# REVEAL: Reasoning-enhanced Forensic Evidence Analysis for Explainable AI-generated Image Detection
**Authors**: Huangsen Cao, Qin Mei, Zhiheng Li, Yuxi Li, Ying Zhang, Chen Li, Zhimeng Zhang, Xin Ding, Yongwei Wang, Jing LYU and Fei Wu
> Huangsen Cao, Qin Mei, Zhiheng Li, Zhimeng Zhang, Yongwei Wang, Fei Wu are with Zhejiang University.
E-mail: huangsen_cao, yongwei.wang, wufei@zju.edu.cn.
Yuxi Li, Ying Zhang, Chen Li, Jing Lyu are with WeChat Vision, Tencent Inc.
Ding Xin is with Nanjing University of Information Science and Technology.
\NAT@set@cites
\justify
Abstract
With the rapid advancement of generative models, visually realistic AI-generated images have become increasingly difficult to distinguish from authentic ones, posing severe threats to social trust and information integrity. Consequently, there is an urgent need for efficient and truly explainable image forensic methods. Recent detection paradigms have shifted towards explainable forensics. However, state-of-the-art approaches primarily rely on post-hoc rationalizations or visual discrimination, lacking a verifiable chain of evidence. This reliance on surface-level pattern matching limits the generation of causally grounded explanations and often results in poor generalization. To bridge this critical gap, we introduce REVEAL-Bench, the first reasoning-enhanced multimodal benchmark for AI-generated image detection that is explicitly structured around a chain-of-evidence derived from multiple lightweight expert models, then records step-by-step reasoning traces and evidential justifications. Building upon this dataset, we propose REVEAL (R easoning- e nhanced Forensic E v id e nce A na l ysis), an effective and explainable forensic framework that integrates detection with a novel expert-grounded reinforcement learning. Our reward mechanism is specially tailored to jointly optimize detection accuracy, explanation fidelity, and logical coherence grounded in explicit forensic evidence, enabling REVEAL to produce fine-grained, interpretable, and verifiable reasoning chains alongside its detection outcomes. Extensive experimental results demonstrate that REVEAL significantly enhances detection accuracy, explanation fidelity, and robust cross-model generalization, benchmarking a new state of the art for explainable image forensics.
Index Terms: AI-generated image detection, Explainable AI, Forensic reasoning.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: AI-Powered Image Authenticity Analysis Workflow
### Overview
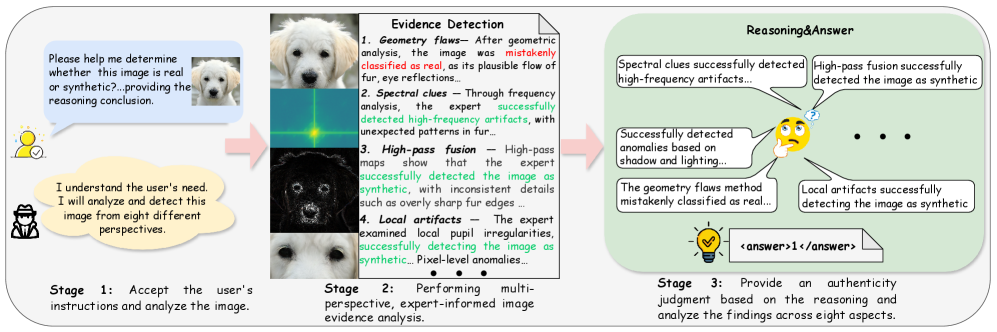
This diagram illustrates a three-stage workflow for determining the authenticity of an image using AI-powered evidence detection and reasoning. The workflow begins with accepting user instructions and analyzing the image, proceeds to multi-perspective evidence analysis, and culminates in providing an authenticity judgment. The diagram visually represents the process with images of dogs as the subject of analysis, and uses speech bubbles and labeled stages to convey information.
### Components/Axes
The diagram is divided into three main stages, labeled "Stage 1", "Stage 2", and "Stage 3", positioned horizontally from left to right. Each stage contains a visual element (image of a dog or a stylized icon) and accompanying text. A central section titled "Evidence Detection" lists four points of analysis. A section on the right, titled "Reasoning/Answer", shows a flow of analysis leading to a final judgment.
### Detailed Analysis or Content Details
**Stage 1: Accept the user’s instructions and analyze the image.**
* Text: "Please help me determine whether this image is real or synthetic…providing the reasoning conclusion."
* Text: "I understand the user’s need. I will analyze and detect this image from eight different perspectives."
* Image: A cartoon-style icon of a person with a question mark.
* Image: A cartoon-style icon of a computer with an image on the screen.
**Stage 2: Performing multi-perspective, expert-informed image evidence analysis.**
* Text: "Evidence Detection"
* 1. Geometry flaws – After geometric analysis, the image was mistakenly classified as real, as its plausible flow of fur, eye reflections.
* 2. Spectral clues – Through frequency analysis, the expert successfully detected high-frequency artifacts with unexpected patterns in fur.
* 3. High-pass fusion – High-pass maps were successfully detected the image as synthetic, with inconsistent details such as overly sharp fur edges.
* 4. Local artifacts – The expert examined local pupil irregularities, successfully detecting the image as synthetic. Pixel-level anomalies.
* Images: Four images of dogs, varying in breed and color.
**Stage 3: Provide an authenticity judgment based on the reasoning and analyze the findings across eight aspects.**
* Text: "Reasoning/Answer"
* Text: "Spectral clues successfully detected high-frequency artifacts."
* Text: "High-pass fusion successfully detected the image as synthetic"
* Text: "Successfully detected anomalies based on shadow and lighting."
* Text: "The geometry flaws method mistakenly classified as real…"
* Text: "Local artifacts successfully detecting the image as synthetic"
* Text: `<answer>!</answer>` (within a stylized speech bubble with a smiling face)
* Visual: A series of connected circles with dots, representing a flow of reasoning.
### Key Observations
* The workflow emphasizes a multi-faceted approach to image authentication, considering geometric, spectral, and local artifact analysis.
* The diagram highlights the potential for initial misclassification (geometry flaws) and the importance of subsequent analysis to correct it.
* The use of dog images throughout the diagram suggests this is an example application, but the workflow is likely applicable to other image types.
* The final "answer" is presented within a stylized speech bubble, indicating a conversational or user-friendly output.
* The diagram uses a visual flow to represent the reasoning process, with connected circles and dots.
### Interpretation
The diagram demonstrates an AI-driven system for image authenticity verification. The system doesn't rely on a single analysis method but integrates multiple perspectives ("eight different perspectives" mentioned in Stage 1) to arrive at a more robust conclusion. The initial misclassification of the image based on geometric analysis underscores the complexity of the task and the need for sophisticated algorithms. The successful detection of artifacts through spectral and high-pass fusion techniques suggests the system is capable of identifying subtle inconsistencies indicative of synthetic images. The final output, presented as an "answer," implies a binary classification (real or synthetic), but the diagram emphasizes the importance of the reasoning process leading to that conclusion. The use of images of dogs is likely illustrative, and the system is designed to be generalizable to other image types. The diagram suggests a system that aims to move beyond simple detection to provide explainable AI, offering insights into *why* an image is deemed authentic or synthetic.
</details>
Figure 1: Overview of the proposed REVEAL framework for reasoning-enhanced explainable synthetic image detection. The framework consists of three main stages: (1) receiving user instructions, (2) performing expert-grounded multi-perspective evidence detection, and (3) conducting reasoning through the chain of evidence (CoE) to derive a reliable decision with justifications.
