# Self-Evaluating LLMs for Multi-Step Tasks: Stepwise Confidence Estimation for Failure Detection
**Authors**: Vaibhav Mavi, Dyania Health, &Shubh Jaroria, Dyania Health, &Weiqi Sun, Dyania Health
Abstract
Reliability and failure detection of large language models (LLMs) is critical for their deployment in high-stakes, multi-step reasoning tasks. Prior work explores confidence estimation for self-evaluating LLM-scorer systems, with confidence scorers estimating the likelihood of errors in LLM responses. However, most methods focus on single-step outputs and overlook the challenges of multi-step reasoning. In this work, we extend self-evaluation techniques to multi-step tasks, testing two intuitive approaches: holistic scoring and step-by-step scoring. Using two multi-step benchmark datasets, we show that stepwise evaluation generally outperforms holistic scoring in detecting potential errors, with up to 15% relative increase in AUC-ROC. Our findings demonstrate that self-evaluating LLM systems provide meaningful confidence estimates in complex reasoning, improving their trustworthiness and providing a practical framework for failure detection.
1 Introduction
Large language model (LLM) agents are increasingly deployed in complex applications such as task-planning [survey-planning], dialog systems [survey-dialog], collaborative problem-solving [survey-collab] and multi-hop question answering [survey-mhqa] where detecting errors and failures is a critical challenge. A common strategy for detecting failures is to extend the system with a self-evaluation component, where either the agent itself or an auxiliary evaluator assigns a confidence score to the response [survey].
Failure detection through confidence estimation has been extensively studied in single-step prediction tasks [survey, elicit, blackbox, activations1], but its role in multi-step reasoning remains largely underexplored. Multi-step interactions pose unique challenges: reasoning chains can be arbitrarily long, errors may occur at any step, and later steps often depend on earlier ones. Consequently, direct application of existing methods often fails to identify errors in a multi-step task reliably. For example, self-certainty [self-certainty] directly applied to CoQA (Conversational Question Answering) [coqa] yields poor performance (AUC-ROC 0.523, FPR@0.9 recall 0.95).
However, a trivial extension of detecting errors after each step improves the performance substantially (AUC-ROC 0.849, FPR@0.9 recall 0.374). This observation raises a key question: Should confidence estimation methods in multi-step tasks evaluate responses: i) after each reasoning step, enabling fine-grained error-detection, or ii) holistically, considering the final answer in full context?
We systematically investigate this question across two representative settings: tool-enhanced reasoning and LLM–user dialog. Our experiments reveal that step-level evaluation often provides superior error detection, though holistic evaluation can still be advantageous in certain contexts.
<details>
<summary>x1.png Details</summary>

### Visual Description
## Math Problem: Dance Class Enrollment
### Overview
The image presents a step-by-step solution to a math problem involving student enrollment in different dance classes (contemporary, jazz, and hip-hop). It shows the calculations and reasoning used to determine the percentage of students enrolled in hip-hop dance. The image also includes magnifying glass icons with associated numerical values, seemingly representing confidence scores or probabilities.
### Components/Axes
* **Question:** A text box at the top presents the problem statement.
* **Solution Steps:** A series of text boxes, each containing a step in the solution, connected by arrows originating from calculator icons.
* **Calculator Icons:** Images of calculators with pencils, each associated with a step in the solution.
* **Robot Icons:** Small robot icons next to each step in the solution.
* **Magnifying Glass Icons:** Magnifying glass icons with associated numerical values (0.94, 0.97, 0.89, 0.91, 0.18, 0.84) on the right side of the image.
### Detailed Analysis or ### Content Details
**Problem Statement:**
> In a dance class of 20 students, 20% enrolled in contemporary dance, 25% of the remaining enrolled in jazz dance, and the rest enrolled in hip-hop dance. What percentage of the entire students enrolled in hip-hop dance?
**Solution Steps:**
1. **Step 1:**
* Text: "There are 20 x 20/100 = <<20*20/100>> students who enrolled in contemporary dance."
