# Neuro-Logic Lifelong Learning
**Authors**: Bowen He, Xiaoan Xu, Alper Kamil Bozkurt, Vahid Tarokh, Juncheng Dong
## Abstract
Solving Inductive Logic Programming (ILP) problems with neural networks is a key challenge in Neural-Symbolic Artificial Intelligence (AI). While most research has focused on designing novel network architectures for individual problems, less effort has been devoted to exploring new learning paradigms involving a sequence of problems. In this work, we investigate lifelong learning ILP, which leverages the compositional and transferable nature of logic rules for efficient learning of new problems. We introduce a compositional framework, demonstrating how logic rules acquired from earlier tasks can be efficiently reused in subsequent ones, leading to improved scalability and performance. We formalize our approach and empirically evaluate it on sequences of tasks. Experimental results validate the feasibility and advantages of this paradigm, opening new directions for continual learning in Neural-Symbolic AI.
Keywords: Neuro-Symbolic AI, ILP, Lifelong Learning
## 1 Introduction
Neuro-Symbolic Artificial Intelligence (Santoro et al. 2017; Manhaeve et al. 2018; Dai et al. 2019; d’Avila Garcez and Lamb 2020; Amizadeh et al. 2020) has emerged as a promising research direction that combines modern neural networks with classic symbolic methods, thereby leveraging the strengths of both. At a high level, neural networks offer the expressivity and end-to-end learning capabilities needed to tackle complex problems where traditional symbolic methods can fall short. Meanwhile, symbolic approaches contribute advantages such as explicit representation of knowledge and reasoning, in which neural networks often underperform (Valmeekam et al. 2023; Li et al. 2024; Sheth, Roy, and Gaur 2023). Although the term Neuro-Symbolic Artificial Intelligence spans a wide range of problems, paradigms, and methodologies, this work focuses specifically on tasks within the field of inductive logic programming (ILP) (Cropper and Dumančić 2022). Unlike standard logic programming, which draws conclusions from a given set of rules, ILP seeks to learn first-order logic rules that best explain observed examples from given relevant background knowledge.
To solve ILP problems using neural networks, researchers have introduced a variety of methods and compared them against traditional ILP solvers (Evans and Grefenstette 2018; Glanois et al. 2021; Payani and Fekri 2019; Dong et al. 2019; Badreddine et al. 2022; Sen et al. 2022; Zimmer et al. 2023), demonstrating that neural network-based methods are both robust to noisy data and more efficient for large-scale tasks.
However, most existing works primarily focus on designing new model architectures, dedicating relatively little attention to investigate learning paradigms beyond the conventional individual tasks setting. To this end, this work takes the first step to investigate the transferability of knowledge between ILP problems. Our insight is that logic rules, by their nature, are compositional and reusable. Specifically, a logic rule learned from one task can be naturally reused for another task within the same domain. Moreover, cognitive scientists have argued that humans learn, think, and reason in a symbolic manner, i.e., “symbolic models of cognition were the dominant computational approaches of cognition” (Castro et al. 2025; Besold and Kühnberger 2023). Thus, to achieve the remarkable capabilities of lifelong learning and meta-learning observed in human intelligence, we envision that the interplay of neural network and symbolic method presents a promising new direction for lifelong learning.
We instantiate the aforementioned insight by introducing a novel lifelong learning problem for ILP. We introduce a compositional structure for neural logic models and evaluate their performance across sequences of tasks. By leveraging rules acquired from previous tasks, the neural logic models achieve significantly improved learning efficiency on new tasks. In comparison to the existing works that primarily focus on the perspective of model parameter optimization—such as regularization-based (Kirkpatrick et al. 2017; Zenke, Poole, and Ganguli 2017), experience replay-based (Rolnick et al. 2019; Buzzega et al. 2020), and architecture-based approaches (Rusu et al. 2016; von Oswald et al. 2020; Li et al. 2019) —lifelong learning for logic rules requires identifying which rules are beneficial for reuse and efficiently constructing new rules based on those already acquired. We take the first step in demonstrating the feasibility of this direction, paving the way for future research. Our empirical results confirm the enhanced learning efficiency achieved through lifelong learning. Furthermore, by simply incorporating experience replay, the model effectively retains its performance across tasks. Additionally, in certain experiments, we observe a backward transfer effect, where training on later tasks further improves performance on earlier tasks.
Contribution Statement. We summarize our contributions as follows:
- We formally introduce lifelong learning in ILP, framing it as a sequential optimization problem.
- We propose a neuro-symbolic approach that leverages the compositionality of logic rules to enable knowledge transfer across tasks.
- We validate on challenging logic reasoning tasks how logic rule transfer improves learning efficiency and the acquisition of a common knowledge base during sequential learning.
Manuscript Organization. We frist briefly review related works in Section 2. We introduce the definition of lifelong ILP problems in Section 3. We elaborate on our implementation in Section 4. After presenting our experiment results in Section 5, we conclude with a discussion for future directions.
## 2 Related Works
We provide review for both inductive logic programming, extending the discussion to more recent neural network based approcach, and lifelong learning that aims to build AI systems that accumulate knowledge in a seuquence of tasks.
### 2.1 Inductive Logic Programming
Inductive Logic Programming (ILP) (Cropper and Dumančić 2022) is a longstanding and still unresolved challenge in artificial intelligence, characterized by its aim to solve problems through logical reasoning. Unlike statistical machine learning, where predications are based on statistical inference, ILP relies on logic inference and learns a logic program that could be used further to solve problems. Its integration with reinforcement learning (RL) further leads to the field of relational RL (Džeroski, De Raedt, and Driessens 2001), where the policy comprises logical rules and decisions are made through logical inference. The goal of ILP is to design AI systems that not only solve problems but do so through logical reasoning, which recent literature shows is lacking in purely neural network-based approaches (Valmeekam et al. 2023; Li et al. 2024). This raises a critical question: can we develop neural-symbolic methods that leverage the scalability of neural networks while also solving tasks through sound logical reasoning? (Evans and Grefenstette 2018) made a pioneering step towards this objective by introducing $\partial$ ILP, which integrates neural networks with inductive logic programming (ILP) and addresses 20 ILP tasks sourced from previous literature or designed by the authors themselves. They showed that, compared to traditional ILP methods, $\partial$ ILP is more robust against mislabeled targets that typically impair the performance of conventional approaches, reflecting the generalization capabilities of neural networks. Furthermore, (Jiang and Luo 2019) extends $\partial$ ILP to the reinforcement learning setting by incorporating logic predicates into the state and action spaces. They evaluate its performance on two tasks, Blocksworld and Gridworld, comparing it against MLP neural networks. Their results demonstrate that MLPs are prone to failure on these tasks represented with logic predicates.
Neural logic machine (NLM) (Dong et al. 2019) represents another line of research that aims to design better neural network architectures for logic reasoning. They proposed a forward chaining approach to represent logical rules, effectively addressing the memory cost issues associated with handling a large number of objects, a challenge previously encountered by the $\partial$ ILP method. Despite the fact that the logic rules learned by NLMs are not explicitly extractable for human readers, they continue to be the most widely used benchmark in further applications (Wang et al. 2025) and related works. Differentiable Logic Machines (Zimmer et al. 2023) builds upon NLM to replace MLPs used by NLM with soft logic operator, providing more interpretability in the cost more computational requirement. (Campero et al. 2018) proposes to learning vector embeddings for both logic predicates and logic rules. It’s further expended by (Glanois et al. 2021) using the forward-chaining perspective as in NLM.
Logic rules, by its nature, provide the property of compositionality, a new logic rule could be always built by composing rules that have been acquired before (Lin et al. 2014). Moreover, logic rules that are learned in a task could be naturally transferred to be used in another task from the same domain. This ability of knowledge transfer and lifelong learing has been considered as essential for human-like AI (Lake et al. 2016). Building on this insight, we investigate the lifelong learning ability of neural logic programming.
### 2.2 Lifelong Learning
Lifelong learning or continual learning, has been proposed as a research direction for developing artificial intelligence systems capable of learning a sequence of tasks continuously (Wang et al. 2024). Ideally, a lifelong learning agent should achieve both forward transfer, where knowledge from earlier tasks benefits subsequent ones, and backward transfer, where learning newer tasks enhances performance on previous ones. At the very least, it should mitigate catastrophic forgetting, a phenomenon where learning later tasks causes the model to lose knowledge acquired from earlier tasks.
Classic lifelong learning methods typically fall into four categories: (i) Regularization-based approaches, which constrain parameter updates within a certain range to mitigate forgetting (Kirkpatrick et al. 2017; Zenke, Poole, and Ganguli 2017; Li and Hoiem 2017)); (ii) Replay-based approaches, which store or generate data samples from past tasks and replay them during training on newer tasks (Rebuffi et al. 2017; Shin et al. 2017; Lopez-Paz and Ranzato 2017; Chaudhry et al. 2018); (iii) Optimization-based methods, which manipulate gradients to preserve previously acquired knowledge (Zeng et al. 2019; Farajtabar et al. 2020; Saha, Garg, and Roy 2021)); and (iv) Architecture-based methods, which expand or reconfigure model architectures to accommodate new tasks or transfer knowledge (Rusu et al. 2016; Yoon et al. 2017). In all cases, these methods are mainly rooted in neural networks and can be broadly categorized as strategies for optimizing model parameters or architectures. In contrast, approaching lifelong learning from a neuro-symbolic perspective offers additional opportunities by leveraging the properties of symbolic methods. Our work, therefore, falls within this emerging paradigm.
One work highly relevant to our study is (Mendez 2022). They propose incorporating compositionality into lifelong training, enabling new tasks to benefit from previously learned neural modules. However, their formulation remains within the domain of pure neural networks and can be categorized as an architecture-based method for lifelong learning. In contrast, we emphasize that logic rules inherently provide compositionality, which can be leveraged for learning. Thus, our work serves as a strong instance of lifelong learning with compositionality, facilitating the systematic reuse and adaptation of learned knowledge across tasks. Another work that explores lifelong learning from a neuro-symbolic perspective is (Marconato et al. 2023). However, their focus is on extracting reusable concepts from sub-symbolic inputs while preventing reasoning shortcuts that could lead to incorrect symbolic knowledge. In contrast, our work centers on the transfer of logic rules, where learning and reusing these rules play a fundamental role.
## 3 Neural Logic Lifelong Learning
### 3.1 Problem Formulation
We introduce our problem definition of ILP. We first define objects and their corresponding types within the domain of interest. Next, we define predicates and operations. Finally, we frame ILP as an optimization problem.
#### Object Sets.
We denote the set of objects in a given domain as $\mathcal{O}$ , while another set $\Lambda=\{\lambda_{1},\lambda_{2},...,\lambda_{n}\}$ defines all possible types that these objects can take, namely, $\forall o\in\mathcal{O},type(o)\in\Lambda$ . A partition of $\mathcal{O}$ is thus induced by grouping objects of the same type into a subset. Formally, we partition the set of objects $\mathcal{O}$ into subsets $\{\mathcal{O}_{\lambda}\}_{\lambda\in\Lambda}$ , where
- Each subset is nonempty: $\mathcal{O}_{\lambda}\neq\varnothing$ ;
- Subsets are pairwise disjoint: $\mathcal{O}_{\lambda}\cap\mathcal{O}_{\lambda^{\prime}}=\varnothing$ for all $\lambda\neq\lambda^{\prime}$ ;
- Their union forms the entire set: $\cup_{\lambda\in\Lambda}\mathcal{O}_{\lambda}=\mathcal{O}$ ;
- Objects within a single subset share the same type: $\forall\lambda\in\Lambda,\forall o_{i},o_{j}\in\mathcal{O}_{\lambda},\ type(o_{i})=type(o_{j})$ .
