# Language-conditioned world model improves policy generalization by reading environmental descriptions
**Authors**:
- Anh (Joe) Nguyen (Oregon State University)
- &Stefan Lee (Oregon State University)
LAW 2025: Bridging Language, Agent, and World Models
## Abstract
To interact effectively with humans in the real world, it is important for agents to understand language that describes the dynamics of the environment—that is, how the environment behaves —rather than just task instructions specifying what to do. For example, a cargo-handling robot might receive a statement like "the floor is slippery so pushing any object on the floor will make it slide faster than usual". Understanding this dynamics-descriptive language is important for human-agent interaction and agent behavior. Recent work [20, 40, 6] address this problem using a model-based approach: language is incorporated into a world model, which is then used to learn a behavior policy. However, these existing methods either do not demonstrate policy generalization to unseen language or rely on limiting assumptions. For instance, assuming that the latency induced by inference-time planning is tolerable for the target task or that expert demonstrations are available. Expanding on this line of research, we focus on improving policy generalization from a language-conditioned world model while dropping these assumptions. We propose a model-based reinforcement learning approach, where a language-conditioned world model is trained through interaction with the environment, and a policy is learned from this model—without planning or expert demonstrations. Our method proposes L anguage-aware E ncoder for D reamer W orld M odel (LED-WM) built on top of DreamerV3 [13]. LED-WM features an observation encoder that uses an attention mechanism to explicitly ground language descriptions to entities in the observation. We show that policies trained with LED-WM generalize more effectively to unseen games described by novel dynamics and language compared to other baselines in several settings in two environments: MESSENGER and MESSENGER-WM. To highlight how the policy can leverage the trained world model before real-world deployment, we demonstrate the policy can be improved through fine-tuning on synthetic test trajectories generated by the world model.
## 1 Introduction
We envision a future where humans can seamlessly command AI agents through natural language to automate repetitive tasks in the real world. Traditionally, language has been used to specify task instructions, such as telling a navigation robot to "go to the door" [2, 17, 1]. However, language can also offer valuable information about environments. Such environmental description not only makes human interaction more natural, but also provides important contextual information about how the environment changes over time. It informs the agent about how the environment behaves —its dynamics, the current state of the world, and how various entities interact with each other and with the agent—not just what to do.
<details>
<summary>x1.png Details</summary>

### Visual Description
## Diagram: Game Scenario Grid with Legend
### Overview
The image displays a diagram composed of two main sections: a grid-based map on the left and an explanatory legend box on the right. The grid contains several pixel-art style icons representing different entities, with dashed lines indicating movement paths. The legend provides definitions for three key elements within the scenario.
### Components/Axes
**Grid Section (Left):**
* **Structure:** A 10x10 square grid with light gray lines on a white background.
* **Icons & Elements:**
1. **Researcher Icon:** A pixel-art figure of a person with brown hair, wearing a white lab coat, located in the top row, 7th column from the left.
2. **Plane Icons:** Three identical white airplane icons. One is in the 4th row, 5th column. Two are in the 5th row, columns 4 and 5.
3. **Ferry Icon:** A blue and white boat/ferry icon located in the 3rd row, 3rd column.
4. **Submarine Icon:** A gray submarine icon located in the 8th row, 3rd column.
5. **Dashed Lines with Arrows:**
* A vertical dashed line with an upward-pointing arrowhead runs from the submarine (row 8, col 3) up to the researcher (row 1, col 7). The line travels straight up column 3 to row 5, then turns right to column 7, then continues up to the researcher.
* A separate vertical dashed line with an upward-pointing arrowhead extends from the plane in row 4, column 5, going straight up off the top of the grid.
**Legend Box (Right):**
* **Structure:** A rectangular box with a black border, positioned to the right of the grid.
* **Content (Transcribed Text):**
* The plane going away from you carries out a message
* The researcher who doesn't move is final goal
* The ferry chasing you is an enemy
### Detailed Analysis
**Spatial Grounding & Element Relationships:**
* The **Researcher** (top-center) is the static endpoint of the primary dashed path.
* The **Submarine** (bottom-left) is the starting point of the primary dashed path, which leads to the Researcher. This suggests the submarine is the player-controlled unit.
* The **Plane** in the center (row 4, col 5) has its own path leading away from the grid, consistent with the legend's description of it "going away."
* The **Ferry** is positioned above and to the left of the submarine's starting point, in a location that could be interpreted as "chasing" or intercepting the path to the goal.
* The two additional **Plane** icons in row 5 are static and do not have associated paths.
### Key Observations
1. **Path Logic:** The primary dashed path is not a straight line. It moves vertically from the submarine, then makes a 90-degree right turn, then another 90-degree turn upward to reach the researcher. This could indicate an obstacle or a specific route requirement.
2. **Icon States:** The legend defines dynamic roles ("going away," "chasing") for the plane and ferry, but the diagram shows them as static icons. Their movement is implied by the text and the path lines, not by animation.
3. **Unexplained Elements:** The two additional plane icons in row 5 are not referenced in the legend. Their purpose is unclear from the provided information.
### Interpretation
This diagram appears to be a **schematic for a simple game or puzzle scenario**. It visually defines the core rules and objectives using a grid map and a legend.
* **Objective:** The player (likely controlling the submarine) must navigate to the stationary researcher (the "final goal").
* **Conflict:** An enemy ferry is present, presumably acting as an obstacle or threat to be avoided.
* **Narrative Element:** A plane is delivering a message, adding a layer of story or a secondary objective.
* **Game Mechanics Implied:** The grid suggests turn-based or tile-based movement. The dashed lines illustrate the intended or possible paths for key entities. The legend translates the visual symbols into game roles (goal, enemy, messenger).
The diagram efficiently communicates a game state or level design by separating the visual layout (grid) from the semantic rules (legend). The spatial arrangement creates immediate tension: the player's path to the goal is not direct and passes near the enemy ferry.
</details>
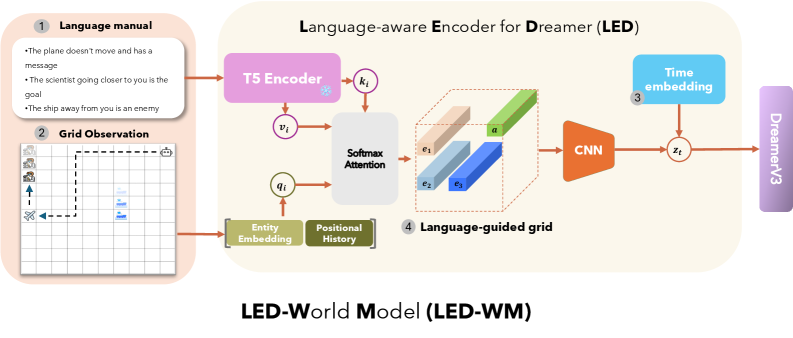
Figure 1: An example of dynamics-descriptive language in a game play. The observation includes a 10 $\times$ 10 grid-world with three entities represented by their associated symbols: (ferry -
<details>
<summary>figures/ferry.png Details</summary>

### Visual Description
## Illustration: Stylized Ship Icon
### Overview
The image is a flat, stylized digital illustration of a ship on water. It is not a chart, diagram, or document containing textual data. The image is purely graphical and symbolic, using simplified shapes and a limited color palette to represent a vessel at sea. There is no embedded text, numerical data, labels, or legends present.
### Components/Axes
As this is an illustration and not a data visualization, there are no axes, scales, or legends. The visual components are:
1. **Ship Structure:**
* **Hull:** A large, solid blue shape forming the main body of the ship. It has a curved bow (front) on the right and a flat stern (back) on the left.
* **Superstructure:** A white, rectangular block sitting atop the hull, representing the bridge or accommodation area.
* **Funnel/Stack:** A bright blue, tapered cylindrical shape positioned on top of the superstructure.
* **Mast/Antenna:** A thin, white vertical line extending upwards from the top of the funnel.
2. **Water:** A light blue, wavy band at the bottom of the image, representing the sea surface. The waves are depicted as a series of connected, smooth curves.
3. **Background:** A solid, light beige or off-white color fills the space behind the ship and above the water.
### Detailed Analysis
* **Color Palette:** The illustration uses a monochromatic blue scheme for the subject, with white accents, against a neutral background.
* Hull: Approximate color value is a medium-dark blue (e.g., #4A6FE3).
* Funnel: A brighter, cyan-like blue (e.g., #00B4FF).
* Superstructure & Mast: White.
* Water: A very light, pastel blue (e.g., #D6F0FF).
* Background: Light beige (e.g., #F5F2EB).
* **Style:** The design is minimalist and iconic, using geometric shapes with soft, rounded corners. There is no shading, texture, or perspective detail, giving it a clean, modern, app-icon-like appearance.
* **Composition:** The ship is centered horizontally and occupies the middle vertical third of the image. The water line sits in the lower third.
### Key Observations
* The image contains **zero textual information**. There are no labels, titles, annotations, or numbers.
* It is a **symbolic representation**, not a technical diagram. It conveys the concept of "ship" or "maritime" rather than specific technical details.
* The design is **non-literal**. For example, the ship lacks specific features like portholes, railings, or a defined deck, and the water is a stylized pattern.
### Interpretation
This image functions as a **visual icon or symbol**. Its purpose is to be immediately recognizable as a ship, likely for use in a user interface, logo, or informational graphic where a simple maritime metaphor is needed. The choice of a calm, blue color palette and smooth shapes suggests themes of transport, travel, logistics, or the sea in a friendly, approachable, and non-technical context. The absence of data or text means its informational content is purely connotative, relying on the viewer's cultural understanding of the ship symbol.
</details>
), (plane -
<details>
<summary>figures/plane.png Details</summary>

### Visual Description
## Icon: Airplane Symbol
### Overview
The image displays a stylized, flat-design icon of a commercial airplane viewed from a top-down perspective. The icon is presented against a plain, light grey background. It contains no textual information, data, charts, or diagrams. It is a purely graphical symbol.
### Components/Axes
* **Primary Subject:** A single airplane icon.
* **Background:** A solid, uniform light grey field (approximate hex: #f0f0f0).
* **Legend/Labels:** None present.
* **Axes/Scale:** Not applicable.
### Detailed Analysis
The icon is constructed with the following visual elements:
* **Outline:** A thick, dark grey (approximate hex: #3a3a3a) border defines the entire shape of the airplane.
* **Fill:** The interior of the airplane is filled with a very light, cool blue (approximate hex: #e6f3ff).
* **Detail:** Two slightly darker blue (approximate hex: #a8c8e8) rectangular stripes are placed on the wings, suggesting engine nacelles or wing markings. One stripe is on the upper-left wing, and the other is on the lower-right wing.
* **Orientation:** The airplane is oriented diagonally, with its nose pointing towards the top-right corner of the image frame and its tail towards the bottom-left.
* **Spatial Grounding:** The icon is centered within the square image frame. The wings extend towards the top-left and bottom-right corners. The fuselage runs diagonally from the bottom-left to the top-right.
### Key Observations
1. **Simplicity:** The design is minimalist, using only three colors (dark grey outline, light blue fill, medium blue detail) and basic geometric shapes to represent the aircraft.
2. **Style:** It follows a common "flat design" or "outline icon" aesthetic, suitable for user interfaces, signage, or informational graphics.
3. **Clarity:** The symbol is immediately recognizable as an airplane due to its distinct silhouette: a central fuselage, two swept-back wings, and a tail assembly.
4. **Lack of Data:** The image contains no quantitative information, trends, labels, or text to extract. It is a symbolic representation, not a data visualization.
### Interpretation
This image serves as a **symbolic identifier**, not a source of factual data. Its meaning is derived from universal visual conventions.
* **Purpose:** The icon is designed to represent concepts related to air travel, aviation, airports, flight, or transportation in a quick, universally understandable manner. It would typically be used in contexts like navigation menus, maps, informational brochures, or signage.
* **Design Choices:** The diagonal orientation conveys a sense of motion or dynamism. The thick outline ensures visibility at small sizes, and the limited color palette aids in clear recognition and potential branding consistency.
* **Underlying Information:** The image itself provides no underlying data trends or investigative findings. Its "information" is purely semiotic: it is a signifier for the concept of an airplane. Any additional meaning (e.g., "departures," "airline logo," "travel section") would be entirely dependent on the context in which this icon is placed.
</details>
), (researcher -
<details>
<summary>figures/scientist.png Details</summary>

### Visual Description
## Icon/Illustration: Scientist with Microscope
### Overview
This is a flat-design, stylized icon or illustration depicting a scientist (or lab technician) looking into a microscope. The image contains no textual information, data, charts, or diagrams. It is a symbolic representation of scientific research, laboratory work, or analysis.
### Components/Axes
* **Primary Subject:** A human figure, shown from the chest up, in profile facing left.
* **Key Object:** A compound microscope positioned in front of the figure.
* **Background:** A solid, light gray background (`#f0f0f0` approximate).
* **Style:** Bold, black outlines define all shapes. Colors are flat with no gradients or shading.
### Detailed Analysis
**Figure Details:**
* **Hair:** Brown, styled with a prominent curl or wave on top.
* **Face:** No facial features are depicted (eyes, nose, mouth are absent).
* **Eyewear:** Large, bright blue safety goggles or glasses.
* **Clothing:** A white lab coat with a black outline. The collar and front seam are indicated.
* **Pose:** The figure is leaning forward, with their head positioned to look into the microscope's eyepiece. Their right arm is bent, with the hand resting on the microscope's arm or focus knob.
**Microscope Details:**
* **Body/Arm:** A curved, yellow arm connects the base to the head.
* **Head/Optical Tube:** Gray, containing the eyepiece (ocular lens) and objective lenses.
* **Stage:** A flat, gray platform where a sample would be placed.
* **Base:** A gray, rectangular base supporting the structure.
* **Knobs:** A prominent, circular yellow knob (likely the coarse focus) is visible on the side of the arm. A smaller black circle may represent a fine focus knob.
* **Nosepiece:** A gray, rotating turret holding the objective lenses is implied below the head.
**Spatial Grounding:**
* The **microscope** occupies the left and central portion of the frame.
* The **scientist** is positioned on the right side, overlapping the microscope.
* The **yellow focus knob** is located at the junction of the arm and the base, slightly below the center of the image.
* The **blue goggles** are the most saturated color element, positioned in the upper-right quadrant of the figure's head.
### Key Observations
1. **Absence of Text:** The image contains zero textual elements—no labels, titles, legends, or annotations.
2. **Symbolic, Not Literal:** The illustration is an archetype. It uses universal symbols (lab coat, microscope, goggles) to convey the concept of "scientist" or "research" rather than depicting a specific person or equipment model.
3. **Simplified Form:** Complex details of the microscope (like specific lenses, adjustment screws, or a light source) and the human figure (facial features, fingers) are omitted for clarity and iconographic impact.
4. **Color Palette:** The palette is limited and functional: white (coat), brown (hair), blue (goggles), yellow (microscope arm/knob), gray (microscope body/background), and black (outlines).
### Interpretation
This image functions as a **visual metaphor**. Its purpose is to quickly and universally communicate ideas related to:
* **Scientific Research & Discovery:** The act of close examination and analysis.
* **Laboratory Work:** A standard setting for biological, chemical, or medical investigation.
* **Precision & Scrutiny:** The microscope symbolizes looking deeper into a subject, studying details invisible to the naked eye.
* **Expertise & Analysis:** The figure represents a trained professional engaged in technical work.
The lack of specific data or text means its information is purely **connotative**. It doesn't present facts but evokes a field of knowledge and a set of activities. In a technical document, this icon would likely serve as a section header, a button label, or an illustrative element to denote a related topic (e.g., "Lab Results," "Microscopic Analysis," "Research Methods"). Its effectiveness lies in its immediate recognizability and its clean, unambiguous design.
</details>
) and one agent (depicted by
<details>
<summary>figures/bot.png Details</summary>

### Visual Description
## Icon/Symbol: Robot Head Line Drawing
### Overview
The image is a simple, monochromatic line drawing of a stylized robot head, presented as a black icon on a light gray background. It contains no textual information, data, charts, or diagrams. The design is minimalist and symbolic, intended to represent a robot or artificial intelligence concept.
### Components
The icon is composed of the following geometric elements:
1. **Head Outline:** A square with rounded corners, drawn with a thick black line.
2. **Eyes:** Two identical, solid black circles placed symmetrically within the head outline, positioned in the upper half.
3. **Antenna:** A vertical line extending from the top center of the head, terminating in a small, hollow circle (a ring).
4. **Ears/Side Panels:** Two identical, vertical rectangular shapes with rounded outer edges, attached to the left and right sides of the head outline. They are drawn with the same line thickness as the head.
### Detailed Analysis / Content Details
* **Textual Content:** None. The image contains no words, labels, numbers, or characters in any language.
* **Data Content:** None. This is not a chart, graph, or data visualization.
* **Color:** The image uses a two-tone palette: black (#000000) for all lines and shapes, and a uniform light gray (approximately #E5E5E5) for the background.
* **Line Style:** All lines are of consistent, medium-heavy weight with no variation. Corners on the head and ears are rounded.
### Key Observations
* The design is highly symmetrical along the vertical axis.
* The icon uses universal, simple geometric shapes (square, circle, rectangle) for immediate recognizability.
* The lack of a mouth or other facial features gives it a neutral, non-expressive appearance.
* The antenna is a classic visual shorthand for "robot" or "wireless communication."
### Interpretation
This image serves as a **symbol or icon**, not a carrier of factual data or complex information. Its purpose is purely representational.
* **What it represents:** The combination of a boxy head, circular eyes, and an antenna is a widely understood visual metaphor for a robot, AI, or automated system. The simplicity suggests it could be used as an app icon, a logo element, or in user interface design to denote a bot, AI assistant, or automated process.
* **Design Intent:** The clean, bold lines and lack of detail ensure the icon remains legible at very small sizes (e.g., a favicon or mobile app icon). The rounded corners soften the mechanical feel, making it appear more friendly or approachable.
* **Notable Absence:** The lack of any text or unique identifying marks means this icon is generic. It does not represent a specific brand, product, or dataset. Its meaning is derived entirely from cultural conventions around how robots are depicted.
</details>
). The observation also has a manual on the right, which describes the dynamics of the game. The agent can navigate the grid using five actions: left, right, up, down, and stay. The agent can only interact with entities when it is in the same grid cell as the entity. The agent’s task is to identify roles of all entities from the manual, go to the messenger, then go to the goal, while avoiding the enemy. Shaded icons indicate one possible scenario of entity movement over time. By observing entity movement patterns and grounding language to entities based on their behaviors, the agent can infer the roles assigned to each entity: (ferry-enemy), (plane-messenger), and (researcher-goal). The agent can then execute an appropriate plan to complete the task. The dashed line in the grid shows such a possible plan.
We illustrate dynamics-descriptive language by using a simple 2D grid-based game in Figure ˜ 1, instantiated by MESSENGER S2 [14]. This is the setting of our testbed environments and will be detailed in Section ˜ 3.1 Each game instance consists of several entities, an agent positioned in a grid-world observation, and a language manual. Each entity has a role among messenger, goal, and enemy. The agent acts as a courier, tasked with picking up a message from the messenger and delivering it to the goal while avoiding the enemy. The manual provides descriptions of the entity attributes, helping the agent understand the environment’s dynamics: what the roles of entities are and how the environment changes as the agent interacts with them. To succeed, the agent must interpret the language manual, identify the entities, and infer their respective roles based on observed behaviors.
Language is valuable because it allows for the description of novel games by recombining known concepts. For instance, consider Figure ˜ 1 as the training reference game and the following example manual: The ship going away from you is the goal you need to go to. The stationary plane is an enemy. The scientist won’t move and has an important message. The example manual describes an unseen dynamics game with known concepts derived from the reference game. To succeed in this environment—where the dynamics have changed but the rules remains the same—the agent must adopt a different behavior than in the reference game. This manual also produces novel surface-level language through synonyms (e.g. "researcher" vs "scientist") and paraphrases ("won’t move" vs "stationary"),
We want to study language grounding and how it affects agent generalizability. Therefore, we abstract away our observation to a discrete grid-world, thus simplifying perception complexity, similar to existing work [14, 26, 20, 40, 6]. Our goal is to develop an agent capable of understanding dynamics-descriptive language by grounding it to discrete entities. More importantly, we aim for the agent to generalize to unseen games described by unseen dynamics and/or novel language, allowing it to adapt agent behavior to new environmental changes.
In the current literature, there are two main approaches to building such an agent: model-free and model-based approach. Model-free methods [14, 26] directly map language to a policy. Language grounding is thus based entirely on policy learning signals, without modeling the environment dynamics. This might be challenging for agent to learn complex mapping from dynamics-descriptive language to action. Meanwhile, model-based methods like EMMA-LWM [40], Reader [6], and Dynalang [20] build a world model [11] simulating trajectories, which are then used to train a policy. Dynamics-descriptive language is incorporated into the world model, enabling it to use language to predict environmental changes.
However, these existing works have some limitations. EMMA-LWM requires expert demonstrations—a constraint that may not be always feasible for real-life tasks. Reader assumes inference-time latency is tolerable for the target tasks. This is because Reader uses a Monte Carlo Tree Search (MCTS) to look ahead and generate a full plan. This approach may not be practical for applications that require quick policy responses. Last, we show that the policy learned from Dynalang fails to generalize over unseen games in Section ˜ 5.1. To address these limitations, we adopt a model-based reinforcement learning (MBRL) approach that builds a language-grounded world model from interaction with the environment, and then use this world model to train a policy. In contrast to previous methods, our approach does not require expert demonstrations, avoids expensive inference-time planning, and can generalize to unseen games.
We propose L anguage-aware E ncoder for D reamer W orld M odel (LED-WM), building on a MBRL framework: DreamerV3 [13]. LED-WM introduces a new encoder for DreamerV3 that explicitly grounds entities to their language descriptions, using a simple yet effective attention mechanism. In this paper, we make the following contributions:
- We show that a language-conditioned MBRL without an explicit language grounding to entities, instantiated by Dynalang [20], fails to generalize over unseen games (see Section ˜ 5.1).
- By using an attention mechanism in LED-WM to do language grounding, we show that a policy trained from LED-WM can generalize over unseen games better than model-free and model-based baselines in several settings MESSENGER and MESSENGER-WM (see Section ˜ 4).
- We demonstrate that given a trained LED-WM, we can improve a trained policy by fine-tuning it in synthetic test trajectories generated by the world model (see Section ˜ 5.2).
## 2 Background
Problem formulation.
We define our problem as a language-conditioned Markov Decision Process, represented by a tuple with common notations: $(\mathcal{S},\mathcal{A},r,T,\gamma,H)$ . $\mathcal{S}$ represents the state space where each state has a 10 $\times$ 10 grid-world observation containing entity symbols and an agent (e.g.
<details>
<summary>figures/ferry.png Details</summary>