1 Introduction
With the rapid evolution of generative artificial intelligence techniques such as Generative Adversarial Networks (GANs) [goodfellow2014generative, karras2019style] and Diffusion Models [dhariwal2021diffusion], the visual realism of synthesized content has advanced to a level that can easily deceive human perception. While these advanced models have unlocked unprecedented creative and economic potential in fields like digital art, design, and film production, they have also raised significant concerns regarding misinformation, privacy violations, and copyright issues. The continual progress in advanced diffusion models such as FLUX [black-forest-labs_flux_2024] and SD3.5 [esser2024scaling], along with autoregressive generation methods (e.g., VAR [tian2024visual]), has further intensified the challenge of distinguishing between real and synthetic content, making reliable detection an urgent research priority.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Diagram: Explainable Classification and REVEAL Models
### Overview
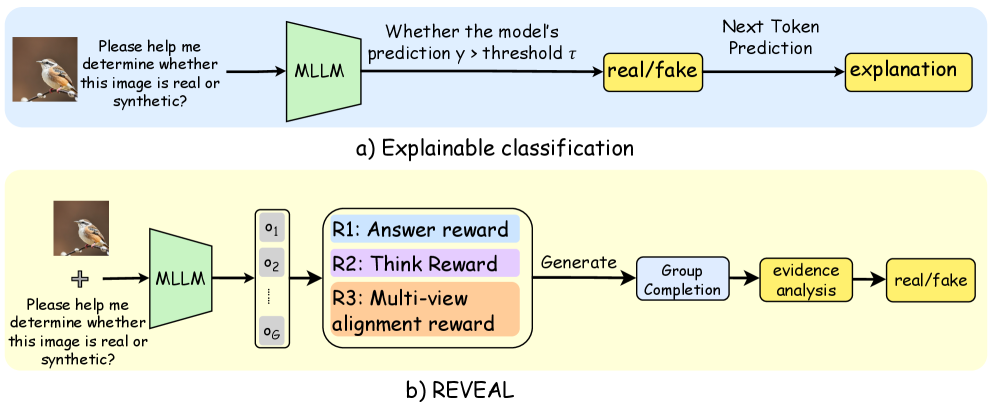
The image presents a comparative diagram illustrating two approaches to determining if an image is real or synthetic: "Explainable classification" (a) and "REVEAL" (b). Both approaches utilize a Multimodal Large Language Model (MLLM) and begin with the same prompt: "Please help me determine whether this image is real or synthetic?". The diagram details the processing steps and outputs for each method.
### Components/Axes
The diagram consists of two main sections, labeled (a) and (b), each representing a different model. Each section contains rectangular blocks representing processing stages, connected by arrows indicating the flow of information. Key components include:
* **MLLM:** Multimodal Large Language Model
* **Threshold (τ):** A value used for classification.
* **R1: Answer reward**
* **R2: Think Reward**
* **R3: Multi-view alignment reward**
* **real/fake:** The final classification output.
* **explanation:** Output from the Explainable classification model.
* **Generate, Group Completion, evidence analysis:** Steps in the REVEAL model.
### Detailed Analysis or Content Details
**a) Explainable classification:**
1. An image of a bird is presented as input.
2. The prompt "Please help me determine whether this image is real or synthetic?" is combined with the image and fed into the MLLM.
3. The MLLM generates a prediction.
4. The prediction is compared to a threshold (τ). If the prediction is greater than the threshold, the output is "real/fake".
5. The MLLM also generates a "Next Token Prediction" which is then used to create an "explanation".
**b) REVEAL:**
1. An image of a bird is presented as input.
2. The prompt "Please help me determine whether this image is real or synthetic?" is combined with the image and fed into the MLLM.
3. The MLLM generates multiple outputs (o1 to o6) represented by a vertical stack of rectangles.
4. These outputs are used to calculate three rewards: "R1: Answer reward", "R2: Think Reward", and "R3: Multi-view alignment reward".
5. The outputs are then processed through "Generate", "Group Completion", and "evidence analysis" stages.
6. The final output is a "real/fake" classification.
### Key Observations
* Both models start with the same input and prompt.
* The Explainable classification model relies on a threshold for classification and provides an explanation.
* The REVEAL model uses a reward system and a multi-stage process to arrive at a classification.
* REVEAL appears to be more complex, involving multiple outputs and reward signals.
* The REVEAL model explicitly incorporates a "Think Reward" suggesting a focus on the reasoning process.
### Interpretation
The diagram contrasts two approaches to image authenticity assessment using MLLMs. The "Explainable classification" method is a more direct approach, relying on a prediction and a threshold, with an added explanation component. The "REVEAL" method is more sophisticated, employing a reward system to guide the MLLM's reasoning and incorporating multiple perspectives ("Multi-view alignment reward") to improve accuracy. The inclusion of "Think Reward" in REVEAL suggests an attempt to encourage the model to articulate its reasoning process, potentially leading to more robust and trustworthy classifications. The diagram highlights a trend towards more complex and interpretable AI systems, where understanding *how* a model arrives at a decision is as important as the decision itself. The REVEAL model appears to be an attempt to address the limitations of simpler classification models by explicitly modeling the reasoning process.
</details>
Figure 2: a) Existing post-hoc rationalization detection. b) REVEAL framework, a reasoning-enhanced paradigm for truly explainable forensic analysis.
Recent research [wang2020cnn, chai2020makes, wang2023dire, ojha2023towards, liu2024forgery, tan2024rethinking] has made notable progress in detecting AI-generated images. However, most traditional methods focus solely on discrimination, offering limited forensic analysis. The emergence of multimodal large language models (MLLMs) offers new opportunities, enabling models to combine visual perception with textual descriptions. Recent endeavours such as GPT-4 based detection [jia2024can], AIGI-Holmes [zhou2025aigi], FakeBench [li2025fakebench], and RAIDX [li2025raidx] have initiated this transition towards explainability. Yet, as illustrated in Figure 2, these methods share fundamental limitations: they primarily rely on post-hoc rationalizations or leverage the MLLMs merely as a powerful general-purpose visual classifier to identify high-level visual anomaly patterns (e.g.“unnatural lighting”, “blurry edge”). They fail to construct a causally grounded reasoning-based forensic pipeline where specialized evidence is systematically collected, analyzed, and synthesized through logical deduction. Specifically, these prior works: 1) use datasets (e.g. FakeBench [li2025fakebench]) that lack fine-grained, structured evidence, limiting support for deep causal reasoning; and 2) rely on methods (e.g. RAIDX [li2025raidx] with RAG) where explanations exhibit surface-level coherence derived from pattern matching, rather than being grounded in verifiable forensic evidence traces.
The critical gap highlights two major challenges in developing reasoning-enhanced synthetic image detection: 1) Lack of a reasoning-oriented forensic dataset. Existing datasets contain either binary labels or shallow textual justifications, without structured and rigorous chain-of-evidence annotations necessary to build auditable forensic judgments. 2) Limited reasoning-based explainability. Current MLLM-based detectors tend to produce post-hoc rationalizations instead of verifiable reasoning chains, leading to fragile generalization and unreliable claims in the forensic context.
To this end, we introduce REVEAL-Bench, a novel reasoning-oriented benchmark for AI-generated image forensics. Our data generation pipeline is fundamentally distinct from existing approaches: we shift from general visual correlation to expert-grounded evidence analysis. For each image, we first leverage eight lightweight expert models to provide structured, reliable, low-level forensic evidence. Such evidence then forms the input for a subsequent large model to generate a chain-of-evidence (CoE) annotation. By consolidating the multi-round forensic analysis from these specialized experts into a single, structured CoE trace, REVEL-Bench becomes the first dataset to explicitly provide an expert-grounded, verifiable forensic analysis that connects low-level cues to high-level conclusions.