#### Predicates.
Next we define predicates, which are the cores of ILP programs. Consider $N\in\mathbb{Z}_{\geq 0}$ . A $N$ -ary predicate $\mathcal{P}$ is a binary-valued function $\mathcal{P}:\mathcal{O}(\mathcal{P})\rightarrow\{0,1\}$ where $\mathcal{O}(\mathcal{P})$ is the Cartesian product of $N$ elements, each of which arbitrarily selected from $\{\mathcal{O}_{\lambda_{1}},\mathcal{O}_{\lambda_{2}},\dots,\mathcal{O}_{\lambda_{n}}\}$ , that is,
$$
\mathcal{O}(\mathcal{P})=\mathcal{O}_{\lambda_{i_{1}}}\times\mathcal{O}_{\lambda_{i_{2}}}\times\dots\times\mathcal{O}_{\lambda_{i_{N}}},
$$
where $\lambda_{i_{k}}\in\Lambda$ for all $1\leq k\leq N$ . Any set of $N$ -ary predicates $\{\mathcal{P}_{1},\mathcal{P}_{2},\dots,\mathcal{P}_{m}\}$ can be composed to form a new predicate $\widetilde{\mathcal{P}}=F(\mathcal{P}_{1},\mathcal{P}_{2},\dots,\mathcal{P}_{m})$ with a logic rule $F$ .
Consider an example with the object set $\mathcal{O}=\{o_{1},o_{2}\}$ where $type(o_{1})=type(o_{2})$ . We define two $1$ -ary predicates $\mathcal{P}_{1}$ and $\mathcal{P}_{2}$ over $\mathcal{O}$ as $\mathcal{P}_{1}(o_{1})=0,\mathcal{P}_{1}(o_{2})=1$ ; $\mathcal{P}_{2}(o_{1})=1,\mathcal{P}_{2}(o_{2})=1.$ With $\mathcal{P}_{1}$ and $\mathcal{P}_{2}$ defined above, we can compose a new predicate $\mathcal{P}_{3}$ defined as $\mathcal{P}_{3}(X)\leftarrow\mathcal{P}_{1}(X)\land\mathcal{P}_{2}(X)$ . Here, the applied logic rule $F(\mathcal{P}_{1},\mathcal{P}_{2})$ is $\mathcal{P}_{1}(X)\land\mathcal{P}_{2}(X)$ , leading to the valuation of $\mathcal{P}_{3}$ as
$$
\mathcal{P}_{3}(o_{1})=0,\mathcal{P}_{3}(o_{2})=1.
$$
#### ILP Problems.
Based on the definitions above, we are now ready to define ILPs. An ILP takes a set of background knowledge $B$ as input. Here, $B$ is a set of $m$ predicates $B=\{\mathcal{P}_{1},\mathcal{P}_{2},...,\mathcal{P}_{m}\}$ . Given a known target predicate $\mathcal{P}^{\star}$ , the goal of an ILP program is to learn a logic rule $F^{\star}$ such that $F^{\star}(B)=\mathcal{P}^{\star}$ . We follow the conventions to assume complete knowledge of $B$ , that is, each $\mathcal{P}_{i}$ from $B$ can be valuated on all possible inputs $o\in\mathcal{O}(\mathcal{P}_{i})$ , where $\mathcal{O}(\mathcal{P}_{i})$ is the input space of $\mathcal{P}_{i}$ . We denote the space of all logic rules in consideration as $\mathcal{F}$ . An instance of the ILP problem is defined by a tuple $(\mathcal{O},\Lambda,B,E)$ , where $(\mathcal{O}$ , $\Lambda$ , $B)$ follow the previous definitions and $E=\{(o,y=\mathcal{P}^{\star}(o))|o\in\mathcal{O}(\mathcal{P}^{\star}),y\in\{0,1\}\}$ describes the knowledge about the target predicate $\mathcal{P}^{\star}$ . The solution to the problem is a logic rule $\widehat{F}$ such that
$$
\displaystyle\widehat{F}\in\operatorname*{arg\,max}_{F\in\mathcal{F}}\sum_{o,y\in E}\mathbb{1}(\widehat{\mathcal{P}}(o)=y)\quad\mathrm{s.t.}\quad\widehat{\mathcal{P}}=F(B) \tag{1}
$$
### 3.2 Lifelong Learning ILP
Now we define the lifelong learning ILP problem (L2ILP). Consider a sequence of target predicates $\{\mathcal{P}_{1}^{\star},\mathcal{P}^{\star}_{2}\,\dots\}$ sharing the same background knowledge $B$ . Intuitively, this means that we observe a common set of foundational knowledge from which different target conclusions are to be inferred. For example, in a medical diagnosis setting, the background knowledge $B$ could include general medical facts such as symptoms and their possible causes. Each target predicate $\mathcal{P}^{\star}_{i}$ could represent a different diagnostic task, such as fever, infection or other specific disease. We note that a naive approach to the above problem is to independently search for the optimal logic rule $\widehat{F}_{t}$ for each target predicate $\mathcal{P}_{t}^{\star}$ . Yet, this method would largely overlook the potentially shared structure of the predicates among target predicates and result in significant computational inefficiency. To this end, the goal of L2ILP is to efficiently find the logic rule $\widehat{F}_{t}$ for target predicate $\mathcal{P}_{t}^{\star}$ , using knowledge of the previously learned logic rules $\{\widehat{F}_{1},\dots,\widehat{F}_{t-1}\}$ for composing the previous target predicates $\{\mathcal{P}_{1}^{\star},\dots,\mathcal{P}^{\star}_{t-1}\}$ . While there may exist multiple approaches for this purpose, we propose to utilize the compositionality of logic rules and predicates by reusing the intermediate predicates composed during the learning of previous target predicates, thereby efficiently composing new predicates.
#### Motivating Example.
Consider an example of learning two target predicates on a graph reasoning task. A graph is described by a binary predicate $IsConnected(X,Y)$ , additionally, several unary predicates are used to describe the colors of the nodes, such as $Red(X)$ , $Yellow(X)$ , $Blue(X)$ , etc. A target predicate $AdjacentToRed(X)$ could be defined from a rule
$$
AdjacentToRed(X)\leftarrow\exists YIsConnected(X,Y)\land Red(Y)
$$
Another target predicate $MultipleRed(X)$ could be similarly defined as
$$
\begin{array}[]{rl}\textit{MultiRed}(X)\leftarrow\exists Y\exists Z\hskip-10.00002pt&IsConnected(X,Y)\land Red(Y))\land\\
&IsConnected(X,Z)\land Red(Z))\land\\
&Is\_Not(Y,Z)\end{array}
$$
Learning these two predicates separately is computationally wasteful because the two rules share a common structure. Following this observation, we propose to solve the optimization problem through the reuse of logic rules across predicate functions, thus achieving forward transfer of knowledge required by lifelong learning.
#### Problem Formulation.
Specifically, recall that $\mathcal{F}$ is the set of all possible logic rules in considerable. The goal of L2ILP to find a shared knowledge base $B_{S}\subset H(B)$ where $H(B)=\{F(B)|F\in\mathcal{F}\}$ is the set of all possible predicates that can composed from the background knowledge $B$ . At time step $t$ where the goal is to find a logic rule $\widehat{F}_{t}$ for $\mathcal{P}_{t}^{\star}$ , we can jointly find $B_{S}$ and $\widehat{F}_{t}$ through the following optimization problem,
$$
\begin{array}[]{rl}\displaystyle\operatorname*{arg\,max}_{B_{S},\widehat{F}_{t}}&\displaystyle\sum_{t^{\prime}=1}^{t}\sum_{o,y\in E_{i}}\mathbb{1}(\widehat{P}_{t^{\prime}}(o)=y)\\[5.0pt]
\text{s.t.}&\widehat{P}_{t^{\prime}}=\widehat{F}_{t^{\prime}}(B_{S}),\quad t^{\prime}\in\{1,\dots,t-1\};\\
&\widehat{P}_{t}=\widehat{F}_{t}(B_{S}),\quad\widehat{F}_{t}\in\widetilde{\mathcal{F}}_{t},\end{array} \tag{2}
$$
where $\widehat{F}_{t^{\prime}}$ for $\{1,\dots,t-1\}$ are the learned logic rules for the target predicates previous to $t$ . Problem (2) tries to identify a shared knowledge base $B_{S}$ that can be (i) used by previously learned logical rules $\widehat{F}_{t^{\prime}}$ for previous target predicts and (ii) used to find the logical rule $\widehat{F}_{t}$ for the current target predicate $\mathcal{P}_{t}^{\star}$ . Notably, since L2ILP uses a shared knowledge base $B_{S}$ to employ the compositionality of logic rules for efficient learning, the search space for $\widehat{F}_{t}$ (i.e., $\widetilde{\mathcal{F}}_{t}$ ) can be chosen to be a much smaller space than the space of all possible logic rules in consideration $\mathcal{F}$ , i.e, $|\widetilde{\mathcal{F}}_{t}|\ll|\mathcal{F}|$ . This can significantly increase the efficiency of learning.
## 4 Compositional Neuro-Logic Model
#### Knowledge Base.
We implement L2ILP using Neural Logic Machine (NLM) (Dong et al. 2019). NLM chains together a sequence of logic layers (i.e., neural network layers with predicates as inputs and outputs), where each layer can be viewed as learning logical rules over the immediate input predicates. In our formulation, each NLM layer can be interpreted as a search space for logical rules, denoted as $\mathcal{F}_{\mathrm{NLM}}$ . Rules in $\mathcal{F}_{\mathrm{NLM}}$ are applied to the input predicates $B$ to construct the output predicate space, i.e., $H_{\mathrm{NLM}}(B)=\{F(B):F\in\mathcal{F}_{\mathrm{NLM}}\}$ . Note that here the search space represented a NLM layer $\mathcal{F}_{\mathrm{NLM}}$ is much smaller than the whole search space $\mathcal{F}$ . While one layer of NLM only generates target predicates with limited variation, chaining multiple layers lead to a complex and expressive target predicate space. Specifically, the target predicate space with $n$ NLM layers can be defined recursively as
$$
\begin{array}[]{rl}H_{\mathrm{NLM}}^{n}(B)=\hskip-8.99994pt&\{F(B\cup H_{\mathrm{NLM}}^{n-1}(B))\mid F\in\mathcal{F}\},\\
\text{where}\hskip-8.99994pt\quad&H_{\mathrm{NLM}}^{1}(B)=H_{\mathrm{NLM}}(B)\end{array}
$$
to represent the predicate space induced by iteratively applying logic rules from $\mathcal{F}_{\mathrm{NLM}}$ .
