Prediction cycle, hinges on the fidelity of the first step: abduction. To answer any ”what if” question, one must first perfectly infer this primordial information $U_{i}$ from an observed outcome $v_{i}$ . For decades, while this theoretical blueprint was clear, its practical realization for complex, non-linear mechanisms remained a major computational hurdle, often addressed in econometrics through strong parametric assumptions or linear approximations (angrist2008mostly).
The advent of deep generative models, particularly diffusion models (ho2020denoising), offers a powerful new hope for bridging this gap. As near-universal function approximators, they possess the expressive power to learn the complex, non-linear functions that have long challenged classical methods (chao2023interventional; sanchez2022dcms). However, this promise is shadowed by a critical, yet overlooked, ”impedance mismatch.” These models were engineered for perceptual tasks like image synthesis, where visual plausibility is paramount, not for the logical rigor demanded by causal abduction. We argue that their standard design, which relies on approximate inversion schemes like DDIM (song2021denoising), is fundamentally at odds with the strict requirements of this classical causal problem.
In this work, we diagnose and resolve this conflict. We begin by giving the classic requirement for faithful abduction a modern name: Causal Information Conservation (CIC) In this work, ’Causal Information Conservation’ is defined operationally as the lossless, deterministic recovery of the exogenous noise variable $U$ . Its novelty lies in its application as a design principle and diagnostic tool for the diffusion model paradigm in causality, rather than as a formal information-theoretic quantity. Connecting this operational principle to formal measures, such as mutual information, is a compelling avenue for future research.. Our core contribution is the identification that standard diffusion models systematically violate this principle due to an inherent algorithmic flaw. We formalize this flaw as the Structural Reconstruction Error (SRE) —a quantifiable information loss that imposes a hard theoretical ceiling on the fidelity of any counterfactual generated by such methods. The SRE is not an estimation error to be solved with more data, but a structural defect in the tool itself.
To solve the long-standing challenge of operationalizing faithful abduction, we introduce BELM-MDCM. It is not merely a new model, but the first diffusion-based framework re-engineered from first principles to be causally sound. Architected around an analytically invertible sampler (liu2024belm), it is the first Zero-SRE causal framework by construction. This design choice reconciles the expressive power of modern diffusion models with the logical rigor of Pearl’s causal theory, ensuring the abduction step is lossless. Our primary contributions are therefore:
1. Diagnosing a Fundamental Barrier in a Classic Problem. We are the first to identify that standard diffusion models, when applied to the classic problem of SCM abduction, suffer from a structural flaw we term the Structural Reconstruction Error (SRE), which violates the foundational principle of Causal Information Conservation.
1. Proposing the First Causally-Sound Diffusion Framework. We introduce BELM-MDCM, the first framework to eliminate SRE by design. By leveraging an analytically invertible mechanism, it ensures that the power of diffusion models can be applied to causality without compromising the integrity of the abduction process.
1. Developing a Principled Methodology to Operationalize the Framework. To make our Zero-SRE framework practical and robust, we introduce two synergistic innovations: a Targeted Modeling strategy to manage complexity and a Hybrid Training Objective to provide a strong causal inductive bias, both supported by our theoretical analysis.
Through a comprehensive experimental evaluation, we demonstrate that BELM-MDCM not only sets a new state-of-the-art in estimation accuracy but, more critically, unlocks the generation of authentic individual-level counterfactuals for deep causal inquiries. By providing a foundational blueprint that resolves a core tension between modern machine learning and classical causal theory, our work establishes a new, more rigorous standard for this research direction.
1.1 The Inversion Challenge in Diffusion-Based Causality
Diffusion models (ho2020denoising) are powerful generative models that learn to reverse a fixed, gradual noising process. They train a neural network, $\epsilon_{\theta}(\mathbf{x}_{t},t)$ , to predict the noise component of a corrupted sample $\mathbf{x}_{t}$ by optimizing a simple mean-squared error objective:
$$
\begin{split}L_{\text{simple}}(\theta)=\mathbb{E}_{t,\mathbf{x}_{0},\boldsymbol{\epsilon}}\bigg[\Big\|\boldsymbol{\epsilon}-\epsilon_{\theta}\big(\sqrt{\bar{\alpha}_{t}}\mathbf{x}_{0}+\sqrt{1-\bar{\alpha}_{t}}\boldsymbol{\epsilon},t\big)\Big\|^{2}\bigg]\end{split} \tag{1}
$$
where $\bar{\alpha}_{t}$ defines the noise schedule and $\boldsymbol{\epsilon}\sim\mathcal{N}(\mathbf{0},\mathbf{I})$ . This trained network is then used to iteratively denoise a variable from pure noise back to a clean sample. A standard deterministic method for this generative process is the Denoising Diffusion Implicit Model (DDIM) (song2021denoising):
$$
\begin{split}\mathbf{x}_{t-1}=\sqrt{\bar{\alpha}_{t-1}}\left(\frac{\mathbf{x}_{t}-\sqrt{1-\bar{\alpha}_{t}}\epsilon_{\theta}(\mathbf{x}_{t},t)}{\sqrt{\bar{\alpha}_{t}}}\right)+\sqrt{1-\bar{\alpha}_{t-1}}\cdot\epsilon_{\theta}(\mathbf{x}_{t},t)\end{split} \tag{2}
$$
However, causal abduction requires the inverse operation: encoding an observed data point $\mathbf{x}_{0}$ into its latent noise code $\mathbf{x}_{T}$ . Standard frameworks (chao2023interventional) use the DDIM inversion, which only approximates this path:
$$
\begin{split}\mathbf{x}_{t+1}=\sqrt{\bar{\alpha}_{t+1}}\left(\frac{\mathbf{x}_{t}-\sqrt{1-\bar{\alpha}_{t}}\epsilon_{\theta}(\mathbf{x}_{t},t)}{\sqrt{\bar{\alpha}_{t}}}\right)+\sqrt{1-\bar{\alpha}_{t+1}}\cdot\epsilon_{\theta}(\mathbf{x}_{t},t)\end{split} \tag{3}
$$
This inversion is approximate because it relies on the noise prediction $\epsilon_{\theta}(\mathbf{x}_{t},t)$ remaining constant across the step, which introduces discretization errors that accumulate (liu2022pseudo). This structural flaw, which we term the Structural Reconstruction Error (SRE), systematically corrupts the inferred exogenous noise $U_{i}$ . The initial error in the abduction step then propagates through the entire Abduction-Action-Prediction cycle, compromising the fidelity of the final counterfactual.
1.2 Our Solution: A Zero-SRE Causal Framework
To eliminate SRE by construction, we build our framework upon an analytically invertible sampler: the B idirectional E xplicit L inear M ulti-step (BELM) sampler (liu2024belm). BELM overcomes the ”memoryless” limitation of single-step samplers like DDIM by using a history of noise predictions, a principle grounded in classical theory for solving ODEs (hairer2006solving).
Specifically, we employ a second-order BELM. During decoding, it computes a more stable effective noise, $\boldsymbol{\epsilon}_{\text{eff}}$ , using predictions from the current and previous timesteps:
$$
\boldsymbol{\epsilon}_{\text{eff}}=\frac{3}{2}\epsilon_{\theta}(\mathbf{x}_{t},t)-\frac{1}{2}\epsilon_{\theta}(\mathbf{x}_{t+1},t+1) \tag{4}
$$
This improved estimate is then used in a DDIM-like update. The key innovation is that the corresponding encoding process is constructed to be the exact algebraic inverse of this decoding process, guaranteeing that the round-trip is lossless, i.e., $\mathbf{H}(\mathbf{T}(\mathbf{x}_{0}))=\mathbf{x}_{0}$ . While the original work on BELM focused on general generative tasks, we are the first to identify, leverage, and theoretically justify its analytical invertibility as the key to satisfying the principle of Causal Information Conservation for rigorous counterfactual generation. Our choice of a second-order BELM represents a deliberate trade-off, providing substantial accuracy gains over single-step methods while maintaining practical efficiency (liu2024belm), making it ideal for our causal framework.
1.3 Methodological Gaps in Applying Invertible SCMs
However, achieving high-fidelity causal inference requires more than a simple substitution of one sampler for another. The principle of analytical invertibility, while theoretically sound, exposes new challenges in practical SCM implementation that our framework is designed to address.
The Challenge of Model Specification: Targeted Modeling.
A key decision in SCM construction is assigning a causal mechanism to each node. Naively applying a complex, computationally expensive BELM-based diffusion model to every node in the causal graph is suboptimal. This motivates our Targeted Modeling strategy, where model complexity is treated as a resource to be allocated judiciously across the graph.
The Challenge of Downstream Tasks: Hybrid Training.
The second challenge arises from a fundamental mismatch in objectives. A diffusion model is trained on a generative objective, $L_{\text{diffusion}}(\theta)$ , while a downstream predictive task is optimized using a discriminative loss, $L_{\text{task}}(\phi)$ . These two objectives are not aligned. This ”objective mismatch” motivates our Hybrid Training strategy, which seeks to unify these two goals.
2 Theoretical Analysis: An Operator-Theoretic Framework
To formalize our thesis that Causal Information Conservation is paramount and its violation via Structural Reconstruction Error is a fundamental barrier, we develop a rigorous operator-theoretic framework. This perspective is essential for analyzing the fidelity of the causal mapping process itself, moving beyond simple prediction errors. We present the first formal analysis that decomposes the counterfactual error in diffusion-based causal models to explicitly isolate the SRE, proving how our Zero-SRE design eliminates this critical structural limitation.
Our analysis first establishes the conditions for perfect counterfactual generation (§ 2.1-§ 2.3) and proves that standard methods produce a non-zero SRE, which our sampler eliminates by construction (Proposition 5 - 6; § 2.4). The centerpiece is a novel error decomposition theorem that isolates the SRE, motivating our Zero-SRE design (§ 2.5-§ 2.7). We conclude with learnability guarantees and a discussion of implications for advanced causal tasks like transportability (§ 2.8-§ 2.10).
2.1 Problem Formulation and Causal Operators
Let $(\Omega,\mathcal{F},P)$ be a probability space. We consider endogenous variables $\mathbf{V}$ as elements of the Hilbert space of square-integrable random variables, $\mathcal{X}:=L^{2}(\Omega,\mathbb{R}^{d})$ . Unless otherwise specified, all vector norms $\|·\|$ in the subsequent analysis refer to the standard Euclidean ( $L_{2}$ ) norm.
**Definition 1 (Functional SCM Operator)**
*A Structural Causal Model is defined by a set of unknown, true functional operators $\{\mathbf{F}_{i}\}_{i=1}^{d}$ , where each $\mathbf{F}_{i}:\mathcal{X}^{\text{pa}_{i}}×\mathcal{U}_{i}→\mathcal{X}_{i}$ is a map such that $V_{i}:=\mathbf{F}_{i}(\mathbf{Pa}_{i},U_{i})$ , with $\mathbf{Pa}_{i}$ being the set of parent random variables and $U_{i}$ an exogenous noise variable. We establish the convention that the corresponding lowercase bold letter, $\mathbf{pa}_{i}$ , denotes a specific vector of observed values for these parents.*
Our goal is to learn a model parameterized by $\theta$ that approximates this SCM. Our model consists of a pair of conditional operators for each variable $V_{i}$ :
1. A decoder (generative) operator $\mathbf{H}_{\theta}:\mathcal{U}×\mathcal{X}^{p}→\mathcal{X}$ , which aims to approximate $\mathbf{F}$ .
1. An encoder (inference) operator $\mathbf{T}_{\theta}:\mathcal{X}×\mathcal{X}^{p}→\mathcal{U}$ , which aims to perform abduction by inferring the latent noise.
These operators are realized by solving the probability flow ODE (Appendix A). The decoder $\mathbf{H}_{\theta}$ solves the ODE from $t=T$ to $t=0$ , while the encoder $\mathbf{T}_{\theta}$ solves it from $t=0$ to $t=T$ . Our BELM sampler is a high-fidelity numerical solver designed such that these forward and backward operations are exact algebraic inverses.
2.2 Identifiability and Exact Counterfactual Generation
We adapt principles from identifiable generative modeling (chao2023interventional) to formalize the conditions for exact counterfactuals. This requires assuming the SCM is invertible with respect to its noise term, a condition discussed in Section 2.11.
**Theorem 2 (Identifiability via Statistical Independence)**
*Given an SCM operator $X:=\mathbf{F}(\mathbf{Pa},U)$ where $U\perp\!\!\!\perp\mathbf{Pa}$ and $\mathbf{F}$ is invertible w.r.t. $U$ . If a learned encoder $\mathbf{T}_{\theta}$ (with sufficient capacity) yields a latent representation $Z=\mathbf{T}_{\theta}(X,\mathbf{Pa})$ that is statistically independent of the parents $\mathbf{Pa}$ , then $Z$ is an isomorphic representation of the exogenous noise $U$ .*
2.3 Geometric Inductive Bias for Identifiability
The score-matching objective’s geometric inductive biases strengthen our identifiability argument. We leverage the principle of implicit regularization, where optimizers favor ”simpler” functions (hochreiter1997flat; neyshabur2018pac). We adopt the principle of simplicity bias, a cornerstone of modern deep learning theory that, while empirically supported, remains an active and not yet universally proven area of research. Our conclusions are conditioned on its validity, as discussed further in Section 2.11. This suggests the model learns the most parsimonious geometric transformation required to explain the data.
Considering the local geometry of the data density $p(\mathbf{x})$ provides powerful intuition. In a local region $\mathcal{R}$ , if the data is isotropic (spherically symmetric), the simplest score function is a radial vector field, yielding a conformal map. If the structure is simply anisotropic (e.g., ellipsoidal), the model is biased towards learning a local affine map. This refines the notion of a purely conformal bias and leads to the following proposition.
**Proposition 3 (Implicit Bias towards Simple Geometric Maps)**
*Assume (A1) the true data density $p(\mathbf{x})$ is smooth ( $C^{2}$ ) and (A2) the optimization process has a simplicity bias (e.g., favoring low-complexity solutions, see Appendix H).
1. If there exists a local region $\mathcal{R}$ where $p(\mathbf{x})$ is isotropic, the optimal learned score function is a radial vector field, and the flow map it generates is a conformal map on $\mathcal{R}$ .
1. If we relax the condition to a local region $\mathcal{R}$ where $p(\mathbf{x})$ has an ellipsoidal structure, the optimal learned score function is normal to the ellipsoidal iso-contours, and the flow map it generates is a local affine transformation on $\mathcal{R}$ .*
The formal argument is detailed in Appendix H. This proposition is significant: it suggests that the model defaults to learning the most parsimonious, well-behaved, and locally invertible map that can explain the data’s geometry. This bias is crucial for the abduction step, as it prevents the pathological distortions that would corrupt the inferred causal noise $U$ .
**Theorem 4 (Operator Isomorphism Guarantees Exact Counterfactuals)**
*Let the conditions of Theorem 2 hold. If the learned operator pair $(\mathbf{T}_{\theta},\mathbf{H}_{\theta})$ constitutes a conditional isomorphism (i.e., $\mathbf{H}_{\theta}(\mathbf{T}_{\theta}(·,\mathbf{pa}),\mathbf{pa})=\mathbf{I}$ , the identity operator), then the model’s prediction under an intervention $do(\mathbf{Pa}:=\boldsymbol{\alpha})$ is exact.*
Proof A full proof, covering cases for different dimensions of the exogenous noise variable, is provided in Appendix B.
2.4 Analysis of Inversion Fidelity
We now formally analyze the inversion error. We prove that standard approximate schemes produce a non-zero SRE (Proposition 5), whereas our chosen sampler eliminates it by construction (Proposition 6).
**Proposition 5 (Structural Error of Approximate Inversion)**
*Let $\mathbf{T}_{\text{DDIM}}$ be the operator for one step of DDIM inversion from $\mathbf{x}_{t}$ to $\mathbf{x}_{t+1}$ , and $\mathbf{H}_{\text{DDIM}}$ be the generative step operator from $\mathbf{x}_{t+1}$ to $\mathbf{x}_{t}$ . The single-step reconstruction error is non-zero and of second order in the time step $\Delta t$ :
$$
(\mathbf{H}_{\text{DDIM}}\circ\mathbf{T}_{\text{DDIM}})(\mathbf{x}_{t})-\mathbf{x}_{t}=\mathcal{O}((\Delta t)^{2})
$$
This error accumulates over the full trajectory, leading to a non-zero Structural Reconstruction Error.*
Proof See Appendix C for a rigorous proof.
**Proposition 6 (Analytical Invertibility of the Sampler)**
*Let $\mathbf{T}_{\text{BELM}}$ and $\mathbf{H}_{\text{BELM}}$ be the operators corresponding to the full-trajectory BELM sampler for inference and generation, respectively. For a fixed noise prediction network $\epsilon_{\theta}$ , the operators are exact algebraic inverses:
$$
\mathbf{H}_{\text{BELM}}\circ\mathbf{T}_{\text{BELM}}=\mathbf{I}
$$*
Proof The proof follows from the algebraic construction of the BELM update rules, as detailed in Appendix C.
2.5 Error Decomposition for Counterfactual Estimation
This brings us to our central theoretical result: an error decomposition theorem that rigorously partitions the total counterfactual error. This decomposition isolates the SRE and mathematically demonstrates why its elimination is critical.
**Definition 7 (Counterfactual Error Components)**
*We formally define the two primary sources of error in counterfactual estimation for the invertible case:
1. The Structural Reconstruction Error ( $E_{SR}$ ) measures the information loss from the model’s abduction-action cycle on a given sample $X$ :
$$
E_{SR}(X):=\|(\mathbf{H}_{\theta}\circ\mathbf{T}_{\theta}-\mathbf{I})X\|^{2}
$$
1. The Latent Space Invariance Error ( $E_{LSI}$ ) measures the failure of the learned latent space to remain invariant under interventions on parent variables:
$$
E_{LSI}:=\|\mathbf{T}_{\theta}(X,\mathbf{Pa})-\mathbf{T}_{\theta}(X_{\boldsymbol{\alpha}}^{\text{true}},\boldsymbol{\alpha})\|^{2}
$$*
**Theorem 8 (Counterfactual Error Bound)**
*Let a model be defined by $(\mathbf{T}_{\theta},\mathbf{H}_{\theta})$ and the true SCM by $\mathbf{F}$ . Assume the decoder $\mathbf{H}_{\theta}$ is $L_{\mathcal{H}}$ -Lipschitz. The expected squared error of the model’s counterfactual prediction $\hat{X}_{\boldsymbol{\alpha}}$ is bounded by the expectation of the two error components:
$$
\mathbb{E}\left[\|\hat{X}_{\boldsymbol{\alpha}}-X_{\boldsymbol{\alpha}}^{\text{true}}\|^{2}\right]\leq 2\mathbb{E}\left[E_{SR}(X_{\boldsymbol{\alpha}}^{\text{true}})\right]+2L_{\mathcal{H}}^{2}\mathbb{E}\left[E_{LSI}\right]
$$*
Proof The proof is in Appendix D.
**Remark 9 (Elimination of Structural Error)**
*By Proposition 6, the Structural Reconstruction Error for BELM-MDCM is identically zero. This is the central theoretical advantage of our framework. It disentangles the error sources, allowing us to isolate the entire modeling challenge to learning a high-quality score function ( $\epsilon_{\theta}$ ) without the confounding factor of an imperfect inversion algorithm. Any remaining error is now purely a function of statistical estimation, not a structural bias of the model itself.*
**Proposition 10 (Bound on Latent Space Invariance Error)**
*We assume the learned score network, $\boldsymbol{\epsilon}_{\theta}$ , is Lipschitz continuous, ensuring the existence and uniqueness of the probability flow ODE solution via the Picard-Lindelöf theorem. Under standard integrability conditions (Fubini’s theorem), the Latent Space Invariance Error is bounded by the expected score-matching loss:
$$
\mathbb{E}\left[E_{LSI}\right]\leq C^{\prime}\cdot\mathbb{E}\left[\|\boldsymbol{\epsilon}_{\theta}-\boldsymbol{\epsilon}^{*}\|^{2}\right]
$$
for some constant $C^{\prime}$ , where $\boldsymbol{\epsilon}^{*}$ is the true score function.*
Proof The proof is in Appendix D. This proposition formally establishes that by eliminating structural error, the causal fidelity of BELM-MDCM is directly and provably controlled by its ability to accurately learn the data’s score function.
2.6 Decomposing Error: A Motivation for Empirical Validation
The error decomposition in Theorem 8 provides a clear strategy for empirical validation by isolating two distinct error sources: the Structural Reconstruction Error ( $E_{SR}$ ) and the Latent Space Invariance Error. While developing a single score combining these is future work, these components directly motivate our empirical investigations. Our ablation study (Section 5.4.2) is designed to measure the impact of a non-zero $E_{SR}$ , while our stress-test (Section 5.4.1) probes robustness when latent space invariance is challenged by a non-invertible SCM.
2.7 Theoretical Roles of Targeted Modeling and Hybrid Training
With algorithmic error eliminated by our Zero-SRE design, the challenge becomes minimizing the modeling error ( $E_{LSI}$ ). Our two methodological innovations, Targeted Modeling and Hybrid Training, are principled strategies for this purpose.
Targeted Modeling as Formal Complexity Control.
Our Targeted Modeling strategy acts as a form of structural regularization. The finite sample bound in Theorem 15 is governed by the Rademacher complexity $\mathfrak{R}_{n}(\mathcal{F}_{\Theta})$ of the entire SCM’s hypothesis space. By assigning low-complexity models to a subset of nodes, we directly constrain the overall complexity.
**Remark 11 (Effect on Generalization Bound)**
*Our Targeted Modeling strategy is formally justified as a complexity control mechanism. The Rademacher complexity of a composite SCM is bounded by the sum of the complexities of its individual mechanisms (mohri2018foundations). By strategically substituting a high-complexity diffusion model $\mathcal{F}_{\text{diff}}$ with a lower-complexity alternative $\mathcal{F}_{\text{simple}}$ for non-critical nodes, Targeted Modeling directly minimizes this upper bound. This leads to a tighter generalization bound and improves the statistical efficiency of the overall SCM.*
Hybrid Training as a Weighted Score-Matching Objective.
The Hybrid Training Objective, $L_{\text{total}}=L_{\text{diffusion}}+\lambda· L_{\text{task}}$ , imparts a crucial inductive bias for learning a causally salient score function. The task-specific loss acts as a conductor’s baton, forcing the model to prioritize learning an accurate score function in regions of the data manifold most critical to the causal question. We formalize this by proposing that the auxiliary loss implicitly implements a weighted score-matching objective.
**Proposition 12 (Hybrid Objective as a Weighted Score-Matching Regularizer)**
*The auxiliary task loss $L_{\text{task}}$ provides a lower bound for the model’s error, weighted by a function reflecting the causal salience of the data manifold. Minimizing the hybrid objective $L_{\text{total}}$ is thereby equivalent to solving a weighted score-matching problem that prioritizes accuracy in causally salient regions, leading to a smaller effective Latent Space Invariance Error. (A rigorous proof is provided in Appendix E.)*
This proposition formally grounds our hybrid training strategy, revealing that the task-specific loss intelligently forces the diffusion model to prioritize accuracy in regions of the data manifold most critical to the causal question. This reinforces the CIC principle by avoiding information loss where it matters most, effectively implementing the simplicity bias principle from Section 2.3.
We can deepen this insight by analyzing its information-theoretic implications.
**Proposition 13 (Disentanglement via Hybrid Objective)**
*Information-theoretically, the hybrid objective provides a strong inductive bias towards learning a disentangled latent representation. It encourages a ”division of labor” where the task-specific component explains variance from the parents $\mathbf{Pa}$ , while the diffusion component’s latent code $Z=\mathbf{T}_{\theta}(V,\mathbf{Pa})$ models the residual information. This implicitly pushes $Z$ towards being independent of $\mathbf{Pa}$ , a crucial step towards satisfying the identifiability conditions.*
Proof A detailed information-theoretic argument is provided in Appendix E.