Building upon this dataset, we propose the REVEAL framework, a two-stage training paradigm designed to enforce reasoning-based forensic evidence analysis. In the first stage, we employ a supervised fine-tuning (SFT) to teach the MLLM the canonical CoE structure. In the second stage, we introduce R-GRPO (Reasoning-enhanced Group Relative Preference Optimization), an expert-grounded policy optimization algorithm, featuring a novel reward function critical for enhancing the logical coherence and verifiability of forensic analysis. Specifically, R-GRPO jointly optimizes (i) detection accuracy, (ii) reasoning stability, and (iii) multi-view consistency. The novel optimization enforces the MLLM to perform logical synthesis over explicit forensic evidence rather than simple visual pattern matching, thereby achieving accurate, reliable, and explainable forensic analysis.
In summary, our work makes three major contributions:
REVEAL-Bench. We pioneer the first reasoning-based and explainable dataset for AI-generated image detection. Unlike prior datasets that offer only post-hoc explanations, REVEAL-Bench is uniquely structured around expert-grounded, verifiable forensic evidence that embeds an explicit chain-of-evidence following a systematic evidence-then-reasoning paradigm.
REVEAL Framework. We introduce the REVEAL Framework, a progressive two-stage training paradigm designed to instill standardized and explainable reasoning in multimodal LLMs. Its core, R-GRPO, optimizes the MLLM to perform logical synthesis for forensic evidence, jointly enhancing accuracy, reasoning consistency, and generalization.
Empirical Performance. Our approach achieves superior detection accuracy, generalization, and explanation fidelity, benchmarking a new state of the art for reasoning-based forensic research.
2 Related Work
Detection of AI-Generated Fake Images
The rapid evolution of generative models, e.g., GANs [goodfellow2014gan, esser2021taming], autoregressive models [oord2017vqvae], diffusion-based models [esser2024rectifiedflow, song2020ddim, ho2020ddpm, gu2022vqdiffusion, saharia2022imagen, ji2025mllm], has driven AI-generated images to near-photorealistic quality, challenging conventional detection methods. Early forensic studies focused on traditional manipulations like splicing or copy-move, analyzing noise inconsistencies, boundary anomalies, or compression artifacts [zhou2018manipulation, li2022splicing]. Researchers then shifted focus to generation artifacts, such as up-sampling grid effects, texture mismatches, or abnormal high-frequency decay [frank2020frequency, liu2020texture, dzanic2020fourier]. For example, the Spectral Learning Detector [karageorgiou2025spectral] models the spectral distribution of authentic images, treating AI-generated samples as out-of-distribution anomalies, achieving consistent detection across generators. However, as generators incorporate post-processing techniques like super-resolution, these low-level statistical clues become increasingly subtle and less reliable for robust detection.
Recent methods employ general-purpose feature extractors, such as CNN- or ViT-based detectors, to learn discriminative features directly. While lightweight CNNs achieve strong benchmark performance [ladevic2024cnn], methods like the Variational Information Bottleneck (VIB) network [zhang2025vib] aim to enhance generalization by constraining feature representations through the information bottleneck principle to retain only task-relevant information. Post-hoc Distribution Alignment (PDA) [wang2025pda] attempts to improve robustness to unseen generators by aligning regenerated and real distributions to detect unseen generators. Recently, NPR [tan2024rethinking] has become a representative approach by capturing low-level artifacts, demonstrating strong generalization capability. Similarly, HyperDet [cao2024hyperdet] and AIDE [yan2024sanity] achieve robust generalization through high-frequency spectrum analysis. Despite their discriminatory power, these approaches remain limited in forensic value, as their conclusions rely on global statistics and lack the semantic, verifiable evidence required for comprehensive explainability.
Explainable AI-generated Image Detection
The emergence of MLLMs [liu2023visual, wang2024qwen2] has accelerated the development of explainable image forensics by leveraging their advanced cross-modal understanding [wu2024comprehensive, talmor2019commonsenseqa]. Early efforts reformulated detection as a Visual Question Answering (VQA) task [jia2024can, keita2025bi, chang2023antifakeprompt], allowing MLLMs to provide accompanying descriptive text. FatFormer [liu2024forgery] extended this with a forgery-aware adapter to improve generalization on the CLIP-ViT [radford2021learning] encoder.
Subsequent studies focused on constructing task-specific multimodal datasets for fine-tuning. FakeBench [li2025fakebench] and LOKI [ye2024loki] provide synthetic images with manually written, high-level forgery descriptions. Holmes-Set [zhou2025aigi] utilized small models for initial image filtering and a Multi-Expert Jury mechanism to generate postt-hoc explanatory texts. At the methodological level, FakeShield [xu2024fakeshield], ForgerySleuth [sun2024forgerysleuth], ForgeryGPT [liu2024forgerygpt] and SIDA [huang2025sida] fine-tune MLLMs to achieve explainable forgery detection and localization. AIGI-Holmes [zhou2025aigi] integrates low-level visual experts with reasoning modules. RAIDX [li2025raidx] combines retrieval-augmented generation (RAG) [lewis2020retrieval] with GRPO optimization to improve the ability to describe texts.
Critically, existing datasets and methods suffer from two key limitations: First, the explanations are attributed to post-hoc rationalizations, often relying on the MLLM’s general knowledge and visual classification capabilities, failing to achieve logical synthesis of specialized forensic evidence. Second, they lack structured, fine-grained forensic evidence required to support a verifiable causal link between low-level artifacts and the final forensic judgments.
3 REVEAL-Bench
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Diagram: Forensic Image Analysis Pipeline
### Overview
This diagram illustrates a pipeline for forensic analysis of images, specifically focusing on detecting whether an image is real or synthetically generated (e.g., by a GAN). The pipeline consists of data curation & pre-filtering, expert-grounded evidence collection, chain-of-evidence synthesis, and consolidation stages. It highlights various clues and analysis techniques used to determine image authenticity. The diagram also includes example outputs and textual explanations of the analysis process.
### Components/Axes
The diagram is structured into four main sections, flowing from left to right:
1. **Data Curation & Pre-filtering:** Includes "Chameleon Fake2M", "Gen1mage", "Autoregressive GAN", "Diffusion", and "Pre-filtering".
2. **Expert-grounded Evidence Collection:** Contains two columns of analysis types: "Local artifacts", "Spectral clues", "Pixel noise", "Spatial consistency" and "Geometry flaws", "Shadow logic", "Texture fusion", "High-pass fusion".
3. **Chain-of-Evidence Synthesis:** Labeled as "Chain-of-Evidence Synthesis" with an arrow pointing to "visual evidence".
4. **Consolidation:** Contains a series of numbered steps within `` tags.
There is also a circular chart at the bottom-left labeled "Image Dataset" with categories "Real" and "Fake".
Textual annotations are present throughout the diagram, providing explanations of the analysis steps and findings.
### Detailed Analysis or Content Details
**1. Data Curation & Pre-filtering:**
* "Chameleon Fake2M" and "Gen1mage" are listed as sources of synthetic images.
* "Autoregressive GAN" and "Diffusion" are listed as image generation methods.
* "Pre-filtering" is a step to prepare the images for further analysis.
* "Expert Filtering (Lightweight Model as Expert)" is a step to filter images.
**2. Expert-grounded Evidence Collection:**
* The left column lists clues: "Local artifacts", "Spectral clues", "Pixel noise", "Spatial consistency".
* The right column lists analysis techniques: "Geometry flaws", "Shadow logic", "Texture fusion", "High-pass fusion".
* Text boxes within this section provide examples of findings:
* "The expert successfully detected that the image is synthetic. Please analyze the local artifacts in the image."
* "The expert successfully detected that the image is synthetic. Please analyze the forgery using spectral clues."
* "The expert failed to detect that the image is synthetic. Please analyze its authenticity using high-pass fusion."
**3. Chain-of-Evidence Synthesis:**
* This section is labeled "Chain-of-Evidence Synthesis" and connects to "visual evidence".
**4. Consolidation:**
* The following steps are listed within `` tags:
1. "Initial observation checks texture and lighting anomalies."
2. "Detailed inspection identifies uniform surfaces and missing imperfections."