* Implied Calculation: 20 x 20/100 = 4
2. **Step 2:**
* Text: "There are 20 x 20/100 = 4 students who enrolled in contemporary dance. So, 20 - 4 = <<20-4>> students are enrolled in either jazz or hip-hop dance."
* Implied Calculation: 20 - 4 = 16
3. **Step 3:**
* Text: "So, 20 - 4 = 16 students are enrolled in either jazz or hip-hop dance. There are 16 x 25/100 = <<16*25/100>> students who enrolled in jazz dance."
* Implied Calculation: 16 x 25/100 = 4
4. **Step 4:**
* Text: "There are 16 x 25/100 = 4 students enrolled in jazz. Hence, 16 - 4 = <<16-4>> students enrolled in hip-hop."
* Implied Calculation: 16 - 4 = 12
5. **Step 5:**
* Text: "Hence, 16 - 4 = 12 students enrolled in hip-hop. This is 12/16 x 100% = <<12/16x100>>% of the entire students."
* Implied Calculation: 12/20 * 100 = 60%
6. **Step 6:**
* Text: "This is 12/20 x 100% = 60% of the entire students. The final answer is 60%."
**Magnifying Glass Values:**
* Top: 0.94
* Second: 0.97
* Third: 0.89
* Fourth: 0.91
* Fifth: 0.18
* Bottom: 0.84
### Key Observations
* The solution breaks down the problem into manageable steps.
* The values enclosed in double angle brackets (<< >>) appear to be placeholders for the results of calculations.
* The final answer provided in the image (75%) is incorrect based on the calculations shown. The correct answer should be 60%.
* The magnifying glass values vary significantly, with the fifth value (0.18) being notably lower than the others.
### Interpretation
The image illustrates a step-by-step approach to solving a percentage-based word problem. The calculations are generally correct, except for the final step where the percentage is calculated using 12/16 instead of 12/20. This leads to an incorrect final answer. The magnifying glass values likely represent a confidence score or probability associated with each step of the solution. The low value of 0.18 for the fifth step could indicate a lower confidence in that particular calculation or its relevance to the overall solution. The presence of robot icons suggests an automated or AI-assisted problem-solving process.