### Visual Description
## Illustration: Stylized Ship Icon
### Overview
The image is a flat, stylized digital illustration of a ship on water. It is not a chart, diagram, or document containing textual data. The image is purely graphical and symbolic, using simplified shapes and a limited color palette to represent a vessel at sea. There is no embedded text, numerical data, labels, or legends present.
### Components/Axes
As this is an illustration and not a data visualization, there are no axes, scales, or legends. The visual components are:
1. **Ship Structure:**
* **Hull:** A large, solid blue shape forming the main body of the ship. It has a curved bow (front) on the right and a flat stern (back) on the left.
* **Superstructure:** A white, rectangular block sitting atop the hull, representing the bridge or accommodation area.
* **Funnel/Stack:** A bright blue, tapered cylindrical shape positioned on top of the superstructure.
* **Mast/Antenna:** A thin, white vertical line extending upwards from the top of the funnel.
2. **Water:** A light blue, wavy band at the bottom of the image, representing the sea surface. The waves are depicted as a series of connected, smooth curves.
3. **Background:** A solid, light beige or off-white color fills the space behind the ship and above the water.
### Detailed Analysis
* **Color Palette:** The illustration uses a monochromatic blue scheme for the subject, with white accents, against a neutral background.
* Hull: Approximate color value is a medium-dark blue (e.g., #4A6FE3).
* Funnel: A brighter, cyan-like blue (e.g., #00B4FF).
* Superstructure & Mast: White.
* Water: A very light, pastel blue (e.g., #D6F0FF).
* Background: Light beige (e.g., #F5F2EB).
* **Style:** The design is minimalist and iconic, using geometric shapes with soft, rounded corners. There is no shading, texture, or perspective detail, giving it a clean, modern, app-icon-like appearance.
* **Composition:** The ship is centered horizontally and occupies the middle vertical third of the image. The water line sits in the lower third.
### Key Observations
* The image contains **zero textual information**. There are no labels, titles, annotations, or numbers.
* It is a **symbolic representation**, not a technical diagram. It conveys the concept of "ship" or "maritime" rather than specific technical details.
* The design is **non-literal**. For example, the ship lacks specific features like portholes, railings, or a defined deck, and the water is a stylized pattern.
### Interpretation
This image functions as a **visual icon or symbol**. Its purpose is to be immediately recognizable as a ship, likely for use in a user interface, logo, or informational graphic where a simple maritime metaphor is needed. The choice of a calm, blue color palette and smooth shapes suggests themes of transport, travel, logistics, or the sea in a friendly, approachable, and non-technical context. The absence of data or text means its informational content is purely connotative, relying on the viewer's cultural understanding of the ship symbol.
</details>
,
<details>
<summary>figures/plane.png Details</summary>

### Visual Description
## Icon: Airplane Symbol
### Overview
The image displays a stylized, flat-design icon of a commercial airplane viewed from a top-down perspective. The icon is presented against a plain, light grey background. It contains no textual information, data, charts, or diagrams. It is a purely graphical symbol.
### Components/Axes
* **Primary Subject:** A single airplane icon.
* **Background:** A solid, uniform light grey field (approximate hex: #f0f0f0).
* **Legend/Labels:** None present.
* **Axes/Scale:** Not applicable.
### Detailed Analysis
The icon is constructed with the following visual elements:
* **Outline:** A thick, dark grey (approximate hex: #3a3a3a) border defines the entire shape of the airplane.
* **Fill:** The interior of the airplane is filled with a very light, cool blue (approximate hex: #e6f3ff).
* **Detail:** Two slightly darker blue (approximate hex: #a8c8e8) rectangular stripes are placed on the wings, suggesting engine nacelles or wing markings. One stripe is on the upper-left wing, and the other is on the lower-right wing.
* **Orientation:** The airplane is oriented diagonally, with its nose pointing towards the top-right corner of the image frame and its tail towards the bottom-left.
* **Spatial Grounding:** The icon is centered within the square image frame. The wings extend towards the top-left and bottom-right corners. The fuselage runs diagonally from the bottom-left to the top-right.
### Key Observations
1. **Simplicity:** The design is minimalist, using only three colors (dark grey outline, light blue fill, medium blue detail) and basic geometric shapes to represent the aircraft.
2. **Style:** It follows a common "flat design" or "outline icon" aesthetic, suitable for user interfaces, signage, or informational graphics.
3. **Clarity:** The symbol is immediately recognizable as an airplane due to its distinct silhouette: a central fuselage, two swept-back wings, and a tail assembly.
4. **Lack of Data:** The image contains no quantitative information, trends, labels, or text to extract. It is a symbolic representation, not a data visualization.
### Interpretation
This image serves as a **symbolic identifier**, not a source of factual data. Its meaning is derived from universal visual conventions.
* **Purpose:** The icon is designed to represent concepts related to air travel, aviation, airports, flight, or transportation in a quick, universally understandable manner. It would typically be used in contexts like navigation menus, maps, informational brochures, or signage.
* **Design Choices:** The diagonal orientation conveys a sense of motion or dynamism. The thick outline ensures visibility at small sizes, and the limited color palette aids in clear recognition and potential branding consistency.
* **Underlying Information:** The image itself provides no underlying data trends or investigative findings. Its "information" is purely semiotic: it is a signifier for the concept of an airplane. Any additional meaning (e.g., "departures," "airline logo," "travel section") would be entirely dependent on the context in which this icon is placed.
</details>
,
<details>
<summary>figures/scientist.png Details</summary>

### Visual Description
## Icon/Illustration: Scientist with Microscope
### Overview
This is a flat-design, stylized icon or illustration depicting a scientist (or lab technician) looking into a microscope. The image contains no textual information, data, charts, or diagrams. It is a symbolic representation of scientific research, laboratory work, or analysis.
### Components/Axes
* **Primary Subject:** A human figure, shown from the chest up, in profile facing left.
* **Key Object:** A compound microscope positioned in front of the figure.
* **Background:** A solid, light gray background (`#f0f0f0` approximate).
* **Style:** Bold, black outlines define all shapes. Colors are flat with no gradients or shading.
### Detailed Analysis
**Figure Details:**
* **Hair:** Brown, styled with a prominent curl or wave on top.
* **Face:** No facial features are depicted (eyes, nose, mouth are absent).
* **Eyewear:** Large, bright blue safety goggles or glasses.
* **Clothing:** A white lab coat with a black outline. The collar and front seam are indicated.
* **Pose:** The figure is leaning forward, with their head positioned to look into the microscope's eyepiece. Their right arm is bent, with the hand resting on the microscope's arm or focus knob.
**Microscope Details:**
* **Body/Arm:** A curved, yellow arm connects the base to the head.
* **Head/Optical Tube:** Gray, containing the eyepiece (ocular lens) and objective lenses.
* **Stage:** A flat, gray platform where a sample would be placed.
* **Base:** A gray, rectangular base supporting the structure.
* **Knobs:** A prominent, circular yellow knob (likely the coarse focus) is visible on the side of the arm. A smaller black circle may represent a fine focus knob.
* **Nosepiece:** A gray, rotating turret holding the objective lenses is implied below the head.
**Spatial Grounding:**
* The **microscope** occupies the left and central portion of the frame.
* The **scientist** is positioned on the right side, overlapping the microscope.
* The **yellow focus knob** is located at the junction of the arm and the base, slightly below the center of the image.
* The **blue goggles** are the most saturated color element, positioned in the upper-right quadrant of the figure's head.
### Key Observations
1. **Absence of Text:** The image contains zero textual elements—no labels, titles, legends, or annotations.
2. **Symbolic, Not Literal:** The illustration is an archetype. It uses universal symbols (lab coat, microscope, goggles) to convey the concept of "scientist" or "research" rather than depicting a specific person or equipment model.
3. **Simplified Form:** Complex details of the microscope (like specific lenses, adjustment screws, or a light source) and the human figure (facial features, fingers) are omitted for clarity and iconographic impact.
4. **Color Palette:** The palette is limited and functional: white (coat), brown (hair), blue (goggles), yellow (microscope arm/knob), gray (microscope body/background), and black (outlines).
### Interpretation
This image functions as a **visual metaphor**. Its purpose is to quickly and universally communicate ideas related to:
* **Scientific Research & Discovery:** The act of close examination and analysis.
* **Laboratory Work:** A standard setting for biological, chemical, or medical investigation.
* **Precision & Scrutiny:** The microscope symbolizes looking deeper into a subject, studying details invisible to the naked eye.
* **Expertise & Analysis:** The figure represents a trained professional engaged in technical work.
The lack of specific data or text means its information is purely **connotative**. It doesn't present facts but evokes a field of knowledge and a set of activities. In a technical document, this icon would likely serve as a section header, a button label, or an illustrative element to denote a related topic (e.g., "Lab Results," "Microscopic Analysis," "Research Methods"). Its effectiveness lies in its immediate recognizability and its clean, unambiguous design.
</details>
,
<details>
<summary>figures/bot.png Details</summary>

### Visual Description
## Icon/Symbol: Robot Head Line Drawing
### Overview
The image is a simple, monochromatic line drawing of a stylized robot head, presented as a black icon on a light gray background. It contains no textual information, data, charts, or diagrams. The design is minimalist and symbolic, intended to represent a robot or artificial intelligence concept.
### Components
The icon is composed of the following geometric elements:
1. **Head Outline:** A square with rounded corners, drawn with a thick black line.
2. **Eyes:** Two identical, solid black circles placed symmetrically within the head outline, positioned in the upper half.
3. **Antenna:** A vertical line extending from the top center of the head, terminating in a small, hollow circle (a ring).
4. **Ears/Side Panels:** Two identical, vertical rectangular shapes with rounded outer edges, attached to the left and right sides of the head outline. They are drawn with the same line thickness as the head.
### Detailed Analysis / Content Details
* **Textual Content:** None. The image contains no words, labels, numbers, or characters in any language.
* **Data Content:** None. This is not a chart, graph, or data visualization.
* **Color:** The image uses a two-tone palette: black (#000000) for all lines and shapes, and a uniform light gray (approximately #E5E5E5) for the background.
* **Line Style:** All lines are of consistent, medium-heavy weight with no variation. Corners on the head and ears are rounded.
### Key Observations
* The design is highly symmetrical along the vertical axis.
* The icon uses universal, simple geometric shapes (square, circle, rectangle) for immediate recognizability.
* The lack of a mouth or other facial features gives it a neutral, non-expressive appearance.
* The antenna is a classic visual shorthand for "robot" or "wireless communication."
### Interpretation
This image serves as a **symbol or icon**, not a carrier of factual data or complex information. Its purpose is purely representational.
* **What it represents:** The combination of a boxy head, circular eyes, and an antenna is a widely understood visual metaphor for a robot, AI, or automated system. The simplicity suggests it could be used as an app icon, a logo element, or in user interface design to denote a bot, AI assistant, or automated process.
* **Design Intent:** The clean, bold lines and lack of detail ensure the icon remains legible at very small sizes (e.g., a favicon or mobile app icon). The rounded corners soften the mechanical feel, making it appear more friendly or approachable.
* **Notable Absence:** The lack of any text or unique identifying marks means this icon is generic. It does not represent a specific brand, product, or dataset. Its meaning is derived entirely from cultural conventions around how robots are depicted.
</details>
in Figure ˜ 1). Each state also has a language manual $L$ , describing environment dynamics: transition function $T(s^{\prime}|s,a)$ and reward function $r(s,a)$ . $L$ consists of $N$ sentences associated with $N$ entities, where each sentence describes the dynamics of each entity. An example of a state is shown in Figure ˜ 1. Action space $\mathcal{A}=\{\texttt{up, down, right, left, stay}\}$ is discrete. The agent must take a sequence of actions $a_{t}\in\mathcal{A}$ over a horizon $H$ , where time step $t\in[1..H]$ , resulting in a state-action trajectory $(s_{1},a_{1},\ldots,s_{H},a_{H})$ . Our goal is to find a policy $\pi:\mathcal{S}\times L\rightarrow\mathcal{A}$ that maximizes the expected sum of discounted rewards: $\mathbb{E}_{\pi,L}\left[\sum_{t=1}^{H}\gamma^{t-1}r(s_{t},a_{t})\right].$
World model DreamerV3.
We base our world model on DreamerV3 [13], which uses Recurrent State-Space Model (RSSM) [12] to build a recurrent world model. DreamerV3 receives a sequence of observations and predicts latent representations of future observations given actions. Specifically, at a time step $t$ , DreamerV3 receives an observation $x_{t}$ , an action $a_{t}$ , and history information $h_{t}$ . These inputs are compressed into a latent representation $z_{t}$ and fed to RSSM with the action $a_{t}$ to predict the next latent representation $z_{t+1}$ . The world model has the following components:
$$
\displaystyle\raisebox{25.00003pt}{
$\text{RSSM}~~\begin{cases}\hphantom{A}\\[-6.0pt]
\hphantom{A}\\[-6.0pt]
\hphantom{A}\end{cases}$}\begin{aligned} &\text{Sequence model:}&\quad h_{t}&=f_{\phi}(h_{t-1},z_{t-1},a_{t-1})\\
&\text{Encoder:}&\quad z_{t}&\sim q_{\phi}(z_{t}\mid h_{t},x_{t})\\
&\text{Dynamics predictor:}&\quad\hat{z}_{t}&\sim p_{\phi}(\hat{z}_{t}\mid h_{t})\\
&\text{Reward predictor:}&\quad\hat{r}_{t}&\sim p_{\phi}(\hat{r}_{t}\mid h_{t},z_{t})\\
&\text{Continue predictor:}&\quad\hat{c}_{t}&\sim p_{\phi}(\hat{c}_{t}\mid h_{t},z_{t})\\
&\text{Decoder:}&\quad\hat{x}_{t}&\sim p_{\phi}(\hat{x}_{t}\mid h_{t},z_{t})\\
\end{aligned} \tag{1}
$$
In this work, we propose to change the encoder of DreamerV3 to better leverage language grounding to learn a more robust world model.
## 3 Environment setup
We adopt MESSENGER [14] and MESSENGER-WM [40] as our test bed environments. Both environments have the same setup as the example game in Figure ˜ 1. To succeed in the game, the agent must understand the language manuals $L$ and use reward and transitional signals to ground the roles, entity names and movement types to the entity symbols in the observation.
### 3.1 MESSENGER
Overview.
As shown in Figure ˜ 1, MESSENGER [14] is a 10 $\times$ 10 grid-world environment. We refer the readers to Figure ˜ 1 for game rules and setup, and Section ˜ C.1.1 for environment dynamics and action. Each game includes a language manual and an observation containing entities and a single agent. For more details about language grounding to entities, we refer the readers to Section ˜ C.1.2.
Evaluation settings.
MESSENGER offers four stages (stage S1, S2, S2-dev, S3) with different levels of generalization for test games. Each stage has its own training set, test set, and development set, all of which are described in detail in Section ˜ C.1.
### 3.2 MESSENGER-WM
Overview.
While providing multiple stages to evaluate policy generalization over out-of-distribution dynamics, MESSENGER does not include a setting for compositional generalization dynamics. To bridge this gap, MESSENGER-WM [40], derived from MESSENGER S2, enables evaluation at compositional generalization for world model and policy. Together, these two environments offer a comprehensive framework for assessing generalization, under varying levels of unseen games.
Evaluation settings.
MESSENGER-WM has three different evaluation settings with different levels of generalization: NewCombo, NewAttr, and NewAll. All settings share the same training set. More details about the evaluation settings are provided in Section ˜ C.3.2 and the original paper [40].
### 3.3 Evaluating generalization to unseen games
Table 1: Summary of generalization capabilities over unseen games in MESSENGER and MESSENGER-WM across stages. Examples with visualizations are provided in Section ˜ C.2.
| | MESSENGER | MESSENGER-WM | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| S1 | S2 | S2-dev | S3 | New | New | New | |
| Combo | Attr | All | | | | | |
| Novel combinations of known entities | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ |
| Novel language (synonyms and paraphrase) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Novel entity-role assignments | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
| Novel entity-movement-role assignments | ✗ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
| Novel game dynamics of known movement behaviors | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ |
| Novel game dynamics from one training dynamic | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
Together, MESSENGER and MESSENGER-WM offer different levels of generalization in test games. We summarize these in Table ˜ 1 and below:
- Novel language: the test manual uses synonyms and paraphrases to create novel language through surface structure.
- Novel combinations of known entities: the test game involve entities that appear in training set but never appear together in one training game.
- Novel entity-role assignments: at least one entity in the test game has a different role from its roles in training games.
- Novel entity-role-movement assignment: at least one entity in the test game has a novel combination of entity-role-movement assignment.
- Novel combinations of known movement behaviors (novel game dynamics): the test game has a novel movement combinations of entities, e.g. (chaser-chaser-chaser) for three entities.
- Novel game dynamics from one training dynamic: Game dynamic is defined by the combination of entity movements. In the training set, there is only one such combination (chasing-fleeing-stationary) across all training games. The test game meanwhile has a novel dynamic, e.g. (chaser-chaser-chaser). This is also the difference between MESSENGER-WM and MESSENGER, which can be found more detailed in Section ˜ C.3.1
See Section ˜ C.2 for visualizations of these settings.
## 4 Method: L anguage-aware E ncoder for D reamer W orld M odel (LED-WM)
To generalize policy across unseen games, we aim to develop a world model capable of doing language grounding to entities in a game. Inspired by EMMA [14], we propose L anguage-aware E ncoder for D reamer (LED), which uses cross-modal attention to align game entities with sentences. The resulting vectors are then placed back into their original entity locations, producing a language-aware grid observation. This grid is passed through a CNN encoder to extract observation features, which are used by the other components of DreamerV3. We call this overall model LED- W orld M odel (LED-WM). We provide an overview of the encoder LED and the world model LED-WM in Figure ˜ 2 and describe each component in the following sections.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Diagram: Language-aware Encoder for Dreamer (LED) / LED-World Model (LED-WM)
### Overview
This image is a technical system architecture diagram illustrating the **LED-World Model (LED-WM)**. It details a pipeline that processes two primary inputs—a natural language manual and a grid-based visual observation—to produce a latent representation (`z_i`) that is fed into the "DreamerV3" agent. The system's purpose is to create a language-aware world model, enabling an AI agent to understand and act upon instructions within a grid-world environment.
### Components/Axes
The diagram is organized into a flow from left to right, with inputs on the left and the final output on the right. It is segmented into four numbered, key components:
1. **Language manual (Top-Left):** A text box containing three example instruction sentences.
2. **Grid Observation (Bottom-Left):** A visual representation of a 2D grid-world state.
3. **Time embedding (Top-Right):** A module providing temporal information.
4. **Language-guided grid (Center):** The core processed representation combining language and visual data.
**Key Processing Blocks & Labels:**
* **T5 Encoder:** Processes the language manual. It outputs a key vector `k_i`.
* **Entity Embedding & Positional History:** Processes the Grid Observation. It outputs a value vector `v_i` and a query vector `q_i`.
* **Softmax Attention:** A mechanism that takes `q_i`, `k_i`, and `v_i` as inputs.
* **CNN (Convolutional Neural Network):** Processes the output of the attention mechanism.
* **DreamerV3:** The final destination for the processed latent vector `z_i`.
**Data Flow & Variables:**
* `k_i`, `v_i`, `q_i`: Key, Value, and Query vectors for the attention mechanism.
* `e_1`, `e_2`, `e_3`: Represent entity embeddings within the 3D "Language-guided grid."
* `a`: Represents an attribute or feature dimension within the grid.
* `z_i`: The final latent state vector output by the CNN, combined with the Time embedding.
### Detailed Analysis
**1. Language Manual (Component 1):**
* **Content:** Contains three bulleted sentences:
* "The plane doesn't move and has a message"
* "The scientist going closer to you is the goal"
* "The ship away from you is an enemy"
* **Function:** Serves as the natural language instruction or context for the agent's task.
**2. Grid Observation (Component 2):**
* **Visual:** A 10x10 grid (approximate) with a light gray background and darker grid lines.
* **Elements:**
* **Icons:** A blue airplane (top-left), a blue scientist figure (center), and a blue ship (bottom-right).
* **Annotations:** A dashed black arrow points from the scientist towards the left. A dashed black rectangle outlines a 3x3 area in the top-left quadrant.
* **Function:** Represents the current visual state of the environment observed by the agent.
**3. Core Processing Pipeline:**
* The **T5 Encoder** processes the language manual, generating a key `k_i`.
* The **Grid Observation** is processed by **Entity Embedding** and **Positional History** modules, generating a value `v_i` and a query `q_i`.
* These three vectors (`q_i`, `k_i`, `v_i`) are fed into a **Softmax Attention** block. This suggests the model is performing cross-modal attention, aligning linguistic concepts (from the manual) with visual entities (from the grid).
* The output of the attention block is visualized as a **3D "Language-guided grid" (Component 4)**. This is a conceptual tensor with dimensions labeled `e_1`, `e_2`, `e_3` (likely representing different entities or features) and an attribute dimension `a`.
* This 3D grid is processed by a **CNN**, which flattens and transforms it into a latent vector `z_i`.
* A **Time embedding (Component 3)** is added to `z_i` (indicated by the `+` symbol), incorporating temporal context.
* The final vector `z_i` (now time-aware) is the output, directed to **DreamerV3**.
### Key Observations
* **Multimodal Fusion:** The architecture explicitly fuses linguistic and visual information early in the pipeline via an attention mechanism, rather than processing them separately.
* **Structured Representation:** The "Language-guided grid" is a key intermediate representation, suggesting the model constructs a structured, entity-centric view of the world informed by language.
* **Temporal Awareness:** The explicit addition of a Time embedding indicates the model is designed for sequential decision-making tasks where timing is crucial.
* **Spatial Grounding:** The dashed arrow and rectangle in the Grid Observation imply the system may track relationships (e.g., "going closer") and regions of interest defined by the language.
### Interpretation
The LED-WM diagram presents a method for grounding natural language instructions in a visual, interactive environment. The system does not merely caption the image or parse the text in isolation; it actively uses the language to *guide* its perception of the grid world.
* **How it works:** The language manual defines goals ("the scientist... is the goal") and threats ("the ship... is an enemy"). The attention mechanism likely weights different parts of the visual grid (e.g., the scientist icon, the ship icon) based on their relevance to these linguistic concepts. The resulting "Language-guided grid" is a rich, context-aware representation where visual features are annotated with semantic meaning derived from the instructions.
* **Why it matters:** This approach is critical for creating AI agents that can follow open-ended, natural language commands in games, simulations, or robotics. By building a world model (`z_i`) that is inherently language-aware, the downstream planner (DreamerV3) can make decisions that are directly aligned with high-level human instructions.
* **Notable Design Choice:** The use of a T5 Encoder (a powerful text-to-text model) suggests the language understanding component is substantial, capable of interpreting complex instructions beyond simple keywords. The transformation of a 2D grid observation into a 3D entity-attribute tensor for CNN processing indicates a sophisticated approach to spatial reasoning.
</details>
Figure 2: Overview of our proposed world model LED-WM. The world model input consists of:
<details>
<summary>x7.png Details</summary>