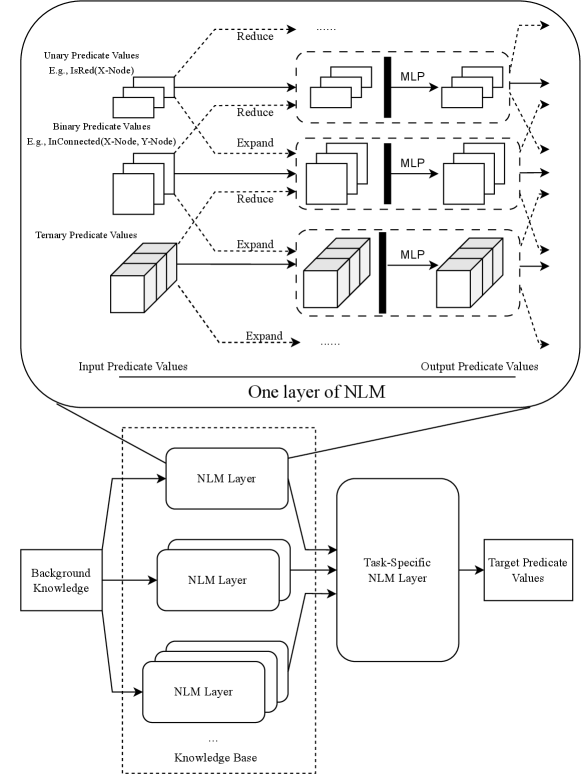
We choose to construct the shared knowledge base $B_{S}\subset\bigcup_{i=1}^{n}H_{\mathrm{NLM}}^{i}(B)$ with the union of target predicates of increasing complexity $i\in\{1,\dots,n\}$ where $n$ is a hyperparameter to control the trade-off between the model complexity and target predicate expressiveness. In particular, by constructing the knowledge base with predicates of varying complexity, we achieve fine-grained predicate composition, reminiscent of the success of multi-scale representation-learning methods in the field of computer vision (Fan et al. 2021). Figure 1 illustrates this concept, where the knowledge base $B_{S}$ is constructed by incorporating NLM layers of varying depths.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Neural Logic Machine (NLM) Architecture
### Overview
The diagram illustrates a multi-layered Neural Logic Machine (NLM) architecture designed to process predicate values (unary, binary, ternary) through reduction/expansion operations, integrate background knowledge, and produce task-specific target predicate values. The flow involves multiple NLM layers, MLPs (Multi-Layer Perceptrons), and hierarchical knowledge integration.
### Components/Axes
1. **Top Section: One Layer of NLM**
- **Input Predicate Values**:
- Unary (e.g., `IsRed(X-Node)`)
- Binary (e.g., `InConnected(X-Node, Y-Node)`)
- Ternary (e.g., `InConnected(X-Node, Y-Node, Z-Node)`)
- **Operations**:
- **Reduce**: Applied to unary and binary predicates (dashed arrows).
- **Expand**: Applied to ternary predicates (dashed arrows).
- **MLP**: Processes reduced/expanded predicates (solid arrows).
- **Output Predicate Values**: Resulting from MLP transformations.
2. **Bottom Section: Full Architecture**
- **Background Knowledge**: Feeds into the base NLM layer.
- **NLM Layers**: Stacked vertically (labeled "NLM Layer" with ellipsis for additional layers).
- **Task-Specific NLM Layer**: Final layer integrating all prior outputs.
- **Target Predicate Values**: Final output of the architecture.
### Detailed Analysis
- **Predicate Value Flow**:
- Unary and binary predicates are reduced (simplified) before MLP processing.
- Ternary predicates are expanded (decomposed) before MLP processing.
- MLPs act as transformation modules between predicate layers.
- **Knowledge Integration**:
- Background knowledge is injected at the base NLM layer, influencing subsequent layers.
- Task-specific logic is encapsulated in the final NLM layer.
### Key Observations
- **Hierarchical Processing**: The architecture uses layered NLM modules to progressively refine predicate values.
- **Dynamic Operations**: Reduction/expansion operations adapt based on predicate arity (unary/binary vs. ternary).
- **MLP Role**: MLPs serve as non-linear transformers between predicate layers, enabling complex feature learning.
### Interpretation
The diagram demonstrates a modular approach to predicate-based reasoning, where:
1. **Reduction/Expansion** tailors input complexity for efficient processing.
2. **Background Knowledge** provides foundational context, enhancing the model’s ability to generalize.
3. **Task-Specific Layers** allow customization for downstream applications (e.g., question answering, logical inference).
The use of MLPs between layers suggests a focus on capturing non-linear relationships in predicate interactions. The architecture’s design implies a balance between symbolic logic (predicates) and neural learning (MLPs), enabling hybrid reasoning capabilities.
**Note**: No numerical data or trends are present in the diagram; it focuses on structural and procedural relationships.
</details>
Figure 1: An illustration of Compositional Logic Model. Compositional Logic Model takes object properties and relations as input and outputs relations of the objects.
#### Task Specific Module.
With the shared knowledge base $B_{S}$ , the task specific module $\widetilde{\mathcal{F}}_{i}$ for $i\in\{1,...,t\}$ is also a NLM layer to take as input all predicates from the knowledge base $B_{S}$ and compose the target predicates for each corresponding task $\mathcal{P}_{i}^{\star}$ . Figure 1 illustrates this concept, showing how a NLM layer utilizes predicates from the knowledge base to compose the target predicates for each task.
#### Training Protocol.
We facilitate the transfer of the knowledge base across tasks while ensuring that task-specific modules remain distinct and independent from one another. This means that the knowledge base is reused from task to task, while task-specific modules are initialized randomly and trained from scratch.
## 5 Experiments
We note that the transfer of logic rules is beneficial to both supervised learning setting (i.e., ILP) and reinforcement learning setting (i.e., Relational RL). To this end, we present experimental results for both settings to comprehensively demonstrate the value of L2ILP. For supervised learning, we build on insights from the experiments conducted by (Dong et al. 2019), (Zimmer et al. 2023), (Glanois et al. 2021), and (Li et al. 2024), proposing task sequences for ILP across three domains: arithmetic, tree, and graph. For reinforcement learning, PDDLGym (Silver and Chitnis 2020) serves as an off-the-shelf tool in which the state and action spaces are represented using logical predicates. We therefore select BlocksWorld from PDDLGym as the testbed, as it is a commonly used benchmark for complex logic reasoning tasks (Džeroski, De Raedt, and Driessens 2001; Glanois et al. 2021; Valmeekam et al. 2023). We provide the code we used for experiments in the supplementary material.
### 5.1 Forward Transfer of Logic Rules
#### ILP Experiments.
The key question regarding the proposed approach is whether the transfer of logical rules is genuinely beneficial. We address this by comparing the learning curves of lifelong learning with those of models trained on tasks individually, while keeping model architectures the same. We provide a detailed description of the sequences of target predicates for each domain in the appendix, and present here the designs for two specific domains: Graph and Tree.
In the Graph domain, $IsConnected(X\text{-}Node,Y\text{-}Node)$ and $IsRed(X\text{-}Node)$ , fully describe all possible graphs. The first predicate defines the connectivity between nodes, while the second specifies node properties—in this case, the color of the nodes. The four target predicates are learned sequentially in the following order:
- $AdjacentToRed(X\text{-Node})$ ,
- $ExactConnectivity2(X\text{-Node},Y\text{-Node})$ ,
- $ExactConnectivity2Red(X\text{-Node})$ ,
- $ExactConnectivity2MultipleRed(X\text{-Node})$ .
The first target predicate determines whether a given node has at least one neighboring node that is red. The second predicate identifies whether the shortest path between two nodes consists of exactly two edges. Building upon this, $ExactConnectivity2Red(X\text{-Node})$ refines the notion of connectivity by verifying whether a node at an exact distance of two from the query node is red. Finally, $ExactConnectivity2MultipleRed(X\text{-Node})$ extends this concept by determining whether there exist multiple such red nodes at the specified distance. We design the tasks in a way that ensures relevance and allows them to share common structures when learning logical rules.
In the Tree domain, $IsParent(X\text{-}Node,Y\text{-}Node)$ is sufficient to specify the structure of any tree. We further define four target predicates to be learned sequentially, following the order below:
- $IsRoot(X\text{-}Node)$
- $HasOddEdges(X\text{-}Node,Y\text{-}Node)$
- $HasEvenEdges(X\text{-}Node,Y\text{-}Node)$
- $IsAncestor(X\text{-}Node,Y\text{-}Node)$
The first predicate identifies the root node of the tree and serves as the foundational predicate. The second and the third predicates determine whether two nodes in the tree are connected by an odd or even number of edges, respectively. Finally, $IsAncestor(X\text{-}Node,Y\text{-}Node)$ checks whether one node is an ancestor of another, based on their relative depths in the tree.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Line Graph: Loss Value vs. Epoch for Training Methods
### Overview
The graph compares the loss value decay over epochs for two training approaches: **Individual Training** (blue line) and **Lifelong Training** (orange line). Three task boundaries are marked at 100, 200, and 300 epochs with vertical dashed lines. Loss values range from 0.0 to 1.0 on the y-axis, while epochs span 0 to 400 on the x-axis.
---
### Components/Axes
- **X-axis (Epoch)**: Labeled "Epoch" with markers at 0, 50, 100, 150, 200, 250, 300, 350, 400.
- **Y-axis (Loss Value)**: Labeled "Loss Value" with increments of 0.2 (0.0, 0.2, 0.4, 0.6, 0.8, 1.0).
- **Legend**: Located in the top-right corner. Blue = Individual Training; Orange = Lifelong Training.
- **Task Markers**: Vertical dashed lines at 100 (Task 0), 200 (Task 1), and 300 (Task 2).
---
### Detailed Analysis
1. **Individual Training (Blue Line)**:
- **Initial Drop**: Starts near 0.8 at epoch 0, dropping sharply to ~0.1 by epoch 50.
- **Task Transitions**:
- At Task 0 (100 epochs): Loss spikes to ~0.7 before dropping to ~0.15 by epoch 150.
- At Task 1 (200 epochs): Loss rises to ~0.6 before falling to ~0.1 by epoch 250.
- At Task 2 (300 epochs): Loss peaks at ~0.8 before declining to ~0.25 by epoch 350.
- **Final Value**: Stabilizes near 0.25 at epoch 400.
2. **Lifelong Training (Orange Line)**:
- **Initial Drop**: Begins at ~0.65, falling to ~0.05 by epoch 50.
- **Task Transitions**:
- Task 0 (100 epochs): Loss rises slightly to ~0.1 before dropping to ~0.05 by epoch 150.
- Task 1 (200 epochs): Loss increases to ~0.15 before falling to ~0.05 by epoch 250.
- Task 2 (300 epochs): Loss rises to ~0.2 before stabilizing at ~0.15 by epoch 350.
- **Final Value**: Remains near 0.15 at epoch 400.
---
### Key Observations
- Both methods show **loss reduction over time**, but Lifelong Training maintains **lower loss values** after each task.
- **Individual Training** exhibits **sharp spikes** at task boundaries (100, 200, 300 epochs), suggesting temporary performance degradation.
- **Lifelong Training** demonstrates **smoother adaptation**, with smaller loss increases during task transitions.
- Final loss values at epoch 400: ~0.25 (Individual) vs. ~0.15 (Lifelong).
---
### Interpretation
The data suggests **Lifelong Training** outperforms Individual Training in **long-term retention** and **adaptation to new tasks**. The spikes in Individual Training at task boundaries indicate **catastrophic forgetting**, where prior knowledge is lost when learning new tasks. In contrast, Lifelong Training’s gradual loss decay implies **better generalization** and **memory preservation**. This aligns with the hypothesis that lifelong learning frameworks mitigate forgetting by continuously updating models without discarding prior knowledge.