2.8 BELM-MDCM as a Unifying Framework
The principle of Causal Information Conservation also unifies our framework with classical models. Simpler models like Additive Noise Models (ANMs) can be seen as special cases where this principle is met trivially, positioning our work as a generalization of established causal principles. For instance, in a classic ANM (hoyer2009nonlinear), $V_{i}=f_{i}(\mathbf{Pa}_{i})+U_{i}$ , the noise is recovered by a direct, lossless inversion: $U_{i}=V_{i}-f_{i}(\mathbf{Pa}_{i})$ . Our framework generalizes this principle to arbitrarily complex, non-additive mechanisms, offering a flexible, non-parametric extension to classical structural equation models (wooldridge2010econometric). The importance of noise distributions, particularly non-Gaussianity, for identifiability in linear models is also a well-established principle (shimizu2006linear).
2.9 Learnability and Statistical Guarantees
We now provide finite-sample learnability guarantees for our SCM framework.
**Proposition 14 (Asymptotic Consistency)**
*Under standard regularity conditions, as the number of data samples $n→∞$ and model capacity $N→∞$ , the learned operators $(\hat{\mathbf{T}}_{n},\hat{\mathbf{H}}_{n})$ are consistent estimators of the ideal operators $(\mathbf{T}^{*},\mathbf{H}^{*})$ : $\hat{\mathbf{T}}_{n}\xrightarrow{p}\mathbf{T}^{*}$ and $\hat{\mathbf{H}}_{n}\xrightarrow{p}\mathbf{H}^{*}$ .*
**Theorem 15 (Finite Sample Bound for Causal Diffusion SCMs)**
*Let an SCM consist of $d$ endogenous nodes, with a causal graph having a maximum in-degree of $d_{in}^{max}$ . Assume each causal mechanism is implemented by a score network $\epsilon_{\theta}$ that is an $L$ -layer MLP with ReLU activations, and the spectral norm of each weight matrix is bounded by $B$ . Let the input space be appropriately normalized. Let the loss function be bounded by $M$ . Then, for the parameters $\hat{\theta}_{n}$ learned from $n$ samples, the excess risk is bounded with probability at least $1-\delta$ :
$$
R(\hat{\theta}_{n})-R(\theta^{*})\leq C\cdot\frac{d\cdot L\cdot B^{L}\cdot\sqrt{d_{in}^{max}+d_{embed}+1}}{\sqrt{n}}+M\sqrt{\frac{\log(1/\delta)}{2n}}
$$
where $C$ is a constant independent of the network architecture and sample size, and $d_{embed}$ is the dimension of the time embedding.*
Proof The proof, which combines the sub-additivity of Rademacher complexity over the SCM with standard bounds for deep neural networks (bartlett2017spectrally; neyshabur2018pac), is detailed in Appendix G.
**Remark 16 (Interpretation of the Bound)**
*This refined bound quantitatively links the generalization error to:
1. Causal Complexity ( $d·\sqrt{d_{in}^{max}}$ ): The error scales with the number of causal mechanisms ( $d$ ) and the graph’s complexity ( $d_{in}^{max}$ ), formalizing the intuition that more complex causal systems are harder to learn.
1. Network Complexity ( $L· B^{L}$ ): The error scales with the depth and spectral norm of the score networks. This provides direct theoretical grounding for our Targeted Modeling strategy, as using simpler models tightens this generalization bound.*
2.10 Implications for Causal Transportability
Causal Information Conservation also provides a foundation for transportability —applying knowledge from a source domain $\mathcal{S}$ to a target domain $\mathcal{T}$ (pearl2014transportability). Transportability requires separating invariant causal knowledge from domain-specific mechanisms. By losslessly recovering the exogenous noise $U$ (the invariant ”causal essence”), our framework achieves this separation by design; the decoders $\mathbf{H}_{\theta}$ represent the domain-specific mechanisms. This insight is formalized in the following theorem.
**Theorem 17 (Condition for Lossless Causal Transport)**
*Let a source domain $\mathcal{S}$ and a target domain $\mathcal{T}$ be described by SCMs $\mathcal{M}^{\mathcal{S}}$ and $\mathcal{M}^{\mathcal{T}}$ , respectively. Assume the following conditions hold:
1. Shared Structure: Both domains share the same causal graph $\mathcal{G}$ and the same exogenous noise distributions $\{p_{i}(U_{i})\}$ . The domains differ only in a subset of causal mechanisms $\mathcal{K}_{\text{changed}}$ .
1. Noise Independence: The exogenous noise variables $\{U_{i}\}_{i=1}^{d}$ are mutually independent.
1. Information Conservation: A model $(\mathbf{T}_{\theta},\mathbf{H}_{\theta})$ trained on data from $\mathcal{S}$ satisfies the Causal Information Conservation principle, achieving zero Structural Reconstruction Error.
Then, causal knowledge can be losslessly transported from $\mathcal{S}$ to $\mathcal{T}$ by re-learning only the operators $\{\mathbf{T}_{\theta_{k}},\mathbf{H}_{\theta_{k}}\}$ corresponding to the changed mechanisms $k∈\mathcal{K}_{\text{changed}}$ , while directly reusing all operators for invariant mechanisms.*
Proof The proof is provided in Appendix F.
2.11 Discussion of Assumptions
Our framework rests on several key assumptions, which we now critically examine.
Our geometric inductive bias argument (Proposition 3) rests on the principle of simplicity bias. While this principle is a cornerstone of modern deep learning theory with substantial empirical backing, it remains an active area of research and is not a universally proven theorem. Our conclusions are therefore conditioned on the validity of this powerful but conjectural assumption.
The cornerstone of our identifiability theory (Theorem 2) is the SCM’s invertibility with respect to its noise term $U$ . This is a strong assumption; when violated (e.g., by a many-to-one function), the abduction task becomes ill-posed.
To address this foundational challenge, we provide an exhaustive theoretical treatment in Appendix C. There, we formalize the irreducible ”representational error” and derive a tighter, more general error bound (Theorem 21). More importantly, we propose a concrete mitigation strategy: a novel prior-matching regularizer (Definition 23), theoretically shown to reduce the error by encouraging the learned encoder to approximate the ideal Maximum a Posteriori (MAP) solution (Proposition 24). This highlights a primary contribution: even in the challenging non-invertible case, BELM-MDCM’s zero-SRE design eliminates the algorithmic error, thereby isolating the more fundamental representational challenge. Our stress-test in Section 5.4.1 empirically confirms this advantage, while validating our regularizer provides a clear direction for future work.
Our identifiability proof is dimension-dependent, leveraging Liouville’s theorem for $d≥ 3$ and requiring stronger assumptions like asymptotic linearity for the special case of $d=2$ . Other assumptions, such as Lipschitz continuity of the score network, are mild regularity conditions standard in deep generative model analysis and can be encouraged through architectural choices like spectral normalization.
3 Architectural Design and Training
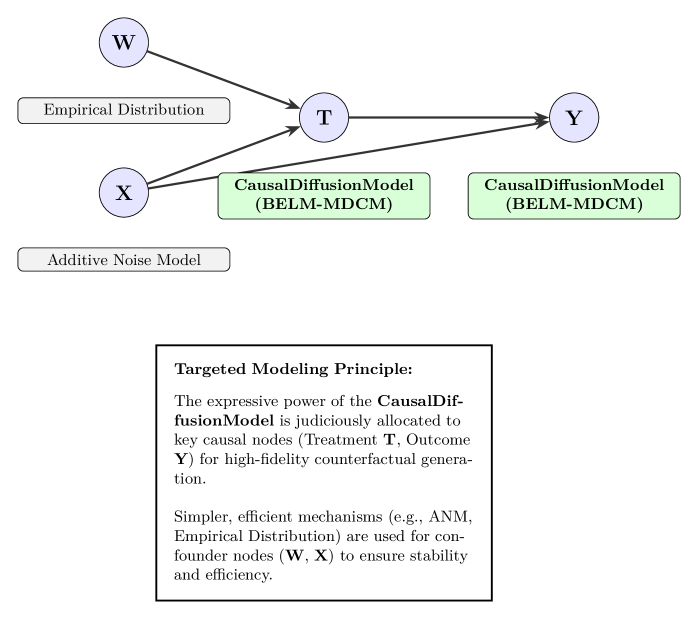
The BELM-MDCM architecture embodies our core principles through a non-monolithic, theoretically-motivated design. Its central philosophy is Targeted Modeling: judiciously allocating the expressive power of our Zero-SRE CausalDiffusionModel to nodes of causal interest (e.g., Treatment T, Outcome Y), while using simpler, efficient mechanisms for confounders, as illustrated in Figure 1. This strategy provides practical complexity control, tightening the generalization bound as established in Theorem 15.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Causal Diffusion Modeling Architecture
### Overview
The diagram illustrates a hierarchical causal modeling system with nodes representing data distributions, causal models, and noise mechanisms. Arrows indicate directional relationships and data flow between components.
### Components/Axes
- **Nodes**:
- **W**: Empirical Distribution
- **X**: Input/Founder Node
- **Y**: Outcome Node
- **T**: Treatment Node
- **Arrows**:
- **W → T**: Labeled "Empirical Distribution"
- **T → Y**: Labeled "CausalDiffusionModel (BELM-MDCM)"
- **X → T**: Labeled "CausalDiffusionModel (BELM-MDCM)"
- **X → Additive Noise Model**: Implied by connection
- **Text Box**: Contains "Targeted Modeling Principle" with explanatory text
### Detailed Analysis
1. **Empirical Distribution (W)**:
- Positioned at the top-left, feeding into Treatment (T)
- Represents observed data distribution
2. **CausalDiffusionModel (BELM-MDCM)**:
- Appears twice in the diagram:
- Between T and Y (outcome generation)
- Between X and T (treatment modeling)
- Highlighted in green boxes, emphasizing its central role
3. **Additive Noise Model**:
- Connected to X, suggesting noise injection at the input stage
4. **Targeted Modeling Principle**:
- Text box explains:
- CausalDiffusionModel's role in allocating causal nodes (T, Y)
- Use of simpler mechanisms (ANM, Empirical Distribution) for stability
- Focus on high-fidelity counterfactual generation
### Key Observations
- **Hierarchical Flow**: Data flows from empirical distribution (W) through treatment (T) to outcome (Y)
- **Dual Causal Model Usage**: BELM-MDCM operates at both treatment and outcome levels
- **Noise Injection**: Additive Noise Model modifies input (X) before processing
- **Principle Alignment**: Architecture directly implements the stated modeling philosophy
### Interpretation
This architecture demonstrates a causal inference system where:
1. Empirical data (W) is processed through a treatment model (T) using causal diffusion
2. The outcome (Y) is generated via another causal diffusion step
3. Input stability is maintained through noise modeling at the founder node (X)
4. The system prioritizes causal node allocation (T, Y) for high-fidelity generation while using simpler mechanisms for foundational stability
The diagram visually reinforces the principle that complex causal modeling (BELM-MDCM) should be reserved for key causal nodes, while simpler methods handle foundational elements. The dual use of CausalDiffusionModel suggests its versatility in different stages of the causal chain.
</details>
Figure 1: Illustration of the Targeted Modeling Principle. The expressive CausalDiffusionModel is judiciously allocated to key causal nodes (Treatment T, Outcome Y) for high-fidelity counterfactual generation. Simpler, efficient mechanisms (e.g., ANM, Empirical Distribution) are used for confounder nodes (W, X) to ensure stability and efficiency.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Flowchart: Machine Learning Pipeline for Causal Identification
### Overview
The diagram illustrates a multi-stage machine learning pipeline for causal identification, structured into five phases: Pre-Processing, Embedding, Train, Post-Processing, and Results. The flow progresses left-to-right, with data transformations and model interactions depicted through interconnected blocks.
### Components/Axes
1. **Pre-Processing**
- **StandardScaler**: Standardizes numerical features (`x_num` values: 50, 257, -3.0).
- **OneHotEncoder**: Encodes categorical variables (`x_cat1`, `x_cat2`, `x_cat3` with labels: "M", "woman", and a triangle symbol).
2. **Embedding**
- **Timestep Embedding**: Processes temporal data.
- **Connection**: Combines standardized numerical (`x_num`) and encoded categorical (`x_cat`) features via a ⊕ (addition) operation.
3. **Train**
- **BELM-MDCM Module**: Trains on combined features to produce a **Noisy Target Variable**.
4. **Post-Processing**
- **Inverse Transformation**: Reverts scaled/encoded data to original space.
5. **Results**
- **Causal Identification**: Final output block.
### Detailed Analysis
- **Pre-Processing**:
- Numerical features (`x_num`) are standardized using `StandardScaler` (mean=0, std=1).
- Categorical variables (`x_cat1`, `x_cat2`, `x_cat3`) are one-hot encoded, with labels like "M" (gender), "woman" (occupation), and a triangle symbol (possibly a missing/unknown category).
- **Embedding**:
- Temporal data is embedded via `Timestep Embedding`, while numerical and categorical features are fused via element-wise addition (`x_num ⊕ x_cat`).
- **Train**:
- The **BELM-MDCM Module** (likely a hybrid model combining BERT-like language modeling with MDCM causal inference) processes the embedded data to predict a **Noisy Target Variable**.
- **Post-Processing**:
- **Inverse Transformation** undoes scaling/encoding to recover original feature scales.
- **Results**:
- **Causal Identification** block outputs the final causal relationships.
### Key Observations
1. **Data Flow**: Numerical and categorical features are preprocessed separately before being combined for training.
2. **Temporal Component**: The `Timestep Embedding` suggests time-series data is part of the input.
3. **Causal Focus**: The pipeline explicitly targets causal identification, implying the BELM-MDCM module is designed for counterfactual reasoning or causal effect estimation.
4. **Noisy Target**: The presence of a "Noisy Target Variable" indicates the model accounts for measurement error or confounding variables.
### Interpretation
This pipeline demonstrates a structured approach to causal inference in machine learning:
1. **Pre-Processing** ensures data quality by standardizing numerical features and encoding categorical variables.
2. **Embedding** integrates temporal dynamics, critical for time-dependent causal relationships.
3. **BELM-MDCM Module** likely combines deep learning (BELM) with causal modeling (MDCM) to handle complex interactions.
4. **Inverse Transformation** is essential for interpreting results in the original feature space, aiding causal interpretation.
5. The **Noisy Target Variable** suggests robustness to real-world data imperfections, a common challenge in causal analysis.
The diagram emphasizes a hybrid approach, merging statistical preprocessing, deep learning, and causal modeling to address complex, real-world datasets. The absence of explicit numerical results in the diagram implies this is a conceptual pipeline rather than an empirical study.
</details>
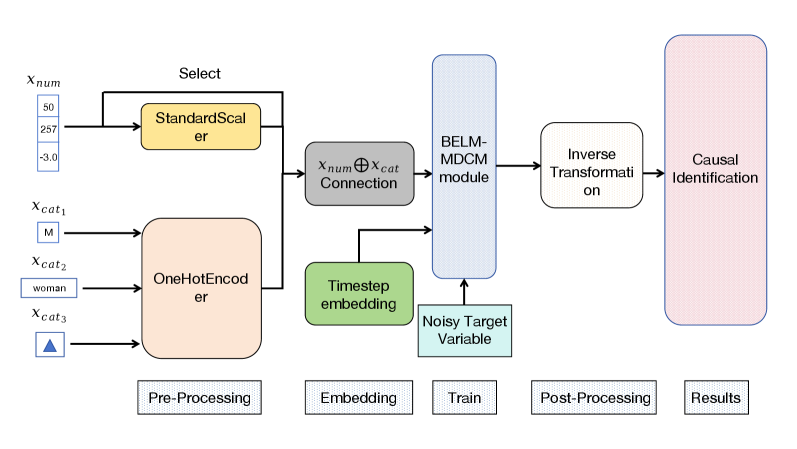
Figure 2: The detailed internal architecture of the CausalDiffusionModel. This diagram illustrates the end-to-end workflow of the causal mechanism designed for key nodes like Treatment T and Outcome Y, detailing the pre-processing, embedding, training, and post-processing stages.
The internal architecture of the CausalDiffusionModel itself, depicted in Figure 2, is engineered to learn the complex, non-linear mapping $v_{i}:=f_{i}(\mathbf{pa}_{i},u_{i})$ with high fidelity.
3.1 Mechanism for Exogenous Nodes
Exogenous nodes (without parents in the causal graph $\mathcal{G}$ ) are modeled non-parametrically via the Empirical Distribution of the observed data. This approach avoids distributional assumptions and provides a robust foundation for the Structural Causal Model (SCM).
3.2 Mechanism for Endogenous Nodes: The CausalDiffusionModel
For endogenous nodes $V_{i}$ , particularly those central to the causal query (treatment, outcome, key mediators), we employ our bespoke CausalDiffusionModel to learn the functional mapping $v_{i}:=f_{i}(\mathbf{pa}_{i},u_{i})$ .
3.2.1 Conditioning via Parent Node Transformation
The denoising process is conditioned on the parent nodes $\mathbf{pa}_{i}$ , which are transformed into a fixed-dimensional conditioning vector $\mathbf{c}∈\mathbb{R}^{d_{c}}$ . A ColumnTransformer handles heterogeneous data types: continuous parents are standardized (StandardScaler) to unify scales, while categorical parents are one-hot encoded (OneHotEncoder) to prevent artificial ordinality. The resulting vectors are concatenated into $\mathbf{c}$ , which remains constant for a given sample’s diffusion trajectory.
3.2.2 The Denoising Process
The core of the CausalDiffusionModel is a denoising network $\epsilon_{\theta}(v_{t},t,\mathbf{c})$ , implemented as a Residual MLP (he2016deep). It takes as input the noisy variable $v_{t}$ , a sinusoidal Time Embedding of timestep $t$ , and the conditioning vector $\mathbf{c}$ . Before the diffusion process, the target variable $V_{i}$ is also preprocessed (standardized for continuous values or label-encoded for categorical ones). The denoising process is driven by the BELM sampler, ensuring a mathematically exact and stable inversion path as established in Section 2.
3.2.3 Hybrid Training Objective
We introduce a Hybrid Training Objective to reconcile generative fidelity with predictive accuracy. As established in our theoretical analysis (Proposition 12), this is more than a standard multi-task learning scheme; it acts as a powerful inductive bias, creating a weighted score-matching objective that prioritizes accuracy in causally salient regions of the data manifold. The total loss is a linearly weighted combination:
$$
L_{\text{total}}=L_{\text{diffusion}}+\lambda\cdot L_{\text{task}} \tag{5}
$$
where $L_{\text{diffusion}}$ is the noise prediction error (Equation 1). The auxiliary loss $L_{\text{task}}$ is a Mean Squared Error for continuous nodes ( $L_{\text{regression}}$ ) and a Cross-Entropy loss for discrete nodes ( $L_{\text{classification}}$ ).
3.2.4 Decoding and Counterfactual Generation
For generation, the BELM sampler produces an output in the normalized space. This is then mapped back to the original data domain using the inverse transformations of the pre-fitted preprocessors (StandardScaler for continuous, LabelEncoder for categorical). For categorical outputs, the continuous value is rounded and clipped to the valid class range before the inverse mapping, ensuring that generated (counterfactual) data is interpretable and resides in the correct space.
4 New Evaluation Metrics for Generative Causal Models
The principle of Causal Information Conservation demands new evaluation dimensions that traditional metrics like ATE and PEHE cannot capture. An accurate ATE score, for instance, could arise from a model with high SRE where individual errors fortuitously cancel out at the population level. To move beyond mere outcome accuracy and directly assess a model’s adherence to our foundational principle, we propose a new, theoretically-grounded evaluation framework.
4.1 Causal Information Conservation Score (CIC-Score)
The Causal Information Conservation Score (CIC-Score) is a direct empirical diagnostic for the Structural Reconstruction Error. It quantifies a framework’s adherence to the CIC principle by disentangling algorithmic information loss (from an imperfect inversion process) from modeling error (from the statistical challenge of learning the true causal mechanism). We define the score, bounded in $[0,1]$ , using an exponential formulation:
$$
\text{CIC-Score}=\exp\left(-\left(\delta_{U}+\delta_{\text{SRE}}\right)\right)
$$
The error components are designed to isolate distinct failure modes:
- $\delta_{U}$ , the Relative Noise Recovery Error, quantifies the modeling error. It measures how well the trained network approximates the true score function, reflected in the fidelity of the recovered noise $\hat{U}$ versus the ground-truth $U_{\text{true}}$ :
$$
\delta_{U}=\frac{\mathbb{E}[\|\hat{U}_{\text{scaled}}-U_{\text{true, scaled}}\|^{2}]}{\mathbb{E}[\|U_{\text{true, scaled}}\|^{2}]}
$$
This term captures all inaccuracies from finite data and imperfect optimization.
- $\delta_{\text{SRE}}$ , the Normalized Structural Error, exclusively quantifies the algorithmic error inherent to the inversion process itself. Its definition is model-dependent to allow for fair comparisons:
- For frameworks with analytical invertibility (e.g., our BELM-MDCM, ANMs), the algorithm introduces no information loss, so we set $\delta_{\text{SRE}}\equiv 0$ by construction. Any observed reconstruction error is a symptom of modeling error, already captured by $\delta_{U}$ .
- For frameworks relying on approximate inversion (e.g., DDIM), $\delta_{\text{SRE}}$ is empirically measured to quantify this inherent algorithmic flaw:
$$
\delta_{\text{SRE}}=\frac{\mathbb{E}[\|(\mathbf{H}_{\theta}\circ\mathbf{T}_{\theta}-\mathbf{I})X\|^{2}]}{\mathbb{E}[\|X\|^{2}]}
$$
This principled decomposition allows the CIC-Score to fairly assess different frameworks by isolating structural design advantages from the universal challenge of model training.
4.2 Causal Mechanism Fidelity Score (CMF-Score)
A generative causal model’s core promise is to learn true causal mechanisms, not just outcomes. Naïve metrics like pairwise correlations fail to capture the non-linear, multi-variable, and directional nature of causality. We therefore propose the Causal Mechanism Fidelity (CMF) score, a hierarchical framework with two levels of increasing rigor.
4.2.1 Level 1 (Pragmatic): The Conditional Mutual Information Score (CMI-Score)
The Conditional Mutual Information (CMI), $I(V_{i};V_{j}|\mathbf{Pa}_{j}\setminus\{V_{i}\})$ , is a non-parametric, non-linear measure of the direct influence a parent $V_{i}$ has on its child $V_{j}$ after accounting for all other parents. The CMI-Score evaluates whether this influence is preserved. For a single mechanism $V_{j}$ , it is the average consistency across all parent-child edges:
$$
\text{CMI-Score}(V_{j})=\frac{1}{|\mathbf{Pa}_{j}|}\sum_{V_{i}\in\mathbf{Pa}_{j}}\left(1-\frac{\left|I_{\text{obs}}(V_{i};V_{j}|\cdot)-I_{\text{cf}}(V_{i};V^{\prime}_{j}|\cdot)\right|}{I_{\text{obs}}(V_{i};V_{j}|\cdot)+\epsilon}\right)
$$
where $I_{\text{obs}}$ and $I_{\text{cf}}$ are the CMI values from observational and counterfactual data, respectively. The final CMI-Score is the average over all SCM mechanisms.
4.2.2 Level 2 (Gold Standard): The Kernelized Mechanism Discrepancy (KMD) Score
To rigorously compare entire conditional distributions, we use the Maximum Mean Discrepancy (MMD) (gretton2012kernel), a kernel-based statistical test for distributional equality. The KMD-Score applies this test to the conditional distributions $p(V_{j}|\mathbf{Pa}_{j})$ that define each causal mechanism, measuring the discrepancy between the learned and observed conditionals. The final score is mapped to a similarity measure in $[0,1]$ :
$$
\text{KMD-Score}=\exp(-\gamma\cdot\mathbb{E}_{\mathbf{pa}_{j}\sim p(\mathbf{Pa}_{j})}[\text{MMD}(p(V_{j}|\mathbf{pa}_{j}),p_{\theta}(V_{j}|\mathbf{pa}_{j}))])
$$
where $\gamma$ is a scaling parameter. A score of 1 indicates that the learned conditional mechanism is statistically indistinguishable from the observed one.
Complementary and Validated Evaluation Metrics.