### Visual Description
Icon/Small Image (23x22)
</details>
a language manual $L$ ,
<details>
<summary>x8.png Details</summary>

### Visual Description
Icon/Small Image (22x22)
</details>
a grid-world observation representing entity and agent symbols, and
<details>
<summary>x9.png Details</summary>

### Visual Description
Icon/Small Image (22x22)
</details>
the current time step $t$ . Entity, agent symbols, and time step are encoded using learned embeddings, while $L$ is encoded via a frozen T5 encoder. To represent each entity, we employ a multi-layer perceptron (MLP) that processes the entity embedding and its temporal information, capturing its movement pattern relative to the agent, to produce a query vector. We apply an attention network between the query vectors and the sentence embeddings to align each entity with its corresponding sentence. The resulting vectors are then put into their respective entity positions. This produces
<details>
<summary>x10.png Details</summary>

### Visual Description
Icon/Small Image (22x22)
</details>
a language-grounded grid $G_{l}$ , which is then processed by a CNN. The extracted feature vector is flattened and concatenated with the time embedding to form final observation representation $x_{t}$ .
### 4.1 Observational inputs
The input to the world model consists of a natural language manual $L$ , a grid observation $o_{t}$ of size $10\times 10$ , containing symbolic entities, and the current time step $t$ . The manual
<details>
<summary>x11.png Details</summary>
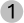
### Visual Description
Icon/Small Image (24x23)
</details>
comprises $N$ sentences, each describing the dynamic of one of the $N$ entities in the observation. Following Lin et al. [20], $N$ sentences in $L$ are encoded using a T5 encoder [30], resulting in $N$ frozen sentence embeddings, denoted by $s_{1},s_{2},...,s_{N}$ . In the grid
<details>
<summary>x12.png Details</summary>
### Visual Description
Icon/Small Image (23x23)
</details>
, the $N$ entities and the agent, represented by entity symbols, are encoded using a learned entity embedding vectors initialized with random weights. This ensures the agent does not have prior knowledge about entity identities, requiring it to infer entities based on the language. This results in $N$ symbol embeddings $sb_{1},sb_{2},...,sb_{N}\in\mathbb{R}^{d_{sb}}$ and a single agent embedding $a\in\mathbb{R}^{d_{sb}}$ . The current time step $t$
<details>
<summary>x13.png Details</summary>
### Visual Description
Icon/Small Image (23x23)
</details>
is encoded as $time_{t}$ using a learned time embedding, also initialized with random weights.
To build position history of each entity $i$ , we capture temporal dynamics by constructing an array $D_{i}$ temporally, with length corresponding to the maximum possible steps in the environment and initial values of $-1$ . At time step $t$ , let the 2D coordinate of the entity $i$ be $p^{t}_{i}$ and that of the agent be $p^{t}_{a}$ . To determine the relative direction of the entity’s movement with respect to the agent, we compute the dot product:
$$
D_{i}^{t}=\frac{p^{t}_{i}-p^{t}_{a}}{\|p^{t}_{i}-p^{t}_{a}\|}\cdot\frac{p^{t}_{i}-p^{t-1}_{i}}{||p^{t}_{i}-p^{t-1}_{i}||},\forall i\in[1..N],\forall t, \tag{2}
$$
where the first term is a normalized vector from the agent to the entity $i$ , and the second term is a normalized velocity vector of the entity $i$ . This dot product quantifies the alignment between the entity’s direction of motion and its position relative to the agent at each time step $t$ .
### 4.2 LED: Building a language-aware encoder
We construct a language-grounded grid representation that aligns the language manual $L$ , which consists of $N$ sentence embeddings, with the observation $o_{t}$ , which includes $N$ entity embeddings and one agent embedding. To align the sentence embeddings with the entity embeddings, we use an attention network. The values are obtained through a linear transformation of the sentence embeddings $s_{i}$ . Meanwhile, the queries are obtained through a multi-layer perception (MLP) applied to the entity embeddings $sb_{i}$ and temporal array $D_{e}$ . Likewise, the keys are obtained through an MLP applied to the sentence embeddings $s_{i}$ :
$$
\displaystyle q_{i} \displaystyle=\text{MLP}([sb_{i},D_{e}]), \displaystyle k_{i} \displaystyle=\text{MLP}(s_{i}), \displaystyle v_{i} \displaystyle=W_{v}s_{i}, \displaystyle q_{i} \displaystyle\in\mathbb{R}^{d}, \displaystyle k_{i} \displaystyle\in\mathbb{R}^{d}, \displaystyle v_{i} \displaystyle\in\mathbb{R}^{d_{\text{val}}}, \tag{3}
$$
where $d$ and $d_{val}$ denote the dimensions of the query/key and value vectors, respectively. We then apply scaled dot-product attention [35]. Given $K\in R^{N\times d}$ as the key matrix where the row $i$ of $K$ is $k_{i}^{T}$ , attention scores $\gamma_{i}\in R^{N}$ and resulting vector $e_{i}\in R^{d_{a}}$ for each entity $i$ are calculated as:
$$
\displaystyle\gamma_{i}=softmax\left(\frac{q_{i}\cdot K}{\sqrt{d}}\right),\quad e_{i}=\sum_{j=1}^{N}\gamma_{ij}v_{j}, \tag{5}
$$
This attention aligns entity symbols in the observation with sentences in the manual based on attribute language descriptions such as movement (e.g., chaser, moving away, stationary) and entity name (e.g., dog, wizard). The resulting $e_{i}$ from the attention is able to represent an associated role for entity $i$ such as enemy, messenger, goal, which is vital information for world model and policy learning.
To retain the spatial information of entities, we place the resulting vectors $e_{i}$ back into the original positions of their corresponding entities in the grid observation. This produces
<details>
<summary>x14.png Details</summary>
### Visual Description
Icon/Small Image (23x23)
</details>
a language-aware grid observation $G_{l}$ of size $h\times w\times d_{val}$ . We then use a CNN encoder to extract a feature map, which is subsequently flattened and concatenated with the time embedding $\text{time}_{t}$ . The combined representation is processed through an MLP to obtain the final feature representation $x_{t}$ for the observation $o_{t}$ at time step $t$ :
$$
\displaystyle x_{t} \displaystyle=\text{MLP}(\text{Flatten}([\text{CNN}(G_{l})),\text{time}_{t}]) \tag{6}
$$
Denoting $\phi$ as the parameters of LED-WM, we can find stochastic variable $z_{t}$ as the function of $x_{t}$ :
$$
\displaystyle z_{t}\sim q_{\phi}(z_{t}|h_{t},x_{t}), \tag{7}
$$
which now replaces the encoder in DreamerV3, as shown in Equation ˜ 1.
### 4.3 LED-WM: Combining LED with Dreamerv3
We replace DreamerV3’s encoder with LED, resulting in our world model LED-WM. We adopt world model and policy learning from DreamerV3. However, we make the following changes to the original architecture to improve policy generalization and sample efficiency: we omit the reconstruction decoder (Decoder in Equation ˜ 1) and adopt multi-step prediction for reward and continue prediction [15, 27]. For more details, we refer the readers to Appendix ˜ D for world model loss and Appendix ˜ E for training procedure.
## 5 Experiments
We want to answer the following questions: 1) Can a policy trained on our world model LED-WM generalize to unseen games? (see Section ˜ 5.1), and 2) Can the world model LED-WM generalize to unseen games? (see Section ˜ 5.2) To answer these, we use two environments: MESSENGER and MESSENGER-WM, which are detailed in Section ˜ 3. We detail the training settings in Appendix ˜ A.
### 5.1 Policy generalization trained from LED-WM
#### 5.1.1 Policy baselines
As baselines, we adopt the following model-free (EMMA,CRL) and model-based (Dynalang, EMMA-LWM) methods:
- EMMA [14] uses attention between entities and sentences to generate language-conditioned observation to the policy. The policy is trained via curriculum learning where the agent is initialized with parameters learned from previous easier game settings. We report EMMA with curriculum learning from the original paper and EMMA without curriculum learning from [40].
- CRL [26] develops a specialized constraint for MESSENGER to overcome spurious correlations between entity identities and their roles in the training data. It has the state-of-the-art win rate performance in test environments of MESSENGER.
- Dynalang [20] use soft actor-critic for policy learning. Because the paper does not report policy generalization performance in MESSENGER, we first reproduce Dynalang using published code and train to convergence according to published hyperparameters and training steps. We then report its policy performance on test environment of MESSENGER in Table ˜ 2.
- EMMA-LWM [40] built a language-conditioned world model. A policy is trained with simulated trajectories from this world model through online imitation learning and filtered behavior cloning. Both methods require expert demonstrations. Online imitation learning is where the expert supervises the optimal action to take in simulated states (from the world model). Meanwhile, in filtered behavior cloning, the expert uses only states from its own expert plan. The agent then only chooses plans that achieve the highest returns according to the world models to imitate.
#### 5.1.2 Evaluation metrics
- Win Rates for MESSENGER: To make our comparison consistent with reported results from EMMA [14] and CRL [26], we adopt win rate as the metric in MESSENGER. Win rate is calculated as the average number of games won by the agent over 1000 episodes.
- Average Sum of Scores for MESSENGER-WM: Likewise to be consistent with EMMA-LWM [40] studying MESSENGER-WM, we adopt average sum of scores as the metric. For each game configuration, we run the policy for 60 trials We find that 60 trials are enough to find a stable average sum of scores to evaluate a policy given a particular game configuration. and compute the average sum of scores. This process is repeated for 1000 games, and we report the average sum across all games.
Table 2: Policy generalization in MESSENGER in terms of win rate. Note that other methods (Dynalang, CRL and LED-WM) do not use curriculum training. Results of Dynalang and LED-WM (∗) are rounded to second decimal place, while results for CRL and EMMA are taken from their original papers. Results are recorded across five training seeds.
| Dynalang ∗ CRL EMMA (w/o curriculum) | 0.03 ± 0.02 88 ± 2.5 85 ± 1.4 | 0.04 ± 0.05 76 ± 5 45 ± 12 | – – – | 0.03 ± 0.05 32 ± 1.9 10 ± 0.8 |
| --- | --- | --- | --- | --- |
| EMMA(w/ curriculum) | 88 ± 2.3 | 95 ± 0.4 | – | 22 ± 3.8 |
| LED-WM (Ours) ∗ | 100 ± 0 | 51.6 ± 2.7 | 96.6 ± 1.0 | 34.97 ± 1.73 |
#### 5.1.3 Results
We report the win rate performance of our method and other baselines for MESSENGER in Table ˜ 2 and the average sum of scores for MESSENGER-WM in Table ˜ 3.
In MESSENGER-WM, LED-WM outperforms EMMA-LWM in all settings without using any expert demonstrations. In MESSENGER, Dynalang fails to generalize to unseen games. We hypothesize that this is because Dynalang lacks an explicit mechanism to ground language to each entity. Meanwhile, LED-WM is better than other baselines in S1 and comparable to CRL in S3.
However, LED-WM underperforms CRL in S2, where the agent is trained on only one movement combination chasing-fleeing-stationary but is evaluated over different unseen movement combinations (unseen dynamics - see Table ˜ 1). In contrast, LED-WM performs well on S2-dev, where its setting is similar to S2, but its test dynamics are the same as the training games. We hypothesize that this occurs because CRL incorporates an explicit mechanism to mitigate the data bias in S2 that there is only one movement combination in the training data and spurious correlations between entity identities and their roles. For instance, the assumption "a dog is always a goal". Therefore, this mechanism might enhance generalization in test scenarios where the dog is either a friend or an enemy. Incorporating such a mechanism in LED-WM might be a promising direction for future work.
Table 3: Policy generalization in MESSENGER-WM in terms of average sum of scores. EMMA-LWM results are taken from its original paper [40]. Results are recorded across five training seeds.
| EMMA-LWM Online IL Filtered BC (near-optimal) | 1.01 $\pm$ 0.12 1.18 $\pm$ 0.10 | 0.96 $\pm$ 0.17 0.75 $\pm$ 0.20 | 0.62 $\pm$ 0.21 0.44 $\pm$ 0.18 |
| --- | --- | --- | --- |
| Filtered BC (suboptimal) | 0.98 $\pm$ 0.13 | 0.29 $\pm$ 0.25 | 0.13 $\pm$ 0.19 |
| LED-WM (Ours) | 1.31 $\pm$ 0.05 | 1.15 $\pm$ 0.08 | 1.16 $\pm$ 0.02 |
### 5.2 World model generalization
To evaluate the generalization of a world model, one pragmatic metric is to measure how its generated rollouts on unseen dynamics benefit policy learning. If the world model can generalize to unseen dynamics in test games, which effectively simulates these dynamics, a policy finetuned on these rollouts should improve in new games.
Finetuning procedure.
Given a trained LED-WM, a trained policy from LED-WM, and a test game, LED-WM takes the initial observation and the manual as input to generate 60 synthetic trajectories. These trajectories are then used to determine whether the policy should be finetuned on this game. We estimate the value of the trained policy from the world model and finetune the policy if the estimated value is smaller than a pre-defined threshold. For each gradient update on the policy finetune, we generate 60 synthetic trajectories. We repeat this process in 2000 optimization steps. We illustrate the finetuning procedure in Appendix ˜ F with a Python-like format.
Table 4: World model generalization over S2-dev and S3 (MESSENGER) through finetune procedure. Finetune results are recorded in average sum of scores across five seeds.
| LED-WM (Ours) After finetune | 1.500 $\pm$ 0 - | - - | 1.4478 $\pm$ 0.01 1.4513 $\pm$ 0.01 | –0.11 $\pm$ 0.05 -0.01 $\pm$ 0.12 |
| --- | --- | --- | --- | --- |
Evaluation metrics and results.
We adopt the average sum of scores due to its robustness to the stochasticity of the environment. We show policy finetune results in Table ˜ 4 for MESSENGER. In MESSENGER, we show that the finetuning procedure improves the trained policy in S2-dev, In S2-dev, we use Wilcoxon signed-rank [37] and hierarchical bootstrap sampling [8] corresponding to two levels of hierarchies in our experiments (episodes and run trials): at a 95% confidence level, hierarchical sampling indicates an improvement between 0.014 and 0.019. and in S3, demonstrating that the world model is generalizable to test trajectories. However, the absolute policy improvement is still limited in our experiments.
## 6 Related work
Due to space limit, we provide a detailed related work in Appendix ˜ B. In this section, we briefly review related work on language-conditioned dynamics using model-based approach. Recent efforts focus on integrating dynamics-descriptive language into world models, resulting in language-conditioned world models. Dynalang [20] shows that such world model improves policy’s sample efficiency compared to model-free approaches. However, it does not demonstrate policy generalization in unseen games. Reader [6] shows that a MCTS planner can generalize to unseen games using a language-conditioned world model. Despite this, its environment (RTFM [43]) does not require language grounding to entities. Zhang et al. [40] introduce MESSENGER-WM, a compositional benchmark based on MESSENGER, and EMMA-LWM—a policy can generalize over unseen games from a language-based world model and expert demonstrations. Though sharing this same goal of policy generalization with our work, these studies rely on limiting assumptions. Planning with an MCTS tree in Reader, involves incurring computational cost to generate plans in inference time. This approach may not be practical for applications that require quick policy responses. On the other hand, EMMA-LWM requires expert demonstrations to use imitation learning and behavior cloning. This assumption may not always be feasible for every application. In contrast, our work lifts these assumptions and demonstrates policy generalization over unseen games in two environments that require language grounding: MESSENGER and MESSENGER-WM.
## 7 Conclusion
We develop an agent that can understand dynamics-descriptive language in interactive tasks. We adopt a model-based reinforcement learning (MBRL) approach, where a language-conditioned world model is trained through interactions with the environment, and a policy is learned from this world model. Unlike existing works, we do not require expert demonstrations or expensive planning during inference. Our method proposes Language-aware Encoder for Dreamer World Model (LED-WM). LED-WM adopts an attention mechanism to explicitly align language description to entities in the observation. We show that policies trained with LED-WM can generalize better to unseen games than existing baselines. We can also further improve the trained policy through fine-tuning on synthetic test trajectories generated by the world model.
## 8 Acknowledgment
We thank everyone from VIRL lab (Oregon State University), especially Skand and Akhil for their valuable feedback and discussions. The first author was personally supported by Amanda Putiza, Nguyen Thi Ngoc Anh, Ngo Thi Bich Lan, Tran Thanh Nhu, Bui Thuy Tien, and Nguyen Hoang Kieu Anh. This work is supported by NSF CAREER Award 2339676. We also thank the anonymous reviewers for their valuable feedback and suggestions.
## References
- Anderson et al. [2017] Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton van den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. arXiv [cs.CV], November 2017.
- Bisk et al. [2016] Yonatan Bisk, Deniz Yuret, and Daniel Marcu. Natural language communication with robots. In Kevin Knight, Ani Nenkova, and Owen Rambow, editors, Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 751–761. Association for Computational Linguistics, June 2016.
- Cao et al. [2023] Tianshi Cao, Jingkang Wang, Yining Zhang, and Sivabalan Manivasagam. Zero-shot compositional policy learning via language grounding. arXiv, April 2023.
- Cheng et al. [2023] Ching-An Cheng, Andrey Kolobov, Dipendra Misra, Allen Nie, and Adith Swaminathan. LLF-bench: Benchmark for interactive learning from language feedback. arXiv, December 2023.
- Chevalier-Boisvert et al. [2019] Maxime Chevalier-Boisvert, Dzmitry Bahdanau, Salem Lahlou, Lucas Willems, Chitwan Saharia, Thien Huu Nguyen, and Yoshua Bengio. BabyAI: A platform to study the sample efficiency of grounded language learning. arXiv, December 2019.
- Dainese et al. [2023] Nicola Dainese, Pekka Marttinen, and Alexander Ilin. Reader: Model-based language-instructed reinforcement learning. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, page 16583–16599, Singapore, December 2023. Association for Computational Linguistics.
- Dainese et al. [2024] Nicola Dainese, Matteo Merler, Minttu Alakuijala, and Pekka Marttinen. Generating code world models with large language models guided by monte carlo tree search. arXiv, October 2024.
- Davison and Hinkley [2013] A C Davison and D V Hinkley. Cambridge series in statistical and probabilistic mathematics: Bootstrap methods and their application series number 1. Cambridge University Press, Cambridge, England, June 2013.
- Du et al. [2023] Yilun Du, Mengjiao Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. arXiv, November 2023.
- Goyal et al. [2019] Prasoon Goyal, Scott Niekum, and Raymond J Mooney. Using natural language for reward shaping in reinforcement learning. arXiv, May 2019.
- Ha and Schmidhuber [2018] David Ha and Jürgen Schmidhuber. World models. March 2018.
- Hafner et al. [2018] Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. arXiv [cs.LG], November 2018.
- Hafner et al. [2024] Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models - new 2024. arXiv, April 2024.
- Hanjie et al. [2021] Austin W Hanjie, Victor Zhong, and Karthik Narasimhan. Grounding language to entities and dynamics for generalization in reinforcement learning. arXiv, June 2021.
- Hansen et al. [2023] Nicklas Hansen, Hao Su, and Xiaolong Wang. TD-MPC2: Scalable, robust world models for continuous control. arXiv, October 2023.
- Kaiser et al. [2020] Lukasz Kaiser, Mohammad Babaeizadeh, Piotr Milos, Blazej Osinski, Roy H Campbell, Konrad Czechowski, Dumitru Erhan, Chelsea Finn, Piotr Kozakowski, Sergey Levine, Afroz Mohiuddin, Ryan Sepassi, George Tucker, and Henryk Michalewski. Model-based reinforcement learning for atari. arXiv, February 2020.
- Krantz and Lee [2022] Jacob Krantz and Stefan Lee. Sim-2-sim transfer for vision-and-language navigation in continuous environments. arXiv, April 2022.
- Krantz et al. [2022] Jacob Krantz, Shurjo Banerjee, Wang Zhu, Jason Corso, Peter Anderson, Stefan Lee, and Jesse Thomason. Iterative vision-and-language navigation. arXiv [cs.CV], October 2022.
