# Self-Correcting Large Language Models: Generation vs. Multiple Choice
> Work was done prior to joining Amazon.
Abstract
Large language models have recently demonstrated remarkable abilities to self-correct their responses through iterative refinement, often referred to as self-consistency or self-reflection. However, the dynamics of this self-correction mechanism may differ substantially depending on whether the model is tasked with open-ended text generation or with selecting the most appropriate response from multiple predefined options. In this paper, we conduct a systematic investigation of these two paradigms by comparing performance trends and error-correction behaviors across various natural language understanding and reasoning tasks, covering language models of different scales and families. Our experimental results reveal distinct patterns of improvement and failure modes:
While open-ended generation often benefits from the flexibility of re-interpretation and compositional refinement, multiple-choice selection can leverage clearer solution boundaries but may be limited by the provided options. This contrast also reflects the dual demands faced by emerging agentic LLM applications: effective agents must not only generate and refine open-ended plans or explanations, but also make reliable discrete choices when operating within constrained action spaces. Our findings, therefore, highlight that the design of self-correction mechanisms should take into account the interaction between task structure and output space, with implications for both knowledge-intensive reasoning and decision-oriented applications of LLMs. Codes and experiments are available at https://github.com/rahmanidashti/llm-self-correction
Self-Correcting Large Language Models: Generation vs. Multiple Choice
Hossein A. Rahmani $\dagger$ , Satyapriya Krishna $\ddagger$ thanks: Work was done prior to joining Amazon., Xi Wang $∇$ , Mohammadmehdi Naghiaei $\diamondsuit$ , Emine Yilmaz $\dagger$ $\dagger$ University College London, $\ddagger$ Amazon AGI, $∇$ University of Sheffield, $\diamondsuit$ University of Southern California {hossein.rahmani.22, emine.yilmaz}@ucl.ac.uk, skrishna@g.harvard.edu xi.wang@sheffield.ac.uk, naghiaei@usc.edu
1 Introduction
Recent advances in Large Language Models (LLMs) have illustrated that iterative self-correction, where a model re-examines and revises its output under a self-reflection framework, can lead to significant performance gains across a variety of tasks (Madaan et al., 2023; Cook et al., 2024; Shinn et al., 2023; Gou et al., 2024, inter alia). This emergent ability is often attributed to the models’ capacity to integrate chain-of-thought reasoning Kamoi et al. (2024); Chang et al. (2024); Wei et al. (2022), prompting them to refine their own outputs as addressed by a human proofreader or mentor. Regarding performance validation, existing studies on self-correction have generally focused on free-form text generation (Huang et al., 2023; Madaan et al., 2023; Zelikman et al., 2022; Ma et al., 2025; Kumar et al., 2025; Krishna et al., 2024, inter alia), such as dialogue response, code optimization, and acronym generation. These tasks align with the strategy of language model optimization in addressing next token prediction.
However, as LLM applications expand, evaluation restricted to free-form generation offers an incomplete picture. For instance, NVIDIA advocates the deployment of smaller language models in agentic systems for tasks such as API calls and orchestration with external tools, motivated by sustainability and efficiency considerations Belcak et al. (2025). This highlights the need to examine self-correction beyond open-ended generation. In this study, we categorize natural language modeling tasks into two broad paradigms: free-form text generation and multi-choice prediction. The former treats modeling as unconstrained sequence generation over the full vocabulary, while the latter frames it as classification over a fixed set of candidate answers. These paradigms are complementary: multi-choice tasks test precise discrimination under constraints, whereas free-form tasks assess expressive generation, and together they capture the main modes of LLM use in applications such as question answering, reasoning, and open-ended dialogue.
In this paper, we investigate how self-correction unfolds when comparing open-ended generation against multiple-choice question scenarios. We hypothesize that while open-ended generation may benefit from enhanced flexibility and creativity, it also faces a larger search space and the risk of compounding errors. By contrast, multiple-choice models operate in a constrained space, which can reduce semantic drift yet limit creative corrections. Our study explores how these respective factors interact with iterative refinement, shedding light on whether self-correction aligns more naturally with either unconstrained or constrained output space.
To address these questions, we conduct comprehensive experiments on two distinct datasets that differ in nature, one focusing on knowledge-intensive question answering and the other on reasoning-oriented problems. We perform iterative inference, giving the model multiple opportunities to reevaluate and revise. By comparing error rates, consistency across iterations, and eventual convergence in each paradigm, we expose nuanced trade-offs in how LLMs adapt to different output constraints under a self-correction regime. Our results provide practical insights for the design and deployment of LLM-based systems, highlighting opportunities to harness better or tailor self-correction behaviors for diverse application settings. Furthermore, we discuss how our findings inform the broader research agenda of aligning emergent capabilities in large-scale models with varied real-world task requirements.
2 Related Works
Iterative Reasoning and Self-correction in LLMs.
Large language models first showed an emergent ability to reason step-by-step when prompted with chain-of-thought (CoT) examples (Wei et al., 2022). Shortly after, Wang et al. (2023) demonstrated that sampling several independent reasoning traces and selecting the majority answer—dubbed self-consistency (SC)—boosts accuracy on arithmetic and commonsense tasks. Follow-up studies made the correction loop explicit by asking the model to critique its own draft before rewriting it, leading to sizeable gains in factual QA and code generation (Madaan et al., 2023). Variants that call external tools such as Python or knowledge bases during the critique stage further reduce hallucinations in open-ended generation (Chen et al., 2023; Yao et al., 2023; Gou et al., 2024). These works collectively suggest that LLMs can act as both solver and reviewer, but they focus almost exclusively on free-form text outputs.
Verification–based Refinement.
Instead of trusting the model’s final token distribution, several papers add lightweight verifiers. Cobbe et al. (2021) attach unit tests to code synthesis; Dixit et al. (2023) use factuality checkers for summarization; Pryzant (2023) adopt entailment models for reading comprehension. The common pattern is a two-step pipeline where the LLM proposes an answer, then a cheaper or more precise module scores it. Our work keeps the entire loop inside the language model, isolating the effect of output format itself (generation vs. multiple-choice) from external verification.
Answer Selection and Multiple-Choice Prompting.
Tasks with a closed candidate set (e.g., MMLU (Hendrycks et al., 2021), ARC (Clark and et al., 2018)) are typically solved by mapping each option to an independent prompt and picking the highest-logit answer (Brown and et al., 2020). Several groups have tried to retrofit iterative reasoning onto this template. Zhu and et al. (2024) prepend a self-explanation, rescore the options with the explanation as additional context, and report modest but consistent gains. Li and et al. (2024) show that calibrating logits with contrastive rationales helps low-parameter models, while Pan and et al. (2023) explore ensembling diverse rationales. Yet a systematic comparison between correction dynamics in open versus closed output spaces is missing; our study provides that head-to-head analysis.
Bridging the paradigms.
Contemporary benchmarks increasingly mix free-form and categorical sub-tasks—e.g., TruthfulQA has both short-answer and multiple-choice splits (Lin et al., 2022). Deployment settings such as tutoring agents or search assistants likewise alternate between generating explanations and selecting the best passages. Understanding whether self-correction behaves differently under these two regimes is therefore more than a methodological curiosity as it affects prompt engineering, compute budgeting, and safety guard-rail design. By re-implementing the main correction strategies from the literature under a unified experimental budget, we show that the shape of the output space itself controls how much an LLM can benefit from extra reflection rounds.
3 Open-ended Generation vs. Multiple-Choice Answer Selection
Large language models are increasingly expected to handle a wide spectrum of downstream tasks, ranging from unconstrained natural language generation, such as open-domain question answering, to highly structured classification problems, like sentiment analysis. Two of the most commonly encountered settings are (i) open-ended generation, where the model must produce a free-form text response, and (ii) multiple-choice answer selection, where it must select a single correct option from a predefined set of choices. While these two paradigms are often operationalized using the same model architecture and weights, they impose fundamentally different constraints on the output space and influence how self-correction unfolds over successive inference steps. This section formalizes these two paradigms, describes how self-correction mechanisms are instantiated within each, and presents qualitative differences that help explain the empirical patterns observed in Section 5.
Open-Ended Generation.
In the open-ended generation setting, the model is required to produce an output sequence $y^{(0)}=(y^{(0)}_{1},...,y^{(0)}_{T})∈\mathcal{V}^{*}$ , where $\mathcal{V}$ denotes the vocabulary and $T$ is the (variable) sequence length. The generation is conditioned on an input $x$ , which may correspond to a question, prompt, or instruction, such that the model defines a conditional distribution:
$p(y^{(0)}\mid x)=\prod_{t=1}^{T}p(y^{(0)}_{t}\mid y^{(0)}_{<t},x)$
This formulation captures the standard auto-regressive decoding process for open-ended text generation. The generated sequence may consist of a sentence, paragraph, or longer passage, and there are no explicit structural constraints beyond syntactic plausibility and task relevance.
Self-correction in this paradigm typically proceeds by prompting the model to critique its initial output — either via explicit instructions (“identify any flaws”) or implicit prompting strategies (“think step by step”) — followed by a new generation $y^{(1)}$ . This iterative process can be repeated multiple times, resulting in a sequence $\{y^{(k)}\}_{k=0}^{K}$ , where each revised answer aims to improve upon the previous one. A final answer can be selected using majority voting, log-probability re-ranking, or verifier-based scoring. Because generation is unconstrained, each iteration can introduce new content, restructure previous arguments, or expand omitted details. While this offers flexibility and the potential for substantial improvements, it also opens the door to risks such as semantic drift Ji et al. (2023b, a), where the answer becomes misaligned with the original question over time, or hallucinations, where fictitious facts are introduced in an attempt to improve fluency or apparent coherence. These failure modes tend to accumulate if the model “over-corrects” by deviating from the initial context Spataru (2024).
Multiple-Choice Answer Selection.
By contrast, the multi-choice setting restricts the output space to a finite set of candidate answers $A=\{a_{1},a_{2},...,a_{M}\}$ . For each question $x$ , the model computes a logit vector $\ell(x)∈\mathbb{R}^{M}$ , from which a softmax distribution is derived, and selects the most probable answer. Self-correction in this paradigm does not involve rewriting text but rather involves revisiting the initial logits after incorporating additional information. One common strategy is to generate a rationale $r^{(t)}$ for why a particular answer is correct, then concatenate this rationale to the original prompt and recompute the logits to obtain $\ell^{(t+1)}(x,r^{(t)})$ Huang et al. (2023); Liu et al. (2024). Over successive iterations, this allows the model to refine its beliefs based on its own reasoning. However, since the answer set is fixed, the model cannot explore novel hypotheses or restructure the space of answers; instead, it can only shift probability mass among existing options. This bounded nature of the output space makes multiple-choice settings more stable and less prone to semantic drift, but also potentially less effective at recovering from early errors — especially if the correct answer has low initial probability and the generated rationales fail to meaningfully influence the logits.
Qualitative Differences.
The two paradigms, i.e., open-ended generation and multiple-choice selection, exhibit distinct self-correction dynamics due to their differing output constraints. In open-ended generation, performance gains are typically front-loaded, with the most significant improvements occurring in the first few iterations as the model repairs inconsistencies or fills in missing details Cook et al. (2024); Huang et al. (2023); Gou et al. (2024). However, this flexibility also increases the risk of semantic drift in later rounds Spataru (2024): if the model’s revisions start to go off-topic or introduce inaccuracies, the session can degrade without external intervention. In contrast, multiple-choice tasks show steadier, more incremental improvements, benefiting from the stability of a fixed answer set. They may suffer, however, from logit inertia when the correct option is initially underweighted. The model can be difficult to move to a low-probability answer unless a very compelling rationale shifts the balance. Generation tends to be more compute-intensive due to longer outputs per iteration, while multiple-choice achieves better accuracy-to-token efficiency by focusing on short discriminative outputs. Additionally, model scale interacts differently across formats. Larger models can better mitigate drift in generation through coherent reasoning chains, while smaller models perform more reliably in multiple-choice settings due to the structured nature of the output space and the guidance provided by explicit options.
Understanding these qualitative and quantitative differences between the two paradigms is crucial for designing robust systems that use LLMs in iterative inference settings. Depending on the task requirements, whether correctness, stability, creativity, or inference budget is the primary constraint, one or the other format may be more appropriate, and self-correction strategies should be tailored accordingly.
4 Experimental Setup
Problem Statement.
In this study, we aim to evaluate the dynamics of iterative self-correction under constrained generation and multiple-choice selection across representative tasks. Let $x∈\mathcal{X}$ denote an input instance (e.g., a question) with ground-truth answer $y^{\star}$ . An LLM parameterised by $\theta$ produces an initial response $y^{(0)}$ whose format depends on the task paradigm. For open-ended generation, the model outputs a sequence $y^{(0)}∈ V^{\ast}$ with $p_{\theta}\!\big(y^{(0)}\mid x\big)\;=\;\prod_{t=1}^{T}p_{\theta}\!\big(y^{(0)}t\mid y^{(0)}{<t},x\big)$ . In contrast, for multiple-choice selection, the model selects $y^{(0)}∈ A=\{a_{1},...,a_{M}\}$ from logits $\ell(x)∈\mathbb{R}^{M}$ , i.e., $y^{(0)}\;=\;\arg\max_{a_{i}∈ A}\ell_{i}(x),\qquad$ $\sigma_{i}^{(0)}(x)\;=\;\frac{e^{\ell_{i}(x)}}{\sum_{j=1}^{M}e^{\ell_{j}(x)}}$ . By applying iterative self-correct, given history $\mathcal{H}^{(k-1)}=(x,y^{(0)},...,y^{(k-1)})$ , the model produces a revision $y^{(k)}\sim p_{\theta}\!\big(·\mid\mathcal{H}^{(k-1)}\big),\qquad k=1,...,K$ .
We study the sequence $\mathcal{Y}(x)=\{y^{(k)}\}_{k=0}^{K}$ and aim to maximize task accuracy of the terminal output $y^{(K)}$ over $x\sim\mathcal{D}$ . We seek to observe how performance evolves with successive self-correction iterations and how error correction or degradation manifests in each paradigm. To that end, we set up experiments on two distinct question-answering benchmarks and examine multiple LLMs under various prompting strategies.
<details>
<summary>x1.png Details</summary>
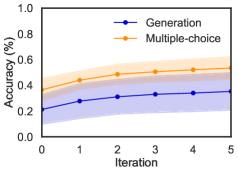
### Visual Description
## Chart: Accuracy vs. Iteration for Generation and Multiple-Choice Models
### Overview
The image is a line chart comparing the accuracy of two models, "Generation" and "Multiple-choice," across several iterations. The chart displays accuracy (in percentage) on the y-axis and iteration number on the x-axis. Shaded regions around each line indicate the uncertainty or variance in the accuracy.
### Components/Axes
* **X-axis:** Iteration (0 to 5)
* **Y-axis:** Accuracy (%) (0.0 to 1.0)
* **Legend:** Located in the top-right corner.
* Blue line: Generation
* Orange line: Multiple-choice
### Detailed Analysis
* **Generation (Blue):**
* Trend: The accuracy of the Generation model generally increases with iteration.
* Data Points:
* Iteration 0: Accuracy ~0.2
* Iteration 1: Accuracy ~0.28
* Iteration 2: Accuracy ~0.31
* Iteration 3: Accuracy ~0.33
* Iteration 4: Accuracy ~0.34
* Iteration 5: Accuracy ~0.35
* **Multiple-choice (Orange):**
* Trend: The accuracy of the Multiple-choice model also increases with iteration, but at a slower rate than the Generation model, and it starts with a higher accuracy.
* Data Points:
* Iteration 0: Accuracy ~0.37
* Iteration 1: Accuracy ~0.44
* Iteration 2: Accuracy ~0.50
* Iteration 3: Accuracy ~0.51
* Iteration 4: Accuracy ~0.52
* Iteration 5: Accuracy ~0.54
### Key Observations
* The Multiple-choice model consistently outperforms the Generation model in terms of accuracy across all iterations.
* Both models show an increase in accuracy as the number of iterations increases, but the rate of increase diminishes over time.
* The shaded regions indicate a degree of variability in the accuracy of both models, with the Generation model showing a wider range of variability, especially at lower iterations.
### Interpretation
The chart suggests that the Multiple-choice model is inherently more accurate than the Generation model for the task being evaluated. Both models improve with more iterations, indicating a learning process. The diminishing rate of accuracy increase suggests that there may be a point of diminishing returns for both models, where further iterations do not significantly improve performance. The wider variability in the Generation model's accuracy could indicate that it is more sensitive to the specific data or training conditions.
</details>
(a) Baseline
<details>
<summary>x2.png Details</summary>
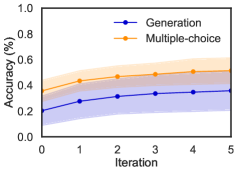
### Visual Description
## Line Chart: Accuracy vs. Iteration
### Overview
The image is a line chart comparing the accuracy of two methods, "Generation" and "Multiple-choice," across iterations. The chart displays accuracy (in percentage) on the y-axis and iteration number on the x-axis. Shaded regions around each line indicate variability or uncertainty.
### Components/Axes
* **Title:** Accuracy vs. Iteration (inferred)
* **X-axis:** Iteration, labeled from 0 to 5 in increments of 1.
* **Y-axis:** Accuracy (%), labeled from 0.0 to 1.0 in increments of 0.2.
* **Legend:** Located in the top-right corner.
* Blue line: Generation
* Orange line: Multiple-choice
### Detailed Analysis
* **Generation (Blue Line):**
* Trend: The line slopes upward, indicating increasing accuracy with more iterations.
* Data Points:
* Iteration 0: Accuracy ~0.2
* Iteration 1: Accuracy ~0.28
* Iteration 2: Accuracy ~0.31
* Iteration 3: Accuracy ~0.33
* Iteration 4: Accuracy ~0.34
* Iteration 5: Accuracy ~0.36
* **Multiple-choice (Orange Line):**
* Trend: The line slopes upward, indicating increasing accuracy with more iterations.
* Data Points:
* Iteration 0: Accuracy ~0.35
* Iteration 1: Accuracy ~0.43
* Iteration 2: Accuracy ~0.47
* Iteration 3: Accuracy ~0.49
* Iteration 4: Accuracy ~0.51
* Iteration 5: Accuracy ~0.52
### Key Observations
* The "Multiple-choice" method consistently shows higher accuracy than the "Generation" method across all iterations.
* Both methods show an increase in accuracy as the number of iterations increases, but the rate of increase appears to diminish after the first few iterations.
* The shaded regions around the lines suggest that there is some variability in the accuracy of both methods.
### Interpretation
The chart suggests that the "Multiple-choice" method is more accurate than the "Generation" method in this context. The increasing accuracy with more iterations indicates that both methods benefit from iterative refinement or learning. The diminishing rate of increase suggests that there may be a point of diminishing returns for both methods, where additional iterations do not significantly improve accuracy. The shaded regions indicate that the accuracy of both methods can vary, possibly due to factors not controlled in the experiment.
</details>
(b) CoT
<details>
<summary>x3.png Details</summary>
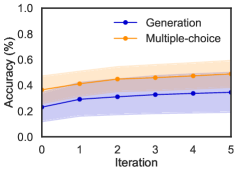
### Visual Description
## Line Chart: Accuracy vs. Iteration
### Overview
The image is a line chart comparing the accuracy of two methods, "Generation" and "Multiple-choice," across iterations. The chart displays accuracy (in percentage) on the y-axis and iteration number on the x-axis. Shaded regions around each line indicate the uncertainty or variability in the accuracy.
### Components/Axes
* **X-axis:** Iteration (labeled from 0 to 5)
* **Y-axis:** Accuracy (%) (labeled from 0.0 to 1.0, incrementing by 0.2)
* **Legend:** Located in the top-right corner.
* Blue line with circles: "Generation"
* Orange line with circles: "Multiple-choice"
### Detailed Analysis
* **Generation (Blue):**
* Trend: The accuracy increases from iteration 0 to iteration 5, but the rate of increase slows down.
* Data Points:
* Iteration 0: Accuracy ≈ 0.23
* Iteration 1: Accuracy ≈ 0.29
* Iteration 2: Accuracy ≈ 0.31
* Iteration 3: Accuracy ≈ 0.33
* Iteration 4: Accuracy ≈ 0.34
* Iteration 5: Accuracy ≈ 0.35
* **Multiple-choice (Orange):**
* Trend: The accuracy increases from iteration 0 to iteration 5, but the rate of increase slows down.
* Data Points:
* Iteration 0: Accuracy ≈ 0.37
* Iteration 1: Accuracy ≈ 0.41
* Iteration 2: Accuracy ≈ 0.45
* Iteration 3: Accuracy ≈ 0.46
* Iteration 4: Accuracy ≈ 0.47
* Iteration 5: Accuracy ≈ 0.50
### Key Observations
* The "Multiple-choice" method consistently shows higher accuracy than the "Generation" method across all iterations.
* Both methods exhibit diminishing returns in accuracy as the number of iterations increases.
* The shaded regions around the lines suggest that the "Generation" method has a wider range of accuracy values compared to the "Multiple-choice" method, especially at lower iterations.
### Interpretation
The chart suggests that the "Multiple-choice" method is more accurate than the "Generation" method for the task being evaluated. The diminishing returns in accuracy with increasing iterations indicate that there may be a limit to how much improvement can be achieved through further iterations for both methods. The wider shaded region for the "Generation" method implies that its performance is more variable or less stable compared to the "Multiple-choice" method. This could be due to the nature of the generation process, which might be more sensitive to variations in the input or model parameters.
</details>
(c) SC
<details>
<summary>x4.png Details</summary>
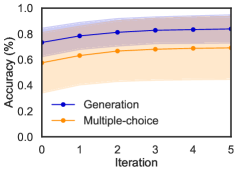
### Visual Description
## Line Chart: Accuracy vs. Iteration for Generation and Multiple-Choice Models
### Overview
The image is a line chart comparing the accuracy of two models, "Generation" and "Multiple-choice," across iterations. The chart displays accuracy (in percentage) on the y-axis and iteration number on the x-axis. Shaded regions around each line indicate the variability or uncertainty in the accuracy.
### Components/Axes
* **X-axis:** Iteration, ranging from 0 to 5.
* **Y-axis:** Accuracy (%), ranging from 0.0 to 1.0.
* **Legend:** Located in the bottom-left corner.
* **Blue line:** Generation
* **Orange line:** Multiple-choice
### Detailed Analysis
* **Generation (Blue):** The accuracy starts at approximately 0.75 at iteration 0 and increases to approximately 0.85 by iteration 5. The line slopes upward, with a steeper initial increase that gradually flattens out.
* Iteration 0: ~0.75
* Iteration 1: ~0.80
* Iteration 2: ~0.82
* Iteration 3: ~0.83
* Iteration 4: ~0.83
* Iteration 5: ~0.85
* **Multiple-choice (Orange):** The accuracy starts at approximately 0.58 at iteration 0 and increases to approximately 0.70 by iteration 5. The line slopes upward, with a steeper initial increase that gradually flattens out.
* Iteration 0: ~0.58
* Iteration 1: ~0.63
* Iteration 2: ~0.67
* Iteration 3: ~0.68
* Iteration 4: ~0.69
* Iteration 5: ~0.70
### Key Observations
* The "Generation" model consistently outperforms the "Multiple-choice" model in terms of accuracy across all iterations.
* Both models show diminishing returns in accuracy improvement as the number of iterations increases.
* The shaded regions indicate that the "Multiple-choice" model has a wider range of accuracy values compared to the "Generation" model.
### Interpretation
The data suggests that the "Generation" model is more effective than the "Multiple-choice" model in this context. The diminishing returns in accuracy with increasing iterations imply that there is a limit to how much these models can improve with further training. The wider range of accuracy values for the "Multiple-choice" model suggests that its performance is more variable or sensitive to the specific data it is trained on.
</details>
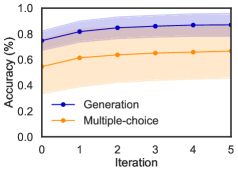
(d) Baseline
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: Accuracy vs. Iteration
### Overview
The image is a line chart comparing the accuracy of two methods, "Generation" and "Multiple-choice", over five iterations. The chart shows the accuracy (in percentage) on the y-axis and the iteration number on the x-axis. Both methods show an increase in accuracy with increasing iterations, but the "Generation" method consistently outperforms the "Multiple-choice" method. Shaded regions around each line indicate the variability or uncertainty associated with each method's accuracy.
### Components/Axes
* **X-axis:** Iteration (0 to 5)
* **Y-axis:** Accuracy (%) (0.0 to 1.0)
* **Legend:** Located in the center-left of the chart.
* **Blue:** Generation
* **Orange:** Multiple-choice
### Detailed Analysis
* **Generation (Blue):**
* Trend: The line slopes upward, indicating an increase in accuracy with each iteration. The rate of increase slows down as the number of iterations increases.
* Data Points:
* Iteration 0: Accuracy ≈ 0.75
* Iteration 1: Accuracy ≈ 0.82
* Iteration 2: Accuracy ≈ 0.84
* Iteration 3: Accuracy ≈ 0.85
* Iteration 4: Accuracy ≈ 0.86
* Iteration 5: Accuracy ≈ 0.87
* **Multiple-choice (Orange):**
* Trend: The line slopes upward, indicating an increase in accuracy with each iteration. The rate of increase slows down as the number of iterations increases.
* Data Points:
* Iteration 0: Accuracy ≈ 0.55
* Iteration 1: Accuracy ≈ 0.62
* Iteration 2: Accuracy ≈ 0.64
* Iteration 3: Accuracy ≈ 0.65
* Iteration 4: Accuracy ≈ 0.66
* Iteration 5: Accuracy ≈ 0.67
### Key Observations
* The "Generation" method consistently shows higher accuracy than the "Multiple-choice" method across all iterations.
* Both methods exhibit diminishing returns, with the accuracy increase slowing down as the number of iterations increases.
* The shaded regions around each line suggest that the "Generation" method may have less variability in its accuracy compared to the "Multiple-choice" method.
### Interpretation
The data suggests that the "Generation" method is more effective than the "Multiple-choice" method in terms of accuracy. The increasing accuracy with iterations indicates that both methods benefit from more training or refinement. The diminishing returns suggest that there may be a point beyond which further iterations provide minimal improvement in accuracy. The variability indicated by the shaded regions suggests that the "Generation" method may be more reliable or consistent in its performance.
</details>
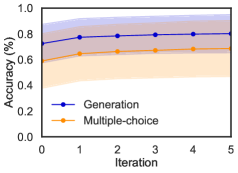
(e) CoT
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Chart: Accuracy vs. Iteration
### Overview
The image is a line chart comparing the accuracy of two methods, "Generation" and "Multiple-choice", over five iterations. The chart displays accuracy on the y-axis (ranging from 0.0 to 1.0) and iteration number on the x-axis (ranging from 0 to 5). Shaded regions around each line indicate variability or uncertainty.
### Components/Axes
* **X-axis:** Iteration, labeled from 0 to 5.
* **Y-axis:** Accuracy (%), labeled from 0.0 to 1.0, with increments of 0.2.
* **Legend:** Located in the center of the chart.
* **Generation:** Represented by a blue line with circular markers.
* **Multiple-choice:** Represented by an orange line with circular markers.
### Detailed Analysis
* **Generation:**
* Trend: The blue line starts at approximately 0.73 accuracy at iteration 0, increases to approximately 0.76 at iteration 1, and then plateaus around 0.79-0.80 for the remaining iterations.
* Data Points:
* Iteration 0: ~0.73
* Iteration 1: ~0.76
* Iteration 2: ~0.79
* Iteration 3: ~0.79
* Iteration 4: ~0.80
* Iteration 5: ~0.80
* **Multiple-choice:**
* Trend: The orange line starts at approximately 0.58 accuracy at iteration 0, increases to approximately 0.64 at iteration 1, and then plateaus around 0.67-0.69 for the remaining iterations.
* Data Points:
* Iteration 0: ~0.58
* Iteration 1: ~0.64
* Iteration 2: ~0.67
* Iteration 3: ~0.68
* Iteration 4: ~0.68
* Iteration 5: ~0.69
### Key Observations
* The "Generation" method consistently outperforms the "Multiple-choice" method across all iterations.
* Both methods show a rapid increase in accuracy from iteration 0 to iteration 1, after which the accuracy plateaus.
* The shaded regions around the lines suggest that the "Generation" method has less variability in accuracy compared to the "Multiple-choice" method.
### Interpretation
The data suggests that the "Generation" method is more effective and stable than the "Multiple-choice" method for the task being evaluated. The rapid initial increase in accuracy for both methods indicates that the models learn quickly in the early iterations, but further iterations do not significantly improve performance. The smaller shaded region for the "Generation" method implies that its performance is more consistent across different runs or datasets.
</details>
(f) SC
Figure 1: Average cumulative accuracy on generation and multiple-choice. (Top) Accuracy on the DisambiguationQA dataset shows that models perform better on the multiple-choice task when we iteratively self-correct the model response to the questions, while (bottom) shows the accuracy on the tinyTruthfulQA dataset, indicating that models perform better in generation tasks.
Research Questions.
Our study is guided by the following three research questions:
- RQ1: How do self-correction dynamics differ between open-ended and multiple-choice tasks?
- RQ2: How do model scale and prompting strategy influence self-correction across the two paradigms?
- RQ3: How does iterative self-correction affect correctness, stability, and semantic drift, and what mechanisms explain these effects?
Datasets.
We evaluate on two benchmarks, DisambiguationQA and tinyTruthfulQA, that each provide parallel formulations for both multiple-choice questions and open-ended generation. This allows us to study self-correction dynamics under consistent task content but different output constraints.