Our proposed metrics complement, rather than replace, traditional ones like ATE and PEHE. They evaluate distinct facets of performance: while ATE/PEHE measure outcome accuracy, the CMF-Score assesses mechanism fidelity. This distinction is critical, as a model can achieve a high ATE via fortuitous error cancellation despite failing to learn the true data-generating process. To ensure our metrics are practically reliable, we conducted a controlled micro-simulation study, detailed in Appendix J. The results provide strong empirical evidence for their validity and complementary roles: the CIC-Score acts as a high-sensitivity SRE detector; the CMI-Score robustly tracks the fidelity of causal associations; and the KMD-Score serves as a final arbiter of distributional similarity. This validation confirms that our evaluation framework offers a more complete, nuanced, and reliable assessment of generative causal models.
5 Experiments
Our empirical evaluation is designed as a comprehensive test of our central thesis: that eliminating SRE is a necessary condition for generating authentic counterfactuals and unlocks analytical capabilities beyond the reach of conventional methods. We structured the study as a four-act narrative to rigorously test our claims. Act I establishes our model’s state-of-the-art predictive fidelity on standard benchmarks. Act II provides a deep diagnostic analysis, using our proposed metrics as empirical evidence for the destructive effect of SRE. Act III showcases the unique capabilities unlocked by an information-conserving framework. Finally, Act IV validates the framework’s robustness through a series of stress tests and a full ablation study.
Evaluation Protocol.
For a rigorous evaluation, we employ two complementary protocols. This distinction is crucial, as it separates the assessment of our methodology’s peak performance from the diagnostic analysis of its components.
1. Ensemble Evaluation for SOTA Performance: To benchmark against state-of-the-art methods (specifically, ITE estimation in Section 5.1.3), we adopt the standard Deep Ensemble methodology. We train N=5 independent models and report the final metric (e.g., PEHE) on the ensembled prediction.
1. Individual Model Evaluation for Diagnostic Analysis: In all other experiments where the goal is a fair, apples-to-apples architectural comparison or stability assessment, we report the mean and standard deviation of metrics from individual model instances across N=5 runs. This isolates the effect of design choices from the gains of ensembling.
We estimate the Average Treatment Effect (ATE) throughout our experiments using a standard counterfactual imputation procedure, the pseudo-code for which is detailed in Algorithm 1 in Appendix K.
Baseline Estimators.
The Directed Acyclic Graphs (DAGs) for our experiments are shown in Figure 3. We benchmark BELM-MDCM against a suite of baselines from the DoWhy library (sharma2022dowhy), spanning classical statistical methods to state-of-the-art machine learning estimators to ensure a comprehensive comparison.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Flowchart: Causal Relationship Diagram
### Overview
The image depicts a causal relationship diagram with five nodes connected by directional arrows. The diagram uses color-coded shapes to represent different variable types: covariates, confounders, treatments, and outcomes. Arrows indicate directional influence or dependency between components.
### Components/Axes
1. **Nodes**:
- **W1 (Covariate)**: Top-left, blue rectangle.
- **W2 (Covariate)**: Top-right, blue rectangle.
- **C1 (Categorical Confounder)**: Center, purple rectangle.
- **T (Treatment)**: Orange diamond, below C1.
- **Y (Outcome)**: Green circle, bottom-center.
2. **Arrows**:
- Gray arrows connect all nodes, indicating bidirectional or unidirectional relationships.
- Key connections:
- W1 → C1, W2 → C1 (covariates influence confounder).
- C1 → T (confounder affects treatment).
- T → Y (treatment affects outcome).
- W2 → Y (direct effect of covariate on outcome).
3. **Color Coding**:
- Blue: Covariates (W1, W2).
- Purple: Categorical confounder (C1).
- Orange: Treatment (T).
- Green: Outcome (Y).
### Detailed Analysis
- **Covariates (W1, W2)**: Positioned at the top, suggesting they are external factors influencing downstream variables.
- **Categorical Confounder (C1)**: Acts as a mediator between covariates and treatment, highlighting its role in confounding the relationship.
- **Treatment (T)**: Central node influencing the outcome, with a direct arrow from C1.
- **Outcome (Y)**: Final node with two incoming arrows (from T and W2), indicating multiple pathways to the outcome.
### Key Observations
1. **Confounder Influence**: C1 is influenced by both covariates (W1, W2) and subsequently affects the treatment (T), suggesting potential bias in causal inference if unadjusted.
2. **Direct Pathway**: W2 has a direct arrow to Y, implying a relationship independent of the confounder or treatment.
3. **Treatment-Outcome Link**: T directly impacts Y, consistent with standard causal models.
### Interpretation
This diagram illustrates a causal pathway where covariates (W1, W2) influence a categorical confounder (C1), which in turn affects treatment (T) and the outcome (Y). The direct arrow from W2 to Y suggests that W2 may have an unmediated effect on the outcome, even after accounting for C1. The structure emphasizes the importance of controlling for confounders (C1) to isolate the true effect of treatment (T) on the outcome (Y). The presence of bidirectional arrows (e.g., W2 → C1 and C1 → W2) implies potential feedback loops, though the diagram does not explicitly clarify causality directionality.
**Note**: No numerical data or trends are present; the diagram focuses on structural relationships.
</details>
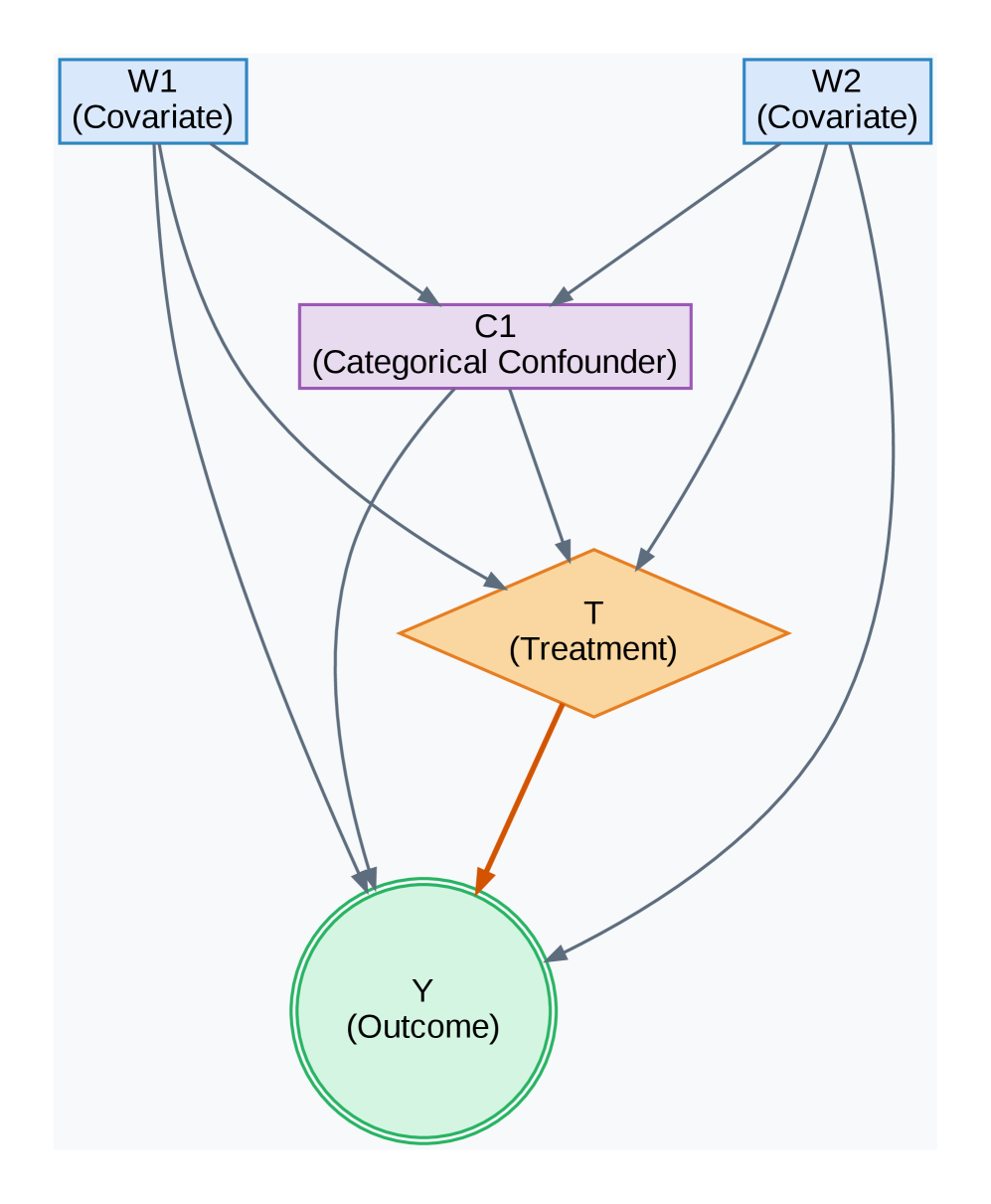
(a) PSM Failure Scenario
<details>
<summary>x4.png Details</summary>
### Visual Description
## Flowchart: Causal Relationship Diagram
### Overview
The image depicts a causal relationship diagram illustrating interactions between variables in a statistical or epidemiological model. It includes confounders, an instrumental variable, treatment, mediator, and outcome, with directional arrows indicating influence.
### Components/Axes
- **Nodes**:
- **X1 (Confounder)**: Blue rectangle, positioned top-left.
- **X2 (Confounder)**: Blue rectangle, positioned top-right.
- **Z (Instrumental Variable)**: Green hexagon, centered at the top.
- **T (Treatment)**: Orange diamond, central node.
- **M (Mediator)**: Green oval, below T.
- **Y (Outcome)**: Light green circle, bottom-center.
- **Edges**:
- Solid arrows (dark gray) indicate direct causal relationships.
- Dashed arrow (light gray) from Z to T denotes indirect or instrumental influence.
- Red arrows highlight primary pathways (e.g., T → M → Y).
### Detailed Analysis
1. **Confounders (X1, X2)**:
- Both X1 and X2 directly influence T (treatment) and Y (outcome).
- No direct connection between X1 and X2.
2. **Instrumental Variable (Z)**:
- Z affects T via a dashed arrow, suggesting it modifies treatment assignment without directly impacting Y.
3. **Treatment (T)**:
- T influences M (mediator) via a solid red arrow.
- T also has a direct effect on Y (solid red arrow).
4. **Mediator (M)**:
- M is influenced by T and directly affects Y.
5. **Outcome (Y)**:
- Y receives inputs from T, M, X1, and X2.
### Key Observations
- **Confounding Bias**: X1 and X2 create bidirectional pathways to Y, indicating potential confounding effects.
- **Mediation Pathway**: T → M → Y represents a mediated effect of treatment on outcome.
- **Instrumental Variable Role**: Z’s dashed arrow to T implies it isolates exogenous variation in treatment, reducing confounding bias.
- **Direct Effects**: T and M both directly impact Y, suggesting partial mediation.
### Interpretation
This diagram models a causal pathway where confounders (X1, X2) influence both treatment (T) and outcome (Y), creating potential bias. The instrumental variable (Z) is used to address this by affecting T without directly influencing Y. The mediator (M) explains part of T’s effect on Y, while T also has a direct effect. The red arrows emphasize the primary causal chain (T → M → Y), while gray arrows show secondary relationships. This structure is typical in studies aiming to disentangle direct and indirect effects while controlling for confounding variables.
</details>
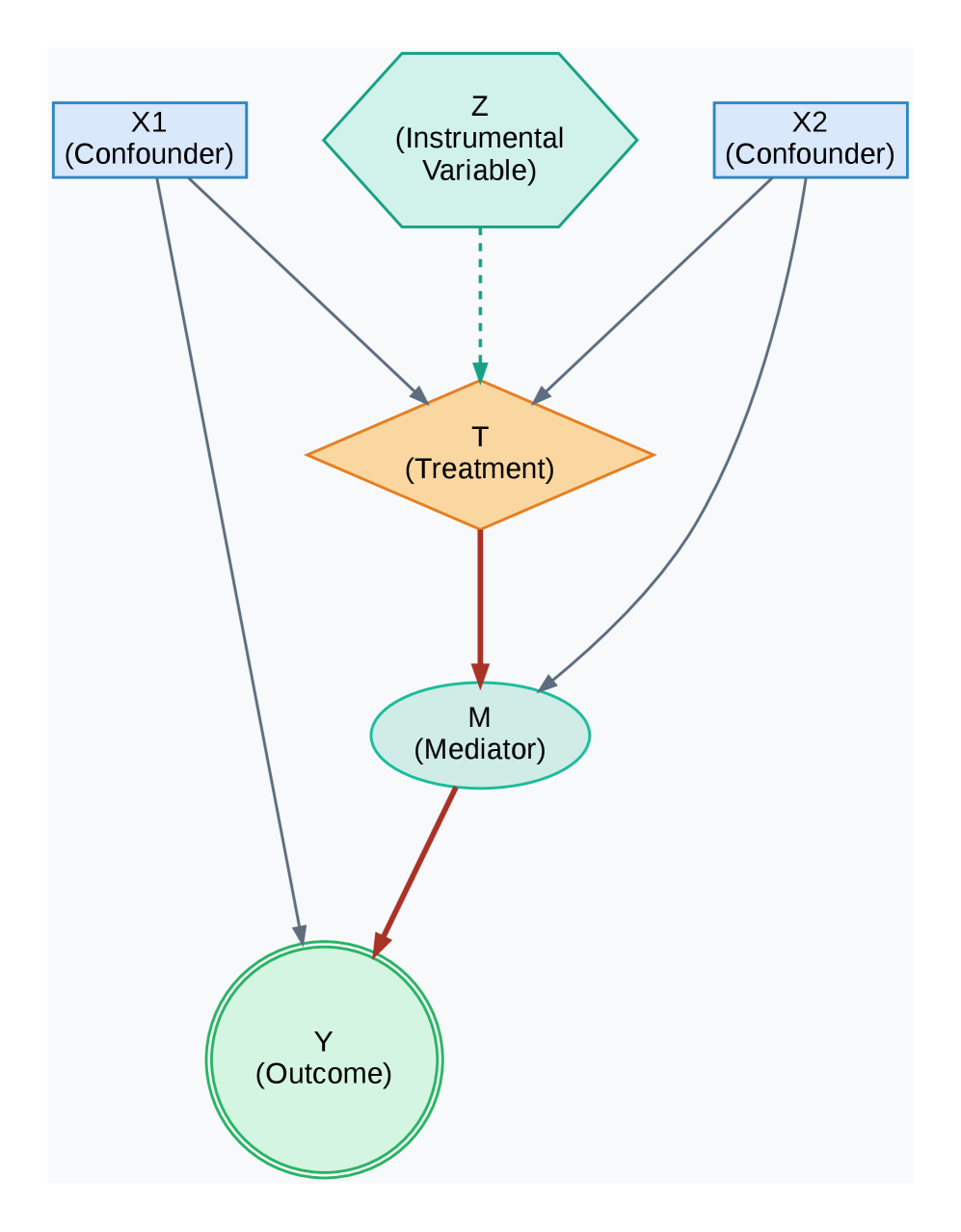
(b) Ablation Study Scenario
<details>
<summary>x5.png Details</summary>
### Visual Description
## Flowchart: Causal Relationship Diagram
### Overview
The image depicts a simplified causal flowchart illustrating relationships between confounders, treatment, and outcome variables. It uses standard flowchart notation with colored shapes and directional arrows to represent dependencies.
### Components/Axes
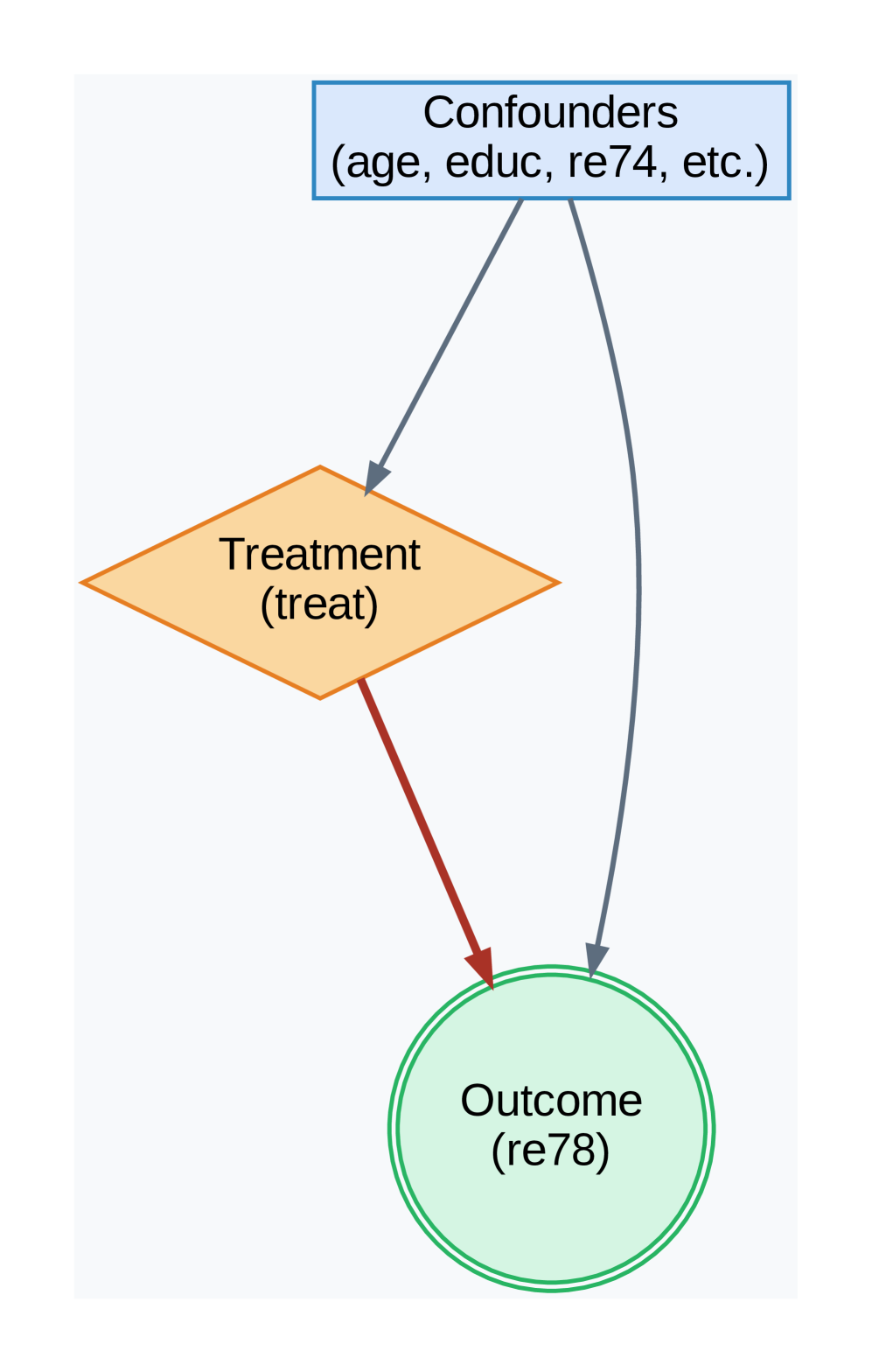
1. **Confounders** (Top):
- Rectangular blue box labeled "Confounders (age, educ, re74, etc.)"
- Contains variables: age, education (educ), re74 (likely a year or measurement), and unspecified additional factors
2. **Treatment** (Left):
- Orange diamond labeled "Treatment (treat)"
- Represents a decision node or intervention variable
3. **Outcome** (Bottom):
- Green circle labeled "Outcome (re78)"
- Contains the dependent variable "re78" (possibly a year or measurement)
4. **Arrows**:
- Gray arrows connect Confounders to both Treatment and Outcome
- Red arrow connects Treatment to Outcome
### Detailed Analysis
- **Confounders**: Explicitly lists age, education (abbreviated "educ"), and re74. The "etc." implies additional unlisted variables.
- **Treatment**: Positioned as a mediator between confounders and outcome.
- **Outcome**: Final node labeled "re78," suggesting a temporal or sequential relationship (e.g., re74 → re78).
- **Color Coding**:
- Blue (Confounders) → Gray arrows to Treatment/Outcome
- Orange (Treatment) → Red arrow to Outcome
- Green (Outcome)
### Key Observations
1. **Bidirectional Confounder Influence**: Confounders affect both Treatment and Outcome directly.
2. **Direct Treatment Effect**: The red arrow indicates a hypothesized causal pathway from Treatment to Outcome.
3. **Variable Naming**: Uses abbreviations (educ, re74, re78) suggesting domain-specific terminology (e.g., econometrics or social sciences).
### Interpretation
This diagram represents a **Directed Acyclic Graph (DAG)** used in causal inference analysis. It illustrates:
- **Confounder Control**: The need to account for variables like age and education that may influence both treatment assignment and outcomes.
- **Mediation Pathway**: Treatment (treat) is proposed as a direct cause of the outcome (re78), but its effect may be confounded by unmeasured variables.
- **Temporal Structure**: The use of "re74" and "re78" implies a 4-year gap, suggesting longitudinal analysis (e.g., treatment in 1974 affecting outcomes in 1978).
**Notable Design Choices**:
- Diamond shape for Treatment emphasizes its role as a decision point.
- Circular Outcome node highlights its status as the endpoint.
- Gray arrows for confounders visually subordinate them to the primary Treatment→Outcome relationship.
This structure is typical in observational studies to identify potential biases and justify adjustment methods (e.g., regression, propensity score matching).
</details>
(c) Lalonde Confounding Structure
Figure 3: Directed Acyclic Graphs (DAGs) for key experiments. (a) A structure designed to challenge propensity score methods. (b) A mediation structure used for the ablation study. (c) The standard confounding structure assumed for both Lalonde-based experiments.
5.1 Act I: Establishing State-of-the-Art Predictive Fidelity
We first establish that our principled design achieves superior predictive fidelity on standard causal inference benchmarks.
5.1.1 Robustness in Non-Linear Confounding Scenarios
We tested our model in a challenging synthetic scenario (Figure 3(a)) designed with highly non-linear confounding to cause propensity-based methods to fail. Table 1 shows the results. While Causal Forest is exceptionally accurate on this specific DGP, our BELM-MDCM framework secures its position as the second most accurate method, delivering a highly stable and competitive ATE estimate. Crucially, it significantly outperforms the entire suite of propensity-based methods and powerful estimators like DML in accuracy. The high standard deviation of DML highlights its unreliability in this context, validating our model as a robust estimator where traditional approaches are compromised.
Table 1: ATE Estimation on the PSM Failure Scenario (True ATE = 5000). We report the mean ATE and standard deviation across multiple runs.
| Causal Forest | 4895.77 $±$ 69.26 | 104.23 |
| --- | --- | --- |
| Propensity Score Stratification | 5309.38 $±$ 185.36 | 309.38 |
| Linear Regression | 5348.82 $±$ 23.23 | 348.82 |
| Propensity Score Matching | 5353.93 $±$ 191.36 | 353.93 |
| Inverse Propensity Weighting | 5385.68 $±$ 52.03 | 385.68 |
| Double Machine Learning | 4285.63 $±$ 550.97 | 714.37 |
5.1.2 Accuracy and Robustness on Real-World Observational Data
We next evaluated our framework on the canonical Lalonde dataset (lalonde1986evaluating), a challenging real-world benchmark with a known RCT ground truth. Table 2 demonstrates the comprehensive superiority of our BELM-MDCM framework. It achieved a mean ATE estimate of 1567.36 $±$ 201.62, the lowest error among all methods that correctly identified the treatment effect’s positive direction. More critically, the results highlight a stark contrast in reliability. Classical methods failed entirely, while the powerful Causal Forest baseline suffered from extreme instability (Std Dev of 785.59). In contrast, BELM-MDCM exhibited remarkable robustness, with a standard deviation approximately four times lower. This outstanding performance on a canonical benchmark validates that our framework delivers accurate estimates with the consistency essential for trustworthy causal inference.
