# A Multi-Agent System for Semantic Mapping of Relational Data to Knowledge Graphs
**Authors**: Milena Trajanoska, Riste Stojanov, Dimitar Trajanov
institutetext: University Ss. Cyril and Methodius, Skopje, N.Macedonia email: {milena.trajanoska,riste.stojanov,dimitar.trajanov}@finki.ukim.mk
## Abstract
Enterprises often maintain multiple databases for storing critical business data in siloed systems, resulting in inefficiencies and challenges with data interoperability. A key to overcoming these challenges lies in integrating disparate data sources, enabling businesses to unlock the full potential of their data. Our work presents a novel approach for integrating multiple databases using knowledge graphs, focusing on the application of large language models as semantic agents for mapping and connecting structured data across systems by leveraging existing vocabularies. The proposed methodology introduces a semantic layer above tables in relational databases, utilizing a system comprising multiple LLM agents that map tables and columns to Schema.org terms. Our approach achieves a mapping accuracy of over 90% in multiple domains.
## 1 Introduction
In today’s data-driven enterprises, information is often distributed across multiple siloed databases, limiting the ability to fully leverage its value. Achieving seamless integration between heterogeneous data sources remains a major challenge, particularly due to differences in schema design, semantics, and data representation. Knowledge Graphs (KGs) [hogan2021knowledge] have emerged as a powerful paradigm for bridging these gaps by creating a unified, semantic view over disparate datasets.
Traditional data integration efforts, however, often require extensive manual work to align schemas and define mappings. Recent advances in Large Language Models (LLMs) [chang2024survey] provide new opportunities to automate complex reasoning tasks, including semantic mapping and knowledge graph construction. LLMs have shown impressive performance in tasks that involve understanding relationships between concepts, making them ideal candidates for assisting in structured data integration.
In this paper, we present a novel semantic multi-agent system that leverages LLM agents to automate the integration of relational databases into a unified knowledge graph. Our approach introduces a semantic layer above relational data by mapping tables and columns to concepts from the Schema.org vocabulary [schemaorg]. Each agent in the system has a dedicated role: mapping relational structures to semantic concepts, establishing relationships between entities, and validating the generated knowledge graph.
We evaluate our system using the Spider dataset [yu2018spider], a complex benchmark featuring databases from diverse domains. By mapping real-world relational schemas to Schema.org concepts, we demonstrate that our multi-agent system effectively automates the semantic integration process, achieving high mapping accuracy across several application domains. Our results highlight the potential of LLM-driven semantic agents to significantly reduce the manual burden of data integration and to build more interoperable enterprise knowledge bases.
## 2 Literature review
Recent research has explored various approaches to knowledge graph (KG) and ontology construction, and data integration, particularly in enterprise and industry contexts.
The Virtual Knowledge Graph (VKG) paradigm [xiao2019virtual] offers an alternative to traditional data integration approaches by providing flexible, virtual graphs that embed domain knowledge over existing data sources. The approach provides tools for Ontology-based data access, which have significant use-cases in multiple industry applications.
In the context of Industry 4.0 (I4.0) where different systems exist, the demand for the creation of an integrated view increases. One such initiative is the Bosch Industry 4.0 Knowledge Graph (BI40KG) [grangel2020knowledge] which was developed with the goal of integrating data from different sources, improving interoperability and traceability across manufacturing systems.
Many efforts have been made for developing enterprise knowledge graphs (EKGs), in line with this, an Enterprise Knowledge Graphs Framework [galkin2016integration] was created, which aims to bridge the gap between the increasing need for EKGs and the lack of formal methods for realising them.
The use of Large Language Models (LLMs) in structured information extraction has gained significant traction recently. Findings suggesting that LLMs excel at reasoning tasks, and are being applied to information extraction tasks more often [xu2024large].
Our previous work in the field compares general-purpose LLMs like ChatGPT with specialized models such as REBEL for joint entity and relation extraction [trajanoska2023enhancing]. Using sustainability-related texts, pipelines for automatic Knowledge Graph construction were built. Results show that LLMs can improve accuracy in extracting structured knowledge, and foundational models also show promise for automated ontology generation.
## 3 Methodology
This section describes the methodology for creating the semantic multi-agent system as well as the data source used in evaluating the approach. The section is divided into the following subsections: Data description - stating the dataset used for evaluation and the semantic vocabularies, Graph-vector store constuction - detailing the process of constructing a hybrid vector store containing subgraphs in a vector representation, and Multi-agent system architecture - detailing the entire flow of the mapping system along with the AI agents’ roles.