3. "Spatial analysis compares object-background alignment and projection logic."
4. "Shadow consistency test detects overly perfect lighting patterns."
5. "High-frequency analysis examines fine-grain texture irregularities."
6. "Frequency spectrum evaluation reveals abnormal energy distributions."
7. "Synthesizing all clues, the image is determined to be synthetic."
**5. Image Dataset Chart:**
* The chart is a semi-circular distribution.
* The "Real" category occupies approximately the upper-right quadrant, with a value around 30000.
* The "Fake" category occupies the lower-left quadrant, with a value around 3000.
* There is a section labeled "hybrid" with a value around 2000.
* The chart also shows a distribution of "image quality" or "confidence" levels, with varying shades of green and red.
**6. Textual Annotations:**
* "Local artifacts: By observing the bird's eyes, we find that the reflection of the eyeball is missing."
* "Spectral clues: Periodic artifacts of the synthesized image are revealed along the spectral axis."
* "High-pass fusion: By examining the high-frequency map, it is observed that the area around the bird appears smooth and contains no signs of forgery."
### Key Observations
* The pipeline emphasizes a multi-faceted approach to image forensics, combining various clues and analysis techniques.
* The "Expert-grounded Evidence Collection" section highlights the importance of both local and global image features.
* The consolidation steps demonstrate a logical progression from initial observation to final determination of image authenticity.
* The Image Dataset chart shows a clear imbalance between real and fake images, with a significantly larger number of real images.
* The textual annotations provide specific examples of how different clues can be used to detect synthetic images.
### Interpretation
The diagram presents a comprehensive framework for detecting synthetic images. The pipeline's strength lies in its integration of multiple analysis techniques, allowing for a more robust and reliable assessment of image authenticity. The use of "expert-grounded evidence" suggests a reliance on human expertise combined with automated analysis. The consolidation steps demonstrate a clear reasoning process, culminating in a final determination of whether an image is real or fake.
The imbalance in the Image Dataset chart (30000 real vs. 3000 fake) could indicate a bias in the training data or a limited number of available synthetic images. The textual annotations provide valuable insights into the specific types of artifacts that can be used to identify synthetic images, such as missing reflections in eyes or periodic artifacts in spectral analysis. The diagram suggests that even when initial analysis fails to detect forgery, further investigation using techniques like high-pass fusion can reveal subtle clues.
The `` tags around the consolidation steps suggest a deliberate attempt to model the thought process of a forensic analyst, making the pipeline more transparent and explainable. The overall message is that detecting synthetic images requires a careful and systematic approach, combining technical analysis with human judgment.
</details>
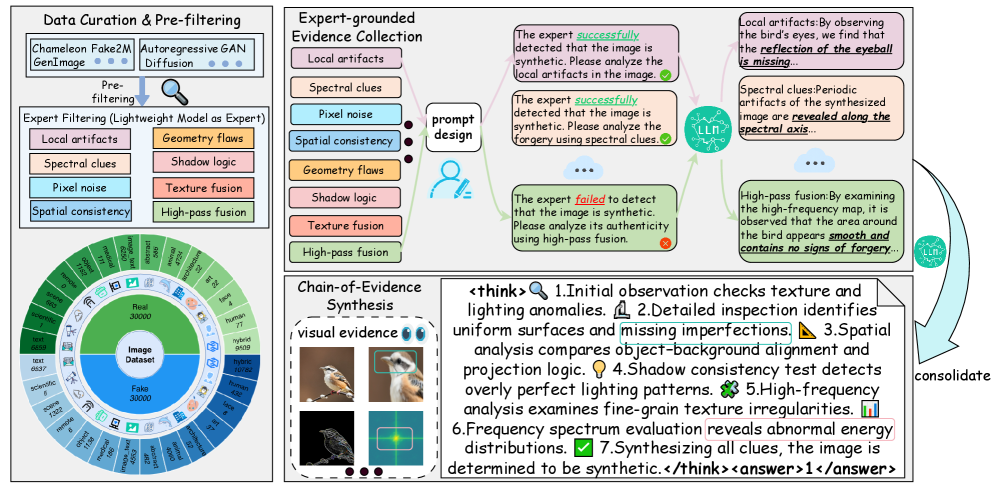
Figure 3: The pipeline of REVEAL-Bench. This figure illustrates our data processing pipeline, which consists of three stages: Data Curation & Pre-filtering, Expert-grounded Evidence Collection, and Chain-of-Evidence (CoE) Synthesis
As illustrated in Figure 3, this study constructs the REVEAL-Bench dataset through a rigorous, three-stage pipeline designed for reasoning-based image forensic: Data Curation & Pre-filtering, Expert-grounded Evidence Collection, and Chain-of-Evidence (CoE) Synthesis. This approach is fundamentally distinct as it replaces manual, subjective labeling with a process that systematically integrates verifiable evidence from specialized models with the logical synthesis capabilities of large vision-language models. The resulting dataset contains explicit, expert knowledge-grounded Chain-of-Evidence annotations, which is crucial for training forensic detectors with superior transparency and generalization capability.
Data Curation & Prefiltering
To ensure sufficient content, generator, and artifact diversity, we aggregate several prominent AI-generated detection benchmarks, including CNNDetection [wang2020cnn], UnivFD [ojha2023towards], AIGCDetectBenchmark [zhong2023patchcraft], GenImage [zhu2023genimage], Fake2M [lu2023seeing], and Chameleon [yan2024sanity]. This yielded in an initial corpus of approximately 5,120K synthetic images and 850K authentic images. To manage annotation costs while ensuring high data quality, we implemented a stratified sampling strategy based on automated quality assessments [talebi2018nima] and image resolution. Specifically, we sampled images based on aesthetic scores (50% high, 30% medium, 20% low), and image resolution, high-resolution ( $≥$ 512 $×$ 512) images at 50%, medium-resolution (384 $×$ 384–512 $×$ 512) images at 30%, and low-resolution ( $<$ 384 $×$ 384) images at 20%. Images were also semantically classified into 13 major categories (e.g., humans, architecture, artworks). After rigorous multi-stage filtering and preprocessing to eliminate non-representative or low-quality samples, we finalized a balanced corpus of 30K synthetic and 30K real images, which serves as the foundation for subsequent expert annotation
Expert-grounded Evidence Collection
To enable fine-grained, verifiable forensic analysis, we design and employ a set of eight lightweight and specialized expert models [li2025improving, sarkar2024shadows, tan2024rethinking, cao2024hyperdet, tan2024frequency, li2025optimized], each dedicated to screening and localizing a distinct category of synthetic artifact (as depicted in Figure 3). This is a crucial distinction from prior work, such as AIGI-Holmes [zhou2025aigi], which uses experts primarily for global filtering. Our experts, by contrast, provide structured, machine-readable evidence, including artifact masks and diagnostic labels. These eight outputs constitute the necessary forensic evidence foundation. By conditioning the LVLM on these high-fidelity, structured references, we ensure the final generated explanations are faithful, logically consistent, and verifiable against objective, low-level artifact data. This expert-grounded decompositional analysis effectively bridges the gap between small-model perception of artifacts and large-model logical reasoning.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Diagram: Two-Stage Real/Synthetic Image Determination Pipeline
### Overview
The image depicts a two-stage pipeline for determining whether an image is real or synthetic. The pipeline utilizes a Multi-modal Large Language Model (MLLM) and incorporates a reward system based on both answer accuracy and reasoning quality. The stages are labeled "Stage 1: CoE Tuning" and "Stage 2: R-GRPO".
### Components/Axes
The diagram consists of two main stages, each with several components. Key elements include:
* **MLLM:** Present in both stages, acting as the core processing unit.
* **Input Images:** Represented by a series of orange rectangles in Stage 1 and individual images in Stage 2.