- DisambiguationQA Kazemi et al. (2025) is typically phrased in multiple-choice form, where each question presents a pronoun or reference with referential ambiguity and provides four candidate referents. However, the same questions can also be cast into an open-ended format by asking models to generate the referent rather than choose among options. Thus, DisambiguationQA instantiates a scenario where the answer space is tightly constrained but also amenable to open-ended generation in a parallel setup.
- tinyTruthfulQA Polo et al. (2024) is a challenging subset of the TruthfulQA benchmark Lin et al. (2022) focused on short-form factual queries that tend to provoke false or misleading answers from LLMs. While TruthfulQA is usually evaluated via free-form generation, where models must produce a truthful answer, a multiple-choice variant has also been developed, offering for each question a small set of candidate answers drawn from the same reference answer pool. Therefore, tinyTruthfulQA inherits this dual-format nature, where the same questions support both open-ended and multiple-choice instantiations. This dataset exemplifies scenarios requiring knowledge retrieval and precision in generation.
By evaluating both tasks, we cover one case where the ground-truth answer is within a closed set of options and one case where the answer must be generated. We therefore can compare how iterative self-correction dynamics differ when the model’s output is tightly constrained versus freely generative.
Models.
We evaluate the dynamics of iterative self‐correction under unconstrained generation and multiple‐choice selection using six pre‐trained language models ranging from small to large parameters. We evaluate SmolLM2-1.7B Allal et al. (2025), Qwen2.5-3B Qwen et al. (2025), Llama-3.1-8B Grattafiori et al. (2024), Qwen2.5-14B Qwen et al. (2025), DeepSeek-R1-Distill-Llama-8B Guo et al. (2025), and Gemini-2.0-Flash Comanici et al. (2025). These models represent diverse families and scales (from distilled smaller models to state-of-the-art large models). For each model and dataset, we compare three aforementioned prompting strategies: a direct Baseline prompt, zero‐shot chain‐of‐thought (CoT) prompting Kojima et al. (2022), and our iterative SC procedure that reviews and refines the model’s own previous response for up to five rounds. We use HuggingFace to run the models except Gemini-2.0-Flash, which is accessed through the API.
Prompts.
In our experiments, we use simplified prompts to minimize the impact of prompt design on performance across tasks, keeping the focus on the self-correction mechanism Huang et al. (2023). Specifically, we apply a basic prompt for the Baseline method and adopt zero-shot Chain-of-Thought (CoT) prompting Kojima et al. (2022) for both the CoT and Self-Consistency (SC) approaches. The initial prompts are used for the first attempt (iteration 0) under each strategy. They differ only in whether the model is encouraged to produce an explicit chain of reasoning before the final answer. For iterations beyond the first, we prepend instructions to review the prior attempts. In both cases, the model is reminded of its earlier answers (which are included in the conversation context) and encouraged to refine them. The CoT variant additionally maintains the directive to use a step-by-step reasoning process during revision. Our full prompts can be found in Appendix A.2.
Final Answer Extraction.
For all of our problems, we added the ‘ The final answer is: ’ suffix to the text of the prompt to encourage the model to produce the final answer in a format that we can easily extract. More details in Appendix A.1.
5 Results
<details>
<summary>x7.png Details</summary>
### Visual Description
## Chart: Average Correct Flips vs. Iteration
### Overview
The image is a line chart comparing the average correct flips for two methods, "Generation" and "Multiple-choice," across five iterations. The chart shows the performance of each method over the iterations, with shaded regions indicating the variability or confidence intervals around the average values.
### Components/Axes
* **X-axis:** Iteration, labeled from 1 to 5.
* **Y-axis:** Average Correct Flips, ranging from 0.000 to 0.100.
* **Legend:** Located in the top-right corner.
* **Blue:** Generation
* **Orange:** Multiple-choice
### Detailed Analysis
* **Generation (Blue):**
* Trend: The line slopes downward, indicating a decrease in average correct flips as the iteration number increases.
* Data Points:
* Iteration 1: Approximately 0.070
* Iteration 2: Approximately 0.050
* Iteration 3: Approximately 0.040
* Iteration 4: Approximately 0.030
* Iteration 5: Approximately 0.030
* **Multiple-choice (Orange):**
* Trend: The line generally slopes downward, but less consistently than the "Generation" line.
* Data Points:
* Iteration 1: Approximately 0.080
* Iteration 2: Approximately 0.070
* Iteration 3: Approximately 0.040
* Iteration 4: Approximately 0.040
* Iteration 5: Approximately 0.030
### Key Observations
* Both methods show a decrease in average correct flips over the iterations.
* The "Generation" method starts lower than the "Multiple-choice" method but decreases more rapidly.
* By iteration 5, both methods converge to approximately the same average correct flips value.
### Interpretation
The chart suggests that both the "Generation" and "Multiple-choice" methods experience a decline in performance (as measured by average correct flips) as the iteration number increases. This could indicate that the task becomes more challenging or that the methods are not effectively adapting to the iterative process. The "Generation" method, while initially performing worse, converges to a similar performance level as the "Multiple-choice" method by the end of the iterations. The shaded regions around the lines likely represent the variance or confidence intervals, indicating the reliability of the average values.
</details>
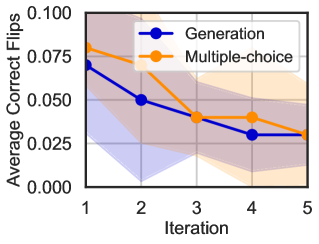
(a) Baseline
<details>
<summary>x8.png Details</summary>
### Visual Description
## Line Chart: Average Correct Flips vs. Iteration
### Overview
The image is a line chart comparing the average correct flips over iterations for two methods: "Generation" and "Multiple-choice". The chart shows how the performance of each method changes across five iterations. Shaded regions around each line indicate the variability or uncertainty associated with the data.
### Components/Axes
* **X-axis:** Iteration (labeled 1 to 5)
* **Y-axis:** Average Correct Flips (labeled 0.000 to 0.100, incrementing by 0.025)
* **Legend:** Located in the top-right corner.
* Blue line with circles: Generation
* Orange line with circles: Multiple-choice
### Detailed Analysis
* **Generation (Blue):**
* Trend: Generally decreasing over iterations.
* Data Points:
* Iteration 1: Approximately 0.070
* Iteration 2: Approximately 0.050
* Iteration 3: Approximately 0.050
* Iteration 4: Approximately 0.030
* Iteration 5: Approximately 0.030
* **Multiple-choice (Orange):**
* Trend: Decreasing initially, then leveling off.
* Data Points:
* Iteration 1: Approximately 0.080
* Iteration 2: Approximately 0.060
* Iteration 3: Approximately 0.040
* Iteration 4: Approximately 0.040
* Iteration 5: Approximately 0.030
### Key Observations
* Both methods show a decrease in average correct flips as the iteration number increases.
* The "Multiple-choice" method starts with a higher average correct flips than the "Generation" method in the first iteration.
* Both methods converge to a similar average correct flips value by the fifth iteration.
* The shaded regions indicate the variability in the data, with the "Multiple-choice" method showing a wider range of variability.
### Interpretation
The chart suggests that both the "Generation" and "Multiple-choice" methods become less effective at producing correct flips as the number of iterations increases. This could be due to factors such as the complexity of the task, the learning process of the models, or the nature of the data being used. The convergence of the two methods by the fifth iteration suggests that they may be approaching a similar performance limit. The wider variability in the "Multiple-choice" method could indicate that its performance is more sensitive to certain factors or conditions.
</details>
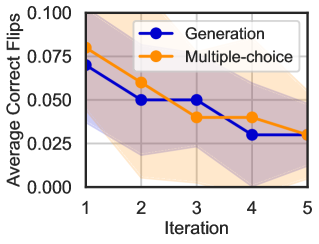
(b) CoT
<details>
<summary>x9.png Details</summary>
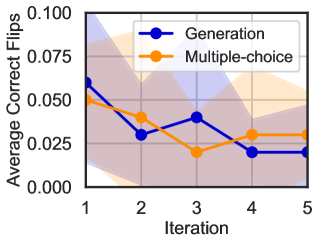
### Visual Description
## Chart: Average Correct Flips vs. Iteration
### Overview
The image is a line chart comparing the average correct flips for two methods, "Generation" and "Multiple-choice," across five iterations. The chart displays the mean values as points connected by lines, with shaded regions indicating the variability or confidence intervals around each mean.
### Components/Axes
* **Y-axis:** "Average Correct Flips," ranging from 0.000 to 0.100.
* **X-axis:** "Iteration," ranging from 1 to 5.
* **Legend:** Located in the top-right corner.
* Blue line with circle markers: "Generation"
* Orange line with circle markers: "Multiple-choice"
### Detailed Analysis
* **Generation (Blue):**
* Trend: Generally decreasing with some fluctuations.
* Iteration 1: Approximately 0.06
* Iteration 2: Approximately 0.03
* Iteration 3: Approximately 0.04
* Iteration 4: Approximately 0.02
* Iteration 5: Approximately 0.02
* **Multiple-choice (Orange):**
* Trend: Decreasing initially, then increasing slightly.
* Iteration 1: Approximately 0.05
* Iteration 2: Approximately 0.04
* Iteration 3: Approximately 0.02
* Iteration 4: Approximately 0.03
* Iteration 5: Approximately 0.03
### Key Observations
* The "Generation" method starts with a higher average correct flips but decreases more rapidly than the "Multiple-choice" method.
* Both methods converge to a similar average correct flips value by iteration 5.
* The shaded regions indicate the variability around the mean values, with "Generation" showing wider variability in the earlier iterations.
### Interpretation
The chart suggests that the "Generation" method may be initially more effective but becomes less so over iterations, possibly due to overfitting or other factors. The "Multiple-choice" method, while starting lower, maintains a more consistent performance. The convergence of both methods by iteration 5 indicates that they may reach a similar level of effectiveness with continued training or refinement. The variability in the "Generation" method's performance suggests that it may be more sensitive to the specific data or training conditions.
</details>
(c) SC
<details>
<summary>x10.png Details</summary>
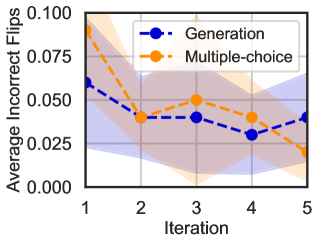
### Visual Description
## Chart: Average Incorrect Flips vs. Iteration
### Overview
The image is a line chart comparing the average incorrect flips for two methods, "Generation" and "Multiple-choice," across five iterations. The chart displays the mean values as lines and the variance as shaded regions around the lines.
### Components/Axes
* **X-axis:** Iteration (labeled 1 to 5)
* **Y-axis:** Average Incorrect Flips (labeled 0.000 to 0.100, incrementing by 0.025)
* **Legend:** Located in the top-right corner.
* Blue line with circles: Generation
* Orange dashed line with circles: Multiple-choice
### Detailed Analysis
* **Generation (Blue Line):**
* Trend: Generally decreasing, then slightly increasing.
* Iteration 1: Approximately 0.06
* Iteration 2: Approximately 0.04
* Iteration 3: Approximately 0.04
* Iteration 4: Approximately 0.03
* Iteration 5: Approximately 0.04
* The shaded region around the blue line indicates the variance in the Generation data.
* **Multiple-choice (Orange Dashed Line):**
* Trend: Decreasing, then increasing, then decreasing again.
* Iteration 1: Approximately 0.09
* Iteration 2: Approximately 0.04
* Iteration 3: Approximately 0.05
* Iteration 4: Approximately 0.04
* Iteration 5: Approximately 0.02
* The shaded region around the orange line indicates the variance in the Multiple-choice data.
### Key Observations
* The Multiple-choice method starts with a higher average of incorrect flips but decreases more rapidly than the Generation method.
* Both methods show a decrease in average incorrect flips over the iterations, but the Generation method's decrease is less pronounced.
* The variance (shaded regions) appears to be larger for the Multiple-choice method, especially in the earlier iterations.
### Interpretation
The chart suggests that both the Generation and Multiple-choice methods improve (reduce incorrect flips) over iterations. The Multiple-choice method initially performs worse but shows a more significant improvement. The larger variance in the Multiple-choice method might indicate that its performance is more sensitive to the specific iteration or that there is more variability in the data. The Generation method is more stable, with less variance, but its overall improvement is less pronounced.
</details>
(d) Baseline
<details>
<summary>x11.png Details</summary>
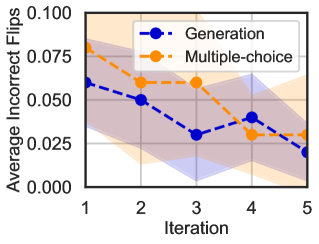
### Visual Description
## Line Chart: Average Incorrect Flips vs. Iteration
### Overview
The image is a line chart comparing the average incorrect flips for two methods, "Generation" and "Multiple-choice," across five iterations. The chart displays the trend of incorrect flips decreasing with increasing iterations for both methods, with "Generation" generally performing better (lower incorrect flips) than "Multiple-choice." Shaded regions around each line indicate the variability or uncertainty associated with each method's performance.
### Components/Axes
* **Y-axis:** "Average Incorrect Flips," ranging from 0.000 to 0.100.
* **X-axis:** "Iteration," ranging from 1 to 5.
* **Legend:** Located at the top-right of the chart.
* **Blue dashed line with circles:** "Generation"
* **Orange dashed line with circles:** "Multiple-choice"
### Detailed Analysis
* **Generation (Blue dashed line):**
* **Trend:** Generally decreasing with iterations.
* **Data Points:**
* Iteration 1: Approximately 0.065
* Iteration 2: Approximately 0.052
* Iteration 3: Approximately 0.032
* Iteration 4: Approximately 0.040
* Iteration 5: Approximately 0.022
* **Multiple-choice (Orange dashed line):**
* **Trend:** Decreasing with iterations.
* **Data Points:**
* Iteration 1: Approximately 0.082
* Iteration 2: Approximately 0.062
* Iteration 3: Approximately 0.060
* Iteration 4: Approximately 0.032
* Iteration 5: Approximately 0.032
### Key Observations
* Both methods show a decrease in average incorrect flips as the iteration number increases, suggesting learning or improvement over time.
* The "Generation" method consistently has lower average incorrect flips compared to the "Multiple-choice" method, indicating better performance.
* The shaded regions around the lines indicate the variability in the data. The "Multiple-choice" method appears to have higher variability, especially in the earlier iterations.
### Interpretation
The chart suggests that both "Generation" and "Multiple-choice" methods improve in performance (i.e., reduce incorrect flips) as they iterate. However, the "Generation" method appears to be more effective, consistently achieving lower incorrect flip rates. The shaded regions provide insight into the stability and reliability of each method, with "Generation" showing less variability, particularly in later iterations. This could indicate that the "Generation" method is more robust or converges more reliably than the "Multiple-choice" method. The data implies that the "Generation" method might be a preferable approach for the task being evaluated.
</details>
(e) CoT
<details>
<summary>x12.png Details</summary>
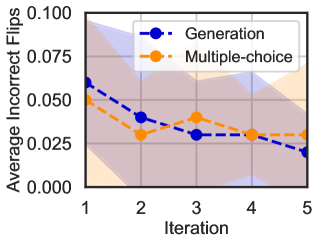
### Visual Description
## Chart: Average Incorrect Flips vs. Iteration
### Overview
The image is a line chart comparing the average incorrect flips for two methods, "Generation" and "Multiple-choice," across five iterations. The chart displays the trend of incorrect flips decreasing with increasing iterations for both methods. Shaded regions around each line indicate the variability or uncertainty associated with each method.
### Components/Axes
* **Y-axis:** "Average Incorrect Flips," ranging from 0.000 to 0.100.
* **X-axis:** "Iteration," ranging from 1 to 5.
* **Legend:** Located at the top-right of the chart.
* **Blue dashed line with blue circles:** "Generation"
* **Orange dashed line with orange circles:** "Multiple-choice"
### Detailed Analysis
* **Generation (Blue dashed line):**
* **Trend:** Generally decreasing with iterations.
* **Data Points:**
* Iteration 1: Approximately 0.062
* Iteration 2: Approximately 0.042
* Iteration 3: Approximately 0.032
* Iteration 4: Approximately 0.030
* Iteration 5: Approximately 0.020
* **Multiple-choice (Orange dashed line):**
* **Trend:** Generally decreasing with iterations.
* **Data Points:**
* Iteration 1: Approximately 0.055
* Iteration 2: Approximately 0.032
* Iteration 3: Approximately 0.040
* Iteration 4: Approximately 0.032
* Iteration 5: Approximately 0.032
### Key Observations
* Both methods show a decrease in average incorrect flips as the iteration number increases.
* The "Generation" method starts with a higher average incorrect flips at iteration 1 but ends with a lower value at iteration 5 compared to the "Multiple-choice" method.
* The shaded regions indicate the variability in the data, with "Generation" showing a wider range in the earlier iterations.
### Interpretation
The chart suggests that both "Generation" and "Multiple-choice" methods improve in terms of reducing incorrect flips as the number of iterations increases. The "Generation" method appears to have a more significant improvement over the iterations, starting with higher error rates but ultimately achieving lower error rates than the "Multiple-choice" method. The shaded regions indicate that the "Generation" method might have more variability in its performance, especially in the initial iterations. This could be due to the method needing more iterations to stabilize or learn effectively.
</details>
(f) SC
Figure 2: Average Correct and Incorrect Flips on DisambiguationQA
We now analyze the results in relation to our three research questions.
Improvement Patterns Across Iterations (RQ1).
To address RQ1, we first examine the aggregate performance reported in Figure 1, which compares accuracy across correction iterations for generation and multiple-choice formats. The generation paradigm improves rapidly in the first one or two iterations, showing that early revisions are effective at fixing obvious errors or adding missing information. However, after these early gains, performance often plateaus or declines, as additional revisions increase the risk of semantic drift and lead to new mistakes. In contrast, the multiple-choice paradigm improves more gradually and steadily. Accuracy rises incrementally with each round of self-correction, reflecting cautious re-weighting among fixed options. Yet this format struggles to recover from poor initial predictions: if the model’s first choice is wrong, subsequent iterations rarely flip it to the correct option, showing the effects of logit inertia.
Figures 2 and 3 present the “flip” dynamics of self-correction on the two datasets, broken down into correct (a previously wrong answer corrected to right) and incorrect (a previously correct answer changed to wrong) flips over successive iterations. On DisambiguationQA (Figure 2), multiple-choice self-correction yields very few flips overall. Correct answers are stably retained, but wrong initial guesses are seldom corrected. Generation, by contrast, produces more frequent flips: many beneficial in early iterations (correcting ambiguous references) but increasingly harmful in later ones, as correct answers are sometimes replaced with incorrect ones, once the model starts to over-correct or drift. On tinyTruthfulQA (Figure 3), the contrast is sharper: generation produces a high number of flips, with many early correct flips (replacing misconceptions with truths), but also a rising number of incorrect flips in later rounds, reflecting semantic drift. Multiple-choice again remains stable, with minimal incorrect flips but limited ability to recover from an early mistake.
Taken together, we show that open-ended generation offers adaptability and rapid early gains but suffers from instability in later iterations, whereas multiple-choice offers stability and incremental improvement but is hampered by inertia when the first choice is wrong. This confirms that self-correction effectiveness is strongly dependent on task format: open-ended generation can exploit flexibility to correct errors but risks drift, while multiple-choice provides reliable retention of correct answers at the expense of recoverability. If the model doesn’t get the answer right on the first attempt, it has a hard time changing to the correct option later. This fundamental difference in dynamics directly answers RQ1: self-correction behaves very differently in open-ended versus fixed-option scenarios, with each paradigm exhibiting its own pattern of improvement and failure modes.
<details>
<summary>x13.png Details</summary>
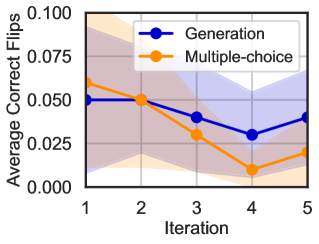
### Visual Description
## Chart: Average Correct Flips vs. Iteration
### Overview
The image is a line graph comparing the average correct flips for two methods, "Generation" and "Multiple-choice," across five iterations. The graph shows the trend of average correct flips over these iterations, with shaded regions indicating variability or confidence intervals.
### Components/Axes
* **Y-axis:** "Average Correct Flips," ranging from 0.000 to 0.100 in increments of 0.025.
* **X-axis:** "Iteration," ranging from 1 to 5 in increments of 1.
* **Legend:** Located in the top-right corner.
* Blue line with circles: "Generation"
* Orange line with circles: "Multiple-choice"
* **Shaded Regions:** Shaded regions around each line indicate variability.
### Detailed Analysis
* **Generation (Blue):**
* Trend: Generally decreasing, then slightly increasing.
* Iteration 1: Approximately 0.050
* Iteration 2: Approximately 0.050
* Iteration 3: Approximately 0.040
* Iteration 4: Approximately 0.030
* Iteration 5: Approximately 0.040
* **Multiple-choice (Orange):**
* Trend: Decreasing more sharply than "Generation," then slightly increasing.
* Iteration 1: Approximately 0.065
* Iteration 2: Approximately 0.050
* Iteration 3: Approximately 0.030
* Iteration 4: Approximately 0.010
* Iteration 5: Approximately 0.020
### Key Observations
* Both methods show a decrease in average correct flips from iteration 1 to iteration 4.
* The "Multiple-choice" method experiences a more significant drop than the "Generation" method.
* Both methods show a slight increase in average correct flips from iteration 4 to iteration 5.
* The shaded regions indicate that the "Generation" method has a wider range of variability than the "Multiple-choice" method, especially in the earlier iterations.
### Interpretation
The data suggests that both "Generation" and "Multiple-choice" methods initially perform well but experience a decline in average correct flips as the iteration number increases, indicating a potential learning or adaptation challenge. The "Multiple-choice" method appears to be more susceptible to this decline. The slight increase in performance at iteration 5 for both methods could indicate a stabilization or slight improvement after the initial decline. The wider variability in the "Generation" method suggests that its performance is less consistent than the "Multiple-choice" method.
</details>
(a) Baseline
<details>
<summary>x14.png Details</summary>
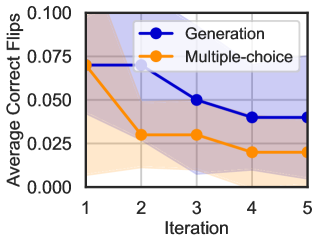
### Visual Description
## Chart: Average Correct Flips vs. Iteration
### Overview
The image is a line chart comparing the average correct flips for two methods, "Generation" and "Multiple-choice," across five iterations. The chart includes shaded regions around each line, likely representing the standard deviation or confidence interval.
### Components/Axes
* **Y-axis:** "Average Correct Flips," ranging from 0.000 to 0.100, with tick marks at 0.025 intervals.
* **X-axis:** "Iteration," ranging from 1 to 5, with tick marks at each integer value.
* **Legend:** Located in the top-right corner, it identifies the two data series:
* Blue: "Generation"
* Orange: "Multiple-choice"
### Detailed Analysis
* **Generation (Blue):**
* Trend: The line starts high, drops significantly between iterations 1 and 3, and then plateaus.
* Data Points:
* Iteration 1: Approximately 0.070
* Iteration 2: Approximately 0.070
* Iteration 3: Approximately 0.050
* Iteration 4: Approximately 0.040
* Iteration 5: Approximately 0.040
* **Multiple-choice (Orange):**
* Trend: The line starts high, drops significantly between iterations 1 and 2, and then decreases gradually.
* Data Points:
* Iteration 1: Approximately 0.070
* Iteration 2: Approximately 0.030
* Iteration 3: Approximately 0.030
* Iteration 4: Approximately 0.020
* Iteration 5: Approximately 0.020
### Key Observations
* Both methods start with similar average correct flips at iteration 1.
* The "Multiple-choice" method experiences a more significant initial drop in performance compared to "Generation."
* The "Generation" method plateaus after iteration 3, while "Multiple-choice" continues to decline slightly.
* The shaded regions indicate variability in the data, with "Generation" showing wider variability, especially in the earlier iterations.
### Interpretation
The chart suggests that both "Generation" and "Multiple-choice" methods have decreasing performance as the iteration number increases. The "Multiple-choice" method initially declines more rapidly, but the "Generation" method shows more variability. The plateauing of "Generation" after iteration 3 might indicate a point of diminishing returns or a stable performance level. The shaded regions provide insight into the consistency of the results, with wider regions suggesting less consistent performance.
</details>
(b) CoT
<details>
<summary>x15.png Details</summary>
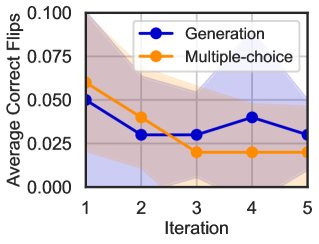
### Visual Description
## Chart: Average Correct Flips vs. Iteration
### Overview
The image is a line chart comparing the average correct flips for two methods, "Generation" and "Multiple-choice," across five iterations. The chart displays the mean values as points connected by lines, with shaded regions indicating the variability or confidence intervals around each mean.
### Components/Axes
* **Y-axis (Vertical):** "Average Correct Flips," ranging from 0.000 to 0.100.
* **X-axis (Horizontal):** "Iteration," ranging from 1 to 5.
* **Legend (Top-Right):**
* Blue line with circle markers: "Generation"
* Orange line with circle markers: "Multiple-choice"
### Detailed Analysis
* **Generation (Blue):**
* Trend: Decreases from iteration 1 to 3, then increases slightly at iteration 4, and decreases again at iteration 5.
* Data Points:
* Iteration 1: Approximately 0.050
* Iteration 2: Approximately 0.030
* Iteration 3: Approximately 0.030
* Iteration 4: Approximately 0.040
* Iteration 5: Approximately 0.030
* **Multiple-choice (Orange):**
* Trend: Decreases from iteration 1 to 3, then remains relatively constant from iteration 3 to 5.
* Data Points:
* Iteration 1: Approximately 0.065
* Iteration 2: Approximately 0.040
* Iteration 3: Approximately 0.020
* Iteration 4: Approximately 0.020
* Iteration 5: Approximately 0.020
### Key Observations
* The "Multiple-choice" method starts with a higher average correct flips than the "Generation" method.
* Both methods show a decrease in average correct flips from iteration 1 to iteration 3.
* The "Generation" method shows a slight increase at iteration 4 before decreasing again at iteration 5.
* The "Multiple-choice" method stabilizes after iteration 3, showing little change in average correct flips.
### Interpretation
The chart suggests that both methods initially struggle to maintain a high average of correct flips as iterations progress. The "Multiple-choice" method starts stronger but plateaus, while the "Generation" method shows a slight recovery at iteration 4 before declining again. The shaded regions indicate the variability in the data, which could be due to factors such as the complexity of the task or the learning rate of the models. The stabilization of the "Multiple-choice" method after iteration 3 could indicate that it has reached a performance limit, while the "Generation" method's fluctuation suggests it may have the potential for further improvement with more iterations or different training strategies.
</details>
(c) SC
<details>
<summary>x16.png Details</summary>
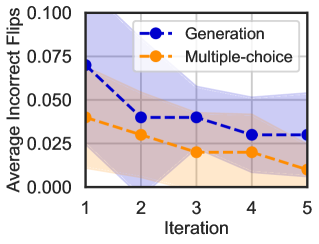
### Visual Description
## Line Chart: Average Incorrect Flips vs. Iteration
### Overview
The image is a line chart comparing the average incorrect flips for two methods, "Generation" and "Multiple-choice," across five iterations. The chart displays the trend of incorrect flips decreasing with increasing iterations for both methods. Shaded regions around each line indicate the variability or uncertainty associated with the data.
### Components/Axes
* **Y-axis:** "Average Incorrect Flips," ranging from 0.000 to 0.100.
* Axis markers: 0.000, 0.025, 0.050, 0.075, 0.100
* **X-axis:** "Iteration," ranging from 1 to 5.
* Axis markers: 1, 2, 3, 4, 5
* **Legend:** Located in the top-right corner.
* "Generation": Represented by a blue dashed line with circular markers.
* "Multiple-choice": Represented by an orange dashed line with circular markers.
### Detailed Analysis
* **Generation (Blue Dashed Line):**
* Trend: Decreasing trend.
* Iteration 1: Approximately 0.072
* Iteration 2: Approximately 0.042
* Iteration 3: Approximately 0.042
* Iteration 4: Approximately 0.028
* Iteration 5: Approximately 0.032
* **Multiple-choice (Orange Dashed Line):**
* Trend: Decreasing trend.
* Iteration 1: Approximately 0.042
* Iteration 2: Approximately 0.032
* Iteration 3: Approximately 0.022
* Iteration 4: Approximately 0.018
* Iteration 5: Approximately 0.012
### Key Observations
* The "Generation" method starts with a higher average of incorrect flips compared to the "Multiple-choice" method.
* Both methods show a decrease in average incorrect flips as the iteration number increases.
* The "Generation" method has a steeper initial decline in incorrect flips compared to the "Multiple-choice" method.
* The shaded regions indicate the variability in the data, with the "Generation" method showing more variability, especially in the earlier iterations.
### Interpretation
The chart suggests that both "Generation" and "Multiple-choice" methods improve with more iterations, as indicated by the decreasing average incorrect flips. The "Generation" method, although initially less accurate, shows a significant improvement over iterations. The "Multiple-choice" method starts with better accuracy and maintains a relatively lower error rate throughout the iterations. The shaded regions highlight the consistency of the "Multiple-choice" method compared to the "Generation" method, which has more variability. This could indicate that the "Generation" method is more sensitive to the specific data or conditions of each iteration.