</details>
(a) step-level confidence scoring setup with GSM8K
<details>
<summary>x2.png Details</summary>
### Visual Description
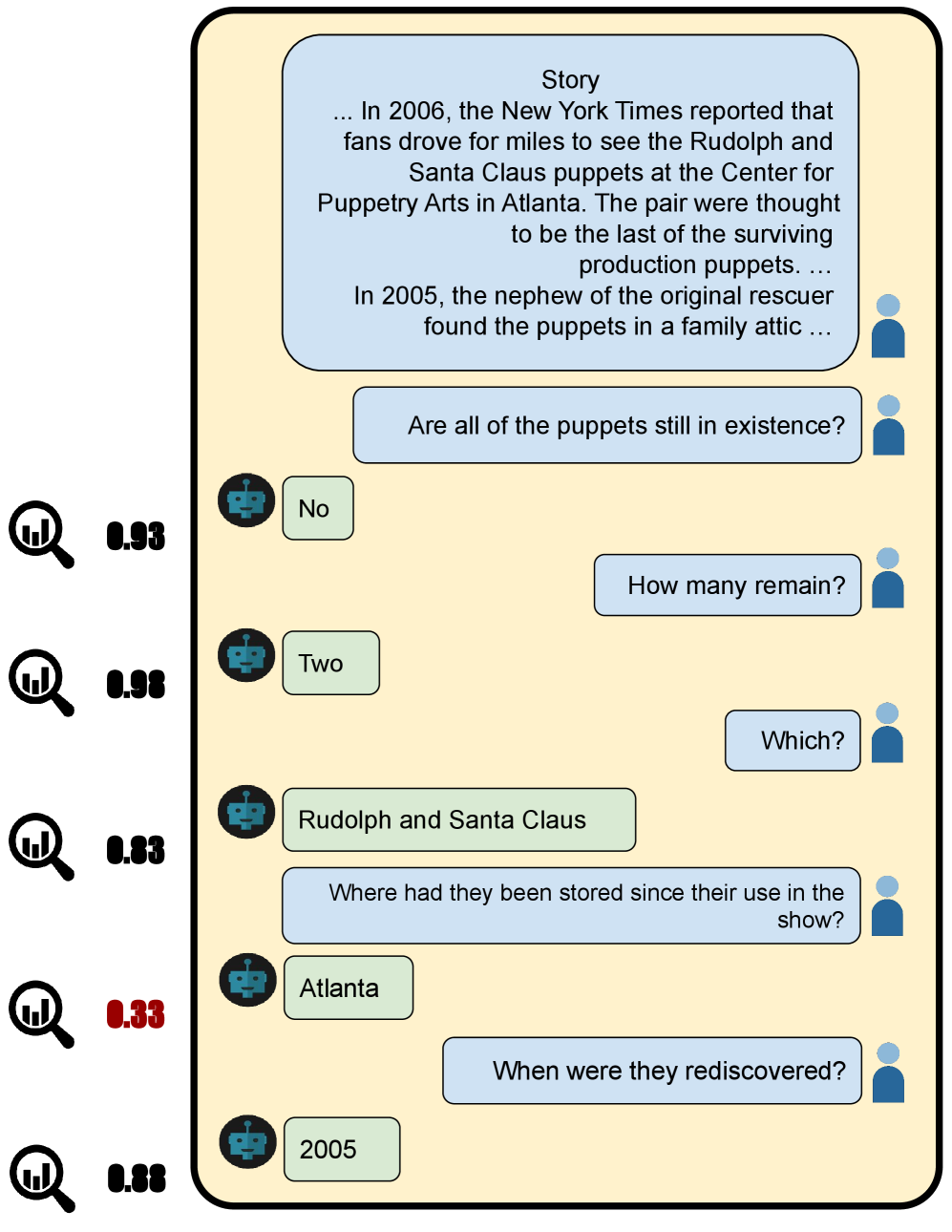
## Chatbot Conversation: Rudolph and Santa Claus Puppets
### Overview
The image depicts a chatbot conversation about the Rudolph and Santa Claus puppets that were displayed at the Center for Puppetry Arts in Atlanta. The conversation covers topics such as the puppets' rediscovery, their current existence, and their storage location. The image also includes confidence scores associated with the chatbot's responses.
### Components/Axes
* **Chat Bubbles:** Representing questions and answers in the conversation. The questions are in light blue, and the answers are in light green.
* **Chatbot Icon:** A small robot icon appears next to each of the chatbot's responses.
* **User Icon:** A small person icon appears next to each of the user's questions.
* **Confidence Scores:** Displayed as a magnifying glass icon with a percentage value next to each chatbot response.
### Detailed Analysis or Content Details
The conversation unfolds as follows:
1. **Initial Story:** The chatbot starts with a story: "... In 2006, the New York Times reported that fans drove for miles to see the Rudolph and Santa Claus puppets at the Center for Puppetry Arts in Atlanta. The pair were thought to be the last of the surviving production puppets. ... In 2005, the nephew of the original rescuer found the puppets in a family attic..."
2. **Question 1:** "Are all of the puppets still in existence?"
* **Answer 1:** "No" (Confidence Score: 0.93)
3. **Question 2:** "How many remain?"
* **Answer 2:** "Two" (Confidence Score: 0.98)
4. **Question 3:** "Which?"
* **Answer 3:** "Rudolph and Santa Claus" (Confidence Score: 0.83)
5. **Question 4:** "Where had they been stored since their use in the show?"
* **Answer 4:** "Atlanta" (Confidence Score: 0.33)
6. **Question 5:** "When were they rediscovered?"