* **Question Prompt:** A text box within each stage asking "Please help me determine whether this image is real or synthetic?".
* **Completion Outputs:** In Stage 2, a series of "Completion" boxes (Completion 1 to Completion G) represent potential answers.
* **Reward Signals:** Represented by green "match" and red "mismatch" signals.
* **Reasoning Blocks:** Text enclosed in `` tags, representing the MLLM's reasoning process.
* **Answer Blocks:** Text enclosed in `<answer>...</answer>` tags, representing the MLLM's final answer.
* **Loss Functions:** Labeled as `L_think` and `L_answer` at the bottom of Stage 1.
* **Legend:** Located in the top-right corner, associating colors with reward outcomes: R-1 (match), R-0 (mismatch), R-0.5 (similar).
### Detailed Analysis or Content Details
**Stage 1: CoE Tuning**
* Input: A sequence of 8 orange rectangles representing images.
* Question: "Please help me determine whether this image is real or synthetic?".
* MLLM processes the input and generates reasoning and an answer.
* Reasoning: ``.
* Answer: `<answer>1</answer>`.
* Outputs: Two loss functions, `L_think` and `L_answer`.
**Stage 2: R-GRPO**
* Input: A single image.
* Question: "Please help me determine whether this image is real or synthetic?".
* MLLM processes the input and generates reasoning and an answer.
* Completion Outputs: A series of "Completion" boxes (Completion 1 to Completion G) are shown.
* **(1) Answer Reward:**
* Input: Completion 1.
* Reasoning: ``.
* Answer: `<answer>...</answer>`.
* Reward: Green "match" signal, labeled "R-1".
* **(2) Think Reward:**
* Input: A green "match" signal.
* Reasoning: ``.
* Reward: Green "match" signal, labeled "R-1".
* **(3) Multi-view alignment reward:**
* Input: A red "mismatch" signal.
* Reasoning: ``.
* Reward: Red "mismatch" signal, labeled "R-0".
**Legend:**
* Green: "match" - R-1, R-0.5
* Red: "mismatch" - R-0
### Key Observations
* The pipeline uses a two-stage approach, starting with CoE Tuning and refining with R-GRPO.
* The R-GRPO stage incorporates multiple reward signals based on both answer accuracy and the quality of the reasoning process.
* The reasoning blocks provide insight into the MLLM's decision-making process.
* The reward signals are color-coded (green for match, red for mismatch) and associated with numerical values (R-1, R-0, R-0.5).
* The diagram highlights the importance of both high-level reasoning and low-level image analysis (zooming in on details).
### Interpretation
The diagram illustrates a sophisticated approach to detecting synthetic images. The two-stage pipeline aims to improve the reliability of the detection process by combining initial coarse-grained analysis (Stage 1) with more refined, multi-faceted evaluation (Stage 2). The use of reward signals for both answer accuracy and reasoning quality suggests a focus on not only *what* the MLLM predicts but also *why* it makes that prediction. The inclusion of detailed reasoning examples (within the `<think>` tags) demonstrates the importance of explainability in this context. The different reward values (R-1, R-0, R-0.5) suggest a graded reward system, allowing for partial credit for reasoning that is partially correct or insightful. The example of the eyeball analysis highlights the use of fine-grained image features to detect subtle artifacts that might indicate synthetic origin. This pipeline is likely designed to address the challenges of increasingly realistic synthetic images, where traditional detection methods may fail.
</details>
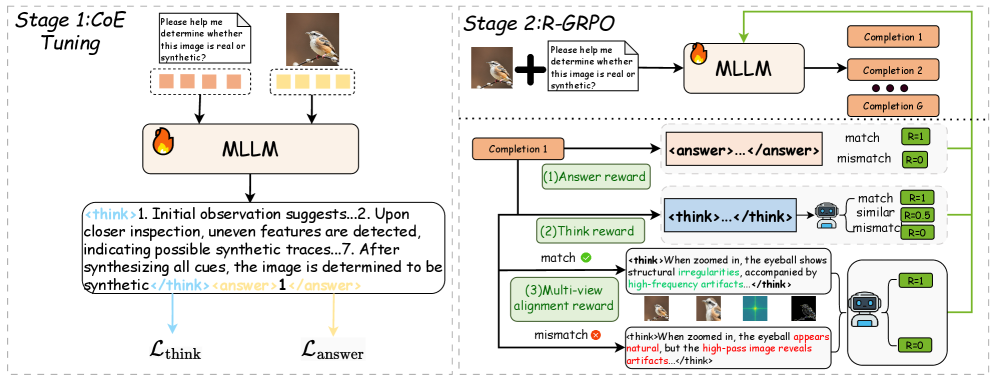
Figure 4: Overview of REVEAL. The pipeline mainly consists of two stages: CoE Tuning and R-GRPO.
Chain-of-Evidence Synthesis
As shown in Figure 3, after the specialized expert annotation, the initial eight rounds of multi-perspective diagnostic outputs are diverse and fragmented. To construct a unified and progressive reasoning dataset suitable for Chain-of-Thought (CoT) fine-tuning, we leverage a high-capacity LVLM (Qwen-2.5VL-72B [bai2025qwen2]) to perform structured knowledge consolidation. This process reconstructs the diverse, specialized evidence into a single, cohesive, and auditable reasoning trace, formatted using a standard <think> $·s$ </think> $·$ <answer> $·s$ </answer> structure.
Fundamentally distinct from existing datasets like AIGI-Holmes [zhou2025aigi] and FakeBench [li2025fakebench], which merely provide generic explanations, REVEAL-Bench explicitly formalizes the link between low-level expert evidence and high-level judgments. This two-stage pipeline transforms the detection tasks into a reasoning task, offering coherent CoE annotations that enhance logical consistency, minimizing annotation noise, and support supervision paradigms with advanced reinforcement learning techniques to improve explanation fidelity and generalization.
4 Methodology
4.1 Overview of REVEAL
As illustrated in Figure 4, the overall training pipeline adopts a two-stage progressive training paradigm inspired by advanced policy optimization-based reinforcement learning techniques [guo2025deepseek].
We first perform supervised fine-tuning (SFT) on a consolidated Chain-of-Evidence (CoE) dataset to obtain a base policy that can deduce the required forensic reasoning procedure. While this stage establishes the fundamental reasoning-based forensic structure, the resulting model still exhibits limitations in logical consistency, forensic accuracy, and robustness. To mitigate these limitations, we propose a novel reinforcement learning algorithm: R easoning- e nhanced Forensic E vid e nce A na l ysis (R-GRPO). R-GRPO extends beyond standard Group Relative Policy Optimization (GRPO) by incorporating a task-specific composite reward that dynamically aligns forensic reasoning trajectories and stabilizes policy updates, significantly enhancing semantic consistency and reasoning robustness.
4.2 Progressive Multimodal Training for AI-Generated Image Detection
We introduce REVEAL (Reasoning-enhanced Forensic Evidence AnaLysis), a progressive multimodal training framework comprising two sequential stages designed to cultivate robust, logically consistent, and verifiable forensic reasoning in multimodal models.
Stage 1: Chain-of-Evidence Tuning (CoE Tuning). In the initial stage, we perform cold-start supervised fine-tuning to establish a stable, stepwise reasoning policy and a consistent output paradigm built upon the REVEAL-Bench dataset. Let $x$ denote the visual input, $z=(z_{1},...,z_{T})$ denote the tokenized reasoning sequence (Chain-of-Evidence, CoE), and $y$ denote the final classification label. We adopt an explicit joint reasoning–decision modeling paradigm, where the final prediction $y$ is conditioned on the explicit reasoning trace $z$ . This formulation enforces a think-then-answer mechanism, fundamentally distinct from post-hoc rationalizations (e.g. modeling $p(y\mid x)$ and then $p(z\mid x,y)$ ), thereby achieving causally grounded genuine explanations.