### 3.1 Data description
The Yale Spider database [yu2018spider] is a benchmark dataset used in semantic parsing and text-to-SQL tasks, featuring real-world relational data from various domains. The Spider challenge aims to create natural language interfaces for databases spanning multiple domains. It includes 10,181 questions and 5,693 distinct complex SQL queries across 200 databases with multiple tables, representing 138 domains.
In this study, the database serves as the foundation for evaluating our multi-agent approach, allowing us to demonstrate the effectiveness of mapping relational data to a knowledge graph.
For creating the mappings, we utilize existing semantic vocabularies, which are defined and maintained by established organizations over a long time period. The reason for this is to avoid hallucinating terms that do not have definitions in any well-known ontologies.
With the goal of including as many general concepts as possible, we use the Schema.org vocabulary [schemaorg], which represents a collection of schemas (types and properties) that can be used to markup content on the Web, enabling search engines to better understand the context of Web pages. It describes entities, their relationships, and actions, and can be readily expanded using a clearly defined extension framework. As of 2024, more than 45 million websites have used Schema.org to annotate their pages, resulting in over 450 billion structured data objects [schemaorg].
### 3.2 Graph-vectore store construction
To enable our use case for generating correct semantic mappings, we have created a custom graph-vector index for retrieval augmented generation [lewis2020retrieval] using the term definitions in Schema.org.
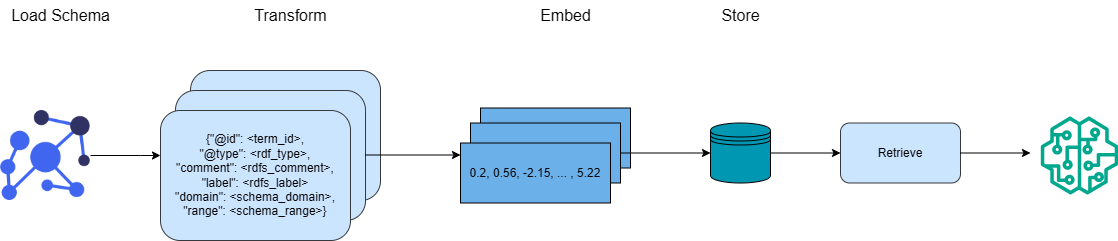
The index creation process is depicted in Figure 1. For each term, we extract its URI, type, human-readable comment, and label, as well as the domain and range for property terms. Based on this information, we construct a one-hop subgraph for each term. This enriched subgraph offers a more detailed semantic context. Finally, each subgraph is transformed into a vector representation using a configurable text embedding transformer model [patil2023survey].
<details>
<summary>images/schema_vector_store_horizontal.png Details</summary>
### Visual Description
## Diagram: Semantic Data Processing Pipeline
### Overview
The image depicts a linear, five-stage technical pipeline for processing structured data, transforming it into embeddings, storing it, and enabling retrieval. The flow moves from left to right, indicated by directional arrows connecting each stage. The diagram uses a combination of icons, text labels, and data representations to illustrate each step.
### Components/Axes
The pipeline consists of five distinct stages, each labeled at the top:
1. **Load Schema** (Far Left)
* **Icon:** A network graph visualization with interconnected nodes of varying sizes and shades of blue.
* **Function:** Represents the ingestion of structured data or a knowledge graph schema.
2. **Transform** (Center-Left)
* **Icon:** Three stacked, light blue document icons, suggesting multiple records or entities.
* **Embedded Text:** A JSON-like structure is visible on the front document:
```
{"@id": <term_id>,
"@type": <rdf_type>,
"comment": <rdfs_comment>,
"label": <rdfs_label>,
"domain": <schema_domain>,
"range": <schema_range>}
```
* **Function:** Represents the transformation of raw schema data into a standardized, semantic format (likely RDF/Schema based on the keys).
3. **Embed** (Center)
* **Icon:** Three stacked, solid blue rectangles, representing vector data.
* **Embedded Text:** A sequence of numerical values is displayed on the front rectangle: `0.2, 0.56, -2.15, ..., 5.22`.
* **Function:** Represents the conversion of the transformed semantic data into numerical vector embeddings.
4. **Store** (Center-Right)
* **Icon:** A teal-colored cylinder, the standard symbol for a database.
* **Function:** Represents the persistence of the generated embeddings into a storage system (e.g., a vector database).
5. **Retrieve** (Far Right)
* **Icon:** A light blue rounded rectangle labeled "Retrieve".
* **Output Icon:** A green brain/circuit icon, symbolizing an AI model or intelligent system.
* **Function:** Represents the querying of the stored embeddings to provide data to an downstream AI application or model.