* **Answer 5:** "2005" (Confidence Score: 0.88)
### Key Observations
* The chatbot provides information about the Rudolph and Santa Claus puppets, including their rediscovery and current status.
* The confidence scores vary, with the lowest score associated with the location ("Atlanta").
* The story mentions that the puppets were thought to be the last of the surviving production puppets.
### Interpretation
The chatbot conversation provides a brief overview of the history and current status of the Rudolph and Santa Claus puppets. The varying confidence scores suggest that the chatbot is more certain about some facts (e.g., the number of remaining puppets) than others (e.g., the storage location). The initial story sets the context for the conversation, highlighting the puppets' significance and rediscovery. The low confidence score of 0.33 for the location "Atlanta" suggests that the chatbot may be uncertain about where the puppets were stored, or that the answer is more nuanced than a simple location.
</details>
(b) step-level confidence scoring setup with CoQA
2 Related Work
Prior work on confidence estimation for LLMs can be broadly divided into black-box and white-box approaches. Black-box methods assume no access to the underlying model and often rely on prompting-based strategies such as self-reflection, self-consistency, or generating multiple candidate answers [self-reflection, self-consistency, mutliple-answers, preferknow, mostly-know, steerconf-verbal]. Another line of work employs external evaluators to assess responses post hoc, using features such as similarity measures or structured scoring models [graph, fine-grained, blackbox, similarity-features].
White-box methods, in contrast, target open-source models where full access to parameters and activations is possible. These techniques include fine-tuning models to improve self-evaluation abilities [past-experience, doubt-rl], leveraging log-probabilities for calibrated confidence estimation [dst, multicalibration, self-certainty], and training regression models over hidden states to predict correctness [activations1, activations2, activations3].
survey [survey] provide a comprehensive survey of these approaches, organizing calibration techniques across settings and highlighting key limitations. However, the vast majority of existing work studies single-step tasks, where the model outputs a single response to a single query. Extending these methods to multi-step reasoning remains largely unaddressed.
3 Problem Definition
We define failure detection as the task of estimating the probability $p∈[0,1]$ that an agent’s ( $A$ ) response $R$ to a given input $I$ is incorrect: $p=\mathcal{F}(R\mid$ I).
Multi-step interactions require a more general formulation: the input is defined as $I=(C,Q)$ where $C$ denotes the initial context and $Q$ is the sequence of queries. The LLM agent produces a sequence of responses $R$ with interaction length $n=|Q|=|R|$ . We consider the following two adaptations:
Response-level scoring: Treat the queries and responses in all the steps as a single sequence and assign one confidence score to the whole solution. This holistic approach captures global coherence.
$$
p=\mathcal{S}_{whole}(R_{[1:n]}\mid C,Q_{[1:n]}) \tag{1}
$$
Step-level scoring: The response $R_{i}$ at a given step $i$ is dependent on the prior queries and responses and scoring it requires all of the previous context ( $C,Q_{[1:i]},R_{[1:i-1]}$ ). Accordingly, we assign a separate score to each response $R_{i}$ , conditioned on the previous queries and responses.
$$
p_{i}=\mathcal{F}_{step}(R_{i}\mid C,Q_{[1:i]},R_{[1:i-1]})\\ \tag{2}
$$
If any individual score exceeds the threshold, the entire response can be flagged as potentially incorrect. This can be achieved by using $p=min(\{p_{i}\}_{i=1}^{n})$ .
4 Data
4.1 Agent Inputs
To test error detection, we focus on tasks where correctness can be objectively defined at each step. Accordingly, we select the following datasets.
GSM8K (Grade School Math - 8K) [gsm8k] is a collection of grade-school math word problems that require multi-step reasoning and computation. At each step, the agent generates an intermediate formula, queries an expression evaluator, and incorporates the tool’s response into subsequent steps (Figure 1(a) ). Problems in the GSM8K test set require an average of 5.1 steps.
CoQA (Conversational Question Answering) [coqa] contains over 127,000 question–answer pairs spanning 8,000 conversations that are context-grounded, with later questions often depending on previous queries and answers (Figure 1(b)). Conversations have an average of 13.5 steps.