</details>
(a) Training dynamics for Arithmetic
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Graph: Task Loss Values Across Epochs
### Overview
The image is a line graph depicting the loss values of multiple tasks over training epochs. The graph includes two data series (orange and blue) with shaded uncertainty regions, and vertical dashed lines marking task boundaries. The x-axis represents epochs (0–400), while the y-axis shows loss values (0–0.7). Tasks are labeled sequentially (Task 0–Task 3) along the x-axis.
---
### Components/Axes
- **X-axis**: Epochs (0–400), segmented by vertical dashed lines at 100, 200, 300, and 400. Labels indicate "Task 0," "Task 1," "Task 2," and "Task 3" at these intervals.
- **Y-axis**: Loss Value (0–0.7), with gridlines for precision.
- **Legend**: Located at the bottom-right. Orange corresponds to "Task 0," and blue corresponds to "Task 1." No legend entries for Tasks 2 or 3.
- **Shaded Regions**: Gray bands around lines indicate uncertainty (standard deviation or confidence intervals).
---
### Detailed Analysis
1. **Task 0 (Orange Line)**:
- **Initial Drop**: Loss plunges from ~0.6 to ~0.1 within the first 50 epochs.
- **Plateau**: Stabilizes near 0.1 for the remainder of the training (epochs 50–400).
- **Uncertainty**: Shaded region narrows sharply during the drop, then widens slightly post-50 epochs.
2. **Task 1 (Blue Line)**:
- **Initial Drop**: Loss decreases from ~0.6 to ~0.2 within the first 100 epochs.
- **Fluctuation**: Gradual decline to ~0.15 by epoch 200, followed by minor oscillations.
- **Uncertainty**: Shaded region remains relatively stable after the initial drop.
3. **Tasks 2 and 3**:
- **No Data Series**: Despite x-axis labels for Tasks 2 and 3, no corresponding lines or shaded regions are present in the graph.
- **Legend Discrepancy**: The legend only includes Tasks 0 and 1, suggesting incomplete or missing data for later tasks.
---
### Key Observations
- **Sharp Initial Convergence**: Both Task 0 and Task 1 exhibit rapid loss reduction in their respective training phases.
- **Task-Specific Plateaus**: Loss values stabilize after initial drops, indicating task-specific convergence.
- **Missing Data**: Tasks 2 and 3 are labeled on the x-axis but lack visual representation, creating ambiguity.
- **Uncertainty Patterns**: Task 0 shows higher uncertainty post-convergence compared to Task 1.
---
### Interpretation
The graph illustrates a multi-task learning scenario where tasks are trained sequentially (100 epochs per task). Task 0 converges faster and achieves lower loss than Task 1, suggesting differences in task complexity or model adaptability. The absence of data for Tasks 2 and 3 raises questions about data completeness or visualization errors. The shaded uncertainty regions highlight variability in model performance, with Task 0 exhibiting greater instability after convergence. This could indicate challenges in maintaining task-specific knowledge over time, potentially pointing to issues like catastrophic forgetting in sequential training.
</details>
(b) Training dynamics for Tree
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Graph: Loss Value Over Epochs for Three Tasks
### Overview
The image is a line graph depicting the loss value of a model across 400 epochs, divided into three sequential tasks. Each task is represented by a distinct colored line (orange for Task 0, blue for Task 1, and orange for Task 2). Vertical dashed lines at epochs 100, 200, and 300 demarcate the start of each task. The y-axis represents loss value (0.0–0.8), and the x-axis represents epochs (0–400). Shaded regions around the lines indicate variability or confidence intervals.
### Components/Axes
- **X-axis (Epoch)**: Labeled "Epoch," with ticks at 0, 50, 100, 150, 200, 250, 300, 350, and 400.
- **Y-axis (Loss Value)**: Labeled "Loss Value," with ticks at 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, and 0.8.
- **Legend**: Located on the right, with:
- **Orange**: Task 0
- **Blue**: Task 1
- **Orange**: Task 2 (note: Task 0 and Task 2 share the same color, which may cause ambiguity).
- **Vertical Dashed Lines**: At epochs 100 (Task 1 start), 200 (Task 2 start), and 300 (Task 3 start, though only three tasks are labeled).
### Detailed Analysis
1. **Task 0 (Orange Line)**:
- **Trend**: Starts at ~0.7 loss at epoch 0, decreases sharply to ~0.3 by epoch 50, and further drops to ~0.1 by epoch 100. After Task 1 begins (epoch 100), the loss continues to decline gradually to ~0.05 by epoch 200, then plateaus near 0.0.
- **Key Data Points**:
- Epoch 0: ~0.7
- Epoch 50: ~0.3
- Epoch 100: ~0.1
- Epoch 200: ~0.05
- Epoch 400: ~0.0
2. **Task 1 (Blue Line)**:
- **Trend**: Begins at epoch 100 with a loss of ~0.6, decreases to ~0.2 by epoch 150, and further drops to ~0.1 by epoch 200. After Task 2 starts (epoch 200), the loss remains stable at ~0.1 until epoch 400.
- **Key Data Points**:
- Epoch 100: ~0.6
- Epoch 150: ~0.2
- Epoch 200: ~0.1
- Epoch 400: ~0.1
3. **Task 2 (Orange Line)**:
- **Trend**: Starts at epoch 200 with a loss of ~0.6, decreases to ~0.3 by epoch 250, and further drops to ~0.2 by epoch 300. The loss remains relatively stable at ~0.2 from epoch 300 to 400.
- **Key Data Points**:
- Epoch 200: ~0.6
- Epoch 250: ~0.3
- Epoch 300: ~0.2
- Epoch 400: ~0.2
### Key Observations
- **Task 0** shows the steepest initial decline, suggesting rapid learning early in training.
- **Task 1** exhibits a slower, more gradual decline compared to Task 0, with a plateau after epoch 200.
- **Task 2** has the slowest rate of improvement, with a loss reduction of only ~0.4 over 100 epochs (200–300).
- The shared orange color for Tasks 0 and 2 in the legend creates potential confusion, as their trends differ significantly.
- After each task's training period, the loss for prior tasks plateaus, indicating possible catastrophic forgetting or stabilization.
### Interpretation
The graph demonstrates how the model's loss evolves across sequential tasks. Task 0's rapid decline suggests effective initial training, while Task 1 and Task 2 show diminishing returns, possibly due to increased complexity or limited data. The shared orange color for Tasks 0 and 2 in the legend is problematic, as their performance trajectories are distinct. The plateauing of loss values after each task's training period highlights potential challenges in retaining knowledge from prior tasks (catastrophic forgetting). The shaded regions around the lines indicate variability in loss measurements, suggesting uncertainty in the model's performance estimates. Overall, the data underscores the trade-offs between task-specific learning and long-term retention in sequential training scenarios.
</details>
(c) Training dynamics for Graph
Figure 2: Epoch training dynamics for individual learning and lifelong learning
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Graph: Evaluation Steps Across Tasks
### Overview
The graph compares the evaluation steps required for two training methods—**Individual Training** (blue) and **Lifelong Training** (orange)—across five sequential tasks (Task 0 to Task 4). The x-axis represents epochs (0–1000), and the y-axis represents evaluation steps (0–350). Vertical dashed lines segment the graph into task-specific regions.
---
### Components/Axes
- **X-axis (Epoch)**: Labeled "Epoch," with markers at 0, 200, 400, 600, 800, and 1000.
- **Y-axis (Evaluation Steps)**: Labeled "Evaluation Steps," ranging from 0 to 350.
- **Legend**: Located in the top-right corner. Blue = Individual Training; Orange = Lifelong Training.
- **Task Boundaries**: Vertical dashed lines separate tasks (e.g., Task 0: 0–200 epochs, Task 1: 200–400 epochs, etc.).
---
### Detailed Analysis
#### Task 0 (0–200 epochs)
- **Individual Training (Blue)**: Flat line at 0 evaluation steps.
- **Lifelong Training (Orange)**: Flat line at 0 evaluation steps.
- **Observation**: Both methods start with perfect performance (0 steps).
#### Task 1 (200–400 epochs)
- **Individual Training (Blue)**: Sharp initial drop from 0 to ~50 steps, followed by stabilization.
- **Lifelong Training (Orange)**: Gradual decline from 0 to ~30 steps, with smoother fluctuations.
- **Observation**: Lifelong Training shows less volatility and lower evaluation steps.
#### Task 2 (400–600 epochs)
- **Individual Training (Blue)**: Starts at ~50 steps, fluctuates between 20–80 steps, then drops to ~20 steps.
- **Lifelong Training (Orange)**: Starts at ~30 steps, fluctuates between 10–50 steps, then drops to ~10 steps.
- **Observation**: Both methods decline, but Lifelong Training maintains lower steps with tighter variability.
#### Task 3 (600–800 epochs)
- **Individual Training (Blue)**: Starts at ~20 steps, fluctuates between 5–40 steps, then drops to ~10 steps.
- **Lifelong Training (Orange)**: Starts at ~10 steps, fluctuates between 0–25 steps, then drops to ~5 steps.
- **Observation**: Lifelong Training consistently outperforms Individual Training in stability and efficiency.
#### Task 4 (800–1000 epochs)
- **Individual Training (Blue)**: Starts at ~10 steps, fluctuates between 0–30 steps, then drops to ~5 steps.
- **Lifelong Training (Orange)**: Starts at ~5 steps, fluctuates between 0–15 steps, then drops to ~2 steps.
- **Observation**: Lifelong Training achieves the lowest evaluation steps, with minimal variability.
---
### Key Observations
1. **Lifelong Training (Orange)** consistently demonstrates lower evaluation steps and smoother trends across all tasks.
2. **Individual Training (Blue)** exhibits sharper declines and higher variability (wider shaded regions), suggesting less reliable performance.
3. **Task-Specific Drops**: Both methods show performance degradation at task boundaries, but Lifelong Training recovers more effectively.
---
### Interpretation
The data suggests that **Lifelong Training** is more effective at retaining knowledge across tasks, as evidenced by its consistently lower evaluation steps and reduced variability. The wider shaded regions for Individual Training indicate higher uncertainty in its performance, likely due to catastrophic forgetting or lack of task adaptation. The sharp drops in Individual Training may reflect abrupt adjustments to new tasks, while Lifelong Training’s gradual declines imply better integration of prior knowledge. This aligns with the hypothesis that lifelong learning frameworks mitigate forgetting in sequential task environments.