**Flow Direction:** Black arrows connect each stage sequentially: Load Schema → Transform → Embed → Store → Retrieve → AI Brain Icon.
### Detailed Analysis
* **Data Transformation:** The "Transform" stage explicitly shows the conversion of entities into a semantic web format. The keys `@id`, `@type`, `comment`, `label`, `domain`, and `range` are standard in RDF Schema (RDFS) and Schema.org vocabularies, indicating this pipeline is designed for knowledge graph processing.
* **Embedding Output:** The "Embed" stage shows a vector starting with `0.2, 0.56, -2.15` and ending with `5.22`, with an ellipsis (`...`) indicating a longer, truncated sequence. This confirms the output is a high-dimensional numerical vector.
* **Spatial Layout:** The stages are evenly spaced horizontally. The legend/labels are positioned directly above their corresponding components. The "Retrieve" box is the only stage with a text label inside its icon.
### Key Observations
1. **Linear, Unidirectional Flow:** The process is strictly sequential with no feedback loops or branching paths shown.
2. **Abstraction of Complexity:** Each stage simplifies a complex technical process (schema loading, RDF transformation, vector embedding, database storage, and retrieval) into a single conceptual step.
3. **Data State Change:** The diagram visually tracks the data's form: from a graph (Load Schema), to structured text (Transform), to numerical vectors (Embed), to persisted storage (Store), and finally to a queryable resource (Retrieve).
4. **Purpose-Driven End Point:** The pipeline culminates in feeding data to an AI/ML model (the brain icon), defining its ultimate purpose as enabling intelligent systems.
### Interpretation
This diagram illustrates a **knowledge graph embedding pipeline**, a fundamental architecture in modern AI systems that combine symbolic knowledge (structured data) with sub-symbolic AI (neural networks).
* **What it demonstrates:** The pipeline shows how human-readable, structured knowledge (like a product catalog or medical ontology) is machine-processed into a form that AI models can efficiently use. The "Transform" step is critical for adding semantic meaning, while the "Embed" step translates that meaning into the mathematical language of AI.
* **Relationships:** Each stage is a prerequisite for the next. You cannot embed without transforming the data into a consistent format, and you cannot retrieve from storage without first storing the embeddings. The final arrow to the brain icon signifies that the entire pipeline's value is realized when it powers inference, search, or recommendation in an AI application.
* **Notable Implication:** The ellipsis in the embedding vector (`...`) is a key detail. It implies high dimensionality (hundreds or thousands of values), which is necessary to capture the nuanced meaning of the original semantic data. This is not a simple 2D or 3D plot but a representation of complex, multi-faceted information.
</details>
Figure 1: Graph - Vector store construction with ontology sub-graphs
The generated vectors are stored in a vector store. The subgraphs are retrieved from the vector store during the table mapping process, depending on their semantic similarity to the columns and values in the table being mapped.
### 3.3 Multi-agent system architecture
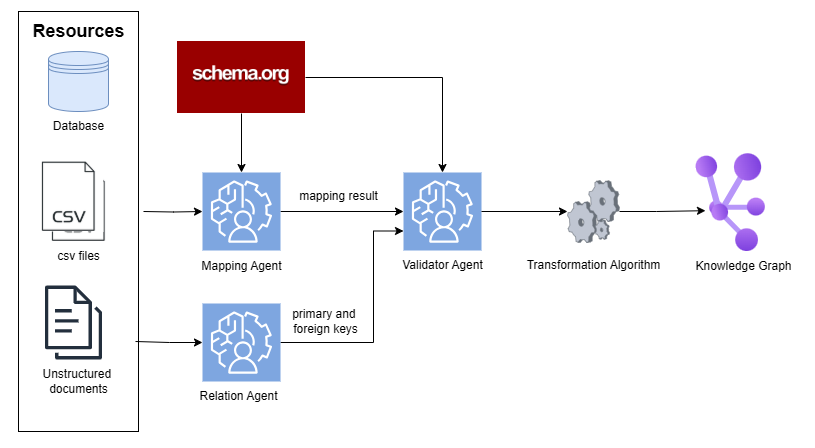
The system consists of multiple GPT-4o-mini [hurst2024gpt] agents with different responsibilities:
1. Mapping agent: Maps columns to corresponding Schema.org terms.
1. Relation agent: Determines primary and foreign keys in tables, creating links between entities in the knowledge graph.
1. Validator agent: Validates and corrects the mapping and relations produced by the two previous agents.
The mapping process is fully represented in Figure 2. The process operateos in a table-wise fashion. For each table, the Mapping agent receives the table name, all its column names, summary statistics for each column’s values, a sample of the first K rows, and any available textual descriptions for the table or its columns.