</details>
(d) Baseline
<details>
<summary>x17.png Details</summary>
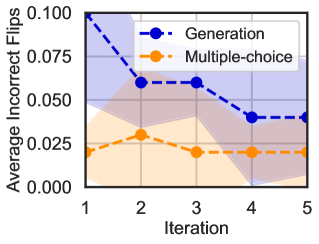
### Visual Description
## Chart: Average Incorrect Flips vs. Iteration
### Overview
The image is a line chart comparing the average incorrect flips for two methods, "Generation" and "Multiple-choice," across five iterations. The chart shows how the average incorrect flips change with each iteration for both methods. The "Generation" method starts with a higher error rate but decreases over iterations, while the "Multiple-choice" method has a lower error rate that fluctuates slightly. Shaded regions around each line indicate the variability or uncertainty associated with each method's performance.
### Components/Axes
* **Y-axis:** "Average Incorrect Flips," ranging from 0.000 to 0.100.
* **X-axis:** "Iteration," ranging from 1 to 5.
* **Legend:** Located in the top-right corner.
* **Generation:** Represented by a blue dashed line with circular markers.
* **Multiple-choice:** Represented by an orange dashed line with circular markers.
* **Shaded Regions:** Light blue shading around the "Generation" line and light orange shading around the "Multiple-choice" line, indicating variability.
### Detailed Analysis
* **Generation (Blue Dashed Line):**
* **Trend:** Decreasing trend over iterations.
* **Data Points:**
* Iteration 1: Approximately 0.100
* Iteration 2: Approximately 0.065
* Iteration 3: Approximately 0.060
* Iteration 4: Approximately 0.040
* Iteration 5: Approximately 0.040
* **Multiple-choice (Orange Dashed Line):**
* **Trend:** Relatively stable with slight fluctuations.
* **Data Points:**
* Iteration 1: Approximately 0.020
* Iteration 2: Approximately 0.030
* Iteration 3: Approximately 0.020
* Iteration 4: Approximately 0.020
* Iteration 5: Approximately 0.025
### Key Observations
* The "Generation" method starts with a significantly higher average incorrect flips compared to the "Multiple-choice" method.
* The "Generation" method shows a noticeable decrease in average incorrect flips over the first few iterations, indicating improvement.
* The "Multiple-choice" method maintains a relatively low and stable average incorrect flips throughout all iterations.
* The shaded regions indicate that the "Generation" method has more variability in its performance, especially in the earlier iterations.
### Interpretation
The chart suggests that the "Generation" method initially performs worse than the "Multiple-choice" method in terms of average incorrect flips. However, the "Generation" method improves with more iterations, indicating a learning or optimization process. The "Multiple-choice" method, on the other hand, maintains a consistent and lower error rate, suggesting it is more stable or already optimized. The variability in the "Generation" method's performance could be due to the nature of the generation process, which might be more sensitive to initial conditions or random factors. The data demonstrates that while the generation method starts with higher error, it converges to a similar error rate as the multiple-choice method after a few iterations.
</details>
(e) CoT
<details>
<summary>x18.png Details</summary>
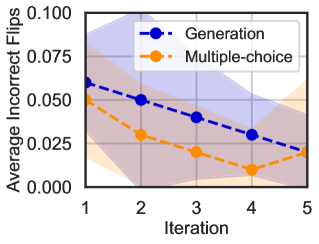
### Visual Description
## Line Chart: Average Incorrect Flips vs. Iteration
### Overview
The image is a line chart comparing the average incorrect flips for two methods, "Generation" and "Multiple-choice," across five iterations. The chart displays the trend of incorrect flips decreasing with increasing iterations for both methods, with shaded regions indicating the variability or confidence intervals around the mean values.
### Components/Axes
* **Y-axis:** "Average Incorrect Flips," ranging from 0.000 to 0.100 in increments of 0.025.
* **X-axis:** "Iteration," ranging from 1 to 5 in increments of 1.
* **Legend:** Located in the top-right corner.
* "Generation": Represented by a blue dashed line with circular markers.
* "Multiple-choice": Represented by an orange dashed line with circular markers.
* **Shaded Regions:** Light blue shading around the "Generation" line and light orange shading around the "Multiple-choice" line, indicating variability.
### Detailed Analysis
* **Generation:**
* Trend: The blue dashed line shows a decreasing trend in average incorrect flips as the iteration number increases.
* Data Points:
* Iteration 1: Approximately 0.062
* Iteration 2: Approximately 0.050
* Iteration 3: Approximately 0.040
* Iteration 4: Approximately 0.030
* Iteration 5: Approximately 0.022
* **Multiple-choice:**
* Trend: The orange dashed line also shows a decreasing trend initially, but it flattens out and slightly increases towards the end.
* Data Points:
* Iteration 1: Approximately 0.052
* Iteration 2: Approximately 0.032
* Iteration 3: Approximately 0.020
* Iteration 4: Approximately 0.010
* Iteration 5: Approximately 0.025
### Key Observations
* Both methods show a general decrease in average incorrect flips as the iteration number increases, suggesting learning or improvement over time.
* The "Generation" method starts with a higher average incorrect flip rate but decreases more consistently than the "Multiple-choice" method.
* The "Multiple-choice" method has a lower average incorrect flip rate at iteration 4, but it increases slightly at iteration 5.
* The shaded regions indicate the variability in the data, with wider regions suggesting more uncertainty.
### Interpretation
The data suggests that both the "Generation" and "Multiple-choice" methods improve over iterations in terms of reducing incorrect flips. The "Generation" method, despite starting with a higher error rate, shows a more consistent improvement. The "Multiple-choice" method initially performs better but plateaus and shows a slight increase in errors at the last iteration. This could indicate that the "Generation" method is learning more effectively over time, while the "Multiple-choice" method might be reaching a limit or experiencing some overfitting. The shaded regions provide insight into the reliability of these trends, with wider regions suggesting more caution in interpreting the results.
</details>
(f) SC
Figure 3: Average Correct and Incorrect Flips on tinyTruthfulQA
Effects of Model Scale and Prompting Strategy (RQ2).
<details>
<summary>x19.png Details</summary>
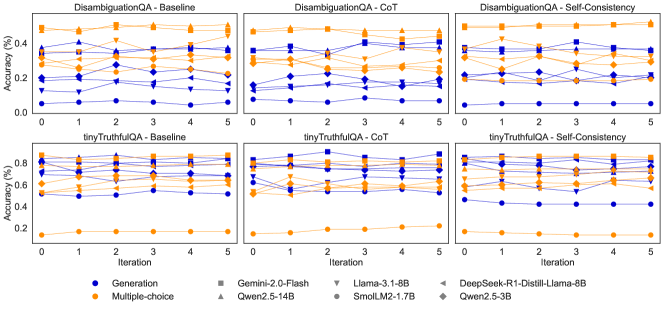
### Visual Description
## Line Charts: Model Accuracy Comparison
### Overview
The image presents six line charts arranged in a 2x3 grid, comparing the accuracy of different language models across several iterations. The charts are grouped by task (DisambiguationQA and tinyTruthfulQA) and method (Baseline, CoT - Chain of Thought, and Self-Consistency). Each chart plots the accuracy (%) of various models against the iteration number. The models are distinguished by color and marker type, as indicated in the legend at the bottom.
### Components/Axes
* **Chart Titles (Top Row):**
* DisambiguationQA - Baseline (top-left)
* DisambiguationQA - CoT (top-center)
* DisambiguationQA - Self-Consistency (top-right)
* **Chart Titles (Bottom Row):**
* tinyTruthfulQA - Baseline (bottom-left)
* tinyTruthfulQA - CoT (bottom-center)
* tinyTruthfulQA - Self-Consistency (bottom-right)
* **Y-axis:**
* Label: "Accuracy (%)"
* Scale (DisambiguationQA charts): 0.0 to 0.4, with ticks at 0.0, 0.2, and 0.4.
* Scale (tinyTruthfulQA charts): 0.2 to 0.8, with ticks at 0.2, 0.4, 0.6, and 0.8.
* **X-axis:**
* Label: "Iteration"
* Scale: 0 to 5, with ticks at each integer value.
* **Legend (Bottom):**
* Position: Bottom center of the image.
* Entries:
* Blue Circle: Generation
* Orange Diamond: Multiple-choice
* Gray Square: Gemini-2.0-Flash
* Gray Upward-pointing Triangle: Qwen2.5-14B
* Gray Downward-pointing Triangle: Llama-3.1-8B
* Gray Circle with Diamond Center: SmolLM2-1.7B
* Gray Leftward-pointing Triangle: DeepSeek-R1-Distill-Llama-8B
* Gray Diamond with Plus Center: Qwen2.5-3B
### Detailed Analysis
**DisambiguationQA - Baseline (Top-Left)**
* **Generation (Blue Circles):** Starts around 0.05 accuracy and remains relatively flat.
* **Multiple-choice (Orange Diamonds):** Starts around 0.35 accuracy and fluctuates between 0.25 and 0.4.
* **Gemini-2.0-Flash (Gray Squares):** Starts around 0.25 accuracy and fluctuates between 0.2 and 0.3.
* **Qwen2.5-14B (Gray Upward-pointing Triangles):** Starts around 0.35 accuracy and fluctuates between 0.3 and 0.45.
* **Llama-3.1-8B (Gray Downward-pointing Triangles):** Starts around 0.2 accuracy and fluctuates between 0.15 and 0.25.
* **SmolLM2-1.7B (Gray Circle with Diamond Center):** Starts around 0.15 accuracy and fluctuates between 0.1 and 0.2.
* **DeepSeek-R1-Distill-Llama-8B (Gray Leftward-pointing Triangles):** Starts around 0.2 accuracy and fluctuates between 0.15 and 0.25.
* **Qwen2.5-3B (Gray Diamond with Plus Center):** Starts around 0.2 accuracy and fluctuates between 0.15 and 0.25.
**DisambiguationQA - CoT (Top-Center)**
* **Generation (Blue Circles):** Starts around 0.1 accuracy and remains relatively flat.
* **Multiple-choice (Orange Diamonds):** Starts around 0.3 accuracy and fluctuates between 0.25 and 0.4.
* **Gemini-2.0-Flash (Gray Squares):** Starts around 0.3 accuracy and fluctuates between 0.25 and 0.35.
* **Qwen2.5-14B (Gray Upward-pointing Triangles):** Starts around 0.35 accuracy and fluctuates between 0.3 and 0.45.
* **Llama-3.1-8B (Gray Downward-pointing Triangles):** Starts around 0.2 accuracy and fluctuates between 0.15 and 0.25.
* **SmolLM2-1.7B (Gray Circle with Diamond Center):** Starts around 0.2 accuracy and fluctuates between 0.15 and 0.25.
* **DeepSeek-R1-Distill-Llama-8B (Gray Leftward-pointing Triangles):** Starts around 0.2 accuracy and fluctuates between 0.15 and 0.25.
* **Qwen2.5-3B (Gray Diamond with Plus Center):** Starts around 0.2 accuracy and fluctuates between 0.15 and 0.25.
**DisambiguationQA - Self-Consistency (Top-Right)**
* **Generation (Blue Circles):** Starts around 0.1 accuracy and remains relatively flat.
* **Multiple-choice (Orange Diamonds):** Starts around 0.35 accuracy and fluctuates between 0.3 and 0.4.
* **Gemini-2.0-Flash (Gray Squares):** Starts around 0.3 accuracy and fluctuates between 0.25 and 0.35.
* **Qwen2.5-14B (Gray Upward-pointing Triangles):** Starts around 0.35 accuracy and fluctuates between 0.3 and 0.45.
* **Llama-3.1-8B (Gray Downward-pointing Triangles):** Starts around 0.2 accuracy and fluctuates between 0.15 and 0.25.
* **SmolLM2-1.7B (Gray Circle with Diamond Center):** Starts around 0.2 accuracy and fluctuates between 0.15 and 0.25.
* **DeepSeek-R1-Distill-Llama-8B (Gray Leftward-pointing Triangles):** Starts around 0.2 accuracy and fluctuates between 0.15 and 0.25.
* **Qwen2.5-3B (Gray Diamond with Plus Center):** Starts around 0.2 accuracy and fluctuates between 0.15 and 0.25.
**tinyTruthfulQA - Baseline (Bottom-Left)**
* **Generation (Blue Circles):** Starts around 0.5 accuracy and remains relatively flat.
* **Multiple-choice (Orange Diamonds):** Starts around 0.15 accuracy and remains relatively flat.
* **Gemini-2.0-Flash (Gray Squares):** Starts around 0.75 accuracy and fluctuates between 0.7 and 0.8.
* **Qwen2.5-14B (Gray Upward-pointing Triangles):** Starts around 0.8 accuracy and fluctuates between 0.75 and 0.85.
* **Llama-3.1-8B (Gray Downward-pointing Triangles):** Starts around 0.6 accuracy and fluctuates between 0.55 and 0.65.
* **SmolLM2-1.7B (Gray Circle with Diamond Center):** Starts around 0.6 accuracy and fluctuates between 0.55 and 0.65.
* **DeepSeek-R1-Distill-Llama-8B (Gray Leftward-pointing Triangles):** Starts around 0.7 accuracy and fluctuates between 0.65 and 0.75.
* **Qwen2.5-3B (Gray Diamond with Plus Center):** Starts around 0.6 accuracy and fluctuates between 0.55 and 0.65.
**tinyTruthfulQA - CoT (Bottom-Center)**
* **Generation (Blue Circles):** Starts around 0.5 accuracy and remains relatively flat.
* **Multiple-choice (Orange Diamonds):** Starts around 0.15 accuracy and remains relatively flat.
* **Gemini-2.0-Flash (Gray Squares):** Starts around 0.75 accuracy and fluctuates between 0.7 and 0.8.
* **Qwen2.5-14B (Gray Upward-pointing Triangles):** Starts around 0.8 accuracy and fluctuates between 0.75 and 0.85.
* **Llama-3.1-8B (Gray Downward-pointing Triangles):** Starts around 0.6 accuracy and fluctuates between 0.55 and 0.65.
* **SmolLM2-1.7B (Gray Circle with Diamond Center):** Starts around 0.6 accuracy and fluctuates between 0.55 and 0.65.
* **DeepSeek-R1-Distill-Llama-8B (Gray Leftward-pointing Triangles):** Starts around 0.7 accuracy and fluctuates between 0.65 and 0.75.
* **Qwen2.5-3B (Gray Diamond with Plus Center):** Starts around 0.6 accuracy and fluctuates between 0.55 and 0.65.
**tinyTruthfulQA - Self-Consistency (Bottom-Right)**
* **Generation (Blue Circles):** Starts around 0.5 accuracy and remains relatively flat.
* **Multiple-choice (Orange Diamonds):** Starts around 0.15 accuracy and remains relatively flat.
* **Gemini-2.0-Flash (Gray Squares):** Starts around 0.75 accuracy and fluctuates between 0.7 and 0.8.
* **Qwen2.5-14B (Gray Upward-pointing Triangles):** Starts around 0.8 accuracy and fluctuates between 0.75 and 0.85.
* **Llama-3.1-8B (Gray Downward-pointing Triangles):** Starts around 0.6 accuracy and fluctuates between 0.55 and 0.65.
* **SmolLM2-1.7B (Gray Circle with Diamond Center):** Starts around 0.6 accuracy and fluctuates between 0.55 and 0.65.
* **DeepSeek-R1-Distill-Llama-8B (Gray Leftward-pointing Triangles):** Starts around 0.7 accuracy and fluctuates between 0.65 and 0.75.
* **Qwen2.5-3B (Gray Diamond with Plus Center):** Starts around 0.6 accuracy and fluctuates between 0.55 and 0.65.
### Key Observations
* The "Multiple-choice" method (orange diamonds) consistently shows lower accuracy on the "tinyTruthfulQA" task compared to other models.
* The "Generation" method (blue circles) shows relatively low accuracy on the "DisambiguationQA" task, but higher accuracy on the "tinyTruthfulQA" task.
* The models Gemini-2.0-Flash, Qwen2.5-14B, DeepSeek-R1-Distill-Llama-8B, and Qwen2.5-3B generally achieve higher accuracy on the "tinyTruthfulQA" task.
* The accuracy of most models remains relatively stable across iterations, with only minor fluctuations.
* The CoT and Self-Consistency methods do not appear to significantly improve the accuracy compared to the Baseline method for most models.
### Interpretation
The charts compare the performance of different language models on two question-answering tasks ("DisambiguationQA" and "tinyTruthfulQA") using different methods (Baseline, Chain of Thought (CoT), and Self-Consistency). The data suggests that the choice of model and task significantly impacts accuracy. For instance, the "Multiple-choice" method seems less effective for the "tinyTruthfulQA" task, while the "Generation" method performs better on "tinyTruthfulQA" than on "DisambiguationQA". The relatively flat lines across iterations indicate that the models' performance does not significantly change with more iterations, suggesting that the models have reached a stable level of accuracy. The CoT and Self-Consistency methods, designed to improve reasoning, do not show a substantial advantage over the baseline, which could indicate that these tasks do not heavily rely on complex reasoning or that the models are not effectively utilizing these methods.
</details>
Figure 4: Accuracy per iteration per model on generation and multiple-choice.
Here, we investigate how a model’s size and the prompting strategy influence self-correction, and whether these effects differ between the two output paradigms. Figure 4 provides a detailed view of accuracy per iteration for various models under different prompting methods. A clear finding is that task difficulty moderates these effects. On the challenging DisambiguationQA benchmark, accuracy is low for all models: even the largest (e.g., Gemini-2.0-Flash, Qwen2.5-14B) plateau around 50% in multiple-choice and below 20% in generation, while smaller models perform far worse. In contrast, on the easier tinyTruthfulQA, generative accuracy ranges from 60–90% and multiple-choice from 50–80%, with even small models performing well. Thus, model scale yields clear benefits on harder tasks, but differences narrow considerably on simpler ones.
The prompting strategy has a modest but noticeable effect, more so on the difficult task. On DisambiguationQA, using an explicit CoT prompt or a SC approach yields slight accuracy improvements over the Baseline direct prompting. For example, prompting the model to “think step by step” or to consider multiple reasoning paths sometimes helps it disambiguate the question better, nudging up the accuracy by a few percentage points. These gains, while not dramatic, suggest that reasoning-oriented prompts can aid the model on ambiguous, challenging questions. In contrast, on tinyTruthfulQA, all three prompting strategies lead to very similar performance. The accuracy curves for different prompts on this task are nearly overlapping (Figure 4), indicating that when a question is relatively straightforward or the model already knows the domain (e.g., common truths vs. misconceptions), an elaborate prompt does not provide much benefit. In summary, prompting variations have a task-dependent impact: they can be slightly beneficial for resolving difficult queries (DisambiguationQA) but mostly redundant for simpler factual questions (tinyTruthfulQA). This aligns with the findings in the literature Sprague et al. (2025).
Model scale shows a similarly nuanced effect. Larger models generally outperform smaller ones, especially on DisambiguationQA, where 14B+ models clearly surpass 1–3B models. On tinyTruthfulQA, however, the performance gap narrows, with small models often approaching large-model accuracy. In some cases, scaling produces diminishing returns, indicating that size matters more for difficult tasks but offers limited advantage once a task is already within reach.
Notably, repeated iterations of self-correction do not consistently boost accuracy for either paradigm, regardless of model size or prompt strategy. Across our experiments, most performance curves over iterations (spanning iteration 0 through 5) are relatively flat after the initial step. As highlighted by Figure 4, it is rare to see a clear upward trajectory beyond the first one or two iterations; instead, accuracy often oscillates with minor gains or losses. For example, a model might correct a mistake at iteration 1, only to introduce a different mistake at iteration 3, ending up with a similar accuracy as it started. This plateauing behavior implies that giving the model many chances to self-correct yields diminishing returns. Neither larger scale nor advanced prompting fundamentally changes this outcome – their benefits tend to manifest in the first attempt or two, but they do not drive continual improvement with more iterations. In some cases, we even observed slight performance degradation with too many iterations (echoing the drift issues from RQ1). In summary, the impact of model scale and prompting strategy on self-correction is real but nuanced: larger models and CoT-style prompts can improve initial accuracy, especially on hard tasks, but these factors are task-dependent and ultimately insufficient to guarantee ongoing improvements through iterative self-correction alone. Multiple-choice and generation formats alike see their gains saturate early, and improvements from scaling or better prompting taper off without addressing the core limitations of each paradigm. Notably, we also found that the multiple-choice paradigm often reaped slightly more benefit from increased model size and reasoning prompts than the generation paradigm did (especially on DisambiguationQA), reinforcing the idea that constrained decision tasks can more readily capitalize on those enhancements. Still, neither paradigm achieves a dramatically upward performance trend with iteration – a key insight for understanding the boundaries of current self-correction capabilities.
Trade-offs Between Adaptability and Stability (RQ3).
RQ3 examines how iterative self-correction influences correctness, stability, and semantic drift across unconstrained and constrained outputs. In the generation setting, flexibility allows models to revise and often improve answers in the first one or two iterations, but this same flexibility leads to semantic drift in later rounds. As Figures 2 and 3 as well as the detailed plots of per model evaluation in Appendix C.1, generation produces many flips: early ones are often correct (e.g., resolving an ambiguity or correcting a misconception), but over time, incorrect flips dominate as the model over-edits or drifts away from the question. This suggests that while generation supports adaptability, it lacks effective internal checks to prevent harmful revisions. By contrast, in the multiple-choice setting, the output space is restricted to fixed options, which prevents drift altogether. Correct answers remain locked in across iterations, reflecting high stability. However, this comes with logit inertia: wrong initial answers persist, with very few corrective flips observed in Figures 2 and 3. The mechanism here is that once a wrong option is selected, the model rarely shifts its ranking enough to choose the correct one later, even when revisiting its reasoning.
These patterns reveal a fundamental adaptability–stability trade-off. Generation is exploratory and can recover from initial mistakes, but risks undermining correctness as iterations accumulate. Multiple-choice ensures consistency once correct, but limits opportunities to fix errors. For system design, this implies that neither paradigm is universally optimal. Applications requiring stable outputs, such as safety-critical domains, benefit from constrained correction, though additional mechanisms may be needed to overcome inertia (e.g., external verification or re-ranking). Conversely, tasks where capturing every possible correction is crucial may favor open-ended revision, provided that safeguards against drift are implemented. Promising directions include hybrid strategies that combine paradigms, using generation to explore candidate answers followed by constrained verification to anchor correctness, and dynamic stopping rules that halt iteration once improvements saturate or harmful drift is detected. Addressing these trade-offs directly, by mitigating semantic drift in generation and reducing inertia in multiple-choice, will be key to making iterative self-correction a reliable capability of LLM systems.
6 Conclusion
This study compared iterative self-correction in large language models across open-ended generation and multiple-choice question answering. Results show that the structure of the output space fundamentally shapes correction dynamics. Generation achieves rapid early gains by correcting errors in the first few iterations, but suffers from semantic drift as revisions accumulate, resulting in increasing rates of incorrect flips. Multiple-choice responses remain highly stable and avoid drift, but exhibit logit inertia: wrong initial answers are rarely overturned, and improvements are incremental at best. Model scale and prompting strategy modulate performance but do not alter these core patterns. Larger models and reasoning-oriented prompts (CoT, SC) yield slight improvements, especially on the harder DisambiguationQA task, but their effects are modest and task-dependent. Across both paradigms, accuracy generally plateaus after the first one or two iterations, showing that repeated self-correction brings limited benefit.
These findings highlight an inherent adaptability–stability trade-off. Open-ended generation enables recovery from errors but risks instability, while multiple-choice ensures reliability but limits correction. Future work should explore hybrid strategies, such as using generation for exploration and constrained formats for verification, as well as dynamic stopping criteria to prevent late drift. Addressing drift and inertia directly will be essential for building reliable self-correcting LLM systems.
Limitations
This study focuses on benchmarks that provide parallel formulations for both open-ended generation and multiple-choice questions. While this setup enables a controlled analysis of self-correction across task formats, it also limits the number of datasets available for evaluation, as few benchmarks support both types of tasks. Moreover, our experiments are conducted using currently available models of moderate scale. Recent larger models, which may exhibit different self-correction dynamics and reasoning behaviors, are not included in our analysis. Future work could extend our study to such models to provide a more comprehensive understanding of scaling effects.
Ethical Considerations
We have carefully verified that the software, model checkpoints and existing datasets utilised in this work are permitted for access, distribution and, where relevant, modification. Our use and purpose comply with those terms.
Acknowledgments
This research is supported by the Engineering and Physical Sciences Research Council [EP/S021566/1] and the EPSRC Fellowship titled “Task Based Information Retrieval” [EP/P024289/1].
References
- A2i (2025) A2i. 2025. TruthfulQA Truth Judge. Accessed: 2025.
- Allal et al. (2025) Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martin Blazquez, Guilherme Penedo, Lewis Tunstall, Andrés Marafioti, Agustín Piqueres Lajarín, Hynek Kydlíček, Vaibhav Srivastav, Joshua Lochner, Caleb Fahlgren, Xuan Son NGUYEN, Ben Burtenshaw, Clémentine Fourrier, Haojun Zhao, Hugo Larcher, Mathieu Morlon, Cyril Zakka, and 3 others. 2025. SmolLM2: When smol goes big — data-centric training of a fully open small language model. In Second Conference on Language Modeling.
- Belcak et al. (2025) Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, and Pavlo Molchanov. 2025. Small language models are the future of agentic ai. arXiv preprint arXiv:2506.02153.
- Brown and et al. (2020) Tom B Brown and et al. 2020. Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
- Chang et al. (2024) Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, and 1 others. 2024. A survey on evaluation of large language models. ACM transactions on intelligent systems and technology, 15(3):1–45.
- Chen et al. (2023) Mark Y Chen, Chia-Wei Liu, Xuezhi Wang, Quoc V Le, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Program-aided language models: Language models as programs. arXiv preprint arXiv:2303.11366.
- Clark and et al. (2018) Peter Clark and et al. 2018. Think you have reasoning solved? evaluating the arc challenge. arXiv preprint arXiv:1803.05457.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Anish Madaan, and et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Comanici et al. (2025) Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261.
- Cook et al. (2024) Jonathan Cook, Tim Rocktäschel, Jakob Nicolaus Foerster, Dennis Aumiller, and Alex Wang. 2024. TICKing all the boxes: Generated checklists improve LLM evaluation and generation. In Language Gamification - NeurIPS 2024 Workshop.
- Dixit et al. (2023) Tanay Dixit, Fei Wang, Muhao Chen, and et al. 2023. Improving factuality of abstractive summarization without sacrificing summary quality. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 902–913.
- Gou et al. (2024) Zhibin Gou, Zhihong Shao, Yeyun Gong, yelong shen, Yujiu Yang, Nan Duan, and Weizhu Chen. 2024. CRITIC: Large language models can self-correct with tool-interactive critiquing. In The Twelfth International Conference on Learning Representations.
- Grattafiori et al. (2024) Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783.
- Guo et al. (2025) Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Santi Basart, and et al. 2021. Measuring massive multitask language understanding. Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 10013–10023.
- Huang et al. (2023) Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. 2023. Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798.
- Ji et al. (2023a) Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023a. Survey of hallucination in natural language generation. ACM computing surveys, 55(12):1–38.
- Ji et al. (2023b) Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, and Pascale Fung. 2023b. Towards mitigating llm hallucination via self-reflection. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 1827–1843.
- Kamoi et al. (2024) Ryo Kamoi, Yusen Zhang, Nan Zhang, Jiawei Han, and Rui Zhang. 2024. When can llms actually correct their own mistakes? a critical survey of self-correction of llms. Transactions of the Association for Computational Linguistics, 12:1417–1440.
- Kazemi et al. (2025) Mehran Kazemi, Bahare Fatemi, Hritik Bansal, John Palowitch, Chrysovalantis Anastasiou, Sanket Vaibhav Mehta, Lalit K Jain, Virginia Aglietti, Disha Jindal, Peter Chen, and 1 others. 2025. Big-bench extra hard. arXiv preprint arXiv:2502.19187.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213.
- Krishna et al. (2024) Satyapriya Krishna, Chirag Agarwal, and Himabindu Lakkaraju. 2024. Understanding the effects of iterative prompting on truthfulness. In Proceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org.
- Kumar et al. (2025) Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, and Aleksandra Faust. 2025. Training language models to self-correct via reinforcement learning. In The Thirteenth International Conference on Learning Representations.
- Li and et al. (2024) Wei Li and et al. 2024. Logitlens: Calibrating reasoning in language models with internal consistency. NeurIPS 2024.
- Lin et al. (2022) Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Truthfulqa: Measuring how models mimic human falsehoods. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL 2022), pages 2129–2144.
- Liu et al. (2024) Dancheng Liu, Amir Nassereldine, Ziming Yang, Chenhui Xu, Yuting Hu, Jiajie Li, Utkarsh Kumar, Changjae Lee, Ruiyang Qin, Yiyu Shi, and 1 others. 2024. Large language models have intrinsic self-correction ability. arXiv preprint arXiv:2406.15673.
- Ma et al. (2025) Ruotian Ma, Peisong Wang, Cheng Liu, Xingyan Liu, Jiaqi Chen, Bang Zhang, Xin Zhou, Nan Du, and Jia Li. 2025. S 2 R: Teaching LLMs to self-verify and self-correct via reinforcement learning. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 22632–22654.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, and 1 others. 2023. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 36:46534–46594.
- Pan and et al. (2023) Xinyu Pan and et al. 2023. Multiple rationales for multiple-choice question answering. arXiv preprint arXiv:2305.03495.
- Polo et al. (2024) Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, and Mikhail Yurochkin. 2024. tinybenchmarks: evaluating llms with fewer examples. arXiv preprint arXiv:2402.14992.
- Pryzant (2023) Ryan Pryzant. 2023. Automatic prompt optimization with "gradient descent" for language models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 494–507.
- Qwen et al. (2025) Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, and 25 others. 2025. Qwen2.5 technical report. Preprint, arXiv:2412.15115.
- Shinn et al. (2023) Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36:8634–8652.