</details>
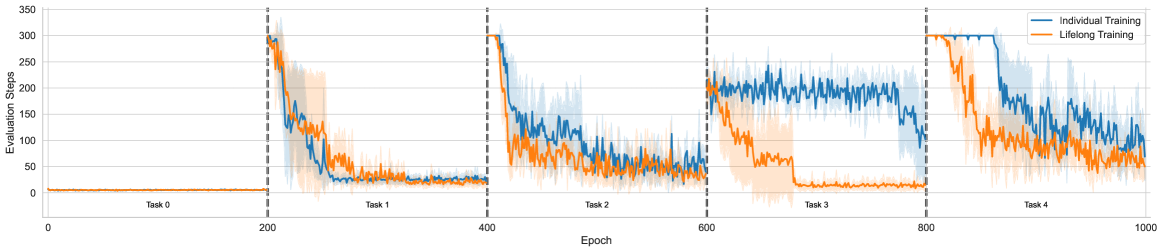
Figure 3: Evaluation steps for BlocksWorld tasks
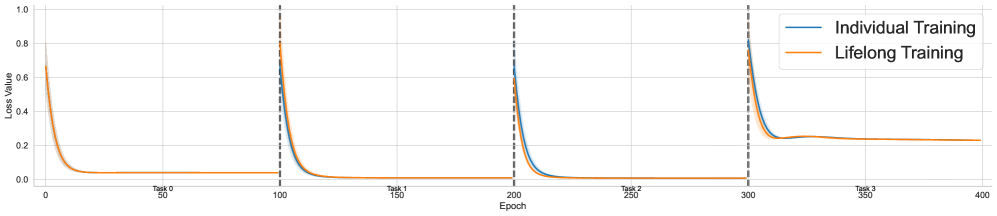
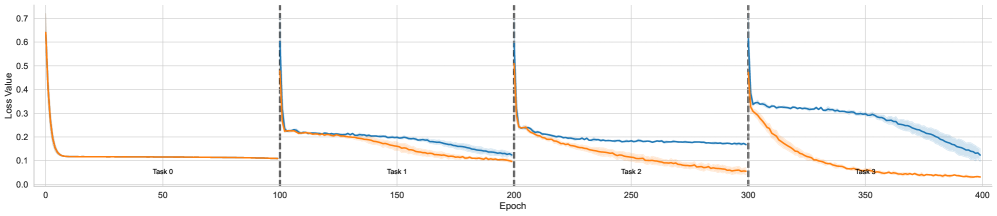
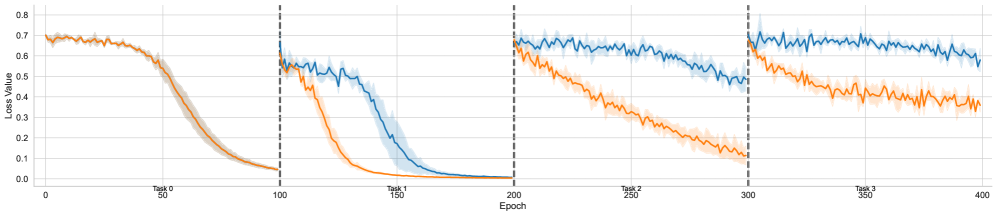
Figure 2 illustrates the training dynamics for each task across all domains. For each task, we conducted experiments with four different seeds and plotted the mean, along with the standard deviation for each data point. From top to bottom, the domains are ordered as arithmetic, tree, and graph, while from left to right, the plots are arranged sequentially for tasks 0 to 3. The tasks in the arithmetic domain are relatively simple, allowing both individual and lifelong learning to converge to optimal performance within a short period. However, we observe that the loss curves in lifelong learning decrease more rapidly, as indicated by a small but noticeable gap. In contrast, for the tree and graph domains, the gaps become more pronounced, with no overlap observed between the paired curves. Notably, for the curves corresponding to the first task across all domains, lifelong learning completely overlaps with individual learning. This is expected, as the first task in lifelong learning does not incorporate any previously acquired knowledge, making it equivalent to its individual learning counterpart.
This result shows that by leveraging the knowledge base acquired in earlier tasks, we could achieve higher learning efficiency on subsequence tasks, demonstrating the forward transfer effect that is essential in lifelong learning setting.
#### Relational RL Experiments.
For the BlocksWorld task from PDDLGym, Table 1 summarizes the predicates used to describe the state and action spaces. Since the number of ground predicates depends on the number of objects in a task, the total number of possible actions can be as high as $2x^{2}+2x$ , where $x$ represents the number of blocks. However, not all of these actions are valid in every state. Additionally, the number of possible states grows factorially with the number of blocks in the environment, making the task increasingly complex as more blocks are added. We note that previous works (Jiang and Luo 2019; Zimmer et al. 2023; Valmeekam et al. 2023) typically use 5 blocks, whereas we extend our experiments to 6 blocks. Furthermore, We set the tasks to follow a sparse reward scheme, where a penalty of -0.1 is given for every step taken, while a reward of 100 is granted upon achieving the desired block configuration. To define the sequence of tasks for BlocksWorld, we assign different desired configurations to each task, progressively increasing the difficulty by making the target configurations more challenging to reach. Refer to Appendix for a detailed discussion.
| Predicates | Arity | Description |
| --- | --- | --- |
| $On(X\text{-}Block,Y\text{-}Block)$ | 2 | Block $X$ is on Block $Y$ |
| $OnTable(X\text{-}Block)$ | 1 | Block $X$ is on the table |
| $Clear(X\text{-}Block)$ | 1 | Block $X$ could be picked up |
| $HandEmpty()$ | 0 | Hand is empty |
| $HandFull()$ | 0 | Hand is full |
| $Holding(X\text{-}Block)$ | 1 | Hand is holding Block $X$ |
| Action Space | | |
| Predicates | Arity | Description |
| $PickUp(X\text{-}Block)$ | 1 | Pick up Block $X$ from the table |
| $PutDown(X\text{-}Block)$ | 1 | Put down Block $X$ onto the table |
| $Stack(X\text{-}Block,Y\text{-}Block)$ | 2 | Stack Block $X$ onto Block $Y$ |
| $Unstack(X\text{-}Block,Y\text{-}Block)$ | 2 | Unstack Block $X$ from Block $Y$ |
Table 1: State and action spaces for BlocksWorld from PDDLGym
Large state and action spaces pose significant challenges for exploration to RL agents, particularly when rewards are sparse and only provided upon goal completion. As a result, our experiments show that training tasks individually fails to yield sufficient exploration to positive rewards, let alone facilitate the learning of any meaningful policies. To address this issue, we adopt an offline reinforcement learning approach, where a replay buffer is collected in advance to ensure that both lifelong learning and individual training have access to data of the same quality. In BlocksWorld tasks, we use a planner to generate optimal actions at each step while incorporating random exploration to ensure adequate coverage of the state and action spaces. Specifically, we set the exploration rate to 0.8 and collect 50,000 transitions for each task.
Figure 3 illustrates the evaluation steps for each task, as the number of steps directly reflects the quality of the learned policy. We ran each experiment using four different seeds and evaluated the policy periodically. For tasks 0–2, lifelong training does not show superior performance compared to individual training, as these tasks are relatively simple. However, for the more challenging tasks 3 and 4, clear gaps emerge: lifelong training converges much faster, while individual training occasionally fails to converge to the optimal policy. This result highlights that forward transfer is not only observed in the relatively straightforward supervised learning setting but also extends to the more complex reinforcement learning paradigm, where effective knowledge transfer accelerates policy learning in later tasks.
### 5.2 Forgetting of Logic Rules
#### Forgetting Experiments.
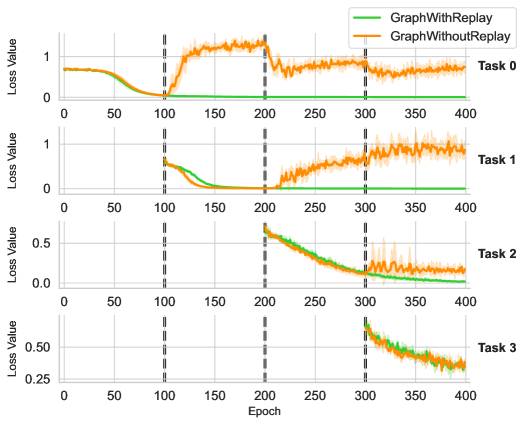
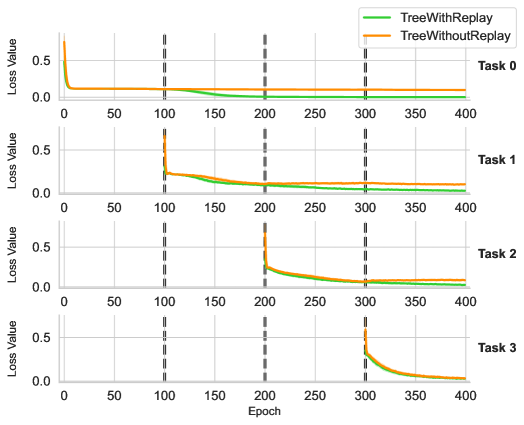
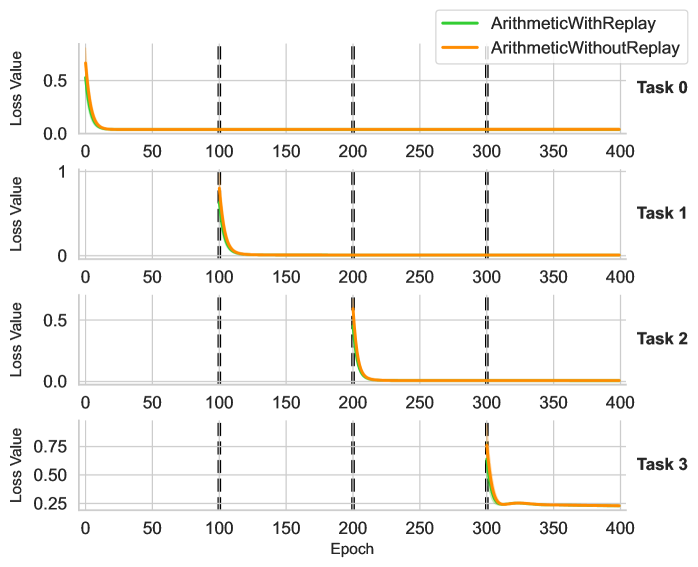
Another fundamental challenge in lifelong learning is assessing the extent to which a model forgets previously acquired knowledge (i.e. catastrophic forgetting) and identifying effective strategies to mitigate this issue. In our case, the knowledge base is continuously updated, which may cause task-specific modules for earlier tasks to fail, as they rely on outdated knowledge representations. To investigate this phenomenon, we track the loss values throughout the entire training process and visualize the corresponding curves for each task. Specifically, in the supervised learning setting, we adhere to the training protocol described in the previous section while recording the tested loss values for each task at every epoch whenever feasible. Figure 4 and Figure 5 illustrate the results for the graph and tree domains, respectively, with each plot representing tasks 0 through 3. For results on arithemetic, please refer to appendix for a detailed description.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Graph: Loss Value vs. Epoch Across Four Tasks
### Overview
The image displays a multi-task line graph comparing the performance of two algorithms ("GraphWithReplay" and "GraphWithoutReplay") across four distinct tasks (Task 0–Task 3). Each task is represented in a separate subplot, with loss values plotted against training epochs (0–400). The graph highlights differences in convergence behavior and stability between the two approaches.
---
### Components/Axes
- **X-Axis**: Epoch (0–400, linear scale)
- **Y-Axis**: Loss Value (ranges vary per task, labeled "Loss Value")
- **Legend**: Located in the top-right corner of the entire graph.
- Green line: "GraphWithReplay"
- Orange line: "GraphWithoutReplay"
- **Subplot Structure**: Four vertically stacked panels, each labeled "Task 0" to "Task 3" in the bottom-right corner of their respective subplots.
---
### Detailed Analysis
#### Task 0
- **Green Line (GraphWithReplay)**:
- Starts at ~0.8 loss, drops sharply to ~0.1 by epoch 100, then stabilizes near 0.05.
- Minimal fluctuation after epoch 100.
- **Orange Line (GraphWithoutReplay)**:
- Begins at ~0.8, rises to ~0.9 by epoch 100, then oscillates between ~0.7–0.9 until epoch 400.
- Sharp drop to ~0.6 at epoch 200, followed by stabilization.