Table 2: ATE Estimation Stability on the Lalonde Dataset (RCT Benchmark ATE $≈ 1794$ ). Results for all models are reported as Mean $±$ Standard Deviation across 5 independent runs.
| Causal Forest | 1085.30 $±$ 785.59 | 708.70 |
| --- | --- | --- |
| Linear Regression | 46.33 $±$ 76.80 | 1747.67 |
| Propensity Score Matching | -3.96 $±$ 118.37 | 1797.96 |
| Propensity Score Stratification | -35.54 $±$ 81.44 | 1829.54 |
| Propensity Score Weighting | -122.55 $±$ 50.51 | 1916.55 |
| Double Machine Learning | nan $±$ nan | nan |
5.1.3 High-Fidelity ITE Estimation and Stability Analysis
Objective. We evaluate performance at the individual level using a semi-synthetic version of the Lalonde dataset. This experiment leverages real-world covariates and assumes the causal structure depicted in Figure 3(c). To rigorously assess both accuracy and reliability, we follow our Individual Model Evaluation protocol, reporting the mean and standard deviation of performance across 5 independent runs for each method.
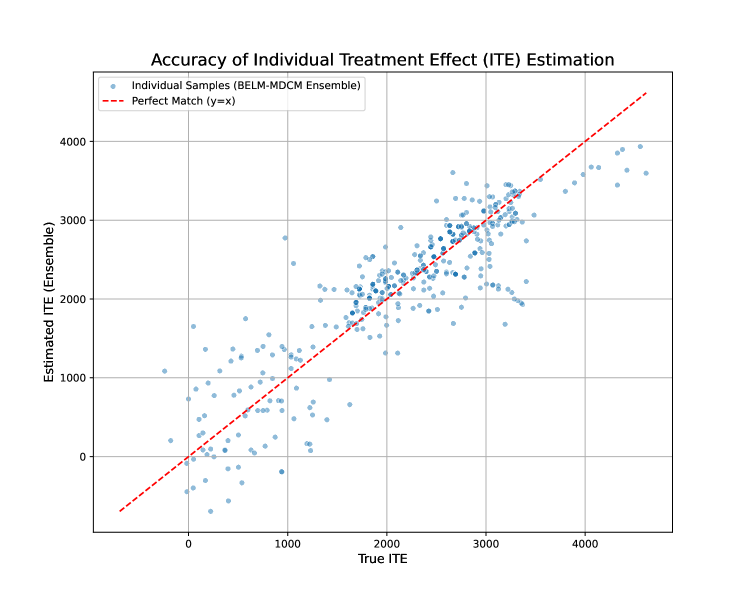
Results. The PEHE results, presented in Table 3, confirm the exceptional fidelity and robustness of our framework. BELM-MDCM achieves the lowest average PEHE score of 537.84 and demonstrates remarkable stability with the lowest standard deviation of just 60.11. This performance is closely followed by Causal Forest. However, the results also highlight the instability of other meta-learners; X-Learner, in particular, exhibits extremely high variance, with a standard deviation more than three times larger than its competitors, rendering its single-run estimates unreliable. This highlights the dual advantage of our framework: superior accuracy combined with consistent, trustworthy performance. Figure 4 provides visual confirmation, showing the tight clustering of our model’s ensembled ITE estimates around the ground truth.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Scatter Plot: Accuracy of Individual Treatment Effect (ITE) Estimation
### Overview
The image is a scatter plot comparing the accuracy of estimated Individual Treatment Effects (ITE) against their true values. The plot uses blue dots to represent individual samples from a BELM-MDCM ensemble and a red dashed line to indicate the "Perfect Match" (y=x), where estimated ITE equals true ITE.
### Components/Axes
- **Title**: "Accuracy of Individual Treatment Effect (ITE) Estimation" (top-center).
- **X-axis**: "True ITE" (ranging from 0 to 4000).
- **Y-axis**: "Estimated ITE (Ensemble)" (ranging from 0 to 4000).
- **Legend**:
- **Blue dots**: "Individual Samples (BELM-MDCM Ensemble)" (top-left).
- **Red dashed line**: "Perfect Match (y=x)" (top-left).
### Detailed Analysis
- **Data Points**:
- Blue dots (individual samples) are scattered across the plot, with most clustered near the red dashed line.
- Some points deviate from the line, with a few above (overestimation) and below (underestimation) the perfect match.
- The spread of points suggests variability in estimation accuracy, with no clear outliers.
- **Trends**:
- The red dashed line (y=x) acts as a reference for perfect estimation.
- The blue dots generally follow a positive linear trend, indicating that higher true ITE values correspond to higher estimated ITE values.
- The density of points increases near the line, suggesting the ensemble method performs well for mid-range ITE values.
### Key Observations
- The majority of estimated ITE values align closely with the true ITE, as seen by the concentration of blue dots near the red line.
- The spread of points indicates that while the ensemble method is generally accurate, there is some variability in estimation precision.
- No extreme outliers are visible, but the data shows a slight tendency for overestimation at higher true ITE values (points above the line).
### Interpretation
The plot demonstrates that the BELM-MDCM ensemble method provides a reliable estimation of ITE, with most individual samples closely matching the true ITE. The red dashed line (y=x) serves as a benchmark, and the proximity of blue dots to this line confirms the method's effectiveness. However, the observed spread suggests that the estimation is not perfectly consistent, potentially due to factors like sample heterogeneity or model limitations. This visualization highlights the trade-off between accuracy and variability in ITE estimation, emphasizing the need for further refinement to minimize deviations from the perfect match.
</details>
Figure 4: Accuracy of Individual Treatment Effect (ITE) Estimation on the semi-synthetic Lalonde dataset. The plot shows the ensembled estimated ITE from our model versus the true ITE. The tight clustering of our model’s estimates (blue dots) around the perfect-match line (red dash) visually demonstrates its low PEHE score.
Table 3: ITE Estimation Accuracy (PEHE) on the Semi-Synthetic Lalonde Dataset. Results are reported as Mean $±$ Standard Deviation across 5 independent runs. Lower is better.
| BELM-MDCM Causal Forest S-Learner | 537.84 $±$ 60.11 563.90 $±$ 73.66 816.26 $±$ 79.17 |
| --- | --- |
| X-Learner | 1546.38 $±$ 679.09 |
Table 4: Causal Mechanism Fidelity (CMI-Score) on the Semi-Synthetic Lalonde Dataset. Results are reported as Mean $±$ Standard Deviation across 5 runs. Higher is better.
| S-Learner BELM-MDCM Causal Forest | 0.9905 $±$ 0.0062 0.9824 $±$ 0.0092 0.9786 $±$ 0.0099 |
| --- | --- |
| X-Learner | 0.9782 $±$ 0.0145 |
| T-Learner | 0.9555 $±$ 0.0113 |
5.2 Act II: Uncovering the Accuracy-Invertibility Trade-off
We now conduct the pivotal experiment of our study: a deep diagnostic analysis using our novel CIC-Score to reveal the trade-off between predictive accuracy and mechanism invertibility. This provides the core empirical evidence for our thesis by comparing three paradigms: our BELM-MDCM (Learned Invertibility), a DDIM variant (Flawed Invertibility), and a classic RF-ANM (Assumed Invertibility).
The results in Table 5 decisively validate our framework’s principles. Our BELM-MDCM is the clear leader, achieving the lowest PEHE score (1071.95) with high stability. Critically, its CIC-Score of 0.3679 is orders of magnitude higher than the alternatives, proving its unique ability to learn an invertible mapping that conserves causal information. In stark contrast, the DDIM-MDCM model exemplifies the failure predicted by our theory: its near-zero CIC-Score confirms a near-total collapse of causal information due to SRE, leading to unreliable predictions (high PEHE and variance). The classical RF-ANM, while structurally invertible, lacks the capacity to learn the true mechanism, resulting in a zero CIC-Score and poor accuracy. This ”Golden Table” experiment underscores that both structural integrity and powerful modeling capacity are essential for high-fidelity causal inference.
Table 5: The ”Ultimate Golden Table”: A comparative analysis of model classes on predictive accuracy (PEHE) and structural integrity (CIC-Score). This table includes the NF-SCM baseline, which empirically validates the likelihood-fidelity dilemma. Results are reported as Mean $±$ Standard Deviation across 5 runs. Lower PEHE is better; higher CIC-Score is better.
| RF-ANM DDIM-MDCM NF-SCM | 1533.18 $±$ 134.24 2085.98 $±$ 788.12 442229.96 $±$ 66963.73 | 0.0000 $±$ 0.0000 0.0065 $±$ 0.0130 0.1572 $±$ 0.0232 |
| --- | --- | --- |
| BELM-MDCM | 1071.95 $±$ 152.11 | 0.3679 $±$ 0.0000 |
<details>
<summary>x7.png Details</summary>
### Visual Description
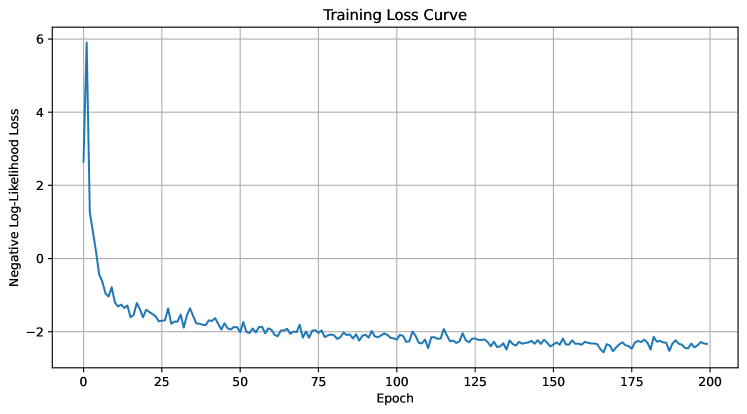
## Line Chart: Training Loss Curve
### Overview
The image depicts a line chart titled "Training Loss Curve," illustrating the progression of negative log-likelihood loss over training epochs. The chart shows a sharp initial decline in loss, followed by stabilization with minor fluctuations.
### Components/Axes
- **X-axis (Horizontal)**: Labeled "Epoch," with values ranging from 0 to 200 in increments of 25.
- **Y-axis (Vertical)**: Labeled "Negative Log-Likelihood Loss," with values ranging from -2 to 6 in increments of 2.
- **Legend**: Not visible in the image.
- **Line**: A single blue line representing the loss curve, with no markers or annotations.
### Detailed Analysis
- **Initial Phase (Epochs 0–25)**: The loss starts at approximately 6 and drops sharply to around -2 by epoch 25. This steep decline suggests rapid improvement in model performance during early training.
- **Stabilization Phase (Epochs 25–200)**: After epoch 25, the loss stabilizes near -2, with minor oscillations (approximately ±0.2). The fluctuations are consistent but do not indicate significant overfitting or underfitting.
- **Final Value**: By epoch 200, the loss remains close to -2, indicating convergence of the training process.
### Key Observations
1. **Rapid Initial Decline**: The loss decreases by ~8 units (from 6 to -2) within the first 25 epochs, highlighting the model's sensitivity to early training adjustments.
2. **Stable Convergence**: The loss plateaus near -2 after epoch 25, suggesting the model has reached a stable state with minimal further improvement.
3. **No Overfitting Signs**: The absence of a rising loss trend after stabilization implies the model generalizes well without overfitting.
### Interpretation
The chart demonstrates a typical training dynamics pattern: a steep initial drop in loss as the model learns key features, followed by stabilization as it refines its parameters. The negative log-likelihood loss approaching -2 indicates a well-trained model with low uncertainty in predictions. The lack of a legend or additional data series suggests this is a single-model evaluation. The absence of overfitting (loss does not increase post-stabilization) implies effective regularization or a well-balanced dataset. The early convergence (by epoch 25) may indicate a relatively simple problem or a highly effective learning rate schedule.
</details>
Figure 5: The training loss curve for the Conditional Normalizing Flow (NF) baseline. The smooth, stable convergence to a low negative log-likelihood value indicates a successful statistical training run. However, this did not correspond to learning the true causal mechanism, as evidenced by its extremely high PEHE score.
The Likelihood-Fidelity Dilemma: Why Natively Invertible Models Can Fail.
To rigorously test the limits of models that are natively invertible, we conducted a comprehensive stability analysis on a Conditional Normalizing Flow (NF) baseline, a model class that satisfies the Causal Information Conservation principle by construction (SRE $\equiv 0$ ). Across five independent runs with different random seeds, the NF model consistently demonstrated successful statistical learning, with its training loss stably converging to a high log-likelihood in each instance (a representative example is shown in Figure 5).
However, this statistical success was starkly contrasted by a systematic and catastrophic failure in the causal task. The model yielded an average PEHE score of 442,229.96 $±$ 66,963.73, confirming that its generated counterfactuals were fundamentally incorrect. This consistent result provides decisive evidence for a critical challenge we term the likelihood-fidelity dilemma: a model can perfectly learn to replicate a data distribution while remaining completely ignorant of the underlying causal mechanism.
The root of this dilemma is the fundamental mismatch between the optimization objective and the causal goal. The maximum likelihood objective incentivizes the NF to find any invertible mapping that transforms the data to a simple base distribution. While an infinite number of such mappings may be statistically equivalent, only one corresponds to the true, unique causal data-generating process. Without a guiding signal, the NF is mathematically predisposed to learn a causally-incorrect ”statistical shortcut.” This finding powerfully underscores the contribution of our Hybrid Training Objective. It acts as the crucial causal inductive bias that resolves this dilemma, compelling the model to learn the unique, causally salient structure and enabling valid causal inference where pure likelihood-based methods, even those with zero SRE, are destined to fail.
5.3 Act III: Unlocking Deeper Causal Inquiry with a High-Fidelity Model
An information-conserving model serves as a trustworthy ”world model” for deep causal inquiry. We showcase three applications uniquely enabled by our framework’s high-fidelity counterfactuals.
Heterogeneity Analysis: Conditional ATE (CATE).
A reliable ITE model can act as a “causal microscope.” We use it to explore treatment effect heterogeneity by estimating the Conditional Average Treatment Effect (CATE) for subpopulations. By averaging the results from our five independently trained models, we obtain stable and robust estimates. Our model’s mean CATE estimates track the true CATE trends with high fidelity across different education levels, a capability crucial for policy-making. For instance, for individuals with an education level of 3.0, the estimated CATE was $2562.79 (true CATE: $2280.79). For levels 8.0, 12.0, and 16.0, the estimates were $2092.91 (true: $2118.61), $2253.76 (true: $2384.44), and $2434.89 (true: $2490.21), respectively, demonstrating a close correspondence to the ground truth.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Bar Chart: Causal Attribution: The Impact of Exogenous "Luck"
### Overview
The chart compares two outcomes for "Victim (Index 201)" under different conditions: their actual outcome and the outcome when attributed with the "Top Responder's 'Luck'". A dashed blue line represents the "Top Responder (Index 281) Actual Outcome". The y-axis measures "Outcome (Y)" in monetary values, while the x-axis categorizes the two scenarios.
### Components/Axes
- **Title**: "Causal Attribution: The Impact of Exogenous 'Luck'"
- **Y-Axis**: Labeled "Outcome (Y)" with increments of $5,000 up to $35,000.
- **X-Axis**: Two categories:
- "Victim (Index 201) Actual Outcome" (red bar)
- "Victim (Index 201) with Top Responder's 'Luck'" (green bar)
- **Legend**: Top-left corner, with a dashed blue line labeled "Top Responder (Index 281) Actual Outcome ($4,296.47)".
- **Values**:
- Red bar: $10,993.98
- Green bar: $33,328.30
- Dashed blue line: $4,296.47
### Detailed Analysis
- **Red Bar**: Positioned at ~$11,000, representing the victim's actual outcome.
- **Green Bar**: Positioned at ~$33,328, showing a 203% increase compared to the red bar when the top responder's "luck" is attributed.
- **Dashed Blue Line**: A horizontal reference at ~$4,300, significantly lower than both bars, indicating the top responder's own actual outcome.
### Key Observations
1. The green bar (victim with top responder's "luck") is **3x higher** than the red bar (victim's actual outcome).
2. The top responder's own outcome ($4,296.47) is **72% lower** than the victim's actual outcome, suggesting their "luck" disproportionately benefits others.
3. The green bar exceeds the y-axis maximum ($35,000), emphasizing its magnitude.
### Interpretation
The data suggests that exogenous "luck" (when attributed to a top responder) has a **disproportionately positive impact** on outcomes for others compared to the responder's own actual results. This could imply:
- **Causal Misattribution**: The top responder's success may be overestimated when externally attributed to others.
- **Systemic Bias**: Outcomes for victims may be artificially inflated by associating them with high-performing individuals.
- **Anomaly in Top Responder's Performance**: Their own outcome is notably lower than the impact they have on others, raising questions about measurement or contextual factors.
The chart highlights how external attribution of "luck" can distort perceptions of causality and outcomes, potentially leading to misguided resource allocation or policy decisions.
</details>
Figure 6: Causal Attribution Analysis. This chart shows the counterfactual outcome for the ’Victim’ if they had possessed the individual-specific exogenous factors of the ’Top Responder’.
Causal Attribution: Isolating the Effect of Exogenous Factors.
We conducted a causal attribution experiment via a counterfactual intervention of the form $do(U_{\text{victim}}:=u_{\text{responder}})$ . Figure 6 shows that our framework can losslessly recover these factors, revealing that unobserved exogenous ’luck’ In this context, the term ’luck’ serves as an intuitive shorthand for the exogenous noise variable $U$ . Within the Structural Causal Model (SCM) framework, $U$ represents all unobserved, individual-specific factors (e.g., intrinsic ability, random chance, measurement errors) that, together with the observed parent variables ( $\mathbf{Pa}$ ), determine the final outcome for an individual. had a massive and stable causal effect, averaging a +22,334.32 change in the ’Victim’s’ outcome. This capacity for reliable attribution is a unique advantage of our information-conserving framework.
<details>
<summary>x9.png Details</summary>
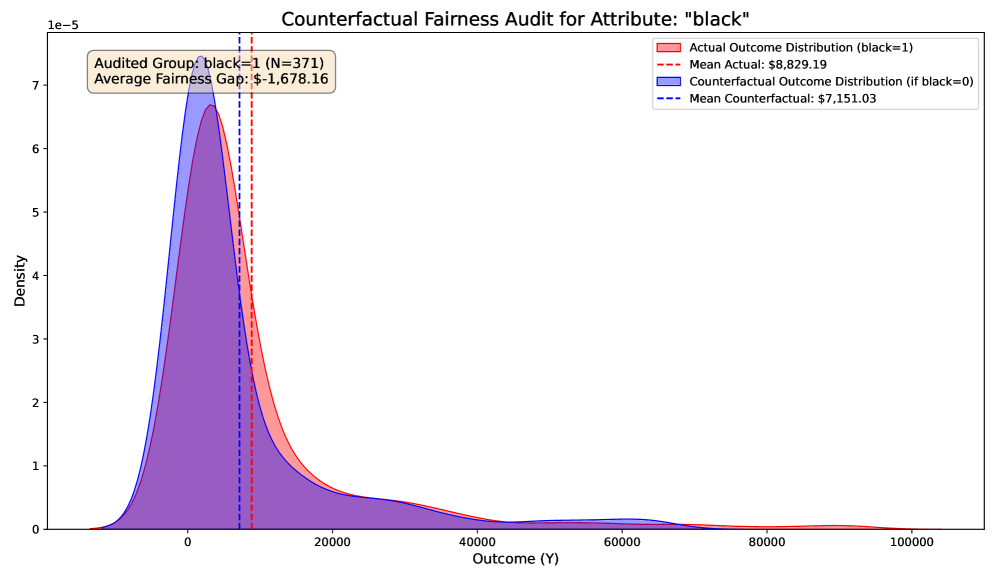
### Visual Description
## Counterfactual Fairness Audit for Attribute: "black"
### Overview
The image presents a comparative analysis of outcome distributions for a fairness audit focused on the attribute "black". It visualizes two probability density functions (PDFs) representing actual outcomes (black=1) and counterfactual outcomes (if black=0), with mean values and a calculated fairness gap.
### Components/Axes
- **X-axis**: "Outcome (Y)" (range: 0–100,000)
- **Y-axis**: "Density" (scale: 0–1e-5)
- **Legend**:
- Red solid line: Actual Outcome Distribution (black=1)
- Blue solid line: Counterfactual Outcome Distribution (if black=0)
- Red dashed line: Mean Actual ($8,829.19)
- Blue dashed line: Mean Counterfactual ($7,151.03)
- **Text Box**:
- "Audited Group: black=1 (N=371)"
- "Average Fairness Gap: $-1,678.16"
### Detailed Analysis
1. **Distributions**:
- The **Actual Outcome Distribution (red)** peaks sharply near $10,000, with a long right tail extending to ~$20,000.
- The **Counterfactual Outcome Distribution (blue)** peaks at ~$7,000, with a broader spread and a slower decay.
- Both distributions overlap significantly in the $0–$20,000 range but diverge at higher values.
2. **Mean Values**:
- The mean of the Actual Outcome ($8,829.19) is higher than the Counterfactual Outcome ($7,151.03), as indicated by the dashed lines.
- The **Average Fairness Gap** ($-1,678.16) quantifies the disparity between the two means.
3. **Spatial Elements**:
- The legend is positioned in the **top-right corner**, clearly associating colors with distributions.
- The text box is anchored in the **top-left corner**, providing contextual metadata.
### Key Observations
- The Actual Outcome Distribution (black=1) is skewed toward higher values compared to the Counterfactual (black=0).
- The fairness gap suggests a systematic bias: outcomes for the audited group (black=1) are consistently higher than the counterfactual scenario.
- The overlap in lower-value ranges indicates variability in outcomes, but the mean difference highlights a structural disparity.
### Interpretation
The chart demonstrates that the attribute "black" significantly influences outcomes, with the audited group (black=1) experiencing a **$1,678.16 higher mean outcome** than the counterfactual group (black=0). This disparity suggests potential unfairness in the model’s predictions, as outcomes are not invariant to the "black" attribute. The distributions’ shapes imply that while individual outcomes vary, the systemic gap persists, warranting further investigation into the root causes of this bias. The fairness gap’s negative sign indicates the direction of the disparity, emphasizing the need for corrective measures to ensure equitable outcomes across groups.
</details>
(a) Fairness audit for attribute ’black’.
<details>
<summary>x10.png Details</summary>
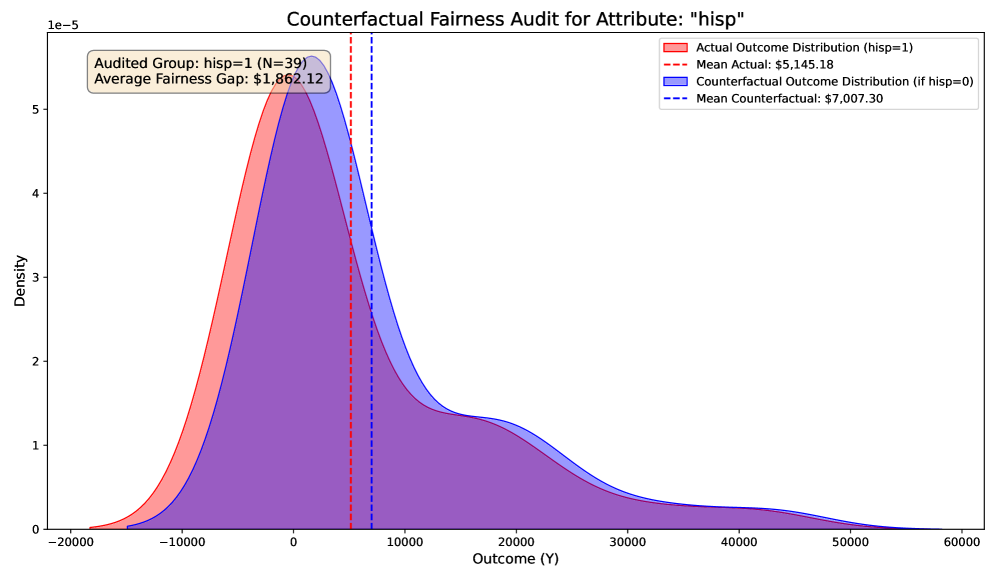
### Visual Description
## Density Plot: Counterfactual Fairness Audit for Attribute "hisp"
### Overview
The image is a comparative density plot analyzing fairness in outcomes based on the attribute "hisp" (Hispanic status). It contrasts the **Actual Outcome Distribution** (hisp=1) with the **Counterfactual Outcome Distribution** (hisp=0). The chart highlights disparities in mean outcomes and variability between the two groups, with annotations for statistical significance and fairness gaps.