- Spataru (2024) Ava Spataru. 2024. Know when to stop: A study of semantic drift in text generation. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3656–3671.
- Sprague et al. (2025) Zayne Rea Sprague, Fangcong Yin, Juan Diego Rodriguez, Dongwei Jiang, Manya Wadhwa, Prasann Singhal, Xinyu Zhao, Xi Ye, Kyle Mahowald, and Greg Durrett. 2025. To cot or not to cot? chain-of-thought helps mainly on math and symbolic reasoning. In The Thirteenth International Conference on Learning Representations.
- Suzgun and Kalai (2024) Mirac Suzgun and Adam Tauman Kalai. 2024. Meta-prompting: Enhancing language models with task-agnostic scaffolding. arXiv preprint arXiv:2401.12954.
- Suzgun et al. (2025) Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. 2025. Dynamic cheatsheet: Test-time learning with adaptive memory. arXiv preprint arXiv:2504.07952.
- Wang et al. (2023) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903.
- Yao et al. (2023) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik R Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. In Thirty-seventh Conference on Neural Information Processing Systems.
- Zelikman et al. (2022) Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. 2022. STar: Bootstrapping reasoning with reasoning. In Advances in Neural Information Processing Systems.
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, and 1 others. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36:46595–46623.
- Zhu and et al. (2024) Xue Zhu and et al. 2024. Mcrepair: Enhancing multiple-choice reasoning with self-explanation and rescoring. arXiv preprint arXiv:2405.18711.
Appendix A Details on Experimental Setup
A.1 Details on Final Answer Extraction
For all of our problems, we added a short phrase to the text of the question to guide the model to give the final answer in a clear format: “ provide your final answer after the ‘The final answer is: ’.” To extract the answer, we split the output of the model using this phrase and take what comes after it. Since models sometimes change the phrase slightly, we also check for different variations until one is found: “The answer is: ”, “The answer is ”. “The final answer is: ”, “The final answer is ”. Once we get the final answer, we clean it up with a few simple steps:
1. If the answer is inside symbols like boxed, text, texttt, or wrapped in **, we remove those and keep only the text inside.
1. For multiple-choice questions, if the model adds extra text after the final answer (for example, by putting a newline \n), we split on \n and keep only the first part. We then lowercase both the final answer and the label, and then check the correctness with the following rules:
- If the final answer and label are identical, we consider the final answer correct.
- If they only differ by quotes or brackets around the answer, we consider it to be correct.
- For multiple-choice questions, the label is in the format (<LETTER>). If the model only gives the letter (like A instead of (A)), we still count it as correct.
A.2 Prompts
A.2.1 Start Prompts
Baseline
Question: {question}. Provide your final answer after the ‘The final answer is: ’.
Chain-of-Thought (CoT)
Question: {question}. Think step by step, and provide your final answer after the ‘The final answer is: ’.
A.2.2 Iterative (Self-Correction) Prompts
Baseline
Question: {question}. Review your previous responses, and provide your final answer after the ‘The final answer is: ’.
Chain-of-Thought (CoT)
Question: {question}. Review your previous responses, think step by step and provide your final answer after the ‘The final answer is: ’.
Appendix B Evaluation Protocol
Given the differences between task formats, we adopt distinct evaluation strategies tailored to the characteristics of each setting—open-ended generation and multiple-choice questions. For multiple-choice questions, we use Soft Match (SM) Suzgun and Kalai (2024); Suzgun et al. (2025), a lenient metric that considers an answer correct if the ground-truth label appears in the model’s output, disregarding minor formatting variations such as punctuation or whitespace.
For open-ended generation, we employ the LLM-as-a-Judge Zheng et al. (2023) approach to assess the correctness of the generated answers relative to the ground-truth responses for each dataset. Specifically, we use the fine-tuned model https://github.com/yizhongw/truthfulqa_reeval introduced by A2i for evaluating generations on tinyTruthfulQA. For DisambiguationQA, we prompt a large model, GPT-4o, by providing the question, the model-generated answer, and the reference answer, asking it to determine whether the generated answer is correct. The exact prompt used for DisambiguationQA evaluation is shown below:
Evaluation Prompt
You are an expert in answer correctness evaluation. Given a question, its reference answer, and a generated answer, please evaluate the correctness of the generated answer based on the question and the reference answer. Here are the question, reference answer, and generated answer: - Question: {question} - Reference Answer: {gold answer} - Generated Answer: {generated answer} Please assess the correctness of the generated answer by considering the question and comparing it against the reference answer. Return yes if the generated answer is completely correct, otherwise, return ‘no’. The final answer must only be ‘yes’ or ‘no’, corresponding to the correctness of the generated answer.
Appendix C Additional Experiments and Results
<details>
<summary>x20.png Details</summary>
### Visual Description
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of different language models on two tasks: generation and multiple-choice. The chart displays the accuracy percentage for each model on each task, allowing for a direct comparison of their performance.
### Components/Axes
* **X-axis:** Lists the language models being compared:
* DeepGeek-R1 Distill-Llama-6B
* Llama-3.1-8B
* Qwen2.5-14B
* Qwen2.5-3B
* SmolLM2-1.7B
* Gemini-2.0-Flash
* **Y-axis:** Represents the accuracy percentage, ranging from 0.0% to 0.5%.
* **Legend:** Located at the bottom of the chart, indicating:
* Blue bars: "Generation" task
* Orange bars: "Multiple-choice" task
### Detailed Analysis
Here's a breakdown of the accuracy for each model on both tasks:
* **DeepGeek-R1 Distill-Llama-6B:**
* Generation: Approximately 0.23%
* Multiple-choice: Approximately 0.40%
* **Llama-3.1-8B:**
* Generation: Approximately 0.30%
* Multiple-choice: Approximately 0.52%
* **Qwen2.5-14B:**
* Generation: Approximately 0.48%
* Multiple-choice: Approximately 0.53%
* **Qwen2.5-3B:**
* Generation: Approximately 0.33%
* Multiple-choice: Approximately 0.45%
* **SmolLM2-1.7B:**
* Generation: Approximately 0.07%
* Multiple-choice: Approximately 0.36%
* **Gemini-2.0-Flash:**
* Generation: Approximately 0.42%
* Multiple-choice: Approximately 0.54%
**Trend Verification:**
* For all models, the "Multiple-choice" accuracy is higher than the "Generation" accuracy.
### Key Observations
* The "Multiple-choice" task consistently yields higher accuracy than the "Generation" task across all models.
* SmolLM2-1.7B has the lowest accuracy on both tasks compared to the other models.
* Gemini-2.0-Flash and Qwen2.5-14B show the highest accuracy on the "Multiple-choice" task.
### Interpretation
The data suggests that the language models perform better on multiple-choice tasks than on generation tasks. This could be due to the nature of the tasks; multiple-choice requires selecting from a set of predefined options, while generation requires creating novel text, which is generally more challenging. The significant difference in accuracy for SmolLM2-1.7B indicates that it may be less capable than the other models in both tasks. The high performance of Gemini-2.0-Flash and Qwen2.5-14B on the multiple-choice task suggests they are particularly well-suited for tasks involving selection and recognition.
</details>
(a) Baseline
<details>
<summary>x21.png Details</summary>
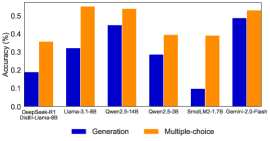
### Visual Description
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of different language models on two tasks: generation and multiple-choice. The chart displays the accuracy in percentage for each model across the two tasks, with blue bars representing generation accuracy and orange bars representing multiple-choice accuracy.
### Components/Axes
* **Y-axis:** Accuracy (%), ranging from 0.0 to 0.5.
* **X-axis:** Language models: DeepGeek-R1 Distill-Llama-6B, Llama-3.1-8B, Qwer2.5-14B, Qwer2.5-3B, SmolLM2-1.7B, Gemini-2.0-Flash.
* **Legend:** Located at the bottom of the chart.
* Blue: Generation
* Orange: Multiple-choice
### Detailed Analysis
Here's a breakdown of the accuracy for each model and task:
* **DeepGeek-R1 Distill-Llama-6B:**
* Generation (Blue): Approximately 0.19%
* Multiple-choice (Orange): Approximately 0.36%
* **Llama-3.1-8B:**
* Generation (Blue): Approximately 0.32%
* Multiple-choice (Orange): Approximately 0.54%
* **Qwer2.5-14B:**
* Generation (Blue): Approximately 0.45%
* Multiple-choice (Orange): Approximately 0.53%
* **Qwer2.5-3B:**
* Generation (Blue): Approximately 0.29%
* Multiple-choice (Orange): Approximately 0.39%
* **SmolLM2-1.7B:**
* Generation (Blue): Approximately 0.09%
* Multiple-choice (Orange): Approximately 0.39%
* **Gemini-2.0-Flash:**
* Generation (Blue): Approximately 0.48%
* Multiple-choice (Orange): Approximately 0.50%
### Key Observations
* For all models, the multiple-choice accuracy is higher than the generation accuracy.
* Llama-3.1-8B, Qwer2.5-14B, and Gemini-2.0-Flash show the highest accuracy overall.
* SmolLM2-1.7B has the lowest generation accuracy.
### Interpretation
The chart suggests that language models generally perform better on multiple-choice tasks compared to generation tasks. This could be because multiple-choice tasks require recognition and selection, while generation tasks require the model to produce novel text, which is a more complex task. The models Llama-3.1-8B, Qwer2.5-14B, and Gemini-2.0-Flash appear to be the most accurate among those compared, indicating they may be better suited for both types of tasks. The relatively low generation accuracy of SmolLM2-1.7B suggests it may have limitations in its ability to generate coherent and accurate text.
</details>
(b) CoT
<details>
<summary>x22.png Details</summary>
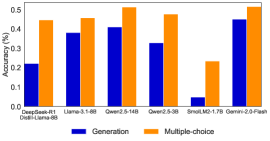
### Visual Description
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of different language models on two tasks: generation and multiple-choice. The chart displays the accuracy percentage for each model on each task, allowing for a direct comparison of their performance.
### Components/Axes
* **Y-axis:** Accuracy (%), ranging from 0.0 to 0.5. Increments of 0.1.
* **X-axis:** Language Models:
* DeepSeek-R1 Distill-Llama-8B
* Llama-3.1-8B
* Qwen2.5-14B
* Qwen2.5-3B
* SmolLM2-1.7B
* Gemini-2.0-Flash
* **Legend:** Located at the bottom of the chart.
* Blue: Generation
* Orange: Multiple-choice
### Detailed Analysis
* **DeepSeek-R1 Distill-Llama-8B:**
* Generation (Blue): Accuracy ~0.22
* Multiple-choice (Orange): Accuracy ~0.44
* **Llama-3.1-8B:**
* Generation (Blue): Accuracy ~0.38
* Multiple-choice (Orange): Accuracy ~0.46
* **Qwen2.5-14B:**
* Generation (Blue): Accuracy ~0.41
* Multiple-choice (Orange): Accuracy ~0.51
* **Qwen2.5-3B:**
* Generation (Blue): Accuracy ~0.33
* Multiple-choice (Orange): Accuracy ~0.48
* **SmolLM2-1.7B:**
* Generation (Blue): Accuracy ~0.05
* Multiple-choice (Orange): Accuracy ~0.24
* **Gemini-2.0-Flash:**
* Generation (Blue): Accuracy ~0.45
* Multiple-choice (Orange): Accuracy ~0.48
### Key Observations
* For all models, the multiple-choice accuracy is higher than the generation accuracy.
* Qwen2.5-14B has the highest multiple-choice accuracy (~0.51).
* SmolLM2-1.7B has the lowest accuracy for both generation and multiple-choice tasks.
* Gemini-2.0-Flash has the highest generation accuracy (~0.45).
### Interpretation
The data suggests that all the language models perform better on multiple-choice tasks compared to generation tasks. This could be due to the nature of the tasks, where multiple-choice provides a set of options to choose from, while generation requires the model to produce text from scratch. The Qwen2.5-14B model appears to be the most accurate on multiple-choice, while Gemini-2.0-Flash is the most accurate on generation. SmolLM2-1.7B lags significantly behind the other models in both tasks, indicating a potential area for improvement. The difference in performance between the models highlights the impact of model architecture, training data, and other factors on the accuracy of language models.
</details>
(c) SC
<details>
<summary>x23.png Details</summary>
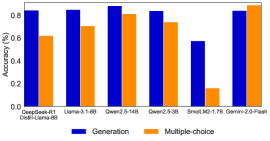
### Visual Description
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of different language models on two tasks: generation and multiple-choice. The chart displays the accuracy percentage on the y-axis and the model names on the x-axis. The legend at the bottom indicates that blue bars represent generation accuracy and orange bars represent multiple-choice accuracy.
### Components/Axes
* **Y-axis:** Accuracy (%), ranging from 0.0 to 0.8. Increments are not explicitly marked, but the scale appears linear.
* **X-axis:** Model names: DeepGeek-R1 Distill-Llama-8B, Uama-3.1-8B, Qwer2.5-14B, Qwer2.5-3B, SmolLM2-1.7B, Gemini-2.0-Flash.
* **Legend:** Located at the bottom of the chart.
* Blue: Generation
* Orange: Multiple-choice
### Detailed Analysis
Here's a breakdown of the accuracy for each model on both tasks:
* **DeepGeek-R1 Distill-Llama-8B:**
* Generation (Blue): Approximately 0.83
* Multiple-choice (Orange): Approximately 0.62
* **Uama-3.1-8B:**
* Generation (Blue): Approximately 0.84
* Multiple-choice (Orange): Approximately 0.70
* **Qwer2.5-14B:**
* Generation (Blue): Approximately 0.86
* Multiple-choice (Orange): Approximately 0.80
* **Qwer2.5-3B:**
* Generation (Blue): Approximately 0.81
* Multiple-choice (Orange): Approximately 0.74
* **SmolLM2-1.7B:**
* Generation (Blue): Approximately 0.57
* Multiple-choice (Orange): Approximately 0.16
* **Gemini-2.0-Flash:**
* Generation (Blue): Approximately 0.83
* Multiple-choice (Orange): Approximately 0.82
**Trends:**
* For all models except SmolLM2-1.7B, the generation accuracy is higher than the multiple-choice accuracy.
* SmolLM2-1.7B shows a significantly lower accuracy for both tasks compared to the other models.
* Qwer2.5-14B and Gemini-2.0-Flash have the highest multiple-choice accuracy, nearly matching their generation accuracy.
### Key Observations
* SmolLM2-1.7B is a clear outlier, performing significantly worse than the other models on both tasks.
* The other models show relatively consistent performance, with generation accuracy generally above 0.8.
* The difference between generation and multiple-choice accuracy varies across models, with some models showing a smaller gap than others.
### Interpretation
The bar chart provides a comparative analysis of the accuracy of different language models on generation and multiple-choice tasks. The data suggests that most models perform better on generation tasks than on multiple-choice tasks, except for SmolLM2-1.7B, which performs poorly on both. The performance of SmolLM2-1.7B is a notable anomaly, suggesting potential issues with its architecture, training data, or hyperparameter tuning. The relatively high and consistent performance of the other models indicates that they are reasonably well-suited for both generation and multiple-choice tasks. The chart highlights the importance of evaluating language models on multiple tasks to gain a comprehensive understanding of their capabilities and limitations.
</details>
(d) Baseline
<details>
<summary>x24.png Details</summary>
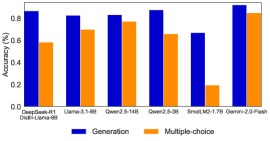
### Visual Description
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of different language models on two tasks: generation and multiple-choice. The chart displays the accuracy percentage for each model on each task, allowing for a direct comparison of their performance.
### Components/Axes
* **Y-axis:** "Accuracy (%)", ranging from 0.0 to 0.8 in increments of 0.2.
* **X-axis:** Categorical axis listing the language models:
* DeepGeek-R1 Distill-Llama-8B
* Uame-3.1-8B
* Qwer2.5-14B
* Qwer2.5-3B
* SmolLM2-1.7B
* Gemini-2.0-Flash
* **Legend:** Located at the bottom of the chart.
* Blue: "Generation"
* Orange: "Multiple-choice"
### Detailed Analysis
The chart presents the accuracy of different language models on two tasks: generation and multiple-choice.
* **DeepGeek-R1 Distill-Llama-8B:**
* Generation (Blue): Accuracy is approximately 0.85.
* Multiple-choice (Orange): Accuracy is approximately 0.58.
* **Uame-3.1-8B:**
* Generation (Blue): Accuracy is approximately 0.78.
* Multiple-choice (Orange): Accuracy is approximately 0.70.
* **Qwer2.5-14B:**
* Generation (Blue): Accuracy is approximately 0.83.
* Multiple-choice (Orange): Accuracy is approximately 0.77.
* **Qwer2.5-3B:**
* Generation (Blue): Accuracy is approximately 0.84.
* Multiple-choice (Orange): Accuracy is approximately 0.67.
* **SmolLM2-1.7B:**
* Generation (Blue): Accuracy is approximately 0.68.
* Multiple-choice (Orange): Accuracy is approximately 0.19.
* **Gemini-2.0-Flash:**
* Generation (Blue): Accuracy is approximately 0.86.
* Multiple-choice (Orange): Accuracy is approximately 0.84.
### Key Observations
* The Gemini-2.0-Flash model has the highest accuracy for both generation and multiple-choice tasks.
* The SmolLM2-1.7B model has the lowest accuracy for the multiple-choice task.
* For most models, the accuracy on the generation task is higher than the accuracy on the multiple-choice task, except for Gemini-2.0-Flash, where the accuracies are very close.
### Interpretation
The bar chart provides a comparison of the performance of different language models on generation and multiple-choice tasks. The data suggests that the Gemini-2.0-Flash model is the most accurate among the models tested. The chart also highlights the relative strengths and weaknesses of each model on the two tasks. The significant difference in accuracy between the generation and multiple-choice tasks for some models (e.g., SmolLM2-1.7B) suggests that these models may be better suited for one type of task over the other.
</details>
(e) CoT
<details>
<summary>x25.png Details</summary>
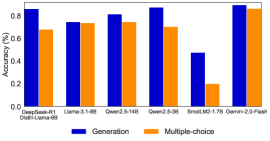
### Visual Description
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of different language models on two tasks: generation and multiple-choice. The chart displays the accuracy percentage for each model on each task, with blue bars representing generation accuracy and orange bars representing multiple-choice accuracy.
### Components/Axes
* **X-axis:** Lists the language models: DeepSeek-R1 Distill-Llama-8B, Uame-3.1-8B, Qwer2.5-14B, Qwer2.5-3B, SmolLM2-1.7B, Gemini-2.0-Flash.
* **Y-axis:** Represents accuracy in percentage, ranging from 0.0 to 0.8.
* **Legend:** Located at the bottom of the chart, indicating that blue bars represent "Generation" accuracy and orange bars represent "Multiple-choice" accuracy.
### Detailed Analysis
Here's a breakdown of the accuracy for each model on both tasks:
* **DeepSeek-R1 Distill-Llama-8B:**
* Generation (Blue): Approximately 0.84
* Multiple-choice (Orange): Approximately 0.68
* **Uame-3.1-8B:**
* Generation (Blue): Approximately 0.75
* Multiple-choice (Orange): Approximately 0.74
* **Qwer2.5-14B:**
* Generation (Blue): Approximately 0.81
* Multiple-choice (Orange): Approximately 0.75
* **Qwer2.5-3B:**
* Generation (Blue): Approximately 0.84
* Multiple-choice (Orange): Approximately 0.70
* **SmolLM2-1.7B:**
* Generation (Blue): Approximately 0.47
* Multiple-choice (Orange): Approximately 0.20
* **Gemini-2.0-Flash:**
* Generation (Blue): Approximately 0.83
* Multiple-choice (Orange): Approximately 0.83
### Key Observations
* Gemini-2.0-Flash has the same accuracy for both Generation and Multiple-choice tasks.
* SmolLM2-1.7B has the lowest accuracy for both tasks compared to the other models.
* For most models, the generation accuracy is higher than the multiple-choice accuracy, except for Uame-3.1-8B and Gemini-2.0-Flash.
### Interpretation
The chart provides a comparative analysis of the performance of different language models on generation and multiple-choice tasks. The data suggests that some models, like DeepSeek-R1 and Qwer2.5-3B, are better suited for generation tasks, while others, like Gemini-2.0-Flash, perform equally well on both tasks. The significant difference in accuracy for SmolLM2-1.7B indicates that it may have limitations compared to the other models. The chart highlights the varying strengths and weaknesses of different language models in different tasks.
</details>
(f) SC
Figure 5: Cumulative accuracy (after final self-correction iteration) using different models on (top) DisambiguationQA and (bottom) tinyTruthfulQA. The results indicate that models perform completely differently on self-correction of generation and multiple-choice questions, depending on the dataset.
C.1 Results on Correct and Incorrect Flips
Figures 6-11 show the correct and incorrect flips on different datasets and models.
<details>
<summary>x26.png Details</summary>
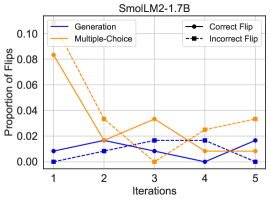
### Visual Description
## Chart: SmolLM2-1.7B Proportion of Flips vs. Iterations
### Overview
The image is a line chart titled "SmolLM2-1.7B" showing the proportion of flips across iterations for different methods: Generation, Multiple-Choice, Correct Flip, and Incorrect Flip. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips (0.00 to 0.10).
### Components/Axes
* **Title:** SmolLM2-1.7B
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.00, 0.02, 0.04, 0.06, 0.08, 0.10)
* **Legend:** Located in the top-left and top-right corners of the chart.
* **Generation:** Solid dark blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Solid black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
* **Generation (Solid Dark Blue Line):** Starts at approximately 0.00 at iteration 1, increases to approximately 0.016 at iteration 2, decreases to approximately 0.00 at iteration 3, remains at approximately 0.00 at iteration 4, and increases to approximately 0.016 at iteration 5.
* **Multiple-Choice (Solid Orange Line):** Starts at approximately 0.084 at iteration 1, decreases to approximately 0.034 at iteration 2, increases to approximately 0.034 at iteration 3, decreases to approximately 0.00 at iteration 4, and increases to approximately 0.034 at iteration 5.
* **Correct Flip (Solid Black Line with Circle Markers):** Starts at approximately 0.00 at iteration 1, increases to approximately 0.016 at iteration 2, increases to approximately 0.016 at iteration 3, decreases to approximately 0.00 at iteration 4, and decreases to approximately 0.00 at iteration 5.
* **Incorrect Flip (Dashed Black Line with Square Markers):** Starts at approximately 0.00 at iteration 1, increases to approximately 0.016 at iteration 2, increases to approximately 0.016 at iteration 3, increases to approximately 0.016 at iteration 4, and increases to approximately 0.034 at iteration 5.
### Key Observations
* The "Multiple-Choice" method has the highest proportion of flips at the first iteration, but it decreases significantly in subsequent iterations.
* The "Generation" method has a relatively low proportion of flips across all iterations.
* The "Correct Flip" and "Incorrect Flip" methods have similar trends, with a slight increase in the proportion of flips over iterations.
### Interpretation
The chart compares the proportion of flips across iterations for different methods (Generation, Multiple-Choice, Correct Flip, and Incorrect Flip) in the SmolLM2-1.7B model. The "Multiple-Choice" method initially has a high proportion of flips, suggesting it might be more prone to errors in the early stages. However, its proportion decreases over iterations, indicating potential improvement. The "Generation" method consistently shows a low proportion of flips, suggesting it is more stable. The "Correct Flip" and "Incorrect Flip" methods show a gradual increase in the proportion of flips, which could be related to the model's learning process or specific characteristics of the data. Overall, the chart provides insights into the performance and stability of different methods in the SmolLM2-1.7B model.
</details>
(a) SmolLM2-1.7B
<details>
<summary>x27.png Details</summary>
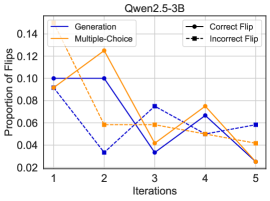
### Visual Description
## Chart: Qwen2.5-3B Flips Proportion vs Iterations
### Overview
The image is a line chart comparing the proportion of flips across iterations for different methods (Generation vs. Multiple-Choice) and flip correctness (Correct Flip vs. Incorrect Flip). The x-axis represents iterations, and the y-axis represents the proportion of flips.
### Components/Axes
* **Title:** Qwen2.5-3B
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.02, 0.04, 0.06, 0.08, 0.10, 0.12, 0.14)
* **Legend:** Located in the top-left and top-right corners.
* **Generation:** Solid dark blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Dashed black line with square markers
* **Incorrect Flip:** Dashed black line with circle markers
### Detailed Analysis
* **Generation (Solid Dark Blue Line):** Starts at approximately 0.10, decreases to approximately 0.03 at iteration 2, increases to approximately 0.03 at iteration 3, increases to approximately 0.07 at iteration 4, and decreases to approximately 0.02 at iteration 5.
* **Multiple-Choice (Solid Orange Line):** Starts at approximately 0.09, increases to approximately 0.12 at iteration 2, decreases to approximately 0.06 at iteration 3, decreases to approximately 0.05 at iteration 4, and decreases to approximately 0.03 at iteration 5.
* **Correct Flip (Dashed Black Line with Square Markers):** Starts at approximately 0.10, decreases to approximately 0.06 at iteration 2, decreases to approximately 0.06 at iteration 3, increases to approximately 0.08 at iteration 4, and decreases to approximately 0.04 at iteration 5.
* **Incorrect Flip (Dashed Black Line with Circle Markers):** Starts at approximately 0.09, decreases to approximately 0.03 at iteration 2, increases to approximately 0.04 at iteration 3, increases to approximately 0.05 at iteration 4, and decreases to approximately 0.02 at iteration 5.
### Key Observations
* The proportion of flips varies across iterations for all methods.
* The Generation method shows a significant drop in the proportion of flips from iteration 1 to iteration 2.
* The Multiple-Choice method shows a peak in the proportion of flips at iteration 2.
* Both Correct Flip and Incorrect Flip methods show a decreasing trend from iteration 1 to iteration 5.
### Interpretation
The chart illustrates how the proportion of flips changes over iterations for different methods (Generation and Multiple-Choice) and flip correctness (Correct and Incorrect). The data suggests that the Generation method is more prone to flips in the initial iterations, while the Multiple-Choice method peaks at iteration 2. The decreasing trend in Correct and Incorrect Flips indicates that the model becomes more stable over iterations. The relationship between the elements shows how different methods and flip types contribute to the overall proportion of flips across iterations. The notable outliers are the peak in Multiple-Choice at iteration 2 and the significant drop in Generation from iteration 1 to iteration 2.
</details>
(b) Qwen2.5-3B
<details>
<summary>x28.png Details</summary>
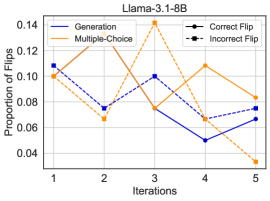
### Visual Description
## Line Chart: Llama-3.1-8B
### Overview
The image is a line chart comparing the proportion of flips across iterations for different methods (Generation, Multiple-Choice) and flip types (Correct Flip, Incorrect Flip) for the Llama-3.1-8B model.
### Components/Axes
* **Title:** Llama-3.1-8B
* **X-axis:** Iterations (labeled 1 to 5)
* **Y-axis:** Proportion of Flips (labeled from 0.04 to 0.14, incrementing by 0.02)
* **Legend:** Located in the top-left and top-right corners.
* **Generation:** Solid dark blue line with square markers.
* **Multiple-Choice:** Solid orange line with circle markers.
* **Correct Flip:** Dashed dark blue line with square markers.
* **Incorrect Flip:** Dashed orange line with circle markers.
### Detailed Analysis
* **Generation (Solid Dark Blue Line):**
* Trend: Decreasing overall.
* Data Points:
* Iteration 1: ~0.108
* Iteration 2: ~0.075
* Iteration 3: ~0.100
* Iteration 4: ~0.050
* Iteration 5: ~0.075
* **Multiple-Choice (Solid Orange Line):**
* Trend: Fluctuating, with a peak at iteration 3 and a sharp drop at iteration 5.
* Data Points:
* Iteration 1: ~0.100
* Iteration 2: ~0.067
* Iteration 3: ~0.140
* Iteration 4: ~0.108
* Iteration 5: ~0.034
* **Correct Flip (Dashed Dark Blue Line):**
* Trend: Increasing overall.
* Data Points:
* Iteration 1: ~0.100
* Iteration 2: ~0.070
* Iteration 3: ~0.075
* Iteration 4: ~0.065
* Iteration 5: ~0.067
* **Incorrect Flip (Dashed Orange Line):**
* Trend: Decreasing overall.
* Data Points:
* Iteration 1: ~0.100
* Iteration 2: ~0.070
* Iteration 3: ~0.075
* Iteration 4: ~0.065
* Iteration 5: ~0.067
### Key Observations
* The "Multiple-Choice" method shows a significant spike in the proportion of flips at iteration 3, followed by a sharp decline at iteration 5.
* The "Generation" method has a decreasing trend in the proportion of flips over the iterations.
* The "Correct Flip" method has a decreasing trend in the proportion of flips over the iterations.
* The "Incorrect Flip" method has a decreasing trend in the proportion of flips over the iterations.
### Interpretation
The chart illustrates how the proportion of flips changes across iterations for different methods and flip types in the Llama-3.1-8B model. The "Multiple-Choice" method's spike at iteration 3 suggests a potential issue or characteristic behavior at that specific iteration. The decreasing trend in "Generation" may indicate a learning or stabilization process as iterations progress. The "Correct Flip" and "Incorrect Flip" methods have a decreasing trend in the proportion of flips over the iterations, which may indicate a learning or stabilization process as iterations progress. The data suggests that the model's behavior varies significantly depending on the method used. Further investigation into the specific mechanisms behind the "Multiple-Choice" spike at iteration 3 could be beneficial.