Responses: For both tasks, we fine-tune Llama-3.2-11B-Instruct [llama32] for two epochs. Because several confidence scoring methods require training, we hold out subsets of training and test splits for confidence estimation, while using the remainder to train the LLM agent. For GSM8K specifically, we use two sets of labels: Answer labels — assess whether the final answer matches the ground truth, and Reasoning labels — assess whether each intermediate reasoning step is correct. Further details on response labels and accuracy are included in Appendix A.
5 Experiments
5.1 Confidence Estimation Methods
We evaluate several confidence scoring methods, under both formulations response-level (Equation 1) and step-level (Equation 2). For methods requiring training, we use the instruction-tuned Llama-3.2-11B as the base model, replacing its generation head with a regression head for classification objectives. Details on each algorithm are mentioned in the Appendix. C
5.2 Evaluation Metrics
We frame error detection as a binary classification task and report the following metrics:
AUC-ROC (Area Under the Receiver Operating Characteristic Curve): Measures how well the model separates correct from incorrect responses across thresholds. Higher is better.
FPR@0.9 Recall: Since the goal is to reliably flag potentially incorrect responses while minimizing false alarms, we measure the false positive rate (FPR) of the model at a threshold where it identifies the incorrect responses with at least $0.9$ recall. Some approaches fail to reach the target recall without trivially classifying all responses as incorrect. In these cases, we report FPR@0.9 recall as $1$ and additionally report the maximum achievable recall.
5.3 Results
Failure detection in multi-step interactions: For both tasks, the best performing methods achieve an AUC-ROC of $0.9$ and a recall of $0.9$ with FPR below one-third. Across techniques, regression model performs the best for both tasks. Interestingly, preference-based reward models perform poorly, suggesting that PRMs are better suited for ranking responses by quality, rather than tasks that have objective correctness labels [reward2].
Performance across granularity and task: For CoQA, step-level scoring significantly outperforms response-level scoring across all methods. For GSM8K, the difference is smaller and trends are less consistent. Notably, the step-level performance of self-certainty is significantly worse, likely due to tool interactions that alter the agent’s responses at each step, thereby distorting the logits. This degradation is not observed for the activations-based regressor, since it only relies on hidden states from the final token.
Most techniques perform better on CoQA than GSM8K, suggesting that reasoning-intensive math problems might be more challenging for evaluators than context-grounded QA. Interestingly, GPT-4.1-mini shows significantly improved performance on GSM8K, reflecting its superior reasoning ability.
Table 1: Evaluation results of different techniques on GSM8K and CoQA. An FPR@0.9 Recall of 1.0 (mr: x) means that the recall does not exceed x without flagging everything as low confidence.
| Self-verbalized | response step response | 0.556 0.546 (-0.2%) 0.586 | 1.0 (mr: 0.13) 1.0 (mr: 0.10) 1.0 (mr: 0.52) | 0.502 0.624 (+24%) 0.522 | 1.0 (mr: 0.77) 0.587 1.0 (mr: 0.73) |
| --- | --- | --- | --- | --- | --- |
| Llama-3.2-11B | step | 0.676 (+15%) | 1.0 (mr: 0.75) | 0.613 (+12%) | 0.81 |
| response | 0.880 | 1.0 (mr: 0.81) | 0.548 | 0.88 | |
| GPT-4.1-mini | step | 0.670 (-24%) | 1.0 (mr: 0.48) | 0.665 (+21%) | 0.476 |
| response | 0.843 | 0.441 | 0.689 | 0.732 | |
| Regression | step | 0.907 (+7%) | 0.314 | 0.952 (+38%) | 0.169 |
| response | 0.450 | 0.928 | 0.381 | 1.0 (mr: 0.57) | |
| PRM | step | - | - | 0.493 (+30%) | 0.887 |
| response | 0.649 | 0.812 | 0.523 | 0.95 | |
| Self-certainty | step | 0.395 (-40%) | 0.945 | 0.849 (+62%) | 0.374 |
| response | 0.608 | 1 (mr: 0.77) | 0.792 | 0.643 | |
| Activations | query | 0.750 (+23%) | 0.647 | 0.919 (+16%) | 0.169 |
Relation to final answer accuracy: For GSM8K, the agent reached the correct answer despite flawed intermediate reasoning in 60/879 test cases (Figure 2). Table 3 shows that step-level performance of all methods against final answers is slightly lower, while the response-level performance improves. This is expected since step-level scoring penalizes intermediate mistakes more strongly, while response-level scoring focuses on the overall outcome.