- Krantz et al. [2023] Jacob Krantz, Shurjo Banerjee, Wang Zhu, Jason Corso, Peter Anderson, Stefan Lee, and Jesse Thomason. Iterative vision-and-language navigation. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14921–14930, Vancouver, BC, Canada, June 2023. IEEE.
- Lin et al. [2023] Jessy Lin, Yuqing Du, Olivia Watkins, Danijar Hafner, Pieter Abbeel, Dan Klein, and Anca Dragan. Learning to model the world with language. arXiv [cs.CL], July 2023.
- Liu et al. [2023] Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Transformers learn shortcuts to automata. arXiv, May 2023.
- McCallum et al. [2023] Sabrina McCallum, Max Taylor-Davies, Stefano V Albrecht, and Alessandro Suglia. Is feedback all you need? leveraging natural language feedback in goal-conditioned reinforcement learning. arXiv, December 2023.
- Mehta et al. [2024] Nikhil Mehta, Milagro Teruel, Patricio Figueroa Sanz, Xin Deng, Ahmed Hassan Awadallah, and Julia Kiseleva. Improving grounded language understanding in a collaborative environment by interacting with agents through help feedback. arXiv, February 2024.
- Nguyen et al. [2022] Khanh Nguyen, Yonatan Bisk, and Hal Daumé, III. A framework for learning to request rich and contextually useful information from humans. arXiv, June 2022.
- Parakh et al. [2023] Meenal Parakh, Alisha Fong, Anthony Simeonov, Tao Chen, Abhishek Gupta, and Pulkit Agrawal. Lifelong robot learning with human assisted language planners. arXiv, October 2023.
- Peng et al. [2023] Shaohui Peng, Xing Hu, Rui Zhang, Jiaming Guo, Qi Yi, Ruizhi Chen, Zidong Du, Ling Li, Qi Guo, and Yunji Chen. Conceptual reinforcement learning for language-conditioned tasks. arXiv, March 2023.
- Peri et al. [2024] Skand Peri, Iain Lee, Chanho Kim, Li Fuxin, Tucker Hermans, and Stefan Lee. Point cloud models improve visual robustness in robotic learners. arXiv, April 2024.
- Piriyakulkij et al. [2025] Wasu Top Piriyakulkij, Yichao Liang, Hao Tang, Adrian Weller, Marta Kryven, and Kevin Ellis. PoE-world: Compositional world modeling with products of programmatic experts. arXiv, May 2025.
- Poudel et al. [2023] Rudra P K Poudel, Harit Pandya, Chao Zhang, and Roberto Cipolla. LanGWM: Language grounded world model. arXiv, November 2023.
- Raffel et al. [2023] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv, September 2023.
- Ren et al. [2023] Yi Ren, Samuel Lavoie, Mikhail Galkin, Danica J Sutherland, and Aaron Courville. Improving compositional generalization using iterated learning and simplicial embeddings. arXiv, October 2023.
- Sharma et al. [2022] Pratyusha Sharma, Balakumar Sundaralingam, Valts Blukis, Chris Paxton, Tucker Hermans, Antonio Torralba, Jacob Andreas, and Dieter Fox. Correcting robot plans with natural language feedback. arXiv, April 2022.
- Tam et al. [2023] Allison C Tam, Neil C Rabinowitz, Andrew K Lampinen, Nicholas A Roy, Stephanie C Y Chan, D J Strouse, Jane X Wang, Andrea Banino, and Felix Hill. Semantic exploration from language abstractions and pretrained representations. arXiv, April 2023.
- Tang et al. [2024] Hao Tang, Darren Key, and Kevin Ellis. WorldCoder, a model-based LLM agent: Building world models by writing code and interacting with the environment. arXiv, May 2024.
- Vaswani et al. [2023] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. arXiv, August 2023.
- Wang et al. [2021] Zhengyong Wang, Liquan Shen, Mei Yu, Kun Wang, Yufei Lin, and Mai Xu. Domain adaptation for underwater image enhancement. arXiv, August 2021.
- Wilcoxon [1945] Frank Wilcoxon. Individual comparisons by ranking methods. Biom. Bull., 1(6):80–83, 1945.
- Xie et al. [2023] Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, and Tao Yu. Text2Reward: Automated dense reward function generation for reinforcement learning. arXiv, September 2023.
- Yu et al. [2023] Zhongwei Yu, Jingqing Ruan, and Dengpeng Xing. Explainable reinforcement learning via a causal world model. arXiv, May 2023.
- Zhang et al. [2024a] Alex Zhang, Khanh Nguyen, Jens Tuyls, Albert Lin, and Karthik Narasimhan. Language-guided world models: A model-based approach to AI control. arXiv, July 2024a.
- Zhang et al. [2024b] Yang Zhang, Shixin Yang, Chenjia Bai, Fei Wu, Xiu Li, Zhen Wang, and Xuelong Li. Towards efficient LLM grounding for embodied multi-agent collaboration. arXiv, May 2024b.
- Zheng et al. [2023] Zhaoheng Zheng, Haidong Zhu, and Ram Nevatia. CAILA: Concept-aware intra-layer adapters for compositional zero-shot learning. arXiv, May 2023.
- Zhong et al. [2021] Victor Zhong, Austin W Hanjie, Sida Wang, Karthik Narasimhan, and Luke Zettlemoyer. SILG: The multi-domain symbolic interactive language grounding benchmark. In Advances in Neural Information Processing Systems, volume 34, page 21505–21519. Curran Associates, Inc., 2021.
- Zhong et al. [2022a] Victor Zhong, Austin W Hanjie, Sida I Wang, Karthik Narasimhan, and Luke Zettlemoyer. SILG: The multi-environment symbolic interactive language grounding benchmark. arXiv, January 2022a.
- Zhong et al. [2022b] Victor Zhong, Jesse Mu, Luke Zettlemoyer, Edward Grefenstette, and Tim Rocktäschel. Improving policy learning via language dynamics distillation. arXiv, September 2022b.
- Zhou et al. [2025] Siyu Zhou, Tianyi Zhou, Yijun Yang, Guodong Long, Deheng Ye, Jing Jiang, and Chengqi Zhang. WALL-E 2.0: World alignment by NeuroSymbolic learning improves world model-based LLM agents. arXiv, April 2025.
- Zhou et al. [2024] Siyuan Zhou, Yilun Du, Jiaben Chen, Yandong Li, Dit-Yan Yeung, and Chuang Gan. RoboDreamer: Learning compositional world models for robot imagination. arXiv, April 2024.
## Appendix A Training details
| Batch size | 30 |
| --- | --- |
| Batch length | 300 |
| Optimizer | Adam |
| World model learning rate | 3e-4 |
| Max. world model gradient norm | 30 |
| Actor learning rate | 2e-4 |
| Max. actor gradient norm | 100 |
| Critic learning rate | 1e-4 |
| Max. critic gradient norm | 100 |
Table 5: Training hyperparameters.
| Dynamics loss scale | $\beta_{dyn}$ | 1 |
| --- | --- | --- |
| Representation loss scale | $\beta_{rep}$ | 0.1 |
| Latent unimix | — | 1% |
| Free nats | — | 1 |
| Sentence embedding dim | $d_{s}$ | 32 |
| Symbol/Agent embedding dim | $d_{sb}$ | 32 |
| MLP layers | — | 3 |
| MLP hidden units | — | 512 |
| Query/key dim | d | 128 |
| Value dim | $d_{val}$ | 128 |
| RSSM deterministic dim | — | 512 |
Table 6: World model hyperparameters. Other hyperparameters are the same as in DreamerV3 [13].
| Hyperparameter | Symbol | S1 | S2 | S2-dev | S3 | MESSENGER-WM |
| --- | --- | --- | --- | --- | --- | --- |
| Number of entities | N | 3 | 3 | 3 | 5 | 3 |
| Episode horizon | H | 4 | 32 | 32 | 32 | 32 |
| Finetune threshold | $thres$ | - | 1.2 | 1.2 | 1.4 | - |
| Training environment steps | - | 1M | 10M | 10M | 20M | 10M |
| Training GPU hours | - | 6 | 24 | 24 | 72 | 24 |
Table 7: Environment hyperparameters. Training GPU hours are estimated based on 1 NVIDIA H100 GPU.
## Appendix B Detailed related work
How language is used in RL tasks?
Language is often employed as step-by-step instructions or goal specification in domains such as 1) visual language navigation (VLN) [18] [19] [1] 2) grid-world games like BabyAI [5] and SILG benchmark [45], and 3) manipulation tasks [31] [42] [25]. Another research direction in language for RL explores how language can accelerate policy learning by providing richer feedback rather than just numerical rewards: language for plan correction [32] [21] [22] [4] [24] [23], providing more descriptions of the current state or current goal [24] [20], generating dense rewards [10] [39] [38], clarifying information [23], and speeding up exploration [33]. This study investigates an alternative use of language in RL problems: describing the dynamics of environments.
Language-conditioned dynamics environments.
In language-conditioned environments, while language can be used as step-by-step instructions [17] [2] [1], language can also be used to describe environment dynamnics—that is, how environments change over time. Formally, language describes the transition function $T(s^{\prime}|s,a)$ and reward function $r(s,a)$ of a MDP system defined in Section ˜ 2. Several environments have been proposed to provide language-conditioned dynamics [3] [43] but their settings do not require understanding entity interaction or grounding language to entities. To fill this gap, as discussed in Section ˜ 3 about the environment setup, Hanjie et al. [14] present MESSENGER, a more challenging game requiring language grounding to entities based on environment dynamics. Zhang et al. [40] later propose MESSENGER-WM built out of MESSENGER to test compositional generalization world model and policy. In this study, we focus on MESSENGER and MESSENGER-WM due to their requirements for language grounding to entities and a history of previous works on these datasets.
How to solve language-conditioned dynamics environments?
Generally speaking, there are two ways to understand language-conditioned dynamics: model-free and model-based learning. First, in model-free approach, language is used to build language-conditioned observation, which is then fed directly to policy in a model-free manner. Second, in model-based learning, language is used to build language-conditioned world model, which is then used to plan or learn policy. Our work focuses on the second category: we use dynamics-related language explicitly for dynamics learning, in model-based RL fashion, thus improving policy performance over model-free approaches.
Language-conditioned dynamics in RL: model-free approach.
In model-free approach, language is used to build language-conditioned observation, which is then fed directly to policy. Hanjie et al. [14] utilize an attention mechanism to ground language to individual entities, forming a language-aware representation for the policy. Zhong et al. [44] develop a model of environmental dynamics learned from language-conditioned and state-only (without action) demonstrations. This dynamics model is then used to initialize and distill to the representation of a policy learner, which helps sample-efficiency and generalization across language RL tasks. Wang et al. [36] proposes compact and invariant concept-like representations through extracting similarities across observations, which is then proved to be useful for policy learning. Wang et al. [36] proposes two-agent system where the manager agent reads the instructions and manuals to devise the plan with sub-goals and the worker agent fulfills the sub-goals in the plan one-by-one. The model, however, assumes access to the sub-goal text instructions to train the manager. Those works use language directly for policy learning while our work uses language for world model learning.
Language-condition instruction-based world model (LWM).
World models in model-based reinforcement learning (RL) involve learning the dynamics of the environment. In visual-understanding interaction domains like robotics and video games, world models have been widely studied and are empirically proven to be sample-efficient for policy learning [16] [13] [27]. However, in language-understanding interaction tasks, most language-conditioned world models have been developed to process task instructions or action descriptions, rather than to capture environmental dynamics. Poudel et al. [29] integrates human language into the world model, however language primarily describes observations rather than environment’s dynamics. For example, a description like "there is an apple on the left, 2 meters from here" describes the future observation of environment without addressing the transition function. Recent works [47] [9] [41] develop LWM with compositional generalizability. While these works use more visually realistic input and require more reasoning to solve their tasks, the language they study is task instruction that involves straightforward mapping from language to objects such as colors and object names, e.g. "Move A Red Block to A Brown Box."
To bridge this gap, we focus on language-conditioned world models that incorporate dynamics-descriptive language—language that explains how entities interact and how the environment changes—rather than just providing direct task instructions. In contrast, the language used in our testbed environments MESSENGER and MESSENGER-WM describes environmental dynamics, which is the focus of our study.
Large language model (LLM) for world model.
Recent work [7] [34] [28] [46] use LLMs to build a world model for policy learning. However, their environments does not require language understanding or language grounding. In other words, they do not build a language-conditioned world model like our work. Further, they do not study the generalization behavior of LLM-based world model in a out-of-distribution (OOD) set up. In contrast, our work focuses on building a world model that requires language grounding to entities. We also study the generalization behavior of a language-conditioned world model and a policy learned from this world model. We achieve this by running experiments in a controlled OOD set up from MESSENGER and MESSENGER-WM.
## Appendix C Environment details
### C.1 MESSENGER
#### C.1.1 Environment Dynamics and Action
Reward and Game Ending.
The agent loses the game and incurs -1 reward In the $S3$ setting of the game, there is an inconsistency in the environment implementation with the description provided in [14]: when the agent collides with two enemy entities, the environment returns a reward of -2 instead of -1. We observe that this rarely happens and thus has no significant impact on expected policy’s behavior. if either of two events occurs - the agent is in the same cell as the enemy or reaches the goal without first getting the message. Reaching the messenger gives the agent a reward of 0.5, and then reaching the goal provides a reward of 1.
Observation change.
The agent can be with or without a message, represented by two different symbols in the observation. The observation changes when the agent interacts with entities according to their roles, specifically:
- When the agent without a message picks up messenger, the messenger disappears from the observation. The agent now has a message and is represented by a different symbol from when it was without a message.
- When the agent loses the game, either by reaching the goal without first getting the message or by touching the enemy, the agent disappears from the observation.
- When the agent wins the game by reaching the goal with the message, the goal disappears from the observation.
Action.
The agent can navigate the grid using five actions: left, right, up, down, and stay. The agent can only interact with entities when it is in the same grid cell as the entity. We observed an inconsistency in the implementation with the environment description outlined in [14]. The agent can collide with entities even when they are not in the same grid cell. This is however deemed acceptable to the policy as the agent is still able to try to either go back or stay away from the other entity. More details can be found in this discussion: https://github.com/ahjwang/messenger-emma/issues/6
#### C.1.2 Entities and Language Manuals
Each game includes a language manual and an observation containing entities and a single agent. There are twelve different entities (e.g., airplane, researcher, etc.) denoted by a fixed set of corresponding symbols that are used consistently across game instances. For instance, symbol
<details>
<summary>figures/plane.png Details</summary>

### Visual Description
## Icon: Airplane Symbol
### Overview
The image displays a stylized, flat-design icon of a commercial airplane viewed from a top-down perspective. The icon is presented against a plain, light grey background. It contains no textual information, data, charts, or diagrams. It is a purely graphical symbol.
### Components/Axes
* **Primary Subject:** A single airplane icon.
* **Background:** A solid, uniform light grey field (approximate hex: #f0f0f0).
* **Legend/Labels:** None present.
* **Axes/Scale:** Not applicable.
### Detailed Analysis
The icon is constructed with the following visual elements:
* **Outline:** A thick, dark grey (approximate hex: #3a3a3a) border defines the entire shape of the airplane.
* **Fill:** The interior of the airplane is filled with a very light, cool blue (approximate hex: #e6f3ff).
* **Detail:** Two slightly darker blue (approximate hex: #a8c8e8) rectangular stripes are placed on the wings, suggesting engine nacelles or wing markings. One stripe is on the upper-left wing, and the other is on the lower-right wing.
* **Orientation:** The airplane is oriented diagonally, with its nose pointing towards the top-right corner of the image frame and its tail towards the bottom-left.
* **Spatial Grounding:** The icon is centered within the square image frame. The wings extend towards the top-left and bottom-right corners. The fuselage runs diagonally from the bottom-left to the top-right.
### Key Observations
1. **Simplicity:** The design is minimalist, using only three colors (dark grey outline, light blue fill, medium blue detail) and basic geometric shapes to represent the aircraft.
2. **Style:** It follows a common "flat design" or "outline icon" aesthetic, suitable for user interfaces, signage, or informational graphics.
3. **Clarity:** The symbol is immediately recognizable as an airplane due to its distinct silhouette: a central fuselage, two swept-back wings, and a tail assembly.
4. **Lack of Data:** The image contains no quantitative information, trends, labels, or text to extract. It is a symbolic representation, not a data visualization.
### Interpretation
This image serves as a **symbolic identifier**, not a source of factual data. Its meaning is derived from universal visual conventions.
* **Purpose:** The icon is designed to represent concepts related to air travel, aviation, airports, flight, or transportation in a quick, universally understandable manner. It would typically be used in contexts like navigation menus, maps, informational brochures, or signage.
* **Design Choices:** The diagonal orientation conveys a sense of motion or dynamism. The thick outline ensures visibility at small sizes, and the limited color palette aids in clear recognition and potential branding consistency.
* **Underlying Information:** The image itself provides no underlying data trends or investigative findings. Its "information" is purely semiotic: it is a signifier for the concept of an airplane. Any additional meaning (e.g., "departures," "airline logo," "travel section") would be entirely dependent on the context in which this icon is placed.
</details>
for entity plane shown in Figure ˜ 1. Note that the observation does not have entity names (e.g. airplane) and the agent must observe the entity’s symbol and ground the entity’s name to its corresponding symbols from the manual.
There are also three movement types for entities: moving, fleeing, and stationary, which describe movement trends relative to the agent’s position. For example, a manual "heading closer and closer to where you are" describes the movement type moving.
For each game, the game engine assigns different roles (enemy, goal, messenger) and movement types (moving, fleeing, stationary) to a set of entities, along with the associated language manuals containing this information. For example, "the plane fleeing from you has the classified report". As a result, two games with the same set of entities and identical grid-world observations can have different language manuals and, consequently, different reward and transition functions.
#### C.1.3 Evaluation settings
MESSENGER provides three stages with different levels of language generalization assessment:
Stage 1 (S1).
This stage tests the agent’s ability to ground entity names in the manual to entity symbols in the observation. Test games offer two different levels of generalization evaluation. First, new languages describing the same entity name using synonyms, e.g. researcher-scholar. Second, new languages describing new combinations of known entities in a game, i.e. the agent has played with entities ferry, plane, researcher in train but not in the same game, and the agent is tasked to play with all of them in a test game.
As shown in Figure ˜ 3, this stage includes three entities, each with one of the three roles: enemy, messenger, and goal, along with their corresponding descriptions. All entities are stationary and placed two steps away from the agent, which starts in the center of the grid. The language descriptions only specify the entities and their roles, with no mention of movement. The agent starts the game either with or without the message.
<details>
<summary>figures/stage_one.png Details</summary>