Concretely, we factorize the joint conditional probability as
$$
p(y,z\mid x)\;=\;p(z\mid x)\,p(y\mid x,z), \tag{1}
$$
which structurally encourages the model to first generate verifiable reasoning evidence and subsequently derive the final prediction conditioned directly on that reasoning process.
Maximizing the likelihood under (1) corresponds to minimizing the following negative log-likelihood loss:
$$
\mathcal{L}_{\mathrm{NLL}}(x,y,z;\theta)\;=\;-\log p_{\theta}(z\mid x)\;-\;\log p_{\theta}(y\mid x,z). \tag{2}
$$
For training control and to explicitly balance the emphasis on reasoning quality versus final decision accuracy, we decompose $\mathcal{L}_{\mathrm{NLL}}$ into two components, the reasoning generation loss $\mathcal{L}_{\mathrm{think}}$ and the answer loss $\mathcal{L}_{\mathrm{answer}}$ ,
$$
\mathcal{L}_{\mathrm{think}}\;=\;-\sum_{t=1}^{T}\log p_{\theta}(z_{t}\mid z_{<t},x), \tag{3}
$$
$$
\mathcal{L}_{\mathrm{answer}}\;=\;-\log p_{\theta}(y\mid x,z), \tag{4}
$$
We then employ a weighted composite SFT loss:
$$
\mathcal{L}_{\mathrm{SFT}}=\begin{aligned} &(1-\alpha)\,\mathcal{L}_{\mathrm{think}}+\alpha\,\mathcal{L}_{\mathrm{answer}}+\eta\,\mathrm{KL}\big(\pi_{\mathrm{pre}}\|\pi_{\theta}\big).\end{aligned} \tag{5}
$$
where $\alpha∈(0,1)$ controls the relative importance of the answer loss versus the reasoning trace, the KL regularization term constrains the fine-tuned policy $\pi_{\theta}$ to remain proximal to the pretrained policy $\pi_{\mathrm{pre}}$ , effectively mitigating catastrophic forgetting.
Stage 2: Reasoning-enhanced Group Relative Policy Optimization (R-GRPO).
Group Relative Policy Optimization (GRPO). Group Relative Policy Optimization (GRPO) is a reinforcement learning technique that stabilizes policy updates by comparing a group of candidate trajectories, rather than relying on the noisy reward signals of individual samples. Given an input $x$ , we sample a group of $K$ trajectories $\{\tau_{i}\}_{i=1}^{K}$ from the current policy $\pi_{\theta}$ , where each trajectory $\tau_{i}$ consists of an intermediate reasoning trace $z_{i}$ and a final output $y_{i}$ . A group-based composite reward $R_{\mathrm{group}}(\tau_{i})$ is computed for each trajectory, and the group-relative advantage $A_{i}$ is defined by subtracting the mean group reward $\overline{R}_{\mathrm{group}}$ :
$$
\displaystyle A_{i} \displaystyle=R_{\mathrm{group}}(\tau_{i})-\overline{R}_{\mathrm{group}}, \displaystyle\overline{R}_{\mathrm{group}} \displaystyle=\frac{1}{K}\sum_{j=1}^{K}R_{\mathrm{group}}(\tau_{j}). \tag{6}
$$
The GRPO objective maximizes the expected group-relative log-probability, regularized by a KL penalty for stable policy convergence:
$$
\max_{\theta}\;\mathbb{E}\Big[\sum_{i=1}^{K}A_{i}\log\pi_{\theta}(\tau_{i}\mid x)\Big]\;-\;\lambda_{\mathrm{KL}}\,\mathrm{KL}\big(\pi_{\mathrm{old}}\|\pi_{\theta}\big). \tag{7}
$$
Reasoning-enhanced GRPO (R-GRPO). To employ GRPO for forensic analysis tasks, we propose R-GRPO, which augments the objective with a task-aware composite reward specifically designed to capture forensic fidelity and reasoning robustness. Let $y$ denote the generated answer, $y^{\ast}$ the reference answer, $z=(z_{1},...,z_{T})$ the reasoning tokens, and $\{v_{m}(x)\}_{m=1}^{M}$ a set of multi-visual visual evidence (e.g., spectral representations, high-pass filtered images, and localized artifact patches).
Rationale for Agent-based Reward Modeling. In preliminary experiments, we observed that simple metric-based rewards (e.g. using cosine similarity of sentence embeddings for $r_{\mathrm{sem}}$ ) fail to adequately reflect the semantic and contextual logic required for high-quality forensic explanations. Therefore, we introduce a dedicated large language model as an intelligent agent (Agent) to evaluate responses. This Agent-based assessment considers contextual logic, explanation coherence, and factual consistency against the provided structured evidence, thereby generating a more human-aligned and interpretable reward signal than purely metric-based approaches (see Appendix A for details).
R-GRPO defines three complementary, evidence-driven reward components:
(1) Answer Reward $r_{\mathrm{sem}}$ . This binary reward ensures the accuracy of the detection:
$$
r_{\mathrm{sem}}(y,y^{\ast})=\begin{cases}1,&\text{if }y=y^{\ast},\\
0,&\text{otherwise.}\end{cases} \tag{8}
$$
(2) Think Reward $r_{\mathrm{think}}$ . This reward quantifies the quality and structural integrity of the reasoning trace $z$ .
Let $z=(z_{1},...,z_{T})$ be the generated reasoning trace and $z^{\ast}=(z^{\ast}_{1},...,z^{\ast}_{T^{\ast}})$ the ground-truth reasoning trace (when available). Define a perturbed trace $\tilde{z}=\operatorname{shuffle}(z)$ . Then
$$
r_{\mathrm{think}}(z,z^{\ast},\tilde{z})\;=\;\mathcal{A}_{\mathrm{sem}}(z,z^{\ast})+\mathcal{A}_{\mathrm{logic}}(z,\tilde{z}), \tag{9}
$$
where $\mathcal{A}_{\mathrm{sem}}$ measures alignment between the generated and reference reasoning, and $\mathcal{A}_{\mathrm{logic}}(z,\tilde{z})$ evaluates the logical coherence of the trace. Crucially, $\mathcal{A}_{\mathrm{logic}}$ evaluates the logical coherence by penalizing the model if minor structural perturbations $\tilde{z}$ severely alter the inferred conclusion. This mechanism forces the model to maintain sequential consistency and ensure the reasoning steps are robustly connected.
(3) Multi-view Alignment Reward $r_{\mathrm{view}}$ . This reward encourages the generated reasoning trace $z$ to be robustly grounded in evidence that persists across different forensic views of the image.
$$
r_{\mathrm{view}}(z,x)\;=\;\mathcal{A}_{\mathrm{view}}\Big(z,\{v_{m}(x)\}_{m=1}^{M}\Big), \tag{10}
$$
where $\mathcal{A}_{\mathrm{view}}$ measures fidelity of the reasoning to the multi-view visual evidence $\{x_{m}\}$ . By requiring alignment with evidence visible under different transformations (e.g., spectral, high-pass), this reward promotes cross-artifact generalization and enables the self-supervised discovery of novel, transformation-invariant artifacts.