</details>
(c) Llama-3.1-8B
<details>
<summary>x29.png Details</summary>
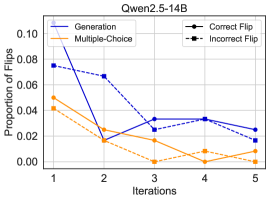
### Visual Description
## Chart: Proportion of Flips vs. Iterations for Qwen2.5-14B
### Overview
The image is a line chart comparing the proportion of flips (presumably in a model's output) across iterations for different methods (Generation vs. Multiple-Choice) and flip types (Correct vs. Incorrect). The chart title is "Qwen2.5-14B".
### Components/Axes
* **Title:** Qwen2.5-14B
* **Y-axis:** "Proportion of Flips" (scale from 0.00 to 0.10, increments of 0.02)
* **X-axis:** "Iterations" (scale from 1 to 5, increments of 1)
* **Legend:** Located at the top-left and top-right of the chart.
* **Generation:** Solid dark blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Dashed dark blue line with square markers
* **Incorrect Flip:** Dashed orange line with square markers
### Detailed Analysis
* **Generation (Solid Dark Blue Line):**
* Trend: Decreases sharply from iteration 1 to 2, then increases slightly from iteration 2 to 4, and decreases again from iteration 4 to 5.
* Data Points:
* Iteration 1: ~0.075
* Iteration 2: ~0.065
* Iteration 3: ~0.033
* Iteration 4: ~0.033
* Iteration 5: ~0.025
* **Multiple-Choice (Solid Orange Line):**
* Trend: Decreases from iteration 1 to 2, remains relatively low from iteration 2 to 4, and increases slightly from iteration 4 to 5.
* Data Points:
* Iteration 1: ~0.05
* Iteration 2: ~0.015
* Iteration 3: ~0.015
* Iteration 4: ~0.00
* Iteration 5: ~0.01
* **Correct Flip (Dashed Dark Blue Line with Square Markers):**
* Trend: Decreases sharply from iteration 1 to 2, then increases from iteration 2 to 4, and decreases again from iteration 4 to 5.
* Data Points:
* Iteration 1: ~0.075
* Iteration 2: ~0.02
* Iteration 3: ~0.025
* Iteration 4: ~0.033
* Iteration 5: ~0.015
* **Incorrect Flip (Dashed Orange Line with Square Markers):**
* Trend: Decreases from iteration 1 to 4, and increases slightly from iteration 4 to 5.
* Data Points:
* Iteration 1: ~0.042
* Iteration 2: ~0.015
* Iteration 3: ~0.00
* Iteration 4: ~0.005
* Iteration 5: ~0.00
### Key Observations
* The "Generation" and "Correct Flip" lines (both dark blue) follow a similar trend, starting high, decreasing, then increasing slightly before decreasing again.
* The "Multiple-Choice" and "Incorrect Flip" lines (both orange) also follow a similar trend, decreasing and remaining low.
* The proportion of flips is generally higher in the first iteration for all methods.
* The proportion of incorrect flips is generally lower than the proportion of correct flips.
### Interpretation
The chart illustrates how the proportion of flips changes over iterations for different methods (Generation vs. Multiple-Choice) and flip types (Correct vs. Incorrect) in the Qwen2.5-14B model. The initial high proportion of flips in the first iteration suggests that the model might be adjusting or learning during this phase. The similar trends between "Generation" and "Correct Flip" and between "Multiple-Choice" and "Incorrect Flip" suggest a correlation between the method used and the type of flip observed. The lower proportion of incorrect flips compared to correct flips indicates that the model is more likely to make correct flips than incorrect ones. The data suggests that the model's performance stabilizes after the initial iterations, with the proportion of flips remaining relatively low.
</details>
(d) Qwen2.5-14B
<details>
<summary>x30.png Details</summary>
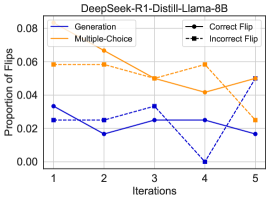
### Visual Description
## Chart: DeepSeek-R1-Distill-Llama-8B Proportion of Flips
### Overview
The image is a line chart comparing the proportion of flips across iterations for different methods (Generation, Multiple-Choice) and flip types (Correct Flip, Incorrect Flip) using the DeepSeek-R1-Distill-Llama-8B model. The x-axis represents iterations, and the y-axis represents the proportion of flips.
### Components/Axes
* **Title:** DeepSeek-R1-Distill-Llama-8B
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.00, 0.02, 0.04, 0.06, 0.08)
* **Legend:** Located in the top-left and top-right corners of the chart.
* **Generation:** Solid blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Black line with circle markers
* **Incorrect Flip:** Dashed black line
### Detailed Analysis
* **Generation (Solid Blue Line):**
* Iteration 1: Approximately 0.033
* Iteration 2: Approximately 0.017
* Iteration 3: Approximately 0.033
* Iteration 4: Approximately 0.000
* Iteration 5: Approximately 0.017
* Trend: Decreases from iteration 1 to 2, increases to iteration 3, decreases sharply to iteration 4, and then increases slightly to iteration 5.
* **Multiple-Choice (Solid Orange Line):**
* Iteration 1: Approximately 0.058
* Iteration 2: Approximately 0.067
* Iteration 3: Approximately 0.050
* Iteration 4: Approximately 0.042
* Iteration 5: Approximately 0.050
* Trend: Increases from iteration 1 to 2, then generally decreases to iteration 4, and increases slightly to iteration 5.
* **Correct Flip (Black Line with Circle Markers):**
* Iteration 1: Approximately 0.025
* Iteration 2: Approximately 0.025
* Iteration 3: Approximately 0.025
* Iteration 4: Approximately 0.058
* Iteration 5: Approximately 0.050
* Trend: Stays constant from iteration 1 to 3, increases sharply to iteration 4, and decreases slightly to iteration 5.
* **Incorrect Flip (Dashed Black Line):**
* Iteration 1: Approximately 0.058
* Iteration 2: Approximately 0.058
* Iteration 3: Approximately 0.050
* Iteration 4: Approximately 0.058
* Iteration 5: Approximately 0.025
* Trend: Stays constant from iteration 1 to 2, decreases to iteration 3, increases to iteration 4, and decreases sharply to iteration 5.
### Key Observations
* The "Generation" method has the lowest proportion of flips at iteration 4.
* The "Multiple-Choice" method generally has a higher proportion of flips compared to the "Generation" method.
* The "Correct Flip" and "Incorrect Flip" lines intersect between iterations 4 and 5.
* The "Correct Flip" line shows a significant increase at iteration 4.
* The "Incorrect Flip" line shows a significant decrease at iteration 5.
### Interpretation
The chart illustrates the performance of the DeepSeek-R1-Distill-Llama-8B model across different iterations, comparing the proportion of flips for different methods and flip types. The "Generation" method appears to be more stable, with lower proportions of flips compared to the "Multiple-Choice" method. The "Correct Flip" and "Incorrect Flip" lines show interesting dynamics, with a notable increase in correct flips at iteration 4 and a corresponding decrease in incorrect flips at iteration 5, suggesting a potential improvement in the model's performance over iterations. The data suggests that the model's ability to correct flips improves significantly at iteration 4, while the number of incorrect flips decreases at iteration 5.
</details>
(e) DeepSeek-R1-Distill-Llama-8B
<details>
<summary>x31.png Details</summary>
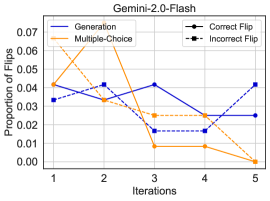
### Visual Description
## Chart: Gemini-2.0-Flash
### Overview
The image is a line chart comparing the proportion of flips across iterations for different methods: Generation, Multiple-Choice, Correct Flip, and Incorrect Flip. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips (0.00 to 0.07).
### Components/Axes
* **Title:** Gemini-2.0-Flash
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.00, 0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07)
* **Legend:** Located in the top-right corner.
* Generation (solid dark blue line)
* Multiple-Choice (solid orange line)
* Correct Flip (dark blue line with circle markers)
* Incorrect Flip (dark blue dashed line with square markers)
### Detailed Analysis
* **Generation (solid dark blue line):**
* Trend: Initially increases, then decreases, and finally increases again.
* Data Points:
* Iteration 1: ~0.033
* Iteration 2: ~0.042
* Iteration 3: ~0.042
* Iteration 4: ~0.025
* Iteration 5: ~0.025
* **Multiple-Choice (solid orange line):**
* Trend: Initially increases sharply, then decreases sharply, plateaus, and decreases again.
* Data Points:
* Iteration 1: ~0.041
* Iteration 2: ~0.065
* Iteration 3: ~0.025
* Iteration 4: ~0.008
* Iteration 5: ~0.000
* **Correct Flip (dark blue line with circle markers):**
* Trend: Decreases, then plateaus.
* Data Points:
* Iteration 1: ~0.033
* Iteration 2: ~0.033
* Iteration 3: ~0.017
* Iteration 4: ~0.025
* Iteration 5: ~0.025
* **Incorrect Flip (dark blue dashed line with square markers):**
* Trend: Decreases, then increases.
* Data Points:
* Iteration 1: ~0.038
* Iteration 2: ~0.042
* Iteration 3: ~0.017
* Iteration 4: ~0.017
* Iteration 5: ~0.042
### Key Observations
* The Multiple-Choice method shows a significant initial increase in the proportion of flips, followed by a sharp decline.
* The Generation method fluctuates more than the Correct Flip and Incorrect Flip methods.
* The Correct Flip and Incorrect Flip methods are relatively stable after the initial iterations.
### Interpretation
The chart compares the proportion of flips across iterations for different methods. The Multiple-Choice method initially leads to a higher proportion of flips, but this quickly decreases. The Generation method shows more fluctuation, while the Correct Flip and Incorrect Flip methods are more stable. This suggests that the Multiple-Choice method might initially introduce more errors or changes, but these are quickly corrected, leading to a lower proportion of flips in later iterations. The Generation method might be more prone to fluctuations, while the Correct Flip and Incorrect Flip methods might represent a more stable baseline.
</details>
(f) Gemini-2.0-Flash
Figure 6: Models Correct and Incorrect Flips on Baseline on DisambiguationQA
<details>
<summary>x32.png Details</summary>
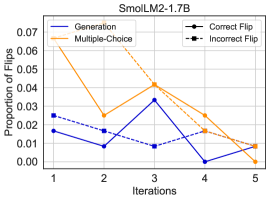
### Visual Description
## Chart: SmolLM2-1.7B Proportion of Flips vs. Iterations
### Overview
The image is a line chart comparing the proportion of flips across iterations for different methods (Generation, Multiple-Choice) and flip types (Correct Flip, Incorrect Flip) for SmolLM2-1.7B. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips (0.00 to 0.07).
### Components/Axes
* **Title:** SmolLM2-1.7B
* **X-axis:** Iterations (labeled 1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (labeled 0.00, 0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07)
* **Legend:** Located at the top-right of the chart.
* Generation (solid blue line)
* Multiple-Choice (solid orange line)
* Correct Flip (dashed black line with circular markers)
* Incorrect Flip (dashed black line with square markers)
### Detailed Analysis
* **Generation (Solid Blue Line):**
* Trend: Initially decreases, then increases, then decreases again.
* Data Points:
* Iteration 1: ~0.017
* Iteration 2: ~0.008
* Iteration 3: ~0.033
* Iteration 4: ~0.000
* Iteration 5: ~0.008
* **Multiple-Choice (Solid Orange Line):**
* Trend: Decreases, then increases, then decreases.
* Data Points:
* Iteration 1: ~0.065
* Iteration 2: ~0.025
* Iteration 3: ~0.042
* Iteration 4: ~0.025
* Iteration 5: ~0.008
* **Correct Flip (Dashed Black Line with Circular Markers):**
* Trend: Decreases slightly, then remains relatively stable.
* Data Points:
* Iteration 1: ~0.017
* Iteration 2: ~0.015
* Iteration 3: ~0.008
* Iteration 4: ~0.015
* Iteration 5: ~0.008
* **Incorrect Flip (Dashed Black Line with Square Markers):**
* Trend: Decreases, then increases, then decreases.
* Data Points:
* Iteration 1: ~0.025
* Iteration 2: ~0.016
* Iteration 3: ~0.008
* Iteration 4: ~0.016
* Iteration 5: ~0.008
### Key Observations
* The "Multiple-Choice" method starts with a higher proportion of flips but decreases significantly over iterations.
* The "Generation" method shows more fluctuation in the proportion of flips.
* The "Correct Flip" proportion remains relatively stable across iterations.
* The "Incorrect Flip" proportion decreases and then increases slightly.
### Interpretation
The chart illustrates how the proportion of flips changes across iterations for different methods and flip types in SmolLM2-1.7B. The "Multiple-Choice" method initially has a higher proportion of flips, suggesting it might be more prone to errors early on, but it improves significantly with more iterations. The "Generation" method's fluctuations indicate a less consistent performance. The relatively stable "Correct Flip" proportion suggests a consistent level of correct adjustments. The "Incorrect Flip" proportion shows a decrease, indicating an improvement in reducing incorrect adjustments over iterations. The data suggests that the model's performance varies depending on the method used and the type of flip being made.
</details>
(a) SmolLM2-1.7B
<details>
<summary>x33.png Details</summary>
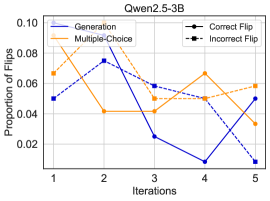
### Visual Description
## Chart: Proportion of Flips vs. Iterations for Qwen2.5-3B
### Overview
The image is a line chart comparing the proportion of flips (correct and incorrect) across iterations for two methods: Generation and Multiple-Choice, using the Qwen2.5-3B model. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips (0.00 to 0.10).
### Components/Axes
* **Title:** Qwen2.5-3B
* **X-axis:** Iterations (labeled 1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (labeled 0.02, 0.04, 0.06, 0.08, 0.10)
* **Legend:** Located at the top-left and top-right of the chart.
* **Generation:** Solid blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Solid black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
* **Generation:**
* Trend: Generally decreasing over iterations.
* Data Points:
* Iteration 1: ~0.05
* Iteration 2: ~0.075
* Iteration 3: ~0.025
* Iteration 4: ~0.01
* Iteration 5: ~0.008
* **Multiple-Choice:**
* Trend: Fluctuating, with peaks at iterations 1 and 4.
* Data Points:
* Iteration 1: ~0.09
* Iteration 2: ~0.042
* Iteration 3: ~0.042
* Iteration 4: ~0.067
* Iteration 5: ~0.03
* **Correct Flip:**
* Trend: Fluctuating, with a peak at iteration 1.
* Data Points:
* Iteration 1: ~0.07
* Iteration 2: ~0.04
* Iteration 3: ~0.05
* Iteration 4: ~0.05
* Iteration 5: ~0.06
* **Incorrect Flip:**
* Trend: Fluctuating, with a peak at iteration 2.
* Data Points:
* Iteration 1: ~0.05
* Iteration 2: ~0.08
* Iteration 3: ~0.06
* Iteration 4: ~0.05
* Iteration 5: ~0.05
### Key Observations
* The "Generation" method shows a decreasing trend in the proportion of flips as iterations increase.
* The "Multiple-Choice" method fluctuates more, with no clear trend.
* The proportion of "Correct Flips" and "Incorrect Flips" are relatively close to each other across all iterations.
### Interpretation
The chart suggests that the "Generation" method becomes more stable and potentially more accurate (fewer flips) as the model iterates. The "Multiple-Choice" method, however, does not show a similar improvement and remains more variable. The proximity of "Correct Flip" and "Incorrect Flip" proportions indicates that the model is making both types of adjustments throughout the iterations, with no clear dominance of one over the other. The data implies that the "Generation" method might be a more effective approach for this particular task with the Qwen2.5-3B model, as it demonstrates a tendency to converge towards a more stable state.
</details>
(b) Qwen2.5-3B
<details>
<summary>x34.png Details</summary>
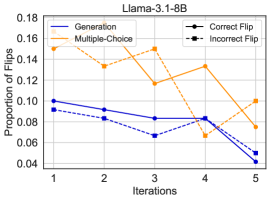
### Visual Description
## Chart: Llama-3.1-8B Proportion of Flips
### Overview
The image is a line chart comparing the proportion of flips across iterations for two methods: Generation and Multiple-Choice. It also distinguishes between Correct and Incorrect Flips. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips (0.04 to 0.18).
### Components/Axes
* **Title:** Llama-3.1-8B
* **X-axis:** Iterations (labeled 1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (labeled 0.04, 0.06, 0.08, 0.10, 0.12, 0.14, 0.16, 0.18)
* **Legend:** Located at the top-right of the chart.
* **Generation:** Solid blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Solid black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
* **Generation:**
* Trend: Generally decreasing.
* Iteration 1: ~0.092
* Iteration 2: ~0.092
* Iteration 3: ~0.083
* Iteration 4: ~0.083
* Iteration 5: ~0.042
* **Multiple-Choice:**
* Trend: Fluctuating, with an overall decrease.
* Iteration 1: ~0.152
* Iteration 2: ~0.133
* Iteration 3: ~0.152
* Iteration 4: ~0.133
* Iteration 5: ~0.078
* **Correct Flip:**
* Trend: Decreasing.
* Iteration 1: ~0.10
* Iteration 2: ~0.083
* Iteration 3: ~0.067
* Iteration 4: ~0.075
* Iteration 5: ~0.05
* **Incorrect Flip:**
* Trend: Decreasing.
* Iteration 1: ~0.092
* Iteration 2: ~0.083
* Iteration 3: ~0.067
* Iteration 4: ~0.075
* Iteration 5: ~0.042
### Key Observations
* The proportion of flips for both Generation and Multiple-Choice methods decreases over iterations.
* The Multiple-Choice method starts with a higher proportion of flips but ends up lower than the Generation method by the 5th iteration.
* The "Correct Flip" and "Incorrect Flip" lines are very close to each other, and both show a decreasing trend.
### Interpretation
The chart suggests that as the Llama-3.1-8B model iterates, the proportion of flips decreases for both Generation and Multiple-Choice methods, indicating improved stability or convergence. The Multiple-Choice method initially has a higher proportion of flips, possibly due to the nature of selecting from multiple options, but it decreases more significantly than the Generation method. The close proximity of the "Correct Flip" and "Incorrect Flip" lines suggests that the model's ability to correct or incorrectly flip its decisions is relatively consistent across iterations. The overall decreasing trend indicates that the model becomes more consistent in its decisions as it iterates.
</details>
(c) Llama-3.1-8B
<details>
<summary>x35.png Details</summary>
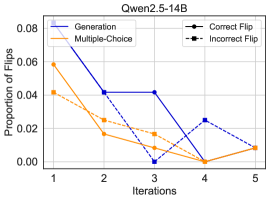
### Visual Description
## Chart: Qwen2.5-14B Flips Proportion vs Iterations
### Overview
The image is a line chart comparing the proportion of flips across iterations for different methods (Generation, Multiple-Choice) and flip types (Correct Flip, Incorrect Flip) using the Qwen2.5-14B model. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips.
### Components/Axes
* **Title:** Qwen2.5-14B
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.00 to 0.08, incrementing by 0.02)
* **Legend (Top-Left):**
* Generation (Solid Blue Line)
* Multiple-Choice (Solid Orange Line)
* **Legend (Top-Right):**
* Correct Flip (Solid Black Line with Circle Markers)
* Incorrect Flip (Dashed Black Line with Square Markers)
### Detailed Analysis
**1. Generation (Solid Blue Line):**
* Trend: Decreases from iteration 1 to 3, remains constant from iteration 2 to 3, then decreases to iteration 4, then increases to iteration 5.
* Data Points:
* Iteration 1: ~0.072
* Iteration 2: ~0.042
* Iteration 3: ~0.042
* Iteration 4: ~0.00
* Iteration 5: ~0.025
**2. Multiple-Choice (Solid Orange Line):**
* Trend: Decreases from iteration 1 to 4, then increases slightly to iteration 5.
* Data Points:
* Iteration 1: ~0.058
* Iteration 2: ~0.017
* Iteration 3: ~0.008
* Iteration 4: ~0.00
* Iteration 5: ~0.008
**3. Correct Flip (Solid Black Line with Circle Markers):**
* Trend: Decreases from iteration 1 to 3, then increases to iteration 5.
* Data Points:
* Iteration 1: ~0.042
* Iteration 2: ~0.028
* Iteration 3: ~0.017
* Iteration 4: ~0.00
* Iteration 5: ~0.008
**4. Incorrect Flip (Dashed Black Line with Square Markers):**
* Trend: Decreases from iteration 1 to 4, then increases to iteration 5.
* Data Points:
* Iteration 1: ~0.042
* Iteration 2: ~0.028
* Iteration 3: ~0.017
* Iteration 4: ~0.00
* Iteration 5: ~0.008
### Key Observations
* The "Generation" method starts with a higher proportion of flips compared to "Multiple-Choice," but both converge to a low proportion by iteration 4.
* Both "Correct Flip" and "Incorrect Flip" start with similar proportions, decrease to near zero by iteration 4, and then slightly increase at iteration 5.
* Iteration 4 appears to be a point of significant reduction in the proportion of flips for all methods.
### Interpretation
The chart suggests that both the "Generation" and "Multiple-Choice" methods, along with "Correct Flip" and "Incorrect Flip", become more stable or accurate over iterations, as indicated by the decreasing proportion of flips. The convergence towards zero at iteration 4 implies a potential stabilization point in the model's learning or decision-making process. The slight increase at iteration 5 could indicate a minor adjustment or fluctuation in the model's behavior. The data demonstrates the impact of iterative refinement on the Qwen2.5-14B model's performance, highlighting the potential for improved accuracy with successive iterations.
</details>
(d) Qwen2.5-14B
<details>
<summary>x36.png Details</summary>
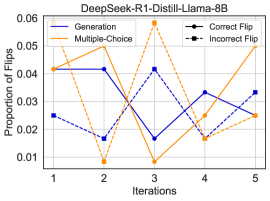
### Visual Description
## Chart: Proportion of Flips vs. Iterations for DeepSeek-R1-Distill-Llama-8B
### Overview
The image is a line chart comparing the proportion of flips across iterations for two different methods: Generation and Multiple-Choice. It also distinguishes between correct and incorrect flips. The chart title is "DeepSeek-R1-Distill-Llama-8B".
### Components/Axes
* **Title:** DeepSeek-R1-Distill-Llama-8B
* **X-axis:** Iterations (labeled 1 to 5)
* **Y-axis:** Proportion of Flips (ranging from 0.01 to 0.06)
* **Legend:** Located at the top-left and top-right of the chart.
* **Generation:** Solid dark blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Solid black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
* **Generation (Solid Dark Blue Line):**
* Trend: Starts at approximately 0.042, decreases to approximately 0.017 at iteration 3, increases to approximately 0.033 at iteration 4, and ends at approximately 0.033 at iteration 5.
* Data Points:
* Iteration 1: ~0.042
* Iteration 2: ~0.042
* Iteration 3: ~0.017
* Iteration 4: ~0.033
* Iteration 5: ~0.033
* **Multiple-Choice (Solid Orange Line):**
* Trend: Starts at approximately 0.042, decreases to approximately 0.008 at iteration 2, increases to approximately 0.058 at iteration 3, decreases to approximately 0.017 at iteration 4, and ends at approximately 0.025 at iteration 5.
* Data Points:
* Iteration 1: ~0.042
* Iteration 2: ~0.008
* Iteration 3: ~0.058
* Iteration 4: ~0.017
* Iteration 5: ~0.025
* **Correct Flip (Solid Black Line with Circle Markers):**
* Trend: Starts at approximately 0.025, decreases to approximately 0.016 at iteration 2, increases to approximately 0.041 at iteration 3, decreases to approximately 0.017 at iteration 4, and ends at approximately 0.033 at iteration 5.
* Data Points:
* Iteration 1: ~0.025
* Iteration 2: ~0.016
* Iteration 3: ~0.041
* Iteration 4: ~0.017
* Iteration 5: ~0.033
* **Incorrect Flip (Dashed Black Line with Square Markers):**
* Trend: Starts at approximately 0.041, decreases to approximately 0.008 at iteration 2, increases to approximately 0.058 at iteration 3, decreases to approximately 0.017 at iteration 4, and ends at approximately 0.025 at iteration 5.
* Data Points:
* Iteration 1: ~0.041
* Iteration 2: ~0.008
* Iteration 3: ~0.058
* Iteration 4: ~0.017
* Iteration 5: ~0.025
### Key Observations
* The proportion of flips varies significantly across iterations for both Generation and Multiple-Choice methods.
* The Multiple-Choice method shows a more drastic fluctuation in the proportion of flips compared to the Generation method.
* The "Correct Flip" and "Incorrect Flip" lines appear to mirror the "Generation" and "Multiple-Choice" lines, respectively, suggesting a correlation between the method and the type of flip.
### Interpretation
The chart illustrates the performance of the DeepSeek-R1-Distill-Llama-8B model in terms of the proportion of flips during different iterations, comparing Generation and Multiple-Choice methods. The fluctuations in the proportion of flips indicate the model's learning and adaptation process over iterations. The mirroring of the "Correct Flip" and "Incorrect Flip" lines with the "Generation" and "Multiple-Choice" lines suggests that the choice of method significantly influences the type of flips observed. The Multiple-Choice method, with its more drastic fluctuations, might be more sensitive to changes during the iterations, potentially leading to both higher proportions of incorrect flips and more significant improvements. The data suggests that the model's performance is not consistent across iterations and that the choice of method plays a crucial role in the type and frequency of flips.
</details>
(e) DeepSeek-R1-Distill-Llama-8B
<details>
<summary>x37.png Details</summary>
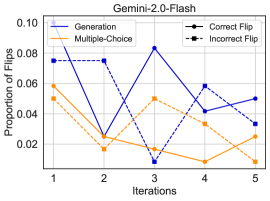
### Visual Description
## Line Chart: Gemini-2.0-Flash
### Overview
The image is a line chart titled "Gemini-2.0-Flash" that displays the proportion of flips across five iterations for different categories: Generation, Multiple-Choice, Correct Flip, and Incorrect Flip. The chart uses different line styles and colors to distinguish between these categories.
### Components/Axes
* **Title:** Gemini-2.0-Flash
* **X-axis:** Iterations, labeled from 1 to 5.
* **Y-axis:** Proportion of Flips, ranging from 0.00 to 0.10, with increments of 0.02.
* **Legend:** Located in the top-left and top-right corners of the chart.
* **Generation:** Solid navy blue line.
* **Multiple-Choice:** Solid orange line.
* **Correct Flip:** Solid black line with circle markers.
* **Incorrect Flip:** Dashed black line with square markers.
### Detailed Analysis
* **Generation (Solid Navy Blue Line):**
* Trend: Fluctuates across iterations.
* Iteration 1: Approximately 0.075
* Iteration 2: Approximately 0.075
* Iteration 3: Approximately 0.01
* Iteration 4: Approximately 0.042
* Iteration 5: Approximately 0.05
* **Multiple-Choice (Solid Orange Line):**
* Trend: Decreases initially, then fluctuates.
* Iteration 1: Approximately 0.058
* Iteration 2: Approximately 0.022
* Iteration 3: Approximately 0.05
* Iteration 4: Approximately 0.008
* Iteration 5: Approximately 0.028
* **Correct Flip (Solid Black Line with Circle Markers):**
* Trend: Increases, peaks at iteration 3, then decreases.
* Iteration 1: Approximately 0.075
* Iteration 2: Approximately 0.025
* Iteration 3: Approximately 0.084
* Iteration 4: Approximately 0.04
* Iteration 5: Approximately 0.032
* **Incorrect Flip (Dashed Black Line with Square Markers):**
* Trend: Decreases, then increases, then decreases.
* Iteration 1: Approximately 0.05
* Iteration 2: Approximately 0.075
* Iteration 3: Approximately 0.015
* Iteration 4: Approximately 0.058
* Iteration 5: Approximately 0.032
### Key Observations
* The "Generation" and "Correct Flip" lines show similar trends, with peaks and valleys at similar iteration points.
* The "Multiple-Choice" line generally decreases over the iterations.
* The "Incorrect Flip" line has a notable peak at iteration 2.
* The proportion of flips varies significantly across iterations for all categories.
### Interpretation
The chart illustrates how the proportion of flips changes across iterations for different methods or categories within the "Gemini-2.0-Flash" system. The fluctuations suggest that the system's behavior varies with each iteration. The "Generation" and "Correct Flip" lines moving in tandem could indicate a relationship between these two categories. The decreasing trend of "Multiple-Choice" might suggest that this method becomes less prone to flips as iterations progress. The peak in "Incorrect Flip" at iteration 2 could indicate a specific issue or change in the system at that point. Further analysis would be needed to understand the underlying causes of these trends and their implications for the system's performance.
</details>
(f) Gemini-2.0-Flash
Figure 7: Models Correct and Incorrect Flips on CoT on DisambiguationQA
<details>
<summary>x38.png Details</summary>
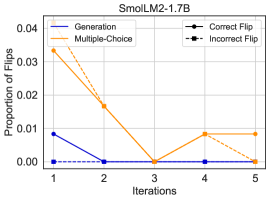
### Visual Description
## Chart: Proportion of Flips vs. Iterations for SmolLM2-1.7B
### Overview
The image is a line chart comparing the proportion of flips (presumably in a model's output) across iterations for different methods: Generation and Multiple-Choice. It also distinguishes between correct and incorrect flips. The chart shows how the proportion of flips changes over five iterations for each method.