### Visual Description
\n
## Diagram: Observation Grid and Manual Instructions
### Overview
The image displays a two-panel diagram on a light gray background. The left panel, titled "Observation," shows an 8x8 grid containing four distinct icons. The right panel, titled "Manual," contains a bordered text box with three bulleted statements that assign roles or attributes to entities represented by the icons.
### Components/Axes
**Panel 1: Observation (Left)**
* **Title:** "Observation" (centered above the grid).
* **Grid:** An 8x8 grid of thin, gray lines on a white background.
* **Icons (with approximate grid positions, counting from top-left as (1,1)):**
1. **Researcher Icon:** A person with brown hair, wearing a white lab coat, looking into a microscope. Positioned at approximately grid cell (3, 4).
2. **Ferry/Ship Icon:** A blue and white vessel on water. Positioned at approximately grid cell (5, 2).
3. **Robot Icon:** A simple, white robot head with two eyes and an antenna. Positioned at approximately grid cell (5, 4).
4. **Plane Icon:** A light blue airplane. Positioned at approximately grid cell (5, 6).
**Panel 2: Manual (Right)**
* **Title:** "Manual" (centered above the text box).
* **Text Box:** A white rectangle with a black border containing three bullet points.
* **Text Content (Transcribed):**
* The ferry is a deadly adversary.
* The plane has the classified report
* The researcher is a vital goal.
### Detailed Analysis
The diagram presents a direct mapping between visual symbols (icons in a grid) and textual descriptions (rules in a manual).
* **Spatial Relationship:** The "Observation" grid appears to represent a state or a map, while the "Manual" provides the rules or context for interpreting that state.
* **Entity-Role Mapping:**
* The **Ferry icon** corresponds to the role of a "deadly adversary."
* The **Plane icon** is associated with possessing a "classified report."
* The **Researcher icon** is designated as a "vital goal."
* **Unreferenced Element:** The **Robot icon** is present in the observation grid but is not mentioned in the manual text. Its role or status is undefined by the provided information.
### Key Observations
1. **Asymmetric Information:** The manual defines the roles for three of the four visible entities, leaving one (the robot) as an unknown variable within the system.
2. **Narrative Setup:** The language ("adversary," "classified report," "vital goal") suggests a scenario involving conflict, intelligence, and objectives, reminiscent of a game, simulation, or tactical briefing.
3. **Spatial Layout:** The icons are not clustered; the researcher is in the top half, while the ferry, robot, and plane are aligned horizontally in the middle row, separated by empty cells. This spacing may imply distance or separation in the conceptual space.
### Interpretation
This diagram functions as a **legend or key for a scenario-based system**. It establishes a foundational relationship between observable symbols and their semantic meanings within a specific context.
* **What it demonstrates:** It shows how abstract icons are given concrete narrative significance. The "Observation" is the raw data (what is seen), and the "Manual" is the intelligence or rulebook (what it means).
* **Relationships:** The core relationship is a **direct assignment of attributes** from the manual to the icons. The grid itself may imply a coordinate system or a field of play, but without axis labels, its specific function (e.g., a map, a state matrix) is not explicitly defined.
* **Notable Anomaly:** The omission of the robot from the manual is the most significant outlier. This creates intentional ambiguity. In a practical application, this could mean the robot is a neutral element, a player-controlled unit, or an entity whose properties are defined elsewhere. Its presence without definition is a critical piece of information, highlighting that the provided manual is incomplete.
* **Underlying Purpose:** The image likely serves as an instructional or setup slide for a game, a logic puzzle, or a training simulation. It efficiently communicates the core stakes (adversary, objective, asset) and the visual language needed to understand a subsequent, more complex display or interaction. The viewer is meant to internalize these associations to interpret future "observations."
</details>
Figure 3: An example game of MESSENGER S1. In this game, the entity does not have message at the beginning of the game. Therefore, it goes to the messenger to retrieve the message and ends the game. All entities except the agent are stationary, thus the manual only describes roles associated with entity names.
<details>
<summary>figures/stage_two.png Details</summary>

### Visual Description
## Diagram: Game or Simulation Scenario - Observation and Manual
### Overview
The image displays a two-part diagram, likely from a game, simulation, or puzzle interface. The left side, titled "Observation," shows a grid-based map with icons representing entities and their movement paths. The right side, titled "Manual," provides a text box with three bullet points explaining the rules or objectives of the scenario. The overall purpose appears to be to present a tactical situation and its governing rules.
### Components/Axes
**1. Main Title Headers:**
* **Left Header:** "Observation" (Top-left, large black font).
* **Right Header:** "Manual" (Top-right, large black font).
**2. Observation Grid (Left Panel):**
* **Structure:** A grid of 8 columns and 7 rows, forming a coordinate system.
* **Icons & Elements (with approximate grid positions, counting from top-left as (1,1)):**
* **Researcher Icon:** A person at a microscope. Located at approximately column 6, row 2.
* **Ship/Ferry Icons (Blue):** Three icons. Two are in column 2, rows 3 and 4. One is in column 3, row 3. They are clustered in the upper-left quadrant.
* **Airplane Icons (Gray):** Three icons in a horizontal line. Located in columns 4, 5, and 6, row 5.
* **Robot Icon:** A simple robot face. Located at column 3, row 6.
* **Movement Paths (Dashed Lines):**
* A path starts at the Robot (3,6), moves horizontally right to column 6, then vertically up to the Airplane at (6,5). An arrowhead points up at the end of this path.
* A separate vertical dashed line extends downward from the Researcher at (6,2) to the Airplane at (6,5).
**3. Manual Text Box (Right Panel):**
* A white rectangular box with a black border containing three bullet points.
* **Text Content (Transcribed):**
* "The plane going away from you carries out a message"
* "The researcher doesn't move is final goal"
* "The ferry chasing you is an enemy"
### Detailed Analysis
**Spatial Grounding & Component Isolation:**
* **Header Region:** Contains the two main titles, clearly separating the visual data ("Observation") from the rule set ("Manual").
* **Observation Grid Region:** This is the core data area. The grid provides a spatial reference. The icons are placed at specific intersections. The dashed lines with an arrow indicate a directed movement or relationship flow: from the Robot, to the right, then up to the Airplane, which is also connected to the stationary Researcher.
* **Manual Region:** The text box is positioned to the right of the grid, providing explanatory context. The bullet points are left-aligned.
**Icon Identification & Relationships:**
* The **Researcher** is the endpoint of a dashed line from an Airplane and is described in the manual as the "final goal" that "doesn't move."
* The **Airplanes** are intermediate points. One is the destination of the Robot's path and the origin of the path to the Researcher. The manual states a plane "going away... carries out a message," suggesting the airplane moving upward (toward the researcher) is the message carrier.
* The **Robot** is the starting point of a movement path, likely representing the player's controllable unit ("you" in the manual).
* The **Ships/Ferries** are clustered in the upper-left. The manual identifies a "ferry chasing you" as an "enemy," implying these blue ship icons are hostile units.
### Key Observations
1. **Clear Objective:** The manual explicitly states the goal is related to the researcher who does not move.
2. **Defined Roles:** Each icon type has a specific function: Goal (Researcher), Messenger (Airplane), Player/Agent (Robot), Enemy (Ferry).
3. **Pathway Logic:** The dashed lines create a clear sequence: Robot -> Airplane -> Researcher. This visually maps the process of the player unit interacting with the messenger unit to reach the goal.
4. **Spatial Separation:** The enemy ferries are positioned away from the primary action path (Robot-Airplane-Researcher), suggesting they may be a secondary threat or obstacle to avoid.
### Interpretation
This diagram outlines a **tactical mission scenario**. The data suggests a multi-step objective:
1. The player controls the **Robot**.
2. The Robot must reach or interact with an **Airplane**.
3. That Airplane then acts as a messenger, traveling to the stationary **Researcher** to complete the "final goal."
4. Meanwhile, **Ferries** act as enemy units that likely pursue the player, adding a layer of threat and urgency.
The "Manual" text is crucial for interpreting the symbolic icons. Without it, the diagram would just show entities and paths. The text assigns narrative meaning (message, goal, enemy) to the visual elements, transforming an abstract grid into a story-driven puzzle or game level. The phrasing "The researcher doesn't move is final goal" contains a minor grammatical error but clearly conveys that the researcher's immobility is a key condition for success. The scenario emphasizes strategy (reaching the correct airplane) and evasion (avoiding the chasing ferries).
</details>
Figure 4: An example of a game play within a 10 × 10 grid-world from MESSENGER S2. The observation on the left includes three entities represented by their associated symbols: (ferry -
<details>
<summary>figures/ferry.png Details</summary>

### Visual Description
## Illustration: Stylized Ship Icon
### Overview
The image is a flat, stylized digital illustration of a ship on water. It is not a chart, diagram, or document containing textual data. The image is purely graphical and symbolic, using simplified shapes and a limited color palette to represent a vessel at sea. There is no embedded text, numerical data, labels, or legends present.
### Components/Axes
As this is an illustration and not a data visualization, there are no axes, scales, or legends. The visual components are:
1. **Ship Structure:**
* **Hull:** A large, solid blue shape forming the main body of the ship. It has a curved bow (front) on the right and a flat stern (back) on the left.
* **Superstructure:** A white, rectangular block sitting atop the hull, representing the bridge or accommodation area.
* **Funnel/Stack:** A bright blue, tapered cylindrical shape positioned on top of the superstructure.
* **Mast/Antenna:** A thin, white vertical line extending upwards from the top of the funnel.
2. **Water:** A light blue, wavy band at the bottom of the image, representing the sea surface. The waves are depicted as a series of connected, smooth curves.
3. **Background:** A solid, light beige or off-white color fills the space behind the ship and above the water.
### Detailed Analysis
* **Color Palette:** The illustration uses a monochromatic blue scheme for the subject, with white accents, against a neutral background.
* Hull: Approximate color value is a medium-dark blue (e.g., #4A6FE3).
* Funnel: A brighter, cyan-like blue (e.g., #00B4FF).
* Superstructure & Mast: White.
* Water: A very light, pastel blue (e.g., #D6F0FF).
* Background: Light beige (e.g., #F5F2EB).
* **Style:** The design is minimalist and iconic, using geometric shapes with soft, rounded corners. There is no shading, texture, or perspective detail, giving it a clean, modern, app-icon-like appearance.
* **Composition:** The ship is centered horizontally and occupies the middle vertical third of the image. The water line sits in the lower third.
### Key Observations
* The image contains **zero textual information**. There are no labels, titles, annotations, or numbers.
* It is a **symbolic representation**, not a technical diagram. It conveys the concept of "ship" or "maritime" rather than specific technical details.
* The design is **non-literal**. For example, the ship lacks specific features like portholes, railings, or a defined deck, and the water is a stylized pattern.
### Interpretation
This image functions as a **visual icon or symbol**. Its purpose is to be immediately recognizable as a ship, likely for use in a user interface, logo, or informational graphic where a simple maritime metaphor is needed. The choice of a calm, blue color palette and smooth shapes suggests themes of transport, travel, logistics, or the sea in a friendly, approachable, and non-technical context. The absence of data or text means its informational content is purely connotative, relying on the viewer's cultural understanding of the ship symbol.
</details>
), (plane -
<details>
<summary>figures/plane.png Details</summary>

### Visual Description
## Icon: Airplane Symbol
### Overview
The image displays a stylized, flat-design icon of a commercial airplane viewed from a top-down perspective. The icon is presented against a plain, light grey background. It contains no textual information, data, charts, or diagrams. It is a purely graphical symbol.
### Components/Axes
* **Primary Subject:** A single airplane icon.
* **Background:** A solid, uniform light grey field (approximate hex: #f0f0f0).
* **Legend/Labels:** None present.
* **Axes/Scale:** Not applicable.
### Detailed Analysis
The icon is constructed with the following visual elements:
* **Outline:** A thick, dark grey (approximate hex: #3a3a3a) border defines the entire shape of the airplane.
* **Fill:** The interior of the airplane is filled with a very light, cool blue (approximate hex: #e6f3ff).
* **Detail:** Two slightly darker blue (approximate hex: #a8c8e8) rectangular stripes are placed on the wings, suggesting engine nacelles or wing markings. One stripe is on the upper-left wing, and the other is on the lower-right wing.
* **Orientation:** The airplane is oriented diagonally, with its nose pointing towards the top-right corner of the image frame and its tail towards the bottom-left.
* **Spatial Grounding:** The icon is centered within the square image frame. The wings extend towards the top-left and bottom-right corners. The fuselage runs diagonally from the bottom-left to the top-right.
### Key Observations
1. **Simplicity:** The design is minimalist, using only three colors (dark grey outline, light blue fill, medium blue detail) and basic geometric shapes to represent the aircraft.
2. **Style:** It follows a common "flat design" or "outline icon" aesthetic, suitable for user interfaces, signage, or informational graphics.
3. **Clarity:** The symbol is immediately recognizable as an airplane due to its distinct silhouette: a central fuselage, two swept-back wings, and a tail assembly.
4. **Lack of Data:** The image contains no quantitative information, trends, labels, or text to extract. It is a symbolic representation, not a data visualization.
### Interpretation
This image serves as a **symbolic identifier**, not a source of factual data. Its meaning is derived from universal visual conventions.
* **Purpose:** The icon is designed to represent concepts related to air travel, aviation, airports, flight, or transportation in a quick, universally understandable manner. It would typically be used in contexts like navigation menus, maps, informational brochures, or signage.
* **Design Choices:** The diagonal orientation conveys a sense of motion or dynamism. The thick outline ensures visibility at small sizes, and the limited color palette aids in clear recognition and potential branding consistency.
* **Underlying Information:** The image itself provides no underlying data trends or investigative findings. Its "information" is purely semiotic: it is a signifier for the concept of an airplane. Any additional meaning (e.g., "departures," "airline logo," "travel section") would be entirely dependent on the context in which this icon is placed.
</details>
), (researcher -
<details>
<summary>figures/scientist.png Details</summary>

### Visual Description
## Icon/Illustration: Scientist with Microscope
### Overview
This is a flat-design, stylized icon or illustration depicting a scientist (or lab technician) looking into a microscope. The image contains no textual information, data, charts, or diagrams. It is a symbolic representation of scientific research, laboratory work, or analysis.
### Components/Axes
* **Primary Subject:** A human figure, shown from the chest up, in profile facing left.
* **Key Object:** A compound microscope positioned in front of the figure.
* **Background:** A solid, light gray background (`#f0f0f0` approximate).
* **Style:** Bold, black outlines define all shapes. Colors are flat with no gradients or shading.
### Detailed Analysis
**Figure Details:**
* **Hair:** Brown, styled with a prominent curl or wave on top.
* **Face:** No facial features are depicted (eyes, nose, mouth are absent).
* **Eyewear:** Large, bright blue safety goggles or glasses.
* **Clothing:** A white lab coat with a black outline. The collar and front seam are indicated.
* **Pose:** The figure is leaning forward, with their head positioned to look into the microscope's eyepiece. Their right arm is bent, with the hand resting on the microscope's arm or focus knob.
**Microscope Details:**
* **Body/Arm:** A curved, yellow arm connects the base to the head.
* **Head/Optical Tube:** Gray, containing the eyepiece (ocular lens) and objective lenses.
* **Stage:** A flat, gray platform where a sample would be placed.
* **Base:** A gray, rectangular base supporting the structure.
* **Knobs:** A prominent, circular yellow knob (likely the coarse focus) is visible on the side of the arm. A smaller black circle may represent a fine focus knob.
* **Nosepiece:** A gray, rotating turret holding the objective lenses is implied below the head.
**Spatial Grounding:**
* The **microscope** occupies the left and central portion of the frame.
* The **scientist** is positioned on the right side, overlapping the microscope.
* The **yellow focus knob** is located at the junction of the arm and the base, slightly below the center of the image.
* The **blue goggles** are the most saturated color element, positioned in the upper-right quadrant of the figure's head.
### Key Observations
1. **Absence of Text:** The image contains zero textual elements—no labels, titles, legends, or annotations.
2. **Symbolic, Not Literal:** The illustration is an archetype. It uses universal symbols (lab coat, microscope, goggles) to convey the concept of "scientist" or "research" rather than depicting a specific person or equipment model.
3. **Simplified Form:** Complex details of the microscope (like specific lenses, adjustment screws, or a light source) and the human figure (facial features, fingers) are omitted for clarity and iconographic impact.
4. **Color Palette:** The palette is limited and functional: white (coat), brown (hair), blue (goggles), yellow (microscope arm/knob), gray (microscope body/background), and black (outlines).
### Interpretation
This image functions as a **visual metaphor**. Its purpose is to quickly and universally communicate ideas related to:
* **Scientific Research & Discovery:** The act of close examination and analysis.
* **Laboratory Work:** A standard setting for biological, chemical, or medical investigation.
* **Precision & Scrutiny:** The microscope symbolizes looking deeper into a subject, studying details invisible to the naked eye.
* **Expertise & Analysis:** The figure represents a trained professional engaged in technical work.
The lack of specific data or text means its information is purely **connotative**. It doesn't present facts but evokes a field of knowledge and a set of activities. In a technical document, this icon would likely serve as a section header, a button label, or an illustrative element to denote a related topic (e.g., "Lab Results," "Microscopic Analysis," "Research Methods"). Its effectiveness lies in its immediate recognizability and its clean, unambiguous design.
</details>
) and one agent (depicted by
<details>
<summary>figures/bot.png Details</summary>

### Visual Description
## Icon/Symbol: Robot Head Line Drawing
### Overview
The image is a simple, monochromatic line drawing of a stylized robot head, presented as a black icon on a light gray background. It contains no textual information, data, charts, or diagrams. The design is minimalist and symbolic, intended to represent a robot or artificial intelligence concept.
### Components
The icon is composed of the following geometric elements:
1. **Head Outline:** A square with rounded corners, drawn with a thick black line.
2. **Eyes:** Two identical, solid black circles placed symmetrically within the head outline, positioned in the upper half.
3. **Antenna:** A vertical line extending from the top center of the head, terminating in a small, hollow circle (a ring).
4. **Ears/Side Panels:** Two identical, vertical rectangular shapes with rounded outer edges, attached to the left and right sides of the head outline. They are drawn with the same line thickness as the head.
### Detailed Analysis / Content Details
* **Textual Content:** None. The image contains no words, labels, numbers, or characters in any language.
* **Data Content:** None. This is not a chart, graph, or data visualization.
* **Color:** The image uses a two-tone palette: black (#000000) for all lines and shapes, and a uniform light gray (approximately #E5E5E5) for the background.
* **Line Style:** All lines are of consistent, medium-heavy weight with no variation. Corners on the head and ears are rounded.
### Key Observations
* The design is highly symmetrical along the vertical axis.
* The icon uses universal, simple geometric shapes (square, circle, rectangle) for immediate recognizability.
* The lack of a mouth or other facial features gives it a neutral, non-expressive appearance.
* The antenna is a classic visual shorthand for "robot" or "wireless communication."
### Interpretation
This image serves as a **symbol or icon**, not a carrier of factual data or complex information. Its purpose is purely representational.
* **What it represents:** The combination of a boxy head, circular eyes, and an antenna is a widely understood visual metaphor for a robot, AI, or automated system. The simplicity suggests it could be used as an app icon, a logo element, or in user interface design to denote a bot, AI assistant, or automated process.
* **Design Intent:** The clean, bold lines and lack of detail ensure the icon remains legible at very small sizes (e.g., a favicon or mobile app icon). The rounded corners soften the mechanical feel, making it appear more friendly or approachable.
* **Notable Absence:** The lack of any text or unique identifying marks means this icon is generic. It does not represent a specific brand, product, or dataset. Its meaning is derived entirely from cultural conventions around how robots are depicted.
</details>
). The game involves three roles: messenger, goal, and enemy. The agent’s task is to identify roles of all entities, locate the messenger, deliver it to the goal, and avoid the enemy. To achieve this objective, the agent must use the manual to infer entity roles based on their described dynamics and observed behavior. In the observation in the example, shaded icons indicate one possible scenario of entity locations over time. By observing entity movement patterns and grounding language to entities based on their according behaviors, the agent can infer the roles are assigned: (ferry-enemy), (plane-messenger), and (researcher-goal). After inferring all entity roles, the agent can execute an appropriate plan to complete the task. The dashed line in the observation shows such a possible plan.
Stage 2 (S2) and S2-dev.
As shown in Figure ˜ 4 This figure is the duplication of Figure 1 and is put here for the sake of reading flow., S2 uses the same set of entities as S1 but introduces movement dynamics: entities can now exhibit one of three movement types: moving, fleeing, or stationary. The agent always starts without the message. During training games, only one movement combination is used: one moving (chasing), one fleeing, and one stationary entity, all of which describe how entities are moving compared to the agent. In test games, the agent must handle scenarios where a movement type can appear multiple times, e.g. moving-moving-fleeing. To examine the impact of this single-movement constraint, MESSENGER provides a different stage S2-dev, a variation of S2 that also features unseen dynamics but maintains the same movement constraint observed during training for all test games.
In addition to the capabilities demonstrated in S1, the objective of the agent in S2 is to generalize across new language featuring novel environmental dynamics. Specifically, the agent must understand the movement descriptions to make optimal actions, but does not need to ground movement descriptions to the entities based on their observed behaviors. This is because the agent can ground the sentences to the entities based on their names in the manual and their associated symbols in the observation. For example, given the game in Figure ˜ 1, the agent can ground the sentence "The plane fleeing from you has the classified report" to entity symbol
<details>
<summary>figures/plane.png Details</summary>