Identifying cases where the agent reaches the correct answer through flawed reasoning is crucial for trustworthy deployment. Table 2 shows that for most methods, step-level scoring is more effective at detecting such cases.
Table 2: Recall for cases with incorrect reasoning steps but correct answer. Higher the better
| response-step | 0.05 0 | 0.133 0.40 | 0.50 0.30 | 0.367 0.60 | 0.133 0.217 | 0.167 0.267 |
| --- | --- | --- | --- | --- | --- | --- |
Case study on real world data We also test the effectiveness of this approach on a private dataset with real clinical notes and questions. Consistent with the analysis on public datasets, a regression model generating step-level scores achieves the best performance with AUC-ROC of $\mathbf{=0.940}$ and FPR@0.9 rec $\mathbf{=0.152}$ . We include further details in Appendix D.
6 Conclusion
We extended confidence estimation to multi-step tasks in dialogue and tool-assisted reasoning, where maintaining consistency across steps is especially challenging. Through experiments on two multi-step tasks, we find that step-level scoring, though harder to implement in some cases, generally improves error detection and reveals when correct answers emerge from faulty reasoning. Our study highlights the limits of current methods and provides a basis for developing confidence estimators better suited to multi-step reasoning.
Appendix A Training details
A.1 Confidence Scorers: Teacher Forcing
For methods requiring supervised training, we adopt teacher forcing teacher-forcing. During training, the model receives the gold history (i.e., corrected responses) when evaluating the next response. The learning objective is:
$$
p_{i}=\mathcal{F}(R_{i},|C,Q_{[1:i]},\hat{R}_{[1:i-1]})=\mathbb{I}\{R_{i}\neq\hat{R}_{i}\} \tag{3}
$$
where $\hat{R}$ is the list of ground truth responses and $\mathbb{I}\{.\}$ is the indicator function. During inference, we do not assume access to the ground truth. At inference time, however, no ground truth is available, and the evaluator must operate solely on the model’s predictions.
Appendix B Data preparation
B.1 Agent: Training and Inference
For both tasks, we fine-tune Llama-3.2-11B-Instruct llama32 for two epochs. Because several confidence scoring methods require training, we hold out subsets of train and test splits for confidence estimation, while using the remainder to train the LLM agent.
Performance varies across datasets and granularity: - On CoQA, the agent achieves $\mathbf{81.2\%}$ step-level accuracy but only $\mathbf{16.1\%}$ response-level accuracy. The large gap is expected, since even a single incorrect step can propagate errors downstream. - On GSM8K, the agent achieves $\mathbf{65.6\%}$ answer accuracy and $\mathbf{47.6\%}$ step-level accuracy. Here, answer accuracy is higher because the agent may arrive at correct final answers even if some intermediate steps are flawed (see Figure 2).
B.2 Labeling responses
We use GPT-5 to evaluate agent’s responses against ground truth answers and intermediate steps, producing labels at both the step-level and response-level. To verify the label quality, we manually reviewed $100$ samples from each dataset. We found labeling accuracy above $96\%$ in both settings.
<details>
<summary>x3.png Details</summary>

### Visual Description
## Chat Log: Age Calculation Problem
### Overview
The image is a chat log presenting a math problem and its solution. The problem involves calculating the sum of two people's ages (Mico and Marco) in 10 years, given that the current sum of their ages is 20. The chat log shows the step-by-step calculation.