The composite trajectory reward $R(\tau)$ combines these terms:
$$
\displaystyle R(\tau)= \displaystyle\lambda_{s}r_{\mathrm{sem}}(y,y^{\ast})+\lambda_{t}r_{\mathrm{think}}(z,z^{\ast},\tilde{z}) \displaystyle+\lambda_{v}r_{\mathrm{view}}(z,x), \tag{11}
$$
where $\lambda_{s},\lambda_{t},\lambda_{v}≥ 0$ are tunable parameters balancing the rewards. For improved stability, rewards are standardized within each sampled group before calculating the advantage $\widehat{A}_{i}$ :
$$
\widehat{R}(\tau_{i})=\frac{R(\tau_{i})-\mu_{\mathrm{group}}}{\sigma_{\mathrm{group}}}, \tag{12}
$$
$$
\mu_{\mathrm{group}}=\frac{1}{K}\sum_{j}R(\tau_{j}), \tag{13}
$$
$$
\sigma_{\mathrm{group}}=\mathrm{std}(\{R(\tau_{j})\}) \tag{14}
$$
and the normalized group-relative advantage is
$$
\widehat{A}_{i}=\widehat{R}(\tau_{i})-\frac{1}{K}\sum_{j}\widehat{R}(\tau_{j}). \tag{15}
$$
Unified GRPO with the R-GRPO objective. Combining the original GRPO formulation (7) with the R-GRPO composite reward (11), the unified optimization objective becomes
$$
\max_{\theta}\;\mathbb{E}\Big[\sum_{i=1}^{K}\widehat{A}_{i}\log\pi_{\theta}(\tau_{i}\mid x)\Big]\;-\;\lambda_{\mathrm{KL}}\,\mathrm{KL}\big(\pi_{\mathrm{old}}\|\pi_{\theta}\big), \tag{16}
$$
where $\widehat{A}_{i}$ encodes both the group-relative comparison and the reasoning-enhanced composite reward.
This evidence-enhanced reward signals can effectively guide the model to optimize its reasoning trajectories, enforcing both stability and logical coherence in verifiable forensic evidence analysis.
5 Experiments
5.1 Experimental Settings
TABLE I: Comparison of REVEAL-bench with previous datasets. REVEAL-bench is the first reasoning dataset for synthetic image detection.
Dataset #Image Explanation Multiview Fusion Reasoning Process CNNDetection [wang2020cnn] 720k ✗ ✗ ✗ GenImage [zhu2023genimage] 1M ✗ ✗ ✗ FakeBench [li2025fakebench] 6K ✓ ✗ ✗ Holmes-Set [zhou2025aigi] 69K ✓ ✓ ✗ REVEAL-bench 60K ✓ ✓ ✓
To comprehensively evaluate the performance of REVEAL, we conduct experiments on two datasets: REVEAL-Bench and GenImage [zhu2023genimage] (see Table I). REVEAL-Bench, the first chain-of-evidence-based explainable dataset for synthetic image detection, serves as the in-domain dataset for training and evaluation. GenImage, a large-scale synthetic image dataset containing images generated by multiple generation methods, is used as an out-of-domain dataset to assess generalization. We train REVEAL on REVEAL-Bench and systematically evaluate its performance on both datasets (see Appendix B for detailed training settings). Building on this evaluation setup, we further investigate several core aspects of REVEAL’s capabilities. In particular, we study the impact of different MLLMs used as vision–language backbones, conduct ablation experiments to quantify the contribution of R-GRPO, and assess the model’s robustness under diverse perturbation settings. Appendix C reports the few-shot training results, and Appendix D provides a systematic comparison with existing large-scale model-based detectors.
Baselines We compare REVEAL with state-of-the-art AI-generated image detection methods, including CNNSpot [wang2020cnn], UnivFD [ojha2023towards], NPR [tan2024rethinking], HyperDet [cao2024hyperdet], AIDE [yan2024sanity] and VIB-Net [zhang2025towards]. To ensure a fair comparison, we retrain these methods using the official code under the same experimental settings and datasets.
Evaluation metrics Following existing research, we adopt Accuracy (ACC) as our evaluation metric. Accuracy is defined as the proportion of correctly predicted samples among the total number of samples, reflecting the overall correctness of a classification model. Since our detection results are provided by the MLLM in textual form (Real/Fake), we convert these texts into binary labels to compute accuracy, while baseline methods use the default thresholds provided by their official code. Moreover, because the output of the MLLM is interpretable text rather than logit values, we do not consider metrics that require logit values for computation, such as Average Precision (AP), in our evaluation.
5.2 Generalization across datasets
TABLE II: REVEAL demonstrates superior generalization across both in-domain and out-of-domain evaluations. REVEAL outperforms the best competing method by 3.87 %.
| CNNSpot [wang2020cnn] UnivFD [ojha2023towards] NPR [tan2024rethinking] | 87.80 86.95 95.40 | 62.45 75.00 84.80 | 74.25 84.35 88.85 | 73.85 80.95 88.05 | 63.55 85.50 85.10 | 73.60 71.75 94.30 | 73.70 82.00 87.05 | 71.35 80.70 84.45 | 39.45 88.45 88.95 | 68.89 81.74 88.55 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| HyperDet [cao2024hyperdet] | 93.25 | 68.40 | 91.85 | 92.30 | 100.0 | 67.05 | 89.20 | 80.45 | 57.65 | 82.24 |
| AIDE [yan2024sanity] | 95.25 | 79.90 | 95.90 | 94.95 | 87.75 | 90.35 | 94.85 | 90.10 | 91.10 | 91.13 |
| VIB-Net [zhang2025towards] | 67.05 | 53.25 | 60.25 | 57.85 | 65.00 | 68.55 | 60.85 | 52.55 | 38.00 | 58.15 |
| REVEAL | 95.31 | 93.75 | 97.81 | 97.19 | 95.00 | 86.88 | 96.25 | 95.94 | 96.88 | 95.00 |
Table II reports the performance of REVEAL on the in-domain dataset REVEAL-bench and the out-of-domain benchmark GenImage. The results indicate that REVEAL, leveraging a Chain-of-Evidence (CoE) reasoning-and-forensics mechanism, achieves superior cross-domain generalization compared to baseline lightweight binary classifiers: it maintains higher accuracy and more stable performance on GenImage. In the in-domain setting, smaller classifiers, such as those using methods like NPR [tan2024rethinking] and AIDE [yan2024sanity], are more prone to overfitting, demonstrating stronger fitting ability to domain-specific statistical regularities and subtle signals. As a result, REVEAL’s performance in-domain is comparable to that of these compact models. However, REVEAL excels in terms of cross-domain generalization. These findings suggest that while smaller models remain attractive for tasks prioritizing computational efficiency and in-domain accuracy, REVEAL better preserves and propagates key reasoning cues across domains. Therefore, there is a clear trade-off between generalization and domain-specific fit that should inform deployment choices. Notably, in the context of synthetic-image detection, reasoning-based forensic approaches, like REVEAL, exhibit particularly robust generalization.
5.3 Generalization across Base MLLMs
TABLE III: Performance across different MLLMs, showing larger models exhibit consistently stronger detection capability.
Training Scheme Phi-3.5 Qwen2.5- VL-3b Qwen2.5- VL-7b llava- v1.5-7b llava- v1.5-13b CoE Tuning 83.75 87.18 85.73 91.56 93.06 CoE Tuning+G-GRPO 87.19 89.06 92.19 92.81 95.31
The proposed algorithm in this study demonstrates strong generalizability and can be flexibly applied to a variety of multimodal large model architectures. To validate the effectiveness of our method, we conduct experiments using Qwen2.5-VL [bai2025qwen2], LLaVA-1.5-VL [liu2023visual], and Phi-3.5 as representative training frameworks. As shown in Table III, the results indicate that our approach achieves excellent detection performance and robust generalization across different multimodal large models.
Furthermore, we observe that as the model size increases, the detection capability improves significantly. This trend suggests the existence of a scaling law for synthetic image detection within the context of large models, similar to other tasks in the large model domain. As multimodal models continue to grow, their ability to handle complex tasks such as synthetic image detection becomes increasingly effective, demonstrating a direct correlation between model scale and performance.