### Visual Description
## Icon: Airplane Symbol
### Overview
The image displays a stylized, flat-design icon of a commercial airplane viewed from a top-down perspective. The icon is presented against a plain, light grey background. It contains no textual information, data, charts, or diagrams. It is a purely graphical symbol.
### Components/Axes
* **Primary Subject:** A single airplane icon.
* **Background:** A solid, uniform light grey field (approximate hex: #f0f0f0).
* **Legend/Labels:** None present.
* **Axes/Scale:** Not applicable.
### Detailed Analysis
The icon is constructed with the following visual elements:
* **Outline:** A thick, dark grey (approximate hex: #3a3a3a) border defines the entire shape of the airplane.
* **Fill:** The interior of the airplane is filled with a very light, cool blue (approximate hex: #e6f3ff).
* **Detail:** Two slightly darker blue (approximate hex: #a8c8e8) rectangular stripes are placed on the wings, suggesting engine nacelles or wing markings. One stripe is on the upper-left wing, and the other is on the lower-right wing.
* **Orientation:** The airplane is oriented diagonally, with its nose pointing towards the top-right corner of the image frame and its tail towards the bottom-left.
* **Spatial Grounding:** The icon is centered within the square image frame. The wings extend towards the top-left and bottom-right corners. The fuselage runs diagonally from the bottom-left to the top-right.
### Key Observations
1. **Simplicity:** The design is minimalist, using only three colors (dark grey outline, light blue fill, medium blue detail) and basic geometric shapes to represent the aircraft.
2. **Style:** It follows a common "flat design" or "outline icon" aesthetic, suitable for user interfaces, signage, or informational graphics.
3. **Clarity:** The symbol is immediately recognizable as an airplane due to its distinct silhouette: a central fuselage, two swept-back wings, and a tail assembly.
4. **Lack of Data:** The image contains no quantitative information, trends, labels, or text to extract. It is a symbolic representation, not a data visualization.
### Interpretation
This image serves as a **symbolic identifier**, not a source of factual data. Its meaning is derived from universal visual conventions.
* **Purpose:** The icon is designed to represent concepts related to air travel, aviation, airports, flight, or transportation in a quick, universally understandable manner. It would typically be used in contexts like navigation menus, maps, informational brochures, or signage.
* **Design Choices:** The diagonal orientation conveys a sense of motion or dynamism. The thick outline ensures visibility at small sizes, and the limited color palette aids in clear recognition and potential branding consistency.
* **Underlying Information:** The image itself provides no underlying data trends or investigative findings. Its "information" is purely semiotic: it is a signifier for the concept of an airplane. Any additional meaning (e.g., "departures," "airline logo," "travel section") would be entirely dependent on the context in which this icon is placed.
</details>
based on the entity name the plane -to-symbol
<details>
<summary>figures/plane.png Details</summary>

### Visual Description
## Icon: Airplane Symbol
### Overview
The image displays a stylized, flat-design icon of a commercial airplane viewed from a top-down perspective. The icon is presented against a plain, light grey background. It contains no textual information, data, charts, or diagrams. It is a purely graphical symbol.
### Components/Axes
* **Primary Subject:** A single airplane icon.
* **Background:** A solid, uniform light grey field (approximate hex: #f0f0f0).
* **Legend/Labels:** None present.
* **Axes/Scale:** Not applicable.
### Detailed Analysis
The icon is constructed with the following visual elements:
* **Outline:** A thick, dark grey (approximate hex: #3a3a3a) border defines the entire shape of the airplane.
* **Fill:** The interior of the airplane is filled with a very light, cool blue (approximate hex: #e6f3ff).
* **Detail:** Two slightly darker blue (approximate hex: #a8c8e8) rectangular stripes are placed on the wings, suggesting engine nacelles or wing markings. One stripe is on the upper-left wing, and the other is on the lower-right wing.
* **Orientation:** The airplane is oriented diagonally, with its nose pointing towards the top-right corner of the image frame and its tail towards the bottom-left.
* **Spatial Grounding:** The icon is centered within the square image frame. The wings extend towards the top-left and bottom-right corners. The fuselage runs diagonally from the bottom-left to the top-right.
### Key Observations
1. **Simplicity:** The design is minimalist, using only three colors (dark grey outline, light blue fill, medium blue detail) and basic geometric shapes to represent the aircraft.
2. **Style:** It follows a common "flat design" or "outline icon" aesthetic, suitable for user interfaces, signage, or informational graphics.
3. **Clarity:** The symbol is immediately recognizable as an airplane due to its distinct silhouette: a central fuselage, two swept-back wings, and a tail assembly.
4. **Lack of Data:** The image contains no quantitative information, trends, labels, or text to extract. It is a symbolic representation, not a data visualization.
### Interpretation
This image serves as a **symbolic identifier**, not a source of factual data. Its meaning is derived from universal visual conventions.
* **Purpose:** The icon is designed to represent concepts related to air travel, aviation, airports, flight, or transportation in a quick, universally understandable manner. It would typically be used in contexts like navigation menus, maps, informational brochures, or signage.
* **Design Choices:** The diagonal orientation conveys a sense of motion or dynamism. The thick outline ensures visibility at small sizes, and the limited color palette aids in clear recognition and potential branding consistency.
* **Underlying Information:** The image itself provides no underlying data trends or investigative findings. Its "information" is purely semiotic: it is a signifier for the concept of an airplane. Any additional meaning (e.g., "departures," "airline logo," "travel section") would be entirely dependent on the context in which this icon is placed.
</details>
mapping. The agent must understand the entity’s behavior to move closer to it, and it can achieve this based on the description "The plane fleeing from you", even without directly observing the behavior.
<details>
<summary>figures/stage_three.png Details</summary>
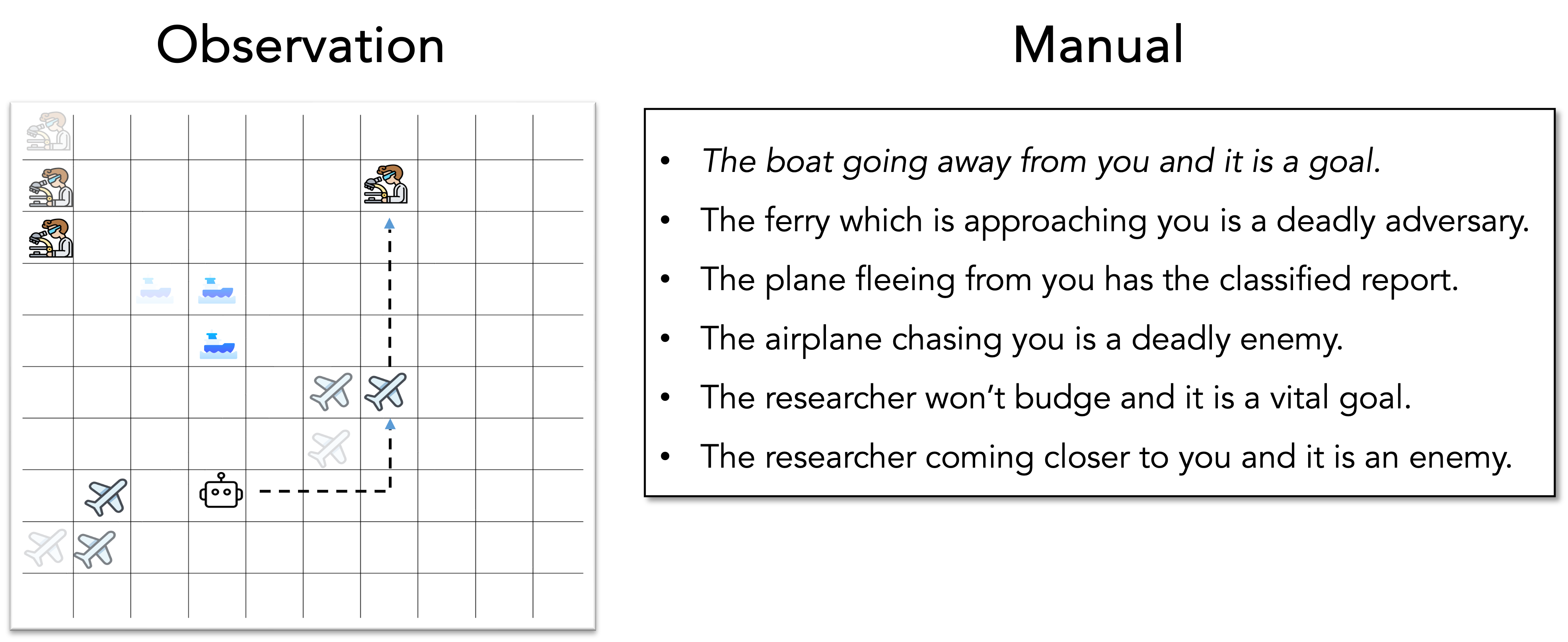
### Visual Description
\n
## Diagram: Observation Grid and Manual Rules
### Overview
The image is a two-part diagram illustrating a scenario-based rule set. On the left is a grid labeled "Observation" containing various icons representing entities (researchers, boats, planes, a robot) and their movement paths. On the right is a text box labeled "Manual" containing a bulleted list of six rules that define the nature and goals of these entities relative to an implied observer or player (referred to as "you").
### Components/Axes
**Left Panel: "Observation"**
* **Structure:** A 10x10 grid (10 columns, 10 rows) with light gray grid lines on a white background.
* **Icons & Positions (Approximate Grid Coordinates, Column-Row, starting from top-left as 1,1):**
* **Researchers (Icon: Person with microscope):**
* (1,1) - Faded/transparent.
* (1,2) - Solid.
* (1,3) - Solid.
* (6,2) - Solid. This researcher is the endpoint of a dashed path.
* **Boats/Ferries (Icon: Ship):**
* (3,4) - Faded/transparent, light blue.
* (4,4) - Solid, blue.
* (4,5) - Solid, blue.
* **Planes (Icon: Airplane):**
* (2,8) - Solid, gray.
* (2,9) - Faded/transparent, gray.
* (3,9) - Solid, gray.
* (5,6) - Faded/transparent, gray.
* (6,6) - Solid, gray.
* (7,6) - Solid, gray.
* **Robot (Icon: Robot head):** Located at (4,8). This is the origin point of a dashed path.
* **Movement Paths (Dashed Lines with Arrows):**
1. A path starts at the Robot (4,8), moves horizontally right to (7,8), then vertically up to the Researcher at (6,2). The path has an arrowhead pointing up at the end.
2. A separate, shorter vertical dashed line with an upward arrow is located between grid cells (6,6) and (6,5), near the planes.
**Right Panel: "Manual"**
* **Structure:** A white text box with a black border containing a bulleted list.
* **Text Content (Transcribed verbatim):**
* The boat going away from you and it is a goal.
* The ferry which is approaching you is a deadly adversary.
* The plane fleeing from you has the classified report.
* The airplane chasing you is a deadly enemy.
* The researcher won't budge and it is a vital goal.
* The researcher coming closer to you and it is an enemy.
### Detailed Analysis
**Icon-State Correlation:**
* **Faded/Transparent Icons:** Likely represent entities in a specific state mentioned in the manual (e.g., "going away," "fleeing," or a starting/inactive state). The faded researcher at (1,1) and planes at (2,9) and (5,6) fit this.
* **Solid Icons:** Likely represent entities in an active or opposing state (e.g., "approaching," "chasing," "coming closer").
* **Color Coding:** Boats are blue, planes are gray, researchers are brown/gray, the robot is black. The manual uses "boat" and "ferry," and "plane" and "airplane" seemingly interchangeably for the same icon types.
**Path Interpretation:**
The primary dashed path shows the Robot (likely the player's avatar or agent) moving to intercept or reach the stationary Researcher at (6,2). This visually corresponds to the manual rule: *"The researcher won't budge and it is a vital goal."* The path's endpoint directly targets that specific researcher icon.
### Key Observations
1. **Rule-Visual Mapping:** Each line in the manual corresponds to a type of entity and its behavioral state (direction relative to "you") which determines its role (goal, adversary, enemy, carrier).
2. **Spatial Storytelling:** The grid depicts a snapshot of a dynamic scenario. The robot's path suggests an active mission towards a goal, while other entities (boats, planes, other researchers) are positioned around the grid, presumably enacting their described rules.
3. **Ambiguity in "You":** The location of "you" (the observer/player) is not explicitly marked on the grid. It is implied to be the perspective from which directions ("going away," "approaching") are judged. The robot's starting point at (4,8) is a candidate for "your" location.
4. **Duplicate Entity Types with Different Roles:** The manual assigns opposite roles to visually identical icons based solely on their movement direction relative to the player (e.g., a fleeing plane has a report, a chasing plane is an enemy).
### Interpretation
This diagram serves as a visual key or legend for a game, simulation, or logic puzzle. It defines a set of **context-dependent rules** where the identity and objective of an entity are not fixed but are determined by its **behavioral vector** (movement towards or away from the player).
The "Observation" grid is not a data chart but a **state diagram** or **scenario map**. It demonstrates how the rules from the "Manual" apply in a concrete spatial arrangement. The core mechanic revealed is **directional intent**: the same type of object (researcher, boat, plane) can be either a target to reach or a threat to avoid based solely on its movement relative to the player's position.
The dashed path is the most critical data point, as it explicitly shows the player's (robot's) intended action—prioritizing the stationary "vital goal" researcher over all other potential interactions shown on the grid. This implies a strategic layer where the player must identify and pursue correct goals while avoiding adversaries, all based on interpreting movement cues.
</details>
Figure 5: An example game of MESSENGER S3. To win the game, the agent must infer the roles of entities given the manual. Specifically, the same entity names (e.g. airplane, plane with different roles (e.g. enemy, messenger) must be disambiguated by their movement dynamics (e.g. chasing, fleeing). Note that we have a italicized sentence describing an extraneous entity that is not available in the game observation. We also have synonyms for entity names and roles, e.g., airplane, plane; adversary, enemy. The shaded entities show possible entity locations over time and the dashed line shows a possible path for the agent to win the game.
Stage 3 (S3).
In addition to the capabilities demonstrated in Stage 1, the objective of the agent in Stage 3 is to generalize over new language featuring new combinations of known entity movement dynamics. Unlike in Stage 2, the agent in S3 must ground the sentences using both entity name-to-symbol mappings and observed entity behavior-to-movement description mappings.
As shown in Figure ˜ 5, this stage includes five entities, three retain the roles of enemy, messenger, and goal. The manual has six sentences featuring these five entities and one extraneous entity, which is not available in the observation. Specifically, its referred sentence has the same name as the enemy entity, but is different in movement and is described as either goal or messenger. Two additional entities are duplicates that share the same entity symbols and names of the messenger and goal accordingly, but they are assigned the role of enemy. To differentiate these entities, their movement dynamics must be used. For example, descriptions like "the fleeing enemy is the dog" versus "the chasing goal is the dog" help the agent identify the correct entities based on their behaviors. In this case, the dog that is consistently going towards the agent can be inferred as the goal.
### C.2 Examples of different level of generalization evaluation in MESSENGER and MESSENGER-WM environment
We illustrate different levels of generalizations, described in Table ˜ 1, by examples in Figure ˜ 6. For each type of generalization, for the sake of simplicity, we consider a hypothetical dataset where a training set consists of only two samples, and one test sample. The best view is in colors.
<details>
<summary>figures/surface.png Details</summary>

### Visual Description
## Textual Comparison Diagram: Training Manuals and Unseen Manual
### Overview
The image displays three rectangular text boxes arranged horizontally against a light gray background. Each box is titled and contains a list of three bullet-pointed sentences. Certain phrases within the sentences are highlighted with a gray background, indicating emphasis or key terms. The content appears to be a structured comparison, likely illustrating examples for a natural language processing (NLP) or machine learning task involving entity relationships and classification.
### Components/Axes
The image is segmented into three distinct, side-by-side components:
1. **Left Box:**
* **Title:** "Training Manual 1"
* **Content:** Three bullet points.
* **Highlight:** The phrase "deadly adversary" in the first bullet point is highlighted.
2. **Center Box:**
* **Title:** "Training Manual 2"
* **Content:** Three bullet points.
* **Highlight:** The phrase "deadly adversary" in the first bullet point is highlighted.
3. **Right Box:**
* **Title:** "Unseen manual"
* **Content:** Three bullet points.
* **Highlight:** The word "enemy" in the second bullet point is highlighted.
### Detailed Analysis / Content Details
**Training Manual 1 (Left Box):**
* Bullet 1: "The ferry is a `deadly adversary`." (Phrase "deadly adversary" is highlighted).
* Bullet 2: "The plane has the classified report"
* Bullet 3: "The researcher is a vital goal."
**Training Manual 2 (Center Box):**
* Bullet 1: "The dog is a `deadly adversary`." (Phrase "deadly adversary" is highlighted).
* Bullet 2: "The wizard has the classified report"
* Bullet 3: "The ferry is a goal."
**Unseen manual (Right Box):**
* Bullet 1: "The ferry is a messenger."
* Bullet 2: "The dog is an `enemy`." (Word "enemy" is highlighted).
* Bullet 3: "The researcher is a vital goal."
### Key Observations
1. **Structural Consistency:** All three manuals follow an identical structure: a title and three declarative sentences in bullet-point format.
2. **Highlighted Terms:** The highlights draw attention to specific relational descriptors: "deadly adversary" (in both training manuals) and "enemy" (in the unseen manual).
3. **Entity Variation:** The subjects of the sentences vary across manuals (ferry, dog, plane, wizard, researcher), while some predicates and objects repeat (e.g., "has the classified report", "is a vital goal").
4. **Semantic Relationship:** The highlighted terms in the training manuals ("deadly adversary") and the unseen manual ("enemy") are semantically similar, suggesting a classification or analogy task. The unseen manual presents a novel combination ("dog is an enemy") not explicitly seen in training, where "dog" was previously linked to "deadly adversary."
### Interpretation
This diagram likely serves as a pedagogical or illustrative example for a machine learning or cognitive science concept. It demonstrates a setup for training a model on specific entity-relationship patterns (e.g., "X is a deadly adversary," "Y has the classified report") and then testing its ability to generalize to new, unseen combinations that require understanding semantic similarity.
* **Training Phase:** Manuals 1 and 2 provide labeled examples. The highlighted "deadly adversary" establishes a strong association for that specific phrase. The model learns that entities like "ferry" and "dog" can fill the subject role for this relationship.
* **Testing/Generalization Phase:** The "Unseen manual" acts as a test set. It presents a new subject ("dog") with a semantically related but lexically different predicate ("enemy" instead of "deadly adversary"). A successful model should infer that "The dog is an enemy" is a valid or plausible statement based on its training, recognizing the synonymy between "deadly adversary" and "enemy."
* **Purpose:** The image visually encapsulates the challenge of moving from rote memorization of training examples to achieving a deeper, generalized understanding of concepts and their relationships, which is a core goal in artificial intelligence and natural language understanding. The consistent structure and deliberate highlighting make the comparison and the intended learning task clear.
</details>
(a) Novel language through synonyms and paraphrase
<details>
<summary>figures/novelcombo.png Details</summary>