#### Task 1
- **Green Line**:
- Starts at ~0.6, drops to ~0.1 by epoch 100, then remains flat near 0.05.
- **Orange Line**:
- Begins at ~0.6, rises to ~0.8 by epoch 100, then fluctuates between ~0.6–0.8 until epoch 400.
- Notable spike to ~0.9 at epoch 300.
#### Task 2
- **Green Line**:
- Starts at ~0.5, decreases steadily to ~0.1 by epoch 200, then stabilizes near 0.05.
- **Orange Line**:
- Begins at ~0.5, drops to ~0.3 by epoch 200, then fluctuates between ~0.2–0.4 until epoch 400.
#### Task 3
- **Green Line**:
- Starts at ~0.5, drops to ~0.2 by epoch 300, then declines to ~0.1 by epoch 400.
- **Orange Line**:
- Begins at ~0.5, rises to ~0.6 by epoch 300, then declines to ~0.4 by epoch 400.
- Converges with the green line near epoch 400.
---
### Key Observations
1. **Consistent Performance Gap**:
- "GraphWithReplay" (green) consistently achieves lower loss values across all tasks, especially after epoch 100.
- "GraphWithoutReplay" (orange) exhibits higher loss and greater instability, with frequent fluctuations.
2. **Phase Transitions**:
- Dashed vertical lines at epochs 100 and 300 suggest potential phase changes (e.g., learning rate adjustments or task transitions).
3. **Convergence Behavior**:
- In Task 3, both algorithms converge near epoch 400, but "GraphWithReplay" maintains a ~20% advantage in loss reduction.
---
### Interpretation
The data demonstrates that incorporating replay mechanisms ("GraphWithReplay") significantly improves training stability and convergence speed across diverse tasks. The orange lines (without replay) show higher loss and erratic behavior, likely due to catastrophic forgetting or insufficient memory of prior tasks. The dashed lines at epochs 100 and 300 may correlate with task-specific milestones or hyperparameter adjustments. Notably, Task 0 and Task 1 highlight the critical role of replay in preventing performance degradation during early training phases. The convergence in Task 3 suggests that replay mechanisms become less impactful as training progresses, though "GraphWithReplay" retains a marginal edge.
</details>
Figure 4: Training dynamics of Graph for each task
In particular, the orange curves illustrate the loss values as described above. As expected, the loss values for earlier tasks increase as training progresses on later tasks, indicating the occurrence of catastrophic forgetting in the model.
#### Replay Experiments.
A straightforward approach to addressing catastrophic forgetting is to replay experience from earlier tasks while training on later ones. We adopt this strategy by replaying data from all previously learned tasks when training on a new task. This approach is particularly beneficial in our case, as we aim to build a shared knowledge base that can be effectively leveraged across multiple tasks. To ensure a fair comparison, we align the curves by recording each data point in terms of the training epoch of the current task. This alignment allows us to directly compare the performance of models trained with and without experience replay, providing deeper insights into its effectiveness in mitigating forgetting and preserving previously acquired knowledge.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Line Chart: Loss Value vs. Epoch Across Four Tasks
### Overview
The image displays four line charts (Task 0–Task 3) comparing the loss values of two models, **TreeWithReplay** (green) and **TreeWithoutReplay** (orange), over 400 epochs. Each task shows distinct convergence patterns, with vertical dashed lines marking epochs 100, 200, 300, and 400.
---
### Components/Axes
- **X-axis**: Epoch (0–400, increments of 50).
- **Y-axis**: Loss Value (0–0.5, increments of 0.1).
- **Legend**:
- Green: TreeWithReplay
- Orange: TreeWithoutReplay
- **Task Labels**: Positioned at the top-right of each subplot (Task 0–Task 3).
---
### Detailed Analysis
#### Task 0
- **TreeWithReplay (Green)**:
- Starts at ~0.5 loss, drops sharply to near 0 by epoch 50, and remains stable.
- **TreeWithoutReplay (Orange)**:
- Starts at ~0.5 loss, declines gradually to near 0 by epoch 100, then stabilizes.
#### Task 1
- **TreeWithReplay (Green)**:
- Drops rapidly to near 0 by epoch 50, maintaining stability.
- **TreeWithoutReplay (Orange)**:
- Starts at ~0.5 loss, spikes to ~0.5 at epoch 100, then declines to near 0 by epoch 200.
#### Task 2
- **TreeWithReplay (Green)**:
- Drops sharply to near 0 by epoch 50, remaining stable.
- **TreeWithoutReplay (Orange)**:
- Declines gradually from ~0.5 to near 0 by epoch 200.
#### Task 3
- **TreeWithReplay (Green)**:
- Drops rapidly to near 0 by epoch 50, stable thereafter.
- **TreeWithoutReplay (Orange)**:
- Starts at ~0.5 loss, spikes to ~0.5 at epoch 300, then declines to near 0 by epoch 400.
---
### Key Observations
1. **Consistent Performance of TreeWithReplay**:
- Across all tasks, TreeWithReplay achieves near-zero loss by epoch 50–100 and remains stable.
2. **Instability in TreeWithoutReplay**:
- Tasks 1 and 3 show abrupt loss spikes (~0.5) at epochs 100 and 300, respectively, before recovery.
3. **Slower Convergence for TreeWithoutReplay**:
- In Tasks 0, 2, and 3, TreeWithoutReplay takes 100–200 epochs to reach near-zero loss compared to TreeWithReplay’s 50–100 epochs.
---
### Interpretation
- **Impact of Replay Mechanism**:
- TreeWithReplay demonstrates faster and more stable convergence, suggesting the replay mechanism mitigates catastrophic forgetting or instability during training.
- **Spike Analysis**:
- The spikes in TreeWithoutReplay (Tasks 1 and 3) may indicate temporary destabilization when learning new tasks without retaining prior knowledge. This aligns with known challenges in continual learning, where models without replay often forget earlier tasks.
- **Practical Implications**:
- The results highlight the importance of replay mechanisms for maintaining performance across sequential tasks, particularly in dynamic or multi-task learning environments.
---
### Spatial Grounding & Verification
- **Legend Position**: Top-right corner, clearly associating colors with model names.
- **Axis Labels**: Y-axis labeled "Loss Value," X-axis labeled "Epoch," with consistent scaling across all subplots.
- **Data Series Alignment**: Green (TreeWithReplay) and orange (TreeWithoutReplay) lines match legend labels in all tasks.
---
### Content Details
- **Task 0**:
- TreeWithReplay: 0.5 → 0 (epoch 0–50).
- TreeWithoutReplay: 0.5 → 0 (epoch 0–100).
- **Task 1**:
- TreeWithReplay: 0.5 → 0 (epoch 0–50).
- TreeWithoutReplay: 0.5 → 0.5 (spike at epoch 100) → 0 (epoch 100–200).
- **Task 2**:
- TreeWithReplay: 0.5 → 0 (epoch 0–50).
- TreeWithoutReplay: 0.5 → 0 (epoch 0–200).
- **Task 3**:
- TreeWithReplay: 0.5 → 0 (epoch 0–50).
- TreeWithoutReplay: 0.5 → 0.5 (spike at epoch 300) → 0 (epoch 300–400).
---
### Final Notes
The chart underscores the efficacy of replay mechanisms in stabilizing training dynamics. The spikes in TreeWithoutReplay suggest potential overfitting or instability when tasks are introduced sequentially without memory retention. Further investigation into the spike causes (e.g., data distribution shifts, hyperparameter sensitivity) could refine model robustness.
</details>
Figure 5: Training dynamics of Tree for each task
The green curves in Figure 4 and Figure 5 illustrate the loss values when experience replay is applied. As the results indicate, during the training phase for each individual task, replaying experience does not significantly interfere with the learning of the current task. The loss curves for training without replay closely align with those for training with replay, indicating that incorporating past experiences does not disrupt the optimization of the current task. More importantly, experience replay effectively mitigates catastrophic forgetting, as evidenced by the green curves maintaining low loss values throughout the entire training process. This suggests that the model successfully constructs retains previously acquired knowledge, leading to the formation of a robust and reusable knowledge base across all tasks.
Surprisingly, we also observe a backward transfer effect in our experiments. The first plot in Figure 5 corresponds to the loss curve for task 0 in the tree domain. Notably, the loss curve plateaus before training on task 1. However, once training on task 1 begins, the loss for task 0 further decreases to zero, indicating that learning task 1 enhances the model’s performance on task 0. This suggests the potential of L2ILP that training on the current task may further improves the performance on previous tasks, as a better knowledge base is acquired during the sequential training.
## 6 Conclusion
Neuro-Symbolic Artificial Intelligence introduces a new research paradigm by integrating neural networks with symbolic methods, which were traditionally studied as separate approaches. This integration opens new research opportunities by enabling the formulation of novel problems and providing solutions to challenges that were previously difficult to address using either approach alone. In this work, we take a step toward studying the lifelong learning problem in this domain and demonstrate that by leveraging the compositionality and transferability of logic rules, it becomes straightforward to construct models that achieve higher learning efficiency on later tasks while preserving performance on earlier ones. However, this problem remains far from solved. As discussed, a key challenge is how to efficiently construct logic rules that are meaningful for tasks within a given domain and how to systematically generate new rules from an evolving knowledge base. Our work represents a small step in this direction, demonstrating its feasibility but leaving many open opportunities for future research. We hope this study inspires further research into more effective methods for representing and constructing logic rules—particularly those that support the dynamic addition and removal of rules from a knowledge base—ultimately enabling more efficient and scalable neuro-symbolic lifelong learning systems.
## References
- Amizadeh et al. (2020) Amizadeh, S.; Palangi, H.; Polozov, A.; Huang, Y.; and Koishida, K. 2020. Neuro-symbolic visual reasoning: Disentangling. In International Conference on Machine Learning, 279–290. Pmlr.
- Badreddine et al. (2022) Badreddine, S.; d’Avila Garcez, A.; Serafini, L.; and Spranger, M. 2022. Logic Tensor Networks. Artificial Intelligence, 303: 103649.
- Besold and Kühnberger (2023) Besold, T. R.; and Kühnberger, K.-U. 2023. Symbolic and Hybrid Models of Cognition, 139–172. Cambridge Handbooks in Psychology. Cambridge University Press.
- Buzzega et al. (2020) Buzzega, P.; Boschini, M.; Porrello, A.; Abati, D.; and Calderara, S. 2020. Dark experience for general continual learning: a strong, simple baseline. In Advances in Neural Information Processing Systems, volume 33, 15920–15930.
- Campero et al. (2018) Campero, A.; Pareja, A.; Klinger, T.; Tenenbaum, J.; and Riedel, S. 2018. Logical rule induction and theory learning using neural theorem proving. arXiv preprint arXiv:1809.02193.
- Castro et al. (2025) Castro, P. S.; Tomasev, N.; Anand, A.; Sharma, N.; Mohanta, R.; Dev, A.; Perlin, K.; Jain, S.; Levin, K.; Éltető, N.; Dabney, W.; Novikov, A.; Turner, G. C.; Eckstein, M. K.; Daw, N. D.; Miller, K. J.; and Stachenfeld, K. L. 2025. Discovering Symbolic Cognitive Models from Human and Animal Behavior. bioRxiv.
- Chaudhry et al. (2018) Chaudhry, A.; Ranzato, M.; Rohrbach, M.; and Elhoseiny, M. 2018. Efficient lifelong learning with a-gem. arXiv preprint arXiv:1812.00420.