<details>
<summary>images/semantic_agents_flow_small.png Details</summary>
### Visual Description
## Diagram: Semantic Data Integration Pipeline
### Overview
The image displays a system architecture diagram illustrating a multi-agent pipeline for transforming heterogeneous data sources into a structured knowledge graph. The process flows from left to right, starting with raw data resources, passing through specialized AI agents for mapping and validation, and culminating in a unified knowledge graph output. The diagram uses icons, labeled boxes, and directed arrows to represent components and data flow.
### Components/Axes
The diagram is organized into three primary regions:
1. **Left Region - Resources:** A large bounding box labeled "Resources" contains three data source types, each with an icon and label:
* **Database:** Represented by a blue cylinder icon.
* **csv files:** Represented by a document icon with "CSV" text.
* **Unstructured documents:** Represented by a document icon with lines of text.
2. **Central Processing Region - Agents & Schema:** This area contains the core processing components:
* **schema.org:** A red rectangular box at the top, acting as an external schema reference.
* **Mapping Agent:** A blue square icon with a brain/gear symbol. It receives input from "csv files" and "schema.org".
* **Relation Agent:** A blue square icon with a brain/gear symbol. It receives input from "Unstructured documents".
* **Validator Agent:** A blue square icon with a brain/gear symbol. It receives inputs from the "Mapping Agent" and "Relation Agent", and also from "schema.org".
* **Transformation Algorithm:** Represented by a gray gear icon.
3. **Right Region - Output:**
* **Knowledge Graph:** Represented by a purple network graph icon with interconnected nodes.
**Data Flow & Labels (Arrows):**
* An arrow from "csv files" to "Mapping Agent".
* An arrow from "Unstructured documents" to "Relation Agent".
* An arrow from "schema.org" to "Mapping Agent".
* An arrow from "schema.org" to "Validator Agent".
* An arrow from "Mapping Agent" to "Validator Agent", labeled **"mapping result"**.
* An arrow from "Relation Agent" to "Validator Agent", labeled **"primary and foreign keys"**.
* An arrow from "Validator Agent" to "Transformation Algorithm".
* An arrow from "Transformation Algorithm" to "Knowledge Graph".
### Detailed Analysis
The pipeline processes two distinct data streams that converge for validation:
1. **Structured Data Stream:** CSV files are fed into the **Mapping Agent**. This agent also references the **schema.org** vocabulary. Its output, termed the **"mapping result"**, is sent to the Validator Agent.
2. **Unstructured Data Stream:** Unstructured documents are processed by the **Relation Agent**. This agent extracts relational information, specifically **"primary and foreign keys"**, which are sent to the Validator Agent.
The **Validator Agent** is the central integration point. It receives three inputs:
* The mapping result for structured data.
* The extracted keys from unstructured data.
* Direct guidance from the **schema.org** standard.
After validation, the consolidated data passes through a **Transformation Algorithm** (gear icon), which presumably converts it into the final graph structure. The end product is a **Knowledge Graph**, visualized as a network of purple nodes and connecting lines.
### Key Observations
* **Dual-Input Architecture:** The system is explicitly designed to handle both structured (CSV, database) and unstructured data sources in parallel before merging them.
* **Centralized Schema Governance:** The `schema.org` standard is applied at two critical points: during initial mapping and during final validation, ensuring consistency.
* **Specialized Agent Roles:** The diagram assigns distinct functions to different agents: "Mapping" for schema alignment, "Relation" for entity extraction, and "Validator" for consistency checking.
* **Explicit Data Contracts:** The labels on the arrows ("mapping result", "primary and foreign keys") define the specific outputs expected from each agent, suggesting a formalized interface between components.
### Interpretation
This diagram represents a **semantic data integration pipeline**. Its purpose is to unify disparate data sources into a single, queryable knowledge graph by leveraging a common semantic vocabulary (`schema.org`).
The process demonstrates a **Peircean investigative approach**:
1. **Abduction (Hypothesis):** The `schema.org` box provides the initial framework or hypothesis about how data should be categorized and related.
2. **Deduction (Prediction):** The Mapping and Relation Agents apply this framework to specific data, predicting what the structured output ("mapping result") and relational structure ("primary and foreign keys") should be.
3. **Induction (Testing):** The Validator Agent tests these predictions against each other and the original schema, confirming or refining the integrated data model before final transformation.
The separation of the **Relation Agent** for unstructured documents is particularly notable. It suggests the system doesn't just convert text to structured fields but actively identifies and extracts the underlying relational schema (keys) from narrative or document-based data, which is a non-trivial task. The final **Knowledge Graph** output implies the end goal is not just a database table, but a rich, interconnected web of entities and relationships suitable for advanced reasoning, search, or AI applications. The pipeline's value lies in automating the labor-intensive process of data harmonization and semantic enrichment.