### Visual Description
## Textual Comparison Diagram: Training Manuals and Unseen Manual
### Overview
The image displays a side-by-side comparison of three text panels, each containing a list of declarative statements. The panels are titled "Training Manual 1," "Training Manual 2," and "Unseen manual." Certain phrases within the statements are highlighted with colored backgrounds (gray, green, cyan), indicating they are key entities or subjects of interest. The layout suggests a demonstration of how information or relationships are presented in training data versus an unseen test case, likely in the context of machine learning, logic, or semantic analysis.
### Components/Axes
The image is structured into three distinct rectangular panels arranged horizontally against a light gray background.
1. **Panel 1 (Left):**
* **Title:** "Training Manual 1" (centered at the top).
* **Content:** A bulleted list of three statements.
* **Highlighting:** The phrase "The ferry" in the first statement has a gray background. The phrase "The researcher" in the third statement has a cyan background.
2. **Panel 2 (Center):**
* **Title:** "Training Manual 2" (centered at the top).
* **Content:** A bulleted list of three statements.
* **Highlighting:** The phrase "The dog" in the first statement has a green background.
3. **Panel 3 (Right):**
* **Title:** "Unseen manual" (centered at the top).
* **Content:** A bulleted list of three statements.
* **Highlighting:** The phrase "The ferry" in the first statement has a gray background. The phrase "The dog" in the second statement has a green background. The phrase "The researcher" in the third statement has a cyan background.
### Detailed Analysis / Content Details
**Training Manual 1 (Left Panel):**
* Statement 1: "The ferry is a deadly adversary." (Entity: "The ferry" - highlighted in gray)
* Statement 2: "The plane has the classified report"
* Statement 3: "The researcher is a vital goal." (Entity: "The researcher" - highlighted in cyan)
**Training Manual 2 (Center Panel):**
* Statement 1: "The dog is a deadly adversary." (Entity: "The dog" - highlighted in green)
* Statement 2: "The wizard has the classified report"
* Statement 3: "The ferry is a goal."
**Unseen manual (Right Panel):**
* Statement 1: "The ferry is a messenger." (Entity: "The ferry" - highlighted in gray)
* Statement 2: "The dog is an enemy." (Entity: "The dog" - highlighted in green)
* Statement 3: "The researcher is a vital goal." (Entity: "The researcher" - highlighted in cyan)
### Key Observations
1. **Entity Consistency:** Three specific entities are consistently highlighted across the panels: "The ferry" (gray), "The dog" (green), and "The researcher" (cyan).
2. **Role Variation:** The roles or attributes assigned to these entities change between manuals.
| Entity | Training Manual 1 | Training Manual 2 | Unseen Manual |
| :--- | :--- | :--- | :--- |
| **The ferry** | deadly adversary | goal | messenger |
| **The dog** | - | deadly adversary | enemy |
| **The researcher** | vital goal | - | vital goal |
3. **Content Mixing:** The "Unseen manual" appears to combine elements from the two training manuals. It uses the entity-highlighting scheme from both (gray, green, cyan) and presents new relationships for those entities ("messenger," "enemy") while retaining one relationship from Training Manual 1 ("vital goal").
4. **Non-Highlighted Elements:** The statements about "The plane" and "The wizard" having "the classified report" are not highlighted and do not appear in the Unseen manual, suggesting they may be distractor items or part of a different pattern.
### Interpretation
This diagram likely illustrates a concept in machine learning, cognitive science, or formal logic, such as **few-shot learning, analogical reasoning, or the testing of a model's ability to generalize from training examples.**
* **What it demonstrates:** The setup shows how a system (e.g., an AI model) is provided with two small "training manuals" that define relationships for specific entities. The "Unseen manual" then tests whether the system can correctly apply or recognize similar patterns for those same entities in a novel context.
* **Relationships between elements:** The colored highlights serve as a visual key, linking the same entity across different contexts. The core task implied is to understand that the entity (e.g., "The ferry") is the constant subject, while its predicate (its role or attribute) is variable and context-dependent.
* **Notable patterns/anomalies:** The most significant pattern is the transfer of the "vital goal" relationship for "The researcher" directly from Training Manual 1 to the Unseen manual without change. This could be a control or a simple copy task. The more complex task involves inferring that "The dog" being a "deadly adversary" (Manual 2) is semantically similar to being an "enemy" (Unseen manual), and that "The ferry" can have multiple, context-specific roles. The absence of the "plane" and "wizard" from the Unseen manual suggests the test focuses only on the pre-highlighted entities.
In essence, the image captures a structured test of **generalization and relational understanding**, where the goal is to see if knowledge about entities from limited training examples can be flexibly applied to new statements.
</details>
(b) Novel combinations of known entities. In test games, entities never appear in the same game during training.
<details>
<summary>figures/novel_entity_role.png Details</summary>

### Visual Description
## Textual Diagram: Training Manual Comparison
### Overview
The image displays a side-by-side comparison of three text boxes, each labeled as a different "manual." The layout consists of three distinct columns, each containing a title and a rectangular box with bulleted text. Some sentences within the boxes are highlighted with a yellow background. The overall presentation suggests an example or illustration, likely from a technical or educational context related to machine learning, natural language processing, or knowledge representation, showing how information is presented in training data versus unseen test data.
### Components/Axes
* **Structure:** Three vertical columns.
* **Column Titles (Top, Centered above each box):**
* Left Column: "Training Manual 1"
* Middle Column: "Training Manual 2"
* Right Column: "Unseen manual"
* **Content Boxes:** Each title is followed by a white rectangular box with a thin black border containing a list of bullet points.
* **Highlighting:** Specific sentences within the boxes are highlighted with a solid yellow background.
* **Text Language:** All text is in English.
### Detailed Analysis
**Training Manual 1 (Left Column):**
* Bullet 1 (Highlighted): "The ferry is a deadly adversary."
* Bullet 2: "The plane has the classified report"
* Bullet 3: "The researcher is a vital goal."
**Training Manual 2 (Middle Column):**
* Bullet 1: "The dog is a deadly adversary."
* Bullet 2: "The wizard has the classified report"
* Bullet 3 (Highlighted): "The ferry is a goal."
**Unseen manual (Right Column):**
* Bullet 1 (Highlighted): "The ferry is a messenger"
* Bullet 2: "The dog is an enemy."
* Bullet 3: "The researcher is a vital goal."
### Key Observations
1. **Entity Consistency and Variation:** The same entities ("ferry," "dog," "researcher") appear across different manuals but are assigned different roles or attributes.
* The "ferry" is described as a "deadly adversary" (Manual 1), a "goal" (Manual 2), and a "messenger" (Unseen manual).
* The "dog" is a "deadly adversary" (Manual 2) and an "enemy" (Unseen manual).
* The "researcher" is consistently called a "vital goal" in both Manual 1 and the Unseen manual.
2. **Highlighting Pattern:** The highlighting does not follow a consistent rule across manuals (e.g., it's not always the first bullet). It appears to draw attention to specific statements about the entity "ferry" in each manual where it appears.
3. **Structural Parallelism:** The manuals share a similar syntactic structure for their statements (e.g., "The [entity] is a [role].", "The [entity] has the [object].").
### Interpretation
This diagram is a pedagogical or illustrative tool, not a data chart. It visually demonstrates a core concept in machine learning and AI: the difference between **training data** and **unseen (test) data**.
* **What it suggests:** The "Training Manuals" (1 & 2) represent the data a model learns from. They provide examples linking entities (ferry, dog, plane, wizard, researcher) to roles or attributes (adversary, goal, owner). The "Unseen manual" represents new, novel data the model must process after training.
* **How elements relate:** The comparison highlights the challenge of **generalization**. A model trained only on Manual 1 might learn that "ferry" is strongly associated with "deadly adversary." However, the Unseen manual presents "ferry" in a completely new role ("messenger"). The model's ability to correctly interpret this new context, without having seen it during training, is a test of its understanding beyond rote memorization.
* **Notable patterns/anomalies:** The consistent description of "researcher" across training and unseen data suggests some concepts may generalize easily. In contrast, the wildly varying descriptions of "ferry" illustrate the problem of **polysemy** (a word having multiple meanings) or **context-dependent meaning**, which is a significant hurdle for AI systems. The diagram effectively sets up a scenario to test if a system can discern meaning from context rather than relying on fixed, pre-learned associations.
</details>
(c) Novel entity-role combinations. In test games, at least one entity-role combination is unseen during training.
<details>
<summary>figures/novel_entity_role_move.png Details</summary>

### Visual Description
## Diagram: Training Manual Comparison
### Overview
The image displays a side-by-side comparison of three text boxes, each labeled as a manual. The content consists of bullet-pointed rules or statements about entities (planes, scientists, ships) and their attributes (movement, role). Certain phrases within the text are highlighted in cyan, green, or yellow, suggesting a categorical or key-term coding system. The layout is horizontal, with the three boxes evenly spaced against a light gray background.
### Components/Axes
* **Main Structure:** Three rectangular boxes with black borders, arranged horizontally.
* **Titles (Top, Centered above each box):**
* Left Box: "Training Manual 1"
* Center Box: "Training Manual 2"
* Right Box: "Unseen manual"
* **Content Format:** Each box contains a bulleted list (using black dots "•") of three statements.
* **Highlighting System:** Text within the statements is highlighted with solid background colors. The colors appear to be consistent across manuals and likely represent specific categories or tags.
* **Cyan:** Applied to the subject noun phrase (e.g., "The plane").
* **Green:** Applied to a phrase describing movement or state (e.g., "going away from you").
* **Yellow:** Applied to a phrase describing a role or classification (e.g., "an enemy").
### Detailed Analysis / Content Details
**Training Manual 1 (Left Box)**
* **Bullet 1:** `•` **[Cyan Highlight]** The plane **[Green Highlight]** going away from you **[No Highlight]** has a message
* **Bullet 2:** `•` The scientist doesn't move is final goal you go to
* **Bullet 3:** `•` The ship chasing you is **[Yellow Highlight]** an enemy
**Training Manual 2 (Center Box)**
* **Bullet 1:** `•` **[Cyan Highlight]** The plane **[No Highlight]** that doesn't move is the final goal
* **Bullet 2:** `•` The scientist moving to you is a messenger
* **Bullet 3:** `•` The ship chasing you is **[Yellow Highlight]** an enemy
**Unseen manual (Right Box)**
* **Bullet 1:** `•` **[Cyan Highlight]** The plane **[Green Highlight]** going away from you **[Yellow Highlight]** is an enemy
* **Bullet 2:** `•` The scientist going away from you is final goal you go to
* **Bullet 3:** `•` The ship chasing you is a messenger
### Key Observations
1. **Consistent Structure:** All manuals follow the same format: three bullet points discussing a plane, a scientist, and a ship.
2. **Highlighting Logic:** The color coding is applied systematically.
* **Cyan** consistently marks "The plane" in the first bullet of each manual.
* **Green** marks movement phrases: "going away from you" (Manual 1, Unseen) and is absent in Manual 2's first bullet.
* **Yellow** marks role descriptors: "an enemy" (Manual 1 & 2, third bullet; Unseen, first bullet).
3. **Rule Variation:** The core rules change between manuals, particularly the role assigned to an entity based on its movement.
* **Plane:** In Manual 1, a moving plane "has a message." In Manual 2, a stationary plane is the "final goal." In the Unseen manual, a moving plane is "an enemy."
* **Scientist:** Roles vary from "final goal" (Manual 1, Unseen) to "messenger" (Manual 2).
* **Ship:** The role of a ship "chasing you" changes from "an enemy" (Manual 1 & 2) to "a messenger" (Unseen manual).
4. **Unseen Manual Synthesis:** The "Unseen manual" appears to combine or test rules from the previous two. Its first bullet merges the cyan subject ("The plane") and green movement ("going away from you") from Manual 1 with the yellow role ("an enemy") from the third bullet of Manuals 1 & 2.
### Interpretation
This diagram likely illustrates a concept in machine learning, logic, or game theory, such as **rule generalization, few-shot learning, or inductive reasoning**.
* **What it demonstrates:** The "Training Manuals" provide examples of rules mapping entity attributes (type + movement) to outcomes (role/goal). The "Unseen manual" presents a novel combination of attributes not explicitly seen together in training (a plane that is "going away from you" being "an enemy"). The task implied is to infer the correct rule for this new case based on the patterns learned from the training examples.
* **Relationship between elements:** The highlighting visually deconstructs the statements into components (Subject, Action, Role). This suggests the underlying system is meant to parse language into these categorical features to make decisions. The change in rules between manuals indicates the training data is not consistent, forcing the learner to find a more abstract or flexible pattern.
* **Notable patterns/anomalies:** The key anomaly is the **contradiction** introduced in the Unseen manual. In Training Manual 1, a plane "going away from you" is associated with having a "message" (potentially benign). In the Unseen manual, the same entity is labeled "an enemy" (hostile). This contradiction is the core of the test: can the system reconcile this new information with its prior training, or does it highlight a flaw or change in the rule set? The diagram effectively visualizes the challenge of applying learned rules to novel, and potentially conflicting, scenarios.
</details>
(d) Novel entity - role - movement combinations. In test games, at least one entity-role-movement combination is unseen during training.
<details>
<summary>figures/novel_dynamic.png Details</summary>