- Cropper and Dumančić (2022) Cropper, A.; and Dumančić, S. 2022. Inductive logic programming at 30: a new introduction. arXiv:2008.07912.
- Dai et al. (2019) Dai, W.-Z.; Xu, Q.; Yu, Y.; and Zhou, Z.-H. 2019. Bridging machine learning and logical reasoning by abductive learning. Advances in Neural Information Processing Systems, 32.
- d’Avila Garcez and Lamb (2020) d’Avila Garcez, A.; and Lamb, L. C. 2020. Neurosymbolic AI: The 3rd Wave. arXiv:2012.05876.
- Dong et al. (2019) Dong, H.; Mao, J.; Lin, T.; Wang, C.; Li, L.; and Zhou, D. 2019. Neural Logic Machines. arXiv:1904.11694.
- Džeroski, De Raedt, and Driessens (2001) Džeroski, S.; De Raedt, L.; and Driessens, K. 2001. Relational reinforcement learning. Machine learning, 43: 7–52.
- Evans and Grefenstette (2018) Evans, R.; and Grefenstette, E. 2018. Learning Explanatory Rules from Noisy Data. arXiv:1711.04574.
- Fan et al. (2021) Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; and Feichtenhofer, C. 2021. Multiscale Vision Transformers. arXiv:2104.11227.
- Farajtabar et al. (2020) Farajtabar, M.; Azizan, N.; Mott, A.; and Li, A. 2020. Orthogonal gradient descent for continual learning. In International conference on artificial intelligence and statistics, 3762–3773. PMLR.
- Glanois et al. (2021) Glanois, C.; Feng, X.; Jiang, Z.; Weng, P.; Zimmer, M.; Li, D.; and Liu, W. 2021. Neuro-Symbolic Hierarchical Rule Induction. arXiv:2112.13418.
- Jiang and Luo (2019) Jiang, Z.; and Luo, S. 2019. Neural Logic Reinforcement Learning. arXiv:1904.10729.
- Kirkpatrick et al. (2017) Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A. A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. 2017. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114(13): 3521–3526.
- Lake et al. (2016) Lake, B. M.; Ullman, T. D.; Tenenbaum, J. B.; and Gershman, S. J. 2016. Building Machines That Learn and Think Like People. arXiv:1604.00289.
- Li et al. (2019) Li, X.; Zhou, Y.; Wu, T.; Socher, R.; and Xiong, C. 2019. Learn to grow: A continual structure learning framework for overcoming catastrophic forgetting. In International Conference on Machine Learning, 3925–3934. PMLR.
- Li et al. (2024) Li, Z.; Cao, Y.; Xu, X.; Jiang, J.; Liu, X.; Teo, Y. S.; wei Lin, S.; and Liu, Y. 2024. LLMs for Relational Reasoning: How Far are We? arXiv:2401.09042.
- Li and Hoiem (2017) Li, Z.; and Hoiem, D. 2017. Learning without forgetting. IEEE transactions on pattern analysis and machine intelligence, 40(12): 2935–2947.
- Lin et al. (2014) Lin, D.; Dechter, E.; Ellis, K.; Tenenbaum, J.; and Muggleton, S. 2014. Bias reformulation for one-shot function induction. In ECAI 2014, 525–530. IOS Press.
- Lopez-Paz and Ranzato (2017) Lopez-Paz, D.; and Ranzato, M. 2017. Gradient episodic memory for continual learning. Advances in neural information processing systems, 30.
- Manhaeve et al. (2018) Manhaeve, R.; Dumančić, S.; Kimmig, A.; Demeester, T.; and Raedt, L. D. 2018. DeepProbLog: Neural Probabilistic Logic Programming. arXiv:1805.10872.
- Marconato et al. (2023) Marconato, E.; Bontempo, G.; Ficarra, E.; Calderara, S.; Passerini, A.; and Teso, S. 2023. Neuro-symbolic continual learning: Knowledge, reasoning shortcuts and concept rehearsal. arXiv preprint arXiv:2302.01242.
- Mendez (2022) Mendez, J. A. 2022. Lifelong Machine Learning of Functionally Compositional Structures. arXiv:2207.12256.
- Payani and Fekri (2019) Payani, A.; and Fekri, F. 2019. Inductive Logic Programming via Differentiable Deep Neural Logic Networks. arXiv:1906.03523.
- Rebuffi et al. (2017) Rebuffi, S.-A.; Kolesnikov, A.; Sperl, G.; and Lampert, C. H. 2017. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2001–2010.
- Rolnick et al. (2019) Rolnick, D.; Ahuja, A.; Schwarz, J.; Lillicrap, T.; and Wayne, G. 2019. Experience replay for continual learning. In Advances in Neural Information Processing Systems, 350–360.
- Rusu et al. (2016) Rusu, A. A.; Rabinowitz, N. C.; Desjardins, G.; Soyer, H.; Kirkpatrick, J.; Kavukcuoglu, K.; Pascanu, R.; and Hadsell, R. 2016. Progressive neural networks. In arXiv preprint arXiv:1606.04671.
- Saha, Garg, and Roy (2021) Saha, G.; Garg, I.; and Roy, K. 2021. Gradient projection memory for continual learning. arXiv preprint arXiv:2103.09762.
- Santoro et al. (2017) Santoro, A.; Raposo, D.; Barrett, D. G.; Malinowski, M.; Pascanu, R.; Battaglia, P.; and Lillicrap, T. 2017. A simple neural network module for relational reasoning. Advances in neural information processing systems, 30.
- Sen et al. (2022) Sen, P.; de Carvalho, B. W.; Riegel, R.; and Gray, A. 2022. Neuro-symbolic inductive logic programming with logical neural networks. In Proceedings of the AAAI conference on artificial intelligence, volume 36, 8212–8219.
- Sheth, Roy, and Gaur (2023) Sheth, A.; Roy, K.; and Gaur, M. 2023. Neurosymbolic AI – Why, What, and How. arXiv:2305.00813.
- Shin et al. (2017) Shin, H.; Lee, J. K.; Kim, J.; and Kim, J. 2017. Continual learning with deep generative replay. Advances in neural information processing systems, 30.
- Silver and Chitnis (2020) Silver, T.; and Chitnis, R. 2020. PDDLGym: Gym Environments from PDDL Problems. arXiv:2002.06432.
- Valmeekam et al. (2023) Valmeekam, K.; Marquez, M.; Sreedharan, S.; and Kambhampati, S. 2023. On the Planning Abilities of Large Language Models : A Critical Investigation. arXiv:2305.15771.
- von Oswald et al. (2020) von Oswald, J.; Henning, C.; Sacramento, J.; and Grewe, B. F. 2020. Continual learning with hypernetworks. In International Conference on Learning Representations.
- Wang et al. (2025) Wang, C.; Ji, K.; Geng, J.; Ren, Z.; Fu, T.; Yang, F.; Guo, Y.; He, H.; Chen, X.; Zhan, Z.; Du, Q.; Su, S.; Li, B.; Qiu, Y.; Du, Y.; Li, Q.; Yang, Y.; Lin, X.; and Zhao, Z. 2025. Imperative Learning: A Self-supervised Neuro-Symbolic Learning Framework for Robot Autonomy. arXiv:2406.16087.
- Wang et al. (2024) Wang, L.; Zhang, X.; Su, H.; and Zhu, J. 2024. A comprehensive survey of continual learning: Theory, method and application. IEEE Transactions on Pattern Analysis and Machine Intelligence.
- Yoon et al. (2017) Yoon, J.; Yang, E.; Lee, J.; and Hwang, S. J. 2017. Lifelong learning with dynamically expandable networks. arXiv preprint arXiv:1708.01547.
- Zeng et al. (2019) Zeng, G.; Chen, Y.; Cui, B.; and Yu, S. 2019. Continual learning of context-dependent processing in neural networks. Nature Machine Intelligence, 1(8): 364–372.
- Zenke, Poole, and Ganguli (2017) Zenke, F.; Poole, B.; and Ganguli, S. 2017. Continual learning through synaptic intelligence. In International Conference on Machine Learning, 3987–3995. PMLR.
- Zimmer et al. (2023) Zimmer, M.; Feng, X.; Glanois, C.; Jiang, Z.; Zhang, J.; Weng, P.; Li, D.; Hao, J.; and Liu, W. 2023. Differentiable Logic Machines. arXiv:2102.11529.
## Appendix A Design for the Supervised Learning Tasks
### A.1 Arithmetic
Input Predicates:
| | | $\displaystyle$ | | True if number $X$ is zero | |
| --- | --- | --- | --- | --- | --- |
Target Predicates:
| | | 1. $Plus(X\text{-}Number,Y\text{-}Number,Z\text{-}Number)$ | | True if $X+Y=Z$ | |
| --- | --- | --- | --- | --- | --- |
### A.2 Tree
Input Predicates:
| | | $\displaystyle$ | | True if $X$ is the parent of $Y$ | |
| --- | --- | --- | --- | --- | --- |
Target Predicates:
| | | 1. $IsRoot(X\text{-}Node)$ | | True if $X$ is the root node | |
| --- | --- | --- | --- | --- | --- |
### A.3 Graph
Input Predicates:
| | | $\displaystyle$ | | True if there is an edge between $X$ and $Y$ | |
| --- | --- | --- | --- | --- | --- |
Target Predicates:
| | | 1. $AdjacentToRed(X\text{-}Node)$ | | True if node $X$ is connected to a red node | |
| --- | --- | --- | --- | --- | --- |
## Appendix B Design for the reinforcement learning tasks
The sequence of tasks in reinforcement learning varies based on their target configurations. For each task, we define specific configurations without considering the order of the blocks and sample a target configuration at the beginning of each episode. For example, if a task’s target configuration requires three blocks to be on the table, two blocks to be stacked on others, and one block to be freely placed anywhere, we first generate possible configurations that meet this requirement and then sample a target configuration accordingly. This task design provides the flexibility to configure the target configuration space, allowing us to adjust the difficulty of the tasks as needed. Thus, we define the five tasks in the following order:
- 5 blocks are on table, 1 block is free
- 3 blocks on table, 2 blocks are stacked, 1 block is free
- 2 blocks on table, 1 block is stacked, 1 block is free
- 4 blocks on table, 1 block is stacked, 1 block is free
- 1 block is on table, 4 blocks are stacked, 1 block is free
The order of the tasks are determined by the performance of the model trained on those tasks individually.
## Appendix C curves for forgetting experiments on arithmetic
<details>
<summary>x8.png Details</summary>
### Visual Description
## Line Graph: Loss Value vs. Epoch Across Four Tasks
### Overview
The image displays four vertically stacked line graphs comparing the loss value convergence of two algorithms ("ArithmeticWithReplay" and "ArithmeticWithoutReplay") across four distinct tasks (Task 0–Task 3). Each graph tracks loss reduction over 400 training epochs, with vertical dashed lines marking key epoch intervals (100, 200, 300).
---
### Components/Axes
- **X-axis**: Epoch (0–400, linear scale)
- **Y-axis**: Loss Value (0–0.75, linear scale)
- **Legend**:
- Green line: ArithmeticWithReplay
- Orange line: ArithmeticWithoutReplay
- **Task Labels**: Task 0 (top), Task 1, Task 2, Task 3 (bottom)
- **Vertical Dashed Lines**: At 100, 200, and 300 epochs (consistent across all tasks)
---
### Detailed Analysis
#### Task 0
- **Green Line (WithReplay)**: Starts at ~0.5 loss, drops sharply to ~0.05 by 50 epochs, then plateaus.