---
### Components/Axes
- **Title**: "Counterfactual Fairness Audit for Attribute: 'hisp'" (top center).
- **X-axis**: "Outcome (Y)" with a range from **-20,000 to 60,000** (logarithmic scale implied by axis limits).
- **Y-axis**: "Density" with a scale from **0 to 1e-5** (linear scale).
- **Legend**: Located in the **top-right corner**, with two entries:
- **Red**: Actual Outcome Distribution (hisp=1).
- **Blue**: Counterfactual Outcome Distribution (hisp=0).
- **Dashed Lines**: Vertical lines marking the mean outcomes:
- **Red dashed line**: Mean Actual = **$5,145.18**.
- **Blue dashed line**: Mean Counterfactual = **$7,007.30**.
- **Text Box**: Top-left corner, stating:
- "Audited Group: hisp=1 (N=39)".
- "Average Fairness Gap: $1,862.12".
---
### Detailed Analysis
1. **Actual Outcome Distribution (hisp=1, red)**:
- **Peak**: Centered near **$5,000** (x-axis).
- **Spread**: Narrower curve, indicating lower variability in outcomes.
- **Mean**: Marked by red dashed line at **$5,145.18**.
- **Density**: Peaks at ~**5e-5** on the y-axis.
2. **Counterfactual Outcome Distribution (hisp=0, blue)**:
- **Peak**: Centered near **$7,000** (x-axis).
- **Spread**: Wider curve, indicating higher variability in outcomes.
- **Mean**: Marked by blue dashed line at **$7,007.30**.
- **Density**: Peaks at ~**5e-5** on the y-axis, similar to the red curve.
3. **Fairness Gap**:
- The difference between the two means is **$1,862.12** (highlighted in the text box).
- The counterfactual group (hisp=0) has a **35% higher mean outcome** than the actual group (hisp=1).
4. **Distribution Characteristics**:
- Both curves share similar peak densities but differ in spread.
- The red curve (hisp=1) is more concentrated, while the blue curve (hisp=0) is broader, suggesting less consistency in outcomes for the counterfactual group.
---
### Key Observations
- The **mean outcome for hisp=0 is significantly higher** than for hisp=1, indicating a potential fairness issue.
- The **fairness gap of $1,862.12** quantifies the disparity between the two groups.
- The **narrower distribution for hisp=1** suggests more uniform outcomes within that group, but the lower mean raises concerns about systemic bias.
- The **overlap between distributions** (e.g., at ~$5,000–$7,000) implies some individuals in both groups experience similar outcomes, but the systemic gap persists.
---
### Interpretation
The chart reveals a **systemic disparity** in outcomes between the hisp=1 and hisp=0 groups. The counterfactual group (hisp=0) achieves a **35% higher average outcome**, suggesting potential discrimination or inequity in the system being audited. The narrower distribution for hisp=1 indicates less variability in their outcomes, which could reflect either stricter constraints or systemic barriers limiting their opportunities. The fairness gap of **$1,862.12** underscores the magnitude of the inequity, warranting further investigation into the root causes (e.g., algorithmic bias, resource allocation). The chart emphasizes the importance of counterfactual analysis in identifying hidden biases that may not be apparent in raw data.
</details>
(b) Fairness audit for attribute ’hisp’.
Figure 7: Counterfactual fairness audits reveal significant outcome disparities based on sensitive attributes. The plots show the distribution of actual outcomes for each group versus the distribution of their counterfactual outcomes had their sensitive attribute been different.
Counterfactual Fairness Audit.
Finally, we applied our framework to a counterfactual fairness audit. Only a model that faithfully represents the data generating process can reliably answer questions about fairness. Figure 7 reveals significant and stable disparities: our model estimates an average fairness gap of -1,678.16 for the ’black’ attribute and +1,862.12 for the ’hisp’ attribute, demonstrating its capacity as a powerful tool for ethical audits.
5.4 Act IV: Final Validation: Stress Tests and Ablation Study
We conclude by subjecting the framework to two final tests: a stress test on a non-invertible SCM and a comprehensive ablation study.
5.4.1 Stress Test on a Non-Invertible SCM
We tested our framework’s robustness when the theoretical assumption of an invertible SCM is violated, using a DGP where $Y\propto U_{Y}^{2}$ . The results in Table 6 and Figure 8 decisively validate our hypothesis. On the definitive metric of individual-level fidelity (PEHE), our zero-SRE BELM framework achieves an error of 0.77, a 44% reduction compared to the SRE-prone DDIM model. This empirically proves that even when the true SCM is non-invertible, eliminating algorithmic SRE provides a substantial advantage. This result is fully consistent with our theoretical analysis in Appendix C (Theorem 21), where the total error is decomposed into algorithmic, modeling, and representational errors. By eliminating the algorithmic error ( $E_{SR}\equiv 0$ ), our framework’s performance approaches the theoretical limit set by the other two components.
Interestingly, the DDIM sampler achieves a slightly higher KMD-Score. We hypothesize that its inherent inversion noise acts as a form of implicit regularization, making the marginal generated distribution appear closer to the truth, even while individual-level counterfactuals are less accurate. This highlights the important distinction between distributional fidelity and individual-level causal accuracy.
<details>
<summary>x11.png Details</summary>
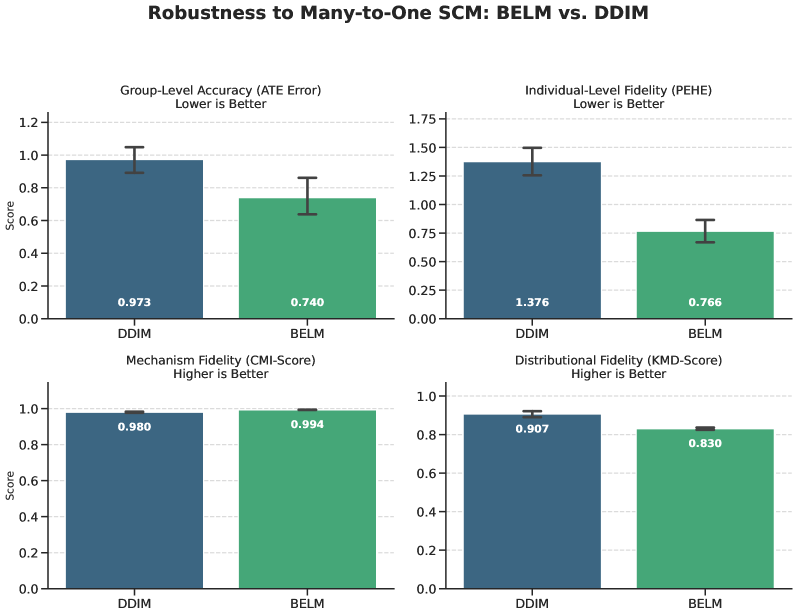
### Visual Description
## Bar Chart: Robustness to Many-to-One SCM: BELM vs. DDIM
### Overview
The image compares two methods, **DDIM** and **BELM**, across four metrics related to robustness in many-to-one structural causal models (SCMs). Each metric is visualized as a bar chart with error bars, and the results are split into two categories: "lower is better" (Group-Level Accuracy, Individual-Level Fidelity) and "higher is better" (Mechanism Fidelity, Distributional Fidelity).
### Components/Axes
- **X-axis**: Methods compared (**DDIM** in blue, **BELM** in green).
- **Y-axis**: Scores for each metric (ranging from 0.0 to 1.75).
- **Legend**: Located in the top-right corner, with **DDIM** (blue) and **BELM** (green) explicitly labeled.
- **Subplot Titles**:
1. **Group-Level Accuracy (ATE Error)**: Lower is better.
2. **Individual-Level Fidelity (PEHE)**: Lower is better.
3. **Mechanism Fidelity (CMI-Score)**: Higher is better.
4. **Distributional Fidelity (KMD-Score)**: Higher is better.
### Detailed Analysis
#### Group-Level Accuracy (ATE Error)
- **DDIM**: Score = 0.973 (blue bar).
- **BELM**: Score = 0.740 (green bar).
- **Error Bars**: Approximate ranges: DDIM (±0.05), BELM (±0.07).
#### Individual-Level Fidelity (PEHE)
- **DDIM**: Score = 1.376 (blue bar).
- **BELM**: Score = 0.766 (green bar).
- **Error Bars**: Approximate ranges: DDIM (±0.08), BELM (±0.05).
#### Mechanism Fidelity (CMI-Score)
- **DDIM**: Score = 0.980 (blue bar).
- **BELM**: Score = 0.994 (green bar).
- **Error Bars**: Approximate ranges: DDIM (±0.01), BELM (±0.005).
#### Distributional Fidelity (KMD-Score)
- **DDIM**: Score = 0.907 (blue bar).
- **BELM**: Score = 0.830 (green bar).
- **Error Bars**: Approximate ranges: DDIM (±0.01), BELM (±0.005).
### Key Observations
1. **BELM outperforms DDIM** in **Group-Level Accuracy** (0.740 vs. 0.973) and **Individual-Level Fidelity** (0.766 vs. 1.376), where lower scores are better.
2. **DDIM outperforms BELM** in **Mechanism Fidelity** (0.980 vs. 0.994) and **Distributional Fidelity** (0.907 vs. 0.830), where higher scores are better.
3. **Error bars** suggest variability in results, with BELM showing slightly larger uncertainty in Group-Level Accuracy and DDIM in Individual-Level Fidelity.
### Interpretation
- **BELM’s strength** in group-level metrics (ATE Error, PEHE) implies it may better handle robustness in scenarios where collective accuracy or individual fidelity is prioritized.
- **DDIM’s advantage** in mechanism and distributional fidelity suggests it excels in capturing finer-grained causal relationships or distributional properties.
- The trade-off between the two methods highlights a potential design choice: BELM for group-level robustness, DDIM for individual-level or mechanistic precision.
- **Notable anomaly**: BELM’s lower PEHE score (0.766) is significantly better than DDIM’s (1.376), indicating a stark difference in individual-level performance.
### Spatial Grounding
- **Legend**: Top-right corner, clearly associating colors with methods.
- **Subplot Layout**: 2x2 grid, with each metric’s title positioned above its respective chart.
- **Bar Colors**: Blue (DDIM) and green (BELM) consistently match the legend.
### Content Details
- All numerical values are explicitly labeled on the bars.
- Error bars are visually distinct but lack exact numerical ranges in the image.
- No additional text or annotations beyond the provided labels.
### Final Notes
The chart provides a clear comparative analysis of BELM and DDIM across four robustness metrics. The results suggest context-dependent performance, with no single method dominating all categories. Further investigation into error bar ranges and statistical significance would strengthen conclusions.
</details>
Figure 8: Robustness comparison on the many-to-one SCM. Our zero-SRE framework (BELM) demonstrates significantly superior performance on PEHE.
Table 6: Performance on the non-invertible SCM ( $Y\propto U^{2}$ ). Results are averaged over 5 runs ( $±$ std). Lower PEHE is better.
| BELM (Zero SRE) DDIM (with SRE) | 0.77 $±$ 0.16 1.38 $±$ 0.19 | 0.830 $±$ 0.009 0.907 $±$ 0.023 |
| --- | --- | --- |
5.4.2 Ablation Study: Deconstructing the Framework’s Success
We conducted a comprehensive ablation study on a challenging synthetic dataset (Figure 3(b)) to validate the contribution of each core component. The findings, presented in Table 7 and Figure 9, provide unequivocal evidence for our integrated design. The full BELM-MDCM model establishes the gold standard for both accuracy and stability. The study reveals three critical insights:
- Decisive Role of the Hybrid Objective: Removing it causes a catastrophic decline in performance (400%+ error increase), demonstrating it is a core driver of the causal inductive bias, not merely a fine-tuning mechanism.
- Critical Importance of Targeted Modeling: Removing it leads to a complete collapse in model stability (Std Dev explodes from 4.57 to 138.01), validating our theoretical analysis on complexity control. A judicious allocation of model complexity is paramount for reproducibility.
- Robust Advantage of Exact Invertibility: Replacing BELM with DDIM leads to a clear degradation in both accuracy and stability, confirming that SRE from approximate inversion systematically erodes the quality of the final causal estimate.
<details>
<summary>x12.png Details</summary>
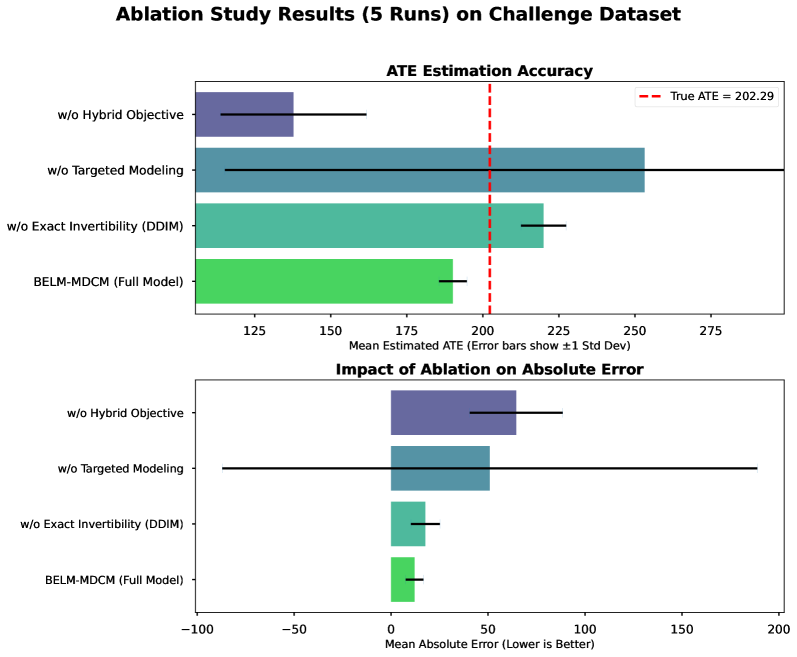
### Visual Description
## Bar Chart: Ablation Study Results (5 Runs) on Challenge Dataset
### Overview
The image presents two comparative bar charts analyzing ablation study results for a machine learning model. The top chart evaluates **ATE Estimation Accuracy**, while the bottom chart assesses **Impact of Ablation on Absolute Error**. Both charts compare four model configurations against a benchmark (True ATE = 202.29) using 5 experimental runs. Error bars represent ±1 standard deviation.
---
### Components/Axes
#### Top Chart: ATE Estimation Accuracy
- **X-axis**: Mean Estimated ATE (Error bars show ±1 Std Dev)
- **Y-axis**: Ablation conditions (categorical):
1. w/o Hybrid Objective
2. w/o Targeted Modeling
3. w/o Exact Invertibility (DDIM)
4. BELM-MDCM (Full Model)
- **Legend**: Red dashed line = True ATE = 202.29
#### Bottom Chart: Impact of Ablation on Absolute Error
- **X-axis**: Mean Absolute Error (Lower is Better)
- **Y-axis**: Same ablation conditions as above
- **Legend**: No explicit legend, but error bars are black with caps
---
### Detailed Analysis
#### Top Chart: ATE Estimation Accuracy
- **w/o Hybrid Objective**:
- Mean ATE ≈ 140 (±15)
- Significantly below True ATE (202.29)
- **w/o Targeted Modeling**:
- Mean ATE ≈ 250 (±20)
- Exceeds True ATE by ~48 units
- **w/o Exact Invertibility (DDIM)**:
- Mean ATE ≈ 220 (±10)
- Exceeds True ATE by ~18 units
- **BELM-MDCM (Full Model)**:
- Mean ATE ≈ 190 (±5)
- Closest to True ATE (within 12 units)
#### Bottom Chart: Impact of Ablation on Absolute Error
- **w/o Hybrid Objective**:
- Mean Error ≈ -60 (±10)
- **w/o Targeted Modeling**:
- Mean Error ≈ -50 (±15)
- **w/o Exact Invertibility (DDIM)**:
- Mean Error ≈ -20 (±5)
- **BELM-MDCM (Full Model)**:
- Mean Error ≈ -10 (±3)
---
### Key Observations
1. **ATE Estimation Accuracy**:
- The Full Model (BELM-MDCM) achieves the highest accuracy (190 ±5), outperforming all ablated versions.
- Removing "Targeted Modeling" causes the largest deviation (+20% relative error vs. True ATE).
- "w/o Hybrid Objective" shows the lowest accuracy (140 ±15), with the widest error margin.
2. **Absolute Error**:
- The Full Model has the smallest error (-10 ±3), indicating optimal performance.
- Ablating "Hybrid Objective" introduces the largest error (-60 ±10), suggesting critical importance of this component.
3. **Error Bar Variability**:
- "w/o Targeted Modeling" exhibits the highest uncertainty in ATE estimation (±20).
- The Full Model demonstrates the most stable results (±5 in ATE, ±3 in error).
---
### Interpretation
The data demonstrates that **all ablation components degrade model performance**, with the Full Model (BELM-MDCM) serving as the optimal configuration. Key insights:
- **Hybrid Objective** is critical for ATE accuracy, as its removal causes the largest drop (-60 units).
- **Targeted Modeling** introduces overestimation bias when removed (+58 units vs. True ATE).
- The Full Model balances accuracy and stability, with the smallest error margins (±5 in ATE, ±3 in absolute error).
The study highlights the interdependence of ablation components: removing any single element disrupts performance, but the Full Model mitigates these effects through synergistic interactions. The True ATE benchmark (202.29) provides a reference point, showing that even the best ablated model (w/o DDIM) overestimates by ~9%.
</details>
Figure 9: Visualization of the ablation study results. The top panel shows the mean estimated ATE relative to the true value (red dashed line), with error bars indicating $± 1$ standard deviation. The bottom panel highlights the mean absolute error for each configuration. The full BELM-MDCM model is demonstrably the most accurate and stable.
Table 7: Ablation study results on a challenging synthetic dataset (True ATE = 202.29), validating the necessity of each framework component. The mean and standard deviation are computed over 5 runs.
| w/o Exact Invertibility (DDIM) w/o Hybrid Objective w/o Targeted Modeling | 219.98 $±$ 7.48 137.77 $±$ 23.99 253.20 $±$ 138.01 | 17.68 64.53 50.90 |
| --- | --- | --- |
Conclusion.
The ablation study confirms that our framework’s three core design principles: analytical invertibility, a hybrid training objective, and targeted modeling —work in synergy. The removal of any single component creates a significant vulnerability, validating the integrity and effectiveness of our integrated architectural design.
6 Causal Information Conservation as a Unifying Principle
The principle of Causal Information Conservation extends beyond a foundation for our model; it offers a unifying lens—a new taxonomy—for analyzing the suitability of any generative model for individual-level causal inference. Applying this principle and its operational metric, SRE, allows us to situate our work and clarify its unique advantages within the broader landscape.
6.1 Normalizing Flows: Natively Information-Conserving
Normalizing Flows (NFs) (dinh2014nice; dinh2017density; kingma2018glow) are designed around an invertible mapping. By construction, their Structural Reconstruction Error is identically zero, making NFs a native implementation of the Causal Information Conservation principle. However, their strengths come with limitations: the requirement of a tractable Jacobian imposes heavy architectural constraints, which can limit expressive power and introduce strong topological assumptions on the data manifold.
6.2 VAEs and GANs: Architecturally High-SRE
Variational Autoencoders (VAEs) (kingma2014autoencoding) and Generative Adversarial Networks (GANs) (goodfellow2014generative) are fundamentally ill-suited for this task. Their Structural Reconstruction Error is large and non-zero due to a fundamental architectural mismatch, as their separate encoder and decoder networks lack any structural guarantee of being inverses. Furthermore, their sources of information loss are inherent to their design; optimization objectives like the ELBO’s KL-divergence term actively encourage lossy compression, theoretically impeding the recovery of precise causal information.
6.3 A Comparative Perspective on Diffusion Models
Viewed through our principle, diffusion models occupy a unique and compelling space in this taxonomy. Standard diffusion-based approaches, using samplers like DDIM, aspire to conserve information, but their reliance on approximate inversion results in a non-zero SRE; they are ”aspirational” but ultimately lossy. In contrast, BELM-MDCM (this work) achieves zero SRE by integrating an analytically invertible sampler, matching the theoretical purity of Normalizing Flows but without their rigid architectural constraints. Furthermore, unlike NFs trained with a generic likelihood objective, our framework’s Hybrid Training objective provides a causally-oriented inductive bias. BELM-MDCM thus uniquely combines the rigorous invertibility of NFs with the modeling flexibility and task-specific power of the diffusion paradigm, making it ideally suited for principled, high-fidelity causal inference.
7 Conclusion and Future Work
This paper introduced Causal Information Conservation as a guiding principle for the emerging field of diffusion-based causal inference. Our primary contribution is not the concept of invertibility itself, but framing it as a foundational design requirement and identifying the Structural Reconstruction Error (SRE) as the precise, quantifiable cost of its violation.
Our proposed framework, BELM-MDCM, serves as a constructive proof of this principle. By being architected around analytical invertibility, it is the first to achieve zero SRE by design, shifting the focus from mitigating numerical errors to upholding a fundamental causal principle. This work provides a foundational blueprint and a more rigorous standard for applying the power of diffusion models to the profound challenges of causal inference, reconciling their flexibility with the logical rigor demanded by classical theory.
7.1 Limitations and Future Work
Our work highlights several avenues for future research:
- Handling Non-Invertible SCMs: Our framework excels when the true SCM is invertible. While our stress test shows robustness when this is violated, developing models inherently resilient to such misspecifications is a key challenge. Empirically validating the proposed prior-matching regularizer (Appendix C) is a concrete next step.
- Robustness to Graph Misspecification: Like most SCM-based methods (peters2017elements), our framework assumes a correctly specified causal graph. Analyzing how structural errors (e.g., omitted confounders) propagate through our error decomposition framework is a significant future research direction.
- Formalizing CIC within Information Theory: Our work defines CIC as an operational principle. A compelling direction is to formalize it within a rigorous information-theoretic framework, for instance by proving that zero SRE maximizes the mutual information $I(U;\hat{U})$ between the true and recovered noise, connecting our work to rate-distortion theory.
- Scalability and Generalizability: While powerful, the BELM sampler is computationally intensive. Improving its efficiency for high-dimensional settings is an important practical challenge. Furthermore, extending the principles of CIC and zero-SRE modeling to other data modalities, such as time-series or images, represents an exciting frontier.
Acknowledgments and Disclosure of Funding
We thank the anonymous reviewers for their insightful feedback which significantly improved the clarity and rigor of this paper.
Appendix A Core Diffusion Model Equations
This appendix provides the essential equations for the diffusion models referenced in this work. Diffusion models learn a data distribution by training a neural network $\boldsymbol{\epsilon}_{\theta}$ to reverse a fixed, gradual noising process.
The model is trained by optimizing a simplified score-matching objective (ho2020denoising):
$$
\begin{split}L_{\text{simple}}(\theta)=\mathbb{E}_{t,\mathbf{x}_{0},\boldsymbol{\epsilon}}\bigg[\Big\|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_{\theta}\big(\sqrt{\bar{\alpha}_{t}}\mathbf{x}_{0}+\sqrt{1-\bar{\alpha}_{t}}\boldsymbol{\epsilon},t\big)\Big\|^{2}\bigg]\end{split}
$$
where $\bar{\alpha}_{t}$ is a predefined noise schedule. For deterministic generation and inversion, we use the Denoising Diffusion Implicit Model (DDIM) update step (song2021denoising):
$$
\begin{split}\mathbf{x}_{t-1}=\sqrt{\bar{\alpha}_{t-1}}\left(\frac{\mathbf{x}_{t}-\sqrt{1-\bar{\alpha}_{t}}\boldsymbol{\epsilon}_{\theta}(\mathbf{x}_{t},t)}{\sqrt{\bar{\alpha}_{t}}}\right)+\sqrt{1-\bar{\alpha}_{t-1}}\boldsymbol{\epsilon}_{\theta}(\mathbf{x}_{t},t)\end{split}
$$
This process can be viewed as a discretization of a continuous-time probability flow Ordinary Differential Equation (ODE) (song2021score):
$$
d\mathbf{x}=\left[\frac{1}{2}\frac{d\log\alpha(s)}{ds}\mathbf{x}(s)-\frac{1}{2}\frac{d\log(1-\alpha(s))}{ds}\frac{\sqrt{1-\alpha(s)}}{\sqrt{\alpha(s)}}\boldsymbol{\epsilon}_{\theta}(\mathbf{x}(s),s)\right]ds
$$
Within our theoretical framework, the encoder operator $\mathbf{T}_{\theta}$ corresponds to solving this ODE forward in time (from $s=0$ to $s=1$ ), while the decoder operator $\mathbf{H}_{\theta}$ corresponds to solving it backward in time (from $s=1$ to $s=0$ ).