### Visual Description
\n
## Textual Comparison Diagram: Training Manuals and Unseen Manual
### Overview
The image displays a side-by-side comparison of three text blocks, each titled as a manual. The content consists of bullet-pointed rules or statements, with specific phrases highlighted in color. The layout is horizontal, with three distinct columns on a light gray background.
### Components/Axes
- **Titles**: Three column headers: "Training Manual 1" (left), "Training Manual 2" (center), "Unseen manual" (right).
- **Content Structure**: Each column contains a list of bullet points.
- **Highlighting**: Specific phrases within the bullet points are highlighted with background colors. The colors used are yellow, green, cyan, and gray.
### Detailed Analysis / Content Details
#### **Training Manual 1 (Left Column)**
* **Bullet 1**: "The plane **going away from you** has a message"
* Highlighted phrase: "going away from you" (Yellow background)
* **Bullet 2**: "The wizard **doesn't move** is final goal you go to"
* Highlighted phrase: "doesn't move" (Green background)
* **Bullet 3**: "The ship **chasing you** is an enemy"
* Highlighted phrase: "chasing you" (Cyan background)
#### **Training Manual 2 (Center Column)**
* **Bullet 1**: "The ship **going away from you** is an enemy"
* Highlighted phrase: "going away from you" (Yellow background)
* **Bullet 2**: "The plane that **doesn't move** is the final goal"
* Highlighted phrase: "doesn't move" (Green background)
* **Bullet 3**: "The scientist **moving to you** is a messenger"
* Highlighted phrase: "moving to you" (Cyan background)
#### **Unseen manual (Right Column)**
* **Bullet 1**: "The plane **going away from you** is an enemy"
* Highlighted phrase: "going away from you" (Yellow background)
* **Bullet 2**: "The wizard **going away from you** is final goal you go to"
* Highlighted phrase: "going away from you" (Yellow background). *Note: A vertical gray bar appears immediately before the highlighted phrase.*
* **Bullet 3**: "The ship **chasing you** is a messenger"
* Highlighted phrase: "chasing you" (Cyan background)
### Key Observations
1. **Consistent Highlighting for Phrases**: The same phrases are highlighted with the same colors across different manuals, suggesting they represent key categorical attributes or conditions.
* **Yellow**: "going away from you"
* **Green**: "doesn't move"
* **Cyan**: "chasing you" / "moving to you" (a related but distinct phrase in Manual 2)
2. **Conflicting Rules**: The manuals assign different meanings (e.g., "enemy," "messenger," "final goal") to objects (plane, ship, wizard, scientist) based on the same or similar highlighted attributes.
* Example: A "plane going away from you" is a messenger in Manual 1 but an enemy in the Unseen manual.
3. **Novel Combination in Unseen Manual**: The "Unseen manual" appears to synthesize or test rules. Its second bullet point combines the subject from Manual 1 ("wizard") with the attribute from Manual 1/2 ("going away from you") to create a new rule not explicitly stated in the training manuals.
4. **Spatial Layout**: The three columns are presented with equal width and spacing, facilitating direct horizontal comparison of corresponding bullet points.
### Interpretation
This image likely illustrates a concept in machine learning, logic, or rule-based systems, such as **few-shot learning**, **rule generalization**, or **concept acquisition**.
* **What the data suggests**: The "Training Manuals" provide examples of rules mapping object-attribute pairs to classifications (e.g., enemy, messenger, goal). The "Unseen manual" represents a test case to see if a system can generalize from the training examples to correctly classify novel combinations.
* **How elements relate**: The highlighted attributes are the critical features. The manuals show how the same feature (e.g., "going away from you") can lead to different classifications depending on the object (plane vs. ship) and the context of the training set. The Unseen manual tests whether the learned association is robust or brittle.
* **Notable patterns/anomalies**: The key anomaly is the second rule in the Unseen manual. It creates a novel, potentially contradictory rule ("wizard going away from you is final goal") by combining elements from the training data. This tests whether a learner has understood the underlying logic or has merely memorized specific examples. The gray bar before this phrase may indicate a point of special attention or a generated output.
**In essence, the diagram visualizes the challenge of moving from memorized training examples to generalized understanding, where the same attribute can imply different outcomes based on context and object type.**
</details>
(e) Novel combinations of known entity movements or novel game dynamics. In training games, there is only one movement combination chasing - fleeing - stationary. In test games, there are more than one movement combination.
Figure 6: Examples of different levels of generalization evaluation in MESSENGER and MESSENGER-WM environments.
### C.3 MESSENGER-WM details
#### C.3.1 Differences between MESSENGER and MESSENGER-WM
Similar to MESSENGER S2, in MESSENGER-WM, there are three entities with three roles: messenger, enemy, and goal. However, unlike S2 where training games only have one movement combination chasing-fleeing-stationary, training games in MESSENGER-WM can have more than one entity having the same movement pattern, e.g. chasing-chasing-stationary. This makes generalization in S2 is more challenging than MESSENGER-WM because the agent must overcome this data bias to generalize over unseen combinations of movement patterns.
#### C.3.2 Evaluation settings
To help ground our descriptions of these settings, consider the following manual for a hypothetical test game:
The hound is a deadly opponent. It is towards you. The whale comes towards you as the secret document. It also has the crucial goal, the queen, and is something that cannot be moved.
This manual describes the entity combination: hound, whale, queen, with the following feature assignments: (hound-chasing-enemy), (whale-chasing-messenger), (queen-stationary-goal). Descriptions of each setting are as follows, based on whether the test game falls into each:
1. NewCombo: Each game represents an unseen combination of entities. However, any entity-role-movement combination in this set also presents in the training games. In this example, the agent never sees entity combination (hound, whale, queen) in the same game during training, although it can see each entity individually across different games.
1. NewAttr: Each game features seen combinations of entities, but at least one attribute (role, movement type, or both) for each entity is novel. In is example, the agent has seen entity combination (hound, whale, queen) during training but each entity-role-movement assignment is new: i.e. the assignment (hound-chasing-enemy) is unseen but (hound-chasing-goal) or (hound-fleeing-messenger) are seen during training.
1. NewAll: This setting combines the challenges of the first two. The combination of entities is novel, and each entity is assigned at least one new attribute. In this example, entity combinations hound, whale, queen and all entity-role-movement (i.e. (hound-chasing-enemy), (whale-chasing-messenger), (queen-stationary-goal)) are unseen.
## Appendix D LED-WM details
Our world model LED-WM is built on the Recurrent State Space Model (RSSM) in [13]. However, we make the following modifications. First, we find that reconstruction decoder in DreamerV3 negatively impacts policy generalization. Therefore, we omit the decoder from DreamerV3 architecture. Second, to improve sample efficiency, we adopt multi-step prediction for reward and continue prediction [15] [27]. Specifically, we rollout the latent states in the future for $H$ steps to supervise reward and continue prediction. We replace the encoder of DreamerV3 with our LED encoder, and keep the rest of the architecture unchanged, resulting in the following components:
$$
\displaystyle\raisebox{22.0pt}{
$\text{RSSM}~~\begin{cases}\hphantom{A}\\[-5.0pt]
\hphantom{A}\\[-5.0pt]
\hphantom{A}\end{cases}$}\begin{aligned} &\text{Sequence model:}&\quad h_{t}&=f_{\phi}(h_{t-1},z_{t-1},a_{t-1})\\
&\text{{LED} (\lx@cref{creftype~refnum}{sec:led}):}&\quad z_{t}&\sim q_{\phi}(z_{t}\mid h_{t},x_{t})\\
&\text{Dynamics predictor:}&\quad\hat{z}_{t}&\sim p_{\phi}(\hat{z}_{t}\mid h_{t})\\
&\text{Reward predictor:}&\quad\hat{r}_{t}&\sim p_{\phi}(\hat{r}_{t}\mid h_{t},z_{t})\\
&\text{Continue predictor:}&\quad\hat{c}_{t}&\sim p_{\phi}(\hat{c}_{t}\mid h_{t},z_{t})\\
\\
\end{aligned} \tag{8}
$$
World model loss.
Given a sequence of observations $o_{1:T}$ , actions $a_{1:T}$ , rewards $r_{1:T}$ and continuation flags $c_{1:T}$ where $T$ is the horizon of a training episode, we optimize the world model parameters $\phi$ to minimize the following loss:
$$
\displaystyle\mathcal{L}(\phi)\doteq\mathbb{E}_{q_{\phi}}\left[\sum_{t=1}^{T}\left(\beta_{\text{pred}}\mathcal{L}_{\text{pred}}(\phi)+\beta_{\text{dyn}}\mathcal{L}_{\text{dyn}}(\phi)+\beta_{\text{rep}}\mathcal{L}_{\text{rep}}(\phi)\right)\right], \tag{9}
$$
where $\mathcal{L}_{pred}$ , $\mathcal{L}_{dyn}$ , and $\mathcal{L}_{rep}$ are prediction loss, dynamics loss, and representation loss, along with their corresponding weights $\beta_{pred}$ , $\beta_{dyn}$ and $\beta_{rep}$ :
1. Prediction loss ( $\mathcal{L}_{pred}$ ): trains the reward predictor via symlog loss and the continue predictor via binary classification loss. To address the issue of slower training caused by removing the decoder and observational reconstruction loss, we adopt multi-step prediction for reward and continue [15] [27], to improve sample efficiency. We rollout the latent states in the future for $H$ steps to supervise reward and continue prediction. Specifically, given a state-action trajectory over $H+1$ step $(x_{t},a_{t},x_{t+1},\ldots,x_{t+H})$ associated with a sequence of rewards $r_{t:t+H}$ and continue flags $c_{t:t+H}$ , we first compute $z_{t}$ as the posterior state from $x_{t}$ . We then rollout this $z_{t}$ over $H$ steps to get prior states $\hat{z}_{t+1...t+H-1}$ and deterministic states $h_{t+1...t+H}$ to predict rewards $r_{t+1:t+H}$ and continue flags $c_{t:t+H}$ :
$$
\displaystyle\mathcal{L}_{pred} \displaystyle=\underbrace{-\ln p_{\theta}(r_{t}|z_{t},h_{t})}_{\text{reward loss}}\underbrace{-\ln p_{\theta}(c_{t}|z_{t},h_{t})}_{\text{continue loss}} \displaystyle\quad\underbrace{-\sum_{k=t+1}^{H}\lambda^{k-t-1}\left[\ln p_{\theta}(r_{k}\mid\hat{z}_{k},h_{k})+\ln p_{\theta}(c_{k}\mid\hat{z}_{k},h_{k})\right],}_{\text{multi-step reward and continue loss}} \tag{10}
$$
where $\lambda=0.9$ is a discount factor when the environment is stochastic and $\lambda=1$ when the environment is deterministic. Recall that $\hat{z}_{k}$ denotes the prior stochastic state generated by the world model, without access to observation at time step $k$ .
1. Dynamics and representation loss: We adopt the dynamics and representation loss unchanged from Dreamerv3.
## Appendix E Training procedure
During world model training, we observe two challenges. First, at the beginning of training, successful episodes in which the agent wins the game and receives positive rewards are rare. As a result, the world model takes longer to learn from these rare instances, leading to reduced sample-efficiency in policy training. Second, as the policy converges and produces mostly successful episodes, the replay buffer becomes dominated by these episodes. This causes the world model to rarely encounter failed episodes where the agent loses the game and receives negative rewards, potentially harming its generalization performance. We therefore adapt the following strategies to improve sample efficiency:
Prioritized Replay Buffer.
We adopt the Prioritized Replay Buffer from [Kauvar2023-pk], where the authors propose the following prioritization strategies:
- Count-based replay: Biases sampling towards recent experiences in the replay buffer.
- Adversarial replay: Prioritizes experiences where the world model makes incorrect predictions.
Balanced weights.
We adopt a balanced weighting technique for handling class imbalance, inspired by methods used in classification tasks [He2009-bj], and apply it to world model training. This weighting ensures that underrepresented classes contribute proportionally more to the training loss, improving sample-efficiency of the policy.
In our setting, for a given episode $e$ with $T$ is the episode horizon and the state-action trajectory: $\tau_{e}=(o_{1},a_{1},\ldots,o_{T},a_{T})$ , we define the "class" $c_{e}$ as the accumulated sum of rewards for the episode:
$$
c_{e}=\sum_{t=1}^{T}r_{t}(o_{t},a_{t}), \tag{12}
$$
representing different gameplay scenarios. For example, in the MESSENGER environment, episodes fall into three classes: 1.5, -0.5, and -1.
To address the imbalance between training instances of negative classes and positive class in the replay buffer, we scale the world model loss $\mathcal{L}_{\text{pred}}$ in each class proportional to the inverse square root of its frequency in the replay buffer. The scaled loss is computed as:
$$
\mathcal{L}_{\text{pred}}=\mathcal{L}_{\text{pred}}\times\sqrt{\frac{|RB|}{\text{count}(c)}}, \tag{13}
$$
where $|RB|$ is the total number of episodes in the replay buffer $RB$ , and $\text{count}(c)$ is the number of instances of class $c$ in the replay buffer.
Increase throughput for replay buffer.
In the original Dreamerv3 implementation, one trajectory with $L$ time steps of observations in the replay buffer is duplicated $L$ times, making the training data throughput inefficient. We therefore remove this duplication to speed up the training throughput in the replay buffer, resulting in more sample-efficient.
## Appendix F Finetune a trained policy using a trained world model
Input: The trained LED-WM, the trained policy $\pi$ , a test game $G$ with the first observation $obs_{o}$ and a language manual $L$ .
Output: A finetuned policy $\hat{\pi}$ if needed
0.8em
Function EstimateReturn ( $\pi$ , LED-WM, $obs_{o}$ , $L$ ):
returns = []
for _ in range(60):
// Generate synthetic test trajectories
traj = LED-WM.GenerateTrajectory( $obs_{o}$ , $L$ )
returns.append(sum_rewards(traj))
$\hat{V}_{\pi}$ = mean(returns)
return $\hat{V}_{\pi}$
Function FineTune ( $\pi$ , LED-WM, $obs_{o}$ , $L$ ):
for gradient_step in range(2000):
trajectories = []
for _ in range(60):
trajectories.append(LED-WM.GenerateTrajectory( $obs_{o}$ , $L$ ))
$\pi$ .train(trajectories)
return $\pi$
0.8em
// Main function: Finetune the policy $\pi$ using LED-WM
Function PolicyFinetune(LED-WM, $\pi$ , $obs_{0}$ , L):
$\hat{V}_{\pi}$ = EstimateReturn(LED-WM, $\pi$ , $obs_{0}$ , $L$ )
if $\hat{V}_{\pi}>=thres$ :
$\hat{\pi}=\pi$
else:
$\hat{\pi}$ = FineTune( $\pi$ , LED-WM, $G$ , $obs_{0}$ , $L$ )
return $\hat{\pi}$
Algorithm 1 Policy Finetune with LED-WM
## NeurIPS Paper Checklist
1. Claims
1. Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope?
1. Answer: [Yes]
1. Justification: Our claim about policy generalization and world model generalization in Section ˜ 1 are reflected in our experiment results in Section ˜ 5.
1. Guidelines:
- The answer NA means that the abstract and introduction do not include the claims made in the paper.
- The abstract and/or introduction should clearly state the claims made, including the contributions made in the paper and important assumptions and limitations. A No or NA answer to this question will not be perceived well by the reviewers.
- The claims made should match theoretical and experimental results, and reflect how much the results can be expected to generalize to other settings.
- It is fine to include aspirational goals as motivation as long as it is clear that these goals are not attained by the paper.
1. Limitations
1. Question: Does the paper discuss the limitations of the work performed by the authors?
1. Answer: [Yes]
1. Justification: We discuss our limitations in policy generalization where CRL [26] outperforms LED-WM in S2 in Section ˜ 5.
1. Guidelines:
- The answer NA means that the paper has no limitation while the answer No means that the paper has limitations, but those are not discussed in the paper.
- The authors are encouraged to create a separate "Limitations" section in their paper.
- The paper should point out any strong assumptions and how robust the results are to violations of these assumptions (e.g., independence assumptions, noiseless settings, model well-specification, asymptotic approximations only holding locally). The authors should reflect on how these assumptions might be violated in practice and what the implications would be.
- The authors should reflect on the scope of the claims made, e.g., if the approach was only tested on a few datasets or with a few runs. In general, empirical results often depend on implicit assumptions, which should be articulated.
- The authors should reflect on the factors that influence the performance of the approach. For example, a facial recognition algorithm may perform poorly when image resolution is low or images are taken in low lighting. Or a speech-to-text system might not be used reliably to provide closed captions for online lectures because it fails to handle technical jargon.
- The authors should discuss the computational efficiency of the proposed algorithms and how they scale with dataset size.
- If applicable, the authors should discuss possible limitations of their approach to address problems of privacy and fairness.
- While the authors might fear that complete honesty about limitations might be used by reviewers as grounds for rejection, a worse outcome might be that reviewers discover limitations that aren’t acknowledged in the paper. The authors should use their best judgment and recognize that individual actions in favor of transparency play an important role in developing norms that preserve the integrity of the community. Reviewers will be specifically instructed to not penalize honesty concerning limitations.
1. Theory assumptions and proofs
1. Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof?
1. Answer: [Yes]
1. Justification: In Section ˜ 1, we stated that our assumption is that our observation is symbolic and confied to a discrete grid-world.
1. Guidelines:
- The answer NA means that the paper does not include theoretical results.
- All the theorems, formulas, and proofs in the paper should be numbered and cross-referenced.
- All assumptions should be clearly stated or referenced in the statement of any theorems.
- The proofs can either appear in the main paper or the supplemental material, but if they appear in the supplemental material, the authors are encouraged to provide a short proof sketch to provide intuition.
- Inversely, any informal proof provided in the core of the paper should be complemented by formal proofs provided in appendix or supplemental material.
- Theorems and Lemmas that the proof relies upon should be properly referenced.
1. Experimental result reproducibility
1. Question: Does the paper fully disclose all the information needed to reproduce the main experimental results of the paper to the extent that it affects the main claims and/or conclusions of the paper (regardless of whether the code and data are provided or not)?
1. Answer: [Yes]
1. Justification: The paper provides the code and hyperparameters for training the world model and the policy in Section ˜ 5 and Appendix ˜ A.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- If the paper includes experiments, a No answer to this question will not be perceived well by the reviewers: Making the paper reproducible is important, regardless of whether the code and data are provided or not.
- If the contribution is a dataset and/or model, the authors should describe the steps taken to make their results reproducible or verifiable.
- Depending on the contribution, reproducibility can be accomplished in various ways. For example, if the contribution is a novel architecture, describing the architecture fully might suffice, or if the contribution is a specific model and empirical evaluation, it may be necessary to either make it possible for others to replicate the model with the same dataset, or provide access to the model. In general. releasing code and data is often one good way to accomplish this, but reproducibility can also be provided via detailed instructions for how to replicate the results, access to a hosted model (e.g., in the case of a large language model), releasing of a model checkpoint, or other means that are appropriate to the research performed.
- While NeurIPS does not require releasing code, the conference does require all submissions to provide some reasonable avenue for reproducibility, which may depend on the nature of the contribution. For example
1. If the contribution is primarily a new algorithm, the paper should make it clear how to reproduce that algorithm.
1. If the contribution is primarily a new model architecture, the paper should describe the architecture clearly and fully.
1. If the contribution is a new model (e.g., a large language model), then there should either be a way to access this model for reproducing the results or a way to reproduce the model (e.g., with an open-source dataset or instructions for how to construct the dataset).
1. We recognize that reproducibility may be tricky in some cases, in which case authors are welcome to describe the particular way they provide for reproducibility. In the case of closed-source models, it may be that access to the model is limited in some way (e.g., to registered users), but it should be possible for other researchers to have some path to reproducing or verifying the results.
1. Open access to data and code
1. Question: Does the paper provide open access to the data and code, with sufficient instructions to faithfully reproduce the main experimental results, as described in supplemental material?
1. Answer: [Yes]
1. Justification: We provide the code and hyperparameters for training the world model and the policy in Section ˜ 5 and Appendix ˜ A.
1. Guidelines:
- The answer NA means that paper does not include experiments requiring code.
- Please see the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
- While we encourage the release of code and data, we understand that this might not be possible, so “No” is an acceptable answer. Papers cannot be rejected simply for not including code, unless this is central to the contribution (e.g., for a new open-source benchmark).
- The instructions should contain the exact command and environment needed to run to reproduce the results. See the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
- The authors should provide instructions on data access and preparation, including how to access the raw data, preprocessed data, intermediate data, and generated data, etc.
- The authors should provide scripts to reproduce all experimental results for the new proposed method and baselines. If only a subset of experiments are reproducible, they should state which ones are omitted from the script and why.
- At submission time, to preserve anonymity, the authors should release anonymized versions (if applicable).
- Providing as much information as possible in supplemental material (appended to the paper) is recommended, but including URLs to data and code is permitted.
1. Experimental setting/details
1. Question: Does the paper specify all the training and test details (e.g., data splits, hyperparameters, how they were chosen, type of optimizer, etc.) necessary to understand the results?
1. Answer: [Yes]
1. Justification: We adopt MESSENGER and MESSENGER-WM environments which follow their standard train/dev/test split. We provide our code and necessary hyperparameters in Appendix ˜ A.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- The experimental setting should be presented in the core of the paper to a level of detail that is necessary to appreciate the results and make sense of them.
- The full details can be provided either with the code, in appendix, or as supplemental material.
1. Experiment statistical significance
1. Question: Does the paper report error bars suitably and correctly defined or other appropriate information about the statistical significance of the experiments?
1. Answer: [Yes]
1. Justification: We use Wilcoxon signed-rank [37], bootstrap sampling [Efron1979-wz], and hierarchical bootstrap sampling [8] to do statistical tests for policy finetune results in Table ˜ 4 in S2-dev.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- The authors should answer "Yes" if the results are accompanied by error bars, confidence intervals, or statistical significance tests, at least for the experiments that support the main claims of the paper.
- The factors of variability that the error bars are capturing should be clearly stated (for example, train/test split, initialization, random drawing of some parameter, or overall run with given experimental conditions).
- The method for calculating the error bars should be explained (closed form formula, call to a library function, bootstrap, etc.)
- The assumptions made should be given (e.g., Normally distributed errors).
- It should be clear whether the error bar is the standard deviation or the standard error of the mean.
- It is OK to report 1-sigma error bars, but one should state it. The authors should preferably report a 2-sigma error bar than state that they have a 96% CI, if the hypothesis of Normality of errors is not verified.
- For asymmetric distributions, the authors should be careful not to show in tables or figures symmetric error bars that would yield results that are out of range (e.g. negative error rates).
- If error bars are reported in tables or plots, The authors should explain in the text how they were calculated and reference the corresponding figures or tables in the text.
1. Experiments compute resources
1. Question: For each experiment, does the paper provide sufficient information on the computer resources (type of compute workers, memory, time of execution) needed to reproduce the experiments?
1. Answer: [Yes]
1. Justification: We provide training time and our used GPU information in Table ˜ 7.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- The paper should indicate the type of compute workers CPU or GPU, internal cluster, or cloud provider, including relevant memory and storage.
- The paper should provide the amount of compute required for each of the individual experimental runs as well as estimate the total compute.
- The paper should disclose whether the full research project required more compute than the experiments reported in the paper (e.g., preliminary or failed experiments that didn’t make it into the paper).
1. Code of ethics
1. Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics https://neurips.cc/public/EthicsGuidelines?
1. Answer: [Yes]
1. Justification: The authors have reviewed the NeurIPS Code of Ethics and the paper conforms to the code of ethics.
1. Guidelines:
- The answer NA means that the authors have not reviewed the NeurIPS Code of Ethics.
- If the authors answer No, they should explain the special circumstances that require a deviation from the Code of Ethics.
- The authors should make sure to preserve anonymity (e.g., if there is a special consideration due to laws or regulations in their jurisdiction).
1. Broader impacts
1. Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed?
1. Answer: [N/A]
1. Justification: We do not have any potential positive or negative societal impacts.
1. Guidelines:
- The answer NA means that there is no societal impact of the work performed.
- If the authors answer NA or No, they should explain why their work has no societal impact or why the paper does not address societal impact.
- Examples of negative societal impacts include potential malicious or unintended uses (e.g., disinformation, generating fake profiles, surveillance), fairness considerations (e.g., deployment of technologies that could make decisions that unfairly impact specific groups), privacy considerations, and security considerations.
- The conference expects that many papers will be foundational research and not tied to particular applications, let alone deployments. However, if there is a direct path to any negative applications, the authors should point it out. For example, it is legitimate to point out that an improvement in the quality of generative models could be used to generate deepfakes for disinformation. On the other hand, it is not needed to point out that a generic algorithm for optimizing neural networks could enable people to train models that generate Deepfakes faster.
- The authors should consider possible harms that could arise when the technology is being used as intended and functioning correctly, harms that could arise when the technology is being used as intended but gives incorrect results, and harms following from (intentional or unintentional) misuse of the technology.
- If there are negative societal impacts, the authors could also discuss possible mitigation strategies (e.g., gated release of models, providing defenses in addition to attacks, mechanisms for monitoring misuse, mechanisms to monitor how a system learns from feedback over time, improving the efficiency and accessibility of ML).
1. Safeguards
1. Question: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse (e.g., pretrained language models, image generators, or scraped datasets)?
1. Answer: [N/A]
1. Justification: We do not have any data or models that have a high risk for misuse.
1. Guidelines:
- The answer NA means that the paper poses no such risks.
- Released models that have a high risk for misuse or dual-use should be released with necessary safeguards to allow for controlled use of the model, for example by requiring that users adhere to usage guidelines or restrictions to access the model or implementing safety filters.
- Datasets that have been scraped from the Internet could pose safety risks. The authors should describe how they avoided releasing unsafe images.
- We recognize that providing effective safeguards is challenging, and many papers do not require this, but we encourage authors to take this into account and make a best faith effort.
1. Licenses for existing assets
1. Question: Are the creators or original owners of assets (e.g., code, data, models), used in the paper, properly credited and are the license and terms of use explicitly mentioned and properly respected?
1. Answer: [Yes]
1. Justification: We cited the original papers for the environments and other baselines.
1. Guidelines:
- The answer NA means that the paper does not use existing assets.
- The authors should cite the original paper that produced the code package or dataset.
- The authors should state which version of the asset is used and, if possible, include a URL.
- The name of the license (e.g., CC-BY 4.0) should be included for each asset.
- For scraped data from a particular source (e.g., website), the copyright and terms of service of that source should be provided.
- If assets are released, the license, copyright information, and terms of use in the package should be provided. For popular datasets, paperswithcode.com/datasets has curated licenses for some datasets. Their licensing guide can help determine the license of a dataset.
- For existing datasets that are re-packaged, both the original license and the license of the derived asset (if it has changed) should be provided.
- If this information is not available online, the authors are encouraged to reach out to the asset’s creators.
1. New assets
1. Question: Are new assets introduced in the paper well documented and is the documentation provided alongside the assets?
1. Answer: [Yes]
1. Justification: We will release the code and instructionsfor our experiments.
1. Guidelines:
- The answer NA means that the paper does not release new assets.
- Researchers should communicate the details of the dataset/code/model as part of their submissions via structured templates. This includes details about training, license, limitations, etc.
- The paper should discuss whether and how consent was obtained from people whose asset is used.
- At submission time, remember to anonymize your assets (if applicable). You can either create an anonymized URL or include an anonymized zip file.
1. Crowdsourcing and research with human subjects
1. Question: For crowdsourcing experiments and research with human subjects, does the paper include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation (if any)?
1. Answer: [N/A]
1. Justification: We do not involve crowdsourcing nor research with human subjects.
1. Guidelines:
- The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
- Including this information in the supplemental material is fine, but if the main contribution of the paper involves human subjects, then as much detail as possible should be included in the main paper.
- According to the NeurIPS Code of Ethics, workers involved in data collection, curation, or other labor should be paid at least the minimum wage in the country of the data collector.
1. Institutional review board (IRB) approvals or equivalent for research with human subjects
1. Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or institution) were obtained?
1. Answer: [N/A]
1. Justification: We do not involve research with human subjects.
1. Guidelines:
- The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
- Depending on the country in which research is conducted, IRB approval (or equivalent) may be required for any human subjects research. If you obtained IRB approval, you should clearly state this in the paper.
- We recognize that the procedures for this may vary significantly between institutions and locations, and we expect authors to adhere to the NeurIPS Code of Ethics and the guidelines for their institution.
- For initial submissions, do not include any information that would break anonymity (if applicable), such as the institution conducting the review.
1. Declaration of LLM usage
1. Question: Does the paper describe the usage of LLMs if it is an important, original, or non-standard component of the core methods in this research? Note that if the LLM is used only for writing, editing, or formatting purposes and does not impact the core methodology, scientific rigorousness, or originality of the research, declaration is not required.
1. Answer: [N/A]
1. Justification: we only use LLM for editing purposes.
1. Guidelines:
- The answer NA means that the core method development in this research does not involve LLMs as any important, original, or non-standard components.
- Please refer to our LLM policy (https://neurips.cc/Conferences/2025/LLM) for what should or should not be described.