- **Orange Line (WithoutReplay)**: Starts at ~0.5 loss, drops sharply to ~0.05 by 50 epochs, then plateaus. Slightly higher loss than green line after 100 epochs.
#### Task 1
- **Green Line**: Starts at ~0.5 loss, drops to ~0.05 by 100 epochs, then plateaus.
- **Orange Line**: Starts at ~0.5 loss, drops to ~0.05 by 100 epochs, then plateaus. Slightly higher loss than green line after 100 epochs.
#### Task 2
- **Green Line**: Starts at ~0.5 loss, drops to ~0.05 by 150 epochs, then plateaus.
- **Orange Line**: Starts at ~0.5 loss, drops to ~0.05 by 150 epochs, then plateaus. Slightly higher loss than green line after 150 epochs.
#### Task 3
- **Green Line**: Starts at ~0.75 loss, drops sharply to ~0.05 by 300 epochs, then plateaus.
- **Orange Line**: Starts at ~0.75 loss, drops sharply to ~0.05 by 300 epochs, then plateaus. Slightly higher loss than green line after 300 epochs.
---
### Key Observations
1. **Consistent Performance Gap**: The "WithReplay" algorithm (green) consistently achieves lower loss values than "WithoutReplay" (orange) across all tasks, with the gap widening in later epochs.
2. **Task-Specific Convergence**:
- Tasks 0–2 show faster convergence (within 50–150 epochs).
- Task 3 requires significantly more epochs (300) to reach stable loss.
3. **Vertical Line Alignment**: All tasks exhibit similar convergence patterns relative to the 100/200/300 epoch markers, suggesting these intervals may represent evaluation checkpoints.
---
### Interpretation
The data demonstrates that the "ArithmeticWithReplay" algorithm outperforms "ArithmeticWithoutReplay" in retaining learned knowledge across tasks, as evidenced by consistently lower loss values. The vertical dashed lines likely indicate milestones where the model's performance is assessed, with Task 3 requiring the longest training to stabilize. This suggests that replay mechanisms mitigate catastrophic forgetting in multi-task learning scenarios, particularly for complex tasks (e.g., Task 3). The uniform trend across tasks implies the replay method generalizes well, though Task 3's higher initial loss may reflect greater inherent complexity.
</details>
Figure 6: Loss Curves of Arithmetic for each task
## Appendix D Task Hyper parameter setting
The choice of task generation hyper parameters impacts the experimental results. Hyper parameters that make the tasks too easy may lead to trivial performance differences, while excessively difficult tasks can hinder learning altogether. We thus report the choice of task generation hyper parameters we selected in the experiments.
### D.1 Arithmetic
- Range of Numbers: 0 to 79
### D.2 Tree
- Number of Nodes: 40
- Maximum Children per Node: 3
- Minimum Children per Node: 2
### D.3 Graph
- Number of Nodes: 30
- Maximum Edge Generation Probability: 0.1
- Minimum Edge Generation Probability: 0.01
## Appendix E Model Hyper parameters
### E.1 ILP
- Knowledge Base Settings:
- $[[8,8,8,8]]$ – 8 predicates of arity 0 through 3, 1 layer
- $[[8,8,8,8],[8,8,8,8]]$ – 8 predicates of arity 0 through 3, 2 layers
- $[[8,8,8,8],[8,8,8,8],[8,8,8,8]]$ – 8 predicates of arity 0 through 3, 3 layers
- $[[8,8,8,8],[8,8,8,8],[8,8,8,8],[8,8,8,8]]$ – 8 predicates of arity 0 through 3, 4 layers
- Task-Specific Module Setting:
- $[[8,8,8,8]]$ – 8 predicates for arity 0 to 3 for composing the target predicate
- Learning Rate: 0.001
### E.2 RL
- Knowledge Base Settings:
- $[[4,4,4,4]]$ – 4 predicates of arity 0 through 3, 1 layer
- $[[4,4,4,4],[4,4,4,4]]$ – 4 predicates of arity 0 through 3, 2 layers
- $[[4,4,4,4],[4,4,4,4],[4,4,4,4]]$ – 4 predicates of arity 0 through 3, 3 layers
- $[[4,4,4,4],[4,4,4,4],[4,4,4,4],[4,4,4,4]]$ – 4 predicates of arity 0 through 3, 4 layers
- Task-Specific Module Setting:
- $[[8,8,8,8]]$ – 8 predicates of arity 0 to 3 for composing the action predicates
- Actor Learning Rate: 0.003
- Critic Learning Rate: 0.003
- Target Network Copy Rate: 0.05
- Actor Update Delay: 0.05
- Temperature for Generating Action Distribution: 1.5
- Activation for generating Action Logits: tanh
- Collected Buffer Size: 50,000
- Random Exploration Rate when Collecting Transitions: 0.8
## Appendix F Background for Logic Programming and ILP
This section includes some background information about logic programming, followed by its learning counterpart, inductive logic programming. Note that the material is primarily adapted from existing sources and can be readily obtained from other resources such as (Cropper and Dumančić 2022).
### F.1 Logic Programming
Logic programming is a programming paradigm that execute based on formal logic sentences, rather than commands or functions typical of conventional programming. Knowledge about a domain is typically represented using logic facts and rules in first-order logic, with computation performed by iteratively applying these rules to deduce new facts. Here we include the definitions and concepts that are commonly used in logic programming.
Predicate A predicate $p$ characterizes a property of an object or describes a relationship among multiple objects. It functions as a Boolean operator, returning either $True$ or $False$ based on its inputs. Consequently, a predicate can be represented as $p(t)$ in the case of a single-variable predicate or $p(t_{1},t_{2},...)$ for predicates involving multiple variables.
Atoms An atom is formed by expressing a predicate along with its terms, which can be either constants or variables. It becomes grounded when all its inputs are replaced by specific constants (objects) within a domain, thereby establishing a definite relationship among these objects, and can be evaluated as $True$ or $False$ . As the fundamental unit in logical expressions, it is aptly termed ”atom”.
Literal A literal is an atom or its negation, representing an atomic formula that contains no other logical connectives such as $\land$ , $\lor$ .
Clauses A clause is constructed using a finite set of literals and connectives. The most commonly used form of clause is the definite clause, which represents a disjunction of literals with exactly one positive literal included. It is expressed as
$$
p_{1}\lor\neg p_{2}\lor\neg p_{3}...\lor\neg p_{n}
$$
The truth value of the expression above is equivalent to that of an implication, allowing it to be rewritten in the form of an implication as follows:
$$
p_{1}\leftarrow p_{2}\land p_{3}...\land p_{n}
$$
The part to the left of the implication arrow is typically referred to as the head of the clause, while the part to the right is known as the body. A clause is read from right to left as the head is entailed by the conjunction of the body. A clause is grounded when all its literals are instantiated with constants from a domain. A ground clause without a body constitutes a fact about the domain, defined by the specific predicate and associated objects. A clause that includes variables is often treated as a rule about a domain.
Logic programming involves defining a set of clauses $R$ including both rules and facts. The consequences of the set $R$ is computed by repeatedly applying the rules in $R$ until no more facts could be derived, where a convergence is considered to have been reached. We take the example from (Evans and Grefenstette 2018) to give an illustration on logic programming. Consider the program R as
| | $\displaystyle edge(a,b)$ | $\displaystyle\quad edge(b,c)\quad edge(c,a)$ | |
| --- | --- | --- | --- |
where $\{a,b,c,d\}$ represents the set of objects considered in the domain, while $\{X,Y,Z\}$ are variables in each predicate rule. Thus, $\{edge(a.b),edge(b,c),edge(c,d\}$ are considered ground facts while the other clauses are considered logic rules that could be applied to derived new facts about a domain.
The computation of consequences of the program could be summarized as
| | $\displaystyle C_{R,1}$ | $\displaystyle=\{edge(a,b),edge(b,c),edge(c,a)\}$ | |
| --- | --- | --- | --- |
Thus, from the single-direction edge predicate and the rules defining the connection between two nodes, we deduce that all nodes are connected, including self-connections. $C_{R,5}$ constitutes the final conclusions of the program, as no additional facts are added beyond $C_{R,4}$ .
### F.2 Inductive Logic Programming
Inductive logic programming(ILP) aims for the opposite goal of logic programming: given a set of facts, it seeks to derive the rules that best explain those facts. We include several more definitions here to better explain the topic.
Background and Target Predicates We categorize the predicates involved in a problem into two sets: background predicates, which provide the foundational facts for logical deductions, and target predicates, which represent the conclusions derived from these deductions.
Extensional and Intentional Predicates In the context of clauses, extensional predicates never appear in the heads of clauses, whereas intentional predicates can. Background predicates, often the starting points for logical deduction, are typically extensional. In contrast, target predicates, which result from logical deductions, are usually intentional. The concept of intentional predicates is crucial, as ILP often requires inventing intermediary intentional predicates to facilitate program solving.
An inductive logic programming problem is defined by a tuple $\{B,E^{+},E^{-}\}$ of ground atoms, where $B$ specifies the background knowledge, which consists of ground atoms formed from the set of background predicates. $E^{+}$ and $E^{-}$ denote the positive and negative targets, respectively, which are ground atoms formed from the set of target predicates.
The solution to an ILP involves finding a set of lifted rules $U$ such that,
| | $\displaystyle\forall e\in E^{+},B\cup U|\hskip-5.0pt=e$ | |
| --- | --- | --- |
where $|\hskip-6.99997pt=$ denotes logic entailment. More intuitively, this means that ground atoms from $E^{+}$ are included in the deduction consequences, while ground atoms from $E^{-}$ are excluded.
We take an example from (Evans and Grefenstette 2018) to illustrate the idea. Suppose a ILP problem represented as
$$
\displaystyle B \displaystyle=\{zero(0),succ(0,1),succ(1,2),.\} \displaystyle E^{+} \displaystyle=\{even(0),even(2),even(4),.\} \displaystyle E^{-} \displaystyle=\{even(1),even(3),even(5),.\} \tag{0}
$$
where the predicates $zero()$ and $succ()$ serve as background predicates that facilitate the definition of the knowledge base, while the predicate $even()$ defines the learning target as the target predicate. A possible solution $R$ for the ILP could be
| | $\displaystyle even(X)$ | $\displaystyle\leftarrow zero(X)$ | |
| --- | --- | --- | --- |
An obvious deduction process would be
$$
\displaystyle C_{R,1} \displaystyle=B \displaystyle C_{R,2} \displaystyle=C_{R,1}\cup\{even(0),succ2(0,2),succ2(2,4),succ2(4,6),.\} \displaystyle C_{R,3} \displaystyle=C_{R,2}\cup\{even(2),even(4),even(6),.\} \displaystyle C_{R,4} \displaystyle=C_{R,2}=con(R) \tag{0}
$$
Clearly, it is satisfied that $\forall e\in E^{+},e\in con(R)$ and $\forall e\in E^{-},e\notin con(R)$ , thus the solution is accepted. The above example is not totally trivial, as it illustrates the concept of predicate invention: $succ2()$ is synthesised to facilitate logic deduction. To connect the example with the concepts defined in the beginning of the section, predicates $zero()$ and $succ()$ are extensional predicates as they never have to be deduced from the rules while $succ2()$ and $even()$ are intentional as they appear in the deduction heads of the rules.