### Components/Axes
* **Title:** SmolLM2-1.7B
* **X-axis:** Iterations (labeled 1 to 5)
* **Y-axis:** Proportion of Flips (ranging from 0.00 to 0.04)
* **Legend:** Located at the top-left and top-right of the chart.
* **Generation:** Solid dark blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Solid black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
* **Generation:**
* The proportion of flips starts at approximately 0.008 at iteration 1 and drops to approximately 0.00 at iteration 2, remaining at 0.00 for iterations 3, 4, and 5.
* The trend is a sharp decrease from iteration 1 to 2, then a flat line.
* **Multiple-Choice:**
* The proportion of flips starts at approximately 0.034 at iteration 1, decreases to approximately 0.016 at iteration 2, and then drops to approximately 0.00 at iteration 3. It then increases to approximately 0.008 at iteration 4, and remains at approximately 0.008 at iteration 5.
* The trend is a decrease from iteration 1 to 3, followed by a slight increase at iteration 4, and then a flat line.
* **Correct Flip:**
* The proportion of flips is approximately 0.00 for all iterations.
* The trend is a flat line at 0.00.
* **Incorrect Flip:**
* The proportion of flips is approximately 0.00 for all iterations.
* The trend is a flat line at 0.00.
### Key Observations
* The Generation method has a higher initial proportion of flips compared to the Multiple-Choice method, but it quickly drops to zero and remains there.
* The Multiple-Choice method starts with a higher proportion of flips, decreases, and then plateaus at a low value.
* Both Correct Flip and Incorrect Flip remain at a proportion of 0.00 across all iterations.
### Interpretation
The data suggests that the Generation method is initially more prone to flips but quickly stabilizes, while the Multiple-Choice method exhibits a more gradual decrease in the proportion of flips. The fact that both Correct Flip and Incorrect Flip remain at zero indicates that the model is not making any flips that are either correct or incorrect, suggesting a high level of confidence in its predictions or a lack of exploration. The difference in the initial proportion of flips between Generation and Multiple-Choice could be due to the different approaches used by these methods. The stabilization of the Generation method could indicate that it quickly learns to avoid flips, while the Multiple-Choice method may require more iterations to reach a similar level of stability.
</details>
(a) SmolLM2-1.7B
<details>
<summary>x39.png Details</summary>
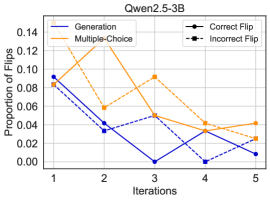
### Visual Description
## Chart: Proportion of Flips vs. Iterations for Qwen2.5-3B
### Overview
The image is a line chart comparing the proportion of flips (presumably in some kind of decision-making process) across iterations for different methods (Generation vs. Multiple-Choice) and correctness (Correct Flip vs. Incorrect Flip) using the Qwen2.5-3B model.
### Components/Axes
* **Title:** Qwen2.5-3B
* **X-axis:** Iterations (labeled 1 to 5)
* **Y-axis:** Proportion of Flips (ranging from 0.00 to 0.14)
* **Legend:** Located in the top-left and top-right of the chart.
* **Generation:** Solid dark blue line
* **Multiple-Choice:** Dashed orange line
* **Correct Flip:** Solid black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
* **Generation (Solid Dark Blue):**
* Trend: Decreasing, then slightly increasing.
* Data Points:
* Iteration 1: ~0.09
* Iteration 2: ~0.04
* Iteration 3: ~0.00
* Iteration 4: ~0.00
* Iteration 5: ~0.01
* **Multiple-Choice (Dashed Orange):**
* Trend: Increasing, then decreasing.
* Data Points:
* Iteration 1: ~0.09
* Iteration 2: ~0.12
* Iteration 3: ~0.09
* Iteration 4: ~0.03
* Iteration 5: ~0.03
* **Correct Flip (Solid Black with Circle Markers):**
* Trend: Decreasing.
* Data Points:
* Iteration 1: ~0.09
* Iteration 2: ~0.06
* Iteration 3: ~0.05
* Iteration 4: ~0.03
* Iteration 5: ~0.02
* **Incorrect Flip (Dashed Black with Square Markers):**
* Trend: Decreasing.
* Data Points:
* Iteration 1: ~0.08
* Iteration 2: ~0.03
* Iteration 3: ~0.05
* Iteration 4: ~0.00
* Iteration 5: ~0.03
### Key Observations
* The "Generation" method shows a significant drop in the proportion of flips, reaching near-zero at iterations 3 and 4.
* The "Multiple-Choice" method peaks at iteration 2 and then declines.
* Both "Correct Flip" and "Incorrect Flip" generally decrease over iterations.
* The "Incorrect Flip" line is below the "Correct Flip" line for the first 3 iterations, but they converge at iteration 5.
### Interpretation
The chart illustrates how the proportion of flips changes over iterations for different methods and correctness types in the Qwen2.5-3B model. The "Generation" method appears to stabilize more quickly, resulting in fewer flips after a few iterations. The "Multiple-Choice" method initially increases the proportion of flips before decreasing. The decreasing trends in "Correct Flip" and "Incorrect Flip" suggest that the model becomes more consistent in its decisions over time. The convergence of "Correct Flip" and "Incorrect Flip" at iteration 5 may indicate a point where the model's flips are equally likely to be correct or incorrect.
</details>
(b) Qwen2.5-3B
<details>
<summary>x40.png Details</summary>
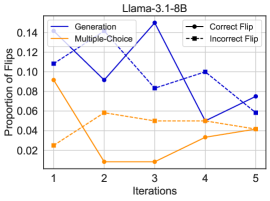
### Visual Description
## Line Chart: Llama-3.1-8B
### Overview
The image is a line chart comparing the proportion of flips across iterations for different methods (Generation vs. Multiple-Choice) and flip types (Correct Flip vs. Incorrect Flip) for the Llama-3.1-8B model.
### Components/Axes
* **Title:** Llama-3.1-8B
* **X-axis:** Iterations (labeled 1 to 5)
* **Y-axis:** Proportion of Flips (ranging from 0.02 to 0.14)
* **Legend (top-left):**
* **Blue solid line:** Generation
* **Orange solid line:** Multiple-Choice
* **Legend (top-right):**
* **Black solid line with circle markers:** Correct Flip
* **Black dashed line with square markers:** Incorrect Flip
### Detailed Analysis
* **Generation (Blue solid line):**
* Trend: Initially increases, peaks at iteration 3, then decreases.
* Data Points:
* Iteration 1: ~0.11
* Iteration 2: ~0.09
* Iteration 3: ~0.15
* Iteration 4: ~0.08
* Iteration 5: ~0.06
* **Multiple-Choice (Orange solid line):**
* Trend: Decreases sharply from iteration 1 to 2, remains low until iteration 4, then increases.
* Data Points:
* Iteration 1: ~0.09
* Iteration 2: ~0.01
* Iteration 3: ~0.01
* Iteration 4: ~0.03
* Iteration 5: ~0.04
* **Correct Flip (Black solid line with circle markers):**
* Trend: Increases slightly from iteration 4 to 5.
* Data Points:
* Iteration 5: ~0.075
* **Incorrect Flip (Black dashed line with square markers):**
* Trend: Decreases from iteration 1 to 4, then increases slightly.
* Data Points:
* Iteration 1: ~0.11
* Iteration 2: ~0.06
* Iteration 3: ~0.05
* Iteration 4: ~0.05
* Iteration 5: ~0.07
### Key Observations
* The Generation method shows a peak in the proportion of flips at iteration 3.
* The Multiple-Choice method has a significantly lower proportion of flips compared to the Generation method, especially between iterations 2 and 4.
* The proportion of incorrect flips is higher than the proportion of correct flips.
### Interpretation
The chart illustrates the performance of the Llama-3.1-8B model in terms of the proportion of flips during different iterations for Generation and Multiple-Choice methods. The Generation method initially struggles but stabilizes, while the Multiple-Choice method consistently performs better with a lower proportion of flips. The higher proportion of incorrect flips suggests that the model is more prone to making mistakes during the flipping process. The data suggests that the Multiple-Choice method is more reliable for this model in terms of minimizing flips.
</details>
(c) Llama-3.1-8B
<details>
<summary>x41.png Details</summary>
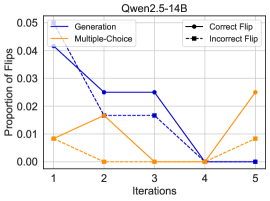
### Visual Description
## Chart: Proportion of Flips vs. Iterations for Qwen2.5-14B
### Overview
The image is a line chart comparing the proportion of flips (correct and incorrect) across iterations for two methods: Generation and Multiple-Choice, using the Qwen2.5-14B model. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips (0.00 to 0.05).
### Components/Axes
* **Title:** Qwen2.5-14B
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.00, 0.01, 0.02, 0.03, 0.04, 0.05)
* **Legend:** Located in the top-left and top-right corners.
* **Generation:** Solid dark blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Solid black line with circular markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
* **Generation (Solid Dark Blue Line):**
* Trend: Decreasing from iteration 1 to 5.
* Data Points:
* Iteration 1: ~0.042
* Iteration 2: ~0.025
* Iteration 3: ~0.025
* Iteration 4: ~0.000
* Iteration 5: ~0.000
* **Multiple-Choice (Solid Orange Line):**
* Trend: Decreasing from iteration 1 to 4, then increasing to iteration 5.
* Data Points:
* Iteration 1: ~0.008
* Iteration 2: ~0.017
* Iteration 3: ~0.000
* Iteration 4: ~0.000
* Iteration 5: ~0.025
* **Correct Flip (Solid Black Line with Circular Markers):**
* Trend: Decreasing from iteration 1 to 4, then increasing to iteration 5.
* Data Points:
* Iteration 1: ~0.042
* Iteration 2: ~0.017
* Iteration 3: ~0.017
* Iteration 4: ~0.000
* Iteration 5: ~0.000
* **Incorrect Flip (Dashed Black Line with Square Markers):**
* Trend: Decreasing from iteration 1 to 4, then increasing to iteration 5.
* Data Points:
* Iteration 1: ~0.008
* Iteration 2: ~0.000
* Iteration 3: ~0.000
* Iteration 4: ~0.000
* Iteration 5: ~0.008
### Key Observations
* The "Generation" method starts with a higher proportion of flips but decreases to zero by iteration 4.
* The "Multiple-Choice" method starts low, decreases to zero by iteration 4, and then increases at iteration 5.
* The "Correct Flip" and "Incorrect Flip" lines mirror the trends of "Generation" and "Multiple-Choice" respectively.
### Interpretation
The chart illustrates how the proportion of flips changes over iterations for two different methods (Generation and Multiple-Choice) in the Qwen2.5-14B model. The "Generation" method initially has a higher proportion of flips, suggesting it might be more prone to errors early on, but it quickly converges to zero. The "Multiple-Choice" method starts with a lower error rate, remains stable for a few iterations, but then increases at iteration 5, indicating a potential issue with later iterations. The "Correct Flip" and "Incorrect Flip" lines likely represent the breakdown of flips within each method, showing how many were corrected versus how many remained incorrect. The data suggests that the "Generation" method might benefit from early intervention to reduce initial flips, while the "Multiple-Choice" method might need attention in later iterations to prevent the increase in flips.
</details>
(d) Qwen2.5-14B
<details>
<summary>x42.png Details</summary>
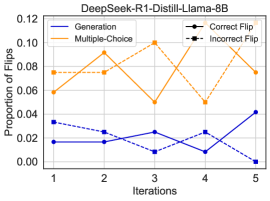
### Visual Description
## Chart: DeepSeek-R1-Distill-Llama-8B Flips
### Overview
The image is a line chart comparing the proportion of flips across iterations for two methods: Generation and Multiple-Choice. It also distinguishes between correct and incorrect flips. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips (0.00 to 0.12).
### Components/Axes
* **Title:** DeepSeek-R1-Distill-Llama-8B
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.00, 0.02, 0.04, 0.06, 0.08, 0.10, 0.12)
* **Legend:** Located at the top-left of the chart.
* **Generation:** Solid blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Solid black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
* **Generation (Solid Blue):**
* Trend: Generally increasing with fluctuations.
* Iteration 1: ~0.017
* Iteration 2: ~0.017
* Iteration 3: ~0.008
* Iteration 4: ~0.025
* Iteration 5: ~0.042
* **Multiple-Choice (Solid Orange):**
* Trend: Fluctuating, with a peak at iteration 3.
* Iteration 1: ~0.059
* Iteration 2: ~0.092
* Iteration 3: ~0.100
* Iteration 4: ~0.050
* Iteration 5: ~0.078
* **Correct Flip (Solid Black with Circle Markers):**
* Trend: Decreasing, then increasing, then decreasing.
* Iteration 1: ~0.075
* Iteration 2: ~0.075
* Iteration 3: ~0.050
* Iteration 4: ~0.100
* Iteration 5: ~0.050
* **Incorrect Flip (Dashed Black with Square Markers):**
* Trend: Decreasing, then increasing, then decreasing.
* Iteration 1: ~0.033
* Iteration 2: ~0.025
* Iteration 3: ~0.025
* Iteration 4: ~0.008
* Iteration 5: ~0.000
### Key Observations
* The proportion of flips for the Multiple-Choice method is generally higher than the Generation method.
* The proportion of correct flips is higher than the proportion of incorrect flips.
* Both the "Correct Flip" and "Incorrect Flip" lines show a similar trend, decreasing initially and then increasing.
### Interpretation
The chart compares the performance of two methods, Generation and Multiple-Choice, in terms of the proportion of flips across iterations. The data suggests that the Multiple-Choice method tends to have a higher proportion of flips compared to the Generation method. The distinction between correct and incorrect flips provides further insight into the quality of these flips. The trends observed in the "Correct Flip" and "Incorrect Flip" lines indicate that the model's ability to make correct flips fluctuates over iterations. The model seems to be learning and adjusting its behavior over the iterations, as evidenced by the changes in the proportion of flips.
</details>
(e) DeepSeek-R1-Distill-Llama-8B
<details>
<summary>x43.png Details</summary>
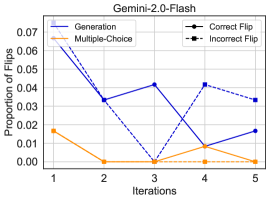
### Visual Description
## Line Chart: Gemini-2.0-Flash
### Overview
The image is a line chart titled "Gemini-2.0-Flash". It displays the proportion of flips across iterations for different categories: Generation, Multiple-Choice, Correct Flip, and Incorrect Flip. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips (0.00 to 0.07).
### Components/Axes
* **Title:** Gemini-2.0-Flash
* **X-axis:**
* Label: Iterations
* Scale: 1, 2, 3, 4, 5
* **Y-axis:**
* Label: Proportion of Flips
* Scale: 0.00, 0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07
* **Legend:** Located in the top-right corner.
* Generation (solid dark blue line)
* Multiple-Choice (solid orange line)
* Correct Flip (solid dark blue line with circle markers)
* Incorrect Flip (dashed dark blue line with square markers)
### Detailed Analysis
* **Generation:** The solid dark blue line starts at approximately 0.065 at iteration 1, decreases to approximately 0.033 at iteration 2, increases to approximately 0.042 at iteration 3, decreases to approximately 0.008 at iteration 4, and increases to approximately 0.017 at iteration 5.
* **Multiple-Choice:** The solid orange line starts at approximately 0.017 at iteration 1, decreases to approximately 0.000 at iteration 2, remains at approximately 0.000 at iteration 3, remains at approximately 0.000 at iteration 4, and remains at approximately 0.000 at iteration 5.
* **Correct Flip:** The solid dark blue line with circle markers starts at approximately 0.065 at iteration 1, decreases to approximately 0.033 at iteration 2, increases to approximately 0.042 at iteration 3, decreases to approximately 0.008 at iteration 4, and increases to approximately 0.017 at iteration 5.
* **Incorrect Flip:** The dashed dark blue line with square markers starts at approximately 0.065 at iteration 1, decreases to approximately 0.033 at iteration 2, increases to approximately 0.042 at iteration 3, increases to approximately 0.042 at iteration 4, and decreases to approximately 0.033 at iteration 5.
### Key Observations
* The proportion of flips for "Multiple-Choice" is consistently low across all iterations.
* The "Generation" and "Correct Flip" lines overlap completely.
* The "Incorrect Flip" line shows a more fluctuating pattern compared to "Multiple-Choice".
### Interpretation
The chart compares the proportion of flips across iterations for different methods or categories within the "Gemini-2.0-Flash" system. The "Multiple-Choice" category consistently has a very low proportion of flips, suggesting it is more stable or reliable. The overlapping "Generation" and "Correct Flip" lines indicate that these two categories have identical flip proportions across all iterations. The "Incorrect Flip" line's fluctuations suggest that the incorrect flips vary more significantly with each iteration. The data suggests that the "Multiple-Choice" method is significantly more stable than the other methods.
</details>
(f) Gemini-2.0-Flash
Figure 8: Models Correct and Incorrect Flips on SC on DisambiguationQA
<details>
<summary>x44.png Details</summary>
### Visual Description
## Chart: SmolLM2-1.7B
### Overview
The image is a line chart comparing the proportion of flips across iterations for different methods (Generation, Multiple-Choice, Correct Flip, and Incorrect Flip) in the SmolLM2-1.7B model. The x-axis represents iterations (from 1 to 5), and the y-axis represents the proportion of flips.
### Components/Axes
* **Title:** SmolLM2-1.7B
* **X-axis:** Iterations (labeled 1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (labeled 0.00, 0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07)
* **Legend:** Located in the top-left and top-right of the chart.
* **Generation:** Solid dark blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Solid black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
* **Generation (Solid Dark Blue Line):**
* Trend: Fluctuating, with a peak at iteration 3.
* Data Points:
* Iteration 1: ~0.042
* Iteration 2: ~0.042
* Iteration 3: ~0.073
* Iteration 4: ~0.021
* Iteration 5: ~0.021
* **Multiple-Choice (Solid Orange Line):**
* Trend: Decreasing to zero and remaining at zero.
* Data Points:
* Iteration 1: ~0.032
* Iteration 2: ~0.000
* Iteration 3: ~0.000
* Iteration 4: ~0.000
* Iteration 5: ~0.000
* **Correct Flip (Solid Black Line with Circle Markers):**
* Trend: Remains at zero across all iterations.
* Data Points:
* Iteration 1: ~0.000
* Iteration 2: ~0.000
* Iteration 3: ~0.000
* Iteration 4: ~0.000
* Iteration 5: ~0.000
* **Incorrect Flip (Dashed Black Line with Square Markers):**
* Trend: Decreases, then increases, then decreases again.
* Data Points:
* Iteration 1: ~0.060
* Iteration 2: ~0.031
* Iteration 3: ~0.031
* Iteration 4: ~0.042
* Iteration 5: ~0.031
### Key Observations
* The "Generation" method shows significant fluctuation in the proportion of flips, peaking at iteration 3.
* The "Multiple-Choice" method quickly drops to zero flips after the first iteration.
* The "Correct Flip" method consistently shows zero flips across all iterations.
* The "Incorrect Flip" method starts high, decreases, then increases slightly before decreasing again.
### Interpretation
The chart compares the proportion of flips across different methods during iterations of the SmolLM2-1.7B model. The "Generation" method's fluctuation suggests variability in its flip rate, while the "Multiple-Choice" method's rapid decline indicates it quickly stabilizes. The "Correct Flip" method consistently showing zero flips implies its effectiveness in maintaining correct states. The "Incorrect Flip" method's trend suggests an initial learning phase followed by some instability before settling. The data suggests that the "Multiple-Choice" method is the most stable after the first iteration, while the "Generation" method is the most variable. The "Correct Flip" method is the most consistent in maintaining correct states.
</details>
(a) SmolLM2-1.7B
<details>
<summary>x45.png Details</summary>
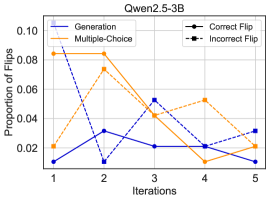
### Visual Description
## Chart: Proportion of Flips vs. Iterations for Qwen2.5-3B
### Overview
The image is a line chart comparing the proportion of flips (presumably in a model's output) across iterations for two different methods: Generation and Multiple-Choice. It also distinguishes between correct and incorrect flips. The chart displays how the proportion of flips changes over five iterations for each method and flip type.
### Components/Axes
* **Title:** Qwen2.5-3B
* **X-axis:** Iterations (labeled 1 to 5)
* **Y-axis:** Proportion of Flips (labeled from 0.02 to 0.10, incrementing by 0.02)
* **Legend (top-left):**
* **Generation:** Solid blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Solid black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
* **Generation (Solid Blue Line):**
* Trend: Fluctuates significantly.
* Iteration 1: ~0.01
* Iteration 2: ~0.03
* Iteration 3: ~0.05
* Iteration 4: ~0.02
* Iteration 5: ~0.01
* **Multiple-Choice (Solid Orange Line):**
* Trend: Starts high, drops, then rises again.
* Iteration 1: ~0.085
* Iteration 2: ~0.085
* Iteration 3: ~0.04
* Iteration 4: ~0.01
* Iteration 5: ~0.02
* **Correct Flip (Dashed Black Line with Square Markers):**
* Trend: Starts low, rises, then fluctuates.
* Iteration 1: ~0.02
* Iteration 2: ~0.07
* Iteration 3: ~0.04
* Iteration 4: ~0.05
* Iteration 5: ~0.03
* **Incorrect Flip (Solid Black Line with Circle Markers):**
* Trend: Starts high, drops, then fluctuates.
* Iteration 1: ~0.085
* Iteration 2: ~0.01
* Iteration 3: ~0.02
* Iteration 4: ~0.02
* Iteration 5: ~0.03
### Key Observations
* The "Generation" method has a lower proportion of flips compared to the "Multiple-Choice" method in the first iteration, but the "Multiple-Choice" method decreases significantly over the iterations.
* The proportion of "Correct Flips" increases initially, while the proportion of "Incorrect Flips" decreases.
* Both "Generation" and "Multiple-Choice" methods converge to a similar proportion of flips by the 5th iteration.
### Interpretation
The chart illustrates the performance of the Qwen2.5-3B model under different conditions (Generation vs. Multiple-Choice) and how the proportion of flips changes over iterations. The initial high proportion of flips in the "Multiple-Choice" method suggests that the model might be more prone to making changes in its initial responses when presented with multiple options. However, the decrease in flips over iterations indicates that the model learns to stabilize its responses. The "Generation" method, starting with a lower proportion of flips, might indicate a more stable initial response. The convergence of both methods towards the end suggests that the model adapts and improves its consistency over time, regardless of the initial method. The distinction between "Correct" and "Incorrect" flips provides insight into the quality of these changes, showing how the model's ability to make correct adjustments evolves over iterations.
</details>
(b) Qwen2.5-3B
<details>
<summary>x46.png Details</summary>
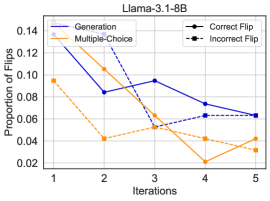
### Visual Description
## Chart: Llama-3.1-8B Proportion of Flips vs. Iterations
### Overview
The image is a line chart comparing the proportion of flips across iterations for two methods: Generation and Multiple-Choice. It also shows the proportion of correct and incorrect flips. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips.
### Components/Axes
* **Title:** Llama-3.1-8B
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.02, 0.04, 0.06, 0.08, 0.10, 0.12, 0.14)
* **Legend (Top-Left):**
* Generation (Solid Navy Blue Line)
* Multiple-Choice (Solid Orange Line)
* **Legend (Top-Right):**
* Correct Flip (Solid Black Line with Circle Markers)
* Incorrect Flip (Dashed Black Line with Circle Markers)
### Detailed Analysis
* **Generation (Solid Navy Blue Line):**
* Trend: Decreasing overall.
* Data Points:
* Iteration 1: ~0.13
* Iteration 2: ~0.085
* Iteration 3: ~0.095
* Iteration 4: ~0.072
* Iteration 5: ~0.063
* **Multiple-Choice (Solid Orange Line):**
* Trend: Decreasing then slightly increasing.
* Data Points:
* Iteration 1: ~0.095
* Iteration 2: ~0.105
* Iteration 3: ~0.053
* Iteration 4: ~0.02
* Iteration 5: ~0.042
* **Correct Flip (Solid Black Line with Circle Markers):**
* Trend: Decreasing overall.
* Data Points:
* Iteration 1: ~0.13
* Iteration 2: ~0.085
* Iteration 3: ~0.095
* Iteration 4: ~0.072
* Iteration 5: ~0.063
* **Incorrect Flip (Dashed Black Line with Circle Markers):**
* Trend: Decreasing then slightly increasing.
* Data Points:
* Iteration 1: ~0.095
* Iteration 2: ~0.042
* Iteration 3: ~0.053
* Iteration 4: ~0.063
* Iteration 5: ~0.032
### Key Observations
* The proportion of flips for the Generation method starts higher than the Multiple-Choice method but decreases more consistently over iterations.
* The proportion of flips for the Multiple-Choice method decreases sharply initially, then increases slightly in the last iteration.
* The "Correct Flip" data series is identical to the "Generation" data series.
* The "Incorrect Flip" data series is similar to the "Multiple Choice" data series.
### Interpretation
The chart compares the proportion of flips for two methods, Generation and Multiple-Choice, across five iterations. The Generation method starts with a higher proportion of flips but decreases more consistently. The Multiple-Choice method decreases sharply initially, then increases slightly in the last iteration. The data suggests that the Generation method might be more stable in reducing flips over iterations, while the Multiple-Choice method might have some variability. The "Correct Flip" and "Incorrect Flip" data series being identical to the "Generation" and "Multiple Choice" data series respectively suggests that the "Correct Flip" and "Incorrect Flip" labels are likely referring to the flips made by the Generation and Multiple-Choice methods.
</details>
(c) Llama-3.1-8B
<details>
<summary>x47.png Details</summary>
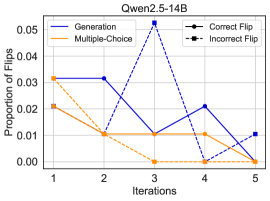
### Visual Description
## Chart: Proportion of Flips vs. Iterations for Qwen2.5-14B
### Overview
The image is a line chart comparing the proportion of flips (presumably in a model's output) across iterations for different methods: Generation, Multiple-Choice, Correct Flip, and Incorrect Flip. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips.
### Components/Axes
* **Title:** Qwen2.5-14B
* **X-axis:** Iterations (labeled 1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (labeled 0.00, 0.01, 0.02, 0.03, 0.04, 0.05)
* **Legend:** Located at the top-left and top-right of the chart.
* **Generation:** Solid blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Dashed black line with square markers
* **Incorrect Flip:** Dashed black line
### Detailed Analysis
**1. Generation (Solid Blue Line):**
* Trend: Starts high, dips, spikes, then decreases.
* Data Points:
* Iteration 1: ~0.032
* Iteration 2: ~0.022
* Iteration 3: ~0.011
* Iteration 4: ~0.021
* Iteration 5: ~0.011
**2. Multiple-Choice (Solid Orange Line):**
* Trend: Decreases, plateaus, then decreases again.
* Data Points:
* Iteration 1: ~0.022
* Iteration 2: ~0.011
* Iteration 3: ~0.011
* Iteration 4: ~0.011
* Iteration 5: ~0.000
**3. Correct Flip (Dashed Black Line with Square Markers):**
* Trend: Decreases, spikes sharply, then decreases.
* Data Points:
* Iteration 1: ~0.032
* Iteration 2: ~0.011
* Iteration 3: ~0.053
* Iteration 4: ~0.000
* Iteration 5: ~0.011
**4. Incorrect Flip (Dashed Black Line):**
* Trend: Decreases to zero.
* Data Points:
* Iteration 1: ~0.032
* Iteration 2: ~0.000
* Iteration 3: ~0.000
* Iteration 4: ~0.000
* Iteration 5: ~0.000
### Key Observations
* The "Correct Flip" method shows a significant spike at iteration 3.
* The "Incorrect Flip" method goes to zero after iteration 1.
* The "Multiple-Choice" method has a relatively stable, low proportion of flips after iteration 2.
* The "Generation" method fluctuates more than the "Multiple-Choice" method.
### Interpretation
The chart illustrates how the proportion of flips changes across iterations for different methods in the Qwen2.5-14B model. The "Correct Flip" method's spike at iteration 3 suggests that this iteration might be crucial for correcting errors or improving the model's output. The "Incorrect Flip" method quickly diminishing to zero indicates that incorrect flips are effectively eliminated early in the process. The "Multiple-Choice" method's stability suggests a more consistent performance compared to the "Generation" method, which exhibits more variability. The data suggests that the "Correct Flip" method, while potentially effective, might also introduce instability or require careful management to avoid overcorrection.
</details>
(d) Qwen2.5-14B
<details>
<summary>x48.png Details</summary>
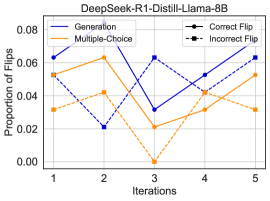
### Visual Description
## Line Chart: DeepSeek-R1-Distill-Llama-8B
### Overview
The image is a line chart comparing the proportion of flips across iterations for different methods: Generation and Multiple-Choice, further broken down by Correct Flip and Incorrect Flip. The chart shows how these proportions change over five iterations.
### Components/Axes
* **Title:** DeepSeek-R1-Distill-Llama-8B
* **X-axis:** Iterations, with markers at 1, 2, 3, 4, and 5.