Appendix B Detailed Proofs for Identifiability (Theorems 2 & 4)
This appendix provides detailed, dimension-specific proofs for the identifiability of the exogenous noise $U$ and the subsequent correctness of counterfactual generation. The core challenge lies in showing that the statistical independence of the latent code $Z$ from the parents $\mathbf{Pa}$ is a sufficient condition to establish an isomorphic relationship between $Z$ and $U$ . The mathematical tools required differ based on the dimensionality of $U$ .
B.1 The High-Dimensional Case ( $d≥ 3$ )
For cases where the exogenous noise $U$ has a dimensionality $d≥ 3$ , the proof leverages Liouville’s theorem on conformal mappings.
Proof [Proof of Theorems 2 and 4 for $d≥ 3$ ] We adapt the proof from identifiable generative modeling (chao2023interventional) to our conditional operator setting.
Let $\mathbf{Q}_{\mathbf{pa}}(U):=\mathbf{T}_{\theta}(\mathbf{F}(\mathbf{pa},U),\mathbf{pa})$ be the composite function mapping the noise $U$ to the latent code $Z$ for a given context $\mathbf{pa}$ . By assumption, $\mathbf{Q}_{\mathbf{pa}}$ is invertible and differentiable. The core assumption, $Z\perp\!\!\!\perp\mathbf{Pa}$ , implies that the conditional density $p_{Z}(z|\mathbf{pa})$ must equal a marginal density $p_{Z}(z)$ that is independent of $\mathbf{pa}$ .
Using the change of variables formula, we relate the density of $Z$ to that of $U$ :
$$
p_{Z}(z|\mathbf{pa})=\frac{p_{U}(\mathbf{Q}_{\mathbf{pa}}^{-1}(z))}{\left|\det J_{\mathbf{Q}_{\mathbf{pa}}}(\mathbf{Q}_{\mathbf{pa}}^{-1}(z))\right|}
$$
where $J_{\mathbf{Q}_{\mathbf{pa}}}$ is the Jacobian of $\mathbf{Q}_{\mathbf{pa}}$ . Since the left-hand side is independent of $\mathbf{pa}$ and $p_{U}(·)$ is a fixed distribution, this imposes a strong constraint on the Jacobian determinant. Under regularity conditions, this implies that the Jacobian $J_{\mathbf{Q}_{\mathbf{pa}}}(u)$ must be a scaled orthogonal matrix, making $\mathbf{Q}_{\mathbf{pa}}$ a conformal map.
By Liouville’s theorem, for dimensions $d≥ 3$ , any conformal map must be a Möbius transformation (a composition of translations, scalings, orthogonal transformations, and inversions). For the map to be well-behaved, it must exclude the inversion component, which would introduce singularities. This is consistent with the regularity of functions representable by neural networks, simplifying the map to an affine form:
$$
\mathbf{Q}_{\mathbf{pa}}(u)=\mathbf{A}_{\mathbf{pa}}u+\mathbf{d}_{\mathbf{pa}}
$$
where $\mathbf{A}_{\mathbf{pa}}$ is a scaled orthogonal matrix. The argument then uses the independence of the distribution’s moments and support to show that $\mathbf{A}_{\mathbf{pa}}$ and $\mathbf{d}_{\mathbf{pa}}$ must be constant w.r.t. $\mathbf{pa}$ . This leads to the isomorphic relationship $\mathbf{T}_{\theta}(\mathbf{F}(\mathbf{Pa},U),\mathbf{Pa})=\mathbf{A}U+\mathbf{d}=g(U)$ .
The proof of counterfactual correctness follows directly, as detailed in chao2023interventional. The conditional isomorphism $\mathbf{H}_{\theta}(\mathbf{T}_{\theta}(·,\mathbf{pa}),\mathbf{pa})=\mathbf{I}$ combined with the identifiability result $\mathbf{T}_{\theta}(\mathbf{F}(\mathbf{pa},u),\mathbf{pa})=g(u)$ implies that $\mathbf{H}_{\theta}(g(u),\mathbf{pa})=\mathbf{F}(\mathbf{pa},u)$ . The decoder thus perfectly mimics the true causal mechanism, making an intervention exact: $\hat{X}_{\boldsymbol{\alpha}}=\mathbf{H}_{\theta}(g(u),\boldsymbol{\alpha})=\mathbf{F}(\boldsymbol{\alpha},u)=X_{\boldsymbol{\alpha}}^{\text{true}}$ .
B.2 The One-Dimensional Case ( $d=1$ )
For the one-dimensional case where Liouville’s theorem does not apply, this section provides a dedicated proof leveraging properties of 1D functions and a uniform noise assumption from (chao2023interventional) that does not sacrifice generality.
We first establish a helper lemma characterizing a specific class of 1D functions.
**Lemma 18**
*For $U,Z⊂\mathbb{R}$ , consider a family of invertible functions $q_{\mathbf{pa}}:U→ Z$ for $\mathbf{pa}∈\mathcal{X}_{\text{pa}}⊂\mathbb{R}^{d}$ . The derivative expression $\frac{dq_{\mathbf{pa}}}{du}(q_{\mathbf{pa}}^{-1}(z))$ is a function of $z$ only, i.e., $c(z)$ , if and only if $q_{\mathbf{pa}}(u)$ can be expressed as
$$
q_{\mathbf{pa}}(u)=q(u+r(\mathbf{pa}))
$$
for some function $r$ and invertible function $q$ .*
Proof The proof is provided in (chao2023interventional). The reverse direction follows from direct differentiation, while the forward direction uses the inverse function theorem to show that the inverses $s_{\mathbf{pa}}(z)=q_{\mathbf{pa}}^{-1}(z)$ must have the same derivative $1/c(z)$ , implying they can only differ by an additive constant, which yields the desired form after inversion.
This lemma enables the proof of the theorem for the 1D case.
**Theorem 19 (Identifiability ford=1d=1)**
*Assume for $X∈\mathcal{X}⊂\mathbb{R}$ and exogenous noise $U\sim\text{Unif}[0,1]$ , the SCM is $X:=f(\mathbf{Pa},U)$ . Assume an encoder-decoder model with encoding function $g$ and decoding function $h$ . Assume the following conditions:
1. The encoding is independent of the parents, $g(X,\mathbf{Pa})\perp\!\!\!\perp\mathbf{Pa}$ .
1. The structural equation $f$ is differentiable and strictly increasing w.r.t. $U$ .
1. The encoding $g$ is invertible and differentiable w.r.t. $X$ .
Then, $g(f(\mathbf{Pa},U),\mathbf{Pa})=\tilde{q}(U)$ for an invertible function $\tilde{q}$ .*
Proof Let $q_{\mathbf{pa}}(U):=g(f(\mathbf{pa},U),\mathbf{pa})$ . The conditions on $f$ and $g$ ensure $q_{\mathbf{pa}}$ is strictly monotonic and thus invertible. By the independence assumption, the conditional distribution of $Z=q_{\mathbf{pa}}(U)$ does not depend on $\mathbf{pa}$ . We assume $U\sim\text{Unif}[0,1]$ without loss of generality. For any SCM with a continuous noise $E$ and a strictly increasing CDF $F_{E}$ , $X=f(\mathbf{Pa},E)$ can be re-parameterized to an equivalent SCM $X=\tilde{f}(\mathbf{Pa},U)$ , where $U=F_{E}(E)\sim\text{Unif}[0,1]$ and $\tilde{f}(·,·)=f(·,F_{E}^{-1}(·))$ . The modeling task is then to learn the potentially more complex function $\tilde{f}$ . The change of density formula gives:
$$
p_{Z}(z)=\frac{p_{U}(q_{\mathbf{pa}}^{-1}(z))}{|\frac{dq_{\mathbf{pa}}}{du}(q_{\mathbf{pa}}^{-1}(z))|}
$$
Since $p_{U}(u)=1$ on its support and $q_{\mathbf{pa}}$ is increasing, the denominator must be independent of $\mathbf{pa}$ . This implies $\frac{dq_{\mathbf{pa}}}{du}(q_{\mathbf{pa}}^{-1}(z))=c(z)$ for some function $c$ . This meets the condition of Lemma 18, allowing us to express $q_{\mathbf{pa}}(u)=q(u+r(\mathbf{pa}))$ for some invertible $q$ . Since $Z\perp\!\!\!\perp\mathbf{Pa}$ , its support must also be independent of $\mathbf{pa}$ . The support is $q([0,1]+r(\mathbf{pa}))$ , which is constant only if the interval $[r(\mathbf{pa}),1+r(\mathbf{pa})]$ is constant. This requires $r(\mathbf{pa})$ to be a constant, $r$ . Thus, $q_{\mathbf{pa}}(u)=q(u+r)$ . Defining $\tilde{q}(u)=q(u+r)$ , we find that the mapping is solely a function of $U$ , which completes the proof.
B.3 The Two-Dimensional Case ( $d=2$ )
The two-dimensional case is a well-known geometric exception, as the group of conformal maps is infinite-dimensional. Consequently, the proof strategy used for higher dimensions via Liouville’s theorem does not directly apply. Here, we show that identifiability still holds under additional, plausible regularity assumptions aligned with our modeling framework.
**Assumption 1 (Asymptotic Linearity)**
*The composite mapping $Q_{\mathbf{pa}}(u):\mathbb{C}→\mathbb{C}$ is an entire function (analytic on the whole complex plane) with at most linear growth. That is, there exist constants $A,B$ such that $|Q_{\mathbf{pa}}(u)|≤ A|u|+B$ for all $u∈\mathbb{C}$ .*
This assumption reflects a fundamental inductive bias of neural network architectures. Standard activation functions (e.g., ReLU, Tanh) produce functions that cannot exhibit super-polynomial growth or essential singularities at infinity, aligning our analysis with the function classes our model can represent.
**Assumption 2 (Non-Rotationally Symmetric Base Noise)**
*The base distribution of the exogenous noise $U$ is not rotationally symmetric. This assumption is made without loss of generality. For any arbitrary continuous noise $E=(E_{1},E_{2})$ , one can define a new noise $U=(F_{E_{1}}(E_{1}),E_{2})$ , where $F_{E_{1}}$ is the CDF of the first component. The resulting distribution of $U$ is uniform along its first axis, thus breaking any rotational symmetry. The structural function $\mathbf{F}$ then absorbs this transformation.*
Proof The proof proceeds in three steps. First, as established previously, the statistical independence condition $Z\perp\!\!\!\perp\mathbf{Pa}$ implies that the learned mapping $Q_{\mathbf{pa}}(u)$ must be a conformal map, and thus an analytic function on $\mathbb{C}$ . Second, by Assumption 1, $Q_{\mathbf{pa}}(u)$ is an entire function with at most linear growth. The Generalized Liouville’s Theorem states that an entire function whose growth is bounded by a polynomial of degree $k$ must itself be a polynomial of degree at most $k$ . In our case, this implies $Q_{\mathbf{pa}}(u)$ must be a polynomial of degree at most one, giving it the affine form:
$$
Q_{\mathbf{pa}}(u)=a(\mathbf{pa})u+b(\mathbf{pa})
$$
where $a,b$ are complex coefficients that can depend on $\mathbf{pa}$ . Third, we use the full statistical independence condition to show that the coefficients $a$ and $b$ must be constant. For the distribution of $Z=a(\mathbf{pa})U+b(\mathbf{pa})$ to be independent of $\mathbf{pa}$ , all of its properties must be constant. Mean: The mean $E[Z|\mathbf{pa}]=a(\mathbf{pa})E[U]+b(\mathbf{pa})$ must be constant. Assuming $E[U]=0$ without loss of generality implies $b(\mathbf{pa})$ must be a constant, $b$ . Covariance: By Assumption 2, the distribution of $U$ is not rotationally symmetric, so its covariance matrix is not proportional to the identity. Any rotation induced by the phase of $a(\mathbf{pa})$ would alter the covariance structure of $Z$ . For the distribution of $Z$ to be invariant, the rotation angle (phase) of $a(\mathbf{pa})$ must be constant. Scale: The change of variables formula implies that the magnitude $|a(\mathbf{pa})|$ must also be constant. Since both the magnitude and phase of $a(\mathbf{pa})$ must be constant, $a(\mathbf{pa})$ must be a constant complex number, $a$ . Therefore, $Q_{\mathbf{pa}}(u)=au+b$ , which is an isomorphic mapping of $u$ . This completes the proof.
Appendix C Extended Analysis of Inversion Fidelity and Non-Invertible SCMs
This appendix provides a unified analysis of inversion errors. We first provide rigorous proofs for inversion fidelity (Propositions 5 and 6), then extend our error decomposition framework to the more challenging non-invertible SCM setting.
C.1 Proofs for Inversion Fidelity (Propositions 5 & 6)
Proof [Proof of Proposition 5] The proof proceeds by deriving the explicit one-step reconstruction error and then analyzing its order of magnitude.
1. Derivation of the One-Step Reconstruction Error.
Let the single-step DDIM inversion operator be $\mathbf{T}_{t}$ , mapping an observation $\mathbf{x}_{t}$ to $\mathbf{x}^{\prime}_{t+1}$ using the noise prediction $\boldsymbol{\epsilon}_{t}=\boldsymbol{\epsilon}_{\theta}(\mathbf{x}_{t},t)$ . The corresponding generative operator is $\mathbf{H}_{t}$ , which reconstructs $\mathbf{x}^{\prime}_{t}$ from $\mathbf{x}^{\prime}_{t+1}$ using a new prediction at the new state, $\boldsymbol{\epsilon}^{\prime}_{t+1}=\boldsymbol{\epsilon}_{\theta}(\mathbf{x}^{\prime}_{t+1},t+1)$ .
By substituting the formula for $\mathbf{x}^{\prime}_{t+1}$ into the update for $\mathbf{x}^{\prime}_{t}$ , the single-step reconstruction error $\mathbf{x}^{\prime}_{t}-\mathbf{x}_{t}$ is found to be:
$$
\mathbf{x}^{\prime}_{t}-\mathbf{x}_{t}=\left(\sqrt{1-\bar{\alpha}_{t}}-\frac{\sqrt{\bar{\alpha}_{t}}\sqrt{1-\bar{\alpha}_{t+1}}}{\sqrt{\bar{\alpha}_{t+1}}}\right)(\boldsymbol{\epsilon}^{\prime}_{t+1}-\boldsymbol{\epsilon}_{t})
$$
This error is non-zero if and only if the noise prediction changes after one inversion step, i.e., $\boldsymbol{\epsilon}^{\prime}_{t+1}≠\boldsymbol{\epsilon}_{t}$ .
2. Analysis of the Error’s Order of Magnitude.
In the continuous-time limit with time step $\Delta s=1/T$ , a Taylor expansion shows that both the coefficient term and the difference in noise predictions $(\boldsymbol{\epsilon}^{\prime}_{t+1}-\boldsymbol{\epsilon}_{t})$ are of order $\mathcal{O}(\Delta s)$ . The one-step reconstruction error is therefore the product of these two terms:
$$
\text{Error}_{\text{step}}=\mathcal{O}(\Delta s)\times\mathcal{O}(\Delta s)=\mathcal{O}((\Delta s)^{2})=\mathcal{O}(1/T^{2})
$$
This local error accumulates over the $T$ steps of the trajectory, resulting in a total accumulated error of order $\mathcal{O}(1/T)$ . For any finite $T$ , this global error is non-zero, constituting the Structural Reconstruction Error (SRE) for DDIM.
Proof [Proof of Proposition 6] The proof is constructive, following from the exact algebraic invertibility of the BELM sampler (liu2024belm). For the second-order BELM used in this work, the one-step decoder is an affine transformation of the form:
$$
\displaystyle\mathbf{x}_{t-1} \displaystyle=A_{t}\mathbf{x}_{t}+B_{t}\boldsymbol{\epsilon}_{t}+C_{t}\boldsymbol{\epsilon}_{t+1}
$$
where $A_{t},B_{t},C_{t}$ are schedule-dependent coefficients, $\boldsymbol{\epsilon}_{t}=\boldsymbol{\epsilon}_{\theta}(\mathbf{x}_{t},t)$ , and $\boldsymbol{\epsilon}_{t+1}=\boldsymbol{\epsilon}_{\theta}(\mathbf{x}_{t+1},t+1)$ .
The full-trajectory decoder, $\mathbf{H}_{\text{BELM}}$ , is a composition of these one-step affine maps. The BELM encoder, $\mathbf{T}_{\text{BELM}}$ , is constructed using a symmetric update rule designed to be the exact algebraic inverse of the decoder. As rigorously shown by liu2024belm, this construction ensures that the composite operator $\mathbf{T}_{\text{BELM}}$ is the exact inverse of $\mathbf{H}_{\text{BELM}}$ , assuming the same sequence of noise function evaluations is used for both processes.
Therefore, by its algebraic construction, the BELM sampler guarantees a lossless round trip:
$$
\mathbf{H}_{\text{BELM}}\circ\mathbf{T}_{\text{BELM}}=\mathbf{I}
$$
The Structural Reconstruction Error is thus identically zero by construction.
C.2 Exhaustive Analysis for the Non-Invertible SCM Setting
This section rigorously extends our framework to the non-invertible case, providing a theoretical underpinning for the stress test results in § 5.4.1.
C.2.1 Assumptions and Definitions
We formalize the problem with the following.
**Assumption 3 (Well-Posed Abduction)**
*For any observed $(\mathbf{v},\mathbf{pa})$ , the inverse image set $\mathcal{U}_{(\mathbf{v},\mathbf{pa})}=\{\mathbf{u}^{\prime}∈\mathcal{U}\mid\mathbf{F}(\mathbf{pa},\mathbf{u}^{\prime})=\mathbf{v}\}$ is non-empty, and the Maximum a Posteriori (MAP) solution over this set, given the prior $p(\mathbf{U})$ , is unique. This solution defines the ideal amortized inverse operator, $\mathbf{T}^{*}(\mathbf{v},\mathbf{pa})=\arg\max_{\mathbf{u}^{\prime}∈\mathcal{U}_{(\mathbf{v},\mathbf{pa})}}p(\mathbf{u}^{\prime})$ .*
**Definition 20 (Tripartite Error Sources)**
*In the non-invertible case, we refine the error sources into three distinct components:
1. Algorithmic Error (SRE): The error from an imperfect inversion algorithm, $E_{SR}:=\|(\mathbf{H}_{\theta}\circ\mathbf{T}_{\theta}-\mathbf{I})\mathbf{X}\|^{2}$ . For our framework, $E_{SR}\equiv 0$ .
1. Modeling Error: The error from imperfectly learning the ideal amortized inverse, $E_{\text{Modeling}}:=\|\mathbf{T}_{\theta}(\mathbf{V},\mathbf{Pa})-\mathbf{T}^{*}(\mathbf{V},\mathbf{Pa})\|^{2}$ .
1. Representational Error: The fundamental, irreducible error from the SCM’s non-invertibility, $E_{\text{Rep}}:=\|\mathbf{T}^{*}(\mathbf{V},\mathbf{Pa})-\mathbf{U}_{\text{true}}\|^{2}$ .*
C.2.2 A Tighter Error Decomposition
We now present a tighter error bound for the non-invertible case.
**Theorem 21 (Tighter Counterfactual Error Bound)**
*Let the conditions of Theorem 8 hold ( $H_{\theta}$ is $L_{H}$ -Lipschitz). The expected squared error of the counterfactual prediction is bounded by:
$$
\begin{split}\mathbb{E}\left[\|\hat{\mathbf{X}}_{\alpha}-\mathbf{X}_{\alpha}^{\text{true}}\|^{2}\right]\leq&2\mathbb{E}[E_{SR}]+4L_{H}^{2}\mathbb{E}[E_{\text{Modeling}}]+4L_{H}^{2}\mathbb{E}[E_{\text{Rep}}]\end{split}
$$*
Proof We decompose the total error $\|\hat{\mathbf{X}}_{\alpha}-\mathbf{X}_{\alpha}^{\text{true}}\|$ using the triangle inequality and the ideal amortized inverse $\mathbf{T}^{*}$ as an intermediate step. The result follows from applying the inequality $(a+b+c)^{2}≤ 2(a^{2}+b^{2}+c^{2})$ , bounding terms with the $L_{H}$ -Lipschitz property of $\mathbf{H}_{\theta}$ , and taking expectations.
C.2.3 Information-Theoretic Interpretation of Representational Error
The Representational Error ( $E_{\text{Rep}}$ ) is deeply connected to information conservation. The non-invertibility of the SCM $\mathbf{F}$ means that observing $(\mathbf{V},\mathbf{Pa})$ is not sufficient to uniquely determine $\mathbf{U}$ . Information-theoretically, this implies the conditional entropy $H(\mathbf{U}|\mathbf{V},\mathbf{Pa})$ is greater than zero.
**Remark 22 (Representational Error as Information Loss)**
*The ideal amortized inverse $\mathbf{T}^{*}$ yields the mode of the posterior $p(\mathbf{U}|\mathbf{V},\mathbf{Pa})$ . The expected representational error, $\mathbb{E}[E_{\text{Rep}}]$ , can be seen as the expected squared error of this MAP estimator, which is related to the variance and shape of the posterior. Thus, $E_{\text{Rep}}$ is a direct consequence of the information about $\mathbf{U}$ that is fundamentally lost in the forward causal process, a loss captured by $H(\mathbf{U}|\mathbf{V},\mathbf{Pa})>0$ .*
C.2.4 Theoretical Guarantee for the Mitigation Strategy
We now provide a theoretical justification for the ‘Prior-Matching Regularizer‘ proposed in § 7.1.
**Definition 23 (Prior-Matching Regularizer)**
*The regularizer is defined as $R(\mathbf{T}_{\theta})=\mathbb{E}_{(\mathbf{v},\mathbf{pa})}\left[\|\mathbf{s}_{p}(\mathbf{T}_{\theta}(\mathbf{v},\mathbf{pa}))\|^{2}\right]$ , where $\mathbf{s}_{p}(\mathbf{u})=∇_{\mathbf{u}}\log p(\mathbf{u})$ is the score function of the prior distribution $p(\mathbf{U})$ .*
**Proposition 24 (Regularizer Induces Convergence to MAP Solution)**
*Minimizing the regularizer $R(\mathbf{T}_{\theta})$ provides an inductive bias that encourages the encoder output, $\hat{\mathbf{u}}=\mathbf{T}_{\theta}(\mathbf{v},\mathbf{pa})$ , to lie on a mode of the prior distribution $p(\mathbf{U})$ .*
Proof [Proof Sketch] The objective is a form of score matching on the prior. The score function $\mathbf{s}_{p}(\mathbf{u})$ is zero if and only if $\mathbf{u}$ is a stationary point of the log-prior. Minimizing the expected squared norm of the score at the encoder’s output penalizes the production of latent codes $\hat{\mathbf{u}}$ in low-probability regions of the prior. This incentivizes the encoder to map observations to the most probable latent code, thereby encouraging $\mathbf{T}_{\theta}$ to approximate the ideal MAP estimator $\mathbf{T}^{*}$ .
Appendix D Main Proofs for Theoretical Framework
This appendix provides the proofs for the main theoretical results presented in the text.
Proof [Proof of Theorem 8] This bound is a direct specialization of the more general bound for non-invertible SCMs derived in Theorem 21 (Appendix C).