</details>
Figure 2: Data flow of the semantic multi-agent system
In addition, the mapping LLM is provided with the most similar terms from Schema.org to the table and column in order to map them accordingly. The most similar terms are retrieved from the custom graph-vector store described in the previous subsection.
In the subsequent step, all mapped tables are integrated into a unified knowledge base by accurately identifying primary and foreign key relationships through the Relation agent. This structured integration enables seamless interaction with the knowledge base by both internal and external systems.
In the final step, the Validator agent inspects and refines each table mapping and the final relation mapping to ultimately produce a more accurate result. The Validator agent may remove or re-map any relations it deems necessary to improve the accuracy.
All the prompts for the different types of agents are available in our GitHub repository [milena_trajanoska_knowledge_graph_agents] under the prompts folder.
All of the agents in the system output a confidence variable which can be one of the three following cateogories: HIGH, MEDIUM or LOW, to describe their confidence in the completion of their dedicated task. The categories are averaged from all steps to produce the final confidence class.
## 4 Results and discussion
The mapping system was evaluated on multiple databases from different domains present in the Spider data source. The accuracy of the generated mappings was assessed through manual validation, evaluating whether the Schema.org terms chosen by the system correctly reflected the semantics of the corresponding database elements. The evaluation dataset can be found in our GitHub repository [milena_trajanoska_knowledge_graph_agents_eval] in the eval folder.
This section summarizes the findings for the entire execution of the system, including the time to generate the mapping result, as well as the accuracy of the mapping process.
Table 1 shows that the execution time generally increases with the number of tables and columns being mapped. This is likely due to the complexity of larger tables and databases in the relationships they model.
Table 1: System execution time based on the number of tables and columns being mapped.
| Number of tables | Number of columns | Execution time (sec) |
| --- | --- | --- |
| 3 | 10 | 122 |
| 6 | 25 | 179 |
| 6 | 31 | 191 |
| 11 | 42 | 342 |
| 12 | 47 | 295 |
Concerning the validity of the generated mappings, we have conducted an evaluation for five different fields, namely: retail, movies, automotive, apartments, and delivery. We gathered all the datasets from these domains present in the Spider database and manually evaluated the accuracy of the mappings in each domain.
The accuracy of the multi-agent system across the five domains is reported in Table 2. Apart from the mapping result, the multi-agent system returns the confidence of the mapping process, which can be one of the following categories: HIGH, MEDIUM, and LOW. For all confidence levels, the results are displayed in the table.
Table 2: Accuracy of the multi-agent system on the five chosen domains presented by human evaluators
| Retail | 78.72 | 95.83 | 64.29 | 55.56 |
| --- | --- | --- | --- | --- |
| Movies | 90 | 85.71 | 100.00 | / |
| Appartments | 93.54 | 100.00 | 88.89 | 50.00 |
| Automotive | 84 | 100.00 | 80.00 | 25.00 |
| Delivery | 80.95 | 96.30 | 66.67 | 0 |
The highest accuracy (93.54%) was observed in the ’Apartments’ domain, while the lowest (78.72%) occurred in the ’Retail’ domain. Even for retail, the score is still satisfactory. It is evident that the mappings with certainty equal to HIGH are, in general, the most correct ones.
## 5 Conclusion
This paper introduced a semantic multi-agent system for enterprise data integration using Knowledge Graphs and LLMs. By aligning relational schemas with Schema.org, our approach enhances interoperability and enables unified, semantically rich graphs across domains.
LLM agents were assigned specialized roles—mapping, extraction, and validation—resulting in a scalable and automated integration pipeline. Experiments on the Spider benchmark showed high mapping accuracy and cross-domain applicability.
The main contributions of this work are:
- The design and implementation of a semantic multi-agent system for automating relational-to-graph data integration.
- The innovative use of LLM agents to perform semantic mapping and reasoning over structured data using existing vocabularies.
- The empirical evaluation on a real-world benchmark, validating the system’s practicality and generalization capability.
Future work includes extending the system to support custom domain ontologies, enhancing the reasoning capabilities of the agents through fine-tuning, and investigating scaling strategies for integrating larger and more heterogeneous datasets.
## 6 Acknowledgements
This publication is based upon work from COST Action CA23147 GOBLIN - Global Network on Large-Scale, Cross-domain and Multilingual Open Knowledge Graphs, supported by COST (European Cooperation in Science and Technology, https://www.cost.eu.