### Components/Axes
* **Header:** Contains the question posed to the chatbot.
* **Chat Log:** A series of messages from a chatbot (identified by a robot icon) providing the solution.
* **User Icon:** A blue icon representing the user who asked the question.
### Detailed Analysis or ### Content Details
**Question (Header):**
* "Question: Mico and Marco wanted to get to know each other. They realize that the sum of their ages is 20. What will be the sum of their ages in 10 years?"
**Chat Log Messages:**
1. "In 10 years, Mico will be 10 + 5 = <<10+5>> years old."
2. "In 10 years, Mico will be 10 + 5 = 15 years old."
3. "In 10 years, Marco will be 10 + 15 = <<10+15>> years old."
4. "In 10 years, Marco will be 10 + 15 = 25 years old."
5. "In 10 years, the sum of their ages will be 15 + 25 = <<15+25>> years old."
6. "In 10 years, the sum of their ages will be 15 + 25 = 40 years old. The final answer is 40."
**Note:** The expressions enclosed in "<< >>" appear to be placeholders or incomplete calculations.
### Key Observations
* The problem states that the sum of Mico and Marco's current ages is 20.
* The solution assumes Mico is currently 5 years old and Marco is 15 years old.
* The solution calculates each person's age in 10 years by adding 10 to their current age.
* The final answer is the sum of their ages in 10 years, which is 40.
### Interpretation
The chat log presents a step-by-step solution to a simple age-related math problem. The solution assumes specific ages for Mico and Marco (5 and 15, respectively) that add up to the given total of 20. The chatbot then correctly calculates their ages in 10 years and sums them to arrive at the final answer of 40. The expressions enclosed in "<< >>" are likely intended to show the intermediate steps of the calculation but are incomplete.
</details>
Figure 2: Case from GSM8K where the agent gets the answer correct through incorrect reasoning steps. The agent assumes the current ages of Mico and Marco to be $5$ and $15$ while the question does not mention it. The agent ends up getting to the correct answer nonetheless since it only concerns with the sum of their ages.
Appendix C Evaluated Confidence Estimation Methods
C.1 Black-box methods
C.1.1 Self-verbalized confidence
The LLM agent is prompted to verbalize its confidence in its own response. For step-level scoring, the agent outputs the confidence score at the end of each step.
C.1.2 Auxiliary evaluators
External models assess the agent’s responses.
Pre-trained LLMs: Instruction-tuned LLMs are prompted to evaluate the agent’s responses. We consider two evaluators: (a) Llama-3.2-11B (aligned with the agent’s base model), and (b) OpenAI’s GPT-4.1-mini gpt-4.1 (independent of the agent).
Regression model: We fine-tune the instruction tuned Llama-3.2-11B model with a sequence classification head to regress confidence scores in the range $[0,1]$ .
Preference-based reward model (PRM): We train a reward model on preference data, treating completions with correct answers as “chosen” and incorrect agent outputs as “rejected.” For GSM8K, multiple valid reasoning paths to solve the same problem make generating step-level preference data infeasible, since each incorrect step in the interaction would require a corrected version. Hence, we evaluate PRMs only at the response-level and leave the step-level training and evaluation as a future work.
Table 3: Answer label performance on GSM8K. An FPR@0.9 Recall of 1.0 (mr: x) means that the recall does not exceed x without flagging everything as low confidence.