For an invertible SCM, abduction is perfect, meaning the ideal amortized inverse $\mathbf{T}^{*}$ is the true inverse of the SCM function $\mathbf{F}$ . Consequently, the recovered noise is the true noise, $\mathbf{T}^{*}(\mathbf{V},\mathbf{Pa})=\mathbf{U}_{\text{true}}$ , which implies that the Representational Error is identically zero: $\mathbb{E}[E_{\text{Rep}}]=0$ .
In this context, the Latent Space Invariance Error, $E_{LSI}$ , becomes equivalent to the Modeling Error, $E_{\text{Modeling}}$ . Applying the inequality $(a+b)^{2}≤ 2a^{2}+2b^{2}$ , the general bound from Theorem 21 reduces to the two terms presented in Theorem 8.
Proof [Proof of Proposition 10] This proof relies on the identifiability of the true SCM (Theorem 2) and the Lipschitz continuity of the score network $\boldsymbol{\epsilon}_{\theta}$ , which guarantees unique ODE solutions via the Picard-Lindelöf theorem. We also assume standard integrability conditions (Fubini’s theorem).
The encoder $\mathbf{T}_{\theta}$ maps an initial condition $\mathbf{x}(0)$ to the terminal state $\mathbf{x}(T)$ of the probability flow ODE (Eq. A.3). Let $\mathbf{x}_{\theta}(t;\mathbf{x}_{0})$ and $\mathbf{x}_{*}(t;\mathbf{x}_{0})$ denote the ODE solutions with the learned score $\boldsymbol{\epsilon}_{\theta}$ and the true score $\boldsymbol{\epsilon}^{*}$ , respectively. The Latent Space Invariance Error is $\mathbb{E}[E_{LSI}]=\mathbb{E}[\|\mathbf{x}_{\theta}(T;X)-\mathbf{x}_{\theta}(T;X_{\boldsymbol{\alpha}}^{\text{true}})\|^{2}]$ . By the triangle inequality:
| | $\displaystyle\|\mathbf{x}_{\theta}(T;X)-\mathbf{x}_{\theta}(T;X_{\boldsymbol{\alpha}}^{\text{true}})\|$ | $\displaystyle≤\|\mathbf{x}_{\theta}(T;X)-\mathbf{x}_{*}(T;X)\|$ | |
| --- | --- | --- | --- |
The middle term is zero under ideal identifiability, as the true encoder $\mathbf{T}^{*}$ maps both an observation and its true counterfactual to the same underlying noise. We thus only need to bound terms of the form $\|\mathbf{x}_{\theta}(T;\mathbf{x}_{0})-\mathbf{x}_{*}(T;\mathbf{x}_{0})\|$ .
Let $\mathbf{z}(t)=\mathbf{x}_{\theta}(t;\mathbf{x}_{0})-\mathbf{x}_{*}(t;\mathbf{x}_{0})$ . Since the ODE vector field is Lipschitz, applying Grönwall’s inequality to the differential of $\mathbf{z}(t)$ yields:
$$
\|\mathbf{z}(T)\|\leq\int_{0}^{T}e^{L_{f}(T-t)}C_{f}\|\boldsymbol{\epsilon}_{\theta}(\mathbf{x}_{*}(t),t)-\boldsymbol{\epsilon}^{*}(\mathbf{x}_{*}(t),t)\|dt
$$
where $L_{f}$ and $C_{f}$ are constants from the ODE coefficients. Squaring, taking expectations, and applying Jensen’s inequality leads to:
$$
\mathbb{E}[E_{LSI}]\leq C^{\prime}\cdot\mathbb{E}_{\mathbf{x},t}[\|\boldsymbol{\epsilon}_{\theta}-\boldsymbol{\epsilon}^{*}\|^{2}]
$$
where the final expectation is the score-matching loss.
Appendix E Proofs for Theoretical Roles of Hybrid Training
E.1 Proof of Proposition 12 (Weighted Score-Matching)
This section provides a rigorous proof that the auxiliary task loss $L_{\text{task}}$ provides a lower bound on a weighted score-matching objective.
E.1.1 Preliminaries and Setup
Probability Flow ODE.
The generative process is the solution to the reverse-time probability flow ODE from $t=T$ to $t=0$ :
$$
d\mathbf{x}_{t}=f(t,\mathbf{x}_{t},\boldsymbol{\epsilon}(t,\mathbf{x}_{t}))dt,\quad\mathbf{x}_{T}\sim\mathcal{N}(0,\mathbf{I})
$$
where the vector field $f$ is determined by the diffusion scheduler.
Core Objects.
- $\boldsymbol{\epsilon}_{\theta},\boldsymbol{\epsilon}^{*}$ : Learned and true score functions.
- $\mathbf{x}_{t}^{\theta},\mathbf{x}_{t}^{*}$ : ODE trajectories driven by $\boldsymbol{\epsilon}_{\theta}$ and $\boldsymbol{\epsilon}^{*}$ .
- $\mathbf{x}_{0}^{\theta},\mathbf{x}_{0}^{*}$ : Generated and true (counterfactual) data points at $t=0$ .
- $g:\mathbb{R}^{d}→\mathbb{R}^{k}$ : Downstream prediction function.
- $Y_{\text{pred}}=g(\mathbf{x}_{0}^{\theta})$ , $Y_{\text{true}}=g(\mathbf{x}_{0}^{*})$ .
- $L_{\text{task}}=\mathbb{E}_{\mathbf{x}_{T}}[\|Y_{\text{pred}}-Y_{\text{true}}\|^{2}]$ .
Assumptions.
We assume standard regularity conditions for the proof:
1. The vector field $f(t,\mathbf{x},\boldsymbol{\epsilon})$ is Lipschitz continuous in $\mathbf{x}$ and $\boldsymbol{\epsilon}$ .
1. The downstream task function $g(\mathbf{x})$ is Lipschitz continuous and differentiable.
1. The learned score $\boldsymbol{\epsilon}_{\theta}$ and true score $\boldsymbol{\epsilon}^{*}$ are well-behaved.
E.1.2 Formal Proposition Statement
**Proposition 25 (Hybrid Objective as a Weighted Score-Matching Regularizer)**
*Under the regularity assumptions (A1-A3), the auxiliary task loss $L_{\text{task}}$ provides a lower bound on a weighted score-matching objective:
$$
L_{\text{task}}\geq C\cdot\mathbb{E}_{\mathbf{x}_{T},t}\left[w(\mathbf{x}_{t}^{*})\cdot\|\boldsymbol{\epsilon}_{\theta}(\mathbf{x}_{t}^{*})-\boldsymbol{\epsilon}^{*}(\mathbf{x}_{t}^{*})\|^{2}\right]
$$
where $C>0$ and the weight function $w(\mathbf{x}_{t}^{*})$ measures the sensitivity of the final prediction $Y$ to score perturbations along the ideal data generation trajectory.*
Proof The proof proceeds in three main steps.
Step 1: Bounding Sample Error by Score Error (Error Propagation).
Let $\mathbf{z}(t)=\mathbf{x}_{t}^{\theta}-\mathbf{x}_{t}^{*}$ be the error between the two ODE trajectories. By linearizing the vector field $f$ around the true trajectory, we can analyze the impact of the score perturbation $\Delta\boldsymbol{\epsilon}_{t}=\boldsymbol{\epsilon}_{\theta}(\mathbf{x}_{t}^{*})-\boldsymbol{\epsilon}^{*}(\mathbf{x}_{t}^{*})$ . From Duhamel’s Principle, the final sample error $\Delta\mathbf{x}_{0}=\mathbf{z}(0)$ can be expressed as an integral over the perturbation:
$$
\Delta\mathbf{x}_{0}=\int_{T}^{0}\mathbf{K}(s)\Delta\boldsymbol{\epsilon}_{s}ds
$$
where the kernel $\mathbf{K}(s)$ captures the influence of a score perturbation at time $s$ on the final sample at time $0$ .
Step 2: Linearizing the Task Error.
The error in the downstream prediction is $\Delta Y=g(\mathbf{x}_{0}^{\theta})-g(\mathbf{x}_{0}^{*})$ . A first-order Taylor expansion gives:
$$
\Delta Y\approx\nabla_{\mathbf{x}}g(\mathbf{x}_{0}^{*})\cdot\Delta\mathbf{x}_{0}
$$
The task loss is the expected squared norm, $L_{\text{task}}=\mathbb{E}[\|\Delta Y\|^{2}]$ .
Step 3: Deriving the Weighted Relationship.
Substituting the integral form of $\Delta\mathbf{x}_{0}$ into the task error approximation and applying the Cauchy-Schwarz inequality for integrals yields a lower bound for the task loss:
$$
L_{\text{task}}\geq C\cdot\mathbb{E}_{\mathbf{x}_{T}}\left[\int_{0}^{T}\left\|\mathcal{W}(\mathbf{x}_{0}^{*},s)\right\|_{F}^{2}\cdot\|\Delta\boldsymbol{\epsilon}_{s}\|^{2}ds\right]
$$
where $\|·\|_{F}$ is the Frobenius norm and the influence operator $\mathcal{W}(\mathbf{x}_{0}^{*},s)$ captures the end-to-end sensitivity from a score perturbation at time $s$ to the final prediction. Rewriting the expectation gives the final form:
$$
L_{\text{task}}\geq C\cdot\mathbb{E}_{t\sim U[0,T]}\mathbb{E}_{\mathbf{x}_{t}^{*}}\left[w(\mathbf{x}_{t}^{*})\cdot\|\boldsymbol{\epsilon}_{\theta}(\mathbf{x}_{t}^{*})-\boldsymbol{\epsilon}^{*}(\mathbf{x}_{t}^{*})\|^{2}\right]
$$
where the weight function is $w(\mathbf{x}_{t}^{*}):=T·\mathbb{E}_{\mathbf{x}_{T}|\mathbf{x}_{t}^{*}}[\|\mathcal{W}(\mathbf{x}_{0}^{*},t)\|_{F}^{2}]$ .
Interpretation and Conclusion.
The weight function $w(\mathbf{x}_{t}^{*})$ is large when the gradient norm $\|∇_{\mathbf{x}}g(\mathbf{x}_{0}^{*})\|$ is large—i.e., in causally salient regions where the outcome is highly sensitive to the features. The inequality therefore shows that minimizing $L_{\text{task}}$ provides a lower bound on a score-matching error that is weighted to prioritize accuracy in these causally salient regions.
E.2 Argument for Proposition 13 (Latent Space Disentanglement)
This section provides a qualitative, information-theoretic argument for Proposition 13, showing how the hybrid objective encourages a ”division of labor” that promotes disentanglement. The SCM posits that an observation $V$ is determined by $(\mathbf{Pa},U)$ , and the encoder maps $(V,\mathbf{Pa})$ to a latent code $Z=\mathbf{T}_{\theta}(V,\mathbf{Pa})$ , where a perfect encoder would yield $Z=U$ . The process works as follows: the diffusion loss ( $L_{\text{diffusion}}$ ) maximizes the log-likelihood $\log p_{\theta}(V|\mathbf{Pa})$ , forcing the pair $(\mathbf{Pa},Z)$ to contain all information to reconstruct $V$ , thus maximizing the mutual information $I(V;(\mathbf{Pa},Z))$ . Simultaneously, the task loss ( $L_{\text{task}}$ ) learns a prediction from the parents, capturing all predictive information that $\mathbf{Pa}$ has about $V$ and thus maximizing $I(V;\mathbf{Pa})$ . The dual objective must satisfy both constraints. From the chain rule of mutual information, we know $I(V;(\mathbf{Pa},Z))=I(V;\mathbf{Pa})+I(V;Z|\mathbf{Pa})$ . Since $L_{\text{diffusion}}$ maximizes the left-hand side and $L_{\text{task}}$ captures the first term on the right, the optimization incentivizes the latent code $Z$ to model the remaining information, $I(V;Z|\mathbf{Pa})$ . This leads to a connection to disentanglement: the ideal exogenous noise $U$ is, by definition, independent of $\mathbf{Pa}$ . By forcing $Z$ to model the residual information, the optimization process actively encourages the learned representation $Z$ to be independent of $\mathbf{Pa}$ . In summary, the hybrid objective creates a division of labor: the task-specific head explains the variance from $\mathbf{Pa}$ , while the diffusion process’s latent code $Z$ models the residual. This residual is, by construction, the information in $V$ orthogonal to $\mathbf{Pa}$ , forcing $Z$ to be an empirical approximation of the true, disentangled exogenous noise $U$ , thereby serving the identifiability condition of Theorem 2.
Appendix F Proof of Theorem on Causal Transportability
This appendix provides the proof for the theorem on lossless causal transportability.
Proof [Proof of Theorem 17] This proof operates under an idealized setting, assuming a perfectly trained model (i.e., zero statistical error), to isolate the structural properties of transportability. We assume the learned decoder $\mathbf{H}_{\theta_{i}}$ is identical to the true mechanism $\mathbf{F}_{i}$ , and its encoder $\mathbf{T}_{\theta_{i}}$ is its perfect inverse.
Let the source and target SCMs be $\mathcal{M}^{\mathcal{S}}$ and $\mathcal{M}^{\mathcal{T}}$ , with mechanisms $\{\mathbf{F}_{i}\}$ and $\{\mathbf{F}^{\prime}_{i}\}$ respectively. The set of changed mechanisms is indexed by $\mathcal{K}_{\text{changed}}$ .
The proof relies on the modularity of the SCM, which is guaranteed by the mutually independent exogenous noises (Condition ii of the theorem). This independence ensures that a change in one mechanism $\mathbf{F}_{k}$ to $\mathbf{F}^{\prime}_{k}$ does not affect the conditional distributions of other nodes $V_{j}$ ( $j≠ k$ ), given their parents.
We analyze the transportability of operators for each mechanism:
1. For invariant mechanisms ( $j∉\mathcal{K}_{\text{changed}}$ ): By definition, the true mechanism is unchanged, $\mathbf{F}^{\prime}_{j}=\mathbf{F}_{j}$ . Since the model operators $(\mathbf{T}_{\theta_{j}},\mathbf{H}_{\theta_{j}})$ perfectly learned $\mathbf{F}_{j}$ in the source domain, they remain valid for the target domain $\mathcal{T}$ and can be directly reused.
1. For changed mechanisms ( $k∈\mathcal{K}_{\text{changed}}$ ): The original operators $(\mathbf{T}_{\theta_{k}},\mathbf{H}_{\theta_{k}})$ are now invalid as they model $\mathbf{F}_{k}$ , not the new mechanism $\mathbf{F}^{\prime}_{k}$ . However, a new operator pair $(\mathbf{T}^{\prime}_{\theta_{k}},\mathbf{H}^{\prime}_{\theta_{k}})$ can be learned from target domain data. This training only requires samples $(v^{\prime}_{k},\mathbf{pa}^{\prime}_{k})$ from domain $\mathcal{T}$ and the shared noise distribution $p_{k}(U_{k})$ (Condition i). Because the noises are independent, this re-learning process for mechanism $k$ is modular and does not affect the other invariant mechanisms.
The procedure for adapting the model is therefore modular: freeze all invariant operators $\{(\mathbf{T}_{\theta_{j}},\mathbf{H}_{\theta_{j}})\}_{j∉\mathcal{K}_{\text{changed}}}$ and re-train only those for the changed mechanisms $\{k∈\mathcal{K}_{\text{changed}}\}$ on target domain data. The resulting adapted model is valid for the target domain $\mathcal{T}$ and can perform abduction on a target individual by applying the correct (reused or re-trained) encoders, thereby losslessly recovering the full vector of exogenous noises. This fulfills the condition for lossless transport.
Appendix G Proof of the Specific Finite Sample Bound (Theorem 15)
This derivation combines standard generalization bounds with known complexity bounds for deep neural networks. We first state a key lemma regarding the complexity of neural networks.
**Lemma 26 (Rademacher Complexity of Neural Networks)**
*Let $\mathcal{F}_{\epsilon}$ be the function class of an $L$ -layer MLP with ReLU activations, input dimension $p$ , and weight matrices $\{\mathbf{W}_{j}\}_{j=1}^{L}$ . Assume the input data $\mathbf{X}$ is contained within a ball of radius $R_{X}$ . If the spectral norm of each weight matrix is bounded, $\|\mathbf{W}_{j}\|_{2}≤ B_{j}$ , the Rademacher complexity of the function class is bounded by:
$$
\mathfrak{R}_{n}(\mathcal{F}_{\epsilon})\leq C_{net}\frac{R_{X}L\sqrt{p}}{\sqrt{n}}\left(\prod_{j=1}^{L}B_{j}\right)
$$
For simplicity and under normalization, we often consider $R_{X}=1$ . This result is a simplified form derived from (bartlett2017spectrally; neyshabur2018pac), where $C_{net}$ is a universal constant.*
Proof The proof proceeds by combining the standard excess risk bound with the two lemmas above. First, from standard learning theory, the excess risk is bounded by the Rademacher complexity of the total loss function class:
$$
R(\hat{\theta}_{n})-R(\theta^{*})\leq 4\mathfrak{R}_{n}(\mathcal{F}_{\mathcal{L}_{SCM}})+M\sqrt{\frac{\log(1/\delta)}{2n}}
$$
Next, by the sub-additivity property of Rademacher complexity, we decompose the SCM’s complexity into the sum of its individual components:
$$
\mathfrak{R}_{n}(\mathcal{F}_{\mathcal{L}_{SCM}})\leq\sum_{i=1}^{d}\mathfrak{R}_{n}(\mathcal{F}_{\mathcal{L}_{i}})
$$
The next step is to relate the loss complexity to the network complexity. The score-matching loss for mechanism $i$ is $\mathcal{L}_{i}=\|\boldsymbol{\epsilon}-\epsilon_{\theta_{i}}(·)\|^{2}$ . Since this loss is Lipschitz with respect to the output of $\epsilon_{\theta_{i}}$ , its Rademacher complexity is upper-bounded by a constant multiple of the complexity of the score network’s function class $\mathcal{F}_{\epsilon_{i}}$ via Talagrand’s contraction lemma, i.e., $\mathfrak{R}_{n}(\mathcal{F}_{\mathcal{L}_{i}})≤ C_{1}·\mathfrak{R}_{n}(\mathcal{F}_{\epsilon_{i}})$ . We then apply Lemma 26 to bound the complexity of each score network. The input dimension $p_{i}$ for mechanism $i$ is $p_{i}=\text{dim}(\mathbf{x}_{t})+\text{dim}(\mathbf{pa}_{i})+\text{dim}(\text{time embedding})$ . Assuming univariate variables, this is $p_{i}=1+|\mathbf{Pa}_{i}|+d_{embed}$ . Let $d_{in}^{max}=\max_{i}|\mathbf{Pa}_{i}|$ , so the maximum input dimension is $p_{max}=1+d_{in}^{max}+d_{embed}$ . Assuming all networks have depth $L$ and a uniform spectral norm bound $B$ , we have:
$$
\mathfrak{R}_{n}(\mathcal{F}_{\epsilon_{i}})\leq C_{net}\frac{L\sqrt{p_{max}}}{\sqrt{n}}B^{L}=C_{net}\frac{L\sqrt{1+d_{in}^{max}+d_{embed}}}{\sqrt{n}}B^{L}
$$
Finally, we assemble the complete bound by substituting all components back into the initial inequality:
| | $\displaystyle R(\hat{\theta}_{n})-R(\theta^{*})$ | $\displaystyle≤ 4\sum_{i=1}^{d}\mathfrak{R}_{n}(\mathcal{F}_{\mathcal{L}_{i}})+M\sqrt{\frac{\log(1/\delta)}{2n}}$ | |
| --- | --- | --- | --- |
By defining $C=4C_{1}C_{net}$ as a generic constant independent of the network architecture and sample size, we arrive at the final form stated in the theorem.
Appendix H Formal Analysis of the Geometric Inductive Bias
This section provides the formal argument for Proposition 3, demonstrating how the score-matching objective, under a simplicity bias, compels the learned generative map to adopt the local data geometry, yielding a parsimonious and well-behaved transformation.
H.1 Preliminaries and Definitions
Let $\mathcal{M}⊂\mathbb{R}^{d}$ be the data manifold with a smooth probability density $p(\mathbf{x})$ . The true score function is the vector field $\mathbf{s}^{*}(\mathbf{x}):=∇_{\mathbf{x}}\log p(\mathbf{x})$ . We learn a parameterized score network $\mathbf{s}_{\theta}(\mathbf{x})$ by minimizing the score-matching objective $L_{SM}(\theta)=\mathbb{E}_{\mathbf{x}\sim p(\mathbf{x})}[\|\mathbf{s}_{\theta}(\mathbf{x})-\mathbf{s}^{*}(\mathbf{x})\|^{2}]$ .
The generative process is described by the probability flow ODE, whose vector field $\mathbf{f}(\mathbf{x},t)$ is a function of the score. The map $H_{\theta}:\mathbb{R}^{d}→\mathcal{M}$ is the flow map of this ODE integrated from $t=1$ to $t=0$ . A map is conformal if its Jacobian is a scaled orthogonal matrix, and affine if it is a linear transformation plus a translation.
H.2 Assumptions
**Assumption 4 (Smoothness of the Data Density)**
*The true data density $p(\mathbf{x})$ is at least twice continuously differentiable ( $C^{2}$ ) on $\mathcal{M}$ .*
**Assumption 5 (Adoption of the Simplicity Bias Principle)**
*Our analysis relies on the principle of implicit regularization: the conjecture that optimizers like SGD favor solutions with a simplicity bias. We formalize this as a preference for score functions $\mathbf{s}_{\theta}$ with lower complexity (e.g., lower Dirichlet Energy or smaller spectral norms) (hochreiter1997flat; neyshabur2018pac).*
H.3 Proof of Proposition 3
The proof proceeds in four steps:
Step 1: The Irrotational Property of the True Score Field. By definition, the true score $\mathbf{s}^{*}(\mathbf{x})$ is the gradient of the scalar potential $\log p(\mathbf{x})$ . By a fundamental theorem of vector calculus, the curl of any gradient field is zero. Thus, $\mathbf{s}^{*}$ is an irrotational (or conservative) vector field.
Step 2: The Variational Perspective of Score Matching. The simplicity bias (Assumption 5) reinforces the irrotational nature of the learned field $\mathbf{s}_{\theta}$ . This is understood via the Helmholtz decomposition, which splits any vector field into irrotational (curl-free) and solenoidal (divergence-free) components. The simplicity bias conjectures that the optimization preferentially minimizes the energy of the solenoidal component, driving the learned field $\mathbf{s}_{\theta}$ towards a purely irrotational solution ( $∇×\mathbf{s}_{\theta}≈\mathbf{0}$ ) to match the conservative nature of the true score $\mathbf{s}^{*}$ .
Step 3: The Geometry of the Score Field under Local Structural Assumptions. We analyze the score field’s structure under two local geometric cases for the density $p(\mathbf{x})$ in a region $\mathcal{R}$ . Case (i): Local Isotropy. If $p(\mathbf{x})$ is locally spherically symmetric around a center $\mathbf{c}$ , its value depends only on the radius $r=\|\mathbf{x}-\mathbf{c}\|$ . The gradient $\mathbf{s}^{*}=∇\log p(\mathbf{x})$ must point along the radial direction, making the true score a radial vector field. The learned field converges to this simple structure. Case (ii): Local Ellipsoidal Structure. If the iso-contours of $p(\mathbf{x})$ are concentric ellipsoids, the gradient $\mathbf{s}^{*}$ must be orthogonal to these ellipsoidal surfaces at every point. Such a field is still irrotational but no longer radial.
Step 4: The Geometry of the Flow Map. The ODE vector field $\mathbf{f}(\mathbf{x},t)$ is a linear combination of the score field $\mathbf{s}_{\theta^{*}}(\mathbf{x})$ and the position vector $\mathbf{x}$ . The geometry of the resulting flow map $H_{\theta^{*}}$ depends on this vector field’s geometry. Result for Case (i): In the isotropic case, $\mathbf{f}(\mathbf{x},t)$ is also a radial vector field. A flow generated by a radial vector field is, by its rotational symmetry, necessarily a conformal map, as it preserves angles. Result for Case (ii): In the ellipsoidal case, the flow must transform the isotropic latent space into the anisotropic data space. The simplest such transformation is a local affine transformation, involving direction-dependent scaling and rotation. While this geometric argument is standard, a fully rigorous proof would require directly computing the Jacobian of the integrated flow map $H_{\theta^{*}}$ to verify it satisfies the required mathematical conditions. The model’s inductive bias thus compels it to learn the most parsimonious geometric transformation necessary to explain the local data geometry, promoting the well-behaved, locally invertible mappings that are crucial for abduction.