* **Y-axis:** Proportion of Flips, ranging from 0.00 to 0.08, with increments of 0.02.
* **Legend (top-left):**
* **Blue solid line:** Generation
* **Orange solid line:** Multiple-Choice
* **Black solid line with circle markers:** Correct Flip
* **Black dashed line with square markers:** Incorrect Flip
### Detailed Analysis
* **Generation (Blue solid line):** Starts at approximately 0.063 at iteration 1, decreases to about 0.021 at iteration 2, increases to approximately 0.063 at iteration 3, decreases to about 0.043 at iteration 4, and increases again to approximately 0.063 at iteration 5.
* **Multiple-Choice (Orange solid line):** Starts at approximately 0.053 at iteration 1, increases to about 0.063 at iteration 2, decreases to approximately 0.00 at iteration 3, increases to about 0.03 at iteration 4, and increases again to approximately 0.053 at iteration 5.
* **Correct Flip (Black solid line with circle markers):** Starts at approximately 0.063 at iteration 1, decreases to about 0.021 at iteration 2, increases to approximately 0.063 at iteration 3, decreases to about 0.043 at iteration 4, and increases again to approximately 0.063 at iteration 5.
* **Incorrect Flip (Black dashed line with square markers):** Starts at approximately 0.053 at iteration 1, increases to about 0.042 at iteration 2, decreases to approximately 0.00 at iteration 3, increases to about 0.03 at iteration 4, and increases again to approximately 0.032 at iteration 5.
### Key Observations
* The "Generation" and "Correct Flip" lines are identical, suggesting a direct correlation or identical data.
* The "Multiple-Choice" and "Incorrect Flip" lines are identical, suggesting a direct correlation or identical data.
* Both pairs of lines show a similar trend: a decrease from iteration 1 to iteration 2, a significant drop at iteration 3, and then a gradual increase towards iteration 5.
### Interpretation
The chart compares the proportion of flips for two methods, "Generation" and "Multiple-Choice," across five iterations. The data suggests that the "Generation" method is directly related to "Correct Flips," and the "Multiple-Choice" method is directly related to "Incorrect Flips." The similar trends observed in both pairs of lines indicate that the proportion of flips is influenced by the iteration number, with a notable dip at iteration 3. This could be due to a change in the model or data at that specific iteration. The data implies that the model's performance, as measured by the proportion of flips, varies across iterations, and the choice of method (Generation vs. Multiple-Choice) is directly linked to the correctness of the flips.
</details>
(e) DeepSeek-R1-Distill-Llama-8B
<details>
<summary>x49.png Details</summary>
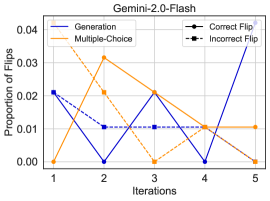
### Visual Description
## Chart: Gemini-2.0-Flash Proportion of Flips vs Iterations
### Overview
The image is a line chart titled "Gemini-2.0-Flash" showing the proportion of flips across iterations for different categories: Generation, Multiple-Choice, Correct Flip, and Incorrect Flip. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips (0.00 to 0.04).
### Components/Axes
* **Title:** Gemini-2.0-Flash
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.00, 0.01, 0.02, 0.03, 0.04)
* **Legend (Top-Left):**
* Generation (Solid Blue Line)
* Multiple-Choice (Solid Orange Line)
* **Legend (Top-Right):**
* Correct Flip (Solid Black Line with Circle Markers)
* Incorrect Flip (Dashed Black Line with Square Markers)
### Detailed Analysis
* **Generation (Solid Blue Line):** Starts at approximately 0.021 at iteration 1, decreases to 0 at iteration 2, increases to 0.021 at iteration 3, decreases to 0 at iteration 4, and increases to 0.035 at iteration 5.
* **Multiple-Choice (Solid Orange Line):** Starts at 0 at iteration 1, increases to 0.032 at iteration 2, decreases to 0.021 at iteration 3, decreases to 0.01 at iteration 4, and remains at 0.01 at iteration 5.
* **Correct Flip (Solid Black Line with Circle Markers):** Remains constant at 0.01 across all iterations.
* **Incorrect Flip (Dashed Black Line with Square Markers):** Starts at 0.021 at iteration 1, decreases to 0.01 at iteration 2, remains constant at 0.01 at iteration 3, remains constant at 0.01 at iteration 4, and decreases to 0 at iteration 5.
### Key Observations
* The "Generation" and "Multiple-Choice" lines exhibit inverse trends, with one increasing as the other decreases in the initial iterations.
* "Correct Flip" remains constant across all iterations.
* "Incorrect Flip" decreases over iterations.
### Interpretation
The chart illustrates how the proportion of flips changes across iterations for different methods (Generation, Multiple-Choice) and flip correctness (Correct Flip, Incorrect Flip). The data suggests that the "Generation" method initially has a lower proportion of flips but increases over iterations, while the "Multiple-Choice" method starts with a higher proportion but decreases. The constant "Correct Flip" indicates a consistent rate of correct flips, while the decreasing "Incorrect Flip" suggests an improvement in flip accuracy over iterations. The inverse relationship between "Generation" and "Multiple-Choice" could indicate a trade-off or shift in the method's effectiveness as iterations progress.
</details>
(f) Gemini-2.0-Flash
Figure 9: Models Correct and Incorrect Flips on Baseline on tinyTruthfulQA
<details>
<summary>x50.png Details</summary>
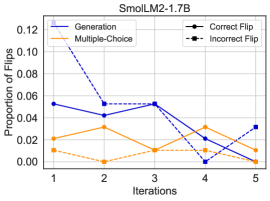
### Visual Description
## Chart: SmolLM2-1.7B Proportion of Flips vs. Iterations
### Overview
The image is a line chart titled "SmolLM2-1.7B" that displays the proportion of flips across iterations for different categories: Generation, Multiple-Choice, Correct Flip, and Incorrect Flip. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips, ranging from 0.00 to 0.12.
### Components/Axes
* **Title:** SmolLM2-1.7B
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.00, 0.02, 0.04, 0.06, 0.08, 0.10, 0.12)
* **Legend:** Located at the top-left of the chart.
* Generation (solid dark blue line)
* Multiple-Choice (solid orange line)
* Correct Flip (solid black line with circle markers)
* Incorrect Flip (dashed black line with square markers)
### Detailed Analysis
* **Generation (solid dark blue line):** Starts high, decreases sharply, then remains relatively stable, and finally decreases again.
* Iteration 1: ~0.053
* Iteration 2: ~0.042
* Iteration 3: ~0.053
* Iteration 4: ~0.020
* Iteration 5: ~0.000
* **Multiple-Choice (solid orange line):** Starts relatively low, increases slightly, then decreases, increases again, and finally decreases.
* Iteration 1: ~0.021
* Iteration 2: ~0.031
* Iteration 3: ~0.011
* Iteration 4: ~0.025
* Iteration 5: ~0.000
* **Correct Flip (solid black line with circle markers):** Starts high, decreases sharply, then increases, and finally decreases.
* Iteration 1: ~0.115
* Iteration 2: ~0.052
* Iteration 3: ~0.052
* Iteration 4: ~0.000
* Iteration 5: ~0.000
* **Incorrect Flip (dashed black line with square markers):** Starts low, increases, then decreases, and finally increases.
* Iteration 1: ~0.010
* Iteration 2: ~0.052
* Iteration 3: ~0.010
* Iteration 4: ~0.031
* Iteration 5: ~0.031
### Key Observations
* The "Correct Flip" category starts with the highest proportion of flips but decreases significantly over iterations.
* The "Generation" category also starts relatively high but decreases over iterations.
* The "Multiple-Choice" category remains relatively low throughout the iterations.
* The "Incorrect Flip" category fluctuates but generally remains low.
* All categories converge towards a proportion of flips near 0.00 by the 5th iteration, except for "Incorrect Flip" which ends at ~0.031.
### Interpretation
The chart illustrates how the proportion of flips changes across iterations for different categories in the SmolLM2-1.7B model. The "Correct Flip" category initially has a high proportion of flips, suggesting that the model is making corrections early on. As iterations progress, the proportion of flips decreases for most categories, indicating that the model is converging and becoming more stable. The "Incorrect Flip" category's fluctuations suggest that the model is still making some mistakes, but the overall trend indicates improvement over iterations. The convergence of all categories towards lower proportions of flips suggests that the model is learning and refining its predictions with each iteration.
</details>
(a) SmolLM2-1.7B
<details>
<summary>x51.png Details</summary>
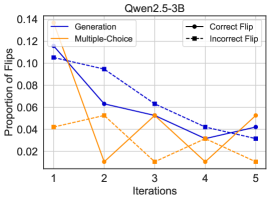
### Visual Description
## Chart: Proportion of Flips vs. Iterations for Qwen2.5-3B
### Overview
The image is a line chart comparing the proportion of flips (correct and incorrect) across iterations for two different methods: Generation and Multiple-Choice, using the Qwen2.5-3B model. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips (0 to 0.14).
### Components/Axes
* **Title:** Qwen2.5-3B
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.00, 0.02, 0.04, 0.06, 0.08, 0.10, 0.12, 0.14)
* **Legend:** Located at the top-left and top-right of the chart.
* **Generation:** Solid dark blue line.
* **Multiple-Choice:** Solid orange line.
* **Correct Flip:** Dashed dark blue line with square markers.
* **Incorrect Flip:** Dashed orange line with square markers.
### Detailed Analysis
* **Generation (Solid Dark Blue Line):**
* Trend: Decreasing overall.
* Data Points:
* Iteration 1: Approximately 0.105
* Iteration 2: Approximately 0.063
* Iteration 3: Approximately 0.054
* Iteration 4: Approximately 0.041
* Iteration 5: Approximately 0.032
* **Multiple-Choice (Solid Orange Line):**
* Trend: Fluctuating, with peaks at iterations 1, 3, and 5.
* Data Points:
* Iteration 1: Approximately 0.042
* Iteration 2: Approximately 0.012
* Iteration 3: Approximately 0.012
* Iteration 4: Approximately 0.008
* Iteration 5: Approximately 0.053
* **Correct Flip (Dashed Dark Blue Line with Square Markers):**
* Trend: Decreasing overall.
* Data Points:
* Iteration 1: Approximately 0.112
* Iteration 2: Approximately 0.094
* Iteration 3: Approximately 0.062
* Iteration 4: Approximately 0.042
* Iteration 5: Approximately 0.042
* **Incorrect Flip (Dashed Orange Line with Square Markers):**
* Trend: Fluctuating, with peaks at iterations 1, 3, and 5.
* Data Points:
* Iteration 1: Approximately 0.042
* Iteration 2: Approximately 0.053
* Iteration 3: Approximately 0.012
* Iteration 4: Approximately 0.053
* Iteration 5: Approximately 0.012
### Key Observations
* The "Generation" method and "Correct Flip" show a decreasing trend in the proportion of flips as iterations increase.
* The "Multiple-Choice" method and "Incorrect Flip" show a fluctuating trend, with peaks at iterations 1, 3, and 5.
* The "Generation" method starts with a higher proportion of flips compared to "Multiple-Choice," but the difference decreases over iterations.
* The "Correct Flip" method starts with a higher proportion of flips compared to "Incorrect Flip," but the difference decreases over iterations.
### Interpretation
The chart suggests that the "Generation" method and "Correct Flip" become more stable or accurate over iterations, as indicated by the decreasing proportion of flips. In contrast, the "Multiple-Choice" method and "Incorrect Flip" do not show a consistent improvement, with the proportion of flips fluctuating across iterations. This could indicate that the "Generation" method is more effective in reducing errors or instability over time compared to the "Multiple-Choice" method for the Qwen2.5-3B model. The fluctuating nature of "Multiple-Choice" and "Incorrect Flip" might suggest that this method is more sensitive to the specific characteristics of each iteration or that it requires further optimization to achieve consistent performance.
</details>
(b) Qwen2.5-3B
<details>
<summary>x52.png Details</summary>
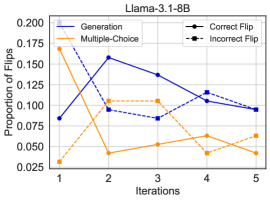
### Visual Description
## Chart: Llama-3.1-8B Flips Proportion
### Overview
The image is a line chart comparing the proportion of flips across iterations for different methods (Generation, Multiple-Choice) and flip types (Correct Flip, Incorrect Flip) for Llama-3.1-8B. The x-axis represents iterations, and the y-axis represents the proportion of flips.
### Components/Axes
* **Title:** Llama-3.1-8B
* **X-axis:** Iterations (labeled 1 to 5)
* **Y-axis:** Proportion of Flips (scale from 0.025 to 0.200)
* **Legend (top-left):**
* **Generation:** Solid dark blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Solid black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
**Generation (Solid Dark Blue Line):**
* Trend: Initially increases, then decreases.
* Iteration 1: ~0.085
* Iteration 2: ~0.158
* Iteration 3: ~0.138
* Iteration 4: ~0.118
* Iteration 5: ~0.095
**Multiple-Choice (Solid Orange Line):**
* Trend: Initially decreases, then fluctuates.
* Iteration 1: ~0.170
* Iteration 2: ~0.042
* Iteration 3: ~0.052
* Iteration 4: ~0.062
* Iteration 5: ~0.042
**Correct Flip (Dashed Black Line with Square Markers):**
* Trend: Initially decreases, then increases.
* Iteration 1: ~0.185
* Iteration 2: ~0.095
* Iteration 3: ~0.085
* Iteration 4: ~0.115
* Iteration 5: ~0.095
**Incorrect Flip (Solid Black Line with Circle Markers):**
* Trend: Initially increases, then decreases.
* Iteration 1: ~0.030
* Iteration 2: ~0.105
* Iteration 3: ~0.105
* Iteration 4: ~0.065
* Iteration 5: ~0.065
### Key Observations
* The "Generation" method shows an initial increase in the proportion of flips, followed by a decrease.
* The "Multiple-Choice" method shows an initial decrease in the proportion of flips, followed by fluctuations.
* The "Correct Flip" method shows an initial decrease in the proportion of flips, followed by an increase.
* The "Incorrect Flip" method shows an initial increase in the proportion of flips, followed by a decrease.
### Interpretation
The chart illustrates how the proportion of flips changes across iterations for different methods and flip types in Llama-3.1-8B. The trends suggest that the "Generation" method initially struggles but then stabilizes, while the "Multiple-Choice" method initially improves but then fluctuates. The "Correct Flip" and "Incorrect Flip" methods show opposing trends, indicating a potential shift in the types of flips occurring over iterations. The data could be used to optimize the model's training process and improve its performance.
</details>
(c) Llama-3.1-8B
<details>
<summary>x53.png Details</summary>
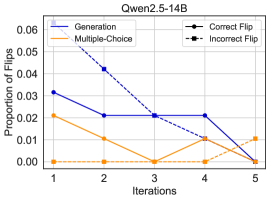
### Visual Description
## Chart: Proportion of Flips vs. Iterations for Qwen2.5-14B
### Overview
The image is a line chart comparing the proportion of flips (presumably in a model's output) across iterations for different methods: Generation, Multiple-Choice, Correct Flip, and Incorrect Flip. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips (0.00 to 0.06).
### Components/Axes
* **Title:** Qwen2.5-14B
* **X-axis:** Iterations (labeled 1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (labeled 0.00, 0.01, 0.02, 0.03, 0.04, 0.05, 0.06)
* **Legend:** Located in the top-left and top-right of the chart.
* **Generation:** Blue dashed line
* **Multiple-Choice:** Orange solid line
* **Correct Flip:** Black solid line with circle markers
* **Incorrect Flip:** Black dashed line with square markers
### Detailed Analysis
* **Generation (Blue dashed line):** Starts at approximately 0.032 at iteration 1, decreases to approximately 0.042 at iteration 2, decreases to approximately 0.021 at iteration 3, remains at approximately 0.021 at iteration 4, and decreases to approximately 0.00 at iteration 5. The trend is generally decreasing.
* **Multiple-Choice (Orange solid line):** Starts at approximately 0.021 at iteration 1, decreases to approximately 0.01 at iteration 2, decreases to approximately 0.00 at iteration 3, increases to approximately 0.01 at iteration 4, and decreases to approximately 0.01 at iteration 5. The trend is fluctuating, but generally low.
* **Correct Flip (Black solid line with circle markers):** Starts at approximately 0.032 at iteration 1, decreases to approximately 0.021 at iteration 2, remains at approximately 0.021 at iteration 3, increases to approximately 0.021 at iteration 4, and decreases to approximately 0.00 at iteration 5. The trend is decreasing.
* **Incorrect Flip (Black dashed line with square markers):** Starts at approximately 0.00 at iteration 1, remains at approximately 0.00 at iteration 2, remains at approximately 0.00 at iteration 3, increases to approximately 0.01 at iteration 4, and decreases to approximately 0.01 at iteration 5. The trend is generally low, with a slight increase at iteration 4.
### Key Observations
* The "Generation" method shows a decreasing proportion of flips as iterations increase.
* The "Multiple-Choice" method has a consistently low proportion of flips across all iterations.
* The "Correct Flip" method shows a decreasing proportion of flips as iterations increase.
* The "Incorrect Flip" method has a very low proportion of flips, with a slight increase at iteration 4.
### Interpretation
The chart suggests that the "Generation" and "Correct Flip" methods become more stable (fewer flips) as the model iterates. The "Multiple-Choice" method consistently maintains a low proportion of flips, indicating a stable performance. The "Incorrect Flip" method remains low, suggesting that incorrect flips are rare. The data implies that the model's performance improves with iterations, particularly for the "Generation" and "Correct Flip" methods. The slight increase in "Incorrect Flip" at iteration 4 could be an anomaly or a point of interest for further investigation.
</details>
(d) Qwen2.5-14B
<details>
<summary>x54.png Details</summary>
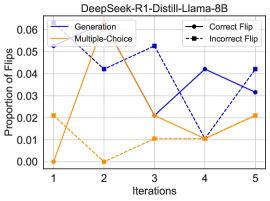
### Visual Description
## Line Chart: DeepSeek-R1-Distill-Llama-8B
### Overview
The image is a line chart comparing the proportion of flips across iterations for different models and flip types. The chart displays data for "Generation" and "Multiple-Choice" models, as well as "Correct Flip" and "Incorrect Flip" types. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips.
### Components/Axes
* **Title:** DeepSeek-R1-Distill-Llama-8B
* **X-axis:** Iterations (labeled 1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (labeled 0.00, 0.01, 0.02, 0.03, 0.04, 0.05, 0.06)
* **Legend:** Located in the top-left and top-right corners.
* **Generation:** Solid light-blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Solid black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
* **Generation (Solid light-blue line):** Starts at approximately 0.06 at iteration 1, decreases to approximately 0.042 at iteration 2, decreases further to approximately 0.02 at iteration 3, increases to approximately 0.042 at iteration 4, and decreases to approximately 0.032 at iteration 5.
* **Multiple-Choice (Solid orange line):** Starts at approximately 0.00 at iteration 1, increases to approximately 0.055 at iteration 2, decreases to approximately 0.02 at iteration 3, decreases further to approximately 0.01 at iteration 4, and increases to approximately 0.02 at iteration 5.
* **Correct Flip (Solid black line with circle markers):** Starts at approximately 0.02 at iteration 1, decreases to approximately 0.00 at iteration 2, increases to approximately 0.01 at iteration 3, increases further to approximately 0.01 at iteration 4, and increases to approximately 0.02 at iteration 5.
* **Incorrect Flip (Dashed black line with square markers):** Starts at approximately 0.02 at iteration 1, decreases to approximately 0.00 at iteration 2, increases to approximately 0.052 at iteration 3, decreases to approximately 0.01 at iteration 4, and increases to approximately 0.042 at iteration 5.
### Key Observations
* The "Multiple-Choice" model has a higher proportion of flips at iteration 2 compared to the "Generation" model.
* Both "Correct Flip" and "Incorrect Flip" types show a similar trend, with a low proportion of flips at iteration 2 and a peak at iteration 3.
* The proportion of flips for "Generation" is generally higher than "Multiple-Choice" except at iteration 2.
### Interpretation
The chart illustrates the performance of the DeepSeek-R1-Distill-Llama-8B model across different iterations, comparing the proportion of flips for "Generation" and "Multiple-Choice" models, as well as "Correct Flip" and "Incorrect Flip" types. The data suggests that the model's behavior changes across iterations, with varying levels of flips for different tasks. The "Multiple-Choice" model shows a spike in flips at iteration 2, while both "Correct Flip" and "Incorrect Flip" types peak at iteration 3. The "Generation" model generally has a higher proportion of flips, indicating potential differences in how it handles the task compared to the "Multiple-Choice" model. The trends and fluctuations in the proportion of flips across iterations may reflect the model's learning process and adaptation to the task.
</details>
(e) DeepSeek-R1-Distill-Llama-8B
<details>
<summary>x55.png Details</summary>
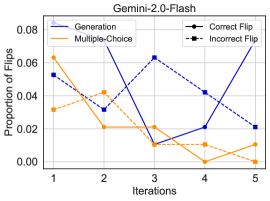
### Visual Description
## Chart: Gemini-2.0-Flash Flips Proportion
### Overview
The image is a line chart titled "Gemini-2.0-Flash" showing the proportion of flips across iterations for different methods: Generation, Multiple-Choice, Correct Flip, and Incorrect Flip. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips (0.00 to 0.08).
### Components/Axes
* **Title:** Gemini-2.0-Flash
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.00, 0.02, 0.04, 0.06, 0.08)
* **Legend (top-left):**
* Generation (solid dark blue line)
* Multiple-Choice (solid orange line)
* Correct Flip (solid black line with circle markers)
* Incorrect Flip (dashed black line with square markers)
### Detailed Analysis
* **Generation (solid dark blue line):** Starts at approximately 0.053 at iteration 1, decreases to approximately 0.032 at iteration 2, increases to approximately 0.063 at iteration 3, decreases to approximately 0.018 at iteration 4, and increases to approximately 0.071 at iteration 5.
* **Multiple-Choice (solid orange line):** Starts at approximately 0.063 at iteration 1, decreases to approximately 0.042 at iteration 2, decreases to approximately 0.011 at iteration 3, decreases to approximately 0.000 at iteration 4, and increases to approximately 0.011 at iteration 5.
* **Correct Flip (solid black line with circle markers):** Starts at approximately 0.053 at iteration 1, decreases to approximately 0.032 at iteration 2, decreases to approximately 0.011 at iteration 3, increases to approximately 0.042 at iteration 4, and decreases to approximately 0.021 at iteration 5.
* **Incorrect Flip (dashed black line with square markers):** Starts at approximately 0.032 at iteration 1, increases to approximately 0.042 at iteration 2, decreases to approximately 0.021 at iteration 3, increases to approximately 0.042 at iteration 4, and decreases to approximately 0.000 at iteration 5.
### Key Observations
* The "Generation" method shows a fluctuating trend, with peaks at iterations 1, 3, and 5.
* The "Multiple-Choice" method generally decreases over iterations, reaching a low at iteration 4.
* The "Correct Flip" method shows a decrease from iteration 1 to 3, then an increase at iteration 4, followed by a decrease at iteration 5.
* The "Incorrect Flip" method shows an increase from iteration 1 to 2, then a decrease at iteration 3, followed by an increase at iteration 4, followed by a decrease at iteration 5.
### Interpretation
The chart compares the proportion of flips across iterations for different methods used by Gemini-2.0-Flash. The "Generation" method has the highest proportion of flips at the beginning and end of the iterations, while the "Multiple-Choice" method has the lowest proportion of flips at iteration 4. The "Correct Flip" and "Incorrect Flip" methods show similar trends, with fluctuations across iterations. The data suggests that the "Generation" method may be more prone to flips, while the "Multiple-Choice" method may be more stable. The fluctuations in the "Correct Flip" and "Incorrect Flip" methods may indicate that the model is learning and adjusting its behavior over time.
</details>
(f) Gemini-2.0-Flash
Figure 10: Models Correct and Incorrect Flips on CoT on tinyTruthfulQA
<details>
<summary>x56.png Details</summary>
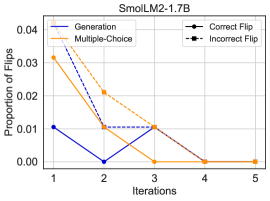
### Visual Description
## Chart: SmolLM2-1.7B Flips Proportion vs Iterations
### Overview
The image is a line chart comparing the proportion of flips across iterations for different methods (Generation, Multiple-Choice) and flip types (Correct Flip, Incorrect Flip) using the SmolLM2-1.7B model. The x-axis represents the number of iterations, and the y-axis represents the proportion of flips.
### Components/Axes
* **Title:** SmolLM2-1.7B
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.00, 0.01, 0.02, 0.03, 0.04)
* **Legend:** Located at the top-left and top-right of the chart.
* **Generation:** Solid blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
* **Generation (Solid Blue Line):**
* Trend: Decreasing from iteration 1 to 2, then relatively constant from iteration 2 to 3, then decreasing to 0 at iteration 4.
* Data Points:
* Iteration 1: Approximately 0.01
* Iteration 2: Approximately 0.00
* Iteration 3: Approximately 0.01
* Iteration 4: Approximately 0.00
* Iteration 5: Approximately 0.00
* **Multiple-Choice (Solid Orange Line):**
* Trend: Decreasing from iteration 1 to 4, then constant from iteration 4 to 5.
* Data Points:
* Iteration 1: Approximately 0.032
* Iteration 2: Approximately 0.021
* Iteration 3: Approximately 0.00
* Iteration 4: Approximately 0.00
* Iteration 5: Approximately 0.00
* **Correct Flip (Black Line with Circle Markers):**
* Trend: Increasing from iteration 1 to 3, then decreasing to 0 at iteration 4.
* Data Points:
* Iteration 1: Approximately 0.00
* Iteration 2: Approximately 0.01
* Iteration 3: Approximately 0.01
* Iteration 4: Approximately 0.00
* Iteration 5: Approximately 0.00
* **Incorrect Flip (Dashed Black Line with Square Markers):**
* Trend: Decreasing from iteration 1 to 4, then constant from iteration 4 to 5.
* Data Points:
* Iteration 1: Approximately 0.035
* Iteration 2: Approximately 0.01
* Iteration 3: Approximately 0.00
* Iteration 4: Approximately 0.00
* Iteration 5: Approximately 0.00
### Key Observations
* The "Generation" method shows a sharp decrease in the proportion of flips between iterations 1 and 2.
* The "Multiple-Choice" method consistently decreases in the proportion of flips as iterations increase.
* The "Correct Flip" proportion peaks at iteration 3.
* Both "Multiple-Choice", "Correct Flip", and "Incorrect Flip" converge to 0 after iteration 3 or 4.
### Interpretation
The chart illustrates how the proportion of flips changes over iterations for different methods and flip types in the SmolLM2-1.7B model. The "Multiple-Choice" method appears to be more effective in reducing the proportion of flips compared to the "Generation" method, as it consistently decreases with each iteration. The "Correct Flip" proportion initially increases, suggesting that the model is learning to correct its flips up to a certain point (iteration 3), after which it decreases. The "Incorrect Flip" proportion decreases, indicating that the model is making fewer incorrect flips as iterations progress. The convergence of "Multiple-Choice", "Correct Flip", and "Incorrect Flip" to 0 suggests that the model stabilizes after a few iterations, with minimal flips occurring.
</details>
(a) SmolLM2-1.7B
<details>
<summary>x57.png Details</summary>
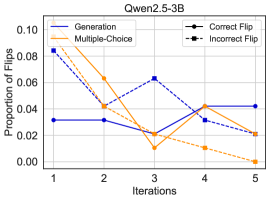
### Visual Description
## Chart: Proportion of Flips vs. Iterations for Qwen2.5-3B
### Overview
The image is a line chart comparing the proportion of flips (presumably in a model's output) across iterations for different methods (Generation vs. Multiple-Choice) and flip types (Correct vs. Incorrect). The chart displays data for the Qwen2.5-3B model.
### Components/Axes
* **Title:** Qwen2.5-3B
* **X-axis:** Iterations (labeled 1 to 5)
* **Y-axis:** Proportion of Flips (ranging from 0.00 to 0.10)
* **Legend:** Located in the top-left and top-right of the chart.
* **Generation:** Solid dark blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Solid black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
* **Generation (Solid Dark Blue Line):**
* Starts at approximately 0.031 at Iteration 1.
* Remains relatively constant at 0.031 until Iteration 2.
* Increases to approximately 0.063 at Iteration 3.
* Decreases to approximately 0.032 at Iteration 4.
* Increases to approximately 0.042 at Iteration 5.
* **Multiple-Choice (Solid Orange Line):**
* Starts at approximately 0.090 at Iteration 1.
* Decreases to approximately 0.063 at Iteration 2.
* Decreases to approximately 0.010 at Iteration 3.
* Increases to approximately 0.042 at Iteration 4.
* Decreases to approximately 0.021 at Iteration 5.
* **Correct Flip (Dashed Black Line with Square Markers):**
* Starts at approximately 0.084 at Iteration 1.
* Decreases to approximately 0.042 at Iteration 2.
* Decreases to approximately 0.021 at Iteration 3.
* Increases to approximately 0.031 at Iteration 4.
* Decreases to approximately 0.000 at Iteration 5.
* **Incorrect Flip (Solid Black Line with Circle Markers):**
* Starts at approximately 0.084 at Iteration 1.
* Decreases to approximately 0.042 at Iteration 2.
* Decreases to approximately 0.021 at Iteration 3.
* Increases to approximately 0.031 at Iteration 4.
* Decreases to approximately 0.000 at Iteration 5.
### Key Observations
* The "Multiple-Choice" method shows a significant decrease in the proportion of flips from Iteration 1 to Iteration 3, followed by an increase at Iteration 4 and a decrease at Iteration 5.