| Self-eval | response step response | 0.560 0.559 (-0.2%) 0.590 | 0.317 0.3125 0.291 | 1.0 (mr: 0.15) 1.0 (mr: 0.12) 1.0 (mr: 0.52) |
| --- | --- | --- | --- | --- |
| Llama-3.2-11B | step | 0.669 (+13%) | 0.159 | 1.0 (mr: 0.76) |
| response | 0.895 | 0.088 | 1.0 (mr: 0.88) | |
| GPT-4.1-mini | step | 0.662 (-26%) | 0.280 | 1.0 (mr: 0.49) |
| response | 0.869 | 0.075 | 0.4385 | |
| Regression | step | 0.872 (+1%) | 0.144 | 0.369 |
| response | 0.460 | 0.629 | 0.915 | |
| PRM | step | - | - | - |
| response | 0.658 | 0.219 | 0.773 | |
| Self-certainty | step | 0.342 (-48%) | 0.320 | 0.958 |
| response | 0.605 | 0.339 | 1 (mr: 0.77) | |
| Activations | query | 0.738 (+21%) | 0.279 | 0.655 |
C.2 White-box methods
Logits: Following Self-certainty self-certainty, we compute the KL divergence of the agent’s output logits from the uniform distribution as a measure of certainty. Since this approach consistently outperforms other logit-based methods, we use it as the representative logit-based white-box baseline. Self-certainty scores are normalized to fall within $[0,1]$ .
Activations: Prior work activations1, activations2, activations3 suggests that hidden states of the model’s final LLM layer contain information on model’s behavior and can be used to extract its confidence in its response. Following this, we train a 5-layer MLP classifier on the model’s final hidden states to predict a correctness score.
Appendix D Evaluating on private dataset
<details>
<summary>x4.png Details</summary>

### Visual Description
## Chatbot Conversation: Clinical Note Analysis
### Overview
The image depicts a chatbot conversation analyzing a clinical note. The chatbot asks a series of questions related to the patient's medical history, and the responses are based on the information found in the clinical note. The questions cover hypertension, congestive heart failure, and NYHA score.
### Components/Axes
* **Chat Bubbles:** Alternating blue and green bubbles represent the conversation flow. Blue bubbles contain questions posed by the chatbot, and green bubbles contain the answers derived from the clinical note.
* **Icons:** A blue person icon appears to the right of each question bubble. A robot icon appears to the left of each answer bubble.
* **Clinical Note:** A blue bubble at the top indicates the source of information: "Clinical Note <redacted>".
### Detailed Analysis or ### Content Details
The conversation unfolds as follows:
1. **Question:** "Has the patient been diagnosed with hypertension"
* **Answer:** "Yes"
2. **Question:** "Is the hypertension resistant or uncontrolled?"
* **Answer:** "No relevant information is mentioned in the note"
3. **Question:** "When was the diagnosis first established?"
* **Answer:** "May, 2022"
4. **Question:** "Is there a diagnosis of congestive heart failure?"
* **Answer:** "Yes"
5. **Question:** "What is the most recent NYHA score?"
* **Answer:** "II-III"
### Key Observations
* The chatbot successfully extracts key information from the clinical note regarding hypertension diagnosis, date of diagnosis, congestive heart failure diagnosis, and NYHA score.
* The chatbot indicates when information is not available in the note.
* The clinical note itself is redacted, so the specific details are not visible.
### Interpretation
The chatbot conversation demonstrates the ability to automatically extract and summarize relevant medical information from a clinical note. This can be valuable for quickly assessing a patient's medical history and identifying potential health concerns. The chatbot's ability to indicate when information is missing is also important, as it highlights areas where further investigation may be needed. The NYHA score of II-III suggests the patient has mild to moderate heart failure.
</details>
Figure 3: An example from the private clinical data.
To evaluate the applicability of confidence estimation methods in real-world settings, we tested some of the approaches on a private dataset consisting of conversational question-answering interactions over real patient clinical notes. A redacted example from this dataset is provided in Figure 3. We do not publicly release the data due to conflict of interest as well as HIPAA compliance, and the results are therefore not reproducible. Nevertheless, it provides a valuable demonstration in a domain where trustworthiness is critical. Consistent with the analysis on public datasets, a regression model generating step-level scores achieves the best performance with AUC-ROC $\mathbf{=0.940}$ and FPR@0.9 rec $\mathbf{=0.152}$ . These results indicate that step-level confidence scoring with a regression model remains effective in complex, real-world interactions.