5.4 Ablation Studies
TABLE IV: Ablation study of the impact of CoE Tuning, GRPO, and R-GRPO on model accuracy on REVEAL-Bench.
| ✗ | ✗ | ✗ | 61.21 |
| --- | --- | --- | --- |
| ✓ | ✗ | ✗ | 85.73 |
| ✓ | ✓ | ✗ | 91.56 |
| ✓ | ✗ | ✓ | 95.31 |
We conducted ablation experiments to investigate the role of reasoning datasets in synthetic image detection. As shown in Table IV, we first evaluated the performance of models trained without reasoning data (i.e., non-Reasoning SFT) and compared them with models fine-tuned using reasoning data (i.e., CoE Tuning). Additionally, we tested the effects of applying simple GRPO and our proposed R-GRPO method on performance improvement. The experimental results demonstrate that reasoning datasets significantly enhance the performance of MLLMs in synthetic image detection, with models lacking reasoning data performing close to random levels. Moreover, applying G-GRPO further improved the performance, highlighting the critical role of R-GRPO in this task.
5.5 Robustness Evaluation of REVEAL
<details>
<summary>x5.png Details</summary>
### Visual Description
## Charts: REVEAL-bench Performance
### Overview
The image presents two line charts comparing the performance of "Ours(REVEAL)" and "NPR(2024CVPR)" on the REVEAL-bench dataset. The left chart shows accuracy (ACC) versus quality, while the right chart shows accuracy versus sigma. Both charts include a horizontal dashed line at an accuracy of 50.
### Components/Axes
* **Left Chart:**
* X-axis: "quality" ranging from 100 to 60.
* Y-axis: "ACC" (Accuracy) ranging from 100 to 50.
* Data Series:
* "Ours(REVEAL)" - Red line with circular markers.
* "NPR(2024CVPR)" - Blue line with triangular markers.
* Horizontal dashed line at y = 50.
* **Right Chart:**
* X-axis: "sigma" ranging from 0 to 4.
* Y-axis: "ACC" (Accuracy) ranging from 100 to 50.
* Data Series:
* "Ours(REVEAL)" - Red line with circular markers.
* "NPR(2024CVPR)" - Blue line with triangular markers.
* Horizontal dashed line at y = 50.
* **Legend:** Located at the top-right of both charts.
* Red circle: "Ours(REVEAL)"
* Blue triangle: "NPR(2024CVPR)"
### Detailed Analysis or Content Details
**Left Chart (Accuracy vs. Quality):**
* **Ours(REVEAL):** The red line slopes downward.
* At quality = 100, ACC ≈ 95.
* At quality = 90, ACC ≈ 80.
* At quality = 80, ACC ≈ 65.
* At quality = 70, ACC ≈ 60.
* At quality = 60, ACC ≈ 58.
* **NPR(2024CVPR):** The blue line is relatively flat.
* At quality = 100, ACC ≈ 55.
* At quality = 90, ACC ≈ 55.
* At quality = 80, ACC ≈ 55.
* At quality = 70, ACC ≈ 55.
* At quality = 60, ACC ≈ 55.
**Right Chart (Accuracy vs. Sigma):**
* **Ours(REVEAL):** The red line slopes downward, but the decrease is less pronounced than in the left chart.
* At sigma = 0, ACC ≈ 95.
* At sigma = 1, ACC ≈ 85.
* At sigma = 2, ACC ≈ 65.
* At sigma = 3, ACC ≈ 60.
* At sigma = 4, ACC ≈ 55.
* **NPR(2024CVPR):** The blue line slopes downward more steeply initially, then flattens out.
* At sigma = 0, ACC ≈ 90.
* At sigma = 1, ACC ≈ 80.
* At sigma = 2, ACC ≈ 60.
* At sigma = 3, ACC ≈ 55.
* At sigma = 4, ACC ≈ 55.
### Key Observations
* In both charts, "Ours(REVEAL)" consistently outperforms "NPR(2024CVPR)" at all measured values.
* The performance of "Ours(REVEAL)" is more sensitive to changes in "quality" than to changes in "sigma".
* The performance of "NPR(2024CVPR)" is relatively stable with respect to "quality".
* The accuracy of both methods degrades as "quality" decreases and as "sigma" increases.
### Interpretation
The data suggests that the "Ours(REVEAL)" method is more effective than "NPR(2024CVPR)" on the REVEAL-bench dataset. The left chart indicates that the accuracy of "Ours(REVEAL)" is significantly affected by the "quality" of the input, while the accuracy of "NPR(2024CVPR)" remains relatively constant. The right chart shows that increasing "sigma" (likely representing noise or uncertainty) reduces the accuracy of both methods, but the impact is more pronounced on "NPR(2024CVPR)" initially.
The horizontal dashed line at 50 likely represents a baseline or threshold for acceptable performance. Both methods perform above this threshold for most values of "quality" and "sigma", but the performance of "NPR(2024CVPR)" approaches this threshold as "sigma" increases.
The relationship between the two charts suggests that "quality" and "sigma" may represent different aspects of the input data. "Quality" could refer to the clarity or completeness of the data, while "sigma" could represent the level of noise or uncertainty. The fact that "Ours(REVEAL)" is more sensitive to "quality" suggests that it relies on high-quality data to achieve optimal performance.
</details>
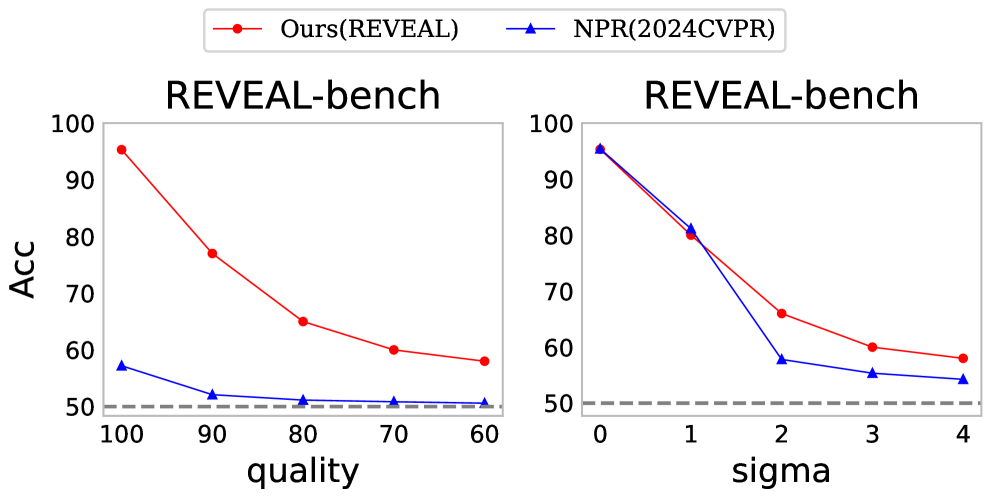
Figure 5: The accuracy comparison between the two methods under various perturbation conditions.
To evaluate the robustness of REVEAL against common post-processing distortions, we conducted a systematic robustness study on the REVEAL-bench dataset. The experiments apply two typical post-processing operations to the original test images: Gaussian blur ( $\sigma=1,2,3,4$ ) and JPEG compression (quality = 90, 80, 70, 60). For each distortion level, we compare REVEAL with the state-of-the-art baseline methods (results are shown in Figure 5). The results indicate that REVEAL demonstrates stronger robustness and improved cross-domain generalization across the considered post-processing settings.
6 Conclusion
We presented REVEAL, a reasoning-centered approach for explainable AI-generated image detection. First, we introduced REVEAL-Bench, the first dataset organized around expert-grounded, verifiable forensic evidence and an explicit chain-of-evidence following an evidence-then-reasoning paradigm. Second, we proposed the REVEAL Framework, a progressive two-stage training scheme whose core component R-GRPO explicitly teaches multimodal LLMs to perform logical synthesis over forensic evidence, jointly improving accuracy, reasoning consistency, and generalization. Empirically, REVEAL attains superior detection accuracy, stronger out-of-domain generalization, and higher explanation fidelity, establishing a new state of the art for reasoning-based image forensics.