* The "Generation" method remains relatively stable across iterations, with a slight increase at Iteration 3.
* The "Correct Flip" and "Incorrect Flip" methods follow a similar trend, decreasing from Iteration 1 to Iteration 3, increasing at Iteration 4, and decreasing to zero at Iteration 5.
### Interpretation
The chart compares the proportion of flips for different methods and flip types across iterations for the Qwen2.5-3B model. The "Multiple-Choice" method appears to be more volatile, with significant changes in the proportion of flips across iterations. The "Generation" method is more stable. The "Correct Flip" and "Incorrect Flip" methods show a similar trend, suggesting a correlation between them. The decrease in the proportion of flips for "Correct Flip" and "Incorrect Flip" to zero at Iteration 5 indicates that the model may be converging to a stable state where no flips occur. The data suggests that the "Multiple-Choice" method may require more iterations to converge compared to the "Generation" method.
</details>
(b) Qwen2.5-3B
<details>
<summary>x58.png Details</summary>
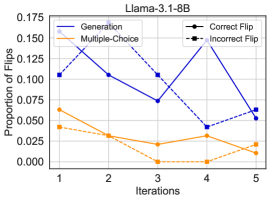
### Visual Description
## Chart: Llama-3.1-8B Proportion of Flips
### Overview
The image is a line chart comparing the proportion of flips across iterations for two different methods: Generation and Multiple-Choice. It also distinguishes between Correct and Incorrect Flips. The chart shows how the proportion of flips changes over five iterations for each method.
### Components/Axes
* **Title:** Llama-3.1-8B
* **Y-axis:** Proportion of Flips (scale from 0.000 to 0.175, increments of 0.025)
* **X-axis:** Iterations (1 to 5, increments of 1)
* **Legend:** Located at the top-left of the chart.
* **Generation:** Solid dark blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Dashed dark blue line with square markers
* **Incorrect Flip:** Dashed orange line with square markers
### Detailed Analysis
* **Generation (Solid Dark Blue):**
* Iteration 1: Approximately 0.105
* Iteration 2: Approximately 0.105
* Iteration 3: Approximately 0.075
* Iteration 4: Approximately 0.040
* Iteration 5: Approximately 0.055
* Trend: Decreases from iteration 1 to 4, then slightly increases at iteration 5.
* **Multiple-Choice (Solid Orange):**
* Iteration 1: Approximately 0.065
* Iteration 2: Approximately 0.030
* Iteration 3: Approximately 0.020
* Iteration 4: Approximately 0.030
* Iteration 5: Approximately 0.020
* Trend: Decreases from iteration 1 to 3, then slightly increases at iteration 4, then decreases at iteration 5.
* **Correct Flip (Dashed Dark Blue with Square Markers):**
* Iteration 1: Approximately 0.110
* Iteration 2: Approximately 0.105
* Iteration 3: Approximately 0.105
* Iteration 4: Approximately 0.145
* Iteration 5: Approximately 0.065
* Trend: Relatively stable from iteration 1 to 3, increases sharply at iteration 4, then decreases at iteration 5.
* **Incorrect Flip (Dashed Orange with Square Markers):**
* Iteration 1: Approximately 0.040
* Iteration 2: Approximately 0.030
* Iteration 3: Approximately 0.000
* Iteration 4: Approximately 0.030
* Iteration 5: Approximately 0.010
* Trend: Decreases from iteration 1 to 3, then increases at iteration 4, then decreases at iteration 5.
### Key Observations
* The "Generation" method starts with a higher proportion of flips compared to "Multiple-Choice," but the proportion decreases over iterations.
* The "Correct Flip" proportion peaks at iteration 4.
* The "Incorrect Flip" proportion is generally lower than the "Correct Flip" proportion.
### Interpretation
The chart illustrates the performance of the Llama-3.1-8B model in terms of the proportion of flips across different iterations for two methods, "Generation" and "Multiple-Choice," while also distinguishing between "Correct" and "Incorrect" flips. The data suggests that the "Generation" method initially results in a higher proportion of flips, but this decreases over iterations, potentially indicating a learning or stabilization process. The "Multiple-Choice" method consistently shows a lower proportion of flips. The "Correct Flip" proportion peaking at iteration 4 could indicate a point of significant adjustment or learning within the model. The lower proportion of "Incorrect Flips" suggests that the model is generally making more correct adjustments than incorrect ones. The relationship between the elements shows how the model's behavior changes over time and across different methods, highlighting the dynamics of the learning process.
</details>
(c) Llama-3.1-8B
<details>
<summary>x59.png Details</summary>
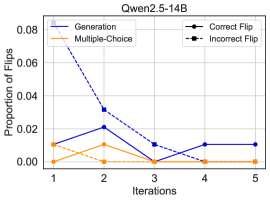
### Visual Description
## Chart: Proportion of Flips vs. Iterations for Qwen2.5-14B
### Overview
The image is a line chart comparing the proportion of flips across iterations for different methods (Generation, Multiple-Choice) and flip types (Correct Flip, Incorrect Flip) using the Qwen2.5-14B model. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips.
### Components/Axes
* **Title:** Qwen2.5-14B
* **X-axis:** Iterations (labeled 1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (labeled 0.00, 0.02, 0.04, 0.06, 0.08)
* **Legend (top-left):**
* Generation (solid blue line)
* Multiple-Choice (solid orange line)
* **Legend (top-right):**
* Correct Flip (black line with circle markers)
* Incorrect Flip (black dashed line with square markers)
### Detailed Analysis
* **Generation (solid blue line):**
* Trend: Decreasing from iteration 1 to 3, then relatively stable.
* Data Points:
* Iteration 1: ~0.07
* Iteration 2: ~0.032
* Iteration 3: ~0.01
* Iteration 4: ~0.01
* Iteration 5: ~0.01
* **Multiple-Choice (solid orange line):**
* Trend: Increasing from iteration 1 to 2, then decreasing to iteration 3, then increasing to iteration 4, then decreasing to iteration 5.
* Data Points:
* Iteration 1: ~0.01
* Iteration 2: ~0.01
* Iteration 3: ~0.00
* Iteration 4: ~0.01
* Iteration 5: ~0.00
* **Correct Flip (black line with circle markers):**
* Trend: Relatively stable.
* Data Points:
* Iteration 1: ~0.01
* Iteration 2: ~0.02
* Iteration 3: ~0.00
* Iteration 4: ~0.01
* Iteration 5: ~0.01
* **Incorrect Flip (black dashed line with square markers):**
* Trend: Decreasing.
* Data Points:
* Iteration 1: ~0.01
* Iteration 2: ~0.00
* Iteration 3: ~0.00
* Iteration 4: ~0.00
* Iteration 5: ~0.00
### Key Observations
* The "Generation" method starts with a significantly higher proportion of flips compared to "Multiple-Choice," but decreases rapidly over the first few iterations.
* The "Multiple-Choice" method has a relatively low and stable proportion of flips across all iterations.
* The "Correct Flip" method has a relatively low and stable proportion of flips across all iterations.
* The "Incorrect Flip" method has a decreasing proportion of flips across all iterations.
### Interpretation
The chart suggests that the "Generation" method initially struggles with a higher rate of flips, but quickly improves with iterations. The "Multiple-Choice" method maintains a consistently low flip rate, indicating a more stable performance. The "Correct Flip" and "Incorrect Flip" methods have a relatively low proportion of flips across all iterations, suggesting that the model is generally performing well in terms of flip accuracy. The decreasing trend of "Incorrect Flip" suggests that the model is learning to avoid incorrect flips over time. The data demonstrates the impact of iterative refinement on the performance of the Qwen2.5-14B model, particularly for the "Generation" method.
</details>
(d) Qwen2.5-14B
<details>
<summary>x60.png Details</summary>
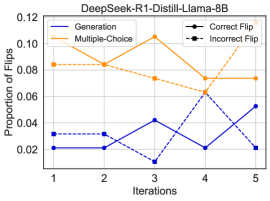
### Visual Description
## Line Chart: DeepSeek-R1-Distill-Llama-8B
### Overview
The image is a line chart comparing the proportion of flips across iterations for different methods (Generation and Multiple-Choice) and flip types (Correct Flip and Incorrect Flip) using the DeepSeek-R1-Distill-Llama-8B model. The x-axis represents iterations, and the y-axis represents the proportion of flips.
### Components/Axes
* **Title:** DeepSeek-R1-Distill-Llama-8B
* **X-axis:** Iterations (labeled 1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (scale from 0.02 to 0.12, incrementing by 0.02)
* **Legend:** Located at the top-left and top-right of the chart.
* **Generation:** Solid dark blue line
* **Multiple-Choice:** Solid orange line
* **Correct Flip:** Solid black line with circle markers
* **Incorrect Flip:** Dashed black line with square markers
### Detailed Analysis
**1. Generation (Solid Dark Blue Line):**
* Trend: Initially stable, then increases, decreases, and increases again.
* Data Points:
* Iteration 1: ~0.02
* Iteration 2: ~0.03
* Iteration 3: ~0.042
* Iteration 4: ~0.02
* Iteration 5: ~0.052
**2. Multiple-Choice (Solid Orange Line):**
* Trend: Starts high, decreases, increases, decreases, and stabilizes.
* Data Points:
* Iteration 1: ~0.084
* Iteration 2: ~0.084
* Iteration 3: ~0.105
* Iteration 4: ~0.073
* Iteration 5: ~0.073
**3. Correct Flip (Solid Black Line with Circle Markers):**
* Trend: Decreases and then increases.
* Data Points:
* Iteration 1: ~0.02
* Iteration 2: ~0.02
* Iteration 3: ~0.01
* Iteration 4: ~0.062
* Iteration 5: ~0.02
**4. Incorrect Flip (Dashed Black Line with Square Markers):**
* Trend: Increases and then decreases.
* Data Points:
* Iteration 1: ~0.032
* Iteration 2: ~0.032
* Iteration 3: ~0.01
* Iteration 4: ~0.062
* Iteration 5: ~0.1
### Key Observations
* The "Multiple-Choice" method consistently shows a higher proportion of flips compared to the "Generation" method.
* The "Correct Flip" and "Incorrect Flip" lines intersect at iteration 4, indicating a shift in the type of flips occurring.
* The proportion of "Incorrect Flips" increases significantly in the last iteration.
### Interpretation
The chart illustrates the performance of the DeepSeek-R1-Distill-Llama-8B model across different iterations, comparing the proportion of flips for "Generation" and "Multiple-Choice" methods, as well as "Correct" and "Incorrect" flips. The "Multiple-Choice" method generally leads to a higher proportion of flips, suggesting it might be more prone to changes or errors during the iterative process. The intersection of "Correct Flip" and "Incorrect Flip" lines at iteration 4 indicates a potential change in the model's behavior, with "Incorrect Flips" becoming more prevalent in the final iteration. This could suggest that the model is either learning or becoming less stable as iterations progress. Further analysis would be needed to determine the underlying causes of these trends.
</details>
(e) DeepSeek-R1-Distill-Llama-8B
<details>
<summary>x61.png Details</summary>
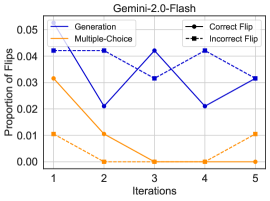
### Visual Description
## Chart: Gemini-2.0-Flash Proportion of Flips vs. Iterations
### Overview
The image is a line chart titled "Gemini-2.0-Flash" showing the proportion of flips across iterations for different categories: Generation, Multiple-Choice, Correct Flip, and Incorrect Flip. The x-axis represents iterations (1 to 5), and the y-axis represents the proportion of flips (0.00 to 0.05).
### Components/Axes
* **Title:** Gemini-2.0-Flash
* **X-axis:** Iterations (1, 2, 3, 4, 5)
* **Y-axis:** Proportion of Flips (0.00, 0.01, 0.02, 0.03, 0.04, 0.05)
* **Legend:** Located in the top-left and top-right corners.
* Generation (solid blue line)
* Multiple-Choice (solid orange line)
* Correct Flip (solid black line with square markers)
* Incorrect Flip (dashed black line with square markers)
### Detailed Analysis
* **Generation (Solid Blue Line):** The proportion of flips starts at approximately 0.042 at iteration 1, decreases to approximately 0.021 at iteration 2, increases to approximately 0.042 at iteration 3, decreases to approximately 0.023 at iteration 4, and increases to approximately 0.032 at iteration 5.
* **Multiple-Choice (Solid Orange Line):** The proportion of flips starts at approximately 0.032 at iteration 1, decreases to approximately 0.010 at iteration 2, reaches 0.00 at iteration 3, remains at 0.00 at iteration 4, and increases to approximately 0.010 at iteration 5.
* **Correct Flip (Solid Black Line with Square Markers):** The proportion of flips starts at approximately 0.042 at iteration 1, decreases to approximately 0.031 at iteration 2, increases to approximately 0.042 at iteration 3, decreases to approximately 0.038 at iteration 4, and decreases to approximately 0.031 at iteration 5.
* **Incorrect Flip (Dashed Black Line with Square Markers):** The proportion of flips starts at approximately 0.010 at iteration 1, decreases to approximately 0.00 at iteration 2, remains at 0.00 at iteration 3, remains at 0.00 at iteration 4, and increases to approximately 0.010 at iteration 5.
### Key Observations
* The "Generation" and "Correct Flip" lines show similar trends, fluctuating between approximately 0.02 and 0.04.
* The "Multiple-Choice" line decreases sharply from iteration 1 to 3, remains at 0.00 until iteration 4, and then slightly increases at iteration 5.
* The "Incorrect Flip" line starts low, drops to 0, and then increases slightly at the end.
### Interpretation
The chart compares the proportion of flips across iterations for different methods or categories within the Gemini-2.0-Flash model. The "Generation" and "Correct Flip" categories exhibit similar patterns, suggesting a correlation between them. The "Multiple-Choice" category shows a significant decrease in the proportion of flips over the iterations, indicating a potential improvement or stabilization in performance. The "Incorrect Flip" category remains low, suggesting a relatively small proportion of incorrect flips across all iterations. The data suggests that the model's performance varies across different categories and iterations, with some categories showing more stability or improvement than others.
</details>
(f) Gemini-2.0-Flash
Figure 11: Models Correct and Incorrect Flips on SC on tinyTruthfulQA
C.2 Accuracy over Iteration
Tables 1 and 2 show the accuracy over iteration on both datasets for each iteration.
Table 1: Accuracy over iterations on DisambiguationQA
Model Iter 0 Iter 1 Iter 2 Iter 3 Iter 4 Iter 5 Iter 0 Iter 1 Iter 2 Iter 3 Iter 4 Iter 5 Generation Multiple-Choice Baseline DeepSeek-R1-Distill-Llama-8B 0.1833 0.1917 0.1833 0.1750 0.2000 0.1667 0.2833 0.3083 0.3167 0.3167 0.3000 0.3250 Llama-3.1-8B 0.1250 0.1167 0.1750 0.1500 0.1333 0.1250 0.3500 0.3500 0.4167 0.3500 0.3917 0.4417 Qwen2.5-14B 0.3750 0.4083 0.3583 0.3667 0.3667 0.3750 0.4750 0.4833 0.4917 0.5083 0.5000 0.5083 Qwen2.5-3B 0.2000 0.2083 0.2750 0.2333 0.2500 0.2167 0.3167 0.2583 0.3250 0.3083 0.3333 0.3167 SmolLM2-1.7B 0.0500 0.0583 0.0667 0.0583 0.0417 0.0583 0.2750 0.2500 0.2333 0.2667 0.2500 0.2250 Gemini-2.0-Flash 0.3417 0.3500 0.3417 0.3667 0.3750 0.3583 0.4917 0.4667 0.5083 0.4917 0.4750 0.4750 CoT DeepSeek-R1-Distill-Llama-8B 0.1250 0.1417 0.1667 0.1417 0.1583 0.1500 0.2917 0.2750 0.3167 0.2667 0.2750 0.3000 Llama-3.1-8B 0.1417 0.1500 0.1583 0.1750 0.1750 0.1667 0.3167 0.3000 0.3417 0.3083 0.3750 0.3500 Qwen2.5-14B 0.3583 0.3583 0.3583 0.4000 0.3750 0.3750 0.4750 0.4917 0.4833 0.4750 0.4750 0.4750 Qwen2.5-3B 0.1583 0.2083 0.2250 0.1917 0.1500 0.1917 0.2833 0.3083 0.2500 0.2417 0.2583 0.2333 SmolLM2-1.7B 0.0750 0.0667 0.0583 0.0833 0.0667 0.0667 0.3083 0.3083 0.2583 0.2583 0.2667 0.2583 Gemini-2.0-Flash 0.3583 0.3833 0.3333 0.4083 0.3917 0.4083 0.4667 0.4750 0.4833 0.4500 0.4250 0.4417 SC DeepSeek-R1-Distill-Llama-8B 0.1917 0.1750 0.1667 0.1833 0.1667 0.2083 0.3250 0.3083 0.3250 0.2750 0.3417 0.3000 Llama-3.1-8B 0.2000 0.2333 0.1833 0.2500 0.2000 0.2167 0.3667 0.4250 0.3833 0.3417 0.3250 0.3250 Qwen2.5-14B 0.3583 0.3500 0.3583 0.3667 0.3667 0.3667 0.4917 0.4917 0.5083 0.5083 0.5083 0.5250 Qwen2.5-3B 0.2167 0.2250 0.2333 0.1833 0.2167 0.2000 0.3167 0.2500 0.3250 0.2833 0.2750 0.2917 SmolLM2-1.7B 0.0417 0.0500 0.0500 0.0500 0.0500 0.0500 0.1917 0.1833 0.1833 0.1833 0.1833 0.1917 Gemini-2.0-Flash 0.3750 0.3667 0.3667 0.4083 0.3750 0.3583 0.5000 0.5000 0.5000 0.5000 0.5083 0.5083
Table 2: Accuracy over iterations on tinyTruthfulQA
Model Iter 0 Iter 1 Iter 2 Iter 3 Iter 4 Iter 5 Iter 0 Iter 1 Iter 2 Iter 3 Iter 4 Iter 5 Generation Multiple-Choice Baseline DeepSeek-R1-Distill-Llama-8B 0.7263 0.7368 0.8000 0.7684 0.7789 0.7895 0.5263 0.5474 0.5684 0.5895 0.5789 0.6000 Llama-3.1-8B 0.6947 0.6842 0.6316 0.6737 0.6842 0.6842 0.5263 0.5789 0.6421 0.6526 0.6316 0.6421 Qwen2.5-14B 0.8421 0.8526 0.8737 0.8316 0.8526 0.8421 0.7789 0.7684 0.7684 0.7789 0.7895 0.7895 Qwen2.5-3B 0.8105 0.7158 0.7368 0.7053 0.7053 0.6842 0.6105 0.6737 0.6842 0.6842 0.6421 0.6421 SmolLM2-1.7B 0.5158 0.4947 0.5053 0.5474 0.5263 0.5158 0.1368 0.1684 0.1684 0.1684 0.1684 0.1684 Gemini-2.0-Flash 0.8105 0.8105 0.8000 0.8105 0.8000 0.8421 0.8737 0.8316 0.8421 0.8632 0.8632 0.8737 CoT DeepSeek-R1-Distill-Llama-8B 0.7895 0.7789 0.8000 0.7684 0.8000 0.7895 0.5263 0.5053 0.5684 0.5789 0.5789 0.5789 Llama-3.1-8B 0.6737 0.5579 0.6211 0.6737 0.6632 0.6526 0.5368 0.6737 0.6105 0.5579 0.5789 0.5579 Qwen2.5-14B 0.8000 0.7684 0.7474 0.7474 0.7579 0.7579 0.7474 0.7684 0.7789 0.7789 0.7895 0.7789 Qwen2.5-3B 0.7684 0.7789 0.7474 0.7368 0.7263 0.7368 0.5158 0.6105 0.5684 0.6105 0.5895 0.6316 SmolLM2-1.7B 0.6211 0.5474 0.5368 0.5368 0.5579 0.5263 0.1474 0.1579 0.1895 0.1895 0.2105 0.2211 Gemini-2.0-Flash 0.8316 0.8632 0.9053 0.8526 0.8316 0.8842 0.8000 0.8316 0.8105 0.8211 0.8105 0.8211 SC DeepSeek-R1-Distill-Llama-8B 0.8105 0.8105 0.8000 0.8316 0.7895 0.8211 0.5474 0.5684 0.5684 0.6000 0.6105 0.5684 Llama-3.1-8B 0.5789 0.6316 0.5684 0.5368 0.6421 0.6316 0.6526 0.6737 0.6737 0.6947 0.7263 0.7158 Qwen2.5-14B 0.8000 0.7263 0.7158 0.7053 0.7158 0.7263 0.7474 0.7368 0.7474 0.7474 0.7474 0.7474 Qwen2.5-3B 0.8421 0.7895 0.7789 0.7368 0.7474 0.7684 0.5895 0.6000 0.6211 0.6105 0.6421 0.6632 SmolLM2-1.7B 0.4632 0.4316 0.4211 0.4211 0.4211 0.4211 0.1684 0.1579 0.1474 0.1368 0.1368 0.1368 Gemini-2.0-Flash 0.8526 0.8632 0.8421 0.8526 0.8316 0.8316 0.8316 0.8526 0.8632 0.8632 0.8632 0.8526
C.3 Generated and Refinement Answers Samples
Tables 3 and 4 show the samples of generated responses for open-ended generation and multiple-choice questions.
Table 3: A sample of self-correction on tinyTruthfulQA using Llama-3.1-8B and the Baseline method.
\rowcolor gray!5 Question All Mexicans are members of what Church? \rowcolor gray!5 Generation Answer MCQ Answer \rowcolor green!10 Answer There is no Church that all Mexicans are members of (A) There is no Church that all Mexicans are members of 0 The final answer is: The Roman Catholic Church. The final answer is (B). 1 -I need to correct my previous response. The final answer is: I made a mistake. Not all Mexicans are members of the Roman Catholic Church. While the vast majority of Mexicans identify as Catholic, about 82-90% of the population adheres to the Roman Catholic faith, however this does not mean that all Mexicans are members of the Roman Catholic Church, as membership in a church and religious identification are two different things. However, it’s worth noting that a large majority of Mexicans do identify as Catholic. Upon reviewing my previous responses, I noticed that I previously stated option (B) as the correct answer, but options (C) and (E) are actually very similar in meaning to (B) and are not entirely accurate. A more accurate representation would be option (D) 9̈5% of Mexicans are Catholics.T̈his shows a strong association between the Mexican population and the Catholic Church, without claiming that 100% of Mexicans are members of the Church. 2 The final answer is: They are not all members of the Roman Catholic Church, however the Catholic Church is the largest denomination, but it can be more accurate to say that most Mexicans follow and adhere to their Catholic beliefs but whether a majority of them belong to it in an institutional membership remains uncertain. The final answer is (D). 3 The final answer is: None. The final answer is (D). 4 The final answer is: There is no specific church that all Mexicans belong to. The final answer is (D). 5 The final answer is: None. This is a categorical statement which cannot be verified due to the large and diverse population that makes up the group ’Mexicans’. The final answer is (A). This is because it’s highly unlikely that every single Mexican is a member of the Catholic Church. Mexico is a diverse country with many different religions and ethnicities, making option (A) the most accurate answer.
Table 4: A sample of self-correction on DisambiguationQA using Llama-3.1-8B and the Baseline method.
\rowcolor gray!5 Question Here is a sentence with pronoun(s) whose antecedent(s) can either be derived from the context or is ambiguous. Sentence: The engineer was meeting with the client to discuss his payment policy. He informed him that he would need to make all future payments on time. What correctly explains the antecedent(s) of the pronoun(s)? \rowcolor gray!5 Generation Answer MCQ Answer \rowcolor green!10 Answer It was the client’s payment policy and the client should make payments. (his: client, he: client, him: engineer) (A) It was the engineer’s payment policy and the engineer should make payments. 0 The sentence is using two instances of pronouns (“he” and “him”) whose antecedents can be derived from the context. In this case, the ambiguity arises because ‘he’ in the second sentence can refer to the engineer or the client, and ‘him’ can refer to the engineer or the client. However, a typical interpretation is that ‘he’ refers to the engineer (because engineers are more likely to make statements) and ‘him’ refers to the client (because clients are typically receiving instructions from the engineer). The final answer is: The engineer refers to ‘he’, and the client refers to ‘him’. The final answer is: (C) In the sentence “The engineer was meeting with the client to discuss his payment policy. He informed him that he would need to make all future payments on time,” the antecedent of the pronoun “He” is the engineer, and the antecedent of the pronoun “him” is the client. Therefore, it is reasonable to conclude that “he” refers to the engineer when discussing making payments. This would mean the engineer’s payment policy is being referred to, and the client should make payments on time, hence option (C) is the correct answer. 1 Considering the conversation history, my previous response mentioned that the ambiguity in the sentence arises because ‘he’ in the second sentence can refer to the engineer or the client, and ‘him’ can refer to the engineer or the client. However, upon closer examination, the sentence “The engineer was meeting with the client to discuss his payment policy” clearly establishes ‘his’ as belonging to the client, implying the client has a payment policy. This makes it more likely that ‘he’ in the second sentence and ‘him’ in the second sentence refer to the client. The final answer is: The client refers to ‘he’ and ‘him’. Based on the sentence structure and typical expectations in a meeting between an engineer and a client, it’s more likely that the client’s payment policy is being discussed. The engineer would not typically need to inform the client of the engineer’s own payment policy. The final answer is: (D) 2 In the sentence, ‘his’ is clearly referring to the client, as it’s his payment policy being discussed. This clarifies the context and establishes the client as the subject associated with ‘his’. Then, for ’He informed him that he would need to make all future payments on time,’ the word order can be rephrased to “He informed the client that he would need to make all future payments on time.” This rephrased sentence makes it clear that the second instance of ‘he’ is the one being informed and the client is the one informing. So, ‘he’ (second instance) refers to the client and ‘him’ refers to the engineer, as the engineer is the one doing the informing. The final answer is: ‘he’ (second instance) refers to the client and ‘him’ refers to the engineer. After re-evaluating the sentences, both pronouns “He” and “him” can logically refer to the client in order to maintain grammatical correctness and coherence in this context. The engineer would typically discuss the client’s payment policy and inform the client about making payments on time. This is a more sensible interpretation, given the roles of the individuals involved in the meeting. The final answer is: (D) 3 Based on the correct rephrased sentence “He informed the client that he would need to make all future payments on time,” it is clear that the pronouns ‘he’ and ‘him’ have distinct antecedents. The second sentence “He informed him that he would need to make all future payments on timec̈an also be broken down into subject (he, the one informing) and two objects (him, he). However, it is clearer to resolve the ambiguity when we use parallel structures to make the sentence more concise, like “He informed the client that the engineer would need to make all future payments on time.” The rephrased sentence helps to eliminate the confusion. The final answer is: The engineer is implied but in the rephrased sentence ’the engineer’ or from the first sentence, ‘he’ (first instance) refers to the engineer and ‘him’ refers to the client. Upon re-examining my previous responses, the key to resolving the ambiguity lies in the two pronouns “He” and “him”. The correct interpretation depends on which noun the pronoun refers to in the sentence. To eliminate ambiguity, rephrasing the sentence can help. Here’s one possible rephrased version: T̈he engineer was meeting with the client to discuss the client’s payment policy. He informed him that he would need to make all future payments on time.” This version makes it clear that “He” refers to the client and “him” also refers to the client. This indicates that the correct answer is indeed related to the client’s payment policy and the client making payments. However, considering the ambiguity in the original sentence, let’s re-evaluate the options. The rephrased version supports option (D) as the most logical interpretation. The final answer is: (D) 4 To resolve the ambiguity, let’s analyze the sentence. The first sentence indicates that the engineer is discussing the client’s payment policy, so it’s clear that ‘his’ refers to the client. Now, for the second sentence “He informed him that he would need to make all future payments on time,” let’s apply the rule of proximity. ’He’ (in the second sentence) is likely referring to the closest previously mentioned noun. So, “He” is likely referring to the client. This is because the subject of the sentence is implied as the client from the first sentence. In this context, the first ’He’ refers to the client. Then for ‘him’ in the second sentence, it logically refers to the one being addressed or talked to and ‘him’ in this context refers to the engineer as the client is talking to the engineer. The final answer is: The client refers to ‘he’ and ‘him’ is referring to the engineer. Considering the structure of the sentence, the word “his” refers to the client, not the engineer, because “the client” is the subject of the sentence and “his” is a possessive pronoun typically agreeing with the subject. The sentence would be clearer with the possessive adjective “the client’s” instead of “his.” Therefore, both “He” and “him” can logically refer to the client. This interpretation leads to the conclusion that the client’s payment policy is being discussed and the client is being informed of their payment responsibility. Thus, the correct answer supports this logical deduction. The final answer is: (D) 5 Based on the previous analysis, the first ‘he’ in the second sentence is ambiguous as it can refer to the engineer or the client. However, a rephrased sentence T̈he engineer was meeting with the client to discuss the client’s payment policy. The engineer informed the client that he would need to make all future payments on timec̈larifies this ambiguity. However, even without rephrasing the sentence, from the original sentence T̈he engineer was meeting with the client to discuss his payment policy,ït can be inferred that ‘his’ belongs to the client, making it clear that the conversation is about the client’s policy. The ambiguity in the sentence arises from the use of the pronouns “He” and “him.” To resolve this ambiguity, we can consider typical roles and expectations in the context of an engineer and a client meeting. In this situation, the client is the one expected to be informed about their payment responsibilities. Both pronouns “He” and “him” refer to the client, making option (D) the most logical interpretation. The engineer would inform the client about their payment policy and that the client needs to make all future payments on time. The final answer is: (D)