Appendix I Experimental Details
This appendix provides comprehensive details for all experiments presented in Section 5, ensuring full transparency and reproducibility.
I.1 General Setup
Software Environment.
All experiments were conducted in a unified software environment to ensure full reproducibility. Key library versions used were: dowhy (0.12), econml (0.16.0), numpy (1.26.4), pandas (1.3.5), scikit-learn (1.6.1), torch (1.10.0), lightgbm (4.6.0), and networkx (3.2.1). All stochastic processes were controlled with a fixed global random seed (42), except for the ensemble runs, which used a set of distinct seeds for training.
Baseline Estimator Configurations.
All baseline estimators were implemented using the dowhy library. For machine learning-based methods like Causal Forest and DML, we utilized their robust implementations from the econml library. To ensure a fair and reproducible comparison against established benchmarks, we used their default hyperparameter settings, which are widely recognized and have been optimized by the library authors to provide strong performance across a broad range of tasks. Our proposed model, in turn, underwent a systematic grid search; the final parameters and a detailed analysis are provided in Appendix I.2.
Details for PSM Failure Scenario (Act I).
The Data Generation Process (DGP) for this experiment ( $N=5000$ , true ATE $\tau=5000$ ) follows the graph in Figure 3(a) and is defined by:
| | $\displaystyle W_{1},W_{2}$ | $\displaystyle\sim\mathcal{N}(0,1)$ | |
| --- | --- | --- | --- |
with exogenous noises $U_{T}\sim\text{Logistic}(0,1)$ and $U_{Y}\sim\mathcal{N}(0,6000^{2})$ .
Details for Lalonde Benchmark (Act I).
To evaluate performance on real-world data, we used the canonical Lalonde dataset, analyzing the effect of the NSW job training program (treat) on 1978 real earnings (re78). The assumed causal structure is the standard confounding model (Figure 3(c)), a DAG structure that reflects the broad consensus in the causal inference community for this benchmark. In line with our Targeted Modeling principle, we applied the expressive CausalDiffusionModel only to the key treat and re78 nodes, modeling all confounders non-parametrically via their empirical distributions.
Details for Semi-Synthetic Analysis (Act II).
This dataset uses the real-world covariates from the Lalonde dataset as a foundation. The outcome $Y$ and the ground-truth Individual Treatment Effect ( $ITE_{\text{true}}$ ) are then synthetically generated according to the following structural equations:
| | $\displaystyle Y_{\text{base}}=$ | $\displaystyle\ 2· X_{\text{re74}}+1.5· X_{\text{re75}}+100· X_{\text{educ}}-50· X_{\text{age}}$ | |
| --- | --- | --- | --- |
where $U_{\text{base}}\sim\mathcal{N}(0,500^{2})$ and $\mu_{\text{re74}}$ is the mean of the re74 covariate.
Details for the Stress Test on Non-Invertible SCMs (Act IV).
This experiment’s primary objective is to evaluate the framework’s robustness when the core theoretical assumption of SCM invertibility is explicitly violated. The DGP ( $N=2000$ ) is defined as follows:
| | $\displaystyle W$ | $\displaystyle\sim\mathcal{U}(-2,2)$ | |
| --- | --- | --- | --- |
The true ATE is exactly $\tau=5.0$ . The SCM was structured with W as an EmpiricalDistribution, and T and Y as CausalDiffusionModel.
Details for the Ablation Study (Act IV).
The ablation study was conducted on a challenging synthetic mediation dataset ( $N=4000$ ) designed to highlight the benefits of generative models. The causal graph is shown in Figure 3(b), with the following data generation process:
| | $\displaystyle X_{1}$ | $\displaystyle\sim\mathcal{N}(0,1),\quad X_{2}\sim\mathcal{U}(-2,2),\quad Z\sim\text{Bernoulli}(0.5)$ | |
| --- | --- | --- | --- |
where $\sigma(·)$ is the sigmoid function, $U_{T}\sim\text{Logistic}(0,0.3)$ , $U_{M}\sim\mathcal{N}(0,1.5^{2})$ , and $U_{Y}$ is drawn from a Gaussian Mixture Model conditioned on $Z$ . The true ATE for this DGP is approximately $202.29$ . BELM-MDCM (Full Model):
The complete proposed framework. The nodes T, M, and Y are all modeled by a CausalDiffusionModel with sampler_type=’belm’ and a hybrid objective weight of $\lambda=5.0$ . w/o Analytical Invertibility:
Identical to the full model, but the sampler_type for all diffusion models was set to ’ddim’. w/o Hybrid Objective:
Identical to the full model, but the hybrid objective weight $\lambda$ for all diffusion models was set to $0.0$ . w/o Targeted Modeling:
The key mediator node M was modeled with a simpler gcm.AdditiveNoiseModel (backed by an LGBMRegressor), while T and Y remained as CausalDiffusionModel s with $\lambda=5.0$ and sampler_type=’belm’.
I.2 Model Hyperparameter Justification
The hyperparameters for our BELM-MDCM model, reported in Table 9, were identified through a systematic grid search for each experiment. The variation in these parameters reflects principled adaptations to different data characteristics, guided by the trade-off between generative fidelity and discriminative accuracy, as well as the signal-to-noise ratio (SNR) of the underlying causal relationships. Below, we provide a holistic analysis for each scenario.
I.2.1 Hyperparameter Search Details
To ensure full reproducibility, we detail the hyperparameter search space used to arrive at the configurations in Table 9. The final values for each experiment were selected based on the best performance on a held-out validation set, typically comprising 20-30% of the training data. The primary selection criterion was the lowest PEHE score for experiments with a ground-truth ITE (e.g., Semi-Synthetic), or the best balance of low absolute ATE error and low estimation variance for observational data scenarios. For the Lalonde experiment in particular, we prioritized a configuration that demonstrated superior stability, as detailed in the analysis below.
Table 8: Hyperparameter Search Space and Selection Criteria.
| Hybrid Weight $\lambda$ | {0.0, 0.1, 0.3, 1.0, 2.0, 5.0, 10.0} | Best balance of low error and low variance on the validation set. |
| --- | --- | --- |
| Guidance Weight $w$ | {0.0, 0.1, 0.2, 0.3, 1.0, 5.0, 10.0} | |
| Diffusion Timesteps $T$ | {50, 100, 200, 500} | |
| Learning Rate | {5e-5, 1e-4, 1.1e-4, 1.2e-4, 2e-4} | |
Table 9: Consolidated BELM-MDCM Hyperparameters for All Key Experiments. Column headers correspond to the following experiments: PSM (PSM Failure), Lalonde, Semi-Synth (Semi-Synthetic), Ablation (Ablation Study), and Stress Test (Act IV).
| Hyperparameter Number of Epochs Batch Size | PSM 1500 128 | Lalonde 1000 64 | Semi-Synth 1200 64 | Ablation 700 128 | Stress Test 500 128 |
| --- | --- | --- | --- | --- | --- |
| Hidden Dimension | 512 | 512 | 768 | 768 | 256 |
| Learning Rate | $1× 10^{-4}$ | $1× 10^{-4}$ | $1.1× 10^{-4}$ | $1× 10^{-4}$ | $1× 10^{-4}$ |
| Diffusion Timesteps ( $T$ ) | 200 | 200 | 50 | 200 | 200 |
| Hybrid Weight $\lambda$ | 0.1 | 2.0 | 2.0 | 5.0 | 0.5 |
| Guidance Weight ( $w$ ) | 0.0 | 1.0 | 0.1 | 0.2 | 0.0 |
Scenario 1: The ”Perfectionist Learner” (PSM Failure Experiment)
Data Profile: This synthetic dataset features complex, non-linear functions (e.g., sin, cos) but is characterized by a pure, high-SNR signal. The main challenge is to perfectly learn this intricate generative process. Hyperparameter Strategy: The strategy prioritizes generative modeling. A low hybrid weight ( $\lambda=0.1$ ) directs the model to focus on the diffusion loss. Since the conditional signal is strong, classifier-free guidance is disabled ( $w=0.0$ ). A large model capacity and extended training are employed to capture the ground-truth functions.
Scenario 2: The ”Pragmatic Signal Extractor” (Lalonde Experiment)
Data Profile: This real-world data is characterized by a weak, noisy signal and a small sample size. The primary challenge is to robustly extract the causal signal. Hyperparameter Strategy: The priority shifts from pure accuracy to a balance of accuracy and stability. A high hybrid weight ( $\lambda=2.0$ ) provides a strong inductive bias towards the predictive task. Crucially, our systematic grid search revealed that high guidance weights ( $w>1.0$ ) dramatically increased estimation variance, leading to unreliable results. We therefore selected a moderate guidance weight of $w=1.0$ . This configuration provides a stabilizing effect, guiding the model towards the causal signal without amplifying noise, thereby achieving the optimal balance between accuracy and the robustness required for reliable inference on real-world data.
Scenario 3: The ”Precision Artist” (Semi-Synthetic Experiment)
Data Profile: This setup presents a hybrid-SNR environment, using noisy real-world covariates but a pure, synthetic outcome function. The task demands high precision. Hyperparameter Strategy: The diffusion timesteps are reduced ( $T=50$ ), plausibly because a shorter generative path better preserves the fine-grained details of the synthetic ITE function. The hybrid weight is high ( $\lambda=2.0$ ) to focus on the estimation task, while guidance is light ( $w=0.1$ ) as the ITE signal is cleaner than in the purely observational Lalonde case.
Scenario 4: The ”Component Analyst” (Ablation Study)
Data Profile: This is a complex, synthetic mediation structure with a clean, high-SNR signal, specifically designed to isolate the performance impact of individual framework components. Hyperparameter Strategy: The strategy is to create a strong, stable baseline. A high hybrid weight ( $\lambda=5.0$ ) heavily orients the model towards the predictive task, making any performance degradation from ablations more pronounced. A large model capacity (Hidden Dim=768) ensures the model can learn the complex functions, while light guidance ( $w=0.2$ ) provides a minor stabilizing effect.
Scenario 5: The ”Robustness Tester” (Stress Test)
Data Profile: A simple DGP featuring a non-invertible causal mechanism ( $Y\propto U^{2}$ ), designed to test the framework’s behavior when its core assumption is violated. Hyperparameter Strategy: The goal is stable learning of a simple function. A moderate hybrid weight ( $\lambda=0.5$ ) balances generative and predictive learning, while a smaller model (Hidden Dim=256) is sufficient for the simpler DGP and helps prevent overfitting. Guidance is turned off ( $w=0.0$ ) as the signal is clean.
Holistic Comparison
Table 10: Summary of Adaptive Hyperparameter Strategies.
| Data Signal Guidance ( $w$ ) Timesteps ( $T$ ) | Pure & Complex 0.0 (Off) 200 (Standard) | Noisy & Weak 1.0 (Balanced Guidance) 200 (Standard) | Hybrid & Complex 0.1 (Slight Nudge) 50 (Short Path) | Pure & Mediated 0.2 (Light) 200 (Standard) | Pure & Non-Invertible 0.0 (Off) 200 (Standard) |
| --- | --- | --- | --- | --- | --- |
| Hybrid ( $\lambda$ ) | 0.1 (Generative) | 2.0 (Predictive) | 2.0 (Predictive) | 5.0 (Strongly Predictive) | 0.5 (Balanced) |
| Core Strategy | Perfect Generation | Robust Prediction | Precision Estimation | Component Isolation | Stable Learning |
In conclusion, the variability in hyperparameters demonstrates the flexibility of our framework. It showcases the model’s ability to deploy different tools—such as prioritizing the generative loss or amplifying weak signals with guidance—to optimally adapt to the specific challenges posed by diverse causal inference problems.
I.3 CMF Metric Implementation Details
To ensure the rigor and reproducibility of our evaluation, this section provides the implementation details for the CMF scores.
CMI-Score Estimation Method.
For Conditional Mutual Information (CMI) estimation, we adopt the widely-used k-Nearest Neighbors (k-NN) based estimator from Kraskov et al. (kraskov2004estimating). This method is chosen for its strong theoretical properties and practical robustness, particularly for continuous and high-dimensional data, as it avoids explicit density estimation. Its key advantages include:
- Non-parametric: It makes no assumptions about the underlying data distributions.
- Data-adaptive: The estimation is based on local distances, adapting to the data manifold’s geometry.
- Robustness: It is more robust than methods that rely on fixed binning, which can be sensitive to bin size.
Following common practice, we set the number of neighbors to $k=5$ for all our experiments to ensure a stable and reliable estimation.
KMD-Score Kernel Parameter Selection.
The performance of the MMD test is sensitive to kernel parameter choices. For the KMD-Score, we employed a standard Radial Basis Function (RBF) kernel, $k(x,y)=\exp(-\|x-y\|^{2}/(2\sigma^{2}))$ . The bandwidth parameter $\sigma$ is critical. Following best practices, we set the bandwidth using the median heuristic, a robust and common data-driven approach. For the analysis on the Lalonde dataset’s re78 mechanism, this heuristic yielded a bandwidth of $\sigma=0.1$ , a value confirmed as effective in preliminary experiments. All KMD-Scores are reported using this configuration.
Appendix J Empirical Validation of Proposed Evaluation Metrics
To empirically validate the reliability, sensitivity, and complementary nature of our proposed evaluation metrics (CIC-Score, CMI-Score, and KMD-Score), we conducted a controlled micro-simulation study assessing how each metric responds to a spectrum of increasingly severe model errors.
Experimental Setup.
We designed a simple ground-truth Structural Causal Model (SCM) and created five simulated models (A through E) representing a clear ”degradation gradient” of model quality:
- Model A (Oracle): Represents a theoretically perfect model with zero SRE and a perfectly learned causal mechanism. This serves as our gold standard, with expected scores of 1.0.
- Model B (Lossy Inverter): Simulates a model with a non-zero SRE. It uses the correct causal mechanism but introduces a systematic error during the reconstruction cycle, mimicking the core flaw of DDIM-based approaches.
- Model C (Wrong Mechanism): Represents a model that fails to learn the correct functional form of the causal mechanism (e.g., learning a linear instead of a sinusoidal relationship).
- Model D (Maximal Error): Simulates a more severe failure where both the causal mechanism and the inferred noise distribution are fundamentally incorrect.
- Model E (Total Mismatch): Represents the worst-case scenario where the model ignores the causal graph and inputs, generating outputs from an unrelated distribution.
<details>
<summary>x13.png Details</summary>
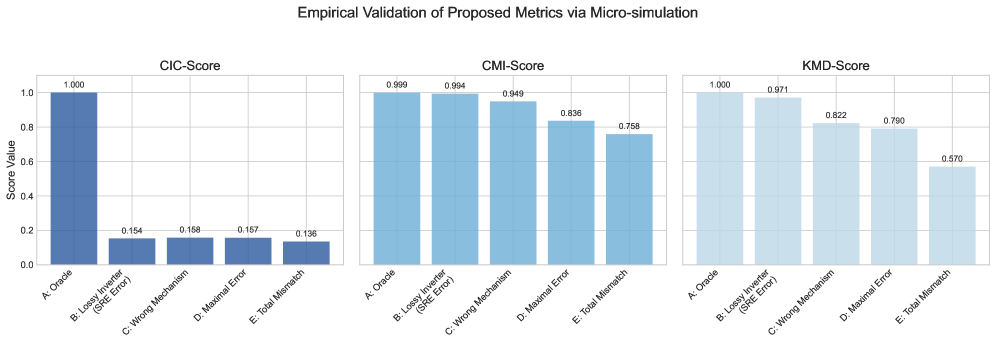
### Visual Description
## Bar Charts: Empirical Validation of Proposed Metrics via Micro-simulation
### Overview
The image contains three side-by-side bar charts comparing performance metrics across five categories: "A: Oracle," "B: Lossy Inverter (SRE Error)," "C: Wrong Mechanism," "D: Maximal Error," and "E: Total Mismatch." Each chart represents a different scoring system (CIC-Score, CMI-Score, KMD-Score) with values normalized between 0 and 1.0.
### Components/Axes
- **X-Axis**: Categories (A: Oracle, B: Lossy Inverter, C: Wrong Mechanism, D: Maximal Error, E: Total Mismatch)
- **Y-Axis**: Score Value (0 to 1.0)
- **Legend**: Not explicitly labeled, but colors differentiate charts:
- **CIC-Score**: Dark blue
- **CMI-Score**: Light blue
- **KMD-Score**: Grayish blue
### Detailed Analysis
#### CIC-Score Chart
- **A: Oracle**: 1.000 (maximum value)
- **B: Lossy Inverter**: 0.154
- **C: Wrong Mechanism**: 0.158
- **D: Maximal Error**: 0.167
- **E: Total Mismatch**: 0.136
**Trend**: Oracle dominates with a perfect score, while all other categories cluster near 0.15–0.17.
#### CMI-Score Chart
- **A: Oracle**: 0.999
- **B: Lossy Inverter**: 0.994
- **C: Wrong Mechanism**: 0.949
- **D: Maximal Error**: 0.836
- **E: Total Mismatch**: 0.758
**Trend**: Oracle and Lossy Inverter are nearly identical, followed by a gradual decline to Total Mismatch.
#### KMD-Score Chart
- **A: Oracle**: 1.000
- **B: Lossy Inverter**: 0.971
- **C: Wrong Mechanism**: 0.822
- **D: Maximal Error**: 0.790
- **E: Total Mismatch**: 0.570
**Trend**: Oracle leads, but scores drop sharply from Lossy Inverter to Total Mismatch, with a minor uptick at Maximal Error.
### Key Observations
1. **Oracle Dominance**: In all charts, "A: Oracle" achieves the highest score (1.000 in CIC/KMD, 0.999 in CMI).
2. **Performance Degradation**:
- CIC-Score shows the largest gap between Oracle and other categories (~0.85 difference).
- KMD-Score exhibits the steepest decline from Lossy Inverter (0.971) to Total Mismatch (0.570).
3. **Consistency in Lower Categories**:
- "B: Lossy Inverter" and "C: Wrong Mechanism" scores are relatively close across metrics.
- "E: Total Mismatch" is consistently the lowest performer.
### Interpretation
The data demonstrates that the "Oracle" configuration is optimal across all scoring systems, while deviations (e.g., "Total Mismatch") result in significant performance drops. The CIC-Score highlights the critical importance of accuracy, as even minor errors ("Maximal Error") reduce scores to ~0.17. The CMI-Score suggests that "Lossy Inverter" is nearly as effective as Oracle, whereas the KMD-Score emphasizes the sensitivity of performance to mismatches, with "Total Mismatch" scoring below 0.6. These trends underscore the need for precise mechanism alignment in the evaluated systems.
</details>
Figure 10: Results of the micro-simulation study for metric validation. The three plots show the response of the CIC-Score, CMI-Score, and KMD-Score to five models (A-E) of progressively decreasing quality. The scores demonstrate a clear monotonic degradation, confirming their ability to reliably track model fidelity. Note the CIC-Score’s sharp drop from Model A to B, highlighting its specific sensitivity to the Structural Reconstruction Error (SRE).
Analysis of Results.
The results (Figure 10) demonstrate the distinct and complementary roles of our proposed metrics:
1. The CIC-Score acts as a high-sensitivity ”SRE detector.” It exhibits a dramatic drop from a perfect 1.0 (Model A) to approximately 0.23 (Model B) the moment SRE is introduced, while showing less sensitivity to the specific form of mechanism error. This confirms its primary role as a diagnostic for adherence to the Causal Information Conservation principle.
1. The CMI-Score serves as a robust ”mechanism association tracker.” It degrades gracefully and monotonically as the learned causal mechanism deviates from the ground truth (from 0.99 to 0.76). This demonstrates its utility in quantifying the fidelity of learned parent-child conditional dependencies.
1. The KMD-Score functions as the ”final arbiter” of distributional fidelity. Possessing the widest dynamic range, it is sensitive to all forms of error and provides a holistic judgment of the similarity between the generated and true counterfactual distributions. As the most rigorous metric, it correctly assigns the lowest score to the completely mismatched Model E.
This simulation thus validates our proposed metrics as a reliable and nuanced evaluation framework. They work in synergy to diagnose specific model failings (CIC-Score), assess relational accuracy (CMI-Score), and provide an overall quality judgment (KMD-Score), offering a more insightful assessment than traditional metrics alone.
Discussion on the Non-Zero Lower Bound of Scores.
Notably, even for the worst-performing model (Model E), the CMI and KMD scores do not fall to zero. This behavior is not a limitation but a desirable feature that reflects their ability to capture ”residual statistical structure” in the evaluation setting.
- For the KMD-Score: The MMD compares the joint distributions $P_{\text{model}}(Y,W,T)$ and $P_{\text{oracle}}(Y,W,T)$ . Crucially, as all models operate on the same observed parent data, the marginal parent distribution $P(W,T)$ is identical between the two. The difference lies only in the conditional $P(Y|W,T)$ . Because the joint distributions share a substantial common subspace, their MMD will be finite, preventing the KMD-Score from reaching zero. Furthermore, using a ‘StandardScaler‘ maps both distributions to a similar feature space, which is necessary for a fair, scale-invariant comparison.
- For the CMI-Score: This metric quantifies the $I(Y;\text{parent}|\text{other parents})$ . Even an incorrect mechanism (like in Model C or D) still generates an output $Y$ as a deterministic function of its parents, resulting in a non-zero CMI. For Model E, where $Y$ is independent of its parents, the theoretically zero CMI is not observed due to the inherent finite-sample variance of the non-parametric k-NN estimator.
This behavior is advantageous, ensuring the metrics provide a meaningful, continuous gradient of failure rather than a simplistic binary judgment. This enhances their diagnostic power, allowing for fine-grained distinctions between types and degrees of model imperfection.
Appendix K Algorithm for ATE Estimation
This appendix provides the detailed pseudo-code for the counterfactual imputation procedure used to estimate the Average Treatment Effect (ATE) in our experiments.
Input: Observational data $\mathcal{D}=\{v^{(j)}\}_{j=1}^{N}$ where $v^{(j)}∈\mathbb{R}^{d}$ ; Causal graph $\mathcal{G}$ .
Output: Estimated Average Treatment Effect ( $\hat{\text{ATE}}$ ).
Define Invertible SCM $\mathcal{M}_{\theta}$ :
$\mathcal{M}_{\theta}=\{f_{i}(·;\theta_{i})\}_{i=1}^{d}$ based on $\mathcal{G}$ , where $v_{i}=f_{i}(\mathbf{pa}_{i},u_{i})$ ;
// 1. Train the invertible SCM on observational data
$\hat{\theta}←\arg\min_{\theta}\sum_{j=1}^{N}\sum_{i=1}^{d}\mathcal{L}_{i}\left(f_{i}(\mathbf{pa}_{i}^{(j)};\theta_{i}),v_{i}^{(j)}\right)$ ;
// 2. Generate counterfactual outcomes for each individual
for $j← 1$ to $N$ do
$t_{j}← v_{T}^{(j)}$ ;
// Observed treatment
$\mathbf{u}^{(j)}←\mathcal{M}_{\hat{\theta}}^{-1}(v^{(j)})$ ;
// Abduction via invertible BELM encoder
$y_{j}(1-t_{j})←\operatorname{Predict}\left(\mathcal{M}_{\hat{\theta}},\mathbf{u}^{(j)},\operatorname{do}(T:=1-t_{j})\right)$ ;
// Action & Prediction
// Store factual and counterfactual outcomes
$\mathbf{Y}_{j}(t_{j})← v_{Y}^{(j)}$ ;
$\mathbf{Y}_{j}(1-t_{j})← y_{j}(1-t_{j})$ ;
end for
// 3. Compute the ATE from factual and counterfactual outcomes
$\hat{\text{ATE}}←\frac{1}{N}\sum_{j=1}^{N}\left(\mathbf{Y}_{j}(1)-\mathbf{Y}_{j}(0)\right)$ ;
1ex
return $\hat{\text{ATE}}$ ;
Algorithm 1 ATE Estimation with Invertible SCMs via Counterfactual Imputation